- 投稿日:2021-01-20T23:35:32+09:00
AWSのアクセスキーを間違えないようにする方法
2社以上の案件を同時にこなしている場合など、AWS Access Key IDを複数切り替えて使いたい場合にキーを間違えて使しまうと、大変なことになってしまいます。そこで、以下のようにすると明示的に切り替えられるので、間違いが減るのではないでしょうか。
aaa社向けのプロファイルを作成する。
>aws configure --profile aaa
AWS Access Key ID [None]: AKIASHE7LMTU4XXXXXXX
AWS Secret Access Key [None]: RlMpPqE19cnfwIS6XGatw3Y5RncQYpIdL+XXXXXX
Default region name [ap-northeast-1]:
Default output format [None]: jsonデフォルトプロファイルが存在するかどうかを確認する。
>aws configure
AWS Access Key ID [*************26WM]:
AWS Secret Access Key [*************h4DB]:
Default region name [ap-northeast-1]:
Default output format [json]:%USERPROFILE%.aws\config および %USERPROFILE%.aws\credentialsの、[default]という項目を消すと、デフォルトプロファイルが消される。
デフォルトプロファイルでs3のバケットリストを取得
>aws s3 ls
Unable to locate credentials. You can configure credentials by running "aws configure".
というエラーが発生。aaaプロファイルを使ってs3のバケットリストを取得
>aws s3 ls --profile aaa
--profileを明示的に指定しないとコマンドを実行できないようになった。
- 投稿日:2021-01-20T23:31:12+09:00
AppSync & GraphQL 入門
AppSync とは?
GraphQL というAPI仕様を用いて「柔軟なAPI」を提供するAWSのマネジメントサービス
ちなみに、従来の REST API 形式だと AWSは API Gateway を提供している
GraphQL とは?
Facebookが開発しているWeb APIのための規格
「クエリ言語」 と 「スキーマ言語」 からなる
REST API は、1URLに対し1つのAPIや情報を提供できるのに対し、
GraphQL は欲しいデータを以下のようなクエリとして発行すると、欲しいデータを欲しいObject形式で得ることができます
// リクエスト query GetCurrentUser { currentUser { id name } }↓
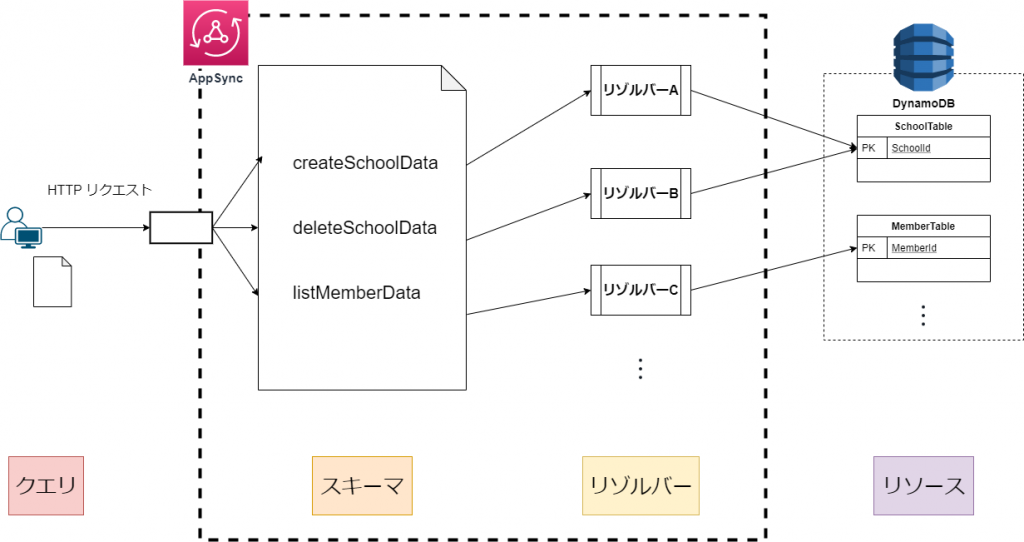
// レスポンス { id: 'hoge', name: 'yamada' }AppSyncの仕組み
AppSyncは直接DynamoDBの値を取得・更新・削除することができます
従来のAPI Gatewayだと、AWS Lambda が間に必要でしたが、
AppSyncは Lambda レス でDynamoDBへのアクセスが可能です
代わりに、AppSync内のリゾルバーという領域にロジックを記述します
クエリ
実行されるGraphQlのこと
スキーマ
どの型の値をどこで使うかを定義する設計書
リゾルバー
関数のこと。ロジックを記述する。
リゾルバーは、
リクエストマッピングテンプレートとレスポンスマッピングテンプレートで構成さる
リクエストマッピングテンプレートは、「変換」と「実行」のロジックが含まれているリソース
データベースのこと。AppSync では
AWS DynamoDBに自動的に接続されるAppSyncの料金
使用した分だけ課金されます
クエリとデータ変更操作
4.00USD ≒ 423.87 円 / クエリおよびデータ変更操作 100 万回あたり
リアルタイム更新
データが更新された際に、リアルタイムに更新する機能
2.00USD ≒ 211.94 円 / リアルタイムアップデート 100 万回
最初の12ヶ月の無料利用枠の対象でもあるようなので、登録後12ヶ月は一定回数は無料で使用できます
試してみる
実際に、AppSyncを用いてイベントを取得・登録する処理を実装してみます、とても簡単です
AppSync API を作成
AWS ログインして、AppSyncページへ移動し、「APIを作成」
サンプルプロジェクトから「イベントアプリ」を選んで「開始」
API 名は
[yourname] Appとしてください左メニューから「クエリ」ページに移動すると、GraphQL Explorer が表示されます
ここで、GraphQLを試すことが可能です
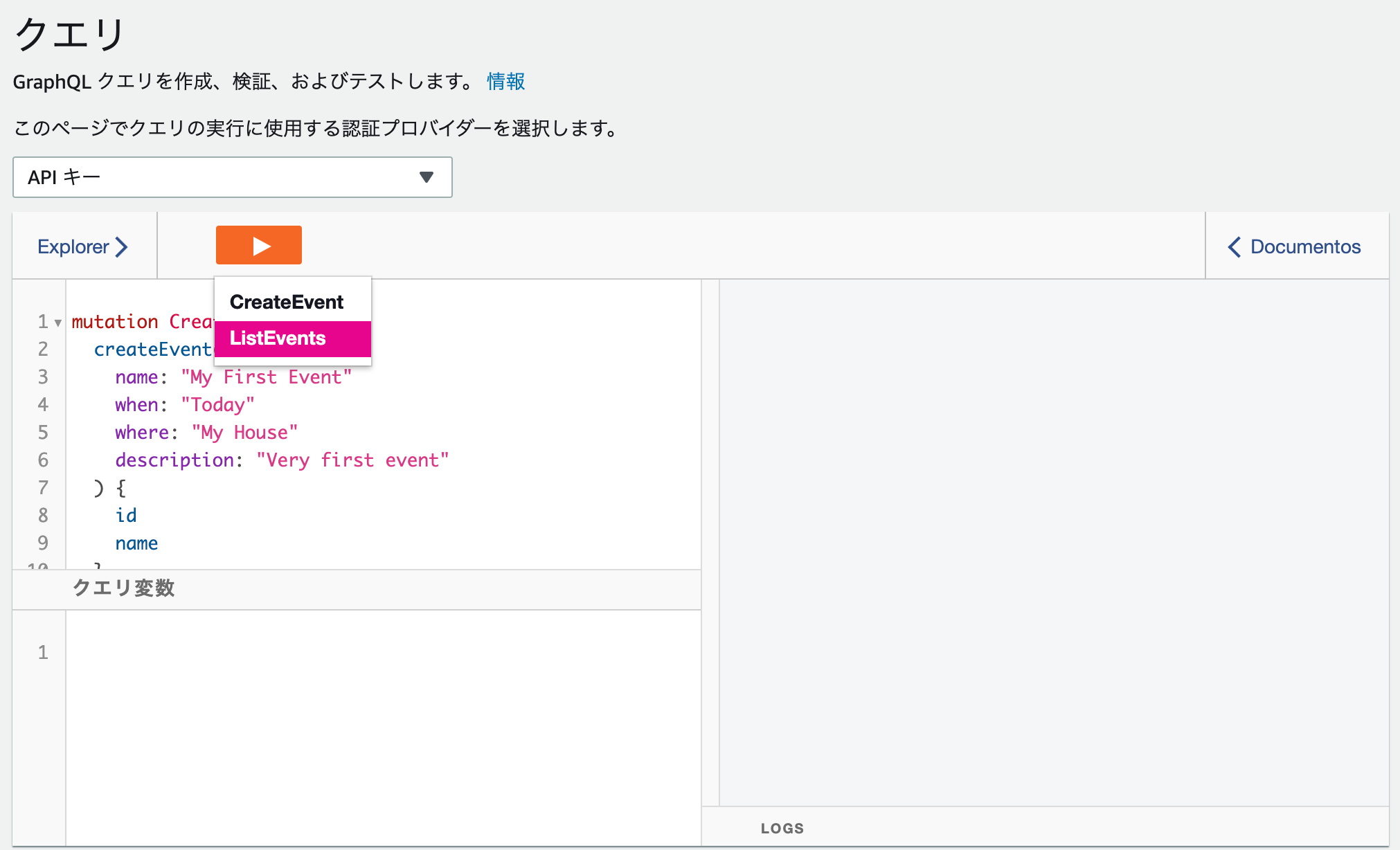
▶︎ボタンから、実行したいクエリを選択してみると、右側に結果が表示されます

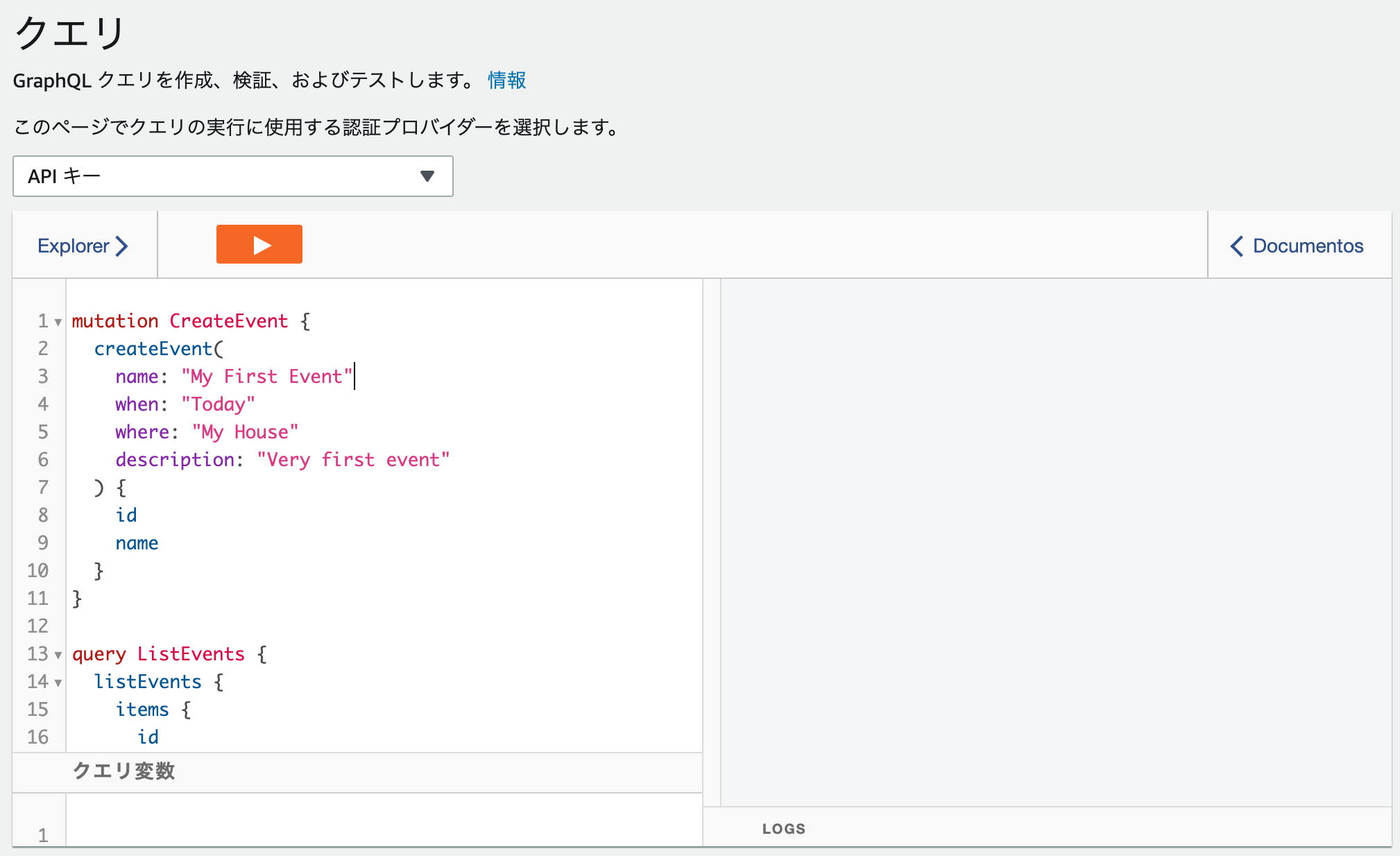
デフォルトで2つのクエリが用意されています
mutation CreateEvent { createEvent( name: "My First Event" when: "Today" where: "My House" description: "Very first event" ) { id name } } query ListEvents { listEvents { items { id name } } }1つめの
mutation CreateEventは、新たな Event のデータを作成するための mutation です2つめの
query ListEventsは、DBに登録されている Event のデータを取得するための query です
CreateEventを何度か実行するとListEventsの結果が変わることがわかりますGraphQLには3種類のクエリがある
| 名前 | 説明 |
| -- | -- |
| query | データ取得 (read) |
| mutation | データ作成/更新/削除 (create / update / delete) |
| subscription | リアルタイムイベントを受け取れる。内部的にはwebsocketが使われている |先ほどのサンプルでは query と mutation を使用しています
実際に Javascript で GraphQL を使ってみる
Axios を使って試してみます
URL と API KEY を AppSyncコンソールの設定ページから見つけて、セットしてみてください
上手くいけば、GraphQLのresultが、consoleに表示されます
const data = await axios.post( API_URL, { query: ` // ここにqueryをかく ` }, { headers: { // header に APIキーを渡す。 appSync設定画面から取得 "x-api-key": "" } } );
request bodyにクエリを記述、request headerにx-api-keyとして API KEY を持たせることで認証されます、とても簡単ですね認証方法
appSyncでは、4つの認証方法が用意されています
| 名前 | 概要 | ユースケース |
| -- | -- | -- |
| API_KEY | 今回使ったもの。最大 365 日間有効に設定可能で、該当日からさらに最大 365 日、既存の有効期限を延長可 | パブリック API の公開が安全であるユースケース、または開発目的での使用が推奨 |
| AWS_IAM | IAMポリシーを紐づけて使用 | IAMロールごとに、特定の機能のみに制限したい場合 |
| OPENID_CONNECT | OpenID Connect (OIDC) トークンを適用 | OpenID Connectを使いたい場合(未調査) |
| AMAZON_COGNITO_USER_POOLS | Amazon Cognito ユーザープールによって提供される OIDC トークンが使用されます | Amazon Cognito ユーザープールによって提供されるOIDCトークンを使いたい場合(未調査) |基本的には、上2つ
API_KEYとAWS_IAMを使うパターンが多いでしょうデータベースの中身を見てみる
左メニューから、
データソースを選択すると、DynamoDBへのリンクがあります
AppSyncが自動生成してくれたテーブルが、ここに表示されています
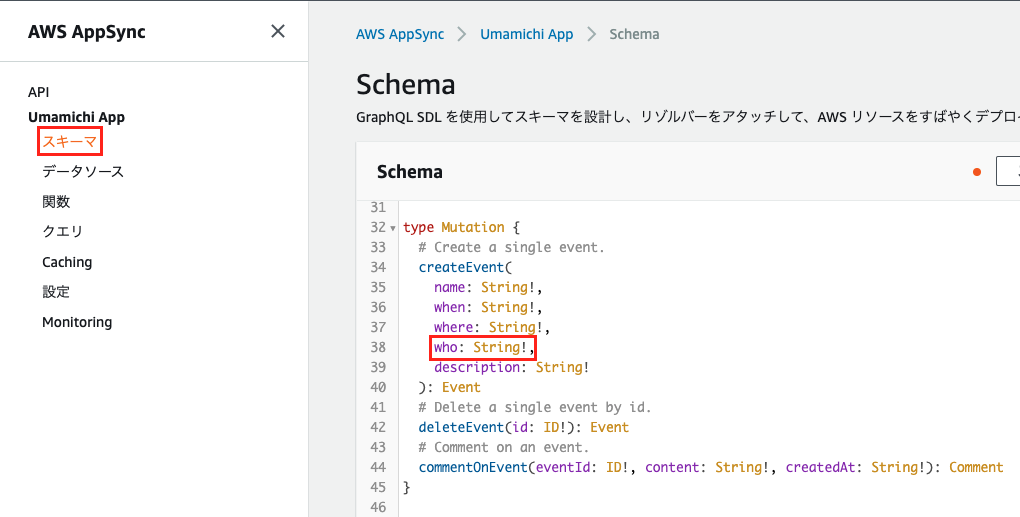
APIを変更・追加してみる
createEvent に
whoという項目を追加してみるAWSコンソールの左メニューから
スキーマを選択すると、定義されている Schema が表示されますこの中から、
Mutationの下にあるcreateEventを見つけ、引数にwhoを追加してみます
右上から
スキーマを保存します
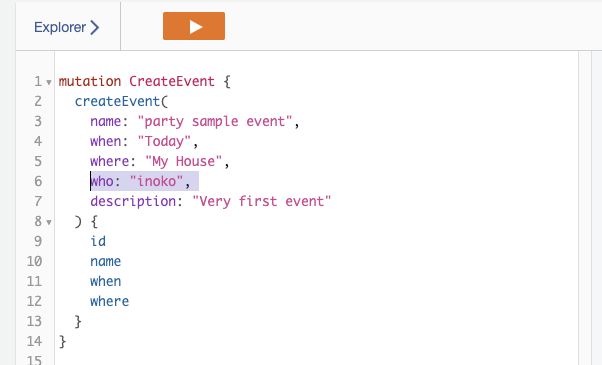
クエリページから、who に適当な値を追加して、実行してみます
これで、dynamoDBに
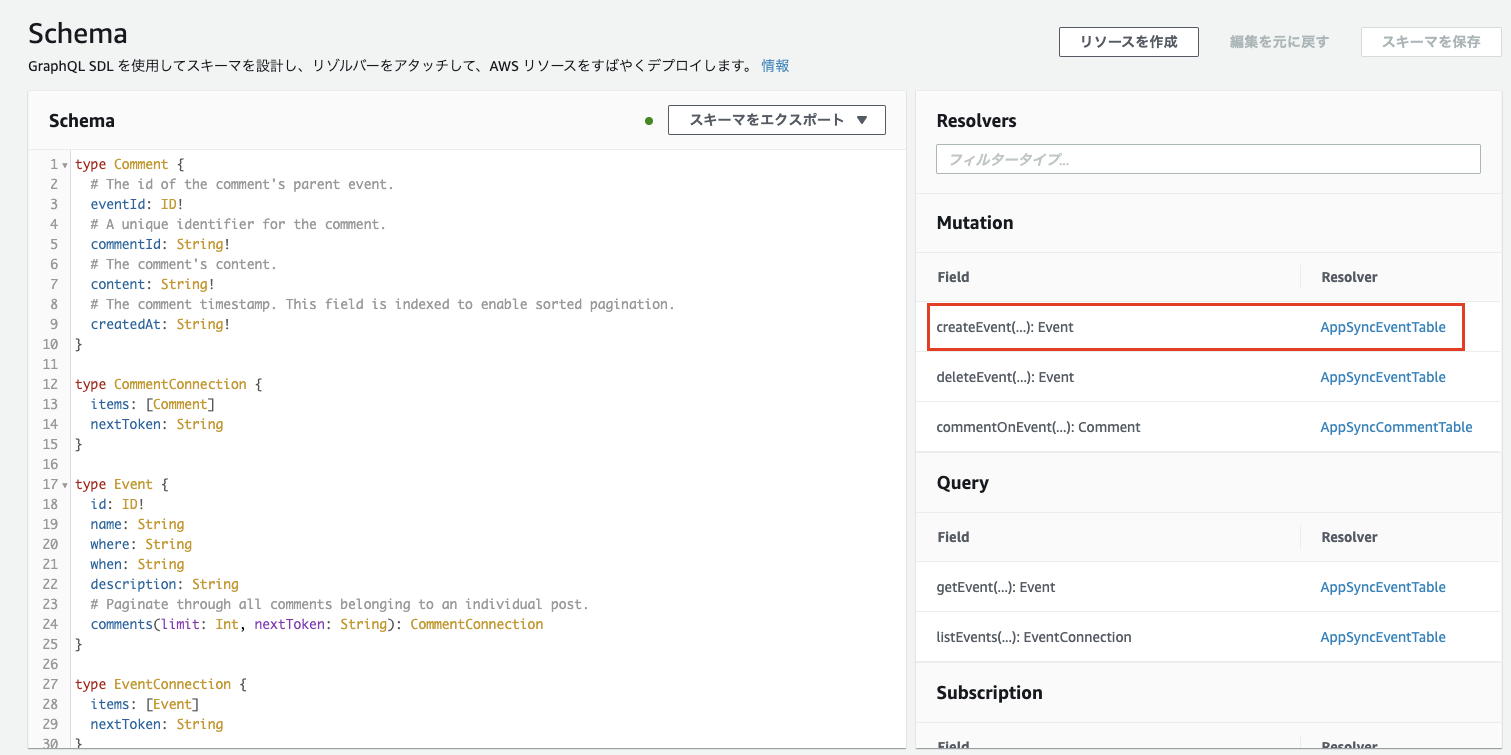
whoが追加されたか確認してみましょう左メニューから
データソース->AppSyncEventTableのリソースを開きますあれ、項目
whoが追加されていると思いましたが、追加されていません?
理由は簡単です、
リゾルバーも変更する必要があります?
リゾルバーとは、このページの冒頭で表示した図にあるように、ロジックを記述する領域です
リゾルバーの変更は、スキーマページの右カラムから可能です
createEventを見つけましょう⤵︎
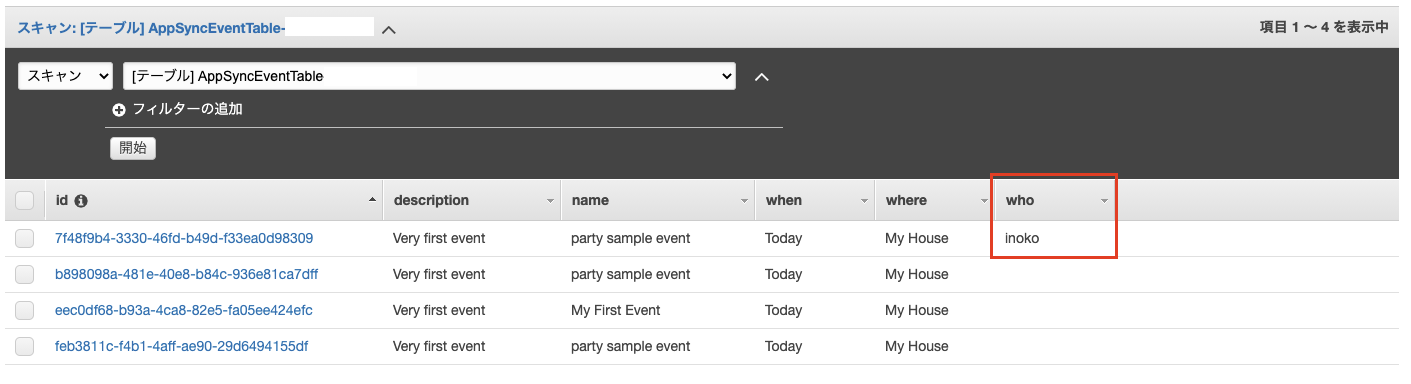
リクエストマッピングテンプレートを以下のようにして、whoを追記します{ "version": "2017-02-28", "operation": "PutItem", "key": { "id": { "S": "$util.autoId()"} }, "attributeValues": { "name": { "S": "$context.arguments.name" }, "where": { "S": "$context.arguments.where" }, "when": { "S": "$context.arguments.when" }, "who": { "S": "$context.arguments.who" }, "description": { "S": "$context.arguments.description" } } }リゾルバーを保存して、実行すると、
who項目が追加されていることが確認できました?
今回は内部の挙動を理解するために、
ブラウザからAWSコンソールを通じてスキーマやリゾルバーの変更を行いましたが、
実際には
AWS CloudformationやAmplify Frameworkなどを用いると良いそうですまとめ
メリット
GraphQL は REST API に比べて欲しいデータを欲しい形式で得ることが可能
GraphQL により、画面や機能ごとに、個別にAPIを定義するコストが削減される
AppSync を使えばリソース(DynamoDB)との連携を楽に行うことができる
既存の REST API を AppSync でラップして、GraphQL を導入することも可能らしい(未調査)
デメリット
GraphQL, Appsync の学習コストがかかる
フロントエンドの都合の良いように、値を返す必要があるため、リゾルバーのロジックが複雑になる
効率的にデータを処理できないので、パフォーマンスが低下し、N+1問題が発生する
※ N+1問題・・・ループ処理の中で都度SQLを発行してしまい、大量のSQLが発行されてパフォーマンスが低下してしまう問題のこと
実際にAppSyncで実装してみたページ
dynamoDB に入っているニュースのデータを AppSync を使って表示しています
これから調べる
AWS_IAMを使った AppSync 認証方法。Cognitoを使うらしいです参考
https://docs.aws.amazon.com/ja_jp/appsync/latest/devguide/welcome.html



- 投稿日:2021-01-20T22:41:03+09:00
Amazon linux2 でsshpassを使う
Amazon linux2 でsshpassを使う
概要
Amazon Linux2でsshpassを使う場合はEPELのリポジトリを有効化する一手間が必要でしたので、その手順をご紹介します。
手順
1. RHEL 7 用の EPEL リリースパッケージをインストールし、EPEL リポジトリを有効にします。
sudo amazon-linux-extras install epel -y sudo yum-config-manager --enable epel2. sshpassをインストール
sudo yum install -y sshpass3. sshpassの設定
sshpass -p {パスワード} ssh {user名前}@{SSH先}参考
- 投稿日:2021-01-20T22:26:38+09:00
GitHubへのpushをトリガにCodePipelineを走らせてテスト・デプロイする
以前の記事(【知識0からのCloudFormation】LambdaをデプロイするCodePipelineを組む)でCodeCommitにPushしたらデプロイするパイプラインの作成までやった。
今回は以下の変更を目標とする。
- デプロイする前にテストコードを挟む。
- ソースコードをGitHubで管理する。
前提
- Admin権限のIAMユーザを作成している。(adminである必要はないがとりあえず面倒なので)
- AWSコンソールに上記ユーザでサインインしている。
- git、aws-cliインストール済。
CodeCommitにリポジトリを用意
秘密鍵と公開鍵の作成
$ ssh-keygen -t rsa -C "hogehoge@gmail.com" Generating public/private rsa key pair. Enter file in which to save the key (/Users/hoge/.ssh/id_rsa): ./codecommit_rsa Enter passphrase (empty for no passphrase): # 何も指定せずEnter。GitHubとミラーリングさせる時にエラーするため。 Enter same passphrase again: Your identification has been saved in codecommit_rsa. Your public key has been saved in codecommit_rsa.pub. The key fingerprint is: SHA256:EG3hs70mTNPFKE0AMJP0s9rij9QIeh1fQRhaPLNVErX hogehoge@gmail.com The key's randomart image is: +---[RSA 2048]----+ | .* + .B#| | = *.%. o.oB|IAMユーザと紐付け
IAM > ユーザ > 自分のユーザ名 > 認証情報(タブ) > AWS CodeCommitのSSHキー に公開鍵をUploadする。以下で中身をまるっとコピペする。
$ cat ~/.ssh/codecommit_rsa.pub
アップロードするとSSHキーIDが発行される。
configファイルの設定
UserはIAMにキーをUploadしたときに発行されるSSHキーID。.ssh/cinfigHost git-codecommit.*.amazonaws.com User APKA**************** IdentityFile ~/.ssh/codecommit_rsaリポジトリ作成
CodeCommitコンソールから
リポジトリを作成をクリックし、リポジトリ名を入力。
作成後gitクローン。$ git clone ssh://git-codecommit.リージョン名.amazonaws.com/v1/repos/リポジトリ名 Cloning into 'リポジトリ名'... warning: You appear to have cloned an empty repository.リファレンス
https://docs.aws.amazon.com/ja_jp/codecommit/latest/userguide/getting-started-cc.html
リポジトリのファイル構成
CodeBuildの実体はubuntuのDockerコンテナなのでその中でpythonのunittestを実行するコマンドを叩いてあげることでテストできる。
なお、コマンドを実行する階層はCodeCommitのリポジトリのルートの階層になる。
コマンドがどこで実行されるか初めわかっておらずはまった。$ ./testRepository └── pipeline_settings ├── buildspec.yml ├── hogehoge.py # デプロイするコード ├── template.yml └── tests └── test_hogehoge.py # UTコード
各ファイル詳細
buildspec.ymlversion: 0.2 phases: build: commands: - echo Build started on `date` - echo Compiling the Python code... - pwd # /codebuild/output/src078561561/src - ls # pipeline_settings - cd pipeline_settings - python3 -m unittest tests.test_hogehoge # tests下のtest_hogehogeを実行。 - | aws cloudformation package \ --template-file template.yml \ --s3-bucket $S3_BUCKET \ --output-template-file $PACKAGED_TEMPLATE_FILE_PATH post_build: commands: - echo Build completed on `date` artifacts: files: - $PACKAGED_TEMPLATE_FILE_PATH - pipeline_settings/* - hogehoge.py discard-paths: yeshogehoge.pyimport json def lambda_handler(event, context): # TODO implement return { 'statusCode': 200, 'body': json.dumps('Hello') }template.ymlAWSTemplateFormatVersion: "2010-09-09" #パラメータにs3Bucketとs3keyを受け取る口を用意。 Parameters: funcName: Type: String Default: deployedLambda # デプロイするLambda関数名 s3Bucket: Type: String s3Key: Type: String Resources: # IAMロール作成 LambdaExecutionRole: Type: AWS::IAM::Role Properties: AssumeRolePolicyDocument: Version: 2012-10-17 Statement: - Effect: "Allow" Principal: # 誰に権限を与えるのか Service: - "lambda.amazonaws.com" Action: # 何の権限を与えるのか - "sts:AssumeRole" # Lambdaに対して一時的な権限を発行する。 ManagedPolicyArns: - "arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole" RoleName: !Ref funcName # 実行時に指定 # コードの参照先を変更。 Function: Type: "AWS::Lambda::Function" Properties: Code: S3Bucket: !Ref s3Bucket S3Key: !Ref s3Key FunctionName: !Ref funcName Handler: "hogehoge.lambda_handler" Role: !GetAtt LambdaExecutionRole.Arn Runtime: "python3.8"リファレンス
https://dev.classmethod.jp/articles/codebuildpipeline-unittest/
パイプラインを作成
CodeCommitにPushしたらCloudFormationを用いてパイプラインを用意する。
以下でスタックpipeline-stackを用意する。$ aws cloudformation deploy --stack-name pipeline-stack --template-file pipeline.yml --capabilities CAPABILITY_NAMED_IAMD
pipeline.yml詳細
pipeline.ymlAWSTemplateFormatVersion: "2010-09-09" Resources: ArtifactBucket: Type: AWS::S3::Bucket BuildProject: Type: AWS::CodeBuild::Project Properties: Name: 'testbuildproj' # buildプロジェクト名を指定 ServiceRole: !GetAtt CodeBuildRole.Arn Artifacts: Type: CODEPIPELINE Environment: Type: LINUX_CONTAINER ComputeType: BUILD_GENERAL1_SMALL Image: aws/codebuild/ubuntu-base:14.04 EnvironmentVariables: # buildspec.yml内で使用する環境変数。 - Name: PACKAGED_TEMPLATE_FILE_PATH Value: 'packaged.yml' - Name: S3_BUCKET Value: !Ref ArtifactBucket Source: Type: CODEPIPELINE BuildSpec: pipeline_settings/buildspec.yml # ルート直下にbuildspecがあるなら指定不要。 # デプロイ時のロール。面倒なので全てAdmin権限を与えておく。 PipelineDeployRole: Type: AWS::IAM::Role Properties: AssumeRolePolicyDocument: Version: '2012-10-17' Statement: - Effect: 'Allow' Principal: Service: - 'cloudformation.amazonaws.com' Action: - 'sts:AssumeRole' ManagedPolicyArns: - 'arn:aws:iam::aws:policy/AdministratorAccess' RoleName: 'cfnrole' # ロール名 # パイプラインのロール。面倒なので全てAdmin権限を与えておく。 PipelineRole: Type: AWS::IAM::Role Properties: AssumeRolePolicyDocument: Version: '2012-10-17' Statement: - Effect: 'Allow' Principal: Service: - 'codepipeline.amazonaws.com' Action: - 'sts:AssumeRole' ManagedPolicyArns: - 'arn:aws:iam::aws:policy/AdministratorAccess' RoleName: 'pipelinerole' # ロール名 # ビルド時のロール。面倒なので全てAdmin権限を与えておく。 CodeBuildRole: Type: AWS::IAM::Role Properties: AssumeRolePolicyDocument: Version: '2012-10-17' Statement: - Effect: 'Allow' Principal: Service: - 'codebuild.amazonaws.com' Action: - 'sts:AssumeRole' ManagedPolicyArns: - 'arn:aws:iam::aws:policy/AdministratorAccess' RoleName: 'buildrole' # ロール名 Pipeline: Type: AWS::CodePipeline::Pipeline Properties: Name: 'testpipeline' # パイプライン名 RoleArn: !GetAtt PipelineRole.Arn ArtifactStore: Type: S3 Location: !Ref ArtifactBucket Stages: - Name: Source Actions: - Name: DownloadSource ActionTypeId: Category: Source Owner: AWS Version: 1 Provider: CodeCommit Configuration: RepositoryName: 'testRepository' # リポジトリ名 BranchName: 'master' OutputArtifacts: - Name: SourceOutput # オブジェクト名 - Name: Build Actions: - InputArtifacts: - Name: SourceOutput # オブジェクト名 Name: Package ActionTypeId: Category: Build Provider: CodeBuild Owner: AWS Version: 1 OutputArtifacts: - Name: BuildOutput # オブジェクト名 Configuration: ProjectName: !Ref BuildProject - Name: Deploy Actions: - Name: CreateChangeSet ActionTypeId: Category: Deploy Owner: AWS Provider: CloudFormation Version: '1' InputArtifacts: - Name: BuildOutput # オブジェクト名 Configuration: ActionMode: CHANGE_SET_REPLACE RoleArn: !GetAtt PipelineDeployRole.Arn StackName: 'system-stack' ChangeSetName: 'system-stack-changeset' Capabilities: CAPABILITY_NAMED_IAM TemplatePath: 'BuildOutput::packaged.yml' ParameterOverrides: | { "s3Bucket": { "Fn::GetArtifactAtt" : [ "BuildOutput", "BucketName" ] }, "s3Key": { "Fn::GetArtifactAtt" : [ "BuildOutput", "ObjectKey" ] } } RunOrder: '1' - Name: ExecuteChangeSet ActionTypeId: Category: Deploy Owner: AWS Provider: CloudFormation Version: '1' InputArtifacts: - Name: BuildOutput # オブジェクト名 Configuration: ActionMode: CHANGE_SET_EXECUTE ChangeSetName: 'system-stack-changeset' StackName: 'system-stack' RunOrder: '2'スタックの作成に成功すると勝手にパイプラインが走りLambdaが生成される。
以降、リポジトリにpushするとLambdaが更新される。GitHubのミラーリング
参考)
https://furiblog.com/github-codecommit-mirroring参考ページに書いてある通り設定したらよい。
なお、環境変数の変数名は任意の名称で可GitHubのリポジトリのSetting > Secretから以下の値を指定する。
CODECOMMIT_SSH_PRIVATE_KEYに秘密鍵をまるっとコピーcodecommit_rsa-----BEGIN OPENSSH PRIVATE KEY----- b6A... (略) ...WCD -----END OPENSSH PRIVATE KEY-----
CODECOMMIT_SSH_PRIVATE_KEY_IDにSSHキーID(前述)をまるっとコピー。
前述の通り、SSHキーにパスフレーズを設定しているとエラーした。Actionでは以下を使わせていただいている。
https://github.com/pixta-dev/repository-mirroring-action.github/workflows/main.ymlname: {任意の名前} on: [ push, delete ] jobs: {任意の名前}: runs-on: ubuntu-18.04 steps: - uses: actions/checkout@v1 - uses: pixta-dev/repository-mirroring-action@v1 with: target_repo_url: ssh://git-codecommit.ap-northeast-1.amazonaws.com/v1/repos/xxxxx ssh_private_key: ${{ secrets.CODECOMMIT_SSH_PRIVATE_KEY }} ssh_username: ${{ secrets.CODECOMMIT_SSH_PRIVATE_KEY_ID }}リファレンス
- 投稿日:2021-01-20T20:39:48+09:00
Amazon Cognitoを利用したIDPとのシングルサインアウトの実現
複数のWebサービスに1つのIDでシングルサインオン (SSO)・シングルログアウト (SLO) できるように、IDプロバイダ (IDP) を構築して各サービスとOpenID Connect (OIDC) やSAMLで連携する構成について考える。このときに、IDPと連携するWebサービスの構築にAWS(Amazon API GatewayやAWS AppSyncなど)を利用する方法を検討した。
IDPと連携してAWSサービスの認証を行うにはAmazon Cognitoを使うのが常套手段となる。SSOのみが要件であれば公式ドキュメントや解説記事も多く悩むポイントは少ないが、SLOの実現についてはあまり取り上げられていない。この記事ではAmazon CognitoでIDP連携する際のSLOの実現方法を整理する。
前提
- IDPと各サービスは異なるドメイン(オリジン)で提供される。
- IDPと各サービスはOpenID Connect (OIDC) もしくはSAMLで連携する。
- AWSサービスとIDPの連携は以下のいずれかの方法で行う。
- Amazon Cognito User Pools (Hosted Web UI) のフェデレーション機能
- Amazon Cognito Federated Identity Poolsの外部IDP連携機能
- SafariやFirefoxにてデフォルトで制限されることとなった、Front-Channelで3rd Partyコンテキストを利用する仕組み(OIDCのFront-Channel Logoutなど)は採用しない。
SLO実現方法
Amazon Cognito User Poolsを使う場合とAmazon Cognito Identity Poolsを使う場合のそれぞれについて、SLOを実現する方法と制限となることを説明する。
Amazon Cognito User Pools
サービス起点のSLO(サービスからログアウトしたときにIDPからもログアウトする)
- IDPとSAMLで連携する場合は、User PoolのSAML連携設定でSLOを有効化すればよい。
- 設定を有効化すると、User PoolのLOGOUT Endpoint呼び出し時に、User Pool (Hosted UI) のセッションが削除された後でIDPにリダイレクトされ(HTTP Redirect Bindingで)SLOリクエストが伝達される。
- 参考:Creating and Managing a SAML Identity Provider for a User Pool (AWS Management Console)
- IDPとOIDCで連携する場合は、User PoolはOIDCでのSLO機能をサポートしていないため、User Poolのログインセッションを無効化後のLOGOUT Endpointからのリダイレクトを受けて、OIDCのRP-Initiated Logoutを行う処理をサービス側に(もしくはIDPの機能として)作り込む必要がある。
- 参考:OpenID Connect RP-Initiated Logout 1.0 - draft 01
IDP起点のSLO(IDPからログアウトしたときにサービスからもログアウトする)
- リアルタイムでのSLOを実現するには、IDPでのログアウト処理にてブラウザをUser PoolのLOGOUT Endpointに一度リダイレクトする必要がある。(IDP側に作り込みが必要となる。)
- OIDC連携、SAML連携のどちらの場合でも、Back-Channel(ブラウザ経由ではなくバックエンド間の通信)を使ってIDPからUser Poolにログアウト要求を送る方法は提供されていない。
- User Poolにはトークン発行等のタイミングにLambdaトリガーを設定する機能があるが、トリガー処理ではIDPとのフェデレーションに関する情報にアクセスできないためIDPのセッション状態を確認することはできず、IDPのセッションが無効な場合にトークン発行をエラーにする、といった対応も実現できない。
- User Pool経由でログインするサービスからは、IDP側のログインセッションに関する情報にアクセスできない(完全に隠蔽される)ため、サービス側でIDPのセッション状態を監視する機能を作り込むこともできない。
その他の制限
- User Poolが発行するアクセストークン・リフレッシュトークンは、ログインセッションとライフサイクルが分離されており、たとえ前述の方法でUser Poolのログインセッションを削除しても有効期限まで有効となる。
- また、User Poolが発行するアクセストークン・リフレッシュトークンをログインセッション単位で無効化する機能も提供されていない。(ユーザーに紐づく全てのトークンを無効化するGlobalSignOut APIが提供されているがログインセッション単位での削除はできない。)
Amazon Cognito ID Pools
- ID Poolsを利用する場合は、サービスとIDPは直接フェデレーション連携を行うこととなる。
- ID Poolsの役割はあくまで、IDPが発行するアサーション(OIDCではIDトークン、SAMLではSAMLアサーション)を検証して、AWSサービスの認証に利用できるTemporary Credentialを発行するまでとなる。
- サービスとIDPのSLOについても通常のOIDC、SAML連携と同様に作り込めばよいが、Temporary Credential(有効期限は最短でも1時間)は個別に無効化ができない。
- 投稿日:2021-01-20T20:39:48+09:00
Amazon Cognitoを利用したIDPとのシングルサインアウト連携の実現
複数のWebサービスに1つのIDでシングルサインオン (SSO)・シングルログアウト (SLO) できるように、IDプロバイダ (IDP) を構築して各サービスとOpenID Connect (OIDC) やSAMLで連携する構成について考える。このときに、IDPと連携するWebサービスの構築にAWS(Amazon API GatewayやAWS AppSyncなど)を利用する方法を検討した。
IDPと連携してAWSサービスの認証を行うにはAmazon Cognitoを使うのが常套手段となる。SSOのみが要件であれば公式ドキュメントや解説記事も多く悩むポイントは少ないが、SLOの実現についてはあまり取り上げられていない。この記事ではAmazon CognitoでIDPと連携する際のSLOの実現方法を整理する。
前提
- IDPと各サービスは異なるドメイン(オリジン)で提供される。
- IDPと各サービスはOpenID Connect (OIDC) もしくはSAMLで連携する。
- AWSサービスとIDPの連携は以下のいずれかの方法で行う。
- Amazon Cognito User Pools (Hosted Web UI) のフェデレーション機能
- Amazon Cognito Federated Identity Poolsの外部IDP連携機能
- SafariやFirefoxにてデフォルトで制限されることとなった、Front-Channelで3rd Partyコンテキストを利用する仕組み(OIDCのFront-Channel Logoutなど)は採用しない。
SLO実現方法
Amazon Cognito User Poolsを使う場合とAmazon Cognito Identity Poolsを使う場合のそれぞれについて、SLOを実現する方法と制限となることを説明する。
Amazon Cognito User Pools
サービス起点のSLO(サービスからログアウトしたときにIDPからもログアウトする)
- IDPとSAMLで連携する場合は、User PoolのSAML連携設定でSLOを有効化すればよい。
- 設定を有効化すると、User PoolのLOGOUT Endpoint呼び出し時に、User Pool (Hosted UI) のセッションが削除された後でIDPにリダイレクトされ(HTTP Redirect Bindingで)SLOリクエストが伝達される。
- 参考:Creating and Managing a SAML Identity Provider for a User Pool (AWS Management Console)
- IDPとOIDCで連携する場合は、User PoolはOIDCでのSLO機能をサポートしていないため、User Poolのログインセッションを無効化後のLOGOUT Endpointからのリダイレクトを受けて、OIDCのRP-Initiated Logoutを行う処理をサービス側に(もしくはIDPの機能として)作り込む必要がある。
IDP起点のSLO(IDPからログアウトしたときにサービスからもログアウトする)
- リアルタイムでのSLOを実現するには、IDPでのログアウト処理にてブラウザをUser PoolのLOGOUT Endpointに一度リダイレクトする必要がある。(IDP側に作り込みが必要となる。)
- OIDC連携、SAML連携のどちらの場合でも、Back-Channel(ブラウザ経由ではなくバックエンド間の通信)を使ってIDPからUser Poolにログアウト要求を送る方法は提供されていない。
- User Poolにはトークン発行等のタイミングでLambdaを実行するLambdaトリガーを設定する機能があるが、トリガー処理ではIDPとのフェデレーションに関する情報にアクセスできないため、ここでIDPのセッション状態を確認することはできない。このため、IDPのセッションが無効な場合にトークン発行をエラーにする、といった作り込みも実現できない。
- User Pool経由でログインするサービスからは、IDP側のログインセッションに関する情報にアクセスできない(完全に隠蔽される)ため、サービス側でIDPのセッション状態を監視する機能を作り込むこともできない。
その他の制限
- User Poolが発行するアクセストークン・リフレッシュトークンは、ログインセッションとライフサイクルが分離されており、たとえ前述の方法でUser Poolのログインセッションを削除しても有効期限まで有効となる。
- また、User Poolが発行するアクセストークン・リフレッシュトークンをログインセッション単位で無効化する機能も提供されていない。(ユーザーに紐づく全てのトークンを無効化するGlobalSignOut APIが提供されているがログインセッション単位での削除はできない。)
Amazon Cognito ID Pools
- ID Poolsを利用する場合は、サービスとIDPは直接フェデレーション連携を行うこととなる。
- ID Poolsの役割はあくまで、IDPが発行するアサーション(OIDCではIDトークン、SAMLではSAMLアサーション)を検証して、AWSサービスの認証に利用できるTemporary Credentialを発行するまでとなる。
- サービスとIDPのSLOについても通常のOIDC、SAML連携と同様に作り込めばよいが、Temporary Credential(有効期限は最短でも1時間)は個別に無効化ができない。
- 投稿日:2021-01-20T20:39:48+09:00
Amazon Cognitoを利用したIDPとのシングルログアウト連携の実現
複数のWebサービスに1つのIDでシングルサインオン (SSO)・シングルログアウト (SLO) できるように、IDプロバイダ (IDP) を構築して各サービスとOpenID Connect (OIDC) やSAMLで連携する構成について考える。このときに、IDPと連携するWebサービスの構築にAWS(Amazon API GatewayやAWS AppSyncなど)を利用する方法を検討した。
IDPと連携してAWSサービスの認証を行うにはAmazon Cognitoを使うのが常套手段となる。SSOのみが要件であれば公式ドキュメントや解説記事も多く悩むポイントは少ないが、SLOの実現についてはあまり取り上げられていない。この記事ではAmazon CognitoでIDPと連携する際のSLOの実現方法を整理する。
前提
- IDPと各サービスは異なるドメイン(オリジン)で提供される。
- IDPと各サービスはOpenID Connect (OIDC) もしくはSAMLで連携する。
- AWSサービスとIDPの連携は以下のいずれかの方法で行う。
- Amazon Cognito User Pools (Hosted Web UI) のフェデレーション機能
- Amazon Cognito Federated Identity Poolsの外部IDP連携機能
- SafariやFirefoxにてデフォルトで制限されることとなった、Front-Channelで3rd Partyコンテキストを利用する仕組み(OIDCのFront-Channel Logoutなど)は採用しない。
SLO実現方法
Amazon Cognito User Poolsを使う場合とAmazon Cognito Identity Poolsを使う場合のそれぞれについて、SLOを実現する方法と制限となることを説明する。
Amazon Cognito User Pools
サービス起点のSLO(サービスからログアウトしたときにIDPからもログアウトする)
- IDPとSAMLで連携する場合は、User PoolのSAML連携設定でSLOを有効化すればよい。
- 設定を有効化すると、User PoolのLOGOUT Endpoint呼び出し時に、User Pool (Hosted UI) のセッションが削除された後でIDPにリダイレクトされ(HTTP Redirect Bindingで)SLOリクエストが伝達される。
- 参考:Creating and Managing a SAML Identity Provider for a User Pool (AWS Management Console)
- IDPとOIDCで連携する場合は、User PoolはOIDCでのSLO機能をサポートしていないため、User Poolのログインセッションを無効化後のLOGOUT Endpointからのリダイレクトを受けて、OIDCのRP-Initiated Logoutを行う処理をサービス側に(もしくはIDPの機能として)作り込む必要がある。
IDP起点のSLO(IDPからログアウトしたときにサービスからもログアウトする)
- リアルタイムでのSLOを実現するには、IDPでのログアウト処理にてブラウザをUser PoolのLOGOUT Endpointに一度リダイレクトする必要がある。(IDP側に作り込みが必要となる。)
- OIDC連携、SAML連携のどちらの場合でも、Back-Channel(ブラウザ経由ではなくバックエンド間の通信)を使ってIDPからUser Poolにログアウト要求を送る方法は提供されていない。
- User Poolにはトークン発行等のタイミングでLambdaを実行するLambdaトリガーを設定する機能があるが、トリガー処理ではIDPとのフェデレーションに関する情報にアクセスできないため、ここでIDPのセッション状態を確認することはできない。このため、IDPのセッションが無効な場合にトークン発行をエラーにする、といった作り込みも実現できない。
- User Pool経由でログインするサービスからは、IDP側のログインセッションに関する情報にアクセスできない(完全に隠蔽される)ため、サービス側でIDPのセッション状態を監視する機能を作り込むこともできない。
その他の制限
- User Poolが発行するアクセストークン・リフレッシュトークンは、ログインセッションとライフサイクルが分離されており、たとえ前述の方法でUser Poolのログインセッションを削除しても有効期限まで有効となる。
- また、User Poolが発行するアクセストークン・リフレッシュトークンをログインセッション単位で無効化する機能も提供されていない。(ユーザーに紐づく全てのトークンを無効化するGlobalSignOut APIが提供されているがログインセッション単位での削除はできない。)
Amazon Cognito ID Pools
- ID Poolsを利用する場合は、サービスとIDPは直接フェデレーション連携を行うこととなる。
- ID Poolsの役割はあくまで、IDPが発行するアサーション(OIDCではIDトークン、SAMLではSAMLアサーション)を検証して、AWSサービスの認証に利用できるTemporary Credentialを発行するまでとなる。
- サービスとIDPのSLOについても通常のOIDC、SAML連携と同様に作り込めばよいが、Temporary Credential(有効期限は最短でも1時間)は個別に無効化ができない。
- 投稿日:2021-01-20T17:58:58+09:00
システムステータスチェックとインスタンスステータスチェックの失敗に備えた対処法
タイトルの内容を設定する方法
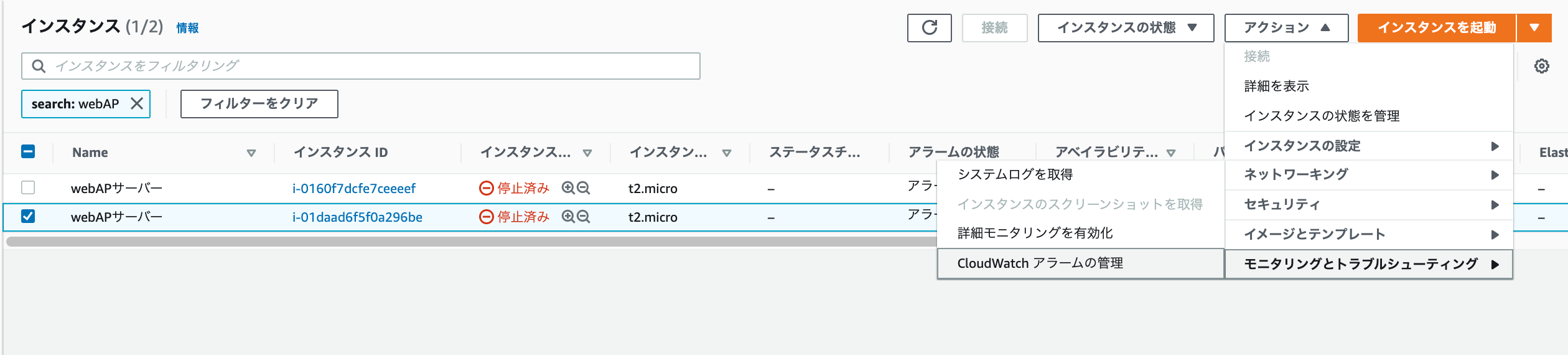
ec2のコンソールを開き、画像のように選択。
アラームアクションは、下記4種類が設定できるが、システムチェックか、インスタンスチェックかで方法が異なる。
システムチェックの場合は、「復旧」を。インスタンスチェックの場合は「再起動」を選択。
システムチェックとインスタンスチェックの詳細は、以下を参考に。
https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/monitoring-system-instance-status-check.html#types-of-instance-status-checks
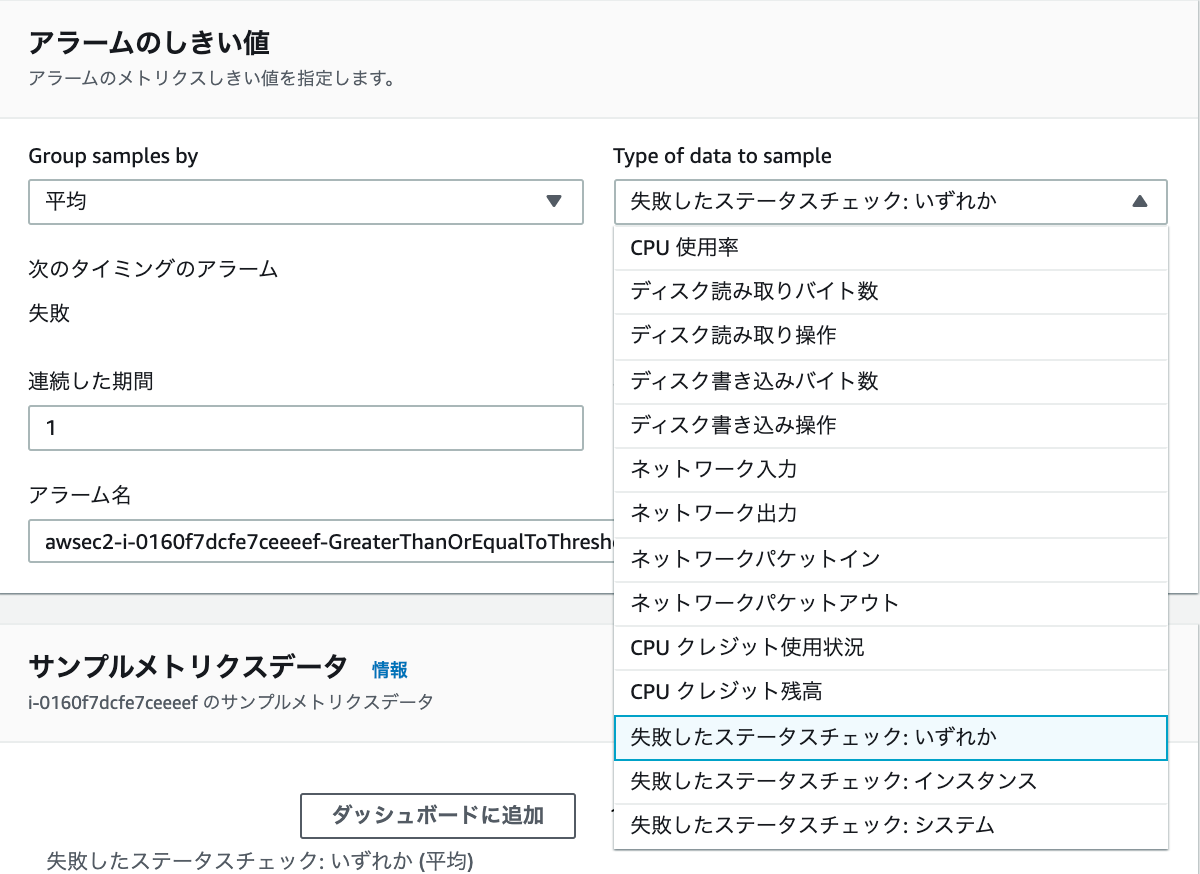
Type of data to sampleの項目で、以下を選択
インスタンスチェックの場合→失敗したステータスチェック:インスタンス
システムチェックの場合→失敗したステータスチェック:システム
ちなみに、Type of data to sampleの項目で、インスタンスチェックの場合→「失敗したステータスチェック:インスタンス」を選択し、アラームアクションで「復旧」を選択すると下記画像のようにエラーが出力されるので、注意。
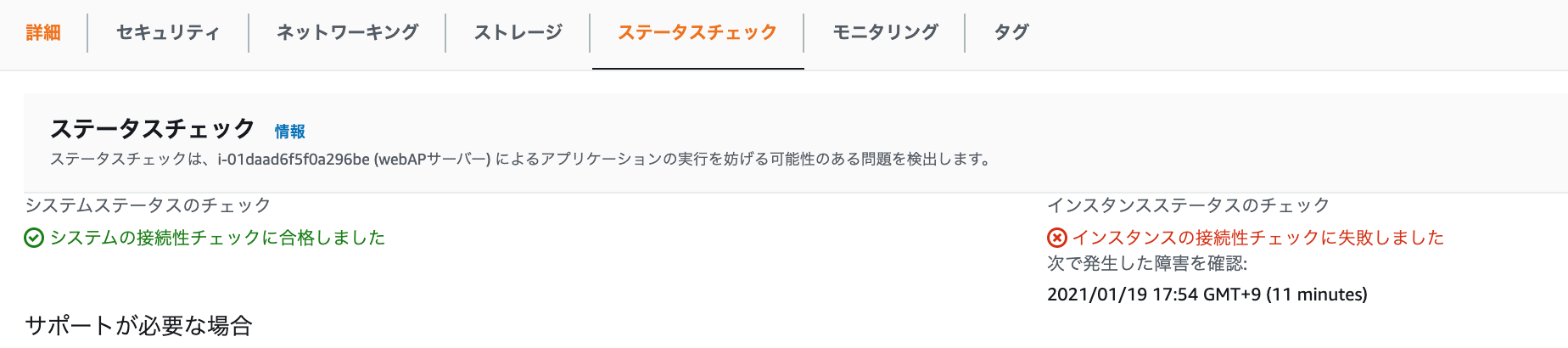
意図的にインスタンスステータスをエラーにする方法
インスタンスに接続した状態で、下記コマンドを実行し、ネットワークインターフェースを切断させる。(root権限)
ifconfig eth0 downifconfigコマンドに関しては、以下を参照。
https://www.atmarkit.co.jp/ait/articles/0109/29/news004.htmlコマンドを実行して、インスタンスのステータスチェックを確認すると下記画像のように、エラーが確認できる。


- 投稿日:2021-01-20T17:32:11+09:00
Multi-AZ構成のRDSを強制フェイルオーバーさせる方法
Multi-AZ構成を構築する方法
下記の2手順で構築可能
1.RDSのコンソール画面を開き、「データベースの作成」を選択
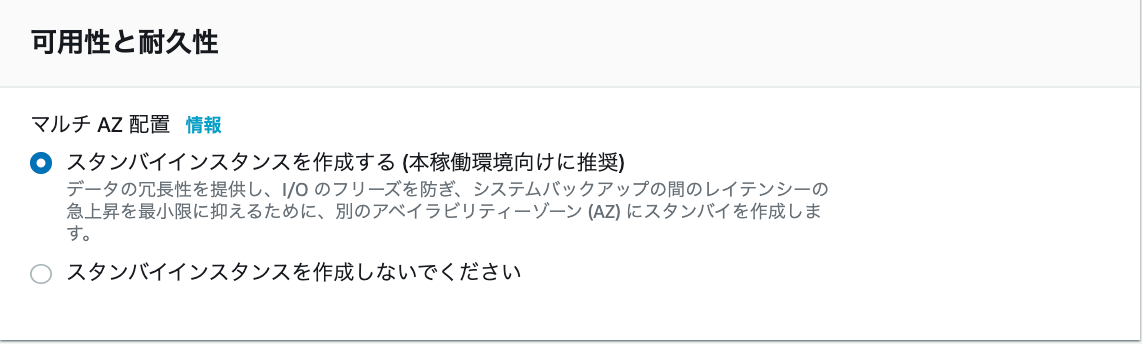
2.次画面の中盤あたりに、下記画像の項目があるので、「スタンバイインスタンスを作成する」を選択(Amazon aurora以外)
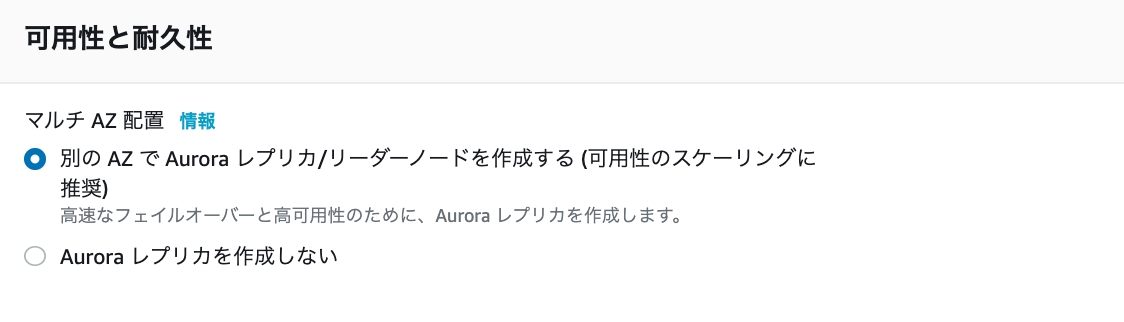
Amazon auroraの場合は、少し表記が異なる。以下画像のように選択。
強制的にフェイルオーバーさせる方法(手動)
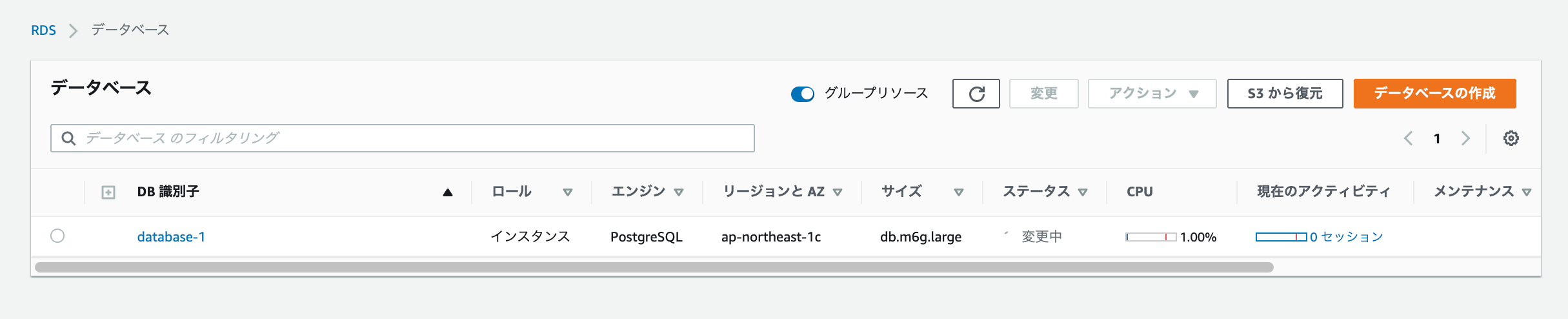
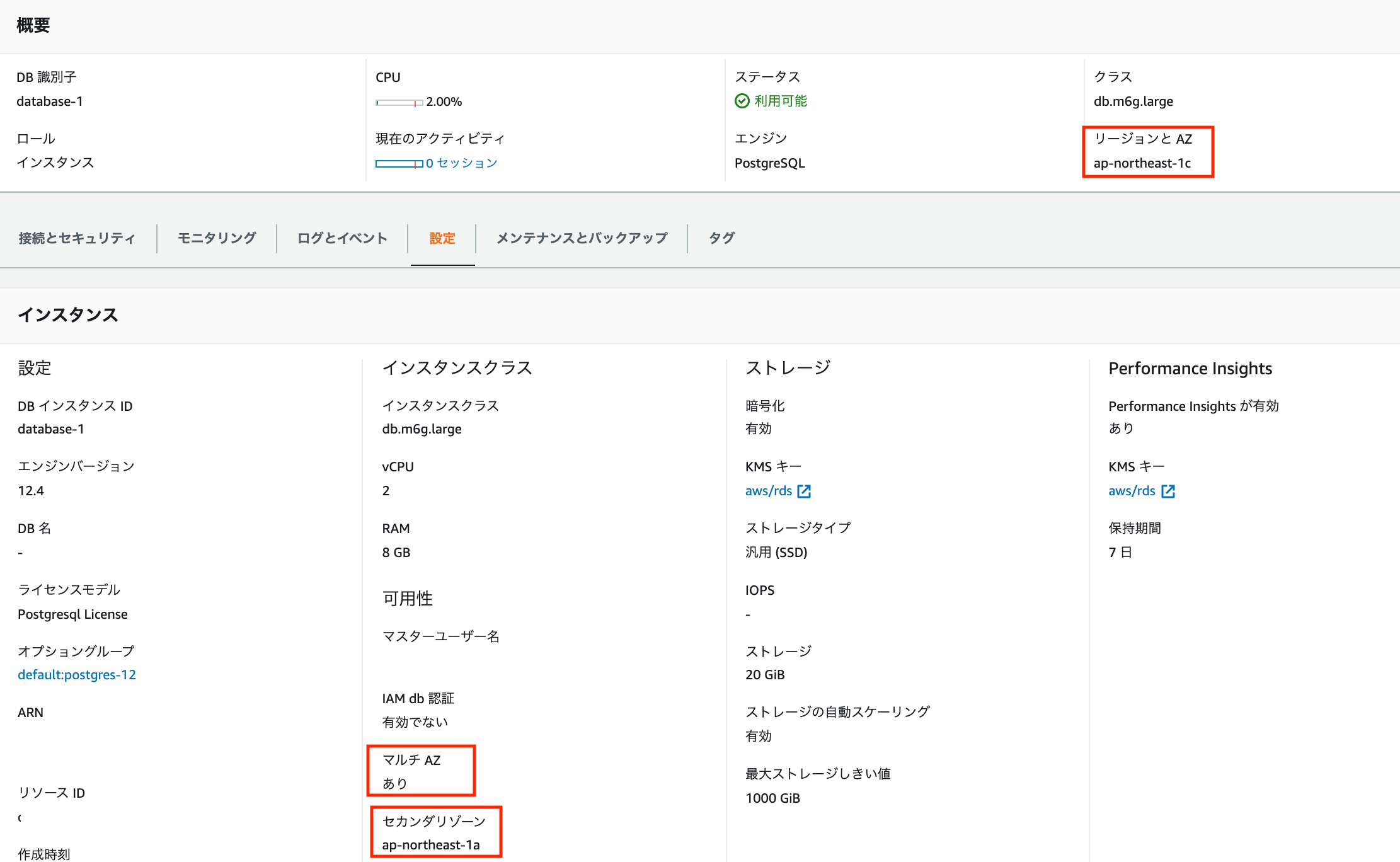
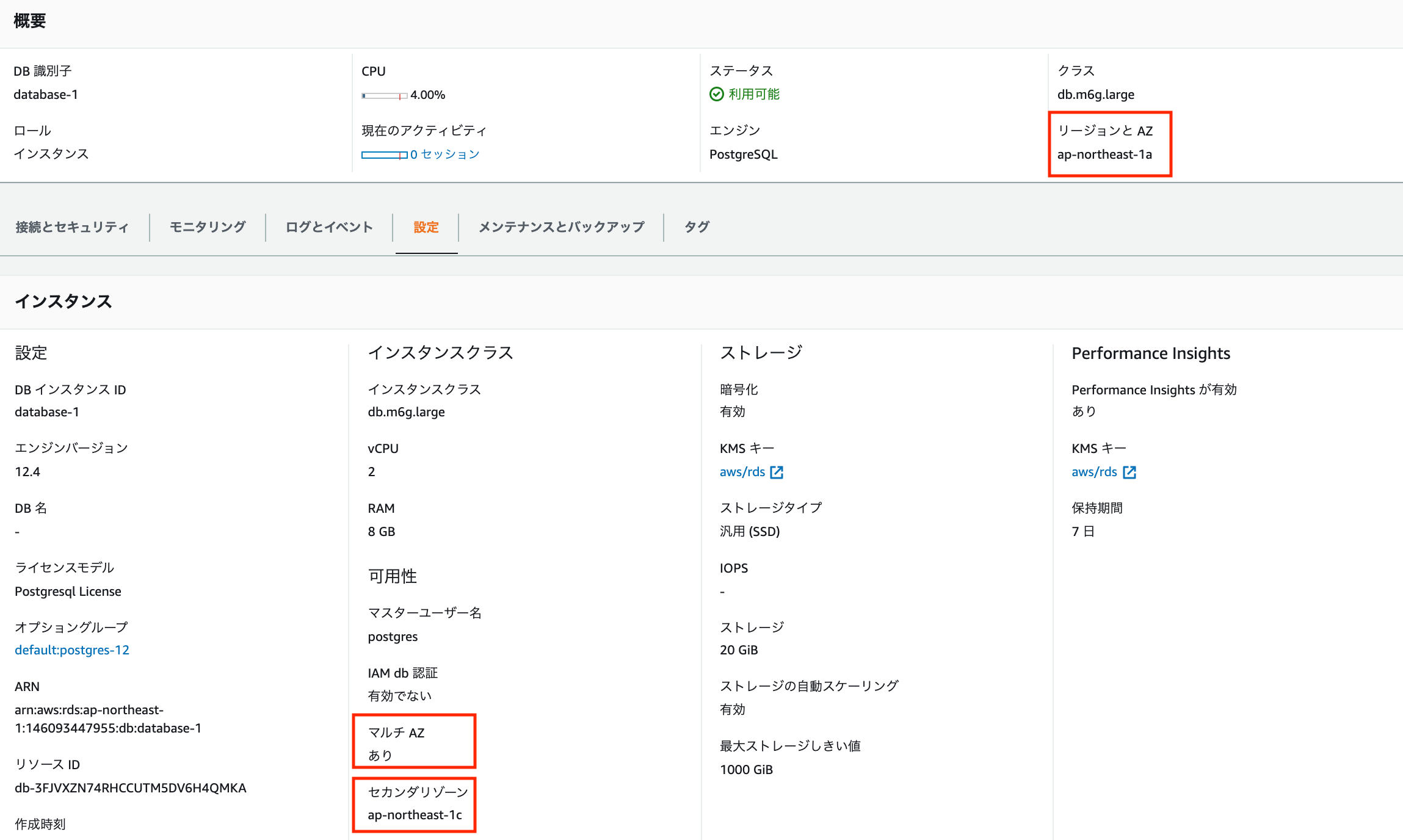
フェイルオーバーさせる前の状況は、以下画像の通り。
プライマリが1cにセカンダリが1aに配置されている。また、マルチAZも「あり」と記載されていて有効だと分かる。
それでは、フェイルオーバー(手動)の作業に入る。
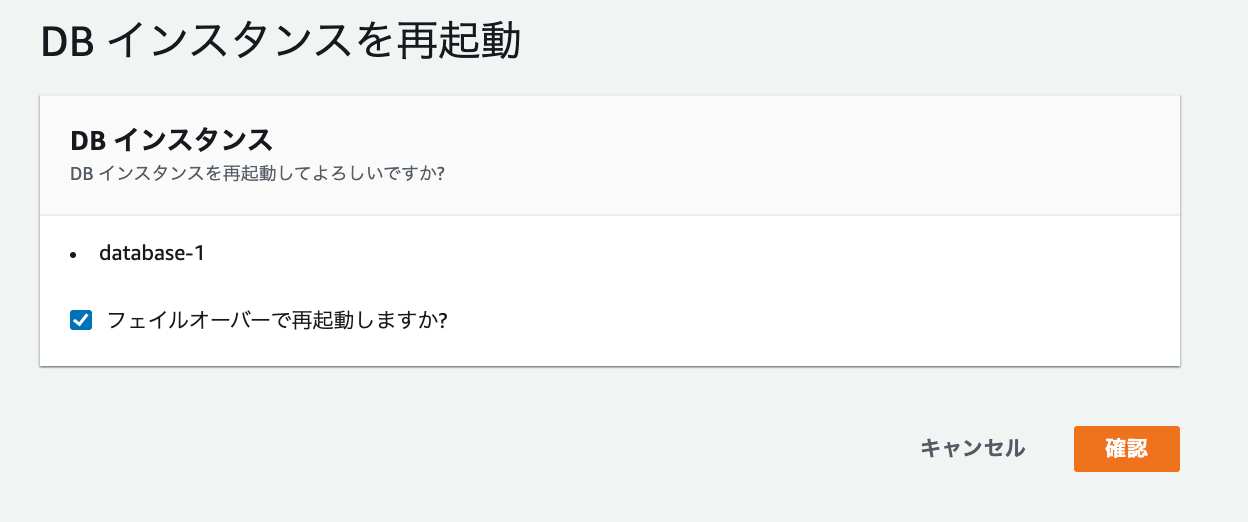
方法は簡単で、「アクション」から「再起動」を実行すれば実現できる。
「フェイルオーバーで起動しますか?」のチェックを忘れずに。
以下画像は再起動後の状態。プライマリが1aに、セカンダリが1cに変更している。
なお、このまま処理を施さなければ、フェイルオーバー前に戻ることはない。
元に戻したい場合は、再度「再起動」を実行する。

- 投稿日:2021-01-20T15:05:43+09:00
AWS ルーティングテーブルの書き換えによるAZまたぎでのフェイルオーバ
オンプレミスとawsをダイレクトコネクト接続するにあたり、ルータのインスタンスを作成しました。awsではVRRPなどを使って冗長化することができませんが、lambdaを使ってawsのルーティングテーブルを書き換えることで、似たようなことが実現できます。
この内容は、以下のブログを参考にしています。
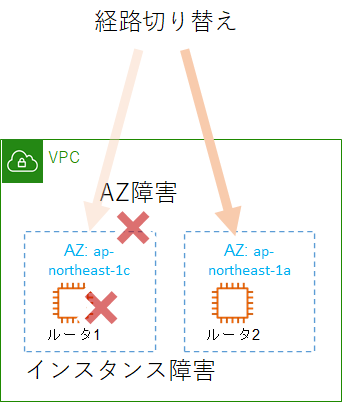
Making Application Failover Seamless by Failing Over Your Private Virtual IP Across Availability Zones以下のように、AZを超えた切り替えを目指します。
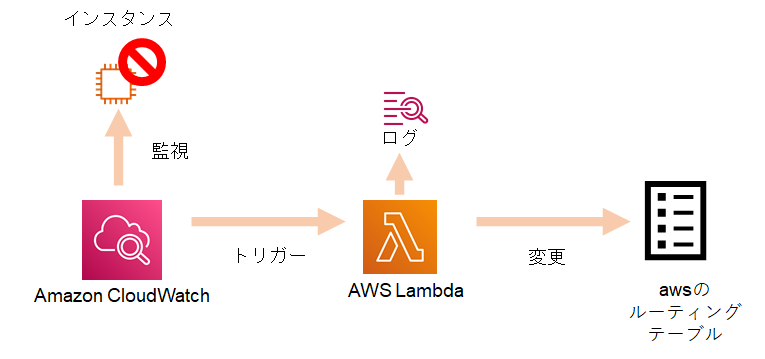
cloudwatchが検知する、インスタンスの"stopping"イベントをトリガーにして切り替えることにしました。cloudwatchの設定で、ステータスチェック(ping)に失敗すると、インスタンスを再起動するようにしてあります。
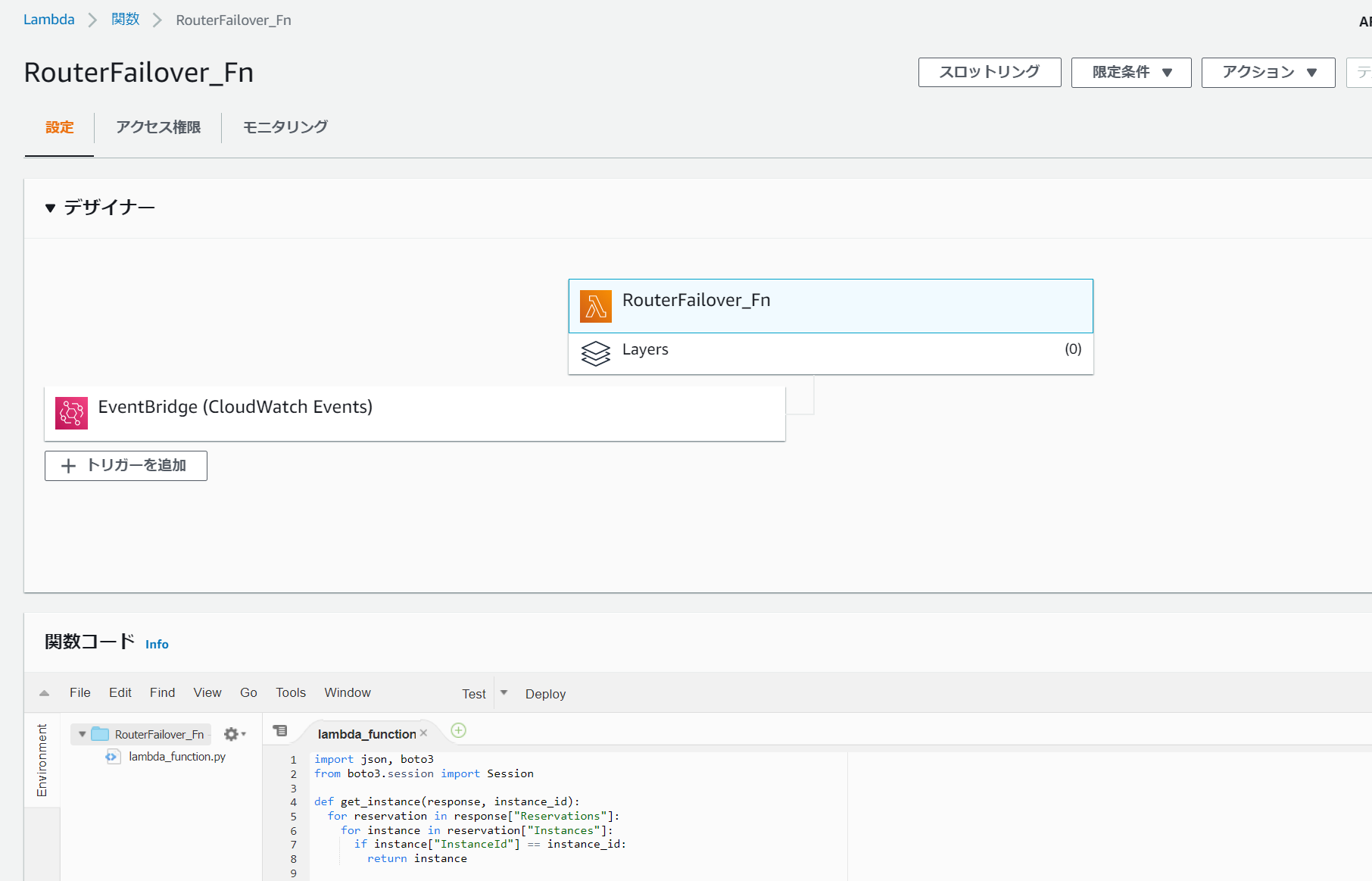
lambdaは以下のように、cloudwatchをトリガにして起動する関数を設定します。
RouterFailover_Fn
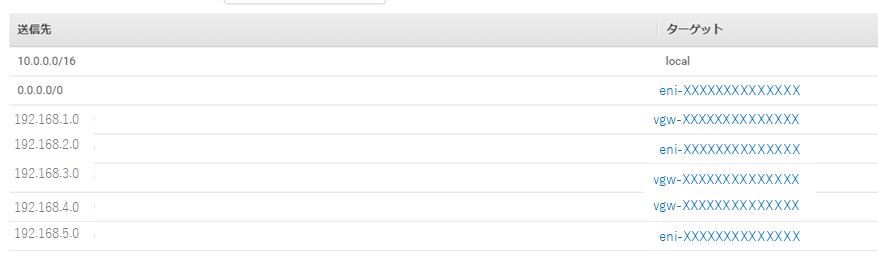
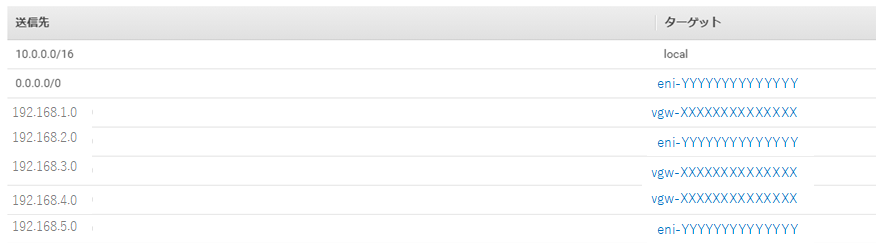
import json, boto3 from boto3.session import Session def get_instance(response, instance_id): for reservation in response["Reservations"]: for instance in reservation["Instances"]: if instance["InstanceId"] == instance_id: return instance def get_iface(instance): if instance.get("NetworkInterfaces", False): return instance["NetworkInterfaces"][0] def lambda_handler(event, context): host1eni = 'eni-XXXXXXXXXXXXXX' #ルータ1のeniをセット host2eni = 'eni-YYYYYYYYYYYYYY' #ルータ2のeniをセット vpcid = 'vpc-qqqqqqqqq' #vpcをセット region = 'ap-northeast-1' #リージョンをセット print(event) my_instance_id = event['detail']['instance-id'] session = boto3.session.Session() ec2client = session.client('ec2', region_name = region) response = ec2client.describe_instances() instance = get_instance(response, my_instance_id) iface = get_iface(instance) print(iface['NetworkInterfaceId']) ifid = iface['NetworkInterfaceId'] if ifid == host1eni: altifid = host2eni elif ifid == host2eni: altifid = host1eni else: return route_table = ec2client.describe_route_tables(Filters=[{'Name': 'vpc-id','Values': [vpcid,]},])['RouteTables'] for iter in route_table: for each_route in iter['Routes']: try: if each_route['NetworkInterfaceId'] == ifid: try: print (iter['RouteTableId'] + " Route Deleting started for "+str(each_route['DestinationCidrBlock'])+" with eniid "+ifid ) ec2client.delete_route(DestinationCidrBlock=each_route['DestinationCidrBlock'],RouteTableId=iter['RouteTableId']) print (iter['RouteTableId'] + " Route Deleted for "+str(each_route['DestinationCidrBlock'])+" with eniid "+ifid ) except Exception as e: print (e) try: print (iter['RouteTableId'] + " Route creating started for "+str(each_route['DestinationCidrBlock'])+" with eniid "+altifid) ec2client.create_route(DestinationCidrBlock=each_route['DestinationCidrBlock'],NetworkInterfaceId=altifid,RouteTableId=iter['RouteTableId']) print (iter['RouteTableId'] + " Route created for "+str(each_route['DestinationCidrBlock'])+" with eniid "+altifid) except Exception as e: print (e) except: continueルータ1のインスタンスを停止させると、対象のeniが書き換わります。
書き換わる前
書き換わった後
最後に
awsのロードバランサはIPレベルでの切り替えができないので、ルータを切り替えたいような
場合に便利なソリューションです。
参考元のブログのように、cloudwatchの検知対象を広げれば、プロセスやサービスレベルのダウンなどのイベントでの切り替えが可能になります。
高度なHAクラスタの仕組みを導入しなくとも、少ないコードだけで実現できるのもリーズナブルで良いのではないでしょうか。
- 投稿日:2021-01-20T14:51:58+09:00
Amazon API GatewayのHTTP APIをOpen APIを利用して定義してみた (1/2)
はじめに
AWS ドキュメントを見ながら、Amazon API GatewayのHTTP APIをOpenAPIを利用して定義する機会があったので、メモとして残します。当記事は手順を簡単に解説し、別記事にて、実際のサンプルを提示したいと思います。
サマリ
- Open APIを利用したAPI定義が可能
- 定義は別ファイルに外部化することも可能
- 外部化したファイルに対してもパラメータや他のスタックのExportした値、擬似変数が利用可能
今回試した設定のもとになる要件
- HTTP APIを採用する
- APIは数十のパスが想定され、メンテナンスが発生しやすい
- 統合先としては、VPC Linkを利用してプライベートなVPCのALBと、AWS Lambda関数がある
- mTLS接続をする。つまり、ためにカスタムドメインとトラストストアの構成,ACMの証明書が必要
- アクセスログを出力する
- いくつかのパスはIAMによる認可が必要
- CORS設定が必要
- DeployはSAM(Serverless Application Model)を利用する
構成
概要
- デフォルトVPCを利用。
- Stack1:ALBやバケットなど周辺リソースを作成
- Stack2: API やVPC Link、Logsなどを作成
定義ファイル
- Stack1用のyaml(SAMテンプレート)
- Stack2用のyaml(SAMテンプレート)
- Stack2から参照するOpenAPI定義(yaml)
デプロイ方法
以下のコマンドでビルド& デプロイ
sam build sam deploy構成の作成手順
ざっくりと
- まず、APIのバックエンドは前述の通りInternal なALB( Internet FacingしないALB)を利用するため、VPC1つ、Subnet2つ(ALBはサブネットが二つ必要)が必要だった。これは、一から作らず、既存のVPC/Subnetを利用することにして手抜きした。(しかもインターネットからアクセス可能なサブネットを利用).
- 続いて、ALBやALBに必要なSecurityGroup、HTTP APIの統合先として指定するALBのListenerをCFnで作成(Stack1)。その際、OutputsでHTTP ListenerやVPC/SubnetをExportとし別スタックで利用できるように作成。
- mTLSで必要になるルートCAの証明書、中間CAの証明書を格納するためのS3バケットを作成(Stack1)し、Bucket名をOutputsでExport
- mTLS用の証明書(ルートCAの証明書、中間CA証明書、クライアント証明書)をコマンドで手作業で発行した。Stack1でExportし、Importできるように構成
- ACMを利用してGUIでAPI Gatewayで利用するためのサーバ証明書を発行、Stack1でExport(別にExportしなくてもよいが気分的にやってみました)
- API GatewayからバックエンドのInternalなALBに接続をするために、VPC Linkと Security Groupを作成(Stack2)
- パスが未定義な状態のAPI Gatewayを定義(Stack2)
- デプロイされたAPI Gatewayにダミーでパスを手動で1つ登録し、OpenAPI 定義をYaml形式でExport
- ExportしたOpenAPIのYAMLを利用してPaths等を定義
- Stack2のUpdate
API GatewayとOpenAPI部分の内容
- API Gatewayのスタックで定義したもの
- API Gatewayが利用するIAM ROle
- API Gatewayのアクセスログ出力先のCloudWatch Logグループ
- API定義
- OpenAPIを定義したファイルのパス指定
- Access Logの設定
- 警告発生時は失敗にする設定
- Domainの設定
- Domain Mappingの設定
- Open APIを定義
- Pathsの定義
- HTTP Method
- Path
- Auth
- Parameter Mappings
- Integration(ALB/Lambda)
- CORS
- Security
API Gatewayの定義をしてからOpen APIの定義をExportし、ExportされたYAMLに対して必要な定義をした方法を選択したのは、APIGatewayのOpenAPI定義について熟練者ではない私にとっては、API Gatewayで定義したものがどういう形でExportされるのか確認し、それを参考に定義するのが速く、正確な方法だと理解したためである。いちから書ける人はダミーのパス登録やExportは不要だが、簡単な方法なので構造を把握するという意味で試すとよい。
次回は実際のコマンドやテンプレートを掲載する予定
- 投稿日:2021-01-20T14:14:46+09:00
CloudWatch Alarmが氾濫しているので停止する。
(備忘録)CloudWatch Alarmがうるさいので、停止した。
目的
わが社ではCloudWatchAlarmを設定し、アラート内容をタスクとしてチケット化するシステムを作っているのですが、不要なアラート(テスト等によるもの)のチケットが氾濫し始めたので、停止する方法を調べました。備忘録です。
手順
CloudWatchの権限を持ったユーザでCloudShellからCLIをたたくだけ。
$ aws cloudwatch disable-alarm-actions --alarm-name 【Alarm名】再開は↓
$ aws cloudwatch enable-alarm-actions --alarm-name 【Alarm名】アラームが停止していることを確認する際は、CloudWatchAlarmのコンソールで、表示設定をいじいじして「アクションが有効になっています」を表示させる。
無効になっていれば停止完了。以上。
- 投稿日:2021-01-20T12:56:50+09:00
AWS概要 セキュリティ、ID管理について
概要
もはや何番煎じているか分かりません。
1月から個人的に始めている未経験AWSチャレンジの一環として、CP試験に向けての個人的なメモとして記述します。※は書き方を模索中ですが、問題を通して思った感想になります
セキュリティ、ID管理
AWS Identity and Access Management(AWS IAM)
AWS利用者に対して、AWSのサービス範囲を制御するサービス
・識別:ユーザーの発行(登録)
・認証:登録されたユーザーかの確認
・認可:登録されているユーザーは何が出来るのか制御・IAMユーザー:個人
・IAMグループ:チーム開発
・IAMロール :サードパーティのIdP(SAML認証)に権限を委任する場合の仕組み
→他のサイトでも個人情報を提供する仕組みのこと(SAML認証があれば、他のサイトで使いまわせる)・IAMポリシー:サービス(リソース側)が使用者を判断する
「どのAWSサービスの」「どんな操作を」「許可する」をJSON形式で記述
”物”側で認証するという考え方AWS Certificate Manager(ACM)
AmazonRoute53でも記述した証明書を発行することが出来る
ELB(ALB)に適用させることで、アプリケーションをHTTPS通信に対応することが出来る※ AWS経験者のPFだとよく取り入れられているのをみます
- 投稿日:2021-01-20T11:17:02+09:00
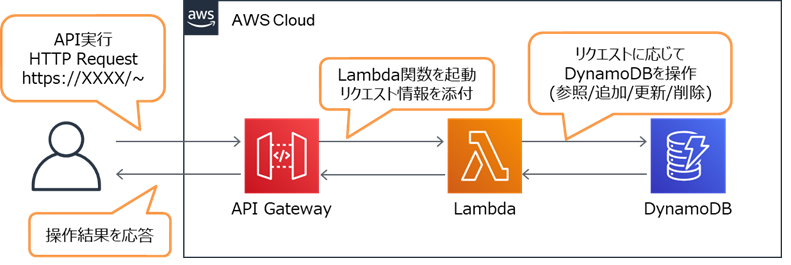
AWSのAPI Gateway + Lambda + DynamoDBでAPI作ってみた
はじめに
はじめまして。筆者の伊藤です。
今回はタイトルにある通りAWSを使ってサーバレスなAPIを作ってみたいと思います。
本記事の目的は以下の通りです。
- アプリ開発未経験者によるAPI設計構築とpython学習(初歩的な内容となります)
- サーバレスAPI構築に必要となるAWSサービスの学習
似た目的の方がいらっしゃれば一度記事に目を通してみて下さい。
APIとは?
そもそもAPIとは何なのか?作る前に改めて確認してみましょう。
API(Application Programing Interface)とは
「サービス・アプリ開発を効率化するためのある機能・データと
その仕様を定め公開しているもの」とのこと。
一般的にインターネット上で公開されているものはWeb APIと呼ばれ、
私たちでも利用することが可能ですね。(Twitter、Facebook、Amazonなど)
APIをサービス・アプリ開発に活用することで
利用者は自身のサービス・アプリに少ない労力で新しい機能や最新情報を追加でき
開発者はAPIを使ってもらうことでAPIの宣伝や利用料を得る
といったメリットがあります。作成するAPIの要件
本記事では以下の要件を満たすAPIを作って公開することを目的にしたいと思います!
APIのプラットフォームはAWSを使用し、流行りのサーバレス構成で構築する。
以下のサンプルデータを外部からHTTPリクエストで参照できるAPIとする。
ProductCatalog
製品ID(ProductId) 製品名(Name) 価格(Price) 製造元(Manufacturer) 100001 Server 200000 AAA Inc. 200001 DesktopPC 100000 BBB Co., Ltd. 300001 HDD 20000 CCC Corp.
- 操作は参照のみとする。(追加や更新、削除は考慮事項が多いため今回は対象外)
https://api.example.com/productcatalog
⇒データの全件参照
https://api.example.com/productcatalog/製品ID
⇒指定したIDの個別参照シンプルなAPIですが勉強がてらさっそく作っていきたいと思います!
DynamoDB
まずはサンプルデータの保管先となるDynamoDBの構築からです。
DynamoDBはAWSが提供するマネージドなNoSQLデータベースですね。まずAWSのマネージドコンソールから「DynamoDB」を選択し、
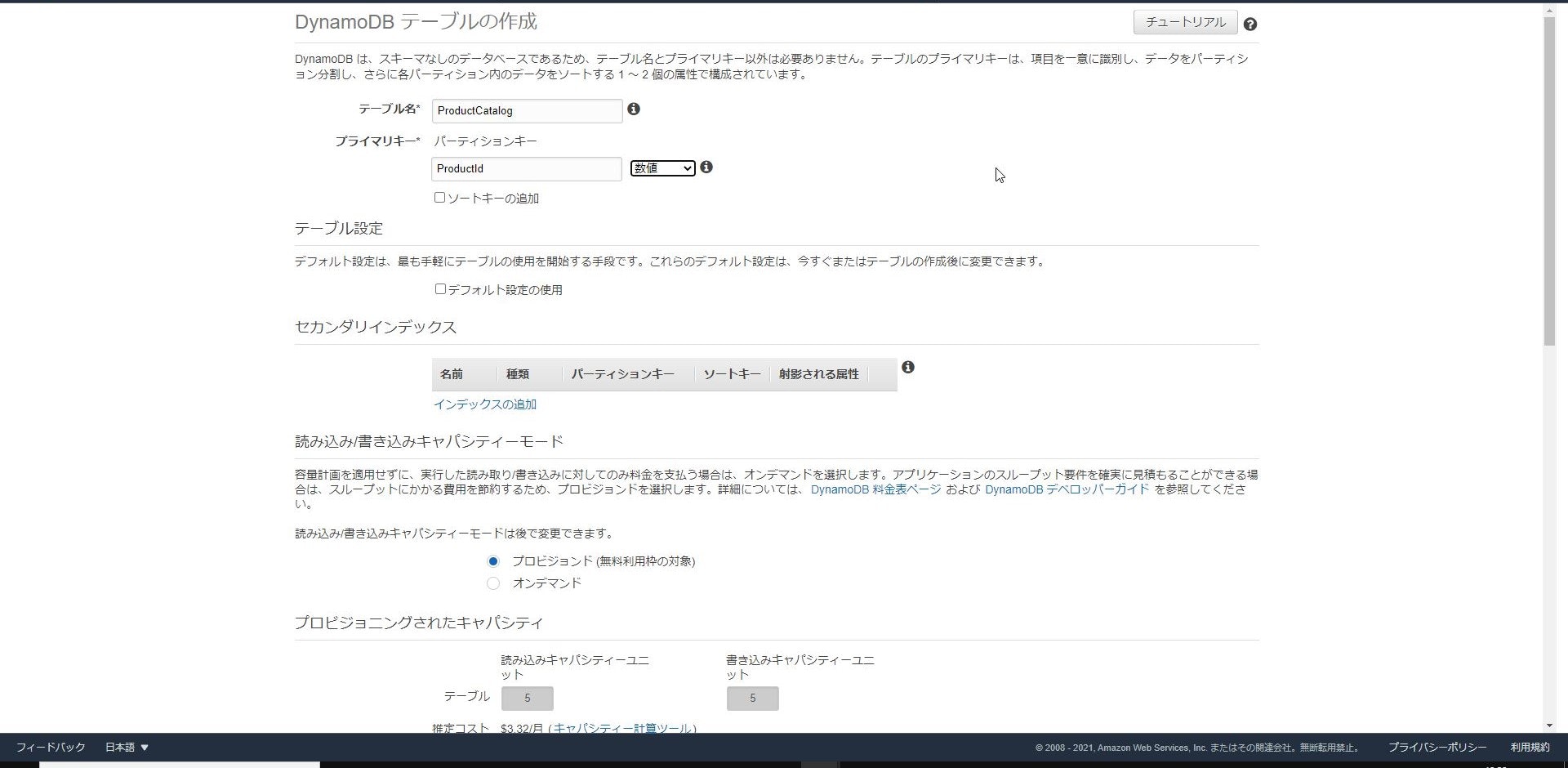
「テーブルの作成」をクリックします。
「テーブル名」は投入するサンプルデータと同じく「ProductCatalog」とし、
「パーティションキー」は「ProductId(数値)」と設定して「作成」をクリックします。
他にデータ検索を効率化するためのセカンダリインデックスやオートスケーリング、
暗号化設定等がありますが今回はデフォルトの設定で進めたいと思います。
無事テーブルが作成されたら次はサンプルデータの投入になります。
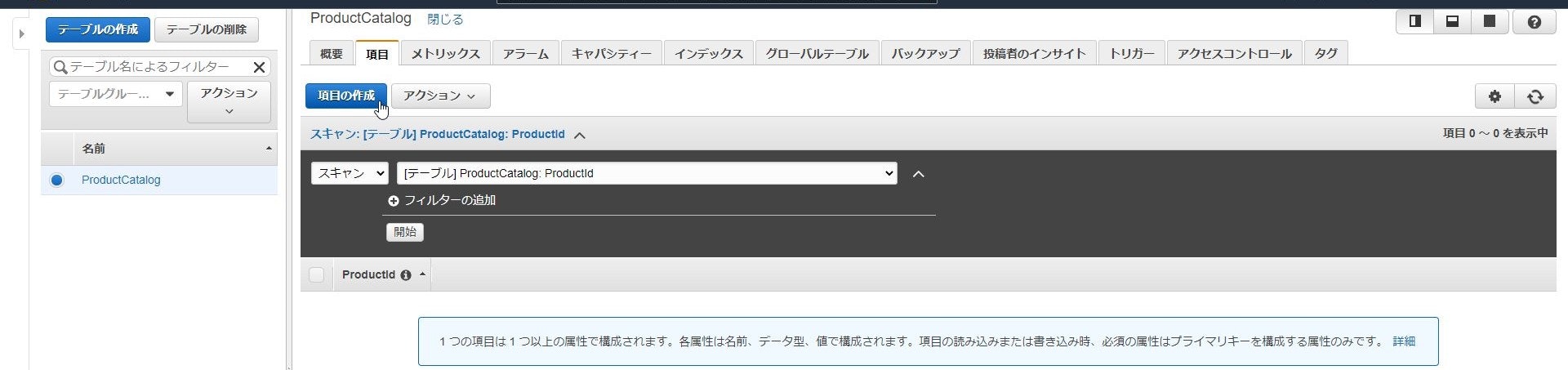
「項目」タブをクリックします。
「項目の作成」を選択して表示されるウィンドウからサンプルデータを投入し、
「保存」をクリックします。
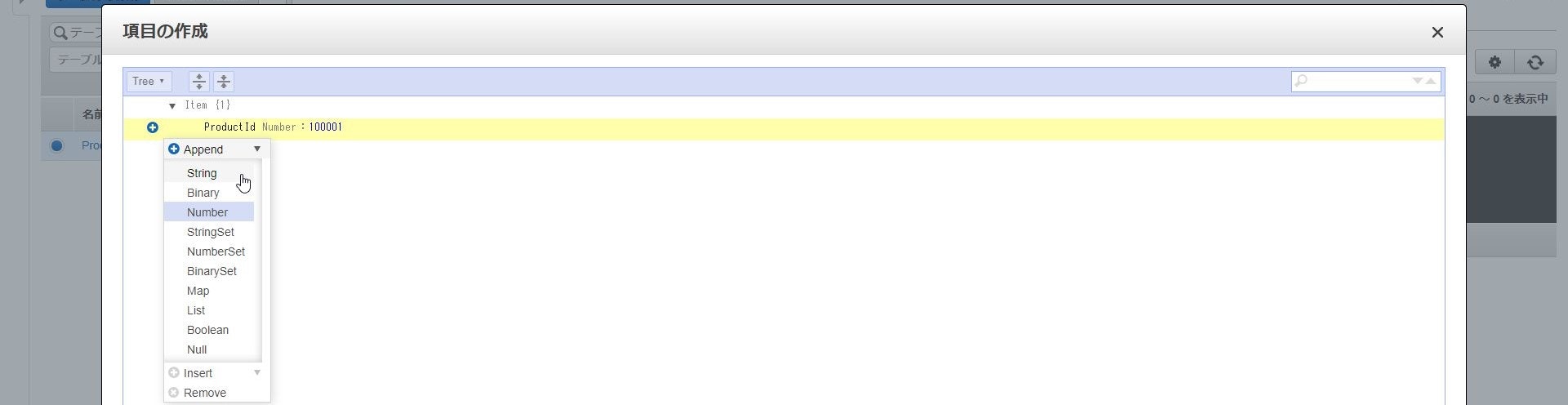
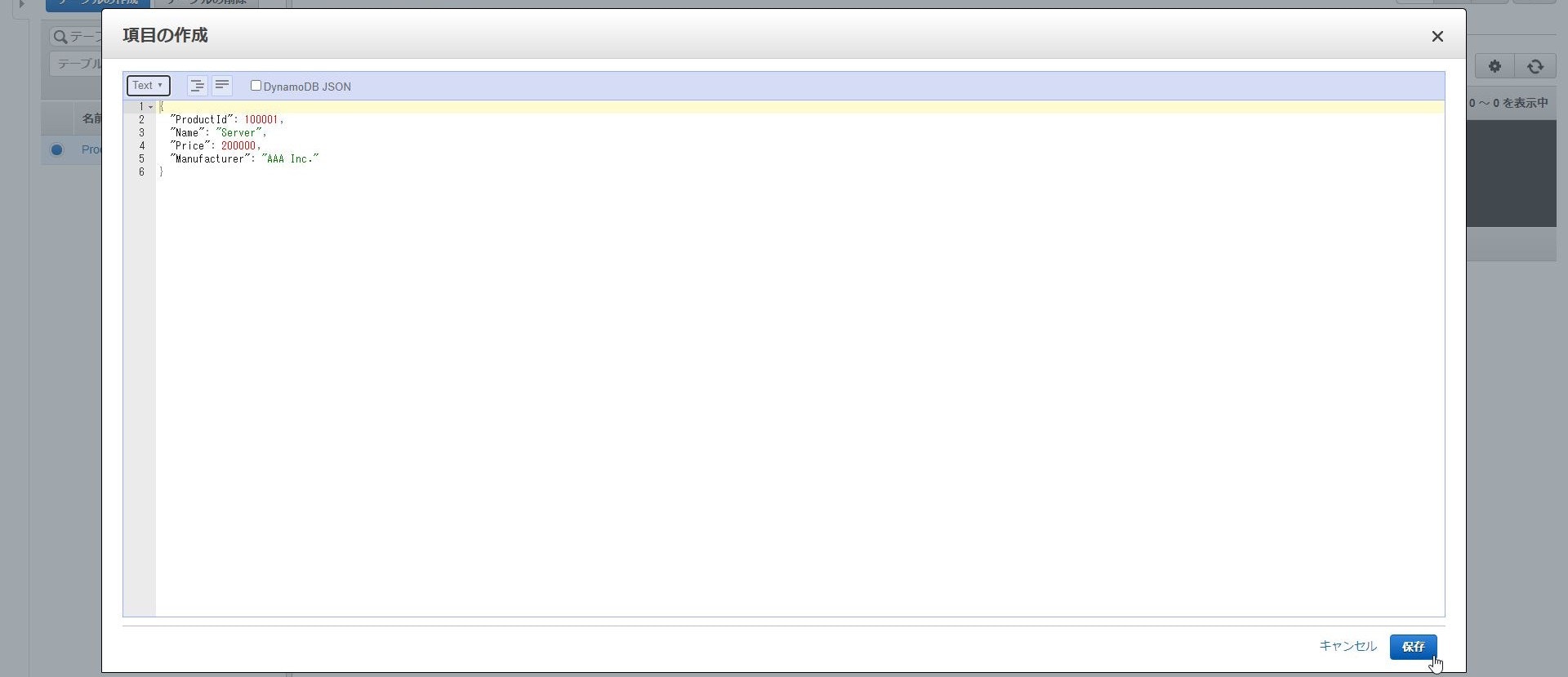
データの編集方式はTreeとTextの2通り存在し、
Treeはデータ型を選択してキーを追加し、その値を入力する、
TextはJsonを直接記載するという編集方式になります。
↓
<Tree形式の編集画面>
↓
↓
↓
<Text形式の編集画面>
これでサンプルデータの投入は完了になります!
Lambda
続いてはAPIの処理部分となるLambdaの構築を進めていきます。
LambdaはAWS上にサーバレスで処理を実装できるサービスですね。
ランタイムは「python3.8」を使用していきます。まずはデータの全件取得用のLambda関数を作成していきます。
またLambdaでDynamoDBを操作する必要があるため
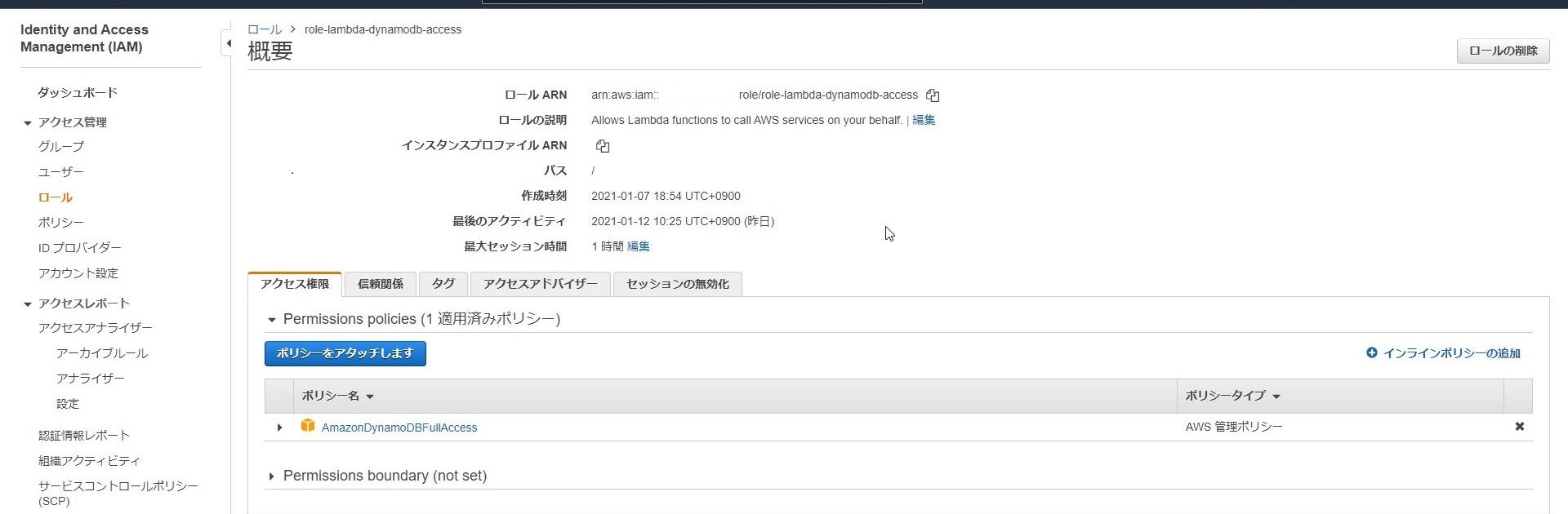
事前に必要な権限を持ったLambda用のIAMロールを作成をしておきます。
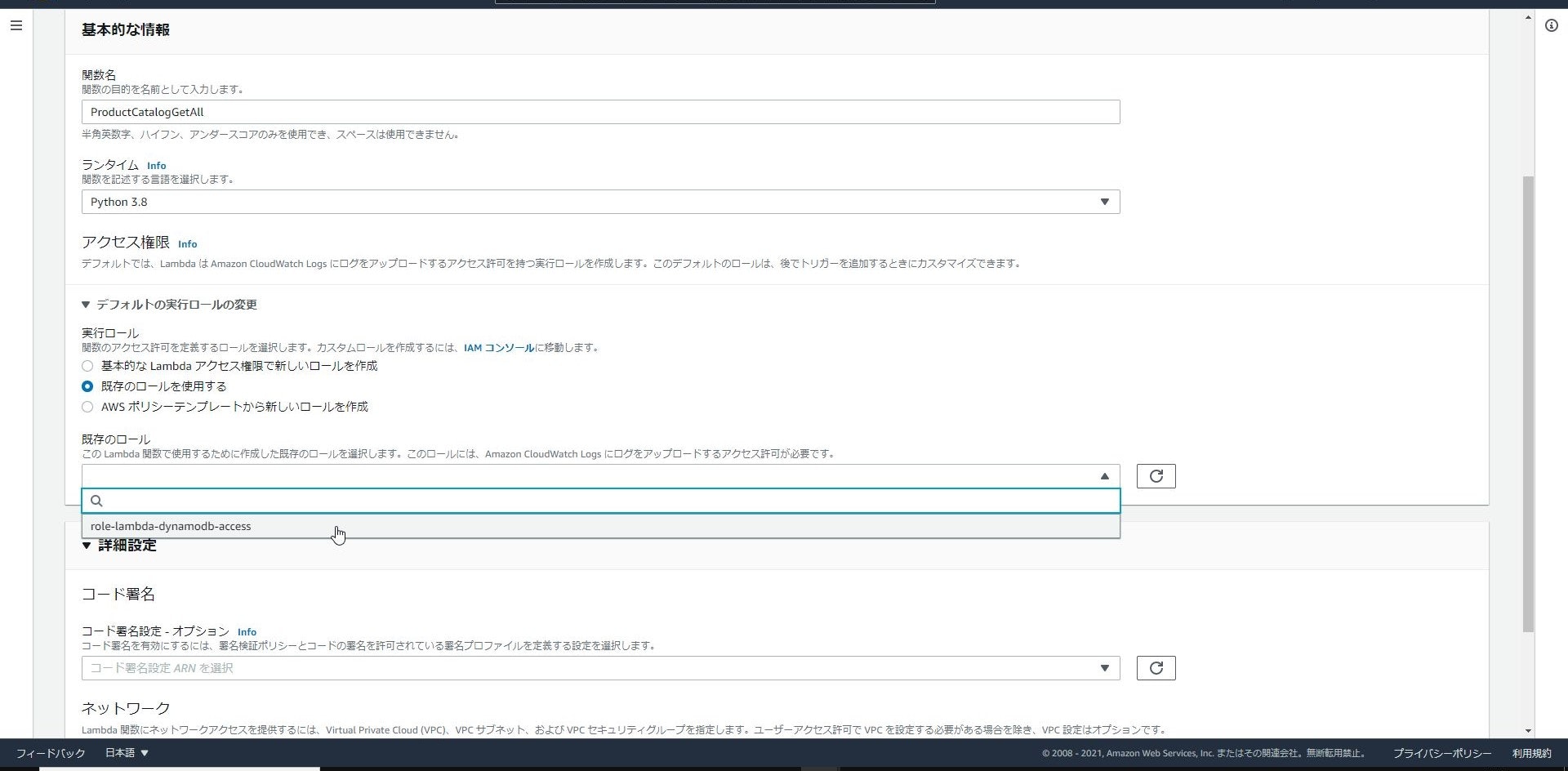
IAMロールの準備ができたらサービス一覧から「Lambda」を選択し、
「関数の作成」をクリックします。
「関数名」は「ProductCatalogGetAll」、「ランタイム」は「python3.8」を設定します。
「実行ロール」については「既存のロールを使用する」にチェックを入れると
先ほど作成したIAMロールが表示されるのでそれを選択して、
「関数の作成」をクリックします。
Lambda関数の信頼性を高めるコード署名のオプションや
VPC内で実行するためのネットワークオプションは
今回は使用しないのでデフォルトのまま進めていきます。
これでLambda関数の枠は作成できたので、実際にDynamoDBからデータを取得するコードを書いていきます。
以下にある今回準備したコードを記載して「デプロイ」をクリックすればLambda関数の構築は終了です!
lambda_function.pyimport json import boto3 #ライブライboto3(AWS SDK for Python)のimport、PythonでAWSを操作するときのおまじない def lambda_handler(event, context): # ここから処理を記載 dynamodb = boto3.resource('dynamodb') table = dynamodb.Table('ProductCatalog') #boto3からdynamodbにアクセスし、事前作成したテーブルProductCatalogにアクセスするための準備 response = table.scan() #scanメソッド(DynamoDBのレコード全件取得)の呼び出し、辞書型 items = response["Items"] #responseから必要なデータのみを取得 return itemsAPI Gateway
続いてはAPIの公開、管理を行うAPI Gatewayの構築を進めていきます。
サービスの一覧から「API Gateway」をクリックし、作成するAPIのタイプを選んで「構築」をクリックします。
今回はREST APIを選択しています。
SwaggerやサンプルAPIを用いた構築もできますが、
今回は一から作成していきたいと思います。
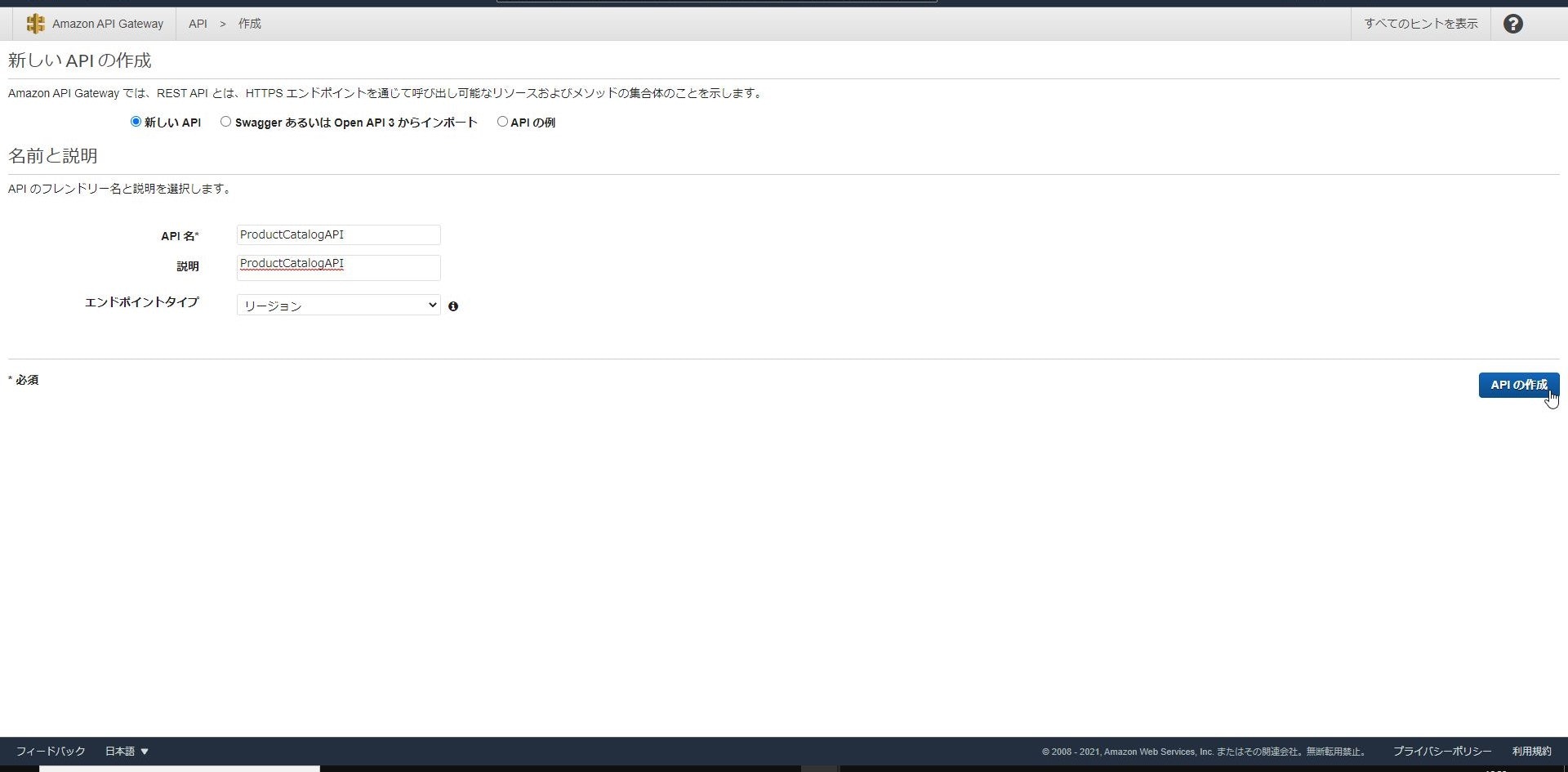
「新しいAPI」にチェックを入れ、「API名」と「説明」は「ProductCatalogAPI」に設定し、
「エンドポイントタイプ」は「リージョン」を選択して「APIの作成」をクリックします。
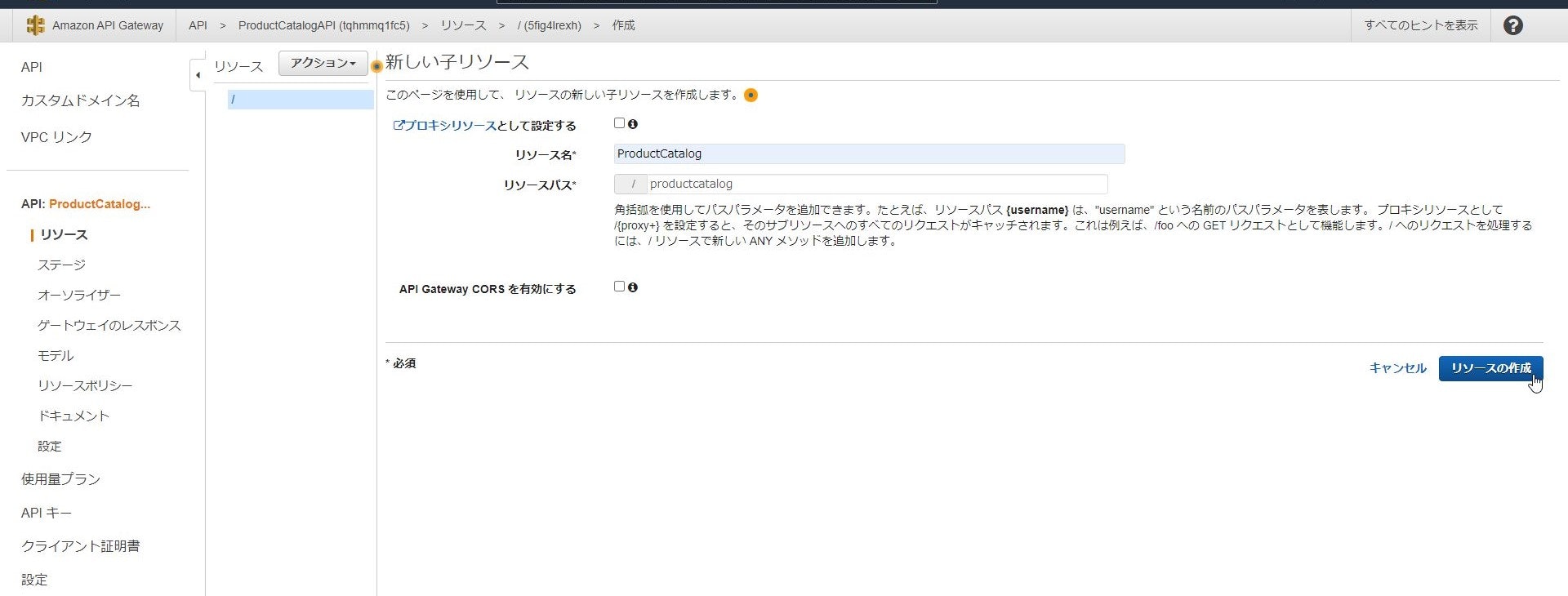
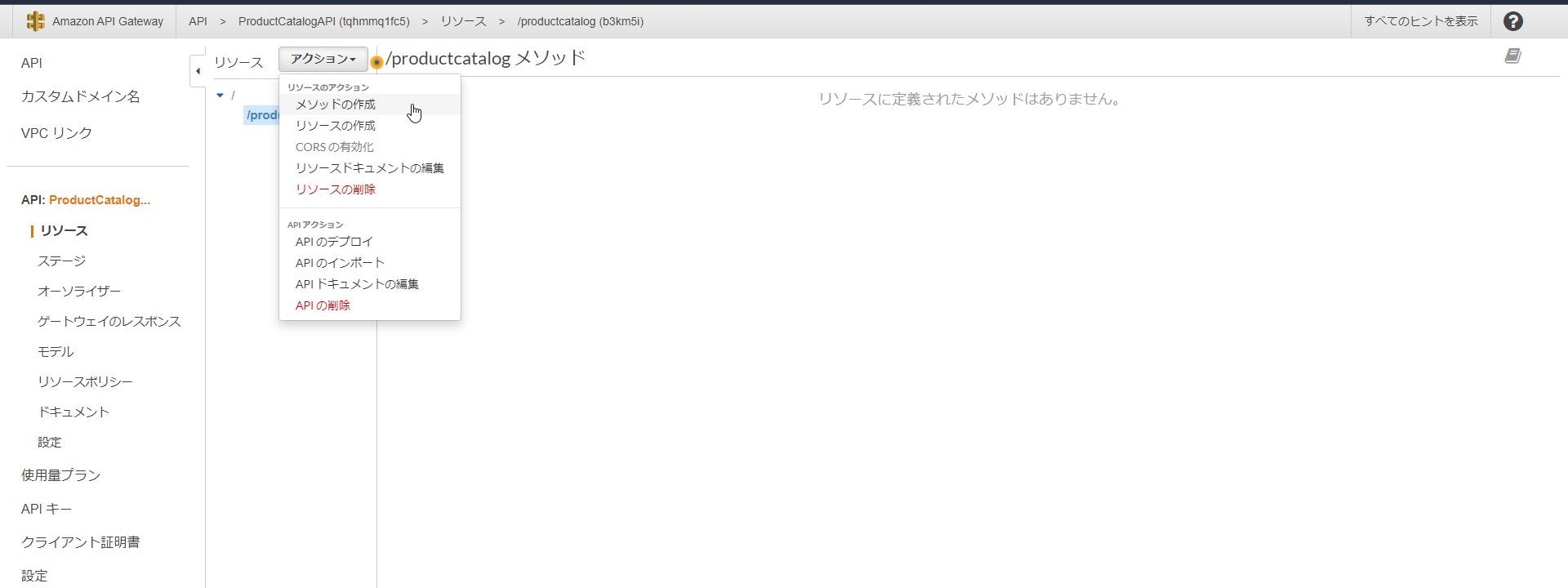
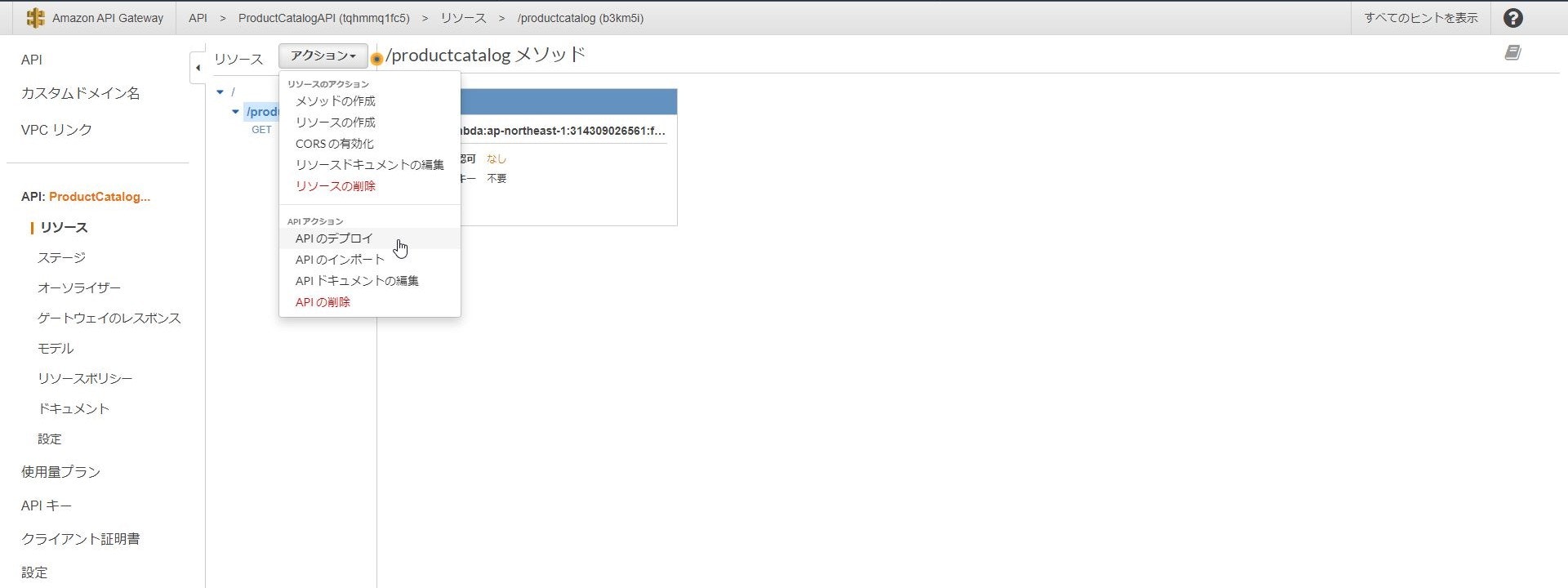
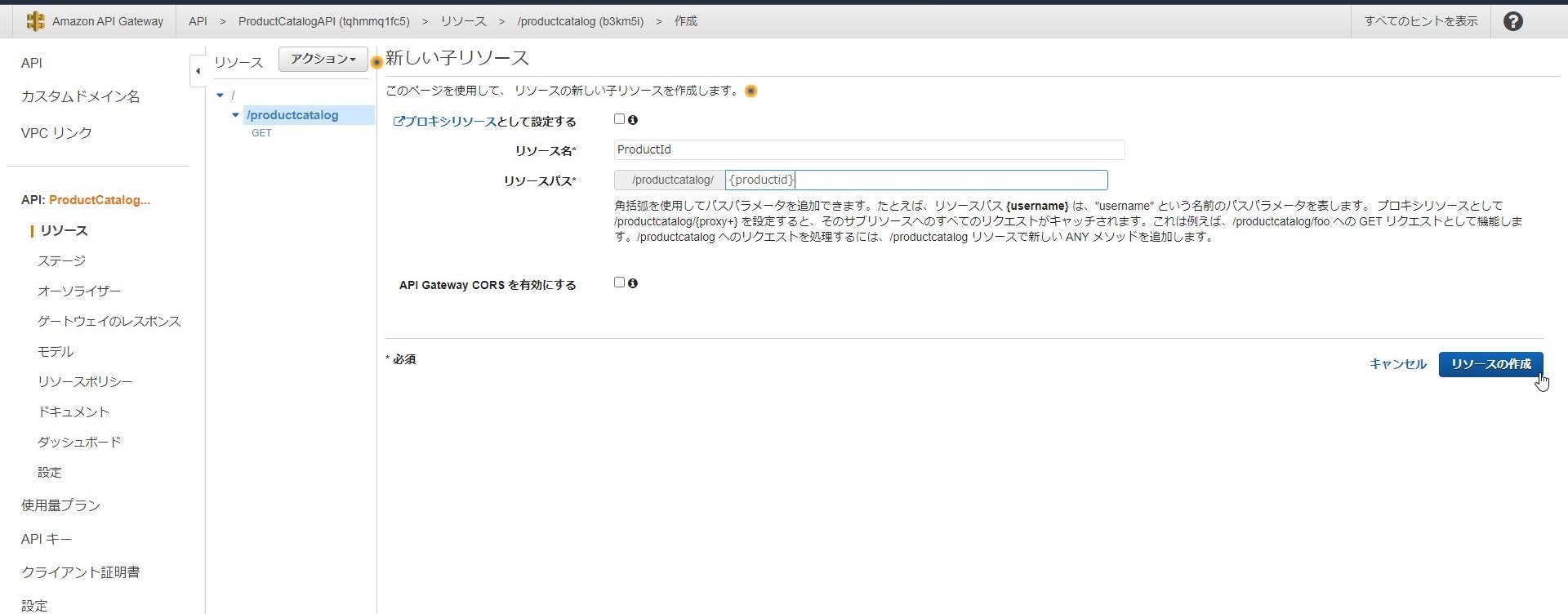
APIが作成されたら「アクション」-「リソースの作成」をクリックし
「リソース名」を「ProductCatalog」、「リソースパス」を「productcatalog(自動入力)」
として今回作成するAPIのURLパスを作成します。
↓
※「プロキシリソースとして設定する」はURLパスを個別に指定せず配下すべてにリクエストを投げる場合に使用します。
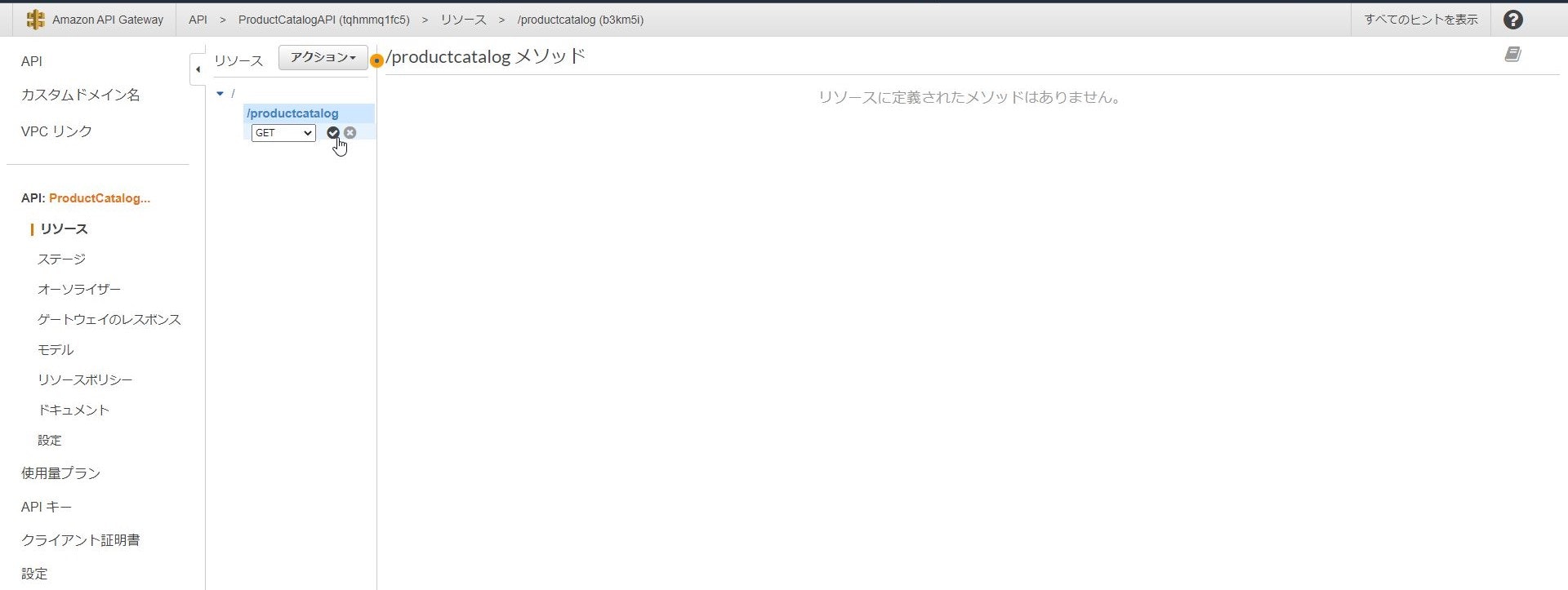
※「API Gateway CORSを有効にする」はクロスドメイン通信を行う場合に使用します。次に作成したリソースに対してメソッドの作成を実施し、
どのバックエンドに対してどのような処理を送るかを定義します。
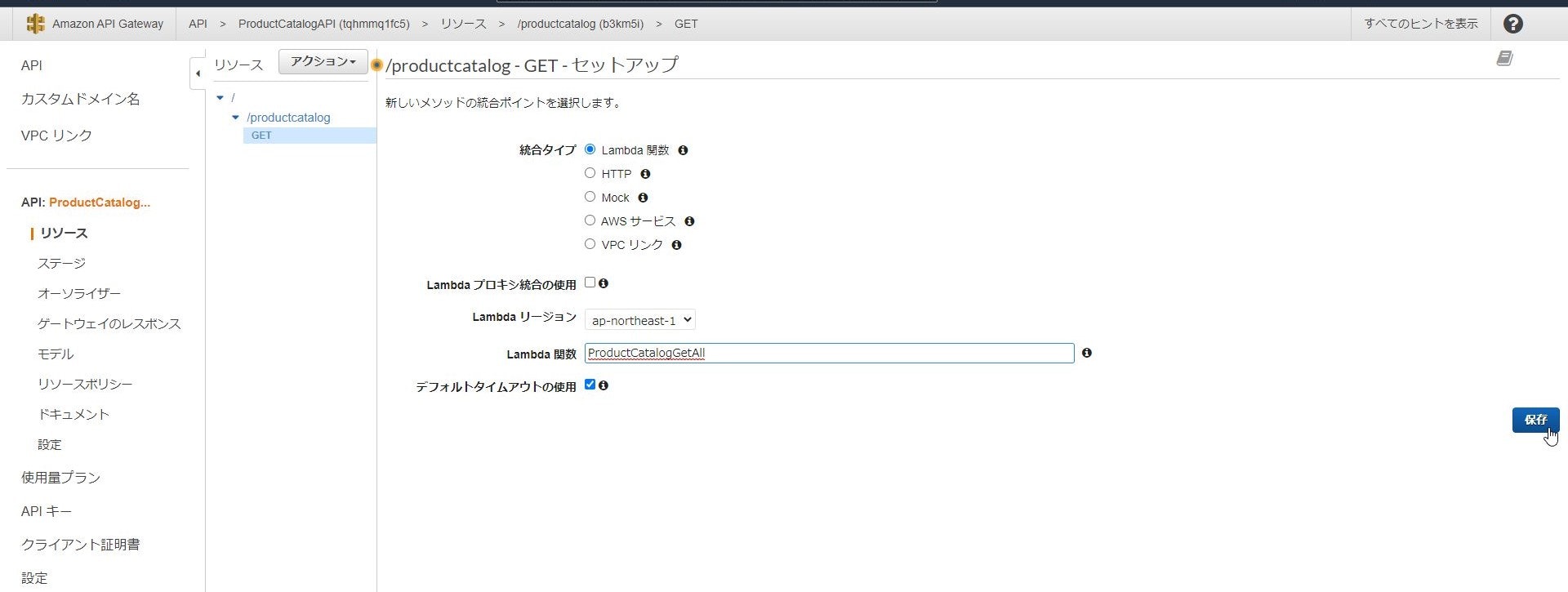
今回はデータの参照なので「GETリクエスト」を指定し、バックエンドは先ほど作成したLambda関数を指定します。
↓
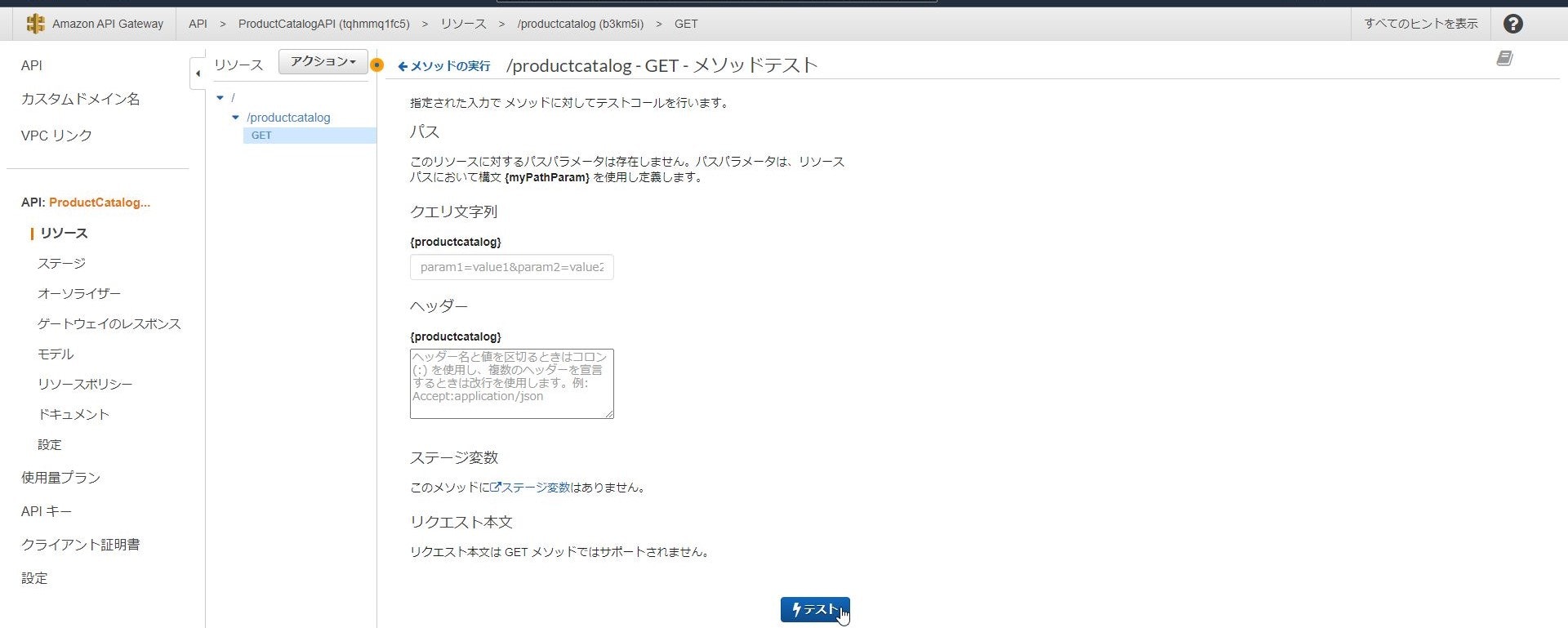
↓
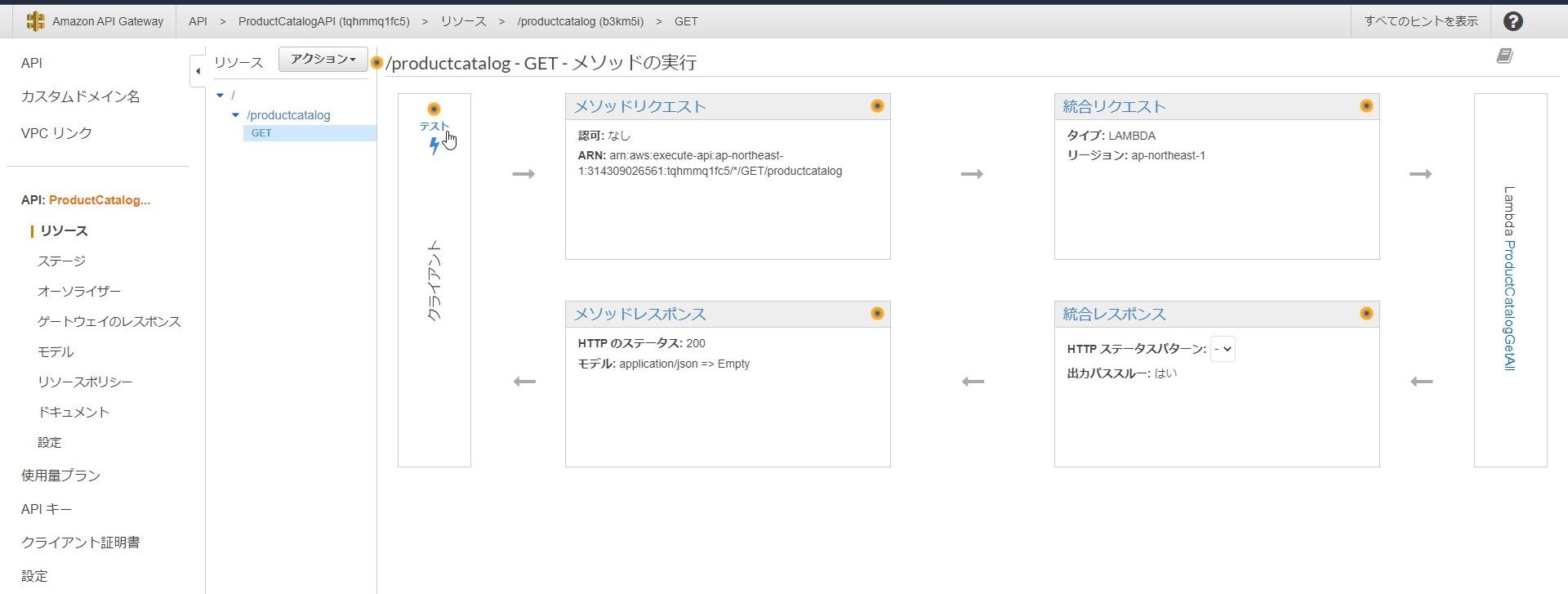
作成したメソッドは公開前に動作確認が可能です。
↓
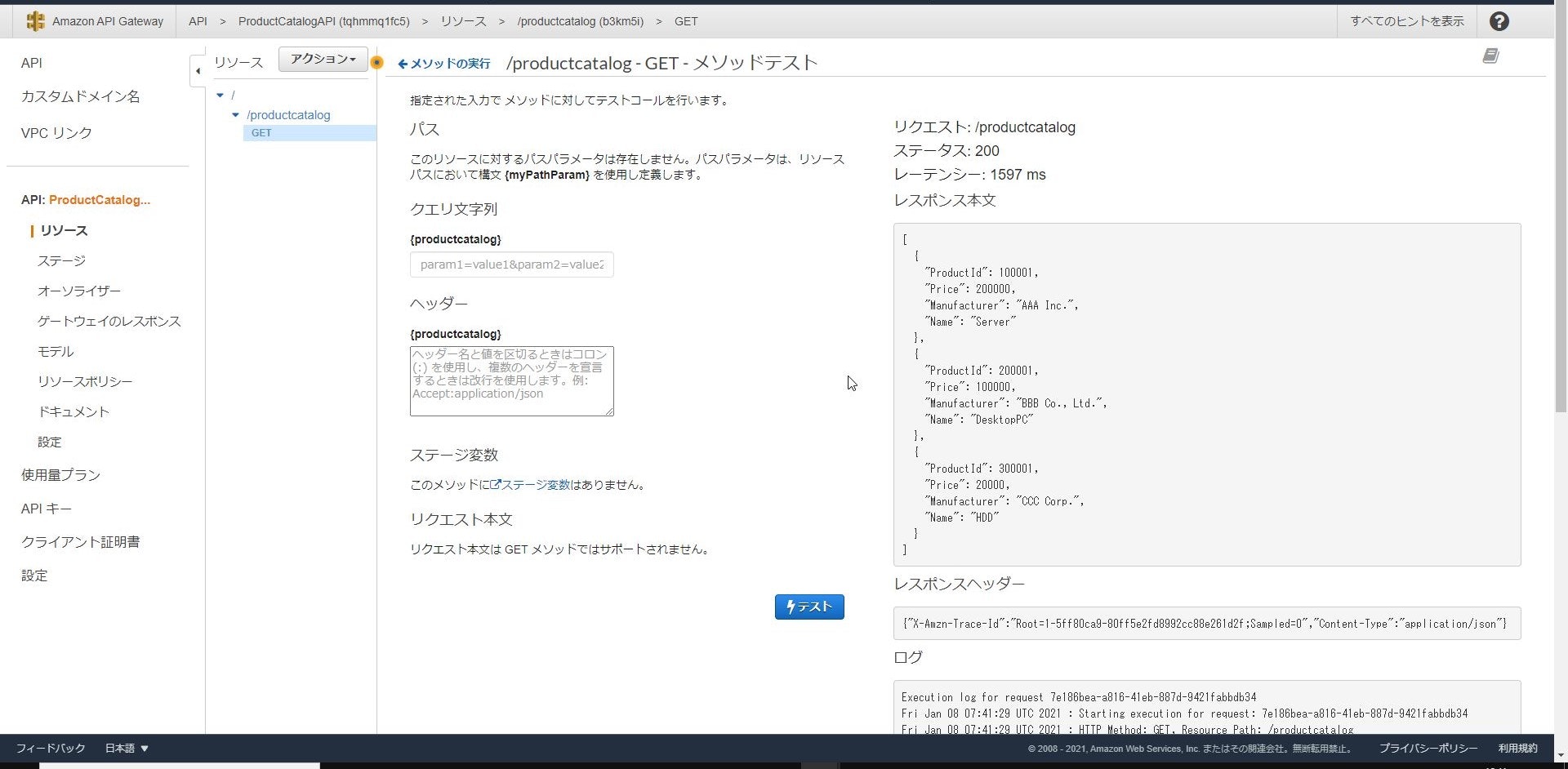
↓
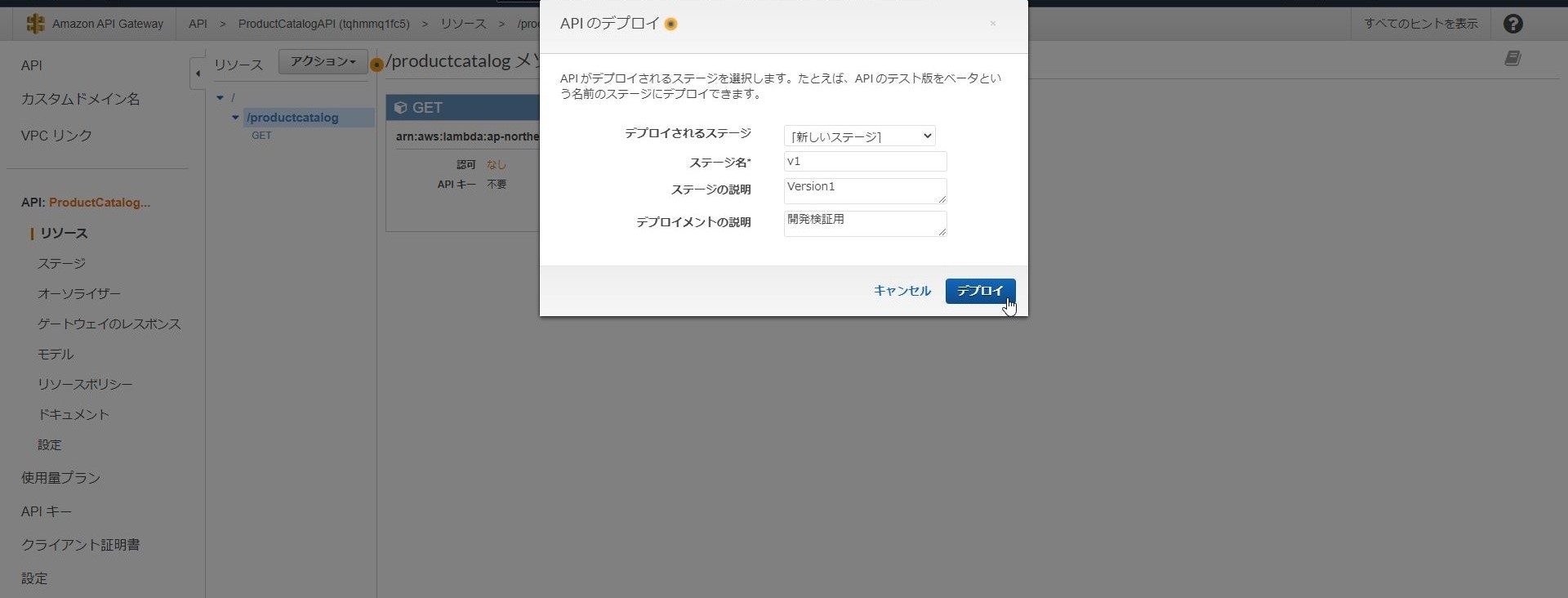
上手くDynamoDBのデータが参照できていますね!APIの動作が問題なければ最後にAPIをデプロイして外部に公開します。
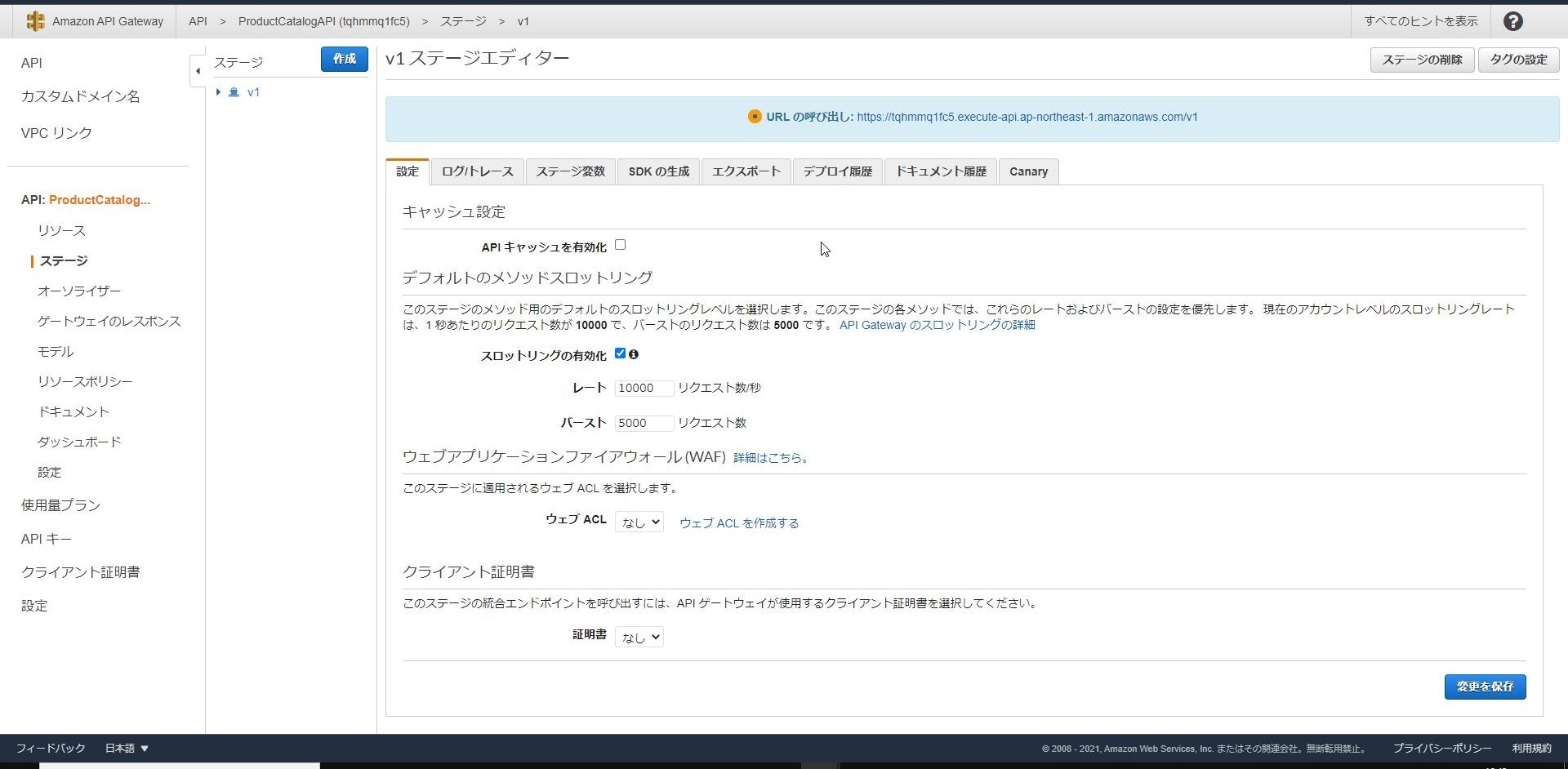
デプロイ時にはステージ(本番、検証、Version等)を指定する必要があり、
ステージ名がURLパスに含まれるため今回はv1としています。
機能追加や改修時にステージを分けることで切り戻し等をしやすくするための機能ですね。
↓
↓
これで外部からAPIを呼び出せるようになっているはずなので試しに呼び出してみましょう。
問題なくDynamoDBにあるデータを呼び出すことができました!!
これでデータの全件参照は実装できたので、続いては指定したIDの個別参照も実装していきたいと思います。個別参照APIの実装
データの全件参照とID指定の個別参照はLambda関数を分けて実装していきます。
全件参照の時と同じ手順で個別参照用の関数を作成し、以下のコードを記載してデプロイをクリックします。lambda_function.pyimport json import boto3 from decimal import Decimal def lambda_handler(event, context): # TODO implement dynamodb = boto3.resource('dynamodb') table = dynamodb.Table('ProductCatalog') id = int(event['pathParameters']['productid']) #API Gatewayのpathparameterにあるproductidを格納 #API Gatewayから渡されたときは文字列で検索に一致しないので数値に変換 response = table.get_item( Key={ 'ProductId': id } ) item = response['Item'] # ---------------------------------------------------------------- # decimalをintに変換 # https://qiita.com/ekzemplaro/items/5fa8900212252ab554a3 def decimal_default_proc(obj): if isinstance(obj, Decimal): return int(obj) raise TypeError # ---------------------------------------------------------------- return { 'statusCode': 200, 'body': json.dumps(item,default=decimal_default_proc) #API Gatewayに返す場合json形式にする必要があり #DynamoDBのdecimal型はjson化できないのでint型に変換 }注意点としては後述するAPI GatewayからLambdaにURLパスを引数として渡しており、
その引数がデフォルトだと文字列となってDynamoDBのキー検索に一致しないので数値に変換しています。
また、LambdaからのレスポンスをJson形式とするため、取得したデータの型を変換する処理を追加しています。続いてAPI Gateway側の設定です。
全件取得用に作成したリソースの配下に
新しく製品IDを取得するためのリソースを作成します。
リソースパスに{}を追加することでURLパスの値を格納することが可能となります。
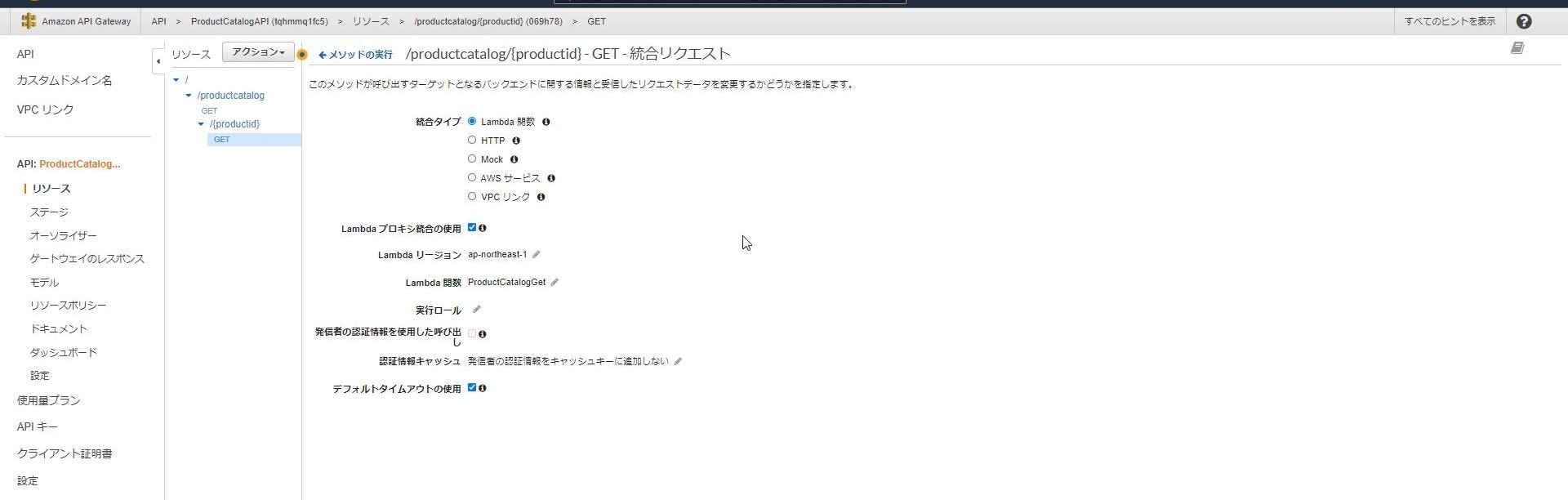
新しく追加したリソースに対しても同様にメソッドの作成を実施します。
GETリクエストで新規作成したLambda関数を呼び出し先として指定しますが
追加で「Lambdaプロキシ統合の使用」にチェックを入れます。
これでURLパスの値をLambda側に渡すことができるようになります。
最後にAPIのデプロイを実施し、実際にURLに製品IDを指定してデータの個別参照ができるか確認してみましょう。
指定したIDのデータのみ、ちゃんと取れてますね!最後に
なんとか要件通りにAPIを実装することができました。
API Gatewayを使用して簡単にバックエンドのLambdaと
パラメーターの連携ができるのが良いなと感じました。
Lambdaだけでなく他のAWSサービスや外部のAPIにリクエストを
流すことも可能です。作業工数としては私の感覚となりますが、
従来のサーバ構成と比較して、NW・サーバ構築やOS・ミドルウェア等の設定が
不要となるので30~50%程度は削減できるのではないかと思われます。本記事がAPI実装やAWSに関して勉強している方の一助になれば幸いです。
※あくまで勉強目的なので作成したAPIは後に削除予定です参考情報
- API関連
https://www.redhat.com/ja/topics/api/what-are-application-programming-interfaces
https://www.otsuka-shokai.co.jp/words/api.html
https://www.internetacademy.jp/it/programming/javascript/how-to-use-web-api.html
https://wp.tech-style.info/archives/683
- DynamoDB関連
https://docs.aws.amazon.com/ja_jp/amazondynamodb/latest/developerguide/Introduction.html
https://qiita.com/shibataka000/items/e3f3792201d6fcc397fd- Lambda関連
https://boto3.amazonaws.com/v1/documentation/api/latest/guide/dynamodb.html
https://qiita.com/UpAllNight/items/a15367ca883ad4588c05
https://recipe.kc-cloud.jp/archives/10420
https://qiita.com/ekzemplaro/items/5fa8900212252ab554a3
- APIGateway関連
https://docs.aws.amazon.com/ja_jp/apigateway/latest/developerguide/api-gateway-create-api-step-by-step.html
https://qiita.com/minsu/items/c9e983f109b1cf5a516e







- 投稿日:2021-01-20T00:57:18+09:00
Google ColaboratoryでAutoGluonをinstall & importする方法
はじめに
普段、Google Colaboratory(Colaboratory)1を利用しているのですが、Colaboratory上でAutoMLであるAutoGluon23をinstall & importして使ってみようと思ったことがありました。しかし、解決までに地味につまずくことがありました。似たような経験をしてせっかくのAutoMLの体験を断念する人もいるかと思い、この記事を書きました。慣れていない人でも再現できるよう手順をなるべく丁寧に書きます。(2021年1月20日の情報です。状況が変わった場合、コメントなどで教えていただけると助かります。)
結論
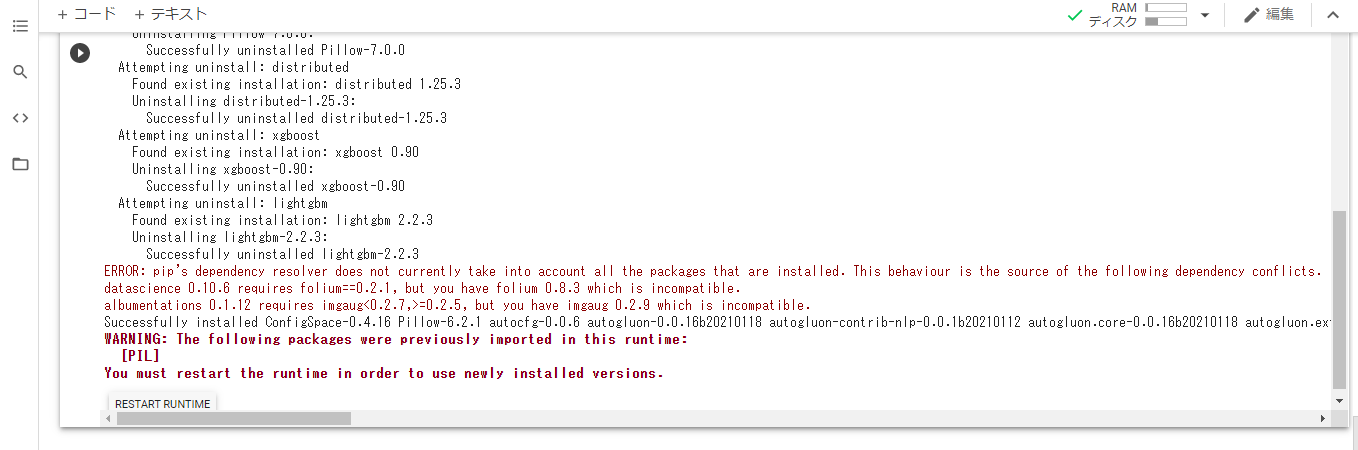
GitHubで公開されているREADME4に記載されている情報を参考に、下記のコマンドを実行します。
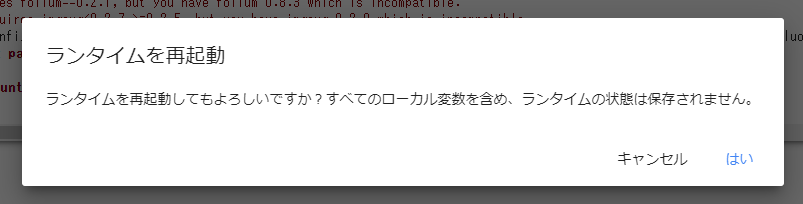
!pip install --upgrade pip !pip install --upgrade setuptools !pip install --upgrade "mxnet<2.0.0" !pip install --pre autogluon不穏な実行結果が表示されます。左下の「RESTART RUNTIME」を押し、ランタイムを再起動します。
「はい」を押します。
すると、以下のようなimport文が実行できるようになります。
from autogluon.tabular import TabularDataset, TabularPredictorもちろん、READMEに記載されているサンプルコードも実行できます。
train_data = TabularDataset(file_path='https://autogluon.s3.amazonaws.com/datasets/Inc/train.csv') test_data = TabularDataset(file_path='https://autogluon.s3.amazonaws.com/datasets/Inc/test.csv') predictor = TabularPredictor(label='class').fit(train_data, time_limit=60) # Fit models for 60s leaderboard = predictor.leaderboard(test_data)とても興味深い実行結果が見られますね!
(省略) Fitting model: WeightedEnsemble_L1 ... Training model for up to 59.61s of the -10.88s of remaining time. 0.8848 = Validation accuracy score 1.07s = Training runtime 0.01s = Validation runtime AutoGluon training complete, total runtime = 72.03s ... TabularPredictor saved. To load, use: TabularPredictor.load("AutogluonModels/ag-20210118_155144/") model score_test score_val pred_time_test pred_time_val fit_time pred_time_test_marginal pred_time_val_marginal fit_time_marginal stack_level can_infer fit_order 0 WeightedEnsemble_L1 0.873989 0.8848 1.739362 0.587412 29.211715 0.025570 0.005142 1.072552 1 True 10 1 LightGBM 0.873375 0.8800 0.101678 0.042709 1.115279 0.101678 0.042709 1.115279 0 True 7 2 CatBoost 0.872761 0.8804 0.032807 0.020380 14.926486 0.032807 0.020380 14.926486 0 True 9 3 LightGBMXT 0.870202 0.8756 0.245106 0.078389 1.704540 0.245106 0.078389 1.704540 0 True 8 4 RandomForestGini 0.859863 0.8600 0.821455 0.215100 9.762229 0.821455 0.215100 9.762229 0 True 1 5 RandomForestEntr 0.858225 0.8612 0.805670 0.315070 12.275200 0.805670 0.315070 12.275200 0 True 2 6 ExtraTreesGini 0.845839 0.8468 1.188539 0.315290 9.466483 1.188539 0.315290 9.466483 0 True 3 7 ExtraTreesEntr 0.845737 0.8432 1.195231 0.316842 8.752100 1.195231 0.316842 8.752100 0 True 4 8 KNeighborsUnif 0.773365 0.7752 0.108888 0.116532 0.319212 0.108888 0.116532 0.319212 0 True 5 9 KNeighborsDist 0.762514 0.7660 0.403860 0.109161 0.311418 0.403860 0.109161 0.311418 0 True 6まとめ
ColaboratoryでAutoGluonをinstall & importする方法を紹介しました。AutoGluonをはじめとするAutoMLをどんどん体験していきましょう!
おまけ
---> 32 from dask.utils import ensure_dict, format_bytes, funcname, stringifyImportError: cannot import name 'stringify'個人的にこのエラー文とエンカウントすることが多かったです。そんな人に届いてほしいので書いておきました。(検索でひっかかれ!)
- 投稿日:2021-01-20T00:49:31+09:00
容量がいっぱいでAWSにデプロイできなかった時の対処方法
今回発生した問題
今回は
「AWS内の『/dev/xvda1』の容量がいっぱいだったためにデプロイできなかった」
という問題が発生したので、その解決策をメモしておきたいと思います。結果的に
「logファイルを500MBほど削除すること」
により、無事デプロイすることができました。背景
個人で作っているRailsアプリをAWSにデプロイしようとした時のことです。
いつものようにターミナルから「bundle exec cap production deploy」でデプロイしたところ、
「SSHKit::Command::Failed」 といったエラーが表示され、デプロイできませんでした。しかし、AWS EC2へのSSH接続は問題なくできました。
ターミナル__| __|_ ) _| ( / Amazon Linux 2 AMI ___|\___|___| https://aws.amazon.com/amazon-linux-2/ 3 package(s) needed for security, out of 7 available Run "sudo yum update" to apply all updates. /home/ec2-user/.rbenv/libexec/rbenv-init: 行 131: ヒアドキュメント用一時ファイルを作成できません: No space left on deviceん?
「No space left on device」とありますね。
調べたところ、「空き容量が不足しているよ」と知らせてくれているようです。SSH接続したままで「df -h」を実行して、空き容量を確認してみます。
ターミナル$ df -h ファイルシス サイズ 使用 残り 使用% マウント位置 devtmpfs 474M 0 474M 0% /dev tmpfs 492M 0 492M 0% /dev/shm tmpfs 492M 428K 492M 1% /run tmpfs 492M 0 492M 0% /sys/fs/cgroup /dev/xvda1 8.0G 8.0G 0M 100% / tmpfs 99M 0 99M 0% /run/user/0 tmpfs 99M 0 99M 0% /run/user/1000dfコマンドは、ファイルシステムの全容量、使用中の容量、残りの容量、使用率(%)、マウント位置を表示するコマンドです。
「-h」というオプションをつけると、「K、M、G」などの単位がついた状態で表示され、わかりやすくなります。その結果、「/dev/xvda1」が使用率100%になっており、デプロイするための容量が全く残っていないことがわかりました。したがって、容量を空けるために、不要なファイルを整理しなければなりません。
※ ちなみにマウント位置の意味に関しては勉強中です。
今わかっていることとして、マウントの意味は、「コンピュータに接続した機器やメディアをコンピュータに認識させ、使える状態にすること」、
マウント位置は「新たに追加したストレージ装置などにアクセスできるように仮想的なディレクトリとして登録したもの」だそうです。解決した方法
まずは容量が大きいディレクトリを調査
まずは、duコマンドでどこのディレクトリの容量が大きいのかを調べます。
そのままでは、権限の関係で一部のディレクトリが読み込めないため、頭にsudoコマンドをつけて全てのディレクトリを読み込めるようにしましょう。ターミナル$ sudo du -sh /* (容量の少ないものは省略) /var 4.9G /usr 1.7Gduコマンドは、指定したファイルやディレクトリの使用容量を表示してくれるコマンドです。
-sオプションは「総計を表示する」という役割があるそうです。これをつけないとサブディレクトリまで全て表示されるため、とんでもない量が表示されてしまいます。
-hオプションはさっきと同じです。「K、M、G」などの単位がついた状態で表示されます。
/*は「0文字以上のディレクトリ」という意味があります。つまり、全てのディレクトリを表示させることができます。
duコマンドの結果、/var(4.9G)と/usr(1.7G)の容量が大きいことがわかったため、ここを整理すればよさそうです。
varディレクトリを調査
それでは、「cd var」でvarディレクトリに移動した後、duコマンドで容量が大きい、上位5位までのディレクトリを表示してみます。
ターミナル$ cd /var [var]$ sudo du -sm ./* | sort -rn | head -5 3971 ./www 733 ./log 217 ./cache 86 ./lib 1 ./tmp-sは、先ほど説明したオプションです。
-mオプションは、M(メガバイト)単位で表示してくれます。sortコマンドは、テキストファイルを並び替えるコマンドです。デフォルトは昇順で並べるため、-rオプションにより降順で表示します。
さらに、-nオプションをつけることで、数字が大きいものから順に表示されるようになります(-nオプションがなければ、「86 → 733 → 3971 → 217 → 1」と表示されてしまう)。headコマンドは、テキストファイルの先頭10行を表示するコマンドです。今回は「-5」というオプションをつけているので、容量の大きさが上位5つのディレクトリが表示されます。
容量が大きい上位5つを表示した結果、wwwディレクトリとlogディレクトリが大きいことがわかりました。
しかし、wwwディレクトリにはアプリのディレクトリ本体が入っているため、削除できるファイルが思いつきませんでした。そのため、2番目に多いlogファイルを整理してみることにしました。
さらにlogファイルを調査
「cd log」でlogファイルに移動し、その中でどのディレクトリの容量が大きいのか調べていきます。先ほどのvarディレクトリと同じように、容量が大きい上位5つのディレクトリを調べていきます。
ターミナル$ cd log [log]$ sudo du -sm ./* | sort -rn | head -5 633 ./journal 37 ./audit 17 ./sa 10 ./btmp 8 ./secure-20201227その結果、journalディレクトリが最も大きいことがわかりました。journalディレクトリには、システムのログなどが記録されているようです。ここ最近のログさえ残っていれば問題ないと考えたため、journalディレクトリ内を整理することにしました。
journalctlコマンドを用いて削除
journalctlコマンドを用いることで、ジャーナルファイルの容量を確認したり、ジャーナルファイルの削除を行うことができます。
今回は、ここ3日分のログだけ残して、それより古いものは削除したいと思います。
以下のコマンドで実行できます。ターミナル$ cd journal [journal]$ sudo journalctl --vacuum-time=3daysちなみに、「sudo journalctl --vacuum-size=100M」で「100M分残し削除する」といった方法もあるようです。
削除が終わったら、logディレクトリに戻り、容量を確認してみます。
ターミナル$ cd /var [var]$ cd log [log]$ sudo du -sm ./* | sort -rn | head -5 57 ./journal 37 ./audit 17 ./sa 10 ./btmp 8 ./secure-20201227これで550M以上削除できました!
「df -h」での容量の確認もしてみると…
ターミナル$ df -h ファイルシス サイズ 使用 残り 使用% マウント位置 devtmpfs 474M 0 474M 0% /dev tmpfs 492M 0 492M 0% /dev/shm tmpfs 492M 428K 492M 1% /run tmpfs 492M 0 492M 0% /sys/fs/cgroup /dev/xvda1 8.0G 7.5G 555M 94% / tmpfs 99M 0 99M 0% /run/user/0 tmpfs 99M 0 99M 0% /run/user/1000/dev/xvda1の使用率が100% → 94%になりました!
この後、「sudo yum update」と「bundle exec cap production deploy」を実行すると、無事デプロイすることができました。
今後の目標
今回は何とかなりましたが、使用率は94%と多いままなので、また100%に戻ってデプロイできない、という事態になるかもしれないですね。
僕自身も、「このファイルなら削除してもいい」ということがまだわかっていないため、「不要なファイルを判断できるようになること」が目標ですね。
または、「AWSの容量自体を拡張する」という対処も考えた方がよさそうです。
あとは、「古いログファイルを定期的に削除する」ということも大事だと感じました。
参考記事
以下、参考にさせていただいた記事です。
ありがとうございました。ディスク空き容量が不足してきた件:
https://www.souichi.club/aws/out-of-disk-space/journalctlログを削除する:
https://mebee.info/2020/07/18/post-14146/
- 投稿日:2021-01-20T00:48:03+09:00
CSVファイルをAWS DynamoDBに自動更新する
はじめに
私はよく、スクレイピングで収集したデータをCSVファイルで出力しています。
しかし、データを効率よく使うには、CSVファイル内のデータをデータベースなどにストアしなくてはいけません。
せっかくデータ収集を省力化しても、データベースの運用に時間を取られるのは苦痛ですよね?
その悩み、クラウドのデータベースサービスで解決しましょう!本投稿では、AWS の DynamoDB にCSVファイル内のデータを自動で反映する方法をご紹介します。
これで煩わしいデータベース更新業務とはオサラバです!目次
今回は、既にAWSで自動更新したいDynamoDBが存在し、スクレイピングなどで取得したCSVファイルでそのファイルを更新したい場合を想定します。
AWS CLI の設定
AWSに接続するために、AWS CLI をインストールして初期設定を行います。
表示に従い、各種設定を登録すればOKです。
アクセスキーとシークレットアクセスキーは、AWSのセキュリティ認証ページから「アクセスキーの作成」を実行して用意してください。
参考:AWS CLIのインストールから初期設定メモ$ sudo pip install awscli $ aws configure AWS Access Key ID [None]: {アクセスキー} AWS Secret Access Key [None]: {シークレットアクセスキー} Default region name [None]: {AWSのリージョン} Default output format [None]: {json, yaml, text, table から出力形式を選ぶ}設定の確認は
aws configure listで行います。DynamoDBのテーブル更新用コード (Python)
例えば、スクレイピングなどで取得した下記のようなCSVファイルがあると仮定します。
揚げもの.csvメンチカツ,パン粉,ひき肉,母 エビフライ,パン粉,エビ,母 エビ天,天ぷら粉,エビ,母 イモ天,天ぷら粉,サツマイモ,母 大福,もち,あんこ,母これを用いて、以下のDynamoDBを更新します
料理(主キー) 衣 中身 料理人 メンチカツ パン粉 ひき肉 母 DynamoDBにCSVの内容を追記するには、下記の更新用コードを実行します。
addDynamoDB.pyimport csv import boto3 from boto3.dynamodb.conditions import Key def addDynamoDB(): dynamodb = boto3.resource("dynamodb", region_name="データベースのリージョン") table = dynamodb.Table("DynamoDBテーブル名") # テーブル名を指定して変数に格納 filepath = "揚げもの.csv" with open(filepath, "r", encoding="utf-8") as f: reader = csv.reader(f) # batch_writer()で、25項目ずつCSVの全てをputする with table.batch_writer() as batch: for row in reader: item = { "料理": row[0], "衣": row[1], "中身": row[2], "料理人": row[3], } batch.put_item(Item=item) if __name__ == "__main__": addDynamoDB()addDynamoDB.py 実行後のデータベース
料理(主キー) 衣 中身 料理人 メンチカツ パン粉 ひき肉 母 エビフライ パン粉 エビ 母 エビ天 天ぷら粉 エビ 母 イモ天 天ぷら粉 サツマイモ 母 大福 もち あんこ 母 これでDynamoDBの更新ができるようになりました。
しかしここで問題があります。大福は揚げ物ではないですよね?
table.batch_writer()はDynamoDBの追記はできますが、項目の削除はできません。
例えば、揚げもの.csvを下記のように修正しても、addDynamoDB.pyではDynamoDBに変化はありません。揚げもの.csvメンチカツ,パン粉,ひき肉,母 エビフライ,パン粉,エビ,母 エビ天,天ぷら粉,エビ,母 イモ天,天ぷら粉,サツマイモ,母DynamoDBとCSVの内容を同期するには、下記の更新用コードを実行します。
updateDynamoDB.pyimport csv import boto3 from boto3.dynamodb.conditions import Key def updateDynamoDB(): dynamodb = boto3.resource("dynamodb", region_name="データベースのリージョン") table = dynamodb.Table("DynamoDBテーブル名") # テーブル名を指定して変数に格納 # DynamoDBに対してクエリを実行、データを取得する response = table.query( IndexName="DynamoDBインデックス名", # インデックス名の指定 # その他オプションがあれば以下に記入する # 例: テーブルの「料理人」が「母」の要素のみを取得したい場合、以下を設定する KeyConditionExpression=Key("料理人").eq("母") # 例 ) dbItems = response['Items'] # レスポンスが1MBを超えた場合、LastEvaluatedKeyが含まれなくなるまでループする while 'LastEvaluatedKey' in response: response = table.query( IndexName="DynamoDBインデックス名", # インデックス名の指定 ExclusiveStartKey=response['LastEvaluatedKey'], # その他オプションがあればここに記入する # 例: テーブルの「料理人」が「母」の要素のみを取得したい場合、以下を設定する KeyConditionExpression=Key("料理人").eq("母") # 例 ) dbItems.extend(response['Items']) csvItems = [] filepath = "揚げもの.csv" with open(filepath, "r", encoding="utf-8") as f: reader = csv.reader(f) # batch_writer()で、25項目ずつCSVの全てをputする with table.batch_writer() as batch: for row in reader: item = { "料理(主キー)": row[0], "衣": row[1], "中身": row[2], "料理人": row[3], } batch.put_item(Item=item) csvItems.append(row[0]) # CSVファイルに存在しない型番は、batch.delete_item()でDBからdeleteする for dbItem in dbItems: if dbItem["料理(主キー)"] not in csvItems: batch.delete_item( Key={ "料理(主キー)": dbItem["料理(主キー)"], } ) if __name__ == "__main__": updateDynamoDB()updateDynamoDB.py 実行後のデータベース
料理(主キー) 衣 中身 料理人 メンチカツ パン粉 ひき肉 母 エビフライ パン粉 エビ 母 エビ天 天ぷら粉 エビ 母 イモ天 天ぷら粉 サツマイモ 母 これで、コードを手動で実行すればDynamoDBが更新できるようになりました。
では、これを自動化するにはどうすれば良いでしょうか?
いくつか方法はありますが、今回はそのうちオススメの二つをご紹介させていただきます。方法1:仮想マシン(VM)からcronで定期実行
クラウド上で、AWS CLI など環境を整えたVMインスタンスを立ち上げるのが一つの方法です。
VMインスタンスは、過去の記事でも取り扱ったGoogle Cloud Engine の無料枠を使います。
過去の記事:クラウドで手軽に始めるクローリングVMインスタンス上に上記のコードを上げて、cronで定期実行しましょう。
cronはcrontab -u < ユーザ名 > -eコマンドで以下ように設定してください。SHELL=/bin/bash CRON_TZ="Japan" 00 00 01 * * python3 /< 任意の絶対パス >/updateDynamoDB.py
00 00 01 * *の部分は、DynamoDBの更新をしたい任意の時間と頻度に変更しましょう。前回の記事のようなクローラーがある場合、クローラーの実行が終了次第、DynamoDB への反映が実行されるように実装すると便利です。
方法2:GitHub Actions
CSVファイルをGitHub上で管理することで、git push時に自動でDynamoDBが更新される実装も可能です。
具体的には、GitHub Actions のワークフローで実行します。Git リポジトリに
.github/workflows/ディレクトリを作成して、その中にYAML形式で定義してください。
YAMLファイルは例えば以下のように記述します。dynamoDB.ymlname: 任意のAction名 on: push: branches: # Run only on changes on master branches - 'master' paths: # Run only on changes on these files - '**/揚げもの.csv' jobs: build: runs-on: ubuntu-latest steps: - uses: actions/checkout@v2 with: fetch-depth: 25 - name: Python3.8の設定 uses: actions/setup-python@v2 with: python-version: 3.8 - name: Pythonライブラリのインストール run: | python -m pip install --upgrade pip pip install boto3 - name: AWS認証情報の設定 uses: aws-actions/configure-aws-credentials@v1 with: aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }} aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }} aws-region: 任意のリージョン - name: DynamoDBの更新 run: | python /< 任意の絶対パス >/updateDynamoDB.pyこれでmasterブランチにpushされたことをトリガーに、
updateDynamoDB.pyが実行されます。YAMLファイルの記法について、GitHub公式と併せて下記の記事が特に参考になりました。ありがとうございます。
参考:Github Actionsの使い方メモ
GitHubアクションの「AWS認証情報の設定」については、詳しいことはGitHub公式ページで確認できます。二つの方法の比較
VMからの実行(GCE) GitHub Actions ファイルのタイムスタンプ 有り 無し 環境構築 GCEのVMインスタンスが必要 GitHubリポジトリとgit 設定が必要 自由度の高い運用1 比較的簡単
(クラウドのサービスも利用できる)難しい トリガー 基本はcronのできる範囲のみ リモートへのpushやpull requestの作成をトリガーにできる 料金 USリージョンのf1-microインスタンス1個だけなら無料。リージョンやインスタンスにより、プランに応じて料金が発生する(E2-mediumで、$0.01005/時間) リポジトリが公開なら無料。非公開なら、Actionsの実行時間が2000分/月を超えると、利用時間に応じて料金が発生する(Linuxで$0.008/分) VMのスペック 選択可能2 固定3 所感としては、
VMからの実行はクラウドサービスを合わせて活用したいタスクや、実行時間が長く複雑なタスクに、
GitHub Actions はgitの更新をトリガーにしたいタスクや、実行時間が少なくシンプルなタスクに向いているように感じました。あなたの目的に合った方を活用してくださいね。
参考
GithubにSSH鍵登録
GithubのSSH通信設定
AWS CLIのインストール
AWS CLIのインストールから初期設定メモ
Github Actionsの使い方メモ
GitHubアクションの「AWS認証情報の設定」アクション
Github Actionsの使い方メモ
Pythonで手軽に始めるWebスクレイピング
クラウドで手軽に始めるクローリング
- 投稿日:2021-01-20T00:24:31+09:00
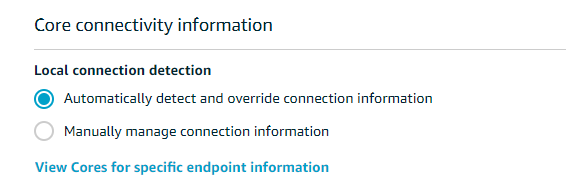
GreengrassのLocal connection detectionの設定をCloudformationから設定する
凄いニッチですが、詰まったので残しておきます。
Greengrass(
V2でなくV1)で、Core connectivity informationという設定項目があります。項目としては以下から選択する形になります。
- Automatically detect and override connection information
- Manually manage connection information
これをどうやってCloudformationやAPIで設定するかを探していたのですが、どこを探しても項目が見つかりません。そんな時に以下のURLを見つけました。
https://forums.aws.amazon.com/thread.jspa?threadID=264237
引用すると以下のコマンドでできます。
arn:aws:lambda:::function:GGIPDetector:1というLambdaを登録するという意味です。aws greengrass create-function-definition-version --function-definition-id <function-definition-id> --functions '[ { "FunctionArn": "arn:aws:lambda:::function:GGIPDetector:1", "Id": "<your-id>", "FunctionConfiguration": { "Pinned": true, "Timeout": 3, "MemorySize": 32768 } } ]'ホントにと思ったのですが、確かに以下のように定義してデプロイすると
Automatically detect and override connection informationが有効になっていることが確認できました。Greengrass GroupのLambdaの項目を見ても該当の
GGIPDetectorというLambdaは見えないので、内部的に利用されるようです。まさか設定にLambdaを登録する形とは思っていませんでした。#省略 FunctionDefinitionVersion: Type: "AWS::Greengrass::FunctionDefinitionVersion" Properties: FunctionDefinitionId: !GetAtt - FunctionDefinition - Id DefaultConfig: Execution: IsolationMode: GreengrassContainer Functions: - Id: GGIPDetector FunctionArn: "arn:aws:lambda:::function:GGIPDetector:1" FunctionConfiguration: Pinned: "true" MemorySize: "32768" Timeout: "3" #省略