- 投稿日:2021-01-15T23:51:07+09:00
yukicoder contest 278 参戦記
yukicoder contest 278 参戦記
A 1335 1337
書くだけ.
A = input() S = input() result = '' for c in S: if c in '0123456789': result += A[int(c)] else: result += c print(result)B 1336 Union on Blackboard
問題文を見た瞬間に★1.5!?ってなった. 2 3 0 や 2 3 1 を手計算してみたところ、どの順序でも同じ数値になったので、順番に関係ないのかと踏んで前から順に処理するコードを書いて AC.
T = int(input()) m = 1000000007 for _ in range(T): N = int(input()) A = list(map(int, input().split())) t = 0 for a in A: t = t * a + (t + a) t %= m print(t)C 1337 Fair Otoshidama
最初に100円も持っているんだったら数字は自由に変えれそうなので、結局 X + Y + Z を3人で分けて同じ数にできるかだけだよなということでこうなった.
X, Y, Z = map(int, input().split()) if (X + Y + Z) % 3 == 0: print('Yes') else: print('No')D 1338 Giant Class
長さ W の配列を初期値 H に初期化して、Y - 1 の最小値を取り、毎回減った数を H * W から引いていけば答えが求まる……と思ったら W≦109 で死んだ(爆). 辞書で記録するようにして AC.
from sys import stdin readline = stdin.readline H, W, Q = map(int, readline().split()) c = H * W t = {} result = [] for _ in range(Q): Y, X = map(int, readline().split()) t.setdefault(X - 1, H) p = t[X - 1] t[X - 1] = min(t[X - 1], Y - 1) c -= p - t[X - 1] result.append(c) print(*result, sep='\n')
- 投稿日:2021-01-15T23:34:37+09:00
Effective Python 学習備忘録 14日目 【14/100】
はじめに
Twitterで一時期流行していた 100 Days Of Code なるものを先日知りました。本記事は、初学者である私が100日の学習を通してどの程度成長できるか記録を残すこと、アウトプットすることを目的とします。誤っている点、読みにくい点多々あると思います。ご指摘いただけると幸いです!
今回学習する教材
- 8章構成
- 本章216ページ
今日の進捗
- 進行状況:87-91ページ
- 第4章:メタクラスと属性
- 本日学んだことの中で、よく忘れるところ、知らなかったところを書いていきます。
getやsetメソッドよりも素のままの属性を使う
getやsetメソッドを定義すると、計算をするときにぎこちないコードになってしまいます。
class OldResistor(object): def __init__(self, ohms): self._ohms = ohms def get_ohms(self): return self._ohms def set_ohms(self, ohms): self._ohms = ohms r0 = OldResistor(100) r0.set_ohms(r0.get_ohms() + 500) print(r0.get_ohms()) # 600それよりも素の属性を使ったほうが計算時にすっきりしたコードになります。
class Resistor(object): def __init__(self, ohms): self.ohms = ohms self.voltage = 0 self.current = 0 r1 = Resistor(50e3) r1.ohms = 400 r1.ohms += 200 print(r1.ohms) # 600後に、属性が設定された時に特別な振る舞いが必要になる場合は、@propertyデコレータとそれに対応する、setter属性を付与すれば良いです。
また、正しく動作するためには、セッターメソッドとゲッターメソッドの両方の名前が、意図しているプロパティ名と一致しないとダメです。class VoltageResistance(Resistor): def __init__(self, ohms): # 初期化 super().__init__(ohms) # ohmsを引数として、親クラスの__init__を呼び出す self._voltage = 0 # インスタンス変数 _voltageを宣言 @property # _voltageに入っている値を返す def voltage(self): return self._voltage @voltage.setter # voltageに新たな値を代入するたびにセッターメソッドが実行される def voltage(self, voltage): # プロパティ名と一致 self._voltage = voltage self.current = self._voltage / self.ohms r2 = VoltageResistance(100) print(r2.current) # 0 r2.voltage = 10 # voltage.setterが呼ばれ、voltageに10を渡す print(r2.current) # 0.1このように、素の属性を使い、@propertyを使うことですっきりしたコードを書きながら機能を拡張することができます。@propertyメソッドを使ってセッターやゲッターを実装する際に、可読性を落とさないために以下のポイントを抑えるべしです。
関連するオブジェクト状態だけを変更し、オブジェクトを超えて、モジュールを動的にインポートする、遅いヘルパー庵数を実行するなどの、呼び出し元が予期しない動作をしないように注意!
また、複雑であったり遅くなるような場合は通常のメソッドを使って実装すべきなようです。
- 投稿日:2021-01-15T23:17:11+09:00
Jupyternotebookでpandas-profilingの日本語部分が文字化けする件について
はじめに
データ分析をする際に初めにやることといえば、データがどのような特徴を持っているのか把握することからだと思います。そんなときにpandas-profilingを使うとEDAを一括して行ってくれるのでとても便利です。しかし、Jupyternotebookで試したところデータの日本語のカラムなどが□□□のように文字化け(豆腐)となってしまったので解決策をまとめていきたいと思います。
環境
- Python3.8
- Docker
- Jupyter notebook
原因
pandas-profilingで文字化けが起きる原因はmatplotlibとseabornが日本語化対応できていないことに起因します。日本語化対応できれば、matplotlibとseabornを利用したpandas-profilingも日本語対応されます。
この記事ではmatplotlibとseabornの日本語化の手順について説明することになります。
Matplotlibとseabornの日本語化
この記事ではDockerを利用したJupyternotebook環境の日本語対応について説明します。
さらに効率の良い方法があるかもしれませんので、その際にはコメントを頂けると嬉しいです。1. 日本語のフォントをダウンロードする
こちらのサイトからipaexg00401.zip(4.0MB)をダウンロードして解凍します。
ipaexg00401フォルダの中にあるipaexg.ttfをDockerfileがあるディレクトリに移動します。2. seabornの日本語対応のためコンテナ上のファイルをホストにコピーする
ここで行う作業は、seabornを日本語化させるために必要なrcmod.pyをローカルにダウンロードして内容を書き換え、docker-compose upの度に、コンテナ上のrcmod.pyをホストの書き換え済みのrcmod.pyで上書きするように設定します。このような流れをとることでdocker-compose upの度にrcmod.pyを書き換えずに済みます。
(本当はDockerfileでコンテナ上のを書き換えたいのですがわかりませんでした)
日本語対応していない状態でdocker-compose upをします。
別のターミナルを開いて、コンテナIDを確認します。# コンテナIDを確認する $ docker ps次にコンテナ上のrcmod.pyをホスト(ローカル上)に保存します。
$ docker cp [コンテナID]:opt/conda/lib/python3.8/site-packages/seaborn/rcmod.py [保存先(C:\Users\....など)]最後に保存したrcmod.pyをDockerfileがあるディレクトリにコピーします。
3. rcmod.pyを書き換える
rcmod.pyを開いて以下の内容を変更します。
86-87行目のdef set(context="notebook", ...)のfontの部分をfont="IPAexGothic"に変更します。
def set_theme(context="notebook", style="darkgrid", palette="deep", font="IPAexGothic", font_scale=1, color_codes=True, rc=None):次に205行目の"font.family": ["sans-serif"]を以下に変更します
"font.family": ["IPAexGothic"]これでseabornの日本語対応のための書き換えは終了です。
4. Dockerfileに以下を追加する
# matplotlibとscipyの日本語化 # 日本語のフォントをコピーする COPY ipaexg.ttf /opt/conda/lib/python3.8/site-packages/matplotlib/mpl-data/fonts/ttf/ipaexg.ttf # 書き換えたrcmod.pyでコンテナ上のrcmod.pyを上書きする COPY settings/localize_ja/rcmod.py /opt/conda/lib/python3.8/site-packages/seaborn/rcmod.py # matplotlibの設定ファイルの最後にfont.family : IPAexGothicを追加する RUN echo "font.family : IPAexGothic" >> /opt/conda/lib/python3.8/site-packages/matplotlib/mpl-data/matplotlibrc # キャッシュを削除する RUN rm -r ./.cacheこれでmatplotlibとseabornの日本語対応が行えます。
以下のコードで文字化けしないか確かめることができます。# matplotlibが日本対応できているか確認する import matplotlib.pyplot as plt plt.plot([1, 2, 3, 4]) plt.xlabel('日本語化') plt.ylabel('matplotlibの') plt.show()# seabornが日本語対応できているか確認する import seaborn as sns sns.set(style="whitegrid") # Load the example Titanic dataset titanic = sns.load_dataset("titanic") # Draw a nested barplot to show survival for class and sex g = sns.catplot(x="class", y="survived", hue="sex", data=titanic, height=6, kind="bar", palette="muted") g.despine(left=True) g.set_ylabels("seabornの日本語化")ラベルに日本語が使われているので、ラベルが文字化け(豆腐)してなければ成功です。
matplotlibとseabornの日本語対応が確認出来たら、pandas-profilingでも日本語対応されているはずです。
終わりに
EDAを行う前にとりあえずpandas-profilingするのが定番になりそうな気がしています。
- 投稿日:2021-01-15T22:25:27+09:00
デバッグ時はprintではなく、Icecreamを使うと便利
この記事を読んでみて、とても便利だなーと思ったので共有したいと思います。
モチベーション
以下のコードを想定しましょう。
num1 = 30 num2 = 40 print(num1) print(num2)出力は
30 40となります。さて、上の出力を見て
30と40がnum1とnum2のどちらに対応しているかすぐに判別がつくでしょうか?
出力変数が少ないうちはこれでも問題はなさそうですが5個とかになると少し面倒くさくなりますね。とりあえずの解決策として次のようにすれば良いでしょう。
num1 = 30 num2 = 40 print('num1', num1) print('num2', num2)出力は
num1 30 num2 40確かに変数名と変数値の対応は元のコードよりは分かりやすくなりました。しかし、問題はコードの記述が面倒という点です。
Icecreamとは?
上のような問題への解決策としてpythonライブラリの
Icecreamがあります。
インストールはpipで行えます。pip install icecreamfrom icecream import ic num1 = 30 num2 = 40 ic(num1) ic(num2)出力は
ic| num1: 30 ic| num2: 40非常にシンプルでいいですね!
Icecreamの便利性はこれだけではありません。関数や条件分岐など使えます。
興味ある人はこちらから調べてみてください。
- 投稿日:2021-01-15T22:23:44+09:00
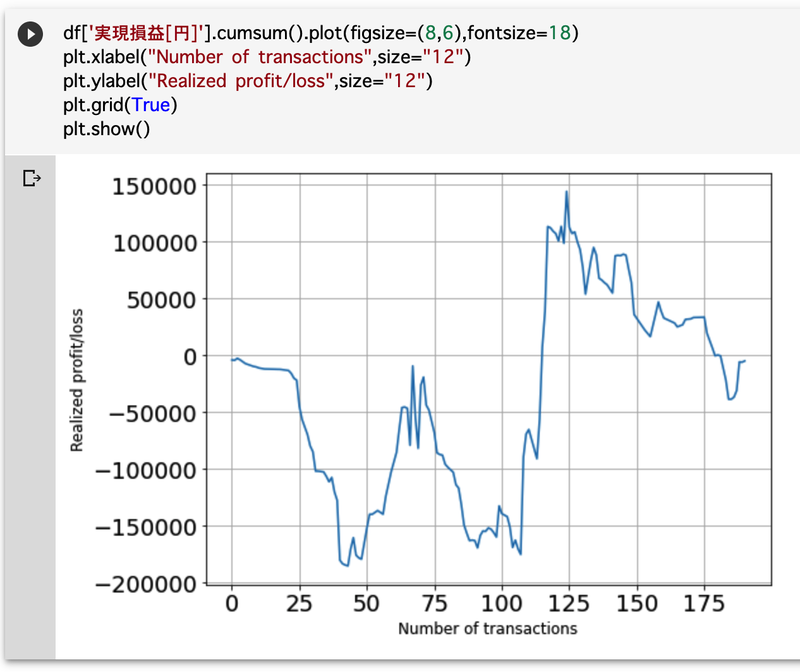
Pythonの基礎も知らない超初心者が、楽天証券の実現損益データをPythonでグラフ化してみた
楽天証券の実現損益データをグラフにしてみました。
実現損益とは、保有する株式などを売却したり決済したりして確定する損益のことを意味します。
それまでは含み損益と呼び、現金化されることでその損益を確定することになります。つまり、実現損益を確認することで、自分が今まで得をしたのか、損をしたのかがわかります。
過去の成績を振り返り、同じミスをしないよう、今後の投資に活かしていきましょう。※元記事→楽天証券の実現損益データをPythonでグラフ化【学習メモ】
csvファイルの取得
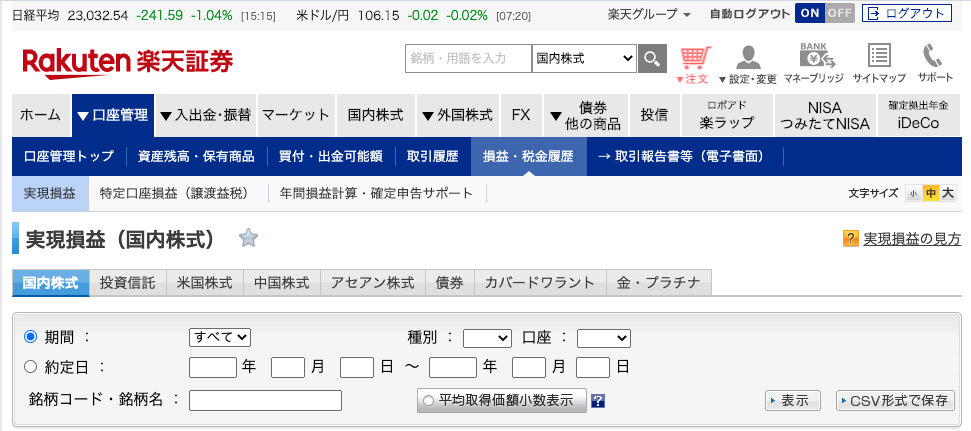
まずは楽天証券から実現損益のデータ(csvファイル)を取得します。
楽天証券にログインし、口座管理→損益・税金履歴→実現損益を開きます。以下のような画面が表示されたら、画面右下の「CSV形式で保存」をクリックして保存します。
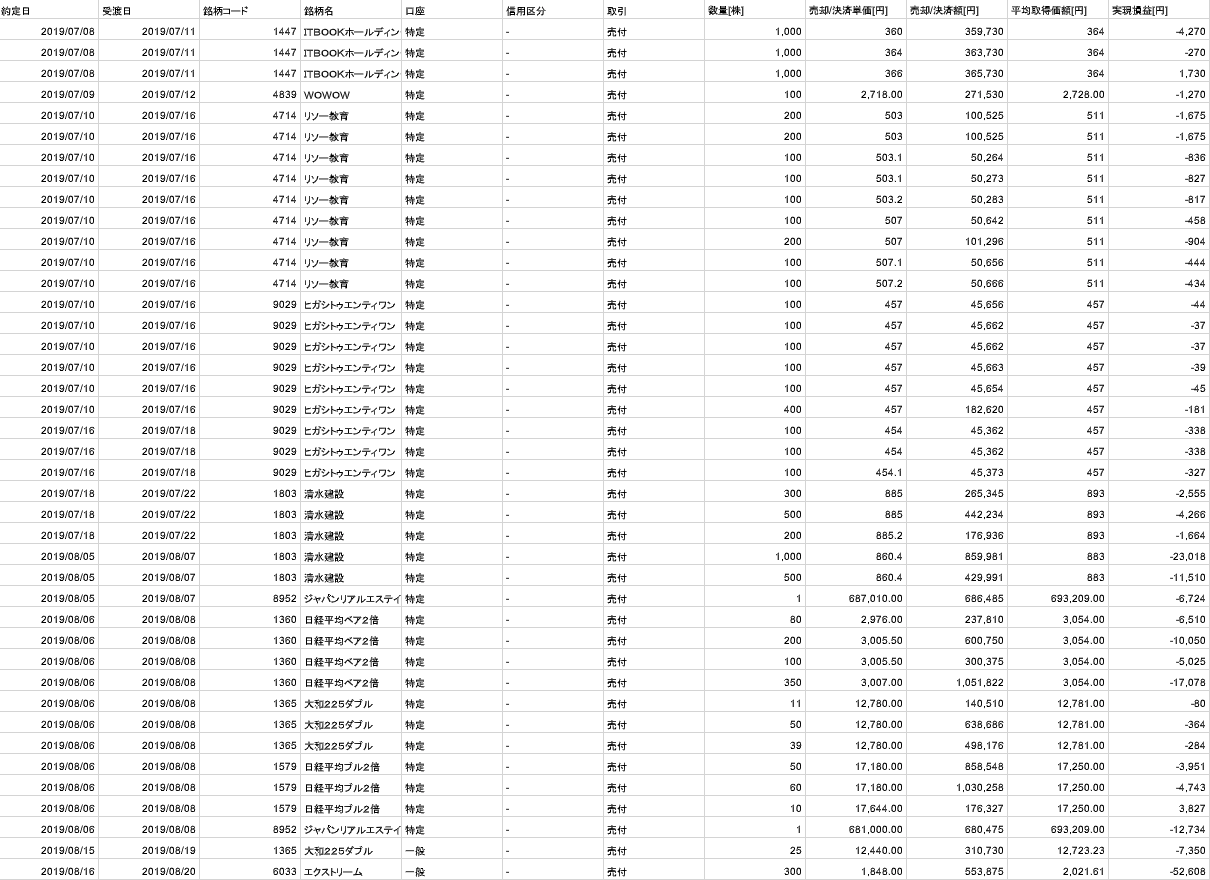
以下のように、楽天証券から実現損益のcsvファイルを取得することができました。(見にくいですが、99%損してます。)
※csvファイルの注意点
楽天証券から持ってくるcsvファイルですが、実は「銘柄コード」以外のすべてのデータ型が「object型」となっています。(dtypesでデータ型を確認)
データ型に関しては、以下の記事をご覧ください。
このままだと計算ができないので、「object型」を「int型」に変換する必要があります。
Pythonを使って型を変換しましょう。と言いたいところでしたが、私にはどうしてもできませんでした。
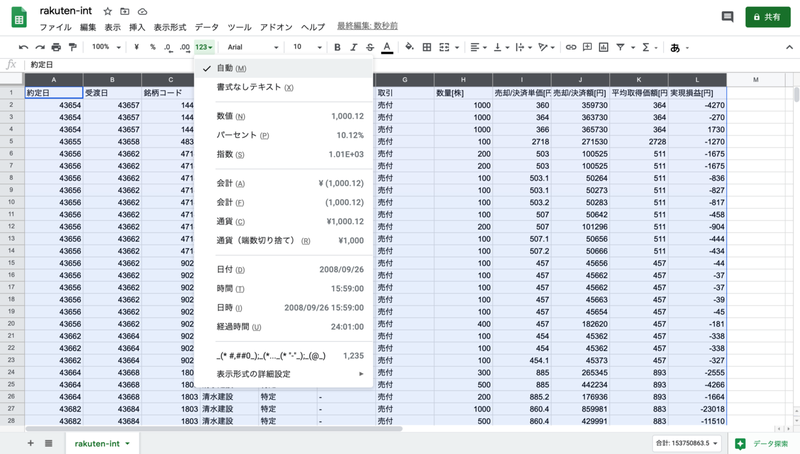
ということで、今回はスプレッドシートで直接「int型」に変換するという苦肉の策をとりました。スプレッドシートでファイルを開き、表示形式を「自動」にします。
これで「object型」を「int型」に変換することができました。
今後の課題ですね。
「こうすればできるよ!」という心優しい方がおられましたら、教えていただけたら幸いです。
作成の手順
それではcsvファイルを読み込み、実現損益をグラフ化していきましょう。
完成したコードはこちら。
from google.colab import drive drive.mount('/content/drive') import pandas as pd import matplotlib.pyplot as plt df = pd.read_csv('drive/My Drive/csv/rakuten-int.csv', encoding='utf-8') df.head() df.dtypes df['実現損益[円]'].cumsum().plot(figsize=(8,6),fontsize=18) plt.xlabel("Number of transactions",size="12") plt.ylabel("Realized profit/loss",size="12") plt.grid(True) plt.show()まず初めに、csvファイルをGoogle Colabで読み込めるようにします。
しかし、Google Colabはインターネット上で実行するため、csvファイルの読み込みには工夫が必要です。
以下のコードを実行
from google.colab import drive drive.mount('/content/drive')「count」ディレクトリ以下の「drive」というフォルダに、Google Driveをマウントするという意味です。
Google Driveのファイルはここで指定したフォルダ「drive」以下の、「drive/My Drive」フォルダに格納されます。
このコードを実行すると認証URLが出てくるので、以下の記事の通り、アップデートまで進めてください。【Google Colab】ファイルを読み込む方法【3分で出来る】
アップデートまで終わったら、csvファイルを読み込むために、pandasとmatplotlibをインポートします。
pandasとmatplotlibをインポート
import pandas as pd import matplotlib.pyplot as pltdfにcsvファイルを代入
df = pd.read_csv('drive/My Drive/csv/rakuten-int.csv', encoding='utf-8 ')read_csv:csvファイルを読み込む際に使用
'drive/My Drive/csv/rakuten-int.csv':csvファイルまでの相対パス
encoding=’utf-8’:文字コード楽天証券から持ってきたcsvファイルは文字コードに問題?があるため、エラーが発生します。
相対パスの後に必ず「encoding=’utf-8’」を記入しましょう。
詳しくは以下の記事をご確認ください。Pythonにおけるunicode decode errorに関する回避方法を現役エンジニアが解説【初心者向け】
データが取得できたか確認
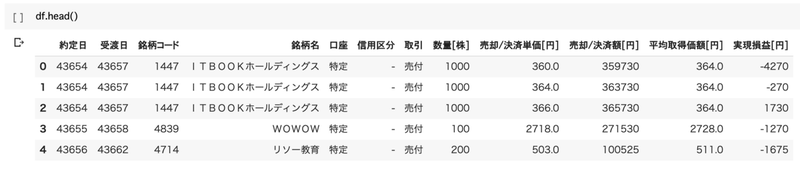
df.head()
データを取得することができました。
実現損益のデータをグラフ化
df['実現損益[円]'].cumsum().plot(figsize=(8,6),fontsize=18) plt.xlabel("Number of transactions",size="12") plt.ylabel("Realized profit/loss",size="12") plt.grid(True) plt.show()df['実現損益[円]']:dfの中の['実現損益[円]']
cumsum():累積和(数列に対して、最初の項からn番目の項まで足したもの)
例えば、日々の売上データからその日までの累計の売上データを出すような計算です。x軸のラベルをプロット
plt.xlabel("Number of transactions",size="12")Number of transactons:x軸の名前(日本語で「取引回数」)
size:フォントサイズy軸のラベルをプロット
plt.ylabel("Realized profit/loss",size="12")Realized profit/loss:y軸の名前(日本語で「実現損益」)
軸のラベルが英語表記なのですが、日本語表記にすると文字化けします。
本当は日本語表記にしたかったのですが、長くなりそうなのでまた別の機会にします。plt.grid(True):グリッド(格子)をグラフに表示する
plt.show():作ったグラフを画面に表示するここまでの実行結果がこちらです。
実現損益のデータをグラフにすることができました。
見事なWボトムからのジリ貧です。
グラフで可視化すると非常にわかりやすいですね。一時はマイナス20万円近くまで行きましたが、急激に取り戻してプラス15万円近くまで回復し、調子に乗って結局マイナスで終わりました。
ちなみに、最終の実現損益は−5,091円です。(2020年4月30日でいったん終了)
1年間かけて資産をおよそ5,000円失いました。
勉強代と思えば安いものですね。今後の課題
- Pythonを使って「object型」を「int型」へ変換する
- 軸のラベルを日本語表記にする
- 実現損益を±0以上にする
もっとPythonのスキルをつけて、詳細な分析ができるようにしたいですね。
そして、恥ずかしくない取引データがお見せできるように、資産運用も引き続き頑張ります。

- 投稿日:2021-01-15T22:00:25+09:00
LightGBMでPartial dependence実行時に出たNotFittedError対処メモ
はじめに
Lightgbmで構築したモデルに対してscikit-learnの
plot_partial_dependenceを実行したときにNotFittedErrorが表示され、うまく実行できませんでした。
その対処についての備忘録です。環境
環境は以下の通り。
$sw_vers ProductName: Mac OS X ProductVersion: 10.13.6 BuildVersion: 17G14042Jupyterlab (Version 0.35.4) 上で作業していたので、python kernelのバージョンも記載しておきます。
Python 3.7.3 (default, Mar 27 2019, 16:54:48) IPython 7.4.0 -- An enhanced Interactive Python. Type '?' for help.やったこと
モデル構築
予測するためのデータとモデルを用意します。
データはscikit-learnで用意されているボストンデータセットを使用しました。import pandas as pd import sklearn.datasets as skd data = skd.load_boston() df_X = pd.DataFrame(data.data, columns=data.feature_names) df_y = pd.DataFrame(data.target, columns=['y'])以下の通り、506行13列のデータで全列がnon-nullのfloat型なのでこのままモデルを作ります。
df_X.info()<class 'pandas.core.frame.DataFrame'> RangeIndex: 506 entries, 0 to 505 Data columns (total 13 columns): CRIM 506 non-null float64 ZN 506 non-null float64 INDUS 506 non-null float64 CHAS 506 non-null float64 NOX 506 non-null float64 RM 506 non-null float64 AGE 506 non-null float64 DIS 506 non-null float64 RAD 506 non-null float64 TAX 506 non-null float64 PTRATIO 506 non-null float64 B 506 non-null float64 LSTAT 506 non-null float64 dtypes: float64(13) memory usage: 51.5 KBLightGBMで、ハイパーパラメタはでほぼデフォルトのままでモデルを構築しておきます。
Training APIの場合
Training APIで用意されている
trainの関数でモデル構築した場合は、Boosterが返されます。
結論からいうと、Boosterをそのままscikit-learnのplot_partial_dependenceに渡すとエラーとなります。どのようなエラーになるのか見ていきたいと思います。
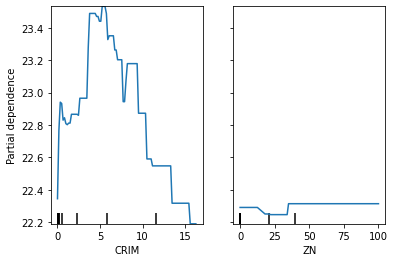
まずはモデルを学習させます。import lightgbm as lgb from sklearn.model_selection import train_test_split df_X_train, df_X_test, df_y_train, df_y_test = train_test_split(df_X, df_y, test_size=0.2, random_state=4) lgb_train = lgb.Dataset(df_X_train, df_y_train) lgb_eval = lgb.Dataset(df_X_test, df_y_test) # Booster params = { 'seed':4, 'objective': 'regression', 'metric':'rmse'} lgbm_booster = lgb.train(params, lgb_train, valid_sets=lgb_eval, num_boost_round=200, early_stopping_rounds=20, verbose_eval=50)(省略) Training until validation scores don't improve for 20 rounds [50] valid_0's rmse: 3.58803 [100] valid_0's rmse: 3.39545 [150] valid_0's rmse: 3.31867 [200] valid_0's rmse: 3.28222 Did not meet early stopping. Best iteration is: [192] valid_0's rmse: 3.27283これで学習させたモデル
lgbm_boosterをplot_partial_dependenceに渡します。from sklearn.inspection import plot_partial_dependence plot_partial_dependence(lgbm_booster, df_X_train, ['CRIM', 'ZN'])--------------------------------------------------------------------------- ValueError Traceback (most recent call last) <ipython-input-7-9a44e58d2f50> in <module> 1 from sklearn.inspection import plot_partial_dependence ----> 2 plot_partial_dependence(lgbm, df_X_train, ['CRIM', 'ZN']) (中略) /anaconda3/lib/python3.7/site-packages/sklearn/inspection/_partial_dependence.py in partial_dependence(estimator, X, features, response_method, percentiles, grid_resolution, method) 305 if not (is_classifier(estimator) or is_regressor(estimator)): 306 raise ValueError( --> 307 "'estimator' must be a fitted regressor or classifier." 308 ) 309 ValueError: 'estimator' must be a fitted regressor or classifier.というわけでValueErrorが出ることが確認できました。
Scikit-learn APIの場合
それではScikit-learn APIでモデルを学習させます。
回帰問題のため、LGBMRegressorを使います。lgbm_sk = lgb.LGBMRegressor(objective=params['objective'], random_state=params['seed'], metric=params['metric']) lgbm_sk.fit(df_X_train, df_y_train)LGBMRegressor(boosting_type='gbdt', class_weight=None, colsample_bytree=1.0, importance_type='split', learning_rate=0.1, max_depth=-1, metric='rmse', min_child_samples=20, min_child_weight=0.001, min_split_gain=0.0, n_estimators=100, n_jobs=-1, num_leaves=31, objective='regression', random_state=4, reg_alpha=0.0, reg_lambda=0.0, silent=True, subsample=1.0, subsample_for_bin=200000, subsample_freq=0)これで学習させたモデル
lgbm_skをplot_partial_dependenceに渡します。plot_partial_dependence(lgbm_sk, df_X_train, ['CRIM', 'ZN'])--------------------------------------------------------------------------- NotFittedError Traceback (most recent call last) <ipython-input-9-d0724528e406> in <module> ----> 1 plot_partial_dependence(lgbm_sk, df_X_train, ['CRIM', 'ZN']) (中略) /anaconda3/lib/python3.7/site-packages/sklearn/utils/validation.py in check_is_fitted(estimator, attributes, msg, all_or_any) 965 966 if not attrs: --> 967 raise NotFittedError(msg % {'name': type(estimator).__name__}) 968 969 NotFittedError: This LGBMRegressor instance is not fitted yet. Call 'fit' with appropriate arguments before using this estimator.このようにNotFittedErrorが発生しました。
ここで使用しているscikit-learnとlightgbmのバージョンはそれぞれ0.22.2.post1と2.3.0です。from sklearn import __version__ as sk_ver print(lgb.__version__) print(sk_ver)2.3.0 0.22.2.post1ここで発生したNotFittedErrorについて調べていると、GithubのIssueでこのエラーについてレポートされていました。
どうもscikit-learnのcheck_is_fittedという関数を使ってモデルがフィット済みか確認しているのですが、check_is_fittedで確認するattributeがlightgbmのfitで設定されていないために起こっているようです。
バージョンアップすることで解決できそうなので、lightgbmをバージョンアップします。
2021年1月14日の段階で最新バージョンは3.1.1だったため、このバージョンを指定しました。conda install -c conda-forge lightgbm=3.1.1バージョンを確認します。
from sklearn import __version__ as sk_ver print(lgb.__version__) print(sk_ver)3.1.1 0.23.1改めてモデルを学習させます。
lgbm_sk = lgb.LGBMRegressor(objective=params['objective'], random_state=params['seed'], metric=params['metric']) lgbm_sk.fit(df_X_train, df_y_train)LGBMRegressor(metric='rmse', objective='regression', random_state=4)```python plot_partial_dependence(lgbm_sk, df_X_train, ['CRIM', 'ZN'])今回はエラーなく実行でき、下図のような結果を得られました。
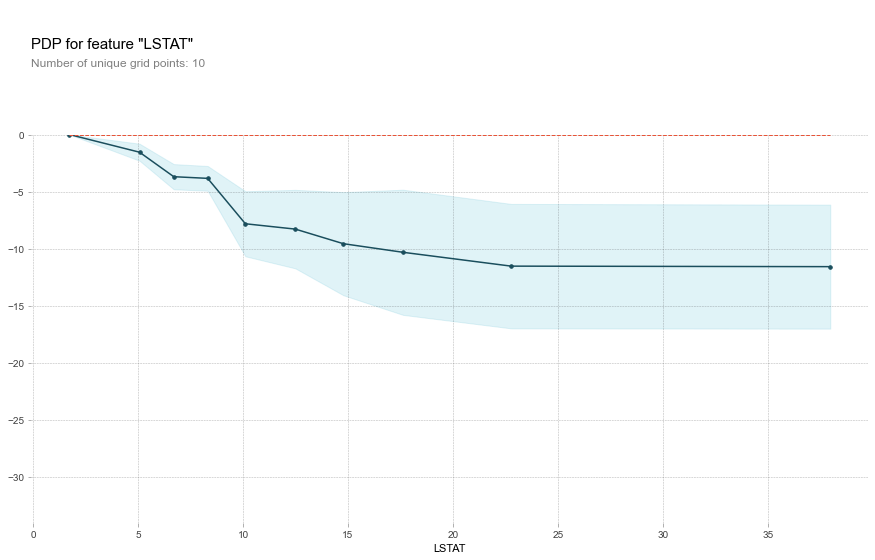
ついでにscikit-learnの他に
pdpboxを使ってpartial dependenceを出してみます。from pdpbox import pdp, get_dataset, info_plots fig = plt.figure(figsize=(14,5)) pdp_goals = pdp.pdp_isolate(model=lgbm_sk, dataset=df_X_train, model_features=df_X_train.columns, feature='LSTAT') # plot it pdp.pdp_plot(pdp_goals,'LSTAT') plt.show()下図のような出力を得られました。scikit-learnよりも見た目はいいです。
まとめ
Lightgbmをscikit-learnの
plot_partial_dependenceに渡したときに発生したNotFittedErrorはLightgbmをバージョンアップすることで解決しました。
- 投稿日:2021-01-15T21:45:28+09:00
【Python, ObsPy】Cartopy+ObsPy で地図上に震源球 (beachball) を描いてみた
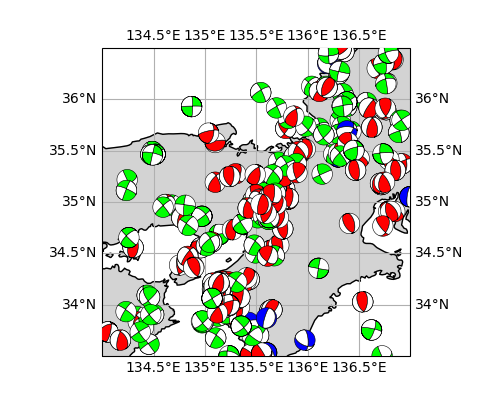
筆者が以前投稿した記事 ( Matplotlib+ObsPyで震源球(beachball)を書いてみた ) の最後で ObsPy と地図ライブラリの Cartopy との連携が未確認であると書きましたが、地図上での描画が可能であるということが判明したので、これについて記述しようと思います。
※表示している地震のデータは防災科学技術研究所が公開している地震のメカニズム ( 防災科研:メカニズム解の検索 ) からランダムに選びダウンロードしたものです。本ページ中の画像は個人がデモンストレーションとして描画したもので、その結果に学術的な意味を求めていません。
※本ページのスクリプトの利用は自己責任でお願いします。
描画例
1. 目次
1. 目次
2. このページの目的
3. 使用環境
4. Cartopy のインストール方法
5. デモンストレーション
6. おわりに
7. 参考文献2. このページの目的
下半球投影の震源球を、地図の上に描画すること。
3. 使用環境
- Windows 10
- conda 4.9.2
- python 3.8.5
- matplotlib 3.3.2
- obspy 1.2.2
- cartopy 0.18.0
cartopy はpipでインストールしました。
4. Cartopy のインストール方法
公式の記述によりますと Anaconda の環境を前提として、conda コマンド
conda install -c conda-forge cartopyで入れるのが手っ取り早いそうです。また、required dependencies が満たされている状態ではpip install cartopyでインストールできるそうです。おそらくですが、Anaconda を使用している場合には pip でインストールしてもこの required dependency は自動で解決してくれるはずです。ここからは蛇足ですが、公式インストーラーやストア経由で windows 10 に「直に」pythonをインストールした場合は、 Cartopy を導入するのは結構大変かもしれません。Anaconda に切り替える前に私が試したとき、 cartopy を pip で入れようとしたら proj のバージョンが低いと言われ、 proj を pip で入れようとしたら必要なバージョン ( proj4 ) がなくてダメで、proj4 をインストールしようとしたら OSGeo4w を入れる羽目になり、OSGeo4w をインストールしたはいいけどどうやって使うの?という状況に陥り、断念しました。初心者の私にもわかる記事があれば教えてください...
ちなみにUbuntuではAnacondaじゃなくても何の問題もなく入りました。Ubuntu は良い子です。
5. デモンストレーション
というわけで適当なスクリプトを実行してみます。筆者の前作で ObsPy は Matplotlib の Collection としてビーチボールを返してくれることが分かったので、地図上に描けることが分かっていれば意外とあっさりと書けます。
使用しているデータの冒頭部分は以下の通り。
temp.csvlongitude latitude depth strike1 dip1 rake1 strike2 dip2 rake2 mantissa exponent type 136.3025 36.2495 11 63 59 94 236 31 84 2.66 21 1 135.5475 35.2028 20 334 85 11 243 79 175 9.92 21 2 136.72 35.1692 14 3 70 105 145 25 55 3.43 21 1 134.8153 34.4015 11 293 87 28 201 62 177 4.23 21 2これを以下のスクリプトと同じディレクトリに入れ、実行します。Cartopy での地図の描画に関しては、公式のスクリプト例およびこの方のブログ (リンクフリーということでしたので掲載させていただきます...)を参考にさせていただきました。地図の描画を工夫したい人はそちらをご覧ください。
cartopy_obspy.pyimport numpy as np import pandas as pd import cartopy.crs as ccrs import matplotlib.pyplot as plt import cartopy.feature as cfeature import matplotlib.ticker as mticker from obspy.imaging.beachball import beach # 地図とグリッドの描画 fig = plt.Figure(figsize=(5,4)) ax = fig.add_subplot(111, projection=ccrs.PlateCarree()) # platecarree (正距円筒図法) で表示 ax.set_extent((134, 137, 33.5, 36.5)) # 領域の限定 grids = ax.gridlines(draw_labels=True) # ラベルありで緯線経線を描画 grids.xlocator = mticker.FixedLocator(np.arange(120,150,0.5)) # 0.5度ずつ grids.ylocator = mticker.FixedLocator(np.arange(20,50,0.5)) ax.coastlines(resolution='10m') # 海岸線を分解能 10 m で描画 ax.add_feature(cfeature.LAND, color="lightgrey") # 陸地を灰色に mfile = pd.read_csv("temp.csv") # データのファイル mech = mfile[["strike1", "dip1", "rake1"]] # 発震機構解 loc = mfile[["longitude", "latitude"]] # 位置 typ = mfile[["type"]] # 正断層型か、など。0 = 正断層, 1 = 逆断層, 2 = 横ずれ断層 pallet = ["blue", "red", "lime"] # 断層タイプにより色分けする for i in range(len(loc)) : beach1 = beach(mech.iloc[i,:], xy=loc.iloc[i,:], width=0.2,linewidth=0.4,facecolor=pallet[int(typ.iloc[i,0])]) ax.add_collection(beach1) fig.savefig("sample.png") plt.close(fig)結果は冒頭と同じ。
6. おわりに
やってみたら簡単でした。ただ現状これでは地図上でのプロットのみが可能であり、鉛直断面に震源球を描画する方法は現時点でも模索中です (たぶんやらない)。そういうのもできるという点でいえば GMT の方が圧倒的に自由度が高い気がします。 Python でやらないといけないという縛りがある状況以外では、このスクリプトに利用価値はないかもしれません。
7. 参考文献
- obspy.imaging - Plotting routines for ObsPy — ObsPy Documentation (1.2.0)
https://docs.obspy.org/packages/obspy.imaging.html- 19. Beachball Plot — ObsPy Documentation (1.2.0)
https://docs.obspy.org/tutorial/code_snippets/beachball_plot.html- obspy.imaging.beachball.beach — ObsPy Documentation (1.2.0)
https://docs.obspy.org/packages/autoge/obspy.imaging.beachball.beach.html#obspy.imaging.beachball.beach- 防災科学技術研究所 広帯域地震観測網 (F-net) メカニズム解の検索
https://www.fnet.bosai.go.jp/event/search.php?LANG=ja- Introduction — cartopy 0.18.0 documentation
https://scitools.org.uk/cartopy/docs/latest/index.html- Using cartopy with matplotlib — cartopy 0.18.0 documentation
https://scitools.org.uk/cartopy/docs/latest/matplotlib/intro.html- Python - (ベースマップ) Cartopyの導入 | ふシゼン
https://www.mitsumatado.com/zen/cartopy/
- 投稿日:2021-01-15T21:18:12+09:00
[Blender×Python] パネル操作Add-onのつくりかた
目次
0.パネル操作を行うサンプルコード
1.Add-onの実行手順
2.サンプルコードの解説0.パネル操作を行うサンプルコード
↓今回のパネル操作Add-onでできること
↓サンプルコード
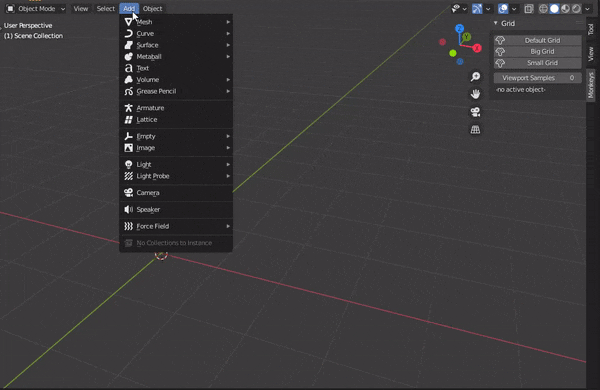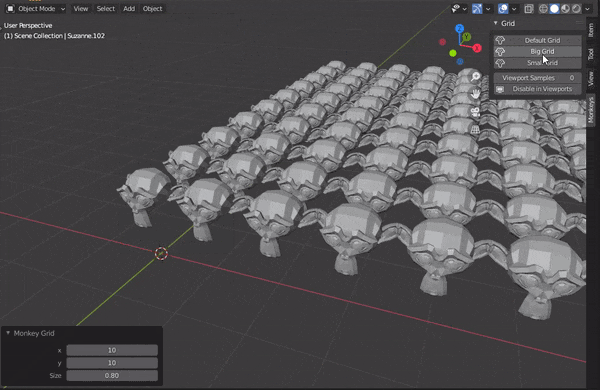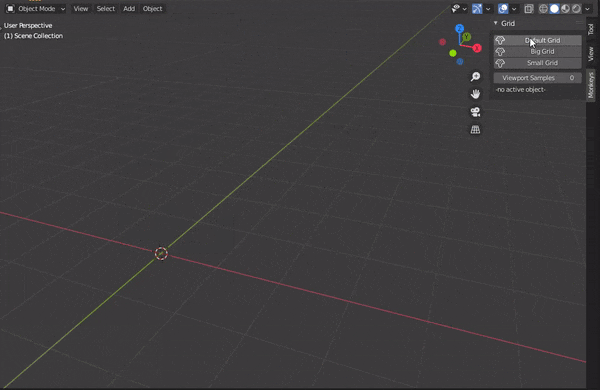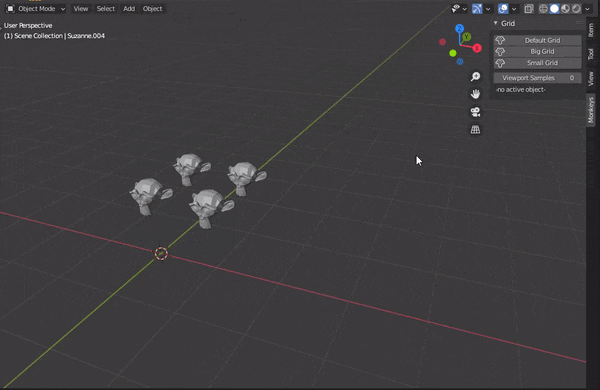
#アドオンの概要 #アドオン作成に必須 bl_info = { "name" : "Monkey grid", "author" : "Yohhei Suzuki", "version" : (1,0), "blender" : (2,83,0), "category" : "Mesh", "location" : "Operator Search", "description" : "More Monkeys", "warning" : "", "doc_url" : "", "tracker_url" : "", } import bpy #猿を整列させるためのクラス #前回の記事から変更なし class MESH_OT_monkey_grid(bpy.types.Operator): bl_idname = "mesh.monkey_grid" bl_label = "Monkey Grid" bl_options = {'REGISTER','UNDO'} count_x: bpy.props.IntProperty( name = "x", description = "Number of Monkeys in the X-direction", default = 3, min = 1,soft_max = 10, ) count_y: bpy.props.IntProperty( name = "y", description = "Number of Monkeys in the Y-direction", default = 2, min = 1,soft_max = 10, ) size: bpy.props.FloatProperty( name = "Size", description = "Size of each Monkey", default = 0.5, min = 0.1,soft_max = 1, ) @classmethod def poll(cls,context): return context.area.type == 'VIEW_3D' def execute(self, context): for i in range(self.count_x * self.count_y): x = i % self.count_x#only amari y = i // self.count_x #only shou bpy.ops.mesh.primitive_monkey_add( size = self.size, location = (x,y,1) ) return {'FINISHED'} #今回追加したクラス #パネルでの操作を可能にする class VIEW3D_PT_monkey_grid(bpy.types.Panel): #クラスの情報 bl_space_type = 'VIEW_3D' bl_region_type = 'UI' bl_category = "Monkeys" bl_label = "Grid" #パネルの表示と、パネルが押された時の変数の値を決めている def draw(self,context): #align = Trueでパネル同士の隙間を埋める col = self.layout.column(align = True) #パネルの表示と props = col.operator('mesh.monkey_grid', text = 'Default Grid', icon = 'MONKEY') #パネルが押された時の変数の値を決定する props.count_x = 3 props.count_y = 2 props.size = 0.5 #大きいmonkeyを多く並べる props = col.operator('mesh.monkey_grid', text = 'Big Grid', icon = 'MONKEY') props.count_x = 10 props.count_y = 10 props.size = 0.8 #小さいmonkeyを1つ並べる props = col.operator('mesh.monkey_grid', text = 'Small Grid', icon = 'MONKEY') props.count_x = 1 props.count_y = 1 props.size = 0.2 #cyclesでのpreview_samplesの値をパネルから操作可能にする col = self.layout.column(align = True) col.prop(context.scene.cycles, 'preview_samples') #アクティブオブジェクトが存在しない場合の表示 if context.active_object is None: col.label(text = '-no active object-') #アクティブオブジェクトが存在する場合はそれを隠す else: col.prop(context.active_object, 'hide_viewport') #add→meshからアドオンを選択できるようにする def mesh_add_menu_draw(self,context): col = self.layout.column(align = True) props = col.operator('mesh.monkey_grid') props.count_x = 3 props.count_y = 2 props.size = 0.5 #Blenderに実行するクラスを登録する def register(): bpy.utils.register_class(MESH_OT_monkey_grid) bpy.utils.register_class(VIEW3D_PT_monkey_grid) bpy.types.VIEW3D_MT_mesh_add.append(mesh_add_menu_draw) def unregister(): bpy.utils.unregister_class(MESH_OT_monkey_grid) bpy.utils.unregister_class(VIEW3D_PT_monkey_grid) bpy.types.VIEW3D_MT_mesh_add.remove(mesh_add_menu_draw)1.Add-onの実行手順
①コードを保存する
●~~.py(ex:monkey_grid_panel.py)と名前をつける→Text→Save as→任意のフォルダに保存
②アドオンを使用可能にする
●Edit→Preferences→Add-ons→Install→保存した~~.py(ex:monkey_grid_panel.py)を選択→Install_Add-on→アドオンにチェックを入れる
③アドオンを実行する
●3D viewportで作成したパネルから操作する。もしくは、Add→mesh→アドオン名(ex:Monkey grid)を選択して実行する。
2.サンプルコードの解説
bl_info = { #---アドオンの概要--- #---アドオン作成に必須--- } import bpy #猿を整列させるためのクラス #前回の記事から変更なし class MESH_OT_monkey_grid(bpy.types.Operator): #---monkeyを整列させる処理--- #今回追加したクラス #パネルでの操作を可能にする class VIEW3D_PT_monkey_grid(bpy.types.Panel): #クラスの情報 bl_space_type = 'VIEW_3D' #実行する場所 bl_region_type = 'UI' #クラスの種類 bl_category = "Monkeys" bl_label = "Grid" #押されたパネルに応じた処理を実行する関数 def draw(self,context): #align = Trueでパネル同士の隙間を埋める col = self.layout.column(align = True) #パネルの表示を決定する #パネルが押されたときにMESH_OT_monkey_gridクラスの処理を行う #MESH_OT_monkey_gridクラス→bl_idname = "mesh.monkey_grid" props = col.operator('mesh.monkey_grid', text = 'Default Grid', icon = 'MONKEY') #パネルが押された時の変数の値を決定する props.count_x = 3 props.count_y = 2 props.size = 0.5 #大きいmonkeyを多く並べる props = col.operator('mesh.monkey_grid', text = 'Big Grid', icon = 'MONKEY') props.count_x = 10 props.count_y = 10 props.size = 0.8 #小さいmonkeyを1つ並べる props = col.operator('mesh.monkey_grid', text = 'Small Grid', icon = 'MONKEY') props.count_x = 1 props.count_y = 1 props.size = 0.2 #cyclesでのpreview_samplesの値をパネルから操作可能にする col = self.layout.column(align = True) col.prop(context.scene.cycles, 'preview_samples') #アクティブオブジェクトが存在しない場合の表示 if context.active_object is None: col.label(text = '-no active object-') #アクティブオブジェクトが存在する場合はそれを隠す else: col.prop(context.active_object, 'hide_viewport') #add→meshからアドオンを選択できるようにする def mesh_add_menu_draw(self,context): col = self.layout.column(align = True) props = col.operator('mesh.monkey_grid') #選択したときの変数の値を指定する props.count_x = 3 props.count_y = 2 props.size = 0.5 #Blenderに実行するクラスを登録する def register(): #monkeyを整列させるクラス(の登録) bpy.utils.register_class(MESH_OT_monkey_grid) #パネルの作成とパネルごとの処理を実行するクラス(の登録) bpy.utils.register_class(VIEW3D_PT_monkey_grid) bpy.types.VIEW3D_MT_mesh_add.append(mesh_add_menu_draw) def unregister(): bpy.utils.unregister_class(MESH_OT_monkey_grid) bpy.utils.unregister_class(VIEW3D_PT_monkey_grid) bpy.types.VIEW3D_MT_mesh_add.remove(mesh_add_menu_draw)
- 投稿日:2021-01-15T20:26:16+09:00
たかしくんに時速10kmで日本全国を最短距離で走らせました
何日で達成できるでしょうか
最適化問題の勉強をしておりまして、思いついてしまった問題。
日本全国を最短距離で巡るのってどれぐらい時間がかかるのだろうか?
という疑問に答えるべく、pythonでちょっと計算してみました。最適化問題をpythonでハンズオンすることが目的なので、問題設定の甘さはご容赦ください。
また、こちらの記事でも書きましたが、結局本命経路以外で円環経路を作ってしまう問題は解決できませんでした。
最適解ではなく近似解です、この辺りの解決法に詳しい方いらっしゃいましたらコメントお願いします!!問題設定
算数の問題で良く出る(本当かは知らん)みんな大好きたかしくんを今回は使います。
たかしくんスペック
・たかしくんは強いので海を渡れます。
・たかしくんは強いので山があろうが谷があろうが一定の速度で走れます。
・たかしくんは強いので24時間走れます。設定
・たかしくんは知的好奇心が旺盛なので日本全国を時速10kmで巡ろうと考えました。
・「日本全国」を今回は「全都道府県庁県庁所在地」と定義します
・たかしくんはせっかちなので移動は全て直線で行うものとします。やってみた
都道府県庁所在地データの取得
都道府県庁所在地の経度と緯度はこちらの記事から引用しました。
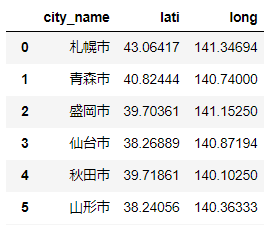
Excelをダウンロード後、所在地名・経度・緯度のデータだけに成形します。import pandas as pd import numpy as np df = pd.read_excel("city_list.xlsx") display(df)データはこんな感じ。latiが緯度(latitude)、longが経度(longitude)になります。
各所在地間の距離計算
47か所の所在地のお互いの距離計算をします。
本来であれば、例えば「沖縄-北海道なんて移動しないだろう」と考え組み合わせを絞るのが良い気もします。
今回はその選抜作業が面倒くさかったのと、何かミラクルが起きるかもという淡い期待からすべての組み合わせを網羅して計算しました。経度・緯度を利用した距離計算はこちらの記事を流用しました。
二点の経度と緯度を引数(それぞれリスト型であることに注意!)として、その間の距離をkmで返す関数です。def cal_rho(lon_a,lat_a,lon_b,lat_b): ra=6378.140 # equatorial radius (km) rb=6356.755 # polar radius (km) F=(ra-rb)/ra # flattening of the earth rad_lat_a=np.radians(lat_a) rad_lon_a=np.radians(lon_a) rad_lat_b=np.radians(lat_b) rad_lon_b=np.radians(lon_b) pa=np.arctan(rb/ra*np.tan(rad_lat_a)) pb=np.arctan(rb/ra*np.tan(rad_lat_b)) xx=np.arccos(np.sin(pa)*np.sin(pb)+np.cos(pa)*np.cos(pb)*np.cos(rad_lon_a-rad_lon_b)) c1=(np.sin(xx)-xx)*(np.sin(pa)+np.sin(pb))**2/np.cos(xx/2)**2 c2=(np.sin(xx)+xx)*(np.sin(pa)-np.sin(pb))**2/np.sin(xx/2)**2 dr=F/8*(c1-c2) rho=ra*(xx+dr) return rhoあとはこの関数に全組み合わせをぶち込んでいきます。
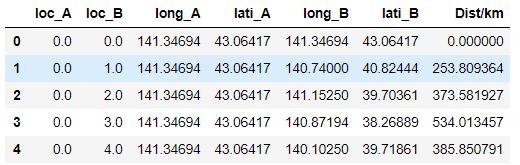
#引数となるリストの入れ物を用意 loc_A = [] lon_A = [] lat_A = [] loc_B = [] lon_B = [] lat_B = [] #ひたすらぶち込む for i in range(47): for j in range(47): loc_A.append(i) lon_A.append(df["long"][i]) lat_A.append(df["lati"][i]) loc_B.append(j) lon_B.append(df["long"][j]) lat_B.append(df["lati"][j]) #計算! rho=cal_rho(lon_A,lat_A,lon_B,lat_B) #結果をデータフレームに combi_df = pd.DataFrame([loc_A,loc_B,lon_A,lat_A,lon_B,lat_B,rho]).T combi_df.columns = ["loc_A","loc_B","long_A","lati_A","long_B","lati_B","Dist/km"] combi_df = combi_df.fillna(0) combi_df.head(5)結果、各地点間の距離を計算することができました。
最短経路の計算
ここについては前回の記事やおおもとの記事とほとんど同じ実装になっていますが、matplotlibによる描画の大きさだけ変えています(参考記事)
図の描画の関数がこちら。import random, numpy as np, pandas as pd, networkx as nx, matplotlib.pyplot as plt from itertools import chain, combinations from pulp import * def draw(g): plt.figure(dpi=150) rn = g.nodes() # ノードリスト pos = nx.spring_layout(g) # ノード位置 """描画""" nx.draw_networkx_labels(g, pos=pos) nx.draw_networkx_nodes(g, node_color='w', pos=pos) nx.draw_networkx_edges(g, pos=pos) plt.show()最適化計算のコードはこちら。
Networkxについてはこちらの記事が読みやすいです!
今回は取りうる値を0,1にした離散最適化問題として解きました(参考記事)。#47地点を定義 n = 47 # ノード数 g = nx.random_graphs.fast_gnp_random_graph(n, 1, 8) #47地点間の距離をインプット for a,b in g.edges(): col_idx = a * 47 + b g.edges[a, b]["dist"] = combi_df.loc[col_idx,"Dist/km"] #いざ計算 source, sink = 0, 46 # 始点, 終点 r = list(enumerate(g.edges())) m = LpProblem() # 数理モデル x = [LpVariable('x%d'%k, lowBound=0, upBound=1,cat="Integer" ) for k, (i, j) in r] # 変数(路に入るかどうか) m += lpSum(x[k] * g.edges[i,j]["dist"] for k, (i, j) in r) # 目的関数 for nd in g.nodes(): m += lpSum(x[k] for k, (i, j) in r if i == nd) \ + lpSum(x[k] for k, (i, j) in r if j == nd) == {source:1, sink:1}.get(nd, 2) # 制約 m.solve() print([(i, j) for k, (i, j) in r if value(x[k]) == 1]) print(LpStatus[m.status]) print(value(m.objective))一つ目のprintは経路の表示、二つ目は最適化計算がうまくいったか、三つめは最適解の表示です。
出力結果はこちら。
optimalとなっているので最適解が叩き出せたみたい!!
そして最短経路は4304km!!
なのでたかしくんは430時間、つまり約17日22時間で日本全国を巡れるらしい!やったーーー!計算できた!!!
と思っていたのもつかの間でした。円環経路問題
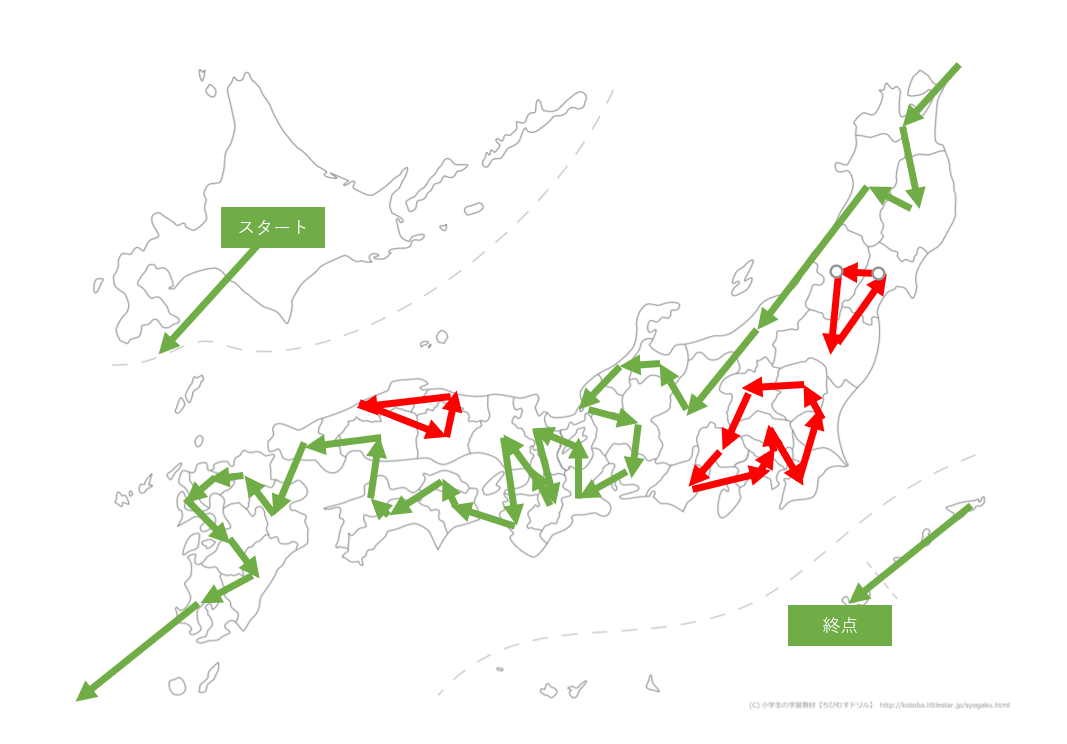
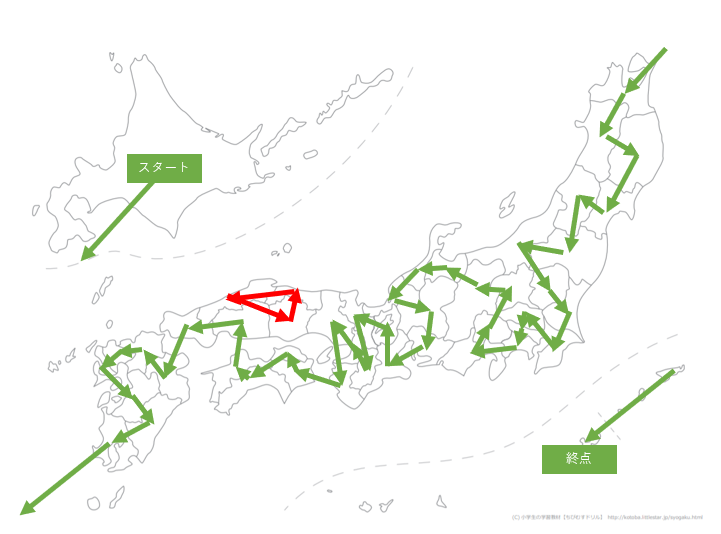
どんな経路を巡ったのだろうか?と思い、描画をしてみました。
最適化結果の確認用のコードはこちら。G = nx.Graph() for k,(i,j) in r: if value(x[k]) ==1: nx.add_path(G, [i, j]) draw(G)描画結果がこちら。
前回の記事でも取り上げた円環生成問題が生じていました。
これは、「ある地点に着目した時に、経由点では2本の道、始点終点では1本の道が伸びている」という制約条件の甘さから生じる問題です。
こちらのサイトから白地図を拝借しプロットしてみました。
東北・関東・中国地方でぐるぐる回ってる場所がありますね。
ここからは経路を少しいじくって、一本の経路にしていこうと思います。
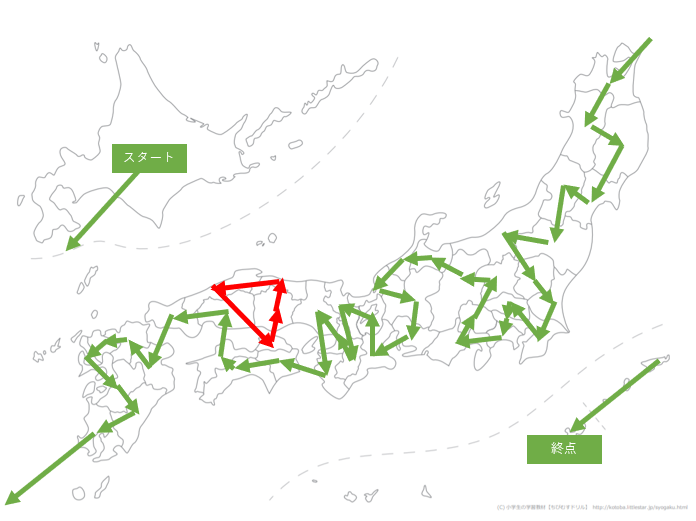
恣意的な操作が加わりますので最適解になるのかが分からなくなりますが、おおよそ近いだろうと踏んで考えてみます。秋田-新潟間を切る
切りたい経路の長さをとてつもなく長くしてみます。
こんな感じです。pair_list = [(4,14),(14,4)] for a,b in pair_list: col_idx = a * 47 + b combi_df.loc[col_idx,"Dist/km"] = 1000000これで最適化計算をしてみます。
結果は地図だけ示しますね。
東北地方の統合に成功しました!!やったぜ。
この場合でも4309kmぐらいなので、経路一つだけの変更ではそこまで影響がなさそうですね。
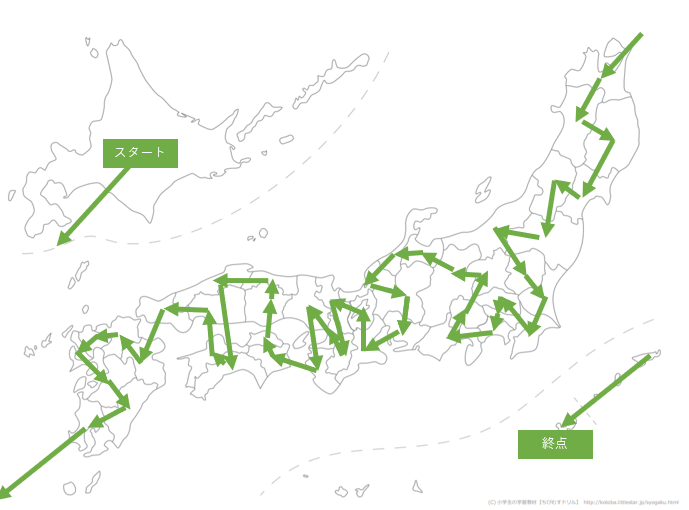
新潟-長野間を切る
関東地方の統合をどうするか悩みました。
そこで、新潟から長野に行かずに群馬へ行き、関東の円環に合流した後に長野へいく、というルートを考えてみました。
なので新潟-長野間の経路を切ってみました。その結果がこちら。
新潟から栃木へ行き、うまく統合することができました。
距離はやや伸びてしまいましたが4326kmとなりました。島根-岡山間を切る
最後、中国地方の統合をどうするか。
島根-岡山間の移動が見られますが、岡山-島根を移動するのであれば鳥取か広島を経由するのが良さそう。
なので島根-岡山間を切ってみます。
香川を巻き込みやがった・・・
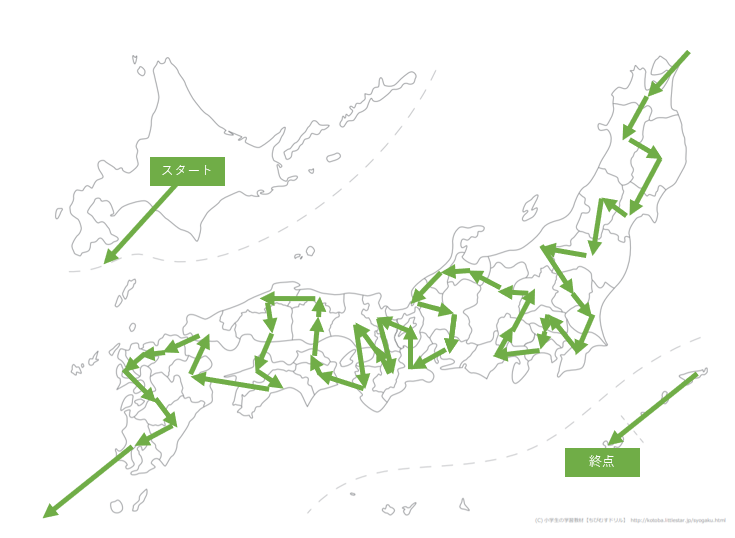
どれだけそこでこじんまりしたいんだよ。島根-香川間を切る
ということで島根-香川間を切ってみます。
その結果がこちら!
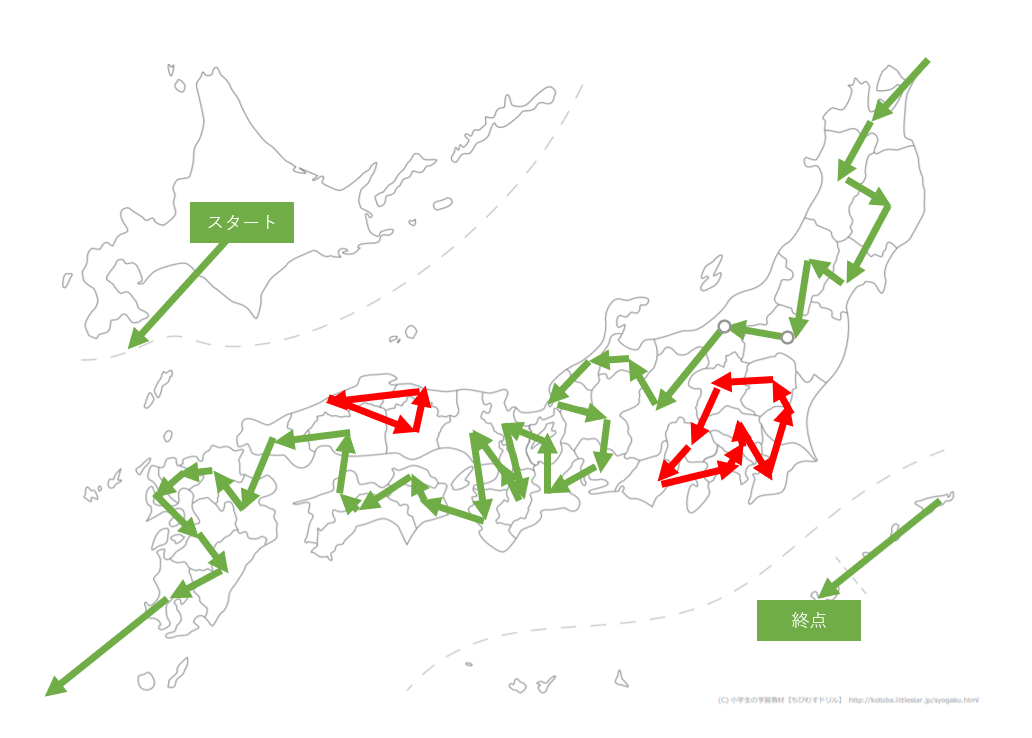
島根から高知へワープしているものの、ついに一本になりました!!
距離は4361kmに。
ちょっと島根-高知間のワープが気になったのでここもぶち切ってみました。
今度は高知から大分へワープして、山口は九州に行ってから拾いに行くようです。
距離も4361kmと同じぐらいになりました。
中国・四国周りは一筆書きするのが難しそうですね。
結論
走る距離:だいたい4361km
走る時間:だいたい18日4時間さいごに
最適化問題面白い!
これからもいろいろ実験してみようと思います。
最後まで読んでいただきありがとうございます、LGTMしていただけると励みになります!


- 投稿日:2021-01-15T20:17:03+09:00
[Python] 動的計画法 ナップザック問題
AOJ Knapsack Problem
個数制限なしのナップサック問題
価値が $v_i$ 重さが $w_i$ であるような $N$ 種類の品物と、容量が $W$ のナップザックがあります。
次の条件を満たすように、品物を選んでナップザックに入れます:
最適化問題に適用する場合、一般的に、以下の2つが適用する問題に成立していないといけない:
- 選んだ品物の価値の合計をできるだけ高くする。
- 選んだ品物の重さの総和は $W$ を超えない。
- 同じ種類の品物はいくつでも選ぶことができる。
価値の合計の最大値を求めてください。
問題の解法
動的計画法による外部設計は次のようになります。
$dp[i+1][j]$の定義:
$i$ 問目までの品物から重さの総和が$j$以下となるように選んだときの、価値の総和の最大値とする。dp初期条件:
dp[0][j]=1dp漸化式の定義:
dp[i+1][j]=max\{dp[i][j-k×w[i]]+k×v[i] \}これだと三重ループになってしまうため、計算量は $O(nW^2)$ となり、タイムオーバーです。漸化式の式変形を行うことで $k$ のループをなくすことができ、計算量を $O(nW)$ とすることができます。この変形は情報処理における重複計算を省く目的です。理解の仕方としては、$dp[i+1][j]$ を求めるには $dp[i][j]$ と $dp[i+1][j-w[i]]+v[i]$ を見れば十分ということであり、逆にループを回すということでもあります。蟻本の解説が分かり易いです。
dp漸化式の変形:
dp[i+1][j]=max(dp[i][j], dp[i+1][j-w[i]]+v[i])求める解:$dp[n][W]$
サンプルコードn = int(input()) w = [] v = [] for i in range(n): w_, v_ = map(int, input().split()) w.append(w_) v.append(v_) W = int(input()) dp = [[0] * (W + 1) for i in range(n + 1)] for i in range(n): for j in range(W + 1): if j < w[i]: dp[i + 1][j] = dp[i][j] else: dp[i + 1][j] = max(dp[i][j], dp[i + 1][j - w[i]] + v[i]) print(dp[n][W])
- 投稿日:2021-01-15T19:20:32+09:00
最適化アルゴリズムを実装していくぞ(くじらさんアルゴリズム)
はじめに
最適化アルゴリズムの実装シリーズです。
まずは概要を見てください。コードはgithubにあります。
くじらさんアルゴリズム
概要
くじらさんアルゴリズム(The Whale Optimization Algorithm; WOA)はクジラの捕食行動に着目して作られたアルゴリズムです。
クジラはバブルネットという群行動によって獲物を捕食します。
バブルネットは図のように円を描きながら獲物を追い詰めて捕食する行動のようです。
参考
・くじらさんアルゴリズム
・Whale Optimization Algorithmアルゴリズム
獲物に近づく、獲物を探す、円を描くの3つの行動のどれかを選んで獲物を見つけます。
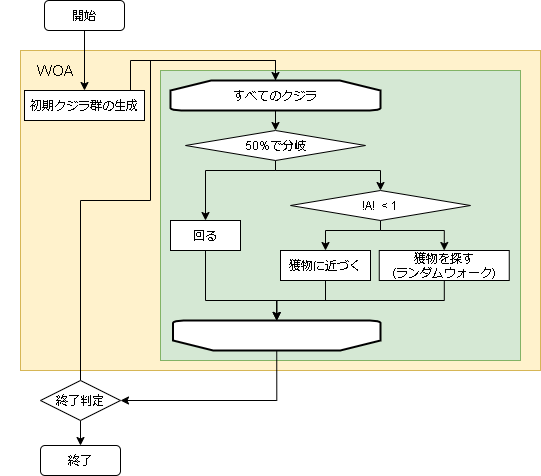
- アルゴリズムのフロー
- 用語の対応
問題 くじらさんアルゴリズム 問題への入力 クジラの位置≒獲物の位置 評価値 クジラの位置における評価値
- ハイパーパラメータに関して
変数名 意味 備考 a_decrease aの減少値 最初はランダムに移動し、後半は獲物に近づく。aはその移行速度 logarithmic_spiral 対数螺旋の係数 大きいほど回るときに大きく動く 獲物に近づく
獲物に近づくと書いていますが実際に獲物がどこにいるかは分からないので、現状で最も評価が高いクジラを獲物と扱い、そこに近づきます。
まずは $\vec{A}$ と $\vec{C}$ を出します。
$$ \vec{A} = 2a\vec{r_1} - a$$
$$ \vec{C} = 2\vec{r_2}$$
$\vec{r_1}$ と $\vec{r_2}$ は座標と同じ次元の 0~1 の乱数です。
$a$ は初期値2から毎step減少していく変数です。($2 \geqq a \geqq 0$)ここで $\vec{A}$ のノルム($|\vec{A}|$)が1以下なら獲物に近づく行動をし、
違う場合は獲物を探す行動をします。獲物に近づく場合の数式は以下です。
$$ \vec{D} = |\vec{C} \vec{X_{best}}(t) - \vec{X}(t)| $$
$$ \vec{X}(t+1) = \vec{X_{best}}(t) - \vec{A}\vec{D} $$$\vec{X}$ が自分の座標を表し、$\vec{X_{best}}$ が最も評価の高いクジラです。
コードだと以下になります。import numpy as np a = 2 # 毎step減少する r1 = np.random.rand(problem.size) # 0-1の乱数を生成 r2 = np.random.rand(problem.size) # 0-1の乱数を生成 A = (2.0 * np.multiply(a, r1)) - a C = 2.0 * r2 i = 対象のクジラのindex if np.linalg.norm(A) < 1: pos = np.asarray(whales[i].getArray()) # 対象クジラの座標 best_pos = np.asarray(best_whale.getArray()) # 最良クジラの座標 D = np.linalg.norm(np.multiply(C, best_pos) - pos) pos = best_pos - np.multiply(A, D)獲物を探す
獲物に近づくで説明した $|A|$ が1以上の場合は獲物に近づきます。
近づき方は"獲物に近づく"場合と同じで、対象のクジラが最も評価の高いクジラからランダムなクジラに変わっただけです。$$ \vec{D} = |\vec{C} \vec{X_p}(t) - \vec{X}(t)| $$
$$ \vec{X}(t+1) = \vec{X_p}(t) - \vec{A}\vec{D} $$$\vec{X_p}$ はランダムなクジラの座標となります。
import numpy as np i = 対象のクジラのindex if np.linalg.norm(A) >= 1: pos = np.asarray(whales[i].getArray()) # 対象クジラの座標 p_pos = np.asarray(whales[random.randint(0, len(whales)-1)].getArray()) # ランダムなクジラの座標 D = np.linalg.norm(np.multiply(C, p_pos) - pos) pos = p_pos - np.multiply(A, D)円を描く
円は獲物(評価値最大のクジラ)を基準に以下の式で描きます。
$$ \vec{D'} = |\vec{X_{best}}(t) - \vec{X}(t)| $$
$$ \vec{X}(t+1) = \vec{D'} e^{bL} \cos(2 \pi L) + \vec{X_{best}}(t) $$$b$ は対数螺旋の係数(はlogarithmic_spiral)、$L$ は[-1, 1]のランダムな値です。
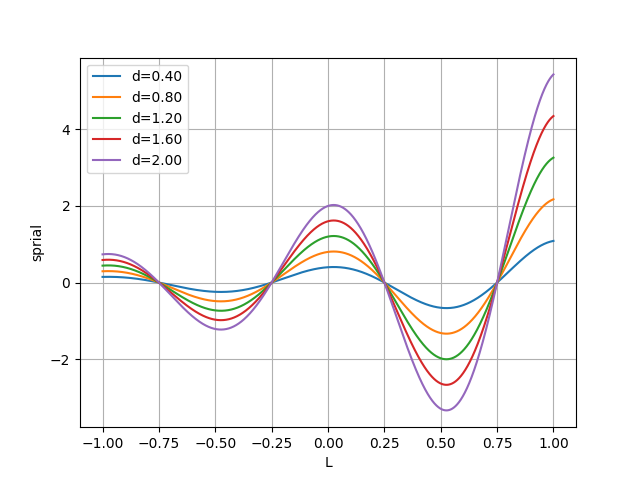
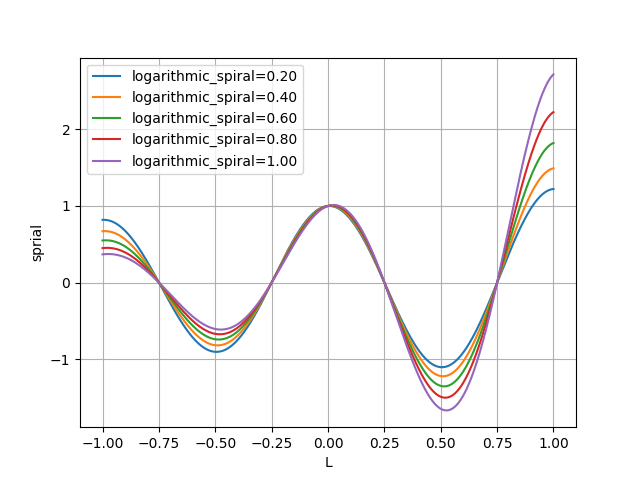
import numpy as np i = 対象のクジラのindex pos = np.asarray(whales[i].getArray()) # 対象クジラの座標 best_pos = np.asarray(best_whale.getArray()) # 最良クジラの座標 # 回る D = np.linalg.norm(best_pos - pos) L = np.random.uniform(-1, 1, problem.size) # [-1,1]の乱数 _b = logarithmic_spiral pos = np.multiply(np.multiply(D, np.exp(_b*r)), np.cos(2.0*np.pi*r)) + best_posスパイラルのグラフ
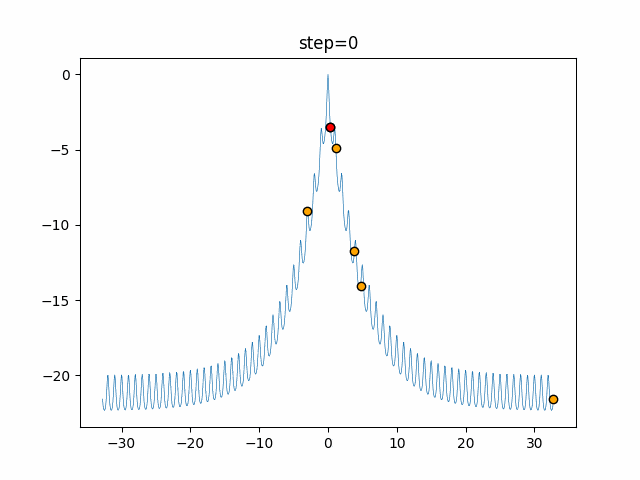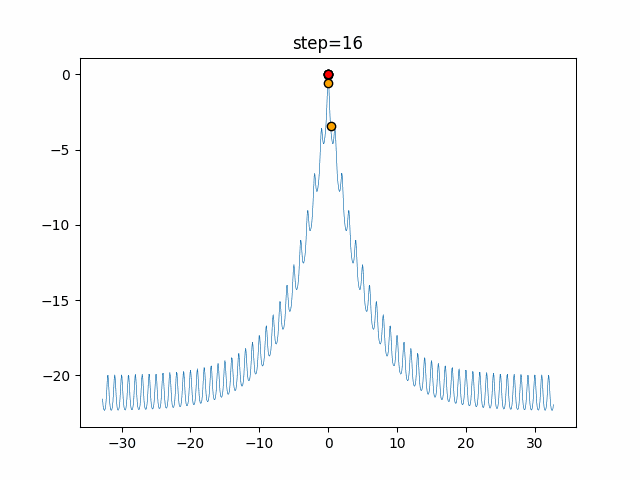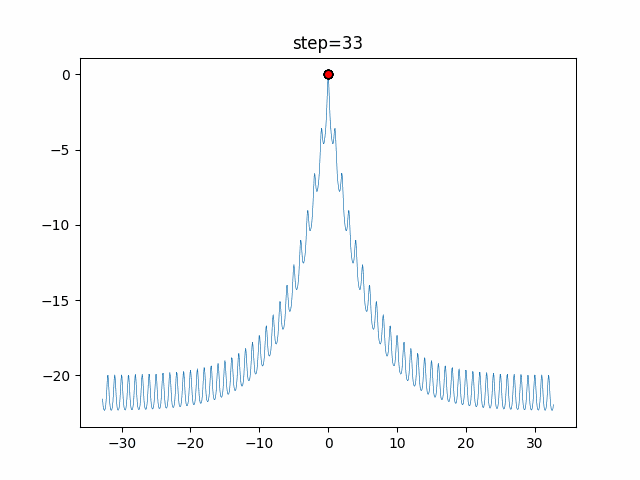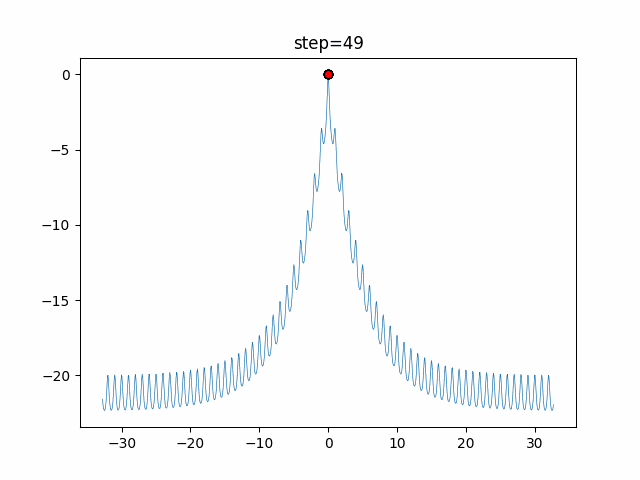
円を描くがどういう移動をしているかを見てみました。
グラフのx軸が-1から1の乱数($L$)で、y軸が移動距離です。
数式だと以下の部分だけをグラフ化しています。$$ spiral = \vec{D'} e^{bL} \cos(2 \pi L) $$
- ユークリッド距離による変化
$b$(logarithmic_spiral) を1に固定して、$\vec{D'}$のみを変化させた場合のグラフです。
$\vec{D'}$ は自分と獲物(最良クジラ)とのユークリッド距離を表しているので、獲物との距離による移動の変化を表しているといえます。
離れているほど大きく移動する可能性が高い事がわかりますね。
- 対数螺旋係数による変化
今度は$b$(logarithmic_spiral)を変化させた場合です。
$D'$ は 1 に固定しています。
$D'$ の場合と同じように $b$ が大きくなれば変化が大きいようです。
コード全体
コード全体です。
コードを作成するにあたりここのコードを参考にしています。import math import random import numpy as np class WOA(): def __init__(self, whale_max, # クジラの数 a_decrease=0.001, # 変数aの減少値 logarithmic_spiral=1, # 対数螺旋の係数 ): self.whale_max = whale_max self.a_decrease = a_decrease self.logarithmic_spiral = logarithmic_spiral def init(self, problem): self.problem = problem self.best_whale = None self.whales = [] for _ in range(self.whale_max): o = problem.create() self.whales.append(o) if self.best_whale is None or self.best_whale.getScore() < o.getScore(): self.best_whale = o.copy() self._a = 2 def step(self): for whale in self.whales: pos = np.asarray(whale.getArray()) if random.random() < 0.5: r1 = np.random.rand(self.problem.size) # 0-1の乱数 r2 = np.random.rand(self.problem.size) # 0-1の乱数 A = (2.0 * np.multiply(self._a, r1)) - self._a C = 2.0 * r2 if np.linalg.norm(A) < 1: # 獲物に近づく new_pos = self.best_whale.getArray() else: # 獲物を探す new_pos = self.whales[random.randint(0, len(self.whales)-1)].getArray() new_pos = np.asarray(new_pos) D = np.linalg.norm(np.multiply(C, new_pos) - pos) pos = new_pos - np.multiply(A, D) else: # 回る best_pos = np.asarray(self.best_whale.getArray()) D = np.linalg.norm(best_pos - pos) L = np.random.uniform(-1, 1, self.problem.size) # [-1,1]の乱数 _b = self.logarithmic_spiral pos = np.multiply(np.multiply(D, np.exp(_b*L)), np.cos(2.0*np.pi*L)) + best_pos whale.setArray(pos) if self.best_whale.getScore() < whale.getScore(): self.best_whale = whale.copy() self._a -= self.a_decrease if self._a < 0: self._a = 0ハイパーパラメータ例
各問題に対して optuna でハイパーパラメータを最適化した結果です。
最適化の1回の試行は、探索時間を5秒間として結果を出しています。
これを100回実行し、最適なハイパーパラメータを optuna に探してもらいました。
問題 a_decrease logarithmic_spiral whale_max EightQueen 0.020366541568838378 1.5723091675627572 45 function_Ackley 0.012846425355295324 1.817054209171554 49 function_Griewank 0.014055305155620233 1.5507180701447845 48 function_Michalewicz 0.019651164901908023 1.7671279692872293 46 function_Rastrigin 0.0173318428180831 0.7578390758302801 46 function_Schwefel 0.007491644624065206 1.6917050129680944 9 function_StyblinskiTang 0.024426401837372255 1.9474471085818506 50 function_XinSheYang 0.005722874915111857 0.4779624408790928 24 g2048 0.043666294831303784 1.09050483219953 37 LifeGame 0.0054058667884643585 0.06834119701477159 50 OneMax 0.014922301994610046 0.8650190784964947 27 TSP 0.0287871077043457 1.3855183848189636 45 実際の動きの可視化
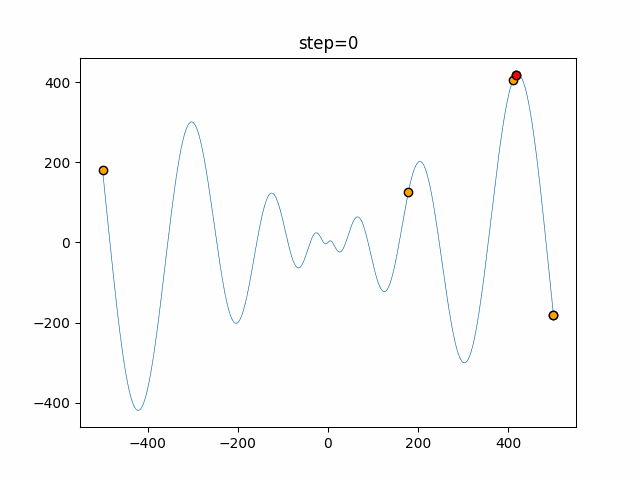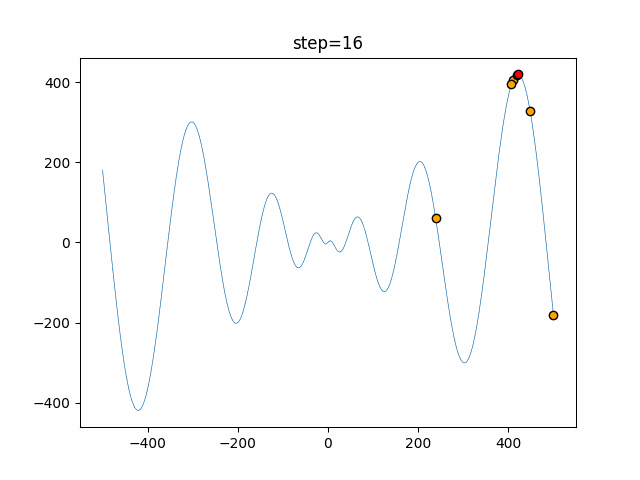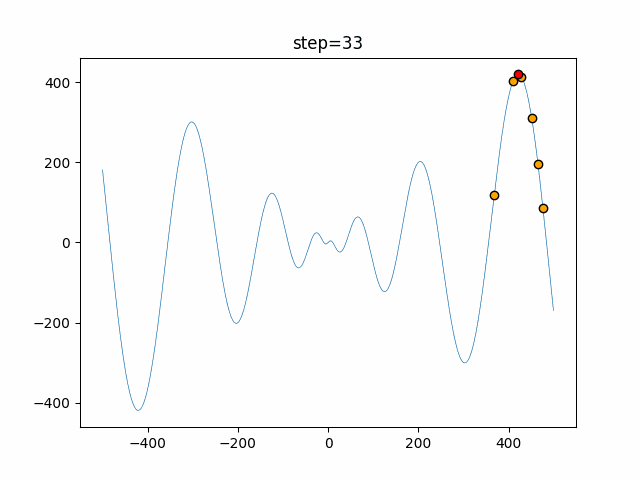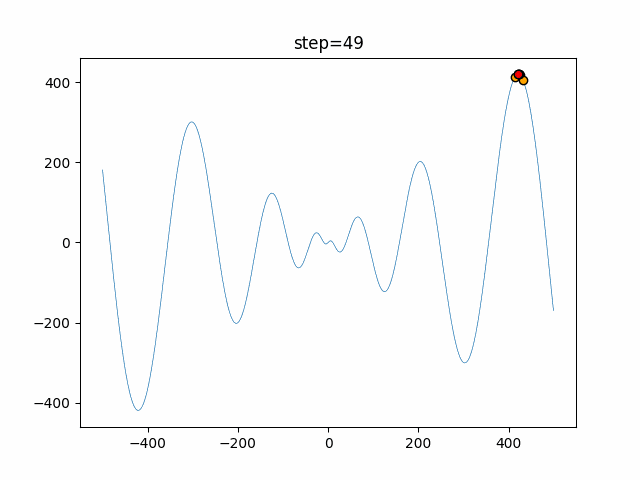
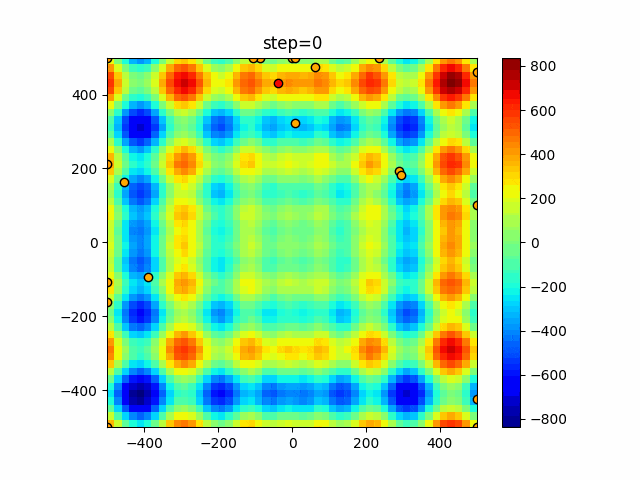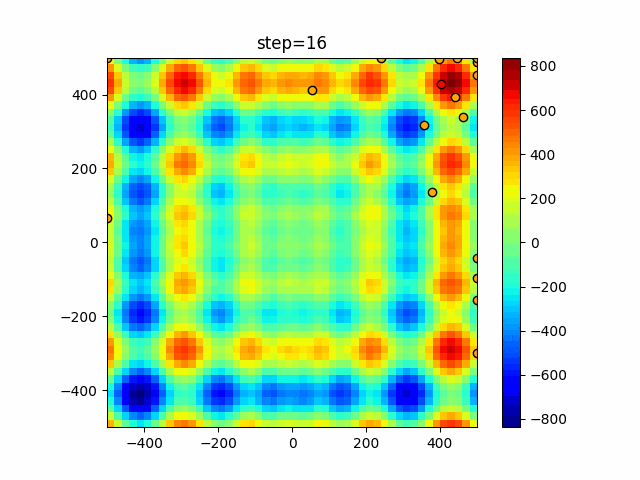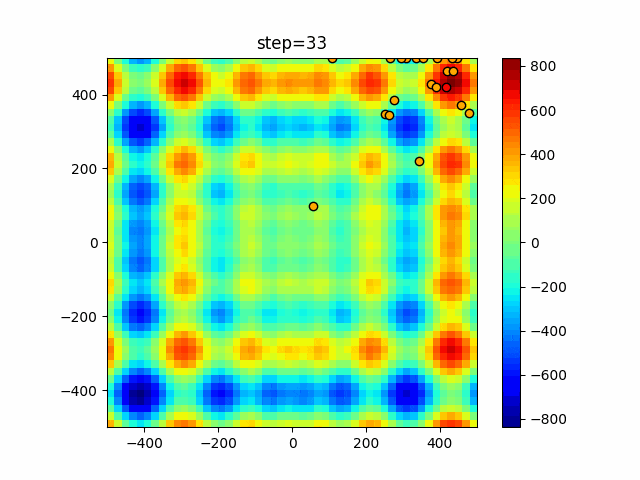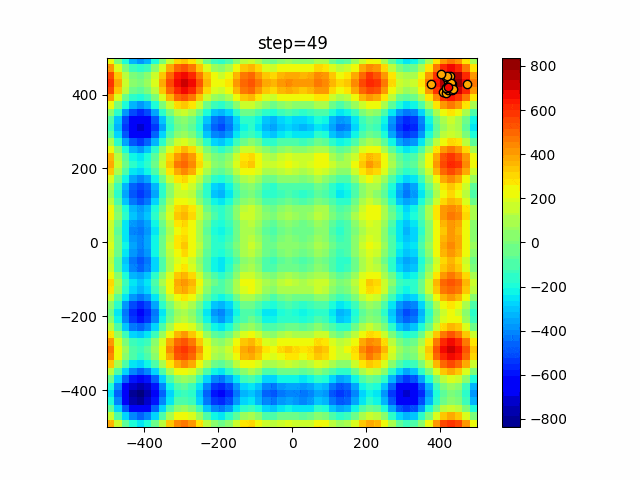
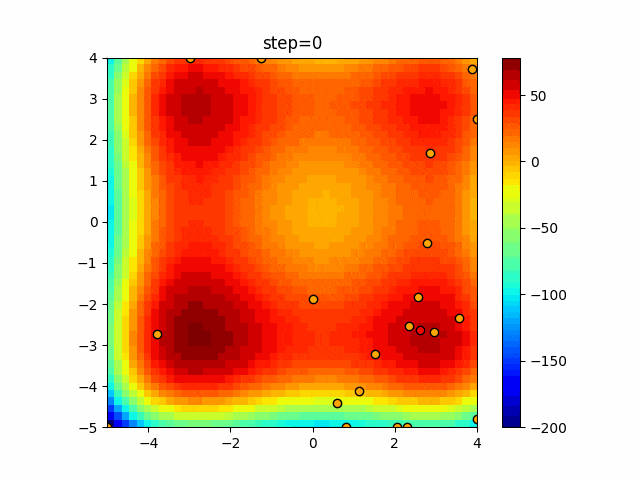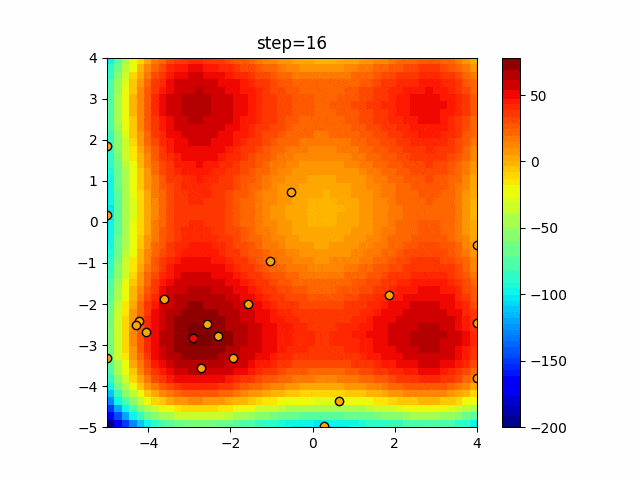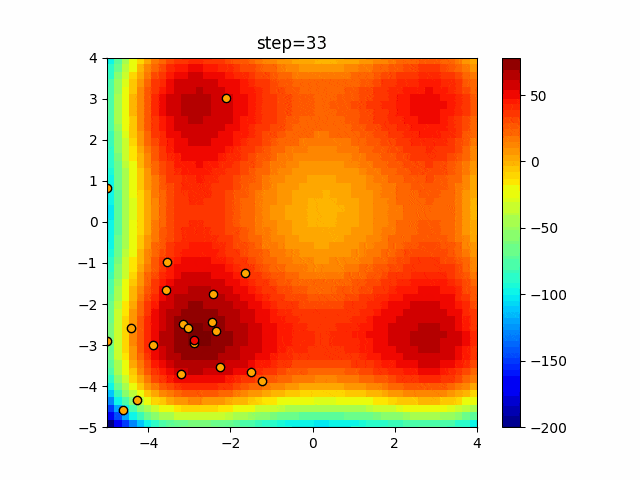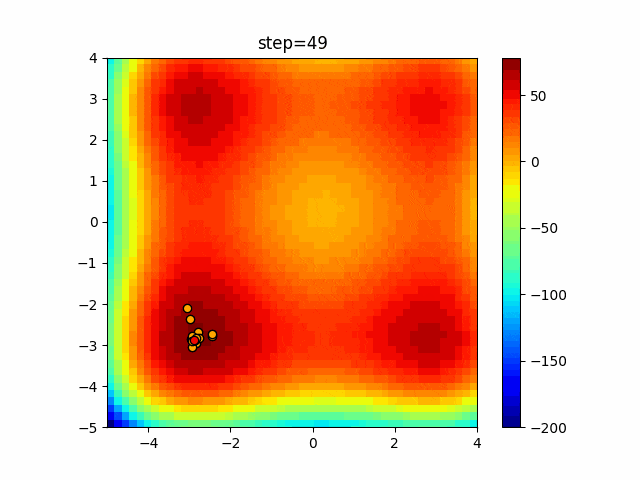
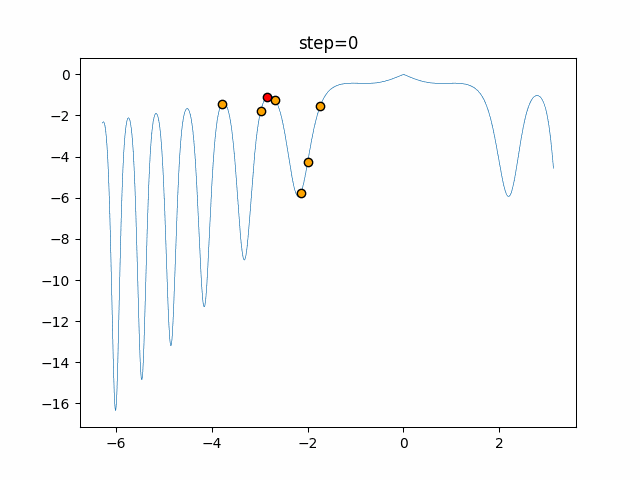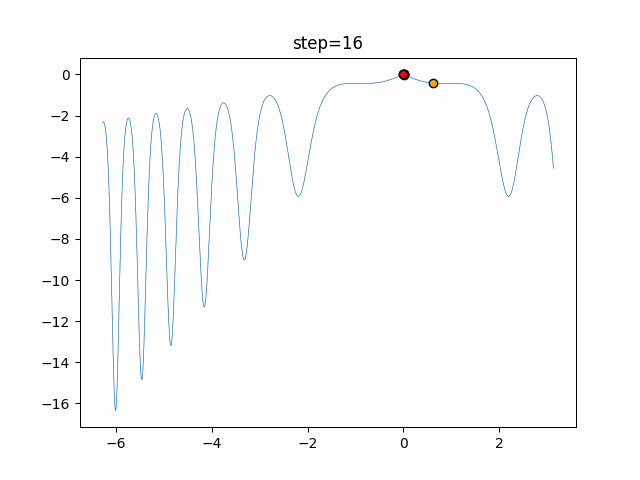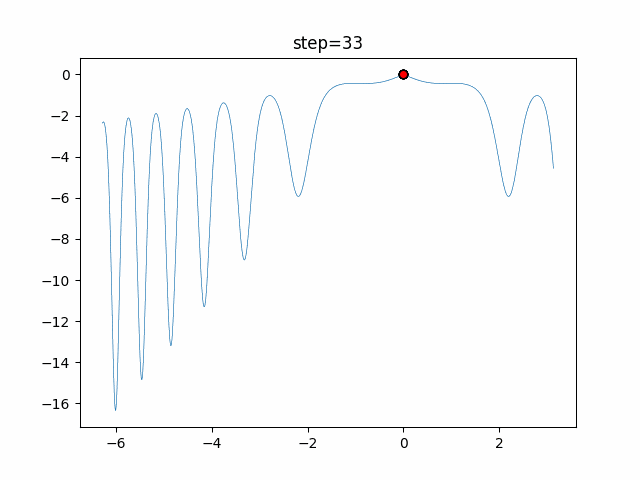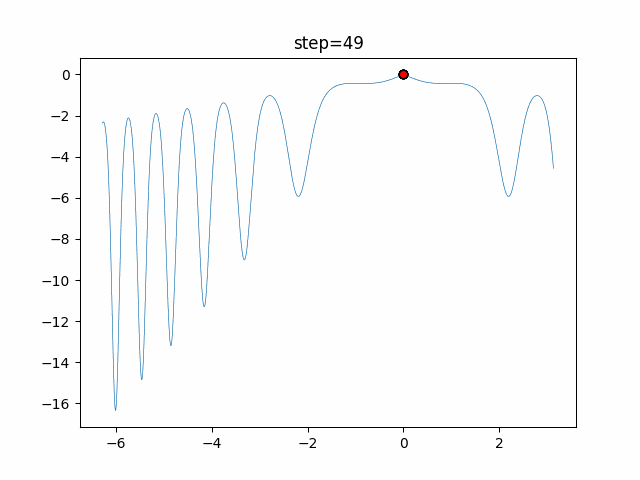
1次元は6個体、2次元は20個体で50step実行した結果です。
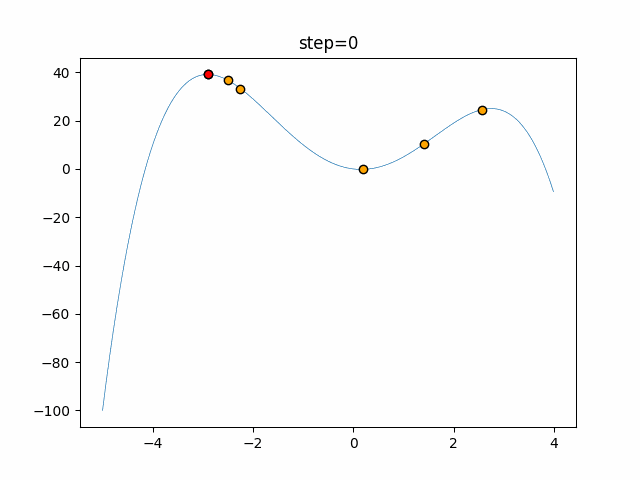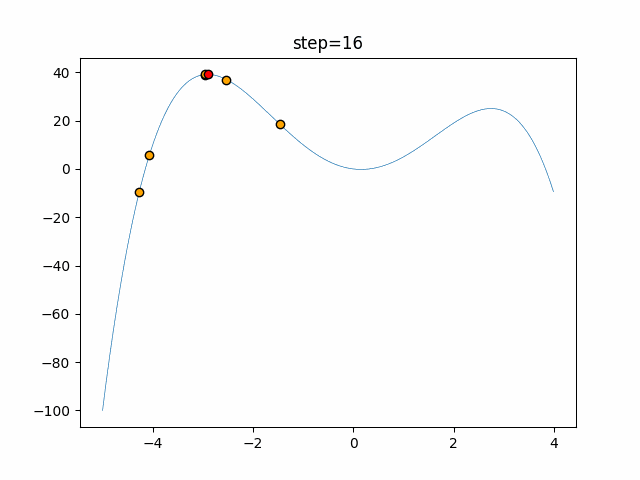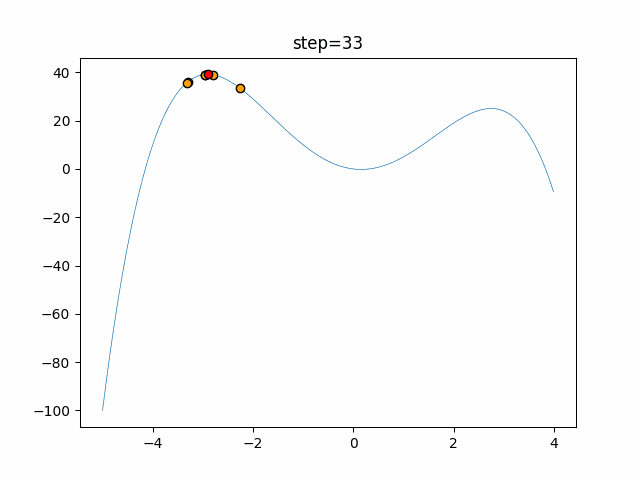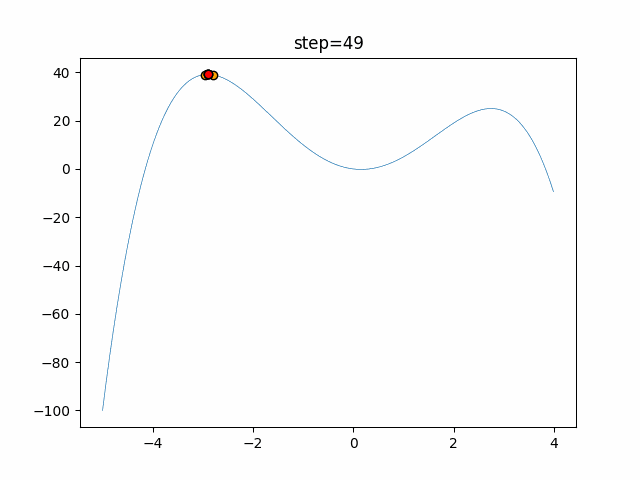
赤い丸がそのstepでの最高スコアを持っている個体となります。パラメータは以下で実行しました。
WOA(N, a_decrease=2/50, logarithmic_spiral=1)function_Ackley
- 1次元
- 2次元
function_Rastrigin
- 1次元
- 2次元
function_Schwefel
- 1次元
- 2次元
function_StyblinskiTang
- 1次元
- 2次元
function_XinSheYang
- 1次元
- 2次元
あとがき
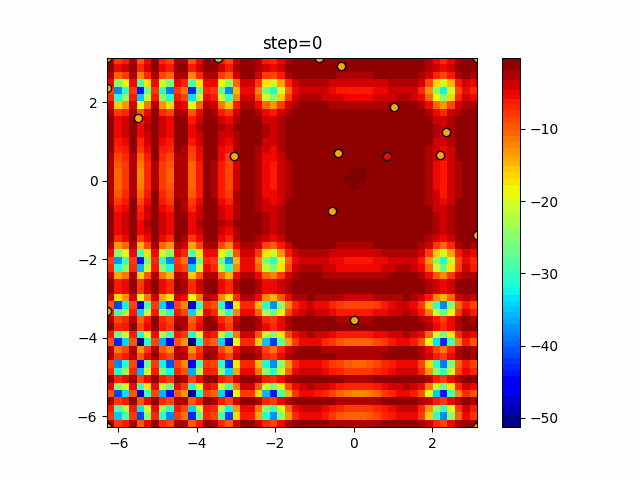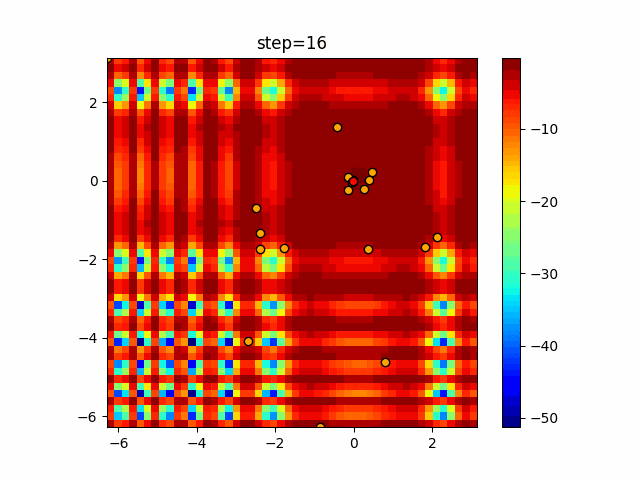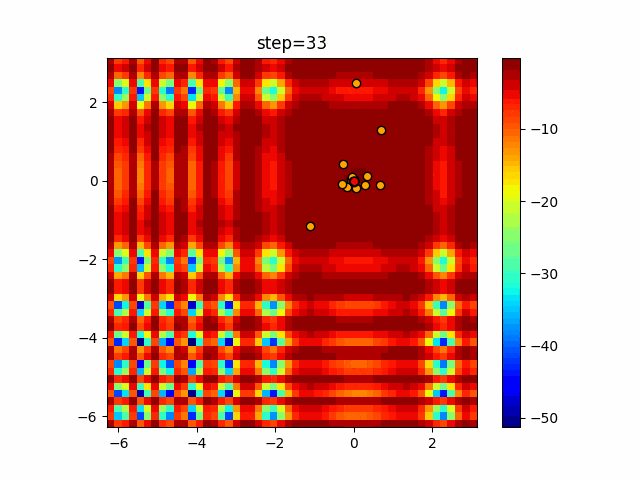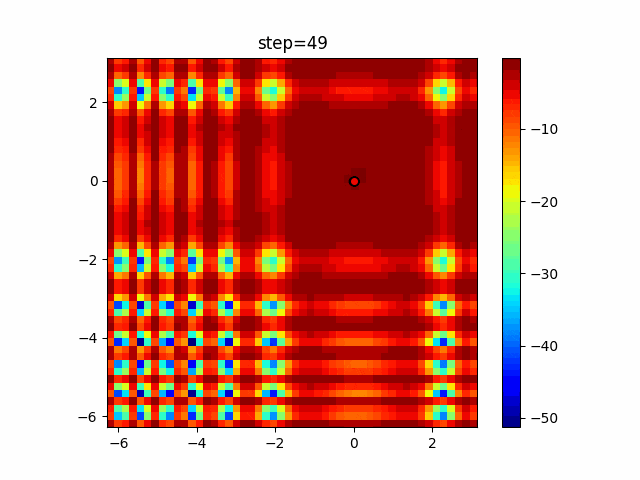
ぐるぐる渦巻きながらいい感じに集まっていきますね。
ただ、一度収束してしまうとそこから脱出することはないので a の値をどう制御するかが重要そうです。
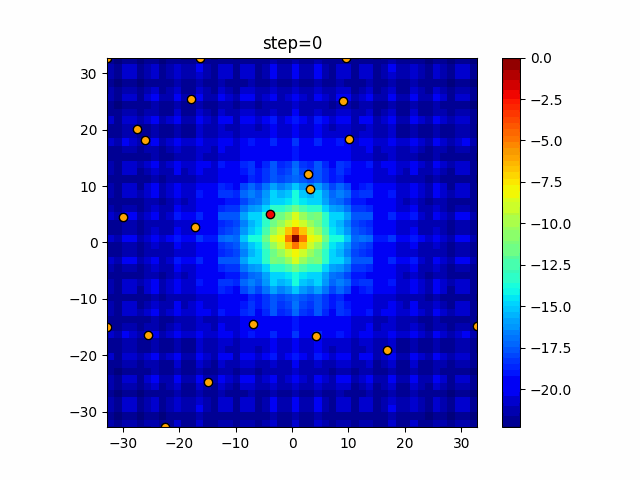
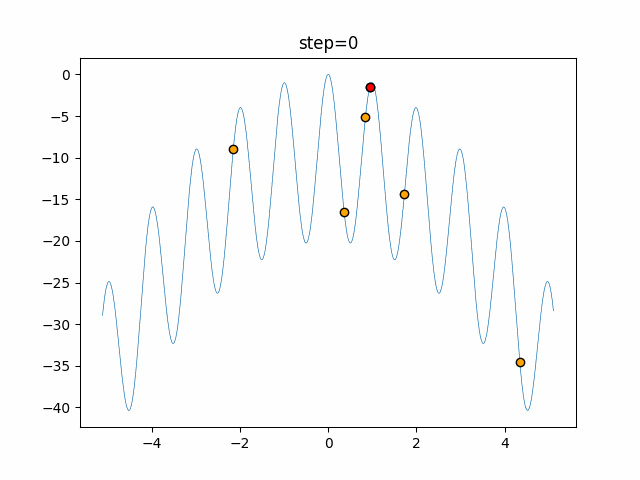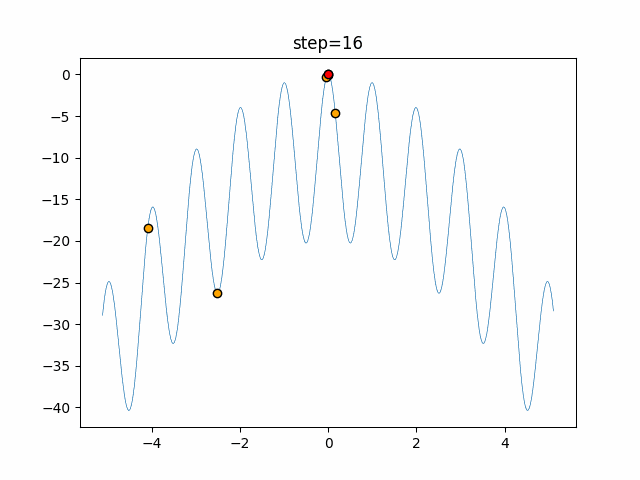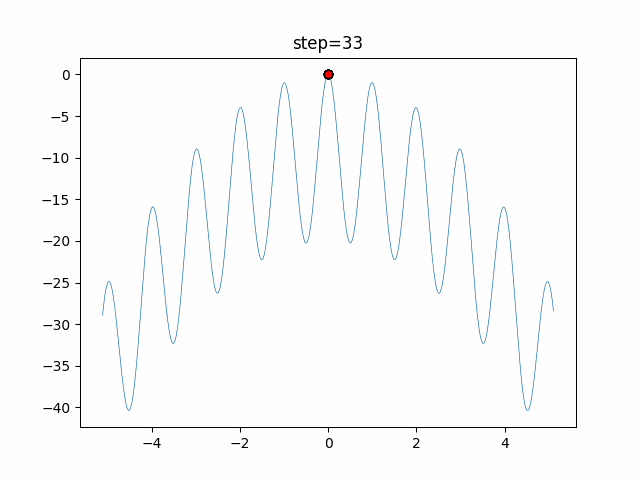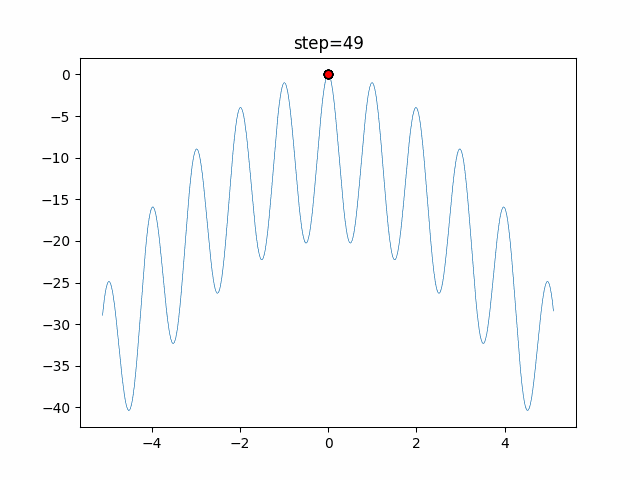
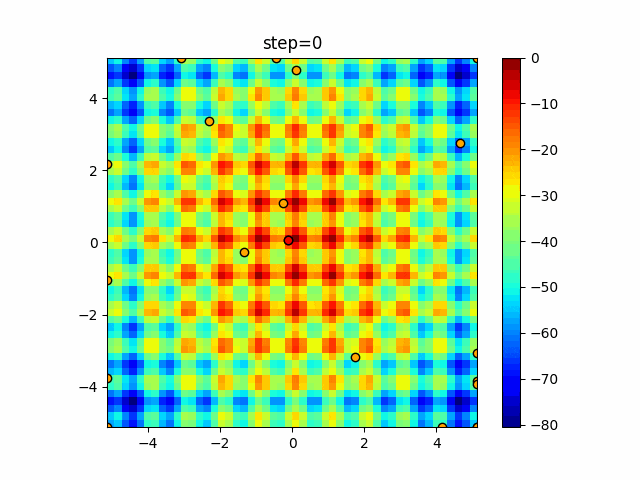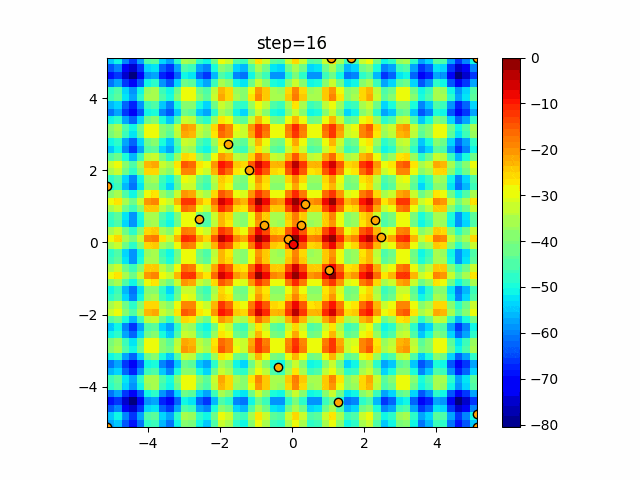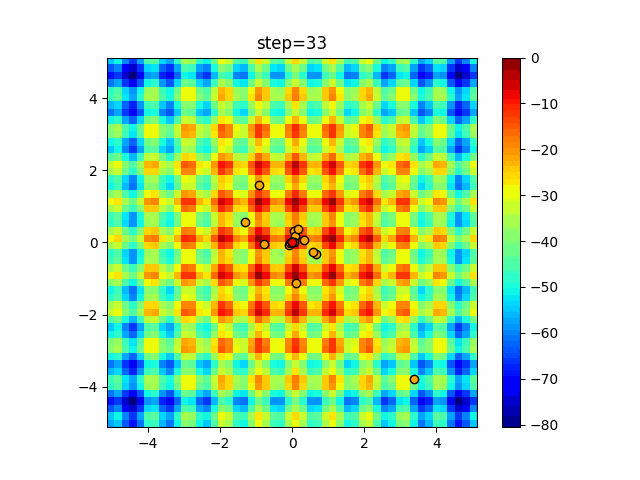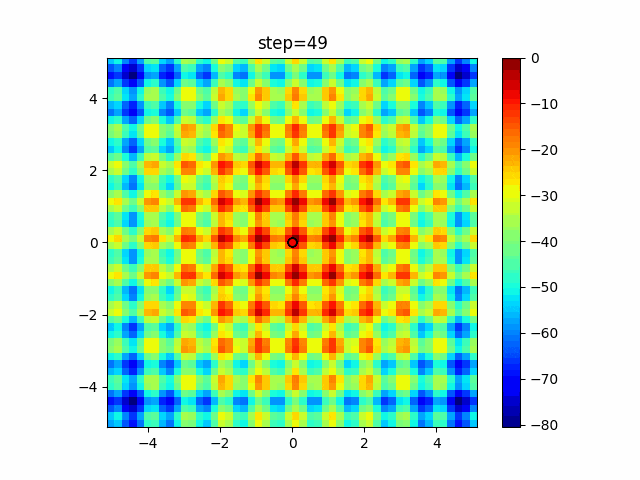
- 投稿日:2021-01-15T18:44:17+09:00
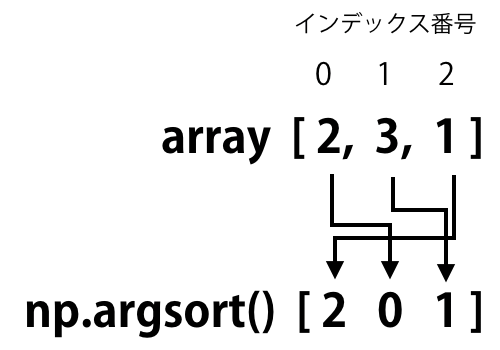
pythonのargsortを理解するまでに時間がかかった話(備忘録)
- 投稿日:2021-01-15T18:35:14+09:00
投資quest:pyhtonでシステムトレードを作る(1)
pythonでシステムトレード:移動平均線を描く
システムトレードの作戦
コロナで世の中大変ですが、株式は21年1月現在コロナ金融緩和バブルの様相を示しています。今はこのトレンドにのって、イケイケですが「節分天井,彼岸底」という格言通り、イケイケは後少しだと思います。その後は次のトレンドが来るまではしばらくレンジ相場が来るような気がします。レンジ相場、トレンド相場に対応できる機械学習を使ったシステムトレードを考えようと思います。
pythonのライブラリーとしては、TA-Libというライブラリーがありますが、勉強のために、なるべく使わずに検討してみようと思います。今回の作戦としては、
1.etfの売買を行う
2.ボリンジャーバンドを指標として使う
3.ボリンジャーバンドのバンドの下限で買い、上限で売りいろいろな指標はありますが、単純なボリンジャーバンド作戦です。
ボリンジャーバンドでpythonの勉強をしたら、他に良い指標(MACD,RSI)がないか、指標を組み合わせたらどうなるかと順番に作っていけたら良いなと思います。最初にボリンジャーバンドのシステムトレードを作りながら
1.で、どのetfが良いか?topix、日経平均、その他の指標でどれが勝率がよいか。
2.3.で、ボリンジャーバンドの何σが勝率がよいか考えるを確認して、システムトレードを作ろうと思います。
データの入手
まずターゲットを1306の野村アセットのTOPIX連動型上場投信で検討します。
スクレイピング技術は後回しです。クリックして、このサイトから集めました。
https://kabuoji3.com/
少し面倒ですが、クリックするだけで2001年から毎年ののcsvファイルが入手できます。
1306_2001.csv ~ 1306_2021.csv
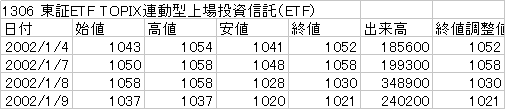
こういう日々のetfの値動きのファイルが入手できます。データの結合
まずはデータの結合です。これは簡単に
pandasで結合しました。
深く考えずに結合してますが、0行目に「1306 東証ETF TOPIX連動型上場投資信託(ETF)」が入っているので、data = pd.read_csv(file,encoding='Shift-Jis',header = 1)として、header=1で1行目の
を
column名として読み込みました。
column名が日本語なので、とりあえず適当な英語に直しました。import pandas as pd import matplotlib.pyplot as plt import datetime import matplotlib.dates as mdates #read_csvですべてのデータを結合する。 #1306_2001から1306_2021 df = None for i in range(2001,2021): file = '1306_' + str(i) + '.csv' print(file) data = pd.read_csv(file,encoding='Shift-Jis',header = 1) df = pd.concat( [df,data],ignore_index=True) df.rename(columns={'日付': 'day', '始値': 'open_price', '高値':'high_price', '安値':'low_price', '終値': 'end_price', '出来高':'volume', '終値調整値':'end_price_ad_value'}, inplace=True) print(df.head())とりあえず
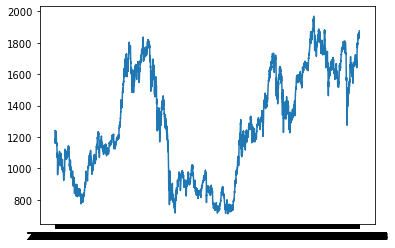
pandasのデータセットができました。グラフを作ると、こんな感じです。今は10年間で最高値です。イケイケですね。
次にボリンジャーバンドの描き方です。
ボリンジャーバンドの描き方
ボリンジャーバンドとは、をMONEX証券のサイトから引用します。
https://info.monex.co.jp/technical-analysis/indicators/003.html
「移動平均線と標準偏差で構成されており、移動平均を表す線とその上下に値動きの幅を示す線を加えた指標で、「価格の大半がこの帯(バンド)の中に収まる」という統計学を応用したテクニカル指標のひとつです。」つまり、株の価格から移動平均線と標準偏差を計算する必要があります。後、「統計学を応用したテクニカル指標」というところで、機械学習にも相性良いかも知れませんね。
最初に移動平均線を計算します。単純移動平均線の計算
単純移動平均線は、一定期間の終値の平均価格になります。そこで、
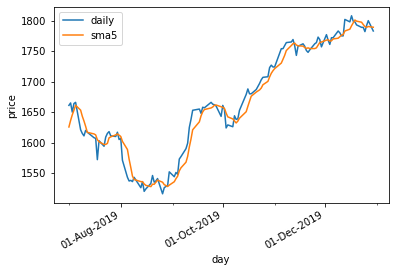
pandasのrolling関数を使います。例えばrolling関数で、rolling(5).mean()とすると、5つの数値の平均を返します。そこで、df["end_price"].rolling(5).mean().round(1)で、計算をして、5日移動平均線を描いてみます。#'day'をdatetimeタイプに変更 df['day'] = pd.to_datetime(df['day']) #'day'をindexにして置き換える。 df.set_index('day', inplace=True) #5日間移動平均線を計算 df["5day_ave"]=df["end_price"].rolling(5).mean().round(1) #2019年の下期7月から12月を取り出す df_temp = df['2019-07':'2019-12'] #グラフに描く plt.plot(df_temp.index, df_temp["end_price"], label="daily") plt.plot(df_temp.index, df_temp["5day_ave"], label="sma5") plt.xlabel("day") plt.ylabel("price") plt.gca().xaxis.set_major_formatter(mdates.DateFormatter('%d-%b-%Y')) plt.gca().xaxis.set_major_locator(mdates.MonthLocator(interval=2)) plt.gca().xaxis.set_minor_locator(mdates.MonthLocator(interval=1)) plt.gcf().autofmt_xdate() plt.legend() plt.show()
移動平均線が描けました。
次は、ボリンジャーバンドを描いていきます。
それは次の「投資quest:pyhtonでシステムトレードを作る(2)」(今下書き中です)で。

- 投稿日:2021-01-15T18:11:22+09:00
Q学習の実戦と理論
はじめに
強化学習の基本となるQ学習について復習も兼ねて書く。
理論
Q学習とは強化学習手法TD学習の一つで、Q値(状態行動価値)をエージェントが行動するたびに更新する手法である。時刻$t$での状態を$s_t$、行動を$a_t$、状態$s_t$のもとで行動$a_t$を起こすことによって得られる報酬を$r_t$とする。また、Q値$Q(s_t,a_t)$とはある状態$s_t$においてある行動$a_t$を取った時の価値のことである。価値の更新は以下のように行われる。
$$
Q(s_t,a_t) \leftarrow Q(s_t,a_t) + \alpha(r_{t+1}+\gamma \max_{a_{t+1}}Q(s_{t+1},a_{t+1})-Q(s_t,a_t))
$$
$\alpha$は学習の大きさを制御するパラメーターで0~1の値を取る。$\gamma$は将来の価値をどれほど考慮するかのパラメータで0~1をとる。$\max_{a_{t+1}}Q(s_{t+1},a_{t+1})$は状態$s_{t+1}$において得られる最大の価値である。この式は$Q(s_t,a_t)$、$\alpha(r_{t+1}-Q(s_t,a_t))$、$\alpha\gamma\max_{a_{t+1}}Q(s_{s_{t+1}}{a_{t+1}})$に分けて考えると理解しやすい。第一式は前回の価値であり、基準と考える。つまり第二式、第三式によって更新の程度が決まる。第二式は前回の価値と報酬の差をなくすように更新している。単に差を加算するだけではその時偶然得た報酬に過剰に依存してしまうため$\alpha$によって制御している。第三式は将来の価値について見積もっている。次に得られる最大の価値を将来の価値として考えており、$\alpha\gamma$によって制御されている。$\alpha$は第二式と同様の制御、$\gamma$は見積もりの不確かさによる割引率である。実戦(具体例)
具体例として2腕バンディット問題について考える。0~2000の数字がランダムに出てくる山Aと0~1000の数字がランダムに出てくる山Bがあるとする。どちらか一方の山から数字を取得とするとき、より大きな数字(報酬)を得ることができる可能性が高い山を選択できるようなモデルを作成する。更新回数$t$(更新回数$t$は理論での時刻$t$とは異なることに注意)での山A、山Bの価値を$Q_t(A),Q_t(B)$とし、その初期値はどちらも0とする。更新するごとに価値を元とに生成した確率で山を選択し、出た数字によって選択した山に対する価値を更新する。選択した山から出た数字は$r_t$とする。確率は$P_t(A),P_t(B)$とし、$$P_{t+1}(A)=\frac{\exp(\beta Q_t(A))}{\exp(\beta Q_t(A))+\exp(\beta Q_t(B))}$$で計算する。価値の更新は$Q_{t+1}(X)=Q_t(X)+\alpha(r_t-Q_t(X))$によって行う。(時間発展はない系を考えているため理論で扱った第三項はない)
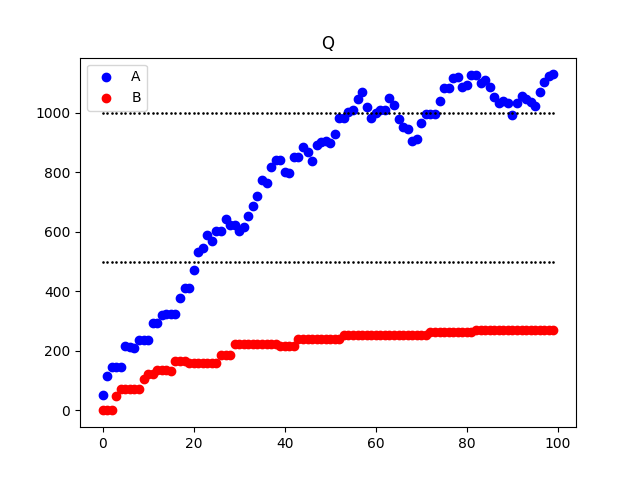
$\alpha=0.05,\beta=0.004$として、以上の設定を100回更新をした。価値は以下のように更新された。
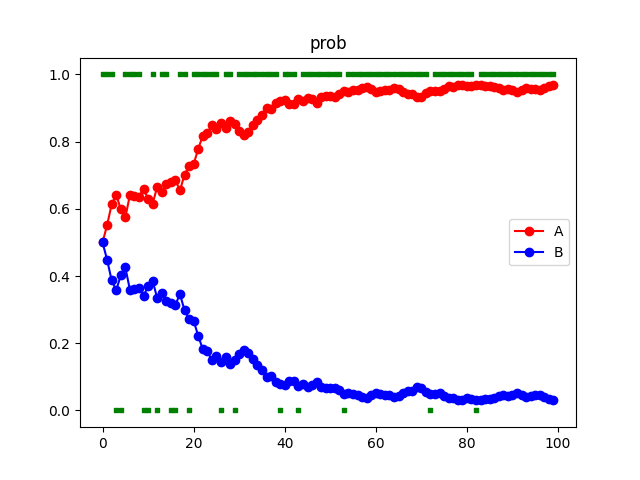
それぞれ山を選ぶ確率は以下のように更新された。
コード
import numpy as np import matplotlib.pyplot as plt # seed値固定 np.random.seed(71) # 引いた総数 N = 100 # 山A:0~2000 pileA = np.array([i for i in range(2001)]) # 山B:0~1000 pileB = np.array([i for i in range(1001)]) # パラメーター alpha = 0.05 beta = 0.004 """ 変数 Q_A: (時間ごと)山Aの価値 Q_A: (時間ごと)山Bの価値 P_A: (時間ごと)山Aを引く確率 P_B: (時間ごと)山Bを引く確率 select_pile: (時間ごと)選択した山 """ Q_A = [0] Q_B = [0] P_A = [] P_B = [] select_pile = [] for i in range(N): P_A.append(np.exp(beta * Q_A[i]) / (np.exp(beta * Q_A[i]) + np.exp(beta * Q_B[i]))) P_B.append(np.exp(beta * Q_B[i]) / (np.exp(beta * Q_A[i]) + np.exp(beta * Q_B[i]))) if P_A[i] >= np.random.rand(): select_pile.append(1) Q_A.append(Q_A[i] + alpha * (np.random.choice(pileA, 1)[0] - Q_A[i])) Q_B.append(Q_B[i]) else: select_pile.append(0) Q_A.append(Q_A[i]) Q_B.append(Q_B[i] + alpha * (np.random.choice(pileB, 1)[0] - Q_B[i])) # 時間 t = np.array([i for i in range(N)]) plt.scatter(t, Q_A[1:], c="blue", marker="o", label="A") plt.scatter(t, 1000*np.ones(N), c="black", marker=".", s=3) plt.scatter(t, Q_B[1:], c="red", marker="o", label="B") plt.scatter(t, 500*np.ones(N), c="black", marker=".", s=3) plt.title("Q") plt.legend() plt.savefig("value.png") plt.show() plt.scatter(t, select_pile, c="green", marker="s", s=10) plt.plot(t, P_A, color=(1,0,0), marker="o", label="A") plt.plot(t, P_B, color=(0,0,1), marker="o", label="B") plt.title("prob") plt.legend() plt.savefig("prob.png") plt.show()時間発展のある系ではコードが大量になるのでここでは紹介しなかった。「cartpole qlearning」などで検索すると多くの記事が出てくるので気になる方はそこを見ていただきたい。
参考
理論:Sutton, Richard S. (1998). Reinforcement Learning: An Introduction.
問題引用:データ分析のための数理モデル
- 投稿日:2021-01-15T17:06:00+09:00
【Python】DP(動的計画法)で次元を減らすテクニック【AtCoder】
この記事はDP初心者向けになります。
そもそもDPって何って人は、けんちょんさんの記事をどうぞ!最近DPの勉強をはじめて、
DPの次元を減らすテクニック
に非常に感動したので記事にしてみます!!!以下の2問を実際に解きながら簡単に解説したいと思います。
- TDPC A - コンテスト →DPを2次元から1次元へ
- ABC 015 D - 高橋くんの苦悩 →DPを3次元から2次元へ
TDPC A - コンテスト
典型的な部分和問題です。
今回の問題はNのMAXが100
→bit全探索とかだと計算量的に無理なのでDPで考える。DP:2次元Ver
普通に、DPを2次元として解くと、こんな感じー
※点数のパターンは0〜100点ではなく、0〜MAX10000(100*100)点であることに注意DP_2D.pyimport itertools,sys def I(): return int(sys.stdin.readline().rstrip()) def LI(): return list(map(int,sys.stdin.readline().rstrip().split())) ############################# N = I() p = LI() dp = [[0]*10001 for _ in range(N+1)] #0:その点数存在しない、1:その点数存在する dp[0][0] = 1 for i,j in itertools.product(range(1,N+1),range(10001)): pi = p[i-1] if j-pi>=0: dp[i][j] = max(dp[i][j],dp[i-1][j-pi]) #選んだ場合 dp[i][j] = max(dp[i][j],dp[i-1][j]) #選ばなかった場合 print(sum(dp[-1])) #1の数字の個数を出力DP:1次元Ver
これをDP1次元にするにはこうする!
DP_1D.pyimport itertools,sys def I(): return int(sys.stdin.readline().rstrip()) def LI(): return list(map(int,sys.stdin.readline().rstrip().split())) ############################# N = I() p = LI() dp = [0]*10001 #0:その点数存在しない、1:その点数存在する dp[0] = 1 for i,j in itertools.product(range(1,N+1),range(10001)[::-1]): pi = p[i-1] if j-pi>=0: dp[j] = max(dp[j],dp[j-pi]) #選んだ場合 #dp[j] = max(dp[j],dp[j]) #選ばなかった場合→不要 print(sum(dp)) #1の数字の個数を出力ポイントはここ!!!
range(10001)[::-1]
※range(10000,-1,-1)でも可逆からループを回すことで、dpを使い回すことができる!!!!!
これがテクニック!!!!!もしdpを使いまわしながら、順番にループを回すと
例えばp=2点の場合に、dp = [1,0,1,0,1,0,1,0,1 ・・・]
と4点、6点、8点・・・も存在することになってしまう・・・
なぜなら、
dp[j] = max(dp[j],dp[j-pi])
2点が1なので4点も1になる。。。
4点が1なので、6点も1になる。。。
・・・しかし、逆からループさせると・・・
dp = [1,0,1,0,0,0,0,0,0 ・・・]
dp[j] = max(dp[j],dp[j-pi])・・・
4点が0なので、6点も0になる!
2点が0なので、4点も0になる!
0点が1なので、2点は1になる!!!
ということでdpを使いまわしながら、正しい結果を得られることができる!!!!!!!!!
→dpの次元を2次元から1次元に落とすことができる!!!!!!!!!!dpの次元が下がることで、
頭で考える量が減ってめちゃくちゃ嬉しい!この感動伝わるかな〜
伝わってくれ〜感動をより実感してもらうためにもう一問!!!
ABC 015 D - 高橋くんの苦悩
Difficulty:1388の水色問題!
ナップサックDPに変数が1つ増えた、少しだけ発展的な問題。DP:3次元Ver
3次元でDPを考えたらできなくもないけど、頭がパンクしそう・・・・・・・・・・
DP_3D.pyimport itertools,sys def I(): return int(sys.stdin.readline().rstrip()) def LI(): return list(map(int,sys.stdin.readline().rstrip().split())) ############################# W = I() N,K = LI() AB = [LI() for _ in range(N)] dp = [[[0]*(W+1) for _ in range(K+1)] for _ in range(N)] #k枚使った時の重要度の最大値を保持 for i,k,w in itertools.product(range(N),range(1,K+1),range(W+1)): A,B = AB[i] if w-A>=0: dp[i][k][w] = max(dp[i][k][w],dp[i-1][k-1][w-A]+B) dp[i][k][w] = max(dp[i][k][w],dp[i-1][k][w]) print(dp[-1][-1][-1])しかしこれではPythonだと計算量的にTLE、PyPyだとMLE
オワタ・・・
DP:2次元Ver
ここで!
さきほどの次元削減テクニックをつかって、
なんとかDPを使えまわすことができないか!
と考えてやってみると・・・
どうやら2次元にできそう・・・!DP_2D.pyimport itertools,sys def I(): return int(sys.stdin.readline().rstrip()) def LI(): return list(map(int,sys.stdin.readline().rstrip().split())) ############################# W = I() N,K = LI() AB = [LI() for _ in range(N)] dp = [[0]*(W+1) for _ in range(K+1)] #k枚使った時の重要度の最大値を保持 for i,k,w in itertools.product(range(N),range(1,K+1)[::-1],range(W+1)[::-1]): A,B = AB[i] if w-A>=0: dp[k][w] = max(dp[k][w],dp[k-1][w-A]+B) #dp[k][w] = max(dp[k][w],dp[k][w]) print(dp[-1][-1])ポイントはここ!!!
range(1,K+1)[::-1],range(W+1)[::-1]
逆からループで、DPを使いまわせる!!!気になる結果は・・・
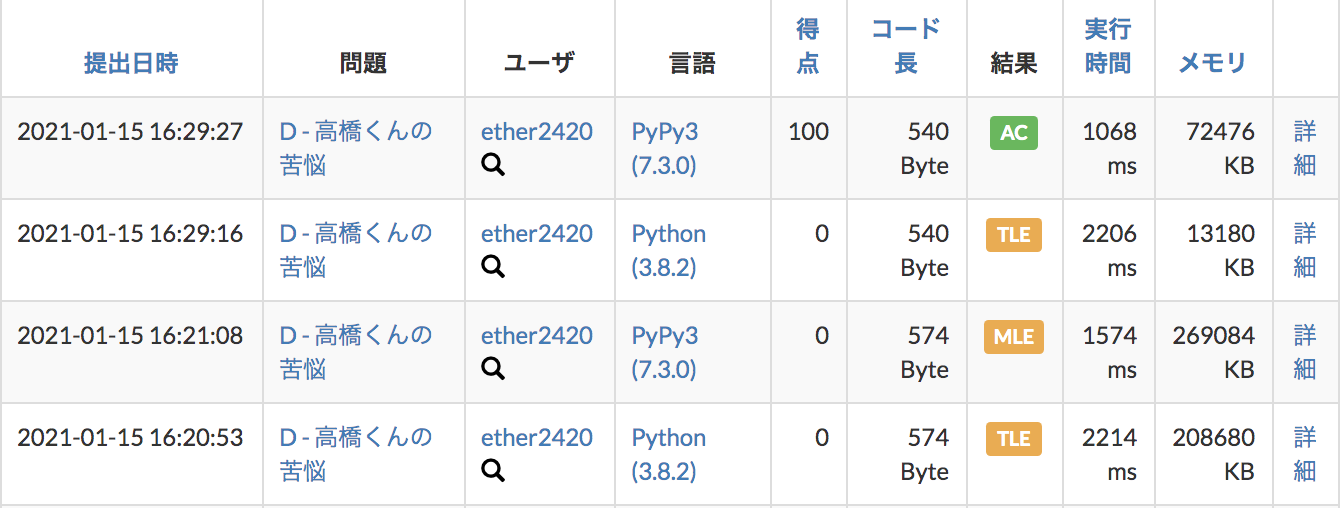
あいかわらず、PythonはTLEでしたがw(次元削減したからといって計算量が削減されるわけではなかったw)
PyPyで無事ACになりました〜!!!今後DP問題が出た時に、次元が2次元以上になりそうだったら、
この次元削減テクニック使えないか考えてみよう〜おわり!!!
- 投稿日:2021-01-15T16:45:04+09:00
緯度経度の座標情報をkepler.glで可視化する
緯度経度の座標情報をkepler.glで可視化する
kepler.glは地図上で様々なデータを可視化することができるツールである。今回はGPSデータを動画で可視化する。
手元にあるもの
gpxデータから作成したcsvファイル。
内訳はこのようになっている。
ID 時刻 経度 緯度 速度 trackID segmentID pointID int datetime float float float int int int このうち、IDとtrackIDで分類すればトリップを一意に特定できるっぽい仕組みになっている。
求められているもの
公式ドキュメントによると、
How to use trip layer to animate path
Data format Currently trip layer support a special geoJSON format where the coordinate linestring has a 4th element denoting timestamp.
In order to animate the path, the geoJSON data needs to contain LineString in its features' geometry, and the coordinates in the LineString need to have 4 elements in the format of [longitude, latitude, altitude, timestamp], with the last element being a timestamp. Valid timestamp formats include unix in seconds such as 1564184363 or in milliseconds such as 1564184363000.ということらしい。要約すると以下が必要である。
- GeoJsonファイル
- LineString形式
- 座標形式:[経度,緯度,標高,UNIX秒]
ありがたいことにサンプルデータもついており、
{ "type": "FeatureCollection", "features": [ { "type": "Feature", "properties": { "vendor": "A" }, "geometry": { "type": "LineString", "coordinates": [ [-74.20986, 40.81773, 0, 1564184363], [-74.20987, 40.81765, 0, 1564184396], [-74.20998, 40.81746, 0, 1564184409] ] } } ] }この形式が求められている。
GeoJsonについて
だいたいJsonと同じらしい。Googleのロケーション履歴をダウンロードしようとするとJson形式で提供されるし、地理情報を含むJsonファイルを区別の意味を込めてGeoJsonと呼んでいるような雰囲気を感じた。実際、同じ内容で拡張子だけ.jsonにしたファイルも同様に読み込むことができた。
改めて先ほどのサンプルデータに注目すると、
- FeatureCollection
- type
- Features
- type
- properties
- type
- vendor
- geometry
- type
- coordinates
という構造になっている。つまり、これを満たす構造にしてやれば読み込まれるということである。
DataFrameから座標リストの作成
各データの列名は以下の通り。(今回は標高データがないので速度データで代用している)
ID 時刻 経度 緯度 速度 trackID segmentID pointID "ID" "time" "longitude" "latitude" "speed" "trackID" "segmentID" "pointID" まず、時刻をdatetime型からtimestamp型(UNIX秒)に変換する。
df["time"] = df["time"].apply(lambda x: x.timestamp()) #DataFrame次にDataFrameから必要な項目だけを取り出す。リストで指定することで複数項目を一気に取得できる。
df_coordinate = df[["longitude","latitude","speed","time"]] #DataFrame次に、IDとtrackIDで分類できるようにする。
g = df_coordinate.groupby(["ID","trackID"]) #DataFrameGroupBy次に各行(df[["longitude","latitude","speed","time"]]の一行ずつ)をリストにする。
coordinate_listにはdf_coordinateのID,trackID毎のリストのSeriesが作成される。coordinate_list= g.apply(lambda d : d.values.tolist()) #Series ここ間違えやすい最後にSeriesをlistに変換する。
coordinate_list = coordinate_list.values.tolist() #listこれで、手元にリスト[経度,緯度,標高,UNIX秒]の1トリップ分のリストのリストができている。
- すべてのトリップの座リスト
- 1トリップのリスト
- 1点のリスト - 経度 - 緯度 - 標高(速度) - 時刻
という構造である。
GeoJson形式への変換
前項で作成したリストを用いて、GeoJsonデータを作成する。これにはgeojsonというライブラリを用いた。
素人目の認識としては、json書式に整えてくれるモジュールである。
先ほども書いた通り、求められるデータは以下の形式である。これらのデータを下から組み立てるように作成していくのが着実である。
- FeatureCollection
- type(自己紹介)
- Features
- type(自己紹介)
- properties(geometoryの詳細)
- type(自己紹介)
- vendor
- geometry(地理データ)
- type(自己紹介)
- coordinates(LineString)
このモジュールは単純で、例えばFeatureを作りたければ以下のようにすればよい。
つまり、自己紹介部分や括弧などを勝手に追加してくれるというものである。> Feature(geometry=my_point) # doctest: +ELLIPSIS {"geometry": {"coordinates": [-3.68..., 40.4...], "type": "Point"}, "properties": {}, "type": "Feature"}この例文を参考に組み立てたものを以下に示す。
#Featureを蓄積するリストを作る feature_list = list() #FeatureリストにFeatureを蓄積させる for i in range(len(coordinate_list)): #ptsに1トリップ分のリストを代入 pts = coordinate_list[i] #lsにptsをGeoJson形式に変換したものを代入 ls = geojson.LineString(pts) #lsをgeometryとし、propertiesと合わせてFeatureを作成 #feature_listの末尾に追加 feature_list.append(geojson.Feature(properties={'tripID': str(i)},geometry=ls)) #feature_listをFeatureCollectionに変換 Tripdata = geojson.FeatureCollection(feature_list)これによってTripdataには求められる形式の平文が入ったものとなる。
ちなみにpropertiesにはFeature毎の識別情報を入れることが可能である。工夫次第では人ごとに分類、時間ごとに分類など様々な分類ができる。
書き出し
ここまで出来ればほぼ終わりである。
新たに拡張子に.geojsonをもつファイルを作成し、そこに平文を書き込むことでデータの完成となる。path = './Tripdata.geojson' with open(path, 'w') as f: f.write(geojson.dumps(Tripdata_dt_ts)) f.close()可視化
大げさに可視化と書いたが、先ほど作成したデータをドラッグ&ドロップするだけで終了である。
propertiesの情報をもとに分類することも可能である。Tipsとまとめ
すべてのデータについて、年月日だけを同じ日にしてやると時間帯のみの可視化ができるので、移動の多い時間帯が一目でわかりやすい。
変換はdatetimeのうちがやりやすいので、UNIX秒に変換する前にreplace()をするとよい。df["time"] = df["time"].apply(lambda x: x.replace(year=2021,month=1,day=1)) df["time"] = df["time"].apply(lambda x: x.timestamp())これら一連の流れでとても見栄えのいい可視化ができるので、ぜひ挑戦してほしい。
- 投稿日:2021-01-15T16:20:16+09:00
python3.9には誰も注目していない新機能が・・・
A. ある。
関連記事
https://qiita.com/sh1ma/items/3d9280084c340b4cd775コードみてね
@lambda f: lambda *args: print(f(*args)) # ←動く!!(3.8まではこれ動かなかった) def f(): return "hello" f() # -> helloウケるw
- 投稿日:2021-01-15T14:11:35+09:00
ABCIで環境構築してMaskTrackRCNNを動かすまで
概要
最新のVideo Instance SegmentationタスクのベースラインとなっているモデルであるMaskTrackRCNNをABCIで動かそうとした際に、度重なるエラーに悩まされたので、ABCIにおける環境構築からモデルの学習までの方法を忘備録として残しておきます。
最後に格闘したエラーとその解決方法をまとめて残しておきました。前提
- 2021/01/15 時点の情報である。
- ABCIのアカウントを持っており、サーバにリモートアクセスできる。
- anaconda3を導入済である。
環境構築
- ABCIにsshでリモートアクセス
GPUノードの起動
以下はGPUを最小構成で最大1時間インタラクティブに利用するコマンド。qrsh -g gcc50560 -l rt_G.small=1 -l h_rt=1:00:00 -m abes必要なモジュールのロード
立ち上げたノードで以下のコマンドを実行し、必要なモジュールをロードしておく。module load cuda/9.0 module load cudnn/7.6/7.6.2 module load nccl/2.3/2.3.7-1仮想環境の作成とセットアップ
以下のbash masktrackrcnn_env.shを実行してレポジトリのクローン、仮想環境構築を行う。masktrackrcnn_env.sh# clone MaskTrackRCNN git clone https://github.com/youtubevos/MaskTrackRCNN.git cd MaskTrackRCNN # create environment conda create -n MaskTrackRCNN python=3.7 -y # >>> conda init >>> __conda_setup="$(CONDA_REPORT_ERRORS=false '$HOME/anaconda3/bin/conda' shell.bash hook 2> /dev/null)" if [ $? -eq 0 ]; then \eval "$__conda_setup" else if [ -f "$HOME/anaconda3/etc/profile.d/conda.sh" ]; then . "$HOME/anaconda3/etc/profile.d/conda.sh" CONDA_CHANGEPS1=false conda activate base else \export PATH="$PATH:$HOME/anaconda3/bin" fi fi unset __conda_setup # <<< conda init <<< # activate environment conda activate MaskTrackRCNN # setup environment conda install -c pytorch pytorch=0.4.1 cudatoolkit=9.0 torchvision -y conda install -c conda-forge opencv -y conda install numpy cython -y conda install -c psi4 gcc-5 -y conda install libgcc -y pip install git+https://github.com/youtubevos/cocoapi.git#"egg=pycocotools&subdirectory=PythonAPI" bash compile.sh pip install . --user pip uninstall mmcv -y pip install mmcv==0.2.0ライブラリの修正
ここまでで必要な環境は整ったが、このままでは学習時に不都合があるので最後に一つ修正を加える。
[python_lib_path]/site-packages/mmcv/runner/checkpoint.py の39行目を以下に変更する。
※ [python_lib_path] には、which pythonが返すパスを入れれば良い。checkpoint.pyprint('While copying the parameter named {}, ' 'whose dimensions in the model are {} and ' 'whose dimensions in the checkpoint are {}.' .format(name, own_state[name].size(), param.size()))環境構築完了!!
データセットの準備
データとラベルのダウンロード
ここからデータとラベルをダウンロードしておく。データセットの配置
以下の構成になるようにシンボリックリンクを貼る。MaskTrackRCNN ├── mmdet ├── tools ├── configs ├── data │ ├── train │ ├── val │ ├── annotations │ │ ├── instances_train_sub.json │ │ ├── instances_val_sub.jsonラベルは元々
train.json,valid.jsonというファイル名で与えられるので、(コピーして)改名しておくと良い。configのファイル名を変更しても良い。# シンボリックリンクの貼り方の一例 $MaskTrackRCNN は MaskTrackRCNNレポジトリのルートまでのパス mkdir $MaskTrackRCNN/data ln -s /path/to/original/data_dir/train $MaskTrackRCNN/data/train ln -s /path/to/original/data_dir/valid $MaskTrackRCNN/data/val ln -s /path/to/original/data_dir/annotations $MaskTrackRCNN/data/annotationsモデルの学習
- GCC7.4のロード
module load gcc/7.4.0- 仮想環境のアクティベート
conda activate MaskTrackRCNNいざ学習
python tools/train.py configs/masktrack_rcnn_r50_fpn_1x_youtubevos.py
以下のようなログが出ていれば正しく学習されていると思われます。このままだと学習に24時間くらいかかりそうですが。2021-01-15 13:36:50,620 - INFO - Epoch [1][50/7669] lr: 0.00199, time: 0.774, data_time: 0.045, loss_rpn_cls: 0.0609, loss_rpn_reg: 0.0465, loss_cls: 0.9336, acc: 84.5996, loss_reg: 0.2753, loss_match: 0.4937, match_acc: 89.2641, loss_mask: 0.7734, loss: 2.5835 2021-01-15 13:37:27,818 - INFO - Epoch [1][100/7669] lr: 0.00233, time: 0.744, data_time: 0.028, loss_rpn_cls: 0.0469, loss_rpn_reg: 0.0442, loss_cls: 0.7820, acc: 84.7695, loss_reg: 0.3567, loss_match: 0.2895, match_acc: 88.3957, loss_mask: 0.6092, loss: 2.1286 2021-01-15 13:38:04,878 - INFO - Epoch [1][150/7669] lr: 0.00266, time: 0.741, data_time: 0.026, loss_rpn_cls: 0.0342, loss_rpn_reg: 0.0342, loss_cls: 0.7171, acc: 85.1309, loss_reg: 0.3467, loss_match: 0.2588, match_acc: 89.5726, loss_mask: 0.5057, loss: 1.8968configs/masktrack_rcnn_r50_fpn_1x_youtubevos.py をいじればエポック数等学習のハイパーパラメータを変更できそうです。
格闘したエラーまとめ
unable to execute 'nvcc': No such file or directory
実行コマンド:
bash masktrackrcnn_env.sh
原因:cuda のロードがうまくできていない
解決方法:module load cuda/{version}を実行すれば解決するはず。シェルスクリプト(masktrackrcnn_env.sh)中にこのコマンドを書いてもうまくいかなかったが、普通にシェルで実行したらうまくいった。AttributeError:module 'torch.nn' has no attribute 'SyncBatchNorm
実行コマンド:
python tools/train.py configs/masktrack_rcnn_r50_fpn_1x_youtubevos.py(学習用スクリプト)
原因:torchのversionが1.1未満(でも著者はversion0.4.1で実行しているはず。)
解決方法:mmcvのバージョンを0.2.0に下げる。pip uninstall mmcv pip install mmcv==0.2.0Traceback (most recent call last): File "tools/train.py", line 4, in <module> from mmcv import Config File "/home/acb11854zq/.local/lib/python3.7/site-packages/mmcv/__init__.py", line 4, in <module> from .fileio import * File "/home/acb11854zq/.local/lib/python3.7/site-packages/mmcv/fileio/__init__.py", line 4, in <module> from .io import dump, load, register_handler File "/home/acb11854zq/.local/lib/python3.7/site-packages/mmcv/fileio/io.py", line 4, in <module> from ..utils import is_list_of, is_str File "/home/acb11854zq/.local/lib/python3.7/site-packages/mmcv/utils/__init__.py", line 29, in <module> from .env import collect_env File "/home/acb11854zq/.local/lib/python3.7/site-packages/mmcv/utils/env.py", line 12, in <module> from .parrots_wrapper import get_build_config File "/home/acb11854zq/.local/lib/python3.7/site-packages/mmcv/utils/parrots_wrapper.py", line 79, in <module> _BatchNorm, _InstanceNorm, SyncBatchNorm_ = _get_norm() File "/home/acb11854zq/.local/lib/python3.7/site-packages/mmcv/utils/parrots_wrapper.py", line 71, in _get_norm SyncBatchNorm_ = torch.nn.SyncBatchNorm AttributeError: module 'torch.nn' has no attribute 'SyncBatchNorm'
ImportError: /home/acb11854zq/.local/lib/python3.7/site-packages/mmdet/ops/nms/gpu_nms.cpython-37m-x86_64-linux-gnu.so: undefined symbol: __cudaPopCallConfiguration
実行コマンド:
python tools/train.py configs/masktrack_rcnn_r50_fpn_1x_youtubevos.py
原因:ビルド時のCUDAのバージョン
解決方法:ビルド時にCUDA9.2 -> CUDA9.0にすれば直る (source) 。この時、CUDA9.0はGCC<6.0を要求することに注意。
RuntimeError: While copying the parameter named bbox_head.fc_cls.weight, whose dimensions in the model are torch.Size([41, 1024]) and whose dimensions in the checkpoint are torch.Size([81, 1024]).
実行コマンド:
python tools/train.py configs/masktrack_rcnn_r50_fpn_1x_youtubevos.py
原因:モデルのbbox_head.fc_cls.weightの次元がチェックポイントのモデルのそれと違う。
解決方法:[python_lib_path]/site-packages/mmcv/runner/checkpoint.py の39行目を以下に変更する(参考1、参考2)。checkpoint.pyprint('While copying the parameter named {}, ' 'whose dimensions in the model are {} and ' 'whose dimensions in the checkpoint are {}.' .format(name, own_state[name].size(), param.size()))Segmentation fault
実行コマンド:
python tools/train.py configs/masktrack_rcnn_r50_fpn_1x_youtubevos.py
原因:issueに依るとbuild時にGCC<4.9.2だったことが問題らしい。
解決方法:conda install -c psi4 gcc-5conda に gcc を入れる(source)。というのも、これの解決方法と矛盾しないように、4.9.2<=GCC<6.0 を使いたいけどABCIにその選択肢がない 。
結果:ビルドには成功しているのでおそらくSegmentation faultの問題は解決できているが、新たにopencvのimport errorが出ている。
ImportError: /home/acb11854zq/anaconda3/envs/test_gcc/bin/../lib/libstdc++.so.6: version `GLIBCXX_3.4.22' not found (required by /home/acb11854zq/.local/lib/python3.7/site-packages/cv2/cv2.cpython-37m-x86_64-linux-gnu.so)
実行コマンド:
python tools/train.py configs/masktrack_rcnn_r50_fpn_1x_youtubevos.py
原因:condaのlibstdc++のバージョンが低い?
解決方法:conda install libgccでとりあえずこの問題は解決するっぽいが、今度はシステムのlibstdc++に関してimport errorが出る。Traceback (most recent call last): File "tools/train.py", line 4, in <module> from mmcv import Config File "/home/acb11854zq/anaconda3/envs/test_gcc/lib/python3.7/site-packages/mmcv/__init__.py", line 5, in <module> from .opencv_info import * File "/home/acb11854zq/anaconda3/envs/test_gcc/lib/python3.7/site-packages/mmcv/opencv_info.py", line 1, in <module> import cv2 File "/home/acb11854zq/.local/lib/python3.7/site-packages/cv2/__init__.py", line 5, in <module> from .cv2 import * ImportError: /home/acb11854zq/anaconda3/envs/test_gcc/bin/../lib/libstdc++.so.6: version `GLIBCXX_3.4.22' not found (required by /home/acb11854zq/.local/lib/python3.7/site-packages/cv2/cv2.cpython-37m-x86_64-linux-gnu.so)
ImportError: /lib64/libstdc++.so.6: version `CXXABI_1.3.8' not found (required by /home/acb11854zq/.local/lib/python3.7/site-packages/cv2/cv2.cpython-37m-x86_64-linux-gnu.so)
実行コマンド:
python tools/train.py configs/masktrack_rcnn_r50_fpn_1x_youtubevos.py
原因:おそらくシステムのlibstdc++が古い? CXXABI_1.3.8はどうやらGCC4.9から導入されている。
解決方法:モデルの学習時にmodule load gcc/7.4.0としてシステムにGCC7.4をロードすることで無理矢理解消できる。bash compile.shによるビルドが終わってからでないとビルド時にエラーが出るので注意。Traceback (most recent call last): File "tools/train.py", line 4, in <module> from mmcv import Config File "/home/acb11854zq/.local/lib/python3.7/site-packages/mmcv/__init__.py", line 5, in <module> from .image import * File "/home/acb11854zq/.local/lib/python3.7/site-packages/mmcv/image/__init__.py", line 2, in <module> from .colorspace import (bgr2gray, bgr2hls, bgr2hsv, bgr2rgb, bgr2ycbcr, File "/home/acb11854zq/.local/lib/python3.7/site-packages/mmcv/image/colorspace.py", line 2, in <module> import cv2 File "/home/acb11854zq/.local/lib/python3.7/site-packages/cv2/__init__.py", line 5, in <module> from .cv2 import * ImportError: /lib64/libstdc++.so.6: version `CXXABI_1.3.8' not found (required by /home/acb11854zq/.local/lib/python3.7/site-packages/cv2/cv2.cpython-37m-x86_64-linux-gnu.so)
- 投稿日:2021-01-15T14:06:52+09:00
Tkinterで試しに電卓を作ってみたので書いてみる
1.作るきっかけ
電卓を自作してみたいと考えていたから。
2.作る材料
Python 3.8
Tkinterとmath
基本的に使ったのはこれだけ。3.苦労した点
桁上がりの処理と、複数の項の計算の実装(今のところ、対応しているのは足し算だけですが)
4.実装コード
4-1:イントロ-GUI表示
今回はtkinterを用い、GUIを作成した。
以下コード
※備忘録程度に書いています。適宜かみ砕いて修正していきます。main.pyimport tkinter as tk import math root=tk.Tk() #root.minsize(640,480) #可変テスト root.geometry('538x720') root.resizable(width=0, height=0) canvas = tk.Canvas(root, width = 538, height = 720,bg = "black") #キャンバスバインド canvas.place(x=0, y=0) #StringVar() #桁上がりチェック up = 0 keisan = 0 output = [] jou = 0 result= tk.StringVar() result.set(keisan) def ichi(): global result global output global x x = 1 output.append(x) print(output) result.set(output) print(len(output)) def ni(): global result global output global x x = 2 output.append(x) print(output) result.set(output) print(len(output)) def san(): global result global output global x x = 3 output.append(x) print(output) result.set(output) print(len(output)) def yon(): global result global output global x x = 4 output.append(x) print(output) result.set(output) print(len(output)) def go(): global result global output global x x = 5 output.append(x) print(output) result.set(output) print(len(output)) def roku(): global result global output global x x = 6 output.append(x) print(output) result.set(output) print(len(output)) def nana(): global result global output global x x = 7 output.append(x) print(output) result.set(output) print(len(output)) def hachi(): global result global output global x x = 8 output.append(x) print(output) result.set(output) print(len(output)) def kyu(): global result global output global x x = 9 output.append(x) print(output) result.set(output) print(len(output)) def zer(): global result global output global x x = 0 output.append(x) print(output) result.set(output) print(len(output)) def delete(): global up global result global keisan global jou global flag #まず一桁分確保 keisan = 0 flag = False result.set('Enter.') a = 0 b= 0 #オペランド0=足し算,1=引き算,2=掛け算,3=割り算 op = 0 #加算分リスト alist = [] def plus(): global output global a global op global alist op =0 map(str, output) #joinで数字を結合 ketsugou = "".join(map(str, output)) a = int(ketsugou) print(a) alist.append(a) print(alist) print(len(alist)) #リストを削除 output.clear() def minus(): global output global a global op global alist op =1 map(str, output) #joinで数字を結合 ketsugou = "".join(map(str, output)) a = int(ketsugou) print(a) alist.append(a) print(alist) print(len(alist)) #リストを削除 output.clear() def kakeru(): global output global a global op global alist op =2 map(str, output) #joinで数字を結合 ketsugou = "".join(map(str, output)) a = int(ketsugou) print(a) alist.append(a) print(alist) print(len(alist)) #リストを削除 output.clear() def waru(): global output global a global op global alist op =3 map(str, output) #joinで数字を結合 ketsugou = "".join(map(str, output)) a = int(float(ketsugou)) print(a) alist.append(a) print(alist) print(len(alist)) #リストを削除 output.clear() def rote(): global output global a global op global result op =4 map(str, output) #joinで数字を結合 ketsugou = "".join(map(str, output)) a = float(ketsugou) r= a**(0.5) if a == "": result.set("Error!") else: result.set(str(r)) print(a) #リストを削除 output.clear() def seigen(): global output global a global op if str(a) == "": result.set("Error!") else: op =5 map(str, output) #joinで数字を結合 ketsugou = "".join(map(str, output)) a = float(ketsugou) sina = math.sin(math.radians(a)) print(sina) if a == 90.0: result.set("1") else: result.set(str(sina)) #リストを削除 output.clear() def yogen(): global output global a global op op =6 map(str, output) #joinで数字を結合 ketsugou = "".join(map(str, output)) a = float(ketsugou) cosa = math.cos(math.radians(a)) print(cosa) if a == "": result.set("Error!") if a == 90.0: result.set("0") else: result.set(str(cosa)) #リストを削除 output.clear() def seisetsu(): global output global a global op op =7 map(str, output) #joinで数字を結合 ketsugou = "".join(map(str, output)) a = float(ketsugou) tana = math.tan(math.radians(a)) print(tana) #45の倍数の時の条件分岐 if a%45 == 0: if a % 90 == 0: result.set("Divison Error!") elif a % 180 == 0: result.set("0") #-1と1の時の条件分岐が式不明 #+90,+270の時が- if a == 45: result.set("1") if a == 135: result.set("-1") else: result.set(str(tana)) #リストを削除 output.clear() #2乗 def jo(): global output global a global op global alist op =8 map(str, output) #joinで数字を結合 ketsugou = "".join(map(str, output)) a = float(ketsugou) result.set(str(int(a))) #リストを削除 output.clear() alist.append(a) #ln def logu(): global output global a global op global alist op =9 map(str, output) #joinで数字を結合 ketsugou = "".join(map(str, output)) a = float(ketsugou) lo = math.log(a) result.set(lo) #リストを削除 output.clear() alist.append(a) def ans(): global output global a global op global alist op=10 wa = 0 #オペランド0=足し算,1=引き算,2=掛け算,3=割り算 #合計を格納 keilist =[] def equal(): global output global b global a global wa global op global alist global keilist global c #最後の数 map(str, output) mix = "".join(map(str, output)) #joinで数字を結合 b = int(mix) if op == 0: c=0 for n in range(0,len(alist)): c+=alist[n] print("現在のaの合計"+str(c)) wa = c+b alist.clear() alist.append(wa) result.set(wa) if op == 1: c=0 for z in range(0,len(alist)): c-=alist[z] sa = c-b alist.clear() result.set(sa) if op == 2: c=0 for q in range(0,len(alist)): c+=alist[q] alist.clear() ka = c*b print("掛け算の結果:"+str(ka)) result.set(ka) if op ==3: if b == 0: result.set("Divison Error!") else: c=0 for u in range(0,len(alist)): c+=alist[u] alist.clear() ru = c/b result.set(float(ru)) if op ==8: jou = a ** (b) alist.clear() alist.append(jou) result.set(str(int(jou))) if op ==9: lo = math.log(a) print("現在の阿知あ"+(lo)) result.set(lo) a=0 b=0 c=0 op=0 output.clear() alist.clear() #以下ボタン seven = tk.Button(text=u'7', width=10,height=4,command=nana) seven.place(x=0,y=343) eight = tk.Button(text=u'8', width=10,height=4,command=hachi) eight.place(x=89,y=343) nine = tk.Button(text=u'9', width=10,height=4,command=kyu) nine.place(x=178,y=343) #height1ずらすと20ずれる,9で94の間隔 four = tk.Button(text=u'4', width=10,height=4,command=yon) four.place(x=0,y=437) five = tk.Button(text=u'5', width=10,height=4,command=go) five.place(x=89,y=437) six = tk.Button(text=u'6', width=10,height=4,command=roku) six.place(x=178,y=437) one = tk.Button(text=u'1', width=10,height=4,command=ichi) one.place(x=0,y=531) two = tk.Button(text=u'2', width=10,height=4,command=ni) two.place(x=89,y=531) three = tk.Button(text=u'3', width=10,height=4,command=san) three.place(x=178,y=531) zero = tk.Button(text=u'0', width=10,height=4,command=zer) zero.place(x=0,y=625) dele = tk.Button(text=u'DEL', width=10,height=4,command=delete) dele.place(x=89,y=625) ac = tk.Button(text=u'AC', width=10,height=4,command=delete) ac.place(x=178,y=625) kake = tk.Button(text=u'×', width=10,height=4,command=kakeru) kake.place(x=267,y=343) war = tk.Button(text=u'÷', width=10,height=4,command=waru) war.place(x=267,y=437) pls = tk.Button(text=u'+', width=10,height=4,command=plus) pls.place(x=267,y=531) mns = tk.Button(text=u'-', width=10,height=4,command=minus) mns.place(x=267,y=625) sin = tk.Button(text=u'sin', width=10,height=4,command=seigen) sin.place(x=356,y=343) cos = tk.Button(text=u'cos', width=10,height=4,command=yogen) cos.place(x=356,y=437) rot = tk.Button(text=u'√', width=10,height=4,command=rote) rot.place(x=356,y=531) eq = tk.Button(text=u'=', width=10,height=4,command=equal) eq.place(x=356,y=625) tang = tk.Button(text=u'tan', width=10,height=4,command=seisetsu) tang.place(x=445,y=343) nijou = tk.Button(text=u'^', width=10,height=4,command=jo) nijou.place(x=445,y=437) log = tk.Button(text=u'ln', width=10,height=4,command=logu) log.place(x=445,y=531) #答えを記憶 da = tk.Button(text=u'Ans', width=10,height=4,command=equal) da.place(x=445,y=625) #計算表示ラベル result_l = tk.Label(textvariable=result,font=("DSEG7 Classic", "18"),fg="orange",bg="black",anchor = 'e',width=45) #寄せるときはwidthを設定しないとanchorが有効にならない result_l.place(x=-580,y=25) root.mainloop()プログラミングを始めてまだ9か月の超初心者が書いたコードです。経験者から見たら余計なコードが多いと思います。
5.考察
市販の関数電卓は高機能で低価格。市販品ってすごいなと思った。
6.参考サイト
三角関数をpythonで使うには https://note.nkmk.me/python-math-sin-cos-tan/
- 投稿日:2021-01-15T13:48:14+09:00
manimの作法 その14
概要
manimの作法、調べてみた。
TextMobject、使ってみた。参考にしたページ。
https://qiita.com/maskot1977/items/c01180cc63aa67ac004e
サンプルコード
from manimlib.imports import * class test(Scene): def construct(self): for x in range(9): for y in range(9): A = TextMobject("{} x {} = {}".format(x + 1, y + 1, (x + 1) * (y + 1))).scale(3) self.play(ShowCreation(A)) self.wait() self.remove(A)生成した動画
https://www.youtube.com/watch?v=p_5P6au5kYQ
以上。
- 投稿日:2021-01-15T13:29:08+09:00
pandasとSQLの対応
pandasでは、SQLと似たデータ操作ができる。
SQLのデータ操作とpandasのデータ操作の対応をメモっておく。
個人的に利用頻度が高い順に書いてる。limit -> head
任意の行数を抽出するために利用する。
select * from table limit 10↓pandas
table.head(10)order by -> sort_values
ソート処理
select * from table order by col1↓pandas
table.sort_values(by='col1')order byとsort_valuesのソートは、デフォルトで昇順になる。
order byなら最後にdescをつけるが、sort_valuesでは、ascending=Falseとする(Trueなら昇順)。table.sort_values(by='col1', ascending=False)また、複数の条件でソートも可能
select * from table order by col1, col2 desc↓pandas
table.sort_values(by=['col1', 'col2'], ascending=[True, False])where -> []
select * from table where col1 = 'a'↓pandas
table[table.col1 == 'a']in句
select * from table where col1 in ('a', 'b')↓pandas
table[table.col1.isin(['a', 'b'])]複数条件
select * from table where col1 = 'a' and col2 = 1↓pandas
table[(table.col1 == 'a')&(table.col2 == 1)]各条件を()で囲って、&で結ぶ。
andではなく、orの場合は、|を利用するtable[(table.col1 == 'a')|(table.col2 == 1)]これらの条件指定は、下に書いてある、deleteやupdateの時にも利用できる。
関数 -> agg
select sum(col1), avg(col1), max(col1), min(col2), count(col2), count(distinct(col2)), from table↓pandas
table.agg({'col1': ['sum', 'mean', 'max'], 'col2': ['min', 'count', 'nunique']})nuniqueが、count distinctに対応。
distinct関数は次のようになる。
select distinct(col1) from talbe↓pandas
table.agg({'col1': 'unique'})sqlでは、集計関数とdistinctは一緒には使えないが、pandasでは利用可能
table.agg({'col1': ['sum', 'mean', 'max', 'min', 'count', 'nunique', 'unique']})のようにできる。
sqlとpandasの関数対応
- sum -> sum
- avg -> mean
- max -> max
- min -> min
- count -> count
- count distinct -> nunique
- distinct -> unique
group by -> groupby
select col1, sum(col2) from table group by col1↓pandas
table.groupby('col1').agg({'col2': 'sum'})groupbyに指定されたカラムは、結果のデータフレームにおいてインデックスになってしまうので、
table.groupby('col1', as_index=False).agg({'col2': 'sum'})のように、as_index=Falseを入れると扱いやすい。
複数のカラムでgroup byする場合
select col1, col2, sum(col3) from table group by col1, col2↓pandas
table.groupby(['col1', 'col2'], as_index=False).agg({'col3': 'sum'})join -> merge
select * from table t left join table2 t2 on table.col1 = table2.col1↓pandas
pd.merge(table, table2, on='col1', how='left')howには、inner、outer、rightも揃ってる。
onで複数のカラムを利用する場合
select * from table t left join table2 t2 on table.col1 = table2.col1 and table.col2 = table2.col2↓pandas
pd.merge(table, table2, on=['col1', 'col2'], how='left')onにリストを指定。
update -> loc[]
update table set col1 = 'b' where col2 = 1↓pandas
table.loc[table.col2 == 1, 'col1'] = 'b'.locの第一引数にwhere条件、第二引数に更新対象のカラムを指定する。
delete -> []
delete from table where col1 = 'a'↓pandas
table = table[table.col1 != 'a']条件一致しないものだけ抽出して、削除する。
columnの別名 -> rename
select col1 as new_col1 from table↓pandas
table.rename(columns={'col1': 'new_col1'})union -> concat
select * from table union select * from table2↓pandas
pd.concat([table, table2], ignore_index=True)concat関数の第一引数は、リストなので3つ以上のデータフレームのユニオンも可能。
ignore_indexを指定しないとインデックスの値は、UNION前のデータフレームのものが引き継がれる。
つまり、インデックスの値がかぶることがあるので、指定しておいた方が良いかも。insert -> append
insert into table( col1, col2 ) values( 'a', '2' )↓pandas
table = table.append({'col': 'a', 'b': 2}, ignore_index=True)ignore_indexは、unionと同様。
case when -> apply
select case when col1 = 'a' then 1 when col1 = 'b' then 2 else 3 end as case_col1 from table↓pandas
def case_when(x): if x.col1 == 'a': return 1 elif x.col1 == 'b': return 2 else: return 3 table.apply(case_when, axis=1)axis=1としているのは、行単位にデータを取ってくるため。axis=0としたらcase_whenのxには、列データが入ってくる。
printでxを表示させればわかりやすい。xの型はpandasのSeries型になる。カラムを追加して返すことも可能。
下の方法は、上の方法で
table['case_col1'] = table.apply(case_when, axis=1)
とした場合と結果は一致する。select *, case when col1 = 'a' then 1 when col1 = 'b' then 2 else 3 end as case_col1 from table↓pandas
def case_when(x): if x.col1 == 'a': ret = 1 elif x.col1 == 'b': ret = 2 else: ret = 3 x['case_col1'] = ret return x table.apply(case_when, axis=1)group by case when -> groupby.apply
select col1, sum(case when col2 < 10 then col3 else 0 end) as sum_under10_col3, sum(case when col2 >= 10 then col3 else 0 end) as sum_over10_col3 from table group by col1↓pandas
def case_when(df): sum_under10_col3 = df[df.col2 < 10].col3.sum() sum_over10_col3 = df[df.col2 >= 10].col3.sum() return pd.Series({'sum_under10_col3': sum_under10_col3, 'sum_over10_col3': sum_over10_col3}) table.groupby('col1').apply(case_when).reset_index()結構煩雑だけど、一応同じことはできる。
case_when関数には、データフレームが送られるので、それらを集計して、その結果をSeriesで返している。
reset_index()は、col1をインデックスから外してる。
applyを使ってる時に、as_index=Falseにするとcol1が自動的に列に加わってくれない。おそらく、case_when関数の中でreturnするときにSeriesの中にcol1を含めないといけない。
それは面倒なので、reset_indexで対応してる。
- 投稿日:2021-01-15T12:07:44+09:00
Pybind11でC++関数をPythonから実行する(Windows & Visual Studio Codeな人向け) デバッグ編
環境構築篇に続き、デバッグの方法を説明します。
1. 呼び出し用スクリプトの準備
ビルドが終わった段階のフォルダーのルートに、
main.pyを追加します。フォルダー構成project_root ├ build │ └ Debug │ └ cmake_example.cp37-win_amd64.pyd ├ pybind11 ├ src │ └main.cpp ├ CMakeLists.txt └ main.py ←これを追加
main.pyはC++関数を呼び出すスクリプトで、内容は次のとおり:main.pyimport os from build.Debug.cmake_example import add print(f'PID: {os.getpid()}') # アタッチしてデバッグするためのもの a = add(1,2) print(a)2. C++拡張のデバッグ
はじめにC++関数部分のみのデバッグ方法を説明します。ブレークポイントを設定できるのはC++のみです。
2.1. デバッグ用の構成(launch.json)の作成
コマンドパレット(
Ctrl+p)からDebug: Open launch.jsonと入力し、C++ (Windows)を選択。launch.jsonが開かれる:launch.json{ // Use IntelliSense to learn about possible attributes. // Hover to view descriptions of existing attributes. // For more information, visit: https://go.microsoft.com/fwlink/?linkid=830387 "version": "0.2.0", "configurations": [ { "name": "(Windows) 起動", "type": "cppvsdbg", "request": "launch", "program": "プログラム名を入力してください (例: ${workspaceFolder}/a.exe)", "args": [], "stopAtEntry": false, "cwd": "${workspaceFolder}", "environment": [], "externalConsole": false } ] }上記を修正。
"program"部分にPythonのパスを、"args"の括弧内に"${file}"を入力する:launch.json(修正例){ "name": "(Windows) 起動", "type": "cppvsdbg", "request": "launch", "program": "c:/programdata/anaconda3/python.exe", //ここと "args": ["${file}"], //ここ "stopAtEntry": false, "cwd": "${workspaceFolder}", "environment": [], "externalConsole": false }注意:
"stopAtEntry"の値はfalseのままにすること。trueにすると、Pythonの実行ファイル(python.exe)をデバッグしようとしてしまい、Unable to open 'python.c'というエラーで止まるため。2.2. デバッグの実行
main.cのreturn i + j;の部分にブレークポイントを設定し、main.pyを開いた状態でデバッグを実行(F5)します。問題なければブレークポイントで止まるはずです。3. PythonとC++拡張の混合デバッグ
今度はPythonとC++拡張の同時デバッグ方法を説明しす。PythonとC++の両方にブレークポイントを設定できます。
Pythonのデバッガーを起動して、そこにC++のデバッガーをアタッチすることで実現します。こちらで非常にわかりやすく解説されていますので、是非ご覧ください。
3.1. デバッグ用の構成(launch.json)の作成
Python用、C++用の二つの構成を追加します。
- C++: コマンドパレットから、
Debug: Select and Start Debugging->構成の追加...->C/C++: (Windows) 接続で追加- Python:
main.pyを開いて、コマンドパレットからDebug: Select and Start Debugging->構成の追加...->Python->Python Fileで追加
launch.jsonに次が追加されます:launch.json{ "name": "Python: Current File", "type": "python", "request": "launch", "program": "${file}", "console": "integratedTerminal" }, { "name": "(Windows) 接続", "type": "cppvsdbg", "request": "attach", "processId": "${command:pickProcess}" }3.2. デバッグの実行
main.pyのa = add(1,2)、main.cのreturn i + j;にブレークポイントを設定します。
デバッグを実行しましょう。まずはPythonから。main.pyを開き、コマンドパレット->Debug: Select and Start Debugging->Python: Current Fileで実行すると、先ほどのブレークポイントで止まります。また、ターミナルにプロセスのIDがPID: xxxxと表示されます(xxxxは数字)。
次にC++。コマンドパレット->Debug: Select and Start Debugging->(Windows) 接続で開始します。"アッタッチするプロセスを選択する"と表示されますので、先ほどのPIDを入力すれば準備完了です。
main.pyに戻り、ステップ実行(F10)すればC++のブレークポイントで止まります。4. (おまけ1)Jupyterとの連携
main.pyと同様の内容を.ipynbファイルで実行し、そのPIDにアタッチすれば、JupyterとC++のデバッグを連携できます。これは便利かも。5. (おまけ2)Excel VBAとPythonとC++拡張の混合デバッグ
ExcelからPythonを呼び出して、そのPythonからC++を呼び出すことがあるかもしれません。各種設定をExcelのシートに入力して、そこからPythonを呼び出して計算して出力するけれど、計算負荷が高そうな(or 既存のC++資産を活かしたい)時にC++を使うという感じで。Excelはフロントエンド、Pythonは全体的な処理と出力、C++は計算を担当する使い方です。
そんんことしねーよという声も聞こえてきましたが、引き続き今回のコードで説明します。
5.1. Excelファイルの準備等
Excel VBAから利用&デバッグ可能な次のファイル
main_xw.pyを準備します。main_xw.pyimport os from build.Debug.cmake_example import add import xlwings as xw @xw.func def xw_add(a, b): return add(int(a), int(b)) if __name__ == '__main__': print(f'PID: {os.getpid()}') xw.serve()Excel VBAとの連携にはxlwingsを使用します。こちらにを参考に
main_xw.pyをExcelから呼び出せるようにしてください。(xlwingsは私の推しメンなんですが、残念なことにopenpyxlに比べて知名度がいまいちです(本が売っていない!)。これを機に是非使ってみてください。ドキュメントもしょぼいですが日本語化されています。)
5.2. デバッグの実行
main_xw.pyのブレークポイントはreturn add(int(a), int(b))に設定します。3.2.と同様に、
main.pyを開き、Python: Current Fileで実行し、(Windows) 接続でアタッチします。xlwingsのデバッグ用のサーバーも立ち上がっているので、ExcelのxliwngsリボンでDebug UDFsにチェックを入れれば準備完了です。適当なセルに
=xw_add(1,2)と入力すれば、VBAからPythonに、PythonからC++にブレークポイントを移動しながら実行することができます。5. トラブルシューティング
(今後追記予定)
参考
以下を参考にさせていただきました。
デバッグ方法
- 投稿日:2021-01-15T11:44:05+09:00
[Blender×Python] Add-onのつくりかた(Part2)
目次
0.Add-onの作成
1.Add-onの実行手順0.Add-onの作成
①前回の記事でつくったコードを準備する
②アドオンとして使用できるようにコードを改変する
↓以下が最終的なコード
bl_info = { #アドオンの名前 "name" : "Monkey grid", #自分の名前 "author" : "Yohhei Suzuki", "version" : (1,0), #Blenderのバージョン "blender" : (2,91,0), "category" : "Mesh", #どこからアクセスできるか "location" : "Operator Search", "description" : "More Monkeys", "warning" : "", "doc_url" : "", "tracker_url" : "", } import bpy class MESH_OT_monkey_grid(bpy.types.Operator): """Let's spread some object""" bl_idname = "mesh.monkey_grid" bl_label = "Monkey Grid" bl_options = {'REGISTER','UNDO'} count_x: bpy.props.IntProperty( name = "x", description = "Number of Monkeys in the X-direction", default = 3, min = 1,soft_max = 10 ) count_y: bpy.props.IntProperty( name = "y", description = "Number of Monkeys in the Y-direction", default = 2, min = 1,soft_max = 10 ) size: bpy.props.FloatProperty( name = "Size", description = "Size of each Monkey", default = 0.5, min = 1,soft_max = 1 ) @classmethod def poll(cls,context): return context.area.type == 'VIEW_3D' def execute(self, context): for i in range(self.count_x * self.count_y): x = i % self.count_x#only amari y = i // self.count_x #only shou bpy.ops.mesh.primitive_monkey_add( size = self.size, location = (x,y,1) ) return {'FINISHED'} def register(): bpy.utils.register_class(MESH_OT_monkey_grid) def unregister(): bpy.utils.unregister_class(MESH_OT_monkey_grid)
Point: 改変部分の解説
●スクリプトから実行しないので以下を削除しています。
if __name__ == '__main__': register()
●アドオンとして使用するために以下のコードを追加しています。
bl_info = { #アドオンの名前 "name" : "Monkey grid", #自分の名前 "author" : "Yohhei Suzuki", "version" : (1,0), #Blenderのバージョン "blender" : (2,91,0), "category" : "Mesh", #どこからアクセスできるか "location" : "Operator Search", "description" : "More Monkeys", "warning" : "", "doc_url" : "", "tracker_url" : "", }
●検索実行(Add-onの実行)可能範囲を制限するために以下のコードをクラスに追加しています。
→3D viewportにカーソルがある場合にのみ検索が実行可能になる
@classmethod def poll(cls,context): return context.area.type == 'VIEW_3D':1.Add-onの実行手順
①コードを保存する
●~~.py(ex:monkey_grid.py)と名前をつける→Text→Save as→任意のフォルダに保存
②アドオンを使用可能にする
●Edit→Preferences→Add-ons→Install→保存した~~.py(ex:monkey_grid.py)を選択→Install_Add-on→アドオンにチェックを入れる
③アドオンを実行する
●3D viewportでスペースキー(もしくはf3キー)を押してアドオンを検索(ex:monkey_grid)して実行(Enterキーを押す)
- 投稿日:2021-01-15T10:28:06+09:00
Raspberry Pi 64bitベータ版のSSDスワップ
前々回 Raspberry Pi OS 64bitβ版にポータブルSSD増設swap では外部USBに接続したSSDにSwapを設定しました。そして今回は、前回の整数型で高次方程式を解くの1000次方程式のpythonプログラムを使って、スワップ動作を確認しました。
結果は、外部USBに接続したSSDにSwapを移動した場合にも、Raspberry Pi OS 64bitベータ版に同梱のThonnyで1000次方程式のpythonプログラムが稼働すること、さらにメモリースワップ機能が正常に動作することが確認できました。以下に確認状況を示しています。
swap起動
SwapをSSDに移動させていますから、起動時はSwapが0になっています。この状態では本体のメインメモリ8GBだけの状態です。手動でSwapを起動します。次の2個のコマンドです。
sudo dphys-swapfile setup sudo dphys-swapfile swapon
Swapのtotalに184.31GBが現れます。Swapのused(使用中)は、Swap起動直後なので、まだ0です。メインメモリーMemの空き(free)は7.03GBあります。その右のshared、buff/cache、availableは今回ふれません。
メインメモリー枯渇前処理
メインメモリーに空きがある時は、メインメモリーだけで処理します。Swapは使いません。メインメモリーが枯渇状態になってからSwapが動き始めます。今回のテーマは、pythonプログラム稼働中、Swap動作の確認です。そこでpythonプログラム稼働前に、あらかじめメインメモリーを枯渇状態にする前処理をしておきます。こうしておけばpythonプログラムが稼働を始めた時、既にメインメモリーは枯渇していますから、Swapがすぐに動作を始めます。実際にメインメモリーを枯渇状態にする前処理は、760MBのBMP画像を10個openするだけです。freeで確認したのが下図です。
メインメモリーの空きは135MBまで減少しています。そしてSwapのusedが937MBとなり、Swapが動作を始めていることがわかります。ThonnyでPythonプログラム開始
Raspberry Pi OSの64bitベータ版に同梱のThonnyで1000次方程式のpythonプログラムを開始します。pythonプログラム開始直後を、freeで確認したのが下図です。
Swapのusedが1049MBとなり、Thonny起動そしてpythonプログラム稼働中も、Swapが正常動作していることが確認できます。計算部分終了時
1000次方程式のプログラムのCalculation Finishedの時です。freeで確認したのが下図です。
Swapのusedが1293MBまで増えています。プログラム全体終了時
1000次方程式のプログラム全体が終了した時です。freeで確認したのが下図です。
Swapのusedが1921MBまで増えています。またThonny上で稼働させた1000次方程式のpythonプログラムは、解1000個をprintして正常に終了しています。全アプリ終了しメモリー開放
Thonnyとopenしていた760MB画像ファイル10個、全てのアプリを終了し、メモリー開放した時です。freeで確認したのが下図です。
Swapのusedが1921MBから79MBまで急減しています。メインメモリーMemのfreeが7.29GBまで回復しています。以上、SSDに移動したSwapは、Thonnyで1000次方程式のpythonプログラムを稼働させた時も、正常に動作することが確認できました。1000次方程式のpythonプログラム自体が20minutesかかりますから、200MB毎のスワップアウトのタイムラグである2~3秒は全く意識されませんでした。それよりも、メインメモリー枯渇によるプログラム停止が回避可能となったことが大きな意義でした。
最後までご覧いただきありがとうございました。
次回、「整数型で高方程式を解く=分散並列処理=」では、Raspberry Pi 4台のsocket通信を使った分散処理により、計算時間を短縮する試行を予定しています。
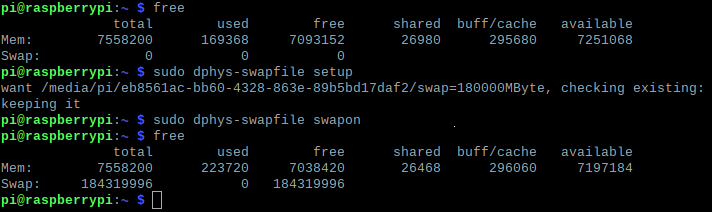

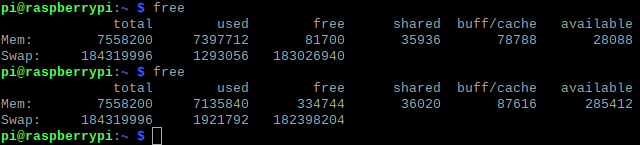
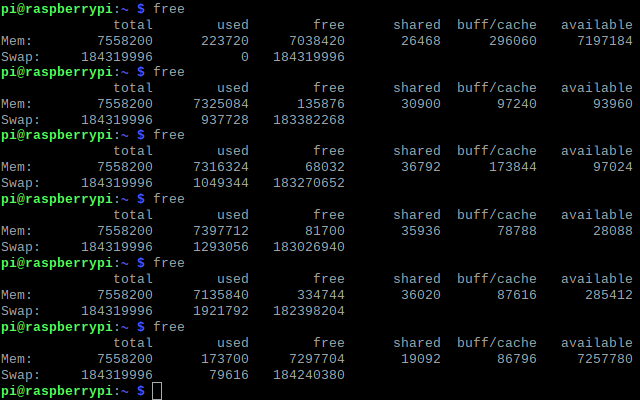
- 投稿日:2021-01-15T10:28:06+09:00
Raspberry Pi OS 64bitβ版にSSDスワップ 動作確認
前々回 Raspberry Pi OS 64bitβ版にポータブルSSD増設swap では外部USBに接続したSSDにSwapを設定しました。そして今回は、前回の整数型で高次方程式を解くの10000次方程式のpythonプログラムを使って、スワップ動作を確認しました。
結果は、外部USBに接続したSSDにSwapを移動した場合にも、Raspberry Pi OS 64bitベータ版に同梱のThonnyで10000次方程式のpythonプログラムが稼働すること、さらにメモリースワップ機能が正常に動作することが確認できました。以下に確認状況を示しています。
swap起動
SwapをSSDに移動させていますから、起動時はSwapが0になっています。この状態では本体のメインメモリ8GBだけの状態です。手動でSwapを起動します。次の2個のコマンドです。
sudo dphys-swapfile setup sudo dphys-swapfile swapon
Swapのtotalに184.31GBが現れます。Swapのused(使用中)は、Swap起動直後なので、まだ0です。メインメモリーMemの空き(free)は7.03GBあります。その右のshared、buff/cache、availableは今回ふれません。
メインメモリー枯渇前処理
メインメモリーMemに空きがある時は、メインメモリーMemだけで処理します。Swapは使いません。メインメモリーMemが枯渇状態になってからSwapが動き始めます。今回のテーマは、pythonプログラム稼働中、Swap動作の確認です。そこでpythonプログラム稼働前に、あらかじめメインメモリーMemを枯渇状態にする前処理をしておきます。こうしておけばpythonプログラムが稼働を始めた時、既にメインメモリーMemは枯渇していますから、Swapがすぐに動作を始めます。実際にメインメモリーMemを枯渇状態にする前処理は、760MBのBMP画像を10個openするだけです。Commandのfreeで確認したのが下図です。
メインメモリーMemの空き(free)は135MBまで減少しています。そしてSwapのusedが937MBとなり、Swapが動作を始めていることがわかります。ThonnyでPythonプログラム開始
Raspberry Pi OSの64bitベータ版に同梱のThonnyで10000次方程式のpythonプログラムを開始します。pythonプログラム開始直後を、Commandのfreeで確認したのが下図です。
Swapのusedが1049MBとなり、Thonny起動そしてpythonプログラム稼働中も、Swapが正常動作していることが確認できます。計算部分終了時
10000次方程式のプログラム途中のCalculation Finishedの時です。Commandのfreeで確認したのが下図です。
Swapのusedが1293MBまで増えています。プログラム全体終了時
10000次方程式のプログラム全体が終了した時です。Commandのfreeで確認したのが下図です。
Swapのusedが1921MBまで増えています。またThonny上で稼働させた10000次方程式のpythonプログラムは、解10000個をprintして正常に終了しています。全アプリ終了しメモリー開放
Thonnyとopenしていた760MB画像ファイル10個、全てのアプリを終了し、メモリー開放した時です。Commandのfreeで確認したのが下図です。
Swapのusedが1921MBから79MBまで急減しています。メインメモリーMemの空き(free)が7.29GBまで回復しています。以上、SSDに移動したSwapは、Thonnyで10000次方程式のpythonプログラムを稼働させた時も、正常に動作することが確認できました。10000次方程式のpythonプログラム自体が40minutesかかりますから、100MB毎のスワップアウトのタイムラグである2~3秒は全く意識されませんでした。それよりも、メインメモリー枯渇によるプログラム停止が回避可能となったことが大きな意義でした。
最後までご覧いただきありがとうございました。
次回、「整数型で高方程式を解く=分散並列処理=」では、Raspberry Pi 4台のsocket通信を使った分散処理により、計算時間を短縮する試行を予定しています。
- 投稿日:2021-01-15T10:10:31+09:00
1 / fで七色にゆらぐPhilips Hueをやってみた
電子工作なんもできんマンです。
今朝1 / f で七色にゆらぐLED照明を電子工作する(入門レベル)をみて, 「Philips Hueを使えば, 電子工作なんもできんマンでもできるのでは?」と思ってやってみました。
1 / fのゆらぎとは
... なんもわからん...。
なんとなくフーリエ変換したら, 強度が周波数に反比例するっぽいことだけはわかった...。
元記事でも参照されていますが, 新規鉄道模型レイアウト制作状況その2:星のゆらぎ表現の記事で, 詳細な説明があります。(ありがてぇ)グラフのおかげで完全に理解した。
作る
(材料一覧)
Philips Hueをプログラムで制御する方法として, パッと思いつくものとしては, Pythonで使えるphueか, Node.jsのcylon.jsがあります。
今回はphueの方を使って, 手早く実装していきましょう。Philips Hueの色空間はHSVです。
我々人類にとってRGB以外の色空間は未知の世界。まさに宇宙。しかし, pythonには標準ライブラリcolorsysにRGBからHSVに変換するrgb_to_hsvがあります。退屈なことはPythonにやらせましょう。
こうして, ゆらぎについてや, HSV色空間など分からないものをすっ飛ばして, チャチャッと仕上げたものがこちら。
# ipythonで実行 !pip install phue from colorsys import rgb_to_hsv from random import uniform, randint from time import sleep from phue import Bridge IP_OF_MY_BRIDGE = "192.168.0.1" # Philips Hue BridgeのIPアドレス GROUP = [1,2,3,4] # 操作したい電球のidリスト MAX_RGB = 255 FLUCTUATION_THRESHOLD = 0.01 # 元記事でいう大きすぎたり小さすぎたりすると変化しなくなる問題の回避のための閾値 (好みで小さくしてみた) def init_rgb(): return [randint(0, MAX_RGB) for _ in range(3)] def fluctuate(x): if x < 0.5: x = x + 2 * x * x else: x = x - 2 * (1.0 - x) * (1.0 - x) if x < FLUCTUATION_THRESHOLD or x > 1 - FLUCTUATION_THRESHOLD: x = uniform(0.1, 0.9) return x def convert_rgb_to_next_state(rgb_list): for idx, rgb in enumerate(rgb_list): rgb_list[idx] = round(fluctuate(rgb/MAX_RGB) * MAX_RGB) return rgb_list def set_right(light_idx,r:int, g:int, b:int): hsv = rgb_to_hsv(r/MAX_RGB, g/MAX_RGB, b/MAX_RGB) light = lights[light_idx] #print(hsv) light.hue = round(hsv[0] * 65535) # max hue is 65535 light.saturation = round(hsv[1] * 255) # max saturation = 255 light.brightness = round(hsv[2] * 255) # max brightness = 255 light.transitiontime = 10 # 1 second def main(): bridge = Bridge(IP_OF_MY_BRIDGE) bridge.connect() lights = bridge.get_light_objects('id') right_rgb_states = [init_rgb() for _ in GROUP] while True: sleep(1) for idx, right_rgb_state in enumerate(right_rgb_states): set_right(GROUP[idx], *right_rgb_state) right_rgb_states[idx] = convert_rgb_to_next_state(right_rgb_state) main()朝にぴったりな遊びでした。
なんも分からなくても意外となんとかなるもんですね。
Philips Hueの活用方法をもっと考えていきたいです。
また, 実装中, 「人類的にはRGBは0-255がええか」と思っていましたが, 実装後に見ると, 普通に小数でいい気がしました。
電子工作にも入門してぇ…。結果(GIF)


- 投稿日:2021-01-15T09:47:38+09:00
Google Cloud Platformを使ったデータ分析と可視化_colaboratoryでデータ前処理
要点
- Google Cloud Platform演習の備忘録。
- オープンデータを使ってデータ取り込み・前処理・可視化までをやってみました。
- 長くなるので3部構成です。今回はデータ取り込みまで記載します。
目的
- BigQueryとデータポータルを用いたデータ整理〜可視化の練習
- ついでに、オープンデータを使ったデータ前処理も実施
全体の流れ
- データの取り込み
- 前処理
- 処理データを格納 ?今回はここまで
- BigQueryへのデータ読み込み
- 可視化と考察
データをPythonで前処理し、BigQueryに読み込ませてデータポータルでの可視化を行います。
BigQuery上でSQLによる前処理も行えるのですが、今回はPythonを使いました。使用するオープンデータを探していたとき、BigQueryで直接読み込めないExcelファイルを多く見かけたためです (今回のデータはcsvでしたが)。
BigQueryに取り込み後の整形や計算はSQLで処理することにしました。前処理後のデータはGoogle Cloud Storage (GCS) に格納してからBigQueryに読み込ませました。BigQueryにはローカルやGoogleドライブから直接ファイルをアップロードできるのですが、今回は練習のためにGCSを使っています。
メソッド
データ
- 厚労省: 新型コロナウイルス感染症について > オープンデータ (2021/1/12時点)
ツール
- Google ドライブ (以下gドライブ)
- Colaboratory (以下colab)
- Google Cloud Platform
- Google Cloud Storage (以下GCS)
- BigQuery
- データポータル
環境
- 端末: iPad Pro 第3世代
- ブラウザ: Google Chrome Ver 87.0.4280.77
実施手順
データの読み込み
データをgドライブに格納
gドライブに10個のファイルをアップロードしました。
今回はドライブ直下に「covid」フォルダを作成してファイルを格納しています。colabをgドライブに接続
colab上でノートを新規作成します (ハンバーガーアイコン¥ファイル¥ノートブックを新規作成)
1. ハンバーガーアイコン¥ファイル ブラウザを表示
2. ファイルメニュー上のgドライブアイコンをクリック
gドライブ上のファイルをcolabで読み書きできるようになりました。モジュールのインポート
ファイルの入出力のために
osを、データをデータフレームとして操作するためにpandasをインポートしました。import os import pandas as pdgドライブへのマウント
ファイルを読み込むため、カレントディレクトリにデータを格納したcovidフォルダを指定します。
os.chdir('/content/drive/MyDrive/covid') # コピーしたパスを貼り付ける files = os.listdir() # データをdict型に取り込む準備ファイルをまとめて処理することを想定し、データをdict型に格納します。
keyはファイル名、valueはファイル内のdataframeとします。# 各データを格納するdict型を生成 data_dict = {} for file in files: data_dict[os.file.splitext(file)[0]] = pd.read_csv(file)
os.file.splitext()はファイル名の拡張子以外の部分と拡張子をtupple型で返します。
os.file.splitext(file)[0]はfileの拡張子以外の部分を取得していることになります。これで、data_dictにフォルダ内の全てのファイルについて名前とデータが格納されました。
ここで各データの行列数を確認します。for data in data_dict: print(data, data_dict[data].shape)pcr_positive_daily (361, 2)
pcr_tested_daily (338, 2)
cases_total (342, 2)
recovery_total (348, 2)
death_total (332, 2)
pcr_case_daily (327, 7)
current_situation (4, 8)
employment_subsidy_week (37, 7)
life_welfare_small_fund (3, 7)
severe_daily (341, 2)300個台の行からなる7ファイルと、より少ない行数からなる3ファイルがあるようです。
ファイルの説明を読むと、前者の7ファイルは「年月日」と「ファイル名が示す特徴量」からなるようです。たとえばpcr_positive_dailyの中身を見てみると...
data_dict['pcr_positive_daily'].head()
日付 PCR 検査陽性者数(単日) 0 2020/1/16 1 1 2020/1/17 0 2 2020/1/18 0 3 2020/1/19 0 4 2020/1/20 0 多くのデータが年月日ごとの時系列データであるため、これらを年月日をキーにして結合したテーブルを作っておけば、観察できる幅が広がりそうです。
時系列データのなかで最も行数が少ない (期間が短い) のはpcr_case_dailyのようなので、このファイルに記載された年月日の範囲内で他の6データを結合していきます。前処理
データの結合
pandasでデータフレームを横方向に結合する関数には
mergeとconcatがあり、それぞれ結合できるデータフレームの条件が異なるようです。
3個以上のデータフレーム 行数の異なるデータフレーム merge × ○ concat ○ × 今回は結合したいデータの列数が異なるので、
concatの使用は難しそうです。
forループにmergeを組み込んで、時系列ファイルを結合することにしました。#時系列データでサイズが最も小さいpcr_case_dailyを主データとしてleft_joinしていく df = data_dict['pcr_case_daily'] #行数がpcr_case_dailyより多いファイルだけ結合する for data in data_dict: if len(data_dict[data]) > len(data_dict['pcr_case_daily']: df = pd.merge(df, data_dict[data], on='日付') print(df.shape) df.head()(324, 13)
日付 国立感染症研究所 検疫所 地方衛生研究所・保健所 民間検査会社 大学等 医療機関 PCR 検査陽性者数(単日) PCR 検査実施件数(単日) 入院治療を要する者 退院、療養解除となった者 死亡者数 重症者数 0 2020/2/18 472 75 398 0.0 79.0 NaN 7 9 31 14 1 6 1 2020/2/19 15 68 609 0.0 0.0 NaN 10 71 35 16 1 7 2 2020/2/20 20 15 758 0.0 0.0 NaN 9 90 52 16 1 9 3 2020/2/21 261 188 902 132.0 108.0 NaN 11 85 62 16 1 10 4 2020/2/22 341 127 677 2.0 19.0 NaN 27 96 96 17 1 11 df.tail()
日付 国立感染症研究所 検疫所 地方衛生研究所・保健所 民間検査会社 大学等 医療機関 PCR 検査陽性者数(単日) PCR 検査実施件数(単日) 入院治療を要する者 退院、療養解除となった者 死亡者数 重症者数 319 2021/1/5 0 0 5831 34704 4726 16521 4885 88446 40908 205212 3718 784 320 2021/1/6 0 0 7333 31352 4701 14939 5946 73967 43423 208621 3790 796 321 2021/1/7 0 0 7539 29584 3157 11848 7537 81440 46780 211900 3856 826 322 2021/1/8 0 0 5619 NaN NaN NaN 7844 63373 51125 215527 3931 827 323 2021/1/9 0 0 3570 NaN NaN NaN 7278 35730 55238 218676 3995 852 特徴数は日付を含んだ13個。結合したい列数と一致しています。
問題なくデータの結合が行えたように見えます。欠損値の対応
データを見ると、"国立感染症研究所"~"医療機関"の列はpcr_case_daily由来で、施設ごとのPCR検査数を表しているようです。このファイル由来の列にNaNが入っているのが見て取れました。
そこで、各特徴量について欠損値がないかチェックしてみます。
df.isnull().sum()日付 0
国立感染症研究所 0
検疫所 0
地方衛生研究所・保健所 0
民間検査会社 2
大学等 2
医療機関 19
PCR 検査陽性者数(単日) 0
PCR 検査実施件数(単日) 0
入院治療を要する者 0
退院、療養解除となった者 0
死亡者数 0
重症者数 0
dtype: int64"民間検査会社""大学等"に2個、"医療機関"に19個の欠損値がありました。
df.tail()の結果から判るように、前者の欠損値は最後の2行にあるようです。
ファイルのダウンロード時点では集計が終わっていなかったものと思われます。
おそらく、最終2行のデータは集計が完了していなかったのでしょう。
今回は行ごと除くことにしました。一方、後者の欠損値は最終2行と最初の17行に見つかりました。
(df.head(30)のようなコマンドで確認しています)
こちらは集計日が古いことから、単に集計していなかったものと思われます。
最終2行と同様に除いても良いのですが、こちらは0で置換することにしました。実際の処理に移ります。
まずは最終2行の除去から。df_dropped = df.dropna(subset=['民間検査会社']) # "民間検査会社"の値が欠損している行をdropnaで除く df_dropped.tail()
日付 国立感染症研究所 検疫所 地方衛生研究所・保健所 民間検査会社 大学等 医療機関 PCR 検査陽性者数(単日) PCR 検査実施件数(単日) 入院治療を要する者 退院、療養解除となった者 死亡者数 重症者数 317 2021/1/3 0 0 3592 7940 1790 8149 3127 20291 38729 198874 3598 731 318 2021/1/4 0 0 4433 16740 5624 19251 3302 84338 39905 201606 3654 771 319 2021/1/5 0 0 5831 34704 4726 16521 4885 88446 40908 205212 3718 784 320 2021/1/6 0 0 7333 31352 4701 14939 5946 73967 43423 208621 3790 796 321 2021/1/7 0 0 7539 29584 3157 11848 7537 81440 46780 211900 3856 826 無事削除できました。
次に、残った欠損値を0で置換します。df_dropped = df_dropped.fillna(0) df_dropped.head()
日付 国立感染症研究所 検疫所 地方衛生研究所・保健所 民間検査会社 大学等 医療機関 PCR 検査陽性者数(単日) PCR 検査実施件数(単日) 入院治療を要する者 退院、療養解除となった者 死亡者数 重症者数 0 2020/2/18 472 75 398 0 79 0 7 9 31 14 1 6 1 2020/2/19 15 68 609 0 0 0 10 71 35 16 1 7 2 2020/2/20 20 15 758 0 0 0 9 90 52 16 1 9 3 2020/2/21 261 188 902 132 108 0 11 85 62 16 1 10 4 2020/2/22 341 127 677 2 19 0 27 96 96 17 1 11 念のため、改めて欠損値チェックを行います。
df_dropped.isnull().sum()日付 0
国立感染症研究所 0
検疫所 0
地方衛生研究所・保健所 0
民間検査会社 0
大学等 0
医療機関 0
PCR 検査陽性者数(単日) 0
PCR 検査実施件数(単日) 0
入院治療を要する者 0
退院、療養解除となった者 0
死亡者数 0
重症者数 0
dtype: int64すべての欠損値について対応を完了しました。
(任意) 列順の変更
必須の行程ではありませんが、自分の好みに列の順番を変更してみました。
未検証ですが、ここをスキップしても次の行程以降でエラーは出ないはずです。# 列の順番をカスタマイズ df_dropped = df_dropped[['日付', 'PCR 検査実施件数(単日)', 'PCR 検査陽性者数(単日)', '入院治療を要する者', '重症者数', '死亡者数', '退院、療養解除となった者', '国立感染症研究所', '検疫所', '地方衛生研究所・保健所', '民間検査会社', '大学等', '医療機関' ]] df_dropped.head()
日付 PCR 検査実施件数(単日) PCR 検査陽性者数(単日) 入院治療を要する者 重症者数 死亡者数 退院、療養解除となった者 国立感染症研究所 検疫所 地方衛生研究所・保健所 民間検査会社 大学等 医療機関 0 2020/2/18 9 7 31 6 1 14 472 75 398 0 79 0 1 2020/2/19 71 10 35 7 1 16 15 68 609 0 0 0 2 2020/2/20 90 9 52 9 1 16 20 15 758 0 0 0 3 2020/2/21 85 11 62 10 1 16 261 188 902 132 108 0 4 2020/2/22 96 27 96 11 1 17 341 127 677 2 19 0 BigQuery読み込み用ファイルの作成
最後に、列名を英語に変換します。
BigQueryでは日本語を正常に読み込めないためです。#key = 日本語の列名, value = 英語の列名 のdict型を作る name_column = { '日付': 'Date', '国立感染症研究所': 'Inspect_NIID', '検疫所': 'Inspect_QS', '地方衛生研究所・保健所': 'Inspect_LIH_HC', '民間検査会社': 'Inspect_Company', '大学等': 'Inspect_Univ', '医療機関': 'Inspect_MI', 'PCR 検査陽性者数(単日)': 'Positive', 'PCR 検査実施件数(単日)': 'PCR', '入院治療を要する者': 'Treated', '退院、療養解除となった者': 'Recovered', '死亡者数': 'Death', '重症者数': 'Severe' } df_new = df_dropped.rename(columns=name_column) df_new.head()
Date PCR Positive Treated Severe Death Recovered Inspect_NIID Inspect_Quarantine Inspect_LHRI_HealthCenter Inspect_Company Inspect_Univ Inspect_Medical 0 2020/2/18 9 7 31 6 1 14 472 75 398 0 79 0 1 2020/2/19 71 10 35 7 1 16 15 68 609 0 0 0 2 2020/2/20 90 9 52 9 1 16 20 15 758 0 0 0 3 2020/2/21 85 11 62 10 1 16 261 188 902 132 108 0 4 2020/2/22 96 27 96 11 1 17 341 127 677 2 19 0 (英語表記がおかしかったらごめんなさい...)
データの保存
作成したデータフレームは、"covid.csv"としてカレントディレクトリ (gドライブのcovidフォルダ)に保存します。
df_new.to_csv('covid.csv', index=False)これでBigQueryに取り込める処理済みのデータができました。
次はこのデータをGCSを介してBigQueryに取り込み、データの可視化・考察を行っていきます。
- 投稿日:2021-01-15T09:36:51+09:00
[Day 10]データベースのマイグレーション
January 15, 2021
←前回:Day 9 モデルの作成注意書き
この記事は単一の記事ではありません。
日記として書いているため、初見の方にはお役に立てないかと思います。
「Djangoを学びたい」とのことでありましたら[Day 1]Djangoの開発環境から読むことをおすすめします。はじめに
今回のテーマは「データベースのマイグレーション」です。
Djangoにはデータベースマイグレーション機能があります。
これを使うことで作成したモデルを元に自動的にデータベースへテーブルを作成してくれます。
Ruby on Railsに馴染みのある方にはお馴染みの機能だと思います。初回のマイグレーション
まず、Django標準のモデルのマイグレーションを行いましょう。
(venv)$ ./manage.py migreteこれを行うと、
「OK
OK
OK
OK...」という感じに表示されます。
これで初回のマイグレーションが終わりました。
現段階では自作のモデルはマイグレーションされません。
自作モデルをマイグレーションするにはmakemigrationsを実行する必要があります。(venv)$ ./manage.py makemigrationsMigrations for 'thread': thread/migrations/0001_initial.py - Create model Category - Create model Comment - Create model Topic - Add field topic to comment - Add field user to comment上記のような出力が得られマイグレーションの準備が出来ました。確認してみましょう。
(venv)$ ./manage.py showmigrationsthread [ ] 0001_initialこのような出力が得られます。[]内がからということは未だマイグレーションされていないということです。マイグレーション前にどのようなSQLが実行されるのか確認する癖はつけておいた方が良いと思います。
(venv)$ ./manage.py sqlmigrate thread 0001これでthreadアプリケーションの0001番のマイグレーション時のSQLを閲覧できます。意図せぬSQLが発行されないか確認しておきましょう。ではマイグレーションしてみましょう。
(venv)$ ./manage.py migrate以下の様に出力されればOKです。
Operations to perform: Apply all migrations: admin, auth, contenttypes, sessions, thread Running migrations: Applying thread.0001_initial... OKおわりに
今日で10日目になりました。
最近思うことは「説明文を書いて意味があるのかな?」と思っています。
説明文は本家の方で説明されていますし、僕がここで書いたところであまり意味を感じません。
しかし、僕が実際手を動かしている以上説明書きがないと訳がわからなくなってしまいそうなので、これからも説明文を入れていきます。それではまたまた
- 投稿日:2021-01-15T05:46:28+09:00
カオスの特性をPythonで簡単に確認
単純な規則に従っているだけなのに、結果として複雑な現象が生じることをカオスといいます(※余談1)。宮脇によると、カオスの特性には以下があります。
- 単純な規則から複雑な振る舞いが生じること
- 初期値の敏感性
前者はほぼ定義通りで、後者は「最初の小さなズレが後々とてつもない差になってしまう」ということを意味しています。バタフライ・エフェクトという名前で知っている方もいるのではないでしょうか。(※余談2)
「カオス」や「バタフライ・エフェクト」をもっと感覚的には理解したいなと思っていたところ、前述の論文に出会い、ロジスティックス写像と呼ばれるものの存在を知りました。
今回はPythonを使ってロジスティックス写像を表現し、カオスの2つの性質を確認することにします。
ロジスティックス写像とは
難しそうな名前をしていますが安心してください。名前以外は難しくありません。
今年の人口から来年の人口を表現するとします。$X_{○○}$を〇〇(今年または来年)における人口とすると、来年の人口は以下の式で表されます。$$X_{来年} = c \cdot{} X_{今年} \cdot{} (1 - X_{今年})$$
中学生で習う二次関数に似ていますね。$X$は0から1までの値をとることに気をつけてください。コミュニティが持ちうる人口に対する現在の人口の割合と理解するのが知れません。
aは係数で、これが大きくなると来年分の変動も大きくなります。僕は合計特殊出生率や基本再生産数と関連して理解しています(※余談3)。
人が増えすぎると食糧や住処などに問題が生じます。人口が増えすぎたときに減らそうとする作用を$(1 - X_{今年})$で表しています。この式を繰り返し計算することで今年から来年、来年から再来年の人口を表現することができるのです。
論文によると係数$c$が3.5699456...以上のとき、ロジスティックス写像の振る舞いがカオスになり$X$は絶対に同じ値を取らず、周期を持たなくなるそうです。さらに、この係数では初期値を少しずらしただけで、後の振る舞いは全く違ったものになるということです。
繰り返しますが上の式はいたってシンプルです。この式から本当に無秩序な結果が出るのかをPythonで確認しましょう。
Pythonで表現
まず、ロジスティックス写像を超単純に表します。
def logistic_map(x, a): return a * x * (1 - x)今回は係数として以下を用意します。
coefs = [1, 2, 3, 3.2, 3.5, 3.6, 3.9, 4, 4.2]初期値を適当な値に設定して、各係数について100年後までの人口推移をグラフで表します。(りすと)
x = 0.3 for c in coefs: Xs = [] Xs.append(x) for _ in range(100): x_old = x x = logistic_map(x_old, c) Xs.append(x) plt.title(f'c = {c}') plt.ylim(0, 1) plt.plot(Xs) plt.show()結果 - 第1性質: 単純なルールから複雑な振る舞い
Wikipedia(ロジスティックス写像)に準じて係数$c$を以下の条件で分け、人口の推移を見ることで、単純なロジスティックス写像の式から複雑な振る舞いが生まれることを確認します。
- cが0以上1以下のとき
- cが1より大きく2以下のとき
- cが2より大きく3以下のとき
- cが3より大きく3.44...以下のとき
- cが3.44...より大きく3.56...以下のとき
- cが3.56...より大きく4より小さいとき (カオス発生)
- c = 4 のとき (ピュアカオス)
- cが4より大きいとき (マイナスの無限大へ)
cが0以上1以下のとき
初期値に関わらずゆっくりと減衰していき最終的には0に収束します。これは式からも想像できますね。以下は$c = 1$におけるグラフです。
きれいに減衰していますね。
cが1より大きく2以下のとき
単調増加(減少)しながら$1 - \frac 1 c$に収束します。この辺はまだ極限をとれば計算できる気がします。以下は$c = 2$におけるグラフです(境界値ばっかで可視化する人?♂️)。
今回は収束値0.5が初期値0.3よりも大きい値だったので単純増加しながら収束しました。
cが2より大きく3以下のとき
$1 - \frac 1 c$付近で振動しながら、最後は$1 - \frac 1 c$に収束します。以下は$c = 3$におけるグラフです(?♂️)。
確かに$\frac 2 3 (0.67= 1 - \frac 1 3)$付近で振動しているように見えますね。これだと本当に収束しているか分かりづらいのでもう少し長い期間の推移を見ましょう。
良さそうですね
cが3より大きく3.44...以下のとき
収束せず、2つの値の間を行ったり来たりします。この2つの値を周期点と呼ぶみたいです。以下は$c = 3.2$におけるグラフです。
0.5と0.8の間あたりを行ったりきたりしていますね。
cが3.44...より大きく3.56...以下のとき
2つあった周期点が4つ、8つ…と倍々に増えていきます。実際の周期点の数は$c$の値によるようです。以下は$c = 3.5$におけるグラフです。
周期点が4つあるように見えますね。
cが3.56...より大きく4より小さいとき (カオス発生)
おめでとうございます、カオス発生です。一貫した収束や周期性がなく、複雑な挙動を示すようになります。以下は$c = 3.6$におけるグラフです。
0.3から0.9くらいの間を不規則に動き回っています。時間によって周期性があったりなかったりします。まさにカオスですね。パット見、$c=3.5$との違いがわかりにくいですが、初期値敏感性を見ると違いがはっきりします(後述)。
c = 4 のとき (ピュアカオス)
より変化量の大きいカオスです。$X$は0から1、つまり取りうる値をどれでもとることができます。
これをピュアカオスというらしいです。中二病っぽい名前ですが、グラフを見るとたしかにカオスです。あの単純なロジスティックス写像の式からは想像もできないような推移をしています。
cが4より大きいとき
マイナスの無限大へと発散します。人口増加や感染症のアナロジーとして考えると興味深いですね。
人口が極限まで増えた結果、人類は滅亡した (※余談4)
結果 - 第2性質:バタフライ・エフェクトの検証
上のグラフを見ただけだと$c=3.6$が本当にカオスなのか少し分かりづらいですね。ここでは、初期値敏感性(バタフライ・エフェクト)を満たすかどうかでカオスの判別をしていきます。
ここでは初期値として$3±0.1$を用意し、元々の初期値と比較します。カオスであればこの小さな初期値の違いに敏感に反応して、推移が異なるグラフになるはずです。c = 3.5のとき (非カオス)
まずは比較対象として非カオスである$c = 3.5$のグラフを見てみましょう。
せっかくグラフにしたのに見づらいですね。基準となる初期値を基準値と呼び、基準値から下にズレた初期値(下ズレ)と基準値から上にズレた初期値(上ズレ)の差分を取ります。
最初の数年こそ初期値の影響を受けていますが、途中からはピッタリと重なっています。初期値が少しズレていてもあまり影響が無いことがわかります。
c = 3.6のとき (カオス)
それではカオスである$c = 3.6$のグラフを見てみましょう。中二病の名前も相まって結果を見るのが少しワクワクします。
なんかキレイですね!カオスアートとかどうですか。
緑の線の後ろでオレンジと青い線がにじみ出ているのが見えますが、これも差分をとってわかりやすくしましょう。
めちゃめちゃわかりやすくカオスですね。
初期値のズレが更に小さい時
初期値のズレをさらに小さくするとカオスが発生するまでの時間は長くなりますが、それでもカオスは生まれます。下のグラフは初期値の比較として$3±0.0001$を使用しています。
カオスが始まったかと思いきや、途中で再びシンクロしだすところ(50年目あたり)がいかにもカオスですね。
まとめ
- 単純な規則からカオスが生まれることを確認した
- カオスにおける初期値敏感性を確認した
余談
人生で一番カオスと書いた。
余談1: カオス理論に出会うまでの経緯
僕が応援している浦和レッズの分析官に林舞輝さんが就任することになりました。彼は戦術的ピリオダイゼーションという複雑系やカオス理論を応用したサッカーの理論にくわしく、僕も詳しくなりたいなと思っていろいろ探していたところ香川大レポジトリにある上述の論文に出会いました。戦術的ピリオダイゼーションを初学者でも分かるように説明してくれているので、詳細を知りたい方には超おすすめです。(カオス理論といえば『ジュラシック・パーク』ですね。ジェフ・ゴールドブラムは194cm)
余談2: 「バタフライ・エフェクト」
日本流にいうと「風が吹けば桶屋が儲かる」が近いですが、論理性の有無が異なります。「風が吹けば桶屋が儲かる」は風が吹いてから桶屋が儲かるまでの流れに(無理やりな部分はあれど)論理が存在しますが、「バタフライ・エフェクト」は蝶々の羽ばたきがどのようにテキサスの竜巻に影響を与えるかの論理的なつながりを知ることができません。(『バタフライ・エフェクト』いい映画ですよね。アシュトン・カッチャー)
余談3: ロジスティックス写像の係数
ロジスティックス写像の係数と合計特殊出生率のアナロジーが正しい自信がないので、出生率うんぬんのところは話半分で読んでください。
「人口維持」に必要な合計特殊出生率は理論的には2(早死を加味すると実際はもう少し上)が必要です。ここでの「人口維持」とは$X$が初期値のままずっと変わらないことを指し、ロジスティックス写像では、例えば初期値0.5で係数2のときに「人口維持」の状態になります(下図参照)。
余談4: 人口が極限まで増えた結果、人類は滅亡した
フィクションです。世界の特殊出生率を見ると4を超えている国は多いので、現実世界はカオスだけでは説明しきれなっかたり、滅亡するまでに時間がかかっていたり、そもそもカオスと特殊出生率の比較が正しくなかったりするんでしょうね。
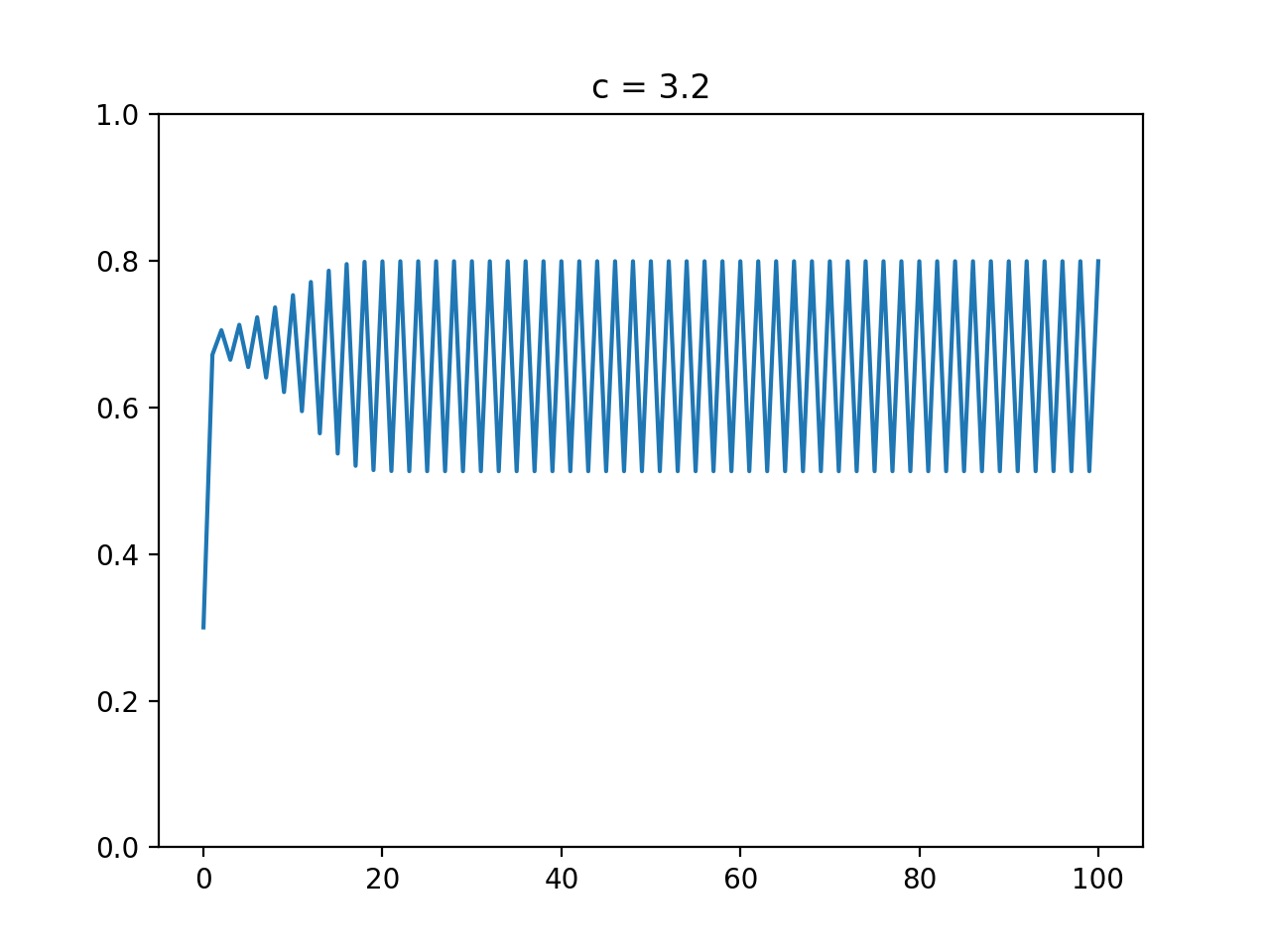
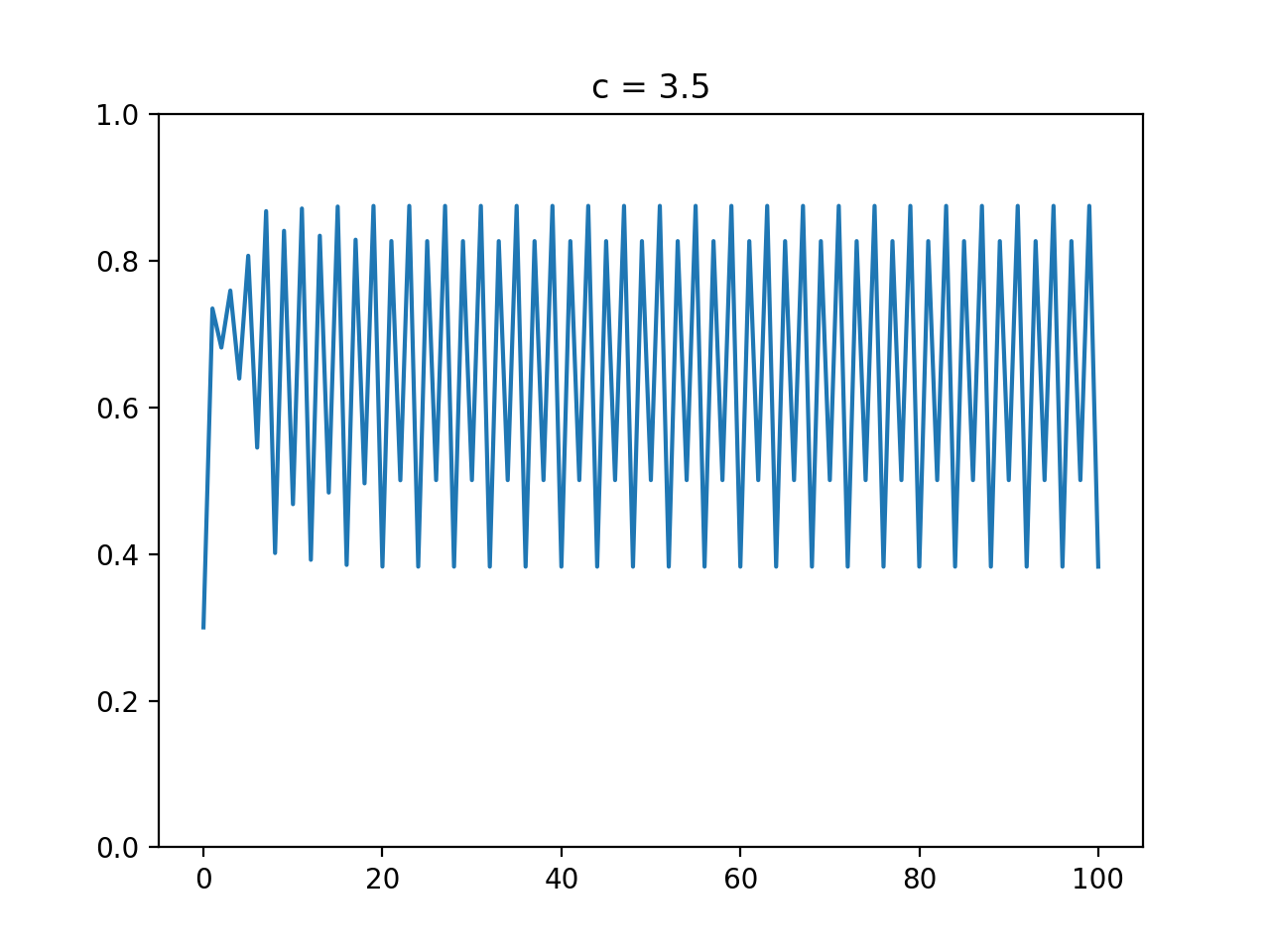
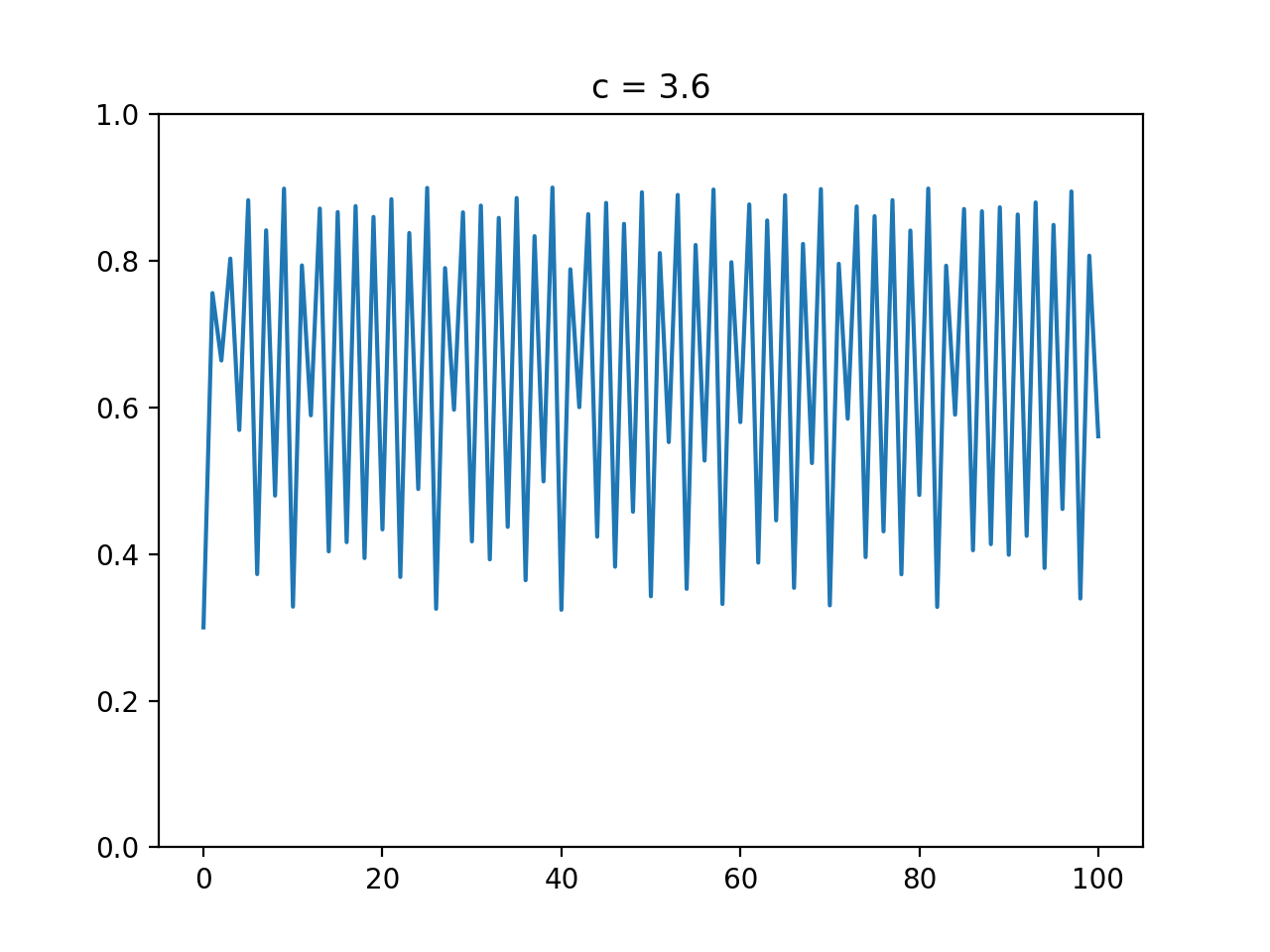
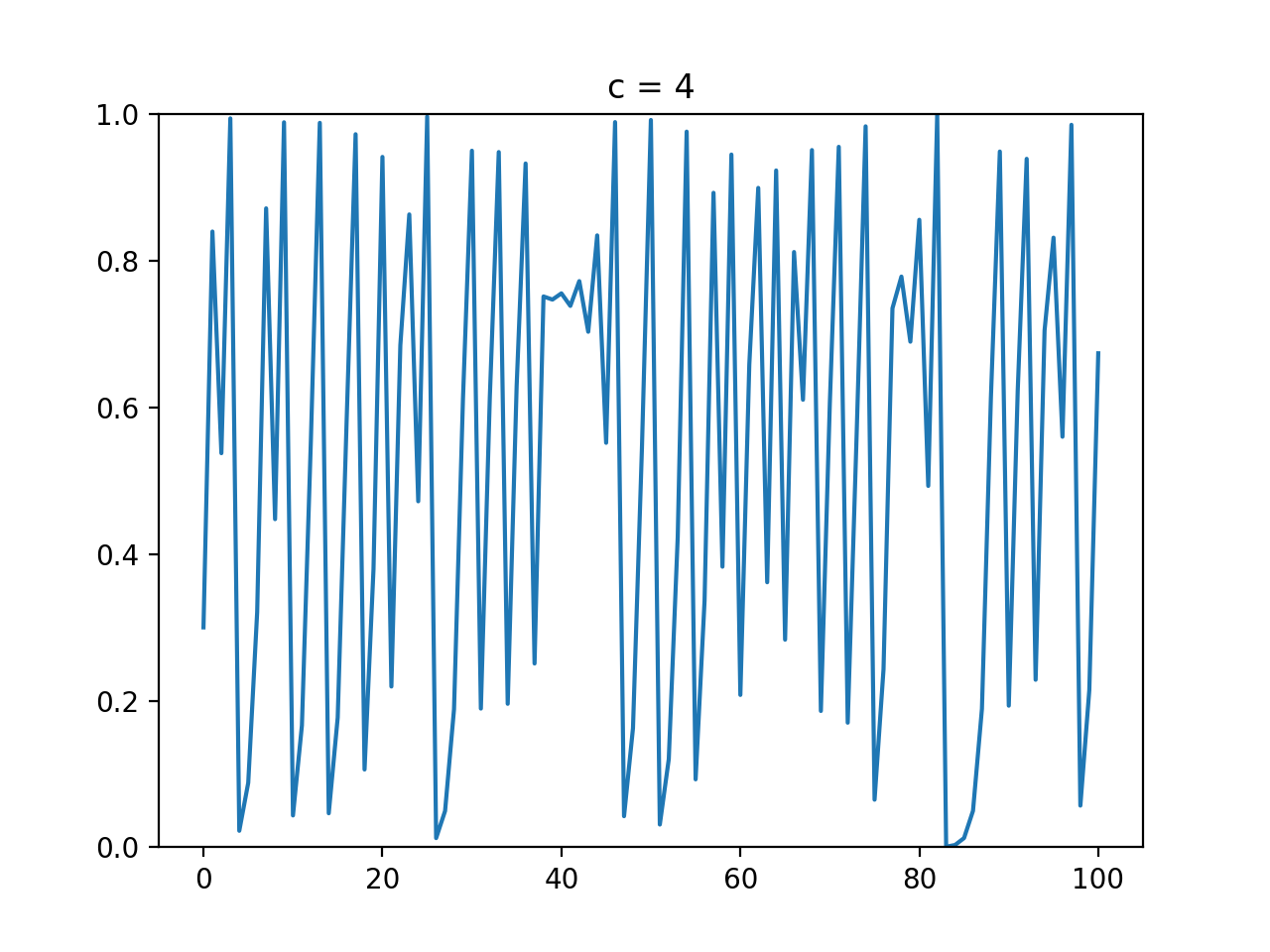
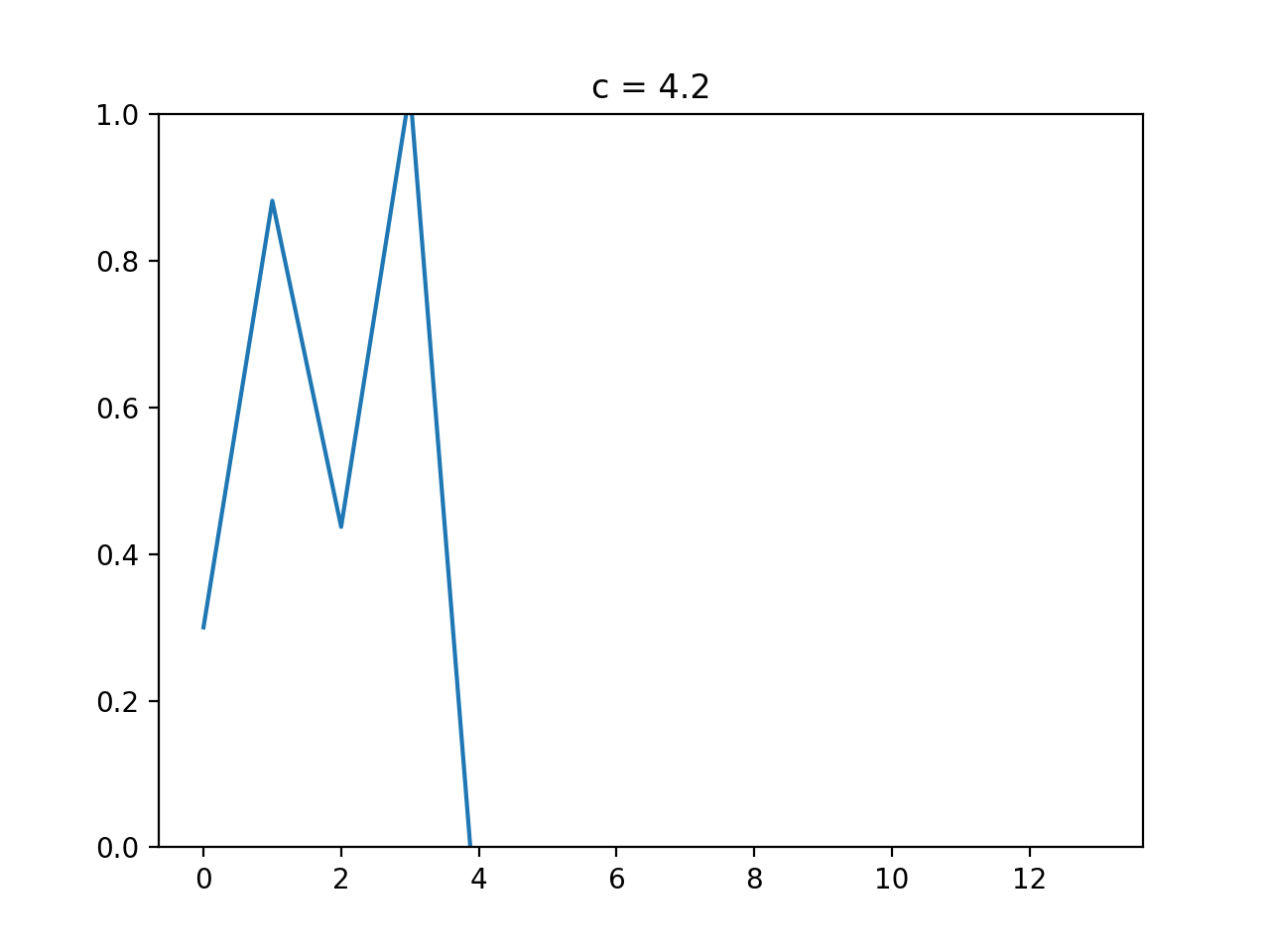
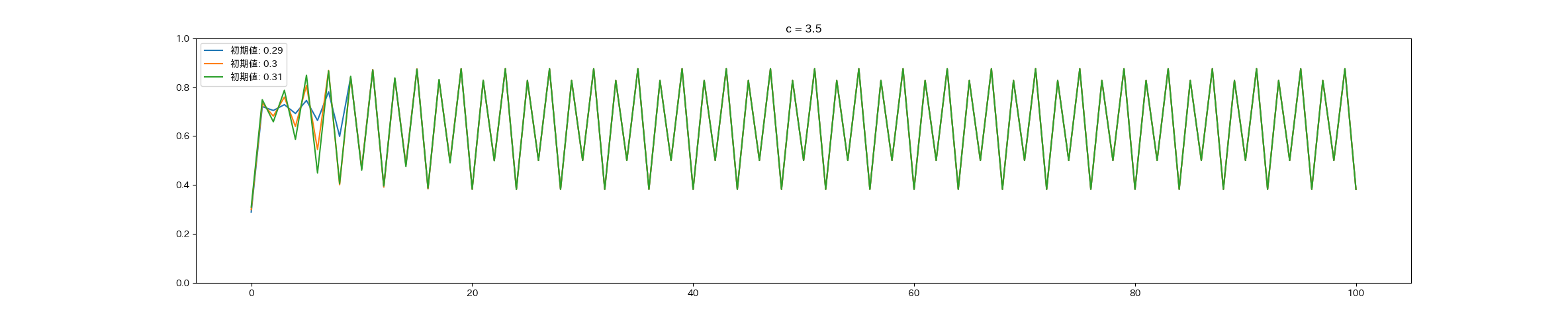
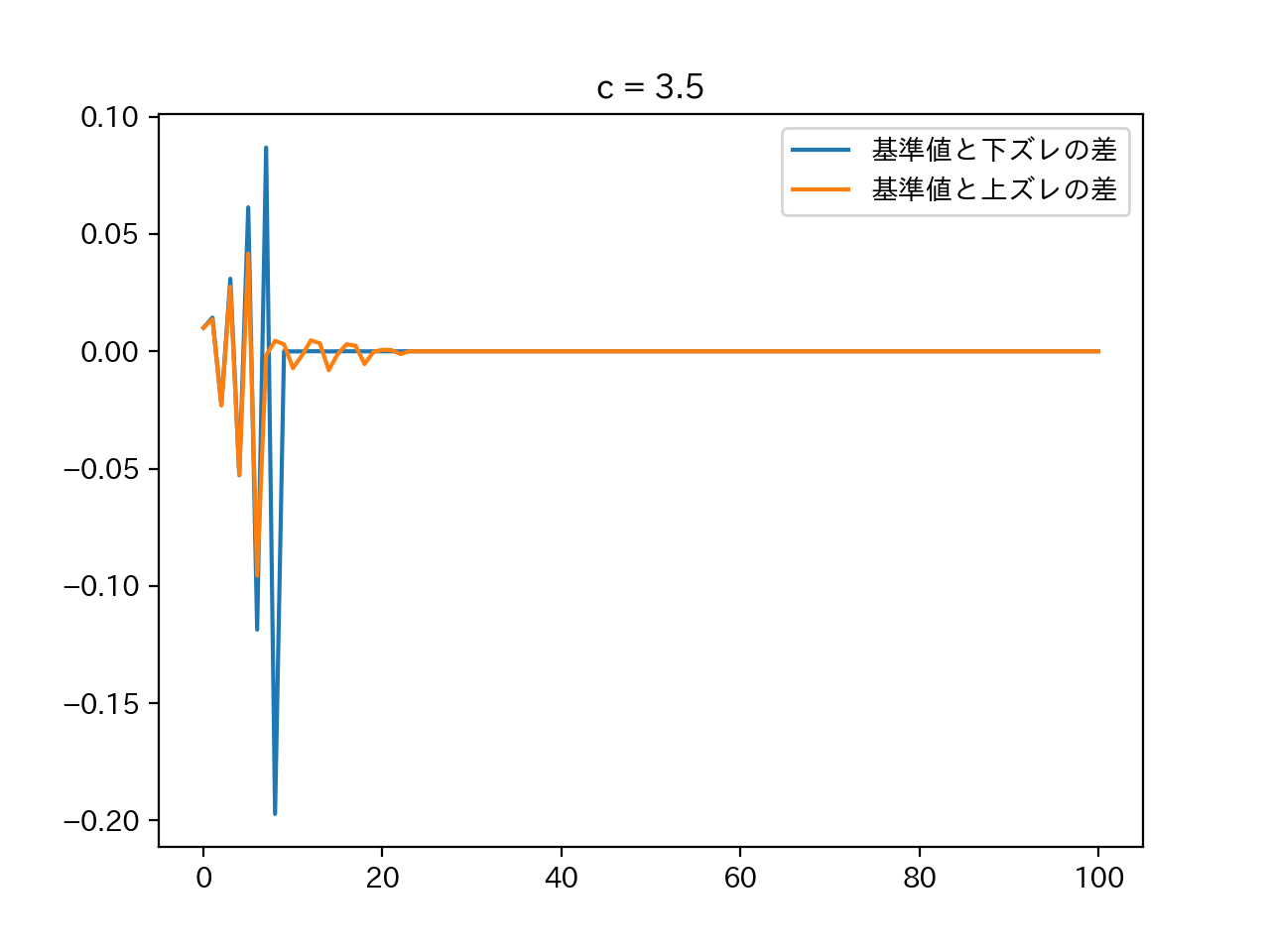

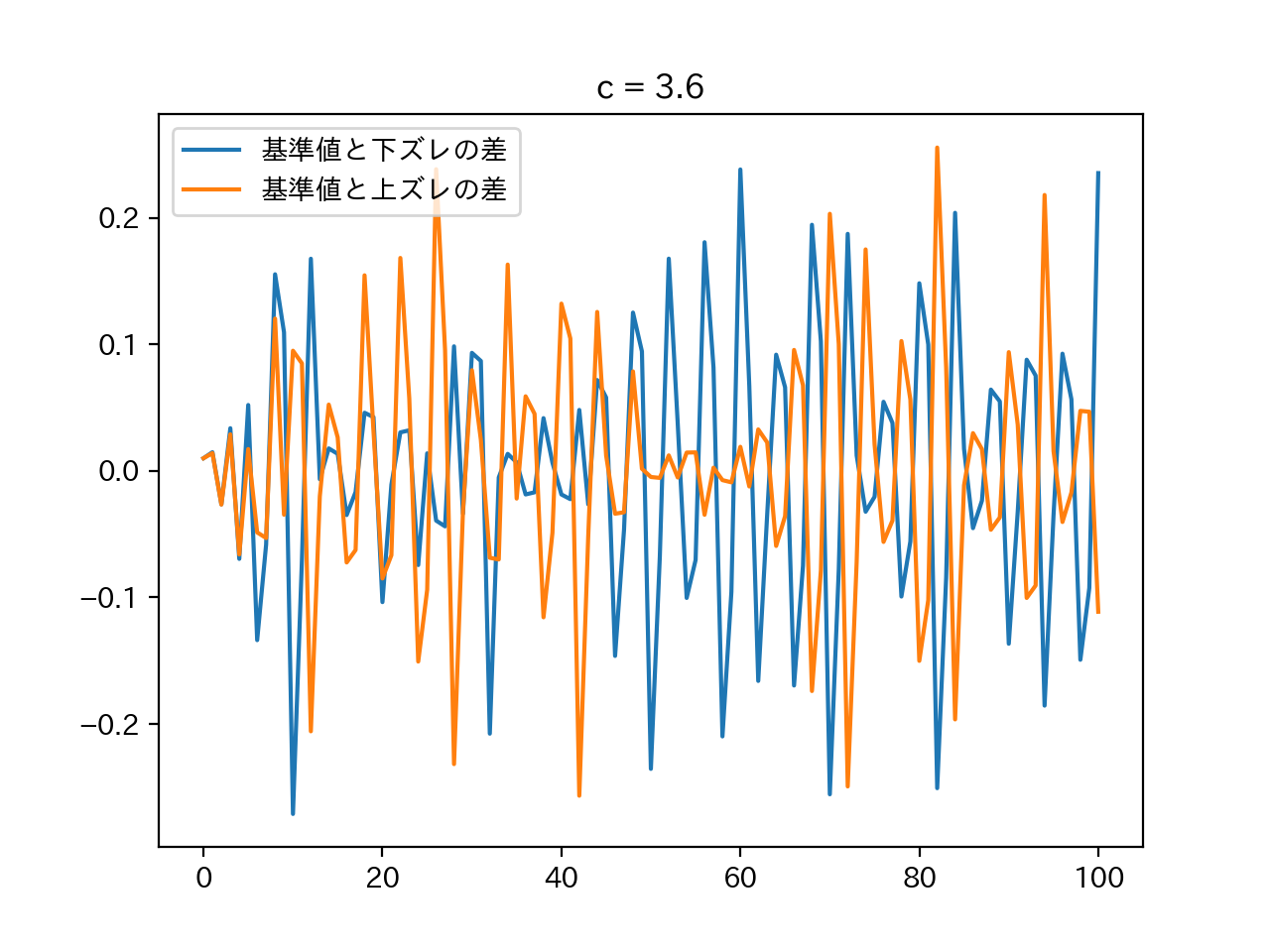
- 投稿日:2021-01-15T03:26:47+09:00
VBAユーザがPython・Rを使ってみた:繰り返し処理
はじめに
機械学習の勉強を始めたVBAユーザです。
備忘録としてPython・Rの文法をVBAと比較しながらまとめていきたいと思います。目次
繰り返し処理
今回は、繰り返し処理(ループ処理)についてまとめます。
for文
まずは、for文です。
シンプルな例
シンプルなfor文の例です。
Python
Python3# for文 for i in range(5): print(i) # 0 # 1 # 2 # 3 # 4 print(range(5)) # range(0, 5) print(type(range(5))) # <class 'range'> print(list(range(5))) # [0, 1, 2, 3, 4]Pythonではfor文のブロックをインデント(字下げ)で表現します。
range(5)は 0,1,2,3,4 という整数を順番に返すイテラブルオブジェクト(iterable object)(反復可能オブジェクト)で、list(range(5))でリスト[0, 1, 2, 3, 4]になります。R
Rfor (i in 0:4) { print(i) } # [1] 0 # [1] 1 # [1] 2 # [1] 3 # [1] 4 print(0:4) # 0 1 2 3 4
0:4は 0 から 4 までの整数値のベクトルです。VBA
VBAFor i = 0 To 4 Debug.Print i Next i ' 0 ' 1 ' 2 ' 3 ' 4他の例
Python
Python3Ns = [2, 3, 5, 7, 11] for i in range(len(Ns)): print(Ns[i]) # 2 # 3 # 5 # 7 # 11 Ns = [2, 3, 5, 7, 11] for n in Ns: print(n) # 2 # 3 # 5 # 7 # 11Pythonでは、リストもイテラブルオブジェクトなので、
inの後に指定できます。R
RNs <- c(2, 3, 5, 7, 11) for (i in 1:length(Ns)) { print(Ns[i]) } # [1] 2 # [1] 3 # [1] 5 # [1] 7 # [1] 11 Ns <- c(2, 3, 5, 7, 11) for (n in Ns) { print(n) } # [1] 2 # [1] 3 # [1] 5 # [1] 7 # [1] 11Rでも、
inの後にベクトルを指定できます。VBA
VBAA = Array(2, 3, 5, 7, 11) For i = LBound(A) To UBound(A) Debug.Print A(i) Next i ' 2 ' 3 ' 5 ' 7 ' 11VBAで、
A = Array(2, 3, 5, 7, 11)と書くと、配列Aのインデックスは(デフォルトの設定では)0から4の整数になります。LBound(A)は配列Aの最小のインデックス(ここでは0)、UBound(A)は配列Aの最大のインデックス(ここでは4)を返します。さらに
Pythonではこのような書き方もできます。
enumerate関数
enumerate関数は、イテラブルオブジェクトに対して(要素番号, 要素)の形のタプルを1つずつ返すイテラブルオブジェクトを返す組み込み関数です。Python
Python3Ns = [2, 3, 5, 7, 11] for i, n in enumerate(Ns): print('Ns[' + str(i) + '] = ' + str(n)) # Ns[0] = 2 # Ns[1] = 3 # Ns[2] = 5 # Ns[3] = 7 # Ns[4] = 11 Ns = [2, 3, 5, 7, 11] for i, n in enumerate(Ns): print('Ns[{}] = {}'.format(i, n)) # Ns[0] = 2 # Ns[1] = 3 # Ns[2] = 5 # Ns[3] = 7 # Ns[4] = 11同じことをRとVBAで書くならこうなります。
RRNs <- c(2, 3, 5, 7, 11) for (i in 1:length(Ns)) { n = Ns[i] cat(paste0("Ns[", i, "] = ", n, "\n")) } # Ns[1] = 2 # Ns[2] = 3 # Ns[3] = 5 # Ns[4] = 7 # Ns[5] = 11VBA
VBAA = Array(2, 3, 5, 7, 11) For i = LBound(A) To UBound(A) Debug.Print "Ns[" & CStr(i) & "] = " & Str(A(i)) Next i ' Ns [0] = 2 ' Ns [1] = 3 ' Ns [2] = 5 ' Ns [3] = 7 ' Ns [4] = 11zip関数
zip関数は、複数のイテラブルオブジェクトに対してそれぞれからの要素のペアを1つずつ返すイテラブルオブジェクトを返す組み込み関数です。Python
Python3numbers = list(range(5)) alphabets = 'abcde' hiraganas = 'あいうえお' for n, s, h in zip(numbers, alphabets, hiraganas): print('{}-{}-{}'.format(n, s, h)) # 0-a-あ # 1-b-い # 2-c-う # 3-d-え # 4-e-おwhile文
次は、while文です。
Python
Python3i = 0 while i < 5: print(i) i = i + 1 # 0 # 1 # 2 # 3 # 4 i = 0 while i < 5: print(i) i += 1 # 0 # 1 # 2 # 3 # 4
i = i + 1は複合代入演算子+=を使ってi += 1とも書けます。R
Ri <- 0 while (i < 5) { print(i) i = i + 1 } # [1] 0 # [1] 1 # [1] 2 # [1] 3 # [1] 4VBA
VBAi = 0 Do While i < 5 Debug.Print i i = i + 1 Loop ' 0 ' 1 ' 2 ' 3 ' 4VBAでは、
Whileの他にUntilもあります。VBAi = 0 Do Until i = 5 Debug.Print i i = i + 1 Loop ' 0 ' 1 ' 2 ' 3 ' 4同じことをPythonとRで書くならこうなります。
PythonPython3i = 0 while not i == 5: print(i) i = i + 1 # 0 # 1 # 2 # 3 # 4R
Ri <- 0 while (!(i == 5)) { print(i) i = i + 1 } # [1] 0 # [1] 1 # [1] 2 # [1] 3 # [1] 4ループの終了
途中でループを抜ける(繰り返し処理を終了する)方法です。
Python
Python3for i in range(5): if i == 2: break print(i) # 0 # 1R
Rfor (i in 0:4) { if (i == 2) { break } print(i) } # [1] 0 # [1] 1VBA
VBAFor i = 0 To 4 If i = 2 Then Exit For End If Debug.Print i Next i ' 0 ' 1VBAでループを抜けるには、Forループの場合は
Exit For、Doループの場合はExit Doを使います。ループのスキップ
途中のループを飛ばして(スキップして)次のループに移る(次の繰り返し処理に進む)方法です。
Python
Python3for i in range(5): if i == 2: continue print(i) # 0 # 1 # 3 # 4R
Rfor (i in 0:4) { if (i == 2) { next } print(i) } # [1] 0 # [1] 1 # [1] 3 # [1] 4VBA
VBAFor i = 0 To 4 If i = 2 Then GoTo continue End If Debug.Print i continue: Next i ' 0 ' 1 ' 3 ' 4VBAにはPythonの
continue文やRのnext文のようなループをスキップする文はありません。どうしても使いたいならGoToを使います。その他
Rには
repeat文というのもありますが、これはwhile (TRUE)(while文の条件式にTRUE(常に真)を入れたもの)と同じことですので、あまり使い道がなさそうです。R
Ri <- 0 repeat { if (i == 2) { break } print(i) i = i + 1 } # [1] 0 # [1] 1 i <- 0 while (TRUE) { if (i == 2) { break } print(i) i = i + 1 } # [1] 0 # [1] 1同じことをPythonとVBAで書くならこうなります。
Python
Python3i = 0 while True: if i == 2: break print(i) i += 1 # 0 # 1VBA
VBAi = 0 Do While True If i = 2 Then Exit Do End If Debug.Print i i = i + 1 Loop ' 0 ' 1まとめ
一覧
各言語で使用する書き方等を一覧にまとめます。
Python R VBA for文 for i in ...:
...
for (i in ...) {
...}For i = ... To ...
...Next iwhile文 while ...:
...while (...) {
...}Do While ...
...Loopuntil文 while not ...:
...while (!(...)) {
...}Do Until ...
...Looprepeat文 while True:
...repeat {
...}Do While True
...Loopbreak文 break break Exit ForExit Docontinue文 continue next プログラム全体
参考までに使ったプログラムの全体を示します。
Python
Python3# for文 for i in range(5): print(i) # 0 # 1 # 2 # 3 # 4 print(range(5)) # range(0, 5) print(type(range(5))) # <class 'range'> print(list(range(5))) # [0, 1, 2, 3, 4] Ns = [2, 3, 5, 7, 11] for i in range(len(Ns)): print(Ns[i]) # 2 # 3 # 5 # 7 # 11 Ns = [2, 3, 5, 7, 11] for n in Ns: print(n) # 2 # 3 # 5 # 7 # 11 Ns = [2, 3, 5, 7, 11] for i, n in enumerate(Ns): print('Ns[' + str(i) + '] = ' + str(n)) # Ns[0] = 2 # Ns[1] = 3 # Ns[2] = 5 # Ns[3] = 7 # Ns[4] = 11 Ns = [2, 3, 5, 7, 11] for i, n in enumerate(Ns): print('Ns[{}] = {}'.format(i, n)) # Ns[0] = 2 # Ns[1] = 3 # Ns[2] = 5 # Ns[3] = 7 # Ns[4] = 11 numbers = list(range(5)) alphabets = 'abcde' hiraganas = 'あいうえお' for n, s, h in zip(numbers, alphabets, hiraganas): print('{}-{}-{}'.format(n, s, h)) # 0-a-あ # 1-b-い # 2-c-う # 3-d-え # 4-e-お # while文 i = 0 while i < 5: print(i) i = i + 1 # 0 # 1 # 2 # 3 # 4 i = 0 while i < 5: print(i) i += 1 # 0 # 1 # 2 # 3 # 4 # untilの代わり i = 0 while not i == 5: print(i) i = i + 1 # 0 # 1 # 2 # 3 # 4 # break文 for i in range(5): if i == 2: break print(i) # 0 # 1 # continue文 for i in range(5): if i == 2: continue print(i) # 0 # 1 # 3 # 4 # repeat文の代わり i = 0 while True: if i == 2: break print(i) i += 1 # 0 # 1R
R# for文 for (i in 0:4) { print(i) } # [1] 0 # [1] 1 # [1] 2 # [1] 3 # [1] 4 print(0:4) # 0 1 2 3 4 Ns <- c(2, 3, 5, 7, 11) for (i in 1:length(Ns)) { print(Ns[i]) } # [1] 2 # [1] 3 # [1] 5 # [1] 7 # [1] 11 Ns <- c(2, 3, 5, 7, 11) for (n in Ns) { print(n) } # [1] 2 # [1] 3 # [1] 5 # [1] 7 # [1] 11 Ns <- c(2, 3, 5, 7, 11) for (i in 1:length(Ns)) { n = Ns[i] cat(paste0("Ns[", i, "] = ", n, "\n")) } # Ns[1] = 2 # Ns[2] = 3 # Ns[3] = 5 # Ns[4] = 7 # Ns[5] = 11 # while文 i <- 0 while (i < 5) { print(i) i = i + 1 } # [1] 0 # [1] 1 # [1] 2 # [1] 3 # [1] 4 # untilの代わり i <- 0 while (!(i == 5)) { print(i) i = i + 1 } # [1] 0 # [1] 1 # [1] 2 # [1] 3 # [1] 4 # break文 for (i in 0:4) { if (i == 2) { break } print(i) } # [1] 0 # [1] 1 # next文 for (i in 0:4) { if (i == 2) { next } print(i) } # [1] 0 # [1] 1 # [1] 3 # [1] 4 # repeat文 i <- 0 repeat { if (i == 2) { break } print(i) i = i + 1 } # [1] 0 # [1] 1 i <- 0 while (TRUE) { if (i == 2) { break } print(i) i = i + 1 } # [1] 0 # [1] 1VBA
VBASub test_repeat() Dim i As Integer Dim A As Variant ' for文 For i = 0 To 4 Debug.Print i Next i ' 0 ' 1 ' 2 ' 3 ' 4 A = Array(2, 3, 5, 7, 11) For i = LBound(A) To UBound(A) Debug.Print A(i) Next i ' 2 ' 3 ' 5 ' 7 ' 11 A = Array(2, 3, 5, 7, 11) For i = LBound(A) To UBound(A) Debug.Print "Ns[" & CStr(i) & "] = " & Str(A(i)) Next i ' Ns [0] = 2 ' Ns [1] = 3 ' Ns [2] = 5 ' Ns [3] = 7 ' Ns [4] = 11 ' while文 i = 0 Do While i < 5 Debug.Print i i = i + 1 Loop ' 0 ' 1 ' 2 ' 3 ' 4 ' until文 i = 0 Do Until i = 5 Debug.Print i i = i + 1 Loop ' 0 ' 1 ' 2 ' 3 ' 4 ' ループからExit For i = 0 To 4 If i = 2 Then Exit For End If Debug.Print i Next i ' 0 ' 1 ' Doループの場合は、Exit Do ' GoToを使ってcontinue文をVBAで実現 For i = 0 To 4 If i = 2 Then GoTo continue End If Debug.Print i continue: Next i ' 0 ' 1 ' 3 ' 4 ' repeat文の代わり i = 0 Do While True If i = 2 Then Exit Do End If Debug.Print i i = i + 1 Loop ' 0 ' 1 End Sub参考