- 投稿日:2021-01-15T22:31:05+09:00
【Rails】seed.rbで初期データを作成する【Faker】【日本語化】
はじめに
- 筆者のスペック
- Rails学習歴:4ヶ月
- 条件
- Rails 6.0.3.2
- Ruby 2.6.6
そのため間違いなどがある可能性があるので鵜呑み厳禁!
gem「Faker」をinstall
- Gemfileに
gem 'fakerを追加- ターミナル上で
bundle installを実行Gemfilegem 'faker'ターミナル$ bundle install「Faker」を日本語化する
- Rails全体を日本語化する OR Fakerのみを日本語化する
config/initializers/locale.rbRails.application.config.i18n.default_locale = :ja ##Rail全体を日本語化する場合 Faker::Config.locale = :ja ##Faker単体のみ日本語化する場合 ## どちらか片方のみでも設定すれば日本語化できます「Faker」の日本語訳をカスタマイズする
- Githubからja.ymlをダウンロードしてくる
- ja.ymlを
config/locales/fakerに配置するconfig.i18n.load_pathでconfig/locales以下のどの階層のディレクトリも読み込ませるようにする- ダウンロードしてきたja.ymlを自分好みにカスタマイズする
ターミナル## wget 【ダウンロードしたいファイルのURL】 -P 【ダウンロードしたファイルを格納したい場所】 $ wget https://raw.githubusercontent.com/faker-ruby/faker/master/lib/locales/ja.yml -P config/locales/fakerconfig/application.rbmodule Club class Application < Rails::Application ... config.i18n.load_path += Dir[Rails.root.join('config', 'locales', '**', '*.{rb,yml}').to_s] ... end endseed.rbでデモデータの投入
前提条件として
Userモデル,Groupモデルとその2つの中間テーブルGroupUserモデルに初期データを投入していく。
1. 初期設定で作成するデモデータの数を決める。
2. テストデータでテストユーザが使用するデータを投入する。
3. ユーザーとグループを作成する。
4. ランダム性として1/5の確率でユーザーがグループに加入するようにする。
5.rails db:migrate:resetでDBをリセットして、rails db:seedで初期データを流し込む。db/seeds.rb# 初期設定 users_number = 20 groups_number = 20 # テストデータ User.create!(name: '佐藤 隆起', email: 'n1@example.com', password: 'password', description: '皆さんよろしくお願いします!!!') Group.create!(name: '水泳', description: '県優勝を目指して日々切磋琢磨しています。') GroupUser.create!(group_id: 1, user_id: 1) # ユーザー users_list = [] users_number.times do users_list << {name: Faker::Name.unique.name, email: Faker::Internet.unique.email, password: 'password', description: 'よろしく!'} end User.create!(users_list) # グループ groups_list = [] groups_number.times do groups_list << {name: Faker::Team.unique.sport, description: 'みんなぜひ入部してください!!'} end Group.create!(groups_list) # 1/5の確率で1つのグループに加入する group_users_list = [] User.all.ids.each do |user_id| Group.all.ids.each do |group_id| if rand(5) == 0 && (user_id != 1 && group_id != 1) group_users_list << { user_id: user_id, group_id: group_id} end end end GroupUser.create!(group_users_list)ターミナル$ rails db:migrate:reset $ rails db:seed配列を用いて複数のデータを一括で作成する
users_listで今回作成するユーザを格納する。(今回は特に使用しないが後々便利になるかも)users_number.timesを用いて、指定の回数分ユーザを作成する。- 1回のブロック処理で
users_listの中に1人のユーザの情報を格納していく。User.create!(users_list)でusers_listに格納されている全てのユーザを作成する。users_list = [] users_number.times do users_list << {name: Faker::Name.unique.name, email: Faker::Internet.unique.email, password: 'password', description: 'よろしく!'} end User.create!(users_list)参考するべき文献
create と create!の使い分けrand()を用いて不規則にデータを作成する
誰がどのグループに加入するかこちらで決めるのは面倒なので
rand()を用いて簡易化します。
1.User.all.ids.each、Group.all.ids.eachで全てのユーザ、グループのIDを取得する。
2.if rand(5) == 0で1/5の確率で実行するようにする。(※rand(5)は0~4の数字をランダムに出力する。)
3.(user_id != 1 && group_id != 1)は上でテストデータとして登録しているので重複しないように除外する。
4.GroupUser.create!(group_users_list)でgroup_users_listに格納されている全てのデータを作成する。group_users_list = [] User.all.ids.each do |user_id| Group.all.ids.each do |group_id| if rand(5) == 0 && (user_id != 1 && group_id != 1) group_users_list << { user_id: user_id, group_id: group_id} end end end GroupUser.create!(group_users_list)参考にすべき文献
【Ruby入門】randomを使いこなす!【数値、文字列、array、secure】
【Ruby eachの応用編】さまざまな使い方を網羅的に理解しよう
【Rails】アソシエーションの初期データを作ってみた
- 投稿日:2021-01-15T21:14:10+09:00
RSpecでよく使うマッチャ
この投稿では、私がRSpecでよく使うmatcher(マッチャ)についてまとめています。
「RSpecのgitURL」
「Relish」1. include
includeは、
expectの引数にincludeの引数が含まれていることを確認するマッチャです。describe "スポーツ" do it "スポーツに野球が含まれている" do expect(["野球", "サッカー", "ラグビー", "テニス"]).to include("野球") end endこのテストコードを実行した場合、想定通り配列のなかに
野球は含まれているため、テストは成功します。2. eq
eqは、
expectの引数とeqの引数が等しいことを確認するマッチャです。describe "足し算" do it "1 + 1の計算結果は2と等しい" do expect(1 + 1).to eq(2) # 1 + 1 = 2 =>正しい end endこのテストコードを実行した場合、想定通り
1 + 1は2と等しいため、テストは成功します。3. be_valid
be_validは、
バリデーション実行時の返り値がtrueであることを確かめるマッチャです。# バリデーションでuserのnicknameは最大5文字まで it "nicknameは5文字以下であれば登録できる" do user.nickname = "あいうえお" # nicknameを上書きする expect(user).to be_valid # be_validでuserが登録できるか判定 endこのテストコードを実行した場合、想定通り
nicknameは5文字以下のため、テストは成功します。4. have_content
expect(page).to have_content('X')
訪れたpageの中に、Xという文字列があるかどうかを判断するマッチャです。
pageは訪れた先のページの見える分だけの情報が格納されています。例えば、ページに「ログイン」と書かれたボタンがある場合、「ログイン」という文字列情報がpageに格納されています。
ただし、カーソルを合わせてはじめて見ることができる文字列はpageの中に含まれません。# ログインページに「ログインボタン」があることを確認する expect(page).to have_content('ログイン')また、have_contentの逆で、文字列が存在しないことを確かめる
have_no_contentマッチャがあります。5. have_link
expect("要素").to have_link 'ボタンの文字列', href: "リンク先のパス"
要素の中に当てはまるリンクがあることを確認するマッチャです。また、have_linkはa要素に対して用います。# ログインページにログイン処理を行うパスが存在する expect(page).to have_link 'ログイン', href: new_user_session_path # このコードでは要素でなくpageを用いています。また、
have_linkの逆で、当てはまるリンクがないことを確認するhave_no_linkマッチャがあります。
expect("要素").to have_no_link 'ボタンの文字列', href: "リンク先のパス"とすることで、要素の中に当てはまるリンクがないことを確認できます。6. change
expect{ "何らかの動作" }.to change { "数が変化するもの" }.by(X)
数がいくつ(X)変化するのかを確認するマッチャです。# pageにある「投稿する」ボタンをclick_onメソッドでクリック expect{ click_on "投稿する" }.to change { Tweet.count }.by(1) # Tweetモデルのレコードのカウントが1つ上がる# 変数aに対して、いくつ変化するか確認 expect { a += 1 }.to change { a }.by(1) # 値の増減を、相対値で検証 # => a = 2 expect { a += 3 }.to change { a }.from(2).to(5) # 状態が何から何に変わったのかを検証 # => a = 5 (aが2から5に変化)まとめ
今回紹介したRSpecのマッチャはは、ごく一部で勉強する中でまだまだ多くのマッチャが存在することを知りました。
今後も、新しい気付きや学んだことを投稿していきたいと思います。何か誤り等あれば、コメントにて教えてください。
- 投稿日:2021-01-15T21:01:50+09:00
Rails アプリの作成初めかた
・画面に表示する
1.Railsでアプリの土台を作る
$ rails 5.2.1 new アプリ名 -d mysql
必要なファイルが一気にできる2.ルーティングを作成
config/routes.rb にdef index end
3.コントローラー作成
$ rails g controller ファイル名
contlloers/applocation_controller.rb
HTTPメソッド 'ファイル名' => 'ファイル名#index'4.ビューファイル
app/views にindex.html.erbファイルを作成し、Hello World!
・データベースに保存する
5. データベースの作成
rails db:create6.モデル作成
rails g model ファイル名
マイグレーションファイルができる7.カラムの作成
db/migrate/ファイル名.rb にカラム記入
カラムデータ型指定 :カラム名8.マイグレート
rails db:migrate
☆WEll DONE(^^♪☆
- 投稿日:2021-01-15T20:28:51+09:00
heroku rake db:migrateが失敗してエラーが出た時の対処
プログラミング初心者で勉強中の身ですが、ググってもなかなか情報が出なかったので報告します。
環境
Mac OS X
Ruby: 2.7.1
Rails: 6.0.3.4
heroku stack: heroku-20(エラーが出た時)
DB: MYSQL起こったこと
https://qiita.com/murakami-mm/items/9587e21fc0ed57c803d0
こちらの記事を参考にherokuへのデプロイを試みたところ、console$ heroku rake db:migrateを実行した時に
consoleMysql2::Error::ConnectionError: SSL connection error: error:1425F102:SSL routines:ssl_choose_client_version:unsupported protocolとエラーが出た。
原因・対処
原因
自身の環境でこのエラーが起きた原因は二つ
➀heroku stackが heroku-20であった
➁config/database.ymlに必要な記述が無かった対処
➀heroku stackが heroku-20であった
→heroku-18を利用できるようにするconsoleheroku stack:set heroku-18 -a <app name>➁config/database.ymlに必要な記述が無かった
productionに以下のコードを追加config/database.ymlproduction: url: <%= ENV['DATABASE_URL'] %>理由
きちんとした理由は随時募集しています。。誰か教えてください。。
➀heroku stackが heroku-20であった
heroku-20に変わることで出てきた、書くべき必要な処理が書けていなかった?
→これまでのheroku-18にすることでとりあえず解決➁config/database.ymlに必要な記述が無かった
config/database.ymlにはこんな記述があるらしいです(自分は何故か消えていた)
config/database.yml# As with config/credentials.yml, you never want to store sensitive information, # like your database password, in your source code. If your source code is # ever seen by anyone, they now have access to your database. # # Instead, provide the password as a unix environment variable when you boot # the app. Read https://guides.rubyonrails.org/configuring.html#configuring-a-database # for a full rundown on how to provide these environment variables in a # production deployment. # # On Heroku and other platform providers, you may have a full connection URL # available as an environment variable. For example: # # DATABASE_URL="mysql2://myuser:mypass@localhost/somedatabase" # # You can use this database configuration with: # # production: # url: <%= ENV['DATABASE_URL'] %>特に今回は後半の記述が大切で
config/database.yml# On Heroku and other platform providers, you may have a full connection URL # available as an environment variable. For example: # # DATABASE_URL="mysql2://myuser:mypass@localhost/somedatabase" # # You can use this database configuration with: # # production: # url: <%= ENV['DATABASE_URL'] %>雑に和訳すると
「Herokuや他のプラットフォーム上で、あなたは環境変数の形で様々なURLをもらえるでしょう。こんなかんじで:
DATABASE_URL="mysql2://myuser:mypass@localhost/somedatabase"
あなたはこのデータ構成をこのように使えます
production:
url: <%= ENV['DATABASE_URL'] %>」要はこの記述が無かったことで、どこのデータベースを使えばいいか分からずにエラーが出ていた。
まとめ
何かおかしいことが起こり、ググっても分からないときは使っているもののバージョンを確認してみよう!
読んでいただきありがとうございました。
- 投稿日:2021-01-15T20:28:51+09:00
heroku rake db:migrateでエラーが出た時の対処
プログラミング初心者で勉強中の身ですが、ググってもなかなか情報が出なかったので報告します。
環境
Mac OS X
Ruby: 2.7.1
Rails: 6.0.3.4
heroku stack: heroku-20(エラーが出た時)
DB: MYSQL起こったこと
https://qiita.com/murakami-mm/items/9587e21fc0ed57c803d0
こちらの記事を参考にherokuへのデプロイを試みたところ、console$ heroku rake db:migrateを実行した時に
consoleMysql2::Error::ConnectionError: SSL connection error: error:1425F102:SSL routines:ssl_choose_client_version:unsupported protocolとエラーが出た。
原因・対処
原因
自身の環境でこのエラーが起きた原因は二つ
➀heroku stackが heroku-20であった
➁config/database.ymlに必要な記述が無かった対処
➀heroku stackが heroku-20であった
→heroku-18を利用できるようにするconsoleheroku stack:set heroku-18 -a <app name>➁config/database.ymlに必要な記述が無かった
productionに以下のコードを追加config/database.ymlproduction: url: <%= ENV['DATABASE_URL'] %>理由
きちんとした理由は随時募集しています。。誰か教えてください。。
➀heroku stackが heroku-20であった
heroku-20に変わることで出てきた、書くべき必要な処理が書けていなかった?
→これまでのheroku-18にすることでとりあえず解決➁config/database.ymlに必要な記述が無かった
config/database.ymlにはこんな記述があるらしいです(自分は何故か消えていた)
config/database.yml# As with config/credentials.yml, you never want to store sensitive information, # like your database password, in your source code. If your source code is # ever seen by anyone, they now have access to your database. # # Instead, provide the password as a unix environment variable when you boot # the app. Read https://guides.rubyonrails.org/configuring.html#configuring-a-database # for a full rundown on how to provide these environment variables in a # production deployment. # # On Heroku and other platform providers, you may have a full connection URL # available as an environment variable. For example: # # DATABASE_URL="mysql2://myuser:mypass@localhost/somedatabase" # # You can use this database configuration with: # # production: # url: <%= ENV['DATABASE_URL'] %>特に今回は後半の記述が大切で
config/database.yml# On Heroku and other platform providers, you may have a full connection URL # available as an environment variable. For example: # # DATABASE_URL="mysql2://myuser:mypass@localhost/somedatabase" # # You can use this database configuration with: # # production: # url: <%= ENV['DATABASE_URL'] %>雑に和訳すると
「Herokuや他のプラットフォーム上で、あなたは環境変数の形で様々なURLをもらえるでしょう。こんなかんじで:
DATABASE_URL="mysql2://myuser:mypass@localhost/somedatabase"
あなたはこのデータ構成をこのように使えます
production:
url: <%= ENV['DATABASE_URL'] %>」要はこの記述が無かったことで、どこのデータベースを使えばいいか分からずにエラーが出ていた。
まとめ
何かおかしいことが起こり、ググっても分からないときは使っているもののバージョンを確認してみよう!
読んでいただきありがとうございました。
- 投稿日:2021-01-15T20:05:38+09:00
投稿を1段3つずつに分割する(each_sliceメソッド)
本記事の目的
- railsで投稿を1段3分割にするやり方の共有
→作成するにあたり、意外にやり方が見つからなかったため記事の対象
- railsで投稿を以下画像の様に1段3分割にしたい方

やり方
each_sliceメソッドを使う。each_sliceメソッドはブロックに渡す要素数を指定することができる。
例えば、、、
sample.rbnumbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] numbers.each_slice(2) do |number1, number2| puts " #{number1} : #{number2}" end↓↓↓↓↓↓↓↓↓↓↓
terminal% ruby sample.rb 1 : 2 3 : 4 5 : 6 7 : 8 9 : 10
もし、配列の要素数が割り切れないと、最後の段のみ要素数が減るsample.rbnumbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] numbers.each_slice(3) do |number1, number2, number3| puts " #{number1} : #{number2}: #{number3}" end↓↓↓↓↓↓↓↓↓↓↓
terminal% ruby sample.rb 1 : 2: 3 4 : 5: 6 7 : 8: 9 10 : :実践
上で示したeach_sliceメソッドの使い方でだいたい検討がつくと思うが、使い方は同じ。
コントローラーのアクション内データベースから全ての投稿情報を取得し、インスタンス変数に代入してから、そのインスタンス変数に対して、each_sliceメソッドを使う。
自分のアプリケーションでは、ユーザー詳細ページ内で、ログインしているユーザーが投稿した情報を全て表示している。
users_controller.rbdef show @records = @user.records.order("date DESC") # ログインしユーザーの投稿を、選択した日付の降順で並び替えて全て取得 end # @userには現在ログインしているユーザーの情報が代入されている。 # userモデルとrecord(記録)モデルを扱っているが、一対多の関係になっている。show.html.erb<div class="card-space"> <% @records.each_slice(3) do |record1,record2,record3| %> <div class="array-space"> <% if record1 != nil %> <div class="card"> <div class="date-wrapper"> <% time1 = record1.date %> <div class="selected-date"><%= record1.date.strftime("%Y/%m/%d(#{@wd[time1.wday]})") %></div> <div class="last-updated-date">最終更新日時:<%= record1.updated_at.to_s(:datetime_jp) %></div> </div> <div class="skip-time-space"> <label class="question-rabel">どのくらいサボった?</label> <div class="skip-time"> <%= "#{record1.time}分" %> </div> </div> <div class="text-space"> <label class="question-rabel">何してた?</label> <div class="what-skip"> <%= record1.skip %> </div> <label class="question-rabel">何すべきだった?</label> <div class="to-do"> <%= record1.to_do %> </div> </div> <div class="update-btns"> <%= link_to edit_record_path(record1.id), method: :get, class:"edit-link" do %> <i class="far fa-edit fa-2x"></i> <% end %> <%= link_to record_path(record1.id), method: :delete, class:"delete-link" do %> <i class="far fa-trash-alt fa-2x"></i> <% end %> </div> </div> <% end %> <% if record2 != nil %> <div class="card"> <div class="date-wrapper"> <% time2 = record2.date %> <div class="selected-date"><%= record2.date.strftime("%Y/%m/%d(#{@wd[time2.wday]})") %></div> <div class="last-updated-date">最終更新日時:<%= record2.updated_at.to_s(:datetime_jp) %></div> </div> <div class="skip-time-space"> <label class="question-rabel">どのくらいサボった?</label> <div class="skip-time"> <%= "#{record2.time}分" %> </div> </div> <div class="text-space"> <label class="question-rabel">何してた?</label> <div class="what-skip"> <%= record2.skip %> </div> <label class="question-rabel">何すべきだった?</label> <div class="to-do"> <%= record2.to_do %> </div> </div> <div class="update-btns"> <%= link_to edit_record_path(record2.id), method: :get, class:"edit-link" do %> <i class="far fa-edit fa-2x"></i> <% end %> <%= link_to record_path(record2.id), method: :delete, class:"delete-link" do %> <i class="far fa-trash-alt fa-2x"></i> <% end %> </div> </div> <% end %> <% if record3 != nil %> <div class="card"> <div class="date-wrapper"> <% time3 = record3.date %> <div class="selected-date"><%= record3.date.strftime("%Y/%m/%d(#{@wd[time3.wday]})") %></div> <div class="last-updated-date">最終更新日時:<%= record3.updated_at.to_s(:datetime_jp) %></div> </div> <div class="skip-time-space"> <label class="question-rabel">どのくらいサボった?</label> <div class="skip-time"> <%= "#{record3.time}分" %> </div> </div> <div class="text-space"> <label class="question-rabel">何してた?</label> <div class="what-skip"> <%= record3.skip %> </div> <label class="question-rabel">何すべきだった?</label> <div class="to-do"> <%= record3.to_do %> </div> </div> <div class="update-btns"> <%= link_to edit_record_path(record3.id), method: :get, class:"edit-link" do %> <i class="far fa-edit fa-2x"></i> <% end %> <%= link_to record_path(record3.id), method: :delete, class:"delete-link" do %> <i class="far fa-trash-alt fa-2x"></i> <% end %> </div> </div> <% end %> </div> <% end %> </div>実際には部分テンプレートを用いているので、一部記述を変えてある。
ここでポイントになるのは、各投稿を表示するコードを、
<% if record1 != nil %> <% end %> <% if record2 != nil %> <% end %> <% if record3 != nil %> <% end %>この様に、分割したブロック変数がnilでなければ表示するという囲いを作ることである。
先ほどの、each_sliceメソッドの紹介の例では、要素数がeach_sliceメソッドで指定した値で割り切れない時は、最後の段のみ要素数が減ったが、Railsでは上記の様に囲いがないと、ビューファイルをレンダリングする時にエラーが発生する。
参考記事
Qiita(@ota-yukiさん)「each_sliceメソッドの使い方」
https://qiita.com/ota-yuki/items/ad91ffa8e95108ba3ef7
(2020年12月頭頃に閲覧)Rubyリファレンスマニュアル「instance method Enumerable#each_slice」
https://docs.ruby-lang.org/ja/latest/method/Enumerable/i/each_slice.html
(2021年1月15日閲覧)
- 投稿日:2021-01-15T18:24:16+09:00
ActiveRecord::InvalidForeignKey: Mysql2::Error: Cannot delete or update a parent row: a foreign key constraint failsのエラーの対処
記事の対象者
・ActiveRecord::InvalidForeignKey: Mysql2::Error: Cannot delete or update a parent row: a foreign key constraint failsのエラーが出た初学者
・上記エラーでググって、dependent: :destroyを追加するものの解決しない方(状況が違ければ、すみません)エラーが出た自身の状況
・モデル:bookが親、reviewが子という関係。又、reviewテーブルのbook_idに外部キー制約を設けている。
・以下のマイグレーションファイルを適用させようとrails db:migrateを実行し、execute 'DELETE FROM books;' の行でbookを削除しようとすると、エラーが発生。
※以下のマイグレーションファイルは、bookに外部キーuser_idをもたせようとしており、その前にuser_idが入っていないbook削除しようとしています。ここはあまり気にしなくて大丈夫です。class AddUserIdToBooks < ActiveRecord::Migration[6.0] def up execute 'DELETE FROM books;' ##この行でuser_idが入っていないbooksを削除してから、 add_reference :books, :user, null: false, index: true ##booksに外部キーのuser_idを追加しようとしているマイグレファイルです。 end def down remove_reference :books, :user, index: true end endActiveRecord::InvalidForeignKey: Mysql2::Error: Cannot delete or update a parent row: a foreign key constraint fails (`book_action_development`.`reviews`, CONSTRAINT `fk_rails_924a0b30ca` FOREIGN KEY (`book_id`) REFERENCES `books` (`id`))エラーを文を読む(外部キー制約が原因で削除できないようである)
外部キーが適切でなく、親の行(本の行)を削除できなかった。外部キー制約が失敗。Reviewの外部キーbook_idと参照先のbookの主キーidが原因で失敗している。と読みました。
ちなみにfk_rails_924a0b30caは、Sequel Proで確認すると外部キーの名前のようです。エラーについて調べてみると、ReviewがBookを参照しているため、Bookのデータを削除できないというエラーのようです。もしBookを削除してしまうと、Reviewが参照しているはずのBookのデータが存在しないものになってしまい、これはいけないということで「削除できません!」というエラーが出ているようです。
dependent: :destroyを記述する(自身の場合、解決策とならなかった...)
上記のエラーで検索すると、
ReviewがBookを参照しているため、Bookのデータを削除できないというエラーだから、dependent: :destroyを記述することにより、bookとreviewが共に削除される設定にすれば解決するよ!という記事を見かけ、以下のようにdependent: :destroyを記述しました。class Book < ApplicationRecord has_many :reviews, dependent: :destroy ## dependent: :destroyを追記 has_one_attached :image # belongs_to :user validates :title, presence: true, length:{ maximum: 50} validates :author, presence: true, length:{ maximum: 30} endそしてrails db:migrate実行、、、状況は変わらず同じエラーが出る。。
自身の状況では、dependent: :destroyを実行しても解決されませんでした。。なぜ?executeの行がSQLを実行する為、dependent: :destroyが効かなかった(原因)
execute 'DELETE FROM books;'の行は、以下のRailsガイド(抜粋)にあるようにexecuteによりSQLを実行する行となっています。つまり、モデル、ActiveRecordを通さずにbookを削除しようとしている行になります。(書籍「現場Rails」の例文を思考停止で参考にしていたので、ここに気づくことができませんでした。)
これ故、モデルで設定したdependent: :destroyを設定しても効かない形になります。Active Recordが提供するヘルパーの機能だけでは不十分な場合、executeメソッドで任意のSQLを実行できます。 Railsガイド(抜粋)より
モデル、Active Recordを通すdestroy_allで削除するよう変更し、dependent: :destroyを効かせる
execute 'DELETE FROM books;'の行をモデル、ActiveRecordを通してBookが削除できるようBook.destroy_allに変更します。(そうすると、dependent: :destroyが効きます)
※destroy_allは、すでにテーブルに存在するレコードを一括で削除するメソッドになります。class AddUserIdToBooks < ActiveRecord::Migration[6.0] def up Book.destroy_all ##この行を変更し、ActiveRecordを通してBookを削除できるようにした。 add_reference :books, :user, null: false, index: true end def down remove_reference :books, :user, index: true end endこれでrails db:migrateしてみると、無事成功し、reviewと紐づくbookを削除することができました。
まとめ
・execute 'DELETE FROM books;'の行は、SQL文を実行する行なのでモデル・ActiveRecordを通さずに削除しようとする。故に、dependent: :destroyは効かない。
参考記事
・dependent: :destroyの解説がわかりやすく書かれており、dependent: :destroyを実行すると子モデルから削除されることがわかりやすく書いておりました。
→https://pikawaka.com/rails/destroy_all・こちらのブログにdestroyとDELETEの違いなどなど書かれていて、問題発見のきっかけとなりました?♂️
→https://www.y-hakopro.com/entry/2020/01/25/Cannot_delete_or_update_a_parent_row%3A_a_foreign_key_constraint_fails%E3%80%90MySQL%E3%82%A8%E3%83%A9%E3%83%BC%E3%80%91
- 投稿日:2021-01-15T18:24:16+09:00
ActiveRecord::InvalidForeignKey: Mysql2::Error: Cannot delete or update a parent row: a foreign key constraint failsのエラー
記事の対象者
・ActiveRecord::InvalidForeignKey: Mysql2::Error: Cannot delete or update a parent row: a foreign key constraint failsのエラーが出た初学者
・上記エラーでググって、dependent: :destroyを追加するものの解決しない方(状況が違ければ、すみません)エラーが出た自身の状況
・モデル:bookが親、reviewが子という関係。又、reviewテーブルのbook_idに外部キー制約を設けている。
・以下のマイグレーションファイルを適用させようとrails db:migrateを実行し、execute 'DELETE FROM books;' の行でbookを削除しようとすると、エラーが発生。
※以下のマイグレーションファイルは、bookに外部キーuser_idをもたせようとしており、その前にuser_idが入っていないbook削除しようとしています。ここはあまり気にしなくて大丈夫です。class AddUserIdToBooks < ActiveRecord::Migration[6.0] def up execute 'DELETE FROM books;' ##この行でuser_idが入っていないbooksを削除してから、 add_reference :books, :user, null: false, index: true ##booksに外部キーのuser_idを追加しようとしているマイグレファイルです。 end def down remove_reference :books, :user, index: true end endActiveRecord::InvalidForeignKey: Mysql2::Error: Cannot delete or update a parent row: a foreign key constraint fails (`book_action_development`.`reviews`, CONSTRAINT `fk_rails_924a0b30ca` FOREIGN KEY (`book_id`) REFERENCES `books` (`id`))エラーを文を読む(外部キー制約が原因で削除できないようである)
外部キーが適切でなく、親の行(本の行)を削除できなかった。外部キー制約が失敗。Reviewの外部キーbook_idと参照先のbookの主キーidが原因で失敗している。と読みました。
ちなみにfk_rails_924a0b30caは、Sequel Proで確認すると外部キーの名前のようです。エラーについて調べてみると、ReviewがBookを参照しているため、Bookのデータを削除できないというエラーのようです。もしBookを削除してしまうと、Reviewが参照しているはずのBookのデータが存在しないものになってしまい、これはいけないということで「削除できません!」というエラーが出ているようです。
dependent: :destroyを記述する(自身の場合、解決策とならなかった...)
上記のエラーで検索すると、
ReviewがBookを参照しているため、Bookのデータを削除できないというエラーだから、dependent: :destroyを記述することにより、bookとreviewが共に削除される設定にすれば解決するよ!という記事を見かけ、以下のようにdependent: :destroyを記述しました。class Book < ApplicationRecord has_many :reviews, dependent: :destroy ## dependent: :destroyを追記 has_one_attached :image # belongs_to :user validates :title, presence: true, length:{ maximum: 50} validates :author, presence: true, length:{ maximum: 30} endそしてrails db:migrate実行、、、状況は変わらず同じエラーが出る。。
自身の状況では、dependent: :destroyを実行しても解決されませんでした。。なぜ?executeの行がSQLを実行する為、dependent: :destroyが効かなかった(原因)
execute 'DELETE FROM books;'の行は、以下のRailsガイド(抜粋)にあるようにexecuteによりSQLを実行する行となっています。つまり、モデル、ActiveRecordを通さずにbookを削除しようとしている行になります。(書籍「現場Rails」の例文を思考停止で参考にしていたので、ここに気づくことができませんでした。)
これ故、モデルで設定したdependent: :destroyを設定しても効かない形になります。Active Recordが提供するヘルパーの機能だけでは不十分な場合、executeメソッドで任意のSQLを実行できます。 Railsガイド(抜粋)より
モデル、Active Recordを通すdestroy_allで削除するよう変更し、dependent: :destroyを効かせる
execute 'DELETE FROM books;'の行をモデル、ActiveRecordを通してBookが削除できるようBook.destroy_allに変更します。(そうすると、dependent: :destroyが効きます)
※destroy_allは、すでにテーブルに存在するレコードを一括で削除するメソッドになります。class AddUserIdToBooks < ActiveRecord::Migration[6.0] def up Book.destroy_all ##この行を変更し、ActiveRecordを通してBookを削除できるようにした。 add_reference :books, :user, null: false, index: true end def down remove_reference :books, :user, index: true end endこれでrails db:migrateしてみると、無事成功し、reviewと紐づくbookを削除することができました。
まとめ
・execute 'DELETE FROM books;'の行は、SQL文を実行する行なのでモデル・ActiveRecordを通さずに削除しようとする。故に、dependent: :destroyは効かない。
参考記事
・dependent: :destroyの解説がわかりやすく書かれており、dependent: :destroyを実行すると子モデルから削除されることがわかりやすく書いておりました。
→https://pikawaka.com/rails/destroy_all・こちらのブログにdestroyとDELETEの違いなどなど書かれていて、問題発見のきっかけとなりました?♂️
→https://www.y-hakopro.com/entry/2020/01/25/Cannot_delete_or_update_a_parent_row%3A_a_foreign_key_constraint_fails%E3%80%90MySQL%E3%82%A8%E3%83%A9%E3%83%BC%E3%80%91
- 投稿日:2021-01-15T18:06:56+09:00
RSpec コントローラーテストの書き方
前提
・deviseが導入されています
・今回書くテストの内容について
・ユーザーがログインしていれば、正しく表示されることapp/controllers/posts_controller.rbclass PostsController < ApplicationController before_action: authenticate_user! def index @posts = Post.all end endファイルの作成・役割について
①spec配下にrequests, factoriesフォルダを作成
・spec/requests/posts_request.rbを作成
→テストの内容を記述するファイル・spec/factories/user.rb
・spec/factories/post.rbを作成
→userとpostに関するダミーデータを作成するファイル②FactoryBotを使えるようにするためにspec配下にsupportフォルダとfactory_bot.rbファイルを作成
spec/support/factroy_bot.rbRSpec.configure do |config| config.include FactoryBot::Syntax::Method #FactoryBotのため config.include Devise::Test::IntegrationHelper, type: :request #deviseのsign_inメソッドが使えるようになる end次にrails_helper.rbの編集
spec/rails_helper.rbrequire 'spec_helper' ... require 'rspec/rails' require 'support/factroy_bot' #←この記述によってFactroyBotを使用できるダミーデータの作成
spec/factories/user.rbFactoryBot.define do factory :user do email { Faker::Internet.email } name { "testuser1" } password { "password" } password_confirmation { "password" } end endspec/factories/post.rbFactroyBot.defind do factory :post do body { Faker::Lorem.charactors(number: 15) } #15文字のダミー文を作成 end endテストコードの作成
spec/requests/post_spec.rbrequire 'rails_helper' RSpec.describe 'post_controllerのテスト', type: :request do let(:user) { create(:user) } let(:post) { create(:post) } describe 'ログイン済みの場合' do before do sign_in user get posts_path end it '投稿一覧ページへのリクエストは200 okとなること' do expect(response.status).to eq 200 end it 'ページタイトルが正しく表示されていること' do expect(response.body).to include('投稿一覧') end end describe "ログインしていない場合" do before do get posts_path end it 'リクエストが401となること' do expect(response.status).to eq 401 end it 'タイトルが表示されない' do expect(response.body).to_not include("投稿一覧") end end endあとはRSpecを動かしてみるのみ!
$ rspec spec/requests最後に
初心者中の初心者の記事なので、十中八九ミスがあると思います。
気づかれた方がおられたら、教えていただけるととてもありがたいです!
!
- 投稿日:2021-01-15T16:02:04+09:00
プロを目指す人のためのRuby入門 配列や繰り返し処理4章
イントロダクション
今回プロを目指す人のためのRuby入門1の続きを書いていこうと思います!
引き続き、自分用アウトプットとなっておりますので、暖かく見ていただけると幸いです!この章で学ぶこと
配列
ブロック
範囲
様々な繰り返し処理
繰り返し処理用の制御構造配列
配列とは複数のデータをまとめて格納できるオブジェクト。
#空の配列 [] #3つの要素が格納された配列 [要素1,要素2,要素3]配列のクラスはArrayクラス
配列はどんなデータ型でも格納できる、それぞれが違ったデータ型だろうと、、、
また配列の中に配列を入れたりも可能a = [1, 2, 3, 4, 5] a.size #=> 5 a.length #=> 5sizeとlegthのメソッドを使うと配列の長さを取得できる。
要素の変更、追加、削除
配列[添字] = 新しい値 a = [1,2,3] a[1] = 20 a #=> [1,20,3] #元の大きさよりも大きい添字をすると間の値がnilになる a[4] = 50 a #=> [1,20,3,nil,50] #<<を使うと最後の配列の最後に要素を追加できる a << 60 a #=> [1,20,3,nil,50,60] #配列ないの要素を削除したい場合は、delete_atを使う a.delete_at(1) a #=> [1,3,nil,50,60] #存在しない添字を指定するとnilが変える a.delete(100) #=> nil a #=> [1,3,nil,50,60]配列を使った多重代入
a, b = [1, 2] a #=> 1 b #=> 2 c, d = [10] c #=> 10 d #=> nil e,f = [100, 200, 300] e #=> 100 f #=> 200
divmodメソッド・・・割り算の章とあまりを配列として返す14.divmod(3) #=> [4, 2] #戻り値を配列のまま受け取る quo_rem = 14.divmod(3) "商=#{quo_rem[0]},余り=#{quo_rem[1]}" #=> "商=4, 余り=2"ブロック
ブロックはメソッドの引数として渡すことができる処理のかたまり。ブロック内で記述した処理は必要に応じてメソッドから呼び出される。
rubyの繰り返し処理
numbers = [1,2,3,4] sum = 0 numbers.each do |n| sum += n end sum #=> 10ここではnumbers.eachメソッドが繰り返し処理をしている
eachメソッド・・・配列の要素を最初から最後まで順番にとりだすことそして取り出した中でそれぞれの要素をどう扱うかはブロックに記述
ここのコードでいうとdoからendまでがブロックです!
そして|n|がブロック引数になる配列の要素を削除する条件を自由に指定
deleteメソッド・・・要素の値と一致したものを削除a = [1,2,3,1,2,3] a.delete(2) a #=> [1,3,1,3]'delete_ifメソッド`・・・条件にあった要素削除
基本的には配列から要素を1つずつ取り出すという点では、eachメソッドと同じですが、そこからdelete_ifは、ブロックの戻り値チェックし、真であればその要素から配列を削除します。よってブロック内のコードは、削除したい条件を記入する
a = [1,2,3,1,2,3] #配列から値が奇数の要素の削除 a.delete_if do |n| n.odd? end a #=> [2,2]ブロック引数とブロック内の変数
ブロック処理が行われる際の要素一つ一つに対しての引数
よって引数名は自由に決められる。また使わない場合は、ブロック引数は、省略可能
numbers = [1,2,3,4] sum = 0 #|n|がブロック引数 numbers.each do |n| sum_value = n.even? ? n * 10 : n sum += sum_value sum #=> 1 3 6 10の順に表示(エラーにならない) end sum_value #=> NameError: ...上記のようにブロック内で定義した変数は、参照できない
しかし変数sumのようにブロックの外部で作成されたローカル変数は、ブロックの内部でも外部でも参照可能注意) ブロック引数をブロックの外にある変数と同じにすると、ブロック引数が優先される。シャドーイングという
do ... endと{}
ブロックは改行を入れなくもrubyの文法上、動作する
numbers = [1,2,3,4] numbers.each do |n| sum += n end sum #=> 10 numbers.each { |n| sum += n }しかし、可読性が低い
またdo ... end以外にも{}でかこんでブロックを作れる
もちろん改行もできるおすすめの使い分け
・改行を含める場合は、do...end
・1行でコンパクトに書きたいときは{}ブロックを使う配列メソッド
使用頻度が高い配列メソッド
・map/collect
・select/find_all/reject
・find/detect
・inject/reducemap/collect
各要素に対してブロックを評価した結果を新しい配列にして返す。(collectはエイリアスメソッド)
numbers = [1,2,3,4,5] new_numbers = [] numbers.each { |n| new_numbers << n * 10 } new_numbers #=> [10,20,30,40.50] #mapメソッドを使うと new_numbers = numbers.map { |n| n * 10 } new_numbers #=> [10,20,30,40.50]このようにmapメソッドを使うとブロックの戻り値が配列の要素として新しい配列が作成される
mapメソッドは、配列に対して、新しい配列を作るselect/find_all/reject
select・・・各要素に対してブロックを評価し、その戻り値が真の要素を集めた新しい配列を返すメソッド(find_allをselectのエイリアスメソッド)
reject・・・selectの逆。偽の要素を集めた新しい配列を返すnumbers = [1,2,3,4,5] even_numbers = numbers.select { |n| n.even? } non_multiples_of_three = numbers.reject {|n| n % 3 === 0 } even_numbers #=> [2,4,6] non_multiples_of_three #=> [1,2,4,5]find/detect
ブロックが戻り値が真になった最初の要素を返す(detectはエイリアスメソッド)
numbers = [1,2,3,4,5] even_number = numbers.find{ |n| n.even? } even_number #=> 2inject/reduce
たたみ込み演算を行う(reduceはエイリアスメソッド)
numbers = [1,2,3,4] sum = numbers.inject(0){ |result, n| result + n } sum #=> 10このコードではinjectメソッドの第一引数には、足していく合計値、第二引数にはそれぞれの要素が入ってくる
1 result = 0 n = 1 + 0
2 result = 1 n = 2 + 1
3 result = 3 n = 3 + 3
4 result = 6 n = 4 + 6
で10が戻り値になる&とシンボルを使って完結に
['ruby', 'java7, 'perl'].map { |s| s.upcase } #=> ["RUBY", "JAVA", "PERL"] #上記のコードを簡潔にすると ['ruby', 'java7, 'perl'].map($:upcase) #=> ["RUBY", "JAVA", "PERL"]mapメソッドやselectメソッドにブロックを渡す代わりに&:メソッド名という引数を渡している
下記の条件が揃ったときに使える
・ブロック引数が1つだけ
・ブロックな中で呼び出すメソッドがない
・ブロックの中では、ブロック引数に足してメソッドを1回呼び出す以外の処理がない注意) 慣れないうちは使わなくてもいい
範囲(Range)
rubyには1から5まで、aからeまでのように値の範囲を表すオブジェクトがある。
これを範囲オブジェクトという#最初の値..最後の値(最後の値を含む) 1..5 a..e #最初の値...最後の値(最後の値を含まない) 1...5 a...e (1...5).class #=> Range範囲オブジェクトはRangeクラス
配列や文字列の一部を抜き出す
a = [1,2,3,4,5] a[1...3] #=> [2,3,4] a = "abcde" a[1...3] "bcd"n以上n以下、n以上n未満を判定
#不等号をつか場合 def liquid?(temperature) 0 <= temperature && temperature > 100 end liquid?(-1) #=> false liquid?(0) #=> true liquid?(99) #=> true liquid?(100) #=> false #範囲オブジェクトを使う場合 def liquid?(temperature) (0...100).include?(temperature) end liquid?(-1) #=> false liquid?(0) #=> true liquid?(99) #=> true liquid?(100) #=> falsecase文を使う
範囲オブジェクトはcase文と組み合わせることもできる
def charge(age) case age when 0...5 0 when 6...12 300 when 13...18 600 else 1000 end charge(3) #=> 0 charge(12) #=> 300 charge(16) #=> 600 charge(25) #=> 1000値が連続する配列を作成
to_aメソッド・・・値が連続する配列を作成(1..5).to_a #=> [1.2.3.4.5] ('a'...'e').to_a #=> ["a","b","c","d"] [*1...5] #=> [1,2,3,4,5][]のなかに*と範囲オブジェクトを書いても同じように配列を作れる
繰り返し処理
numbers = (1..4).to_a sum = 0 numbers.each {|n| sum += n } sum #=> 10 sum2 = 0 (1..4).each{ |n| sum2 += n } sum2 #=> 10 numbers2=[] (1..10).step(2){ |n| numbers2 << n } numbers #=> [1,3,5,7,9]
stepメソッド・・・値を増やす感覚を指定できる配列について詳しく
a = [1,2,3,4,5] a[1,3] #=> [2,3,4] a.value_at(0,2,4) #=> 1,3,5 a[a.size -1] #=> 5 a[-1] #=> 5 a[-2] #=> 4 a[-2, 2] #=> [4,5] a.last #=> 5 a.last(2) #=> [4,5] a.first #=> 1 a.first(2) #=> [1,2]様々な要素の変更方法
a = [1,2,3] a[-3] = -10 #=> [-10,2,3] #2つ目から3要素分を100で置き換える b = [1,2,3,4,5] b[1,3] = 100 b #=> [1,100,5] #pushは>>と同じ挙動のメソッド c = [] c.push(1) #=> [1] c.push(2,3) #=> [1,2,3] d = [1,2,3,1,2,3] d.delete(2) #=> 2 d #=> [1,3,1,3] d.delete(5) #=> nil d #=> [1,3,1,3]注意)指定可能位置よりも小さくなった場合や大きくなった場合は、エラーになる
配列の連結
2つの配列を連結したい場合は、concatメソッドか+演算子を使う
違いは元の配列を変更するかどうかという点a = [1] b = [2,3] a.concat(b) #=> [1,2,3] a #=> [1,2,3]変更される b #=> [2,3]変更されない c = [1] d = [2,3] c + b #=> [1,2,3] c #=> [1]変更されない d #=> [2,3]変更されない+演算子を使うことをお勧めする
配列の和集合、差集合、積集合
rubyの配列は、
|,-,&を使って和集合、差集合、積集合を求められるいずれも元の配列は変更しません
a = [1,2,3] b = [3,4,5] a | b #=> [1,2,3,4,5] a - b #=> [1,2] a && b #=> [3]多重代入で残りの全要素を入れとして受け取る
#このように残りの300は通常切り捨てられる a, b = 100,200,300 a #=> 100 b #=> 200 #*を使うと残りの値は配列として取得できる c, *d = 100,200,300 c #=> 100 d #=> [200,300]一つの配列を複数の配列の引数として展開
配列の引数に配列を渡す時、展開して1つの配列にしたい時は、引数を
*引数名とするa = [1] b = [2,3] a.push(b) #=> [1,[2,3]]となってしまう a.push(*b) #=> [1,2,3]個数に制限のない引数のことを可変長引数という。自分で定義するメソッドで可変長引数を使う場合は引数名の前に*をつける
==で等しい配列かどうか判断する
[1,2,3] == [1,2,3] #=> true [1,2,3,4] == [1,2,3] #=> false%記法で配列で文字列の配列を簡潔に作る
#w!で文字列配列 %w!apple melon orange! #=> ["apple","melon","orange"]また文字列の空白を入れたい場合は、/(バックスラッシュ)でエスケープする
囲うのは、!!ではなく()でも問題ない
\nや\tを含め痛い場合はwを大文字(W)にする文字列を配列に変換する
chartsメソッド・・・1文字1文字を配列の要素にする"Ruby".charts #=> ['R','u','b','y']
splitメソッド・・・引数で渡した区切り文字で文字列を配列に分割するメソッド"ruby,java,perl,php".split(',') #=> ["ruby","java","perl","php"]
配列に初期値を設定する
#a = []と同じ a = Array.new a = Array.new(5) a #=> [nil,nil,nil,nil] a = Array.new(5,0) a #=> [0,0,0,0,0] a = Array.new(10){|n| n % 3 + 1} a #=> [1,2,3,1,2,3,1,2,3,1]ミュータブルとイミュータブル
ミュータブル・・・変更可能(破壊的)
イミュータブル・・・変更不可(非破壊的)rubyのイミュータブルなクラス
・数値
・シンボル
・ture/false(TrueClassとFlaseClass)
・nilブロックについて詳しく
添字付きの繰り返し処理
each_with_index・・・ブロック引数の第二引数に添字を渡してくれる(要素が今配列の中で何番目かわかる)fruits = ['apple','orange','melon'] fruits.each_with_index{|fruit,i| puts "#{i}: #{fruit}"} #=> 0: apple # 1: orange # 2: melonその他の配列メソッドで使う時は.with_indexメソッド使う
fruits.map.with_index{|fruit, i| "#{i}: #{fruit}"} #=> ["0: apple", "1: orange", "2: melon"]map以外のメソッドでも使える!!
添字を0以外の文字から始めたい場合は、with_index(始めたい添字)
注意)eact_with_indexには引数は渡せないため、使いたい時は、each.with_index()で使う配列がブロック引数に渡される場合
配列の中に配列が入っている場合、配列処理の中のブロック引数に配列が入ってくる!
dimensions = [ [10,20] [30,40] [50,60] ] areas = [] #ここのブロック引数(dimension)には配列が入ってくる dimensions.each do |dimension| lengh = dimension[0] width = dimension[1] area << length * width end area #=> [200,1200,3000] #引数を二つ受け取れるようにするとコードがシンプルになる areas2 = [] dimensions.each do |length, width| areas2 << length * width end areas2 #=> [200,1200,3000]注意)指定したブロック引数の数が配列の要素より多い場合は、はみ出しているブロック引数は、nilになる
#with_indexを使う場合 dimensions = [ [10,20] [30,40] [50,60] ] dimensions.each_width_index do |dimension, i| #配列をそのまま取り出すようにする end #また()で受け取っても良い dimensions.each_width_index do |(length, width), i| #これだと配列の要素と添字を一気に受け取れる endブロックローカル変数
ブロック引数を;で区切り、続けて変数を宣言すると、ブロックのみで有効な独立したローカル変数を宣言できる
余り使う機会はないと思われる。numbers = [1,2,3,4] sum = 0 numbers.each do |n; sum| sum = 10 sum += n p sum end #=> 11 # 12 # 13 # 14 sum #=> 0様々な繰り返し処理
timeメソッド
配列を使わずに、単純にn回処理を繰り返したい、という場合はIntegerクラスのtimesメソッドを使う
sum = 0 #処理を5回繰り返すnには0,1,2,3,4の順に入る 5.times {|n| sum += n} sum #=> 10ブロック引数が必要ない場合は省略可能!
uptoメソッドとdowntoメソッド
nからmまで数値を1つずつ増やしながら何かの処理をしたい場合はuptoを減らしながら行いたい場合はdowntoを使う
a = [] 10.upto(14) {|n| a << n} a #=> [10,11,12,13,14] b = [] 14.downto(10){|n| b << n} b #=> [14,13,12,11,10]stepメソッド
1,3,5,7のようにnからmまで数値をx個ずつ増やしながら何か処理をしたい場合は、Numericクラスのstepメソッドを使う
a = [] 1.step(10, 2){|n| a << n} a #=> [1,3,5,7,9] b = [] 10.step(1,-2){|n| b << n} b #0> [10,8,6,4,2]while文とuntil文
繰り返し処理ようのメソッド
while文は条件が真である間、処理を繰り返す
unless文は条件が偽である間、処理を繰り返すa = [] #配列が5より小さい間は、1を配列に追加 while a.size < 5 a << 1 end a #=>[1,1,1,1,1] b = [1,2,3,4,5] #配列の長さが3より小さくない場合、配列の最後から要素を消していく until a.size <= 3 a.delete_at(-1) end a #=> [1,2,3]for文
繰り返し処理メソッド
numbers = [1,2,3,4] sum = 0 for n in numbers sum += n end sum #=> 10 sum = 0 for n in numbers do sum += n end sum #=> 10見ての通りeachの挙動とほとんど同じ
ちがいは、for文の中で宣言したローカル変数もfor文の外でも使えるnumbers = [1,2,3,4] sum = 0 for n in numbers sum_value = n.even ? ? n * 10 * n sum += sum._value end n #=> 4 sum_value #=> 40loopメソッド
ループ処理を行うときに使用
loop do #無限ループ用の処理 end無限ループからの脱出はbreakを使う
numbers = [1,2,3,4,5] loop do #sampleメソッドでランダムに要素を1つ取得する n = numbers.sample puts n break if n === 5 end #=> 3 # 2 # 5 5が出たから処理終了do...endを使うのでブロック処理となる。そのためローカル変数を参照できない
whileはdo...end(ブロック)を使わないから参照できる繰り返し処理用の制御構造
繰り返し処理の動きを制御するためのキーワード
・break
・next
・redobreak
繰り返し処理からの脱出
#shuffleメソッドで配列の要素をランダムに並び替える numbers = [1,2,3,4,5].shuffle #5が出たら処理終了 numbers.each do |n| puts n break if n === 5 end while i < numbers.size n = numbers[i] puts n break if n == 5 i += 1 end #=> 2 # 4 # 5breakに引数を渡すと、while文やfor文の戻り値になる
ない場合戻り値はnilになるret = while true break 123 end ret #=> 123breakは繰り返し処理が重なっていた場合一番内側の繰り返し処理しか脱出できない
throwとcatchをつかった大域脱出
breakは繰り返し処理が重なっていた場合一番内側の繰り返し処理しか脱出できない
と言いましたが、一番外側のループまで脱出したい場合は、throwとcatchメソッドを使う
catch タグ do #繰り返し処理など throw endfruits = ['apple', 'melon', 'orange'] numbers = [1,2,3] catch :done do fruits.shuffle.each.do |fruit| numbers.shuffle.each do |n| puts "#{fruit}, #{n}" if fruit == "orange" && n == 3 #全ての繰り返し処理を脱出する throw :done end end end end #melon, 2 #orage, 3 ここで終了 #またthrowの第二引数(タグ名の後)に戻り値を指定できる ret = catch :done do throw :done ,123 end ret #=> 123 #throwで何も第二引数を指定しなければnil繰り返し処理で使うbreakとreturnの違い
主な違い
break・・・繰り返し処理からの脱出
return・・・メソッドからの脱出
処理の中に配列処理があった場合、
breakは、配列処理のみからの脱出
returnだとメソッド全体から脱出してしまうまたreturnはメソッドからの脱出なので、配列処理の中で使用するとエラーになる
next
繰り返し処理を途中でちゅ出し、次の繰り返し処理に進める
numbers = [1,2,3,4,5] numbers.each do |n| next if n.even? puts n end #=> 1 # 3 # 5一番内側のループだけが中断の対象になるeachだけではなく他の繰り返しの中でも使えることは、breakと同じ
redo
繰り返し処理をやり直しする
foods = ["ピーマン","トマト","セロリ"] foods.each do |food| print "#{food}は好きですか? => " answer = ["はい","いいえ"].sample puts answer count += 1 #はいと答えなければまたいいえと答えた回数が2回までの間は、もう一度聞き直す redo unless answer != "はい" && count < 2 endずっといいえが出る場合無限ループになるので注意して使う!
やり直しの制限を設けておくことが最適である。その他でてきたメソッド
rjust・・・右寄せするメソッド第一引数には桁数、第二引数は空白の文字を何にするか指定できる
hex・・・16進数を10進数に変換するメソッド
scan・・・一気に文字列を3つの16進数に分割できる 戻り値がそのまま配列になる
Set(クラス)・・・本格的に集合演算を使うときに利用する
shuffle・・・配列の要素をランダムに並び替える
sample・・・配列からランダムの要素を取得
- 投稿日:2021-01-15T12:46:31+09:00
単体テストコードの実装
私自身の備忘録として簡単にテストコードの実装をここに残しておきます。
前提条件として、今回はユーザーの新規登録の単体テストコードを作成します。
テストする内容はnickname、email、password、password_confirmationの4つをテストします。gemの準備
まずテストするためのgemをgemfileに記述
※記述する箇所はgroup :development, :test doの中に記述すること
ここに記述するとテストする時にだけ使えるようになるためgemfilegroup :development, :test do gem 'rspec-rails' #この4行を記述、テストするためのgem gem 'factory_bot_rails' #この4行を記述、テンプレート的なやつを作るgem gem 'faker' #この4行を記述、テキトーな文字列などを入れてくれるgem gem 'pry-rails' #この4行を記述、binding.pryで処理を止めれるようにするgem # Call 'byebug' anywhere in the code to stop execution and get a debugger console gem 'byebug', platforms: [:mri, :mingw, :x64_mingw] end上記の記述をしたら以下をターミナルで実行
ターミナル% bundle install % rails g rspec:installこれらのファイルが作成されたら完璧
ターミナルcreate .rspec create spec create spec/spec_helper.rb create spec/rails_helper.rb.rspecのファイルに以下を記述
.rspec--require spec_helper #デフォルトで入ってる --format documentation #この行を追加この記述は、テストコードの結果をターミナル上に可視化するための記述です。
モデルの準備
以下のコマンドでモデルの作成をします(今回はuserモデルを作成)
ターミナル% rails g rspec:model userこれらが作成されたらおk
ターミナルcreate spec/models/user_spec.rb invoke factory_bot create spec/factories/users.rbテスト内容の洗い出し
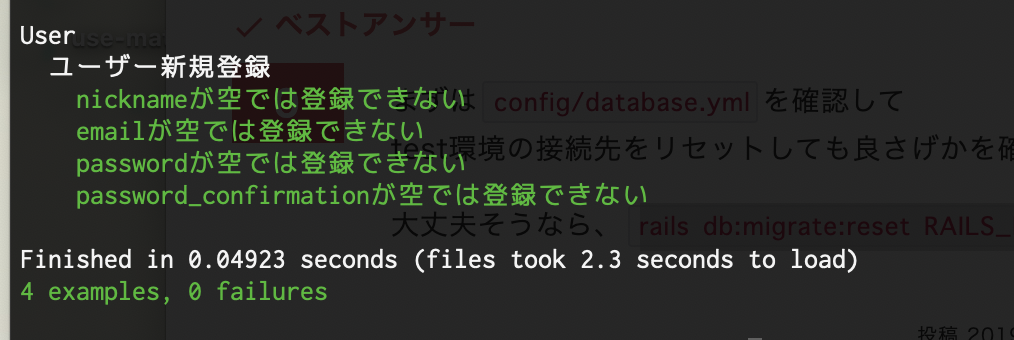
spec/models/user_spec.rbrequire 'rails_helper' RSpec.describe User, type: :model do describe "ユーザー新規登録" do it "nicknameが空では登録できない" do # nicknameが空では登録できないテストコードを記述します end it "emailが空では登録できない" do # emailが空では登録できないテストコードを記述します end it "passwordが空では登録できない" do # passwordが空では登録できないテストコードを記述します end it "password_confirmationが空では登録できない" do # password_confirmationが空では登録できないテストコードを記述します end end endかる〜く解説知ってたらスルーしてよし
①describe "行いたいテストの内容" do〜end
"行いたいテストの内容"のなかに内容を記述、今回はユーザー管理機能のテストを記述②it '条件'do〜end
'条件'の部分にテストしたい条件を記述ちゃんとできてるか確認するためにコマンドを実行
ターミナル% bundle exec rspec spec/models/user_spec.rb
これがターミナルに出力されたらおk
FactoryBotとFakerを使う
まずspecのディレクトリの中にfactoriesと言うディレクトリを作り、その中にuser.rbを作成する
作成したusers.rbに以下を記述
spec/factories/users.rb(Fakerを使わない場合)FactoryBot.define do factory :user do nickname {"test"} email {"test@example"} password {"000000"} password_confirmation {password} end endspec/factories/users.rb(Fakerを使う場合)FactoryBot.define do factory :user do nickname {Faker::Name.initials(number: 2)} email {Faker::Internet.free_email} password {Faker::Internet.password(min_length: 6)} password_confirmation {password} end endこれでfactorybotの準備完了!
①user_spec.rbのファイルに戻ってRSpec.describe User, type: :model doの下に以下の3行を追加
②it do〜endの処理の中に実際行う処理をそれぞれ記述するspec/models/user_spec.rbrequire 'rails_helper' RSpec.describe User, type: :model do #⬇︎この3行を追加 before do @user = FactoryBot.build(:user) end #⬆︎この3行を追加 describe "ユーザー新規登録" do it "nicknameが空では登録できない" do @user.nickname = "" @user.valid? expect(@user.errors.full_messages).to include("Nickname can't be blank") end it "emailが空では登録できない" do #⬇︎実際に行う処理 @user.email = "" @user.valid? expect(@user.errors.full_messages).to include("Email can't be blank") #⬆︎実際に行う処理 end it "passwordが空では登録できない" do @user.password = "" @user.valid? expect(@user.errors.full_messages).to include("Password can't be blank") end it "password_confirmationが空では登録できない" do @user.password_confirmation = "" @user.valid? expect(@user.errors.full_messages).to include("Password confirmation doesn't match Password") end end end実行しましょう!
ターミナル% bundle exec rspec spec/models/user_spec.rb
これらが表示されたらおk
もしエラーが出てしまうならエラー箇所にbinding.pryを記述し実行しましょう!spec/models/user_spec.rbit "nicknameが空では登録できない" do @user.nickname = "" @user.valid? binding.pry #ここで処理が止まる expect(@user.errors.full_messages).to include("Nickname can't be blank") end※処理を止めてエラーの内容を確認する手順は以下の通りです
ターミナルpry(#<RSpec::ExampleGroups::User>)> @user.valid? #エラーが出ているかの確認 pry(#<RSpec::ExampleGroups::User>)> @user.errors.full_messages #エラーメッセージの確認 pry(#<RSpec::ExampleGroups::User>)> exit #railsコンソールから脱出

- 投稿日:2021-01-15T11:54:29+09:00
expected `Product.count` to have changed by -1, but was changed by 0
※CRUD操作の内、destroyアクションにしか言及しません。
request specでdestroyアクションのテストを行っていて、
userに関連づいたproductを削除してもテストコード内でcountが−1されず、0のままになっていて長い間困っていた。web上で探してみてもいい感じの記事が見つからなかったので今後同じようなエラーに悩まされた人がいた場合に備えて私の解決策を残しておく。
これがエラー文expected `Product.count` to have changed by -1, but was changed by 0改善前のソースコード
describe 'DELETE #destroy' do context 'ログインしているユーザー' do ??let(:product_params) do { product: { title: "削除用", language: "PHP", detail: "ウオウオの実", period: "8年", user: user } } end subject { delete product_path(product_params) } it '投稿数が一つ減っている' do sign_in_as(user) expect { subject }.to change(Product, :count).by(-1) endだが、これだと上記のようなエラーが出てしまう。流れの解説としては、まずlet(:product_params)~内で削除するproductの準備をする。
そしてsubject(繰り返しを避けるために共通化しておく)内でproduct_paramsの削除を行い、
expectでProductの数が1つ減っているかの確認をする。ここからが改善策
describe 'DELETE #destroy' do context 'ログインしているユーザー' do it '投稿数が一つ減っている' do ?? product_params = user.products.create(title: "削除用",language: "PHP",detail: "ウオウオの実",period: "8年",user: user) sign_in_as(user) expect{ product_params.destroy }.to change{ Product.count }.by(-1) end最初のコードと違う点は、
product_params = user.products.create(title: "削除用",language: "PHP",detail: "ウオウオの実",period: "8年",user: user)ここでproduct_paramsを作成している点だ。最初のコードではproductの情報をcreateしていないのに削除(destroty)していたので、それではcountが0のままなのも今となっては理解ができる。
では、productを作成する書き方として、以下のようなコードはどうだろうか?post products_path, params: product_params理由はよくわからないが、これでは動かなかった。
今後RSpecでControllerのテストの中で削除するためなど、一時的にデータを保存しておきたい場合はpostで送るのではなく,createを使っていこうと思う。
- 投稿日:2021-01-15T11:31:51+09:00
ActiveStorageを導入した時のimageカラムのテストコード
初心者の私がactivestorageを使ったときのテストコードで1時間ほど詰まったのでその備忘録です
まず前提として、必要なactivestorageやfactorybot、specのインストールは済ませているものとします。
済ませていなければ以下のgemをgemfileに記述しbundle installしましょう
その後RSpecのインストールをしましょうrails g rspec:installgemfilegroup :development, :test do gem 'rspec-rails' #この3行を記述、テストをするためのgem gem 'factory_bot_rails' #この3行を記述、テスト用のテンプレートを作成するためのgem gem 'pry-rails' #この3行を記述、bindind.pryを実行するためのgem # Call 'byebug' anywhere in the code to stop execution and get a debugger console gem 'byebug', platforms: [:mri, :mingw, :x64_mingw] endターミナル% bundle install % rails g rspec:installまずpublicのディレクトリ下にimagesと言うファイルを作成する
そのimagesの中に適当な画像のデータを保存する(今回はa.pngと言う名前の画像を用意します)今このような状態
public/images/a.pnga.pngは適当な画像のデータです
次にそのデータを参照したいのでfactoriesディレクトリの中にあるテンプレートの中にimageカラムを作成します今回私は「item」と言うモデルをテストするのでractories/items.rbになります
ractories/items.rb(モデル名.rb)FactoryBot.define do factory :item do name {"名前"} price {500} text {"テスト"} judgement_id {1} category_id {1} prefecture_id {2} day_id {1} status_id {1} user #userとのアソシエーション after(:build) do |message| message.image.attach(io: File.open('public/images/a.png'), filename: 'a.png') end end endゆるく解説
・judgement_idやcategory_idなどの「_id」の項目はactivehashを使って導入したので無視して大丈夫です。
・userと言う記述はuserモデルとのアソシエーションを意味してます、これを記述することでuser_idを入力しなくてすみます。
今回の注目していただきたいのはuserの下にある記述です
ractories/items.rb(モデル名.rb)after(:build) do |message| message.image.attach(io: File.open('public/images/a.png'), filename: 'a.png') endこの記述により実際に存在する写真を参照するようになります。
ダメな例
ractories/items.rb(モデル名.rb)FactoryBot.define do factory :item do name {"名前"} price {500} text {"テスト"} judgement_id {1} category_id {1} prefecture_id {2} day_id {1} status_id {1} image {"a.png"} #ダメな例です user end endこうしてしまうと、文字列しか登録できていないため、エラーになりますちなみにエラー内容は以下になります。
エラーを確かめたい場合はbinding.pryを記述して処理を止めましょう!ターミナル[1] pry(#<RSpec::ExampleGroups::Item>)> @item.valid? ActiveSupport::MessageVerifier::InvalidSignature: ActiveSupport::MessageVerifier::InvalidSignature同じエラーに出会した方の参考になれば幸いです。
- 投稿日:2021-01-15T09:05:26+09:00
【Rails】スコープでfind_byを使用して、条件に一致するレコードがないとnilではなくレコード全件が返される理由
なにこれ
タイトルの通り、筆者が業務でRailsを書いている時に、scope内でfind_byを使用しました。
そこで、条件に一致しなかった場合にnilではなく該当テーブルのレコード全件が返される事象に遭遇したので、解決策と原因を備忘録として残しておきます。注意書き
ドキュメントに答えは書いてあります。
Active Record クエリインターフェイス
検索しても同様の記事がヒットしなかった。ドキュメントに書いてあるからかな?結論(解決策)
1.scopeではなくクラスメソッドを使用する。
そうすることで、条件に一致するものがなかった場合、レコード全件ではなく
nilが返ります。product.rb# bad scope :find_by, ->(product_id) { find_by(product_id: product_id) } #=> ActiveRecord::Relation # good def self.find_by(product_id) find_by(product_id: product_id) end #=> nil2.find_by!メソッドに変更して例外を投げる(一番下の余談を参照)
原因
なぜクラスメソッドだとnilが返るのか?
それを説明するために、スコープとクラスメソッドの違いを確認します。
そもそもスコープとは具体的になんぞや
Railsガイド 14 スコープ
公式から引用します。スコープを設定することで、関連オブジェクトやモデルへのメソッド呼び出しとして参照される、よく使用されるクエリを指定することができます。スコープでは、where、joins、includesなど、これまでに登場したすべてのメソッドを使用できます。どのスコープメソッドも、常にActiveRecord::Relationオブジェクトを返します。このオブジェクトに対して、別のスコープを含む他のメソッド呼び出しを行なうこともできます。
伝えたいことを要約すると、スコープは常に
ActiveRecord::Relationオブジェクトを返します。
検索結果がnilだった場合でも、ActiveRecord::Relationオブジェクトを返します。絶対にです。絶対に!!めっちゃ大事なことなので2回言いました。じゃあActiveRecord::Relationってなんだよ
ActiveRecord::Relationについて簡単にまとまってる良い記事があったので引用させていただきます。
ActiveRecord::Relationとは一体なんなのか上記の記事から要約します。
ProductなるモデルがあったとするとProduct.allやProduct.where(name: "hoge")などで返ってくるものがActiveRecord::Relationのインスタンスです。ざっくり言うと、
ActiveRecord::Relationは複数のレコード(インスタンス?)を持ったやつです。
where.classをすると、Product::ActiveRecord_Relationが返されてるのが確認できます。
find_by.classをすると、Productクラス自身を返します。[31] pry(main)> Product.where(id: 1).class => Product::ActiveRecord_Relation [32] pry(main)> Product.find_by(id: 1).class Product Load (2.1ms) SELECT `products`.* FROM `products` WHERE `products`.`id` = 1 LIMIT 1 => Product(id: integer, name: string)クラスメソッドとスコープの違い
下記の記事が非常に分かりやすかったので引用させてください。
ActiveRecordのscopeでnilを返すと…
クラスメソッドはスコープと全く動きをします。
(スコープはインスタンスメソッドではありません。筆者はここを勘違いしてました。)下記2つが行う動作はほぼ同じです。違うのは
nilやUser.noneの場合返り値だけ。user.rbclass User < ActiveRecord::Base scope :hoge, -> (fuga) { find_by(fuga: fuga) } end class User < ActiveRecord::Base def self.hoge(fuga) find_by(fuga: fuga) end end結局なんでスコープだとダメなの?
スコープだとレコード全件返す理由は、常に
ActiveRecord::Relationオブジェクトを返すからです。
常にActiveRecord::Relationを返すので、nilだった場合は自動的に全てのレコードを返します。クラスメソッドを使用すると、メソッド本来の動きをするので
nilが返されます。
これが答えです。茶番劇
スコープくん「よっしゃ、DBにアクセスしてレコードを絞り込むで〜」
⬇️SQL実行
スコープくん「は!?一致するもんなくて
nilなんやが。。。」スコープくん「でも、ワイは絶対
ActiveRecord::Relationオブジェクトを返すって決められてるからなあ。。。」スコープくん「うーん、
nilを返したら規約違反だし、しょうがないからレコード全件返すべ!」みたいなことが繰り広げられてると思ってます。笑
(スコープで実行したのと同じSQLを実行したら、nilの時は0件で表示されます。)感想
ActiveRecord::Relationについて全く知らなかったので、初めて今回の事象に遭遇した時に「Railsのバグじゃね!?」と思ってました。Railsを疑ってすみません。バリバリ仕様でした。
find_byでレコードが1件も一致しないことがレアケースだと思いますが、こういった事象が起こることを頭の片隅のギリギリにでも置いてもらえたら幸いです。別解:where + take
find_byは、そもそも内部の動き的にはwhere(wheres).limit(1)をしています。
whereで絞り込んだ後にtakeメソッドを呼び出すことで、find_byを再現できます。[32] pry(main)> Product.where(id: 1).take.class Product Load (2.1ms) SELECT `products`.* FROM `products` WHERE `products`.`id` = 1 LIMIT 1 => Product(id: integer, name: string)状況によっては、
where + takeの方が適切な場面がありそう(nilを返して欲しい時とか)ここでややこしいのが、
where + takeしてもスコープで1件もヒットしない場合は、同じく該当テーブルのレコード全件が返されます。
nilが返される + スコープはActiveRecord::Relationを返すっていう仕様のため。余談にもありますが、
take!メソッドは、ActiveRecord::RecordNotFound例外を投げるため、find_by!を代用できそうです。余談(find_by!のススメ)
ここまで長々と書いてきましたが、
find_byで一致するものが無い可能性がある時は、find_by!メソッドにしてActiveRecord::RecordNotFound例外を投げた方がエラーハンドリングできるし処理的に良さそう?
(そもそも、find_byで一致しないことが異常事態な気がするから)# product.rb scope :hoge, ->(product_id) { find_by!(product_id: product_id) } # product_controller.rb def fuga product = Product.hoge(params[:product_id]) render json: product, status: :ok rescue ActiveRecord::RecordNotFound => e render json: e, status: :not_found end
- 投稿日:2021-01-15T02:34:47+09:00
管理画面生成gem Administrate の紹介と導入
Railsで管理画面を作るとき、どうしてますでしょうか。
ちゃんと作りたいなら自作のがよいと思いますが、個人開発など、そこまで工数割けないよ!という時のために、
管理画面生成gem Administrate を紹介したいと思います。Administrate とは
管理画面を自動生成するRailsライブラリ。
技術者以外のユーザーに、アプリケーション内の任意のレコードの作成、編集、検索、削除をできるクリーンなインターフェースを提供します。(公式より)文面を見ても分からないと思うので、公式のデモを触るのが早いです。
公式サイト(英語): https://administrate-prototype.herokuapp.com/
公式デモ: https://administrate-prototype.herokuapp.com/admin
公式Github (thoughtbot/administrate): https://github.com/thoughtbot/administrate※注意
version 1.0 以前なので、APIに大きな変更が加えられる可能性があります。
updateする前にリリースノートを確認した方がよさそうです。Administrate is still pre-1.0, and there may be occasional breaking changes to the API.
導入
Gemfileに追記
# Gemfile gem "administrate"bundle install 後、インストラーを実行する
# デフォルト設定での install (デフォルトのnamespace: admin) $ rails generate administrate:install # 任意のnamespaceを使いたいとき (namespace: supervisor) $ rails generate administrate:install --namespace=supervisor
config/routes.rbに/adminのルートが追加され、app/controllers/admin/application_controller.rbが生成されます。
また、ActiveRecordリソースごとに Dashboard と Controller が生成されます。
- app/controllers/admin/foos_controller.rb
- app/dashboards/foo_dashboard.rb
※namespaceを指定した際は、ルートもディレクトリ名も変わります
# --namespace=supervisor の場合 http://localhost:3000/supervisor app/controllers/supervisor/application_controller.rb終わりに
これで導入が完了し、一通りの機能(作成、編集、検索、削除)が使えるようになりました。
Administrateは、使いやすいように色々とカスタマイズ出来るので、次回いくつか紹介したいと思います。