- 投稿日:2020-11-29T23:46:52+09:00
mp3を一括でCBR 320k 48Khzにアップコンバートするコマンド
これは何
特定のビットレート以下のmp3を一括でアップコンバートするコマンド。
もちろん、もとの音質が悪すぎる場合はやっても効果はないです。mp3って非可逆圧縮だし。source
requires
ffmpeg
soxinstall
cloneしてから
install.shで /usr/local/bin/upconvert_mp3 が配置される
usage
upconvert_mp3 [-b アップコンバート先ビットレート デフォは320] [-t これ以下のビットレートなら320kにアップコンバートするよという指定 デフォは160] [-r アップコンバート先ビットレート デフォは48000] [-d 対象フォルダ]以上!((c)厚切りジェイソン)
- 投稿日:2020-11-29T23:37:23+09:00
音源を一括でmp3に変換するコマンド
枕
1.USBメモリでDJする場合
rekordbox – CLOUD-CONNECTED PROFESSIONAL DJ PLATFORM
経由でUSBメモリに音源を転送する際に、Windowsだと対応機種に読み込ませるために
USBメモリをFAT32でしかフォーマットできないため、USBメモリの上限が32GBである2.iPhoneでDJする場合
DJ App for iPad and iPhone - djay by Algoriddim
で使用するためにiPhoneに音源を転送する必要がある(Spotify連携はしたことがないし、連携対応自体ディスコンになっている)が、
自分が所有している初代iPhone SEの容量が128GBであるつまり
wavとかflacみたいな非可逆圧縮音声ファイルだとすぐ容量が一杯になっちゃうの。
そこでmp3ながらもDJでの使用に差し支えない(個人の感想です)CBR 320K 48Khzの音質に圧縮する必要がある。src
require
lame
sox
gitベースのstaticビルドのffmpeg 64bit 最新版をインストールするshell - Qiita のffmpeginstall
cloneしてから
bash install.shで /usr/local/bin/convert_to_mp3 が配置される。
usage
convert_to_mp3 [一括でmp3へ変換したいフォルダ]以上!((c)厚切りジェイソン)
- 投稿日:2020-11-29T23:29:50+09:00
Linux 標準シェル(bash)の主な環境設定ファイル
【Linux 標準シェル(bash)の主な環境設定ファイル】
全ユーザー
bash起動時に読み込み
・/etc/bash.bashrc
→bash起動時に実行させたい処理(Debian系)・/etc/bash.rc
→bash起動時に実行させたい処理(RedHat系)ログイン時
・/etc/profile
→環境変数、利用環境にかかわるもの各ユーザー 個別
ログイン時
・~/.bash_profile
→環境変数などユーザー環境にかかわるもの※ このファイルのパーミッションには、読み取り権が必要。
このホームディレクトリの所有者であるユーザは読み書き権限を持つ。・~/.bash_login
→/bash_profileがない場合の読み込み次候補(/.bash_profileと内容同じ)・~/.profile
→/.bash_loginがない場合の読み込み次候補(/.bash_profileと内容同じ)bash起動時
・~/.bashrc
→bash起動時に実行させたい処理ログアウト時
・~/.bash_logout
→ログアウト時に実行させたい処理
- 投稿日:2020-11-29T23:29:50+09:00
Linuxの標準シェル(bash)の主な環境設定ファイル
【Linuxの標準シェル(bash)の主な環境設定ファイル】
全ユーザー
bash起動時に読み込み
・/etc/bash.bashrc
→bash起動時に実行させたい処理(Debian系)・/etc/bash.rc
→bash起動時に実行させたい処理(RedHat系)ログイン時
・/etc/profile
→環境変数、利用環境にかかわるもの各ユーザー 個別
ログイン時
・~/.bash_profile
→環境変数などユーザー環境にかかわるもの・~/.bash_login
→/bash_profileがない場合の読み込み次候補(/.bash_profileと内容同じ)・~/.profile
→/.bash_loginがない場合の読み込み次候補(/.bash_profileと内容同じ)bash起動時
・~/.bashrc
→bash起動時に実行させたい処理ログアウト時
・~/.bash_logout
→ログアウト時に実行させたい処理
- 投稿日:2020-11-29T22:59:55+09:00
gitベースのstaticビルドのffmpeg 64bit 最新版をインストールするshell
これ何?
John Van Sickle - FFmpeg Static Builds
から手動でDLするのが面倒になったので作ったshell。git
https://github.com/tknr/install_ffmpeg_amd64
使い方
git cloneして
sudo su - bash install_ffmpeg_amd64.shで /usr/loca/bin/ffmpeg がインストールされます。
64bit版以外の場合
適宜 install_ffmpeg_amd64.sh の9行目辺り
curl https://johnvansickle.com/ffmpeg/builds/ffmpeg-git-amd64-static.tar.xz -O || exit 1を書き換えたらいいです
- 投稿日:2020-11-29T22:47:15+09:00
イベント報告/Event Report
Followed by English content.
OpenChainのISO化の話からは少し外れますが、今週は12/1にOpen Compliance Summit、12/2-4にOpen Source Summit Japanと大きなイベントが続きましたので、その報告です。
Open Compliance Summitとは?
Open Compliance Summitは、毎年この時期に日本で開催されているイベントです。名前の通りOSSのコンプライアンスについて議論する場です。Linux Foundationのメンバーだったり招待してもらったりしないと参加できません。チャタムハウスルールが適用されますし、その分濃密な話を期待して良いです。今年は新型コロナの影響でオンラインでの開催になりました。
今年の内容
コンプライアンス関連で2020年の一番大きな出来事としては、もちろんOpenChain 2.1のISO化ですね。SPDXもISO化に向けて活動していることも紹介されていました。
2021年に向けては、ISO化もあって「可視化はできた、これからは最適化だ」だそうです。その流れを踏まえてかコンプライアンスのツールに関する発表が多かった印象です。
個人的は一番は、有名な著作権ゴロが昨年PostgreSQLに関わっていたというのを知ったことです。昨年ということはリリース12の謝辞に載ってますね。あ、ということは私の名前も彼のと並んで書かれているってことになります。Open Source Summit Japanとは?
Open Source Summit Japanとは毎年春の終わりから夏の初め辺りに日本で開催されているイベントです。こちらはコンプライアンスに限定せずOSSについて広く議論する場です。今年はオリンピックと重なるのでそもそもいつもと違う時期に予定されていましたが、新型コロナの影響でこの時期にオンラインでの開催になりました。
今年の内容
1日目
基調講演では最初に、2020年は感染爆発や貿易摩擦などがあった中、OSSは上手くやってきた、という話がありました。それどころか、感染爆発と闘うのにもOSSが使われているそうです。(皆さんの身近なところでは東京都の新型コロナウイルス感染症対策サイトもそうですよね。)
次にAutomotive Grade Linux UCB バージョン10.0の紹介がありました。自動車にはあまり詳しくないので、これ以上は書けませんが、次のバージョンの愛称がKooky Koiだそうです。Kookyの意味は分かりませんが、Koiは鯉のことです。
また、スーパーコンピューター富岳でLinuxが使われていることも紹介されました。2日目
LF Energyについて基調講演の中でも触れられましたし、基調講演の後LF Energyミニサミットが開催されました。また、LF Edgeに関するセッションもありました。LF EnergyもLF Edgeも単純にその名前のOSSと対応する団体というわけではなく抽象的なもののようですので、会議の名前には「オープンソース」とありますが対象がかなり広がっているのを感じます。
3日目
RISC-Vについて基調講演でも触れられましたし、RISC-Vを扱うセッションもありました。(他の日にもありましたが。)RISC-Vはオープンハードウェアですから、もう「オープンソース」の範囲を超えてますよね。
また、マイクロソフトの人がこのようなLinux関連の会合で組み込みの話をしていたのには、時代は変わったのだなと、感銘を受けました。明日は?
「他の会社ではOSSライセンスのコンプライアンス活動にどう取り組んでいるのだろう」というのは皆さんもとても気になることではないでしょうか。OpenChain Japan WGではそのような疑問に答える調査を行ない、論文としてまとめました。明日はその論文の著者の一人である遠藤さんが調査結果について書きます。楽しみにしていてください。
It's a little off the topic of ISOization of OpenChain, but this week we had a big event such as Open Compliance Summit on 12/1 and Open Source Summit Japan on 12/2-4. So I will report them here.
What is Open Compliance Summit?
The Open Compliance Summit is an annual event held in Japan at this time of year. As the name implies, it is a place to discuss OSS compliance. To join this event, you must be a member of the Linux Foundation or invited. Chatham House rules apply, so you can expect a deeper discucssion. This year, due to COVID-19, it was held online.
Contents of this year
Of course, the biggest event in 2020 related to compliance is ISOization of OpenChain 2.1. It was also introduced that SPDX is also working toward ISOization.
For 2021, it is said that "visualization has became possible, so optimization will be in turn" due to ISOization. Based on that trend, I have the impression that there were many announcements about compliance tools.
The biggest thing for me is that I learned that the famous copyright troll was involved in PostgreSQL last year. So he is mentioned in Acknowledgments for Release 12. Oh, that means my name is written alongside his name...What is Open Source Summit Japan?
Open Source Summit Japan is an event held in Japan from the end of spring to the beginning of summer every year. This is a place to discuss OSS widely, not limited to compliance. This year was scheduled for a different time than usual because it overlaps with the Olympics, but due to COVID-19, it was held online at this time.
Contents of this year
1st day
In the keynote speech it was said that OSS was well going in 2020, despite the pandemic and trade conflicts. On the contrary, OSS is also used to combat pandemic. (This is also true of Tokyo's stopcovid19 site, isn't it?)
Next, Automotive Grade Linux UCB version 10.0 was introduced. I'm not very familiar with cars, so I can't write any more, but the next version is nicknamed Kooky Koi. I don't know what Kooky means, but Koi is a carp in Japanese.
It was also introduced that Linux is used in the supercomputer FUGAKU.2nd day
LF Energy was mentioned in the keynote speech, and the LF Energy Mini Summit was held after the keynote speech. There was also a session about LF Edge. It seems that neither LF Energy nor LF Edge is one OSS name, so although the name of the conference says "open source", I feel that the scope of this summit has expanded considerably.
3rd day
RISC-V was mentioned in the keynote speech, and there was also a session dealing with RISC-V. (Although it happened on other days.) RISC-V is open hardware, so it's already beyond the scope of "open source".
I was also impressed that the times have changed when a person from Microsoft talked about embedded systems at such Linux-related meetings.tomorrow?
Everyone might be wondering, "How are other companies working on OSS license compliance activities?" The OpenChain Japan WG conducted a survey to answer such questions and compiled it as a treatise. Tomorrow, one of the authors of the treatise, Endo-san, will talk about the survey results. I hope you all will enjoy it.
- 投稿日:2020-11-29T22:30:57+09:00
Amazon LinuxインスタンスにRails6をインストールするまでの手順
この記事でやろうとしていること
タイトルの通りですが、Amazon LinuxインスタンスにRails6.0.3をインストールするまでの流れです。
なぜRails6.0.3か?というのは、おなじみ「Railsチュートリアル」の第6版で指定されているバージョンだから、というだけです。RailsチュートリアルではAWSの統合開発環境 (IDE)「Cloud9」の利用を前提としています。Cloud9はRailsをインストールする上での前提パッケージが既に入っているので、
$ gem install rails -v 6.0.3と叩くだけですんなりRailsが入ってくれますが、一歩cloud9という温室から外に出るとそうはいきません。
というわけで、何番煎じかはわかりませんが、少なくとも筆者はいろいろググって何とか解決したので、需要はあるはず。さっそく解説に入っていきます。
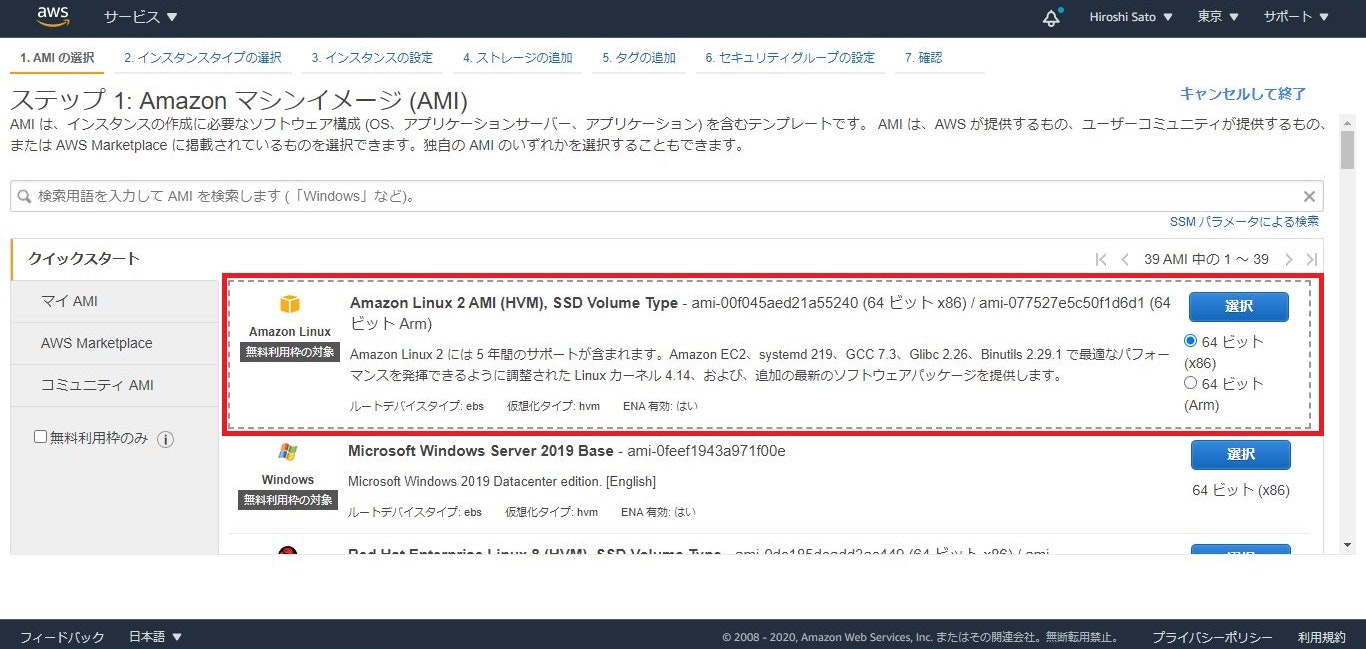
まず、Amazon Linuxインスタンスの詳細は↓の通り。普通にEC2インスタンスをデプロイする際の一番最初に出てくるやつです。
Gitインストール
まずはGitをインストールする必要があります。
後述の手順で、Gitレポジトリをクローンしていろいろとインストールするためです。ここは特に迷いなく、
# yum install gitでOKです。
rbenvインストール
rbenvとは、複数のRubyのバージョンを管理し、プロジェクトごとにRubyのバージョンを指定して使うことを可能としてくれるツールです。
また、(本記事においてはここが重要なのですが)Rubyのインストールもサポートしてくれます。基本的にはGitHubのrbenvレポジトリのREADMEに書いている通りに従う流れですが、
Gitレポジトリをクローン # git clone https://github.com/rbenv/rbenv.git ~/.rbenv ディレクトリ移動後、ソースからインストール # cd ~/.rbenv && src/configure && make -C src warning: gcc not found; using CC=cc aborted: compiler not found: ccと、gccがインストールされていないとコケてしまいますので、
# yum install gccでインストールしてから、再度ソースインストールしましょう。
# cd ~/.rbenv && src/configure && make -C srcrbenvインストール完了後も引き続きREADMEに従って、
# echo 'export PATH="$HOME/.rbenv/bin:$PATH"' >> ~/.bash_profileとパスを通してから、rbenv init コマンドで初期設定します。
# ~/.rbenv/bin/rbenv init # Load rbenv automatically by appending # the following to ~/.bash_profile: eval "$(rbenv init -)"と出るので、従いましょう。
# eval "$(rbenv init -)"パスがしっかり通っていることも確認して、
# source ~/.bash_profile # echo $PATH /root/.rbenv/shims:/root/.rbenv/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/binrenv-doctorスクリプトを使用して、rbenvが正しく設定されていることを確認します。
# curl -fsSL https://github.com/rbenv/rbenv-installer/raw/master/bin/rbenv-doctor | bash Checking for `rbenv' in PATH: /root/.rbenv/bin/rbenv Checking for rbenv shims in PATH: OK Checking `rbenv install' support: not found Unless you plan to add Ruby versions manually, you should install ruby-build. Please refer to https://github.com/rbenv/ruby-build#installation Counting installed Ruby versions: none There aren't any Ruby versions installed under `/root/.rbenv/versions'. You can install Ruby versions like so: rbenv install 2.2.4 Checking RubyGems settings: OK Auditing installed plugins: OK出力結果の3行目に「Checking `rbenv install' support: not found」と出力されています。
これが使えないと最新版のRubyをrbenvでインストールできないので、ここからはruby-buildをインストールします。ruby-buildインストール
ここからは、GitHubのruby-buildレポジトリのREADMEに書いている通りに従っていきます。
rbenvのディレクトリに「plugins」ディレクトリを作って、レポジトリをクローンしてプルするだけです。# mkdir -p "$(rbenv root)"/plugins # git clone https://github.com/rbenv/ruby-build.git "$(rbenv root)"/plugins/ruby-build # git -C "$(rbenv root)"/plugins/ruby-build pullRubyインストール
さあ、これで晴れてrbenvを使ってRubyインストールが出来るようになりました。
まずはインストール可能なRubyのバージョンを確認しましょう。# rbenv install --list 2.5.8 2.6.6 2.7.2 jruby-9.2.13.0 maglev-1.0.0 mruby-2.1.2 rbx-5.0 truffleruby-20.3.0 truffleruby+graalvm-20.3.0 Only latest stable releases for each Ruby implementation are shown. Use 'rbenv install --list-all' to show all local versions.ここでは最新版の「2.7.2」をインストールすることとします。
# rbenv install 2.7.2 Downloading ruby-2.7.2.tar.bz2... -> https://cache.ruby-lang.org/pub/ruby/2.7/ruby-2.7.2.tar.bz2 Installing ruby-2.7.2... BUILD FAILED (Amazon Linux 2 using ruby-build 20201118) Inspect or clean up the working tree at /tmp/ruby-build.20201128132117.3587.qONaMm Results logged to /tmp/ruby-build.20201128132117.3587.log Last 10 log lines: from ./tool/rbinstall.rb:846:in `block (2 levels) in install_default_gem' from ./tool/rbinstall.rb:279:in `open_for_install' from ./tool/rbinstall.rb:845:in `block in install_default_gem' from ./tool/rbinstall.rb:835:in `each' from ./tool/rbinstall.rb:835:in `install_default_gem' from ./tool/rbinstall.rb:799:in `block in <main>' from ./tool/rbinstall.rb:950:in `block in <main>' from ./tool/rbinstall.rb:947:in `each' from ./tool/rbinstall.rb:947:in `<main>' make: *** [do-install-all] Error 1おや、makeでコケていますね。
結論としては「openssl-devel」パッケージが必要なところ、インストールされていなかったことが原因です。
私は正直、ここで小1時間あれやこれや調べて、当てずっぽうで問題解決に至ったのですが、じつは↓にruby-buildに必要な前提パッケージが説明されていました。
公式に勝る情報はないですね。
https://github.com/rbenv/ruby-build/wiki#suggested-build-environmentopenssl-develはサクっとyumでインストールしましょう。
# yum install -y openssl-develその後、
# rbenv install 2.7.2で無事にrubyの最新版をインストールすることに成功しました。
rubyのパスが2つある件(未解決)
ここまでの手順でrubyをインストール完了しましたが、パスが通っていません。
ruby本体の在り処を探してみますと・・・# ll ~/.rbenv/shims/ruby -rwxr-xr-x 1 root root 385 Nov 28 13:53 /root/.rbenv/shims/ruby # ll ~/.rbenv/versions/2.7.2/bin/ruby -rwxr-xr-x 1 root root 184688 Nov 28 13:52 /root/.rbenv/versions/2.7.2/bin/rubyあれ。2箇所にある。別にシンボリックリンクってわけでもないし。ファイルサイズがかなり違う…
以下のように、どちらもrubyコマンドとして実行できます。# ~/.rbenv/shims/ruby -v ruby 2.7.2p137 (2020-10-01 revision 5445e04352) [x86_64-linux] # ~/.rbenv/versions/2.7.2/bin/ruby -v ruby 2.7.2p137 (2020-10-01 revision 5445e04352) [x86_64-linux]ちょっとこの点、ちゃんと調べられていないのですが、rbenvで確認すると後者のパスで認識してるっぽいので、筆者の場合はそちらでパスを通し、Rubyインストールを終了としました。
# rbenv versions * 2.7.2 (set by /root/.rbenv/version) # echo 'export PATH="$HOME/.rbenv/versions/2.7.2/bin:$PATH"' >> ~/.bash_profile # source ~/.bash_profileRailsインストール
お膳立ては整いましたので、あとはRailsチュートリアルの通り、Rails6.0.3をインストールするだけです。
# gem install rails -v 6.0.3 # rails -v Rails 6.0.3お疲れ様でした。
- 投稿日:2020-11-29T22:22:22+09:00
【IT用語】CUIとGUIと違いについて【初心者向け】
パソコンを操作する方法には、2種類の方法があります。IT業界ではよくCUIとGUIと呼ばれます。今回はこれについて、簡単に説明使用と思います。
GUI
僕たちが普段パソコンやスマホを触る時は、画面上にあるアイコンやボタン、検索窓などを利用して、操作していると思います。
結論、これが
GUIと呼ばれる物です。Macのパソコンの場合は、こんな感じですね。
ちなみに
GUIの正式名称は、Graphical user interface(グラフィカルユーザーインターフェース)と言う名前で、視覚的な感じでパソコンやスマホを操作する方法のことです。
CUI
対して
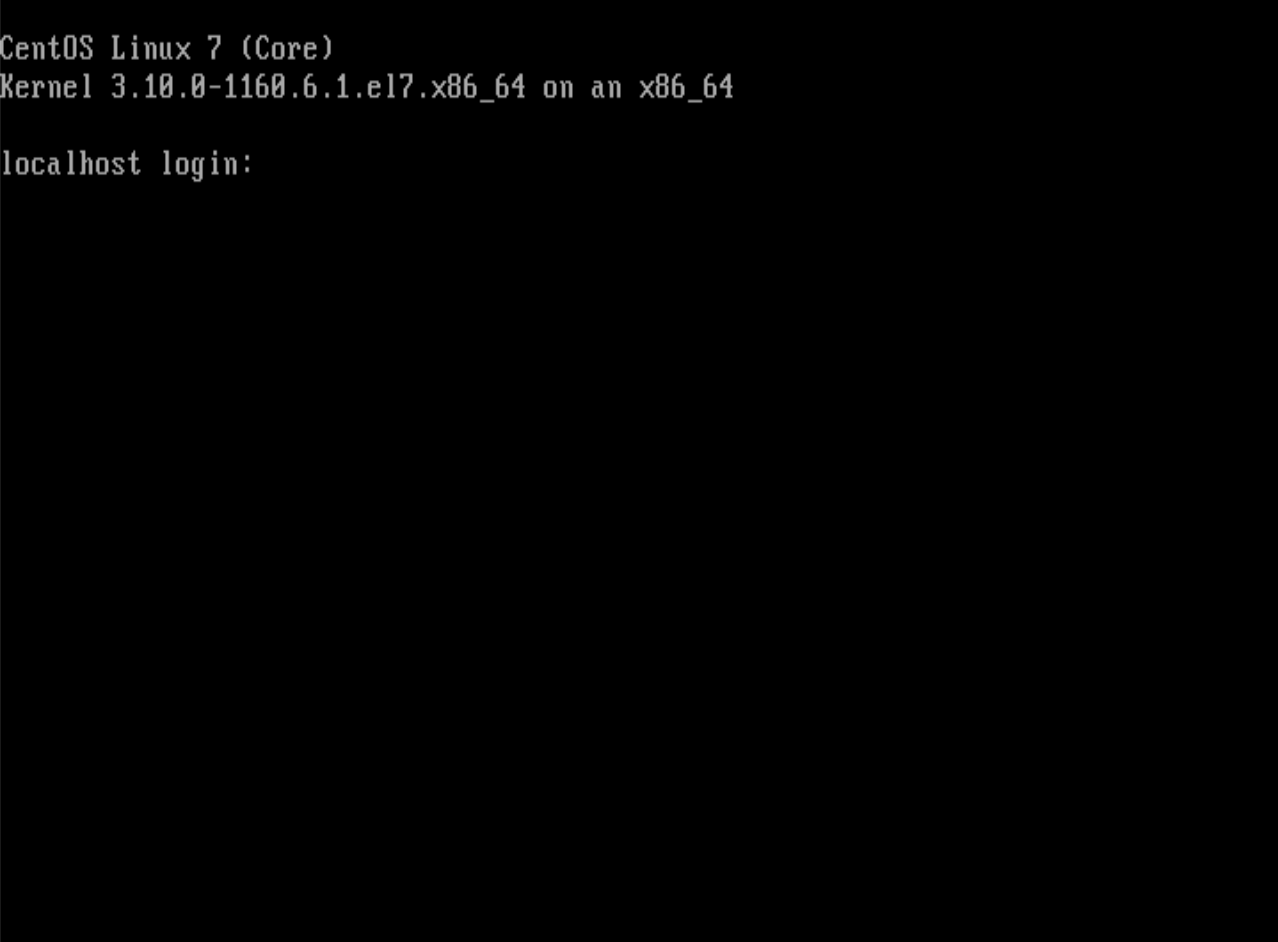
CUIとはCharacter user interface(キャラクターユーザーインターフェース)と言う正式名称で、Characterとは文字と言う意味です。要するに、文字を入力することで、パソコンなどを操作する方法のことです。いわゆる黒い画面と言われ、画像で見るとこんな感じですね。
IT業界の中でも、バックエンドやインフラ系のエンジニアしか、あまり触れることの無い物です。あと視覚的な認識ではなく、コマンドと言われる特定の文字列での操作になりますので、最初はイメージがしづらく難しいと感じる人も多いです。
ただ、これが使えるようになると、何かWeb開発をする際に自分で環境を構築することもでき、仕事の幅も広がるものになります。
まとめ
今回は、IT業界でよく言われる
CUIとGUIの言葉について、解説しました。こう言う用語は、知らないと
会話ができないものになりますので、しっかり抑えておくと役に立ちます。最後まで読んでいただき、ありがとうございました!
筆者:yuki|学習10日目で初案件獲得→現在はフルスタックエンジニア転職に向けて学習中
Qiita:https://qiita.com/yuki4839
Twitter:https://twitter.com/yuki35522891

- 投稿日:2020-11-29T20:40:07+09:00
mv コマンドつかい方
mv ファイル 移動先ディレクトリ
こうすることによってmvコマンドでファイルを移動させることができる。
例
mv pink.jpg app/assets/images/mv ファイル1 ファイル2 ファイル3 ディレクトリA
ファイルを複数同時にやることもできる
Linuxコマンドをちゃんと勉強して息を吸うように使用できるレベルにならないといけないなと感じた。
- 投稿日:2020-11-29T20:37:11+09:00
HDDのパーティションを完全削除する方法
問題
ずっとsda2のパーティションが残ってて消えない。。。
sudo fdisk -l /dev/sda >> Disk /dev/sda: 14.5 GiB, 15504900096 bytes, 30283008 sectors Disk model: Silicon-Power16G Units: sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disklabel type: dos Disk identifier: 0x500a0dff Device Boot Start End Sectors Size Id Type /dev/sda1 1948285285 3650263507 1701978223 811.6G 6e unknown /dev/sda2 0 0 0 0B 74 unknown Partition table entries are not in disk order.
fdiskを使用して削除を試みても消すことができなかった。sudo fdisk /dev/sda >> Welcome to fdisk (util-linux 2.33.1). Changes will remain in memory only, until you decide to write them. Be careful before using the write command. Command (m for help): d Partition number (1,2, default 2): 2 Could not delete partition 2解決
ddコマンドにより、HDDのデータを全てNULLで埋め尽くすことで解決できた。sudo dd if=/dev/zero of=/dev/sda bs=1K count=1
- if=/dev/zero: 読み出し元を常にNULL文字を出力するデバイス/dev/zeroに設定
- of=/dev/sda: 書き込み先をHDDのデバイス/dev/sdaに設定
- bs=1K: 1Kbyte単位で書き込み
- count=1: 書き込み回数1
これを実行後に確認するとパーティションが全て消えていることがわかる。
sudo fdisk -l /dev/sda >> Disk /dev/sda: 14.5 GiB, 15504900096 bytes, 30283008 sectors Disk model: Silicon-Power16G Units: sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disklabel type: dos Disk identifier: 0x435be661後は
fdiskで以下のように新たにパーティションを作成すればOK。sudo fdisk /dev/sda >> Welcome to fdisk (util-linux 2.33.1). Changes will remain in memory only, until you decide to write them. Be careful before using the write command. Command (m for help): n Partition type p primary (0 primary, 0 extended, 4 free) e extended (container for logical partitions) Select (default p): p Partition number (1-4, default 1): First sector (2048-30283007, default 2048): Last sector, +/-sectors or +/-size{K,M,G,T,P} (2048-30283007, default 30283007): Created a new partition 1 of type 'Linux' and of size 14.4 GiB. Command (m for help): w The partition table has been altered. Calling ioctl() to re-read partition table. Syncing disks.パーティション確認。
sudo fdisk -l /dev/sda >> Disk /dev/sda: 14.5 GiB, 15504900096 bytes, 30283008 sectors Disk model: Silicon-Power16G Units: sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disklabel type: dos Disk identifier: 0x435be661 Device Boot Start End Sectors Size Id Type /dev/sda1 2048 30283007 30280960 14.4G 83 Linuxフォーマットも
fdiskで以下のようにお好みで。sudo fdisk /dev/sda Welcome to fdisk (util-linux 2.33.1). Changes will remain in memory only, until you decide to write them. Be careful before using the write command. Command (m for help): t Selected partition 1 Hex code (type L to list all codes): L 0 Empty 24 NEC DOS 81 Minix / old Lin bf Solaris 1 FAT12 27 Hidden NTFS Win 82 Linux swap / So c1 DRDOS/sec (FAT- 2 XENIX root 39 Plan 9 83 Linux c4 DRDOS/sec (FAT- 3 XENIX usr 3c PartitionMagic 84 OS/2 hidden or c6 DRDOS/sec (FAT- 4 FAT16 <32M 40 Venix 80286 85 Linux extended c7 Syrinx 5 Extended 41 PPC PReP Boot 86 NTFS volume set da Non-FS data 6 FAT16 42 SFS 87 NTFS volume set db CP/M / CTOS / . 7 HPFS/NTFS/exFAT 4d QNX4.x 88 Linux plaintext de Dell Utility 8 AIX 4e QNX4.x 2nd part 8e Linux LVM df BootIt 9 AIX bootable 4f QNX4.x 3rd part 93 Amoeba e1 DOS access a OS/2 Boot Manag 50 OnTrack DM 94 Amoeba BBT e3 DOS R/O b W95 FAT32 51 OnTrack DM6 Aux 9f BSD/OS e4 SpeedStor c W95 FAT32 (LBA) 52 CP/M a0 IBM Thinkpad hi ea Rufus alignment e W95 FAT16 (LBA) 53 OnTrack DM6 Aux a5 FreeBSD eb BeOS fs f W95 Ext'd (LBA) 54 OnTrackDM6 a6 OpenBSD ee GPT 10 OPUS 55 EZ-Drive a7 NeXTSTEP ef EFI (FAT-12/16/ 11 Hidden FAT12 56 Golden Bow a8 Darwin UFS f0 Linux/PA-RISC b 12 Compaq diagnost 5c Priam Edisk a9 NetBSD f1 SpeedStor 14 Hidden FAT16 <3 61 SpeedStor ab Darwin boot f4 SpeedStor 16 Hidden FAT16 63 GNU HURD or Sys af HFS / HFS+ f2 DOS secondary 17 Hidden HPFS/NTF 64 Novell Netware b7 BSDI fs fb VMware VMFS 18 AST SmartSleep 65 Novell Netware b8 BSDI swap fc VMware VMKCORE 1b Hidden W95 FAT3 70 DiskSecure Mult bb Boot Wizard hid fd Linux raid auto 1c Hidden W95 FAT3 75 PC/IX bc Acronis FAT32 L fe LANstep 1e Hidden W95 FAT1 80 Old Minix be Solaris boot ff BBT Hex code (type L to list all codes): 86 Changed type of partition 'Linux' to 'NTFS volume set'. Command (m for help): w The partition table has been altered. Calling ioctl() to re-read partition table. Syncing disks.
- 投稿日:2020-11-29T19:32:51+09:00
gnome の閉じるボタンとかの位置を変更
環境
- Ubuntu 20.04.1 LTS
- GNOME Shell 3.36.4
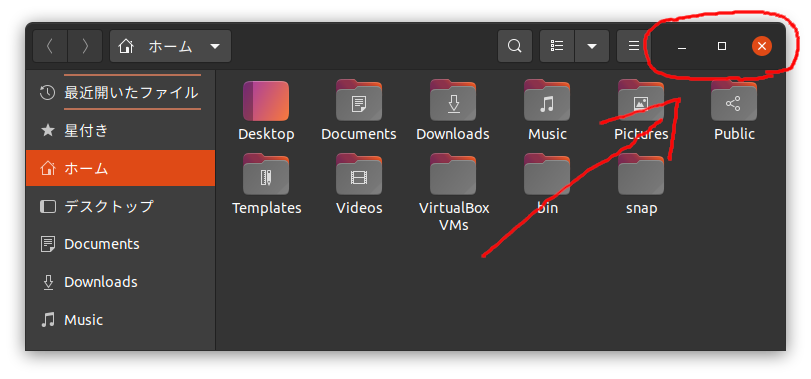
gnome のボタン
こいつらのことです
現在の設定を確認
$ gsettings get org.gnome.desktop.wm.preferences button-layout ':minimize,maximize,close'設定を変更
Mac みたいに左側に出す
$ gsettings set org.gnome.desktop.wm.preferences button-layout 'close,minimize,maximize:'
もとに戻す
$ gsettings reset org.gnome.desktop.wm.preferences button-layoutおわり
おわりです
- 投稿日:2020-11-29T13:01:24+09:00
Linuxでバッチファイル的なものを作って実行したい(Windowsのbatみたいなやつ)
どんなことをしたいん?
Windowsでいう batファイルにあたるもの をLinuxでも作って実行したいん。
タイトルそのままやんけ(´・ω・`)せっかくだからDocker Desktop使ってみよう
Windows10でDockerをインストールしてCentOS8の検証環境を作るところまでやってみましょい!
でDockerを導入したので、今回はDocker上のCentOS8でいろいろ試してみます。
作ったコンテナを起動して…
端末起動!
新規ファイル作成
まずは下記コマンドでシェルスクリプトファイルを作成します。
touch test1.sh下記コマンドで、作ったシェルスクリプトファイルをviで開きます。
vi test1.sh
iを押してviの編集モードに移る。下記を入力。
#!/usr/bin/bash echo herou-wa-rudo入力終わったら
Escで編集モード抜ける。
:wqで書き込み&viを終了。1行目の
#!/usr/bin/bashで どのシェルで実行するか を指定しています。シェルスクリプトファイルをいろんなフォルダーに置いても実行できるように
#!/usr…と絶対パスで指定した方が都合がよいと思います。作ったシェルスクリプトファイルに対して実行権限を与えてあげる
chmod 755 test1.shほいじゃあ、自作シェルスクリプトを実行してみよう
./test1.shOKっすね。
シェルスクリプト実行時注意点
同じフォルダにあるからといってパスの先頭を省略しちゃダメ。
省略すると下図のようになっちゃいます。
『test1.sh』という ファイル ではなく コマンド を探して実行しようとして、こけます。相対パスで指定する場合でも頭に『./』を付けるように。
蛇足
Dockerが役に立ってくれましたん。
CentOS8にRcloneインストールしてGoogleDriveの特定フォルダの中身表示するとこまでやるん
のRcloneのインストール検証でもDockerを使いました。参考サイトさん
https://uxmilk.jp/8395
https://eng-entrance.com/linux-shellscript-doバージョン
Windows10 Pro バージョン1909 OSビルド19042.630
Docker Desktop:2.5.0.1(49550) Engine:19.03.13
CentOS Linux release 8.2.2004 (Core)




- 投稿日:2020-11-29T02:46:28+09:00
Linuxでのプロセス置換
はじめに
導入
Linuxで使うbash等のシェルには、様々な○○置換という機能がありますが、その中でも「プロセス置換」(
<(コマンド)や>(コマンド)) というのはなかなかイメージし辛いのではないかと思います。
※特にコマンド置換 ($(コマンド)や`コマンド`) と名前が紛らわしいというのもあります。これはパイプと機能的にも仕組み的にも近いものですので、この機会にパイプとの関連性も含め、仕組みを紹介したいと思います。
環境
bash,zsh共にプロセス置換の機能を持っていますが、以下ではbashを前提として仕組みを説明します。
なお、各動作確認は x86_64 WSL1(Win10)/Ubuntu18.04.2 LTS, bash4.4.19(1) で行っています。プロセス置換の概要
利用目的
bash manページのプロセス置換の項にも説明はあるのですが、なかなかそれだけではイメージし辛いのではないかと思います。
そこで利用目的から把握するとなると、次のようになります。
- 2つ以上のプログラム間でデータをやり取りさせるために
- ユーザが一時ファイルを明示的に作ることなく
- かつ、データをやり取りする複数のプログラムを並行して動作させられる
- パイプラインよりも柔軟な使い方ができる機能
次の章で、実際の利用シーンを見てみます。
利用シーン
利用シーンとしては、データをやり取りするプログラムの内、「読み込みを行う方」「書き込みを行う方」どちらを主体として見るかで、2通りの使い分けがあります。
それぞれ、<( LIST ),>( LIST )という記載を使い分けます。
※LISTの部分はコマンドリストであり、パイプ・リダイレクト含め一般のコマンドと変わりありません読み込み主体
典型的な使い方としては、「コマンドを2つ実行したときのそれぞれの出力結果が同一内容か、あるいはどのような差分があるか、diffで確認する」が挙げられます。
この場合、読み込みを行う diff が主体ということです。もしプロセス置換を使わない場合、次のようにリダイレクトを使うことが考えられます。この場合一時ファイル ( この場合
tmp1.out,tmp2.out) を作る必要がありますし、diff を開始するには、それぞれのコマンド ( この場合command1,command2) の終了を待つ必要があります。プロセス置換を使わない場合$ command1 > tmp1.out $ command2 > tmp2.out $ diff tmp1.out tmp2.out $ rm tmp1.out tmp2.outこれに対し、プロセス置換を使うと次のようになります。
プロセス置換を使う場合$ diff <( command1 ) <( command2 )使わない例に比較して、コマンドを1つにまとめてスッキリさせられるというメリットの他、ファイルを作らずに済む、並行動作が可能というメリットが生まれるのです。
実際に、tr と sed による英字の大文字化の効果が同じであることを diff + プロセス置換 で試した例が次のようになります。差分が出力されていないので、ちゃんと同じだと判断されていることが分かります。
diff+プロセス置換の実例$ hostname angel $ hostname | tr a-z A-Z ANGEL $ hostname | sed -e 's/.*/\U&/' ANGEL $ diff <( hostname | tr a-z A-Z ) <( hostname | sed -e 's/.*/\U&/' ) $書き込み主体
もう一例、書き込み主体としては、tee によってリアルタイムで出力されるログにデータ加工をかけてファイルに保存するような、そういう用途も考えられます。
プロセス置換を使わない場合$ tee tmp.out $ command < tmp.out > save.out $ rm tmp.outプロセス置換を使う場合$ tee >( command > save.out )tee を使う主目的は、標準出力経由でコンソール等にデータを出力させつつ、同一内容を別途ファイルに保存することですが、プロセス置換を使うことで「リアルタイムに」データを加工する用途に転換させられるのです。
パイプラインとの違い
「プログラム間のデータのやり取り」「一時ファイル不要」「並行動作」という意味では、各種シェルでサポートしている「パイプライン」という仕組みがあります。
実は、いずれもパイプという種類のファイルを活用するのは共通なのですが、その利用方法に違いがあります。
※パイプについては、「Linuxのファイルの種類」のパイプ(FIFOスペシャル) を参考にどうぞ。
※その他パイプを活用する機能としては、bash4のコプロセスのチュートリアルで取り上げた「コプロセス ( co-process )」もありますが、ここでは割愛します。パイプライン
パイプラインのイメージ
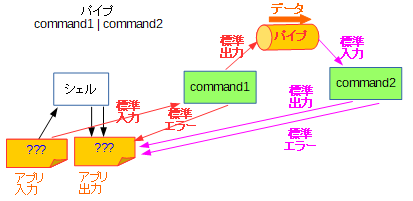
パイプラインは、よく知られる通り
command1 | command2の形式でコマンドを指定することで、両者の標準出力・標準入力を同一のパイプに接続し、データのやり取りを可能にする機能です。イメージとしては次の図のようになります。
参考: 「標準入力・標準出力ってなに?」のリダイレクト・パイプラインパイプラインの処理の流れ
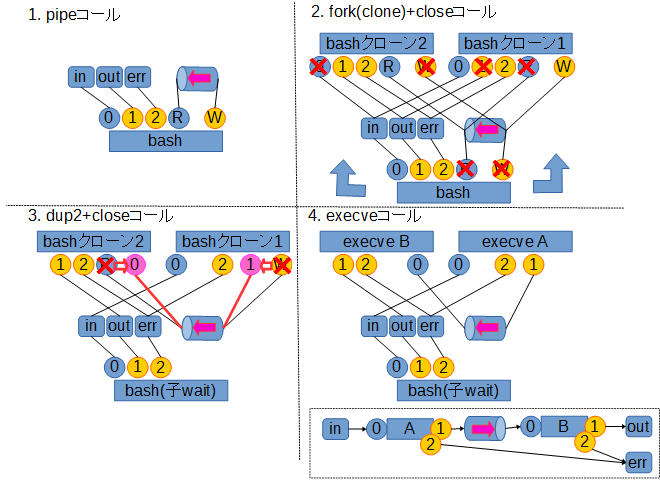
実際にこれを実現するためには、シェルがプログラム実行に持ち込むまでに各種システムコールを駆使して、標準入力(ファイルディスクリプタ0番)・標準出力(ファイルディスクリプタ1番)をパイプに接続し直す処理を行います。
中でも鍵を握るのは、無名のパイプとそこに接続されたファイルディスクリプタを生成する pipe システムコールと、ファイルディスクリプタの複製を行う dup2 システムコールです。
以下、A | Bというパイプラインを実行する時の処理の流れをまとめたものです。
※図中の○で表現されているのは、実際に(パイプを含む)ファイルに接続される、ファイルディスクリプタを表します
※一部余分な close コールが入っていますがそこは気にしないでください
参考: 「1>/dev/null 2>&1と2>&1 1>/dev/nullの違い」へのご指摘の調査へのコメント
パイプラインの制約
このように、パイプを通じてデータをやり取りすることができるのですが、幾つかの制約があります。
- データの経路が直列のみ
A | B | C | …という形式で、直列にデータの流れを設けることはできますが、A→B と同時に A→C というように、複数並列にデータの経路を設けることができません- 標準入力・標準出力以外の手段がない
標準入力・標準出力を繋ぎなおすため、プログラム側で特別な対応なしに使うことができますが、逆にファイルを指定してデータをやり取りするプログラムでは使えませんこのような制約のため、今回紹介しているプロセス置換の方がより柔軟に使えるという面があります。
プロセス置換
プロセス置換のイメージ
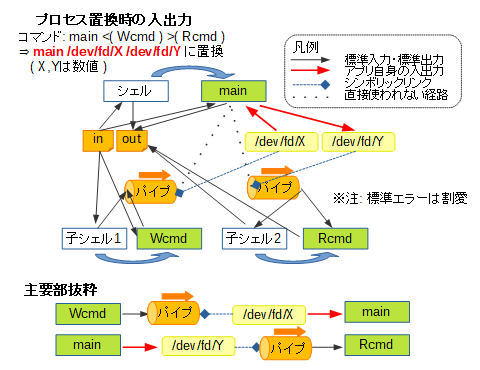
一方でプロセス置換を使った場合のデータの経路は、次のようなイメージになります。
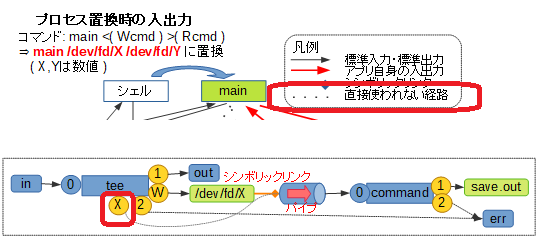
これは、main <( Wcmd ) >( Rcmd )というコマンド、2種類のプロセス置換を同時に使った場合のイメージです。
ここで次の注意点があります。
- 標準入力・標準出力のつなぎ替え
標準入力・標準出力のつなぎ替えが発生するのは、<( LIST ),>( LIST )で指定されたLIST部分を実行するための子シェル以降であり、主体となるコマンドでつなぎ替えが発生しないこと- 置換内容
<( LIST ),>( LIST )で指定された部分は、コマンド実行時には/dev/fd/X( Xはシェルが決めた数値 ) というファイル名に置き換えられること- シンボリックリンク
置換によって得られた/dev/fd/Xは、生成されたパイプへのシンボリックリンクとなること- 主体となるプログラムからの入出力
置換によって得られた/dev/fd/Xを入力あるいは出力に用いるのは、主体となるプログラム自身で行う必要がある、すなわち、主体となるプログラムは与えられたファイル名に基づき処理を行う機能を要すること
※ただし、この点はA < <( B )やA > >( B )のようにリダイレクトを併用することで、標準入力・標準出力での入出力に対応させることができますなので、パイプラインとは大分使い勝手が変わってくることになります。
プロセス置換の処理の流れ
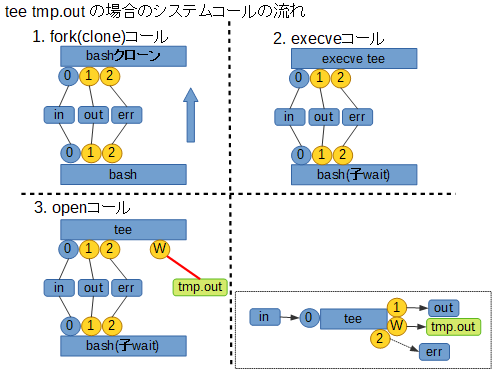
さて、この時どのように処理が行われるか、上で紹介した tee コマンドを例に挙げて見てみます。
まず前提として、tee を単純に使用した場合、コマンドライン引数として与えたファイルを tee 自身が open して使う、という点に注意が必要です。処理の流れは次のようになり、結果的に標準出力経由と、指定したファイルの両方にデータを出力することになります。
一方でプロセス置換を使った場合、パイプでの入出力経路が整えられた状態で各プログラムが起動されます。
その上で主体となる tee は、コマンドライン引数として ( 置換によって指定された )/dev/fd/Xを open することでパイプへの経路を確保します。
以下の図をご覧ください。
結局のところ、プロセス置換によるデータ連携は
/dev/fd/Xがパイプへのシンボリックリンクになっているから実現できることですが、シンボリックリンクの生成に tee自身はもちろんシェルも関与しません。これは後述しますが、Linux kernel の procfs の機能によるものです。プロセス置換の特長と制限
上述のような処理を行うため、プロセス置換には次のような特長があります。
- 並列複数のデータ経路
置換を複数設けることで、並列にデータ経路 ( パイプ ) を複数設けることができます- ファイル名ベースでのアクセス
主体となるプログラムの方では、ファイル名ベースで入出力を扱う延長線上で、パイプへの入出力を行うことができます- パイプラインの解消
A | while read VAR; do シェル変数設定; doneのような複合コマンドとパイプラインが混在するケースの場合、途中で設定したシェル変数を大本のシェルに反映させることができません。これは、パイプラインを構成する各コマンドが子シェルの中で実行されるためです。
しかしこれを、while read VAR; do シェル変数設定; done < <( A )のプロセス置換に書き直してパイプラインを解消することで、大本のシェルに反映させられる形にできますただし、1点パイプラインの時と異なり、注意する点があります。
- プロセス置換で起動したプログラムの非同期性
パイプラインA | B | …については、シェルがまとめて1個のジョブとして扱い、A,B,… 全ての終了を待ち合わせた上でジョブの完了とします。また、個々のコマンドの終了ステータスもPIPESTATUSというシェル変数から取得することができます。
しかし、<( LIST )や>( LIST )で起動したLIST部分は非同期扱いとなるため、処理の完了待ちや終了ステータスの取得をシェルがサポートしてくれません。必要に応じて自前で対処を考える必要がでてきます。procfsの機能
いくつかの疑問点
これまでプロセス置換の具体的な処理内容を見てきましたが、よくよく考えると疑問に思える出てくるかも知れません。
- シンボリックリンク名
/dev/fd/Xの衝突
異なるシェル上のプロセス置換でそれぞれ/dev/fd/Xのシンボリックを利用する際、名前が衝突して不都合が生じないか
- 無名パイプへのシンボリックリンク
そもそもデータ連携に用いるパイプは無名ファイルであるところ、どうやってシンボリックリンクを作っているのか- 使われない入出力経路
これまでの画像に出てきた「直接使われない経路」や用途の不明なファイルディスクリプタ ( 図中 X で表されるもの ) は何のために存在しているのか
これらの点を解決しているのが、Linux kernel の持つ procfs の機能です。
procfsによるサポート
procfs は、タイプ proc によって
/procにマウントされる仮想的なファイルシステムです。
以下のように mount コマンドによってマウント状況を見ることができます。procのマウント状況確認例$ mount -t proc proc on /proc type proc (rw,nosuid,nodev,noexec,noatime)procfsの機能は多岐に渡るため、詳細はproc(5)manページ等を参照いただくのが良いかと思いますが、プロセス置換については以下に挙げる機能が関わってきます。
- プロセスに応じて内容の変化する
/proc/self/
procfsは、/proc/プロセスID/というディレクトリ毎にプロセス情報へアクセスする各種仮想的なサブディレクトリ・ファイルを管理していますが、/proc/self/という特殊なディレクトリはアクセスするプロセス自身の情報を管理するディレクトリとして働きます。
プロセス置換で現れる/dev/fdというのは、この特殊ディレクトリの配下の/proc/self/fd/へのシンボリックリンクになっているため、/dev/fd/Xは/proc/self/fd/Xと等価であり、その内容もプロセス毎に変化することになります。なので、シンボリックリンク名/dev/fd/Xの衝突が問題にならないのです。- アクセス中のファイル実体へのシンボリックリンク機能
/proc/プロセスID/fd/あるいは/proc/self/fd/以下は、当該プロセスがアクセスしているファイル実体へのシンボリックリンクが、ファイルディスクリプタの番号に応じて procfsの機能により配置されています。これは、実体がパイプのような無名ファイルであっても使える優れものです。
参考:「Linuxのファイルの種類」の使用中のファイルを参照するシンボリックリンク
ただし、プログラムが/dev/fd/X( =/proc/self/fd/X) の形式でアクセスするためには、既にファイルディスクリプタ X を通じてパイプ実体へ接続されていなければなりません。
これまで出てきた「直接使われない経路」というのは、実はこの/dev/fd/Xを作り出すために存在する、パイプへのアクセス経路を確保するためのものだったのです。procfsでの見え方
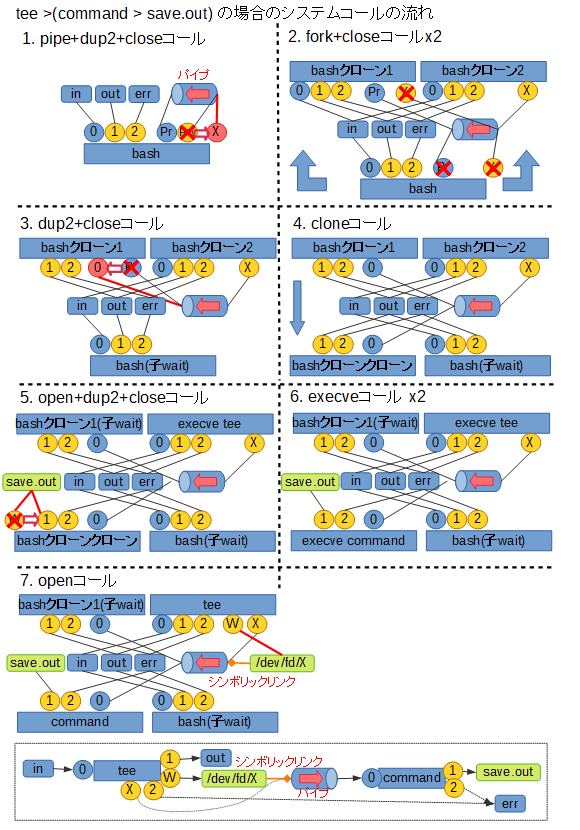
では実際に、プロセス置換を使った場合に procfs 上でファイルアクセス状況がどう見えるか、例を挙げます。
ここで実行コマンドは
tee >( cat -n > save.out )とします。
pstree でプロセスの親子関係を見ると次のようになります。
なお、この例ではシェルのPIDが213、プロセス置換によってできるシンボリックリンク名は/dev/fd/63となっています。プロセス置換を使うコマンドのプロセス親子関係$ pstree -ap 213 bash,213 ├─bash,329 │ └─cat,331 -n └─tee,330 /dev/fd/63この状況で、主体となっている tee ( PID 330 )、プロセス置換で実行されている cat ( PID 331 ) それぞれのファイルアクセス状況は、procfs上で次のように見えます。
procfsでのファイルアクセス状況確認angel:~$ ls -l /proc/{330,331}/fd /proc/330/fd: total 0 lrwx------ 1 angel angel 0 Nov 28 21:47 0 -> /dev/tty1 lrwx------ 1 angel angel 0 Nov 28 21:47 1 -> /dev/tty1 lrwx------ 1 angel angel 0 Nov 28 21:46 2 -> /dev/tty1 l-wx------ 1 angel angel 0 Nov 28 21:47 3 -> 'pipe:[384]' l-wx------ 1 angel angel 0 Nov 28 21:46 63 -> 'pipe:[384]' /proc/331/fd: total 0 lr-x------ 1 angel angel 0 Nov 28 21:47 0 -> 'pipe:[384]' l-wx------ 1 angel angel 0 Nov 28 21:47 1 -> /tmp/save.out lrwx------ 1 angel angel 0 Nov 28 21:46 2 -> /dev/tty1ここで出てくる
pipe:[384]というのがパイプ実体を表しています。これは実際のファイル名ではなく、kernel 内部の inode 384番で管理されている無名パイプです。
tee の方はファイルディスクリプタ63番への経路を元に/dev/fd/63を open し、結果ファイルディスクリプタ3番での接続を実際の出力に使っています。
cat の方はシェルによるつなぎ替えによって、標準入力 ( ファイルディスクリプタ0番 ) で同じパイプに接続されていることが分かります。その他の使い方
最後の話題として、最近他の方のアイデアで興味深いものを見かけたため、紹介したいと思います。
名前付きパイプの代替
このプロセス置換も、ファイル名ベースでパイプに接続できるため、単純に使ったとしても名前付きパイプに近いのですが、しかしそのファイル名は「その場限り」になってしまうため、複数回のコマンド実行を通じて使える、本当の名前付きパイプとは少し違うところがあります。
しかし、Linuxであれば次のようにして、かつ一時的な名前付きパイプを作らずに、プロセス置換を名前付きパイプの代替とできるのではないかと分かりました。
※オリジナルのアイデアは、Bashのファイルディスクリプタを名前付きパイプのように使ってよいか(teratail) によるものです。典型的には次のような手順になります。
exec {tp}< <(:)でテンポラリなパイプの作成と、ファイルディスクリプタの割り当て/dev/fd/$tpを出力ファイルとするプログラムの実行 ( バックグラウンド )/dev/fd/$tpを入力ファイルとするプログラムの実行
※<&$tpによる入力リダイレクトでも可exec {tp}<&-でファイルディスクリプタの解放ファイルディスクリプタを割り当てている間、
/dev/fd/$tpが一時的な名前付きパイプの代わりに使えるということです。なお、手順中出てくるtpはファイルディスクリプタを保存する変数名であり、好みの文字列に替えて構いません。実際に名前付きパイプを使用するのは難しい面がある ( 条件を整えれば不要になることも多い ) のですが、一例として次のような場面で試してみました。
- 2ホスト(shost,dhost)間のSSHベースのファイル転送
- ただし直に通信ができないため、中継ホスト上から各ホストへSSH接続して中継する
- SSHは鍵認証ができない環境のため、パスワード認証でなんとかする
- 容量の関係上中継ホストには中間ファイルを残さない
- 帯域の問題から、通信速度に上限を設ける
要は scp の
-3オプション ( 中継ホストを介した remote-remote ファイル転送 ) 相当、あるいは帯域制限やパスワード認証の問題がなければssh shost cat FILE | ssh dhost 'cat > FILE'ができれば良かったところですが、これをパイプの仲介による scp,ssh の連携 ( scpがパイプラインの場合の前段ssh shost cat FILEの代わりになる ) で実現したということです。
操作は次のようになります。2拠点間ファイル転送例(shostのin.dat->dhostのout.dat)$ exec {tp}< <(:) $ scp -l 10000 suser@shost:in.dat /dev/fd/$tp # 10000Kbpsに帯域制限 suser@shost's password: ^Z [1]+ Stopped scp -l 10000 suser@shost:/tmp/zero.dat /dev/fd/$tp $ ssh duser@dhost 'cat > out.dat' <&$tp duser@dhost's password: ^Z [2]+ Stopped ssh duser@dhost 'cat > out.dat' 0<&$tp $ bg [2]+ ssh duser@dhost 'cat > out.dat' 0<&$tp & $ fg %1 scp -l 10000 suser@shost:in.dat /dev/fd/$tp $ exec {tp}<&- [2]+ Done ssh duser@dhost 'cat > out.dat' 0<&$tp $途中、
^Zとあるのは、Ctrl-Z 入力により、パスワード認証成立直後のscp,ssh コマンドを一時停止しているものです。そうして、フォアグラウンド実行・バックグラウンド実行を調整して、並列に処理を走らせています。終わりに
プロセス置換は、パイプラインと並び、あるいはそれ以上に、複数プログラム間のデータ連携に有用な機能です。この記事で機能やイメージを把握し、より活用につなげて頂ければ幸いです。
- 投稿日:2020-11-29T01:11:31+09:00
【Samba】セクション名と共有するフォルダの名前が違うとWindowsから接続できない
まずセクション名とはなにか
smb.conf内に書かれているものの中の[]で囲まれているものです。smb.conf[セクション名] force user = pi ...(いろいろな設定)実行環境
- Raspberry Pi 4B 2GB
uname -a=>Linux raspberrypi 5.4.72-v8+ #1356 SMP PREEMPT Thu Oct 22 13:58:52 BST 2020 aarch64 GNU/Linuxsmbd --version=>Version 4.9.5-Debian- 500GBの外付けUSBHDD全体をext4でフォーマットした。
/mnt/hd0にマウントした。本題
上記のセクション名と
pathで指定されているフォルダの名前と異なるとWindowsから接続できませんでした。
"Windowsから"というのは理由があって、Android機からは普通に接続できます。
これはWindows側の仕様なのでしょうかね・・・?
具体的なconfファイルを下に示します。smb.conf(上側省略 デフォルトのものの下に追記している) [share] comment = KickKick force user = pi guest ok = Yes path = /mnt/hd0/sharing read only = Noセクション名が
share、共有フォルダが/mnt/hd0/sharingとなっています。
この設定をしたときにWindowsからはアクセスできず、Androidからはアクセスできるという状況が生まれます。
読み取り、書き込み権限はすべて適切に設定されているはずです・・・/mnt以下をchownでnobody, nogroupにしています。どうしたか
pathに指定するフォルダ名とセクション名を一致させると接続することができるようになりました。
フォルダをmvでリネームしてもいいし、セクション名側を変更してもいいでしょう。
今回私はフォルダをmvしました。
何かもっといい方法がある気がする....