- 投稿日:2021-01-19T23:38:44+09:00
Rspecコマンドが面倒だからRakeコマンド一発でRspecが実行できるようにしてみました
元々の状況・課題
Rubyでチケット料金モデリングに挑戦中。
Rspecでテストを書いているが、ターミナルに毎回Rspecコマンドを入力するのが面倒になった。目的
Rspecを簡単に実行したい。
やったこと・結果
①Rakeというライブラリを使った。
②ターミナルにrakeコマンドを入力するだけで、全てのspecファイルが一括で実行できるようになった。
③楽になりました。Rakeとは(ざっくり)
Rakefileに実行したいことを書いて、Rakefileに書いた内容をrakeコマンドで簡単に実行できる。
ターミナルに長々とコマンドを打たなくても良くなる。ディレクトリ構成は、ざっくりですがこんな感じです。
├── lib │ ├── user.rb │ └── ticket.rb │ ├── spec │ ├── user_spec.rb │ └── ticket_spec.rb │ │── Rakefile ※手順2で作成します。やったことの手順
1. rakeのインストール
gem install rake2. Rakefileを作成し、Rakefileにコードを書く。
Rakefile① require "rspec/core/rake_task" ##これでrakeコマンドのみで,③が実行できる。 ② task :default => :spec ##rakeコマンドを実行した際に、rspecディレクトリ配下のファイルを自動でテストファイルとして認識し、テストを実行する。 ③ RSpec::Core::RakeTask.new(:spec)(補足説明)
・こちらにspecディレクトリ配下のファイルを指定している旨のコードがあります。
・③について、こちらの記事が勉強になりました。「::」は、「クラス」や「モジュール」や「メソッド」の呼出しです。
または「::」は、名前解決をする際に入れ子(ネスト)環境下での場所を特定します。
単純に言うと、場所を特定します。(概念を分かりやすく説明するのは難しいです)
「RSpec」クラスを呼び出す場合 → RSpec
「RSpec」クラスの中の「Core」クラス or モジュール or メソッドを呼び出す場合 → RSpec::Core
「RSpec」モジュールの中の「Core」モジュールの中の「RakeTask」モジュールを呼び出す場合 → RSpec::Core::RakeTask3. rakeコマンドの実行
ターミナルで、rakeコマンドを実行すると、specディレクトリ配下の
**_spec.rbが一括で実行されます。rake参考
- https://docs.ruby-lang.org/ja/latest/library/rake.html
- https://rubydoc.info/github/rspec/rspec-core/RSpec/Core/RakeTask
- https://msp-greg.github.io/rspec/RSpec/Core/RakeTask.html
- https://github.com/rspec/rspec-core/blob/main/lib/rspec/core/rake_task.rb#L28-L28
- https://qiita.com/hikao/items/36d514cc4e6349bb40cd
- https://go-journey.club/archives/7695#Rake_%E3%81%A8%E3%81%AF%EF%BC%9F
- 投稿日:2021-01-19T23:28:12+09:00
Heroku + CarrierWave + S3で画像投稿する方法
1. 作業の流れ
まず最初にS3のバケットを作成します。
最初に行う理由は後からローカルで開発しているRailsのアプリケーションにS3で決めた設定を
入力するからです。S3のバケットの作り方ですが、参考資料をみて行うと問題なく進みます。
流れとしては、
- まず
IAMでユーザーを作成する。(ここで作成したアクセスキーIDとシークレットアクセスキーをcarrierwaveの設定で使用する。)
- S3のバケットを作成する。(画像を保存する箱を作る)
- gemの
fog-awsを導入して設定ファイルなどを作成する。の様に進んでいきます。
1. IAMユーザーの作成
まずAWSにアカウント登録すると
rootというめちゃくちゃ強い権限を持ったアカウントが作成される。
公式ではセキュリティ上の観点からrootユーザーを日常的に使用するのは推奨していないのでIAMというサービスを使用して、別の権限のユーザーを日常使い様に作成します。つまり、自分のAWSアカウントだとしてももう一人権限が小さいユーザーを作って管理するイメージです。※作成方法は最後に書いてあるリンクに記載されています。
2. S3のバケットを作成
画像を保存する箱を作成します。
参考資料ではrootユーザーのままでアクセスできると、書いていますがIAMユーザーでやってもできました。
ここの設定は、すごく丁寧に参考資料にまとめられていたので、そのまま使用すれば問題ないかと思います。参考資料
上記2つの参考リンクです。ここの通りにやればできます。
【Rails】CarrierWaveチュートリアル3. fog-awsを導入したRailsの設定諸々
fog-awsは外部のストレージサービスを使用する時に簡単にしてくれるgemくらいの認識でOKまず
fog-awsをインストールする
Gemfile
gem 'fog-aws'
bundle installを実行して次はどの環境で:fog(S3)を使用するのかをRails側に設定する。
app/uploaders/image_uploader# Include RMagick or MiniMagick support: # include CarrierWave::RMagick include CarrierWave::MiniMagick <= ここのコメントアウトを外す。 # Choose what kind of storage to use for this uploader: このIf文を追加することで、環境毎にどこに保存するかを指定している。 この場合はproduction環境のみS3を使用する。 if Rails.env.development? storage :file elsif Rails.env.test? storage :file else storage :fog end ....次に、事前にAWSで作成したIAMユーザーの情報とS3の情報を設定する。
まず設定ファイルであるcarrierwave.rbをconfig/initializersいかに作成する。
この場所におけば、初期化に必要なものと判断されて、自動で読み込まれるので作成してしまって構いません。touch config/initializers/carrierwave.rb上記コマンドでファイルを作成して設定を記載します。
config/initializers/carrierwave.rbunless Rails.env.development? || Rails.env.test? <= プロダクション環境のみ動作する。 require 'carrierwave/storage/abstract' require 'carrierwave/storage/file' require 'carrierwave/storage/fog' CarrierWave.configure do |config| config.storage :fog config.fog_provider = 'fog/aws' config.fog_directory = 'carrierwave-test-app' <=作成したS3のバケット名を記入 config.fog_credentials = { provider: 'AWS', aws_access_key_id: Rails.application.credentials.dig(:aws, :access_key_id), #最初にコピーしたIAMユーザーのaccess_key aws_secret_access_key: Rails.application.credentials.dig(:aws, :secret_access_key), #最初にコピーしたIAMユーザーのaws_secret_access_key region: 'ap-northeast-1' <=作成したS3のリージョンを記入。 } end endコメントを入れているところを細かく説明していくと
unless Rails.env.development? || Rails.env.test? <= プロダクション環境のみ動作する。ここはそのままです。
config.fog_directory = 'carrierwave-test-app' <=作成したS3のバケット名を記入最初に作成したS3のページに行って確認してみると良いです。
タイポがないか確認もしましょう。aws_access_key_id: Rails.application.credentials.dig(:aws, :access_key_id), #最初にコピーしたIAMユーザーのaccess_key aws_secret_access_key: Rails.application.credentials.dig(:aws, :secret_access_key), #最初にコピーしたIAMユーザーのaws_secret_access_keyここでは
credentials.yml.encにIAMユーザーのaccess_keyとaws_secret_access_keyを指定している。
理由はここに直接記入してしまうとgithubなどでファイルを共有できなくなってしまうので環境変数に入れて外からわからない様にしています。今回は
credentials.yml.encを使用しましたが参考記事ではdotenv-railsが使用されています。
要は外部からキーの中身を見えなくするという目的がある事を抑えておくと良いです。■参考資料
【Rails】dotenv-railsの導入方法と使い方を理解して環境変数を管理しよう!production環境でテストする。
ここまで、設定し終わったらproduction環境でS3に画像がアップされているかテストしてみようと思います。
production環境の設定方法を現場Rails(p274〜)に記入されているのでそちらを参考にしてやってください。
最初にアセットプリコンパイル。
ターミナル
bin/rails assets:precompile
静的ファイル配信サーバを設定
cofig/environments/production.rb
config.public_file_server.enabled = ENV[:RAILS_SERVE_STATIC_FILES]
これをtrueにしたいので
~/.bash_profile
export RAILS_SERVE_STATIC_FILES = 1
とするとtrueになる。
production環境のデータベース作成
rails db:createではデフォルトではdevelopmentとtestしかDBが作成されないので
production用も作成する。postgresqlの場合
createuser -d -P アプリ名
パスワードを聞かれるので確認用も含めて2回記入して終了
config/database.ymlに反映させる作業
~/.bash_profile
export App名_DATABASE_PASSWORD = 設定したパスワード
ここまでやるとproduction環境でサーバーを立ち上げてみましょう。
ターミナルbin/rails s --environment=productionこれでサーバーが立ち上がるはずです。この辺りは現場Railsを買って読むと、詳しく書いています。
現場Railsここで画像を投稿して正しく表示されれば設定が間違っていなければS3にもアップロードされているはずです。
長々と読んでいただきありがとうございます。
間違いなどありましたら、教えていただければありがたいです。その他
ここではあくまで、carrierwaveとS3の連携に対して話をしましたのでherokuなどの設定には触れていません。
下記に参考になる記事を載せておきますので役立ててください。■Railsアプリのデプロイ
【初心者向け】railsアプリをherokuを使って確実にデプロイする方法【決定版】
■master_keyのコピーの仕方(最後に乗ってる)
Herokuで画像を投稿できるようにする方法(ActiveStorage + Amazon S3)
- 投稿日:2021-01-19T23:06:26+09:00
mp3のタグ(ID3v1)をRubyで読み込む(ライブラリ不使用)
ソースコード
mp3tagID3V1read.rb#!/usr/bin/ruby if ARGV.size() == 0 then print "need an argument." else if File.exist?(ARGV[0]) then stat = File.stat(ARGV[0]) a = File.binread(ARGV[0], 128, stat.size-128) if (a[0..2]=="TAG") then title = a[ 3..32].force_encoding("Shift_JIS").rstrip artist = a[33..62].force_encoding("Shift_JIS").rstrip album = a[63..92].force_encoding("Shift_JIS").rstrip yearStr = a[93..96].rstrip trackMark = a[125] genreNo = a[127] if trackMark == "\0" then # track info exists comment = a[97..124].force_encoding("Shift_JIS").rstrip trackNo = (a[126].bytes)[0].to_s else comment = a[97..126].force_encoding("Shift_JIS").rstrip trackNo = "" end print "track : <" + trackNo + ">\n" print "album : <" + album + ">\n" print "artist: <" + artist + ">\n" print "title : <" + title + ">\n" print "year : <" + yearStr + ">\n" print "comment: <" + comment +">\n" end end end※拡張子チェックとファイルサイズチェック入れ忘れた・・
所感
久々にRuby書いてみた。
binreadで得られるデータの型が、配列ではなく、ASCII-8BITエンコーディングのstringっていうややこしさよ。
ただ、添え字の書きやすさ・見やすさがイイ。これに慣れるとSubstringとかで切り出すのダルくなりそう。環境
OS : Windows 10
Ruby 2.6.5 (C:\Ruby26-x64\bin\ruby.exe)参考
- 投稿日:2021-01-19T22:58:50+09:00
【Ruby】each_with_indexなどの添字付きの繰り返し処理を初心者向け解説!
皆さん添字付きの繰り返し処理はご存知でしょうか?
添字付きの繰り返し処理とは、each_with_indexメソッドやwith_indexメソッドのことです。
これらを使うことで、人間にわかりやすく配列を表現したりするなど、情報の使い方にレパートリーが増えるので、是非理解してみてください!
each_with_indexを解説!
each_with_indexとは、配列の要素に添字をいれることのできるメソッドです。
とは言っても、これだとわかりにくいので、コードを確認してみましょう。
fruits = ['orange', 'apple', 'melon'] # 下のブロックの引数のiには0,1,2...と要素の添字が入る fruits.each_with_index {|fruit, i| puts "#{i}: #{fruits}"} #=> 0: apple # 1: orange # 2: melonまず、fruitsという変数に配列を渡します。
そして、fruitsにeach_with_indexメソッドを使用し、doとendを省略したブロックを定義します。
それを出力すると、各要素に定義した通り添字が入るという流れです。
putsブロック内のputs以降をうまく定義してあげることで、人間にわかりやすい内容を出力することができます。
いろんな組み合わせができるwith_indexを解説!
実は、each_with_indexメソッドのような方法以外にも、配列の要素に添字をつけることができる方法があります。
それはwith_indexメソッドです。
このメソッドはeach以外に、mapやdelete_ifなどのメソッドに適用することができます。そして、それらのメソッドを使用する際に添字をつけることができます。
使用する方法はeach_with_indexとほとんど変わりません。
fruits = ['orange', 'apple', 'melon'] fruits.delete_if.with_index {|fruits, i| fruit.include?('a') && i.odd?} #=> ["apple", "melon"]このように、delete_ifなどのメソッドにwith_indexメソッドを使用するだけです。
まとめ
どうでしたでしょうか。
このようなメソッドも使うこともあるかもしれないので、知っておくと便利かもしれません。
これからも1日1記事を目標に、初心者に向けて基本的な知識を記事にしていくので、よろしくお願いします。
- 投稿日:2021-01-19T21:37:12+09:00
性能測定の準備をまとめてみました
はじめに
最近始まったプロジェクトの中で、開発しているSaaSのアプリケーションの性能測定を行うことになりました。
自分の頭の中を整理するためにも性能測定でやることをまとめました。
これから「準備」「計測」「報告」の3stepに分けて、記事を配信していこうと考えています。
第一回目は「性能測定の準備」についてです。※間違いや不明点などありましたらご指摘いただけると幸いです。
事前知識と背景
なぜ性能測定は必要なのか?
ソフトウェアを開発するときには、それが何をするのか=機能、それがどのように動作するのか=非機能を決めることが求められます。そして、ソフトウェアの品質を高めるためには、機能、非機能の観点で要件通りに動作するのかをテストする必要があります。
機能テストは注意深く行われますが、非機能テストが行われないケースはしばしば見受けられます。
以下は、ISOによって定められた製品品質モデルと呼ばれるもので、検証すべき品質特性の分類です。
品質特性 概要 機能適合性 明示された状況下で使用するとき、明示的ニーズ及び暗黙のニーズを満足させる機能を、製品又はシステムが提供する度合い。 性能適合性 明記された状態(条件)で使用する資源の量に関係する性能の度合い。 互換性 同じハードウェア環境又はソフトウェア環境を共有する間、製品、システム又は構成要素が他の製品、システム又は構成要素の情報を交換することができる度合い、及び/又はその要求された機能を実行することができる度合い。 使用性 明示された利用状況において、有効性、効率性及び満足性をもって明示された目標を達成するために、明示された利用者が製品又はシステムを利用することができる度合い。 信頼性 明示された時間帯で、明示された条件下に、システム、製品又は構成要素が明示された機能を実行する度合い。 セキュリティ 人間又は他の製品若しくはシステムが、認められた権限の種類及び水準に応じたデータアクセスの度合いをもてるように、製品又はシステムが情報及びデータを保護する度合い。 保守性 意図した保守者によって、製品又はシステムが修正することができる有効性及び効率性の度合い。 移植性 一つのハードウェア、ソフトウェア又は他の運用環境若しくは利用環境からその他の環境に、システム、製品又は構成要素を移すことができる有効性及び効率性の度合い。 (ISO/IEC 25010:2011)
様々にありますが、この記事では「性能適合性」の品質を検証するための、性能テストについて述べていきます。
システムの性能とは何か?
性能について調べてみると、下記のように表現されていました。
性能とは、「システムが処理結果を返す力」です。
https://gihyo.jp/dev/serial/01/tech_station/0008(他にも書かれていましたが、なんとなくこちらがしっくりきたので、、、)
性能=「処理結果を返す力」の要因が大きく以下の3つです。
レスポンスタイム = 処理の応答時間
スループット = 時間あたりの処理能力
リソース使用量 = 処理を行うための必要な資源最終的にこれらの測定を行い、性能的に問題ないかを見ていくことがゴールになります。
それぞれの測定対象、測定方法は以下を用います。
性能の指標 測定対象 測定方法 レスポンスタイム api、画面のレスポンス速度 Jmeter、devtool スループット 複数スレッドの時間あたりのapiの処理件数 Jmeter リソース使用量 CPU、ディスク、メモリ、ネットワーク AWSのモニタリング ※スループットについて
https://codezine.jp/article/detail/9614背景
今回、性能測定を行うに至った理由は、開発しているアプリケーションの機能要件を大きく変更することになったからです。この機能要件の変更により、大量データの作成、取得を行う必要があるため、非機能要件を満たすかを検証する必要がありました。
この性能検証の結果で非機能要件を満たせなければ、ユーザーにとっては嬉しいであろう機能要件も変更せざるを得なくなります。そのため、今回の結果がプロジェクトの生死を分かつとっていっても過言ではありません。性能測定の準備
大きな流れ
筆者は最初、性能測定をするとなったので、
「よし、早速apiのレスポンス速度を測ってみよう」
などと思っていましたが、そう簡単なことではありませんでした。
性能測定の序盤ではこんなやり取りもありました。先輩
「そもそも、測定対象何かわかっている?」
「そもそも、機能要件を満たすための大量データがある状態で、測定を行う必要あるけど、その大量データってどんなデータがどのくらい必要かわかっている?」
「そもそも、まだ機能自体完成していないから、データなんてないよ。データ作成する必要あるけど、データの作成の仕方わかっている?」
筆者
「どれも、どうやるのか全然わからないです。」整理すると、
性能測定をするためには、機能要件を満たした場合、
どんなデータが必要かを調べて、そのデータを作成して、そのデータによって影響のある対象を測定する必要があります。
それぞれの工程とそのアウトプット物は以下になります。
工程 アウトプット物 データ要件定義 データ要件定義書 データ作成 データ作成用のスクリプト、データ作成手順書 測定対象のスコープ決め 測定対象一覧シート やることが少しクリアになったところでこれからそれぞれの工程を詳しくみていきます。
データ要件定義
まず、どんなデータが必要かを考えていきます。
ここでのアウトプットは、データ要件定義書です。
今回性能測定するソフトウェアは、Saasプロダクトのため、企業単位でどんなデータが必要かを決めていきます。
データ要件定義の中では、やることは大きく以下の2つです。・データ定義する項目を決める(ex.ユーザー数)
・データ量がどのくらいを決める(ex.ユーザー数:1万人)データ定義する項目を決める
データ定義が必要な項目は、今回利用するデータと依存関係のあるデータ項目です。
例えば、企業の地域あたりのユーザー数が利用するデータの場合、そのデータと依存関係のあるユーザー数と地域数という項目のデータ量を定義する必要があります。データ量がどのくらいを決める
データを定義する項目が決まると、項目ごとのデータ量を決める必要があります。
データ量を決める上で大事なのが想定される最大のデータ量を考えることです。
何年後までを想定した仕様にするか、その時の最大規模の企業での項目ごとのデータ量はどの程度か(企業数も含めて)によりデータ量が変わります。
これは、事業戦略として何年後にどのくらいの規模の企業にプロダクトを納品するか、といったビジネスサイドの話が大きく関わってきます。データの作成
必要なデータが分かったら、次にそのデータを作成していきます。
ここでのアウトプットは、データ作成手順書、データ作成用のスクリプトになります。今回変更する機能は、まだできていないため利用するデータを作成する必要があります。
データの作成の中でやることは、大きく以下の2つです。・実際に測定を行うときに必要なデータを作成するプロセスを手順化する。
・データを作成する方法を明らかにし、必要であればスクリプトを作成する。データ作成手順書
下記のようなデータ作成手順書を作成し、データ要件定義で決めたデータを作成する上で何が必要かを考えます。
no 工程 1 測定環境の構築 2 ユーザーデータの作成 3 地域データの作成 4 地域あたりのユーザーの集計 データ作成方法
データを作成する工程については、大きく下記の方法で実現していきます。
・アプリケーション側からデータを設定する
・スクリプトを作成する今後の測定も考えた上で一番早い方法を選択し、必要があればスクリプトを新たに作成して、データを作成します。
測定対象のスコープ決め
必要なデータが準備できたら、測定対象のスコープを決めていきます。
ここでのアウトプットは、測定対象の一覧になります。
測定対象は大きく下記の2つがあるので、分けて測定対象のスコープを決めます。・アプリケーション側で呼ばれる画面、api
・非同期で実行されるバッチ処理画面、api
画面、apiに関しては、今回大量作成されるデータに関する値が返ってくるものを測定対象とします。
スコープの特定はdevtoolを用いて行います。バッチ処理
今回のアプリケーションでは、重めの処理を非同期でアプリケーションサーバーとは別のサーバーで実行しています。
api同様に、今回大量作成するデータに対して、CRUD操作を行うものに絞って、測定対象のスコープを決めます。
スコープの特定はソースコードから行います。まとめ
今回は、性能測定するまでの準備をまとめてみました。
非機能要件を満たしていなかったら、機能要件も見直す必要もあるので、新たに機能を追加する上で性能検証はすごい重要なことだと感じました。
自分でアウトプットしようとすると、怪しい点がいくつも出てきたので、よかったです。
次は具体的に性能測定方法などを書こうと思います。まだまだ理解が不足していることもあると思うので、ご意見、FBあればお願いします!
- 投稿日:2021-01-19T21:35:05+09:00
外部キーを持つデータの削除でdependentオプションが効かず焦った
開発環境
Mac OS Catalina 10.15.7
ruby 2.6系
rails 6.0系各モデルのアソシエーション
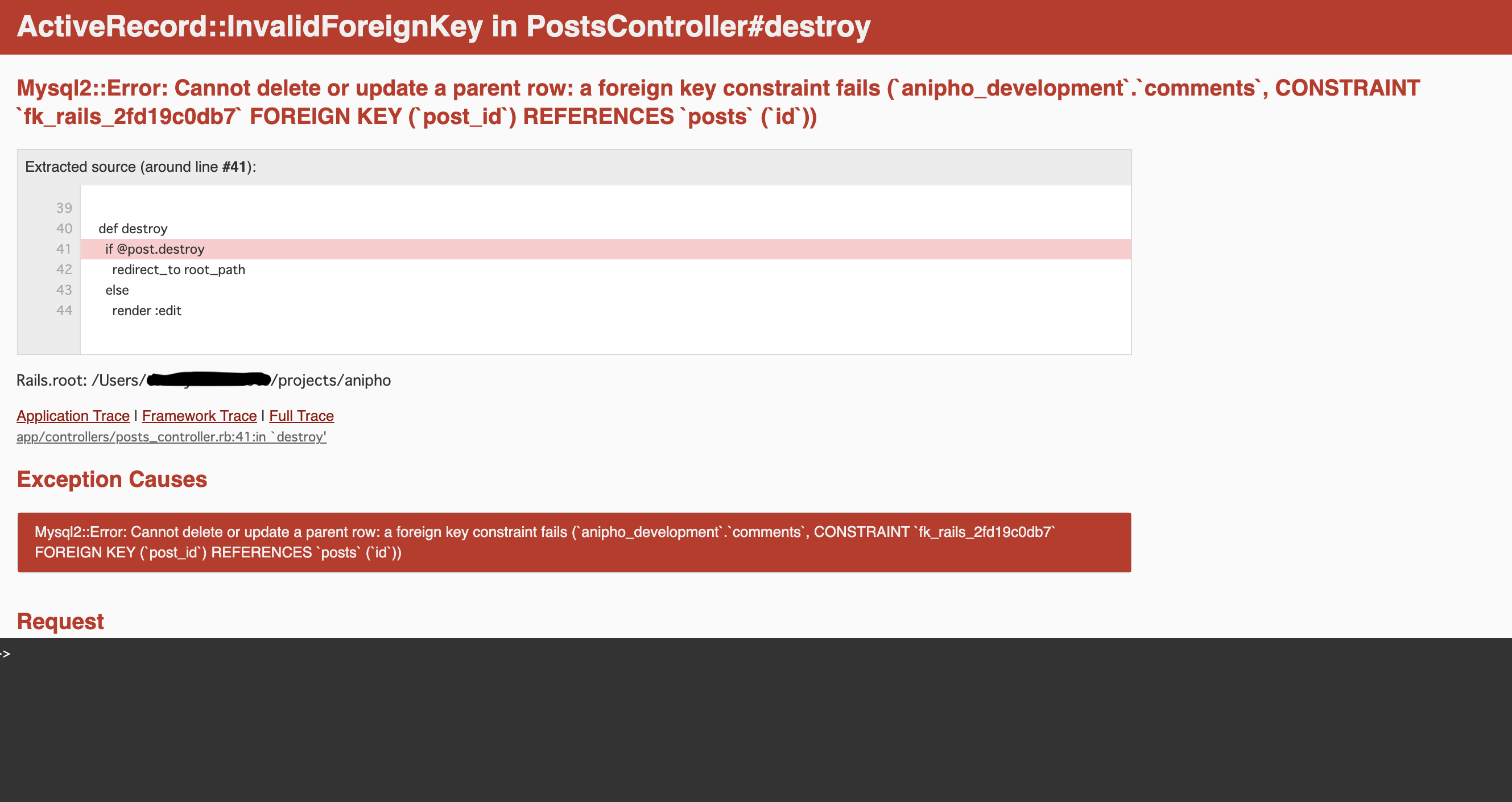
user.rbhas_many :posts has_many :commentspost.rbbelongs_to :user has_many :commentscomment.rbbelongs_to :user belongs_to :postエラー内容
ActiveRecord::InvalidForeignKey in PostsController#destroy Mysql2::Error: Cannot delete or update a parent row: a foreign key constraint failsこのエラー自体は過去にも見たことがあったので、「あ〜はいはい、外部キーを持つデータの削除だから、dependentオプション付けなきゃダメなんでしょ」とdependentオプションを付けて再度削除を試みました。
user.rbhas_many :posts has_many :comments, dependent: :destroypost.rbbelongs_to :user has_many :comments, dependent: :destroyしかし、エラーは解決せず、、、
解決法
なかなか原因がわからなかったので、関連ファイルをあたってみたところ、マイグレーションファイル内に怪しいコードを発見しました。
エラー時のコード
class CreateComments < ActiveRecord::Migration[6.0] def change create_table :comments do |t| t.references :user, null: false, foreign_key: true t.references :post, null: false, foreign_key: true t.string :content, null: false t.timestamps end end end
解決後のコード
class CreateComments < ActiveRecord::Migration[6.0] def change create_table :comments do |t| t.references :user, foreign_key: true t.references :post, foreign_key: true t.string :content, null: false t.timestamps end end end
結論マイグレーションファイル内に記述していたnull:falseがよくなかったみたいです。
まとめ
正直にいうと、原因を的確には説明できないのですが、過去にアプリケーションを作成したときは外部キーにnull:falseは付けてなかったなと思い、変更してみたらうまくいきました。
まだまだ、理解しているようで理解できていないことが多いですね。説明できる方いましたら、教えていただけると幸いです。
- 投稿日:2021-01-19T20:00:39+09:00
Kaminariを使用した非同期ページネーションの作り方
この記事で説明する事
- SJRを使用して非同期ページネーション実装する。
- ページネーション自体はgemの
kaminariを使用する。簡単にアプリの作りを説明
インスタのクローンアプリで、ユーザーがいて、画像を投稿する事が出来る様な仕組みになっています。
user has many postsの形になっていて、今回はPostsに対してページネーションを付け様と思います。参考までにテーブル構成乗っけてます。
usersテーブルcreate_table "users", options: "ENGINE=InnoDB DEFAULT CHARSET=utf8", force: :cascade do |t| t.string "email", null: false t.string "crypted_password" t.string "salt" t.datetime "created_at", null: false t.datetime "updated_at", null: false t.string "username", null: false t.string "avatar" t.index ["email"], name: "index_users_on_email", unique: true end
postsテーブルcreate_table "posts", options: "ENGINE=InnoDB DEFAULT CHARSET=utf8", force: :cascade do |t| t.string "images", null: false t.text "body", null: false t.bigint "user_id" t.datetime "created_at", null: false t.datetime "updated_at", null: false t.index ["user_id"], name: "index_posts_on_user_id" end何はともあれkaminariを導入する。
Gemfilegem 'kaminari'いつも通り
bundle install今回はユーザーが投稿したpostsにページネーションを付けるので
posts_controllerの記述を変更する。
posts_controllerdef index @posts = Post.page(params[:page]).includes(:user).order(created_at: :desc) endここまではテーブル構成が同じであれば、非同期でも同期でも同じになリます。
これでページネーションのボタンを押せば自動的に対応するpostsを取ってきてくれるようになります。
通常なら後はviewにpaginate @postsと記述するだけで普通のページネーションが実装できます。ただ今回は、非同期ページネーションなのでここからが少し違う実装になります。
※そもそも非同期ってなんぞや!って人はこの記事がめちゃわかりやすいので貼っておきます。
初心者目線でAjaxの説明実装のイメージ
今回の実装イメージを説明しておきます。
上の記事を読んでいただいた方は、分かると思いますが非同期処理はものすごく雑に言うと
ページ全体ではなく、必要な部分だけ画面に反映させると言えます。なので今回の要件に当てはめると
①反映させる画面をまず決める。今回は
posts/index.html.slim
②①で決めたファイルの中で。ポスト一覧部分だけを特定する(今回はidを付与して特定する。)
③posts/index.html.slimから先ほど特定したpost一覧部分だけを、スバっと入れ替える。(この部分だけレスポンスを返してあげる)このようなイメージで実装していきたいと思います!!
実装
では先ほどのイメージ通りに行きたいと思います。
①反映させる画面をまず決める
今回はpostの一覧画面に反映させるので
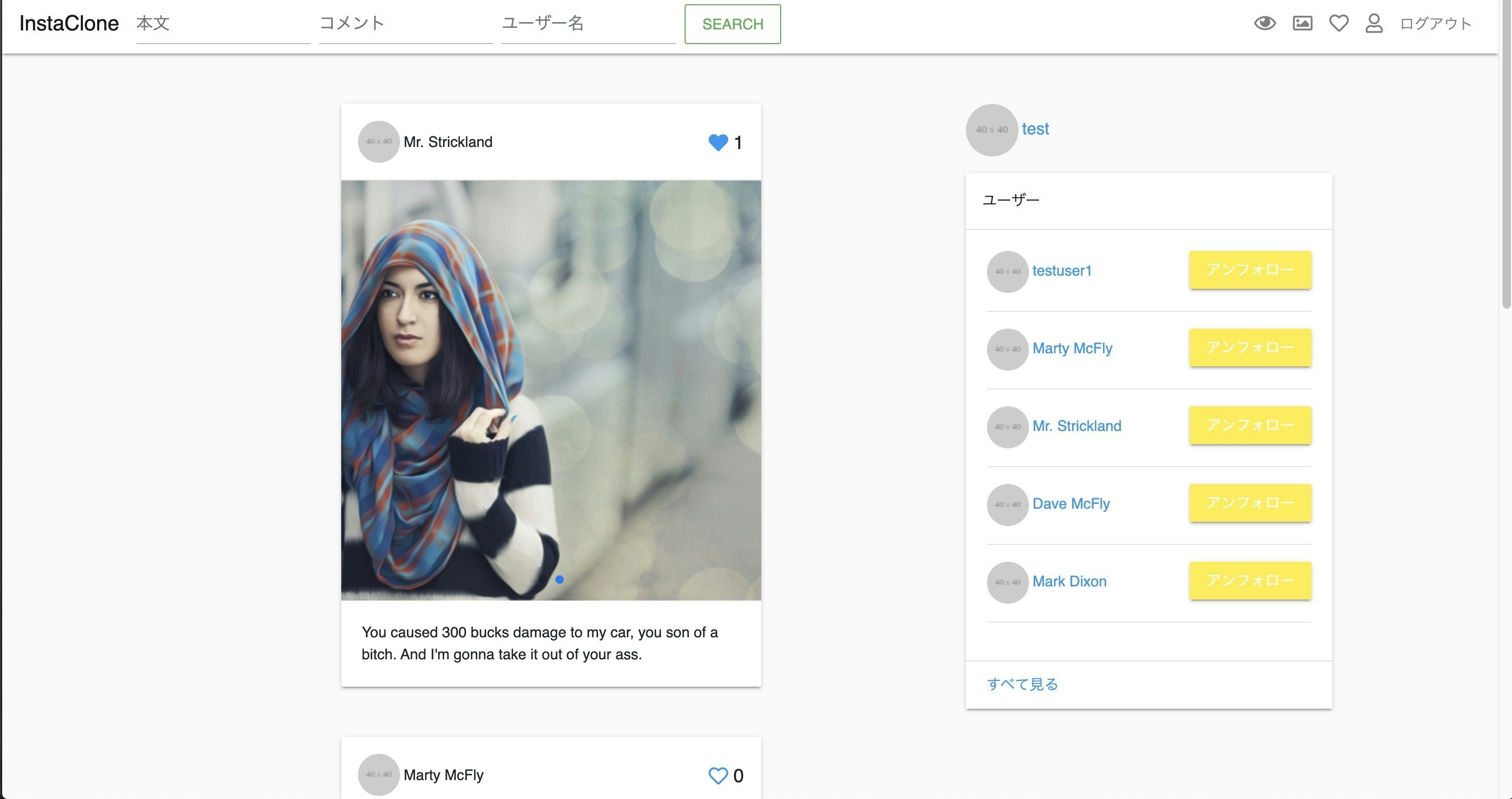
posts/index.html.slimになります。ページ全体の画像
コード
.container .row #posts.col-md-8.col-12 = render @posts = paginate @posts .col-md-4.col-12 - if logged_in? .profile-box.mb-3 = image_tag 'profile-placeholder.png', size: '50x50', class: 'rounded-circle mr-1' = current_user.username .users-box .card .card-header | ユーザー .card-body - @dummy_names.each do |name| .user.mb-3 = image_tag 'profile-placeholder.png', size: '40x40', class: 'rounded-circle mr-1' = name .card-footer = link_to 'すべて見る', '#'このコードが①で説明した部分的に入れ替えられる元になるコードです。
ではこの中から更新したい部分がどこか調べていきましょう。②①の画像の中でポスト一覧だけを特定する
コードを良く読んでみるとpost一覧はそっくりそのままパーシャルに切り出されているのが分かりました!(4行目)
5行目にはページネーション の記述を予め追加しています。
posts/index.html.slim.container .row .col-md-8.col-12 = render @posts <= この部分がpost一覧 = paginate @posts <= ページネーションつまりこのパーシャルとページネーションの部分を非同期通信でスバっと入れ替えればいい事が分かります。
ではどうやってこの2つの部分を特定するのか?このような場合は
idやclassを付与して、入れ替える場所の目安を作ってあげましょう。
今回は#postsというidを親要素に付与します。
※後々にJSでQuerySelectorやgetElementbyIdメソッドを使用して場所が特定できます。.container .row #posts.col-md-8.col-12 = render @posts <= この部分がpost一覧 = paginate @posts <= これはページネーションちょうどこの部分です。
#postsがついているのが分かりますね!これで非同期処理で入れ替える場所の特定が出来ました。③
posts/index.html.slimから先ほど特定したポスト一覧部分をズバっと差し替える。ここまでで
差し替える行われるページとページ内の差し替える場所の特定ができました。
なので非同期処理を実装していきましょう。
kaminariで非同期処理を行うのは、非常に簡単です。おなじみのremote: trueを付けるだけでjs形式のリクエストを送信する事が出来ます。話が少しそれますが、この実装が終わった後、開発者ツールのNetworkタグのContentTypeを見てみましょう。remote: trueにするとこの項目がhtmlからjavascriptに変更されます。remote: trueなし Content-Type: text/html; charset=utf-8 remote: true あり Content-Type: text/javascript; charset=utf-8すこし寄り道しましたが、下記の様に
remote:trueを付けます
posts/index.html.slim.container .row #posts.col-md-8.col-1 = render @posts = paginate @posts, remote: trueこれでJS形式のリクエストを送信する事が出来る様になりました。
またページネーションのボタンを押した時に自動的に呼び出されるテンプレートファイルもアクション名.js.erbが呼び出されるようになります。このままではどこまで入れ替えるのかちょっと分かり辛いのでこの2つをパーシャルにまとめてしまいます。
posts/_posts_paginate.html.slim= render posts = paginate posts, remote: true
posts/index.html.slim.container .row #posts.col-md-8.col-12 = render 'posts_paginate', posts: @postsこれで
_posts_paginate.html.slimを差し替える処理をindex.js.erbに書けばいいという事になります。
posts/index.js.erbvar postsPaginate = document.querySelector('#posts'); //ここで設定したidを特定。constでも動くかも postsPaginate.innerHTML = "<%= j render 'posts_paginate', posts: @posts%> "//innerHTMLで中身を置き換える。 history.replaceState( "", "" ,"?page=<%= @page %>");//リロードできる様にURLを書き換えている1行目で場所の特定をしています。つまり
#postsの場所を指定しています。
2行目でinnerHTMLメソッドを使用して、子要素を入れ替えています。今回子要素は#posts.col-md-8.col-12 = render 'posts_paginate', posts: @postsパーシャル
= render 'posts_paginate', posts: @postsだけになります。
つまり2行目では同じ内容で@postsの中身だけkaminariによって置き換えられているという事です。
3行目では、リロードの処理をするために、replaceStateというメソッドを使用してURLを書き換えています。ちなみに@pageの中身はdef index # kaminariの処理 @page = params[:page] endです。ここは本筋とちょっと外れるので説明は割愛して、リンクだけ貼っておきます。
JavaScriptでURLを操作するメモここまで実装出来たら非同期でページネーションが動くようになっているはずです。
非同期処理と言うと、最初はハマりがちなところなのですが
①idで置き換える場所を特定する。
②置き換えたい場所をできればパーシャルにしてしまう。(した方がjsのメソッドで置き換えが簡単)
③js.erbの中でパーシャル部分をそのまま置き換える。この考え方で実装するようになってから僕はRailsのSJRに関しては簡単に実装できる様になりました。
最後に参考資料も貼っておくので良かったら読んでみてください。参考資料
差し替える場所を特定するには
querySelectorメソッドの使い方
【JavaScript入門】getElementByIdを完全理解する3つのコツ!差し替える為のメソッド
- 投稿日:2021-01-19T19:48:18+09:00
[Rails]検索機能を実装する
はじめに
今回は検索フォームを実装です。
今回は記事のタイトルを検索すると指定したキーワードで記事を検索することができるというものを実装していきます。
実装
routes
今回は「collection」を使用しますが
データを特定したい場合は「member」を使用します。
「member」を使用するとルーティングに「id」がつきます。このように記述されています。↓
またそのアクションを動かすときにparamsで「:id」を受け取りたい場合はmemberを使用し、
特にidを指定して特定のページにいく必要がない場合は、collectionを使用してアクションを追加する。Rails関連のことを調べてみた:routes.rbのcollectionとmemberについて詳しく学習
そしてその他参考にしたのがこちらです。
config/routes.rbresources :albums do collection do get 'search' end endcontroller
コントローラには「search」メソッドを使用し、「 (params[:keyword]) 」と記述し、
「:keyword」を取得できるようにします。
controllers/albums_controller.rbdef search @albums = Album.search(params[:keyword]) endmodels
こちらには検索内容を指定しています。
WhereメソッドとLIKEは以前学習しています。詳しくはこちら
「LIKE」 を使う
「LIKE」 を使うと特殊な記号も使用することができます。「 % 」パーセント記号 → 任意の文字列(空白文字列を含む)(1文字以上)
「 _ 」アンダースコア記号 → 任意の1文字
さらにわかりやすいのはこちら
pikawaka:【Rails】whereメソッドを使って欲しいデータの取得をしよう!
models/album.rbdef self.search(search) if search !="" # 空じゃなければ検索します。 Album.where('title LIKE(?)', "%#{search}%") else Album.all end endviews
検索する部分は「form_with」を使用して実装していきます。
「text_field」の部分には「:keyword」と記述します。
ルーティングをはじめのように設定するとこのようになっています。
controllerの部分で記述した通り、送信すると
「:keyword」(検索したいワード)がparamsに入り
whereメソッドで検索して
urlの部分の「search_albums_path」に送られます。
views/pics/index.html.erb<%= form_with(url: search_albums_path, local: true, method: :get, class: "search-form") do |f| %> <div class="search-inside"> <%= f.text_field :keyword, placeholder: "記事を検索する", class: "search-box" %> </div> <div class="search-inside"> <%= f.submit "検索", class: "search-btn btn" %> </div> <% end %>検索部分はこのような感じになっています。
CSSの部分は省略していますがお好みで装飾します。
表示する部分はこのように記述しています。
views/albums/search.html.erb<% @albums.each do |album| %> <li class="list"> <%= link_to album_path(album) do %> <div class="pic-img-content"> <%= image_tag album.image, class: "pic-img" if album.image.attached? %> </div> <div class="pic-info"> <div class="pic-title"> <p><%= album.created_at %></p> <h3><%= album.title %></h3> </div> <div class="pic-text"> <div class="text-box"> <p><%= album.text %></p> <div> </div> </div> <% end %> </li> <% end %>
試しに用意していたものが表示されました!!
まとめ
少し時間がかかりましたが無事に実装できました。
次回はもう少し早く少し違ったものもできるようにしたいです。

- 投稿日:2021-01-19T19:36:40+09:00
入社して約3ヶ月半、レビュー頂いた事を糧にするためのアウトプット記事
なぜ書くのか
TECH::CAMPを卒業し、プロのエンジニアの方々のもとで、働き始め、3ヶ月半...
先輩方のリソースを、多く割いてしまったと痛感している事、No,1は、そう、コードレビュー。多くのリソースを割いていただいているからこそ、必ず学びに + 誰かの役に立てたらと思い、この記事を書きます。
言語はRuby on Railsです。
その1 命名はきっちりつける
まず基本中の基本ですが、意外に最初はできない変数やメソッド名などの命名についてです。
これは、変更を加える際や、他の人がコードを読んだときの可読性に大いに影響します。(僕は英語読めないので恩恵は受けにくいですが)以下のコードを見てください。
a = "strawberry" b = 100極端な例ですが、この変数をどこがで使用する際にこんな変数名だと、何が入ってるのか全く推測できず、コードを読む際のストレスが大きくなります。
当たり前ですが、明示的に変数の内容がわかる、命名を心がけるべきです。product_name = "strawberry" price = 100こうすることで別の場所で変数を使用する際に、変数の中身に何が入っているのか憶測することができ、わざわざ代入のところまで遡る必要がなくなります。
その2 インデックス番号を極力使用しない
入社間もない頃まで、私自身、必要なデータを、全て配列にぶち込み、それを引き回すという事をやっていました。
全く可読性に配慮もなかったために、下記のような要素呼び出しも、お構いなしに使ってました。data = [["soccer", "baseboll"], ["taro", "ichiro"]] #basebollをやっている子の名前を取りたい puts data[0][1] #=>baseboll puts data[1][1] #=>ichiro上記のような記述がコードの中に乱立すると、書き手以外は、0番目の、2番の要素が何かを理解するために、かなりの労力をかけなければわかりません。
いや、少し経てば、書き手ですら、何のことやらわからなくなるはずです。メンテナンス性を上げるためにも、読み手にも、そして自分にも理解しやすいコードにするためには、こういったデータを使用する際には、必ずハッシュを用いるようにしましょう
data = {soccer: "taro", baseboll: "ichiro"} puts data.key("ichiro") #=>baseboll puts data[:baseboll] #=>ichiro上記のように記述することで、呼び出している要素が何なのかが、読み手に明確に伝わるようになります。
Keyを元にValueを取得するのも、簡単ですし逆も然りです。その3 Railsのコントローラにてindexメソッドを使用する際に、最初からワンレコードのみを取得することを想定したようなコードは書かない
こちらは現在行っているiOSアプリとRailsのバックエンドとのつなぎ込みを行う際にレビュー頂いた事です。
iOSから一つのテーブルの主キーを送り、複数のテーブルにまたがる検索をかけた後、結果として得られたワンレコードを、iOS側に返すという実装でした。
ワンレコードを返すのであればshowだろうと最初は思ったのですが、そのテーブルの情報は何一つ、Swift側からは知ることができないので断念...ということでindexアクションを使用し、書いたコードがこちら(改変してあります + モデルに切り分けてるところも切り分けず集約しています)
def index render json: Item.includes(item_stores: :item_store_customer) .find_by(item_stores:{consignment_item_store_customers: {customer_id: (params[:customer_id]}})) end一見問題ないようにも見えるのですが、よくよく考えてみると、indexアクションとは、リストを返すものなので、最初から、ワンレコード目的の探査を書くのは、おかしいということですね。スコープとして切り分けたとしても、再利用性も低くなりますし、何より、他の人が見たときに、indexアクションの振る舞いとしておかしいので混乱します。
結果としては以下のコードに変更しました。
def index render json: Item.includes(item_stores: :item_store_customer) .where(item_stores:{consignment_item_store_customers: {customer_id: (params[:customer_id]}})) endfind_byをwhereに変更しただけですが、こちらの方がindexアクションの振る舞いとしては正しく見えます。
アプリケーション全体としてみたときに、それぞれの振る舞いがお作法に則っているか、確認する癖を付けたいなと。
Rails側での振る舞いが正しくなり、Swift側では、配列の0番目を抽出するだけで取得できます。その4 updateアクションを使用する際、必要であれば、対象がnilである可能性も考慮した方がいい
Railsのコントローラにてよく目にするこの記述
def update item = Item.find(params[:id]) render json: item.update(item_params) end上記の記述でもいいこともあるのですが(理由は後述します)、findメソッドは、万が一、レコードが見つからなかった際に、ActiveRecord::RecordNotFoundの例外が発生します。
「そもそもこのupdateのタイミングでデータを喪失しているのはおかしい」
「ここからupdateのリクエストを飛ばして、中身が存在していないことは許されない」と言う場合には、例外を発生させて、きちんと、エラーを把握する必要があるかもしれませんが、データが存在していないことが、考えうる場合には、下記のような記述が好ましいと思います。
def update item = Item.find_by(params[:id]) render json: item&.update(item_params) endまず、findをfind_byに変更します。find_byであれば、対象のレコードがもし存在していなかったとしても、例外が発生するのではなく、nilが返ります。そして、item&.updateのように書くことにより、itemの中身がnilだった場合、&よりも後ろのコードは、読まれなくなります。
レコードが存在していないことが、アプリケーション的に、あり得る&許される場合には、存在していない場合の動きもきちんと掌握する必要があると言うことですね。
その5 一つのメソッドで、多くのことをしない
続いては、メソッドを肥大化、させすぎないということです。
例えば次のような、働いた時間と時給をもとに日給を計算するメソッド。
労働時間が8時間を超えていた場合には、その超過分の残業代は、1.25倍になるよう計算します。def calculate_salary(working_time, hourly_wage) if working_time <= 8 hourly_wage * working_time else hourly_wage * 8 + ((working_time - 8) * hourly_wage * 1.25) end end p calculate_salary(8, 100) #=>800 p calculate_salary(9, 100) #=>925.0 p calculate_salary(10, 100) #=>1050.0上記のコードにはもちろんワンサカ問題点はありますが、まずはここで、一つ目を解決します。
上記は給与を計算するメソッドです。そうした視点で考えてみると、超過分の残業代を求める部分の処理は別のメソッドに投げた方が良さそうですし、他に投げて抽象化することで、「別のところで使いたくなった!」なんてときに簡単に再利用することができます。なのでいっそのことメソッドを切り分けちゃいましょう✊
def calculate_salary(working_time, hourly_wage) if working_time <= 8 hourly_wage * working_time else hourly_wage * 8 + excess_payroll(working_time - 8, hourly_wage) end end def excess_payroll(overtime, hourly_wage) overtime * hourly_wage * 1.25 end p calculate_salary(8, 100) #=>800 p calculate_salary(9, 100) #=>925.0 p calculate_salary(10, 100) #=>1050.0上記のように、給与のうち、超過分の給料のみ切り分けるようにすれば、より処理の流れが明確になり、演算を行うコードもグッと読みやすくなります。
その6 引数の情報をもとに条件分岐をしない
次に、引数についてです。メソッドで引数を受け取り処理を行う際に、受け取った引数の情報を元に、条件分岐をするのはやめよう、と言うものです。
じゃあどうするか。
分岐する処理それぞれをメソッドに分てしまい、呼び出す時点で、処理を確定してしまうのが好ましいです。先ほどの、給与計算を行うコードでみてみましょう。
def calculate_salary(working_time, hourly_wage) if working_time <= 8 hourly_wage * working_time else hourly_wage * 8 + excess_payroll(working_time - 8, hourly_wage) end end def excess_payroll(overtime, hourly_wage) overtime * hourly_wage * 1.25 end p calculate_salary(8, 100) #=>800 p calculate_salary(9, 100) #=>925.0 p calculate_salary(10, 100) #=>1050.0みてみると、calculate_salaryメソッド内で引数として渡された労働時間(working_time)の情報を元に条件分岐がされています。
これを細分化し、メソッドを呼ぶ段階で時間超過をしているのか、そうではないのかを切り分けましょう。def calculate_salary(working_time, hourly_wage) hourly_wage * working_time end def calculation_of_overtime(working_time, hourly_wage) hourly_wage * 8 + excess_payroll(working_time - 8, hourly_wage) end def excess_payroll(overtime, hourly_wage) overtime * hourly_wage * 1.25 end working_time = gets.to_i if working_time <= 8 p calculate_salary(working_time, 100) #=>working_time = 8 A.800 else p calculation_of_overtime(working_time, 100) #=>working_time = 9 A.925.0 endそもそも時間を超過しているのかしていないのかをメソッド呼び出し前に分岐し、一つのメソッドの処理を呼び出し前から確定させることができました。
その7 マジックナンバーを使用しない
続いてはマジックナンバーについてです。
マジックナンバーとは、プログラム中に突如現れる意図のわからない数字のことです。
僕自身はインデックス番号に近いものだと思っていて、これがまた、コードの中に乱立すると、次に読む人が「理解できない」と言うことが起こります。また先ほどから使用している給与計算をするプログラムを例に取りましょう。
def calculate_salary(working_time, hourly_wage) hourly_wage * working_time end def calculation_of_overtime(working_time, hourly_wage) hourly_wage * 8 + excess_payroll(working_time - 8, hourly_wage) end def excess_payroll(overtime, hourly_wage) overtime * hourly_wage * 1.25 end working_time = gets.to_i if working_time <= 8 p calculate_salary(working_time, 100) #=>working_time = 8 A.800 else p calculation_of_overtime(working_time, 100) #=>working_time = 9 A.925.0 endパッと目につくプログラム中の謎の数字は「8」と「1.25」、そして「100」ではないでしょうか?
こうしたものがプログラムの中に乱立することで、影響範囲の把握が困難になり、変更に手間と、リスクが伴うようになります。ではどうするか?メソッドで包み込み、マジックナンバーに名前をつけましょう。
def regular_working_hours 8 end def hourly_wage_increase_for_overtime 1.25 end def hourly_wage_price 100 end def calculate_salary(working_time, hourly_wage) hourly_wage * working_time end def calculation_of_overtime(working_time, hourly_wage) hourly_wage * regular_working_hours + excess_payroll(working_time - regular_working_hours, hourly_wage) end def excess_payroll(overtime, hourly_wage) overtime * hourly_wage * hourly_wage_increase_for_overtime end working_time = gets.to_i if working_time <= regular_working_hours p calculate_salary(working_time, hourly_wage_price) #=>working_time = 8 A.800 else p calculation_of_overtime(working_time, hourly_wage_price) #=>working_time = 9 A.925.0 endこのようにすることで、後から別の人が読んだ際に、なんの数字だ?なんて聞くこともなく、変数を見て、「なるほど、時給か!」となることができます。
また、時給を変えたくなった際に変更するのは、「hourly_wage_price」の中の数字を変更するだけなので、変更漏れのリスクも同時に減らすことができます。その8 不必要な代入をしない
これが僕自身結構やってしまうことが多く、何度も指摘をいただいてしまいました。
たとえば以下のようなコードです。def index item_list = Item.all render json: item_list endなんとなく良さげにも見えますが、DB返されたデータ、データをそのまま返しているだけです。
取得したデータや、代入したモノをその後の処理で使用することなく、出力するならば、不要な代入をせず、そのまま使用しましょう。def index render json: Item.all endこれでかなりスッキリしました。
その9 コードレビューを依頼する際に、レビュワーが必ず、実行環境にあるとは限らないため、テストと機能実装はセットでレビュー依頼を出す。
これも一度指摘いただきました。
レビューしてくださる方が、実装した機能を、実行できる環境にあるかどうかはわかりません。
実行できない環境の場合、コードを見て、処理がうまく流れるかどうかを、頭の中で考える必要があります。
レビュワーに負担をかけない、余計なことを考えさせないようにするために、「動く」という指標をたてるためのテストを、必ず、レビューの中に含めようということです。これは、時と場合、状況によっても違うとは思いますが、ある程度成熟したプロジェクト(テストの基準、方針等が定まっている)であれば、「このテストが通るってことは基準は満たしているな」という判断材料になります。
とにかくレビュー依頼はコードの品質を見ていただく場にする、という根本的なモノです。
その10 配列として結果を受け取る場合、同じ挙動になるならば、eachではなく、mapを使う
eachメソッドを使用している箇所を見てmapに置き換えられそうな場合、極力mapを使用しましょう、ということです。
パフォーマンスの面でも、可読性の面でも、eachよりもmapの方が優れています。#each int_list = (1..3).to_a int_to_double = [] int_list.each do |i| int_to_double << i * 2 end p int_to_double #=>[2, 4, 6] #map int_list = (1..3) int_to_double = int_list.map do |i| i * 2 end p int_to_double #=>[2, 4, 6]配列に格納するための空配列の準備がいらなくなるためかなりスッキリ描くことができます。
最後に
コードレビューの際に、いただいた指摘は必ず、自分に落とし込むよう心がけましょう。
レビューしてくださる方は、わざわざ自分の手を止めて、コードを読んでくれています。
どんな指摘も真摯に受け止め、誠実に対応しましょう。
- 投稿日:2021-01-19T18:05:25+09:00
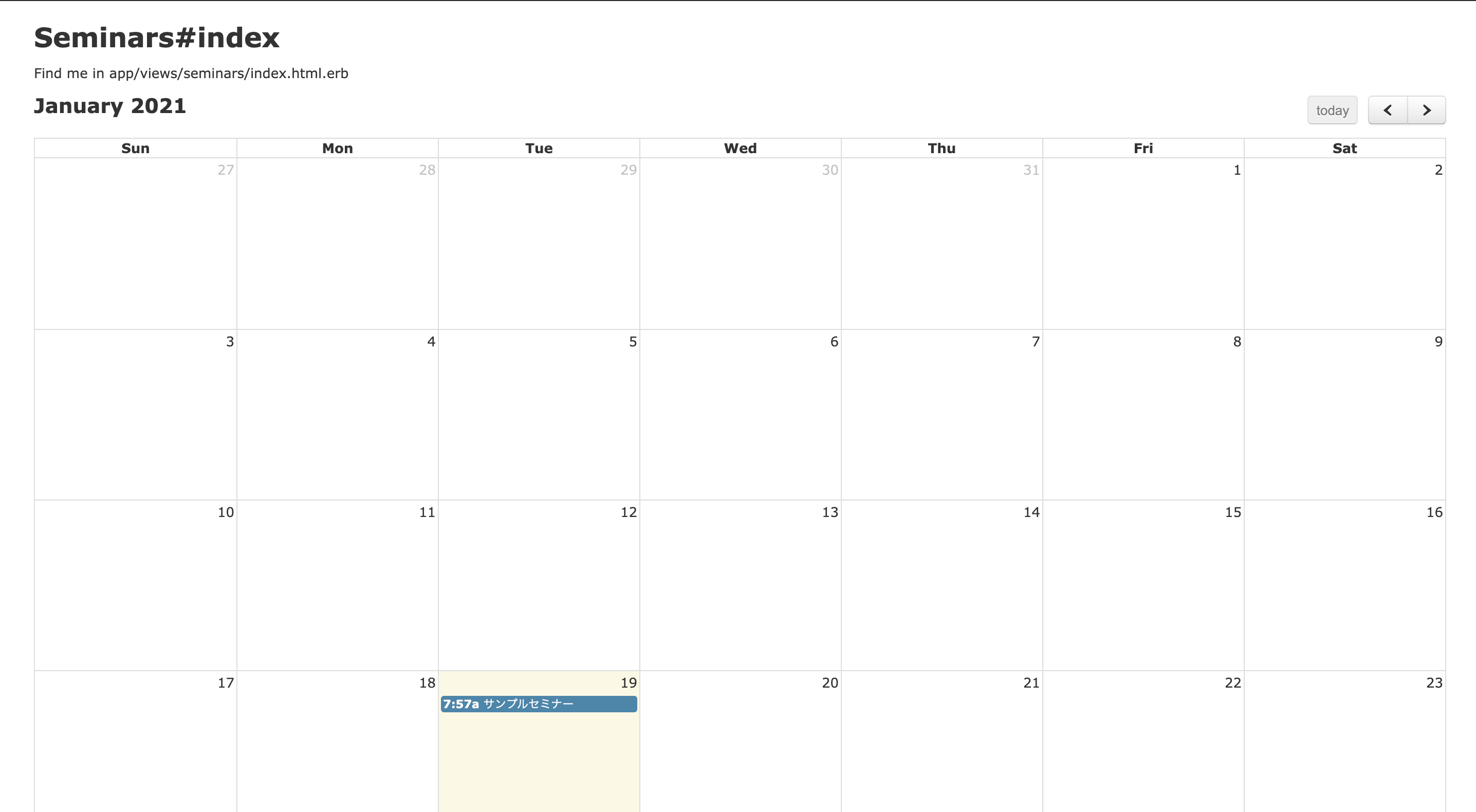
【Rails】FullCalendarを使う
予定を保存するテーブルとモデルを作成
例として、
seminarsテーブルとモデルを作ります。$ rails g model seminar title starts_at:datetime ends_at:datetime $ rails db:migrate予定を管理するコントローラーとルーティングを作成
$ rails g controller seminars indexapp/controllers/seminars_controller.rbclass SeminarsController < ApplicationController def index @seminars = Seminar.all end endconfig.routes.rbresources :seminars, only: [:index]予定のダミーデータを投入
$ rails c 2.6.3 :001 > Seminar.create(title: 'サンプルセミナー', starts_at: Time.zone.now, ends_at: Time.zone.now)Gemを追加
Gemfilegem 'jquery-rails', '4.3.3' gem 'fullcalendar-rails' gem 'momentjs-rails'$ bundle installapp/assets/javascript/application.js//= require jquery //= require moment //= require fullcalendarカレンダーを表示するスクリプトを記述
app/assets/javascript/application.js$(function () { $(document).on('turbolinks:load', function () { function eventCalendar() { return $('#calendar').fullCalendar({}); }; function clearCalendar() { $('#calendar').html(''); }; $(document).on('turbolinks:load', function () { eventCalendar(); }); $(document).on('turbolinks:before-cache', clearCalendar); }); });CSSの設定
app/assets/stylesheets/application.css... *= require_tree . *= require_self *= require fullcalendar */カレンダーの表示領域を作成
app/views/seminars/index.html<div id="calendar"></div>これで空のカレンダーが表示されます。
予定を表示
$ touch app/views/seminars/index.json.jbuilderapp/views/seminars/index.json.jbuilderjson.array!(@seminars) do |seminar| json.extract! seminar, :id, :title json.start seminar.starts_at json.end seminar.ends_at end↑の記述で/seminars.jsonにアクセスした時に以下のデータが返ってくるようになる。
[ { "id":1, "title":"サンプルセミナー", "start":"2021-01-19T07:57:23.329Z", "end":"2021-01-19T07:57:23.329Z" }, { "id":2, "title":"ホゲホゲセミナー", "start":"2021-01-19T07:57:23.329Z", "end":"2021-01-19T07:57:23.329Z" }, ... ]最後にイベントを表示するスクリプトを追加して完成。
app/assets/javascript/application.js$(function () { $(document).on('turbolinks:load', function () { function eventCalendar() { return $('#calendar').fullCalendar({}); }; function clearCalendar() { $('#calendar').html(''); }; $(document).on('turbolinks:load', function () { eventCalendar(); }); $(document).on('turbolinks:before-cache', clearCalendar); //以下を追加 $('#calendar').fullCalendar({ events: '/seminars.json' }); }); });
オプション
FullCalendarの日本語化やオプションいろいろ | Fire Sign Blog
ajaxでイベントを登録
参考
- 投稿日:2021-01-19T16:37:57+09:00
railsでテスト実行
引用先
Railsチュートリアルテストとは
言葉そのまんまで機能が正しく実装されたことを確認することです。
テストを書けばいざというときのセーフティネットにもなり、それ自体がアプリケーションのソースコードの「実行可能なドキュメント」にもなります。
テストが揃っていれば、バグを追うために余分な時間を使わずに済むため、正しく行えばむしろテストがないときよりも確実に開発速度がアップします。テストのメリット
1.機能停止に陥るような回帰バグを防止できる。
2.コードを安全にリファクタリング(改善)できる。
3.テストコードは、アプリケーションコードから見ればクライアントとして動作するので、アプリケーションの設計やシステムの他の部分とのインターフェイスを決めるときにも役に立つ。テストの実行
ターミナルにてrails generate controllerを実行した時点でテストファイルが作成されている。
ターミナル# 例 $ rails generate controller StaticPages home help↓
test/controllers/static_pages_controller_test.rbrequire 'test_helper' class StaticPagesControllerTest < ActionDispatch::IntegrationTest test "should get home" do ←homeページのテスト get static_pages_home_url ←GETリクエストをhomeアクションに対して送信 assert_response :success ←リクエストに対するレスポンスは[成功]になるはず end test "should get help" do get static_pages_help_url assert_response :success end end↓
ターミナル$ rails db:migrate # システムによっては必要 $ rails test 2 tests, 2 assertions, 0 failures, 0 errors, 0 skips0errorsのため問題なくコードが実装されている。
わざとエラーを出してみる
aboutページを追加したと想定してコードを追加してみる。
test/controllers/static_pages_controller_test.rbrequire 'test_helper' class StaticPagesControllerTest < ActionDispatch::IntegrationTest test "should get home" do get static_pages_home_url assert_response :success end test "should get help" do get static_pages_help_url assert_response :success end test "should get about" do get static_pages_about_url assert_response :success end endテスト実行
ターミナル$ rails test NameError: undefined local variable or method `static_pages_about_url' 3 tests, 2 assertions, 0 failures, 1 errors, 0 skipsAboutページへのURLが見つからないとエラーメッセージ。
ルーティングファイルを修正してみる。config/routes.rbRails.application.routes.draw do get 'static_pages/home' get 'static_pages/help' get 'static_pages/about' ←追加 root 'application#hello' endテスト実行
ターミナル$ rails test AbstractController::ActionNotFound: The action 'about' could not be found for StaticPagesControllerStaticPagesコントローラにaboutアクションがないとエラーメッセージ。
aboutアクションを追加してみる。app/controllers/static_pages_controller.rbclass StaticPagesController < ApplicationController def home end def help end def about ←追加 end ←追加 endテスト実行
ターミナル$ rails test ActionController::UnknownFormat: StaticPagesController#about is missing a template for this request format and variant.テンプレート(ビュー)がないとエラーメッセージ。
下記コマンドか右クリックでビューファイルを作成。ターミナル$ touch app/views/static_pages/about.html.erbテスト実行
ターミナル$ rails test 3 tests, 3 assertions, 0 failures, 0 errors, 0 skips0errorsになったのでテスト完了!!
テストが完了したのでコードをリファクタリングする
(今回はリファクタリングするコードがないため完了)これを、「red ・ green ・ REFACTOR」のサイクルという。
- 投稿日:2021-01-19T15:10:19+09:00
[PostgreSQL] Railsアプリを削除するなら、先にデータベースを削除する!
はじめに
学習中にサンプルアプリを作っては消すを繰り返していると、
ふと「フォルダ削除するだけでいいの?」と疑問に感じました。調べてみると、、
フォルダを削除する前に、DB(データベース)を削除しなければいけないらしいです!
以下、2通りの方法をメモしておきます。
- DB削除 → アプリフォルダ削除
- アプリフォルダを削除してしまった後のDB削除方法
環境
- macOS Catalina
- Ruby 2.7.2
- Rails 6.0.3
- PostgreSQL 13.1
① DB削除 → アプリフォルダ削除
該当アプリのフォルダ内で
$ rails db:drop親ディレクトリに移動して
$ rm -rf アプリ名必ず上記①の手順で削除するのが良さそうです。
ここからは、もしもアプリフォルダを先に削除してしまった場合の方法です。② アプリフォルダを削除してしまった後のDB削除方法
$ psql -l (DB名を一覧表示#実行結果(sampleアプリを削除したい場合) List of databases Name | Owner | Encoding | Collate | Ctype | Access privileges -----------------------+-------+----------+---------+-------+------------------- sample_development | user | UTF8 | C | C | sample_test | user | UTF8 | C | C | postgres | user | UTF8 | C | C | template0 | user | UTF8 | C | C | =c/user + | | | | | user=CTc/user template1 | user | UTF8 | C | C | =c/user + | | | | | user=CTc/user (5 rows)$ psql postgres (PostgreSQLにログイン --- (postgres=#) \du (ユーザーと権限を確認 (postgres=#) \q (PostgreSQLからログイン --- $ dropdb -U ユーザー名 消したいDB名※削除してはいけないDB(デフォルト)
postgres
template0
template1私はこのデフォルトであろう
postgresを削除してしまいました。。(大反省)
学習用のアプリばかりだったので、PostgreSQLをアンインストールしました。
再インストール後に確認すると、上記3つのDBは初めからありました!!上記デフォルトを削除してしまった後の手順を、自戒の意を込めて記しておきます。
アンインストール方法
$ ls /usr/local/Cellar/postgresql (インストール済みPostgreSQLバージョン確認 $ brew info postgresql (現時点の最新バージョン確認 $ brew uninstall --force postgresql (全てのバージョンをアンインストール $ ls -l /usr/local/var/postgres (設定ファイル、ログ、データ等を表示 $ rm -rf /usr/local/var/postgres (設定ファイル、ログ、データ等も削除その後のインストールは、初めてインストールした時と同様に。
さいごに
学習中はサンプルアプリが増えていく一方でしたが、
私はこの方法で解決できました。
間違っているところがあればご指摘いただけるとありがたいです。参考記事
Ruby on Rails 削除関連まとめ
PostgreSQLで強制的にデータベースを削除する
[MacOS] PostgreSQL の全バージョンをアンインストールする方法 ~ Homebrew 編
PostgreSQLドキュメント「dropdb」
- 投稿日:2021-01-19T11:39:47+09:00
【Ruby on Rails】yarn install --check-files
導入
Rails環境で、node_moduleをインストールしたら発生したエラー。
======================================== Your Yarn packages are out of date! Please run `yarn install --check-files` to update. ======================================== To disable this check, please change `check_yarn_integrity` to `false` in your webpacker config file (config/webpacker.yml). yarn check v1.22.5 info Visit https://yarnpkg.com/en/docs/cli/check for documentation about this command.解決方法
このエラーは、package.jsonにあるパッケージコンテンツのバージョンとハッシュ値がyarn.lockに記載されているものと一致しない場合に表示される。
つまり、package.jsonとyarn.lockに記載しているもののバージョンを一致させれば良い。
※ 公式:コマンドリファレンス1.
yarn upgradeを実行# package.jsonで指定されたバージョン範囲に基づいて、依存関係を最新バージョンに更新。 $ yarn upgrade2. package.jsonとyarn.lockを比較して、バージョンが一致しているかを確認
package.jsonとyarn.lockを比較すると、
- package.jsonでは、2.X.Xをダウンロードするように指定(当時、2.7.3が最新版)
- yarn.lockでは、package.jsonで
^2.7.3と指定されているので、2.9.4をダウンロードしている。※ 参考:package.json:リファレンス
package.json"dependencies": { "chart.js": "^2.7.3" }yarn.lockchart.js@^2.7.3: version "2.9.4" resolved "https://registry.yarnpkg.com/chart.js/-/chart.js-2.9.4.tgz#0827f9563faffb2dc5c06562f8eb10337d5b9684" integrity sha512-B07aAzxcrikjAPyV+01j7BmOpxtQETxTSlQ26BEYJ+3iUkbNKaOJ/nDbT6JjyqYxseM0ON12COHYdU2cTIjC7A== dependencies: chartjs-color "^2.1.0" moment "^2.10.2"したがって、package.jsonのバージョン指定をyarn.lockのものと同様にする。
$ yarn upgrade chart.js@^2.9.4"dependencies": { - "chart.js": "^2.7.3" + "chart.js": "^2.9.4" }3. Railsを起動してみる
$ rails s => Booting Puma => Rails 6.X.X application starting in development => Run `rails server --help` for more startup options [1] Puma starting in cluster mode... [1] * Version 4.3.7 (ruby 2.X.X-p137), codename: Mysterious Traveller [1] * Min threads: 5, max threads: 5 [1] * Environment: development [1] * Process workers: 1 [1] * Preloading application [1] * Listening on tcp://0.0.0.0:3000 [1] Use Ctrl-C to stop [1] - Worker 0 (pid: 81) booted, phase: 04. Docker環境の場合
なぜ、解決出来たのかわからないが、Dockerを使用している場合
上記の方法でも解決出来なかったが、Dockerプロセスを削除し、再ビルドしたら解決する場合もあった。$ docker rm (docker ps -q -a) # コンテナの全削除 $ docker-compose up参考
- 投稿日:2021-01-19T11:19:40+09:00
gemのransackで複数カラムを検索対象にする方法
始めに
僕自身複数カラムを検索対象にするのは難しいと思っていたのですが、思っていたより簡単にできたので是非参考にしてもらえたらなと思い、書くことにしました。
前提
僕はPostモデルのtitleとdescriptionを検索対象にやっていきます。
class CreatePosts < ActiveRecord::Migration[5.2] def change create_table :posts do |t| t.string :title ⬅️⬅️⬅️⬅️⬅️⬅️これ t.integer :recommended t.text :description ⬅️⬅️⬅️⬅️これ t.references :user, foreign_key: true t.timestamps end add_index :posts, [:user_id, :created_at] end endやり方
始めにviewの一部を変えていきます。
titleだけを検索対象の場合は、<%= f.search_field :title_cont, placeholder: "キーワード検索", class: 'form-control font-awesome' %>titleとdescriptionの複数を検索対象にする場合、
<%= f.search_field :title_or_description_cont, placeholder: "キーワード検索", class: 'form-control font-awesome' %>比較すると、titleだけ検索対象の方はtitle_contなのに対し、複数検索対象の方はtitle_or_description_contとなっています。orを入れるだけです!
次はcontrollerです。
僕の場合、titleだけ検索対象だと、def set_search if logged_in? @search_word = params[:q][:title_cont] if params[:q] @q = current_user.feed.page(params[:page]).per(10).ransack(params[:q]) @feed_items = current_user.feed.page(params[:page]).per(10) @posts = @q.result(distinct: true) end end複数検索対象だと、ここも先ほどのviewと一緒で一部変更するだけです!
@search_word = params[:q][:title_or_description_cont] if params[:q]これで複数カラムを検索対象にできました!!!
- 投稿日:2021-01-19T10:37:12+09:00
クラスとインスタンス
クラスとは?
設計図や料理のレシピのような物です。新しい物を作るのにその度に一から作るのは手間と時間がかかります。
それを避けるために、共通のルールを守った上で個別のデータを作ることが出来るようにする物です。
クラスは共通の処理と属性を決めるだけで、単体でデータを扱うことはできません。class クラス名 # 変数やメソッドの定義 end今回はジャムを作るJamクラスを定義して見ましょう。
class Jam endインスタンスとは
実際に作られる『もの』のことです。
クラスを定義しましたがクラスだけでは何のデータも持ちません。
データを持つインスタンスをクラスから生成します。
クラスは定義しなくてもnewというメソッドを始めから持っていてこれを実行することで
データを持つインスタンスが生成されます。インスタンスを生成したあとからデータを追加したり、メソッドを実行できるようにするために
変数に代入して作ります。変数名 = クラス名.new実際にインスタンスを生成してみると
class Jam end strawberry_jum = Jam.new今はレシピに何も書かれていないので空の状態です。
インスタンスメソッド
名前の通りインスタンスが使用できるメソッドでクラスに記述します
class クラス名 def メソッド名 # 処理 end end実際にインスタンスメソッドを定義してみましょう。
class Jam def make_jam #処理を記入 end end strawberry_jum = Jam.new strawberry_jum.make_jamまだメソッドの中身を定義していないので何も起きません。(後ほど中身を記入して使います。)
インスタンス変数
データの持つ属性を定義する物です。
定義しておくことで全てのインスタンスは同じ属性を持ちますが
それぞれ異なる値を設定することができます。
例えば同じ『ボール』という属性を定義したとしても値は『サッカーボール』や『バスケットボール』や『野球ボール』と様々な値がありますよね。変数の頭に@をつけてこのように定義します。
class クラス名 def メソッド名 @変数名 = 値 # インスタンス変数 end endインスタンス変数のスコープは、そのクラスのすべてのインスタンスメソッドなのでインスタンスの全ての動作に使用できます。
initializeメソッド
インスタンスが生成されると同時に、定義した処理が実行されるインスタンスメソッドです。
今回の場合newメソッドでインスタンスが作られた時に同時に生成されますインスタンス変数とinitializeメソッドを使ってみましょう。
class Jam def initialize(jam_taste,jam_color,jam_price) #渡した引数が代入される @taste = jam_taste #jam_tasteにstrawberryが代入されている @color = jam_color #jam_colorにredが代入されている @price = jam_price #jam_priceに300が代入されている end def make_jam end end strawberry_jum = Jam.new('イチゴ','赤',300)#引数を渡す strawberry_jum.make_jamインスタンスメソッドmake_jamに処理を記述して使ってみましょう。
class Jam def initialize(jam_taste,jam_color,jam_price) @taste = jam_taste @color = jam_color @price = jam_price end def make_jam puts "#{@taste}味のジャムを作ります。色は#{@color}色で値段は{@price}円です" end strawberry_jum = Jam.new('イチゴ','赤',300) strawberry_jum.make_jam #イチゴ味のジャムを作ります。色は赤色で値段は300円です と出力される。 endちなみに、みかん味のジャムが作りたくなったらどうするかというと
class Jam def initialize(jam_taste,jam_color,jam_price) @taste = jam_taste @color = jam_color @price = jam_price end def make_jam puts "#{@taste}味のジャムを作ります。色は#{@color}色で値段は{@price}円です" end strawberry_jum = Jam.new('イチゴ','赤',300) strawberry_jum.make_jam orange_jum = Jam.new('みかん','オレンジ','250') orange_jum.make_jum #みかん味のジャムを作ります。色はオレンジ色で値段は250円です と出力される。 endこのようになります。
クラスメソッド
クラスで共通した処理を定義したい時に使います。
メソッド名の頭に self をつけて定義しますclass クラス名 def self.メソッド名 # 処理 end end実際に使ってみましょう。
class Jam def self.use puts "パンに塗って使います" end def initialize(jam_taste,jam_color,jam_price) @taste = jam_taste @color = jam_color @price = jam_price end def make_jam puts "#{@taste}味のジャムを作ります。色は#{@color}色で値段は{@price}円です" end strawberry_jum = Jam.new('イチゴ','赤',300) strawberry_jum.make_jam orange_jum = Jam.new('みかん','オレンジ','250') orange_jum.make_jum #みかん味のジャムを作ります。色はオレンジ色で値段は250円です と出力される。 Jam.use #パンに塗って使います と出力される。 end以上です。
- 投稿日:2021-01-19T09:47:20+09:00
fizz_buzz問題で使用された表現
前回投稿したfizz_buzz問題
記述を見ていると基礎的な表現が多い様に感じたので、
実際に使われたいた表現に関して整理してみる。実際のfizz_buzz問題解説はこちらから
fizz_buzz問題def fizz_buzz num = 1 while (num <= 100) do if num % 15 == 0 puts "FizzBuzz" elsif (num % 3) == 0 puts "Fizz" elsif (num % 5) == 0 puts "Buzz" else puts num end num = num + 1 end end fizz_buzz代入演算子
代入演算子num = 1 # 変数名 = 格納する値
上記の記述による作用
代入と呼ばれる記述を用いて変数に値を格納している。
代入
- 変数の後の
=を記述することで`変数の箱の中に入れる事ができる。=のことを代入演算子と呼ぶ。 Rubyに置いて = が1つの式は「右側の値を左の変数に代入する」という意味になる。変数とは
変数とは値を入れる箱のようなもの どの様な値が入っているのかをわかりやすい様に変数名を定義する。再代入
再代入num = num + 1
- 1度値を代入したあとの変数に、別の値を再び代入すること
- プログラム中に何度でも変更可能
- 以下の記述で簡潔にまとめる事も可能
再代入の省略形(自己代入演算子を採用)num += 1if文 + elsif
if文とは
- 「もし〇〇だったら△△をする」と処理を分けることができます。
elsif
- 条件式を追加できます。
正しいときとそうでない時の条件分岐if num % 15 == 0 # 条件式1 puts "FizzBuzz" # 条件式1が真(true)のときに実行する処理 elsif (num % 3) == 0 # 条件式2 puts "Fizz" # 条件式1が偽(false)+条件式2が真(true)のときに実行する処理 elsif (num % 5) == 0 # 条件式3 puts "Buzz" # 条件式1と条件式2がどちらとも偽(false)+条件式3が真(true)のとき実行する処理 else # 当てはまらない時 puts num # 上記の条件式に当てはまらなかった時に実行する処理 end比較演算子 + 代数演算子
比較演算子+代数演算子while (num <= 100) do # numは100以下か if num % 15 == 0 # 剰余(割った余り)は # 0と等しいか elsif (num % 3) == 0 # 剰余(割った余り)は # 0と等しいか elsif (num % 5) == 0 # 剰余(割った余り)は # 0と等しいか
比較演算子
A > BAはBより大きいかA >= BAはB以上かA < BAはBより小さいかA <= BAはB以下かA == BAとBは等しいか代数演算子
+足し算-引き算*かけ算/割り算%剰余(割った余り)
- 投稿日:2021-01-19T06:55:54+09:00
【Rubyトリビア】elsif の条件式は省略可能!?
Rubyのif文ではelsifを使って複数の条件を書くことができます。
def greet_to(name) if name == 'Alice' puts 'Hi, Alice!' elsif name == 'Bob' puts 'Hi, Bob!' end end greet_to('Alice') #=> Hi, Alice! greet_to('Bob') #=> Hi, Bob!それでは次のようにelsifの条件式を無くすとどうなるでしょうか?
def greet_to(name) if name == 'Alice' puts 'Hi, Alice!' - elsif name == 'Bob' + elsif puts 'Hi, Bob!' end end答えはこうです。(あれ、さっきと同じ!?)
greet_to('Alice') #=> Hi, Alice! greet_to('Bob') #=> Hi, Bob!条件式なしのelsifは
elsif trueと同じ意味になるんでしょうか??
ためしに今度はifの条件式もなくしてみましょう。def greet_to(name) - if name == 'Alice' + if puts 'Hi, Alice!' elsif puts 'Hi, Bob!' end endこれだと結果はどうなるんでしょうか?というか、そもそもこんなコード、動くんでしょうか?
greet_to('Alice') #=> Hi, Alice! # Hi, Bob! greet_to('Bob') #=> Hi, Alice! # Hi, Bob!動いた〜!けど、なんだこれ?AliceもBobも両方出力されてますね……。
種明かし
実はこれ、こう書いたのと同じ意味になっています。
def greet_to(name) if puts 'Hi, Alice!' # Do nothing elsif puts 'Hi, Bob!' # Do nothing end endつまり、putsの呼び出しが条件式として扱われているわけですね。
で、putsの戻り値はnilなのでputs 'Hi, Alice!'は偽として扱われ、続いてelsifの条件式puts 'Hi, Bob!'が実行される、というわけです。なので、たとえばputsの代わりにpメソッドを使うと結果が変わります。(pメソッド戻り値は引数として渡したオブジェクト自身になり、真と評価されるため)
def greet_to(name) if p 'Hi, Alice!' elsif p 'Hi, Bob!' end end greet_to('Alice') #=> "Hi, Alice!" greet_to('Bob') #=> "Hi, Alice!"最初に見せたコードも条件式をわざと改行させるとこんなふうに書けます。(よい子はマネしちゃいけません)
def greet_to(name) if name == 'Alice' puts 'Hi, Alice!' elsif name == 'Bob' puts 'Hi, Bob!' end end greet_to('Alice') #=> Hi, Alice! greet_to('Bob') #=> Hi, Bob!こんなコードをわざわざ書く人はいないでしょうし、書くべきでもないですが、if/elseと書くつもりがうっかりif/elsifと書いてしまうと、構文エラーにならない代わりに予期しない不具合を起こすかもしれないので気をつけましょう。
def greet_to(name) if name == 'Alice' puts 'Hi, Alice!' elsif # ← 本当はelseと書くつもりが間違えた puts 'Hi, Bob!' end endなお、ifやelsifのうしろには条件式が必要なので、次のようなコードを書いたときは構文エラーになります。
def greet_to(name) if name == 'Alice' puts 'Hi, Alice!' elsif # elsifに対応する条件式がない(構文エラー) end end #=> syntax error, unexpected `end' # syntax error, unexpected end-of-input, expecting `end'おまけ:case/whenだったら?
以下のようにcase/whenを使った条件分岐で、
when 'Bob'をwhenだけにしてみるとどうなるでしょうか?def greet_to(name) case name when 'Alice' puts 'Hi, Alice!' when puts 'Hi, Bob!' end end #=> syntax error, unexpected string literal, expecting `do' or '{' or '(' # puts 'Hi, Bob!'むむむ、構文エラーが起きました。
が、次のように()付きでputsを呼び出すとエラーになりません。def greet_to(name) case name when 'Alice' puts 'Hi, Alice!' when puts('Hi, Bob!') end end greet_to('Alice') #=> Hi, Alice! greet_to('Bob') #=> Hi, Bob!とはいえ、これもif/elsifの場合と同じく、
puts('Hi, Bob!')がwhen節の条件式になっているだけです。def greet_to(name) case name when 'Alice' puts 'Hi, Alice!' when puts('Hi, Bob!') # (こう書いてるのと同じ) end end