- 投稿日:2020-11-23T21:40:15+09:00
Djangoで外部の既存データベースを参照する
概要
- 既存でデータベースを運用していたが、新規で構築するDjangoアプリケーションからそのデータベースを参照したかった。
- DjangoのデフォルトDB以外も参照できる。
- Mysqlでしか試していないがPostgresも同様にできると思われる。
設定方法
DB情報を追記
- DATABASES が辞書形式になっているので追記する。
settings.pyDATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', 'NAME': db, 'USER': user, 'PASSWORD': password, 'HOST': 'mysql01', 'PORT': '3306', }, 'otherdb': { 'ENGINE': 'django.db.backends.mysql', 'NAME': otherdb, 'USER': user, 'PASSWORD': password, 'HOST': 'mysql02' 'PORT': '3306', } }モデルを設定
- 通常と同様にモデルを定義する。
- メタデータとして「db_table」に参照したいDB内のテーブル名をしてする。
- 指定しないと「<アプリケーション名>_<クラス名>」の形で表示された。(デバッグで確認)
application/models.pyfrom django.db import models class <クラス名>(models.Model): class Meta: db_table = '<テーブル名>' id = models.IntegerField(primary_key=True) name = models.CharField(max_length = 255)ビューの設定
- 「db_manager」を利用してsettings.pyで追記したDBを指定することで外部DBを参照できる。
- TablesName
application/views.pyfrom django.shortcuts import render from .models import <クラス名> def index(request): data = <クラス名>.objects.db_manager("<DB名>").all() params = { 'data': data } return render(request, 'sample.html', params)マイグレーションも忘れない
$ python3 ./manage.py makemigrations $ python3 ./manage.py migrate
- 投稿日:2020-11-23T21:04:02+09:00
Rails wheneverをdockerで実行する
動機
Railsの定期実行を行う
wheneverを使おうとしたのですが、Mac上で直接実装すると環境変数や権限管理で大変だったのでdockerで行うことにしました前提条件
実行環境は下記のようになります
・ ruby 2.6.3
・ Rails 5.2.4
・ MySQL 8.0.19Docker関係
Dockfile、docker-compose.ymlは以下のようになります
通常のdockerの設定とあまり変わらないのですが、今回はwheneverを利用するのでcornのインストールとcronをフォアグラウンド実行するための設定を追記しています。FROM ruby:2.6.3 #rubyのバージョン指定 #gemのインストール RUN apt-get update -qq && \ apt-get install -y build-essential \ libpq-dev \ nodejs # cronインストール RUN apt-get install -y cron RUN mkdir /my_app WORKDIR /my_app COPY Gemfile /my_app/Gemfile COPY Gemfile.lock /my_app/Gemfile.lock RUN gem install bundler RUN bundle install COPY . /my_app # wheneverでcrontab書き込み RUN bundle exec whenever --update-crontab # cronをフォアグラウンド実行 CMD ["cron", "-f"]docker-compose.ymlversion: '2' services: db: image: mysql:8.0.19 command: --default-authentication-plugin=mysql_native_password volumes: - ./mysql-confd:/etc/mysql/conf.d - mysql-data:/var/lib/mysql #データの永続化のため ports: - "3306:3306" restart: always environment: MYSQL_ALLOW_EMPTY_PASSWORD: 1 # MYSQL_DATABASE: app_development MYSQL_USER: root # MYSQL_PASSWORD: password TZ: Asia/Tokyo app: build: . command: bundle exec rails s -p 3000 -b '0.0.0.0' volumes: - .:/my_app - bundle:/usr/local/bundle ports: - "3000:3000" links: - db volumes: mysql-data: bundle: #bundle installした後buildし直さなくてよくなるwhenever関係
config/schedule.rb# wheneverにrailsを起動する必要があるためRails.rootを使用 require File.expand_path(File.dirname(__FILE__) + "/environment") # 環境変数をうまい感じにやってくれる ENV.each { |k, v| env(k, v) } # ログを書き出すようファイル set :output, error: 'log/crontab_error.log', standard: 'log/crontab.log' set :environment, :development #2分毎に`sample_task`の`scheduled_task`を実行する every 2.minutes do rake 'sample_task:scheduled_task' # runner "Test.yakisoba", :environment => :development # runnnerの例 end実行したいコマンド
/lib/tasks/sample_task.rbnamespace :sample_task desc "scheduled_task" task scheduled_task: :environment do ..... 実行したい関数 end end end
- 投稿日:2020-11-23T15:13:24+09:00
読みやすいSQLについて
読みやすいSQLについて
はじめましてこんにちは
@cosemi001 と申します。貴重なお時間に本記事の閲覧いただき、感謝いたします。
本題に入ります。
様々な案件の成果物のSQLを見たときに
可読性が低い書き方が多く含まれていました。その事が気になったので
自分が読みやすいとSQL記述方法を
「NG例」と「OK例」 併せて紹介いたします。なお私も勉強中の人間なので、すべて鵜呑みにせず
今後の参考になれば幸いです。
ご意見ございましたらコメントにてご指摘ください。■改行とインデント(字下げ)を利用しましょう。
・NG例
select * from users;・修正例
select * from users;・解説
何故こうするか?
「SELECT」「FROM」はそれぞれ役割が異なるので
役割が異なるたび改行と字下げを行いましょう。「SELEC」Tは取得したいフィールドをこれから指定するよ宣言です select -- フィールドを指定するときはインデントを一つ下げましょう -- そうするとSELECTで指定されたフィールド名がわかりやすくなります。 フィールド名,「フィールド名毎に改行しましょう」 フィールド名 「FROM」はデータを取得するテーブルを指定するよ宣言です from -- テーブルを指定するときはインデントを一つ下げましょう -- そうするとFROMで指定されたテーブルがわかりやすくなります。 テーブル名;■予約語は大文字にしましょう。
SQLには予約語というものが存在します。
[Tip]予約語とは?
役割を与えられた言葉です。
たとえば「SELECT」はこれからフィールドを指定するよ!という役割を持ちます。
細かいことは割愛いたします。(いっぱい出て来るからググってね!)では早速書き直してみましょう
・NG例
select name, email, address from users where name like "名前";・修正例
SELECT name, email, address FROM users WHERE name LIKE "名前";・解説
いかがでしょうか?
「字下げ」+「予約語を大文字」にするとメリハリが出て
可読性は向上すると思います。□補足
DB設計にて「テーブル名」、「フィールド名」を大文字で定義する案件が存在します。
その場合は予約語を小文字にするなどになるかと思いますが、臨機応変に使用してください。■テーブル名に別名を使用してみよう
テーブル設計を行うときに
テーブルの役割を具体化するときどうしても名前が長くなるケースがあります。
その場合、テーブル名を英語読みした時の頭文字を大文字にして使用しましょう。・普通に書いた例
SELECT mst_company_details.id, mst_company_details.name, mst_company_details.address, FROM mst_company_details WHERE mst_company_details.name LIKE "サンプル株式会社";・修正例
SELECT MCD.id, MCD.name, MCD.address, FROM -- 対象のテーブル記述した後に「AS」を使用して定義します(ASは省略可能で半角スペースあけた後に別名定義も可能です) mst_company_details AS MCD WHERE MCD.name LIKE "サンプル株式会社";・解説
いかがでしょうか
SQL文の横伸びが短くなるだけでも、可読性は向上すると思います。□補足
1.
別名をつける際にASを使用する可はプロジェクトの方針に従うようにしましょう。私は「AS」をつけて今から別名つけるよ感を出して
別名をつけている事を認識し易くするのが好きです。2.
テーブル名が短い場合[userなど]は無理に別名を使うとわかりにくいケースもあります。
その場合は無理に別名を使用せず、そのまま使ってもよいかもしれません■TABLE JOINも改行インデントしてみよう
SQLの書き方で「JOIN」というものが存在します。
[Tip]JOINとは
テーブル同士などを結合する事ができます。
具体的には、結合するテーブルのフィールド値の関係性を指定することにより
指定した条件で結合しデータを取得可能となります。・NG例
SELECT * FROM mst_company AS MC INNER JOIN mst_company_details AS MCD ON MC.id = MCD.company_id INNER JOIN mst_users AS MU ON MC.id = MU.company_id FROM MC LIKE "テスト株式会社";・修正例
SELECT * FROM mst_company AS MC INNER JOIN mst_company_details AS MCD ON MC.id = MCD.company_id INNER JOIN mst_users AS MU ON MC.id = MU.company_id FROM MC LIKE "テスト株式会社";・解説
SELECT * FROM mst_company AS MC -- 「INNER JOIN」は結合するテーブル定義宣言なので「改行」+「インデント下げ」を行います INNER JOIN mst_company_details AS MCD -- 「ON」はよくあるケースはテーブル同士の結合条件なので「改行」+「インデント下げ」を行います ON MC.id = MCD.company_id -- 次の「JOIN」はJOINのインデントまで戻りましょう INNER JOIN mst_users AS MU ON 以下略~NG例と見比べると読みやすくなっていると思います。
この改行で何故見やすくなったか解説すると
NG例では
SQLを上から下に読みながら
左右にも読み解かなければいけません修正例では
SQLを上から下に読む事が可能です。
インデントがある事により役割ごとに階層が分かれている為
各行が何の役割かすぐ理解できるようになります。■CASE句も改行してみよう
・普通の例
SELECT CASE WHEN users.age > 20 THEN "下級生" ELSE "上級生" END AS class_type FROM users;・修正例
SELECT CASE WHEN users.age > 20 THEN "下級生" ELSE "上級生" END AS class_type FROM users;・解説
上の解説同様
上から下に読む事が出来てると思います。某初心者向けサイトは
条件と結果を一行で書いたサンプルを上げていますが
条件分岐と出力結果が同じ行に存在し可読性を低下させます。NGではないがGoodではない例:
CASE
WHEN users.age > 20 THEN "下級生"
ELSE "上級生"
END AS class_type■サブクエリも「改行」+「インデント下げ」+その他諸々
・NG例
SELECT * FROM mst_users AS MU INNER JOIN (select trn_user_options.* from trn_user_options where trn_user_options.type like "A" ) AS TUO ON users.email = TUO.email・修正例
SELECT * FROM mst_users AS MU INNER JOIN ( SELECT TUO.* FROM trn_user_options AS TUO WHERE TUO.type like "A" ) AS TUO ON users.email = TUO.email・解説
サブクエリの中身もわかりやすくなったと思います。
サンプルサブクエリ自体はかなり無意味な処理なのでそこはご愛嬌で・・
■まとめ(長い構文も同じように書き換えよう)
・業務で見たことある酷い例の再現
SELECT MC.name,MC.sex,TLC.name AS "chileren_cat", CASE WHEN MC.age > 20 THEN"若い猫"ELSE"年老いた猫"END AS age_type FROM mst_cat AS MC INNER JOIN tbl_lettle_cat AS TLC ON MC.id = TLC.channel_id INNER JOIN(SELECT AVG(height) AS height,AVG(weight) AS weight FROM tbl_cat_status WHERE alive = true AND delete_flag = false GROUP BY cat_id) AS TCS WHERE MC.id = 1 AND TLC like "ミケ"AND TCS < 40 GROUP BY MC.id ORDER BY MC.id LIMIT 10・修正例
SELECT MC.name, MC.sex, TLC.name AS "chileren_cat", CASE WHEN MC.age > 20 THEN "若い猫" ELSE "年老いた猫" END AS age_type FROM mst_cat AS MC INNER JOIN tbl_lettle_cat AS TLC ON MC.id = TLC.channel_id INNER JOIN ( SELECT AVG(height) AS height, AVG(weight) AS weight FROM tbl_cat_status WHERE alive = true AND delete_flag = false GROUP BY cat_id ) AS TCS WHERE MC.id = 1 AND TLC like "ミケ" AND TCS < 40 GROUP BY MC.id ORDER BY MC.id LIMIT 10後者のほうが見やすいでしょ!?
未来の自分の為にも
引継ぐ後任の為にも
見やすい書き方を意識してみんなで幸せになりましょう。「めんどくせぇ!!」「何もしてないけど勝手に壊れた!!」という人向け
おまけ
細かいことは端折りますが
MySQL WorkBenchなら「Ctrl」+「B」を押すと自動インデントしてくれます
(完璧ではないケースがあります)上記紹介したケースはこの機能では網羅できませんが、
ある程度整いますよ
- 投稿日:2020-11-23T12:14:19+09:00
相関サブクエリで宿泊期間の重複を抽出する
以下のデータがある。
select * from reservations; +----------+------------+------------+ | reserver | start_date | end_date | +----------+------------+------------+ | 内田 | 2006-11-03 | 2006-11-05 | | 堀 | 2006-10-31 | 2006-11-01 | | 山本 | 2006-11-03 | 2006-11-04 | | 木村 | 2006-10-26 | 2006-10-27 | | 水谷 | 2006-11-06 | 2006-11-06 | | 荒木 | 2006-10-28 | 2006-10-31 | +----------+------------+------------+宿泊期間が重複しているレコードを抽出する。
select * from reservations r1 where exists ( select 'X' from reservations r2 where r1.reserver <> r2.reserver and (r1.start_date between r2.start_date and r2.end_date -- 開始日が他の期間内にある or r1.end_date between r2.start_date and r2.end_date -- 終了日が他の期間内にある ) and (r2.start_date between r1.start_date and r1.end_date -- 開始日が他の期間内にある or r2.end_date between r1.start_date and r1.end_date -- 終了日が他の期間内にある ) ) +----------+------------+------------+ | reserver | start_date | end_date | +----------+------------+------------+ | 内田 | 2006-11-03 | 2006-11-05 | | 堀 | 2006-10-31 | 2006-11-01 | | 山本 | 2006-11-03 | 2006-11-04 | | 荒木 | 2006-10-28 | 2006-10-31 | +----------+------------+------------+こちらを参考にさせていただきました。
達人に学ぶSQL徹底指南書 第2版 初級者で終わりたくないあなたへ
- 投稿日:2020-11-23T11:48:00+09:00
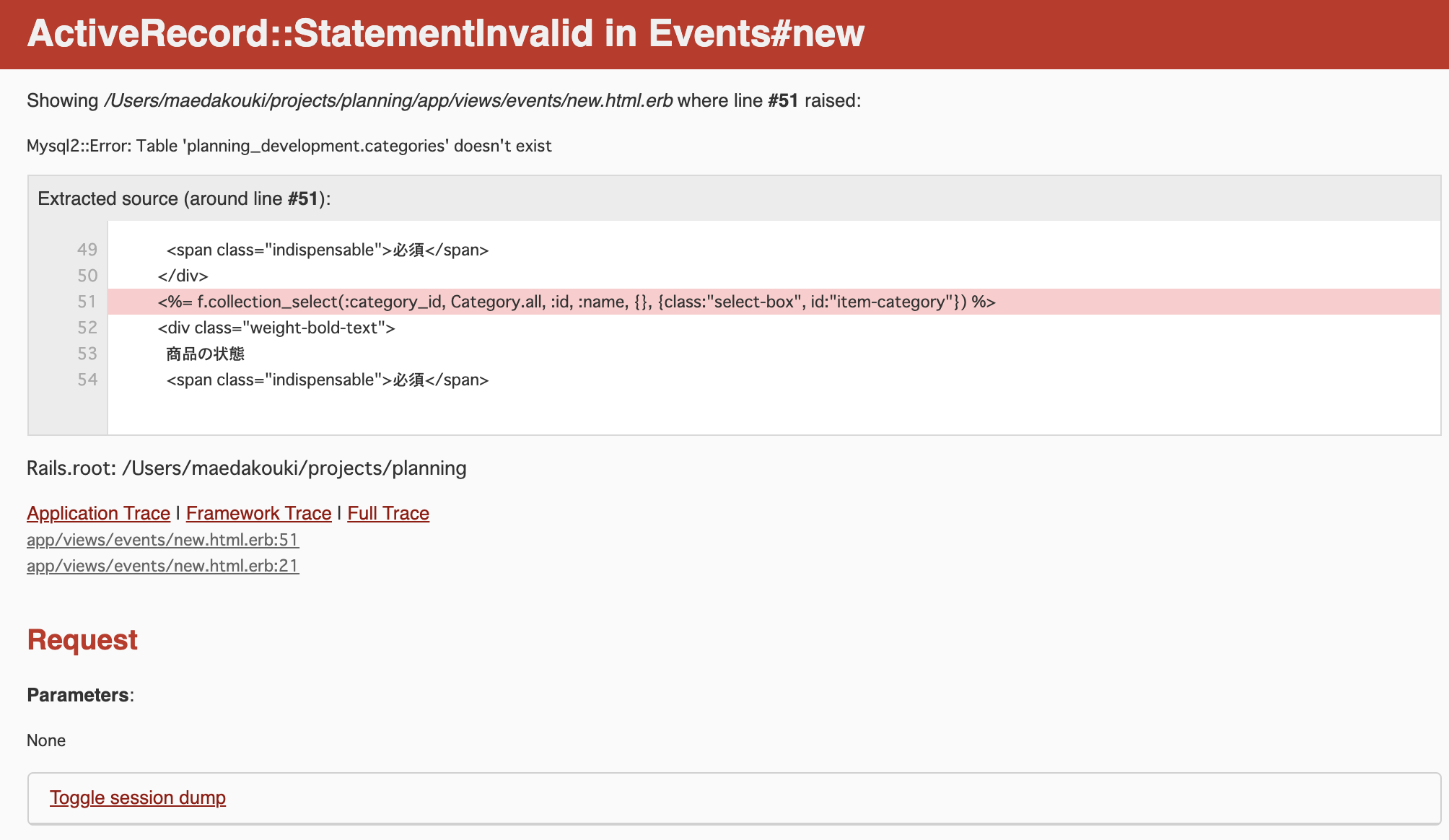
プルダウンを使おうとするとエラーになる件
ActiveRecord::StatementInvalid
他のf.text_areaは使えるのに、、テーブルがないよと言ってますね。
いちよマイグレの確認upにされてるし、カラムも間違えてないのに。。。
datebase.ymlいじっても変化なし。ActiveHash::Base
ActiveHash::Baseは、あるモデル内(クラス内)でActiveHashを用いる際に必要となるクラスです。ActiveHashのGemに定義されています。
また、ActiveHash::Baseを継承することで、ActiveRecordと同じようなメソッドを使用できるmodel/category.rbclass Category < ApplicationRecord include ActiveHash::Associations has_many :events end継承をすっかり忘れていました。⬇️
model/category.rbclass Category < ActiveHash::Base include ActiveHash::Associations has_many :events end
- 投稿日:2020-11-23T11:38:54+09:00
入出金を記録するテーブルから累計を求める
以下のようなテーブルがある
select * from accounts; +------------+---------+ | prc_date | prc_amt | +------------+---------+ | 2006-10-26 | 12000 | | 2006-10-28 | 2500 | | 2006-10-31 | -15000 | | 2006-11-03 | 34000 | | 2006-11-04 | -5000 | | 2006-11-06 | 7200 | | 2006-11-11 | 11000 | +------------+---------+各処理日の累計和を求める
select prc_date ,prc_amt ,( select sum(prc_amt) from accounts a2 where a1.prc_date >= a2.prc_date ) onhand_amt from accounts a1 +------------+---------+------------+ | prc_date | prc_amt | onhand_amt | +------------+---------+------------+ | 2006-10-26 | 12000 | 12000 | | 2006-10-28 | 2500 | 14500 | | 2006-10-31 | -15000 | -500 | | 2006-11-03 | 34000 | 33500 | | 2006-11-04 | -5000 | 28500 | | 2006-11-06 | 7200 | 35700 | | 2006-11-11 | 11000 | 46700 | +------------+---------+------------+次は処理3回単位の累計を求める
select prc_date ,a1.prc_amt ,( select sum(prc_amt) from accounts a2 where a1.prc_date >= a2.prc_date and ( select count(*) from accounts a3 where a3.prc_date between a2.prc_date and a1.prc_date )<=3 ) mvg_sum from accounts a1 +------------+---------+---------+ | prc_date | prc_amt | mvg_sum | +------------+---------+---------+ | 2006-10-26 | 12000 | 12000 | | 2006-10-28 | 2500 | 14500 | | 2006-10-31 | -15000 | -500 | | 2006-11-03 | 34000 | 21500 | | 2006-11-04 | -5000 | 14000 | | 2006-11-06 | 7200 | 36200 | | 2006-11-11 | 11000 | 13200 | +------------+---------+---------+こちらを参考にさせていただきました。
達人に学ぶSQL徹底指南書 第2版 初級者で終わりたくないあなたへ
- 投稿日:2020-11-23T06:57:46+09:00
【コード・出力結果付き】よく使うMySQLの関数まとめ
MySQLの学習を進める中で、知識のストックができてきたので、アウトプットがてら使用頻度が高そうな関数クエリについて、まとめて行きたいと思います。
用語解説
テーブル名:nameList
id name age 1 Abe 42 2 Ide 31 3 Hide 24 4 Ide 39 テーブル
表の事。(上記なら nameList というテーブル名。)
レコード
表の行の事。(上記なら4つのレコードが存在する。)
カラム
表の列の事。(上記なら3つのカラムが存在する。)
数値の表示に関する関数
絶対値 - ABS()
SELECT ABS(-10); SELECT ABS(10);
ABS()は括弧の中の値の、絶対値を求める事ができます。
出力結果はこちら。10 10
四捨五入 - ROUND()
SELECT ROUND(2.4); SELECT ROUND(2.5);
ROUND()は括弧の中の値を、四捨五入した結果を求めます。
出力結果はこちら。2 3
小数点以下を切り上げ - CELL()
SELECT CEIL(2.4); SELECT CEIL(2.5);
CEIL()は括弧の中の小数点以下の値を、切り上げした結果を求めます。
出力結果はこちら。3 3
小数点以下を切り下げ - FLOOR()
SELECT FLOOR(2.4); SELECT FLOOR(2.5);
FLOOR()は括弧の中の小数点以下の値を、切り下げした結果を求めます。
出力結果はこちら。2 2
少数の桁数を指定 - TRUNCATE()
SELECT TRUNCATE(1.7589012, 4); SELECT TRUNCATE(1.75, 4);
TRUNCATE()は第一引数の小数点以下の表示桁数を、第二引数で指定する事ができます。
出力結果はこちら。1.7589 1.7500
数値の計算を行う関数
使用するテーブル名:nameList
id name age 1 Abe 42 2 Ide 31 3 Hide 24 4 Ide 39
レコード数を取得 - COUNT()
SELECT COUNT(id) FROM nameList; SELECT COUNT(id) FROM nameList WHERE name = "Ide";
COUNT()はレコードの数を取得する事ができます。条件を指定すれば、その条件に当てはまるレコード数が取得できます。利用例:注文数の集計、会員者数の集計 ...etc
上記の2行目なら、
nameListテーブルでnameカラムがIdeのレコード数を取得する事ができます。(引数はどのカラム名でも同じ結果。)
出力結果はこちら。4 2
合計値を取得 - SUM()
SELECT SUM(age) FROM nameList; SELECT SUM(age) FROM nameList WHERE name = "Ide";
SUM()は合計値を取得する事ができます。また条件を指定すれば、その条件に当てはまるレコードで、合計値が取得できます。利用例:注文した商品の合計金額を求める、月間の売り上げ金額を求める ...etc
上記の2行目なら、
nameListテーブルでnameカラムがIdeのレコードで、ageカラムの合計値が取得できます。
出力結果はこちら。136 70
平均値を取得 - AVG()
SELECT AVG(age) FROM nameList; SELECT AVG(age) FROM nameList WHERE name = "Ide";
AVG()は平均値を取得する事ができます。また条件を指定すれば、その条件に当てはまるレコードで、平均値が取得できます。利用例:利用者の平均注文金額を求める、月別で平均売り上げを求める ...etc
上記の2行目なら、
nameListテーブルでnameカラムがIdeのレコードで、ageカラムの平均値が取得できます。
出力結果はこちら。34 35Ideさんの平均年齢は35歳のようです。
最大値を取得 - MAX()
SELECT MAX(age) FROM nameList; SELECT MAX(age) FROM nameList WHERE name = "Ide";
MAX()は最大値を取得する事ができます。また条件を指定すれば、その条件に当てはまるレコードで、最大値が取得できます。利用例:最も値段の高い商品を求める、最も売り上げた月の金額を求める ...etc
上記の2行目なら、
nameListテーブルでnameカラムがIdeのレコードで、ageカラムの最大値が取得できます。
出力結果はこちら。42 39Ideさんの中で一番上の年齢は、39歳のようですね。
最小値を取得 - MIN()
SELECT MIN(age) FROM nameList; SELECT MIN(age) FROM nameList WHERE name = "Ide";
MIN()は選択された範囲内の最小値を取得する事ができます。また条件を指定すれば、その条件に当てはまるレコードで、最小値が取得できます。利用例:最も値段の高い商品を求める、最も売り上げた月の金額を求める ...etc
上記の2行目なら、
nameListテーブルでnameカラムがIdeのレコードで、ageカラムの最小値が取得できます。
出力結果はこちら。24 31Ideさんの中で一番下の年齢は、31歳のようです。
文字に関する関数
使用するテーブル名:nameList
id name age 1 Abe 42 2 Ide 31 3 Hide 24 4 Ide 39
文字列の連結 - CONCAT()
SELECT CONCAT("これは", "見本です。"); SELECT CONCAT(name, "は", age, "歳です。") FROM nameList;
CONCAT()は文字列の連結した結果を取得する事ができます。また数値の連結や、数値と文字列の連結、カラムから取得した数値や文字列の連結にも使用できます。使用例:利用者の名前と注文した商品名を任意の文字列で連結して出力 ...etc
上記の2行目なら、
nameListテーブルから取得したnameカラムの値とageカラムの値を、文字列として取得する事ができます。
出力結果はこちら。これは見本です。 Abeは32歳です。 Ideは31歳です。 Hideは24歳です。 Ideは39歳です。
文字列の小文字化 - LOWER()
SELECT LOWER("ABC abc"); SELECT LOWER(name) FROM nameList;
LOWER()は括弧内の文字列を小文字化した結果を取得する事ができます。使用例:入力された値を小文字化してデータベースに保存(INSERT)、データベースに保存されている値を小文字化して取得(SELECT) ...etc
上記の2行目なら、
nameListテーブルのnameカラムを小文字化して取得する事ができます。
出力結果はこちら。abc abc abe ide hide ide
文字列の大文字化 - UPPER()
SELECT UPPER("ABC abc"); SELECT UPPER(name) FROM nameList;
UPPER()は括弧内の文字列を大文字化した結果を取得する事ができます。使用例:入力された値を大文字化してデータベースに保存(INSERT)、データベースに保存されている値を大文字化して取得(SELECT) ...etc
上記の2行目なら、
nameListテーブルのnameカラムを大文字化して取得する事ができます。
出力結果はこちら。ABC ABC ABE IDE HIDE IDE
文字列の文字数 - CHAR_LENGTH()
SELECT CHAR_LENGTH("abcd"); SELECT CHAR_LENGTH("日本語"); SELECT CHAR_LENGTH(name) FROM nameList;
CHAR_LENGTH()は括弧内の文字列の文字数を計算した結果を取得する事ができます。(日本語も使用可能)使用例:パスワードなどの入力された値が8文字以上か判断する材料 ...etc
上記の3行目なら、
nameListテーブルのnameカラムの文字数を取得する事ができます。
出力結果はこちら。4 3 3 3 4 3※わかりやすくする為に、改行を挟んでいます。
日付に関する関数
現在の年月日と時刻 - CURRENT()
SELECT CURRENT_DATE(); SELECT CURRENT_TIME(); SELECT CURRENT_TIMESTAMP()
CURRENT_DATE()は現在の年月日を取得。
CURRENT_TIME()は現在の時刻を取得。
CURRENT_TIMESTAMP()は現在の年月日と時刻を取得。仮に2020年1月1日、10時20分30秒の時の出力結果はこちら。
2020-01-01 10:20:30 2020-01-01 10:20:30因みにデフォルトの設定のままで、これを取得しようとすると、日本のタイムゾーンとは異なるので、日本のタイムゾーンで取得したい場合は、別途設定が必要になります。(これは日付に関する関数全般に関わります。)
曜日の取得 - DAYNAME()
SELECT DAYNAME("2020-01-01");
DAYNAME()は括弧内の曜日を取得する事ができます。
出力結果はこちら。Wednesday2020年1月1日の曜日は、Wednesday(水曜日)のようです。
まとめ
ここで紹介した以外にも関数はありますが、個人的に使用頻度が低そうだったので、除外しております。もし他にも知りたい場合は、MySQLの公式リファレンスや他の記事を参照してみてください。
最後まで読んでくださり、ありがとうございました!
- 投稿日:2020-11-23T06:57:46+09:00
【コード・出力結果付き】よく使うMySQLの関数をわかりやすく説明【16選】
MySQLの学習を進める中で、知識のストックができてきたので、アウトプットがてら使用頻度が高そうな関数クエリについて、まとめて行きたいと思います。
用語解説
テーブル名:nameList
id name age 1 Abe 42 2 Ide 31 3 Hide 24 4 Ide 39 テーブル
表の事。(上記なら nameList というテーブル名。)
レコード
表の行の事。(上記なら4つのレコードが存在する。)
カラム
表の列の事。(上記なら3つのカラムが存在する。)
数値の表示に関する関数
絶対値 - ABS()
SELECT ABS(-10); SELECT ABS(10);
ABS()は括弧の中の値の、絶対値を求める事ができます。
出力結果はこちら。10 10
四捨五入 - ROUND()
SELECT ROUND(2.4); SELECT ROUND(2.5);
ROUND()は括弧の中の値を、四捨五入した結果を求めます。
出力結果はこちら。2 3
小数点以下を切り上げ - CELL()
SELECT CEIL(2.4); SELECT CEIL(2.5);
CEIL()は括弧の中の小数点以下の値を、切り上げした結果を求めます。
出力結果はこちら。3 3
小数点以下を切り下げ - FLOOR()
SELECT FLOOR(2.4); SELECT FLOOR(2.5);
FLOOR()は括弧の中の小数点以下の値を、切り下げした結果を求めます。
出力結果はこちら。2 2
少数の桁数を指定 - TRUNCATE()
SELECT TRUNCATE(1.7589012, 4); SELECT TRUNCATE(1.75, 4);
TRUNCATE()は第一引数の小数点以下の表示桁数を、第二引数で指定する事ができます。
出力結果はこちら。1.7589 1.7500
数値の計算を行う関数
使用するテーブル名:nameList
id name age 1 Abe 42 2 Ide 31 3 Hide 24 4 Ide 39
レコード数を取得 - COUNT()
SELECT COUNT(id) FROM nameList; SELECT COUNT(id) FROM nameList WHERE name = "Ide";
COUNT()はレコードの数を取得する事ができます。条件を指定すれば、その条件に当てはまるレコード数が取得できます。利用例:注文数の集計、会員者数の集計 ...etc
上記の2行目なら、
nameListテーブルでnameカラムがIdeのレコード数を取得する事ができます。(引数はどのカラム名でも同じ結果。)
出力結果はこちら。4 2
合計値を取得 - SUM()
SELECT SUM(age) FROM nameList; SELECT SUM(age) FROM nameList WHERE name = "Ide";
SUM()は合計値を取得する事ができます。また条件を指定すれば、その条件に当てはまるレコードで、合計値が取得できます。利用例:注文した商品の合計金額を求める、月間の売り上げ金額を求める ...etc
上記の2行目なら、
nameListテーブルでnameカラムがIdeのレコードで、ageカラムの合計値が取得できます。
出力結果はこちら。136 70
平均値を取得 - AVG()
SELECT AVG(age) FROM nameList; SELECT AVG(age) FROM nameList WHERE name = "Ide";
AVG()は平均値を取得する事ができます。また条件を指定すれば、その条件に当てはまるレコードで、平均値が取得できます。利用例:利用者の平均注文金額を求める、月別で平均売り上げを求める ...etc
上記の2行目なら、
nameListテーブルでnameカラムがIdeのレコードで、ageカラムの平均値が取得できます。
出力結果はこちら。34 35Ideさんの平均年齢は35歳のようです。
最大値を取得 - MAX()
SELECT MAX(age) FROM nameList; SELECT MAX(age) FROM nameList WHERE name = "Ide";
MAX()は最大値を取得する事ができます。また条件を指定すれば、その条件に当てはまるレコードで、最大値が取得できます。利用例:最も値段の高い商品を求める、最も売り上げた月の金額を求める ...etc
上記の2行目なら、
nameListテーブルでnameカラムがIdeのレコードで、ageカラムの最大値が取得できます。
出力結果はこちら。42 39Ideさんの中で一番上の年齢は、39歳のようですね。
最小値を取得 - MIN()
SELECT MIN(age) FROM nameList; SELECT MIN(age) FROM nameList WHERE name = "Ide";
MIN()は選択された範囲内の最小値を取得する事ができます。また条件を指定すれば、その条件に当てはまるレコードで、最小値が取得できます。利用例:最も値段の高い商品を求める、最も売り上げた月の金額を求める ...etc
上記の2行目なら、
nameListテーブルでnameカラムがIdeのレコードで、ageカラムの最小値が取得できます。
出力結果はこちら。24 31Ideさんの中で一番下の年齢は、31歳のようです。
文字に関する関数
使用するテーブル名:nameList
id name age 1 Abe 42 2 Ide 31 3 Hide 24 4 Ide 39
文字列の連結 - CONCAT()
SELECT CONCAT("これは", "見本です。"); SELECT CONCAT(name, "は", age, "歳です。") FROM nameList;
CONCAT()は文字列の連結した結果を取得する事ができます。また数値の連結や、数値と文字列の連結、カラムから取得した数値や文字列の連結にも使用できます。使用例:利用者の名前と注文した商品名を任意の文字列で連結して出力 ...etc
上記の2行目なら、
nameListテーブルから取得したnameカラムの値とageカラムの値を、文字列として取得する事ができます。
出力結果はこちら。これは見本です。 Abeは32歳です。 Ideは31歳です。 Hideは24歳です。 Ideは39歳です。
文字列の小文字化 - LOWER()
SELECT LOWER("ABC abc"); SELECT LOWER(name) FROM nameList;
LOWER()は括弧内の文字列を小文字化した結果を取得する事ができます。使用例:入力された値を小文字化してデータベースに保存(INSERT)、データベースに保存されている値を小文字化して取得(SELECT) ...etc
上記の2行目なら、
nameListテーブルのnameカラムを小文字化して取得する事ができます。
出力結果はこちら。abc abc abe ide hide ide
文字列の大文字化 - UPPER()
SELECT UPPER("ABC abc"); SELECT UPPER(name) FROM nameList;
UPPER()は括弧内の文字列を大文字化した結果を取得する事ができます。使用例:入力された値を大文字化してデータベースに保存(INSERT)、データベースに保存されている値を大文字化して取得(SELECT) ...etc
上記の2行目なら、
nameListテーブルのnameカラムを大文字化して取得する事ができます。
出力結果はこちら。ABC ABC ABE IDE HIDE IDE
文字列の文字数 - CHAR_LENGTH()
SELECT CHAR_LENGTH("abcd"); SELECT CHAR_LENGTH("日本語"); SELECT CHAR_LENGTH(name) FROM nameList;
CHAR_LENGTH()は括弧内の文字列の文字数を計算した結果を取得する事ができます。(日本語も使用可能)使用例:パスワードなどの入力された値が8文字以上か判断する材料 ...etc
上記の3行目なら、
nameListテーブルのnameカラムの文字数を取得する事ができます。
出力結果はこちら。4 3 3 3 4 3※わかりやすくする為に、改行を挟んでいます。
日付に関する関数
現在の年月日と時刻 - CURRENT()
SELECT CURRENT_DATE(); SELECT CURRENT_TIME(); SELECT CURRENT_TIMESTAMP()
CURRENT_DATE()は現在の年月日を取得。
CURRENT_TIME()は現在の時刻を取得。
CURRENT_TIMESTAMP()は現在の年月日と時刻を取得。仮に2020年1月1日、10時20分30秒の時の出力結果はこちら。
2020-01-01 10:20:30 2020-01-01 10:20:30因みにデフォルトの設定のままで、これを取得しようとすると、日本のタイムゾーンとは異なるので、日本のタイムゾーンで取得したい場合は、別途設定が必要になります。(これは日付に関する関数全般に関わります。)
曜日の取得 - DAYNAME()
SELECT DAYNAME("2020-01-01");
DAYNAME()は括弧内の曜日を取得する事ができます。
出力結果はこちら。Wednesday2020年1月1日の曜日は、Wednesday(水曜日)のようです。
まとめ
ここで紹介した以外にも関数はありますが、個人的に使用頻度が低そうだったので、除外しております。もし他にも知りたい場合は、MySQLの公式リファレンスや他の記事を参照してみてください。
最後まで読んでくださり、ありがとうございました!
筆者:yuki|学習10日目で初案件獲得→現在はフルスタックエンジニア転職に向けて学習中
Qiita:https://qiita.com/yuki4839
Twitter:https://twitter.com/yuki35522891
- 投稿日:2020-11-23T00:47:31+09:00
SQL初心者〜中級者のための練習問題&解答例3
第3弾を作ってみました。
SQL力向上のためにお役立てください。その1: SQL初心者〜中級者のための練習問題&解答例1
その2: SQL初心者〜中級者のための練習問題&解答例2題材
ユーザーテーブル
ユーザーID ユーザー名 メールアドレス 年齢 1 もっくん mokkun@example.com 19 2 みみこ mimiko@example.net 20 3 さくら sakura@example.com 31 4 ひよこ hiyoko@example1.jp 23 5 すずき suzuki@example.jp 28 フォローテーブル
フォロワーID フォロイーID 1 2 1 3 1 4 1 5 3 1 3 2 4 5 5 1 5 2 5 3 5 4
Schema SQL
CREATE TABLE `users` ( `id` int(11) unsigned NOT NULL AUTO_INCREMENT PRIMARY KEY, `name` varchar(255) NOT NULL, `email` varchar(255) NOT NULL, `age` int(3) unsigned NOT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci; INSERT INTO `users` (`id`, `name`, `email`, `age`) VALUES (1, 'もっくん', 'mokkun@example.com', 19), (2, 'みみこ', 'mimiko@example.net', 20), (3, 'さくら', 'sakura@example.com', 31), (4, 'ひよこ', 'hiyoko@example1.jp', 23), (5, 'すずき', 'suzuki@example.jp', 28); CREATE TABLE `follows` ( `follower_id` int(11) unsigned NOT NULL, `followee_id` int(11) unsigned NOT NULL, PRIMARY KEY(`follower_id`, `followee_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci; INSERT INTO `follows` (`follower_id`, `followee_id`) VALUES (1, 2), (1, 3), (1, 4), (1, 5), (3, 1), (3, 2), (4, 5), (5, 1), (5, 2), (5, 3), (5, 4);問1
さくらがフォローしているユーザーの名前を一覧で表示せよ。
name もっくん みみこ
解答例
SELECT u2.name FROM users u1 INNER JOIN follows f ON u1.id = f.follower_id INNER JOIN users u2 ON f.followee_id = u2.id WHERE u1.id = 3問2
誰もフォローしていないユーザーの名前を表示せよ。
name みみこ
解答例
SELECT u.name FROM users u LEFT JOIN follows f ON u.id = f.follower_id WHERE f.follower_id IS NULL問3
10代、20代、30代といった年代別にフォロー数の平均を表示せよ。
age_group avg_count 10代 4.0000 20代 1.6667 30代 2.0000
解答例1
SELECT CONCAT((FLOOR(age / 10) * 10), '代') AS age_group, AVG(count) AS avg_count FROM ( SELECT u.age, SUM(CASE WHEN f.follower_id IS NOT NULL THEN 1 ELSE 0 END) AS count FROM users u LEFT JOIN follows f ON u.id = f.follower_id GROUP BY u.id ) follows_count GROUP BY CONCAT((FLOOR(age / 10) * 10), '代')
解答例2(提供: @takahasinaoki さん)
SELECT CONCAT(age_group * 10, '代') AS age_group, AVG(count) AS avg_count FROM ( SELECT FLOOR(age / 10) AS age_group, count(f.follower_id) AS count FROM users u LEFT JOIN follows f ON u.id = f.follower_id GROUP BY u.id ) follows_count GROUP BY age_group問4
相互フォローしているユーザーのIDを表示せよ。
なお、重複は許さないものとする。
id1 id2 1 3 1 5 4 5
解答例1
SELECT CASE WHEN f1.follower_id > f1.followee_id THEN f1.followee_id ELSE f1.follower_id END AS id1, CASE WHEN f1.follower_id > f1.followee_id THEN f1.follower_id ELSE f1.followee_id END AS id2 FROM follows f1 INNER JOIN follows f2 ON f1.follower_id = f2.followee_id AND f1.followee_id = f2.follower_id GROUP BY CASE WHEN f1.follower_id > f1.followee_id THEN f1.followee_id ELSE f1.follower_id END, CASE WHEN f1.follower_id > f1.followee_id THEN f1.follower_id ELSE f1.followee_id END
解答例2(提供: @takahasinaoki さん)
SELECT f1.follower_id As id1, f1.followee_id As id2 FROM follows f1 INNER JOIN follows f2 ON f1.follower_id = f2.followee_id AND f1.followee_id = f2.follower_id WHERE f1.follower_id < f1.followee_id
- 投稿日:2020-11-23T00:40:51+09:00