- 投稿日:2021-01-19T23:41:20+09:00
見えないけど存在する、devise:controllers
はじめに
昨日、deviseのコントローラー内で用いられている
superについて言及しました。本日は少しだけその続きです。昨日の投稿↓
deviseコントローラーで出逢ったsuperについて調べてみたdeviseの元のコントローラーはどこだ?
% rails g devise:controller上のコマンドでは、deviseの様々なコントローラーの継承元を生成することができませんでした。
次のコマンドで生成可能です。% rails g devise:controllers [scope]まぁ、わざわざ元のdeviseのコントローラーを生成しなくても、オーバーライドでメソッドをいじることができるのですが…
終わりに
コマンドで出てきたスコープという概念、よくわかってない…
ファイルを生成させなくても処理が動くということがとても不思議。
- 投稿日:2021-01-19T23:34:12+09:00
マイグレーションファイルをupの状態で削除してしまった場合の解決法
はじめに
railsでアプリを作っていたところ、不要なテーブルをマイグレートしてしまい、そのマイグレーションファイルを手入力で削除してしまった。
マイグレーションファイルをupの状態で消してしまうとStatus Migration ID Migration Name -------------------------------------------------- up 20210116053731 ********** NO FILE ********** up 20210118091408 Devise create usersこのように NO FILEという表示になってしまい、同じファイルを作ろうと思ったら、
「そのファイル名はすでにあるよ!」と怒られてしまい、途方に暮れたので、忘備録としてメモ。結論
結論からいうと、別のマイグレーションファイルを作って、そこにファイルを消すような指示を出す、ということ。
今回だと、まず、dbディレクトリの配下にMigration IDを持ったファイルを作る。
上の例ならば、
「20210116053731_sample.rb」
というファイルを作る。
そして、その状態でrails db:migrate:statusとターミナルに打ち込むと
Status Migration ID Migration Name -------------------------------------------------- up 20210116053731 Sample down 20210118091408 Devise create usersというようにファイル名が変わる。そして、その状態で
rails db:rollbackと打ち込むことで、マイグレーションファイルはdownの状態になる。
Status Migration ID Migration Name -------------------------------------------------- down 20210116053731 Sample down 20210118091408 Devise create usersそして、downになったことを確認したら、手動で先ほどのマイグレーションファイルを削除する。
そうすると、テーブルを消すことができる。まとめ
Migration IDから新しくファイルを作って、そこから、マイグレートやロールバックをして削除する方法があったとはいろいろな方法がある物だと感心した。
90分ほど時間をとってしまったので、次は3分で解決できるな!
- 投稿日:2021-01-19T23:28:34+09:00
ActiveRecordで特定のユーザーに関する全データを抽出する
特定のユーザーのデータを全て抽出したい!
サービス運営をしていると、極まれに特定のユーザーに関する全データを抽出したいことがある。
きっと、水平分割や、物理削除してしまったデータの復旧作業をする日がやってくる。そんな面倒な作業をすることになったあなたのために、今回は特定ユーザーのデータ抽出・インポート方法を紹介する。
ステップ1. 特定のユーザーに紐づく全てのデータを取得する
ActiveRecordを使っていれば、全てのテーブルはモデル層で関連づけられている。
そのため、Userクラスを起点に関連を辿れば、全ての必要なデータを引っ張ってくることができるはずである。今回は、自前で書いたactive_record_depth_query.rbを使って、関連するレコードを一発で引っ張ってくる。
これを使うと、普段利用しているpreloadのように引数にArray/Hashを渡すことで、外部キーを探索してレコードを取得することができる。あっという間に、ユーザーに関する全てのレコードを抽出することができた。楽ちん。
depth_query = ActiveRecordDepthQuery.new(user, [:addresses, { cart: :items, orders: [:line_items, :address }]]) depth_query.each do |relation| relation #=> 第二引数で指定したレコードのActiveRecord::Relationが順番に入ってくる endステップ2. 抽出したデータを別のDBにコピーする
ステップ1で抽出したデータを、別のDBにコピーする処理を紹介する。
今回はRails6の複数DBの機能と、activerecord-importを利用したので、環境が違う人は適宜書き換えてください。下記の処理では、古いDB→新しいDB にデータを移すために、
古いDBからレコードを抽出した後、新しいDBに接続を切り替えてからbulk insertしている。作業としては単純なので、下記のコードで特定のユーザーのデータを抽出・保存することができた。
require 'activerecord-import' class RecordsFromBackupDatabase # インポート対象の関連一覧 USER_ASSOCIATIONS = [:addresses, { cart: :items, orders: [:line_items, :address] }].freeze # 古いDBの接続先 OLD_DATABASE_HOST = 'old-database.host' # 新しいDBの接続先 NEW_DATABASE_HOST = 'new-database.host' # @param user_ids [Array<Integer>] インポート対象のユーザーID # # @return [void] def perform(user_ids) # 古いDB/新しいDBを設定する。共有するプロセスに影響するのでwebサーバーではなくrails consoleで作業すること reconnect_database ActiveRecord::Base.transaction do # 古いDBに接続する connected_to_old_database do users = User.where(id: user_ids) # ユーザーを先に復旧しておく import_relation(users) users.find_each do |user| # ユーザー毎のデータを復旧する restore_user(user) end end end end private def reconnect_database # 接続中のDBを切断する ActiveRecord::Base.connection.disconnect! # writing/readingの2系統を定義して、新旧のDBを切り替えられるようにする config = ActiveRecord::Base.connection_pool.spec.config ActiveRecord::Base.configurations = { "#{Rails.env}": config.merge(host: NEW_DATABASE_HOST, replica: false), "#{Rails.env}_replica": config.merge(host: OLD_DATABASE_HOST, replica: true) } ActiveRecord::Base.connects_to( database: { writing: Rails.env.to_sym, reading: :"#{Rails.env}_replica" } ) end def connected_to_old_database(&block) ActiveRecord::Base.connected_to(role: :reading, &block) end def connected_to_new_database(&block) ActiveRecord::Base.connected_to(role: :writing, &block) end def restore_user(user) # ユーザーのassociationを順に探索して、古いDBのレコードを、新しいDBにインポートする ActiveRecordDepthQuery.new(user, USER_ASSOCIATIONS).each do |relation| relation.find_in_batches do |records| klass = relation.klass # 本番のDBにレコードをインポートする connected_to_new_database do klass.import(records, validate: false) end end end end endまとめ
今回は、preloadライクなインターフェースでレコードを抽出するActiveRecordDepthQueryと、それを利用したデータの復旧方法を紹介した。
願わくば、今回の処理が再び使う日が来ないことを祈るのみだが、もしもそんなオペレーションが必要になった時は、どうぞお使いください。
- 投稿日:2021-01-19T23:28:12+09:00
Heroku + CarrierWave + S3で画像投稿する方法
1. 作業の流れ
まず最初にS3のバケットを作成します。
最初に行う理由は後からローカルで開発しているRailsのアプリケーションにS3で決めた設定を
入力するからです。S3のバケットの作り方ですが、参考資料をみて行うと問題なく進みます。
流れとしては、
- まず
IAMでユーザーを作成する。(ここで作成したアクセスキーIDとシークレットアクセスキーをcarrierwaveの設定で使用する。)
- S3のバケットを作成する。(画像を保存する箱を作る)
- gemの
fog-awsを導入して設定ファイルなどを作成する。の様に進んでいきます。
1. IAMユーザーの作成
まずAWSにアカウント登録すると
rootというめちゃくちゃ強い権限を持ったアカウントが作成される。
公式ではセキュリティ上の観点からrootユーザーを日常的に使用するのは推奨していないのでIAMというサービスを使用して、別の権限のユーザーを日常使い様に作成します。つまり、自分のAWSアカウントだとしてももう一人権限が小さいユーザーを作って管理するイメージです。※作成方法は最後に書いてあるリンクに記載されています。
2. S3のバケットを作成
画像を保存する箱を作成します。
参考資料ではrootユーザーのままでアクセスできると、書いていますがIAMユーザーでやってもできました。
ここの設定は、すごく丁寧に参考資料にまとめられていたので、そのまま使用すれば問題ないかと思います。参考資料
上記2つの参考リンクです。ここの通りにやればできます。
【Rails】CarrierWaveチュートリアル3. fog-awsを導入したRailsの設定諸々
fog-awsは外部のストレージサービスを使用する時に簡単にしてくれるgemくらいの認識でOKまず
fog-awsをインストールする
Gemfile
gem 'fog-aws'
bundle installを実行して次はどの環境で:fog(S3)を使用するのかをRails側に設定する。
app/uploaders/image_uploader# Include RMagick or MiniMagick support: # include CarrierWave::RMagick include CarrierWave::MiniMagick <= ここのコメントアウトを外す。 # Choose what kind of storage to use for this uploader: このIf文を追加することで、環境毎にどこに保存するかを指定している。 この場合はproduction環境のみS3を使用する。 if Rails.env.development? storage :file elsif Rails.env.test? storage :file else storage :fog end ....次に、事前にAWSで作成したIAMユーザーの情報とS3の情報を設定する。
まず設定ファイルであるcarrierwave.rbをconfig/initializersいかに作成する。
この場所におけば、初期化に必要なものと判断されて、自動で読み込まれるので作成してしまって構いません。touch config/initializers/carrierwave.rb上記コマンドでファイルを作成して設定を記載します。
config/initializers/carrierwave.rbunless Rails.env.development? || Rails.env.test? <= プロダクション環境のみ動作する。 require 'carrierwave/storage/abstract' require 'carrierwave/storage/file' require 'carrierwave/storage/fog' CarrierWave.configure do |config| config.storage :fog config.fog_provider = 'fog/aws' config.fog_directory = 'carrierwave-test-app' <=作成したS3のバケット名を記入 config.fog_credentials = { provider: 'AWS', aws_access_key_id: Rails.application.credentials.dig(:aws, :access_key_id), #最初にコピーしたIAMユーザーのaccess_key aws_secret_access_key: Rails.application.credentials.dig(:aws, :secret_access_key), #最初にコピーしたIAMユーザーのaws_secret_access_key region: 'ap-northeast-1' <=作成したS3のリージョンを記入。 } end endコメントを入れているところを細かく説明していくと
unless Rails.env.development? || Rails.env.test? <= プロダクション環境のみ動作する。ここはそのままです。
config.fog_directory = 'carrierwave-test-app' <=作成したS3のバケット名を記入最初に作成したS3のページに行って確認してみると良いです。
タイポがないか確認もしましょう。aws_access_key_id: Rails.application.credentials.dig(:aws, :access_key_id), #最初にコピーしたIAMユーザーのaccess_key aws_secret_access_key: Rails.application.credentials.dig(:aws, :secret_access_key), #最初にコピーしたIAMユーザーのaws_secret_access_keyここでは
credentials.yml.encにIAMユーザーのaccess_keyとaws_secret_access_keyを指定している。
理由はここに直接記入してしまうとgithubなどでファイルを共有できなくなってしまうので環境変数に入れて外からわからない様にしています。今回は
credentials.yml.encを使用しましたが参考記事ではdotenv-railsが使用されています。
要は外部からキーの中身を見えなくするという目的がある事を抑えておくと良いです。■参考資料
【Rails】dotenv-railsの導入方法と使い方を理解して環境変数を管理しよう!production環境でテストする。
ここまで、設定し終わったらproduction環境でS3に画像がアップされているかテストしてみようと思います。
production環境の設定方法を現場Rails(p274〜)に記入されているのでそちらを参考にしてやってください。
最初にアセットプリコンパイル。
ターミナル
bin/rails assets:precompile
静的ファイル配信サーバを設定
cofig/environments/production.rb
config.public_file_server.enabled = ENV[:RAILS_SERVE_STATIC_FILES]
これをtrueにしたいので
~/.bash_profile
export RAILS_SERVE_STATIC_FILES = 1
とするとtrueになる。
production環境のデータベース作成
rails db:createではデフォルトではdevelopmentとtestしかDBが作成されないので
production用も作成する。postgresqlの場合
createuser -d -P アプリ名
パスワードを聞かれるので確認用も含めて2回記入して終了
config/database.ymlに反映させる作業
~/.bash_profile
export App名_DATABASE_PASSWORD = 設定したパスワード
ここまでやるとproduction環境でサーバーを立ち上げてみましょう。
ターミナルbin/rails s --environment=productionこれでサーバーが立ち上がるはずです。この辺りは現場Railsを買って読むと、詳しく書いています。
現場Railsここで画像を投稿して正しく表示されれば設定が間違っていなければS3にもアップロードされているはずです。
長々と読んでいただきありがとうございます。
間違いなどありましたら、教えていただければありがたいです。その他
ここではあくまで、carrierwaveとS3の連携に対して話をしましたのでherokuなどの設定には触れていません。
下記に参考になる記事を載せておきますので役立ててください。■Railsアプリのデプロイ
【初心者向け】railsアプリをherokuを使って確実にデプロイする方法【決定版】
■master_keyのコピーの仕方(最後に乗ってる)
Herokuで画像を投稿できるようにする方法(ActiveStorage + Amazon S3)
- 投稿日:2021-01-19T21:59:32+09:00
パンくずリスト実装
はじめに
利用しているユーザーがどのページにアクセスしているのかを一目で分かりやすくするために、パンくず機能を実装したので、載せておこうと思います。
今回はgretel(リンクを設置したリストを表示するGem)を用いて、実装しました。1.Gemの導入・ファイル作成
**1.Gemfileに gretel を記述し、bundle installする。
Gemfilegem 'gretel'ターミナル% bundle install2.パンくずリストの親子関係を記述するファイルを作成する。
ターミナル% rails g gretel:installすると、config / breadcrumbs.rb が作成される。
2.パンくずリスト親子関係記述
1 で作成した breadcrumbs.rb にコードを記述していく
config/breadcrumbs.rbcrumb "viewで呼び出す時のページ名" do link "リストの表示名", "アクセスするページのパス" parent :前のページ名 endconfig/breadcrumbs.rbcrumb :root do link "トップページ", root_path end crumb :new_idea do link "アイデア新規投稿", new_idea_path parent :root end crumb :idea_show do |idea| link "アイデア詳細", idea_path(idea.id) parent :root end crumb :edit_idea do |idea| link "アイデア編集", edit_idea_path parent :idea_show,idea end # 中略3.viewで呼び出す
2 で作成した親子関係をviewに呼び出す。
views/ideas/show.html.erb<% breadcrumb :idea_show ,@idea%> <!--呼び出したいパンくずを記述--> <%= breadcrumbs separator: " › " %> <!--パンくず間の区切りである「>」を示す-->
ひとまず実装完了!!! あとはCSSで整えていく感じです。
最後に
実装したパンくず機能はあらゆるサイトやアプリなどに用いられているので、今回の実装は勉強になりました。
活用できる機会があれば用いていきたいと思います。
- 投稿日:2021-01-19T21:35:05+09:00
外部キーを持つデータの削除でdependentオプションが効かず焦った
開発環境
Mac OS Catalina 10.15.7
ruby 2.6系
rails 6.0系各モデルのアソシエーション
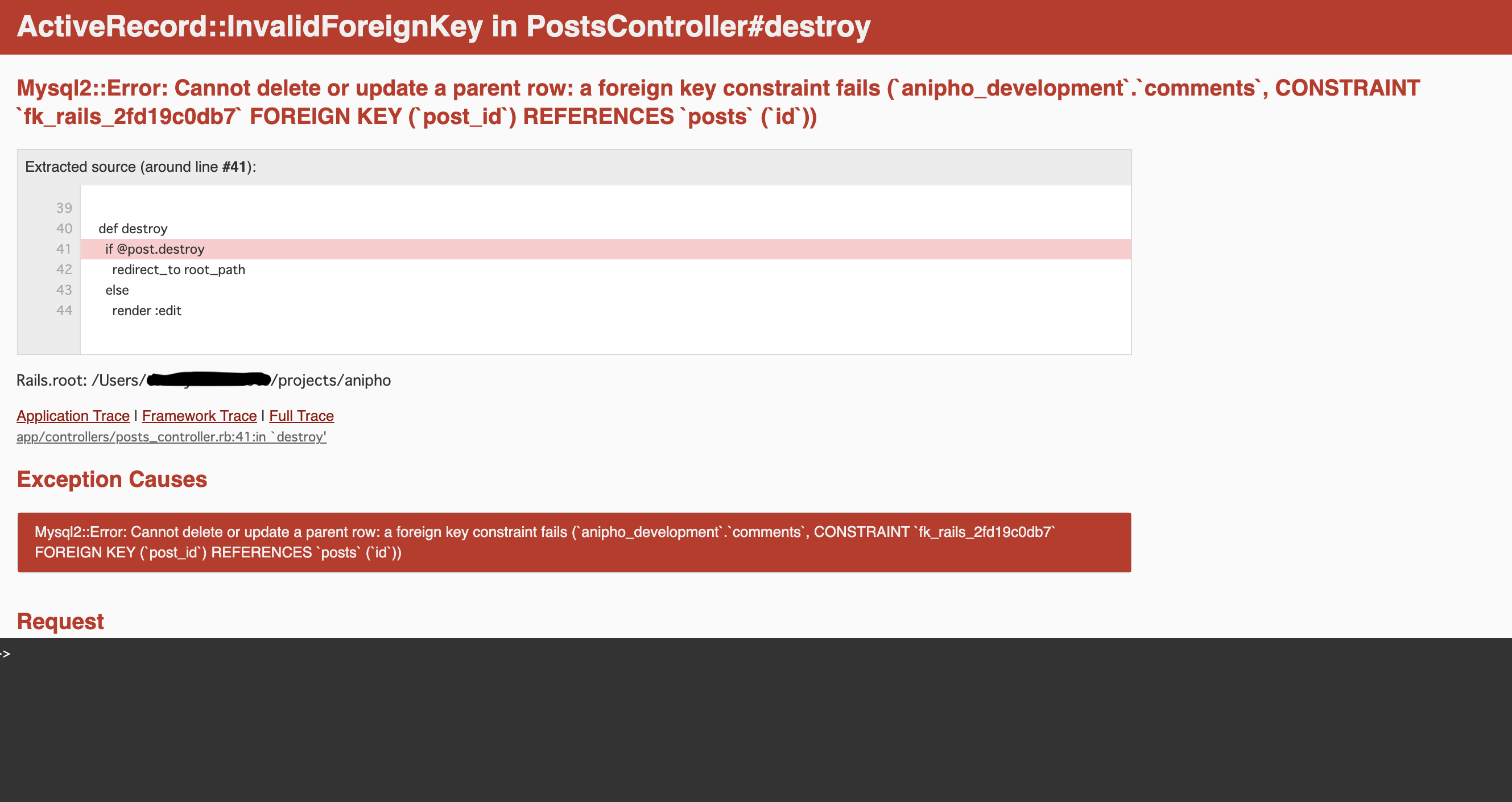
user.rbhas_many :posts has_many :commentspost.rbbelongs_to :user has_many :commentscomment.rbbelongs_to :user belongs_to :postエラー内容
ActiveRecord::InvalidForeignKey in PostsController#destroy Mysql2::Error: Cannot delete or update a parent row: a foreign key constraint failsこのエラー自体は過去にも見たことがあったので、「あ〜はいはい、外部キーを持つデータの削除だから、dependentオプション付けなきゃダメなんでしょ」とdependentオプションを付けて再度削除を試みました。
user.rbhas_many :posts has_many :comments, dependent: :destroypost.rbbelongs_to :user has_many :comments, dependent: :destroyしかし、エラーは解決せず、、、
解決法
なかなか原因がわからなかったので、関連ファイルをあたってみたところ、マイグレーションファイル内に怪しいコードを発見しました。
エラー時のコード
class CreateComments < ActiveRecord::Migration[6.0] def change create_table :comments do |t| t.references :user, null: false, foreign_key: true t.references :post, null: false, foreign_key: true t.string :content, null: false t.timestamps end end end
解決後のコード
class CreateComments < ActiveRecord::Migration[6.0] def change create_table :comments do |t| t.references :user, foreign_key: true t.references :post, foreign_key: true t.string :content, null: false t.timestamps end end end
結論マイグレーションファイル内に記述していたnull:falseがよくなかったみたいです。
まとめ
正直にいうと、原因を的確には説明できないのですが、過去にアプリケーションを作成したときは外部キーにnull:falseは付けてなかったなと思い、変更してみたらうまくいきました。
まだまだ、理解しているようで理解できていないことが多いですね。説明できる方いましたら、教えていただけると幸いです。
- 投稿日:2021-01-19T20:52:12+09:00
enum で性別選択欄作ってみた
新規投稿の時に性別を選択できるようにする
① enumを使用する時のデータ型は gender:integer にする
② enum gender: { man: 0, woman: 1 } をモデルに記述
③ view 作成
<%= f.label :man %> <%= f.radio_button :gender, :man %> <%= f.label :woman %> <%= f.radio_button :gender, :woman %>完成
なんだけど、これだと viewでは man か woman と出でしまうので、
私は
enum gender: { 男: 0, 女: 1 }<%= f.label :男 %> <%= f.radio_button :gender, :男 %> <%= f.label :女 %> <%= f.radio_button :gender, :女 %>という風にしました。
いいのかわかんないけど英語を日本語にするgemを使った方かいいのかな??
- 投稿日:2021-01-19T20:00:39+09:00
Kaminariを使用した非同期ページネーションの作り方
この記事で説明する事
- SJRを使用して非同期ページネーション実装する。
- ページネーション自体はgemの
kaminariを使用する。簡単にアプリの作りを説明
インスタのクローンアプリで、ユーザーがいて、画像を投稿する事が出来る様な仕組みになっています。
user has many postsの形になっていて、今回はPostsに対してページネーションを付け様と思います。参考までにテーブル構成乗っけてます。
usersテーブルcreate_table "users", options: "ENGINE=InnoDB DEFAULT CHARSET=utf8", force: :cascade do |t| t.string "email", null: false t.string "crypted_password" t.string "salt" t.datetime "created_at", null: false t.datetime "updated_at", null: false t.string "username", null: false t.string "avatar" t.index ["email"], name: "index_users_on_email", unique: true end
postsテーブルcreate_table "posts", options: "ENGINE=InnoDB DEFAULT CHARSET=utf8", force: :cascade do |t| t.string "images", null: false t.text "body", null: false t.bigint "user_id" t.datetime "created_at", null: false t.datetime "updated_at", null: false t.index ["user_id"], name: "index_posts_on_user_id" end何はともあれkaminariを導入する。
Gemfilegem 'kaminari'いつも通り
bundle install今回はユーザーが投稿したpostsにページネーションを付けるので
posts_controllerの記述を変更する。
posts_controllerdef index @posts = Post.page(params[:page]).includes(:user).order(created_at: :desc) endここまではテーブル構成が同じであれば、非同期でも同期でも同じになリます。
これでページネーションのボタンを押せば自動的に対応するpostsを取ってきてくれるようになります。
通常なら後はviewにpaginate @postsと記述するだけで普通のページネーションが実装できます。ただ今回は、非同期ページネーションなのでここからが少し違う実装になります。
※そもそも非同期ってなんぞや!って人はこの記事がめちゃわかりやすいので貼っておきます。
初心者目線でAjaxの説明実装のイメージ
今回の実装イメージを説明しておきます。
上の記事を読んでいただいた方は、分かると思いますが非同期処理はものすごく雑に言うと
ページ全体ではなく、必要な部分だけ画面に反映させると言えます。なので今回の要件に当てはめると
①反映させる画面をまず決める。今回は
posts/index.html.slim
②①で決めたファイルの中で。ポスト一覧部分だけを特定する(今回はidを付与して特定する。)
③posts/index.html.slimから先ほど特定したpost一覧部分だけを、スバっと入れ替える。(この部分だけレスポンスを返してあげる)このようなイメージで実装していきたいと思います!!
実装
では先ほどのイメージ通りに行きたいと思います。
①反映させる画面をまず決める
今回はpostの一覧画面に反映させるので
posts/index.html.slimになります。ページ全体の画像
コード
.container .row #posts.col-md-8.col-12 = render @posts = paginate @posts .col-md-4.col-12 - if logged_in? .profile-box.mb-3 = image_tag 'profile-placeholder.png', size: '50x50', class: 'rounded-circle mr-1' = current_user.username .users-box .card .card-header | ユーザー .card-body - @dummy_names.each do |name| .user.mb-3 = image_tag 'profile-placeholder.png', size: '40x40', class: 'rounded-circle mr-1' = name .card-footer = link_to 'すべて見る', '#'このコードが①で説明した部分的に入れ替えられる元になるコードです。
ではこの中から更新したい部分がどこか調べていきましょう。②①の画像の中でポスト一覧だけを特定する
コードを良く読んでみるとpost一覧はそっくりそのままパーシャルに切り出されているのが分かりました!(4行目)
5行目にはページネーション の記述を予め追加しています。
posts/index.html.slim.container .row .col-md-8.col-12 = render @posts <= この部分がpost一覧 = paginate @posts <= ページネーションつまりこのパーシャルとページネーションの部分を非同期通信でスバっと入れ替えればいい事が分かります。
ではどうやってこの2つの部分を特定するのか?このような場合は
idやclassを付与して、入れ替える場所の目安を作ってあげましょう。
今回は#postsというidを親要素に付与します。
※後々にJSでQuerySelectorやgetElementbyIdメソッドを使用して場所が特定できます。.container .row #posts.col-md-8.col-12 = render @posts <= この部分がpost一覧 = paginate @posts <= これはページネーションちょうどこの部分です。
#postsがついているのが分かりますね!これで非同期処理で入れ替える場所の特定が出来ました。③
posts/index.html.slimから先ほど特定したポスト一覧部分をズバっと差し替える。ここまでで
差し替える行われるページとページ内の差し替える場所の特定ができました。
なので非同期処理を実装していきましょう。
kaminariで非同期処理を行うのは、非常に簡単です。おなじみのremote: trueを付けるだけでjs形式のリクエストを送信する事が出来ます。話が少しそれますが、この実装が終わった後、開発者ツールのNetworkタグのContentTypeを見てみましょう。remote: trueにするとこの項目がhtmlからjavascriptに変更されます。remote: trueなし Content-Type: text/html; charset=utf-8 remote: true あり Content-Type: text/javascript; charset=utf-8すこし寄り道しましたが、下記の様に
remote:trueを付けます
posts/index.html.slim.container .row #posts.col-md-8.col-1 = render @posts = paginate @posts, remote: trueこれでJS形式のリクエストを送信する事が出来る様になりました。
またページネーションのボタンを押した時に自動的に呼び出されるテンプレートファイルもアクション名.js.erbが呼び出されるようになります。このままではどこまで入れ替えるのかちょっと分かり辛いのでこの2つをパーシャルにまとめてしまいます。
posts/_posts_paginate.html.slim= render posts = paginate posts, remote: true
posts/index.html.slim.container .row #posts.col-md-8.col-12 = render 'posts_paginate', posts: @postsこれで
_posts_paginate.html.slimを差し替える処理をindex.js.erbに書けばいいという事になります。
posts/index.js.erbvar postsPaginate = document.querySelector('#posts'); //ここで設定したidを特定。constでも動くかも postsPaginate.innerHTML = "<%= j render 'posts_paginate', posts: @posts%> "//innerHTMLで中身を置き換える。 history.replaceState( "", "" ,"?page=<%= @page %>");//リロードできる様にURLを書き換えている1行目で場所の特定をしています。つまり
#postsの場所を指定しています。
2行目でinnerHTMLメソッドを使用して、子要素を入れ替えています。今回子要素は#posts.col-md-8.col-12 = render 'posts_paginate', posts: @postsパーシャル
= render 'posts_paginate', posts: @postsだけになります。
つまり2行目では同じ内容で@postsの中身だけkaminariによって置き換えられているという事です。
3行目では、リロードの処理をするために、replaceStateというメソッドを使用してURLを書き換えています。ちなみに@pageの中身はdef index # kaminariの処理 @page = params[:page] endです。ここは本筋とちょっと外れるので説明は割愛して、リンクだけ貼っておきます。
JavaScriptでURLを操作するメモここまで実装出来たら非同期でページネーションが動くようになっているはずです。
非同期処理と言うと、最初はハマりがちなところなのですが
①idで置き換える場所を特定する。
②置き換えたい場所をできればパーシャルにしてしまう。(した方がjsのメソッドで置き換えが簡単)
③js.erbの中でパーシャル部分をそのまま置き換える。この考え方で実装するようになってから僕はRailsのSJRに関しては簡単に実装できる様になりました。
最後に参考資料も貼っておくので良かったら読んでみてください。参考資料
差し替える場所を特定するには
querySelectorメソッドの使い方
【JavaScript入門】getElementByIdを完全理解する3つのコツ!差し替える為のメソッド
- 投稿日:2021-01-19T19:51:54+09:00
Rails6[APIモード]+ MySQL5.7 を Docker で環境構築
はじめに
自分用です
Rails6 APIモード + MySQL5.7 を Docker(docker compose) で環境構築Dockerそのものの導入は省略
はじめに環境構築に必要なファイルを作成
- 以下のファイルを作成する
- アプリ用のトップレベルディレクトリ
- Dockerfile
- docker-compose.yml
- Gemfile
- Gemfile.lock
アプリ用のトップレベルディレクトリ作成&移動
$ cd $ mkdir sample_app $ cd sample_app
Dockerfile, docker-compose.yml, Gemfile, Gemfile.lock作成
sample_app$ touch {Dockerfile,docker-compose.yml,Gemfile,Gemfile.lock} sample_app$ ls Dockerfile docker-compose.yml Gemfile Gemfile.lock
ファイルの中身書いていく
sample_app/Dockerfileファイル
DockerfileFROM ruby:2.6.5 # 必要なパッケージのインストール(Rails6からWebpackerがいるので、yarnをインストールする) RUN curl -sS https://dl.yarnpkg.com/debian/pubkey.gpg | apt-key add - \ && echo "deb https://dl.yarnpkg.com/debian/ stable main" | tee /etc/apt/sources.list.d/yarn.list \ && apt-get update -qq \ && apt-get install -y build-essential libpq-dev nodejs yarn # 作業ディレクトリの作成 RUN mkdir /myapp WORKDIR /myapp # ホスト側(ローカル)(左側)のGemfileを、コンテナ側(右側)のGemfileへ追加 ADD ./Gemfile /myapp/Gemfile ADD ./Gemfile.lock /myapp/Gemfile.lock # Gemfileのbundle install RUN bundle install ADD . /myapp
sample_app/docker-compose.yml
docker-compose.ymlversion: '3' services: db: image: mysql:5.7 environment: MYSQL_ROOT_PASSWORD: password MYSQL_DATABASE: root ports: - "3306:3306" web: build: . command: /bin/sh -c "rm -f tmp/pids/server.pid && bundle exec rails s -p 3001 -b '0.0.0.0'" tty: true stdin_open: true depends_on: - db ports: - "3001:3001" volumes: - .:/myapp
sample_app/Gemfile
Gemfilesource 'https://rubygems.org' gem 'rails', '~> 6.0.3'
Gemfile.lockは空のまま
docker-compose run コマンドで Rails アプリを作成
- APIモードなので
--apiオプション付与- バージョン6以降なので、
--webpackerオプション付与$ docker-compose run web rails new . --force --database=mysql --skip-bundle --api --webpacker
database.yml ファイルを修正
- sample_app/config/database.yml ファイルに、コンテナに作成されたDB情報を記述する
database.ymldefault: &dafault adapter: mysql2 encoding: utf8 pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %> username: root password: password # docker-compose.ymlの MYSQL_ROOT_PASSWORD host: db # docker-compose.ymlの service名
Dockerコンテナを起動する
- コンテナの実行
$ docker-compose build
- コンテナを起動
-dオプション付与でバックグラウンド実行をする。これを実行すると、コンテナを起動したままプロンプト画面へ戻る$ docker-compose up -d
DBを作成する
- まだコンテナを起動していない場合はしておく
$ docker-compose up -d
- コンテナID確認
$ docker ps -a
- 確認したIDより、コンテナに入る
$ docker exec -it <コンテナのID> /bin/bash
- DB作成
$ rails db:create $ rails db:migrate
- コンテナから出る
$ exit
- コンテナに入らず、ローカルから実行する場合。コンテナ起動後に、
docker-compose runコマンドを実行する$ docker-compose run web rails db:create $ docker-compose run web rails db:migrate
構築は以上。
localhost:3001で開くようになった。
その他
サーバーを止める場合
- Ctrl + C で止めないこと。コンテナが残って次回起動時にエラーが出る
- もしやってしまった場合、tmp/pids/server.pid を削除して、再びdocker-compose upで再起動する
$ docker-compose down
Dockerfileやdocker-compose.ymlの変更を反映、railsサーバー再起動
$ docker-compose up --build
bundle install などのコマンドを実行したい場合
# docker-compose run { サービス名 } { 任意のコマンド } $ docker-compose run web bundle install
ローカルからMySQLコンテナに接続
- コンテナ起動してない場合は起動
$ docker-compose up -d
- mysqlのidを確認
$ docker ps
- MySQLコンテナにログイン
$ docker exec -it <MySQLのコンテナのID> /bin/bash
$ mysql -u root -p -h 0.0.0.0 -P 3306 --protocol=tcp mysql> // 脱出 mysql> quit
以上。
参考にさせて頂いた記事
丁寧すぎるDocker-composeによるrails5 + MySQL on Dockerの環境構築(Docker for Mac)
【Rails】Rails 6.0 x Docker x MySQLで環境構築
- 投稿日:2021-01-19T19:48:18+09:00
[Rails]検索機能を実装する
はじめに
今回は検索フォームを実装です。
今回は記事のタイトルを検索すると指定したキーワードで記事を検索することができるというものを実装していきます。
実装
routes
今回は「collection」を使用しますが
データを特定したい場合は「member」を使用します。
「member」を使用するとルーティングに「id」がつきます。このように記述されています。↓
またそのアクションを動かすときにparamsで「:id」を受け取りたい場合はmemberを使用し、
特にidを指定して特定のページにいく必要がない場合は、collectionを使用してアクションを追加する。Rails関連のことを調べてみた:routes.rbのcollectionとmemberについて詳しく学習
そしてその他参考にしたのがこちらです。
config/routes.rbresources :albums do collection do get 'search' end endcontroller
コントローラには「search」メソッドを使用し、「 (params[:keyword]) 」と記述し、
「:keyword」を取得できるようにします。
controllers/albums_controller.rbdef search @albums = Album.search(params[:keyword]) endmodels
こちらには検索内容を指定しています。
WhereメソッドとLIKEは以前学習しています。詳しくはこちら
「LIKE」 を使う
「LIKE」 を使うと特殊な記号も使用することができます。「 % 」パーセント記号 → 任意の文字列(空白文字列を含む)(1文字以上)
「 _ 」アンダースコア記号 → 任意の1文字
さらにわかりやすいのはこちら
pikawaka:【Rails】whereメソッドを使って欲しいデータの取得をしよう!
models/album.rbdef self.search(search) if search !="" # 空じゃなければ検索します。 Album.where('title LIKE(?)', "%#{search}%") else Album.all end endviews
検索する部分は「form_with」を使用して実装していきます。
「text_field」の部分には「:keyword」と記述します。
ルーティングをはじめのように設定するとこのようになっています。
controllerの部分で記述した通り、送信すると
「:keyword」(検索したいワード)がparamsに入り
whereメソッドで検索して
urlの部分の「search_albums_path」に送られます。
views/pics/index.html.erb<%= form_with(url: search_albums_path, local: true, method: :get, class: "search-form") do |f| %> <div class="search-inside"> <%= f.text_field :keyword, placeholder: "記事を検索する", class: "search-box" %> </div> <div class="search-inside"> <%= f.submit "検索", class: "search-btn btn" %> </div> <% end %>検索部分はこのような感じになっています。
CSSの部分は省略していますがお好みで装飾します。
表示する部分はこのように記述しています。
views/albums/search.html.erb<% @albums.each do |album| %> <li class="list"> <%= link_to album_path(album) do %> <div class="pic-img-content"> <%= image_tag album.image, class: "pic-img" if album.image.attached? %> </div> <div class="pic-info"> <div class="pic-title"> <p><%= album.created_at %></p> <h3><%= album.title %></h3> </div> <div class="pic-text"> <div class="text-box"> <p><%= album.text %></p> <div> </div> </div> <% end %> </li> <% end %>
試しに用意していたものが表示されました!!
まとめ
少し時間がかかりましたが無事に実装できました。
次回はもう少し早く少し違ったものもできるようにしたいです。

- 投稿日:2021-01-19T19:36:40+09:00
入社して約3ヶ月半、レビュー頂いた事を糧にするためのアウトプット記事
なぜ書くのか
TECH::CAMPを卒業し、プロのエンジニアの方々のもとで、働き始め、3ヶ月半...
先輩方のリソースを、多く割いてしまったと痛感している事、No,1は、そう、コードレビュー。多くのリソースを割いていただいているからこそ、必ず学びに + 誰かの役に立てたらと思い、この記事を書きます。
言語はRuby on Railsです。
その1 命名はきっちりつける
まず基本中の基本ですが、意外に最初はできない変数やメソッド名などの命名についてです。
これは、変更を加える際や、他の人がコードを読んだときの可読性に大いに影響します。(僕は英語読めないので恩恵は受けにくいですが)以下のコードを見てください。
a = "strawberry" b = 100極端な例ですが、この変数をどこがで使用する際にこんな変数名だと、何が入ってるのか全く推測できず、コードを読む際のストレスが大きくなります。
当たり前ですが、明示的に変数の内容がわかる、命名を心がけるべきです。product_name = "strawberry" price = 100こうすることで別の場所で変数を使用する際に、変数の中身に何が入っているのか憶測することができ、わざわざ代入のところまで遡る必要がなくなります。
その2 インデックス番号を極力使用しない
入社間もない頃まで、私自身、必要なデータを、全て配列にぶち込み、それを引き回すという事をやっていました。
全く可読性に配慮もなかったために、下記のような要素呼び出しも、お構いなしに使ってました。data = [["soccer", "baseboll"], ["taro", "ichiro"]] #basebollをやっている子の名前を取りたい puts data[0][1] #=>baseboll puts data[1][1] #=>ichiro上記のような記述がコードの中に乱立すると、書き手以外は、0番目の、2番の要素が何かを理解するために、かなりの労力をかけなければわかりません。
いや、少し経てば、書き手ですら、何のことやらわからなくなるはずです。メンテナンス性を上げるためにも、読み手にも、そして自分にも理解しやすいコードにするためには、こういったデータを使用する際には、必ずハッシュを用いるようにしましょう
data = {soccer: "taro", baseboll: "ichiro"} puts data.key("ichiro") #=>baseboll puts data[:baseboll] #=>ichiro上記のように記述することで、呼び出している要素が何なのかが、読み手に明確に伝わるようになります。
Keyを元にValueを取得するのも、簡単ですし逆も然りです。その3 Railsのコントローラにてindexメソッドを使用する際に、最初からワンレコードのみを取得することを想定したようなコードは書かない
こちらは現在行っているiOSアプリとRailsのバックエンドとのつなぎ込みを行う際にレビュー頂いた事です。
iOSから一つのテーブルの主キーを送り、複数のテーブルにまたがる検索をかけた後、結果として得られたワンレコードを、iOS側に返すという実装でした。
ワンレコードを返すのであればshowだろうと最初は思ったのですが、そのテーブルの情報は何一つ、Swift側からは知ることができないので断念...ということでindexアクションを使用し、書いたコードがこちら(改変してあります + モデルに切り分けてるところも切り分けず集約しています)
def index render json: Item.includes(item_stores: :item_store_customer) .find_by(item_stores:{consignment_item_store_customers: {customer_id: (params[:customer_id]}})) end一見問題ないようにも見えるのですが、よくよく考えてみると、indexアクションとは、リストを返すものなので、最初から、ワンレコード目的の探査を書くのは、おかしいということですね。スコープとして切り分けたとしても、再利用性も低くなりますし、何より、他の人が見たときに、indexアクションの振る舞いとしておかしいので混乱します。
結果としては以下のコードに変更しました。
def index render json: Item.includes(item_stores: :item_store_customer) .where(item_stores:{consignment_item_store_customers: {customer_id: (params[:customer_id]}})) endfind_byをwhereに変更しただけですが、こちらの方がindexアクションの振る舞いとしては正しく見えます。
アプリケーション全体としてみたときに、それぞれの振る舞いがお作法に則っているか、確認する癖を付けたいなと。
Rails側での振る舞いが正しくなり、Swift側では、配列の0番目を抽出するだけで取得できます。その4 updateアクションを使用する際、必要であれば、対象がnilである可能性も考慮した方がいい
Railsのコントローラにてよく目にするこの記述
def update item = Item.find(params[:id]) render json: item.update(item_params) end上記の記述でもいいこともあるのですが(理由は後述します)、findメソッドは、万が一、レコードが見つからなかった際に、ActiveRecord::RecordNotFoundの例外が発生します。
「そもそもこのupdateのタイミングでデータを喪失しているのはおかしい」
「ここからupdateのリクエストを飛ばして、中身が存在していないことは許されない」と言う場合には、例外を発生させて、きちんと、エラーを把握する必要があるかもしれませんが、データが存在していないことが、考えうる場合には、下記のような記述が好ましいと思います。
def update item = Item.find_by(params[:id]) render json: item&.update(item_params) endまず、findをfind_byに変更します。find_byであれば、対象のレコードがもし存在していなかったとしても、例外が発生するのではなく、nilが返ります。そして、item&.updateのように書くことにより、itemの中身がnilだった場合、&よりも後ろのコードは、読まれなくなります。
レコードが存在していないことが、アプリケーション的に、あり得る&許される場合には、存在していない場合の動きもきちんと掌握する必要があると言うことですね。
その5 一つのメソッドで、多くのことをしない
続いては、メソッドを肥大化、させすぎないということです。
例えば次のような、働いた時間と時給をもとに日給を計算するメソッド。
労働時間が8時間を超えていた場合には、その超過分の残業代は、1.25倍になるよう計算します。def calculate_salary(working_time, hourly_wage) if working_time <= 8 hourly_wage * working_time else hourly_wage * 8 + ((working_time - 8) * hourly_wage * 1.25) end end p calculate_salary(8, 100) #=>800 p calculate_salary(9, 100) #=>925.0 p calculate_salary(10, 100) #=>1050.0上記のコードにはもちろんワンサカ問題点はありますが、まずはここで、一つ目を解決します。
上記は給与を計算するメソッドです。そうした視点で考えてみると、超過分の残業代を求める部分の処理は別のメソッドに投げた方が良さそうですし、他に投げて抽象化することで、「別のところで使いたくなった!」なんてときに簡単に再利用することができます。なのでいっそのことメソッドを切り分けちゃいましょう✊
def calculate_salary(working_time, hourly_wage) if working_time <= 8 hourly_wage * working_time else hourly_wage * 8 + excess_payroll(working_time - 8, hourly_wage) end end def excess_payroll(overtime, hourly_wage) overtime * hourly_wage * 1.25 end p calculate_salary(8, 100) #=>800 p calculate_salary(9, 100) #=>925.0 p calculate_salary(10, 100) #=>1050.0上記のように、給与のうち、超過分の給料のみ切り分けるようにすれば、より処理の流れが明確になり、演算を行うコードもグッと読みやすくなります。
その6 引数の情報をもとに条件分岐をしない
次に、引数についてです。メソッドで引数を受け取り処理を行う際に、受け取った引数の情報を元に、条件分岐をするのはやめよう、と言うものです。
じゃあどうするか。
分岐する処理それぞれをメソッドに分てしまい、呼び出す時点で、処理を確定してしまうのが好ましいです。先ほどの、給与計算を行うコードでみてみましょう。
def calculate_salary(working_time, hourly_wage) if working_time <= 8 hourly_wage * working_time else hourly_wage * 8 + excess_payroll(working_time - 8, hourly_wage) end end def excess_payroll(overtime, hourly_wage) overtime * hourly_wage * 1.25 end p calculate_salary(8, 100) #=>800 p calculate_salary(9, 100) #=>925.0 p calculate_salary(10, 100) #=>1050.0みてみると、calculate_salaryメソッド内で引数として渡された労働時間(working_time)の情報を元に条件分岐がされています。
これを細分化し、メソッドを呼ぶ段階で時間超過をしているのか、そうではないのかを切り分けましょう。def calculate_salary(working_time, hourly_wage) hourly_wage * working_time end def calculation_of_overtime(working_time, hourly_wage) hourly_wage * 8 + excess_payroll(working_time - 8, hourly_wage) end def excess_payroll(overtime, hourly_wage) overtime * hourly_wage * 1.25 end working_time = gets.to_i if working_time <= 8 p calculate_salary(working_time, 100) #=>working_time = 8 A.800 else p calculation_of_overtime(working_time, 100) #=>working_time = 9 A.925.0 endそもそも時間を超過しているのかしていないのかをメソッド呼び出し前に分岐し、一つのメソッドの処理を呼び出し前から確定させることができました。
その7 マジックナンバーを使用しない
続いてはマジックナンバーについてです。
マジックナンバーとは、プログラム中に突如現れる意図のわからない数字のことです。
僕自身はインデックス番号に近いものだと思っていて、これがまた、コードの中に乱立すると、次に読む人が「理解できない」と言うことが起こります。また先ほどから使用している給与計算をするプログラムを例に取りましょう。
def calculate_salary(working_time, hourly_wage) hourly_wage * working_time end def calculation_of_overtime(working_time, hourly_wage) hourly_wage * 8 + excess_payroll(working_time - 8, hourly_wage) end def excess_payroll(overtime, hourly_wage) overtime * hourly_wage * 1.25 end working_time = gets.to_i if working_time <= 8 p calculate_salary(working_time, 100) #=>working_time = 8 A.800 else p calculation_of_overtime(working_time, 100) #=>working_time = 9 A.925.0 endパッと目につくプログラム中の謎の数字は「8」と「1.25」、そして「100」ではないでしょうか?
こうしたものがプログラムの中に乱立することで、影響範囲の把握が困難になり、変更に手間と、リスクが伴うようになります。ではどうするか?メソッドで包み込み、マジックナンバーに名前をつけましょう。
def regular_working_hours 8 end def hourly_wage_increase_for_overtime 1.25 end def hourly_wage_price 100 end def calculate_salary(working_time, hourly_wage) hourly_wage * working_time end def calculation_of_overtime(working_time, hourly_wage) hourly_wage * regular_working_hours + excess_payroll(working_time - regular_working_hours, hourly_wage) end def excess_payroll(overtime, hourly_wage) overtime * hourly_wage * hourly_wage_increase_for_overtime end working_time = gets.to_i if working_time <= regular_working_hours p calculate_salary(working_time, hourly_wage_price) #=>working_time = 8 A.800 else p calculation_of_overtime(working_time, hourly_wage_price) #=>working_time = 9 A.925.0 endこのようにすることで、後から別の人が読んだ際に、なんの数字だ?なんて聞くこともなく、変数を見て、「なるほど、時給か!」となることができます。
また、時給を変えたくなった際に変更するのは、「hourly_wage_price」の中の数字を変更するだけなので、変更漏れのリスクも同時に減らすことができます。その8 不必要な代入をしない
これが僕自身結構やってしまうことが多く、何度も指摘をいただいてしまいました。
たとえば以下のようなコードです。def index item_list = Item.all render json: item_list endなんとなく良さげにも見えますが、DB返されたデータ、データをそのまま返しているだけです。
取得したデータや、代入したモノをその後の処理で使用することなく、出力するならば、不要な代入をせず、そのまま使用しましょう。def index render json: Item.all endこれでかなりスッキリしました。
その9 コードレビューを依頼する際に、レビュワーが必ず、実行環境にあるとは限らないため、テストと機能実装はセットでレビュー依頼を出す。
これも一度指摘いただきました。
レビューしてくださる方が、実装した機能を、実行できる環境にあるかどうかはわかりません。
実行できない環境の場合、コードを見て、処理がうまく流れるかどうかを、頭の中で考える必要があります。
レビュワーに負担をかけない、余計なことを考えさせないようにするために、「動く」という指標をたてるためのテストを、必ず、レビューの中に含めようということです。これは、時と場合、状況によっても違うとは思いますが、ある程度成熟したプロジェクト(テストの基準、方針等が定まっている)であれば、「このテストが通るってことは基準は満たしているな」という判断材料になります。
とにかくレビュー依頼はコードの品質を見ていただく場にする、という根本的なモノです。
その10 配列として結果を受け取る場合、同じ挙動になるならば、eachではなく、mapを使う
eachメソッドを使用している箇所を見てmapに置き換えられそうな場合、極力mapを使用しましょう、ということです。
パフォーマンスの面でも、可読性の面でも、eachよりもmapの方が優れています。#each int_list = (1..3).to_a int_to_double = [] int_list.each do |i| int_to_double << i * 2 end p int_to_double #=>[2, 4, 6] #map int_list = (1..3) int_to_double = int_list.map do |i| i * 2 end p int_to_double #=>[2, 4, 6]配列に格納するための空配列の準備がいらなくなるためかなりスッキリ描くことができます。
最後に
コードレビューの際に、いただいた指摘は必ず、自分に落とし込むよう心がけましょう。
レビューしてくださる方は、わざわざ自分の手を止めて、コードを読んでくれています。
どんな指摘も真摯に受け止め、誠実に対応しましょう。
- 投稿日:2021-01-19T18:05:25+09:00
【Rails】FullCalendarを使う
予定を保存するテーブルとモデルを作成
例として、
seminarsテーブルとモデルを作ります。$ rails g model seminar title starts_at:datetime ends_at:datetime $ rails db:migrate予定を管理するコントローラーとルーティングを作成
$ rails g controller seminars indexapp/controllers/seminars_controller.rbclass SeminarsController < ApplicationController def index @seminars = Seminar.all end endconfig.routes.rbresources :seminars, only: [:index]予定のダミーデータを投入
$ rails c 2.6.3 :001 > Seminar.create(title: 'サンプルセミナー', starts_at: Time.zone.now, ends_at: Time.zone.now)Gemを追加
Gemfilegem 'jquery-rails', '4.3.3' gem 'fullcalendar-rails' gem 'momentjs-rails'$ bundle installapp/assets/javascript/application.js//= require jquery //= require moment //= require fullcalendarカレンダーを表示するスクリプトを記述
app/assets/javascript/application.js$(function () { $(document).on('turbolinks:load', function () { function eventCalendar() { return $('#calendar').fullCalendar({}); }; function clearCalendar() { $('#calendar').html(''); }; $(document).on('turbolinks:load', function () { eventCalendar(); }); $(document).on('turbolinks:before-cache', clearCalendar); }); });CSSの設定
app/assets/stylesheets/application.css... *= require_tree . *= require_self *= require fullcalendar */カレンダーの表示領域を作成
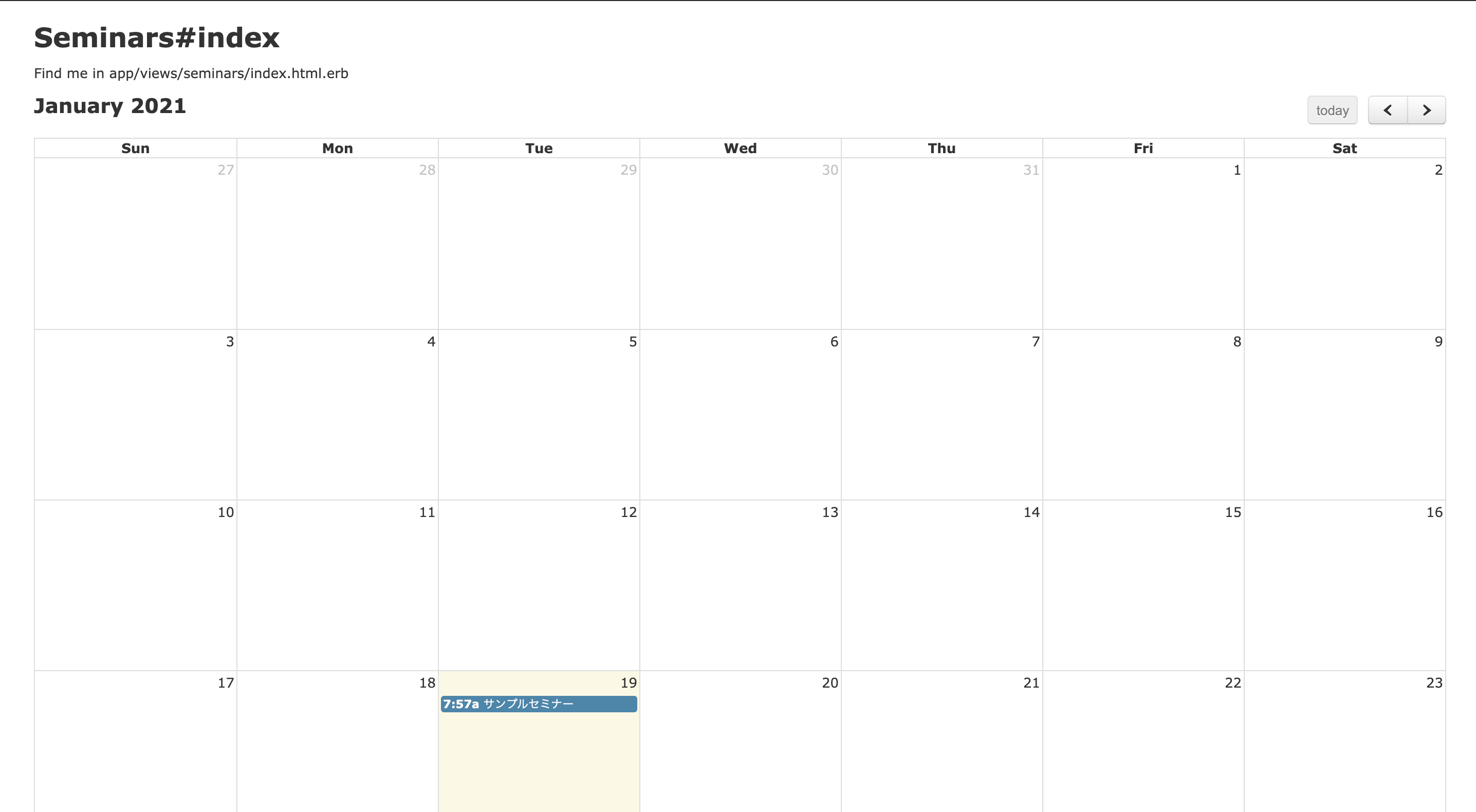
app/views/seminars/index.html<div id="calendar"></div>これで空のカレンダーが表示されます。
予定を表示
$ touch app/views/seminars/index.json.jbuilderapp/views/seminars/index.json.jbuilderjson.array!(@seminars) do |seminar| json.extract! seminar, :id, :title json.start seminar.starts_at json.end seminar.ends_at end↑の記述で/seminars.jsonにアクセスした時に以下のデータが返ってくるようになる。
[ { "id":1, "title":"サンプルセミナー", "start":"2021-01-19T07:57:23.329Z", "end":"2021-01-19T07:57:23.329Z" }, { "id":2, "title":"ホゲホゲセミナー", "start":"2021-01-19T07:57:23.329Z", "end":"2021-01-19T07:57:23.329Z" }, ... ]最後にイベントを表示するスクリプトを追加して完成。
app/assets/javascript/application.js$(function () { $(document).on('turbolinks:load', function () { function eventCalendar() { return $('#calendar').fullCalendar({}); }; function clearCalendar() { $('#calendar').html(''); }; $(document).on('turbolinks:load', function () { eventCalendar(); }); $(document).on('turbolinks:before-cache', clearCalendar); //以下を追加 $('#calendar').fullCalendar({ events: '/seminars.json' }); }); });
オプション
FullCalendarの日本語化やオプションいろいろ | Fire Sign Blog
ajaxでイベントを登録
参考
- 投稿日:2021-01-19T17:38:21+09:00
サムネ付きで削除可能なファイルフォームの状態確認シート
いつも混乱するのでまとめておこうと思います。
前提
<input type=file name=logo_image /> <!-- (1) --> <figure id=thumb_logo_image><img/></figure> <!-- (2) --> <input type=hidden name=remove_logo_image value=on /> <!-- (3) --> <button id=btn_remove_logo_img /> <!-- (4)-->
- こんな要素があるとします
- 保存済みのファイルがある場合は(2)にサムネが表示されるものとします
- ファイルを選択した直後もJSで(2)にサムネをセットするものとします
- ※サーバーにはまだ送っていない状態
remove_属性名に値をセットして送れば保存済みのファイルが削除ができる実装だとします
- 削除フィールドに値があったまま新しいファイルを送信してもきちんと新しいファイルに交換される実装になっているものとします
- (4)の削除用のボタンが押されると、(2)サムネ、(3)削除用フィールド、(4)削除用ボタンがHTMLから消えると想定します
状態の洗い出し
- 保存済みのファイルがあるかないか
- 新しいファイルが選択されているかいないか
- ファイル選択ダイアログを出したあとに「キャンセル」ボタンで戻ったかどうか
- 削除用のボタンが押されたか押されていないか
- 削除用のボタンが押された後にまたファイル選択をしたかどうか
- 保存済みのファイルがある状態で新しいファイルを選択したが、新しいファイルはキャンセルした場合
状態変数の洗い出し
Object savedValue
- 保存済みのファイル
String savedValueUrl
- 保存済みファイルのサムネ用URL
Object inputValue
- 新たに選択されたファイル
- ※(1)ファイルフィールド のvalue値
- ※ファイルフィールドの仕様により、JSからは再設定不可でリセット(nullの代入)のみ可能
String inputValueUrl
- 新たに選択されたファイルのサムネ用URL
Bool thumbVisible
- (2)サムネ を表示するかどうか
String thumbSrc
- (2)サムネタグにセットする値
savedValueUrlorinputValueUrlBool readyToRemove
- (3)保存済みファイルを削除するかどうか
Bool removeBtnVisible
- (4)削除用ボタンを表示するかどうか
状態確認シート
- この行数分リロードと操作を繰り返せば動作確認完了な想定
- ※
nullとfalseのセルは省略。見にくくなったので- (1)..
inputValue- (2)..
thumbSrc兼thumbVisible- (3)..
readyToRemove- (4)..
removeBtnVisible保存済みのファイルがない場合
操作\ (1) (2) (3) (4) 初期状態 ファイルが選択された Object inputValueUrltrue ファイル選択後に
削除用ボタンが押されたファイル選択後に
再度ファイル選択が開かれたが
キャンセルが押された保存済みのファイルがある場合
操作\ (1) (2) (3) (4) 初期状態 savedValueUrltrue 削除用ボタンが押された true ファイルが選択された Object inputValueUrltrue ファイル選択が開かれたが
キャンセルが押されたsavedValueUrltrue 削除用ボタンが押されてから
ファイルが選択されたObject inputValueUrltrue ファイル選択されてから
削除用ボタンが押されたsavedValueUrltrue ファイル選択されてから
削除ボタンが押されて
再度削除ボタンが押されたtrue ファイル選択されてから
削除ボタンが押されて
再度ファイル選択が開かれたが
キャンセルが押されたsavedValueUrltrue おわり
あーややこしい

- 投稿日:2021-01-19T16:37:57+09:00
railsでテスト実行
引用先
Railsチュートリアルテストとは
言葉そのまんまで機能が正しく実装されたことを確認することです。
テストを書けばいざというときのセーフティネットにもなり、それ自体がアプリケーションのソースコードの「実行可能なドキュメント」にもなります。
テストが揃っていれば、バグを追うために余分な時間を使わずに済むため、正しく行えばむしろテストがないときよりも確実に開発速度がアップします。テストのメリット
1.機能停止に陥るような回帰バグを防止できる。
2.コードを安全にリファクタリング(改善)できる。
3.テストコードは、アプリケーションコードから見ればクライアントとして動作するので、アプリケーションの設計やシステムの他の部分とのインターフェイスを決めるときにも役に立つ。テストの実行
ターミナルにてrails generate controllerを実行した時点でテストファイルが作成されている。
ターミナル# 例 $ rails generate controller StaticPages home help↓
test/controllers/static_pages_controller_test.rbrequire 'test_helper' class StaticPagesControllerTest < ActionDispatch::IntegrationTest test "should get home" do ←homeページのテスト get static_pages_home_url ←GETリクエストをhomeアクションに対して送信 assert_response :success ←リクエストに対するレスポンスは[成功]になるはず end test "should get help" do get static_pages_help_url assert_response :success end end↓
ターミナル$ rails db:migrate # システムによっては必要 $ rails test 2 tests, 2 assertions, 0 failures, 0 errors, 0 skips0errorsのため問題なくコードが実装されている。
わざとエラーを出してみる
aboutページを追加したと想定してコードを追加してみる。
test/controllers/static_pages_controller_test.rbrequire 'test_helper' class StaticPagesControllerTest < ActionDispatch::IntegrationTest test "should get home" do get static_pages_home_url assert_response :success end test "should get help" do get static_pages_help_url assert_response :success end test "should get about" do get static_pages_about_url assert_response :success end endテスト実行
ターミナル$ rails test NameError: undefined local variable or method `static_pages_about_url' 3 tests, 2 assertions, 0 failures, 1 errors, 0 skipsAboutページへのURLが見つからないとエラーメッセージ。
ルーティングファイルを修正してみる。config/routes.rbRails.application.routes.draw do get 'static_pages/home' get 'static_pages/help' get 'static_pages/about' ←追加 root 'application#hello' endテスト実行
ターミナル$ rails test AbstractController::ActionNotFound: The action 'about' could not be found for StaticPagesControllerStaticPagesコントローラにaboutアクションがないとエラーメッセージ。
aboutアクションを追加してみる。app/controllers/static_pages_controller.rbclass StaticPagesController < ApplicationController def home end def help end def about ←追加 end ←追加 endテスト実行
ターミナル$ rails test ActionController::UnknownFormat: StaticPagesController#about is missing a template for this request format and variant.テンプレート(ビュー)がないとエラーメッセージ。
下記コマンドか右クリックでビューファイルを作成。ターミナル$ touch app/views/static_pages/about.html.erbテスト実行
ターミナル$ rails test 3 tests, 3 assertions, 0 failures, 0 errors, 0 skips0errorsになったのでテスト完了!!
テストが完了したのでコードをリファクタリングする
(今回はリファクタリングするコードがないため完了)これを、「red ・ green ・ REFACTOR」のサイクルという。
- 投稿日:2021-01-19T15:10:19+09:00
[PostgreSQL] Railsアプリを削除するなら、先にデータベースを削除する!
はじめに
学習中にサンプルアプリを作っては消すを繰り返していると、
ふと「フォルダ削除するだけでいいの?」と疑問に感じました。調べてみると、、
フォルダを削除する前に、DB(データベース)を削除しなければいけないらしいです!
以下、2通りの方法をメモしておきます。
- DB削除 → アプリフォルダ削除
- アプリフォルダを削除してしまった後のDB削除方法
環境
- macOS Catalina
- Ruby 2.7.2
- Rails 6.0.3
- PostgreSQL 13.1
① DB削除 → アプリフォルダ削除
該当アプリのフォルダ内で
$ rails db:drop親ディレクトリに移動して
$ rm -rf アプリ名必ず上記①の手順で削除するのが良さそうです。
ここからは、もしもアプリフォルダを先に削除してしまった場合の方法です。② アプリフォルダを削除してしまった後のDB削除方法
$ psql -l (DB名を一覧表示#実行結果(sampleアプリを削除したい場合) List of databases Name | Owner | Encoding | Collate | Ctype | Access privileges -----------------------+-------+----------+---------+-------+------------------- sample_development | user | UTF8 | C | C | sample_test | user | UTF8 | C | C | postgres | user | UTF8 | C | C | template0 | user | UTF8 | C | C | =c/user + | | | | | user=CTc/user template1 | user | UTF8 | C | C | =c/user + | | | | | user=CTc/user (5 rows)$ psql postgres (PostgreSQLにログイン --- (postgres=#) \du (ユーザーと権限を確認 (postgres=#) \q (PostgreSQLからログイン --- $ dropdb -U ユーザー名 消したいDB名※削除してはいけないDB(デフォルト)
postgres
template0
template1私はこのデフォルトであろう
postgresを削除してしまいました。。(大反省)
学習用のアプリばかりだったので、PostgreSQLをアンインストールしました。
再インストール後に確認すると、上記3つのDBは初めからありました!!上記デフォルトを削除してしまった後の手順を、自戒の意を込めて記しておきます。
アンインストール方法
$ ls /usr/local/Cellar/postgresql (インストール済みPostgreSQLバージョン確認 $ brew info postgresql (現時点の最新バージョン確認 $ brew uninstall --force postgresql (全てのバージョンをアンインストール $ ls -l /usr/local/var/postgres (設定ファイル、ログ、データ等を表示 $ rm -rf /usr/local/var/postgres (設定ファイル、ログ、データ等も削除その後のインストールは、初めてインストールした時と同様に。
さいごに
学習中はサンプルアプリが増えていく一方でしたが、
私はこの方法で解決できました。
間違っているところがあればご指摘いただけるとありがたいです。参考記事
Ruby on Rails 削除関連まとめ
PostgreSQLで強制的にデータベースを削除する
[MacOS] PostgreSQL の全バージョンをアンインストールする方法 ~ Homebrew 編
PostgreSQLドキュメント「dropdb」
- 投稿日:2021-01-19T13:47:06+09:00
既存Rails6アプリのDocker環境への移行
はじめに
ローカル環境でrailsを使用し開発を進めていましたが、今後のデプロイを考慮し、環境をDockerによるコンテナで管理することとしました。
初めてでかなり時間がかかってしまったため、備忘録として残します。
同様の環境構築が必要な方の参考になれば幸いです。環境構築にあたっての目標
- ローカルの環境をコンテナ化し、本番環境構築時に容易にしたい。
- Dockerのイメージは、効率化を考慮し、できるだけ軽量化したい。
- bundleやyarnのモジュールを永続化することにより、起動にかかる時間を減らしておきたい。
- DBはsqliteを使用していたので、ついでにMysqlにしたい。
構築した環境
コンテナの構成
- db
- web
- webpacker←webpack_dev_server実行用
バージョン
- ruby 2.7.2
- Rails 6.0.3
- Mysql 8.0.22
一覧
今回変更した箇所のみ記載しています。
ルートディレクトリはrailsアプリのルートディレクトリとしています。. ├── config │ ├── database.yml #更新 │ └── webpacker.yml #更新 ├── docker │ └── rails │ └── Dockerfile #新規作成 ├── docker-compose.yml #新規作成 ├── .env #新規作成 └── Gemfile #更新Dockerfile
Dockerfile#軽量化のため、alpineを使用。 FROM ruby:2.7.2-alpine3.12 ENV TZ="Asia/Tokyo" \ LANG="C.UTF-8" \ APP_ROOT="/app" \ ENTRYKIT_VERSION="0.4.0" WORKDIR $APP_ROOT #ENTRY KITの導入 RUN wget https://github.com/progrium/entrykit/releases/download/v${ENTRYKIT_VERSION}/entrykit_${ENTRYKIT_VERSION}_Linux_x86_64.tgz \ && tar -xvzf entrykit_${ENTRYKIT_VERSION}_Linux_x86_64.tgz \ && rm entrykit_${ENTRYKIT_VERSION}_Linux_x86_64.tgz \ && mv entrykit /bin/entrykit \ && chmod +x /bin/entrykit \ && entrykit --symlink RUN apk update \ && apk add --no-cache \ alpine-sdk \ bash \ build-base \ mysql-client \ mysql-dev \ nodejs \ tzdata \ yarn COPY . $APP_ROOT ENTRYPOINT [ \ "prehook", "bundle install -j4 --quiet", "--", \ "prehook", "yarn install --check-files --ignore-optional", "--"]イメージの軽量化
今後の作業の効率化のため、イメージの軽量化するために、alpineを使用しています。
約1.6GB→約400MBまで容量が減りました。マルチステージビルドを使用し、nodejsのインストールを別にすることで、さらにイメージの軽量化ができそうです。
ある程度軽量化できたので、今回はここまでとしました。ENTRY KITの導入
ENTRY KITを使用し、コンテナ起動時に
yarn install、bundle installを実行するようにしています。
調べた記事では、Dockerfile内で実行しているものが多かったですが、以下の問題があるため今回は見送りました。
- gem等の追加が必要となった時は、コンテナのbuildからやり直す必要がある。
- コンテナをdownすると、installしたgem等が保持されない。
そのためコンテナ起動時の実行かつ、モジュールを永続化することで、上記の問題を解決する構成としました。
docker-compose.yml
docker-compose.ymlversion: '3' services: db: image: mysql:8.0.22 command: mysqld --character-set-server=utf8 --collation-server=utf8_unicode_ci ports: - '3306:3306' volumes: - db_data:/var/lib/mysql environment: MYSQL_DATABASE: ${DATABASE} MYSQL_ROOT_PASSWORD: ${ROOTPASS} MYSQL_USER: ${USERNAME} MYSQL_PASSWORD: ${USERPASS} web: &app_base build: context: . dockerfile: ./docker/rails/Dockerfile command: bash -c "rm -f tmp/pids/server.pid && bundle exec rails s -p 3000 -b 0.0.0.0" depends_on: - db ports: - "3000:3000" volumes: - .:/app - gem_modules:/vendor/bundle - node_modules:/node_modules tty: true #binding.pry実行用 stdin_open: true #binding.pry実行用 environment: WEBPACKER_DEV_SERVER_HOST: webpacker #webpack_dev_server実行用のコンテナを指定 BUNDLE_APP_CONFIG: ./.bundle NODE_ENV: development RAILS_ENV: development webpacker: #webpack_dev_server実行用のコンテナ <<: *app_base command: bash -c "bundle exec bin/webpack-dev-server" depends_on: - web ports: - '3035:3035' tty: false #binding.pry不要なのでfalseへ変更 stdin_open: false #binding.pry不要なのでfalseへ変更 environment: BUNDLE_APP_CONFIG: ./.bundle WEBPACKER_DEV_SERVER_HOST: 0.0.0.0 NODE_ENV: development RAILS_ENV: development volumes: db_data: gem_modules: node_modules:
- DBのユーザ情報は別ファイルとしておきたかったので、変数化し
.envに記載しています。- コンテナをdownさせても、DB、モジュールのデータが失われないよう、永続化しています。
database.yml
database.ymldefault: &default - adapter: sqlite3 + adapter: mysql2 + username: app + password: password + host: db #サービス名を指定 development: <<: *default - database: db/development.sqlite3 + database: mysql_developmentwebpacker.yml
webpacker.ymldefault: &default dev_server: - host: localhost + host: webpack #サービス名を指定Gemfile
Gemfile-gem 'sqlite3', '~> 1.4' +gem 'mysql2', '0.5.3'.env
.envDATABASE=mysql_development USERNAME=app USERPASS=password ROOTPASS=password疑問点・解消できなかったこと
コンテナ初回起動時エラー(stack Error: getaddrinfo EAI_AGAIN nodejs.org)
コンテナ初回起動時の
yarn install実行中に、エラーが発生することがあります。
調べた結果、原因はDNSで名前解決できていないことだそう。解決方法と思われるホスト側のDNS変更や、
docker-compose.ymlでのDNSの指定等試しましたが、解決しませんでした。
2回目起動時はエラーが発生せず、コンテナの再起動を解決方法としている記事もあったため、このままとしておきます。error /app/node_modules/node-sass: Command failed. web_1 | Exit code: 1 web_1 | Command: node scripts/build.js web_1 | Arguments: web_1 | Directory: /app/node_modules/node-sass web_1 | Output: web_1 | Building: /usr/bin/node /app/node_modules/node-gyp/bin/node-gyp.js rebuild --verbose --libsass_ext= --libsass_cflags= --libsass_ldflags= --libsass_library= web_1 | gyp info it worked if it ends with ok web_1 | gyp verb cli [ web_1 | gyp verb cli '/usr/bin/node', web_1 | gyp verb cli '/app/node_modules/node-gyp/bin/node-gyp.js', web_1 | gyp verb cli 'rebuild', web_1 | gyp verb cli '--verbose', web_1 | gyp verb cli '--libsass_ext=', web_1 | gyp verb cli '--libsass_cflags=', web_1 | gyp verb cli '--libsass_ldflags=', web_1 | gyp verb cli '--libsass_library=' web_1 | gyp verb cli ] web_1 | gyp info using node-gyp@3.8.0 web_1 | gyp info using node@12.20.1 | linux | x64 web_1 | gyp verb command rebuild [] web_1 | gyp verb command clean [] web_1 | gyp verb clean removing "build" directory web_1 | gyp verb command configure [] web_1 | gyp verb check python checking for Python executable "python2" in the PATH web_1 | gyp verb `which` succeeded python2 /usr/bin/python2 web_1 | gyp verb check python version `/usr/bin/python2 -c "import sys; print "2.7.18 web_1 | gyp verb check python version .%s.%s" % sys.version_info[:3];"` returned: %j web_1 | gyp verb get node dir no --target version specified, falling back to host node version: 12.20.1 web_1 | gyp verb command install [ '12.20.1' ] web_1 | gyp verb install input version string "12.20.1" web_1 | gyp verb install installing version: 12.20.1 web_1 | gyp verb install --ensure was passed, so won't reinstall if already installed web_1 | gyp verb install version not already installed, continuing with install 12.20.1 web_1 | gyp verb ensuring nodedir is created /root/.node-gyp/12.20.1 web_1 | gyp verb created nodedir /root/.node-gyp web_1 | gyp http GET https://nodejs.org/download/release/v12.20.1/node-v12.20.1-headers.tar.gz web_1 | gyp WARN install got an error, rolling back install web_1 | gyp verb command remove [ '12.20.1' ] web_1 | gyp verb remove using node-gyp dir: /root/.node-gyp web_1 | gyp verb remove removing target version: 12.20.1 web_1 | gyp verb remove removing development files for version: 12.20.1 web_1 | gyp ERR! configure error web_1 | gyp ERR! stack Error: getaddrinfo EAI_AGAIN nodejs.org web_1 | gyp ERR! stack at GetAddrInfoReqWrap.onlookup [as oncomplete] (dns.js:66:26) web_1 | gyp ERR! System Linux 4.19.121-linuxkit web_1 | gyp ERR! command "/usr/bin/node" "/app/node_modules/node-gyp/bin/node-gyp.js" "rebuild" "--verbose" "--libsass_ext=" "--libsass_cflags=" "--libsass_ldflags=" "--libsass_library=" web_1 | gyp ERR! cwd /app/node_modules/node-sass web_1 | gyp ERR! node -v v12.20.1 web_1 | gyp ERR! node-gyp -v v3.8.0 web_1 | gyp ERR! not okマルチステージビルドでのイメージの軽量化
時間短縮等、更なる効率化が必要となった時に試してみようと思います。
最後に
新規のRailsアプリをDockerで環境構築する記事はあったのですが、既存のRailsアプリをコンテナ化する記事はあまりなかったので苦労しました。
開発環境として一旦構築したので、テスト環境や本番環境の分け方・構築も検討して取り組んでいきます。他にも以下の内容も取り組んでいきたいので、実施できれば記事にしようかと思います。
- webサーバとしてnginxの導入
- CI/CDの導入
- AWS上での環境構築
参考にさせて頂いた記事
・開発しやすいRails on Docker環境の作り方 - Qiita
・Rails newからproductionモードで動くようになるまで - Qiita
・Rails 6.0 × MySQL8でDocker環境構築(Alpineベース) - Qiita
・Docker Composeのvolumesを使ってもっと効率的に - Qiita
・【Dockerfile全解説】Rails本番環境のための一番シンプルなDockerイメージを作る - Qiita
・【Docker】Rails開発で知っておきたい!gemの永続化による作業効率アップの話 | Enjoy IT Life
・docker-composeでの環境構築で留意しておきたいところ - Qiita
・Rails + webpacker on Dockerの環境をdocker-composeで構築する - RoadMovie
- 投稿日:2021-01-19T12:49:41+09:00
CircleCi + Capistrano でEC2へデプロイ
記事を書いた理由
今回が初めての記事作成なので、微妙にハマる部分があったためCircleCi+CapistranoでEC2へデプロイするための方法を他の記事を参考にデプロイしたのでその内容をまとめてみました。
前提条件
- CircleCiのGUIは執筆時(2021年1月19日)のもの。
- ローカルでCapistranoでEC2インスタンスへのデプロイは完了済み。
- すでにCircleCi上でRSpecやRuboCopなどは動く。(まだであればこちらが参考になりました。)
注意:この記事ではEC2インスタンスへのSSH接続がどのIPアドレスでも接続可能な場合の記事です。(対応次第追加します。)
下準備(SSH鍵の形式変更)
最初にCircleCiへ登録するためのにSSH鍵の形式を変更します。
こちらの記事を参考にして、過去にEC2インスタンスへアクセスするために作成したであろう
手元のSSH鍵(~/.ssh/your_app_key_rsa)の形式を変更するため以下の操作を行います。$ chmod 700 ~/.ssh/your_app_key_rsa $ ssh-keygen -p -m PEM -f ~/.ssh/your_app_key_rsa $ chmod 400 ~/.ssh/your_app_key_rsa $ cat ~/.ssh/your_app_key_rsa #このコマンドで表示されるファイルの内容をCircleCiに登録します。ファイルの内容が以下のように 「BEGIN RSA PRIVATE KEY」 になっていればOKです。
-----BEGIN RSA PRIVATE KEY-----
数字を含む文字の羅列
-----END RSA PRIVATE KEY-----CircleCiでの操作(SSH鍵登録 環境変数登録)
SSH鍵登録
次に先ほど形式を変更したSSH鍵をCircleCiへ登録するために以下の操作を行います。
1. CircleCiに登録しているリポジトリページの画面右上にある 「Project Settings」 をクリック 2. 画面左側の「SSH KEYS」を選択。 3. 画面下の「Additional SSH Keys」項目の右側にある「Add SSH Key」を選択。 4. 表示される項目の「Hostname」にEC2インスタンスに割り当てている「Elastic IP」を入力します。 5.「Private Key*」に「~/.ssh/your_app_key_rsa」の内容をコピーして貼り付けます。 6.「Hostname」と「Private Key* 」が入力できたら「Add SSH Key」でSSH鍵を登録します。補足
5では、数字と文字の羅列だけじゃなく以下も含めてコピーしてください。
-----BEGIN RSA PRIVATE KEY-----
-----END RSA PRIVATE KEY-----
6で登録が完了すると「Additional SSH Keys」の項目に「Hostname」には「Elastic IP」が、
「Fingerprint」には「12:34:56:ab...」のような内容が表示されているはずです。
表示されている「Fingerprint」はこの後に行う「環境変数」の登録に使います。(環境変数では「:」は含みません。)ファイルが生成される場合、 ~/.ssh/id_rsa_ の後にFingerprintから:を抜いたものとして生成されます。
登録したSSH鍵を使用する場合は自動的に「ssh-agent」に追加されます。
サーバー環境からGitHubへ接続するのに「ssh-agent」を使用している場合でも、ローカルからEC2インスタンスへの接続に使うためのSSH鍵の1個の登録のみで済みます。環境変数登録
次にCircleciに環境変数を追加します。
1. 現在の画面(「SSH KEYSの画面」)の左側にある「Environment Variables」を選択します。 2. 次に「Add Environment Variable」を選択します。 3. SSH鍵の登録と同じような項目が出るので、「Name*」 に変数名として「PRODUCTION_SSH_KEY」と入力。 4. 「Value*」に「~/.ssh/id_rsa_123456abcd」 のように ~/.ssh/id_rsa_ の後ろに先ほど登録した SSH鍵の「Fingerprint」の内容から「:」を省いて入力します。 5. 「Add Environment Variable」で環境変数を登録します。補足
CircleCiにSSH鍵を複数登録した場合でも、「~/.ssh」配下に「id_rsa_Fingerprint : 抜き」のファイル名として保存されるため、環境変数としてSSH鍵へのパスを登録している。
確認したい場合は、公式のSSH を使用したデバッグを参考にしてください。Capistranoファイルの編集
keys:の変更だけなのですぐに終わります。
config/deploy/production.rbserver Rails.application.credentials.dig(:amazon, :ec2_ip), user: Rails.application.credentials.dig(:amazon, :ec2_user), roles: %w[web app db] set :ssh_options, { keys: (ENV['PRODUCTION_SSH_KEY']), #ここだけ編集 forward_agent: true }CircleCiファイルの編集
CircleCIでSystemSpec(RSpec)とRubocopを走らせるの内容を参考に自分用に編集したものです。
.circleci/config.yml(編集前)version: 2.1 orbs: ruby: circleci/ruby@1.1.2 jobs: build: docker: - image: circleci/ruby:2.7.2-node environment: - BUNDLER_VERSION: 2.1.4 steps: - checkout - ruby/install-deps test: parallelism: 3 docker: - image: circleci/ruby:2.7.2-node environment: - DB_HOST: 127.0.0.1 - RAILS_ENV: test - BUNDLER_VERSION: 2.1.4 - image: circleci/mysql:8.0 command: | mysqld --default-authentication-plugin=mysql_native_password environment: - MYSQL_ROOT_PASSWORD: password - MYSQL_USER: root - MYSQL_ROOT_HOST: '%' - image: selenium/standalone-chrome:latest name: chrome steps: - checkout - ruby/install-deps - run: mv config/database.yml.ci config/database.yml - run: name: Wait for DB command: dockerize -wait tcp://localhost:3306 -timeout 1m - run: bundle exec rake db:create - run: bundle exec rake db:schema:load # Run rspec in parallel - ruby/rubocop-check - ruby/rspec-test workflows: version: 2 build_and_test: jobs: - build - test: requires: - buildこれにCircleCI + Capistrano + AWS(EC2) + Railsで自動デプロイしてみたを参考に以下の部分を追加します。
.circleci/config.yml(追加箇所)#省略 deploy: docker: - image: circleci/ruby:2.7.2-node environment: BUNDLER_VERSION: 2.1.4 steps: - checkout - ruby/install-deps - add_ssh_keys: fingerprints:"XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX" - deploy: name: Capistrano deploy command: bundle exec cap production deploy workflows: version: 2 build_accept_deploy: jobs: - build - test: requires: - build - deploy: requires: - test filters: branches: only: master.circleci/config.yml(全体)version: 2.1 orbs: ruby: circleci/ruby@1.1.2 jobs: build: docker: - image: circleci/ruby:2.7.2-node environment: - BUNDLER_VERSION: 2.1.4 steps: - checkout - ruby/install-deps test: parallelism: 3 docker: - image: circleci/ruby:2.7.2-node environment: - DB_HOST: 127.0.0.1 - RAILS_ENV: test - BUNDLER_VERSION: 2.1.4 - image: circleci/mysql:8.0 command: | mysqld --default-authentication-plugin=mysql_native_password environment: - MYSQL_ROOT_PASSWORD: password - MYSQL_USER: root - MYSQL_ROOT_HOST: '%' - image: selenium/standalone-chrome:latest name: chrome steps: - checkout - ruby/install-deps - run: mv config/database.yml.ci config/database.yml - run: name: Wait for DB command: dockerize -wait tcp://localhost:3306 -timeout 1m - run: bundle exec rake db:create - run: bundle exec rake db:schema:load # Run rspec in parallel - ruby/rubocop-check - ruby/rspec-test deploy: docker: - image: circleci/ruby:2.7.2-node environment: BUNDLER_VERSION: 2.1.4 steps: - checkout - ruby/install-deps - add_ssh_keys: fingerprints: "XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX" - deploy: name: Capistrano deploy command: bundle exec cap production deploy workflows: version: 2 build_accept_deploy: jobs: - build - test: requires: - build - deploy: requires: - test filters: branches: only: master補足
- add_ssh_keys: fingerprints: "XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX"の部分は、
1. CircleCiに登録しているリポジトリページの画面右上にある「Project Settings」をクリック 2. 画面左側の「SSH KEYS」を選択。 3. 画面一番下に追加したSSH鍵があるのでそこのFingerprint( 12:34:56:ab:cd:ef:... みたいなの) をコピーして貼り付け。注意
CircleCiで使用されるIPアドレスは常に同じではないため、ここまで内容ではセキュリティグループでSSH接続可能なIPアドレスを限定している場合はデプロイできません。(限定していない場合はデプロイ可能)
続きはこのセキュリティに関する問題への対処です。参考:CircleCIでSystemSpec(RSpec)とRubocopを走らせる
CircleCI + Capistrano + AWS(EC2) + Railsで自動デプロイしてみた特定のIPアドレスでのみデプロイを許可する
次にSSH接続可能なIPアドレスをセキュリティグループで限定したIPアドレス(マイIP)と、CircleCi上で使用されるIPアドレスでのみデプロイができるようにしていきます。
AWSでの設定
まずはこちらの記事を参考にIAMユーザーを作成しCSVを必ずダウンロードしてください(CSVの内容をCircleCiに環境変数として登録するため)。
次に以下の操作を行います。1. サービスから「EC2」を選択。 2. EC2のダッシュボードから「セキュリティグループ」を選択。 3. 画面右上の「セキュリティグループを作成」を選択。 4.「セキュリティグループ名 」と「説明」に「CircleCi-SecurityGroup」と入力。 5.「VPC」にデプロイ先のインスタンスがあるVPCを選択。 6.「セキュリティグループを作成」選択して作成。 7. EC2のダッシュボードから「インスタンス」を選択。 8. デプロイ先のインスタンスの「アクション」から「セキュリティグループを変更」を選択 9.「関連付けられたセキュリティグループ」に作成したセキュリティグループを追加します。これでAWSでの設定は終了です。
補足
セキュリティグループ作成時にインバウンドルールなどを追加する必要はありません。
作成したセキュリティグループのIDを後ほどCircleCiへ環境変数として登録します。CircleCiでの設定
CircleCIでは以下の4つを環境変数として追加します。
「AWS_ACCESS_KEY_ID」「AWS_SECRET_ACCESS_KEY」「AWS_DEFAULT_REGION」「SECURITY_GROUP_ID」先ほどダウンロードしたCSVの内容を以下の名称で2つ登録します。
Nameを「AWS_ACCESS_KEY_ID」、Valueに「Access key ID」の値を登録。 Nameを「AWS_SECRET_ACCESS_KEY」、「Secret access key」の値を登録。残り2つの環境変数を登録します。
Nameを「AWS_DEFAULT_REGION」、Valueに「ap-northeast-1」を入力して登録。 Nameを「SECURITY_GROUP_ID」、Valueに「先ほど作成したセキュリティグループのID」を登録。これでCircleCiでの設定は終了です。
補足
「AWS_DEFAULT_REGION」の値は基本的に「ap-northeast-1」だと思いますが、もし違った場合は適切なリージョン名を登録して下さい。
ファイルの編集とシェルスクリプトの作成
それでは設定ファイルを編集していきます。(一番最後にソースコード全体があります)
.circleci/config.yml(変更箇所)orbs: ruby: circleci/ruby@1.1.2 aws-cli: circleci/aws-cli@1.3.2 #追加 jobs: #省略 deploy: docker: - image: circleci/ruby:2.7.2-node environment: BUNDLER_VERSION: 2.1.4 steps: - checkout - ruby/install-deps - aws-cli/install #追加 - add_ssh_keys: fingerprints: "XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX" - deploy: name: Capistrano deploy command: ./deploy.sh #シェルスクリプトの実行に変更次にシェルスクリプトをこちらの記事を参考に「deploy.sh」という内容で作成します。(こちらの記事を参考に内容を少し編集しました)
deploy.sh#!/bin/sh set -ex IP=`curl -f -s ifconfig.me` trap "aws ec2 revoke-security-group-ingress --group-id ${SECURITY_GROUP_ID} --protocol tcp --port 22 --cidr ${IP}/32" 0 1 2 3 15 aws ec2 authorize-security-group-ingress --group-id ${SECURITY_GROUP_ID} --protocol tcp --port 22 --cidr ${IP}/32 bundle exec cap production deploy最後に「deploy.sh」の権限を以下のコマンドで変更します。
$ chmod +x deploy.sh補足
これでCircleCiからEC2インスタンスへのデプロイはできますが、確認としてデプロイ時に作成したセキュリティーグループにCircleCiのIPアドレスが追加されることや、デプロイ終了後または失敗時には追加されたIPアドレスが削除されていることを確認してください。
参考:CircleCI から deploy させる話
CircleCIからCapistranoを利用してAWS(EC2)にデプロイするソースコード
先人に倣ってソースコードを置いておきます。
.circleci/config.ymlversion: 2.1 orbs: ruby: circleci/ruby@1.1.2 aws-cli: circleci/aws-cli@1.3.2 jobs: build: docker: - image: circleci/ruby:2.7.2-node environment: - BUNDLER_VERSION: 2.1.4 steps: - checkout - ruby/install-deps test: parallelism: 3 docker: - image: circleci/ruby:2.7.2-node environment: - DB_HOST: 127.0.0.1 - RAILS_ENV: test - BUNDLER_VERSION: 2.1.4 - image: circleci/mysql:8.0 command: | mysqld --default-authentication-plugin=mysql_native_password environment: - MYSQL_ROOT_PASSWORD: password - MYSQL_USER: root - MYSQL_ROOT_HOST: '%' - image: selenium/standalone-chrome:latest name: chrome steps: - checkout - ruby/install-deps - run: mv config/database.yml.ci config/database.yml - run: name: Wait for DB command: dockerize -wait tcp://localhost:3306 -timeout 1m - run: bundle exec rake db:create - run: bundle exec rake db:schema:load # Run rspec in parallel - ruby/rubocop-check - ruby/rspec-test deploy: docker: - image: circleci/ruby:2.7.2-node environment: BUNDLER_VERSION: 2.1.4 steps: - checkout - ruby/install-deps - aws-cli/install - add_ssh_keys: fingerprints: "XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX" - deploy: name: Capistrano deploy command: ./deploy.sh workflows: version: 2 build_accept_deploy: jobs: - build - test: requires: - build - deploy: requires: - test filters: branches: only: masterdeploy.sh#!/bin/sh set -ex IP=`curl -f -s ifconfig.me` trap "aws ec2 revoke-security-group-ingress --group-id ${SECURITY_GROUP_ID} --protocol tcp --port 22 --cidr ${IP}/32" 0 1 2 3 15 aws ec2 authorize-security-group-ingress --group-id ${SECURITY_GROUP_ID} --protocol tcp --port 22 --cidr ${IP}/32 bundle exec cap production deployconfig/deploy/production.rbserver 'Elastic IP', user: 'ユーザー名', roles: %w[web app db] set :ssh_options, { keys: (ENV['PRODUCTION_SSH_KEY']), forward_agent: true }config/deploy.rb# config/credentials.yml.encの内容を使えるようにする require File.expand_path('./environment', __dir__) # config valid for current version and patch releases of Capistrano lock '~> 3.15.0' # アプリケーション名 set :application, 'app_name' # githubのurl。プロジェクトのgitホスティング先を指定する set :repo_url, 'git@github.com:user_name/app_name.git' # デプロイ先のサーバーのディレクトリ。フルパスで指定 set :deploy_to, '/var/www/rails/app_name' # Rubyのバージョンを指定 set :rbenv_ruby, '2.7.2' # シンボリックリンクのファイルを指定、具体的にはsharedに入るファイル append :linked_files, 'config/master.key' # シンボリックリンクのディレクトリを生成 append :linked_dirs, 'log', 'tmp/pids', 'tmp/cache', 'tmp/sockets' # タスクでsudoなどを行う際に必要 set :pty, true # 保持するバージョンの個数(※後述) set :keep_releases, 3 # 出力するログのレベル。 set :log_level, :debug # puma set :puma_init_active_record, true # Nginxの設定ファイル名と置き場所を修正 set :nginx_sites_enabled_path, '/etc/nginx/conf.d' set :nginx_config_name, "#{fetch(:application)}.conf"Gemfilesource 'https://rubygems.org' git_source(:github) { |repo| "https://github.com/#{repo}.git" } ruby '2.7.2' gem 'bcrypt' gem 'bootsnap', require: false gem 'bootstrap' gem 'devise' gem 'devise-i18n' gem 'image_processing' gem 'jbuilder' gem 'jquery-rails' gem 'kaminari' gem 'kaminari-bootstrap' gem 'mini_magick' gem 'mysql2' gem 'puma', '< 5' gem 'rails', '~> 6.0.3', '>= 6.0.3.4' gem 'rails-i18n' gem 'sassc-rails' gem 'turbolinks' gem 'uglifier' group :development, :test do gem 'byebug', platforms: %i[mri mingw x64_mingw] gem 'factory_bot_rails' gem 'rspec-rails' end group :development do gem 'bcrypt_pbkdf' gem 'capistrano' gem 'capistrano3-puma', '< 5' gem 'capistrano-bundler' gem 'capistrano-rails' gem 'capistrano-rbenv' gem 'capistrano-rbenv-vars' gem 'ed25519' gem 'listen' gem 'rubocop', require: false gem 'rubocop-performance', require: false gem 'rubocop-rails', require: false gem 'rubocop-rspec' gem 'spring' gem 'spring-watcher-listen' gem 'sshkit-sudo' gem 'web-console' end group :test do gem 'capybara' gem 'capybara-email' gem 'database_cleaner' gem 'rspec_junit_formatter' gem 'selenium-webdriver' end group :production do gem 'aws-sdk-s3', require: false end
- 投稿日:2021-01-19T12:49:41+09:00
CircleCi + Capistrano でEC2にデプロイ
記事を書いた理由
今回が初めての記事作成です。CircleCi+CapistranoでEC2へデプロイするための方法を他の記事を参考にデプロイできたので、記事作成の練習として内容をまとめてみました。
前提条件
- CircleCiのGUIは執筆時(2021年1月19日)のもの。
- ローカルでCapistranoでEC2インスタンスへのデプロイは完了済み。
- すでにCircleCi上でRSpecやRuboCopなどは動く。(まだであればこちらが参考になりました。)
注意:この記事ではEC2インスタンスへのSSH接続がどのIPアドレスでも接続可能な場合の記事です。(対応次第追加します。)
下準備(SSH鍵の形式変更)
最初にCircleCiへ登録するためのにSSH鍵の形式を変更します。
こちらの記事を参考にして、過去にEC2インスタンスへアクセスするために作成したであろう
手元のSSH鍵(~/.ssh/your_app_key_rsa)の形式を変更するため以下の操作を行います。$ chmod 700 ~/.ssh/your_app_key_rsa $ ssh-keygen -p -m PEM -f ~/.ssh/your_app_key_rsa $ chmod 400 ~/.ssh/your_app_key_rsa $ cat ~/.ssh/your_app_key_rsa #このコマンドで表示されるファイルの内容をCircleCiに登録します。ファイルの内容が以下のように 「BEGIN RSA PRIVATE KEY」 になっていればOKです。
-----BEGIN RSA PRIVATE KEY-----
数字を含む文字の羅列
-----END RSA PRIVATE KEY-----CircleCiでの操作(SSH鍵登録 環境変数登録)
SSH鍵登録
次に先ほど形式を変更したSSH鍵をCircleCiへ登録するために以下の操作を行います。
1. CircleCiに登録しているリポジトリページの画面右上にある 「Project Settings」 をクリック 2. 画面左側の「SSH KEYS」を選択。 3. 画面下の「Additional SSH Keys」項目の右側にある「Add SSH Key」を選択。 4. 表示される項目の「Hostname」にEC2インスタンスに割り当てている「Elastic IP」を入力します。 5.「Private Key*」に「~/.ssh/your_app_key_rsa」の内容をコピーして貼り付けます。 6.「Hostname」と「Private Key* 」が入力できたら「Add SSH Key」でSSH鍵を登録します。補足
5では、数字と文字の羅列だけじゃなく以下も含めてコピーしてください。
-----BEGIN RSA PRIVATE KEY-----
-----END RSA PRIVATE KEY-----
6で登録が完了すると「Additional SSH Keys」の項目に「Hostname」には「Elastic IP」が、
「Fingerprint」には「12:34:56:ab...」のような内容が表示されているはずです。
表示されている「Fingerprint」はこの後に行う「環境変数」の登録に使います。(環境変数では「:」は含みません。)ファイルが生成される場合、 ~/.ssh/id_rsa_ の後にFingerprintから:を抜いたものとして生成されます。
登録したSSH鍵を使用する場合は自動的に「ssh-agent」に追加されます。
サーバー環境からGitHubへ接続するのに「ssh-agent」を使用している場合でも、ローカルからEC2インスタンスへの接続に使うためのSSH鍵の1個の登録のみで済みます。環境変数登録
次にCircleciに環境変数を追加します。
1. 現在の画面(「SSH KEYSの画面」)の左側にある「Environment Variables」を選択します。 2. 次に「Add Environment Variable」を選択します。 3. SSH鍵の登録と同じような項目が出るので、「Name*」 に変数名として「PRODUCTION_SSH_KEY」と入力。 4. 「Value*」に「~/.ssh/id_rsa_123456abcd」 のように ~/.ssh/id_rsa_ の後ろに先ほど登録した SSH鍵の「Fingerprint」の内容から「:」を省いて入力します。 5. 「Add Environment Variable」で環境変数を登録します。補足
CircleCiにSSH鍵を複数登録した場合でも、「~/.ssh」配下に「id_rsa_Fingerprint : 抜き」のファイル名として保存されるため、環境変数としてSSH鍵へのパスを登録している。
確認したい場合は、公式のSSH を使用したデバッグを参考にしてください。Capistranoファイルの編集
keys:の変更だけなのですぐに終わります。
config/deploy/production.rbserver Rails.application.credentials.dig(:amazon, :ec2_ip), user: Rails.application.credentials.dig(:amazon, :ec2_user), roles: %w[web app db] set :ssh_options, { keys: (ENV['PRODUCTION_SSH_KEY']), #ここだけ編集 forward_agent: true }CircleCiファイルの編集
CircleCIでSystemSpec(RSpec)とRubocopを走らせるの内容を参考に自分用に編集したものです。
.circleci/config.yml(編集前)version: 2.1 orbs: ruby: circleci/ruby@1.1.2 jobs: build: docker: - image: circleci/ruby:2.7.2-node environment: - BUNDLER_VERSION: 2.1.4 steps: - checkout - ruby/install-deps test: parallelism: 3 docker: - image: circleci/ruby:2.7.2-node environment: - DB_HOST: 127.0.0.1 - RAILS_ENV: test - BUNDLER_VERSION: 2.1.4 - image: circleci/mysql:8.0 command: | mysqld --default-authentication-plugin=mysql_native_password environment: - MYSQL_ROOT_PASSWORD: password - MYSQL_USER: root - MYSQL_ROOT_HOST: '%' - image: selenium/standalone-chrome:latest name: chrome steps: - checkout - ruby/install-deps - run: mv config/database.yml.ci config/database.yml - run: name: Wait for DB command: dockerize -wait tcp://localhost:3306 -timeout 1m - run: bundle exec rake db:create - run: bundle exec rake db:schema:load # Run rspec in parallel - ruby/rubocop-check - ruby/rspec-test workflows: version: 2 build_and_test: jobs: - build - test: requires: - buildこれにCircleCI + Capistrano + AWS(EC2) + Railsで自動デプロイしてみたを参考に以下の部分を追加します。
.circleci/config.yml(追加箇所)#省略 deploy: docker: - image: circleci/ruby:2.7.2-node environment: BUNDLER_VERSION: 2.1.4 steps: - checkout - ruby/install-deps - add_ssh_keys: fingerprints:"XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX" - deploy: name: Capistrano deploy command: bundle exec cap production deploy workflows: version: 2 build_accept_deploy: jobs: - build - test: requires: - build - deploy: requires: - test filters: branches: only: master.circleci/config.yml(全体)version: 2.1 orbs: ruby: circleci/ruby@1.1.2 jobs: build: docker: - image: circleci/ruby:2.7.2-node environment: - BUNDLER_VERSION: 2.1.4 steps: - checkout - ruby/install-deps test: parallelism: 3 docker: - image: circleci/ruby:2.7.2-node environment: - DB_HOST: 127.0.0.1 - RAILS_ENV: test - BUNDLER_VERSION: 2.1.4 - image: circleci/mysql:8.0 command: | mysqld --default-authentication-plugin=mysql_native_password environment: - MYSQL_ROOT_PASSWORD: password - MYSQL_USER: root - MYSQL_ROOT_HOST: '%' - image: selenium/standalone-chrome:latest name: chrome steps: - checkout - ruby/install-deps - run: mv config/database.yml.ci config/database.yml - run: name: Wait for DB command: dockerize -wait tcp://localhost:3306 -timeout 1m - run: bundle exec rake db:create - run: bundle exec rake db:schema:load # Run rspec in parallel - ruby/rubocop-check - ruby/rspec-test deploy: docker: - image: circleci/ruby:2.7.2-node environment: BUNDLER_VERSION: 2.1.4 steps: - checkout - ruby/install-deps - add_ssh_keys: fingerprints: "XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX" - deploy: name: Capistrano deploy command: bundle exec cap production deploy workflows: version: 2 build_accept_deploy: jobs: - build - test: requires: - build - deploy: requires: - test filters: branches: only: master補足
- add_ssh_keys: fingerprints: "XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX"の部分は、
1. CircleCiに登録しているリポジトリページの画面右上にある「Project Settings」をクリック 2. 画面左側の「SSH KEYS」を選択。 3. 画面一番下に追加したSSH鍵があるのでそこのFingerprint( 12:34:56:ab:cd:ef:... みたいなの) をコピーして貼り付け。注意
CircleCiで使用されるIPアドレスは常に同じではないため、ここまで内容ではセキュリティグループでSSH接続可能なIPアドレスを限定している場合はデプロイできません。(限定していない場合はデプロイ可能)
続きはこのセキュリティに関する問題への対処です。参考:CircleCIでSystemSpec(RSpec)とRubocopを走らせる
CircleCI + Capistrano + AWS(EC2) + Railsで自動デプロイしてみた特定のIPアドレスでのみデプロイを許可する
次にSSH接続可能なIPアドレスをセキュリティグループで限定したIPアドレス(マイIP)と、CircleCi上で使用されるIPアドレスでのみデプロイができるようにしていきます。
AWSでの設定
まずはこちらの記事を参考にIAMユーザーを作成しCSVを必ずダウンロードしてください(CSVの内容をCircleCiに環境変数として登録するため)。
次に以下の操作を行います。1. サービスから「EC2」を選択。 2. EC2のダッシュボードから「セキュリティグループ」を選択。 3. 画面右上の「セキュリティグループを作成」を選択。 4.「セキュリティグループ名 」と「説明」に「CircleCi-SecurityGroup」と入力。 5.「VPC」にデプロイ先のインスタンスがあるVPCを選択。 6.「セキュリティグループを作成」選択して作成。 7. EC2のダッシュボードから「インスタンス」を選択。 8. デプロイ先のインスタンスの「アクション」から「セキュリティグループを変更」を選択 9.「関連付けられたセキュリティグループ」に作成したセキュリティグループを追加します。これでAWSでの設定は終了です。
補足
セキュリティグループ作成時にインバウンドルールなどを追加する必要はありません。
作成したセキュリティグループのIDを後ほどCircleCiへ環境変数として登録します。CircleCiでの設定
CircleCIでは以下の4つを環境変数として追加します。
「AWS_ACCESS_KEY_ID」「AWS_SECRET_ACCESS_KEY」「AWS_DEFAULT_REGION」「SECURITY_GROUP_ID」先ほどダウンロードしたCSVの内容を以下の名称で2つ登録します。
Nameを「AWS_ACCESS_KEY_ID」、Valueに「Access key ID」の値を登録。 Nameを「AWS_SECRET_ACCESS_KEY」、「Secret access key」の値を登録。残り2つの環境変数を登録します。
Nameを「AWS_DEFAULT_REGION」、Valueに「ap-northeast-1」を入力して登録。 Nameを「SECURITY_GROUP_ID」、Valueに「先ほど作成したセキュリティグループのID」を登録。これでCircleCiでの設定は終了です。
補足
「AWS_DEFAULT_REGION」の値は基本的に「ap-northeast-1」だと思いますが、もし違った場合は適切なリージョン名を登録して下さい。
ファイルの編集とシェルスクリプトの作成
それでは設定ファイルを編集していきます。(一番最後にソースコード全体があります)
.circleci/config.yml(変更箇所)orbs: ruby: circleci/ruby@1.1.2 aws-cli: circleci/aws-cli@1.3.2 #追加 jobs: #省略 deploy: docker: - image: circleci/ruby:2.7.2-node environment: BUNDLER_VERSION: 2.1.4 steps: - checkout - ruby/install-deps - aws-cli/install #追加 - add_ssh_keys: fingerprints: "XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX" - deploy: name: Capistrano deploy command: ./deploy.sh #シェルスクリプトの実行に変更次にシェルスクリプトをこちらの記事をもとに「deploy.sh」という内容で作成しました。(こちらの記事を参考に内容を少し編集しています。)
deploy.sh#!/bin/sh set -ex IP=`curl -f -s ifconfig.me` trap "aws ec2 revoke-security-group-ingress --group-id ${SECURITY_GROUP_ID} --protocol tcp --port 22 --cidr ${IP}/32" 0 1 2 3 15 aws ec2 authorize-security-group-ingress --group-id ${SECURITY_GROUP_ID} --protocol tcp --port 22 --cidr ${IP}/32 bundle exec cap production deploy最後に「deploy.sh」の権限を以下のコマンドで変更します。
$ chmod +x deploy.sh補足
これでCircleCiからEC2インスタンスへのデプロイはできますが、確認としてデプロイ時に作成したセキュリティーグループにCircleCiのIPアドレスが追加されることや、デプロイ完了後または失敗時には追加されたIPアドレスが削除されていることを確認してください。
参考:CircleCI から deploy させる話
CircleCIからCapistranoを利用してAWS(EC2)にデプロイするソースコード
先人に倣ってソースコードを置いておきます。
.circleci/config.ymlversion: 2.1 orbs: ruby: circleci/ruby@1.1.2 aws-cli: circleci/aws-cli@1.3.2 jobs: build: docker: - image: circleci/ruby:2.7.2-node environment: - BUNDLER_VERSION: 2.1.4 steps: - checkout - ruby/install-deps test: parallelism: 3 docker: - image: circleci/ruby:2.7.2-node environment: - DB_HOST: 127.0.0.1 - RAILS_ENV: test - BUNDLER_VERSION: 2.1.4 - image: circleci/mysql:8.0 command: | mysqld --default-authentication-plugin=mysql_native_password environment: - MYSQL_ROOT_PASSWORD: password - MYSQL_USER: root - MYSQL_ROOT_HOST: '%' - image: selenium/standalone-chrome:latest name: chrome steps: - checkout - ruby/install-deps - run: mv config/database.yml.ci config/database.yml - run: name: Wait for DB command: dockerize -wait tcp://localhost:3306 -timeout 1m - run: bundle exec rake db:create - run: bundle exec rake db:schema:load # Run rspec in parallel - ruby/rubocop-check - ruby/rspec-test deploy: docker: - image: circleci/ruby:2.7.2-node environment: BUNDLER_VERSION: 2.1.4 steps: - checkout - ruby/install-deps - aws-cli/install - add_ssh_keys: fingerprints: "XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX" - deploy: name: Capistrano deploy command: ./deploy.sh workflows: version: 2 build_accept_deploy: jobs: - build - test: requires: - build - deploy: requires: - test filters: branches: only: masterdeploy.sh#!/bin/sh set -ex IP=`curl -f -s ifconfig.me` trap "aws ec2 revoke-security-group-ingress --group-id ${SECURITY_GROUP_ID} --protocol tcp --port 22 --cidr ${IP}/32" 0 1 2 3 15 aws ec2 authorize-security-group-ingress --group-id ${SECURITY_GROUP_ID} --protocol tcp --port 22 --cidr ${IP}/32 bundle exec cap production deployconfig/deploy/production.rbserver 'Elastic IP', user: 'ユーザー名', roles: %w[web app db] set :ssh_options, { keys: (ENV['PRODUCTION_SSH_KEY']), forward_agent: true }config/deploy.rb# config/credentials.yml.encの内容を使えるようにする require File.expand_path('./environment', __dir__) # config valid for current version and patch releases of Capistrano lock '~> 3.15.0' # アプリケーション名 set :application, 'app_name' # githubのurl。プロジェクトのgitホスティング先を指定する set :repo_url, 'git@github.com:user_name/app_name.git' # デプロイ先のサーバーのディレクトリ。フルパスで指定 set :deploy_to, '/var/www/rails/app_name' # Rubyのバージョンを指定 set :rbenv_ruby, '2.7.2' # シンボリックリンクのファイルを指定、具体的にはsharedに入るファイル append :linked_files, 'config/master.key' # シンボリックリンクのディレクトリを生成 append :linked_dirs, 'log', 'tmp/pids', 'tmp/cache', 'tmp/sockets' # タスクでsudoなどを行う際に必要 set :pty, true # 保持するバージョンの個数(※後述) set :keep_releases, 3 # 出力するログのレベル。 set :log_level, :debug # puma set :puma_init_active_record, true # Nginxの設定ファイル名と置き場所を修正 set :nginx_sites_enabled_path, '/etc/nginx/conf.d' set :nginx_config_name, "#{fetch(:application)}.conf"Gemfilesource 'https://rubygems.org' git_source(:github) { |repo| "https://github.com/#{repo}.git" } ruby '2.7.2' gem 'bcrypt' gem 'bootsnap', require: false gem 'bootstrap' gem 'devise' gem 'devise-i18n' gem 'image_processing' gem 'jbuilder' gem 'jquery-rails' gem 'kaminari' gem 'kaminari-bootstrap' gem 'mini_magick' gem 'mysql2' gem 'puma', '< 5' gem 'rails', '~> 6.0.3', '>= 6.0.3.4' gem 'rails-i18n' gem 'sassc-rails' gem 'turbolinks' gem 'uglifier' group :development, :test do gem 'byebug', platforms: %i[mri mingw x64_mingw] gem 'factory_bot_rails' gem 'rspec-rails' end group :development do gem 'bcrypt_pbkdf' gem 'capistrano' gem 'capistrano3-puma', '< 5' gem 'capistrano-bundler' gem 'capistrano-rails' gem 'capistrano-rbenv' gem 'capistrano-rbenv-vars' gem 'ed25519' gem 'listen' gem 'rubocop', require: false gem 'rubocop-performance', require: false gem 'rubocop-rails', require: false gem 'rubocop-rspec' gem 'spring' gem 'spring-watcher-listen' gem 'sshkit-sudo' gem 'web-console' end group :test do gem 'capybara' gem 'capybara-email' gem 'database_cleaner' gem 'rspec_junit_formatter' gem 'selenium-webdriver' end group :production do gem 'aws-sdk-s3', require: false end
- 投稿日:2021-01-19T12:49:41+09:00
CircleCi + Capistrano で自動デプロイ
記事を書いた理由
今回が初めての記事作成なので、あまり量を書かない内容+微妙にハマる部分があったためCircleCi+Capistrano記事を書いてみることにしました。
今回はCircleCI + Capistrano + AWS(EC2) + Railsで自動デプロイしてみたの記事を参考にして構築した結果、微妙に違った部分や補足などを書いています。
この記事ではEC2インスタンスへのSSH接続がどのIPアドレスでも接続可能な場合の記事です。(対応次第追加します。)前提条件
- CircleCiのGUIは執筆時(2021年1月19日)のもの。
- ローカルでCapistranoでEC2インスタンスへのデプロイは完了済み。
- すでにCircleCi上でRSpecやRuboCopなどは動く。(まだであればこちらが参考になりました。)
注意:この記事ではEC2インスタンスへのSSH接続がどのIPアドレスでも接続可能な場合の記事です。(対応次第追加します。)
下準備(SSH鍵の形式変更)
最初にCircleCiへ登録するためのにSSH鍵の形式を変更します。
こちらの記事を参考にして、過去にEC2インスタンスへアクセスするために作成したであろう
手元のSSH鍵(~/.ssh/your_app_key_rsa)の形式を変更するため以下の操作を行います。$ chmod 700 ~/.ssh/your_app_key_rsa $ ssh-keygen -p -m PEM -f ~/.ssh/your_app_key_rsa $ chmod 400 ~/.ssh/your_app_key_rsa $ cat ~/.ssh/your_app_key_rsa #このコマンドで表示されるファイルの内容をCircleCiに登録します。ファイルの内容が以下のように 「BEGIN RSA PRIVATE KEY」 になっていればOKです。
-----BEGIN RSA PRIVATE KEY-----
数字を含む文字の羅列
-----END RSA PRIVATE KEY-----CircleCiでの操作(SSH鍵登録 環境変数登録)
SSH鍵登録
次に先ほど形式を変更したSSH鍵をCircleCiへ登録するために以下の操作を行います。
1. CircleCiに登録しているリポジトリページの画面右上にある 「Project Settings」 をクリック 2. 画面左側の 「SSH KEYS」 を選択。 3. 画面下の 「Additional SSH Keys」 項目の右側にある 「Add SSH Key」 を選択。 4. 表示される項目の 「Hostname」 にEC2インスタンスに割り当てている 「Elastic IP」 を入力します。 5. 「Private Key*」 に 「~/.ssh/your_app_key_rsa」 の内容をコピーして貼り付けます。 6. 「Hostname」 と 「Private Key*」 が入力できたら 「Add SSH Key」 でSSH鍵を登録します。補足
5では、数字と文字の羅列だけじゃなく以下も含めてコピーしてください。
-----BEGIN RSA PRIVATE KEY-----
-----END RSA PRIVATE KEY-----
6で登録が完了すると「Additional SSH Keys」の項目に 「Hostname」 には 「Elastic IP」 が、
「Fingerprint」 には 「12:34:56:ab...」のような内容が表示されているはずです。
表示されている 「Fingerprint」 はこの後に行う「環境変数」 の登録に使います。(環境変数では 「:」は含みません。)
ここで登録したSSH鍵は自動的に「ssh-agent」に追加されます。
ファイル名は ~/.ssh/id_rsa_ の後にFingerprintから:を抜いたものです
サーバー環境からGitHubへ接続するのに「ssh-agent」を使用している場合でも、ローカルからEC2インスタンスへの接続に使うためのSSH鍵の1個の登録のみで済みます。環境変数登録
次にCircleciに環境変数を追加します。ブラウザ上での操作はこれで終わりです。この後はファイルを編集するだけです。
1. 現在の画面(「SSH KEYSの画面」)の左側にある 「Environment Variables」 を選択します。 2. 次に 「Add Environment Variable」 を選択します。 3. SSH鍵の登録と同じような項目が出るので、 「Name*」 に変数名として 「PRODUCTION_SSH_KEY」 と入力。 4. 「Value*」 に 「~/.ssh/id_rsa_123456abcd」 のように ~/.ssh/id_rsa_ の後ろに先ほど登録した SSH鍵の「Fingerprint」の内容から「:」を省いて入力します。 5.「Add Environment Variable」 で環境変数を登録します。補足
CircleCiにSSH鍵を複数登録した場合でも、「~/.ssh」配下に「id_rsa_Fingerprint : 抜き」のファイル名として保存されるため、環境変数としてSSH鍵へのパスを登録している。
確認したい場合は、公式のSSH を使用したデバッグを参考にしてください。Capistranoの編集
keys:の変更だけなのですぐに終わります。
config/deploy/production.rb#省略 set :ssh_options, { keys: (ENV['PRODUCTION_SSH_KEY']), forward_agent: true }CircleCiの編集
CircleCIでSystemSpec(RSpec)とRubocopを走らせるの内容を参考に自分用に編集したものです。
.circleci/config.yml(編集前)version: 2.1 orbs: ruby: circleci/ruby@1.1.2 jobs: build: docker: - image: circleci/ruby:2.7.2-node environment: - BUNDLER_VERSION: 2.1.4 steps: - checkout - ruby/install-deps test: parallelism: 3 docker: - image: circleci/ruby:2.7.2-node environment: - DB_HOST: 127.0.0.1 - RAILS_ENV: test - BUNDLER_VERSION: 2.1.4 - image: circleci/mysql:8.0 command: | mysqld --default-authentication-plugin=mysql_native_password environment: - MYSQL_ROOT_PASSWORD: password - MYSQL_USER: root - MYSQL_ROOT_HOST: '%' - image: selenium/standalone-chrome:latest name: chrome steps: - checkout - ruby/install-deps - run: mv config/database.yml.ci config/database.yml - run: name: Wait for DB command: dockerize -wait tcp://localhost:3306 -timeout 1m - run: bundle exec rake db:create - run: bundle exec rake db:schema:load # Run rspec in parallel - ruby/rubocop-check - ruby/rspec-test workflows: version: 2 build_and_test: jobs: - build - test: requires: - buildCircleCI + Capistrano + AWS(EC2) + Railsで自動デプロイしてみたを参考に以下の部分を追加して終了です。
.circleci/config.yml(追加箇所)#省略 deploy: docker: - image: circleci/ruby:2.7.2-node environment: BUNDLER_VERSION: 2.1.4 steps: - checkout - ruby/install-deps - add_ssh_keys: fingerprints:"XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX" - deploy: name: Capistrano deploy command: bundle exec cap production deploy workflows: version: 2 build_accept_deploy: jobs: - build - test: requires: - build - deploy: requires: - test filters: branches: only: master補足
- add_ssh_keys: fingerprints: "XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX"の部分は、
1. CircleCiに登録しているリポジトリページの画面右上にある 「Project Settings」 をクリック 2. 画面左側の 「SSH KEYS」 を選択。 3. 画面一番下に追加したSSH鍵があるのでそこのFingerprint( 12:34:56:ab:cd:ef:... みたいなの) をコピーして貼り付け。参考:CircleCIでSystemSpec(RSpec)とRubocopを走らせる
CircleCI + Capistrano + AWS(EC2) + Railsで自動デプロイしてみたソースコード
先人に倣ってソースコードを置いておきます。
.circleci/config.ymlversion: 2.1 orbs: ruby: circleci/ruby@1.1.2 jobs: build: docker: - image: circleci/ruby:2.7.2-node environment: - BUNDLER_VERSION: 2.1.4 steps: - checkout - ruby/install-deps test: parallelism: 3 docker: - image: circleci/ruby:2.7.2-node environment: - DB_HOST: 127.0.0.1 - RAILS_ENV: test - BUNDLER_VERSION: 2.1.4 - image: circleci/mysql:8.0 command: | mysqld --default-authentication-plugin=mysql_native_password environment: - MYSQL_ROOT_PASSWORD: password - MYSQL_USER: root - MYSQL_ROOT_HOST: '%' - image: selenium/standalone-chrome:latest name: chrome steps: - checkout - ruby/install-deps - run: mv config/database.yml.ci config/database.yml - run: name: Wait for DB command: dockerize -wait tcp://localhost:3306 -timeout 1m - run: bundle exec rake db:create - run: bundle exec rake db:schema:load # Run rspec in parallel - ruby/rubocop-check - ruby/rspec-test deploy: docker: - image: circleci/ruby:2.7.2-node environment: BUNDLER_VERSION: 2.1.4 steps: - checkout - ruby/install-deps - add_ssh_keys: fingerprints: "XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX" - deploy: name: Capistrano deploy command: bundle exec cap production deploy workflows: version: 2 build_accept_deploy: jobs: - build - test: requires: - build - deploy: requires: - test filters: branches: only: masterconfig/deploy.rb# config/credentials.yml.encの内容を取り出す。 require File.expand_path('./environment', __dir__) # config valid for current version and patch releases of Capistrano lock '~> 3.15.0' # アプリケーション名 set :application, 'app_name' # githubのurl。プロジェクトのgitホスティング先を指定する set :repo_url, 'git@github.com:user_name/app_name.git' # デプロイ先のサーバーのディレクトリ。フルパスで指定 set :deploy_to, '/var/www/rails/app_name' # Rubyのバージョンを指定 set :rbenv_ruby, '2.7.2' # シンボリックリンクのファイルを指定、具体的にはsharedに入るファイル append :linked_files, 'config/master.key' # シンボリックリンクのディレクトリを生成 append :linked_dirs, 'log', 'tmp/pids', 'tmp/cache', 'tmp/sockets' # タスクでsudoなどを行う際に必要 set :pty, true # 保持するバージョンの個数(※後述) set :keep_releases, 3 # 出力するログのレベル。 set :log_level, :debug # puma set :puma_init_active_record, true # Nginxの設定ファイル名と置き場所を修正 set :nginx_sites_enabled_path, '/etc/nginx/conf.d' set :nginx_config_name, "#{fetch(:application)}.conf"config/deploy/production.rbserver Rails.application.credentials.dig(:amazon, :ec2_ip), user: Rails.application.credentials.dig(:amazon, :ec2_user), roles: %w[web app db] set :ssh_options, { keys: (ENV['PRODUCTION_SSH_KEY']), forward_agent: true }Gemfilesource 'https://rubygems.org' git_source(:github) { |repo| "https://github.com/#{repo}.git" } ruby '2.7.2' gem 'bcrypt' gem 'bootsnap', require: false gem 'bootstrap' gem 'devise' gem 'devise-i18n' gem 'image_processing' gem 'jbuilder' gem 'jquery-rails' gem 'kaminari' gem 'kaminari-bootstrap' gem 'mini_magick' gem 'mysql2' gem 'puma', '< 5' gem 'rails', '~> 6.0.3', '>= 6.0.3.4' gem 'rails-i18n' gem 'sassc-rails' gem 'turbolinks' gem 'uglifier' group :development, :test do gem 'byebug', platforms: %i[mri mingw x64_mingw] gem 'factory_bot_rails' gem 'rspec-rails' end group :development do gem 'bcrypt_pbkdf' gem 'capistrano' gem 'capistrano3-puma', '< 5' gem 'capistrano-bundler' gem 'capistrano-rails' gem 'capistrano-rbenv' gem 'capistrano-rbenv-vars' gem 'ed25519' gem 'listen' gem 'rubocop', require: false gem 'rubocop-performance', require: false gem 'rubocop-rails', require: false gem 'rubocop-rspec' gem 'spring' gem 'spring-watcher-listen' gem 'sshkit-sudo' gem 'web-console' end group :test do gem 'capybara' gem 'capybara-email' gem 'database_cleaner' gem 'rspec_junit_formatter' gem 'selenium-webdriver' end group :production do gem 'aws-sdk-s3', require: false end
- 投稿日:2021-01-19T12:31:09+09:00
【Rails】ローカル環境でS3の画像投稿ができるのに、Heroku上でS3が機能しない問題
現象
ローカル環境でうまくS3に画像を保管出来た!!
しかし、Heroku側にマージしてもなぜかHerokuのDB上で画像を保管している。。。
エラーも出ない。。
なぜだろうか。。。原因
今思えば当たり前の話なのですが、、
原因は環境用(Heroku)のファイルにActiveStorageの設定をしていないというものでした。
種類 環境 設定ファイル 開発環境 ローカル環境 development.rb 本番環境 Heroku production.rb(⇦こっちに設定入れてなかった) ** 同じミスをしないように手順を残しておきます **
ローカル環境での設定(※aws側の設定は割愛)
①S3を使用するために必要なGemfileを導入
Gemfile.gem "aws-sdk-s3", require: false②追記したら、ターミナルにて開発中のアプリに入り「bundle install」を実行
ターミナル.% bundle install③development.rbとstorage.ymlファイルも更新
config/environments/development.rb# S3にて保存されるように設定を変更 # config.active_storage.service = :local config.active_storage.service = :amazonconfig/storage.yml# S3の設定を追記 amazon: service: S3 region : ap-southeast-1 # リージョンをaws側で確認して記載 bucket : furimabucket # バケット名をaws側で確認して記載 access_key_id: <%= ENV['AWS_ACCESS_KEY_ID'] %> secret_access_key: <%= ENV['AWS_SECRET_ACCESS_KEY'] %>④環境変数の追記
③のstorage.ymlにて「AWS_ACCESS_KEY_ID」「AWS_SECRET_ACCESS_KEY」を設定しているので開発中のアプリにて環境変数を追記。
ターミナル.% vim ~/.zshrc「i」で編集モードにして2つの変数を登録
ターミナル.export AWS_ACCESS_KEY_ID="Access key IDの値" export AWS_SECRET_ACCESS_KEY="Secret access keyの値"編集が終わったら、[ESC]→:wqで終了
続いて、環境変数の設定ファイルを読み込み直すターミナル.% source ~/.zshrcこれで、ローカル環境でS3の画像投稿ができた!!!!!!
以降は、Herokuまでの反映手順になります。
Herokuへの反映
①まずは忘れずにproduction.rbの更新
storage.ymlは特に変更なし。config/environments/production.rb# 本番環境でもS3にて保存されるように設定 config.active_storage.service = :amazon②ターミナルにてHerokuにログイン
ターミナル.% heroku login --interactive③本番環境でも環境変数を設定
環境変数を確認したい場合は「% heroku config」ターミナル.% heroku config:set AWS_ACCESS_KEY_ID="Access key IDの値" % heroku config:set AWS_SECRET_ACCESS_KEY="Secret access keyの値"④あとはコミットして完了
ターミナル.% git add . % git commit -m "ストレージの変更(S3)" % git push heroku master
お疲れ様でした。
- 投稿日:2021-01-19T12:31:09+09:00
【Rails】ローカル環境でS3の画像投稿ができるのに、Heroku上でS3に切り替わらない問題
現象
ローカル環境でうまくS3に画像を保管出来た!!
しかし、Heroku側にマージしてもなぜかHerokuのDB上で画像を保管している。。。
エラーも出ない。。
なぜだろうか。。。原因
今思えば当たり前の話なのですが、、
原因は本番環境用(Heroku)のファイルにActiveStorageの設定をしていないというものでした。
種類 環境 設定ファイル 開発環境 ローカル環境 development.rb 本番環境 Heroku production.rb(⇦こっちに設定入れてなかった) ** 同じミスをしないように手順を残しておきます **
ローカル環境での設定(※aws側の設定は割愛)
①S3を使用するために必要なGemfileを導入
Gemfile.gem "aws-sdk-s3", require: false②追記したら、ターミナルにて開発中のアプリに入り「bundle install」を実行
ターミナル.% bundle install③development.rbとstorage.ymlファイルも更新
config/environments/development.rb# S3にて保存されるように設定を変更 # config.active_storage.service = :local config.active_storage.service = :amazonconfig/storage.yml# S3の設定を追記 amazon: service: S3 region : ap-southeast-1 # リージョンをaws側で確認して記載 bucket : furimabucket # バケット名をaws側で確認して記載 access_key_id: <%= ENV['AWS_ACCESS_KEY_ID'] %> secret_access_key: <%= ENV['AWS_SECRET_ACCESS_KEY'] %>④環境変数の追記
③のstorage.ymlにて「AWS_ACCESS_KEY_ID」「AWS_SECRET_ACCESS_KEY」を設定しているので開発中のアプリにて環境変数を追記。
ターミナル.% vim ~/.zshrc「i」で編集モードにして2つの変数を登録
ターミナル.export AWS_ACCESS_KEY_ID="Access key IDの値" export AWS_SECRET_ACCESS_KEY="Secret access keyの値"編集が終わったら、[ESC]→:wqで終了
続いて、環境変数の設定ファイルを読み込み直すターミナル.% source ~/.zshrcこれで、ローカル環境でS3の画像投稿ができた!!!!!!
以降は、本番環境(Heroku)への反映手順となります。本番環境(Heroku)への反映
①まずは忘れずにproduction.rbの更新
storage.ymlは特に変更なし。config/environments/production.rb# 本番環境でもS3にて保存されるように設定 config.active_storage.service = :amazon②ターミナルにてHerokuにログイン
ターミナル.% heroku login --interactive③本番環境でも環境変数を設定
環境変数を確認したい場合は「% heroku config」ターミナル.% heroku config:set AWS_ACCESS_KEY_ID="Access key IDの値" % heroku config:set AWS_SECRET_ACCESS_KEY="Secret access keyの値"④あとはコミットして完了
ターミナル.% git add . % git commit -m "ストレージの変更(S3)" % git push heroku master
- 投稿日:2021-01-19T11:19:40+09:00
gemのransackで複数カラムを検索対象にする方法
始めに
僕自身複数カラムを検索対象にするのは難しいと思っていたのですが、思っていたより簡単にできたので是非参考にしてもらえたらなと思い、書くことにしました。
前提
僕はPostモデルのtitleとdescriptionを検索対象にやっていきます。
class CreatePosts < ActiveRecord::Migration[5.2] def change create_table :posts do |t| t.string :title ⬅️⬅️⬅️⬅️⬅️⬅️これ t.integer :recommended t.text :description ⬅️⬅️⬅️⬅️これ t.references :user, foreign_key: true t.timestamps end add_index :posts, [:user_id, :created_at] end endやり方
始めにviewの一部を変えていきます。
titleだけを検索対象の場合は、<%= f.search_field :title_cont, placeholder: "キーワード検索", class: 'form-control font-awesome' %>titleとdescriptionの複数を検索対象にする場合、
<%= f.search_field :title_or_description_cont, placeholder: "キーワード検索", class: 'form-control font-awesome' %>比較すると、titleだけ検索対象の方はtitle_contなのに対し、複数検索対象の方はtitle_or_description_contとなっています。orを入れるだけです!
次はcontrollerです。
僕の場合、titleだけ検索対象だと、def set_search if logged_in? @search_word = params[:q][:title_cont] if params[:q] @q = current_user.feed.page(params[:page]).per(10).ransack(params[:q]) @feed_items = current_user.feed.page(params[:page]).per(10) @posts = @q.result(distinct: true) end end複数検索対象だと、ここも先ほどのviewと一緒で一部変更するだけです!
@search_word = params[:q][:title_or_description_cont] if params[:q]これで複数カラムを検索対象にできました!!!
- 投稿日:2021-01-19T02:45:19+09:00
【エラー】ActiveRecord::NoDatabaseError FATAL: database does not exist
ターミナルにて、
rails db:createをするとRailsが自動で決めた名前でデータベースを作ってくれました。