- 投稿日:2021-01-19T23:14:32+09:00
Well-ArchitectedFrameworkの設計原則
記事の目的
・well-architectedFramework とは何かについて簡単に学ぶ
・well-architectedFrameworkTool とは何をする為のツールなのか簡単に学ぶwell-architectedFramework について
AWSの基本的な5つの設計原則。
原則 概要 信頼性 可用性、回復力、信頼性の高いアーキテクチャの設計がされている。 パフォーマンス効率 コンピューティングリソースの効率的な使用に焦点を当てた設計が成されている。 セキュリティ 情報とシステムの保護(機密性と完全性)に焦点を当てた設計がされている。 コスト最適化 不要なコストの回避が出来ている設計がされている。 オペレーショナルエクセレンス ビジネス価値を提供するためのシステムの実行とモニタリング、およびプロセスと手順の継続的な改善に焦点を当てた設計が出来ている。 well-architectedFrameworkを実現するための補助
・上記の設計原則はAWSの Well-architectedFrameworkホワイトペーパーに記載されている。
・AWSのSA、認定パートナーによるコンサル( well-architectedFrameworkを実現方法について )
・セルフチェック向けのwell-architectedTool( well-architectedFrameworkに沿った設計ができているか )基本のアーキテクチャ設計
1つのリージョンで複数のAZに跨ってマルチAZをするのが基本中の基本
【マルチAZ構成】
VPC領域に複数のAZを跨らせてサブネットを確保してEC2インスタンス(サーバー)やDBなど構成していく、ELBを使用して冗長化(可用性、耐障害性、信頼性を高める)させていく。
※ELBとはトラフィック分散を行い可用性、耐障害性、信頼性を高める。自動でスケーリングするように設定も可能。
※スケーリングとはトラフィックの増加に伴って処理能力を増強する際に、単体の性能を向上(スケールアップ)させたり、稼働数を増やして処理を分散し、全体として処理能力を高める。(スケールアウト)
例)AZ1に10.0.1.0/24のサブネット確保、AZ2に10.0.2.0/24のサブネットを確保
=> 冗長構成を確立させる事で高い可用性を実現させる。さらに可用性を高める為に。。。
【マルチリージョン構成】
route53を介して2つのリージョンに跨って同じ2つのシステム構成をフェイルオーバーすることが可能。
基本はマルチAZを採用して冗長化を図るがより可用性を高めたいときはマルチリージョン型も検討する。
もしくは別のリージョンにバックアップをとっておく。大きな地震や災害にも耐えられる。
- 投稿日:2021-01-19T23:12:50+09:00
【AWS】Amazon EFSとAmazons3の違い
- 投稿日:2021-01-19T22:57:12+09:00
React.js & Next.js, Material UI + AWS Lambdaでお問合せフォームを作ってみた
はじめに
今回の記事は以下2冊の書籍の復習を兼ねて作成した内容になります。
- React.js & Next.js 超入門(掌田津耶乃さん 著)
- AWS Lambda実践ガイド(大澤文孝さん 著)
何を作ったのか
今回は上記2冊で学んだ内容を総動員ということで以下のようなお問合せフォームを作成してみました。
こちらに内容を記載し、「送信」ボタンをクリックすると管理人へメールが飛ぶ仕様です。
まあこれだけですとわざわざライブラリ等を利用するほどでもないのですが、一応復習ということで敢えて利用して作りました。
フロントエンドではReact.js & Next.js, CSS, Material UIを利用し、バックエンドではLambda(Python), S3, DynamoDB, API Gatewayを利用しています。
実装内容
簡単ではありますが実装内容を振り返っていきたいと思います。
画面系
こちらはコンポーネントとして「ヘッダー」「フォーム画面」「フッター」「レイアウト」とそれぞれ分けてファイルを作成しています。
https://github.com/Oooooomin2/ContactForm/tree/main/components個人的にはMaterial UIの破壊力といいますか、便利さとデザインの綺麗さに圧倒されてしまいました。
今までは「簡単にデザイン等を作りたい」という時はBootstrapを使っていたのですが、こちらの方がデザインが今風で綺麗ですね。
以下のコードのみでテキストフィールドやヘッダーが作れちゃいました(送信ボタンとフッターは別途CSSで作成しています。)ContactForm.jsimport React, { Component } from 'react'; import { TextField, Input } from '@material-ui/core'; import Grid from '@material-ui/core/Grid'; class ContactForm extends Component { render() { return ( <Grid container alignItems="center" justify="center"> <form id="ContactForm" action=""> <Grid className="gridItems" item md={12}> <TextField required fullWidth id="Username" label="お名前" variant="outlined" color="secondary" /> </Grid> <Grid className="gridItems" item md={12}> <TextField required fullWidth id="MailAddress" label="メールアドレス" variant="outlined" color="secondary" /> </Grid> <Grid className="gridItems" item md={12}> <TextField fullWidth id="PhoneNumber" label="電話番号" variant="outlined" color="secondary" /> </Grid> <Grid className="gridItems" item md={12}> <TextField required fullWidth rows={15} multiline id="Contact" label="お問合せ内容" variant="outlined" /> </Grid> <Grid id="SubmitButtonGrid" className="gridItems" item md={12}> <Input id="SubmitButton" type="submit" variant="outlined" /> </Grid> </form> </Grid> ); } } export default ContactForm;Header.jsimport React, { Component } from 'react'; import { AppBar, Toolbar, Typography } from '@material-ui/core'; class Header extends Component { render() { return ( <header> <AppBar position="static"> <Toolbar> <Typography variant="h6"> お問合せフォーム </Typography> </Toolbar> </AppBar> </header> ); } } export default Header;今回のお問合せフォームでは感じませんでしたが、UIを「コンポーネント」という部品で細かく管理していくReactは大きなサービスを作るにあたってはかなり有用だなと感じました。次回以降趣味等でアプリを作る際はReactが大活躍するよう大きめのアプリを作ってみようと思います。
サーバ側
サーバ側の処理の流れは以下になります。
(アプリはS3の静的ウェブサイトホスティング機能を用いて配信しています。)
- 「送信」ボタンを押します。
- API Gatewayを通してLambda関数へフォームデータが渡ります。
- DynamoDBに問い合わせ内容を格納します。
- Amazon SESを用いて管理者へ問い合わせ通知メールを送ります。
Lambda関数は以下です。
こちらのコードは上記の「AWS Lambda実践ガイド」に記載されたコードへ少々変更を加えて作成しています。
Lambda関数を作る際はAWS側が提供してくれる設計図(1からコードを書かなくてもいいように用途ごとに用意されている大まかなサンプルコード)がありますが僕にとっては本のコードが設計図になりました。
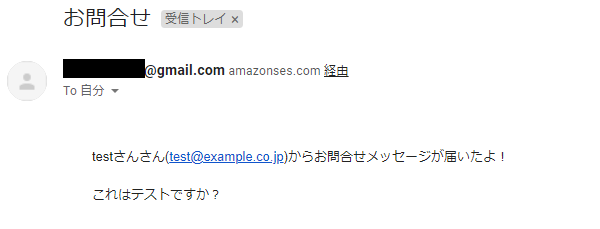
凄く勉強になりました。ありがとうございます。Contact.pyimport json import boto3 import urllib.parse import time import decimal import base64 dynamodb = boto3.resource('dynamodb') MAILFROM='メールアドレス' def sendmail(to, subject, body): client = boto3.client('ses') response = client.send_email( Source=MAILFROM, ReplyToAddresses=[MAILFROM], Destination={ 'ToAddresses': [ to ] }, Message={ 'Subject': { 'Data': subject, 'Charset': 'UTF-8' }, 'Body' :{ 'Text': { 'Data': body, 'Charset': 'UTF-8' } } } ) def next_seq(table, tablename): response = table.update_item( Key={ 'tablename': tablename }, UpdateExpression="set seq = seq + :val", ExpressionAttributeValues={ ':val' : 1 }, ReturnValues='UPDATED_NEW' ) return response['Attributes']['seq'] def lambda_handler(event, context): try: seqtable=dynamodb.Table('sequence') nextseq = next_seq(seqtable, 'contact') body = base64.b64decode(event['body']) param = urllib.parse.parse_qs(body.decode('utf-8')) username=param['username'][0] mailaddress=param['mailaddress'][0] phonenumber=param['phonenumber'][0] contact=param['contact'][0] host=event['requestContext']['http']['sourceIp'] now=time.time() contacttable = dynamodb.Table("ContactInfo") contacttable.put_item( Item={ 'id': nextseq, 'username': username, 'mailaddress': mailaddress, 'phonenumber' :phonenumber, 'contact': contact, 'accepted': decimal.Decimal(str(now)), 'host': host } ) mailbody = """ {0}さん({1})からお問合せメッセージが届いたよ! {2} """.format(username, mailaddress, contact) sendmail(MAILFROM, 'お問合せ', mailbody) return { 'statusCode': 200, 'headers' : { 'content-type': 'text/html' }, 'body':'<!DOCTYPE html><html><head><meta charset="UTF-8"></head><body>お問合せありがとうございました。</body></html>' } except: import traceback traceback.print_exc() return { 'statusCode': 500, 'headers': { 'content-type': 'text/html' }, 'body': '<!DOCTYPE html><html><head><meta charset="UTF-8"></head><body>内部エラーが発生しました。</body></html>' }※エラーが発生した場合はCloudWatchにログが出力されますので確認してみてください。僕は何度もエラー出しました。
使ってみる
いざお問合せフォームを入力して「送信」ボタンを押すとメールも届いてDynamoDBにもしっかりと情報が格納されていました。
さいごに
作成したアプリのコード類は以下のGithubにて公開しております。
https://github.com/Oooooomin2/ContactForm今後の展望としましては、自分が普段から使っているASP.NET Core MVCにReactやMaterial UIを組み込んでアプリを作ってみたいです(いつもフロントはjQueryとBootstrapなので)。Lambdaを使ったサーバレスアーキテクチャもだいぶイメージがつきましたので引き続き色々なものを作ったりして知識を定着させていこうと思います。
おまけ
今回、お問合せフォームをS3に配置するにあたってNext.jsの機能であるStatic HTML ExportにてHtmlを作成して配置しました。
その際に対象のエンドポイントにアクセスしても毎回403エラーが出力されたんですよね...。解決策としまして、S3のバケットのアクセス許可だけではなく、その中に配置したオブジェクト一つ一つをアクセス許可することで解消できました。盲点でした。次からはハマらないように気をつけます(;^_^A

- 投稿日:2021-01-19T22:11:47+09:00
AWS ソリューションアーキテクト合格までのまとめ
目次
0. はじめに
先日、AWS ソリューションアーキテクト アソシエート に合格したので、忘れないうちに色々とアウトプットしておこうと思います。これから受験を考えている方の役にたてればと思います。
どんな人間がどのくらいの時間をかけて取得したのかを説明するために、少しだけ自分語りをさせてください。
24歳のインフラエンジニアです。現在は GCP とか AWS を仕事で触ってます。クラウドは触り始めて半年くらいです。ネットワークは少しだけ詳しいですが、プログラミングはほとんどできません。持ってる資格はこんな感じ
1.受験動機
クラウドを触り始めたはいいけどどこから手をつければいいのかわからず、体系的に学習するために受験を決めました。
2.出題の範囲
まーあ広いです。細かな内容はここにはかけませんが、設問に出てくる課題に対して、どのサービスを使えば解決できるのかを引き出せるようにしておくといいかもしれないです。
3.勉強方法
Udemy の講座と問題集のみを教材にし、わからないところを公式のドキュメントで埋め合わせるような勉強方法で進めました。
Udemy で購入した教材はこちらです。
これだけでOK! AWS 認定ソリューションアーキテクト – アソシエイト試験突破講座(SAA-C02試験対応版)
【SAA-C02版】AWS 認定ソリューションアーキテクト アソシエイト模擬試験問題集(6回分390問)
上記の2つで合格はできるかなと思います。
私の場合は、講座の方は1.5倍速 + ハンズオンは設定画面を見るだけという進めかたをしたため、勉強時間は 30h ほどでした。サービスの細かなオプションはいったん飛ばして、概念や構成を優先的に理解していくと効率がいいのかなと感じました。(どんな資格にも言えますが、概念をしっかり理解しないと、ただの暗記ゲーになってしまいます)
また、試験に出てくる問題の配分も講座内で解説があるため、何を重点的に学習するのかを決めておくことは、合格への戦略の一つかと思います。4.試験に活きたメモ
実際の試験に活きた学習メモを残そうと思いましたが、メモがぐちゃぐちゃなので少しずつ更新していきます。
4.1 EC2
インスタンスタイプ
スケジュールドリザーブドインスタンス
特定の期間で定期的にインスタンスを使用する場合に選択する
日次、週次、月次の単位で予約することができる
例えば、毎週金曜日だけバッチ処理用のインスタンスが必要など
オンデマンドインスタンス
利用時間に応じた料金を支払う
ハードウェア占有インスタンス
AWS アカウント単位で、物理的なサーバを占有することができる
同じ AWS アカウントとは 物理サーバを共有する可能性がある
Dedicated インスタンス
同じ AWS アカウントでも IAM の権限単位で物理的なサーバを占有することができる
同一サーバに他テナントを入れいてはいけないなどの、セキュリティ面での制約がある場合に使用する
リザーブドインスタンス(コンバーティブル)
途中でインスタンスファミリー、OS、テナンシー、支払オプションを変更することができる
4.2 S3
ブロックパブリックアクセス
バケット単位、またはアカウント単位での、全てのパブリックアクセスをブロックすることができる
デフォルトでは有効になっているため、インターネット上にバケットを公開するには、無効化する必要がある
ライフサイクル管理
オブジェクトのライフサイクルを設定することができる
使用頻度の高いクラスから低いクラスへの移動はできるが、その逆はできない
例えば、Glacier から Standerd への移動はできない
S3 Select
シンプルな SQL ステートメントを使用することで、オブジェクトの内容をフィルタリングし、取り出しデータのコスト削減、待ち時間を軽減できる
高度なデータ解析には向いていない
クロスリージョンレプリケーション
リージョン間でバケットをレプリケーションする際に使用する
レプリケーションのトリガーはバケット内の変更になるため、バージョニング機能を有効にする必要がある
別アカウントとバケットと共有する場合も、別アカウントのリージョンが異なる場合は、クロスリージョンレプリケーションを使用する必要がある
アクセスポイント
バケットにアタッチされた名前付きのネットワークエンドポイント
S3 への大規模なデータアクセスの管理を簡素化することができる
→1つのバケットに対して、接続元ごとに複数のバケットポリシー を作成するのはめんどい
S3 MFA Delete
オブジェクトを削除する際に、MFA 認証を必須とすることができる
→ 誤操作でのオブジェクトの削除などを防ぐことができる
Transfer Acceleration
クライアントと S3 バケット間のファイル転送を、高速・簡単・安全に行える
Cloud Front のエッジロケーションを使用する
例えば、クライアントが世界規模の場合などに使用すると効果的

- 投稿日:2021-01-19T22:11:47+09:00
AWS ソリューションアーキテクト アソシエート合格までのまとめ
目次
0. はじめに
先日、AWS ソリューションアーキテクト アソシエート に合格したので、忘れないうちに色々とアウトプットしておこうと思います。これから受験を考えている方の役にたてればと思います。
どんな人間がどのくらいの時間をかけて取得したのかを説明するために、少しだけ自分語りをさせてください。
24歳のインフラエンジニアです。現在は GCP とか AWS を仕事で触ってます。クラウドは触り始めて半年くらいです。ネットワークは少しだけ詳しいですが、プログラミングはほとんどできません。持ってる資格はこんな感じ
1.受験動機
クラウドを触り始めたはいいけどどこから手をつければいいのかわからず、体系的に学習するために受験を決めました。
2.出題の範囲
まーあ広いです。細かな内容はここにはかけませんが、設問に出てくる課題に対して、どのサービスを使えば解決できるのかを引き出せるようにしておくといいかもしれないです。
3.勉強方法
Udemy の講座と問題集のみを教材にし、わからないところを公式のドキュメントで埋め合わせるような勉強方法で進めました。
Udemy で購入した教材はこちらです。
これだけでOK! AWS 認定ソリューションアーキテクト – アソシエイト試験突破講座(SAA-C02試験対応版)
【SAA-C02版】AWS 認定ソリューションアーキテクト アソシエイト模擬試験問題集(6回分390問)
上記の2つで合格はできるかなと思います。
私の場合は、講座の方は1.5倍速 + ハンズオンは設定画面を見るだけという進めかたをしたため、勉強時間は 30h ほどでした。サービスの細かなオプションはいったん飛ばして、概念や構成を優先的に理解していくと効率がいいのかなと感じました。(どんな資格にも言えますが、概念をしっかり理解しないと、ただの暗記ゲーになってしまいます)
また、試験に出てくる問題の配分も講座内で解説があるため、何を重点的に学習するのかを決めておくことは、合格への戦略の一つかと思います。4.試験の感想
とにかく問題分が長いです。(プロフェッショナルはもっと長いらしい)これを 65 問は真面目に読んでるとかなりしんどいし、時間も迫ってくると思います。
ですが、問題文の要点を2、3つ抑えればあとは消去法で解けるような問題でした。
例えば、可用性を担保したいのか、コストより性能をとるのか、運用負荷をさげたいのかなどなど
問題文を1文にまとめれれば、あとは知識勝負って感じです5.試験に活きたメモ
実際の試験に活きた学習メモを残そうと思いましたが、メモがぐちゃぐちゃなので少しずつ更新していきます。
6.1 EC2
インスタンスタイプ
スケジュールドリザーブドインスタンス
特定の期間で定期的にインスタンスを使用する場合に選択する
日次、週次、月次の単位で予約することができる
例えば、毎週金曜日だけバッチ処理用のインスタンスが必要など
オンデマンドインスタンス
利用時間に応じた料金を支払う
ハードウェア占有インスタンス
AWS アカウント単位で、物理的なサーバを占有することができる
同じ AWS アカウントとは 物理サーバを共有する可能性がある
Dedicated インスタンス
同じ AWS アカウントでも IAM の権限単位で物理的なサーバを占有することができる
同一サーバに他テナントを入れいてはいけないなどの、セキュリティ面での制約がある場合に使用する
リザーブドインスタンス(コンバーティブル)
途中でインスタンスファミリー、OS、テナンシー、支払オプションを変更することができる
6.2 S3
ブロックパブリックアクセス
バケット単位、またはアカウント単位での、全てのパブリックアクセスをブロックすることができる
デフォルトでは有効になっているため、インターネット上にバケットを公開するには、無効化する必要がある
ライフサイクル管理
オブジェクトのライフサイクルを設定することができる
使用頻度の高いクラスから低いクラスへの移動はできるが、その逆はできない
例えば、Glacier から Standerd への移動はできない
S3 Select
シンプルな SQL ステートメントを使用することで、オブジェクトの内容をフィルタリングし、取り出しデータのコスト削減、待ち時間を軽減できる
高度なデータ解析には向いていない
クロスリージョンレプリケーション
リージョン間でバケットをレプリケーションする際に使用する
レプリケーションのトリガーはバケット内の変更になるため、バージョニング機能を有効にする必要がある
別アカウントとバケットと共有する場合も、別アカウントのリージョンが異なる場合は、クロスリージョンレプリケーションを使用する必要がある
アクセスポイント
バケットにアタッチされた名前付きのネットワークエンドポイント
S3 への大規模なデータアクセスの管理を簡素化することができる
→1つのバケットに対して、接続元ごとに複数のバケットポリシー を作成するのはめんどい
S3 MFA Delete
オブジェクトを削除する際に、MFA 認証を必須とすることができる
→ 誤操作でのオブジェクトの削除などを防ぐことができる
Transfer Acceleration
クライアントと S3 バケット間のファイル転送を、高速・簡単・安全に行える
Cloud Front のエッジロケーションを使用する
例えば、クライアントが世界規模の場合などに使用すると効果的
- 投稿日:2021-01-19T22:10:26+09:00
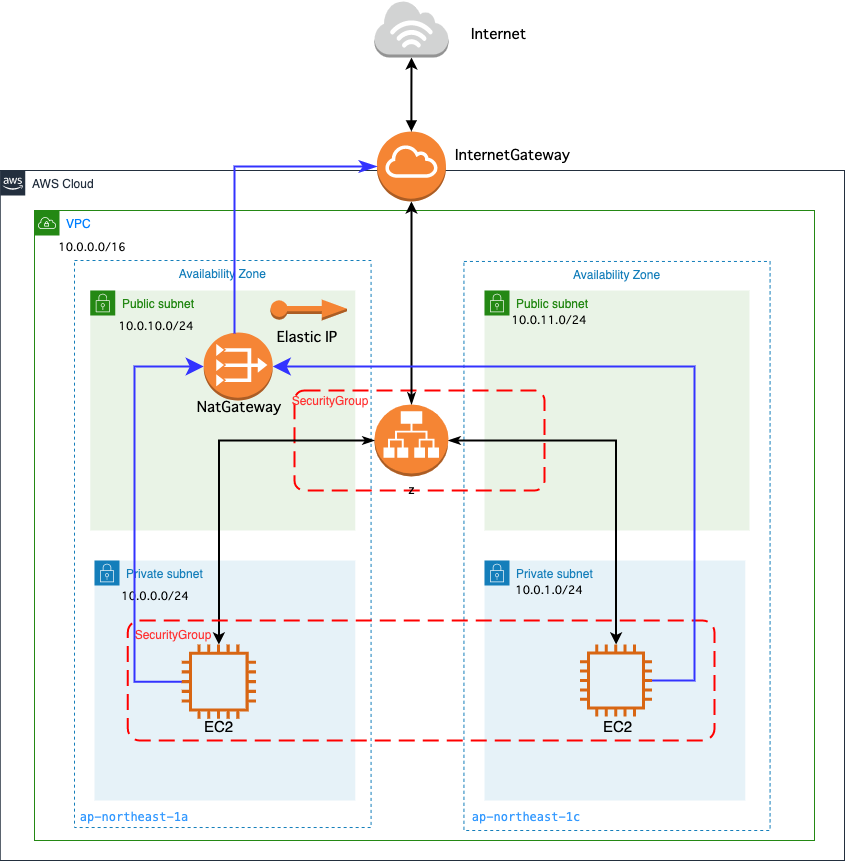
CloudFormationでELBの構築②
前回
概要
EC2インスタンスはプライベートサブネット
ELBはパブリックサブネットに配置したネットワーク構築をCloudFormationベースで紹介します。
またプライベートサブネット内のEC2インスタンスをWEBサーバーにするため、
各パッケージをインストールしなくてはいけません。今回の方法は、NatGatewayを配置し、
NatGateway経由でパッケージのインストールを行いたいと思います。対象者
- AWSの管理コンソールからELBを構築された経験がある方
- CloudFormationの知見がある方
構築されるもの
- VPC
- InternetGateway
- Subnet
- RouteTable
- NatGateway
- Elastic IP
- EC2
- ELB
- SecurityGroup
- TargetGroup
構成図
セクション説明
セクション 意味 備考 AWSTemplateFormatVersion テンプレートバージョン 2010-09-09 であり、現時点で唯一の有効な値 Description テンプレートを説明するテキスト ---- Metadata テンプレートバージョン ---- Parameters パラメーターの定義 ---- Resources スタックに含める AWS リソースの宣言 ---- Outputs 出力値を宣言 他のスタックでインポートできる 組み込み関数説明
組み込み関数 意味 備考 Ref 指定したパラメータまたはリソースの値 --- Sub 特定した値の入力文字列にある変数の代わりになる 文字列内に変数を挿入する GetAtt テンプレートのリソースから属性の値を返す --- その他用語説明
ロードバランサー
アプリケーションへのトラフィックを複数のターゲットに自動的に分散するサービス。
ターゲット
ELBがトラフィックを転送するEC2インスタンスなどのリソースやエンドポイント。
ターゲットグループ
登録されているターゲットにリクエストをルーティングするための設定
ヘルスチェック
登録されたターゲットに定期的にリクエストを送信するステータスのテスト
リスナー
外部からアクセスするプロトコルやポートの設定
スティッキーセッション
ELBがサーバにリクエスト振り分ける際、特定のCookieを確認することで、特定のクライアントからのリクエストを特定のサーバに紐付けることが出来る機能
テンプレートファイル
下記においてあります。ご自由にお使いください
https://github.com/toyoyuto/cloudformation_alb2テンプレートファイル(解説付き)
alb.ymlAWSTemplateFormatVersion: "2010-09-09" Description: ALB construction Metadata: # コンソールでパラメータをグループ化およびソートする方法を定義するメタデータキー "AWS::CloudFormation::Interface": # パラメーターグループとそのグループに含めるパラメーターの定義 ParameterGroups: # Project名に関するグループ - Label: default: "Project Name Prefix" Parameters: - PJPrefix # ネットワーク設定に関するグループ - Label: default: "Network Configuration" # 記述された順番に表示される Parameters: - KeyName # パラメーターのラベル ParameterLabels: KeyName: default: "Key Name" # ------------------------------------------------------------# # Input Parameters # ------------------------------------------------------------# Parameters: PJPrefix: Type: String KeyName: Type: "AWS::EC2::KeyPair::KeyName" Resources: # ------------------------------------------------------------# # VPC # ------------------------------------------------------------# # VPC Create VPC: Type: "AWS::EC2::VPC" Properties: CidrBlock: "10.0.0.0/16" # VPC に対して DNS 解決がサポートされているか EnableDnsSupport: "true" # VPC 内に起動されるインスタンスが DNS ホスト名を取得するか EnableDnsHostnames: "true" # VPC 内に起動されるインスタンスの許可されているテナンシー InstanceTenancy: default Tags: - Key: Name Value: !Sub "${PJPrefix}-vpc" # InternetGateway Create InternetGateway: Type: "AWS::EC2::InternetGateway" Properties: Tags: - Key: Name Value: !Sub "${PJPrefix}-igw" # IGW Attach InternetGatewayAttachment: Type: "AWS::EC2::VPCGatewayAttachment" Properties: InternetGatewayId: !Ref InternetGateway VpcId: !Ref VPC # ------------------------------------------------------------# # Subnet # ------------------------------------------------------------# # Public1 Subnet Create Public1Subnet: Type: "AWS::EC2::Subnet" Properties: AvailabilityZone: "ap-northeast-1a" CidrBlock: "10.0.0.0/24" VpcId: !Ref VPC Tags: - Key: Name Value: !Sub "${PJPrefix}-public1-subnet" # Public2 Subnet Create Public2Subnet: Type: "AWS::EC2::Subnet" Properties: AvailabilityZone: "ap-northeast-1c" CidrBlock: "10.0.1.0/24" VpcId: !Ref VPC Tags: - Key: Name Value: !Sub "${PJPrefix}-public2-subnet" # Private1 Subnet Create Private1Subnet: Type: "AWS::EC2::Subnet" Properties: AvailabilityZone: "ap-northeast-1a" CidrBlock: "10.0.10.0/24" VpcId: !Ref VPC Tags: - Key: Name Value: !Sub "${PJPrefix}-private1-subnet" # Private2 Subnet Create Private2Subnet: Type: "AWS::EC2::Subnet" Properties: AvailabilityZone: "ap-northeast-1c" CidrBlock: "10.0.11.0/24" VpcId: !Ref VPC Tags: - Key: Name Value: !Sub "${PJPrefix}-private2-subnet" # ------------------------------------------------------------# # NAT Gateway # ------------------------------------------------------------# NATGateway: Type: "AWS::EC2::NatGateway" Properties: # NAT ゲートウェイに関連付ける Elastic IPアドレスの割り当て ID AllocationId: !GetAtt NATGatewayAEIP.AllocationId SubnetId: !Ref Public1Subnet Tags: - Key: Name Value: !Sub "${PJPrefix}-natgw" # NATGateway For Elastic IP Create NATGatewayAEIP: Type: "AWS::EC2::EIP" Properties: # ------------------------------------------------------ # Elastic IP アドレスが VPC のインスタンスで使用するか、 # EC2-Classic のインスタンスで使用するか # ------------------------------------------------------ Domain: vpc # ------------------------------------------------------------# # RouteTable # ------------------------------------------------------------# # Public RouteTable Create PublicRouteTable: Type: "AWS::EC2::RouteTable" Properties: VpcId: !Ref VPC Tags: - Key: Name Value: !Sub "${PJPrefix}-public1-route" # Private RouteTable Create PrivateRouteTable: Type: "AWS::EC2::RouteTable" Properties: VpcId: !Ref VPC Tags: - Key: Name Value: !Sub "${PJPrefix}-private1-route" # ------------------------------------------------------------# # Routing # ------------------------------------------------------------# # Public Route Create PublicRoute: Type: "AWS::EC2::Route" Properties: RouteTableId: !Ref PublicRouteTable DestinationCidrBlock: "0.0.0.0/0" GatewayId: !Ref InternetGateway PrivateRoute: Type: "AWS::EC2::Route" Properties: RouteTableId: !Ref PrivateRouteTable DestinationCidrBlock: "0.0.0.0/0" NatGatewayId: !Ref NATGateway # ------------------------------------------------------------# # RouteTable Associate # ------------------------------------------------------------# # Public1RouteTable Associate PublicSubnet Public1SubnetRouteTableAssociation: Type: "AWS::EC2::SubnetRouteTableAssociation" Properties: SubnetId: !Ref Public1Subnet RouteTableId: !Ref PublicRouteTable Public2SubnetRouteTableAssociation: Type: "AWS::EC2::SubnetRouteTableAssociation" Properties: SubnetId: !Ref Public2Subnet RouteTableId: !Ref PublicRouteTable Private1SubnetRouteTableAssociation: Type: "AWS::EC2::SubnetRouteTableAssociation" Properties: SubnetId: !Ref Private1Subnet RouteTableId: !Ref PrivateRouteTable Private2SubnetRouteTableAssociation: Type: "AWS::EC2::SubnetRouteTableAssociation" Properties: SubnetId: !Ref Private2Subnet RouteTableId: !Ref PrivateRouteTable # ------------------------------------------------------------# # EC2 # ------------------------------------------------------------# # Web1Serverインスタンス Web1Server: Type: AWS::EC2::Instance Properties: ImageId: ami-00f045aed21a55240 KeyName: !Ref KeyName InstanceType: t2.micro NetworkInterfaces: # IPv4 アドレスを割り当てるか - AssociatePublicIpAddress: "false" # ------------------------------------------------------ # アタッチの順序におけるネットワークインターフェイスの位置。 # ネットワークインターフェイスを指定する場合必須 # ------------------------------------------------------ DeviceIndex: "0" SubnetId: !Ref Private1Subnet GroupSet: - !Ref Web1ServerSG # インスタンスの作成時に実行するコマンドなどを記述 UserData: !Base64 | #!/bin/bash yum update -y amazon-linux-extras install -y lamp-mariadb10.2-php7.2 php7.2 yum install -y httpd mariadb-server systemctl start httpd systemctl enable httpd usermod -a -G apache ec2-user chown -R ec2-user:apache /var/www chmod 2775 /var/www find /var/www -type d -exec chmod 2775 {} \; find /var/www -type f -exec chmod 0664 {} \; echo `hostname` > /var/www/html/index.html Tags: - Key: Name Value: !Sub "${PJPrefix}-web1-server" # Web1Serverセキュリティグループ Web1ServerSG: Type: AWS::EC2::SecurityGroup Properties: GroupName: web1-sg-cf GroupDescription: web1 server sg VpcId: !Ref VPC Tags: - Key: Name Value: !Sub "${PJPrefix}-web1-server-sg" # Web1ServerSGのインプットルール Web1ServerSGIngress: Type: "AWS::EC2::SecurityGroupIngress" Properties: IpProtocol: tcp FromPort: 80 ToPort: 80 SourceSecurityGroupId: !GetAtt [ ALBSecurityGroup, GroupId ] GroupId: !GetAtt [ Web1ServerSG, GroupId ] # Web2Serverインスタンス Web2Server: Type: AWS::EC2::Instance Properties: ImageId: ami-00f045aed21a55240 KeyName: !Ref KeyName InstanceType: t2.micro NetworkInterfaces: # IPv4 アドレスを割り当てるか - AssociatePublicIpAddress: "false" # ------------------------------------------------------ # アタッチの順序におけるネットワークインターフェイスの位置。 # ネットワークインターフェイスを指定する場合必須 # ------------------------------------------------------ DeviceIndex: "0" SubnetId: !Ref Private2Subnet GroupSet: - !Ref Web2ServerSG # インスタンスの作成時に実行するコマンドなどを記述 UserData: !Base64 | #!/bin/bash yum update -y amazon-linux-extras install -y lamp-mariadb10.2-php7.2 php7.2 yum install -y httpd mariadb-server systemctl start httpd systemctl enable httpd usermod -a -G apache ec2-user chown -R ec2-user:apache /var/www chmod 2775 /var/www find /var/www -type d -exec chmod 2775 {} \; find /var/www -type f -exec chmod 0664 {} \; echo `hostname` > /var/www/html/index.html Tags: - Key: Name Value: !Sub "${PJPrefix}-web2-server" # Web2Serverセキュリティグループ Web2ServerSG: Type: AWS::EC2::SecurityGroup Properties: GroupName: web2-sg-cf GroupDescription: web2 server sg VpcId: !Ref VPC Tags: - Key: Name Value: !Sub "${PJPrefix}-web2-server-sg" # Web2ServerSGのインプットルール Web2ServerSGIngress: Type: "AWS::EC2::SecurityGroupIngress" Properties: IpProtocol: tcp FromPort: 80 ToPort: 80 SourceSecurityGroupId: !GetAtt [ ALBSecurityGroup, GroupId ] GroupId: !GetAtt [ Web2ServerSG, GroupId ] # ------------------------------------------------------------# # Target Group # ------------------------------------------------------------# TargetGroup: Type: "AWS::ElasticLoadBalancingV2::TargetGroup" Properties: VpcId: !Ref VPC Name: !Sub "${PJPrefix}-tg" # ターゲットにトラフィックをルーティングするために使用するプロトコル Protocol: HTTP Port: 80 # ターゲットでヘルスチェックを実行するときにロードバランサーが使用するプロトコル HealthCheckProtocol: HTTP # ヘルスチェックのターゲットの送信先である HealthCheckPath: "/" # ターゲットでヘルスチェックを実行するときにロードバランサーが使用するポート HealthCheckPort: "traffic-port" # 非正常なインスタンスが正常であると見なすまでに必要なヘルスチェックの連続成功回数 HealthyThresholdCount: 2 # ターゲットが異常であると見なされるまでに必要なヘルスチェックの連続失敗回数 UnhealthyThresholdCount: 2 # ヘルスチェックを失敗と見なす、ターゲットからレスポンスがない時間 HealthCheckTimeoutSeconds: 5 # 個々のターゲットのヘルスチェックの概算間隔 HealthCheckIntervalSeconds: 10 # ターゲットからの正常なレスポンスを確認するために使用する HTTP コード Matcher: HttpCode: 200 Tags: - Key: Name Value: !Sub "${PJPrefix}-tg" # ターゲットグループの属性 TargetGroupAttributes: # 登録解除するターゲットの状態が draining から unused に変わるのをELBが待機する時間 - Key: "deregistration_delay.timeout_seconds" Value: 300 # スティッキーセッションが有効か¥ - Key: "stickiness.enabled" Value: false # スティッキーセッションのタイプ - Key: "stickiness.type" Value: lb_cookie # クライアントからのリクエストを同じターゲットにルーティングする必要がある期間 - Key: "stickiness.lb_cookie.duration_seconds" Value: 86400 Targets: - Id: !Ref Web1Server Port: 80 - Id: !Ref Web2Server Port: 80 # ------------------------------------------------------------# # ALB # ------------------------------------------------------------# InternetALB: Type: "AWS::ElasticLoadBalancingV2::LoadBalancer" Properties: Name: !Sub "${PJPrefix}-alb" Tags: - Key: Name Value: !Sub "${PJPrefix}-alb" # 内部向けかインターネット向け Scheme: "internet-facing" # ロードバランサーの属性 LoadBalancerAttributes: # 削除保護が有効化されているかどうかを示します - Key: "deletion_protection.enabled" Value: false # アイドルタイムアウト値 - Key: "idle_timeout.timeout_seconds" Value: 60 SecurityGroups: - !Ref ALBSecurityGroup Subnets: - !Ref Public1Subnet - !Ref Public2Subnet ALBListener: Type: "AWS::ElasticLoadBalancingV2::Listener" Properties: # デフォルトルールのアクション DefaultActions: - TargetGroupArn: !Ref TargetGroup # ルールアクションタイプ # forwardは指定されたターゲットグループにリクエストを転送 Type: forward LoadBalancerArn: !Ref InternetALB Port: 80 Protocol: HTTP # InternetALBのセキュリティグループ ALBSecurityGroup: Type: "AWS::EC2::SecurityGroup" Properties: VpcId: !Ref VPC GroupName: !Sub "${PJPrefix}-alb-sg" GroupDescription: "-" Tags: - Key: "Name" Value: !Sub "${PJPrefix}-alb-sg" # ALBSecurityGroupのインプットルール ALBSecurityGroupIngress: Type: "AWS::EC2::SecurityGroupIngress" Properties: IpProtocol: tcp FromPort: 80 ToPort: 80 CidrIp: "0.0.0.0/0" GroupId: !GetAtt [ ALBSecurityGroup, GroupId ] # ALBSecurityGroupのアウトプットルール ALBSecurityGroupEgress1: Type: "AWS::EC2::SecurityGroupEgress" Properties: IpProtocol: tcp FromPort: 80 ToPort: 80 SourceSecurityGroupId: !GetAtt [ Web1ServerSG, GroupId ] GroupId: !GetAtt [ ALBSecurityGroup, GroupId ] ALBSecurityGroupEgress2: Type: "AWS::EC2::SecurityGroupEgress" Properties: IpProtocol: tcp FromPort: 80 ToPort: 80 SourceSecurityGroupId: !GetAtt [ Web2ServerSG, GroupId ] GroupId: !GetAtt [ ALBSecurityGroup, GroupId ] # ------------------------------------------------------------# # Output Parameters # ------------------------------------------------------------# Outputs: # VPC VPC: Value: !Ref VPC Export: Name: !Sub "${PJPrefix}-vpc" # Subnet Public1Subnet: Value: !Ref Public1Subnet Export: Name: !Sub "${PJPrefix}-public1-subnet" Public2Subnet: Value: !Ref Public2Subnet Export: Name: !Sub "${PJPrefix}-public2-subnet" Public1Subnet: Value: !Ref Public1Subnet Export: Name: !Sub "${PJPrefix}-public1-subnet" Public2Subnet: Value: !Ref Public2Subnet Export: Name: !Sub "${PJPrefix}-public2-subnet" # EC2 Web1Server: Value: !Ref Web1Server Export: Name: !Sub "${PJPrefix}-web1-server" Web2Server: Value: !Ref Web2Server Export: Name: !Sub "${PJPrefix}-web2-server" # ALB InternetALB: Value: !Ref InternetALB Export: Name: !Sub "${PJPrefix}-alb"参考
- 投稿日:2021-01-19T16:40:46+09:00
Amazon Linux 2にstrongSwan5.9.1をインストールする
Amazon Linux 2でEPELを有効化しstrongSwanをインストールすると、strongSwan5.7がインストールされます。しかし、swanctlのインストール方法が見つけられなかったため、公式サイトより2021/1時点でのCurrent ReleaseであるstrongSwan5.9.1をダウンロードしインストールします。
といっても、configureしてmakeしてmake installするだけなのですが、自分用の覚書として残しておきます。環境
- Amazon Linux 2 minimal x64 (ami-0115f8fe26e0858d9)
インストール手順
ダウンロードは以下のサイトから。
https://www.strongswan.org/download.html
ルートユーザーでインストールしないとうまくいかなかったため、最初にsudo su -してます。sudo su - #rootユーザーに切り替え yum update -y yum install wget gcc gmp-devel -y wget https://download.strongswan.org/strongswan-5.9.1.tar.gz md5sum strongswan-5.9.1.tar.gz #ハッシュ値が一致するか確認 tar xzvf strongswan-5.9.1.tar.gz cd strongswan-5.9.1 ./configure make make installsystemctlの設定
/etc/systemd/system/strongswan.service[Unit] Description=strongSwan [Service] Type=forking ExecStart=/usr/local/sbin/ipsec start ExecStop=/usr/local/sbin/ipsec stop [Install] WantedBy=multi-user.target起動時にswanctlの設定を読み込む
/usr/local/etc/strongswan.confcharon { (省略) start-scripts { swanctl = /usr/local/sbin/swanctl -q } (省略) }swanctlの設定ファイルは以下のフォルダ内に置きます。
/usr/local/etc/swanctl/conf.d/xxx.conf参考にしたサイト
- 投稿日:2021-01-19T12:31:09+09:00
【Rails】ローカル環境でS3の画像投稿ができるのに、Heroku上でS3が機能しない問題
現象
ローカル環境でうまくS3に画像を保管出来た!!
しかし、Heroku側にマージしてもなぜかHerokuのDB上で画像を保管している。。。
エラーも出ない。。
なぜだろうか。。。原因
今思えば当たり前の話なのですが、、
原因は環境用(Heroku)のファイルにActiveStorageの設定をしていないというものでした。
種類 環境 設定ファイル 開発環境 ローカル環境 development.rb 本番環境 Heroku production.rb(⇦こっちに設定入れてなかった) ** 同じミスをしないように手順を残しておきます **
ローカル環境での設定(※aws側の設定は割愛)
①S3を使用するために必要なGemfileを導入
Gemfile.gem "aws-sdk-s3", require: false②追記したら、ターミナルにて開発中のアプリに入り「bundle install」を実行
ターミナル.% bundle install③development.rbとstorage.ymlファイルも更新
config/environments/development.rb# S3にて保存されるように設定を変更 # config.active_storage.service = :local config.active_storage.service = :amazonconfig/storage.yml# S3の設定を追記 amazon: service: S3 region : ap-southeast-1 # リージョンをaws側で確認して記載 bucket : furimabucket # バケット名をaws側で確認して記載 access_key_id: <%= ENV['AWS_ACCESS_KEY_ID'] %> secret_access_key: <%= ENV['AWS_SECRET_ACCESS_KEY'] %>④環境変数の追記
③のstorage.ymlにて「AWS_ACCESS_KEY_ID」「AWS_SECRET_ACCESS_KEY」を設定しているので開発中のアプリにて環境変数を追記。
ターミナル.% vim ~/.zshrc「i」で編集モードにして2つの変数を登録
ターミナル.export AWS_ACCESS_KEY_ID="Access key IDの値" export AWS_SECRET_ACCESS_KEY="Secret access keyの値"編集が終わったら、[ESC]→:wqで終了
続いて、環境変数の設定ファイルを読み込み直すターミナル.% source ~/.zshrcこれで、ローカル環境でS3の画像投稿ができた!!!!!!
以降は、Herokuまでの反映手順になります。
Herokuへの反映
①まずは忘れずにproduction.rbの更新
storage.ymlは特に変更なし。config/environments/production.rb# 本番環境でもS3にて保存されるように設定 config.active_storage.service = :amazon②ターミナルにてHerokuにログイン
ターミナル.% heroku login --interactive③本番環境でも環境変数を設定
環境変数を確認したい場合は「% heroku config」ターミナル.% heroku config:set AWS_ACCESS_KEY_ID="Access key IDの値" % heroku config:set AWS_SECRET_ACCESS_KEY="Secret access keyの値"④あとはコミットして完了
ターミナル.% git add . % git commit -m "ストレージの変更(S3)" % git push heroku master
お疲れ様でした。
- 投稿日:2021-01-19T12:31:09+09:00
【Rails】ローカル環境でS3の画像投稿ができるのに、Heroku上でS3に切り替わらない問題
現象
ローカル環境でうまくS3に画像を保管出来た!!
しかし、Heroku側にマージしてもなぜかHerokuのDB上で画像を保管している。。。
エラーも出ない。。
なぜだろうか。。。原因
今思えば当たり前の話なのですが、、
原因は本番環境用(Heroku)のファイルにActiveStorageの設定をしていないというものでした。
種類 環境 設定ファイル 開発環境 ローカル環境 development.rb 本番環境 Heroku production.rb(⇦こっちに設定入れてなかった) ** 同じミスをしないように手順を残しておきます **
ローカル環境での設定(※aws側の設定は割愛)
①S3を使用するために必要なGemfileを導入
Gemfile.gem "aws-sdk-s3", require: false②追記したら、ターミナルにて開発中のアプリに入り「bundle install」を実行
ターミナル.% bundle install③development.rbとstorage.ymlファイルも更新
config/environments/development.rb# S3にて保存されるように設定を変更 # config.active_storage.service = :local config.active_storage.service = :amazonconfig/storage.yml# S3の設定を追記 amazon: service: S3 region : ap-southeast-1 # リージョンをaws側で確認して記載 bucket : furimabucket # バケット名をaws側で確認して記載 access_key_id: <%= ENV['AWS_ACCESS_KEY_ID'] %> secret_access_key: <%= ENV['AWS_SECRET_ACCESS_KEY'] %>④環境変数の追記
③のstorage.ymlにて「AWS_ACCESS_KEY_ID」「AWS_SECRET_ACCESS_KEY」を設定しているので開発中のアプリにて環境変数を追記。
ターミナル.% vim ~/.zshrc「i」で編集モードにして2つの変数を登録
ターミナル.export AWS_ACCESS_KEY_ID="Access key IDの値" export AWS_SECRET_ACCESS_KEY="Secret access keyの値"編集が終わったら、[ESC]→:wqで終了
続いて、環境変数の設定ファイルを読み込み直すターミナル.% source ~/.zshrcこれで、ローカル環境でS3の画像投稿ができた!!!!!!
以降は、本番環境(Heroku)への反映手順となります。本番環境(Heroku)への反映
①まずは忘れずにproduction.rbの更新
storage.ymlは特に変更なし。config/environments/production.rb# 本番環境でもS3にて保存されるように設定 config.active_storage.service = :amazon②ターミナルにてHerokuにログイン
ターミナル.% heroku login --interactive③本番環境でも環境変数を設定
環境変数を確認したい場合は「% heroku config」ターミナル.% heroku config:set AWS_ACCESS_KEY_ID="Access key IDの値" % heroku config:set AWS_SECRET_ACCESS_KEY="Secret access keyの値"④あとはコミットして完了
ターミナル.% git add . % git commit -m "ストレージの変更(S3)" % git push heroku master
- 投稿日:2021-01-19T11:54:57+09:00
Cloud9でno space left on deviceが出た時の対応
EC2インスタンスの再起動
まずはCloud9が動いているEC2インスタンスを再起動。
結果変わらず。エラーの原因
- ディスク容量を使い果たした
- inode の枯渇
のどちらか
問題の特定
ディスク容量を使い果たした
$ df -h Filesystem Size Used Avail Use% Mounted on devtmpfs 483M 60K 483M 1% /dev tmpfs 493M 0 493M 0% /dev/shm /dev/xvda1 9.8G 9.6G 68M 100% /100%って書いてあるのでたぶんこれが原因。
inodeの枯渇
inode とは、ファイルのサイズとか、更新日時とか、属性情報が書かれたデータのことで、実ファイルとは別に存在している。このデータ領域がなくなることを「 inode の枯渇」と呼ぶ
$ df -i Filesystem Inodes IUsed IFree IUse% Mounted on devtmpfs 123467 434 123033 1% /dev tmpfs 126142 1 126141 1% /dev/shm /dev/xvda1 655360 427041 228319 66% /こっちは66%だから大丈夫そう。やはり原因はディスク容量
どこが重いのか確認
ディスク容量を使い果たしているとのことなので、データを削除すればたぶん解決する。
削除の前にどこが重いのかを確認してみる。$ sudo du -sh /* 7.1M /bin 72M /boot 4.0K /cgroup 60K /dev 12M /etc 2.1G /home 209M /lib 21M /lib64 4.0K /local 16K /lost+found 4.0K /media 4.0K /mnt 12K /nvm-install.txt 896M /opt du: cannot access ‘/proc/5597/task/5597/fd/4’: No such file or directory du: cannot access ‘/proc/5597/task/5597/fdinfo/4’: No such file or directory du: cannot access ‘/proc/5597/fd/4’: No such file or directory du: cannot access ‘/proc/5597/fdinfo /4’: No such file or directory 0 /proc 51M /root 16K /run 14M /sbin 4.0K /selinux 4.0K /srv 0 /sys 96M /tmp 2.9G /usr 3.3G /var重いのは
home、usr、varの3つ。
このうちusrとvarはデフォルトでこれくらい重いっぽいので(新たにCloud9の環境を作って確認した)、homes内のファイルを削除していく。ファイルの削除
homes/environment内に自分が作ったアプリがあるので、不要になったアプリを削除。- 削除しないアプリに関しても、キャッシュは一旦
$ rails tmp:cache:clearで削除。これでとりあえず解決しました。
その他
今回はファイルを削除して対応したけど、Cloud9の容量を増やして解決する方法もある。
なんかお金かかりそうだからなるべくやりたくないけど、いよいよ容量が足りなくなったらその方法しかなさそう。参考
- 投稿日:2021-01-19T11:15:28+09:00
【React】ユーザー認証をCognito + Amplifyで構築してみた ~サインインページカスタマイズ編~
はじめに
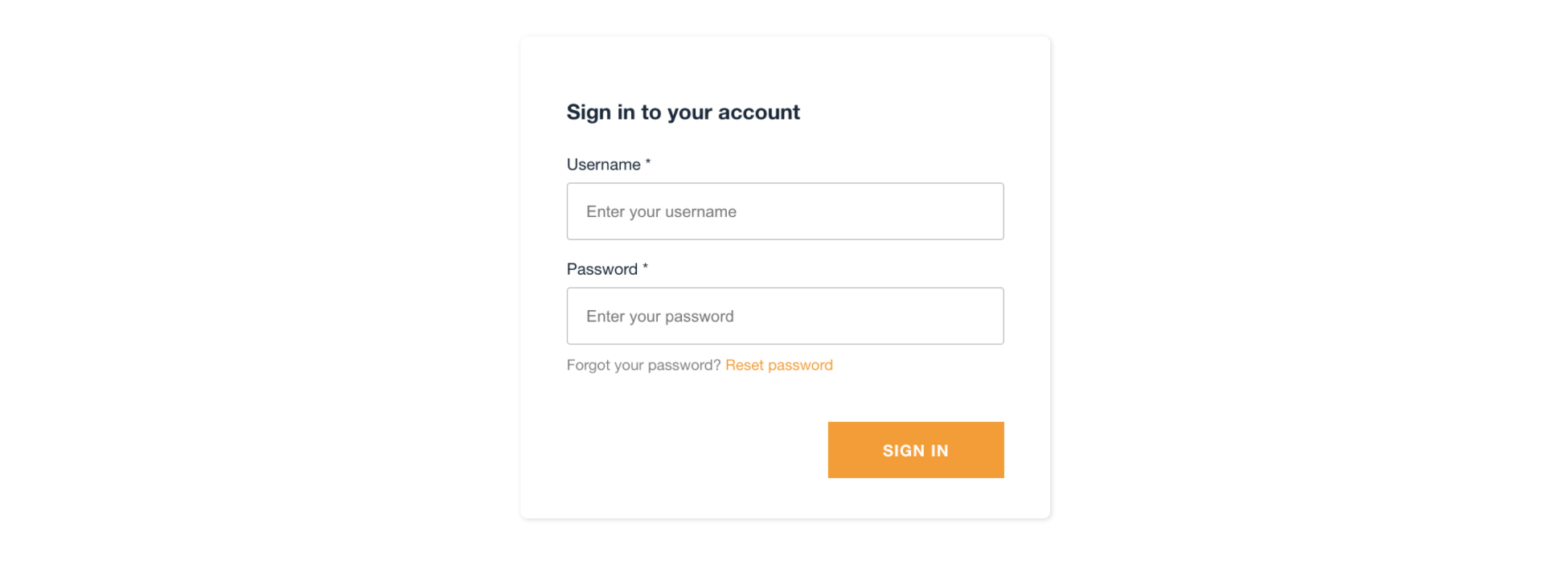
Reactで作成したWebアプリケーションのユーザー認証部分をCognito + Amplifyフレームワークで構築してみました。「【React】ユーザー認証をCognito + Amplifyで構築してみた」の構築準備編と構築完成編を経て、現状下記のようなサインインページのWebアプリケーションが出来上がっています。
ただ、このWebアプリケーションは管理者が事前にユーザーを登録し、登録されているユーザーのみが使用できるようにしたいので、今回はサインインページにあるサインアップボタンを非表示にしたいと思います。
既存のソースコード
※↓クリックするとソースコードが見れます。
既存のソースコード
App.jsimport React, {useEffect} from "react"; import Amplify, {Auth} from 'aws-amplify'; import awsconfig from './aws-exports'; import {withAuthenticator} from "@aws-amplify/ui-react"; Amplify.configure(awsconfig); function App() { const [currentUserName, setCurrentUserName] = React.useState(""); useEffect(() => { const init = async() => { const currentUser = await Auth.currentAuthenticatedUser(); setCurrentUserName(currentUser.username); } init() }, []); const signOut = async() => { try { await Auth.signOut(); } catch (error) { console.log('error signing out: ', error); } document.location.reload(); } return ( <div> <h1>{currentUserName}さんこんにちは!</h1> <button onClick={signOut}>サインアウト</button> </div> ); } export default withAuthenticator(App);既存のものは、
withAuthenticatorコンポーネントでラップすることでサインイン画面等を表示していました。ただ、withAuthenticatorだとサインアップボタンを非表示にする方法を見つけられず、<AmplifyAuthenticator>というUIコンポーネントを使う方法だと簡単にサインアップボタンを非表示にできそうだったので、<AmplifyAuthenticator>を使うことにしました。やってみる
公式ドキュメントを参考に実装していきます。
サインアップボタンを削除する
まず、サインインページにあるサインアップボタンを非表示にするために、UIコンポーネント
<AmplifySignIn/>内にhideSignUp={true}を挿入します。これでサインアップボタンを非表示にすることができます。<AmplifyAuthenticator > <AmplifySignIn slot="sign-in" hideSignUp={true} /> </AmplifyAuthenticator>この他にもさまざまなプロパティが用意されています。デフォルトのユーザー認証にはユーザー名が使われています。例えば、ユーザー認証にメールアドレスを使いたいとなれば、
<AmplifySignIn/>内にusernameAlias="email"を指定するだけで簡単に変更することができます。ログイン判定
既存のソースでは
withAuthenticatorコンポーネントでラップしていたので、ログインしているかどうかを特に気にしていませんでしたが、<AmplifyAuthenticator>を使うことで、ログインしている人としていない人で表示するコンポーネントを分ける必要があります。
ここで分けないと、Uncaught (in promise) not authenticatedというエラーが出て、ログイン後にユーザー情報が取得できません。return authState === AuthState.SignedIn && user ? ( <TopPage /> ) : ( <AmplifyAuthenticator > <AmplifySignIn slot="sign-in" hideSignUp={true} /> </AmplifyAuthenticator> );ステータスが
SignedInになっているか、ユーザー情報が取得できているかを確認することで、ログイン済みかどうかを判定しています。MFAを使っている場合、一段階目のユーザー名とパスワードでの認証後には、
userにユーザー情報が入ってしまうので、authStateも確認する必要があります。逆のパターンは見つけることができず・・、authStateだけで判定している方も見かけましたが、今回は公式に沿って、ステータスとユーザー情報の有無で判定するようにしています。完成したソースコード
上記を踏まえて完成したソースコードです。
既存のものでは、ラップしていただけなので、トップページも同じコンポーネントにまとめていましたが、今回は分けることにしました。
TopPage.jsの内容はほとんど既存App.jsのものと同じです。App.jsimport React, {useEffect} from "react"; import Amplify from 'aws-amplify'; import awsconfig from './aws-exports'; import {AmplifyAuthenticator, AmplifySignIn} from "@aws-amplify/ui-react"; import {AuthState, onAuthUIStateChange} from "@aws-amplify/ui-components"; import TopPage from "./TopPage"; Amplify.configure(awsconfig); function App() { const [authState, setAuthState] = React.useState(); const [user, setUser] = React.useState(); useEffect(() => { onAuthUIStateChange((nextAuthState, authData) => { setAuthState(nextAuthState); setUser(authData); }); }, []); return authState === AuthState.SignedIn && user ? ( <TopPage /> ) : ( <AmplifyAuthenticator > <AmplifySignIn slot="sign-in" hideSignUp={true} /> </AmplifyAuthenticator> ); } export default App;TopPage.jsimport React, {useEffect} from "react"; import Amplify, {Auth} from 'aws-amplify'; import awsconfig from './aws-exports'; Amplify.configure(awsconfig); function TopPage() { const [currentUserName, setCurrentUserName] = React.useState(""); useEffect(() => { const init = async() => { const currentUser = await Auth.currentAuthenticatedUser(); setCurrentUserName(currentUser.username); } init() }, []); const signOut = async() => { try { await Auth.signOut(); } catch (error) { console.log('error signing out: ', error); } document.location.reload(); } return ( <div> <h1>{currentUserName}さんこんにちは!</h1> <button onClick={signOut}>サインアウト</button> </div> ); } export default TopPage;完成画面
サインアップボタンを非表示にすることができました!
サインアップボタンが非表示になっただけで、画面の動き等は冒頭の完成画面と同じです。
おわりに
サインインページのカスタマイズも完成です!
実はこの実装をしたのが半年以上前で、そもそもこの情報がなかったのか、あったのにうまく調べきることができなかったのかは分かりませんでした。2日調べてサインアップボタンが消せなかったので、当時はUIコンポーネントの文言を日本語化する要領で無理やり消しました(笑)
今回この記事を書くにあたり、再度調べてみると、すごくあっさり見つけることができ、しかも実装も簡単で、こんなに簡単にできるんかーいという気持ちです。でも、今回正解の実装方法を知ることができたので、いい機会になりました。
- 投稿日:2021-01-19T10:53:53+09:00
AWS Client VPN構築・設定(相互認証、プライベートDNS)
はじめに
AWSのClientVPNを利用したクライアントVPN構築・設定の行った際のメモ。
再度構築設定する際に参考にするために記録する。前提
- 認証方式は、相互認証
- Route53プライベートDNSの利用
- サーバ証明とクライアント証明書は同一環境(EC2)で作成
各種証明書作成
1. OpenVPN easy-rsaをダウンロード
$ wget https://github.com/OpenVPN/easy-rsa/releases/download/v3.0.7/EasyRSA-3.0.7.tgz $ tar zxfv EasyRSA-3.0.7.tgz $ cd EasyRSA-3.0.72. PKI環境を初期化
※サーバ証明書の有効期限を延長させる場合は事前に下記のように設定する
(EASYRSA_CERT_EXPIREは、日数)$ cp vars.example vars $ vi vars set_var EASYRSA_CERT_EXPIRE 365 $ ./easyrsa init-pki3. 認証機関 (CA) を構築
$ ./easyrsa build-ca nopass common nameは指定なしで進む(デフォルト)CAのルート証明書が作成される (デフォルトで有効期限は10年)
pki/ca.crt
下記コマンドで内容を確認
$ openssl x509 -text -noout -in pki/ca.crtValidityに有効期限がひょうじされる。
4. サーバーとクライアント向けに証明書とキーを生成
サーバー向け
$ ./easyrsa build-server-full server nopassクライアント向け
$ ./easyrsa build-client-full {クライアント識別名} nopass接続元クライアントごとに作成する。
5. 主要ファイルを別フォルダにコピーしておく
サーバー証明書とキー、およびクライアント証明書とキーを別フォルダへコピー
$ mkdir ~/vpn_key/ $ cp pki/ca.crt ~/vpn_key/ $ cp pki/issued/server.crt ~/vpn_key/ $ cp pki/private/server.key ~/vpn_key/ $ cp pki/issued/{クライアント識別名}.crt ~/vpn_key/ $ cp pki/private/{クライアント識別名}.key ~/vpn_key/ $ cd ~/vpn_key/6. ACMに証明書をインポート
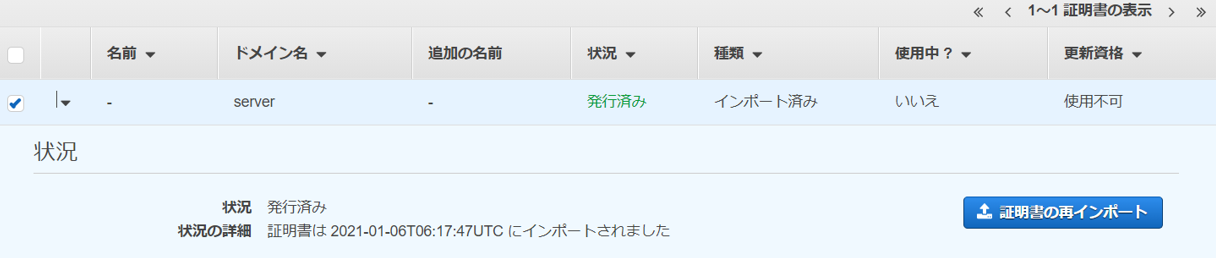
「クライアント証明書の認証機関 (発行者) がサーバー証明書の認証機関 (発行者) と異なる場合にのみ、クライアント証明書を ACM にアップロードする必要があります。」
今回は、クライアント証明書とサーバー証明書で同じ認証機関を利用しているため、サーバー証明書だけをACMに登録します。$ aws acm import-certificate --certificate fileb://server.crt --private-key fileb://server.key --certificate-chain fileb://ca.crt --region {リージョン}※ACMにアクセスできるようにEC2(サーバ)のIAMロールに対し「AWSCertificateManagerFullAccess 」ポリシーを一時的に付与しておく必要あり。
インポートした証明書が表示される
インターネットアクセスや他のVPN接続を許可していない環境のEC2である場合、SSMセッションマネージャで接続することになる。この場合、作成した証明書をダウンロードするには一度S3にアップロードして、ダウンロードする方法で対応した。
事前にEC2のIAMロールにS3のアクセス権(一時的であれば「AmazonS3FullAccess」ポリシー)を付与しておく。
S3にバケットも用意しておく。必要に応じてバケットポリシーも設定しておくと良い。S3へコピー
$ aws s3 cp ./{クライアント識別名}.crt s3://{バケット名} $ aws s3 cp ./{クライアント識別名}.key s3://{バケット名}クライアントVPNエンドポイントの作成
クライアント IPv4 CIDR
CIDRは、VPCと重複しないように指定する。
今回は「192.168.0.0/16」とした。サーバー証明書 ARN
先程登録したACMのサーバ証明書を選択
認証オプション
「相互認証の使用」を選択
クライアント接続の詳細を記録しますか?
必要であれば「はい」にして、予め用意したCloudWatchロググループを選択
クライアント接続ハンドラを有効化しますか?
接続元IPによるアクセス制御を行いたい場合など有効にし、制御ロジックを実装したLambdaファンクションを作成して選択。
DNS サーバー 1 IP アドレス
Route53によるプライベートDNSを利用する場合、VPCのCIDRに合わせてAmazon-provided DNSのIPを指定する。
VPCのCIDRが「10.0.0.0/16」の場合は、「10.0.0.2」を指定する。トランスポートプロトコル
「UDP」を選択
スプリットトンネルを有効にする
Route53によるプライベートDNSを利用する場合は、無効にする必要がある。
VPC ID
接続先VPCを選択
VPN ポート
「443」を選択
必要に応じて変更セルフサービスポータルを有効にする
相互認証の場合は利用できないため無効にしておく。
エンドポイント作成後
「関連付」でVPN接続で接続可能にするサブネットを設定する。
「認証」で接続先の許可CIDRを設定VPN接続設定ファイル
「クライアント設定のダウンロード」ボタンを選択し、「downloaded-client-config.ovpn」をダウンロード
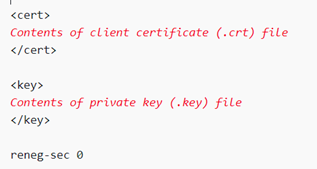
ダウンロードした設定ファイルをテキストエディタで開き、下記の通りと情報を追記する。
※クライアント証明書と秘密鍵を別途ファイルで管理する場合は、パスを指定する方法でも良いが、モバイル端末(iosやAndroid)の場合は、設定ファイルに含めた方法で配布すること。
VPNクライアントをインストール
AWS公式のクライアントアプリの場合
AWS Clinet VPNアプリをダウンロード
https://aws.amazon.com/jp/vpn/client-vpn-download/インストールが完了後、起動してプロファイルの登録を行う
設定ファイル「xxxxx-client-config.ovpn」を選択。
接続ボタンを選択して接続できれば完了
OpenVPNクライアントアプリの場合
下記より、インストーラをダウンロード
https://www.openvpn.jp/download/下記手順でインストール
https://www.openvpn.jp/document/install-windows/Windowsの場合は、スタートメニューから「OpenVPN GUI」を選択
画面右下のアイコンにOpenVPNのアイコンが表示されたら、右クリックで「Import file」を選択
VPN接続設定ファイル「xxxxx-client-config.ovpn」を選択。
OpenVPNのアイコンを右クリックでインポートしたファイル名を選択して「接続」を選択します。



- 投稿日:2021-01-19T10:34:36+09:00
AWS Braket を使ってQAOAを実装してみる②
この記事について
AWS Braket が公開されてから、一般の人にとっても量子コンピュータの実機に触れる機会が増え、それに伴い、私も量子コンピュータのお勉強をしています。
Braketではゲート型の最適化を行うにあたってQAOAというアルゴリズムを使用します。
AWS Braketのサンプル上ではGraph Coloring Problem という問題を解いており、「各ノードに赤や青の色をつけ、色の異なるノード間の各枝に点数をつけていきより良い点をしよう」という問題の求解を行っています。
こちらの問題ですが、以下の式で表されるコスト関数を定義し、($z_n= {-1,1}$, $J$は枝間の重み)それを最小化する問題に帰着できます。H_{C}=\sum_{i>j} J_{i,j} z_{i} z_{j},このような問題に帰着できるものであれば、AWS Braketのサンプルを流用することで動かすことができますが、最適化問題をより一般的に表すには、以下の通り線形項も加味する必要があります。
H_{C}=\sum_{i>j} J_{i,j} z_{i} z_{j} + \sum_{i=1}^{n} h_{i} z_{i}AWSのサンプルをそのまま動かすだけでは上記の問題を正確に解くことができません。(近似アルゴリズムなので別のアプローチでももちろん正確ではないが、そのまま使うよりは正確です。)
なのでこういった最適化問題を解くことができるような実装をAWS Braket上で行いました。
以前の記事では、AWS BraketのQAOAのサンプル実装の説明を行っていったのでそれを活用して、今回は少し応用的に実装していこうと思います。
まずはAWS Braket の解説を見たいという方は上記の記事を見てみてください。なお、量子コンピュータ関係の他の記事は、こちらのページで一覧にしています
問題定義
今回扱う問題は以下のような形式になっている必要があります。
H_{C}=\sum_{i>j} J_{i,j} z_{i} z_{j} + \sum_{i=1}^{n} h_{i} z_{i}最低一つの$i$において$h_i > 0$となっていないと今回やりたいことができません。
なのでとりあえずそれを実現するために何かしらの問題を定義します。こういった形の問題は探せば結構あります。例えば巡回セールスマン問題や重みつきMax Cut問題等があります。
あまり難しいことはやりたくないので今回は直感的に理解しやすい巡回セールスマン問題を扱っていきます。また、巡回セールスマン問題は0, 1バイナリ変数で扱うことが多いので今回も0, 1バイナリにマッピングしながらやっていこうと思います。
あくまで今回の焦点はQAOAなので問題設定は既存で定義されているほかの方の問題を採用させていただきたいと思います。
こちらの
D-Waveとblueqat.optで巡回セールスマン問題とmaxcut問題、クリーク問題、自然数分割問題
という記事に記載の問題と全く同じ問題を使用させていただきます。
なので説明は割愛させていただきますが、結果として以下のような行列で示すことができるのでそれを使っていこうと思います。
詳しくは上記の記事を参考にしてみてください。J1 = np.array([ [-2,2,2,2,2,0,0,0,2,0,0,0,2,0,0,0], [0,-2,2,2,0,2,0,0,0,2,0,0,0,2,0,0], [0,0,-2,2,0,0,2,0,0,0,2,0,0,0,2,0], [0,0,0,-2,0,0,0,2,0,0,0,2,0,0,0,2], [0,0,0,0,-2,2,2,2,2,0,0,0,2,0,0,0], [0,0,0,0,0,-2,2,2,0,2,0,0,0,2,0,0], [0,0,0,0,0,0,-2,2,0,0,2,0,0,0,2,0], [0,0,0,0,0,0,0,-2,0,0,0,2,0,0,0,2], [0,0,0,0,0,0,0,0,-2,2,2,2,2,0,0,0], [0,0,0,0,0,0,0,0,0,-2,2,2,0,2,0,0], [0,0,0,0,0,0,0,0,0,0,-2,2,0,0,2,0], [0,0,0,0,0,0,0,0,0,0,0,-2,0,0,0,2], [0,0,0,0,0,0,0,0,0,0,0,0,-2,2,2,2], [0,0,0,0,0,0,0,0,0,0,0,0,0,-2,2,2], [0,0,0,0,0,0,0,0,0,0,0,0,0,0,-2,2], [0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,-2], ]) J2 = np.array([ [0,0,0,0,0,2,0,2,0,1,0,1,0,3,0,3], [0,0,0,0,2,0,2,0,1,0,1,0,3,0,3,0], [0,0,0,0,0,2,0,2,0,1,0,1,0,3,0,3], [0,0,0,0,2,0,2,0,1,0,1,0,3,0,3,0], [0,0,0,0,0,0,0,0,0,4,0,4,0,2,0,2], [0,0,0,0,0,0,0,0,4,0,4,0,2,0,2,0], [0,0,0,0,0,0,0,0,0,4,0,4,0,2,0,2], [0,0,0,0,0,0,0,0,4,0,4,0,2,0,2,0], [0,0,0,0,0,0,0,0,0,0,0,0,0,2,0,2], [0,0,0,0,0,0,0,0,0,0,0,0,2,0,2,0], [0,0,0,0,0,0,0,0,0,0,0,0,0,2,0,2], [0,0,0,0,0,0,0,0,0,0,0,0,2,0,2,0], [0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0], [0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0], [0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0], [0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0], ]) J = J1 + 0.2*J2これをAWSのisingハミルトニアンと置き換えるようにソースコードを変更し、
QAOAを動かしていきたいと思います。実装
失敗してみる
失敗してみることが大切なのでまずは失敗してみます。
一応、イジングモデルを0, 1で定義しました。
なのでAWS Braketのサンプルコードのイジングモデル部分の定義、そして、{-1, 1}で表されているマッピングの部分だけソースコードを編集してみます。イジングモデルの定義
# set Ising matrix Jfull = nx.adjacency_matrix(G).todense() Jfull = np.array(Jfull) # get off-diagonal upper triangular matrix J = np.triu(Jfull, k=1).astype(np.float64)こちらのソースコードを先ほど紹介したモデルに変更します。
具体的には以下のように変更します。J1 = np.array([ [-2,2,2,2,2,0,0,0,2,0,0,0,2,0,0,0], [0,-2,2,2,0,2,0,0,0,2,0,0,0,2,0,0], [0,0,-2,2,0,0,2,0,0,0,2,0,0,0,2,0], [0,0,0,-2,0,0,0,2,0,0,0,2,0,0,0,2], [0,0,0,0,-2,2,2,2,2,0,0,0,2,0,0,0], [0,0,0,0,0,-2,2,2,0,2,0,0,0,2,0,0], [0,0,0,0,0,0,-2,2,0,0,2,0,0,0,2,0], [0,0,0,0,0,0,0,-2,0,0,0,2,0,0,0,2], [0,0,0,0,0,0,0,0,-2,2,2,2,2,0,0,0], [0,0,0,0,0,0,0,0,0,-2,2,2,0,2,0,0], [0,0,0,0,0,0,0,0,0,0,-2,2,0,0,2,0], [0,0,0,0,0,0,0,0,0,0,0,-2,0,0,0,2], [0,0,0,0,0,0,0,0,0,0,0,0,-2,2,2,2], [0,0,0,0,0,0,0,0,0,0,0,0,0,-2,2,2], [0,0,0,0,0,0,0,0,0,0,0,0,0,0,-2,2], [0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,-2], ]) J2 = np.array([ [0,0,0,0,0,2,0,2,0,1,0,1,0,3,0,3], [0,0,0,0,2,0,2,0,1,0,1,0,3,0,3,0], [0,0,0,0,0,2,0,2,0,1,0,1,0,3,0,3], [0,0,0,0,2,0,2,0,1,0,1,0,3,0,3,0], [0,0,0,0,0,0,0,0,0,4,0,4,0,2,0,2], [0,0,0,0,0,0,0,0,4,0,4,0,2,0,2,0], [0,0,0,0,0,0,0,0,0,4,0,4,0,2,0,2], [0,0,0,0,0,0,0,0,4,0,4,0,2,0,2,0], [0,0,0,0,0,0,0,0,0,0,0,0,0,2,0,2], [0,0,0,0,0,0,0,0,0,0,0,0,2,0,2,0], [0,0,0,0,0,0,0,0,0,0,0,0,0,2,0,2], [0,0,0,0,0,0,0,0,0,0,0,0,2,0,2,0], [0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0], [0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0], [0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0], [0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0], ]) J = J1 + 0.2*J2 print(J)そうするとIsing matrixが以下のような定義になるのがわかるかと思います。
{0,1}への変更
{-1, 1}で表されているマッピングの部分の変更を行います。
util_qaoa.pyの以下の部分を変更します。変更前
# convert results (0 and 1) to ising (-1 and 1) meas_ising = result.measurements meas_ising[meas_ising == 0] = -1変更後
# convert results (0 and 1) to ising (-1 and 1) meas_ising = result.measurements #meas_ising[meas_ising == 0] = -1実行
では実行してみます。
ValueError: Operator qubit count 2 must be equal to size of target qubit set QubitSet([Qubit(0)])直訳すると「演算子のビットカウント2はターゲットビットセットの数と同じでなければなりません。」とのことです。
エラーの意味はあまりわかりませんが、
こちらの記事にも書いた通り、AWS Braketのサンプルコードでは{-1, 1}のイジングモデルの線形項や{0, 1}モデルの対角成分を扱うことができません。
なのでそこの部分を修正していこうと思います。修正①:量子複製不能原理に対しての修正
まず量子コンピュータの基本的な原理として「量子複製不能原理」というものがあります。
古典回路と比べて述べると簡単に説明できるのですが、簡単に言うと
「古典回路ではファンアウト操作により、1つの入力を複製することが可能であったが、量子回路ではそれができない。」といったものになります。実際にAWS Braketのソースコードを見るとわかるかと思います。
util_qaoa.pyのソースコードの以下のコードを見てみてください。# helper function for evolution with cost Hamiltonian def cost_circuit(gamma, n_qubits, ising, device): """ returns circuit for evolution with cost Hamiltonian """ # instantiate circuit object circ = Circuit() # get all non-zero entries (edges) from Ising matrix idx = ising.nonzero() edges = list(zip(idx[0], idx[1])) # ここで行列の比ゼロ要素を取得している # apply ZZ gate for every edge (with corresponding interation strength) for qubit_pair in edges: # get interaction strength from Ising matrix # qubit_pair[0]==qubit_pair[1]があった場合でもZZGateを適用してしまっている。 int_strength = ising[qubit_pair[0], qubit_pair[1]] # for Rigetti we decompose ZZ using CNOT gates if device.name == 'Rigetti': gate = ZZgate(qubit_pair[0], qubit_pair[1], gamma*int_strength) circ.add(gate) # classical simulators and IonQ support ZZ gate else: gate = Circuit().zz(qubit_pair[0], qubit_pair[1], angle=2*gamma*int_strength) circ.add(gate) return circ上記ソースコードに日本語のコメントで書いている通り、ising変数の対角要素が比ゼロの場合であってもZZGateが適用されるようになっています。
なので上記のfor文の中身の部分を以下に変更すれば量子複製不能原理に触れるエラーは回避できます。for qubit_pair in edges: if (qubit_pair[0] != qubit_pair[1]): #この行を追加 # get interaction strength from Ising matrix int_strength = ising[qubit_pair[0], qubit_pair[1]] # for Rigetti we decompose ZZ using CNOT gates if device.name == 'Rigetti': gate = ZZgate(qubit_pair[0], qubit_pair[1], gamma*int_strength) circ.add(gate) # classical simulators and IonQ support ZZ gate else: gate = Circuit().zz(qubit_pair[0], qubit_pair[1], angle=2*gamma*int_strength) circ.add(gate)実行
変更を行ったのでプログラムを実行してみようと思います。
少し時間はかかりますが、実際に実行すると以下のような結果が返ってきます。
(ランダムなので多少結果は異なります。)Circuit depth hyperparameter: 3 Problem size: 16 Starting the training. ==================================================================== OPTIMIZATION for circuit depth p=3 Param "verbose" set to False. Will not print intermediate steps. ==================================================================== Optimization terminated successfully. Current function value: 9.080000 Iterations: 5 Function evaluations: 606 Final average energy (cost): 9.080000000000002 Final angles: [3.84038054 3.6674896 3.95335633 1.96342744 1.12175435 1.33671581] Training complete. Code execution time [sec]: 142.866375207901 Optimal energy: -6.6 Optimal classical bitstring: [0 0 0 1 0 0 1 0 1 0 0 0 0 1 0 0]「Optimal classical bitstring」は$[q_0, q_1, q_2, ..., q_{15}]$の順で並んでいるのでそれをもとに実際の巡回路に落とし込むと「C → D → B → A」となります。(参考:D-Waveとblueqat.optで巡回セールスマン問題とmaxcut問題、クリーク問題、自然数分割問題)
実際の経路の長さを求めると、7となり、明らかに最適解であることがわかります。
(*)式で(添え字を0~15に変更した状態をもとに戻して)計算しなおすと上記の「Optimal energy」になることがわかり、これが最適解であることがわかるかと思います。実は上記変更は足りない部分があります。
(というより正直最適解が出なくてほしかった。。。のですが、しょうがない。)
なぜかというと今回行った変更を思い出してください。
同じ量子ビット同士の演算を飛ばしています。
なのでそこの部分を表現しないといけません。
と言いつつ、今回最適解を獲得できた理由は厳密にはわかりませんが、以下の二つがあるかと思っています。
(わかる方いたら教えていただけると幸いです。)
- 結局基底状態を求めるためのパラメータ最適化は量子回路の外側で行われています。なのでそれなりの今回の最適解を求めるのに最適なパラメータ設定が行われた。
- 今回の最適化における対角成分は結局のところすべての値が同じ値でした。つまり、(対角成分を表現しない基底状態) $\supset$ (対角成分を表現する基底状態) なので対角成分を表現しない基底状態を求めるパラメータ調整においても一番最適な状態に持っていくことができれば最適化状態となりうる?
といったようなことがあるのかな。と思っています。
(本当に何となくの考察なのでわかる方いたら教えていただけると幸いです。)ということで対角成分を表現していきましょう。
修正②:対角成分の表現
対角成分を表すのに数式的にどのように表現するかはこちらをぜひ参考にしてください。
結論だけ述べると以下の通り、$R_Z$回転で表すことができます。
(各ビットは0,1で表されるので$q_iq_i = q_i$で一次項として表すことができることに注意)e^{-i\gamma_{i} Z} = R_{Z}(2\gamma_{i})実際のソースコードに起こしてみましょう。
ソースコードに起こす際もそれほど難しくなく、ZZGateを適用した後にそれぞれの量子ビットに対して$R_Z$回転を加えます。# apply ZZ gate for every edge (with corresponding interation strength) for qubit_pair in edges: if (qubit_pair[0] != qubit_pair[1]): # get interaction strength from Ising matrix int_strength = ising[qubit_pair[0], qubit_pair[1]] # for Rigetti we decompose ZZ using CNOT gates if device.name == 'Rigetti': gate = ZZgate(qubit_pair[0], qubit_pair[1], gamma*int_strength) circ.add(gate) # classical simulators and IonQ support ZZ gate else: gate = Circuit().zz(qubit_pair[0], qubit_pair[1], angle=2*gamma*int_strength) circ.add(gate) # 線形項に対応する量子ゲートを追加 for qubit_pair in edges: if (qubit_pair[0] == qubit_pair[1]): gate = Circuit().rz(qubit_pair[0], 2 * gamma) circ.add(gate)準備はできたので実際に動かしてみましょう。
実行
変更を行ったのでプログラムを実行してみようと思います。
少し時間はかかりますが、実際に実行すると以下のような結果が返ってきます。
(ランダムなので多少結果は異なります。)Circuit depth hyperparameter: 3 Problem size: 16 Starting the training. ==================================================================== OPTIMIZATION for circuit depth p=3 Param "verbose" set to False. Will not print intermediate steps. ==================================================================== Optimization terminated successfully. Current function value: 5.500000 Iterations: 2 Function evaluations: 292 Final average energy (cost): 5.500000000000001 Final angles: [5.66357773 4.31982407 4.72149979 1.63593414 1.0267231 2.03051354] Training complete. Code execution time [sec]: 74.82601428031921 Optimal energy: -6.6 Optimal classical bitstring: [0 0 0 1 0 0 1 0 1 0 0 0 0 1 0 0]「Optimal classical bitstring」は$[q_0, q_1, q_2, ..., q_{15}]$の順で並んでいるのでそれをもとに実際の巡回路に落とし込むと「C → D → B → A」となります。(参考:D-Waveとblueqat.optで巡回セールスマン問題とmaxcut問題、クリーク問題、自然数分割問題)
これは修正①での結果と同じ結果でありますが、巡回順が変わった結果が出力されることや近似アルゴリズムなので最適解出ない結果が出ることももちろんありますが、今回は最適解であることがわかります。
以上のようにして対角成分を表した計算をAWS Braket上で行うことができました。最後に
今回はAWS Braket上でより一般的に近い最適化問題を解いてみました。
今後もより柔軟な回路設計をして最適化問題を解いてみようかと思っているのでまた記事にできそうならばしてみようかと思います。

- 投稿日:2021-01-19T10:30:09+09:00
AWS Braket を使ってQAOAを実装してみる①
この記事について
AWS Braket が公開されてから、一般の人にとっても量子コンピュータの実機に触れる機会が増え、それに伴い、私も量子コンピュータのお勉強をしています。
Braketではゲート型の最適化を行うにあたってQAOAというアルゴリズムを使用します。
AWS Braketのサンプル上ではGraph Coloring Problem という問題を解いており、「各ノードに赤や青の色をつけ、色の異なるノード間の各枝に点数をつけていきより良い点をしよう」という問題の求解を行っています。
こちらの問題ですが、以下の式で表されるコスト関数を定義し、($z_n= {-1,1}$, $J$は枝間の重み)それを最小化する問題に帰着できます。H_{C}=\sum_{i>j} J_{i,j} z_{i} z_{j},このような問題に帰着できるものであれば、AWS Braketのサンプルを流用することで動かすことができますが、最適化問題をより一般的に表すには、以下の通り線形項も加味する必要があります。
H_{C}=\sum_{i>j} J_{i,j} z_{i} z_{j} + \sum_{i=1}^{n} h_{i} z_{i}AWSのサンプルをそのまま動かすだけでは上記の問題を正確に解くことができません。(近似アルゴリズムなので別のアプローチでももちろん正確ではないが、そのまま使うよりは正確です。)
なのでこういった最適化問題を解くことができるような実装をAWS Braket上で行いました。
とはいえ、それを紹介する前にAWS Braket上でQAOAがどのように表現されているかを示す必要があるかと思い、本記事ではまずAWS Braket上でQAOAがどのように実装されているかを解説していこうと思います。
上記背景から本記事はあくまでAWS BraketのQAOAサンプルコードを解説するという記事となっています。
ソースコード等一切変更せず解説を行っているのでご注意ください。なお、量子コンピュータ関係の他の記事は、こちらのページで一覧にしています
解説の対象
今回はAWS Braketのサンプルを直接解説していこうと思いますので こちらのソースコードを解説していきます。
こちのソースコードはBraketを起動した際に notebookインスタンス内に自動で連携され、だれでも最初から使えるようになるので
実際に動かして使ってみたい人は Braketの利用開始をしてみて実際に使ってみてください。起動直後に連携されるソースコード内の
/Braket examples/ hybrid_quantum_algorithms/QAOAのなかに入っているはずなのでそちらを見て触ってみてもいいかと思います。(2021/01/18現在)
ソースコードの概要
BraketのQAOAサンプルコード内を見てみると以下の3つのソースコードが入っているかと思います。
- QAOA_braket.ipynb
- utils_classical.py
- utils_qaoa.py
QAOA_braket.ipynb では、QAOAの簡単な概要、問題の定義、QAOAのパラメータ定義、QAOAの呼び出し、古典最適かとの比較などの呼び出し側で記述したり、比較したりするようなソースコードが書かれています。
util_classical.py は比較用に使う古典最適化の実体が記述されています。そのため、今回はこちらの説明は本質的ではないため、割愛させていただきます。
utils_qaoa.py はQAOAの実体が記述されており、実際の回路等の記載が行われています。ということなので今回は
- QAOA_braket.ipynb
- utils_qaoa.py
特に、utils_qaoa.pyの解説をしていこうと思います。
詳細
QAOA_braket.ipynb
まずはQAOAを呼び出す元のソースコードから解説していきます。
こちらnotebook用のソースコードであるのでQAOAの簡単な説明も記載してあります。
というわけでせっかくなのでその辺も追っていきながら説明をしていきます。QAOA の概要
QAOAの概要が記載されています。
QAOAはあくまで近似最適化アルゴリズムであることやNISQアルゴリズムとして有力な手段として認識されていて、古典計算と量子計算を組み合わせて行うハイブリッド量子アルゴリズムに分類されます。
Braket では、オープンソースのscipyを使うことで古典最適化部分を行っています。※注意点ですが、本記事で説明を割愛させていただくutils_classical.pyはQAOAのハイブリッドの古典計算とは全く関係ありません。
QAOAの古典計算はutils_qaoa.pyに記載してあり、utils_qaoa.pyは今回の説明の対象なので安心してください。さらに興味深い話がありこちらのソースコード上でQAOAがDeep Learningと似ているよねという話が以下の図を用いて示されていました。
引用: https://github.com/aws/amazon-braket-examples/blob/main/hybrid_quantum_algorithms/QAOA/QAOA_braket.ipynb本稿の趣旨ではないので説明は割愛します。
興味のある方はソースコードを読んでみてください。バイナリ二次計画問題
今回はGraph Coloring 問題という問題を使用していきます。
なのでこちらでさっさとGraph Coloring 問題の定式化を説明していきましょう。
とは言ってもかなり簡単なので構えずに読み流す程度で大丈夫だと思います。Graph Coloring Problem は「各ノードに赤や青の色をつけ、色の異なるノード間の各枝に点数をつけていきより良い点をしよう」という問題の求解を行っています。
つまり、なるべく隣り合うものは別の色で塗ろう!という配色問題ですね。今回は簡単にサンプルを実装しているようなので2色で色分けをしている問題となりmさう。
こちらの問題ですが、以下の式で表されるコスト関数を定義し、($z_n= {-1,1}$, $J$は枝間の重み)それを最小化する問題に帰着できます。
H_{C}=\sum_{i>j} J_{i,j} z_{i} z_{j},QAOAの流れ
QAOAの流れは
こちらの記事 をぜひ見ていただきたいのですが、本記事でも簡単に触れます。以下QAOAの手順となります。
- 重ね合わせ状態$|s\rangle = |+\rangle^{\otimes n}$を作る。
- パラメータ$\beta, \gamma$で指定されるユニタリゲート$U_C(\gamma_{i}),U_X(\beta_{i})$をかけていき、状態$|\beta, \gamma \rangle$を得る。
- 量子コンピュータで期待値 $\langle \beta, \gamma |C(Z)|\beta, \gamma \rangle$ を測定する
- $\langle \beta, \gamma |C(Z)|\beta, \gamma \rangle$ が小さくなるように古典コンピュータでパラメータ $\beta, \gamma$ を更新する。
- 最適解 $\beta^{ * }$,$\gamma^{ * }$を得るまで1~4を繰り返す。
- $|\beta^{ * } , \gamma^{ * } \rangle$ をZ基底で測定し、良さそうな測定結果を解として出力する。
特に2ではAWS Braketのソースコード上でも触れられている以下の式を適用するのと同値です。
|\beta, \gamma \rangle = U_{x}(\beta_{p})U_{zz}(\gamma_{p}) \cdots U_{x}(\beta_{1})U_{zz}(\gamma_{1}) |s\rangleまた、
{e^{-i\gamma_{i} (Z_iZ_j)}= CX_{i, j} R_{Z_j}(2\gamma_{i}) CX_{i, j}} \\ {e^{-i\gamma_{i} (X)}= R_{X}(2\beta)}であることを念頭に置けば回路に落とし込むことができそうです。
ソースコードの流れ
ではソースコードの流れを追っていきます。
まずインポート分野AWS S3 Bucketの設定などがありますが、このあたりの説明は省略します。問題の定義
まずはグラフの定義をしていきます。
AWS Braket上は以下の通りのグラフ定義になっています。# setup Erdos Renyi graph n = 10 # number of nodes/vertices m = 20 # number of edges # define graph object G = nx.gnm_random_graph(n, m, seed=seed) # positions for all nodes pos = nx.spring_layout(G) # choose random weigths for (u, v) in G.edges(): G.edges[u,v]['weight'] = random.uniform(0, 1) # draw graph nx.draw(G, pos) plt.show()口頭で補足すると
n個のノード、 m個の枝のグラフを定義しています。
つまり、今回だと10個のノードを定義し、その中で20個の枝に対して0, 1の範囲内でランダムな数を割りあてノード間の重みを定義しているという意味合いになります。実際につながっているノード間を可視化すると以下のようになります。
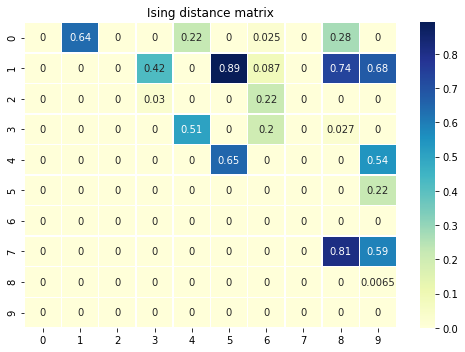
前処理として、上記のグラフ構造を対角成分のない上三角行列で表します。
アルゴリズム的に対角成分のない行列でないといけないことはないですが、おそらくコーディング上計算式が簡単になるのでこうしているのだと思います。
(対角成分を表したい(イジングモデル的に言うと線形項を表したい)場合にAWS Braketで実装しようとすると別途工夫がいるので次回の記事にでも述べようと思います。)以下前処理のソースコードと可視化です。
# set Ising matrix Jfull = nx.adjacency_matrix(G).todense() Jfull = np.array(Jfull) # get off-diagonal upper triangular matrix J = np.triu(Jfull, k=1).astype(np.float64) # plot Ising matrix plt.figure(1, figsize=[7, 5]) sns.heatmap(J, annot=True, linewidths=.5, cmap="YlGnBu", annot_kws = {'alpha': 1}) plt.title('Ising distance matrix'); plt.tight_layout();
QAOAの実行準備
注意したいのはQAOAの本体は util_qaoa.pyで定義しているということです。
なので util_qaoa をインポートすることを忘れないでください。Ansatzの説明
QAOAの流れの中で適用されるユニタリゲート群をAnsatzと呼びます。
どういう意図でこういった名前になっているかはわかりませんが、おそらくAnsatzというのはドイツ語で仮設という意味らしいので
QAOAにおいて基底状態を求めるのに適切なユニタリゲート群をパラメータを用いて仮定してアルゴリズムの中で求める。といった背景からそういった名前で呼ばれている気がします。
とりあえず、以下の式で示される $U_{x}(\beta_{p})U_{zz}(\gamma_{p}) \cdots U_{x}(\beta_{1})U_{zz}(\gamma_{1})$がAnsatzと呼ばれる認識で良いと思います。|\beta, \gamma \rangle = U_{x}(\beta_{p})U_{zz}(\gamma_{p}) \cdots U_{x}(\beta_{1})U_{zz}(\gamma_{1}) |s\rangleではこういったAnsatzって実際に回路上ではどうなっているのか?
といったところがAWS Braketのサンプル上の
VISUALIZATION OF THE QAOA ANSATZで記述されています。ソースコードが書かれていますが、どちらかというと気にしないといけないのは実際に目に見てわかる可視化部分です。サンプルコードを見ると結果として以下の二つの可視化が示されています。
一つ目は、ステップ数 ($p$) が1で $\gamma_1=0.2, \beta_1=0.6$
二つ目は、ステップ数 ($p$) が2で $\gamma_1=0.2, \beta_1=0.6, \gamma_2=0.4, \beta_2=0.8$です。Printing test circuit: T : |0|1| 2 | 3 | q0 : -X-H-ZZ(0.2)-Rx(0.6)- | q1 : -X-H-ZZ(0.2)-Rx(0.6)- T : |0|1| 2 | 3 |Printing test circuit: T : |0|1| 2 | 3 | 4 | 5 | q0 : -X-H-ZZ(0.2)-Rx(0.6)-ZZ(0.4)-Rx(0.8)- | | q1 : -X-H-ZZ(0.2)-Rx(0.6)-ZZ(0.4)-Rx(0.8)- T : |0|1| 2 | 3 | 4 | 5 |実際のQAOAではこれらのパラメータを最適化しながらより良い(基底状態を求めるのに適した)回路を作っていくことで全体の最適化を行っていきます。
QAOAの実行
** QAOA SIMULATION ON LOCAL SCHROEDINGER SIMULATOR **にてQAOAの実行を行っています。
以下のソースコードはパラメータの調整を行っています。################################################################################## # set up hyperparameters ################################################################################## # User-defined hypers DEPTH = 3 # circuit depth for QAOA SHOTS = 10 # number measurements to make on circuit OPT_METHOD = 'Powell' # SLSQP, COBYLA, Nelder-Mead, BFGS, Powell, ... # set up the problem n_qubits = J.shape[0] # initialize reference solution (simple guess) bitstring_init = -1 * np.ones([n_qubits]) energy_init = np.dot(bitstring_init, np.dot(J, bitstring_init)) # set tracker to keep track of results tracker = { 'count': 1, # Elapsed optimization steps 'optimal_energy': energy_init, # Global optimal energy 'opt_energies': [], # Optimal energy at each step 'global_energies': [], # Global optimal energy at each step 'optimal_bitstring': bitstring_init, # Global optimal bitstring 'opt_bitstrings': [], # Optimal bitstring at each step 'costs': [], # Cost (average energy) at each step 'res': None, # Quantum result object 'params': [] # Track parameters } # set options for classical optimization options = {'disp': True, 'maxiter': 500} # options = {'disp': True, 'ftol': 1e-08, 'maxiter': 100, 'maxfev': 50} # example optionsざっくり説明すると
DEPTHはユニタリゲートの繰り返し回数、つまり、前述したユニタリゲートを示す$p$の値になります。
SHOTSはパラメータを決定した後、測定する回数と同値ととらえていただければ良いです。
QAOAの流れでは「量子コンピュータで期待値 $\langle \beta, \gamma |C(Z)|\beta, \gamma \rangle$ を測定する」と記載しましたが、ここの部分でどこまでが量子でどこからが古典かが多少わかりにくくなります。
量子計算で行うのはあくまで、$|\beta, \gamma \rangle$の量子状態を求めるところまでです。
この後、観測することでたった一つのビット配列を古典コンピュータで表現することとなります。ここの観測されるビット配列は、量子回路で作られた$|\beta, \gamma \rangle$の量子状態に基づく確率で決まります。そのため、実際に複数回測定して測定結果を測定回数で割り算してあげることで期待値を求めることととなります。
(後述する utils_qaoa.pyのソースコード上にも表れてきます。)
OPT_METHODは古典最適化で使用する最適化手法です。(デフォルトはPowellになってます。)
n_qubitsは量子ビットの数、bitstring_init, energy_init は古典最適化で最初の状態を定義する必要があるのでとりあえず定義してあげます。(適切な定義方法がある気がしますが、本質ではないので割愛します。)
optionsのmaxiterはQAOAの繰り返し回数の最大値を示しています。
パラメータの推定回数と言い換えてもいいかもしれません。以下でQAOAを実際に動かしています。
################################################################################## # run QAOA optimization on graph ################################################################################## print('Circuit depth hyperparameter:', DEPTH) print('Problem size:', n_qubits) # kick off training start = time.time() result_energy, result_angle, tracker = train( device = device, options=options, p=DEPTH, ising=J, n_qubits=n_qubits, n_shots=SHOTS, opt_method=OPT_METHOD, tracker=tracker, s3_folder=s3_folder, verbose=verbose) end = time.time() # print execution time print('Code execution time [sec]:', end - start) # print optimized results print('Optimal energy:', tracker['optimal_energy']) print('Optimal classical bitstring:', tracker['optimal_bitstring'])上記によりQAOAを動かすことができます。
QAOA_braket.ipynbのサンプル上ではこれ以降は出力の説明や古典アルゴリズムとの比較を行っていたりするだけですので、説明は割愛します。
QAOA本体の utils_classical.pyの説明に入っていこうと思います。utils_qaoa.py
では実際にQAOAの本体のソースコードに触れていこうかと思います。
Ansatzで使用する回路の定義
まずAnsatzで使用する回路を定義してあげる必要があります。特に注意しないといけないのはRigettiではZZ回路(とりあえずそう呼んでいますが、正式な呼び方かどうかはわかりません。)が用意されていないのでCNOTと$R_Z$回路を用いて自分で作ってあげる必要があります。(参考:Amazon Braket のゲート型量子コンピュータで指定できる量子回路)
(あくまでRigetti用です。IonQでは用意されているのでそれを使いましょう)# function to implement ZZ gate using CNOT gates def ZZgate(q1, q2, gamma): """ function that returns a circuit implementing exp(-i \gamma Z_i Z_j) using CNOT gates if ZZ not supported """ # get a circuit circ_zz = Circuit() # construct decomposition of ZZ circ_zz.cnot(q1, q2).rz(q2, gamma).cnot(q1, q2) return circ_zz次に$U_{x}(\beta_{p})U_{zz}(\gamma_{p}) \cdots U_{x}(\beta_{1})U_{zz}(\gamma_{1})$で示される $U_{x}(\beta_{i})$と$U_{zz}(\gamma_{i})$を定義していきます。
AWS Braketでは$U_{x}(\beta_{i})$と$U_{zz}(\gamma_{i})$はそれぞれdriver、cost_circuitと定義しているようで、以下のようにソースコード上では定義されています。driverは以下となります。
# function to implement evolution with driver Hamiltonian def driver(beta, n_qubits): """ Returns circuit for driver Hamiltonian U(Hb, beta) """ # instantiate circuit object circ = Circuit() # apply parametrized rotation around x to every qubit for qubit in range(n_qubits): gate = Circuit().rx(qubit, 2*beta) circ.add(gate) return circcost_circuitは以下となります。
# helper function for evolution with cost Hamiltonian def cost_circuit(gamma, n_qubits, ising, device): """ returns circuit for evolution with cost Hamiltonian """ # instantiate circuit object circ = Circuit() # get all non-zero entries (edges) from Ising matrix idx = ising.nonzero() edges = list(zip(idx[0], idx[1])) # apply ZZ gate for every edge (with corresponding interation strength) for qubit_pair in edges: # get interaction strength from Ising matrix int_strength = ising[qubit_pair[0], qubit_pair[1]] # for Rigetti we decompose ZZ using CNOT gates if device.name == 'Rigetti': gate = ZZgate(qubit_pair[0], qubit_pair[1], gamma*int_strength) circ.add(gate) # classical simulators and IonQ support ZZ gate else: gate = Circuit().zz(qubit_pair[0], qubit_pair[1], angle=2*gamma*int_strength) circ.add(gate) return circ※以下「再開」部分まで少し深めの話なので飛ばしても大丈夫です。興味ある方だけ読んでください。
driverは特に気にする点はありませんが、cost_circuitでは注意が必要です。
前述したとおり、今回定義した最適化モデルは線形項が含まれていません。そして、対角成分も含まれていません。線形項を含めたい場合、このcost_circuit関数の引数に新たに線形項を示す変数を定義してそれに対する演算を行う必要があります。
また、cost_circuitに引数として定義しているisingに対角成分を無理やり入れてしまうとゲート定義の際にエラーを起こしてしまいます。
対角成分は$z_iz_i$と示されますが、量子複製不能原理により同じビット同士の演算は行うことができません。
そのため、対角成分の演算はできないことに注意してください。
(${-1, 1}$イジングモデルだと対角成分はありませんが、${0,1}$モデルだと対角成分を定義できるので注意が必要です。)
${0,1}$モデルで対角成分の計算を行う方法、もしくは${-1, 1}$イジングモデルで線形項を含める方法は別記事で説明しようと思いますのでまた参考にしてみてください。※再開
では、driverとcost_circuitを定義できたので全体の回路を定義しましょう。# function to build the QAOA circuit with depth p def circuit(params, device, n_qubits, ising): """ function to return full QAOA circuit; depends on device as ZZ implementation depends on gate set of backend """ # initialize qaoa circuit with first Hadamard layer: for minimization start in |-> circ = Circuit() X_on_all = Circuit().x(range(0, n_qubits)) circ.add(X_on_all) H_on_all = Circuit().h(range(0, n_qubits)) circ.add(H_on_all) # setup two parameter families circuit_length = int(len(params) / 2) gammas = params[:circuit_length] betas = params[circuit_length:] # add QAOA circuit layer blocks for mm in range(circuit_length): circ.add(cost_circuit(gammas[mm], n_qubits, ising, device)) circ.add(driver(betas[mm], n_qubits)) return circまず初期状態を定義しています。
今回は $|-\rangle^{\otimes n} $を初期状態としていますが、QAOAの流れで示した通り、$|+\rangle^{\otimes n} $を初期状態としても問題ありません。
Xゲートの基底状態である量子状態を初期状態とすれば何でも大丈夫です。参考目的関数
QAOAでは量子回路を適用してより最適なパラメータ $\beta, \gamma$ を求めることで最適解を求めていきます。
これはつまり、量子回路を適用することによって得られた結果を目的関数値とし、それを最適化していくこととなります。
もう少し詳しく言うと、量子ゲートを適用して複数回観測し、観測結果に基づいて期待値を求めます。
それを目的関数値として最適化することとなります。
ということなので目的関数値 objective_functionを定義します。
AWS Braketの関数では少し長めのコードになっているので一つ一つ説明していきます。重要な変数
- params: パラメータ$\beta, \gamma$を持つ変数
- device: 適用する実機 or シミュレータ(デバイス識別子)
- ising: イジングモデル n × n 行列(対角成分のない上三角行列)
- n_shots: ショット数
- tracker: 結果や過程等の様々な変数を保存していく場所、主に古典最適化のために使う想定
- s3_folder: s3の保存先
- verbose: 出力するかどうか
主な流れ
1. qaoa_circuitに使用する回路を定義する
# get a quantum circuit instance from the parameters qaoa_circuit = circuit(params, device, n_qubits, ising)2. 量子コンピュータ or シミュレータを実行し、結果を保存する
# classically simulate the circuit # execute the correct device.run call depending on whether the backend is local or cloud based if device.name == 'DefaultSimulator': task = device.run(qaoa_circuit, shots=n_shots) else: task = device.run(qaoa_circuit, s3_folder, shots=n_shots, poll_timeout_seconds=3*24*60*60) # get result for this task result = task.result()3. 観測値をマッピングする
今回は -1, 1で定義したので0 → -1に変更するマッピングする必要がありますが、0,1のでもうまくマッピングが行えればそれでも計算可能です。# get metadata metadata = result.task_metadata # convert results (0 and 1) to ising (-1 and 1) meas_ising = result.measurements meas_ising[meas_ising == 0] = -14. すべての観測結果に対してエネルギーを求める
# get all energies (for every shot): (n_shots, 1) vector all_energies = np.diag(np.dot(meas_ising, np.dot(ising, np.transpose(meas_ising))))4. 最適値を更新する
# find minimum and corresponding classical string energy_min = np.min(all_energies) tracker['opt_energies'].append(energy_min) optimal_string = meas_ising[np.argmin(all_energies)] tracker['opt_bitstrings'].append(optimal_string) # store optimal (classical) result/bitstring if energy_min < tracker['optimal_energy']: tracker.update({'optimal_energy': energy_min}) tracker.update({'optimal_bitstring': optimal_string})6. 期待値を求めパラメータなどの更新を行う
# store global minimum tracker['global_energies'].append(tracker['optimal_energy']) # energy expectation value energy_expect = np.sum(all_energies) / n_shots if verbose: print('Minimal energy:', energy_min) print('Optimal classical string:', optimal_string) print('Energy expectation value (cost):', energy_expect) # update tracker tracker.update({'count': tracker['count']+1, 'res': result}) tracker['costs'].append(energy_expect) tracker['params'].append(params)以上が古典で量子回路のパラメータを最適化していくプロセスとなります。
初期値の定義とインターフェース
パラメータの初期値を定義したり、別のプログラムから関数を呼び出すためのインターフェースとして train関数が定義されています。
こちらはパラメータの初期値を定義して、最適化関数を呼び出す程度のことしか行っていないため、割愛させていただきます。まとめ
以上より、QAOAを実際に動かすために最低限必要な実装をAWSBraketのコードを見ながら解説していきました。
本文でも少しふれましたが、こちらはあくまでAWS Braketで公開されているサンプルコードを何も手を付けずに説明したものとなります。
なのでもう少し応用的な内容もやろうと思えばいくつかやれることがあるので
次回の記事では少し応用的な内容に触れていければと思っています。参考
- 投稿日:2021-01-19T01:46:17+09:00
Amplify 学習資料
AWS 公式 Slideshare
20200520 AWS Black Belt Online Seminar AWS Amplify
AWS Black Belt Online Seminar AWS Amplify
[CTO Night & Day 2019] AWS Amplify で Web/Mobile 爆速スケーラブル Serverless 開…
AWS 公式ハンズオン
AWS Amplifyハンズオン with Vue.js :: Amplifyハンズオン with Vue.js
その他ブログ
React + Amplify + AppSync + DynamoDB でサーバレスなWebアプリを作成する公式チュートリアルをやってみた | Developers.IO
書籍 (Booth)
- 投稿日:2021-01-19T01:25:30+09:00
EC2インスタンス起動後に「DeleteOnTermination」を変更する
EC2インスタンス起動後に「DeleteOnTermination」を変更する
⓪対象のインスタンスの詳細を調べる
マネジメントコンソールから、「DeleteOnTermination」を変更したいEBSがアタッチされているEC2インスタンスの詳細を調べる。記録しておく情報は以下の通り。
・対象EBSがアタッチされているEC2インスタンスのインスタンスID
・対象EBSのデバイス名①インスタンスの状態を調べる
以下のコマンドをAWS CLIから入力して、ボリューム情報を参照する。
aws ec2 describe-instances --instance-id <インスタンスID> --query Reservations[].Instances[].BlockDeviceMappings[]
②①で表示された内容から以下の内容を確認する。
・⓪で確認した対象EBSのデバイス名
・⓪で確認した対象EBSのデバイス名の「DeleteOnTermination」の値(boolean)③「DeleteOnTermination」の値を更新する
以下のコマンドをAWS CLIから入力して、ボリューム情報を更新する。
aws ec2 modify-instance-attribute --instance-id <インスタンスID> --block-device-mappings DeviceName=<デバイス名>,Ebs={DeleteOnTermination=<false or true>}
※この時、IAMでEC2インスタンスを変更できるロールを保持していること。④インスタンスの状態を調べる
以下のコマンドをAWS CLIから入力して、ボリューム情報を参照する。
aws ec2 describe-instances --instance-id <インスタンスID> --query Reservations[].Instances[].BlockDeviceMappings[]
- 投稿日:2021-01-19T00:58:45+09:00
Amazon Connectを利用してコールセンターを構築してみた
概要
ちょっと事情があってコールセンターについて理解を深めてみようと思い、手軽に構築を試せるAmazonConnectを利用して構築してみました。
随分と前に記事の投稿を試して以来久々の投稿なので緊張しています。
何番煎じかわかりませんが、良かったら読んでいってください。コールセンターの仕組み
そもそもコールセンターの仕組みってどんなものでしょうか。
改めて何か調べてみました。コールセンターとは
コールセンターは企業における電話応対を担う部門や事業所・またそのための設備を指すようです。ここで言う電話応対は顧客からの電話受付1や、セールスなどで顧客への電話を掛ける対応2も行うことができます。
ところで、よくよく考えてみるとこのコールセンターシステム構築にかかる要件定義はかなり大変そうです。
コールセンターは通常、顧客を待たせてしまうことのないように大人数のオペレータ3で構成されています。
ということは、顧客から来た電話を効率よく割り振るような仕組みが必要になるはずです。4
また、逆に架電する際も、誰がどこにかけたか、どこにかけていないかをシステムで統制できないと混迷を極める状況になります。そこで、多くのコールセンターシステムはPBXと呼ばれる機能を有しています。
PBX
PBXは、"Private Virtual eXchange"の略で、電話交換機のような役割を持つらしいです。
ようは、複数の外線電話と内線電話を接続するための機能(機器)で、複数の顧客から来た着信は、一度このPBXで受け付けて、そこから内線に回すという仕組みです。
わーお。5さて、これだけでもコールセンターは成り立ちそうなものですが、技術の進歩というのは人類の可能性を広げるもので、コールセンターに関わる業務をよりシステム化できるようになっています。
そう、コンピュータと電話の統合による、業務のシステム化です。CTI
CTIは、"Computer Telephony Integration"の略で、要は、電話機にコンピュータをドッキングして、コールセンターにかかる業務をシステム化しようという考えです。
実は上で紹介したPBXも、今ではシステム制御しているはずなので、CTIの一部という言い方が出来るのかもしれません。6
具体的にどんなことが出来るようになったでしょうか。
IVR
IVRとは、"Interactive Voice Response"の略で、顧客から電話を受けたとき自動応答する機能になります。サポートセンターに問い合わせした時に、「〇〇に関する問い合わせは1を、××に関する問い合わせは2を押してください。」といったように顧客の要望に応じて割り振りを行うように実装することが出来ます。
ACD
ACDは、"Automatic Call Distributor"の略で、顧客からのコールを、事前に定めたルール通りに割り振る機能になります。
サーバーで言うところの、ロードバランシング的な機能ですね。例えば、オペレーターになるべく均等に割り振ったり、キュー7に入っている時間が長い=待機時間が長い顧客からのコールを優先に割り振ったりといったことが出来ます。
CRM連携
CRMは、"Customer Relationship Management"の略で、顧客情報管理システムを指します。コールセンターシステムとCRMを連携することで、電話をかけてきた顧客のそれまでの購入履歴や過去の問い合わせ履歴を参照することが出来るようになり、より適切な対応を行うことが出来るようになります。
その他
最近では、これに加えて顧客との電話を録音→分析したり、チャットボットを導入したり、自動応答の幅を広げたりといったようにコールセンターシステムも進化しています。
Amazon Connectの構築
お待たせしました。
ようやく本題です。
Amazon Connectを構築してみたので、ダイジェストで紹介していきたいと思います。
すみません、数枚スクショ撮り忘れました。見てのお楽しみということで。インスタンスを立ち上げる
Connectを始める際はまずインスタンスを立ち上げる必要があります。
ここで、コールセンターシステムを構築する土台を作るイメージです。
以下Topページから"今すぐ始める"をクリックして始めることが出来ます。
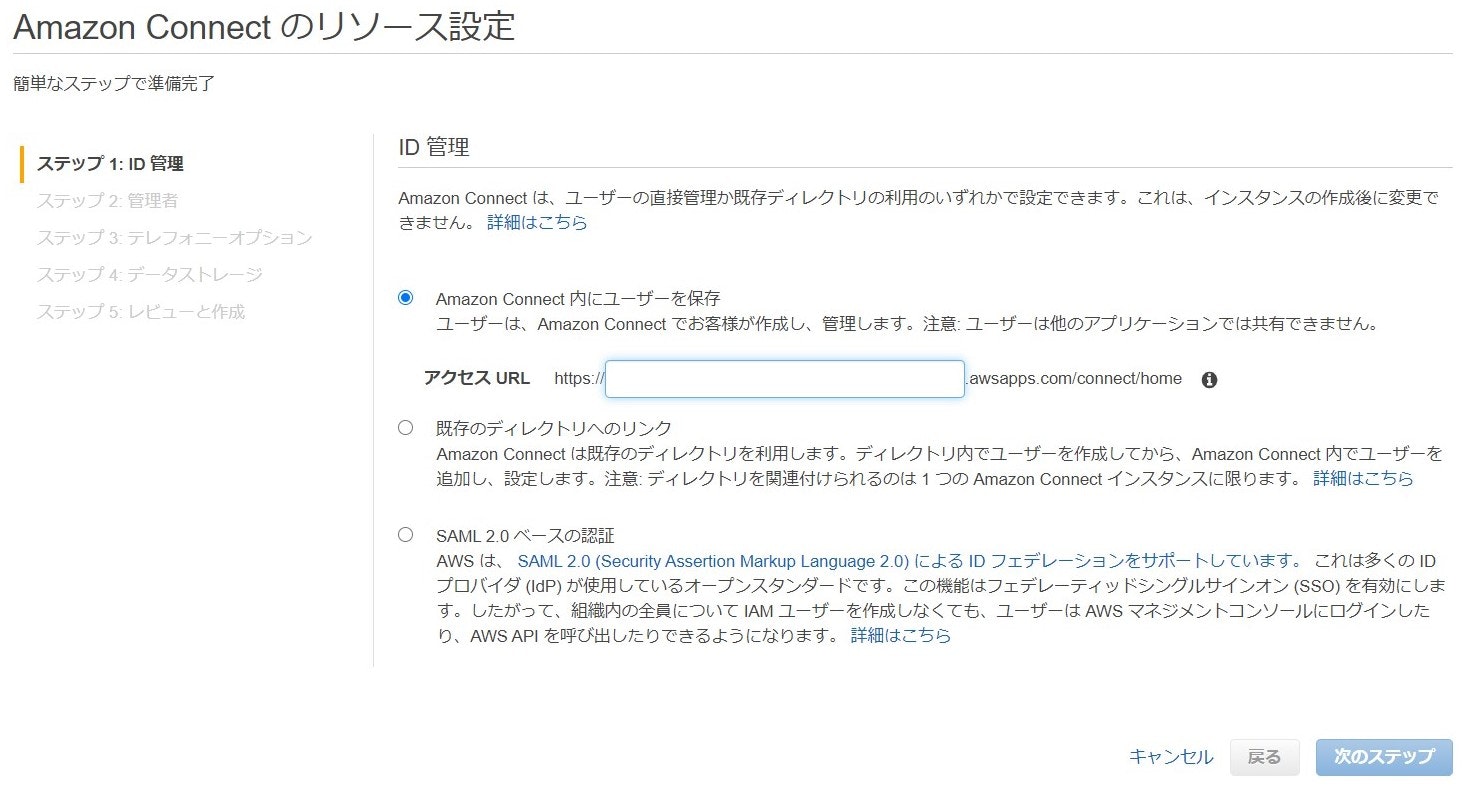
初めに、ユーザーを管理するディレクトリの設定を行います。
Connect内にユーザーが保存できるのはイメージ通りでしたが、SAML認証も対応してるんですね。既存のADがある場合は組み合わせて使うと便利かもしれません。管理者の作成
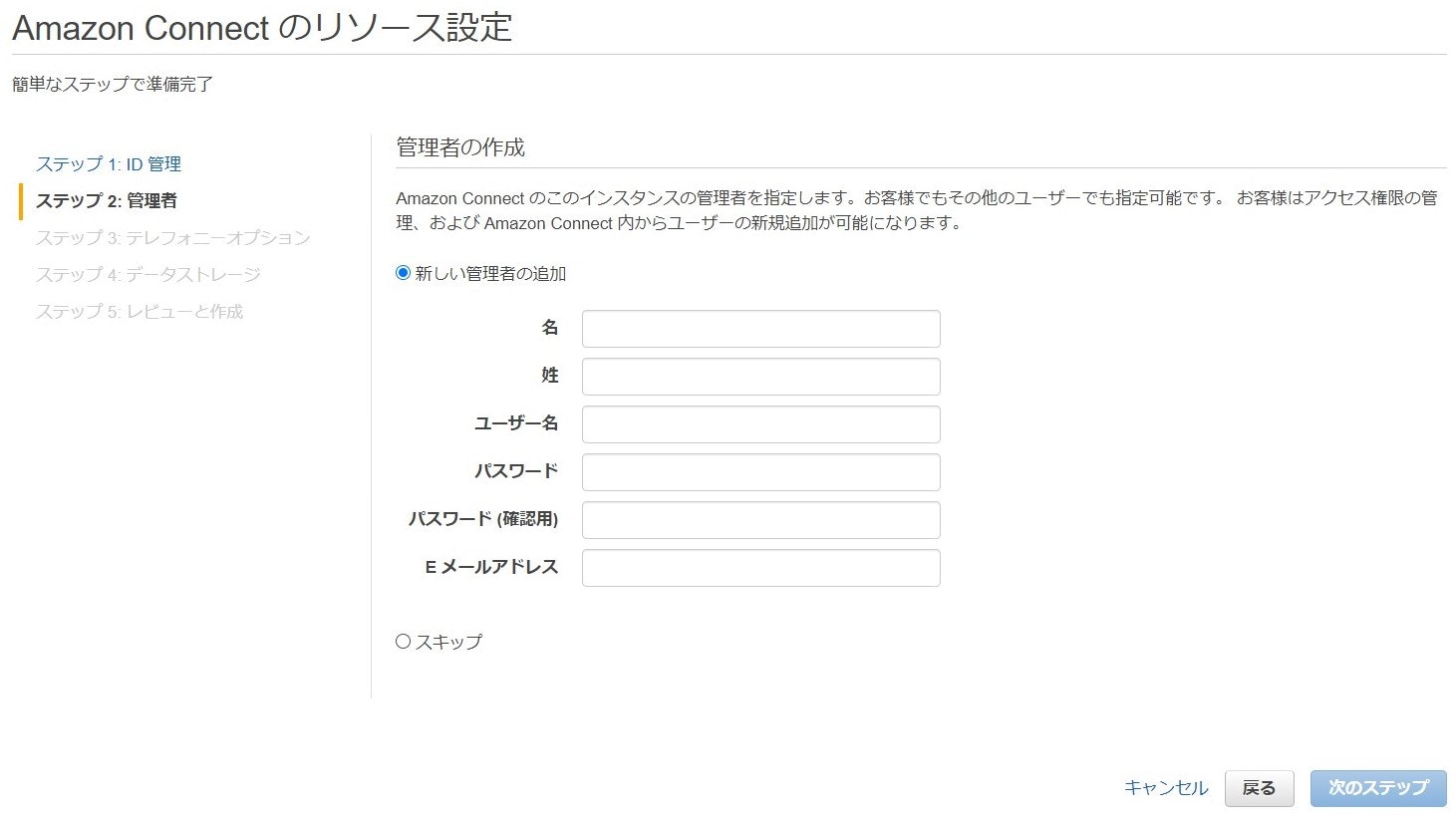
次に管理者の作成を行います。好きなように設定すると良いと思います。次にテレフォニーオプションを設定します。
立ち上げる予定のコールセンターシステムで、着信を行うのか、発信を行うのか、あるいはどちらも行うのかを設定します。
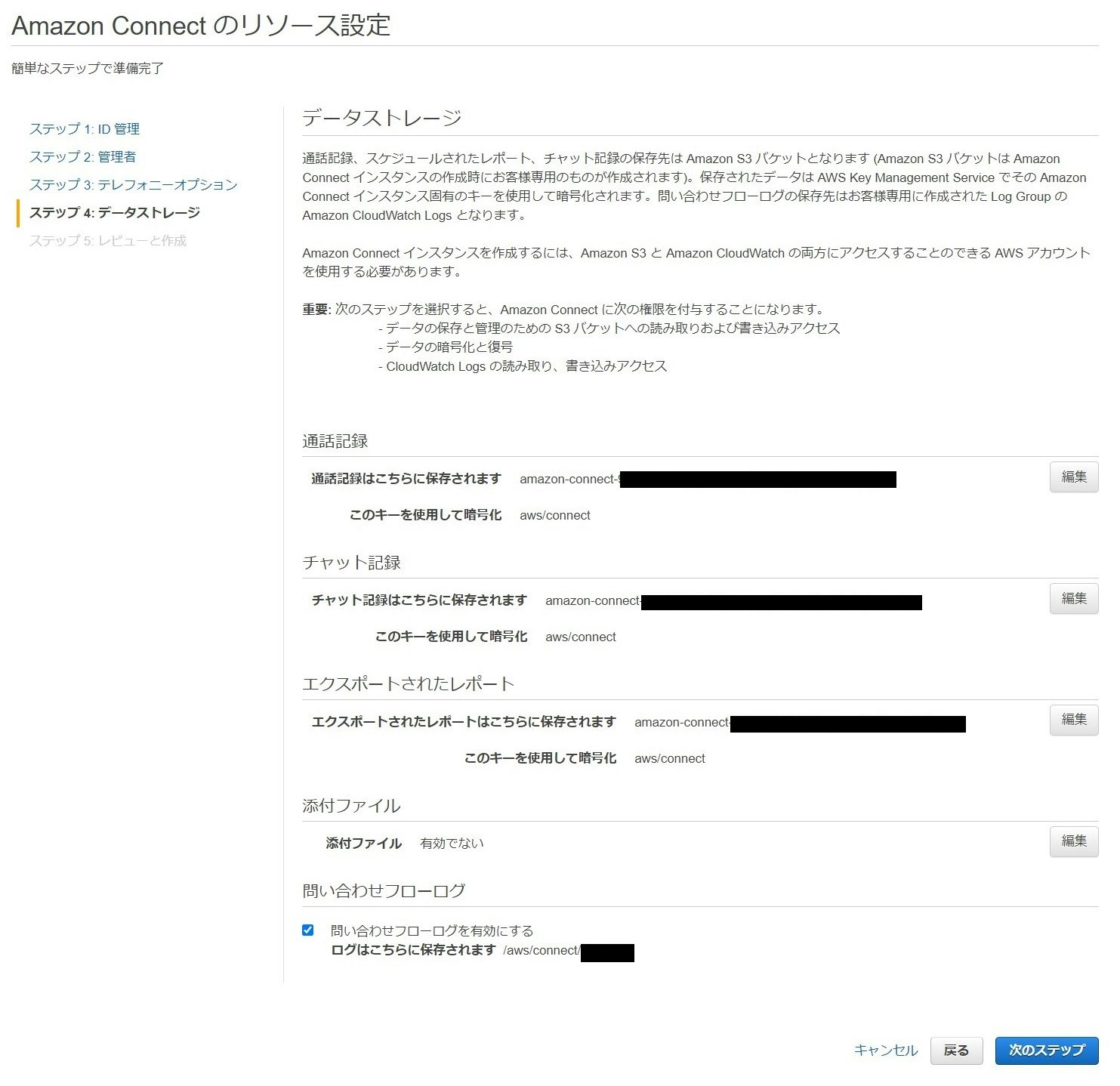
要件に応じて設定していただければよいと思います。データストレージの設定
コールセンターシステムで記録されるログなどをどこに保存するかの確認を行います。
特に問題がなければそのまま次のステップに進めばよいですが、もし何か設定を行いたい場合は”設定のカスタマイズ”から詳細に設定できるようです。
↓設定のカスタマイズ
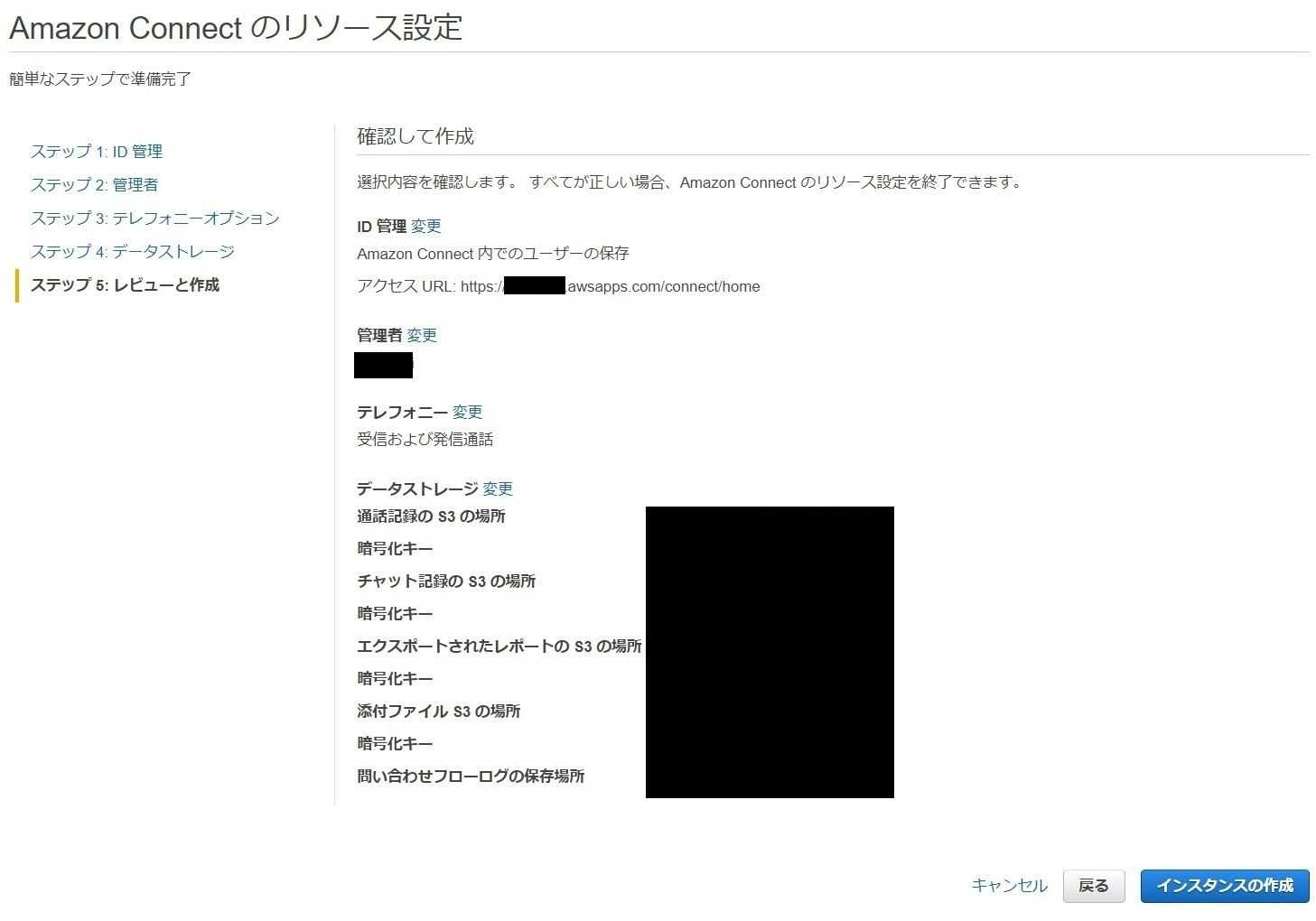
設定項目の確認
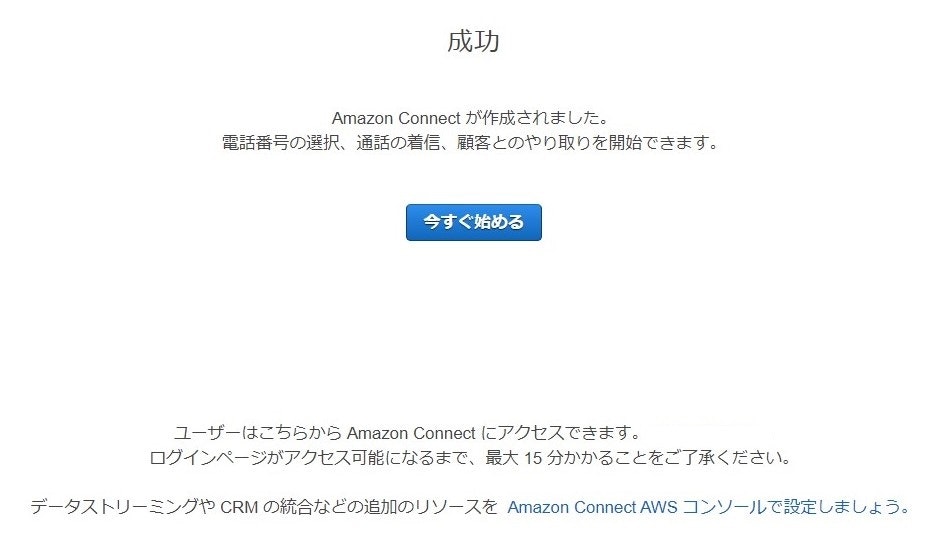
最後に設定した内容を確認して、”インスタンスの作成”をクリックすればインスタンスで作成できます!
コールセンターシステムの構築
さて、インスタンスを立ち上げたところで、実際にコールセンターシステムの構築を行いましょう。
設定開始
立ち上げたConnectを開くと以下のような画面が立ち上がるので”今すぐ開始”をクリックして設定を開始してみます。
電話番号の取得
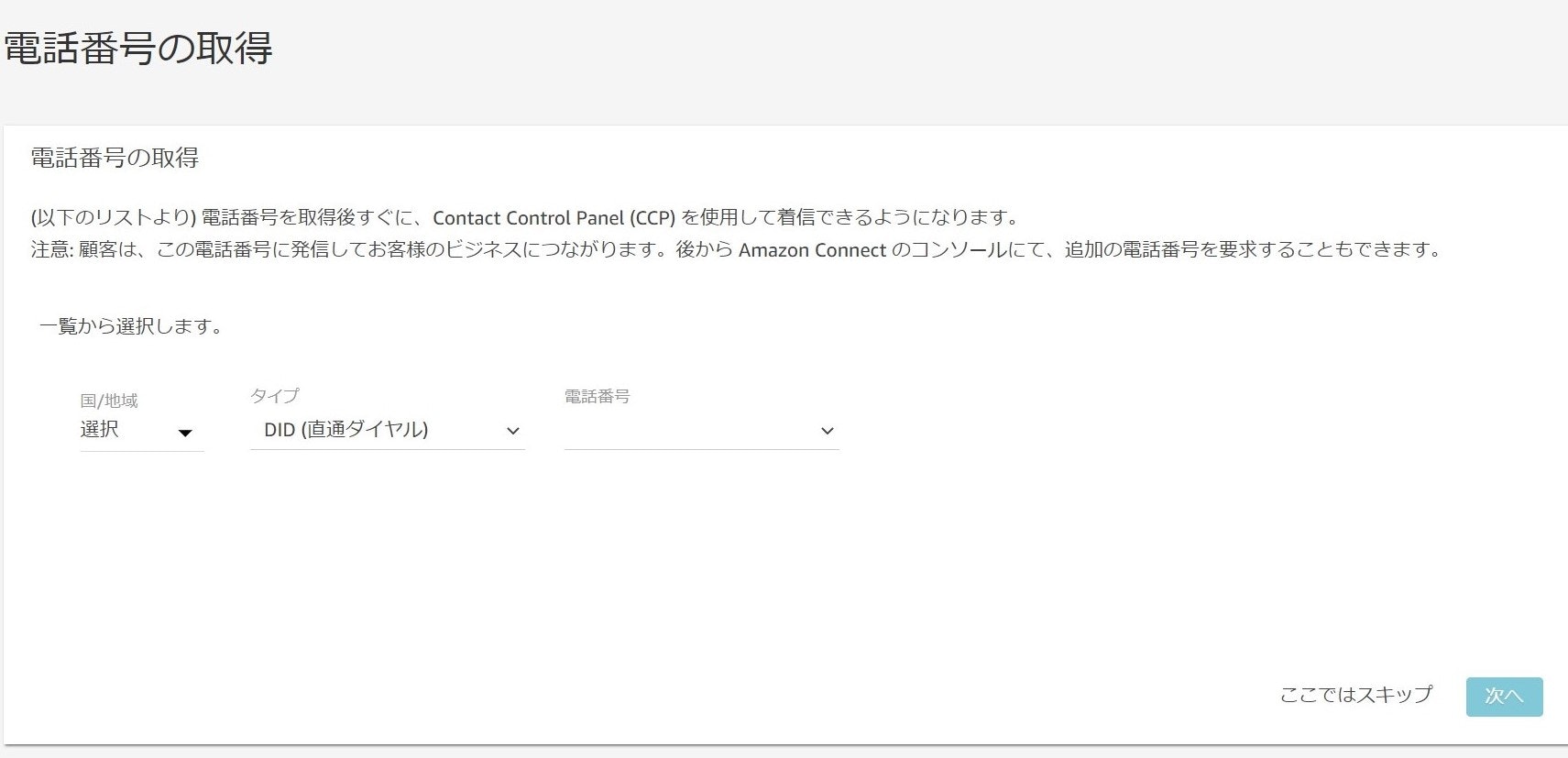
最初のステップは電話番号の取得です。
以下の設定画面から電話番号の取得を行います。
※日本の番号を取得するには、サポートに連絡の上一週間程度待つ必要があるようです。今回はテストで利用するだけなので、すぐに取得可能な国の番号を取得しました。
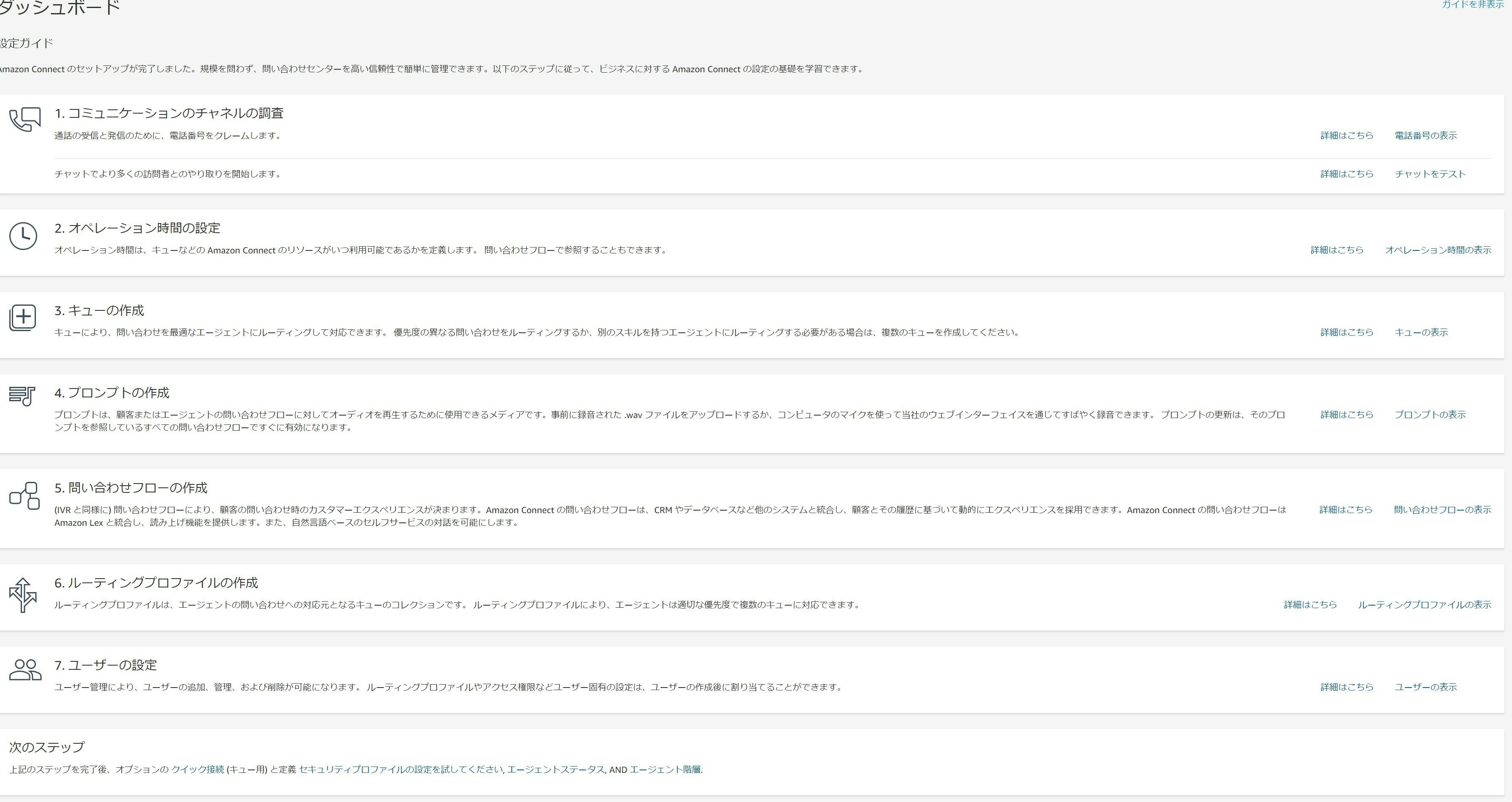
ご自身で試される際はそのあたり自己責任でお願いします。設定ガイド
電話番号の取得が完了すると、Connectの画面上に設定ガイドが現れました。
今回はこのガイドに沿って、設定を行ってみます。
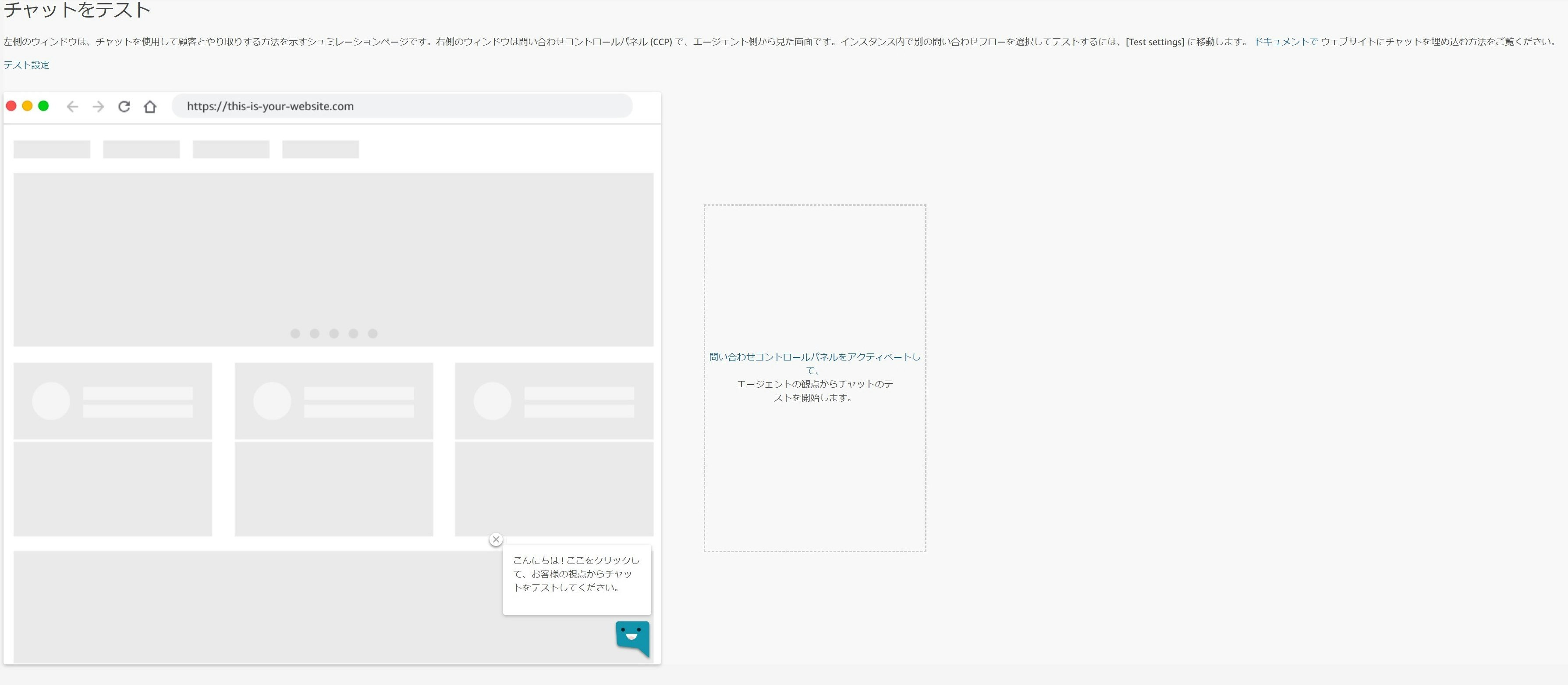
電話番号の確認とチャットのテスト
最初のステップでは電話番号の確認とチャットのテストが指示されますのでそれぞれ確認しましょう。
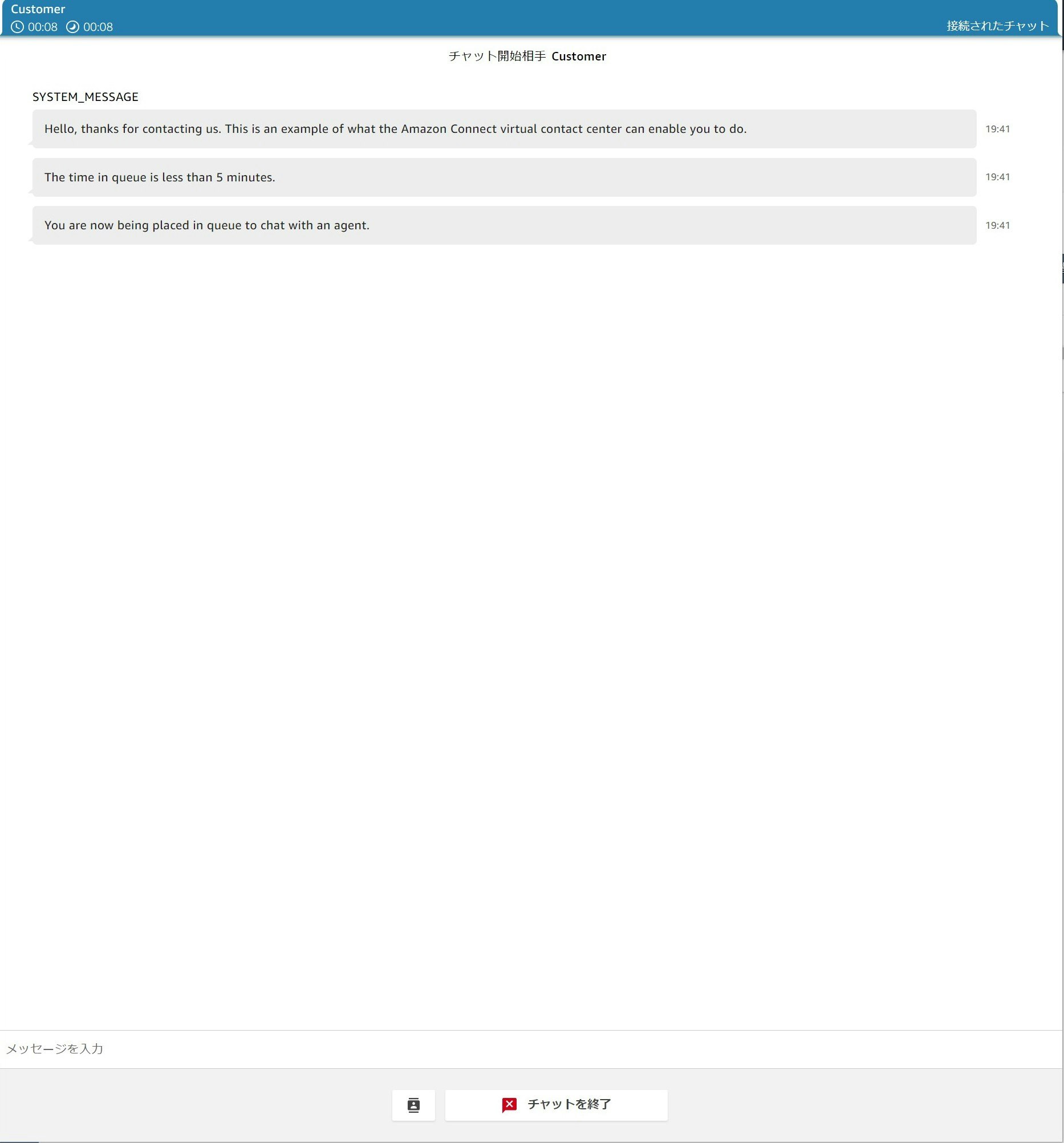
なお、チャットのテストは以下のような画面で行うことが出来ます。
とても便利。
オペレーション時間の設定
次にオペレーション時間を設定することが出来ます。
これは、例えば平日は17時までの受付といったように、受付可能な時間を設定するものです。8
キューの作成
続いて、キューの作成を行います。
キューとは、顧客からの問い合わせの待機場所を意味しており、どんどんたまっていく問い合わせをどのように捌くかのルールを、キュー毎に変えることが出来ます。9
また、キューは以下のように設定できるようです。
プロンプトの作成
プロンプトとは、オーディオを再生するためのメディアです。
サポートセンターに電話をかけたときに流れるボイスメッセージのあれです。
デフォルトでいくつか登録されていますが、必要なものがあれば自分で用意することもできます。
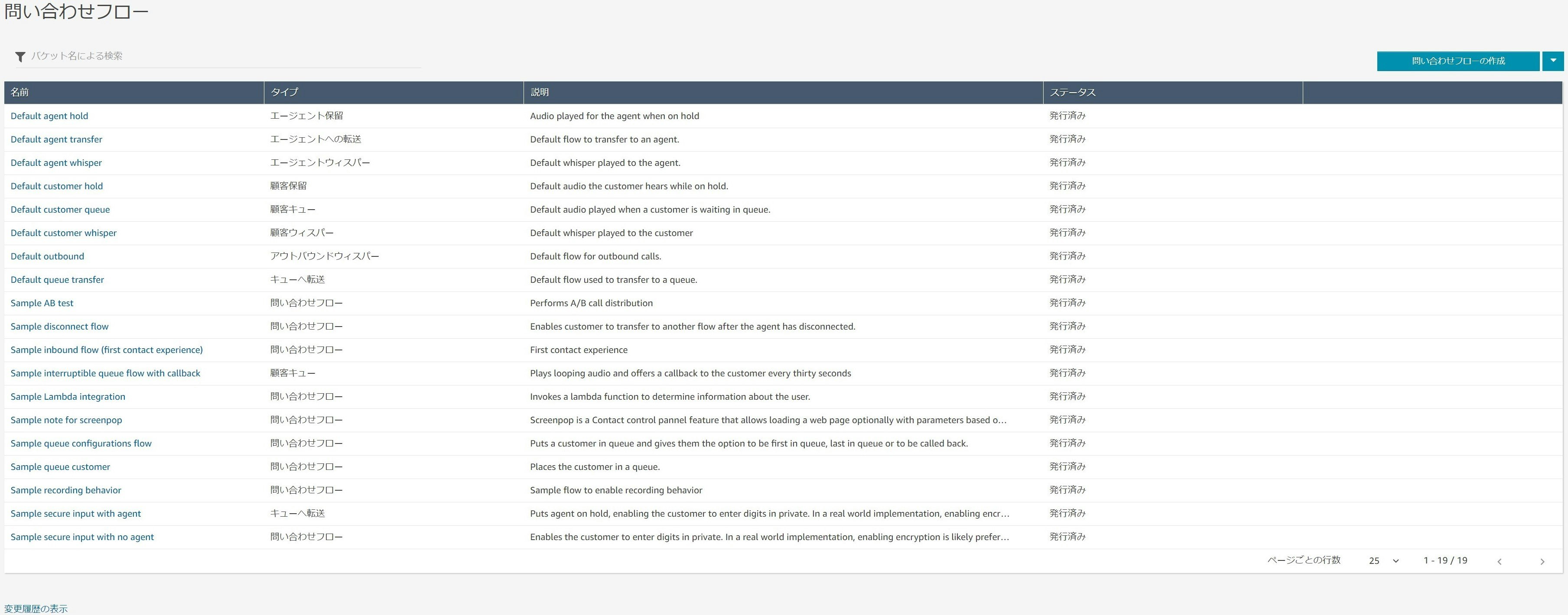
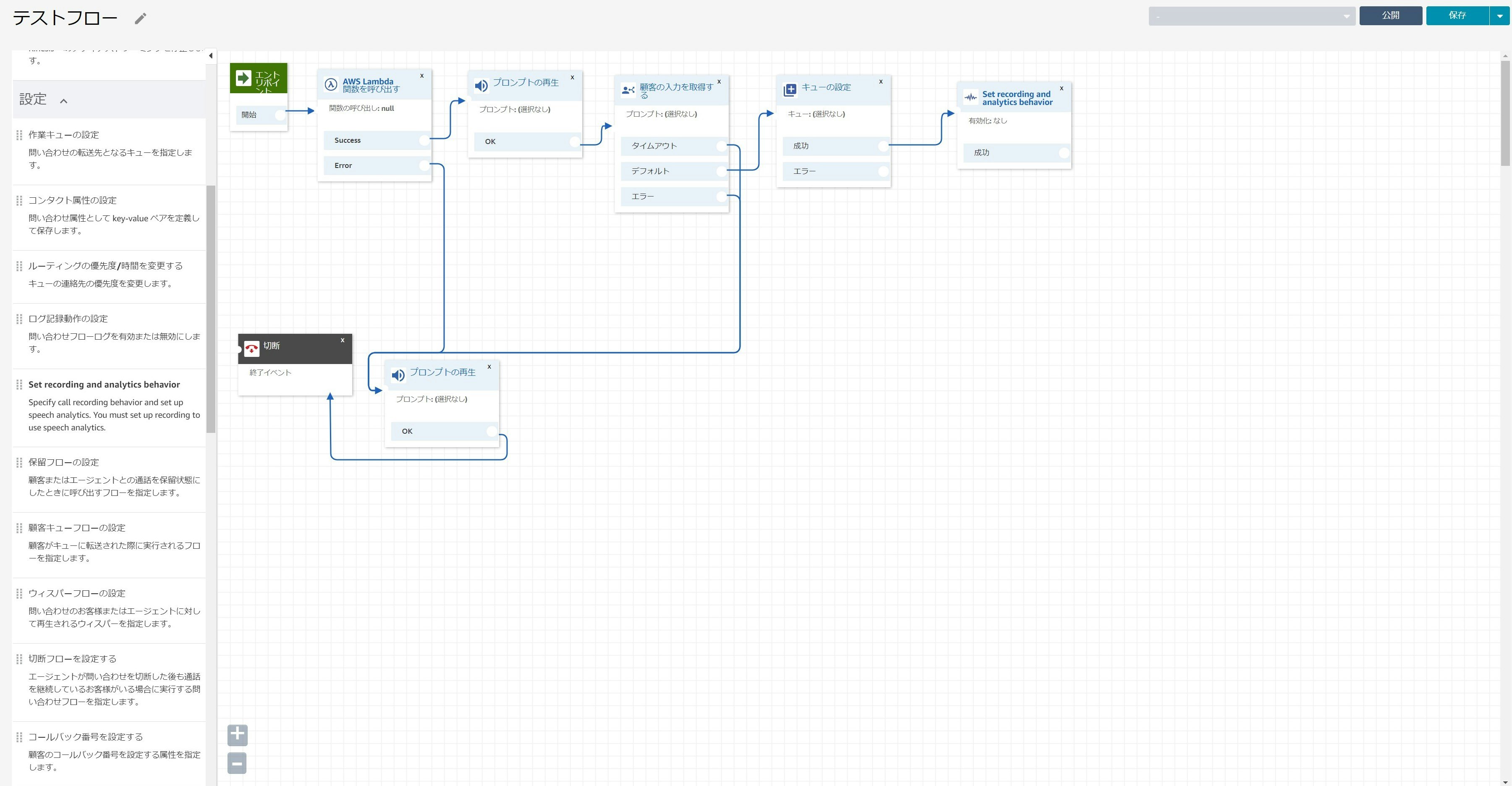
問い合わせフローの作成
問い合わせフローに関しては以下の図を見ていただくとわかりやすいかと思います。
※図はサンプルとしてとりあえず繋げただけなので実際には動かせません。
この図で示されているように、受信した問い合わせをどのようなフローで処理するかをGUIベースで定義したものです。
何が良いってここでLambdaを噛ませられるのがいいですよね。ルーティングプロファイルの作成
ルーティングプロファイルを設定することで、そのエージェントが受信できる問い合わせのタイプとルーティングの優先度が決められるみたいです。
例えば、ルーティングAにキューA,Bを割り当て、それをユーザーに割り当てることで、そのユーザーはキューA,Bの問い合わせに対応する、といった仕組みです。
ルーティングプロファイルは複数のユーザーに割り当てることができ、ユーザーはただ1つのルーティングプロファイルを持ちます。
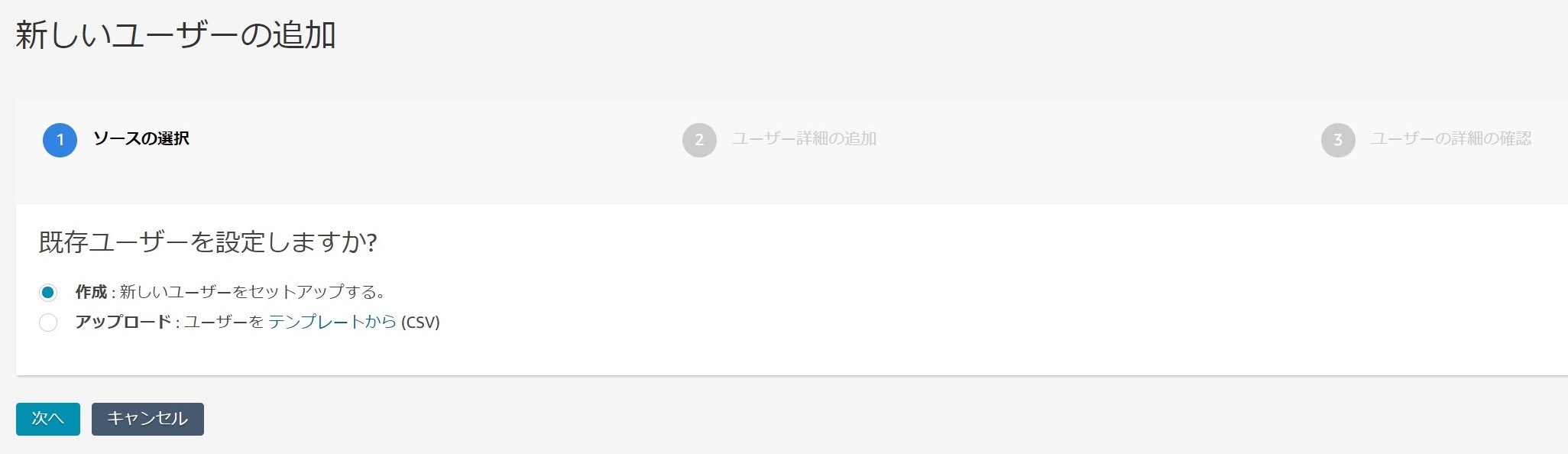
ユーザーの設定
設定ガイドの最後のステップとして、ユーザーの作成と設定を行います。
ユーザーの追加は以下の画面から行うことが出来ます。
1ユーザーずつ作成することもできますが、CSVでまとめて作成もできそうです。
1ユーザーずつ作成する場合は以下のように各項目を埋めて作成すればOKです。
作成されたユーザーはそれぞれ、最初に決めたURLからログイン画面に入り、ユーザー作成時に設定したメールアドレスとパスワードでログインして利用を開始します。
利用イメージは以下の通りです。
※チャットを利用したイメージ
料金
詳細はこちら10を参照してください。
ざっくりいうと、料金は以下の要素で構成されているようです。
①取得した電話番号につき1日当たりの料金
②取得した電話番号につき、1分当たりの受信通話料金
③音声・チャット・etcのAmazon Connect利用料金良いなと思ったところ
- 構築が簡単でシンプル
- LambdaやLens、S3など他のAWSサービスと接続しやすい。
- SDKで開発ができるっぽい(未検証)
良くないなと思ったところ
- 個々に合わせたきめ細やかなカスタマイズが難しい。
- 電話番号取得が面倒くさい
まとめ
ということで、コールセンターについてまとめた上でAmazon Connectを利用してみました。
コールセンターシステムって個人では用意できないだろうと思っていましたが、30分程度でできてしまったのでお手軽に試す分には良いですね。
実際に現場で開発した方に使い勝手を聞いてみたいです。これだけお手軽にできるなら、固定電話代わりに自前のConnect構築しちゃうのもありだなあと思いました。
次はその辺挑戦してみます!
サポセンに電話した時につながるあれ ↩
ちなみに、電話をかけることを架電というそうな ↩
電話を受ける人 ↩
職場で電話を取るみたいに、電話かかってきたから誰か取って!とかしていると効率が悪すぎる ↩
ちなみに、昔は手動で電話の交換を行っていたらしい。 ↩
歴史的な話をすると、90年代にデジタル制御するPBXとコンピュータを統合した新技術が生まれ、それがCTIの始まりとのこと。 ↩
キューイングって言葉はコールセンターシステムでも使うんですね。ちなみにキューとは、応答待ちになっている顧客からのコールが順番に格納されている状態を指します。 ↩
後述しますが、日本の祝日の設定ができません。必要な場合はLambdaを噛ませる必要があるっぽいです。 ↩
詳細→https://docs.aws.amazon.com/ja_jp/connect/latest/adminguide/concepts-queues-standard-and-agent.html ↩