- 投稿日:2021-01-16T22:58:22+09:00
Keras + OpenCV で画像認識による簡易的なアンケート読み取りシステムを作ってみた②
この記事について
飲食店のテーブルなどに置いてあるアンケート用紙。そのアンケートの集計はお店のスタッフがExcelなどの表計算ツールに打ち込んで集計していたりします。こういう非効率な作業を自動化できないかと思って、OCRに関する知識が全くない状態でアンケート用紙を読み取って自動集計する簡易的なシステムを作って見ました。この記事はその備忘録です。
システムの概要については前回の記事をご覧ください。
Keras + OpenCV で画像認識による簡易的なアンケート集計システムを作ってみた①
前回の記事ではOCR処理の対象となるアンケート項目を画像として抽出するまでの処理を行いました。ここからは、切り抜いたアンケート項目の記入数値を判定する処理を実装してみます。
深層学習で画像認識モデルを作成する
ディープラーニングの手法の1つである畳み込みニューラルネットワーク(CNN:Convolutional Neural Network)を使って画像認識モデルを作成しました。
具体的には以下の手順で進めました。
- 学習用に画像を用意する
- 画像の水増しを行う
- 学習モデルの作成&評価を行う
- KerasモデルをTensorFlowモデルに変換する
開発環境
[ハードウェア]
OS: Windows10 Home 64bit
CPU: Intel Core i7
GPU: NVIDIA Geforce GTX 1070 8GB
HDD: 1TB
[ソフトウェア]
Python: 3系
Tensorflow: 1.14.0
Keras: 2.2.4
Cuda: 8.0
cuDNN: 5.1
OpenCV: 2系1. 学習用に画像を用意する
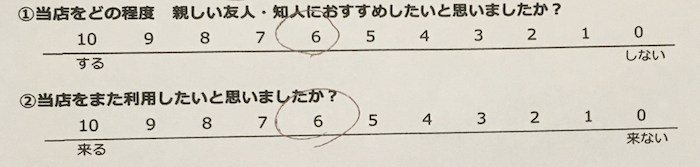
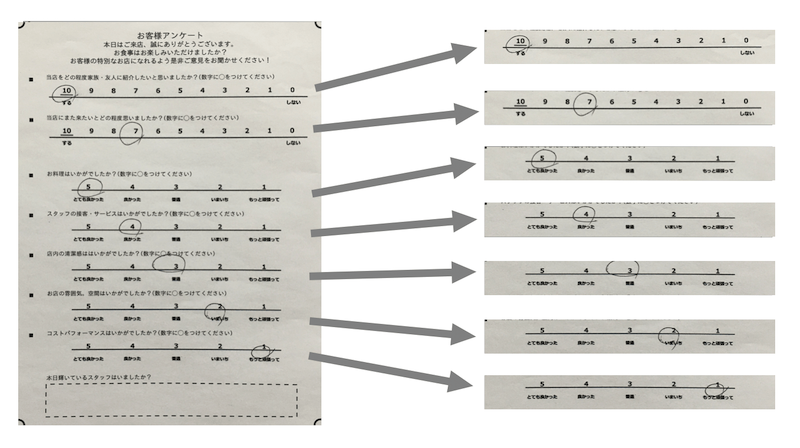
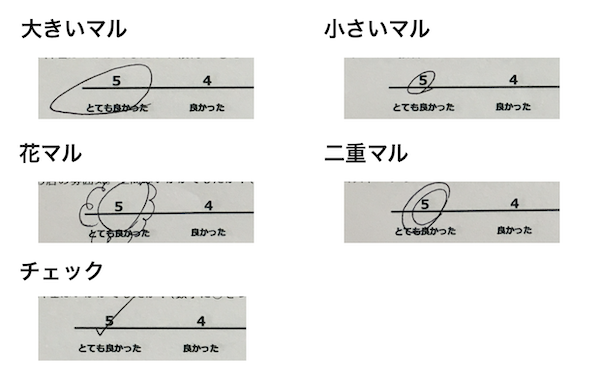
まず5点尺度のみ、11点尺度のみを記載したアンケート用紙をそれぞれ用意し、各数値にひたすらマルを記入していきました。記入する際には、学習モデルの精度を上げるためにあらかじめ想定される記入パターンを洗い出しておきました。
そして、それに基づいてひたすら下記のアンケート用紙に記入していきました。
各数値ごとに50枚ずつ記入し、各アンケート用紙をスマホで撮影していきました。また、数値が未記入の場合にも対応させるために未記入のアンケートも撮影しました。
前回の記事でアンケート用紙の撮影画像からアンケート項目を切り出す処理を実装していたので、この処理方法で撮影画像から各アンケート項目を切り抜いていきました。(切り抜く際には画像サイズを400×30に小さくしました。変更理由はCNNによる学習モデルを作成する際にメモリ不足になるのを防ぐためです。)
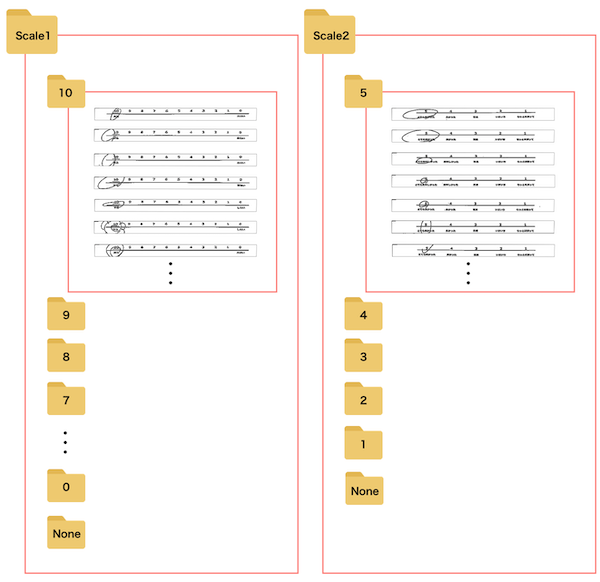
切り抜いた画像は下記のフォルダ構成で記入数値ごとにフォルダを分け、各フォルダごとに約500枚の画像を保存しました。("None"というフォルダには未記入のアンケートを保存)
2. 画像の水増しを行う
画像の水増しは最初考慮していませんでした。当初は1の画像数で後工程の学習モデルの作成を行なってみたのですが全く精度が上がりませんでした(正解率50%以下)。そこで、精度を上げるために画像の水増しを行い学習データを増やすことにしました。
画像の水増しにはKerasのImageDataGeneratorクラスを使用しました。
ImageDataGeneratorクラス
画像に対して変換処理(反転、拡大、縮小など)を加えることで、学習データの「水増し」を行うことができます。このクラスは下記のオプションを設定することでどのような変換処理を加えるか指定することができます。
オプション 内容 rotation_range 画像を回転させる角度の上限 width_shift_range ランダムに水平方向にシフトを行う範囲を指定 height_shift_range ランダムに垂直方向にシフトを行う範囲を指定 horizontal_flip 水平方向にランダムで反転させる vertical_flip 垂直方向にランダムで反転させる shear_range ランダムに引っ張る角度の範囲を指定 zoom_range ランダムにズームする範囲を指定 今回実装したコードは以下です。
import os import glob import numpy as np from keras.preprocessing.image import ImageDataGenerator, load_img, img_to_array, array_to_img def generate_images(generator, x, dir_name, index): save_name = 'extened-' + str(index) g = generator.flow(x, batch_size=1, save_to_dir=output_dir, save_prefix=save_name, save_format='jpg') # 1枚の画像から3枚拡張する for i in range(3): bach = g.next() for count in range(0, 10): # 出力先ディレクトリの設定 output_dir = "extend_scale1/" + str(count) if not(os.path.exists(output_dir)): os.mkdir(output_dir) # フォルダ内の全画像のパスを取得 images = glob.glob(os.path.join('scale1/' + str(count), "*.jpg")) # ImageDataGeneratorの設定 generator = ImageDataGenerator( width_shift_range=0.001, # 水平方向にランダムでシフト shear_range=0.001, # 斜め方向(pi/10まで)に引っ張る ) # 読み込んだ画像を拡張していく for i in range(len(images)): img = load_img(images[i]) x = img_to_array(img) x = np.expand_dims(x, axis=0) generate_images(generator, x, output_dir, i)このコードを実行することで学習用画像を3倍に増やしました。
3. 学習モデルの作成&評価を行う
学習用のデータは用意できたので、いよいよ学習モデルを作成します。
ここでは深層学習の畳み込みニューラルネットワーク(CNN)という画像認識に使われる手法を採用しました。深層学習(Deep Learning)
深層学習(Deep Learning)とは、ニューラルネットワークの中間層を多層に組み合わせたものをいいます。
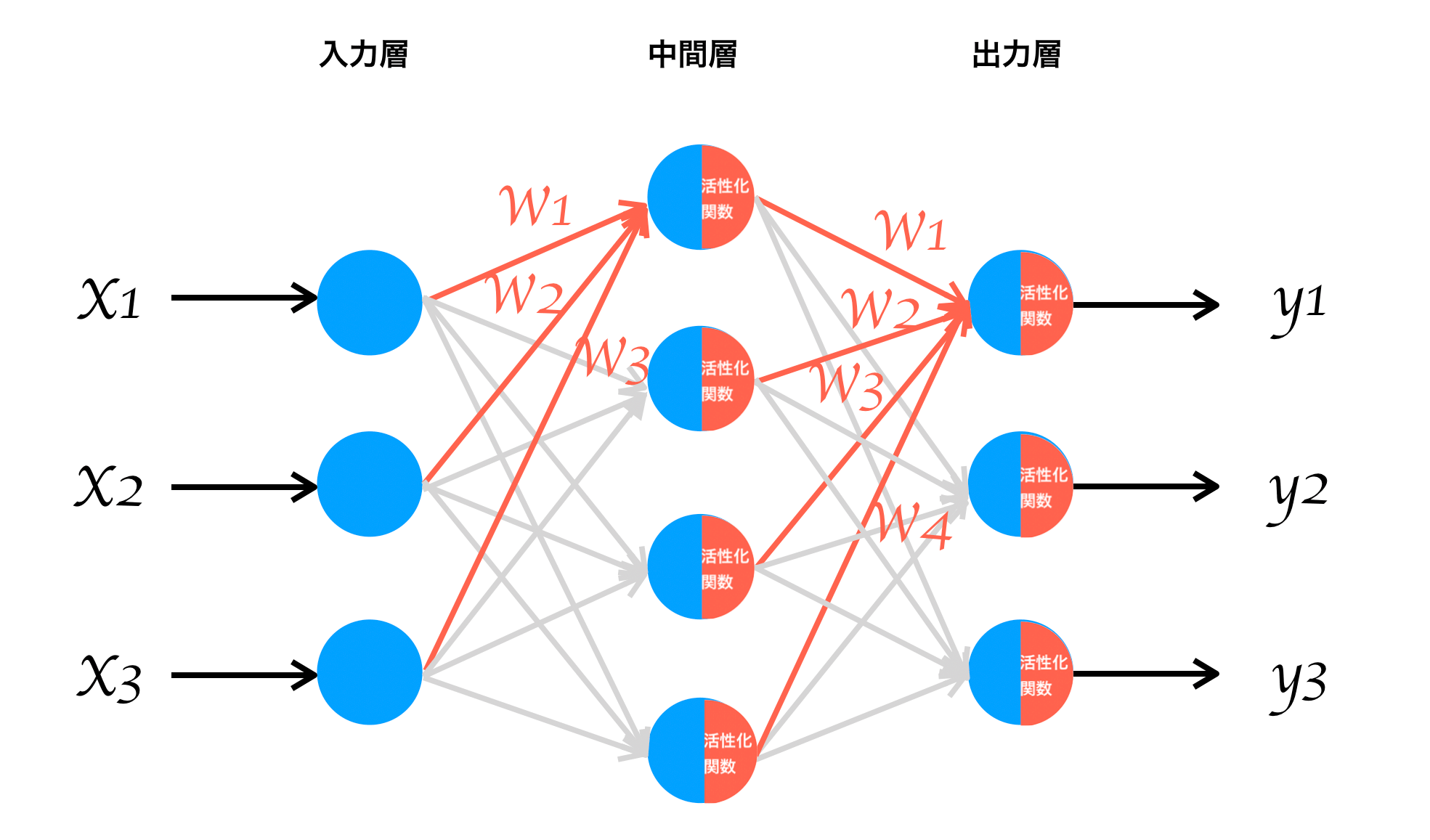
ニューラルネットワークとは下図のように入力層、中間層、出力層といった構成要素から成るネットワークのことで、x1,x2,x3といったデータを渡すことでy1,y2,y3といった出力結果を取得する仕組みです。ネットワークの途中過程ではwという重みを掛け合わせ、活性化関数を経由することで出力結果を調整します。このwは最初は明らかではありませんが、入力xと出力yの既知のデータから求めることができます(誤差逆伝播法)。
wが明らかになれば、別の入力データxから出力すべきyを予測することができます。
畳み込みニューラルネットワーク(CNN)
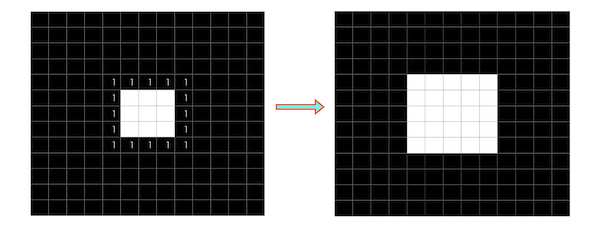
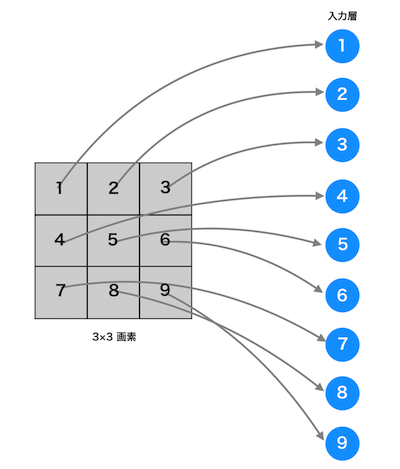
上記のようなニューラルネットワークに画像データを渡す場合は、その画素数やチャネル数に関係なく1次元のデータにする必要があります。例えば、白と黒で構成される3×3画素のモノクロ画像の場合は以下のようになります。
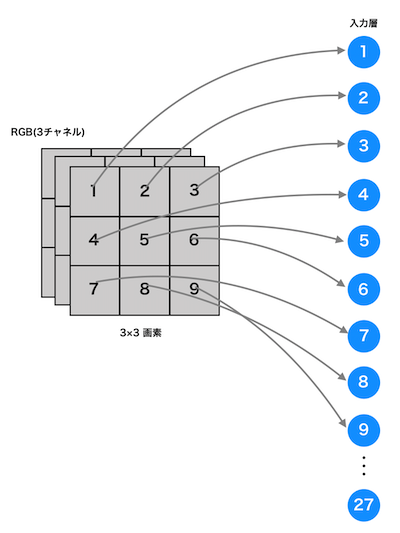
カラー画素の場合も、RGB3チャネルにはなりますがモノクロ画像と同じように1次元の入力データになります。
この方法では画像データが一列で表現されてしまうため下記のような空間的な情報は考慮されなくなってしまいます。
・空間的に近い画素は似たような値をとる
・RGBの各チャネル間には密接な関連性がある
・距離の離れた画素同士には、あまり関連性がないこういった情報も含めておくことができるのが畳み込みニューラルネットワーク(CNN)です。CNNは「畳み込み層」と「プーリング層」を含むニューラルネットワークになります。
畳み込み層
畳み込み層では、認識対象となるオブジェクトの特徴をまとめたいくつものフィルタを使って畳み込み演算を行います。
畳み込み演算とは、入力データ(画像)に対してフィルタを一定の間隔でスライドさせながら、フィルタの数値と入力データの数値を乗算し、その総和を求めるというものです。
このフィルタを使用することで、点ではなく領域を考慮した特徴抽出が可能になり、画像によってオブジェクトの位置や形が多少異なっていても特徴を抽出することが可能となります。
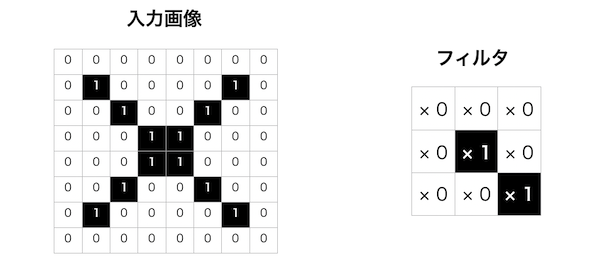
例えば、下記のような「×」マークを模した白黒の二値画像に対して右のフィルタを使った畳み込み演算を行ってみます。
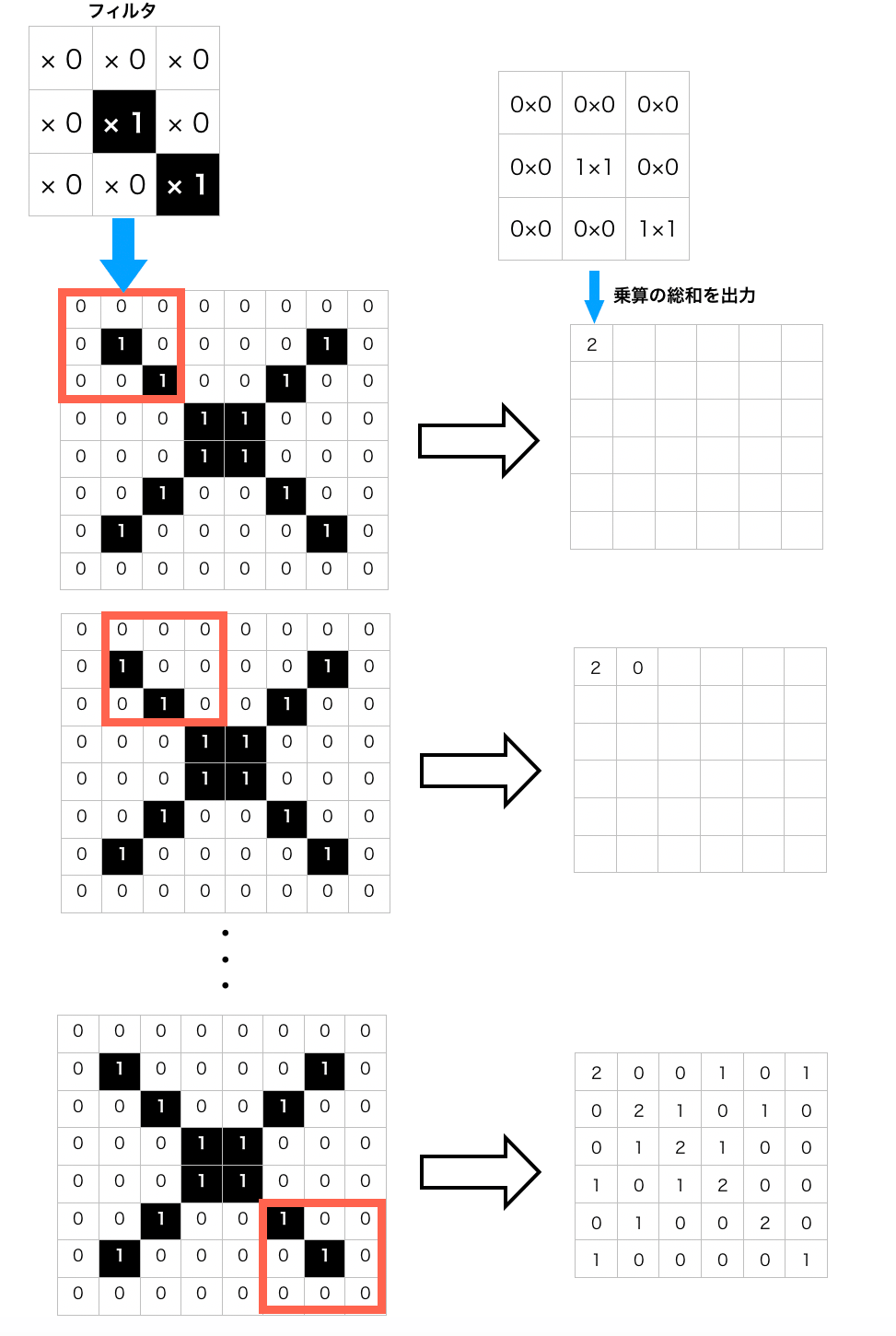
フィルタを1ピクセルずつスライドさせながら対応するマス同士の乗算の総和を出力していきます。
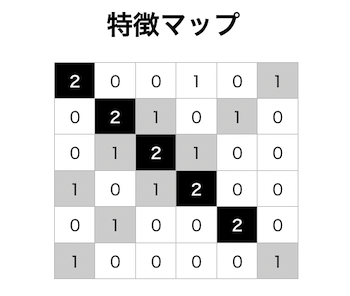
フィルタを最後までスライドさせて出力されたものを「特徴マップ」といいます。
畳み込み層では同じ演算処理をフィルタの数だけ行います。フィルタの値は重み(w)であり、既知の入力データ(画像)と出力データ(画像に写っているものが何か)を使った学習を行うことで値が設定されます。
プーリング層
プーリング層では、入力データの特徴を絞り込むことでより扱いやすい形に変形します。
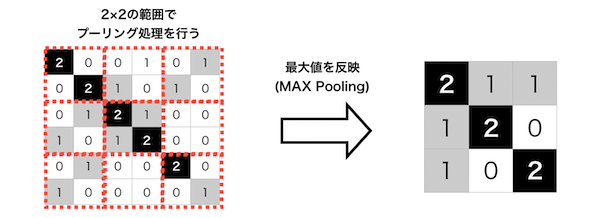
畳み込み層に比べると演算方法は単純であらかじめ決めておいた範囲内における最大値や平均値を出力するだけです。例えば、先ほどの特徴マップにプーリング処理(範囲内の最大値を出力するMaxPooling)を行うと以下のような出力結果になります。
このようにすると元データの特徴を維持しながら、圧縮することができます。
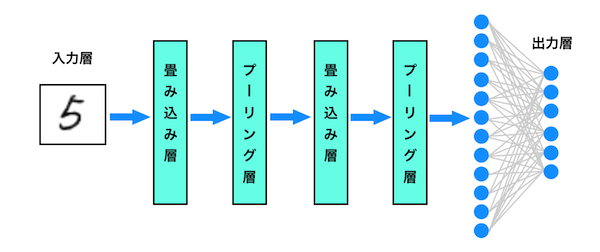
そのため、計算コストを下げることができる上に微妙な位置変化に対しても頑健になります。これら「畳み込み層」「プーリング層」を何層にも重ねることで画像の特徴を抽出していきます。そして最終的に各フィルタの特徴を1次元のデータに変換することで認識結果を出力していきます。
実装コード
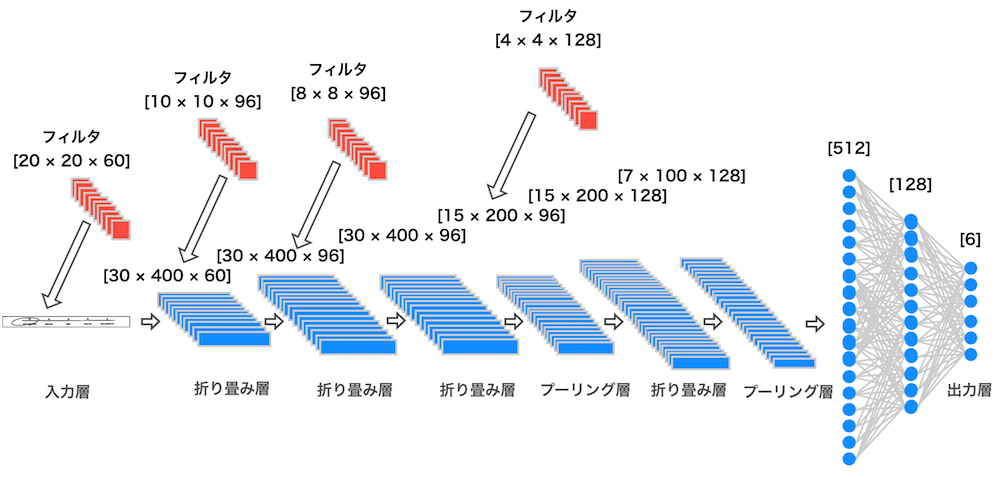
まず、5段階尺度のアンケートの判別を行うための学習モデルを構築していきました。構築していく過程で
・フィルタサイズやフィルタ数を調整
・過学習を防ぐためにドロップアウト層を追加
・Batch Normalizationの追加といった対応を行い、最終的にはテストデータに対する予測精度が最も高かった下図の学習モデルを構築しました。
以下、実装コード
import tensorflow as tf import os import keras from keras.utils.np_utils import to_categorical from keras.utils import np_utils import numpy as np import cv2 from PIL import Image from keras.layers.normalization import BatchNormalization from keras.models import Sequential from keras.layers.convolutional import Convolution2D, MaxPooling2D from keras.layers.core import Dense, Dropout, Activation, Flatten from keras.preprocessing.image import array_to_img, img_to_array from keras.callbacks import EarlyStopping, CSVLogger from keras import backend as K import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split image_list = [] label_list = [] for dir in os.listdir("C:/Users/~/extend_scale2"): if dir == ".DS_Store": continue img_dir = "C:/Users/~/extend_scale2/" + dir # フォルダごとにラベル分けする if dir == "none": label = 0 if dir == "1": label = 1 elif dir == "2": label = 2 elif dir == "3": label = 3 elif dir == "4": label = 4 elif dir == "5": label = 5 for file in os.listdir(img_dir): if file != ".DS_Store": # 配列label_listに正解ラベルを追加 label_list.append(label) # 配列image_listに画像の配列データを追加 filepath = img_dir + "/" + file img = cv2.imread(filepath, 0) image = img_to_array(img) image_list.append(image) # パラメータ nb_classes = 6 # 分類するクラス数 nb_epoch = 50 # 最適化計算のループ回数 batch_size = 10 # バッチサイズ # Numpy配列に変換 image_list = np.asarray(image_list) label_list = np.asarray(label_list) X = image_list.astype('float32') # 画像データ(X)には0〜255の画素値が入っているため0.0〜1.0に正規化 X = X / 255.0 # 正解クラスをone-hot-encoding Y = np_utils.to_categorical(label_list, nb_classes) # 学習用データ(67%)とテストデータ(33%)に分ける x_train, x_test, y_train, y_test = train_test_split(X, Y, test_size=0.33, random_state=111) # 入力データの形状を設定(二値画像のため1チャネル) img_rows, img_cols = 30, 400 input_shape = (img_rows, img_cols,1) # 学習モデルを定義 model = Sequential() model.add(Convolution2D(input_shape=input_shape, filters=60, kernel_size=(20, 20), strides=(1, 1), padding="same")) model.add(Activation("relu")) model.add(BatchNormalization()) model.add(Convolution2D(filters=96, kernel_size=(10, 10), strides=(1, 1), padding="same")) model.add(Activation("relu")) model.add(BatchNormalization()) model.add(Convolution2D(filters=96, kernel_size=(8, 8), strides=(1, 1), padding="same")) model.add(Activation("relu")) model.add(BatchNormalization()) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Convolution2D(filters=128, kernel_size=(4, 4), strides=(1, 1), padding="same")) model.add(Activation("relu")) model.add(BatchNormalization()) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Flatten()) # 全結合層入力のためのデータの一次元化する model.add(Dense(512)) model.add(Activation("relu")) model.add(BatchNormalization()) model.add(Dropout(0.3)) model.add(Dense(128)) model.add(Activation('relu')) model.add(BatchNormalization()) model.add(Dropout(0.3)) model.add(Dense(6)) model.add(Activation('softmax')) model.summary() # モデルのコンパイル model.compile(loss="categorical_crossentropy", optimizer="adadelta", metrics=["accuracy"]) es = EarlyStopping(monitor='val_loss', patience=2) csv_logger = CSVLogger('training.log') hist = model.fit(x_train, y_train, batch_size=batch_size, epochs=nb_epoch, verbose=1, validation_split=0.1, callbacks=[es, csv_logger]) # モデルの評価を行う (返り値:モデルの予測精度) score = model.evaluate(x_test, y_test, verbose=0) print('test loss:', score[0]) print('test acc:', score[1]) # plot results loss = hist.history['loss'] val_loss = hist.history['val_loss'] epochs = len(loss) plt.plot(range(epochs), loss, marker='.', label='loss') plt.plot(range(epochs), val_loss, marker='.', label='val_loss') plt.legend(loc='best') plt.grid() plt.xlabel('epoch') plt.ylabel('loss') plt.show() # モデルを保存 model.save("C:/Users/~/scale2_predict_model.h5")以下、出力結果
name: GeForce GTX 1070 major: 6 minor: 1 memoryClockRate (GHz) 1.683 pciBusID 0000:01:00.0 Total memory: 8.00GiB Free memory: 6.64GiB 2020-12-26 15:46:30.235852: I c:\tf_jenkins\home\workspace\release-win\m\windows-gpu\py\35\tensorflow\core\common_runtime\gpu\gpu_device.cc:961] DMA: 0 2020-12-26 15:46:30.238814: I c:\tf_jenkins\home\workspace\release-win\m\windows-gpu\py\35\tensorflow\core\common_runtime\gpu\gpu_device.cc:971] 0: Y 2020-12-26 15:46:30.242432: I c:\tf_jenkins\home\workspace\release-win\m\windows-gpu\py\35\tensorflow\core\common_runtime\gpu\gpu_device.cc:1030] Creating TensorFlow device (/gpu:0) -> (device: 0, name: GeForce GTX 1070, pci bus id: 0000:01:00.0) 2020-12-26 15:46:30.879476: I c:\tf_jenkins\home\workspace\release-win\m\windows-gpu\py\35\tensorflow\core\common_runtime\gpu\gpu_device.cc:1030] Creating TensorFlow device (/gpu:0) -> (device: 0, name: GeForce GTX 1070, pci bus id: 0000:01:00.0) _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d_1 (Conv2D) (None, 30, 400, 60) 24060 _________________________________________________________________ activation_1 (Activation) (None, 30, 400, 60) 0 _________________________________________________________________ batch_normalization_1 (Batch (None, 30, 400, 60) 240 _________________________________________________________________ conv2d_2 (Conv2D) (None, 30, 400, 96) 576096 _________________________________________________________________ activation_2 (Activation) (None, 30, 400, 96) 0 _________________________________________________________________ batch_normalization_2 (Batch (None, 30, 400, 96) 384 _________________________________________________________________ conv2d_3 (Conv2D) (None, 30, 400, 96) 589920 _________________________________________________________________ activation_3 (Activation) (None, 30, 400, 96) 0 _________________________________________________________________ batch_normalization_3 (Batch (None, 30, 400, 96) 384 _________________________________________________________________ max_pooling2d_1 (MaxPooling2 (None, 15, 200, 96) 0 _________________________________________________________________ conv2d_4 (Conv2D) (None, 15, 200, 128) 196736 _________________________________________________________________ activation_4 (Activation) (None, 15, 200, 128) 0 _________________________________________________________________ batch_normalization_4 (Batch (None, 15, 200, 128) 512 _________________________________________________________________ max_pooling2d_2 (MaxPooling2 (None, 7, 100, 128) 0 _________________________________________________________________ flatten_1 (Flatten) (None, 89600) 0 _________________________________________________________________ dense_1 (Dense) (None, 512) 45875712 _________________________________________________________________ activation_5 (Activation) (None, 512) 0 _________________________________________________________________ batch_normalization_5 (Batch (None, 512) 2048 _________________________________________________________________ dropout_1 (Dropout) (None, 512) 0 _________________________________________________________________ dense_2 (Dense) (None, 128) 65664 _________________________________________________________________ activation_6 (Activation) (None, 128) 0 _________________________________________________________________ batch_normalization_6 (Batch (None, 128) 512 _________________________________________________________________ dropout_2 (Dropout) (None, 128) 0 _________________________________________________________________ dense_3 (Dense) (None, 6) 774 _________________________________________________________________ activation_7 (Activation) (None, 6) 0 ================================================================= Total params: 47,333,042 Trainable params: 47,331,002 Non-trainable params: 2,040 _________________________________________________________________ Train on 13212 samples, validate on 1469 samples Epoch 1/50 13212/13212 [==============================] - 389s 29ms/step - loss: 0.1170 - acc: 0.9623 - val_loss: 8.3242 - val_acc: 0.2587 Epoch 2/50 13212/13212 [==============================] - 386s 29ms/step - loss: 0.0173 - acc: 0.9957 - val_loss: 0.3054 - val_acc: 0.8816 Epoch 3/50 13212/13212 [==============================] - 387s 29ms/step - loss: 0.0108 - acc: 0.9973 - val_loss: 2.6781e-05 - val_acc: 1.0000 Epoch 4/50 13212/13212 [==============================] - 386s 29ms/step - loss: 0.0087 - acc: 0.9975 - val_loss: 4.8810 - val_acc: 0.5303 Epoch 5/50 13212/13212 [==============================] - 386s 29ms/step - loss: 0.0083 - acc: 0.9975 - val_loss: 3.6730e-05 - val_acc: 1.0000 test loss: 0.0001827530876174434 test acc: 0.9913174490688059テストデータによる検証では99%の精度を示しました。
同じ要領で、11段階尺度のアンケートの学習モデルも作成しました。こちらのモデルはテストデータに対する検証で最も高い98.5%の予測精度を示したモデルを採用しました。
4. KerasモデルをTensorFlowモデルに変換する
学習モデルを構築したので、実際に未知の画像に対する予測を行っていきたいのですが、この学習モデルはKerasで構築されている( .h5ファイル)ため、TensorFlowモデル( .pbファイル)に変換します。
なぜ、変換するかというと処理速度の向上を行うためです。こちらの記事にあるようにKerasとTensorFlowでは、モデルの実行速度に差があります。
実際にそれぞれの学習モデルで1つのアンケート項目の記入数値判定の処理を行った結果、以下のように処理時間に差が出ました。※環境はEC2(t2.medium, vCPUs:2)
ライブラリ 処理時間 Keras 5.1秒 Tensorflow 3.6秒 変換作業は、こちらのリポジトリを活用させていただきました。
アンケートの記入数値の判定(画像認識)を行う
学習済みモデルを用意できたので、実際にアンケートの記入数値の判定処理を行ってみます。
import numpy as np import tensorflow as tf import cv2 # 学習済みモデルのファイルパス SCALE1_PREDICT_MODEL = 'model/scale1_predict_model.pb' # 11点尺度の記入数値判定モデル SCALE2_PREDICT_MODEL = 'model/scale2_predict_model.pb' # 5点尺度の記入数値判定モデル # 11点尺度の記入数値判定 def scale1_cnn_predict(scale_img_list): scale1_predict_result = [] for img in scale_img_list: sess = tf.Session() # 学習済みモデルの読み込み with tf.gfile.FastGFile(SCALE1_PREDICT_MODEL,'rb') as f: graph_def = tf.GraphDef() graph_def.ParseFromString(f.read()) _ = tf.import_graph_def(graph_def,name = '') # 認識処理を実行 prediction = predict_model_run(sess, img) tf.reset_default_graph() #グラフをリセット scale1_predict_result.append(int(np.argmax(prediction))) return scale1_predict_result # 5点尺度の記入数値判定 def scale2_cnn_predict(scale_img_list): scale2_predict_result = [] for img in scale_img_list: sess = tf.Session() # 学習済みモデルの読み込み with tf.gfile.FastGFile(SCALE2_PREDICT_MODEL,'rb') as f: graph_def = tf.GraphDef() graph_def.ParseFromString(f.read()) _ = tf.import_graph_def(graph_def,name = '') # 認識処理を実行 prediction = predict_model_run(sess, img) tf.reset_default_graph() #グラフをリセット scale2_predict_result.append(int(np.argmax(prediction))) return scale2_predict_result # 対象画像を学習モデルに読み込ませる def predict_model_run(sess, img): image = cv2.imread(img, 0) image = cv2.resize(image, (400, 30)) image = np.reshape(image, (30, 400, 1)) image_list = [image] image = np.asarray(image_list) X = image.astype('float32') X = X / 255.0 prediction = sess.run('strided_slice:0',{'conv2d_1_input:0':X}) return prediction # アンケート用紙から切り抜いた各アンケート項目の画像(前回の記事参照) scale1_img_list = ['images/q_img_0.jpg', 'images/q_img_1.jpg'] scale2_img_list = ['images/q_img_2.jpg', 'images/q_img_3.jpg', 'images/q_img_4.jpg', 'images/q_img_5.jpg', 'images/q_img_6.jpg'] # 予測処理 scale1_predict_result = scale1_cnn_predict(scale1_img_list) scale2_predict_result = scale2_cnn_predict(scale2_img_list) print('-------------') for i in range(len(scale1_predict_result)): print( '11点尺度_'+str(i+1)+'の判定値:'+ str(scale1_predict_result[i])) for i in range(len(scale2_predict_result)): print( '5点尺度_'+str(i+1)+'の判定値:'+ str(scale2_predict_result[i])) print('-------------')実行結果
------------- 11点尺度_1の判定値:10 11点尺度_2の判定値:8 5点尺度_1の判定値:5 5点尺度_2の判定値:5 5点尺度_3の判定値:4 5点尺度_4の判定値:3 5点尺度_5の判定値:4 -------------第三者に記入してもらったアンケート用紙の撮影画像を使って
上記のコードで数値判定を行ったところ下記のような判定結果になりました。
モデル 対象画像数 正解数 正解率 11点尺度 200 184 92% 5点尺度 200 191 96.5% 誤判定した画像を確認すると、下記のようにアンケート項目の切り抜きの部分がうまくできていなかったり、アンケート用紙が曲がっていたりというパターンが見受けられました。
そういう意味では、アンケート項目の切り抜き処理が安定すれば判定精度は向上できるのではないかという印象です。
前回の記事に記載したアンケート用紙の撮影画像の傾き補正や物体検出の処理を含めると以下のようなコードになります。
import cv2 import numpy as np import os import tensorflow as tf # 読み込み対象のアンケート用紙の撮影画像のパス image_path = "images/~.JPG" # アンケートの項目数 Q_NUMBERS = 7 #物体候補となる矩形が、最低でも含んでいなければならない近傍矩形の数(値が小さいほど誤検出は増え、大きいほど検出漏れが増える) (物体候補領域が何個以上重なっていたらそれを一つの物体として検出する) MIN_NEIGHBORS = [1, 2, 3, 4, 5] #カスケード分類器 Cascade = cv2.CascadeClassifier('cascade/cascade.xml') # 学習済みモデルのファイルパス SCALE1_PREDICT_MODEL = 'model/scale1_predict_model.pb' # 11点尺度の記入数値判定モデル SCALE2_PREDICT_MODEL = 'model/scale2_predict_model.pb' # 5点尺度の記入数値判定モデル #二値化しノイズ除去を行う def image_thresholding(img_path): img = cv2.imread(img_path, cv2.IMREAD_COLOR) #画像を二値化する gray_image = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) gray_image = cv2.GaussianBlur(gray_image, (9,9), 0) binary_image = cv2.adaptiveThreshold(gray_image, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 19, 2) #白黒反転させる invgray = cv2.bitwise_not(binary_image) #ノイズ除去を行うフィルターサイズの設定 kernel = np.ones((4,4),np.uint8) #ノイズ除去処理 none_noiz_img = cv2.morphologyEx(invgray, cv2.MORPH_OPEN, kernel) #再度反転 image = cv2.bitwise_not(none_noiz_img) return image #傾き補正した画像からアンケート項目を検出する def detect_questionnaire_topic(dst): gray_image = cv2.cvtColor(dst, cv2.COLOR_BGR2RGB) results = False for min_neightbor in MIN_NEIGHBORS: point = Cascade.detectMultiScale(gray_image, 1.1, min_neightbor) if len(point) == Q_NUMBERS: results = True break return results, point #検出した"■"マークの縦幅を取得 def get_square_height(point): h_list = [int(p[3]) for p in point] return min(h_list) * 5 #切り出す画像をy座標を元に昇順に並び替え def sort_img(img_y_list): q_img_list = [] for k, v in sorted(img_y_list.items()): q_img_list.append(str(v)) return q_img_list #検出した"■"マークを始点にアンケート項目を別画像として切り出す関数 def export_questionnaire_topic_img(dst, point): q_img_dict = {} square_height = get_square_height(point) for i, p in enumerate(point): save_path = 'images/q_img_'+str(i)+'.jpg' imgs = dst[p[1] + p[3] : p[1] + square_height, p[0] + p[2] : 3000] cv2.imwrite(save_path, imgs) q_img_dict[p[1]] = save_path return q_img_dict #cv2.HoughCircles()によって検出された円のx,y座標を取得する def get_circle_coordinate(circles): circle_list = [] for circle in circles[0]: circle_list.append([circle[0], circle[1]]) return circle_list #画像の中心を軸として右上、右下、左上、左下それぞれの円の座標を確認する def sort_coordinate(circle_list, center_point): for i in range(0, 4): if circle_list[i][0] > center_point["x"] and circle_list[i][1] > center_point["y"]: #右上: x >1000 and y>1000 upper_right = [circle_list[i][0],circle_list[i][1]] elif circle_list[i][0] > center_point["x"] and circle_list[i][1] < center_point["y"]: #右下: x >1000 and y<1000 under_right = [circle_list[i][0],circle_list[i][1]] elif circle_list[i][0] < center_point["x"] and circle_list[i][1] > center_point["y"]: #左上: x <1000 and y>1000 upper_left = [circle_list[i][0],circle_list[i][1]] elif circle_list[i][0] < center_point["x"] and circle_list[i][1] < center_point["y"]: #左下: x <1000 and y<1000 under_left = [circle_list[i][0],circle_list[i][1]] return { "upper_right" : upper_right, "under_right" : under_right, "upper_left" : upper_left, "under_left" : under_left } #取得した円座標を元に射影変換を行う def perspective_transform(circle_list, height_rate): height_value = round(3000 * height_rate) before_pts = np.float32([circle_list["upper_right"], circle_list["under_right"], circle_list["under_left"], circle_list["upper_left"]]) after_pts = np.float32([[3000, height_value], [3000, 0], [0, 0], [0, height_value]]) M = cv2.getPerspectiveTransform(before_pts, after_pts) dst = cv2.warpPerspective(img, M, (3000, height_value)) return dst # 11点尺度の記入数値判定 def scale1_cnn_predict(scale_img_list): scale1_predict_result = [] for img in scale_img_list: sess = tf.Session() # 学習済みモデルの読み込み with tf.gfile.FastGFile(SCALE1_PREDICT_MODEL,'rb') as f: graph_def = tf.GraphDef() graph_def.ParseFromString(f.read()) _ = tf.import_graph_def(graph_def,name = '') # 認識処理を実行 prediction = predict_model_run(sess, img) tf.reset_default_graph() #グラフをリセット scale1_predict_result.append(int(np.argmax(prediction))) return scale1_predict_result # 5点尺度の記入数値判定 def scale2_cnn_predict(scale_img_list): scale2_predict_result = [] for img in scale_img_list: sess = tf.Session() # 学習済みモデルの読み込み with tf.gfile.FastGFile(SCALE2_PREDICT_MODEL,'rb') as f: graph_def = tf.GraphDef() graph_def.ParseFromString(f.read()) _ = tf.import_graph_def(graph_def,name = '') # 認識処理を実行 prediction = predict_model_run(sess, img) tf.reset_default_graph() #グラフをリセット scale2_predict_result.append(int(np.argmax(prediction))) return scale2_predict_result # 対象画像を学習モデルに読み込ませる def predict_model_run(sess, img): image = cv2.resize(img, (400, 30)) image = np.reshape(image, (30, 400, 1)) image_list = [image] image = np.asarray(image_list) X = image.astype('float32') X = X / 255.0 prediction = sess.run('strided_slice:0',{'conv2d_1_input:0':X}) return prediction #画像を読み込む img = cv2.imread(image_path, cv2.IMREAD_COLOR) #画像ピクセルサイズ取得 h, w, c = img.shape #画像の横幅に対する高さ比率を取得 height_rate = round((h / w), 2) #画像の中心座標を求める center_point = {"x" : round((w / 2), 2), "y" : round((h / 2), 2)} #画像にぼかしを入れる gray_image = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) blur_image = cv2.GaussianBlur(gray_image, (29, 29), 0) #アンケート用紙の四隅にある円を検出させる minDistList = [2600, 2400, 2200] param1List = [30, 20, 10] param2List = [40, 30, 20] for minDist in minDistList: for param1 in param1List: for param2 in param2List: circles = cv2.HoughCircles(blur_image, cv2.HOUGH_GRADIENT, 1, minDist, param1=param1, param2=param2, minRadius=15, maxRadius=100) if len(circles) == 4: break else: continue break else: continue break if len(circles[0]) != 4 or isinstance(circles,type(None)) == True: print('検出エラー') else: #検出した4つの円の座標を取得 circle_list = get_circle_coordinate(circles) #右上,右下,左上,左下それぞれの座標を取得 circle_list = sort_coordinate(circle_list, center_point) #射影変換による傾き補正 dst = perspective_transform(circle_list, height_rate) results, point = detect_questionnaire_topic(dst) q_img_dict = export_questionnaire_topic_img(dst, point) q_img_list = sort_img(q_img_dict) # 画像を二値化 scale_img_list = [] for img_path in q_img_list: image = image_thresholding(img_path) scale_img_list.append(image) # アンケート用紙から切り抜いた各アンケート項目の画像(前回の記事参照) scale1_img_list = scale_img_list[:2] # 上から2つが11点尺度の画像 scale2_img_list = scale_img_list[2:] # 上から3つ目以降が11点尺度の画像 # 予測処理 scale1_predict_result = scale1_cnn_predict(scale1_img_list) scale2_predict_result = scale2_cnn_predict(scale2_img_list) print('-------------') for i in range(len(scale1_predict_result)): print( '11点尺度_'+str(i+1)+'の判定値:'+ str(scale1_predict_result[i])) for i in range(len(scale2_predict_result)): print( '5点尺度_'+str(i+1)+'の判定値:'+ str(scale2_predict_result[i])) print('-------------')上記のコードを走らせて見たところ、アンケートの撮影画像を読み込んでから記入数値の認識処理までの合計処理時間が約30秒程度かかりました。KerasモデルをTensorflowモデルに変換したことで多少は改善されていますが、リアルタイム性の観点で考えると少し厳しい印象です。
今後は、処理速度の問題も考慮しながら、画像認識によって出力された数値をDBに保存し、表やグラフで集計できるようなシステムを検討したいと思います。


- 投稿日:2021-01-16T22:57:26+09:00
Keras + OpenCV で画像認識による簡易的なアンケート読み取りシステムを作ってみた①
この記事について
飲食店のテーブルなどに置いてあるアンケート用紙。そのアンケートの集計はお店のスタッフがExcelなどの表計算ツールに打ち込んで集計していたりします。こういう非効率な作業を自動化できないかと思って、OCRに関する知識が全くない状態でアンケート用紙を読み取る簡易的なシステムを作って見ました。この記事はその備忘録です。
システム概要
作成するシステムはざっくり以下のような流れを想定しています。
1.記入済みのアンケートを撮影する
2.撮影されたアンケート画像に対してOCR処理を行う
3.OCRによる読み取り結果を出力するアンケートの記入形式
リッカート尺度に基づく11段階評価と5段階評価による記入形式で
該当する数字にマルをつけてもらう形式です。
OCRの仕組み
アンケート用紙のOCR処理は下記のような仕組みにしました。
① 傾き補正を行う
② 11点尺度&5点尺度の各アンケート項目を画像として切り抜く
③ノイズ処理を行う(平滑化)
④ 切り抜いた画像に対してあらかじめディープラーニング(CNN:Convolutional Neural Network)で学習した画像認識モデルを利用してアンケート項目の記入数値の判定処理を行う
⑤ 判定結果(集計データ)をDBに保存する傾き補正
撮影されたアンケート画像が傾いていると、後工程で記入数値の判定を行うモデルを構築する際にその傾きも考慮しておく必要があります。しかし開発環境のリソースは限られていたため、前処理として傾き補正を行なっておく必要がありました。傾き補正は射影変換を用いました。
射影変換とは
射影変換とはある平面を別の平面に射影することができる変換手法です。例えば、斜めから見たものを、あたかも正面から見たように表現することができます。
どのような仕組みかというと
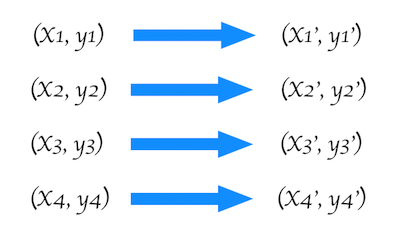
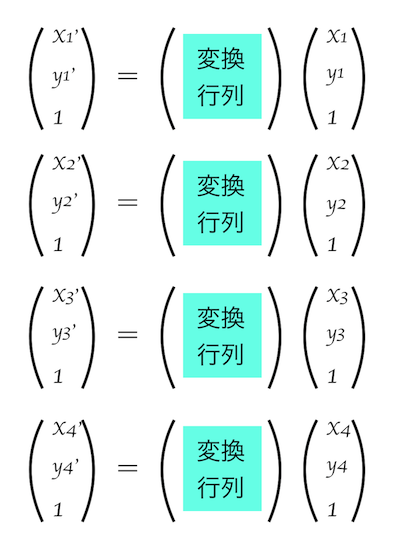
まず下記のように4点の座標を、それぞれの別の座標に移動させるとします。
それぞれの移動先の座標は移動前の座標を用いて行列で以下のように表すことができます。
上記の変換行列(3×3)は連立方程式によって求めることができます。この変換行列を用いてすべての座標を移動させると移動前の元画像のオブジェクトの形状を維持したまま、まるで違う向きから見たような表示が可能になります。
今回は傾き補正を具体的に以下の手順で行いました。
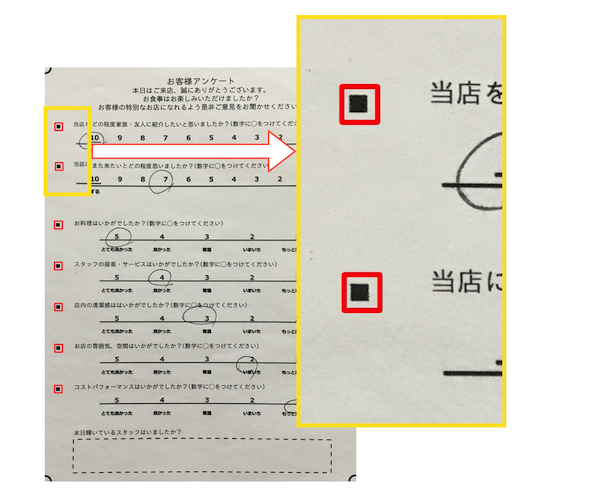
- アンケート用紙の四隅に"○"マークを記載しておきます。
- OpenCVの
cv2.HoughCircles()関数を使って円検出を行い、それぞれの座標を取得します。- 2の座標を元に射影変換を行います。
1. アンケート用紙の四隅に"○"マークを記載
傾き補正では対象のオブジェクトの輪郭検出を行なった後に頂点の座標を取得する処理がよく行われますが、今回はあらかじめアンケート用紙の四隅に記載した"○"マークを頂点の代わりに利用します。
2. 円検出
OpenCVの
cv2.HoughCircles()関数を使って四隅の円検出を行います。アンケートは該当数字にペンでマルをつける記入形式を想定しているので、そのマルを誤検出されないように意図的に画像にぼかしを入れます。ぼかしを入れることで細い線は検出されずらくなります。
#画像を読み込む img = cv2.imread(image_path, cv2.IMREAD_COLOR) #画像にぼかしを入れる gray_image = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) blur_image = cv2.GaussianBlur(gray_image, (29, 29), 0)
cv2.GaussianBlur()は指定の画像に対してぼかしを入れる関数になります。第2引数はぼかし処理に使うフィルタのサイズ指定になり、この値が大きければ大きいほどぼかしの度合いは強くなります。この状態で円検出を行うことで四隅のマルを検出されやすくします。
#アンケート用紙の四隅にある円を検出させる circles = cv2.HoughCircles(blur_image, cv2.HOUGH_GRADIENT, 1, 2400, param1=30, param2=40, minRadius=15, maxRadius=100)以下、
cv2.HoughCircles()の引数の詳細です。
値 内容 第一引数 blur_image 対象画像。 第二引数 cv2.HOUGH_GRADIENT 変換手法。現在、選択できる手法は cv2.HOUGH_GRADIENT のみ。 第三引数 dp=1 処理するときに元画像の解像度を落として検出する場合は増やす。元画像のままなら1を指定。 第四引数 minDist=2400 検出される円同士が最低限離れていなければならない距離。 第五引数 param1=30 値が低いほどより多くのエッジを検出できるらしいです。 第六引数 param2=30 円の中心を検出する際の閾値。低い値だと誤検出が増え、高い値だと未検出が増える。 第七引数 minRadius=15 検出する円の半径の下限値。 第八引数 maxRadius=100 検出する円の半径の上限値。 今回は円検出の精度を上げるためパラメータの数値を変化させながら4つの円が検出されるまで繰り返し処理を行いました。
minDistList = [2600, 2400, 2200] param1List = [30, 20, 10] param2List = [40, 30, 20] for minDist in minDistList: for param1 in param1List: for param2 in param2List: circles = cv2.HoughCircles(blur_image, cv2.HOUGH_GRADIENT, 1, minDist, param1=param1, param2=param2, minRadius=15, maxRadius=100) if len(circles) == 4: break else: continue break else: continue break返値
circlesには検出された円の座標と半径が配列として入ります。[[[ 238.5 3613.5 56. ] [ 484.5 241.5 54.5] [2651.5 3717.5 52. ] [2843.5 465.5 51. ]]]この状態では各座標が四隅のどの"○"マークの座標かわからないため整理します。
#画像を読み込む img = cv2.imread(image_path, cv2.IMREAD_COLOR) #画像ピクセルサイズ取得 h, w, c = img.shape #画像の横幅に対する高さ比率を取得 height_rate = round((h / w), 2) #画像の中心座標を求める center_point = {"x" : round((w / 2), 2), "y" : round((h / 2), 2)} #cv2.HoughCircles()によって検出された円のx,y座標を取得する def get_circle_coordinate(circles): circle_list = [] for circle in circles[0]: circle_list.append([circle[0], circle[1]]) return circle_list #画像の中心を軸として右上、右下、左上、左下それぞれの円の座標を確認する def sort_coordinate(circle_list, center_point): for i in range(0, 4): if circle_list[i][0] > center_point["x"] and circle_list[i][1] > center_point["y"]: upper_right = [circle_list[i][0],circle_list[i][1]] elif circle_list[i][0] > center_point["x"] and circle_list[i][1] < center_point["y"]: under_right = [circle_list[i][0],circle_list[i][1]] elif circle_list[i][0] < center_point["x"] and circle_list[i][1] > center_point["y"]: upper_left = [circle_list[i][0],circle_list[i][1]] elif circle_list[i][0] < center_point["x"] and circle_list[i][1] < center_point["y"]: under_left = [circle_list[i][0],circle_list[i][1]] return { "upper_right" : upper_right, "under_right" : under_right, "upper_left" : upper_left, "under_left" : under_left } circle_list = get_circle_coordinate(circles) circle_list = sort_coordinate(circle_list)3. 射影変換
円検出によって四隅の"○"マークの座標が取得できたはずなので、先ほど説明した射影変換を行います。
変換後の出力画像は横幅3000に固定し、縦幅は元画像のアスペクト比により算出しました。
変換行列はcv2.getPerspectiveTransform()によって生成し、その変換行列を使ってcv2.warpPerspective()によって射影変換を行なっています。#取得した円座標を元に射影変換を行う def perspective_transform(circle_list, height_rate): height_value = round(3000 * height_rate) before_pts = np.float32([circle_list["upper_right"], circle_list["under_right"], circle_list["under_left"], circle_list["upper_left"]]) after_pts = np.float32([[3000, height_value], [3000, 0], [0, 0], [0, height_value]]) M = cv2.getPerspectiveTransform(before_pts, after_pts) dst = cv2.warpPerspective(img, M, (3000, height_value)) return dst dst = perspective_transform(circle_list, height_rate)ここまでの実装コードをまとめたものが下記になります。
import cv2 import numpy as np #cv2.HoughCircles()によって検出された円のx,y座標を取得する def get_circle_coordinate(circles): circle_list = [] for circle in circles[0]: circle_list.append([circle[0], circle[1]]) return circle_list #画像の中心を軸として右上、右下、左上、左下それぞれの円の座標を確認する def sort_coordinate(circle_list, center_point): for i in range(0, 4): if circle_list[i][0] > center_point["x"] and circle_list[i][1] > center_point["y"]: #右上: x >1000 and y>1000 upper_right = [circle_list[i][0],circle_list[i][1]] elif circle_list[i][0] > center_point["x"] and circle_list[i][1] < center_point["y"]: #右下: x >1000 and y<1000 under_right = [circle_list[i][0],circle_list[i][1]] elif circle_list[i][0] < center_point["x"] and circle_list[i][1] > center_point["y"]: #左上: x <1000 and y>1000 upper_left = [circle_list[i][0],circle_list[i][1]] elif circle_list[i][0] < center_point["x"] and circle_list[i][1] < center_point["y"]: #左下: x <1000 and y<1000 under_left = [circle_list[i][0],circle_list[i][1]] return { "upper_right" : upper_right, "under_right" : under_right, "upper_left" : upper_left, "under_left" : under_left } #取得した円座標を元に射影変換を行う def perspective_transform(circle_list, height_rate): height_value = round(3000 * height_rate) before_pts = np.float32([circle_list["upper_right"], circle_list["under_right"], circle_list["under_left"], circle_list["upper_left"]]) after_pts = np.float32([[3000, height_value], [3000, 0], [0, 0], [0, height_value]]) M = cv2.getPerspectiveTransform(before_pts, after_pts) dst = cv2.warpPerspective(img, M, (3000, height_value)) return dst #画像サイズ取得(imageは最初にノイズ処理&二値化した画像) h, w, c = image.shape #画像の横幅に対する高さ比率を取得 height_rate = round((h / w), 2) #画像の中心座標を求める center_point = {"x" : round((w / 2), 2), "y" : round((h / 2), 2)} #画像にぼかしを入れる gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) blur_image = cv2.GaussianBlur(gray_image, (47, 47), 0) #アンケート用紙の四隅にある円を検出させる minDistList = [2600, 2400, 2200] param1List = [30, 20, 10] param2List = [40, 30, 20] for minDist in minDistList: for param1 in param1List: for param2 in param2List: circles = cv2.HoughCircles(blur_image, cv2.HOUGH_GRADIENT, 1, minDist, param1=param1, param2=param2, minRadius=15, maxRadius=100) if len(circles) == 4: break else: continue break else: continue break if len(circles[0]) != 4 or isinstance(circles,type(None)) == True: error = '検出エラー' else: #検出した4つの円の座標を取得 circle_list = get_circle_coordinate(circles) #右上,右下,左上,左下それぞれの座標を取得 circle_list = sort_coordinate(circle_list, center_point) #射影変換による傾き補正 dst = perspective_transform(circle_list, height_rate)これで傾き補正ができました。
物体検出
用紙に記載されている各アンケート項目をそれぞれ別画像として切り抜きます。
OpenCVでは特定のオブジェクトを検出する学習器を作成することができます。そこで、各アンケート項目を物体検出することを検討しましたが、大量のサンプルデータが必要であり、検出する際の矩形のサイズのバラ付きがありそうだったため他の方法を検討しました。
採用した方法は以下のような内容です。
1. "■"マークをアンケート項目の左側に記載
2. "■"マークを検出するための学習器を作成
3. "■"マークを物体検出
4. 検出した"■"マークを始点として、アンケート項目を切り抜き画像として保存1. "■"マークをアンケート項目の左側に記載
"■"マークをアンケート項目の左側に記載し、このマークを物体検出の対象オブジェクトとします。
2. "■"マークを検出するための学習器を作成
OpenCVでは特定のオブジェクトを検出するカスケード分類器を作成することができます。今回は"■"マークを検出するカスケード分類器を作成しました。
カスケード分類器とは
物体検出を行う際には、検出したい物体がどのような特徴を有しているのか把握しておく必要があります。そこで、あらかじめ該当する物体を含む画像と含まない画像を用意し、検出したい物体の特徴を抽出しておきます。この抽出された特徴をまとめたものをカスケード分類器と言います。
カスケード分類器の作り方については下記の記事を参照
3. "■"マークを物体検出
2で作成したカスケード分類器を使って、"■"マークを物体検出します。
import cv2 import numpy as np import os #アンケートの項目数 Q_NUMBERS = 7 #物体候補となる矩形が、最低でも含んでいなければならない近傍矩形の数(値が小さいほど誤検出は増え、大きいほど検出漏れが増える) MIN_NEIGHBORS = [1, 2, 3, 4, 5] #カスケード分類器を読み込む Cascade = cv2.CascadeClassifier('cascade.xml') #傾き補正した画像からアンケート項目を検出する def detect_questionnaire_topic(dst): gray_image = cv2.cvtColor(dst, cv2.COLOR_BGR2RGB) results = False for min_neightbor in MIN_NEIGHBORS: point = Cascade.detectMultiScale(gray_image, 1.1, min_neightbor) if len(point) == Q_NUMBERS: results = True break return results, point results, point = detect_questionnaire_topic(dst) #引数の"dst"は傾き補正済みの画像上記のコードを実行させると下図のように"■"マークが検出されます(赤枠の矩形)。
また、変数
pointには検出したオブジェクト("■"マーク)の座標が配列で保存されます。ここでいうx座標とy座標は矩形の左上の頂点の座標を指します。#[x座標, y座標, 横幅, 縦幅] [[ 91 531 76 76] [ 96 930 76 76] [ 92 1479 76 76] [ 93 1875 74 74] [ 96 2272 71 71] [ 96 2667 74 74] [ 93 3061 73 73]]4. 検出した"■"マークを始点としてアンケート項目を切り抜き、画像として保存
3で検出した"■"マークを始点としてアンケート項目を切り抜きます。
始点および縦幅、横幅以下のように設定しました。
項目 内容 始点 x座標 : "■"マークのx座標 + "■"マークの横幅
y座標 : "■"マークのy座標 + "■"マークの縦幅縦幅 "■"マークの縦幅 × 4 横幅 始点から画像の右端まで
切り抜き方としてはあまり綺麗ではありませんが、リソースが限られていたため、今回はこちらの方法で進めます。
#検出した"■"マークの縦幅を取得 def get_square_height(point): h_list = [int(p[3]) for p in point] return min(h_list) * 4 #切り出す画像をy座標を元に昇順に並び替え def sort_img(img_y_list): q_img_list = [] for k, v in sorted(img_y_list.items()): q_img_list.append(str(v)) return q_img_list #検出した"■"マークを始点にアンケート項目を別画像として切り出す関数 def export_questionnaire_topic_img(dst, point): q_img_dict = {} square_height = get_square_height(point) for i, p in enumerate(point): save_path = 'images/q_img_'+str(i)+'.jpg' imgs = dst[p[1] + p[3] : p[1] + square_height, p[0] + p[2] : 3000] cv2.imwrite(save_path, imgs) q_img_dict[p[1]] = save_path return q_img_dict q_img_dict = export_questionnaire_topic_img(dst, point) q_img_list = sort_img(q_img_dict)
q_img_dictは切り出した画像の始点のy座標と画像ファイルのパスが入っています。{531: 'images/q_img_0.jpg', 930: 'images/q_img_1.jpg', 1479: 'images/q_img_2.jpg', 1875: 'images/q_img_3.jpg', 2272: 'images/q_img_4.jpg', 2667: 'images/q_img_5.jpg', 3061: 'images/q_img_6.jpg'}この連想配列をsort_img()によってy座標を軸に並び替えます。そして、画像パスの配列
q_img_listを作っておきます。['images/q_img_0.jpg', 'images/q_img_1.jpg', 'images/q_img_2.jpg', 'images/q_img_3.jpg', 'images/q_img_4.jpg', 'images/q_img_5.jpg', 'images/q_img_6.jpg']これで各アンケート項目を別画像として切り抜くことができました。
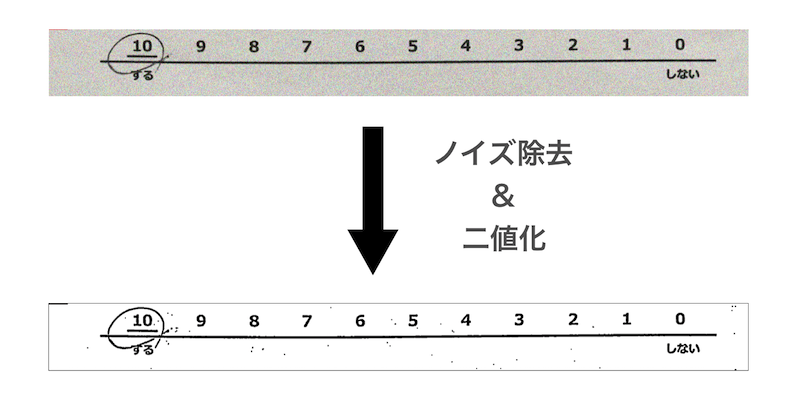
ノイズ除去&二値化
切り出した画像に対してノイズ除去と二値化を行います。
元々はこれらの処理は考慮していませんでした。しかし、CNNによる数値判定モデルを作成する際に、開発環境でメモリ不足に陥ってしまったため、白黒の二値画像かつノイズを除去したものに学習データを絞ることでメモリ負荷を軽減させる必要が出てきました。それが契機でノイズ除去&二値化を加えました。ノイズ除去にはモルフォロジー変換という手法を使います。
モルフォロジー変換
モルフォロジー変換とは、画像中のオブジェクトに対して、「収束」や「膨張」を行うことでオブジェクトの周りあるいはオブジェクトの中に含まれているノイズを除去する手法です。この手法には「オープン処理」「クロージング処理」「モルフォロジー勾配処理」など複数のモードがありますが、今回は収束させたあとに膨張させる処理を行う「オープン処理」を採用しました。(※モルフォロジー変換は、二値画像を対象とするため、最初に対象画像の二値化を行なっておく必要があります。)
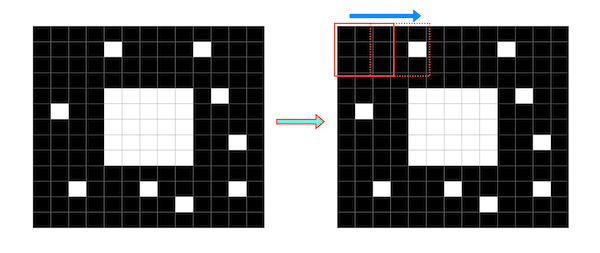
収束
画像に対してカーネル(フィルタ)をスライドさせていきます。画像中の(1か0のどちらかの値を持つ)画素は、カーネルの領域に含まれる画素の画素値が全て1(白)であれば1(白)となり,そうでなければ0(黒)として出力されます。
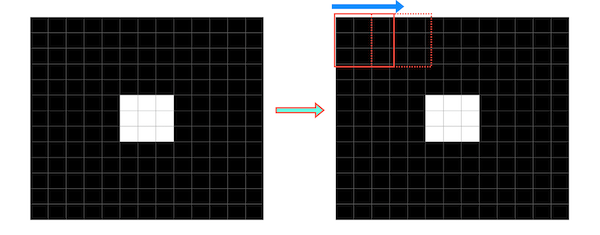
例えば下記のような二値化された画像があるとします。中央にある白のブロックの周辺に散らばる小さな白色のブロックをノイズだと仮定します。この画像にフィルタ(サイズは3×3とします)をスライドさせて「収束」を行います。
スライドさせた結果、一部のブロックが白から黒に変わり、ノイズが除去されます。
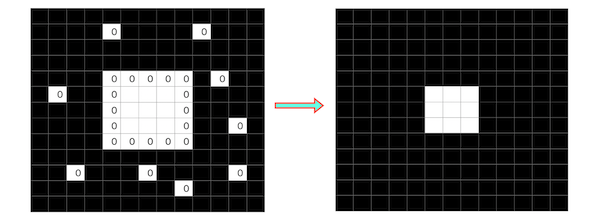
ノイズは除去されましたが、中央の白のブロックは1回り小さくなってしまいました。これを膨張によって元の大きさに近づけます。
膨張
収束と同じように画像に対してカーネル(フィルタ)をスライドさせていきます。ただし、収束とは逆でカーネルの領域に含まれる画素の画素値が全て0(黒)であれば0(黒)となり,そうでなければ1(白)として出力されます。
スライドさせた結果、一部のブロックが黒から白に変わり、収縮された中央のブロックが元の大きさに近づきます。
このようにモノフォロジー変換(収束→膨張)を行うことで画像内のノイズを除去することができます。
以下が実装コードになります。物体検出で切り出した各アンケートの画像(
q_img_list)に対して二値化とノイズ除去を行なってきます。#二値化しノイズ除去を行う def image_thresholding(img_path): img = cv2.imread(img_path, cv2.IMREAD_COLOR) #画像を二値化する gray_image = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) gray_image = cv2.GaussianBlur(gray_image, (9,9), 0) binary_image = cv2.adaptiveThreshold(gray_image, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 19, 2) #白黒反転させる invgray = cv2.bitwise_not(binary_image) #ノイズ除去を行うフィルターサイズの設定 kernel = np.ones((4,4),np.uint8) #ノイズ除去処理 none_noiz_img = cv2.morphologyEx(invgray, cv2.MORPH_OPEN, kernel) #再度反転 image = cv2.bitwise_not(none_noiz_img) return image for img_path in q_img_list: image = image_thresholding(img_path) cv2.imwrite(img_path, image)これで画像を白と黒に二値化しノイズ除去もできました。
ここからは、切り出した画像に対してディープラーニングで構築した記入数値判定モデルを使った画像認識を行なっていきます。