- 投稿日:2021-01-16T23:49:59+09:00
[Blender×Python] Blender Python tips(10/100)
この記事はCGBoostさんの100+ Tips to Boost Modeling in Blender中の操作をPythonに置き換えてみたものです。
目次
0.BlenderPython tips
1.モードの切り替え
2.シェーダーモードの切り替え
3.透過モードの切り替え
4.MATCAPSの設定
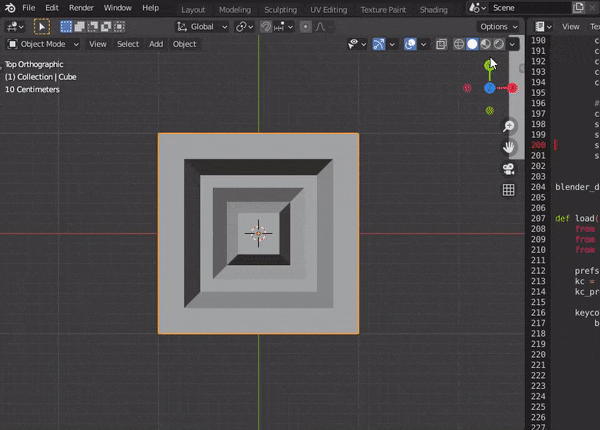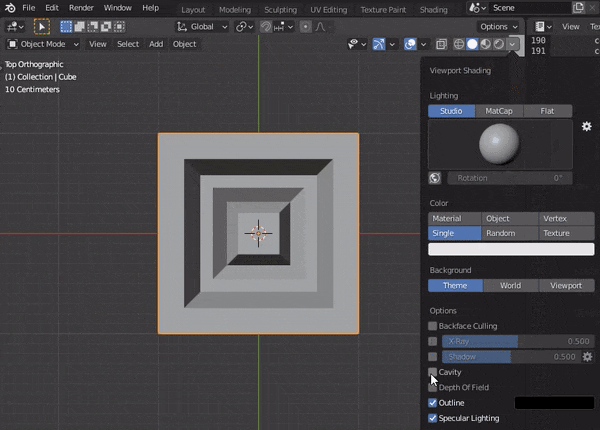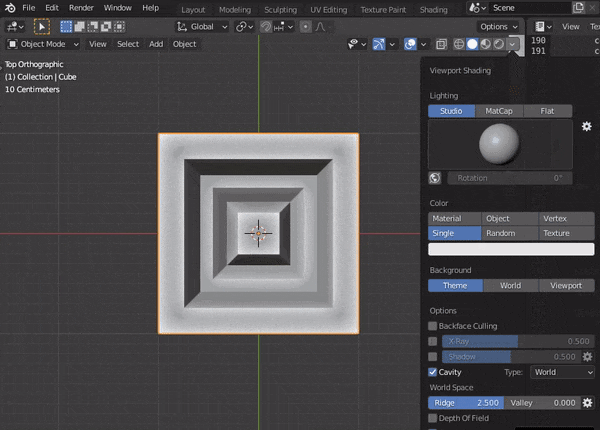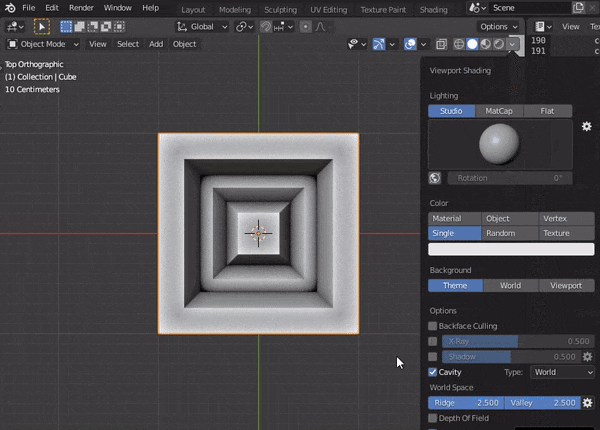
5.CAVITYの調整
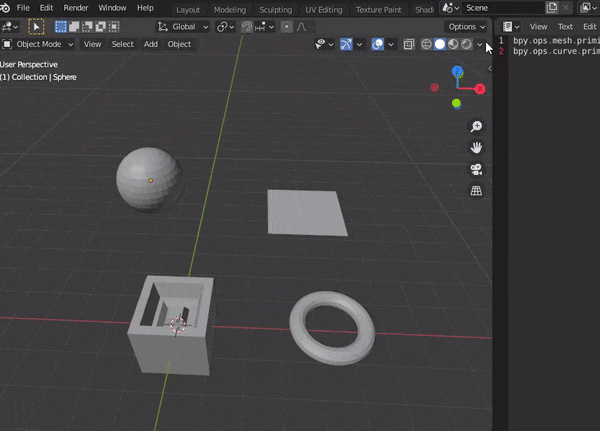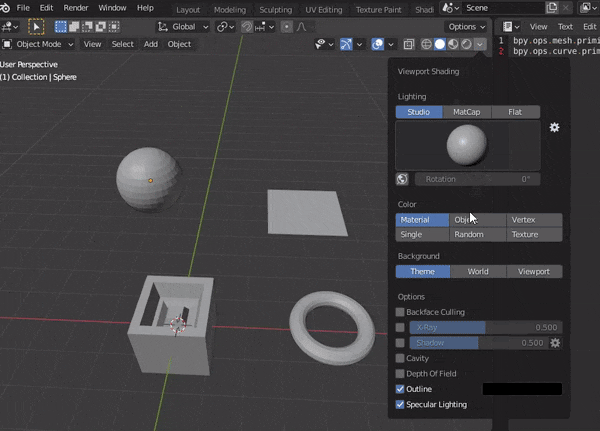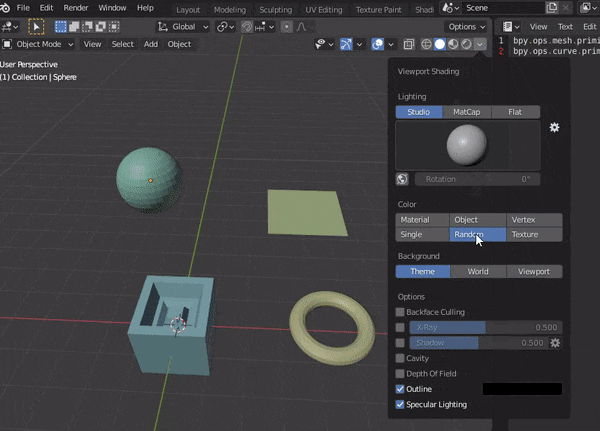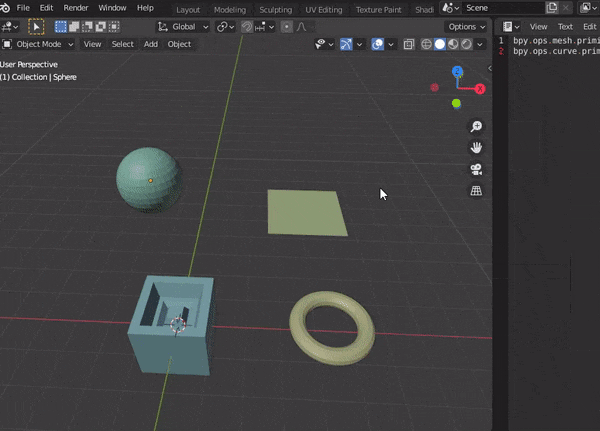
6.オブジェクトの色をランダムにする
7.オブジェクトにフォーカスする
8.3D viewportの操作性をあげる
9.選択したオブジェクトのみを表示できるようにする
10.選択した面に視点をそろえる0.BlenderPython tips
●実行したコードはすべてInfoに表示される
Infoの場所:Scripting→Info(画面左下)
●Python tool tipsを有効にすると操作コードがパネル部分に表示される
有効にする方法:
Edit→preferences→TooltipsとPython Tooltipsにチェックをいれる●Blender内のパネル(ボタン)にカーソルを乗せた状態で[ctrl+C] を押すとPythonコードがコピーされる
1.モードの切り替え
オブジェクトモードや編集モードのこと↓
#Object Modeにする bpy.ops.object.mode_set(mode='OBJECT') #Edit Modeにする bpy.ops.object.mode_set(mode='EDIT') #Sculpt Modeにする bpy.ops.object.mode_set(mode='SCULPT') #Vertex Paintにする bpy.ops.object.mode_set(mode='VERTEX_PAINT') #Weight Modeにする bpy.ops.object.mode_set(mode='WEIGHT_PAINT') #Texture Modeにする bpy.ops.object.mode_set(mode='TEXTURE_PAINT')
2.シェーダーモードの切り替え
ワイヤーフレームやレンダーモードのこと↓
#WIREFRAMEモードにする bpy.context.space_data.shading.type = 'WIREFRAME' #SOLIDモードにする bpy.context.space_data.shading.type = 'SOLID' #MATERIALモードにする bpy.context.space_data.shading.type = 'MATERIAL' #RENDEREDモードにする bpy.context.space_data.shading.type = 'RENDERED'
3.透過モードの切り替え
#透過モードにする bpy.ops.view3d.toggle_xray()
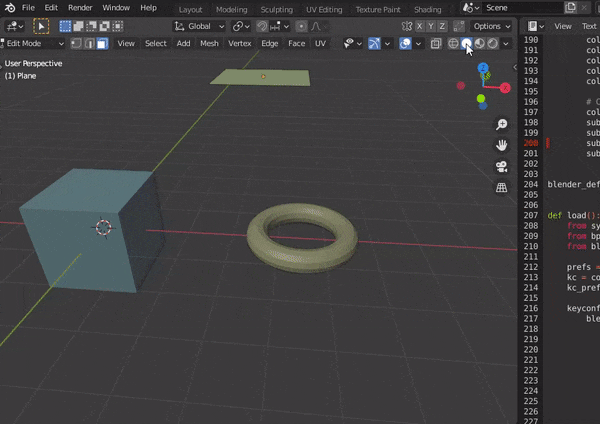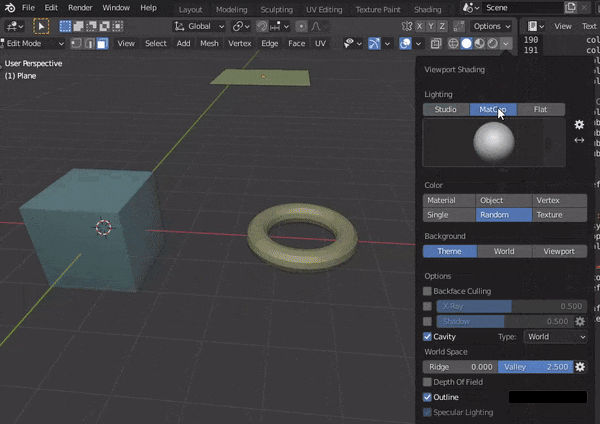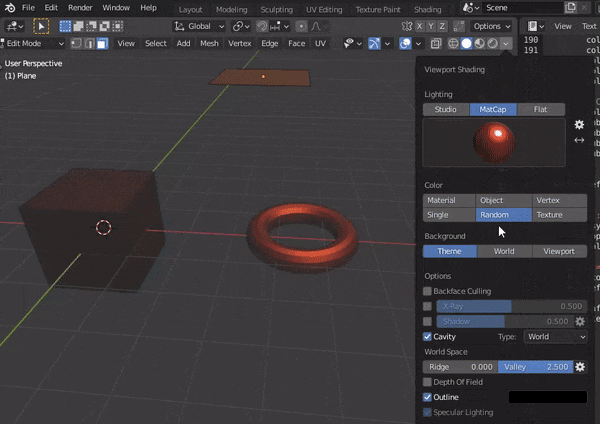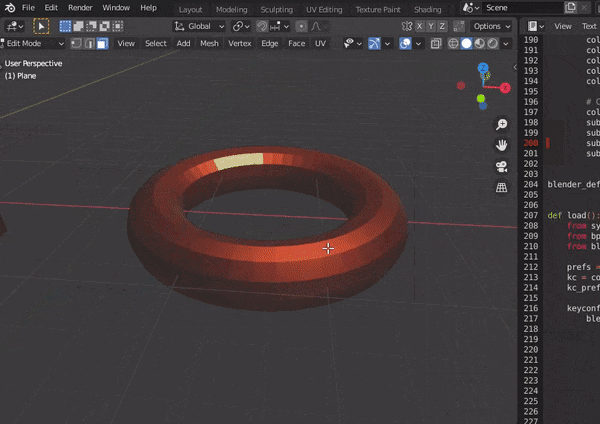
4.MATCAPSの設定
表面のへこみなどがみやすくなる↓
bpy.context.space_data.shading.type = 'SOLID' bpy.context.space_data.shading.light = 'MATCAP' #好みのものを選択する bpy.context.space_data.shading.studio_light = 'metal_carpaint.exr'
5.CAVITYの調整
構造が見やすくなる↓
bpy.context.space_data.shading.show_cavity = True bpy.context.space_data.shading.cavity_type = 'WORLD' #ridgeは隆起部 bpy.context.space_data.shading.cavity_ridge_factor = 1 #valleyは陥没部 bpy.context.space_data.shading.cavity_valley_factor = 1
6.オブジェクトの色をランダムにする
bpy.context.space_data.shading.type = 'SOLID' bpy.context.space_data.shading.color_type = 'RANDOM'
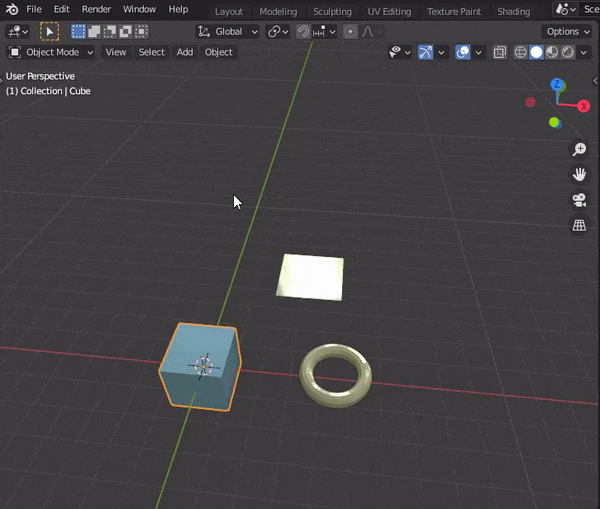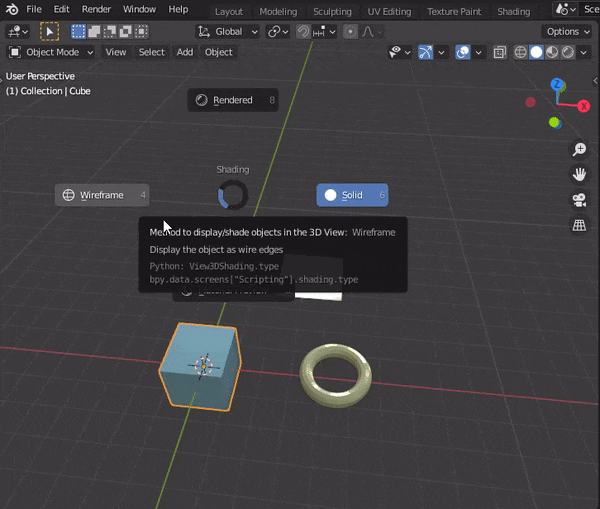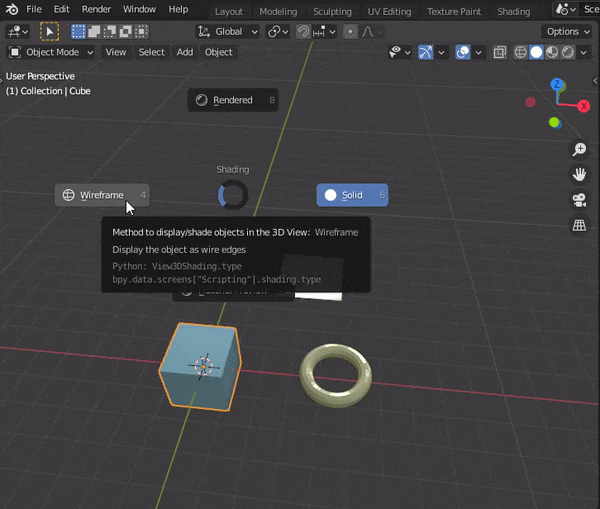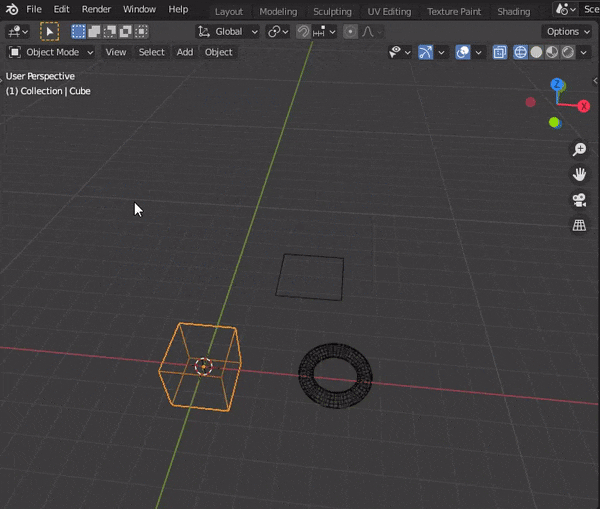
7.オブジェクトにフォーカスする
bpy.ops.view3d.view_selected(use_all_regions = False)8.3D viewportの操作性をあげる
●マウスがある場所にズームする
PreferencesInput.use_zoom_to_mouse●物体の近くまでズームできるようにする
PreferencesInput.use_mouse_depth_navigate●選択したオブジェクトを中心にして視野を回転できるようにする
●編集モードでも使用可能
PreferencesInput.use_rotate_around_active9.選択したオブジェクトのみを表示できるようにする
bpy.ops.view3d.localview()10.選択した面に視点をそろえる
#以下のtypeのぶぶんには、TOP,BOTTOM,FRONT,BACK,RIGHT,LEFTのいずれかが入ります。 bpy.ops.view3d.view_axis(type = 'TOP',align_active = True)

- 投稿日:2021-01-16T23:49:59+09:00
[Blender×Python] Blender Python tips(11/100)
この記事はCGBoostさんの100+ Tips to Boost Modeling in Blender中の操作をPythonに置き換えてみたものです。
目次
0.BlenderPython tips
1.モードの切り替え
2.シェーダーモードの切り替え
3.透過モードの切り替え
4.MATCAPSの設定
5.CAVITYの調整
6.オブジェクトの色をランダムにする
7.オブジェクトにフォーカスする
8.3D viewportの操作性をあげる
9.選択したオブジェクトのみを表示できるようにする
10.選択した面に視点をそろえる0.BlenderPython tips
●実行したコードはすべてInfoに表示される
Infoの場所:Scripting→Info(画面左下)
●Python tool tipsを有効にすると操作コードがパネル部分に表示される
有効にする方法:
Edit→preferences→TooltipsとPython Tooltipsにチェックをいれる●Blender内のパネル(ボタン)にカーソルを乗せた状態で[ctrl+C] を押すとPythonコードがコピーされる
1.モードの切り替え
オブジェクトモードや編集モードのこと↓
#Object Modeにする bpy.ops.object.mode_set(mode='OBJECT') #Edit Modeにする bpy.ops.object.mode_set(mode='EDIT') #Sculpt Modeにする bpy.ops.object.mode_set(mode='SCULPT') #Vertex Paintにする bpy.ops.object.mode_set(mode='VERTEX_PAINT') #Weight Modeにする bpy.ops.object.mode_set(mode='WEIGHT_PAINT') #Texture Modeにする bpy.ops.object.mode_set(mode='TEXTURE_PAINT')
2.シェーダーモードの切り替え
ワイヤーフレームやレンダーモードのこと↓
#WIREFRAMEモードにする bpy.context.space_data.shading.type = 'WIREFRAME' #SOLIDモードにする bpy.context.space_data.shading.type = 'SOLID' #MATERIALモードにする bpy.context.space_data.shading.type = 'MATERIAL' #RENDEREDモードにする bpy.context.space_data.shading.type = 'RENDERED'
3.透過モードの切り替え
#透過モードにする bpy.ops.view3d.toggle_xray()
4.MATCAPSの設定
表面のへこみなどがみやすくなる↓
bpy.context.space_data.shading.type = 'SOLID' bpy.context.space_data.shading.light = 'MATCAP' #好みのものを選択する bpy.context.space_data.shading.studio_light = 'metal_carpaint.exr'
5.CAVITYの調整
構造が見やすくなる↓
bpy.context.space_data.shading.show_cavity = True bpy.context.space_data.shading.cavity_type = 'WORLD' #ridgeは隆起部 bpy.context.space_data.shading.cavity_ridge_factor = 1 #valleyは陥没部 bpy.context.space_data.shading.cavity_valley_factor = 1
6.オブジェクトの色をランダムにする
bpy.context.space_data.shading.type = 'SOLID' bpy.context.space_data.shading.color_type = 'RANDOM'
7.オブジェクトにフォーカスする
bpy.ops.view3d.view_selected(use_all_regions = False)8.3D viewportの操作性をあげる
●マウスがある場所にズームする
PreferencesInput.use_zoom_to_mouse●物体の近くまでズームできるようにする
PreferencesInput.use_mouse_depth_navigate●選択したオブジェクトを中心にして視野を回転できるようにする
●編集モードでも使用可能
PreferencesInput.use_rotate_around_active9.選択したオブジェクトのみを表示できるようにする
bpy.ops.view3d.localview()10.選択した面に視点をそろえる
#以下のtypeのぶぶんには、TOP,BOTTOM,FRONT,BACK,RIGHT,LEFTのいずれかが入ります。 bpy.ops.view3d.view_axis(type = 'TOP',align_active = True)
- 投稿日:2021-01-16T23:43:09+09:00
キューとスタック
キュー
先に格納したデータから先に取り出す、先入れ先出し型(FIFO:First In First Out)のデータ構造。
queue.py# First In First Out que = [i for i in range(0, 10)] # enqueue for i in que: print(i) # dequeueスタック
キューとは逆に、後に格納したデータから先に取り出す後入れ先出し型(LIFO:Last In First Out)のデータ構造。
stack.py# Last In First Out stack = [i for i in range(0, 10)] # push stack.reverse() for i in stack: print(i) # pop
- 投稿日:2021-01-16T23:38:04+09:00
[Blender] Blender Modeling tips まとめ(11/100)
この記事はCGBoostさんの100+ Tips to Boost Modeling in Blender中の操作をまとめたものです。
目次
0.ショートカットのカスタマイズ
1.モードパイメニューを表示する
2.シェーダーパイメニューを表示する
3.透過モードの切り替え
4.表面の凹凸検証のためにMATCAPSを使用する
5.オブジェクトの輪郭をわかりやすくする
6.オブジェクトの色をランダムにする
7.選択したオブジェクトにフォーカスする
8.3D viewportの操作性をあげる
9.選択したオブジェクトのみを表示できるようにする
10.選択した面に視点をそろえる0.ショートカットのカスタマイズ
●NumPadがなくてショートカットが使えない
●ショートカットを変更したい
●よく使う操作にショートカットを割り当てたいというような問題は、以下のように解決することができます。
○ショートカットの変更
以下のgifはplane追加ショートカットを[alt+P]にカスタマイズしたものです。
①変更したい操作パネルの上で右クリック
②Change Shortcutを押す
③設定したいキーを押す
○Favorites(お気に入り)に追加
①変更したい操作パネルの上で右クリック
②Add to Quick Favoritesを押す
③Qキーをおして呼び出す
1.[TAB+ドラッグ]でモードパイメニューを表示する
設定方法
①Editを押す
②preferencesを押す
③KeyMapを押す
④3D View / Pie Menu on Dragにチェックをいれる2.[Z + ドラッグ]でシェーダーパイメニューを表示する
※デフォルトで設定されている
3.[Alt + Z]で透過モードの切り替え
①3D Viewportで[Alt + Z]を押す
4.表面の凹凸検証のためにMATCAPSを使用する
①solidモードにする
②viewport shadingのタブを押す
③MatCapを押す
④球体を押す
⑤好きなものを選択5.CAVITYでオブジェクトの輪郭をわかりやすくする
①viewport shadingのタブを押す
②Options/Cavityにチェックをいれる
③Typeを選択
④隆起部(山)と陥没部(谷)の強さ調整
6.オブジェクトの色をランダムにする
●3D viewport内ののオブジェクトにランダムな配色が可能
①solidモードにする
②viewport shadingのタブを押す
③Color/Randomを押す7.NumPadのピリオド([.])で、選択したオブジェクトにフォーカスする
①オブジェクトを選択する
②ピリオド([.])を押す●編集モードでも選択した頂点、辺、面にフォーカス可能
●Blender画面右上のアウトライナーで選択したオブジェクトにも適用可能
NumPadがない場合
①viewを押す
②Frame Selectedを押す8.3D viewportの操作性をあげる
○マウスがある場所にズームする
①Editを押す
②preferencesを押す
③Navigationを押す
④Zoom/Zoom to Mouse Positionにチェックをいれる○物体の近くまでズームできるようにする
①Editを押す
②preferencesを押す
③Navigationを押す
④Orbit&Pan/Auto/Depthにチェックをいれる○選択したオブジェクトを中心にして視野を回転できるようにする
①Editを押す
②preferencesを押す
③Navigationを押す
④Orbit&Pan/Orbit Around Selectionにチェックをいれる●編集モードでも使用可能
9.選択したオブジェクトのみを表示できるようにする
①表示したいオブジェクトをshiftキーを押しながら選択
②NumPadの[/]を押す
③もう一度[/]を押せばもとにもどる
※Local Viewから特定のオブジェクトを外したい場合は、[M]を押す
●NumPadがない場合
①viewを押す
②Local Viewを押す
③Remove from Local Viewを押す10.選択した面に視点をそろえる
①編集モードにする
②
[shift + NumPad1]を押す→手前からの視点
[shift + NumPad3]を押す→右横からの視点
[shift + NumPad7]を押す→正面からの視点※[ctrl +shift + NumPad7]のように[ctrl]をつけるとそれぞれが逆からの視点になる。
●NumPadがない場合
①viewを押す
②Align Viewを押す
③Align View to Activeを押す
④見たい方向を選択する

- 投稿日:2021-01-16T23:21:07+09:00
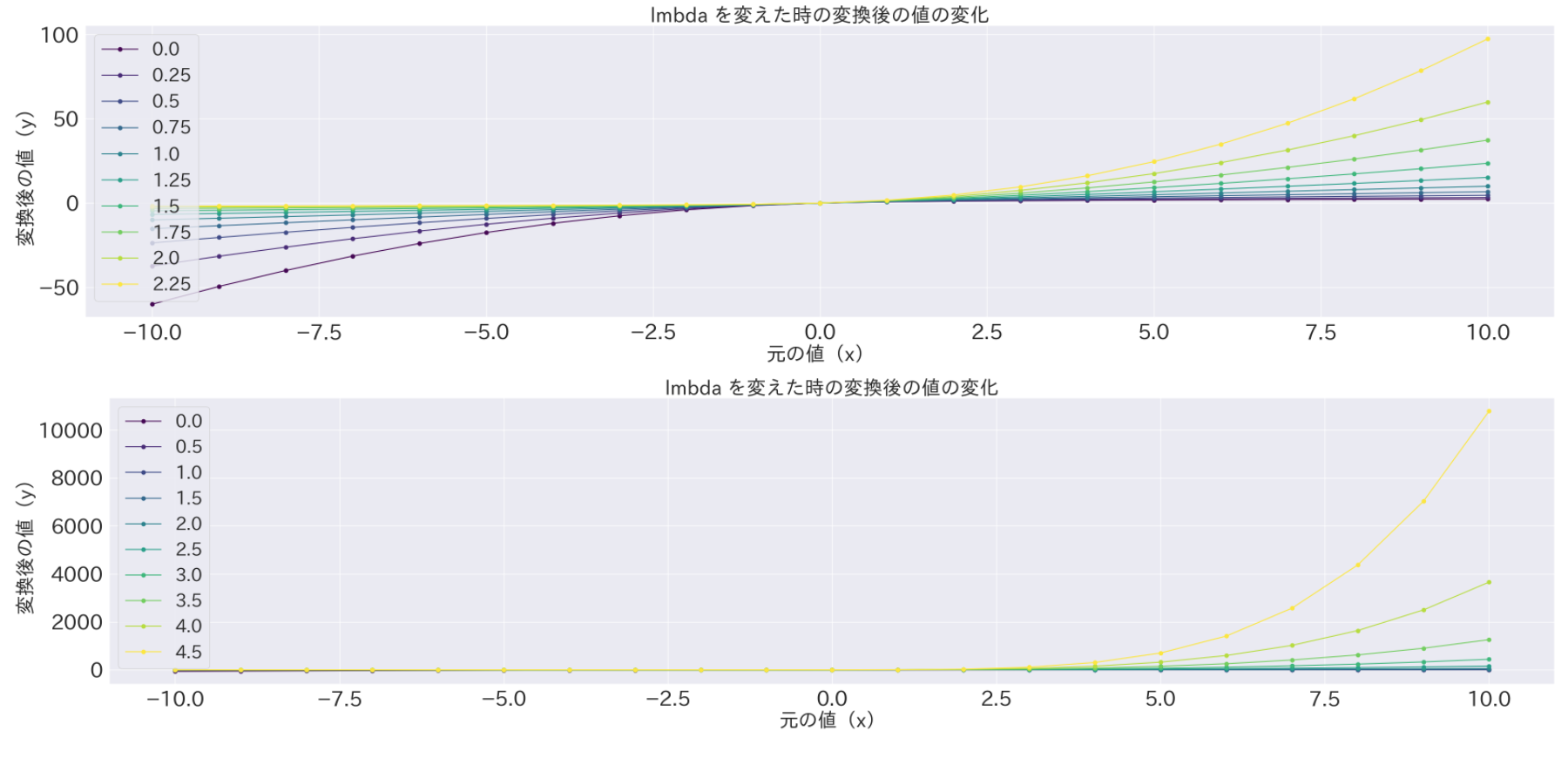
[python] yeojohnson変換の変換前後の値をプロット
pythonimport numpy as np import pandas as pd # ここの式をコピー # https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.yeojohnson.html def yeojohnson(lmbda, x): if x >= 0 and lmbda != 0: y = ((x + 1)**lmbda - 1) / lmbda elif x >= 0 and lmbda == 0: y = np.log(x + 1) elif x < 0 and lmbda != 2: y = -((-x + 1)**(2 - lmbda) - 1) / (2 - lmbda) elif x < 0 and lmbda == 2: y = -np.log(-x + 1) else: # 到達しないはず raise return y # 変換する値 x_ary = np.arange(21)-10 # 2パターンの lmbda の組み合わせを試す for lmbda_ary in [np.arange(10)*0.25, np.arange(10)*0.5]: # 変換して df にまとめる X_dic = {} for lmbda in lmbda_ary: X_dic[lmbda] = [yeojohnson(lmbda, float(x)) for x in x_ary] df = pd.DataFrame(X_dic, index=x_ary) # 描画 df.plot(cmap='viridis', marker='.') plt.xlabel('元の値(x)') plt.ylabel('変換後の値(y)') plt.title('lmbda を変えた時の変換後の値の変化') plt.show()output:
- 投稿日:2021-01-16T22:43:48+09:00
【Python】in 検索した結果のカラムのみ表示させる
経緯
先日試しで作った関数が結構便利かなっと思いましたのでメモ ✍️
250カラムほどある中から、"賞味期限xx"のようなカラムだけ抽出したやりたいこと
df[["賞味期限1", "賞味期限2",:...]]のような手打ちが減る ? ここを改善したかった- "賞味期限1", "賞味期限2" :... のようなカラムがある場合一度に検索抽出できる
作成した関数
# in 検索した結果のカラムのみ表示させる def in_search_col_list(df, cols="賞味期限", head=2) -> List: """ in search した colの結果を返す params ---------- df(DataFrame): 取り込みデータ cols(str): 検索にかけたいグローバルの値 head(int): 先頭から抽出するレコード数 return ---------- df(IndexList) in search したカラムリスト結果を返す """ return df[[for col in list(df.columns) if cols in col]].head(head)使用例
サンプルデータ(実際は, *tabファイルを読み込んでいたりします。)
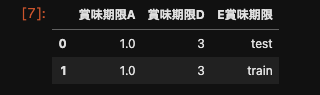
df = pd.DataFrame({ '賞味期限A' : 1., '保管場所B' : pd.Timestamp('20130102'), '保管場所C' : pd.Series(1,index=list(range(5)),dtype='float32'), '賞味期限D' : np.array([3] * 5,dtype='int32'), 'E賞味期限' : pd.Categorical(["test","train","test","train", "test"]), '食品個F' : 'foo', '期間限定G' : ['1000', np.nan, '123', '1234', '']})実行処理
import pandas as pd import numpy as np from typing import List def in_search_col_list(df, cols="賞味期限", head=2) -> List: """ in search した colの結果を返す params ---------- df(DataFrame): 取り込みデータ cols(str): 検索にかけたいグローバルの値 head(int): 先頭から抽出するレコード数 return ---------- df(DataFrame) in 検索した結果をListで返す """ return df[[ col for col in list(df.columns) if cols in col]].head(head) # 実行 in_search_col_list(df, cols="賞味期限", head=2)出力結果
まとめ
colsの引数名に検索したい文字列を入れれば、一発で検索できるので便利
- 投稿日:2021-01-16T22:29:47+09:00
ABC188 C問題 with python3
ABC188 C問題 ABC Tournament
ひとこと
リストでremove()を使ったせいでtleで不正解になってしまった。C問題からは計算量オーダーを意識したい。
正解コード
N=int(input()) A=list(map(int,input().split())) survive=list(range(1,2**N+1)) for j in range(N-1): winner=[] for k in range(0, len(survive), 2): first=survive[k] second=survive[k+1] if A[first-1]>A[second-1]: winner.append(first) else: winner.append(second) survive=winner first=survive[0] second=survive[1] if A[first-1]>A[second-1]: print(second) else: print(first)解説
まず全員分のデータを入れたリストを作る。そこからトーナメントで負けた人をリストから削除していき、残った二人のうちレートの低い方の番号を出力すれば良い。
ここで負けた人のデータを削除していくリストの作り方は2通り考えられる。
レートのデータを格納したリストを作るか番号のデータを格納したリストを作るかだ。前者の場合出力したいデータが番号なのに対して残ったデータがレートになってしまうので番号順にレートを格納したリストを別にとっておいてレートのインデックスを調べる必要があり手間がかかる。
後者の場合残った番号をそのまま出力すればいいだけなので番号のデータを格納したリストを作ることにする。リストから敗者の番号を消していく方法は単純にremove()を使うと消えた分データのインデックスがずれて面倒なので残っている人の番号を格納するsurviveリストと勝った人の番号を格納する空のwinnerリストを作り、surviveリストの内から勝った方だけwinnerリストに追加していく。処理が一周終わったらsurvive=winnerとする。これを繰り返すことで実装する。
この方法はリストから特定の条件を満たす要素を削除したい かつ 削除する条件にインデックスが絡んでくる時に使うと上手くいく。
簡単な類題
リストA=[2,3,1,5,6,7,3]からインデックスが奇数の要素を削除したものを出力せよ
回答
A=[2,3,1,5,6,7,3] ans=[] for i in range(len(A)): if i%2==0: ans.append(A[i]) print(ans) #ちゃんと答えが[2,1,6,3]になるはずです。まとめ
・実装方法が2つ考えられるときはある程度先までシュミレートして楽な方を選ぶ
・リストから特定の条件を満たす要素を削除したい かつ 削除する条件にインデックスが絡んでくる時は空のリストを用意してそこに生き残った要素を入れていけば良い
- 投稿日:2021-01-16T22:02:41+09:00
PythonでWordPressに画像付き記事を投稿する
はじめに
WordPressでブログ記事を書く際に、Pythonで集計したグラフを入れてそのままPythonから画像付き記事を投稿出来ないか調べた備忘録です。
PythonからWordPressに投稿する方法
2種類方法があるらしいですが、ここでは Python-wordpress-xmlrpc を使用しました。
使用環境
$python -V Python 3.8.3インストール
python-wordpress-xmlrpcのインストールはpipでします。
私はAnacondaを使用しているので、本来はcondaでインストールしたいのですが見つかりませんでした。pip install python-wordpress-xmlrpc画像付き記事を投稿するサンプルコード
# import import os from wordpress_xmlrpc import Client, WordPressPost from wordpress_xmlrpc.methods import media from wordpress_xmlrpc.methods.posts import GetPosts, NewPost from wordpress_xmlrpc.methods.users import GetUserInfo def upload_image(in_image_file_name, out_image_file_name): if os.path.exists(in_image_file_name): with open(in_image_file_name, 'rb') as f: binary = f.read() data = { "name": out_image_file_name, "type": 'image/png', "overwrite": True, "bits": binary } media_id = wp.call(media.UploadFile(data))['id'] print(in_image_file_name.split('/') [-1], 'Upload Success : id=%s' % media_id) return media_id else: print(in_image_file_name.split('/')[-1], 'NO IMAGE!!') # Set URL, ID, Password WORDPRESS_ID = "YourID" WORDPRESS_PW = "YourPassword" WORDPRESS_URL = "YourURL/xmlrpc.php" wp = Client(WORDPRESS_URL, WORDPRESS_ID, WORDPRESS_PW) # Picture file name & Upload imgPath = "picture.png" media_id = upload_image(imgPath, imgPath) # Blog Title title = "記事タイトル" # Blog Content (html) body = """ <p>本文本文本文本文本文本文本文本文本文本文本文本文本文本文</p> <h2>見出し</h2> <figure class="wp-block-image alignwide size-large"> <img src="YourURL/wp-content/uploads/year/month/%s" alt="" class="wp-image-%s"/> </figure> """ %(imgPath, media_id) # publish or draft status = "draft" #Category keyword cat1 = 'category1' cat2 = 'category2' cat3 = 'category3' #Tag keyword tag1 = 'tag1' tag2 = 'tag2' tag3 = 'tag3' slug = "slug" # Post post = WordPressPost() post.title = title post.content = body post.post_status = status post.terms_names = { "category": [cat1, cat2, cat3], "post_tag": [tag1, tag2, tag3], } post.slug = slug # Set eye-catch image post.thumbnail = media_id # Post Time post.date = datetime.datetime.now() - datetime.timedelta(hours=9) wp.call(NewPost(post))課題
画像リンクがもっといい書き方があるのではないかと思いますが、改良方法が見つかれば修正します。
効果
データをPythonで処理してグラフ作成し、そのままグラフ付き記事にしてWordPressに投稿と自動化できるためとても楽です。これから活用していきたいです。
参考サイト
色々な記事を参考にさせていただきました。ありがとうございます。
- 投稿日:2021-01-16T21:37:50+09:00
scikit-learn 0.24.0でちょっと便利になったpartial_dependenceを使ってみた
はじめに
昨年の12月にscikit-learnの0.24.0がリリースされました。
https://scikit-learn.org/stable/whats_new/v0.24.html#version-0-24-0
partial_dependenceの機能が拡張されたので、試してみました。環境
環境は以下の通り。
$sw_vers ProductName: Mac OS X ProductVersion: 10.13.6 BuildVersion: 17G14042Jupyterlab (Version 0.35.4) 上で作業していたので、python kernelのバージョンも記載しておきます。
Python 3.7.3 (default, Mar 27 2019, 16:54:48) IPython 7.4.0 -- An enhanced Interactive Python. Type '?' for help.やったこと
scikit-learnのバージョンアップ
Anacondaの環境を使っているので、
condaでバージョンアップします。conda install -c conda-forge scikit-learn=0.24.0scikit-learnとこのあと使うlightgbmのバージョンは次の通りです。
from sklearn import __version__ as sk_ver print(lgb.__version__) print(sk_ver)3.1.1 0.24.0モデル構築
モデルを用意します。
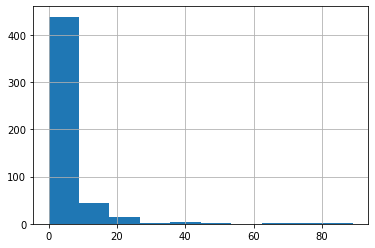
データはscikit-learnで用意されているボストンデータセットを使用しました。import pandas as pd import sklearn.datasets as skd data = skd.load_boston() df_X = pd.DataFrame(data.data, columns=data.feature_names) df_y = pd.DataFrame(data.target, columns=['y'])目的変数の分布は下図の通りで、20あたりにピークを持つような形になっています。
説明変数については、506行13列のデータで全列がnon-nullのfloat型なのでこのままモデルを作ります。
以前の記事で述べましたが、APIの仕様を合わせるため、LightgbmはScikit-learn APIで学習させます。import lightgbm as lgb from sklearn.model_selection import train_test_split df_X_train, df_X_test, df_y_train, df_y_test = train_test_split(df_X, df_y, test_size=0.2, random_state=4) lgbm_sk = lgb.LGBMRegressor(objective='regression', random_state=4, metric='rmse') lgbm_sk.fit(df_X_train, df_y_train)LGBMRegressor(metric='rmse', objective='regression', random_state=4)partial-dependenceの変更箇所と試したこと
partial_dependenceのドキュメントを見ると、引数は次のようになっています。sklearn.inspection.partial_dependence(estimator, X, features, *, response_method='auto', percentiles=0.05, 0.95, grid_resolution=100, method='auto', kind='legacy')このうち、
kindのパラメータが0.24.0で追加されました。
kindについてドキュメントではkind{‘legacy’, ‘average’, ‘individual’, ‘both’}, default=’legacy’
Whether to return the partial dependence averaged across all the samples in the dataset or one line per sample or both. See Returns below.Note that the fast method='recursion' option is only available for kind='average'. Plotting individual dependencies requires using the slower method='brute' option.
New in version 0.24.
Deprecated since version 0.24: kind='legacy' is deprecated and will be removed in version 1.1. kind='average' will be the new default. It is intended to migrate from the ndarray output to Bunch output.
と記載されています。現デフォルトの
legacyはそのうちなくなるとのことですが、‘legacy’, ‘average’, ‘individual’, ‘both’の4種類を試してみました。kind = 'legacy'
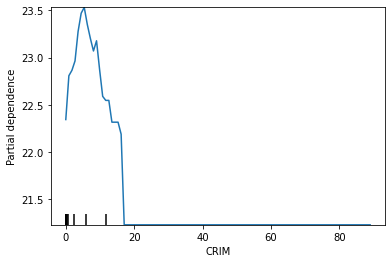
kind = 'legacy'でCRIMという説明変数についてのpartial dependenceを出してみます。from sklearn.inspection import partial_dependence result_pd_legacy = partial_dependence(lgbm_sk, features=['CRIM'], percentiles=(0,1), X=df_X_train, kind='legacy') result_pd_legacy返り値はndarrayとListがtupleで入っているような形になっています。
(array([[22.34455464, 22.80833098, 22.86597834, 22.96513457, 23.27716791, 23.47015226, 23.53235471, 23.35070292, 23.20272559, 23.07065778, 23.1786901 , 22.87241557, 22.59017997, 22.54737655, 22.54737655, 22.31672465, 22.31672465, 22.31672465, 22.18968352, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113]]), [array([6.32000000e-03, 9.05005657e-01, 1.80369131e+00, 2.70237697e+00, 3.60106263e+00, 4.49974828e+00, 5.39843394e+00, 6.29711960e+00, 7.19580525e+00, 8.09449091e+00, 8.99317657e+00, 9.89186222e+00, 1.07905479e+01, 1.16892335e+01, 1.25879192e+01, 1.34866048e+01, 1.43852905e+01, 1.52839762e+01, 1.61826618e+01, 1.70813475e+01, 1.79800331e+01, 1.88787188e+01, 1.97774044e+01, 2.06760901e+01, 2.15747758e+01, 2.24734614e+01, 2.33721471e+01, 2.42708327e+01, 2.51695184e+01, 2.60682040e+01, 2.69668897e+01, 2.78655754e+01, 2.87642610e+01, 2.96629467e+01, 3.05616323e+01, 3.14603180e+01, 3.23590036e+01, 3.32576893e+01, 3.41563749e+01, 3.50550606e+01, 3.59537463e+01, 3.68524319e+01, 3.77511176e+01, 3.86498032e+01, 3.95484889e+01, 4.04471745e+01, 4.13458602e+01, 4.22445459e+01, 4.31432315e+01, 4.40419172e+01, 4.49406028e+01, 4.58392885e+01, 4.67379741e+01, 4.76366598e+01, 4.85353455e+01, 4.94340311e+01, 5.03327168e+01, 5.12314024e+01, 5.21300881e+01, 5.30287737e+01, 5.39274594e+01, 5.48261451e+01, 5.57248307e+01, 5.66235164e+01, 5.75222020e+01, 5.84208877e+01, 5.93195733e+01, 6.02182590e+01, 6.11169446e+01, 6.20156303e+01, 6.29143160e+01, 6.38130016e+01, 6.47116873e+01, 6.56103729e+01, 6.65090586e+01, 6.74077442e+01, 6.83064299e+01, 6.92051156e+01, 7.01038012e+01, 7.10024869e+01, 7.19011725e+01, 7.27998582e+01, 7.36985438e+01, 7.45972295e+01, 7.54959152e+01, 7.63946008e+01, 7.72932865e+01, 7.81919721e+01, 7.90906578e+01, 7.99893434e+01, 8.08880291e+01, 8.17867147e+01, 8.26854004e+01, 8.35840861e+01, 8.44827717e+01, 8.53814574e+01, 8.62801430e+01, 8.71788287e+01, 8.80775143e+01, 8.89762000e+01])])2つ目のListはfeaturesのパラメータの入力に掃討していて、今はCRIMのみ指定しているので、中身は100個分(パラメータgridのデフォルト値)のCRIMのデータポイントになっています。
1つ目のndarrayの中身が、各データポイントに対する予測値の平均となっています。
これを図示すると、いわゆるpartial dependenceのプロットを得られます。plt.plot(result_pd_legacy[1][0].tolist(), result_pd_legacy[0][0].tolist(), lw=2) plt.show()
scikit-learnの
plot_partial_dependenceでも図示してみると、上を同じことがわかります。from sklearn.inspection import plot_partial_dependence plot_partial_dependence(lgbm_sk, features=['CRIM'], percentiles=(0,1), X=df_X_train)
ちなみにCRIMの分布は下図の通りです。
df_X['CRIM'].hist()
kind = 'individual'
次に、
kind = 'individual'でCRIMについてのpartial dependenceを出してみます。result_pd_individual = partial_dependence(lgbm_sk, features=['CRIM'], percentiles=(0,1), X=df_X_train, kind='individual') result_pd_individual返り値は
sklearn.utils.Bunch型になっています。{'individual': array([[[35.65076711, 36.80808717, 36.80808717, ..., 36.30216375, 36.30216375, 36.30216375], [13.75253977, 13.88194832, 13.88194832, ..., 11.88607485, 11.88607485, 11.88607485], [25.40068607, 26.19198637, 26.19198637, ..., 26.32272304, 26.32272304, 26.32272304], ..., [13.44052832, 13.37887547, 13.49894852, ..., 9.30373171, 9.30373171, 9.30373171], [22.68308121, 24.31486889, 24.30242905, ..., 23.9277052 , 23.9277052 , 23.9277052 ], [20.91061255, 19.55812895, 19.54568912, ..., 16.7640575 , 16.7640575 , 16.7640575 ]]]), 'values': [array([6.32000000e-03, 9.05005657e-01, 1.80369131e+00, 2.70237697e+00, 3.60106263e+00, 4.49974828e+00, 5.39843394e+00, 6.29711960e+00, 7.19580525e+00, 8.09449091e+00, 8.99317657e+00, 9.89186222e+00, 1.07905479e+01, 1.16892335e+01, 1.25879192e+01, 1.34866048e+01, 1.43852905e+01, 1.52839762e+01, 1.61826618e+01, 1.70813475e+01, 1.79800331e+01, 1.88787188e+01, 1.97774044e+01, 2.06760901e+01, 2.15747758e+01, 2.24734614e+01, 2.33721471e+01, 2.42708327e+01, 2.51695184e+01, 2.60682040e+01, 2.69668897e+01, 2.78655754e+01, 2.87642610e+01, 2.96629467e+01, 3.05616323e+01, 3.14603180e+01, 3.23590036e+01, 3.32576893e+01, 3.41563749e+01, 3.50550606e+01, 3.59537463e+01, 3.68524319e+01, 3.77511176e+01, 3.86498032e+01, 3.95484889e+01, 4.04471745e+01, 4.13458602e+01, 4.22445459e+01, 4.31432315e+01, 4.40419172e+01, 4.49406028e+01, 4.58392885e+01, 4.67379741e+01, 4.76366598e+01, 4.85353455e+01, 4.94340311e+01, 5.03327168e+01, 5.12314024e+01, 5.21300881e+01, 5.30287737e+01, 5.39274594e+01, 5.48261451e+01, 5.57248307e+01, 5.66235164e+01, 5.75222020e+01, 5.84208877e+01, 5.93195733e+01, 6.02182590e+01, 6.11169446e+01, 6.20156303e+01, 6.29143160e+01, 6.38130016e+01, 6.47116873e+01, 6.56103729e+01, 6.65090586e+01, 6.74077442e+01, 6.83064299e+01, 6.92051156e+01, 7.01038012e+01, 7.10024869e+01, 7.19011725e+01, 7.27998582e+01, 7.36985438e+01, 7.45972295e+01, 7.54959152e+01, 7.63946008e+01, 7.72932865e+01, 7.81919721e+01, 7.90906578e+01, 7.99893434e+01, 8.08880291e+01, 8.17867147e+01, 8.26854004e+01, 8.35840861e+01, 8.44827717e+01, 8.53814574e+01, 8.62801430e+01, 8.71788287e+01, 8.80775143e+01, 8.89762000e+01])]}Bunchの中に'individual'と'values'というkeyがあってそれぞれndarrayとListになっています。
kind = 'legacy'のときの返り値に対応していますが、'individual'の出力がちょっと違います。ndarrayのshapeをみて見ると、result_pd_individual['individual'].shape(1, 404, 100)という形になっています。404というのは、
partial_dependenceに渡しているdf_X_trainの行数になります。len(df_X_train)404ということで、いままでは予測値の平均しか返ってきていなかったですが、各データの予測値そのものが返るようになっています。
例えば、CRIMのgridの1点目に対して、404個の予測値の平均をとると、result_pd_individual['individual'][0,:,0].mean()22.344554644753032となって、
kind = 'legacy'で得られた1点目の予測値の平均22.34455464と一致します。kind = 'average'
次に、
kind = 'average'でCRIMについてのpartial dependenceを出してみます。result_pd_average = partial_dependence(lgbm_sk, features=['CRIM'], percentiles=(0,1), X=df_X_train, kind='average') result_pd_average返り値は
sklearn.utils.Bunch型になっています。{'average': array([[22.34455464, 22.80833098, 22.86597834, 22.96513457, 23.27716791, 23.47015226, 23.53235471, 23.35070292, 23.20272559, 23.07065778, 23.1786901 , 22.87241557, 22.59017997, 22.54737655, 22.54737655, 22.31672465, 22.31672465, 22.31672465, 22.18968352, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113]]), 'values': [array([6.32000000e-03, 9.05005657e-01, 1.80369131e+00, 2.70237697e+00, 3.60106263e+00, 4.49974828e+00, 5.39843394e+00, 6.29711960e+00, 7.19580525e+00, 8.09449091e+00, 8.99317657e+00, 9.89186222e+00, 1.07905479e+01, 1.16892335e+01, 1.25879192e+01, 1.34866048e+01, 1.43852905e+01, 1.52839762e+01, 1.61826618e+01, 1.70813475e+01, 1.79800331e+01, 1.88787188e+01, 1.97774044e+01, 2.06760901e+01, 2.15747758e+01, 2.24734614e+01, 2.33721471e+01, 2.42708327e+01, 2.51695184e+01, 2.60682040e+01, 2.69668897e+01, 2.78655754e+01, 2.87642610e+01, 2.96629467e+01, 3.05616323e+01, 3.14603180e+01, 3.23590036e+01, 3.32576893e+01, 3.41563749e+01, 3.50550606e+01, 3.59537463e+01, 3.68524319e+01, 3.77511176e+01, 3.86498032e+01, 3.95484889e+01, 4.04471745e+01, 4.13458602e+01, 4.22445459e+01, 4.31432315e+01, 4.40419172e+01, 4.49406028e+01, 4.58392885e+01, 4.67379741e+01, 4.76366598e+01, 4.85353455e+01, 4.94340311e+01, 5.03327168e+01, 5.12314024e+01, 5.21300881e+01, 5.30287737e+01, 5.39274594e+01, 5.48261451e+01, 5.57248307e+01, 5.66235164e+01, 5.75222020e+01, 5.84208877e+01, 5.93195733e+01, 6.02182590e+01, 6.11169446e+01, 6.20156303e+01, 6.29143160e+01, 6.38130016e+01, 6.47116873e+01, 6.56103729e+01, 6.65090586e+01, 6.74077442e+01, 6.83064299e+01, 6.92051156e+01, 7.01038012e+01, 7.10024869e+01, 7.19011725e+01, 7.27998582e+01, 7.36985438e+01, 7.45972295e+01, 7.54959152e+01, 7.63946008e+01, 7.72932865e+01, 7.81919721e+01, 7.90906578e+01, 7.99893434e+01, 8.08880291e+01, 8.17867147e+01, 8.26854004e+01, 8.35840861e+01, 8.44827717e+01, 8.53814574e+01, 8.62801430e+01, 8.71788287e+01, 8.80775143e+01, 8.89762000e+01])]}Bunchの中に'average'と'values'というkeyがあってそれぞれndarrayとListになっています。
'average'の中身はkind = 'legacy'のときの返り値と同じですので、前バージョンまでの出力に相当しています。kind = 'both'
次に、
kind = 'both'でCRIMについてのpartial dependenceを出してみます。result_pd_both = partial_dependence(lgbm_sk, features=['CRIM'], percentiles=(0,1), X=df_X_train, kind='both') result_pd_both{'average': array([[22.34455464, 22.80833098, 22.86597834, 22.96513457, 23.27716791, 23.47015226, 23.53235471, 23.35070292, 23.20272559, 23.07065778, 23.1786901 , 22.87241557, 22.59017997, 22.54737655, 22.54737655, 22.31672465, 22.31672465, 22.31672465, 22.18968352, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113, 21.23030113]]), 'individual': array([[[35.65076711, 36.80808717, 36.80808717, ..., 36.30216375, 36.30216375, 36.30216375], [13.75253977, 13.88194832, 13.88194832, ..., 11.88607485, 11.88607485, 11.88607485], [25.40068607, 26.19198637, 26.19198637, ..., 26.32272304, 26.32272304, 26.32272304], ..., [13.44052832, 13.37887547, 13.49894852, ..., 9.30373171, 9.30373171, 9.30373171], [22.68308121, 24.31486889, 24.30242905, ..., 23.9277052 , 23.9277052 , 23.9277052 ], [20.91061255, 19.55812895, 19.54568912, ..., 16.7640575 , 16.7640575 , 16.7640575 ]]]), 'values': [array([6.32000000e-03, 9.05005657e-01, 1.80369131e+00, 2.70237697e+00, 3.60106263e+00, 4.49974828e+00, 5.39843394e+00, 6.29711960e+00, 7.19580525e+00, 8.09449091e+00, 8.99317657e+00, 9.89186222e+00, 1.07905479e+01, 1.16892335e+01, 1.25879192e+01, 1.34866048e+01, 1.43852905e+01, 1.52839762e+01, 1.61826618e+01, 1.70813475e+01, 1.79800331e+01, 1.88787188e+01, 1.97774044e+01, 2.06760901e+01, 2.15747758e+01, 2.24734614e+01, 2.33721471e+01, 2.42708327e+01, 2.51695184e+01, 2.60682040e+01, 2.69668897e+01, 2.78655754e+01, 2.87642610e+01, 2.96629467e+01, 3.05616323e+01, 3.14603180e+01, 3.23590036e+01, 3.32576893e+01, 3.41563749e+01, 3.50550606e+01, 3.59537463e+01, 3.68524319e+01, 3.77511176e+01, 3.86498032e+01, 3.95484889e+01, 4.04471745e+01, 4.13458602e+01, 4.22445459e+01, 4.31432315e+01, 4.40419172e+01, 4.49406028e+01, 4.58392885e+01, 4.67379741e+01, 4.76366598e+01, 4.85353455e+01, 4.94340311e+01, 5.03327168e+01, 5.12314024e+01, 5.21300881e+01, 5.30287737e+01, 5.39274594e+01, 5.48261451e+01, 5.57248307e+01, 5.66235164e+01, 5.75222020e+01, 5.84208877e+01, 5.93195733e+01, 6.02182590e+01, 6.11169446e+01, 6.20156303e+01, 6.29143160e+01, 6.38130016e+01, 6.47116873e+01, 6.56103729e+01, 6.65090586e+01, 6.74077442e+01, 6.83064299e+01, 6.92051156e+01, 7.01038012e+01, 7.10024869e+01, 7.19011725e+01, 7.27998582e+01, 7.36985438e+01, 7.45972295e+01, 7.54959152e+01, 7.63946008e+01, 7.72932865e+01, 7.81919721e+01, 7.90906578e+01, 7.99893434e+01, 8.08880291e+01, 8.17867147e+01, 8.26854004e+01, 8.35840861e+01, 8.44827717e+01, 8.53814574e+01, 8.62801430e+01, 8.71788287e+01, 8.80775143e+01, 8.89762000e+01])]}返り値は
sklearn.utils.Bunch型になっていて、'average'と'individual'の両方が入っています。自作のpartial dependenceプロット
せっかく各データ点の予測値が返るようになったので、ちょっと遊んでみました。
partial dependenceのプロットとして、平均値だけでなく、範囲と、とあるデータ点も一緒にプロットしてみます。import matplotlib.pyplot as plt import numpy as np def pdp_plot(model, X, features, n_cols=3, pred_data=None): n_cols = min(len(features), n_cols) n_rows = int(np.ceil( len(features) / n_cols )) fig = plt.figure(figsize=(4*n_cols, 4*n_rows)) ymin = 999 ymax = -999 for i, feature in enumerate(features): result_pd_individual = partial_dependence(model, features=[feature], percentiles=(0.05,1-0.05), X=X, kind='individual') feature_grid = result_pd_individual['values'][0] pd_mean = result_pd_individual['individual'][0,:,:].mean(axis=0) pd_perc_25pct = np.percentile(a=result_pd_individual['individual'][0,:,:], q=25, axis=0) pd_perc_75pct = np.percentile(a=result_pd_individual['individual'][0,:,:], q=75, axis=0) ax = fig.add_subplot(n_rows, n_cols, i+1) ax.plot(feature_grid, pd_mean, label='average') ax.fill_between(feature_grid, pd_perc_25pct, pd_perc_75pct, alpha=0.2, label='25 - 75 percentile') if pred_data is not None: pred = model.predict(pred_data) ax.scatter(pred_data[feature], pred, marker='X', label='predicted data') ax.set_xlabel(feature) if (i+1) % n_cols == 1: ax.set_ylabel('Partial dependence') else: ax.set_ylabel('') ax.grid() if i == 0: ax.legend(loc=1) ymin_, ymax_ = ax.get_ylim() ymin = min(ymin_, ymin) ymax = max(ymax_, ymax) #plt.ylim(ymin*0.9, ymax*1.1) for iax in fig.axes: iax.set_ylim(ymin*0.9, ymax*1.1) plt.show() pdp_plot(model=lgbm_sk, X=df_X_train, features=['CRIM', 'LSTAT', 'TAX', 'ZN'], pred_data=pd.DataFrame([df_X_test.iloc[0, :]]))とあるモデルの予測値の平均、25 - 75パーセンタイルの範囲の中に、とあるデータの説明変数の値+そのデータに対する予測値の情報を一緒にプロットしてみました。
なんとなくですが、なんでその予測値になったのかイメージつきやすいかなーと思った次第です。
まとめ
scikit-learnのバージョンが0.24.0になったことで、次の変更がありました。
- kindというパラメータが追加された。
- デフォルト('legacy')ではいままで通りの出力を得られる。ただし、今後'legacy'はなくなる。
- 今後のデフォルトは'average'となり、返り値はBunch型となる。
- 'individual'にすると各データに対する予測値を得られる。


- 投稿日:2021-01-16T20:38:48+09:00
termuxアプリでlinux
アンドロイドアプリtermuxを使うとlinuxコマンドが打てるので使ってみた。
まず最初にこれ打っておくと使いやすくなる。
termux-setup-storage□できたこと
・apt get update
・apt get upgrade
・pip install --upgrade pip
・pip install pandas
・pip install numpy
・pip install matplotlib
□できなかったこと
・pip install tkinter
下記が参考になる。
https://www.google.com/amp/s/www.lisz-works.com/entry/termux-init%3famp=1
- 投稿日:2021-01-16T20:33:58+09:00
動きながら動画を再生するPGM(python版)
以前JavaScriptで作った動いているとyoutube上の動画をコマ送りで動かす
もののpython版を作りました。これはすでにダウンロードされた動画を動いている間だけコマ送りで再生します。(オフライン上で動作)
サンプルPGM
githubURL:https://github.com/NanjoMiyako/WalkingAndMovie_python
使い方コマンドプロンプトから当該PGM(WalkingAndMovie.py)に以下のコマンドライン引数を
入力して実行します。
コマンドライン引数1: 再生する動画ファイルパス
コマンドライン引数2: 動画変化を判定する際の差分率(例:5%の時'5.0')
スクリーンショット

- 投稿日:2021-01-16T19:39:04+09:00
Google ColabでMeCabとneologdを使う
結論
以下コマンドを実行。
!apt-get -q -y install sudo file mecab libmecab-dev mecab-ipadic-utf8 git curl python-mecab > /dev/null !git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git > /dev/null !echo yes | mecab-ipadic-neologd/bin/install-mecab-ipadic-neologd -n > /dev/null 2>&1 !pip install mecab-python3 > /dev/null !ln -s /etc/mecabrc /usr/local/etc/mecabrc !echo `mecab-config --dicdir`"/mecab-ipadic-neologd"使い方
import MeCab path = "-d /usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologd" tagger = MeCab.Tagger(path) text = '鬼滅の刃、流行ってる。' node = tagger.parseToNode(text) while node: print(node.feature) node = node.next # 以下、出力結果 # BOS/EOS,*,*,*,*,*,*,*,* # 名詞,固有名詞,一般,*,*,*,鬼滅の刃,キメツノヤイバ,キメツノヤイバ # 記号,読点,*,*,*,*,、,、,、 # 動詞,自立,*,*,五段・ラ行,連用タ接続,流行る,ハヤッ,ハヤッ # 動詞,非自立,*,*,一段,基本形,てる,テル,テル # 記号,句点,*,*,*,*,。,。,。 # BOS/EOS,*,*,*,*,*,*,*,*nodeからは以下の情報が取得できる。
- surface: 分割された単語
- posid: 品詞のID
- feature: 詳細情報
リファレンス
- 投稿日:2021-01-16T19:15:11+09:00
テスト
- 投稿日:2021-01-16T18:44:50+09:00
pandas の簡素な説明(Cheat Sheet)
私英語が苦手なのですが、絵で見て何となくわかるので重宝してます。
pandas Getting startedの下の方にCheat Sheetへのリンクがあります。Getting startedのページも参考になります。(私は英語が苦手なので「日本語に翻訳」様にいつも助けてもらいます)


- 投稿日:2021-01-16T18:32:36+09:00
「人流シミュレーションのパラメータ推定手法」の論文の実装(非公式)
はじめに
NTTソフトウェアイノベーションセンタによる論文「人流シミュレーションのパラメータ
推定手法」をPythonで実装しました。
実装したコードはgithubに載せています。
パッケージとして内容を実行することも可能です。
実装コードすべてを解説すると長くなるので、ここでは実装の概要とパッケージとしての利用法を解説します。(githubのREADME.mdにも同様の内容が書いてあります。)実装の概要
- Social Force Model (SFM)を用いた人流モデルの実装
- 人流データを1.のモデルに適用したときのパラメータの最適化に使う目的関数の評価モデルの実装
- 人流データを1.のモデルに適用したときのパラメータを求めるモデルを、2.の結果をもとに構築
論文からの変更点
- 人流シミュレーションにおいて遷移パラメータ(論文参照)を目的地ごとに決めるのではなく人ごとに正規分布で決定した。
- パラメータ推定方法の評価において、ヒートマップの作り方はGridのみを用い、Voronoiは使わなかった。また、ヒートマップのGridの目の粗さに関しても評価せず、固定した。
- パラメータ推定において、論文通りの推定法に加え、1種類のパラメータのみを推定して他のパラメータを固定する推定方法も実装した。
パッケージとしての利用
実行に必要なパッケージ
- numpy (version 1.19.2)
- matplotlib (version 3.3.2)
- optuna (version 2.4.0)
人流シミュレーション
引数を指定
people_num: シミュレーションする人数。
v_arg: 人の速さに関連する2つの要素を持つリスト型の変数。1つ目の要素は平均の速さ、2つ目の要素は速さの標準偏差を表す。
repul_h: 人の間の反発力に関連する2つの要素を持つリスト型の変数。
(詳細:人流シミュレーションのパラメータ推定手法
3.人流シミュレーションモデル 3.1 Social Force Model)repul_m: 人と壁の間の反発力に関連する2つの要素を持つリスト型の変数。
(詳細:人流シミュレーションのパラメータ推定手法
3.人流シミュレーションモデル 3.1 Social Force Model)target: 形が(N,2)のリスト型の変数。Nは目的地の数。2次元目の要素は目的地のxy座標を表す。最後の目的地は出口と見なされる。
R: 人(粒子として表される)の半径
min_p: 目的地にいる人が次の目的地に移動する確率の最小値。この確率の逆数が目的地での滞在時間の期待値として使われる。
p_arg: 目的地にいる人が次の目的地に移動する確率を決定する2次元のリスト型の変数。1次元目の要素数は目的地の数から1を引いた数の因数。
2次元目の1つ目の要素は確率の平均、2つ目の要素は標準偏差となる。この確率の逆数が目的地に滞在する時間の期待値として使われる。
なお、1次元目の要素数が目的地の数から1引いた数より小さいとき、numpyのようにブロードキャストしてしようされる。wall_x: 壁のx座標(左端は0であり右端がこの変数により決定される)
wall_y: 壁のy座標(下端は0であり上端がこの変数により決定される)
in_target_d: 人と目的地の間の距離がこの変数より小さければ、その人は目的地に到着したと見なす。)
dt: 人の状態(位置、速さなど)を更新するときに利用する微小時間の大きさ
disrupt_point: 経過時間がこの変数を超えたらシミュレーションを停止する。(シミュレーション1/dt回で経過時間の1単位となる)
save_format: シミュレーション結果を保存する形式を指定する。現在は"heat_map"だけしか使えない。"None"であれば結果を保存しない。
save_params: 結果を保存するのに使う変数。"heat_map"であれば2つの要素を持ったリスト型の変数が必要で、1つ目の要素はヒートマップの行数と列数を指定するタプル、2つ目の要素は保存する頻度を指定する変数。頻度の単位は"disrupt_point"と同じ。
people_num = 30 v_arg = [6,2] repul_h = [5,5] repul_m = [2,2] target = [[60,240],[120,150],[90,60],[240,40],[200,120],[170,70],[150,0]] R = 3 min_p = 0.1 p_arg = [[0.5,0.1]] wall_x = 300 wall_y = 300 in_target_d = 3 dt = 0.1 save_format = "heat_map" save_params = [(30,30),1]シミュレーションするインスタンスを生成
import people_flow model = people_flow.simulation.people_flow(people_num,v_arg,repul_h,repul_m,target,R,min_p,p_arg,wall_x,wall_y,in_target_d,dt,save_format=save_format,save_params=save_params)シミュレーションを実行(結果のヒートマップを得る)
maps = model.simulate()実行中、シミュレーション状況がmatplotlibにより描画される。
パラメータ推定における目的関数の評価
assessment_frameworkとassessment_framework_detailがありassessment_framework_detailは1種類ずつパラメータを推定して他を固定する方法を使っているが、パッケージとしての実行の手順は同じ。
引数を指定
maps: 3次元numpy.ndarray。パラメータ推定する人流データを表現するヒートマップ(各時刻においてGridの中にいる人数を表す)。
people_num, target, R, min_p, wall_x, wall_y, in_target_d, dt, save_params: 人流シミュレーションに使う変数。人流シミュレーション参照v_range: (2,2)の形であるリスト型の変数。人の速さの平均と標準偏差を推定するとき、それぞれがとりうる値の範囲を表す。
repul_h_range: (2,2)の形であるリスト型の変数。人の間の反発力に関する2つのパラメータを推定するとき、それぞれがとりうる値の範囲を表す。
(詳細:人流シミュレーションのパラメータ推定手法 3.人流シミュレーションモデル 3.1 Social Force Model)repul_m_range: (2,2)の形であるリスト型の変数。人と壁の間の反発力に関する2つのパラメータを推定するとき、それぞれがとりうる値の範囲を表す。
(詳細:人流シミュレーションのパラメータ推定手法 3.人流シミュレーションモデル 3.1 Social Force Model)p_range: (2,2)の形であるリスト型の変数。次の目的地に移動する確率の平均と標準偏差を推定するとき、それぞれがとりうる値の範囲を表す。
なお、パラメータ推定では、次の目的地に移動する確率はどの目的地においても等しいものとして計算する。n_trials: 推定したパラメータを最適化する回数
people_num = 30 v_arg = [6,2] repul_h = [5,5] repul_m = [2,2] target = [[60,240],[120,150],[90,60],[240,40],[200,120],[170,70],[150,0]] R = 3 min_p = 0.1 p_arg = [[0.5,0.1]] wall_x = 300 wall_y = 300 in_target_d = 3 dt = 0.1 save_params = [(30,30),1] v_range = [[3,8],[0.5,3]] repul_h_range = [[2,8],[2,8]] repul_m_range = [[2,8],[2,8]] p_range = [[0.1,1],[0.01,0.5]] n_trials = 10評価するインスタンスを生成
assessment = people_flow.assessment_framework.assess_framework(maps, people_num, v_arg, repul_h, repul_m, target, R, min_p, p_arg, wall_x, wall_y, in_target_d, dt, save_params, v_range, repul_h_range, repul_m_range, p_range, n_trials)すべての目的関数を用いてパラメータ推定を実行
assessment.whole_opt()最高の目的関数の組み合わせを求める
best_combination = assessment.assess()パラメータ推定結果を正解と比較してグラフ化
assessment.assess_paint()
パラメータ推定
パラメータ推定を行う。
inference_frameworkとinference_framework_detailがありinference_framework_detailは1種類ずつパラメータを推定して他を固定する方法を使っている。パッケージとしての実行の手順は引数の指定以外同じ。
inference_framework_detailを使う場合、inference_frameworkでパラメータを推定した後、そのパラメータを用いてさらに一つずつパラメータ最適化をinference_framework_detailで行う。
引数を指定
人流シミュレーション、パラメータ推定における目的関数の評価を参照# inference_frameworkの場合 # in case of inference_framework people_num = 30 target = [[60,240],[120,150],[90,60],[240,40],[200,120],[170,70],[150,0]] R = 3 min_p = 0.1 wall_x = 300 wall_y = 300 in_target_d = 3 dt = 0.1 save_params = [(30,30),1] v_range = [[3,8],[0.5,3]] repul_h_range = [[2,8],[2,8]] repul_m_range = [[2,8],[2,8]] p_range = [[0.1,1],[0.01,0.5]] n_trials = 10# inference_framework_detailの場合 # in case of inference_framework_detail people_num = 30 v_arg = [6,2] repul_h = [5,5] repul_m = [2,2] target = [[60,240],[120,150],[90,60],[240,40],[200,120],[170,70],[150,0]] R = 3 min_p = 0.1 p_arg = [[0.5,0.1]] wall_x = 300 wall_y = 300 in_target_d = 3 dt = 0.1 save_params = [(30,30),1] v_range = [[3,8],[0.5,3]] repul_h_range = [[2,8],[2,8]] repul_m_range = [[2,8],[2,8]] p_range = [[0.1,1],[0.01,0.5]] n_trials = 10推定するインスタンスを生成
# inference_frameworkの場合 # in case of inference_framework inference = people_flow.inference_framework.inference_franework(maps, people_num, target, R, min_p, wall_x, wall_y, in_target_d, dt, save_params, v_range, repul_h_range, repul_m_range, p_range, n_trials)# inference_framework_detailの場合 # in case of inference_framework_detail inference_detail = people_flow.inference_framework.inference_franework_detail(maps, people_num, v_arg, repul_h, repul_m, target, R, min_p, p_arg, wall_x, wall_y, in_target_d, dt, save_params, v_range, repul_h_range, repul_m_range, p_range, n_trials)パラメータ推定を実行(推定したパラメータを得る)
# inference_frameworkの場合 # in case of inference_framework inferred_params = inference.whole_opt()# inference_framework_detailの場合 # in case of inference_framework_detail inferred_params_detail = inference_detail.whole_opt()おわりに
NTTソフトウェアイノベーションセンタによる論文「人流シミュレーションのパラメータ
推定手法」のPythonによる実装の概要とgithubに載せた実装コードのパッケージとしての利用法を説明しました。
不明な点、実装コードに関するアドバイス、パッケージとして利用する際の問題などありましたらコメントお願いします。

- 投稿日:2021-01-16T18:25:56+09:00
【Dockerfile】tzdataの設定について
目的
Docker上のubuntuにjupyterlabをインストールするため、docker imageを作成しようとした。
詰まった問題
Dockerfileからdocker imageを作成するため、下記のファイル(dockerfile)をコマンドで実行しようとする…
dockerfileFROM ubuntu RUN apt-get update RUN apt-get install -y sudo RUN sudo apt install -y python3-pip RUN sudo apt install -y language-pack-ja RUN sudo update-locale LANG=ja_JP.UTF-8 RUN sudo apt install -y nodejs npm RUN pip3 install jupyterlab RUN pip3 install pandas RUN pip3 install matplotlib RUN pip3 install sklearnコマンドは以下の通り。
docker build -t jupyterlab:latest ./しかし、実行途中に以下のように表示されてしまう
Please select the geographic area in which you live. Subsequent configuration questions will narrow this down by presenting a list of cities, representing the time zones in which they are located. 1. Africa 4. Australia 7. Atlantic 10. Pacific 13. Etc 2. America 5. Arctic 8. Europe 11. SystemV 3. Antarctica 6. Asia 9. Indian 12. US Geographic area:このとき、6と入力しEnterを押すも反応せず…
どうやらタイムゾーンを選択すると解決するようだ。解決法
上記のdockerfileにタイムゾーンを設定する文を追加することにより解決した。(追加した文)
FROM ubuntu RUN apt-get update RUN apt-get install -y sudo RUN sudo apt install -y python3-pip RUN sudo apt install -y language-pack-ja RUN sudo update-locale LANG=ja_JP.UTF-8 #追加した文↓ ARG DEBIAN_FRONTEND=noninteractive ENV TZ=Europe/Moscow RUN apt-get install -y tzdata RUN sudo apt install -y nodejs npm RUN pip3 install jupyterlab RUN pip3 install pandas RUN pip3 install matplotlib RUN pip3 install sklearn
- 投稿日:2021-01-16T17:48:41+09:00
プロご用達 Pythonコードの質を保つために入れておきたいパッケージ4選
プロご用達 Pythonコードの質を保つために入れておきたいパッケージ4選
flake8 ... コードチェック
black ... コード自動整形
isort ... インポートをソート
mypy ... 静的型チェック全部 pip で入る。
コミットタイミングでJenkinsなどでチェックするのが良い。
レビューのコストが下がり、コードの品質が保たれるのでやったほうがいいflake
以下のような気持ち悪いコード、見ると吐き気がしますね。。。
from flask import Blueprint sample = Blueprint("sample1", __name__) @sample.route("/") def index(): print( "sample.index" ) return "sample.index"flakeコマンドを実行すると修正すべき箇所が表示される。
$ flake8 ./app/views/sample.py ./app/views/sample.py:5:1: E302 expected 2 blank lines, found 1 ./app/views/sample.py:8:1: W293 blank line contains whitespaceblack
flakeはコードチェックだけで修正まではしてくれません
blackはコード自動整形を行いflakeの修正箇所を修正$ black ./app/views/sample.py reformatted app/views/sample.py All done! ✨ ? ✨ 1 file reformatted.修正後のコードいい感じに
from flask import Blueprint sample = Blueprint("sample1", __name__) @sample.route("/") def index(): print("sample.index") return "sample.index"isort
公式サイトより、このようなコード殺意覚えますね。。。
from my_lib import Object print("Hey") import os from my_lib import Object3 from my_lib import Object2 import sys from third_party import lib15, lib1, lib2, lib3, lib4, lib5, lib6, lib7, lib8, lib9, lib10, lib11, lib12, lib13, lib14 import sys from __future__ import absolute_import from third_party import lib3 print("yo")isort コマンド実行
$ isort ./app/views/sample2.py Fixing /Users/takashimorita/Sites/weekend-hackathon/app/views/sample2.pyこのように綺麗にまとめてくれる。
from my_lib import Object print("Hey") from __future__ import absolute_import import os import sys from my_lib import Object2, Object3 from third_party import (lib1, lib2, lib3, lib4, lib5, lib6, lib7, lib8, lib9, lib10, lib11, lib12, lib13, lib14, lib15) print("yo")mypy
mypyはそのままだと警告が出るので、許容すべきオプションを付けて実行すると良い。
下のオプションは一例--ignore-missing-imports ... import先のチェックはしない
--no-warn-no-return ... returnが無くても警告しない
--disallow-untyped-calls ... アノテーションされていない関数呼出しを禁止する。
--disallow-untyped-defs ... アノテーションされていない関数を禁止する。
--strict-optional ... None に関する型チェックdef main(num): return num + 1 if __name__ == "__main__": main(123)このサンプルに対してmypyを実行すると
main関数の返り値とmain関数の引数にアノテーションがないので警告される$ mypy -i --ignore-missing-imports --no-warn-no-return --disallow-untyped-calls --disallow-untyped-defs --strict-optional ./app/views/sample3.py app/views/sample3.py:1: error: Function is missing a type annotation app/views/sample3.py:6: error: Call to untyped function "main" in typed context Found 2 errors in 1 file (checked 1 source file)アノテーションを設定する
def main(num: int) -> int: return num + 1 if __name__ == "__main__": main(123)再度、mypyを実行すると成功する
$ mypy -i --ignore-missing-imports --no-warn-no-return --disallow-untyped-calls --disallow-untyped-defs --strict-optional ./app/views/sample3.py Success: no issues found in 1 source file
- 投稿日:2021-01-16T17:47:57+09:00
Pythonで学ぶアルゴリズム 第19弾:並べ替え(ヒープソート)
#Pythonで学ぶアルゴリズム< ヒープソート >
はじめに
基本的なアルゴリズムをPythonで実装し,アルゴリズムの理解を深める.
その第19弾としてヒープソートを扱う.ヒープソート
前回扱ったスタックとキューに対して,ヒープソートはヒープと呼ばれる木構造によりデータを扱う.
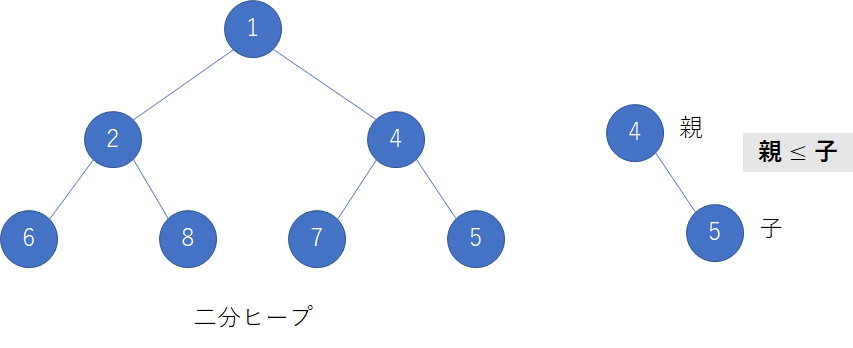
ヒープは子ノード間での制約はないが親ノードと子ノードでの大小関係の制約がある.場合により,
(親$\le$子),(親$\ge$子)のようになる.今回は小さいものからデータを扱うために制約は(親$\le$子)とする.そのイメージ図を次に示す.
1親ノードに対して2子ノードの構造をもつヒープを特に二分ヒープという.
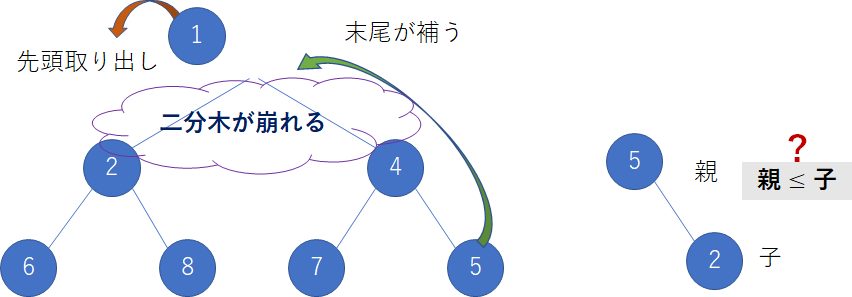
これを今まで扱ってきたようにリストのデータをこのヒープ構造に落としこむ.このときヒープ構造に落としこむということは木の上から順に小さな値となっていることが分かる.すなわち,一番上の親ノードを取り出すと,そのときの最小値が得られる.その様子を次に示す.
図にあるように,二分木が崩れてしまう.そのときには一時的に末尾が一番上に移動し,二分木構造を補う.しかしながら,必然的に親ノードと子ノードの制約条件を満たさないことが多くなる.ヒープソートでは常にヒープ構造を保とうと,再び制約条件に従いヒープ構造を整える.その様子を次に示す.
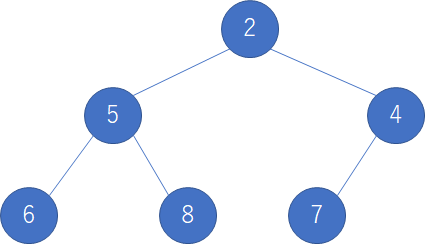
このヒープ構造修正後も次に示す.
上図より,再びヒープが構成され,そのときの最小値が一番上の親ノードにあることが分かる.
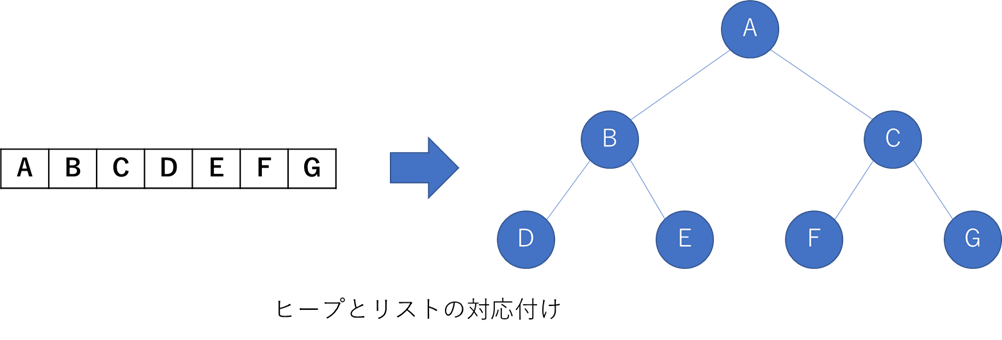
この操作を繰り返すことで,昇順に並べ替える.ここで,リストとヒープの対応付けを次に示す.
実装
Pythonの標準ライブラリを用いたコードとそのときの出力を以下に示す.
コード
heap_sort.py""" 2021/01/16 @Yuya Shimizu ヒープソート """ import heapq #ヒープを扱うPython標準ライブラリ def heap_sort(data): DATA_FOR_HEAP = data.copy() #ヒープを作るためのデータを格納 heapq.heapify(DATA_FOR_HEAP) #ヒープ生成(最小順に並んだ木構造) return [heapq.heappop(DATA_FOR_HEAP) for _ in range(len(data))] #heappop関数で順に取り出す if __name__ == '__main__': DATA = [6, 15, 4, 2, 8, 5, 11, 9, 7, 13] sorted_data = heap_sort(DATA) print(f"{DATA} → {sorted_data}")出力
[6, 15, 4, 2, 8, 5, 11, 9, 7, 13] → [2, 4, 5, 6, 7, 8, 9, 11, 13, 15]計算量
スタックとキューではオーダー記法で表すと計算量は$O(n^2)$であったが,ヒープソートではその計算量が$O(log(n))$となる.$n$の数(データ数)が大きくなった時でもそこまで計算量が大きくならないことが分かる.
感想
標準ライブラリを用いず,再帰などを駆使してアルゴリズムを記述方法も紹介されていたが,ここでは省く.アルゴリズムについては理解できたし,Pythonに標準ライブラリがあるならそれを使えばよいのではないかと思う.アルゴリズム自体は理解しているため,必要となれば,そのときに改めてアルゴリズムに立ち返ればよいと考える.残りはマージソートとクイックソートの2つで並べ替えアルゴリズムの終わりが見えてきた.次回も楽しみである.
参考文献
Pythonで始めるアルゴリズム入門 伝統的なアルゴリズムで学ぶ定石と計算量
増井 敏克 著 翔泳社

- 投稿日:2021-01-16T17:36:36+09:00
AWS Amplify + API Gateway + Lambda + Pythonで正常なレスポンスを返す
AWS AmplifyでLambda+API Gatewayを構成しているときに、テスト実行をしてみても正常なレスポンスが得られずに少し困ることがあっりあました。なので、AmplifyでのAPIの追加の仕方と合わせて、備忘録と学習を兼ねて書きます。
結論
結論からいうと、API GatewayからLambda関数を呼び出すときは、以下のようなレスポンスを返すようにする必要があるようです。
return { "isBase64Encoded": true|false, "statusCode": httpStatusCode, "headers": { "headerName": "headerValue", ... }, "multiValueHeaders": { "headerName": ["headerValue", "headerValue2", ...], ... }, "body": "..." }
headersやnultiValueHeadersは特別必要ではなく、最低限statusCodeとbodyを返してあげればいいようです
。手順
環境
- WIndows10 バージョン20H2
- WSL2(Ubuntu-20.04)
- amplify CLI 4.41.0
AmplifyでLambda関数を追加する
Amplfyでプロジェクトが作成されているところから始めます。
Lambda関数を追加します。
$ amplify add function ? Select which capability you want to add: Lambda function (serverless function) ? Provide an AWS Lambda function name: myfunc ? Choose the runtime that you want to use: Python Only one template found - using Hello World by default. Available advanced settings: - Resource access permissions - Scheduled recurring invocation - Lambda layers configuration ? Do you want to configure advanced settings? No ? Do you want to edit the local lambda function now? YesDo you want to edit the local lambda function now?をYesで応えると、テキストエディタが開き、以下のような初期コードが表示されます。
def handler(event, context): print('received event:') print(event) return { 'message': 'Hello from your new Amplify Python lambda!' }通常、Lambdaをpythonで書くと、ハンドラ名が
lambda_handlerとなっていますが、Amplifyで作る場合は、handlerだけのようです。Lambdaで指定されているハンドラ名も合わせて変更されているので、特に修正する必要はありません。正常なレスポンスとなるように変更
このままだと、API Gatewayが期待するレスポンスになっていないので、コードを以下のように修正します。
def handler(event, context): print('received event:') print(event) return { 'isBase64Encoded': False, 'statusCode': 200, 'headers': {}, 'body': '{"message": "Hello from your new Amplify Python lambda!"}' }ターミナルでEnterキーを入力すると、AmplifyプロジェクトにLambda関数が追加されます。
? Press enter to continue Successfully added resource myfunc locally. Next steps: Check out sample function code generated in <project-dir>/amplify/backend/function/myfunc/src "amplify function build" builds all of your functions currently in the project "amplify mock function <functionName>" runs your function locally "amplify push" builds all of your local backend resources and provisions them in the cloud "amplify publish" builds all of your local backend and front-end resources (if you added hosting category) and provisions them in the cloudAPIの追加
AmplifyプロジェクトにAPIを追加します。
$ amplify add api ? Please select from one of the below mentioned services: REST ? Provide a friendly name for your resource to be used as a label for this category in the project: myapi ? Provide a path (e.g., /book/{isbn}): /items ? Choose a Lambda source Use a Lambda function already added in the current Amplify project ? Choose the Lambda function to invoke by this path myfunc ? Restrict API access No ? Do you want to add another path? No Successfully added resource myapi locally Some next steps: "amplify push" will build all your local backend resources and provision it in the cloud "amplify publish" will build all your local backend and frontend resources (if you have hosting category added) and provision it in the cloudAmplifyプロジェクトの展開
このままではローカルに追加されただけなので、AmplifyプロジェクトをAWSアカウント上に展開します。
プロジェクトをAWS上に展開するには、
amplify pushというコマンドを使います。
このコマンドを実行すると、以下のようにクラウド上にリソースがプロビジョニングされます。!
APIのテスト実行
デフォルトではANYとしてメソッドが登録されているので、ANYを選びます。
クライアントのテストを選ぶと、メソッドやクエリ文字列を入力できる画面が表示されます。
今回はGETでテストを実行します。
期待通りのレスポンスが返ってきました。これが、ステータスコード等が不足した正しくない形式でLambda関数のレスポンスを返すと、以下のようになります。
まとめ
Lambda + API Gatewayを使うときは、レスポンスを正しい形式にする必要があります。
また、Amplifyは簡単にAPIを実装することができて、とても楽しいです。




- 投稿日:2021-01-16T17:26:37+09:00
Synology DSMのタスクスケジューラーでpython実行時に起こるインポートエラーの回避方法
起こったエラー
Synology の DS118 内にあるPythonのスクリプトを、DSM のタスクスケジューラーから実行しようとしたところ、モジュールのインポートエラーが起きました。
DSMから届いたメールに記載されたエラーTraceback (most recent call last): File "hoge.py", line 1, in <module> import tweepy ModuleNotFoundError: No module named 'tweepy'おかしいぞ?
SSH接続ではできるのに。。しかもこれ、以前
requestsでも同様のエラーに遭ってしまいましたが、その時はそれほどタスクスケジューラーでやる必要性がなかったことから、放置していました。
ですが今回はタスクスケジューラーでやる必要があったので、本腰を入れて対処してみることに。分からないなりに調べると、パスが通ってない感じに思え。
おそらく、SSHで実行するのとタスクスケジューラーで実行するのと、微妙に異なるのでしょう。というわけで、以下の通り対処してみました。
なお、pythonはパッケージセンターからインストールしてあってバージョンは
3.8.2、SDKのバージョンはDSM 6.2.3-25426 Update 3です。パスの確認
SSH接続とタスクスケジューラーの各々から、以下のコードを実行してパスのリストに差があるか確認します。
check_module_path.pyimport sys path_list = sys.path with open('/your_storage/your_directory/check_module_path.txt', 'w', encoding='utf-8') as f: for path in path_list: f.write(path + '\n')SSH接続から実行した場合
SSH接続から実行した場合のパス/my_storage/my_directory /var/packages/py3k/target/usr/local/lib/python38.zip /var/packages/py3k/target/usr/local/lib/python3.8 /var/packages/py3k/target/usr/local/lib/python3.8/lib-dynload /var/services/homes/synology_user_name/.local/lib/python3.8/site-packages /var/packages/py3k/target/usr/local/lib/python3.8/site-packages /usr/lib/python3/site-packagesタスクスケジューラーから実行した場合
タスクスケジューラーから実行した場合のパス/my_storage/my_directory /var/packages/py3k/target/usr/local/lib/python38.zip /var/packages/py3k/target/usr/local/lib/python3.8 /var/packages/py3k/target/usr/local/lib/python3.8/lib-dynload /var/packages/py3k/target/usr/local/lib/python3.8/site-packages /usr/lib/python3/site-packagesう~~ん、、
/var/services/homes/synology_user_name/.local/lib/python3.8/site-packagesが、SSH接続にはあってタスクスケジューラーにはないですね。
ここにtweepyやrequestsのモジュールがいそうですので、SSH接続からこのディレクトリ内をls -lで確認してみます。ls -l /var/services/homes/synology_user_name/.local/lib/python3.8/site-packages # 略(多数) # drwxrwxrwx+ 3 synology_user_name users 4096 Jan 14 05:57 tweepy # 略(多数)
tweepyありました!
もちろん、requestsもありました!対処方法
対処方法は、二つあります。
一つ目は、スクリプト内に2行ほどコードを加える方法で、こちらの方が簡単。
もちろん私は、迷ったら簡単な方を選ぶ怠惰なやつです。。二つ目は、タスクスケジューラーからデフォルトのパスを通す方法。
おそらくこちらで対処すべきなんでしょうけど、私のレベルではやり方が分からず。。
でも、とりあえず書くだけ書いておきます。スクリプト内で対処する方法
以下のコードを、モジュールのimport文の前に記述します。
モジュールのimport文の前に記述!import sys sys.path.append('/var/services/homes/synology_user_name/.local/lib/python3.8/site-packages')これだけで、エラー回避ができます!
分かると簡単なのですが、分かるまでが大変ですよね、こいういうのって。タスクスケジューラーからデフォルトのパスを通す方法
パスを通すには、
~/.bashrcからvi等のエディタで以下を追記すればいいのかもなのですが、これをタスクスケジューラー上でやるのってどうすればいいのか分からず。。export PATH=$PATH:"/var/services/homes/synology_user_name/.local/lib/python3.8/site-packages"タスクスケジューラーのスクリプトの中で、
viってできるんですかね??
ご存じの方いらっしゃいましたら、ご教示いただけますとありがたいですm(_ _)m参考
Pythonでimportの対象ディレクトリのパスを確認・追加(sys.pathなど) | note.nkmk.me
【Python環境構築】環境変数について解説! | WEBCAMP NAVI
pythonのパッケージの保存場所 - Qiita
Python内のデフォルトパスを通す方法(Windows, Linux) - Qiita
- 投稿日:2021-01-16T16:51:19+09:00
マストドンBot作成時のメモ:その3 リプライ編
あらすじ
さくらVPNとかTeraTermとかcrontabとかを駆使して
マストドンBotの通常ツイートができるようになった。今回はリプライをできるようにします。→前の記事
参考にしたサイトさん(今さらだけどサイトさんって…Qiitaとかってサイトって言うのかな? 死語?)
Pythonで自動で返信する機能付きのMastodon botをつくる参考サイトさんのを簡単な感じに改変
reply.py# -- coding: utf-8 -- from mastodon import Mastodon, StreamListener import requests class Stream(StreamListener): def __init__(self): #継承 super(Stream, self).__init__() # self.logger = logging.getLogger def on_notification(self,notif): #通知が来た時に呼び出されます if notif['type'] == "mention": #通知の内容がリプライかチェック content = notif['status']['content'] #リプライの本体です id = notif['status']['account']['username'] st = notif['status'] print("【リプライ】" + st) #確認用 main(content, st, id) def main(content,st,id): resr = "うんうんっ、テストのリプライをぼくに頼むなんて、きみってぼくのことが大好きなんだね? 良い日和っ♪" mastodon.status_reply(st, resr, id, visibility='private') #非公開! # 「未収載」 -> 'unlisted' # 「公開」 -> 'public' # 「非公開」 -> 'private' # 「ダイレクト」 -> 'direct' mastodon = Mastodon( client_id = "client.secret", access_token = "user.secret", api_base_url = "https://uuuchu.com") #インスタンス url = "" #APIのURLです notif = mastodon.notifications() #通知を取得 count = 0 while True: if notif[count]['type'] == 'mention': if notif[count]['status']['replies_count'] == 0: #リプライが既にされてないのかの確認 content = notif[count]['status']['content'] id = notif[count]['status']['account']['username'] st = notif[count]['status'] main(content, st, id) count += 1 else: break else: count += 1 count += 1 mastodon.stream_user(Stream()) #ストリームの起動頭が悪いので、あんまり呟き部分がよく分からず最低限(多分)まで減らしましたが、
一応呟けました。
url という変数、何を入れるのかよくわからないので空欄にしたんですけど…
普通に動きました。ただ……
Traceback (most recent call last): File "reply.py", line 42, in <module> if notif[count]['type'] == 'mention': IndexError: list index out of range↑というエラーが出るんですよね
見てみたら、mentionの前にfollowの通知があるのを拾っていて
それがいつまでも反応するみたいなので
最初のmentionかどうかっていうIfの前に
tryとか入れれば何とかなるのかなと思いますが、
ひとさまのコードについてとやかく考えるのは面倒くさいし
きちんと呟けることは呟けるし、この場では後回しにしますPythonやるひとにとっては当然なのかな、
私はいつもインデントをタブでやる派だったけど、
なんか半角スペース4つが無難みたく見たので
最近気をつけてたんですが、癖でタブにしてしまった(混ざった)ら、
Pythonさんそんなことでエラー出してくるんですね… こわいreply.py内でランダム返信させる
次は、bot.pyと似たようなことをしてみましょうか~~
Edenの四人にランダムでお返事していただきます。reply.py# -- coding: utf-8 -- from mastodon import Mastodon, StreamListener import requests import random class Stream(StreamListener): def __init__(self): #継承 super(Stream, self).__init__() # self.logger = logging.getLogger def on_notification(self,notif): #通知が来た時に呼び出されます if notif['type'] == "mention": #通知の内容がリプライかチェック content = notif['status']['content'] #リプライの本体です id = notif['status']['account']['username'] st = notif['status'] main(content, st, id) def main(content,st,id): resr = [ '凪砂:…………うん? ごめん、本を読んでて聞いてなかった', '日和:うんうんっ、このぼくに来てもらえるなんてきみはとっても果報者だね!', '茨:アイ・アイ! 自分を呼びましたか? 本日の夜ごはんでしたら八宝菜であります!', 'ジュン:うぃ~っす、パシリですか? まぁ今は暇なんで良いですけどねぇ~' ] tootContent = random.choice(resr) #配列の内容をランダムで変数に入れる print("【リプライ】" + tootContent) #確認用 mastodon.status_reply(st, tootContent, id, visibility='private') #公開範囲 # 「未収載」 -> 'unlisted' # 「公開」 -> 'public' # 「非公開」 -> 'private' # 「ダイレクト」 -> 'direct' mastodon = Mastodon( client_id = "client.secret", access_token = "user.secret", api_base_url = "https://uuuchu.com") #インスタンス url = "" #APIのURLです notif = mastodon.notifications() #通知を取得 count = 0 while True: if notif[count]['type'] == 'mention': if notif[count]['status']['replies_count'] == 0: #リプライが既にされてないのかの確認 content = notif[count]['status']['content'] id = notif[count]['status']['account']['username'] st = notif[count]['status'] main(content, st, id) count += 1 else: break else: count += 1 count += 1 mastodon.stream_user(Stream()) #ストリームの起動まぁそのまんまですね。
Randomのインポートを忘れないようにするぐらい?リプライ内容を外部ファイルにする
私は「Edenの四人の名前をつけてリプライするとその相手が返事をする」
という機能を後からつけるので、という理由が大きいですが、
それにしてもリプライ内容が多くなるとこのreply.pyのみだと
ちょっと扱いにくいかなと思いますので、リプのトゥートを外部ファイルに…します!とりあえず普通は一人(?)分でしょうから、今回は凪砂ちゃんのみ。
reply_nagisa.txt凪砂:……おはよう、{name}さん。よく眠れたかな。…コーヒーとか飲む? せっかくだから私が淹れてみようかな 凪砂:……あぁ、もうそんな時間か。おはよう{name}さん。起きるのを待ってた 凪砂:……ん、もうそんな時間なんだね。私もそろそろ寝ようかな。おやすみ、{name}さん 凪砂:……おやすみなさい、{name}さん。明日もまた顔を見れると嬉しいTwitterのbotのをそのまま持ってきただけですが、とりあえずこれで試します。
({name}部分はEasyBotterさんを利用していた名残、次に変換できるようにする)reply.py# -- coding: utf-8 -- from mastodon import Mastodon, StreamListener import requests import random class Stream(StreamListener): def __init__(self): #継承 super(Stream, self).__init__() # self.logger = logging.getLogger def on_notification(self,notif): #通知が来た時に呼び出されます if notif['type'] == "mention": #通知の内容がリプライかチェック content = notif['status']['content'] #リプライの本体です id = notif['status']['account']['username'] st = notif['status'] main(content, st, id) def main(content,st,id): # 呟きファイルの指定 path = 'reply_nagisa.txt' # ファイルを読み込んで呟く with open(path, 'r') as f: l = f.readlines() # 最初に「//」がある行は飛ばして再度Tootを選ぶののループ while True: tootContent = random.choice(l) if (content[0:2] != '//'): break else: print('※コメント行なので飛ばします') # 確認用 print("【リプライ】" + tootContent) #確認用 mastodon.status_reply(st, tootContent, id, visibility='private') #公開範囲 # 「未収載」 -> 'unlisted' # 「公開」 -> 'public' # 「非公開」 -> 'private' # 「ダイレクト」 -> 'direct' mastodon = Mastodon( client_id = "client.secret", access_token = "user.secret", api_base_url = "https://uuuchu.com") #インスタンス url = "" #APIのURLです notif = mastodon.notifications() #通知を取得 count = 0 while True: if notif[count]['type'] == 'mention': if notif[count]['status']['replies_count'] == 0: #リプライが既にされてないのかの確認 content = notif[count]['status']['content'] id = notif[count]['status']['account']['username'] st = notif[count]['status'] main(content, st, id) count += 1 else: break else: count += 1 count += 1 mastodon.stream_user(Stream()) #ストリームの起動{name}を名前に変換できるようにする!
reply.py# -- coding: utf-8 -- from mastodon import Mastodon, StreamListener import requests import random import re class Stream(StreamListener): def __init__(self): #継承 super(Stream, self).__init__() # self.logger = logging.getLogger def on_notification(self,notif): #通知が来た時に呼び出されます if notif['type'] == "mention": #通知の内容がリプライかチェック content = notif['status']['content'] #リプライの本体です id = notif['status']['account']['username'] st = notif['status'] disname = notif[count]['status']['account']['display_name'] main(content, st, id, disname) def main(content,st,id,disname): # 呟きファイルの指定 path = 'reply_nagisa.txt' # ファイルを読み込んで呟く with open(path, 'r') as f: l = f.readlines() while True: tootContent = random.choice(l) # 最初に「//」がある行は飛ばして再度Tootを選ぶ if (tootContent[0:2] != '//'): break else: print('※コメント行なので飛ばします') # 確認用 # {name}をおなまえに変換する nameChange = re.sub("\{name\}",disname,tootContent) print("【リプライ】" + nameChange) #確認用 mastodon.status_reply(st, nameChange, id, visibility='private') #公開範囲 # 「未収載」 -> 'unlisted' # 「公開」 -> 'public' # 「非公開」 -> 'private' # 「ダイレクト」-> 'direct' mastodon = Mastodon( client_id = "client.secret", access_token = "user.secret", api_base_url = "https://uuuchu.com") #インスタンス notif = mastodon.notifications() #通知を取得 count = 0 while True: if notif[count]['type'] == 'mention': if notif[count]['status']['replies_count'] == 0: #リプライが既にされてないのかの確認 content = notif[count]['status']['content'] id = notif[count]['status']['account']['username'] st = notif[count]['status'] disname = notif[count]['status']['account']['display_name'] main(content, st, id, disname) count += 1 else: break else: count += 1 count += 1 mastodon.stream_user(Stream()) #ストリームの起動大きく変えたことは、re をインポートして、disnameという変数・引数をつくったことです。
urlという変数も、消してなんともないみたいなので削除しました。同じTootに返信しないようにする
この参考コードさんはそういうのを想定してないみたいですね。
何回も同じTootへ返信させるのをやめさせます。なんかよく分からないんですけど(……)
['replies_count']っていうのはそのTootについている
リプライの総数なんじゃないだろうかと思いまして、
このアカウントからリプライをしたかどうかの判断にはならないんじゃないかな?と
消しました。何か違ったら教えてください…。とりあえず新しいコード
reply.py# -- coding: utf-8 -- from mastodon import Mastodon, StreamListener import requests import random import re class Stream(StreamListener): def __init__(self): #継承 super(Stream, self).__init__() # self.logger = logging.getLogger def on_notification(self,notif): #通知が来た時に呼び出されます if notif['type'] == "mention": #通知の内容がリプライかチェック content = notif['status']['content'] #リプライの本体です id = notif['status']['account']['username'] st = notif['status'] disname = notif['status']['account']['display_name'] main(content, st, id,disname) def main(content,st,id,disname): # 呟きファイルの指定 path = 'reply_nagisa.txt' # ファイルを読み込んで呟く with open(path, 'r') as f: l = f.readlines() while True: tootContent = random.choice(l) # 最初に「//」がある行は飛ばして再度Tootを選ぶ if (tootContent[0:2] != '//'): break else: print('※コメント行なので飛ばします') # 確認用 # {name}をおなまえに変換する nameChange = re.sub("\{name\}",disname,tootContent) print("【リプライ】" + nameChange) #確認用 mastodon.status_reply(st, nameChange, id, visibility='private') #公開範囲 # 「未収載」 -> 'unlisted' # 「公開」 -> 'public' # 「非公開」 -> 'private' # 「ダイレクト」-> 'direct' mastodon = Mastodon( client_id = "client.secret", access_token = "user.secret", api_base_url = "https://uuuchu.com") #インスタンス notif = mastodon.notifications() #通知を取得 count = len(notif) - 1 while True: # 逆(古い方)からTootを数える(0/最後まできたらbreak) if count >= 0: print("【" + str(count) + "】" + notif[count]['type']) #確認用 if notif[count]['type'] == 'mention': # Toot形成... と思われる content = notif[count]['status']['content'] id = notif[count]['status']['account']['username'] st = notif[count]['status'] disname = notif[count]['status']['account']['display_name'] idStr = str(notif[count]['status']['id']) # Toot main(content, st, id, disname) else: # 最後まで通知を拾い終わったらNotificationsをClear print("■ 通知をクリアします") #確認用 mastodon.notifications_clear() break count -= 1 #mastodon.stream_user(Stream()) #ストリームの起動はちゃめちゃに苦戦したよ!!
Whileの中をほぼまるっきり変えてしまいました
というかreplyLog.txtみたいなやつに
最後リプライしたステータスのIDとか記録してたんですが、
Mastodonさん、そんなことしなくても通知の記録を消したりできるんですね…変えたことと分かったこと
- countは通知の数から始めて、0になるまでwhileする(それはnotifications_clearに気付いてなかったときの名残なので、今はたぶん普通に0から++でいいはず)
- そのあとは「mention」の通知について、未返信のTootへ返信して、通知がなくなったらおしまいみたいなことをしてる
- whileから出るとき(全てに返信し終えたとき)mastodon.notifications_clear()で通知を全て消す(きちんと消していかないと前に返したTootも一生拾いつづけて、まぁ今回私が作るようなbotだと通知も大した量にならないはずですが、残したまんまだと良くないと思うので消していきましょう)
- 最後の行、ストリームの起動はしなくてもいいみたい…(cronで動かさない場合は要るのかな?)
以上!
特定単語に反応するようにする!
むっちゃ苦戦した?
とりあえず、↓のような反応語句のテキストファイルはこんなふうにしときます。
(反応語句)::(反応語句に対するリプライ)という内容です。reply_nagisa.txtおはよう::凪砂:……おはよう、{name}さん。1 おはよう::凪砂:……おはよう、{name}さん。2 おはよう::凪砂:……おはよう、{name}さん。3 おやすみ::凪砂:……おやすみ、{name}さん。1 おやすみ::凪砂:……おやすみ、{name}さん。2 おやすみ::凪砂:凪砂:……おやすみ、{name}さん。3 //おやすみ::凪砂:……おやすみ、{name}さん。4 //おやすみ::凪砂:……おやすみ、{name}さん。5 . . . //おやすみ::凪砂:……おやすみ、{name}さん。18 //おやすみ::凪砂:……おやすみ、{name}さん。19適当! ちなみに分かりにくいんですが「::」は半角で「凪砂:」は全角です。
きちんとコメント行を飛ばせるか確認するためにコメント行を多めに入れてます。
以下がreply.pyの新しいコードですreply.py# -- coding: utf-8 -- from mastodon import Mastodon, StreamListener import requests import random import re class Stream(StreamListener): def __init__(self): #継承 super(Stream, self).__init__() # self.logger = logging.getLogger def main(content,st,id,disname): # 呟きファイルの指定 path = 'reply_nagisa.txt' # ファイルを読み込んで呟く with open(path, 'r') as f: l = f.readlines() count = len(l) - 1; selectedList = [] edenToot = '' # 反応語句を含む行を抽出 while count >= 0: tmpList = l[count].split('::') if tmpList[0] in st['content']: selectedList.append(tmpList) count -= 1 # 抽出したリストからランダムに一つ選ぶ if len(selectedList) != 0: count = len(selectedList) - 1; while True: replyNo = random.randint(0,count) # 「//」を含む行は飛ばして再度Tootを選ぶ if re.search('\/\/', selectedList[replyNo][0]): # なぜかFalseにできない… print('※ コメント行なのでもう一度') else: edenToot = selectedList[replyNo][1] break # {name}をおなまえに変換する nameChanged = re.sub("\{name\}",disname,edenToot) # ↓何もトゥートがなかったときの処理、そのうち変える if nameChanged == '': nameChanged = '凪砂:……ごめん、今何か言った?' print("【リプライ】" + nameChanged) #確認用 mastodon.status_reply(st, nameChanged, id, visibility='private') #公開範囲 # 「未収載」 -> 'unlisted' # 「公開」 -> 'public' # 「非公開」 -> 'private' # 「ダイレクト」-> 'direct' mastodon = Mastodon( client_id = "client.secret", access_token = "user.secret", api_base_url = "https://uuuchu.com") #インスタンス notif = mastodon.notifications() #通知を取得 count = len(notif) - 1 while True: # 逆(古い方)からTootを数える(0/最後まできたらbreak) if count >= 0: if notif[count]['type'] == 'mention': # Toot形成... と思われる content = notif[count]['status']['content'] id = notif[count]['status']['account']['username'] st = notif[count]['status'] disname = notif[count]['status']['account']['display_name'] idStr = str(notif[count]['status']['id']) # Toot main(content, st, id, disname) else: # 最後まで通知を拾い終わったらNotificationsをClear mastodon.notifications_clear() break count -= 1ほぼ全く変えてるのでとりあえずめっちゃ解説のようなことをします
前と変えたとこ 前半
- class Stream() の def on_notification() のくだりをまるごと消しました(たぶんStreamを使うときに必要だったのだと思われる。Streamを起動しなくしたので不要…と思われる)
- with open の中はもう色々やったのであんまり覚えていません! というか selectedList と edenToot(この変数名は私のbot…Edenの子が呟くとこから来てるので大きな意味はない)とか、こういうふうに宣言しなきゃいけなかったんでしたっけ!? 教えてください識者のかた
反応語句を含む行を抽出 らへん
- ここの while では『l』= reply_nagisa.txt の行が一次元のリスト型で入ってるはずなので、tmpList に::の前と後で分けてリスト型で入れます。tmpList[0]には反応語句、tmpList[1]には反応語句に対する返事がこの場では入ります
- if!もし今 while で回してる『l』の一行の tmpList[0](反応語句)が st['content'](お相手からのリプライToot)内に含まれていたら、さっき宣言しておいた selectedList に tmpList をリスト型のままぶっこみます
- ぶっこまなくてもぶっこまなくても count - 1 するので、この while は『l』の長さ?分まわります。selectedList には最終的に、反応語句が含まれる tmpList のパターンが選ばれて入ることになります。今回の reply_nagisa.txt で「おはよう」とリプライすると「おはよう::……おはよう、{name}さん。」の1~3が入ることになります。
- 今気付いたけどこの場合『凪砂』『おはよう』『好き』という反応語句が reply_nagisa.txt にあるとして「凪砂ちゃんおはよう大好きだよ」って言ったときどうなるんですかね?(聞くな)(後で考えます)
抽出したリストからランダムに一つ選ぶ らへん
- selectedList が何もなくなかったら、count に selectedList の数(ひく1)を入れてまた while します。
- replyNo には selectedList の0番目1番目!みたいな意味で数字を入れています。0 から count の中のランダムな int が入ります
- 多重配列だと [0:2] みたいのがうまくいかない気がしたので re.search を使いましたが、//が入ってる行は省く動作は同じです。正規表現を調べるのがめんどかったのでたぶん反応語句の後ろに//が入ってたとしても反応しますが、私はそんなことしないので、そういうひねくれたことをしたい方はご自分で調べて行頭しか反応しないようになさってくださいまし
- ここ! PHP(か何だったか忘れたけどそういう言語あった気がする)みたく if !(hoge) みたくできないんですか!? というか試してないかもしれない。無駄な else を使うことになってしまう…。識者のかた教えてください。とにかく edenToot にはランダムで選ばれた反応語句のお返事が入ります
今回いじったとこの後半
- どうでもいいですが、名前を変換したあとのを入れる変数なので nameChanged に名前を変えました
- nameChanged、中身なにもなかったら re.sub でエラー出ないのかな?と思うのですが、今のところ出ていない。一応、何も反応語句がなかったときのために nameChanged には仮のリプライを入れました
他は変えてないはず!
同じような関数…関数? を別ので使ったりしてます
私もよく分からないけど何かものによってできたりできなかったりして試行錯誤したんですよ、、許して応用:キャラを呼び分けれるようにする!
reply.py# -- coding: utf-8 -- from mastodon import Mastodon, StreamListener import requests import random import re class Stream(StreamListener): def __init__(self): #継承 super(Stream, self).__init__() # self.logger = logging.getLogger def main(content,st,id,disname): # 呟きファイルの指定 path = 'reply_pattern.txt' if re.search("凪砂|なぎさ", st['content']): path = 'reply_pattern_n.txt' elif re.search("日和|ひよ|おひい", st['content']): path = 'reply_pattern_h.txt' elif re.search("茨|いばら", st['content']): path = 'reply_pattern_i.txt' elif re.search("ジュン|じゅん", st['content']): path = 'reply_pattern_j.txt' else: print('■ だれもちがいます!<br />') #確認用 # ファイルを読み込んで呟く with open(path, 'r') as f: l = f.readlines() count = len(l) - 1; selectedList = [] edenToot = '' # 反応語句を含む行を抽出 while count >= 0: tmpList = l[count].split('::') if tmpList[0] in st['content']: selectedList.append(tmpList) count -= 1 # 抽出したリストからランダムに一つ選ぶ if len(selectedList) != 0: count = len(selectedList) - 1; while True: replyNo = random.randint(0,count) # 「//」を含む行は飛ばして再度Tootを選ぶ if re.search('\/\/', selectedList[replyNo][0]): # なぜかFalseにできない… print('※ コメント行なのでもう一度') else: edenToot = selectedList[replyNo][1] break # {name}をおなまえに変換する nameChanged = re.sub("\{name\}",disname,edenToot) # ↓何もトゥートがなかったときの処理、そのうち変える if nameChanged == '': nameChanged = '凪砂:……ごめん、今何か言った?' print("【リプライ】" + nameChanged) #確認用 mastodon.status_reply(st, nameChanged, id, visibility='private') #公開範囲 # 「未収載」 -> 'unlisted' # 「公開」 -> 'public' # 「非公開」 -> 'private' # 「ダイレクト」-> 'direct' mastodon = Mastodon( client_id = "client.secret", access_token = "user.secret", api_base_url = "https://uuuchu.com") #インスタンス notif = mastodon.notifications() #通知を取得 count = len(notif) - 1 while True: # 逆(古い方)からTootを数える(0/最後まできたらbreak) if count >= 0: if notif[count]['type'] == 'mention': # Toot形成... と思われる content = notif[count]['status']['content'] id = notif[count]['status']['account']['username'] st = notif[count]['status'] disname = notif[count]['status']['account']['display_name'] idStr = str(notif[count]['status']['id']) # Toot main(content, st, id, disname) else: # 最後まで通知を拾い終わったらNotificationsをClear mastodon.notifications_clear() break count -= 1変えたところは、ifで呼ばれてる名前ごとにpathを切り替えるというだけです。
st['content']は相手からのリプライ…ってどこかに書きましたっけ?
でも最初re.searchがなぜか使えなかったりして苦戦したんですよ~~~まとめ
次の記事で書きます!
♪
- 投稿日:2021-01-16T16:21:50+09:00
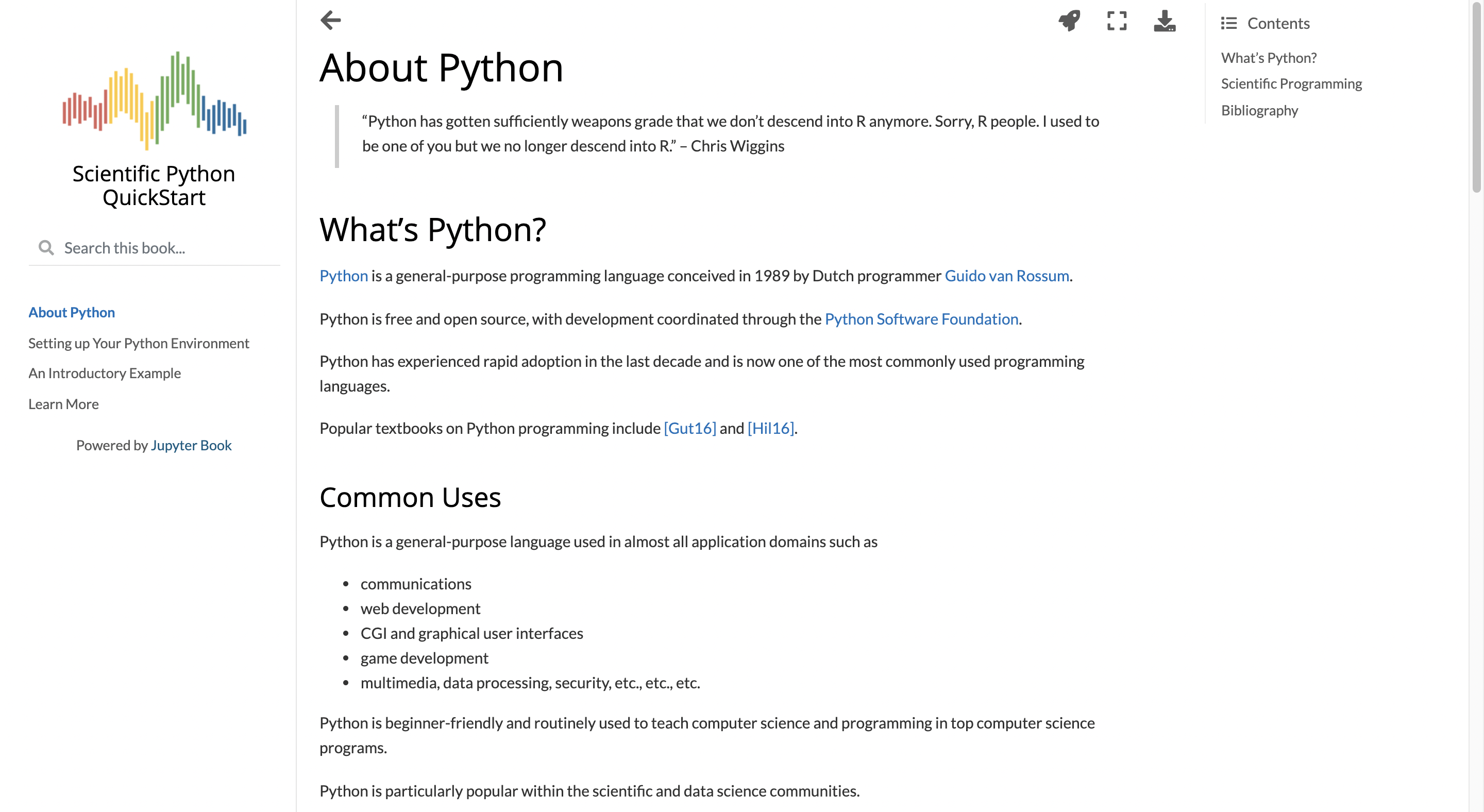
.ipynbから出版品質の本やドキュメントを作成できる「Jupyter Book」の使い方
Jupyter Bookとは?
タイトルの通り、Jupyter Notebookファイル(.ipynb)やMarkdownファイル(.md)から、美しい出版品質の本やドキュメント(HTMLやPDFなど)を作成できるのが「Jupyter Book」です。URL先の公式リファレンスも、「Jupyter Book」を使って作成されています。
名前がJupyter Notebookと似ていますが別のもので、「Project Jupyter」や「The Executable Book Project」のプロジェクトの1つです。自分が探した限りでは日本語のリファレンスがなかったので、Jupyter Bookについて簡単な紹介をしていこうと思います。
インストール方法
pipやcondaを使って簡単にインストールすることができます。自分はmacOSでpipとJupyter Labとzshを使っているので、そのスクリーンショットと共に説明していきます。Jupyter Labのインストール方法はこちらの記事がおすすめです。まずターミナルを起動します。
次にpip/condaコマンドでインストールします。% pip install -U jupyter-book
基本的なコマンド
インストール後、適当なディレクトリに移動してJupyter Bookプロジェクトを作成してみましょう。Jupyter Bookは、
jupyter-bookまたはjbコマンドを使用します。どちらも違いはありませんので、以降は短いjbを使用します。jb create
jb createで「test_book」という名前のJupyter Bookプロジェクトを作成します。プロジェクト名は変更して構いません。ここでは使用していませんが、createでは--cookiecutterオプションを付加することもできます。% jb create test_booktest_book/にテンプレートのJupyter Bookが作成されました。
jb build
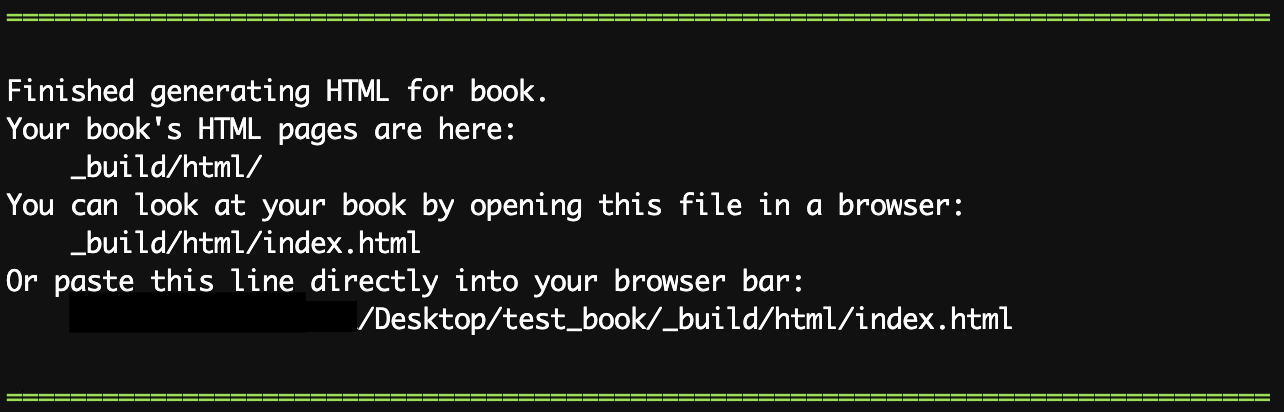
jb buildでJupyter Bookをビルドすることができます。% cd test_book % jb build .長々としたログが表示された後、ビルドが完了すると、以下のように表示されます。
test_book/_build/htmlにHTMLファイルが作成されています。Chromeなどのブラウザで表示させてみましょう。ブラウザにHTMLのパスを直接打ち込むか、以下のようなコマンドを使ってください。% open /Applications/Google\ Chrome.app _build/html/index.html次のように表示されるはずです。簡単にドキュメントを作成することができました。
公式デモブック
公式デモブックも用意されています。ビルド時にエラーが発生することがあるので、ビルド時の実行をしないオプションを個人的に推奨します。
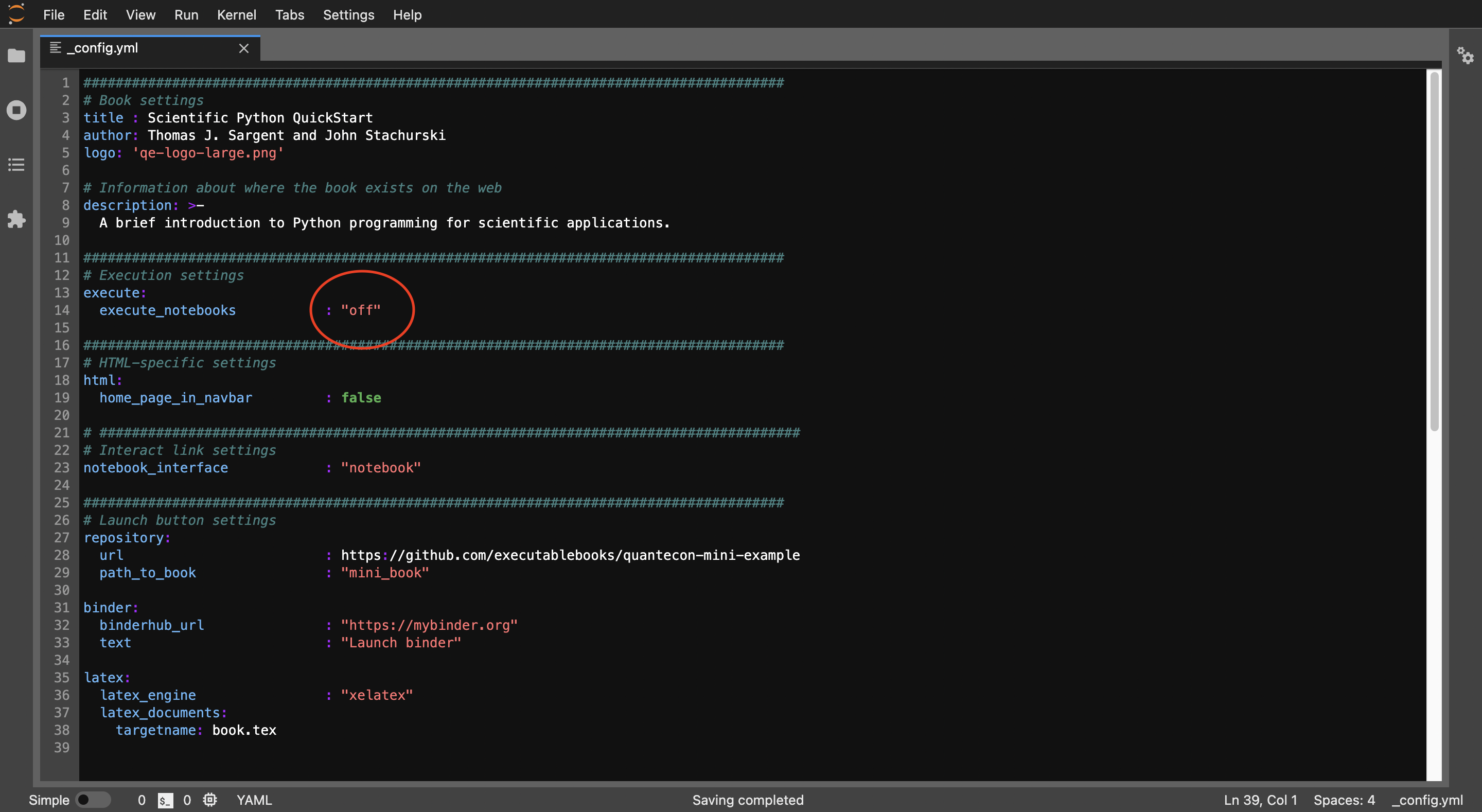
% git clone https://github.com/executablebooks/quantecon-mini-example % cd quantecon-mini-example/mini_book % cat _config.ymlここで_config.ymlの
execute_notebooksを"off"に書き換えます。
ビルドしてブラウザで表示させてみましょう。% jb build . % open /Applications/Google\ Chrome.app _build/html/index.html
PDFを作成する
HTMLと同様に、PDFの作成も簡単にすることができます。2通りの方法があり、少し違いがあります。
① ブラウザから作成する方法
ブラウザでHTMLを表示すると、右上にダウンロードボタンがあります。クリックすると、ダウンロードする形式を指定できます。.pdfをクリックするとPDFファイルを保存することができます。これで完了です。
② ビルドして作成する方法
こちらの方法にはpyppeteerが必要なので、インストールします。
% pip install pyppeteerJupyter Bookでは、1ページ単位でビルドすることもできます。先ほど作った
test_bookの中のnotebook.ipynbをPDFにしてみましょう。buildのときに--builder pdfhtmlを指定します。% cd test_book % jb build notebooks.ipynb --builder pdfhtml以下のように表示されたら、PDFの完成です。
こちらの方法では、①で右側に表示されていたバーが表示されていませんでした。
この他にも、「.tex」ファイルを作成したり、 $\LaTeX$ を使用してPDFを作成することもできます。詳しくは公式リファレンスのPDFページをご覧ください。Jupyter Bookのカスタマイズ
ここまでで「.ipynbや.md」→「HTMLやPDF」という変換をする方法を紹介しました。ここでは、Jupyter Bookのページ内容や構成を変更する方法を取り上げます。ここでのコードは、後ほど取り上げる通りGitHubで公開していますので、コピーなどしたい場合はそちらからご参照ください。
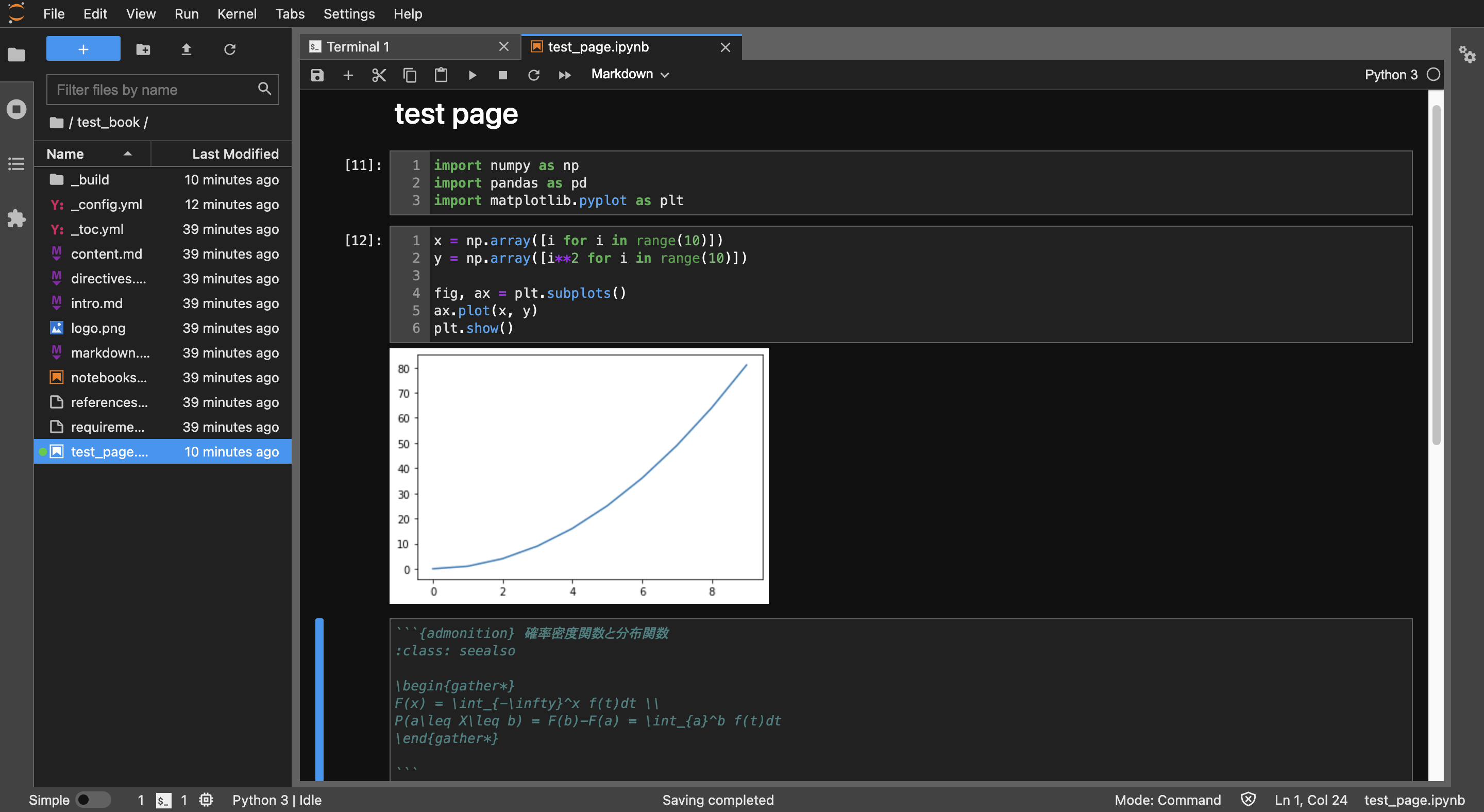
ページの追加
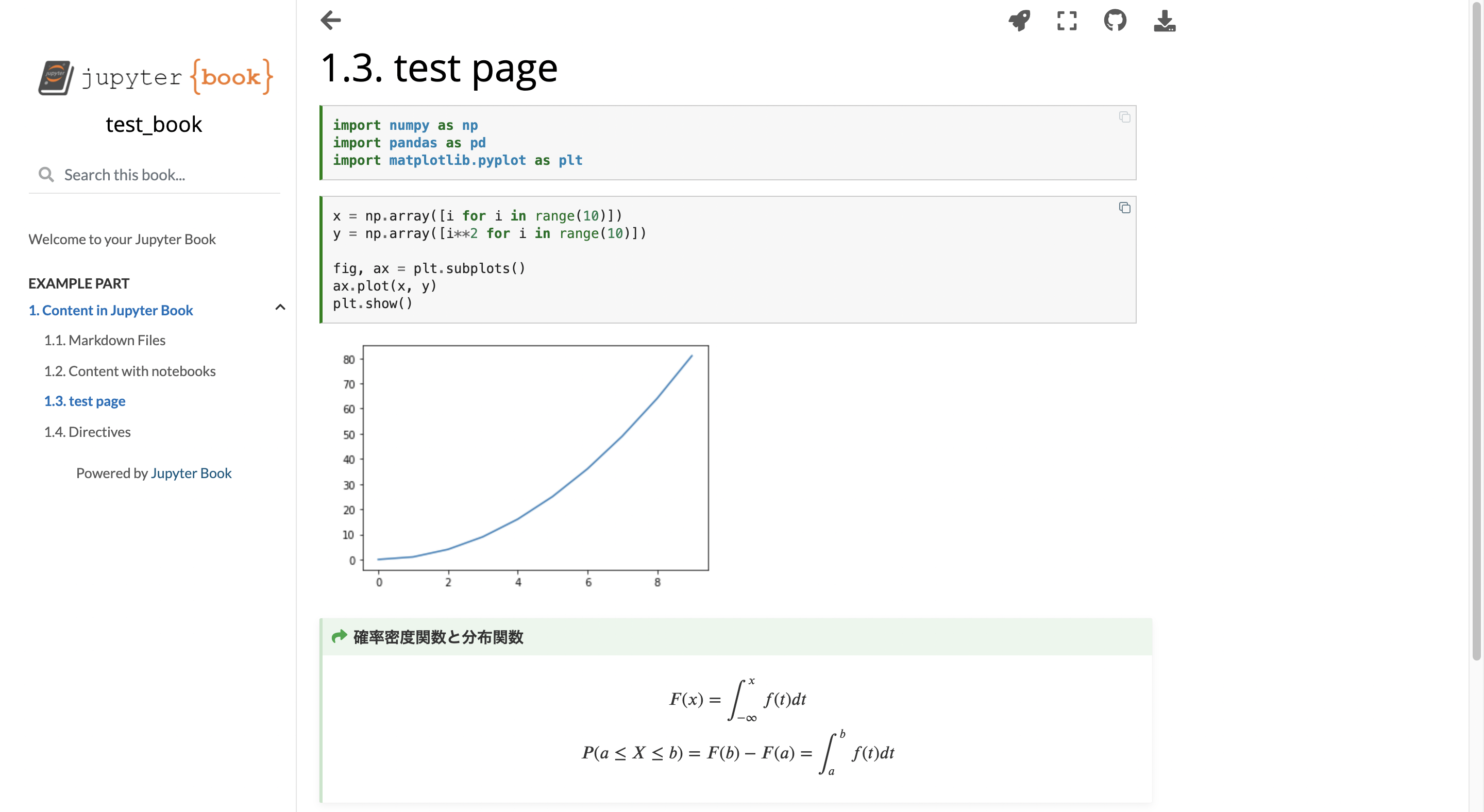
ページを追加するには、ディレクトリに「.ipynb」か「.md」を追加します。ここでは「test_page.ipynb」を作成します。例えば次のような内容で作成します。
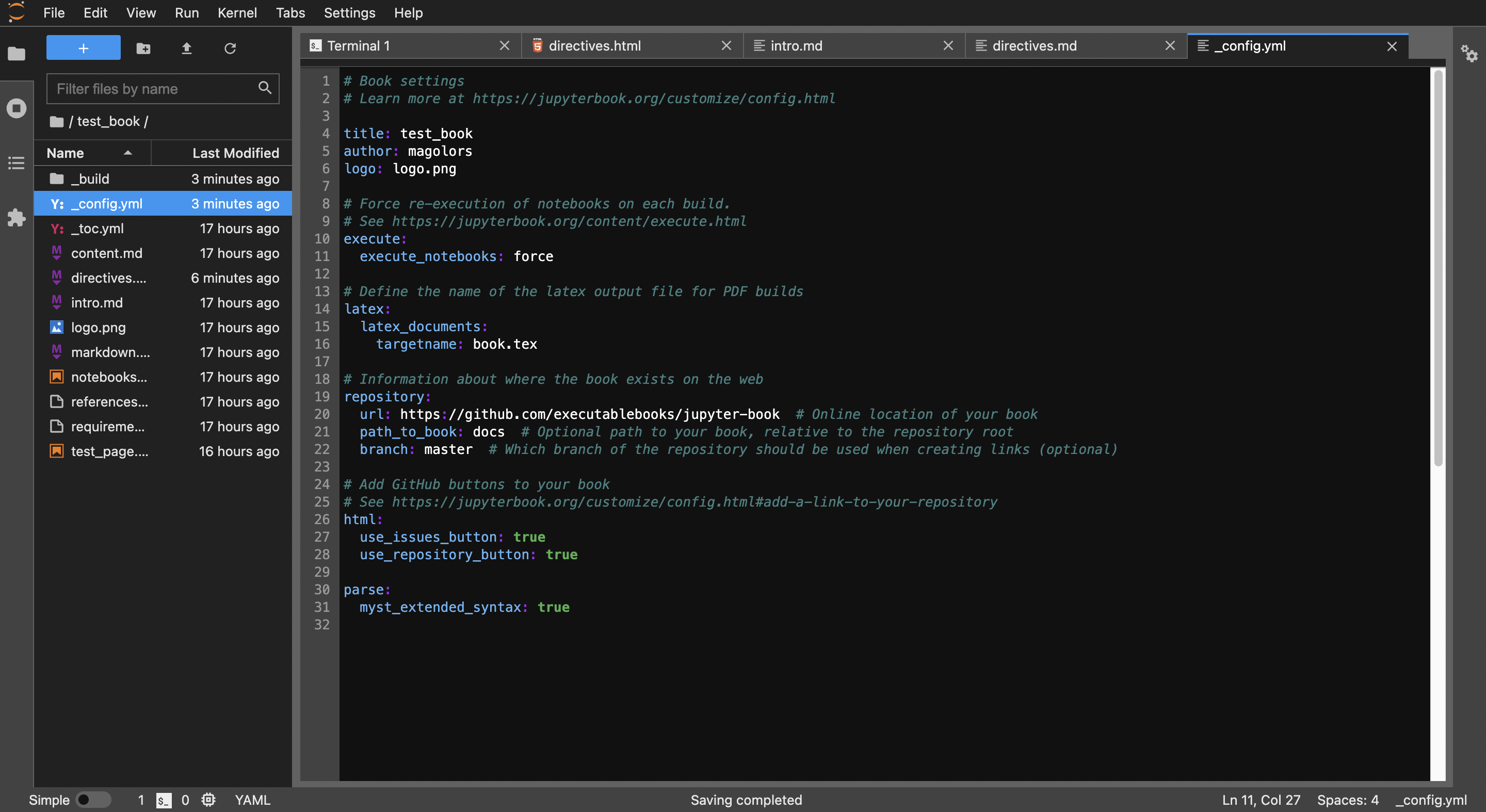
_config.yml
_config.ymlを編集します。このファイルは、Jupyter Bookの設定を記述するものです。詳しくは公式リファレンスのconfigページをご覧ください。ここではtitleとauthor、execute_notebooksを編集しました。ついでに、数式を使えるように1番下に追記しました。
_toc.yml
_toc.ymlを編集します。このファイルは、Jupyter Bookの構造を記述するものです。詳しくは公式リファレンスのtocページをご覧ください。ここでは、以下のようなページ構造にしました。
この内容でビルドすると、以下のように表示されます。ページの追加と、目次の構成を変えることができました。
MyST Markdown
Jupyter Bookでは、MyST Markdownという拡張されたMarkdownを使用することができます。ここでは個人的に使用頻度が高いDirectivesとRolesについて説明します。
通常のMarkdownについては、Qiita公式のMarkdownの書き方をご覧ください。MyST Markdownにも公式リファレンスとチートシートがあるので、ぜひそちらもご覧ください。
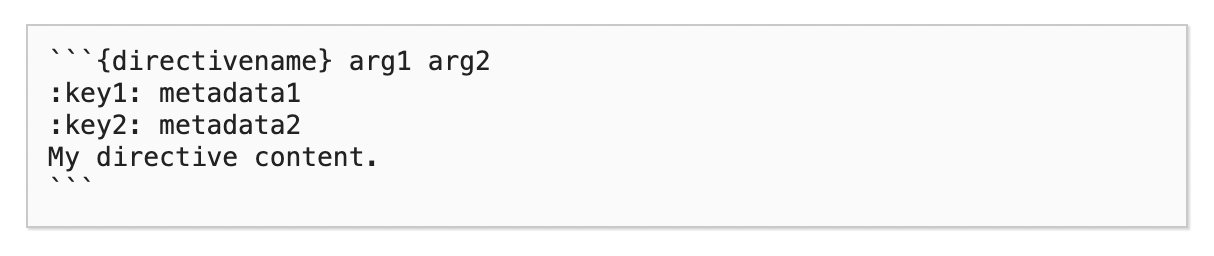
Directives
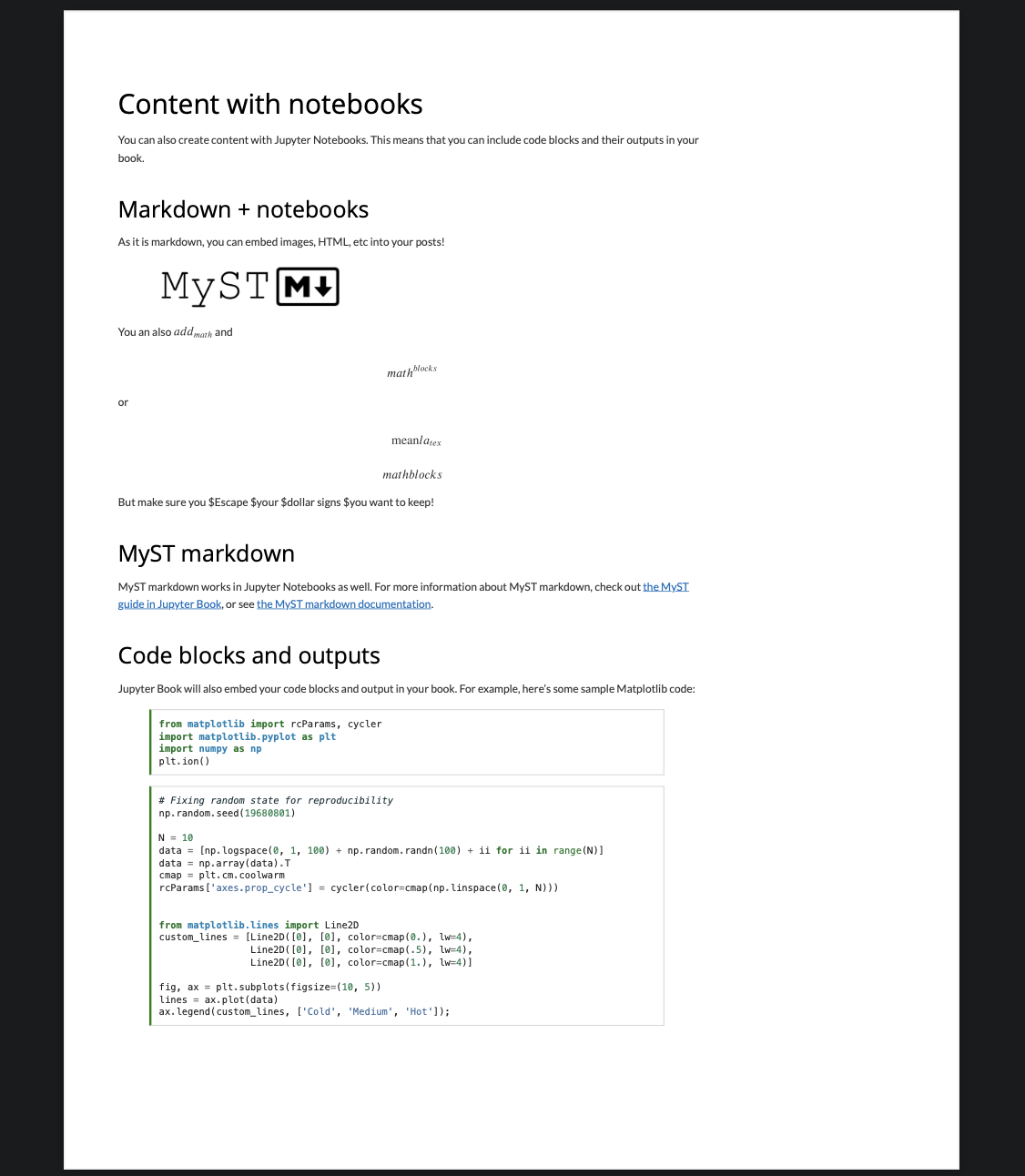
Directiveは、先ほどの「test page」の1番下にあったようなコンテンツブロックを作成することができる機能です。書式はこの通りです。
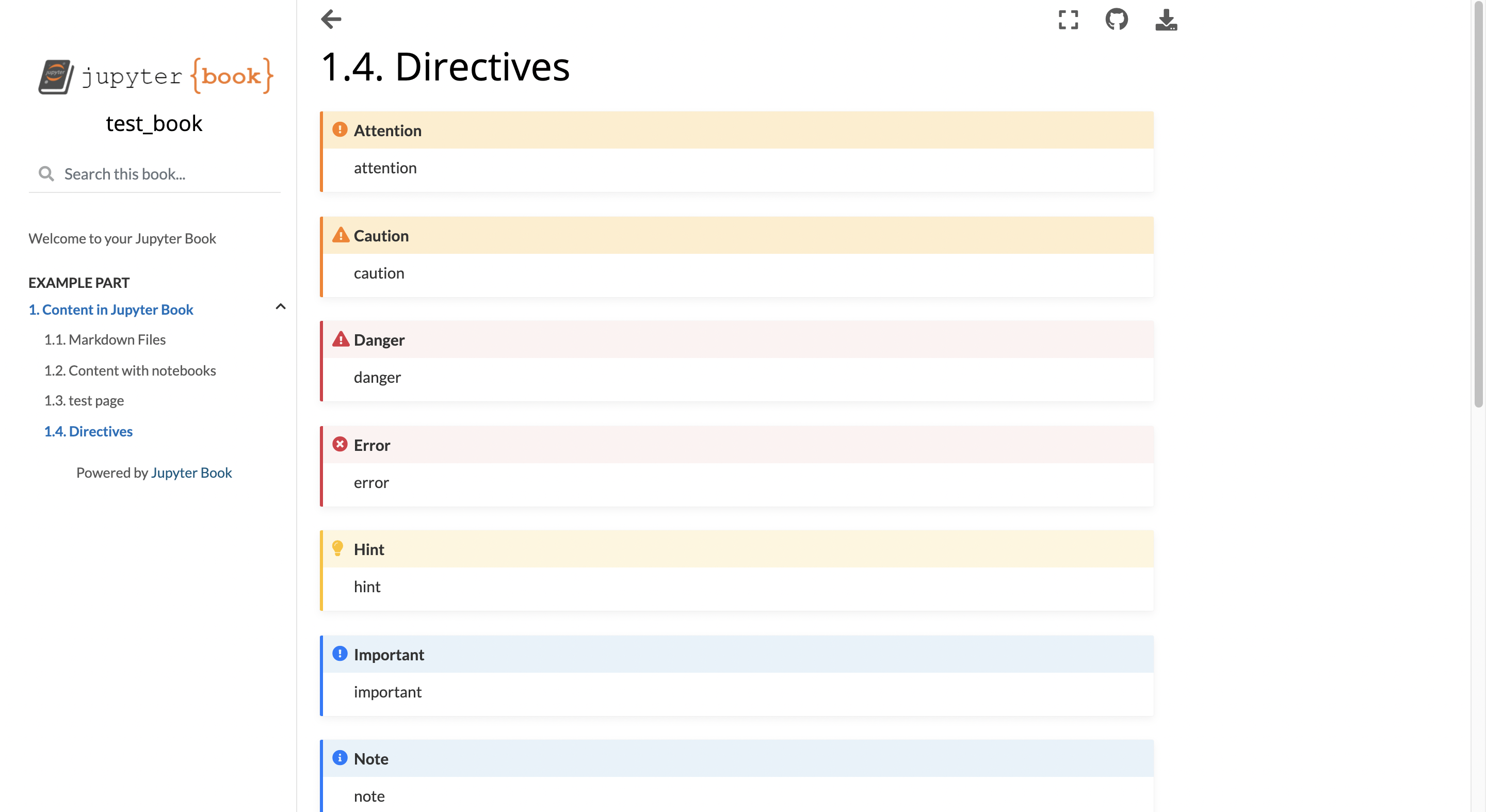
directives.mdというファイルを作成して種類と書式を紹介します。以下のように書くと、コンテンツブロックを作成できます。
admonitionは特殊な書式で、自由にタイトルとクラスを設定することができます。この例では:class: tipでtipのコンテンツブロックを指定しています。
code-blockと言語を指定すると、それぞれの言語にそって表示してくれます。
コンテンツブロックはこのように表示されます。ここではコンテンツブロックのなかに、{}内に書くべきワードを書いています。内容がないと、エラーが出てしまうので注意してください。
{code-block}ではなく{code-cell}を指定して、.mdファイルの1番最初にJupytTextというものを記述すると、コードを表示するだけでなく実行結果を表示させることもできます。また、ネストすることも可能です。
この他にも多くの書式がありますので、Jupyter BookのMyST Markdownページや、MySTのDirectiveページをご覧ください。
Roles
RolesはDerectivesと違って、1行でこのように書きます。
例えば以下のように書くと、チェックマークを表示させることができます。
この他にも多くの書式がありますので、MySTのRolesページをご覧ください。Jupyter Bookの公開
Jupyter BookはHTMLを生成するので、静的Webサイトを構成することができます。ここでは、GitHub Pagesを使ってJupyter Bookを公開してみましょう。
リポジトリの初期設定
GitHubでJupyter Bookのための新しいリポジトリを作ります。以下のページにアクセスしてください。
今回は、
test_book_onlineという名前のリポジトリを作りました。Jupyter Bookでリポジトリへのリンクを変更するため、_config.ymlのrepository部を編集します。
ここからリポジトリを設定します。まずmasterブランチの設定を以下のコマンドで行います。ユーザ名やリポジトリ名は自分のものに置き換えてください。% cd test_book % git init % git add . % git commit -m "adding my first book" % git remote add origin https://github.com/<ユーザ名>/<リポジトリ名>.git % git push origin masterこれでリポジトリの設定をすることが出来ました。次はPythonの
ghp-importというパッケージを使ってGitHub Pagesの設定をします。ghp-importがgh-pagesブランチを自動で作ってくれるので、git branch gh-pagesなどを実行する必要はありません。% pip install ghp-import % ghp-import -n -p -f _build/html少し待ったあと、
https://<ユーザ名>.github.io/<リポジトリ名>にアクセスすると、test_bookの内容が表示されていると思います。自分の場合は、https://magolors.github.io/test_book_online と置き換えます。これで公開することが出来ました。もしよろしければ、リポジトリにStar★をつけて下さると嬉しいです。 リポジトリへは、右上のGitHubマークから飛ぶことができます。
リポジトリの更新
Jupyter Bookのソースコードを更新したいときは、
% cd test_book % jb build . % git checkout master % git push origin masterGitHub Pagesを更新したいときは、以下のように実行してください。
git checkout gh-pagesを実行する必要はありません。% cd test_book % jb build . % git checkout master % ghp-import -n -p -f _build/htmlこの方法の他に、GitHub Actionsを利用してJupyter Bookが更新されると自動でGitHub Pagesも更新するという方法もあります。
最後に
ここまでJupyter Bookの簡単な紹介をしてきました。ここで取り上げたもの以外にも、非常に多くの機能があるので、ぜひ公式リファレンスをご参照ください。また、他にDirectiveの種類があったり、何か間違いなどありましたらコメントにて連絡をお願いします。
ここまで読んでいただきありがとうございました。 面白いと思った方はLGTMを押していただけると励みになります













- 投稿日:2021-01-16T16:08:10+09:00
便利にkaggle Datasetにアップロード
kaggle notebook縛りのcode competition
最近kaggleでは、推論時にkaggleのnotebook環境しか使えないcode competitionが増えて、深層学習を使う系のコンペですと頻繁にローカルで学習済みのモデルのパラメータファイルをkaggle Datasetにアップロードして使うことがあります。
kaggle APIコマンドでもまだ面倒
Kaggle APIコマンドを使うことで、WebUIでの手作業は省けてデータダウンロード・アップロードが自動化できるのですが、メタデータのJSONファイルやAPIコマンドの編集・作成が面倒だったりします。
そこで、pythonで実行できるwrapper関数を作りましたので、供養しておきます。
関数の入力と、実験パラメータの記載されているyamlファイルと連携すると、実験条件等を自動でデータセットのコメントなどに反映できミスの予防や省力化に繋がります。必要な前準備
- kaggle APIのインストールとAPIトークンの生成が必要です。詳細は関連記事をご覧ください。
- 当然ながら、アップロードしたいファイルのパスにデータがないといけません。
- この関数はmodelというディレクトリに様々な実験ごとに更にmodel_exp_XXとサブディレクトリがあり、その中にモデルのパラメータファイルがあることを前提しています。
- 関数の引数ではモデルファイルの拡張子を指定して、.pth、.h5など適宜変更します。
- loggerを用意すると、ログファイルに出力するように一応しています。
import subprocess import glob import json import os def upload_to_kaggle( title: str, k_id: str, path: str, comments: str, update:bool, logger=None, extension = '.pth', subtitle='', description="", isPrivate = True, licenses = "unknown" , keywords = [], collaborators = [] ): ''' >> upload_to_kaggle(title, k_id, path, comments, update) Arguments ========= title: the title of your dataset. k_id: kaggle account id. path: non-default string argument of the file path of the data to be uploaded. comments:non-default string argument of the comment or the version about your upload. logger: logger object if you use logging, default is None. extension: the file extension of model weight files, default is ".pth" subtitle: the subtitle of your dataset, default is empty string. description: dataset description, default is empty string. isPrivate: boolean to show wheather to make the data public, default is True. licenses = the licenses description, default is "unkown"; must be one of / ['CC0-1.0', 'CC-BY-SA-4.0', 'GPL-2.0', 'ODbL-1.0', 'CC-BY-NC-SA-4.0', 'unknown', 'DbCL-1.0', 'CC-BY-SA-3.0', 'copyright-authors', 'other', 'reddit-api', 'world-bank'] . keywords : the list of keywords about the dataset, default is empty list. collaborators: the list of dataset collaborators, default is empty list. ''' model_list = glob.glob(path+f'/*{extension}') if len(model_list) == 0: raise FileExistsError('File does not exist, check the file extention is correct \ or the file directory exist.') if path[-1] == '/': raise ValueError('Please remove the backslash in the end of the path') data_json = { "title": title, "id": f"{k_id}/{title}", "subtitle": subtitle, "description": description, "isPrivate": isPrivate, "licenses": [ { "name": licenses } ], "keywords": [], "collaborators": [], "data": [ ] } data_list = [] for mdl in model_list: mdl_nm = mdl.replace(path+'/', '') mdl_size = os.path.getsize(mdl) data_dict = { "description": comments, "name": mdl_nm, "totalBytes": mdl_size, "columns": [] } data_list.append(data_dict) data_json['data'] = data_list with open(path+'/dataset-metadata.json', 'w') as f: json.dump(data_json, f) script0 = ['kaggle', 'datasets', 'create', '-p', f'{path}' , '-m' , f'\"{comments}\"'] script1 = ['kaggle', 'datasets', 'version', '-p', f'{path}' , '-m' , f'\"{comments}\"'] #script0 = ['echo', '1'] #script1 = ['echo', '2'] if logger: logger.info(data_json) if update: logger.info(script1) logger.info(subprocess.check_output(script1)) else: logger.info(script0) logger.info(script1) logger.info(subprocess.check_output(script0)) logger.info(subprocess.check_output(script1)) else: print(data_json) if update: print(script1) print(subprocess.check_output(script1)) else: print(script0) print(script1) print(subprocess.check_output(script0)) print(subprocess.check_output(script1))こうすることでもっと効率よくできてるよという方がいましたら、ぜひコメントください。
関連記事:
- Kaggle APIで楽にGCPにデータをダウンロード
- Github 上の自分のコードを Kaggle Code Competition で使うのを CI で自動化
- 投稿日:2021-01-16T15:39:37+09:00
Covit-19をDartsを使って予測してみた
時系列データの予測はFacebookが開発してくれたProphetがわかりやすくて長く愛用してきましたが、最近Prophetをsklearn-likeに使うことができて、他の時系列解析手法もラッピングしてくれているDartsというライブラリがあるのを知ったので、Covit-19のデータを用いてその使い勝手を確かめてみたので解説します。
Dartsとは
https://github.com/unit8co/darts
Dartsはスイスの企業が2020年6月に後悔したライブラリ。
ProphetやLSTMなどのDeeplearning、ARIMAなどの統計モデルも全てsklearnベースのAPIで扱えるライブラリでかなり便利そう。。。インストール方法
インストールはpipでインストールできます。
pip install 'u8darts[all]'[all]を付けずに
pip install u8dartsでもインストールできますが、そうするとLSTMを実行する際のpytorchなどがインストールされないようでエラーになりました。とりあえず使用感を確かめたいくらいであればいらないかもしれません。実行環境
OS: macOS ver11.1
CPU: core i5
メモリ: 16GB
python: 3.8.7
Darts: 0.5.0データの準備
今回はCovit-19のデータを利用したと思います。
厚生労働省のサイトにダウンロードリンクが貼られてある日付別の陽性者数のデータをダウンロード。
https://www.mhlw.go.jp/content/pcr_positive_daily.csv
陽性者予測するにはPCR検査数なども使わないといけないようなーとは思いつつ、今回はDartsの検証なの単純に過去の陽性者数から未来の陽性者数を予測するモデルの構築をおこないます。使ってみた
ライブラリのインストール
import warnings warnings.simplefilter('ignore') #warningがたくさん出るので気になる人はやったほうがいい import pandas as pd import darts from darts import TimeSeries #Dartsのデータ型変換モジュール import matplotlib.pyplot as pltデータの読み込み
df = pd.read_csv('https://www.mhlw.go.jp/content/pcr_positive_daily.csv') #記事作成時点で1月14日までのデータがダウンロード可能データの中身はこんな感じ。おしい!ちょうど1年分に1日足りず!
データ型の変換。
DartsはpandasのDataFrameからの変換をTimeSeriesモジュールで行ってくれる。今回は202012月01日以降を予測する形で行うようにする。このあたりがsklearnのAPIベースでかなり助かる。直感的にわかりやすい。
ts = TimeSeries.from_dataframe(df, time_col='日付', value_cols='PCR 検査陽性者数(単日)') train, val = ts.split_after(pd.Timestamp('20201201'))学習モデルの作成
かなり豊富に学習モデルを用意してくれている。
Deeplearning系の学習モデルはデータの変換にもうひと手間必要なのでそれ以外のモデルをfor文で実行。
あと何度も書いてますが、やっぱりsklearnベースは楽。fitとpredictという何度やったかわからない書き方でそのまま実行。# modelのインポート from darts.models import ExponentialSmoothing, NaiveSeasonal, NaiveDrift, Prophet, ARIMA from darts.models import AutoARIMA, StandardRegressionModel, Theta, FFT models = [ExponentialSmoothing(), NaiveSeasonal(), NaiveDrift(), Prophet(daily_seasonality=True, yearly_seasonality=True), Prophet(daily_seasonality=True, yearly_seasonality=True, weekly_seasonality=True),# 曜日によって検査数にばらつきがあるので週の周期性を見るバージョンもせっかくなので準備 ARIMA(), AutoARIMA(), StandardRegressionModel(), Theta(), FFT()] for model in models: print(model.__str__()) try: #実行したときにエラーになってしまうモデルもあったので回避用です model.fit(train) #sklearnのやり方 prediction = model.predict(len(val)) # 可視化による確認 plt.figure(figsize=(12, 5)) ts.split_after(pd.Timestamp('20201101')) [1].plot(label='actual', lw=1) #最初から表示すると大事な予測結果との乖離部分が見えにくかったので20201101からのプロット prediction.plot(label='forecast', lw=1) plt.legend() plt.xlabel('Day') plt.show() except Exception as e: print('error¥t :{}'.format(e))実行結果
Exponetial smoothing
Naive seasonal model
Naive drift model
Prophet
Prophet(Weekly True)
ARIMA
Auto-ARIMA
Theta
errorでした!公式ドキュメントみないとだめですね。。。FFT
結果はARIMAモデルとExponetial smoothingがうまく学習できてそうです。
ProphetのWeeklyはデフォルトでAutoになっているので結果変わらずでした。
実績のラインをみても4月以降は爆発的に上がってるんですね。これは緊急事態宣言出して収束させたのも納得です。Deeplearningモデルを試してみた
LSTMを試してみます。
パラメーターは参考にさせていただいた記事に書いてあったパラメーターを使わせていただきました。記事はページの一番下に載せてあります。データの加工
from darts.models import TCNModel, RNNModel from darts.dataprocessing.transformers import Scaler from darts.metrics import mape, r2_score from darts.utils.missing_values import fill_missing_values # データの準備。Scalerは0,1で正規化するsklearnラッパーらしいです。 scaler = Scaler() train_tr = scaler.fit_transform(train) val_tr = scaler.transform(val) ts_tr = scaler.transform(ts)LSTM
そこそこ時間かかります。
model = RNNModel( model='LSTM', output_length=1, # 出力(=予測)のタイムステップ数 hidden_size=25, # RNNにおける隠れ状態の数 n_rnn_layers=3, # RNNの隠れ層の数 input_length=12, # Number of previous time stamps taken into account.(?分からなかった…) dropout=0.4, batch_size=16, n_epochs=400, optimizer_kwargs={'lr': 1e-3}, log_tensorboard=True, random_state=42 ) model.fit(train_tr, val_training_series=val_tr, verbose=True)実行結果確認
prediction = model.predict(len(val)) fig = plt.figure(figsize=(12, 5)) ts_tr_after10 = ts_tr.drop_before(pd.Timestamp('20201001')) ts_tr_after10.plot(label='actual') prediction.plot(label='forecast', color='red') plt.legend()
精度は微妙ですね・・・まとめ
Dartsはかなり便利に感じました。今後はないとは思いますが、元のProphetを使った時の精度と比べて精度が劣化していないかなどを調べて問題なさそうならDartsを使っていこうと思います。sklearn-likeなのでhyperparameterの探索とかガンガンやってみたいと思います。
あと、当たり前ですがデフォルトパラメーターでデータの工夫も全くせずに実行しただけなので精度は出ていないです。これはライブラリのせいではなく私がサボったせいです。あと、バックテストの仕組みとかも充実しているのでその辺りも試せたらいいなと思っています。ご挨拶
今回緊急事態宣言も出て、家にこもっていないと行けなくなったので初めて記事を書いてみました。せっかくやり始めたので今後も少しずつ書けて行けたらなと思います。コードの修正部分など気軽にコメントいただけると嬉しいです。参考にさせていただきます。
参考記事
https://blog.ikedaosushi.com/entry/2020/08/25/003557
https://qiita.com/hironey/items/d1d8a80c8329d5d46c16

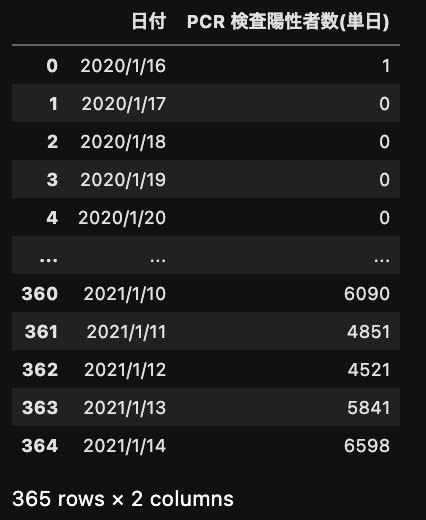

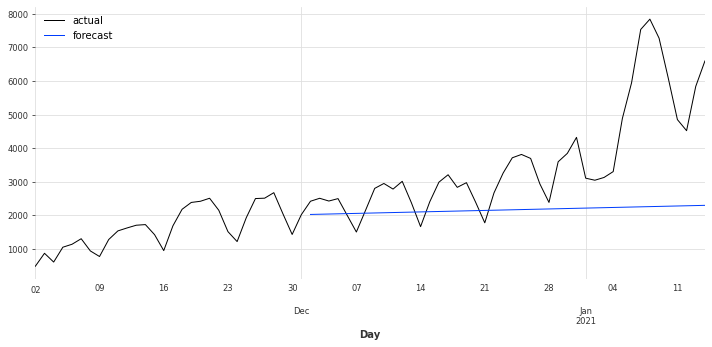

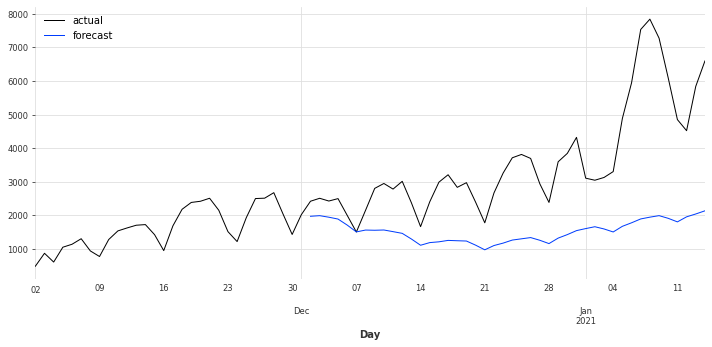

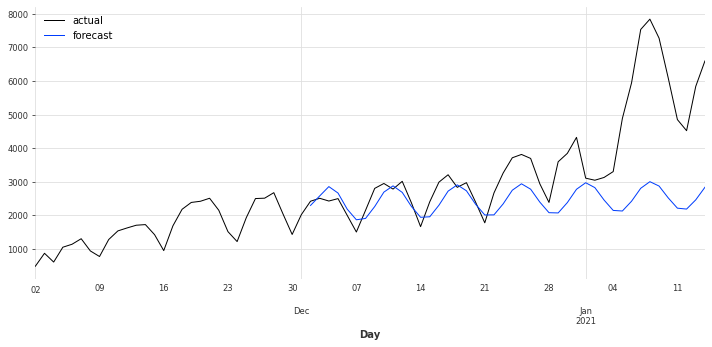

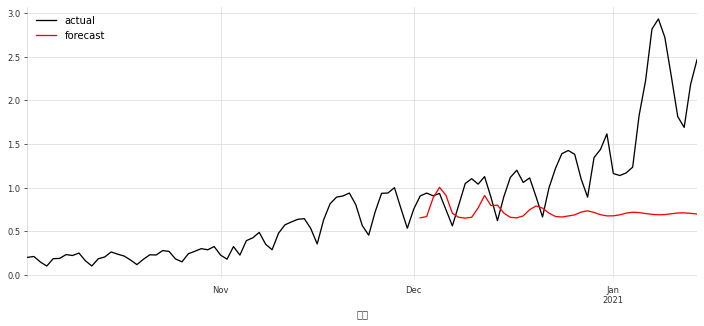
- 投稿日:2021-01-16T15:39:37+09:00
Covid-19をDartsを使って予測してみた
時系列データの予測はFacebookが開発してくれたProphetがわかりやすくて長く愛用してきましたが、最近Prophetをsklearn-likeに使うことができて、他の時系列解析手法もラッピングしてくれているDartsというライブラリがあるのを知ったので、Covid-19のデータを用いてその使い勝手を確かめてみたので解説します。
Dartsとは
https://github.com/unit8co/darts
Dartsはスイスの企業が2020年6月に後悔したライブラリ。
ProphetやLSTMなどのDeeplearning、ARIMAなどの統計モデルも全てsklearnベースのAPIで扱えるライブラリでかなり便利そう。。。インストール方法
インストールはpipでインストールできます。
pip install 'u8darts[all]'[all]を付けずに
pip install u8dartsでもインストールできますが、そうするとLSTMを実行する際のpytorchなどがインストールされないようでエラーになりました。とりあえず使用感を確かめたいくらいであればいらないかもしれません。実行環境
OS: macOS ver11.1
CPU: core i5
メモリ: 16GB
python: 3.8.7
Darts: 0.5.0データの準備
今回はCovid-19のデータを利用したと思います。
厚生労働省のサイトにダウンロードリンクが貼られてある日付別の陽性者数のデータをダウンロード。
https://www.mhlw.go.jp/content/pcr_positive_daily.csv
陽性者予測するにはPCR検査数なども使わないといけないようなーとは思いつつ、今回はDartsの検証なの単純に過去の陽性者数から未来の陽性者数を予測するモデルの構築をおこないます。使ってみた
ライブラリのインストール
import warnings warnings.simplefilter('ignore') #warningがたくさん出るので気になる人はやったほうがいい import pandas as pd import darts from darts import TimeSeries #Dartsのデータ型変換モジュール import matplotlib.pyplot as pltデータの読み込み
df = pd.read_csv('https://www.mhlw.go.jp/content/pcr_positive_daily.csv') #記事作成時点で1月14日までのデータがダウンロード可能データの中身はこんな感じ。おしい!ちょうど1年分に1日足りず!
データ型の変換。
DartsはpandasのDataFrameからの変換をTimeSeriesモジュールで行ってくれる。今回は202012月01日以降を予測する形で行うようにする。このあたりがsklearnのAPIベースでかなり助かる。直感的にわかりやすい。
ts = TimeSeries.from_dataframe(df, time_col='日付', value_cols='PCR 検査陽性者数(単日)') train, val = ts.split_after(pd.Timestamp('20201201'))学習モデルの作成
かなり豊富に学習モデルを用意してくれている。
Deeplearning系の学習モデルはデータの変換にもうひと手間必要なのでそれ以外のモデルをfor文で実行。
あと何度も書いてますが、やっぱりsklearnベースは楽。fitとpredictという何度やったかわからない書き方でそのまま実行。# modelのインポート from darts.models import ExponentialSmoothing, NaiveSeasonal, NaiveDrift, Prophet, ARIMA from darts.models import AutoARIMA, StandardRegressionModel, Theta, FFT models = [ExponentialSmoothing(), NaiveSeasonal(), NaiveDrift(), Prophet(daily_seasonality=True, yearly_seasonality=True), Prophet(daily_seasonality=True, yearly_seasonality=True, weekly_seasonality=True),# 曜日によって検査数にばらつきがあるので週の周期性を見るバージョンもせっかくなので準備 ARIMA(), AutoARIMA(), StandardRegressionModel(), Theta(), FFT()] for model in models: print(model.__str__()) try: #実行したときにエラーになってしまうモデルもあったので回避用です model.fit(train) #sklearnのやり方 prediction = model.predict(len(val)) # 可視化による確認 plt.figure(figsize=(12, 5)) ts.split_after(pd.Timestamp('20201101')) [1].plot(label='actual', lw=1) #最初から表示すると大事な予測結果との乖離部分が見えにくかったので20201101からのプロット prediction.plot(label='forecast', lw=1) plt.legend() plt.xlabel('Day') plt.show() except Exception as e: print('error¥t :{}'.format(e))実行結果
Exponetial smoothing
Naive seasonal model
Naive drift model
Prophet
Prophet(Weekly True)
ARIMA
Auto-ARIMA
Theta
errorでした!公式ドキュメントみないとだめですね。。。FFT
結果はARIMAモデルとExponetial smoothingがうまく学習できてそうです。
ProphetのWeeklyはデフォルトでAutoになっているので結果変わらずでした。
実績のラインをみても4月以降は爆発的に上がってるんですね。これは緊急事態宣言出して収束させたのも納得です。Deeplearningモデルを試してみた
LSTMを試してみます。
パラメーターは参考にさせていただいた記事に書いてあったパラメーターを使わせていただきました。記事はページの一番下に載せてあります。データの加工
from darts.models import TCNModel, RNNModel from darts.dataprocessing.transformers import Scaler from darts.metrics import mape, r2_score from darts.utils.missing_values import fill_missing_values # データの準備。Scalerは0,1で正規化するsklearnラッパーらしいです。 scaler = Scaler() train_tr = scaler.fit_transform(train) val_tr = scaler.transform(val) ts_tr = scaler.transform(ts)LSTM
そこそこ時間かかります。
model = RNNModel( model='LSTM', output_length=1, # 出力(=予測)のタイムステップ数 hidden_size=25, # RNNにおける隠れ状態の数 n_rnn_layers=3, # RNNの隠れ層の数 input_length=12, # Number of previous time stamps taken into account.(?分からなかった…) dropout=0.4, batch_size=16, n_epochs=400, optimizer_kwargs={'lr': 1e-3}, log_tensorboard=True, random_state=42 ) model.fit(train_tr, val_training_series=val_tr, verbose=True)実行結果確認
prediction = model.predict(len(val)) fig = plt.figure(figsize=(12, 5)) ts_tr_after10 = ts_tr.drop_before(pd.Timestamp('20201001')) ts_tr_after10.plot(label='actual') prediction.plot(label='forecast', color='red') plt.legend()
精度は微妙ですね・・・まとめ
Dartsはかなり便利に感じました。今後はないとは思いますが、元のProphetを使った時の精度と比べて精度が劣化していないかなどを調べて問題なさそうならDartsを使っていこうと思います。sklearn-likeなのでhyperparameterの探索とかガンガンやってみたいと思います。
あと、当たり前ですがデフォルトパラメーターでデータの工夫も全くせずに実行しただけなので精度は出ていないです。これはライブラリのせいではなく私がサボったせいです。あと、バックテストの仕組みとかも充実しているのでその辺りも試せたらいいなと思っています。ご挨拶
今回緊急事態宣言も出て、家にこもっていないと行けなくなったので初めて記事を書いてみました。せっかくやり始めたので今後も少しずつ書けて行けたらなと思います。コードの修正部分など気軽にコメントいただけると嬉しいです。参考にさせていただきます。
参考記事
https://blog.ikedaosushi.com/entry/2020/08/25/003557
https://qiita.com/hironey/items/d1d8a80c8329d5d46c16
- 投稿日:2021-01-16T15:16:28+09:00
manimの作法 その17
概要
manimの作法、調べてみた。
練習問題、「九九」やってみた。参考にしたページ。
https://qiita.com/maskot1977/items/c01180cc63aa67ac004e
サンプルコード
from manimlib.imports import * class test(Scene): def construct(self): for x in range(9): for y in range(9): A = TextMobject("{} x {} = {}".format(x + 1, y + 1, (x + 1) * (y + 1))).scale(3) A.shift(UP * 3) self.play(ShowCreation(A)) points = [] for i in range(x + 1): for j in range(y + 1): X = j * 0.5 - 3 Y = 2 - i * 0.5 points.append(Dot(point = np.array([X, Y, 0.0]))) group = VGroup(*points) self.play(ShowIncreasingSubsets(group, run_time = 2.0)) self.wait() self.remove(group) self.remove(A)生成した動画
https://www.youtube.com/watch?v=WhoECILZ5RY
以上。
- 投稿日:2021-01-16T15:06:39+09:00
manimの作法 その16
概要
manimの作法、調べてみた。
ShowIncreasingSubsets、使ってみた。サンプルコード
from manimlib.imports import * class test(Scene): def construct(self): points = [] for x in range(-5, 6): points.append(Dot(point = np.array([x, 0.0, 0.0]))) group = VGroup(*points) self.play(ShowIncreasingSubsets(group, run_time = 3.0)) self.remove(group) self.wait()生成した動画
https://www.youtube.com/watch?v=x5fCYTdwWys
以上。
- 投稿日:2021-01-16T14:31:21+09:00
Djangoの前に、仮想環境(venv)をつくるメモ
pythonでDjangoを使ってwebアプリをつくる。
↑そのためにまず仮想環境を作る。カンタン3ステップ。仮想環境つくる手順
今回の仮想環境のファイル名は dj_kasou とする。
①仮想環境つくる
python -m venv dj_kasoumacでうまくいかなければこっち
python3 -m venv dj_kasou
②仮想環境はいる
cd dj_kasou
③仮想環境実行する
Macの場合:
source bin/activate完了。
Windowsの場合:
Scripts\activatePSSecurityExceptionのエラーがでるので以下実行。
Set-ExecutionPolicy RemoteSigned -Scope Process→実行ポリシー「Y」で応えて、もう一回実行。
Scripts\activate完了。
仮想環境の構築が済んだら、作業ごとに入ったり出たり繰り返すので以下コマンドのメモ。仮想環境ファイルに入る
cd dj_kasou仮想環境を実行
source bin/activate仮想環境内の作業ディレクトリに入る
cd NOWPROJECT仮想環境を終了
deactivate
そもそもなぜ仮想環境が必要?
ライブラリのバージョン違いによって起こるトラブルを防ぐ。仮想環境を作ればアプリごとにバージョンを管理できる。
- 投稿日:2021-01-16T13:45:53+09:00
【Python】Cartopy+Matplotlib で震源の3次元散布図を作りたい!
Matplotlib の特徴の一つに、非常に簡単に3次元グラフを描画できるという特徴があります。この特徴を利用して、地図ライブラリ Cartopy で地図を表示させた状態で震源の3次元散布図を描画することを試みました。
※表示している地震のデータは防災科学技術研究所が公開している地震のメカニズム ( 防災科研:メカニズム解の検索 ) からランダムに選びダウンロードしたものです。本ページ中の画像は個人がデモンストレーションとして描画したもので、その結果に学術的な意味を求めていません。
※本ページのスクリプトの利用は自己責任でお願いします。
描画例
1. 目次
1. 目次
2. このページの目的
3. 使用環境
4. 地図を3次元グラフにどう落とし込むか
5. デモンストレーション
6. おわりに
7. 参考文献2. このページの目的
震源の3次元位置をプロットした後、深さ0kmの位置に地図を描画すること。
3. 使用環境
- Windows 10
- conda 4.9.2
- python 3.8.5
- matplotlib 3.3.2
- obspy 1.2.2
- cartopy 0.18.0
4. 地図を3次元グラフにどう落とし込むか
さて、現状 Cartopy は Matplotlib における3次元プロットにそれほど対応していません。であるからして3次元プロットに表示させるには Matplotlib が対応している何かしらの形式に変換してあげる必要があります。ここでは Collection という形式に着目します。
基本的な方法については stackoverflow に前例があります。ユーザー mtb-za の質問 「contourf in 3D Cartopy」 に対してユーザー pelson が回答しており、本ページのスクリプトもこれを参考にしています。しかし同サイトでも指摘されている通り、pelson の回答ではエラーが出てしまいます。これについては今回はその場限りの解決策でしのいでいます。
pelson の回答したスクリプトは基本的に次のような流れになっています。
- Cartopy から描画する feature を指定
- feature から geometry のみを取得
- geometry を描画したい投影法 (ここでは正距円筒図法) に変換
- 描画している matplotlib の axes から描画範囲を取得し、これと交差する geometry との間で intersection なるメソッドを適用
- geometry を path に変換
- path を polygon に変換
- polygon を collection に変換
ところが intersection をする際にいくつかの geometry が invalid であるというエラーが出ます。想像するに geometry を構成する線分の一部が互いに交差したりしていると思われます。これではスクリプトが動かないので、 intersection の前に invalid な geometry を排除するコードを挿入しました。見た感じ特に問題がない結果が表示されました (ほかの領域、投影法でどうなるかまでは追っていません)。
5. デモンストレーション
使用しているデータの冒頭部分は以下の通り。
temp.csvlongitude latitude depth strike1 dip1 rake1 strike2 dip2 rake2 mantissa exponent type 136.3025 36.2495 11 63 59 94 236 31 84 2.66 21 1 135.5475 35.2028 20 334 85 11 243 79 175 9.92 21 2 136.72 35.1692 14 3 70 105 145 25 55 3.43 21 1 134.8153 34.4015 11 293 87 28 201 62 177 4.23 21 2このうち経度緯度深さそして主応力軸の方向から判定した断層の種類(type)を描画に用います。
cartopy_3d.pyimport itertools import pandas as pd import cartopy.feature import cartopy.crs as ccrs import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import Axes3D from cartopy.mpl.patch import geos_to_path from matplotlib.collections import PolyCollection mfile = pd.read_csv("temp.csv") # データ loc = mfile[["longitude", "latitude", "depth"]] typ = mfile[["type"]] # 正断層型か、など。0 = 正断層, 1 = 逆断層, 2 = 横ずれ断層 pallet = ["blue", "red", "lime"] # 断層タイプにより色分けする pallet_list = [] # 色をリスト化 for i in range(len(typ)) : pallet_list.append(pallet[int(typ.iloc[i,0])]) # メインのプロット fig = plt.figure() ax3d = fig.add_subplot(111, projection='3d') # 領域の指定 ax3d.set_xlim(134.0,137.0) ax3d.set_ylim(33.5,36.5) ax3d.set_zlim(25,0) # ラベル ax3d.set_xlabel("longitude") ax3d.set_ylabel("latitude") ax3d.set_zlabel("depth") # 散布図 ax3d.scatter(loc["longitude"],loc["latitude"],loc["depth"],"o", c=pallet_list,s=10,depthshade=0) # 地図のためのaxisを設定 proj_ax = plt.figure().add_subplot(111, projection=ccrs.PlateCarree()) proj_ax.set_xlim(ax3d.get_xlim()) proj_ax.set_ylim(ax3d.get_ylim()) # a usefull function concat = lambda iterable: list(itertools.chain.from_iterable(iterable)) # geometryの取得 target_projection = proj_ax.projection feature = cartopy.feature.NaturalEarthFeature('physical', 'land', '10m') geoms = feature.geometries() # 領域取得 boundary = proj_ax._get_extent_geom() # 投影方法の変換 geoms = [target_projection.project_geometry(geom, feature.crs) for geom in geoms] # invalid な geometryの排除 geoms2 = [] for i in range(len(geoms)) : if geoms[i].is_valid : geoms2.append(geoms[i]) geoms = geoms2 # intersection geoms = [boundary.intersection(geom) for geom in geoms] # geometry to path to polygon to collection paths = concat(geos_to_path(geom) for geom in geoms) polys = concat(path.to_polygons() for path in paths) lc = PolyCollection(polys, edgecolor='black', facecolor='green', closed=True, alpha=0.2) # 挿入 ax3d.add_collection3d(lc, zs=0) ax3d.view_init(elev=30, azim=-120) plt.close(proj_ax.figure) # 閉じないと plt.showで2個出てくる fig.savefig("sample2.png") plt.show() #plt.close(fig)表示結果
ちなみに intersection しないと描画領域から地図がはみ出すと思います。
6. おわりに
いかがでしたでしょうか。3D プロットをマウスで動かして遊ぶの楽しいですよね(笑)。ほかの投影法については Cartopy の公式サイトにも記載がありますのでそれらをご活用ください。
7. 参考文献
- 防災科学技術研究所 広帯域地震観測網 (F-net) メカニズム解の検索
https://www.fnet.bosai.go.jp/event/search.php?LANG=ja- Introduction — cartopy 0.18.0 documentation
https://scitools.org.uk/cartopy/docs/latest/index.html- Using cartopy with matplotlib — cartopy 0.18.0 documentation
https://scitools.org.uk/cartopy/docs/latest/matplotlib/intro.html- matplotlib - contourf in 3D Cartopy - Stack Overflow
https://stackoverflow.com/questions/48269014/contourf-in-3d-cartopy

- 投稿日:2021-01-16T13:15:12+09:00
現在実行中のpython.exeのパスを取得するには
現在、当スクリプト.pyファイルを実行中のpython.exeのパスを取得するには:
sys.base_prefixConsoleimport sys sys.base_prefix結果'C:\\python-3.7.4.amd64'
P.S.
一方、Pythonで実行中の当スクリプト.pyファイルのパスを取得するには:
__file__test.pyprint(__file__)結果'C:\\test.py'