- 投稿日:2020-11-29T23:38:58+09:00
ドメインを取得して、Route53を使ってIPアドレスと紐付けた
はじめに
現在作成中のポートフォリオのアプリにちゃんとURLを付けたくて、Route53とドメインを他で取得して、IPアドレスに紐づけた。
流れ
- お名前.comでドメインを取得
- AWSのRoute53で紐付け
- お名前.comでネームサーバーを変更
1. お名前.comでドメインを取得
お名前.comにサインアップして、ドメインを購入。300円弱。2. AWSのRoute53で紐付け
Route53でホストゾーンの作成をする。そのホストゾーンで先程取得したドメインと以前からデプロイしていたIPアドレスを紐づける。
この紐づけるというのは、ドメイン名で接続すれば、Route53側でドメイン名をIPアドレスに読み替えて、IPアドレスに接続してくれるということ。3. お名前.comでネームサーバーを変更
お名前.comでネームサーバーを登録する。先のRoute53でドメインを登録した時に、4つ生成されるものを、お名前.comに登録する感じ。
最後に
これで、URLで接続できるようになったが、httpのため、
安全ではありませんの表示がでる。やはり、httpsで接続できるようにするべきなのか、悩む。
- 投稿日:2020-11-29T23:26:55+09:00
AWS cloud9でAngularの環境構築をしよう
編集履歴
201129 初版(アプリの起動はできていない)
実際に実行したコマンド
- cd environment/
- npm install -g @angular/cli
- ng new sample-angular-app
- CSSの形式を選択
- ng serve
ec2-user:~ $ cd environment/ ec2-user:~/environment $ npm install -g @angular/cli npm WARN deprecated debug@4.2.0: Debug versions >=3.2.0 <3.2.7 || >=4 <4.3.1 have a low-severity ReDos regression when used in a Node.js environment. It is recommended you upgrade to 3.2.7 or 4.3.1. (https://github.com/visionmedia/debug/issues/797) npm WARN deprecated request@2.88.2: request has been deprecated, see https://github.com/request/request/issues/3142 npm WARN deprecated har-validator@5.1.5: this library is no longer supported /home/ec2-user/.nvm/versions/node/v10.23.0/bin/ng -> /home/ec2-user/.nvm/versions/node/v10.23.0/lib/node_modules/@angular/cli/bin/ng > @angular/cli@11.0.2 postinstall /home/ec2-user/.nvm/versions/node/v10.23.0/lib/node_modules/@angular/cli > node ./bin/postinstall/script.js ? Would you like to share anonymous usage data with the Angular Team at Google under Google’s Privacy Policy at https://policies.google.com/privacy? For more details and how to change this setting, see http://angular.io/analytics. Yes Thank you for sharing anonymous usage data. If you change your mind, the following command will disable this feature entirely: ng analytics off + @angular/cli@11.0.2 added 253 packages from 201 contributors in 22.622sec2-user:~/environment $ ng new sample-angular-app ? Do you want to enforce stricter type checking and stricter bundle budgets in the workspace? This setting helps improve maintainability and catch bugs ahead of time. For more information, see https://angular.io/strict Yes ? Would you like to add Angular routing? Yes ? Which stylesheet format would you like to use? CSS CREATE sample-angular-app/README.md (1025 bytes) CREATE sample-angular-app/.editorconfig (274 bytes) CREATE sample-angular-app/.gitignore (631 bytes) CREATE sample-angular-app/angular.json (3719 bytes) CREATE sample-angular-app/package.json (1208 bytes) CREATE sample-angular-app/tsconfig.json (737 bytes) CREATE sample-angular-app/tslint.json (3185 bytes) CREATE sample-angular-app/.browserslistrc (703 bytes) CREATE sample-angular-app/karma.conf.js (1113 bytes) CREATE sample-angular-app/tsconfig.app.json (287 bytes) CREATE sample-angular-app/tsconfig.spec.json (333 bytes) CREATE sample-angular-app/src/favicon.ico (948 bytes) CREATE sample-angular-app/src/index.html (302 bytes) CREATE sample-angular-app/src/main.ts (372 bytes) CREATE sample-angular-app/src/polyfills.ts (2826 bytes) CREATE sample-angular-app/src/styles.css (80 bytes) CREATE sample-angular-app/src/test.ts (753 bytes) CREATE sample-angular-app/src/assets/.gitkeep (0 bytes) CREATE sample-angular-app/src/environments/environment.prod.ts (51 bytes) CREATE sample-angular-app/src/environments/environment.ts (662 bytes) CREATE sample-angular-app/src/app/app-routing.module.ts (245 bytes) CREATE sample-angular-app/src/app/app.module.ts (393 bytes) CREATE sample-angular-app/src/app/app.component.css (0 bytes) CREATE sample-angular-app/src/app/app.component.html (25757 bytes) CREATE sample-angular-app/src/app/app.component.spec.ts (1093 bytes) CREATE sample-angular-app/src/app/app.component.ts (222 bytes) CREATE sample-angular-app/e2e/protractor.conf.js (904 bytes) CREATE sample-angular-app/e2e/tsconfig.json (274 bytes) CREATE sample-angular-app/e2e/src/app.e2e-spec.ts (669 bytes) CREATE sample-angular-app/e2e/src/app.po.ts (274 bytes) ⠇ Installing packages (npm)...
- 読みこみ(1分くらい)
. . . ✔ Packages installed successfully. Successfully initialized git.ec2-user:~/environment/sample-angular-app (master) $ ng serve ? Would you like to share anonymous usage data about this project with the Angular Team at Google under Google’s Privacy Policy at https://policies.google.com/privacy? For more details and how to change this setting, see http://angular.io/analytics. Yes Thank you for sharing anonymous usage data. Would you change your mind, the following command will disable this feature entirely: ng analytics project off Compiling @angular/core : es2015 as esm2015 Compiling @angular/common : es2015 as esm2015 Compiling @angular/platform-browser : es2015 as esm2015 Compiling @angular/platform-browser-dynamic : es2015 as esm2015 Compiling @angular/router : es2015 as esm2015 ✔ Browser application bundle generation complete. Initial Chunk Files | Names | Size vendor.js | vendor | 2.65 MB polyfills.js | polyfills | 141.30 kB main.js | main | 59.57 kB runtime.js | runtime | 6.15 kB styles.css | styles | 119 bytes | Initial Total | 2.85 MB Build at: 2020-11-29T03:05:01.936Z - Hash: 17942e8011a7f3f95453 - Time: 13784ms ** Angular Live Development Server is listening on localhost:4200, open your browser on http://localhost:4200/ ** ✔ Compiled successfully. ✔ Browser application bundle generation complete. Initial Chunk Files | Names | Size styles.css | styles | 119 bytes 4 unchanged chunks Build at: 2020-11-29T03:05:03.640Z - Hash: 6e0a04f592b2325ab15c - Time: 1419ms ✔ Compiled successfully.準備完了
- 投稿日:2020-11-29T23:07:04+09:00
新入社員がAWS Solution Architect Associate-C02に合格できた話
新入社員がAWS Solution Architect Associate-C02に合格できた話
Qiita初投稿になります。
よろしくお願いいたします。今回は先日合格しましたAWS SAA-C02についての勉強法、合格するために必要なものを書いていきたいと思います!!!
筆者はSAA-C02の参考書などが見つからず苦労したため、合格できずに苦労している方や今から受ける方などに参考になればと思います。目次
1.はじめに
2.受験1~3回目
3.受験4回目
4.おすすめ勉強法
5.まとめ1. はじめに
筆者のスペックを書いていきます。
●社会人1年目の社会人、クラウドに触り始めたのは半年ほど前から
●業務でAWSなどのクラウド構築に従事、主要サービスは作成、説明可能
●3か月前にCloud Practitioner取得続いては実際に受験した際の勉強法や感想などを書いていきます。
2. 受験1~3回目
受験1回目・勉強時間
1日1時間×2週間
・勉強法
Udemyの問題集を2割、iPhoneのアプリ8割くらい
・結果
652点(720点合格)
・感想
今回は圧倒的な勉強時間不足。もっとUdemyやるべきだった。。(Udemyは5割くらいしか取れていなかったです。。)
受験2回目・前回の受験から空けた期間
2週間程度(AWSの資格は再受験の場合、2週間空けないと再受験できないのです。。)
・勉強時間
1日1時間×2週間
・勉強法
Udemyの問題集を5割、iPhoneのアプ5割+3日間のオンライン講座(バウチャー付き)
・結果
624点(720点合格)
・感想
オンライン講座を受けたことで受かると決め込んでいたため勉強に身が入らないことが多かった
受験3回目・前回の受験から空けた期間
2週間程度
・勉強時間
1日1時間×2週間
・勉強法
今回はUdemy+Udemyで間違えた選択肢などの解説をエクセルなどにまとめた(Udemyは7割まで取れるようにした、エクセルは作成したがあまり復習できなかった。。)
・結果
700点(720点合格)
・感想
試験範囲の中で触ったことがないサービスについてとにかく触るようにした。(しかし、触ったことがないサービス=あまりメジャーでないサービスだったので試験に役に立ったかといわれると。。)
20点分は運が悪かったと割り切ったが試験直後は見直しをもっとしっかりしていれば。。。と後悔しましたw3. 受験4回目
・前回の受験から空けた期間
3週間程度
・勉強時間
1日1時間×2週間
・勉強法
Udemy+Udemyで間違えた選択肢などの解説をエクセルなどにまとめ、寝る前などに読み物として読んでいた(Udemyは8割以上取れるようにしました)
・結果
729点(720点合格)←とてもギリギリでした。。。
・感想
エクセルで作成した読み物を完璧にしたことが大きかった。
後は受験4回目だったので、ここで落ちたら再受験まで少し時間空けようと考えていた。そのため今までの3回の受験より気合が入っていた。4. おすすめ勉強法
一番おすすめの勉強法は「Udemy」の問題集をひたすら解くことです。
この問題集で8割~9割取れるようにしていけばよい結果が手に入るかな?と思います(あくまで個人の意見です)
また、AWSアカウントを持っている方は実際に触れてみることもいいかなと思いました。(特にEC2、S3に関しては問題に直接絡んでくることもあったかなと思います!)5. まとめ
まとめとして筆者がAWS SAA-C02での後悔などを記載します。
まず一番の後悔は金銭面です。。
ただ、Cloud Practitionerを合格していた時のバウチャー(試験50%オフ)のものとオンライン講座のバウチャーがあったためまだ出費を抑えられました(それでも出費は出費ですが)
また、AWS公式の模擬試験も受験しなかったため、受験していればよかったかなと思いました。
いかがでしたでしょうか?
筆者の生の声をなるべく詳細に書いたつもりなので、受験の際は参考にしていただければと思います。
次回はAzureの資格受験の体験談を書ければと思います!
次回もよろしくお願いいたします!
- 投稿日:2020-11-29T22:59:50+09:00
インフラエンジニアでもできる!データ基盤の構築に役立つコンテンツ6選
Global Mobility Service Advent Calendar 2020の1日目の投稿です。
データ基盤(もしくはデータ分析基盤)と呼ばれるシステムの構築を行なっています。
データ基盤とは、組織内のあらゆるデータを活用し、意思決定を可能にするためのデータを集めるシステムのことです。筆者はいわゆるインフラエンジニアの業務を主に行っています。例えば、コンテナを使ったアプリケーションインフラの構築などです。
データ基盤もシステムのインフラと捉えることができるので、インフラエンジニアの領域のような感じがします。
ただ実際には、アプリケーションインフラとは異なるデータ基盤特有の難しさがありました。本記事では、インフラエンジニアの筆者がデータ基盤を構築するのに役立ったコンテンツを紹介します。
これらのコンテンツによって、アプリケーションインフラとデータ基盤インフラの違いを理解し、データ基盤の構築を効果的に進めることができています。
インフラエンジニアとしてデータを活用するインフラ作りを担当しなければいけなくなった方々に参考になる情報だと思います。なお、筆者の環境の都合により、AWSを前提としています。
データ基盤の全体像を掴む
Data Platform Guide - 事業を成長させるデータ基盤を作るには #DataEngineeringStudy / 20200715 - Speaker Deck
データ基盤を構築するにあたっての前提となる考え方、それを実現するためのテクノロジーや実践方法といった内容が発表資料という形で簡潔にまとめられている資料です。全体像を掴むには最適なコンテンツです。
個人的には、一度作ったら終わりではなく、継続的に実験、改善するといった考えが印象的な内容です。
ある程度やるべきプラクティスが確立されているアプリケーションインフラと異なり、データ基盤は試行錯誤が必要な領域なんだと理解できます。
データマネジメントの知識体系(DMBOK)に沿った内容を具体的な例とともに解説している書籍です。
データマネジメントとは、データを資産と捉え、体系的に価値を引き出すための手法です。
本書では、データマネジメントの手法が数多く紹介されています。
個人的には、インフラエンジニアとしてはどうしても気になる信頼性に注目しました。信頼性については、多くの内容、具体例が掲載されています。
この中で、データの信頼性を保証するためのメタデータ管理の考え方がなるほどと思いました。実例
事業のグロースを支えるDataOpsの現場 #DataOps #DevSumi #デブサミ / 20180727
「Data Platform Guide - 事業を成長させるデータ基盤を作るには」における具体的な事例の資料です。
技術の話にとどまらず、プロセス、チーム、文化に渡る内容を紹介しており、データ基盤構築の難しさ、奥深さを感じます。
MVPの考え方をデータ活用に利用するアプローチは参考になります。
データ収集の基本と「JapanTaxi」アプリにおける実践例
こちらの資料では、データ収集に関する技術を網羅しています。
データ収集における手法が体系的に整理されていて、発表資料ながら書籍のような充実した内容です。
なんとなくやっていたことがより理解できた感じがしました。
個人的にはDBからのデータ収集方法について、これほど多くのアプローチがあることに驚きました。データベース
データ基盤に触れると、データを扱うためのソリューションが色々あることに気がつきます。
この資料はそのようなソリューションの傾向、ユースケースに合わせた使い分けを理解することができます。
個人的には、各ソリューションを性能という観点で分類しているのが分かりやすいです。AWS
AWSにおいて、データ基盤を作るのに必要な情報が解説されています。
筆者の場合、データ基盤の構築をある程度行なってからこの本を読みました。
感想としてはもっと早くこの書籍の情報を知りたかったです。
AWSでは、Glue、Athena、Redshiftといったデータ活用向けのAWSサービスがありますが、それらの具体的な使い方が説明されています。
Glueに色々な機能があってよくわからないという問題が本書で解決できます。おわりに
今回紹介した質の高いコンテンツを提供してくれている作成者の方々に感謝致します。
このようなコンテンツのおかげで、インフラエンジニアな自分でもデータ基盤を構築することができています。
皆様にも本記事が参考になれば幸いです。
- 投稿日:2020-11-29T22:57:43+09:00
Amazon FSx for Windows のTips
先日、構築方法を記事にしたAmazon FSx for Windows について、実際に運用していくにあたりデフォルト設定からチューニングすることがあると思いますので、役立ちそうな設定のTipsを紹介します。ご参考までにd(`・ω・’)
前提条件
- FSx は構築済み ※構築が完了済みでない場合はこちらを元に構築してみください
- FSxを操作するコントローラとして、FSxと同じVPCにEC2(Windows OS)をデプロイする
- FSxを結合したADの管理者ユーザのユーザID/PWを利用できる
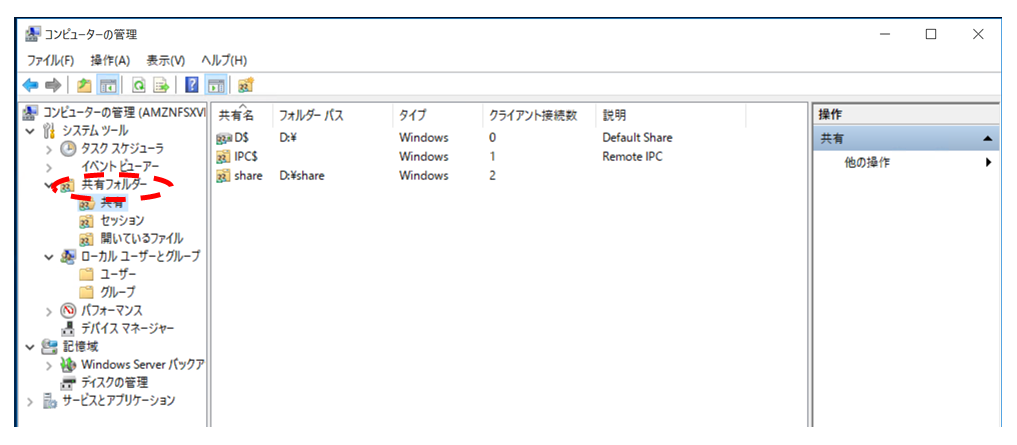
Tips① "¥Share"配下以外に共有フォルダを作成する
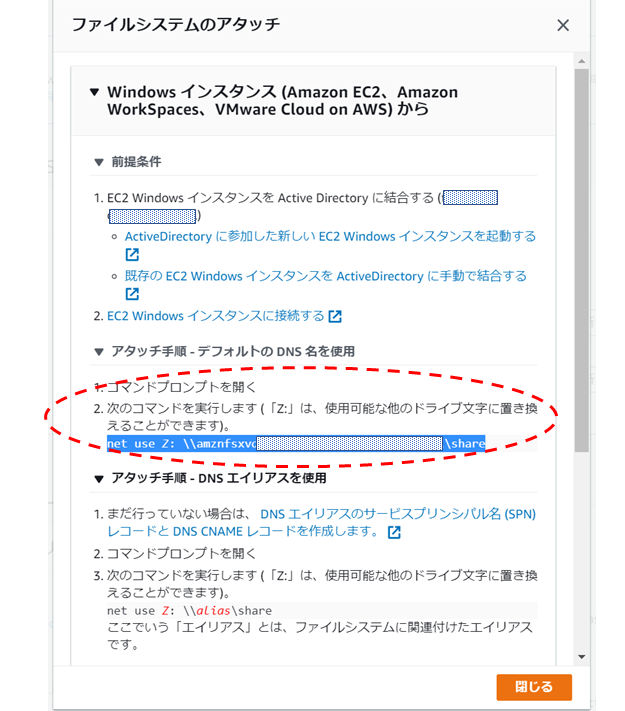
FSxの共有フォルダは初期設定では“¥¥amznfsxxxxxxx.domain.internal¥share"のような形で¥shareから始まるフォルダ階層になっており、FSxの管理コンソール画面で「アタッチ」をクリックすると以下のようなマウントのコマンドが表示されます。
実際の運用では共有フォルダを¥Shareではなく、別の名前のフォルダ階層で作りたいということが多々あると思います。そんなときの設定です。
設定方法
①FSxと同一VPCにEC2をデプロイし、ドメイン参加させておく
②ファイル共有設定画面へ接続し、新しい共有の設定
③新しく設定した共有をネットワークマウント
④フォルダアクセス権を設定まず①ですがWindows OSのEC2をデプロイします。ここは特に変わった設定はないので割愛します。
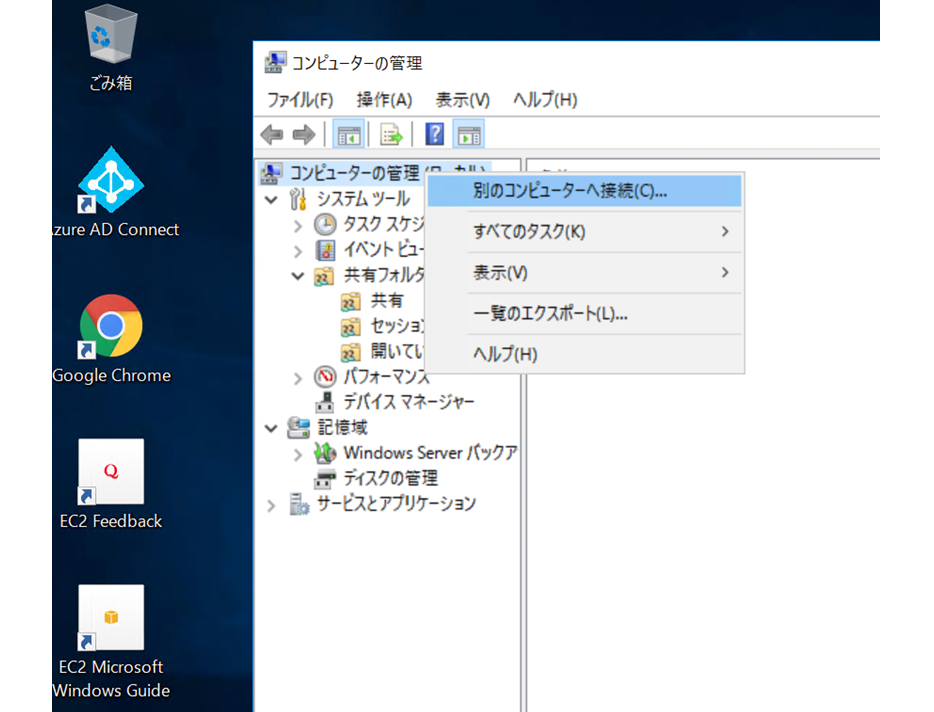
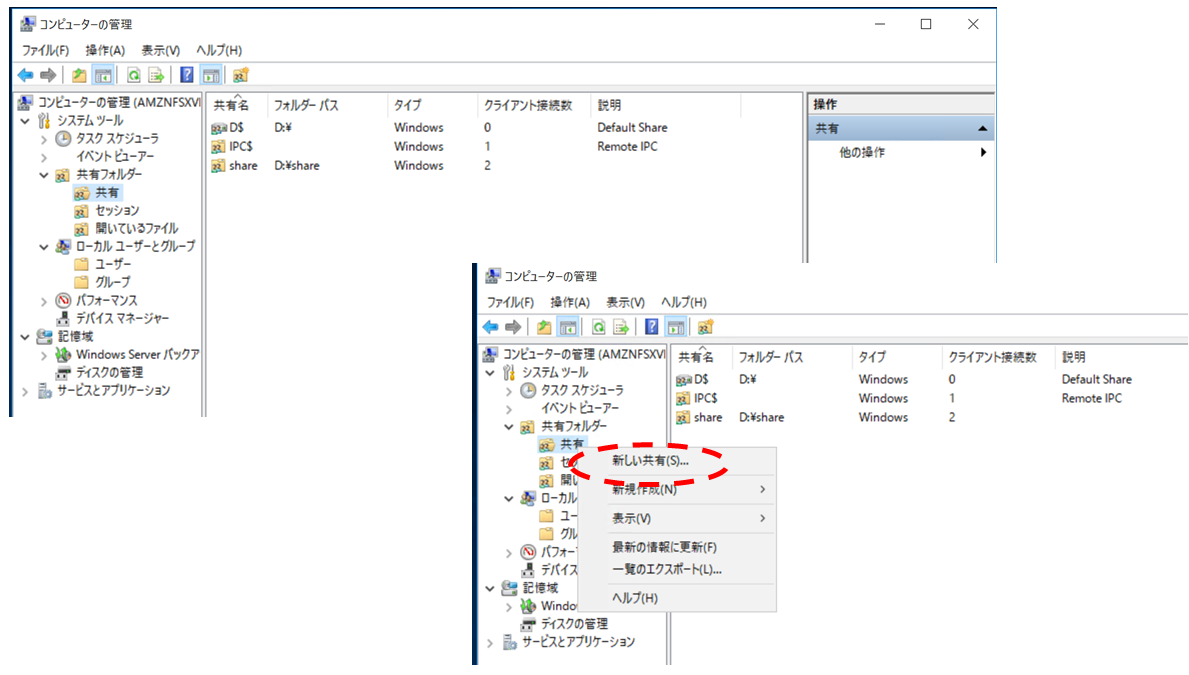
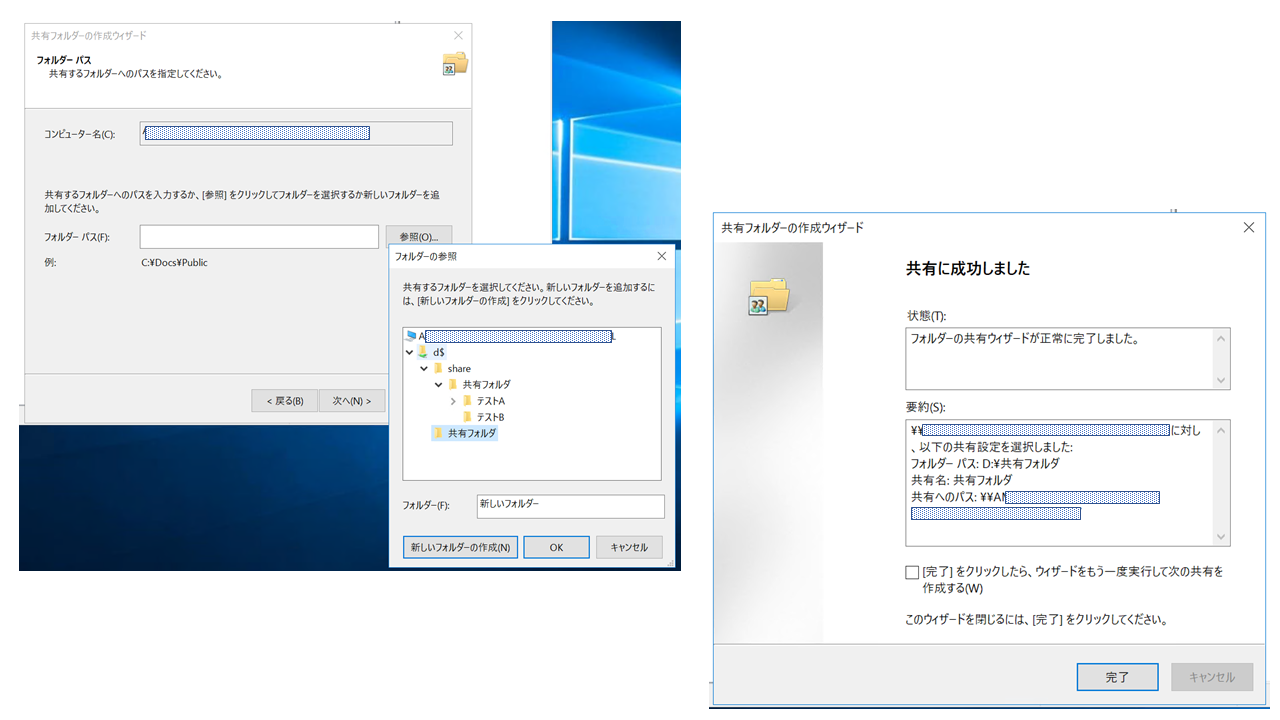
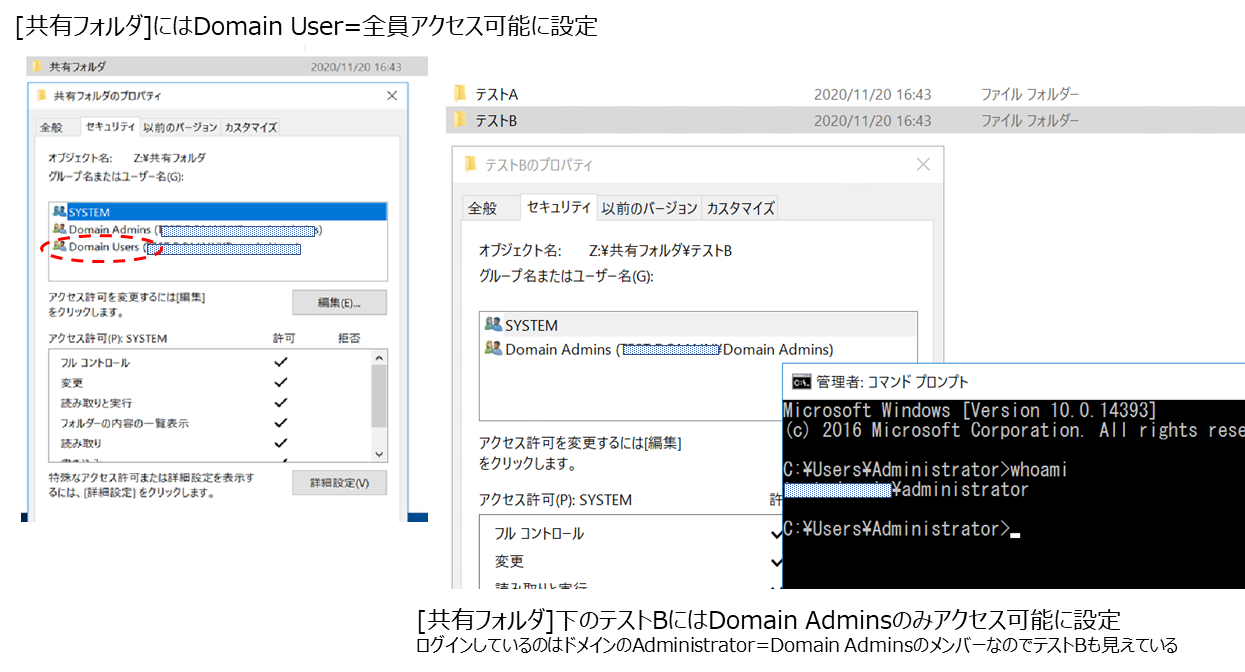
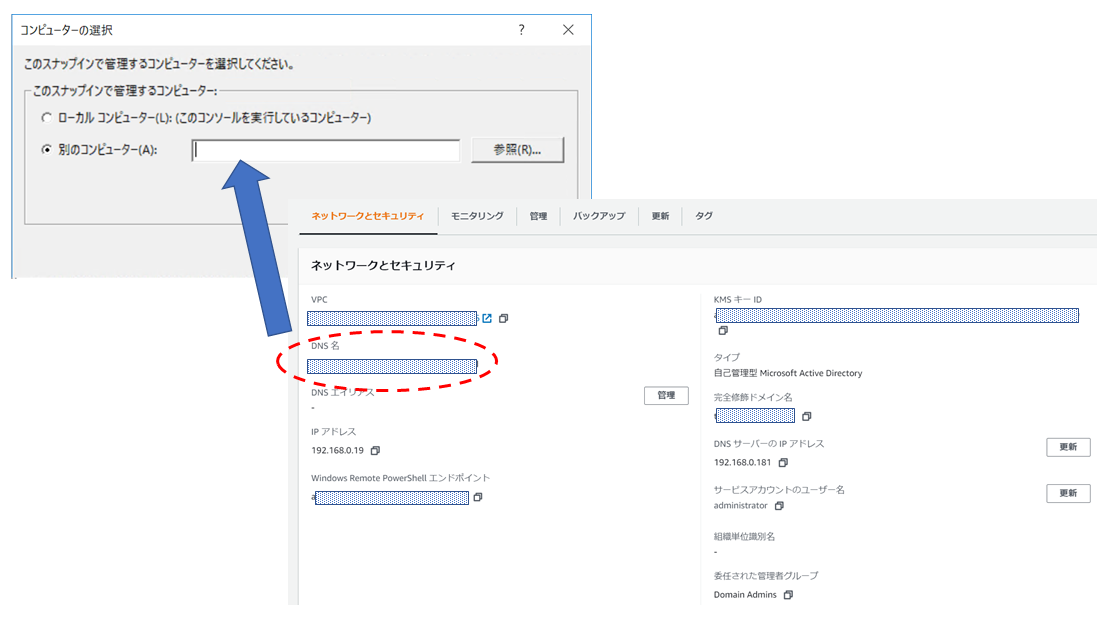
とりあえず、デプロイしたEC2へRDPでき、ドメイン参加出来ているようならOKです。次に②ですが、EC2へRDPして、スタートボタンを右クリック-[コンピュータの管理]を選択-一番上の[コンピュータの管理]で右クリックして、[別のコンピュータへ接続(C)]を選択します。
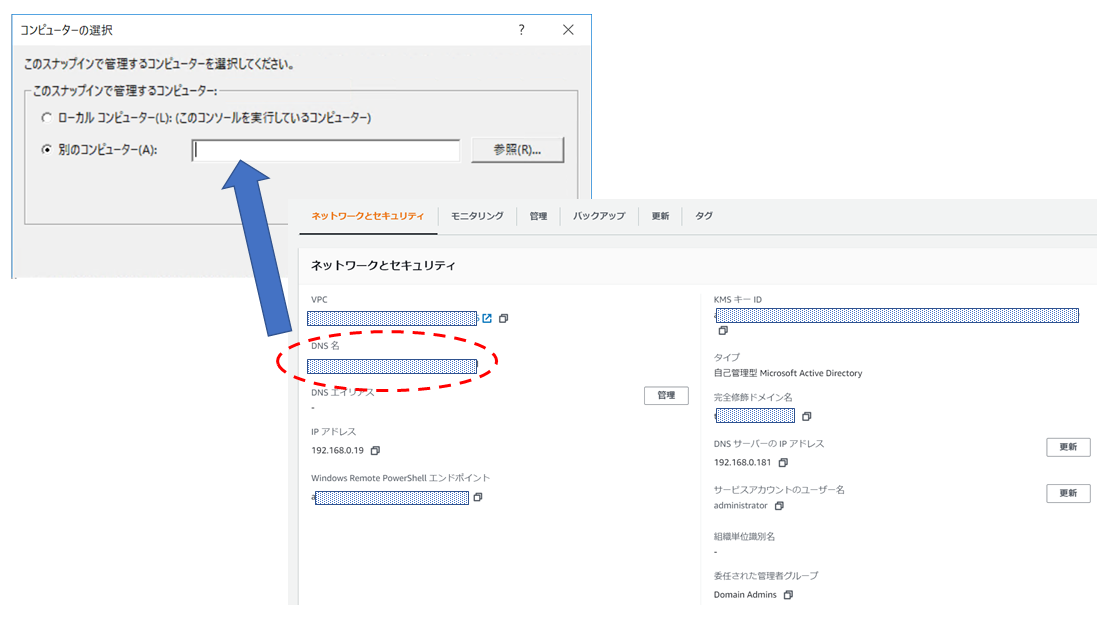
どのコンピュータへ接続するか入力する画面が出てくるので、[別のコンピュータ(A)]を選択し、FSxコンソール画面のDNS名の値を入力してください。
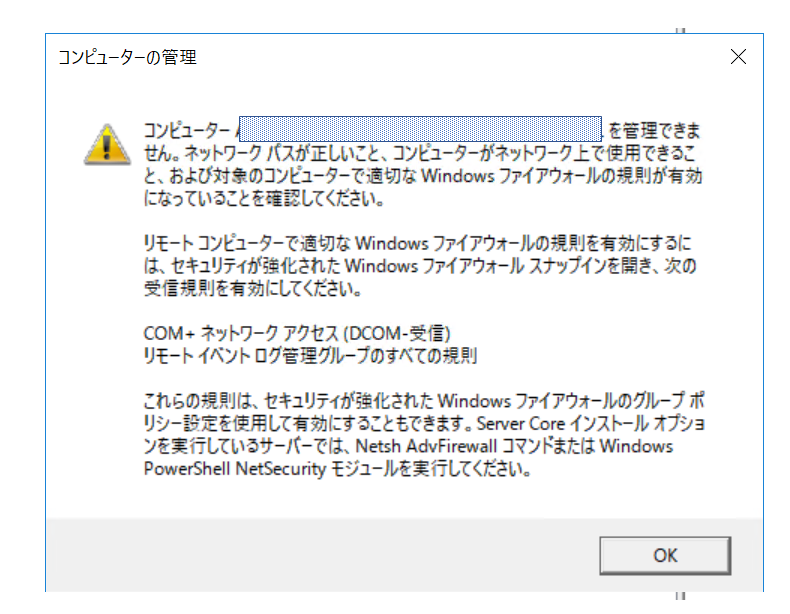
※Windows Remote Powershellエンドポイントの値ではありません!しばらくしてこんな感じのメッセージが表示されますが、無視してOKです。
共有設定画面が表示されたら、[共有フォルダ]下の[共有]を右クリックし、[新しい共有(S)]を選択してください。
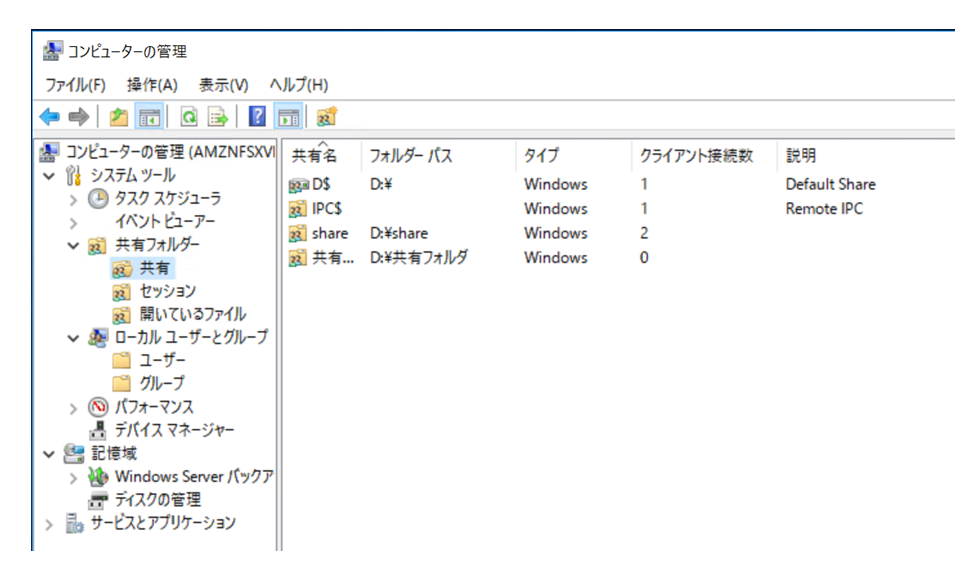
あとはどの階層に新しい共有フォルダを作成するか選択していき、設定が完了すると以下の画面が表示されます。今回は新しい共有の名前を「共有フォルダ」にしています。
共有設定の画面からも新しく作成した共有の「共有フォルダ」が確認できます。
これで②は完了なので、あとは③のネットワークマウントを行います。
最初にも書きましたがデフォルトではマウントコマンドがnet use Z:¥¥amznfsxxxxxxx.domain.xxx¥shareとなっています。
このマウントコマンドの後ろを変えてnet use Z:¥¥amznfsxxxxxxx.domain.xxx¥共有フォルダとしてやれば、[共有フォルダ]から始まる共有フォルダ階層を設定することができます。
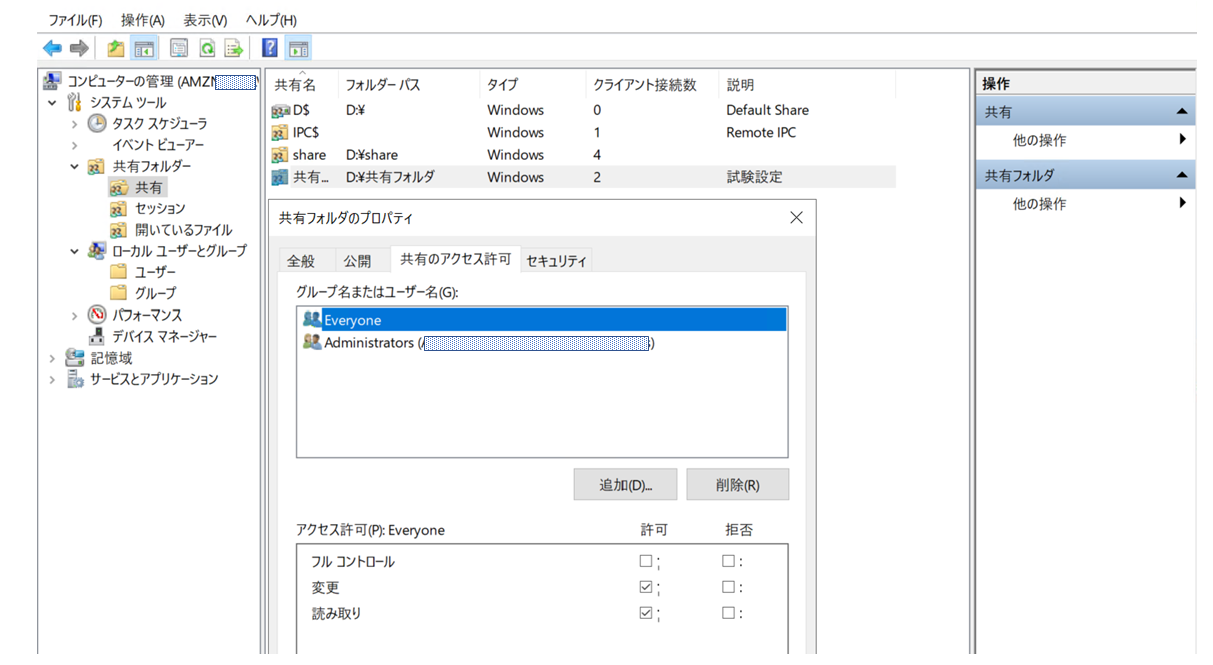
④最後にフォルダアクセス権を設定してあげましょう。
あたらしく作成した共有だと初期設定で権限があるのはFSxのAdministators だけでDomain Adminユーザにも権限がついていないので...
図ではとりあえずEveryoneの権限設定にしています。
Tips② シャドウコピー機能の設定
シャドウコピー機能とはフォルダを右クリックして、プロパティの中にある「以前のバージョン」で、指定した日時の状態に復元できるようにする、あの機能のことです。
FSxでの設定はPowershellでの操作になります。
シャドウコピーの設定は以前に記事にしたことがあり、設定方法はそれと同じですので割愛します。
リンク先記事の一番最後におまけのところでコマンド類を記載していますので、ご参考までに。Tips③ Windows ABE機能(access-based enumeration)の設定
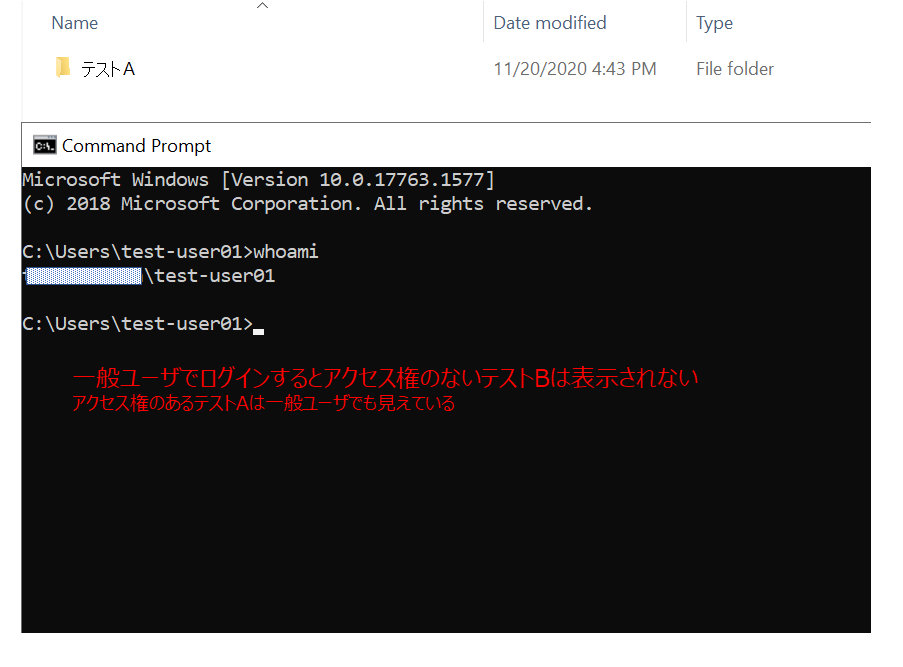
ABE機能とはアクセス権のないフォルダを見えなくする設定です。例えばDomain admins グループにしかアクセス権を割り当ててないフォルダは一般ユーザには表示もされないので、存在自体を秘匿することができます。FSxではローカルフォルダ(共有設定されていないフォルダ)を作ることができないので、ABEを設定しないとフォルダの存在自体はユーザに見えてしまいます。コンプライアンスの都合とかで、どうして見せれないフォルダがあるときに便利な機能です。
シャドウーコピーのときと同じくGUIでは設定できないので、同一VPC/ドメイン上のEC2からPowershellで設定していきます。
設定方法
①FSxと同一VPCにEC2をデプロイし、ドメイン参加させておく
②EC2上でPowershell を管理者権限で起動させて、コマンド実行
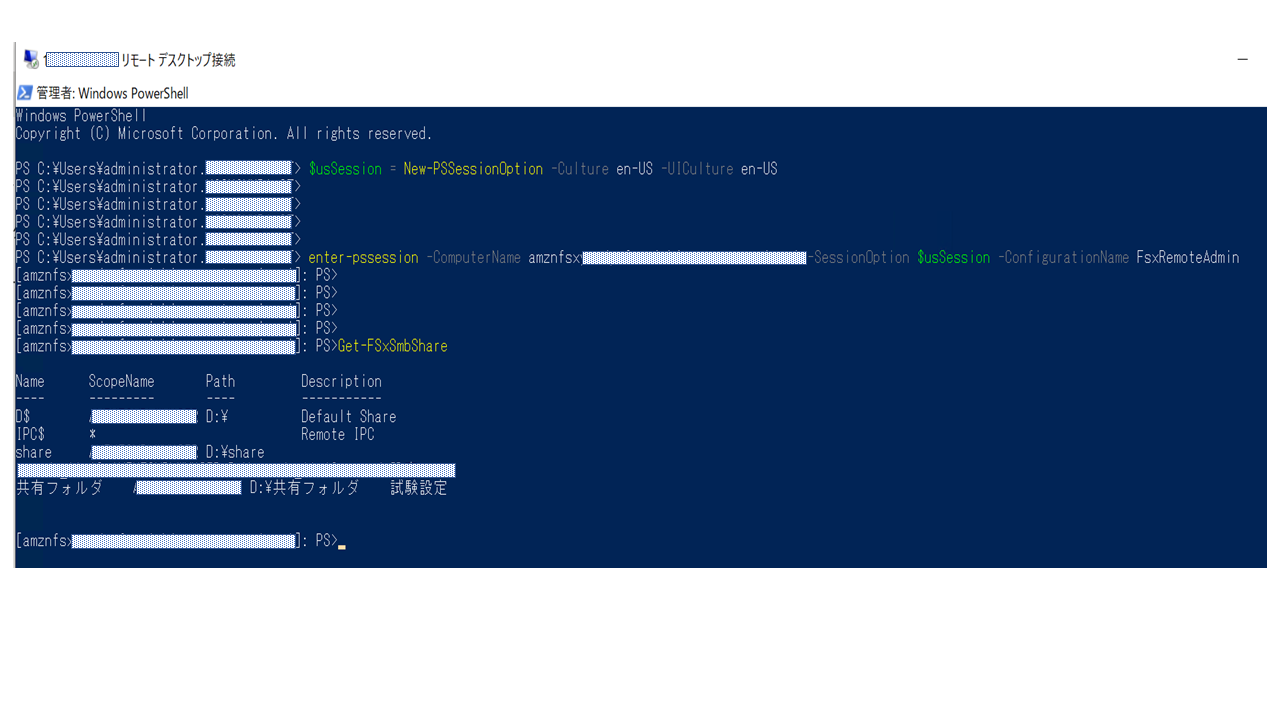
③フォルダアクセス権を設定最初の①は割愛しますので、②から進めていきます。
#日本語版AMIのEC2からだとコマンドを受付けないため、セッションの言語を英語指定にします $usSession = New-PSSessionOption -Culture en-US -UICulture en-US #ビルトインのセキュリティグループ FSxRemoteAdminのユーザ権限でセッション開始します enter-pssession -ComputerName "Windows Remote PowerShell Endpoint" -SessionOption $usSession -ConfigurationName FsxRemoteAdmin #現状の共有設定を確認します。 Get-FSxSmbShare #上記のコマンドで表示された共有フォルダに対してABE機能を有効にします 今回は共有名[共有フォルダ]に対してABE機能を有効化します set-FSxSmbShare -name 共有フォルダ -FolderEnumerationMode AccessBased -Confirm:$falseコマンド実行後にアクセス権を付与して、実際の画面で確認してみましょう。
ちなみにコマンド実行した実際のPowerShellの画面はこんな感じです。
ハマったところ
①GUIから操作するときにWindows Remote Powershell エンドポイント でアクセスできない
→別のブログなどで Windows Remote Powershell エンドポイントを入力するという旨の記事もありますがAWS公式情報によるとFSx管理コンソールにあるDNS名を使います。 AWSサポートもそうおっしゃっております。※なぜか構築直後は接続できた記憶がありますが...
②[共有フォルダ]で右クリックするとフリーズする
→原因は分かりません... ちゃんと下の[共有]で右クリックしましょう!参考にしたページ
https://virtual-oji.hatenablog.com/entry/2020/09/04/123000
https://itnews.jp/?p=13200
https://docs.aws.amazon.com/ja_jp/fsx/latest/WindowsGuide/managing-file-shares.html#shared-folders-tool最後に
マネージドサービスなので、仕様については結構ブラックボックスなところがあります。特にセキュリティについては開示してもらえないのでよく分からないんですよね~。
マネージドサービスだから「サーバOSにログインできない」=「セキュリティソフト」のインストール不可なので、アンチウィルスの部分でもう少し安心感を与えてくれると私みたいな単純人間は顧客にホイホイ提案してしまいます(笑)。
- 投稿日:2020-11-29T22:30:57+09:00
Amazon LinuxインスタンスにRails6をインストールするまでの手順
この記事でやろうとしていること
タイトルの通りですが、Amazon LinuxインスタンスにRails6.0.3をインストールするまでの流れです。
なぜRails6.0.3か?というのは、おなじみ「Railsチュートリアル」の第6版で指定されているバージョンだから、というだけです。RailsチュートリアルではAWSの統合開発環境 (IDE)「Cloud9」の利用を前提としています。Cloud9はRailsをインストールする上での前提パッケージが既に入っているので、
$ gem install rails -v 6.0.3と叩くだけですんなりRailsが入ってくれますが、一歩cloud9という温室から外に出るとそうはいきません。
というわけで、何番煎じかはわかりませんが、少なくとも筆者はいろいろググって何とか解決したので、需要はあるはず。さっそく解説に入っていきます。
まず、Amazon Linuxインスタンスの詳細は↓の通り。普通にEC2インスタンスをデプロイする際の一番最初に出てくるやつです。
Gitインストール
まずはGitをインストールする必要があります。
後述の手順で、Gitレポジトリをクローンしていろいろとインストールするためです。ここは特に迷いなく、
# yum install gitでOKです。
rbenvインストール
rbenvとは、複数のRubyのバージョンを管理し、プロジェクトごとにRubyのバージョンを指定して使うことを可能としてくれるツールです。
また、(本記事においてはここが重要なのですが)Rubyのインストールもサポートしてくれます。基本的にはGitHubのrbenvレポジトリのREADMEに書いている通りに従う流れですが、
Gitレポジトリをクローン # git clone https://github.com/rbenv/rbenv.git ~/.rbenv ディレクトリ移動後、ソースからインストール # cd ~/.rbenv && src/configure && make -C src warning: gcc not found; using CC=cc aborted: compiler not found: ccと、gccがインストールされていないとコケてしまいますので、
# yum install gccでインストールしてから、再度ソースインストールしましょう。
# cd ~/.rbenv && src/configure && make -C srcrbenvインストール完了後も引き続きREADMEに従って、
# echo 'export PATH="$HOME/.rbenv/bin:$PATH"' >> ~/.bash_profileとパスを通してから、rbenv init コマンドで初期設定します。
# ~/.rbenv/bin/rbenv init # Load rbenv automatically by appending # the following to ~/.bash_profile: eval "$(rbenv init -)"と出るので、従いましょう。
# eval "$(rbenv init -)"パスがしっかり通っていることも確認して、
# source ~/.bash_profile # echo $PATH /root/.rbenv/shims:/root/.rbenv/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/binrenv-doctorスクリプトを使用して、rbenvが正しく設定されていることを確認します。
# curl -fsSL https://github.com/rbenv/rbenv-installer/raw/master/bin/rbenv-doctor | bash Checking for `rbenv' in PATH: /root/.rbenv/bin/rbenv Checking for rbenv shims in PATH: OK Checking `rbenv install' support: not found Unless you plan to add Ruby versions manually, you should install ruby-build. Please refer to https://github.com/rbenv/ruby-build#installation Counting installed Ruby versions: none There aren't any Ruby versions installed under `/root/.rbenv/versions'. You can install Ruby versions like so: rbenv install 2.2.4 Checking RubyGems settings: OK Auditing installed plugins: OK出力結果の3行目に「Checking `rbenv install' support: not found」と出力されています。
これが使えないと最新版のRubyをrbenvでインストールできないので、ここからはruby-buildをインストールします。ruby-buildインストール
ここからは、GitHubのruby-buildレポジトリのREADMEに書いている通りに従っていきます。
rbenvのディレクトリに「plugins」ディレクトリを作って、レポジトリをクローンしてプルするだけです。# mkdir -p "$(rbenv root)"/plugins # git clone https://github.com/rbenv/ruby-build.git "$(rbenv root)"/plugins/ruby-build # git -C "$(rbenv root)"/plugins/ruby-build pullRubyインストール
さあ、これで晴れてrbenvを使ってRubyインストールが出来るようになりました。
まずはインストール可能なRubyのバージョンを確認しましょう。# rbenv install --list 2.5.8 2.6.6 2.7.2 jruby-9.2.13.0 maglev-1.0.0 mruby-2.1.2 rbx-5.0 truffleruby-20.3.0 truffleruby+graalvm-20.3.0 Only latest stable releases for each Ruby implementation are shown. Use 'rbenv install --list-all' to show all local versions.ここでは最新版の「2.7.2」をインストールすることとします。
# rbenv install 2.7.2 Downloading ruby-2.7.2.tar.bz2... -> https://cache.ruby-lang.org/pub/ruby/2.7/ruby-2.7.2.tar.bz2 Installing ruby-2.7.2... BUILD FAILED (Amazon Linux 2 using ruby-build 20201118) Inspect or clean up the working tree at /tmp/ruby-build.20201128132117.3587.qONaMm Results logged to /tmp/ruby-build.20201128132117.3587.log Last 10 log lines: from ./tool/rbinstall.rb:846:in `block (2 levels) in install_default_gem' from ./tool/rbinstall.rb:279:in `open_for_install' from ./tool/rbinstall.rb:845:in `block in install_default_gem' from ./tool/rbinstall.rb:835:in `each' from ./tool/rbinstall.rb:835:in `install_default_gem' from ./tool/rbinstall.rb:799:in `block in <main>' from ./tool/rbinstall.rb:950:in `block in <main>' from ./tool/rbinstall.rb:947:in `each' from ./tool/rbinstall.rb:947:in `<main>' make: *** [do-install-all] Error 1おや、makeでコケていますね。
結論としては「openssl-devel」パッケージが必要なところ、インストールされていなかったことが原因です。
私は正直、ここで小1時間あれやこれや調べて、当てずっぽうで問題解決に至ったのですが、じつは↓にruby-buildに必要な前提パッケージが説明されていました。
公式に勝る情報はないですね。
https://github.com/rbenv/ruby-build/wiki#suggested-build-environmentopenssl-develはサクっとyumでインストールしましょう。
# yum install -y openssl-develその後、
# rbenv install 2.7.2で無事にrubyの最新版をインストールすることに成功しました。
rubyのパスが2つある件(未解決)
ここまでの手順でrubyをインストール完了しましたが、パスが通っていません。
ruby本体の在り処を探してみますと・・・# ll ~/.rbenv/shims/ruby -rwxr-xr-x 1 root root 385 Nov 28 13:53 /root/.rbenv/shims/ruby # ll ~/.rbenv/versions/2.7.2/bin/ruby -rwxr-xr-x 1 root root 184688 Nov 28 13:52 /root/.rbenv/versions/2.7.2/bin/rubyあれ。2箇所にある。別にシンボリックリンクってわけでもないし。ファイルサイズがかなり違う…
以下のように、どちらもrubyコマンドとして実行できます。# ~/.rbenv/shims/ruby -v ruby 2.7.2p137 (2020-10-01 revision 5445e04352) [x86_64-linux] # ~/.rbenv/versions/2.7.2/bin/ruby -v ruby 2.7.2p137 (2020-10-01 revision 5445e04352) [x86_64-linux]ちょっとこの点、ちゃんと調べられていないのですが、rbenvで確認すると後者のパスで認識してるっぽいので、筆者の場合はそちらでパスを通し、Rubyインストールを終了としました。
# rbenv versions * 2.7.2 (set by /root/.rbenv/version) # echo 'export PATH="$HOME/.rbenv/versions/2.7.2/bin:$PATH"' >> ~/.bash_profile # source ~/.bash_profileRailsインストール
お膳立ては整いましたので、あとはRailsチュートリアルの通り、Rails6.0.3をインストールするだけです。
# gem install rails -v 6.0.3 # rails -v Rails 6.0.3お疲れ様でした。
- 投稿日:2020-11-29T21:57:51+09:00
CDKのサンプルプロジェクトのリポジトリを作成・公開した
1. はじめに
みなさん、AWSしてますか?
値段も安くて、触りやすく、記事も豊富にあるので、僕はかなり好きです。ただ、そうは言っても、個人で触りたいとなると料金の面で利用できるものとそうでない物が出てきたり、
一旦作成したサービスを忘れることなく全て削除したりするのは面倒な気がします。
また、WebのコンソールやCLIで作成した物は属人性が高くなり、手順やノウハウが残らないためよくないです。そこで、便利なのがCDKです!
2. CDKとは
AWSが公式に提供する
Infrastructure as Code(=IaC)のライブラリです(GitHub)。
CloudFormationをラップしており、TypescriptやPythonなどを用いて実装することで、サービスを作成することが可能です。
IaCとしては、前述のCloudFormationやTerraformなどもありますが、
これらはJsonで記述する必要があり(VSCodeだとプラグインで入力補助もある。)、
作成するサービスの量が多くなると見通しが悪くなる可能性があります。2.1 CDKのメリット
- AWSが公式に提供しているので利用できなくなるなどの不安はない(と思う)
- ドキュメントをみながら必要なパラメータを付与していくことになるので、必要な設定などがわかりやすい
- スタックの名前を変えれば同じ内容のサービスを複数個展開できるため、開発と本番の環境分離なども容易に行える
- ただし、同一の名前のサービスはできないので、環境ごとに名前を変える必要な場合がある(基本的には)
- リソースの作成・削除が容易(IaCのメリット)
- コードでサービスの管理ができるので属人性を排除できる(IaCのメリット)
2.2 CDKのデメリット
- リリースされたばかりのサービス(機能)は対応できないことがある
- CloudFormationが対応されたのち、CDKの対応がされるため
- (新サービスのLambda Containerは4時間くらいで更新されていたので、必ずしもそうとは言い切れなくなりましたね・・・笑)
- リリースの速度がかなり早く、過去に作成したコードが利用できなる可能性がある
- 2020年12月07日時点で、6日に1度のペースでリリース
- (とはいえ、破壊的な変更はそこまでない印象)
- ローカルからのコマンドでの削除が失敗することがある
- IAMにCDKで管理していないPolicyを付与などした場合
3. さわってみる
メリット・デメリットは実際に触ってみて感じるのが一番だと思うので、
早速、利用方法を書いていきます。3.1 環境構築
macの場合はbrewにてCDKをインストールできます。
$ brew install aws-cdkその後、各プロジェクトに必要なCDKのPythonライブラリを入れていく形になります。
$ pip install aws-cdk.aws-lambda必要になったら、都度パッケージを入れていくことになるのですが、
pypi aws_cdk athenaなどと必要なサービス名を含めて調べるとどのパッケージを入れればいいかわかります。3.1 公式サンプルプロジェクト
ゼロから、このライブラリをドキュメントから利用方法を探っていくのはかなり大変だと思うので、その際に有用なのがサンプルプロジェクトです。
AWSの公式が容易したaws-cdk-exampleが本家大元なので、一番信頼できます。
ただ、Pythonのプロジェクトとなると意外と少なかったり、更新日時が古く動かないサンプルなどもあります。3.2 作成したサンプルプロジェクト
そのため、私も同じようなフォーマットで、
Pythonのみのサンプルプロジェクト一覧aws-cdk-small-examplesを作成してみました。
記事作成時点はCDKのバージョンが1.76.0なのですが、その時点で全てのサンプルプログラムが動くようになっています。
作成してみたサンプルプロジェクトの数は12個です。
(本家公式は25個なので、半分程度はあります。ただ、かぶっているサンプルは2個程度のみです。)対応しているサービスなどは以下の通りです。
- Lambda
- VPC
- AWS Batch
- Step Functions
- DynamoDB
- API Gateway
- CloudFront
- S3
- Glue
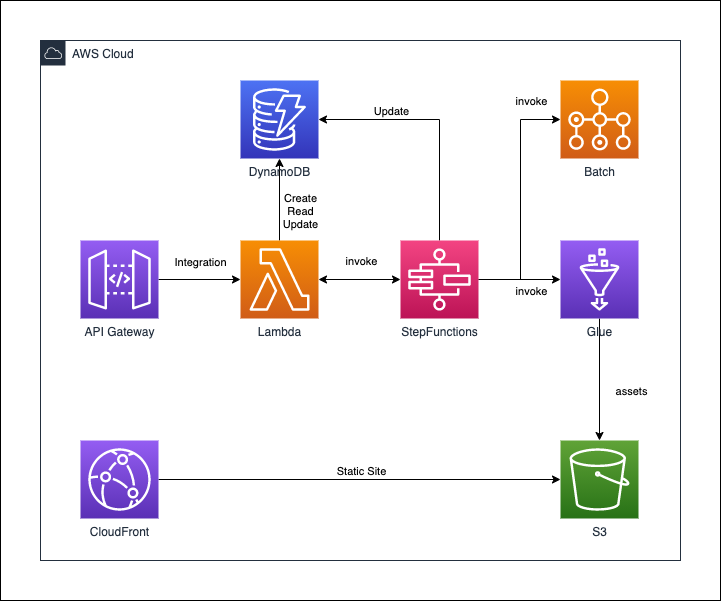
作成したリポジトリにて、公開しているサービスとその関連を表した図です。
(※注意:これらのサービスが一度にデプロイされるわけではありません。)
次の節から公開している、構成図の一部を紹介します。
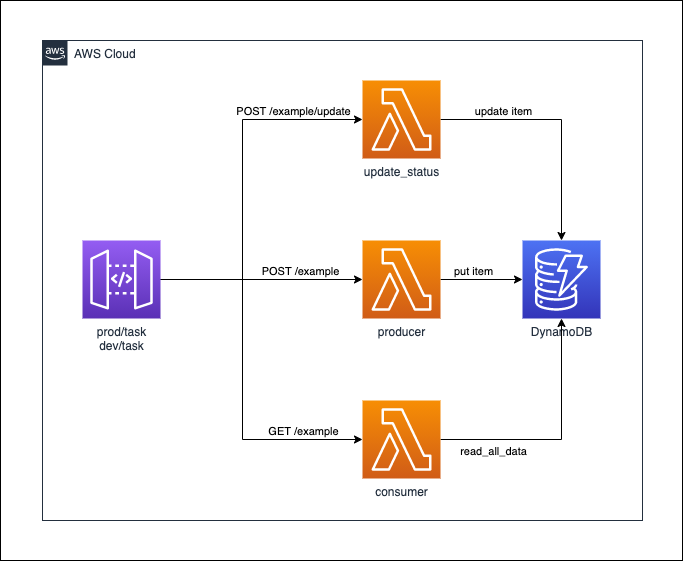
3.2.1 API Gateway + Lambda + DynamoDB
この例では、3つのLambdaを作成し、DynamoDBにアクセスするapp.pyを公開しています。
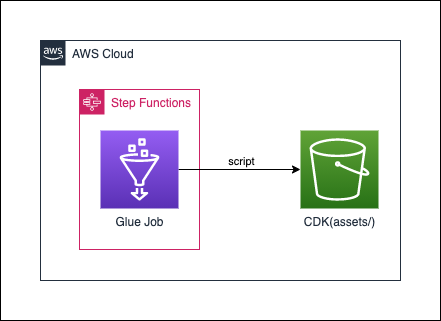
3.2.2 Glue + StepFunctions
この例では、GlueのJobを定義して、それをStepFunctionsから実行するapp.pyを公開しています。
意外とGlueの例は少ないので、もし利用するような方がいれば参考になるかなと思います。
3.2.3 Lambda Container
ここでは、reInvent2020で発表された新サービスの1つである、Lambda Containerの例も作成しています。
細かい使い方などは別のQiitaの記事でも紹介しておりますで、合わせてどうぞ!
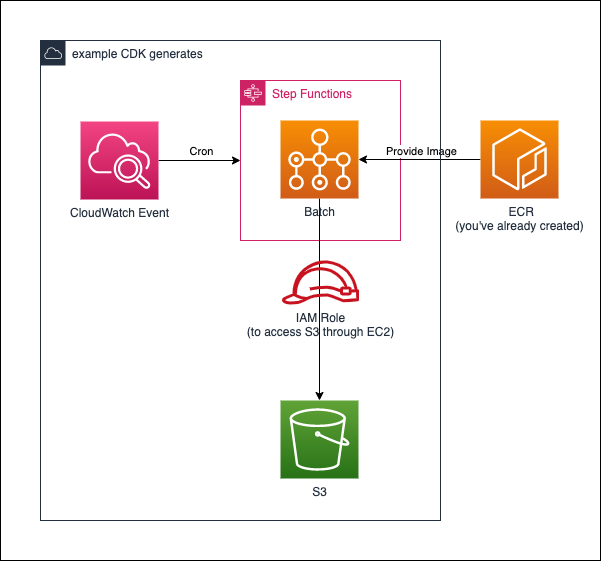
3.2.4 AWS Batch + StepFunctions
この例では、AWS BatchをStepFunctionsとCloudWatch Eventを利用して定期実行するapp.pyを公開しています。
VPCなども一から作成しており、結構長いコードとなっております。
細かい説明などは、Qiitaの記事にて、紹介しております!
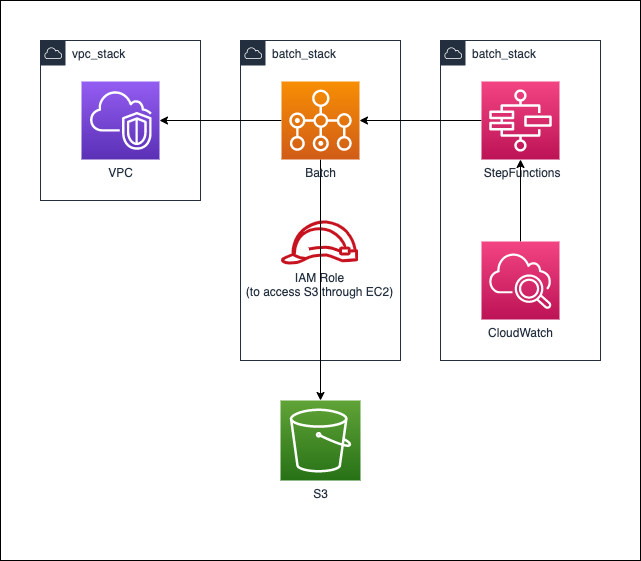
3.2.5 NESTED AWS Batch + StepFunctions
CloudFormationがnestに対応したので、3.2.4の構成をnestを利用した例を作成しております。
nestを利用することのメリットとしては、作成したStackの責任を明確にできることが大きいです。例では、以下のように分離させています。
* VPCのスタック:ベース
* Bathcのスタック:処理などを実際に行う部分
* StepFunctions + CloudWatch Eventのスタック:定期的に処理を走らせる部分
3.3 おすすめの記事
- こちら本家のAPI referenceです。Python専用のdocsもありますが、こちらの方が参考になります。
4. おわりに
自分の中で、CDKはかなり好きなので、いろんな人にCDKを使っていただきたいなと思います!
IaCを進めるという意味でもかなり良いです!また、これからも、随時GitHubのサンプルは増やしていく予定なので、ぜひチェックなどをお願いいたします!!
- 投稿日:2020-11-29T19:42:34+09:00
30代未経験からRails, AWS, Docker, CircleCIでポートフォリオを作成するまで
プログラミング未経験の31歳男がRuby on Rails, jQuery, AWS, Docker, CircleCIといった技術を使ってWebアプリを作りました。
この記事では、最初にアプリの紹介をした後に、
- どれくらいの時間かけて作ったのか
- なぜこれらの技術を使うことにしたのか
- 特に大変だったところ
- どのように学習したのか
といったことについて、お伝えできればと思います。
どんなアプリを作ったのか
減量アプリです。(筋トレしてる人が健康的に体脂肪を減らすためのアプリ)
「これなら自分でも続けられる」をコンセプトに「PFC MASTER」というアプリを開発しました。
アプリのURLはこちらです。
https://pfcmaster.work/
(レスポンシブ対応しておりスマホからも見られますが、グラフが崩れます)Githubはこちらです。
https://github.com/naota7118/pfc-masterなんでこのアプリを作ったのか
僕自身が「減量がなかなか続かなくて、まだ腹筋を割れたことがない」という悩みを抱えていました。
自分自身の悩みを解決するようなアプリを作りたいと思い、減量アプリを作ることにしました。「どうしたら減量を途中で挫折せずに続けられるようになるかな?」
今まで減量に挫折した原因を考えたところ、下記の2つが思い当たりました。
〈これまで減量が続かなかった原因〉
- 1日どれくらい食べれば体脂肪落とせるのかわからなくて、適当に食べてしまっていた。
- 減量が進んでいるのかどうか、進捗がわからなくてモチベーションが保てなかった。
このような原因に対してどうしたら減量を続けやすくなるか考えた結果、下記の2つを思いつきました。
- 「1日何キロカロリーまで食べていいのか」を自分の体重から自動で計算してくれて、食べるごとに確認できたらカロリーコントロールしやすくなるのではないか。
- 体重やカロリーの推移をグラフで見られるようにすれば、成果が出てるのがわかってモチベーションが保てるのではないか。
このように原因やそれを解決する策を考えて、グラフ機能をメインとした減量アプリを作ることにしました。
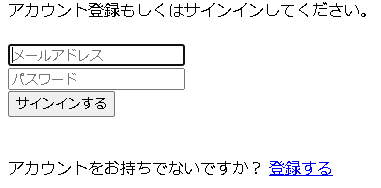
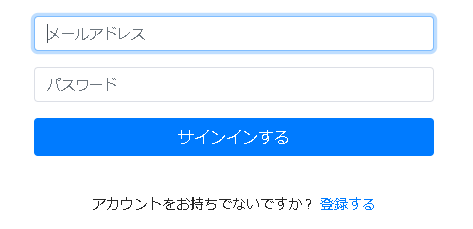
アプリの写真と説明
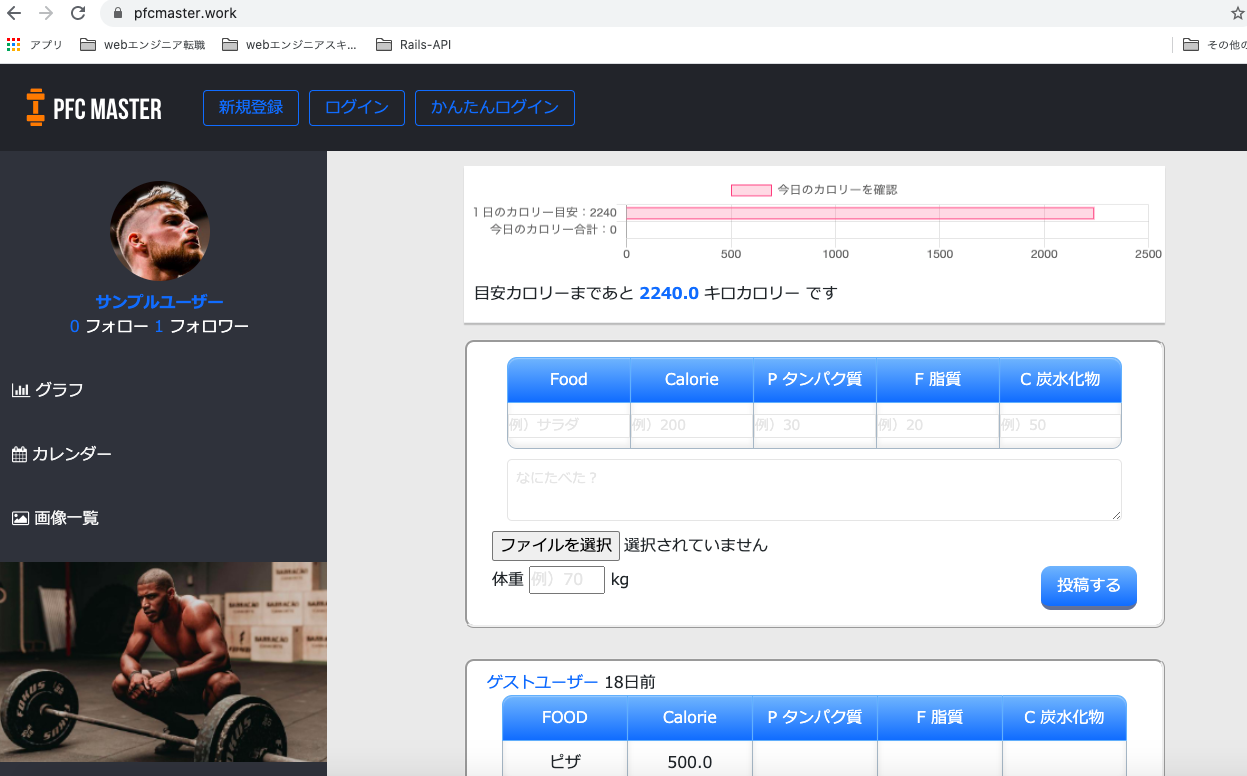
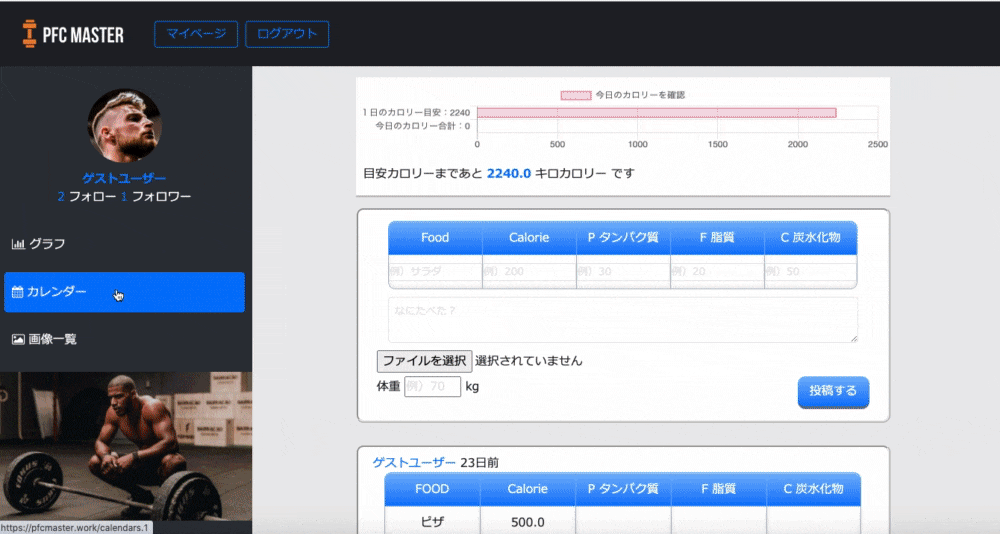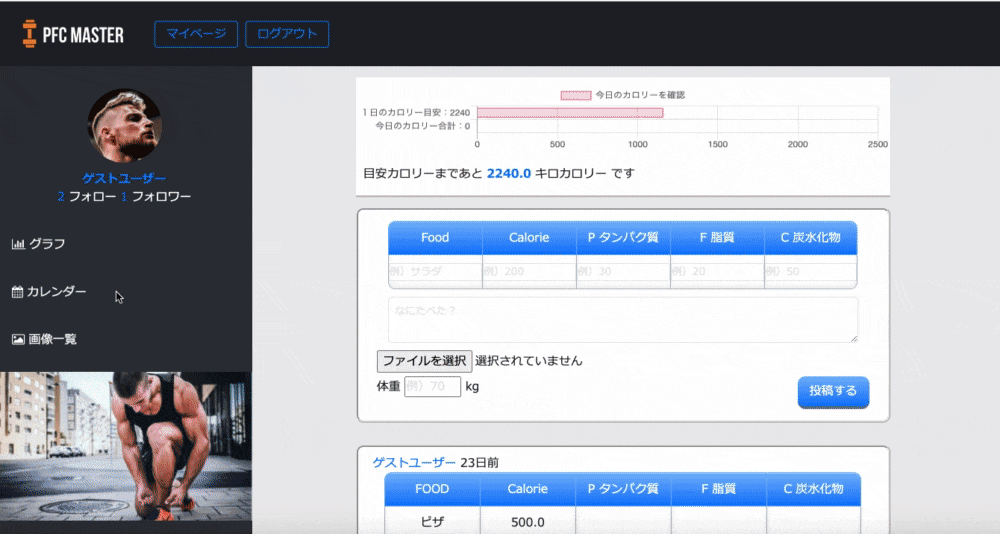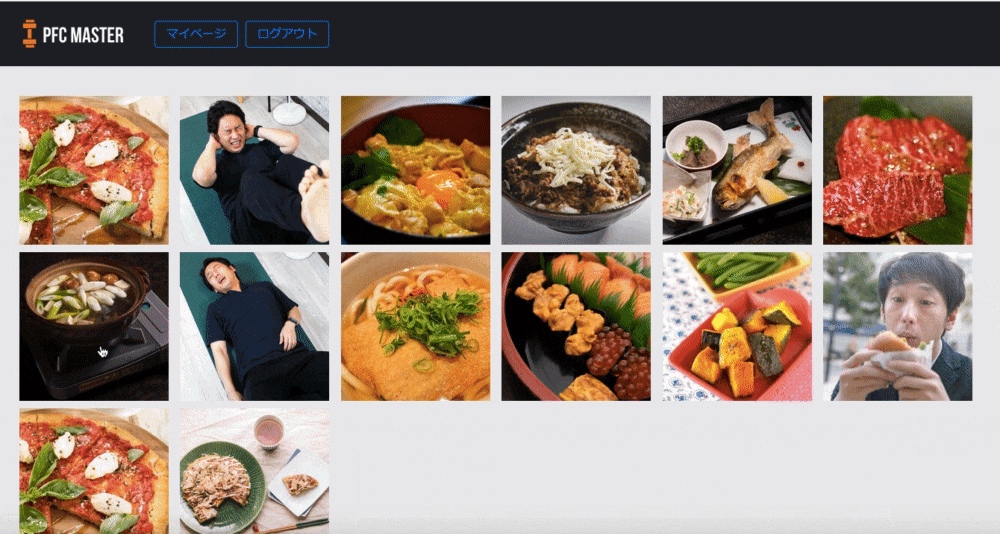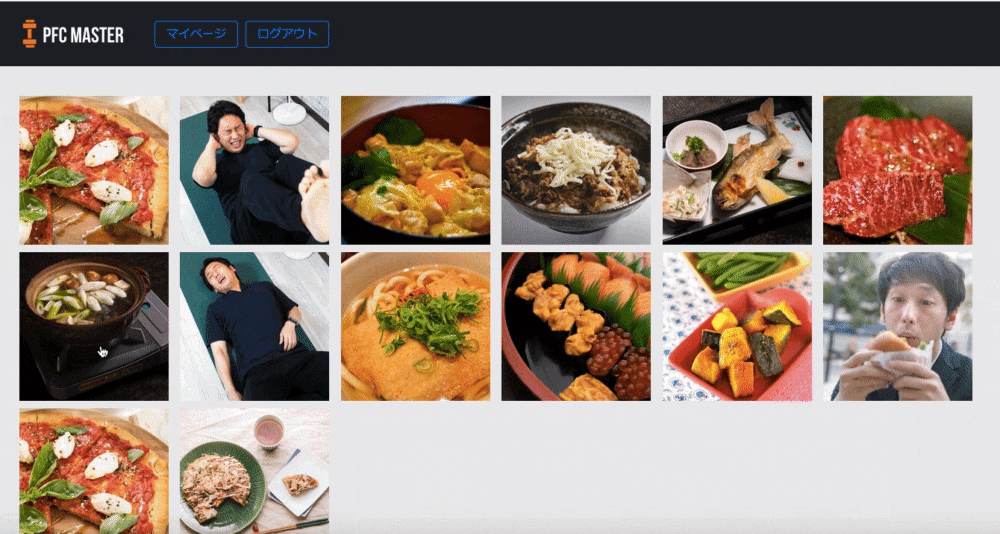
トップページ
使い方を細かく説明しなくても、パッと見て一目で使い方わかる外観を意識して作りました。
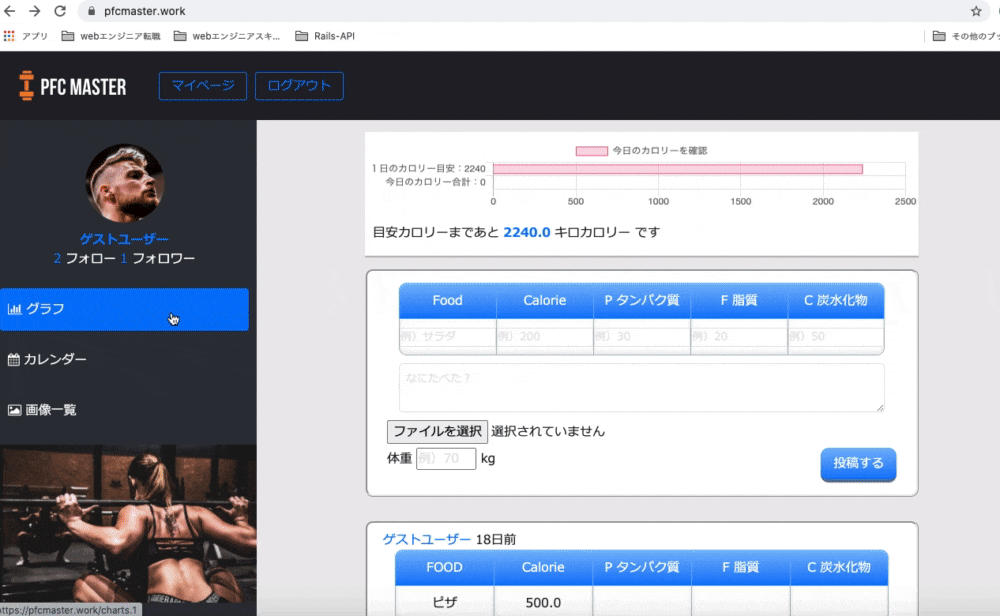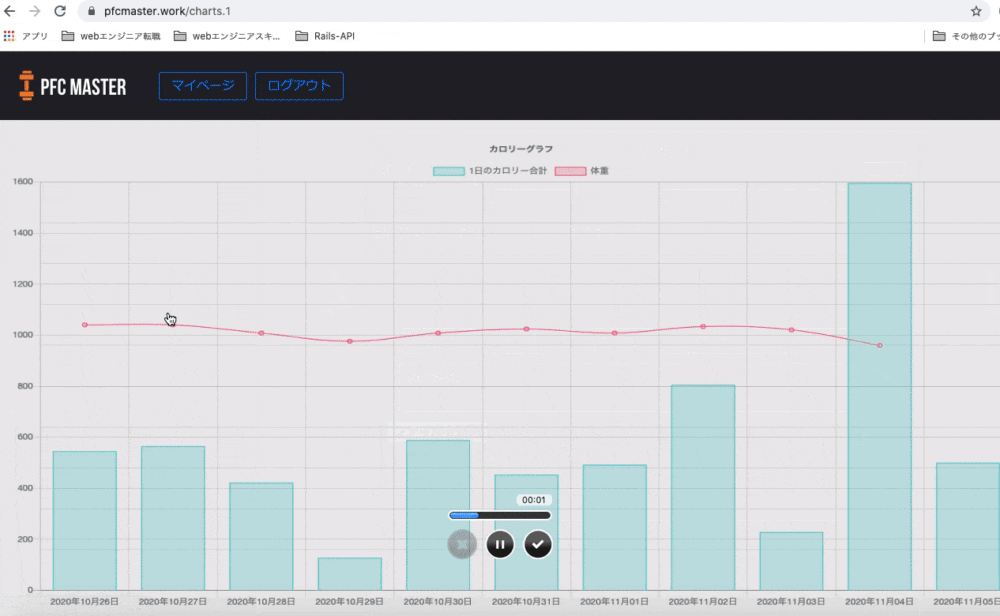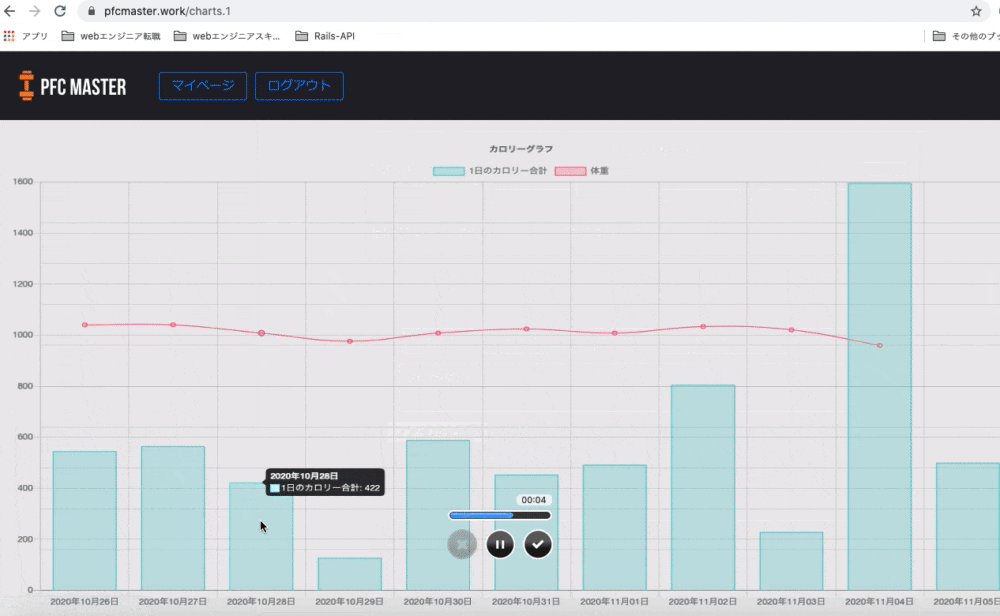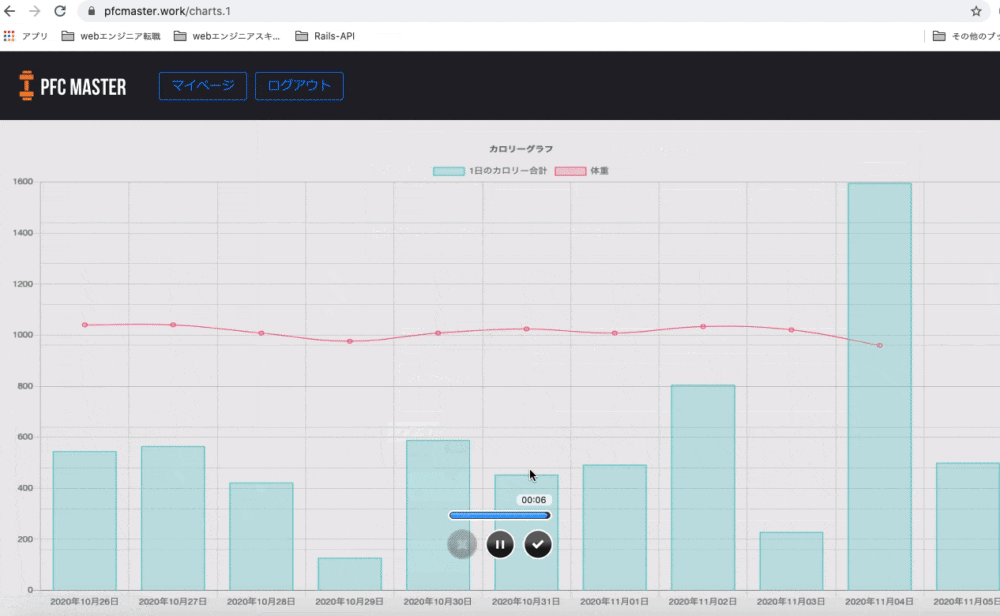
グラフ
体重とカロリーの推移がグラフという形で見られるようにしました。
自分の頑張りが目に見えることで「よし、いい感じだ。もっと頑張ろう」と思えるのではないかと考えたのです。
カレンダーと画像一覧
食べたものや筋トレをカレンダーや写真で記録して確認できるようにしました。
写真でカラダの変化を可視化することでそれもモチベーションにつながると考えました。
また、他の減量に成功した方がどんなものを食べて減量できたのか知って真似できるため、という目的もあります。
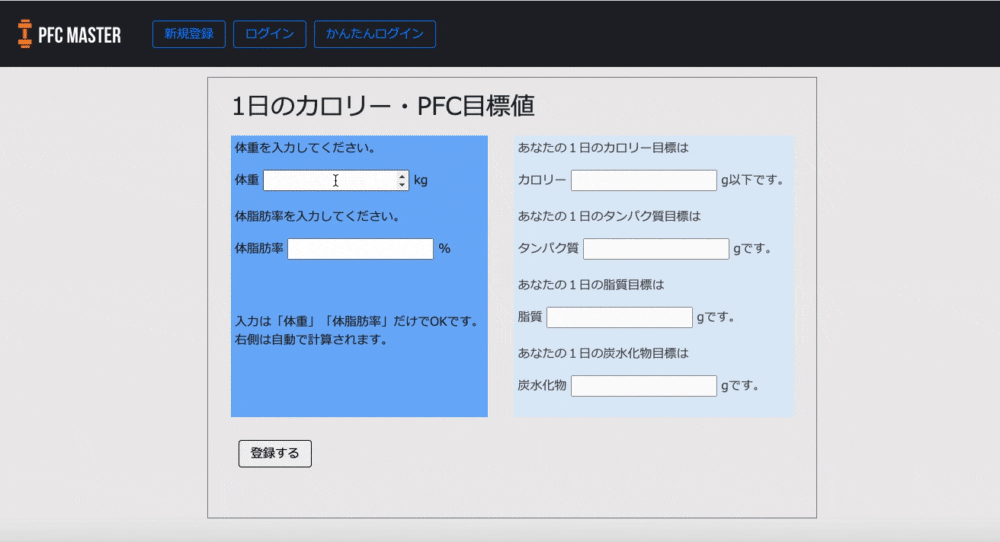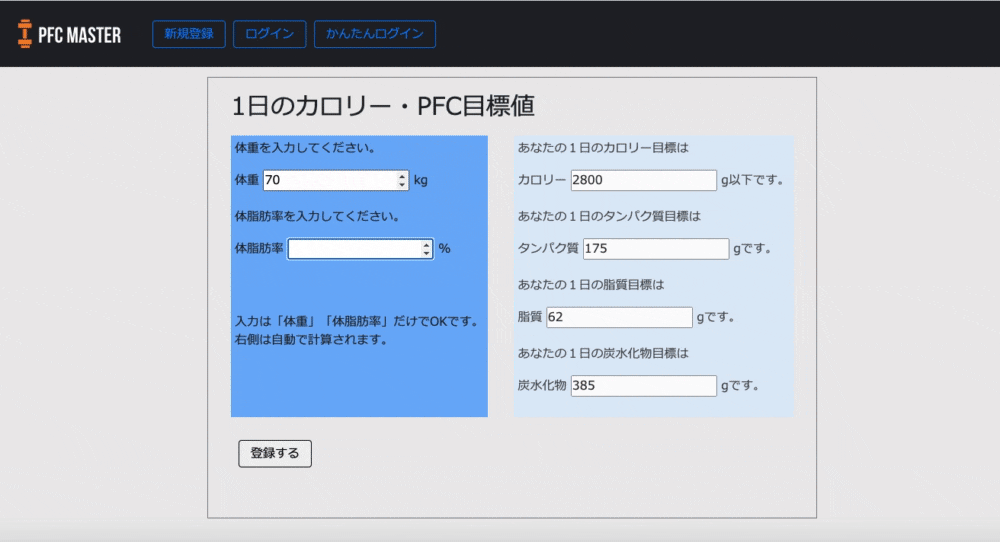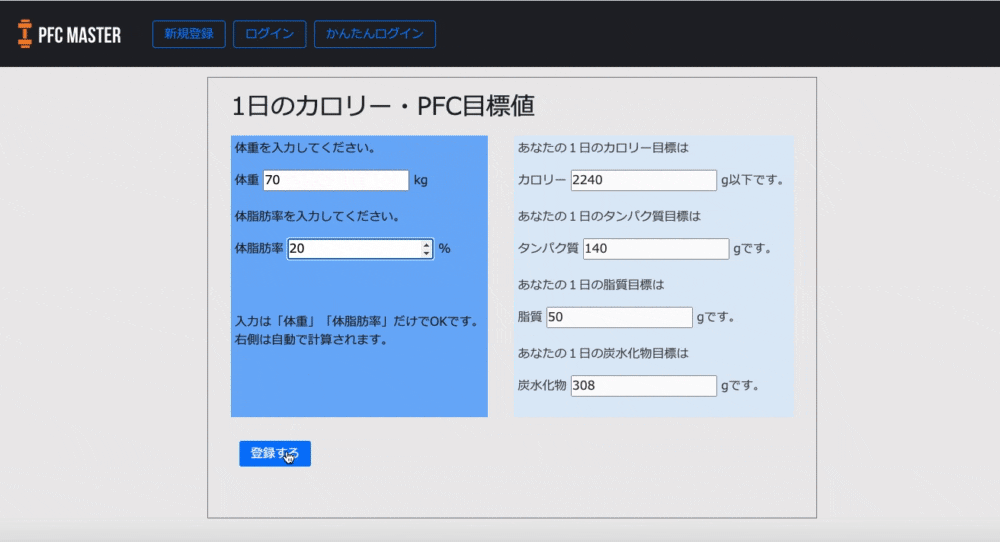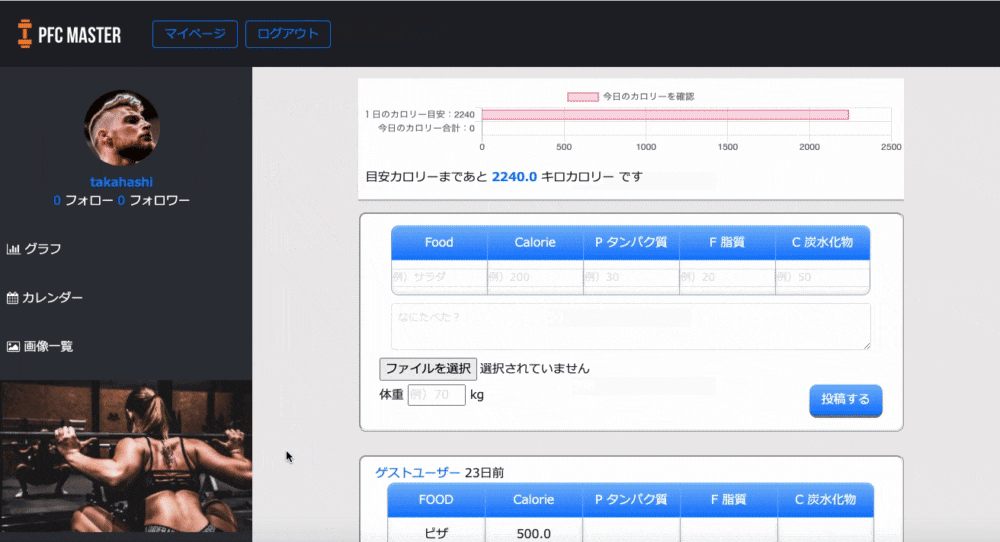
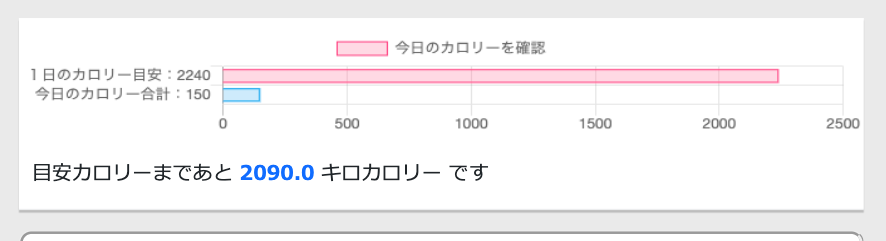
カロリーの自動計算
「1日○キロカロリー食べれば体脂肪を落とせる」という減量の目安となる"1日の摂取カロリー目をユーザーが体重と体脂肪率を入力したら自動で計算されるようにしました。
※ちなみに、摂取カロリーの計算式はバズーカ岡田先生の著書『除脂肪メソッド』を参考にしました。
自動計算機能によって、「今日あと何キロカロリーまで食べて大丈夫か」がわかるようにしました。
これで減量の成功率を高められると考えました。
使用技術
フロントエンド
HTML(Haml), CSS(Sass), jQuery, boostrap4サーバーサイド
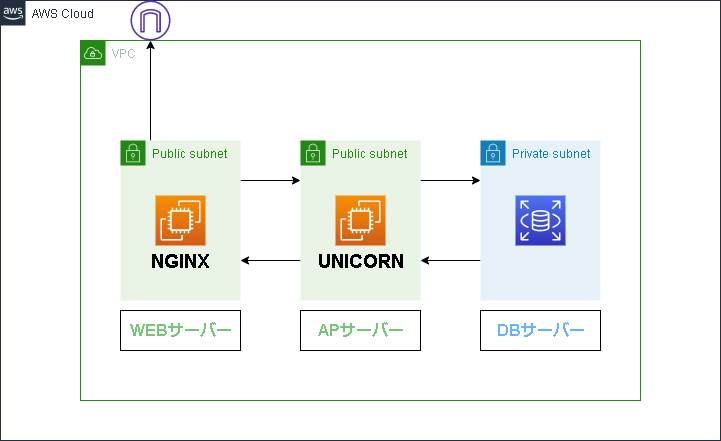
Ruby 2.5.1, Rails 5.2.4.3インフラ
CircleCI, Nginx, MySQL, Docker/Docker-compose, AWS(VPC, EC2, RDS, IAM, Route53, S3)サーバーサイドはRuby on Rails、フロントエンドはSassとjQueryで実装しました。
開発環境にはDocker-composeを使用しました。CI/CDパイプラインに関しては、CircleCIによりmasterブランチにmergeしたら自動でRSpecのテストとRubocopのリファクタリングが実行されるように設定しました。
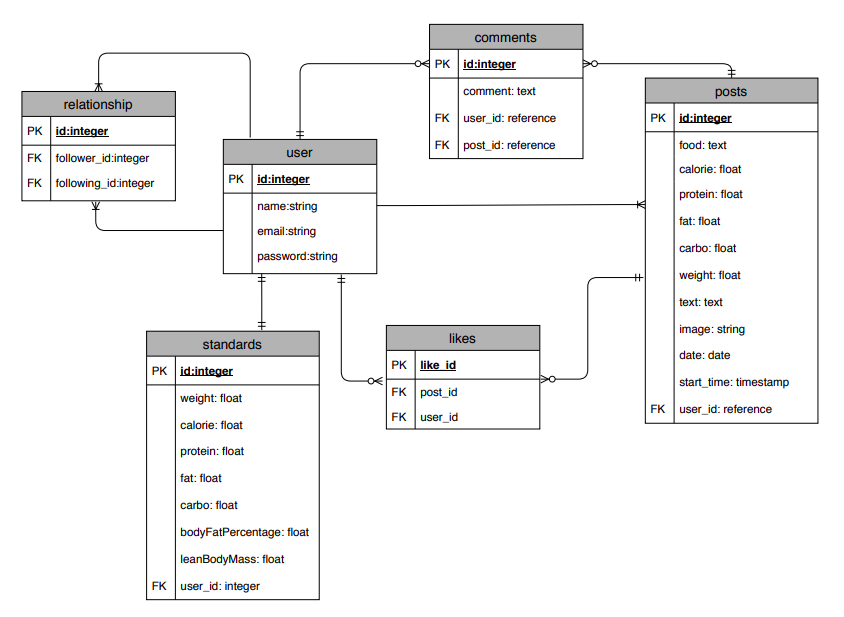
ER図
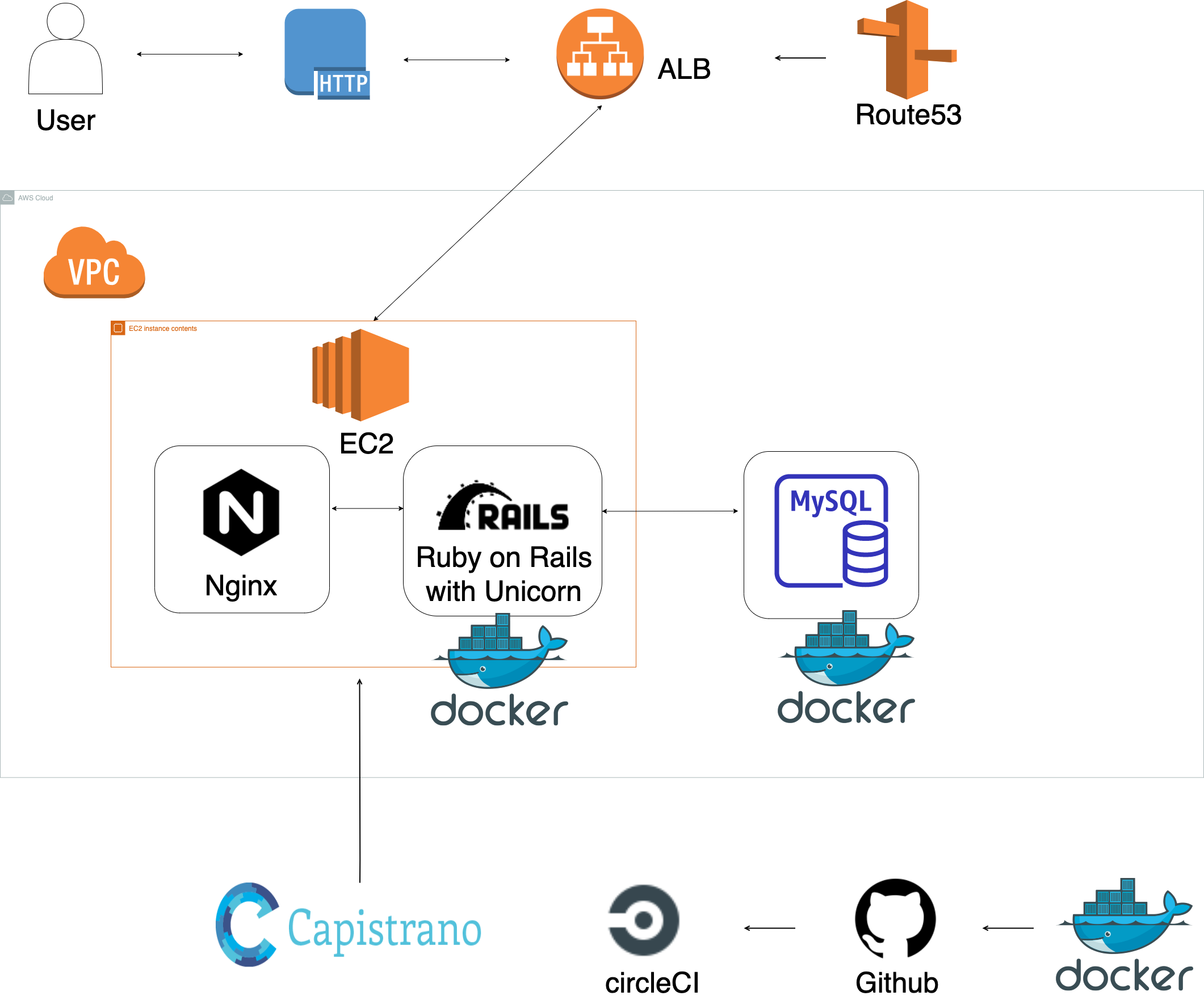
インフラ構成図
アプリを作るのにかかった期間
トータル6ヶ月です。
当初の予定では8月にはAWSにデプロイした時点で転職活動を始める予定でしたが、「DockerやCirlcleCIを導入するところまでやり切りたい」と思い、結局6ヶ月かかりました。半年間どのように進めてきたかは下記の通りです。
期間 やったこと 2020年4月 テーマを決めた。データベース設計。 2020年5〜7月 (スクールのチーム開発と並行する形で)
RailsのCRUD機能、いいね機能(非同期通信)、コメント機能(非同期通信)、フォロー機能。
Chart.jsを使ったグラフ機能、jQueryを使った自動計算機能。2020年8月 Unicorn, Nginxを使ってAWSにデプロイ。
Capistranoを使って自動デプロイ。2020年9月 Haml, Sassで各ページのマークアップ。
Boostrapを使ってレスポンシブ対応させる。
Dockerを使って開発環境を構築。2020年10月 CircleCIでRSpecの自動テスト、Rubocopの自動リファクタリングを通す。
Gitのエラー解決で誤ってGitリポジトリのファイルを消してしまい、その修復のためAWSへのデプロイをやり直す。2020年11月 TwitterAPIを使って投稿するとTwitterに自動投稿されるように設定(ローカル環境のみ)。
転職活動開始。現在PHPで2つ目のアプリを開発中。なぜ6ヶ月もかかってしまったのか
誰にも相談せず1人でエラーを解決することにこだわり過ぎて、エラー解決に時間をかけ過ぎたことがいちばんの原因です。
エンジニアになるためには、「エラーに直面した時に"すぐ質問せず自分で問題解決する力"が求められる」との考えから、できるだけ自分でエラーを解決することにこだわっていました。
今振り返ると、リミットを設けてある程度自分で考えたら、リミットがきた時点で質問すべきだったと思います。
実際の仕事では1人のエラー解決をずっと待ってもらえないからです。現在、「2020年中に完成させる」というリミットを決めて2つめのアプリを開発しています。
なぜRails, jQuery, Docker, CircleCIを使うことにしたのか?
RailsとjQueryを選んだ理由
最速で開発する方法として、これらの技術を選びました。なるべく早くアプリを完成させ、転職活動を開始し、1日も早くエンジニアとして働きたいと思ったためです。
(結果的に半年もかかったので説得力ありませんが...)なぜRubyとjQueryを使えば最速で開発できると思ったかというと、スクールで簡単なCRUD機能を持ったアプリを開発した経験があり、他の言語に比べて理解していた部分が大きく開発する「こうやって作っていくんだ」というイメージがしやすかったためです。
AWS, Docker, CircleCIを使うことにした理由
これらの技術を使用した理由は、wantedlyで求人情報を見たところ、多くの企業でこれらの技術を使用していたためです。
「多くの企業で使われている技術はどんな技術なのだろう」と興味を持ったのと、実務で使うことを見越して「早いうちから自分で使って慣れておきたい」と考えたためです。特に大変だったところ
特に挙げるとすると、下記の6点です。
詰まったエラーの解決法をQiita記事にアウトプットしていました。
- Chart.jsを用いたグラフ機能
体重とカロリーをどうやってグラフで表示させるかで苦労しました。ただ大変さを感じると同時に、自分でロジックを考えるのが楽しく、プログラミングを始めて以来いちばん面白さを瞬間でもありました。
- AWSへのデプロイ
Qiita記事:デプロイしたのにアプリがブラウザに表示されない原因はunicorn.rbの設定にあった
Qiita記事:Can't connect to local MySQL server through socket '/var/lib/mysql/mysql.sock'の解決法
Qiita記事:libmysqlclient.so.18: cannot open shared object file: No such file or directoryの解決法
- Capistranoでの自動デプロイ
Qiita記事:bundle exec cap production deployで生じた6つのエラーの解決法(bundle exec cap production deployで生じた6つのエラーの解決法)
- CirlcleCIのconfig.ymlの設定
Qiita記事:CicleCIでRspecとRubocop通すまでにつまずいたところとその解決法
- Gitの中身が大きすぎる問題の解決
誤ってGitオブジェクトの中身を削除してしまい、その修復に苦労しました。
Qiita記事:[エラー解決プロセス説明].gitディレクトリ階下の容量が大きすぎるので小さくしたいどのように学習したのか
技術 学習方法 HTML/CSS/Ruby/Rails/jQuery スクールのカリキュラム Boostrap4 Boostrap日本語リファレンス AWS AWS:ゼロから実践するAmazon Web Services。手を動かしながらインフラの基礎を習得
(デプロイ編①)世界一丁寧なAWS解説。EC2を利用して、RailsアプリをAWSにあげるまでDocker 米国AI開発者がゼロから教えるDocker講座 CircleCI 米国AI開発者がゼロから教えるDocker講座 Chart.js Chart.js日本語ドキュメント 今後の課題
- 2日連続投稿した時に「すごい!!」と表示されるようにする。
- プロフィール画像を登録できるようにする。(現状は女性ユーザーも外国人男性がプロフィール画像になってしまう。)
- 運動した日と運動しなかった日をカレンダーでわかるようにする。
企業の方へ
ここまでお読みいただきありがとうございました。
現在、webエンジニアになるため転職活動を行っております。
少しでも興味を持って頂けましたら、Twitterの@naota7118までDM頂ければ幸いです。
何卒よろしくお願いいたします。
- 投稿日:2020-11-29T19:42:34+09:00
30代未経験からRails, AWS, Docker, CircleCIを使って減量アプリを作りました
プログラミング未経験の31歳男がRuby on Rails, jQuery, AWS, Docker, CircleCIといった技術を使ってWebアプリを作りました。
この記事では、最初にアプリの紹介をした後に、
- どれくらいの時間かけて作ったのか
- なぜこれらの技術を使うことにしたのか
- 特に大変だったところ
- どのように学習したのか
といったことについて、お伝えできればと思います。
どんなアプリを作ったのか
減量アプリです。(筋トレしてる人が健康的に体脂肪を減らすためのアプリ)
「これなら自分でも続けられる」をコンセプトに「PFC MASTER」というアプリを開発しました。
アプリのURLはこちらです。
https://pfcmaster.work/
(レスポンシブ対応しておりスマホからも見られますが、グラフが崩れます)Githubはこちらです。
https://github.com/naota7118/pfc-masterなんでこのアプリを作ったのか
僕自身が「減量がなかなか続かなくて、まだ腹筋を割れたことがない」という悩みを抱えていました。
自分自身の悩みを解決するようなアプリを作りたいと思い、減量アプリを作ることにしました。「どうしたら減量を途中で挫折せずに続けられるようになるかな?」
今まで減量に挫折した原因を考えたところ、下記の2つが思い当たりました。
〈これまで減量が続かなかった原因〉
- 1日どれくらい食べれば体脂肪落とせるのかわからなくて、適当に食べてしまっていた。
- 減量が進んでいるのかどうか、進捗がわからなくてモチベーションが保てなかった。
このような原因に対してどうしたら減量を続けやすくなるか考えた結果、下記の2つを思いつきました。
- 「1日何キロカロリーまで食べていいのか」を自分の体重から自動で計算してくれて、食べるごとに確認できたらカロリーコントロールしやすくなるのではないか。
- 体重やカロリーの推移をグラフで見られるようにすれば、成果が出てるのがわかってモチベーションが保てるのではないか。
このように原因やそれを解決する策を考えて、グラフ機能をメインとした減量アプリを作ることにしました。
アプリの写真と説明
トップページ
使い方を細かく説明しなくても、パッと見て一目で使い方わかる外観を意識して作りました。
グラフ
体重とカロリーの推移がグラフという形で見られるようにしました。
自分の頑張りが目に見えることで「よし、いい感じだ。もっと頑張ろう」と思えるのではないかと考えたのです。
カレンダーと画像一覧
食べたものや筋トレをカレンダーや写真で記録して確認できるようにしました。
写真でカラダの変化を可視化することでそれもモチベーションにつながると考えました。
また、他の減量に成功した方がどんなものを食べて減量できたのか知って真似できるため、という目的もあります。
カロリーの自動計算
「1日○キロカロリー食べれば体脂肪を落とせる」という減量の目安となる"1日の摂取カロリー目をユーザーが体重と体脂肪率を入力したら自動で計算されるようにしました。
※ちなみに、摂取カロリーの計算式はバズーカ岡田先生の著書『除脂肪メソッド』を参考にしました。
自動計算機能によって、「今日あと何キロカロリーまで食べて大丈夫か」がわかるようにしました。
これで減量の成功率を高められると考えました。
使用技術
フロントエンド
HTML(Haml), CSS(Sass), jQuery, boostrap4サーバーサイド
Ruby 2.5.1, Rails 5.2.4.3インフラ
CircleCI, Nginx, MySQL, Docker/Docker-compose, AWS(VPC, EC2, RDS, IAM, Route53, S3)サーバーサイドはRuby on Rails、フロントエンドはSassとjQueryで実装しました。
開発環境にはDocker-composeを使用しました。CI/CDパイプラインに関しては、CircleCIによりmasterブランチにmergeしたら自動でRSpecのテストとRubocopのリファクタリングが実行されるように設定しました。
ER図
インフラ構成図
アプリを作るのにかかった期間
トータル6ヶ月です。
当初の予定では8月にはAWSにデプロイした時点で転職活動を始める予定でしたが、「DockerやCirlcleCIを導入するところまでやり切りたい」と思い、結局6ヶ月かかりました。半年間どのように進めてきたかは下記の通りです。
期間 やったこと 2020年4月 テーマを決めた。データベース設計。 2020年5〜7月 (スクールのチーム開発と並行する形で)
RailsのCRUD機能、いいね機能(非同期通信)、コメント機能(非同期通信)、フォロー機能。
Chart.jsを使ったグラフ機能、jQueryを使った自動計算機能。2020年8月 Unicorn, Nginxを使ってAWSにデプロイ。
Capistranoを使って自動デプロイ。2020年9月 Haml, Sassで各ページのマークアップ。
Boostrapを使ってレスポンシブ対応させる。
Dockerを使って開発環境を構築。2020年10月 CircleCIでRSpecの自動テスト、Rubocopの自動リファクタリングを通す。
Gitのエラー解決で誤ってGitリポジトリのファイルを消してしまい、その修復のためAWSへのデプロイをやり直す。2020年11月 TwitterAPIを使って投稿するとTwitterに自動投稿されるように設定(ローカル環境のみ)。
転職活動開始。現在PHPで2つ目のアプリを開発中。なぜ6ヶ月もかかってしまったのか
誰にも相談せず1人でエラーを解決することにこだわり過ぎて、エラー解決に時間をかけ過ぎたことがいちばんの原因です。
エンジニアになるためには、「エラーに直面した時に"すぐ質問せず自分で問題解決する力"が求められる」との考えから、できるだけ自分でエラーを解決することにこだわっていました。
今振り返ると、リミットを設けてある程度自分で考えたら、リミットがきた時点で質問すべきだったと思います。
実際の仕事では1人のエラー解決をずっと待ってもらえないからです。現在、「2020年中に完成させる」というリミットを決めて2つめのアプリを開発しています。
なぜRails, jQuery, Docker, CircleCIを使うことにしたのか?
RailsとjQueryを選んだ理由
最速で開発する方法として、これらの技術を選びました。なるべく早くアプリを完成させ、転職活動を開始し、1日も早くエンジニアとして働きたいと思ったためです。
(結果的に半年もかかったので説得力ありませんが...)なぜRubyとjQueryを使えば最速で開発できると思ったかというと、スクールで簡単なCRUD機能を持ったアプリを開発した経験があり、他の言語に比べて理解していた部分が大きく開発する「こうやって作っていくんだ」というイメージがしやすかったためです。
AWS, Docker, CircleCIを使うことにした理由
これらの技術を使用した理由は、wantedlyで求人情報を見たところ、多くの企業でこれらの技術を使用していたためです。
「多くの企業で使われている技術はどんな技術なのだろう」と興味を持ったのと、実務で使うことを見越して「早いうちから自分で使って慣れておきたい」と考えたためです。特に大変だったところ
特に挙げるとすると、下記の6点です。
詰まったエラーの解決法をQiita記事にアウトプットしていました。
- Chart.jsを用いたグラフ機能
体重とカロリーをどうやってグラフで表示させるかで苦労しました。ただ大変さを感じると同時に、自分でロジックを考えるのが楽しく、プログラミングを始めて以来いちばん面白さを瞬間でもありました。
- AWSへのデプロイ
Qiita記事:デプロイしたのにアプリがブラウザに表示されない原因はunicorn.rbの設定にあった
Qiita記事:Can't connect to local MySQL server through socket '/var/lib/mysql/mysql.sock'の解決法
Qiita記事:libmysqlclient.so.18: cannot open shared object file: No such file or directoryの解決法
- Capistranoでの自動デプロイ
Qiita記事:bundle exec cap production deployで生じた6つのエラーの解決法(bundle exec cap production deployで生じた6つのエラーの解決法)
- CirlcleCIのconfig.ymlの設定
Qiita記事:CicleCIでRspecとRubocop通すまでにつまずいたところとその解決法
- Gitの中身が大きすぎる問題の解決
誤ってGitオブジェクトの中身を削除してしまい、その修復に苦労しました。
Qiita記事:[エラー解決プロセス説明].gitディレクトリ階下の容量が大きすぎるので小さくしたいどのように学習したのか
技術 学習方法 HTML/CSS/Ruby/Rails/jQuery スクールのカリキュラム Boostrap4 Boostrap日本語リファレンス AWS AWS:ゼロから実践するAmazon Web Services。手を動かしながらインフラの基礎を習得
(デプロイ編①)世界一丁寧なAWS解説。EC2を利用して、RailsアプリをAWSにあげるまでDocker 米国AI開発者がゼロから教えるDocker講座 CircleCI 米国AI開発者がゼロから教えるDocker講座 Chart.js Chart.js日本語ドキュメント 今後の課題
- 2日連続投稿した時に「すごい!!」と表示されるようにする。
- プロフィール画像を登録できるようにする。(現状は女性ユーザーも外国人男性がプロフィール画像になってしまう。)
- 運動した日と運動しなかった日をカレンダーでわかるようにする。
ここまでお読みいただきありがとうございました。
現在、webエンジニアになるため転職活動を行っております。
もし企業の採用担当者の方で、この記事を読んで少しでも興味を持って頂くなんてことがもしありましたら、Twitterの@naota7118までDM頂ければ幸いです。
何卒よろしくお願いいたします。
- 投稿日:2020-11-29T18:33:29+09:00
第1回 AWSに自動でテスト/デプロイしてくれるインフラの設定・構築(AWS構築)
本シリーズ集
タイトル 0 目標・やりたいこと 1 AWS編 2 rails開発環境構築編(未) 3 Nginx・MySQL編(未) 4 Capistrano編(未) 5 CircleCI編(未) 6 総集編(未) AWSとは
本記事では、AWSの EC2(Elastic Compute Cloud)、 VPC(Virtual Private Cloud)を使用して、サーバを構築していく。
今回は、VPC を構築し、その中にサブネットを構築。そして、そのサブネットの中に、EC2を使用して、Webサーバ、APサーバ、DBサーバを立てていく。
ちなみに、AWSには、コンテナ用のサービスECS(Elastic Container Service)や、RDB用のサービスRDS(Relational Database Service)もあるが、今回は使わず、全部EC2とDockerで済ます。(追々、ECSの使い方も学んでいきたいと思ってます)
参考サイト・記事・書籍
参考サイト・書籍は以下。(書籍(AmazonWebServices〜)は執筆時点ではKindle Unlimited登録者は無料)
・(サイト)(下準備編)世界一丁寧なAWS解説。EC2を利用して、RailsアプリをAWSにあげるまで
・(書籍)Amazon Web Services 基礎からのネットワーク&サーバー構築・(書籍)AWSをはじめよう
1. VPC構築
VPC(Virtual Private Cloud)は、自前で構築できる仮想的なLANのようなもの。
この章では、VPCの作成方法を示していく
- AWSのサービスの(検索でも可能)VPCページにいく。
- 左側に表示されるサイドバーの『VPC』をクリック
- [VPCを作成]をクリック
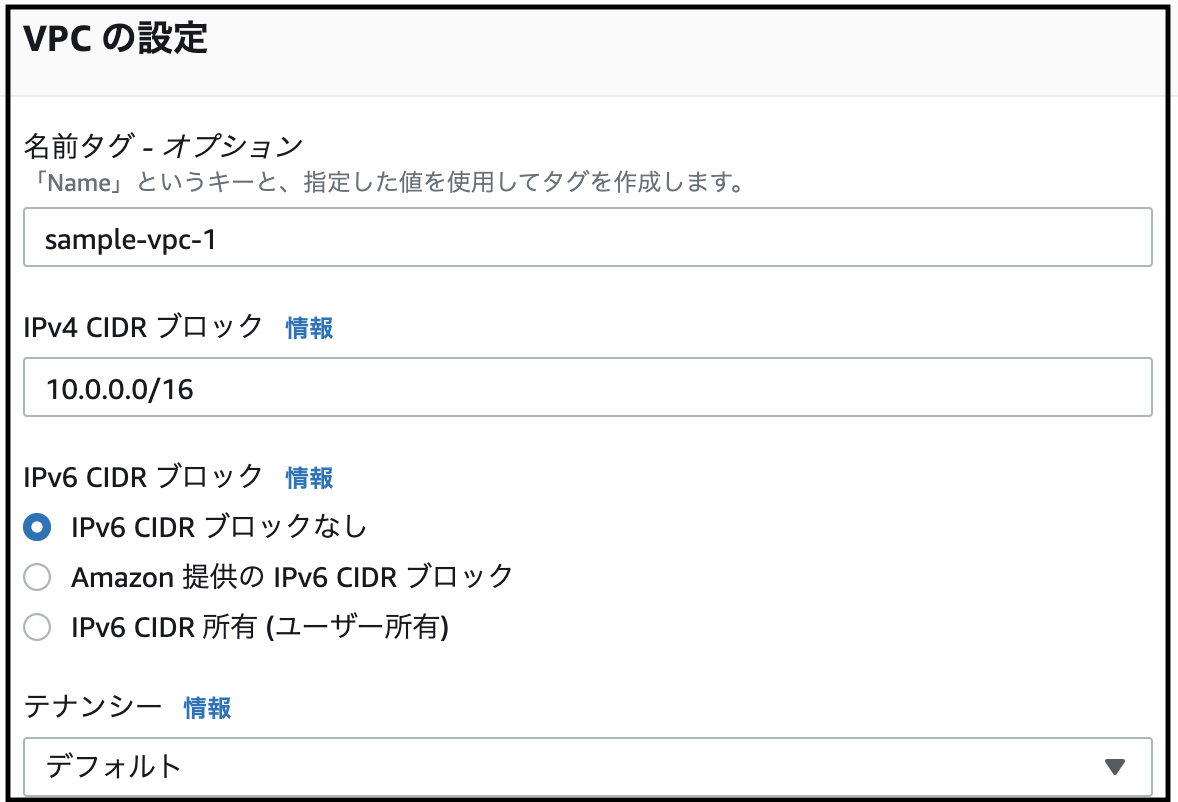
- [名前タグ] に好きな名前を。 [IPv4CIDRブロック]には、『10.0.0.0/16』と入力 [IPv6 CIDR ブロック]は『なし』 [テナンシー]・[タグ]はデフォルトのままでOK
- [VPCの作成]をクリック
->作成完了
続いて、サブネットを構築していく2. サブネット構築
- ページはそのままで、サイドバーの[サブネット]をクリック
- 表示された画面で[サブネットを作成]をクリック
- [VPC ID]に、先程作成したVPCを紐付ける。
- また、その下のサブネットの設定画面では、 [サブネット名]に『パブリックサブネット』 [アベイラビリティゾーン]に任意の設定(覚えておく必要あり)を [IPv4 CIDR ブロック] に 『10.0.1.0/24』 を入力
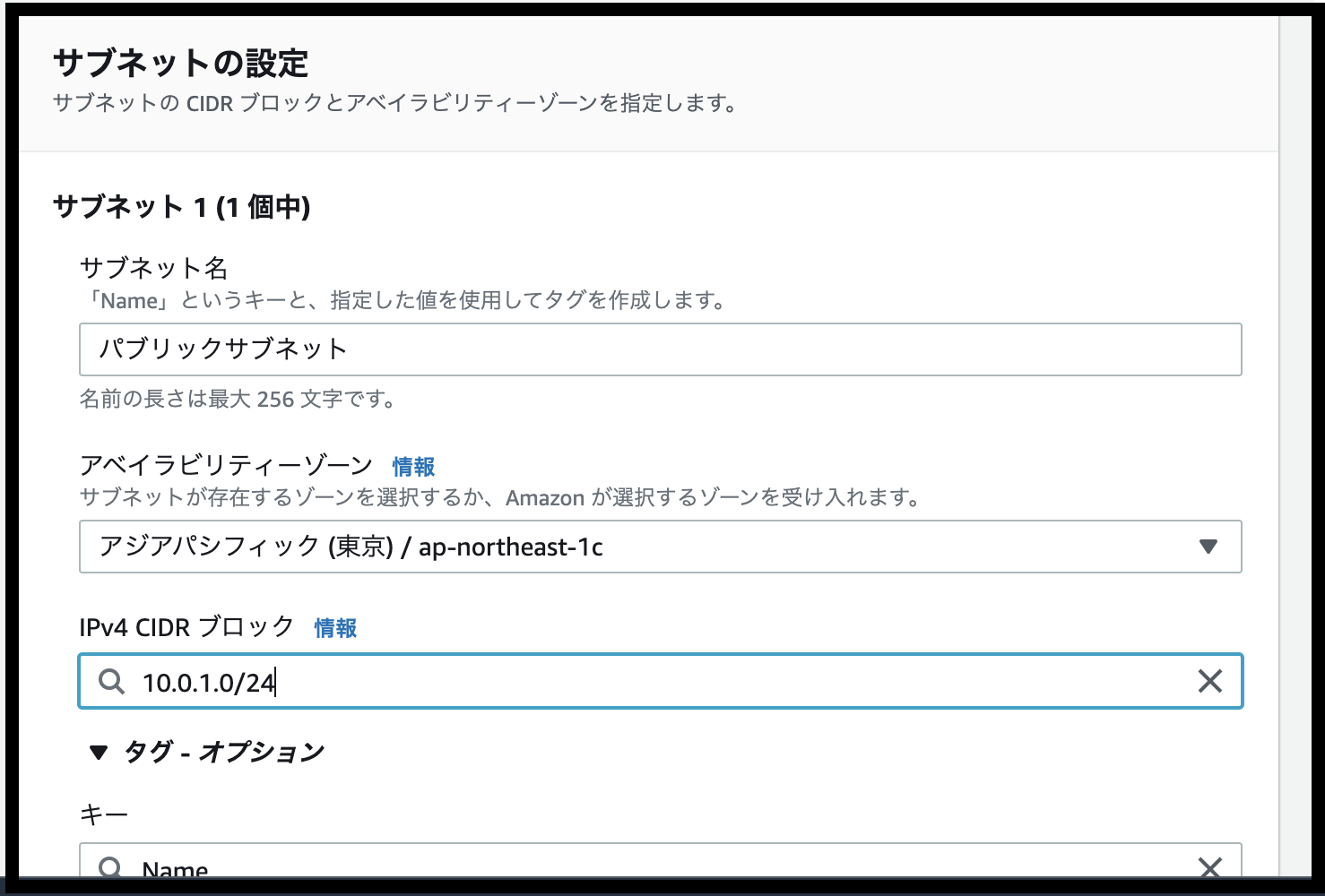
- [サブネットを作成]をクリック
-> サブネット作成終了
3. ルートテーブル作成
そのままの画面で、ルートテーブルを作成していく。
- サイドバーの[ルートテーブル]をクリック。
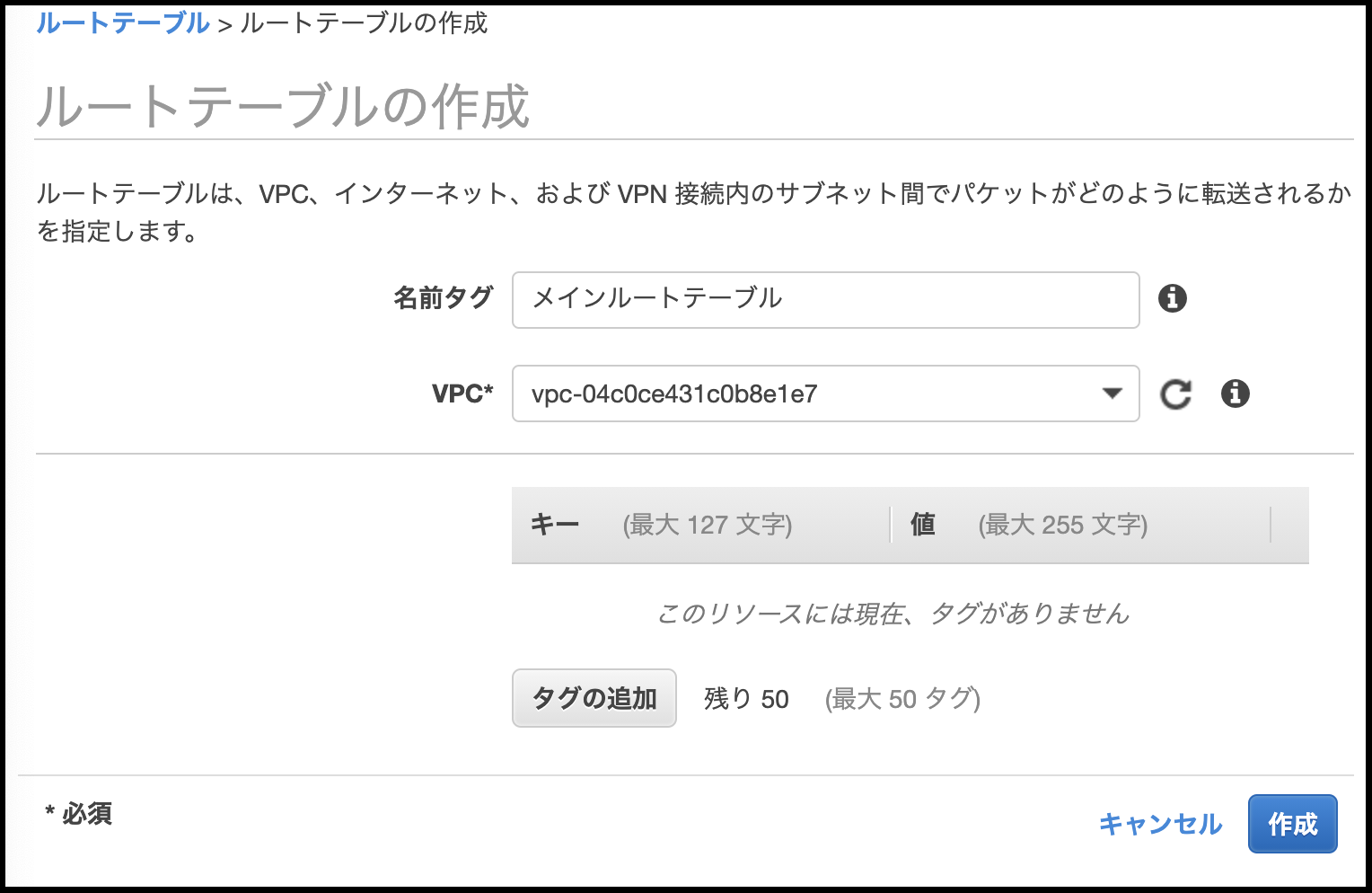
開かれる画面で[ルートテーブルの作成]をクリック。
[名前タグ] に、任意の名前を入れ、
[VPC] に、先程作成したVPCを選択し、
[作成] をクリックして作成完了
4. インターネットゲートウェイの作成
そのまま作成したルートテーブルを編集する...前に、
『インターネットゲートウェイの作成』をする。
これをしないと、サブネット内がインターネット上で通信できないままになってしまう。
- サイドバーの[インターネットゲートウェイ]をクリック
- 表示される画面で、[インターネットゲートウェイの作成]をクリック
- [名前タグ] に任意の名前をつけて、[インターネットゲートウェイの作成]をクリックして終了。
5. ルートテーブル更新
- インターネットゲートウェイ作成後、また、[ルートテーブル]画面に戻る。
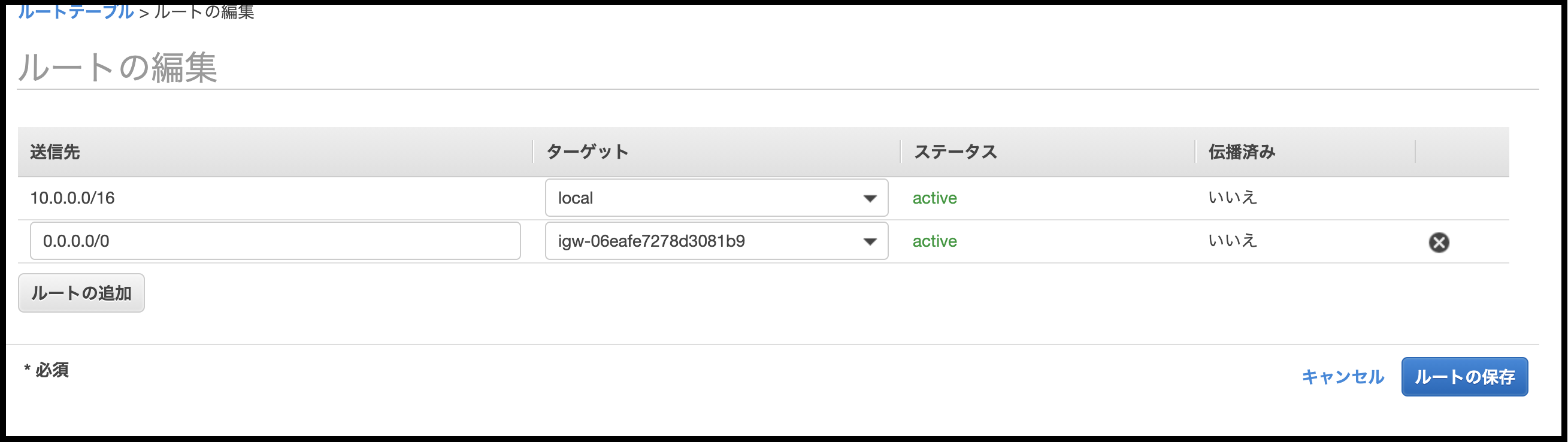
ルートテーブル一覧で、『先程作成したルートテーブル』のチェックボックスにチェックを入れると、下側に『概要』、『ルート』等が表示されるので、その『ルート』タブをクリックしたら表示される[ルートの編集]をクリックする。
ルーティングテーブルの編集ができる画面が表示されるので、[送信先]に『0.0.0.0/0』、[ターゲット]に、Internet Gateway(igw-xxxx) を選択する。
[ルートの保存] をクリック。
-> ルートテーブル編集終了。
あとは、元のルートテーブル一覧の表示画面に戻るので、[サブネットの関連づけ] から、作成したサブネット(筆者はパブリックサブネット)に関連づければ、OK。
WEBサーバ用EC2インスタンス作成方法
EC2とは
EC2は、一言で言うと、『仮想サーバ構築サービス』
イメージとしては、『自分でサーバを立ててその中で好き勝手動かせますよー』て感じなやつ。
AWSでは、EC2の一つ一つを『インスタンス』と呼ぶ。(他のCloudサービスはどうか知らんけど)
- サービスのEC2からEC2の画面へ行く
- サイドバーの[インスタンス]をクリック
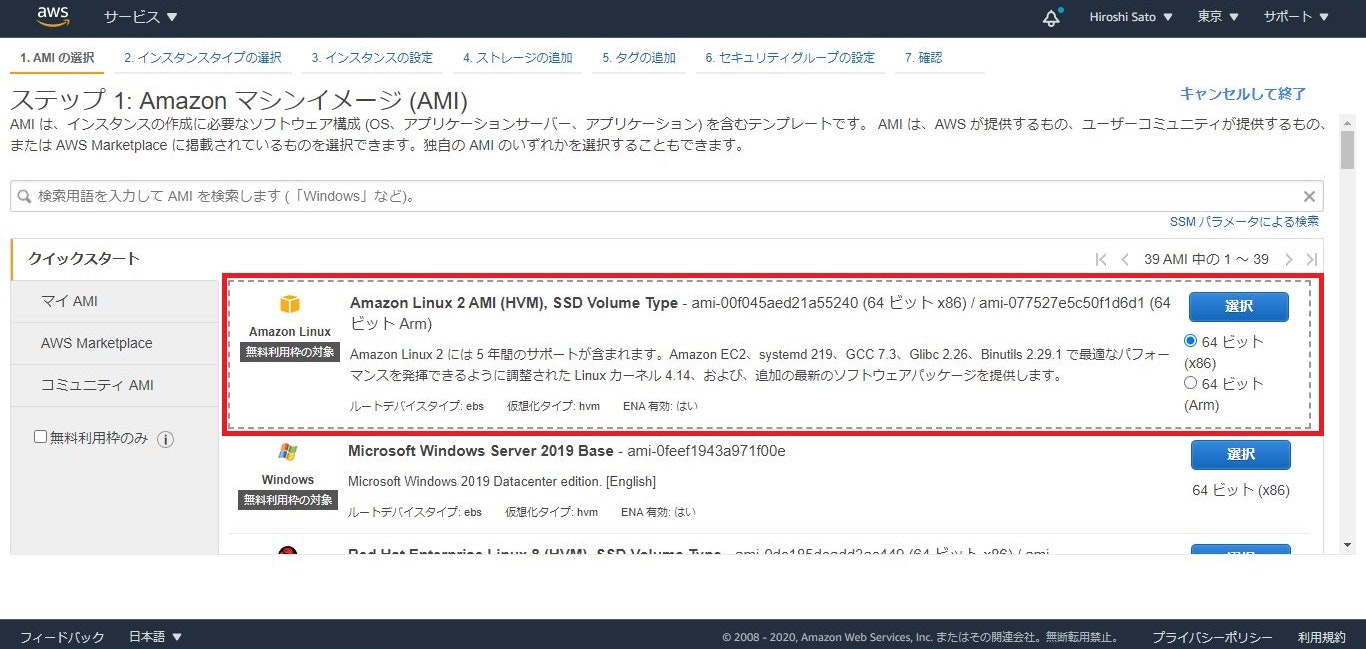
- 表示された画面で、[インスタンスを起動]をクリック
Amazon Linux 2 AMI (HVM), SSD Volume Type - ami-を選択[t2.micro](デフォルトで選択されている)を選択し、[次のステップ:インスタンスの詳細の設定]をクリック
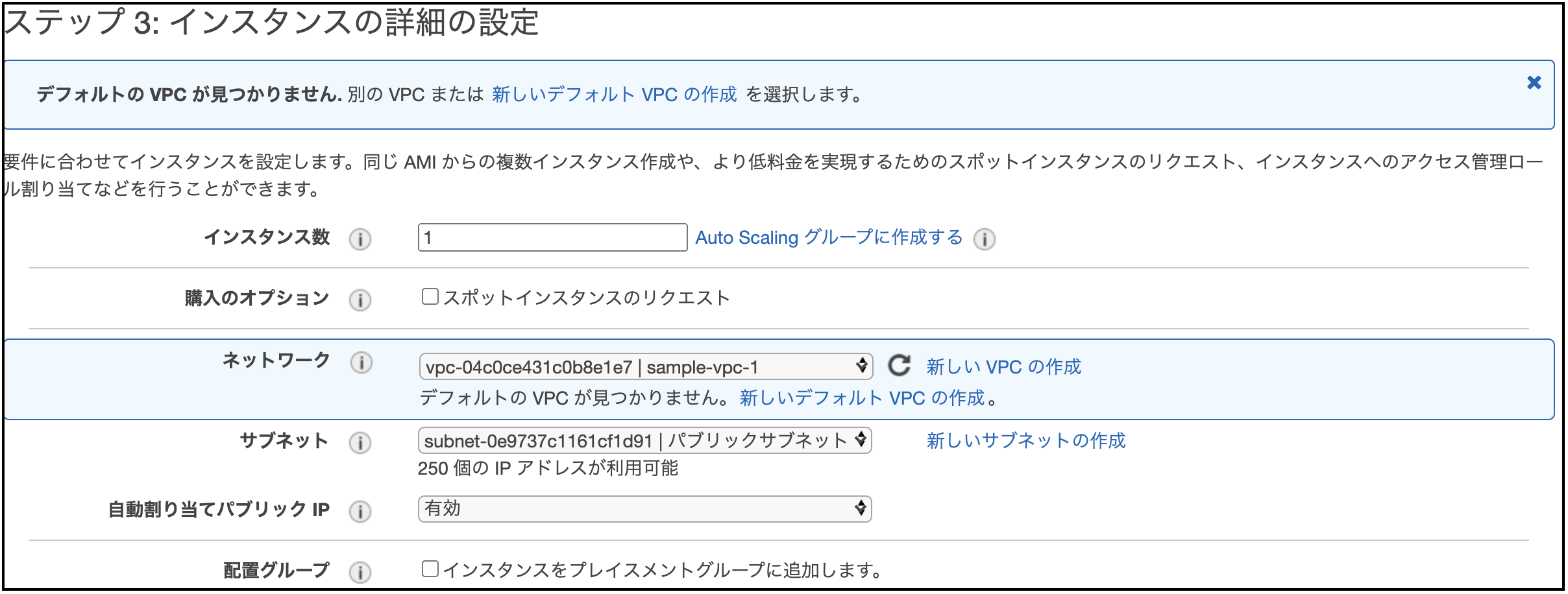
遷移先の画面では、インスタンスの詳細設定を行う画面が表示されるので、
[ネットワーク]に、先程作成したVPCを、
[サブネット]に、先程作成した『パブリックサブネット』を、
[自動割り当てパブリックIP] は、『有効』を
各々セットし、その他はデフォルトのままでOK。
全て設定終わったら、[次のステップ:ストレージの追加]をクリック『ストレージの追加』画面 では、AMIに設定するサイズ等が選択できるが、ここは好みで(30GiBまでは無料)。
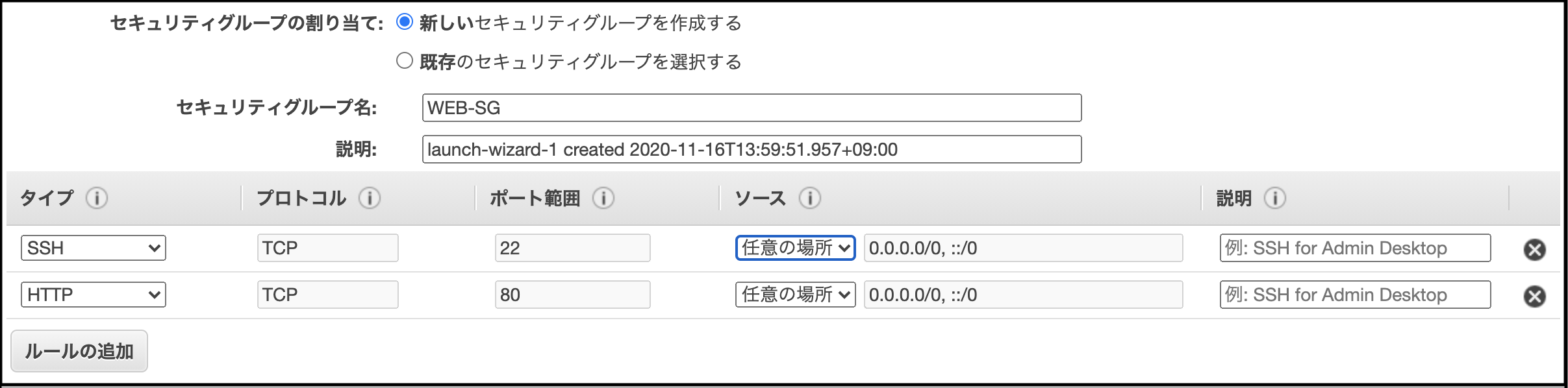
『(※)セキュリティグループの設定』画面 に遷移すると、セキュリティグループを設定する画面が出てくるので、
[新しいセキュリティグループを作成する]にチェックをつけ、
[セキュリティグループ名]に、『WEB-SG』と名付け、その内容は、全てのSSH、HTTPを通すように設定する。
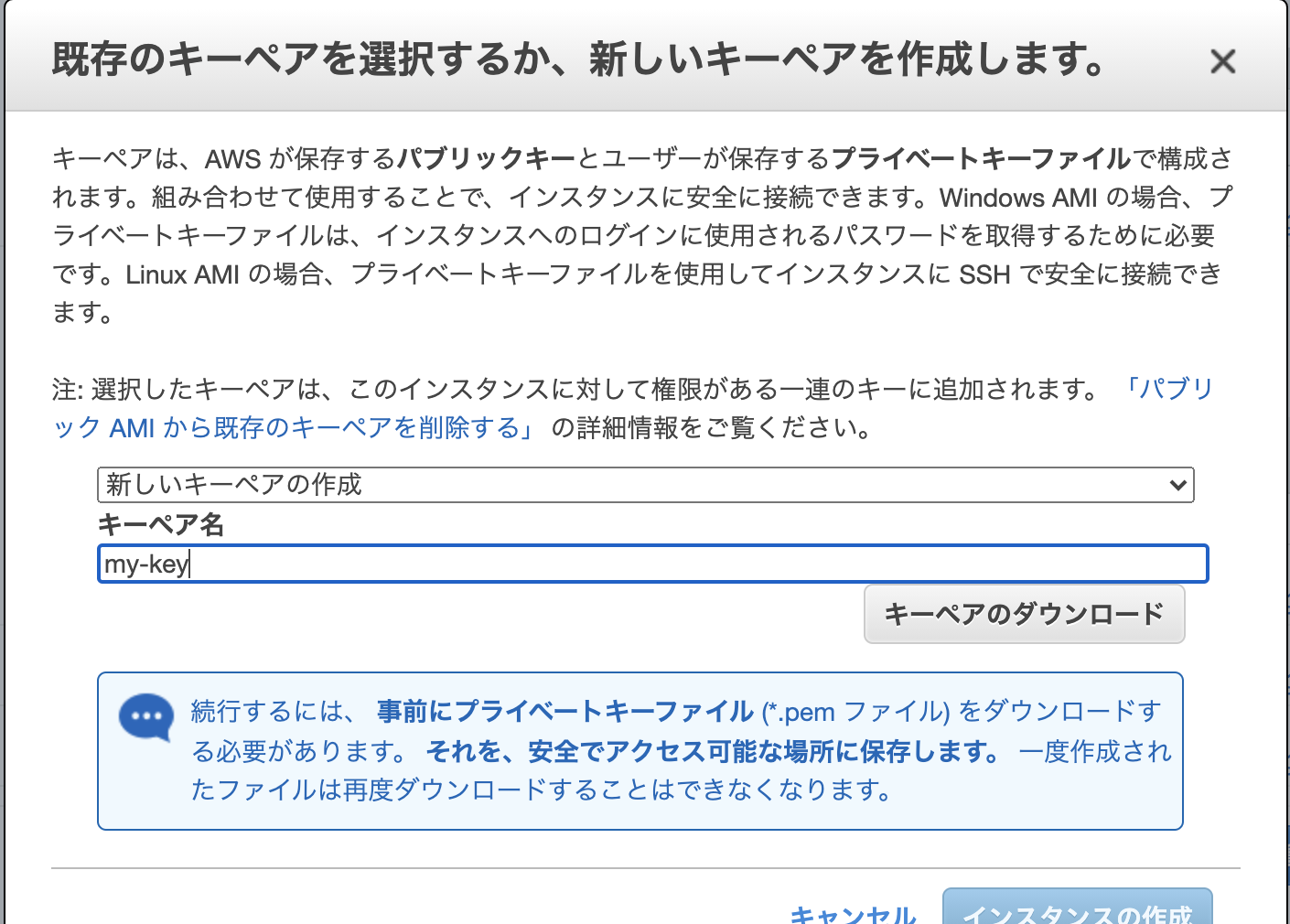
[確認と作成]をクリック(もしかすると、セキュリティが甘い等の警告が出るかもしれないので、出たら無視してそのまま[起動]をクリック)すると、モーダルが開かれる(下図)ので、そこで
[新しいキーペアの作成]を選択し、キーペア名に任意の名前をつけて[インスタンスの作成]をクリック
-> インスタンス作成完了。
※ セキュリティグループ... ファイアウォールのような設定を行えるサービス。複数インスタンスに紐づけることができる。
EC2インスタンスへのアクセス方法
ローカルのPCからターミナルでEC2インスタンスへアクセスする方法を示す。
まず、EC2インスタンスのパブリックIPを確認する。
確認方法は、EC2インスタンスの対象インスタンスにチェックマークをつけた際に表示される『詳細』タブに表示される『パブリックIPv4アドレス』の欄を確認する。
次に
chownコマンドを使用してEC2インスタンス作成時にダウンロードした鍵の権限を変更する。$ chmod 400 【鍵のPATH】これで(最低でも)作成者のみ 読み取りできるようにしておく。そして、
$ ssh -i 【鍵のPATH】 ec2-user@【IPアドレス】でAWSにアクセスできるようになる。
パブリックIPを固定化する
これで、終了したかと思いきや、AWSには思わぬ落とし穴がある。
それは、『インスタンスのパブリックIPは、起動毎に変更されてしまう』ということである。
なので、これを固定化するために、[Elastic IP]を使用する。
ElasticIPの設定方法
- EC2サービス画面のサイドバーから、[Elastic IP] をクリックする
- [Elastic IP アドレスの割り当て]をクリックする。
- 表示される画面で、全て設定はデフォルト(AmazonのUPv4アドレスプールにチェック)のまま[割り当て]をクリック
- 画面が切り替わるので、切り替わった先で、[アクション]-> [Elastic IP アドレスの関連付け]をクリックし、遷移先の画面で、関連付けしたいインスタンスによしなに関連付けする。
これで、起動毎に変更することない、不変なIPアドレス をインスタンスに割り当てることができた。
この、『EC2作成』->『ElasticIP設定』をAPサーバ・DBサーバ それぞれにやっていけばOK。
SSH接続後、EC2インスタンス上でやっておくこと
1. docker のインストール
https://docs.aws.amazon.com/ja_jp/AmazonECS/latest/developerguide/docker-basics.html
このサイトに則ってコマンドを打っていく。
詳細
1.$ sudo yum update -yコマンドでyum をアップデートする。
2.$ sudo yum install dockerでdockerをインストール。
3.$ sudo service docker startでdockerを起動
現行では、一々dockerコマンドを呼び出すのに、sudoを付けなきゃいけないから、権限を変更する。
4.$ sudo usermod -a -G docker ec2-user
これで、EC2を一度シャットダウンして再びログインすれば、dockerコマンドをsudoなしで使用できるようになる。
2. docker-compose のインストール
https://qiita.com/kichise/items/f8e56c6d2d08eaf4a6a0
この記事に従ってdocker-composeをインストールする。
3. git のインストール(capistranoで使用する)
$ sudo yum install gitとコマンドを打つ。終わりに
本来(きちんと世に送り出すもの)であれば、サブネットを パブリック・プライベートにわけ、
・『パブリック』にWEBサーバ
・『プライベート』にAPサーバ・DBサーバ(APサーバはおそらく。)
という分け方をするべきなのだが、NATゲートウェイの設定やらセキュリティグループの設定やらで、めんどくさくなったので説明が長くなってしまうので、本シリーズの中では全てパブリックサブネットに収まる形で構築しました。
- 投稿日:2020-11-29T18:14:36+09:00
[AWS][Aurora]テーブルにレコードが挿入された際にLambdaを呼び出す方法
はじめに
"Aurora DBのテーブルにレコードが挿入されたらLambda関数を呼び出す"という方法に関して情報が少なかったため、備忘録として残しておきます。
参考
Amazon Aurora MySQL DB クラスターからの Lambda 関数の呼び出し
AuroraへのInsert TriggerでLambdaを呼びだしてServerlessで処理する
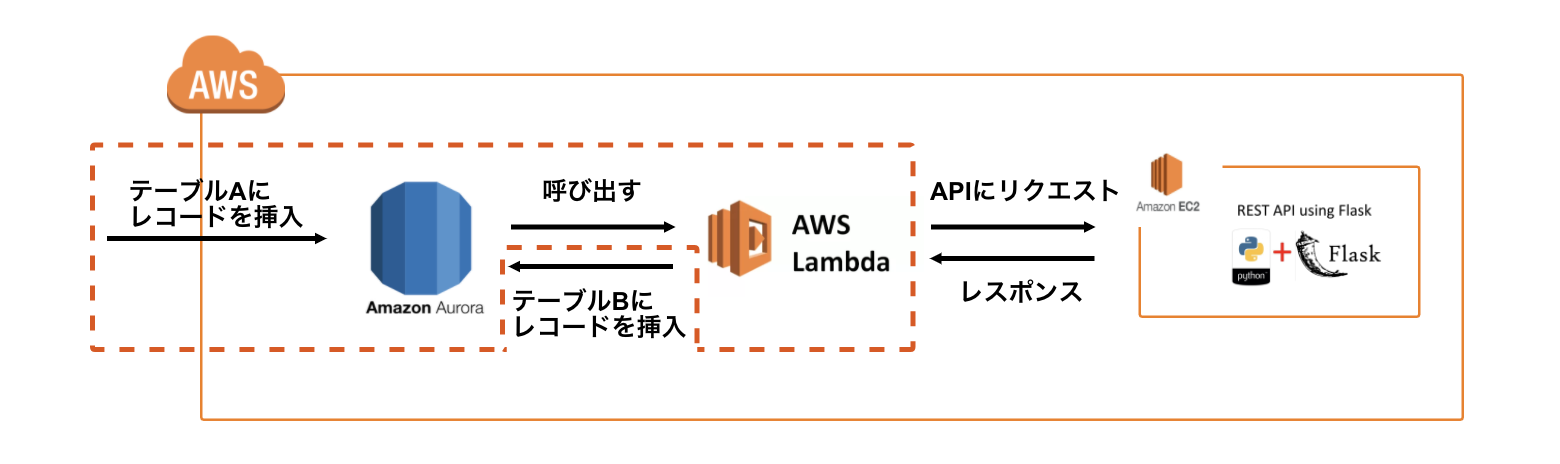
ストアドプロシージャの基本的ななにか何がしたかったか
以下の処理を実現させるために、AuroraのInsert Triggerを利用してLambdaを呼び出す実装を行いました。
①DBのテーブルAにレコードが挿入されたら、そのレコードのidをAPIに渡す。
②レコードの内容を使ってAPIがある処理を行い、レスポンスを返す。
③レスポンスに含まれるデータをテーブルBに挿入する。
実装手順
DBエンジンにAuroraを使用したデータベースが構築されていることに加え、RDSとLambdaのIAM RoleおよびLambda関数が作成されていることを前提とします。作成手順が不明な方はこちらの記事を参照。
1.プロシージャを作成
プロシージャとはデータベース上で行う一連の処理(複数のSQL文)を関数として保存することで、それらの処理をいつでも呼び出せるようにしたものです。一般的な関数と違って戻り値はありませんが、引数を渡すことはできます。
ここでは「test_procedure」という名前のプロシージャを作成します。
DROP PROCEDURE IF EXISTS test_procedure; DELIMITER ;; CREATE PROCEDURE test_procedure (IN id INT) LANGUAGE SQL BEGIN CALL mysql.lambda_async('arn:aws:lambda:ap-northeast-1:9xxxxxxxxxx0:function:test_lambda_function', CONCAT('{ "target_id" : "', id, '" }') ); END ;; DELIMITER ;以下、詳しく解説します。
まずは「test_procedure」という名前のプロシージャが既に存在しないかチェックし、存在する場合は削除します。DROP PROCEDURE IF EXISTS test_procedure;次にDELIMITER を使って, 区切り文字を一時的に変更します。なぜ変更するのかというとSQL文は通常はセミコロン(;)が処理の区切りとされますが、もし複数の処理を定義したい場合はこれでは都合が悪くなってしまいます。そのため、DELIMITER を使って区切り文字を一時的に変更し、後述する
BEGIN〜END内に複数の処理を定義します。DELIMITER ;;これでセミコロン2つ
;;が区切り文字として扱われます。
CREATE PROCEDUREでプロシージャを作成します。(IN id INT)は引数を意味します。ここではint型のidを引数にするという定義になります。もし引数が複数ある場合は(IN 〜, IN 〜)という形にします。CREATE PROCEDURE test_procedure (IN id INT) LANGUAGE SQL
BEGIN〜END内に行いたい処理(SQL文)を定義します。BEGIN CALL mysql.lambda_async('arn:aws:lambda:ap-northeast-1:9xxxxxxxxxx0:function:test_lambda_function', CONCAT('{ "target_id" : "', id, '" }') ); END ;; DELIMITER ;
CALLによってプロシージャを呼び出します。ここで呼び出しているmysql.lambda_asyncはAurora上でデフォルトで定義されているプロシージャです。引数に指定のLambda関数のリソースネーム(ARN)を渡すことで、その関数を呼び出す処理を行ってくれます。また、CONCAT()で Lambda関数に渡すパラメータを指定(上記の場合は、挿入されたレコードのID)することができます。このパラメータはLambda関数で呼び出す際は
lambda_handler(event, context)
のeventに格納されているのでevent['target_id']みたいな感じで呼び出します。なお、ここでは1つのSQL文しか書いていませんが、
;区切りで複数のSQL文を定義できます。BEGIN SQL文1; SQL文2; END最後に先ほど定義した区切り文字
;;を入れてプロシージャの定義を完了させ、DELIMITER ;で本来の区切り文字に戻します。;; DELIMITER ;2.トリガーを設定
CREATE TRIGGERによって、テーブル(table_a)にレコードが挿入された際に上記で作成したプロシージャ(test_procedure)を呼び出す設定を行います。DELIMITER ;; CREATE TRIGGER trigger_test_procedure AFTER INSERT ON table_a FOR EACH ROW BEGIN CALL test_procedure(NEW.id); END ;; DELIMITER ;
AFTER INSERT ON table_aでプロシージャの実行タイミングを定義しています。もしBEFORE INSERT ON table_aとした場合は、テーブルAにレコードが挿入される前にプロシージャが実行されます。プロシージャの引数にある
NEWとは、挿入されたレコードを指します。つまり、NEW.idとは挿入されたレコードのidを意味します。3.動作確認
あとはテーブルにレコードを挿入し、Lambdaの実行が確認できれば完了です。
- 投稿日:2020-11-29T17:47:06+09:00
Nginx+Unicorn(WEB/APサーバーの分離構成)で静的ファイルが読み込めない対処について
アプリをAPサーバー側にデプロイし、Nginxを使ったリバースプロキシ設定を行ったところ、以下画像のようにcssがうまく読み込めない問題が発生したので、その解決までの工程を忘れないようにメモしておきます。
今回の環境
- WEBサーバーにはNginx
- APサーバーにはUnicorn
- ruby -v 2.6.6
- rails -v 5.2.4.4
- PC Windows10
Google Chromeで検証
Chromeでエラーの出ているページを開いたら、F12か右クリックの検証を選択。
すると以下のようなエラーが確認された。
リソースのロードに失敗したと表示されている。
この時の404は表示させているWEBサーバー側、つまりNginxから404が出ている。
念のため、ログでエラーが出ていないかチェックしたいので、APサーバー側(Unicorn)を調べてみる。APサーバー(Unicorn)のログ確認
rails配下のlogを確認する。
/var/www/rails/hoge$ cd log $tail -f unicorn.log # -fはファイルの記述を監視。 INFO -- : worker=1 ready INFO -- : worker=0 ready INFO -- : reaped #<Process::Status: pid 3997 exit 0> worker=0 INFO -- : reaped #<Process::Status: pid 3998 exit 0> worker=1 INFO -- : master complete INFO -- : Refreshing Gem list INFO -- : listening on addr=0.0.0.0:3000 fd=9 INFO -- : master process ready INFO -- : worker=1 ready INFO -- : worker=0 ready一度ブラウザをリロード。
特にそれっぽいエラーはないのでctrl+cで離脱。WEBサーバー(Nginx)のエラーログ確認
Nginx配下(/etc/nginx)にあるnginx.confをvimで開いてみる。
/etc/nginx$ sudo vim nginx.conf user nginx; worker_processes auto; error_log /var/log/nginx/error.log; pid /run/nginx.pid; #error_logの場所が記述されているのでこれをコピー。 $ sudo tail -f /var/log/nginx/error.logsudo tail -fを叩いてブラウザを一度リロードしてみたが、特にエラーは出なかった。
nginx.confのaccses_logを確認する
先ほどのnginx.confをvimで開いて、accses_logを確認してみる。
/etc/nginx$ sudo vim nginx.conf user nginx; worker_processes auto; error_log /var/log/nginx/error.log; pid /run/nginx.pid; access_log /var/log/nginx/access.log main; #access_logの場所が記述されているのでこれをコピー。 $ sudo tail -f /var/log/nginx/access.log叩いて、ブラウザをリロード。
すると、
"GET /assets/application-03e8ae3db0f190f7147e6299a7a6cb74a90a3f8de03988a2de0595377b02fa60.css HTTP/1.1" 404 1722assetsの404エラーが確認できた。
railsアプリのpublic配下にassetsがあるので行ってみる。/var/www/rails/hoge/public$ cd assets $ ls application-03e8ae3db0f190f7147e6299a7a6cb74a90a3f8de03988a2de0595377b02fa60.cssブラウザのエラーも"03e8"から始まるcssなので一致。
プリコンパイルする際に何かあるっぽい
アプリをデプロイする際、productionでpreconpileしている。
bundle exec rake assets:precompile RAILS_ENV=productionproduction環境をチェックしたいのでconfig配下のenvironmentsに移動してみる。
/var/www/rails/hoge/config$ cd environments $ vim prodaction.rb #prodaction.rbをvimで開く。 config.public_file_server.enabled = ENV['RAILS_SERVE_STATIC_FILES'].present? #これが静的ファイルを読み込んでいない原因らしいので環境変数を定義してあげる。 $ export RAILS_SERVE_STATIC_FILES=true $ env | grep RAILS $ RAILS_SERVE_STATIC_FILES=true # 反映されていたらOK $ unset RAILS_SERVE_STATIC_FILES # 以前の環境に戻す場合。
- 補足
present?メソッドはnil, “”, “ “(半角スペースのみ), 空の配列, 空のハッシュが含まれている場合falseつまり、偽とするので元々設定されていない状態だとfalseを返す。
なのでRAILS_SERVE_STATIC_FILESに=falseの状態でもpresent?メソッドは「何か入ってるよ!」つまり真となるのでexport RAILS_SERVE_STATIC_FILES=falseでも結果としてはapサーバ側から静的ファイル
を読み込めるようになるらしい。UnicornとNginxを再起動させる
Unicornをkillして起動。
Nginxを停止して起動。
これで静的ファイルの読み込みが行われていれば成功。
ブラウザに戻ってWEBサーバーのIPアドレスを叩くと……
やった(´▽`)!
参考

- 投稿日:2020-11-29T17:21:46+09:00
AWSのEC2にOracle19cをインストールしてDBを作成する
Oracle Bronzeの資格学習のため、AWSにOracleDB環境を構築する事にしたが、とても苦戦したのでメモ。
→結論:インストール可能。しかし、Oracle19cはRedHat8には対応してなさそう。(java関連のエラーが発生した)
勉強に使う分には問題無い思う!環境
EC2のOS : Red Hat Enterprise Linux 8
Oracle : Oracle Database 19c準備作業
・OSがRedHatのEC2作成
・Oracleアカウントの作成
・自身のPCにOracle Database 19cのLinux x86-64のRPMをダウンロード
・EBSを30Gに拡張しておく。(無料枠のマックス)Oracle 19cをEC2に配置
scpを使って、ダウンロードしたRPMをEC2にアップロードする。
PEM_FILE : 鍵のパス
INSTANCE_IP : 接続先IPアップロードsudo scp -i PEM_FILE oracle-database-ee-19c-1.0-1.x86_64.rpm ec2-user@INSTANCE_IP:/home/ec2-user/前提パッケージをインストール
以下のパッケージがインストールされていないと、Oracle19cのインストールに失敗する。
ダウンロード# EC2ログイン後 /home/ec2-user/配下 curl -o compat-libcap1-1.10-7.el7.x86_64.rpm http://mirror.centos.org/centos/7/os/x86_64/Packages/compat-libcap1-1.10-7.el7.x86_64.rpm curl -o compat-libstdc++-33-3.2.3-72.el7.x86_64.rpm http://mirror.centos.org/centos/7/os/x86_64/Packages/compat-libstdc++-33-3.2.3-72.el7.x86_64.rpm curl -o oracle-database-preinstall-19c-1.0-1.el7.x86_64.rpm https://yum.oracle.com/repo/OracleLinux/OL7/latest/x86_64/getPackage/oracle-database-preinstall-19c-1.0-1.el7.x86_64.rpmインストールsudo yum -y localinstall compat-libcap1-1.10-7.el7.x86_64.rpm sudo yum -y localinstall compat-libstdc++-33-3.2.3-72.el7.x86_64.rpm sudo yum -y localinstall oracle-database-preinstall-19c-1.0-1.el7.x86_64.rpmOracle19cのインストール
sudo yum -y localinstall oracle-database-ee-19c-1.0-1.x86_64.rpmJava関連のエラーが大量に出るが、インストール出来ているっぽい。
DB作成&接続
このサイトからほぼコピペ。
DB作成/etc/init.d/oracledb_ORCLCDB-19c configure環境変数の設定。再度ログイン時も保持したいので、
/etc/profile.d/oracle.shを作成する。sudo vi /etc/profile.d/oracle.sh/etc/profile.d/oracle.shexport ORACLE_HOME=/opt/oracle/product/19c/dbhome_1 export ORACLE_SID=ORCLCDB export NLS_LANG=Japanese_Japan.AL32UTF8 export PATH=$ORACLE_HOME/bin:$PATH接続source /etc/profile.d/oracle.sh sudo su - su - oracle sqlplus / as sysdba SQL*Plus: Release 19.0.0.0.0 - Production on 日 11月 29 08:02:07 2020 Version 19.3.0.0.0 Copyright (c) 1982, 2019, Oracle. All rights reserved. アイドル・インスタンスに接続しました。 SQL>終わりに
大分時間かかったけど、CUIで簡単にインストールする方法を見つけることが出来たので満足!
GUIでインストールするよりも圧倒的に楽なのでお薦め。
ようやくBronzeの勉強に移れるぞ〜
- 投稿日:2020-11-29T16:37:51+09:00
AWS S3で1000件以上のオブジェクトを操作する方法
こんにちは。フューチャー株式会社TIG所属2020年新卒の大西です。
フューチャー Advent Calendar 2020 3日目を担当します。現在業務でAWS(特にS3やGlue Jobなど)を使うことが多いのため、私自身の業務で躓いた経験を元に 「AWS初心者が躓きやすいポイントとその解消法」 というテーマでブログを書いていきます。
まず、今日扱うテーマは 「Boto3を用いた1,000件以上のS3オブジェクトの操作」 です。
躓きポイントの概要
Boto3はPythonを介してAWSを操作するためのライブラリです。
Boto3を用いてAWSを操作する方は、
list_objects_v2やobjects.filter等の関数を使って複数のオブジェクトを取得する機会があるのではないでしょうか。
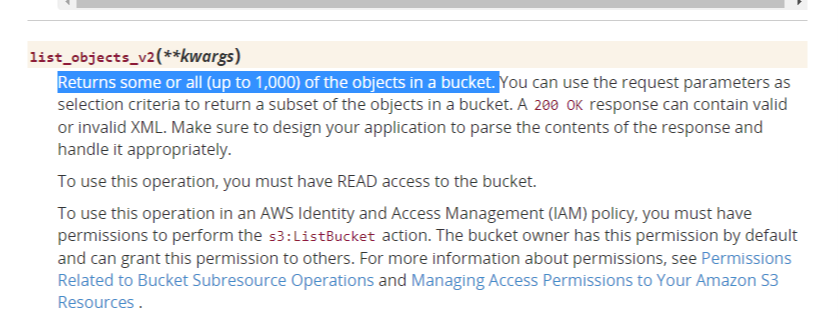
list_object_v2をもちいたオブジェクトの取得例get_objects.pyimport boto3 s3 = boto3.resource("s3") bucket = s3.Bucket(bucket_name) prefix = "S3バケットへのパス" objects = bucket.meta.client.list_objects_v2(Bucket=bucket.name, Prefix=prefix)しかし、上記の関数には 「一度のリクエストで取得できるオブジェクトの数は1,000件まで」 というルールがあり、1001件目以降のオブジェクトは取得することができません。
Boto3の公式ドキュメント内のS3に関する記述部分を読むと、S3では下記の関数に同様のルールが存在しているようです。
- get_bucket_replication()
- list_bucket_analytics_configurations()
- list_bucket_inventory_configurations()
- list_bucket_metrics_configurations()
- list_multipart_uploads()
- list_object_versions()
- list_objects()
- list_objects_v2()
- list_parts()
- put_bucket_analytics_configuration()
- put_bucket_inventory_configuration()
- put_bucket_lifecycle_configuration()
- put_bucket_metrics_configuration()
- put_bucket_replication()
- object_versions.filter()
- objects.filter()
- BucketLifecycleConfiguration.put()
解決方法
今回は例として
list_objects_v2を用いる場合の解決方法を書きます。list_objects_v2の返り値のdictには、結果が切り捨てられているかどうかを示す
IsTruncatedが含まれています。
そして、取得するオブジェクト数の上限を指定せずlist_objects_v2を実行し、取得したオブジェクトの数が1000件を超えていた場合は、objects["IsTruncated"]にTrueがセットされて返ってきます。
また、list_objects_v2は引数のStartAfterを設定することで、指定したS3ファイルの次のファイルからオブジェクトを取得してくれます。よって、
objects["IsTruncated"]==Trueだった場合は、1000件目のS3キーをStartAfterに設定して再度list_objects_v2を実行するという処理を["IsTruncated"]==Falseになるまで繰り返すことで、1,000件以上のオブジェクトでも取得することができます。ソース
get_objects.pys3 = boto3.resource("s3") bucket = s3.Bucket(source_bucket) prefix = "S3バケットへのパス" keys = get_all_keys(bucket.name, prefix, [], "") def get_all_keys(bucket_name: str, prefix: str, keys: List[str], marker: str) -> List[str]: """ S3の指定したパスに存在するオブジェクトのキーを全て取得する Parameters ---------- bucket_name: String 対象のBucket prefix: String 対象のディレクトリのパス keys: List[str] marker: String 関数の中から呼び出す時のための引数。通常はkeys = [], marker = "" で呼び出す Returns ------- List[str] 取得したキーのリスト """ s3 = boto3.resource("s3") bucket = s3.Bucket(bucket_name) objects = bucket.meta.client.list_objects_v2(Bucket=bucket.name, Prefix=prefix, StartAfter=marker) if "Contents" in objects: keys.extend([content["Key"] for content in objects["Contents"]]) # 返り値のIsTruncatedがTrueかどうかを確認する if objects.get("isTruncated"): # marker引数に取得したkeysの末尾の値を設定して再度get_all_keysを実行する return get_all_keys(bucket_name=bucket_name, prefix=prefix, keys=keys, marker=keys[-1]) return keys最後に
今回は 「AWS初心者が躓きやすいポイントとその解消法」 の第一弾として
IsTruncatedを用いた1,000件上限の解決についてまとめました。大量のオブジェクトを一度に取得したい方はぜひ参考にしてみてください。

- 投稿日:2020-11-29T15:26:32+09:00
Golangはじめて物語(第6話: DynamoDB local+testingでお手軽に回帰テストする)
はじめに
Golangのテスト方法については、第一話でも少し触れたが、実際に動かす際には、DynamoDB等のAWSサービスの本物に接続するか、モックが必要になったりして、あの内容だけでは実用部分に欠けていた。
今回は、DynamoDB local をモックとしてローカル環境で動かし、実際にそこに接続するための実装を整理する。
ベースとなるソースコードは、上記の第一話のソースコードにする。
DynamoDB local を起動する
毎度手動で起動してから
go testを実行するのは面倒なので、make testの中でサクっと起動できるようにしてしまいたい。
以下のように docker-compose の力を借りて起動をしよう。docker-compose.ymlversion: '3' services: dynamodb-local: image: amazon/dynamodb-local ports: - "8000:8000"main_test.go の変更点
dynamoDB に接続する箇所について以下のように変更する。
main_test.gosvc := dynamodb.New(sess, &aws.Config{Endpoint: aws.String("http://localhost:8000")})どうせテストコードはテスト環境でしか動かさないので、固定してしまえば良いだろう。必要があれば、環境変数やプロパティから渡すようにしておこう。
また、以前の記事ではデータ敷き込み時にテーブルが既に作られていることを前提に書いていたが、今回は DynamoDB local は毎回起動時に真っ新になるので、以下のように setup() 関数内でテーブルを作っておく。
main_test.goinput := &dynamodb.CreateTableInput{ AttributeDefinitions: []*dynamodb.AttributeDefinition{ { AttributeName: aws.String("id"), AttributeType: aws.String("S"), }, }, KeySchema: []*dynamodb.KeySchemaElement{ { AttributeName: aws.String("id"), KeyType: aws.String("HASH"), }, }, ProvisionedThroughput: &dynamodb.ProvisionedThroughput{ ReadCapacityUnits: aws.Int64(1), WriteCapacityUnits: aws.Int64(1), }, TableName: aws.String("[テーブル名]"), } _, err := svc.CreateTable(input) if err != nil { return fmt.Errorf("setup() error: %w", err) }気になるなら、以下のように teardown() 関数でテーブル削除をしておこう。
毎回 DynamoDB local を停止させるなら不要な操作ではある。main_test.goinput := &dynamodb.DeleteTableInput{ TableName: aws.String("[テーブル名]"), } _, err := svc.DeleteTable(input) if err != nil { return fmt.Errorf("teardown() error: %w", err) }プロダクトコードの変更点
プロダクトコード側は、以下のようにして dynamoDB への接続を制御する。
起動時に環境変数がexport MODE_UT=TRUEされているときだけ、ローカルに接続し、そうでない場合はデフォルトのプロファイルでアクセスする。main_test.gosvc := func(mode_ut string) *dynamodb.DynamoDB { if(mode_ut != "TRUE"){ return dynamodb.New(sess) } else { return dynamodb.New(sess, &aws.Config{Endpoint: aws.String("http://localhost:8000")}) } }(os.Getenv("MODE_UT"))別に svc を切り出して普通に if で分岐しても良いのだけど、なんか var にあれこれ書くの格好悪くてな……。
Makefileの変更点
makefile では test のマクロを以下のようにする。
Makefiletest: docker-compose up -d; \ export MODE_UT=TRUE; \ go clean -testcache; \ go test -v -coverprofile=./c.out ./...; \ go tool cover -func=c.out; \ docker-compose down; \ rm ./c.out .PHONY: test
test clean -testcacheはお好みで入れても入れなくても。
まあ、test -vも好みで良い(入れないとOKのときは何もログが出なくなる)。
-coverprocileすることで、カバレッジ用の情報をダンプし、go tool coverでその情報をもとに実行結果を出してくれる。↓こんな感じだ。
ok モジュール名 0.965s coverage: 55.6% of statements モジュール名/main.go:19: init 0.0% モジュール名/main.go:22: main 0.0% モジュール名/main.go:26: handler 57.7% total: (statements) 55.6%この方法は Docker があれば使えるので、ローカル環境でもできるだろうし、AWS の EC2 上で起動してローカル環境からアクセスするようにしても良いだろう。CodeBuild でもできるような気がするが、未検証。docker-compose をインストールするか、docker run で直接走らせるかの工夫は必要になるだろう。
- 投稿日:2020-11-29T13:57:13+09:00
BoltとServerless Frameworkを使ってSlackチャットボットをAWS Lambdaで実行する
はじめに
AWS LambdaとBoltフレームワークを使って、Slackのチャットボットを作成しました。
Bolt入門ガイドの手順では、ngrokを使ってローカルPC上にボットを起動します。
実際の運用ではローカルPC上ではなくサーバ上にアプリを起動すると思いますが、AWS環境へのデプロイ方法の詳細は記載されていないため、備忘録も兼ねて投稿します。各種ツールやライブラリの概要
名称 概要 Slack チャットツール。アプリを作成しカスタマイズできる。 Bolt Slackアプリ開発のためのフレームワーク。 AWS Lambda AWSが提供するサーバレス環境。 Serverless Framework AWS Lambdaを始めとしたサーバレス環境にデプロイするためのフレームワーク。 ngrok ローカル環境をhttpsで公開できるサービス。開発環境として利用。 今回実行した環境
項目 バージョン OS macOS Catalina nodejs v10.16.0 @slack/bolt 2.0.1 Serverless Framework 1.68.0 手順
- Bolt入門ガイドに沿ってアプリを作成。
seratch/serverless-slack-bolt-awsをテンプレートとしてアプリを作成。- ngrokを使ってURLを生成、テスト。
- sls deployを使ってLambdaに公開。
1. Bolt入門ガイドに沿ってアプリを作成。
Bolt入門ガイドの手順に従って、Slackのアプリを新規作成します。
こちらの手順を完了すると、ローカルマシン上でボットを起動し、Slackチャンネルから応答させることができます。
上記手順ではngrokの利用方法について記載はないので、以下を参考にインストールしてください。
- ngrokが便利すぎる - https://qiita.com/mininobu/items/b45dbc70faedf30f484e
2.
seratch/serverless-slack-bolt-awsをテンプレートとしてアプリを作成。AWS Lambdaにコードをデプロイするために、Serverless Frameworkを使います。
npmを使ってServerless Frameworkをインストールします。npm i -g serverless
seratch/serverless-slack-bolt-awsという便利なテンプレートが公開されていますので、こちらを使ってアプリを作成します。
以下の手順に従って、アプリのインストールとトークンの設定を行います。上記手順で生成した
handler.jsのApplication Logicというコメント箇所を、作成した自分のボットのコードで置き換えます。
.envファイルには、先の手順で使用したSLACK_SIGNING_SECRET、SLACK_BOT_TOKENをそれぞれ設定ください。
AWS_ACCESS_KEY_ID、AWS_SECRET_ACCESS_KEYは、デプロイ先のAWSアカウントで作成したIAMのものを利用します。ngrokを使ってURLを生成、テスト。
以下のコマンドでローカルPCでボットを起動し確認できます。
$ sls offline起動後、先の手順と同じように
ngrokを使ってURLを生成しします。$ ngrok http 3000Slackアプリの
Event SubscriptionsメニューにあるRequest URLに生成したURLを入力します。
URLの末尾には/dev/slack/eventsを加えてください。
例えば以下のようなURLになります。https://xxxxxxxx.ngrok.io/dev/slack/eventssls deployを使ってLambdaに公開。
以下コマンドでAWS環境にデプロイできます。
$ sls deployURLが生成されますので、
ngrokの時と同様、Request URLに入力します。
Slackのチャンネルでボットが応答すれば設定完了です。以上、Boltフレームワークで作成したSlackチャットボットをAWSにデプロイする方法でした。
現在は、個人的な利用目的でしかチャットボットを運用していませんが、AWS CodePipelineなどと組み合わせれば、Slackから運用しているサービスのデプロイなどもできると思います。
ぜひ参考いただければと思います。参照
- Slack Bolt 入門ガイド - https://slack.dev/bolt-js/ja-jp/tutorial/getting-started
- Serverless Framework の Bolt 用テンプレート - https://github.com/seratch/serverless-slack-bolt-aws
- 投稿日:2020-11-29T13:22:37+09:00
AWS ソリューションアーキテクトアソシエイト向け問題 VPC編
概要
今回は会社の後輩向けにAWS ソリューションアーキテクトアソシエイト向けの問題を作成したのでそちらの公開を。
元ネタは公式の問題、BlackBeltなどからとっております
今回はVPCをみようと思います。VPC関係
- ネットワークACL,セキュリティグループについて説明している文で以下の中から正しいものを1つ選択してください。
- ネットワークACLはサーバレベルで効果を発揮する。
- ネットワークACLはAllow/DenyをIN・OUTで指定可能。
- ネットワークACLはすべてのルールを適用する。
- セキュリティグループはステートレスなので戻りのトラフィックも明示的に許可する必要がある。
- ネットワークACLはステートフルなので戻りのトラフィックを考慮する必要はない。
回答
- 正解は
2. ネットワークACLはAllow/DenyをIN・OUTで指定可能。 * ネットワークACLを使うことで接続を禁止することもできます。 * セキュリティグループはAllowのみを指定できるので接続先を追加したいときに設定します。
- 以下不正解の理由
1. ネットワークACLはサブネットレベルで効果を発揮します。サーバによって接続先を制御したいときはセキュリティグループを使います。 3. ネットワークACLは番号の順序通りに適用します。上位に優先したい条件を指定することで絞り込めます。 4. セキュリティグループはステートフルです 5. ネットワークACLはステートレスです
- あるアプリケーションをプライベートサブネットに配置したEC2インスタンス(t3.nano)で実行しそこからS3にアクセスすることを予定しています。しかしS3へアクセスできないようです。IAMロールの設定やバケットポリシーについては問題ないとします。この場合の対処法を以下から選びなさい。(2つ)
- EC2インスタンスのインスタンスタイプをt3.micro以上にする。
- EC2インスタンスをプライベートサブネットではなくパブリックサブネットに配置する。
- AWS Transit Gatewayの設定を行う。
- VPC Endopointをプライベートサブネットに対して作成する。
- インスタンスに対してEIPのみを設定する。
回答
- 正解は
2. EC2インスタンスをプライベートサブネットではなくパブリックサブネットに配置する。 4. VPC Endpointをプライベートサブネットに対して作成する。 * パブリックサブネットに配置することでインターネットに接続できるためS3へアクセスできるようになります。 * VPC Endpointを設定することでインターネットに接続しなくてもアクセスが可能です。DynamoDBなどほかのAWSサービスへの接続を行いたいときもVPC Endpointの設定を行います。
- 以下不正解の理由
1. インスタンスタイプは関係ありません。 3. AWS Transit Gateway は1000以上のVPCとオンプレミス環境を接続するときに使用します。 5. EIPのみでなくNAT ゲートウェイまたはNATインスタンスの設定が必要ですこの2つを設定することでS3へアクセスは可能です。
- 投稿日:2020-11-29T11:55:25+09:00
[Fargate 入門] ECS(Fargate)でrakeタスクを実行するまで
Fargateで単純なrakeタスクを実行するまでの手順。
タスク定義やコンテナの設定などがややこしかったため備忘録として。準備
実行するrakeタスクとコンテナイメージを用意します。
rakeタスクの作成
今回はrakeタスク実行が確認できれば良いので単純なタスクを用意。
namespace :ecs_task do task :hoge do puts "task started" end endコンテナイメージの用意
以下のようなDockerfileを作成し、rakeタスクが実行できる環境を用意します。
DockerfileFROM ruby:2.5.3 # 環境変数 ENV LANG C.UTF-8 ENV APP_ROOT /app # ソースをコンテナに転送 ADD ./ $APP_ROOT # コンテナ内の作業ディレクトリの設定 WORKDIR $APP_ROOT # gemのインストール RUN gem update bundler RUN bundle installコンテナイメージをECRへプッシュする
Fargateでタスクを実行するためにDockerfileからイメージを作成してECRにプッシュします。
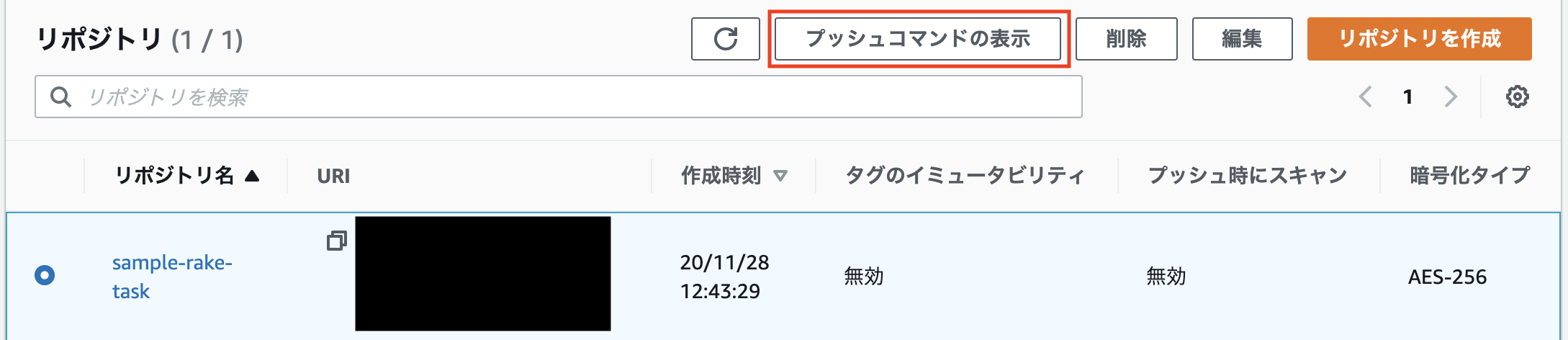
(Docker Hubでも良いですが今回はECRを利用)マネジメントコンソールからリポジトリを作成しましょう。
下記のようにリポジトリが作成されたらOKです。
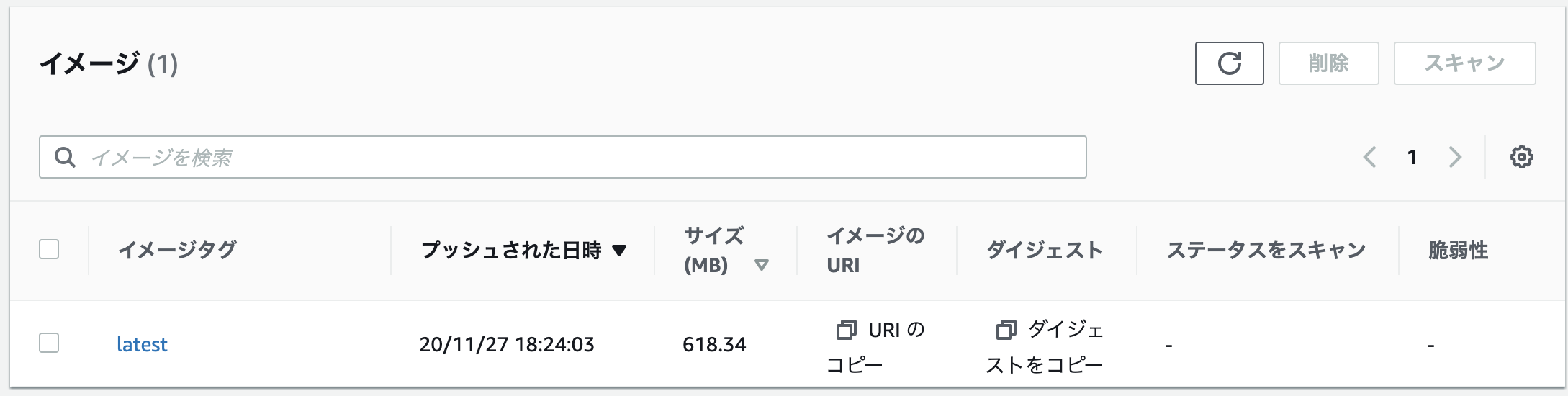
プッシュコマンドの表示を押すと、ECRへイメージをプッシュする手順が表示されるので、手順にしたがってプッシュします。
プッシュ後、下記のようにイメージが存在すればOKです。
準備は完了したので、ECSでクラスターとタスク定義を作成していきましょう。
ECS
マネジメントコンソール上でクラスターとタスク定義を作成していきます。
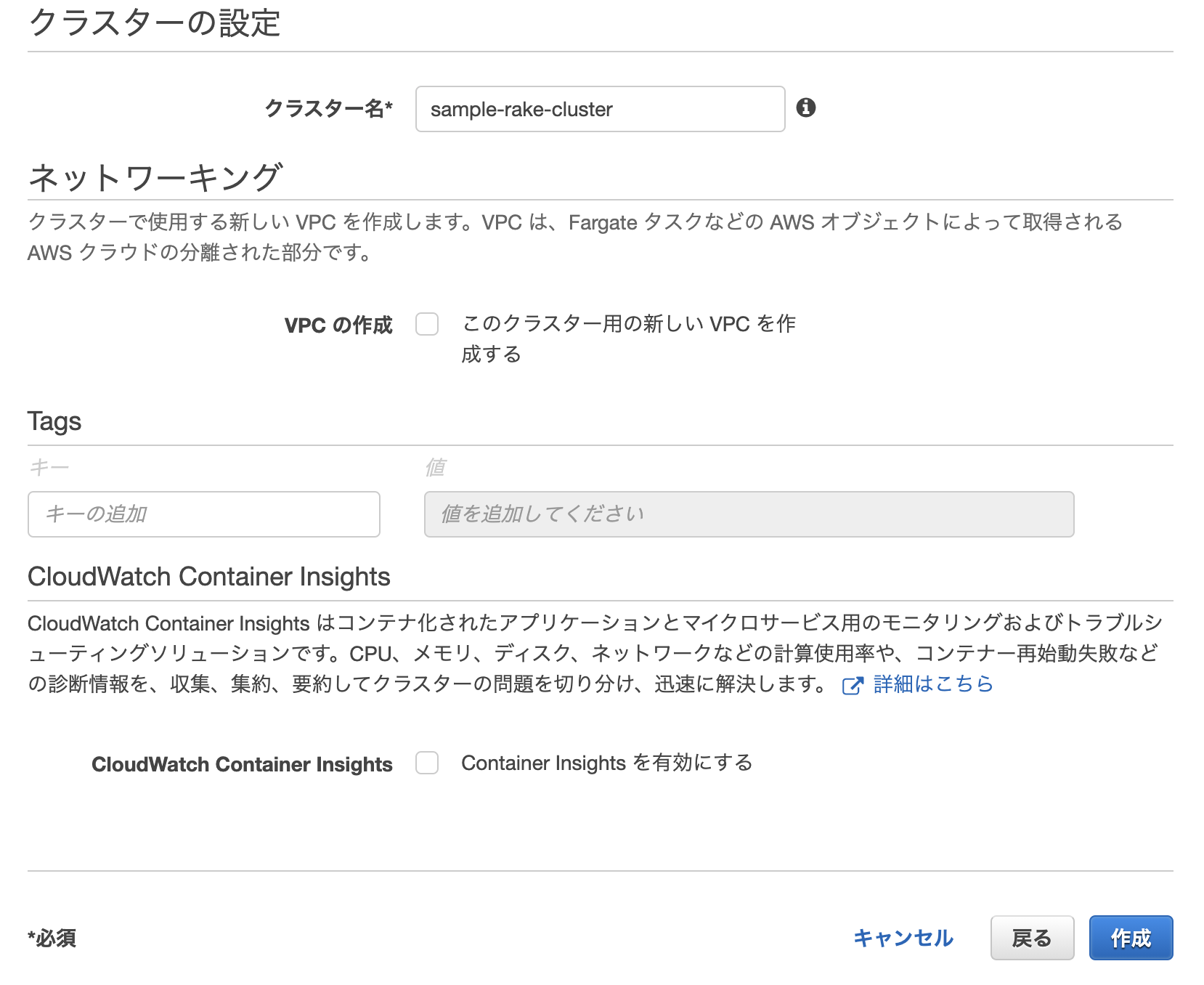
クラスターの作成
ECS > クラスターからクラスターを作成します。
今回はFargateを利用するので、ネットワーキングのみ(AWS Fargateを使用)を選択。
クラスターの名前を入れて作成。
今回は既存のVPCを利用するのでVPCは作成しませんでした。
これでクラスター作成は完了しました。タスク定義の作成
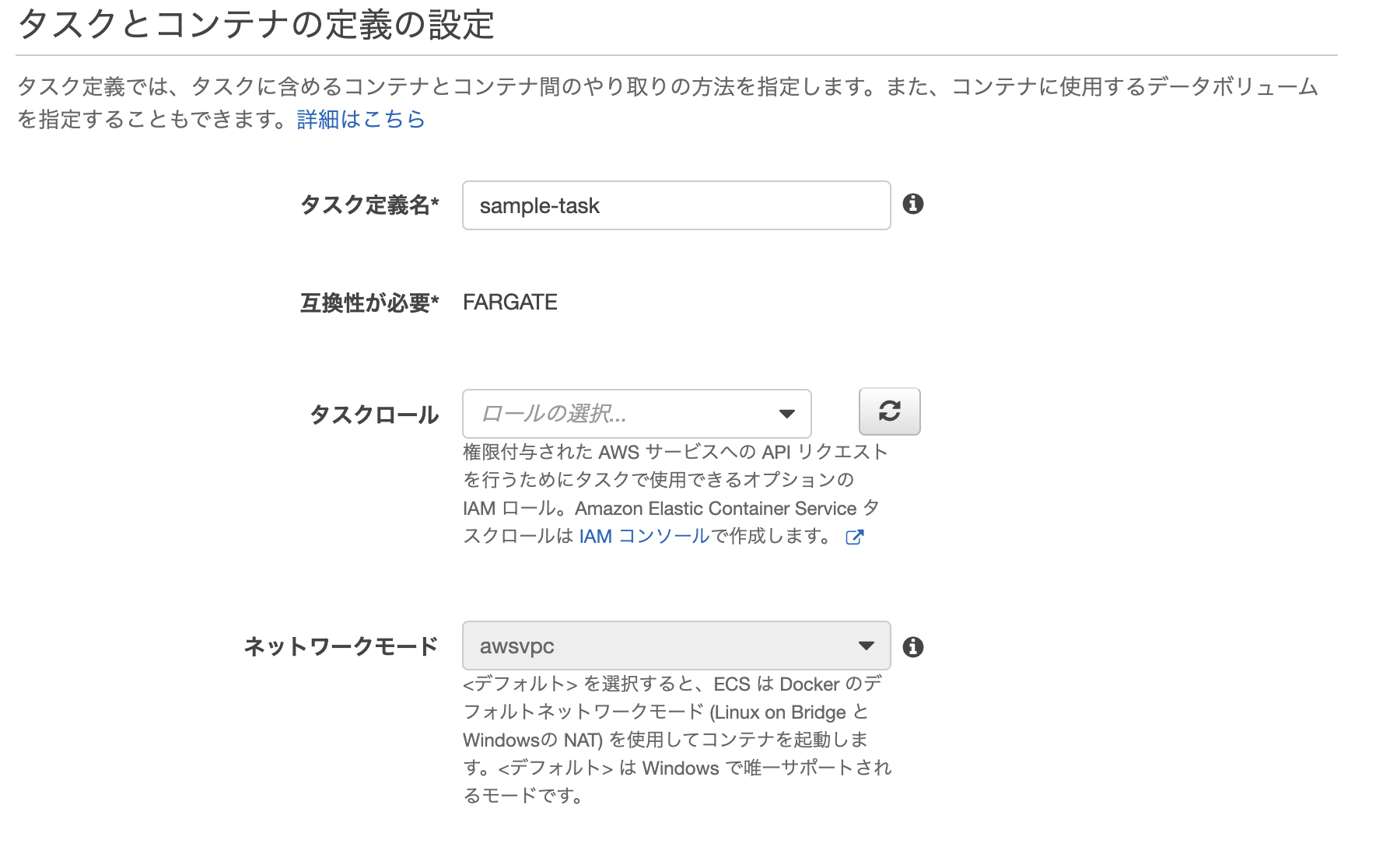
次にクラスターで実行させるタスクを作成していきます。
起動タイプの互換性の選択で、こちらもFargateを選択します。タスクとコンテナの設定
次にタスクとコンテナの設定をしていきます。
タスクロール
タスクを実行するコンテナに付与するIAMロールです。タスクでS3やRDSなどAWSサービスにアクセスする必要がある場合は、必要な権限を持ったロールを設定します。
今回は不要なのでスキップ。タスクの実行IAMロール
タスクを実行(開始)するために必要なロールです。
説明にもありますが、コンテナイメージをECRからプルしたり、コンテナのログをCloudWatch Logsに吐き出すための権限を持ったロールが必要になります。
初回は新しいロールの作成で自動的に必要なロールを作成してくれるのでこのままでOK。タスクサイズ
タスクの実行に使用されるメモリとCPUを設定します。(Fargateでは必須)
ひとまず最小限のメモリとCPUを設定しました。
コンテナの設定
タスク実行に必要なコンテナの設定をします。
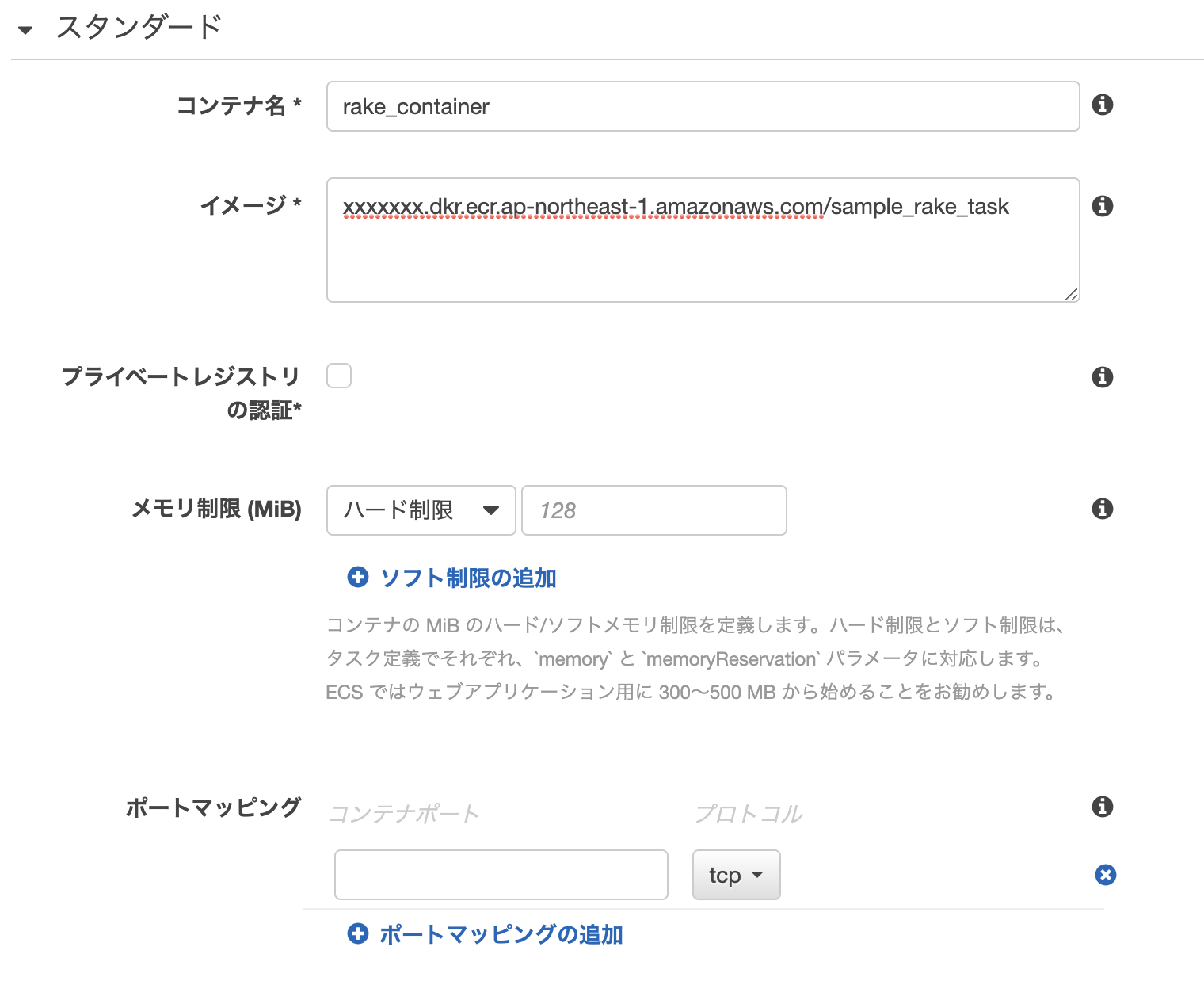
基本設定
スタンダード(基本設定) コンテナ名 コンテナの名前 イメージ コンテナのURI(ECRからコピーできます) プライベートレジストリの認証 プライベートのリポジトリからイメージをプルする場合に必要(ECRを利用する場合は不要) メモリ制限(MiB) コンテナに対するメモリの制限ですが、Fargateではタスクに対してサイズを設定しているので、コンテナで制限をかける意味はよくわかっていません。 ポートマッピング コンテナのポートとホストインスタンスのポートを紐づける場合に設定します。
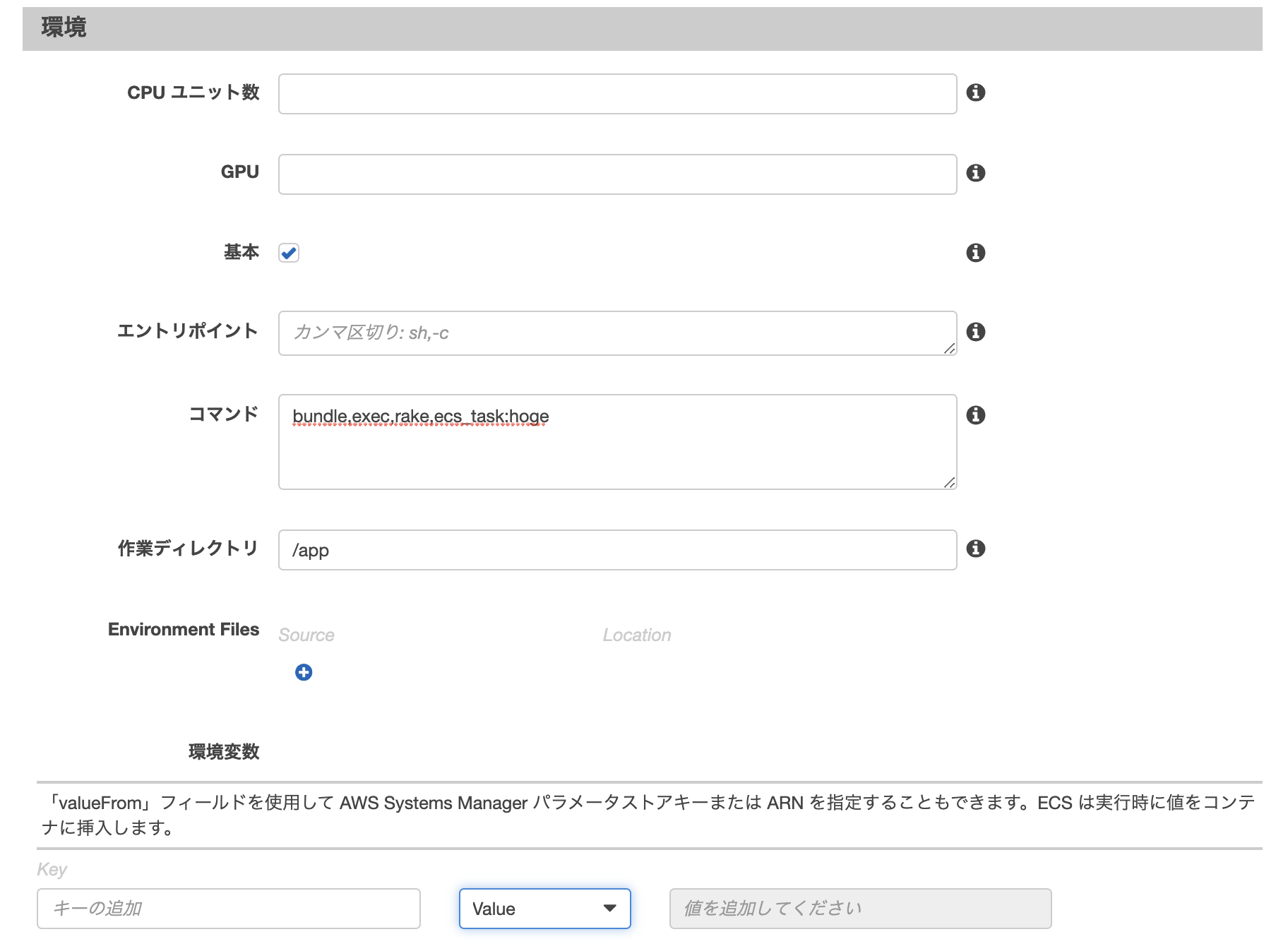
今回は単純なrake実行のみなので使用しません。環境
コンテナ環境で実行したいコマンドと作業ディレクトリを以下のように指定。
その他
ヘルスチェックやネットワークの設定などがありますが今回は使用しないので入力する必要はありません。
以上でタスク定義の設定は終了です。
タスクの実行
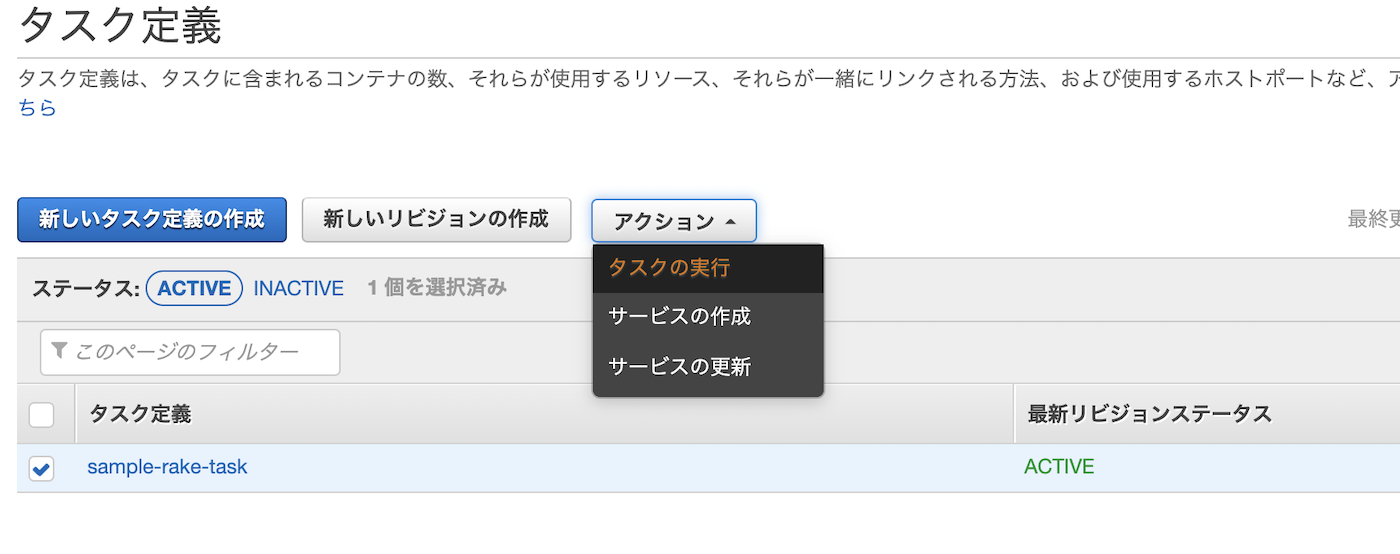
さっそくタスクを実行していきましょう。
タスクにチェックを入れてタスクの実行をクリック。
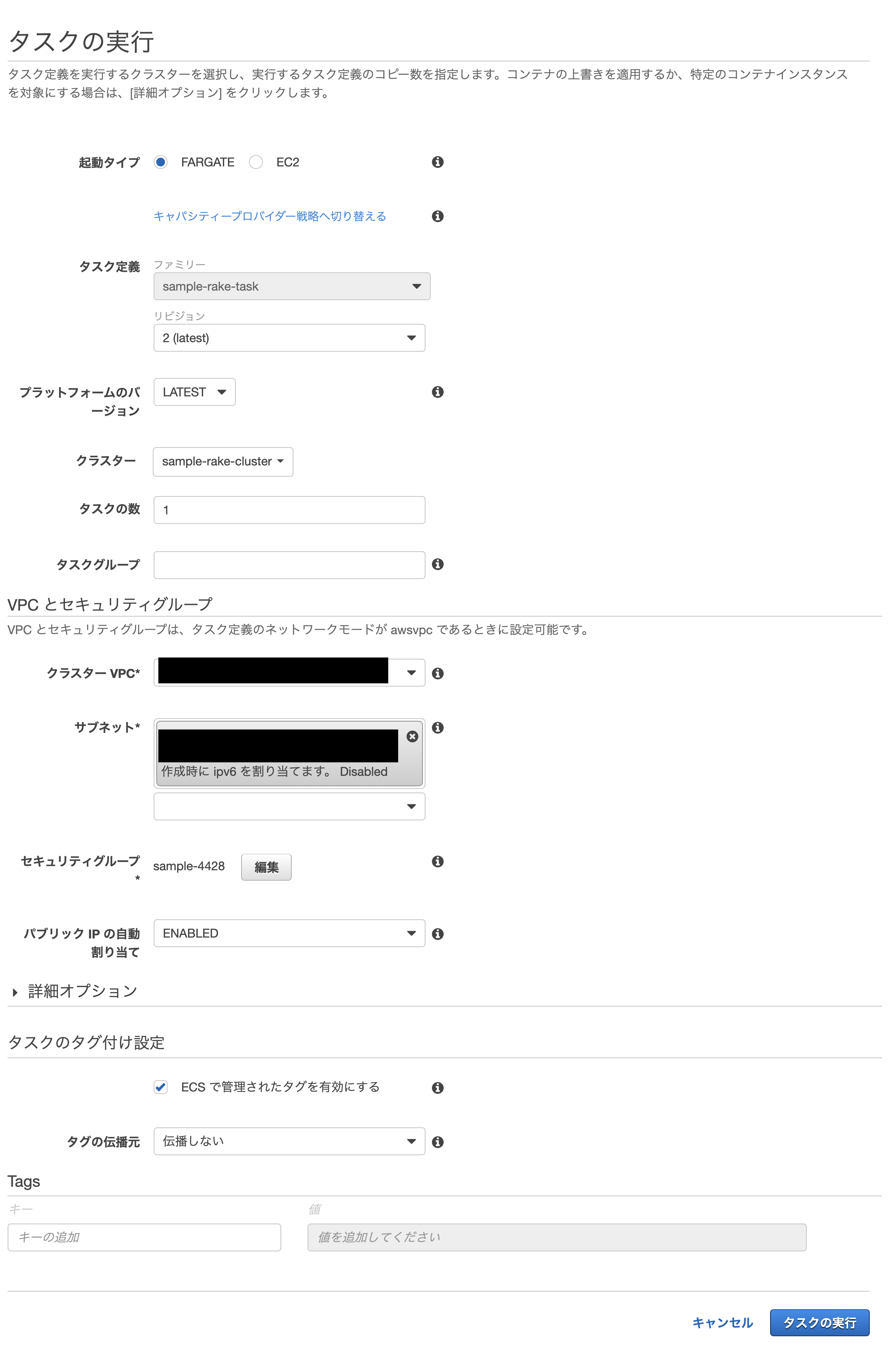
タスク実行時の設定を入力していきます。
起動タイプはFARGATE、タスクを実行するVPCやサブネットなどを入力し、タスクの実行をクリック。
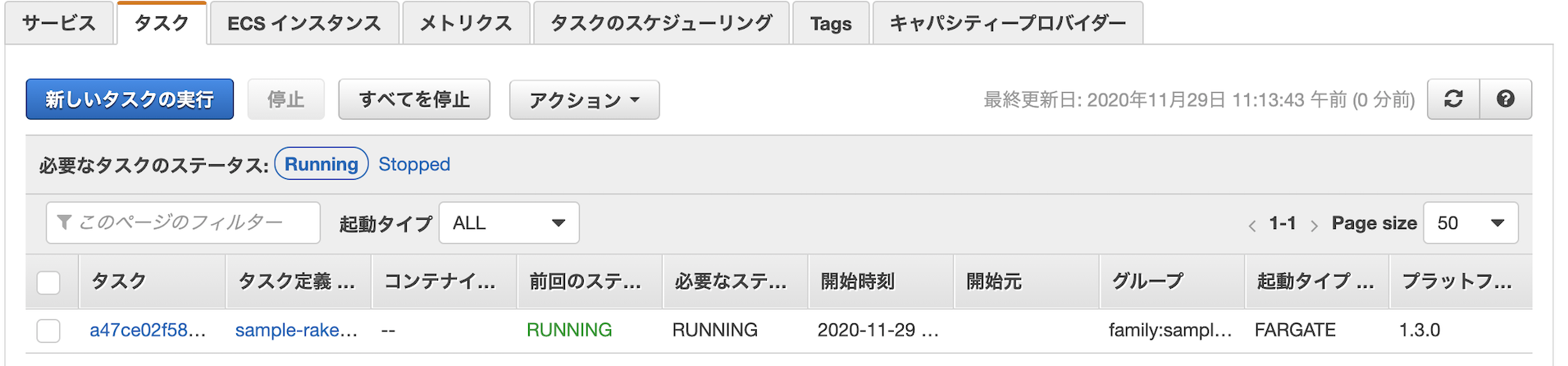
タスクのプロビジョニングが開始されます。
しばらく待っているとRUNNINGに。
ログの確認
ちゃんとタスクが実行されているかログを確認してみましょう。
タスクの実行ログはデフォルトではCloudWatch Logsに吐き出されます。ロググループに
/ecs/タスク名が作成されていますのでクリック。
タスクが実行されたことがわかりました。
所感
初めてECSを触ったということもありますが、色々設定することが多く初めは手間取りました。
タスク定義(コンテナ周り)など、まだまだ今回使っていない設定項目は多数あるので、今後調べていきます。
また今回は1コンテナ、単純なrakeタスクの実行しかしていないので、複数コンテナの連携(フロント、バックエンド、DB)などをECSで行ってみようと思います。




- 投稿日:2020-11-29T11:33:05+09:00
AWS Lambdaで傘予報LINE BOTをつくってみた
はじめに
外出時に雨が降ることを知らずに傘を忘れてしまった経験はありませんか?
私はよく傘を忘れます。。。
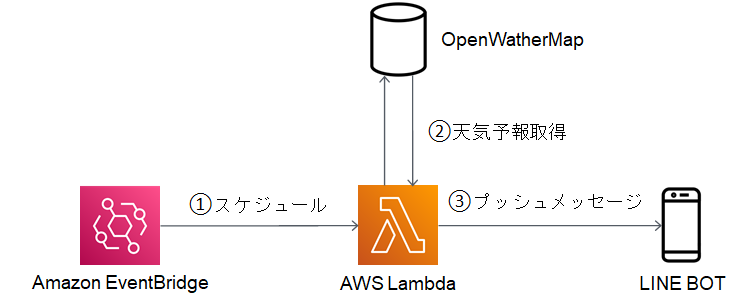
そこでAWS Lambdaで傘予報をしてくれるLINE BOTをつくってみたいと思います。アーキテクチャ
①スケジュール
Amazon EventBridgeを使用して、毎日AM 6:00にAWS Lambdaを起動するようスケジュールします。
②天気予報取得
OpenWeatherMapのAPIを使用して、天気予報情報を取得します。
③プッシュメッセージ
天気予報情報から傘予報を行い、LINE BOTにプッシュメッセージを送信します。
OpenWeatherMap
現在の天気や予報などの気象データを提供しているサービスです。
傘予報をする為に天気予報情報を取得します。OpenWeatherMap APIを使用する為の事前準備などについては、
公式サイト「How to start using Weather API」を参照ください。LINE BOT
傘予報を通知する為にLINE BOTを作成します。
LINE Massaging APIを使用する為の事前準備などについては、
公式サイト「Messaging APIを始めよう」を参照ください。AWS Lambda
OpenWeatherMap APIで天気予報を取得して、LINE BOTにMessaging APIでプッシュメッセージを送信するLambda関数を作成します。
OpenWeatherMap API
OpenWeatherMapの次のAPIを使用して、天気予報の降水量(daily.rain)を取得します。
One Call API
URL
https://api.openweathermap.org/data/2.5/onecallパラメーター
パラメータ 必須 説明 lat, lon required Geographical coordinates (latitude, longitude) appid required Your unique API key (you can always find it on your account page under the "API key" tab) exclude optional By using this parameter you can exclude some parts of the weather data from the API response.
It should be a comma-delimited list (without spaces).
Available values:
・current
・minutely
・hourly
・daily
・alertsunits optional Units of measurement. standard, metric and imperial units are available.
If you do not use the units parameter, standard units will be applied by default.lang optional You can use the lang parameter to get the output in your language. レスポンス
- daily Daily forecast weather data API response
- daily.dt Time of the forecasted data, Unix, UTC
- daily.sunrise Sunrise time, Unix, UTC
- daily.sunset Sunset time, Unix, UTC
- daily.temp Units – default: kelvin, metric: Celsius, imperial: Fahrenheit. How to change units used
- daily.temp.morn Morning temperature.
- daily.temp.day Day temperature.
- daily.temp.eve Evening temperature.
- daily.temp.night Night temperature.
- daily.temp.min Min daily temperature.
- daily.temp.max Max daily temperature.
- daily.feels_like This accounts for the human perception of weather. Units – default: kelvin, metric: Celsius, imperial: Fahrenheit. How to change units used
- daily.feels_like.morn Morning temperature.
- daily.feels_like.day Day temperature.
- daily.feels_like.eve Evening temperature.
- daily.feels_like.night Night temperature.
- daily.pressure Atmospheric pressure on the sea level, hPa
- daily.humidity Humidity, %
- daily.dew_point Atmospheric temperature (varying according to pressure and humidity) below which water droplets begin to condense and dew can form. Units – default: kelvin, metric: Celsius, imperial: Fahrenheit.
- daily.wind_speed Wind speed. Units – default: metre/sec, metric: metre/sec, imperial: miles/hour. How to change units used
- daily.wind_gust (where available) Wind gust. Units – default: metre/sec, metric: metre/sec, imperial: miles/hour. How to change units used
- daily.wind_deg Wind direction, degrees (meteorological)
- daily.clouds Cloudiness, %
- daily.uvi Midday UV index
- daily.pop Probability of precipitation
- daily.rain (where available) Precipitation volume, mm
- daily.snow (where available) Snow volume, mm
- daily.weather
- daily.weather.id Weather condition id
- daily.weather.main Group of weather parameters (Rain, Snow, Extreme etc.)
- daily.weather.description Weather condition within the group (full list of weather conditions). Get the output in your language
- daily.weather.icon Weather icon id. How to get icons
LINE Messaging API
Messaging APIを使用して、LINE BOTに傘予報のプッシュメッセージを送信します。
今回は、ライブラリ(line-bot-sdk)を使用します。URL
https://api.line.me/v2/bot/message/pushパラメーター
パラメータ 必須 説明 to 必須 送信先のID。
Webhookイベントオブジェクトで返される、
userId、groupId、またはroomIdの値を使用します。
LINEに表示されるLINE IDは使用しないでください。message 必須 送信するメッセージ
最大件数:5notificationDisabled 任意 true:メッセージ送信時に、ユーザーに通知されない。
false:メッセージ送信時に、ユーザーに通知される。
ただし、LINEで通知をオフにしている場合は通知されません。
デフォルト値はfalseです。レスポンス
ステータスコード200と空のJSONオブジェクトを返します。Lambda関数
OpenWeatherMap APIで取得した降水量(daily.rain)が0以上であれば、
Messaging APIでLINE BOTに傘予報を通知するLambda関数を作成します。import json import requests from datetime import date from linebot import LineBotApi from linebot.models import TextSendMessage from linebot.exceptions import LineBotApiError LINE_USER_ID = '*****' # LINEユーザーID LINE_CHANNEL_ACCESS_TOKEN = '*****' # LINEアクセストークン OPEN_WEATHER_FORECAST_URL = 'https://api.openweathermap.org/data/2.5/onecall' OPEN_WEATHER_API_KEY = '*****' # APIキー def create_message(forecast): return date.today().strftime("%m/%d") + 'は雨の予報です。' + '\n' + \ '外出時は傘を忘れずに!' + '\n' + \ '天気:' + str(forecast['weather'][0]['description']) + '\n' + \ '降水量:' + str(forecast['rain']) + 'mm' def push_message(message): try: line_bot_api = LineBotApi(LINE_CHANNEL_ACCESS_TOKEN) line_bot_api.push_message(LINE_USER_ID, TextSendMessage(text=message)) except LineBotApiError as e: print(e) def lambda_handler(event, context): try: params = { 'lat': '*****', # 予報場所(緯度) 'lon': '*****', # 予報場所(経度) 'units': 'metric', 'lang': 'ja', 'appid': OPEN_WEATHER_API_KEY } response = requests.get(OPEN_WEATHER_FORECAST_URL, params=params) print(json.dumps(response.json()['daily'], indent=2, ensure_ascii=False)) today_forecast = response.json()['daily'][0] if 'rain' in today_forecast: push_message(create_message(today_forecast)) except requests.exceptions.RequestException as e: print(e)デプロイ
Lambda関数のデプロイパッケージを作成して、デプロイします。
以下のライブラリをデプロイパッケージに含めます。
- line-bot-sdk
次にLambda関数のトリガーに「EventBridge (CloudWatch Events)」を追加します。
これで雨の日のAM6:00にLINE BOTへ傘予報が通知されるようになりました。
さいごに
AWS Lambdaを使用して傘予報のLINE BOTを作成してみましたが、
想像していたより簡単に完成することができました。
AWS Lambdaは無料枠内でも色々と出来るので、本当に便利ですね。
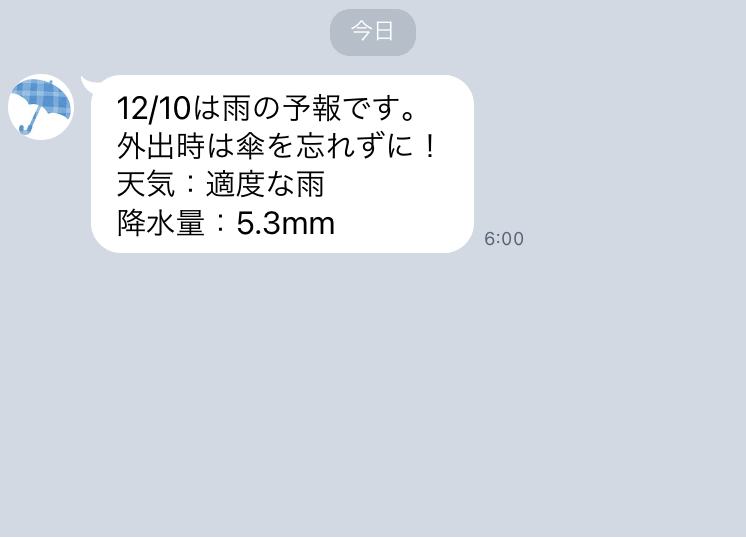
これで傘を忘れなくなるかな…
最後まで読んでいただきありがとうございました。※ AWS Lambda 初心者なので、至らない点があればコメントいただけると幸いです。
- 投稿日:2020-11-29T02:15:55+09:00
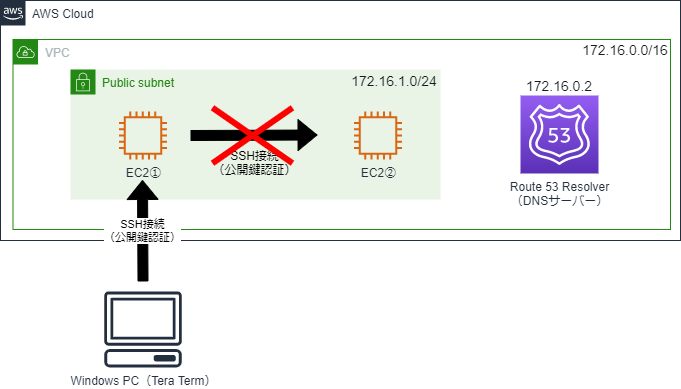
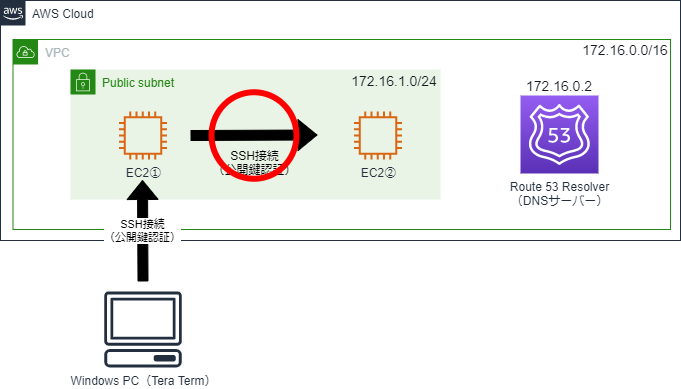
<AWS>VPCのDNS ホスト名を『有効』にするということ
背景
以前、EC2から同じサブネット内のEC2に秘密鍵を指定して「ssh」コマンドを実行した際、下記のようにエラーが出力され、SSH接続できないということがありました。
$ ssh -i id_rsa [ユーザー名]@[ホスト名] ssh: Could not resolve hostname [ホスト名]: Name or service not known接続先へは公開鍵を配置していて、セキュリティグループにも問題がない状態です。
結果的に、VPCのDNS ホスト名を『有効』にすることで解決したのですが、それまで全くこの機能について意識できていませんでした。
この記事で、VPCのDNS ホスト名を『有効』にするのとしないのとではどう違うのか、簡単に整理します。DNS ホスト名が『無効』の場合
まず、VPCを作成すると、デフォルトではDNS 解決のみ『有効』になっており、DNS ホスト名は『無効』になっています。
この状態だと、ホストアドレス「.2」が割り当てられたDNSサーバー(Amazon Route 53 Resolver)はVPCに存在するのですが、名前解決ができません。
そのため、EC2①からEC2②に秘密鍵を指定して「ssh」コマンドを実行しても、エラーになってしまいます。DNS ホスト名が『有効』の場合
VPCのDNS ホスト名を『有効』にすると、DNSサーバー(Amazon Route 53 Resolver)が機能し、名前解決を行ってくれるので、秘密鍵を指定して「ssh」コマンドを実行すると、EC2①からEC2②にSSH接続することができます。参考ドキュメント
以下、この記事を書く際に使用した公式ドキュメントです。
・Amazon DNS サーバー(Amazon Route 53 Resolver)
・VPC での DNS の使用
・VPC の DNS サポート
・IPv4 用の VPC とサブネットのサイズ設定
- 投稿日:2020-11-29T01:45:16+09:00
【AWS】EC2に紐づくEBSボリュームを差し替える
はじめに
AWS上で構築していたGNS3サーバ(UbuntuOS)の2台目が必要になったので、AMIを取得して複製したところ、インスタンスのステータスチェックが失敗しました。
これまでに1,2回しか出会ったことがない事象、たまたまかな?と思いEC2を停止起動したり、AMIを取得しなおして再作成してもダメでした。
色々調べた結果、起動に失敗するEC2のEBSを正常なEC2に紐づけて、/var/log/messages を確認してみることにしました(AWSコンソール上で見ることができるシステムログは確認済み)目次
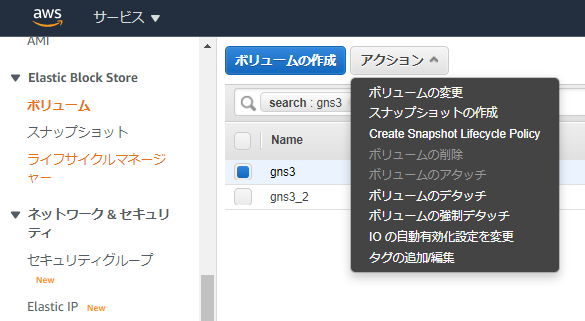
1.EC2からEBSをデタッチする
EC2にアタッチされているEBSボリュームをそれぞれデタッチします。
2.問題のあるEBSを正常なEC2にアタッチ
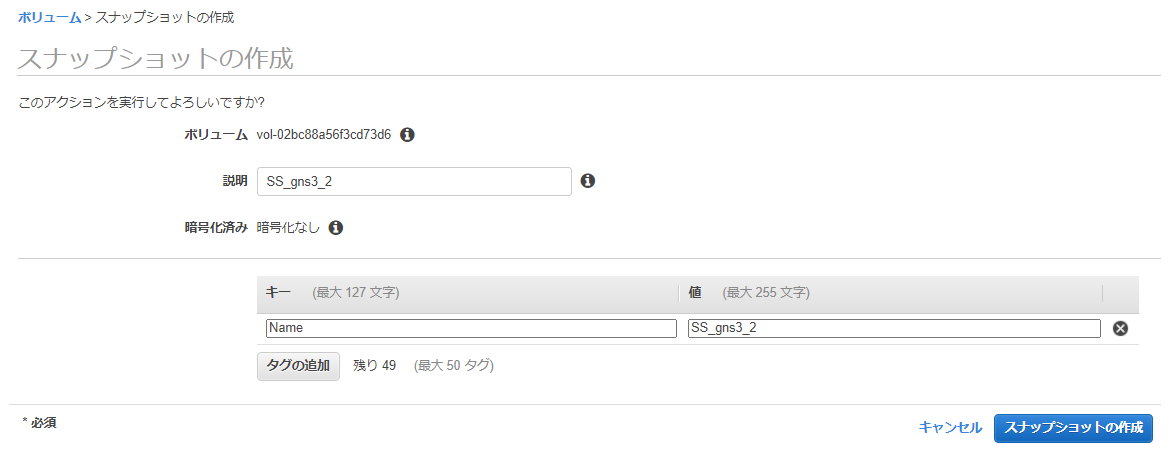
...しようと思っていましたが、AZが異なるためそのままではアタッチできないことが判明...
仕方がないので、一度EBSボリュームからスナップショットを作成して、さらにそのスナップショットからボリュームを再作成する際に別AZを指定することで、解決しました。
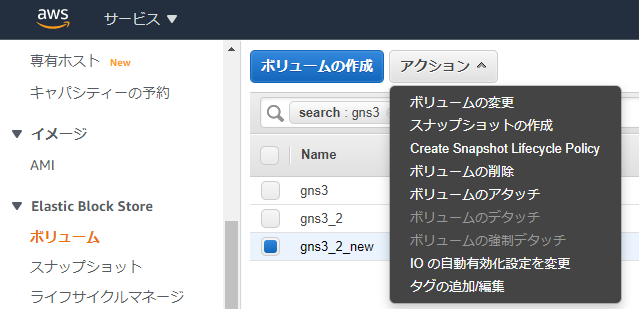
ちょっと遠回りしましたが何とかアタッチできたので、EC2を起動しました。
なお、ボリュームをアタッチする際はデバイスを/dev/sda1に変更しないとEC2が認識してくれません(ルートデバイス名はEC2のストレージタブにて確認)
3.EC2にSSHログインする
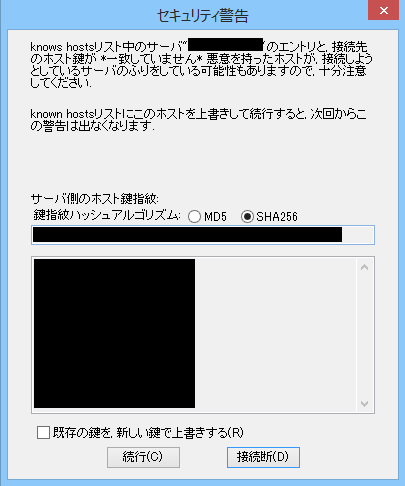
EC2が問題なく起動してくれたので、SSHでログインします。
鍵が一致しないと警告が出てしまいましたが、鍵の上書きはせずに続行をクリック。
なお、鍵を上書きしなかったせいなのかは分かりませんが、ユーザ名/パスワードではSSHもRDPも失敗したため、pem鍵を使用してログインしました。4.ログを確認する
「あれ、/var/log/messagesがない...?」と思って調べたら、Ubuntuは/var/log/syslog を見るらしい。勉強になります。
参考:見るべきログを知っておく (/var/log/ 配下のファイル紹介)
ログの場所も把握して、いざ/var/log/syslogを確認したのですが...
原因がさっぱりわかりません。amazon-ssm-agentの起動に関してERRORが出ていることは確認できましたが、あまり関係無さそう。ただ、ここにきて「問題のあると思われるEBS」を正常なEC2にアタッチして無事起動できているということは、問題があるのはEBSではなくEC2の方では?ということに気づきました。
てことで元々正常なEC2にアタッチされていたEBS(からスナップショットを作成⇒別AZにてボリューム作成したもの)を疑惑の出たEC2にアタッチして、起動すると...
やはり失敗しました。今回悪いのはEBSではなくEC2(もしくはAMI)みたいです。
ただ、AMI取り直しも、AMIからEC2作成も何度か試していて毎回失敗するので、もしかしたら別の要因があるかもしれません(進展あれば適宜更新)さいごに
EBSボリュームを別AZに存在するEC2にアタッチする場合、一旦スナップショットを作成して回避する、などは今後も使えそうだなと思いました。
参考文献
本記事はこちらの文献を参考に執筆しました。この場を借りてお礼申し上げます。