- 投稿日:2021-01-20T23:57:41+09:00
コロナ・ショック後から株価上昇し続けている15銘柄
はじめに
新型コロナウイルス感染症が世界的に流行し始めたことによって,2020年2月末頃から3月にかけて,世界的に株価が大暴落しました(コロナ・ショック).日経平均株価は直前ピークと比べ,3割も暴落し約1万6千円の安値を付けました.
景気対策として行われた各国の中央銀行による大規模な金融緩和の影響もあり,5月以降株価の上昇傾向がはじまり,最近では日経平均株価は約2万8500円の値をつけ,30年5か月ぶりの高値となりました.
最近の高値の要因としては,米国の追加の財政出動などへの期待が高まっていることもあるようです(【日経新聞】日経平均、30年ぶり2万8000円台回復 米財政出動期待で).
このように,日経平均株価はコロナ・ショック後から現在にかけて,常に上昇し続けています.そこで,個別銘柄についても同じように常に価格上昇しているものは存在しないのかについて疑問に思いました.
今回の記事では,「コロナ・ショック後から株価上昇し続けている銘柄は存在するのか」を東京証券取引所に上場している全銘柄の中から調査しました.その結果,株価上昇し続けている銘柄は15銘柄存在することがわかりました.
さらに,その15銘柄のうち,コロナショック後営業利益が上昇し続けている,またはV字回復している銘柄を選定したところ,より今後の株価上昇が期待できる銘柄として10銘柄に絞ることができました.
株価上昇し続けている銘柄は?
【検証方法】
・東京証券取引所に上場している全銘柄の株価データを,Yahoo FinanceのAPIを利用し,取得します.
・月ごとに株価上昇率を,データを取得した全銘柄について計算します.計算方法は,株価上昇率=\frac{今月初日終値-前月初日終値}{前月初日終値}です.株価上昇率の計算には休日を除く月初日の株価終値を利用しています.
・2020年5月から2021年1月まで (8か月間)の期間において,常に株価上昇率がプラスであるものを選択していきます.
※ データ取得,分析はすべてPythonでおこなっています.詳しい検証方法は記事の一番下の付録を参照してください.【検証結果】
2020年5月から2021年1月までの期間において,株価が上昇し続けていた銘柄は15銘柄あることがわかりました.以下はその15銘柄のリストです.
- 株価上昇し続けている15銘柄
証券コード 銘柄名 1か月の株価上昇率(%) 1400 ルーデン・ホールディングス 10.03 1431 Lib Work 13.95 2413 エムスリー 14.33 2484 出前館 16.72 3922 PR TIMES 19.12 3948 光ビジネスフォーム 4.44 4673 川崎地質 7.32 5217 テクノクオーツ 12.71 6365 電業社機械製作所 7.60 6391 加地テック 11.79 6563 みらいワークス 12.36 6622 ダイヘン 6.90 6723 ルネサスエレクトロニクス 13.37 7975 リヒトラブ 2.77 9468 KADOKAWA 12.0 PR TIMES,エムスリー,KADOKAWA,出前館(情報通信サービス業を展開)は特に高い株価上昇率となっており,株価上昇率だけを見ると,今後も株価上昇が大きく期待できる銘柄と言えるでしょう.そのほかには,建築業,機械,電気機器メーカーなど様々な業種がリスト入りしています.
以下のグラフは,各銘柄の株価上昇率の推移です.
2-4月はコロナショックで,ほとんどの銘柄に関して,株価が大きく下落しています.しかし,その後,5月以降は常に株価が上がっていることがわかると思います.
特徴的なものとして,医療情報系ベンチャー企業であるエムスリー(2413)はコロナショックでも,ほとんど株価が下がることはなく,その後常に株価を上げてきました.ルネサスエレクトロニクス(6723)はコロナショックによって,40%以上株価を下げましたが,その後40%株価を上げ,コロナショック後,常に株価を上げてきました.出前館(7975)は9月の株価上昇率が60%を超えており,株価が急上昇しました.
さらに,15銘柄の営業利益の状況をみて,今後株価上昇が期待できそうな銘柄を考えていきます.
- 四半期売上・営業利益の状況
さらに,株価上昇し続けている15銘柄の四半期売上・営業利益の状況です.
証券コード 銘柄名 売上
1Q売上
2Q売上
3Q営業利益
1Q営業利益
2Q営業利益
3Q1400 ルーデン・ホールディングス 722 577 623 35 -9 28 1431 Lib Work 962 1230 1011 -68 -77 -195 2413 エムスリー 34654 35478 39544 7404 11253 12678 2484 出前館 2994 3484 4228 -619 -1015 -3194 3922 PR TIMES 819 922 1028 277 354 472 3948 光ビジネスフォーム 1695 2045 1705 57 190 123 4673 川崎地質 2979 1549 1980 345 -58 39 5217 テクノクオーツ 2341 3020 3175 334 613 662 6365 電業社機械製作所 10875 2938 3517 2322 -152 53 6391 加地テック 2263 772 1234 242 2 177 6563 みらいワークス 1095 1014 1034 26 14 13 6622 ダイヘン 44770 30546 32485 4521 1150 2532 6723 ルネサスエレクトロニクス 178743 166672 178678 13313 17256 17249 7975 リヒトラブ 2466 1920 2006 210 47 129 9468 KADOKAWA 54476 47023 50530 -373 3581 4266 (単位:百万円)
1Q:1~3月,2Q:4~6月,3Q:7~9月(川崎地質のみ、1Q:3~5月、2Q:6~8月、3Q:9~11月)以下は各銘柄の営業利益をグラフにしたものです.営業利益の絶対値が大きいものと小さいもので分けています.
表やグラフから,15銘柄にうち、営業利益が右肩上がり,または,V字回復している銘柄は以下の10銘柄です.
・ルーデン・ホールディングス
・エムスリー
・PR TIMES
・光ビジネスフォーム
・テクノクオーツ
・加地テック
・ダイヘン
・ルネサスエレクトロニクス
・リヒトラブ
・KADOKAWAまた,出前館は,上記で示したように,高い平均株価上昇率を示していましたが,今回提示したリストには含まれておらず,営業利益の状況を見てみると赤字が拡大し続けているので,危険な投資先とも言えるかもしれません.
おわりに
コロナショック後(2020年5月から2021年1月までの期間),東証に上場している全銘柄の中で,株価が上昇し続けていた銘柄を調査したところ,15銘柄あることがわかりました.さらに,そのうちの4半期の営業利益を調べたところ,10銘柄は右肩上がり,またはV字回復しているということがわかりました.その10銘柄は以下の通りです.
- ルーデン・ホールディングス
- エムスリー
- PR TIMES
- 光ビジネスフォーム
- テクノクオーツ
- 加地テック
- ダイヘン
- ルネサスエレクトロニクス
- リヒトラブ
- KADOKAWA
株価が上昇し続けている,営業利益が右肩上がり,またはV字回復であることを考えると,この10銘柄が今後も株価上昇が期待できます.
逆に,残りの5銘柄は上がり続けてはいますが,少し注意が必要でしょう。
<過去記事>
・【5年分データ分析】ゴールデンクロスの数日後に株価は上がっているのか
・日経225全銘柄の投資効率を検証
・日経平均株価が上がった次の日に上がる銘柄を見つけたい
・どの暗号資産が効率よく稼げるか
・1株1千円以下の価格変動が大きい銘柄に投資してパフォーマンスをあげる
・第1回緊急事態宣言のときに上がった銘柄TOP10を調査
付録(検証方法)
- 準備
・フォルダ「data」を作成します.これは株価データを保存するための場所です.
・東証上場銘柄一覧(2020年12月末)にあるdata_j.xlsをダウンロードします.data_j.xlsをエクセルなどで開き,csvファイル(data_j.csv)として,保存しなおします.Pythonではcsvファイルを読み込めるようにしているので,この操作をしています.
- 株価時系列データ取得プログラム
今回はPythonのライブラリpandas_datareaderを用いて,Yahoo Financeからデータを取得します.以下のプログラムは,
data_j.csvを参照して,東京証券取引所に上場している全銘柄の株価データを取得します.全銘柄の時系列データを取得するので,かなり時間がかかります.途中でプログラムを止めても問題ないように,データ取得していない銘柄の時系列データのみダウンロードするように設計しています.したがって,タイムエラーなどによって,株価データ取得に失敗することがありますが,その場合はもう1度プログラムを実行すれば,その未取得データのみが取得できます.
get_data_price.pyimport pandas as pd import glob import pandas_datareader.data as web # 東証全銘柄リスト def get_tokyo(): tokyo = pd.read_csv("data_j.csv", engine="python", names=("date","code", "name","market", "CodeIndustry33", "ClassificationIndustry33", "CodeIndustry17", "ClassificationIndustry17", "CodeScale", "ClassificationScale"), skiprows=1, usecols=[1,2], encoding="utf-8") return tokyo # 株価取得(日足) csv保存 def get_price_csv(stock_name,start='2015-1-1',end=None): data = web.DataReader(stock_name,"yahoo",start,end) data.to_csv("./data_price/"+stock_name+".csv") def get_all(list_stock_name, dir_name, func, filetype='csv'): for code in list_stock_name.code: code = str(code) if not ('.T' in code): code+='.T' filename = '{}\\{}.{}'.format(dir_name, code, filetype) if filename in glob.glob(f"{dir_name}/*"): pass else: print(code, 'GET... ', end='') try: func(str(code)) print('SUCCESS') except Exception as e: print('FAIL:', e) if __name__ == '__main__': list_stock_name = get_tokyo() get_all(list_stock_name, './data_price', get_price_csv) # 株価取得
- 分析プログラム
以下のプログラムは,ダウンロードした時系列データを読み込み,各月の株価上昇率を計算し,2020年5-2021年1月において,常に株価が上昇している銘柄を選択します.
最後に各月の株価上昇率,その平均値の結果がcsvファイルとして保存されます.このとき,各月の株価上昇率のグラフの作成されます.
stock_price_rise.pyimport pandas as pd # 東証上場全銘柄のリスト def get_tokyo(): tokyo = pd.read_csv("data_j.csv", engine="python", names=("date","code", "name","market", "CodeIndustry33", "ClassificationIndustry33", "CodeIndustry17", "ClassificationIndustry17", "CodeScale", "ClassificationScale"), skiprows=1, usecols=[1,2], encoding="utf-8") return tokyo # 価格の時系列データフレーム作成 def make_df_price(list_stock_name, item): data = {} # 自己資本 stock_name = str(list_stock_name.code[0]) if not ('.T' in stock_name): stock_name+='.T' dummy = pd.read_csv('./data_price/' + stock_name + '.csv')[item] for code in list_stock_name.code: stock_name = str(code) if not ('.T' in stock_name): stock_name+='.T' try: data[stock_name] = pd.read_csv('./data_price/' + stock_name + '.csv', index_col=0)[item] except: data[stock_name] = dummy # エラー発生時はダミーを入れる return pd.DataFrame(data) # 東証上場全銘柄のリスト作成 list_stock_name = get_tokyo() # 価格の時系列データフレーム作成 df_closes = make_df_price(list_stock_name, 'Close')['2020-01-06':'2021-01-04'] # 特定の日の株価データフレーム作成 df_closes2 = df_closes.loc[['2020-01-06', '2020-02-03', '2020-03-02', '2020-04-01', '2020-05-01', '2020-06-01', '2020-07-01', '2020-08-03', '2020-09-01', '2020-10-02', '2020-11-02', '2020-12-01', '2021-01-04',]] # 株価上昇率の計算 result = ((df_closes2-df_closes2.shift(1))/df_closes2.shift(1)*100).T # 2020年5月から収益率がプラスのものを検索 result_rise = result[#(result['2020-02-03']>0)&\ #(result['2020-03-02']>0)&\ #(result['2020-04-01']>0)&\ (result['2020-05-01']>0)&\ (result['2020-06-01']>0)&\ (result['2020-07-01']>0)&\ (result['2020-08-03']>0)&\ (result['2020-09-01']>0)&\ (result['2020-10-02']>0)&\ (result['2020-11-02']>0)&\ (result['2020-12-01']>0)&\ (result['2021-01-04']>0) ] # 証券コードと銘柄名の対応表を作成 result_rise_name = pd.DataFrame(index=list(result_rise.index), columns=['name']) for stock_code in list(result_rise.index): result_rise_name.loc[stock_code] = list_stock_name[list_stock_name.code == int(stock_code[0:-2])]['name'].iloc[0] # 結果リスト mean = pd.DataFrame(result_rise.T['2020-05-01':'2021-01-04'].mean(), columns=['ave']) result = pd.concat([result_rise, result_rise_name, mean], axis=1) # 結果を出力 result = result.drop(['1329.T', '1365.T', '1626.T', '2068.T'])# ETFは除く result.to_csv('result.csv', encoding="cp932") print(result) # グラフ作成 result_rise.T.plot(figsize=(9, 6), title='Return')



- 投稿日:2021-01-20T23:24:30+09:00
Python環境構築
OS Windows10 Pro
Vagrant 2.2.14
Ubuntu 16.04.4 LTSDockerで今後管理したいため、Pythonをインストールし、pipをインストール、numpyをインストールしようとしたらエラーが発生。
````python3 -m pip install numpy Collecting numpy Using cached https://files.pythonhosted.org/packages/51/60/3f0fe5b7675a461d96b9d6729beecd3532565743278a9c3fe6dd09697fa7/numpy-1.19.5.zip Complete output from command python setup.py egg_info: Traceback (most recent call last): File "<string>", line 1, in <module> File "/tmp/pip-build-ayy5xg9l/numpy/setup.py", line 68 f"NumPy {VERSION} may not yet support Python " ^ SyntaxError: invalid syntax ---------------------------------------- Command "python setup.py egg_info" failed with error code 1 in /tmp/pip-build-ayy5xg9l/numpy/ You are using pip version 8.1.1, however version 20.3.3 is available. You should consider upgrading via the 'pip install --upgrade pip' command. 調べて pipをアップグレードした。sudo pip install --upgrade pip The directory '/home/vagrant/.cache/pip/http' or its parent directory is not owned by the current user and the cache has been disabled. Please check the permissions and owner of that directory. If executing pip with sudo, you may want sudo's -H flag. The directory '/home/vagrant/.cache/pip' or its parent directory is not owned by the current user and caching wheels has been disabled. check the permissions and owner of that directory. If executing pip with sudo, you may want sudo's -H flag. Collecting pip Downloading https://files.pythonhosted.org/packages/54/eb/4a3642e971f404d69d4f6fa3885559d67562801b99d7592487f1ecc4e017/pip-20.3.3-py2.py3-none-any.whl (1.5MB) 100% |████████████████████████████████| 1.5MB 110kB/s Installing collected packages: pip Found existing installation: pip 8.1.1 Not uninstalling pip at /usr/lib/python2.7/dist-packages, outside environment /usr Successfully installed pip-20.3.3再度、numpyをインストール
````agrant@vagrant-ubuntu-trusty-64:~$ pip install numpy WARNING: pip is being invoked by an old script wrapper. This will fail in a future version of pip. Please see https://github.com/pypa/pip/issues/5599 for advice on fixing the underlying issue. To avoid this problem you can invoke Python with '-m pip' instead of running pip directly. DEPRECATION: Python 2.7 reached the end of its life on January 1st, 2020. Please upgrade your Python as Python 2.7 is no longer maintained. pip 21.0 will drop support for Python 2.7 in January 2021. More details about Python 2 support in pip can be found at https://pip.pypa.io/en/latest/development/release-process/#python-2-support pip 21.0 will remove support for this functionality. Defaulting to user installation because normal site-packages is not writeable Collecting numpy Downloading numpy-1.16.6-cp27-cp27mu-manylinux1_x86_64.whl (17.0 MB) |████████████████████████████████| 17.0 MB 116 kB/s Installing collected packages: numpy WARNING: The scripts f2py, f2py2 and f2py2.7 are installed in '/home/vagrant/.local/bin' which is not on PATH. Consider adding this directory to PATH or, if you prefer to suppress this warning, use --no-warn-script-location.無事インストールできました。
- 投稿日:2021-01-20T23:19:12+09:00
RocketChatをAPI/Pythonでイジる
RokcetChatのREST APIをPythonでなしかいじったものです。
Public,Privateで使い分けが必要になります(いまいっぽ。。。)。なので利用者にはその使い分けを意識せずに情報をとれるようにしてみました。
原理としては
responseの存在により
- publicチャンネル→private用API
- privateチャンネル→public用API
の組み合わせになった際にはresponseの有無で
格納処理をスルーするようにすることで
なんとかしている仕組みにしてみました。#!/opt/anaconda3/bin/python3 # -*- coding: utf-8 -*- '''RocketChat Channelメンテナンス RocketChatのチャンネル管理を行う Todo: * まだRedmineとRocketChatのみ。他のOSSに対しても同様に作る def __init__(self, HEADERS, URL): def _getChannelPublicMap(self): def _getChannelPrivateMap(self): def exchangeMapkeyToList(self, map): def getChannelMap(self): def getChannelUserMap(self, list_channelname): def getDifftimeLastUpdateSec(self, _targetTime): def _getChannel_id(self, channelname): def sendMessageToRocketChat(self, channel, msg): def closeTargetChannel(self, roomname): def _ISOtimeToDatetime(self, target): def _CreateMapFromChannelIDtoChannelname(self): def _CreateMapFromChannelnameToChannelID(self, self._CreateMapFromChannelIDtoChannelname()): def _judgeRocketChatMessage(self, target_date, limit): def _JudgeDeleteChannelMessages(self, roomname, LIMIT): def JudgeDeleteChannelMessages(self, LIMIT): ''' ################################################ # library ################################################ import dateutil import json import pandas as pd import requests import sys from datetime import date from datetime import datetime from datetime import timedelta from dateutil import parser from pprint import pprint from pytz import timezone ################################################ # 環境変数取得 ################################################ ################################################ # RocketChatChannelManager ################################################ class RocketChatChannelManager(object): def __init__(self, HEADERS, URL): '''RESTを呼ぶ形式 classの __init__処理 REST APIでCallするために HEADERSとURLを共有する。 RedmineXXXXXManager classとはことなりインスタンスは 生成しない。 ''' # 引数チェック 型 if not isinstance(HEADERS, dict): print(f'引数:HEADERSの型が正しくありません dict <-> {type(HEADERS)}') raise TypeError # 引数チェック 型 if not isinstance(URL, str): print(f'引数:URLの型が正しくありません str <-> {type(URL)}') raise TypeError # パラメータ共有 self.HEADERS = HEADERS self.URL = URL def _getChannelPublicMap(self): '''パブリックチャネルのリストと最終更新時間のマップ パブリックチャンネル名とチャンネル最終更新時間のマップを作成する。 Args: Returns: map: パブリックチャンネル名と最終更新時間のマップ Raises: API実行時のエラー Examples: >>> map = self._getChannelPublicMap() Note: publicとprivateで取得関数が異なるという。。。 ''' # 結果格納 _map = {} # API定義 API = f'{self.URL}/api/v1/channels.list' # 取得処理 response = None try: response = requests.get( API, headers=self.HEADERS,) except Exception as e: print(f'API実行エラー: {API}') print(f'Error: {e}') return False else: for l in response.json()['channels']: _map[l['name']] = l['_updatedAt'] # mapを返す return _map def _getChannelPrivateMap(self): '''プライベートチャネルのリストと最終更新時間のマップ プライベート名とチャンネル最終更新時間のマップを作成する。 Args: Returns: map: プライベートチャンネル 名と最終更新時間のマップ Raises: API実行時のエラー Examples: >>> map = self._getChannelPrivateMap() Note: publicとprivateで取得関数が異なるという。。。 ''' # 結果格納 _map = {} # API定義 API = f'{self.URL}/api/v1/groups.listAll' # 取得処理 try: response = requests.get( API, headers=self.HEADERS,) except Exception as e: print(f'API実行エラー: {API}') print(f'Error: {e}') return False finally: for l in response.json()['groups']: _map[l['name']] = l['_updatedAt'] # mapを返す return _map def exchangeMapkeyToList(self, map): '''mapのkeyを要素とするlistを生成する ちょっとめんどい変換なのでヘルパー関数として作成したもの ''' # 引数チェック 型 if not isinstance(map, dict): print(f'引数:mapの型が正しくありません dict <-> {type(map)}') raise TypeError # 入れ物 _list = [] # mapループ for key in map.keys(): _list.append(key) return _list def getChannelMap(self): '''チャンネル一覧およびチャンネルの最終更新時間を取得する パブリック、プライベート両方のチャンネルをまとめて処理する Args: Returns: map: チャンネル名と所属ユーザリストのマップ Raises: API実行時のエラー Examples: >>> map_ = R.getChannelMap() Note: self._getChannelPubliclist() self._getChannelPrivatelist() パブリック、プライベートまとめて取得 ''' # public,privateそれぞれ取得 _map_public = self._getChannelPublicMap() _map_private = self._getChannelPrivateMap() # mapを結合して返す if ((_map_public) and (_map_private)): _map_public.update(_map_private) return _map_public # public Channelのみの場合 elif _map_public : return _map_public # private Channelのみの場合 elif _map_private : return _map_private else: return {} def getChannelUserMap(self, list_channelname): '''指定チャンネルの登録ID一覧 listに格納したチャンネルに所属するユーザ一覧を チャンネル名と参加しているユーザリストのマップを返す パブリック、プライベートをまとめて実施 Args: list_channelname(list): 探索対象のチャンネル名リスト Returns: map: チャンネル名をKeyとする所属ユーザリストのマップ Raises: API実行時のエラー Examples: >>> map = getChannelUserMap(['aaaa','bbbb']) Note: ''' # 引数チェック 型 if not isinstance(list_channelname , list): print(f'引数:list_channelnameの型が正しくありません list <-> {type(list_channelname)}') raise TypeError # 結果全体格納するMap _map = {} # MSG送信API定義 # パブリックもプライベートもまとめて実施 APIS = [f'{self.URL}/api/v1/channels.members', f'{self.URL}/api/v1/groups.members'] # 1000人は超えないだろう。。。から COUNT = '1000' # 対象チャンネル名リストでループ for channel in list_channelname: # MSG組み立て msg = (('roomName', channel),('count',COUNT),) # API発行 for api in APIS: try: response = requests.get( api, params=msg, headers=self.HEADERS,) except Exception as e: print(f'API実行エラー: {API}') print(f'Error: {e}') return False else: # ユーザたちを格納するList _list = [] # 結果を得られた場合のみ格納 if response: # 所属するユーザlistを生成 for l in response.json()['members']: _list.append(f'{l["username"]}') # mapにchannel名をKeyにしてユーザリストを格納 _map[channel] = _list # mapを返す return _map def getDifftimeLastUpdateSec(self, _targetTime): '''最終更新時間からの経過秒を返す Public,Privateそれぞれ指定が可能 Args: _targetTime(str): 比較したい時間 ISO時間フォーマット Returns: list: ユーザ一覧を格納したlist Raises: API実行時のエラー Examples: >>> list_AllUser = R.getAllUserList() Note: ''' # 引数チェック 型 if not isinstance(_targetTime, str): print(f'引数:_targetTimeの型が正しくありません str <-> {type(_targetTime)}') raise TypeError # 今時間生成 jst_now = datetime.now(timezone('Asia/Tokyo')) target = parser.parse(_targetTime).astimezone(timezone('Asia/Tokyo')) # いま時間とターゲット時間の差分を秒で返す return (jst_now - target).total_seconds() def _getChannel_id(self, channelname): '''Channel名の _id情報を取得する チャンネル名からチャンネルIDを取得する RocketChatAPIではチャンネル名ではなくチャンネルIDを 要求するケースが多数ある。 Args: channelname: チャンネル名 Returns: str: チャンネル名に対するチャンネルID Raises: API実行時のエラー Examples: >>> R._getChannel_id('general') Note: ''' # 引数チェック 型 if not isinstance(channelname, str): print(f'引数:channelの型が正しくありません str <-> {type(channelname)}') raise TypeError # ユーザ情報取得API定義 API = f'{self.URL}/api/v1/rooms.info' # MSG組み立て msg = {'roomName': channelname,} # MSG送信 try: response = requests.get( API, params=msg, headers=self.HEADERS,) except Exception as e: print(f'API実行エラー: {API}') print(f'Error: {e}') return False else: if response.json()['success']: return response.json()['room']['_id'] else: return False def sendMessageToRocketChat(self, channel, msg): '''指定チャネルにメッセージを送る 指定チャンネルにメッセージを送信する Args: channel: チャンネル名 msg: 送信メッセージ Returns: 処理結果, HTTP ステータスコード Raises: API実行時のエラー Examples: '>>> R.getUser_id('geneal', 'こんにちわ') Note: ''' # 引数チェック 型 if not isinstance(channel, str): print(f'引数:channelの型が正しくありません str <-> {type(channel)}') raise TypeError if not isinstance(msg, str): print(f'引数:msgの型が正しくありません str <-> {type(msg)}') raise TypeError # MSG送信API定義 API = f'{self.URL}/api/v1/chat.postMessage' # MSG組み立て msg = {'channel': channel, 'text' : msg,} # 指定チャンネルが存在する場合のみ実行 if self._getChannel_id(channel): # MSG送信 try: response = requests.post( API, data=json.dumps(msg), headers=self.HEADERS,) except Exception as e: print(f'API実行エラー: {API}') print(f'Error: {e}') return False else: pprint(f'Status code: {response.status_code}') return True else: print(f'指定したチャンネルが存在しません: {channel}') return False def closeTargetChannel(self, roomname): '''パブリック、プライベート区別なくチャンネルを削除する 指定したチャンネル名を削除する Args: roomname(str): 削除するチャンネル名 Returns: Raises: API実行時のエラー Examples: >>> R.closeTargetChannel('テストチャンネル') Note: まとめて消す仕様ではない、1チャンネルづつターゲットで ''' # 引数チェック 型 if not isinstance(roomname, str): print(f'引数:roomnameの型が正しくありません str <-> {type(roomname)}') raise TypeError # 削除API定義 # パブリックもプライベートも区別なくまとめて実施 APIS = [f'{self.URL}/api/v1/channels.delete', f'{self.URL}/api/v1/groups.delete'] # MSG組み立て msg = {'roomId': self._getChannel_id(roomname)} # まとめてチャンネル削除を遂行 for API in APIS: try: response = requests.post(API, data=json.dumps(msg), headers=self.HEADERS,) except Exception as e: print(f'API実行エラー: {API}') print(f'Error: {e}') else: # 結果を得られた場合のみ処理コードを返す if response: return response.json()['success'] def _ISOtimeToDatetime(self, target): '''ISOフォーマット時刻文字列をJST変換してdatetime型で返す Args: target: str ISO形式のUTC時刻文字列 Returns: datetime: JST変換後 Raises: API実行時のエラー Examples: >>> self._ISOtimeToDatetime('2021-01-20T00:23:10.256Z') Note: ''' return parser.parse(target).astimezone(timezone('Asia/Tokyo')) def _CreateMapFromChannelIDtoChannelname(self): '''チャンネルIDに対するチャンネル名をもつmapを生成する。 チャンネルIDをkeyにしてチャンネル名をValueに持つmapを生成する。 RocketChatから還元される情報が何かとチャンネルIDで返してくるのだが 還元する立場だとチャンネルIDだとわかりにくい問題がある。 チャンネル名に置き換えることでデータ利便性を上げる。 -> cf. _getChannel_id(self, channelname): チャンネル名からチャンネルIDを取得 Args: Returns: map: Key:チャンネルID、Value: チャンネル名 Raises: API実行時のエラー Examples: >>> _MapChannelIDtoChannelName = self._CreateMapFromChannelIDtoChannelname() Note: つどつどAPIを叩いて情報収集する仕掛けだとレスポンス懸念あり。 mapを予め作成し変換パフォーマンスを向上させる。 TODO: チャンネル名 -> チャンネルIDのmapも作っておくべきかもしれない。 ''' # パブリック、プライベート合算でチャンネル名を取得する ## Class内メソッドを使ってチャンネル名をまとめて取得 _map = self.getChannelMap() # 蓄積するDataFrame生成 channelMap = {} # 処理ループ for key in _map.keys(): _key = self._getChannel_id(key) channelMap[_key] = key # 蓄積結果を返す return channelMap def _CreateMapFromChannelnameToChannelID(self, self._CreateMapFromChannelIDtoChannelname()): '''ChannelID->ChannelNameのmapを利用してChannelName->ChannelID mapを生成する 内包を使用してkey/valueを反転させる Args: map: map ChannelID->ChannelKeyマップ Returns: map: map key/valueを反転させたmap Raises: API実行時のエラー Examples: >>> _map = self._CreateMapFromChannelnameToChannelID(self._CreateMapFromChannelIDtoChannelname()) Note: ''' # ChannelID -> Channel NameMap _map = self._CreateMapFromChannelIDtoChannelname # ChannelID -> Channel NameMapのKey/Valueを反転させる swap_map = {v: k for k, v in _map.items()} return swap_map def _judgeRocketChatMessage(self, target_date, limit): '''メッセージ作成日付から保管する、しない判定を行う limitで指定した期間のMSGを保管する、しない判定を行いTrue/Falseで返す。 日付差分計算はdatetime型のサポートにより行う。timedeltaオブジェクトを使用し 差分日付けに対する判定処理を行う。 Args: target_date: datetime 判定対象の時間データ limit : int RocketChatメッセージ保存期間 Returns: True/False: Boolean True 保存、False 削除対象 Raises: API実行時のエラー Examples: >>> self._judgeRocketChatMessage(target_datetime, 10) Note: ''' today = date.today() diff_date = timedelta(limit) return (today - target_date.date() > diff_date) def _JudgeDeleteChannelMessages(self, roomname, LIMIT): '''roomnameに対しLIMIT超過日数を超えたメッセージに削除判別フラグを設定したデータを生成する。 指定したroomnameに対し、メッセージ作成日からの日数が LIMITを超過している場合に削除判定フラグをつけて DataFrameを生成する。 Args: roomname: str 探索対象のチャンネル名 LIMIT: int 保存期間(日数) Returns: df: DataFrame: ['チャンネル','MSG_ID','更新時間','削除対象','MSG'] Raises: API実行時のエラー Examples: >>> _df = self._JudgeDeleteChannelMessages(key, LIMIT) Note: _CreateMapFromChannelIDtoChannelname _MapChannelIDtoChannelName _ISOtimeToDatetime _judgeRocketChatMessage ''' # 引数チェック 型 if not isinstance(roomname, str): print(f'引数:roomnameの型が正しくありません str <-> {type(roomname)}') raise TypeError if not isinstance(LIMIT, int): print(f'引数:LIMITの型が正しくありません int <-> {type(LIMIT)}') raise TypeError # MSG抽出API定義 # パブリックもプライベートも区別なくまとめて実施 APIS = [f'{self.URL}/api/v1/channels.messages', f'{self.URL}/api/v1/groups.messages'] # MSG組み立て channel_id = self._getChannel_id(roomname) params = ( ('roomId', channel_id), ) ## この書き方だと失敗する #params = ( # ('roomId', channel_id) #) # 変換Map作成 _MapChannelIDtoChannelName = self._CreateMapFromChannelIDtoChannelname() # 両パターンに対応する入れ物を用意 _list = [] for API in APIS: pprint(f'API={API}') try: response = requests.get(API, headers=self.HEADERS, params=params,) except Exception as e: print(f'API実行エラー: {API}') print(f'Error: {e}') else: # 結果をログっぽく返す # 結果を得られた場合のみログを返す pprint(f'response={response}') if response: # 結果チェック pprint(response) pprint(len(response.json()['messages'])) # 削除対象判定結果をDataFrameに組み込んでで返す for _ in response.json()['messages']: _list.append([_MapChannelIDtoChannelName[_['rid']], _['_id'], self._ISOtimeToDatetime(_['_updatedAt']), self._judgeRocketChatMessage(self._ISOtimeToDatetime(_['_updatedAt']), LIMIT), _['msg']]) # DataFrameにして結果を返す df= pd.DataFrame(_list) df.columns = ['チャンネル','MSG_ID','更新時間','削除対象','MSG'] return df def JudgeDeleteChannelMessages(self, LIMIT): '''削除対象フラグを持ったDataFrameをまとめて1つのDataFrameにする。 サブメソッド _JudgeDeleteChannelMessagesから得られる パブリック、プライベート両方から得られたDataFrameを蓄積する。 Args: LIMIT: int 保存期間(日数) Returns: df: DataFrame 蓄積したDataFrame Raises: API実行時のエラー Examples: Note: self._JudgeDeleteChannelMessages(key, LIMIT): 削除対象フラグをつけたDataFrameを作成 ''' if not isinstance(LIMIT, int): print(f'引数:LIMITの型が正しくありません int <-> {type(LIMIT)}') raise TypeError # パブリック、プライベート合算でチャンネル名を取得する ## Class内メソッドを使ってチャンネル名をまとめて取得 _map = self.getChannelMap() # 蓄積するDataFrame生成 df = pd.DataFrame(index=[]) # 処理ループ for key in _map.keys(): _df = self._JudgeDeleteChannelMessages(key, LIMIT) df = pd.concat([df, _df], axis=0) # 蓄積結果を返す return df.reset_index(drop=True)
- 投稿日:2021-01-20T23:15:04+09:00
sudachipyで簡易的に同義語辞書をつかう
TL;DR
- sudachiの同義語辞書(synonym.txt)から同義語グループidと代表語の組み合わせを生成
- 生成した組み合わせをつかってsudachipyで簡易的に同義語辞書を使えるようにする
- 例としてわかちがき後同義語辞書をつかって正規化する
目的
テキストからの情報抽出やテキストの類似度計算などのタスクを行う際に、sudachiでの形態素解析で同義語を使いたかったのですが、sudachipyではsudachiの同義語辞書を利用できませんでした。
簡易的でいいので、sudachipyで簡易的に同義語辞書が使えるようにします。
今回の目的は、あくまでも形態素解析後の正規化です。特に、わかちがき後に同義語を同じ見出しに揃えることを目的としています。したがって、同義語の展開は行いません。sudachiの同義語辞書
sudachiの同義語辞書はドキュメントによると、
Sudachi 辞書に登録されている語に対して同義語情報を付与したものです。 Sudachi 辞書と同じライセンスで提供されます。
とのことです。
同義語辞書のソースはテキストファイルで公開されています。
https://github.com/WorksApplications/SudachiDict/blob/develop/src/main/text/synonyms.txtpythonでsudachiを使う
pythonでsudachiを使う場合は、pipを使ってinstallすることができます。
pip install sudachipy sudachidict_core以下の要領で形態素を取得できます。
from sudachipy import tokenizer from sudachipy import dictionary tokenizer_obj = dictionary.Dictionary().create() mode = tokenizer.Tokenizer.SplitMode.B token = tokenizer_obj.tokenize("食べ", mode)[0] token.surface() # => '食べ' token.dictionary_form() # => '食べる' token.reading_form() # => 'タベ' token.part_of_speech() # => ['動詞', '一般', '*', '*', '下一段-バ行', '連用形-一般']また、sudachiは文字の正規化ができます。
token.normalized_form()同義語辞書の編集
ここからが本題。
同義語ファイルを一部抜粋すると、以下のように形式で作成されています。
000001,1,0,1,0,0,0,(),曖昧,, 000001,1,0,1,0,0,2,(),あいまい,, 000001,1,0,2,0,0,0,(),不明確,, 000001,1,0,3,0,0,0,(),あやふや,, 000001,1,0,4,0,0,0,(),不明瞭,, 000001,1,0,5,0,0,0,(),不確か,, 000002,1,0,1,0,0,0,(),宛て先,, 000002,1,0,1,0,0,2,(),あて先,, 000002,1,0,1,0,0,2,(),宛先,, 000002,1,0,2,0,0,0,(),送り先,, 000002,1,0,3,0,0,0,(),送付先,, 000002,1,0,4,0,0,0,(),届け先,, 000002,1,0,5,0,0,0,(),発送先,, 000002,1,0,6,0,0,0,(),配送先,,1語1行で記述し、同義語グループ間は空行で区切られて、フォーマットは以下の通りです。
0 : グループ番号 1 : 体言/用言フラグ (省略可) 2 : 展開制御フラグ (省略可) 3 : グループ内の語彙番号 (省略可) 4 : 同一語彙素内での語形種別 (省略可) 5 : 同じ語形の語の中での略語情報 (省略可) 6 : 同じ語形の語の中での表記ゆれ情報 (省略可) 7 : 分野情報 (省略可) 8 : 見出し 9 : 予約 10 : 予約詳細な説明は、ドキュメントを参照してください。
今回重要なのは
- 0 : グループ番号
- 3 : グループ内の語彙番号
- 6 : 同じ語形の語の中での表記ゆれ情報
の3つです。
グループ番号は、ソース内で同義語の管理・識別に使用する6桁の数字です。
グループ内の語彙番号は、グループ内における、語彙素の管理番号です。"1"始まりで連番を付与します。
同じ語形の語の中での表記ゆれ情報は、同じ略語・略称形の語 (3、4、5の番号が同じもの) における、表記の関連性を示す情報です。0がその略語・略称形の語の代表語になります。すべてを確認したわけではないですが、synonym.txtでは各値の昇順に並んでいます。
つまり、各同義語グループの先頭は複数ある語彙素のうちいずれかの代表語です。
また、管理番号1の語彙素を同義語グループの代表的な語彙素であるとすることで、各同義語グループの先頭の語をその同義語グループの代表語として扱うことができます。このルールに則って、グループ番号と同義語グループの代表語の見出しの組み合わせを作成します。
import csv with open("synonyms.txt", "r") as f: reader = csv.reader(f) data = [r for r in reader] output_data = [] synonym_set = [] synonym_group_id = None for line in data: if not line: if synonym_group_id: base_keyword = synonym_set[0] output_data.append([ synonym_group_id, base_keyword ]) synonym_set = [] continue else: synonym_group_id = line[0] synonym_set.append(line[8]) with open("synonyms_base.csv", "w") as f: writer = csv.writer(f) writer.writerows(output_data)sudachipyで同義語を使う準備
sudachipyでは同義語辞書を取得できませんが、トークンが該当する同義語グループのidを取得することができます。
token.synonym_group_ids() # => [1]この取得した同義語グループidで先程生成した組み合わせから同義語の代表語を取得します。
一点注意するのは、synonym.txtの同義語グループのidは6桁の数字の文字列ですが、取得できるidはintであることです。import csv with open('synonym_base.csv', "r") as f: reader = csv.reader(f) data = [[int(r[0]), r[1]] for r in reader] synonyms = dict(data) synonym_group_ids = token.synonym_group_ids() if synonym_group_ids: # 複数ありうるけどとりあえず先頭を選択 surface = synonyms[synonym_group_ids[0]]わかちがき
生成した同義語のデータを使って、わかちがきを正規化します。
fetch_synonym_surfaceでは同義語があった場合は同義語グループの代表語を、同義語がない場合は正規化された見出し語を返すようにします。import csv with open('synonym_base.csv', "r") as f: reader = csv.reader(f) data = [[int(r[0]), r[1]] for r in reader] synonyms = dict(data) def fetch_synonym_surface(token): synonym_group_ids = token.synonym_group_ids() if synonym_group_ids: # 複数ありうるけどとりあえず先頭を選択 surface = synonyms[synonym_group_ids[0]] else: surface = token.normalized_form() return surface以下は、
1. わかちがきだけ
2. わかちがき + 正規化
3. わかちがき + 同義語正規化のコードと結果の比較です。
def wakati(sentence): tokenizer_obj = dictionary.Dictionary().create() mode = tokenizer.Tokenizer.SplitMode.C return " ".join([m.surface() for m in tokenizer_obj.tokenize(sentence, mode)]) def wakati_normalized(sentence): tokenizer_obj = dictionary.Dictionary().create() mode = tokenizer.Tokenizer.SplitMode.C return " ".join([m.normalized_form() for m in tokenizer_obj.tokenize(sentence, mode)]) def wakati_synonym_normalized(sentence): tokenizer_obj = dictionary.Dictionary().create() mode = tokenizer.Tokenizer.SplitMode.C return " ".join([fetch_synonym_surface(m) for m in tokenizer_obj.tokenize(sentence, mode)]) sentence = "アドビはアメリカのお金であるmoneyを生み出す会社" print("1:", wakati(sentence)) print("2:", wakati_normalized(sentence)) print("3:", wakati_synonym_normalized(sentence))1: アドビ は アメリカ の お金 で ある money を 生み出す 会社 2: アドビ は アメリカ の お金 だ 有る マネー を 生み出す 会社 3: アドビシステムズ は アメリカ合衆国 の お金 だ 有る お金 を 生み出す 会社
- 投稿日:2021-01-20T21:47:10+09:00
1分で基礎をおさらい!Python 高速で最小値を取れる優先度付きキュー
概要
リストから最小値を高速で取り出したいときに用いる優先度付きキューがPythonにはheapqという便利なものがあるのでさくっと見直しましょう。AtCoderでも頻出内容
急いでる人向け
この記事のすべて。三行目を
q = heapq.heapify(a)
としても動かないため注意a = [1,2,3,4,6,7,8] #list をheapifyでヒープ化する。 heapq.heapify(a) #heappush で5を追加する。 heapq.heappush(a,5) #heap内のの要素を小さい順にheappopで取り出す。 while a: print(heapq.heappop(a)) ######実行結果###### 1 2 3 4 5 6 7 8かんたんな説明
・heap*.heapify(list)*
リストを与えるとヒープ化してくれる・heap.heappush(heap,要素)
heapに新しい要素を追加する(listにおけるappendのheap版)・heap.heapop(heap)
heap内の最小の値を取り出す。取り出した要素はheapから削除される。応用
最大値を取り出す優先度付きキューを作りたい
すべての値の符号を逆転させればよい。
a = [1,2,3,4,6,7,8] #要素の符号を逆転 for i in range(len(a)): a[i] = a[i]*(-1) heapq.heapify(a) while a: #出力の符号を戻してやる print(heapq.heappop(a)*(-1)) ######実行結果###### 8 7 6 4 3 2 1参考にしたサイト
より詳しい解説はこっち
https://docs.python.org/ja/3/library/heapq.html
- 投稿日:2021-01-20T21:27:41+09:00
教師あり学習 ~入門者のメモ~ (scikit-learn)
本記事の内容
「東京大学のデータサイエンティスト育成講座」を読んで、scikit-learn の各モデルについての概要が掴めたので、忘れないうちにメモ。
書籍で言うと:Chapter 8 機械学習の基礎(教師あり学習)初心者の自分にとっては、機械学習モデルの種類が多く感じてしまうので、シンプルに整理してみた。
実装サンプルのパラメータは、本の中で使ったもののみ。scikit learn の機械学習モデル全体像
チートシート
ここでのポイントは、ザックリ、上が教師あり学習、下が教師なし学習。
今回は上の部分の説明。
教師あり学習
- classification: 分類=予測したい変数がクラス (例:「合格/不合格」、「晴れ/曇り/雨/雪」)
- regression: 回帰=予測したい変数が値 (例:体重「66.6kg, 32.3kg, ...」)
教師なし学習
- clustering: クラスタリング (似ているデータのグループ化)
- dimensionality reduction: 次元削減 (多数の特徴=>少数の本質的な特徴に減らす、主成分分析とも)
教師あり学習
説明変数(または特徴量:X)から目的変数(y)を予測するモデルを求める手法。
教師あり学習モデルの全体像(例の本の8章)
雑に言えば、以下4つ。
1. 線形モデル
2. 決定木
3. kNN (k近傍法)
4. SVM (サポートベクターマシン)それぞれに分類と回帰のモデルがある。
右側の図がポイント。各論
モデルの詳細や数学的背景は他の記事が沢山あるので割愛(←
まだ上手く説明できないだけ)1. 線形モデル
イメージ
線形なので、一次多項式(y=ax+by+cz)のイメージ
本当はこうみたい。y = w_0x_0+w_1x_1+w_2x_2+\cdots基本的なものだけでも複数のモデルがある。
正則化項のある回帰とか、名前がかっこよすぎて、どっちがどっちかいつも忘れる。単回帰、重回帰
単回帰:説明変数が1つ。
y = ax+b重回帰:説明変数が複数。
y = w_0x_0+w_1x_1+w_2x_2+\cdots最小二乗法(「正解-予測値」の2乗の総和=正解からどれぐらいかけ離れているかというペナルティを最小にする方法)で各項の最適な係数(重み)を求める。
以下の損失関数(loss function)が最小になれば勝ち。loss = \sum_{i=1}^n(y_i-f(x_i))^2モデル作成
from sklearn.linear_model import LinearRegression model = LinearRegression()パラメータ:あれ、何も設定しなかったや。。
ラッソ回帰、リッジ回帰
正則化の話。
正則化とは、ザックリ言うと、モデルが複雑になり過ぎるのを防ぐ手法。
訓練データに適応し過ぎるが故に未知のデータをいい感じに予測できない現象(=過学習)を防ぎたい。ほんで、汎化性能(テストデータのような未知のデータに対する予測精度)を高めたい。
ペナルティに正則化項(モデルが複雑になると大きくなる)を加えることで、複雑になることを防ぐ。loss = \sum_{i=1}^n(y_i-f(x_i))^2+\lambda\sum_{j=1}^m|w_j|^qラッソ(Lasso): q=1: 正則化項(L1ノルム)=重みの(1乗の)総和を加える
リッジ(Ridge): q=2: 正則化項(L2ノルム)=重みの2乗の総和
ルンバ(roomba):ロボット掃除機
思わず「あいうえお作文」したくなる。ついでに、本の内容超えるけど、以下のポイントを風の噂で聞きました。
知らんけど。Lasso は、不要な説明変数(特徴量)の係数を0にしてくれるので、不要なパラメータを削りたい時に便利らしい(スパース推定だってさ)。おや、教師なし学習の次元削減と、どう使い分けるのだろう・・・???
Ridge は、多重共線性(相関の高い特徴量が含まれるため、それらの係数がいい感じに決まらない)により通常の線形回帰では上手くいかない場面でも、いい感じに推定できるようにしてくれるらしい。因みに、L1ノルムとL2ノルムを合体させると Elastic Net !だってさ。
知らんけど。ついでに、正則化項(Lpノルム)をグラフにしたらこんな感じらしいっす。
ついでに、ここの「Ridge回帰」のとこにある図が気に入った。(って、おい、上からw)ついでのついでに、なんで、Lasso の場合だけ係数(パラメータ)を0にできるかと言うと・・・パラメーターの値を変える意味合いが違うんだって。
Ridge の場合、パラメーターの二乗がペナルティ=大きい値のパラメータを小さくするほうが、元々小さい値のパラメータをさらに小さくするより効果ある(そりゃそうだね)。だから、特定のパラメータを0に近づけるより、別の大きなパラメータを減らす方向に動く。なので、係数が0になりにくいとのこと。
Lasso の場合、パラメーターの絶対値なので、元々の値の大きさに関わらず、係数を1小さくしたら、ペナルティが1減る。なので、簡単に0まで減らせる。だってさ。(そうだよね)モデル作成(Lasso)
from sklearn.linear_model import Lasso model = Lasso(alpha=1.0, random_state=0)パラメータ:alpha(上の loss にある「λ(ラムダ)」の値、default=1)
モデル作成(Ridge)
from sklearn.linear_model import Ridge model = Ridge(random_state=0)パラメータ:random_state
ロジスティック回帰
線形モデルで分類問題を解くにはコイツ。
シグモイド(sigmoid)関数とか使うと、二値分類ができる。多クラス分類は、それを「1対その他」に拡張するだけ。グラフだと分かりやすいが、以下の x の部分にさっきの一次多項式が入る予定。
何となく、yが50%以上の奴らは上、それ以外は下って分類すればよさそうだけど、この閾値(50%)をどこに設定するかというのも重要。モデル学習の過程では、予測値が正解に近づくように、正解から遠い予測値が出されるとペナルティが大きくなるように定義された損失関数を使う。ペナルティが最小になるようにモデルを構築できれば(=いい感じの係数を見つけられれば)勝ち。
ペナルティ(交差エントロピー誤差)はこんな感じ。
関数にするなら、
(教えて!google先生「y=- log x graph」)-log(予測値)0が正解の場合は、関数を左右反転。
(教えて!google先生「- log -(x-1) graph」)-log(-(予測値-1))モデル作成
from sklearn.linear_model import LogisticRegression model = LogisticRegression()パラメータ:あれ、何も設定しなかったや。。
2. 決定木
前処理が楽。(今回、前処理とか詳細割愛)
スケーリングが不要(分岐条件が値の大小関係なので影響がない)
何なら欠損値処理も不要(欠損値を特別な値として処理してくれる)コンペでよく使われる xgboost とか LightGBM とかのベースになるやつやから、頑張って勉強しとこ。
表面ツラだけてか、ここ見たらええよ、マジで。
分類
リンクの「分類木」参照、マジで。
モデル作成
from sklearn.tree import DecisionTreeClassifier model = DecisionTreeClassifier(criterion='entropy', max_depth=5, random_state=0)パラメータ:
- criterion : {“gini”, “entropy”}, default=”gini”
- max_depth : 木の最大深さ回帰
リンクの「回帰木」参照、マジで。
モデル作成
from sklearn.tree import DecisionTreeRegressor model = DecisionTreeRegressor()パラメータ:あれ、何も設定しなかったや。。
3. kNN (k近傍法)
属性が近いk個による多数決
てか、ここ見たらええよ。マジで。(キノコの話、おもろ)分類
キノコの種類、教えて~(リンク先PDF参照)
モデル作成
from sklearn.neighbors import KNeighborsClassifier model = KNeighborsClassifier(n_neighbors=5)パラメータ:n_neighbors : k個の数
回帰
キノコの直径、教えて~(リンク先PDF参照)
モデル作成
from sklearn.neighbors import KNeighborsRegressor model = KNeighborsRegressor(n_neighbors=5)パラメータ:n_neighbors : k個の数
4. SVM (サポートベクターマシン)
カテゴリを識別する境界線を、マージンが最大になるように引く手法。
図で言うと、左でも右でもなく、真ん中。
てか、ここ見たらええよ。マジで。
分類
上の記事そのまんまやな。
モデル作成1
from sklearn.svm import LinearSVC model = LinearSVC()パラメータ:あれ、何も・・・(ry
モデル作成2
from sklearn.svm import SVC model = SVC(probability=True)パラメータ:
- probability : 予測の結果として、最終的に判断された分類クラスではなく、各分類クラスに該当する確率を取得できる関数 predict_proba を使うには True にする必要がある。回帰
だからここ見たらええって。マジで。
モデル作成
from sklearn.svm import SVR model = SVR()パラメータ:あれ、何も・・・(ry
実装
処理の流れ
- モデル作成(上の各論参照)
- モデルの訓練
- モデルの評価
# モデルは何でもいいよ。ここでは重回帰。 model = LinearRegression() # 訓練 model.fit(X_train, y_train) # 評価 print('train:', model.score(X_train, y_train)) print('test:', model.score(X_test, y_test))model.score について
0 ~ 1 の値で、実際は以下を計算している。
分類の場合、accuracy
回帰の場合、決定係数: R^2もっと全体像
import pandas as pd from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression # データロード iris = load_iris() # テストデータを分割 X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=0) # モデルの構築~評価 model = LogisticRegression() model.fit(X_train, y_train) print('train:', model.score(X_train, y_train)) print('test:', model.score(X_test, y_test))結果:
train: 0.9821428571428571
test: 0.9736842105263158モデル比較
import pandas as pd from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression from sklearn.tree import DecisionTreeClassifier from sklearn.neighbors import KNeighborsClassifier from sklearn.svm import SVC iris = load_iris() X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=0) models = { 'linear': LogisticRegression(), 'tree': DecisionTreeClassifier(), 'knn': KNeighborsClassifier(n_neighbors=3), 'svm': SVC() } scores = {} for name, model in models.items(): # モデルの構築~評価 model.fit(X_train, y_train) scores[(name, 'train')] = model.score(X_train, y_train) scores[(name, 'test')] = model.score(X_test, y_test) pd.Series(scores).unstack()結果:
まとめ
今回学んだ教師あり学習のモデルは以下4つ。
- 線形モデル
- 決定木
- kNN (k近傍法)
- SVM (サポートベクターマシン)
それぞれに、回帰と分類のためのモデルがあるよ。
感想
こうやって整理してみると結構シンプル。
説明書いたのほぼ線形モデルのみで、あとはリンク集(苦笑)。
今後、気が向いたら深堀していけばいいと思うけど、理論の詳細を追いかけるより、xgboost とか LightGBM とか使ってスコア改善する方が楽しそう。
近いうちに9章の教師なし学習についてもメモしたい。










- 投稿日:2021-01-20T21:27:27+09:00
Django - Qiita上のtutorial appを概観し、機能をプラスする(2)
はじめに
前回Django - Qiita上のtutorial appを概観し、機能をプラスする(1)の続きです。
Djangoにはログイン機能について標準でユーザー認証(login)機能がついていますが、ユーザー登録(signup)機能は備わっていません。
今回はユーザー認証機能とユーザー登録機能とそれら画面を実装していきます。
ログアウト画面も作ってよいのですが、今回はログイン画面に遷移させることで対応します。参照記事は以下です。
Django2 でユーザー認証(ログイン認証)を実装するチュートリアル -2- サインアップとログイン・ログアウト以下前回の機能も付与してgitにあげたものです。
https://github.com/Rio157/crud-image-accounts.git完成型
ログイン画面
ユーザー登録画面ユーザー認証機能(login)とその画面
まずはurlの指定から。
settings.py(project下)LOGIN_REDIRECT_URL = '/' LOGOUT_REDIRECT_URL='/' # login後、logout後にリダイレクトするページを指定します。 # ここでは一覧画面に飛ぶようにします。urls.py(project下)path('accounts/', include('django.contrib.auth.urls')), # urlspatternsに追加。これでdjangoの標準でついている認証機能が有効になりました。次にtemplatesをつくっていきます。
_base.html(templates/app下){% block customcss %} {% endblock customcss %} <!--headタグに追加。_base.htmlを継承したときにcssファイルを読み込むことができます。--> <!--また、bodyタグ内で管理サイト、ログアウトと並んで、--> <li class="nav-item"> <a class="nav-link" href="{% url 'accounts:signup'%}">ユーザー登録</a> </li> <!--を追加。また、ログアウトでは--> <li class="nav-item"> <a class="nav-link" href="{% url 'logout'%}">ログアウト</a> </li> <!--{% url 'admin:logout'%}→{% url 'logout' %}とします。管理者用の認証機能によるログアウト画面に遷移させないためです。-->login.html(templates下にregistrationフォルダ作成、registration下){% extends 'app/_base.html' %} {% load static %} {% block customcss %} <link rel='stylesheet' type='text/css' href="{% static 'app/css/style.css' %}"> {% endblock customcss %} {% block content %} <section class="common-form"> {% if form.errors %} <p class="error-msg">Your username and password didn't match. Please try again.</p> {% endif %} {% if next %} {% if user.is_authenticated %} <p class="error-msg">Your account doesn't have access to this page. To proceed, please login with an account that has access.</p> {% endif %} {% endif %} <form class="form-signin" method="POST" action="{% url 'login'%}">{% csrf_token %} <h1 class="h3 mb-3 font-weight-normal">Please login</h1> <table> <tr> <td>{{ form.username.label_tag }}</td> <td>{{ form.username }}</td> </tr> <tr> <td>{{ form.password.label_tag }}</td> <td>{{ form.password }}</td> </tr> </table> <div class="checkbox mb-3"> </div> <button class="btn btn-lg btn-primary btn-block" type="submit">Log in</button> <p class="mt-5 mb-3 text-muted">© 2017-2020</p> </form> </section> {% endblock %}{% extends 'ファイル名' %}で継承。cssを読み込むときは{% load static %}と追加します。
先にユーザー登録画面も含めたcssファイルを作成しておきます。
style.css(app/static/app/css下)div, p, ul, ol, li, dl, dt, dd, h1, h2, h3, h4, h5, h6 label, input, textarea, select, button { margin: 0; padding: 0; color: #555555; font-size: 1rem; line-height: 1.8; box-sizing: border-box; } h1{ font-size: 2rem; padding-top: 20px; padding-bottom: 15px; } section { margin: 0 0 8px; } .container { margin: 0 auto; width: 100%; max-width: 800px; } .content { padding: 0 8px; } .common-form label { display: block; } .common-form p { margin-bottom: 8px; } .common-form input, .common-form textarea { padding: 4px; width: 100%; margin-bottom: 8px; } .common-form select { padding: 4px; margin-bottom: 8px; } .common-form .submit { margin-top: 8px; margin-bottom: 8px; padding: 8px 36px; border: none; color: #ffffff; text-align: center; text-decoration: none; display: inline-block; background-color: #4CAF50; border-radius: 2px; } .common-form .delete { background-color: #f44336; } .form-signin { width: 100%; max-width: 315px; padding: 15px; margin: auto; } .form-signin .checkbox { font-weight: 400; } .form-signin h1{ margin-top: 50px; }ログイン画面と同様に、ユーザー登録画面でもstyle.cssを読み込みます。
ちなみにこのcssはbootstrapのサンプルページ画面からとってきたものです。ユーザー登録機能(signup)とその画面
まずは新たにアプリを立ち上げます。
terminalで以下を実行。django-admin startapp accounts python3 manage.py makemigrations python3 manage.py migrateプロジェクトにおいて新しいアプリを認証してもらいます。
settings.py(project下)INSTALLED_APPS = [..., 'accounts.apps.AccountsConfig', ]urls.py(project下)path('accounts/', include('accounts.urls')), #urlpatternsに追加。 #これでaccountsアプリのurlがブラウザで探せるようになりました。accountsアプリに戻ります。
accountsアプリ下にurls.pyを新たに作成します。urls.py(accounts下)from django.urls import path from . import views # set the application namespace # https://docs.djangoproject.com/en/2.0/intro/tutorial03/ app_name = 'accounts' urlpatterns = [ # ex: /accounts/signup/ path('signup/', views.SignUpView.as_view(), name='signup'), ]views.py(accounts下)from django.contrib.auth.forms import UserCreationForm from django.urls import reverse_lazy from django.views import generic class SignUpView(generic.CreateView): form_class = UserCreationForm success_url = reverse_lazy('login') template_name = 'accounts/signup.html' #ユーザー登録のフォーム自体はDjangoに標準で備わっているので、 #UserCreationFormを指定、reverse_lazyでログイン画面に遷移すると追加、templatesのディレクトリを指定します。accounts下にtemplates/accountsディレクトリを作成後、
signup.html{% extends 'app/_base.html' %} {% load static %} {% block customcss %} <link rel='stylesheet' type='text/css' href="{% static 'app/css/style.css' %}"> {% endblock customcss %} {% block content %} <h1>Sign up</h1> <section class="common-form"> <form method="post"> {% csrf_token %} {{ form.as_p }} <button type="submit" class="submit">Sign up</button> </form> </section> {% endblock %}ログイン画面と同様style.cssを読み込みます。
振り返り
お疲れさまでした。
今回は最小限の機能と見栄えを実装しました。諸々改善できる点(ログイン失敗時の画面はcssできれいにしていない、signupにある注意事項が嘘になっているとか)はありますが、ひとまず作業フロー全体を捉えることはできました。
個人的には昨年末あたりにやっていた作業をまとめたので、いい復習になりました。その点、書き漏れなどあるかもしれませんが、悪しからず。


- 投稿日:2021-01-20T21:13:44+09:00
この2つの書籍を同じ人が出されているって、知りませんでした。
知らなかった
以下のような記事を書いたことがある。
良書「ゼロから作るDeep Learning -- Pythonで学ぶディープラーニングの理論と実装」を読む
良書『入門 Python3』、説明に失敗しているところN選(N=3)。
つまり、対象としている書籍は、
- ゼロから作るDeep Learning -- Pythonで学ぶディープラーニングの理論と実装
- 入門 Python3
これ、両方!
斎藤康毅
という方が、(後者は、訳本なので監訳であるが、)出されているよう。
巨人ですね。。。それをふまえ
以下のような記事も書いたが。。。
良書「ゼロから作るDeep Learning 」のGitHub
「ゼロから作るDeep Learning 」でModuleNotFoundError: No module named 'dataset.mnist'が出る理由。
⇒この辺のPythonコードは、かなり、しっかりしたものと考えていいようです!!
ちょっと、ひっかかっていた部分
「ゼロから作るDeep Learning -- Pythonで学ぶディープラーニングの理論と実装」
の1章(ページ数:20)が、
Python入門
となっており、
20ページで、Pythonをざくっと説明されているのだが、
そんな量の説明では、無理でしょーーー、他の書籍とかに任せればーーー
と気になっていましたが、、、ド、プロなんですね。この記事の目的
これらの書籍、良書です。
良書×良書
なので、かなり信頼できるのでは?という情報の共有。
「本」は、重要です。<--買いましょう。
ただ、お金がかかるし、紙の本は場所もとるし、重いし、
もとをとるために、良書だった場合には、筆者がネットで公開している良い情報をタダで得て、元を取りましょう!!
- 投稿日:2021-01-20T21:13:44+09:00
ゼロから! 入門 Python3! この2つの書籍を同じ人が出されているって。
知らなかった
以下のような記事を書いたことがある。
良書「ゼロから作るDeep Learning -- Pythonで学ぶディープラーニングの理論と実装」を読む
良書『入門 Python3』、説明に失敗しているところN選(N=3)。
つまり、対象としている書籍は、
- ゼロから作るDeep Learning -- Pythonで学ぶディープラーニングの理論と実装
- 入門 Python3
これ、両方!
斎藤康毅 という方が、(後者は、訳本なので監訳であるが、)出されているよう。
巨人ですね。。。それをふまえ
以下のような記事も書いたが。。。
良書「ゼロから作るDeep Learning 」のGitHub
「ゼロから作るDeep Learning 」でModuleNotFoundError: No module named 'dataset.mnist'が出る理由。
⇒この辺のPythonコードは、かなり、しっかりしたものと考えていいようです!!
ちょっと、ひっかかっていた部分
「ゼロから作るDeep Learning -- Pythonで学ぶディープラーニングの理論と実装」
の1章(ページ数:20)が、
Python入門
となっており、
20ページで、Pythonをざくっと説明されているのだが、
そんな量の説明では、無理でしょーーー、他の書籍とかに任せればーーー
と気になっていましたが、、、Pythonの ド、プロ なんですね。この記事の目的
これらの書籍、良書です。
良書 ×? 良書 という情報の共有。
以下、余談。
「本」は、いまだ、重要です。<--買いましょう。
ただ、お金がかかるし、紙の本は場所もとるし、重いし、
もとをとるために、
良書だった場合には、
筆者がネットで公開している良い情報をタダで得て、元を取りましょう!!
(というような活動を実践しようとした、2つの書籍を同じ人が出されていることに気づいた(驚いた)ので記事にした次第です。)
- 投稿日:2021-01-20T21:04:40+09:00
Django - Qiita上のtutorial appを概観し、機能をプラスする(1)
1年ほど前に書いた記事です。
Publicに公開できるようにQiitaに投稿いたします。
はじめに
この記事では
- Djangoアプリケーションのそれぞれのファイルの相関と大まかな役割を理解できる
- 既存のアプリケーションを概観し、適切な変更を加えられるようになる
- Djangoを知らない人には、ほう、そんな感じか、というイメージを持ってもらえることが目的です。個人的には復習のつもりで取り組みます。
以下の記事のアプリを概観し、
[Python] Djangoチュートリアル - 汎用業務Webアプリを最速で作る今回は、
ログイン機能とその画面の作成(2)と
画像ファイルのアップロード・表示を可能にする(1)作業を行います。以下は今回の(1)の作業を終えたもの
https://github.com/Rio157/crud-image-app.git開発環境
- Windows10
- Ubuntu LTS18.04 - Windows for Linux Terminal
- Visual Studio Code にてUbuntuを開いています。
完成型
アイテムの一覧画面
アイテムの詳細画面機能
今回は画像のアップロードと一覧画面、詳細画面にてアップロードされた画像の表示を施します。
今回は便宜上サーバー側の処理とフロントエンド側の操作をはっきり分けて書きます。
また、画像に関してはまずterminalで
pip3 install pillows
として画像をDjangoで扱えるようにしておきます。画像のアップロード処理
画像アップロードの処理はほとんど定型的です。
コード操作とその意図を#コメントアウトに書いていきます。サーバー側で画像を受け取れるようにしていきます。
settings.py(project下)MEDIA_ROOT = os.path.join(BASE_DIR, 'media') MEDIA_URL = '/media/' #まずは画像ファイルの保管、受取先を指定します。最終行当たりに追加。 #MEDIA_ROOT:projectと同じ階層にmediaフォルダがある #MEDIA_URL:(Djangoでは画像ファイルに1対1でURLが対応するため)メディアファイル公開時のURL指定です。urls.py(project下)urlpatterns += static(settings.MEDIA_URL, document_root=settings.MEDIA_ROOT) #メディアファイル公開用のURLを追加します。最終行当たりに追加。forms.pyclass ItemForm(forms.ModelForm): class Meta: model = Item fields = ('name','age','sex','memo','images') widgets = { 'name': forms.TextInput(attrs={'placeholder':'記入例:山田 太郎'}), 'age': forms.NumberInput(attrs={'min':1}), 'sex': forms.RadioSelect(), 'memo': forms.Textarea(attrs={'rows':4}), 'images': forms.ClearableFileInput(attrs={'multiple': False}), } #imagesを追加します。これによりメディアファイルをデータベース化し、'images'として引き出すことができるようになりました。models.pyimages = models.ImageField( verbose_name='画像ファイル', upload_to='', default='defo.png' ) #class Item(models.Model):に追加。upload_to=''でsettings.py上に書いた保存先が指定される。 #defaultにメディアファイルをアップロードしていないときに表示する画像を指定します。mediaフォルダ下にdefo.pngを配置。画像の表示
データベース化された画像を引き出し、一覧画面と詳細画面に表示します
フロントエンドをいじるので、templates下の操作になります。item_filter.html(一覧画面の各アイテムの項目)<!--一覧において画像を表示したい--> <div class="row"> <div class="col-3"> <p>画像</p> </div> <div class="col-9"> <img src="{{ item.images.url }}" width=150> </div> </div> <!--同階層に並ぶ名前、登録日の下に追加します。--> <!--Djangoではサーバー側のデータを引き出すときに{{}}や{%%}で囲むことでディレクトリを指定したりします。-->item_card.html(アイテムの詳細画面)<div class="row"> <div class="col-3"> <p>画像ファイル</p> </div> <div class="col-9"> <form method="post" enctype="multipart/form-data"> <!--入力した画像を表示させたい--> <img src="{{ object.images.url }}" width=300> </form> {{ form.media }} </div> </div> <!--項目名:備考の上に追加します。-->item_forms.html(アイテム作成画面)<div class="row"> <div class="col-12"> <!-- enctype=...の追加--> <form method="post" id="myform" enctype="multipart/form-data"> {% crispy form%} </form> </div> </div> <!--{%crispy form%}にメディアファイルを含むデータが格納されてますので、enctypeを指定する必要があります。--> <!-- なおcrispyについて詳しくは省きますが、crispy_forms appにより入力項目をきれいに整理してくれます。-->振り返り
今回は画像アップロード機能とその画像表示についてDjangoで実装しました。
ほんとは作成画面、編集画面においてプレビュー機能の実装と、複数画像のアップロード・表示についてもやりたかったですが、(プレビュー機能はJavaScriptでできるようです)今回は簡易な実装で簡易な機能をという趣旨だったので省かせてもらいました。また、今回の以下記事がメディアファイルでなく、他ファイルのアップロードについて書いていますが、操作はほとんど同じですので比較の参考にしてください。
[Django] ファイルアップロード機能の使い方 [基本設定編]次回
次回はDjangoでログイン機能の実装を行います。
Djangoではログイン機能が標準で備わっているわけですが、プロジェクト内に新しくアプリケーションをつくる形で実装します。


- 投稿日:2021-01-20T21:04:35+09:00
Streamlitで作ったデータ閲覧用のWebアプリをherokuで公開する
概要
- 前回、Streamlitを使ってWebアプリを作れるようになった
- せっかくだから公開しよう
- ということで、できたもの → Chocolate Ball Viewer
前提
- herokuにアカウントを作っておく(無料でOK)
- githubのアカウントがある
アプリ作成
こちらなどを参考にアプリを作成します。本記事ではStreamlitの記法などについては触れません。
$ streamlit run [python-file]で、期待通りにアプリが作成されていることを確認しときます。
herokuにデプロイ
ここからが本記事の本編です。
手順の概要としては次の通りです。
- herokuデプロイに必要なファイルの用意
- herokuにアプリの作成
- デプロイ
- 自動デプロイの確認をしてみよう
必要なファイルの用意
herokuにpythonアプリを公開するには次の2つのファイルが必要です。
- Procfile
- 実行コマンドを書く
- requirements.txt
- 必要なライブラリなどを書いておく
これだけでも十分ですが、streamlitの設定ファイルを作るためのスクリプトを作っておきます。port番号などを指定するものです。(Procfileで起動オプションとして指定してもOK)
- setup.sh
これらをまとめて、Streamlitアプリをherokuで公開するためのテンプレートを作ってくれている方がいます。
https://github.com/patryk-oleniuk/streamlit-heroku-template今回はこんな感じで作りました。ほぼほぼstreamlit-heroku-templateからコピーしてきました。
Procfile
web: sh setup.sh && streamlit run src/choco_view.pyrequirements.txt(バージョン固定したほうが安心っすね)
pylint pandas scipy matplotlib seaborn streamlitsetup.sh
mkdir -p ~/.streamlit/ echo "[server] headless = true port = $PORT enableCORS = false " > ~/.streamlit/config.tomlこれらをまとめてgithubにpushしておきます。プライベートリポジトリでもOKです。
herokuにアプリの作成
herokuのアプリ作成はCLIを使ってコマンドで実行もできますが(herokuチュートリアルはCLIですね)、githubリポジトリと連携させるのであればWeb管理画面からも簡単です。今回はWebから作成します。
右上の「Create New App」からサービス名を設定して「Create app」します。
これだけ
デプロイ
createすると、デプロイ方法の選択になります。今回は「GitHub」タブを選択して連携するリポジトリを指定します。
連携できると、デプロイ画面に遷移します。
ここで、「Enable Automatic Deploys」を押して自動デプロイを有効にすると、連携したGitHubリポジトリの指定したブランチに更新があれば自動でデプロイされます。
準備ができたらManualDeployメニューから「Deploy Branch」を押してデプロイ開始です。
自動デプロイの確認
データを更新などしてgithubにpushしてみよう。
herokuの管理画面を眺めているとデプロイされているのが見えます(楽しい)。
できた
僕は趣味でチョコボールデータの計測をやっているので、その計測データを可視化するアプリを公開しました(詳しくはチョコボール統計をみてね)。
https://chocolate-view.herokuapp.com/Flavorを選択できる
銀のエンゼルが当たるまでに必要な購入数のシミュレーション
おわり
参考




- 投稿日:2021-01-20T21:02:11+09:00
正方形の二次配列を渦状に取得する方法!
1. はじめに
皆さん、初めまして!
今、大学でソフトウェア工学を専攻しているモナ坊です。読まれる前に、読者にはコードよりも考え方を参考として読んで欲しいという希望があります。
突然ですが、皆さん配列の流れに困惑したことはありますでしょうか?
そのくらい分かるわ!とつっこまれるかも知れませんが、もう少し読んでください。では、正方形の配列をポインターで渦状に移動させる方法はご存知でしょうか?
詳しく説明致します。
本題
では、さっそく本題に入ります。
正方形の二次配列が存在するとします。
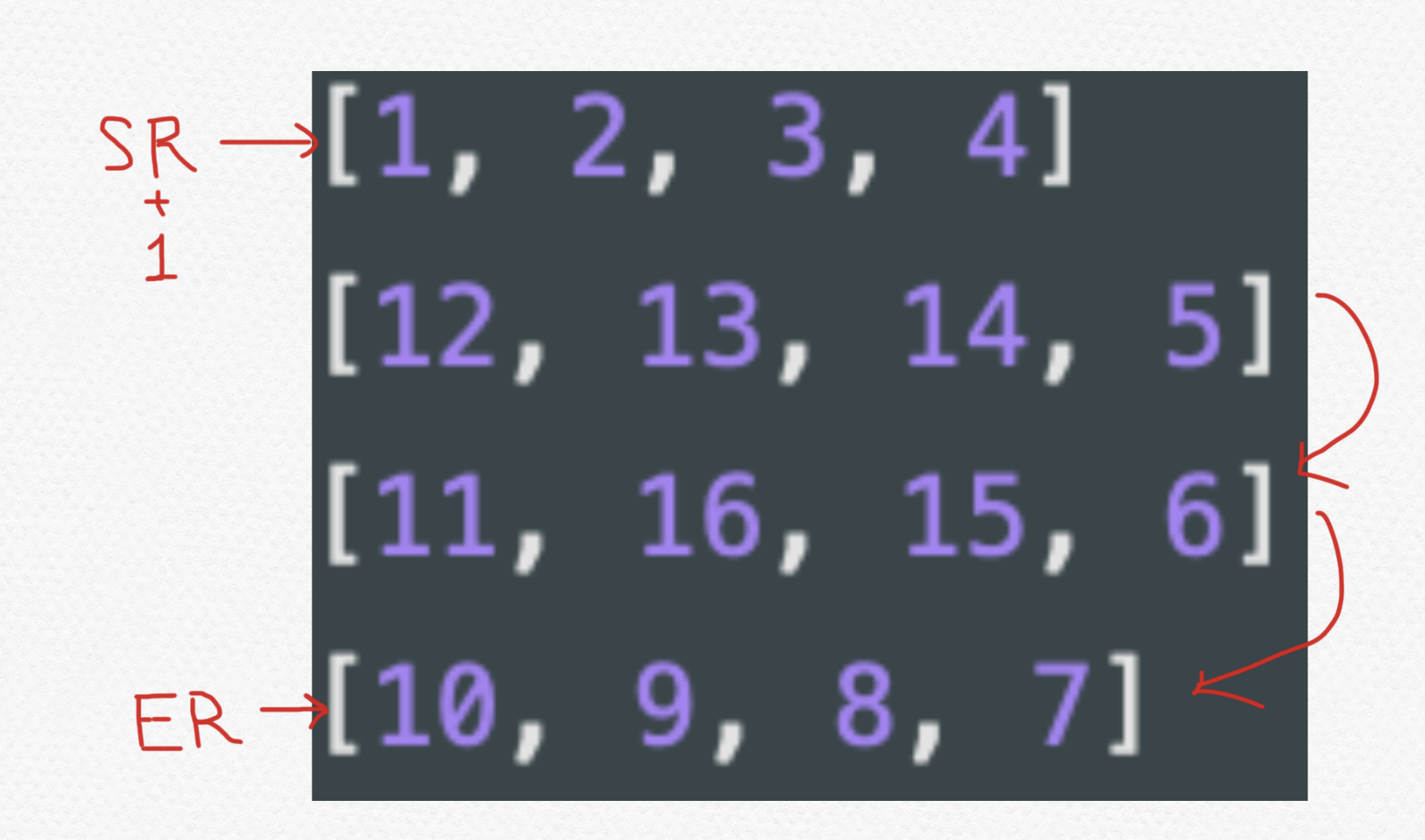
例.)array_traversal.pyarray = [ [1, 2, 3, 4] [12, 13, 14, 5] [11, 16, 15, 6] [10, 9, 8, 7] ]この 縦x横の二次配列を渦状に一つ一つの要素を渡り、一次配列を取得してください。(時間計算量はO(n))
出力例[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16]考え方
まずは考え方からです。
1. 少し視点を変えて見てみる
1つ目の画像:
1つ目の画像をみるとわかりやすいかも知れません。
渦巻状に取得はするものの、そこで少し視点を変えて問題に取り組んでみると
外側の四角と内側の四角に分けることができます。そう見てみると少し、複雑さがなくなりました。ね?
次にこの四角を迂回するにあたって、ポインターが2つ(ロウとカラム用)あると考えてください。
ここでのポインターは、簡潔に言うと処理を指示する為に「この処理をここでしてね!」とコンピューターに伝えるためのものと捉えてください。このポインター2つを渦状に取得させるために考慮する点が1つあります。
それは、二重計上(double counting)の制御です。
補足:
ここでは、ロウは横列、カラムは縦列を指しているます。
二重計上(double counting) は簡潔に言いますと、処理にあたって同じ要素が被ってしまことです。
2. 二重計上の制御
次の画像をご覧ください。
2つ目:
こうすることによってお互いに境界線を作ることができ、また二重計上も防ぐことができるので効率の良い解き方になってくると思います
*SC, EC, SR, ERとは??
SCがカラムのはじめ、ECがカラムの終わり
SRがロウのはじめ、ERがロウの終わり
となっています。
3. 一連の処理の流れ(外側)
それでは、最後に準備が整ったところで流れを説明します。
3.1 トップロウ([1, 2, 3, 4])をカラム用のポインターで取得します
ここは、普段使われているfor loopの仕方でできますね。
サンプルコード:
for col in range(sc, ec + 1): result.append(array[sr][col])3.2 ECが指しているカラムをERまでロウ用のポインターで取得します。(ここでは、[5, 6, 7]ですね。)
サンプルコード:
for row in range(sr + 1, er + 1): result.append(array[row][ec])3.3 ボトムロウ([10, 9, 8])を逆方向にカラム用のポインターで取得します。
ここは、reverseというbuilt-in function を使って逆方向のfor loop を実装します。
サンプルコード:
for col in reversed(range(sc, ec)): result.append(array[er][col])3.4 最後に、2行目の[12]と3行目の[11]を取得したいのでSR+1 ~ ER区間で逆方向にロウ用のポインターで取得します。
ここも、reverse を使います。
サンプルコード:
for row in reversed(range(sr + 1, er)): result.append(array[row][sr])
これで、やっと外側の四角の要素を全て渦状に取得できました。
4. 一連の処理の流れ(内側)
次は、内側の四角です。
でも、このまま処理を同じように回すとhard codingになってしまいますね?なので、SRとSCを1つ足して内側に寄せます。また、ECとERを1つ足して内側に寄せることによって1~5で作ったものを再利用することができます!ECOですね〜笑
#内側の正方形の処理 sr += 1 er -= 1 sc += 1 ec -= 1以下からは、画像とコードでの説明を省略致します。
トップロウ([13, 14])をカラム用のポインターで取得します
こちらも同様に、普段使われているfor loopの仕方でできますね。ECが指しているカラムをERまでロウ用のポインターで取得します。(ここでは、[15]ですね。)
ボトムロウ([16])を逆方向にカラム用のポインターで取得します。
ここは、reverseというbuilt-in function を使って逆方向のfor loop を実装します。最後に、SRがERと等しくなるのでrangeが0になり何も取得できないようになります。
完成コード
array_traversal.pydef spiralTraverse(array): result = [] sr, er = 0, len(array) - 1 sc, ec = 0, len(array[0]) - 1 while sr <= er and sc <= ec: for col in range(sc, ec + 1): result.append(array[sr][col]) for row in range(sr + 1, er + 1): result.append(array[row][ec]) for col in reversed(range(sc, ec)): result.append(array[er][col]) for row in reversed(range(sr + 1, er)): result.append(array[row][sr]) sr += 1 er -= 1 sc += 1 ec -= 1 return result終わりに
あくまで、1つの考え方なので、他にも解答方法はいくつもあります。例えば、再帰法を使った処理など。
注意点として、エッジケースをここでは考慮していないのでそこは問題に合わせて対応してください。長くなりましたが、以上となります!お疲れ様でした!
LGTM よろしくお願いします!






- 投稿日:2021-01-20T20:58:36+09:00
PySImpleGUIでファイルの更新履歴や簡単なリリースノートを作成するGUI
はじめに
仕事ではチーム開発などはなく、個人でコードを作成することが多いので、
いままでほとんどコードの更新履歴やリリースノートを書いたことがありませんでした。
(リリースしてないのでリリースノートを書いたことがない)ふとリリース前にバージョン管理はしっかりしておいた方がいいと思い立ちました。
GitHubをローカルで使う方法もありますが、
使うOSがばらばらで使い方を覚えるのも億劫だったので、
簡易的なバージョン管理ツールを作るに至りました。開発環境
Windows10
PySImpleGUI 4.29.0
Python 3.7.6
pyinstaller(exe化で使用) 4.1GUI
GUIは以下のようになります。今回はテーマがLightBrown3です。
更新履歴は事細かに記載する予定なので、リリースより細かい更新が入ります。
そのため、同じファイル名で二度以上更新する場合もありますので、
更新時間をファイル名に追加し、更新したファイルを別のフォルダにコピーします。
それにより、テキストの履歴と実際のファイルの紐づけを取ります。リリースノートの「タイトル」は、なんとなく変更の概要が書けるようにしました。
[更新] … 履歴保存時の時間を更新します。(※押し忘れ防止のために5分おきの自動更新を追加予定)
[選択] … 更新対象のファイルを選択します。
[反映] … 更新履歴をhistory.txtに書き込みます。開発者が具体的に変更点がわかるように書きます。
同時に、更新時間をファイル名に追加した更新対象ファイルをhistoryフォルダにコピーします。
[書き込み] … release.txtにアップデート内容を書き込みます。ユーザーに分かりやすい言葉で書きます。コード
以下コードです。
make_note_app.pyimport PySimpleGUI as sg import datetime import os import shutil class MainDisp: def __init__(self,now): sg.theme("LightBrown3") #好きなテーマ設定 self.layout = [ [sg.Text(text="更新時間"), sg.Input(default_text=now, size=(20,1), key=("-TIME-"), use_readonly_for_disable=True), sg.Button(button_text="更新", key=("-UPDATE-"))], [sg.Text(text="ファイル"), sg.InputText(size=(50,1), key='-FILE-'), sg.FileBrowse("選択", target=("-FILE-"))], [sg.Text(text="更新履歴")], [sg.Multiline(size=(200,5), key=("-HIST-"))], [sg.Button(button_text="反映", key=("-HANEI-"))], [sg.Text(text="リリースノート")], [sg.Text(text="タイトル"), sg.Input(size=(50,1), key=("-TITLE-"))], [sg.Multiline(size=(200,5), key=("-RELEASE-"))], [sg.Button(button_text="書き込み", key=("-WRITE-"))] ] self.window = sg.Window(title="MakeReleaseNote", layout=self.layout, size=(500,400)) def writefile(self,type): time = self.window["-TIME-"].get() filename = self.window["-FILE-"].get() #更新履歴ver if type == "history": hist = self.window["-HIST-"].get() path = "../history.txt" if os.path.exists(path): ''' 更新した情報をファイルの上部に書き込みたいので、 一度ファイルの中身を全部読んでから、頭に新しい情報を付け足して再度書き込む ''' with open(path,"r") as f: all = f.read() write = "更新時間:{}\n更新ファイル:{}\n変更内容:\n{}\n".format( time,os.path.basename(filename),hist) + all else: write = "更新時間:{}\n更新ファイル:{}\n変更内容:\n{}\n".format( time,os.path.basename(filename),hist) #更新したファイルをhistoryフォルダにコピー #ただしファイル名に時刻を反映するために一回形を整え直す s_time = datetime.datetime.strptime(time,"%y/%m/%d %H:%M:%S") shutil.copy2(filename,"../history/"+ s_time.strftime("%y%m%d_%H%M%S_")+os.path.basename(filename)) #リリースノートver elif type == "release": hist = self.window["-RELEASE-"].get() title = self.window["-TITLE-"].get() path = "../release.txt" ''' 更新した情報をファイルの上部に書き込みたいので、 一度ファイルの中身を全部読んでから、頭に新しい情報を付け足して再度書き込む ''' if os.path.exists(path): with open(path,"r") as f: all = f.read() write = "File:{}\nTitle:{}\nComment:\n{}\n".format( os.path.basename(filename),title,hist) + all else: write = "File:{}\nTitle:{}\nComment:\n{}\n".format( os.path.basename(filename),title,hist) with open(path,"w") as f: f.write(write) def main(self): while True: event, values = self.window.read() if event == None: #closeボタン break elif event == "-UPDATE-": #時刻更新ボタン self.window["-TIME-"].update(gettimenow()) elif event == "-HANEI-": #更新履歴反映ボタン self.writefile("history") elif event == "-WRITE-": #リリースノート書き込みボタン self.writefile("release") self.window.close() #現在時刻をstrで返す関数 def gettimenow(): time = datetime.datetime.now() return time.strftime("%y/%m/%d %H:%M:%S") if __name__ == "__main__": maindisp = MainDisp(gettimenow()) maindisp.main()出力ファイル
更新履歴のテキストファイルはこのように最新の情報が上部に記載されます。
historyフォルダ内は上記の履歴の更新時間と同じ時刻で
更新されたファイルの名前が変更され、コピーされています。
リリースノートのテキストファイルは下記のようになります。
タイトルがある分、ちょっと体裁が違います。
リリースノートでは本来ファイル名にバージョンを付与した状態で作成する予定だったので、
更新時間は記載していません。ファイル名が更新時間のようなものです。
(下記の例ではファイル名を同じにしてしまったのでわかりにくいですが…)
おまけ:exe化
pyinstallerをインストールします。
pip install pyinstaller--noconsoleを入れると起動時にコンソールがでません。
pyinstaller [exe化したいファイルのパス] --noconsoleexe化するとdistと言うフォルダの中に、ファイル名と同じフォルダが作成されます。
その中に、ずらっと必要なファイルがあり、そこにexeも存在します。本来の位置からずれたディレクトリに作成されるので、
相対パスを使用していた場合エラーになりますのでご注意ください。相対パスでなければならない場合は、exeと同じディレクトリにあるファイル全てをコピーして、
あってほしい場所に展開すれば実行可能になります。
exeだけの移動ではだめです。私はアプリ自体がどこにおいても使えるように汎用的であってほしかったので、
絶対パスに書き換えるのではなく、相対パスのまま環境を移動させました。おわりに
GitHubなどちゃんとバージョン管理している人にはこんなもの関係ないですが、
何が言いたいかと言うと、このくらいのことならPySImpleGUIでならすぐにできるということです。
思いついたことをすぐに実現できる、PythonとPySImpleGUIの組み合わせは本当におすすめです。




- 投稿日:2021-01-20T20:58:36+09:00
PySImpleGUIでファイルの更新履歴や簡単なリリースノートを作成
はじめに
仕事ではチーム開発などはなく、個人でコードを作成することが多いので、
いままでほとんどコードの更新履歴やリリースノートを書いたことがありませんでした。
(リリースしてないのでリリースノートを書いたことがない)ふとリリース前にバージョン管理はしっかりしておいた方がいいと思い立ちました。
GitHubをローカルで使う方法もありますが、
使うOSがばらばらで使い方を覚えるのも億劫だったので、
簡易的なバージョン管理ツールを作るに至りました。開発環境
Windows10
PySImpleGUI 4.29.0
Python 3.7.6
pyinstaller(exe化で使用) 4.1GUI
GUIは以下のようになります。今回はテーマがLightBrown3です。
更新履歴は事細かに記載する予定なので、リリースより細かい更新が入ります。
そのため、同じファイル名で二度以上更新する場合もありますので、
更新時間をファイル名に追加し、更新したファイルを別のフォルダにコピーします。
それにより、テキストの履歴と実際のファイルの紐づけを取ります。リリースノートの「タイトル」は、なんとなく変更の概要が書けるようにしました。
[更新]
履歴保存時の時間を更新します。
(※押し忘れ防止のために5分おきの自動更新を追加予定)[選択]
更新対象のファイルを選択します。[反映]
更新履歴をhistory.txtに書き込みます。
開発者が具体的に変更点がわかるように書きます。
同時に、更新時間をファイル名に追加した更新対象ファイルを
historyフォルダにコピーします。[書き込み]
release.txtにアップデート内容を書き込みます。
ユーザーに分かりやすい言葉で書きます。コード
以下コードです。
make_note_app.pyimport PySimpleGUI as sg import datetime import os import shutil class MainDisp: def __init__(self,now): sg.theme("LightBrown3") #好きなテーマ設定 self.layout = [ [sg.Text(text="更新時間"), sg.Input(default_text=now, size=(20,1), key=("-TIME-"), use_readonly_for_disable=True), sg.Button(button_text="更新", key=("-UPDATE-"))], [sg.Text(text="ファイル"), sg.InputText(size=(50,1), key='-FILE-'), sg.FileBrowse("選択", target=("-FILE-"))], [sg.Text(text="更新履歴")], [sg.Multiline(size=(200,5), key=("-HIST-"))], [sg.Button(button_text="反映", key=("-HANEI-"))], [sg.Text(text="リリースノート")], [sg.Text(text="タイトル"), sg.Input(size=(50,1), key=("-TITLE-"))], [sg.Multiline(size=(200,5), key=("-RELEASE-"))], [sg.Button(button_text="書き込み", key=("-WRITE-"))] ] self.window = sg.Window(title="MakeReleaseNote", layout=self.layout, size=(500,400)) def writefile(self,type): time = self.window["-TIME-"].get() filename = self.window["-FILE-"].get() #更新履歴ver if type == "history": hist = self.window["-HIST-"].get() path = "../history.txt" if os.path.exists(path): ''' 更新した情報をファイルの上部に書き込みたいので、 一度ファイルの中身を全部読んでから、頭に新しい情報を付け足して再度書き込む ''' with open(path,"r") as f: all = f.read() write = "更新時間:{}\n更新ファイル:{}\n変更内容:\n{}\n".format( time,os.path.basename(filename),hist) + all else: write = "更新時間:{}\n更新ファイル:{}\n変更内容:\n{}\n".format( time,os.path.basename(filename),hist) #更新したファイルをhistoryフォルダにコピー #ただしファイル名に時刻を反映するために一回形を整え直す s_time = datetime.datetime.strptime(time,"%y/%m/%d %H:%M:%S") shutil.copy2(filename,"../history/"+ s_time.strftime("%y%m%d_%H%M%S_")+os.path.basename(filename)) #リリースノートver elif type == "release": hist = self.window["-RELEASE-"].get() title = self.window["-TITLE-"].get() path = "../release.txt" ''' 更新した情報をファイルの上部に書き込みたいので、 一度ファイルの中身を全部読んでから、頭に新しい情報を付け足して再度書き込む ''' if os.path.exists(path): with open(path,"r") as f: all = f.read() write = "File:{}\nTitle:{}\nComment:\n{}\n".format( os.path.basename(filename),title,hist) + all else: write = "File:{}\nTitle:{}\nComment:\n{}\n".format( os.path.basename(filename),title,hist) with open(path,"w") as f: f.write(write) def main(self): while True: event, values = self.window.read() if event == None: #closeボタン break elif event == "-UPDATE-": #時刻更新ボタン self.window["-TIME-"].update(gettimenow()) elif event == "-HANEI-": #更新履歴反映ボタン self.writefile("history") elif event == "-WRITE-": #リリースノート書き込みボタン self.writefile("release") self.window.close() #現在時刻をstrで返す関数 def gettimenow(): time = datetime.datetime.now() return time.strftime("%y/%m/%d %H:%M:%S") if __name__ == "__main__": maindisp = MainDisp(gettimenow()) maindisp.main()出力ファイル
更新履歴のテキストファイルはこのように最新の情報が上部に記載されます。
historyフォルダ内は上記の履歴の更新時間と同じ時刻で
更新されたファイルの名前が変更され、コピーされています。
リリースノートのテキストファイルは下記のようになります。
タイトルがある分、ちょっと体裁が違います。
リリースノートでは本来ファイル名にバージョンを付与した状態で作成する予定だったので、
更新時間は記載していません。ファイル名が更新時間のようなものです。
(下記の例ではファイル名を同じにしてしまったのでわかりにくいですが…)
おまけ:exe化
pyinstallerをインストールします。
pip install pyinstaller--noconsoleを入れると起動時にコンソールがでません。
pyinstaller [exe化したいファイルのパス] --noconsoleexe化するとdistと言うフォルダの中に、ファイル名と同じフォルダが作成されます。
その中に、ずらっと必要なファイルがあり、そこにexeも存在します。本来の位置からずれたディレクトリに作成されるので、
相対パスを使用していた場合エラーになりますのでご注意ください。相対パスでなければならない場合は、exeと同じディレクトリにあるファイル全てをコピーして、
あってほしい場所に展開すれば実行可能になります。
exeだけの移動ではだめです。私はアプリ自体がどこにおいても使えるように汎用的であってほしかったので、
絶対パスに書き換えるのではなく、相対パスのまま環境を移動させました。おわりに
GitHubなどちゃんとバージョン管理している人にはこんなもの関係ないですが、
何が言いたいかと言うと、このくらいのことならPySImpleGUIでならすぐにできるということです。
思いついたことをすぐに実現できる、PythonとPySImpleGUIの組み合わせは本当におすすめです。
- 投稿日:2021-01-20T20:50:20+09:00
長野県の市町村別コロナ発生状況をグラフで見れるサイトの作成(コード付き)
自分
経理屋です。35才から趣味でpythonを始めて3年が経ちました。最近は徐々にwebアプリなんかも作れるようになってきてすごく楽しいです。よろしくお願いします。
まだまだ未熟ですが、誰かの役に立てばいいなと思って記事を書いてみました。とっかかり
ここ最近まで長野県は新型コロナの発生が少なかったんですが、最近になってかなり増えてきました。出かける時もどこに出かければいいか少々不安です。
そんなタイミングで長野県のホームページにコロナ発生状況のCSVデータが公開されているのを見つけたので(今さら)グラフで見れるサイトを作って見ました。
出来上がりはこちら →covid19 in nagano全体イメージ
手順
目次
- データ確認
- streamlitでアプリケーション作成
- herokuへアップ
- GASでherokuを起こす設定
番外編: 継続管理
1.データ確認
下記リンクに長野県内のコロナ発生状況がアップされているので、お手軽にgoogle colaboratoryで内容を確認します。
今回は最終的にstreamlitでアプリを作成するので、データ分析に使ったpythonコードはstreamlit用のファイルでも使います。
import pandas as pddf = pd.read_csv('https://www.pref.nagano.lg.jp/hoken-shippei/kenko/kenko/kansensho/joho/documents/200000_nagano_covid19_patients.csv', encoding='cp932', header=1) df.head()
いろんな項目がありますが、必要なデータだけに絞り込みます。
項目名をわかりやすい名前に変更します。
ついでに日付のデータ型をdatetimeに変換します。df.columnsdf = df[['No', '事例確定_年月日', '患者_居住地', '備考']] df.rename(columns={'事例確定_年月日': '日付', '患者_居住地': '市町村'}, inplace=True) df['日付'] = pd.to_datetime(df['日付']) df.head(10)
東京に住んでて長野で発症したみたいな人は居住地が東京で備考に県内の市町村名が記載されているので、そういった人については市町村を「帰省先:」の後の文字列に変換します。
def change_location(x): if str(x['備考'])[:3] == '帰省先': x['市町村'] = str(x['備考']).replace('帰省先:', '') return x df = df.apply(change_location, axis=1) df.head(10)
変換された市町村を見ると、まだ市町村名でないものが含まれているので、仕方ないので手作業でリストを作って市町村名のものだけ抽出します。それ以外のものは「その他」に変換します。
市町村名も'南箕輪村'だったり'上伊那郡南箕輪村'だったり'上伊那郡\r\n南箕輪村'だったりしているので、バシッと1本に統一します。
また、このリストに含まれていない市町村もあるので、たまにそういった市町村が新たに出てきていないか確認してリストを更新してやる必要があります。
この辺は少し大変です。もっといいアイデアがあれば教えて欲しいです。df['市町村'].unique()towns = ['長野市', '山ノ内町', '上田市', '松本市', '筑北村', '安曇野市', '佐久穂町', '諏訪市', '須坂市', '南箕輪村', '小諸市', '飯田市', '中野市', '軽井沢町', '御代田町', '坂城町', '大町市', '岡谷市', '生坂村', '佐久市', '東御市', '千曲市', '長和町', '茅野市', '青木村', '原村', '飯山市', '信濃町', '富士見町', '下諏訪町', '伊那市', '栄村', '木島平村', '小布施町', '立科町', '宮田村', '塩尻市', '上伊那郡南箕輪村', '南佐久郡川上村', '駒ヶ根市', '野沢温泉村', '木曽町', '飯綱町', '飯島町', '辰野町', '南木曽町', '白馬村', '髙山村', '箕輪町', '小谷村', '上松町', '天龍村', '高森町', '中川村', '朝日村', '山形村', '池田町', '下條村', '北佐久郡御代田町', '上伊那郡\r\n南箕輪村', '下高井郡\r\n野沢温泉村', '阿南町', '駒ケ根市', '小川村', '喬木村', '松川町'] def change_towns(x): if x['市町村'] not in towns: x['市町村'] = 'その他' return x df = df.apply(change_towns, axis=1) df['市町村'] = df['市町村'].str.replace('上伊那郡南箕輪村', '南箕輪村') df['市町村'] = df['市町村'].str.replace('上伊那郡\r\n南箕輪村', '南箕輪村') df['市町村'] = df['市町村'].str.replace('下高井郡\r\n野沢温泉村', '野沢温泉村') df['市町村'] = df['市町村'].str.replace('南佐久郡川上村', '川上村') df['市町村'] = df['市町村'].str.replace('北佐久郡御代田町', '御代田町') df['市町村'].unique()
pivot_tableすると無事に市町村別の発生件数が集計されました。pivot_daily = df.pivot_table(index='日付', columns='市町村', values='No', aggfunc=len, dropna=False).fillna(0) pivot_daily.tail()
累計はcumsumです。pivot_daily_cum = df.pivot_table(index='日付', columns='市町村', values='No', aggfunc=len, dropna=False).fillna(0).cumsum() pivot_daily_cum.tail()
2.streamlitでアプリケーション作成
データが確認できたので、streamlitで実際のアプリケーションを作成します。
streamlitをインストールし、pythonファイルを作成します。streamlitの使い方に関しては私よりわかりやすく説明されている方がネット上に大勢いるのでそちらにお任せします。
またstreamlitは公式のtutorialが非常に充実しているので、そちらを一通りやるだけでわかった気になれます。大丈夫です。view.pyimport streamlit as st import plotly.express as px import pandas as pd import datetime df = pd.read_csv('https://www.pref.nagano.lg.jp/hoken-shippei/kenko/kenko/kansensho/joho/documents/200000_nagano_covid19_patients.csv', encoding='cp932', header=1) df = df[['No', '事例確定_年月日', '患者_居住地', '備考']] # 項目名を変更、日付のデータ型変更 df.rename(columns={'事例確定_年月日':'日付', '患者_居住地':'市町村'}, inplace=True) df['日付'] = pd.to_datetime(df['日付']) # 備考に「帰省先:」と入っているデータは市町村を変換 def change_location(x): if str(x['備考'])[:3] == '帰省先': x['市町村'] = str(x['備考']).replace('帰省先:', '') return x df = df.apply(change_location, axis=1) # 市町村欄に市町村名以外のものが入っていたら変換 towns = ['長野市', '山ノ内町', '上田市', '松本市', '筑北村', '安曇野市', '佐久穂町', '諏訪市', '須坂市', '南箕輪村', '小諸市', '飯田市', '中野市', '軽井沢町', '御代田町', '坂城町', '大町市', '岡谷市', '生坂村', '佐久市', '東御市', '千曲市', '長和町', '茅野市', '青木村', '原村', '飯山市', '信濃町', '富士見町', '下諏訪町', '伊那市', '栄村', '木島平村', '小布施町', '立科町', '宮田村', '塩尻市', '上伊那郡南箕輪村', '南佐久郡川上村', '駒ヶ根市', '野沢温泉村', '木曽町', '飯綱町', '飯島町', '辰野町', '南木曽町', '白馬村', '髙山村', '箕輪町', '小谷村', '上松町', '天龍村', '高森町', '中川村', '朝日村', '山形村', '池田町', '下條村', '北佐久郡御代田町', '上伊那郡\r\n南箕輪村', '下高井郡\r\n野沢温泉村', '阿南町', '駒ケ根市', '小川村', '喬木村', '松川町'] def change_towns(x): if x['市町村'] not in towns: x['市町村'] = 'その他' return x df = df.apply(change_towns, axis=1) df['市町村'] = df['市町村'].str.replace('上伊那郡南箕輪村', '南箕輪村') df['市町村'] = df['市町村'].str.replace('上伊那郡\r\n南箕輪村', '南箕輪村') df['市町村'] = df['市町村'].str.replace('下高井郡\r\n野沢温泉村', '野沢温泉村') df['市町村'] = df['市町村'].str.replace('南佐久郡川上村', '川上村') df['市町村'] = df['市町村'].str.replace('北佐久郡御代田町', '御代田町') # sidemenu st.sidebar.markdown( '# Covid-19 in Nagano' ) town_selected = st.sidebar.selectbox( "市町村", list(df['市町村'].unique()), 1 # デフォルトではリスト番号1の'長野市'を表示 ) st.sidebar.markdown( '「その他」には、「松本保健所管内」や「東京都」などの、市町村名でない表記のものが含まれます。' ) today = datetime.date.today() start_date = st.sidebar.date_input('開始日', df['日付'].min()) end_date = st.sidebar.date_input('終了日', today) if start_date < end_date: st.sidebar.success('OK') else: st.sidebar.error('Error:終了日は開始日より後の日付にしてください。') df = df[df['日付'].between(pd.to_datetime(start_date), pd.to_datetime(end_date))] # body # 1日あたり発生件数グラフ st.markdown( '# 市町村別発生件数(日付別)' ) st.markdown( 'チャートをドラッグすると拡大できます。' ) pivot_daily = df.pivot_table(index='日付', columns='市町村', values='No', aggfunc=len, dropna=False).fillna(0) st.write( px.bar(pivot_daily, x=pivot_daily.index, y=town_selected) ) # 発生件数累計推移のグラフ st.markdown( '# 市町村別発生件数(累計)' ) pivot_daily_cum = df.pivot_table(index='日付', columns='市町村', values='No', aggfunc=len, dropna=False).fillna(0).cumsum() st.write( px.area(pivot_daily_cum, x=pivot_daily_cum.index, y=town_selected) ) # 市町村別累計発生件数の全市町村比較 st.markdown( '# 市町村別発生件数(累計, 全市町村比較)' ) data_span = st.radio( "集計期間", ('直近30日', '全期間') ) if data_span == '直近30日': df = df[df['日付'] >= str(today - datetime.timedelta(days=30))] town_cum = pd.DataFrame(df.groupby('市町村')['No'].count().sort_values()) town_cum.rename(columns={'No':'発生件数累計'}, inplace=True) st.write( px.bar(town_cum, x='発生件数累計', y=town_cum.index, orientation='h', height=1500, hover_data=['発生件数累計', town_cum.index]) )Terminalでview.pyのあるディレクトリにcdしてrunするとアプリケーションが立ち上がります。
$ streamlit run view.py3.herokuへアップ
herokuへのアップする方法は全然わからなかったので、下記のサイト様を参考にさせていただきました。
→【簡単爆速第2弾】Streamlitをherokuにデプロイ
他にも色々なサイト様を見せていただいたんですが覚えていません。すみません。よくわかっていませんが、下記の手順でやったら動きました。
・必要なディレクトリとファイルを自分のPC内に準備
Porocfileweb: sh setup.sh && streamlit run view.pyrequirements.txtstreamlit==0.74.1 plotly==4.14.3 pandas※下記のメールアドレス部分はご自分のものに変更してください。
setup.shmkdir -p ~/.streamlit/ echo "\ [general]\n\ email = \"mailaddress@dmain.com\"\n\ " > ~/.streamlit/credentials.toml echo "\ [server]\n\ headless = true\n\ enableCORS=false\n\ port = $PORT\n\ " > ~/.streamlit/config.toml・herokuにアカウント作成
・Terminalを立ち上げて下記を実行
※appnameの部分は自分の好きなアプリ名に変えてください。$ heroku login $ heroku create appname $ git init $ heroku git:remote -a sample $ heroku buildpacks:set heroku/python $ git add . $ git commit -m "1st commit" $ git push heroku master $ heroku open上手くいっていればこれでCSVをグラフ化したページが見れると思います。
間違えてたらすみません。4.GASでherokuを起こす設定
herokuは30分間何も実行されないと自動的にスリープになってしまい、次の立ち上がりの時に時間がかかってしまうようです。そこで定期的にherokuにアクセスしてherokuをスリープさせないようにしました。
いろんなやり方があるようですが、自分はherokuにクレジット登録をしないでおこうと思ったのでGASを選びました。「GAS heroku」で検索すると、非常に丁寧に説明してくれているサイトがたくさん出てきました。ありがたや。継続管理
データ分析の中で少し触れましたが、今回のプロジェクトでは市町村のリスト(towns)を手で作成して使っています。なのでこの先townsに入っていない市町村名がCSVに入力されてくるとグラフ用の集計から漏れてしまいます。
そのためどうしても手作業で市町村名の漏れがないかどうかの確認が必要になってしまいます。めんどいですね。
1/20の例だと、早速松川町が新たに出てきてました。import pandas as pd towns = ['長野市', '山ノ内町', '上田市', '松本市', '筑北村', '安曇野市', '佐久穂町', '諏訪市', '須坂市', '南箕輪村', '小諸市', '飯田市', '中野市', '軽井沢町', '御代田町', '坂城町', '大町市', '岡谷市', '生坂村', '佐久市', '東御市', '千曲市', '長和町', '茅野市', '青木村', '原村', '飯山市', '信濃町', '富士見町', '下諏訪町', '伊那市', '栄村', '木島平村', '小布施町', '立科町', '宮田村', '塩尻市', '上伊那郡南箕輪村', '南佐久郡川上村', '駒ヶ根市', '野沢温泉村', '木曽町', '飯綱町', '飯島町', '辰野町', '南木曽町', '白馬村', '髙山村', '箕輪町', '小谷村', '上松町', '天龍村', '高森町', '中川村', '朝日村', '山形村', '池田町', '下條村', '北佐久郡御代田町', '上伊那郡\r\n南箕輪村', '下高井郡\r\n野沢温泉村', '阿南町', '駒ケ根市', '小川村', '喬木村'] df = pd.read_csv('https://www.pref.nagano.lg.jp/hoken-shippei/kenko/kenko/kansensho/joho/documents/200000_nagano_covid19_patients.csv', encoding='cp932', header=1) df[~df['患者_居住地'].isin(towns)]['患者_居住地'].unique()
目視で漏れを確認
↓
手元でview.pyを編集してherokuにpush
もしくはherokuで直接編集でしょうか?
自分は前者でやってます。終わりに
今回は長野県のCSVデータでやってますが、他県でも似たようなデータを公開している(そして自動的に毎日更新されていく)ものがあれば今回の手順がすぐに応用できると思います。
たいしたコードではないですがもし参考になる部分があれば使って、他県のグラフも作っていただければと思います。
そして今より少しでも世の中便利になっていけばいいなと思います。また、自分は独学で勉強してきたので、もっといいやり方あるよとかここのコードはこう書いた方がいいよとかありましたら教えていただけるとありがたいです。よろしくお願いします。
終わり。










- 投稿日:2021-01-20T20:50:20+09:00
streamlitとherokuで市町村別コロナ発生状況グラフをリリース
自分
経理屋です。35才から趣味でpythonを始めて3年が経ちました。最近は徐々にwebアプリなんかも作れるようになってきてすごく楽しいです。よろしくお願いします。
まだまだ未熟ですが、誰かの役に立つかなーと思って記事を書いてみました。とっかかり
ここ最近まで長野県は新型コロナの発生が少なかったんですが、最近になってかなり増えてきました。出かける時もどこに出かければいいか少々不安です。
そんなタイミングで長野県のホームページにコロナ発生状況のCSVデータが公開されているのを見つけたので(今さら)グラフで見れるサイトを作って見ました。
出来上がりはこちら →covid19 in nagano全体イメージ
手順
目次
- データ確認
- streamlitでアプリケーション作成
- herokuへアップ
- GASでherokuを起こす設定
番外編: 継続管理
1.データ確認
下記リンクに長野県内のコロナ発生状況がアップされているので、お手軽にgoogle colaboratoryで内容を確認します。
今回は最終的にstreamlitでアプリを作成するので、データ分析に使ったpythonコードはstreamlit用のファイルでも使います。
import pandas as pddf = pd.read_csv('https://www.pref.nagano.lg.jp/hoken-shippei/kenko/kenko/kansensho/joho/documents/200000_nagano_covid19_patients.csv', encoding='cp932', header=1) df.head()
いろんな項目がありますが、必要なデータだけに絞り込みます。
項目名をわかりやすい名前に変更します。
ついでに日付のデータ型をdatetimeに変換します。df.columnsdf = df[['No', '事例確定_年月日', '患者_居住地', '備考']] df.rename(columns={'事例確定_年月日': '日付', '患者_居住地': '市町村'}, inplace=True) df['日付'] = pd.to_datetime(df['日付']) df.head(10)
東京に住んでて長野で発症したみたいな人は居住地が東京で備考に県内の市町村名が記載されているので、そういった人については市町村を「帰省先:」の後の文字列に変換します。
def change_location(x): if str(x['備考'])[:3] == '帰省先': x['市町村'] = str(x['備考']).replace('帰省先:', '') return x df = df.apply(change_location, axis=1) df.head(10)
変換された市町村を見ると、まだ市町村名でないものが含まれているので、仕方ないので手作業でリストを作って市町村名のものだけ抽出します。それ以外のものは「その他」に変換します。
市町村名も'南箕輪村'だったり'上伊那郡南箕輪村'だったり'上伊那郡\r\n南箕輪村'だったりしているので、バシッと1本に統一します。
また、このリストに含まれていない市町村もあるので、たまにそういった市町村が新たに出てきていないか確認してリストを更新してやる必要があります。
この辺は少し大変です。もっといいアイデアがあれば教えて欲しいです。df['市町村'].unique()towns = ['長野市', '山ノ内町', '上田市', '松本市', '筑北村', '安曇野市', '佐久穂町', '諏訪市', '須坂市', '南箕輪村', '小諸市', '飯田市', '中野市', '軽井沢町', '御代田町', '坂城町', '大町市', '岡谷市', '生坂村', '佐久市', '東御市', '千曲市', '長和町', '茅野市', '青木村', '原村', '飯山市', '信濃町', '富士見町', '下諏訪町', '伊那市', '栄村', '木島平村', '小布施町', '立科町', '宮田村', '塩尻市', '上伊那郡南箕輪村', '南佐久郡川上村', '駒ヶ根市', '野沢温泉村', '木曽町', '飯綱町', '飯島町', '辰野町', '南木曽町', '白馬村', '髙山村', '箕輪町', '小谷村', '上松町', '天龍村', '高森町', '中川村', '朝日村', '山形村', '池田町', '下條村', '北佐久郡御代田町', '上伊那郡\r\n南箕輪村', '下高井郡\r\n野沢温泉村', '阿南町', '駒ケ根市', '小川村', '喬木村', '松川町'] def change_towns(x): if x['市町村'] not in towns: x['市町村'] = 'その他' return x df = df.apply(change_towns, axis=1) df['市町村'] = df['市町村'].str.replace('上伊那郡南箕輪村', '南箕輪村') df['市町村'] = df['市町村'].str.replace('上伊那郡\r\n南箕輪村', '南箕輪村') df['市町村'] = df['市町村'].str.replace('下高井郡\r\n野沢温泉村', '野沢温泉村') df['市町村'] = df['市町村'].str.replace('南佐久郡川上村', '川上村') df['市町村'] = df['市町村'].str.replace('北佐久郡御代田町', '御代田町') df['市町村'].unique()
pivot_tableすると無事に市町村別の発生件数が集計されました。pivot_daily = df.pivot_table(index='日付', columns='市町村', values='No', aggfunc=len, dropna=False).fillna(0) pivot_daily.tail()
累計はcumsumです。pivot_daily_cum = df.pivot_table(index='日付', columns='市町村', values='No', aggfunc=len, dropna=False).fillna(0).cumsum() pivot_daily_cum.tail()
2.streamlitでアプリケーション作成
データが確認できたので、streamlitで実際のアプリケーションを作成します。
streamlitをインストールし、pythonファイルを作成します。streamlitの使い方に関しては私よりわかりやすく説明されている方がネット上に大勢いるのでそちらにお任せします。
またstreamlitは公式のtutorialが非常に充実しているので、そちらを一通りやるだけでわかった気になれます。大丈夫です。view.pyimport streamlit as st import plotly.express as px import pandas as pd import datetime df = pd.read_csv('https://www.pref.nagano.lg.jp/hoken-shippei/kenko/kenko/kansensho/joho/documents/200000_nagano_covid19_patients.csv', encoding='cp932', header=1) df = df[['No', '事例確定_年月日', '患者_居住地', '備考']] # 項目名を変更、日付のデータ型変更 df.rename(columns={'事例確定_年月日':'日付', '患者_居住地':'市町村'}, inplace=True) df['日付'] = pd.to_datetime(df['日付']) # 備考に「帰省先:」と入っているデータは市町村を変換 def change_location(x): if str(x['備考'])[:3] == '帰省先': x['市町村'] = str(x['備考']).replace('帰省先:', '') return x df = df.apply(change_location, axis=1) # 市町村欄に市町村名以外のものが入っていたら変換 towns = ['長野市', '山ノ内町', '上田市', '松本市', '筑北村', '安曇野市', '佐久穂町', '諏訪市', '須坂市', '南箕輪村', '小諸市', '飯田市', '中野市', '軽井沢町', '御代田町', '坂城町', '大町市', '岡谷市', '生坂村', '佐久市', '東御市', '千曲市', '長和町', '茅野市', '青木村', '原村', '飯山市', '信濃町', '富士見町', '下諏訪町', '伊那市', '栄村', '木島平村', '小布施町', '立科町', '宮田村', '塩尻市', '上伊那郡南箕輪村', '南佐久郡川上村', '駒ヶ根市', '野沢温泉村', '木曽町', '飯綱町', '飯島町', '辰野町', '南木曽町', '白馬村', '髙山村', '箕輪町', '小谷村', '上松町', '天龍村', '高森町', '中川村', '朝日村', '山形村', '池田町', '下條村', '北佐久郡御代田町', '上伊那郡\r\n南箕輪村', '下高井郡\r\n野沢温泉村', '阿南町', '駒ケ根市', '小川村', '喬木村', '松川町'] def change_towns(x): if x['市町村'] not in towns: x['市町村'] = 'その他' return x df = df.apply(change_towns, axis=1) df['市町村'] = df['市町村'].str.replace('上伊那郡南箕輪村', '南箕輪村') df['市町村'] = df['市町村'].str.replace('上伊那郡\r\n南箕輪村', '南箕輪村') df['市町村'] = df['市町村'].str.replace('下高井郡\r\n野沢温泉村', '野沢温泉村') df['市町村'] = df['市町村'].str.replace('南佐久郡川上村', '川上村') df['市町村'] = df['市町村'].str.replace('北佐久郡御代田町', '御代田町') # sidemenu st.sidebar.markdown( '# Covid-19 in Nagano' ) town_selected = st.sidebar.selectbox( "市町村", list(df['市町村'].unique()), 1 # デフォルトではリスト番号1の'長野市'を表示 ) st.sidebar.markdown( '「その他」には、「松本保健所管内」や「東京都」などの、市町村名でない表記のものが含まれます。' ) today = datetime.date.today() start_date = st.sidebar.date_input('開始日', df['日付'].min()) end_date = st.sidebar.date_input('終了日', today) if start_date < end_date: st.sidebar.success('OK') else: st.sidebar.error('Error:終了日は開始日より後の日付にしてください。') df = df[df['日付'].between(pd.to_datetime(start_date), pd.to_datetime(end_date))] # body # 1日あたり発生件数グラフ st.markdown( '# 市町村別発生件数(日付別)' ) st.markdown( 'チャートをドラッグすると拡大できます。' ) pivot_daily = df.pivot_table(index='日付', columns='市町村', values='No', aggfunc=len, dropna=False).fillna(0) st.write( px.bar(pivot_daily, x=pivot_daily.index, y=town_selected) ) # 発生件数累計推移のグラフ st.markdown( '# 市町村別発生件数(累計)' ) pivot_daily_cum = df.pivot_table(index='日付', columns='市町村', values='No', aggfunc=len, dropna=False).fillna(0).cumsum() st.write( px.area(pivot_daily_cum, x=pivot_daily_cum.index, y=town_selected) ) # 市町村別累計発生件数の全市町村比較 st.markdown( '# 市町村別発生件数(累計, 全市町村比較)' ) data_span = st.radio( "集計期間", ('直近30日', '全期間') ) if data_span == '直近30日': df = df[df['日付'] >= str(today - datetime.timedelta(days=30))] town_cum = pd.DataFrame(df.groupby('市町村')['No'].count().sort_values()) town_cum.rename(columns={'No':'発生件数累計'}, inplace=True) st.write( px.bar(town_cum, x='発生件数累計', y=town_cum.index, orientation='h', height=1500, hover_data=['発生件数累計', town_cum.index]) )Terminalでview.pyのあるディレクトリにcdしてrunするとアプリケーションが立ち上がります。
$ streamlit run view.py3.herokuへアップ
herokuへのアップする方法は全然わからなかったので、下記のサイト様を参考にさせていただきました。
→【簡単爆速第2弾】Streamlitをherokuにデプロイ
他にも色々なサイト様を見せていただいたんですが覚えていません。すみません。よくわかっていませんが、下記の手順でやったら動きました。
・必要なディレクトリとファイルを自分のPC内に準備
Porocfileweb: sh setup.sh && streamlit run view.pyrequirements.txtstreamlit==0.74.1 plotly==4.14.3 pandas※下記のメールアドレス部分はご自分のものに変更してください。
setup.shmkdir -p ~/.streamlit/ echo "\ [general]\n\ email = \"mailaddress@dmain.com\"\n\ " > ~/.streamlit/credentials.toml echo "\ [server]\n\ headless = true\n\ enableCORS=false\n\ port = $PORT\n\ " > ~/.streamlit/config.toml・herokuにアカウント作成
・Terminalを立ち上げて下記を実行
※appnameの部分は自分の好きなアプリ名に変えてください。$ heroku login $ heroku create appname $ git init $ heroku git:remote -a sample $ heroku buildpacks:set heroku/python $ git add . $ git commit -m "1st commit" $ git push heroku master $ heroku open上手くいっていればこれでCSVをグラフ化したページが見れると思います。
間違えてたらすみません。4.GASでherokuを起こす設定
herokuは30分間何も実行されないと自動的にスリープになってしまい、次の立ち上がりの時に時間がかかってしまうようです。そこで定期的にherokuにアクセスしてherokuをスリープさせないようにしました。
いろんなやり方があるようですが、自分はherokuにクレジット登録をしないでおこうと思ったのでGASを選びました。「GAS heroku」で検索すると、非常に丁寧に説明してくれているサイトがたくさん出てきました。ありがたや。継続管理
データ分析の中で少し触れましたが、今回のプロジェクトでは市町村のリスト(towns)を手で作成して使っています。なのでこの先townsに入っていない市町村名がCSVに入力されてくるとグラフ用の集計から漏れてしまいます。
そのためどうしても手作業で市町村名の漏れがないかどうかの確認が必要になってしまいます。めんどいですね。
1/20の例だと、早速松川町が新たに出てきてました。import pandas as pd towns = ['長野市', '山ノ内町', '上田市', '松本市', '筑北村', '安曇野市', '佐久穂町', '諏訪市', '須坂市', '南箕輪村', '小諸市', '飯田市', '中野市', '軽井沢町', '御代田町', '坂城町', '大町市', '岡谷市', '生坂村', '佐久市', '東御市', '千曲市', '長和町', '茅野市', '青木村', '原村', '飯山市', '信濃町', '富士見町', '下諏訪町', '伊那市', '栄村', '木島平村', '小布施町', '立科町', '宮田村', '塩尻市', '上伊那郡南箕輪村', '南佐久郡川上村', '駒ヶ根市', '野沢温泉村', '木曽町', '飯綱町', '飯島町', '辰野町', '南木曽町', '白馬村', '髙山村', '箕輪町', '小谷村', '上松町', '天龍村', '高森町', '中川村', '朝日村', '山形村', '池田町', '下條村', '北佐久郡御代田町', '上伊那郡\r\n南箕輪村', '下高井郡\r\n野沢温泉村', '阿南町', '駒ケ根市', '小川村', '喬木村'] df = pd.read_csv('https://www.pref.nagano.lg.jp/hoken-shippei/kenko/kenko/kansensho/joho/documents/200000_nagano_covid19_patients.csv', encoding='cp932', header=1) df[~df['患者_居住地'].isin(towns)]['患者_居住地'].unique()
目視で漏れを確認
↓
手元でview.pyを編集してherokuにpush
もしくはherokuで直接編集でしょうか?
自分は前者でやってます。終わりに
今回は長野県のCSVデータでやってますが、他県でも似たようなデータを公開している(そして自動的に毎日更新されていく)ものがあれば今回の手順がすぐに応用できると思います。
たいしたコードではないですがもし参考になる部分があれば使って、他県のグラフも作っていただければと思います。
そして今より少しでも世の中便利になっていけばいいなと思います。また、自分は独学で勉強してきたので、もっといいやり方あるよとかここのコードはこう書いた方がいいよとかありましたら教えていただけるとありがたいです。よろしくお願いします。
終わり。
- 投稿日:2021-01-20T19:49:15+09:00
manimの作法 その23
概要
manimの作法、調べてみた。
VectorScene使ってみた。サンプルコード
from manimlib.imports import * class test(VectorScene): def construct(self): two_dot = TexMobject("2\\cdot") equals = TexMobject("=") self.add_axes() v = self.add_vector([3, 1]) v_coords, vx_line, vy_line = self.vector_to_coords(v, clean_up = False) self.play(ApplyMethod(v_coords.to_edge, UP)) two_dot.next_to(v_coords, LEFT) equals.next_to(v_coords, RIGHT) two_v = self.add_vector([6, 2], animate = False) self.remove(two_v) self.play(Transform(v.copy(), two_v), Write(two_dot, run_time = 1)) two_v_coords, two_v_x_line, two_v_y_line = self.vector_to_coords(two_v, clean_up = False) self.play(ApplyMethod(two_v_coords.next_to, equals, RIGHT),Write(equals, run_time = 1)) self.wait(2) x, y = v_coords.get_mob_matrix().flatten() two_v_elems = two_v_coords.get_mob_matrix().flatten() x_sym, y_sym = list(map(TexMobject, ["x", "y"])) two_x_sym, two_y_sym = list(map(TexMobject, ["2x", "2y"])) #VMobject(x_sym, two_x_sym).set_color(X_COLOR) #VMobject(y_sym, two_y_sym).set_color(Y_COLOR) syms = [x_sym, y_sym, two_x_sym, two_y_sym] #VMobject(*syms).scale(VECTOR_LABEL_SCALE_FACTOR) for sym, num in zip(syms, [x, y] + list(two_v_elems)): sym.move_to(num) #self.play(Transform(x, x_sym), Transform(y, y_sym), FadeOut(VMobject(*two_v_elems))) self.wait() #self.play(Transform(VMobject(two_dot.copy(), x.copy()), two_x_sym), Transform(VMobject(two_dot.copy(), y.copy() ), two_y_sym)) #self.wait(2)生成した動画
https://www.youtube.com/watch?v=Kq7Ptpt6YZQ
以上。
- 投稿日:2021-01-20T19:34:07+09:00
python codeの自動整形をするアクションを作ってみた
Why
- チーム開発をしていると、コードフォーマットの差が大きい
- やる人もいれば、やらない人もいる
- フォーマッタが異なる
- コード整形のみのコミットを入れたくない
開発者に手間を掛けさせず、且つローカル環境の依存をなくしたい
- black, autopepなどのライブラリをローカル環境に依存したくない
- vscodeやemacsなどエディタに依存したくない
github actionsを触ってみたかった
- 初めてのお題としては丁度いいと思った
What
- 作ったもの
- 所定のbranchにpushした時に、所定(今回の例だと、workspace/python以下)の*.pyコードをサーチし、対象となったpythonファイルにblackによるコード整形を実行する
- プルリク→マージも想定して、マージ先のブランチにマージされた時にも、上記コード整形を実行する
- リポジトリ
- 前提
- コード整形にはblackを用いる
- ブランチは適当に、main/developの2つ
- ディレクトリ構成
- code-format.ymlが今回のアクションの中身
├─.github │ └─workflows │ code-format.yml │ └─python │ pyproject.toml │ └─source a.py b.pyHow
- code-format.ymlは以下のようにしました
code-format.ymlname: python auto code format on: push: branches: - main - develop paths: - 'python/**' workflow_dispatch: jobs: black: name: Check code style with Black runs-on: ubuntu-latest defaults: run: working-directory: ./python steps: - name: Checkout uses: actions/checkout@v2 - name: Set up Python 3.6.8 uses: actions/setup-python@v2 with: python-version: 3.6.8 - name: Install black run: pip install black - name: run code format run: find . -type f -name "*.py" | xargs black - name: git settings run: | git config --local user.email "github-actions[bot]@users.noreply.github.com" git config --local user.name "github-actions[bot]" - name: Extract branch name id: extract_branch run: echo "##[set-output name=BRANCH_NAME;]$(echo ${GITHUB_REF#refs/heads/})" - name: commit run: git commit -m "python modules changed auto format." -a || echo "No changes to commit." - name: push run: | echo target branch is ${{ steps.extract_branch.outputs.BRANCH_NAME }} git pull git push origin ${{ steps.extract_branch.outputs.BRANCH_NAME }}
確認方法
- developブランチから、適当なtopicブランチを作成する
- 適当なtopicブランチで、適当なコード(今回はb.py)編集(フォーマットを崩す)
- commit & push
- github上でプルリク生成
- 適当なtopicブランチ→developにmerge
- アクションが走る
- developブランチのb.pyが、コード整形された状態でpushされている
actionsの様子
developブランチのコミット履歴
- ちょっとわかりにくいですが以下、github actionsがコミットした履歴が残っており、きれいにフォーマットされているのが確認できます

lastly
今回はtopicブランチ→developブランチを想定して行いましたが、develop→mainも同様です
また、このケースだと、main or developブランチにダイレクトコミットした場合もactionsが走ります

- 投稿日:2021-01-20T18:49:22+09:00
manimの作法 その22
概要
manimの作法、調べてみた。
ZetaTransformationScene使ってみた。サンプルコード
from manimlib.imports import * #import mpmath #mpmath.mp.dps = 7 def zeta(z): max_norm = FRAME_X_RADIUS try: return np.complex(mpmath.zeta(z)) except: return np.complex(max_norm, 0) def d_zeta(z): epsilon = 0.01 return (zeta(z + epsilon) - zeta(z))/epsilon class ZetaTransformationScene(ComplexTransformationScene): CONFIG = { "anchor_density" : 35, "min_added_anchors" : 10, "max_added_anchors" : 300, "num_anchors_to_add_per_line" : 75, "post_transformation_stroke_width" : 2, "default_apply_complex_function_kwargs" : { "run_time" : 5, }, "x_min" : 1, "x_max" : int(FRAME_X_RADIUS+2), "y_min" : 1, "y_max" : int(FRAME_X_RADIUS+2), "extra_lines_x_min" : -2, "extra_lines_x_max" : 4, "extra_lines_y_min" : -2, "extra_lines_y_max" : 2, } def prepare_for_transformation(self, mob): for line in mob.family_members_with_points(): if not isinstance(line, Line): line.insert_n_curves(self.min_added_anchors) continue p1 = line.get_start()+LEFT p2 = line.get_end()+LEFT t = (-np.dot(p1, p2-p1))/(get_norm(p2-p1)**2) closest_to_one = interpolate(line.get_start(), line.get_end(), t) diameter = abs(zeta(complex(*closest_to_one[:2]))) target_num_curves = np.clip(int(self.anchor_density*np.pi*diameter),self.min_added_anchors,self.max_added_anchors,) num_curves = line.get_num_curves() if num_curves < target_num_curves: line.insert_n_curves(target_num_curves-num_curves) line.make_smooth() def add_extra_plane_lines_for_zeta(self, animate = False, **kwargs): dense_grid = self.get_dense_grid(**kwargs) if animate: self.play(ShowCreation(dense_grid)) self.plane.add(dense_grid) self.add(self.plane) def get_dense_grid(self, step_size = 1./16): epsilon = 0.1 x_range = np.arange(max(self.x_min, self.extra_lines_x_min),min(self.x_max, self.extra_lines_x_max),step_size) y_range = np.arange(max(self.y_min, self.extra_lines_y_min),min(self.y_max, self.extra_lines_y_max),step_size) vert_lines = VGroup(*[Line(self.y_min*UP,self.y_max*UP,).shift(x*RIGHT) for x in x_range if abs(x-1) > epsilon]) vert_lines.set_color_by_gradient(self.vert_start_color, self.vert_end_color) horiz_lines = VGroup(*[Line(self.x_min*RIGHT,self.x_max*RIGHT,).shift(y*UP) for y in y_range if abs(y) > epsilon]) horiz_lines.set_color_by_gradient(self.horiz_start_color, self.horiz_end_color) dense_grid = VGroup(horiz_lines, vert_lines) dense_grid.set_stroke(width = 1) return dense_grid def add_reflected_plane(self, animate = False): reflected_plane = self.get_reflected_plane() if animate: self.play(ShowCreation(reflected_plane, run_time = 5)) self.plane.add(reflected_plane) self.add(self.plane) def get_reflected_plane(self): reflected_plane = self.plane.copy() reflected_plane.rotate(np.pi, UP, about_point = RIGHT) for mob in reflected_plane.family_members_with_points(): mob.set_color(Color(rgb = 1-0.5*color_to_rgb(mob.get_color()))) self.prepare_for_transformation(reflected_plane) reflected_plane.submobjects = list(reversed(reflected_plane.family_members_with_points())) return reflected_plane def apply_zeta_function(self, **kwargs): transform_kwargs = dict(self.default_apply_complex_function_kwargs) transform_kwargs.update(kwargs) self.apply_complex_function(zeta, **kwargs) class test(ZetaTransformationScene): CONFIG = { "anchor_density" : 15, } def construct(self): self.add_transformable_plane() self.add_extra_plane_lines_for_zeta() self.prepare_for_transformation(self.plane) print(sum([mob.get_num_points() for mob in self.plane.family_members_with_points()])) print(len(self.plane.family_members_with_points())) #self.apply_zeta_function() self.wait()生成した動画
https://www.youtube.com/watch?v=glq_Jw-U0qE
以上。
- 投稿日:2021-01-20T18:38:53+09:00
manimの作法 その21
概要
manimの作法、調べてみた。
ZoomedScene使ってみた。サンプルコード
from manimlib.imports import * class test(ZoomedScene): CONFIG = { "zoom_factor": 0.3, "zoomed_display_height": 1, "zoomed_display_width": 6, "image_frame_stroke_width": 20, "zoomed_camera_config": { "default_frame_stroke_width": 3, }, } def construct(self): dot = Dot().shift(UL * 2) image = ImageMobject(np.uint8([[0, 100, 30, 200], [255, 0, 5, 33]])) image.set_height(7) frame_text = TextMobject("Frame", color = PURPLE).scale(1.4) zoomed_camera_text = TextMobject("Zoomed camera", color = RED).scale(1.4) self.add(image, dot) zoomed_camera = self.zoomed_camera zoomed_display = self.zoomed_display frame = zoomed_camera.frame zoomed_display_frame = zoomed_display.display_frame frame.move_to(dot) frame.set_color(PURPLE) zoomed_display_frame.set_color(RED) zoomed_display.shift(DOWN) zd_rect = BackgroundRectangle(zoomed_display, fill_opacity = 0, buff = MED_SMALL_BUFF) self.add_foreground_mobject(zd_rect) unfold_camera = UpdateFromFunc(zd_rect, lambda rect: rect.replace(zoomed_display)) frame_text.next_to(frame, DOWN) self.play(ShowCreation(frame), FadeInFrom(frame_text, direction = DOWN)) self.activate_zooming() self.play(self.get_zoomed_display_pop_out_animation(), unfold_camera) zoomed_camera_text.next_to(zoomed_display_frame, DOWN) self.play(FadeInFrom(zoomed_camera_text, direction = DOWN)) scale_factor = [0.5, 1.5, 0] self.play(frame.scale, scale_factor, zoomed_display.scale, scale_factor, FadeOut(zoomed_camera_text), FadeOut(frame_text)) self.wait() self.play(ScaleInPlace(zoomed_display, 2)) self.wait() self.play(frame.shift, 2.5 * DOWN) self.wait() self.play(self.get_zoomed_display_pop_out_animation(), unfold_camera, rate_func = lambda t: smooth(1 - t)) self.play(Uncreate(zoomed_display_frame), FadeOut(frame)) self.wait()生成した動画
https://www.youtube.com/watch?v=GetSZncd4lY
以上。
- 投稿日:2021-01-20T17:43:39+09:00
過少学習と過学習
過少学習と過学習
過少学習 モデルがデータの裏にある時ロジックをとらえる事ができていない
過学習 訓練がトレーニングデータに対して過剰に適合しており本質から逸脱しているライブラリのインポート
import numpy as np from sklearn.model_selection import train_test_splita/train_test_splita = 名前を見てわかる通り訓練用のモジュール/
分割するデータの作成
a = np.arange(1,101)a分割したデータの出力
array([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13,
14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26,
27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39,
40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52,
53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65,
66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78,
79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91,
92, 93, 94, 95, 96, 97, 98, 99, 100])
1~100までの値が配列として格納されているのが分かる
/ここでデータが配列であることがポイントである
→データを二つに区切る手順が楽になる/b = np.arange(501,601) barray([501, 502, 503, 504, 505, 506, 507, 508, 509, 510, 511, 512, 513, 514, 515, 516, 517, 518, 519, 520, 521, 522, 523, 524, 525, 526, 527, 528, 529, 530, 531, 532, 533, 534, 535, 536, 537, 538, 539, 540, 541, 542, 543, 544, 545, 546, 547, 548, 549, 550, 551, 552, 553, 554, 555, 556, 557, 558, 559, 560, 561, 562, 563, 564, 565, 566, 567, 568, 569, 570, 571, 572, 573, 574, 575, 576, 577, 578, 579, 580, 581, 582, 583, 584, 585, 586, 587, 588, 589, 590, 591, 592, 593, 594, 595, 596, 597, 598, 599, 600])a .bと両方に分割データを作成
データの分割
train_test_split(a) #(b)にして同じデータの分割ができるか確認[array([87, 32, 90, 1, 2, 8, 51, 73, 22, 95, 4, 57, 27, 58, 48, 99, 96, 74, 72, 29, 76, 64, 3, 12, 53, 6, 18, 16, 65, 66, 63, 46, 39, 17, 91, 25, 15, 78, 83, 19, 45, 68, 33, 98, 97, 14, 44, 86, 80, 34, 70, 47, 54, 93, 94, 85, 42, 60, 92, 41, 61, 71, 89, 23, 21, 11, 84, 13, 82, 59, 49, 79, 36, 55, 5]), array([ 24, 56, 40, 9, 69, 75, 10, 28, 38, 30, 62, 67, 100, 88, 37, 20, 7, 31, 77, 43, 35, 26, 81, 52, 50])]2つのデータ(オブジェクト)を4つに分割していきます
a_train, a_test = train_test_split(a, b, test_size=0.2, random_state=365)結果の確認
形状の確認
a_train,shape.a_test,shape
((80,), (20,))データの中身の確認
a_train
array([ 25, 32, 99, 73, 91, 66, 3, 59, 94, 1, 8, 15, 90, 54, 31, 20, 77, 82, 30, 35, 95, 42, 38, 7, 11, 50, 21, 48, 2, 17, 10, 58, 68, 43, 41, 16, 88, 72, 79, 100, 80, 39, 24, 86, 22, 23, 62, 76, 18, 47, 55, 26, 60, 19, 71, 64, 51, 63, 65, 28, 12, 78, 13, 44, 75, 87, 40, 4, 29, 49, 37, 57, 27, 74, 6, 45, 92, 34, 53, 83])/この状態で出力した場合はデータがシャッフルされている状態
殆どの場合はデータはシャッフしています。/データの中身の確認
a_test
array([ 9, 69, 81, 56, 33, 93, 84, 61, 46, 89, 85, 67, 97, 5, 70, 36, 98, 96, 14, 52])/rain_test_splitのメリット
配列もしくわ行列おランダムな訓練用とテスト用データに分けることができる/
- 投稿日:2021-01-20T17:07:52+09:00
manimの作法 その20
概要
manimの作法、調べてみた。
MovingCameraScene使ってみた。サンプルコード
from manimlib.imports import * class test(GraphScene, MovingCameraScene): def setup(self): GraphScene.setup(self) MovingCameraScene.setup(self) def construct(self): self.camera_frame.save_state() self.setup_axes(animate = False) graph = self.get_graph(lambda x: np.sin(x), color = BLUE, x_min = 0, x_max = 3 * PI) moving_dot = Dot().move_to(graph.points[0]).set_color(ORANGE) dot_at_start_graph = Dot().move_to(graph.points[0]) dot_at_end_grap = Dot().move_to(graph.points[-1]) self.add(graph, dot_at_end_grap, dot_at_start_graph, moving_dot) self.play(self.camera_frame.scale, 0.5, self.camera_frame.move_to, moving_dot) def update_curve(mob): mob.move_to(moving_dot.get_center()) self.camera_frame.add_updater(update_curve) self.play(MoveAlongPath(moving_dot, graph, rate_func = linear)) self.camera_frame.remove_updater(update_curve) self.play(Restore(self.camera_frame))生成した動画
https://www.youtube.com/watch?v=63cCz1Rou3Q
以上。
- 投稿日:2021-01-20T14:53:27+09:00
PyInstallerでエラーが出るとき
PyInstallerを使うと、Pythonで作ったプログラムを実行ファイルに変換できるので、とても便利です。しかも、以下のような感じで書くと、ライブラリも全部まとめて一つのファイルになります。かなり便利。
test.pyをtest.exeに変換する方法:
$ pyinstaller test.py --onefilePyInstallerのインストール
以下のようにpipを使って、PyInstallerをインストールできます。
$ pip install pyinstallerエラーが出る場合 - PythonバージョンやmacOS
macOSや新しいPythonのバージョンの対応は遅れています。対応バージョンを使いましょう。
エラーが出る場合 - 暗黙的なインポート
暗黙的なインポートがある場合、エラーが出ます。以下のように、『--hidden-import=パッケージ名』を追記することで暗黙的なモジュールも追記します。
$ pyinstaller -F --hidden-import="sklearn.utils._cython_blas" --hidden-import="sklearn.neighbors.typedefs" --hidden-import="sklearn.neighbors.quad_tree" --hidden-import="sklearn.tree._utils" test.pyまた、プログラム内に「import xxx」と暗黙的なモジュールを記載しておくこともできます。
EXE化すると __file__ や __dir__ は使えない
そこで、exeファイルのパスはsys.argv[0]で取得します。
test.pyimport os, sys exe = os.path.abspath(sys.argv[0]) exe_dir = os.path.dirname(exe)参考
- 投稿日:2021-01-20T14:01:13+09:00
【Django】メモリを節約しつつ大容量ファイルをダウンロードする。
Django で大容量ファイルをダウンロードする際にメモリエラーを回避する方法。
StreamingHttpResponseとwsgiref.util.FileWrapperを使う。※関数ベースのviewの実装例を記載
HttpResponseを使う場合from django.http import HttpResponse def download_view(request, *args, **kwargs): with open('path/to/dir/small.csv', 'rb') as f: response = HttpResponse(f.read(), content_type='text/csv') response['Content-Disposition'] = 'attachment; filename=small.csv' return response
f.read()の部分でファイルの全容量をメモリに読み込んでしまう。
StreamingHttpResponseとFileWrapperを使う場合import os from wsgiref.util import FileWrapper from django.http import StreamingHttpResponse # 8MB ずつ読み込む chunksize = 8 * (1024 ** 2) def streaming_download_view(request, *args, **kwargs): path = os.path.join('path/to/dir', 'large.csv') response = StreamingHttpResponse( FileWrapper(open(path, 'rb'), chunksize), content_type='text/csv' ) response['Content-Length'] = os.path.getsize(path) response['Content-Disposition'] = 'attachment; filename=large.csv' return responseなお
FileWrapperの第一引数には"filelike-object"を指定するが、コンテキストマネージャを使うと(なぜか)エラーが発生する。
あんまり調査していないが、ドキュメントの使用例と同じようにopen()を使うのが無難である。失敗する例(コンテキストマネージャを使用)... def streaming_download_view(request, *args, **kwargs): path = os.path.join('path/to/dir', 'large.csv') with open(path, 'rb') as f: response = StreamingHttpResponse( FileWrapper(f, chunksize), content_type='text/csv' ) ... return responseエラー出力Traceback (most recent call last): File "/home/ec2-user/.pyenv/versions/3.7.7/lib/python3.7/wsgiref/handlers.py", line 138, in run self.finish_response() File "/home/ec2-user/.pyenv/versions/3.7.7/lib/python3.7/wsgiref/handlers.py", line 183, in finish_response for data in self.result: File "/home/ec2-user/.pyenv/versions/3.7.7/lib/python3.7/wsgiref/util.py", line 30, in __next__ data = self.filelike.read(self.blksize) ValueError: read of closed file応用: ダウンロード後にファイルを削除する
ダウンロードするファイルを一時ファイル的に扱いたい場合には
TemporaryDirectoryと組み合わせることで実現できる。import os from tempfile import TemporaryDirectory from wsgiref.util import FileWrapper from django.http import StreamingHttpResponse # 8MB ずつ読み込む chunksize = 8 * (1024 ** 2) def generate_return_file(target_dir): # ダウンロード対象のファイルを指定ディレクトリ配下に作成する何らかの処理 pass def streaming_download_view_with_tempdir(request, *args, **kwargs): with TemporaryDirectory() as tempdir: path = os.path.join(tempdir, 'large.csv') # tempdir 配下に対象ファイルを作成する generate_return_file(tempdir) response = StreamingHttpResponse( FileWrapper(open(path, 'rb'), chunksize), content_type='text/csv' ) response['Content-Length'] = os.path.getsize(path) response['Content-Disposition'] = 'attachment; filename=large.csv' return response
- 投稿日:2021-01-20T13:07:00+09:00
開発未経験者が覆面算ソルバーを作ったはなし
はじめに
こんにちは。0kayu806059です。
この記事がQiita初投稿となります。
タイトルにもある通り、この度私は、覆面算ソルバーを作りました。
とても簡単なWebアプリですが、完成までに至った経緯をここに残したいと思います。そもそも覆面算とは?
覆面算とは、数字の一部(または全部)がアルファベットに置き換えられた数式が与えられるので、各アルファベットに当てはまる数字を見つけて数式が成り立つようにするパズルです。
例えば、
ABC + BAC = CACA
といった数式が与えられます。この場合A、B、Cにどんな数字が入るかを考えるといった感じです。中学受験とかで見るやつですね。ちなみに答えは、A = 2, B = 9, C = 1 となります。実際に数を代入してみると、
291 + 921 = 1212 となり、確かに成り立っていることがわかります。
基本的なルールとしては3つあります。
1. 各文字には0〜9までの1つの数字が入ります。
2. 同じ数字が別の文字にはいうことはありません。(つまり、A = 1, B = 1というのはダメ)
3. 各項の先頭にある文字に'0'が入ることはありません。(先程の例で言うと、A、B、Cはいずれも項の先頭にあるため'0'は入りません。)作ろうと思ったきっかけ
私は普段、競技プログラミングをしています。レートを上げるためにプログラミングの勉強をしているうちに、せっかくだから何か作ってみよう!と思ったことがきっかけです。
何を作ろうかと考えたときに、そのとき読んでいたアルゴリズムの本に、虫食い算(覆面算のアルファベットが全て□に置き換わったもの)はDFSで作れると言うようなことが書いてありました。それを読んで、「虫食い算の作り方はわかった。じゃあ覆面算は作れるだろうか?」と思ったので作ってみました。苦労した点
苦労したところは2つあります。覆面算ソルバーのアルゴリズムとWebアプリにする際の答えの出力方法です。
1. 覆面算ソルバーのアルゴリズム
はじめに考えたのは、虫食い算と同様にDFSで解くことです。しかし、上手い実装方法が思い浮かばずにかなり悩みました。そこで、ルールを見返してみると、各文字には1つの数字しか入らず、違う文字に同じ数が入ることはないので、登場する文字の種類は高々10種類であることに気づきました。そしたら答えの候補は高々10!(= 3628800)個なので答えは数秒で求められることになります。実際に書いたコードがこれです。def solver(s): s = s.replace(" ", "") left_terms = [] now = 0 alphabet = [] equal = 0 right_term = "" operation = ['+', '-', 'x', '/'] ope_num = [0] ZeroNine = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9'] # 式に含まれる項と登場する文字をリスト化 for i in range(len(s)): if s[i] not in alphabet and s[i] not in operation and s[i] != '=' and s[i] not in ZeroNine: alphabet.append(s[i]) if s[i] in operation: tmp = s[now:i] left_terms.append(tmp) now = i + 1 if s[i] == '+': ope_num.append(0) elif s[i] == '-': ope_num.append(1) elif s[i] == 'x': ope_num.append(2) else: ope_num.append(3) if s[i] == '=': equal = i left_terms.append(s[now:equal]) right_term = s[equal+1:] # 登場した文字をソート alphabet = sorted(alphabet) number = len(alphabet) # 0〜9の中から答えの候補を全探索 for i in itertools.permutations(ZeroNine, number): cur = list(i) answer = {} # 各文字についての対応表を作る for j in range(number): answer[alphabet[j]] = cur[j] # 対応表に基づき、数式を作る ok = 1 # 左辺の計算 Leftside, Rightside = 0, 0 for j in range(len(left_terms)): # 数式の復元 tmp = "" for k in left_terms[j]: if k in ZeroNine: tmp += k else: tmp += answer[k] if tmp[0] == '0': ok = 0 else: if ope_num[j] == 0: Leftside += int(tmp) elif ope_num[j] == 1: Leftside -= int(tmp) elif ope_num[j] == 2: Leftside *= int(tmp) else: Leftside /= int(tmp) # 右辺の計算 tmp = "" for k in right_term: if k in ZeroNine: tmp += k else: tmp += answer[k] if tmp[0] == '0': ok = 0 Rightside += int(tmp) # ok では、最高位が0出ないという条件を満たしているかを確認している if ok == 1: if Leftside == Rightside: res = "" for key in answer: res += str(key) res += ": " res += str(answer[key]) res += " " return res return "答えが見つかりませんでした"2. Webアプリにしたときの答えの出力方法
自分でWebアプリを作った経験がないため、どのようにアプリにするのかとても苦労しました。フレームワークにはFlaskを使いました。Pythonの有名なフレームワークとしてFlaskの他にDjangoがあり、どちらを使うか悩みましたが、小規模な開発にはFlaskを用いることが多いといったことや、今回の自分の開発に、フルスタックフレームワークは必要ないといった理由からFlaskを選びました。
どう出力するかと言うのはググってなんとか解決しました。ググるの大事ですね〜(自力で解決しようとして1日溶かしました...)自分にはHTMLとCSSの知識が欠けているようです。Webアプリを作っていく上での今後の課題です。最後に
実際に動かしてみるとこのようになります。
ここでは入力として、最初にあげた例を入れています。
実はこの覆面算ソルバーには欠点があります。括弧がついた式はそのまま計算できないのです。括弧を外してやれば良いのだけなのですが入力する側からすると割と面倒かもしれません。
今までWebアプリというと、本を写経したり、動画の真似をして作ったりといったことしかなく、自分で考えて作ったことはなかったので、非常に良い経験になりました。読んでいただきありがとうございました。

- 投稿日:2021-01-20T12:59:36+09:00
PyPIにパッケージをトークンを用いてアップロードする
はじめに
Pythonではよりお手軽に
pipでインストールするためにPyPIに作成したライブラリをアップロードすることができます。このとき、通常はユーザー名・パスワードをアップロード時に手動でコンソールに入力する必要がありますが、APIトークンを発行すればこれらユーザ名・パスワードを省略することができます。
PyPIへのアップロード (トークンを使用しない)
pipenv install --dev wheel twineパッケージ化とアップロードのために
wheelとtwineをdevで入れます。
wheelはパッケージの1形式であり、かつその形式を作成するためのライブラリです。 (gemみたい)
twineはPyPIにアップロードをするためのライブラリです。アップロードするときは、以下のシェルスクリプトを自分は利用しています。
#!/usr/bin/env bash rm -f -r {your-library-name}.egg-info/* dist/* python setup.py bdist_wheel twine upload dist/*このとき、ユーザー名とパスワードをtwineを利用時に打つ必要があります。
APIトークン
Add API tokenから発行できます。
APIトークンを発行したら、以下の内容をホームディレクトリに~/.pypircとして置いてあげます。.pypirc[pypirc] servers = pypi [pypi] username: __token__ password: your_token
__token__は、いかにも個々に別の名前のトークン入れる感じみたいな名前ですが、そのままプレーンテキストで__token__とそのまま打ってあげればいいです。
passwordの方に関しては設定が必要で、先程発行したAPIトークンを書く必要があります。参考リンク
- 投稿日:2021-01-20T12:43:30+09:00
Djangoのテンプレートでパラメータの値を取得
- 投稿日:2021-01-20T12:28:12+09:00
Pythonとは。何に使われているのか。
Pythonに関して話す機会ができたので、経験範囲(Pythonをゆるゆる2年)でのPython知識をまとめていこうと思います。
私の思うPythonな内容も多めです。
間違いなどがありましたらご指摘ください。全3編を予定
- Pythonとは。何に使われているのか。(←今ここ)
- Pythonの環境構築
- モジュールとパッケージ
基本情報
開発元・運営母体
- Python Software Foundation
- > Python Software Foundation は、Python バージョン 2.1 以降の著作権を保持する独立の非営利組織です。
- PSF のドキュメントの日本語訳はこちらから読めます
Python とは言語仕様のこと
- 複数の実装があり、特に断りのない場合は大体はCPythonのことを指しています
- CPythonのコード
- CPython、PyPy、etc
- Rust の実装などもあります
- Python 仕様説明や開発の議論はPEP(Python Enhancement Proposal) で行われています
- https://www.python.org/dev/peps/
- PEPに関してはsphinx-users.jpさんの翻訳記事で詳しく知ることができます
- PEP説明の原典はこちら
- PEPを読んでみましょう
インタプリタ言語
Pythonはインタプリタ言語です。
Pythonが実行するまでに行われることは以下が参考になりました。
https://qiita.com/intermezzo-fr/items/3ae7645bd7d4414d9607Python のバージョンに関して
- 各種versionの開発ステータスとサポート期限などがここで見れます
- 2021年現在Python2系のサポートは切れています
Python の使われ方に関して
Python は何に使われているのか (Python を使って仕事をする人々の種類)
Python=機械学習と言われがちなので、
いろいろな職種の人が色々なPython製のものを使っているよと言いたいのが趣旨です。
- データサイエンティスト
- MLエンジニア
- テーブルデータ・自然言語・メディア(画像・音声・動画)
- データエンジニア
- アプリケーションエンジニア
- インフラ・システム管理者
- Ansible
- Airflow
- Pyhonスクリプトをグルーに使っている例も結構見る
- 組み込み・ロボット
- Raspberry Pi
- ROS
- 各種研究者
- スクレイピングしている人達
- Selenium, Beautiful Soup, Scrapy
- 私がPython使い始めたのはスクレイピングするためです
PyconJp 2019のアンケートだと機械学習やwebアプリケーション開発が多いですね
参考: 引用 (https://pyconjp.blogspot.com/2020/03/questionnaire-2019-result.html)どんなライブラリがあるかを見て何に使われているのかを推測するのも面白いです。
-> Pythonの人気ライブラリやアプリの紹介Pythonと言えば..な海外企業
- Docstring(Googleスタイルとか)、ClIフレームワーク、機械学習フレームワーク,etc でお世話になっています
- NetFlix
- DropBox
- グイドが所属した会社
- グイド氏への感謝を込めて
- Microsoft
- グイドは引退したと思ったらMSに行った
- Pythonの生みの親グイド・ヴァンロッサム氏がオープンソースに積極的になったMicrosoftに入社 | TechCrunch Japan
個人的に調べものをしていて度々お世話になる企業
個人的に調べものをしていてテックブログやQiitaや社員さんの個人ブログでお世話になっている企業。
- ZOZOテクノロジーズ
- リクルート 系列
- JX通信社
- エムスリー
- ISID
- ブレインパッド
Pythonとは。何に使われているのか。編 は以上です。
間違いなどがありましたらご指摘ください。

- 投稿日:2021-01-20T12:13:13+09:00
numpy : 単一型の ndarray を structured array に変換したい
これは何か
単一の型で定義された通常の ndarray を structured array に変換する方法です。
動機
- 複数のデータが時系列であり (2次元配列)、key を使って辞書のようにアクセスしたくなった
- numpy だけで完結させたい
- record array を使えばできる (Stack Overflow : Converting a 2D numpy array to a structured array) という記事もあったが、recarray は numpy の後方互換のため現在も残っているが structured array の方がより新しい (Stack Overflow : NumPy “record array” or “structured array” or “recarray”) という議論もあるようなので、structured array で実現する事にします
方法 1 : タプルのリストを経由させる
- numpy のドキュメントには、データは tuple のリストで渡すように指示されています
コード例
- 例えば以下のようなコードになります
import numpy # d1, d2, d3 の 3 つのデータがあるとします d1 = numpy.arange(0, 1000, dtype='int32') d2 = numpy.arange(1000, 2000, dtype='int32') d3 = numpy.arange(2000, 3000, dtype='int32') # くっつけます d = numpy.array([d1, d2, d3]).T # d はこんな感じです # array([[ 0, 1000, 2000], # [ 1, 1001, 2001], # [ 2, 1002, 2002], # ..., # [ 997, 1997, 2997], # [ 998, 1998, 2998], # [ 999, 1999, 2999]], dtype=int32) # dtype を定義しときます dtype1 = [ ('d1', 'int32'), ('d2', 'int32'), ('d3', 'int32'), ] # structured array に変換します sa1 = numpy.array(list(map(tuple, d)), dtype=dtype1) # sa1 はこんな感じ # array([( 0, 1000, 2000), ( 1, 1001, 2001), ( 2, 1002, 2002), # ( 3, 1003, 2003), ( 4, 1004, 2004), ( 5, 1005, 2005), # ( 6, 1006, 2006), ( 7, 1007, 2007), ( 8, 1008, 2008), # ... # (993, 1993, 2993), (994, 1994, 2994), (995, 1995, 2995), # (996, 1996, 2996), (997, 1997, 2997), (998, 1998, 2998), # (999, 1999, 2999)], # dtype=[('d1', '<i4'), ('d2', '<i4'), ('d3', '<i4')]) # 個別のデータに key でアクセスできるようになりました sa1['d1'] # array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, # 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, # ... # 975, 976, 977, 978, 979, 980, 981, 982, 983, 984, 985, 986, 987, # 988, 989, 990, 991, 992, 993, 994, 995, 996, 997, 998, 999], # dtype=int32)パフォーマンス
- numpy.ndarray から tuple への変換をしており、やや遅いです
- 手元の環境では 3 ms ほどかかっていました
%time numpy.array(list(map(tuple, d)), dtype=dtype1) # CPU times: user 2.63 ms, sys: 0 ns, total: 2.63 ms # Wall time: 2.64 ms方法 2 : バッファを経由させる
- もっと速くしたいです
- structured array は numpy.frombuffer() を使えば、バイナリファイルをそのまま開けてとても便利です。
- ndarray のメモリ上のデータを tobytes() で取り出し、frombuffer() で再解釈させれば、きっと速いに違いありません
コード例
- 例えば以下のようなコードになります
import numpy # data を作ります d1 = numpy.arange(0, 1000, dtype='int32') d2 = numpy.arange(1000, 2000, dtype='int32') d3 = numpy.arange(2000, 3000, dtype='int32') d = numpy.array([d1, d2, d3]).T # dtype を定義します dtype1 = [ ('d1', 'int32'), ('d2', 'int32'), ('d3', 'int32'), ] ### ここまでは、方法 1 と同じです ### # structured array に変換します sa2 = numpy.frombuffer(d.tobytes(), dtype=dtype1) # sa1 と sa2 の値は全く同じです all(sa2 == sa1) # >> Trueパフォーマンス
- 手元の環境では 80 us になりました
- タプル経由に比べて、30 倍ほど速いです
- 大満足です
%time numpy.frombuffer(d.tobytes(), dtype=dtype1) # CPU times: user 75 µs, sys: 0 ns, total: 75 µs # Wall time: 83.9 µsもう少しまじめに比較
- 方法 1 と、方法 2 の計算時間を計測してみました
- データ点数 n を変化させます
- 各点数に対して、100 回計算させて所要時間を平均しました
コード
import numpy import time dtype1 = [ ('d1', 'int32'), ('d2', 'int32'), ('d3', 'int32'), ] def run(num, func): d = numpy.arange(num*3, dtype='int32').reshape((3, num)).T t0 = time.time() [func(d) for i in range(100)] t1 = time.time() return (t1 - t0) / 100 func1 = lambda x: numpy.array(list(map(tuple, x)), dtype=dtype1) func2 = lambda x: numpy.frombuffer(x.tobytes(), dtype=dtype1) # 計測します nums = numpy.logspace(2, 5, 10, dtype=int) t1 = [run(i, func1) for i in nums] t2 = [run(i, func2) for i in nums] # プロットします import matplotlib.pyplot fig = matplotlib.pyplot.figure() ax = fig.add_subplot(111, aspect=1) ax.plot(nums, t1, 'o-', label='tuple') ax.plot(nums, t2, 'o-', label='bytes') ax.set_xscale('log') ax.set_yscale('log') ax.set_xlabel('# of data points') ax.set_ylabel('Calculation time [s]') ax.grid(True, color='#555555') ax.grid(True, which='minor', linestyle=':', color='#aaaaaa') ax.legend() fig.savefig('results.png', dpi=200)

- 投稿日:2021-01-20T12:07:21+09:00
Google App EngineにPythonアプリをデプロイしGitHubと連携させる
動機
Heroku、AWS Beanstalk、Azureに同じPythonのアプリをデプロイしてみて、ここまできたらGoogle Cloud Platformでも同じことをやってみるかと思いやってみた。が、他のサービスに比べて圧倒的にややこしかった。
GitHubと連携させるところで随分悩んだが、最終的にとても簡単にできることがわかったので、その顛末をここに記す。前提
- ローカル、あるいは他のPaaS, IaaSなどで動くことを確認済みのPythonアプリケーションがあること
- 上記アプリがGitHubのリポジトリに上がっていること
- Google Cloud Platformのアカウントがあること
手動でデプロイ
最初はGitHubとの連携はさせず、ローカルから手動でデプロイしてみようと思った。公式のチュートリアル通り、Google Cloud SDKをインストールし、コマンドラインからgcloud app deployでデプロイ。初めはapp.yamlがなくて動かなかったり、app.yamlを追加した後もentrypointのアプリケーション名がappじゃなくてmainになっていてエラーになったりしたが、そのあたりはわりとすぐに解決できた。(エラーログを見つけるのに少々時間がかかったが。)
GitHub連携〜ハマる
じゃあ次はGitHubと連携させてみるかとやってみるが、まずネットでググるとGoogle Cloud RunとGoogle Cloud Buildを使ってGitHubと連携させる方法が出てくる。これがいけなかった。
とりあえず、Cloud Runのサービス作ってGitHubと連携するCloud Buildのトリガーを作ったら、pushのたびにちゃんとトリガーが動いて、正常にデプロイされるんだけど、App Engineの方でWebページを開いてみても一向に反映されず、???となる。Cloud Runが何なのかよくわかっていなかったので、App Engineとは別個のものとして動いていることに気づいていなかったのだ。
Cloud Runのサービス詳細ページを見ていて、URLというリンクがあることに気づき、クリックしたら最新のGitHubリポジトリの内容が反映されたページが表示された。ああ、そういうことかとようやく理解する。公式ドキュメントを見よ
結論としては公式ドキュメントに全て書いてあった。
Cloud Runなんて最初からいらなかったんだ。
https://cloud.google.com/source-repositories/docs/quickstart-triggering-builds-with-source-repositories?hl=ja必要なのは
Cloud Buildの設定でGAEとの連携を許可、
Cloud Buildでデプロイするための構成情報を記述したcloudbuild.yamlをプロジェクトに追加、
ビルドトリガーを作成し、[ビルド構成] - [Cloud Build 構成ファイル] に上記で作成したcloudbuid.yamlを指定する。
これであとはGitHubのリポジトリにpushするたびに自動的にApp Engineの方にデプロイされる。
なぜ初めからこのページにたどり着けなかったのか・・・。残る疑問
GitHubにあるソースを動かすんならCloud RunとCloud Buildだけでよくね?という疑問が湧く。
App Engineは何のためにあるんや?他のPaasと同じイメージで使うんならApp EngineとCloud Buildなのかな?
使い分けがわからんです。