- 投稿日:2020-11-29T23:55:59+09:00
pythonでjsonの配列にアクセスする
pythonでjsonの配列にアクセスする時のメモ
jsonファイル
test.json{ "section1":{ "key":"key1", "number": [ ["a", "b"], ["c", "d"], ["e", "f"] ] }, "section2":{ "key":"key2", "number": 2 } }pythonファイル
test.pyimport json json_open = open('test.json', 'r') json_load = json.load(json_open) print(json_load) print(json_load["section1"]["number"][0]) print(json_load["section1"]["number"][1]) print(json_load["section1"]["number"][2]) print(json_load["section1"]["number"][0][0]) print(json_load["section1"]["number"][0][1])実行
$ python test.py {'section1': {'key': 'key1', 'number': [['a', 'b'], ['c', 'd'], ['e', 'f']]}, 'section2': {'key': 'key2', 'number': 2}} ['a', 'b'] ['c', 'd'] ['e', 'f'] a b参考
- 投稿日:2020-11-29T23:51:08+09:00
GDALをインストールするときに「Solving environment: faild ~」となった際の対処法
この記事は・・・
pythonで地理空間情報を扱えるGDALをインストールする際に環境設定がうまく行かなかったようで、色々と対処をしたのでその記録です。
結果として、インストール中にしばらく待つだけで解決してたかもしれないので、参考にされる方は自己責任でお願いします。インストールを行った環境
Anaconda3 ver.1.7.2
python 3.7.9不具合の内容
まずはcondaコマンドを使ってインストールを試行しました。
conda install -c conda-forge gdalその結果、「Solving environment: faild ~」となってインストールが完了しません。
確か5分ほどはインストールがすすまずに同じようなメッセージが続きました。一旦インストールを中断して対処法を探しました。
対処法
対処1
・Anacondaのアップデート
これは当たり前ですかね。以下のコマンドを実行してAnacondaのすべてのパッケージを最新にアップデートしました。conda update --allしかし相変わらず同様のエラーが出てインストールが完了しない。
対処2
・環境変数の設定
以下の記事を参考にして環境変数を追加しました。「anacondaでconda createを実行しようとすると「 Solving environment: failed 」と出て実行できなかった」
https://qiita.com/kizul/items/43a15a21346d121907c6それでも相変わらずエラーが出ます・・・
対処法3
・バージョンを指定してインストール
以下の記事を参考にしました。「【超初歩】AnacondaにGDALをインストールしてみた」
https://qiita.com/skperfarming/items/34b18d7cdce20982aa03どうやらバージョンを指定したほうがいいらしい?
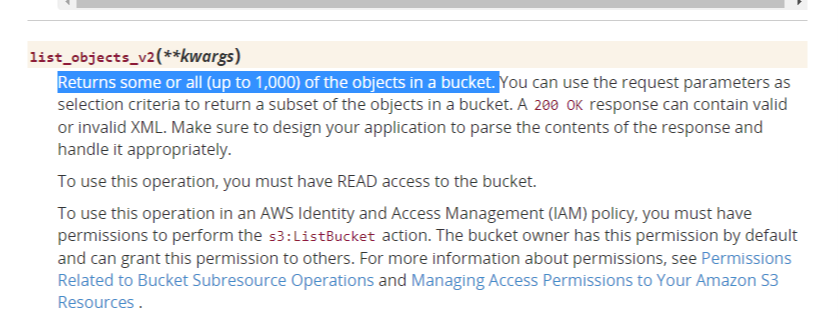
バージョンの確認は以下のコマンドで可能です。conda search gdal結果
本記事執筆時点(2020/11)では、3.0.2が最新のようです。
以下を実行する。conda install gdal==3.0.2これでも同じようなエラーが出ます。
結局・・・
対処法3を適用してもだめだったので、プロンプトをそのまま放置して更に対処法探しを再開します。
すると10分くらい経ったところで処理が進みました!え?
インストールするときにある程度のところでプロンプトの表示が更新されるので、ログは拾えていませんが(真っ黒になって遡れなくなる)、インストール自体は完了したらしい。
動作確認のためにpythonコンソールで以下を実行。>>>from osgeo import gdal >>>え?通った・・・?
あまり腑に落ちませんが、時間の問題ってだけで待っていればインストールできたのではないかと思います。
必要だったとしたらバージョンの指定で、環境変数は必要ないかもしれません。
ちょっと疑問は残りましたが、GDALが使えるようになったのでOKとしましょう。
- 投稿日:2020-11-29T22:53:10+09:00
PySide2で作成したウィンドウを半透過させる
この記事はTakumi Akashiro ひとり Advent Calendar 2020の3日目になります。
前置きの前置き
はい、Advent Calenderの3日目にして、もうネタが無くなりました。
最初の方にはちょっと実用的な記事を書く意識1がありましたが
仕方ないので、ここから来週の月曜までは好き勝手調べた内容を書いてきます。
TAとかまったく関係ないです。というわけで、3日目の記事、どうぞ!
前置き
皆さんはウィンドウの透過処理、使ったことありますか?自分は今までの仕事では一回も無いですね!
突然、ウィンドウにオーバーレイさせるアプリケーションとか作りたくなったので、ちょっと覚えていこうと思います(投げやり)ウィンドウを半透過するには得手不得手があり、使い分けが必要だったので、
今日の記事はその辺を踏まえながら解説していきたいと思います!本日のサンプルコード
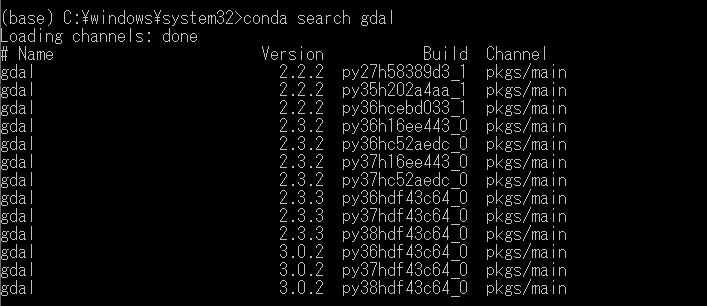
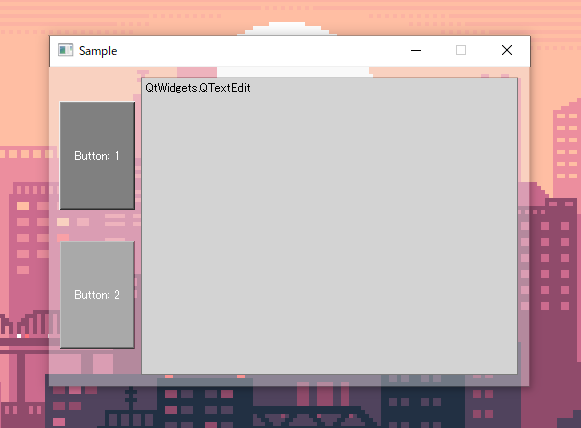
#!python3 # encoding:utf-8 from PySide2 import QtWidgets from PySide2 import QtCore class Window(QtWidgets.QWidget): def __init__(self, *args, **kwargs): super().__init__(*args, **kwargs) self.setWindowTitle("Sample") self.setStyleSheet("background-color:white;") self.setFixedSize(480, 320) hbox = QtWidgets.QHBoxLayout() vbox = QtWidgets.QVBoxLayout() hbox.addLayout(vbox) button_first = QtWidgets.QPushButton("Button: 1") button_first.setStyleSheet("background-color:gray; color:white;height:100%") vbox.addWidget(button_first) button_second = QtWidgets.QPushButton("Button: 2") button_second.setStyleSheet("background-color:darkgray; color:white;height:100%") vbox.addWidget(button_second) textedit = QtWidgets.QTextEdit("QtWidgets.QTextEdit") textedit.setStyleSheet("background-color:lightgray;") hbox.addWidget(textedit) self.setLayout(hbox) if __name__ == "__main__": app = QtWidgets.QApplication() window = Window() window.show() exit(app.exec_())
はい、Qt製の何の変哲もない雑なウィンドウですね。
本日はこれを透過させてみたいと思います。手法1 ウィンドウ背景の透明化オプションをセットする
self.setWindowFlagsに「WA_TranslucentBackground」をセットすることで1ウィンドウの背景が透過するようになります。
ただしそのままでは、「WA_TranslucentBackground」をセットした時に
追加される背景を描画しない「WA_NoSystemBackground」の影響で背景色が描画されないので、
paintEvent側で背景色を描画する必要があります。class Window(QtWidgets.QWidget): def __init__(self, *args, **kwargs): # ~中略~ self.setAttribute(QtCore.Qt.WA_TranslucentBackground) self.setWindowFlags(QtCore.Qt.FramelessWindowHint) self.setStyleSheet("background-color: rgba(255, 255, 255, 127);") def paintEvent(self, event): # NOTE: トップレベルのWidgetはWA_TranslucentBackgroundフラグが立つと、 # 背景が描画されなくなるので、paintEvent側で描画する。 painter = QtGui.QPainter(self) painter.fillRect(0, 0, self.width(), self.height(), painter.background())
メリット 特定Widgetのみを透過できる デメリット ウィンドウのWidgetの透過には
WindowFlagsのFramelessWindowHintが必要なため、
タイトルバーが消えてしまう手法2 ウィンドウに直接透明度を適用する
class Window(QtWidgets.QWidget): def __init__(self, *args, **kwargs): # ~中略~ self.setWindowOpacity(0.5)
メリット めちゃくちゃ簡単に透過を実装できる デメリット Widget個別に透過度を設定できない
締め
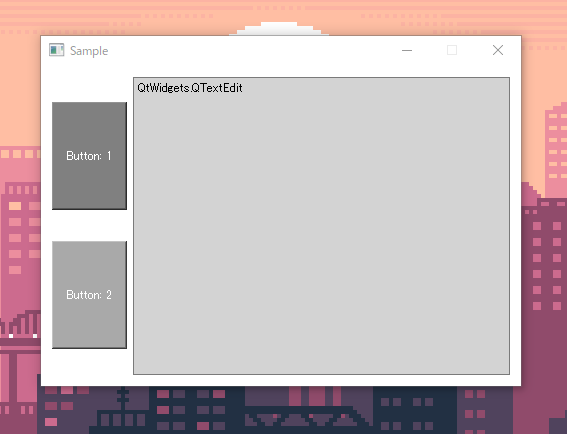
評価ラベル ランク(5段階) おすすめ度 ★ 難易度 ★ ニッチ ★★★★ 汎用性 ★ もやもや度 ★★★★
(上記は加工した画像です)
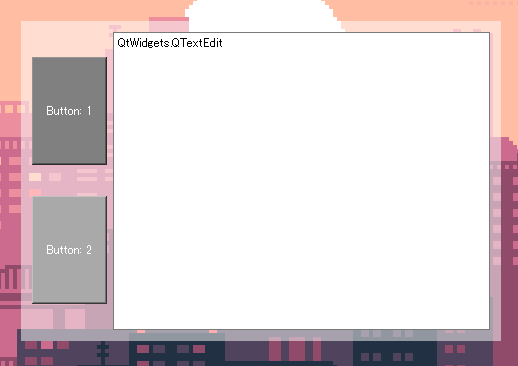
今回、実はオーバーレイの件とは別件でこういう感じをやりたくて、調べていたんですがダメでした……
一応PySide2+Qtをビルドしなおして、QtWinモジュールを追加すれば、Win7時代によくあったガラスフレームが使えるようで、
上記の画像っぽい感じになるんですが…今回はそこまでの情熱はないです……まあ手法1に自作のタイトルバーを追加すればいいだけなんで、問題はないんですけどね!!!!(精一杯の負け惜しみ)
というわけで個人的には若干消化不良な結果になりましたが、
今日の記事はここまでで終わりです。ではでは!
そこら辺の話は土曜当たりの記事で書く予定です。 ↩

- 投稿日:2020-11-29T21:57:51+09:00
CDKのサンプルプロジェクトのリポジトリを作成・公開した
1. はじめに
みなさん、AWSしてますか?
値段も安くて、触りやすく、記事も豊富にあるので、僕はかなり好きです。ただ、そうは言っても、個人で触りたいとなると料金の面で利用できるものとそうでない物が出てきたり、
一旦作成したサービスを忘れることなく全て削除したりするのは面倒な気がします。
また、WebのコンソールやCLIで作成した物は属人性が高くなり、手順やノウハウが残らないためよくないです。そこで、便利なのがCDKです!
2. CDKとは
AWSが公式に提供する
Infrastructure as Code(=IaC)のライブラリです(GitHub)。
CloudFormationをラップしており、TypescriptやPythonなどを用いて実装することで、サービスを作成することが可能です。
IaCとしては、前述のCloudFormationやTerraformなどもありますが、
これらはJsonで記述する必要があり(VSCodeだとプラグインで入力補助もある。)、
作成するサービスの量が多くなると見通しが悪くなる可能性があります。2.1 CDKのメリット
- AWSが公式に提供しているので利用できなくなるなどの不安はない(と思う)
- ドキュメントをみながら必要なパラメータを付与していくことになるので、必要な設定などがわかりやすい
- スタックの名前を変えれば同じ内容のサービスを複数個展開できるため、開発と本番の環境分離なども容易に行える
- ただし、同一の名前のサービスはできないので、環境ごとに名前を変える必要な場合がある(基本的には)
- リソースの作成・削除が容易(IaCのメリット)
- コードでサービスの管理ができるので属人性を排除できる(IaCのメリット)
2.2 CDKのデメリット
- リリースされたばかりのサービス(機能)は対応できないことがある
- CloudFormationが対応されたのち、CDKの対応がされるため
- (新サービスのLambda Containerは4時間くらいで更新されていたので、必ずしもそうとは言い切れなくなりましたね・・・笑)
- リリースの速度がかなり早く、過去に作成したコードが利用できなる可能性がある
- 2020年12月07日時点で、6日に1度のペースでリリース
- (とはいえ、破壊的な変更はそこまでない印象)
- ローカルからのコマンドでの削除が失敗することがある
- IAMにCDKで管理していないPolicyを付与などした場合
3. さわってみる
メリット・デメリットは実際に触ってみて感じるのが一番だと思うので、
早速、利用方法を書いていきます。3.1 環境構築
macの場合はbrewにてCDKをインストールできます。
$ brew install aws-cdkその後、各プロジェクトに必要なCDKのPythonライブラリを入れていく形になります。
$ pip install aws-cdk.aws-lambda必要になったら、都度パッケージを入れていくことになるのですが、
pypi aws_cdk athenaなどと必要なサービス名を含めて調べるとどのパッケージを入れればいいかわかります。3.1 公式サンプルプロジェクト
ゼロから、このライブラリをドキュメントから利用方法を探っていくのはかなり大変だと思うので、その際に有用なのがサンプルプロジェクトです。
AWSの公式が容易したaws-cdk-exampleが本家大元なので、一番信頼できます。
ただ、Pythonのプロジェクトとなると意外と少なかったり、更新日時が古く動かないサンプルなどもあります。3.2 作成したサンプルプロジェクト
そのため、私も同じようなフォーマットで、
Pythonのみのサンプルプロジェクト一覧aws-cdk-small-examplesを作成してみました。
記事作成時点はCDKのバージョンが1.76.0なのですが、その時点で全てのサンプルプログラムが動くようになっています。
作成してみたサンプルプロジェクトの数は12個です。
(本家公式は25個なので、半分程度はあります。ただ、かぶっているサンプルは2個程度のみです。)対応しているサービスなどは以下の通りです。
- Lambda
- VPC
- AWS Batch
- Step Functions
- DynamoDB
- API Gateway
- CloudFront
- S3
- Glue
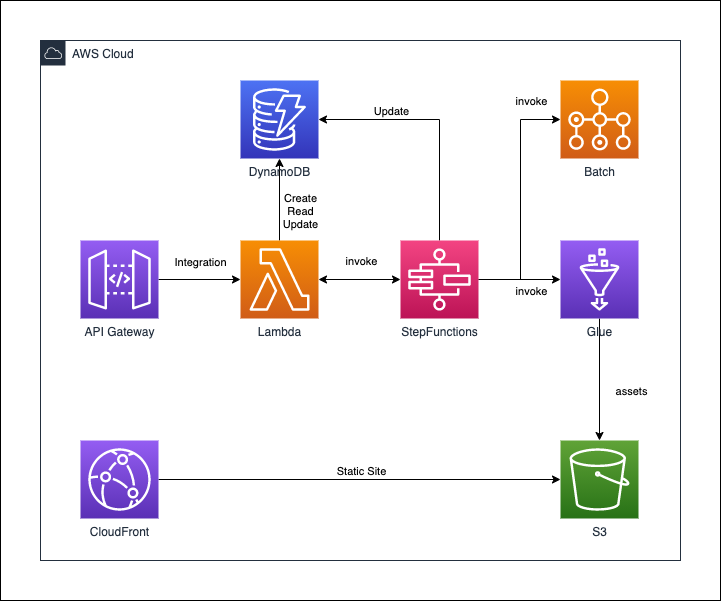
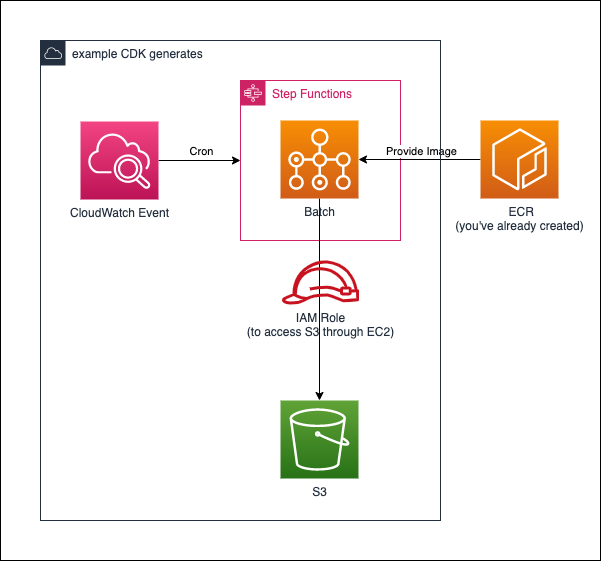
作成したリポジトリにて、公開しているサービスとその関連を表した図です。
(※注意:これらのサービスが一度にデプロイされるわけではありません。)
次の節から公開している、構成図の一部を紹介します。
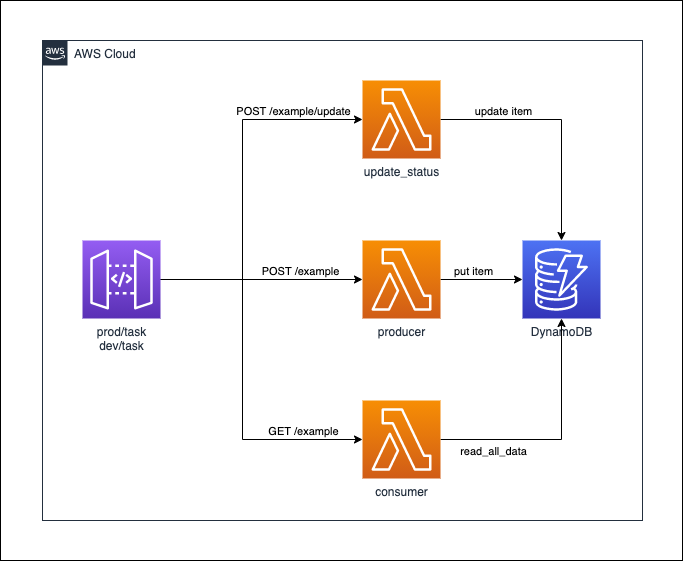
3.2.1 API Gateway + Lambda + DynamoDB
この例では、3つのLambdaを作成し、DynamoDBにアクセスするapp.pyを公開しています。
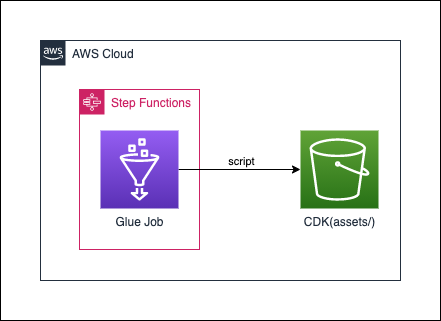
3.2.2 Glue + StepFunctions
この例では、GlueのJobを定義して、それをStepFunctionsから実行するapp.pyを公開しています。
意外とGlueの例は少ないので、もし利用するような方がいれば参考になるかなと思います。
3.2.3 Lambda Container
ここでは、reInvent2020で発表された新サービスの1つである、Lambda Containerの例も作成しています。
細かい使い方などは別のQiitaの記事でも紹介しておりますで、合わせてどうぞ!
3.2.4 AWS Batch + StepFunctions
この例では、AWS BatchをStepFunctionsとCloudWatch Eventを利用して定期実行するapp.pyを公開しています。
VPCなども一から作成しており、結構長いコードとなっております。
細かい説明などは、Qiitaの記事にて、紹介しております!
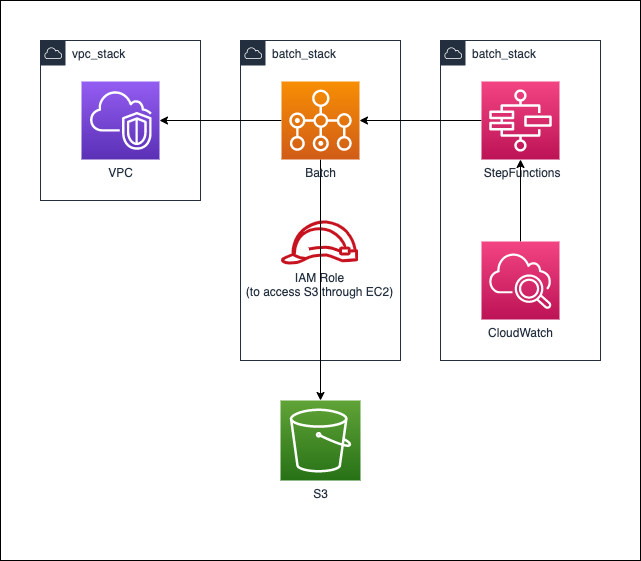
3.2.5 NESTED AWS Batch + StepFunctions
CloudFormationがnestに対応したので、3.2.4の構成をnestを利用した例を作成しております。
nestを利用することのメリットとしては、作成したStackの責任を明確にできることが大きいです。例では、以下のように分離させています。
* VPCのスタック:ベース
* Bathcのスタック:処理などを実際に行う部分
* StepFunctions + CloudWatch Eventのスタック:定期的に処理を走らせる部分
3.3 おすすめの記事
- こちら本家のAPI referenceです。Python専用のdocsもありますが、こちらの方が参考になります。
4. おわりに
自分の中で、CDKはかなり好きなので、いろんな人にCDKを使っていただきたいなと思います!
IaCを進めるという意味でもかなり良いです!また、これからも、随時GitHubのサンプルは増やしていく予定なので、ぜひチェックなどをお願いいたします!!
- 投稿日:2020-11-29T21:44:33+09:00
Pythonで音声ファイル(モノラル・ステレオ両対応)のスペクトログラム描画
Pythonで音声ファイルのスペクトログラム描画をしてみました。とてもよくあるパターンではありますが、モノラル・ステレオ両対応になっているのが特徴です。
後でも述べますが、スペクトログラム描画により、人間が話しているところと、無音もしくは人間の会話周波数と異なるノイズとを、一目瞭然で区別することが可能です。例えば、話者識別の教師データを作る場合など、スペクログラムを見ることで、やりやすくなるでしょう。
なお、音声分析にはlibrosaを使う場合も多いようです。
細かい説明はコードに書かれていますが、以下概要です。
- pysoundfileでwaveファイルを読み込み
- 冒頭5分のみ切り出し(必須ではありませんが処理速度の関係で時間を短くしました)
- 高速フーリエ変換
- 7kHz未満の周波数のみ切り出し(人間の音声は3.4kHz未満がほとんどで、7kHz未満でも高音質)
- 音圧をdBに変換(相対dB)
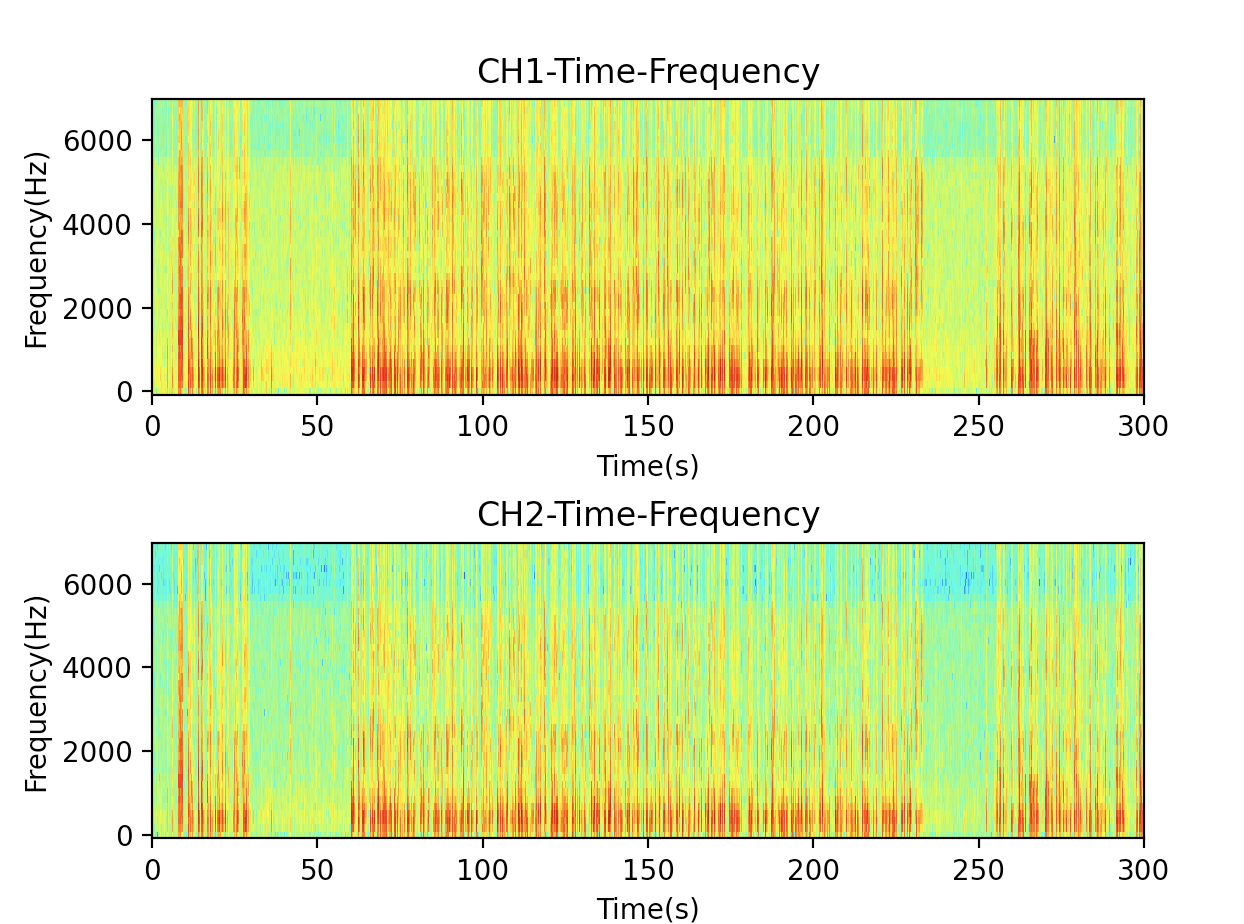
- 結果を、縦軸が周波数・横軸が経過時間とし、dB値によるカラーマップを、グラフ描画(ステレオだとCHごとにグラフ描画)
以下がコードです。
import numpy as np import matplotlib.pyplot as plt import soundfile as sf from scipy import signal as sg # 入力はwavファイルであること(mp3等は入力前にツールで変換する) x, fs = sf.read('sample.wav') x = x[:fs*300] # 最初の5分間だけを分析する # モノラル音声のndarrayをステレオ音声と同等形式に変換 if len(x.shape) == 1: x = x.reshape(-1, 1) # stftのパラメータ nperseg = 256 noverlap = nperseg // 2 # ウインドウがぴったりと切り分けられるように入力配列の後ろを少し削る # stftしたデータを逆stftをするときに、この前処理が効いてくる x = x[:-((len(x) - nperseg) % (nperseg - noverlap))] # soundfileの形式をstftするには転置する f, t, Zxx = sg.stft(x.T, fs=fs, nperseg=nperseg, noverlap=noverlap) # 人間の声を分析するため7kHz以上の高音はカット f = f[f < 7000] Zxx = Zxx[:,:len(f)] # スペクトログラムを描画するために相対デシベルを求める dB = 20 * np.log10(np.abs(Zxx)) # スペクトログラムの描画 channels = dB.shape[0] fig, ax = plt.subplots(channels) if channels == 1: ax = (ax,) #チャネル1つの時はaxがスカラーなので調整 for i in range(channels): ax[i].set_title(f'CH{i+1}-Time-Frequency') ax[i].set_xlabel('Time(s)') ax[i].set_ylabel('Frequency(Hz)') ax[i].pcolormesh(t, f, dB[i], shading='auto', cmap='jet') plt.subplots_adjust(wspace=0.5, hspace=0.5) plt.show()出力結果
赤っぽいところが人が話をしている箇所、青っぽいところが無音です。会話なのか、会話ではないのかの区別は容易になりそうです。しかし、このグラフを人間が見ただけでは、話者の違いまでを判別するのは難しそうです。左右の短い話をしている人と、真ん中の長い話をしている人は、別人なのですが、その違いは、目で見てもわからないでしょう。
- 投稿日:2020-11-29T21:40:26+09:00
fairseqで自分でトレーニングしたTransformerモデルをロードする
はじめに
機械翻訳のTransformerモデルをトレーニングする機会があり,Pytorchベースのfairseqを使ったんですが,アプリ用のコードでモデルのロードにハマってしまいました.備忘録のために記事を書きます.
fairseqとは
Facebookの人工知能研究チームが開発している,機械翻訳用のフレームワークです.Facebookが開発元ということもあり,Pytorchがベースになっています.最近はHuggingfaceのTransformersが人気でTransformerモデルを扱うならPytorchだよね,ということもあり,こちらをフレームワークとして選びました.
その他の機械翻訳フレームワークとしては,MarianNMT,OpenNMT(こちらもPytorchベース)などがあります.基本的な機能はどのフレームワークも大差ない印象ですが,論文実装のコードはfairseqが選ばれている場合が多いです.モデルのトレーニング方法
fairseqはドキュメントが充実しているため,チュートリアル通りにやれば,自分でも機械翻訳モデルをトレーニングすることができます.チュートリアルは英語のみですが,日本語のドキュメントが不足しているのは,他の機械翻訳フレームワークでも同様です.
トレーニングのためのコード(fairseqの公式ドキュメントから)> mkdir -p checkpoints/fconv > CUDA_VISIBLE_DEVICES=0 fairseq-train data-bin/iwslt14.tokenized.de-en \ --lr 0.25 --clip-norm 0.1 --dropout 0.2 --max-tokens 4000 \ --arch fconv_iwslt_de_en --save-dir checkpoints/fconvトレーニングコードの
save-dirは学習済みモデルの格納フォルダですが,このフォルダには,各エポックにおける学習済みモデル(checkpoint(n).pt),精度が一番よかった学習済みモデル(checkpoint_best.pt),最終エポックにおける学習済みモデル(checkpoint_last.pt)が格納されます.checkpoints_fconv$ ls -alF checkpoint1.pt checkpoint2.pt ... checkpoint99.pt checkpoint_bes.pt checkpoint_last.pt推論の際は,
checkpoint_best.ptを読み込むことになるかと思います.インタラクティブモードでの推論
fairseqの公式ドキュメントには,シェル上のインタラクティブモードでの推論についてはチュートリアルがありますが,Pythonのコード内でモデルをロードする方法などは紹介されていません.
fairseq-interactiveによ推論(fairseqの公式ドキュメントから)> MODEL_DIR=wmt14.en-fr.fconv-py > fairseq-interactive \ --path $MODEL_DIR/model.pt $MODEL_DIR \ --beam 5 --source-lang en --target-lang fr \ --tokenizer moses \ --bpe subword_nmt --bpe-codes $MODEL_DIR/bpecodes | loading model(s) from wmt14.en-fr.fconv-py/model.pt | [en] dictionary: 44206 types | [fr] dictionary: 44463 types | Type the input sentence and press return: Why is it rare to discover new marine mammal species? S-0 Why is it rare to discover new marine mam@@ mal species ? H-0 -0.0643349438905716 Pourquoi est-il rare de découvrir de nouvelles espèces de mammifères marins? P-0 -0.0763 -0.1849 -0.0956 -0.0946 -0.0735 -0.1150 -0.1301 -0.0042 -0.0321 -0.0171 -0.0052 -0.0062 -0.0015Pythonのコード内で学習済みモデルをロードする方法
modelsクラスを使うのが正解でした.インタラクティブモードの場合と異なり,いくつかの引数は自動でロードされるようです.
>>> from fairseq.models.transformer import TransformerModel >>> model = TransformerModel.from_pretrained('wmt14.en-fr.fconv-py', 'model.pt', 'wmt14.en-fr.fconv-py') >>> text = 'Why is it rare to discover new marine mam@@ mal species ?' >>> model.translate(text, beam=5) 'Pourquoi est @-@ il rare de découvrir de nouvelles espèces de mammifères marins ?'まとめ
fairseqは日本語ドキュメントが少ないですが,HuggingfaceのTransformersを使っている人であれば使いやすいですし,Pytorchベースということにも将来性を感じます.
論文実装のコードも多いですし,今後も触っていきたいフレームワークですね.
- 投稿日:2020-11-29T21:23:03+09:00
AzureのStorageに保存されたcsvファイルをDataFrameとして取得できるライブラリ作った。
1. はじめに
みなさん、Azureライフ楽しんでいますでしょうか?
私は、Azure FunctionsやDatabricksを主に利用し、とても楽しい毎日を送っております!!とても、Azureが提供するサービスはどれも素晴らしいのですが、
Azure FunctionsからBlobStorageにアクセスしてファイル操作、
となると既存のライブラリ群ではちょっとラッパー関数が必要になって大変でした。
(もしかしたら、そんな操作をすることは少ないかもなのですが・・・。)そこで、Azureから提供されているライブラリをラッパーして扱いやすいライブラリを作りました!
その名もAzFS(Azure File System)です。
リポジトリはこちらです。
(ただ、FileSystemとしての機能は2020年11月現在ではほぼないです。)2. 利用方法
AzFSとは
Azure Storage Account上にあるcsvやparquet、pickleなどのファイルをpandasのDataFrameとして読み込めるライブラリです。
また、jsonの読み書きや、とあるディレクトリ以下のファイルのリストなども対応しています。2.1 インストール
pipを利用してインストールできます
$ pip install azfs2.2 インスタンスの作成
動かす環境によって、認証情報の取得方法が異なり、インスタンスに渡す引数が異なります。
現在対応している認証方法は、以下の2つです。
- Azure Active Directory
- Connection String
import azfs # Azure Active Directory上で動かす場合は、`AzFileClient`への引数は不要です。 azc = azfs.AzFileClient() # 接続文字列(connection string)を利用する場合 connection_string = "DefaultEndpointsProtocol=https;AccountName=xxxx;AccountKey=xxxx;EndpointSuffix=core.windows.net" azc = azfs.AzFileClient(connection_string=connection_strin)また、環境変数に以下の情報を入れてあげると、引数なしでも動くようになります。
2.3 ファイルのリスト
とあるディレクトリ以下のファイルリストを取得する方法は次の通りです。
path = "https://testazfs.blob.core.windows.net/test_caontainer" file_list = azc.ls(path)また、特定のファイル名に合致するファイルだけを取得するようなglob関数にも対応しています。
path_pattern = "https://testazfs.blob.core.windows.net/test_caontainer/*.csv" file_list = azc.glob(path_pattern)2.4 ファイルの読み込み
csvなどのファイルは
pandas-likeとspark-likeの2通りの方法で読み込みことができます。
また、いずれの方法もpandasのDataFrameを返すようになっています。
機能 pandas-like pyspark-like ファイル読み込み 単一 複数 pandasの引数を渡す O O 読み込み時のフィルタ処理 X O 並列読み込み X O csv azc.read_csv()azc.read().csv()parquet azc.read_parquet()azc.read().parquet()pickle azc.read_pickle()azc.read().pickle()2.4.1 pandas-likeな読み込み
pandasのメソッドのように記述し、DataFrameとして読み込むことができます。
# Blob Storageのpathを指定 path = "https://testazfs.blob.core.windows.net/test_caontainer/test_file.csv" df = azc.read_csv(path) # pandasの引数にも対応 df = azc.read_csv(path, skiprows=4, header=None) # with句を利用して、pandasのメソッドのように振る舞うことも可能です。 # read_csv_az という別の関数名になってしまうところだけ注意 import pandas as pd with azc: df = pd.read_csv_az(path)2.4.2 spark-likeな読み込み
複数のデータを一度に読むことがある場合は、こちらの方法を利用した方が効率よく読み込むことが可能です。
path = "https://testazfs.blob.core.windows.net/test_caontainer/*.csv" df = azc.read().csv(path) # また、並列処理も引数を指定するだけです。 df = azc.read(use_mp=True).csv(path) # 並列処理でファイルを読み込んでいる際に、各ファイルに処理を加えたい場合は、 # 関数を定義し、それを渡してあげると処理します。 def some_function(_df: pd.DataFrame) -> pd.DataFrame: _df['new_column'] = _df['price'] * 1.1 return _df df = azc.read(use_mp=True).apply(function=some_function).csv(path)2.5 ファイルの書き込み
ファイルの書き込みに関しては、pandas-likeの方法しかないです。
# 書き込み path = "https://testazfs.blob.core.windows.net/test_caontainer/test_written_file.csv" azc.write_csv(df, path, index=False) # readの時と同じようにwith句でpandasのDataFrameから直接関数を実行することも可能です。 # ただし、こちらも関数名がread_csv_azと微妙に異なる点のみ注意してください。 with azc: df.write_csv_az(path, index=False)3. おわりに
冒頭でもお伝えしたように、AzFSは、FileSystemとしての機能はほぼないです。
そのため、Pull RequestやFileSystemにするためのissueを挙げてくれると大変嬉しいです!!このライブラリを利用して多くの方がAzureライフを謳歌できたらいいいなと思います!
- 投稿日:2020-11-29T20:45:54+09:00
docker-composeで都合の良いPython3実行環境を作成する
概要
- Python3の都合の良い実行環境が欲しくなったのでdockerで作成しました。
- いつも使ってるOSがCentOS7だ(ubuntuではない。。)
- ENVを切るのがめんどくさい。
- 検証のたびにサーバを準備したくない。
- 検証が終わったら消したい。
事前準備
- 下記をインストールし実行できること。
- docker
- docker-compose
ディレクトリ構成
./---docker-compose.yml |--Dockerfile |--requirements.txt # pipインストール用 利用しなければ不要 |--.env # 環境変数用 利用しなければ不要 |--src # pyファイルを配置するディレクトリ |-- sample.py各種ファイルの配置
docker-compose.ymldocker-compose.ymlversion: '3' services: python3: restart: always build: . container_name: 'python3' working_dir: '/root/src' tty: true volumes: - ./src:/root/src env_file: - .env
DockerfileFROM python:3 USER root RUN apt-get update RUN apt-get -y install locales && \ localedef -f UTF-8 -i ja_JP ja_JP.UTF-8 ENV LANG ja_JP.UTF-8 ENV LANGUAGE ja_JP:ja ENV LC_ALL ja_JP.UTF-8 ENV TZ JST-9 ENV TERM xterm RUN apt-get install -y vim less RUN pip install --upgrade pip RUN pip install --upgrade setuptools ADD requirements.txt /root/ RUN pip install -r /root/requirements.txt
requirements.txt
- pipインストールする必要があれば記載する
requirements.txtrequests
.env
- 環境変数を設定する必要があれば記載する
SAMPLE_USER ='root'
sample.pysample.pyprint("hello world")実行
コンテナを起動
$ docker-compose up -dスクリプトの実行
$ docker-compose exec python3 python3 sample.py hello worldrequirements.txtや.envを修正したとき
- 一度停止して再ビルド
$ docker-compose down $ docker-compose build $ docker-compose up -d
- 投稿日:2020-11-29T20:44:15+09:00
CSVをサクっとSDFに変換する
はじめに
SDFをサクっとCSVに変換するの逆バージョン。
なぜこんなことをしたいかというと、SMILESが含まれたCSVの化合物データに対し、SDF形式でしか表現できない情報(3次元座標や原子プロパティ等)を付加したいため。
仕様
- CSVの中のSMILESプロパティと、プロパティ項目を指定し、SDFとして出力
- 化学構造はSMILESを元に生成
- プロパティ項目は1つだけ指定可能(とりあえず機械学習の目的変数を1つ入れたいだけなので)
ソース
csv2sdf.pyimport pandas as pd from rdkit import Chem import argparse def main(): parser = argparse.ArgumentParser() parser.add_argument("-input", type=str, required=True) parser.add_argument("-output", type=str, required=True) parser.add_argument("-smiles_col", type=str, default="SMILES") parser.add_argument("-target_col", type=str, required=True) args = parser.parse_args() # CSVの読み込み print(args.input) df = pd.read_csv(args.input) # SMILES列を取り出し smiles_list = df[args.smiles_col].values # target列の取得 targets = df[args.target_col].values mols = [] for i, (smiles, target) in enumerate(zip(smiles_list, targets)): # SMILESからmolを生成 mol = Chem.MolFromSmiles(smiles) # Targetの値を設定 mol.SetProp(args.target_col, str(target)) mols.append(mol) # SDFへの出力 sdf_wtr = Chem.SDWriter(args.output) for mol in mols: sdf_wtr.write(mol) sdf_wtr.close()解説
特になし。
3次元化したいとか、原子プロパティを埋め込みたい等したい場合は、ソース中のRDKitのmolオブジェクトに色々操作を加えてみてください。
- 投稿日:2020-11-29T20:30:57+09:00
Pythonでべき乗・累乗 ** と pow() の違い
0. はじめに
Pythonでべき乗・累乗を計算するには2つの方法があります。
例えば $3^4$ を計算する場合、
3 ** 4pow(3,4)のどちらでも計算できます。1
本記事ではこれらの違いについて説明します。内容は3章構成で以下の通りです。
第1章 **とpow()の違い
この章では主にPython初心者を対象に2つの方法の違いについて説明します。
第2章 速度の比較
この章では競技プログラミングなどの理由で計算速度を求める方を対象に2つの方法の実行時間を比較した結果を説明します。
第3章 Python内部のはなし
この章では第2章で見た結果の理由が知りたい方を対象にそれぞれの方法でPython内部で行われていることを説明します。
1. **とpow()の違い
この章ではPythonの基本事項を含め2つの方法の違いを説明します。
1.1. Python内での立場
1番の大きな違いはPython内での立場です。具体的にいうと
**は演算子pow()は関数です。
演算子は演算を行う指示で
**は「べき乗という演算をする」という意味があります。
+,%,!=,andなども全て演算子です。関数は演算子などを用いて行う一連の処理をまとめたものです。
pow()は「べき乗計算を行う」という関数なので以下のコードと一緒だと思っておけば良いでしょう。def pow(a, b): result = a ** b return result1.2. 第3の引数
少し発展的な内容となりますが、
pow()関数には第3の引数があり、整数を指定することができます。
これを指定した場合、べき乗の結果を指定した整数で割ったあまりが得られます。指定しなかった場合はデフォルトでNoneが設定されているので前節で見た通りです。なお、第3の引数を指定する場合は第1、第2の引数も整数でなければなりません。
なのでpow()関数は実は以下のようなものです。2def pow(a, b, c=None): result = a ** b if c != None: result = result % c # %はあまりを求める演算子 return result1.3. まとめ
**とpow()は演算子と関数という違いがあります。
また、pow()は第3引数を指定することができ、指定した整数で割ったあまりを求めることができます。
このような違いがありますが、基本的にはどちらを使って書いても良いです。
例えば 「3の4乗を5で割ったあまり」は以下のように様々な書き方ができます。# 以下のものは全て正しい答え(=1)が得られる 3 ** 4 % 5 pow(3, 4) % 5 pow(3, 4, 5)ただし、2番目のようにわざわざ関数と演算子を混ぜる必要はないので1番目か3番目のように書くといいでしょう。
2. 速度の比較
この章では
**とpow()の実行速度を比較します。2.1. 計測方法
正整数 $x, n, m$ について
x ** npow(x, n)x ** n % mpow(x, n, m)の4種類を計算しました。
実行時間の計測にはAtCoderのコードテスト Python(3.8.2)を使用し、各計算法について5回の計測の平均をとりました。計測に使用したコードは以下のものです。
def main(): x = 3 n = 10 m = 17 loop = 10000000 for _ in range(loop): result = x ** n #result = pow(x, n) #result = x ** n % m #result = pow(x, n, m) #pass if __name__ == "__main__": main()2.2. 計測結果
結果は以下のようになりました。
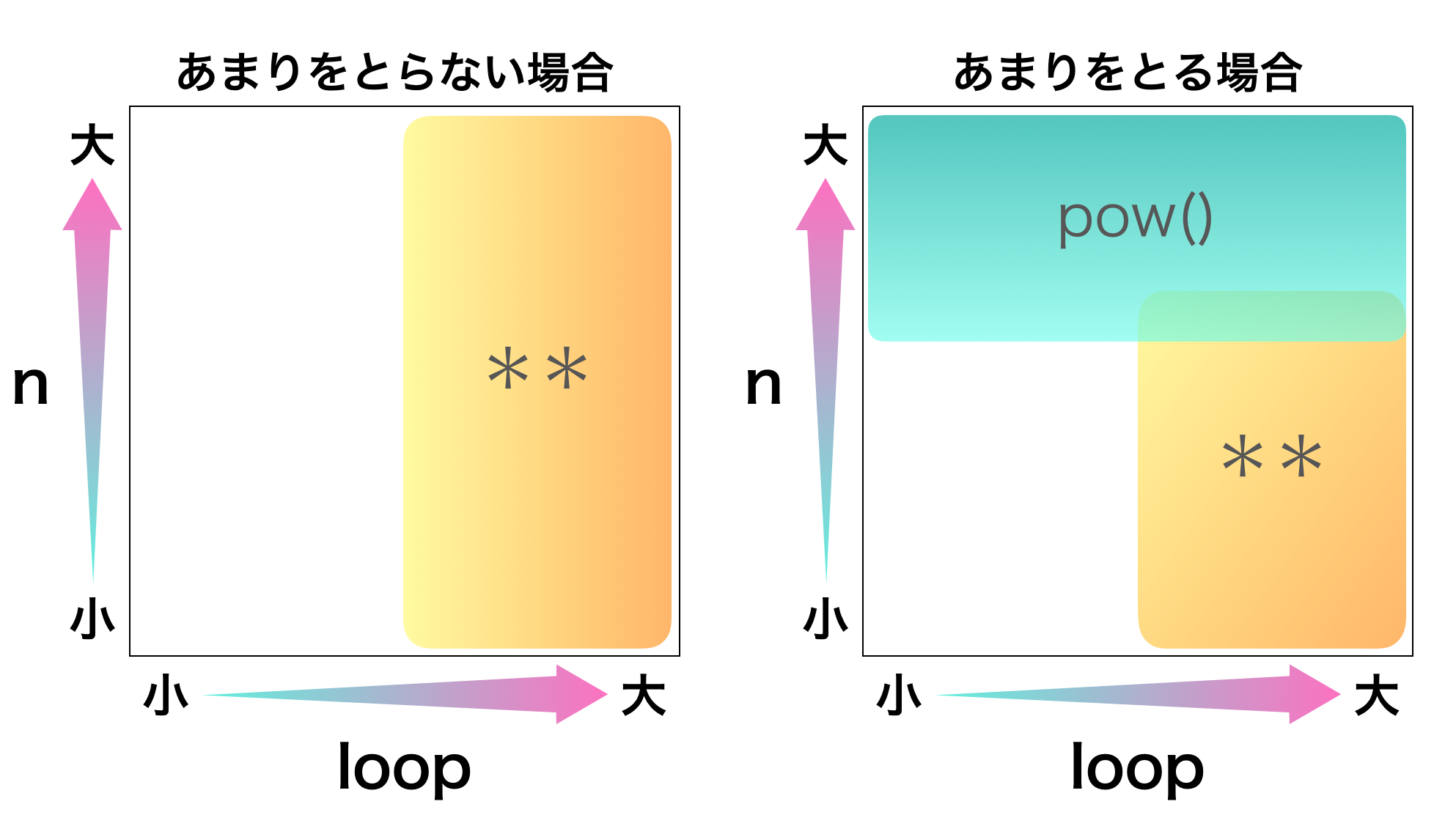
$x=3, m = 17$ は固定でnとloopを変え計測しました。なお、$loop = 10^7$ でfor文内が
passの場合は$196\rm{ms}$ でした。(i)あまりをとらない場合
n loop x ** npow(x, n)$10$ $1$ $21\rm{ms}$ $22\rm{ms}$ $10$ $10^7$ $1885\rm{ms}$ $2163\rm{ms}$ $10^7$ $1$ $2526\rm{ms}$ $2516\rm{ms}$ $10^3$ $2 \times10^6$ $2311\rm{ms}$ $2436\rm{ms}$ (ii)あまりをとる場合
n loop x ** n % mpow(x, n, m)$10$ $1$ $22\rm{ms}$ $22\rm{ms}$ $10$ $10^7$ $2074\rm{ms}$ $6319\rm{ms}$ $10^7$ $1$ $2553\rm{ms}$ $25\rm{ms}$ $10^3$ $2 \times10^6$ $3652\rm{ms}$ $1430\rm{ms}$ 2.3. まとめ
結果をまとめると下図のようになります。
速度を重視したい場合に推奨する方法を示します。
空白部分はどちらでも大きな違いはありません。
当然ですが、べき乗計算にどちらの方法を使うか考えるよりもアルゴリズム自体を洗練させることに時間を使った方が良いです。べき乗計算の違いが重要になってくる場面は特定の場面(nが大きい & あまりをとる)を除いてほとんどないでしょう。
なのでこの結果はなんかちょっと違うらしいな程度にとどめて、実際はコードの統一性などで決めた方がいいと思います。
- n(正確には$x^n$)が大きい & あまりをとる $\rightarrow$
pow()を使う- その他 $\rightarrow$ コードの統一性などで決める
3. Python内部のはなし
競技プログラミングを始めて間もない頃、べき乗計算について調べてみると次のような文言をよく目にしました。
Pythonの組み込み関数
pow()は繰り返し二乗法を用いて実装されている
当時は「ふーんそうなんだ、便利だな」としか思わなかったのですが、これを確かめたことはないなと思い調べてみたのがこの記事を書いたきっかけです。
この章では実際にPythonのソースコードをみて**とpow()の違いについて調べた結果を説明します。
なお、底、指数は整数のみを想定します。参考にしたソースコード
オリジナルの、C言語で実装されたいわゆるCPythonで、バージョンは3.8です。以下のリンクからみることができます。https://github.com/python/cpython/tree/3.8
3.1. 調べる方法
Python標準のdisモジュールを使います。このモジュールを使うことで、コードを実行した際に内部で行われている処理を人間がわかる形でみることができます。
例えば、以下のようなコードを書きます。test.pyx = 1 y = 2 x + yそして
terminal$ python -m dis test.pyと実行すると
terminal1 0 LOAD_CONST 0 (1) 2 STORE_NAME 0 (x) 2 4 LOAD_CONST 1 (2) 6 STORE_NAME 1 (y) 3 8 LOAD_NAME 0 (x) 10 LOAD_NAME 1 (y) 12 BINARY_ADD 14 POP_TOP 16 LOAD_CONST 2 (None) 18 RETURN_VALUEこのような結果が表示されると思います。
ここから、BINARY_ADDというのが足し算をしているようだということがわかります。
あとはソースコードからBINARY_ADDの定義を探して追っていけば内部での処理がわかります。3.2. **の場合
以下のコードを使って調べました。
x = 3 y = 4 x ** yすると以下のようになります。
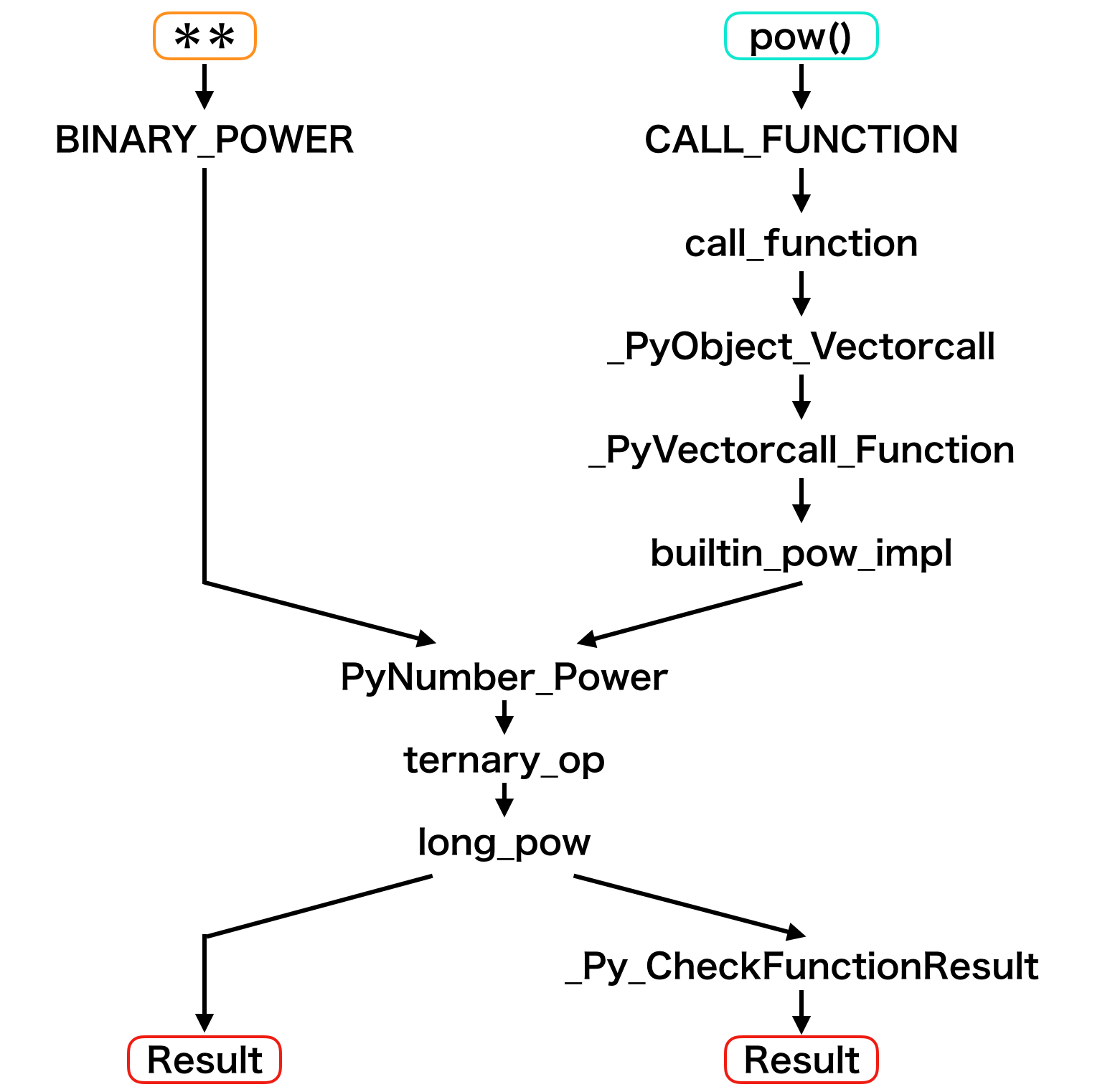
terminal1 0 LOAD_CONST 0 (3) 2 STORE_NAME 0 (x) 2 4 LOAD_CONST 1 (4) 6 STORE_NAME 1 (y) 3 8 LOAD_NAME 0 (x) 10 LOAD_NAME 1 (y) 12 BINARY_POWER 14 POP_TOP 16 LOAD_CONST 2 (None) 18 RETURN_VALUEよってBINARY_POWERというものを探します。
これを追っていくと次のようになります。BINARY_POWER $\rightarrow$ PyNumber_Power $\rightarrow$ ternary_op $\rightarrow$ long_pow
3.3. pow()の場合
以下のコードを使って調べました。
x = 3 y = 4 pow(x, y)すると以下のようになります。
terminal1 0 LOAD_CONST 0 (3) 2 STORE_NAME 0 (x) 2 4 LOAD_CONST 1 (4) 6 STORE_NAME 1 (y) 3 8 LOAD_NAME 2 (pow) 10 LOAD_NAME 0 (x) 12 LOAD_NAME 1 (y) 14 CALL_FUNCTION 2 16 POP_TOP 18 LOAD_CONST 2 (None) 20 RETURN_VALUE
pow()の場合はBINARY_POWERではなくCALL_FUNCTIONとなります。
これは、組み込み関数だけでなくコード中に自分で書いた関数など、全ての関数がCALL_FUNCTIONになります。CALL_FUNCTIONからソースコードを追ってみると次のようになります。
CALL_FUNCTION $\rightarrow$ call_function $\rightarrow$ _PyObject_Vectorcall
そして_PyObject_Vectorcallのなかで以下のことが行われます。
\begin{aligned} \rm{func} &= \rm{\_PyVectorcall\_Function}\\ &= \rm{builtin\_pow\_impl}\\ &= \rm{PyNumber\_Power}\\ &= \rm{ternary\_op}\\ &= \rm{\mathbf{long\_pow}}\\ \rm{result} &= \rm{func}()\\ &\rm{\_Py\_CheckFunctionResult} \end{aligned}3.4. long_pow
実はどちらの方法でべき乗計算をしようとしても結局long_powという関数にたどり着きます。
long_powをPythonで書いてみるとだいたい以下のようになります。(参照カウントや桁が大きい場合の処理などは省略しています。)
def long_pow(base, exp, mod): #base, exp, modはint negativeOutput = 0 # 指数が負でmodがない場合はfloatの累乗へ移る if exp < 0 and mod == None: return float_pow(base, exp, mod) # modが指定されている場合の処理 if mod != None: #mod = 0はエラー if mod == 0: raise ValueError #modが負ならnegativeOutputフラグを立ててmodを正にする if mod < 0: negativeOutput = 1 mod = -mod # mod = 1なら必ず0 if mod == 1: return 0 # 指数が負なら指数を正にして底をmodを法とした逆元で置き換える if exp < 0: exp = -exp base = long_invmod(base, mod) # 底が負もしくはmodより大きいならmodで割った余りに置き換える if base < 0 or base > mod: _, base = divmod(base, mod) """ ここまででmodが指定されている場合はbase, exp, modが非負になる。 modが指定されていない場合はbaseが負の場合もある。 """ # modが指定されている場合、xをmodで割った余りに置き換える def REDUCE(x): if mod != None: _, x = divmod(x, mod) return x # xとyの掛け算。modが指定されている場合はあまりをとる def MULT(x, y): result = x * y result = REDUCE(result) return result # 右向きバイナリ法(繰り返し二乗法) j = 1 << exp.bit_length() - 1 z = 1 while j: z = MULT(z, z) if exp & j: z = MULT(z, base) j >>= 1 # negativeOutputの場合は結果を負にする if negativeOutput and z != 0: z -= mod return z以上より「Pythonの組み込み関数
pow()は繰り返し二乗法を用いて実装されている」という文言は正しいですが誤解を含んでいると思います。(私が勝手に誤解していただけかもしれません。)正しい
確かに組み込み関数pow()は繰り返し二乗法を用いて実装されています。誤解(?)
pow()""は"" 繰り返し二乗法を~ということは**は違う?
$\rightarrow$**も繰り返し二乗法を用いて実装されています。
そもそも、どちらも同じ関数を使っています。以降では、ここまででわかったことを基に2章の結果を説明します。
3.5. あまりをとらない場合
まず、あまりをとらない場合を見ていきます。
この場合どちらもlong_pow(x, n, None)が実行されるだけなので
x ** npow(x, n)はアルゴリズムの面では完全に等しいです。したがって、$n$ がどのような大きさであっても2つに違いはありません。
1章で述べた通り、
**は演算子、pow()は関数です。ここではこの違いが重要になります。ここで3.2, 3.3でわかったPython内部の動きをまとめてみると下図のようになります。
この図からわかるように、関数を呼び出す際にはコスト(関数呼び出しのオーバーヘッド)を支払うことになります。
1回の呼び出しでは体感できる差は生まれませんが、呼び出し回数が増えれば大きな差になります。このような理由から、
- n の大きさに依存しない
- loopが大きくなるほど演算子である
**が関数であるpow()より速度面で優位になるという2章の結果を説明できます。
3.6. あまりをとる場合
続いて、あまりをとる場合を見ていきます。
この場合も演算子と関数の違いからloopの大きさによって演算子の優位性が見えてきます。一方、あまりをとらない場合と違うのはアルゴリズムの面でも2つは異なるという部分です。
x ** n % mではあまりを求めるのは最後だけなのに対し、pow(x, n, m)は乗算ごとにあまりを求めます。ここからはこれらの違いが n の大きさによってどのように影響するかを見ていきます。n が小さい場合
この場合、「割り算のコストは小さくない」という事実が重要になってきます。あまりを求めるというのは割り算をすることに他ならないので何度もあまりを求めるpow(x, n, m)は一度しかあまりを求めないx ** n % mに比べて計算コストが大きくなります。n が大きい場合
この場合、「大きな数の掛け算のコストが無視できない」という事実が重要になります。$x^n$ は指数関数ですので n が大きくなると $x^n$ は非常に大きくなります。そのため、一時的に $x^n$ そのものを求めるx ** n % mは常に m 未満の数の掛け算をするpow(x, n, m)に比べて計算コストが大きくなります。これらをまとめると
- n が小さく loop が大きい場合は割り算と関数呼び出しのコストが支配的になり
pow()の方が**より遅くなる- n が大きく loop が小さい場合は大きな数の掛け算のコストが支配的になり
**の方がpow()より遅くなる- n と loop が共に大きい場合はこれらのせめぎ合いになるが、$x^n$ が指数関数だということをふまえると概ね
**の方がpow()より遅くなるというように2章の結果を説明できます。
3.7. まとめ
**とpow()は共にlong_powという関数につながっていて、long_powは繰り返し二乗法を用いて実装されています。
**とpow()の実行速度を比較するポイントは
- あまりをとらない場合は「関数呼び出しのオーバーヘッド」
- あまりをとる場合は加えて「割り算」と「大きな数の掛け算」
でこれらのコストのうちどれが支配的になるかを考えることによって判断できます。
4. おわりに
実用性はあまりなさそうな内容ですが、Pythonについて理解が深まったのでよかったです。
説明の間違いやバグ等ありましたらお知らせください。
- 投稿日:2020-11-29T20:25:50+09:00
Fusion 360にCSVから点をインポートする
Autodesk Fusion 360にはいつもお世話になっています. (教育機関ライセンス無料なので)
別途生成した座標データを含むCSVがあり, それを点としてインポートする方法がわからなかったのでメモを残します.
自分の用途的に, 同一平面内の点のインポートがスコープです.課題
Fusionにビルトインであるスクリプト(ImportSplineCSV.py)はCSVの座標をスプラインとしてインポートするもの > 余計なことをせずに点がいい
目的
Pythonスクリプトで, CSVに含まれる座標を点としてxy平面のスケッチにインポートする
入力するCSV
CSVの書式はカンマ区切りで, 1行に1つの点のx,y,z座標をいれる. (zは全て0)
input.csv1.5,3.6,0 8.4,2.8,0 3.4,6.1,0スクリプト
フローとしては, ダイアログで指定したCSVファイルに対して, カンマ区切りをばらして座標を抽出し, ポイントとしてスケッチに追加する, という作業を各行に対して行います.
下記コードを.pyファイルに記入し, 適当な場所に配置します.
(自分の場合はC:\Users\USERNAME\AppData\Roaming\Autodesk\Autodesk Fusion 360\API\Scriptsあたり)あとはFusion 360を開き, 画面上部から
Tools > ADD-INS > Scripts and Ad-Ins...と進み, My Scripts欄のプラスボタンを押してファイルを保存したディレクトリを指定すればOKです.
ディレクトリ追加直後にはスクリプトが反映されず, ウィンドウを閉じたり開いたりしていたら表示されるようになりました.ImportCSVPoints.pyimport adsk.core, adsk.fusion, traceback import io def run(context): ui = None try: app = adsk.core.Application.get() ui = app.userInterface product = app.activeProduct design = adsk.fusion.Design.cast(product) title = 'Import points from csv' if not design: ui.messageBox('No active Fusion design', title) return dlg = ui.createFileDialog() dlg.title = 'Open CSV File' dlg.filter = 'Comma Separated Values (*.csv);;All Files (*.*)' if dlg.showOpen() != adsk.core.DialogResults.DialogOK : return filename = dlg.filename with io.open(filename, 'r', encoding='utf-8-sig') as f: root = design.rootComponent sketch = root.sketches.add(root.xYConstructionPlane) line = f.readline() data = [] while line: pntStrArr = line.split(',') for pntStr in pntStrArr: try: data.append(float(pntStr)) except: break if len(data) >= 3 : sketchPoints = sketch.sketchPoints point = adsk.core.Point3D.create(data[0], data[1], data[2]) sketchPoint = sketchPoints.add(point) line = f.readline() data.clear() except: if ui: ui.messageBox('Failed:\n{}'.format(traceback.format_exc()))※未検証なのでわかりませんが… スケッチにxy平面を指定しているので, z座標に何か数字が入ったら動かないかもしれません. あるいは3次元スケッチになるのかな…? あまり使いこなせていないのでよくわかってないです.
検証された方がいればコメントにてご教授ください.余談
このスクリプトですが, 個数にして700弱の点をインポートするのに使っていますが, 問題なく動いています.
同様の方法で
SketchCirclesメソッドを使ってCSVから丸をインポートしようとしましたが, 200ぐらいに数を減らしてもFusionがフリーズしてしまい使い物になりませんでした.
ここを見る限り一般的な問題のようで, 回避するにはスケッチを分けるといいようです.私の用途としてはインポートした座標を元にバルクに穴を開けたいだけだったので, 円としてインポートしなくても穴径は指定できたのと, スケッチを分けると後工程が面倒になると思ったので思い切って点としてインポートしました.
- 投稿日:2020-11-29T19:39:10+09:00
OpenCVでベジェ曲線で遊ぶ ~異空間を操る~
はじめに
葉っぱや唇のようになだらかな山の曲線を描きたいと思った。ガウス関数(正規分布のアレ)も悪くはないが、両端をまっすぐにしたい。そう考えて思いついたのがベジェ曲線だった。
ベジェ曲線
matplotlibでグラフを描く
ベジェ曲線そのものを勉強したいわけではないので、基本的な部分は先人のプログラムを流用させていただく。
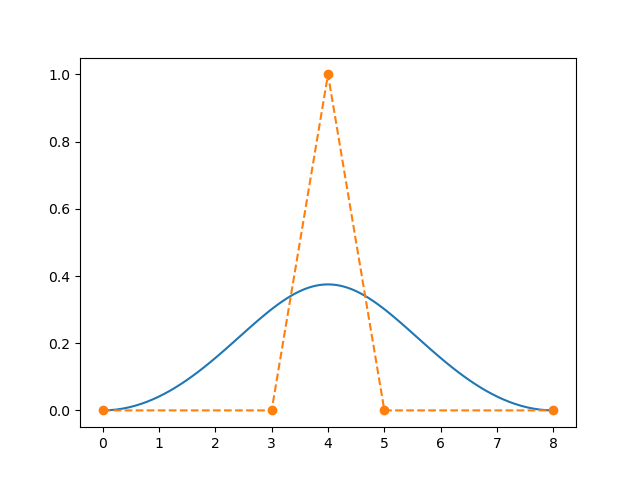
Pythonでベジエ曲線を描く(TadaoYamaokaの日記)bezier_matplotlib.py#import scipy.misc as scm # 元サイトのこのインポートは古い from scipy.special import comb # 現在はこのcombを使う import numpy as np import matplotlib.pyplot as plt def bernstein(n, i, t): return comb(n, i) * t**i * (1 - t)**(n-i) # 元サイトから修正 scm.comb -> comb def bezier(n, t, q): p = np.zeros(2) for i in range(n + 1): p += bernstein(n, i, t) * q[i] return p # 当然、制御点は改変している q = np.array([[0, 0], [3, 0], [4, 1],[5, 0], [8, 0]], dtype=np.float) list = [] for t in np.linspace(0, 1, 100): list.append(bezier(len(q)-1, t, q)) # 元サイトから改良 3を決め打ち -> 制御点の数に従う P = np.array(list) plt.plot(P.T[0], P.T[1]) plt.plot(q.T[0], q.T[1], '--o') plt.show()
両端が水平の山形を作ることができた。線分の両端(0番目と4番目)が決まったら1番目と3番目の制御点を線分上で適当に決めてやれば、自由なのはただ一つ2番目だけとなる。OpenCVで自由に描く
GUIでxy平面上に自由にこの曲線を描けるようにする。
せっかく細かい計算をしているのにOpenCVにすると整数上の話になってしまうのが残念なところではあるが。
マウスイベントについてはこちらを参照のこと。bezier_opencv.pyfrom scipy.special import comb import numpy as np import cv2 def bernstein(n, i, t): return comb(n, i) * t**i * (1 - t)**(n-i) def bezier(n, t, pts): p = np.zeros(2) for i in range(n + 1): p += bernstein(n, i, t) * pts[i] return p def MouseEvent(event, x, y, flag, params): global pts, cnt, clicking # 左クリックの挙動 if event == cv2.EVENT_LBUTTONDOWN: if cnt == 0: # 最初の点を決める cnt += 1 pts[0] = (x,y) elif cnt == 1 and (x,y) is not pts[0]: # 線分を確定すると同時に制御点も決める cnt += 1 pts[4] = (x,y) pts[1] = pts[0]*0.7 + pts[4]*0.3 pts[2] = pts[0]*0.5 + pts[4]*0.5 pts[3] = pts[0]*0.3 + pts[4]*0.7 draw_bezier(pts) else: # 線分が確定したらドラッグモード clicking = True # 左ボタンから手を離す if event == cv2.EVENT_LBUTTONUP: clicking = False # 左クリック(ドラッグ)中はその座標を中央の制御点とする if clicking: pts[2] = (x, y) draw_bezier(pts) # 右クリックでベジェ曲線をリセットする if event == cv2.EVENT_RBUTTONDOWN: pts[2] = pts[0]*0.5 + pts[1]*0.5 draw_bezier(pts) def draw_bezier(pts): img = img1.copy() curve1 = [] for t in np.linspace(0, 1, 50): curve1.append(bezier(4, t, pts)) curve = np.array(curve1, np.int32) cv2.polylines(img, [curve], False, (255,0,0), thickness = 5) cv2.imshow(winname, img) winname = "kupa" img1 = np.full((240,320,3), (0,128,128), np.uint8) pts = np.zeros((5, 2), dtype=np.float32) cnt = 0 clicking = False cv2.imshow(winname, img1) cv2.setMouseCallback(winname, MouseEvent) cv2.waitKey(0) cv2.destroyAllWindows()
葉っぱ曲線
幾何の問題
話は変わるが、高校数学で「直線に対して対称な点の座標を求める」という問題がよくあった。だが、そのほとんどは直線や点の座標が具体的に明記されており、汎用化された式を目にすることはなかった。
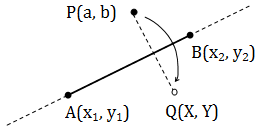
そこで頑張って解いてみた。
答えは、X = (2x_1-a) - 2(x_1-x_2)t \\ Y = (2y_1-b) - 2(y_1-y_2)t \\ ここで t = \frac{(x_1-x_2)(x_1-a) + (y_1-y_2)(y_1-b)}{(x_1-x_2)^2+(y_1-y_2)^2}\\だ。これから頑張ってtを消すと複雑かつ美しい式が現れるが、数学の問題ではなくプログラムとして実装していく話なのでこの形で十分だろう。それにしてもここまで複雑な式になるとは思わなかった。道理で高校数学の問題としては出てこないわけだ。
葉っぱ曲線を実装する
ソースは略。あとで完成形を紹介します。
応用
閉曲線の内部を別画像にすればいろいろ面白いことができる。
葉っぱとか唇とか書いたが実は私が想定していたのは八雲紫だった。スキマ妖怪に限らずとも空間に生じた裂け目と考えれば、そこから地獄が顔をのぞかせていたり宇宙とつながっていたり巨大な目玉がこちらを睨みつけていたりと様々な妄想をカタチにすることができる。必要とあらば(?)「くぱぁ」も可能だ。ここでは単一の画像で簡単に実装できるそこそこエモい例として、閉曲線の中は色を反転させるようにした。遊んでいるうちに魔空空間とかポドリアルスペースとかいろいろ懐かしい言葉が思い浮かんできて涙が止まらなくなった。
ソース
kupa.pyfrom scipy.special import comb import numpy as np import cv2 def bernstein(n, i, t): # bezier_opencv.pyと同 def bezier(n, t, pts): # bezier_opencv.pyと同 def MouseEvent(event, x, y, flag, params): # bezier_opencv.pyと同 def get_symmetry_points(pts): x1, y1 = pts[0] x2, y2 = pts[4] a, b = pts[2] t = ((x1-x2)*(x1-a)+(y1-y2)*(y1-b))/((x1-x2)**2+(y1-y2)**2) X = (2*x1-a)-2*(x1-x2)*t Y = (2*y1-b)-2*(y1-y2)*t q = pts.copy() q[2] = (X, Y) return q def draw_inner_kupa(img1, img2): # 元画像に(0,0,0)という色があるとおかしくなる img1 = np.where(img1==(0,0,0), img2, img1) return img1 def draw_bezier(pts): # ptsと両端の線分で対象な点を持つ座標群を作る # ptsと対称だからといってqtsという変数名は我ながらどうかと思う qts = get_symmetry_points(pts) # ptsおよびqtsを制御点とするベジェ曲線を作る curve1, curve2 = [], [] for t in np.linspace(0, 1, 50): curve1.append(bezier(4, t, pts)) curve2.append(bezier(4, t, qts)) # curve2の順序を逆にし、curve1とcurve2を連結して閉曲線とする curve = np.concatenate((curve1, curve2[::-1]), axis =0) curve = np.array(curve, np.int32) img = img1.copy() cv2.fillPoly(img, [curve], (0,0,0)) img = draw_inner_kupa(img, img2) cv2.imshow(winname, img) winname = "kupa" filename = "hoge.jpg" img1 = cv2.imread(filename) img2 = 255 - img1 pts = np.zeros((5, 2), dtype=np.float32) cnt = 0 clicking = False cv2.imshow(winname, img1) cv2.setMouseCallback(winname, MouseEvent) cv2.waitKey(0) cv2.destroyAllWindows()実行結果
元画像は新宿の高層ビルの写真素材(ぱくたそ)。いろいろなサイトで使われてるな、この画像。
終わりに
「ギャバンやウィングマンを例に出してるけどそういう演出なら○○のほうが適切ですよ」といったマサカリ、お待ちしています。



- 投稿日:2020-11-29T19:01:57+09:00
Jupyter Notebook を日本語で書き出す
この記事は jupyter notebook を 日本語を含む pdf に書き出す方法についてのものです.
環境
version OS macOS Big Sur 11.0.1 (Catalina でも動作確認済) jupyter notebook 6.1.4 jupyter nbconvert 6.0.7 jupyter nbextensions 6.1.4 texlive 2020 (2017 でも動作確認済) pandoc 2.11 nbconvert をインストールする
conda や pip を使って nbconvert をインストールする.
詳しくは公式ページを参照.テンプレートを作る
デフォルトでは,notebook を pdf に書き出す際に日本語が埋め込まれない.
これは,.ipynb->.tex->
そのため, latex に変換する際に日本語用のテンプレートを用意する必要がある.以下のような jinja2 のテンプレートファイル (
.tex.j2多分拡張子はなんでも良い) を作る.名前はなんでもよいが,以下ではja_template.tex.j2とする.ja_template.tex.j2(texlive2020)((*- extends 'index.tex.j2' -*)) %=============================================================================== % Latex Article %=============================================================================== ((* block docclass *)) \documentclass[xelatex, ja=standard, 11pt]{bxjsarticle} ((* endblock docclass *))ja_template.tex.j2(texlive2017)((*- extends 'index.tex.j2' -*)) %=============================================================================== % Latex Article %=============================================================================== ((* block docclass *)) \documentclass[xelatex, 11pt]{bxjsarticle} \usepackage{zxjatype} \setjamainfont{ipaexm.ttf} \setjasansfont{ipaexg.ttf} \setjamonofont{ipaexg.ttf} ((* endblock docclass *))texlive 2017 の場合は, ja=standard だと
font-not-foundのエラーがでた.この場合上記のように対処するとうまくいく.詳しくはtexwikiを参照.※ 本当は docclass の block の中にフォントの設定を書くのはよろしくないと思いますが,うまく行ってしまったのでちゃんとしたやり方を調べていません...
テンプレートについて詳しく知りたい方は公式ページを参照してください.ファイルの保存場所カレントディレクトリや
~/.jupyter/などどこでもよい.ためしてみる
コマンドラインで以下を実行してうまくいくか確かめる.
--no-inputはコードを隠すオプションのためお好みで.jupyter nbconvert --to pdf --no-input --template-file path/to/ja_template.tex.j2 hoge.ipynbワンクリックで pdf 化できるようにする
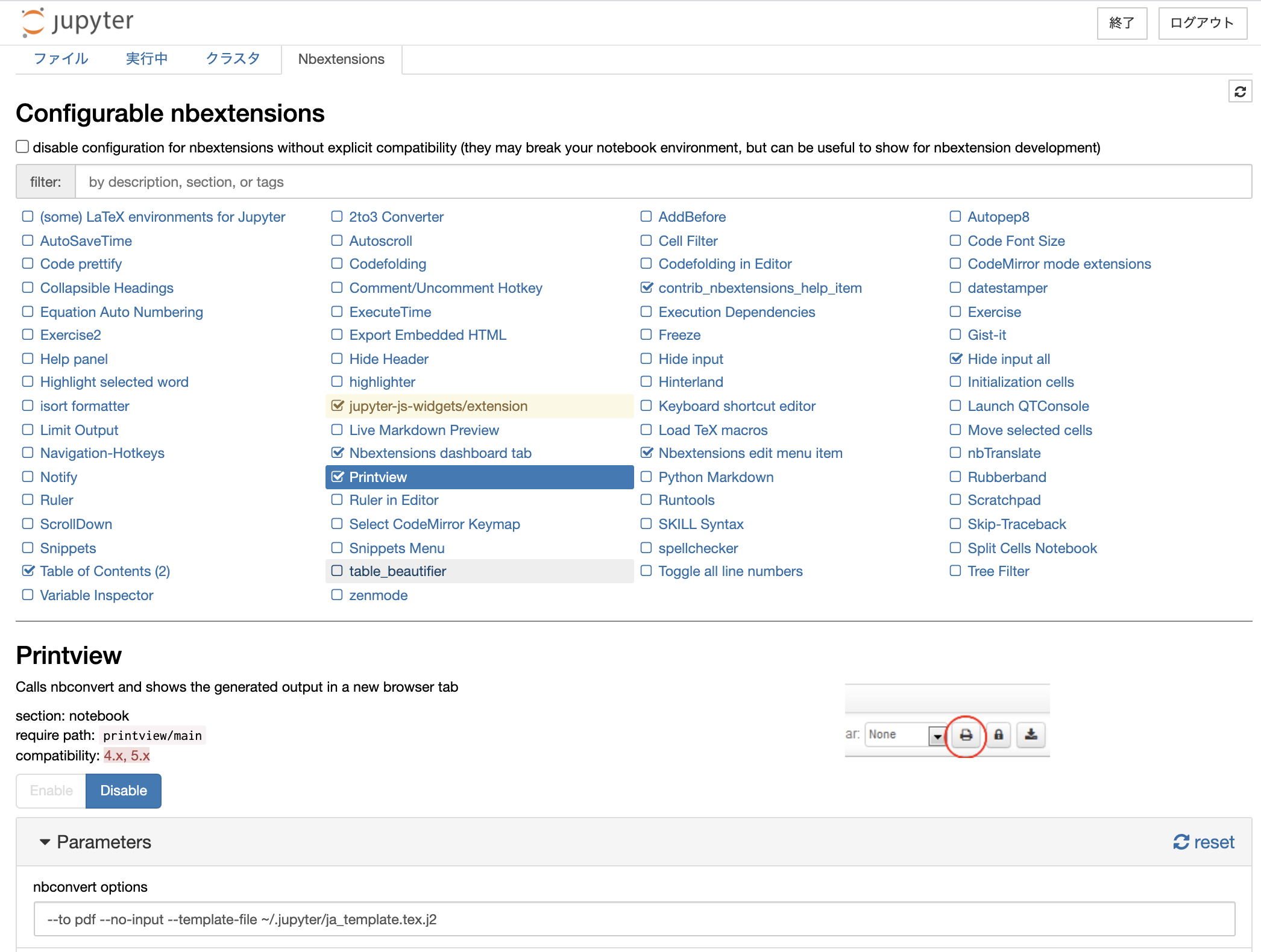
まず nbextensions を入れる.詳しくは公式ページを参照.
jupyter を開き,Nbextensions の設定画面を開く.
Printview を有効にし,nbconvert options に以下を入力する.--to pdf --no-input --template-file path/to/ja_template.tex.j2
あとは pdf 化したい notebook を開いた状態で,プリントマークをクリックしたら OK.
- 投稿日:2020-11-29T18:35:05+09:00
kaggleがんばる帳
目的:kaggle学習中に得た新しい知識を記録、再利用
内容:kaggleやプログラミングの知識
備考:はじめのうちは無秩序にメモを保存していく。数が増えてきたら整理したい【notebookで自作モジュールを扱う】
実行中ipynbファイルがあるフォルダか、pip,condaなどのインストールフォルダにimportしたいパッケージがない場合、sysでパスを通してあげる。
import sys
sys.path.append('/Users/~~~')【EDAはじめにやること】
・train,testにデータをいれる
・'.shape'で要素数、カラム数を確認
・'.dtypes'で各カラムの型を確認
・'.head()'でdfの内容をざっと確認
・目的変数に対し'.describe()'で統計量確認
・目的変数に対し'.plot.hist()'で分布を確認【
- 投稿日:2020-11-29T18:31:06+09:00
今日の積み上げ python 学習記録#3
本日の学習 9:00~12:00 15:00~18:30
昨日に引き続きprogate 有料版 python編をしています。
午前中に最後まで行ったのでもう一周しています。progateを何周もするのは良くないと聞きますが 関数、クラス、継承 などVBAでやらなかったところは、理解が怪しいので2周と言わず3周するかも。
時間がなければ飛ばしたほうが良いのだろうが昨日youtubeでシリコンバレーのエンジニアさんが基礎だけでも3か月はかかるみたいなこと言ってたので安心してじっくり取り掛かりたいと思う。ただ寝てても書けるような事はしないつもりです。
短期的な目標としてはスクレイピングをして作りたいツールがあるのだけど、先日買ったudemyのスクレイピングの講座でHTML、CSSがわからない人はprogateで勉強しろみたいな事書いてたので遠回りになりますがタイミングみてさくっと勉強してみようと思います。
やること多すぎますが楽しんでやってるので良しとしましょう!!
- 投稿日:2020-11-29T18:20:51+09:00
小テスト前なので、嫁に一問一答させてみた。(5分クオリティ)
一日の半分をパソコンの前で過ごす生活を一週間続けていたら、両手が腱鞘炎になりました。
はじめに
生化学の小テスト前!
対策問題を見返してみたけど、『DNA』しかわからない!
(あすぱらぎん酸...?めちおにん????おいしい??)勉強しなきゃ。。。。
うぅぅ。PC依存症すぎて、手がキーボードから離れない。。。
いや、待てよ。てきとーにPythonで一問一答作ったら、勉強した気になれるだろ!
???「今回の小テスト、割とまじで終了だねwww」今回したかったこと
・友達がQiitaデビュー&初投稿していて、なんでもいいから久しぶりにQiitaに投稿したかった。
・嫁(MacBook)に問題を出してもらいたかった。
・今後も使える一問一答ツールを作りたかった。
???「今回の小テストはマジでそんなことしてる場合じゃない」→毎回の小テストの度に関数を追加したら、最強の一問一答ツールに(?)!
嫁(MacBook)「GitHub使って、クラスのみんなで問題を作れば毎回のテストで勉強できるね!」
そんな目標・モチベを持って、第1回目の関数を記録しておきました。
今回の作成関数:
「順不同の用語を答える問題。すべて正しければ正解とする。」一問一答ツールプロジェクト第1回目
QandA.pydef gudge(inp, ans): inp_list = inp.split("、") if len(inp_list) != len(ans): print("不正解。(回答数が足りません。)\n答え:") print(ans) else: for i in range(len(ans)-1): if ans[i] in inp_list: print("正解:", ans[i]) inp_list.remove(ans[i]) else: print("不正解。\n答え:") print(ans) break print("正解") return def question(que, num, ans): print(que) num_tsu = str(num) + "つ:" inp = input(num_tsu) gudge(inp, ans) return def q_ex1(): que = "中性アミド酸。5つの中分類に分けられる。\n( )アミノ酸、( )アミノ酸、( )アミノ酸、( )、( )の5つである。" num = 5 ans = ["イミノ酸","芳香族","含硫","酸アミド","脂肪族"] question(que, num, ans) if __name__ == "__main__": q_ex1():まとめ
???「ふつうにプリントで勉強しろ。」
(『一問一答ツールプロジェクト』第2回目は未定です。だれか作ってください。)
Result
作業 時間 コーディング 5分 デバック 5分 Qiita 50分 合計 60分
俺の一時間返して。(泣)
- 投稿日:2020-11-29T18:16:12+09:00
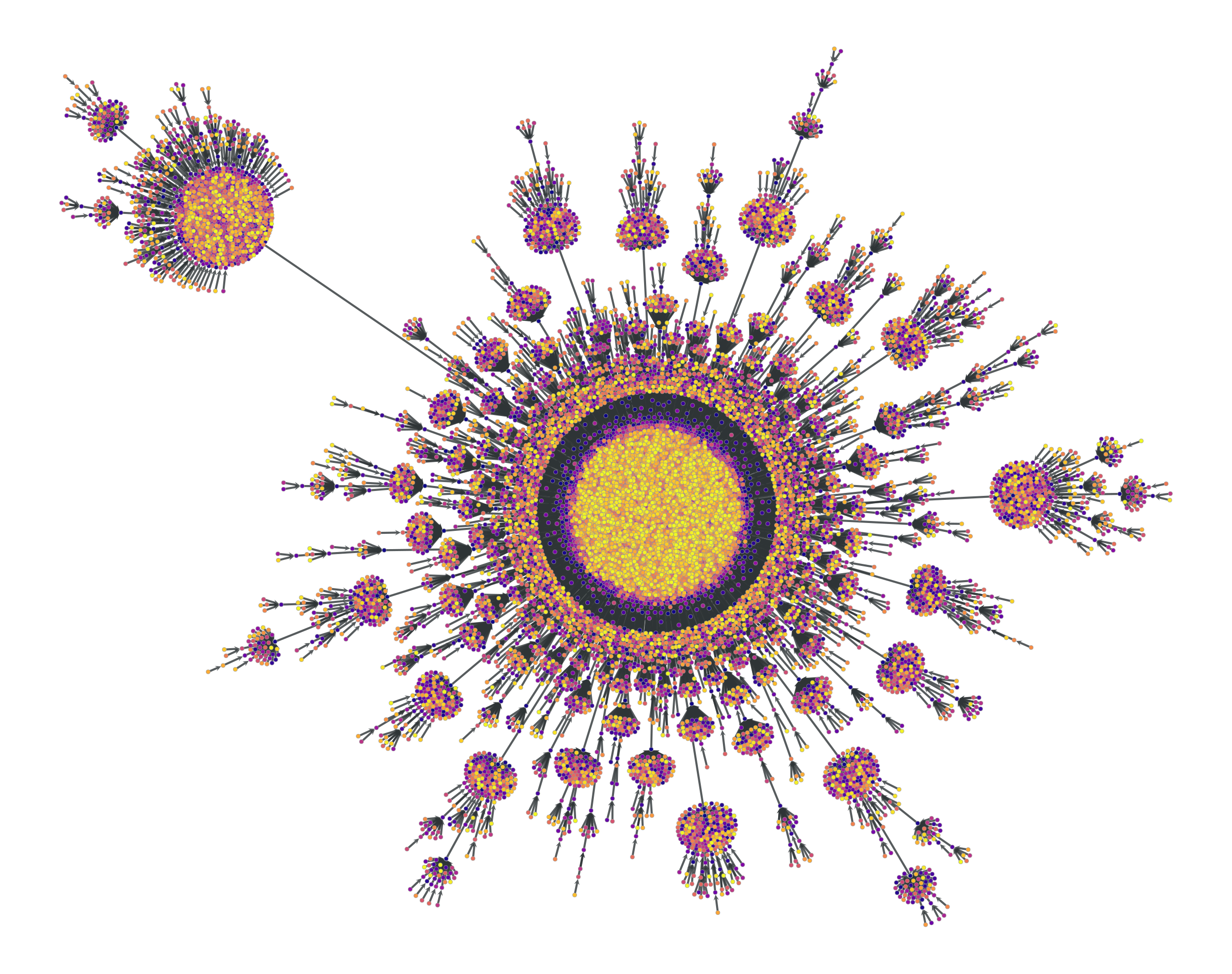
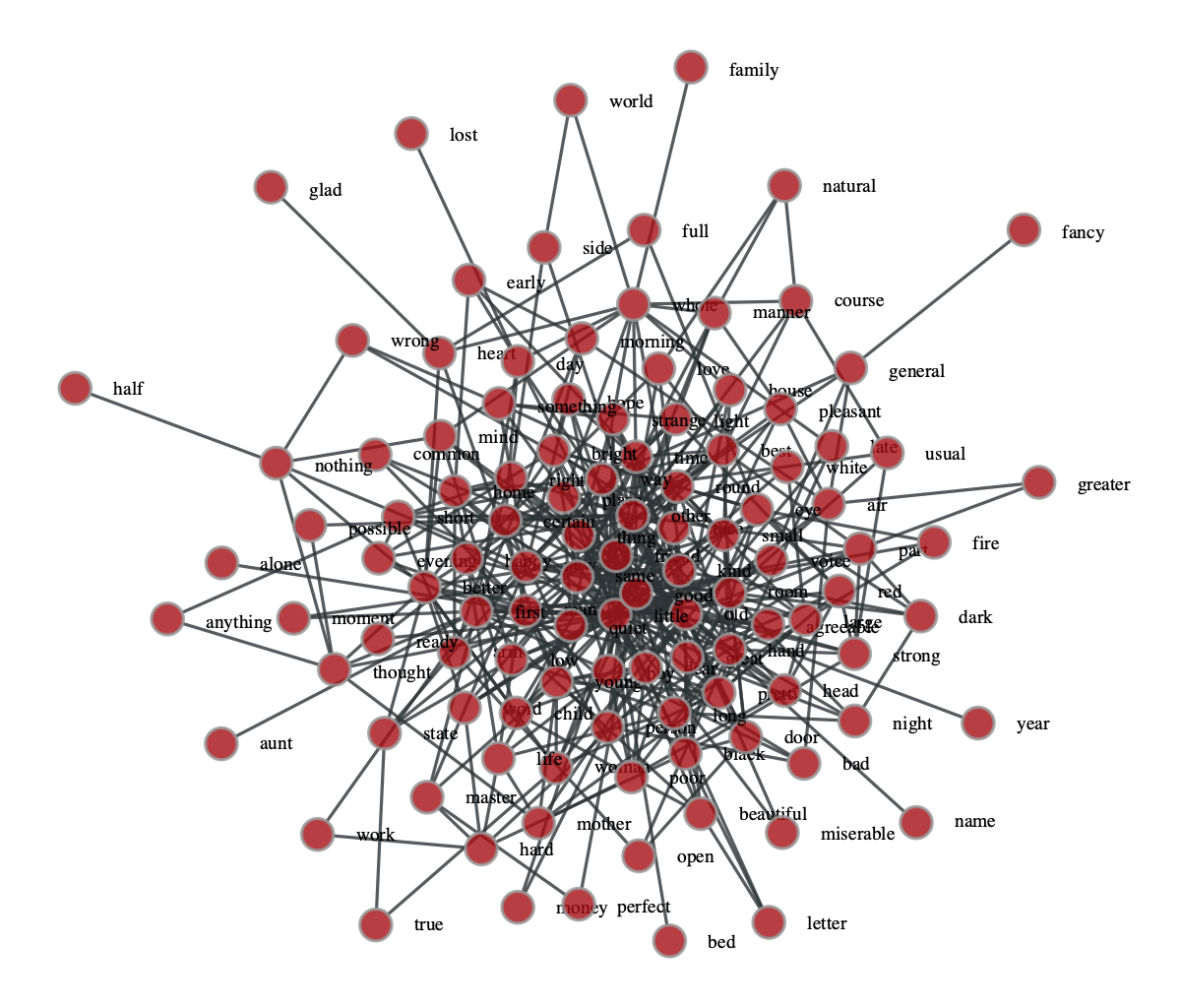
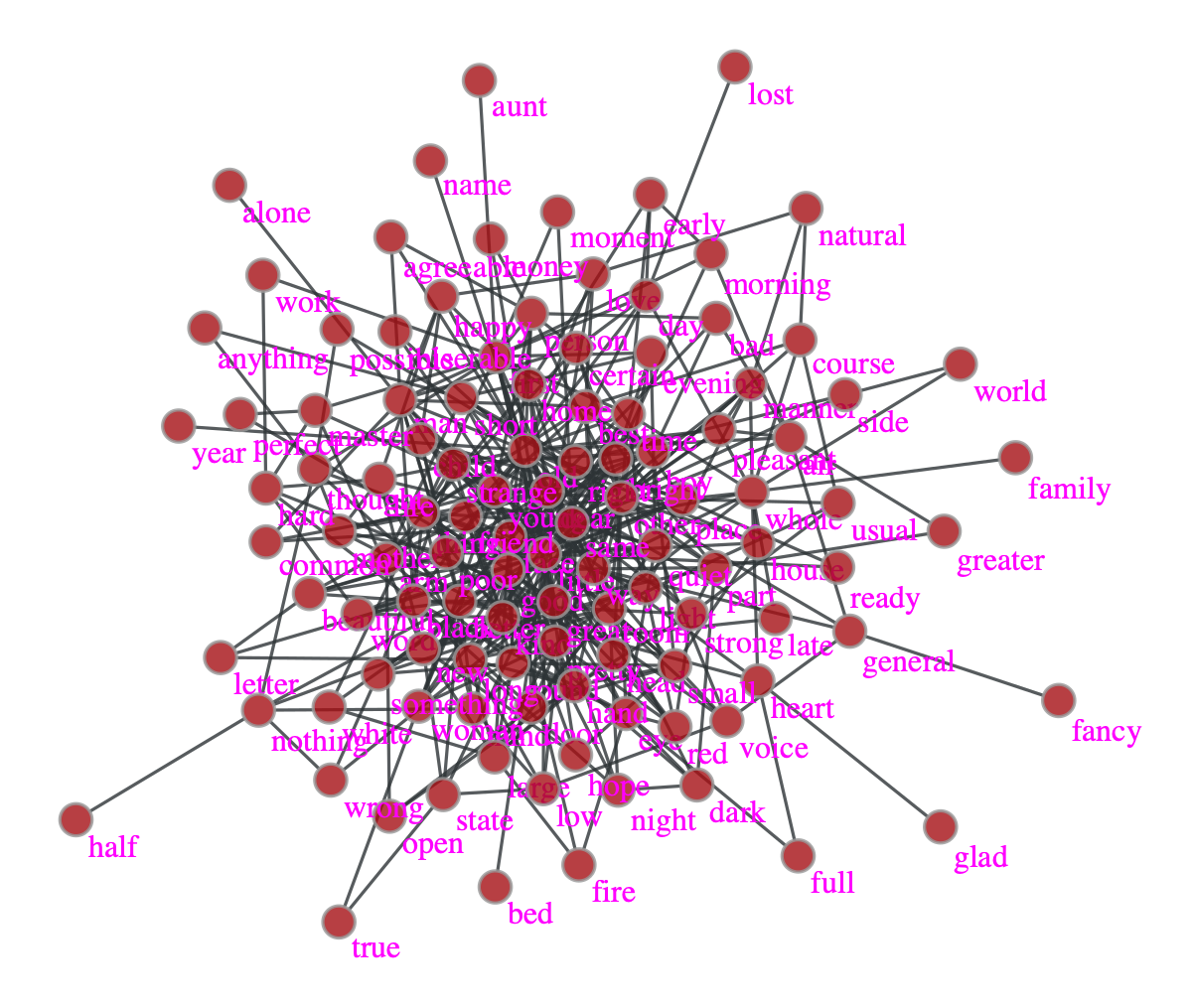
graph-tool チートシート(可視化編)
はじめに
グラフの可視化のツールは様々なものがあるが、graph-toolはその中でも最も強力といっても過言ではないだろう。
いろいろな可視化の方法が実装されているだけでなく、OpenMP化したC++で実装されているのでかなり大きなネットワークでも描画することができる。
例えばこのような可視化ができる。( https://graph-tool.skewed.de/ より )
ここではgraph-toolを用いた可視化について典型的な処理をまとめていく。
reference
https://graph-tool.skewed.de/static/doc/draw.html
動作環境
動作確認環境は以下の通り
- python 3.9.0
- graph-tool 2.35
- numpy, matplotlib
以後のサンプルコードでは、前提条件として以下のモジュールをimportしている。
import graph_tool.all as gt import numpy as np import matplotlib.pyplot as pltまたサンプルデータとして以下のものを用いる。(ある小説における名詞と形容詞の隣接関係から構築したネットワーク)
g = gt.collection.data['adjnoun']Jupyter notebookで実行するかターミナルから実行するか
graph-toolで可視化するコードを実行する場合、jupyter notebookで実行するかターミナルで実行するかに依存して若干挙動が異なる。
可視化するスクリプトをjupyterから実行した場合、ノートブック内にインラインで表示される。
一方でスクリプトをターミナルから実行した場合、interactiveなGUI windowに描画される。ノードをマウスでドラッグ&ドロップして動かしたり、選択したノードとそのエッジをハイライトしたりできる。用途に応じて使い分けたい。
コード
とりあえず描画する
gt.graph_drawメソッドを呼べば良いgt.graph_draw( g )
ファイル出力する
outputオプションにファイル名を指定する。拡張子に応じてフォーマットを決めてくれる。
pdf, svg, png, jpgなど様々な形式に対応している。gt.graph_draw(g, output = 'graph.pdf')pngなどのラスタ形式の画像で画像の大きさを変えたい場合は、
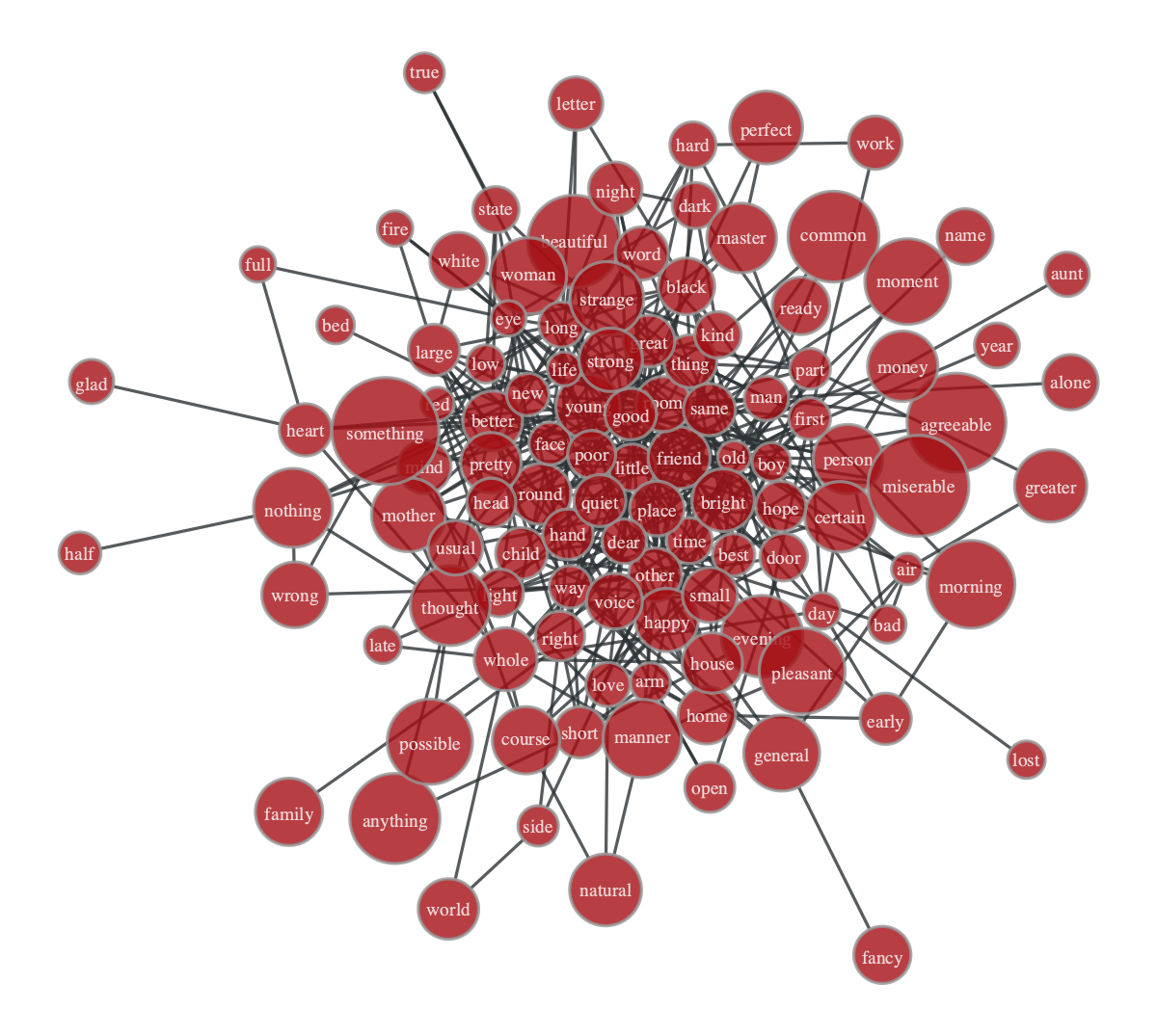
output_sizeオプションを指定するgt.graph_draw(g, output = 'graph.png', output_size=(1000,1000))ノードにラベルを表示する
VertexPropertyで指定する文字列を表示するには
vertex_textオプションを指定する。gt.graph_draw(g, vertex_text = g.vp.label)
ノードの外側に表示したいときは
vertex_text_position = 0を指定する。gt.graph_draw(g, vertex_text = g.vp.label, vertex_text_position = 0)
その他、オプションをいじることでテキストの色やフォントなど細かく調整できる。
gt.graph_draw(g, vertex_text = g.vp.label, vertex_text_position = 0, vertex_font_size = 16, vertex_text_offset = [-1,1], vertex_text_color=(255,0,255,255))
レイアウトを変更する
graph-toolには様々なlayoutアルゴリズムが用意されている。まずレイアウトを計算し、得られた位置情報を
graph_drawの引数に渡す。pos = gt.radial_tree_layout(g, 0) gt.graph_draw(g, pos = pos)
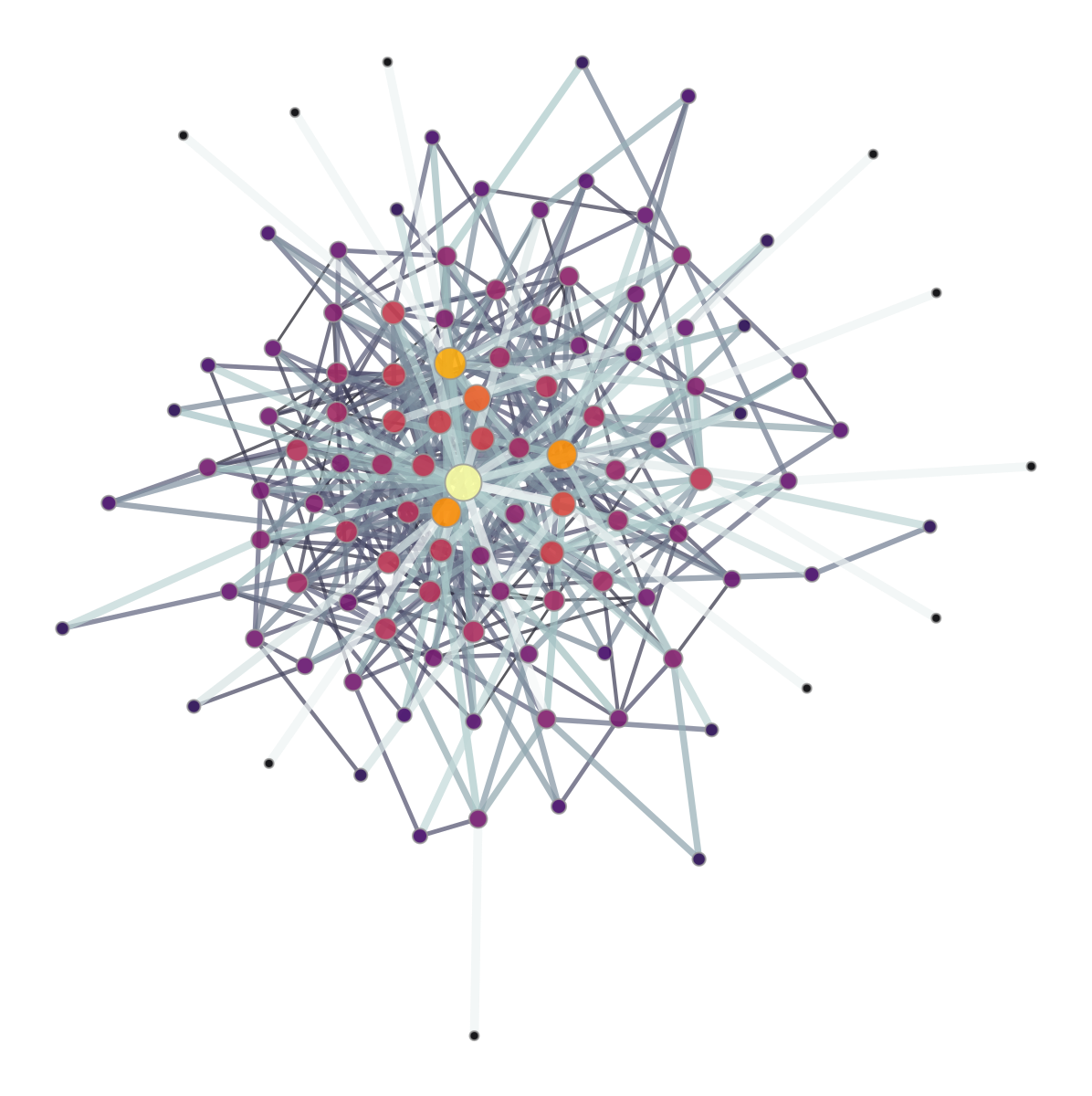
ノードやエッジの見た目を次数などの統計量に応じて変更する
ノードやエッジのサイズや色を次数や他のネットワーク統計量に応じて変更することができる。
例えば、次数に応じてノードの大きさを変更するには以下のようにする。deg = g.degree_property_map("total") gt.graph_draw(g, vertex_size = deg)スケールをうまく調整するには
gt.prop_to_sizeメソッドを使うと良い。指定した最小値、最大値になるように適切にスケーリングしてくれる。logスケールにすることもできる。gt.graph_draw(g, vertex_size = gt.prop_to_size(deg,mi=5,ma=20,log=False) )
工夫すれば他にも幅や色味など色々と変更できる。
deg = g.degree_property_map("total") ebet = gt.betweenness(g)[1] # edge betweeness gt.graph_draw(g, vertex_size=gt.prop_to_size(deg,mi=5,ma=20,log=False), vertex_fill_color=gt.prop_to_size(deg,log=False), vcmap=(matplotlib.cm.inferno, .9), vorder=deg, edge_color=gt.prop_to_size(ebet), eorder=ebet, edge_pen_width=gt.prop_to_size(ebet,mi=1,ma=5,log=False), ecmap=(matplotlib.cm.bone, .7) )




- 投稿日:2020-11-29T18:15:41+09:00
SVRで学習モデルを作って遺伝的アルゴリズム(Platypus)で最適解を求めてみた
最適解で何を求めたいか?
みんな大好きBostonの家の価格のデータセットがありますよね。このデータセットを使って、最適解を求めたいと思いました。
カラム 説明 CRIM 犯罪率 ZN 住宅の密集度 INDUS 非小売業の割合 CHAS チャーリーズ川ダミー変数(川の周辺1、それ以外0) NOX 酸化窒素濃度 RM 1住戸あたりの平均部屋数 AGE 1940年以前に建設された物件割合 DIS 5つのボストンの雇用センターまでの距離 RAD 大きな道路へのアクセス距離 TAX 10,000ドルあたりの税率 PTRATIO 教師あたりの生徒数 B 町における黒人の割合 LSTAT 人口当たり給料の低い率 MEDV 住宅の中央値 例えば、家の価格(MEDV)が安くて、部屋の数(RM)が多いところに住みたいよね。部屋数が多くて価格が安いのが皆さんうれしいですよね。この最適解モデルができれば、SUUMOとかホームメイトとか、賃貸業者に売れるかもしれません。
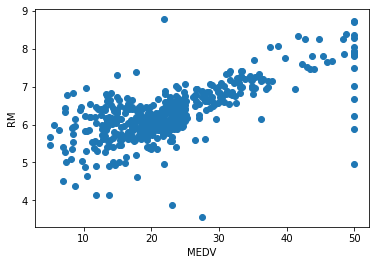
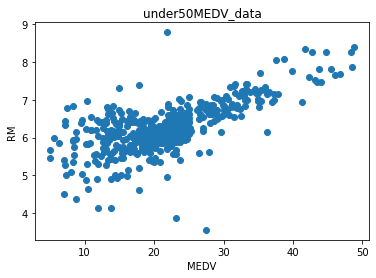
とりあえずボストンのデータセットをもとに、遺伝的アルゴリズムでパレート最適解を求めてみよう。特徴量と目的変数、データの可視化
目的変数が、(MEDV,RM)で、それ以外を特徴量にしました。
その特徴量で、それぞれ目的変数として、サポートベクター回帰を使いMEDVとRMの学習モデルを作りました。モデル1として、家の価格(MEDV)の予測モデルを作ります。
特徴量 目的変数 CRIM,ZN,INDUS,CHAS,,NOX,AGE,DIS,RAD,TAX,PTRATIO,B,LSTAT MEDV モデル2として部屋の数(RM)の予測モデルを作ります。
特徴量 目的変数 CRIM,ZN,INDUS,CHAS,NOX,AGE,DIS,RAD,TAX,PTRATIO,B,LSTAT ,RM まず家の価格と部屋の数は結構相関があるんですよね。だから、これをお互いのモデルを作るときに、特徴量からはずすと、精度があがらないような気がします。
後、見てわかるように、家の価格の50のところにグラフの上ではデータが縦に並んでいます。そこで、家の価格50以上は除きました。
SVRでの予測で価格と部屋の数の予測結果
まずSVRで学習モデルを作りましたが。。。
ここのアルゴリズムは何でもよくて、サポートベクターでもランダムフォレストでもお好きなもので。
サポートベクターのハイパーパラメーターは、optunaで決定しました。学習モデル1は、
optimised_svr_MEDVに、学習モデル2は、optimised_svr_RMに入れました。予測結果はこういう感じです。
MEDVの学習精度:0.873
MEDVのテスト精度:0.748
RMの精度:0.628
RMの精度:0.439確かに家の価格は、部屋数がなくても、他の要因で説明できそうです。
でも、部屋の数は、犯罪率や大きな道路へのアクセスとか、関係あるとは思えません。予想通り、精度はあがりませんでした。
まぁ仕方がないので、このまま遺伝的アルゴリズム(GA)にかけようと思います。NSGAⅡでの価格と部屋のパレート最適解
ここまできて、ふと思った。部屋の数とか整数のはずなのに、
dtypesで型を見てみるとfloat型になっている。
とりあえず今回は全部float型で計算をした。
アルゴリズムはNSGAⅡで、遺伝子は1000個、10000回繰り返して計算した。#ライブラリーのインポート from platypus import NSGAII, Problem, Real #遺伝子による変数の設定と学習モデル(目的関数)による予測結果 def objective(vars): crim = vars[0] zn = vars[1] indus = vars[2] chas = vars[3] nox = vars[4] age = vars[5] dis = vars[6] rad = vars[7] tax = vars[8] ptratio = vars[9] bb = vars[10] lstat = vars[11] ga_data = [[crim,zn,indus,chas,nox,age,dis,rad,tax,ptratio,bb,lstat]] #遺伝子を標準化 ga_data_std = scaler.transform(ga_data) #学習モデルによる予測 ga_MEDV_np = optimised_svr_MEDV.predict(ga_data_std) ga_RM_np = optimised_svr_RM.predict(ga_data_std) ga_MEDV = ga_MEDV_np[0] ga_RM = ga_RM_np[0] return [ga_MEDV,ga_RM] #Platypus遺伝的アルゴリズムの設定 #変数が12個、目的関数が2個 problem = Problem(12, 2) #変数の設定。すべて実数Realとした。また、最大値最小値は、元データの最大値と最小値にした。 problem.types[:] = [Real(0.006, 88.976),Real(0.00, 100.00),Real(0.740, 27.740),Real(0.00,1.00),Real(0.385, 0.871),Real(2.9000, 100.00), Real(1.137, 12.126),Real(1.00, 24.00),Real(187.00, 711.00),Real(12.60, 22.00),Real(0.32, 396.90), Real(1.980, 37.90)] problem.function = objective #価格を最小に、部屋数を最大にする。 problem.directions[:] = [Problem.MINIMIZE, Problem.MAXIMIZE] algorithm = NSGAII(problem,population_size=1000) algorithm.run(10000)計算結果は、後で処理しやすいように
pandasで保存します。空のデータフレームを作って、そこにalgorithm.resultのvariablesの中に変数(遺伝子)が、objectivesに結果が入っていますので、それを空のpandasに取り込んでから、保存しました。ga_result = pd.DataFrame(columns=['CRIM','ZN','INDUS','CHAS','NOX','AGE','DIS','RAD','TAX','PTRATIO','B','LSTAT','MEDV','RM']) for i in range(len(algorithm.result)): ga_result.loc[i] = algorithm.result[i].variables[:] + algorithm.result[i].objectives[:] ga_result.to_csv("ga_result.csv")部屋の数と家の価格のパレート最適解は
青いプロットが元のデータ。赤のプロットが遺伝的アルゴリズムが計算した結果です。
これを見るとほかの条件を気にしなければ、部屋数が6で価格が10くらいの家が、部屋が多くて家族が多くなっても暮らしやすくて価格が安いということになりますね。
元のデータだと、単純な相関のように見えるけど、遺伝的アルゴリズム的には、変曲点が見えているようです。
草薙素子チックにつぶやくと。。。
「そうささやくのよ、わたしの遺伝子が。。。」3カ月くらいplatypusいじってます。マニュアルがあっさり書いてあるので、初心者の私にはだいぶ難しいのですが、とりあえずここまでできました。

- 投稿日:2020-11-29T18:12:17+09:00
低い解像度の衛星画像から車を検出できるのか?
【注意】本記事は適宜更新します.
概要
衛星画像には30cmの高分解能のものから,Copernicusで無料で提供されている10mの中分解能のものと,解像度がそれぞれ異なります.高い解像度のものを使いたいのですが,高価なため入手するのは難しいです.でも,目的によってはそれほどの解像度は不要なのではと考え,車を検出することをターゲット として実験しました.
(credit: Cars Overhead With Context (COWC))ここで用いたコードは近々整理し,Githubにてシェアします.
1. 衛星画像の分解能と物体検知のレベルについて.
衛星画像でどこまで見えるのか?例えば,報告されているものに以下があります.
(credit: FAS, Intelligence Resource Program)
ここでは,10cm分解能であれば一つ一つの車がわかり,25cm分解能で車の区別は可能,50cm分解能では車種まではわからず,1m分解能になると車とはわかるけども,車種までわからない,と報告されています.
これは20年以上前の評価であり,このときの”見える,見えない”は,人が”見える,見えない”が判断基準であり,人によっては見え方も異なり,統一されていません.また,現在であれば衛星画像から人が判読するよりも,機械に自動で判読させるほうが,品質および処理速度を考えると望ましい(当たり前?)であると思います.
では,どこまで見えるのだろう?,ということで実験してみます.1.1 衛星画像の分解能について
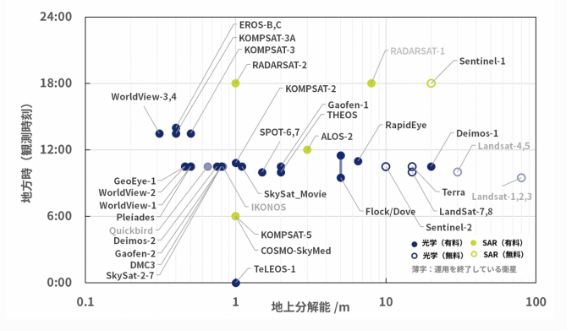
衛星画像の分解能については,以下の宙畑さんの記事がよくまとめられていますので,ご参考にしてください.
人工衛星から人は見える?~衛星別、地上分解能・地方時まとめ~
(クレジット:宙畑)
この図から,一番高い分解能が30cm(WorldView-3,4)であることがわかります.縦軸は地方時といって,観測時刻と思ってください.(この図のみ横軸のスケールが記載されていたので用いました.)
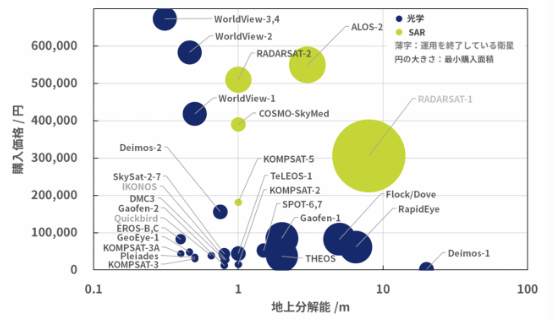
また,高い分解能の衛星画像は非常に高価になります.
(クレジット:宙畑)
高い分解能の画像ほどきれいな画像なのでほしいのですが,目的によってはそこまでの分解能の画像は必要ないかもしれません.価格を低く抑えられるのであれば,より広範囲や異なる時期の多数の画像を入手できますね.1.2 航空写真による車検知について.
下記の記事で紹介しましたが,航空写真より車の検出精度を競うプログラムに, Cars Overhead With Context (COWC)があります.
PyTorchによる人工衛星画像から車の推定分布地図を作成してみる.
ここでは,4カ国・6都市の航空写真(15cm分解能)の画像が提供されており,それぞれ一般自動車(トラックや重機は含まれません)の中心位置と間違うかもしれない物体の位置のアノテーションデータがセットで提供されています.
今回の評価ではこのデータ・セットを用いました.まずは,15cmの分解能の画像より得られた車の検出率を基準として,画像をResizeすることで擬似的に分解能を落とし,その検出精度がどのようになるのか調べます.
こちらにこのデータセットを用いた論文が紹介されていますが,極めて高い精度で検出できることが報告されています.興味のある方は,ご参考にしてください.1.3 物体検知モデル
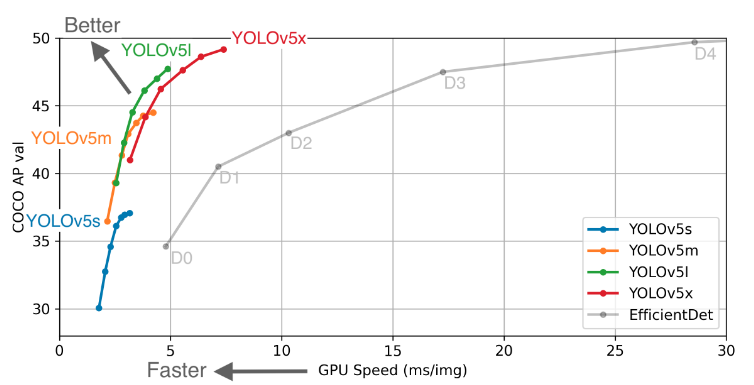
物体検知(Object Detection)としては,有名なSSDやその他各種の手法があります.今回は,最近リリースされたYOLO v5 を用いました.
Yolo(You Only Look Once)は有名なので多くの方がご存知かと思いますが,画像や動画より物体の位置と種類を検出する機械学習アルゴリズムです.そのVersion5が今年の春にリリースされました.(過去のYoloの開発者と異なるため,これをv5と言ってもよいのか,議論されているみたいです.)
(credit:YOLO v5)このアルゴリズムの精度評価が掲載されています.
動画での高い精度の適用が考えられており,他のモデル(Efficient Det)と比べて高い精度で速く検知できるかが特徴になります.
今回は,航空写真や衛星画像は静止画像ですので,一番精度の高いYOLOv5xを用いることとしました.2.異なる解像度の航空写真・衛星画像から車を検出してみる.
2.1 環境構築(YOLOv5を準備する.).
YOLOv5のサイトより以下のコマンドでモデルをダウンロードします.(私はYOLOv5の仮想環境を構築し,その環境で使用しています.)
git clone https://github.com/ultralytics/yolov5.git次に,yolov5を動作させるために,必要なモジュールを下記のコマンドより準備します.
pip install -r requirements.txtこちらのコマンドにより,以下のモジュールがインストールされます.
Cython matplotlib>=3.2.2 numpy>=1.18.5 opencv-python>=4.1.2 Pillow PyYAML>=5.3 scipy>=1.4.1 tensorboard>=2.2 torch>=1.6.0 torchvision>=0.7.0 tqdm>=4.41.0これでYolov5が利用できる環境が整いました.ここからは,動作を確認するために,jupyter labで実行します.
次に,今回は画像分類で有名なcocoのパラメータをベースとしたFine tuningを行います.そのため,必要なWeightsをダウンロードします.以下のサイトから必要なWeightsをダウンロードし,YOLOv5に置きます.これでYolov5を用いる環境が構築できましたので,次に学習データである航空写真データを取得します.
2.2 COWCより学習データの取得,およびデータの前処理.
1.1項で述べたように,航空写真およびそのアノテーションデータ(車と非車の位置情報)をCOWCのサイトよりダウロードします.サイトの下部にダウンロード方法がいくつか紹介されていますが,私はhttpよりファイル(cowc-everything.txz)を選びダウンロードしました.
ダウンロードしたファイルは圧縮されていますので,解凍して以下のファイルを確認します.
ディレクトリ名は都市名になっており,そこに航空写真(png)とその画像のアノテーションデータ(車(annotated_cars)と非車(annotated_negatives)のpng)があります.
航空写真は学習時のimage sizeに分割し,アノテーション画像からはYOLOv5に用いるための位置情報のtxtを作成します.その手順を紹介します.
はじめに使用するモジュールを宣言します.import os import shutil import numpy as np from PIL import Image import matplotlib.pyplot as plt import numpy as np import cv2 import pandas as pd Image.MAX_IMAGE_PIXELS = 1000000000次に,都市名のディレクトリ構成を確認します.
dir_path = "../cowc/" dirs =os.listdir(dir_path) dirs出力が以下となります.
['Toronto_ISPRS', 'Potsdam_ISPRS', 'Vaihingen_ISPRS', 'Utah_AGRC', 'Columbus_CSUAV_AFRL', 'Selwyn_LINZ',]'Vaihingen_ISPRS'と 'Columbus_CSUAV_AFRL'はモノクロ画像でしたので,今回の対象から省きました.
では, Toronto_ISPRSのファイルを確認し,航空写真の確認,リサイズによる衛星画像のシミュレーション,アノテーション画像よりYOLOv5を実行するための位置情報のtxtファイルを作成します.dirs_image = dirs[0] image_path = dir_path + dirs_image image_files =os.listdir(image_path) image_filesこちらを実行することで,ディレクトリ内のファイル情報を取得します.出力結果がこちらとなります.
['03553.png', '03553_Annotated.xcf', '03553_Annotated_Cars.png', '03559_Annotated_Cars.png', '03559_Annotated_Negatives.png', '03559.png', '03747_Annotated_Negatives.png', 'README.ISPRS.txt', '03747.png', '03747_Annotated.xcf', '03559_Annotated.xcf', '03553_Annotated_Negatives.png', '03747_Annotated_Cars.png']これより,都市の航空写真とそのファイルと同じ名前と車の位置情報画像(Annotated_Cars)と非車の位置情報画像(Annotated_Negatives)で構成されているのがわかります.まず,航空写真のファイルのみを選択します.
#RGB画像のみのファイルリストを作成する. file_name =[] for i in image_files: if 'Annotated'in i: #print(i) pass else: if 'png' in i: file_name.append(i) else: pass file_name上記を実行すると,以下のファイルであることがわかります.
['03553.png', '03559.png', '03747.png']では,03553.pngの航空写真を確認します.
file_image_name = file_name[0] #opencvで画像のよみこみ im = cv2.imread(dir_path + dirs_image +'/'+ file_image_name) print(im.shape) print(file_image_name) im_rgb = cv2.cvtColor(im, cv2.COLOR_BGR2RGB) plt.imshow(im_rgb)
カナダの都市トロントの都市域の航空写真です.一部を拡大してみます.
plt.imshow(im_rgb[0:500,100:1500])
車が多数写っているのがわかります.では,この画像を512x512の画像サイズに分割します.このとき,航空写真から衛星画像の分解能の異なる模擬画像を作成するため分解能を設定します.ここでは,現在の画像サイズの1/2や1/4とすることで,その解像度を低下させます.
#分解能に合わせて,リサイズの分母を決める. #分解能30cmだと2,60cmで4,90cmで6となる. rs = 1 #1, 2, 4, 6im=Image.open(dir_path + dirs_image +'/'+ file_image_name) img_resize = im.resize((im.size[0]//rs, im.size[1]//rs)) #ここで解像度をリサイズして変更している. print(file_image_name) file_name = os.path.splitext(os.path.basename(file_image_name))[0] print(file_name) DIR_OUTPUTS = '../cowc/crop_image' height = 512 width = 512 img_size_v = img_resize.size[1] img_size_h = img_resize.size[0] #画像の分割処理関数 def ImgSplit(im): # 読み込んだ画像を256*256のサイズで144枚に分割する buff = [] # 縦の分割枚数 for v1 in range(int(img_size_v/height)): # 横の分割枚数 for h1 in range(int(img_size_h/width)): h2 = h1 * width v2 = v1 * height #print(w2, h2, width + w2, height + h2) c = im.crop((h2, v2, width + h2, height + v2)) buff.append(c) return buff #画像の分割処理の実行 hi=0 for ig in ImgSplit(img_resize): hi=hi+1 #print(hi) # 保存先フォルダの指定 ig_jpeg = ig.convert('RGB') ig_jpeg.save(DIR_OUTPUTS + "/" + str(file_name) + '_' + str(hi) + ".jpg") #yolo v5にはpngはNG?このとき,2行目のresize関数にて画像の分解能をシミュレートします.後半でResizeした画像を512で分割し,DIR_OUTPUTS に保存します.
次に,アノテーション画像を同様の処理を行います.im=Image.open(dir_path + dirs_image +'/'+ file_name + '_Annotated_Cars.png') img_resize = im.resize((im.size[0]//rs, im.size[1]//rs)) #ここで解像度をリサイズして変更している. print(file_name + '_Annotated_Cars.png') print(file_name) DIR_OUTPUTS_p = '../cowc/crop_annotated' height = 512 width = 512 img_size_v = img_resize.size[1] img_size_h = img_resize.size[0] #画像の分割処理関数 def ImgSplit(im): # 読み込んだ画像を256*256のサイズで144枚に分割する buff = [] # 縦の分割枚数 for v1 in range(int(img_size_v/height)): # 横の分割枚数 for h1 in range(int(img_size_h/width)): h2 = h1 * width v2 = v1 * height c = im.crop((h2, v2, width + h2, height + v2)) buff.append(c) return buff #画像の分割処理の実行 hi=0 for ig in ImgSplit(img_resize): hi=hi+1 # 保存先フォルダの指定 ig.save(DIR_OUTPUTS_p + "/" + str(file_name) + '_' + str(hi) + ".png")この処理を行うことによって,車のアノテーション画像がリサイズされ512サイズに分割されます.同じく,非車のアノテーション画像も同様の処理を行います.
im=Image.open(dir_path + dirs_image +'/'+ file_name + '_Annotated_Negatives.png') img_resize = im.resize((im.size[0]//rs, im.size[1]//rs)) #ここで解像度をリサイズして変更している. print(file_name + '_Annotated_Negatives.png') print(file_name) DIR_OUTPUTS_n = '../cowc/crop_annotated_negatives' height = 512 width = 512 img_size_v = img_resize.size[1] img_size_h = img_resize.size[0] #画像の分割処理関数 def ImgSplit(im): # 読み込んだ画像を256*256のサイズで144枚に分割する buff = [] # 縦の分割枚数 for v1 in range(int(img_size_v/height)): # 横の分割枚数 for h1 in range(int(img_size_h/width)): h2 = h1 * width v2 = v1 * height c = im.crop((h2, v2, width + h2, height + v2)) buff.append(c) return buff #画像の分割処理の実行 hi=0 for ig in ImgSplit(img_resize): hi=hi+1 # 保存先フォルダの指定 ig.save(DIR_OUTPUTS_n + "/" + str(file_name) + '_' + str(hi) + ".png")アノテーション画像は分割後にそれぞれ,'../cowc/crop_annotated'と'../cowc/crop_annotated_negatives'に保存されます.
次に,分割したアノテーション画像から,車および非車位置のtxtデータを作成します.このtxtデータは,Yoloのフォーマットにあわせて作成します.
YOLOのアノテーション情報(txt)は以下のフォーマットとなります.# class x_center y_center width height #Classは車であれば0,非車は1に,x-center, y-centerは対象の中心位置,widthとheightは対象物体の周囲枠(Box)のサイズとなります.
このサイズは,ここでは20ピクセル(300cm)としました.車の縦幅より小さいですが,狭い間隔で駐車している車も識別したいため,まずはこの値としました.解像度を変えた場合,このピクセル値も300cmにあわせてみましたが,それよりも20ピクセルのまま(解像度によってBox値を変えた)場合のほうがPrecisionが高かったため,20ピクセルで固定しました.ここは,解像度によってパラメータを最適化する部分ですね.
今回は,512サイズで統一しましたので,それぞれを512で割って規格化しました.
では,アノテーション画像よりYOLOに用いるアノテーションファイルを作成します.DIR_OUTPUTS_labels = '../cowc/crop_label' for i in range(len(os.listdir(DIR_OUTPUTS))): crop_file_name_jpg = os.path.splitext(os.path.basename(crop_file_name[i]))[0] im = cv2.imread(DIR_OUTPUTS_p + '/' + crop_file_name_jpg +'.png') im_rgb = cv2.cvtColor(im, cv2.COLOR_BGR2GRAY) row, cow = np.where(im_rgb==76) arr = [] for ii in range(len(row)): arr.append([row[ii],cow[ii]]) arr = np.array(arr) if not len(arr) == 0: array_pd = pd.DataFrame(arr) array_ppd = array_pd.copy() array_pd[0] = array_ppd[1]/512 array_pd[1] = array_ppd[0]/512 array_pd[2] = 20/512 array_pd[3] = 20/512 array_pd.insert(0,'car',0) else: array_pd = pd.DataFrame() im = cv2.imread(DIR_OUTPUTS_n + '/' + crop_file_name_jpg +'.png') im_rgb = cv2.cvtColor(im, cv2.COLOR_BGR2GRAY) row, cow = np.where(im_rgb==29) arr = [] for ii in range(len(row)): arr.append([row[ii],cow[ii]]) arr = np.array(arr) if not len(arr) == 0: array_nd = pd.DataFrame(arr) array_nnd = array_nd.copy() array_nd[0] = array_nnd[1]/512 array_nd[1] = array_nnd[0]/512 array_nd[2] = 20/512 array_nd[3] = 20/512 array_nd.insert(0,'car',1) else: array_nd = pd.DataFrame() array_all = [] array_all = pd.concat([array_pd, array_nd]) text_name = crop_file_name_jpg array_all.to_csv(DIR_OUTPUTS_labels + '/' + text_name + '.txt', sep=' ', index=False, header=False)アノテーションファイルは以下に'../cowc/crop_label'保存されます.
例えば,以下となります.0 0.966796875 0.248046875 0.0390625 0.0390625 0 0.896484375 0.26953125 0.0390625 0.0390625 0 0.82421875 0.291015625 0.0390625 0.0390625 0 0.490234375 0.32421875 0.0390625 0.0390625 0 0.55859375 0.375 0.0390625 0.0390625 0 0.5625 0.375 0.0390625 0.0390625 0 0.470703125 0.408203125 0.0390625 0.0390625 0 0.3828125 0.43359375 0.0390625 0.0390625 0 0.037109375 0.45703125 0.0390625 0.0390625 0 0.29296875 0.4609375 0.0390625 0.0390625 0 0.0625 0.53515625 0.0390625 0.0390625 1 0.83984375 0.541015625 0.0390625 0.0390625 1 0.873046875 0.625 0.0390625 0.0390625 1 0.763671875 0.630859375 0.0390625 0.0390625 1 0.314453125 0.6484375 0.0390625 0.0390625 1 0.65625 0.666015625 0.0390625 0.0390625 1 0.75390625 0.8125 0.0390625 0.0390625 1 0.41796875 0.986328125 0.0390625 0.0390625この処理をそれぞれの都市で行い,Train用およびValidation用の画像とアノテーションファイルを準備します.このとき,Train用とValidation用のデータは分け,その割合は約7:3となります.
2.3 航空写真によるモデルの構築と検証.
YOLOv5のモデルは,githubのチュートリアルを参考に実行します.
はじめに必要なモジュールをインポートします.import torch from IPython.display import Image, clear_output # to display images clear_output() print('Setup complete. Using torch %s %s' % (torch.__version__, torch.cuda.get_device_properties(0) if torch.cuda.is_available() else 'CPU'))次に,学習結果を可視化するためにTensorboardを実行します.
# Start tensorboard %load_ext tensorboard %tensorboard --logdir runsここでTensorboardを実行状態すると,学習後にRecallやPrecisionなどの学習結果のグラフ化や異なる学習の比較を行うのに便利です.
そして,次のコマンドで学習を始めます.%cd ../yolov5 !python train.py --img 512 --batch 5 --epochs 100 --data ../cowc/data_resize_30cm.yaml --cfg models/yolov5x.yaml --nosave --cache --name cowc_test_15cm_ep100 --weights yolov5x.pt--img : 学習画像のサイズ
--bath :バッチサイズ
--epochs : エポック数
--data :train およびvalidationデータの場所とクラスの設定
--cfg :用いるモデルの設定
--name :学習名
--weights : fine tuningを行うときは,ここで設定します.詳細は,train.py --helpを実行すると,各パラメータの説明があるのでご参照ください.ここでは,データを示data.yamlについて説明します.
train: ../cowc/data_train val: ../cowc/data_val nc: 2 names: ['car', 'not_car']上記の通り,trainとvalのデータのアドレス,およびクラス数とその名前を設定しています.
trainとvalディレクトリにはimagesとlabelsのディレクトリがあり,imagesに画像ファイルが,labelsにアノテーションファイルが入っています.この画像とアノテーションファイルは同じファイル名(拡張子は異なる)である必要があります.ご注意ください.
Test用の画像およびモデルにて車検出後の画像の合成を行います.dir_path = "../cowc/" dirs =os.listdir(dir_path) dirs_image = dirs[0] #'Toronto_ISPRS' image_path = dir_path + dirs_image image_files =os.listdir(image_path) #RGB画像のみのファイルリストを作成する. file_name =[] for i in image_files: if 'Annotated'in i: #print(i) pass else: if 'png' in i: file_name.append(i) else: pass file_image_name = file_name[2] #'03747.png'まずは,Train用の画像準備と同じく対象となる画像を選択します.では,画像を確認します.
#opencvで画像のよみこみ im = cv2.imread(dir_path + dirs_image +'/'+ file_image_name) print(file_image_name) im_rgb = cv2.cvtColor(im, cv2.COLOR_BGR2RGB) #Image.fromarray(im_rgb).save('test.jpg') plt.imshow(im_rgb)
それでは,この画像を512サイズに分割してTest用の画像を準備します.方法はTrainと同じです.
DIR_OUTPUTS = '../cowc/test_512/images_resize/' im=Image.open(dir_path + dirs_image +'/'+ file_image_name) img_resize = im.resize((im.size[0]//1, im.size[1]//1)) print(file_image_name) file_name = os.path.splitext(os.path.basename(file_image_name))[0] print(file_name) height = 512 width = 512 img_size_v = img_resize.size[1] img_size_h = img_resize.size[0] #画像の分割処理関数 def ImgSplit(im): buff = [] # 縦の分割枚数 for v1 in range(int(img_size_v/height)): # 横の分割枚数 for h1 in range(int(img_size_h/width)): h2 = h1 * width v2 = v1 * height c = im.crop((h2, v2, width + h2, height + v2)) buff.append(c) return buff #画像の分割処理の実行 hi=0 for ig in ImgSplit(img_resize): hi=hi+1 # 保存先フォルダの指定 ig_jpeg = ig.convert('RGB') ig_jpeg.save(DIR_OUTPUTS + "/" + str(file_name) + '_' + str(hi) + ".jpg")その後,分割されたファイル数をx軸(width)とy軸(height)の数を確認します.
img_size_v = int(img_size_v/width) img_size_h = int(img_size_h/height)出力が以下となります.
img_size_v * img_size_h #308 img_size_v #14 img_size_h #22念の為,ファイル数も確認しておきます.
image_list = os.listdir(DIR_INPUTS) image_list_sort=natsorted(image_list) len(image_list_sort)出力
308これでTest用の画像が準備できました.次に,学習したモデルを用いてテスト画像から車を検出させます.ここでは,Trainに用いた画像ではなくValidationで準備した画像を用いました.
!python detect.py --weights runs/train/cowc_test_15cm_ep100/weights/last.pt --img 512 --conf 0.4 --source ../cowc/test_512/images_resize/ --save-txt --class 0 --name cowc_15cm--weights: train.pyの実行時に作成したWeightsを呼び出します.ファイル名は,train.pyを実行結果の下部に示されますのでご確認ください.
--img : テスト画像のファイルサイズ
--conf : テスト結果で車の有無を判断するためのしきい値
--source : テスト画像があるディレクトリのアドレス
--save-txt : 検出結果をtxtでも保存
-- class : 識別するクラスの指定.ここでは”0”としたため,車のみを検出します.
--name :検出結果の画像を保存するディレクトリ解析処理後,データを確認します.このとき,yolov5のdetect.pyをCloneしたまま用いると,検出された車のBoxやその確信度(信頼度,Confidence)が大きく表示されるため,車が密集しているところではその違いが分かり難いです.そのため,utilsディレクトリにあるplot.pyのファイルの解析結果を表示するBoxのライン幅や信頼度のfontサイズを変更しました.コードで提供されているため,自分の利用方法にあわせて変更されることをお薦めします.
では,処理されたTest画像を確認し,合成します.height = 512 #512 width = 512 #512 DIR_INPUTS = '../yolov5/runs/detect/cowc_15cmresize/'#detect のディレクトリを指定. DIR_OUTPUTS = '../cowc/test_512/build_picture/' #合成後の画像ファイルのアドレス image_list = os.listdir(DIR_INPUTS) image_list_sort=natsorted(image_list) max_height = width * img_size_v total_width = height * img_size_h new_im = Image.new("RGB", (int(total_width), int(max_height))) h = 0 w = 0 for i in range(img_size_v*img_size_h): new_im.paste(Image.open(DIR_INPUTS + "/"+ image_list_sort[i]), (w*width,h*height)) w = w +1 if img_size_h - w == 0: w = 0 h = h +1 new_im.save(DIR_OUTPUTS + 'test_15cm_resize.jpg')画像の合成後にファイルを確認します.
img = Image.open(DIR_OUTPUTS + 'test_90cm_resize.jpg') #画像をarrayに変換 im_list = np.asarray(img) #貼り付け plt.imshow(im_list) #表示 plt.show()
これで,航空写真(15cm分解能)のモデルの構築,およびそのモデルを用いた解析プロダクトが作成できました.画像を拡大して確認してみます.
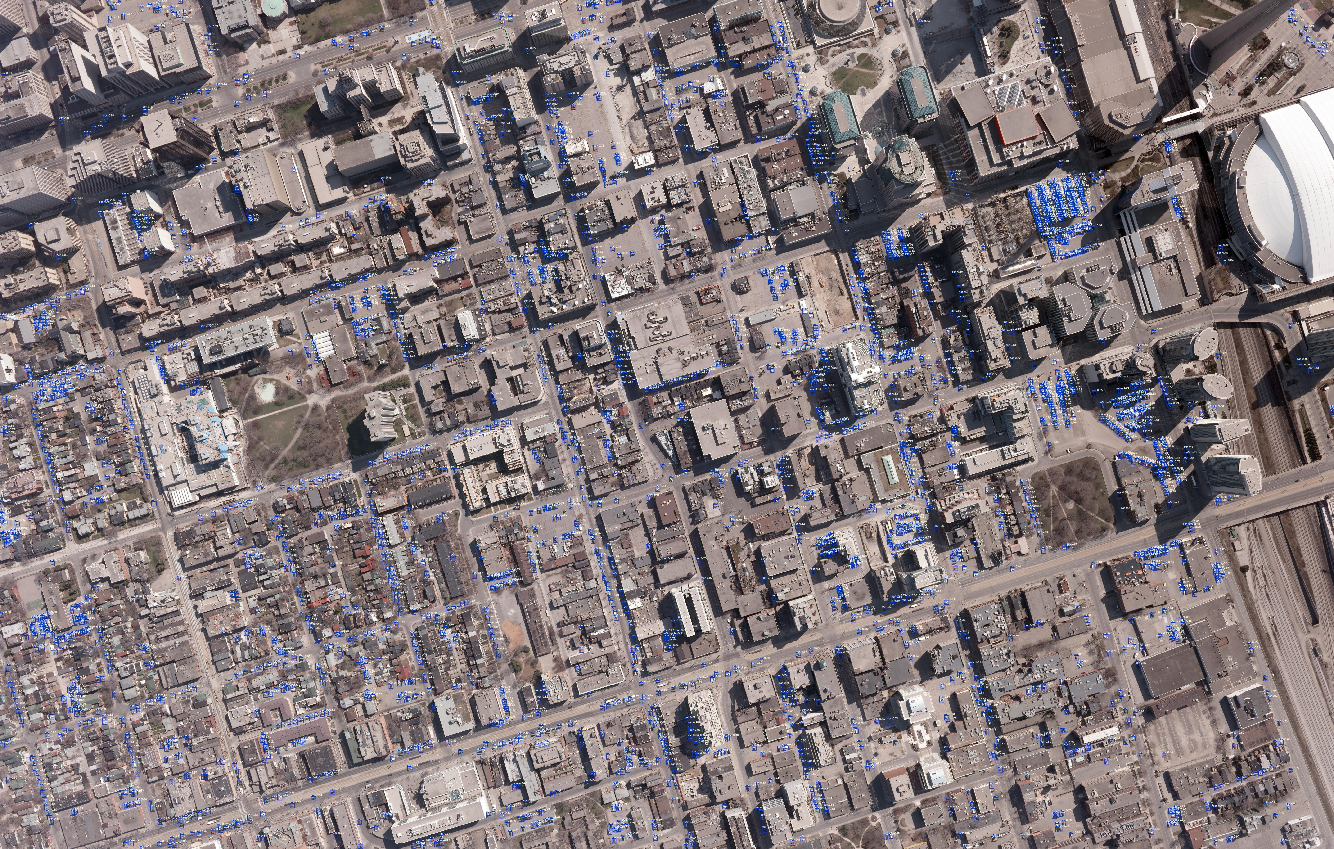
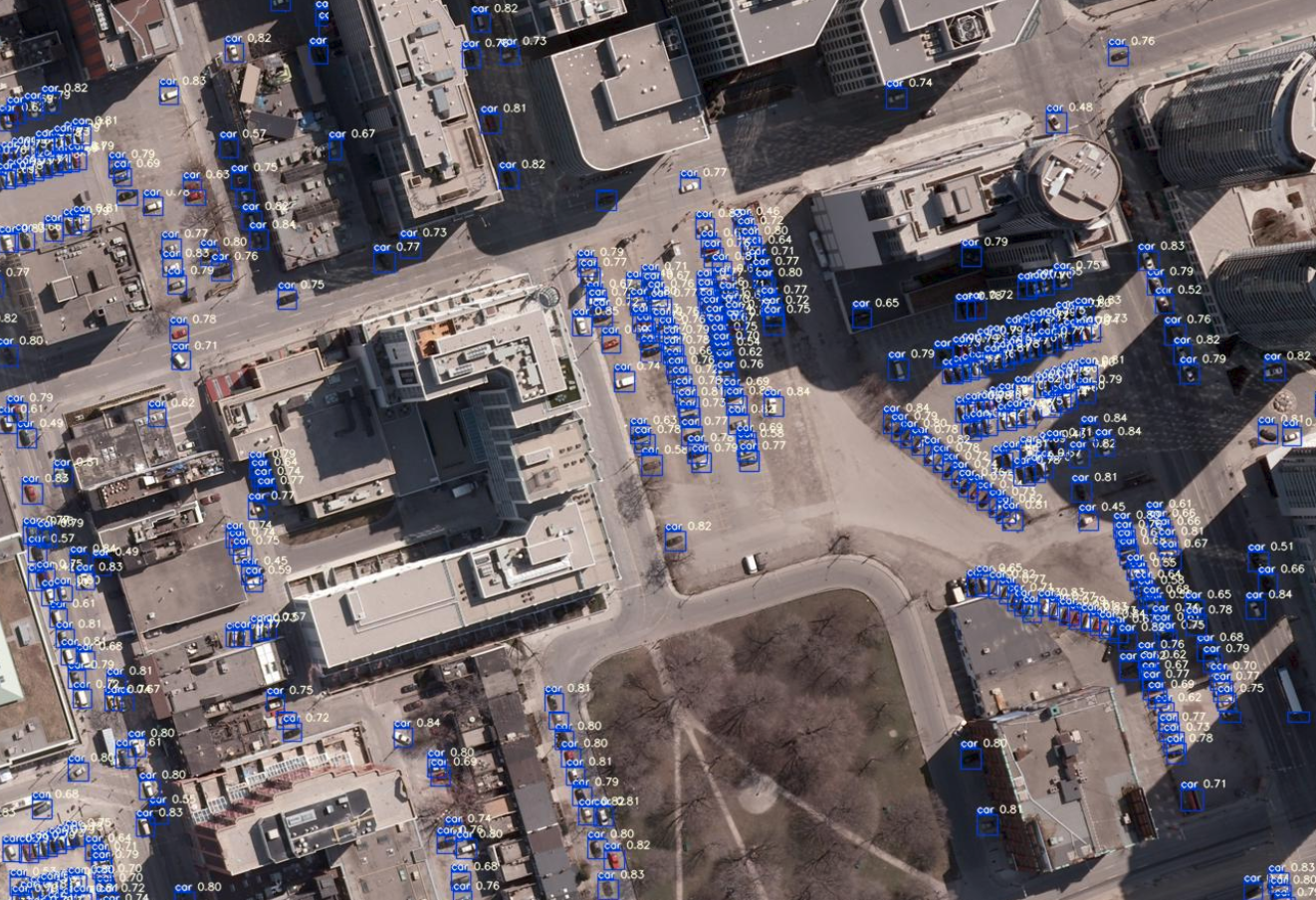
航空写真(15cm分解能)の解析により検出された車こちらの航空写真に写っているほぼすべての車が検知されており,その確信度は0.7以上と高い値となっています.
次に,航空写真をResizeすることで分解能を模擬的に低下させ,同様の処理を行い,結果にどのような違いとなるのか,評価してみます.2.4 異なる解像度の衛星画像と検知精度
コードは2.3項で用いたものと同じになります.ただし,模擬する分解能に合わせてrsの値を変えます.例えば,分解能が半分の30cmにするのであればrsを2にします.
#分解能に合わせて,リサイズの分母を決める. #分解能30cmだと2,60cmで4,90cmで6となる. rs = 1 #1, 2, 4, 6TrainデータおよびValデータが作成したのち,前項とおなじくdata.yamlにて対象とするデータのディレクトリを指定し,train.pyを実行します.そして,実行にて作成されたそれぞれのweightを指定して,Test画像(比較のために,すべて同じカナダ・トロントの画像(Validationで使用))に解析処理を行い車を推定します.
それでは,すべての処理画像を比較します.
模擬衛星画像(30cm分解能)の解析により検出された車
模擬衛星画像(60cm分解能)の解析により検出された車
模擬衛星画像(90cm分解能)の解析により検出された車Test画像のそれぞれの解像度における車の検出結果を比較すると,15cm分解能と比べても,他の解像度でも多くは検出できているように見えます.それぞれの結果を比較してみます.
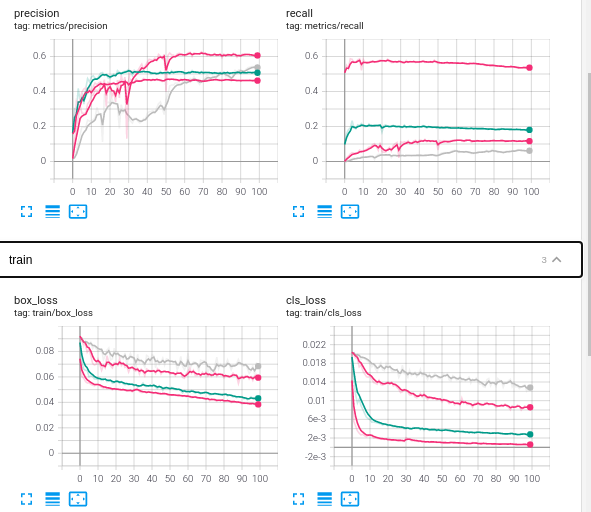
こちらは,Tesorboardの結果の一部になります.ValidationデータのPrecisionをみると,解像度に変わらずほぼ同じ値になっています.一方,Recallをみると,解像度が15cm(濃い赤)が一番高いですが,ほかは大きく低下しています.これから,解像度に依存せず車と推定されたものは多くは正解となりますが,解像度が低下すると取りこぼしが多いことが予想されます.
ただ,Trainデータのロス(Class loss)をみるとかなり低い値をとっており,解像度が90cmであっても学習量を100エポックより大きくすることで,より低下することが期待できます.
Trainの結果は保存されているため,それより比較してみます.run_dir = "../yolov5/runs/train/" train_dirs =os.listdir(run_dir ) train_dirs.sort() train_dirs上記を実行すると,それぞれの学習結果が保存されているのがわかります.
['.ipynb_checkpoints', 'cowc_test_15cm_ep100', 'cowc_test_30cmresize_ep100', 'cowc_test_60cmresize_ep100', 'cowc_test_90cmresize_ep100']では,15cmの解像度の画像の学習結果を見てみます.
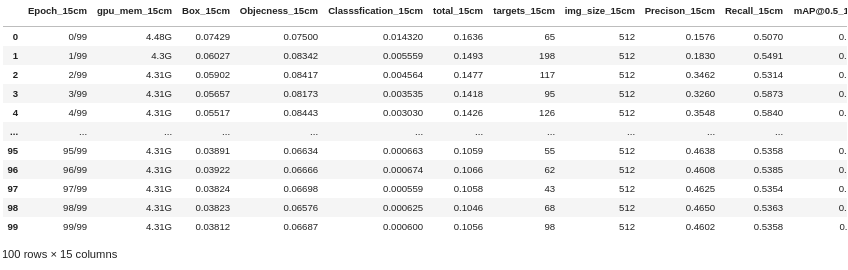
df_15= pd.read_table(run_dir +train_dir + '/results.txt', header=None, delim_whitespace=True) columns = ['Epoch','gpu_mem','Box','Objecness','Classsfication','total','targets','img_size','Precison','Recall','mAP@0.5','mAP@0.5:0.95','val Box','val Objectness','val Classification'] RS = '_15cm' for i in range(len(columns)): column = columns[i] + RS columns[i] = column df_15.columns = columns df_15出力.
ここから,PrecisionとRecall,それぞれからf1scoreを求めてグラフにします.
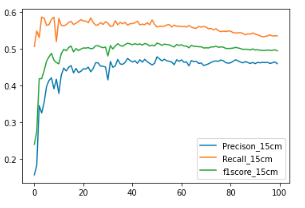
df_15['f1score_15cm'] = 2 * df_15['Precison_15cm'] * df_15['Recall_15cm'] / (df_15['Precison_15cm'] + df_15['Recall_15cm']) df_15[['Precison_15cm','Recall_15cm', 'f1score_15cm']].plot()
同様の処理を30cm,60cm,90cmの学習結果よりそれぞれのパラメータを比較します.
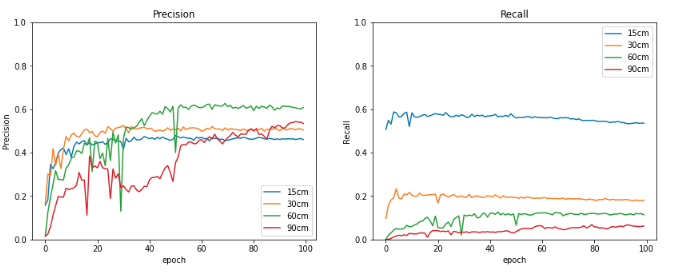
#学習結果のグラフ化 fig = plt.figure(figsize=(14, 5)) ax1 = fig.add_subplot(1, 2, 1) line1, = ax1.plot(df_15.index.values,df_15['Precison_15cm'],label='15cm') line2, = ax1.plot(df_30.index.values,df_30['Precison_30cm'],label='30cm') line3, = ax1.plot(df_60.index.values,df_60['Precison_60cm'],label='60cm') line4, = ax1.plot(df_90.index.values,df_90['Precison_90cm'],label='90cm') ax1.set_ylim(0.0, 1.0) ax1.set_title("Precision") ax1.set_xlabel('epoch') ax1.set_ylabel('Precision') ax1.legend(loc='lower right') ax2 = fig.add_subplot(1, 2, 2) line1, = ax2.plot(df_15.index.values,df_15['Recall_15cm'],label='15cm') line2, = ax2.plot(df_30.index.values,df_30['Recall_30cm'],label='30cm') line2, = ax2.plot(df_30.index.values,df_60['Recall_60cm'],label='60cm') line2, = ax2.plot(df_30.index.values,df_90['Recall_90cm'],label='90cm') ax2.set_ylim(0.0, 1.0) ax2.set_title("Recall") ax2.set_xlabel('epoch') ax2.set_ylabel('Recall') ax2.legend(loc='upper right') plt.show()
TensorboardのグラフをMatplotlibでグラフ化しただけですが,出力パラメータの加工や組み合わせによって,より詳細に解像度による違いを考察できそうです.
3.まとめ.
解像度が15cmの航空写真をベースに,低解像度の画像をResize処理により模擬し,車の検出ができるのかどうか,Yolov5モデルを用いて評価しました.
1m以下の解像度であれば,学習画像の作り方や,モデルのパラメータを最適化することで,高解像度と変わらない精度で検出できそうです.今回の結果をベースとして,色々試してみます.
こちらの記事がみなさんの活動のご参考になれば幸いです.間違いやコメントなどありましたら,いただければ励みになりますのでお気軽にご連絡ください.参考記事:
Deep Learning で航空写真から自動車をカウントする
PyTorchによる人工衛星画像から車の推定分布地図を作成してみる.
Cars Overhead With Context (COWC)
YOLO v5
人工衛星から人は見える?~衛星別、地上分解能・地方時まとめ~
FAS, Intelligence Resource Program









- 投稿日:2020-11-29T18:00:10+09:00
graph-toolチートシート(グラフ構築、統計量編)
この記事ではグラフ解析ライブラリgraph-toolで行う典型的な処理をまとめた。
特にグラフの構築と、次数分布などのグラフの基本的な統計量を計算する方法をまとめる。動作確認環境は以下の通り
- python 3.9.0
- graph-tool 2.35
- numpy, matplotlib
以後のサンプルコードでは、前提条件として以下のモジュールをimportしている。
import graph_tool.all as gt import numpy as np import matplotlib.pyplot as plt基本操作
グラフの構築
グラフオブジェクトの作成
g = gt.Graph() # => <Graph object, directed, with 0 vertices and 0 edges, at 0x7fbf8897c100>デフォルトで有向グラフになる。undirected graphを構築するには
directed=Falseを引数で指定するug = gt.Graph(directed=False)ノード追加
v = g.add_vertex() # => <Vertex object with index '0' at 0x7fbfd8c718d0> vlist = g.add_vertex(3) # 複数のノードの追加 # => [<Vertex object with index '1' at 0x7fbfd8c71690>, <Vertex object with index '2' at 0x7fbfd8c71b10>, <Vertex object with index '3' at 0x7fbfd8c71bd0>] # get the number of vertices g.num_vertices() # => 4 # get vertex object by index v2 = g.vertex(2) # => <Vertex object with index '2' at 0x7fbfd8c71b10>この例でみたようにNodeをindexから取得するときには
g.vertex(idx)とすれば取得することができる。
逆にvertexvがあるときにそこからindexを取得する際にはint(v)と整数に変換すれば取得できる。エッジ追加
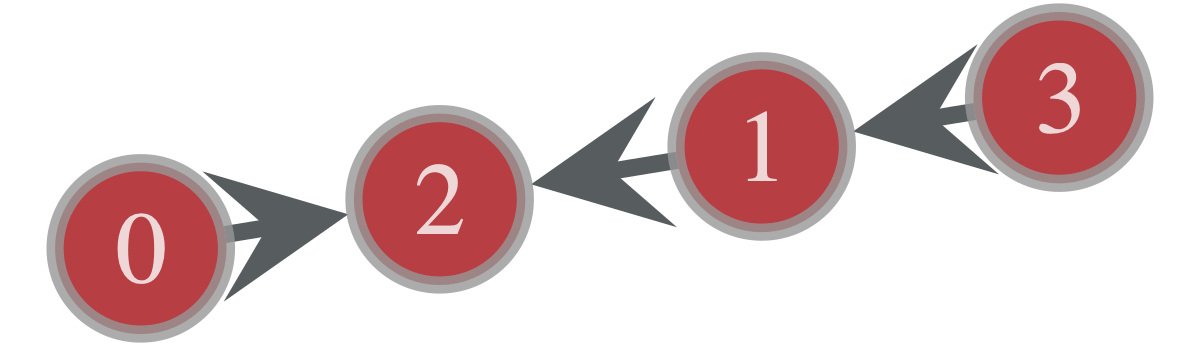
e = g.add_edge(g.vertex(0), g.vertex(2)) # => 0,2 の間にエッジを作る ( e.source(), e.target() ) # => vertex0, vertex2 をそれぞれ取得 # 短縮してintegerを引数に渡すこともできる e1 = g.add_edge(3, 1) e2 = g.add_edge(1, 2)試しにこの状態で可視化してみると以下のようになる。
gt.graph_draw(g, vertex_text = g.vertex_index)
同じノードペアに対して複数のエッジ(multiedge)を作成したり、始点と終点が同一な self-loopを作ることも同様の手順でできる。
イテレーション
エッジおよびノードに対してイテレーションする処理は以下のように書ける
# iterations over vertices for v in g.vertices(): for e in v.out_edges(): print(e.source(), e.target()) # iterations over edges for e in g.edges(): print(e.source(), e.target())エッジ数、ノード数の取得
g.num_vertices() # => 4 g.num_edges() # => 3属性の追加
ノードおよびエッジに属性を指定することができ、それぞれ
VertexProperty,EdgePropertyと呼ばれる。(グラフ全体に対しても属性 GraphProperty を付与することができるが、主に使うのはVertexとEdgeだけだろう)例えば、重み付きのグラフのエッジの重みは
double型のEdgePropertyとして指定することができる。
int,doubleといった数値的な型だけではなく、bool,string,vector<int>,vector<double>,objectといった様々な型の属性を付与することができる。
たとえばノードの名前をstring型のVertexPropertyとして保持したり、マルチレイヤーネットワークのリンクのレイヤーの情報をint型のEdgePropertyとして持つことができる。たとえば重み付きグラフを構築する手順は以下の通りになる。
g = gt.Graph() g.ep["weight"] = g.new_edge_property("double") # `ep` (edge property)の"weight" という名前でdouble型のedge propertyを作成 g.list_properties() # => weight (edge) (type: double)以後、
g.ep.weightでアクセスでき、さらにg.ep.weight.aで内部のnumpy.arrayが取得できるg.ep.weight # => <EdgePropertyMap object with value type 'double', for Graph 0x7fbf8897c100, at 0x7fbfcb2e3ee0> g.ep.weight.a # PropertyArray([0., 0., 0.])要素にアクセスするには
[]に edge (vertex) を渡す。
EdgePropertyおよびVertexPropertyはedge(vertex)を引数にして要素アクセスできる配列のようなものだと考えておけば良い。e1 = g.edge( g.vertex(0), g.vertex(2) ) # node-(0,2) の間のedgeを取得 g.ep.weight[e] # => weight of edge e基本統計量の計算
以後、以下のサンプルデータを用いて説明する。このサンプルデータには
g.ep.valueに重みが格納されている。g = gt.collection.data["celegansneural"]degree distribution
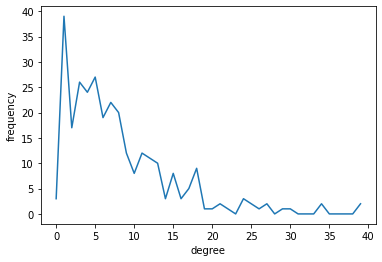
vertex_histメソッドで取得する。in-degree, out-degree, total-degreeの場合、第2引数に"in", "out", "total" という文字列をそれぞれ渡す。
参考 : https://graph-tool.skewed.de/static/doc/stats.html#graph_tool.stats.vertex_histpk,k = gt.vertex_hist(g, "out") plt.xlabel("degree") plt.ylabel("frequency") plt.plot(k[:-1], pk) # `k`の最後の1要素は除く
pk,kともにnumpy.arrayで返るが、pkの方がサイズが一つ大きい。
これはkの方に、それぞれのbinの最大値、最小値が入るため。プロットするときにはkの最後の要素を取り除く必要がある。第二引数に文字列ではなくVertexPropertyを渡すことで、次数以外の任意のVertexPropertyの分布を計算することもできる。
average_degree
avg,sdv = gt.vertex_average(g, "out") # => (7.942760942760943, 0.39915717608995005)第二引数に "in", "out", "total" の文字列を指定すると、それぞれin-degree, out-degree, total-degree の平均値が計算され、平均と標準偏差が返り値として得られる。
また、次数以外にもVertexのPropertyの平均値も同様に計算することができる。
edge weight distribution
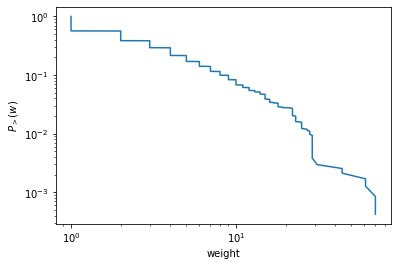
参考: https://graph-tool.skewed.de/static/doc/stats.html#graph_tool.stats.edge_hist
pw,w = gt.edge_hist(g, g.ep.value) # => (array([0.000e+00, 1.023e+03, 4.250e+02, 2.200e+02, 1.820e+02, 1.070e+02, 7.000e+01, 6.000e+01, 3.800e+01, 3.800e+01, 3.700e+01, 1.500e+01, 1.600e+01, 7.000e+00, 1.000e+01, 2.000e+01, 1.100e+01, 2.000e+00, 1.100e+01, 2.000e+00, 0.000e+00, 1.000e+00, 1.700e+01, 1.000e+01, 0.000e+00, 9.000e+00, 0.000e+00, 2.000e+00, 4.000e+00, 1.400e+01, 1.000e+00, 1.000e+00, 0.000e+00, 0.000e+00, 0.000e+00, 0.000e+00, 0.000e+00, 0.000e+00, 0.000e+00, 0.000e+00, 0.000e+00, 0.000e+00, 0.000e+00, 0.000e+00, 2.000e+00, 0.000e+00, 0.000e+00, 0.000e+00, 0.000e+00, 0.000e+00, 0.000e+00, 0.000e+00, 0.000e+00, 0.000e+00, 0.000e+00, 0.000e+00, 0.000e+00, 0.000e+00, 0.000e+00, 0.000e+00, 0.000e+00, 2.000e+00, 0.000e+00, 0.000e+00, 0.000e+00, 0.000e+00, 0.000e+00, 0.000e+00, 0.000e+00, 0.000e+00, 2.000e+00]), array([ 0., 1., 2., 3., 4., 5., 6., 7., 8., 9., 10., 11., 12., 13., 14., 15., 16., 17., 18., 19., 20., 21., 22., 23., 24., 25., 26., 27., 28., 29., 30., 31., 32., 33., 34., 35., 36., 37., 38., 39., 40., 41., 42., 43., 44., 45., 46., 47., 48., 49., 50., 51., 52., 53., 54., 55., 56., 57., 58., 59., 60., 61., 62., 63., 64., 65., 66., 67., 68., 69., 70., 71.]))
vertex_histのedgeバージョン。任意のEdgePropertyの分布を計算することができる。また、complementary cumulative distribution function は以下のようにプロットできる
# complementary cumulative distribution function weights = np.sort(g.ep.value.a) ccdf = np.linspace(1.0, 0.0, num=g.num_edges(), endpoint=False) plt.xlabel("weight") plt.ylabel(r"$P_{>}(w)$") plt.xscale("log") plt.yscale("log") plt.plot(weights, ccdf)
average edge weight
vertex_averageのedgeバージョン。gt.edge_average(g, g.ep.value)参考 : https://graph-tool.skewed.de/static/doc/stats.html#graph_tool.stats.edge_average
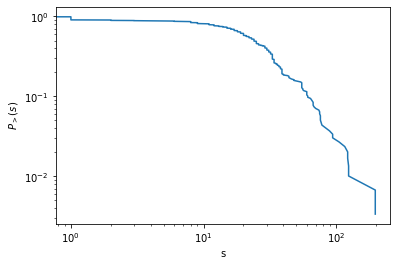
node strength
node strengthは自分でイテレートして計算する必要がある。
"double"のvertex_propertyを作成して、その中にnode strengthを格納する。out_strength = g.new_vertex_property("double") for v in g.vertices(): weights = [g.ep.value[e] for e in v.out_edges()] out_strength[v] = np.sum(weights) ps,s = gt.vertex_hist(g, out_strength) # plot of complementary cumulative distribution function s = np.sort(out_strength.a) ccdf = np.linspace(1.0, 0.0, num=g.num_vertices(), endpoint=False) plt.xlabel("s") plt.ylabel(r"$P_{>}(s)$") plt.xscale("log") plt.yscale("log") plt.plot(s, ccdf)
clustering coefficient
参考 : https://graph-tool.skewed.de/static/doc/clustering.html#graph_tool.clustering.global_clustering
gt.global_clustering(g) # => (0.19795997218143885, 0.027169317947021772)clustering spectrum c(k)
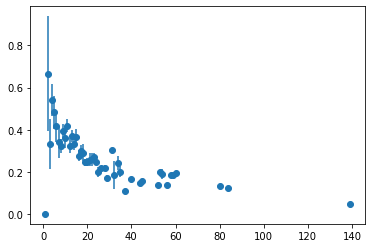
nodeにおける属性間の相関をみるには
avg_combined_corrを使う。
degreeとlocal clustering coefficientだけでなく、任意のVertexProperty間の相関を計算できる。
参考 : https://graph-tool.skewed.de/static/doc/correlations.html#graph_tool.correlations.avg_combined_corr# correlation between k and local clusteirng gt.local_clustering(g) # => double type の VertexProperty h = gt.avg_combined_corr(g, "total", gt.local_clustering(g)) plt.errorbar( h[2][:-1], h[0], yerr=h[1], fmt="o")
hは (bin, average, stddev) のタプル
degree correlation
参考 : https://graph-tool.skewed.de/static/doc/correlations.html#graph_tool.correlations.avg_neighbor_corr
隣接ノード間のVertexPropertyの相関を計算することができる。文字列"in", "out", "total" を引数に渡すと次数相関を計算できる。
# average degree correlation knn = gt.avg_neighbor_corr(g, "total", "total") plt.xlabel("k") plt.ylabel("average neighbor degree") plt.errorbar( knn[2][:-1], knn[0], yerr=knn[1], fmt="o")
centrality
参考 : https://graph-tool.skewed.de/static/doc/centrality.html
さまざまなcentralityの指標を計算できるが、ここではpagerankを計算してみよう。
gt.pagerankでpagerankを計算してVertexPropertyとして取得できる。その値に応じて色をつけて描画してみる。prc = gt.pagerank(g, weight = g.ep.value) gt.graph_draw(g, vertex_fill_color = prc, pos = g.vp.pos)
pagerankの他にもbetweeness centrality, Katz centrality, eigen-vector centrality など一通り揃っている。
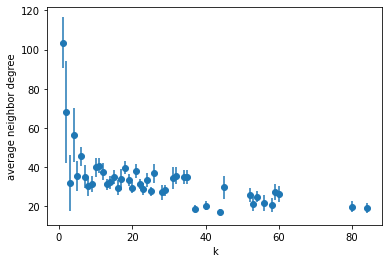

- 投稿日:2020-11-29T17:59:12+09:00
python xlwing関数 指定した標準偏差と中央値で、任意の行・列数のデータを作成する
python の関数
myproject.pyimport xlwings as xw import numpy as np @xw.func @xw.ret(expand = "table") def randstd(mean, std, rows, columns): return np.random.normal(mean, std, (int(rows), int(columns)))excel設定
1.上部の 「UDF MODULEs:」 のところに上記のpythonファイル名(myproject)を入れる。
(※myprojectはexcelファイルと同じフォルダに入っていると仮定)適当なセルに、任意の中央値、標準偏差、テーブルの行数、列数を書き込む。
下記のように関数を入れる。
結果
以上。

- 投稿日:2020-11-29T17:55:20+09:00
ラズパイ4で人感センサーを使ってみる(HiLetgo HC-SR501)
概要
- ラズパイに人感センサーを取り付けて動作することを確認します。
事前準備
- ラズパイのセットアップが完了していること。
- 人感センサー
- HiLetgo® 3個セット HC-SR501
- 安いので3個セットを購入しましたが、1個で十分です。
- ジャンパーワイヤー
- ブレッドボードジャンパーワイヤー
- 持っているものがあれば購入は必要ありませんが、安くて「オス-オス」、「メス-メス」、「オス-メス」が各40本ずつあるのでなければ購入しちゃいましょう。(コスパ良)
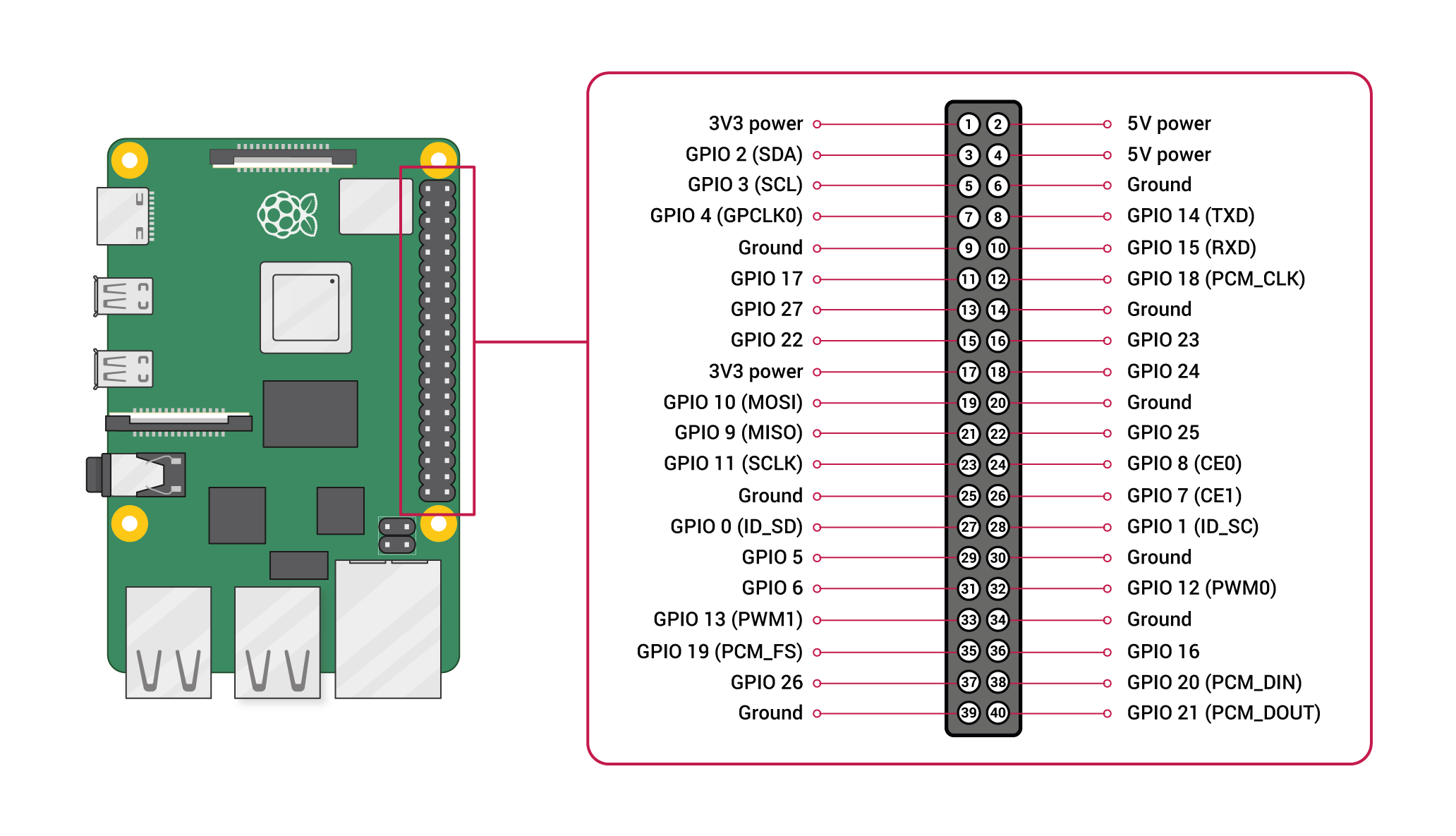
GPIO配置図
- 下記を参考に接続していきます。
手順
- まずはセンサーを見ていきましょう

- オレンジ色のピン?ネジ?がありますが、今回は写真の向きで両方を左側にプラスドライバーを使って回転させます。(ゆびでも行ける)
- 左側が検知する距離の調整(3m~7m)
- 右側が検知した状態の保持時間(3秒~5分)
- ラズパイにセンサーを接続します。
- 赤枠で囲ったpinは左から「5V」、「OUT」、「GND」となっています。

- 下記のようにそれぞれ接続します。(GPIO配置図を参考にしてください。)
- センサーの「5V」はラズパイの5V Power(pin4)
- センサーの「OUT」はラズパイのGPIO 18(pin12)
- センサーの「GND」はラズパイのGround(pin9)
接続するとこのようになると思います。
- 今回はブレッドボードは利用せずに直結してます。

ラズパイにテスト用スクリプトを準備します。
sample.pyimport time import RPi.GPIO as GPIO GPIO_PIN = 18 GPIO.setmode(GPIO.BCM) GPIO.setup(GPIO_PIN,GPIO.IN) while True: if(GPIO.input(GPIO_PIN) == GPIO.HIGH): print("検知!!") break print("-") time.sleep(1) GPIO.cleanup()
- 実行して手をかざしてみると「検知!!」と表示されました。
- 手をかざさなければ1秒毎に「-」と表示されます。
$ python3 sample.py - - - 検知!!
- 投稿日:2020-11-29T17:54:02+09:00
ハフ変換で直線を検出する
ハフ変換で直線を検出する
ハフ変換でどの辺に直線があるかを検出します。
厳密にどこからどこに直線があったかまでの検出は行わず描画範囲内のある距離・ある角度に直線が存在しているかの検出だけを行います、ハフ変換自体は解説が多いので解説はせず実装だけを乗せていきます。
実装する上で参考にしたサイトは下記です。
http://www.allisone.co.jp/html/Notes/image/Hough/index.html
https://jp.mathworks.com/discovery/image-transform.html
https://qiita.com/YSRKEN/items/ee94c7c22599c2374722
https://codezine.jp/article/detail/153
https://qiita.com/tifa2chan/items/d2b6c476d9f527785414おおまかな手順
1.画像を2値化(白黒画像化)する
2.描画されている点全てにハフ変換を実行して角度と距離を算出する
3.X軸を距離、Y軸を角度とした2次元配列で「2」のデータを2次元ヒストグラム(ヒートマップ)化する
4.「3」のデータの頂点(角度・距離が同一で数の多い点)の線が存在している可能性が分かる
5.「4」のデータ数の多い上位n個を検出された線とする手順「3~4」の2次元ヒストグラムの頂点検出はそのままでは困難であるためガウシアンフィルタで平滑化を行ってから行う、その際の誤検出については上位n個というフィルタでだいたい弾かれるので問題無いというスタンスである
「3.X軸を距離、Y軸を角度とした~」部分について本実装のプロットではX軸Y軸が逆になっているが、実データでは解説の通りである、ハフ変換プロットと向きを合わせるため解説に合わせずにそのままにしてある。
実装
以下実装となります、jupyterにコピペすれば動くはずです。
サンプル画像を作る所から実装してあります。import inspect import math import matplotlib import matplotlib.pyplot as plt import numpy as np import PIL.Image import random import scipy.ndimage CANVAS_WIDTH = 300 CANVAS_HEIGHT = 200 def plotLine(dst, x1, y1, x2, y2, broken=1, variance=1): xd = x2 - x1 yd = y2 - y1 xsize = len(dst[0]) ysize = len(dst) if xd == 0: if y1 > y2: y1, y2 = y2, y1 for i in range(int(y1), int(y2), 1): dst[i][x1] = 1 return if yd == 0: if x1 > x2: x1, x2 = x2, x1 for i in range(int(x1), int(x2), 1): dst[y1][i] = 1 return rad = math.atan2(yd, xd) distance = math.sqrt((xd ** 2) + (yd ** 2)) for i in range(int(distance)): if broken >= 2 and not (i % broken) == 0: continue x = x1 + i * math.cos(rad) y = y1 + i * math.sin(rad) if variance > 0: x += int(random.random() * variance) - (variance / 2) y += int(random.random() * variance) - (variance / 2) if x < 0: x = 0 if x >= xsize: x = xsize - 1 if y < 0: y = 0 if y >= ysize: y = ysize - 1 dst[int(y)][int(x)] = 1 def createSampleImage(width, height): x = np.zeros((height, width)).astype(np.uint8) for i in range(4): x1 = int(random.uniform(0, CAMVAS_WIDTH)) y1 = int(random.uniform(0, CAMVAS_HEIGHT)) x2 = int(random.uniform(0, CAMVAS_WIDTH)) y2 = int(random.uniform(0, CAMVAS_HEIGHT)) plotLine(x, x1, y1, x2, y2, broken=0, variance=0) return x # 直線のサンプル画像を作成する random.seed(63) imageData = createSampleImage(CANVAS_WIDTH, CANVAS_HEIGHT) plt.imshow(imageData) plt.savefig("./002_sample_image.png") plt.show()
# ハフ変換 def houghConvertSub(theta, x, y): distance = [] for t in theta: d = x * math.cos(t) + y * math.sin(t) distance.append(d) return distance PY, PX = np.where(imageData == 1) # # ピクセル座標の取得 DegreeDiscrete = 180 # pi をいくつに分割するか(粒度をどの程度にするか)、100とか200でも良い theta_arr = [math.pi * (i / DegreeDiscrete) for i in range(0, DegreeDiscrete)] PR = [] for x, y in zip(PX, PY): p = houghConvertSub(theta_arr, x, y) PR.append(p) PR = np.array(PR) plt.plot(theta_arr, PR.transpose()) plt.savefig("./003_haough_convert.png") plt.show() print("len(PX)", len(PX)) print("len(PY)", len(PY)) print("len(theta_arr)", len(theta_arr))
# 2次元配列にして交差している点をカウントする # 対角線の長さを求め距離の最大値とする diagonalDistance = math.sqrt((CANVAS_WIDTH ** 2) + (CANVAS_HEIGHT ** 2)) diagonalDistance = round(diagonalDistance) # 交差点の交差数を投票する2次元配列を作成 vote = np.zeros((diagonalDistance * 2, len(theta_arr))) print("ballot.shape", ballot.shape) for P in PR: for x, p in enumerate(P): y = int(round(p)) vote[y + diagonalDistance][x] += 1 # 標準化しておく vote = (vote - np.mean(vote)) / np.std(vote) plt.figure(figsize=(6,6),dpi=200) plt.imshow(vote, cmap='jet', interpolation='nearest') plt.savefig("./004_haough_convert_vote.png") plt.show()
# 角度がループする都合上、先頭列と列の末尾はデータとしては連続している # 列末尾に先頭列をいくつか追加しておく事で一括で処理できるよう準備する appendMat = np.flipud(vote[:,:10]) newVote = np.c_[vote, appendMat] print("newVote.shape", newVote.shape) plt.figure(figsize=(6,6),dpi=200) plt.imshow(newVote, cmap='jet', interpolation='nearest') plt.savefig("./005_haough_convert_vote_ex.png") plt.show()
# ガウシアンフィルタをかけて頂点をできるだけ検出しやすくする filteredVote = scipy.ndimage.gaussian_filter(newVote, sigma=0.5) plt.figure(figsize=(6,6),dpi=200) plt.imshow(filteredVote, cmap='jet', interpolation='nearest') plt.savefig("./006_haough_convert_vote_gaussian.png") plt.show()
def detectPeak1D(x): conv1 = np.convolve(x, [1, -1], mode="full") flag1 = (conv1 > 0).astype(int) flag2 = (conv1 <= 0).astype(int) flag1 = flag1[:-1] flag2 = flag2[1:] flag3 = flag1 & flag2 return flag3 def detectPeak2D(x): peaks1 = [] for ix in x: peak = detectPeak1D(ix) peaks1.append(peak) peaks1 = np.array(peaks1) peaks2 = [] for ix in x.transpose(): peak = detectPeak1D(ix) peaks2.append(peak) peaks2 = np.array(peaks2).transpose() flag = (peaks1 & peaks2).astype(int) return flag # ピーク検出を行う # 誤検知については後の処理で投票数の少ない頂点を間引く事で対応する peaks = detectPeak2D(filteredVote) xidx, yidx = np.where(peaks == 1) print("np.max(filteredVote)", np.max(filteredVote)) for x, y in zip(xidx, yidx): if filteredVote[x][y] > 10: peaks[x][y] = 1 else: peaks[x][y] = 0 plt.figure(figsize=(8,8),dpi=200) plt.imshow(peaks, cmap='spring', interpolation='nearest') plt.savefig("./007_haough_convert_peaks.png") plt.show()
# ピークからθのインデックスを取り出す idxs = np.where(peaks != 0) peakValues = filteredVote[idxs] print(idxs[0]) print(idxs[1]) distances = idxs[0] thetaIndexes =[] for idx in idxs[1]: if idx >= DegreeDiscrete:# 先頭末尾を繋げた部分について、インデックスを修正する idx = idx - DegreeDiscrete thetaIndexes.append(idx) distances = np.array(distances) thetaIndexes = np.array(thetaIndexes) print(distances) print(thetaIndexes) print("len(PX)", len(PX)) print("len(PY)", len(PY)) print("len(PR)", len(PR)) print("len(THETA)", len(THETA)) # ピークの上位10個だけを採用する idxs = np.argsort(peakValues)[::-1] idxs = idxs[:10] distances = distances[idxs] thetaIndexes = thetaIndexes[idxs] # 検出された直線を実際に描画して確認する #y = -(math.cos(rad) / math.sin(rad)) * x + ((yidx[0] - diagonalDistance) / math.sin(rad)) #x = -(math.sin(rad) / math.cos(rad)) * y + ((yidx[0] - diagonalDistance) / math.cos(rad)) x = np.zeros((CANVAS_HEIGHT, CANVAS_WIDTH)).astype(np.uint8) threshold1 = math.pi * (3/4) threshold2 = math.pi * (1/4) for idx, d in zip(thetaIndexes, distances): rad = theta_arr[idx] #x= -y sinθ/cosθ +ρ/ cosθ #x1 = if rad > (threshold1) or rad < (threshold2): y1 = 0 y2 = CANVAS_HEIGHT x1 = -(math.sin(rad) / math.cos(rad)) * y1 + ((d - diagonalDistance) / math.cos(rad)) x2 = -(math.sin(rad) / math.cos(rad)) * y2 + ((d - diagonalDistance) / math.cos(rad)) else: x1 = 0 x2 = CANVAS_WIDTH y1 = -(math.cos(rad) / math.sin(rad)) * x1 + ((d - diagonalDistance) / math.sin(rad)) y2 = -(math.cos(rad) / math.sin(rad)) * x2 + ((d - diagonalDistance) / math.sin(rad)) print(rad, x1, x2, y1, y2) plotLine(x, int(x1), int(y1), int(x2), int(y2), broken=1, variance=0) plt.imshow(x) plt.savefig("./009_haough_convert_lines.png") plt.show()
解説が足りないですが、興味ある方はソースコードとコメントを読んでみてください。
以上です。
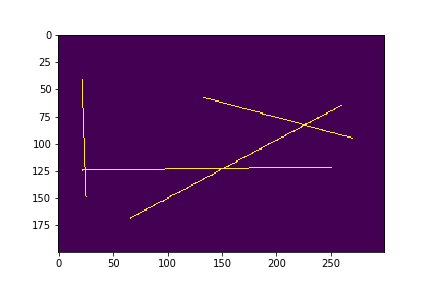
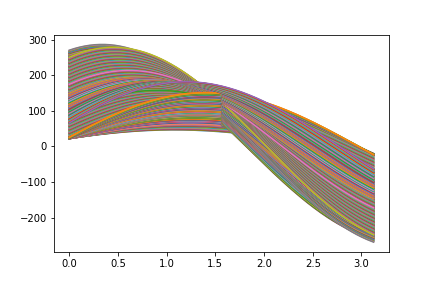
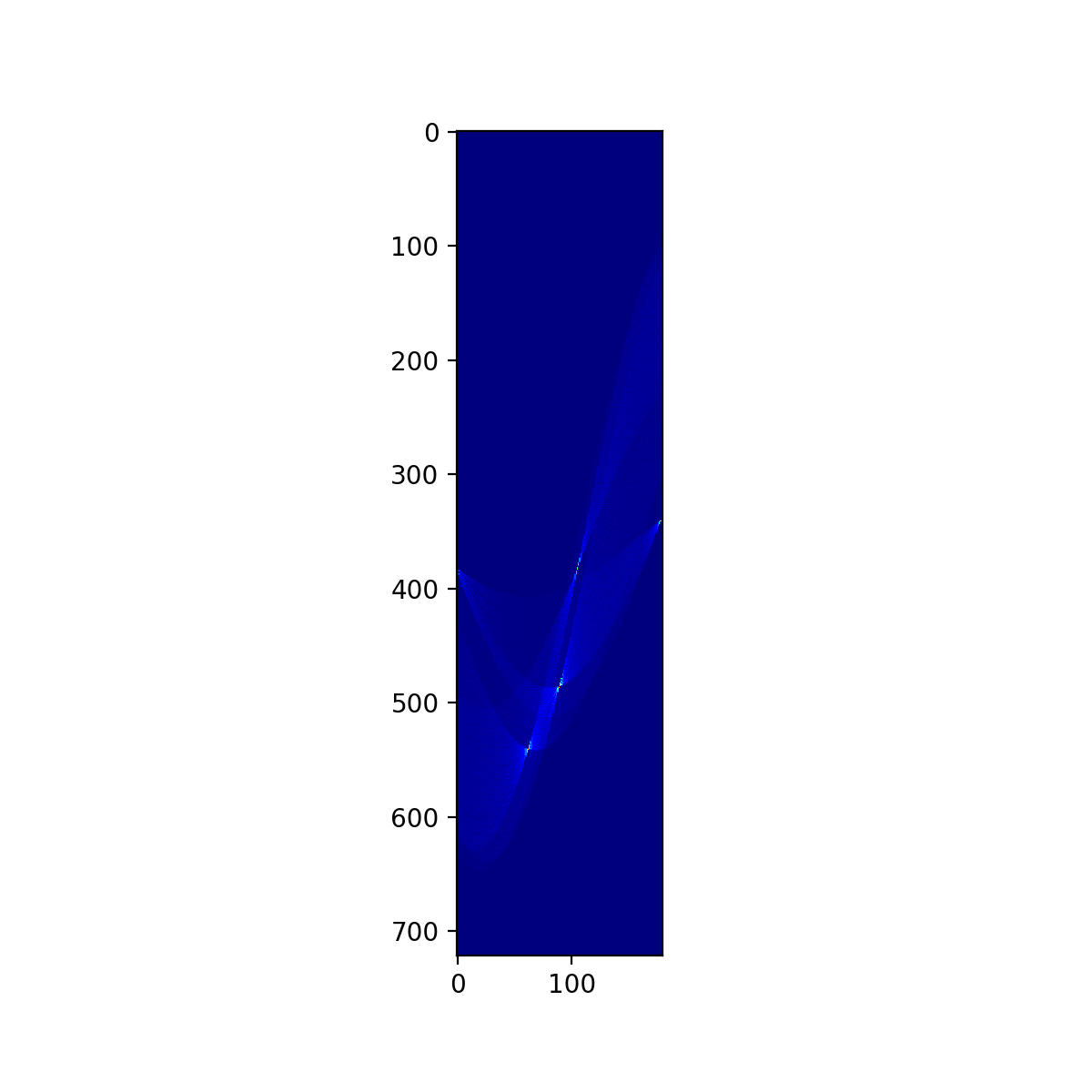
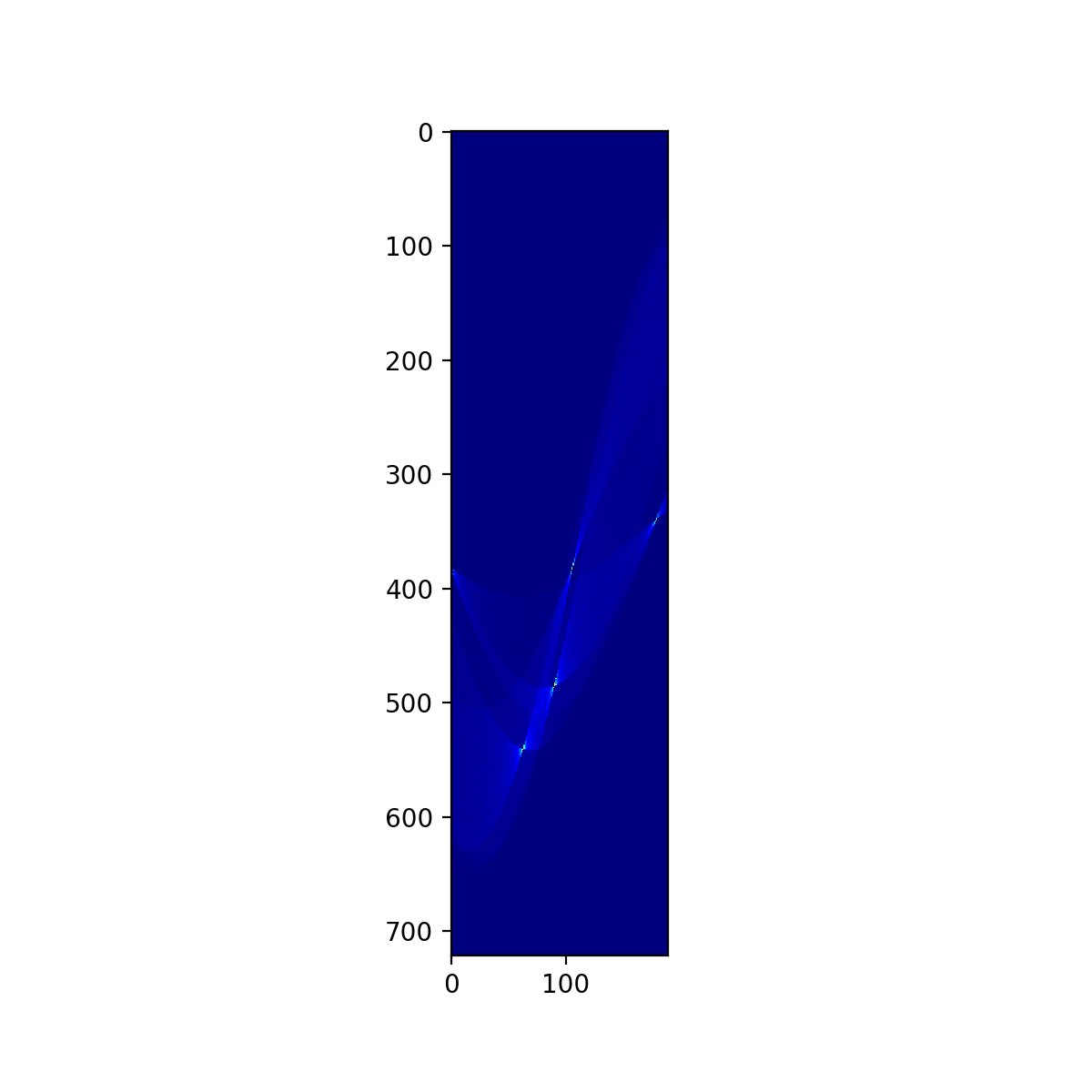
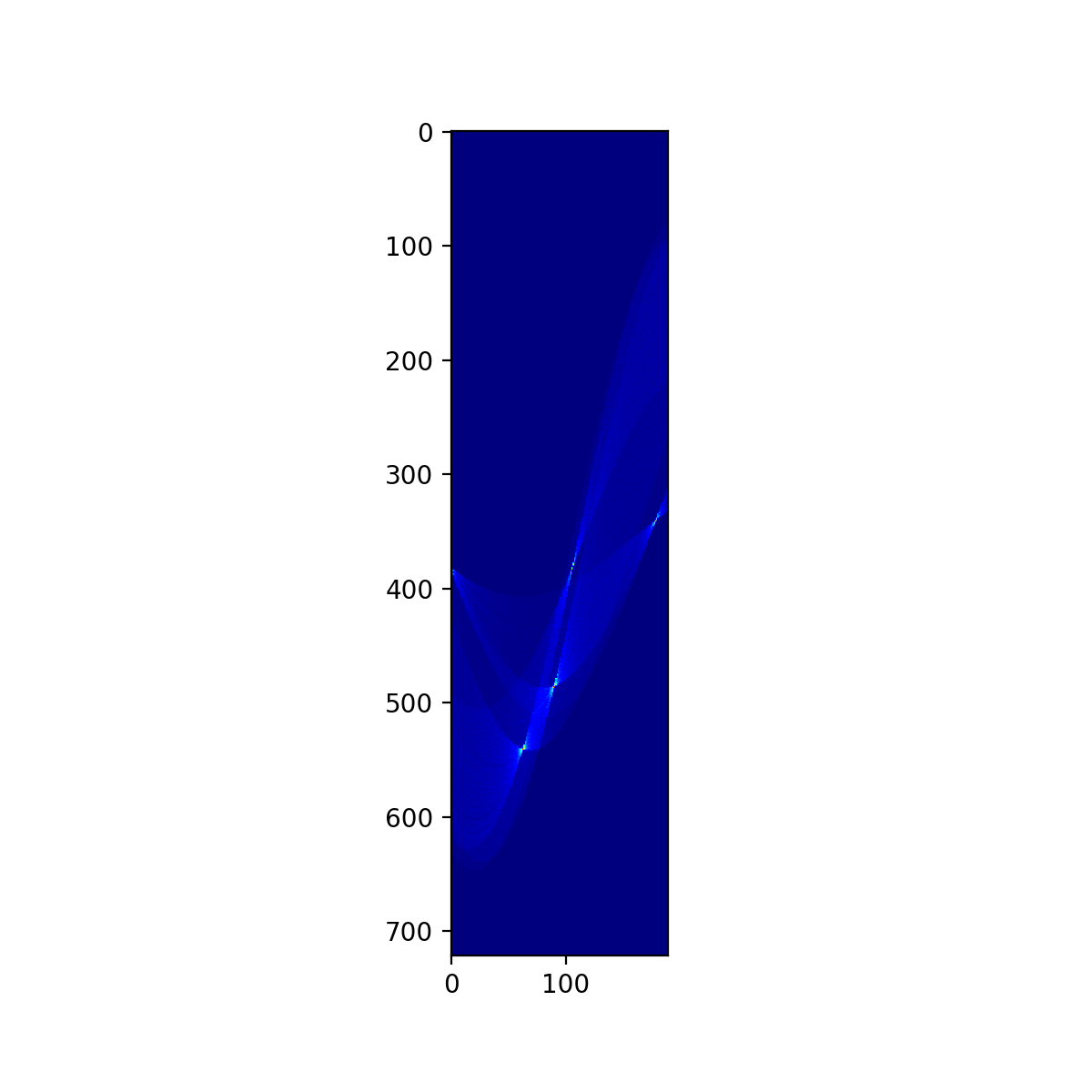
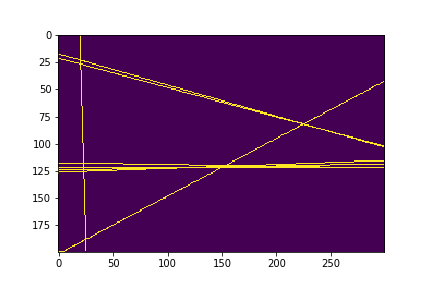
- 投稿日:2020-11-29T17:51:17+09:00
AlexaからGCEのマイクラサーバ(統合版)を起動する
この記事は
KLab Engineer Advent Calendar 2020とGoogle Cloud + Gaming Advent Calendar 2020の10日目の記事です。こんにちはhamasan05です。
今年は一家でマイクラにハマった年だったので、マイクラ絡みでなにか書けないかと思い、
勉強がてらやっていたGCPとAlexaの話を記事にしました。前提としてGCPのサインアップとプロジェクトの作成、
alexa developer consoleのサインアップまでは済ませているものとします。レシピ
- GCEでマイクラサーバを作る
- GCFで起動の処理を作る
- Alexaからつなぎこむ
GCEでマイクラサーバを作る
今回はGCEのインスタンス作成の細かい手順は割愛して
- rcスクリプトへの登録
- サーバの自動停止までを実施することにします。
※細かい手順は「Google Cloud + Gaming Advent Calendar 2020」3日目の記事が参考になると思います。VMの作成
GCPのダッシュボードの画面からVMインスタンスを選択して作成をします。
マイクラ統合版のサーバは実用はともかくとして動かすだけなら完全無料枠のusリージョンのf1-microで十分です。
必要に応じてスケールすればよいと思います。
OSは無難にUbuntuにしておきましょう。
ほかのLinuxのOSでもマイクラ統合版のサーバプログラムは動作しますが公式サイトによるとUbuntu用とのことです。
ネットワークについてはVPCネットワークから静的アドレスを予約して
一つIPv4のアドレスを確保しておくとよいと思います。
準備が済んだらVMを起動してSSH接続をします。
私はブラウザからのsshは不便なので、ユーザーの追加、wheelグループなどの追加をしました。マイクラ統合版のサーバプログラムのインストール
サーバプログラムは日本語のサイトだとダウンロードできない場合もあるので英語のサイトからダウンロードするとよいです。
規約に同意するチェックボックスをクリックして、ダウンロードボタンを右クリックしてURLをコピーしておきます。コマンド例:
$ mkdir be $ cd be $ curl -O https://minecraft.azureedge.net/bin-linux/bedrock-server-1.16.101.01.zip $ unzip bedrock-server-1.16.101.01.zipマイクラのサーバプログラムは標準入力を使うのでscreenを使ってバックグラウンドで動作できるようにします。
$ sudo apt-get install screen下記のような内容のstartスクリプトを作成しておきます。
ほかにも起動時に何かしたいことがあったら記載しておくとよいと思います。$ cd $ vi start.shstart.sh#!/bin/bash cd /home/xxx/be screen -dmS be ./bedrock_server正直これだけだったら直接後述の
/etc/rc.localに記載してもいいかな感はありますが
homeディレクトリにあるもので制御できるようにしておくと、後でいろいろいじるときに楽です。OS起動時にマイクラ統合版サーバプログラムを自動起動する
今回はサービス化せずにシンプルに起動するだけの処理を書くことにします。
OS起動時に呼ばれる/etc/rc.localに起動スクリプトを登録しておきます。$ sudo vi /etc/rc.local/etc/rc.local#!/bin/sh sudo -u xxx /home/xxx/start.shこれでOSが起動したらマイクラ統合版のサーバプログラムも自動で起動するようになりました。
最後に停止忘れの防止のために深夜0時になったらインスタンスを停止するようにcronを仕込んでおきます$ crontab -e0 0 * * * sudo shutdown -h now > /dev/nullいったんこの時点でVMを再起動してマイクラから接続確認をしておきましょう
確認できたらダッシュボードからVMを停止しておきます。GCFで起動の処理を作る
関数の作成
GCPのダッシュボードからCloud Functionsの画面に行き関数を作成します。
関数名は任意のもの、リージョンはGCEと同じ場所にします。
認証は未認証の呼び出しを許可にします。
公開APIとして作成して、別途Alexaから送られてくるJSONで認証するからです。
ほかはデフォルトでよいです。ランタイムは
Python 3.8を選択してエントリポイントをalexaとします。
main.pyを開いて以下の通り入力します。
設定類は各自調べて入力してください。
AlexaのIDの部分はあとから入力するので変更しないでOKです。main.pyimport threading from typing import Optional import googleapiclient.discovery from flask import json from oauth2client.client import GoogleCredentials PROJECT = "{GCPのプロジェクトID}" ZONE = "{GCEのリージョン}" INSTANCE_NAME = "{GCEのインスタンス名}" USER_ID = [ "amzn1.ask.....形式のAlexaのID(コンソール用)", "amzn1.ask.....形式のAlexaのID(デバイス用)", ] dictionary: dict = { "started": "起動しました", "stopped": "停止しました", "alreadyStarted": "すでに起動しています", "alreadyStopped": "すでに停止しています", "NotSupportedFunction": "その操作はサポートしていません", "NotAuthorized": "権限がありません", "LeaveItToMe": "私にお任せください", } def alexa(request): ret = _auth_alexa(request) if ret: return _build_response(ret) thread = threading.Thread(target=_execute, args=(["start"])) thread.start() return _build_response("LeaveItToMe") def _execute(function) -> str: if function == "start": compute = _init() ret = _start_instance(compute, PROJECT, ZONE, INSTANCE_NAME) if ret: return "started" return "alreadyStarted" elif function == "stop": compute = _init() ret = _stop_instance(compute, PROJECT, ZONE, INSTANCE_NAME) if ret: return "stopped" return "alreadyStopped!" return "NotSupportedFunction" def _init(): credentials = GoogleCredentials.get_application_default() return googleapiclient.discovery.build("compute", "v1", credentials=credentials) def _auth_alexa(request) -> Optional[str]: request_json = request.get_json(silent=True) if request_json["context"]["System"]["user"]["userId"] not in USER_ID: print(f'alexa: {request_json["context"]["System"]["user"]["userId"]}') return "NotAuthorized" return None def _start_instance(compute, project: str, zone: str, name: str) -> bool: instance = ( compute.instances().get(project=project, zone=zone, instance=name).execute() ) if instance["status"] == "TERMINATED": compute.instances().start(project=project, zone=zone, instance=name).execute() return True else: return False def __start_instance(compute, project: str, zone: str, name: str): compute.instances().start(project=project, zone=zone, instance=name).execute() def _stop_instance(compute, project: str, zone: str, name: str) -> bool: instance = ( compute.instances().get(project=project, zone=zone, instance=name).execute() ) if instance["status"] == "RUNNING": compute.instances().stop(project=project, zone=zone, instance=name).execute() return True else: return False def _build_response(message: str) -> str: response = { "version": "1.0", "response": { "outputSpeech": { "type": "PlainText", "text": _translate(message), } }, } return json.dumps(response) def _translate(message: str) -> str: return dictionary[message]GCEインスタンスの起動時にバックグラウンドでの実行をしているのですが、これはGCFのガイドに反するような内容になっています。
バックグラウンドにしている理由としては、処理に時間がかかりすぎてAlexaがなかなか返事をしてくれなかったりタイムアウトしてしまうからです。
業務等に使う場合にはGCF(フロント) -> Pub/Sub -> GCF(バックエンド)のようにして
フロントで一旦レスポンスを返して、バックエンド側でGCEインスタンスの起動処理を行うのが良いと思います。続いて
requirements.txtです。
テンプレートからのコピー+αなので余計なものが混ざっているかもしれませんがとりあえず下記で動くようです。
作業した時期が割と前なので実行すると若干ログに警告的なものが出てしまってます・・・ので気が向いたら訂正しておきます。cachetools==4.0.0 certifi==2019.11.28 chardet==3.0.4 Click==7.0 Flask==1.1.1 google-api-core==1.16.0 google-api-python-client==1.7.11 google-auth==1.11.2 google-auth-httplib2==0.0.3 google-cloud-core==1.3.0 google-cloud-error-reporting==0.33.0 google-cloud-logging==1.15.0 google-cloud-storage==1.26.0 google-resumable-media==0.5.0 googleapis-common-protos==1.51.0 grpcio==1.27.2 httplib2==0.17.0 idna==2.9 itsdangerous==1.1.0 Jinja2==2.11.1 MarkupSafe==1.1.1 oauth2client==4.1.3 protobuf==3.11.3 pyasn1==0.4.8 pyasn1-modules==0.2.8 pytz==2019.3 requests==2.23.0 rsa==4.0 six==1.14.0 uritemplate==3.0.1 urllib3==1.25.8 Werkzeug==1.0.0入力が終わったらデプロイボタンを押します。
このままだとAlexaからアクセスしても認証エラーでこけてしまうので
Alexa側のセットアップが終わったら再度関数を編集します。Alexaとつなぎこむ
スキルの作成
まずはalexa developer consoleからスキルを作成します。
1. スキルに追加するモデルを選択をカスタム
2. スキルのバックエンドリソースをホスティングする方法を選択をユーザー定義のプロビジョニング
で作成します。
スキルに追加するテンプレートを選択はスクラッチで作成を選択します。スキルのカスタマイズ
呼び出し名
呼び出し名はAlexaに話しかけるときのキーワードなので何か好きなものを入力してください。
スキル名がデフォルトで入っているのでそのままでもよいです。
私はマイクラのサーバを起動してにしました。対話モデル
インテントに
HelloWorldIntentがあるので削除します。
今回に関してはあっても実害はないのですが使わないものがおいてあると気持ち悪い程度の感じです。エンドポイント
デフォルトでは
AWS LambdaのARNが選択されているのでHTTPSにしてからデフォルトの地域に
GCPのダッシュボードからGCFのトリガーからURLをコピーして貼り付けます。
おそらく下記のようなURLになっていると思います
https://{リージョン名}-{プロジェクトID}.cloudfunctions.net/{関数名}
SSL証明書の種類を選択は
開発用のエンドポイントは証明機関が発行したワイルドカード証明書を持つドメインのサブドメインですを選択します。
これ間違えると全く動きません。よく考えれば当たり前のことでしたが。
エンドポイントを保存します。テスト
alexa developer consoleの
テストタブから操作します。
スキルテストが有効になっているステージを開発中に変更します。
入力またはマイクを長押しして発話に呼び出し名(マイクラのサーバを起動して)をテキストで入力してEnterを押します。
権限がありませんと返事があったら成功です。ユーザーIDの追加
再びGCPのダッシュボードに戻ってGCFの関数名(
alexa)をクリックしてログを見ます。
alexa: amzn1.ask.xxxxxというログがあるのでamzn1以降をコピーしてログ画面の上部にある編集を押して次へを押して
main.pyのUSER_IDのamzn1.ask.....形式のAlexaのID(コンソール用)を置き換えてデプロイを押します。この状態でalexa developer consoleからの動作するはずです。
※起動したらGCPのダッシュボードからGCEのVMインスタンスを停止しておきましょうAmazon Echoなどの実機で使う
alexa developer consoleの
公開タブから操作します。
スキルのプレビューとプライバシーとコンプライアンスを適切に入力します。
公開範囲のベータテストを選んでベータテスト管理者用Eメールアドレスとスキルのベータテストを
どちらもAlexaが動いているAmazonのアカウントに紐づいたメールアドレスを入力します。
ベータテストを有効化を押すと
You're invited to beta test a new Alexa skillというタイトルのメールが届くので下記をクリックして有効化します。JP customers: To get started, follow this link: Enable Alexa skill "スキル名"Echoなどの実機でスキル名でコールするとスキルが動くのですが、権限がありませんと返答されるはずです。
ユーザーIDの追加で記載した通りのことを再び実施するとEchoなどの実機から動作するようになったと思います。最後に
AmazonのスマートスピーカーとGoogleのクラウドサービスを連携させるという珍しいことをやってみましたが
Alexaから何らかのサーバを起動するということだけに関していうと
おそらくAWSのEC2インスタンス上に作ったサーバを起動するほうがはるかに楽だと思います。
alexa developer console側に標準でLambdaに連携する機能があるので
通信のところで悩むところが減るはずです。収穫としてはAlexaのスキルがエンドポイントに送ってくるJSONの中身を詳しく見ることができたというところだと思います。
この辺りはマニュアルを読んでいても一番よくわからないところでした。
今回はインスタンスの停止まではやっていませんが、同じ要領で停止は可能です。
main.pyにその機能はありますが、Alexaからのつなぎこみをしていないのでその部分だけ作りこめば良いはずです。GCPを触ってみてよかったなと思ったところは、
- GCEのインスタンス/静的アドレスの無料枠
- サインアップ時にGooglePlayのクレジットカードを連携できる
という点で、学習するまでのハードルが低いと感じました。
試行錯誤する範囲については無料というのは初めて触るときに安心ですよね。
※比べられるほど他社のクラウドを触り込んでないので割と表層的なところですが・・・単にマイクラをオンラインで遊びたいだけならRealms PlusやConoHa VPSをお勧めします。
が・・・私は本格的にマイクラサーバを使うとなったらこのままGCEを使うんだろうなぁという気持ちです。
途中にも書きましたが、まだまだ色々整備できるところがあるので、それを楽しんでいきたいと思っているからです。
GCPやAlexaをスキル勉強したいけど事務的に触ってみるのはツラいという方の参考になればと思います。記事にはしませんでしたが試行錯誤するにあたってgcloudコマンドラインツールやPyCharmにお世話になりました。
コマンドラインツールやIDEは開発の強い味方ですね。感謝感謝。
- 投稿日:2020-11-29T17:50:21+09:00
ファイル内に登場する「人名」や「組織名」を全件表示後、選択した「人名」・「組織名」を主語に持つ「主語・述語」ペアを表示
作ったもの
Terminalpython3 tkinter_ner_sub_pred_pair.pyスクリプトファイルを実行すると、Tkinterが起動して、次のGUI画面が立ち上がります。
- スクリプトファイルと同じディレクトリにあるsample.txtを相対パスで入力。
- 「人名」のラジオボタンを選択後、「ファイルから指定した種類の単語を洗い出す」ボタンを押す。
『着目する「主語」』入力欄に「1」を入力して、「入力した単語の番号の単語を主語に持つ「主語述語ペア」を表示します。」ボタンを押す。
次は、「地名」のラジオボタンを選択。「ファイルから指定した種類の単語を洗い出す」ボタンを押す。
『着目する「主語」』入力欄に「2」を入力して、「入力した単語の番号の単語を主語に持つ「主語述語ペア」を表示します。」ボタンを押す。
『着目する「主語」』入力欄に「4」を入力して、「入力した単語の番号の単語を主語に持つ「主語述語ペア」を表示します。」ボタンを押す。
次は、「組織名」のラジオボタンを選択。「ファイルから指定した種類の単語を洗い出す」ボタンを押す。
『着目する「主語」』入力欄に「1」を入力して、「入力した単語の番号の単語を主語に持つ「主語述語ペア」を表示します。」ボタンを押す。
( 読み込んだテキストファイル )
NHK NewsWebから、ある日のニュース記事を拝借しました。
sample.txt新型コロナウイルスの治療薬として日本で特例承認されている、抗ウイルス薬レムデシビルについて、WHO=世界保健機関は、世界各地の臨床試験を分析した結果、「死亡率の低下などにつながる重要な効果はなかった」として、入院患者への投与は勧められないとする指針を公表しました。 レムデシビルを開発した製薬会社ギリアド・サイエンシズは、患者が回復に至るまでの期間は大幅に短縮しているなどと反論しています。 WHOは20日、抗ウイルス薬レムデシビルを使った世界各地の入院患者に対する臨床試験を分析し、治療に関する指針を公表しました。 それによりますと、 ▽死亡率の低下や ▽人工呼吸器の必要性、 それに ▽症状の改善にかかる時間について、 「重要な効果はなかった」としています。 このため、WHOはレムデシビルについて「症状の軽い重いにかかわらず、入院患者への投与は勧められない」としています。 レムデシビルについては、アメリカのFDA=食品医薬品局が、ことし5月、緊急での使用を許可し、これを受けて日本も特例で使用を承認していて、アメリカでは先月、新型コロナウイルスの治療薬として正式に承認されています。 製薬会社 ギリアド・サイエンシズが声明 ギリアド・サイエンシズは、WHOが指針を公表したことに対して声明を出しました。 それによりますと「製品は、アメリカ、日本、イギリス、ドイツの信頼度の高い多くの治療指針で、入院患者への標準治療薬として認識されている。これらの推奨は、複数の試験からの強固なエビデンスに基づいていて行われている」としています。 そのうえで「患者が回復に至るまでの期間の大幅な短縮などの効果は、医療機関に恩恵をもたらしている。WHOの指針はこのエビデンスを軽視しているように見え、残念に思う。現在世界中で患者数が劇的に増加している中、およそ50か国で、初めてかつ唯一の承認された治療薬として、医師たちに信頼されている」としています。 厚生労働省「承認 見直す予定ない」 レムデシビルは、日本で初めての新型コロナウイルスの治療薬として、ことし5月に承認されました。 アメリカで重症患者に対する緊急的な使用が認められたことを受けて、厚生労働省は審査を大幅に簡略化する「特定承認」の制度を適用し、製薬会社の申請から3日という異例の早さで承認しました。 厚生労働省が公表している「診療の手引き」では、原則、人工呼吸器や人工心肺装置=ECMOなどを装着する重症患者に投与することとしています。 レムデシビルは新型コロナウイルスの増殖を抑える作用がある治療薬としては、今も国内で承認された唯一の薬となっています。 供給量が限定されるため、現在は厚生労働省から使用を希望する医療機関に配付されています。 今回のWHOの指針について、厚生労働省は「承認時に根拠にした治験のデータが否定されたわけではないうえ、有効性がないという結果でもないため、承認について見直す予定はない」と話しています。 加藤官房長官は閣議のあとの記者会見で、指針について「レムデシビルの効果がないとまでは証明されておらず、また、レムデシビルに効果があるとする十分なエビデンスもないという説明などが記載されている」と述べました。 そのうえで「日本ではアメリカでの緊急使用許可を契機に、複数の臨床試験の結果から一定の有効性が確認できたことから、5月に特例承認を行い、現在、レムデシビルを使った治療がなされている。厚生労働省では特段、承認について見直す必要はないというのが、現時点での認識だと承知している」と述べました。 現場の医師「効果を実感 引き続き使っていく」 これまでレムデシビルを使った治療を行ってきた、東京 渋谷区の日本赤十字社医療センターの出雲雄大呼吸器内科部長は、「日本で特例承認されてから、これまでおよそ40人の新型コロナウイルスの重症患者に対してレムデシビルを投与してきたが、生存率の向上や、人工呼吸器から離脱できるようになるなど、効果を実感してきた。レムデシビルは、1人に25万円程度かかるなど高価なこともあり、WHOは『推奨しない』と判断したのかもしれないが、命はお金より重いはずだ。ほかに特効薬が出るまでは、私たちとしては引き続き使っていくことになる」と話していました。事前準備
CaboChaをインストール
・ @/minetta30さんのQiita記事 「Mac(Catalina)にcabocha-pythonがインストールできないときの対処法」実装コード
以下のコードのうち、CaboChaを使って、strオブジェクトから、"係り受け元単語 -> 係り受け先単語"の配列を得る処理は、@ayuchiyさんのQiita記事を参考にしました。
・ @ayuchiyさんのQiita記事 「CaboCha & Python3で文節ごとの係り受けデータ取得」
tkinter_ner_sub_pred_pair.py# Tkinterのライブラリを取り込む import tkinter, spacy, collections, CaboCha, os from typing import List, TypeVar from tkinter import * from tkinter import ttk from tkinter import filedialog from tkinter import messagebox from spacy.matcher import Matcher # グローバル変数の宣言 exracted_entity_word_list = "" user_input_text = "" named_entity_label = "" T = TypeVar('T', str, None) Vector = List[T] # ファイルの参照処理 def click_refer_button(): fTyp = [("","*")] iDir = os.path.abspath(os.path.dirname(__file__)) filepath = filedialog.askopenfilename(filetypes = fTyp, initialdir = iDir) file_path.set(filepath) # 固有表現抽出処理 def extract_words_by_entity_label(text, named_entity_label): nlp = spacy.load('ja_ginza') text = text.replace("\n", "") doc = nlp(text) words_list = [ent.text for ent in doc.ents if ent.label_ == named_entity_label] return words_list # 出力処理 def click_export_button(): # 入力されたテキストファイルの相対パスを取得 path = file_path.get() # 選択された固有表現の種別名を取得 named_entity_label = flg.get() if path[-4:] == '.txt': global user_input_text f = open(path, encoding="utf-8") user_input_text = f.read() label_word_list = extract_words_by_entity_label(user_input_text, named_entity_label) # 指定された固有表現に該当する単語を取得した結果(単語リスト)を、{単語文字列 : 出現回数}の辞書に変換する count_per_word = collections.Counter(label_word_list) # 出現回数の多い順番に並べる freq_per_word_dict = dict(count_per_word.most_common()) #output_list = ["{k} : {v}".format(k=key, v=value) for (key, value) in freq_per_word_dict.items()] # 単語数を取得する unique_word_num = len(freq_per_word_dict) if unique_word_num > 0: message = "{num}件の{label}が見つかりました。\n\n出現回数順に並べた結果は以下です。\n\n".format(num=unique_word_num, label=named_entity_label) word_list = list(freq_per_word_dict.keys()) word_freq_list = list(freq_per_word_dict.values()) for i in range(unique_word_num): tmp = "{rank}番目の単語 : {word}\n出現回数 : {count}\n\n===================\n".format(rank=i+1, word=word_list[i], count=word_freq_list[i]) message += tmp else: message = "{num}件の{label}が見つかりました。\n\n".format(num=unique_word_num, label=named_entity_label) textBox.insert(END, message) global exracted_entity_word_list exracted_entity_word_list = word_list return exracted_entity_word_list else: textBox.insert(END, '\nファイルがテキストファイルではありません') return [] def get_subject_predicate_pair_list(sentence: str, subject_word: str) -> Vector: T = TypeVar('T', str, None) c = CaboCha.Parser() tree = c.parse(sentence) # 形態素を結合しつつ[{c:文節, to:係り先id}]の形に変換する chunks = [] text = "" toChunkId = -1 for i in range(0, tree.size()): token = tree.token(i) text = token.surface if token.chunk else (text + token.surface) toChunkId = token.chunk.link if token.chunk else toChunkId # 文末かchunk内の最後の要素のタイミングで出力 if i == tree.size() - 1 or tree.token(i+1).chunk: chunks.append({'c': text, 'to': toChunkId}) # ループの中で出力される「係り元→係り先」文字列をlistに格納 pair_list = [] # for chunk in chunks: if chunk['to'] >= 0: pair_list.append(chunk['c'] + " → " + chunks[chunk['to']]['c']) output_list = [pair for pair in pair_list if subject_word in pair] return output_list def click_export_button2(): # 入力された主語単語の文字列を取得 order_num = int(subject_num.get())-1 #ユーザが1を入力したとき、配列の0番地を指定する。 subject_string = exracted_entity_word_list[order_num] output_list = get_subject_predicate_pair_list(user_input_text, subject_string) result = "\n".join(output_list) message = """ 単語:「{subject_word}」を主語に持つ「主語と述語」のペアは、以下が見つかりました。 ========================================================================= {result} ========================================================================= 以上です。 """.format(subject_word=subject_string, result=result) textBox.insert(END, message) if __name__ == '__main__': # ウィンドウを作成 root = tkinter.Tk() root.title("固有表現計数カウンター") # アプリの名前 root.geometry("730x500") # アプリの画面サイズ # Frame1の作成 frame1 = ttk.Frame(root, padding=10) frame1.grid() # 「ファイル」ラベルの作成 s = StringVar() s.set('ファイル名:') label1 = ttk.Label(frame1, textvariable=s) label1.grid(row=0, column=0) #テキストボックス1(テキストファイルパス入力欄)の作成 file_path = StringVar() filepath_entry = ttk.Entry(frame1, textvariable=file_path, width=50) filepath_entry.grid(row=0, column=1) # 「」ラベルの作成 t = StringVar() t.set('着目する「主語」:') label1 = ttk.Label(frame1, textvariable=t) label1.grid(row=1, column=0) #テキストボックス2(「主語述語ペア」の「主語」入力欄)の作成 subject_num = StringVar() subject_num_entry = ttk.Entry(frame1, textvariable=subject_num, width=50) subject_num_entry.grid(row=1, column=1) # ラジオボタンの作成 #共有変数 flg= StringVar() #ラジオ1 rb1 = ttk.Radiobutton(frame1, text='人名',value="PERSON", variable=flg) rb1.grid(row=2,column=0) #ラジオ2 rb2 = ttk.Radiobutton(frame1, text='地名',value="LOC", variable=flg) rb2.grid(row=2,column=1) #ラジオ3 rb3 = ttk.Radiobutton(frame1, text='組織名', value="ORG", variable=flg) rb3.grid(row=2,column=2) #ラジオ4 rb4 = ttk.Radiobutton(frame1, text='日付',value="DATE", variable=flg) rb4.grid(row=3,column=0) #ラジオ5 rb5 = ttk.Radiobutton(frame1, text='イベント名',value="EVENT", variable=flg) rb5.grid(row=3,column=1) #ラジオ6 rb6 = ttk.Radiobutton(frame1, text='金額',value="MONEY", variable=flg) rb6.grid(row=3,column=2) # Frame2の作成 frame2= ttk.Frame(root, padding=10) frame2.grid() # 固有表現単語を抽出した結果を表示させるボタンの作成 export_button = ttk.Button(frame2, text='ファイルから指定した種類の単語を洗い出す', command=click_export_button, width=70) export_button.grid(row=0, column=0) # 「主語述語ペア」を抽出した結果を表示させるボタンの作成 export_button2 = ttk.Button(frame2, text='入力した番号の単語を主語に持つ「主語述語ペア」を表示します', command=click_export_button2, width=70) export_button2.grid(row=1, column=0) # テキスト出力ボックスの作成 textboxname = StringVar() textboxname.set('\n\n処理結果 ') label3 = ttk.Label(frame2, textvariable=textboxname) label3.grid(row=1, column=0) textBox = Text(frame2, width=100) textBox.grid(row=3, column=0) # ウィンドウを動かす root.mainloop()( その他、参考にしたサイト )
(参考1)
from typing import List, TypeVar T = TypeVar('T', str, None) def get_subject_predicate_pair_list(subject_word: str) -> List(T): コンストラクタなど、処理を定義とすると、
TypeError: Type List cannot be instantiated; use list() insteadになりました。
・ kb84tkhrのブログ 「寄り道:Type Hint」
本記事では、上記のWebページを参考にして、
from typing import List T = TypeVar('T', str, None) Vector = List[T]としました。
zhttps://docs.python.org/ja/3.8/library/typing.html)には、
以下のように書いてあるのですが。この型は次のように使えます: T = TypeVar('T', int, float) def vec2(x: T, y: T) -> List[T]: return [x, y] def keep_positives(vector: Sequence[T]) -> List[T]: return [item for item in vector if item > 0](参考2)
Tkinterで、ボタンが押された時にイベント駆動されるメソッドを定義する際、このメソッドがreturn文で返す「返り値」を、このメソッドの外で受け取ることができませんでした。
ここは、以下のサイトを参考に、メソッドの外で定義したグローバル変数を、メソッドの中でglobalを付けて呼び出して、グローバル変数のなかに、必要なデータを格納することで対処しました。
・ 「コマンドで使用される関数からのPython tkinter戻り値」
・ 日曜プログラマーの休日 「関数の中でグローバル変数に代入する」今後やってみたいこと
- GUIアプリではなく、Webブラウザアプリを、Streamlitで作ってみたい。
( 参考 )
・ @Nate0928さんのQiita記事 「[簡単爆速]HTMLファイル要らずのStreamlitで数分でWebアプリを作る」
・ @keisuke-otaさんのQiita記事 「Streamlit を用いたデータ分析アプリ制作」
・ @SatoshiTerasakiさんのQiita記事 「Streamlit を使ってデータ可視化ツールを作る」
- 以下の記事で作ったファイル読み込みメソッドを使って、拡張子が「.txt」のテキストファイルだけでなく、PDFファイルやPowerPointファイル、Wordファイル、Excelファイルを読み込めるように拡張したい。

- 投稿日:2020-11-29T17:50:21+09:00
文書中の「人名」・「組織名」を固有表現抽出器で出力後、選択した固有表現単語を起点に持つ「主語->述語」ペアを出力する
作ったもの
Terminalpython3 tkinter_ner_sub_pred_pair.pyスクリプトファイルを実行すると、Tkinterが起動して、次のGUI画面が立ち上がります。
- スクリプトファイルと同じディレクトリにあるsample.txtを相対パスで入力。
- 「人名」のラジオボタンを選択後、「ファイルから指定した種類の単語を洗い出す」ボタンを押す。
『着目する「主語」』入力欄に「2」を入力して、「入力した単語の番号の単語を主語に持つ「主語述語ペア」を表示します。」ボタンを押す。
次は、「地名」のラジオボタンを選択。「ファイルから指定した種類の単語を洗い出す」ボタンを押す。
『着目する「主語」』入力欄に「2」を入力して、「入力した単語の番号の単語を主語に持つ「主語述語ペア」を表示します。」ボタンを押す。
『着目する「主語」』入力欄に「4」を入力して、「入力した単語の番号の単語を主語に持つ「主語述語ペア」を表示します。」ボタンを押す。
次は、「組織名」のラジオボタンを選択。「ファイルから指定した種類の単語を洗い出す」ボタンを押す。
『着目する「主語」』入力欄に「1」を入力して、「入力した単語の番号の単語を主語に持つ「主語述語ペア」を表示します。」ボタンを押す。
( 読み込んだテキストファイル )
NHK NewsWebから、ある日のニュース記事を拝借しました。
sample.txt新型コロナウイルスの治療薬として日本で特例承認されている、抗ウイルス薬レムデシビルについて、WHO=世界保健機関は、世界各地の臨床試験を分析した結果、「死亡率の低下などにつながる重要な効果はなかった」として、入院患者への投与は勧められないとする指針を公表しました。 レムデシビルを開発した製薬会社ギリアド・サイエンシズは、患者が回復に至るまでの期間は大幅に短縮しているなどと反論しています。 WHOは20日、抗ウイルス薬レムデシビルを使った世界各地の入院患者に対する臨床試験を分析し、治療に関する指針を公表しました。 それによりますと、 ▽死亡率の低下や ▽人工呼吸器の必要性、 それに ▽症状の改善にかかる時間について、 「重要な効果はなかった」としています。 このため、WHOはレムデシビルについて「症状の軽い重いにかかわらず、入院患者への投与は勧められない」としています。 レムデシビルについては、アメリカのFDA=食品医薬品局が、ことし5月、緊急での使用を許可し、これを受けて日本も特例で使用を承認していて、アメリカでは先月、新型コロナウイルスの治療薬として正式に承認されています。 製薬会社 ギリアド・サイエンシズが声明 ギリアド・サイエンシズは、WHOが指針を公表したことに対して声明を出しました。 それによりますと「製品は、アメリカ、日本、イギリス、ドイツの信頼度の高い多くの治療指針で、入院患者への標準治療薬として認識されている。これらの推奨は、複数の試験からの強固なエビデンスに基づいていて行われている」としています。 そのうえで「患者が回復に至るまでの期間の大幅な短縮などの効果は、医療機関に恩恵をもたらしている。WHOの指針はこのエビデンスを軽視しているように見え、残念に思う。現在世界中で患者数が劇的に増加している中、およそ50か国で、初めてかつ唯一の承認された治療薬として、医師たちに信頼されている」としています。 厚生労働省「承認 見直す予定ない」 レムデシビルは、日本で初めての新型コロナウイルスの治療薬として、ことし5月に承認されました。 アメリカで重症患者に対する緊急的な使用が認められたことを受けて、厚生労働省は審査を大幅に簡略化する「特定承認」の制度を適用し、製薬会社の申請から3日という異例の早さで承認しました。 厚生労働省が公表している「診療の手引き」では、原則、人工呼吸器や人工心肺装置=ECMOなどを装着する重症患者に投与することとしています。 レムデシビルは新型コロナウイルスの増殖を抑える作用がある治療薬としては、今も国内で承認された唯一の薬となっています。 供給量が限定されるため、現在は厚生労働省から使用を希望する医療機関に配付されています。 今回のWHOの指針について、厚生労働省は「承認時に根拠にした治験のデータが否定されたわけではないうえ、有効性がないという結果でもないため、承認について見直す予定はない」と話しています。 加藤官房長官は閣議のあとの記者会見で、指針について「レムデシビルの効果がないとまでは証明されておらず、また、レムデシビルに効果があるとする十分なエビデンスもないという説明などが記載されている」と述べました。 そのうえで「日本ではアメリカでの緊急使用許可を契機に、複数の臨床試験の結果から一定の有効性が確認できたことから、5月に特例承認を行い、現在、レムデシビルを使った治療がなされている。厚生労働省では特段、承認について見直す必要はないというのが、現時点での認識だと承知している」と述べました。 現場の医師「効果を実感 引き続き使っていく」 これまでレムデシビルを使った治療を行ってきた、東京 渋谷区の日本赤十字社医療センターの出雲雄大呼吸器内科部長は、「日本で特例承認されてから、これまでおよそ40人の新型コロナウイルスの重症患者に対してレムデシビルを投与してきたが、生存率の向上や、人工呼吸器から離脱できるようになるなど、効果を実感してきた。レムデシビルは、1人に25万円程度かかるなど高価なこともあり、WHOは『推奨しない』と判断したのかもしれないが、命はお金より重いはずだ。ほかに特効薬が出るまでは、私たちとしては引き続き使っていくことになる」と話していました。事前準備
CaboChaをインストール
・ @/minetta30さんのQiita記事 「Mac(Catalina)にcabocha-pythonがインストールできないときの対処法」実装コード
以下のコードのうち、CaboChaを使って、strオブジェクトから、"係り受け元単語 -> 係り受け先単語"の配列を得る処理は、@ayuchiyさんのQiita記事を参考にしました。
・ @ayuchiyさんのQiita記事 「CaboCha & Python3で文節ごとの係り受けデータ取得」
tkinter_ner_sub_pred_pair.py# Tkinterのライブラリを取り込む import tkinter, spacy, collections, CaboCha, os from typing import List, TypeVar from tkinter import * from tkinter import ttk from tkinter import filedialog from tkinter import messagebox from spacy.matcher import Matcher # グローバル変数の宣言 exracted_entity_word_list = "" user_input_text = "" named_entity_label = "" T = TypeVar('T', str, None) Vector = List[T] # ファイルの参照処理 def click_refer_button(): fTyp = [("","*")] iDir = os.path.abspath(os.path.dirname(__file__)) filepath = filedialog.askopenfilename(filetypes = fTyp, initialdir = iDir) file_path.set(filepath) # 固有表現抽出処理 def extract_words_by_entity_label(text, named_entity_label): nlp = spacy.load('ja_ginza') text = text.replace("\n", "") doc = nlp(text) words_list = [ent.text for ent in doc.ents if ent.label_ == named_entity_label] return words_list # 出力処理 def click_export_button(): # 入力されたテキストファイルの相対パスを取得 path = file_path.get() # 選択された固有表現の種別名を取得 named_entity_label = flg.get() if path[-4:] == '.txt': global user_input_text f = open(path, encoding="utf-8") user_input_text = f.read() label_word_list = extract_words_by_entity_label(user_input_text, named_entity_label) # 指定された固有表現に該当する単語を取得した結果(単語リスト)を、{単語文字列 : 出現回数}の辞書に変換する count_per_word = collections.Counter(label_word_list) # 出現回数の多い順番に並べる freq_per_word_dict = dict(count_per_word.most_common()) #output_list = ["{k} : {v}".format(k=key, v=value) for (key, value) in freq_per_word_dict.items()] # 単語数を取得する unique_word_num = len(freq_per_word_dict) if unique_word_num > 0: message = "{num}件の{label}が見つかりました。\n\n出現回数順に並べた結果は以下です。\n\n".format(num=unique_word_num, label=named_entity_label) word_list = list(freq_per_word_dict.keys()) word_freq_list = list(freq_per_word_dict.values()) for i in range(unique_word_num): tmp = "{rank}番目の単語 : {word}\n出現回数 : {count}\n\n===================\n".format(rank=i+1, word=word_list[i], count=word_freq_list[i]) message += tmp else: message = "{num}件の{label}が見つかりました。\n\n".format(num=unique_word_num, label=named_entity_label) textBox.insert(END, message) global exracted_entity_word_list exracted_entity_word_list = word_list return exracted_entity_word_list else: textBox.insert(END, '\nファイルがテキストファイルではありません') return [] def get_subject_predicate_pair_list(sentence: str, subject_word: str) -> Vector: T = TypeVar('T', str, None) c = CaboCha.Parser() tree = c.parse(sentence) # 形態素を結合しつつ[{c:文節, to:係り先id}]の形に変換する chunks = [] text = "" toChunkId = -1 for i in range(0, tree.size()): token = tree.token(i) text = token.surface if token.chunk else (text + token.surface) toChunkId = token.chunk.link if token.chunk else toChunkId # 文末かchunk内の最後の要素のタイミングで出力 if i == tree.size() - 1 or tree.token(i+1).chunk: chunks.append({'c': text, 'to': toChunkId}) # ループの中で出力される「係り元→係り先」文字列をlistに格納 pair_list = [] # for chunk in chunks: if chunk['to'] >= 0: pair_list.append(chunk['c'] + " → " + chunks[chunk['to']]['c']) output_list = [pair for pair in pair_list if subject_word in pair] return output_list def click_export_button2(): # 入力された主語単語の文字列を取得 order_num = int(subject_num.get())-1 #ユーザが1を入力したとき、配列の0番地を指定する。 subject_string = exracted_entity_word_list[order_num] output_list = get_subject_predicate_pair_list(user_input_text, subject_string) result = "\n".join(output_list) message = """ 単語:「{subject_word}」を主語に持つ「主語と述語」のペアは、以下が見つかりました。 ========================================================================= {result} ========================================================================= 以上です。 """.format(subject_word=subject_string, result=result) textBox.insert(END, message) if __name__ == '__main__': # ウィンドウを作成 root = tkinter.Tk() root.title("固有表現計数カウンター") # アプリの名前 root.geometry("730x500") # アプリの画面サイズ # Frame1の作成 frame1 = ttk.Frame(root, padding=10) frame1.grid() # 「ファイル」ラベルの作成 s = StringVar() s.set('ファイル名:') label1 = ttk.Label(frame1, textvariable=s) label1.grid(row=0, column=0) #テキストボックス1(テキストファイルパス入力欄)の作成 file_path = StringVar() filepath_entry = ttk.Entry(frame1, textvariable=file_path, width=50) filepath_entry.grid(row=0, column=1) # 「」ラベルの作成 t = StringVar() t.set('着目する「主語」:') label1 = ttk.Label(frame1, textvariable=t) label1.grid(row=1, column=0) #テキストボックス2(「主語述語ペア」の「主語」入力欄)の作成 subject_num = StringVar() subject_num_entry = ttk.Entry(frame1, textvariable=subject_num, width=50) subject_num_entry.grid(row=1, column=1) # ラジオボタンの作成 #共有変数 flg= StringVar() #ラジオ1 rb1 = ttk.Radiobutton(frame1, text='人名',value="PERSON", variable=flg) rb1.grid(row=2,column=0) #ラジオ2 rb2 = ttk.Radiobutton(frame1, text='地名',value="LOC", variable=flg) rb2.grid(row=2,column=1) #ラジオ3 rb3 = ttk.Radiobutton(frame1, text='組織名', value="ORG", variable=flg) rb3.grid(row=2,column=2) #ラジオ4 rb4 = ttk.Radiobutton(frame1, text='日付',value="DATE", variable=flg) rb4.grid(row=3,column=0) #ラジオ5 rb5 = ttk.Radiobutton(frame1, text='イベント名',value="EVENT", variable=flg) rb5.grid(row=3,column=1) #ラジオ6 rb6 = ttk.Radiobutton(frame1, text='金額',value="MONEY", variable=flg) rb6.grid(row=3,column=2) # Frame2の作成 frame2= ttk.Frame(root, padding=10) frame2.grid() # 固有表現単語を抽出した結果を表示させるボタンの作成 export_button = ttk.Button(frame2, text='ファイルから指定した種類の単語を洗い出す', command=click_export_button, width=70) export_button.grid(row=0, column=0) # 「主語述語ペア」を抽出した結果を表示させるボタンの作成 export_button2 = ttk.Button(frame2, text='入力した番号の単語を主語に持つ「主語述語ペア」を表示します', command=click_export_button2, width=70) export_button2.grid(row=1, column=0) # テキスト出力ボックスの作成 textboxname = StringVar() textboxname.set('\n\n処理結果 ') label3 = ttk.Label(frame2, textvariable=textboxname) label3.grid(row=1, column=0) textBox = Text(frame2, width=100) textBox.grid(row=3, column=0) # ウィンドウを動かす root.mainloop()( その他、参考にしたサイト )
(参考1)
from typing import List, TypeVar T = TypeVar('T', str, None) def get_subject_predicate_pair_list(subject_word: str) -> List(T): コンストラクタなど、処理を定義とすると、
TypeError: Type List cannot be instantiated; use list() insteadになりました。
・ kb84tkhrのブログ 「寄り道:Type Hint」
本記事では、上記のWebページを参考にして、
from typing import List T = TypeVar('T', str, None) Vector = List[T] def get_subject_predicate_pair_list(sentence: str, subject_word: str) -> Vector:としました。
以下の公式サイトにある「型エイリアス」のサンプルコードを参考にしたものです。
・ Python3.9.1rc1 Documentation » Python 標準ライブラリ » 開発ツール »「typing --- 型ヒントのサポート」
Vector = list[float] def scale(scalar: float, vector: Vector) -> Vector: return [scalar * num for num in vector] # typechecks; a list of floats qualifies as a Vector. new_vector = scale(2.0, [1.0, -4.2, 5.4])・Python 3.8.6 Documentation » Python 標準ライブラリ » 開発ツール »「typing --- 型ヒントのサポート」には、
以下のように書いてあるのですが。この型は次のように使えます: T = TypeVar('T', int, float) def vec2(x: T, y: T) -> List[T]: return [x, y] def keep_positives(vector: Sequence[T]) -> List[T]: return [item for item in vector if item > 0](参考2)
Tkinterで、ボタンが押された時にイベント駆動されるメソッドを定義する際、このメソッドがreturn文で返す「返り値」を、このメソッドの外で受け取ることができませんでした。
ここは、以下のサイトを参考に、メソッドの外で定義したグローバル変数を、メソッドの中でglobalを付けて呼び出して、グローバル変数のなかに、必要なデータを格納することで対処しました。
・ 「コマンドで使用される関数からのPython tkinter戻り値」
・ 日曜プログラマーの休日 「関数の中でグローバル変数に代入する」今後やってみたいこと
- GUIアプリではなく、Webブラウザアプリを、Streamlitで作ってみたい。
( 参考 )
・ @Nate0928さんのQiita記事 「[簡単爆速]HTMLファイル要らずのStreamlitで数分でWebアプリを作る」
・ @keisuke-otaさんのQiita記事 「Streamlit を用いたデータ分析アプリ制作」
・ @SatoshiTerasakiさんのQiita記事 「Streamlit を使ってデータ可視化ツールを作る」
- 拡張子が「.txt」のテキストファイルだけでなく、PDFファイルやPowerPointファイル、Wordファイル、Excelファイルも読み込めるように拡張したい。
( 過去に作成した拙記事 )
・ 「PDF・Word・PowerPoint・Excelファイルからテキスト部分を一括抽出するメソッド」
- 投稿日:2020-11-29T17:00:59+09:00
React(next.js), TypeScript, python, Azure Functions, GASでアプリを作ってみた
前提
・開発経験1年半程度のエンジニアです
・普段はPHP(laravel)のバックエンド開発がメインです
・javaScript(jQuery)も実務で使います(たまに)
・vue(next)も少し学習したことはあります
・なのでフロントエンドに関しては未経験に毛が生えた程度の知識です
・フロントエンドフレームワークの勉強しようと思い、React, TypeScriptで簡単なアプリを作りましたこの記事では作成したアプリと使用技術、その技術の勉強方法を紹介しますが、各技術の詳細、ソースコードの記述は割愛しておりますのでご了承ください。
成果物
https://news-app-ruby.vercel.app
*css等が整えられていないですが、「done is better than perfect」の精神で公開してます笑
おいおい直していこうかと思います
機能
・主要ニュースサイトの記事タイトル、記事URLをまとめたアプリ
・NewYorkTimes、The GuardianはAPIを提供しているのでAPIでニュースデータを取得
・上記以外のニュースサイトはAPIを提供していないので、各サイトのTOPページからスクレイピングでTOP記事データ(記事タイトル、記事URL)を取得
・NewYorkTimes、The Guardian、BBC NEWSの原文が英語のニュースはタイトルをマウスオーバーすると日本語翻訳される(GoogleAppsScript使用)
・どのニュースページも構造は同じなので、Reactのコンポーネントを使いまわしています(開発がすごい楽でした)
・UI/UXはまるでなっていませんが、割と便利なアプリで自分で日常的な情報収集用途として使っています使用技術とその目的
1.React(Next.js) + TypeScript
APIデータの取得、SSG(static site generation)でページ描画2.Python
ニュースデータを各サイトからscrapingで取得。JSONデータに変換してReact側に渡す3.Azure Functions
上記pythonファイルのAPIサーバーとして使用4.GoogleAppsScript(GAS)
英語→日本語に翻訳する際使用。JSONデータに変換してReact側に渡す5.Vercel
上記アプリのデプロイ先勉強方法と所感
1. TypeScript
・【世界で7万人が受講】Understanding TypeScript - 2020年最新版というUdemyの教材をメインに学習しました。かなりボリュームがありますが、包括的にTypeScriptを学べるのでおすすめです。
・javascriptに関しても、今までは実務で必要にかられたときにググりながら局所的に使用していたのみなので、今回包括的に学べてすごくためになりました。またES2015についても学べたのでこれもためになりました
・javascript知らない人でも問題なく理解できる教材かと思います。2.React
・これも下記のUdemy教材をメインで学習しました。
1:【はむ式】フロントエンドエンジニアのための React ・ Redux アプリケーション開発入門
2:最短・最速で作る Youtube クローンアプリ React・React Hooks編
・2つとも完走はしておりません。1の前半でReactの概要を学習しつつ、2のアプリ制作の過程で知識の定着を図りました。
・1のReduxの箇所は難しかったので今回は飛ばしました(笑)。(おいおい学び直します。多分。。。)
・代わりにHooksを、公式サイトで少し学習しました。Hooksの方がとっつきやすかったです
・reduxが「Reactは難しい」という考えの一つの遠因のような気が個人的にします3.Next.js, Vercel
・公式サイトのチュートリアルがわかりやすかったです。半日もあれば1
周できると思います。(next.jsを使って簡単なブログアプリを作る)
・vercelへのデプロイ方法も上記のチュートリアルで学べます
・複雑な設定なしでgithubにpushするだけで自動的にvercelにデプロイできるので、革命的に便利に感じました
・個人利用の場合は費用等はかからないそうです
・TypeScriptの導入方法も公式のドキュメント通りにやれば簡単にできました4.Python
・実はPythonもほぼ初めて触りましたが、BeautifulSoupの公式ドキュメントみながらスクレイピング実装しただけなので、腰を据えて学習はしてないです
・PHPより簡潔にかけるなと少し感動しました。人気言語であるのは頷けます
・ただPythonは公式ドキュメントが読みづらいと思いました5.Azure Functions
・スクレイピングをサーバレスで動かしたかったので利用しました
・AWS lamdaでもよかったかもしれませんが、Azureは無料枠があったのと、VSCODEとの連携が楽と聞いていたので今回はAzure Functionsを利用しました
・Azure Functions の Python 開発者向けガイドという公式のチュートリアルで学習しました
・VSCODEにextencion入れればVSCODE内で開発、テスト、デプロイが簡単にできるので、便利でした。このやり方も公式ドキュメントがわかりやすかったです最後に
以上、簡単なアプリ開発を通して、React,TypeScript,next.js,Azureの触りの部分を学習しました。
React,Next.jsは公式ドキュメントが充実していたので初心者でも学習しやすかったです。ちなみに上記技術スタックの学習に約2〜3週間(仕事終わりの1、2時間、休日2,3時間)費やし、アプリ自体は概ね3日間程で作成しました。
Reactは触っていて単純に楽しかったです。
下記の記事にもあるように、HTML側で、JS/TSを制御するより、JSXでJS/TSでHTML側を制御する方が自分にはとっつきやすかったです。
参照:JSXが実はベターな解だったのではないか?
現に今の職場では巨大なHTML文の中に所狭しとjqueryの制御が埋め込まれているのでかなりコードの可読性が悪くなっております。スタートアップ等を中心にバックエンド、フロントエンドの垣根が低くなってきているようなので(ベンチャー、スタートアップの面接で実際に何度か聞いたことがあります)、折に触れてフロントエンドの学習もしていきたいと思います。
ただ、次の開発のアイディアが浮かびません。。。

- 投稿日:2020-11-29T17:00:59+09:00
初心者がReact(next.js), TypeScript, python, Azure Functions, GASでアプリを作ってみた
前提
・開発経験1年半程度のエンジニアです
・普段はPHP(laravel)のバックエンド開発がメインです
・javaScript(jQuery)も実務で使います(たまに)
・vue(next)も少し学習したことはあります
・なのでフロントエンドに関しては未経験に毛が生えた程度の知識です
・フロントエンドフレームワークの勉強しようと思い、React, TypeScriptで簡単なアプリを作りましたこの記事では作成したアプリと使用技術、その技術の勉強方法を紹介しますが、各技術の詳細、ソースコードの記述は割愛しておりますのでご了承ください。
成果物
https://news-app-ruby.vercel.app
*css等が整えられていないですが、「done is better than perfect」の精神で公開してます笑
おいおい直していこうかと思います
機能
・主要ニュースサイトの記事タイトル、記事URLをまとめたアプリ
・NewYorkTimes、The GuardianはAPIを提供しているのでAPIでニュースデータを取得
・上記以外のニュースサイトはAPIを提供していないので、各サイトのTOPページからスクレイピングでTOP記事データ(記事タイトル、記事URL)を取得
・NewYorkTimes、The Guardian、BBC NEWSの原文が英語のニュースはタイトルをマウスオーバーすると日本語翻訳される(GoogleAppsScript使用)
・どのニュースページも構造は同じなので、Reactのコンポーネントを使いまわしています(開発がすごい楽でした)
・UI/UXはまるでなっていませんが、割と便利なアプリで自分で日常的な情報収集用途として使っています使用技術とその目的
1.React(Next.js) + TypeScript
APIデータの取得、SSG(static site generation)でページ描画2.Python
ニュースデータを各サイトからscrapingで取得。JSONデータに変換してReact側に渡す3.Azure Functions
上記pythonファイルのAPIサーバーとして使用4.GoogleAppsScript(GAS)
英語→日本語に翻訳する際使用。JSONデータに変換してReact側に渡す5.Vercel
上記アプリのデプロイ先勉強方法と所感
1. TypeScript
・【世界で7万人が受講】Understanding TypeScript - 2020年最新版というUdemyの教材をメインに学習しました。かなりボリュームがありますが、包括的にTypeScriptを学べるのでおすすめです。
・javascriptに関しても、今までは実務で必要にかられたときにググりながら局所的に使用していたのみなので、今回包括的に学べてすごくためになりました。またES2015についても学べたのでこれもためになりました
・javascript知らない人でも問題なく理解できる教材かと思います。2.React
・これも下記のUdemy教材をメインで学習しました。
1:【はむ式】フロントエンドエンジニアのための React ・ Redux アプリケーション開発入門
2:最短・最速で作る Youtube クローンアプリ React・React Hooks編
・2つとも完走はしておりません。1の前半でReactの概要を学習しつつ、2のアプリ制作の過程で知識の定着を図りました。
・1のReduxの箇所は難しかったので今回は飛ばしました(笑)。(おいおい学び直します。多分。。。)
・代わりにHooksを、公式サイトで少し学習しました。Hooksの方がとっつきやすかったです
・reduxが「Reactは難しい」という考えの一つの遠因のような気が個人的にします3.Next.js, Vercel
・公式サイトのチュートリアルがわかりやすかったです。半日もあれば1
周できると思います。(next.jsを使って簡単なブログアプリを作る)
・vercelへのデプロイ方法も上記のチュートリアルで学べます
・複雑な設定なしでgithubにpushするだけで自動的にvercelにデプロイできるので、革命的に便利に感じました
・個人利用の場合は費用等はかからないそうです
・TypeScriptの導入方法も公式のドキュメント通りにやれば簡単にできました4.Python
・実はPythonもほぼ初めて触りましたが、BeautifulSoupの公式ドキュメントみながらスクレイピング実装しただけなので、腰を据えて学習はしてないです
・PHPより簡潔にかけるなと少し感動しました。人気言語であるのは頷けます
・ただPythonは公式ドキュメントが読みづらいと思いました5.Azure Functions
・スクレイピングをサーバレスで動かしたかったので利用しました
・AWS lamdaでもよかったかもしれませんが、Azureは無料枠があったのと、VSCODEとの連携が楽と聞いていたので今回はAzure Functionsを利用しました
・Azure Functions の Python 開発者向けガイドという公式のチュートリアルで学習しました
・VSCODEにextencion入れればVSCODE内で開発、テスト、デプロイが簡単にできるので、便利でした。このやり方も公式ドキュメントがわかりやすかったです最後に
以上、簡単なアプリ開発を通して、React,TypeScript,next.js,Azureの触りの部分を学習しました。
React,Next.jsは公式ドキュメントが充実していたので初心者でも学習しやすかったです。ちなみに上記技術スタックの学習に約2〜3週間(仕事終わりの1、2時間、休日2,3時間)費やし、アプリ自体は概ね3日間程で作成しました。
Reactは触っていて単純に楽しかったです。
下記の記事にもあるように、HTML側で、JS/TSを制御するより、JSXでJS/TSでHTML側を制御する方が自分にはとっつきやすかったです。
参照:JSXが実はベターな解だったのではないか?
現に今の職場では巨大なHTML文の中に所狭しとjqueryの制御が埋め込まれているのでかなりコードの可読性が悪くなっております。スタートアップ等を中心にバックエンド、フロントエンドの垣根が低くなってきているようなので(ベンチャー、スタートアップの面接で実際に何度か聞いたことがあります)、折に触れてフロントエンドの学習もしていきたいと思います。
ただ、次の開発のアイディアが浮かびません。。。
- 投稿日:2020-11-29T16:40:59+09:00
Pythonのファイル・フォルダのループ処理
globを使えばよいだけなのですが、実用的には絶対パス化、ディレクトリ・ファイルのフィルタリング、ソートも行った方がよいため、コードもいくらか長くなります。トップディレクトリ以下の全サブディレクトリを処理する
import os from glob import glob # トップディレクトリをセットする sys.argv[1]など top_level_dir_path = '/home/user' # サブディレクトリ、ファイルの絶対パスのリストを得る # 再帰処理(サブディレクトリ以下のディレクトリも処理する)したい場合は recursive=True にする # recursive=False の場合はワイルドカードは '/*' でよいが recursive=Trueの場合は '/**' とする # Windows, Linuxどちらもパスの区切り文字は/でOK paths = list(map(os.path.abspath, glob(top_level_dir_path + '/**', recursive=False))) # ディレクトリのみフィルタリングする paths = list(filter(os.path.isdir, paths)) # ソートされていないので昇順にソートする paths.sort() # 1つずつ処理する for i, p in enumerate(paths): print('[%s / %s] Start processing %s' % (i + 1, len(paths), p))トップディレクトリ以下のファイル名パターンにマッチしたファイルを処理する
import os from glob import glob # トップディレクトリをセットする sys.argv[1]など top_level_dir_path = '/home/user' # サブディレクトリ、ファイルの絶対パスのリストを得る # この例ではjpgファイルを取得している # ファイル名に特定の文字列が含まれる場合は *tokutei*.jpg とする # /**はrecurseive=Trueと合わせて再帰的にディレクトリを全列挙するという意味 paths = list(map(os.path.abspath, glob(top_level_dir_path + '/**/*.jpg', recursive=True))) # ファイルのみフィルタリングする paths = list(filter(os.path.isfile, paths)) # ソートされていないので昇順にソートする paths.sort() # 1つずつ処理する for i, p in enumerate(paths): print('[%s / %s] Start processing %s' % (i + 1, len(paths), p))参考
ファイル・ディレクトリの名前のパターンマッチングについては公式ドキュメントを参照してください。
- 投稿日:2020-11-29T16:37:51+09:00
AWS S3で1000件以上のオブジェクトを操作する方法
こんにちは。フューチャー株式会社TIG所属2020年新卒の大西です。
フューチャー Advent Calendar 2020 3日目を担当します。現在業務でAWS(特にS3やGlue Jobなど)を使うことが多いのため、私自身の業務で躓いた経験を元に 「AWS初心者が躓きやすいポイントとその解消法」 というテーマでブログを書いていきます。
まず、今日扱うテーマは 「Boto3を用いた1,000件以上のS3オブジェクトの操作」 です。
躓きポイントの概要
Boto3はPythonを介してAWSを操作するためのライブラリです。
Boto3を用いてAWSを操作する方は、
list_objects_v2やobjects.filter等の関数を使って複数のオブジェクトを取得する機会があるのではないでしょうか。
list_object_v2をもちいたオブジェクトの取得例get_objects.pyimport boto3 s3 = boto3.resource("s3") bucket = s3.Bucket(bucket_name) prefix = "S3バケットへのパス" objects = bucket.meta.client.list_objects_v2(Bucket=bucket.name, Prefix=prefix)しかし、上記の関数には 「一度のリクエストで取得できるオブジェクトの数は1,000件まで」 というルールがあり、1001件目以降のオブジェクトは取得することができません。
Boto3の公式ドキュメント内のS3に関する記述部分を読むと、S3では下記の関数に同様のルールが存在しているようです。
- get_bucket_replication()
- list_bucket_analytics_configurations()
- list_bucket_inventory_configurations()
- list_bucket_metrics_configurations()
- list_multipart_uploads()
- list_object_versions()
- list_objects()
- list_objects_v2()
- list_parts()
- put_bucket_analytics_configuration()
- put_bucket_inventory_configuration()
- put_bucket_lifecycle_configuration()
- put_bucket_metrics_configuration()
- put_bucket_replication()
- object_versions.filter()
- objects.filter()
- BucketLifecycleConfiguration.put()
解決方法
今回は例として
list_objects_v2を用いる場合の解決方法を書きます。list_objects_v2の返り値のdictには、結果が切り捨てられているかどうかを示す
IsTruncatedが含まれています。
そして、取得するオブジェクト数の上限を指定せずlist_objects_v2を実行し、取得したオブジェクトの数が1000件を超えていた場合は、objects["IsTruncated"]にTrueがセットされて返ってきます。
また、list_objects_v2は引数のStartAfterを設定することで、指定したS3ファイルの次のファイルからオブジェクトを取得してくれます。よって、
objects["IsTruncated"]==Trueだった場合は、1000件目のS3キーをStartAfterに設定して再度list_objects_v2を実行するという処理を["IsTruncated"]==Falseになるまで繰り返すことで、1,000件以上のオブジェクトでも取得することができます。ソース
get_objects.pys3 = boto3.resource("s3") bucket = s3.Bucket(source_bucket) prefix = "S3バケットへのパス" keys = get_all_keys(bucket.name, prefix, [], "") def get_all_keys(bucket_name: str, prefix: str, keys: List[str], marker: str) -> List[str]: """ S3の指定したパスに存在するオブジェクトのキーを全て取得する Parameters ---------- bucket_name: String 対象のBucket prefix: String 対象のディレクトリのパス keys: List[str] marker: String 関数の中から呼び出す時のための引数。通常はkeys = [], marker = "" で呼び出す Returns ------- List[str] 取得したキーのリスト """ s3 = boto3.resource("s3") bucket = s3.Bucket(bucket_name) objects = bucket.meta.client.list_objects_v2(Bucket=bucket.name, Prefix=prefix, StartAfter=marker) if "Contents" in objects: keys.extend([content["Key"] for content in objects["Contents"]]) # 返り値のIsTruncatedがTrueかどうかを確認する if objects.get("isTruncated"): # marker引数に取得したkeysの末尾の値を設定して再度get_all_keysを実行する return get_all_keys(bucket_name=bucket_name, prefix=prefix, keys=keys, marker=keys[-1]) return keys最後に
今回は 「AWS初心者が躓きやすいポイントとその解消法」 の第一弾として
IsTruncatedを用いた1,000件上限の解決についてまとめました。大量のオブジェクトを一度に取得したい方はぜひ参考にしてみてください。