- 投稿日:2021-01-19T23:53:24+09:00
Redmine User一覧をDataFrameで取得
クラスの一部分ですが切り出して記載。
コメント、、、ちゃんと書く(TODO)Resourceからの情報取り出しがちょっと特殊な感じなので
ここに書いておく。もっといい方法がありましたら教えてください。
######################################################## # ユーザID一覧作成 ######################################################## def getAllRedmineUsers(self): ''' Args: Returns: df: DataFrame Redmine登録全ユーザを格納したDataFrame Raises: TypeError: 引数型の不備 Exception: ID登録時の例外 Examples: >>> df = self.getAllRedmineUsers() Note: あまりこまごまとした入力チェックをやっていませんので 利用の際には慎重に w ''' # 登録処理 print(f'ユーザID一覧を取得します') try: # ユーザ取得:API users = self.redmine.user.all() except Exception as e: print(f'ユーザ一覧取得に失敗しました') print(f'エラー詳細:{e}') print() else: # Resourceから情報取り出し _list = [] for _ in users: _list.append(list(_)) # 取り出した情報を加工 ## ログインID、名前(first,last)、ID作成日、最終ログイン時間を抽出 ## TODO 抽出時間(GMT)をJSTに変換する(ライブラリは会社に置いてある、それつかう) __list = [] for i in range(len(_list)): __list.append([f'{_list[i][5][1]}', f'{_list[i][7][1]} {_list[i][8][1]}', f'{_list[i][10][1]}', f'{_list[i][11][1]}']) # DataFrame化 df = pd.DataFrame(__list) df.columns = ['LoginID','Name', 'Created','LastLogin'] return df ```
- 投稿日:2021-01-19T22:53:48+09:00
自宅内の見守りカメラをアップデートした:②お試し動作で課題にぶつかった編
はじめに
本記事はこちらのパート②にあたります。
もし内容に興味を持たれましたら、他のパートもご覧頂けると幸いです。(順次執筆中…)要約
- 前回(ハードウェア準備編)、ついに念願のRasberryPiを使って見守りカメラを起動に成功!
- しかし課題が発覚。さてどうしよう

- 改修ポイントを整理してみよう。
何が課題だったか
カメラ画像を取得しきれない時がある
数秒に一度画像を取得する仕様としたのですが、時折画像がブラックアウトしたり、画角の一部だけが引き延ばされたような画像が取得されることがありました。
Python3のOpencv-pythonライブラリを使ってカメラ映像のキャプチャを行っていたのですが、その動作が所望の更新間隔内で収まっていないのかもしれません。
試しにノートPC上でシステムを稼働させた際は現象を再現しなかったため、ハードウェア要因→パフォーマンスの問題だと考えました。
(要因検証をこれ以上深くは行いませんでした)HTTPサーバーの応答が遅い
システム構成としては、ラズパイ上でHTTPサーバーを稼働させ、手持ちのスマートフォン等からアクセスすることで、カメラ画像を閲覧する仕様にしたのですが、スマートフォンからアクセスした際に、ページが読み込まれるまでのレスポンスが異常に遅いです。(10秒~20秒程度)
こちらも試しにノートPC上でシステムを稼働させた際は現象を再現しなかったため、ハードウェア要因→パフォーマンスの問題だと考えました。
現状はカメラから静止画を取得するためだけにOpenCVを使ったりしているので、改善ポイントは多々あるだろうな…とは思いつつ、うわぁ、そこに手を付けないかんのか…という気持ちになりました
画像の明るさが不適切
2つの問題がありました。
- 画像を取得するたびに明るさやホワイトバランスが再調整されるため、無駄に毎フレーム間の画像の変化が多い。結果的に、本当に着目したい子どもの動きが見づらい。
- 画像の更新レートを固定(1秒)にしているが、特に暗い場合、その時間では明るさやホワイトバランス調整が適切に終わらず、暗い画像しか取れない。(例えば同じ環境でラズパイの標準コマンドである
raspistillを使って静止画を取得すると、明るさが適切な画像が取得できた)前者に対しては画像取得設定の固定化(都度キャリブレーションをしない)、後者に対してはキャリブレーションモードの実装という手段で乗り切れそうです。
おわりに:課題と対応手段のまとめ
項目 対応 パフォーマンス改善 やりたいのは静止画の取得とHTTPサーバだけなので、ミニマム仕様で実装する 画像の明るさ適当化 画像取得設定の固定化と、キャリブレーションモードの実装 前者についてはもはや一から作り直しです…!
どうせ作り直すなら、新しい学びが得られるように勉強中の別言語で作っちまうか…?と考えた私は、Go言語によるリファインを心に決めたのでした(つづく)。

- 投稿日:2021-01-19T22:45:28+09:00
Streamlitでデータを可視化する
概要
- データをインタラクティブに可視化できるWebアプリを作りたい
- D3.jsなどを生で使うのはちょっと重たい(技術力的に)
- そもそもWeb系の知識が謙遜抜きでほぼ0(Vue?React?なにそれ美味しいの?)
- じゃあStreamlit使ってみよう
環境構築
こんな記事読まずに公式ドキュメントを読もうぜ。
インストール
pipでインストールします。
$ pip install streamlit動作確認
$ streamlit helloこれでローカルに8063番ポート(デフォルト設定)でwebサーバが立ちます。
ということで、ブラウザでhttp://localhost:8063/にアクセスするとサンプルページを確認できます。ちなみに、streamlitをimportしたpythonファイルでWebアプリを立ち上げたい場合には、以下のようにrunの後にpythonファイルを指定します。
$ streamlit run [python-file]基本的な書式
公式ドキュメントが充実しているのでそちらを参照されるのが速いです。
ここでは雰囲気だけ。
テキスト
見出しは、streamlit.headerや
subheaderで指定できます。
文章は、streamlit.textや、streamlit.writeで書くことができます。
また、Markdownも使えます(streamlit.markdown)。例えば
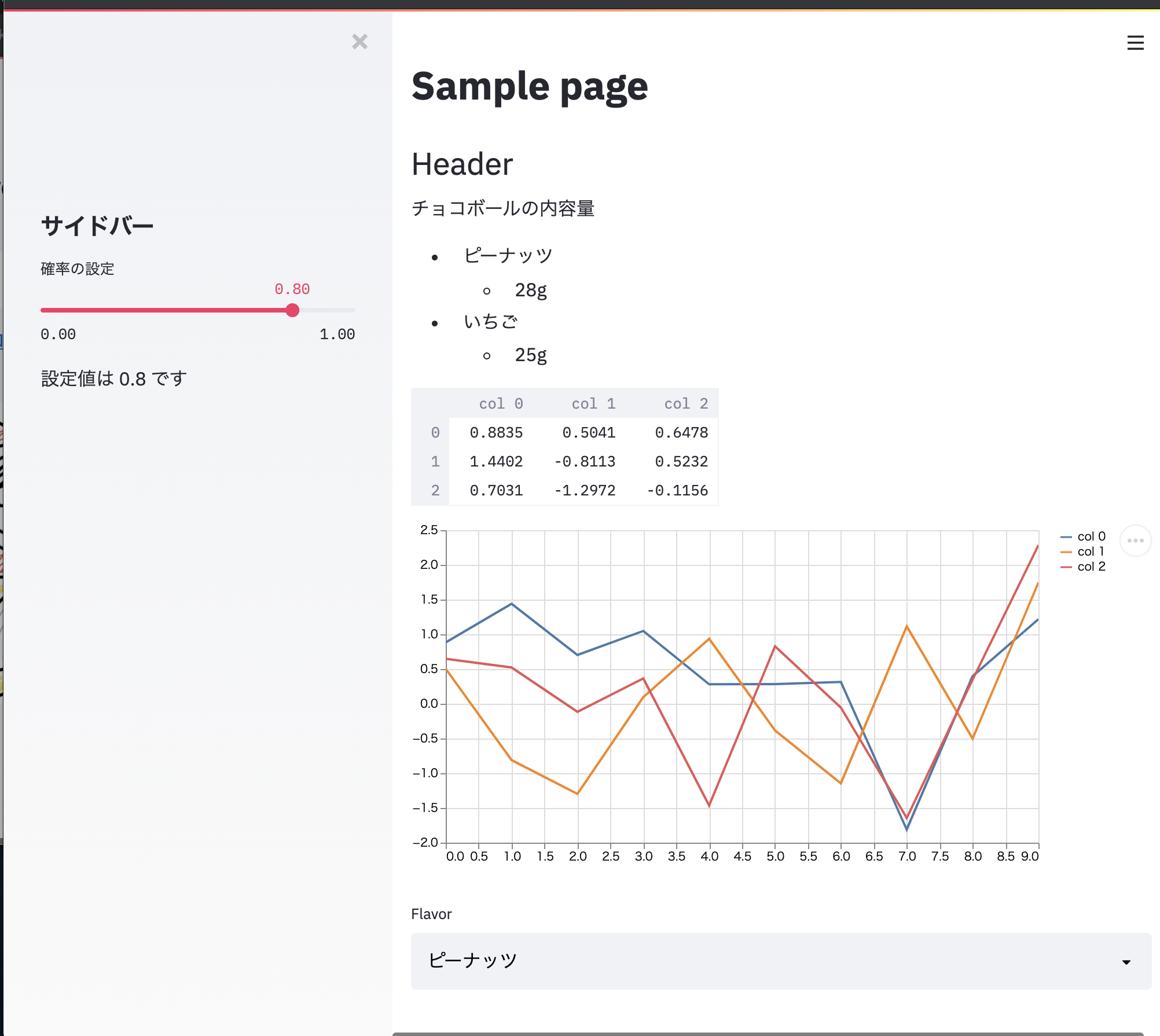
st.title('Sample page') st.markdown(''' チョコボールの内容量 - ピーナッツ - 28g ''')データフレーム(表)
pandas.DataFrameを使って表を描けます。
streamlit.tableやstreamlit.dataframeを使います。st.dataframeは特定の条件でセルをハイライトできたり、ソートできたりと高機能です。例えば
def rand_df(r=10, c=5): df = pd.DataFrame( np.random.randn(r, c), columns=('col %d' % i for i in range(c))) return df dataframe = rand_df(c=3, r=2) st.dataframe(dataframe)グラフ
チャートなどの描画はstreamlitでチャートを描く方法とmatplotlibのfigureオブジェクトなどを描画する方法があります。
例えば
dataframe = ... st.line_chart(dataframe)デフォルトでカラム毎の折れ線グラフが描画されます。また、マウスホイールの操作で拡大/縮小ができたり、ドラッグすることで位置を動かしたりできます。(インタラクティブ!)
また、matplotlibに慣れている場合はstreamlit.pyplotでfigureオブジェクトを描画することもできます。当然seabornなども使えます。
fig = plt.Figure(figsize=(6,2)) ax = fig.subplots(1,1) dataframe.plot(ax=ax) st.pyplot(fig)ただしこれだと拡大/縮小などはできないです(当然ですが)。
他にもbokehのチャートを描画できたりもしますし、いろいろサポートされているので公式ドキュメントを(以下略)Widget
データの選択などが行える各種のWidgetが用意されています。
例えば
lst_flavors = ['ピーナッツ', 'いちご'] select_taste = st.selectbox('Flavor', lst_flavors)プルダウンで選択項目が出てきます。
様々なものが用意されているので、ドキュメントを確認してください。サイドバー
st.sidebar.xxxと指定するとサイドバーが左端に現れます。xxxには上記のコマンドがそのまま使えます。例えば
st.sidebar.header('サイドバー') p = st.sidebar.slider('確率の設定', min_value=0.0, max_value=1.0, value=0.8) st.sidebar.write(f'設定値は {p} です')こんな感じ。
キャッシュ
streamlitはWidgetなどで要素に変更があると、pythonファイルを上から順に全て実行しなおします。そのため、変更した要素に関係なくても、ちょっと重たい計算などをしていると毎回その処理が走ります。
そこで、関係する要素に変更が無ければキャッシュを利用するようにしたいです。
streamlitでは、@st.cacheデコレータを使います。例えば
@st.cache def rand_df(r=10, c=5): df = pd.DataFrame( np.random.randn(r, c), columns=('col %d' % i for i in range(c))) return df dataframe = rand_df(c=7)こうすれば、Widgetなどに変更があっても
dataframeは更新されません。サンプルソースコード
上で記載した例をそのまま使って、ただのサンプルなWebアプリを作ってみます。
e.g.sample.pyimport numpy as np import pandas as pd import streamlit as st import matplotlib.pyplot as plt # テキストの描画 st.title('Sample page') st.header('Header') st.markdown(''' チョコボールの内容量 - ピーナッツ - 28g - いちご - 25g ''') @st.cache def rand_df(r=10, c=5): df = pd.DataFrame( np.random.randn(r, c), columns=('col %d' % i for i in range(c))) return df dataframe = rand_df(c=3, r=10) # 表の描画 st.dataframe(dataframe.head(n=3)) # チャートの描画 st.line_chart(dataframe) # widget lst_flavors = ['ピーナッツ', 'いちご'] select_taste = st.selectbox('Flavor', lst_flavors) # Sidebar st.sidebar.header('サイドバー') p = st.sidebar.slider('確率の設定', min_value=0.0, max_value=1.0, value=0.8) st.sidebar.write(f'設定値は {p} です')ローカルにテストサーバを立ててブラウザで確認してみます。
streamlit run src/sample2.pyこれでこんな感じのアプリができます
おしまい
参考
- 投稿日:2021-01-19T22:01:45+09:00
【Python】Udemyでif文について学んだのでアウトプットするよ
Udemyの超人気コース[『100 Days of Code - The Complete Python Pro Bootcamp』][4]にてPythonを学んでいます!
ここでの学習のアウトプットとしてつまづいたところなどを中心にQiitaにまとめていきます

今日はPythonの条件分岐であるif文の書き方について学びました!
使用環境
Python3.8
VScodePythonのif文について
ゴタゴタと語るのは煩わしいので、早速コードから。
▼課題①
number = int(input("Which number do you want to choose?")) if number % 2 == 0: print("This is an even number.") else: print("This is an odd number.")このコードでは、好きな数字を入力して、その数が偶数(even number)である場合は"これは偶数です(This is an even number.)"を返し、奇数(odd number)である場合は"これは奇数です(This is an odd number.)"を返すようにしています。
まず、
ifで偶数(even number)である場合 = すなわち2で割って余りがゼロになるということと同じと考えればnumber % 2 == 0と書けます。さらに、それ以外は全て奇数であると考えられるので、else(それ以外)には条件文は加えずに、シンプルに「これは奇数です(This is an odd number)」と返してあげればいいでしょう。
ポイントは
ifとelseを使う際にこの :(コロン)を忘れないように注意してください。Rubyから学んだ私は特に、このコロンを忘れがちです。
(幸い、VScodeでpythonのプラグイン を使用しているため、忘れている場合はすぐに波線で教えてくれます)
あとはこんなのもやりました。
▼課題②
#pizza order print("Welcome to Python Pizza Deliveries!") size = input("What size pizza do you want? S, M , L ?") add_pepperoni = input("Do you want pepperoni? Y, N ?") extra_cheese = input("So you want extra cheese? Y, N ?") bill = 0 #code if size == "S": bill += 15 print("Small pizza: $15 ") elif size == "M": bill += 20 print("Medium pizza: $20 ") elif size == "L": bill += 25 print("Large pizza: $25 ") if add_pepperoni == "Y": if size == "S": bill += 2 else: bill += 3 if extra_cheese == "Y": bill += 1 print(f"Your final bill is ${bill}. ")ピザのサイズ(S・M・L)を聞いて、それにトッピングがいるかどうか聞き、最終的な支払い金額を教えてくれるプログラムです。
これも先ほどのほぼ一緒で、if文とセットで
elif(else ifの略)を使用している点が違います。先ほどの単純な if 文や if else 文では、分岐条件は 1 つだけです。
ではelif 文は、どういう時に使うのかというと、そこにさらに分岐条件を加えたい場合に使います。
また、elifはいくつでも追加できるので、分岐条件を制限なく作ることが可能になります。ここでは、コードの内容を詳しく解説しませんが面白いのでぜひ解読して実行してみてください!
あとは少々トリッキーな分岐条件の課題もやったので軽く紹介します。
▼課題③
print("Welcome to the rollercoaster!") height = int(input("What is your height in cm?")) bill = 0 if height >= 120: print("You can ride the rollercoaster!") age = int(input("What is your age?")) if age < 12: bill += 7 print("Child tickets are $7.") elif age <= 18: bill += 10 print("Youth tickets are $10.") elif age >= 45 and age <= 55: print("Everything is going to be okay. Have a free ride on us!") else: bill = 12 print("Adult tickets are $12.") answer = input("Do you want a photo taken? $3 Y or N.") if answer == "Y": bill += 3 print(f"So your totall bill is ${bill}. ") else: print("Sorry, you have to grow taller before you can ride.")ジェットコースター問題です。
身長を聞いて、120cmであれば、年齢に応じてチケット料金が変わります。さらにそこから写真のオプションをつけるかどうか聞いて、つけると聞いたら最終金額はチケット代にその写真代が加算された値段になります。この課題はif文の中にelse文やelif文が囲まれていますが、落ち着いて読み解いて行けば簡単です。
講師も言っていましたが、分岐条件が分からなくなったときのポイントはロジックツリーを手書きで書いてみることです。
そうすることでどのように書けばいいかある程度見当がつくと思います。
では、今日はこんな感じで!
また明日も楽しみです
- 投稿日:2021-01-19T21:53:04+09:00
Pythonで3次元空間認識を自作した話
はじめに
まずはものから
こちらがそれです
この前にあげたPTAMの改良版
— よだかのもやし (@night_moyashi) January 19, 2021
Qiita全部書き直しますhttps://t.co/5DbJhH49vj pic.twitter.com/1tkkSQDsVH見ての通り、画像から3次元空間を認識しています
アルゴリズム
簡単に言えばベクトルの差を利用します
どういうことかというと、まず、画像上の特徴点を見つけ二枚の画像でマッチングを行います
その後、画像平面が実空間にあると仮定し、画像平面の中心とカメラ間の距離を求めますそして、画像の中央を原点とした特徴点の座標と先ほど求めた原点とカメラ間距離からカメラからの距離で二枚の画像それぞれから、カメラを原点としたベクトルが導かれます。
ここまでが下準備です。
ここまでの過程で導かれたベクトルのうち、一枚目の画像から導かれたベクトルを
\vec{a}=(a_1,a_2,a_3)二枚目の画像から導かれたベクトルを
\vec{b}=(b_1,b_2,b_3)この二枚の画像の間にカメラが動いたベクトルを
\vec{c}=(c_1,c_2,c_3)とすると、$\vec{a}$と$\vec{b}$の交点$O$とそれぞれの撮影地点$A(\vec{a}),B(\vec{b})$は同一平面上にあるから
-l\vec{a}=\vec{c}-k\vec{b}\\ k\vec{b}-l\vec{a}=\vec{c}となります
この式から\left\{ \begin{array}{l} c_1=kb_1-la_1\\ c_2=kb_2-la_2\\ c_3=kb_3-la_3 \end{array} \right.とういう連立方程式が成り立ちますが、このままでは行列を使って解こうとすると
\begin{vmatrix} b_{1}&-a_{1}\\ b_{2}&-a_{2}\\ b_{3}&-a_{3}\\ \end{vmatrix} \begin{vmatrix} k\\ l\\ \end{vmatrix} = \begin{vmatrix} c_{1}\\ c_{2}\\ c_{3} \end{vmatrix}\\ \begin{vmatrix} k\\ l\\ \end{vmatrix} = \begin{vmatrix} c_{1}\\ c_{2}\\ c_{3} \end{vmatrix} \begin{vmatrix} b_{1}&-a_{1}\\ b_{2}&-a_{2}\\ b_{3}&-a_{3}\\ \end{vmatrix}^{-1}となってしまい、
\begin{vmatrix} b_{1}&-a_{1}\\ b_{2}&-a_{2}\\ b_{3}&-a_{3}\\ \end{vmatrix}は正則行列ではないので方程式は解けません。
そこで、連立方程式を変形して\left\{ \begin{array}{l} (c_1+c_2)=k(b_1+b_2)-l(a_1+a_2)\\ (c_2+c_3)=k(b_2+b_3)-l(a_2+a_3)\\ \end{array} \right.として、これを行列を用いて$k,l$を導き出します。
そして$k\vec{b}$が$B$からの距離となります。
プログラム
プログラムはこちらで公開しています
GitHub
一応、コードの中で核となる部分をばmatch.pydef convert(data): data_converted=[] for loc in data: data_converted.append(convert_3d(loc)) A=np.matrix([ [-1*sum(data_converted[1][:2]),sum(data_converted[0][:2])], [-1*sum(data_converted[1][1:]),sum(data_converted[0][1:])], ]) Y=np.matrix([ [-0.6], [0], ]) coe = np.linalg.solve(A,Y).reshape(-1,).tolist() return data_converted[1][0]*coe[0][0],data_converted[1][1]*coe[0][0],data_converted[1][2]*coe[0][0]問題点
作った本人である以上、問題点を上げておかなければなりません。
冒頭のtweetでも見受けられたようにどうしても外れ値が出てきます
どうにもこの外れ値は$\vec{c}$の精度が強く影響しているようですなぜ、このような問題が発生するのかというと同一平面上にあると仮定しているからです。
つまり、$\vec{c}$が少しでもずれると外れ値が出るようです。これに関しては、まだ補正の方法に見当がついていません。
修正次第、加筆します。とまあ、こんな感じのお話でした。
それでは
- 投稿日:2021-01-19T20:59:10+09:00
[python] Redmine APIで情報を読み込む
初めに
プロジェクト管理SWであるRedmineに関して、pythonを用いて情報を読み込む操作をまとめた。
以下の環境で実施した。
os windows python 3.7.1 python-redmine 2.3.0 anaconda 4.8.5 python-redmine
pythonからredmineを操作できるAPI。
チケットやプロジェクトの作成、読み込み、更新、削除が可能。
本記事は読み込みのみを対象とする。インストール
anaconda cloud からインストール。
$ conda install -c auto python-redmine接続
Redmineへ接続するにはRemine側とpython側で設定する必要がある。
Redmine側
管理者権限を有するユーザが、Redmine設定を行う。
[管理] → [設定] → [REST APIによるWebサービスを有効にする] を有効にする。python側
アクセスするユーザの情報(ユーザ名およびパスワード)もしくは、APIアクセスキーを使用する。
from redminelib import Redmine REDMINE_URL = r'http://user/redmine' # redmineのパス REDMINE_KEY = 'xxxxxx' # APIアクセスキー redmine = Redmine(REDMINE_URL, key = REDMINE_KEY)もしくは
from redminelib import Redmine REDMINE_URL = r'http://user/redmine' # redmineのパス USER = 'hoge' # ユーザ名 PASS = 'hogehoge' # パスワード redmine = Redmine(REDMINE_URL, username = USER, password = PASS)チケット情報の取得
redmineのチケット情報を取得するには、get()かall()かfilter()の3通りで取得できる。
特定のチケットのみを取得する場合はredmine.issue.get(チケットID)で取得する。
取得したチケット内の情報は戻り値になっているオブジェクト内にある。
対象とするチケットIDのチケットが存在しない場合は、redmine.exceptions.ResourceNotFoundError例外が発生する。from redminelib import Redmine from redminelib.exceptions import ResourceNotFoundError REDMINE_URL = r'http://user/redmine' # redmineのパス REDMINE_KEY = 'xxxxxx' # APIアクセスキー redmine = Redmine(REDMINE_URL, key = REDMINE_KEY) ticket_id = 4 try: issue = redmine.issue.get(ticket_id) except(ResourceNotFoundError): print('Ticket ID %s not found' % ticket_id)チケット情報
python-redmineに詳細記載されている内容をまとめる。
https://python-redmine.com/resources/issue.html
なお、チケットに該当の情報が登録されていない場合、ISSUEのプロパティ自体が存在していない。
そのため、情報取得に関して該当のプロパティを所持しているか判定を行う必要がある。info = issue.property if hasattr(issue, 'property') else None
Redmine情報 ISSUE内情報 チケットID issue.id チケットURL issue.url トラッカーID issue.tracker.id トラッカー issue.tracker.name 題名 issue.subject 説明 issue.description ステータスID issue.status.id ステータス issue.status.name 優先度ID issue.priority.id 優先度 issue.priority.name 担当者ID issue.assigned_to.id 担当者名 issue.assigned_to.name 親チケットID issue.parent 開始日 issue.start_date 期日 issue.due_date 予定工数 issue.estimated_hours プロジェクトID issue.project.id プロジェクト issue.project.name 作成者ID issue.author.id 作成者名 issue.author.name 進捗率 issue.done_ratio 作成日 issue.created_on 更新日 issue.updated_on 作業時間 issue.spent_hours なお、複数の情報があるものはそれぞれのオブジェクトに各情報が入っている。
ウォッチャー issue.watchers ウォッチャーID .id ウォッチャー名 .name カスタム領域 issue.custom_fields カスタムID .id カスタム名 .name カスタム値 .value 送付ファイル issue.attachments ファイルID .id ファイル名 .filename ファイル説明 .description ファイルサイズ .filesize ファイル著者 .author ファイルURL .content_url ファイル作成日 .created_on コミットログ issue.changesets 子チケット issue.children 子チケットID .id 子チケットタイトル .subject 関連するチケット issue.relations 関連ID .id 関連する自分のID .issue_id 関連する相手のID .issue_to_id 関連のタイプ .relation_type 参考
https://qiita.com/mima_ita/items/1a939db423d8ee295c85
https://python-redmine.com/resources/issue.html
- 投稿日:2021-01-19T20:44:49+09:00
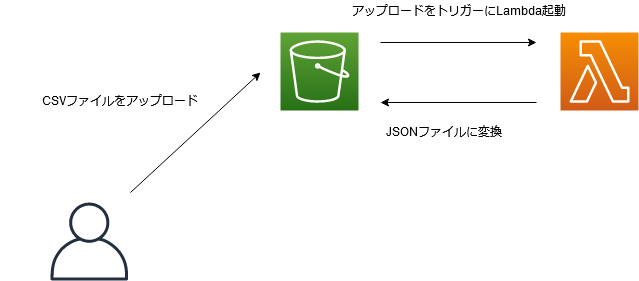
【Python】S3にアップロードされたCSVファイルをAWS LambdaでJSONファイルに変換する
本記事で目指す構成
S3にCSVファイルをアップロード → Lambda起動 → JSONファイルに変換
使用技術
言語: Python 3.8
AWS: S3、Lambda下準備
まず最初にIAMユーザーやIAMロール、S3バケットなどの準備を行います。
IAMユーザーを作成
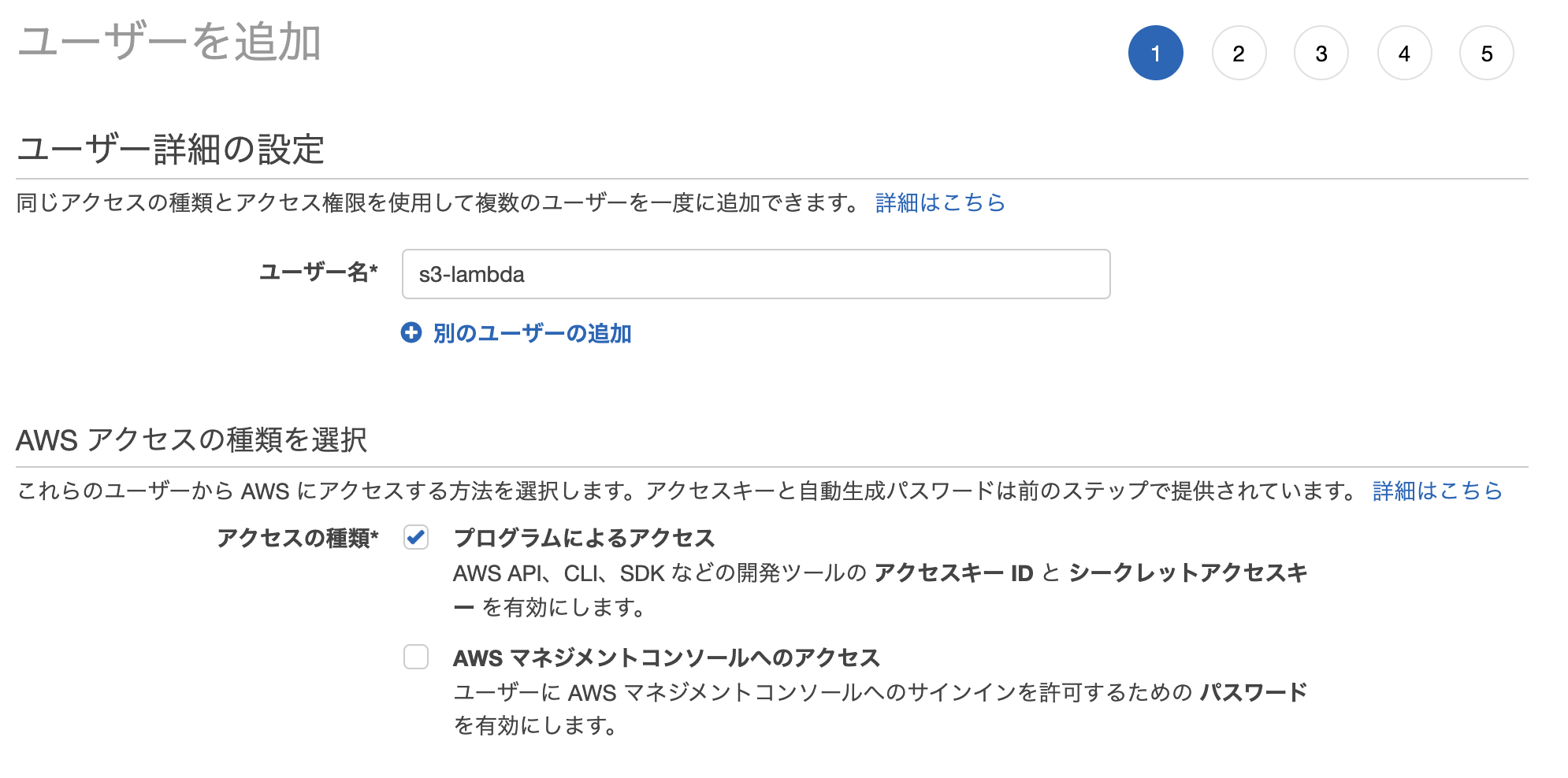
今回はAWS CLIを使って作業していくので、専用のIAMユーザーを作成します。
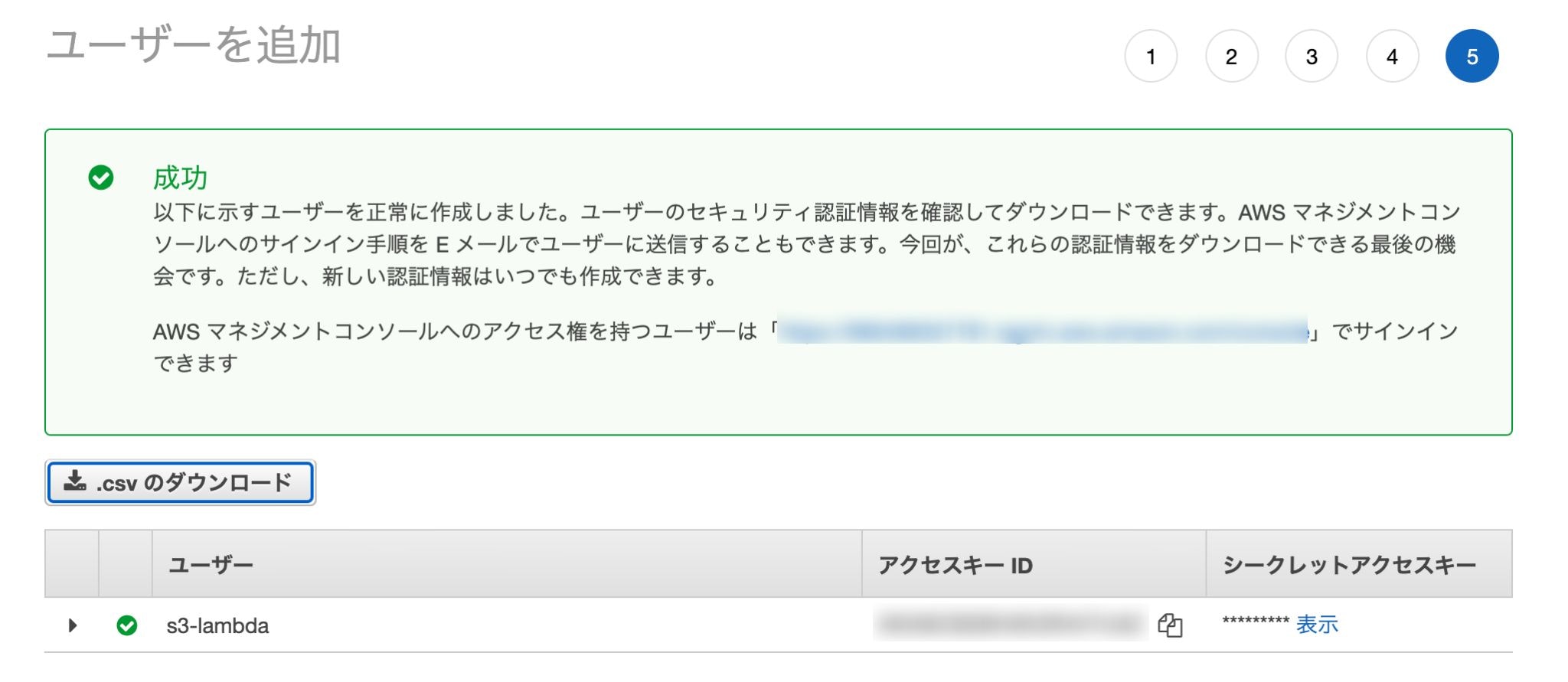
「IAM」→「ユーザー」→「ユーザーを追加」
ユーザー名: 任意
アクセスの種類: 「プログラムによるアクセス」にチェック
今回はS3バケットの作成、ファイルのアップロードや削除などS3に関する基本的な動作を行いたいので「AmazonS3FullAccess」ポリシーをアタッチしておきます。
作成完了すると
- アクセスキーID
- シークレットアクセスキー
の2つが発行されるのでメモに控えておきましょう。
$ aws configure --profile s3-lambda AWS Access Key ID [None]: ***************** # 自分のアクセスキーIDを入力 AWS Secret Access Key [None]: ************************** # 自分のシークレットアクセスキーを入力 Default region name [None]: ap-northeast-1 Default output format [None]: jsonターミナルで上記コマンドを打つと対話形式で情報を聞かれるので、指示に従いながら入力していきます。
S3バケットを作成
先ほど設定したAWS CLIを使ってちゃちゃっと作成してしまいます。
$ aws --profile s3-lambda s3 mb s3://test-bucket-for-converting-csv-to-json-with-lambda make_bucket: test-bucket-for-converting-csv-to-json-with-lambdaバケット名は全世界においてユニークでないといけないので、各自オリジナルのものを考えてください。
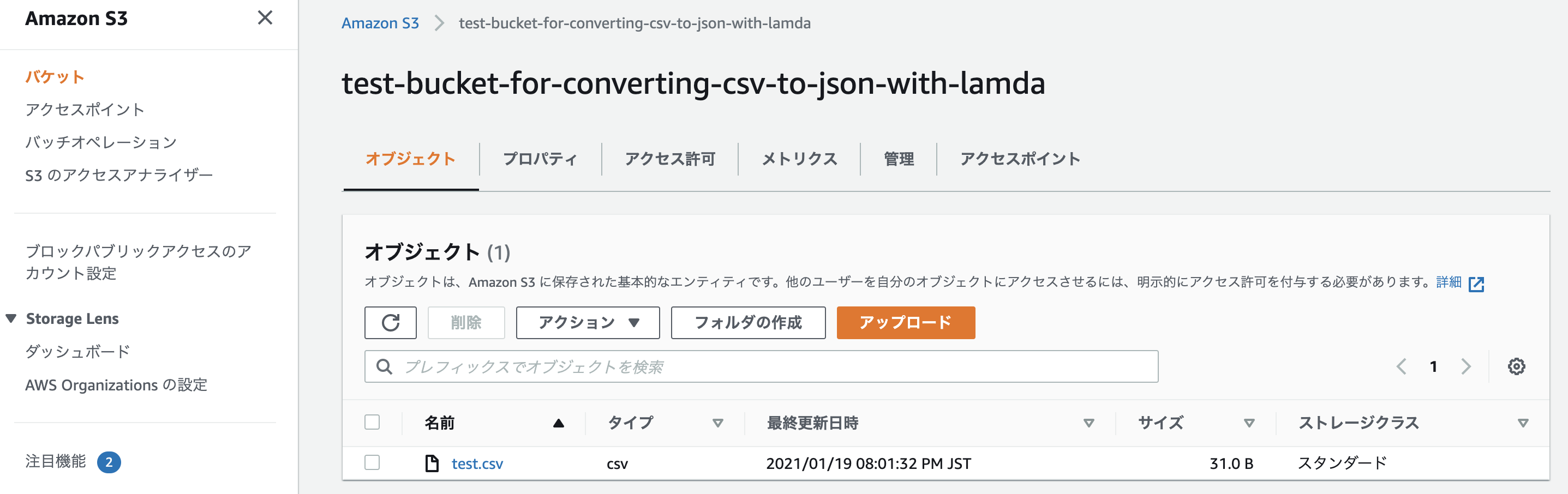
テスト用CSVファイルを作成して試しにアップロードしてみる
$ mkdir ./workspace/ $ cat > ./workspace/test.csv << EOF heredoc> Name,Age,Country heredoc> Taro,20,Japan heredoc> EOF$ aws --profile s3-lambda s3 sync ./workspace s3://test-bucket-for-converting-csv-to-json-with-lambda upload: ./test.csv to s3://test-bucket-for-converting-csv-to-json-with-lambda/test.csv
ちゃんとバケット内に入っていれば成功。
$ aws --profile s3-lambda s3 rm s3://test-bucket-for-converting-csv-to-json-with-lambda/test.csv動作確認が済んだので消しておきます。
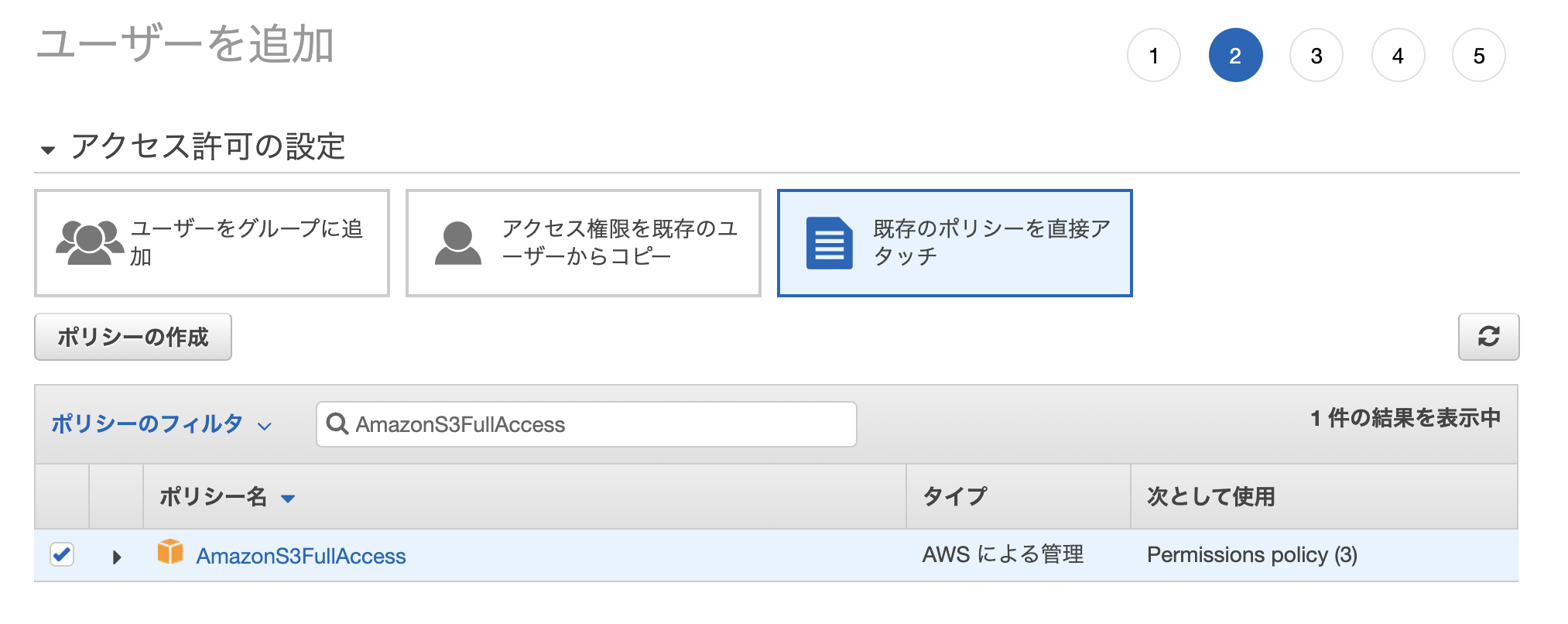
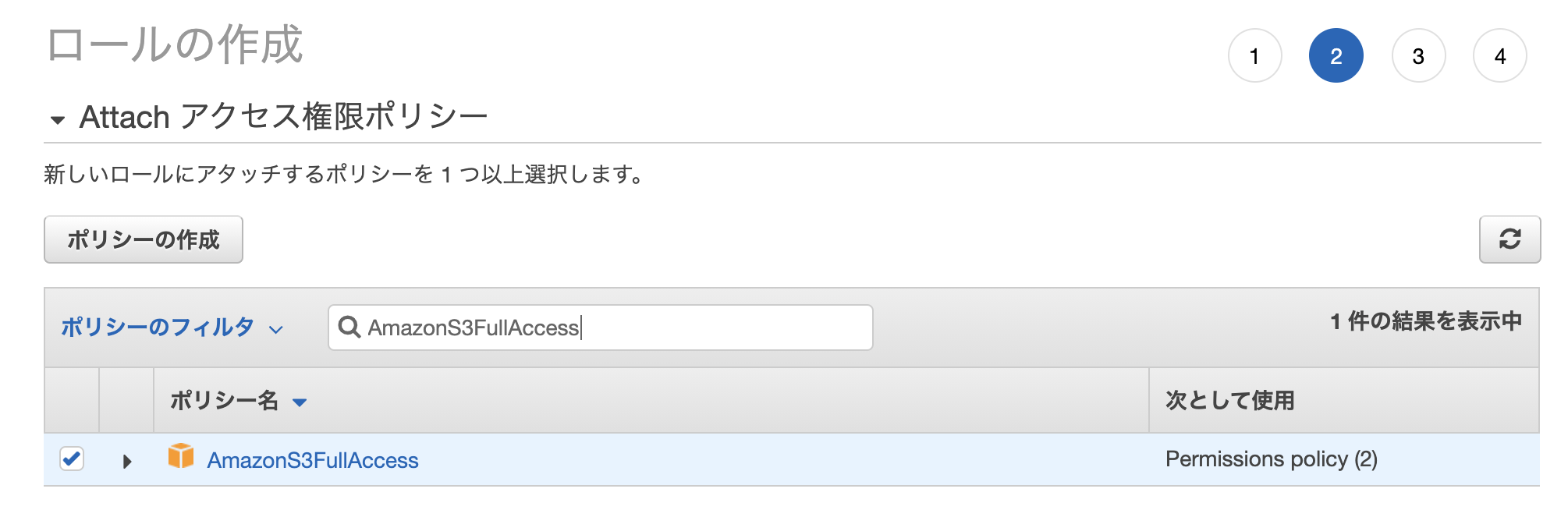
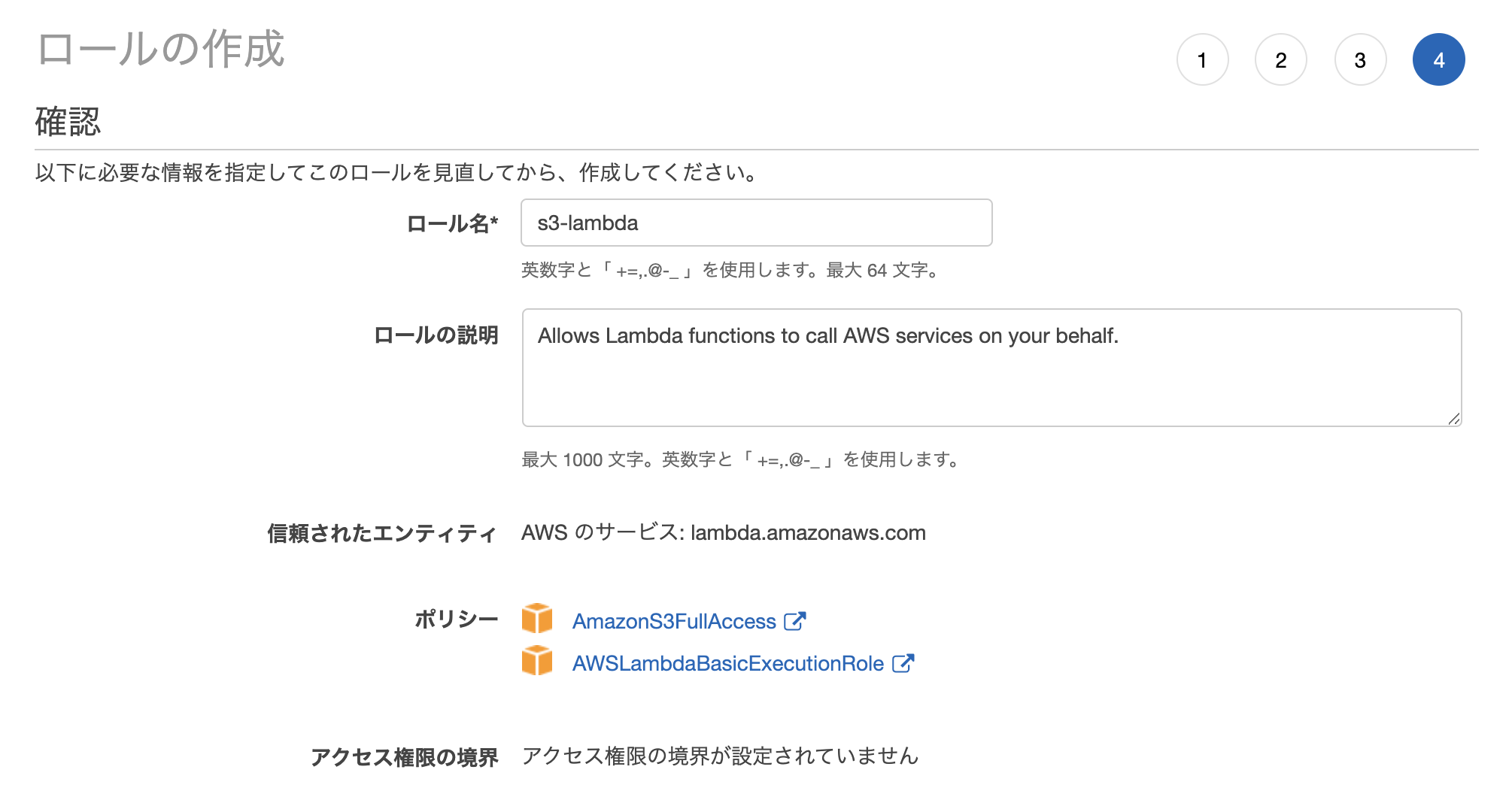
IAMロールを作成
Lambdaに割り当てる用のIAMロールを作成します。
「IAM」→「ロール」→「ロールの作成」
- AmazonS3FullAccess
- AWSLambdaBasicExecutionRole
今回は上記2つのポリシーがあればOK。
適当に名前や説明文を入力して作成してください。
実装
下準備が終わったのでいよいよここから実装を行っていきます。
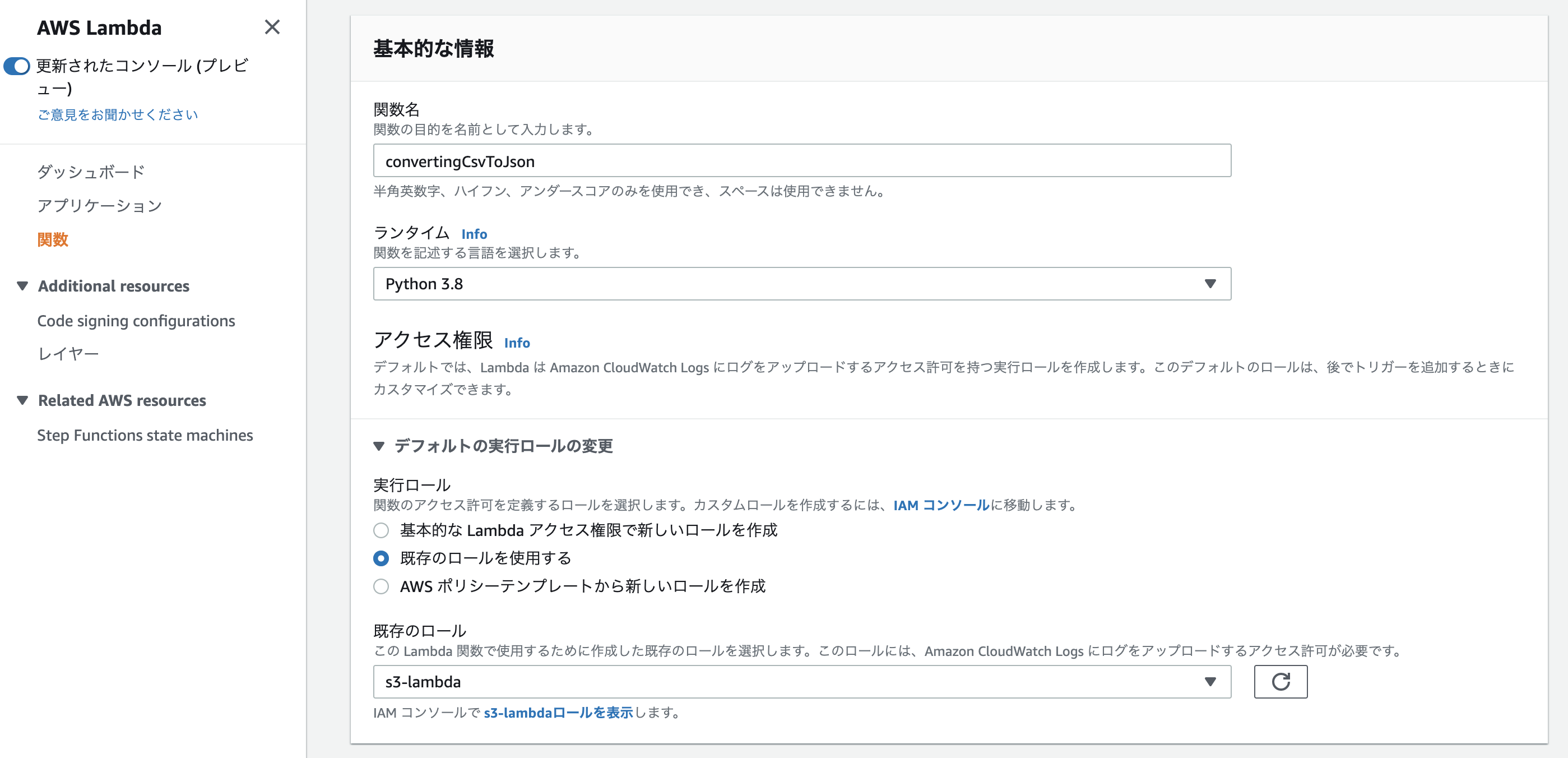
Lambda関数を作成
「Lambda」→「関数の作成」
- オプション: 一から作成
- 関数名: 任意
- ランタイム: Python 3.8
- 実行ロール: 既存のロール(先ほど作した「s3-lambda」)
- その他: デフォルトでOK
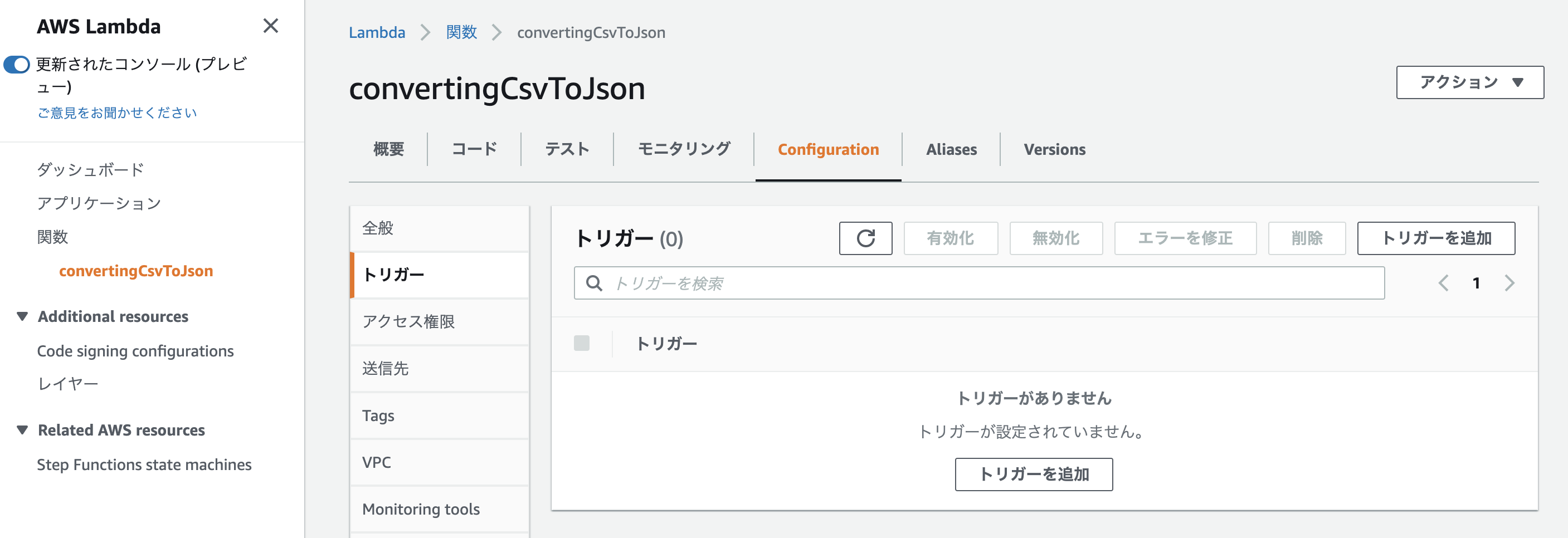
トリガーを作成
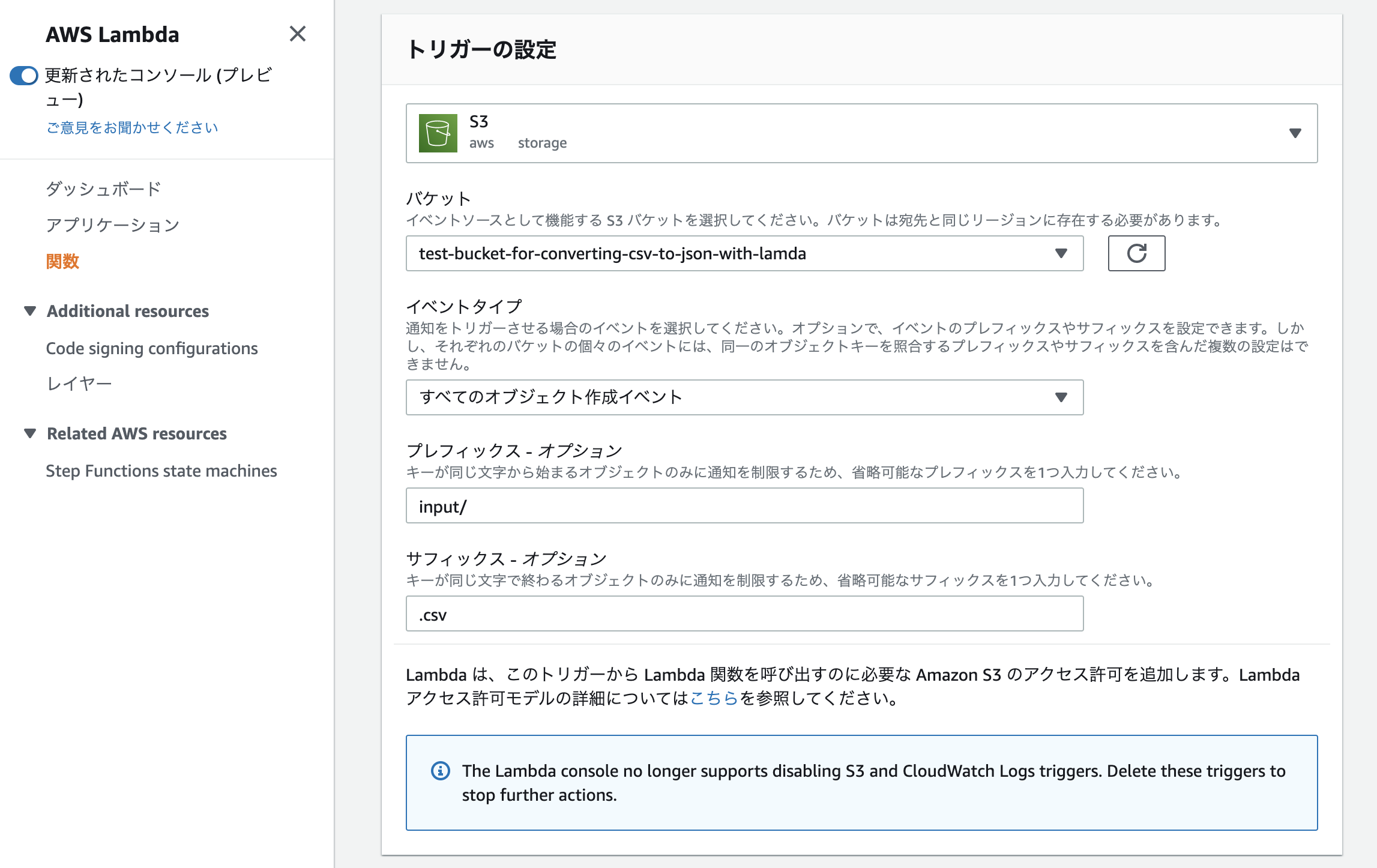
どんなイベントが発生した際にLambdaを起動させるのかを決めるために、「Configuration」→「トリガーを追加」へ進んでください。
必要事項を記入していきます。
- トリガー: S3
- バケット: 先ほど作成したバケット名
- イベントタイプ: すべてのオブジェクト作成イベント
- プレフィックス: input/
- サフィックス: .csv
今回は「input」というフォルダ配下に「.csv」ファイルがアップロードされた事を検知した後、Lambdaを起動させる事を想定しています。
コード
import json import csv import boto3 import os from datetime import datetime, timezone, timedelta s3 = boto3.client('s3') def lambda_handler(event, context): json_data = [] # TZを日本に変更 JST = timezone(timedelta(hours=+9), 'JST') timestamp = datetime.now(JST).strftime('%Y%m%d%H%M%S') # 一時的な読み書き用ファイル(後で消す) tmp_csv = '/tmp/test_{ts}.csv'.format(ts=timestamp) tmp_json = '/tmp/test_{ts}.json'.format(ts=timestamp) # 最終的な出力ファイル outputted_json = 'output/test_{ts}.json'.format(ts=timestamp) for record in event['Records']: bucket_name = record['s3']['bucket']['name'] key_name = record['s3']['object']['key'] s3_object = s3.get_object(Bucket=bucket_name, Key=key_name) data = s3_object['Body'].read() contents = data.decode('utf-8') try: with open(tmp_csv, 'a') as csv_data: csv_data.write(contents) with open(tmp_csv) as csv_data: csv_reader = csv.DictReader(csv_data) for csv_row in csv_reader: json_data.append(csv_row) with open(tmp_json, 'w') as json_file: json_file.write(json.dumps(json_data)) with open(tmp_json, 'r') as json_file_contents: response = s3.put_object(Bucket=bucket_name, Key=outputted_json, Body=json_file_contents.read()) os.remove(tmp_csv) os.remove(tmp_json) except Exception as e: print(e) print('Error getting object {} from bucket {}. Make sure they exist and your bucket is in the same region as this function.'.format(key, bucket)) raise eこれでS3バケット名「test-bucket-for-converting-csv-to-json-with-lambda/input/」にCSVファイルがアップロードされると「test-bucket-for-converting-csv-to-json-with-lambda/output/」にJSON形式に変換されたファイルが吐き出されるようになります。
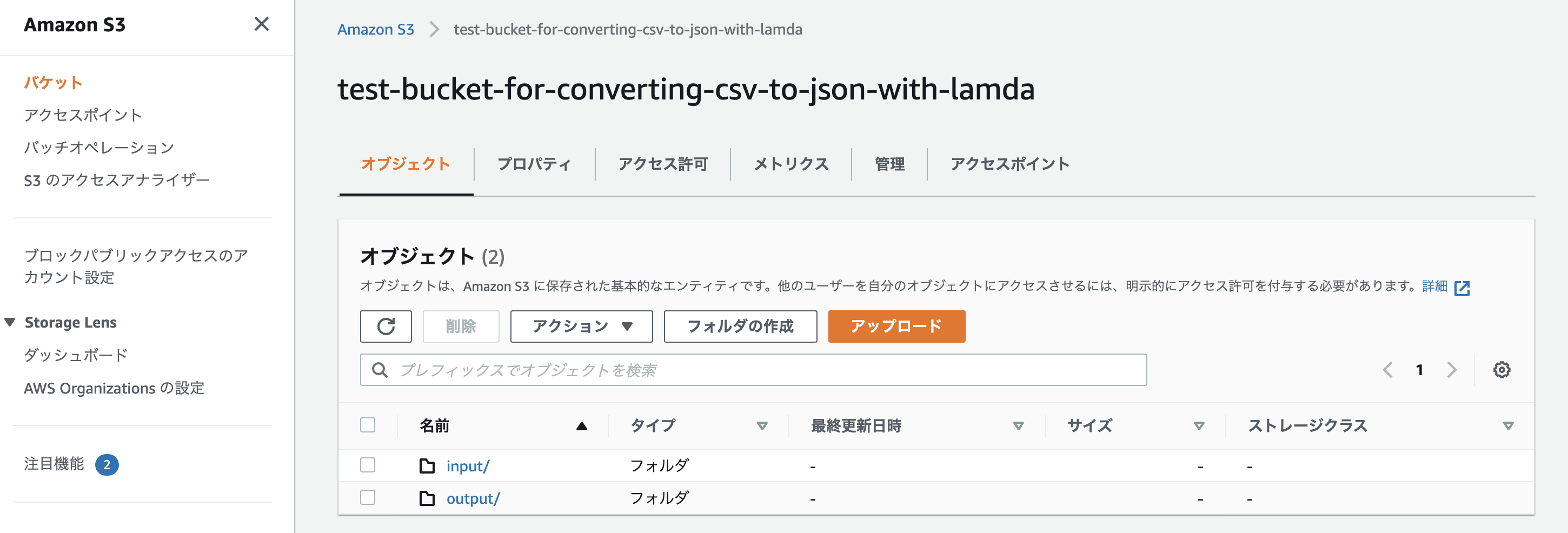
$ aws --profile s3-lambda s3 sync ./workspace s3://test-bucket-for-converting-csv-to-json-with-lambda/input upload: ./test.csv to s3://test-bucket-for-converting-csv-to-json-with-lambda/input/test.csv再度、AWS CLIでファイルをアップロードしてみましょう。
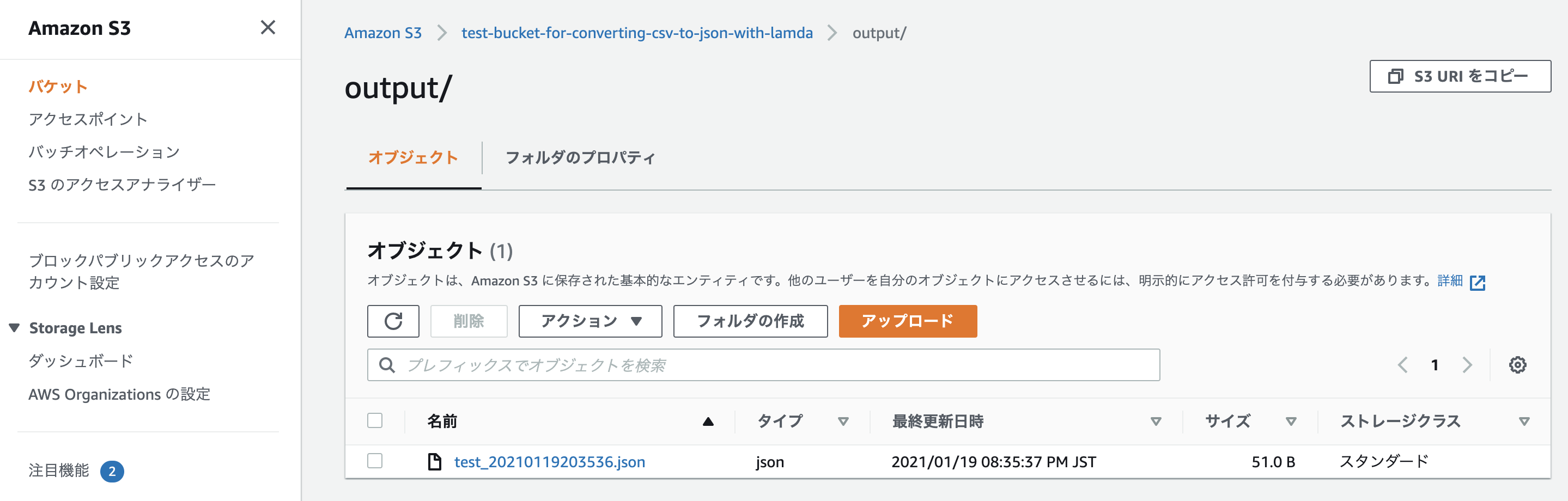
バケットを確認すると「output」というフォルダが新たに作成され、中にJSONファイルが入っているはず。
[ { "Name": "Taro", "Age": "20", "Country": "Japan" } ]中身を確認し、しっかりとJSON形式に変換されていれば完了です。
あとがき
お疲れ様でした。今回はCSV→JSONへの変換でしたが、同じ要領で他のパターンも色々実現できると思います。
少しでも参考になれば幸いです。
参照記事
- 投稿日:2021-01-19T20:23:14+09:00
初心者がpythonの変数の基本で知ったこと
記事のようなものを書くのが初めてなので見づらかったり、わかりにくかったりするかとと思いますが、精進していきますのでご了承ください
pythonの変数の基本で知ったこと
データの型の宣言
javaと違って
int num = 1やString str = "aaa"みたいにせずにnum = 1str = "aaa"で変数の定義が可能data = 1 data ="aaa" print(data)上記のような整数を変数に入れた後に文字列を入れても問題なく動作する。
データの取り扱いに関しては気を付けないと何となくで動作してしまいそうなので気を付ける必要がある??型の確認方法
データの型を確認する方法にtype()関数が存在する
num = 1 num2 = 1.5 str ="aaa" listData = [0,1,2] print(type(num)) print(type(num2)) print(type(str)) print(type(listData)) #=> <class 'int'> #=> <class 'float'> #=> <class 'str'> #=> <class 'list'>追記:データの型の詳しい内容はコメントして頂いた内容を含め、java,python両方とも自分なりに調べてみたいと思います。
- 投稿日:2021-01-19T19:56:35+09:00
理系用グラフ作成プログラム ~python~
1. はじめに
理系用にグラフ作成のあれこれをまとめる。Spyder上でプログラムを実装した。個人的にSpyderが変数の中身を見やすかったりするのでおすすめしたい。
2. Excelからのデータ所得
任意のファイル(今回はtest.xlse)からpythonにデータをロードさせる。
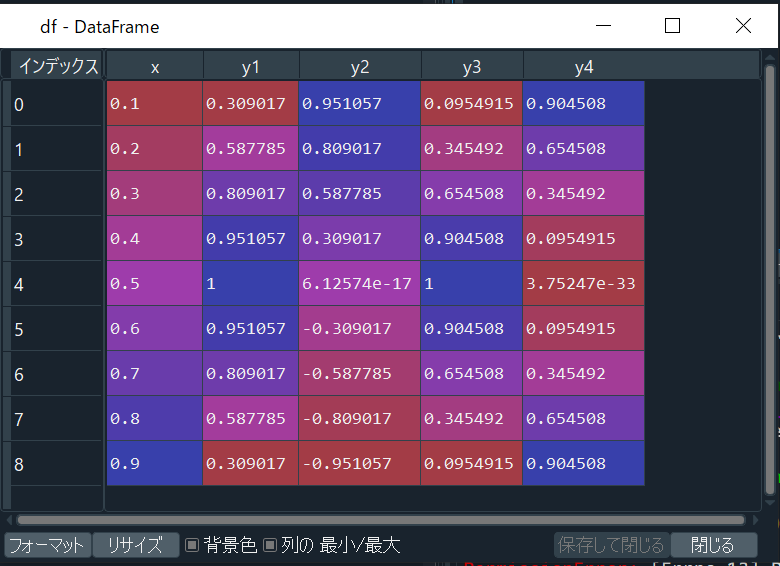
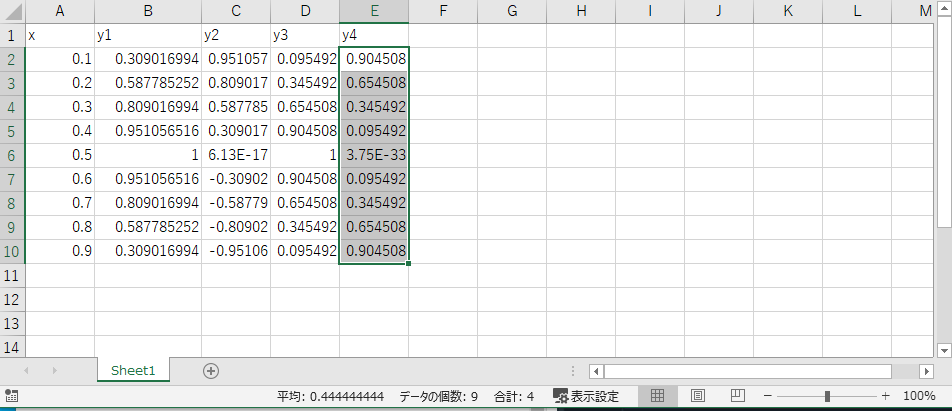
#ライブラリの設定 import pandas as pd #データロード df = pd.read_excel("test.xlsx")これでExcelからデータを所得できる。df内はこのようになっている。
また元ファイルはこうなっている。
このとき、同じファイル内に両ファイルを置いておくことに注意する。(両ファイルを同じところにおかなくてもディレクトリを指定すれば可能)
3. グラフ化
3.1グラフの基本設定
一般的な理系のグラフを作成するために以下のようにグラフ全体の設定をしておく。
import matplotlib.pyplot as plt #フォントをTimes New Romanに plt.rcParams['font.family'] = 'Times New Roman' #フォントサイズを20に plt.rcParams["font.size"] = 20 #グラフの向きを内側に plt.rcParams['xtick.direction'] = 'in' plt.rcParams['ytick.direction'] = 'in'また、
plt.savefig("任意の名前.png")で同じファイルに保存できる。
3.2 グラフ一つ
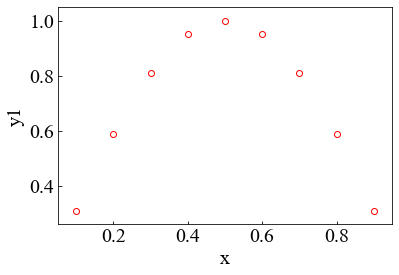
x-y1でのグラフを作成する。
#データのインデックス x = "x" y = ["y"+str(i+1) for i in range(4)] #y = [y1,y2,y3,y4]になる #プロット plt.scatter(df[x],df[y[0]],c="white",linewidths="1",edgecolors="red") #plt.scatter(df.iloc[:,0],df.iloc[:,1],c="white",linewidths="1",edgecolors="red")でも可能 #df.ilocはdf.iloc[行数,列数]で指定する。 plt.xlabel("x") plt.ylabel("y1")plt.scatterではなく、plt.plot(df[x],df[y[0]])で折れ線グラフにできるのでデータ数が多いときはこちらを使う。これらのデータの描写方法を変えたいときはplt.scatterかplt.plotでggると細かく変えられる。
・logスケールで表したいとき
matplotlib ログスケール表示とグリッド表示
3.3 複数のグラフ
#(a)~(z)の名前リスト abc = ["(" + chr(ord('a') + i) + ")" for i in range(26)] #全体のグラフの大きさ plt.figure(figsize = (12,7)) for i in range(len(y)): #中のグラフの位置決め #subplot(縦に何個並べるか,横に何個並べるか,左上から1.2...としたときの位置) plt.subplot(2,2,i+1) #左上に(a)...を示す plt.title(abc[i],loc="left") plt.scatter(df[x],df[y[i]],c="white",linewidths="1",edgecolors="red") #plt.scatter(df.iloc[:,0],df.iloc[:,i+1],c="white",linewidths="1",edgecolors="red")でも可能 plt.xlabel("x") plt.ylabel(y[i]) #万能コマンド 文字がかぶらないようにしてくれる plt.tight_layout()
3.4 複数のデータを同じところに
#色の指定 color = ["red","blue","green","purple","aqua"] plt.figure() for i in range(len(y)): plt.plot(df[x],df[y[i]],c=color[i],label = y[i]) #plt.plot(df.iloc[:,0],df.iloc[:,i+1],c=color[i],label = y[i])でも可能 plt.ylabel(y[i]) plt.xlabel(x) plt.legend(loc = "best",fontsize = 15)
3.5 豆知識
グラフの軸上に点をプロットする
plt.scatter(x,y,clip_on=False)4 全部のコード
#ライブラリの設定 import pandas as pd import matplotlib.pyplot as plt #データロード df = pd.read_excel("test.xlsx") #前設定 plt.rcParams['font.family'] = 'Times New Roman' #フォント一括 plt.rcParams["font.size"] = 20 plt.rcParams['xtick.direction'] = 'in' plt.rcParams['ytick.direction'] = 'in' #データのインデックス x = "x" y = ["y"+str(i+1) for i in range(4)] #プロット plt.scatter(df[x],df[y[0]],c="white",linewidths="1",edgecolors="red") plt.xlabel("x") plt.ylabel("y1") #(a)~(z)の名前リスト abc = ["(" + chr(ord('a') + i) + ")" for i in range(26)] #全体のグラフの大きさ plt.figure(figsize = (12,7)) for i in range(len(y)): #中のグラフの位置決め #subplot(縦に何個並べるか,横に何個並べるか,左上から1.2...としたときの位置) plt.subplot(2,2,i+1) #左上に(a)...を示す plt.title(abc[i],loc="left") plt.scatter(df[x],df[y[i]],c="white",linewidths="1",edgecolors="red") plt.xlabel("x") plt.ylabel(y[i]) #万能コマンド 文字がかぶらないようにしてくれる plt.tight_layout() #色の指定 color = ["red","blue","green","purple","aqua"] plt.figure() for i in range(len(y)): plt.plot(df[x],df[y[i]],c=color[i],label = y[i]) plt.ylabel("y") plt.xlabel(x) plt.legend(loc = "best",fontsize = 15)
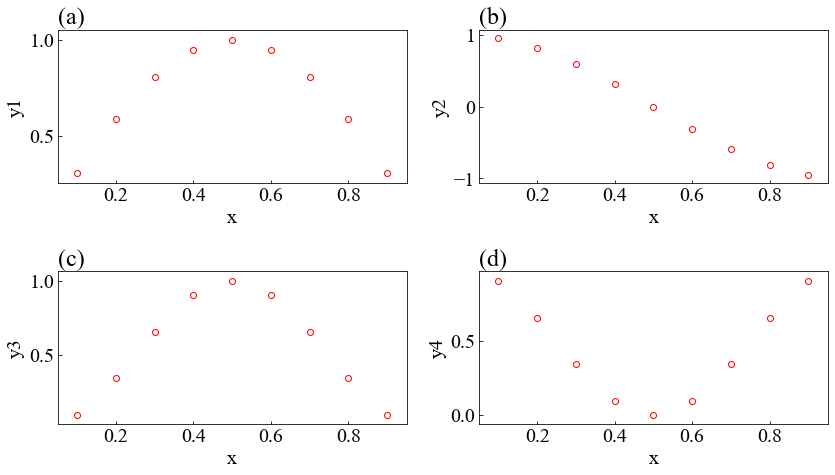
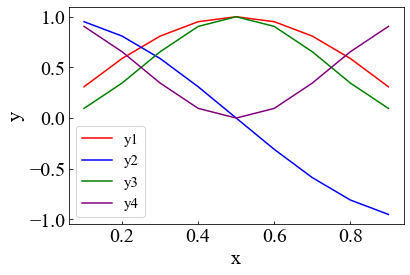
- 投稿日:2021-01-19T19:20:08+09:00
Redmine チケット及び期限切れチケットをpython-redmineとRESTの両方で
Redmineのチケット、期限切れチケットの一覧を
DataFrameで還元するコード。テストコードは引き続き書き中。
dataframe→Mardownテーブル化→Chat投入の流れで使用します。
Markdownテーブル化、チャット投入ライブラリは
既に作ってあります。
#!/opt/anaconda3/bin/python3 # -*- coding: utf-8 -*- """Redmineチケット状態を管理する チケット情報を得て状況分析を行う Todo: * まだRedmineとRocketChatのみ。他のOSSに対しても同様に作る """ ################################################ # library ################################################ import datetime import redminelib import requests import pandas as pd import sys from pprint import pprint from redminelib import Redmine # 個別ライブラリLoad ################################################ # 独自例外定義 ################################################ #class MaxRetryError(Exception): # pass # ################################################ # 情報定義 ################################################ # ## Redmine Instance #HOST = "http://xxxxxxxxxxxxxxxxxxxxxxxxxx:3100/" #API_KEY = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx47ac" # ## 抽出対象 #PROJECT_ID = 'wbs-kaisui' #PROJECT_NAME = '個別WBS(開発推進)' #TRACKER_NAME ='やること' # ## Dataframe columns定義 #COLUMNS = ['Project','Tracker','Sprint','親チケットID','チケットID','TicketTitle','担当', 'Status','開始日','期限'] # ## 探索条件 #QUERY = '開始日 <= @TODAY and 期限 < @TODAY' # ## Sort条件 #SORT_KEY = ['担当','期限'] # ################################################ # RedmineTicketManager ################################################ class RedmineTicketManager(): """Redmineチケット管理Class Attributes: API_KEY (int) : Redmineのadmin API key HOST (bool) : Redmineのホスト """ def __init__(self, HOST, API_KEY): """Redmineインスタンス生成 API_KEY,HOSTからRedmineインスタンスを返す Args: HOST (str): Redmine Host API_KEY (str): adminに応じたAPI_KEY Returns: Raises: TypeError: 引数型の不備 Exception: Redmineインスタンス生成不備 Examples: >>> redmine = RedmineUserManager(HOST, API_KEY) Note: Redmineのグループは事前に存在する必要があります。 新しいグループが記載されたとしても自動でRedmine上で作成しません。 __init__ではboolを返してはならないので留意 """ # 引数チェック 型 if not isinstance(HOST, str): print(f'引数:HOSTの型が正しくありません str <-> {type(HOST)}') raise TypeError if not isinstance(API_KEY, str): print(f'引数:API_KEYの型が正しくありません str <-> {type(API_KEY)}') raise TypeError #TODO 引数チェク追加 # Redmineインスタンス生成(self.redmine) try: self.redmine = Redmine(HOST, key=API_KEY) except exception as e: print(f'Redmine Instance生成に失敗しました') print(f'エラー詳細:{e}') else: if not isinstance(self.redmine, redminelib.Redmine): print(f'Redmine Instance生成に失敗しました') raise Exception ######################################################## # 期限切れチケット探索処理 ######################################################## def createOverdueTicket(self, PROJECT_ID, TRACKER_NAME): '''期限切れチケットを探索する プロジェクト、トラッカーを指定して期限超過チケットを探索する。 Args: PROJECT_ID : str RedmineプロジェクトID(プロジェクト名ではない) TRACKER_NAME: str Redmine検索対象とするトラッカー名 Returns: プロジェクト、トラッカー上限にヒットするチケット全量: DataFrame プロジェクト、トラッカー条件にヒットし、かつ期限超過チケット: DataFrame Raises: TypeError: 引数型の不備 Exception: チケット探索時の例外 Examples: >>> RTM = RedmineTicketManager(HOST, API_KEY) >>> df, df_overdue = RTM.createOverdueTicket(PROJECT_ID, TRACKER_NAME) Note: ''' # Dataframe columns定義 COLUMNS = ['Project','Tracker','Sprint','親チケットID','チケットID','TicketTitle','担当', 'Status','開始日','期限'] # 探索条件 QUERY = '開始日 <= @TODAY and 期限 < @TODAY' # Sort条件 SORT_KEY = ['担当','期限'] # 今日日付生成 TODAY = datetime.date.today() pprint(f'判定基準日: {TODAY}') INIT_DATE = datetime.date(1900, 1, 1) pprint(f'始まりの日: {INIT_DATE}') print('-'*80) print(f'Redmineチケットを探索します') try: # 管理者権限で全てのチケットを取得 tickets=self.redmine.issue.filter( project_id=PROJECT_ID, tracker_name=TRACKER_NAME, ) except Exception as e: print(f'チケット取得に失敗しました:{PROJECT_ID} {TRACKER_NAME}') print(f'エラー詳細:{e}') print() else: # チケット遅延判定処理、データ作成 # 仮の入れ物を用意 _list = [] # チケット成形処理 for ticket in tickets: # ticketインスタンスから情報取得 projectName = ticket.project.name id = ticket.id subject = ticket.subject authorName = ticket.author.name authorID = ticket.author.id status = ticket.status.name tracker = ticket.tracker.name fixed_version = ticket.fixed_version.name # 担当者が設定されていない場合は未設定と表示 try: assigned_to = ticket.assigned_to.name except: assigned_to = "未設定" # 開始日が設定されていない場合は始まりの日を設定 try: startDate = ticket.start_date except: startDate = INIT_DATE # 期日が設定されていない場合は始まりの日を設定 try: dueDate = ticket.due_date except: dueDate = INIT_DATE # 親チケットが設定されていいない場合は0を設定 try: parent = ticket.parent except: parent = 0 # 蓄積 _list.append([projectName, tracker, fixed_version, parent, id, subject, assigned_to, status, startDate, dueDate]) print(f'チケット抽出が完了しました') # DataFrame化 df = pd.DataFrame(_list) df.columns = COLUMNS # 遅延チケット抽出 # 開始日が今日以前、期限が本日超過しているものを対象とする df_overdue = df.query(QUERY).sort_values(SORT_KEY).reset_index(drop=True) print(f'期限超過Redmineチケットを抽出しました') print(f'期限超過チケット件数: {len(df_overdue)}') return df ,df_overdue ######################################################## # 期限切れチケット探索処理 by REST ######################################################## def createOverdueTicketByREST(self, RESTAPI, HEADERS, PROJECT_ID, TRACKER_ID): '''期限切れチケットを探索する By REST プロジェクト、トラッカーを指定して期限超過チケットを探索する。 python_redmineを使用せず直接RESTを使って情報取得する。 Args: PROJECT_ID : str RedmineプロジェクトID(プロジェクト名ではない) TRACKER_ID: str Redmine検索対象とするトラッカーID(トラッカー名ではない) Returns: プロジェクト、トラッカー上限にヒットするチケット全量: DataFrame プロジェクト、トラッカー条件にヒットし、かつ期限超過チケット: DataFrame Raises: TypeError: 引数型の不備 Exception: チケット探索時の例外 Examples: >>> RTM = RedmineTicketManagerByREST(HOST, API_KEY) >>> df, df_overdue = RTM.createOverdueTicketByREST(PROJECT_ID, TRACKER_ID) Note: NAMEなのかIDなのか、使い分けがめんどい感じがある。。。 ''' # request parameter生成 #URL = f'http://192.168.10.104:3100' #API = f'{URL}/projects/{PROJECT_ID}/issues.json?tracker_id={TRACKER_ID}' #HEADERS = { 'Content-Type': 'application/json', 'X-Redmine-API-Key': '864b3f0933e8084295d47380bf07a168ba2947ac'} # 今日日付生成 TODAY = datetime.date.today() pprint(f'判定基準日: {TODAY}') # Dataframe columns定義 COLUMNS = ['Project','Tracker','Sprint','親チケットID','チケットID','TicketTitle','担当', 'Status','開始日','期限'] # 探索条件 QUERY = '開始日 <= @TODAY and 期限 < @TODAY' # Sort条件 SORT_KEY = ['担当','期限'] # 探索処理実行 ## 入れ物を用意 _list = [] # 探索実施 try: response = requests.get(RESTAPI, headers=HEADERS) except Exception as e: print(f'Redmineチケット探索に失敗しました') print(f'{e}') else: # 結果加工 for _ in response.json()['issues']: # 親と担当者はデータとして存在しないケースあり # try〜catchで判定する必要がある try: parent = _['parent']['id'] except: parent = 0 try: assigned_to = _['assigned_to']['name'] except: assigned_to = "None" # 開始、期限は存在する。 # 設定がない場合は Noneが入っている if _['start_date'] != None: startDate = _['start_date'] else: startDate = '1900-01-01' if _['due_date'] != None: dueDate = _['due_date'] else: dueDate = '1900-01-01' # データ蓄積 _list.append([_['project']['name'], _['tracker']['name'], _['fixed_version']['name'], parent, _['id'], _['description'], assigned_to, _['status']['name'], startDate, dueDate, ]) # DataFrameに変換して抽出処理実施 df = pd.DataFrame(_list) df.columns = COLUMNS df['開始日'] = pd.to_datetime(df['開始日']) df['期限'] = pd.to_datetime(df['期限']) # 遅延チケット抽出 # 開始日が今日以前、期限が本日超過しているものを対象とする df_overdue = df.query(QUERY).sort_values(SORT_KEY).reset_index(drop=True) print(f'期限超過Redmineチケットを抽出しました') print(f'期限超過チケット件数: {len(df_overdue)}') return df ,df_overdue
- 投稿日:2021-01-19T18:35:29+09:00
Python 時間帯と実行頻度を指定してスケジュールを実行する方法
指定した時間で実施する、もしくは指定した間隔で実行する説明が多いですが、
時間帯と実行頻度を同時に指定する事例が見当たらなかったため、以下の方法で実装しました。
もっと良い方法があれば、ご教示いただけますと幸いです。import datetime import time import schedule # 開始のジョブ def startJob(): # 10分毎に実施するジョブ登録 schedule.every(10).minutes.do(runJob) print('startJob:' + str(datetime.datetime.now())) # 実際に実行したいメイン処理 def runJob(): print('runJob:' + str(datetime.datetime.now())) # 終了のジョブ def endJob(): print('endJob:' + str(datetime.datetime.now())) for jobV in schedule.jobs: if 'runJob()' in str(jobV): # メイン処理のジョブを削除 schedule.cancel_job(jobV) break # 開始するジョブと終了するジョブを定義する schedule.every().day.at("12:00").do(startJob) schedule.every().day.at("13:00").do(endJob) while True: schedule.run_pending() time.sleep(1)
- 投稿日:2021-01-19T18:09:25+09:00
pandasひらがな→カタカナ変換
pandasを利用してCSVを編集する場合、特定の列全体の値を変換したいです。
ネット上で調べて半角文字→全角文字へ変更する処理がありますが、ひらがな→カタカナ変換する処理が見つかりませんでした。
changeKanaのメソッドを作って、maketrans経由でchangeKanaを呼ぶように実装しました。df = pandas.read_csv(file, encoding='cp932', engine='python', dtype=object) 半角→全角 df[列名] = df[列名].str.translate(str.maketrans({chr(0x0021 + i): chr(0xFF01 + i) for i in range(94)})) ひらがな→カタカナ df[列名] = df[列名].str.translate(str.maketrans({chr(x):changeKana(chr(x)) for x in range(12353, 12436)})) # パターン1:半角→全角 # パターン2:ひらがな→カタカナ def changeKana(in_Word): # 本当は半角→全角の変更は不要 changeWord = jaconv.h2z(in_Word) changeWord = jaconv.hira2kata(changeWord) return changeWord
- 投稿日:2021-01-19T18:00:12+09:00
社会人がサブスキルとしてプログラミングを学ぶならpython一択の理由
はじめに
私は、プログラミングで生計を立てようとは思っていません。
電気系とはあまり関係の無い仕事に就いています。
ある程度、本職のスキルを極めたら サブスキルを学ぶ事で
より幅を持たせることができるのではないだろうか?そう考えると プログラミングは サブスキルとしても
とても有用な技能の一つとです。
なぜなら、現代においては ほとんどの仕事でコンピュータと
縁があるからです。しかし、プログラミングを始めると言っても プログラミング言語は
たくさんあります。それぞれ文法も単語もバラバラなので どの言語を
習得するか非常に迷います。
特に社会人には時間がありません。私はpythonを選びました。
同じような悩みを持つ人の参考になればいいなと思って 記事にしました。※ 一部、知識が浅く間違った表現があるかもしれません。
私の主観に基づいた判断・感想で書きました。
「違う!」という方がおられましたら、ご容赦ください。前提となる条件
社会人がサブスキルとして 趣味と実益を兼ねて学ぶので、
以下の条件を定義した。会社でも家でも使えるって条件です。一般的に会社に普及しているWindowsのアプリが作成できる。
出来れば、MACでも動く事もできる。
ipad/iphoneやandroidでも 動く。
Linuxは、趣味や専門的な部署でなければあまり無さそうなので対象外。
(個人的には趣味でいじってみたいけど。。。)office製品の操作やRPA的な事もできる。
gameも簡単なものなら作れる。と、考えました。
いろいろなプログラミング言語の長所・短所
python
良い点:今流行っている。(流行っているという事は皆がいろいろな記事を出してくれるという事)
可読性が高く、学習コストが低い。
ライブラリが豊富で、エクセルや他のソフトとも親和性が高い。
Windows・MAC・ipad/iphone・androidのどれでも動く。
商業利用でも無料。
悪い点:動作が遅い傾向がある。VisialBasic
良い点:Excel等と親和性が高い。
Excelに付随しているので、インストールとか不要。すぐに始められる。
学習コストが低め。
本や記事が豊富。
商業利用でも無料。
悪い点:動作が遅い傾向がある。
Excel等office製品以外との連携が苦手。C言語
良い点:何でもできる。
悪い点:学習コストが極めて高い。
開発ツールが有料。(VSC等無料ツールが使えるようです。)
基本的にどのOSでも動くが、os毎にプログラムを変える必要がある。Swift
良い点:新しい言語なので、機能が豊富。
学習コストはそこそこ高い。
悪い点:基本的にapple用。Windowsアプリも2020/9月から開発可能になったみたい。
ただ、新しい分 Windowsアプリの制作に関するドキュメントが少なそう。
androidでは動作するのか 不明。JavaScript
良い点:習得難易度が低め。
web作成には欠かせない。
どんなosでも動く。ブラウザ無くても、サーバで動くものもあるようです。
商業利用でも無料。
悪い点:基本的にインタネットブラウザ上でしか動かない。
Excelやメールソフトを動かす様な場合には使えない。Java
良い点:最も人気が高い。つまり、ドキュメントや記事が多い。
どんなosでも、ほぼなんでもできる。
悪い点:習得難易度が高い。
少し、時代遅れ感が出てきた。Ruby
良い点:日本人が作ったので ドキュメントも文法もわかりやすい。
学習コストが非常に低い。
web系に強い。
悪い点:人によって異なる記述でコードが書けるので、混乱しそう。選考過程
今回は「サブスキル」としてプログラミングを学びます。
つまり、汎用性が高い事が重要です。
様々なosで使用できる。様々なアプリをコントロールできる(RPAとかも将来視野に入れたい)。
そして、本職の学習ではない為、コストは少ない方が良い。(お金・時間)
まずは、小さなプログラムが簡単に 少し 動くまでに、どれだけ時間がかかるか?が重要です。逆に、アプリケーションが限られていたり、web限定だと 用途が限られる為不向きです。
上記から考えると、
VisialBasic;基本的にoffice製品限定なので、落選。
C言語:学習コストが高いので、落選。
Swift:学習コストが高いので、落選。
JavaScript:web専用では、困るので落選。
Java:学習コストが高いので、落選。となりました。
残るは、python と Ruby です。
共に、学習コストが低く 汎用性もあります。個人的には 国産言語のRubyを選びたい気もします。
しかし、今 世の中で中で注目を集めているのはどちらか?といわれれば、
pythonに軍配が上がります。
しかも、ビジネス書や日経新聞等でもpythonはちょくちょく名前が出てきます。
プログラミングを学んでいない(学ぶ気もない)会社の上司様方も 「プログラミング?
うーんITだね。DXだね。これからは必要だよね。よくわからないけど、必要そうだね。」
って 感じの印象は残っていそうです。
残念ながら Rubyは、IT業界に近い方々にしか知られていません。つまり!(何も知らない系の PCに疎い系の)上司とかお偉いさんに アピールできる!!
のです。
社会人には、上司へのアピールは重要です。
仮に プログラミングを途中で挫折してもOKです。
アピールした事で 新しい仕事が廻ってくるかもしれませんが、それはそれで
業務範囲が広くなるのですから チャンスです。
広くなった業務範囲の分だけ、給料や権限を挙げてもらいましょう!結論
以上の選考を経て サブスキルとして社会人がプログラミングを学ぶなら、python 一択。
と、なりました。しかし、何かやりたいことが決まっている方は それに向いた言語を選択しましょう。
会社で 本業以外に広報としてwebページ作成してとか言われて学習するような場合は、
サブスキルでは無くて本職スキルですから、pythonじゃなくてJavaScriptとかが
選択肢になるかもしれません。私の場合は あくまで サブスキル。何かやりたい事があったわけではなく、
何ができるの?的に 学習を開始しています。
後で 何かやりたくなった時に ある程度なんでもできる言語という点が重要でした。ちなみに、pythonは Windows・MAC・Linuxでexe化もできます。iphone・ipadでも
pythonistaとか購入すればアプリの様に動かせます。
- 投稿日:2021-01-19T17:46:55+09:00
[python]EOL while scanning string literalの解決
- 投稿日:2021-01-19T16:19:30+09:00
manimの作法 その19
概要
manimの作法、調べてみた。
LinearTransformationScene使ってみた。サンプルコード
from manimlib.imports import * class test(LinearTransformationScene): CONFIG = { "matrix": [[2, -5.0 / 3], [-5.0 / 3, 2]], "v": [1, 2], "w": [2, 1], "v_label": "v", "w_label": "w", "v_color": YELLOW, "w_color": MAROON_B, "rhs1": "> 0", "rhs2": "< 0", "foreground_plane_kwargs": { "x_radius": 2 * FRAME_WIDTH, "y_radius": 2 * FRAME_HEIGHT, }, "equation_scale_factor": 1.5, } def construct(self): v_mob = self.add_vector(self.v, self.v_color, animate=False) w_mob = self.add_vector(self.w, self.w_color, animate=False) kwargs = { "transformation_name": "T", "at_tip": True, "animate": False, } v_label = self.add_transformable_label(v_mob, self.v_label, **kwargs) w_label = self.add_transformable_label(w_mob, self.w_label, **kwargs) start_equation = self.get_equation(v_label, w_label, self.rhs1) start_equation.to_corner(UR) self.play(Write(start_equation[0::2]), ReplacementTransform(v_label.copy(), start_equation[1]), ReplacementTransform(w_label.copy(), start_equation[3]), ) self.wait() self.add_foreground_mobject(start_equation) self.apply_matrix(self.matrix) self.wait() end_equation = self.get_equation(v_label, w_label, self.rhs2) end_equation.next_to(start_equation, DOWN, aligned_edge=RIGHT) self.play(FadeIn(end_equation[0]), ReplacementTransform(start_equation[2::2].copy(), end_equation[2::2], ), ReplacementTransform(v_label.copy(), end_equation[1]), ReplacementTransform(w_label.copy(), end_equation[3]), ) self.wait(2) def get_equation(self, v_label, w_label, rhs): equation = VGroup(v_label.copy(), TexMobject("\\cdot"), w_label.copy(), TexMobject(rhs), ) equation.arrange(RIGHT, buff=SMALL_BUFF) equation.add_to_back(BackgroundRectangle(equation)) equation.scale(self.equation_scale_factor) return equation生成した動画
https://www.youtube.com/watch?v=YXsK0QDOSGg
以上。
- 投稿日:2021-01-19T16:17:09+09:00
【Python】文系だけど頑張ってbit全探索を理解する
はじめに
※自分用メモ
https://qiita.com/gogotealove/items/11f9e83218926211083a
こちらの記事でものすごく丁寧にbit全探索を解説されている。
しかし、生まれながらにして文系の自分の頭では読んだだけじゃ全く理解が追い付かなかったので、自分でコードを書いてひとつずつ理解しながらじっくり取り組んでみた。コード
みかんりんごぶどう.py# 参考:https://qiita.com/gogotealove/items/11f9e83218926211083a # -例題- # みかん(100円)りんご(200円)ぶどう(300円)が # それぞれ1つずつ果物屋さんにありました。 # 財布の中には300円ありますが、 # 考え得るすべての買い物パターンを列挙しなさい。 # -考え方- # 全ての買い物パターンで合計金額を計算し、 # その中から300円以下で済んだものを列挙する # 2~3 = 8パターンの中から300円以下のものを列挙する money = 300 item = (("みかん",100),("りんご",200),("ぶどう",300)) n = len(item) # 各アイテムを買うor買わないを # 「2進数のそれぞれの桁が0であるのか1であるのか(左からみかん、りんご、ぶどう)」 # で表現すると、以下のような表になる。 # -10進数表記- -2進数表記- -買い物リスト- # 0 000 何も買わない # 1 001 ぶどう # 2 010 りんご # 3 011 りんご+ぶどう # 4 100 みかん # 5 101 みかん+ぶどう # 6 110 みかん+りんご # 7 111 みかん+りんご+ぶどう # 全パターンループ for i in range(2 ** n): bag = [] total = 0 # アイテムの個数分ループ for j in range(n): # 順に右にシフトさせ、最下位bitのチェックを行う # 下から0桁目が1であればぶどう入り # 下から1桁目が1であればりんご入り # 下から2桁目が1であればみかん入り #2進数の一番右からチェックを開始していく # ex)i = 6、j = 0の場合(ぶどうチェック) # 6の2進数「110」を0ビット右シフトすると「110」 # 最下位の値を1で論理和をとるとfalseになるので「ぶどう無し」 # ex)i = 6、j = 1の場合(りんごチェック) # 6の2進数「110」を1ビット右シフトすると「011」 # 最下位の値を1で論理和をとるとtrueになるので「りんご入り」 # ex)i = 6、j = 2の場合(みかんチェック) # 6の2進数「110」を2ビット右シフトすると「001」 # 最下位の値を1で論理和をとるとtrueになるので「みかん入り」 if((i >> j) & 1): # フラグが立っていたら、bagに果物をつめる # [j](itemの要素番号) [0](果物名) bag.append(item[j][0]) # 買い物累計額にも加算 # [1](果物金額) total += item[j][1] # totalが300以下の時、合計金額と配列bagに格納されている果物名を出力 if(total <= money): print(total,bag) def test(): # 2進数表記した場合の下から数えてn桁目(一番下の桁を0とする)が # 1であるかどうかをチェックするコードは「(i >> n) & 1」である。 # これは、「iをn回右にシフトして1(2進数001)と論理積をとる(最下位の桁が1であるかどうかチェックする」 # ということになる。 i = 5 # 5を2進数で表記すると101 bin(i) # 5を2回右にシフトすると001 bin(i >> 2) # 5を2回右にシフトしたものと # 1の論理積は1(=True) print((i >> 2) & 1)
- 投稿日:2021-01-19T16:16:00+09:00
manimの作法 その18
概要
manimの作法、調べてみた。
SampleSpaceScene使ってみた。サンプルコード
from manimlib.imports import * class test(SampleSpaceScene): def construct(self): sample_space = self.get_sample_space() self.add_prior_division() self.add(sample_space) self.add_conditional_divisions() prior_label = sample_space.horizontal_parts.labels[0] final_labels = self.final_labels hard_to_see = TextMobject("Hard to see") hard_to_see.scale(0.7) hard_to_see.next_to(prior_label, UP) hard_to_see.to_edge(UP) hard_to_see.set_color(YELLOW) arrow = Arrow(hard_to_see, prior_label) self.wait() anims = self.get_division_change_animations(sample_space, sample_space.horizontal_parts, 0.001, new_label_kwargs = {"labels" : final_labels}) self.play(*anims, run_time = 2) self.wait() self.play(Write(hard_to_see, run_time = 2), ShowCreation(arrow)) self.wait(2) def add_prior_division(self): sample_space = self.sample_space sample_space.divide_horizontally(0.1) initial_labels, final_labels = [VGroup(TexMobject("P(\\text{Disease})", s1), TexMobject("P(\\text{Not disease})", s2),).scale(0.7) for s1, s2 in (("", ""), ("= 0.001", "= 0.999"))] sample_space.get_side_braces_and_labels(initial_labels) sample_space.add_braces_and_labels() self.final_labels = final_labels def add_conditional_divisions(self): sample_space = self.sample_space top_part, bottom_part = sample_space.horizontal_parts top_brace = Brace(top_part, UP) top_label = TexMobject("P(", "+", "|", "\\text{Disease}", ")", "=", "1") top_label.scale(0.7) top_label.next_to(top_brace, UP) top_label.set_color_by_tex("+", GREEN) self.play(GrowFromCenter(top_brace)) self.play(FadeIn(top_label)) self.wait() bottom_part.divide_vertically(0.95, colors = [BLUE_E, YELLOW_E]) bottom_label = TexMobject("P(", "+", "|", "\\text{Not disease}", ")", "=", "1") bottom_label.scale(0.7) bottom_label.set_color_by_tex("+", GREEN) braces, labels = bottom_part.get_bottom_braces_and_labels([bottom_label]) bottom_brace = braces[0] self.play(FadeIn(bottom_part.vertical_parts),GrowFromCenter(bottom_brace), ) self.play(FadeIn(bottom_label)) self.wait()生成した動画
https://www.youtube.com/watch?v=MeoD6IpM2AM
以上。
- 投稿日:2021-01-19T16:03:31+09:00
【Python】OpenCVで使うパスに日本語を入れてはならない
はじめに
タイトルの通り。
OpenCVがどうしてもパスを読み込んでくれずにハマってしまったので、どうしたものかと調べてみるとどうやら、パスに日本語を入れると正常に動作しないということがわかった。想定ファイル構成
C:
↓
ユーザー
↓
test01.jpg TestOpenCV.pyだめな例
TestOpenCV.pyimport cv2 filename = "C:/ユーザー/test01.jpg" # ファイルパスの「ユーザー」がアウトで読み込んでくれない img = cv2.imread(filename,0) # img = Noneになる解決方法
日本語をパスに含めないか、相対パスを使う。
よい例
TestOpenCV.pyimport cv2 filename = "C:/User/test01.jpg" # 「ユーザー」を「User」にする filename = "./test01.jpg" # 名前を変えられない場合はTestOpenCV.pyから見た相対パスにする img = cv2.imread(filename,0) # きちんと画像を読み込んでくれる
- 投稿日:2021-01-19T16:02:14+09:00
【MNIST】ImangeNetのモデルを利用してFineTuningやってみた
①はじめに
AIを勉強するにあたりFineTuningも勉強しておきたいなと思って、今回は
ImageNet学習済みのDenseNet121モデルを利用して、MNISTを実施してみたいと思います。
②ファインチューニングとは
FineTuningとは和訳すると微調整という意味です。AIでのファインチューニングとは、
既存のモデルの一部を再利用して、新しいモデルを構築する手法のことです。■ファインチューニングと転移学習の違い
ファインチューニングに似たようなものとして、転移学習があります。ファインチューニングと転移学習が、いつもごっちゃになってしまうので、ここで整理します。
ファインチューニング
ファインチューニングは、学習済みモデルの重みを初期値として、再度学習します。メリットは、既存モデルの重みを初期値として追加学習することで、より効率的に高精度なモデル構築が行えます。
転移学習
転移学習は、学習済みモデルの重みは固定し、追加した層のみを使用して学習します。メリットは、学習済のモデルをベースに追加学習を行うため、少ないデータで、かつ短い時間でモデルの構築を行うことができます。■で、今回はどっち?
すでに出来上がった画像分類モデルを再利用して、数字の分類を実施したいと思います。今回は、「ImageNetで学習した重みをもつ画像分類のモデル」を利用して、「数字画像の分類」をさせたいと思います。ですので、今回は
ファインチューニングになります。③ファインチューニングのやり方
ファインチューニング元とするモデルは
DenseNet121を利用したいと思います。こちらのモデルは軽量だけどそこそこ認識率も良いというモデルになっております。MNISTの学習データは、28 x 28 x 1ch、DenseNet121の入力レイヤーは、32以上 x 32以上 x 3chとなっているので、これらを合わせる必要があります。合わせる方法として、以下2通りがあります。
③-(1)MNISTの画像を合わせる方法
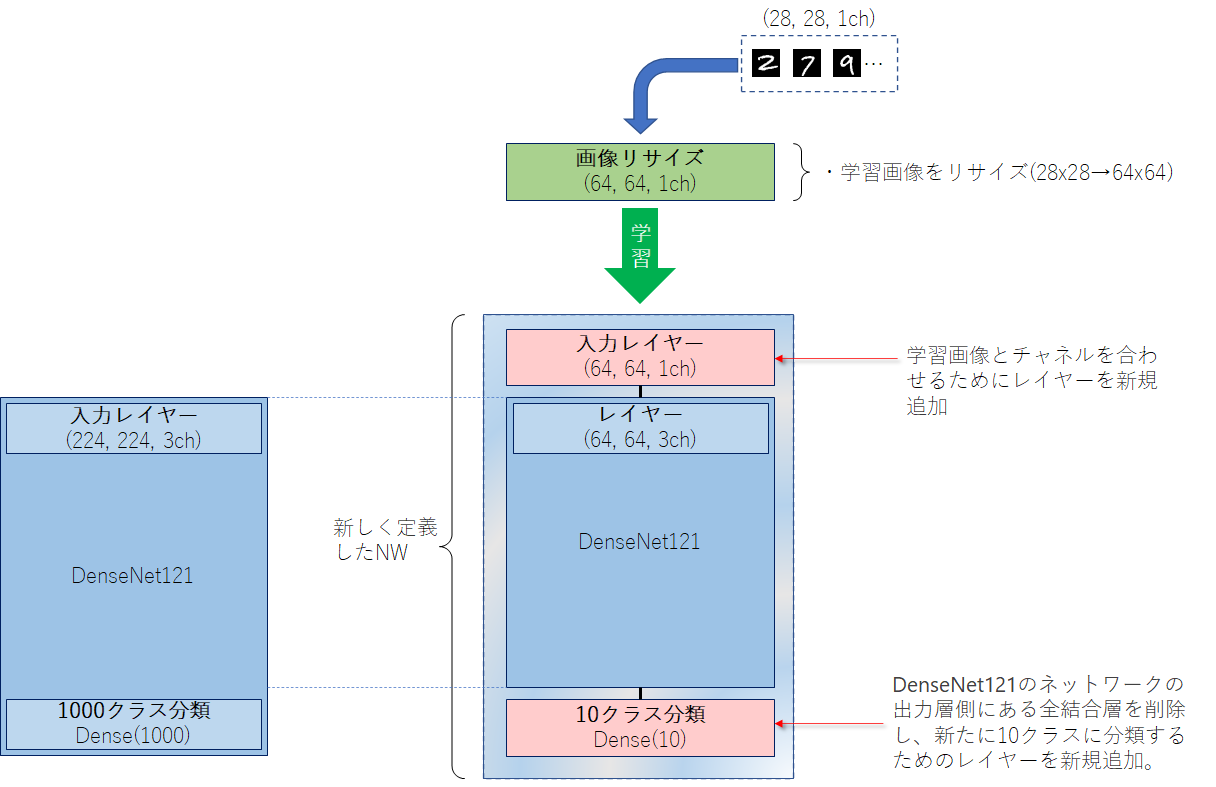
③-(2)モデルの入力レイヤーを変更する方法➊MNISTの画像を合わせる方法
DenseNet121の入力形式は、(height=32以上, width=32以上, channels=3ch)となっています。
MNISTの画像形式は、(height=28, width=28, channels=1ch)となっています。学習画像サイズはDenseNet121のネットワーク定義から32以上x32以上x3chは必須となっているので、以下の処理を施します。
- 画像を64x64にリサイズ
- グレースケール1chからRGB3chに変換
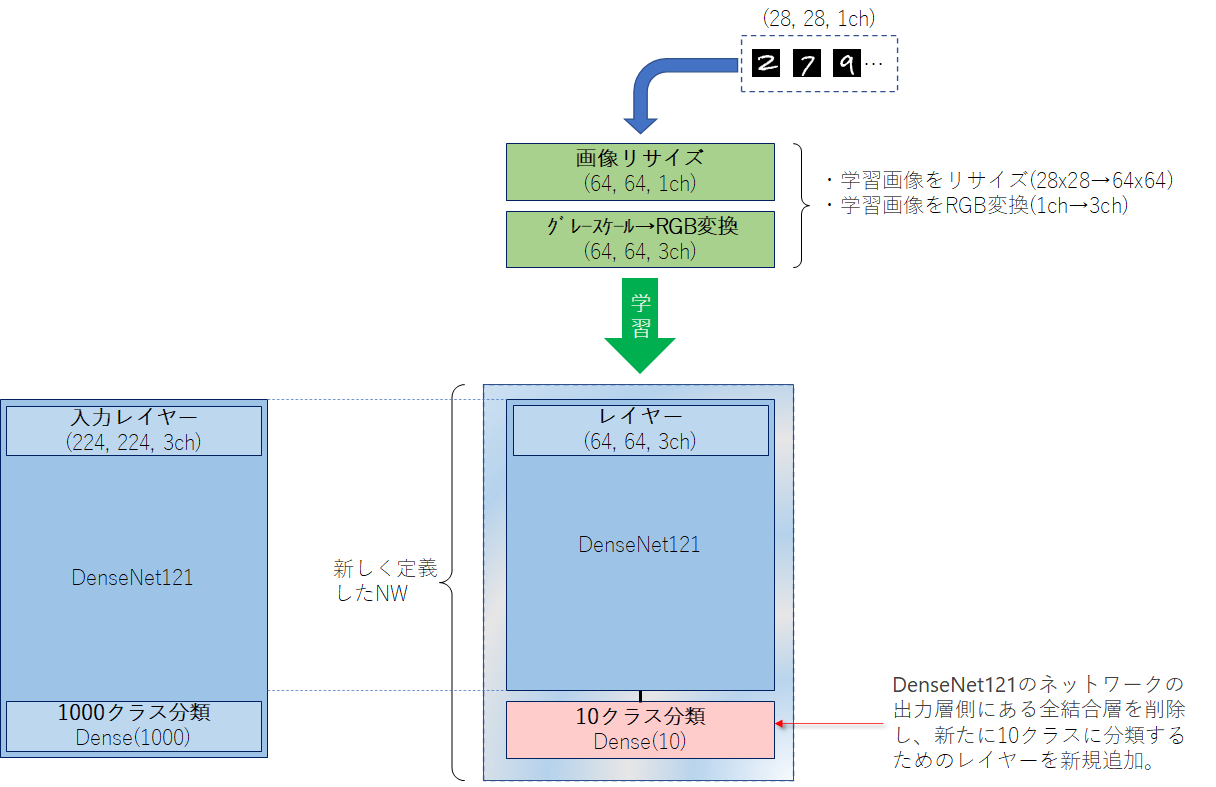
➋モデルの入力レイヤーを変更する方法
DenseNet121の入力形式は、(height=32以上, width=32以上, channels=3ch)となっています。
MNISTの画像形式は、(height=28, width=28, channels=1ch)となっています。学習画像サイズはDenseNet121のネットワーク定義から32以上x32以上x3chは必須となっているので、以下の処理を施します。
- 画像を64x64にリサイズ
- 1chの入力レイヤーを追加
④MNISTの画像を合わせる方法
基本的には、以下の➊~➎の手順でファインチューニングの実施が可能です。
➊学習済みの重みをダウンロード
「
keras.applications.densenet.DenseNet121」のAPIにより、簡単にDensenet121でimagenetを学習させた重みをダウンロードすることができます。毎回ダウンロードするのは大変なので、Google Driveに保存しておきます。from keras.applications.densenet import * model = DenseNet121(weights='imagenet') model.save(fullpath)➋MNISTのデータ変換
DenseNet121の入力形式(height, width, channels)に合わせて、MNISTの画像を(28, 28, 1)から(64, 64, 3)に変換します。
import cv2 import numpy as np from keras.datasets import mnist img_w, img_h, img_ch = 64, 64, 3 num_classes = 10 def pretreatment(x): # 画像サイズをリサイズ X = [] for i in range(len(x)): dst = cv2.resize(x[i], (img_h, img_w), interpolation=cv2.INTER_CUBIC) dst = cv2.cvtColor(dst, cv2.COLOR_GRAY2RGB) X.append(dst) # リシェイプ X = np.array(X).reshape(len(x), img_h, img_w, img_ch) # 0〜255 までの範囲のデータを 0〜1 までの範囲に変更 ret = X.astype('float32') / 255 return ret # ■MNISTデータ読み込み (x_train, y_train), (x_test, y_test) = mnist.load_data() x_train, x_valid, y_train, y_valid = train_test_split(x_train, y_train, test_size=0.2) # ■学習(Train)データ x_train = pretreatment(x_train) y_train = np_utils.to_categorical(y_train, num_classes) # ■学習(Valid)データ x_valid = pretreatment(x_valid) y_valid = np_utils.to_categorical(y_valid, num_classes) # ■テストデータ x_test = pretreatment(x_test) y_test = np_utils.to_categorical(y_test, num_classes)➌DneseNet121のネットワーク構築を行う
(1)DneseNet121ネットワーク構築
kerasでは「
keras.applications.densenet.DenseNet121」のAPIにより、簡単にDensenet121のネットワーク構築することができます。include_topをFalseにしておくことで、ネットワークの出力層側にある全結合層を含めないようにすることができます。input_tensor = x_train.shape[1:] model = DenseNet121(include_top=False, weights=None, input_shape=input_tensor)(2)出力層追加
ネットワークの出力層側の全結合層を構築
DenseNet121(ImageNet)は画像分類として1000クラスを判別していましたが、今回実施するのはMNISTなので0~9の10分類にクラス分けができるようにします。from keras.layers import * from keras.models import Model x = Flatten()(model.layers[-1].output) x = Dense(10, activation="softmax")(x) Model(model.inputs, x)➍学習済みの重みを読み込む
ネットワーク構成後、➊でダウンロードした重みを読み込みます。weightsはこちらの「
load_weights」メソッドで読み込みます。model.load_weights(fullpath, by_name=True)➎学習する
あとは通常通り学習させればFineTuningができます。
➏実行結果
●TEST:検証結果 Test loss : 0.01561666838824749 Test accuracy: 0.9944000244140625
⑤モデルの入力レイヤーを変更する方法
基本的には、以下の➊~➍の手順でファインチューニングの実施が可能です。
➊学習済みの重みをダウンロード
「
keras.applications.densenet.DenseNet121」のAPIにより、簡単にDensenet121でimagenetを学習させた重みをダウンロードすることができます。毎回ダウンロードするのは大変なので、Google Driveに保存しておきます。from keras.applications.densenet import * model = DenseNet121(weights='imagenet') model.save(fullpath)➋MNISTのデータ変換
DenseNet121の入力形式(height, width, channels)に合わせて、MNISTの画像を(28, 28, 1)から(64, 64, 1)に変換します。
import cv2 import numpy as np from keras.datasets import mnist img_w, img_h, img_ch = 64, 64, 1 num_classes = 10 def pretreatment(x): # 画像サイズをリサイズ X = [] for i in range(len(x)): dst = cv2.resize(x[i], (img_h, img_w), interpolation=cv2.INTER_CUBIC) # dst = cv2.cvtColor(dst, cv2.COLOR_GRAY2RGB) ← 1chなので実行しない X.append(dst) # リシェイプ X = np.array(X).reshape(len(x), img_h, img_w, img_ch) # 0〜255 までの範囲のデータを 0〜1 までの範囲に変更 ret = X.astype('float32') / 255 return ret # ■MNISTデータ読み込み (x_train, y_train), (x_test, y_test) = mnist.load_data() x_train, x_valid, y_train, y_valid = train_test_split(x_train, y_train, test_size=0.2) # ■学習(Train)データ x_train = pretreatment(x_train) y_train = np_utils.to_categorical(y_train, num_classes) # ■学習(Valid)データ x_valid = pretreatment(x_valid) y_valid = np_utils.to_categorical(y_valid, num_classes) # ■テストデータ x_test = pretreatment(x_test) y_test = np_utils.to_categorical(y_test, num_classes)➌DneseNet121を利用して新たなネットワーク構築を行う
(1)DneseNet121の入力層の前に独自の入力層を追加
from keras.layers import * from keras.models import Model, Sequential input_tensor = x_train.shape[1:] input_model = Sequential() input_model.add(InputLayer(input_shape=input_tensor)) input_model.add(Conv2D(3, (3, 3), padding='same')) input_model.add(BatchNormalization()) input_model.add(Activation('relu'))(2)DneseNet121ネットワーク構築
kerasでは「
keras.applications.densenet.DenseNet121」のAPIにより、簡単にDensenet121のネットワーク構築することができます。include_topをFalseにしておくことで、ネットワークの出力層側にある全結合層を含めないようにすることができます。model = DenseNet121(include_top=False, weights=None, input_tensor=input_model.output)(3)出力層追加
DenseNet121(ImageNet)は画像分類として1000クラスを判別していましたが、今回実施するのはMNISTなので0~9の10分類にクラス分けができるようにします。
x = Flatten()(model.layers[-1].output) x = Dense(num_classes, activation="softmax")(x) return Model(model.inputs, x)➍学習済みの重みを読み込む
ネットワーク構成後、➊でダウンロードした重みを読み込みます。weightsはこちらの「
load_weights」メソッドで読み込みます。model.load_weights(fullpath, by_name=True)➎学習する
あとは通常通り学習させれば、FineTuningができます。
➏実行結果
●TEST:検証結果 Test loss : 0.019007695838809013 Test accuracy: 0.9934999942779541
⑥ソースコード
今回学習させたときは、ImageDataGeneratorを使用し、以下の様な回転・縮小画像を含めて学習させ、汎化性能も考慮させています。
全体のソースコードはこちら ▶ github
⑦以上
お疲れさまでした。
ImageNet学習済みのDenseNet121モデルをベースにしているので1epocの計算量は多いものの、FineTuningなので30epocくらいでほぼ収束します。正解率、損失値もそこそこ良いです。今回は、FineTuningのために重みを読み込みましたが、学習を途中まで実施し再度学習を始める場合等へ応用がきくので、本手順を理解しておくと良いと思います。

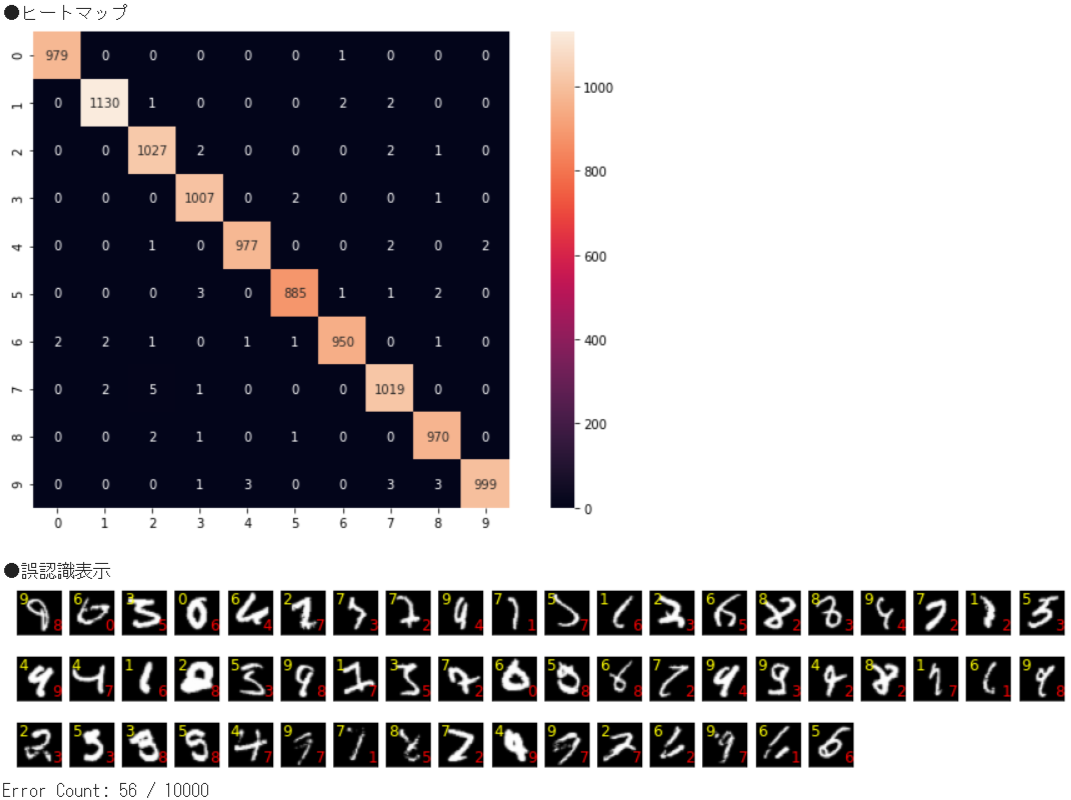
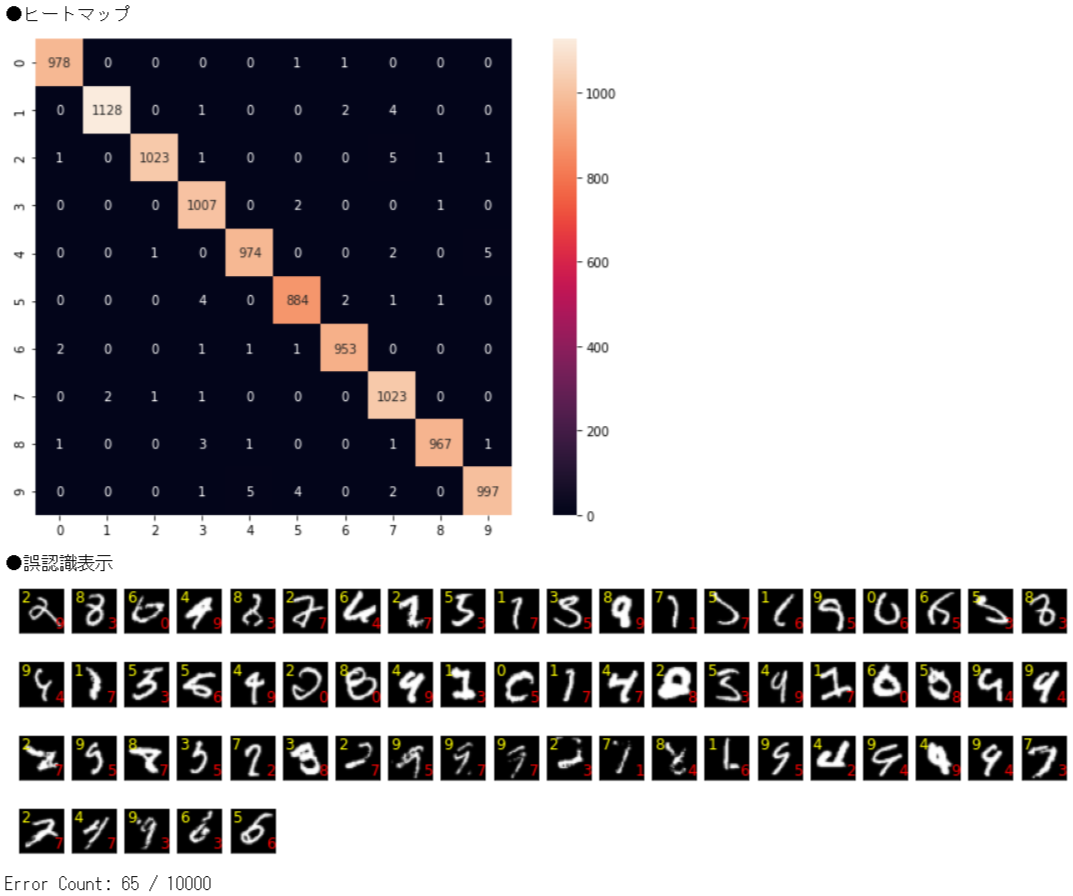
- 投稿日:2021-01-19T14:55:52+09:00
Most wanted pandas functions (Part 02)
Here, I'm going to extend the last article I have written some time ago.
You guys can read it in here Most wanted pandas functions (Part 01)1. Applying a function.
When dealing with the data, we often have to use functions. There are few ways to use a function over a DataFrame. We should avoid iterating approaches since it is slow going through the panda's rows.
We can use .apply() in this case.pandas_funcs.ipynb# Add $ to values of the Fare column. def add_dolor_mark(money_str): money_str = '$ '+str(money_str) return money_str df['Fare'] = df['Fare'].apply(add_dolor_mark) df.head()
2. Renaming columns.
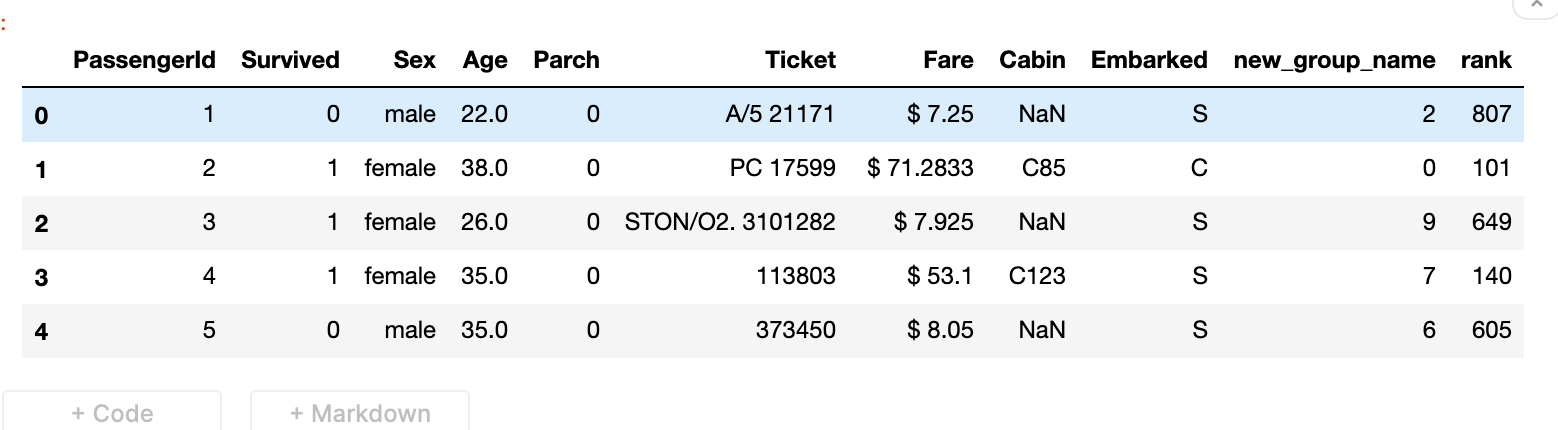
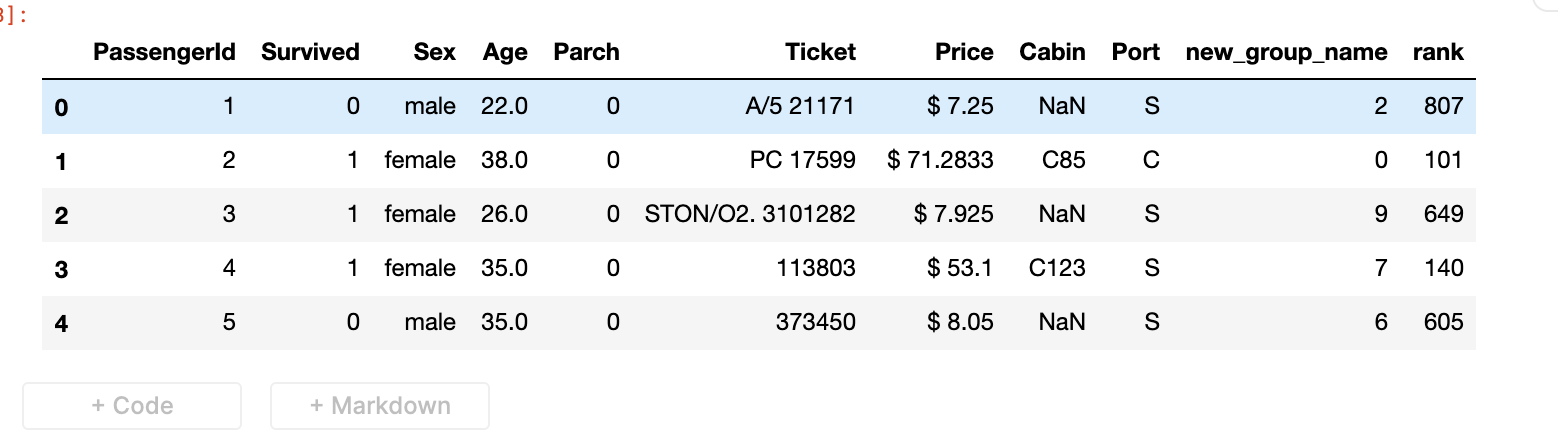
Sometimes it is necessary to rename columns of our DataFrame.
We can pass dictionary {‘column_1’ : ’new_column_1’, ‘column_2’ : ’new_column_2’} to .rename()
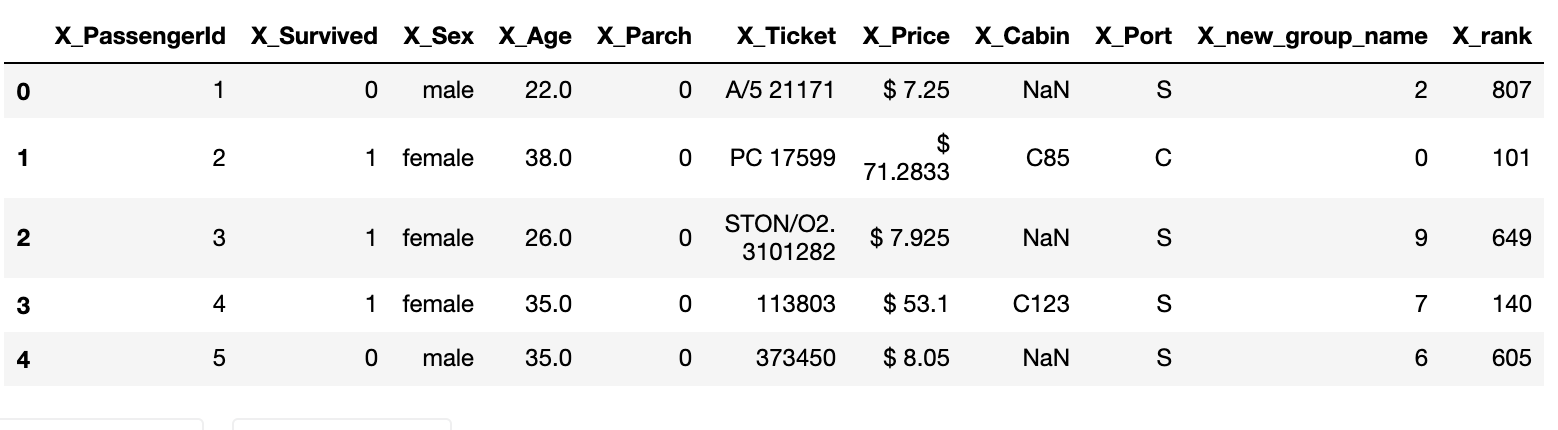
Let's try to rename Embarked into Port and Fare into Price.pandas_funcs.ipynbdf.rename(columns = {'Embarked':'Port', 'Fare':'Price'}, inplace=True) df.head()
3. Adding prefixes or suffixes to column names.
In this case we can use add_prefix() and add_suffix()
pandas_funcs.ipynbdf = df.add_prefix('X_') df.head()
4. Conditional replacing.
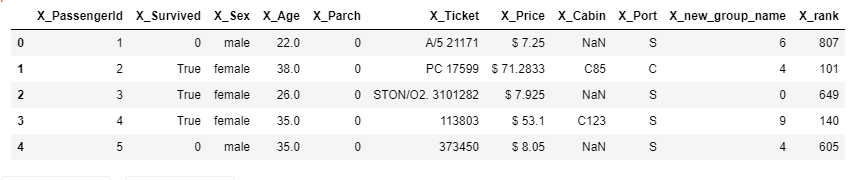
“Where” can be used to replace the values in rows or columns based on a condition. The way where is works a bit different. It is crucial to identify the way “where” works. "Where" select values based on the condition, then the remaining values are replaced with the specified value.
So "where" is behaving like a masking operation.pandas_funcs.ipynb# we need to replace survied people with True df['X_Survived'] = df['X_Survived'].where(df['X_Survived'] == 0 , True) df.head()
5. Melting
This is a bit infamous function. But very useful. We can use melt to convert wide DataFrame to narrow ones.
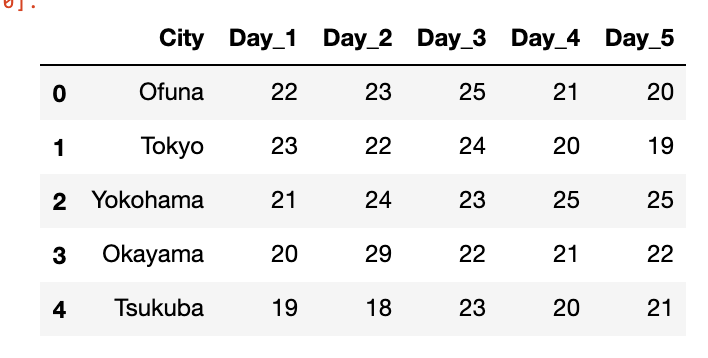
Let's assume we have measured the temperature of 5 cities and for a week. And the data is looking like this.
(we can create a sample DataFrame as follows)
pandas_funcs.ipynbimport pandas as pd temp = {'City': ['Ofuna','Tokyo','Yokohama','Okayama', 'Tsukuba'], 'Day_1': [22,23,21,20,19], 'Day_2': [23,22,24,29,18], 'Day_3': [25,24,23,22,23], 'Day_4': [21,20,25,21,20], 'Day_5': [20,19,25,22,21], } df = pd.DataFrame(temp, columns = ['City', 'Day_1', 'Day_2', 'Day_3', 'Day_4', 'Day_5’])pandas_funcs.ipynbdf = df.melt(id_vars=['City']) df
6. Save as csv
In some situations, we have to save processed DataFrame. In that case, we can use the to_csv function.
pandas_funcs.ipynbdf.to_csv('myfile.csv')7. Query
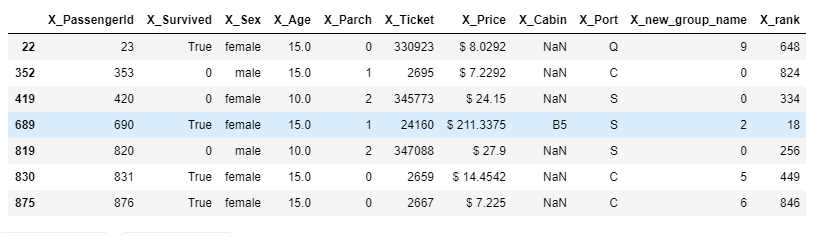
Among the several filtering methods query is another filtering method that we can quickly and easily access to the subsections of the DataFrame.
pandas_funcs.ipynb#letes assume that we want to get list of age of 10 and 15 seek_age = [10,15] df.query("X_Age in @seek_age")
8. Memory usage
How much memory is used by a pandas DataFrame is really beneficial when dealing with large DataFrames. So we can avoid trouble with dead kernel due to out of memory
pandas_funcs.ipynbdf.memory_usage()
For total Memory usage we can use,
pandas_funcs.ipynbdf.memory_usage().sum()9. Profile report
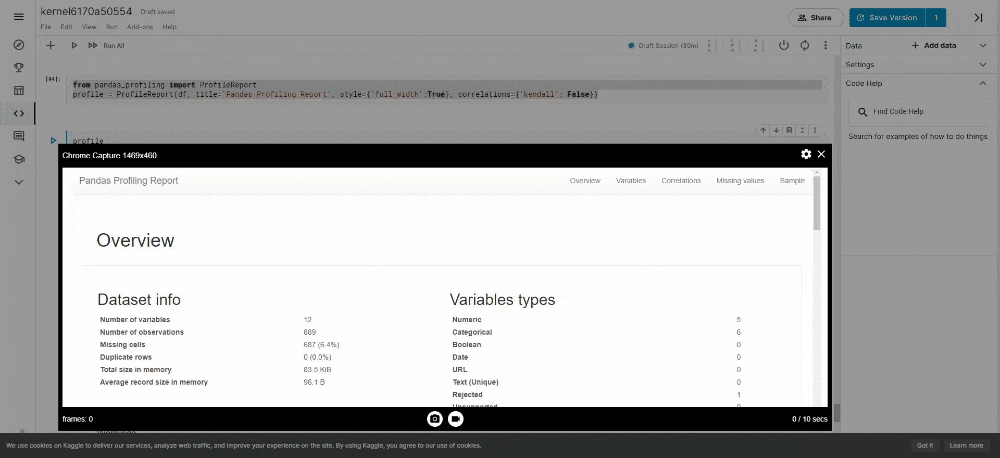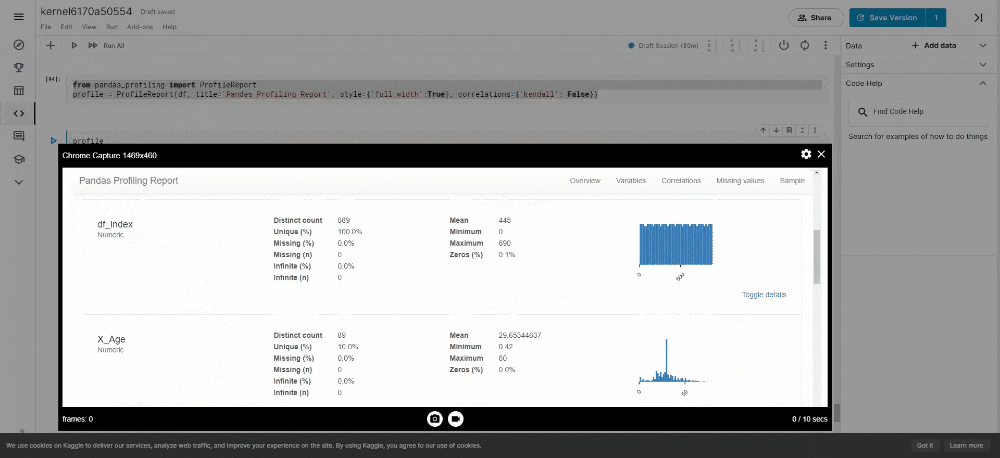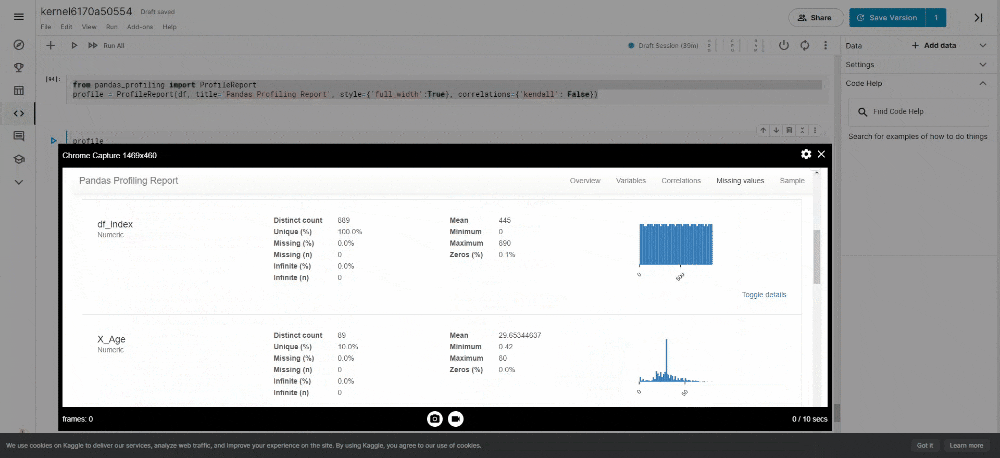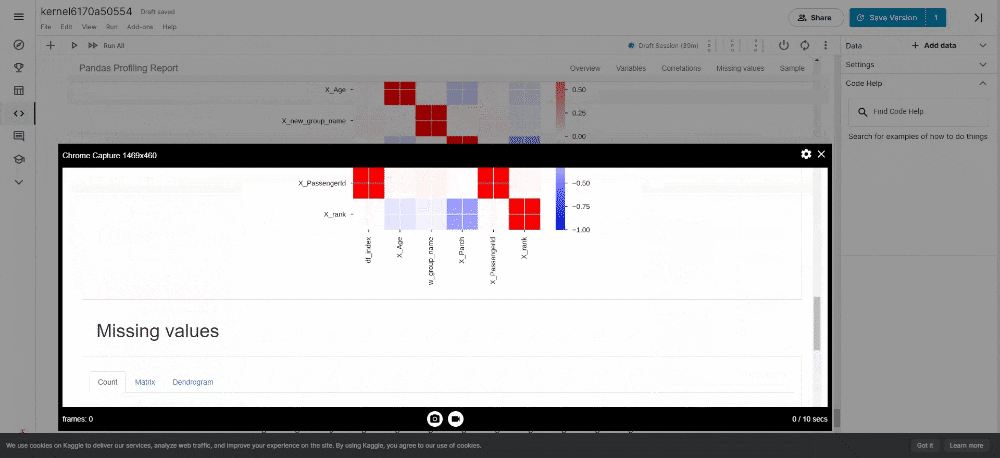
It generates reports from a pandas DataFrame. The pandas df.describe() function is handy but a little basic for good exploratory data analysis. pandas_profiling extends the capability for quick data analysis.
pandas_funcs.ipynbfrom pandas_profiling import ProfileReport profile = ProfileReport(df, title='Pandas Profiling Report', style={'full_width':True}, correlations={'kendall': False}) profile
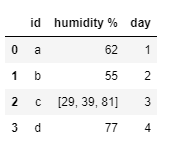
10. Explode
Let's think that our data set holds multiple entries in a single row. But for our analysis, we need to analyze them on separate rows. In that case, we can use the explode function.
(First lets create example DataFrame)pandas_funcs.ipynbdf_ = pd.DataFrame({'id':['a','b','c','d'], 'humidity %':[62,55,[29,39,81],77], 'day':[1,2,3,4]}) df_
pandas_funcs.ipynbdf_.explode('humidity %')
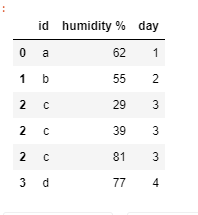
11. Crosstab
It is used to group 2 or more variables and make a summary table. It is used to get insight of columns. Please note that crosstab() works with categorical data.
For example, let's think that we need to get how many people survived/not-survived according to their ports.
pandas_funcs.ipynb#First lets replace True with 1 in X_Survived column. df['X_Survived'] = df['X_Survived'].where(df['X_Survived'] == 0 , 1) port_survived = pd.crosstab(df["X_Port"],df["X_Survived"]) port_survived
There are more many useful functions for analyzing data. I will introduce few more functions in the next article.
Hope this will help you....
*本記事は @qualitia_cdevの中の一人、@nuwanさんが書いてくれました。
*This article is written by @nuwan a member of @qualitia_cdev.

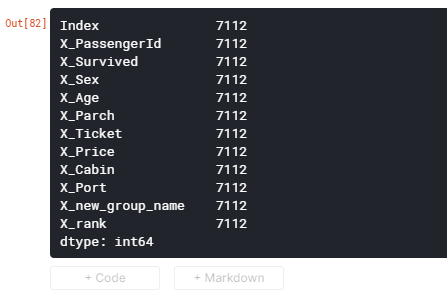
- 投稿日:2021-01-19T13:37:14+09:00
Pythonの高速化
はじめに
Pythonの高速な書き方のことだと思って, うっかり見てしまったため, 気になって仕方がないのです.
多くの環境で速くならないと意味がないので環境は書きません.ベースライン
import math def is_prime(x : int) -> bool: if x <= 1: return False if x % 2 == 0: return x == 2 upper = math.floor(math.sqrt(x)) + 1 for i in range(3, upper, 2): if x % i == 0: return False return True def minimum_prime_number(x : int): maxx = 10 ** 14 + 32 for i in range(x, maxx): if is_prime(i): return i if __name__ == '__main__': result = minimum_prime_number(100000000000000) print(result)100000000000031 0.504 secondsミラー–ラビン素数判定法
確率的判定法を追加しますが, ほとんど変わらず.
def miller_rabin_test(n : int) -> bool: k = 50 if n <= 1: return False if n % 2 == 0: return n == 2 if n % 3 == 0: return n == 3 if n % 5 == 0: return n == 5 s, d = 0, n-1 while d % 2 == 0: s, d = s+1, d>>1 while 0<k: k = k-1 a = random.randint(1, n-1) t, y = d, pow(a, d, n) while t != n-1 and y != 1 and y != n-1: y = pow(y, 2, n) t <<= 1 if y != n-1 and t % 2 == 0: return False return True def is_prime(x : int) -> bool: if False == miller_rabin_test(x): return False upper = math.floor(math.sqrt(x)) + 1 for i in range(3, upper, 2): if x % i == 0: return False return True100000000000031 0.501 seconds3の倍数をスキップする
計算コストの方が上回ってしまった.
def is_prime(x : int) -> bool: if False == miller_rabin_test(x): return False upper = math.floor(math.sqrt(x)) count = 5 step = 4 while count<=upper: if x % count == 0: return False step = 6 - step count += step return True100000000000031 0.569 secondsまとめ
そろそろ飽きてきたため終了です. C++を呼び出してしまったら, それはもうC++で書けということなのでやりません.
- 投稿日:2021-01-19T13:32:23+09:00
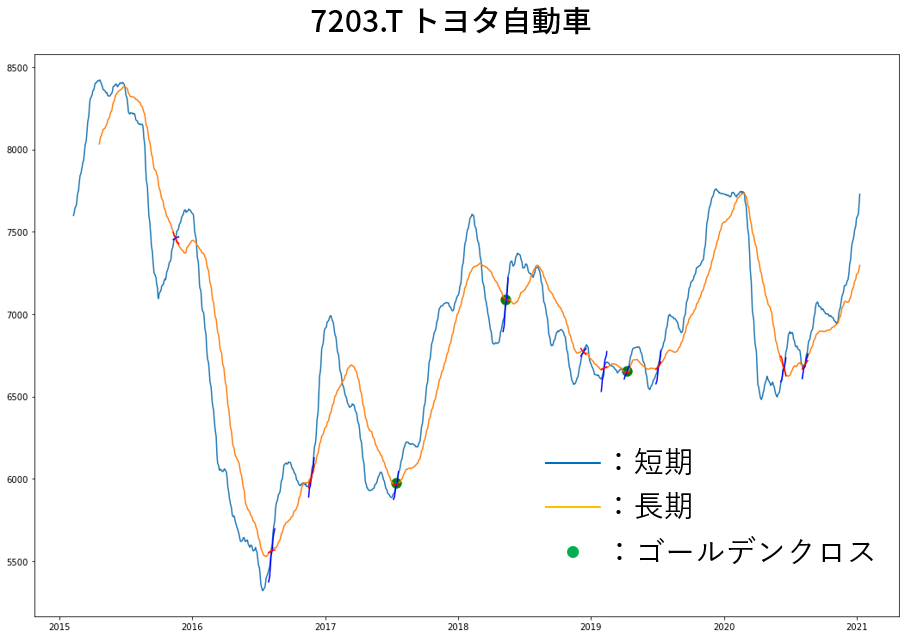
【5年分データ分析】ゴールデンクロスの数日後に株価は上がっているのか
<あらすじ>
テクニカル分析の初歩「ゴールデンクロス」が実際にはどれだけ役に立つのか?
TOPIX500銘柄を対象に5年分のデータを使って検証しました。<結論>
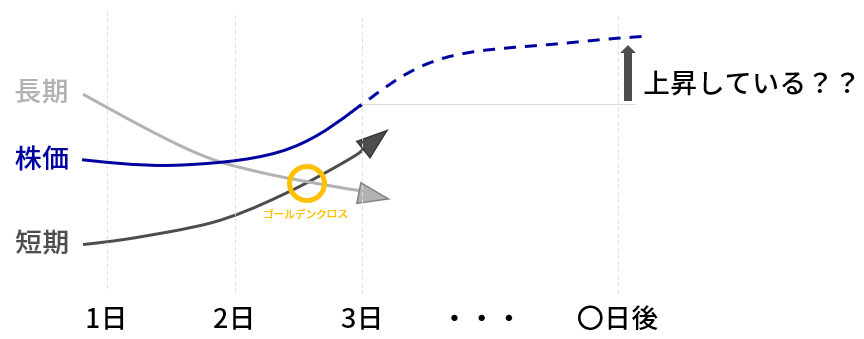
・ゴールデンクロス単体だけで買いタイミングを判断してはいけないゴールデンクロス
ゴールデンクロス:短期の移動平均が長期の移動平均を下から上に突き抜ける現象
⇒ 上昇期入りのシグナル/買いシグナル/買いサイン
テクニカル分析に興味を持った人は必ず聞いたことがあるのではないでしょうか。
一番最初に学ぶテクニカル分析と言っても過言ではないと思います。そんなゴールデンクロスですが、大きな欠点があります。
「だましには要注意」「確実に上昇するとは言い切れない」「あくまで傾向であり必ずとは限りません」
ゴールデンクロスを紹介している記事の多くが保険を掛けています。
そんなこと言っていたら結局ゴールデンクロスを参考にしていいのかわからないと思うわけです。
※ だまし:誤ったサインそこで過去のデータを使ってゴールデンクロスの数日後に株価は上がっているのか検証したいと思います。
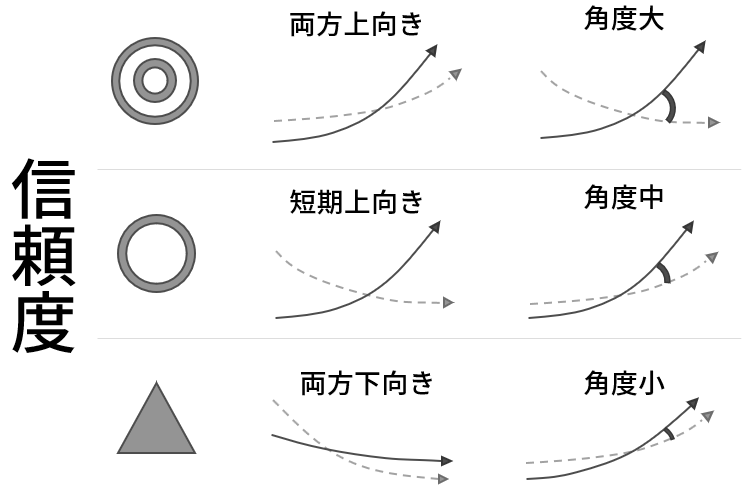
信頼度
ゴールデンクロスには信頼度があると言われています。
直観的にも交差の角度が大きいほど上昇が見込めると考えられます。▼ゴールデンクロスの信頼度
この信頼度がどれだけ信頼できるのかも検証したいと思います。
検証方法
大まかな流れはTOPIX500銘柄を対象に5年分のデータからゴールデンクロスしたタイミングを見つけ、その数日後に株価が上がっているのかを調査します。また、交差時の方向や角度から信頼度別にゴールデンクロスを分類して評価します。
一旦、検証パラメータを羅列しますが、後ほど例を使って説明します。
【検証期間】
2015年1月1日~2020年1月8日の約5年間【対象銘柄】
TOPIX500銘柄【移動平均の期間】
1. 短期:5日,長期:25日
2. 短期:5日,長期:50日
3. 短期:5日,長期:75日
4. 短期:25日,長期:50日
5. 短期:25日,長期:75日【株価の上昇を確認する日】
1. 1日後
2. 3日後
3. 5日後
4. 10日後【条件】
1. なし
2. 方向:短期線が上向き,長期線が下向き
3. 方向:短期線が上向き,長期線も上向き
4. 角度:30度以上
5. 角度:45度以上
6. 角度:60度以上
7. 方向:短期線が上向き,長期線も上向き かつ 角度:60度以上例
下図のようにゴールデンクロスの数日後に株価が上昇しているかを確認します。
図は交差を確認するために大袈裟に描いてありますが、実際には交差の点と日付の間隔はもっと狭いです。
▼検証方法の概要
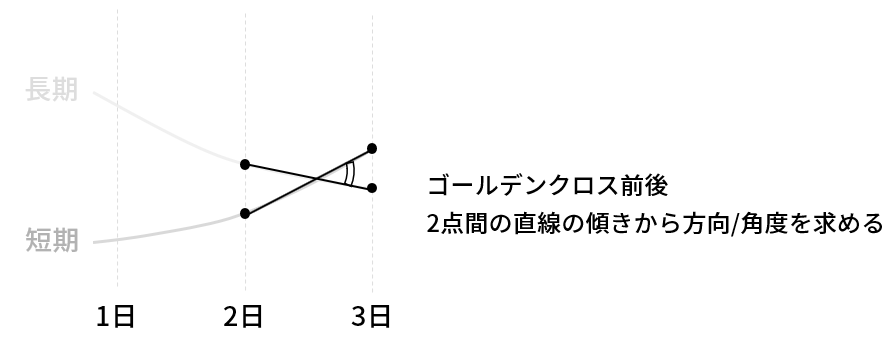
次に、信頼度の判断方法です。
信頼度がどれだけ信頼できるのかを検証するために、ゴールデンクロスに条件を加えます。
条件の判断基準となる方向/角度は下図の方法で求めます。
▼信頼度の判断方法
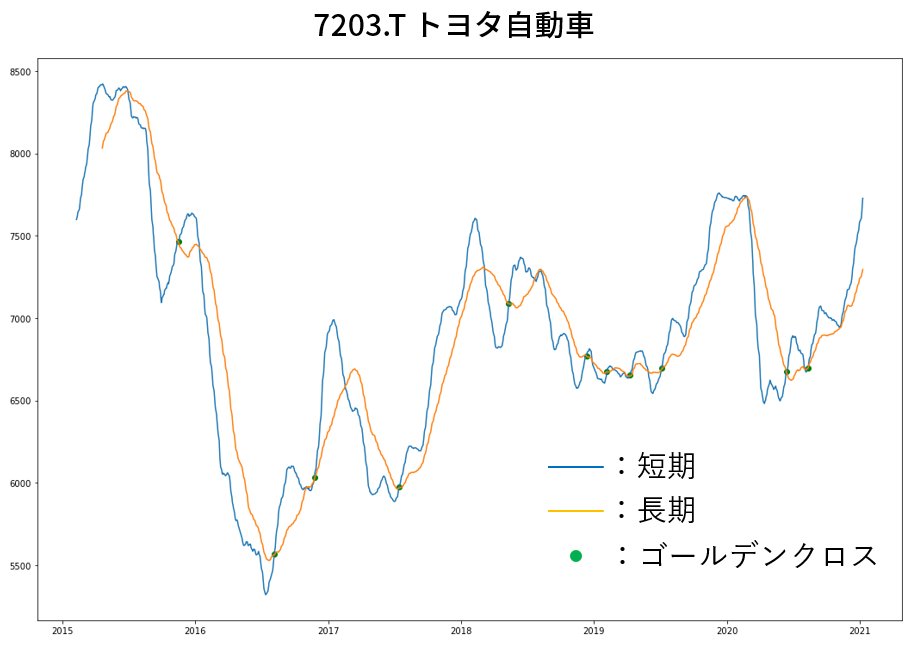
例としてトヨタ自動車の場合を記載します。
緑の丸がゴールデンクロスのタイミングを示します。
ゴールデンクロス:短期の移動平均が長期の移動平均を下から上に突き抜ける現象
⇒ 青線が黄線を下から上に突破
▼短期:25日移動平均, 長期:75日移動平均の場合
次は信頼度を検証するために条件をつけてゴールデンクロスを取捨選択します。
下図は角度:45度以上のゴールデンクロスのみにしたものです。
▼交差の条件からゴールデンクロスを選択(角度:45度以上の場合)
最後に選択されたタイミングから〇日後上昇しているか確認します。
以上の方法でTOPIX500銘柄を対象に5年分のデータを検証しました。
※検証のPythonプログラムは記事の最後に記載検証結果
ここでは結果の一部を記載します。
その他の結果は記事の最後にまとめて記載します。
使用するデータは前述の通りTOPIX500銘柄の5年間です。【移動平均の期間】
1. 短期:5日,長期:25日
2. 短期:25日,長期:75日【株価の上昇を確認する日】
1. 1日後
2. 3日後
3. 5日後
4. 10日後【条件】
1. なし
2. 方向:短期線が上向き,長期線も上向き
3. 角度:45度以上
早速ですが結果を表にまとめました。
<結果>
▼短期:5日,長期:25日の結果
▼短期:25日,長期:75日の結果
表の通り、いずれの場合も〇日後に上昇している確率は約50%という結果が得られました。
条件がある/なしに関わらず約50%です。
ゴールデンクロスも信頼度も全く意味がないことが分かります。
記事の最後に記載していますが、短期,長期の期間/信頼度の条件を変更しても同様の結果となります。ゴールデンクロスの意味とは?...
まとめ
買いサインとして最も有名なゴールデンクロスについて検証したところ、ゴールデンクロスも信頼度も全く意味がないことが分かりました。移動平均は一定期間の価格の平均値を線で結んだもののため、移動平均線の動きは価格の動きよりも遅延します。そのためゴールデンクロスでは買うタイミングとしては遅すぎると考えられます。
また、ゴールデンクロス前にその株式を所有する賢い投資家は「ゴールデンクロスが出たから買いサインだ」と考える一般の投資家が多いことを知っています。そのため、賢い投資家は「ゴールデンクロスは売りサインだ」と真逆に考え、仕込んでおいた株を売るわけです。
その養分にならないように、ゴールデンクロス単体だけでは買いタイミングを判断しないことをお勧めします。次は
単純な移動平均のゴールデンクロスでは買いタイミングとして遅すぎるということが明らかになりました。
そこで遅延が少ない指数移動平均を使用するMACDならばどうなるのかを検証してみたいと思います。
<過去記事>
・日経225全銘柄の投資効率を検証
・日経平均株価が上がった次の日に上がる銘柄を見つけたい
・どの暗号資産が効率よく稼げるか
・1株1千円以下の価格変動が大きい銘柄に投資してパフォーマンスをあげる
・第1回緊急事態宣言のときに上がった銘柄TOP10を調査
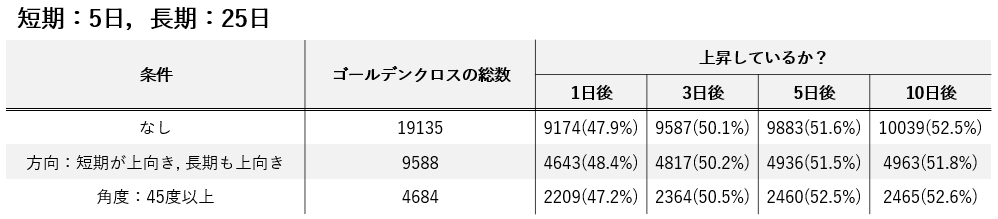
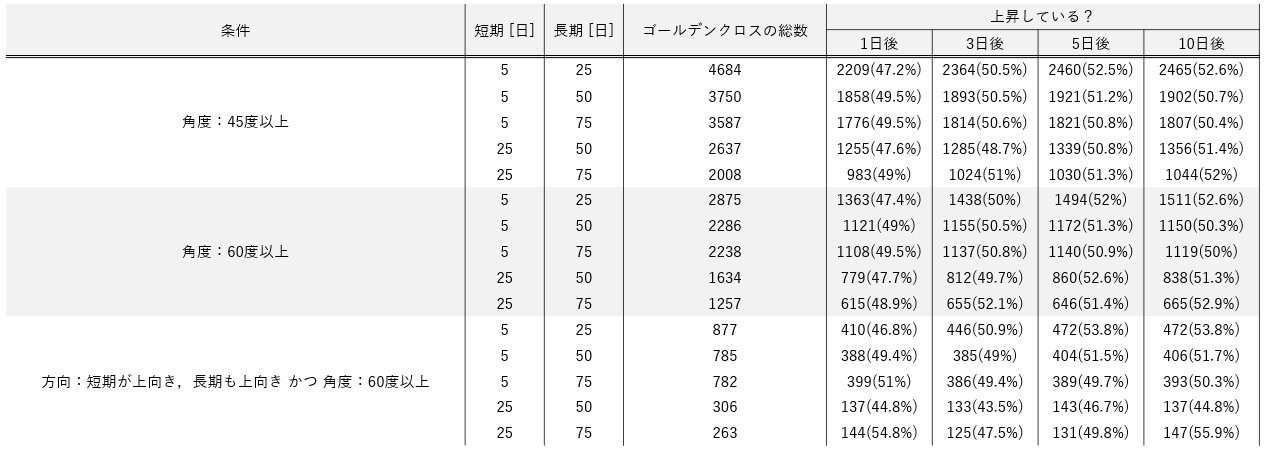
結果の一覧
検証条件と結果の一覧
【検証期間】
2015年1月1日~2020年1月8日の約5年間【対象銘柄】
TOPIX500銘柄【移動平均の期間】
1. 短期:5日,長期:25日
2. 短期:5日,長期:50日
3. 短期:5日,長期:75日
4. 短期:25日,長期:50日
5. 短期:25日,長期:75日【株価の上昇を確認する日】
1. 1日後
2. 3日後
3. 5日後
4. 10日後【条件】
1. なし
2. 方向:短期線が上向き,長期線が下向き
3. 方向:短期線が上向き,長期線も上向き
4. 角度:30度以上
5. 角度:45度以上
6. 角度:60度以上
7. 方向:短期線が上向き,長期線も上向き かつ 角度:60度以上▼条件1~4
▼条件5~7
検証プログラム
# 株価分析用に自作した関数をまとめたもの from trade_module import trade_module as tm import pandas as pd import numpy as np # 銘柄コードの読み込み stock = tm.get_topix500() ## resultデータフレーム作成 day = [1,3,5,10] # 〇日後に上昇しているかの〇を設定 col=["g_p_count"] # ゴールデンクロスの総数 period = [[5,25],[5,50],[5,75],[25,50],[25,75]] # 移動平均の期間 for d in day: col.append("roc_d"+str(d)+"_plus") result = pd.DataFrame(data=0,index=range(len(period)),columns=col) for p in range(len(period)): for code in stock.code: print(code) # 用意した株価データの読み込み data = pd.read_csv("./data/"+code+".csv",index_col=0, parse_dates=True) # 単純移動平均を計算 tm.add_sma_tmp(data, period=(period[p][0],50,period[p][1])) data["g_point"] = False # ゴールデンクロスのタイミングを取得 for i in range(len(data.index)-1): if(data.sma_s[i]<data.sma_l[i] and data.sma_s[i+1]>data.sma_l[i+1]): data["g_point"].iat[i+1] = True # ゴールデンクロス時の傾き/角度を算出 data["sma_s_line"] = np.nan data["sma_l_line"] = np.nan data["sma_s_slop"] = np.nan data["sma_l_slop"] = np.nan data["sma_deg"] = np.nan for g in data.index[data.g_point]: # 2点間の直線を算出 a1 = data.sma_s[g] - data.sma_s[len(data.Close[:g])-1-1] b1 = data.sma_s[g] - a1*len(data.Close[:g]) data["sma_s_slop"].at[g]=a1 a2 = data.sma_l[g] - data.sma_l[len(data.Close[:g])-1-1] b2 = data.sma_l[g] - a2*len(data.Close[:g]) data["sma_l_slop"].at[g]=a2 data["sma_deg"].at[g] = np.rad2deg(np.arctan(abs((a1-a2)/(1+a1*a2)))) # plot用に直線データ追加 for i in range(11): x = len(data.Close[:g])-1+i-5 if(x<=len(data.Close)-1): data["sma_s_line"].iat[x]= a1*x+b1 data["sma_l_line"].iat[x]= a2*x+b2 # 除くゴールデンクロスを選択 for g in data.index[data.g_point]: # 角度の条件設定 if(data["sma_deg"].at[g] < 60): data["g_point"].at[g] = False # 向き(傾き)の条件設定 if(not(data["sma_s_slop"].at[g]>0 and data["sma_l_slop"].at[g]>0)): data["g_point"].at[g] = False # 〇日後に上昇しているか確認 for g in data.index[data.g_point]: for d in day: if(len(data.Close[:g])+d<=len(data.Close)): data.at[g,"roc_d"+str(d)] = (data.Close[len(data.Close[:g])+d-1]-data.Close[g])/data.Close[g]*100 else: data.at[g,"roc_d"+str(d)] = (data.Close[-1]-data.Close[g])/data.Close[g]*100 if(data.at[g,"roc_d"+str(d)]>0): data.at[g,"roc_d"+str(d)+"_point"] = 1 else: data.at[g,"roc_d"+str(d)+"_point"] = 0 # 上昇していたらカウンタを加算 data.dropna(inplace=True) if(len(data.index[data.g_point])>0): result["g_p_count"].iat[p] += len(data.index) for d in day: result["roc_d"+str(d)+"_plus"].iat[p]+=sum(data["roc_d"+str(d)+"_point"]) print(result)


- 投稿日:2021-01-19T10:58:47+09:00
[Python] Altairの凡例(legend)をプロットエリア内に表示させる
How To Place Legend Inside the Plot area in Altair
この記事について
最近はpandas/dataframeと相性がいいAltairが気にいって使っています。
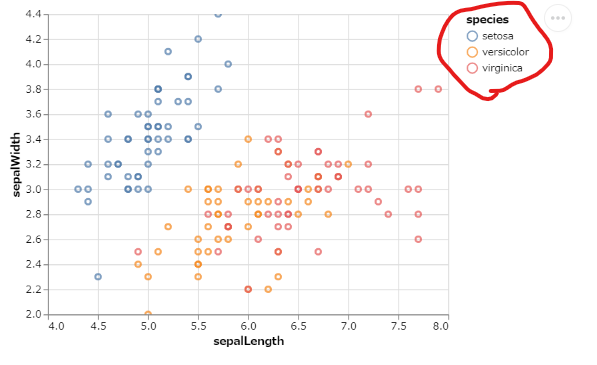
しかし、凡例の位置はmatplotlibだとプロット内に表示されるのに、Altairだと外になってしまい、位置の調節の仕方が分かりませんでした。英語でもなかなか資料が見つからなかったのですが、AltairがパースしているVega-Liteのドキュメントなどをみて解決しましたので、記事にします。非常に参考にさせていただいた、こちらのサイトよりIrisのデータのグラフにて説明したいと思います。
Altairのすすめ!Pythonによるデータの可視化BEFORE デフォルトでは右側に出てしまいます
import altair as alt from vega_datasets import data iris = data.iris() alt.Chart(iris).mark_point().encode( alt.X("sepalLength", scale=alt.Scale(zero=False)), alt.Y("sepalWidth", scale=alt.Scale(zero=False)), color="species" ).interactive()AFTER plot areaの任意の場所に移せます
import altair as alt from vega_datasets import data iris = data.iris() alt.Chart(iris).mark_point().encode( alt.X("sepalLength", scale=alt.Scale(zero=False)), alt.Y("sepalWidth", scale=alt.Scale(zero=False)), color=alt.Color("species", legend=alt.Legend(orient='none', legendX=250, legendY=5, ## orientをnoneに設定するとlegenX,legendYが指定できる strokeColor='blue', fillColor='white', padding=10)) ## legendの四角の設定 )凡例設定のポイント
コードをみていただければ分かるかと思いますが、alt.Legendでいろいろと細かく調整できます。
LegendXとLegendYで位置を調整できますが、その際にoriend='none'としておくのがポイントです。なお、このxとyの数値は何なのか、ちょっと分かりません・・なんとなくできてしまいますが、誰かご存知でしたら教えてください以下、参考にしたVeg-Liteのdocumentの大事なところをスクショして載せます。
Legend | Vega-Lite
https://vega.github.io/vega-lite/docs/legend.html
こちらの記事とは関係ありませんが、この中国の方のサイトの例は充実していました。
Python Altair COVID-19疫情数据可视化实践经验分享
https://www.cnblogs.com/dotlink/archive/2004/01/13/covid-19.html
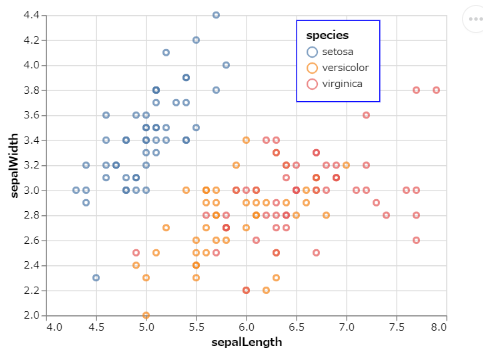


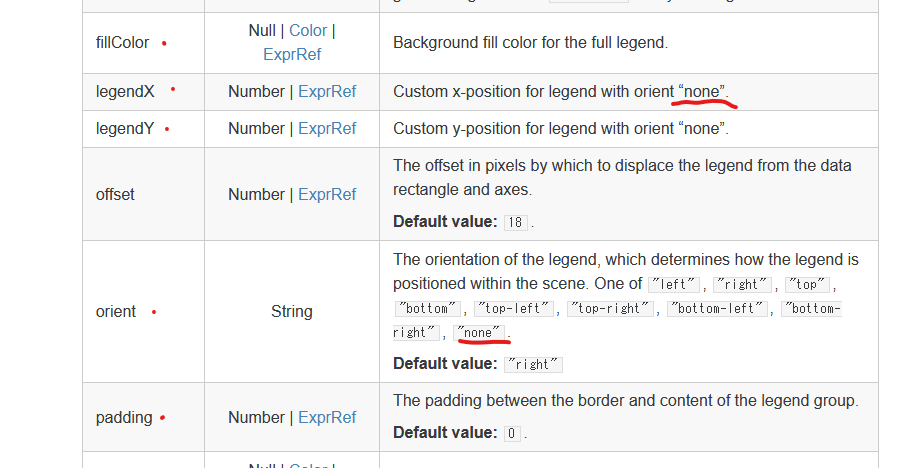
- 投稿日:2021-01-19T10:54:11+09:00
github webhook で slack通知を行う簡易アプリをgoogle cloud function(python)に実装する際のsecretsの認証周りメモ
背景
githubには発生したイベントをhookにリクエストを送信するwebhookという機能がある。例えば、github webhook + googlo cloud function + slack などを組み合わせると、独自のgithub -> slackの通知機能を実装することができる。
github secretにはsecrets設定ができる。これを使うことでよりセキュアなwebhookアプリケーションが作れる。
今回は、google cloud function で通知アプリを実装する際に、このセキュア実装をどうやるかをメモ。
実装
import hmac import hashlib def verify_github_secrets(req) -> bool: secret_value = "YOUR_SECRET" sigExpected = request.headers.get("X-Hub-Signature").split('sha1=')[-1].strip() sigCalculated = hmac.new(secret_value.encode(), request.data, hashlib.sha1).hexdigest() return hmac.compare_digest(sigCalculated, sigExpected) def main(req): if not verify_github_secrets(req): return "fail github auth" # TODO 実装 return "ok"参考
- 投稿日:2021-01-19T10:47:38+09:00
Cloud RunとPython(Flask)で爆速WEBサイト構築
Cloud RunとPython(Flask)で爆速WEBサイト構築
#週末ハッカソン用のWEBサイトを作成したので公開することにした
AWSやレンタルサーバーなど選択肢は沢山あるが今回はサーバーレスでほぼ無料で運用可能なCloud Runを使うことにしたGoogle Cloud SDKのインストール
Google Cloud SDK よりダウンロード
ダウンロードディレクトリに移動しsh実行、基本yで進む
インストール後ターミナルを再起動$ sh install.shバージョン確認
$ gcloud version Google Cloud SDK 321.0.0 bq 2.0.64 core 2020.12.11 gsutil 4.57SDK設定
ブラウザが開くので操作アカウントでログイン
次に操作プロジェクトを選択$ gcloud initプロジェクト変更したい場合
$ gcloud config set project [プロジェクト名]ビルド
Cloud Build を使用して Docker イメージをビルド
Dockerfile を作成
※ ./app コードはこちら を参考FROM python:3.7.4 WORKDIR /app ADD . /app RUN apt-get update && apt-get clean; RUN pip install -r requirements.txt ENV TZ = "Asia/Tokyo" ENV FLASK_APP /app/app.py ENV PYTHONPATH $PYTHONPATH:/app ENV PORT 8080 EXPOSE 8080 CMD ["python", "app.py"]ビルド実行
$ gcloud builds submit --tag gcr.io/weekend-hackathon/weekend-hackathon
デプロイ
Cloud Run を使いビルドしたコンテナをデプロイ
$ gcloud run deploy weekend-hackathon --project=weekend-hackathon --image=gcr.io/weekend-hackathon/weekend-hackathon --region=us-central1 --platform=managed --no-allow-unauthenticated Deploying container to Cloud Run service [weekend-hackathon] in project [weekend-hackathon] region [us-central1] ✓ Deploying new service... Done. ✓ Creating Revision... ✓ Routing traffic... Done. Service [weekend-hackathon] revision [weekend-hackathon-00001-teq] has been deployed and is serving 100 percent of traffic. Service URL: https://weekend-hackathon-leopsotyca-uc.a.run.app権限を追加
$ gcloud run services add-iam-policy-binding weekend-hackathon --region=us-central1 --member="allUsers" --role="roles/run.invoker" --platform=managed Updated IAM policy for service [weekend-hackathon]. bindings: - members: - allUsers role: roles/run.invoker etag: BwW5NtPWfrM= version: 1URLにアクセスしサイトが表示されれば完了
https://weekend-hackathon-leopsotyca-uc.a.run.app
補足
運用ではdeploy_run.shを作り一括してデプロイできるようにする
ローカルのDocker環境がそのまま公開できるので爆速で公開が可能
また Cloud Runはアクセス単位の料金なので初期リリースには最適是非お試しあれ
- 投稿日:2021-01-19T10:31:43+09:00
TCC関連のkernelパラメータを変更
今回は、「整数型で高方程式を解く=分散並列処理=」というタイトルの投稿を予定していました。しかし投稿用のsocket通信のプログラムを作成しているとき「予期せぬ出来事」があり、先に報告することにしました。
この「予期せぬ出来事」は、今回のタイトルにある「TCP関連のkernelパラメータ」に起因するものでした。最初は整数型の長大な桁数のdataを送受信できるプログラムということで、送信する数字のリストをどんどん大きくしていきました。初めはclient側送信量とserver側受信量はピッタリ一致していました。しかしある時点から、client側からの送信量に比べて、server側での受信量が少なくなる現象が出始めました。以下に経過を示します。Raspberry Pi 4Bのメモリー8GBの機種で、Raspberry Pi OS(2020-AUG-23, 64bitベータ版)に同梱のThonnyを使っています。
予期せぬ出来事
tcpのsocket通信をするための、serverプログラムとclientプログラムを、以下に示しています。
tcp-server.pyimport socket import time s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) s.bind(('192.168.2.20', 60020)) s.listen(5) clientsocket, address = s.accept() print(f"Connection from {address}") list0en = b'' list0en = clientsocket.recv(1016) list0str = list0en.decode("utf-8") len_list0str = int(list0str) print(len_list0str) initial_time=time.time() q, mod = divmod(len_list0str, 1016) list1stren = b'' if mod > 0: q += 1 for i in range(q): list1stren += clientsocket.recv(1016) print('recv finished') list1str = list1stren.decode("utf-8") print(str(time.time() - initial_time)) if len_list0str==len(list1str): print('length OK') clientsocket.close() s.close() print(list1str) time.sleep(10)tcp-client.pyimport socket import time s1 = socket.socket(socket.AF_INET, socket.SOCK_STREAM) s1.connect(('192.168.2.20', 60020)) tmp_0=1234567890123456 list0 = [] Su16b=800#14,400byte OK #Su16b=1000#18,000byte loss #Su16b=10000#180,000byte loss #Su16b=100000#1.75MB loss #Su16b=600000#10MB loss for i in range(Su16b): list0.append(tmp_0) list0str = str(list0) len_list0str = len(list0str) len_list0str_str = str(len_list0str) s1.send(bytes(len_list0str_str, 'utf-8')) q, mod = divmod(len_list0str, 1016) for i in range(q): temp_21str = list0str[1016*i:1016*(i+1)] s1.send(bytes(temp_21str, 'utf-8')) if mod > 0: temp_21str = list0str[1016*q:] s1.send(bytes(temp_21str, 'utf-8')) s1.close() time.sleep(10)clientプログラム中にSu16b=800#14,400byteがありますが、ここまでは問題なく送受信できていました。次にSu16b=1000#18,000byteと送信量を増やした時にserver側で受信するbyte数が少ない現象が出ました。Su16b=10000と更に増やしてもserver側で受信するbyte数が足りません。送信量が14,400byteより少し増えると受信量が合わなくなります。更にserverプログラムはsocketを閉じたはずですが、60020のportが使用中のままです。RaspberryPi本体を再起動して回復しました。再びserverプログラムを動かし受信すると、再び受信量が合わない、そして再び60020のportも使用中のままの繰り返しです。
ここで問題が2点生じています。1つはserver側の60020のportが使用中のままであること。もう1つは送信量より受信量が少ないことです。以下で別々に解決していきます。
使用中のportを開放
今回はRaspberryPi本体を再起動することで解決しました。
少ない受信を解決
初めに思いついたのがよく見かけるバッファーもれです。さらに「送信量が14,400byteより少し増えると受信量が合わなくなる。」ことに着目しました。受信バッファーが足りないと予想しました。そこでkernelパラメータが見れるsysctlコマンドで確認しました。kernelパラメータはふれたこともありませんから少し気が重かったのですが。
sudo sysctl -a
net.core.rmem_default=212992
net.core.wmem_default=212992
net.ipv4.tcp_rmem=4096 131072 6291456
net.ipv4.tcp_wmem=4096 16384 4194304
受信バッファーrmemはdefaultが131,072byteもありますから14,400byte付近からのバッファーもれとは関係なさそうです。一方、送信バッファーwmemのdefaultが16,384byteです。14,400byte付近からのバッファーもれに近いです。受信バッファーもれではなく、送信バッファーもれだと仮定しました。もともと受信バッファーは自動的な拡張がデフォルトでONになっているので受信バッファーもれは生じないようです。送信バッファーもれだと仮定すると、送信バッファーを増やせばいいことです。まずpython.orgのソケットプログラミングの以下のページはあらかじめ読んでいました。「socketを確実にcloseする」ように書かれていました。さらに「(信じられないかもしれないが) 一回の recv で 5 文字を全部受け取ることができるとは限らないからだ。・・・高負荷ネットワークのもとでは、recv ループをふたつ使わないコードは、あっと言う間にダメになってしまう」の部分は、高負荷になるとあるのかもしれないと参考にしてプログラムを書きました。
ソケットプログラミング HOWTO 著者:Gordon McMillanそして今回のバッファーもれ現象です。最初にkernelパラメータを変えていいのだろうかと色々調べました。よく見かけるのがWebサーバーのチューニングです。kernelパラメータをどんどん変えています。以下のページも参考にしました。
Linuxカーネルのチューニング .github
synアタックプロテクトなど公開Webサーバー向けのチューニングなども含まれていました。しかし今回は奥の奥にある閉鎖的なLANで、さらに送受信方法も決めたTCP通信です。公開サーバー向けのsynアタックなどは関係ありません。今回は送信量増大に伴う、送受信バッファー関連だけ変更しました。
sudo mousepad /etc/sysctl.conf
mousepadでetcフォルダーのsysctl.confファイルを開き、以下の6行を追加しました。
net.core.rmem_default=4194304
net.core.wmem_default=4194304
net.core.rmem_max=16777216
net.core.wmem_max=16777216
net.ipv4.tcp_rmem=4096 4194304 16777216
net.ipv4.tcp_wmem=4096 4194304 16777216
RaspberryPi本体を再起動後、前述のserverプログラムとclientプログラムを実行したところ、10MBまで正確に送受信できるようになりました。ただバッファーMAXが16MB程ですから、送信量が10MBを超えた場合は、分割して送信する必要があることもわかりました。今回のkernelパラメータ変更の問題点: Raspberry Piでインターネットを見ることは無いです。しかし仮に、この設定でインターネットを見るとします。例えば10kbyteの小さな画像アイコンが100種類配置されたWebページを閲覧したとします。Webページに配置された100個の画像のリクエストのため、100x送信バッファー4,194,304byte、100x受信バッファー4,194,304byte、合計で約840MBのメモリーを瞬間的に使うことになります。但しメモリーを使い過ぎるとsocket毎がminの4,096byteに自動的に縮小されるようなのでフリーズは回避できると思います。しかし受信バッファー4,096byteで10kbyteの画像ファイルを受信しなければならなくなります。多分受信もれが生じます。何かデコボコのチューニングです。これから考えると、今回のdefaultの4194304byteは、通常は大きくてもこの1/40程度、131072byteほどが推奨されているようです。またRaspberryPiでもメモリー1GBおよび500MBの機種では、少ないメモリーのためにチューニングがより繊細になりますから、チューニングの難易度がさらに上がりそうです。
今回は、ふれたこともないkernelパラメーターのTCP関連の設定変更になりました。整数型の長大な桁数のdataを送受信する目的で、支障が出ない最小範囲だけ変更したつもりですが、わかりません。投稿するのも少し気が重かったのですが、プログラム作成中に生じた1つの現象と試行した1つの解決策として今回報告しました。
肥大化した送受信量のプログラム中、バッファーもれにより離反化していく現象が生じ始め、順調に進んでいるように見えたプログラムに落日の予兆が、ぽつぽつと垣間見え始めていることがわかりました。
最後までご覧いただいて、ありがとうございました。
今回はQiitaの主旨に同意して投稿していますので、公開したプログラムはコピー、改変などでのご使用は自由です。著作権に関する問題も発生しません。
ただし、Raspberry Pi 4Bを使う場合にはCPUに特に大きめのヒートシンクが必須です。LAN通信の頻度の少ない今回のプログラムのような場合、LANチップは熱くなりません。しかし計算時間が継続するとCPUの激しい発熱で分かるように相当電力を使っています。電源UCB Cタイプの後ろにある黒い小さなチップも熱くなりますので、ファンでの風流も必要です。
次回、「整数型で高方程式を解く=分散並列処理=」では、Raspberry Pi 4台のsocket通信を使った分散処理により、計算時間を短縮する試行を予定しています。
- 投稿日:2021-01-19T10:09:38+09:00
リスト、タプル、辞書、集合の使い分け
Udemyの講座、現役シリコンバレーエンジニアが教えるPython 3 入門 + 応用 +アメリカのシリコンバレー流コードスタイルのメモです。
リスト
任意の型(整数、浮動小数点数、文字列など)のデータを格納できる。要素には順序があり、インデックスを用いて要素を指定できる。リストの要素は変更可能。他のプログラミング言語における「配列」的な使い方をする。
使用例
タクシーのシートに人が乗れるかの判定
>>> seat = [] >>> min = 0 >>> max = 4 >>> min <= len(seat) < max True >>> seat.append("person") >>> len(seat) 1 >>> seat.append("person") >>> seat.append("person") >>> seat.append("person") >>> min <= len(seat) < max False >>> seat.pop(0) "person"タプル
任意の型(整数、浮動小数点数、文字列など)のデータを格納できる。要素には順序があり、インデックスを用いて要素を指定できる。リストとは異なり、タプルの要素は変更不可能
使用例
クイズ
>>> chose_from_two = ("A", "B", "C") >>> answer = [] >>> answer.append("A") >>> answer.append("C")辞書型
キーと値の組で表されるデータを格納する。要素は順序を持たない(インデックスによる要素の指定ができない)。他のプログラミング言語における「連想配列」に相当する
使用例
果物のECサイト
>>> fruits = {"apple": 100, "banana": 200, "orange": 300} >>> fruits.items() dict_items([('apple', 100), ('banana', 200), ('orange', 300)]) >>> fruits.keys() dict_keys(['apple', 'banana', 'orange']) >>> fruits.values() dict_values([100, 200, 300]) >>> fruits["apple"] 100 >>> fruits.get("apple") 100 >>> fruits.pop("apple") 100 >>> "apple" in fruits False集合
数学でいう「集合」を扱うための型。各要素は重複することがなく、順序を持たない(インデックスによる要素の指定ができない)
使用例
SNSで「共通の友達」を探す
>>> my_friends = {"A", "C", "D"} >>> A_friends = {"B", "D", "E", "F"} >>> my_friends & A_friends {'D'} >>> fruits = ["apple", "banana", "apple", "banana"] >>> kind = set(fruits) >>> kind {'apple', 'banana'}
- 投稿日:2021-01-19T09:29:54+09:00
[Python]変数や引数として扱うCallableオブジェクトに対する型アノテーションの書き方
Pythonで関数やメソッドを変数や引数(Callableオブジェクト)として扱う必要が出て来る時があります。
そういった時の型アノテーション周りについて備忘録も兼ねて記事にしておきます。
使う環境
- Python 3.8.5
- VS Code
- VS Code拡張機能のPylance(型チェックや補完用)
- ※詳細は以前書いた[Python]PylanceのVS Code拡張機能をさっそく使ってみた。などの記事をご確認ください。
まずは型アノテーションの無い状態
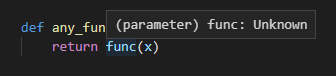
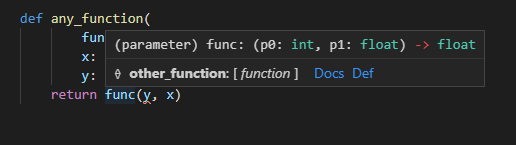
とある以下のような関数があり、引数に関数のオブジェクト(
func)と任意の値(x)を受け付けるとします。def any_function(func, x): return func(x)当たり前ですがこれだとVS Code上でマウスオーバーしてみても型などの情報がUnknownとなってしまいます。Pylance(Pyright)などでも型のチェックなどは行われません。docstringなどで詳細を詳しく書いておくという対策もありますが、このままだと曖昧でミスをしがちです。
Callableの型アノテーションを行う
続いてfunc引数にCallableの型アノテーションをします。Callableはビルトインのtypingパッケージ内に存在します。ついでにx引数などに対しても型アノテーションをしておきます。
from typing import Callable def any_function(func: Callable, x: int) -> int: return func(x)こうするとVS Code上でマウスオーバーなどをするとfunc引数は呼び出せるなんらかの関数やメソッドだということを認識してくれます。
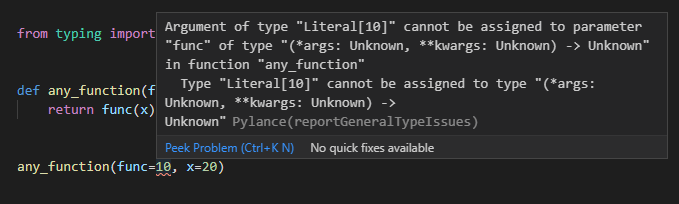
また、func引数に関数など以外を指定すればPylanceのチェックで引っかかってくれます。
any_function(func=10, x=20)
ただしマウスオーバーした際の引数や返却値の情報はUnknownのままです。
引数や返却情報の型アノテーションを行う
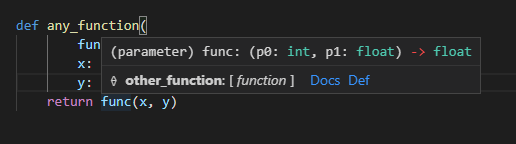
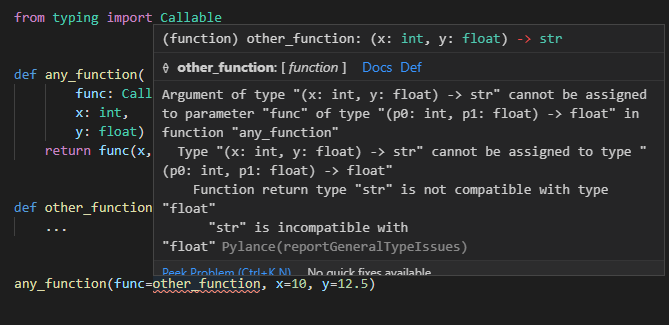
func関数を第一引数にint、第二引数にfloat、返却値にfloatを返すといった型アノテーションをしていきます(サンプルの引数にも、
yというflaotの引数を追加していきます)。書き方としては
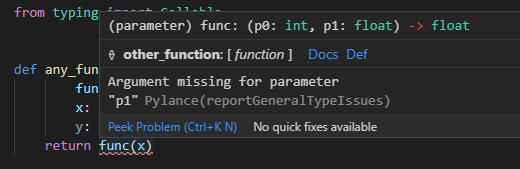
Callable[[第一引数の型, 第二引数の型], 返却値の型]といったように書きます。引数が増減した場合にはコンマ区切りで増やしたり減らしたりします。def any_function( func: Callable[[int, float], float], x: int, y: float) -> float: return func(x, y)これによって、マウスオーバー時に関数の引数や返却値の型情報が表示されたり、func引数を呼び出した際に引数が足りなかったり型が一致していなければエラーで検知できるようになります。
func呼び出し箇所で引数が足りていないサンプルdef any_function( func: Callable[[int, float], float], x: int, y: float) -> float: return func(x)
func呼び出しで型が一致していないサンプルdef any_function( func: Callable[[int, float], float], x: int, y: float) -> float: return func(y, x)
引数に渡す時などにも指定した関数の構造が一致しているかがチェックされます。
引数に渡しているCallableの返却値が一致しておらずチェックに引っかかるサンプルdef any_function( func: Callable[[int, float], float], x: int, y: float) -> float: return func(x, y) def other_function(x: int, y: float) -> str: ... any_function(func=other_function, x=10, y=12.5)
ここまでの対応でも型アノテーションの無いケースと比べると大分堅牢な感じになってきました。
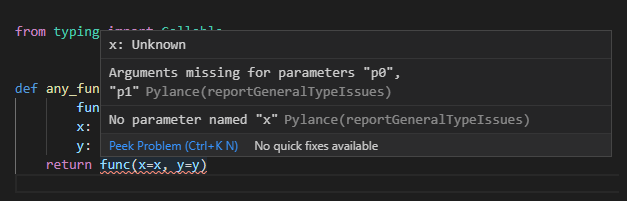
ただしこの場合キーワード引数の指定が元の引数名が使えません。引数名は保持されず、p0, p1, ...という名前が割り振られます。例えば以下のようにキーワード引数付きで書くとPylanceのチェックで引っかかってしまいます。
def any_function( func: Callable[[int, float], float], x: int, y: float) -> float: return func(x=x, y=y)
多くのケースではこれでも特に問題にならない場合も多いですが、例えば引数が多かったり同じ型の引数がたくさんあるとキーワード引数を使いたくなってきます。
引数名の情報を保持する形で型アノテーションを行う
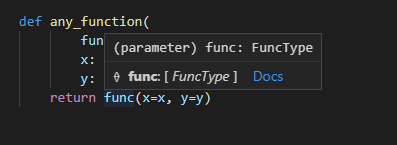
実はtypingパッケージのProtocolを使うと、引数名も保持した状態で型アノテーションをすることができます(最近知りました)。
使い方としては、Protocolを継承した形でクラスを定義し、
__call__メソッドに必要な引数や返却値・型の情報などを定義します(今回はサンプルとしてFuncTypeという名前にしました)。あとはそのクラス(FuncType)をfunc引数の型アノテーションに指定すればOKです。from typing import Callable, Protocol class FuncType(Protocol): def __call__(self, x: int, y: float) -> float: ... def any_function( func: FuncType, x: int, y: float) -> float: return func(x=x, y=y)これでキーワード引数を使ってもPylance上でエラーが出なくなります。
ProtocolはPython3.8以降で利用ができます。Python3.7以前のバージョンで使いたい場合や配布ライブラリなどで過去のPythonバージョンもサポートしたい場合にはバックポート的にpipなどでtyping-extensionsライブラリをインストールする必要があります。mypyなどをインストールした場合には一緒にインストールされます。
importの記述もtypingモジュールではなくtyping_extensionsというように記述が変わります。挙動や使い方はtypingのProtocolもtyping_extensionsのProtocolも変わりません。
from typing_extensions import Protocol参考サイト・参考文献まとめ

- 投稿日:2021-01-19T07:20:48+09:00
pyqtgraphでヒートマップを作成する
はじめに
リアルタイムでヒートマップを作成する機会があり、matplotlibでは処理速度が不安だった為pyqtgraphを使用しました。しかしpyqtgraphは日本語の情報が少なく、ヒートマップに使うカラーバーもデフォルトでは無かった為色々調べた結果を記載します。
環境
Mac OS
Python 3.8.1pipでインストールしたもの
colour 0.1.5
numpy 1.19.2
pgcolorbar 1.0.0
PyQt5 5.15.2
PyQt5-sip 12.8.1
pyqtgraph 0.11.0
pip install colour numpy pgcolorbar PyQt5 PyQt5-sip pyqtgraphpgcolorbar
pyqtgraphでカラーバーを作成してくれるライブラリです。
pipでインストールした後下記コマンドでdemoが見れます。
pgcolorbar_demo詳細
リアルタイム描画は今回見送りしてヒートマップのみの説明をします。
最終的に以下の画面を作成します。
(2021/01/19 修正前)
サンプルデータ
説明に使用するサンプルデータです。色々やってますが特に意味はありません。
2次元配列の為RGB情報はありません。# サンプル配列 data = np.random.normal(size=(200, 200)) data[40:80, 40:120] += 4 data = pg.gaussianFilter(data, (15, 15)) data += np.random.normal(size=(200, 200)) * 0.1画像表示の最小コード(とする)
以降は下記コードに追記してヒートマップを作成していきます。
行っていることは
- ウィンドウ作成
- 画像作成
- 画像をビューに追加
- グラフを作成(画像の座標表示の為)
- グラフに3.で作成したビューを追加
- ウィンドウにグラフを追加
- 表示
です
"""pyqtgraphで画像を表示する最小コード(とする)""" import sys import numpy as np from PyQt5 import QtWidgets import pyqtgraph as pg # サンプルデータのコードは省略 # GUIの制御オブジェクト app = QtWidgets.QApplication(sys.argv) # ウィンドウ作成 window = pg.GraphicsLayoutWidget() # 画像オブジェクト作成 & 画像をセット image = pg.ImageItem() image.setImage(data) # 画像を格納するボックス作成 & 画像オブジェクトをセット view_box = pg.ViewBox() view_box.addItem(image) # プロットオブジェクト作成 & 上で作成したview_boxをセット plot = pg.PlotItem(viewBox=view_box) # ウィンドウにplotを追加 window.addItem(plot) # ウィンドウ表示 window.show() # プログラム終了 sys.exit(app.exec_())この状態で実行すると以下の画面が作成されます。
ViewBox
以下を追加します。
view_box.setAspectLocked(lock=True)view_boxのアスペクト比を固定します。画像サイズが200×200の正方形の為、ウィンドウサイズが変わった時に形が変わってほしくないからです。
追加した周辺のコード
view_box = pg.ViewBox() view_box.setAspectLocked(lock=True) # Add view_box.addItem(image)実行した時の画面
PlotItem
編集する個所はありません。
ImageItem
追記した箇所とその周辺を下記に記載します。
################## Add ####################### from colour import Color blue, red = Color('blue'), Color('red') colors = blue.range_to(red, 256) colors_array = np.array([np.array(color.get_rgb()) * 255 for color in colors]) look_up_table = colors_array.astype(np.uint8) ################## Add ####################### image = pg.ImageItem() image.setLookupTable(look_up_table) # Add image.setImage(data)実行した時の画面
from colour import Color
中身の詳細を記載します。この項で作成したいものはRGB情報の2次元配列(符号なし8bit整数)です
[[R, G, B],
[R, G, B],
...
[R, G, B],]blue, red = Color('blue'), Color('red') # >>> <class 'colour.Color'> <class 'colour.Color'> blue.get_rgb() # >>> (0.0, 0.0, 1.0) colors = blue.range_to(red, 256) # 青から赤までの色を256分割 # >>> generator リストにして中身を見ると # >>> [<Color blue>, <Color #0004ff>, <Color #0008ff>, ..., <Color red>] colors_array = np.array([np.array(color.get_rgb()) * 255 for color in colors]) # >>> [[ 0. 0. 255.] # [ 0. 4. 255.] # [ 0. 8. 255.] # ... # [255. 0. 0.]] float64 look_up_table = colors_array.astype(np.uint8) # 符号なし8bit整数に変換 # >>> [[ 0 0 255] # [ 0 3 255] # ... # [255 0 0]] uint8Look Up Table
入力色データに対応する出力色データをLook Up(参照)するTable(対応表)
第一回 LUTの基本 | TVLogicらしいです。(あまり詳しくなくてすみません、、、)
サンプルデータの値をRGB情報に変換してくれる表のようなイメージです。2021/01/19 追記
image.setOpts(axisOrder='row-major')上記コードを追加して下さい。
pg.PlotItemはデフォルトでは列 -> 行で2次元配列を読み込みます。
2次元配列は基本的に行列なので行 -> 列で読み込む為に必要です。
書かなかった場合、元データの転置行列のように読み込まれます。修正後のコード
################## Add ####################### from colour import Color blue, red = Color('blue'), Color('red') colors = blue.range_to(red, 256) colors_array = np.array([np.array(color.get_rgb()) * 255 for color in colors]) look_up_table = colors_array.astype(np.uint8) ################## Add ####################### image = pg.ImageItem() image.setOpts(axisOrder='row-major') # 2021/01/19 Add image.setLookupTable(look_up_table) # Add image.setImage(data)ColorLegendItem
カラーバーを作成します
以下を追加します。################## Add ####################### from pgcolorbar.colorlegend import ColorLegendItem color_bar = ColorLegendItem(imageItem=image, showHistogram=True) color_bar.resetColorLevels() window.addItem(color_bar) ################## Add #######################
imgeItemにはpg.imgItemを渡します。showHistogramはカラーバー横のヒストグラムを表示するかを決められます。デフォルトはTrueの為何もしなければ表示されます。
resetColorLevels()でカラーバーの範囲をデータの最大、最小値に設定します。実行した画面(2021/01/19 修正前)
全体
全体のコード
"""全体コード""" import sys from colour import Color import numpy as np from pgcolorbar.colorlegend import ColorLegendItem from PyQt5 import QtWidgets import pyqtgraph as pg # サンプル配列 data = np.random.normal(size=(200, 200)) data[40:80, 40:120] += 4 data = pg.gaussianFilter(data, (15, 15)) data += np.random.normal(size=(200, 200)) * 0.1 app = QtWidgets.QApplication(sys.argv) window = pg.GraphicsLayoutWidget() blue, red = Color('blue'), Color('red') colors = blue.range_to(red, 256) colors_array = np.array([np.array(color.get_rgb()) * 255 for color in colors]) look_up_table = colors_array.astype(np.uint8) image = pg.ImageItem() image.setOpts(axisOrder='row-major') # 2021/01/19 Add image.setLookupTable(look_up_table) image.setImage(data) view_box = pg.ViewBox() view_box.setAspectLocked(lock=True) view_box.addItem(image) plot = pg.PlotItem(viewBox=view_box) color_bar = ColorLegendItem(imageItem=image, showHistogram=True) color_bar.resetColorLevels() window.addItem(plot) window.addItem(color_bar) window.show() sys.exit(app.exec_())参考
GitHub - titusjan/pgcolorbar: Color bar to use in PyQtGraph plots
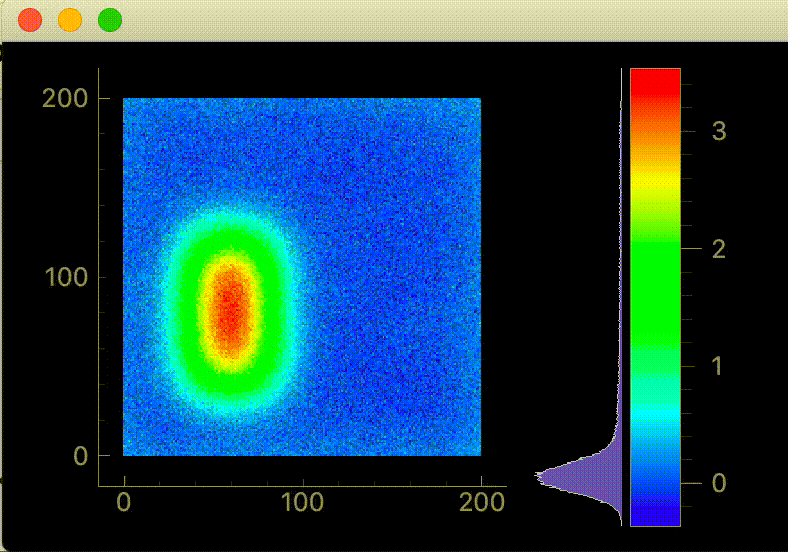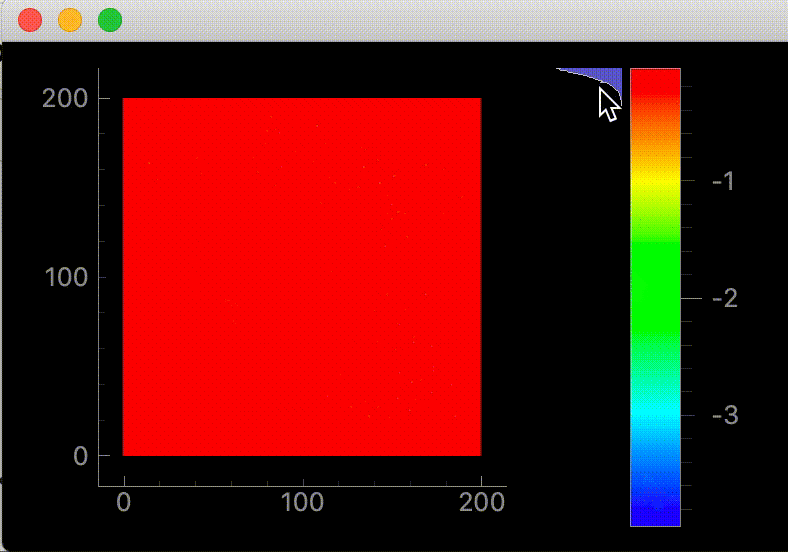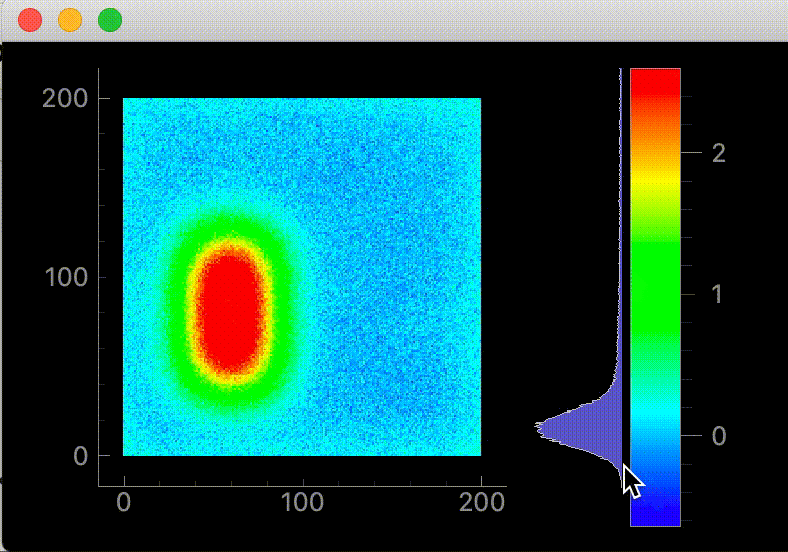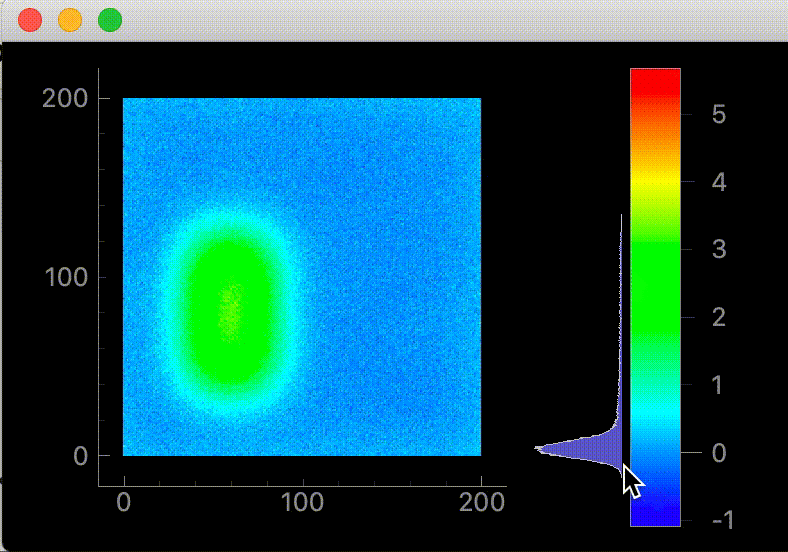


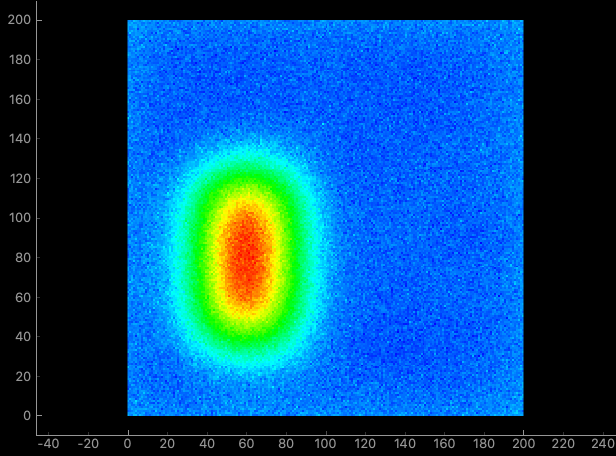
- 投稿日:2021-01-19T00:48:43+09:00
Google Keepのアカウント間データコピーをPythonで
Googleアカウント移行
Googleアカウントのデータを別のGoogleアカウントに移行するには各サービス単位で頑張って行う必要があります。
過去に以下の方法で移行しました。
データ 移行方法 メール 移行しなかったがThunderbirdなどから新旧アカウントにIMAP接続すればできそう ドライブ ダウンロード&アップロード カレンダー エクスポート&インポート YouTube ブランドアカウントを利用し、新アカウントをユーザー追加し管理者とする フォト 共有機能を利用する Keep HTML形式でダウンロードしたものを手動でコピペしてメモを作り直す Keepデータの移行をPythonで
今回またGoogleアカウントを移行することになり上記の手法で行うことにしたのですが、Keepデータが前回よりも増えたので、Keepの移行はPythonで自動化することにしました。
PythonからKeepの操作を行えるgkeepapiというライブラリがあるのでそれを利用することにします。
gkeepapiのインストール
Anaconda環境でしたが、condaではgkeepapiライブラリがなかったのでpipでインストールしました。
pip install gkeepapiPythonスクリプト
以下のスクリプトを書いて実行。
手作業でやると半日かかりそうな処理が数秒で終わりました!
スクリプトの作成&デバッグには1日かかりましたが良い勉強になりました。cpgkeep.pyimport gkeepapi # 移行元へログイン src_keep = gkeepapi.Keep() src_success = src_keep.login('old-account@gmail.com', 'old-password') # 移行先へログイン dst_keep = gkeepapi.Keep() dst_success = dst_keep.login('new-account@gmail.com', 'new-password') # ラベルのコピー src_labels = src_keep.labels() for src_label in src_labels: if dst_keep.findLabel(src_label.name) is None: # 同名のラベルが存在しないことを確認して作成 dst_label = dst_keep.createLabel(src_label.name) print('created label => [' + src_label.name + ']') # 同期 dst_keep.sync() # メモ(ノート)のコピー src_gnotes = src_keep.all() for src_gnote in src_gnotes: # ノートの作成(タイトルの重複は可なので同名チェックは行わない) dst_gnote = dst_keep.createNote(src_gnote.title, src_gnote.text) # ピン留めのコピー dst_gnote.pinned = src_gnote.pinned # ラベルのコピー src_labels = src_gnote.labels.all() for src_label in src_labels: dst_label = dst_keep.findLabel(src_label.name) dst_gnote.labels.add(dst_label) print('created note => [' + src_gnote.title + ']') # 同期 dst_keep.sync()このスクリプトでやってることはシンプルなメモデータのコピーです。
個人的に「ピン留め」と「ラベル」機能を多用してたので、それらにも対応させました。Windows環境のPython3.6と3.8で動作することを確認しています。
苦労したポイント
メモにラベルを追加する処理です。
移行前のメモからラベルを取得する必要がありますが、それを実現する関数やメソッドがドキュメントに記載されてなかったのです。
心が折れかかりましたが、頑張ってGitHubのモジュールをながめたところ、NodeLabelsクラスにdef all(self):というドキュメントに無いメソッドが定義されており、もしかしてこれ使えるんじゃね?ということでsrc_gnote.labels.all()と書いて試したら的中でした。
隠しコマンドを見つけたような気分になれましたね。認証が失敗するケース
下記のようなエラーメッセージが出て認証に失敗する環境がありました。
gkeepapi.exception.LoginException: ('NeedsBrowser', 'To access your account, you must sign in on the web. Touch Next to start browser sign-in.')原因は良くわかりませんが、該当の端末から移行元・移行先の両Googleアカウントで下記URLにブラウザでアクセスし、「次へ」ボタンを押した後に、再度Pythonスクリプトを実行すると認証が通ります。
https://accounts.google.com/b/0/DisplayUnlockCaptcha但し、しばらく時間が経つとまた認証エラーが出るようになるので再度ブラウザでアクセスしてから実行する必要があります。
認証処理についてはパスワードなどハードコーディングしてるので見直ししたほうが良いかもしれません。
resume.pyでトークンを使った認証をしているので時間があったらまた試してみたいと思います。