- 投稿日:2020-11-23T23:37:37+09:00
【設計検討1】PC操作自動化システムの設計検討1
概要
本日よりPC自動化システムの開発を行う。
以下をまとめる
要件定義
画面イメージ
ユーザ操作要件定義
クリック操作、キーボード入力を自動化したい
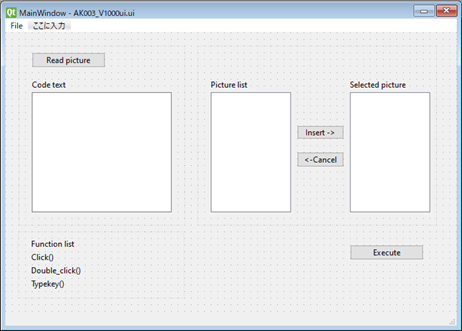
画面イメージ
Read picture:
クリックするとフォルダ選択フォームが開く
フォルダ内の画像をすべて読み込むPicture list
Read pictureによって読み込んだ画像が表示される。Code text
コード入力テキストExecute
Code text内の関数を実行するユーザ操作
ユーザが行う操作フローを示す。
Gui起動
⇒Gui画面が開く
Read pictureをクリック
⇒フォルダ選択画面が開く
選択をクリック
⇒Picture listに画像ファイル一覧が表示する
Picture listからクリック対象の画像を選択
Insertをクリック
⇒Target pictureに選択した画像が表示
Code text内にコード記述
Executeをクリック
⇒Code text内のコードを上から順番に実行する今後
詳細フローを設計する
- 投稿日:2020-11-23T23:35:33+09:00
プログラミング始めて2ヶ月半の初心者がFlaskを使ってWebアプリを作った日
はじめに
まずこの記事を読んでくださってありがとうございます!
以前、データ分析の記事を出してから約2週間が経ちました。
今回はAidemyさんのAIアプリコースを受講し終えたので、Webアプリを作っていきたいと思います。
アプリは画像分類をしてくれるアプリです。
誰のための記事か?
プログラミングを始めようとしている、あるいは始めて間もない方々です。特に社会人でプログラミング学習に
関心があるかたに読んでくださると、参考の一つになると思います。というのも、私がアプリ制作をしたのは仕事
終わりの少しの時間と休日を割いて使った時間です。そのため「仕事をしながらプログラミングをすると、どの
程度のことをプログラミングできるのか?」という、社会人でありプログラミング初心者が気になる疑問に対する
答えのサンプルの一つを提供できると思っています。
読者様への注意点
アウトプットをすること自体を重要視しているので、コードの内容を厳密に理解しているわけではないので、
細かい説明が出来ない場合があります。申し訳ございません。
コードを厳密に理解していなくても、プログラミングにおいてアウトプットは出来るということがこの記事を
通して発信したいことです。これは私の最近の気付きの中でも重要なものです。それを少しでも表現し、読者の
方々に少しでも伝われば幸いです。
環境
MacBookAir
macOS : Catalina 10.15.5
Atom : 1.53.0
JupyterNotebook本文
0.テーマ設定と最終目標
今回のアプリは画像認識を使ったアプリです。人間の目で見たら、似ているものを機械が簡単に判別できたら、
いいなと思ったので、とりあえず適当に似ている2つのものを考えていきました。バターとマーガリン、カレイと
ヒラメ、阿藤快と加藤あい。色々と考えた末にキャベツとレタスにしました。画像データを集めやすかった
からです。
キャベツかレタスかを判別してくれるアプリをWeb上で実装する。これを最終目標とします。
今回はAtomというテキストエディタを使うのですが、Atom上で作った最終的なディレクトリの構造を
あらかじめのせておきます。
cabbage_lettuce/
├ image/
│ └ additional_image
│ ├ cabbage
│ └ lettuce
├ model.h5/
│ └ my_model
├ static/
│ └ stylesheet.css
├ template/
│ └ index.html
├ exe.py
└ imagenet.py
1.データ収集
まずcabbage_lettuceという名前を付けたディレクトリを作ります。その下にimagenet.pyというファイルを
作ります。この節ではimagenet.pyの構築をしていきます。画像データはImageNetというデータソースからダウン
ロードします。
imagenet.pyの内容は以下の参考文献をほとんどコピペしているので詳しくは以下のページを御覧ください。よろしくお願い致します。
(参考文献)
ImageNet
ImageNetのダウンロード方法imagenet.pyを書き終えたら、コマンドラインを使います。コマンドラインの使い方はProgateさんで学習
しました。コマンドラインの学習講座は無料で受講できるので詳しくない方は試してみてください。とても
わかりやすいです。
私はMacを使っているのでターミナルというコマンドラインを使います。ターミナルを使って、imagenet.pyを
起動するには「python imagenet.py」とすればよいのですが、そのためにはimagenet.pyが存在する場所の
1つ上の階層にあるディレクトリに移動している必要があります。上に書いたディレクトリ構造を見ていただく
と、cabbage_lettuceディレクトリから始まっディレクトリやファイルが枝分かれしていってますが、これを
逆向きに辿っていくと階層を上がっていることになります。この説明によると、imagenet.pyの1つ上の階層にある
ディレクトリはcabbage_lettuceディレクトリです。
cdコマンドを使って別のディレクトリへ移動します。cabbage_lettuceの1つ上の階層にいるならば、下記の
コードをターミナル上で実行すると、cabbage_lettuceに移動できます。cabbage_lettuceの上の階層は
MacではFinderという既存のアプリから確認できます。
ターミナルcd cabbage_lettuce「username cabbage_lettuce %」と表示されたら成功です。成功したら以下を実行し、レタスとキャベツの
画像をダウンロードします。
ターミナルpython imagenet.py2.モデル構築
モデルはJupyterNotebookで作っていきます。データを細かくいじる際にはとても便利です。
JupyterNotebookfrom sklearn.model_selection import train_test_split from keras.callbacks import ModelCheckpoint from keras.layers import Conv2D, MaxPooling2D, Dense, Dropout, Flatten from keras.models import Sequential from keras.utils import np_utils from keras import optimizers from keras.preprocessing.image import img_to_array, load_img import keras import glob import numpy as np import matplotlib.pyplot as plt # 画像ディレクトリのパス root_dir = '/cabbage_lettuce/image/' # 画像ディレクトリ名 veg = ['cabbage', 'lettuce'] X = [] # 画像の2次元データを格納するlist y = [] # ラベル(正解)の情報を格納するlist for label, img_title in enumerate(veg): file_dir = root_dir + img_title img_file = glob.glob(file_dir + '/*') for i in img_file: try: img = img_to_array(load_img(i, target_size=(128, 128))) X.append(img) y.append(label) except: print(i + " の読み込みに失敗") # Numpy配列を4次元リスト化(*, 244, 224, 3) X = np.asarray(X) y = np.asarray(y) # 画素値を0から1の範囲に変換 X = X.astype('float32') / 255.0 # ラベルをOne-hotにしたラベルに変換 y = np_utils.to_categorical(y, 2) # データを分ける X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0) xy = (X_train, X_test, y_train, y_test) model = Sequential() # 入力層,隠れ層(活性化関数:relu) model.add ( Conv2D ( 32, (3, 3), activation='relu', padding='same', input_shape=X_train.shape[1:]) ) model.add ( MaxPooling2D ( pool_size=(2, 2) ) ) model.add ( Conv2D ( 32, (3, 3), activation='relu', padding='same' ) ) model.add ( MaxPooling2D ( pool_size=(2, 2) ) ) model.add ( Conv2D ( 64, (3, 3), activation='relu' ) ) model.add ( MaxPooling2D ( pool_size=(2, 2) ) ) model.add ( Conv2D ( 128, (3, 3), activation='relu' ) ) model.add ( MaxPooling2D ( pool_size=(2, 2) ) ) model.add ( Flatten () ) model.add ( Dense ( 512, activation='relu' ) ) model.add ( Dropout ( 0.5 ) ) # 出力層(2クラス分類)(活性化関数:softmax) model.add ( Dense ( 2, activation='softmax' ) ) # コンパイル(学習率:1e-3、損失関数:categorical_crossentropy、最適化アルゴリズム:RMSprop、評価関数:accuracy(正解率)) rms = optimizers.RMSprop ( lr=1e-3 ) model.compile ( loss='categorical_crossentropy', optimizer=rms, metrics=['accuracy'] ) # 学習モデルのエポック epoch = 10 # 構築したモデルで学習 model.fit (X_train,y_train,batch_size=64,epochs=epoch,validation_data=(X_test, y_test) ) model.save('/cabbage_lettuce/model.h5/my_model') scores = model.evaluate(X_test, y_test, verbose=1) print('Test accuracy:', scores[1])このコードはほとんどテンプレートに近いので細かい説明は他の方が書いた記事を読んでもらったほうがモデル構築の
仕方をより理解して頂けると思います。一つだけ説明するとしたら、for文の中のtryとexcept文によって、
画像データの中に混じっていた、読み込めない不良の画像データを特定できるようにしてあります。これに
よって、画像データの編集が少し簡単になりました。
上のコードによってこのモデルの正答率を出力してます。結果は
Test accuracy: 0.3184931506849315
31%!?ひどい精度ですね、僕も丸かじりするまで判別出来ないので僕と同じくらいの精度です(笑)
今回の目標はアプリ制作にあるので、精度を上げる作業をしなくても目的には支障がありません。これ以上は時間
を掛けたくないので、先に進みます。
3.アプリをWeb上で表現する
Webアプリを作れるツールのFlaskと、アプリの見た目を作るHTML&CSSの部分を作っていきます。
exe.pyimport os from flask import Flask, request, redirect, url_for, render_template, flash from werkzeug.utils import secure_filename from tensorflow.keras.models import Sequential, load_model from tensorflow.keras.preprocessing import image import numpy as np classes = ["cabbage","lettuce"] num_classes = len(classes) image_size = 128 UPLOAD_FOLDER = "./image/additional_image" ALLOWED_EXTENSIONS = set(['png', 'jpg', 'jpeg', 'gif']) app = Flask(__name__) def allowed_file(filename): return '.' in filename and filename.rsplit('.', 1)[1].lower() in ALLOWED_EXTENSIONS model = load_model('./model.h5/my_model')#学習済みモデルをロードする @app.route('/', methods=['GET', 'POST']) def upload_file(): if request.method == 'POST': if 'file' not in request.files: flash('ファイルがありません') return redirect(request.url) file = request.files['file'] if file.filename == '': flash('ファイルがありません') return redirect(request.url) if file and allowed_file(file.filename): filename = secure_filename(file.filename) file.save(os.path.join(UPLOAD_FOLDER, filename)) filepath = os.path.join(UPLOAD_FOLDER, filename) #受け取った画像を読み込み、np形式に変換 img = image.load_img(filepath,grayscale=False,target_size=(image_size,image_size)) img = image.img_to_array(img) data = np.array([img]) #変換したデータをモデルに渡して予測する result = model.predict(data)[0] predicted = result.argmax() pred_answer = "これは " + classes[predicted] + " です" return render_template("index.html",answer=pred_answer) return render_template("index.html",answer="") if __name__ == "__main__": port = int(os.environ.get('PORT', 8080)) app.run(host ='0.0.0.0',port = port)ユーザーが画像ファイルを提出できるようにし、提出されたデータを先程作った画像認識モデルの中に入れて、
出力を返すという内容です。
index.html<!DOCTYPE html> <html lang="ja"> <head> <meta charset="UTF-8"> <title>CL_Discriminator</title> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <meta http-equiv="X-UA-Compatible" content="ie=edge"> <link rel="stylesheet" href="./static/stylesheet.css"> </head> <body> <header> </header> <div class="main"> <h2> 送信された画像がキャベツかレタスかを識別します</h2> <p>画像を送信してください</p> <form method="POST" enctype="multipart/form-data"> <input class="file_choose" type="file" name="file"> <input class="btn" value="提出する" type="submit"> </form> <div class="answer">{{answer}}</div> </div> </body> </html>stylesheet.cssheader { background-color: #76B55B; height: 60px; margin: -8px; display: flex; flex-direction: row-reverse; justify-content: space-between; } .main { height: 370px; } h2 { color: #444444; margin: 90px 0px; text-align: center; } p { color: #444444; margin: 70px 0px 30px 0px; text-align: center; } .answer { color: #444444; margin: 70px 0px 30px 0px; text-align: center; } form { text-align: center; }これで準備が整いました。
ターミナル上で、exe.pyのひとつ上のディレクトリに移動(cabbage_lettuceへ)してから以下を実行します。
ターミナルpython exe.py出力結果の中にURLが載っているので、そこへ移動するとWeb上にアプリが表現されました。
試しにネットから拾ってきたレタスの画像を提出してみます。
冷静に返してきましたが、間違えてますね。
さて、ここで成果物報告を終わりにしたいと思います。
おわりに
さいごにこれまでの学習の反省とアプリの反省をしていきたいと思います。直近の約1ヶ月は学習のスピードを
意識して、プログラミング学習をしており、学習についてのある程度のまとまった意見が出来てきたので、
それについて書いていきます。学習にスピードを求めようとしたら、今まで学生時代に行ってきたようなインプッ
ト→アウトプット学習のパラダイムから脱出しなければならないと思いました。なので、アウトプット→インプッ
ト学習、つまり作りたいものをまずは決めて、作成過程でつまづいたら、その都度調べて(インプットして)どう
にか成果物に仕上げるという方法を採りました。ただ独学をしていた私自身の体験から、これは結構むずかしい
という問題があります。私はオンラインスクールに通うことで、実務経験のある方に質問できる環境を作ること
で、アウトプット→インプットの学習を成立させることが出来るようになりました。今回のアプリ制作では何回も
つまづき、そのたびにメンターの方に何回も助けて頂きました。もちろん誰かに質問して適切なフィードバックが
返ってくる環境であれば、手段がなんであれ、初学者でも早く学習が出来てしまいます。ただ問題点もあり
ます。それはコードの内容を熟知せず曖昧な理解でもとりあえず想定したとおりに動いたから問題ない、と学習
を先に進めてしまう点です。今回の記事でも分かったように、プログラミング学習が更に高度になるにつれて、
より複雑な問題が現れ、総合的な能力が必要になってくると予想できます。今のように浅い理解のままで進み
続けると、つまづくポイントが多くなりすぎて、逆に効率が悪くなってしまうと思います。これが今後の
課題だと考えています。最後に、最近知って痺れた言葉が、僕自身も含めたプログラミング初学者に適していると
思ったので、その言葉を引用して記事を書き終えたいと思います。
私たちのすべての探求の終わりは、
始まりの場所に戻ることであり、
その場所をはじめて知ることである。
――T.S.エリオット今後は色々な角度からプログラミングを学んでいく予定です。その先にまたデータ分析をし、アプリを再び作る
ころには今いる場所を深く理解し、クオリティーの高くなった成果物を作れているようになっていると考えると
すごいワクワクします。
読者様の中に私と同じく初学者の方がいらっしゃったら一緒に頑張りましょう!
記事を最後まで読んでくださり本当にありがとうございました!!
参考文献
AidemyのAIアプリコース
プログラミング始めて2ヶ月の初心者が日本の実質GDPをSARIMAモデルで時系列分析してみた
ImageNet
ImageNetのダウンロード方法
CNNを用いた画像認識 馬と鹿
環境情報の書きかたまとめ
Qiita記事作成方法 初心者の備忘録


- 投稿日:2020-11-23T23:24:24+09:00
構造解析と数理最適化
この記事は数理最適化 Advent Calendar 2020の13日目の記事です.
はじめに
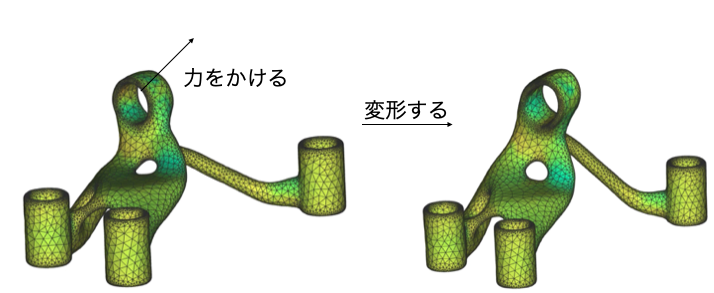
この記事では数理計画の方法論ではなく,自然現象への実装について書きます.自然現象の多くは,連立の偏微分方程式で表されます.そして工学的には有限要素法などの近似的方法で解決します.ここでは連続体の構造解析を例に取りたいと思います.特にカーボン材料内部のカーボン繊維をどのような向きで配置したら一番効率的なのかを考えることにします.図のように葉脈を思わせる曲線的な配向が最適化結果から出てきます.
連続体の構造解析とは,構造に対し,荷重などが作用して力が釣り合っている場合に,物体がどのような変形をするかを予測するものです.さて構造設計はそのプロセスがまさに最適化です.最小化したい指標 $f$ があり,設計者が決められる寸法などが $\mathbf x \in \mathcal R^d$ あったとします.ここで $d$ は設計変数の数になります.このとき構造設計とは以下のような数理計画となります.
$$
\min_{\mathbf x} f \ \ \mbox{ sbject to }\ \
\mathbf x_{min}<\mathbf x < \mathbf x_{max},\ f > f_{min}
$$
より具体的には,構造はできるだけ変形量が小さい方がいいですから,材料の変形のしやすさを表すコンプライアンス(=1/剛性)を最小化する,コンプライアンス最小化問題があります.この場合構造の全体コンプライアンスが目的関数 $f$ であり,設計変数は例えば構造の各種寸法だったりします.では各種寸法が決まったとして,どのように目的関数を決めたら良いでしょうか?ここで有限要素法による構造解析の出番となります.設計変数が決まり,その評価を行うためのシミュレータとして登場するのです.ところで有限要素法のソフトは高価で,自分好みにカスタマイズするためにはかなりの労力を使います.
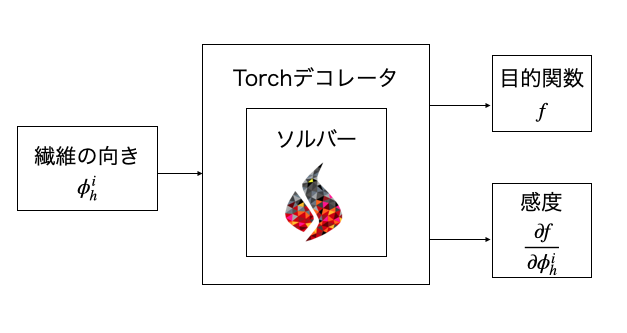
ここではFEniCSというオープンソースの有限要素ソルバーをPyTorchの計算グラフの中で使うことを考えます.torch-fenicsというライブラリの力を借りています.
材料主軸の最適化問題と定式化
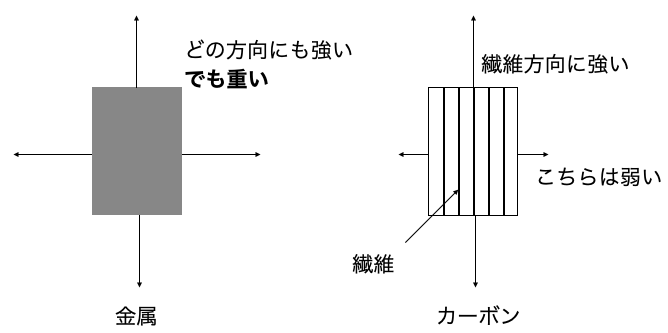
材料のなかにはある特定の方向だけとても強く,それ以外の方向には弱い材料というのがあります.例えば繊維を樹脂で固めたもの(一般にカーボン)がそうです.金属はどの方向に力をかけても強いかわりに重いのですが,カーボンは繊維方向にだけ強いかわりに軽いです.特に車などは軽くしないといけないですから本当はカーボンを使いたいわけです.しかし構造内部で繊維をどの方向に向けたら良いか?これは難しい問題です.そこで最適化の力を借りることにします.
最適化問題の定式化
構造の各所で繊維の向きを $\phi(x)$ とします.これは構造内部の場所の関数です.適当な有限要素で離散化し, $i$ 番目の節点での繊維の向きを $\phi_h^i$ とします.構造のコンプライアンスを $f$ とすれば,これは制約なしの以下の問題
$$
\min_{\phi_h^i} f
$$
となります.繊維の向き$\phi_h^i$を例えば次の勾配降下法
$$
\phi_h^i\leftarrow \phi_h^i + \alpha \frac{∂f}{∂\phi^i_h}
$$
で更新していけば(局所)最適化できます.本記事ではAdaGradを使用したため,この更新とは若干異なること注意しておきます.最適化の準備は簡単ですがこれで以上です.最適化の専門の方はぜひアドバイスください.
構造解析の定式化
上の最適化で必要なシミュレータはおよそ次のような物です.すなわち場所場所の繊維の向き$\phi_h^i$を入力すれば,その構造のコンプラアンス$f$並びに設計変数に対するコンプライアンスの感度$∂f/∂\phi_h^i$が出力されるアルゴリズムです.ここではカーボンのように繊維方向にのみ強い材料を仮定し,2次元の穴が空いた板の引張問題について考えます.
構造の場所場所で繊維の向きがことなりますから,剛性は場所の関数となります.この点だけ注意し,以下の釣り合い方程式を有限要素法で近似的に解きます.
今,解きたい釣り合いを満たす変位場(つまり解)を$u_h$とします.この釣り合いから$\delta u_h$だけ変位させたときに生じる内部応力$\sigma$の仕事$a$は,内部のひずみ$\epsilon$,および剛性$A(\phi(x))$を用いて
$$
a(u_h,\delta u_h)=\int_\Omega \sigma(u_h):\epsilon(\delta u_h)d\Omega=\int_\Omega A(\phi(x))\epsilon(u_h):\epsilon(\delta u_h)d\Omega
$$
となります.さらに構造の境界$∂\Gamma$で外力$T$が作用していた場合,この外力がしてしまう仕事は単に
$$
l(\delta u_h)=\int_{∂\Gamma} T\cdot\delta u_h d\Gamma
$$
です.もしも変位場$u_h$で構造が釣り合っているならば,変位$\delta u_h$を与えても仕事は0になるはずですね.これを式で書くと
$$
F = a(u_h,\delta u_h)-l(\delta u_h)=0
$$
となります.適当な節点と補間関数を用意すれば,これは節点数*自由度の連立方程式となり解くことができます.これが構造解析の有限要素法における定式化になります.より詳しい説明は例えば数値解析の原理をご覧ください.またFEniCSの詳しい使い方は(需要があるのであれば)別の記事に書かせていただきます.最適化の結果
勾配降下法の学習率$\alpha=0.1$で,AdaGradによって200回の最適化を行った例を示します.簡単な例題ですが,非常に興味深い配向が得られています.外側の繊維は孔の縁に接するような曲線にそって流れており,孔後方からはそれを支えるように繊維が配置されています.これらの繊維は衝突し,交わっていますがこの境界は何を意味しているのでしょうか?
おわりに
自然界の多くの材料はカーボンのようにある方向に特化して高い特性を発揮します.そしてこれらは材料内部で合理的に配置され,軽量で高い性能を発揮しています.今回のような簡単な実装でも,最適化の力を借りればこのような構造を再現できます.
これまで人間が設計してきた構造の多くは自然的ではありません.これは人間の手に負える数のオプション,すなわち数十の設計変数の組み合わせ最適化が職人的に解かれてきたためです.コンピューティングの発達により,設計変数は人間の手に負える数にする必要がなくなりました.今回の最適設計は1分程度で完了しますが,設計変数は2000を超えています.
参考
以下のライブラリを使用しました.
- 有限要素法による偏微分ソルバー FEniCS
- tensor計算のライブラリ PyTorch
- fenicsをpytorchで使えるようにするライブラリ fenics-torch
- 可視化ツール Paraview
以下の本を参考にしました.
- 菊池文雄先生 斎藤宣一先生 数値解析の原理
本記事で得られた結果は以下のリポジトリにあるコードで生成しました.
https://github.com/Naruki-Ichihara/qiita_advent2020
https://hub.docker.com/repository/docker/ichiharanaruki/fem_torch



- 投稿日:2020-11-23T23:23:13+09:00
PythonからAPIを使ってAnsibleを実行する
初めに
Ansibleって便利ですよね。同じ作業をたくさんのサーバで行う時は神様だと思います。
Playbookを叩くだけでも十分自動化している感ありますが、Playbookの実行も良い感じに自動化したいと思いました。
シェルスクリプトを書いても良いんですが、結果などをパースするのは面倒です。そこで今回は、Pythonから良い感じにAnsibleを叩いてみたいと思います。
意外と記事が見つからなかったです。ソースコード
__main__から読むとわかりやすいです。
192.168.0.1でls -la /を実行するPlaybookです。
Ansibleをコマンドで使ったことがあれば簡単に読めると思います。
所々簡単なコメントを入れているのでご参考に。pip3 install ansibleimport json import shutil from ansible.module_utils.common.collections import ImmutableDict from ansible.parsing.dataloader import DataLoader from ansible.vars.manager import VariableManager from ansible.inventory.manager import InventoryManager from ansible.playbook.play import Play from ansible.executor.task_queue_manager import TaskQueueManager from ansible.plugins.callback import CallbackBase from ansible import context import ansible.constants as C class ResultCallback(CallbackBase): def __init__(self, *args, **kwargs): super(ResultCallback, self).__init__(*args, **kwargs) self.host_ok = {} self.host_unreachable = {} self.host_failed = {} def v2_runner_on_unreachable(self, result): host = result._host self.host_unreachable[host.get_name()] = result def v2_runner_on_ok(self, result, *args, **kwargs): host = result._host self.host_ok[host.get_name()] = result def v2_runner_on_failed(self, result, *args, **kwargs): host = result._host self.host_failed[host.get_name()] = result def ansible_run(play_source, host_list): # ansible-playbookで指定できる引数と同じ context.CLIARGS = ImmutableDict( tags={}, listtags=False, listtasks=False, listhosts=False, syntax=False, connection='ssh', module_path=None, forks=100, private_key_file=None, ssh_common_args=None, ssh_extra_args=None, sftp_extra_args=None, scp_extra_args=None, become=False, become_method='Sudo', become_user='root', verbosity=True, check=False, start_at_task=None ) # 鍵認証が優先され、パスワードを聞かれた場合のみ利用する。書きたくない場合は適当でOK passwords = dict(vault_pass='secret') # コールバックのインスタンス化 results_callback = ResultCallback() # インベントリを1ライナー用フォーマットに変換 sources = ','.join(host_list) if len(host_list) == 1: sources += ',' loader = DataLoader() inventory = InventoryManager(loader=loader, sources=sources) # 値をセット variable_manager = VariableManager(loader=loader, inventory=inventory) play = Play().load(play_source, variable_manager=variable_manager, loader=loader) # 実行 tqm = None try: tqm = TaskQueueManager( inventory=inventory, variable_manager=variable_manager, loader=loader, passwords=passwords, stdout_callback=results_callback, ) result = tqm.run(play) finally: # 終了後に一時ファイルを削除している if tqm is not None: tqm.cleanup() # Remove ansible tmpdir shutil.rmtree(C.DEFAULT_LOCAL_TMP, True) return results_callback if __name__ == "__main__": # 実行ホストを指定(インベントリにも指定される) host_list = [ "root@192.168.0.1" ] # プレイブックを定義 play_source = dict( name = "Ansible Play", hosts = host_list, gather_facts = 'no', tasks = [ dict(action=dict(module='shell', args='ls -l /'), register='shell_out') ] ) results = ansible_run(play_source=play_source, host_list=host_list) for host, result in results.host_ok.items(): print(host) print(json.dumps(result._result, indent=4)) for host, result in results.host_failed.items(): print(host) print(json.dumps(result._result, indent=4)) for host, result in results.host_unreachable.items(): print(host) print(json.dumps(result._result, indent=4))実行結果の辞書はこんな感じで取得できます。以下のはJsonで出力したものを抜粋してます。
{ "cmd": "ls -l /", "stdout": "total 28\nlrwxrwxrwx. 1 root root 7 May 11 2019 bin -> usr/bin\ndr-xr-xr-x. 6 root root 4096 Nov 12 18:17 boot\ndrwxr-xr-x. 7 root root 65 Nov 17 00:41 data\ndrwxr-xr-x. 21 root root 3580 Nov 23 12:10 dev\ndrwxr-xr-x. 104 root root 8192 Nov 22 14:11 etc\ndrwxr-xr-x. 6 root root 4096 Nov 20 13:06 gvolume0\ndrwxr-xr-x. 3 root root 4096 Nov 17 00:47 gvolume1\ndrwxr-xr-x. 3 root root 19 Nov 10 01:24 home\nlrwxrwxrwx. 1 root root 7 May 11 2019 lib -> usr/lib\nlrwxrwxrwx. 1 root root 9 May 11 2019 lib64 -> usr/lib64\ndrwxr-xr-x. 2 root root 6 May 11 2019 media\ndrwxr-xr-x. 2 root root 6 May 11 2019 mnt\ndrwxr-xr-x. 2 root root 6 May 11 2019 opt\ndr-xr-xr-x. 1056 root root 0 Nov 22 14:04 proc\ndr-xr-x---. 4 root root 192 Nov 23 11:27 root\ndrwxr-xr-x. 32 root root 1100 Nov 22 14:46 run\nlrwxrwxrwx. 1 root root 8 May 11 2019 sbin -> usr/sbin\ndrwxr-xr-x. 2 root root 6 May 11 2019 srv\ndr-xr-xr-x. 13 root root 0 Nov 22 14:04 sys\ndrwxrwxrwt. 9 root root 212 Nov 23 22:51 tmp\ndrwxr-xr-x. 12 root root 144 Nov 10 01:22 usr\ndrwxr-xr-x. 21 root root 4096 Nov 10 01:28 var", "stderr": "", "rc": 0, "start": "2020-11-23 22:51:11.787866", "end": "2020-11-23 22:51:11.793951", "delta": "0:00:00.006085", "changed": true, "invocation": { "module_args": { "_raw_params": "ls -l /", "_uses_shell": true, "warn": true, "stdin_add_newline": true, "strip_empty_ends": true, "argv": null, "chdir": null, "executable": null, "creates": null, "removes": null, "stdin": null } }, "stdout_lines": [ "total 28", "lrwxrwxrwx. 1 root root 7 May 11 2019 bin -> usr/bin", "dr-xr-xr-x. 6 root root 4096 Nov 12 18:17 boot", "drwxr-xr-x. 7 root root 65 Nov 17 00:41 data", "drwxr-xr-x. 21 root root 3580 Nov 23 12:10 dev", "drwxr-xr-x. 104 root root 8192 Nov 22 14:11 etc", "drwxr-xr-x. 6 root root 4096 Nov 20 13:06 gvolume0", "drwxr-xr-x. 3 root root 4096 Nov 17 00:47 gvolume1", "drwxr-xr-x. 3 root root 19 Nov 10 01:24 home", "lrwxrwxrwx. 1 root root 7 May 11 2019 lib -> usr/lib", "lrwxrwxrwx. 1 root root 9 May 11 2019 lib64 -> usr/lib64", "drwxr-xr-x. 2 root root 6 May 11 2019 media", "drwxr-xr-x. 2 root root 6 May 11 2019 mnt", "drwxr-xr-x. 2 root root 6 May 11 2019 opt", "dr-xr-xr-x. 1056 root root 0 Nov 22 14:04 proc", "dr-xr-x---. 4 root root 192 Nov 23 11:27 root", "drwxr-xr-x. 32 root root 1100 Nov 22 14:46 run", "lrwxrwxrwx. 1 root root 8 May 11 2019 sbin -> usr/sbin", "drwxr-xr-x. 2 root root 6 May 11 2019 srv", "dr-xr-xr-x. 13 root root 0 Nov 22 14:04 sys", "drwxrwxrwt. 9 root root 212 Nov 23 22:51 tmp", "drwxr-xr-x. 12 root root 144 Nov 10 01:22 usr", "drwxr-xr-x. 21 root root 4096 Nov 10 01:28 var" ], "stderr_lines": [], "ansible_facts": { "discovered_interpreter_python": "/usr/libexec/platform-python" }, "_ansible_no_log": false }終わりに
結果もPythonで使いやすいので他のシステムとの結合も簡単です。
私は趣味で書いているPythonのシステムからAnsibleを叩きたいと思ってこの方法を探してました。
他の方のお役に立てれば何よりです。参考
- 投稿日:2020-11-23T23:21:34+09:00
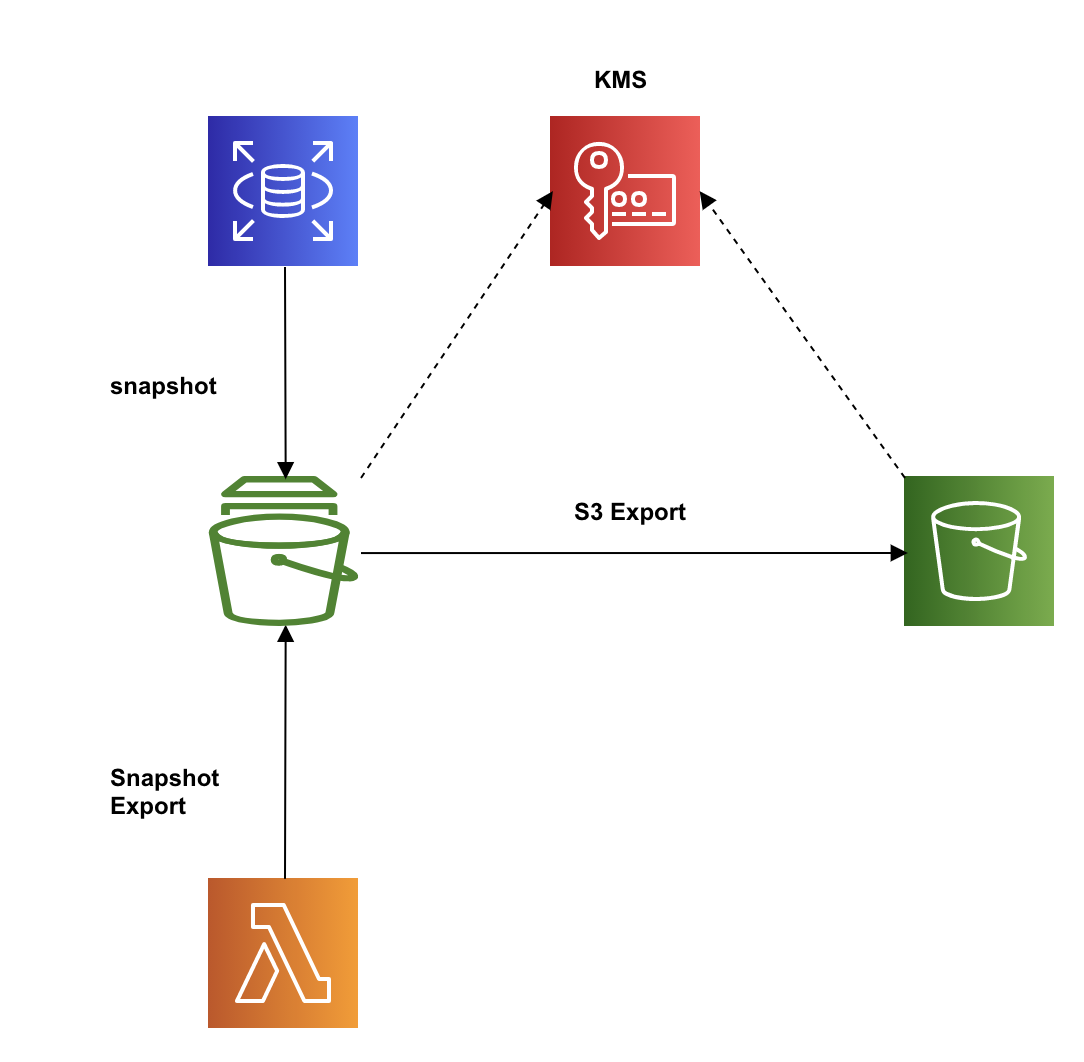
Lambda(Python)でRDSスナップショットをS3にエクスポートする
はじめに
RDSのデータを参照する際
・日時のdumpジョブなどを用意していない
・リードレプリカがない
・商用環境ログインには問答無用で承認が必要などの理由で直接RDSの中身を覗くことが困難な場合がありました。
そんな時、Amazon RDSにはスナップショットをS3にエクスポートし、Athenaで参照することが可能とのことでしたので実際にLambdaを使ってRDSスナップショットのS3エクスポートを試してみました。全体像
RDSスナップショットのS3へのエクスポートをLambdaにて実行する。
エクスポートされたデータはKMSにより暗号化されるため、KMSキーも用意する必要がある。前提
・RDS及びスナップショットを作成してある。
・エクスポート先のS3バケットを作成してある。手順
1.RDSスナップショットをS3エクスポートする際に使用するポリシー、ロールの作成
1-1.ポリシー作成
スナップショットエクスポートタスクからS3にアクセスするためのポリシーを以下のjsonで作成する。
(Resourceのyour-s3-bucketはエクスポート先とするS3バケットを指定){ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": [ "s3:ListBucket", "s3:GetBucketLocation" ], "Resource": "arn:aws:s3:::*" }, { "Sid": "VisualEditor1", "Effect": "Allow", "Action": [ "s3:PutObject*", "s3:GetObject*", "s3:DeleteObject*" ], "Resource": [ "arn:aws:s3:::your-s3-bucket", "arn:aws:s3:::your-s3-bucket/*" ] } ] }1-2.ロール作成
ロールを作成し、上記で作成したポリシーをアタッチする。
信頼関係の編集から以下のようにアクセスコントロールポリシードキュメントを編集する。
(Serviceがexport.rds.amazonaws.comになる){ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "export.rds.amazonaws.com" }, "Action": "sts:AssumeRole" } ] }2.KMSキーの作成
エクスポートデータの暗号化に使用するキーをKMSで作成する。
1.マネジメントコンソールからKMSにて
カスタマー管理型のキーを選択。
2.キーの作成にて作成ウィザードを表示する。
3.ステップ 1/5 キーのタイプ:対象
4.ステップ 2/5 エイリアス:任意のキーの名前を入力
5.ステップ 3/5 キー管理者:キーと管理者となるユーザーを選択
6.ステップ 4/5 キーの使用アクセス許可を定義: ここでは特に指定しない
7.ステップ 5/5 完了3.Lambda作成
3-1.ロール、ポリシー作成
Lambda関数作成時に同時に作成することができる
AWSLambdaBasicExecutionRoleのロールを作成。
スナップショットエクスポートに必要となる以下ポリシーを別途作成し上記ロールにアタッチする。{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "iam:PassRole", "rds:StartExportTask" ], "Resource": "*" } ] }3-2.Lambdaコード作成
pyhton:lambda_handler.pyimport json import boto3 from datetime import datetime SOURCE_ARN="YOUR_SOURCE_ARN" S3_BUCKET_NAME="YOUR_S3_BUCKET_NAME" IAM_ROLE_ARN="YOUR_IAM_ROLE_ARN" KMS_KEY_ID="YOUR_KMS_KEY_ID" client = boto3.client('rds') def lambda_handler(event, context): export_task_identifier="mysnapshot" + datetime.now().strftime("%Y%m%d%H%M%S") response = client.start_export_task( ExportTaskIdentifier=export_task_identifier, SourceArn=SOURCE_ARN, S3BucketName=S3_BUCKET_NAME, IamRoleArn=IAM_ROLE_ARN, KmsKeyId=KMS_KEY_ID, )・コード内の以下変数は各自の環境に合わせて設定する。
変数名 値 SOURCE_ARN エクスポート対象とするRDSスナップショットのARN S3_BUCKET_NAME 出力先となるS3バケット名 IAM_ROLE_ARN 手順1で作成したS3エクスポートする際に使用するロールのARN KMS_KEY_ID 作成したKMSキーのARN ・
ExportTaskIdentifierについては以下制約があるため今回は日時をつけたものにしています。エクスポート識別子
エクスポートを識別するための名前を入力します。この名前は、AWS アカウントが現在の AWS リージョンで所有する、すべてのスナップショットエクスポート間で一意である必要があります。4.KMSキーのキーユーザーにLambdaロールを追加
手順2で作成したキーのキーユーザーに手順3のLambdaにて使用しているロールを追加する。
この作業を行わないと、Lambda実行時に
An error occurred (KMSKeyNotAccessibleFault)というエラーが表示される。本作業後、Lambdaを実行することでRDSスナップショットがS3へエクスポートされる。
おわりに
スナップショットをS3にエクスポートするだけであればマネジメントコンソールでも同様のことが可能ですが、データソースをシステムスナップショットにし、日時でデータ更新を行いたかったためLambdaでの実行を試しました。
RDSもDynamoDBのようにちょっとした参照であればマネジメントコンソール上で確認できると嬉しいですが、今回のスナップショットを参照にする方法も安全で簡単な方法だと感じました。
参考文献
この記事は以下の情報を参考にして執筆しました。

- 投稿日:2020-11-23T22:42:26+09:00
[Python] DP ABC184D
金貨がX枚、銀貨がY枚、銅貨がZ枚のときの答えをdp(X,Y,Z)とします。X,Y,Zのいずれかが100のときdp(X,Y,Z)=0 です。そうでないとき、どの硬貨を引いたか3通りの場合を考えることで、
dp(X,Y,Z)= \frac{X}{X+Y+Z}(dp(X+1,Y,Z)+1) +\frac{Y}{X+Y+Z}(dp(X,Y+1,Z)+1) +\frac{Z}{X+Y+Z}(dp(X,Y,Z+1)+1)となります。(金貨を引く確率×金貨を引いた時の操作回数の期待値+銀貨を……)
この式に従ってDPを行うと答えを求めることができます。実装はメモ化再帰により行うと容易です。
サンプルコードimport sys sys.setrecursionlimit(10 ** 6) def dfs(a, b, c): # メモ化再帰 if dp[a][b][c] >= 0: # 既に値がわかっている場合はそのまま返す. ret = dp[a][b][c] else: # 値がわかっていない場合、漸化式により値を求める. ret = 0 S = a + b + c ret += a / S * (dfs(a + 1, b, c) + 1) ret += b / S * (dfs(a, b + 1, c) + 1) ret += c / S * (dfs(a, b, c + 1) + 1) dp[a][b][c] = ret return ret A, B, C = map(int, input().split()) M = 100 dp = [[[-1] * (M + 1) for _ in range(M + 1)] for _ in range(M + 1)] # 終端条件(初期化) for i in range(A, M + 1): for j in range(B, M + 1): for k in range(C, M + 1): if i == M or j == M or k == M: dp[i][j][k] = 0 # dp(A, B, C)が求める答え print(dfs(A, B, C))
- 投稿日:2020-11-23T21:40:15+09:00
Djangoで外部の既存データベースを参照する
概要
- 既存でデータベースを運用していたが、新規で構築するDjangoアプリケーションからそのデータベースを参照したかった。
- DjangoのデフォルトDB以外も参照できる。
- Mysqlでしか試していないがPostgresも同様にできると思われる。
設定方法
DB情報を追記
- DATABASES が辞書形式になっているので追記する。
settings.pyDATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', 'NAME': db, 'USER': user, 'PASSWORD': password, 'HOST': 'mysql01', 'PORT': '3306', }, 'otherdb': { 'ENGINE': 'django.db.backends.mysql', 'NAME': otherdb, 'USER': user, 'PASSWORD': password, 'HOST': 'mysql02' 'PORT': '3306', } }モデルを設定
- 通常と同様にモデルを定義する。
- メタデータとして「db_table」に参照したいDB内のテーブル名をしてする。
- 指定しないと「<アプリケーション名>_<クラス名>」の形で表示された。(デバッグで確認)
application/models.pyfrom django.db import models class <クラス名>(models.Model): class Meta: db_table = '<テーブル名>' id = models.IntegerField(primary_key=True) name = models.CharField(max_length = 255)ビューの設定
- 「db_manager」を利用してsettings.pyで追記したDBを指定することで外部DBを参照できる。
- TablesName
application/views.pyfrom django.shortcuts import render from .models import <クラス名> def index(request): data = <クラス名>.objects.db_manager("<DB名>").all() params = { 'data': data } return render(request, 'sample.html', params)マイグレーションも忘れない
$ python3 ./manage.py makemigrations $ python3 ./manage.py migrate
- 投稿日:2020-11-23T21:33:11+09:00
バッチファイルで python 仮想環境を有効化後、pythonファイルを実行する
- 投稿日:2020-11-23T21:30:48+09:00
統計的仮説検定についてまとめてPythonで実施する
はじめに
統計的仮説検定についてまとめました。後々「検出力」や「効果量」について整理した記事を書きたいと思っておりその前段として本記事を書きました。
筆者は統計の専門家ではないため誤りがあればご指摘いただけると幸いです。参考
「統計的仮説検定」についてまとめるあたって下記を参考にしています。
統計的仮説検定について
統計的仮説検定についてその流れを整理し最後にPythonで実施します。
統計的仮説検定とは何か
統計的仮説検定についてはwikipediaは下記以下のように説明されています。
統計的仮説検定(statistical hypothesis testing)とは、母集団分布の母数に関する仮説を標本から検証する統計学的方法のひとつ。日本工業規格では、仮説(statistical hypothesis)を「母数又は確率分布についての宣言。帰無仮説と対立仮説がある。」と定義している。検定(statistical test)を「帰無仮説を棄却し対立仮説を支持するか,又は帰無仮説を棄却しないかを観測値に基づいて決めるための統計的手続き。その手続きは,帰無仮説が成立しているにもかかわらず棄却する確率がα以下になるように決められる。このαを有意水準という。」と定義している。
「帰無仮説」や「対立仮説」、「有意水準」など専門用語が出てきて定義が難しくなっていますが、私は下記のような論理で検証を実施する手法であると理解しています。
ある仮説が正しいと仮定した時に、実際に観測されたデータからその仮説の状態になる確率を計算した時、その確率が十分に小さい場合はその仮説は成り立ちそうにないと判断する
統計的仮説検定の手順
統計的仮説検定は下記のような手順で実施をします。
- 帰無仮説を立てる
- 検定の方法を決定する
- 有意水準と棄却域を決定する
- 統計量を計算する
- 帰無仮説の棄却または採択を行う
手順だけ羅列すると抽象的でわかりにくいので具体例を上げて説明します。
統計的仮説検定の具体例
コイントスを5回実施して、表が出たら500円はらい、裏が出たら500円もらうゲームを行った。
すると結果5回とも表が出て2500円払うはめになった。何となくイカサマの匂いがするがこのコインはインチキであると言えるだろうか
「5回連続表が出るくらいはたまにはあるんじゃない?」という人もいれば、「5回も連続で表が出るなんておかしい」という人もいると思います。そういったもの統計的仮説検定を使用して客観的に判断することができます。
帰無仮説を立てる
今回は無に帰したい仮説(否定したい仮説)としてこのコインはインチキではないという仮説を立てます。インチキではないということは表が出る確率$p=0.5$なので下記のように表されます。
帰無仮説:$H_{0}:p=0.5$
またその対立仮説(表が出る確率は50%以上である)は下記のようになります。
対立仮説:$H_{0}:p>0.5$
検定の方法を決定する
今回は二項検定を採用します。(サンプル数が多い場合、二項分布は正規分布に近似できるためその他の手法も使用することが可能です。)
有意水準と棄却域を決定する
今回の検定では有意水準を5%と設定します。帰無仮説:$H_{0}:p=0.5$という前提において観測データが得られる確率が5%以下であれば帰無仮説が棄却される(すなわちこのコインはインチキである)ということになります。
また今回はコインが異常に表がでやすいのではないかという疑惑を検証する検定のため片側検定を行います。棄却域は片側のみにおくことになります。
統計量の計算を行う
p値と呼ばれる統計量は帰無仮説が正しいとしたときに、観測データの実現値が得られる確率、またはそれ以上に極端なデータが得られる確率を表します。
従って今回におけるp値は、表が出る確率が$50\%$であると仮定した時に表が5回とも出る確率にあたります。
$(\frac{1}{2})^5 = \frac{1}{32} \fallingdotseq 0.03125$
帰無仮説の棄却または採択を行う
仮説検定に必要な情報は出そろったので、帰無仮説の棄却または採択の判断を行います。
今回の仮説検定の有意水準は$0.05$($5\%$)で統計量(p値)は計算した結果$0.03125$でした。$0.03125 < 0.05$なので帰無仮説は棄却され、対立仮説が採用されます。
従って$H_{0}:p>0.5$(このコインはインチキである)ということが検証できました。
Pythonで統計的仮説検定を実施する
先ほどの計算はPythonで簡単に実施することができます。
以下がscipyの1.3.1を使用して二項検定を行った結果です。from scipy import stats # xは観測データの成功回数 # nは試行回数 # pは想定する成功確率 # alternativeは両側検定か片側検定か、また片側検定であればどちら側であるかを指定する p = stats.binom_test(x = 5, n = 5, p = 0.5, alternative = 'greater' ) print(p)出力結果はこちらです。指定した引数に合わせてp値を出力することできます。
0.03125上記を使用して設定した有意水準に合わせて棄却または採択の判断をすれば簡単に二項検定を実施できます。(別の検定を実施する場合は別のメソッド使用します。)
Pythonで分布を描画する
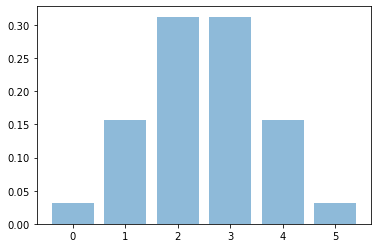
先ほどまでは計算だけで仮説検定を実施しましたが、実際に分布を描画すると非常にわかりやすくなります。
コイントスを5回実施して表が出る回数の分布を描画します。import numpy as np import matplotlib.pyplot as plt import math %matplotlib inline def comb_(n, k): result = math.factorial(n) / (np.math.factorial(n - k) * np.math.factorial(k)) return result def binomial_dist(p, n, k): result = comb_(n, k) * (p**k) * ((1 - p) ** (n - k)) return result x = np.arange(0, 6, 1) y = [binomial_dist(0.5, 5, i) for i in x] plt.bar(x, y, alpha = 0.5)
上記が描画した結果ですが、表が5回とも出る確率は有意水準の0.05を下回っていることがすぐにわかります。
NEXT
次回は仮説検定における第一種の過誤、第二種の過誤、そして検出力についてまとめます。
- 投稿日:2020-11-23T20:57:15+09:00
疎構造学習による異常検知を実装してみた
- 製造業出身のデータサイエンティストがお送りする記事
- 今回は製造業で使える異常検知手法を実装し整理しました。
はじめに
前回の異常検知手法(MSPC)に引続き、今回は疎構造学習による異常検知手法を整理しました。
疎構造学習による異常検知とは
異常検知手法として有名なホテリングの$T^2$法や$MSPC$は平均値が変化しないデータの監視をする時に用いる手法です。
一方、製造現場では必ずしもそのようなデータばかりではなく、変数間に一定の関係性を保ちながら値が変化するデータ構造の設備や操業データがあるかと思います。その時に変数間の関係(相関関係、等)に着目した異常検知手法の一つに疎構造学習による異常検知手法があります。手法の概要
1. 変数間の相関関係を求めるために、データの背後に多変量正規分布を仮定し、精度行列(共分散行列の逆数)を求めます。
2. 実データでは意味のある相関関係のみを抽出することが困難(ノイズの影響)なため、今回は、正則化項付きの共分散行列推定(Sparse Inverse Covariance Matrix Estimation)を用います。
3. 異常度は正常時と評価時(オンライン監視時)の確率分布の差(KL距離)を異常度として定義します。手法の詳細は(異常検知と変化点検知)を読んで頂けると理解が深まるかと思います。私もこの本を読んで勉強し、実際の業務で実践しました。
疎構造学習による異常検知手法の実装
今回、サンプル用にUCI機械学習リポジトリのWater Treatment Plantというデータセットを使用しました。
正常データを100件、残りの279件を評価データとして正常状態からどれだけ逸脱しているのかを見ました。pythonのコードは下記の通りです。
# 必要なライブラリーのインポート import pandas as pd import numpy as np from matplotlib import pyplot as plt %matplotlib inline from scipy import stats from sklearn.preprocessing import StandardScaler from sklearn.neighbors.kde import KernelDensity from sklearn.covariance import GraphicalLassoCV df = pd.read_csv('watertreatment_mod.csv', encoding='shift_jis', header=0, index_col=0) df.head() window_size = 10 cr = 0.99
インプットデータは上記のような感じです。
次に学習データと評価データを分割し、標準化を行っていきます。
# 分割ポイント split_point = 100 # 学習データ(train)と評価データ(test)に分割 train_df = df.iloc[:(split_point-1),] test_df = df.iloc[split_point:,] # データを標準化 sc = StandardScaler() sc.fit(train_df) train_df_std = sc.transform(test_df) test_df_std = sc.transform(test_df)次に共分散の推定を行います。
# 共分散の推定 n_samples, n_features = train_df_std.shape emp_cov = np.dot(train_df_std.T, train_df_std) / n_samples model = GraphicalLassoCV() model.fit(train_df_std) cov_ = model.covariance_ prec_ = model.precision_次にKL距離を求める関数を定義しておきます。
def Calc_KL(cov_, prec_, xtest): """KL距離の計算を行う Parameters ---------- cov_ : np.array 学習データの共分散行列 prec_ : np.array 学習データの精度行列 df : pd.DataFrame データセット Returns ------- d_ab : pd.DataFrame KL距離 """ n_samples, n_features = xtest.shape d_abp=np.zeros(n_features) d_abm=np.zeros(n_features) d_ab=np.zeros(n_features) model_test = GraphicalLassoCV() try: model_test.fit(xtest) except FloatingPointError: print("floating error") return d_ab cov__test = model_test.covariance_ prec__test = model_test.precision_ # 変数毎に相関の崩れの大きさを計算する for i in range(n_features): temp_prec_a = np.r_[prec_[i:n_features,:], prec_[0:i,:]] temp_prec_a = np.c_[temp_prec_a[:,i:n_features], temp_prec_a[:,0:i]] temp_prec_b = np.r_[prec__test[i:n_features,:], prec__test[0:i,:]] temp_prec_b = np.c_[temp_prec_b[:,i:n_features], temp_prec_b[:,0:i]] temp_cov_a = np.r_[cov_[i:n_features,:], cov_[0:i,:]] temp_cov_a = np.c_[temp_cov_a[:,i:n_features], temp_cov_a[:,0:i]] temp_cov_b = np.r_[cov__test[i:n_features,:], cov__test[0:i,:]] temp_cov_b = np.c_[temp_cov_b[:,i:n_features], temp_cov_b[:,0:i]] La = temp_prec_a[:-1, :-1] la = temp_prec_a[:-1, -1] lama = temp_prec_a[-1, -1] Wa = temp_cov_a[:-1, :-1] wa = temp_cov_a[:-1, -1] sigmaa = temp_cov_a[-1, -1] Lb = temp_prec_b[:-1, :-1] lb = temp_prec_b[:-1, -1] lamb = temp_prec_b[-1, -1] Wb = temp_cov_b[:-1, :-1] wb = temp_cov_b[:-1, -1] sigmab = temp_cov_b[-1, -1] d_abp[i] = np.dot(wa, la)+0.5*(np.dot(np.dot(lb, Wb), lb)-np.dot(np.dot(la, Wa), la))+0.5*(np.log(lama/lamb)+sigmaa-sigmab) d_abm[i] = np.dot(wb, lb)+0.5*(np.dot(np.dot(la, Wa), la)-np.dot(np.dot(lb, Wb), lb))+0.5*(np.log(lamb/lama)+sigmab-sigmaa) d_ab[i] = max(-d_abp[i], -d_abm[i]) return d_ab次に管理限界をカーネル密度推定によって算出する関数を用意します。
def cl_limit(x, cr=0.99): """管理限界の計算を行う Parameters ---------- x : np.array KL距離 cr : float 管理限界の境界 Returns ------- cl : float 管理限界の境界点 """ X = x.reshape(np.shape(x)[0],1) bw= (np.max(X)-np.min(X))/100 kde = KernelDensity(kernel='gaussian', bandwidth=bw).fit(X) X_plot = np.linspace(np.min(X), np.max(X), 1000)[:, np.newaxis] log_dens = kde.score_samples(X_plot) prob = np.exp(log_dens) / np.sum(np.exp(log_dens)) calprob = np.zeros(np.shape(prob)[0]) calprob[0] = prob[0] for i in range(1,np.shape(prob)[0]): calprob[i]=calprob[i-1]+prob[i] cl = X_plot[np.min(np.where(calprob>cr))] return cl学習データをクロスバリデーションをして管理限界を算出します。
K = 5 cv_data_size = np.int(np.shape(train_df_std)[0]/5) n_train_samples = np.shape(train_df_std)[0] counter = 0 for i in range(K): cv_train_data=np.r_[train_df_std[0:i*cv_data_size,], train_df_std[(i+1)*cv_data_size:,]] if i < K-1: cv_test_data=train_df_std[i*cv_data_size:(i+1)*cv_data_size,] else: cv_test_data=train_df_std[i*cv_data_size:,] model_cv = GraphicalLassoCV() model_cv.fit(cv_train_data) cov__cv = model.covariance_ prec__cv = model.precision_ for n in range(window_size, np.shape(cv_test_data)[0]): count = i*cv_data_size + n tempX = cv_test_data[n-window_size:n,:] d_ab_temp = Calc_KL(cov__cv, prec__cv, tempX) if 0 == counter: d_ab = d_ab_temp.reshape(1,n_features) TimeIndices2 = TimeIndices[count] else: d_ab = np.r_[d_ab,d_ab_temp.reshape(1,n_features)] #ここでerror TimeIndices2 = np.vstack((TimeIndices2,TimeIndices[count])) counter = counter + 1 split_point = np.shape(d_ab)[0] d_ab_cv = d_ab[np.sum(d_ab,axis=1)!=0,:] cl = np.zeros([n_features]) for i in range(n_features): cl[i] = cl_limit(d_ab_cv[:,i],cr)最後に評価データの共分散を推定し、可視化します。
# 評価データに対しても共分散を推定 n_test_samples = np.shape(test_df_std)[0] for n in range(window_size, n_test_samples): tempX = test_df_std[n-window_size:n,:] d_ab_temp = Calc_KL(cov_, prec_, tempX) d_ab = np.r_[d_ab,d_ab_temp.reshape(1,n_features)] TimeIndices2 = np.vstack((TimeIndices2,TimeIndices[n+n_train_samples])) x2 = [0, np.shape(d_ab)[0]] x3 = [split_point, split_point] x = range(0, np.shape(TimeIndices2)[0],20) NewTimeIndices = np.array(TimeIndices2[x]) for i in range(38): plt.figure(figsize=(200, 3)) plt.subplot(1, 38, i+1) plt.title('%s Contribution' % (i)) plt.plot(d_ab[:, i], marker="o") plt.xlabel("Time") plt.ylabel("Contribution") plt.xticks(x,NewTimeIndices,rotation='vertical') y2 = [cl[i],cl[i]] plt.plot(x2,y2,ls="-", color = "r") y3 = [0, np.nanmax(d_ab[:,i])] plt.plot(x3,y3,ls="--", color = "b") plt.show()さいごに
最後まで読んで頂き、ありがとうございました。
今回は、疎構造学習による異常検知について実装しました。訂正要望がありましたら、ご連絡頂けますと幸いです。

- 投稿日:2020-11-23T20:54:14+09:00
PythonでオプションをJSONファイルとコマンドライン引数の双方から取得する
別記事、RubyでオプションをJSONファイルとコマンドライン引数の双方から取得する の Python 版です。
最近は Python の利用が増えているので、同じことを Python ならどう書くのだろう…という検討の結果を共有します。基本的なコンセプト
- オプションは一つのオブジェクトに集める。
例:class Options- オブジェクト生成時に、JSONファイルからオプションを読み込む。
例:opt = Options('some.json')とするとJSONファイルからオプションを読み込む。- オプションにアクセスするときはオブジェクトの attribute を使う。
例:opt.option_1のような感じでアクセスできる。- コマンドライン引数は Argparse を使って取り込む。
- オプションのオブジェクトは、Arguparse の生成した結果から値を取り込むメソッドを持つ。
例:opt.import_opt(options)のような感じでインポートする。実装例
https://gist.github.com/aikige/470f4ef93753638cc3a18d62e195eb19
#!/usr/bin/env python import json import os class Options: OPTS = { 'option_1': 'bool', 'option_2': 'str' } def __init__(self, filename='config.json'): if (os.path.exists(filename)): with open(filename) as f: self.import_dict(json.load(f)) def import_attr(self, key, value): if (value is None): return if (isinstance(value, eval(self.OPTS[key]))): setattr(self, key, value) else: raise ValueError("invalid type") def import_dict(self, d): for key in self.OPTS.keys(): if (key in d.keys()): self.import_attr(key, d[key]) def import_opt(self, args): for key in self.OPTS.keys(): if (hasattr(args, key)): self.import_attr(key, getattr(args, key)) if __name__ == '__main__': import argparse opt = Options() print(vars(opt)) parser = argparse.ArgumentParser() parser.add_argument('-1', '--option_1', action='store_true', default=None) parser.add_argument('-2', '--option_2', type=str) args = parser.parse_args() print(vars(args)) opt.import_opt(args) print(vars(opt))Ruby版 との主な違い
- Ruby と違って Python には
bool型があるので、型判定を比較的簡単に組み込める(import_attr)。- Python の場合、オプション解析に Arrgparse を使うので、JSON解析と引数解析のメソッドが統一できておらず、若干冗長になる。
- Python の場合、attribute を読み取り専用にするのが少し難しそうなので、省略している。
- 投稿日:2020-11-23T20:43:06+09:00
Grove - Temperature&Humidity Sensor(DHT11)をRaspberry Piで使用する
はじめに
HAT基盤と温度センサーを買ったのはよかったけど、動かしていなかったので、動作検証代わりに行った。
お値段等
* 千石電商 Grove Base Hat for Raspberry Pi ¥1304
* Grove - デジタル温度・湿度センサー ¥662Grove Base Hat for Raspberry Piの準備
Seeed Studioの商品ページを参考に
以下のコマンドを入力してセットアップをする。curl -sL https://github.com/Seeed-Studio/grove.py/raw/master/install.sh | sudo bash -s -実行しばらく待つと以下のメッセージが表示される。
Successfully installed grove.py-0.6 ####################################################### Lastest Grove.py from github install complete !!!!! #######################################################Grove - Temperature&Humidity Sensor(DHT11)を動作する。
Seeed Studioの商品ページを参考にして、
センサーをHat基盤のPWMに接続をする。以下のコマンドでライブラリをインストールする。
git clone https://github.com/Seeed-Studio/Seeed_Python_DHT.git cd Seeed_Python_DHT sudo python setup.py installインストールしたら以下の通りメッセージが表示される。
Installed /usr/local/lib/python2.7/dist-packages/seeed_python_dht-0.0.1-py2.7.egg Processing dependencies for seeed-python-dht==0.0.1 Finished processing dependencies for seeed-python-dht==0.0.1サンプルコードがgitからコピーしたフォルダ内にあるので、実行する
python examples/dht_simpleread.py実行すると以下の通り温度と湿度を返す。
DHT11, humidity 66.0%, temperature 23.0* DHT11, humidity 68.0%, temperature 21.0* DHT11, humidity 74.0%, temperature 21.0* DHT11, humidity 74.0%, temperature 21.0*余談
goで温度を測定するプログラムは以下のサイトを参考にする
https://github.com/d2r2/go-dhtexample1のサンプルコードで以下の修正を加えて
sensorType := dht.DHT11 pin := 12rootユーザで実行すれば温度・湿度測定ができる。
- 投稿日:2020-11-23T20:04:25+09:00
【Python】ゼロから始めるDjangoソースコードリーディング View編②
前回のお話
初投稿記事でしたが、思ったより閲覧数が伸びていました!
LGTMもいただけてとても励みになります。ありがとうございます。前回はViewクラスがどやってHTTPリクエストメソッドとインスタンスメソッドを対応付けているか確認しました
環境や前提知識もこちらに書いてあるので、初見の方はさらっと読んでみてください今回のお話
FormViewを読んでみます
SPAなWebサービスでなければ利用頻度が高いので、このあたりを理解するとカスタマイズの幅が広がるかもしれません環境
前回と同じです。
Djangoのソースコードは
$ python -c "import django; print(django.__path__)"でインストール場所を確認するか、公式リポジトリから引っ張ってきましょう。$ python --version Python 3.8.5 $ python -m django --version 2.2.17FormViewの動作を確認
サンプルコード: https://github.com/tsuperis/read_django_sample
サーバーを起動したらhttp://localhost:8000/form_sample で動作確認できます
form_sample/views.pyclass MyFormView(FormView): """FormViewサンプル""" form_class = MyForm success_url = reverse_lazy('form_sample:index') template_name = 'form_sample/form_sample.html' def form_valid(self, form): # バリデーション成功時にメッセージを表示 msg = form.cleaned_data['message'] messages.success(self.request, f'フォーム送信を受け付けました: {msg}') return super().form_valid(form)form_sample/forms.pyclass MyForm(forms.Form): message = forms.CharField() def clean_message(self): msg = self.cleaned_data['message'] if '不正' in msg: raise forms.ValidationError('不正な文字列が含まれています') return msg前回より少しごちゃごちゃしていますが、大事なのはこの2クラスです。
仕様としては
- フォーム送信をPOSTメソッドで受け付ける
- Messageに「不正」という文字列が入っていればバリデーションエラー
- バリデーション成功時に「フォーム送信を受け付けました」というメッセージを出力する
だけの簡単なアプリケーションです。
POST時の動的な処理を追ってみましょう。
読んでみる、その前に
多重継承とMixin
他の言語では許可されていないこともありますが、Pythonでは言語仕様として多重継承が許可されています。
多重軽傷によって複数の基底クラスを取ることができるので、単一責任の原則に則って「タスクA関連の処理ははクラスAのメソッドで実装」
「タスクB関連の処理ははクラスBのメソッドで実装」といったようにクラスごとの責務を明確に分離できて良さそうに見えます。
class BaseReader: def read(self, filename): with open(filename, 'r') as f: return f.read() + '\n==========' class BaseWriter: def write(self, filename, content): with open(filename, 'a') as f: f.write(content)多重継承地獄
多重継承は便利ではあるのですが、扱い方が難しく厄介な存在にもなりがちです。
こんな場合を考えてみましょう。class Base000: text = 'python' def get_text(self): return self.text def print(self): print(self.get_text() + 'です') class Base001(Base000): text = 'python3' def foo(self): bar() class Base002(Base000): text = 'base' def print(self): print('djangoです') def baz(self): time.sleep(1) class A(Base001, Base002): passこのとき
A().print()はなにを出力するでしょうか?.....
....
...
..
.答えは「djangoです」です
多重継承で属性名が重複した場合、先に継承されたクラス優先されます。
参照順序は__mro__という特殊メソッドで確認することも可能です。(重要)>>> A.__mro__ (<class '__main__.A'>, <class '__main__.Base001'>, <class '__main__.Base002'>, <class '__main__.Base000'>, <class 'object'>)なのでこの場合
AにBase001にBase002にとなるわけです。
このくらいのサイズのクラスであればルールを把握していれば問題ないかもしれません。モジュールが分割されていたら…
似たような名前の関数が存在したら…
引数がばらばらだったら…
2回、3回...と継承回数が増えたら…すぐにどのメソッドが優先されるか読み取れるでしょうか?
完璧な解決方法ではないMixin
ここで出てくるのが
Mixinとよばれるクラスです。サブクラスによって継承されることにより機能を提供し、単体で動作することを意図しないクラスである。
わかりにくいですが、簡単にいえば「共通関数(メソッド)をまとめたクラス」をMixinといいます。
上の例で言えば次のようにMixinをくくりだすことができます(他のパターンもあると思います)class PrintMixin: def print(self): print(self.text + 'です') class Base001: text = 'python3' def foo(self): bar() class Base002: text = 'django' def baz(self): time.sleep(1) class A(PrintMixin, Base001, Base002): passこれだと先程よりはわかりやすくなったと思います。
Base000クラスをPrintMixinに置き換えて、各実装クラス内でself.textを定義すれば
(PrintMixin.printはPrintMixin単体では動作しません)このような形で多重継承の恩恵に預かりつつ、なるべく継承による名前解決の複雑さを取り除こうとすることを目的にしています。
ただし、Mixinクラスを利用してもMixinを継承したりそれ自体のサイズが膨れてくるとわかりやすさが損なわれてしまうため完璧な解決方法ではないことに注意してください。あまりこの話ばかりしていると本筋からそれていってしまうのでこのあたりで切り上げますが、こんな手法があることを知っておいてください。
[Python入門]多重継承とmixin
ミックスインってなに?Pythonのコードで見るミックスインのやり方使い方
ミックスイン | Python Language Tutorialあらためて読んでみる
あらためて
FormViewの処理を追っていきましょう。
まず、継承関係を確認してみましょう。>>> from django.views.generic import FormView >>> FormView.__mro__ (<class 'django.views.generic.edit.FormView'>, <class 'django.views.generic.base.TemplateResponseMixin'>, <class 'django.views.generic.edit.BaseFormView'>, <class 'django.views.generic.edit.FormMixin'>, <class 'django.views.generic.base.ContextMixin'>, <class 'django.views.generic.edit.ProcessFormView'>, <class 'django.views.generic.base.View'>, <class 'object'>)多いですね。全部のクラスを読むのは骨が折れそうです。
先程の話でMixinは
サブクラスによって継承されることにより機能を提供し、単体で動作することを意図しないクラスである。
ということがわかっているので、Mixin単体で読んでもわかりにくい気がします
なので、Mixinは一旦無視してFormViewBaseFormViewProcessFormView(Viewは前回読みましたね)を意識しながら読んでみることにします
FormView(djangoインストールパス)/django/views/generic/edit.pyclass FormView(TemplateResponseMixin, BaseFormView): """A view for displaying a form and rendering a template response."""
getメソッドもpostメソッドも何もないですね。次にいきます。
BaseFormView(djangoインストールパス)/django/views/generic/edit.pyclass BaseFormView(FormMixin, ProcessFormView): """A base view for displaying a form."""また何もないです。次にいきます。
ProcessFormView(djangoインストールパス)/django/views/generic/edit.pyclass ProcessFormView(View): """Render a form on GET and processes it on POST.""" def get(self, request, *args, **kwargs): """Handle GET requests: instantiate a blank version of the form.""" return self.render_to_response(self.get_context_data()) # -- (A)(B) def post(self, request, *args, **kwargs): """ Handle POST requests: instantiate a form instance with the passed POST variables and then check if it's valid. """ form = self.get_form() # -- (C) if form.is_valid(): # is_validはFormクラスのメソッド、バリデーション成功した場合の処理 return self.form_valid(form) # -- (D) else: # バリデーションエラー時の処理 return self.form_invalid(form) # -- (E) # PUT is a valid HTTP verb for creating (with a known URL) or editing an # object, note that browsers only support POST for now. def put(self, *args, **kwargs): return self.post(*args, **kwargs)知らないメソッドがいくつか出ていてますね。
メソッド名である程度何をしているか判断できそうなので、処理内容に当たりをつけてみます。(A)
render_to_response: レンダリングしてHTTPレスポンスを返す?
(B)get_context_data: ?????
(C)get_form: フォームクラスを取得?
(D)form_valid: バリデーション成功時の処理(何をしているのかはわからない)
(E)form_invalid: バリデーション失敗時の処理(何をしているのかはわからない)まだ正解はわかりませんがこんなかんじでしょうか?(A,BはGETリクエスト時のメソッドなのでさらっと流します)
(余談)メソッドの定義場所の確認方法
お好みのIDEやエディタにタグジャンプ機能があればそれを使えばいいですが、ツールが使えない場合にもコードを全部追う必要はありません。
inspect --- 活動中のオブジェクトの情報を取得する — Python 3.8.6 ドキュメント
inspectという便利モジュールがあるのでこれを使って、メソッドが定義されているファイルやソースコード、定義行を取得することができます。inspectモジュール使用例>>> inspect.getsourcefile(FormView.get_context_data) # 定義されているファイル名を表示 '/home/tsuperis/.local/share/virtualenvs/read_django-RZSPYucy/lib/python3.8/site-packages/django/views/generic/edit.py' >>> inspect.getsourrcelines(FormView.get_context_data) # 定義内容と定義業を表示 ([' def get_context_data(self, **kwargs):\n', ' """Insert the form into the context dict."""\n', " if 'form' not in kwargs:\n", " kwargs['form'] = self.get_form()\n", ' return super().get_context_data(**kwargs)\n'], 63)(A)
render_to_response(djangoインストールパス)/django/views/generic/base.pyclass TemplateResponseMixin: """A mixin that can be used to render a template.""" template_name = None template_engine = None response_class = TemplateResponse content_type = None def render_to_response(self, context, **response_kwargs): """ Return a response, using the `response_class` for this view, with a template rendered with the given context. Pass response_kwargs to the constructor of the response class. """ response_kwargs.setdefault('content_type', self.content_type) return self.response_class( request=self.request, template=self.get_template_names(), context=context, using=self.template_engine, **response_kwargs )
TemplateResponseをインスタンス化して返しています。テンプレートをレンダリングしているみたいですね。(B)
get_context_data(djangoインストールパス)/django/views/generic/edit.pyclass FormMixin(ContextMixin): ...snip... def get_context_data(self, **kwargs): """Insert the form into the context dict.""" if 'form' not in kwargs: kwargs['form'] = self.get_form() return super().get_context_data(**kwargs)(djangoインストールパス)/django/views/generic/base.pyclass ContextMixin: """ A default context mixin that passes the keyword arguments received by get_context_data() as the template context. """ extra_context = None def get_context_data(self, **kwargs): kwargs.setdefault('view', self) if self.extra_context is not None: kwargs.update(self.extra_context) return kwargs前回見た可変長キーワード引数が引数になっています。
ContextMixinの方で
view=self(MyFormViewインスタンス)、FormMixinのほうでform=self.get_form()を設定していましたテンプレートファイルで
formが使われていますが、ここで設定されたものです。form_sample/templates/form_sample/index.html...snip... {# フォーム本体 #} <form action="" method="post"> {{ form }} {% csrf_token %} <input type="submit"> ...snip... </form>(C)
get_form(djangoインストールパス)/django/views/generic/edit.pyclass FormMixin(ContextMixin): """Provide a way to show and handle a form in a request.""" initial = {} form_class = None success_url = None prefix = None def get_initial(self): """Return the initial data to use for forms on this view.""" return self.initial.copy() def get_prefix(self): """Return the prefix to use for forms.""" return self.prefix def get_form_class(self): """Return the form class to use.""" return self.form_class def get_form(self, form_class=None): """Return an instance of the form to be used in this view.""" if form_class is None: form_class = self.get_form_class() return form_class(**self.get_form_kwargs()) def get_form_kwargs(self): """Return the keyword arguments for instantiating the form.""" kwargs = { 'initial': self.get_initial(), 'prefix': self.get_prefix(), } if self.request.method in ('POST', 'PUT'): # リクエストメソッドがPOSTやPUTだったら引数を追加する kwargs.update({ 'data': self.request.POST, 'files': self.request.FILES, }) return kwargs
get_formでやっていることは
get_form_classでFormクラスを取得(インスタンス化はしない)get_form_kwargsででFormクラスに与える引数を作る- 1で取得したFormクラスに2で作成した引数を与えてインスタンス化する
です。ここでのポイントは
get_form_kwargsです。詳細は省きますが
Formクラスでバリデーションチェックを実行するには、dataもしくはfilesをインスタンス化の引数として与える必要があります。
逆にFormViewのバリデーションチェックはデフォルトではPOSTリクエストやPUTリクエストのときにしか実行されないと言うこともできます。一瞬戻って
ProcessFormViewを確認してみると、確かにPOSTとPUTのときにしかフォームのバリデーションチェック(form.is_valid())が実行されていないことがわかります。余談ですが、このメソッドをオーバーライドするとPOST/PUTメソッド以外でもフォームのバリデーションが利用できます。
この辺の仕様を知っていると、FormViewを使って検索ページを作成する場合、get_form_kwargsをオーバーライドすればいいことがわかります。(D)
form_valid(djangoインストールパス)/django/views/generic/edit.pyclass FormMixin(ContextMixin): ...snip... success_url = None ...snip... def get_success_url(self): """Return the URL to redirect to after processing a valid form.""" if not self.success_url: raise ImproperlyConfigured("No URL to redirect to. Provide a success_url.") return str(self.success_url) # success_url may be lazy def form_valid(self, form): """If the form is valid, redirect to the supplied URL.""" return HttpResponseRedirect(self.get_success_url()) def form_invalid(self, form): """If the form is invalid, render the invalid form.""" return self.render_to_response(self.get_context_data(form=form))コードを見ていただければ解説は不要だと思いますが
form_validは指定したURLsuccess_urlにリダイレクトするだけのメソッドです。サンプルコードでもオーバーライドしていますが、これはリダイレクト前にDjangoのメッセージフレームワークを介したメッセージ送付を行っているということです。
このフレームワークは
Cookie とセッションをベースにしたメッセージング
なのでリダイレクト前に設定されたメッセージをリダイレクト後に表示させることができます。
(E)
form_invalid(djangoインストールパス)/django/views/generic/edit.pyclass FormMixin(ContextMixin): ...snip... def form_invalid(self, form): """If the form is invalid, render the invalid form.""" return self.render_to_response(self.get_context_data(form=form))こちらも簡単で
FormView.getとほとんど同じ内容ですただしひとつだけ
get_context_dataの引数にform=formとあります。右辺の
formは言わずもがな、MyFormインスタンスですね
左辺のformは何でしょうか?
get_context_dataの定義をもう一度見てみますdef get_context_data(self, **kwargs): """Insert the form into the context dict.""" if 'form' not in kwargs: kwargs['form'] = self.get_form() return super().get_context_data(**kwargs)"form"引数が与えられなかった場合に
get_formメソッドで新規にFormインスタンスを生成しています
form_invalidで設定されたFormインスタンスとget_formメソッドで生成されたFormインスタンスは同じクラスのインスタンスですが別物ですヒントは
postメソッドとget_form_kwargsメソッドです
少し時間をとって何が違うのか見てみると良いかもしれません.....
....
...
..
.ポイントだけ抽出すると
def get_form_kwargs(self): ...snip... if self.request.method in ('POST', 'PUT'): kwargs.update({ 'data': self.request.POST, 'files': self.request.FILES, }) def post(self, request, *args, **kwargs): ...snip... form = self.get_form() if form.is_valid():つまり
form_invalidに渡されるFormインスタンスは
- 値を設定済み
- バリデーション実行済(バリデーションエラー)
となっています
これがバリデーションエラー時に{{ form }}でエラーメッセ−ジが出力される理由です
バリデーションエラーの情報がFormインスタンスに含まれているんですまとめ
FormViewは継承しているクラスは少し多いですが、やっていることは
Formインスタンスの生成方法をリクエストメソッドごとに変える- バリデーションチェック成功時と失敗時の処理はそれぞれ別のメソッドで行う
- 成功時はリダイレクト
- 失敗時は
getメソッドと(ほぼ)同じだけです。メソッド名で処理内容がなんとなくわかるので比較的読みやすいコードになっていると思います。
デバッグ方法として
__mro__やinspectもご紹介しましたが、このあたりを使うと読まなければいけない箇所はある程度絞り込まれます。
簡単なデバッグなど日常的にもよく使うので覚えておいて損はありません!次回
Modelの触りを読んでみようかなと思っています(リクエストあればコメントください)
- 投稿日:2020-11-23T20:04:00+09:00
「伸び悩んでいる3年目Webエンジニアのための、Python Webアプリケーション自作入門」を更新しました
本を更新しました
チャプター「Request / Response / View クラスを作って見通しを良くする」 を更新しました。
続きを読みたい方は、ぜひBookの「いいね」か「筆者フォロー」をお願いします ;-)
以下、書籍の内容の抜粋です。
リファクタリングする
動的レスポンスを生成するエンドポイントも3つになってきて、
workerthread.pyも200行近くになってきました。現時点でも、1ファイルで多種多様なことをやっているため、200行でもかなり見通しが悪くごちゃごちゃしたモジュールになってきてしまいました。
しかも、皆さんがこのWebアプリケーションを進化させていくとエンドポイントはますます増えていきます。
そのたびにworkerthread.pyに追記していたのではメンテナンスできなくなるのは目に見えています。
責務の切り分けとファイル分割を行ってworkerthread.pyの見通しを良くしていく必要がでてきたといえるしょう。つまり、そろそろリファクタリングの季節がやってきたというわけです。
本章では、「エンドポイントごとに動的にレスポンスボディを生成している処理」を外部モジュールへ切り出して行きます。
STEP1: 単に関数として切り出してみる
まずは、エンドポイントごとのHTML生成処理を、単純にまるっと別のモジュールへ切り出してみましょう。
切り出す先のモジュールの名前は、
viewsとします。
コネクションがどうとか、ヘッダーのパースがこうとか、そういったHTTPの事情は関知せず、見た目(view)の部分(= リクエストボディ)を生成することだけを責務として持つモジュールだからです。ソースコード
study/workerthread.py
https://github.com/bigen1925/introduction-to-web-application-with-python/blob/main/codes/chapter16/workerthread.py#L50-L59
study/views.py
https://github.com/bigen1925/introduction-to-web-application-with-python/blob/main/codes/chapter16/views.py解説
study/workerthread.py57-66行目
if path == "/now": response_body, content_type, response_line = views.now() elif path == "/show_request": response_body, content_type, response_line = views.show_request( method, path, http_version, request_header, request_body ) elif path == "/parameters": response_body, content_type, response_line = views.parameters(method, request_body)前回まで、HTMLを生成する処理をpathごとにベタベタと書いていたのですが、まずはその部分を
viewsモジュールの関数に切り出すことにしました。これによって、
workerthread.pyは、HTTPリクエストを受け取り、解析(パース)して、pathに応じたviewsモジュールの関数からレスポンスの内容を取得し、HTTPレスポンスを構築してクライアントへ返す。views.pyは、pathごとに応じた関数を持ち、リクエストの内容を受け取り動的に生成したレスポンスの内容を返すという責務分担となり、「パスに応じたレスポンスの内容を動的に生成する」という仕事が
viewsに切り出せました。
study/views.pyimport textwrap import urllib.parse from datetime import datetime from pprint import pformat from typing import Tuple, Optional def now() -> Tuple[bytes, Optional[str], str]: """ 現在時刻を表示するHTMLを生成する """ html = f"""\ <html> <body> <h1>Now: {datetime.now()}</h1> </body> </html> """ response_body = textwrap.dedent(html).encode() # Content-Typeを指定 content_type = "text/html; charset=UTF-8" # レスポンスラインを生成 response_line = "HTTP/1.1 200 OK\r\n" return response_body, content_type, response_line def show_request( method: str, path: str, http_version: str, request_header: dict, request_body: bytes, ) -> Tuple[bytes, Optional[str], str]: """ HTTPリクエストの内容を表示するHTMLを生成する """ html = f"""\ <html> <body> <h1>Request Line:</h1> <p> {method} {path} {http_version} </p> <h1>Headers:</h1> <pre>{pformat(request_header)}</pre> <h1>Body:</h1> <pre>{request_body.decode("utf-8", "ignore")}</pre> </body> </html> """ response_body = textwrap.dedent(html).encode() # Content-Typeを指定 content_type = "text/html; charset=UTF-8" # レスポンスラインを生成 response_line = "HTTP/1.1 200 OK\r\n" return response_body, content_type, response_line def parameters( method: str, request_body: bytes, ) -> Tuple[bytes, Optional[str], str]: """ POSTパラメータを表示するHTMLを表示する """ # GETリクエストの場合は、405を返す if method == "GET": response_body = b"<html><body><h1>405 Method Not Allowed</h1></body></html>" content_type = "text/html; charset=UTF-8" response_line = "HTTP/1.1 405 Method Not Allowed\r\n" elif method == "POST": post_params = urllib.parse.parse_qs(request_body.decode()) html = f"""\ <html> <body> <h1>Parameters:</h1> <pre>{pformat(post_params)}</pre> </body> </html> """ response_body = textwrap.dedent(html).encode() # Content-Typeを指定 content_type = "text/html; charset=UTF-8" # レスポンスラインを生成 response_line = "HTTP/1.1 200 OK\r\n" return response_body, content_type, response_lineこちらも難しいことは特にないでしょう。
もともとworkerthread.pyにかかれていたレスポンスの動的生成の処理をそっくりそのまま持ってきただけです。
views関数を切り出したのは良いのですが、今のままでは関数ごとに引数の数が違い、
「このpathを処理する仮数はコレとコレの引数が必要で、こっちのpathを処理する関数はアレとアレとアレの引数が必要で・・・」
といった具合に呼び出す側が、呼び出される側の詳細を知っていなくてはいけなくなっています。プログラミングの世界では、片方のモジュールが、相手のモジュールの詳細をできるだけ知らなくて良いように作ると、ソースコードはシンプルになることが知られています。
次のSTEPではもう少しリファクタリングを進め、そのことを実感していきましょう。
STEP2: views関数のインターフェースを統一する
今
WorkerThreadクラスがviews関数の詳細を知らなくてはいけないのは、関数ごとに引数として何がいくつ必要かわからないと関数が呼び出せないからです。この状態を解消するのに簡単な方法は、「各関数がどのパラメータを使うかはしらないけど、とにかく全部渡しちゃう」 というやり方です。
ソースコード
実際に、ソースコードを見てみましょう。
study/workerthread.py
https://github.com/bigen1925/introduction-to-web-application-with-python/blob/main/codes/chapter16-2/workerthread.py
study/views.py
https://github.com/bigen1925/introduction-to-web-application-with-python/blob/main/codes/chapter16-2/views.py解説
study/views.pyまずは
views.pyから見ておきましょう8-14行目, 66-72行目
def now( method: str, path: str, http_version: str, request_header: dict, request_body: bytes, ) -> Tuple[bytes, Optional[str], str]:def parameters( method: str, path: str, http_version: str, request_header: dict, request_body: bytes, ) -> Tuple[bytes, Optional[str], str]:全てのview関数で引数を統一し、全てのリクエスト情報を受取れるようにしました。
関数内ではこれらの引数は使わないのですが、受け取れるようにしておいてあげることで、呼び出す側は「何が必要で何が不要」かは考えなくて済むようになります。
study/workerthread.py次に、view関数を呼び出す側です。
29-34行目
# pathとview関数の対応 URL_VIEW = { "/now": views.now, "/show_request": views.show_request, "/parameters": views.parameters, }pathとview関数の対応を定数として定義しました。
pathをキーとして、pathに対応するview関数を値にもつ辞書です。コラム: pythonの関数は第一級オブジェクト
言語によっては、上記のように「"関数"を辞書(or 連想配列)の値としてセット」したり、「"関数"を変数に代入」したりすることに驚く人もいるかもしれません。
しかし、pythonではこれは正当な扱い方です。
変数への代入や、演算や関数への(引数・戻り値として)受け渡しなど、値としての全ての扱いが可能なオブジェクトを第一級オブジェクトといいます。
pythonでは全てのオブジェクトが第一級オブジェクトであり、関数も例外ではありません。そのため、変数に関数を代入したり、関数を受け取り関数を返す関数などを作成することも可能です。
後者は「メタプログラミング」として知られており、興味がある方は調べてみると良いでしょう。
64-69行目
# pathに対応するview関数があれば、関数を取得して呼び出し、レスポンスを生成する if path in self.URL_VIEW: view = self.URL_VIEW[path] response_body, content_type, response_line = view( method, path, http_version, request_header, request_body )
path in self.URL_VIEWでは、self.URL_VIEWという辞書のキーの中にpathが含まれているかどうかを調べています。
つまり、pathに対応するview関数が登録されているか確認しています。登録されていた場合、そのキーに対応する辞書の値を取得し、変数
viewへ代入しています。
つまり、変数viewには(view関数を呼び出した返り値ではなく)view関数が代入されます。最後の行では
view(~~)とすることで、変数viewに代入された関数を呼び出し、返り値を取得しています。
注目すべきなのは、全てのview関数が同じ引数(
method, path, http_version, request_header, request_body)を受け取るようになったことで、view関数が抽象化されている点です。以前までは関数ごとに引数が違ったので、ひとくちに「view関数を呼び出す」と言っても「その関数が具体的になんという関数なのか」が分からないと正しく呼び出せませんでした。
しかし、引数が統一(= インターフェースが統一)されることで、「具体的に何ていう関数なのかは知らないけど、とにかく呼び出せる」 ようになっているのです。これにより、
workerthread内ではpath(または関数)に応じたif分岐が不要になりました。コラム: 抽象化
このように、「それが具体的なモノの中から、共通な性質の一部だけを抜き出すことで、具体的なモノを扱わなくてすむようにする」ことを抽象化すると呼び、プログラミングにおいては非常に重要なテクニックとなります。
今回でいうと、
now()show_rewuest()parametersといった具体的な関数から、インターフェースを統一することで
「method, path, http_version, request_header, request_bodyという5つの引数を受け取り、response_body, response_lineという2つの値を返す」
という性質だけを抜き出す(=抽象化する)ことで、呼び出す側は
「具体的に何関数かしらないけど、5つの引数を与えて呼び出す」
というように扱えるようにしたということです。あるいは、「抽象化するためにインターフェースを統一した」とも言えるでしょう。
STEP3: view関数のインターフェースを簡略化する
view関数のインターフェースが共通化され、呼び出す側の見通しがよくなったのは良いことですが、いかんせん引数5つは多いです。
HTTPリクエストがたくさんの情報を持っていること自体は逃げられない事実ではありますが、それがバラバラの変数に分散して格納されているのはどうも扱いにくいです。
なので、HTTPリクエストを表現するクラスを作成し、そちらに情報をまとめることにしましょう。
これにより、view関数のインターフェースも簡略化されます。
続きはBookで!
- 投稿日:2020-11-23T18:37:46+09:00
データサイエンス関連の書籍を紹介する。
大学3年生の時に統計学の勉強をし始めて、今年で4年目を迎えています。
せっかくなので、自分がどういう勉強をしてきたか振り返りながら書籍を紹介できたら、誰かの役に立つかなと思い書きました。どれくらいのレベルの時に、どれくらいの本を読んで、どんな感じになったのかという紹介は意外と少ないと思います。
この記事のモチベーション
ここ数年で一気に統計学や機械学習の良書が日本語で登場し、コミュニティ等もたくさん生まれているようです。私が就活していた時には、Google先生に「統計学 仕事」なんて聞いてみても、まともな情報はあまり多く返ってきませんでした。かろうじてデータサイエンティストという仕事があるらしいということを知るだけでも中々苦労したのを思い出します。
それが3年前とかの話なので、どれだけ急激に普及したのかが感じられると思います。就活の時には、そういう目的で話を聞きに行ったわけではないところでも、割と普通にデータサイエンティストとかいう単語は耳にしたと記憶しています。
就活生などに話を聞くと、現在でもこの勢いは衰えていないらしく、依然として企業はデータ分析に強い人間を求めているようです。それだけ社会に普及しているのもあって、日本語で書かれた良書がたくさん出てきているというわけなんでしょうね。
一方で良い本が出すぎているために、どの本を読むのかという選択が難しくなっているという側面もあると思います。
というわけで今回は、私の統計学における勉強の軌跡を振り返りながら、その時々に読んだ本を紹介していこうと思います。本の画像はAmazonへのリンクになっているので、そこに書いてあるレビューなども参考になると思います。ここではなるべくAmazonレビューには書いていないことを書ければなと思っています。
※アフィリエイトとかじゃないのでご安心ください。っていうかQiitaってアフィリエイト禁止だよね。たしか。
そもそもなんで統計学を勉強し始めたのか
勉強を始めるきっかけというのは、聞いてみると人それぞれ意外と面白いものです。
私の場合は、単純に授業で統計学を学んだ時に「え、おもしろ」と思ったのがきっかけです。
何が面白かったのかというと検定です。私の中では昔から、「何かを測って比較した時に、どこまで同じでどこから違うと言っていいんだろう?」という疑問がありました。例えば、身長を測って友達よりも大きい小さい同じという話になったときに、0.1mmの差は同じ?じゃあ1mmは?1mm差は同じだよねっていうけど1.1mm差は同じじゃないの?というような、人に言ったらちょっと嫌われそうな疑問です。
普通に生きている分には、本人たち同士の感覚任せでいいと思いますが、客観的に評価したいときはどうしたらいいんだろう?とずっと考えていました。ググるにもなんて調べたらいいのか分からず、人に聞くにも嫌われそうだったので聞かず、そしたら授業で突然登場したんですよね。ちょっぴり感動したのをよく覚えています。
で、どういう根拠でその差を評価しているのかとかを知りたくて、統計学の勉強を始めたという具合でした。
最初は失敗
私は経営システム工学科出身なので、品質管理やらなんやらって、統計学にはある程度授業で触れていました。レベル感でいうと、統計検定2級ぐらいのことは分かるという感じでした。
そういうレベルからのスタートで、何を勉強していいのかよくわからず、まず始めたのが統計検定準1級の範囲の勉強でした。理由は単純で、一番範囲が広く、それっぽい単語が並んでいて、網羅的な知識が得られそうだったからです。
正直言って、これは実力をつけるという意味では失敗だったかなと思います。
範囲が広いのに、これ用のテキストはないため、1つの分野を勉強するのに教科書を1冊読むハメになりました。証明などはすっ飛ばし、概要をひたすらに取り込む作業です。学校の実験や課題も山のようにあったために時間を確保しにくい中、モヤモヤが爆発しそうになりながらとりあえず全体を網羅的に把握することに努めました。
そんなことをしていたので、水溜まり並みに浅い知識しか身に付かず、、、
という失敗があったので、ちゃんと理解しないとなと思い、実力が着実に付きそうな勉強を始めることにしました。
まずはここから(1年目)
失敗したとはいえ、収穫はありました。まず、ちゃんと地に足をつけて勉強をしないと使えるレベルにすらならなさそうだということ。また、大前提として統計学には確率分布の知識が必要だということが分かったということです。そして私にはそれが圧倒的に不足していました。ということで手を付けたのがこの本。
1.大学生の確率・統計
この本を選択したのは大正解でした。
この本のいいところは、受験勉強のノリで演習問題を通じて知識を身に着けられるところです。
基本的な確率分布の知識はもちろん、中心極限定理や積率母関数などの使い方、多次元分布の変数変換もあれば、条件付き期待値の計算も学ぶことができます。また、マルコフ連鎖やポアソン過程などの確率過程の初歩も練習することができます。
これらの内容を、手を動かした計算を通じて習得することができます。難解な本に進むのでなければ、しばらくは確率の勉強をしなくても大丈夫なくらいの知識を得られるのではないかなと思います。統計の参考書などで当たり前に使われていたり、当たり前すぎて端折られていたりする基本的な計算テクニックを身に付けることができるのも結構ありがたいです。
ちなみに最後の章は保険数理になっていますが、ここはやらなくてもいいかなと思います。
2.自然科学の統計学
基本的な確率の知識が身に付いたところで、さて統計学を勉強するぞと選んだのがこの本。
いわゆる青本といわれるものですが、多くの人は赤本から始める人が多いようです。赤本をやろうか迷っていた時に立ち読みした感じでは、先に上げた確率の本や授業でやったような内容とだいぶ被るなと思い、私はスキップしましたが、良書みたいなのでこちらをやるのもいいと思います。
もちろん青本を選んだのも正解でした。まず、線形モデルの知識がある程度ちゃんと身に付いたのは良かったです。機械学習の入門書だと、誤差の分布がどうとか検定の話には中々踏み込まないので、ここで勉強できたことは貴重でした。
また、検定の話についてレベルが高すぎないながらも、比較的ちゃんと書かれているので非常に勉強になりました。最尤法から検定の話に行くまでの流れが結構好きです。「○○検定っていうのがあるけど、なんでその検定がいいの?」とか疑問を持っている人が読むと腑に落ちるかもしれません。
ちなみに、この本を勉強しながら線形代数の知識の重要性が分かったので、線形代数の復習をしたりもしました。
カーネル多変量解析
なんかSVMすごいらしいということで、先生に聞いてみたらこの本をお勧めされました。
当時の私の頭の中には、そもそも数学でいうところの空間という概念がなかったので、特徴空間だとか、標本空間だとか、再生核ヒルベルト空間だとか、いろいろな空間が出てきてめちゃくちゃ困惑したのを覚えています。あと、高校や大学1年ぐらいの数学だと、一般的に成り立つような性質を学ぶことが多いと思うのですが、そういう性質を持ったものを対象にしているとか、そんな初歩的なことによく躓いていたのも覚えています。
ある程度の数学レベルがないとちょっと厳しいかなと思いますが、本の内容的には結構分かりやすい部類に入ると思います。この段階でこの本を読むことは、レベル感からいってお勧めできませんが、いつかカーネル法について学んでみたいという人であればお勧めです。
多変量統計解析法
かなり古い本(1983年の本)ですが、結構好きな1冊です。基本的な多変量解析法(回帰分析、主成分分析、判別分析、数量化法、因子分析、グラフ解析法、クラスター分析)について学べます。よくある、理論を一通り説明してから具体例という流れではなく、具体的なデータ例とこのデータを使って知りたいことは~というモチベーションの話から導入が始まって、理論と具体的なデータでの計算が並走して進んでいくので、実際にデータ分析をしている時と同じ感覚で勉強することができます。
今見ると話しや計算が具体的すぎるなと思いますが、当時の実力だとこれぐらいの具体的さが非常にありがたかったです。
多変量解析は他にも『データ解析の実際』を読みましたが、こちらも初学者にはお勧めです。多次元尺度法について扱っている本をあまり知らないので貴重かなと思います。
1年目まとめ
1年目はこんな感じで、まず失敗して反省し、基本的な確率の知識や統計学の発想、多変量解析などの使える手法の勉強を中心にしていました。測度論とかいう言葉も聞いていたのですが、レベル的に無理だなぁと思って手を出さなかったのは正解だったと思います。
また、大学1年時に習った線形代数や微積分の知識が重要だと認識し、横着しないで復習できたのもよかったです。勉強していくうえで大切なことは続けることだと思うので、そういう意味でも勉強を続けられる体力を身につけられたのは、その後にも活きてきているのでよかったなと思います。
機械学習に入門(2年目)
2年目は大学4年生で、応用統計学研究室に配属されました。金銭的な都合で大学院には進学する予定がなかったので、就職してからも役に立ち続けるのは勉強だと思っていました。そこで先生には研究室を決める際に「研究よりは勉強がしたいのですが、それでも大丈夫ですか?」と聞いたところ快くOKしてくれました。(研究をした後にこの発想は誤りで、研究で得たことも役に立ち続けると分かりましたが、あえてそこには突っ込まず快諾してくれた先生には感謝です。)
AIというものは、どうやら機械学習と呼ばれるものらしいということを聞いていたので、まずは機械学習について勉強することにしました。
統計的学習の基礎
先生に機械学習を勉強するにあたっておすすめを聞いて、紹介されたのがこの本でした。
機械学習の基本的な手法を網羅的に扱っていて、理論的背景について詳しく統計的な発想で説明がされているので非常に好みの1冊です。今でも辞書的によく使っています。
分厚いだけあって、各手法の繋がりや比較なども詳しいです。個人的には、バギングからランダムフォレストへの発想とか、区分的多項式からスプラインへの発展、みたいな流れが好きです。
教師なし学習や正則化なんかについて広く扱っている本は少ないので、そこをカバーしているのもおすすめポイントです。あとは、kaggleなどで流行っているブースティング系の話が基礎からちゃんと書かれている本をこの本しか知らないので、その点もおすすめです。(ブースティングは行間を埋めただけの記事を前に書いたのでリンクだけ張っておきます。)
(いろいろな意味で)非常に重く、特に式変形の行間を埋めるのがとても大変だったなとか、行間を一生懸命埋めて先生に持っていったら「行間は埋まってるけど、理解はできていないね」と言われて出直したり、いろいろな思い出があります。
参考文献が非常に多く、こんな文献ですよという説明とともに紹介されているので、理解の及ばないところはそれらも読みました。ここで紹介されているのは良い論文ばかりなので、卒研に入る前の論文を読むいい練習にもなりました。
確率モデルの考え方
全部読んだわけではなく、確率過程の部分だけ読みました。
比較的わかりやすい本だったと思いますが、確率過程をその後使う機会がなかったので細かい内容はあまり覚えておらず。。。確率過程の基本的な話は、これで結構理解することができたという感想を持ったというのは覚えています。
ロバスト統計: 外れ値への対処の仕方
卒業研究のテーマがロバスト統計学だったので、まずはこの本で勉強しました。というかロバスト統計学の和書って、たぶんこの本ぐらいしかないと思います。(他に知っているのは『頑健回帰推定(蓑谷)』ぐらいですかね。)
藤澤先生のこの本は、めちゃくちゃ分かりやすくて非常にお勧めです。日本語で読める本がこの1冊ぐらいしかないのに、分かりやすくて神はいたんだなという気持ちになったのを覚えています。
洋書ですが、ロバスト統計に関して他に読んだものは、『Robust Statistics: Theory and Methods(Maronna,Martin,Yohai)』と『Robust Statistics(Huber,Ronchetti)』ですかね。あとは論文をたくさん漁ったという感じでした。ロバスト統計学に関しては思うところもあったのですが、この話は長くなるので割愛します。
数理統計学の基礎
卒業研究を通して、基礎的な統計学の知識を身に着けたいなと思って購入。内容は決して軽くないですが、統計学における本格的な知識が得られたので良かったです。数理統計学の本の中では、いまのところ一番好きな本です。
内容的には、確率の話はあっさりめで、統計モデルや収束、検定、推定、について詳しく書かれています。数理統計学に関する一般的な話は一通り書かれていると思います。本格的な入門書という表現がしっくりくると思います。
行間が埋まらなかったりしたときは、『Theory of Point Estimation』を参考にするといいかなと思います。英語ですが、説明や書き方が分かりやすくて割と好きでした。特に漸近理論の部分は結構詳しく書いてあったと思います。いつか全部読みたいですが、読まないんだろうなぁ。。。
(ちなみにTheory of Point Estimationは、先生に勧められたか、この書評(pdf直リンク)を読んで覗いてみたんだったと思います。詳しく書評されているので一読の価値はあると思います。)
(Theory of Point Estimationは、PDFがネットに落ちていたと思います。)
論文も読んでいたよ
統計的学習の基礎のところでも書きましたが、結構論文を読みました。いやたくさん読んだからなんだっていう話ではなくて、この後の本はそれぐらいのレベル感まで来たところで読んだよということは書いておいた方が参考になるかなと思ったので。。。
話を戻して、、、統計的学習の基礎で参考文献に上がっていた論文は、幸いにも読みやすいものが多かったので良い練習になりました。最初は本などで参考文献として取り上げられている論文を読み、そこにまた書かれている参考文献を辿ったりして、それぞれの手法や理論に至った発想、解決した問題など理解が深まって面白かったです。また、論文内で参考文献に上げられている論文を読むことで、広がりやつながりを知ることもできたのもよかったです。
卒研のために読んだ論文は、必ずしも読みやすいものばかりではありませんでしたが、全部読まなきゃという意識もなかったり、ある程度耐性がついていたりだったので割と何とかなりました。もちろん先生にたくさん助けていただいたのは言うまでもありませんが、学部卒で論文を比較的ストレスなく読めるようになったのは大きかったかなと思います。
2年目まとめ
こんな感じで2年目の勉強を終えました。ざっくり言うと、前半は機械学習の勉強、後半は卒業研究を通してロバスト統計学と数理統計学の勉強をしていたという感じですね。ちなみに卒研ではMATLABを使っていました。私は結構好きでしたね。
この1年での成長は非常に大きく、1年目の勉強をしていた時には想像もできなかったぐらい力をつけることができました。
といっても自分の努力のおかげというよりは、研究室の先生のおかげなんですけどね。私が理解できるようにきちんと教育してくれたのが大きかったです。細かい話は別の機会にしようと思いますが、こういうのを教育っていうんだろうなと感じました。また、学問上の指導だけではなく、人としてというか、社会人として必要な、根本的な考え方や姿勢などについても教育してもらいました。これは働くうえでも非常に大きなアドバンテージになっています。
(なんか「教育してもらいました」って語感があまりよくないですね。けど、指導とか訓練とかじゃ言葉的に物足りなく、教育って言葉がぴったりなんですよね)社会人になったよ(3年目)
3年目は社会人1年目で、データサイエンティストとして働くようになりました。機械学習エンジニアではなく、ビジネスサイドのデータサイエンティストで、コンサル系の仕事がとても多いです。最初にやった仕事はマーケティングのコンサルでしたしね。学生の時は、授業では応用を(経営工学だったので応用の話が多かったです)、自分の勉強では理論よりの話を中心に勉強してきたのですが、社会人になってもこのバランスは維持したいなという意識で勉強しました。
仕事上どうしても統計よりもドメイン知識の習得に努める必要があり、統計の勉強は控えめになってしまいました。これはちょっと残念だった面もありますが、この仕事を続けていくのであれば有益だったと思います。
パターン認識と機械学習(通称PRML)
統計的学習の基礎の基礎を読んだので、もうひとつの必読本に数えられているPRMLを読みました。感覚的にはベイベイベイズって感じで、式変形を追いかけたりするのが大変でした。しかし、さすがは有名本というところでしょうか、ネットで調べると参考になるサイトやブログやスライドがたくさん出てきます。統計的学習の基礎はこれが少ないので苦労しましたが、PRMLはこの点勉強しやすかったです。
特にこのページがおすすめです。PDFは無料で配信されていますが、私はこれの紙版を買いました。556円でこの内容はめちゃくちゃありがたいです。まじ神様。
個人的な好みですが、私はPRMLよりも統計的学習の基礎の方が好きですね。
統計的学習の基礎でもそうなのですが、こういう勉強をするときに大事なのことは、愚直に手を動かすことかなと思います。もちろん私レベルの話なので、私より強い人の感覚は分かりませんが、、、
テキストアナリティクス
仕事でテキストデータを扱うことが多そうだったので購入。内容自体は良かったのですが、期待していたものとは違ったというのが正直なところです。でも内容はよかったですよ。
ひとつひとつの手法について丁寧にっていうよりは、テキストデータの分析はこんなアプローチがありますよーというのを俯瞰的に知ることができました。
欠測データ処理
実務(じゃなくてもそうだけど)では欠測データのオンパレードです。当然のことながら欠測データをどのように処理すればいいのか知識が必要になります。そこで手に取ったのがこの本です。
基本的に多重代入法をメインにしている本で、いろいろな手法における多重代入法を扱っていて内容的にも満足でしたが、最後の「おわりに」という章がとてもよかったです。
他にも例えば、ロジスティック回帰における多重代入法の章で、ロジスティック回帰そのものの説明(なぜロジスティック回帰を使うのか)もとてもよかったです。
ゼロから作るDeepLearning
こういう仕事についていると「Deep Learning分かるんでしょ」みたいなことを言われるのですが、お恥ずかしながらあまり興味が持てずに今まで勉強してきませんでした。んでも全く知らないって言い続けるのもよくないなと思いまして、とりあえずこの本で勉強してみることにしました。
中でどんな風に動いているのかを知るには最適な入門書になっていると思います。
機械学習のための特徴量エンジニアリング
それまでなんとなく知っている範囲で、数少ない選択肢の中から特徴量を作っていました。これではあまりよくないなと思って、この本を手に取りました。
内容的には、特徴量の作り方がメインという感じです。
正直言って知らないことはほとんどなかったのですが、こうやって1冊の本に整理されているものを読むのは、自分の頭の中も整理できるのでとてもよかったです。また、テキストデータの分析について勉強した時に知りたかったのは、むしろこの本に書いてあったという印象は受けました。
この本は今でも分析するときにはよく参照しています。
統計的因果探索
統計的因果推論を勉強したいなぁと思うのは、おそらく多くの人が思うことだと思います。私もそう思って色々な本を調べたところ、良さそうだったのがこの本です。
統計的因果推論の基礎的な話から始まって、著者が考案したLiNGAMという手法の解説という流れになっています。説明は分かりやすく「これこれ、こういう説明が欲しかったんよ」というような気持のよい感覚で読み進めることができました。めちゃくちゃお勧めです。
残念ながら実務では、ここまできちんとした分析を求められることは多くないのですが、いつかは重要性を認識してもらいたいなと思っています。(でも非分析者にこれを説くのは難しいだろうな・・・)
入門 実験計画法
昨年デミング賞を受賞された永田先生の本です。
正しいデータ分析には正しいデータの取得からということで、実験計画法については前々から勉強したいなと思っていたのですが、ちょっと面倒くさいなと思って放置していました。。。社会人になってからは学生の時のように、しっかり時間をとって勉強するというのが難しくなってしまったので、軽く読んでも(がっつり手を動かして長考しなくても)理解できそうな実験計画法はむしろぴったりでした。勉強してみると結構面白いですね。まぁ考えてみれば当たり前のようなことが書いてあるのですが、意識していないとというか知らないと見逃すようなことばかりでした。
勉強の仕方や各分野とのつながりなどの話も載っていて、独学している者にとって非常に親切な構成になっていると思います。式展開がかなり丁寧なので冗長に感じる人もいるかもしれませんが、ここもありがたいと感じる人の方が多いと思います。
最後の章50ページほどがQ&Aになっていて、ここも非常に読み応えがあります。
ただこれも残念なことに、ちゃんとした実験計画をするべきだと思うのですが、実務っていうかビジネスだと中々ちゃんとした実験計画を立てるというのは難しいんですよね。。。もちろん分野によりますが。
機械学習のエッセンス
話題になっていたので買ったのに卒研が大変で積んでいた本でした。前提知識は本当に高校数学までという珍しい本です。説明も非常に分かりやすく、初学者にかなり配慮されているなという印象を受けました。
なかなか類を見ない内容になっていて、機械学習を学び始めるのに必要な知識(実行環境の準備、Pythonの基本、線形代数、微積分、数値計算)の習得に270ページぐらい割かれており、残りの100ページぐらいが機械学習という構成です。
この本が出るまでは、機械学習の勉強を始めてみたけど前提知識を勉強しているうちに挫折したという話を少なからず聞いたので、めちゃくちゃいい本が出たなと思いました。この本を読めば機械学習にすんなり入門することができると思います。機械学習を勉強したいんだけど何がいいかな?という質問には、例外なくこの本を勧めています。
私もこの本で入門したかったよぉ。
3年目まとめ
仕事が始まったりマーケティングやらマネジメントやらドメイン知識やらも勉強していて、あまり統計学を勉強する時間が取れなかった割には結構読んでたなぁというのが正直な感想です。2年目で基礎力がある程度ついて、そこそこのレベルなら比較的スムーズに読めるようになったからというのもあると思いますが、PRML以外につらい本はなく、丁寧に説明されていたのが大きかったと思います。このあたりに良い本がたくさん出ているなという空気は感じますね。
統計的学習の基礎やPRMLは、今でもよく勧められている本だと思うのですが、実際どうなんですかね。こう良書がたくさん出ている中では、必ずしも初めの方に読む必要はなくなってきているのかもしれません。ある程度力がついてから、手法間の繋がりを知りたかったり、一貫した性格で一通りの手法を勉強したいという段階になってからでいいんじゃないかなと思います。確かに良書だと思うんですけどね、それを学ぶのに適した時期というのはあるような気がします。
社会人も2年目だよ(4年目)
今年の話ですね。今年は昨年のこの時期には考えもしなかった新型コロナウイルスに散々振り回されました。仕事でも危機に陥っていたため全ての時間的リソースを仕事に振り切ったりと更に勉強する時間がなかったです。さすがに最近は自分のことも大切にしないとなという気持ちになったことと、自分がそんな姿勢で取り組んでいると他人にも強制感のある影響を与えかねないなということに気が付いたというのもあって、通常運転に戻しまして勉強時間もある程度確保できるようになりましたが。。。
まぁそんな話はいいとして、今年はこれまでより少し基礎によった勉強をしていました。
統計学への確率論,その先へ
色々な本で「測度論的確率論の知識は必要としない」という記述をよく見かけると思います。この記述を見ると「測度論的確率論の知識って必要なのかな」という気持ちになって、学んでみるけど当然爆死という経験を繰り返した人は多いと思います。もちろん私も再三爆死しています。
この本はそんな方にピッタリな一冊です。
数理統計学を理解するための確率論を学ぶことを通じて、測度論の重要事項も学べるという内容でした。測度論的確率論自体の習得を目的としているわけではなく、数理統計学を学ぶための、いわゆる応用に耐えうるだけの基礎力を養うことを目的としている人に向いていると思います。
「多くの統計的な問題では $\Omega=R^d$ としておけばほぼ問題ない」というような記述やホップの拡張定理の証明を省略していて「この定理は確率測度を構成する上では本質的なもので、これを証明するにはやはり測度論を学ばねばならない。しかしながら、定理の主張を理解することはさほど難しくないだろう。この定理を認めてしまうと、測度論初期の多くのステップを省略できる。統計学などへの応用確率論の理解を目指すなら、とりあえずこの定理を認めてしまって先に進むのがよいと筆者は思っている。」というような記述がこの本の性格をよく表していると思います。
説明の仕方が教育的で、専門書によくある淡々とした説明ではなく、講義口調で説明してくれます。仮定を落としたらどうなるかとか、この話が何に繋がるかとか、そういう話にしっかりと文字数が割かれていて独学する人にすごくありがたい説明になっていました。
工学のための関数解析
統計学の本ではないのですが、非常に勉強になったので紹介です。特に「統計学への確率論,その先へ」などを読む前とか読みながらこの本の学習も進めると理解が深まると思います。
「工学のための」と書いてありますが、これを工学部でやっている学校があるのか・・・?と恐怖する内容になっています。(「工学のため」と書いてあるだけで「工学部でやっている」ではない。)
注意したいのは、やはり「工学のための」という文字を見て誤解することで、これは厳密性を排除して直感的にという意味ではなく、工学で使われている関数解析について扱っているよという意味だということです。だからこの本を読むと数理統計とか最適化とか確率論の理解が深まるってことなんだと思います。
ただし、工学の人にとってありがたいことに証明がほとんどされていて、しかも行間がほとんどないという点は「まさに工学のため」といえるかもしれません!まじ神様!
あと、参考文献の紹介のページで、それぞれの文献にコメントが添えられているのも特徴かなと思います。私は辿ったわけではありませんが、コメントは熱いので余裕のある方は是非!
効果検証入門
話題になっていたので購入しましたが、話題になるだけあって非常に良い本でした。学生というよりはビジネスをかなり意識して書かれているので、非常に実践的な内容になっていると感じました。
内容についての書評は色んなところで書かれているのでここでは割愛します。
個人的には前書きと後書きが大好きで、赤べこのように首を上下に振っていました。ここを読むだけでも良書だということが分かると思います。
Scikit-learnとTensorFlowによる実践機械学習
仕事ではExcelばかりでRやPythonを使う機会がほとんどありませんでした。Rは学生の時に使っていたので、それなりに統計チックな分析をするときにはRを使いますが、Pythonは全く使ったことがありませんでした。機械学習のエッセンスやゼロから作るDeepLearningなどではPythonを触りましたが、どちらもゼロからコードを書くので実務で使うと思われるツールを使えるようにしておきたいなと購入。
まず前半部分はScikit-Learnがかなりシンプルで便利だということが分かったけど、それどまりかなという感じです。
最序盤は当たり前の(かつ理想的な)話が書いてあり、この本全体にわたって実践的な話が展開されるのかなと思わされます。しかし、それは最序盤だけの話。あとはアルゴリズムの解説やら何やらが展開されていて、「実践どこ行ったねん」みたいな感情にさせられます。アルゴリズムにフォーカスするのはいいのですが、そのアルゴリズムを使っているとよくあたる問題や誤りの対処やらが読みたかったかなという感想でした。
あと、理論の解説はいらなかったかなというところですかね。するのであれば、もう少ししっかり書いてほしかったです。しかし、趣旨は理論ではないはずなので、発想やアウトラインだけ書いてggrksとしつつ、上に書いた問題への対処などに紙面を割いてほしかったです。
コードに関してはGitHubで公開されているものが個人的にはかなりいいなと思いました。これは価値が高いと思います。
また、この本ではTensorFlowのバージョンが1なのですが、現在はTensorFlow2という。。。
んでも基本的なScikit-Learnの使い方が学べたのは大きな収穫でした。不満は少々ありつつも、目的は達することはできたので個人的には満足しています。
※2020/11/4にこの本の第2版が出たようです。こちらは第1版よりも260ページも増量されているようです。O'REILLYのページによると「第2版では教師なし学習と深層ネットワーク訓練手法、コンピュータビジョンテクニック、自然言語処理、Tensor Flowの大規模な訓練や効率的なデータの取り扱いについての解説を拡充し、新たに畳み込みニューラルネットワークを使ったシーケンス処理とGANによる画像生成の説明を追加しました。サンプルコードはすべてTensorFlow2に準拠しています。」とのことです。
4年目まとめ
今年は仕事に大半の時間的リソースを投入してしまったので勉強をする時間があまりとれませんでしたが、実力をワンランクアップさせることができたかなと思います。仕事での成果は大きかったので、総合点ではまぁ合格点がもらえるのではないかなと思います。
今年を通して思ったのは、比較的基礎によった勉強がそこそこできるようになったのは大かったなというところです。そして比較的基礎によった内容でも独学で頑張れるような本が出てきていて、非常にありがたい環境になってきているということも忘れてはいけません。
また、仕事で使うことが皆無だったり、コードを書きながら理解するというのがどうも合わない私なのですが、さすがにそろそろそんなことも言ってられないだろうということで、よく使われているPythonとか勉強し始めたのも進歩かなと思います。(卒研ではMATLABで授業はRだったのでPythonはほとんど初めて触りましたが分かりやすくていいですね。)
今後は、引き続きPythonなどの習得を進めつつ、時系列解析や強化学習、それからベイズ統計学なんかに入門していきたいですね。あとは自分のキャリアを考えながらというところでしょうか。
まとめ
それぞれの本を読んだ段階で、どれくらいの知識があって、どんな感想を抱いたのかは割と整理できたんじゃないかなと思います。誰かの参考になれば嬉しいです。
おまけ:現在進行形の本
①ベイズ統計の理論と方法
ベイズ統計学に入門しようと購入。噂通りの難解というか、今持っている知識と結び付けていくのが難しく、行間も結構広いので全く進んでいないのが現状です。これについては時間がかかってもいいと思っているので、ゆっくりじっくりまったり進めていこうと思います。ちなみに7章から眺めるといいよというアドバイスを頂いて、そうしてみたら確かにかなり良かったです。1章と7章を読んでから2章以降に進むといいのかなと思います。
②Python機械学習プログラミング
TensorFlow2に対応した書籍が欲しいなと思っていて、本当はとかげの本の第2版を買おうとしていたのですが、なんか同じ本を買うのは癪に障るので別の本を探していました。そんな中でPython機械学習プログラミングの第3版が出たというのを目にしたので購入。第1版、第2版とも評判が良かったので、そんなに心配していなかったのですが、理論よりもどう使っていくか良い方法を知りたいという私のニーズにはピッタリ合った本だと思います。
まだ大して進んでいませんが、ここまで読んだ範囲で好きな点はこんな感じ。
・コードが簡潔で分かりやすい。
・コードひとつひとつにコメントが添えられている。
・注釈によって恐ろしくかゆいところにも手が届いている。
・numpyやscikit-learnをちょっと触ったことがあるレベルなら無理なく理解できる。ということで引き続き頑張っていきます。今年度中にはこの2冊の内容を習得できるといいな~。























- 投稿日:2020-11-23T18:37:46+09:00
データサイエンス関連の本を紹介する。
大学3年生の時に統計学の勉強をし始めて、今年で4年目を迎えています。
せっかくなので、自分がどういう勉強をしてきたか振り返りながら書籍を紹介できたら、誰かの役に立つかなと思い書きました。どれくらいのレベルの時に、どれくらいの本を読んで、どんな感じになったのかという紹介は意外と少ないと思います。
この記事のモチベーション
ここ数年で一気に統計学や機械学習の良書が日本語で登場し、コミュニティ等もたくさん生まれているようです。私が就活していた時には、Google先生に「統計学 仕事」なんて聞いてみても、まともな情報はあまり多く返ってきませんでした。かろうじてデータサイエンティストという仕事があるらしいということを知るだけでも中々苦労したのを思い出します。
それが3年前とかの話なので、どれだけ急激に普及したのかが感じられると思います。就活の時には、そういう目的で話を聞きに行ったわけではないところでも、割と普通にデータサイエンティストとかいう単語は耳にしたと記憶しています。
就活生などに話を聞くと、現在でもこの勢いは衰えていないらしく、依然として企業はデータ分析に強い人間を求めているようです。それだけ社会に普及しているのもあって、日本語で書かれた良書がたくさん出てきているというわけなんでしょうね。
一方で良い本が出すぎているために、どの本を読むのかという選択が難しくなっているという側面もあると思います。
というわけで今回は、私の統計学における勉強の軌跡を振り返りながら、その時々に読んだ本を紹介していこうと思います。本の画像はAmazonへのリンクになっているので、そこに書いてあるレビューなども参考になると思います。ここではなるべくAmazonレビューには書いていないことを書ければなと思っています。
※アフィリエイトとかじゃないのでご安心ください。っていうかQiitaってアフィリエイト禁止だよね。たしか。
そもそもなんで統計学を勉強し始めたのか
勉強を始めるきっかけというのは、聞いてみると人それぞれ意外と面白いものです。
私の場合は、単純に授業で統計学を学んだ時に「え、おもしろ」と思ったのがきっかけです。
何が面白かったのかというと検定です。私の中では昔から、「何かを測って比較した時に、どこまで同じでどこから違うと言っていいんだろう?」という疑問がありました。例えば、身長を測って友達よりも大きい小さい同じという話になったときに、0.1mmの差は同じ?じゃあ1mmは?1mm差は同じだよねっていうけど1.1mm差は同じじゃないの?というような、人に言ったらちょっと嫌われそうな疑問です。
普通に生きている分には、本人たち同士の感覚任せでいいと思いますが、客観的に評価したいときはどうしたらいいんだろう?とずっと考えていました。ググるにもなんて調べたらいいのか分からず、人に聞くにも嫌われそうだったので聞かず、そしたら授業で突然登場したんですよね。ちょっぴり感動したのをよく覚えています。
で、どういう根拠でその差を評価しているのかとかを知りたくて、統計学の勉強を始めたという具合でした。
最初は失敗
私は経営システム工学科出身なので、品質管理やらなんやらって、統計学にはある程度授業で触れていました。レベル感でいうと、統計検定2級ぐらいのことは分かるという感じでした。
そういうレベルからのスタートで、何を勉強していいのかよくわからず、まず始めたのが統計検定準1級の範囲の勉強でした。理由は単純で、一番範囲が広く、それっぽい単語が並んでいて、網羅的な知識が得られそうだったからです。
正直言って、これは実力をつけるという意味では失敗だったかなと思います。
範囲が広いのに、これ用のテキストはないため、1つの分野を勉強するのに教科書を1冊読むハメになりました。証明などはすっ飛ばし、概要をひたすらに取り込む作業です。学校の実験や課題も山のようにあったために時間を確保しにくい中、モヤモヤが爆発しそうになりながらとりあえず全体を網羅的に把握することに努めました。
そんなことをしていたので、水溜まり並みに浅い知識しか身に付かず、、、
という失敗があったので、ちゃんと理解しないとなと思い、実力が着実に付きそうな勉強を始めることにしました。
まずはここから(1年目)
失敗したとはいえ、収穫はありました。まず、ちゃんと地に足をつけて勉強をしないと使えるレベルにすらならなさそうだということ。また、大前提として統計学には確率分布の知識が必要だということが分かったということです。そして私にはそれが圧倒的に不足していました。ということで手を付けたのがこの本。
1.大学生の確率・統計
この本を選択したのは大正解でした。
この本のいいところは、受験勉強のノリで演習問題を通じて知識を身に着けられるところです。
基本的な確率分布の知識はもちろん、中心極限定理や積率母関数などの使い方、多次元分布の変数変換もあれば、条件付き期待値の計算も学ぶことができます。また、マルコフ連鎖やポアソン過程などの確率過程の初歩も練習することができます。
これらの内容を、手を動かした計算を通じて習得することができます。難解な本に進むのでなければ、しばらくは確率の勉強をしなくても大丈夫なくらいの知識を得られるのではないかなと思います。統計の参考書などで当たり前に使われていたり、当たり前すぎて端折られていたりする基本的な計算テクニックを身に付けることができるのも結構ありがたいです。
ちなみに最後の章は保険数理になっていますが、ここはやらなくてもいいかなと思います。
2.自然科学の統計学
基本的な確率の知識が身に付いたところで、さて統計学を勉強するぞと選んだのがこの本。
いわゆる青本といわれるものですが、多くの人は赤本から始める人が多いようです。赤本をやろうか迷っていた時に立ち読みした感じでは、先に上げた確率の本や授業でやったような内容とだいぶ被るなと思い、私はスキップしましたが、良書みたいなのでこちらをやるのもいいと思います。
もちろん青本を選んだのも正解でした。まず、線形モデルの知識がある程度ちゃんと身に付いたのは良かったです。機械学習の入門書だと、誤差の分布がどうとか検定の話には中々踏み込まないので、ここで勉強できたことは貴重でした。
また、検定の話についてレベルが高すぎないながらも、比較的ちゃんと書かれているので非常に勉強になりました。最尤法から検定の話に行くまでの流れが結構好きです。「○○検定っていうのがあるけど、なんでその検定がいいの?」とか疑問を持っている人が読むと腑に落ちるかもしれません。
ちなみに、この本を勉強しながら線形代数の知識の重要性が分かったので、線形代数の復習をしたりもしました。
カーネル多変量解析
なんかSVMすごいらしいということで、先生に聞いてみたらこの本をお勧めされました。
当時の私の頭の中には、そもそも数学でいうところの空間という概念がなかったので、特徴空間だとか、標本空間だとか、再生核ヒルベルト空間だとか、いろいろな空間が出てきてめちゃくちゃ困惑したのを覚えています。あと、高校や大学1年ぐらいの数学だと、一般的に成り立つような性質を学ぶことが多いと思うのですが、そういう性質を持ったものを対象にしているとか、そんな初歩的なことによく躓いていたのも覚えています。
ある程度の数学レベルがないとちょっと厳しいかなと思いますが、本の内容的には結構分かりやすい部類に入ると思います。この段階でこの本を読むことは、レベル感からいってお勧めできませんが、いつかカーネル法について学んでみたいという人であればお勧めです。
多変量統計解析法
かなり古い本(1983年の本)ですが、結構好きな1冊です。基本的な多変量解析法(回帰分析、主成分分析、判別分析、数量化法、因子分析、グラフ解析法、クラスター分析)について学べます。よくある、理論を一通り説明してから具体例という流れではなく、具体的なデータ例とこのデータを使って知りたいことは~というモチベーションの話から導入が始まって、理論と具体的なデータでの計算が並走して進んでいくので、実際にデータ分析をしている時と同じ感覚で勉強することができます。
今見ると話しや計算が具体的すぎるなと思いますが、当時の実力だとこれぐらいの具体的さが非常にありがたかったです。
多変量解析は他にも『データ解析の実際』を読みましたが、こちらも初学者にはお勧めです。多次元尺度法について扱っている本をあまり知らないので貴重かなと思います。
1年目まとめ
1年目はこんな感じで、まず失敗して反省し、基本的な確率の知識や統計学の発想、多変量解析などの使える手法の勉強を中心にしていました。測度論とかいう言葉も聞いていたのですが、レベル的に無理だなぁと思って手を出さなかったのは正解だったと思います。
また、大学1年時に習った線形代数や微積分の知識が重要だと認識し、横着しないで復習できたのもよかったです。勉強していくうえで大切なことは続けることだと思うので、そういう意味でも勉強を続けられる体力を身につけられたのは、その後にも活きてきているのでよかったなと思います。
機械学習に入門(2年目)
2年目は大学4年生で、応用統計学研究室に配属されました。金銭的な都合で大学院には進学する予定がなかったので、就職してからも役に立ち続けるのは勉強だと思っていました。そこで先生には研究室を決める際に「研究よりは勉強がしたいのですが、それでも大丈夫ですか?」と聞いたところ快くOKしてくれました。(研究をした後にこの発想は誤りで、研究で得たことも役に立ち続けると分かりましたが、あえてそこには突っ込まず快諾してくれた先生には感謝です。)
AIというものは、どうやら機械学習と呼ばれるものらしいということを聞いていたので、まずは機械学習について勉強することにしました。
統計的学習の基礎
先生に機械学習を勉強するにあたっておすすめを聞いて、紹介されたのがこの本でした。
機械学習の基本的な手法を網羅的に扱っていて、理論的背景について詳しく統計的な発想で説明がされているので非常に好みの1冊です。今でも辞書的によく使っています。
分厚いだけあって、各手法の繋がりや比較なども詳しいです。個人的には、バギングからランダムフォレストへの発想とか、区分的多項式からスプラインへの発展、みたいな流れが好きです。
教師なし学習や正則化なんかについて広く扱っている本は少ないので、そこをカバーしているのもおすすめポイントです。あとは、kaggleなどで流行っているブースティング系の話が基礎からちゃんと書かれている本をこの本しか知らないので、その点もおすすめです。(ブースティングは行間を埋めただけの記事を前に書いたのでリンクだけ張っておきます。)
(いろいろな意味で)非常に重く、特に式変形の行間を埋めるのがとても大変だったなとか、行間を一生懸命埋めて先生に持っていったら「行間は埋まってるけど、理解はできていないね」と言われて出直したり、いろいろな思い出があります。
参考文献が非常に多く、こんな文献ですよという説明とともに紹介されているので、理解の及ばないところはそれらも読みました。ここで紹介されているのは良い論文ばかりなので、卒研に入る前の論文を読むいい練習にもなりました。
確率モデルの考え方
全部読んだわけではなく、確率過程の部分だけ読みました。
比較的わかりやすい本だったと思いますが、確率過程をその後使う機会がなかったので細かい内容はあまり覚えておらず。。。確率過程の基本的な話は、これで結構理解することができたという感想を持ったというのは覚えています。
ロバスト統計: 外れ値への対処の仕方
卒業研究のテーマがロバスト統計学だったので、まずはこの本で勉強しました。というかロバスト統計学の和書って、たぶんこの本ぐらいしかないと思います。(他に知っているのは『頑健回帰推定(蓑谷)』ぐらいですかね。)
藤澤先生のこの本は、めちゃくちゃ分かりやすくて非常にお勧めです。日本語で読める本がこの1冊ぐらいしかないのに、分かりやすくて神はいたんだなという気持ちになったのを覚えています。
洋書ですが、ロバスト統計に関して他に読んだものは、『Robust Statistics: Theory and Methods(Maronna,Martin,Yohai)』と『Robust Statistics(Huber,Ronchetti)』ですかね。あとは論文をたくさん漁ったという感じでした。ロバスト統計学に関しては思うところもあったのですが、この話は長くなるので割愛します。
数理統計学の基礎
卒業研究を通して、基礎的な統計学の知識を身に着けたいなと思って購入。内容は決して軽くないですが、統計学における本格的な知識が得られたので良かったです。数理統計学の本の中では、いまのところ一番好きな本です。
内容的には、確率の話はあっさりめで、統計モデルや収束、検定、推定、について詳しく書かれています。数理統計学に関する一般的な話は一通り書かれていると思います。本格的な入門書という表現がしっくりくると思います。
行間が埋まらなかったりしたときは、『Theory of Point Estimation』を参考にするといいかなと思います。英語ですが、説明や書き方が分かりやすくて割と好きでした。特に漸近理論の部分は結構詳しく書いてあったと思います。いつか全部読みたいですが、読まないんだろうなぁ。。。
(ちなみにTheory of Point Estimationは、先生に勧められたか、この書評(pdf直リンク)を読んで覗いてみたんだったと思います。詳しく書評されているので一読の価値はあると思います。)
(Theory of Point Estimationは、PDFがネットに落ちていたと思います。)
論文も読んでいたよ
統計的学習の基礎のところでも書きましたが、結構論文を読みました。いやたくさん読んだからなんだっていう話ではなくて、この後の本はそれぐらいのレベル感まで来たところで読んだよということは書いておいた方が参考になるかなと思ったので。。。
話を戻して、、、統計的学習の基礎で参考文献に上がっていた論文は、幸いにも読みやすいものが多かったので良い練習になりました。最初は本などで参考文献として取り上げられている論文を読み、そこにまた書かれている参考文献を辿ったりして、それぞれの手法や理論に至った発想、解決した問題など理解が深まって面白かったです。また、論文内で参考文献に上げられている論文を読むことで、広がりやつながりを知ることもできたのもよかったです。
卒研のために読んだ論文は、必ずしも読みやすいものばかりではありませんでしたが、全部読まなきゃという意識もなかったり、ある程度耐性がついていたりだったので割と何とかなりました。もちろん先生にたくさん助けていただいたのは言うまでもありませんが、学部卒で論文を比較的ストレスなく読めるようになったのは大きかったかなと思います。
2年目まとめ
こんな感じで2年目の勉強を終えました。ざっくり言うと、前半は機械学習の勉強、後半は卒業研究を通してロバスト統計学と数理統計学の勉強をしていたという感じですね。ちなみに卒研ではMATLABを使っていました。私は結構好きでしたね。
この1年での成長は非常に大きく、1年目の勉強をしていた時には想像もできなかったぐらい力をつけることができました。
といっても自分の努力のおかげというよりは、研究室の先生のおかげなんですけどね。私が理解できるようにきちんと教育してくれたのが大きかったです。細かい話は別の機会にしようと思いますが、こういうのを教育っていうんだろうなと感じました。また、学問上の指導だけではなく、人としてというか、社会人として必要な、根本的な考え方や姿勢などについても教育してもらいました。これは働くうえでも非常に大きなアドバンテージになっています。
(なんか「教育してもらいました」って語感があまりよくないですね。けど、指導とか訓練とかじゃ言葉的に物足りなく、教育って言葉がぴったりなんですよね)社会人になったよ(3年目)
3年目は社会人1年目で、データサイエンティストとして働くようになりました。機械学習エンジニアではなく、ビジネスサイドのデータサイエンティストで、コンサル系の仕事がとても多いです。最初にやった仕事はマーケティングのコンサルでしたしね。学生の時は、授業では応用を(経営工学だったので応用の話が多かったです)、自分の勉強では理論よりの話を中心に勉強してきたのですが、社会人になってもこのバランスは維持したいなという意識で勉強しました。
仕事上どうしても統計よりもドメイン知識の習得に努める必要があり、統計の勉強は控えめになってしまいました。これはちょっと残念だった面もありますが、この仕事を続けていくのであれば有益だったと思います。
パターン認識と機械学習(通称PRML)
統計的学習の基礎の基礎を読んだので、もうひとつの必読本に数えられているPRMLを読みました。感覚的にはベイベイベイズって感じで、式変形を追いかけたりするのが大変でした。しかし、さすがは有名本というところでしょうか、ネットで調べると参考になるサイトやブログやスライドがたくさん出てきます。統計的学習の基礎はこれが少ないので苦労しましたが、PRMLはこの点勉強しやすかったです。
特にこのページがおすすめです。PDFは無料で配信されていますが、私はこれの紙版を買いました。556円でこの内容はめちゃくちゃありがたいです。まじ神様。
個人的な好みですが、私はPRMLよりも統計的学習の基礎の方が好きですね。
統計的学習の基礎でもそうなのですが、こういう勉強をするときに大事なのことは、愚直に手を動かすことかなと思います。もちろん私レベルの話なので、私より強い人の感覚は分かりませんが、、、
テキストアナリティクス
仕事でテキストデータを扱うことが多そうだったので購入。内容自体は良かったのですが、期待していたものとは違ったというのが正直なところです。でも内容はよかったですよ。
ひとつひとつの手法について丁寧にっていうよりは、テキストデータの分析はこんなアプローチがありますよーというのを俯瞰的に知ることができました。
欠測データ処理
実務(じゃなくてもそうだけど)では欠測データのオンパレードです。当然のことながら欠測データをどのように処理すればいいのか知識が必要になります。そこで手に取ったのがこの本です。
基本的に多重代入法をメインにしている本で、いろいろな手法における多重代入法を扱っていて内容的にも満足でしたが、最後の「おわりに」という章がとてもよかったです。
他にも例えば、ロジスティック回帰における多重代入法の章で、ロジスティック回帰そのものの説明(なぜロジスティック回帰を使うのか)もとてもよかったです。
ゼロから作るDeepLearning
こういう仕事についていると「Deep Learning分かるんでしょ」みたいなことを言われるのですが、お恥ずかしながらあまり興味が持てずに今まで勉強してきませんでした。んでも全く知らないって言い続けるのもよくないなと思いまして、とりあえずこの本で勉強してみることにしました。
中でどんな風に動いているのかを知るには最適な入門書になっていると思います。
機械学習のための特徴量エンジニアリング
それまでなんとなく知っている範囲で、数少ない選択肢の中から特徴量を作っていました。これではあまりよくないなと思って、この本を手に取りました。
内容的には、特徴量の作り方がメインという感じです。
正直言って知らないことはほとんどなかったのですが、こうやって1冊の本に整理されているものを読むのは、自分の頭の中も整理できるのでとてもよかったです。また、テキストデータの分析について勉強した時に知りたかったのは、むしろこの本に書いてあったという印象は受けました。
この本は今でも分析するときにはよく参照しています。
統計的因果探索
統計的因果推論を勉強したいなぁと思うのは、おそらく多くの人が思うことだと思います。私もそう思って色々な本を調べたところ、良さそうだったのがこの本です。
統計的因果推論の基礎的な話から始まって、著者が考案したLiNGAMという手法の解説という流れになっています。説明は分かりやすく「これこれ、こういう説明が欲しかったんよ」というような気持のよい感覚で読み進めることができました。めちゃくちゃお勧めです。
残念ながら実務では、ここまできちんとした分析を求められることは多くないのですが、いつかは重要性を認識してもらいたいなと思っています。(でも非分析者にこれを説くのは難しいだろうな・・・)
入門 実験計画法
昨年デミング賞を受賞された永田先生の本です。
正しいデータ分析には正しいデータの取得からということで、実験計画法については前々から勉強したいなと思っていたのですが、ちょっと面倒くさいなと思って放置していました。。。社会人になってからは学生の時のように、しっかり時間をとって勉強するというのが難しくなってしまったので、軽く読んでも(がっつり手を動かして長考しなくても)理解できそうな実験計画法はむしろぴったりでした。勉強してみると結構面白いですね。まぁ考えてみれば当たり前のようなことが書いてあるのですが、意識していないとというか知らないと見逃すようなことばかりでした。
勉強の仕方や各分野とのつながりなどの話も載っていて、独学している者にとって非常に親切な構成になっていると思います。式展開がかなり丁寧なので冗長に感じる人もいるかもしれませんが、ここもありがたいと感じる人の方が多いと思います。
最後の章50ページほどがQ&Aになっていて、ここも非常に読み応えがあります。
ただこれも残念なことに、ちゃんとした実験計画をするべきだと思うのですが、実務っていうかビジネスだと中々ちゃんとした実験計画を立てるというのは難しいんですよね。。。もちろん分野によりますが。
機械学習のエッセンス
話題になっていたので買ったのに卒研が大変で積んでいた本でした。前提知識は本当に高校数学までという珍しい本です。説明も非常に分かりやすく、初学者にかなり配慮されているなという印象を受けました。
なかなか類を見ない内容になっていて、機械学習を学び始めるのに必要な知識(実行環境の準備、Pythonの基本、線形代数、微積分、数値計算)の習得に270ページぐらい割かれており、残りの100ページぐらいが機械学習という構成です。
この本が出るまでは、機械学習の勉強を始めてみたけど前提知識を勉強しているうちに挫折したという話を少なからず聞いたので、めちゃくちゃいい本が出たなと思いました。この本を読めば機械学習にすんなり入門することができると思います。機械学習を勉強したいんだけど何がいいかな?という質問には、例外なくこの本を勧めています。
私もこの本で入門したかったよぉ。
3年目まとめ
仕事が始まったりマーケティングやらマネジメントやらドメイン知識やらも勉強していて、あまり統計学を勉強する時間が取れなかった割には結構読んでたなぁというのが正直な感想です。2年目で基礎力がある程度ついて、そこそこのレベルなら比較的スムーズに読めるようになったからというのもあると思いますが、PRML以外につらい本はなく、丁寧に説明されていたのが大きかったと思います。このあたりに良い本がたくさん出ているなという空気は感じますね。
統計的学習の基礎やPRMLは、今でもよく勧められている本だと思うのですが、実際どうなんですかね。こう良書がたくさん出ている中では、必ずしも初めの方に読む必要はなくなってきているのかもしれません。ある程度力がついてから、手法間の繋がりを知りたかったり、一貫した性格で一通りの手法を勉強したいという段階になってからでいいんじゃないかなと思います。確かに良書だと思うんですけどね、それを学ぶのに適した時期というのはあるような気がします。
社会人も2年目だよ(4年目)
今年の話ですね。今年は昨年のこの時期には考えもしなかった新型コロナウイルスに散々振り回されました。仕事でも危機に陥っていたため全ての時間的リソースを仕事に振り切ったりと更に勉強する時間がなかったです。さすがに最近は自分のことも大切にしないとなという気持ちになったことと、自分がそんな姿勢で取り組んでいると他人にも強制感のある影響を与えかねないなということに気が付いたというのもあって、通常運転に戻しまして勉強時間もある程度確保できるようになりましたが。。。
まぁそんな話はいいとして、今年はこれまでより少し基礎によった勉強をしていました。
統計学への確率論,その先へ
色々な本で「測度論的確率論の知識は必要としない」という記述をよく見かけると思います。この記述を見ると「測度論的確率論の知識って必要なのかな」という気持ちになって、学んでみるけど当然爆死という経験を繰り返した人は多いと思います。もちろん私も再三爆死しています。
この本はそんな方にピッタリな一冊です。
数理統計学を理解するための確率論を学ぶことを通じて、測度論の重要事項も学べるという内容でした。測度論的確率論自体の習得を目的としているわけではなく、数理統計学を学ぶための、いわゆる応用に耐えうるだけの基礎力を養うことを目的としている人に向いていると思います。
「多くの統計的な問題では $\Omega=R^d$ としておけばほぼ問題ない」というような記述やホップの拡張定理の証明を省略していて「この定理は確率測度を構成する上では本質的なもので、これを証明するにはやはり測度論を学ばねばならない。しかしながら、定理の主張を理解することはさほど難しくないだろう。この定理を認めてしまうと、測度論初期の多くのステップを省略できる。統計学などへの応用確率論の理解を目指すなら、とりあえずこの定理を認めてしまって先に進むのがよいと筆者は思っている。」というような記述がこの本の性格をよく表していると思います。
説明の仕方が教育的で、専門書によくある淡々とした説明ではなく、講義口調で説明してくれます。仮定を落としたらどうなるかとか、この話が何に繋がるかとか、そういう話にしっかりと文字数が割かれていて独学する人にすごくありがたい説明になっていました。
工学のための関数解析
統計学の本ではないのですが、非常に勉強になったので紹介です。特に「統計学への確率論,その先へ」などを読む前とか読みながらこの本の学習も進めると理解が深まると思います。
「工学のための」と書いてありますが、これを工学部でやっている学校があるのか・・・?と恐怖する内容になっています。(「工学のため」と書いてあるだけで「工学部でやっている」ではない。)
注意したいのは、やはり「工学のための」という文字を見て誤解することで、これは厳密性を排除して直感的にという意味ではなく、工学で使われている関数解析について扱っているよという意味だということです。だからこの本を読むと数理統計とか最適化とか確率論の理解が深まるってことなんだと思います。
ただし、工学の人にとってありがたいことに証明がほとんどされていて、しかも行間がほとんどないという点は「まさに工学のため」といえるかもしれません!まじ神様!
あと、参考文献の紹介のページで、それぞれの文献にコメントが添えられているのも特徴かなと思います。私は辿ったわけではありませんが、コメントは熱いので余裕のある方は是非!
効果検証入門
話題になっていたので購入しましたが、話題になるだけあって非常に良い本でした。学生というよりはビジネスをかなり意識して書かれているので、非常に実践的な内容になっていると感じました。
内容についての書評は色んなところで書かれているのでここでは割愛します。
個人的には前書きと後書きが大好きで、赤べこのように首を上下に振っていました。ここを読むだけでも良書だということが分かると思います。
Scikit-learnとTensorFlowによる実践機械学習
仕事ではExcelばかりでRやPythonを使う機会がほとんどありませんでした。Rは学生の時に使っていたので、それなりに統計チックな分析をするときにはRを使いますが、Pythonは全く使ったことがありませんでした。機械学習のエッセンスやゼロから作るDeepLearningなどではPythonを触りましたが、どちらもゼロからコードを書くので実務で使うと思われるツールを使えるようにしておきたいなと購入。
まず前半部分はScikit-Learnがかなりシンプルで便利だということが分かったけど、それどまりかなという感じです。
最序盤は当たり前の(かつ理想的な)話が書いてあり、この本全体にわたって実践的な話が展開されるのかなと思わされます。しかし、それは最序盤だけの話。あとはアルゴリズムの解説やら何やらが展開されていて、「実践どこ行ったねん」みたいな感情にさせられます。アルゴリズムにフォーカスするのはいいのですが、そのアルゴリズムを使っているとよくあたる問題や誤りの対処やらが読みたかったかなという感想でした。
あと、理論の解説はいらなかったかなというところですかね。するのであれば、もう少ししっかり書いてほしかったです。しかし、趣旨は理論ではないはずなので、発想やアウトラインだけ書いてggrksとしつつ、上に書いた問題への対処などに紙面を割いてほしかったです。
コードに関してはGitHubで公開されているものが個人的にはかなりいいなと思いました。これは価値が高いと思います。
また、この本ではTensorFlowのバージョンが1なのですが、現在はTensorFlow2という。。。
んでも基本的なScikit-Learnの使い方が学べたのは大きな収穫でした。不満は少々ありつつも、目的は達することはできたので個人的には満足しています。
※2020/11/4にこの本の第2版が出たようです。こちらは第1版よりも260ページも増量されているようです。O'REILLYのページによると「第2版では教師なし学習と深層ネットワーク訓練手法、コンピュータビジョンテクニック、自然言語処理、Tensor Flowの大規模な訓練や効率的なデータの取り扱いについての解説を拡充し、新たに畳み込みニューラルネットワークを使ったシーケンス処理とGANによる画像生成の説明を追加しました。サンプルコードはすべてTensorFlow2に準拠しています。」とのことです。
4年目まとめ
今年は仕事に大半の時間的リソースを投入してしまったので勉強をする時間があまりとれませんでしたが、実力をワンランクアップさせることができたかなと思います。仕事での成果は大きかったので、総合点ではまぁ合格点がもらえるのではないかなと思います。
今年を通して思ったのは、比較的基礎によった勉強がそこそこできるようになったのは大かったなというところです。そして比較的基礎によった内容でも独学で頑張れるような本が出てきていて、非常にありがたい環境になってきているということも忘れてはいけません。
また、仕事で使うことが皆無だったり、コードを書きながら理解するというのがどうも合わない私なのですが、さすがにそろそろそんなことも言ってられないだろうということで、よく使われているPythonとか勉強し始めたのも進歩かなと思います。(卒研ではMATLABで授業はRだったのでPythonはほとんど初めて触りましたが分かりやすくていいですね。)
今後は、引き続きPythonなどの習得を進めつつ、時系列解析や強化学習、それからベイズ統計学なんかに入門していきたいですね。あとは自分のキャリアを考えながらというところでしょうか。
まとめ
それぞれの本を読んだ段階で、どれくらいの知識があって、どんな感想を抱いたのかは割と整理できたんじゃないかなと思います。誰かの参考になれば嬉しいです。
おまけ:現在進行形の本
①ベイズ統計の理論と方法
ベイズ統計学に入門しようと購入。噂通りの難解というか、今持っている知識と結び付けていくのが難しく、行間も結構広いので全く進んでいないのが現状です。これについては時間がかかってもいいと思っているので、ゆっくりじっくりまったり進めていこうと思います。ちなみに7章から眺めるといいよというアドバイスを頂いて、そうしてみたら確かにかなり良かったです。1章と7章を読んでから2章以降に進むといいのかなと思います。
②Python機械学習プログラミング
TensorFlow2に対応した書籍が欲しいなと思っていて、本当はとかげの本の第2版を買おうとしていたのですが、なんか同じ本を買うのは癪に障るので別の本を探していました。そんな中でPython機械学習プログラミングの第3版が出たというのを目にしたので購入。第1版、第2版とも評判が良かったので、そんなに心配していなかったのですが、理論よりもどう使っていくか良い方法を知りたいという私のニーズにはピッタリ合った本だと思います。
まだ大して進んでいませんが、ここまで読んだ範囲で好きな点はこんな感じ。
・コードが簡潔で分かりやすい。
・コードひとつひとつにコメントが添えられている。
・注釈によって恐ろしくかゆいところにも手が届いている。
・numpyやscikit-learnをちょっと触ったことがあるレベルなら無理なく理解できる。ということで引き続き頑張っていきます。今年度中にはこの2冊の内容を習得できるといいな~。
- 投稿日:2020-11-23T18:21:42+09:00
簡単にWeb画面を作成できるgradioを利用して画像の解像度をあげるモデルを実行するWebページを作成する
概要
深層学習などでモデルを作成した後そのモデルの性能を効果的にデモとして見せるには、CUIで実行するよりもGUIで見せられる方が多くの人(特に非エンジニア)にとっては馴染みが深く好ましい。しかし、デモの度にそのモデルに適合したGUIの画面を作るのは大変で、開発者はほとんどの場合モデルの学習やパラメータ調整に神経をすり減らし終わった後のため、GUIまで実装する気力が残っていない(←個人の経験によるもので異論は認めます)。
そんな時、最小限のコーディングのみでシンプルなWebGUIを作成できるGradioというものを見つけたので、実際にどんなものか使ってみた。
今回はTensorhubに公開されている画像の解像度を4倍に拡大するGANの手法であるESRGANの実行を、WebGUIから行うものを開発する。
作成されるWeb画面は以下のような感じ。
実行環境
- Ubuntu18.04
- Python3.8.0
すぐ始めたい人
以下のコマンドを実行後、http://127.0.0.1:7860/ にアクセスする。
git clone https://github.com/sey323/gradio-esrgan.git cd gradio-esrgan pip install -r requirements.txt python gradio-esrgan.py実装
0. 全体像
ソースコードの全体像
import gradio as gr import tensorflow as tf import tensorflow_hub as hub model = hub.load("https://tfhub.dev/captain-pool/esrgan-tf2/1") def predict( inp, ): """ ESRGANを用いて、入力画像を4倍の解像度に変換する。 https://tfhub.dev/captain-pool/esrgan-tf2/1 inp : 入力画像 """ h, w, c = inp.shape # 入力画像から画像サイズを取得する inp = inp.reshape((-1, h, w, c)) inp = tf.cast(inp, tf.float32) output = model(inp) output = tf.cast(tf.clip_by_value(output[0], 0, 255), tf.uint8) return output def gradio_gui(): """ gradioのGui画面を定義する """ image = gr.inputs.Image(label="Input Image",) output = gr.outputs.Image(label="Output Image", type="numpy") interface = gr.Interface(fn=predict, inputs=image, outputs=output) interface.launch() if __name__ == "__main__": gradio_gui()1. tensorflow hub, gradioのインストール
tensorflow hubのインストール
公式サイトを参考にTensorflow hubをインストールする。
pip install "tensorflow>=2.0.0" pip install --upgrade tensorflow-hubgradioのインストール
公式サイトを参考にインストールする。
pip install gradio2. Tensorflow hubのモデルを利用する
TensorFlow Hubの公式サイトを参考に、今回利用する低解像度の画像を高解像度に変換するESRGANのモデルのダウンロードと利用するプログラムの作成を行う。
Gradioで実行できるように、入力画像をTensorflowで学習できる形式に変換し、高解像度の画像を返すmethodを作成した。import tensorflow as tf import tensorflow_hub as hub model = hub.load("https://tfhub.dev/captain-pool/esrgan-tf2/1") def predict( inp, ): """ ESRGANを用いて、入力画像を4倍の解像度に変換する。 https://tfhub.dev/captain-pool/esrgan-tf2/1 inp : 入力画像 """ h, w, c = inp.shape # 入力画像から画像サイズを取得する inp = inp.reshape((-1, h, w, c)) inp = tf.cast(inp, tf.float32) output = model(inp) output = tf.cast(tf.clip_by_value(output[0], 0, 255), tf.uint8) return output3. gradioを用いたWeb画面の定義
gradioは大きく分けて3つのクラスで構成されている。
クラス 概要 gr.inputs モデルに与える入力(Image, Textbox, Audioなど) gr.outputs モデルの出力(Image, Textbox, Audioなど) gr.Interface Gradioで実行する関数、入力、出力を定義し、Web画面を描画する。 inputsとoutputsには、画像以外にもテキスト、音声、チェックボックスやSliderといった物も選択できるため、利用するモデルに応じて柔軟に対応できる。
今回用いるESRGANは、入力出力ともにImegeしか利用しないので、Imageを選択する。
Imageはpillowの形式で受け渡される。import gradio as gr ~~~~省略~~~~~ def gradio_gui(): """ gradioのGui画面を定義する """ image = gr.inputs.Image(label="Input Image",) output = gr.outputs.Image(label="Output Image", type="numpy") interface = gr.Interface(fn=predict, inputs=image, outputs=output) interface.launch() if __name__ == "__main__": gradio_gui()動作確認
上記のプログラムを作制したら以下のコマンドで実行する。
$ python gradio-esrgan.py 2020-11-23 01:39:34.566267: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x7f9d83e7e520 initialized for platform Host (this does not guarantee that XLA will be used). Devices: 2020-11-23 01:39:34.566291: I tensorflow/compiler/xla/service/service.cc:176] StreamExecutor device (0): Host, Default Version Running locally at: http://127.0.0.1:7860/ To get a public link for a hosted model, set Share=True Interface loading below... <IPython.lib.display.IFrame object at 0x147170040>実行後とURLが表示されるので、そちらにアクセスする。
* http://127.0.0.1:7860/
Web画面にアクセスすると以上のような画面が表示される。
左のパネルにgr.inputsに指定した入力する要素、出力にgr.outputsに指定した出力される要素が表示されている。
試しにマンドリルの画像を拡大してみる。入力する画像は、ドラックアンドドロップでinputエリアに持っていけば良い。
数秒待つと「OUTPUT IMAGE」のエリアに処理済みの画像が表示される。
右クリックからの画像を保存でダウンロードし、単純に拡大した画像と比較してみる。
左がFinderで同じサイズに拡大した画像、右が生成された画像である。
ESRGANで拡大したものの方が、毛並みの線や輪郭線がかなりシャープに表現されていることが確認できる。終わりに
Gradioを使ってTensorflowで作成したモデルを簡単に公開できるWeb画面を作成できた。
Web画面の定義も3つのモジュールについて記述するだけで良いので、慣れてきたら10分もかからずWebページが作成できそう。GradioHubにはそれ以外の様々な興味的なサンプルがあるので、他のテキストや音声を利用した場合にどうなるかは、こちらも参照いただきたい。

- 投稿日:2020-11-23T18:18:53+09:00
pythonの基本的な「文字列操作」の文法で暗記したいこと
(自分メモ)pythonの基本的な文法で暗記したいこと
はじめに
自分がpthonの基本を忘れないように、自分向けに書く。
※このページを見て頂いた方すみません。完全な初心者向けではありません。
また、よく知っている人向けに、特別なことは書いていません。
コメントアウト
すべての言語で、最初に覚えなければならないのは「コメントアウト」ですね。
python1.py#コメントアウト他の記載方法もあるようですが、#だけ覚えれば十分
スライス(基本)
スラスト(変数の後ろの[])はpython独自(?)の使い方である。結構使える。
またpython初心者には、配列にしか見えないので解読を難解にする。
これより先に関数を覚えても、スライスでつまずく。python2.pynum="0123456789" #左から「1番目」を取得 ※左から見たとき、一番左は「0番」 a1=num[1] # '1' #「右」から「1番目」を取得 ※右から見たとき、一番右は「-1番」 <ここまでなんとかわかる a2=num[-1] # '9' #「3番目~5番目」を取得 <この辺でつまづく。5個ではなく5番目 a3=num[3:5] # '34' #「3番目~」を取得 <「:」と「~」の関係に注目 a4=num[3:] # '3456789' #「~3番目」を取得 a5=num[:3] # '012' #「2個飛ばし」で取得 ※0から始まるので、たまたま偶数になった a6=num[::2] # '02468' #「逆順(後ろから順番)」に取得 a7=num[::-1] # '9876543210'つまり、[start:stop:step]というルールである。(マイナスは逆順)
スライス(応用)
python3.py#あえてスライスを記入して、元と同じように表示するに次の通り(デフォルト値?) a1=num[0::1] #a # '0123456789' #組み合わせても使える #「逆順」にして「2個飛ばし」で取得。「逆順」にする。※文字列の最後が9で奇数だったので、たまたま奇数になった a2=num[::-1][::2][::-1] # '13579' #リスト型でも使える。「2個飛ばし」で取得 numl=[0,1,2,3,4,5,6,7,8,9] n1=numl[::2] # [0, 2, 4, 6, 8]参考
スライスについて、細かく知りたい方はこちらが良いかと思います。
シーケンス内部の処理について解説してくれています。
https://qiita.com/tanuk1647/items/276d2be36f5abb8ea52e
文字列検索・置換・比較
よくある感じ。簡単です。
python4.pynum="0123456789" #表示位置を取得する foo=num.find("1") # 1 #検索して指定した文字へ変換する foo=num.replace("1","a") # '0a23456789' abc1="abc" abc2="abc" #単純比較は演算子で簡単 abc1==abc2 # True #部分比較 "bc" in abc1 # True
「文字列⇒リスト」・「リスト⇒文字列変換」
区切り文字が「空白」というのがポイント
python5.pyabc='a b c d e f' #文字列⇒リストへ変換する。 ※空白区切り abcl = abc.split() # ['a','b','c','d','e','f'] #リスト(文字)⇒文字列に変換する ※空白区切り a1=" ".join(abcl) # 'a,b,c,d,e,f' numl=[0,1,2,3,4,5,6,7,8,9] #リスト(数字)⇒文字列に変換する ※空白区切り <mapで事前にstr型にするのがポイント n1=" ".join(map(str,numl)) # '0 1 2 3 4 5 6 7 8 9'join splitについて詳しくはこちら
https://techacademy.jp/magazine/28688
https://note.nkmk.me/python-split-rsplit-splitlines-re/
https://hydrocul.github.io/wiki/programming_languages_diff/string/join.html
文字を結合・余分な空白を消す
これも覚えれば簡単
python6.pyst="hello" ed=" world" #2つの文字を結合 l1=st+ed # 'hello world' #余分な空白を消す ed.strip() # 'world'
- 投稿日:2020-11-23T18:05:40+09:00
【備忘録】ubuntuにてdockerインストールからJupyterLab起動までの流れ
はじめに
VPSサーバのubuntu内にdokcerをインストールして、jupyterlabの起動までを行います
前提
今回はAWSのlightsailを用いてubuntu環境を用意しました
https://qiita.com/s-inoue-git/items/1bcf1a28ed73090c3d86目次
- dockerインストール
- Dockerfileの転送
- containerの起動
1. dockerのインストール
sudo apt-get update sudo apt-get install docker.io docker --version #Docker version 19.03.8, build afacb8b7f0バージョン情報が確認できればインストールの成功です!
dockerコマンドのたびにsudoを入力するのが面倒なため、ユーザ(ubuntu)をdocker groupのなかに加えます
sudo gpasswd -a ubuntu docker #Adding user ubuntu to group docker exit #ログアウトしないとグループの追加が反映されません2. Dockerfileの転送
#sftp接続 sftp -i ~/.ssh/Lightsail_ubuntu_20201123.pem ubuntu@3.112.200.82 sftp> put Dockerfile今回は以下チュートリアルで作成したDockerfileを転送しました
https://qiita.com/s-inoue-git/items/2b5c65a1f11a1ba4a38e3. containerの起動
docker runのコマンドを実行
docker run -v $(pwd)/volume:/home/work -p 8888:8888 --name anaconda-env -it anaconda-imgあとは、ファイヤウオールの設定を変更して、どこからでもアクセスできるようにすれば、「パブリックIP:ポート番号」でアクセスできるようになります
今回は学習用なのでセキュリティー設定ガバガバです。。。
jupyter-labにアクセスできれば完了です!
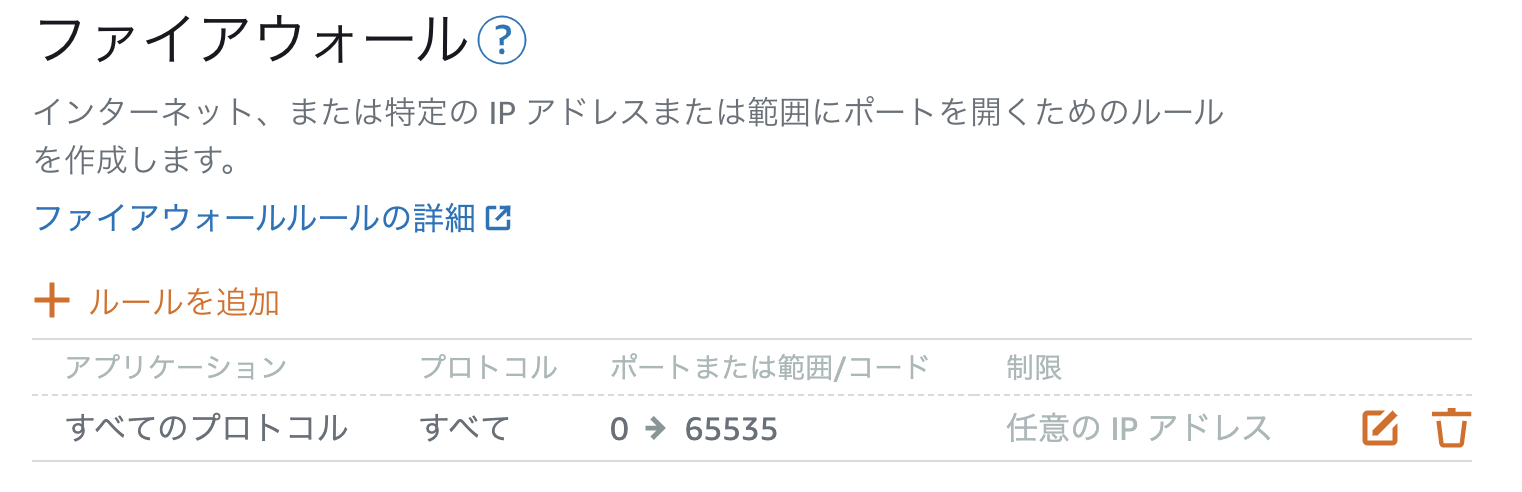
- 投稿日:2020-11-23T17:27:35+09:00
REST API開発での仕様書生成、コード生成(Python編)
内容
- REST API開発の効率化のため、ツールを使って仕様書生成、コード生成、スタイルチェック、自動フォーマットをすると思います。
- Pythonを対象に、私が便利だと思っているツールをまとめます。
- 開発エディターは、VSCodeです。
REST API関連
- OpenAPI仕様をyaml形式で書いて、REST APIのインターフェース仕様書生成とコード生成をします。
- インターフェース仕様書
- サーバー側のスタブ(コントローラー、HTTPリクエスト・レスポンスのモデル)
- フロント側のREST API用のクライアントSDK
- サーバースタブの生成は非常に便利です。
- PythonでFlaskのコードを生成すると、OpenAPI仕様をベースにHTTPリクエストの制御をするFlaskアプリ(connexionというライブラリでラップされている)のコントローラーまでできます。
- OpenAPI仕様を基に、HTTPリクエストのバリデーションをしてくれるので、自分でバリデーションのコードを開発する必要がありません。
- また、クライアント側に対しては、サーバー側が完成するまでのスタブサーバーとして利用することもできます。
- クライアントSDKも便利です。自分でエンドポイントやリクエストを作っていくより簡単です。
- 使用するツールは下記です。
用途 ツール名 説明 リンク OpenAPI仕様の編集 VSCode + OpenAPI Editor(拡張機能) VSCode上で、OpenAPI仕様を書きます。左サイドに、パスやスキーマの目次ができるのが便利です。 https://marketplace.visualstudio.com/items?itemName=42Crunch.vscode-openapi OpenAPI仕様の参照 VSCode + Swagger Viewer(拡張機能) OpenAPI仕様をドキュメントとして参照することができます。 https://marketplace.visualstudio.com/items?itemName=Arjun.swagger-viewer OpenAPI仕様のバリデーション openapi-generator CLIでOpenAPI仕様のバリデーションができます。
OpenAPI Editorでは検出しきれないエラーも検出できます。ただ、これでも検出しきれないバグはあります。例えば、スキーマでrequiredに設定した項目が、実はプロパティ定義されていないとか。こういったものは、サーバースタブをコード生成して、起動してみるとエラーするので気づきます。https://github.com/OpenAPITools/openapi-generator コード生成 openapi-generator OpenAPI仕様(yamlファイル)からコード生成(サーバースタブ、クライアントSDK)できます。 同上 ドキュメント生成 openapi-genrator REST APIインターフェース仕様書をHTML形式で生成します。 同上 Python関連
- 開発したコードから、クラス図、クラス仕様書を生成します。
- クラス仕様書を生成する前提として、docstringを書く必要があります。
- コード開発では、Linter(スタイルチェック)とFormatter(自動フォーマット)も便利です。
- 使用するツールは下記です。
用途 ツール名 説明 リンク クラス図の生成 Pyreverse クラス図生成 https://pypi.org/project/pylint/ クラス仕様書の生成 Sphinx クラス仕様書生成 https://www.sphinx-doc.org/ja/master/
Sphinxインストール手順docstringの記載補助 VSCode + Python Docstring Generator コードからdocstringの雛形を生成することができます。例えば、メソッドの場合は、サマリー行、引数の名前、型、戻り値の型がコードから生成されるので、自分では説明を書くだけでOKです。 https://marketplace.visualstudio.com/items?itemName=njpwerner.autodocstring Pythonのスタイルチェック VSCode + flake8 pep8に準拠しているかチェックして結果表示してくれます。 https://pypi.org/project/flake8/ Pythonの自動フォーマット VSCode + autopep8 ある程度、自動でpep8に準拠するようにコードを自動修正してくれます。例えば、クラス定義の上に2行空白行を開けるとか、引数に半角スペースを入れるとか。 https://pypi.org/project/autopep8/ DB関連
- コード開発では多くのケースでDBを利用します。
- GUIで、ER図、テーブル定義、DDL生成ができる便利なツールがあるので紹介します。
- EclipseのプラグインのERMasterです。
- ER図をGUIで書けば、そこからExcelのテーブル仕様書、DDL文を生成することができます。
- 概念データモデルはパワポやdraw.ioで書いて、論理データモデルからERMasterで書くと良いと思います。
用途 ツール名 説明 リンク ER図、テーブル定義、DDL生成 ERMaster Eclipseのプラグインで、GUIで、ER図、テーブル定義、DDL生成ができます。 http://ermaster.sourceforge.net/index_ja.html
- 投稿日:2020-11-23T17:21:10+09:00
【 Python】GoogleColaboratoryの最大の弱点・デメリット【初心者向き】
GoogleColaboratoryとは、という話は割愛しますが、普段GoogleColaboratoryを使用していて、「これは・・・」というデメリットがあったので、それを説明します。
主にデメリットは2つあります。
1.定期実行ができない
通称「12時間/90分ルール」ですね。
連続使用12時間という制約はそんな重たい操作をするわけではないので、そこまで困ることはないのですが、やはり定期実行できないというのはデメリットだなと感じました。
GUIが使用できない
個人的にこれが一番大きなデメリットでした。
例えばブラウザ操作の自動実行で、特にJavaScriptが使用されているサイトのスクレイピングの時に困ってました。
もちろん要素が指定できるのなら問題ないのですが、canvas要素をダウンロードする時とかはどうしてもGUIを使用します。これが使用できないというのが個人的にデメリットだと感じました。
結局、ローカルで環境構築した方が良い
結局のところ、ローカルで環境構築した方が良いです。
もちろん環境構築でエラーが多発するとイライラするので・・・
入り口としてGoogleColaboratoryは良いと思いますが、できることが増えてプログラミングにも慣れた勉強も兼ねてローカルでの環境構築はやった方がいいですね。あとはGoogleColaboratoryはスペックが非常に良いので、大量データの取り扱いは向いてますね。
ブラウザ操作とかは、できるけどやっぱりローカル環境の方が良いと思いました。ある程度プログラミングに慣れた今は環境構築もそんなに苦ではないです。
やはり何も知らないところでdockerやらAnacondaなどと言われてもわかりませんからね。
いきなり真っ赤なエラー文言見せつけられたら嫌になりますし、しかも英語だし。そういった点に耐性ついてから環境構築でも良いのかなと思います。
- 投稿日:2020-11-23T17:07:36+09:00
配列を繰り返して取り出す処理が言語によって微妙に違う…
for文で配列を1つづつ取り出して変数に代入したいことってよくありますよね。
色々な言語による微妙な違いで脳がやられます。ここではPython,JavaScript,PHPを取り上げます。
Pythonだと
for(変数 in 配列) #繰り返したい処理inなんですよね。そしてPythonは{}なしでインデントで表します。
でみんな大好きJSだと
//配列のとき for(変数 of 配列){ //繰り返したい処理 }ofなんですよね。ちなみにオブジェクトだとinを使います。
で、PHPだと
foreach($配列 as $変数){ //繰り返したい処理 }for文ではなくforeach使ってしかもasです。
混同しそうです………
- 投稿日:2020-11-23T16:54:26+09:00
〔備忘録〕pythonでHelloworldの出力
基本の基本
まずはこれですよね。Helloworldの出力をします。この程度の記事だけど1日1投稿頑張りたいです。
開発環境
- Windows10
- corei5
- エディタはAnacondaから導入したVisual Studio Codeさっそくやってみる
まずアナコンダを起動します。いま知ったのですがshift+Windowsキー+sで範囲をしていしてスクショを取れるんですね。しかもそのままコピペできます。便利。左下のVS Codeを起動します。
Vscodeが起動しました。もうすでにコードが記載されていますが、とりあえず備忘録のためそのまま行きます。
左上の作業用フォルダ(名前は任意。今回はqiita用とする。)を選択します。フォルダがない場合はフォルダ作成アイコンをクリックして任意の作業フォルダを作成してください。その後ファイル作成アイコンをクリックし「hello.py」というファイルを作成します。拡張子は.pyにするとパイソン用のファイルとなります。多少画像を加工してみました。パワーポイントで加工してます。
ファイルが作成されました。右側の部分がコード入力領域です。
下記のとおりコードを入力します。ちなみにMarkdownでqiitaの入力の際、下記のようにコード挿入する場合バッククオートでコードを囲む必要があります。バッククオートの出し方はWindowsの場合はshift+@で入力可能です。hello.pyprint("hello world")
今後実行しますが、一度保存しないと実行できないので、Ctrl+sで保存をしましょう。これ重要です。さあ実行です。実行には右上のターミナルでpythonファイルを実行をクリックします。すると右下のターミナルに実行結果が表示されます。なんだか達成感があります。

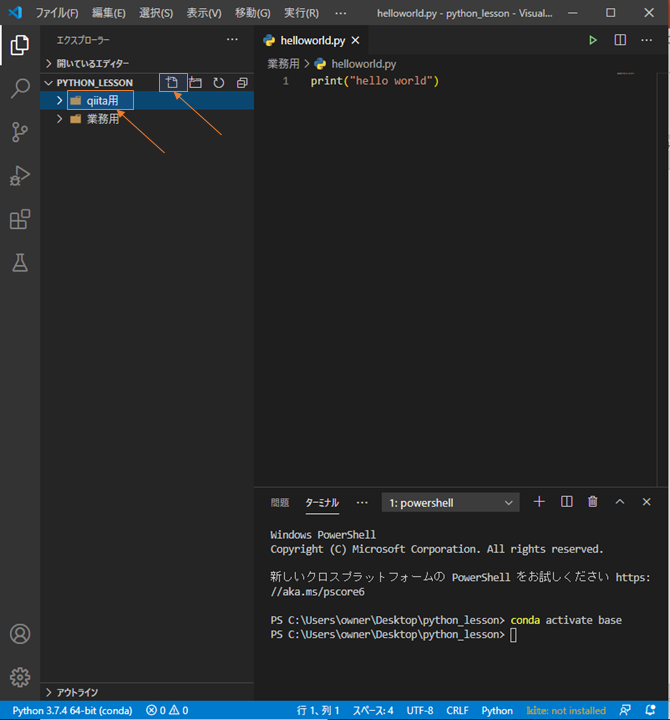
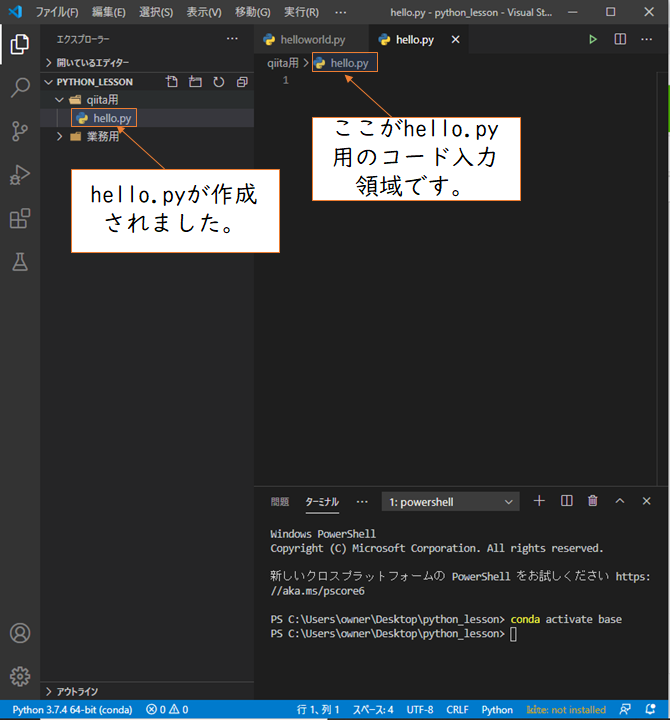

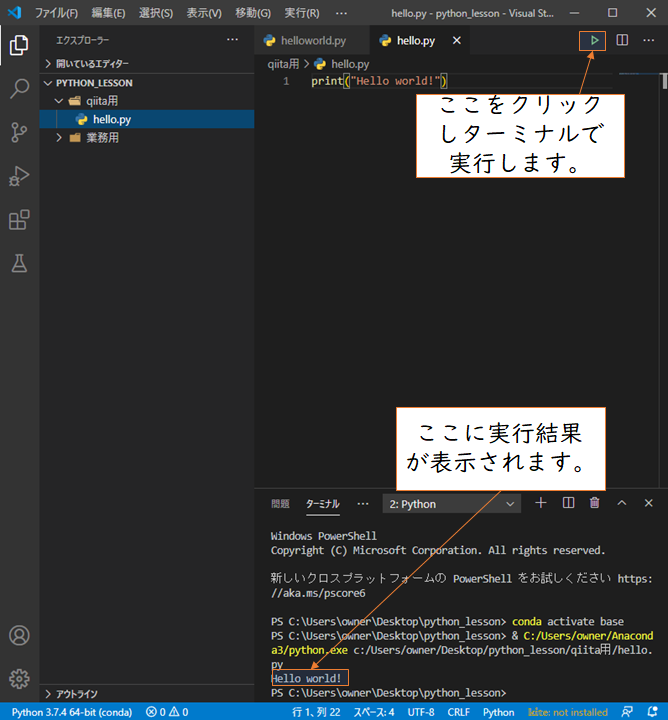
- 投稿日:2020-11-23T16:53:56+09:00
医療保険料のEDAと回帰問題
概要
会社で機械学習の知識がない課員にAIとかいうものの教育をする機会があるので、米国の医療保険料データを使ったEDA,クラスタリング,回帰問題の教材を作ることとした
データセットはKaggleのこれを使う
ざっと作ってみた感触は、ちょっと難しく感じられるかもしれなくって教材には使用しない
もっと簡単なものを別に用意することとしよう
- 実施期間: 2020年11月
- 環境:Google Colaboratory
データセット
insurance.csvの構成は下図の通り
医療保険料を示すchargesを今回の回帰による予測対象とする
各列の説明を転記しておく
Columns
age: age of primary beneficiary
sex: insurance contractor gender, female, male
bmi: Body mass index, providing an understanding of body, weights that are relatively high or low relative to height,
objective index of body weight (kg / m ^ 2) using the ratio of height to weight, ideally 18.5 to 24.9
children: Number of children covered by health insurance / Number of dependents
smoker: Smoking
region: the beneficiary's residential area in the US, northeast, southeast, southwest, northwest.
charges: Individual medical costs billed by health insuranceEDA(Explanatory Data Analysis)
馴染みのない言葉の方もおられるかもしれない
解析対象のデータセットの構造を確認し、どのように解析するか作戦を最初に立てるプロセスのこと(と思っている)
ツールの種類や慣れ、直感が必要
解析方法は人それぞれなので、以下は参考までにとどめていただきたいまず、ファイルを開いて中身とデータに欠損がないか確認する
import numpy as np import pandas as pd import os from sklearn.preprocessing import LabelEncoder import matplotlib.pyplot as plt import seaborn as sns df = pd.read_csv('insurance.csv') # Datasetの表示 print(df.tail()) # NaNの有無を確認 df.isnull().sum()
欠損がないことがわかる(あれば少し面倒なのでラッキー)
カテゴリデータが含まれているので、それらをLabelEncoderで数値化する# カテゴリデータのエンコード # sex le = LabelEncoder() le.fit(df.sex.drop_duplicates()) df.sex = le.transform(df.sex) # smoker or not le.fit(df.smoker.drop_duplicates()) df.smoker = le.transform(df.smoker) # region le.fit(df.region.drop_duplicates()) df.region = le.transform(df.region) # Datasetの表示 print(df.tail())
整数に置き換わっている
全体の相関係数を眺めて、chargesに影響を与えている説明変数にあたりをつけるprint(df.corr())
0.787251でsmokerがとても強い相関を示している
次が0.299008のage、肥満度を示すbmi(=体重/身長^2)の相関係数が思ったより小さいのが気になる
しかし、たった".corr()"だけで一発計算なので、Python使っててよかったと思うね全体の分布を表示する
sns.pairplot(df.loc[:, ['age', 'sex', 'bmi', 'children', 'smoker', 'region', 'charges']], height=2);
特徴的な分布は下図なので、age,bmi,smokerに集中する
どうも3つのグループに分けられそうだが、何が原因で3つに分割されたのか解析する
age-charges分布がとても特徴的
相関が強かったsmokerについて掘ってみる# smoker-chargesをハコヒゲで見てみる sns.boxplot(x="smoker", y="charges", data=df) # 数字で確認 df_s0 = df[df['smoker'] == 0] # 非喫煙者 df_s1 = df[df['smoker'] == 1] # 喫煙者 pd.set_option('display.max_rows', 20) pd.set_option('display.max_columns', None) print(' non smoker:\n' + str(df_s0.describe())) print('\n smoker:\n' + str(df_s1.describe())) print('\n 非喫煙者の医療保険料は、' + str(df_s1['charges'].mean() / df_s0['charges'].mean()) + '倍もかかっている。')
箱ひげ図から非喫煙者はchargesヒストグラムの左の高い山に相当することがわかる
逆に喫煙者のオレンジはchargesヒストグラムの低い2つの山がまとまったものといえる
非喫煙者だけで分布を確認する
sns.pairplot(df_s0.loc[:, ['age', 'bmi', 'charges']], height=2);
前述のage-charges分布が分離できた
あの特徴的な分布は喫煙か否かが影響してたらしい
非喫煙者でも年齢にかかわらず一定の割合で病院にかかるから、age-charges分布の上部散らばりがそれを表しているのか?
この散らばりとbmi-charges分布の散らばりがリンクしているようにみえるので、クラスタリングしてみるfrom sklearn.cluster import KMeans #from sklearn.cluster import MiniBatchKMeans df_wk = df_s0.drop(['sex', 'children', 'smoker', 'region'], axis=1) kmeans_model = KMeans(n_clusters=2, random_state=1, init='k-means++', n_init=10, max_iter=300, tol=0.0001, algorithm='auto', verbose=0).fit(df_wk) #kmeans_model = MiniBatchKMeans(n_clusters=2, random_state=0, max_iter=300, batch_size=100, verbose=0).fit(df_wk) df_wk['cluster'] = kmeans_model.labels_ labels = kmeans_model.labels_ print(labels.sum()) color_codes = {0:'r', 1:'g', 2:'b'} colors = [color_codes[x] for x in labels] ax1 = df_wk.plot.scatter(x='age', y='charges', c=colors) ax1 = df_wk.plot.scatter(x='bmi', y='charges', c=colors)
キレイに分離できなかったのは残念だが、前出の2つの分布図の散らばりはお互いに呼応しているといえる
ただ、BMIの大小にかかわらず全年齢でchargesが高い理由がわからない
childrenとregionはまだ調べてなく、どちらかというとchildrenのほうがbmiのばらつきに関係していそう
非喫煙者のchildren(=扶養家族数)ごとの分布を見れば、家族構成とbmiの関係がわかりそうdf_c0 = df_s0[df_s0['children'] == 0] # children = 0 df_c1 = df_s0[df_s0['children'] == 1] # children = 1 df_c2 = df_s0[df_s0['children'] == 2] # children = 2 df_c3 = df_s0[df_s0['children'] == 3] # children = 3 df_c4 = df_s0[df_s0['children'] == 4] # children = 4 df_c5 = df_s0[df_s0['children'] == 5] # children = 5 plt.figure(figsize=(12, 6)) plt.hist([df_c0['charges'], df_c1['charges'], df_c2['charges'], df_c3['charges'], df_c4['charges'], df_c5['charges']]
charges > 15000のヒストグラムに注目すると、chargesと子供の数に特徴は見えない
やっぱり、「非喫煙者でも年齢にかかわらず一定の割合で病院にかかるから」純粋にばらついているだけなのか?
charges > 15000においてbmiが正規分布でばらついているか検定してみるdf_b0 = df_s0[df_s0['charges'] > 15000] # children = 0 plt.hist([df_b0['bmi']])
import scipy.stats as stats stats.probplot(df_b0['bmi'], dist="norm", plot=plt) stats.shapiro(df_b0['bmi'])(0.9842953681945801, 0.3445127308368683)
ヒストグラムもQQプロットもシャピロ–ウィルク検定(p値=0.3445)も正規分布と言えないとは言えないことを示している
結局原因はなんかよくわからなかった
まぁ、正規分布ってことで、自然にばらついたことにしておこう…今度は喫煙者だけで分布を確認する
sns.pairplot(df_s1.loc[:, ['age', 'bmi', 'charges']], height=2);
直感的に下図のようにageとbmiが呼応しているように見える
非喫煙者のときと同様にクラスタリングしてみるdf_wk = df_s1.drop(['sex', 'children', 'smoker', 'region'], axis=1) kmeans_model = KMeans(n_clusters=2, random_state=1, init='k-means++', n_init=10, max_iter=300, tol=0.0001, algorithm='auto', verbose=0).fit(df_wk) df_wk['cluster'] = kmeans_model.labels_ labels = kmeans_model.labels_ print(labels.sum()) color_codes = {0:'r', 1:'g', 2:'b'} colors = [color_codes[x] for x in labels] ax1 = df_wk.plot.scatter(x='age', y='charges', c=colors) ax1 = df_wk.plot.scatter(x='bmi', y='charges', c=colors)
思っていたとおりだが、今度はキレイに分離できたEDAの結論
喫煙癖にかかわらず医療保険料が高額なのはBMIが高い人たちだが、年齢は関係ない(耳が痛い…)
喫煙者のデータからbmi=30を境に医療保険料が一段上昇することがわかった
この境がはっきりしすぎているので、例えば30を超えたら高額な検査項目が強制的に追加されるような行政上の縛りがあるのではないだろうかsns.regplot(x="bmi", y="charges", data=df_wk)
つまり、例えば上図のような回帰直線を引いてはならないことが今回のEDAからわかる単回帰、重回帰問題
非喫煙者について、chargesを回帰問題予測してみる
具体的には単回帰(ageのみ)と重回帰(age, bmi)でcharges予測精度の違いをRMSEで評価する
クラスタリング結果は使用しないので、ばらつきは含んだままとするfrom sklearn.model_selection import train_test_split from sklearn.neighbors import KNeighborsClassifier from sklearn.metrics import mean_squared_error from sklearn import metrics from sklearn import linear_model cv_alphas = [0.01, 0.1, 1, 10, 100] #交差検証用のα df_wk = df_s0.drop(['sex', 'children', 'smoker', 'region'], axis=1) # Predict結果の評価とプロット def regression_prid(clf_wk, df_wk, intSample=20, way='single'): arr_wk = df_wk.values[:intSample] arr_age, arr_agebmi, arr_charges = arr_wk[:,0], arr_wk[:,0:2], arr_wk[:,2] if way == 'single': arr_prid = clf_wk.predict(arr_age.reshape([intSample,1])) titel1='simple regression' titel2='RMSE(single) =\t' else: arr_prid = clf_wk.predict(arr_agebmi.reshape([intSample,2])) titel1='multiple regression' titel2='RMSE(multi) =\t' rmse = np.sqrt(mean_squared_error(arr_charges, arr_prid)) print(titel2 + str(rmse)) # プロット arr_chart = df_wk.values[:intSample].reshape([intSample,3]) arr_chart = np.hstack([arr_chart, arr_prid.reshape([intSample,1])]) fig = plt.figure(figsize=(8, 5)) ax = fig.add_subplot(1,1,1) ax.scatter(arr_chart[:,0],arr_chart[:,2], c='red') ax.scatter(arr_chart[:,0],arr_chart[:,3], c='blue') ax.set_title(titel1) ax.set_xlabel('age') ax.set_ylabel('charges') fig.show()最小二乗法による単回帰
clf = linear_model.LinearRegression() # 単回帰問題 clf.fit(df_wk[['age']], df_wk['charges']) regression_prid(clf, df_wk, 50, 'single') # 重回帰問題 clf.fit(df_wk[['age', 'bmi']], df_wk['charges']) regression_prid(clf, df_wk, 50, 'multi')
上がageで予測した単回帰で下がageとbmiで予測した重回帰
RMSEは20点で予測させた時のもので、単回帰のほうがやや精度が高い
元データがほぼ線形なので単回帰でも重回帰でも予測は直線に乗っているL2正則化による回帰
Ridge
RidgeCV
ちなみにCVはCloss Validation、交差検証のこと
交差検証の詳細はググってくださいcv_flag = True # True:交差検証 if cv_flag: clf = linear_model.RidgeCV(alphas=cv_alphas ,cv=3, normalize=False) # 単回帰問題 clf.fit(df_wk[['age']], df_wk['charges']) print("alpha =\t", clf.alpha_) regression_prid(clf, df_wk, 50, 'single') # 重回帰問題 clf.fit(df_wk[['age', 'bmi']], df_wk['charges']) print("alpha =\t", clf.alpha_) regression_prid(clf, df_wk, 50, 'multi') else: clf = linear_model.Ridge(alpha=1.0) # 単回帰問題 clf.fit(df_wk[['age']], df_wk['charges']) regression_prid(clf, df_wk, 50, 'single') # 重回帰問題 clf.fit(df_wk[['age', 'bmi']], df_wk['charges']) regression_prid(clf, df_wk, 50, 'multi')
交差検証を使って予測してみたが、やはり重回帰のほうがよろしくない
交差検証しなくてもRMSEはそれほど変わらない
やはりchargesがリニアに上昇しているから回帰手法による精度差が出にくなったと思うL1正則化による回帰
Lasso
LassoCV
上のコード中のRidgeをLassoに置き換えるだけなので省略
RMSEはほとんど変わらなかった
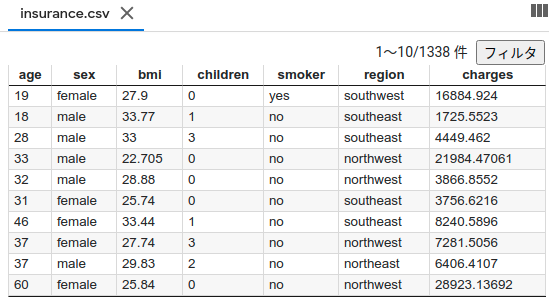
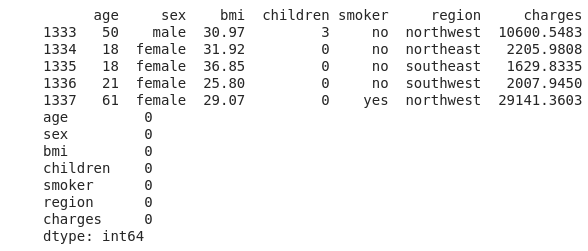

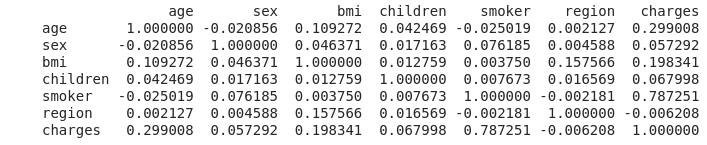
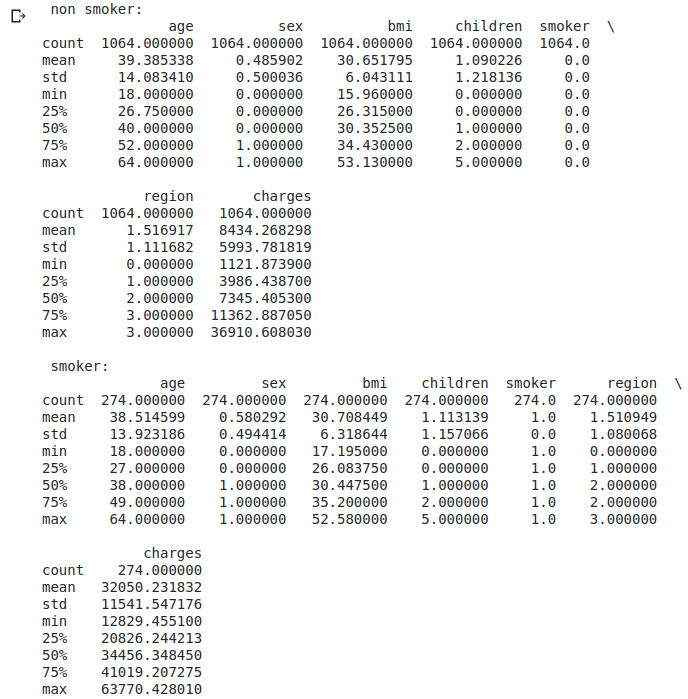
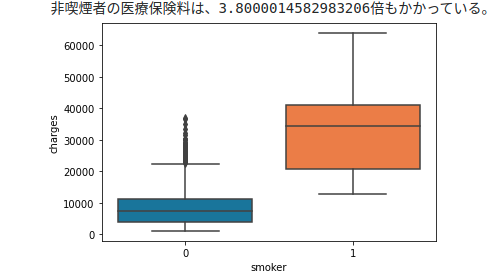
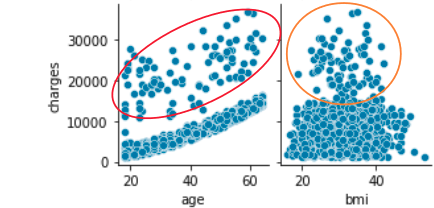


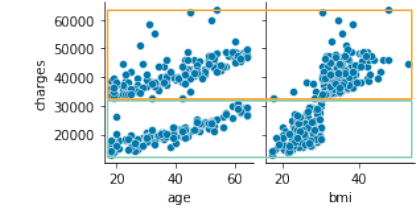
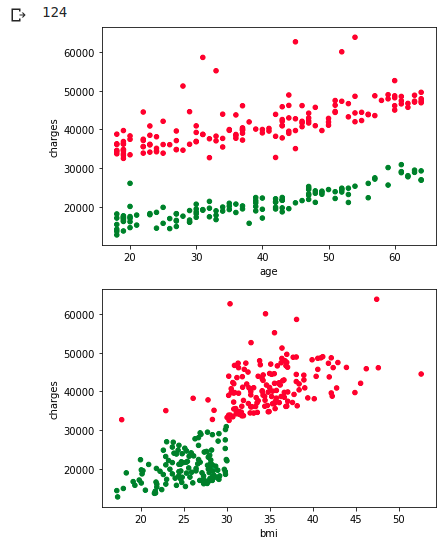

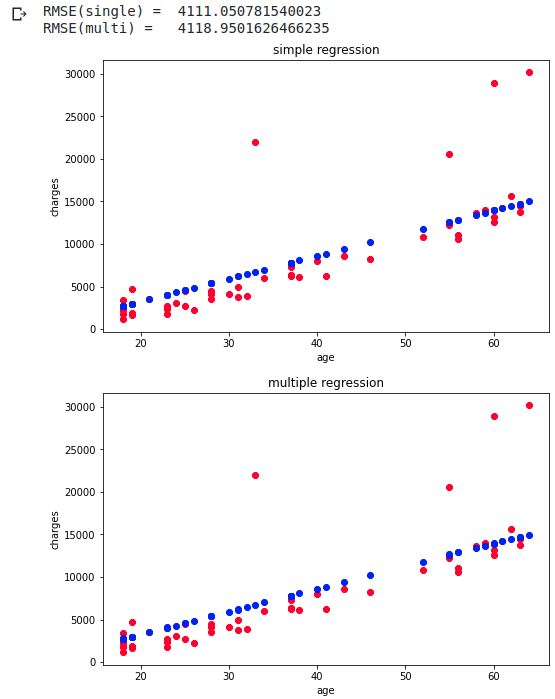
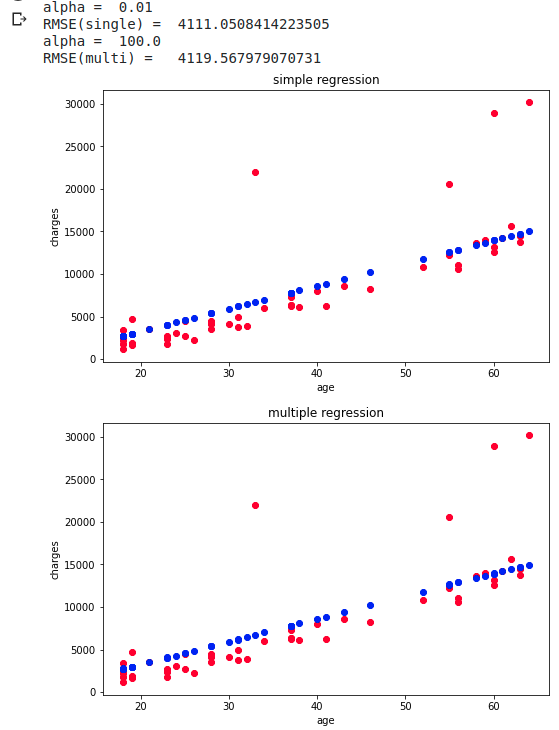
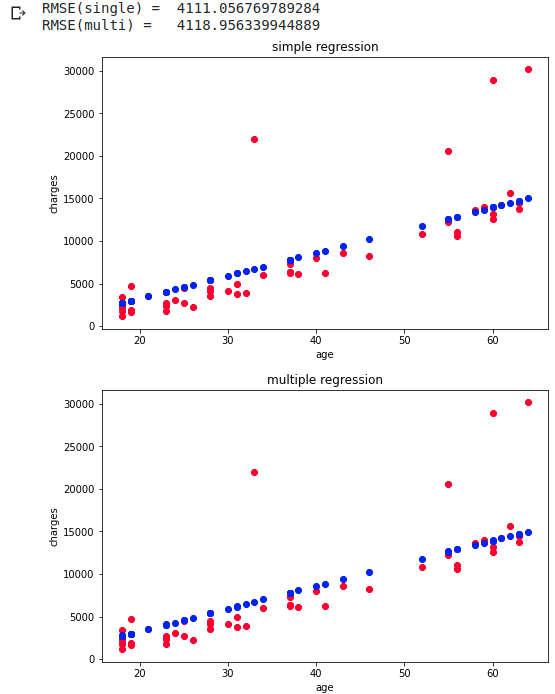
- 投稿日:2020-11-23T16:23:17+09:00
BERTがクイズショルダータックルにチャレンジする
はじめに
まずはこちらをご覧ください。
クイズショー
https://www.youtube.com/watch?v=m50H_0B78aQ&feature=emb_logo動作環境
- Google Colaboratory
- Huggingface Transformers 2.5.1
- Pytorch 1.5.0
- wikipedia 1.4.0
検証内容
- Wikipediaをコーパスとして学習したBERTが1000万相当の奴を獲得できるのかを検証する。
- ただし下記の制約あり。
- 画像、音声は文章化したうえで出題する。
- 発言カードは使えない。
実装内容
- ソースコードはほとんど下記サイトから引用。出題部を今回用に改変する。
- Building a QA System with BERT on Wikipedia
- 実装上、Answerを複数出す可能性があるので、一番先頭のAnswerをBERTの回答とする。
- 例:Answer: A / Bの場合、回答はAとみなす。
- 出題内容はこちら。
- 現在日本の首都は?
- アメリカの首都は?
- フランスの首都は?
- ドリンクを飲みますか?
- イギリスの首都は?
- ボツワナ共和国の首都は?
- オーストラリアの首都は?
- Noice or Roice?
- 回答できない場合、BERTは黙ってしまう。
ソースコード(出題部のみ)
questions = [ 'Where is the capital of Japan?', 'Where is the capital of the United States of America?', 'Where is the capital of France?', 'Would you like something to drink?', 'Where is the capital of the United Kingdom?', 'Where is the capital of Republic of Botswana?', 'Where is the capital of Australia?', 'Roise or Noise?' ] reader = DocumentReader("deepset/bert-base-cased-squad2") # if you trained your own model using the training cell earlier, you can access it with this: #reader = DocumentReader("./models/bert/bbu_squad2") for question in questions: answer = "" print(f"Question: {question}") results = wiki.search(question) for result in results: try: #page = wiki.page(results[0]) page = wiki.page(result) #print(f"Top wiki result: {page}") text = page.content reader.tokenize(question, text) except: print('PageError ocurred! Searching another page..') answer = reader.get_answer() if len(answer) >0: print(f"Answer: {answer}\n") break else: print("...")実行結果
それでは早速クイズショルダータックルを始めてみましょう。
- 【第1問】現在日本の首都は?
Question: Where is the capital of Japan? ... Answer: Tokyo / Heian - kyō ( modern Kyoto ) / Tokyo / Tokyo /正解ですね。平安京も答えに出てくるとは思いませんでしたが。
- 【第2問】アメリカの首都は?
Question: Where is the capital of the United States of America? ... Answer: Washington , D . C . / The District of Columbia /正解です。
- 【第3問】フランスの首都は?
Question: Where is the capital of France? Answer: Saint - Denis / Paris / [CLS] Where is the capital of France ? [SEP]toile , while the working - class neighbourhood of the Faubourg Saint - Antoine on the eastern site of the city grew more and more crowded with poor migrant workers from other regions of France . Paris was the centre of an explosion of philosophic and scientific activity known as the Age of Enlightenment . Diderot and d ' Alembert published their Encyclopédie in 1751 , and the Montgolfier Brothers launched the first manned flight in a hot - air balloon on 21 November 1783 , from the gardens of the Château de la Muette . Paris was the financial capital of continental Europe / Paris / Paris / Paris ' 16th arrondissement /畳みかけるように回答されてしまいました。
サン=ドニと答えていますね。次点でParisを回答しているの△でしょうか。
- 【第4問】ドリンクを飲みますか?
Question: Would you like something to drink? Answer: juice or soda /はい、飲んでください。
- 【第5問】イギリスの首都は?
Question: Where is the capital of the United Kingdom? ... Answer: London / London / Edinburgh /正解です。
- 【第6問】ボツワナ共和国の首都は?
Question: Where is the capital of Republic of Botswana? Answer: Gaborone / Gaborone /難問ですが、正解です。
- 【第7問】オーストラリアの首都は?
Question: Where is the capital of Australia? Answer: Canberra / Canberra / Canberra /こちらも正解ですね。
- 【第8問】Noice or Roice?
Question: Noice or Roice? ...黙り込んでしまいました。
運命を変える質問への答えはWikipediaにはなかったのかもしれません。まとめ
結局ポイントがどのくらい貯まったのか分からなかったので、1000万円の奴はまた次週にお預けとしましょう。
参考リンク
参考にさせていただきました。ありがとうございました。
Building a QA System with BERT on Wikipedia
チョコレートプラネットチャンネル
- 投稿日:2020-11-23T16:18:15+09:00
Actor-Criticモデル強化学習でブロック崩しを挑戦
はじめに
OpenAI Gymのブロック崩しを挑戦します。
OpenAIからお借りしたイメージ
https://gym.openai.com/videos/2019-10-21--mqt8Qj1mwo/Breakout-v0/poster.jpg今回はKerasを使ってActor-Criticモデルを構築して訓練ます。Kerasはより簡単にディープラーニングを導入するAPI、自分で調整する必要がある変数や関数が少ないので初心者向けいいサンプルだと思います。
Actor-Criticモデルは強化学習モデルの一つです。詳しい説明はTensorflowのブログに載せています。 (https://www.tensorflow.org/tutorials/reinforcement_learning/actor_critic) しかしリンクのCartPole例と違って、今回ブロック崩しをやります。CartPoleのような4つの変数より、ブロック崩し(每フレーム1枚84x84の画像)の方が遥かに多いのでCNNネットワークを使います。詳しい構成は後で説明します。
この記事は7月にGithubに投稿した記事に基づいて作成します。
https://github.com/leolui2004/atari_rl_ac結果
先に結果を載せます。1回訓練 = 1ゲームで、8時間をかけて5000回訓練した(episode)。結果はラスト50回の平均を取ります。1枚目はスコア、2枚目はステップ数(timestep)となります。
スコアは若干増えた感じがありますがステップ数の方がかなりいい結果が出ました。ちなみに最初は50回を平均取れないので異常に見えてしまいます。
やり方
ゲームプレイと強化学習分かれて説明します。ゲームプレイの部分はOpenAIのGym環境の中にゲームをやります。強化学習の部分はゲームからもらった変数を訓練して、予測したアクションをゲームに反映されます。
ゲームプレイ
import gym import random import numpy as np env = gym.make('Breakout-v4') episode_limit = 5000 random_step = 20 timestep_limit = 100000 #永遠にプレーできないように制限 model_train = 1 #0にすると訓練しない(ただのランダムプレー) log_save = 1 #0にするとログ保存しない log_path = 'atari_ac_log.txt' score_list = [] step_list = [] for episode in range(episode_limit): #毎回プレーする前に環境をリセット observation = env.reset() score = 0 #ボールの位置をランダムさせるために最初のランダムのステップ数で何もしない for _ in range(random.randint(1, random_step)): observation_last = observation observation, _, _, _ = env.step(0) #行動したの観測データをエンコード(後ほど説明) state = encode_initialize(observation, observation_last) for timestep in range(timestep_limit): observation_last = observation #予測するアクションをモデルから取得(後ほど説明) action = action_choose(state[np.newaxis, :], epsilon, episode, action_space) #予測したアクションに基づいて行動 observation, reward, done, _ = env.step(action) #行動したの観測データをエンコード(後ほど説明) state_next = encode(observation, observation_last, state) if model_train == 1: #行動したの観測データをモデルに送って学習させる(後ほど説明) network_learn(state[np.newaxis, :], action, reward, state_next[np.newaxis, :], done) state = state_next score += reward #ゲーム終わりもしくはtimestep_limit到達(強制終了) if done or timestep == timestep_limit - 1: #結果を記録 score_list.append(score) step_list.append(timestep) if log_save == 1: log(log_path, episode, timestep, score) print('Episode {} Timestep {} Score {}'.format(episode + 1, timestep, score)) break #アクションを一定の程度にランダムさせる関数(後ほど説明) epsilon = epsilon_reduce(epsilon, episode) env.close()強化学習
エンコードの部分はグレースケール転換、リサイズと4つ連続の84x84の画像(フレーム)を合成します。これによるとよりボールのアクションを記録できて、訓練しやすいということです。
from skimage.color import rgb2gray from skimage.transform import resize frame_length = 4 frame_width = 84 frame_height = 84 def encode_initialize(observation, last_observation): processed_observation = np.maximum(observation, last_observation) processed_observation_resize = np.uint8(resize(rgb2gray(processed_observation), (frame_width, frame_height)) * 255) state = [processed_observation_resize for _ in range(frame_length)] state_encode = np.stack(state, axis=0) return state_encode def encode(observation, last_observation, state): processed_observation = np.maximum(observation, last_observation) processed_observation_resize = np.uint8(resize(rgb2gray(processed_observation), (frame_width, frame_height)) * 255) state_next_return = np.reshape(processed_observation_resize, (1, frame_width, frame_height)) state_encode = np.append(state[1:, :, :], state_next_return, axis=0) return state_encodeネットワークと訓練の部分は一番難しいですが、最初に図で表現するとこんな感じです。
先エンコードしたデータを2階層のConv2D層に送ります。そして平坦化して、2階層のDense層に送ります。最後に出力は4つ(OpenAI Gym Breakout-v4の仕様上で NOPE, FIRE, LEFT, RIGHT)となります。ちなみに活性化関数はreluで、ロス関数は論文通り、学習率はactor, critic両方とも0.001、それぞれを設定します。
from keras import backend as K from keras.layers import Dense, Input, Flatten, Conv2D from keras.models import Model, load_model from keras.optimizers import Adam from keras.utils import plot_model verbose = 0 action_dim = env.action_space.n action_space = [i for i in range(action_dim)] # ['NOOP', 'FIRE', 'RIGHT', 'LEFT'] discount = 0.97 actor_lr = 0.001 #actorの学習率 critic_lr = 0.001 #criticの学習率 pretrain_use = 0 #1にすると訓練されたモデルを使う actor_h5_path = 'atari_ac_actor.h5' critic_h5_path = 'atari_ac_critic.h5' #モデル構築 input = Input(shape=(frame_length, frame_width, frame_height)) delta = Input(shape=[1]) con1 = Conv2D(32, (8, 8), strides=(4, 4), padding='same', activation='relu')(input) con2 = Conv2D(64, (4, 4), strides=(2, 2), padding='same', activation='relu')(con1) fla1 = Flatten()(con2) dense = Dense(128, activation='relu')(fla1) #prob, valueをシェア prob = Dense(action_dim, activation='softmax')(dense) #actor部分 value = Dense(1, activation='linear')(dense) #critic部分 #ロス関数の定義 def custom_loss(y_true, y_pred): out = K.clip(y_pred, 1e-8, 1-1e-8) #限界を設定 log_lik = y_true * K.log(out) #方策勾配 return K.sum(-log_lik * delta) if pretrain_use == 1: #訓練されたモデルを使う actor = load_model(actor_h5_path, custom_objects={'custom_loss': custom_loss}, compile=False) critic = load_model(critic_h5_path) actor = Model(inputs=[input, delta], outputs=[prob]) critic = Model(inputs=[input], outputs=[value]) policy = Model(inputs=[input], outputs=[prob]) actor.compile(optimizer=Adam(lr=actor_lr), loss=custom_loss) critic.compile(optimizer=Adam(lr=critic_lr), loss='mean_squared_error') #アクションを予測 def action_choose(state, epsilon, episode, action_space): #epsilonは最初に1に設定して徐々に下げる #毎回行動する時ランダム数字と比べて #epsilonの方が大きいならランダムアクションを取る if epsilon >= random.random() or episode < initial_replay: action = random.randrange(action_dim) else: probabiliy = policy.predict(state)[0] #予測した結果は4つのアクションに対してそれぞれ確率がある #その確率に沿ってアクションを選ぶ action = np.random.choice(action_space, p=probabiliy) return action #データを学習 def network_learn(state, action, reward, state_next, done): reward_clip = np.sign(reward) critic_value = critic.predict(state) critic_value_next = critic.predict(state_next) target = reward_clip + discount * critic_value_next * (1 - int(done)) delta = target - critic_value actions = np.zeros([1, action_dim]) actions[np.arange(1), action] = 1 actor.fit([state, delta], actions, verbose=verbose) critic.fit(state, target, verbose=verbose)この部分は他の機能として強化学習との直接関係がないですけどを合わせて書きます。
import matplotlib.pyplot as plt model_save = 1 #0にするとモデルを保存しない score_avg_freq = 50 epsilon_start = 1.0 #epsilon開始時の確率 epsilon_end = 0.1 #epsilon最低の確率(最低でも10%でランダムアクション) epsilon_step = episode_limit epsilon = 1.0 epsilon_reduce_step = (epsilon_start - epsilon_end) / epsilon_step initial_replay = 200 actor_graph_path = 'atari_ac_actor.png' critic_graph_path = 'atari_ac_critic.png' policy_graph_path = 'atari_ac_policy.png' #epsilon下げさせるの関数 def epsilon_reduce(epsilon, episode): if epsilon > epsilon_end and episode >= initial_replay: epsilon -= epsilon_reduce_step return epsilon #ログを書く def log(log_path, episode, timestep, score): logger = open(log_path, 'a') if episode == 0: logger.write('Episode Timestep Score\n') logger.write('{} {} {}\n'.format(episode + 1, timestep, score)) logger.close() if pretrain_use == 1: if model_save == 1: actor.save(actor_h5_path) critic.save(critic_h5_path) else: if model_save == 1: actor.save(actor_h5_path) critic.save(critic_h5_path) #モデル構成を図に出力 plot_model(actor, show_shapes=True, to_file=actor_graph_path) plot_model(critic, show_shapes=True, to_file=critic_graph_path) plot_model(policy, show_shapes=True, to_file=policy_graph_path) #結果を図に出力 xaxis = [] score_avg_list = [] step_avg_list = [] for i in range(1, episode_limit + 1): xaxis.append(i) if i < score_avg_freq: score_avg_list.append(np.mean(score_list[:])) step_avg_list.append(np.mean(step_list[:])) else: score_avg_list.append(np.mean(score_list[i - score_avg_freq:i])) step_avg_list.append(np.mean(step_list[i - score_avg_freq:i])) plt.plot(xaxis, score_avg_list) plt.show() plt.plot(xaxis, step_avg_list) plt.show()

- 投稿日:2020-11-23T15:15:59+09:00
PyCUDAのビルドエラー備忘録
PyCUDAの環境構築後,ビルドエラーに悩まされるので対処法を備忘録メモとして残しておこうと思います。
環境情報
- OS: Ubuntu20.04 LTS
- GPU: NVIDIA RTX2080 SUPER
- CUDA: 10.1
- Python: 3.8
エラーの内容
GPU上に行列を作ろうとする(内部でソースビルド処理)時にエラーが発生します。これはgcc, g++のバージョン(C,C++のコンパイラ)のバージョンに起因します。Ubuntu20.04ではgcc, g++のバージョン9がデフォルトですが,PyCUDAではGCC8までしか対応していません。故にダウングレードが必要です。
CompileError: nvcc preprocessing of /tmp/tmpu7gbjsl2.cu failed [command: nvcc --preprocess -arch sm_75 -I/opt/conda/lib/python3.8/site-packages/pycuda/cuda /tmp/tmpu7gbjsl2.cu --compiler-options -P] [stderr: b'In file included from /usr/local/cuda-10.1/bin/../targets/x86_64-linux/include/cuda_runtime.h:83,\n from <command-line>:\n/usr/local/cuda-10.1/bin/../targets/x86_64-linux/include/crt/host_config.h:129:2: error: #error -- unsupported GNU version! gcc versions later than 8 are not supported!\n 129 | #error -- unsupported GNU version! gcc versions later than 8 are not supported!\n | ^~~~~\n']gcc,g++のバージョンの確認
gcc, g++のバージョンを確認します。gcc, g++共に
バージョン9がデフォルトであることが分かります。$ gcc -v Using built-in specs. COLLECT_GCC=gcc COLLECT_LTO_WRAPPER=/usr/lib/gcc/x86_64-linux-gnu/9/lto-wrapper OFFLOAD_TARGET_NAMES=nvptx-none:hsa OFFLOAD_TARGET_DEFAULT=1 Target: x86_64-linux-gnu Configured with: ../src/configure -v --with-pkgversion='Ubuntu 9.3.0-17ubuntu1~20.04' --with-bugurl=file:///usr/share/doc/gcc-9/README.Bugs --enable-languages=c,ada,c++,go,brig,d,fortran,objc,obj-c++,gm2 --prefix=/usr --with-gcc-major-version-only --program-suffix=-9 --program-prefix=x86_64-linux-gnu- --enable-shared --enable-linker-build-id --libexecdir=/usr/lib --without-included-gettext --enable-threads=posix --libdir=/usr/lib --enable-nls --enable-clocale=gnu --enable-libstdcxx-debug --enable-libstdcxx-time=yes --with-default-libstdcxx-abi=new --enable-gnu-unique-object --disable-vtable-verify --enable-plugin --enable-default-pie --with-system-zlib --with-target-system-zlib=auto --enable-objc-gc=auto --enable-multiarch --disable-werror --with-arch-32=i686 --with-abi=m64 --with-multilib-list=m32,m64,mx32 --enable-multilib --with-tune=generic --enable-offload-targets=nvptx-none=/build/gcc-9-HskZEa/gcc-9-9.3.0/debian/tmp-nvptx/usr,hsa --without-cuda-driver --enable-checking=release --build=x86_64-linux-gnu --host=x86_64-linux-gnu --target=x86_64-linux-gnu Thread model: posix gcc version 9.3.0 (Ubuntu 9.3.0-17ubuntu1~20.04) $ ll /usr/bin/gcc lrwxrwxrwx 1 root root 14 Nov 23 05:53 /usr/bin/gcc -> /usr/bin/gcc-9* $ g++ -v Using built-in specs. COLLECT_GCC=g++ COLLECT_LTO_WRAPPER=/usr/lib/gcc/x86_64-linux-gnu/9/lto-wrapper OFFLOAD_TARGET_NAMES=nvptx-none:hsa OFFLOAD_TARGET_DEFAULT=1 Target: x86_64-linux-gnu Configured with: ../src/configure -v --with-pkgversion='Ubuntu 9.3.0-17ubuntu1~20.04' --with-bugurl=file:///usr/share/doc/gcc-9/README.Bugs --enable-languages=c,ada,c++,go,brig,d,fortran,objc,obj-c++,gm2 --prefix=/usr --with-gcc-major-version-only --program-suffix=-9 --program-prefix=x86_64-linux-gnu- --enable-shared --enable-linker-build-id --libexecdir=/usr/lib --without-included-gettext --enable-threads=posix --libdir=/usr/lib --enable-nls --enable-clocale=gnu --enable-libstdcxx-debug --enable-libstdcxx-time=yes --with-default-libstdcxx-abi=new --enable-gnu-unique-object --disable-vtable-verify --enable-plugin --enable-default-pie --with-system-zlib --with-target-system-zlib=auto --enable-objc-gc=auto --enable-multiarch --disable-werror --with-arch-32=i686 --with-abi=m64 --with-multilib-list=m32,m64,mx32 --enable-multilib --with-tune=generic --enable-offload-targets=nvptx-none=/build/gcc-9-HskZEa/gcc-9-9.3.0/debian/tmp-nvptx/usr,hsa --without-cuda-driver --enable-checking=release --build=x86_64-linux-gnu --host=x86_64-linux-gnu --target=x86_64-linux-gnu Thread model: posix gcc version 9.3.0 (Ubuntu 9.3.0-17ubuntu1~20.04) $ ll /usr/bin/g++ lrwxrwxrwx 1 root root 14 Nov 23 05:54 /usr/bin/g++ -> /usr/bin/g++-9*ダウングレードの実施
gcc8, g++8のインストール
パッケージマネージャーの
aptを用いてgcc-8,g++-8をインストールします。sudo apt install -y gcc-8 g++-8シンボリックリンクの作成
gcc,g++のデフォルトのバージョンが8になる様にシンボリックリンクを作成します。sudo ln -fs /usr/bin/gcc-8 /usr/bin/gcc sudo ln -fs /usr/bin/g++-8 /usr/bin/gcc
- 投稿日:2020-11-23T15:15:59+09:00
PyCUDAのビルドエラー対処備忘録
PyCUDAの環境構築後,ビルドエラーに悩まされるので対処法を備忘録メモとして残しておこうと思います。
環境情報
- OS: Ubuntu20.04 LTS
- GPU: NVIDIA RTX2080 SUPER
- CUDA: 10.1
- Python: 3.8
- PyCUDA: 2020.1
エラーの内容
GPU上に行列を作ろうとする(内部でソースビルド処理)時にエラーが発生します。これはgcc, g++のバージョン(C,C++のコンパイラ)のバージョンに起因します。Ubuntu20.04ではgcc, g++のバージョン9がデフォルトですが,PyCUDAではGCC8までしか対応していません。故にダウングレードが必要です。
CompileError: nvcc preprocessing of /tmp/tmpu7gbjsl2.cu failed [command: nvcc --preprocess -arch sm_75 -I/opt/conda/lib/python3.8/site-packages/pycuda/cuda /tmp/tmpu7gbjsl2.cu --compiler-options -P] [stderr: b'In file included from /usr/local/cuda-10.1/bin/../targets/x86_64-linux/include/cuda_runtime.h:83,\n from <command-line>:\n/usr/local/cuda-10.1/bin/../targets/x86_64-linux/include/crt/host_config.h:129:2: error: #error -- unsupported GNU version! gcc versions later than 8 are not supported!\n 129 | #error -- unsupported GNU version! gcc versions later than 8 are not supported!\n | ^~~~~\n']gcc,g++のバージョンの確認
gcc, g++のバージョンを確認します。gcc, g++共に
バージョン9がデフォルトであることが分かります。$ gcc -v Using built-in specs. COLLECT_GCC=gcc COLLECT_LTO_WRAPPER=/usr/lib/gcc/x86_64-linux-gnu/9/lto-wrapper OFFLOAD_TARGET_NAMES=nvptx-none:hsa OFFLOAD_TARGET_DEFAULT=1 Target: x86_64-linux-gnu Configured with: ../src/configure -v --with-pkgversion='Ubuntu 9.3.0-17ubuntu1~20.04' --with-bugurl=file:///usr/share/doc/gcc-9/README.Bugs --enable-languages=c,ada,c++,go,brig,d,fortran,objc,obj-c++,gm2 --prefix=/usr --with-gcc-major-version-only --program-suffix=-9 --program-prefix=x86_64-linux-gnu- --enable-shared --enable-linker-build-id --libexecdir=/usr/lib --without-included-gettext --enable-threads=posix --libdir=/usr/lib --enable-nls --enable-clocale=gnu --enable-libstdcxx-debug --enable-libstdcxx-time=yes --with-default-libstdcxx-abi=new --enable-gnu-unique-object --disable-vtable-verify --enable-plugin --enable-default-pie --with-system-zlib --with-target-system-zlib=auto --enable-objc-gc=auto --enable-multiarch --disable-werror --with-arch-32=i686 --with-abi=m64 --with-multilib-list=m32,m64,mx32 --enable-multilib --with-tune=generic --enable-offload-targets=nvptx-none=/build/gcc-9-HskZEa/gcc-9-9.3.0/debian/tmp-nvptx/usr,hsa --without-cuda-driver --enable-checking=release --build=x86_64-linux-gnu --host=x86_64-linux-gnu --target=x86_64-linux-gnu Thread model: posix gcc version 9.3.0 (Ubuntu 9.3.0-17ubuntu1~20.04) $ ll /usr/bin/gcc lrwxrwxrwx 1 root root 14 Nov 23 05:53 /usr/bin/gcc -> /usr/bin/gcc-9* $ g++ -v Using built-in specs. COLLECT_GCC=g++ COLLECT_LTO_WRAPPER=/usr/lib/gcc/x86_64-linux-gnu/9/lto-wrapper OFFLOAD_TARGET_NAMES=nvptx-none:hsa OFFLOAD_TARGET_DEFAULT=1 Target: x86_64-linux-gnu Configured with: ../src/configure -v --with-pkgversion='Ubuntu 9.3.0-17ubuntu1~20.04' --with-bugurl=file:///usr/share/doc/gcc-9/README.Bugs --enable-languages=c,ada,c++,go,brig,d,fortran,objc,obj-c++,gm2 --prefix=/usr --with-gcc-major-version-only --program-suffix=-9 --program-prefix=x86_64-linux-gnu- --enable-shared --enable-linker-build-id --libexecdir=/usr/lib --without-included-gettext --enable-threads=posix --libdir=/usr/lib --enable-nls --enable-clocale=gnu --enable-libstdcxx-debug --enable-libstdcxx-time=yes --with-default-libstdcxx-abi=new --enable-gnu-unique-object --disable-vtable-verify --enable-plugin --enable-default-pie --with-system-zlib --with-target-system-zlib=auto --enable-objc-gc=auto --enable-multiarch --disable-werror --with-arch-32=i686 --with-abi=m64 --with-multilib-list=m32,m64,mx32 --enable-multilib --with-tune=generic --enable-offload-targets=nvptx-none=/build/gcc-9-HskZEa/gcc-9-9.3.0/debian/tmp-nvptx/usr,hsa --without-cuda-driver --enable-checking=release --build=x86_64-linux-gnu --host=x86_64-linux-gnu --target=x86_64-linux-gnu Thread model: posix gcc version 9.3.0 (Ubuntu 9.3.0-17ubuntu1~20.04) $ ll /usr/bin/g++ lrwxrwxrwx 1 root root 14 Nov 23 05:54 /usr/bin/g++ -> /usr/bin/g++-9*ダウングレードの実施
gcc8, g++8のインストール
パッケージマネージャーの
aptを用いてgcc-8,g++-8をインストールします。sudo apt install -y gcc-8 g++-8シンボリックリンクの作成
gcc,g++のデフォルトのバージョンが8になる様にシンボリックリンクを作成します。sudo ln -fs /usr/bin/gcc-8 /usr/bin/gcc sudo ln -fs /usr/bin/g++-8 /usr/bin/gccまとめ
以上の方法でビルドエラーは発生しなくなります。PyCUDAは他にもCUDA10.1までにしか対応していないなど環境構築に厄介な条件をクリアしないと使えないことがしばしば有ります。今後改善されることを願いたい(コントリビュートも検討)ものです。記念すべき50報目の記事がエラー対処の記事になりました。2020年は投稿50報目達成を目標にやってきましたが,想定とは違う形で達成となりました。2021年も引き続き毎月1報以上を目標にやっていきたいと思います。
Reference
- 投稿日:2020-11-23T14:33:22+09:00
多クラス分類の ROC 曲線
目的
xlsx や csv 形式で保存した多クラス分類の予測値を pandas で読み込んで ROC 曲線を書くときの備忘録。
あとは、Qiita の記事作成練習も兼ねています。ROC 曲線について
基本的な話に関しては、本稿では触れません。
ROC 曲線の話については こちら の記事が判りやすいです。ラベルの形式変更
まずは、データ形式を確認。
- GT は 0, 1, 2 の数値を持っており、各ラベルに対応している。
- C1, C2, C3: 各ラベル C1 = 0.0, C2 = 1.0, C3 = 2.0
- M1, M2, M3: 各モデルROC 曲線は 0, 1 のバイナリに変換する必要があるため、
from sklearn.preprocessing import label_binarize y_test = label_binarize(df.iloc[:, 0], classes=[0,1,2])sklearn の label_binarize を使い、バイナリ変換します。
ちょっと長いので、上の部分のみ。
バイナリ変換した結果、C1 = [1, 0, 0], C2 = [0, 1, 0], C3 = [0, 0, 1] になりました。予測値のリスト化
ラベルをバイナリ化した後は、各モデルの予測値も対応するリストに変換する必要があります。
M1_y_score = [] M2_y_score = [] M3_y_score = [] for i in df.index: M1_y_score.append(([df.iloc[i, 1], df.iloc[i, 2], df.iloc[i, 3]])) M2_y_score.append(([df.iloc[i, 4], df.iloc[i, 5], df.iloc[i, 6]])) M3_y_score.append(([df.iloc[i, 7], df.iloc[i, 8], df.iloc[i, 9]])) M1_y_score = M1_y_score M2_y_score = M2_y_score M3_y_score = M3_y_scoreこんな感じで、ループ処理を実行し、予測値を格納しました。
一応この時点で、from sklearn.metrics import roc_auc_score auc_m1 = roc_auc_score(y_test, M1_y_score, multi_class="ovo") print(auc_m1)と打つと、多クラスの AUC を求めることができます。
引数 multi_class は "ovo" か "ovr" のどちらかを設定しないとエラーを吐くようです。
詳しくは sklearn のドキュメント に記載されています。FPR, TPR の計算
この部分が少し躓いたところです。
M1_fpr = dict() M1_tpr = dict() M1_roc_auc = dict() M2_fpr = dict() M2_tpr = dict() M2_roc_auc = dict() M3_fpr = dict() M3_tpr = dict() M3_roc_auc = dict()データを格納する空の辞書を作成した後、
n_class = 3 from sklearn.metrics import roc_curve, auc for i in range(n_classes): M1_fpr[i], M1_tpr[i], _ = roc_curve(y_test[:, i], M1_y_score[:, i]) M1_roc_auc[i] = auc(M1_fpr[i], M1_tpr[i]) M2_fpr[i], M2_tpr[i], _ = roc_curve(y_test[:, i], M2_y_score[:, i]) M2_roc_auc[i] = auc(M2_fpr[i], M2_tpr[i]) M3_fpr[i], M3_tpr[i], _ = roc_curve(y_test[:, i], M3_y_score[:, i]) M3_roc_auc[i] = auc(M3_fpr[i], M3_tpr[i])ラベルの数だけループして、各モデルの fpr と tpr を格納するのですが、
何故かエラーが出てしまう!
予測値を格納する際に、ndarray にしていなかったのが原因でした。
なので、上記のコードを少し変えて…M1_y_score = np.array(M1_y_score) M2_y_score = np.array(M2_y_score) M3_y_score = np.array(M3_y_score)ndarray 型にすることで、辞書にデータを格納できるようになりました。
あとは、公式ドキュメント通りにコーディングすれば OK!M1_all_fpr = np.unique(np.concatenate([M1_fpr[i] for i in range(n_classes)])) M2_all_fpr = np.unique(np.concatenate([M2_fpr[i] for i in range(n_classes)])) M3_all_fpr = np.unique(np.concatenate([M3_fpr[i] for i in range(n_classes)])) M1_mean_tpr = np.zeros_like(M1_all_fpr) M2_mean_tpr = np.zeros_like(M2_all_fpr) M3_mean_tpr = np.zeros_like(M3_all_fpr) for i in range(n_classes): M1_mean_tpr += np.interp(M1_all_fpr, M1_fpr[i], M1_tpr[i]) M2_mean_tpr += np.interp(M2_all_fpr, M2_fpr[i], M2_tpr[i]) M3_mean_tpr += np.interp(M3_all_fpr, M3_fpr[i], M3_tpr[i]) M1_mean_tpr /= n_classes M2_mean_tpr /= n_classes M3_mean_tpr /= n_classes M1_fpr["macro"] = M1_all_fpr M1_tpr["macro"] = M1_mean_tpr M1_roc_auc["macro"] = auc(M1_fpr["macro"], M1_tpr["macro"]) M2_fpr["macro"] = M2_all_fpr M2_tpr["macro"] = M2_mean_tpr M2_roc_auc["macro"] = auc(M2_fpr["macro"], M2_tpr["macro"]) M3_fpr["macro"] = M3_all_fpr M3_tpr["macro"] = M3_mean_tpr M3_roc_auc["macro"] = auc(M3_fpr["macro"], M3_tpr["macro"])ROC 曲線の描写
ここまでできたら後は、matplotlib を使ってグラフ化するだけです。
import matplotlib.pyplot as plt from matplotlib import cm lw=1 colors = [cm.gist_ncar(190), cm.gist_ncar(30), cm.gist_ncar(10)] sns.color_palette(colors) sns.set_palette(colors, desat=1.0) plt.figure(figsize=(6, 6)) plt.plot(M1_fpr["macro"], M1_tpr["macro"], label='M1', color=colors[0], linestyle='-', linewidth=2) plt.plot(M2_fpr["macro"], M2_tpr["macro"], label='M2', color=colors[1], linestyle='-', linewidth=2) plt.plot(M3_fpr["macro"], M3_tpr["macro"], label='M3', color=colors[2], linestyle='-', linewidth=2) plt.plot([0, 1], [0, 1], 'k--', lw=lw) plt.xlim([0.0, 1.0]) plt.ylim([0.0, 1.05]) plt.xlabel('False Positive Rate') plt.ylabel('True Positive Rate') plt.legend(loc="lower right") plt.show()
マクロ平均を使った多クラス分類の ROC 曲線が描写できました。

- 投稿日:2020-11-23T14:15:19+09:00
Pythonで設定ファイルを作ってみた
Pythonベースで設定ファイル作ってみた
色々なファイル形式を使ったが、jsonとyaml、toml以外は可読性が低いことjsonはコメントが書けないことが不満だったのと、ラムダ式が入れれないのが不満なので作ってみた。
※以下のPysonはPYthon Setting Object Notationから。
pyson.pyimport sys import argparse class File(dict): @classmethod def Load(cls,path): data = None with open(path,'r',encoding="utf-8") as fln: var = [] for f in fln.read(): if(f.strip() == "" or f.strip()[0:1] == '#' or f.strip().split('(')[0] == '__import__'): continue else: var.append(f) data = cls.__Ld(var) ret = eval(data) return ret @classmethod def __Ld(cls,var): ret = "" for val in var: ret += val return ret load = File.LoadClasses.pyson{ "Vector3":lambda:[0 for var in range(3)], "Vector4":lambda:[0 for var in range(4)], "Matrix3x3":lambda:[[0 for x in range(3)]for y in range(3)], "Matrix4x4":lambda:[[0 for x in range(4)]for y in range(4)], #単位行列化 "Identity":lambda mat:[[1 if x==y else 0 for x in range(len(mat[y]))]for y in range(len(mat))], "is_liveing":True }Setting.pyson( "1",True,3.5 )app.pyimport pyson ldfil = pyson.load("Classes.pyson") stngfil = pyson.load("Setting.pyson") mat = ldfil["Identity"](ldfil["Matrix4x4"]()) print("単位行列(4x4):",mat) print("設定出来ている?:",stngfil[1])単位行列(4x4):[[1,0,0,0],[0,1,0,0],[0,0,1,0],[0,0,0,1]] 設定出来ている?:True感想
結構満足できるものが作れられたので良かった。改良もやってみたい。