- 投稿日:2020-11-23T23:21:34+09:00
Lambda(Python)でRDSスナップショットをS3にエクスポートする
はじめに
RDSのデータを参照する際
・日時のdumpジョブなどを用意していない
・リードレプリカがない
・商用環境ログインには問答無用で承認が必要などの理由で直接RDSの中身を覗くことが困難な場合がありました。
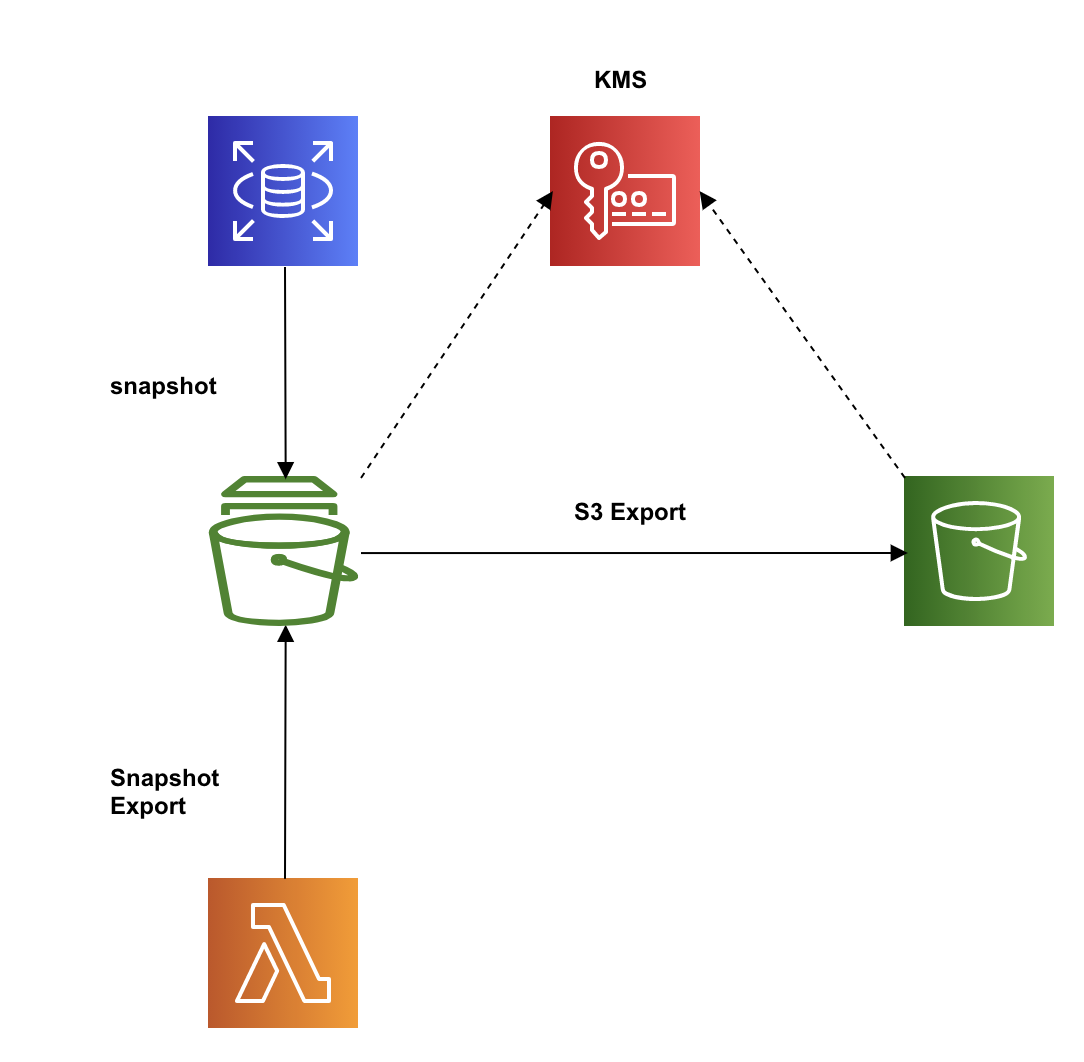
そんな時、Amazon RDSにはスナップショットをS3にエクスポートし、Athenaで参照することが可能とのことでしたので実際にLambdaを使ってRDSスナップショットのS3エクスポートを試してみました。全体像
RDSスナップショットのS3へのエクスポートをLambdaにて実行する。
エクスポートされたデータはKMSにより暗号化されるため、KMSキーも用意する必要がある。前提
・RDS及びスナップショットを作成してある。
・エクスポート先のS3バケットを作成してある。手順
1.RDSスナップショットをS3エクスポートする際に使用するポリシー、ロールの作成
1-1.ポリシー作成
スナップショットエクスポートタスクからS3にアクセスするためのポリシーを以下のjsonで作成する。
(Resourceのyour-s3-bucketはエクスポート先とするS3バケットを指定){ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": [ "s3:ListBucket", "s3:GetBucketLocation" ], "Resource": "arn:aws:s3:::*" }, { "Sid": "VisualEditor1", "Effect": "Allow", "Action": [ "s3:PutObject*", "s3:GetObject*", "s3:DeleteObject*" ], "Resource": [ "arn:aws:s3:::your-s3-bucket", "arn:aws:s3:::your-s3-bucket/*" ] } ] }1-2.ロール作成
ロールを作成し、上記で作成したポリシーをアタッチする。
信頼関係の編集から以下のようにアクセスコントロールポリシードキュメントを編集する。
(Serviceがexport.rds.amazonaws.comになる){ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "export.rds.amazonaws.com" }, "Action": "sts:AssumeRole" } ] }2.KMSキーの作成
エクスポートデータの暗号化に使用するキーをKMSで作成する。
1.マネジメントコンソールからKMSにて
カスタマー管理型のキーを選択。
2.キーの作成にて作成ウィザードを表示する。
3.ステップ 1/5 キーのタイプ:対象
4.ステップ 2/5 エイリアス:任意のキーの名前を入力
5.ステップ 3/5 キー管理者:キーと管理者となるユーザーを選択
6.ステップ 4/5 キーの使用アクセス許可を定義: ここでは特に指定しない
7.ステップ 5/5 完了3.Lambda作成
3-1.ロール、ポリシー作成
Lambda関数作成時に同時に作成することができる
AWSLambdaBasicExecutionRoleのロールを作成。
スナップショットエクスポートに必要となる以下ポリシーを別途作成し上記ロールにアタッチする。{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "iam:PassRole", "rds:StartExportTask" ], "Resource": "*" } ] }3-2.Lambdaコード作成
pyhton:lambda_handler.pyimport json import boto3 from datetime import datetime SOURCE_ARN="YOUR_SOURCE_ARN" S3_BUCKET_NAME="YOUR_S3_BUCKET_NAME" IAM_ROLE_ARN="YOUR_IAM_ROLE_ARN" KMS_KEY_ID="YOUR_KMS_KEY_ID" client = boto3.client('rds') def lambda_handler(event, context): export_task_identifier="mysnapshot" + datetime.now().strftime("%Y%m%d%H%M%S") response = client.start_export_task( ExportTaskIdentifier=export_task_identifier, SourceArn=SOURCE_ARN, S3BucketName=S3_BUCKET_NAME, IamRoleArn=IAM_ROLE_ARN, KmsKeyId=KMS_KEY_ID, )・コード内の以下変数は各自の環境に合わせて設定する。
変数名 値 SOURCE_ARN エクスポート対象とするRDSスナップショットのARN S3_BUCKET_NAME 出力先となるS3バケット名 IAM_ROLE_ARN 手順1で作成したS3エクスポートする際に使用するロールのARN KMS_KEY_ID 作成したKMSキーのARN ・
ExportTaskIdentifierについては以下制約があるため今回は日時をつけたものにしています。エクスポート識別子
エクスポートを識別するための名前を入力します。この名前は、AWS アカウントが現在の AWS リージョンで所有する、すべてのスナップショットエクスポート間で一意である必要があります。4.KMSキーのキーユーザーにLambdaロールを追加
手順2で作成したキーのキーユーザーに手順3のLambdaにて使用しているロールを追加する。
この作業を行わないと、Lambda実行時に
An error occurred (KMSKeyNotAccessibleFault)というエラーが表示される。本作業後、Lambdaを実行することでRDSスナップショットがS3へエクスポートされる。
おわりに
スナップショットをS3にエクスポートするだけであればマネジメントコンソールでも同様のことが可能ですが、データソースをシステムスナップショットにし、日時でデータ更新を行いたかったためLambdaでの実行を試しました。
RDSもDynamoDBのようにちょっとした参照であればマネジメントコンソール上で確認できると嬉しいですが、今回のスナップショットを参照にする方法も安全で簡単な方法だと感じました。
参考文献
この記事は以下の情報を参考にして執筆しました。

- 投稿日:2020-11-23T22:53:29+09:00
【AWS】Lightsailで作成したWordpressにRoute53で独自ドメインを紐づける
はじめに
先日LightsailにWordpressをインストールしてサイトを立ち上げたのですが、Route53を使った独自ドメイン紐づけに苦戦したので、備忘録を残します。
(ググって出てきたやり方だと見事に全滅しました。。許すまじ)
おおまかな流れ
- Route53で独自ドメイン取得
- LightsailインスタンスにStatic IPを紐づける。
- LightsailでDNSゾーン作成。
- 作成したDNSゾーン内に、Aレコードを作成し、取得したドメインとStatic IPを関連付ける。
- Route53で登録したドメインのネームサーバーを、Lightsailで作成したDNSゾーンのネームサーバーの値に書き換える。
- 数分待ってアクセスしてみる。
- 完了
手順解説
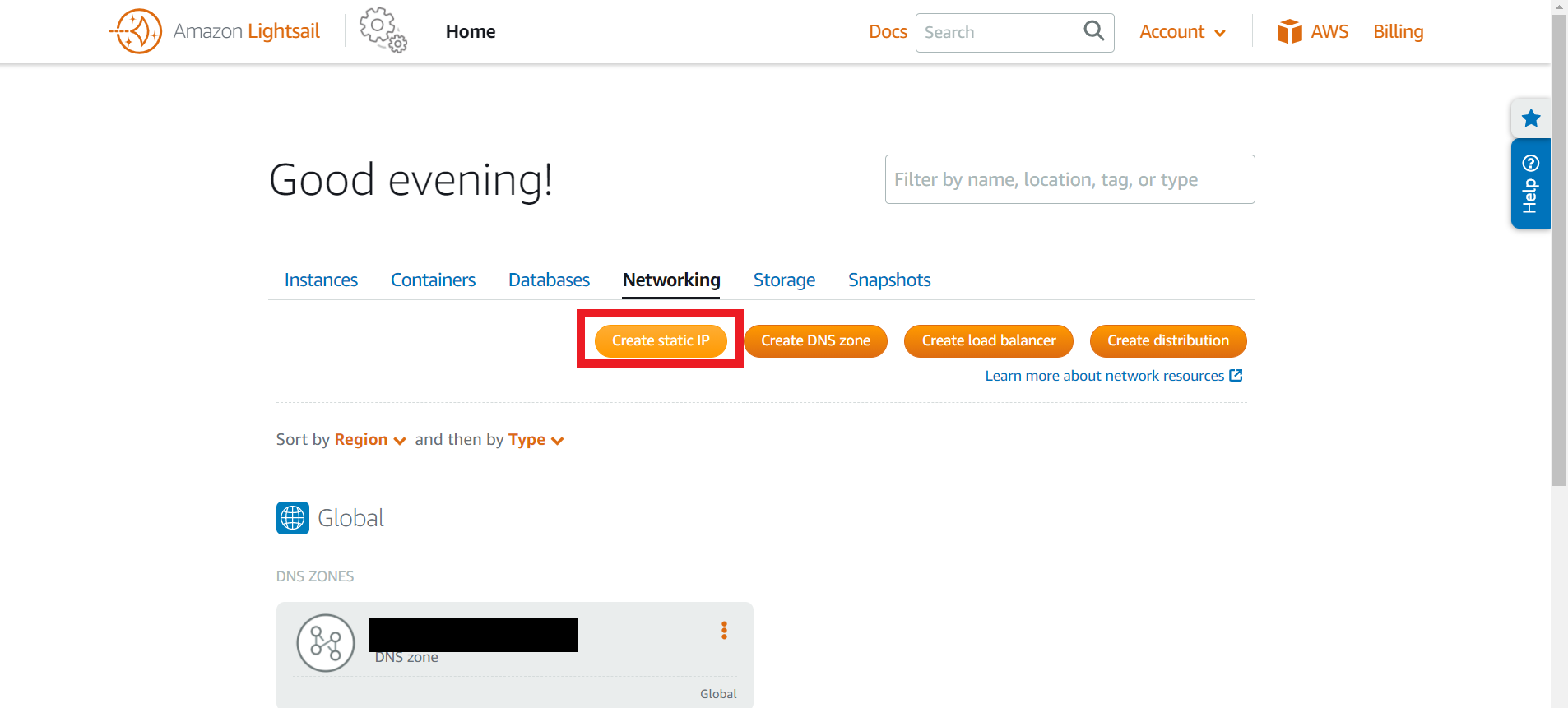
インスタンスにstatic IPを紐づける
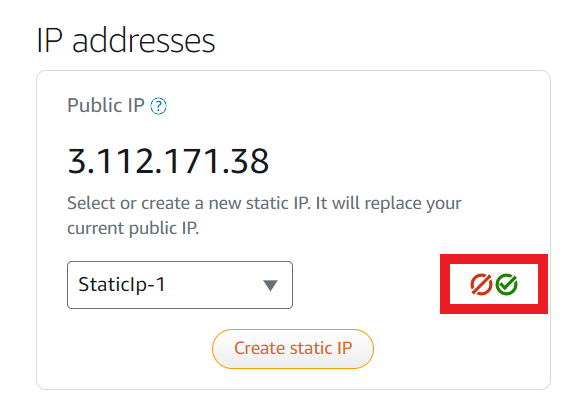
AWSにログインし、Lightsail>home>Networkingの順にクリックし、「Create static IP」をクリック。Static IPを作成する。
名前を付け、「Create」をクリック。これでStatic IPが作成される。
先ほど作成したStatic IPを選択し、赤枠内の緑のチェックマークをクリック。赤がキャンセル、緑がOK。(本当分かりづらい。。。何度「Create StaticIP」をクリックして首をかしげたことやら。。
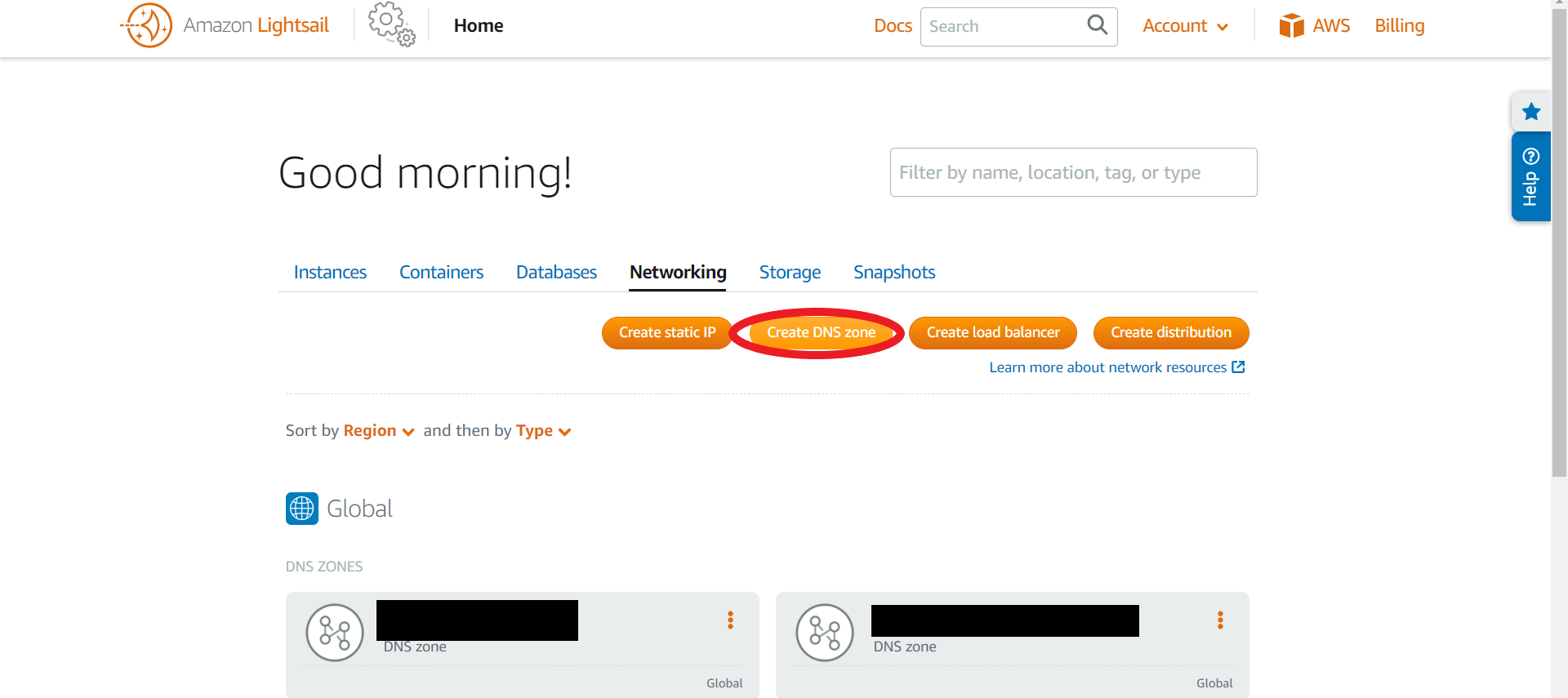
LightsailでDNSゾーンを作成する。
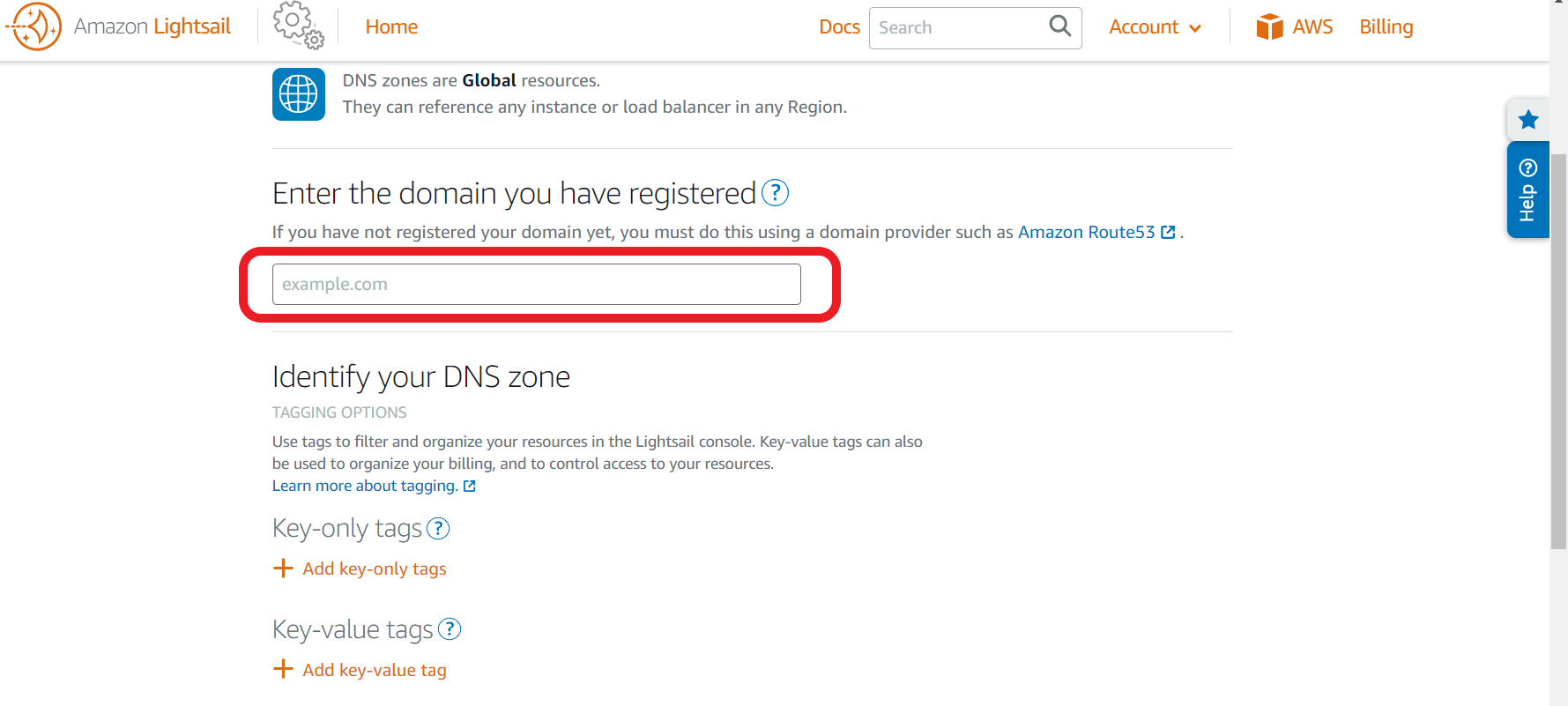
home>Netwirkingから「Create DNS zone」をクリック。
Route53で取得したドメインを入力し、「Create DNS zone」と書かれたボタンをクリック。
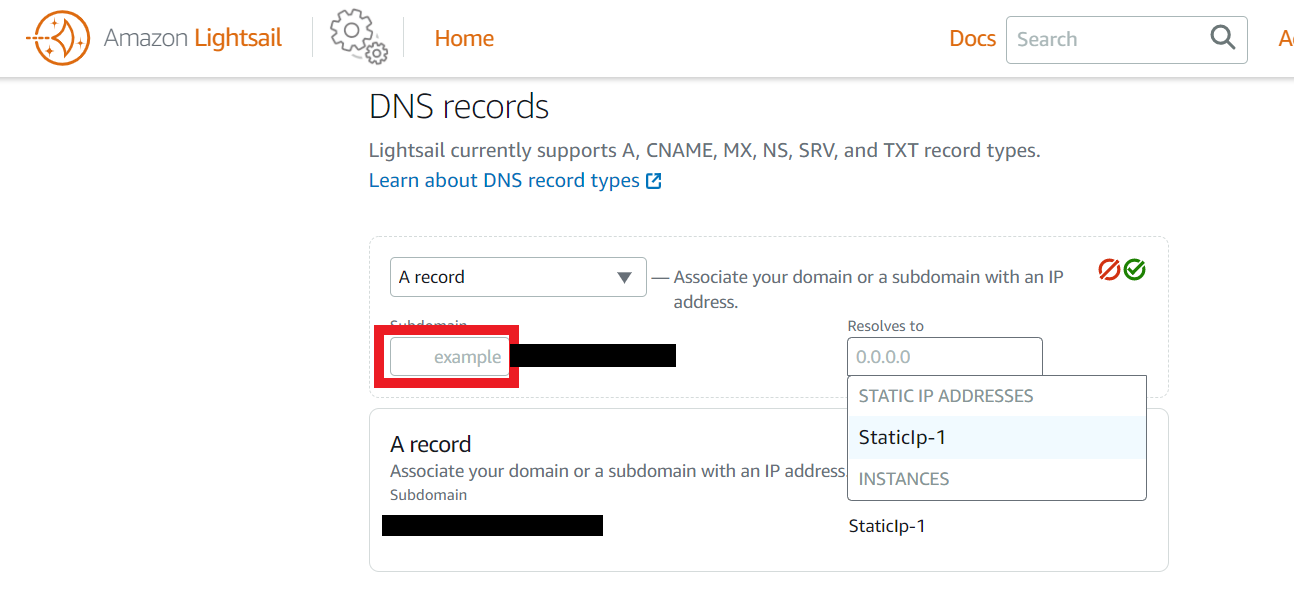
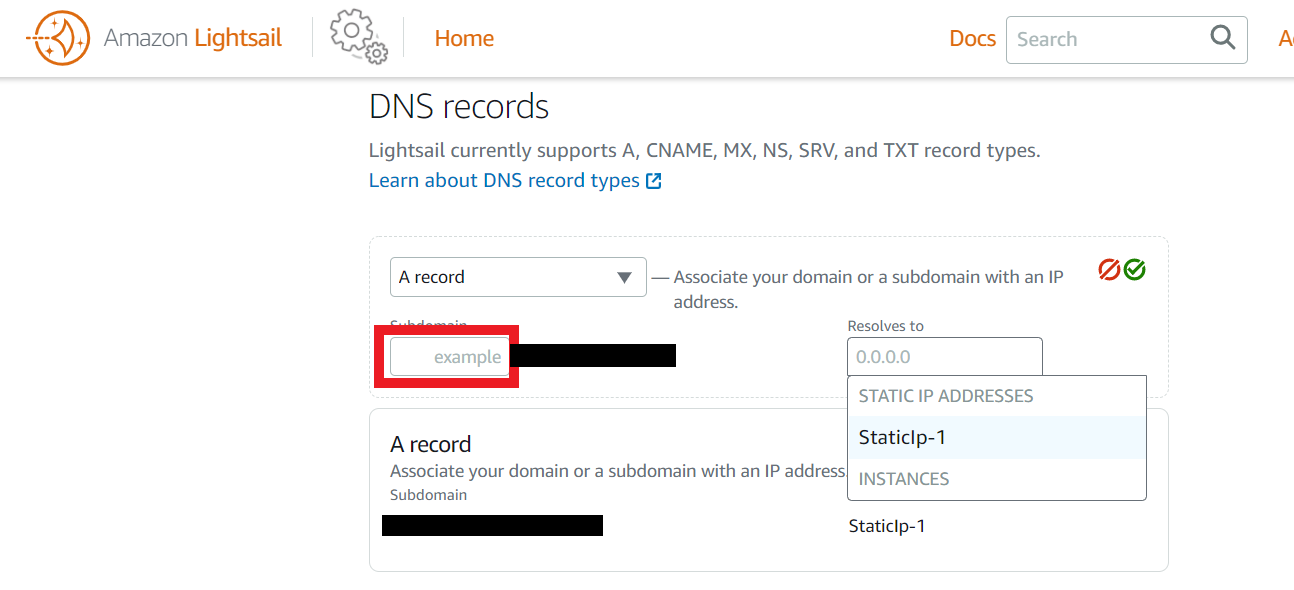
作成したDNSゾーン内にAレコードを作成
home>Netwirkingに先ほど作成したDNSゾーンが表示されるのでクリック。次に「+add record」をクリックしてAレコードを作成する。
赤枠内にサブドメインを入力し、インスタンスに紐づけたStatic IPアドレスを選択。先ほどと同じく分かりづらい緑のOKボタンをクリック。
これでDNSゾーン内にAレコードが作成されます。
Route53にLightsailで作成したDNSゾーンのネームサーバーを設定する。
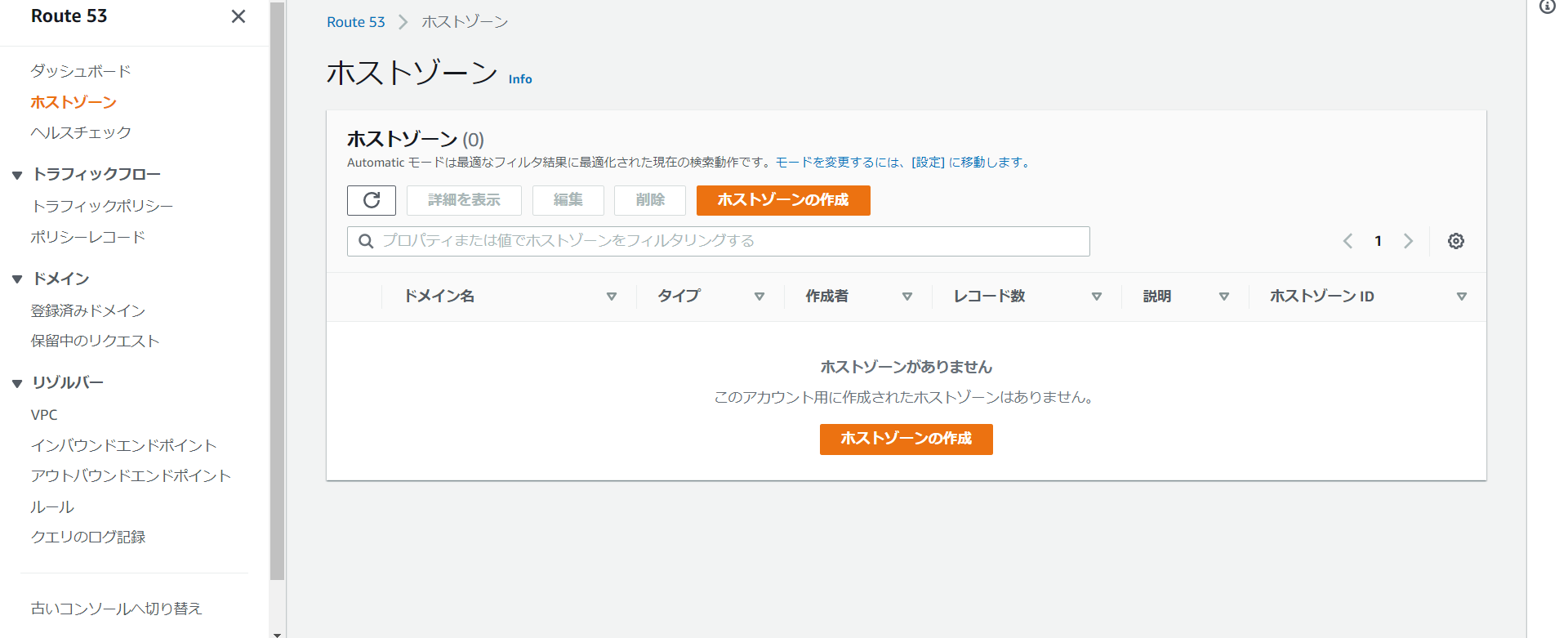
ここまで来たらあと一息です。Route53を開いて、「登録済みドメイン」より、自分で取得したドメインをクリックしてください。
もしRoute53で設定したいドメインのホストゾーンを作成していたら、削除してください。下の画像のようになっていたら正解です。(他にドメインを取得している場合は、ホストゾーンが表示されています。)
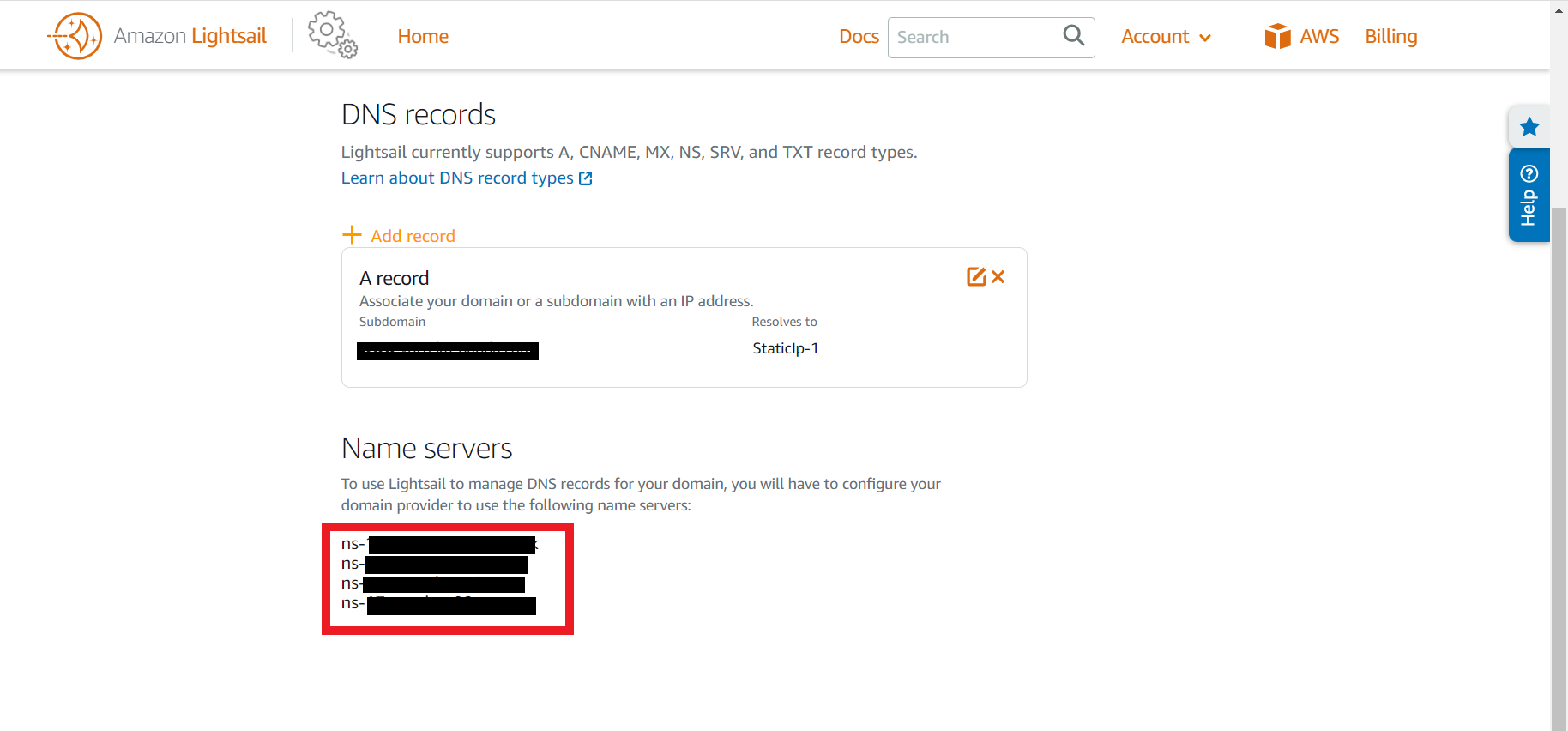
Lightsailで作成したDNSゾーンのネームサーバーをRoute53に設定します。Lightsailに戻り、作成したDNSゾーン名をクリックするとネームサーバーが表示されます。
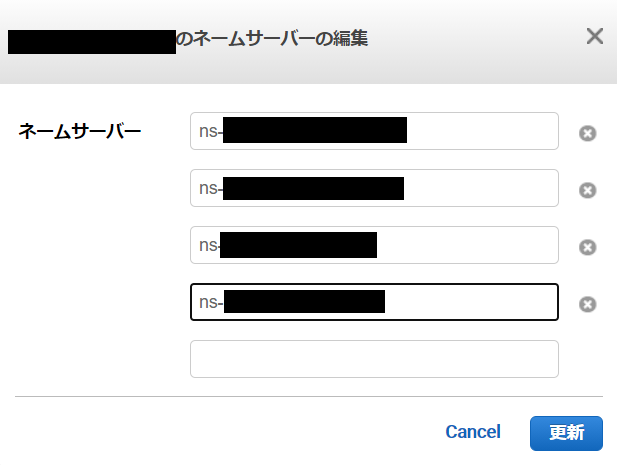
Route53に戻り、取得したドメインをクリック。赤枠で囲まれた「ネームサーバーの追加/編集」をクリック
現在表示されているネームサーバー名を、Lightsailで作成したDNSゾーンのネームサーバー名に書き換えます。
完了!
更新ボタンを押すとAWSから更新通知のメールが届きます。その後数分待ってアクセスしてみましょう。アクセスできたら無事完了です!お疲れさまでした。


- 投稿日:2020-11-23T22:34:29+09:00
【AWS】新規インスタンス(EC2)作成手順
AWSの知識皆無ですが、勉強用に無料アカウントを作ってみました。
EC2インスタンス作成時のメモです。アカウント作成
AWSのサイトからアカウントを作成
- アカウント作成自体は無料
- ベーシックプランは無料
サインイン
AWSサイトからマネージメントコンソールへログイン
コンソールにサインイン>ルートユーザー>サインイン
EC2インスタンスの作成
コンソール画面の「サービス」から「EC2」を選択
ダッシュボードで「インスタンスを起動」を選択
(無料アカウント用なのか、既にインスタンスが生成されていました。)
AMI(Amazon Machine Image)の選択
(とりあえず無料枠から選びました。)
インスタンスタイプの選択
ファイアーウォールの設定
「セキュリティグループの編集」から利用するプロトコルを編集
- セキュリティグループ名を適当な名前に編集
- 説明はデフォルトのまま(作成時のタイムスタンプ)
- 「ルールの追加」からHTTP、HTTPSを追加
→起動ボタンを押すと、キーペア選択画面が表示される。
キーペアの作成
- プルダウンから「新しいキーペアの作成」を選択
- キーペア名を適当な名前に編集
→「キーペアのダウンロード」を押すと、pemファイルが自動でダウンロードされる。
インスタンスの作成
「インスタンスの作成」ボタンを押して完了!
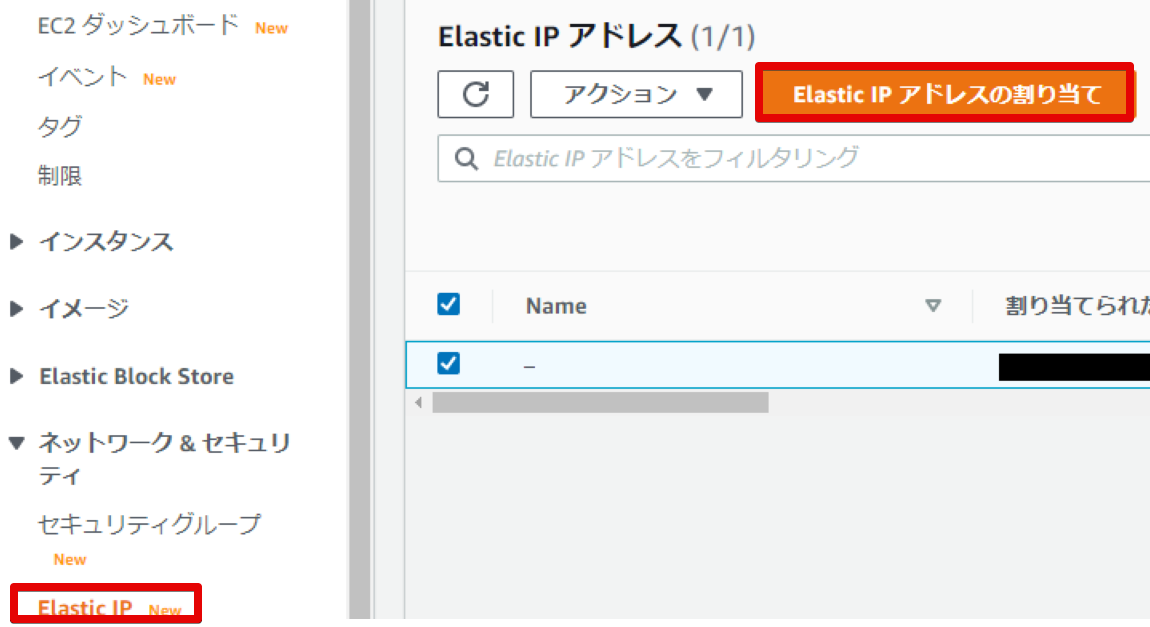
Elastic IPの割り当て
AWSでは、設定していないと時間の経過とともにIPアドレスの割り当てが変化するようです。
Elastic IPを割り当てるとIPアドレスが固定されます。毎回IPアドレスが変わると設定が面倒そうなので、EIPを割り当てました。
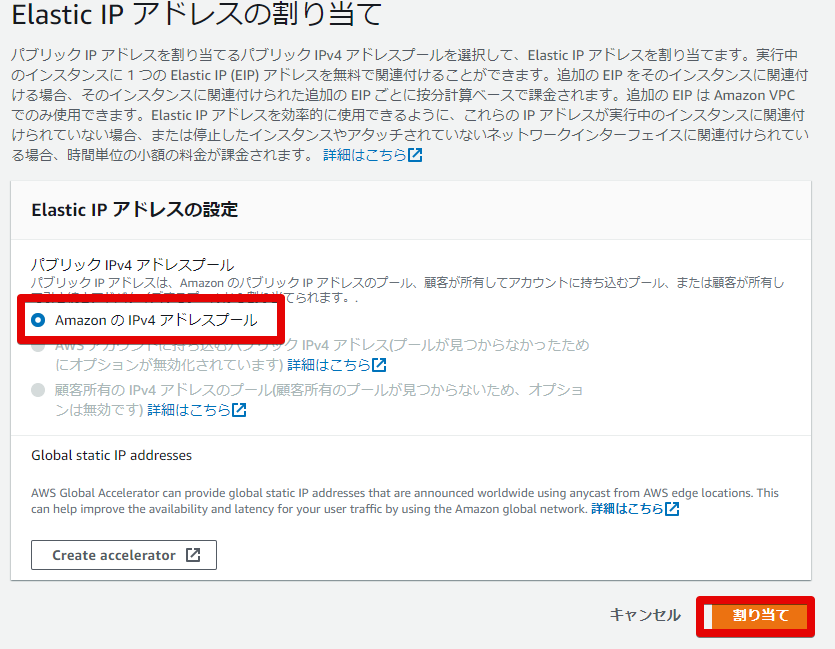
Elastic IPアドレスの取得
- 左側のメニューから「Elastic IP」を選択
- Elastic IPアドレスの割り当て>(デフォルトのまま)割り当て
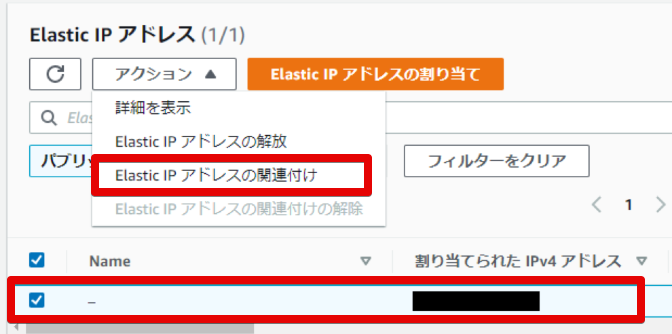
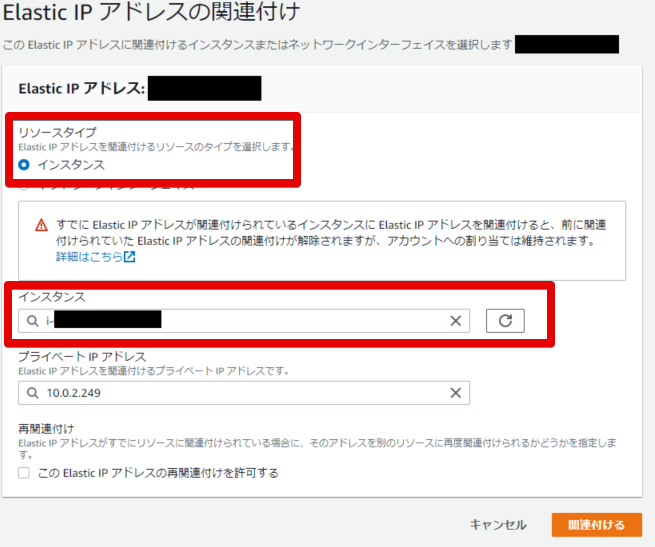
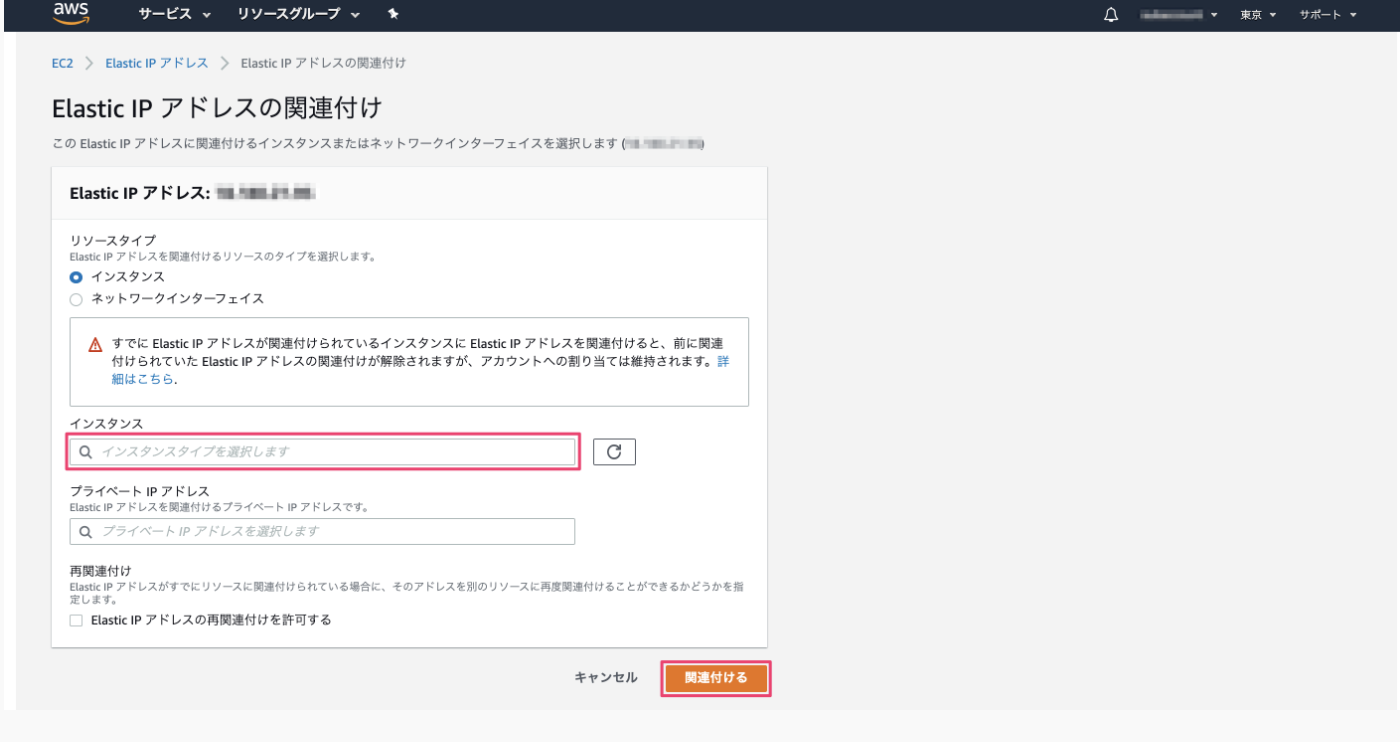
EIPをインスタンスに紐づけ
- アクションタブから「Elastic IPアドレスの関連付け」を選択
- インスタンスを選択(プライベートIPアドレスは特に設定しない)
- 「関連付ける」ボタンを押して完了
接続確認
PowerShell起動
スタートを右クリック>Windows PowerShell
接続自動化のための準備
① PowerShellに表示されているデフォルトのパスの直下に「.ssh」フォルダを作成
→C:\Users\(ユーザー名).ssh② インスタンス作成時にダウンロードしたpemファイルを「.ssh」フォルダにコピー
③ 「.ssh」フォルダ直下にconfigファイルを作成 ※拡張子なし
confighost ec2 User ec2-user hostname (インスタンスに割り当てたElastic IPアドレス) port 22 identityfile C:\Users\(ユーザー名)\.ssh\trial_key.pem接続
Power Shellで以下のコマンドを実行
ssh ec2”Are you sure you want to continue connecting (yes/no)? ”と表示されるので、
”yes”と入力→EC2のロゴが表示され、リモート接続完了
インスタンスにアパッチWebサーバーをインストール
PowerShellで以下コマンドを実行する
sudo yum install httpd Is this ok [y/d/N]: y sudo systemctl start httpd sudo systemctl status httpd→active(running)が表示されれば起動完了
ChromeブラウザからWebサーバに接続
ブラウザから”http://(Elastic IPアドレス)”にアクセス
→Apacheのテストページが表示される参考サイト
- AWSのサポートプランの種類4つ|AWSが提供するサポート内容6つ
- Amazon Elastic Compute Cloud Linux インスタンス用ユーザーガイド ーElastic IP アドレス
- 「Amazon EC2 インスタンスタイプ」
- AWS EC2インスタンスを作成する(AMI:Amazon Linux / Amazon EBSの設定など)
- SSH公開鍵認証で接続するまで
- インフラエンジニアじゃなくても押さえておきたいSSHの基礎知識
- 【 sudo 】コマンド――スーパーユーザー(rootユーザー)の権限でコマンドを実行する
- 【 yum 】コマンド(基礎編)――ソフトウェア(パッケージ)をインストールする/アンインストールする





- 投稿日:2020-11-23T22:18:58+09:00
AWS AmplifyでReactアプリをデプロイする。
この記事のゴール
本記事は、AWS amplifyを用いて、CRA(Create React App)をデプロイする流れを記載した記事になります。
n番煎じ感ある記事ですが、備忘のために記事にしてみました。※前提
Githubアカウントを持っていて、CRAをプッシュしたリポジトリを持っていること。
はじめに
まずは、CRAでReactアプリを作成します。アプリの作成方法に関しては、今回は割愛させていただきます。
※過去にDockerでReactサンプルアプリを作成した記事を掲載させていただきます。React.js (Create React App) × TypeScript対応プロジェクトをdockerで作成する。
https://qiita.com/koh97222/items/a53cacd0ff85c896bf11手順1. AWSマネジメント コンソールにログインする。
AWSのアカウントを作成して、AWSのコンソール画面を開きます。
手順2. Amplifyで検索!
Amplify console 画面を開きます。「右上のアプリの作成」ボタンを押します。
手順3. Githubを選択し、Continue
手順4. デプロイしたいリポジトリを選択し、「次へ」ボタン押下。
手順5. ビルド設定を修正する。
ビルドの設定を修正します。
アプリの名前は任意で設定しましょう。ビルド設定のymlはテンプレートを参考にこんな感じにしてみました。
https://docs.aws.amazon.com/ja_jp/amplify/latest/userguide/build-settings.htmlamplify.ymlversion: 0.1 frontend: phases: # IMPORTANT - Please verify your build commands preBuild: commands: - cd ./front/my-app - npm install -g build: commands: - npm run build artifacts: # IMPORTANT - Please verify your build output directory baseDirectory: ./front/my-app/build files: - '**/*' cache: paths: node_modules/**/*
手順6. 設定を確認後、保存してデプロイボタン押下。
ビルドとデプロイが開始されます。
ビルドの様子などは、コンソールの各タブからそれぞれ確認できます。
詰まった点
- 手順5でビルドの設定でymlファイルを修正しなければならないが、自動検出されたデフォルトで行けると勘違いしていた。(デフォルトの状態だと、amplifyコンソール上ではデプロイに成功している表示がされますが、ブラウザ上からアクセスすると、502エラーになります。)
デプロイができなかった or デプロイできたけど、画面が表示されなかった場合は、設定ファイルをしっかりと確認し、適宜修正しましょう。。
所感
今回初めてAmplifyでWebアプリをデプロイしたのですが、ブランチにプッシュしたタイミングで自動的にデプロイされたり、設定をいじるだけで簡易的に世に公開できるのはとても面白いなと感じました。もっと勉強して色々使いこなせるようになりたい。。
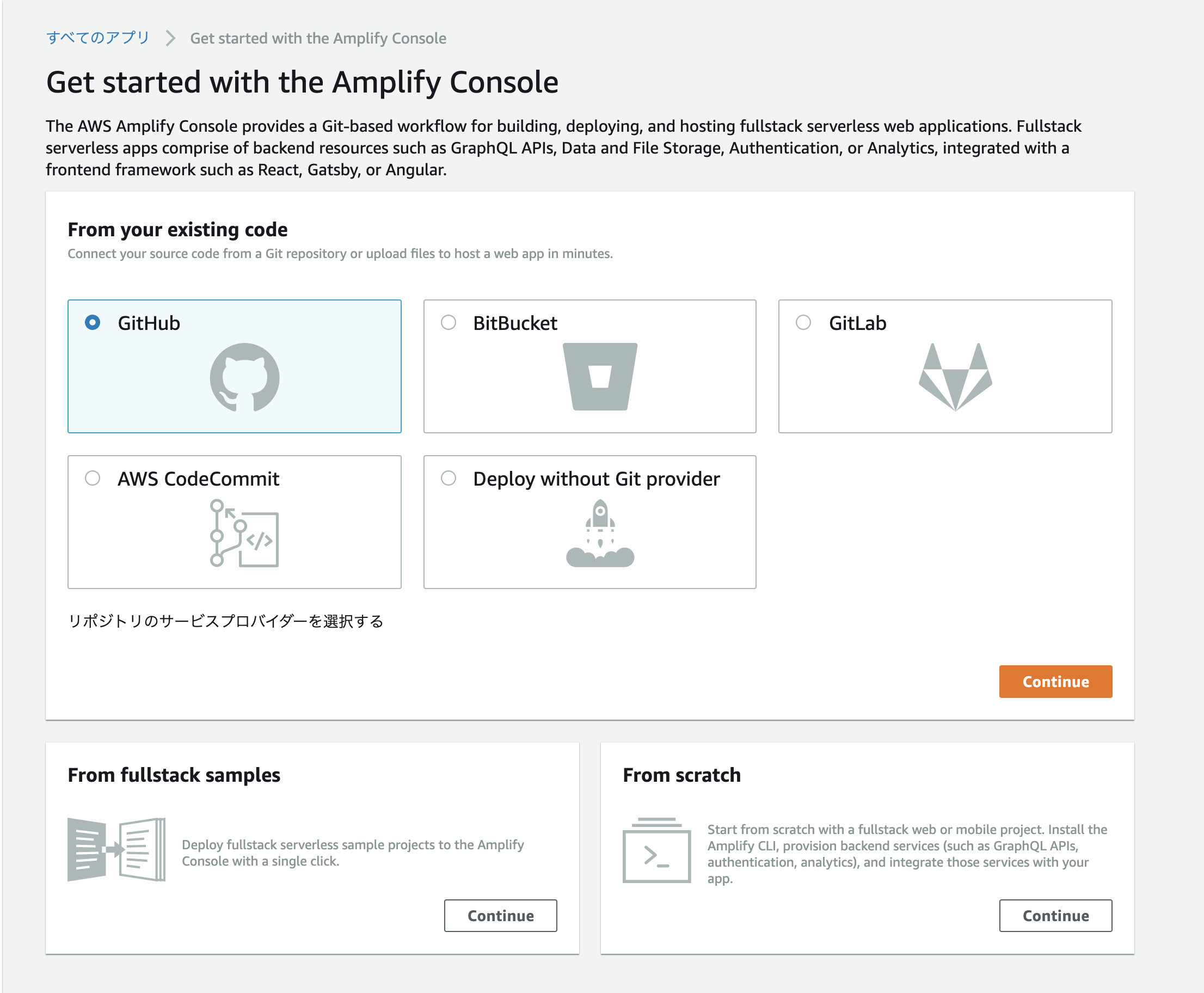
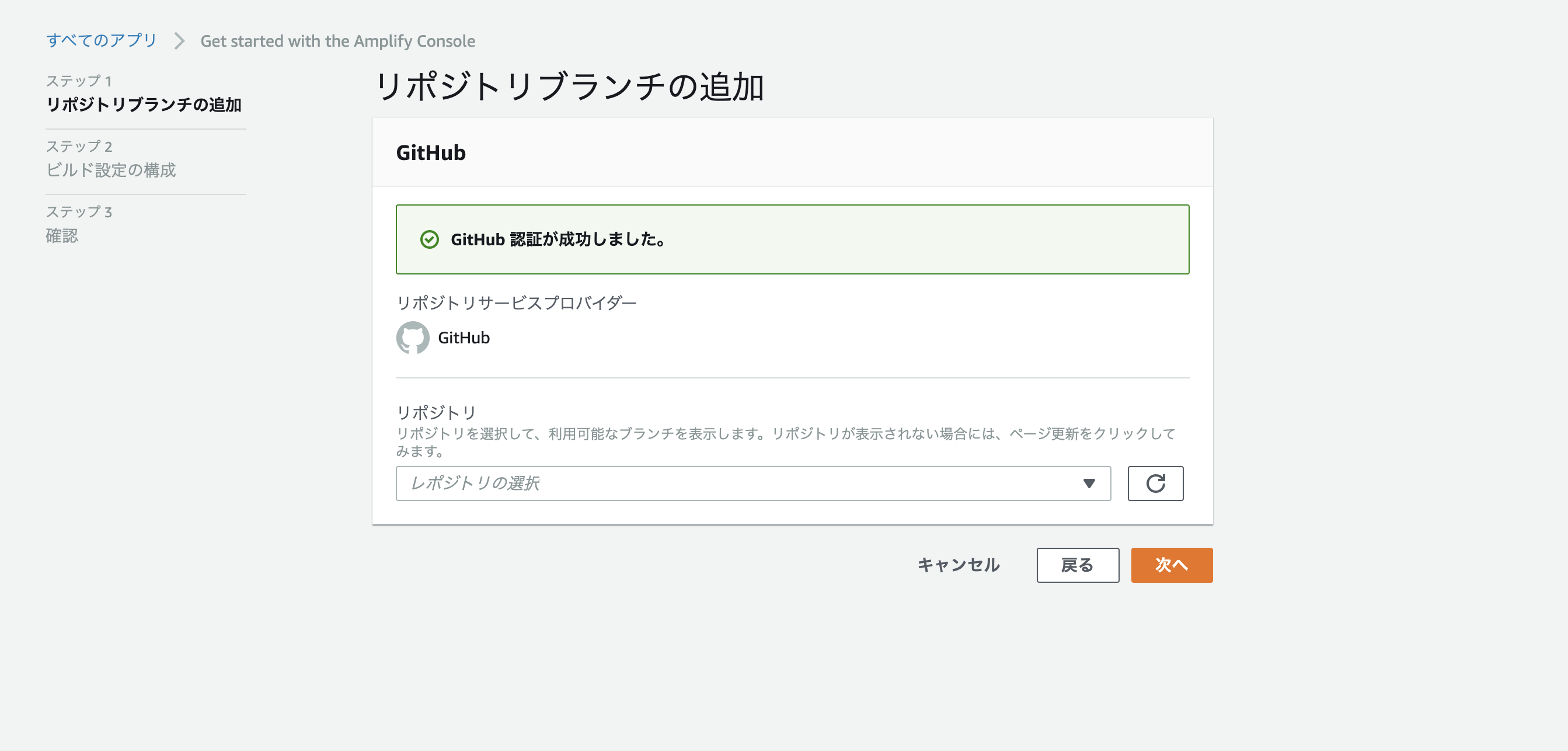
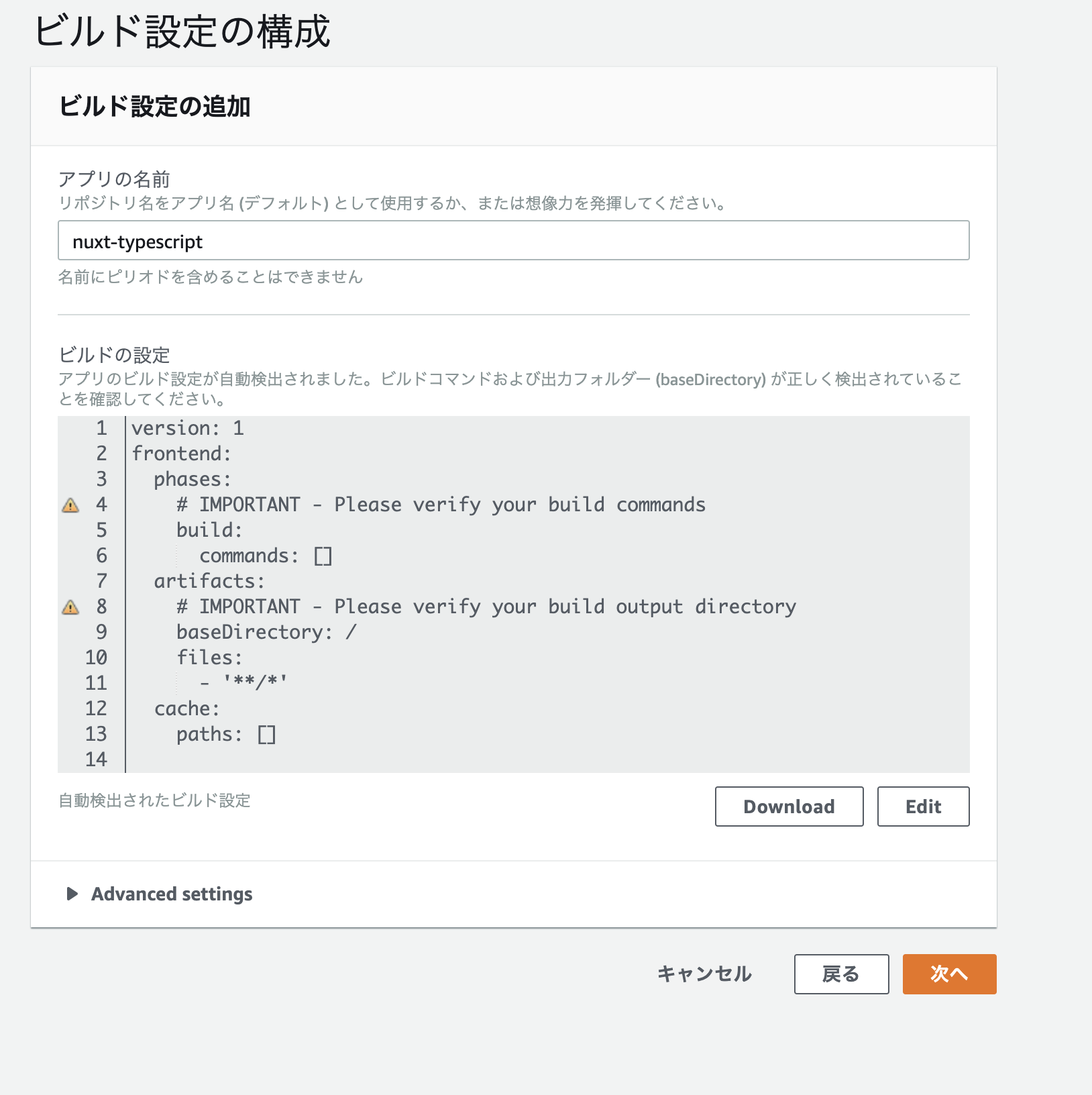
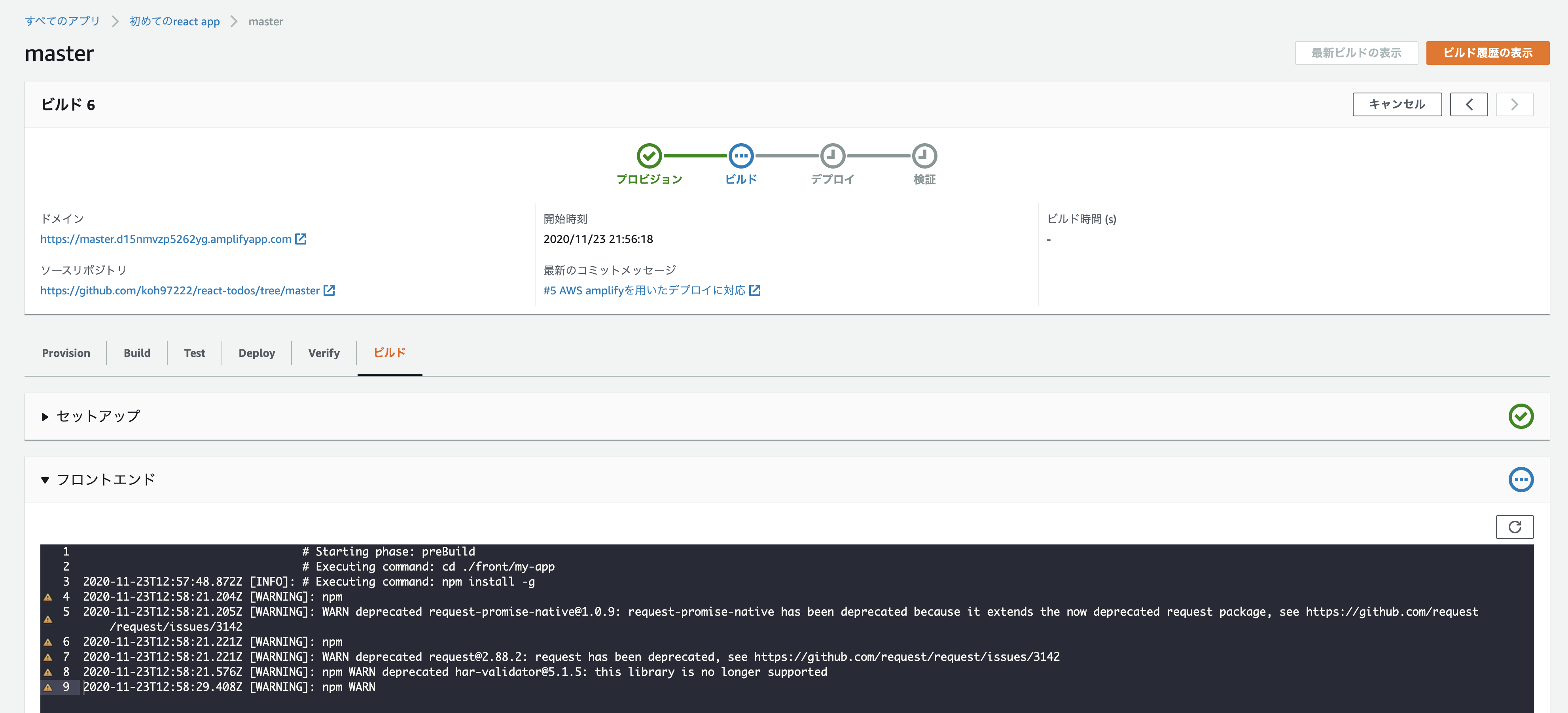
- 投稿日:2020-11-23T22:15:01+09:00
【合格体験記】実務経験半年くらいの初心者エンジニアが3週間でAWS SAA資格を取得するまでにやった事まとめ
概要
タイトル通り、実務経験半年くらいの初心者エンジニアが3週間で「AWS認定 ソリューション・アーキテクト・アソシエイト(SAA)」の資格を取得するまでにやった事についてまとめていきます。
この手の記事はすでに世間でたくさん溢れているため、もう何番煎じかわかりません。ただ、人それぞれスペックや経歴というのは全く違うわけで、それらが参考になるかどうかはまた別問題。
普段からAWSに触る機会のあった人が書く合格体験記と、これまでほとんど触れる機会の無かった人が書く合格体験記というのは読み手によって全く違う価値をもたらすでしょう。
なので、たとえ何番煎じと言われようが、記録を残しておく事には意味があると自分は考えています。
今回は、自分のようにまだ実務経験が浅い初心者エンジニアの参考になれば幸いです。
筆者のスペック
- 年齢: 20代後半(まだまだ脳は柔らかいと信じたい)
- エンジニア歴: 半年くらい(インフラはほとんど触らないポジションにいるため、AWSに関する知識はほとんど無しの状態でスタート)
- 学歴: 早慶上理レベルの大学卒(ある程度試験範囲の決まっている暗記は比較的得意な方)
典型的な駆け出しエンジニアといった感じのプロフィールです。 実務経験が浅いのでこれと言って得意な技術は見当たらず。
また、弊社にはインフラ専門のエンジニアが在籍しており、インフラに関しては基本その方たちに任せる事になっているため、自分が業務の中でAWSに触れるという事はありません。
転職活動の際に作成したポートフォリオもHerokuにデプロイするだけのお粗末なものだったので、ほとんどゼロ知識からのスタートだったと言って良いでしょう。
ただ、学生時代それなりに受験勉強を結構頑張っていた事もあり、いわゆる「試験のための勉強」は得意という点は多少の救いなのかもしれません。
実際の試験結果
だいぶギリギリでした...。全然余裕が無いところもリアルと言えばリアル。
3週間の学習でやった事
トータルの学習時間
一口に「3週間」と言っても、人それぞれ想定する内容は異なると思います。実際にどれくらいの時間を勉強に割けるかでだいぶ変わりますから。
僕の場合、平日は普通に10時〜19時勤務なので、定時を超えた後の自主勉強がメインといった感じでした。(1日3時間くらい)
したがって、これに土日を加えた時間がトータルの学習時間になります。平日:(3時間×5日×3週間) + 土日: (8時間×2日×3週間) = 約93時間
この数字が多いのかどうかはわかりませんが、たまに見かける「〇〇時間で合格!」みたいな数字には当てはまらなそうなので、決して少なくはないと思います。
覚えなければいけない範囲が広く、決して裏技のようなものは無いため、やはりそれなりに長時間の勉強を覚悟した方が良いと思います。(僕みたいに経験の浅いエンジニアは特に)
特にAWS SAAの場合、それっぽい選択肢が複数紛れ込んでいる事もザラなので、付け焼き刃の知識だと答えを絞りきれません。
「単純に目的を果たすだけであればどの選択肢もアリだけど、よりコスト最適かつ可用性が高いのはどの組み合わせでしょうか?」みたいな意地の悪い問われ方が特徴的です。
「〇〇はどんなサービスですか?」みたいな一問一答形式のものはほとんど出ないと考えてください。
各サービスの特徴を深く理解し、かつそれらの強み・弱みを十分に比較できるような状態で臨まないと基本的に◯はもらえないようになっています。
使用した教材
- この1冊で合格! AWS認定ソリューションアーキテクト - アソシエイト テキスト&問題集
- 足掛かりにとりあえず買ってみた参考書。全体的に要点がまとまっていて個人的には良かった。ただ、この手の参考書は割と何でも良い感がある。掲載されている内容自体はそれほど大きくは変わらないはず。
- これだけでOK! AWS 認定ソリューションアーキテクト – アソシエイト試験突破講座(SAA-C02試験対応版)
- 本を読んでいるだけではモチベーションが続かないため購入。動画と音声でテンポ良く進んでくれるのに加え、実際にハンズオンでAWSの各サービスに触れられるのが嬉しい。文章だけでイメージするのと実際の操作を目にするのとではまるで違うので、これは絶対にやった方が良いと思う。
- 【SAA-C02版】AWS 認定ソリューションアーキテクト アソシエイト模擬試験問題集(6回分390問)
- ひたすら問題を解くために購入。全体的に難易度は高いものの、本番に近い形式になっているため、こちらも絶対にやっておいた方が良い。最初は5割とかしか取れないと思うが、複数回繰り返して8割以上を狙いたい。
- AWS認定資格 無料WEB問題集&徹底解説
- 同じ問題ばかり繰り返していると、嫌でも解答そのものを覚えてしまってあまりタメにならないと感じ、補助的な目的で使用。ところどころで解答が複数可能な問題もあったりするため、そのクオリティに疑問視する方もいるかもしれないが、無料で使わせてもらえるので贅沢は言わない事。
- AWS サービス別資料(通称: ブラックベルト)
- 最後の仕上げ用。AWSが公式に公開しているドキュメントという事もあり、市販の教材では触れられていない部分もたくさん掲載されているので非常に勉強になる。単純に最低スコア狙いで合格するだけなら必須ではないと思うが、ここに書いてあるマニアックな問題が運良く解けると他で多少落としてもリカバリーが可能なので余裕があれば目を通しておくべき。
具体的なステップ
1週目
- 基礎固めの1週間目。
- まず最初にUdemy講座の「これだけでOK! AWS 認定ソリューションアーキテクト – アソシエイト試験突破講座(SAA-C02試験対応版)」を一気に最後まで視聴。(いきなり書籍から入ると退屈で飽きてしまうので、まずは動画でサラッとなぞりAWSに対する抵抗感を減らす)
- 次に書籍(自分の場合は「この1冊で合格! AWS認定ソリューションアーキテクト - アソシエイト テキスト&問題集」)を読み、動画で頭の中に入れた知識と照らし合わせながら理解を深めていく。
先に「動画で慣らす」というのが最大のポイント。書籍の場合、馴染みの無い言葉などが出てくると途端に頭がこんがらかったりして躓いてしまちがちですが、動画であれば時間の経過とともに否が応でも先に進んでくれるため、リズムが作りやすくなります。
何でもそうですが、勉強の際は「わからなくてもとりあえず先に進む」事が非常に重要だと思う(何度も繰り返し触れればそのうち嫌でも覚える)ので、それを強制してくれる動画教材は非常に優秀だなと感じました。
Udemyの動画は全部で20時間以上あるのでめちゃくちゃ膨大に見えましたが、倍速機能を使えばかなり短縮が可能です。(講師の方もゆっくり喋ってくれるため、1.75倍とかでも割と余裕で聞き取れる)
ダラダラやってもしょうがないので、最初の数日間で一気に最後まで進んでしまいました。で、残りの数日は書籍を読むのに使いました。先に動画でサラッと触れている分、本を読み進めるのも容易になるはず。
2週目
- 問題演習に挑戦してみる2週間目。
- Udemy講座の「【SAA-C02版】AWS 認定ソリューションアーキテクト アソシエイト模擬試験問題集(6回分390問)」を解いていく。また、答え合わせの際はたとえ正解でも不正解でも解説を良く読み込むように。(前述のように、AWS SAAはそれっぽい選択肢が複数紛れ込んでいる事もザラなので、何が良くて何がダメなのか一つ一つの選択肢を考察していく必要がある)
- 余裕があったので「AWS認定資格 無料WEB問題集&徹底解説」にも挑戦。
- 問題演習の中で腑に落ちない箇所があった場合、別でメモなどに残して後で細かく復習できるように。
ここは特に言う事はありません。とにかく問題を解いていました。
理想と現実のギャップを強く感じる厳しい期間でしたが、何とか気合で乗り切ります。3週目
- これまでの総復習&仕上げに入る3週間目。
- 模擬試験の間違えた部分を中心に繰り返し問題を解いていく。初回ではないため、答え合わせも含めてそれほど時間はかからない。3回目くらいで大体8割以上取れるようになっていた。
- 一定数出題されるややマニアックな問題に対応するため、「AWS サービス別資料(通称: ブラックベルト)」に目を通す。全てが全て必要な知識というわけではないので、基本は流し読みしつつ出題されそうな箇所(コストに関する部分など)を重点的に読むように。(ある程度問題演習をこなすと、「ここは問われそうだな」という部分が何となくわかるようになる)
いよいよラストスパート。絶えずアウトプット(問題演習)は続け、特に抜けていると感じる箇所の補強に努めました。
ブラックベルトの資料は一つ一つが割と長めのスライドなので読むのに苦労しましたが、ある程度目星を付ける事で効率的に目を通す事ができたと思います。(全部覚えようとするのはさすがに無理なので、捨てて良さそうなところは素直に捨てる)
あとがき
以上、自分の場合はこんな感じで学習を進めました。かなりギリギリの勝負になってしまったと思いますが、ダラダラやるよりは短期集中で一気に終わらせたい派なので、あえて余裕の無い戦いに挑んだ感じです。
スコア自体は全然大した事無いですし、全くイキれるようなものではありませんが、自分のような経験の浅いエンジニアでも何とかなるという事が少しでも伝われば良いなと。
おまけ
ここから先は、試験の申込方法や当日の立ち回りなどについて書いておきたいと思います。個人的な見解も多いですが、もし良ければおまけ程度に読んでみてください。
申込方法
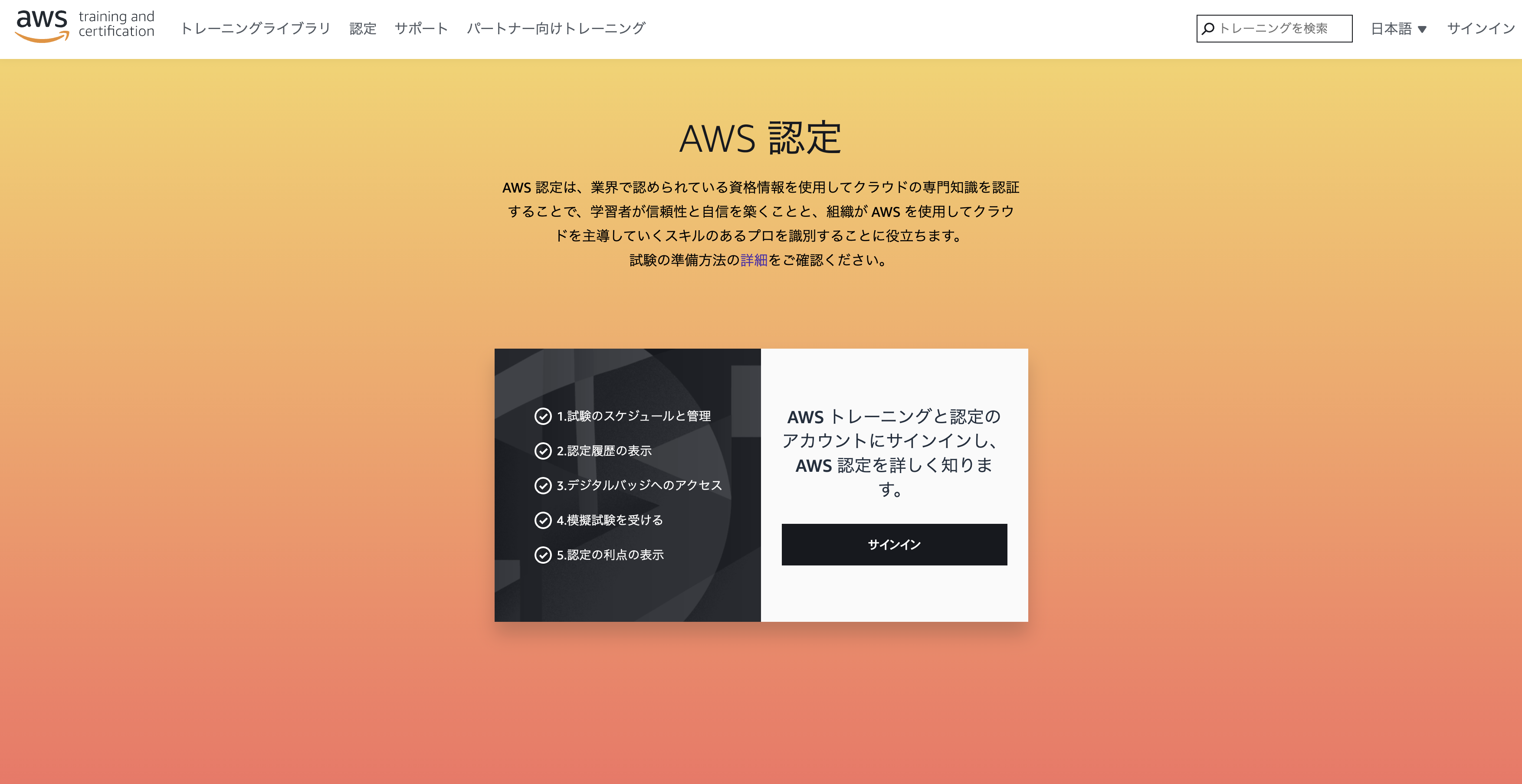
https://www.aws.training/certification上記リンクからサインインします。(まだアカウントを作成していない場合は適宜作成)
サインインに成功するとこんな感じのページに飛ばされるので「新しい試験の予約」をクリック。
どの試験を受けるか選択できるので、希望のものを選んでください。
- PSIによるスケジュール
- ピアソンVUEによるスケジュール
とありますが、これらは試験を実施してくれる業者のようなものなので、どちらでも好きな方を選べば良いと思います。(ちなみに僕はPSIで受験)
あとは日時だったり支払い方法の選択が出てくるはずなので、指示にしたがって手続きを進めていけばOK。
当日の立ち回り
その時々によって変わるかもしれませんが、僕が確認した限りだとAWSの認定試験は平日の10時、14時と1日2回実施されているようです。
なので、基本的にはそのあたりの時間帯を確保した上でスケジュールを組みましょう。(試験時間は130分)
時間に余裕を持って試験会場を目指す
どこで受験するかにもよりますが、AWSの認定試験を受けられるテストセンターは割とひっそりとした場所にある事が多い印象です。しかも大学受験みたいに一気に大量の人が集まってくるわけでもないため、ぱっと見でここが試験会場だとわかりにくかったりします。
特に方向感覚に自身の無い方は、早めに試験会場へ向かうようにしましょう。念のため、僕は試験の1時間前くらいには会場の場所を確認し、近くの喫茶店で時間を潰していました。
時間ギリギリで動くと変に緊張しますし、そういう意味でもある程度余裕を持って動く事は合否を大きく左右すると思います。
持ち物は身分証明書2点が必要
人によってどの書類で身分証明を行うかは異なるかもしれませんが、僕は
- パスポート
- クレジットカード
の2点を持参しました。
何か不備があったりするとせっかくの試験を受けられなくなるので、忘れ物が無いか何度もチェックしましょう。(部屋を出る前に1回、電車に乗る前に1回など)
なお、試験会場には何も持ち込む事ができないため、身分証明書以外のものは必要ありません。筆記用具なども一切持ち込み禁止です。(中でメモと鉛筆は貸してもらえるが、私物はダメ)
荷物は全てロッカーに入れた上で自分の体だけを試験会場内へ持ち込むような感じなので、基本的には身軽な状態で向かえばOK。
試験中は問題文の英語切り替えも可能
これは実際に試験を受けてみると良くわかるのですが、AWSの認定試験はとにかく不自然な日本語が多かったりします。誤字脱字はほぼ当たり前のようにありますし、助詞(「て・に・を・は」)の使い方などもいまいち綺麗に翻訳できなかったりするため、設問の意図がわかりにくかったりする事もザラだったり...。
市販されている模擬試験(Udemyのヤツとか)がいかにちゃんとした問題を作っているかを実感する事間違い無しです。
なので、もしどうしても設問の内容が入ってこない場合、表示言語を英語に切り替えてみたりすると良いかもしれません。確か画面の右上くらいに変更するためのボタンがあった気がします。
英語が問題無く読める事前提にはなってしまうものの、設問によっては英文の方がよっぽどわかりやすかったりするので、選択肢として頭の片隅に置いておいていただければと。
見直しは欠かさずに
こんなのわざわざ言う事ではないと思いますが、たとえ制限時間に余裕を持って解き終わったとしても見直しはしっかりと行った方が良いです。前述のように、AWSの認定試験は問題文が日本語として不自然だったりする事も普通にあるため、もしかすると自身を持って選んだ回答が間違っている可能性も十分にあります。
130分というとかなりの長期戦ではありますが、なるべく時間いっぱい使って何度も見直しする事をおすすめしたいです。

- 投稿日:2020-11-23T21:44:36+09:00
無料枠のRDSをマルチAZ構成化させ、手動でフェイルオーバーする
はじめに
※本記事は、AWS初心者がマルチAZ構成の練習した際の情報をまとめたものです。
無料枠のRDSでは初期設定でマルチAZ構成のオプションが使えないため、「無料枠でつくったRDSでは無理か……」と思っていましたが、実は後からの設定できるようなのでマルチAZ構成化させてみます。
そして、手動でフェイルオーバーを起こして切り替わっているか確認してみます。そこまで時間のかからない作業内容ですが、変更作業に数分以上待ち時間が発生します。
筆者は別の練習も並行したため数時間稼働しましたが0.19$しか掛かっていません。注意
- 低額ですが、料金は発生します。無料枠はシングルAZのRDSが対象だからです。
料金は1時間辺り「0.052USD」(db.t3.micro(東京・MariaDB))だと思われます。
※2020年11月23日時点練習後、放置すると料金が加算されていきますので、ちゃんと消しましょう。
料金に関する部分はAWS公式でご確認して下さい。
※Amazon RDS for MariaDB の料金
※流石に料金はご自身でご確認した方が良いと思います。目的
- 無料枠で作ったRDSをマルチAZ構成化させたい。
- RDSのフェイルオーバーを体験・練習したい。
- 低料金でRDSのマルチAZの練習がしたい。
全体の流れ
1.サブネットグループの作成
2.無料枠RDSの作成
3.マルチAZ化のオプションを適用化させる
4.RDSを再起動させ、手動のフェイルオーバーを実行1.サブネットグループの作成
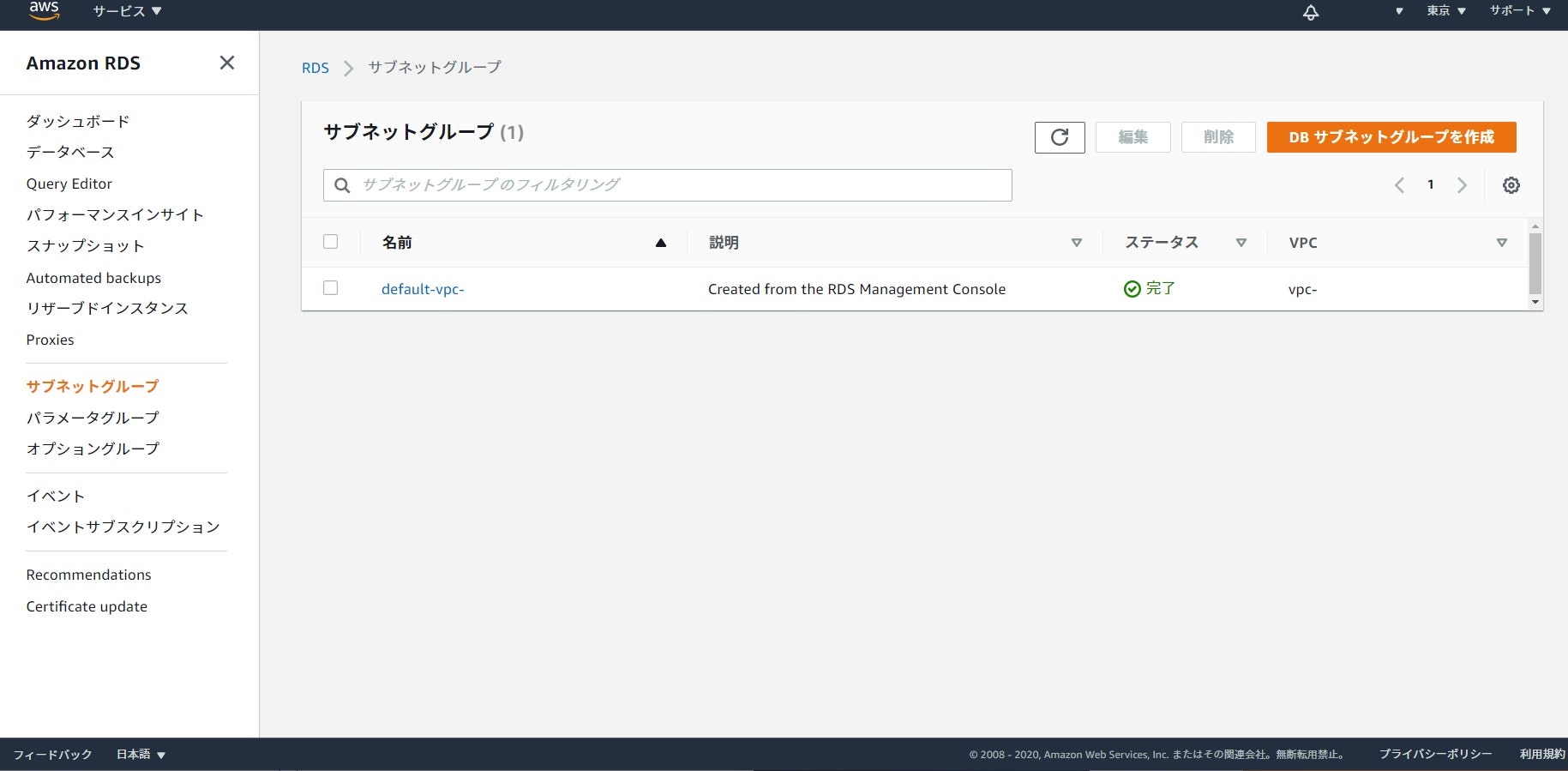
「サブネットグループ」はマルチAZの際にRDSが配置されうるサブネットをグループ化させた物です。
RDSをマルチAZ化する場合はこのグループの作成が必要になります。
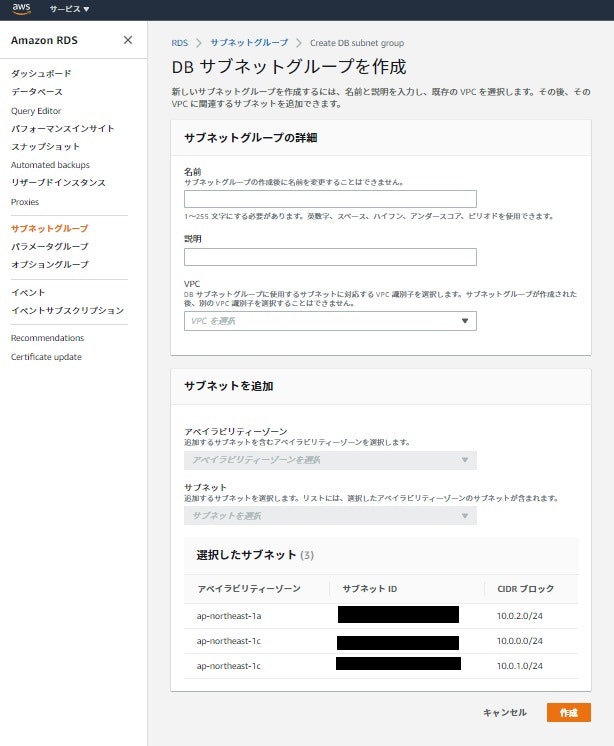
予め使用するVPC・AZ毎のサブネットとグループ用のセキュリティグループは作成しておきましょう。サブネットグループの作成設定
RDSのコンソールメニューを開き、その中のサブネットグループを選択します。
そして「DBサブネットグループを作成」を押します。
名前・使用するVPC・AZ(アベイラリティゾーン)・サブネットを入力・選択します。
作成を押せばサブネットグループが出来ているはずです。2.無料枠RDSの作成
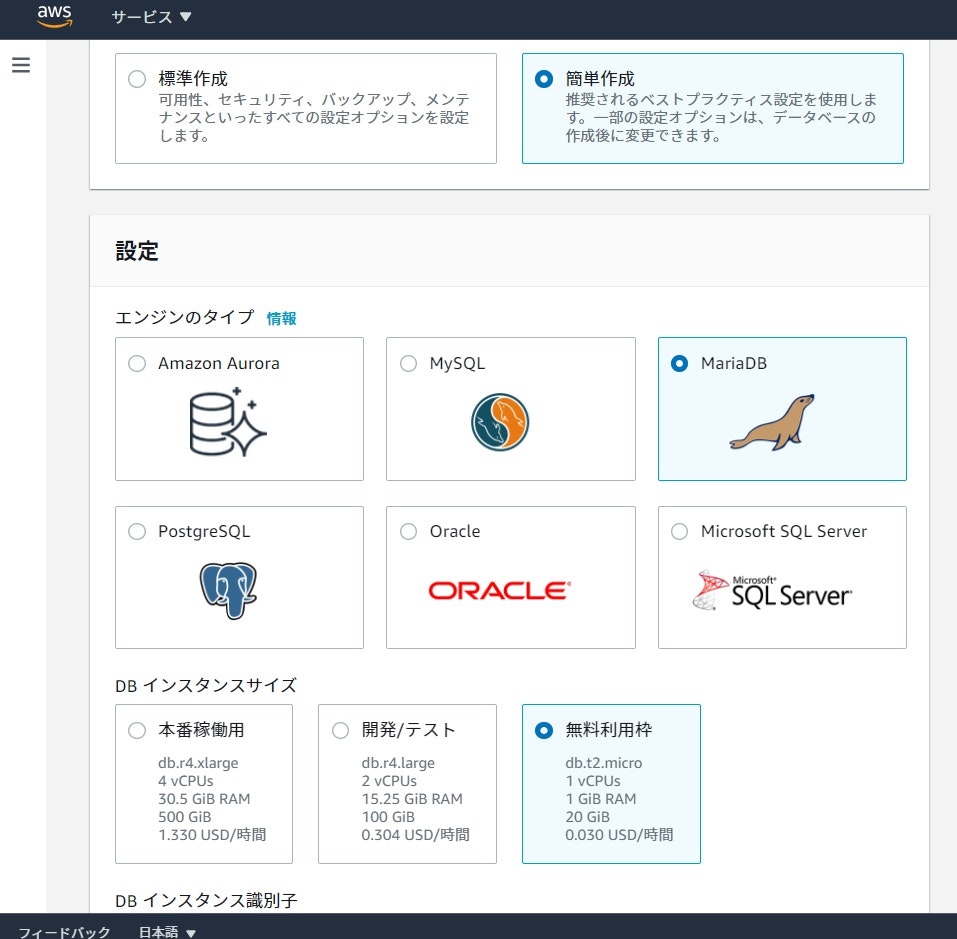
※既に無料枠でRDSを作っている方は省略して下さい。
RDSの作成
特に弄る事なく無料枠のRDSを作成します。(DBはMariaDB)
無料枠の場合、初期作成の段階ではマルチAZのオプションは押せなくなっています。
マルチAZは無料枠ではないから押せなくしているのでしょう。
無料枠で作成した後、オプションを変更させていきます。3.マルチAZ化のオプションを適用化させる
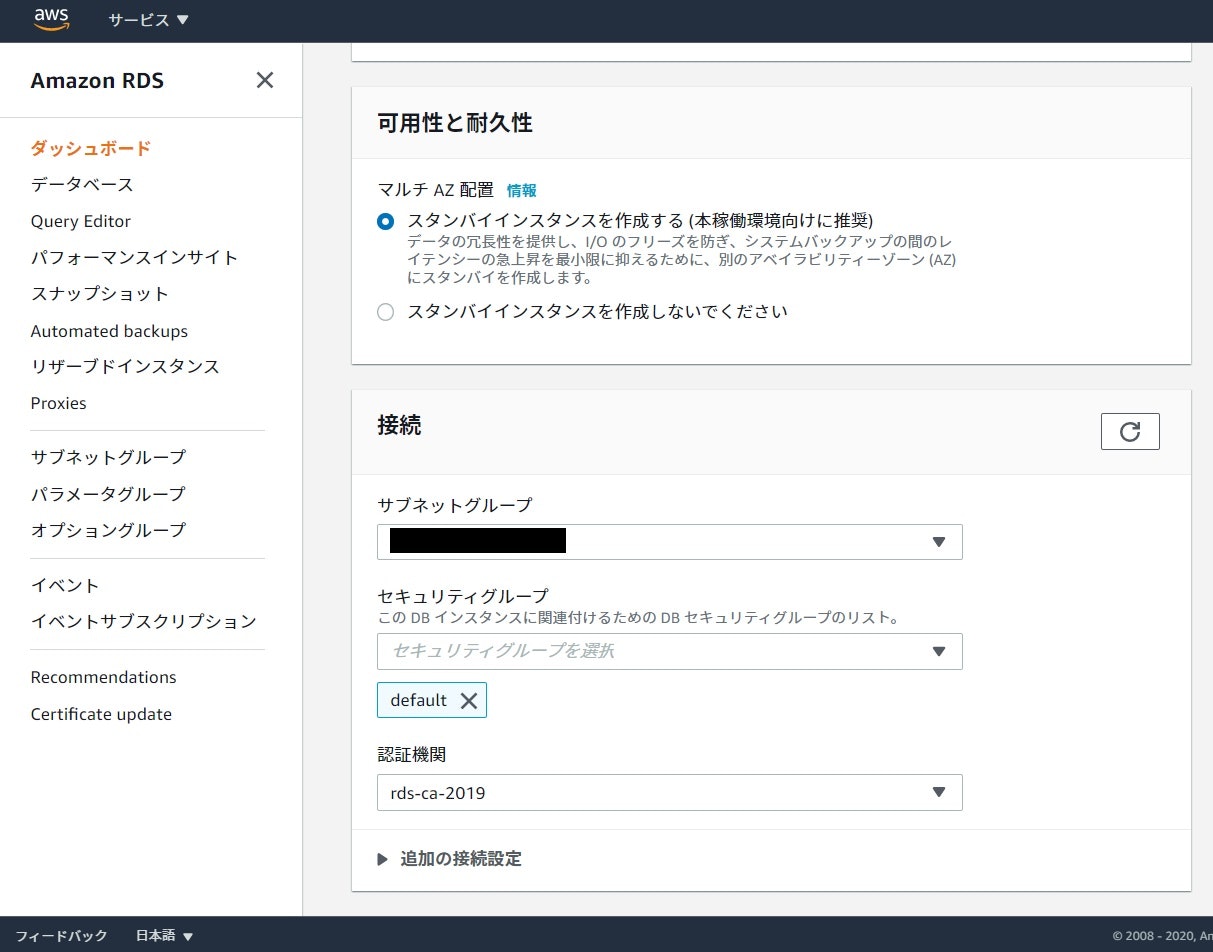
データベースの設定変更
作成したRDSの詳細画面から変更ボタンを押して、DBインスタンスの変更画面に移行します。
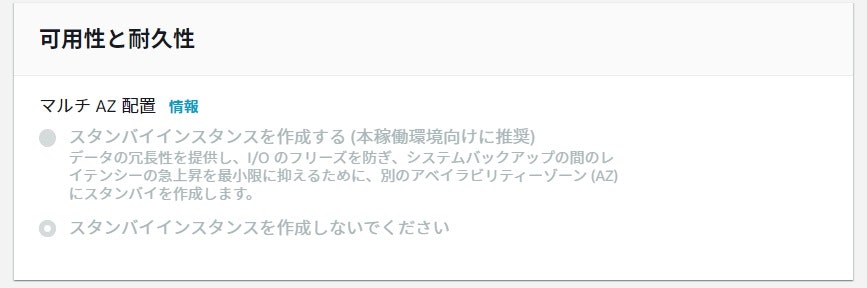
先程押せなかった、マルチAZ配置が設定できるようになっています。
「スタンバイインスタンスを作成する」にチェックを入れます。
先程、設定したサブネットグループ等を選択し、他の部分はそのままで変更をかけます。
次の画面で「変更を適用するタイミング」は「すぐに適用」を設定しましょう。待機
数分から十数分位、待ちましょう。
変更がかかるのにそれくらいの時間がかかります。確認
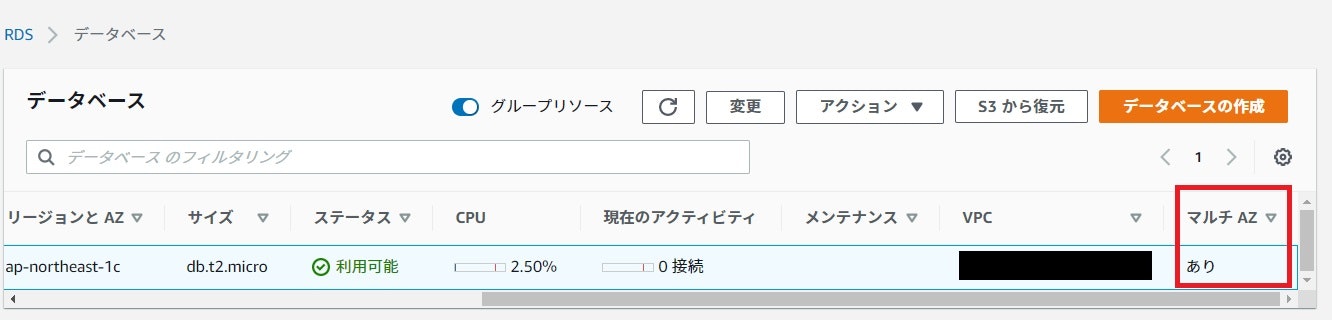
「マルチAZあり」と表記されているので変更完了です。
無料枠用のRDSをマルチAZ化させる事が出来ました。4.RDSを再起動させ、手動のフェイルオーバーを実行
ここからはフェイルオーバーの練習を行います。
RDSを再起動させる際にフェイルオーバー、別AZのスタンバイRDSに切り替わります。元の状態を確認
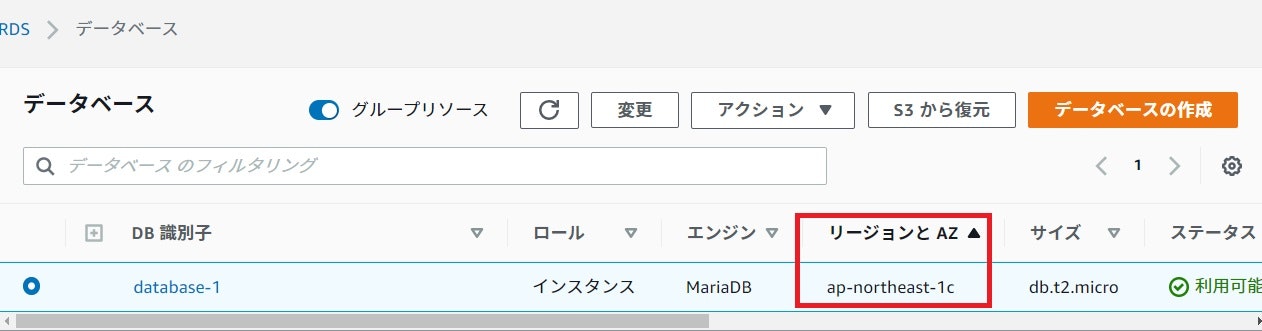
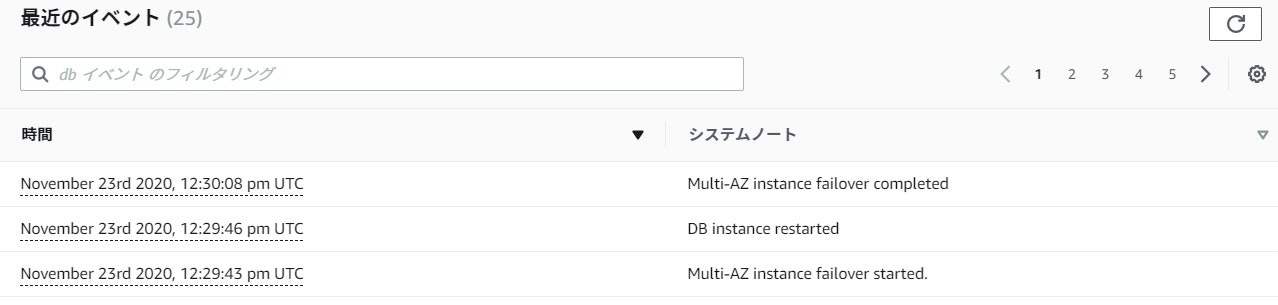
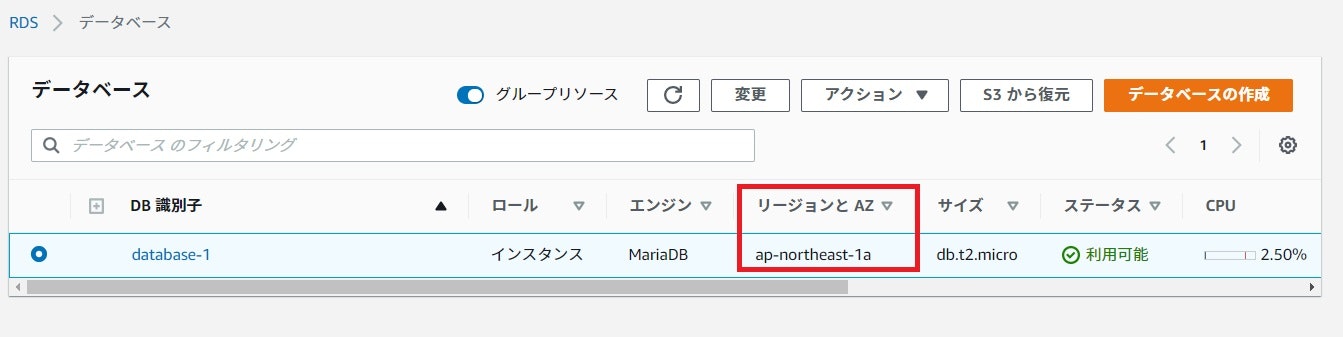
フェイルオーバーの前に、現在のRDSがどのAZの物か確認しましょう。
現在のAZは「ap-northeast-1c」である事がわかりました。再起動
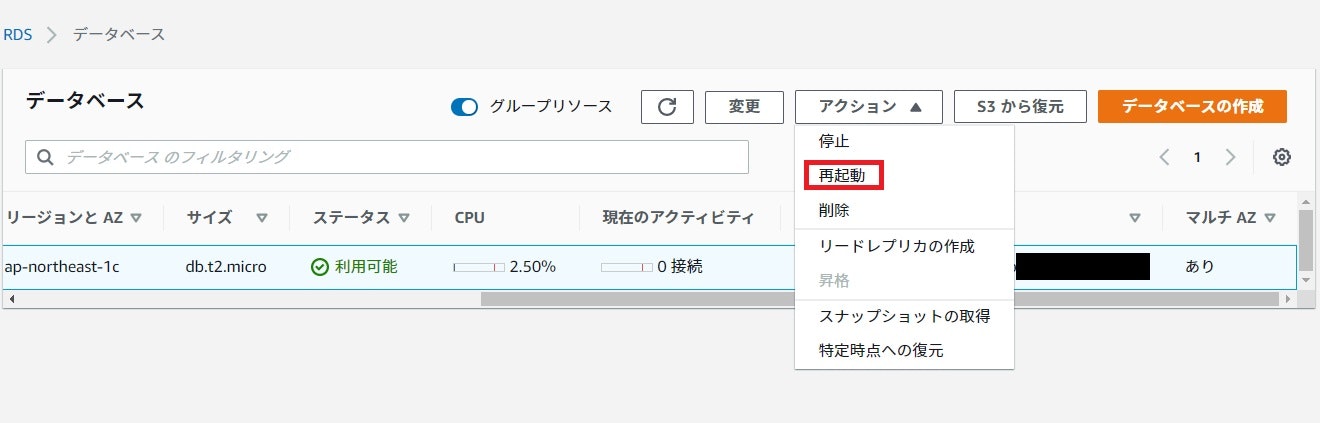
データベースを選択し、アクション→再起動を押します。
「フェイルオーバーで再起動しますか?」にチェックを入れて確認を押します。
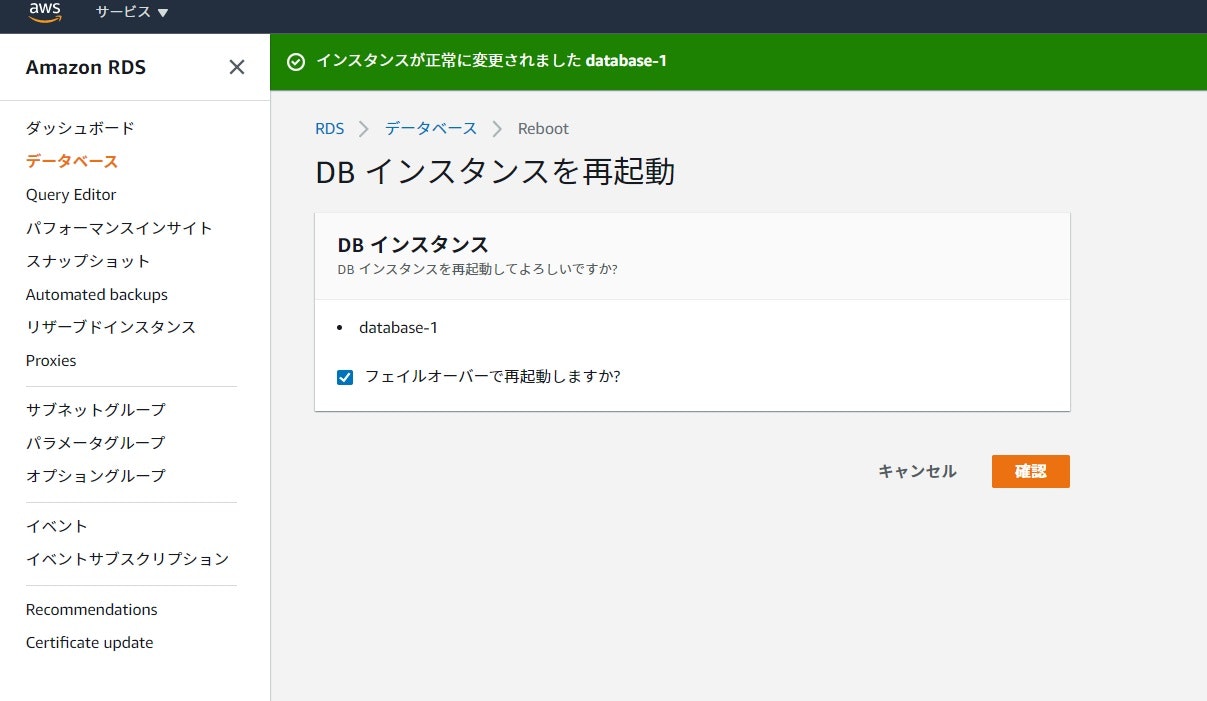
変更されたか確認
再起動した後、フェイルオーバーはされていますがコンソールには即座に反映されません。
コンソールの反映には数分待ちましょう。待っている間、データーベースの詳細情報にあるログとイベントでフェイルオーバーが行われた事は表示されているので確認してみましょう。
フェイルオーバーの確認
もう一度確認してましょう
AZは「ap-northeast-1a」になっていました。
無事、別AZ上のRDSにフェイルオーバーしている事がわかります。参考URL
- 投稿日:2020-11-23T21:30:23+09:00
【AWS】「InstanceStateとInstanceStatusは違う」という紛らわしいお話【EC2】
1. はじめに
タイトルだけで完結してしまっているような気もしますが、
「そうなんだ!」と思った方は少しスクロールしていただけると幸いです。2. とりあえず取得してみる
早速
describe-instance-statusを叩いてみましょう。
と言いつつ、自分はリファレンスの実行例をコピペしましたが。~describe-instance-status$ aws ec2 describe-instance-status --instance-id i-1234567890abcdef0 { "InstanceStatuses": [ { "InstanceId": "i-1234567890abcdef0", "InstanceState": { "Code": 16, "Name": "running" }, "AvailabilityZone": "us-east-1d", "SystemStatus": { "Status": "ok", "Details": [ { "Status": "passed", "Name": "reachability" } ] }, "InstanceStatus": { "Status": "ok", "Details": [ { "Status": "passed", "Name": "reachability" } ] } } ] }InstanceStateとInstanceStatusが登場しますが、StateとStatusって一緒じゃないの?ってなりますよね。
辞書を引いてみると、どちらも「状態」と訳せるようです。3. 原典にあたる
InstanceState:running、InstanceStatus:okの他にどのような値があるのか、公式から引用しました。1. InstanceState
稼働状況と考えるのがよさそうです。
Valid Values: pending | running | shutting-down | terminated | stopping | stopped
https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/APIReference/API_InstanceState.html
2. InstanceStatus
ざっくりと言うと、問題の有無ということでしょうか。
Valid Values: ok | impaired | insufficient-data | not-applicable | initializing
https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/APIReference/API_InstanceStatusSummary.html
4. 使いどころ
例えば検証環境のインスタンスを夜間に停止し、翌朝に起動するというようなLambda関数(やシェルスクリプト)を作る場合は。。。
1. State
停止/起動を実行した後に確認し、結果に応じて待機したり再度実行したりという風に使えます。
2. Status
起動後に確認し、OKでなければ再起動するとかエラーを吐くという処理を実装しても良いかもしれません。
ただし、ec2 wait instance-status-okには注意が必要です。5. ちなみに
「status vs state」論争に終止符を打つという記事がありました。論争になるほどなんですね。
少なくともInstance{State|Status}については、以下の記載がしっくりきます。Status = 調子はどう?
State = 何をしているか?6. おわりに
4. 使いどころで例に挙げたLambda関数を作成する際にこのあたりを詳しく調べたのですが、
だいぶ前のことなので割と忘れてしまっている部分もありました。
ナレッジはすぐに形にしないといけませんね。。。
- 投稿日:2020-11-23T21:07:22+09:00
AWS AthenaでWAFで検知したDoS攻撃の内容を調査する
目的
AWS WAFで設定した、DoS攻撃検知用のルールが稼働していると思われるログがあったので、DoS攻撃の詳細内容を調査した時の方法をまとめておくものです。
前提となる環境
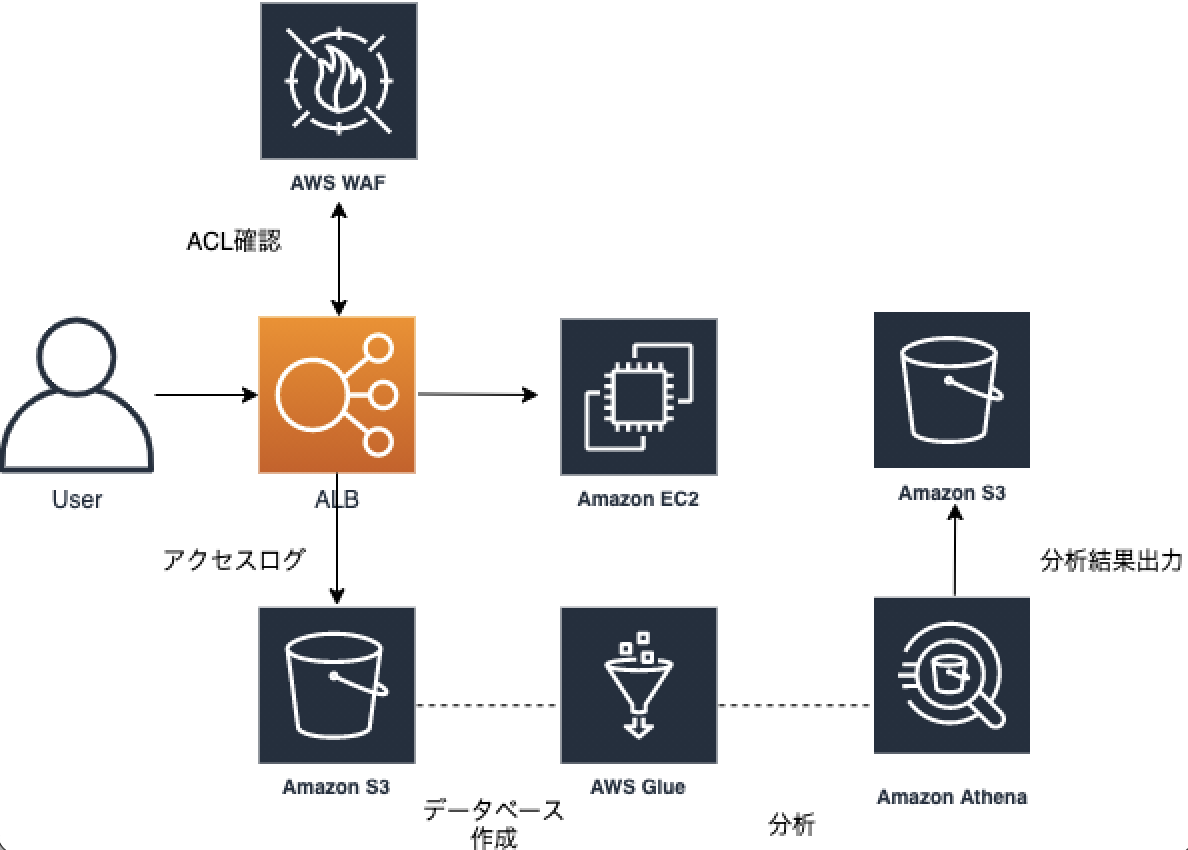
以下のサービスが有効になっている環境での調査方法となります。
※ この環境ではWAF自体のロギングを有効としていないため、ALBのログを調査します。
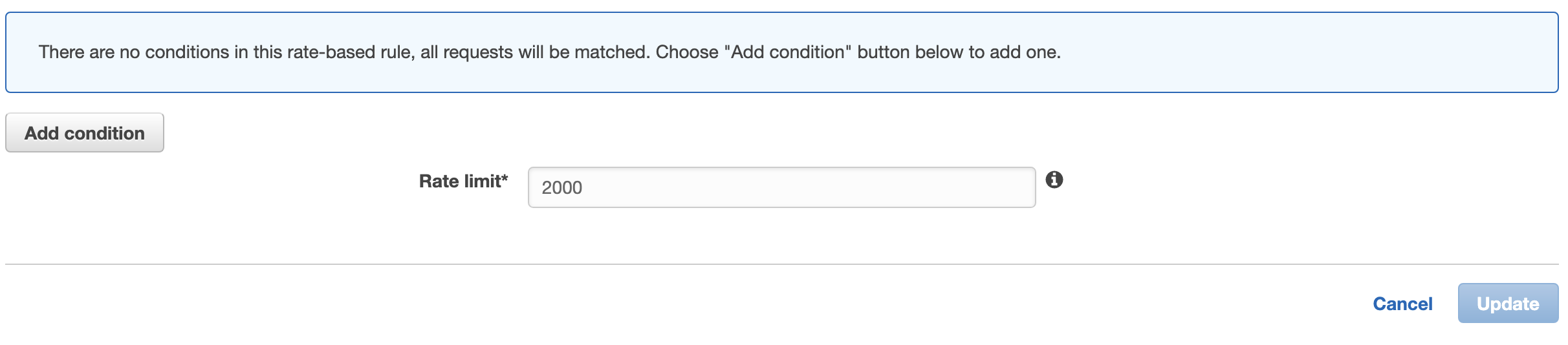
AWS WAF
- AWS WAFにて、ACL(アクセスコントロールリスト)として5分辺りのリクエスト件数を低閾値としたrate limit baseのルール設定が可能です。該当の環境では2000件を設定しており、これを越した時をDoS攻撃とみなしています。
AWS ALB
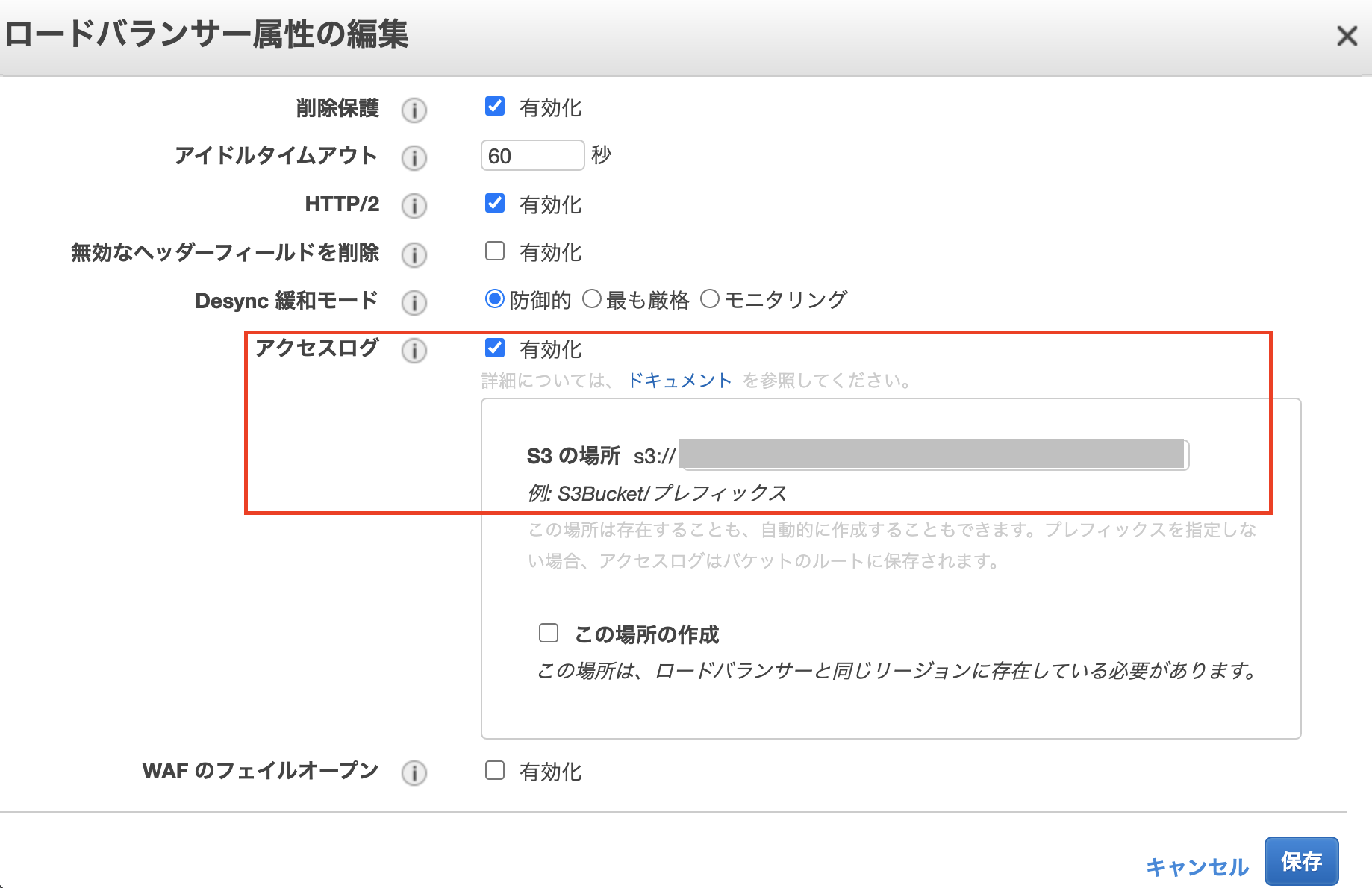
- 有効にしたWAFはALBに割り当てます。
- Athenaで検索するために、ALBのログをs3に保管しておく必要があります。
なお、対象となるs3のオブジェクトを特定することが出来れば、Athenaを利用しなくてもs3単体でクエリを実行することも可能です。
AWS Glue
- AWS Athenaは AWS Glueのデータカタログを使用してS3に格納されたデータに接続し、テーブルや列名などのメタデータを格納できます。そのため、あらかじめAWS GlueにALBのログを保管したs3を指定してのデータベースを作成しておく必要があります。
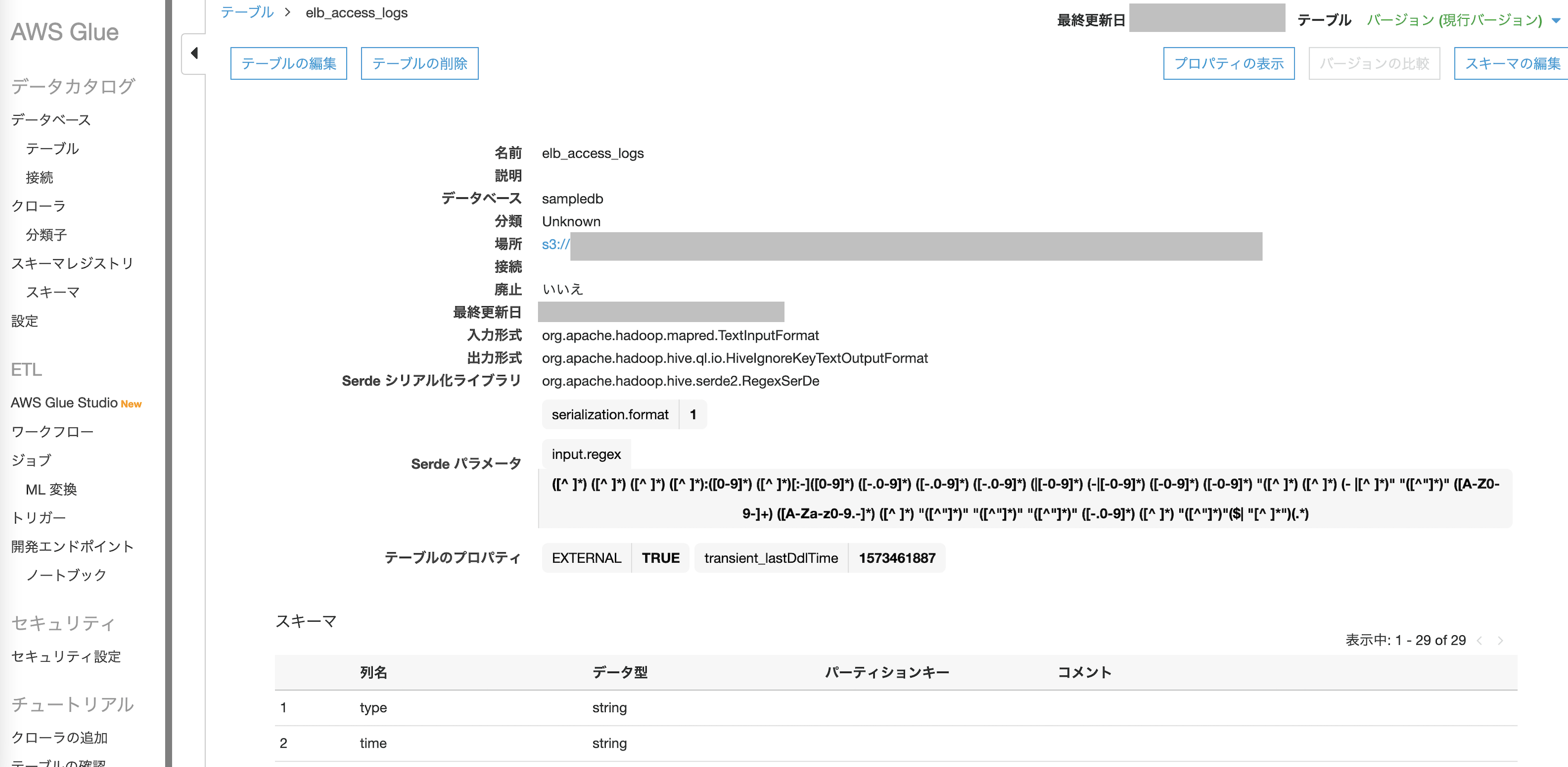
AWS Athena
- 上記3サービスの準備が出来ればAthenaを使った分析が可能になります。
調査
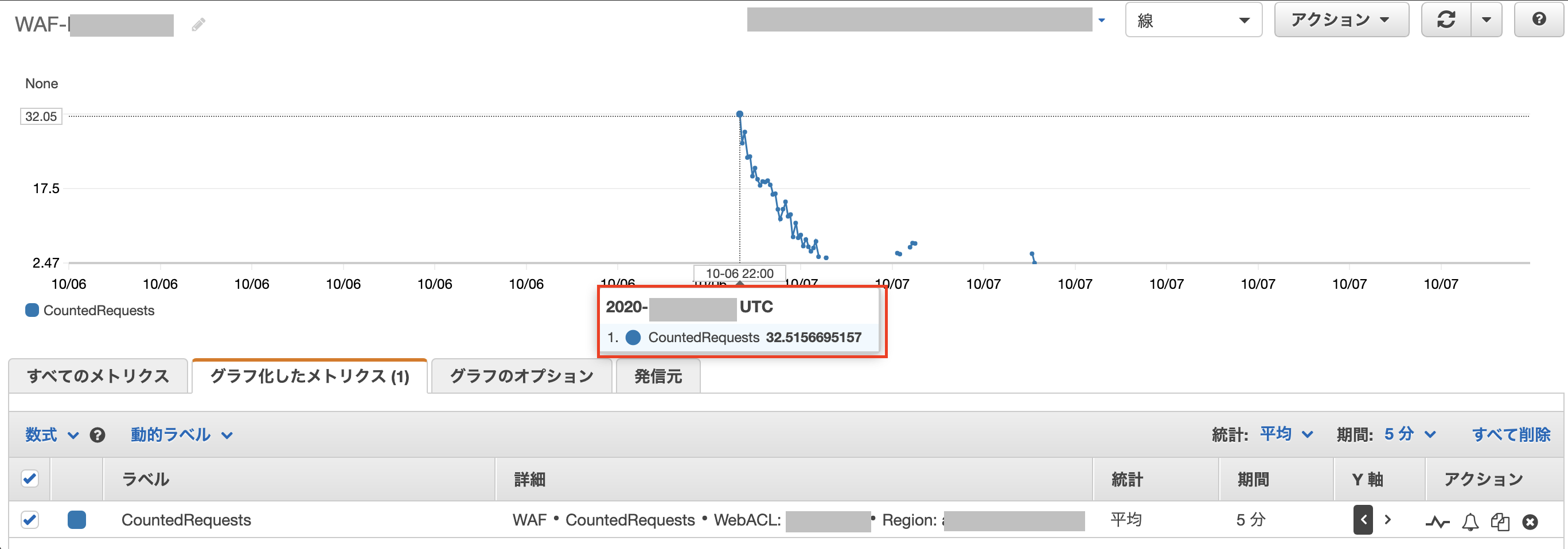
CloudWatch
WAFのメトリクスを指定します。
DoS攻撃検知用のルールに合致している日時を確認します。
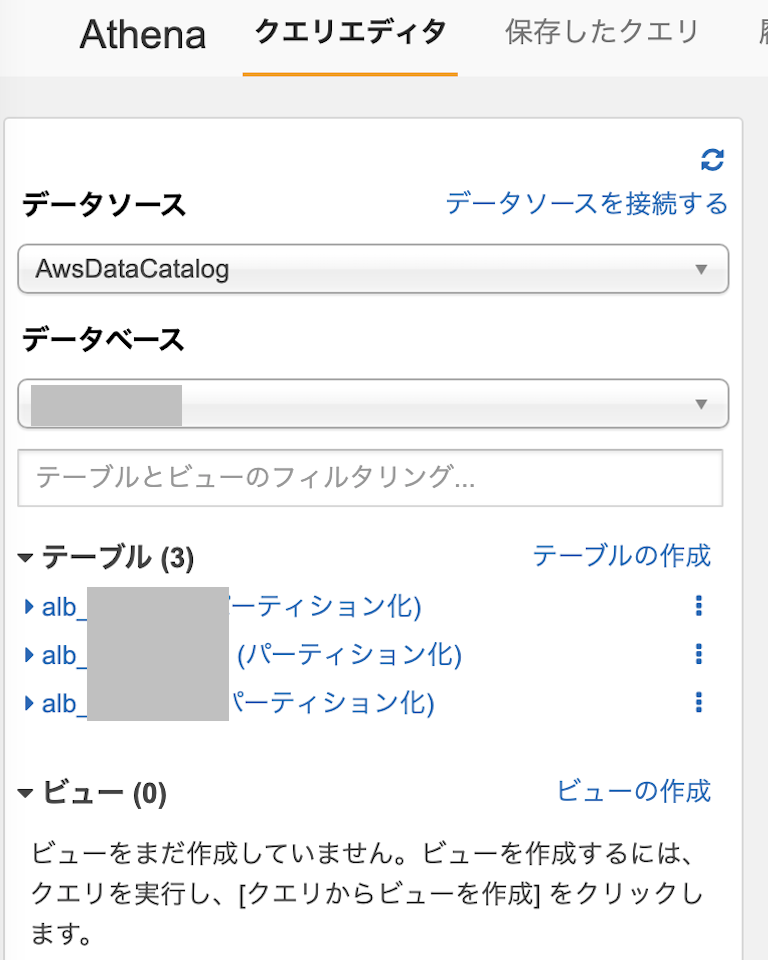
AWS Athena
最初にクエリを実行するためのデータソースを指定します。
Glueで定義したALBのデータベースが選択できるので、対象のデータベースを選択するとALBのログを保管したs3テーブルが表示されます。
DoS攻撃検知用のルールが稼働していた日時をfrom~toで指定し、結果を保存するためのs3を指定してクエリを実行します。
クエリの内容は今回は以下のような内容です。SELECT * FROM alb_web_logs WHERE parse_datetime(time,'yyyy-MM-dd''T''HH:mm:ss.SSSSSS''Z') BETWEEN parse_datetime('2020-xx-xx-x:00:00','yyyy-MM-dd-HH:mm:ss') AND parse_datetime('2020-yy-yy-y:00:00','yyyy-MM-dd-HH:mm:ss') ORDER BY received_bytes DESCクエリが成功すると、実行結果は管理画面でも表示されます。
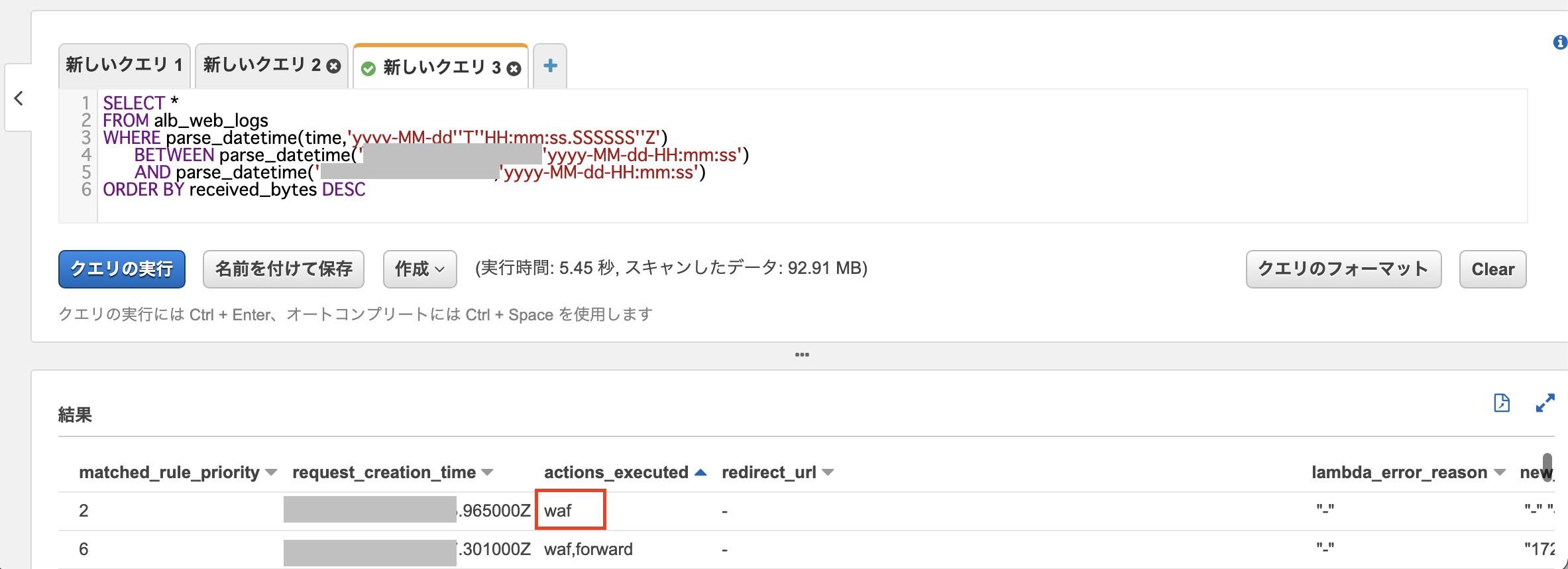
結果はcsvでも出力可能です。今回ALBログの項目で注目するのは
actions_executed項目です。
値がwaf,forwardであればALBでリクエストをターゲットに転送したという内容となりますが、
WAFのDoS攻撃検知用のルールに合致してリクエストを拒否する必要があると判別した場合、以下のようにwafという値になります。
wafとなった該当ログのうち、主に以下の項目を確認して攻撃内容を把握します。
項目名 確認内容 elb 対象となったALB request_url 対象となったURL client_ip アクセス元のIPアドレス client_port 利用ポート 全項目の内容は以下の通りです。
【公式ドキュメント】Application Load Balancer のアクセスログ結果
ALBログからWAFの検知した時の状況を確認することが出来ました。
対応としてはAWS WAFでActionをCountに設定しておくと検知した内容をログとして残しておくだけですが、Blockに設定しておくと、 HTTPステータス403(Forbidden)を返します。
Blockにする場合、rate limit baseのルールが正当なアクセスをblockすることのないように閾値を調整する必要があります。参考
- 投稿日:2020-11-23T20:17:38+09:00
Lambdaの非同期処理のリトライ設計値をまとめる(Streams/SQS編)
はじめに
Lambdaの非同期処理の設定値と動作は複雑でわかりにくい。
しかも、DynamoDB Streams/Kinesis のストリーム系の非同期処理と、SQS といったイベント系の非同期処理では設定値が異なる。今回は、上記の非同期系処理を適切にリトライするための設計値をまとめる。
また、Terraformで設定する際のリソースと設定値も付記しておこう。ちなみに、今回書いた機能では、Lambdaのリトライや保持期間、DLQの設定は無視されるので注意が必要。
ストリーム系非同期処理の設計値
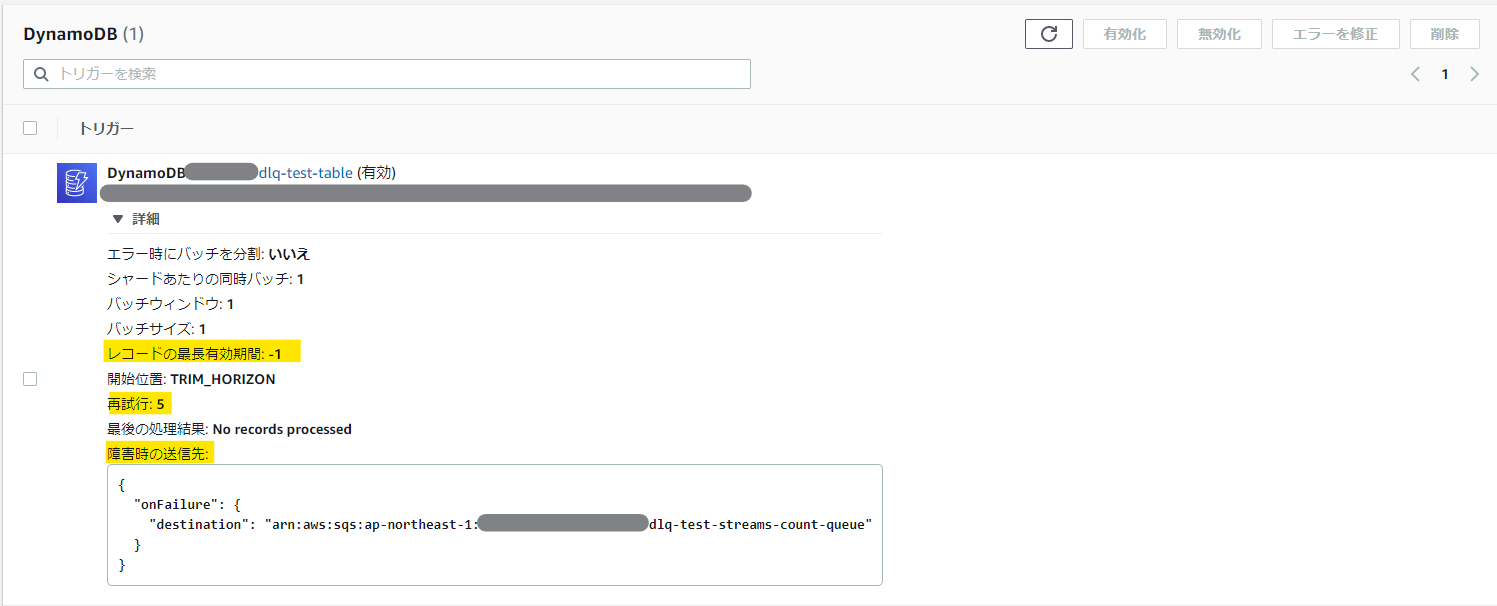
ストリーム系非同期処理の設計値は、以下の項目が重要になる。
マネージメントコンソールの設定値 Terraformリソース Terraformの設定値 デフォルト値 レコードの最長有効期間 aws_lambda_event_source_mapping maximum_record_age_in_seconds -1(無制限) 再試行 aws_lambda_event_source_mapping maximum_retry_attempts -1(無制限) 障害時の送信先 aws_lambda_event_source_mapping destination_config - on_failure 未設定 マネージメントコンソールの画面では以下の項目を見ると良い。
障害時の送信先は、下記のように定義する。なお、本設定を行う場合は、Lambda の IAM ロールに
sqs:SendMessageの実行権を付与しておく必要がある。resource "aws_lambda_event_source_mapping" "test" { // (中略) destination_config { on_failure { destination_arn = aws_sqs_queue.test.arn } } }SQSの設計値
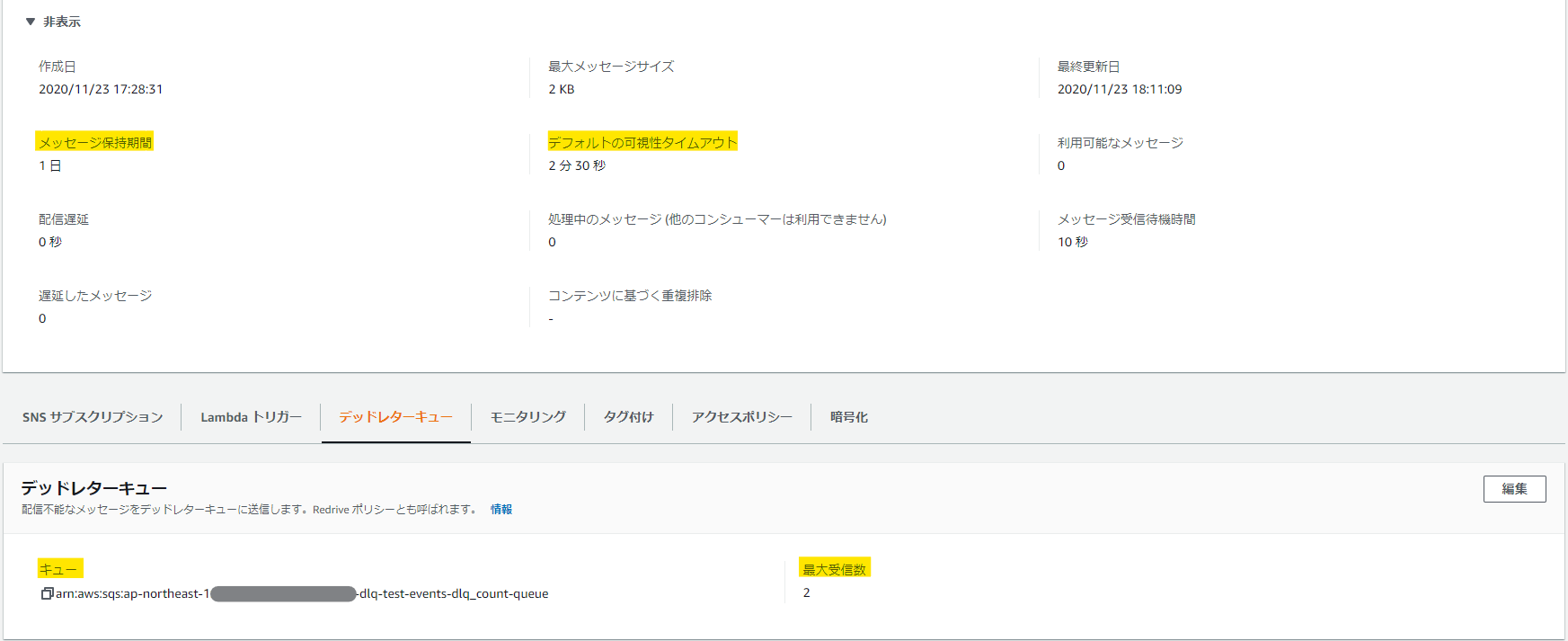
ストリーム系非同期処理の設計値は、以下の項目が重要になる。
マネージメントコンソールの設定値 Terraformリソース Terraformの設定値 デフォルト値 タイムアウト aws_lambda_function timeout 3秒 デフォルトの可視性タイムアウト aws_sqs_queue visibility_timeout_seconds 30秒 メッセージ保持期間 aws_sqs_queue message_retention_seconds 345600(4日) 最大受信数 aws_sqs_queue redrive_policy - maxReceiveCount 未設定 デッドレターキュー aws_sqs_queue redrive_policy - deadLetterTargetArn 未設定 マネージメントコンソールの画面で関連する部分は以下。
ここで、気を付けなければいけないのは以下の制限事項だ。
- 可視性タイムアウトの設定値は>Lambdaのタイムアウト値 でないといけない
- メッセージの保持期間>デフォルトの可視性タイムアウト×最大受信数 でないといけない(保持期間を過ぎるとDLQに入らず消滅する)
詳細な動作については以下の記事が分かりやすかった。
【Qiita】SQS → Lambdaのリトライ処理について整理してみた
これで、どちらのパターンでもエラー処理のキューに格納することができるようになった。
あとは、エラー処理のキューを監視するなりの設定を入れておくのが良い。
- 投稿日:2020-11-23T18:41:46+09:00
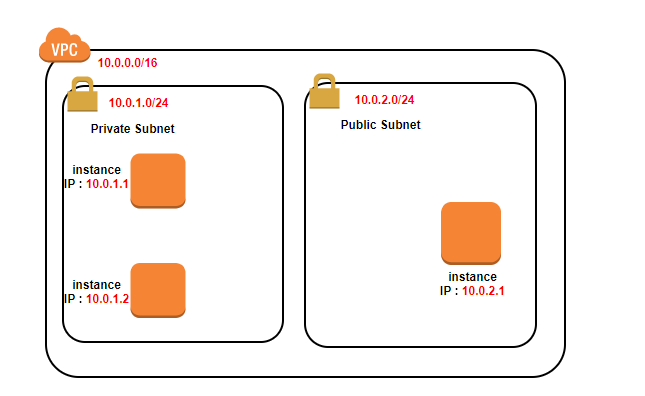
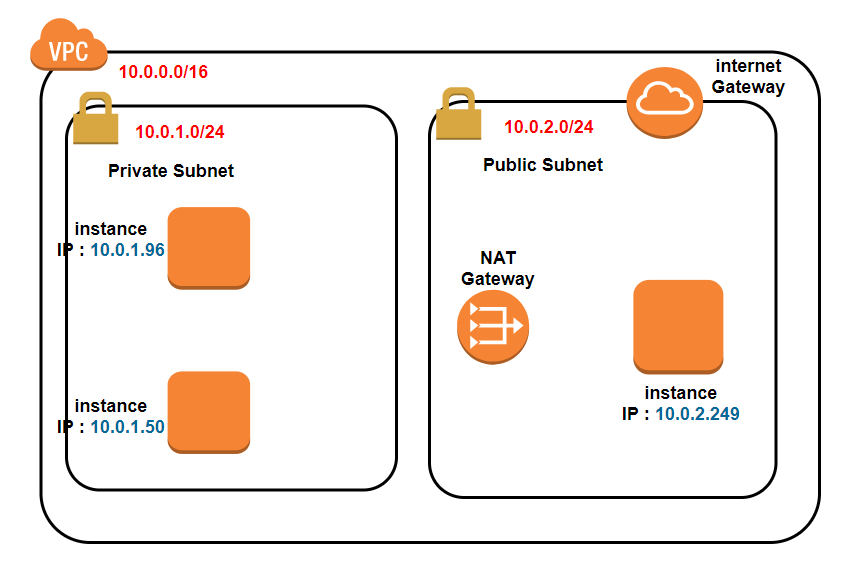
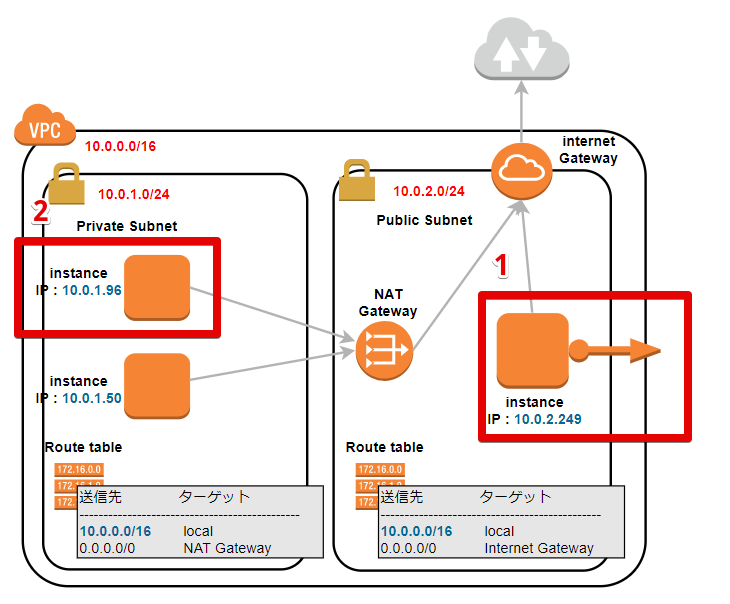
実際に構築してみる(Internet gateway と NAT gateway)
実際にVPCを構築してみる(VPCとサブネット)でやった続きです。
※完成してません、試行錯誤中です。勉強前イメージ
インターネットゲートウェイとNATゲートウェイについてはこれでなんとなくやったけど、
実際の構築イメージはわかない....Internet gateway と NAT gateway
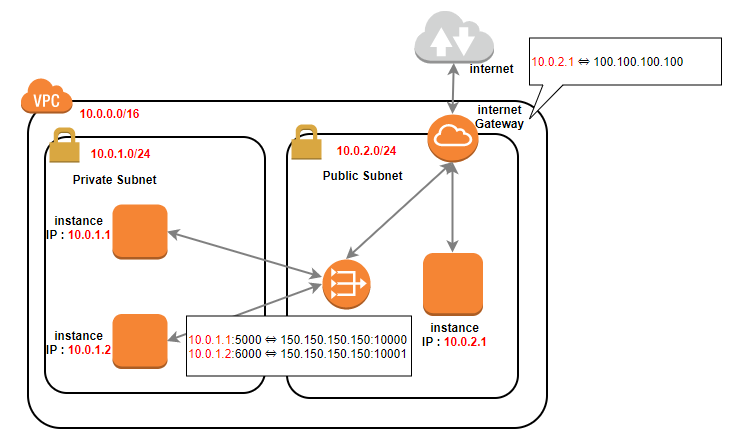
AWSのVPCのよく使われるコンポーネントについて で書いたイメージから、
前回 からの修正を行ったイメージ図が以下です。
今回、このようなイメージで設定していきたいと思います。
※修正を行ったのが赤文字の箇所です。
設定を行う
VPCとサブネットの設定は 前回 を見てください。
EC2インスタンスを作成する
完成後イメージはこんな感じ
3つも書くのめんどくさいので、1インスタンスだけ書きます。
- インスタンスを起動
- AMIイメージを選択
- インスタンスタイプを選択
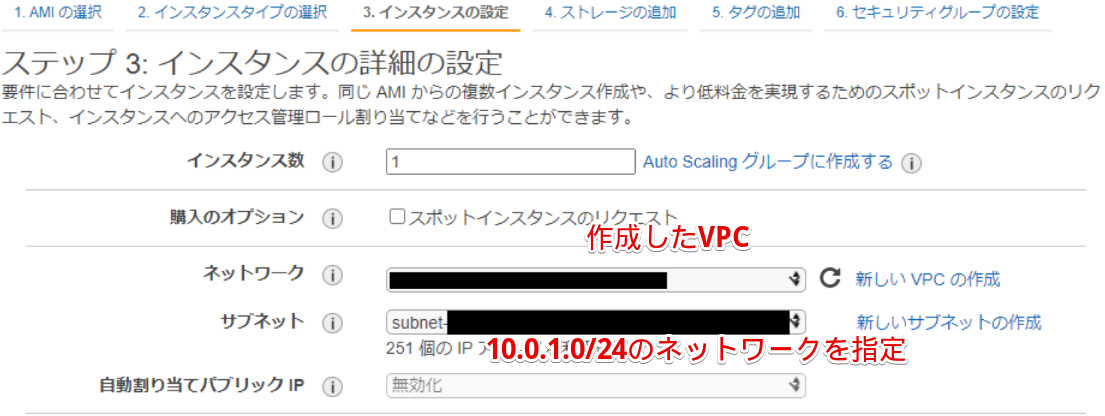
- インスタンスの詳細の設定を行う
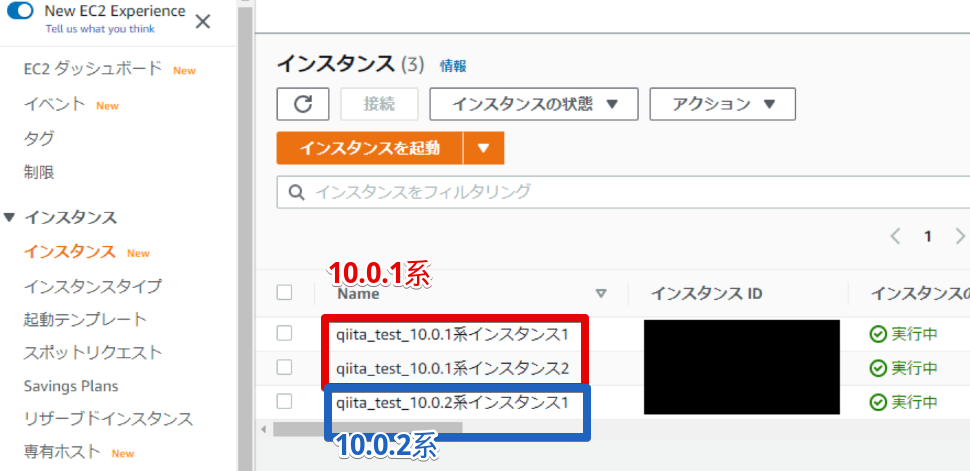
10.0.1系を2つ作成
10.0.2系を1つ作成
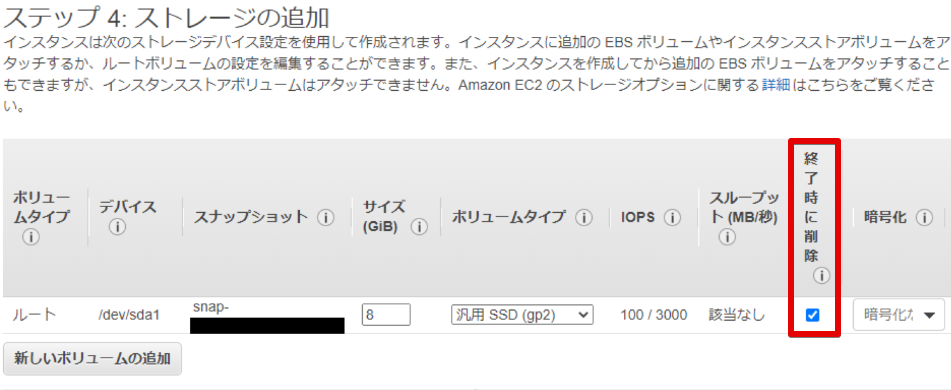
- ストレージを設定
インスタンス削除時に一緒にストレージも消えるように「終了時に削除」にチェックを入れる
- タグの追加
今回はしません。
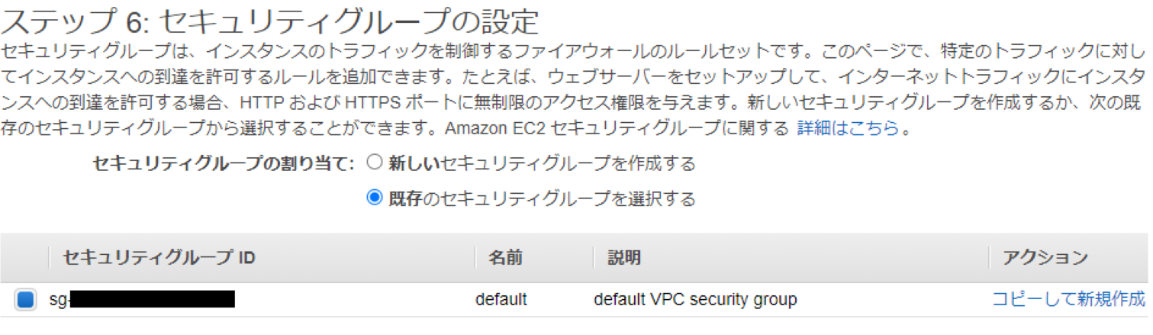
- セキュリティグループの設定
一旦デフォルトの設定
- 最終確認
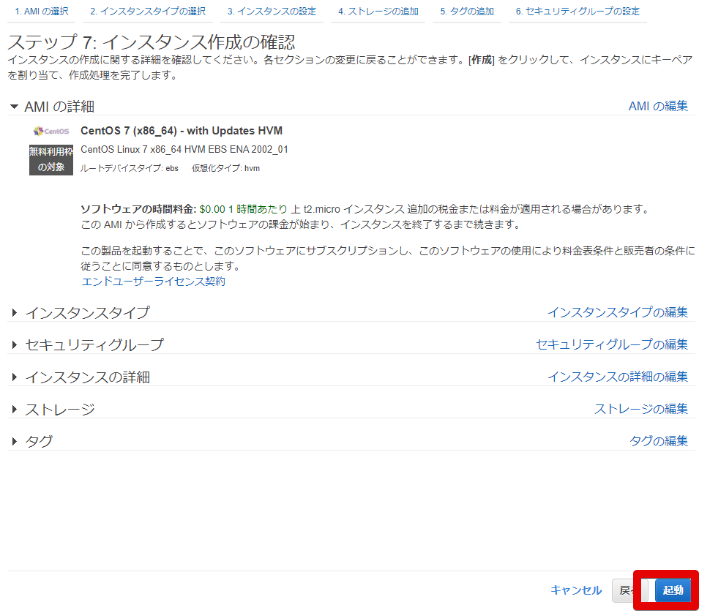
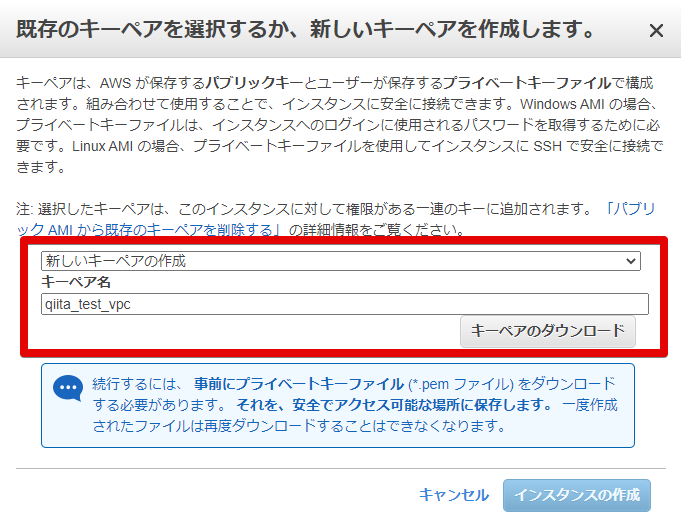
- キーペアの作成
これを3つ作ります。
- 3つ作りました
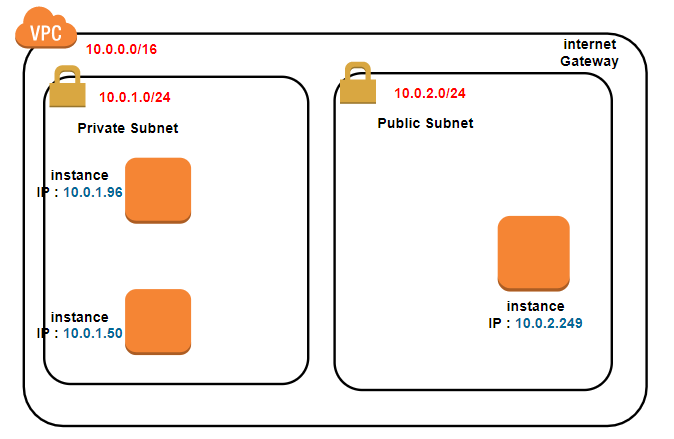
- 実際構築図
ローカルIP勝手に割り振られたので、青文字のIPアドレスになりました。
NATGateway を作成
EC2を作ったので、NATGateway と InternetGateway を作成する
- NATGatewayを作成します
- NATゲートウェイを作成します
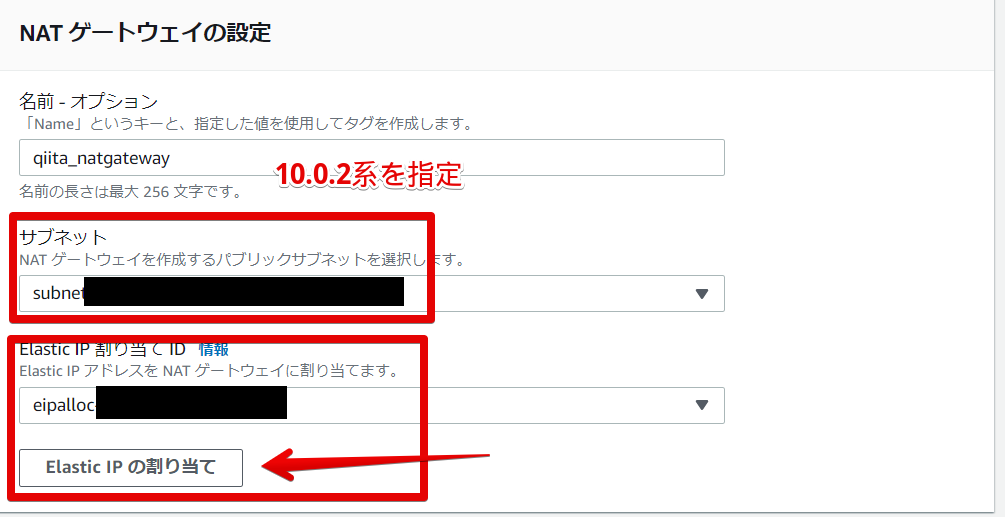
名前はわかりやすいように。
サブネット は10.0.2系のサブネットを指定。
ElastixIP は、「Elastic IP の割り当て」をクリックするとIDが割り当てられます。
ここにはないのですが、タグは何も記載していません。
こちらせ作成を行います。
- できました
Internet Gateway を作成
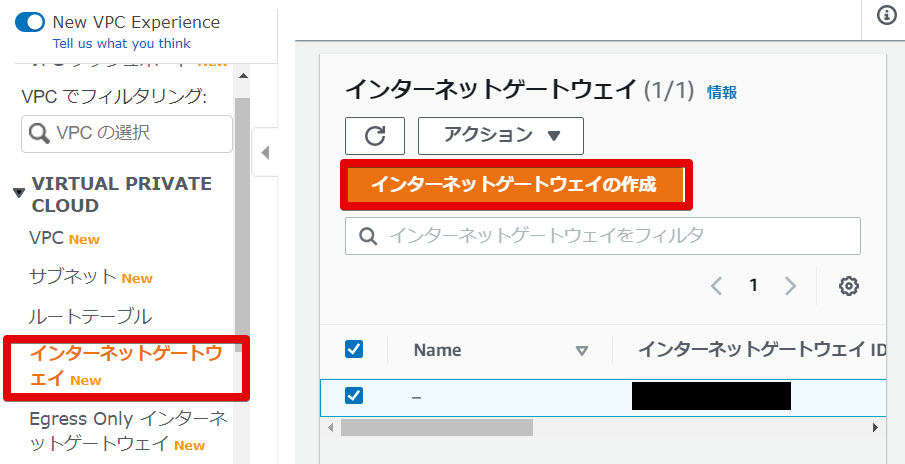
- インターネットゲートウェイの作成
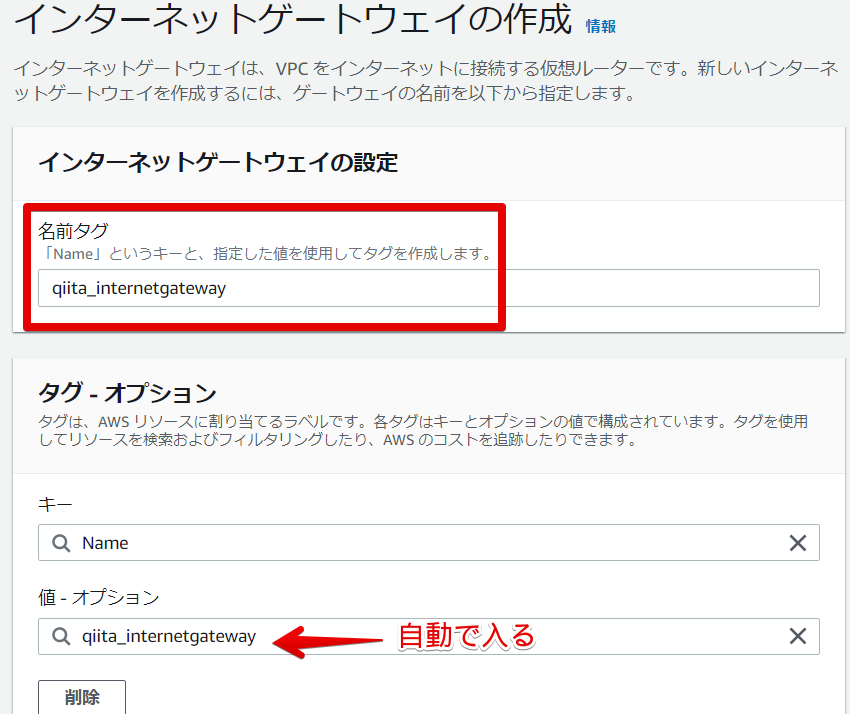
- インターネットゲートウェイの設定
名前はわかりやすいようにつけました。
タグは自動で入りました。
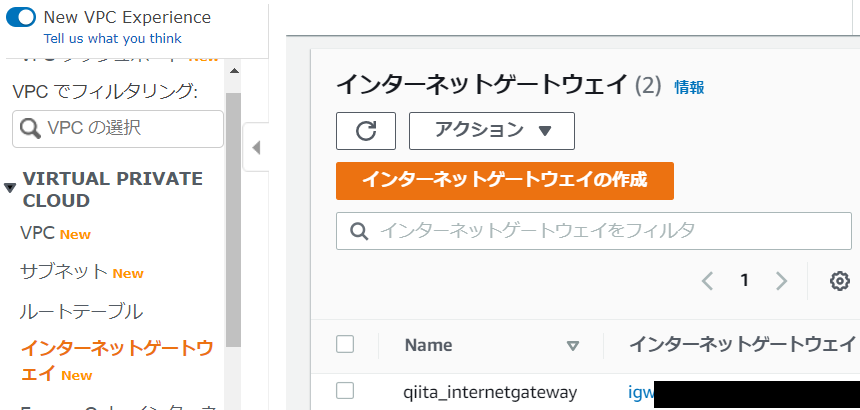
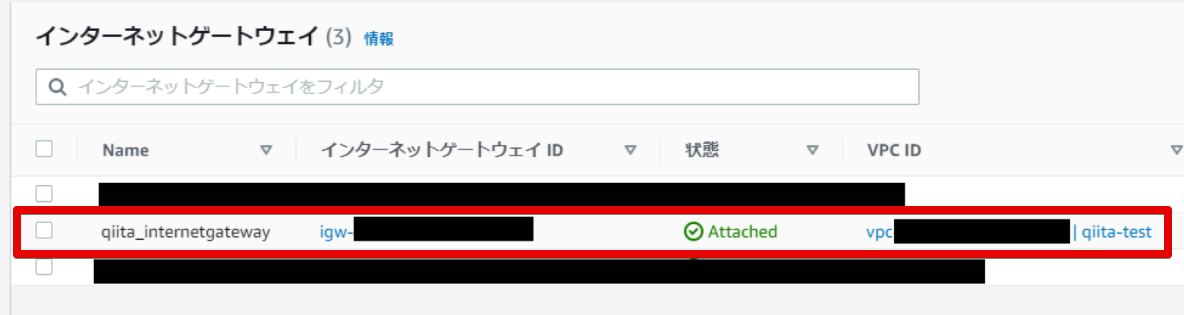
- できました。
インターネットゲートウェイができました。
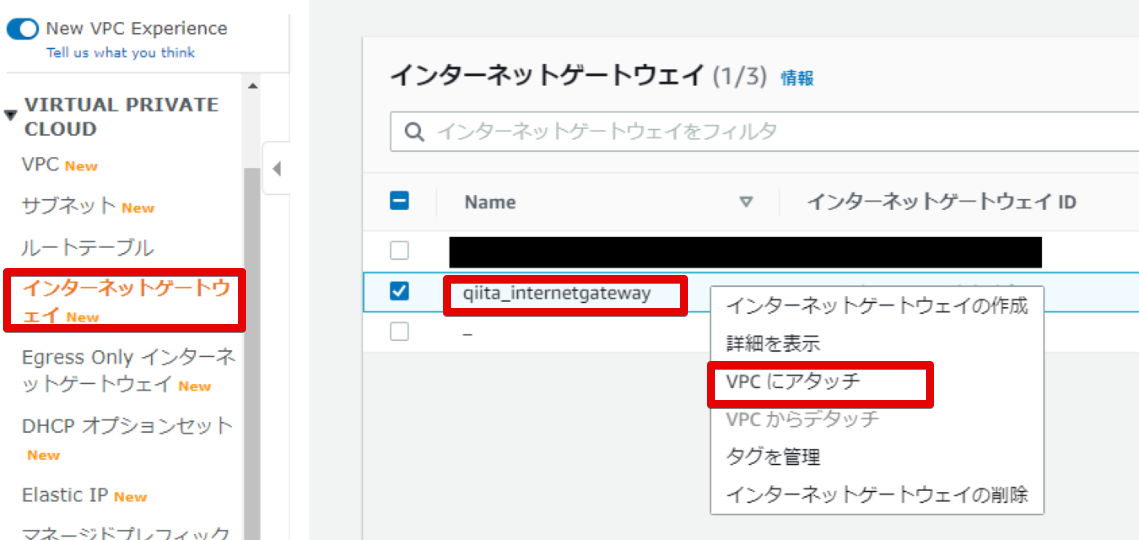
- インターネットゲートウェイをVPCにアタッチしないといけない ※1
注意書きがされているのは、次に進んだらわかりますが
アタッチしてないことによって戸惑ったので....VPCにインターネットゲートウェイをアタッチします。
そうだよね。。。作るだけじゃどこに置いたらいいかわからんもんね....
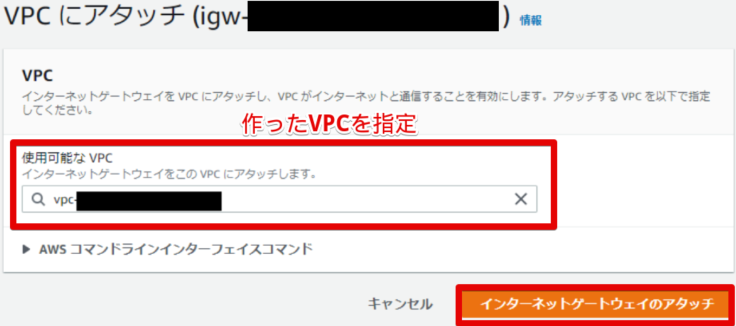
- アタッチを行う
作ったVPCを選択してアタッチします。
- アタッチされました
アタッチできました。
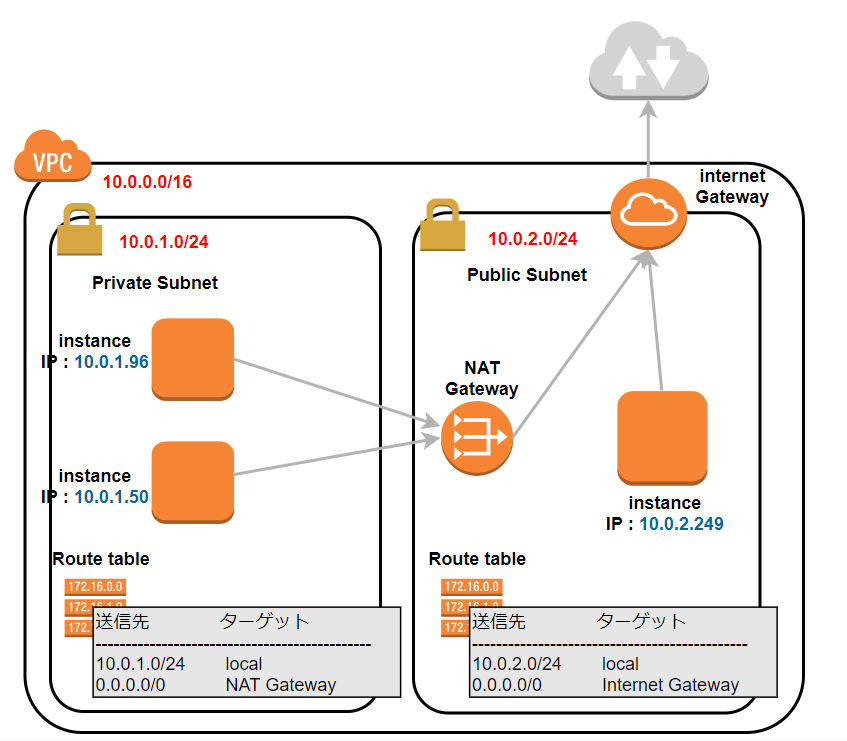
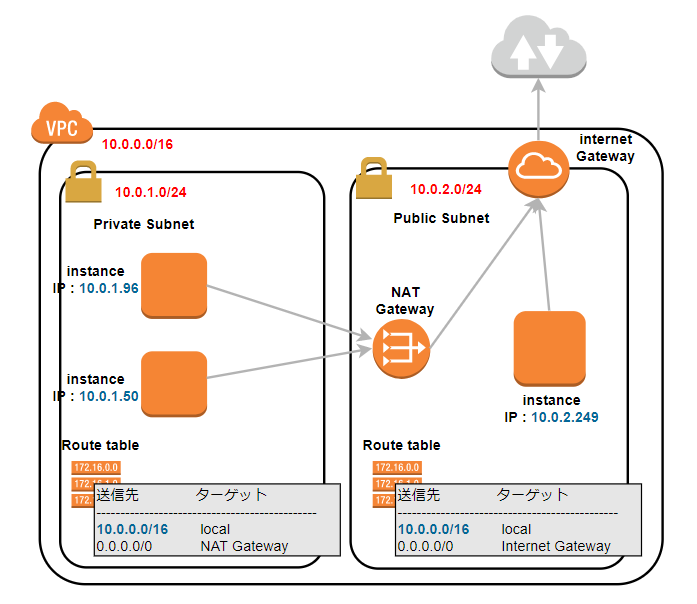
Route tableの設定
前回 では書けていなかったのですが、
調査しているうちにNAT Gateway と Internet Gateway を使うには subnet の Route table を変更しないといけないようです。
イメージ図としては以下です。
- subnet 10.0.1.0/24 のRoute table
10.0.1.1 - 10.0.1.254 までは先がlocalにあります。
それ以外(0.0.0.0/0) は NAT Gateway に聞きに行きましょう
送信先 ターゲット 10.0.1.0/24 local 0.0.0.0/0 NAT Gateway
- subnet 10.0.2.0/24 のRoute table
10.0.2.1 - 10.0.2.254 までは先がlocalにあります。
それ以外(0.0.0.0/0) は Internet Gateway に聞きに行きましょう
送信先 ターゲット 10.0.2.0/24 local 0.0.0.0/0 Internet Gateway まず....
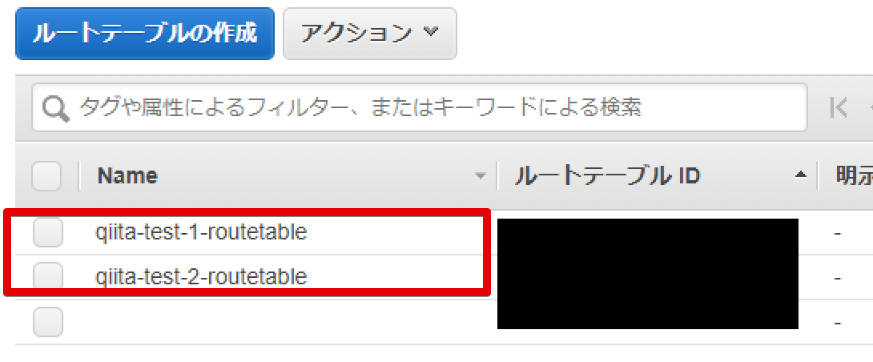
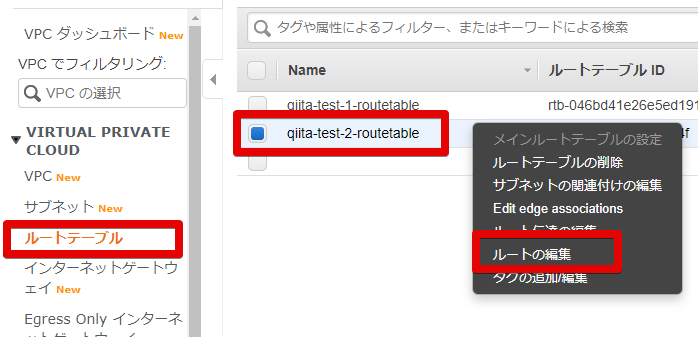
10.0.1系(qiita-test-1) , 10.0.2系(qiita-test-2) のルートテーブルが一緒でした...
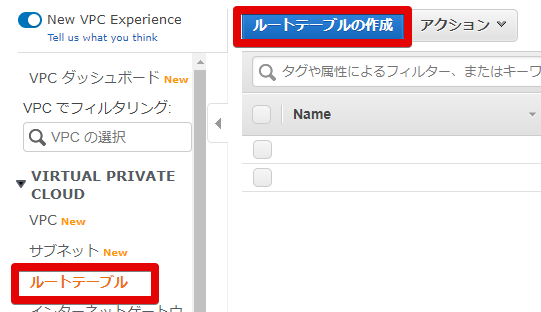
ですので、どちらか(今回は10.0.1系のqiita-test-1)のルートテーブルを別途作成します。
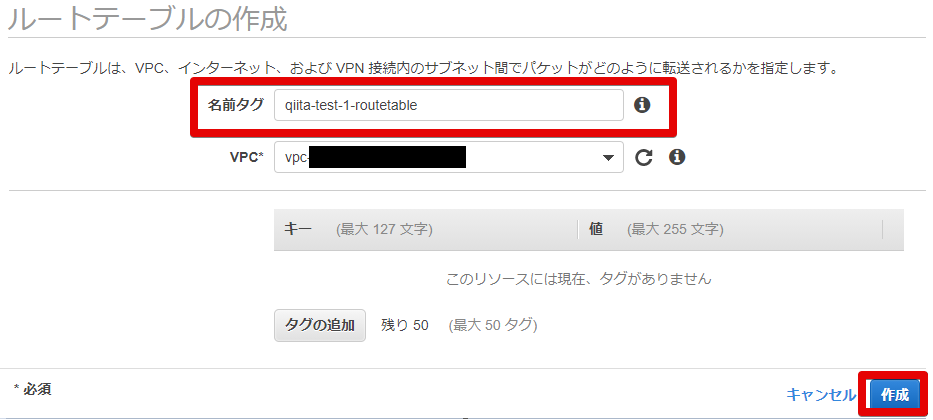
- ルートテーブルの作成
ルートテーブルからルートテーブルの作成を行います
- ルートテーブルの設定
名前タグはわかりやすいように。
VPCは作成したVPCを指定します。
- できました
ルートテーブルできました。
ついでにわかりやすいように 10.0.2系(qiita-test-2)のルートテーブルの名前も変えておきました。
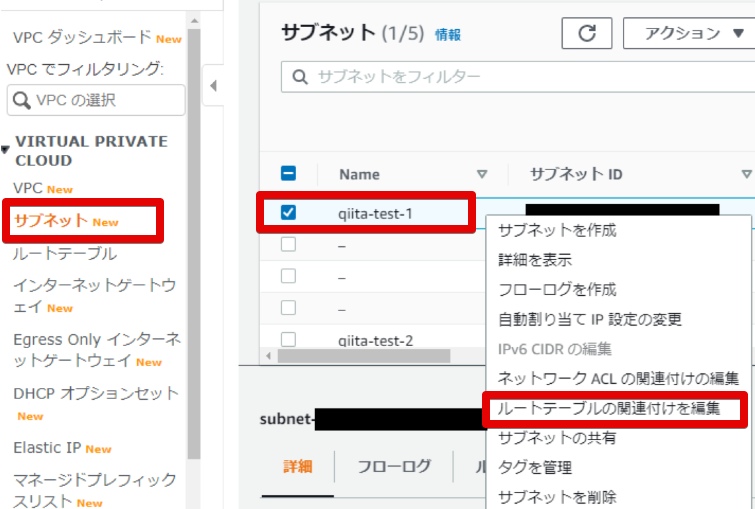
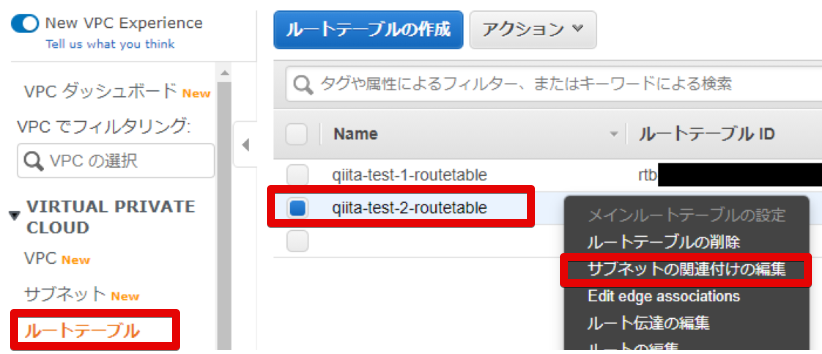
- 10.0.1系のサブネットにアタッチするためにルートテーブルの関連付けを編集
作るだけじゃだめで、サブネットに作ったルートテーブルを関連付けしないといけないので、
「ルートテーブルの関連付けを編集」します
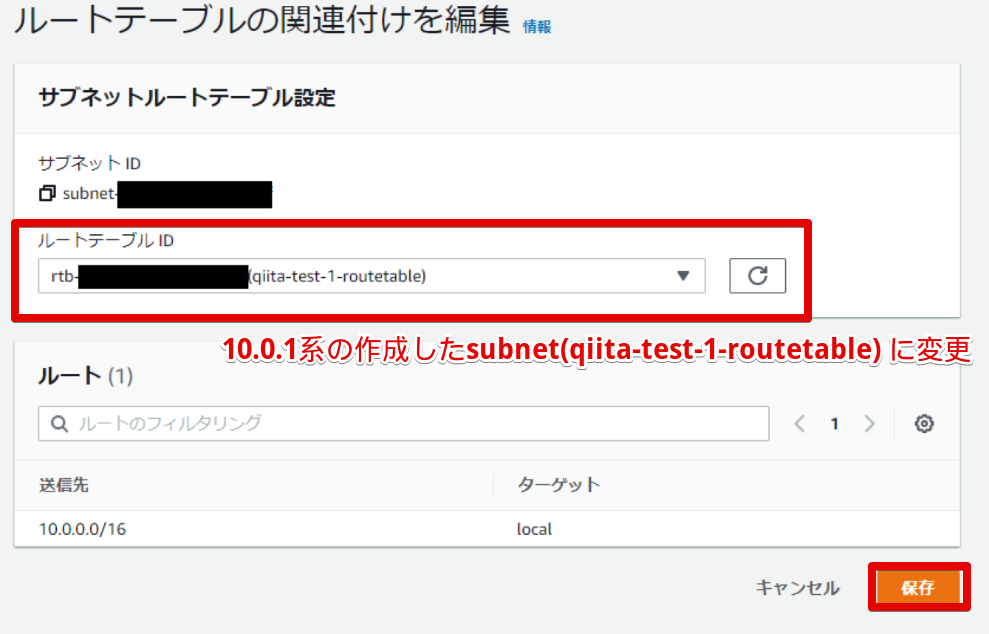
- ルートテーブルの編集
ルートテーブルIDに先程作成した
qiita-test-1-routetableを指定します。
- ルートテーブル変えれました
そしたら、10.0.1系も10.0.2系もルートテーブルが別々になりました!
10.0.1系のRoute tableの変更
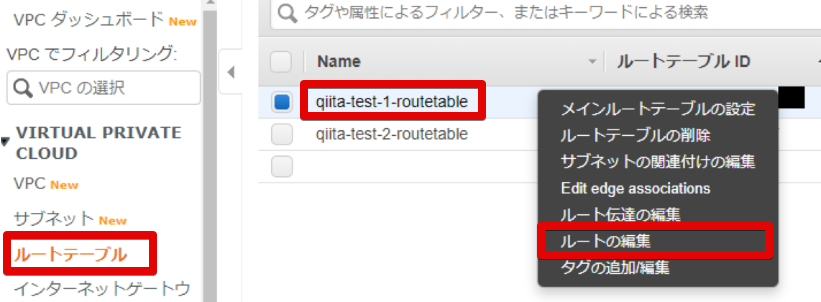
- ルートの編集
- ルートの変更
以下のように設定したいと思います。
送信先 ターゲット 10.0.1.0/24 local 0.0.0.0/0 NAT Gateway あれ....送信先....10.0.1.0じゃなくて....
10.0.0.0では・・・?
localってsubnet内じゃなくてVPC内ってこと?しかもNAT Gateway なくなってる...消えてる....deleteになってる・・・なぜーーー
もう1回作り直しました。
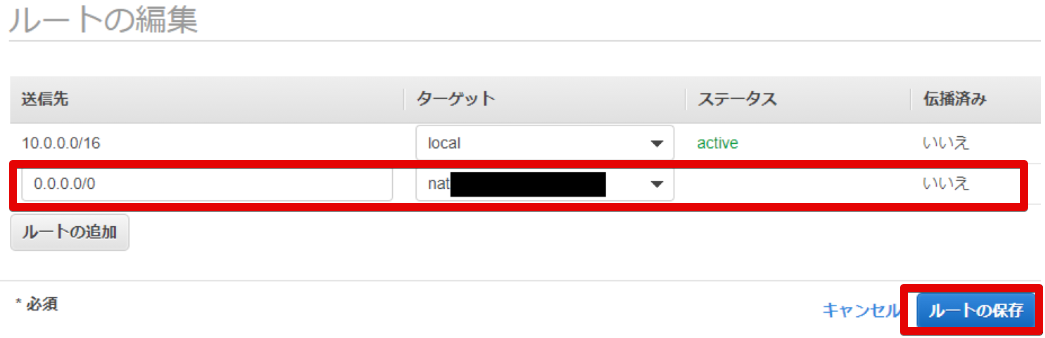
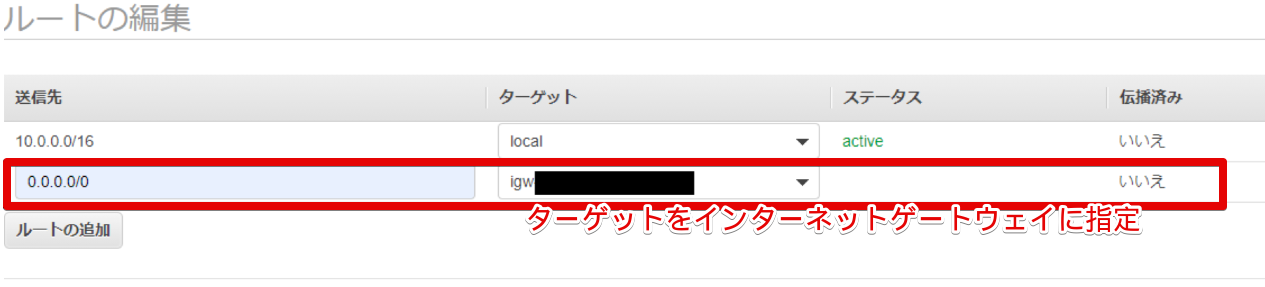
10.0.2系のRoute tableの変更
- ルートの編集
- ルートの変更
10.0.1系のRoute table変更する際にlocalの送信先は10.0.0.0/16と分かったので↓は変更します。
送信先 ターゲット 10.0.0.0/16 local 0.0.0.0/0 Internet Gateway しかもこっちもInternet Gatewayがdeleteになってる・・・
これは作ったインターネットゲートウェイをVPCにアタッチするの忘れてました・・・
※1 の手順を抜かしてました(後から書いた
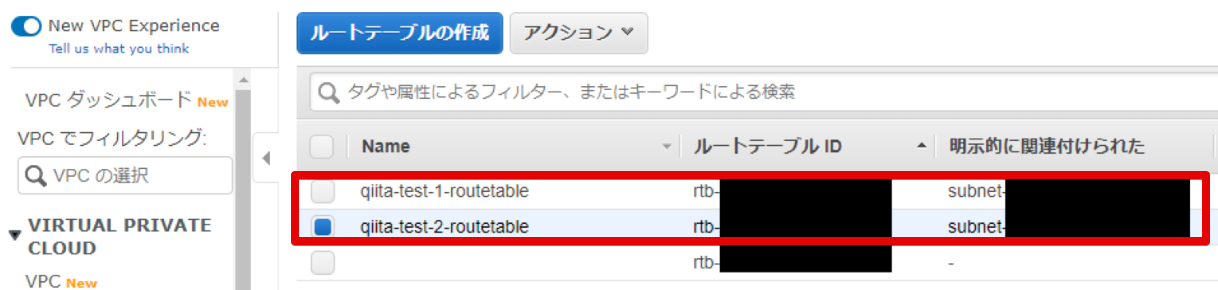
- できたんだけど・・・
Route table できたんだけど・・qiita-test-2-routetableの明示的に関連付けられたサブネットがない・・・
明示的にするべき?
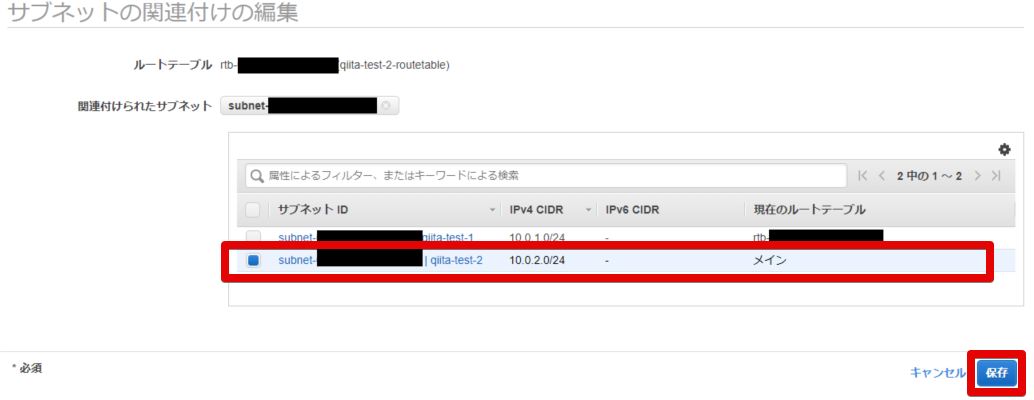
- 明示的にサブネットを関連付ける
- 関連付けを編集
- 明示的に関連付けられました
結果
実際に構築してみて、青文字のところが変更点です。
全然想像どおりにはならない....
通信をしてみる
↑で作ったものがきちんと通信できるのか、
10.0.1.96 と 10.0.2.249 にログインしてみて確かめてみます。ログインするには、以下が必要なので行っていきます。
- 10.0.2.249のサーバにelasticIPを振る
- ↑に関連してセキュリティグループの変更が必要10.0.2.249のサーバにelasticIPを振る
- EC2に移動してElastic IPの割り当てを行います
- 割り当てをします
Amazon のIPv4 アドレスプールから割り当てを行います
- 割り当てられました
できました。
- 割り当てられたElastic IP を 10.0.2.249 に関連付けします
- 関連付けします
リソースタイプはインスタンス。
インスタンスは10.0.2.249 のインスタンスに割り当てます。
セキュリティグループを家から繋げられるように変更
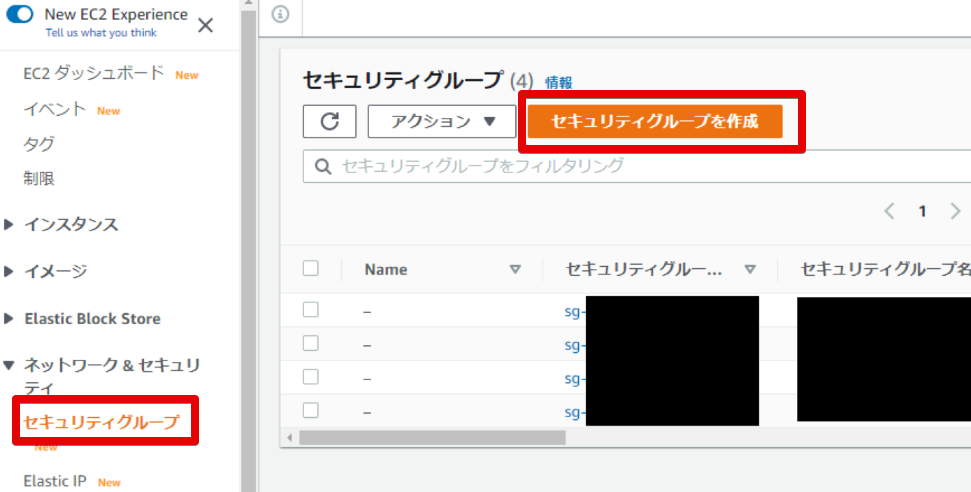
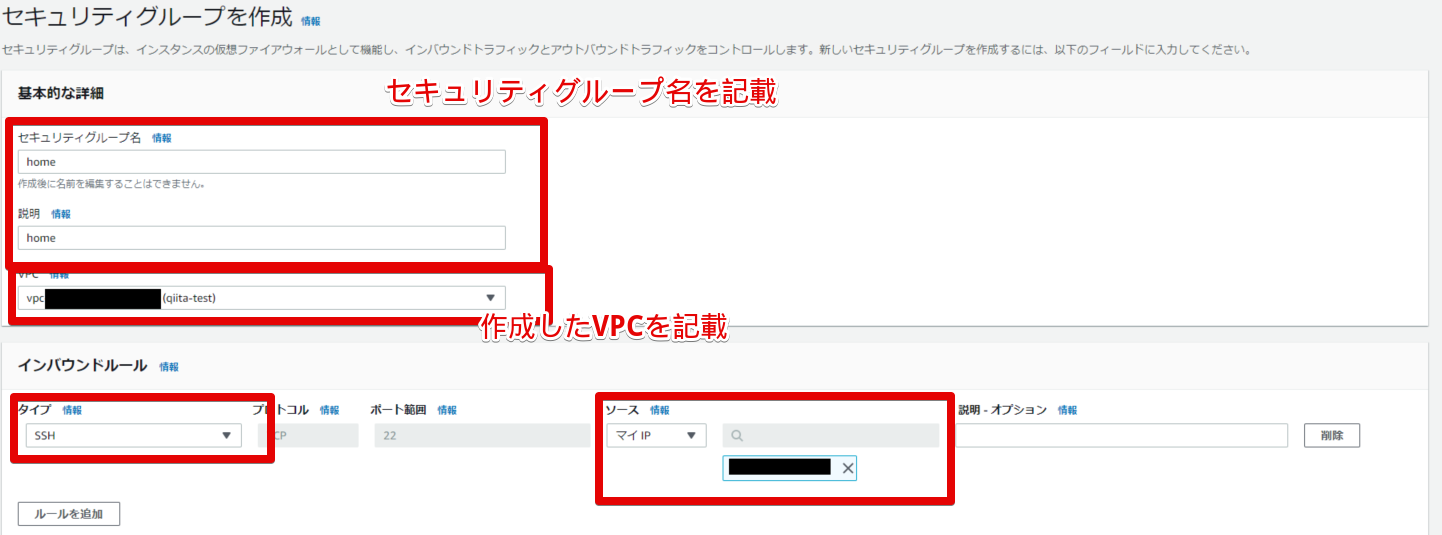
- 家から繋げられるセキュリティグループの作成
今はlocal(10.0.0.0/16)同士しか繋げられないから.....
- セキュリティグループの設定
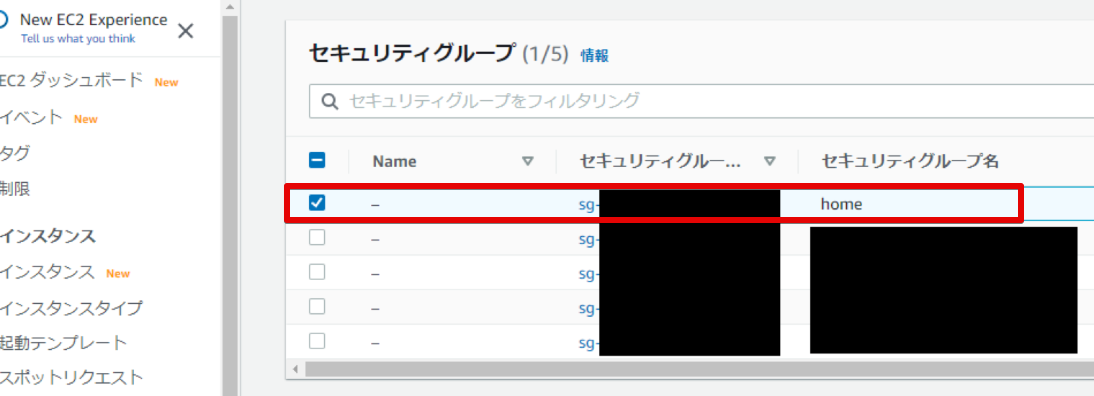
適当にhomeというセキュリティグループを作りました。
許可はSSHのみ。
- セキュリティグループができました
- 「home」セキュリティグループの割り当て
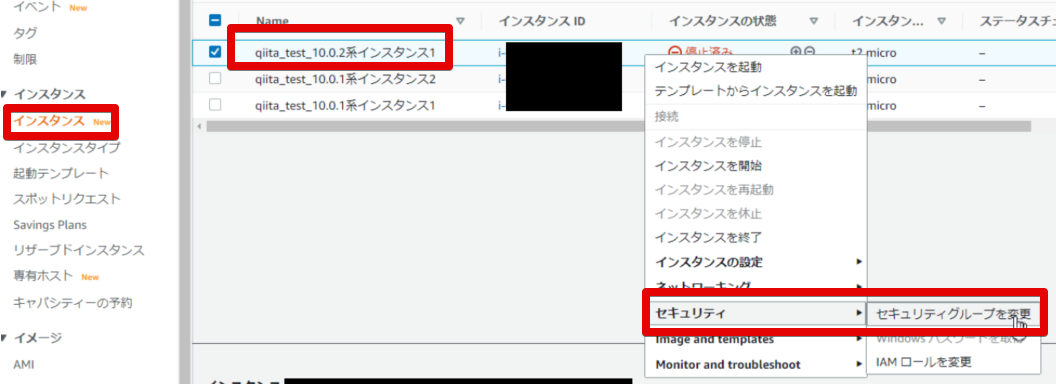
インスタンスから10.0.2.249 のインスタンスを選択
右クリックで セキュリティ > セキュリティグループの変更 で進みます。
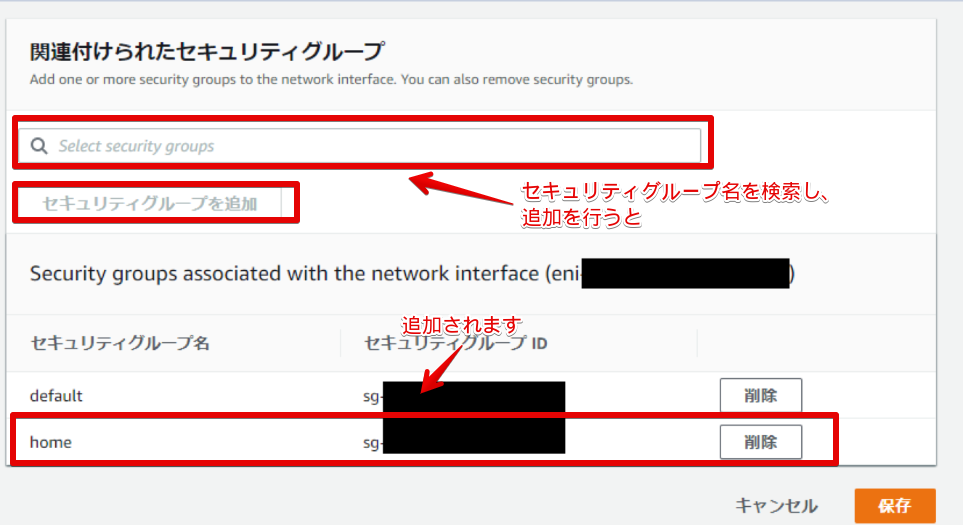
- セキュリティグループの追加
セキュリティグループ名を検索して、追加を行うと下に追加されるのでそれで保存
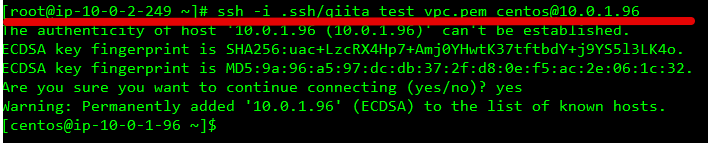
接続確認
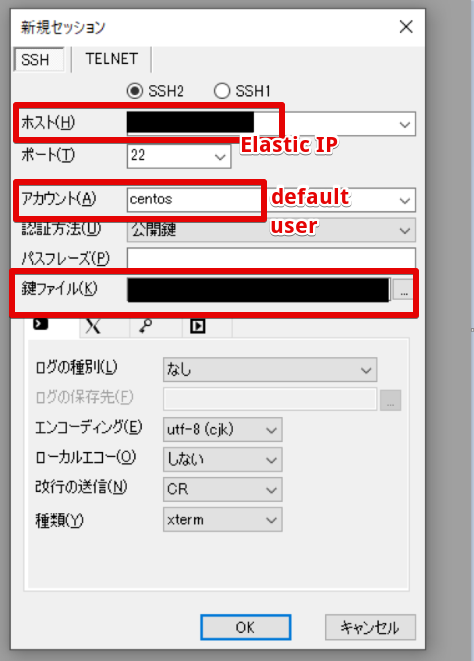
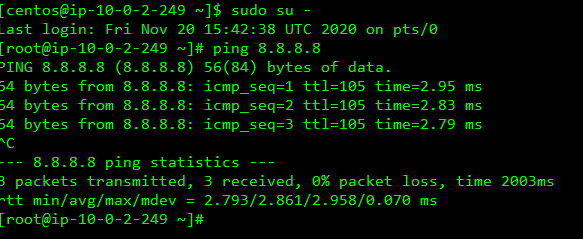
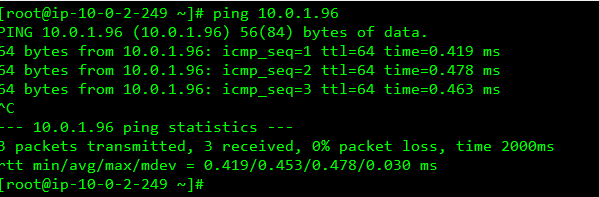
1 : 10.0.2.249 がElasticIPを通じてSSH接続出来るのか。
2 : 10.0.1.96 が 10.0.2.249 からSSH接続できて、ping 8.8.8.8 が出来るのか。
1 : 10.0.2.249 がElasticIPを通じてSSH接続出来るのか。
- 接続
- 外部への接続は出来る
SSHできたし、外部への通信もできた
- 内部への接続もできる
10.0.1系へのpingも通った
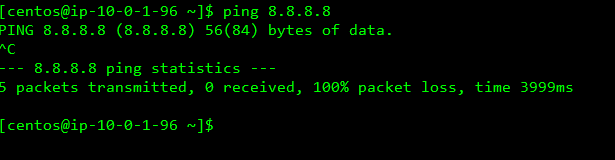
2 : 10.0.1.96 が 10.0.2.249 からSSH接続できて、ping 8.8.8.8 が出来るのか。
- 10.0.2.249 → 10.0.1.96 にSSHが出来るか
入った!!!!
- 外部への接続が出来るか
pingはとおらんかったか....
勉強後イメージ
一応組んでみたもののpingは通らなかったです....
あとたぶんすっごい見ずらいし、完成してないしですいません。
最後までやるべきだろうけど体力不足..また今度リトライします。
結構難しかった参考



- 投稿日:2020-11-23T18:15:12+09:00
S3 Storage Lens
Storage Lens
S3の利用状況(容量やPUT APIリクエスト数のトレンドを見たり、ストレージクラスをスタンダードで使ってる割合分布を見たり)を可視化して分析するものです。多分。
アカウント、リージョン、ストレージクラスなどの軸でトップNなど見れて、個人的にいい感じです。ダッシュボード作成
S3のメニューから"Sotrage Lens"->"ダッシュボード"をクリックして、右上の[ダッシュボードを作成]をクリックし、必要な値を設定してダッシュボードを作成します。48時間くらいかかります。
設定値
- ホームリージョン:このダッシュボードがあるリージョン
- ダッシュボードの範囲:Organization配下の任意のアカウント含めたり、リージョンやバケットを限定したり
- メトリクスの選択:無料メトリクスだけか有料のメトリクスも含めるか
概要 タブ
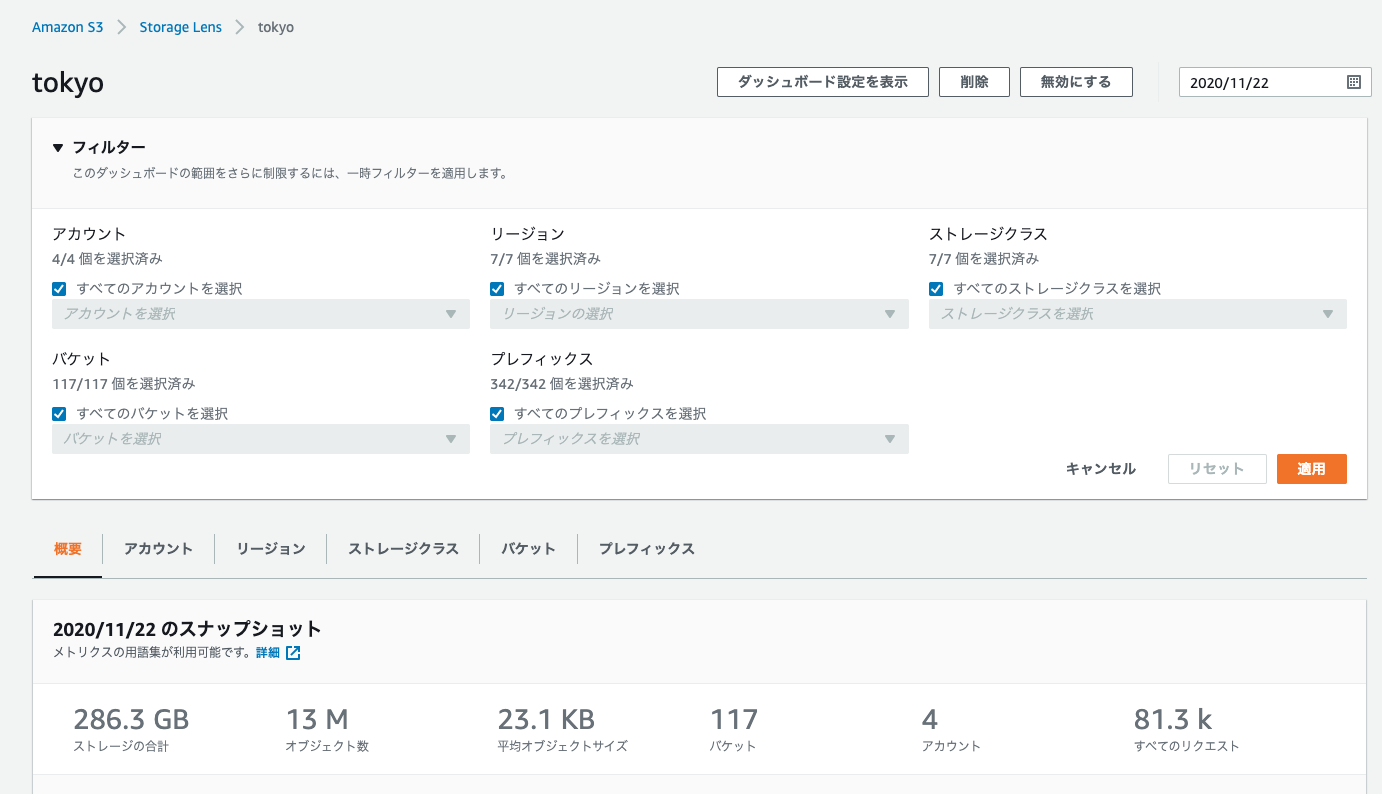
概要タブに、登録したAWSアカウント(今回4つ)の合計"ストレージ容量"、"オブジェクト数"、"平均オブジェクトサイズ"、"バケット数"、"アカウント数"、"リクエスト数"が表示されている
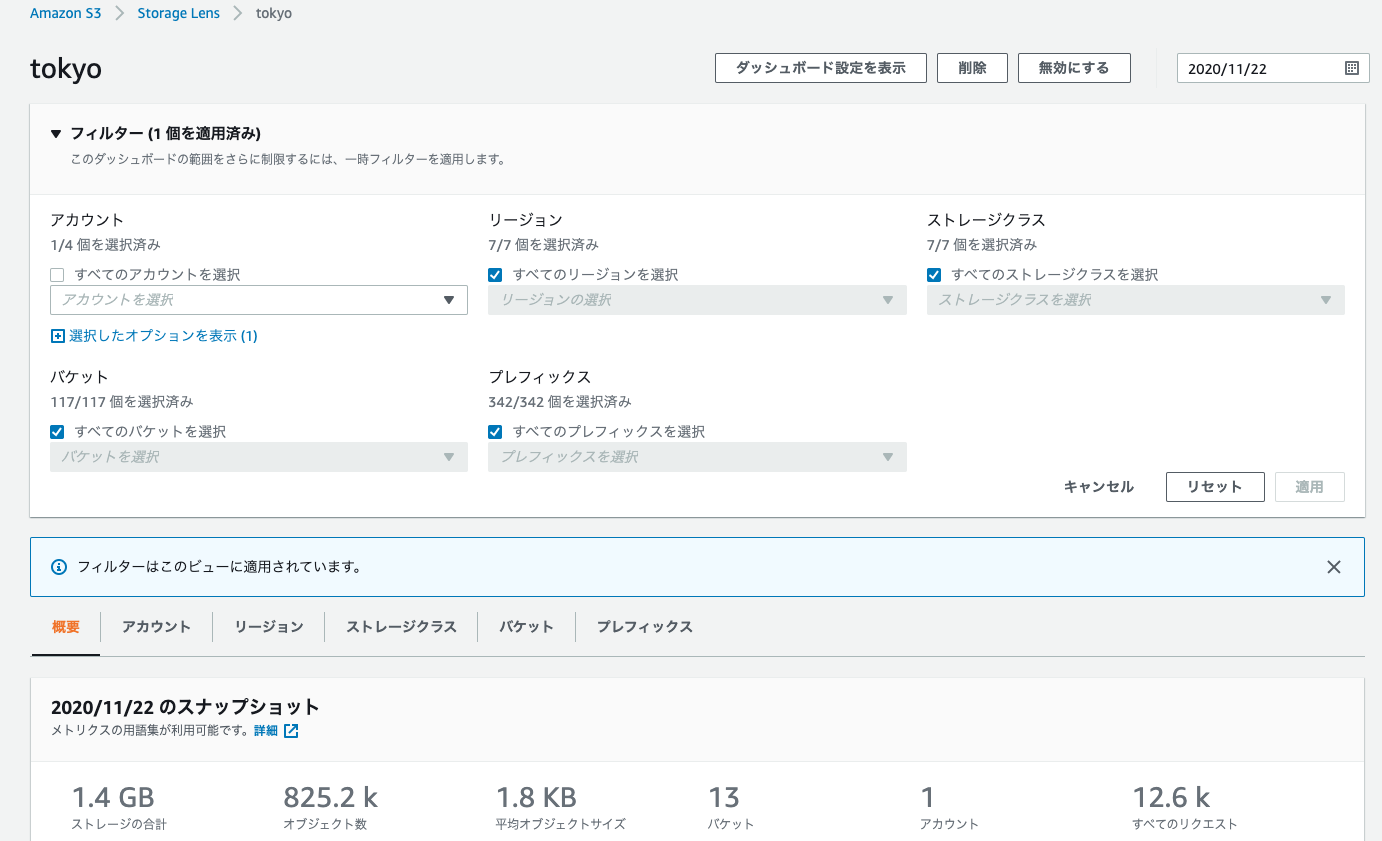
フィルタの設定で、"AWSアカウント"、"リージョン"、"ストレージクラス"、"バケット"、"プレフィックス"でフィルタリングできる
AWSアカウントを1つ指定しフィルタリングすると、以下のように概要の値が変化しフィルタリングが効いている事がわかる
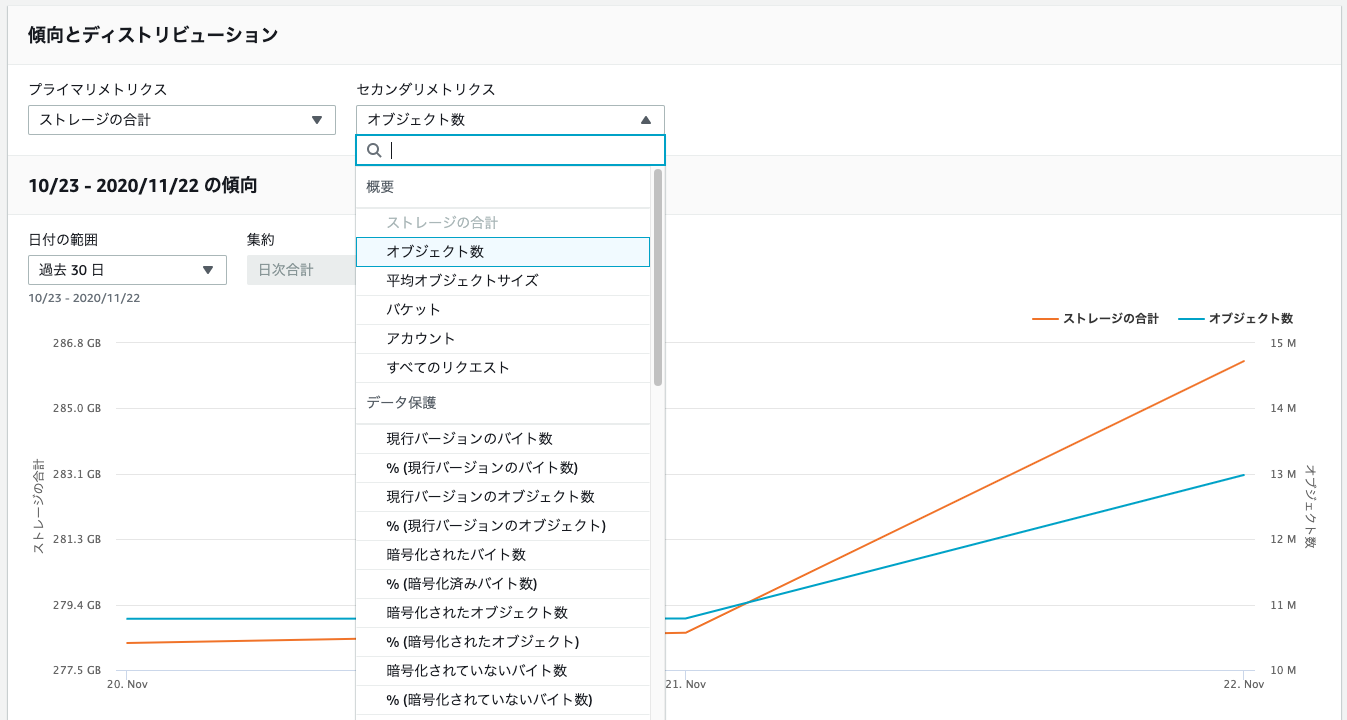
傾向とディストリビューション
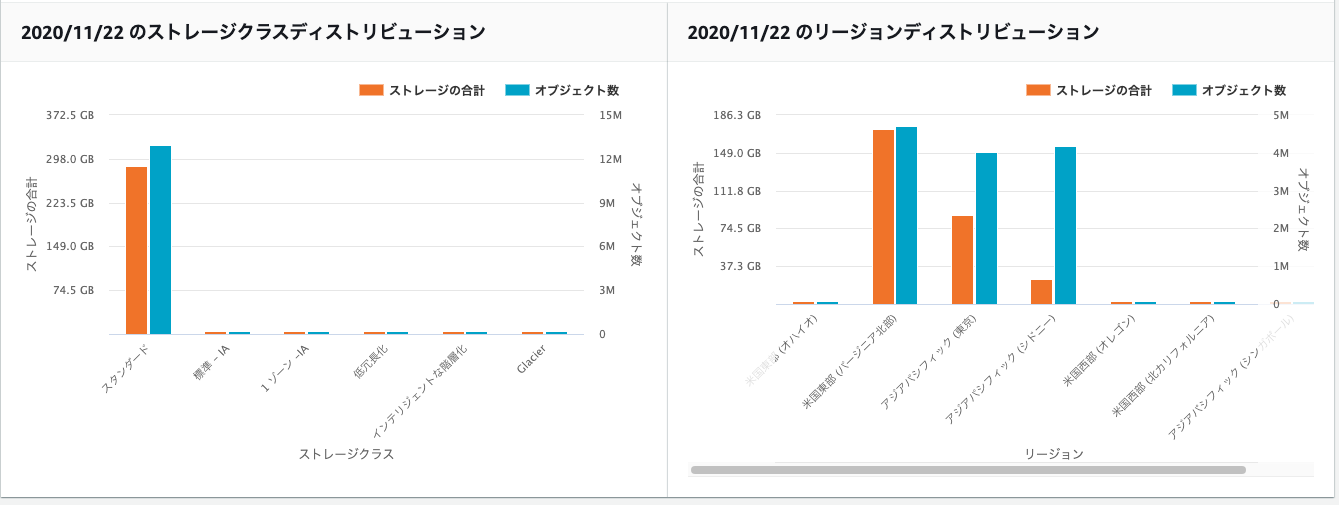
ストレージクラスやリージョンの割合
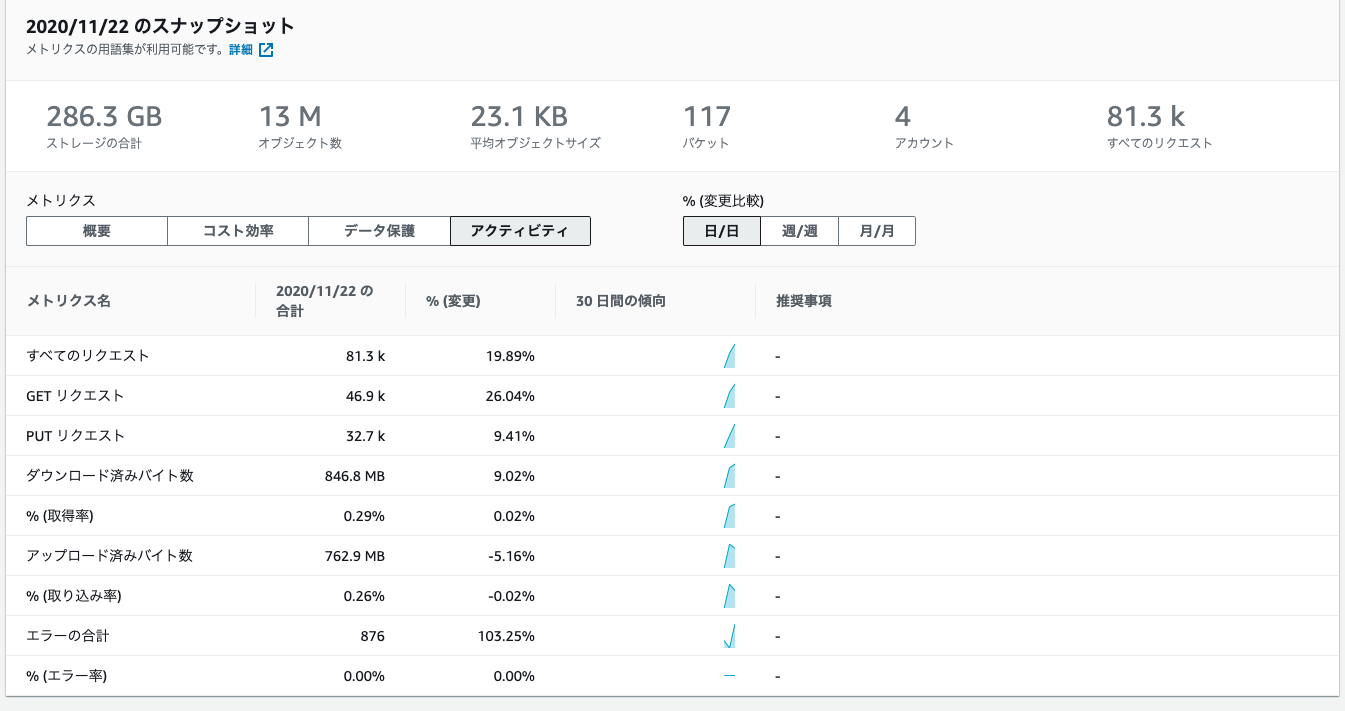
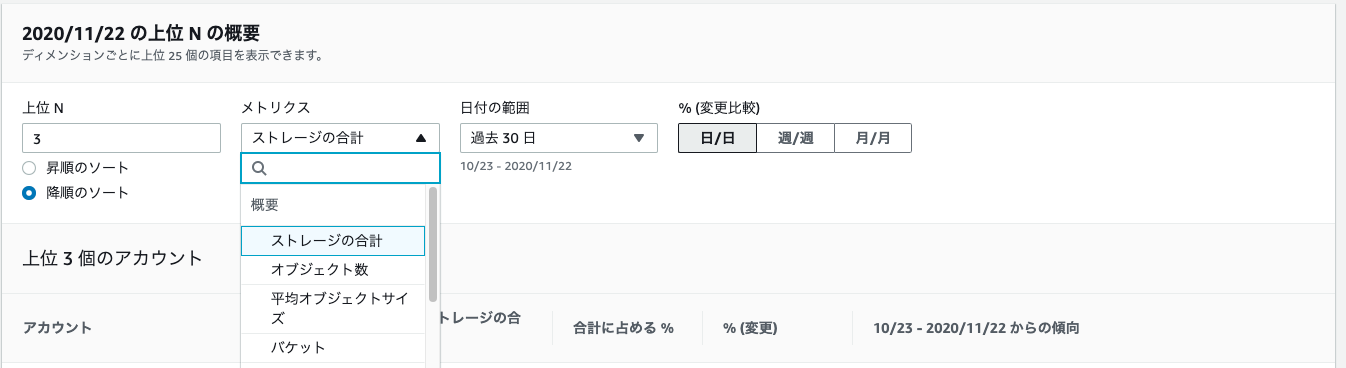
上位 N の概要
以下の図の下のほうに、上位3つが表示されます。
どういう上位かというと、メトリクスの箇所でプルダウンされている"ストレージの合計"、"オブジェクト数"などえらび、それぞれのメトリクスで、上位3つのAWSアカウント、リージョン、バケット、プレフィックスが表示されてます。図では詳細は割愛してます。図の下の方に出力されてます。いい感じですね。
PUT(やGET)リクエストの上位3つで、プレフィックスが出てくるの役立ちそう
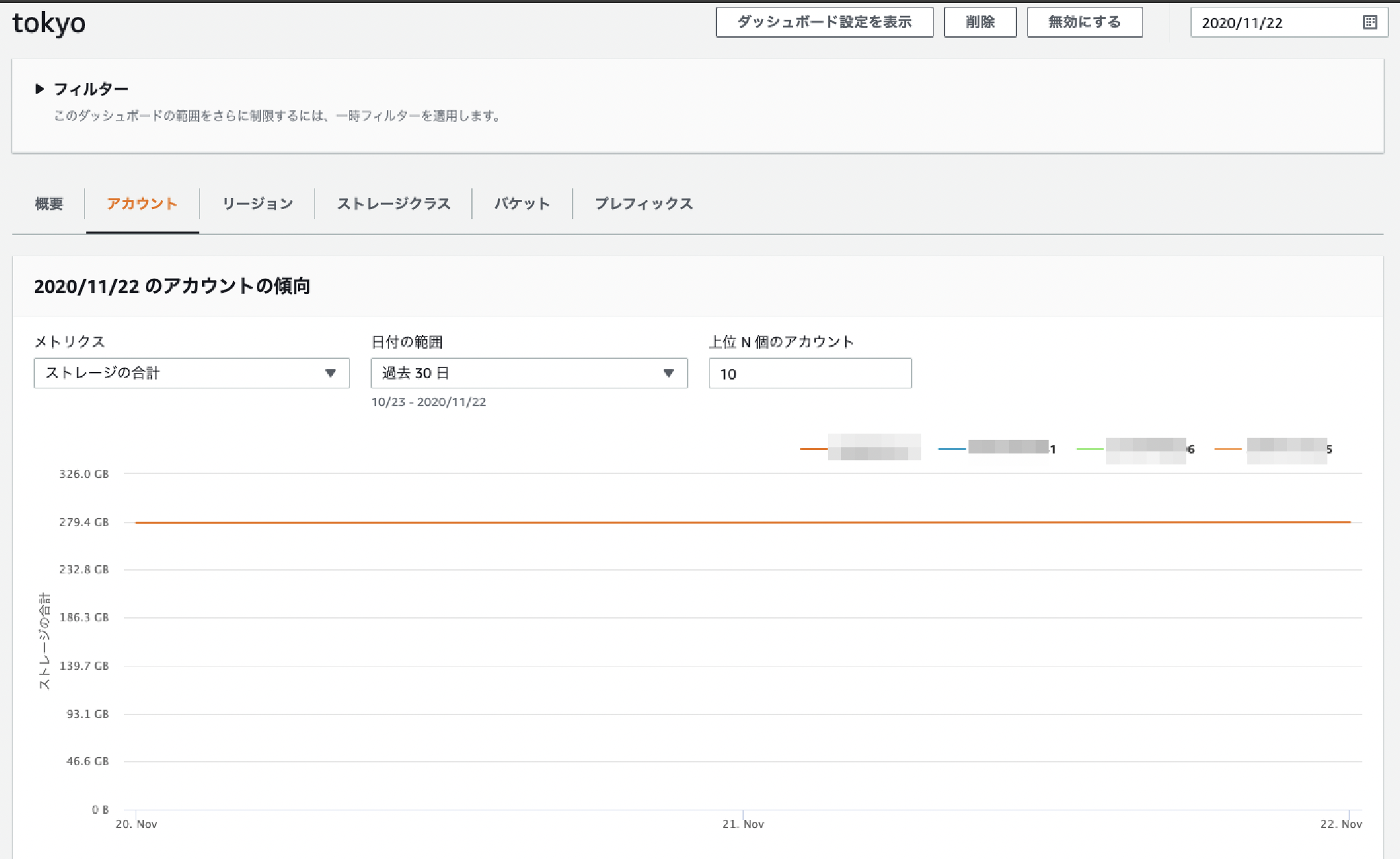
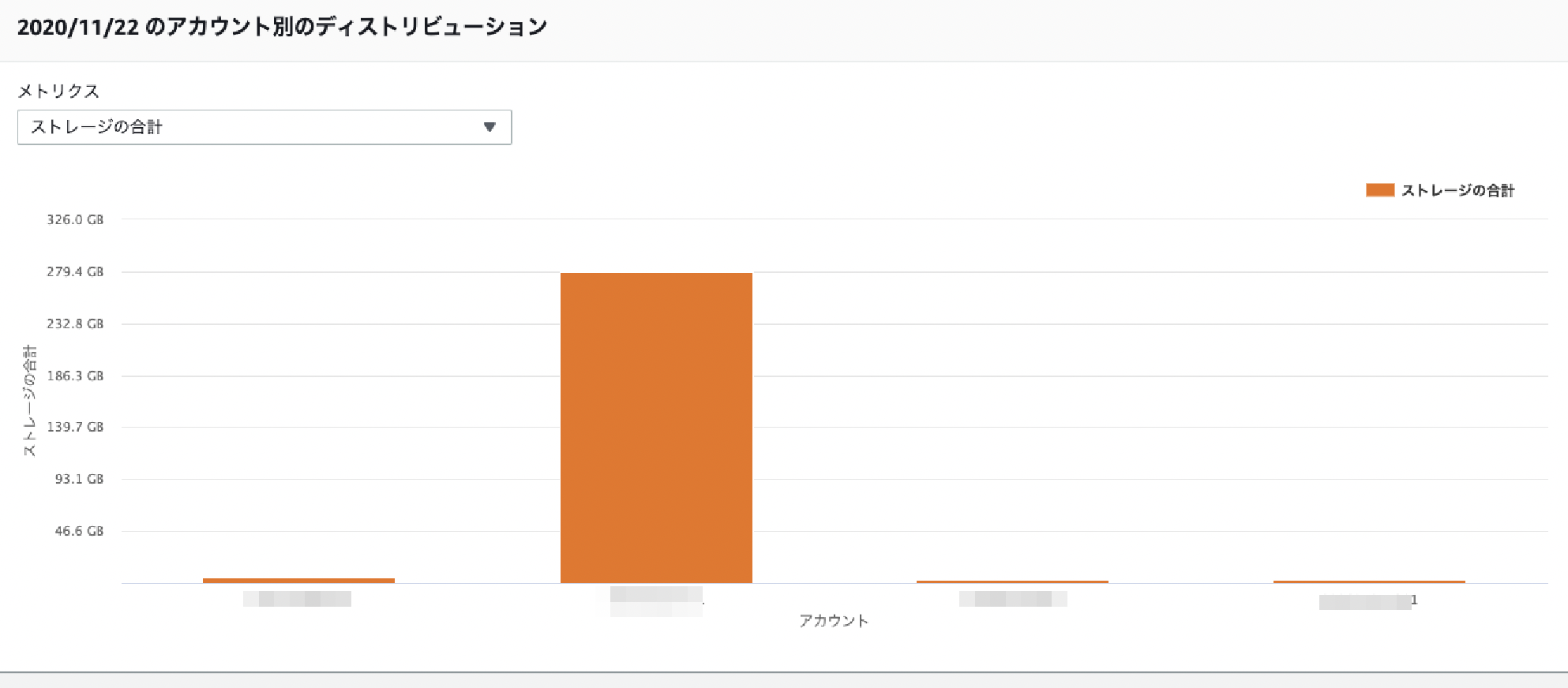
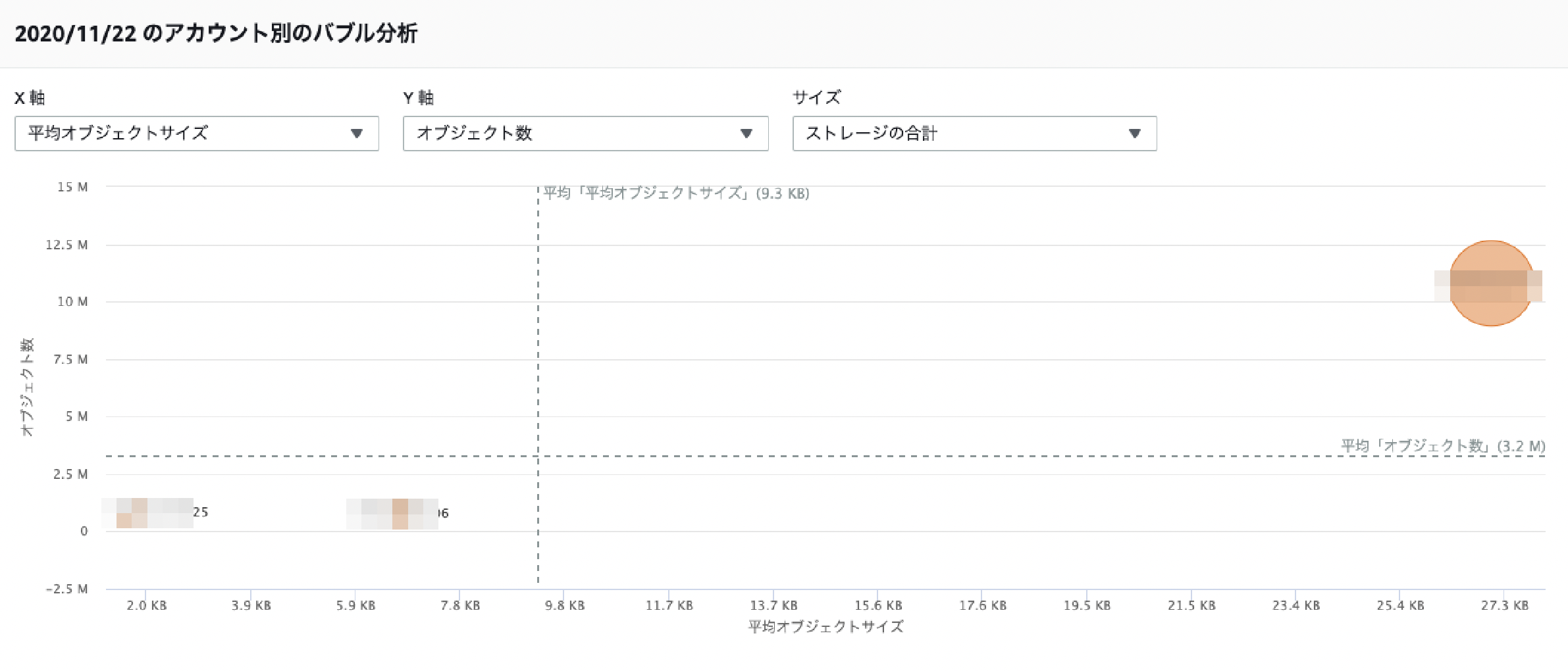
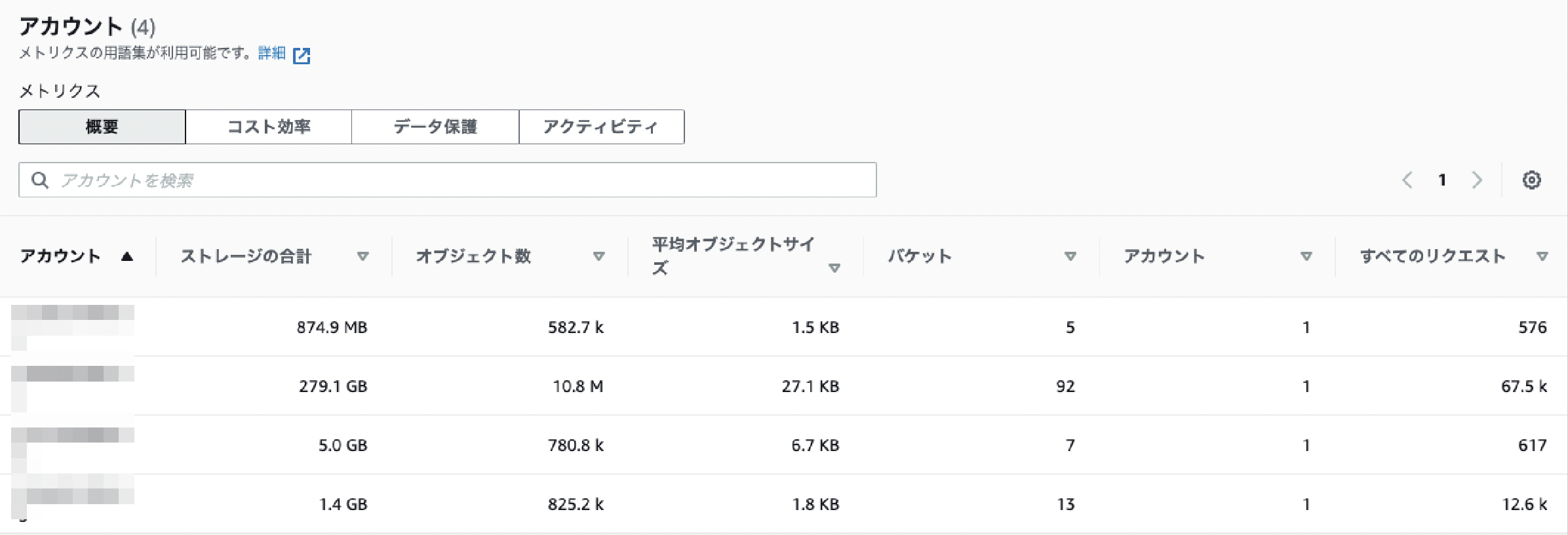
アカウント タブ
アカウントの軸で分析できます。
メトリクスに"ストレージ合計"、"オブジェクト数"を指定することでアカウントごとのメトリクス推移がわかります。「上位N個のアカウント」フィルタがあるのがいいですね。
この下にも、棒グラフ、バブル分析、表などが表示されています。
棒グラフ
バブル分析
表
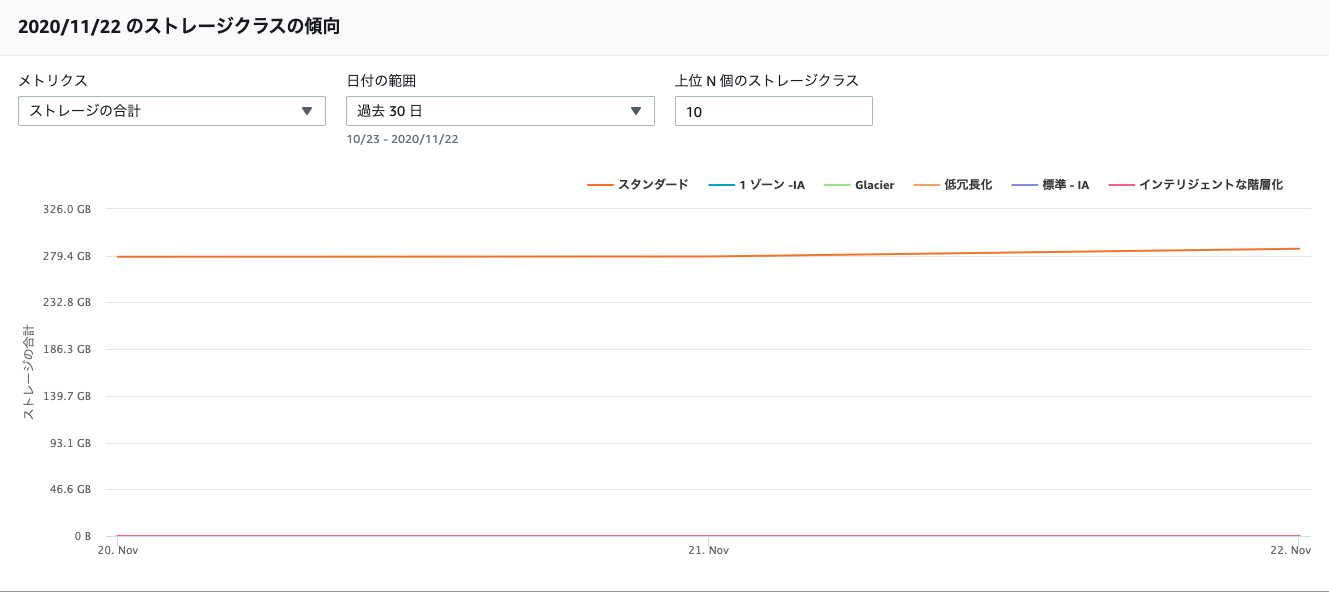
リージョン、ストレージクラス、バケット、プレフィックス タブ
これらも"アカウント"と同じく、この軸で分析ができます。表示される形式は同じです。
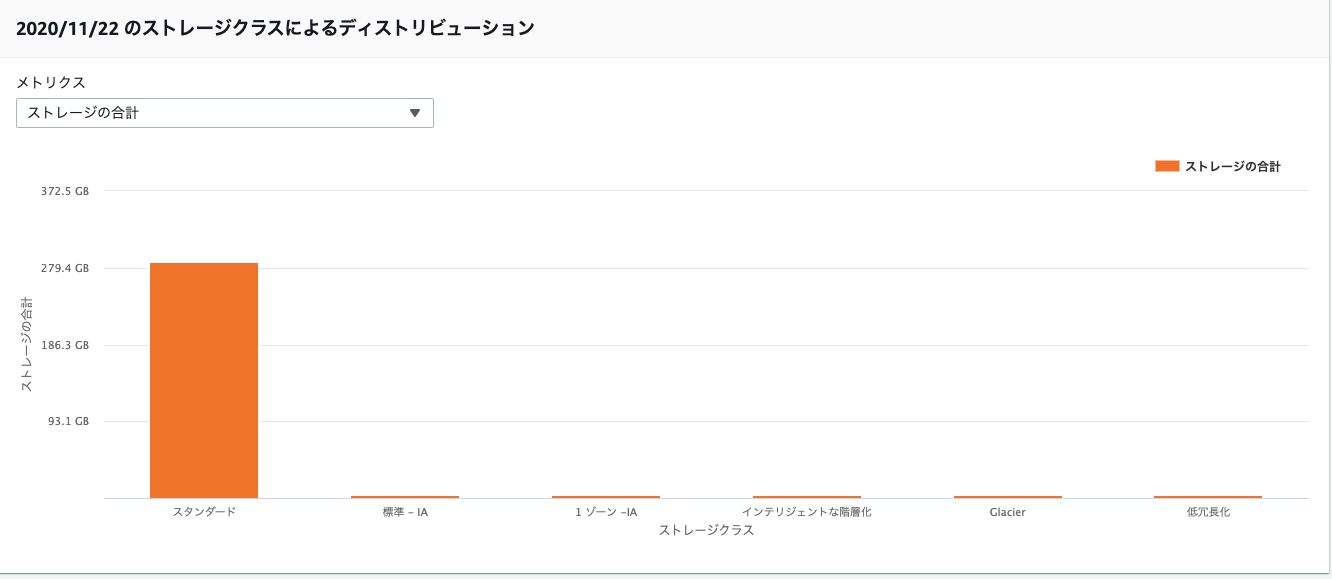
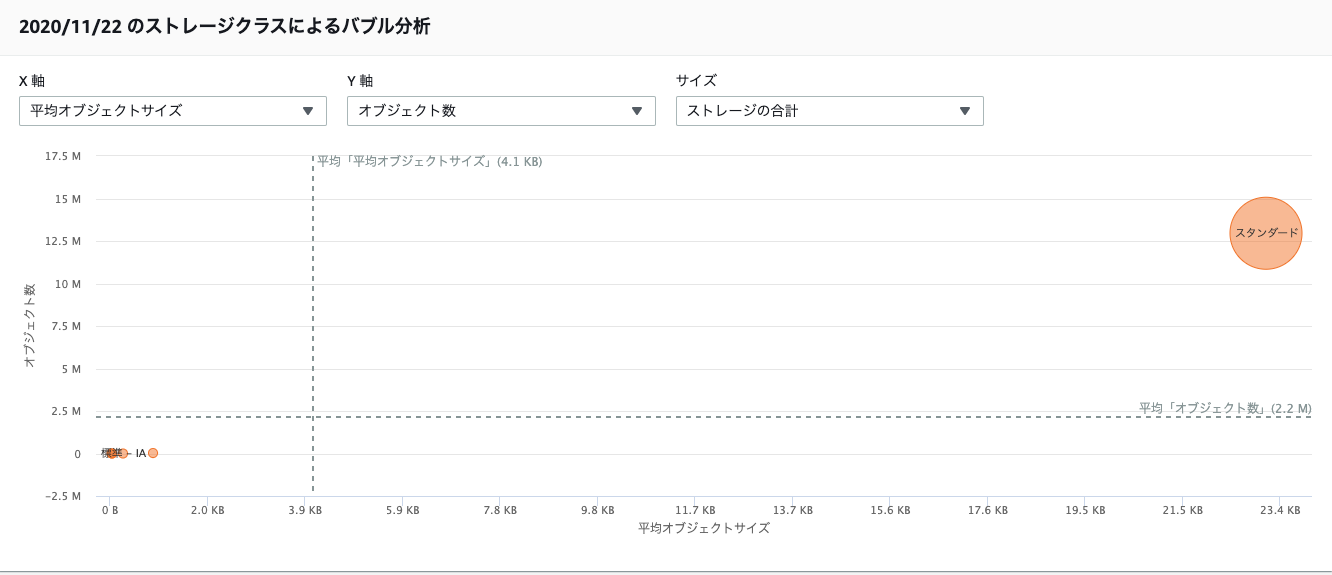
以下はストレージクラス タブでの確認結果です。
線グラフ
棒グラフ
バブル分析
表
- 投稿日:2020-11-23T16:49:48+09:00
AWS DynamoDB を API Gateway で変更する
- 目的
- AWS Lambda の設定値を変更したい
- 背景
- 社内向けのLambdaがあり「AWS LambdaのJsonを編集してください」が他の部署では敷居が高い。
- config.jsonをS3に置いたりしたが、S3は直接プレビューできなかったり。
- DynamoDBがコード的にも楽だった。
- 作業
- DynamoDB を使ってAPI Gateway→Lambda→DynamoDB で値を変更。
- 利点
- 完全サーバーレス!
- 補足
- 今回の記事はDynamoDBを変更するLambdaです。運用中のLambdaは別です。
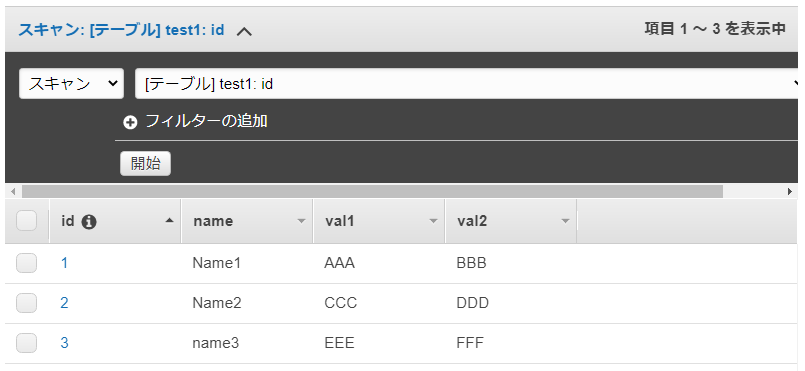
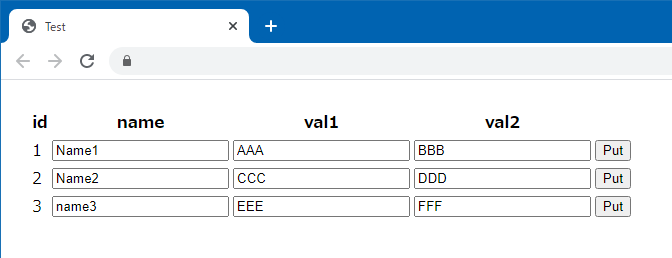
完成イメージ
- DynamoDB を Web で変更できます。
AWS Lambda
- GET のとき、DynamoDB を読み込んで Json を返します。
- PUT のとき、DynamoDB を Update します。PUT の Json は引数の event に入ります。
pythonimport boto3 import json def lambda_handler(event, context): message = {'message':''} table= boto3.resource('dynamodb').Table('test1') id = event.get('id', None) name = event.get('name', None) val1 = event.get('val1', None) val2 = event.get('val2', None) # PUT のとき if id: r = table.update_item( Key={'id': int(id)}, UpdateExpression="set #name=:n, val1=:v1, val2=:v2", ExpressionAttributeNames= {'#name':'name'}, ExpressionAttributeValues={':n':name, ':v1':val1, ':v2':val2} ) return message # GET のとき list = [] records = table.scan() records['Items'] = sorted(records['Items'], key=lambda x:x['id']) for r in records['Items']: try: list.append({ 'id':r['id'] ,'name':r['name'] ,'val1':r['val1'] ,'val2':r['val2'] }) except Exception as err: print('error except ', err) message['list'] = list return message補足
- IAM ロールに DynamoDB のアクセス権限を付けてください。
- errorMessage "An error occurred (ValidationException) when calling the UpdateItem operation: Invalid UpdateExpression: Attribute name is a reserved keyword; reserved keyword: name", というエラーが出たとき、上記のように {'#name':'name'} としてください。理由:name という名前は使用できない為。
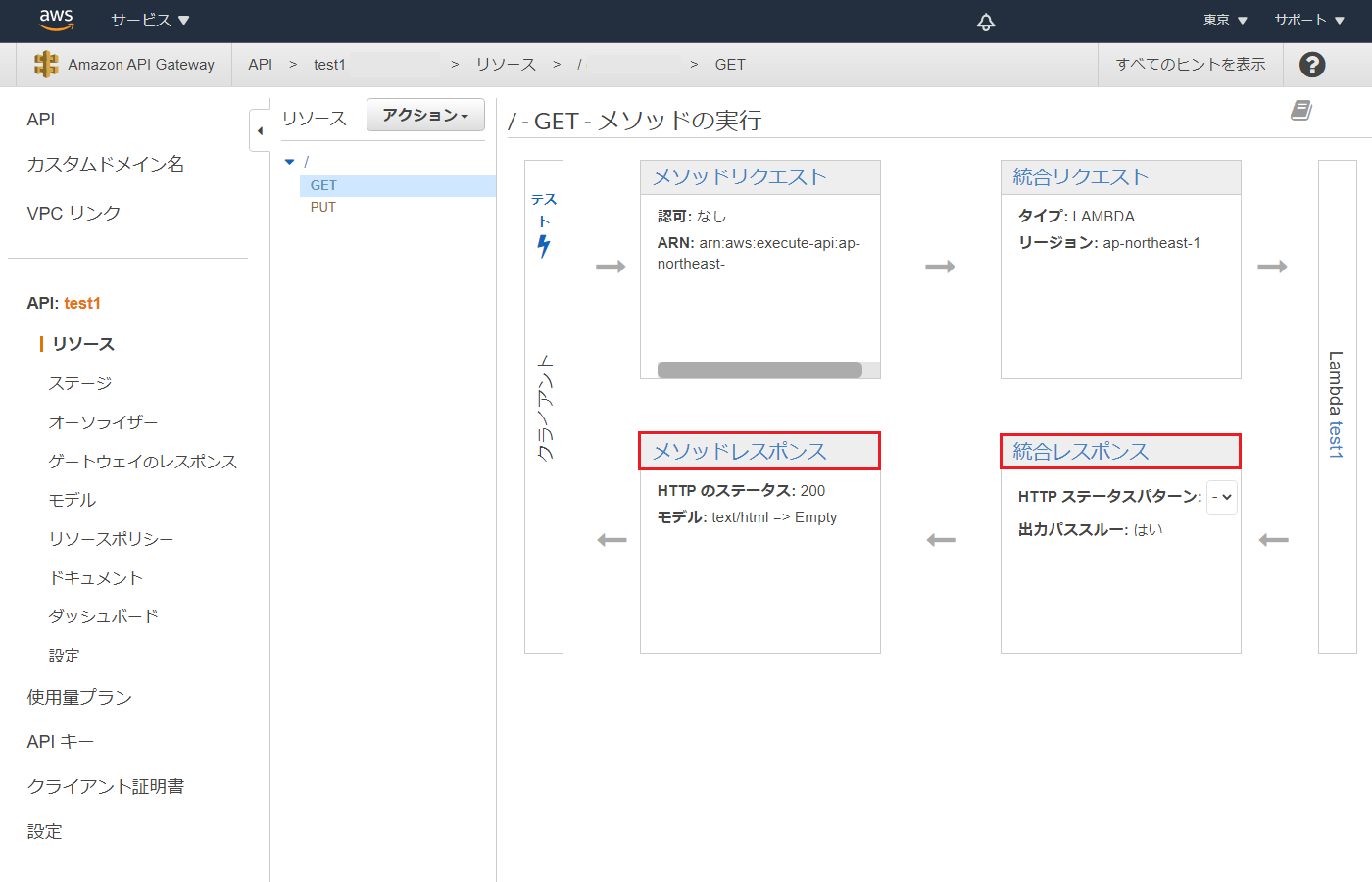
API Gateway
- API Gateway で HTML を返します。これで簡単なWebページが作れます。
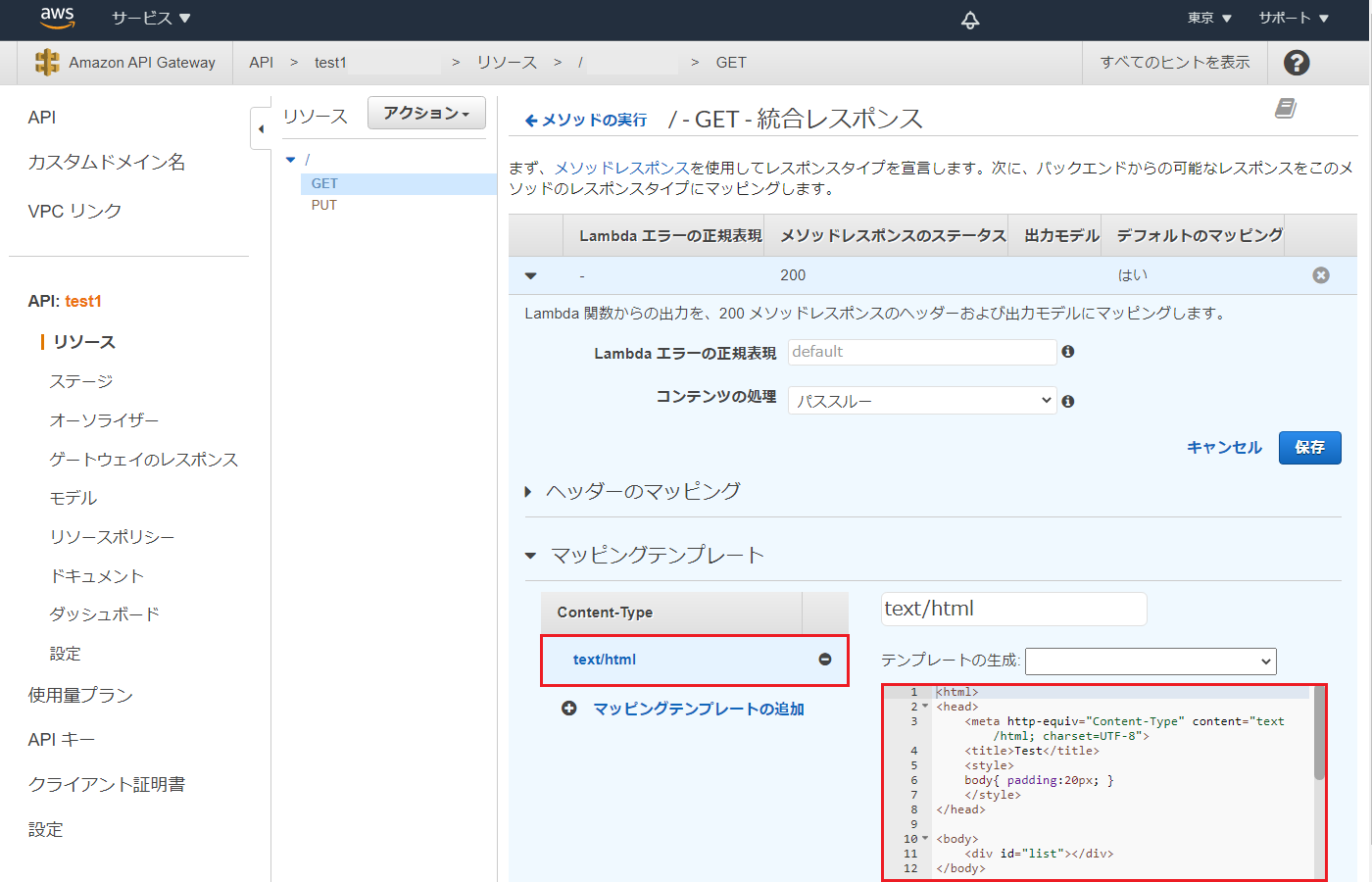
APIタイプ REST API 結合タイプ Lambda GET- メソッドレスポンス レスポンス本文を json から text/html に変更 GET- 統合レスポンス マッピングテンプレートを json から text/html に変更 API Gateway で HTML を返す
- 統合レスポンス マッピングテンプレートの text/html に以下をコピーします。
html<html> <head> <meta http-equiv="Content-Type" content="text/html; charset=UTF-8"> <title>Test</title> <style> body{ padding:20px; } </style> </head> <body> <div id="list"></div> </body> <script src="https://ajax.googleapis.com/ajax/libs/jquery/1.12.4/jquery.min.js"></script> <script type="text/javascript"> var API_URL = 'https://xxxx.execute-api.ap-northeast-1.amazonaws.com/1/'; var data = { list: '$input.path("$.list")' } redraw(); function redraw() { if (data['list']) { var t = ""; t += '<table>'; t += '<tr><th>id<th>name<th>val1<th>val2<th>'; JSON.parse(data['list']).forEach(function(d) { var id = d['id']; t += '<tr><td>'+d['id']; t += '<td><input type="text" id="name'+id+'" value="'+d['name']+'">'; t += '<td><input type="text" id="val1'+id+'" value="'+d['val1']+'">'; t += '<td><input type="text" id="val2'+id+'" value="'+d['val2']+'">'; t += '<td><input type="button" value="Put" onClick="put('+id+')">'; }); t += '</table>'; $("#list").html(t); } } function put(id) { var n = document.getElementById("name"+id).value; var v1 = document.getElementById("val1"+id).value; var v2 = document.getElementById("val2"+id).value; var json = '{"id":"'+id+'", "name":"'+n+'", "val1":"'+v1+'", "val2":"'+v2+'"}'; putjson(json); } function putjson(json) { $.ajax({ url: API_URL, type: 'PUT', contentType: 'application/json', dataType: 'json', data: json, }).then( data => redraw(data), error => alert('error') ); } </script> </html>API Gateway をIPアドレスで制限
- API Gateway は誰でもアクセスできてしまうので、会社のグローバルIPで制限します。
API Gateway リソースポリシー IP 範囲の許可リスト
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": "*", "Action": "execute-api:Invoke", "Resource": [ "arn:aws:execute-api:ap-northeast-1:xx:xx/*/GET/", "arn:aws:execute-api:ap-northeast-1:xx:xx/*/PUT/" ], "Condition": { "IpAddress": { "aws:SourceIp": [ "xxx.xxx.xxx.xxx/32", "xxx.xxx.xxx.xxx/32" ] } } } ] }補足
- arn はリソースに書いてあります。
- 変更後リソースをデプロイして1分待ちます。
まとめ
AWS Lambda と DynamoDB と API Gateway だけで簡単なWebページが作れました。これだけでちょっとしたシステムが作れそうです。もうこれでええやん。
- 投稿日:2020-11-23T16:46:49+09:00
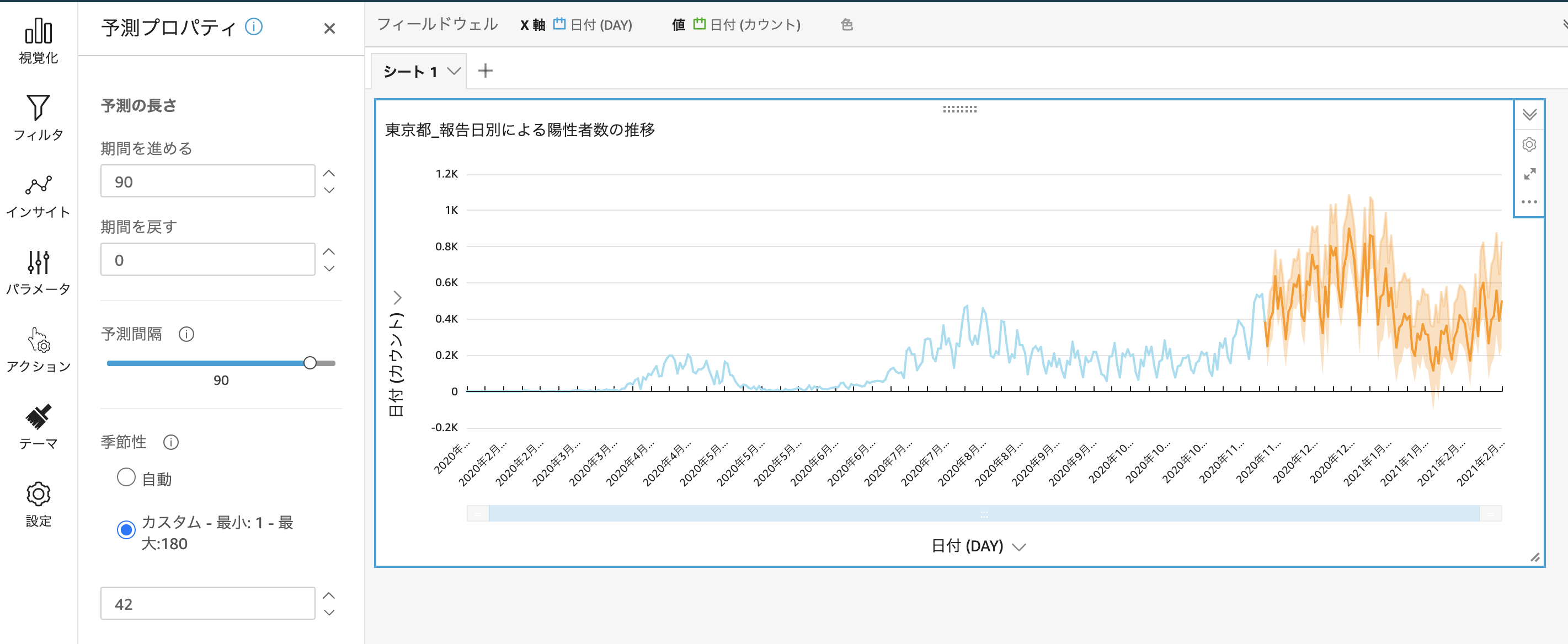
QuickSightで東京都の陽性者数を予測
陽性者数の推移を予測を使用と思った経緯
東京に観光や出張したいと思ったとき、今の東京は、大丈夫なのか?感染リスクを予測しようと思った時、東京都の陽性者数の推移の予測は、1つの指標になるのでは、ないかと思った。
Amazon QuickSight
機械学習のテクノロジーをベースとしたインタラクティブなダッシュボードを簡単に作成して公開。ダッシュボードは、あらゆるデバイスからアクセスでき、アプリケーション、ポータル、ウェブサイトに埋めることが可能。
Amazon QuickSightML を使用した予測をしようする
Amazon QuickSight を使用すると、非技術系のユーザーは自社の主要ビジネスメトリクスを自信を持って予測できます。内蔵の ML Random Cut Forest アルゴリズムは、外れ値を除く季節性や傾向の検出、欠損値の入力など、複雑な現実のシナリオを自動的に処理します。ポイントアンドクリックで簡単にデータを操作できます。
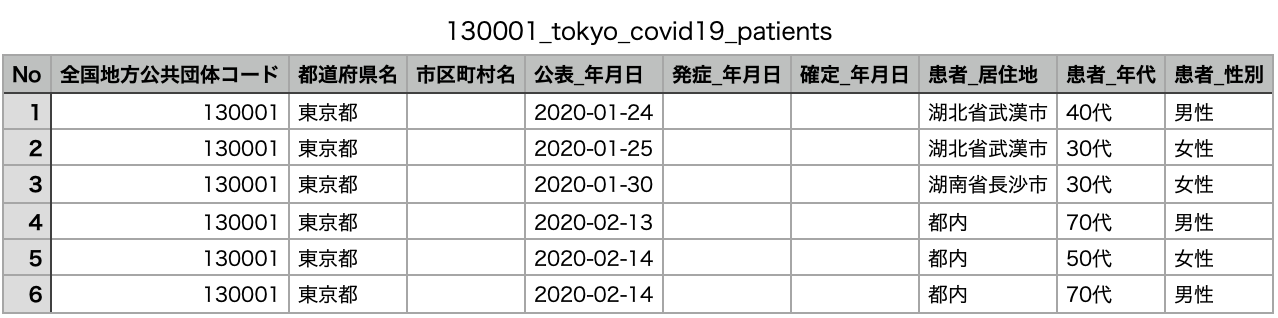
MLを利用した予測東京都のオープンデータからダウンロード
東京都 新型コロナウイルス対策サイト で公開している都内 新型コロナウイルス陽性患者の詳細データです。(注)公表年月日:患者情報を公表した年月日。発症年月日:症状があらわれた年月日。確定_年月日:検査により陽性であることを医師が確認した年月日。退院済フラグには、死亡退院含む。
CSVファイルの中身
今回は、「公表_年月日」のカラムを「日付」に変更し、データ分析に必要のない列は、全て消した。CSVファイルの文字コードをUTF-8にする
東京都のオープンデータ(130001_tokyo_covid19_patients.csv)の文字コードは、「Shift-JS」になっており、QuickSight上でデータをインポートした場合、文字化けが発生するので、「Shift-JS」から「UTF-8」に変更します。
macでファイルの文字コードを変換する『nkfコマンド』の使い方とオプション一覧$ nkf -w --overwrite 130001_tokyo_covid19_patients.csvAmazon QuickSight動かしてみる
まずは、AWSアカウントにログインします。次に、QuickSightに移動して、QuickSight専用のHPに移動します。
サッと始める QuickSight の使い方のQiita記事をもとにQuickSightを動かしました。実行結果
Amazon QuickSightの勉強の仕方
AWS Japan 亀田さんのGithubから講義資料をダウンロードすることを進めます。
考察
QuickSight ML Insightsの機能を使用することによって誰でもノンプログラミングでできるので簡単です。
これから東京都は、陽性者数増加傾向にあるので、気をつけていきたい。
- 投稿日:2020-11-23T16:43:42+09:00
既存 AWS VPC の中に EKS を構築する時の注意点
AWS EKS を構築する手順に関して、このサンプルを見ると「簡単にできる」と思いませんか?
eksctl で例をあげるとapiVersion: eksctl.io/v1alpha5 kind: ClusterConfig metadata: name: basic-cluster region: eu-north-1 nodeGroups: - name: node-group-hoge instanceType: m5.large desiredCapacity: 1 volumeSize: 100 ssh: allow: true publicKeyPath: ~/.ssh/ec2_id_rsa.pub - name: node-group-fuga instanceType: m5.xlarge desiredCapacity: 2 volumeSize: 100 ssh: allow: true publicKeyPath: ~/.ssh/ec2_id_rsa.pubawscliの認証が設定済みであれば、下記のコマンドを打つだけで10分間ぐらい後に EKS クラスターが出来上がります。
eksctl create cluster -f cluster.yaml但し、上記のコマンドは、eksctlが eks cluster を作るだけではなく、勝手にvpcを新規で作ってしまいます。
では、 どうやって既存 VPC に eks cluster を構築するのでしょうか?
ざっくり言うと、 cluster yaml に vpc の設定を入れるのです。下記のよう
apiVersion: eksctl.io/v1alpha5 kind: ClusterConfig metadata: name: basic-cluster region: eu-north-1 vpc: subnets: private: eu-north-1a: { id: subnet-praa } eu-north-1b: { id: subnet-prcc } eu-north-1c: { id: subnet-prdd } public: eu-north-1a: { id: subnet-puaa } eu-north-1b: { id: subnet-pucc } eu-north-1c: { id: subnet-pudd }でも、この場合には、罠が結構あります。本文では筆者がづらかったことと注意点をまとめておきます。
(公式ドキュメントのこの3つ 1 2 3 を丹心に読んだら罠をうまく避けるはずですが、簡単なまとめをまず読んでみたい方は、本文を読んでもいいと思います。)node が kubenetes cluster に join できない問題
現象 : eksctl で 既存 VPC に cluster を作る時に、すべての node が cluster に join できません。下記のエラーになります。
Error: timed out (after 25m0s) waiting for at least 1 nodes to join the cluster and become ready in "node-group-hoge"
kubectl で nodes を見ると、nodeのStatusが
NotReadyになっています。kubectl get nodes NAME STATUS ROLES AGE VERSION ip-10-113-208-246.ap-northeast-1.compute.internal NotReady <none> 10h v1.17.11-eks-cfdc40原因は node がインタネット接続できない
ssh で node にログインして見ると、インタネット接続できないことを気づきました。
原因は、
public subnet に置かれる node が 自動にグローバルIPを付けてないため、インタネットアクセスできなくで、 kubenetes master api にアクセスできませんでした。ついてに、 private subnet に node を置く場合もまとめてみると、インタネットアクセスできるようにする方法は:
- public subnet に node を置く場合: subnet の
map_public_ip_on_launchをtrueに設定すべき- private subnet に node を置く場合: subnet の nat gateway をちゃんと設定すべき
ついてに、高可用性のため、正しい eks ネットワーク環境の構成は下記だと思います:
- VPC
- internet gateway
- public subnet が 3つ
- それぞれの アベイラビリティーゾーン に置く
- internet gateway に関する route table等の設定
- nat gateway が3つ
- nat gateway の subnet が それぞれの public subnetに設定
- private subnet が 3つ
- それぞれの アベイラビリティーゾーン に置く
- 同じ アベイラビリティーゾーンに置かれる nat gateway を使う
- route table 等の設定
VPC と subnet の Tag 対応
vpc subnet tagging の文章によると、上記だけではなく、 VPC と subnet に Tag をつけることも必要になります。
- VPC に下記のタグをつける
kubernetes.io/cluster/<cluster-name>=>shared- subnet に下記のタグをつける
kubernetes.io/cluster/<cluster-name>=>shared- public subnet に下記のタグをつける
kubernetes.io/role/elb=>1- private subnet に下記のタグをつける
kubernetes.io/role/internal-elb=>1一部 node が cluster に join できますが、一部は join できない問題
現象: eksctl で cluster を作る時に、一部 node が
Readyになっていますが、一部はNotReadyになっていますError: timed out (after 25m0s) waiting for at least 2 nodes to join the cluster and become ready in "tidb" kubectl get nodes NAME STATUS ROLES AGE VERSION ip-10-113-208-238.ap-northeast-1.compute.internal Ready <none> 10h v1.17.11-eks-cfdc40 # node-group-hoge ip-10-113-208-246.ap-northeast-1.compute.internal NotReady <none> 10h v1.17.11-eks-cfdc40 # node-group-fuga ip-10-113-208-253.ap-northeast-1.compute.internal Ready <none> 10h v1.17.11-eks-cfdc40 # node-group-fuga問題になったサーバーに入って見ると
amazon-k8s-cniがエラーになっていたっぽいです。[ec2-user@ip-10-113-208-246 ~]$ ps -ef|grep kube root 4611 1 1 Nov10 ? 00:09:08 /usr/bin/kubelet --node-ip=10.113.208.246 --node-labels=alpha.eksctl.io/nodegroup-name=tidb,dedicated=tidb,alpha.eksctl.io/cluster-name=dig-ec-tidb-cluster,node-lifecycle=on-demand,alpha.eksctl.io/instance-id=i-02f495832c6f511a6 --max-pods=29 --register-node=true --register-with-taints=dedicated=tidb:NoSchedule --cloud-provider=aws --container-runtime=docker --network-plugin=cni --cni-bin-dir=/opt/cni/bin --cni-conf-dir=/etc/cni/net.d --pod-infra-container-image=602401143452.dkr.ecr.ap-northeast-1.amazonaws.com/eks/pause:3.1-eksbuild.1 --kubeconfig=/etc/eksctl/kubeconfig.yaml --config=/etc/eksctl/kubelet.yaml root 5629 5598 0 Nov10 ? 00:00:15 kube-proxy --v=2 --config=/var/lib/kube-proxy-config/config[ec2-user@ip-10-113-208-246 ~]$ docker ps --all CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES e9f4a894192b 602401143452.dkr.ecr.ap-northeast-1.amazonaws.com/amazon-k8s-cni "/bin/sh -c /app/ent…" 3 minutes ago Exited (137) About a minute ago k8s_aws-node_aws-node-c7dmc_kube-system_e7c4fe7c-8621-4b8b-9cb4-68aedfba905f_157 a128c1ebcd69 602401143452.dkr.ecr.ap-northeast-1.amazonaws.com/eks/kube-proxy "kube-proxy --v=2 --…" 11 hours ago Up 11 hours k8s_kube-proxy_kube-proxy-b8cst_kube-system_13a4b302-0e5d-4c2b-847a-c6c1fa7e15a7_0 f71de18a5c35 602401143452.dkr.ecr.ap-northeast-1.amazonaws.com/amazon-k8s-cni-init "/bin/sh -c /init/in…" 11 hours ago Exited (0) 11 hours ago k8s_aws-vpc-cni-init_aws-node-c7dmc_kube-system_e7c4fe7c-8621-4b8b-9cb4-68aedfba905f_0 a3ea54d25272 602401143452.dkr.ecr.ap-northeast-1.amazonaws.com/eks/pause:3.1-eksbuild.1 "/pause" 11 hours ago Up 11 hours k8s_POD_aws-node-c7dmc_kube-system_e7c4fe7c-8621-4b8b-9cb4-68aedfba905f_0 6cd9cfff6472 602401143452.dkr.ecr.ap-northeast-1.amazonaws.com/eks/pause:3.1-eksbuild.1 "/pause" 11 hours ago Up 11 hours k8s_POD_kube-proxy-b8cst_kube-system_13a4b302-0e5d-4c2b-847a-c6c1fa7e15a7_0
Exited (137) About a minute agoの docker 気になります[ec2-user@ip-10-113-208-246 ~]$ docker logs e9f4a894192b {"level":"info","ts":"2020-11-11T01:16:13.871Z","caller":"entrypoint.sh","msg":"Install CNI binary.."} {"level":"info","ts":"2020-11-11T01:16:13.889Z","caller":"entrypoint.sh","msg":"Starting IPAM daemon in the background ... "} {"level":"info","ts":"2020-11-11T01:16:13.897Z","caller":"entrypoint.sh","msg":"Checking for IPAM connectivity ... "}ログをみても原因を特定できていないですが、 aws console で subnet 状況をみたら、 「利用可能な IPv4」 が 0 になったことに気になりました。
原因は IP Address が足りない
cluster の log を
enableにすると、正しいエラーメッセージを見つけました。eksctl utils update-cluster-logging --enable-types=all --region=ap-northeast-1 --cluster=dig-ec-tidb-cluster --approve Error: InvalidRequestException: Provided subnets subnet-08e***df Free IPs: 2 subnet-0e***02 Free IPs: 0 , need at least 3 IPs in each subnet to be free for this operation { RespMetadata: { StatusCode: 400, RequestID: "1638fedc-9599-42da-973a-ad12dae6541e" }, Message_: "Provided subnets subnet-08efd8c4cc627d9df Free IPs: 2 subnet-0e51****02 Free IPs: 0 , need at least 3 IPs in each subnet to be free for this operation" }開発環境のVPCなので、VPC の CIDR は
/24で、 各 subnet に CIDR が/28で、1つの subnet に IPv4 のが 16 個しかありませんでした。IPが足りないため、 VPC の CIDR の
/24配下のすべての ip-range を使ってみました。
- public subnet が 2つ : CIDR が
/26で 64 個 IP address- private subnet が 2つ : CIDR が
/26で 64 個 IP addressすべての subnet が合わせて 256 個 IP address で全部です。
これで cluster 自体が構築できましたが、 IP address がまた大量に使われているようで、 private subnet の 「利用可能な IPv4」 がなんと僅か
8になっています。なぜ EKS がこんなに大量な IP address を使うのか、AWSに問い合わせてみました。
結論は
- AWS EKS の CNI が amazon-vpc-cni-k8s というもの
- 利点としては、pod に普通な VPC の IP をつけることができて、Security Groupの設定などを柔軟に設定可能
- pod を作る時に 迅速に IP address をつけるため、ある程度事前に IP Address を確保することで、 Warm Pool という機構が存在する
- Warm Pool のサイズが調整可能
- 小さく調整したら、 pod が auto-scaling の時に迅速に対応できないかもしれないので要注意
解決方法
ということで、うちの場合はそんなに迅速に大量 scale-out しないので、早速調整してみます。
kubectl set env ds aws-node -n kube-system AWS_VPC_K8S_CNI_CUSTOM_NETWORK_CFG=true kubectl set env ds aws-node -n kube-system WARM_IP_TARGET=3暫く待ったら 利用可能なIPv4 の数がある程度に戻りました。
まとめ
既存 VPC に EKS を構築する時に、 下記のことを注意したほうがいいと思います
- VPC のネットワーク環境整備
- インタネット接続できる状態にしておく
- 複数 アベイラビリティーゾーン (AZ) を持つこと
- VPC/Subnet に Tag をつけること
- IP Address の計画
WARM_IP_TARGETの環境変数で Warm Pool のサイズを調整することTODO:
私の実験には node が kubenetes master にアクセスする endpoint はグローバルIPになっていたこと、気になります。
完全に private kubenetes cluster を構築する場合もあるので、 下記のドキュメントを参考して続けて検証しておきたいです。
- 投稿日:2020-11-23T16:41:42+09:00
【備忘録】AWS LightSailでterminalからssh接続
はじめに
AWS LightSailでデータサイエンス環境構築の練習の備忘録です
目次
- LightSailでインスタンスを作成
- shh接続
1. AWSのlightsailでインスタンスを作成する
https://lightsail.aws.amazon.com
2. ssh接続
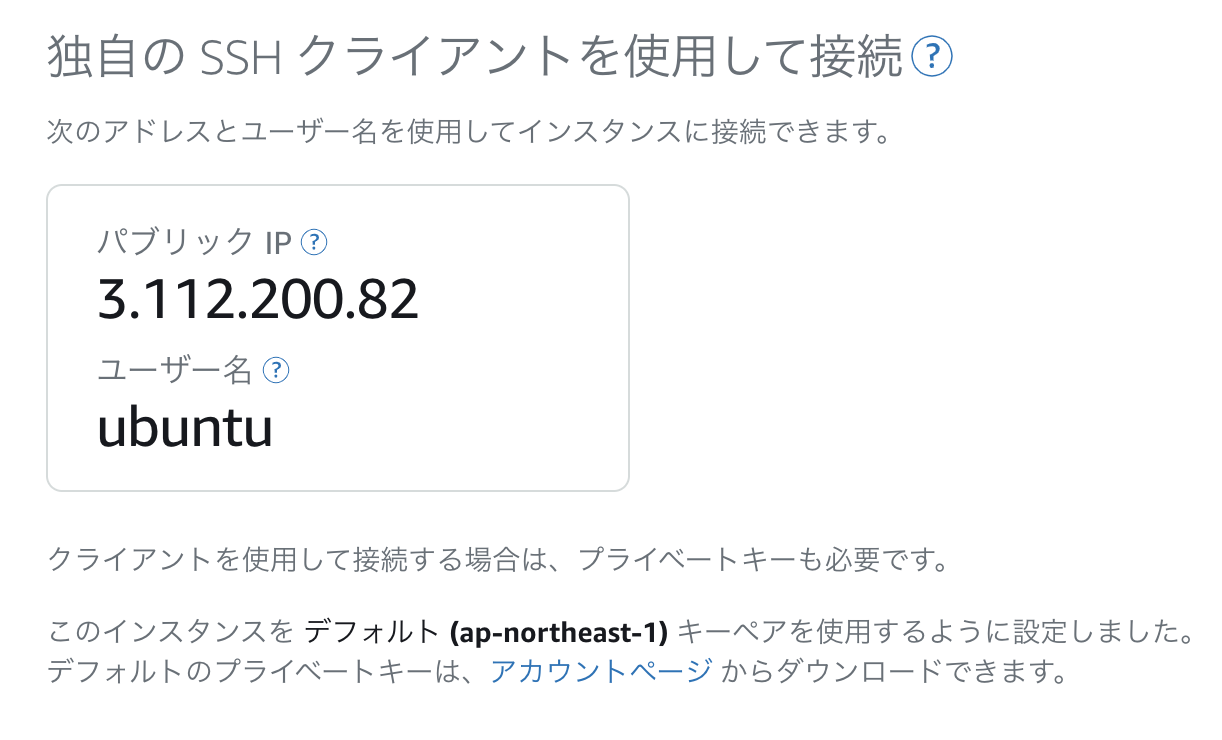
アカウントページからプライベートキーをダウンロードする
アカウントページ
プライベートキーと設定ファイルを「~/.shh」ディレクトリに格納する
cd ~/.ssh ls Lightsail_ubuntu_20201123.pem config #Lightsail_ubuntu_20201123.pem・・・プライベートキー #config・・・設定ファイル~/.ssh/confighost lightsail_ubuntu HostName 3.112.200.82 Port 22 User ubuntu IdentityFile ~/.ssh/Lightsail_ubuntu_20201123.pemssh接続
ssh lightsail_ubuntuもしくは、configファイルを設定せずにプライベートキーのオプションをつける方法もあります
ssh -i Lightsail_ubuntu_20201123.pem ubuntu@3.112.200.82これで接続完了です!
参考
・Amazon Lightsailのサーバにssh接続する
https://nana4-story.com/ssh-amazon-lightsail


- 投稿日:2020-11-23T16:36:28+09:00
Code for Japanに飛び込んで、GitHub ActionsでElastic BeanstalkへのCI/CDを構築した流れ
背景
コロナで外出しづらくなったこともあり、以前から興味のあったCode for Japanに参加しました。
今回のプロジェクトは、Ruby on Railsでした。私は、Ruby初心者なので、コンテナやAWSまわりの足回りを固めるために活動してます。
私が、プロジェクトの参加からCI/CD構築までの流れを紹介します。興味がある方の参考になると嬉しいです。
3文まとめ
- Code for Japanに参加するのは簡単
- 当然だけど、AWSを触るのはNDAが必要
- GitHub ActionsでCI/CDを構築するは簡単
Code for Japan プロジェクト参加のきっかけ
東京都のコロナ対策サイトで気になって、ROM専でSlackにいました。
Slack コミュニティ - Code for Japanから、気軽に参加できます。
たまたま、slack上でメンバーの募集を見かけ、市民の政治参加に興味があり参加しますと声を掛けました。
Ruby初心者でしたが、心よく受け入れて頂きました。笑参加したDIY City プロジェクト(市民参加型合意形成プラットフォーム)
地域で暮らす人たちや、その地域を愛する人たちが主役になり、自分たちでどんなまちにしたいのか、そのためにどんなことが必要なのかを考え、手を動かし、自分たちでつくっていく都市です。できるだけ多様な人がまちづくりに関わり、「要望する」のではなく「つくる」側として参画します。
上記のような構想をもとに、市区町村と協力してサービスを提供するプロジェクトです。市民が積極的に参加することで、より良い町づくりを目指します。
日本では、加古川市で2020/11から本稼働しています。
OSS decidim
上記のサイトは、Decidim (Free Open-Source participatory democracy for cities and organizations)をベースに構築されています。Ruby on railsで構築されており、これにパッチ修正をあてて稼働しています。翻訳など本家に取り込んでも問題ないものは、本家を修正しています。
このOSSで数年前から、バルセロナやヘルシンキなどいくつかの複数の都市で運用されています。都市ごとに、カスタマイズされており、どれも個性的で興味深いです。
バルセロナでは、うまく軌道にのり、下記のような成果が出ているようです。
2016年から2019年の3年間で、すでに市民の70%が登録しており、9000以上の市民からの新たな政策提案が集まっている
NDA締結
今回、CI/CD構築のため、AWSを触るので、NDA締結が必要でした。
一般的な内容で、クラウドサインで締結しました。※私が勤めている弁護士ドットコムのサービスを使ってくれていました。
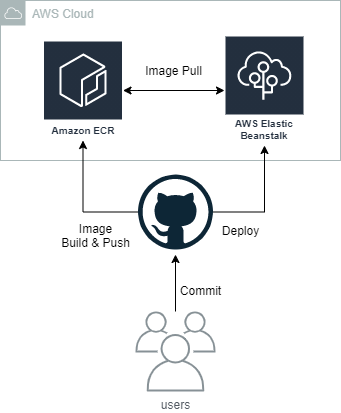
CI/CD概要
既にソースコードをGitHubで管理していたので、GitHub上で完結するGitHub Actionsを採用しました。
ユーザーがGitHubにコードをcommit pushすると、GitHub ActionsでイメージをBuildして、ECRにpush。その後、AWS ECRを使用してElastic Beanstalkにデプロイする非常にシンプルなパイプラインです。
AWS ECR作成
ECRは、Cloud Formationで作成しました。
AWSTemplateFormatVersion: "2010-09-09" Description: Create ECR Resources: TestEcrPoc: Type: AWS::ECR::Repository Properties: RepositoryName: hoge ImageScanningConfiguration: scanOnPush: "true" ImageTagMutability: "MUTABLE" LifecyclePolicy: LifecyclePolicyText: | { "rules": [ { "rulePriority": 1, "description": "Delete image without tag after 7 days", "selection": { "tagStatus": "untagged", "countType": "sinceImagePushed", "countUnit": "days", "countNumber": 7 }, "action": { "type": "expire" } } ] }イメージスキャン
イメージスキャン - Amazon ECRを有効化しています。Pushするたびに、スキャンされます。
イメージスキャンは、オープンソースのClairプロジェクトからCommon Vulnerabilities and Exposures(CVE)データベースを使用してスキャンし、GUI上から結果を確認できる機能です。
ライフサイクルポリシー
タグなしのイメージだけ、7日経過後に削除するライフサイクルポリシーを設定しています。
ライフサイクルポリシーだけJSONで記述する必要があります。yamlの中なので、補完が効かず書きづらいですが、仕方がありません。AWS IAMユーザーの作成
Elastic Beanstalkのアクセス権だけでなく、上記で作成したECRへのReadWriteアクセスも必要です。
GitHub Actionsで使うSecretsの設定
GitHubでは、レポジトリごとにSecretsが設定できます。
それを使用して、下記のキーで、上記で作成したIAMのアクセス情報とECRのレポジトリ名を保存します。
レポジトリ名は場合によっては、Secretsでなくてもいいと思います。AWS_ACCESS_KEY_ID: ********************* AWS_SECRET_ACCESS_KEY: ********************* AWS_ECR_REPO_NAME: hogeAWS ECRへのイメージのpush
github/workflows/deploy.yml- name: Configure AWS Credentials uses: aws-actions/configure-aws-credentials@v1 with: aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }} aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }} aws-region: ap-northeast-1 - name: Login to Amazon ECR id: login-ecr uses: aws-actions/amazon-ecr-login@v1 - name: Build, tag, and push image to Amazon ECR env: ECR_REGISTRY: ${{ steps.login-ecr.outputs.registry }} ECR_REPOSITORY: ${{ secrets.AWS_ECR_REPO_NAME }} IMAGE_TAG: staging run: | docker build -t $ECR_REGISTRY/$ECR_REPOSITORY:$IMAGE_TAG . docker push $ECR_REGISTRY/$ECR_REPOSITORY:$IMAGE_TAGAWS ECRへのログイン & Push
公式で、下記のActionが提供されているので、非常に簡単にpushできます。
aws-actions/amazon-ecr-login: Logs into Amazon ECR with the local Docker client.
Dockerrun.aws.jsonの作成
/deployments/Dockerrun.aws.json{ "AWSEBDockerrunVersion": "1", "Logging": "/app/log", "Image": { "Name": "{RepositoryName}", "Update": "true" }, "Ports": [ { "ContainerPort": "3000" } ] }
${RepositoryName}はデプロイ時に、タグ付きのレポジトリ名にリプレイスします。あえて
deploymentsディレクトリを掘って、その下に置いています。同じ階層にDockerfileがあると、そちらが優先されてしまうためです。また、デプロイ時にDockerrun.aws.jsonだけをzipすることで転送量を減らすのが狙いです。Loggingセクションに コンテナ内のディレクトリを指定することで、ebの管理下にあるLogディレクトリにログを出力できます。
またGUI上のコンソールからLogの閲覧も可能になります。AWS Elastic Beanstalkへのデプロイ
github/workflows/deploy.yml- uses: actions/setup-python@master with: python-version: "3.7" - name: Install awsebcli run: pip install -U awsebcli - name: Deploy to Elastic Beanstalk env: ECR_REGISTRY: ${{ steps.login-ecr.outputs.registry }} ECR_REPOSITORY: ${{ secrets.AWS_ECR_REPO_NAME }} IMAGE_TAG: staging EB_ENVIRONMENT_NAME: staging run: | cd deployments sed -i -e "s|{RepositoryName}|$ECR_REGISTRY/$ECR_REPOSITORY:$IMAGE_TAG|g" Dockerrun.aws.json eb deploy ${EB_ENVIRONMENT_NAME}今回は、極力公式のActionだけにしたかったので、有志のBeanstalk Deploy · Actions · GitHub Marketplaceを使用しませんでした。要件次第では、使った方が楽だと思います。
eb コマンドを使用しているので、python環境の構築後にコマンドのインストールを行っています。
まとめ
GitHub Actionsを使用することで、比較的簡単にパイプラインが構築できました。
デジタル庁の民間登用やCode for Japanの東京都コロナ対策サイト、COCOAなどを契機に、一般市民がテクノロジーを活用して、行政サービスの問題や社会課題を解決するCivitechはこれから盛り上がっていくと思います。
コードの全体は、codeforjapan/decidim-cfj: Code for Japan Decidimにあります。
ぜひあなたのコントリビュートをお待ちしております。
参考
- 投稿日:2020-11-23T15:46:47+09:00
AWSのEC2にGUI環境を構築する
学習環境が欲しくて、EC2にGUI環境を構築したら、思いのほか苦戦したのでメモ。
環境
サーバー : Amazon Linux 2
クライアント : Mac事前準備
・AWSのアカウント作成
・EC2作成
・EC2にSSH接続GUI環境構築
公式から、ほぼコピペして進める。
# MATEデスクトップ環境のインストール $ sudo amazon-linux-extras install mate-desktop1.x # 全てのユーザーにMATEをデフォルト設定 $ sudo bash -c 'echo PREFERRED=/usr/bin/mate-session > /etc/sysconfig/desktop' # TigerVNCをインストール $ sudo yum install tigervnc-server # VNCのパスワード設定をした後に画面表示専用のパスワードを聞かれるので「n」で入力 $ vncpasswd起動時に常にVNCサーバーを起動するように設定。
$ sudo cp /lib/systemd/system/vncserver@.service /etc/systemd/system/vncserver@.service $ sudo sed -i 's/<USER>/ec2-user/' /etc/systemd/system/vncserver@.service $ sudo systemctl daemon-reload $ sudo systemctl enable vncserver@:1 $ sudo systemctl start vncserver@:1xstartupファイルにMATEを実行するコマンドを追加する。(これを追加しないと繋がっても真っ黒い画面になり操作できない・・・ここで苦戦した)
~/.vnc/xstartup#!/bin/sh exec mate-session 〜(以下略)〜VNCサーバーを再起動。
$ sudo systemctl daemon-reload $ sudo systemctl restart vncserver@:1Google Chromeのインストール
公式から引用。
$ sudo amazon-linux-extras install epel $ sudo yum install chromiumMacからリモート接続
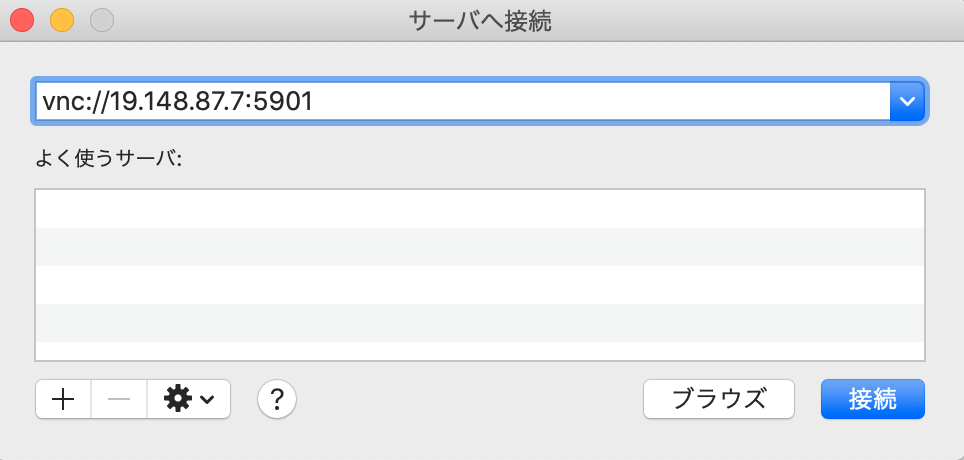
sshでポートフォワーディングを有効にするオプションを付けて繋ぎなおす。
PEM_FILE : 鍵のパス
INSTANCE_IP : 接続先IPssh -L 5901:localhost:5901 -i PEM_FILE ec2-user@INSTANCE_IPFinder→移動→サーバへ接続
接続するとパスワードを聞かれるので、先ほど設定したVNCのパスワードを入力する。
ログインに成功すると以下の画面になる。
終わりに
無事に作業環境を構築できて良かった〜!
余裕があれば他のOSも挑戦したい。
- 投稿日:2020-11-23T15:42:33+09:00
SAAとった勉強方法と実務経験して感じた事
この記事は AWS Advent Calendar 2020 17日目の記事です。
はじめに
AWSの認定資格であるソリューションアーキテクト・アソシエイト(以下SAA)を取得して、AWSを本格的に業務で構築するようになったので、資格をとった事によるメリットを書いていきたいと思います。
「資格取りたいけど・・・実際のところどうなん?」と、迷っている方の助力になれたらなと思います。
資格を取ろうと思った経緯
会社が費用を出してくれるからです
本音を書くと一行で終わってしまうので具体的にいうと、やはりサーバーサイドエンジニアとしてAWSはやっておくとメリットは大きいと思ったからです。主に以下の通り。
1、パブリッククラウドでAWSがトップである
エンジニアならインフラやってなくても誰もが知っているであろうAWS。
その仕組みを理解しておくことは、サーバーサイドの開発を行う上でも大きな力になります。2、クラウドの特性を活かしたシステムを作る事ができる
クラウドならではのインスタンス性を利用したオートスケールとかはその最もたる例だと思います。
AWS独自の仕様もかなり多いので、理解すると最適化して組む事が出来るようになります。3、キャリアの幅が広がる
他の領域との組み合わせでスキルを持っておくと、その分、エンジニアとしての能力の幅が広がります。
特にサーバーサイドエンジニアの方にとっては、親和性も高いのでメリットは大きいと思います。と、色々と書いていきましたが、役に立つ立たないに限らず、何らかの目に見える結果があると自分がレベルアップした感覚になるので、自信をつけるという意味でも良いと思います。
勉強のプロセス
本題に入る前に、SAAをどのように勉強したかを簡単に書いておきます。
実際に取ろうと思う方は参考にして頂けると幸いです。
私が取得したのは2019年10月なので、現在の試験内容とは違う点もあると思うので、あくまで参考でおねがいします1、参考書を何周もやった
試験勉強定番のやり方ですね。参考書を買ってひたすら読んで付属の演習問題を理解出来るまでやりました。
「読むだけでは頭に入ってこない」という意見もありますが、私的には言葉の意味や仕組みを目で追うだけでも意味はあると思っています。
というのもじっくり見るわけではなく、とにかく全ての章をざっと何周もするやり方でやったからです。
この方法だと初回よりも2周目、2周目よりも3周目と繰り返すうちに理解度が上がっていくのを感じる事ができます。
大体6、7割程度の理解で次の章に進むのがよいでしょう。
5周くらいやる頃にはほぼ理解しているはずです。2、BlackBeltスライドをひたすら読んだ
私の読んだ参考書は深い所まで解説はしていなかったので、理解を深める為にもBlackBeltのスライドを各サービス毎に読んで理解することを繰り返しました。
ただスライドを見てもらうと分かるのですが・・・枚数が非常に多い!
一つのサービスで80くらいあります。じっくり読んでいたらめちゃくちゃ時間かかります。
なので私は全部ではなくEC2やS3など主要サービスに絞って繰り返しました。どれが主要サービスなのかは参考書で説明しているサービスがそれだと思ってもらって問題ないと思います。BlackBeltの資料はこちらになります。
3、全体像を理解することに注力した
SAAはその名の通り、アーキテクト的な問題が殆どです。
サービス単体に関しての質問もあると言えばあるのですが、割合的には少なかった気がします。
なのでAWS上に各サービスを連携してどのように作っていくのがいいのか。を頭で描く練習をしておくといいかなと。まとめると以上のような感じでしょうか。
3つにまとめましたが、ほぼこれだけで一発合格しました。
私はスコアが750だったので結構ギリギリでしたがw分からない問題は後に回すという基本テクニックでなんとか乗り切りました。実務を担当した結果
SAAを取る前はほぼAWS触った事のない素人だったのですが、取得をきっかけに担当になることになりました。
かなりざっくりとですが、既存アーキテクチャの見直し、EC2からECSへの移行など、かなりダイナミックにやらせて頂きました。まず一番のメリットは各サービスの特性を分かっている状態で入れた事です。
ググったり調べながらやるのと比べて体系的に理解しているので、「あーこれそういうことね」という余裕感たっぷりなスタイルで見ることができます。
もちろんやってるうちに想定外の事は起きるものなのですが、それでも何とか乗り切ろうとするモチベーションを保ち続ける事が出来ました。もう一つはベストプラクティスを念頭におきながら進められた事です。
AWSでは「AWSのベストプラクティス」という最適解というものが公式にあります。基本的にSAAはこのベストプラクティスに沿ってアーキテクチャを構築する事が求められるのですが、これを意識しながら出来たのは大きいメリットでした。
ある程度マネージドなしくみになっていて自由度は損なわれているとはいえ、適当に構築して動かす事も出来る訳ですからね。
特にセキュリティ面に関してはこのメリットが大きかったと感じました。セキュリティグループとかIAM周りとか雑に作ってももなんとかなりますもん。逆にデメリットは決定的な差になるわけではないという所でしょうか。
上記で挙げたメリットもめちゃくちゃ大きい訳ではなく、普通に自分で勉強したり、詳しい人に聞いたりする事でも身につくポイントではあります。あとは受験にお金がかかる事。アソシエイトはプロフェッショナルより安いとはいえ1万以上出ていきます。
まとめ
結論としては列挙したメリットが良いと思うのなら、取ってから実務に入るとスムーズに進められると思います。
履歴書の資格欄が何もなくて寂しい方にもオススメです。私のことですが。
今後の方針としてはプロフェッショナルも取得したいなと思います。高額ですが、有効期限切れる前にキープしておきたいです。
- 投稿日:2020-11-23T15:27:40+09:00
【AWSクラウドプラクティショナー受験用】混同しやすい用語リスト
AWSクラウドプラクティショナーの受験に向けて個人的に混同しやすいと思った用語をまとめてみました。
※初心者のため、認識違いの箇所がありましたら、ご指摘いただけると幸いです。セキュリティグループとネットワークACLの違い
- セキュリティグループ・・・EC2インスタンス向けのトラフィック管理
- ネットワークACL・・・サブネット向けトラフィック管理
リードレプリカとは
- マスタからレプリケーションされた読み込み専用のDB
- レプリカを複数作成しておくことで、全体の読み込みスループットを向上させることが出来る
InspectorとConfigの違い
- Inspector・・・テンプレに基づいて、EC2インスタンスを分析する(デプロイされたAPの脆弱性チェック)
- Config・・・AWSリソースの設定変更を継続的にモニタリングする
VPCとEC2の違い
- EC2・・・仮想サーバ、立てたサーバ一つ一つのことをインスタンスと呼ぶ
- VPC・・・ユーザ専用のプライベートなクラウド環境を提供=仮想サーバ(EC2)でネットワークの設定をする際に、VPCと接続する
- VPCと接続することでEC2はネットワークと接続可能になる
デフォルトで自動バックアップを行うDB
- Aurora・・・RDSの上位互換
- RDS
- 注:Redshift・・・スナップショットを自動で作成する
- 注:ElastiCashe Redis・・・デフォルトではないが設定可能
- 注:DynamoDB・・・マネジメントコンソールンかCLIを使用して継続的バックアップを有効にする)
- 注:EBS(ストレージであり、スナップショットとして手動でバックアップを取得可能)
デフォルトでマルチAZ構成のサービス
- DynamoDB
- S3
KinesisとAthenaの違い
- Athena・・・S3にあるデータを直接、標準SQLによって抽出することを可能にする
- Kinesis・・・ストリーミングデータをリアルタイムで取得、処理、分析を行う
キーペアとアクセスキー・シークレットアクセスキーの違い
- キーペア・・・インスタンス(EC2等)への接続時に身分証明に使用する
- プライベートキー(秘密鍵)とパブリックキー(公開鍵)で構成される
- ユーザーは認証の際に秘密鍵を使用するので、厳重な管理が必要である
- アクセスキー・シークレットアクセスキー・・・AWSアカウントの認証の際に利用される
OpsWorks・Elastic Beanstalk・CloudFormationの違い
- CloudFormation・・・インフラ構築の自動化
- OpsWorks・・・PuppetやChefを使用して、クラウドエンタープライズでアプリケーションの設定及び運用をするための設定管理サービス(自動化)
- Elastic Beanstalk・・・AWSクラウドでアプリケーションを素早くデプロイし、管理する
簡易見積もりツール・TCO(総保有コスト)計算ツール・Cost Explore・AWS料金計算ツールの違い
- 簡易見積もりツール・・・その名の通り料金を見積もる
- TCO(総保有コスト)計算ツール・・・オンプレミスサーバとのコスト比較によってクラウド導入の可否を判断するための比較結果を導出するツール
- Cost Explorer・・・過去12カ月のデータから、今後12カ月のコストを予測する
- AWS料金計算ツール・・・AWSのサービスを調べたり、AWSのユースケースのコストの見積もりを行うことが出来る
AWS KMSとCloud HSMの違い
- AWS KMS・・・暗号化キーを簡易に作成して管理する。幅広いAWSのサービスやAPでの使用を制御出来るようになる
- Cloud HSM・・・CloudHSM は規格にも準拠しているので、ユーザの設定に応じて、商用で利用可能な他のほとんどの HSMにキーをすべてエクスポートできるようになる
Infrastructure Event Managementとは
- 繁忙期などアクセスが集中する時に、アーキテクチャとスケーリングのガイダンスと運用サポートを実施する
バックアップ・レプリケーションの違い
- バックアップ・・・システム障害時に元の状態に戻す(データの完全性を目的としている)
- レプリケーション・・・障害発生時にマスタDBからフェールオーバーするが、そのためにデータを別サーバへコピーしておくこと
ヘルスチェックを行うサービス
- ELB
- NLB
- EC2
- Route53
ベストプラクティスの設計原則
- セキュリティ
- 信頼性
- パフォーマンス効率
- コストの最適化
使用したデータ量に対して課金されるストレージ
- Redshift
- S3
EC2のプレイスメントグループとは
- ネットワークパフォーマンスの向上や物理サーバ障害時の影響範囲を限定させるために、インスタンスをグループ化することができる
- クラスター(AZ別)・分散・パーティションのグループの概念がある
サブネットとインスタンスの違い
- サブネット・・・ネットワークをさらに分割して作った小さなネットワークのこと(AWSの場合はVPC内にサブネットを構成する)
- サブネットの中にEC2等のインスタンスを配置する
ALBとNLBの違い
- ALB・・・Webサービスに発生する負荷を分散するロードバランシングサービス
- NLB・・・上記ネットワーク版
スレーブとは
- DBマスタのバックアップのようなものだが、通常のバックアップと異なり、マスタDBへの変更を即座に反映することが出来るバックアップ
強い整合性モデル・結果整合性モデル
- 結果整合性のある読み込み・・・最新の書き込み結果がDBに反映されていないことがあるが、時間がたてば最新のデータで読み込みが出来る
- 強力な整合性のある読み込み・・・上記の上位互換
Web API Gatewayとは
- 開発者がAPIの作成・公開・保守・モニタリング・保護を行うことが出来る
- リアルタイム双方向通信アプリケーションを実現するWebSocket APIを作成することが出来る
- トラフィック管理、CORS サポート、認可とアクセスコントロール、スロットリング、モニタリング、API バージョン管理など、最大数十万規模の同時 API コールの受け入れと処理に伴うすべてのタスクを取り扱う
- API Gateway内部でCloudFrontの仕組みを利用している
AWS Directory Service for Microsoft Active Directoryとは
- Simple ADでAWS上にAWS Managed Microsoft ADのサブセットを構築できる
- AWS Managed Microsoft AD(AWS マネージド型のインフラで稼働する実際のMicrosoft Active Directory)内のユーザやデバイスを管理できる
- AD ConnectorでAWS Directoryサービスを既存のエンタープライズディレクトリに接続できる
継承される統制とは
- ユーザがAWSから完全に継承する統制のこと
- 物理統制と環境統制がある
Amazon Managed Apache CassandraとDynamo DBの違い
- Amazon Managed Apache Cassandra・・・サーバーレスであり、使用したリソースに対してのみ料金が発生し、オープンソースと互換性がある
- Dynamo DB・・・AWS専用のNoSQLサービスであり、オープンソースとは互換性がない
- 投稿日:2020-11-23T11:13:00+09:00
S3にファイルをアプロードして メタデータに content-disposition を設定する
ゴール
- Webブラウザを使ってアップロードしたファイルをCloudFront経由でダウンロードする。
- ダウンロードしたファイルをブラウザで保存する時のダイアログには、S3のKeyとは別の任意のファイル名を指定できる。
上の「iOS の画像 (1).jpg」を
content-dispositionで指定する。バージョン情報
- JDK: amazon-corretto-11.0.3.7.1-windows-x64
- Spring boot : 2.2.4.RELEASE
- AWS SDK for Java: 2.14.28
はまりポイント
PutObjectRequest.Builder#contentDisposition(string)) の引数はURLエンコードを行う必要がある。
PutObjectRequest.builder().contentDisposition( "attachment; filename=\"iOS の画像(1).jpg\"")と書くと、下のエラーになる。software.amazon.awssdk.services.s3.model.S3Exception: The request signature we calculated does not match the signature you provided. Check your key and signing method. (Service: S3, Status Code: 403, Request ID: XXXXXXXXXXXXXXXX, Extended Request ID: YYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYY
)今回は、下の通りにした。
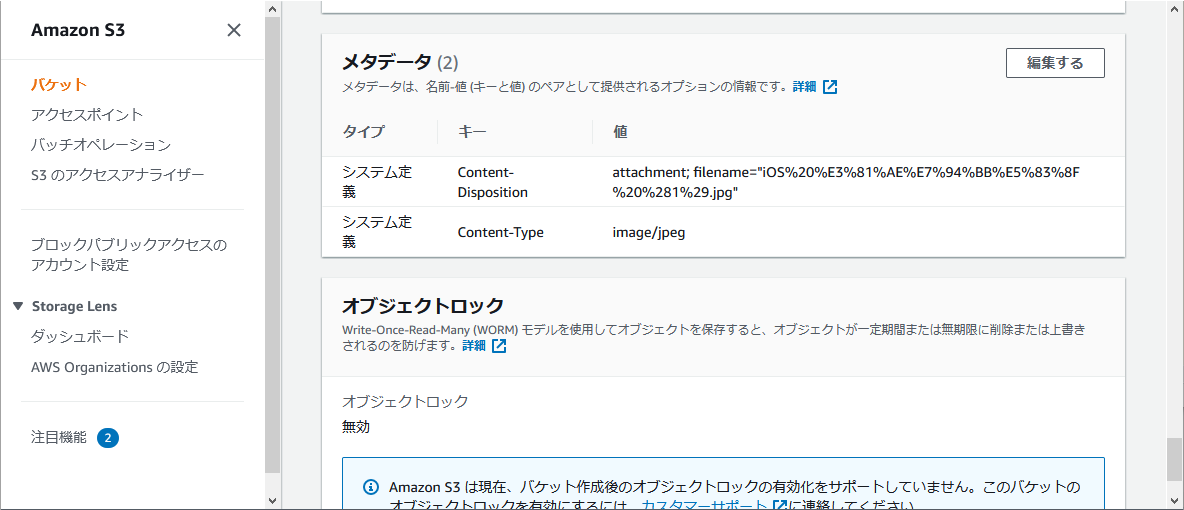
+を%20に置換する理由はファイル名の半角スペースがあるとURLエンコードで%20に変換されるので半角スペースに戻すため。PutObjectRequest.builder().contentDisposition( "attachment; filename=\"" + URLEncoder.encode(fileName, "UTF-8").replace("+", "%20") + "\"")設定した content-disposition の値は AWSコンソールのメタデータで確認できる。
コントローラーの実装
コントローラー@RestController public class SummernoteApiController { private WyswygService wyswygService; public SummernoteApiController(@Autowired WyswygService wyswygService) { this.wyswygService = wyswygService; } @PostMapping("/api/attachfile") public String attachfile(@RequestParam("upload_file") MultipartFile uploadFile) { if (uploadFile.isEmpty()) { throw new ResponseStatusException(HttpStatus.BAD_REQUEST, "添付するファイルを指定してください"); } try { String publishedUrl = wyswygService.uploadToS3(uploadFile); return publishedUrl; } catch (IOException | S3Exception e) { e.printStackTrace(); throw new ResponseStatusException(HttpStatus.INTERNAL_SERVER_ERROR, e.getMessage()); } } }サービスクラス(WyswygService.java)@Component public class WyswygService { /** AWSのリージョン */ @Value("${aws.region}") private String regsion; /** 画像などをアップロードするS3バケット */ @Value("${aws.s3.assetsBucket}") private String assetsBucket; /** S3バケットに保存する時のパスのPrefix */ @Value("${aws.s3.assetsPrefix}") private String assetsPrefix; /** CloudFrontのホスト名 */ @Value("${aws.s3.cloudFrontHost}") private String cloudFrontHost; /** https://github.com/huxi/sulky/tree/master/sulky-ulid */ private ULID ulid = new ULID(); /** * ファイルをAmazonS3にアップロードする * * @param uploadFile アップロードするファイル * @return CloudForntからアクセスできるパス * @throws IOException */ public String uploadToS3(MultipartFile uploadFile) throws IOException { String contentType = uploadFile.getContentType() != null ? uploadFile.getContentType() : "application/octet-stream "; String fileName = uploadFile.getOriginalFilename() != null ? uploadFile.getOriginalFilename() : "attached_file.dat"; String s3key= this.genrateS3KeyPrefix() + fileName.substring(fileName.lastIndexOf(".")); String cloudFrontUrl = String.format("https://%s%s", this.cloudFrontHost, key); PutObjectRequest putObject = PutObjectRequest.builder() .bucket(this.assetsBucket) .key(s3key.startsWith("/") ? s3key.substring(1) : s3key) // 先頭に「/」があると重複するので削除する .contentType(contentType) .contentDisposition( "attachment; filename=\"" + URLEncoder.encode(fileName, "UTF-8").replace("+", "%20") + "\"") .build(); s3Client.putObject(putObject, RequestBody.fromInputStream(uploadFile.getInputStream(), uploadFile.getSize())); return cloudFrontUrl ; } /** * S3のキー(ファイルパス)のプレフィックスを生成する * ulidを使って時間でソートできる一意な文字列で保存する。 */ private String genrateS3KeyPrefix() { String month = DateTimeFormatter.ofPattern("yyyy-MM").format(LocalDate.now()); return String.format( "%s/%s/%s", this.assetsPrefix, month, ulid.nextValue().increment().toString()); } }
- 投稿日:2020-11-23T10:58:27+09:00
AWS失敗と対策 仮想マシンのIPアドレスが勝手に変更される
はじめに
仮想マシンサービスのAmazon EC2 は、稼働時間による従量課金なので、夜間のような使わない時間帯は停止(Stop)させていたのですがEC2インスタンスを再起動した際に画面が映らなくなってしまいました。
なぜそうなったのか原因と対策を調べていきます。
原因
Stop したEC2 インスタンス(仮想マシンの実体)を起動(Start)し直すと、自動的に割り当てられるグローバルIP アドレスが変わっていたためでした。。。。
ドメイン名を取得していたのでそこで設定していたIPアドレスが変わる前の物に設定してあったので画面が表示されていませんでした。
解決法
アプリケーション名.confの編集
次に、/etc/nginx/conf.d/アプリケーション名.confを作成します。下記のコマンドを入力してください。
$ sudo vi /etc/nginx/conf.d/アプリケーション名.confupstream puma { server unix:///home/ec2-user/アプリケーション名/tmp/sockets/puma.sock; } server { listen 80; server_name EC2のIPアドレスもしくはドメイン取得している方はドメイン名を設定; //新しいIPアドレスに変更 root /home/ec2-user/アプリケーション名/public; access_log /var/log/nginx/access.log main; error_log /var/log/nginx/error.log; sendfile on; tcp_nopush on; tcp_nodelay on; keepalive_timeout 65; types_hash_max_size 2048; client_max_body_size 100M; include /etc/nginx/mime.types; location / { proxy_pass http://puma; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; proxy_set_header X-Real-IP $remote_addr; proxy_redirect off; proxy_connect_timeout 30; } location ^~ /assets/ { gzip_static on; expires max; add_header Cache-Control public; root /home/ec2-user/アプリケーション名/public; } }AWSにアクセスしてAWS Route 53で設定しているIPアドレスを変更する。
これで解決できました!
対策
IPアドレスを固定する!
IP アドレスを固定するには、グローバルIP アドレスサービスの「Elastic IP アドレス」を使う。
「EIP(Elastic IP)」は、EC2インスタンスにパブリックIPアドレスを付与するサービスです。
EC2インスタンスでは、サービス停止後に再起動すると、パブリックIPアドレスが変わってしまいます。
アクセスのたびにIPアドレスが変わると、そのサービスはユーザにも利用しにくいものになってしまいます。
EIPを使うことで、同じパブリックIPアドレスを継続して利用できるようになります。EIPとは?
「EIP(イーアイピー)」は、AWSで固定IPアドレスを利用したいときに便利なサービスです。
一度発行されたIPアドレスは、削除しない限り、消えることはありません。このため、サーバ停止後に再起動しても同じパブリックIPを利用できます。※EIPは料金が発生する場合があります。
EIPの設定は、「EC2ダッシュボード」画面で行います。
左下の「ネットワーク&セキュリティ」メニューで「Elastic IP」を選択します。
「新しいアドレスの割り当て」画面が表示されます。
まず、新しいIPアドレスを作成します。「新しいアドレスの割り当て」タブをクリックします。
画面右上の「Elastic IP アドレスの割り当て」ボタンをクリックします。
「Elastic IPの割り当て」画面が表示されるので、右下の「割り当て」ボタンをクリックします。
「割り当て」ボタンをクリックすると、IPアドレスが発行されます。
発行されたIPアドレスを、どのEC2インスタンスで使用するのか、アドレスを関連付けます。IPアドレスを選択し、「アクション(Actions)」メニューの「Elastic IP アドレスの関連付け」をクリックします。
「Elastic IP アドレスの関連付け」画面が表示されます。
まず、「リソースタイプ」で「インスタンス」を選択します。
「インスタンス」メニューをクリックすると、候補が表示されるので、正しいインスタンスを選択します。
最後に、「関連付ける」ボタンをクリックします。
「関連付けられた Elastic IP アドレスです。」と表示されます。
対象のEIPにインスタンスが関連付けられたことを確認できます。
あとは解決法の所でもやった通り、アプリケーション名.confの編集をすればIPアドレスが固定できます!
注意
原因はわかりませんが一度インスタンスを停止して再度起動するとIPアドレスは変わらないですがブラウザで確認すると
うまく表示されなくなってしまうので再度.sshでEC2にログインし、再度本番環境のアプリを再起動する
アプリケーションサーバ(Puma)を起動する
※EC2上のRailsアプリケーションのルートディレクトリにいることを確認してください。
以下のコマンドを入力してアプリケーションサーバの起動を行います。$ rails s -e productionこれでうまく表示されると思います!
最後に
説明がうまくないかもしれませんがご了承ください。
また、間違っているところがあればご教授いただけると幸いです。
最後までありがとうございました。

- 投稿日:2020-11-23T10:44:02+09:00
AWS, Docker, CircleCI, Laravelでポートフォリオを作成してみた【参考リンク付き】
初めに
今回はDocker, CircleCI, AWS等、人気の高まっているインフラ技術を一から学んで、Webアプリを作成してみました。
バックエンドはLaravel、フロントエンドにVue.js等といった構成です。この記事では、アプリ開発にあたって苦労した点や、
各機能実装の際に参考にした記事や教材についてもご紹介していければと思います。アプリの概要
朝活をテーマをしたSNSアプリです。
- 朝活仲間を作り、「コツコツ」継続できる
- 朝活習慣の「コツ」を共有して、朝活の挫折を防ぐ
ことをコンセプトに、「朝活」を文字って「AsaKotsu」というサービスを開発しました。
URLはこちら↓です。よければ、ご自由に動かしてみてください^^アプリのURL:https://pf.asakotsu.com/
(※まだスマホ対応が完了していないので、PCでの閲覧推奨です^^;)GitHubのURL:https://github.com/ngsw877/asakotsu
使用画面のイメージ
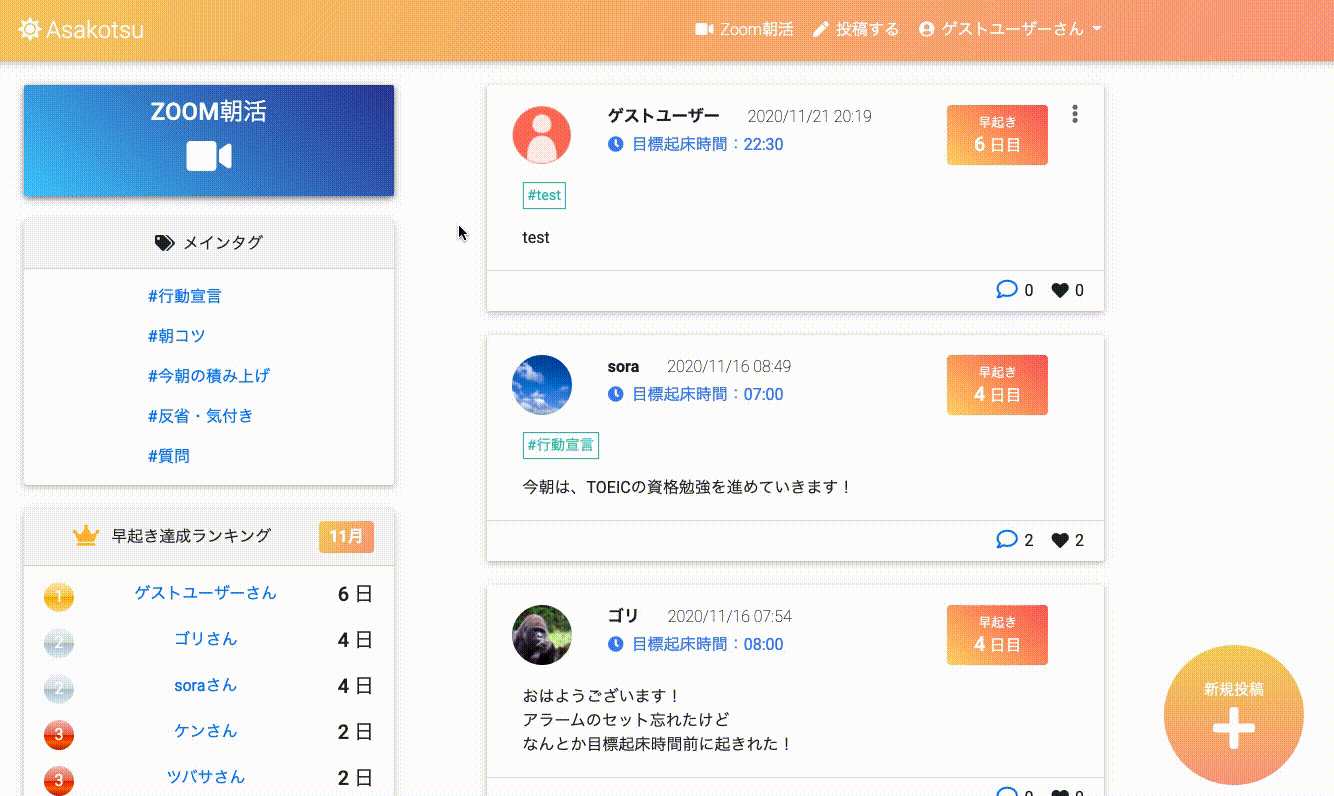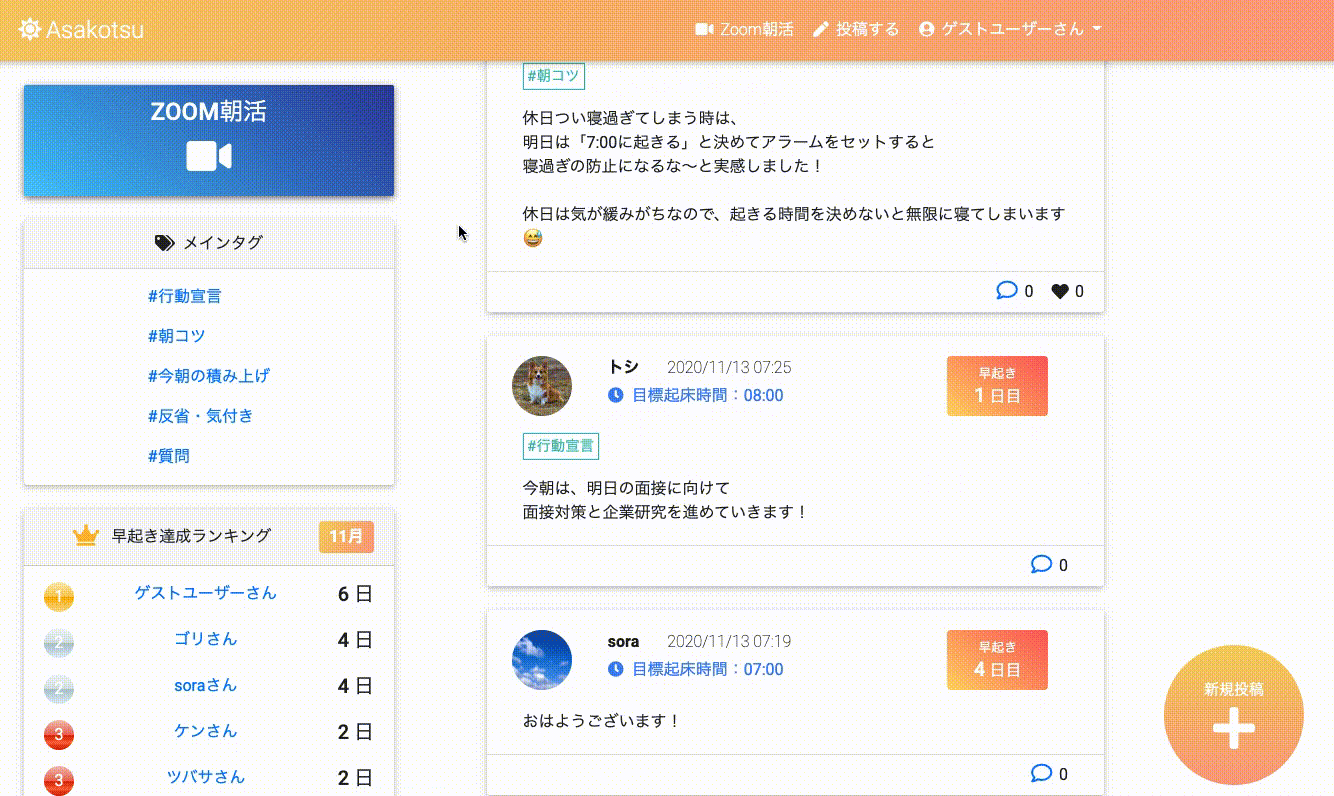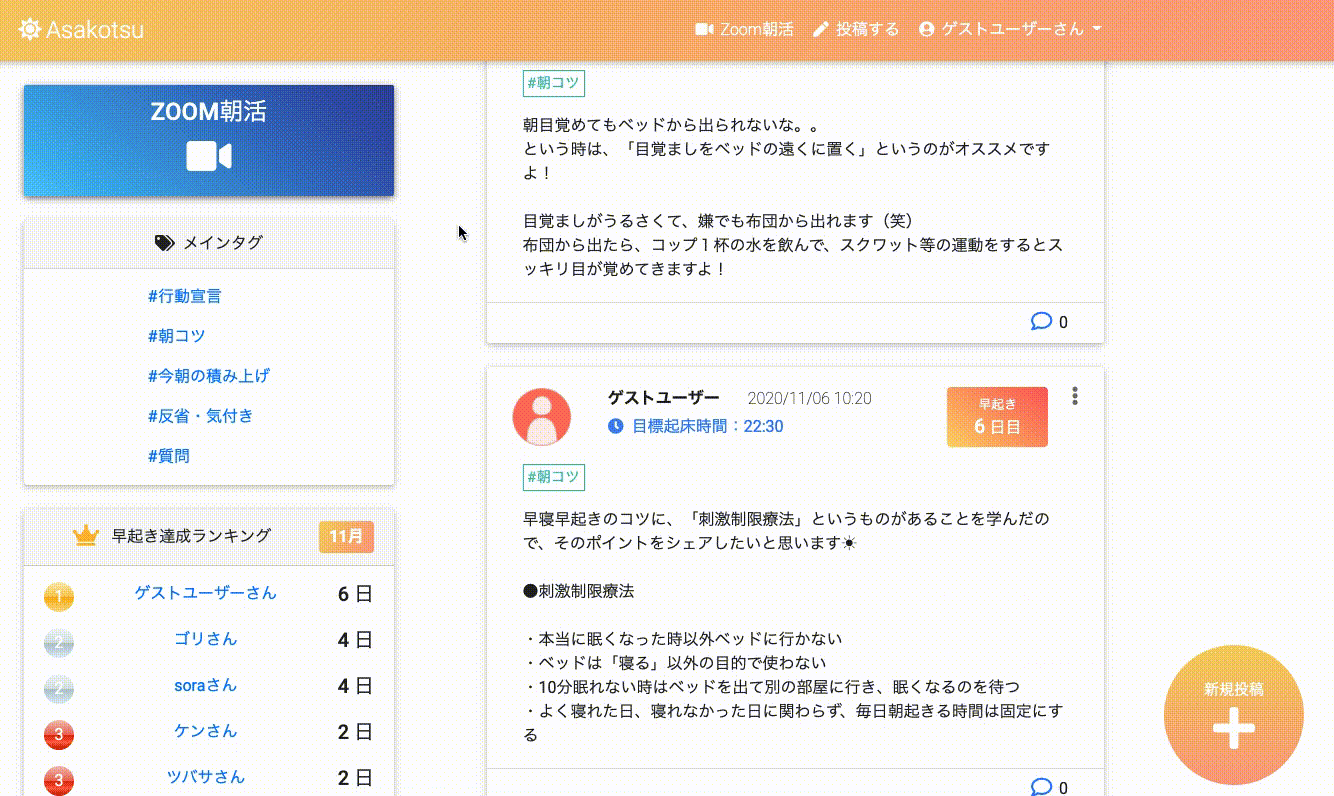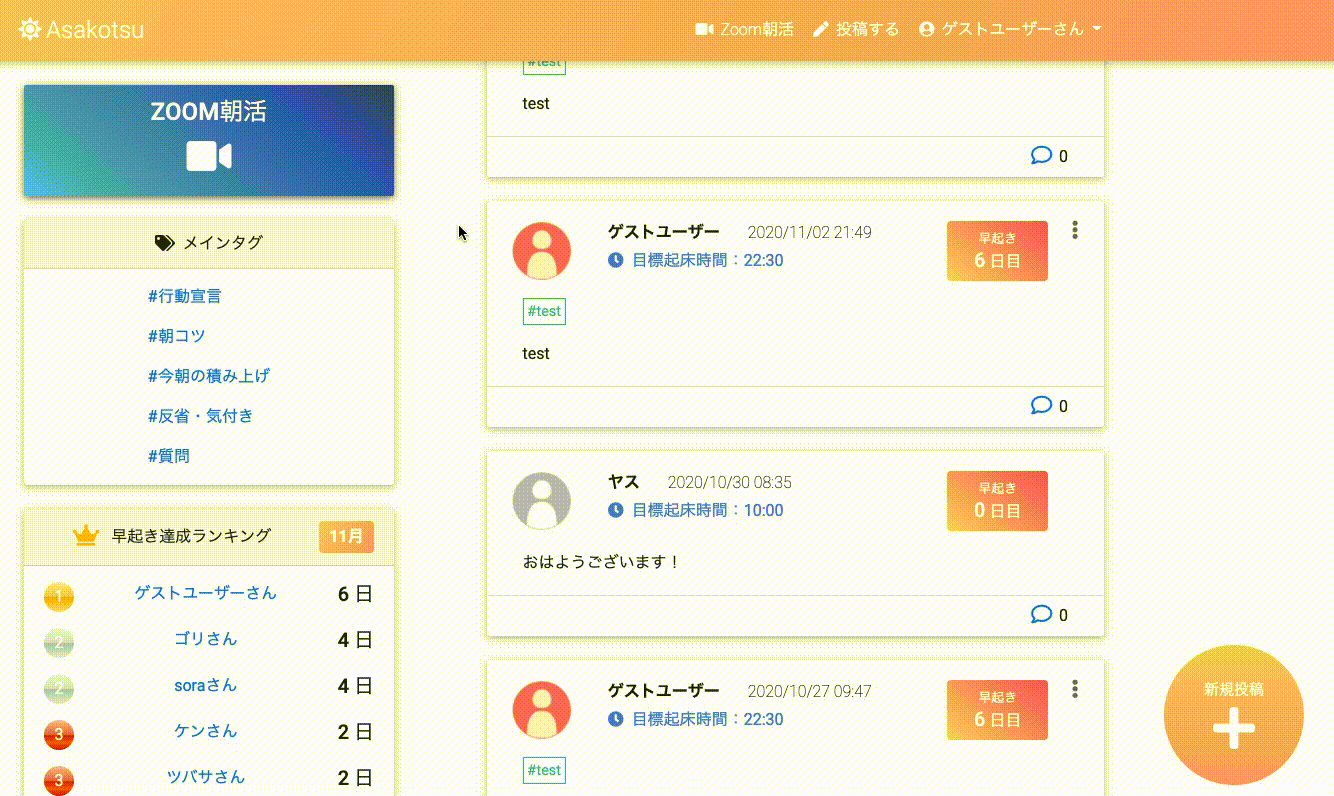
トップページ(投稿一覧とランキング等)
タグ毎の投稿一覧
投稿詳細と、コメント一覧
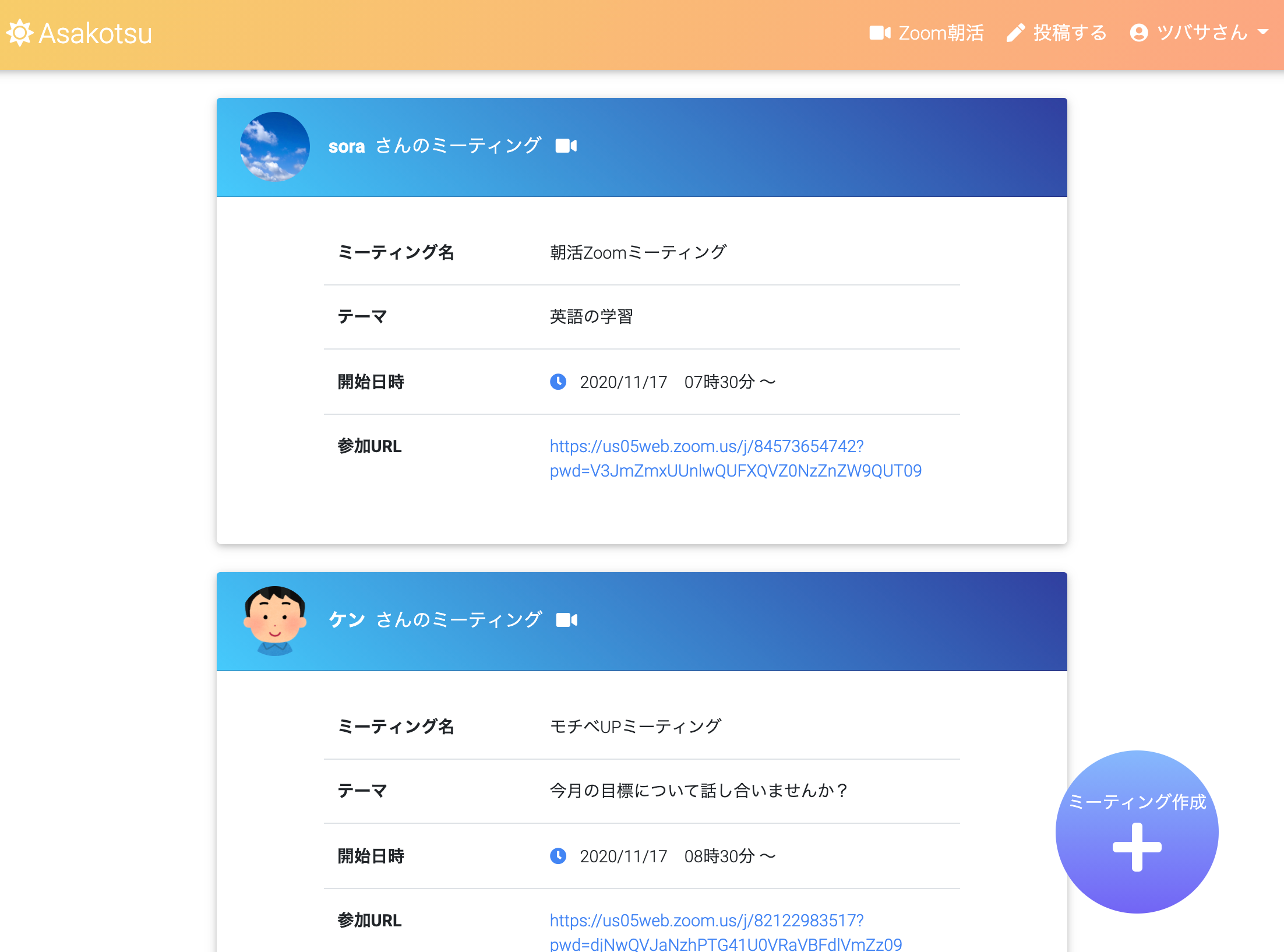
Zoomミーティング一覧
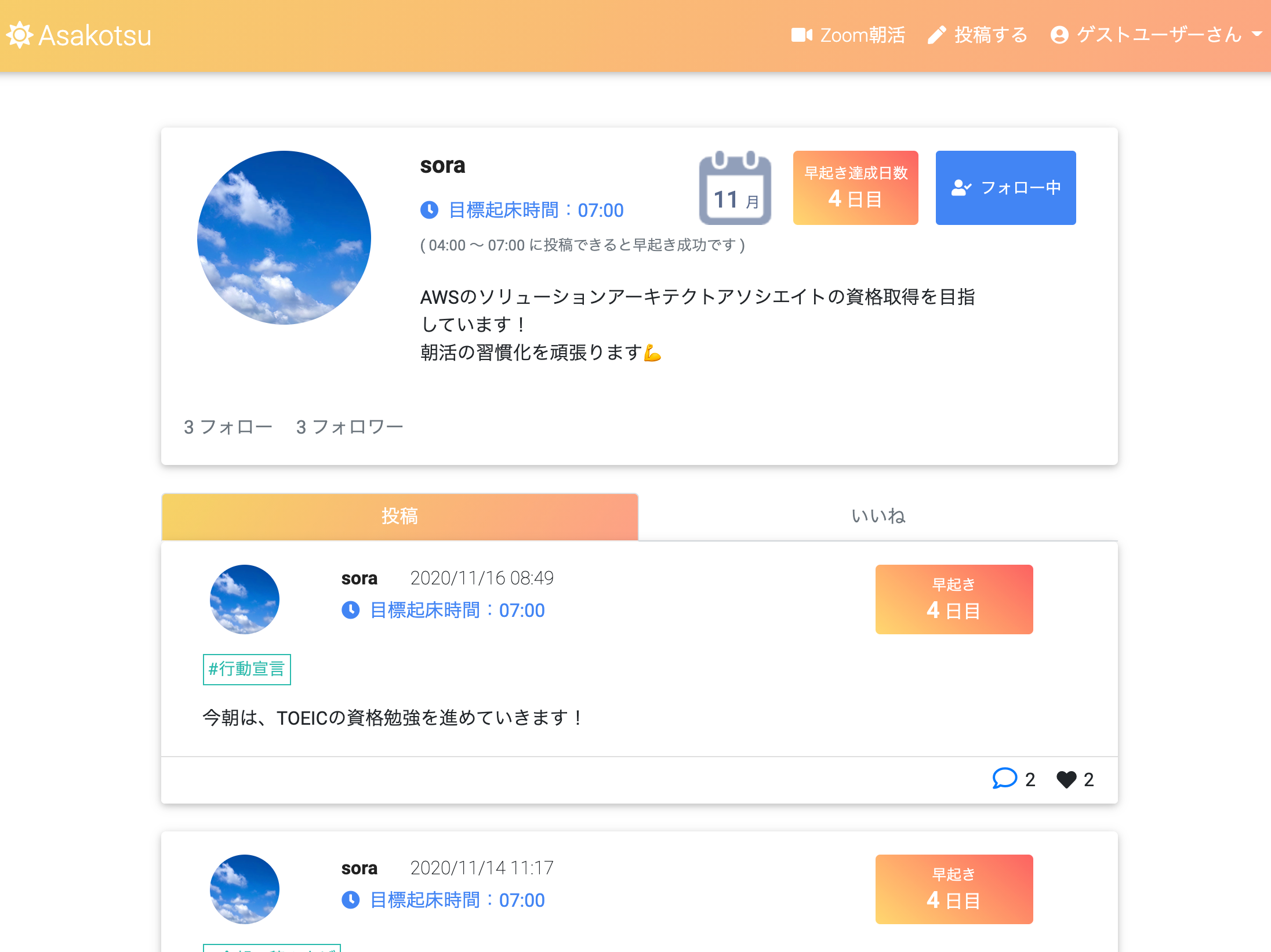
ユーザー詳細画面
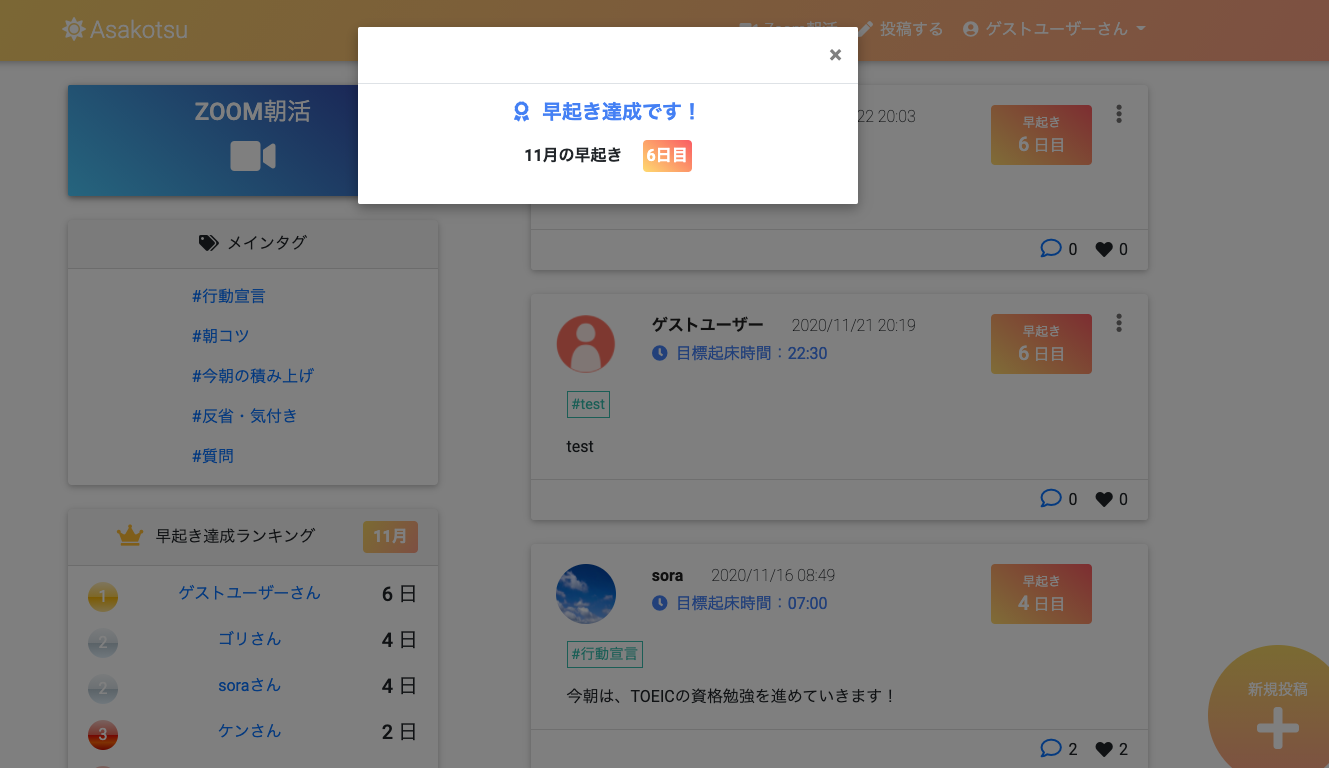
早起き達成時
無限スクロール
このアプリの特徴
基本的にはtwitterのような投稿、コメント、いいね、フォロー機能のあるSNSですが、
その他に以下のような特徴のあるアプリです。
- アプリから、朝活Zoomミーティングを作成、編集、削除できる(ZoomAPI連携)
- 目標起床時間を設定して、早起き達成日数を記録することができる
- 早起き達成日数のランキング機能(1ヶ月ごとに集計)
- 投稿にタグ付けし(カテゴリ)、「朝コツ」タグ等で朝活のコツを共有することができる
使用技術
フロントエンド
- Vue.js 2.6.11
- jQuery 3.4.1
- HTML / CSS / Sass / MDBootstrap
バックエンド
- PHP 7.4.9
- Laravel 6.18.36
- PHPUnit 8.5.8
- ZoomAPI (guzzlehttp/guzzle 7.0.1)
インフラ
- CircleCi
- Docker 19.03.12 / docker-compose 1.26.2
- nginx 1.18
- mysql 5.7.31 / PHPMyAdmin
- AWS ( EC2, ALB, ACM, S3, RDS, CodeDeploy, SNS, Chatbot, CloudFormation, Route53, VPC, EIP, IAM )
サーバーサイドのロジックはPHP/Laravelでプログラミングし、
フロントエンドの細かいデザインはSassで整え、動きを付けたい時はVue.jsやjQueryで実装しました。
開発環境にDocker/docker-composeを使用し、
CI/CDパイプラインに関しては、CircleCIで自動テスト・ビルドを行い、
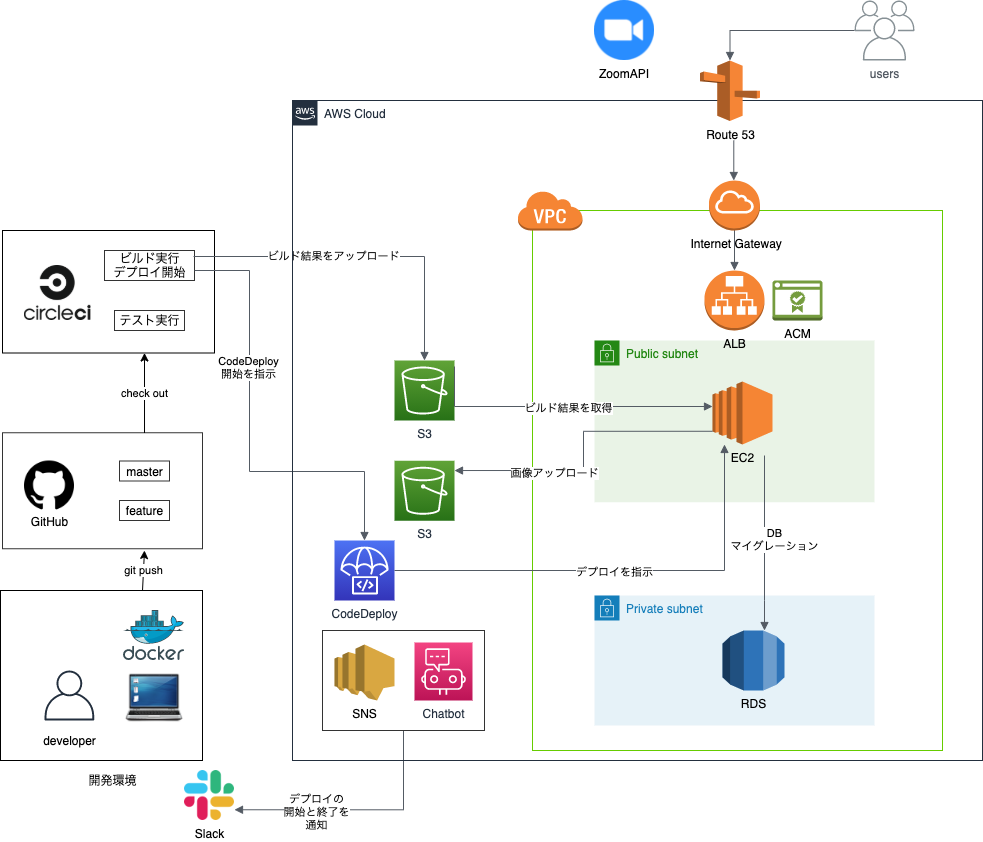
AWSのCodeDeployで自動デプロイを実現するようにしています。インフラ構成図
開発環境、本番環境について
開発環境に
Docker / docker-composeを使用しており、以下の4つの用途のコンテナを使用しています。
- Webサーバーのコンテナ: Nginx
- アプリケーションのコンテナ: PHP / Laravel / Vue.js
- DBのコンテナ: MySQL
- DB管理用のコンテナ: PHPMyAdmin
参考リンク:
本番環境のAWS上ではECSでデプロイしたかったのですが、
難易度が高く断念・・
ひとまずEC2でのデプロイ経験にも慣れるため、今回はEC2上で環境構築していく形で進めていきました。SSL証明書の発行
SSL証明書を発行してHTTPS化も実現したかったため、
ACM(AWS Certificate Manager)を使用しています。ACMを使用するためには、EC2に加えて、
ALB(ELB)やCloudFrontも必要になってくるため、今回はALBを導入することにしました。
なお、ALBを使用しているものの、節約のため現状では負荷分散やスケールアウトする程のアクセスが見込まれないため、EC2インスタンスは1つのみ用意しています。
なお、アドレスバーに鍵マークがついても、Laravel側のプロキシ設定をしないとcssやjsファイルが読み込まれなかったり、ルーティングがhttps化されなくなるので要注意な印象。。参考リンク:
- AWS:無料でSSL証明書を取得する方法
- 信用するプロキシの設定S3バケットへのアップロード
S3は、以下の2つの用途別に用意しています。
CircleCIでビルドしたソースを格納
EC2上のアプリでアップロードした画像データを格納
2に関しては、S3のバケットポリシーの設定や、Laravel側でS3用パッケージのインストールが必要だったりと意外にやるべきことがありました。
参考リンク:
Slackへの通知設定
CodeDeployとSNS、Chatbotを連携して、自動デプロイの開始と終了のタイミングでSlackアカウントに通知が飛んでくるようにしています。なかなか便利。機能一覧
ユーザー登録関連
- 新規登録、プロフィール編集機能
- ログイン、ログアウト機能
- かんたんログイン機能(ゲストユーザーログイン)
ZoomAPI連携
- 朝活Zoomミーティング機能(CRUD)
- ミーティングの新規作成、一覧表示、編集、削除機能
早起き達成の判定機能
- ユーザー毎に目標起床時刻を設定可能(4:00〜10:00まで)
- 目標起床時間より前に投稿をすることができれば、早起き達成記録が1日分増えます。
- ※深夜過ぎ等に投稿した場合も早起き成功とならぬよう、
目標起床時間より3時間前に投稿しても無効になるよう対処しています。
(例)目標起床時間を07:00に設定した場合、04:00~07:00に投稿できたら早起き達成ユーザーの早起き達成日数のランキング機能(1ヶ月毎)
無限スクロール機能 (jQuery / inview.js / ajax)
ユーザー投稿関連(CRUD)
コメント機能
タグ機能 (Vue.js / Vue Tags Input)
いいね機能 (Vue.js / ajax)
フォロー機能
- フォロー中/フォロワー一覧(ページネーション)
フラッシュメッセージ表示機能 (jQuery/ Toastr)
- 投稿、編集、削除、ログイン、ログアウト時にフラッシュメッセージを表示
画像アップロード機能 (AWS S3バケット)
PHPUnitテスト
DB設計
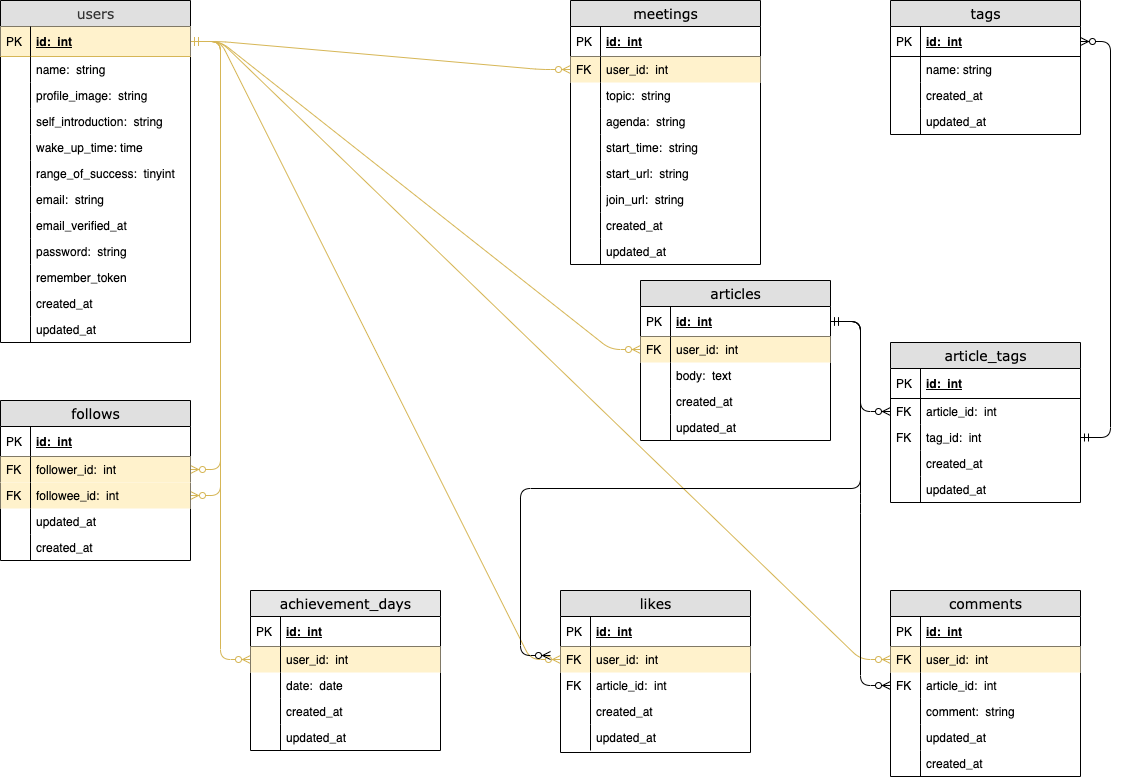
ER図
各テーブルについて
テーブル名 説明 users 登録ユーザー情報 follows フォロー中/フォロワーのユーザー情報 achievement_days ユーザーが早起き達成した日付を、履歴として管理 meetings ユーザーが作成したZoomミーティング情報 articles ユーザー投稿の情報 tags ユーザー投稿のタグ情報 article_tags articleとtagsの中間テーブル likes 投稿への、いいねの情報 comments ユーザー投稿への、コメントの情報 早起き達成機能 関連のポイント
usersテーブルの
wake_up_timeはユーザーの目標起床時間を意味しています。
この時間よりも早い時間にユーザーが投稿をできれば、その日の早起きが達成となります。
なお、
「目標起床時間が07:00で、深夜1:00に投稿した」
というように、早過ぎる時間にユーザーが投稿した
場合にも早起き達成とならないように設定しています。
その仕組みとして、usersテーブルのrange_of_successの値が利用されています。
これは、
「目標起床時間より何時間前までに投稿すれば早起き達成となるのか、その範囲を表す整数値」
です。
デフォルトは3で、例えば目標起床時間を07:00に設定している場合は、その3時間前の
04:00 〜 07:00 の間に投稿できれば早起き達成となります。こうして早起き達成をすることができたら、achievement_daysテーブルの
dateに達成日の日付が履歴として記録されていきます。
例) 2020-11-22
この日付データを利用して、以下の機能を実現しています。① 1ヶ月毎の早起き達成日数を算出
② ①の日数を利用したランキング機能当初は、早起き継続日数のランキングにしようかとも考えていましたが、
ユーザーのモチベーション維持等の観点から1ヶ月毎の早起き達成日数を採用することにしました。苦労したこと
開発からデプロイまで、どの工程でももれなくエラーで苦戦しましたがw、
ここでは特に印象に残っている点をまとめます。CircleCIで苦労したこと
- CircleCIの設定ファイルである、config.ymlの設定
- 自動ビルド、自動テストの流れの理解
config.ymlの設定においては、だいぶエラーに悩まされました。。
特に、コマンドやパスを指定する時は、パスのルートはどこが起点になっているのかを理解することが重要な印象。
テスト失敗時の対策としては、ビルドされたコンテナにSSHログインしてエラーログを確認し、原因を解消していくようにしていました。参考リンク: SSH を使用したデバッグ
AWSデプロイで苦労したこと
- ACMでのSSL証明書発行
- Laravelで画像をS3にアップロードする設定
- CodeDeployでの、自動デプロイ設定(特にappspec.yml)
- EC2インスタンスのセットアップ
上述した、
SSL証明書の発行
S3バケットへのアップロード
周りでエラーにハマりがちでした。
また、今回はECSでなくEC2でデプロイすることとしましたが、EC2にSSHログインしてから
インストールしたり設定するファイルが多く、その辺りの作業も大変でした。
この工程を考えると、ますますECSを扱えるようになりたく思いましたね^^;フロントエンドで苦労したこと
- UI/UXの調整(Sass)
- Ajax全般
バックエンドでの苦労
- DB設計
- DBリレーション関連の処理
- PHPUnitでのテスト全般
リレーション周りについては当初かなり苦戦しました。
どのテーブルとどのテーブルを関連付けるのか、また関連付けた情報をどうやって取得すれば良いのか?
また、
- $article->user()
- $article->user
例えばこの2つの違いについても重要なポイントと感じました。
PHPUnitのテストコードについては、体系的に学べる情報がなかなか見つからなかったので、情報収集に苦労しました。
ZoomAPI連携で苦労したこと
- Guzzleの理解
- ZoomAPIの理解
アプリ上からZoomミーティングを作成したり編集できる機能をつけることにしましたが、
これまで外部APIを利用したことがなかったこともあり、文法的なものや、API通信の仕組みについて理解するまでが難しく感じました。実装にあたり、まずLaravelでZoomAPIと通信を行うために、PHPのHTTPクライアントである
Guzzleをインストールしました。参考リンク:
次に、Zoomアプリマーケットプレイスでアプリを登録し、公式ドキュメントを読んでみるも、英語な上初めはどこのページの何を見れば良いのかわからず苦戦しました。。^^;
Laravelで、ZoomAPIと通信を行う処理のサンプルコードを紹介している
海外の記事を参考にしたりしているうちに、次第に公式ドキュメントから必要な情報を探せるようにもなってきました。参考リンク:
ただ、今回Laravel6系でアプリを開発していたため、通常Laravel7系で使用できるGuzzleラッパーが使えず、ややコードを書き換えないといけない点にも苦労しました。
参考にした学習教材等
基本的には、UdemyとTechpitで学習してきました。
この2つはとてもわかりやすいです。
個人的には、Udemyで基礎を学んでから、応用編としてTechpitで手を動かしながら学ぶのが良いと感じました。Docker / docker-compose
PHPUnit / CircleCI / AWS
AWS
- 【Udemy】AWS:ゼロから実践するAmazon Web Services。手を動かしながらインフラの基礎を習得
- 【Udemy】これだけでOK! AWS 認定ソリューションアーキテクト – アソシエイト試験突破講座(SAA-C02試験対応版)
- 【書籍】Amazon Web Services 基礎からのネットワーク&サーバー構築 改訂3版
Laravel
Laravel / Vue.js
Sass
今後の課題
- レスポンシブWebデザイン(スマホ対応)
- デザイン面の改善
- 無限スクロールの不具合修正(読み込まれた投稿のいいねボタンが消える)
- ALBにAuto Scalingを追加し、EC2を冗長化
- ECS(EKS)でのデプロイ
- RDSの冗長化
- インフラのコード化
- 検索機能の追加
- テストコードの充実
- 投稿時に別画面へ遷移するのではなく、入力フォームをモーダルで表示させるようにする
- 開始前のZoomミーティング、終了ミーティングのソート機能
まだ課題も多いですが、一つずつ改善してよりブラッシュアップしていきたく思います。
だいぶ長い記事になってしまいましたが、ここまで読んでくださりありがとうございました!^^
- 投稿日:2020-11-23T07:50:22+09:00
【IoT DIY レシピ】IoTで朝確実に起きたい
はじめに
本記事はソラコム株式会社による「SORACOM IoT レシピチャレンジ!」企画の投稿記事です。
できるだけ本家のIoT DIY レシピの形式に近い感じで記載します。
IoTで朝確実に起きたい
公開日: 2020年11月
レシピ難易度:★★★☆☆
朝確実に起きたい、というのは、僕のみならず、比較的多くの人にとって課題ではないかと思います。
朝起きるのが遅れると遅刻して心配や迷惑をかけることもありますし、そこまでいかなくても出勤時間に余裕がなくなると焦ってしまいます。車出社で時間に余裕がないのに道が混んでて普段使わない裏道使ったらT字路で右から来る車を見落として衝突する、というようなことが起こらないようにしないといけません。
課題としては、寝起き時の僕はめっちゃ頭悪いことです。頭悪いというか1分でも多く寝ることしか考えてません。出発までのマージンが5分だったら、あと5分寝れるな、と考えて二度寝します。起きた後に、寝れるわけないだろとセルフツッコミを入れるのですが、起きてる時の論理は寝起きの自分には通用しません。別人と考えた方がいいでしょう。目覚まし3つかければさすがに起きるだろ、と思っても、目覚まし3つ止めて寝ます。そういう奴を相手にしないといけない。
現状の解決策は、ちゃんと起きるまではモーニングコールをかけ続けてもらうことです。朝決まった時間までに起きていなければモーニングコールをかけ、起きていなければ何度でもかけます。これは何度止めても何度でもかかってきて想像以上に鬱陶しいので、寝起きの状態には持っていけます。問題は何を持って起きたことを判定するかですが、これは洗面台に置いたSORACOM LTE-Mボタンを押したことで判定するようにしています。その場では止められないというのがポイントで、布団を出て洗面台にたどり着いて洗面すればまあまあ起きます。いったん起きてる状態に入れば、寝起き状態に戻ることはそんなにありません。
このIoTシステムにおける僕の状態遷移は以下になります。ボタンがなくても時間経過で起きますが、時間ギリギリになりがちです。
このレシピでは、以上の解決策を実現する「朝確実に起きるためのIoTシステム」を作ります。利用するデバイスは、電源不要でどこでも設置でき、クラウドに簡単に状態を伝えられる「SORACOM LTE-M Button for Enterprise」です。クラウド側の要素として、システムから電話をかけることができる「Amazon Connect」、クラウドにプログラムを配置するだけで実行できる「AWS Lambda」、キューに処理すべきメッセージを登録できる「Amazon SQS」、定時にイベントを発生させる「Amazon EventBridge」、ボタンをクリックした履歴を簡単に保存できる「SORACOM Harvest Data」を利用します。
IoTシステムの技術要素として、システムからの電話連絡、外部アプリケーションからのSORACOMデータ参照、定時処理の実行、タスクの終了が確認されるまで実行されるリトライを体験できます。
システムの構成
今回作成するシステムは以下のような構成となっています。
本レシピを行うのに必要な時間、概算費用
本レシピは以下の通りです。
必要な時間: 約90分
概算費用: 約6000円 + 約500円/月準備
本レシピを行うためには以下のものをご用意ください。
ハードウェア
品名 数量 価格 購入先 備考 SORACOM LTE-M Button for Enterprise 1 5,980円 ソラコム SORACOM LTE-M Button Plus でも代用可能です。 スマートフォン/電話 1 - - ・着信可能な電話番号を持っていること パソコン 1 - - ・インターネット接続が可能でサイトへの接続が自由であること。
・Google Chrome 等の最新ブラウザーが利用可能な事。※ 金額はレシピ作成時となります。税抜き・送料別です。
その他必要なもの
品名 費用 作成方法など SORACOMアカウント 無料※ SORACOMアカウントの作成(JP) AWSアカウント 無料※ AWSアカウントの作成(JP) ※ アカウント作成・維持の費用の料金です。
SORACOM LTE-M Buttonの設定
1. コンソールにログイン
SORACOM コンソールにログインします。
2. SIMの登録
発注済みのSIMを登録する(JP)を参考に、SIMを登録します
3. グループの作成
[Menu] > [SIM管理] とクリックしてSIM管理画面を開きます。
購入したLTE-M ButtonのSIMにチェックをつけ、[操作] > [所属グループ変更] とクリックします。
「新しい所属グループ」のプルダウンボックスをクリックした後、[新しいグループを作成...]をクリックします。
「グループ作成」のグループ名を入力して[グループ作成]をクリックします。
項目 例 備考 グループ名 goodmorning-button 自由に入力可能です。日本語も設定可能です。
新しい所属グループが先ほど作成したグループになっていることを確認したら[グループ変更]をクリックします。
自動的に SIM 管理画面に戻ります。
SIM の「グループ」に先ほど作ったグループが設定されていることを確認してください。
4. グループの設定
グループに「バイナリパーサー機能」「SORACOM Harvest Data」の2つの設定を行います。
SIM 管理画面から、SORACOM LTE-M Button に割り当てたグループ名をクリックします。
[SORACOM Air for Cellular 設定]をクリックして設定ができるように開きます。
「SORACOM Air for Cellular 設定」で以下のように設定します。
項目 設定値 備考 バイナリパーサー機能 ON スイッチはクリックすることで OFF から ON に切り替えることができます。 バイナリ―パーサー設定 / フォーマット @button 半角英数で入力してください。
最後に[保存]をクリックしてください。同じページの中にある[SORACOM Harvest Data 設定]をクリックして設定ができるように開きます。
「SORACOM Harvest Data 設定」で以下のように設定します。
項目 設定値 備考 (スイッチ) ON スイッチはクリックすることで OFF から ON に切り替えることができます。
最後に[保存]をクリックしてください。
その後表示される「SORACOM Harvest Data が有効になっています」のダイアログでは[OK]をクリックしてください。SAM ユーザーの作成
外部のプログラムからSORACOM Harvestのデータを取得するためには、SAMユーザーを作成する必要があります。
1. ユーザーの作成
ユーザーコンソールの右上にあるユーザー名をクリックし [セキュリティ]をクリックします。
[ユーザー] > [ユーザー作成]をクリックします。
下記の情報をユーザー情報として記入し、作成します。
項目 例 備考 名前 goodmorning-user 利用できる文字: A-Z, a-z, 0-9, -, _
文字数: 1 文字以上 50 文字以内概要 任意に入力 自由に入力可能、省略可能です
作成が終わると自動的にユーザー一覧画面に戻ります。
2. 権限の設定
作成したユーザーをクリックします。
権限設定にて、テンプレート選択から「Harvestのデータの参照のみ許可」を選択し、権限をコピーしたら、左の枠にペーストして、保存します。
3. 認証キーの生成
認証設定のタブを選択し、「認証キーを生成」をクリックします。
生成ダイアログにて表示される認証キーをコピーし、保存しておきます。
これでSORACOM側の設定は終わりです。
Amazon Connectの設定
電話が発信できるようAmazon Connectの設定をします。
1. Amazon Connect インスタンスの作成
AWSのコンソールにログインします。
サービス一覧からAmazon Connectを選択します。
Amazon Connectを未使用の状態であれば以下の画面になります。「今すぐ始める」をクリックします。
ID情報を以下のように入力して次のステップへ
項目 例 備考 アクセスURL goodmorning 半角英数字とURLで使用可能な記号で入力します
管理者情報を以下のように入力して次のステップへ
項目 例 備考 名 太郎 自由に入力可能 姓 山田 自由に入力可能 ユーザー名 Administrator 使用可能文字: 半角英数-_.
文字数制限: 1文字以上20文字以下パスワード ランダムなパスワード 使用可能文字: 半角英大文字、小文字、数字を1文字以上
文字数制限: 8文字以上64文字以下パスワード(確認用) ランダムなパスワード パスワードと同じ文字とする Eメールアドレス Administrator@example.com メールアドレス形式
テレフォニーオプションを以下のように設定して次のステップへ
項目 設定値 備考 着信 OFF 着信を使う用途があればONにしても良い 発信通話 ON
データストレージ設定は特に設定の必要はありません。内容を確認して次のステップへ
内容を確認して、「インスタンスの作成」をクリックします。
しばらく待ちます。
成功画面が表示されたら、「今すぐ始める」をクリックします。
2. Amazon Connectの電話番号を取得
英語で表示されていたら日本語に変更します。
今すぐ始めるをクリックします。
電話番号を取得します。2020/11/21現在において、日本の番号は申請しないと取得できないようでした。代わりにUSの番号を取得します。(こちらの方が料金も安い。)以下の項目を入力して次へをクリックします。
項目 設定値 備考 国/地域 US +1 取得できる国であればどちらでも良い タイプ DID(直通ダイヤル) 電話番号 表示された番号から選択
3. 問い合わせフローの作成
Amazon Connectでは、「問い合わせフロー」という処理に従って、発信、受信を制御します。今回は発信だけなので、発信用の問い合わせフローを作成します。完成すると以下のようになります。
ここから問い合わせフローの作り方を説明します。
画面左側の上から3番目のアイコンにマウスオーバーし、表示された問い合わせフローをクリックします。
「問い合わせフローの作成」をクリックします。
名前の入力の右側の鉛筆アイコンをクリックし、フロー名を入力します。
項目 例 備考 問い合わせフロー名 goodmorning 1文字以上で自由に設定可能
設定タブを開く
メニュー内の「音声の設定」をフロー内にドラッグ&ドロップし、エントリポイントの「開始」の右側にある○印からドラッグして線をつなぎます。フロー内の「音声の設定」をクリックします。
音声の設定を以下のように設定し、保存します
項目 設定値 備考 言語 日本語 音声 Mizuki Mizuki(女性音声)とTakumi(男性音声)のいずれかを選択します
操作タブを開き、メニュー内の「プロンプトの再生」をフロー内にドラッグ&ドロップし、音声の設定の「成功」の右側にある○印からドラッグして線をつなぎます。フロー内の「プロンプトの設定」をクリックします。
電話の内容をプログラムから指定できるよう、以下のように設定し、保存します。
項目 設定値 備考 プロンプト テキストの読み上げまたはチャットテキスト 入力 動的に入力する タイプ ユーザー定義 属性 message プログラムから指定する属性名。任意に入力可能 解釈する テキスト 抑揚をつけたい場合などはSSMLを選択
終了/転送タブを開き、メニュー内の「切断」をフロー内にドラッグ&ドロップし、プロンプトの再生の「OK」の右側にある○印からドラッグして線をつなぎます。
画面右上の「公開」ボタンをクリックします。確認ダイアログが表示されるので、確認して「公開」をクリックします。
公開されたら画面左上の「追加のフロー情報の表示」をクリックし、ARNを確認します。instanceの右に表示されるインスタンスID、contact-flowの右側に表示される問い合わせフローIDが電話発信の際に必要になります。
以上でAmazon Connectの設定は終了です。
Amazon SQSの設定
メッセージを登録するキューを管理するサービスであるSQSを利用します。
これを使うことで、「正常に処理が終わるまでリトライする」といった処理が簡単に実装できます。1. キューを作成
サービス一覧からAmazon SQSを選択します。
「キューを作成」をクリックします。
以下の項目を入力して、キューを作成します。他の項目はデフォルト値とします。
項目 設定値 / 例 備考 キュータイプ 標準 名前 GoodMorningQueue 使用可能文字: 半角英数-_
文字数制限: 1文字以上80文字以下可視性タイムアウト 1分 処理されなかった時に再処理するまでの時間を設定します。このシステムの場合は電話される間隔になります
以上でAmazon SQSの設定は終了です。
AWS Lambdaの設定
AWS Lambdaはサーバーなどのプログラム実行環境を自分で構築、維持することなくプログラムが実行できる、いわゆるサーバレスな実行環境です。今回はプログラムをここに配置します。
1. 関数の作成
サービス一覧からAWS Lambdaを選択します。
「関数の作成」をクリックします。
以下の情報を入力し、「関数を作成」をクリックします。詳細設定はデフォルトとします。
項目 設定値 / 例 備考 作成方法 一から作成 関数名 goodMorningFunction 使用可能文字: 半角英数-_
文字数制限: 1文字以上64文字以下ランタイム Ruby 2.7 自由に選んで良いですが、サンプルコードはRubyで記載しています 実行ロール AWSポリシーテンプレートから新しいロールを作成 ロール名 goodMorningFunctionRole 使用可能文字: 半角英数-_
文字数制限: 1文字以上51文字以下ポリシーテンプレート Amazon SQSポーリングアクセス権限 Connectの権限はここではつけられないため、後で追加します
2. コードの編集
関数コードの編集領域に以下のコードをペーストし、「デプロイ」ボタンをクリックします。
require 'json' require 'aws-sdk-connect' require 'net/http' require 'uri' def lambda_handler(event:, context:) token = get_soracom_token event['Records'].each do |record| message = JSON.parse(record["body"]) if sleeping?(imsi: message['imsi'], token: token) call(call_to: message['callTo'], message: message['message']) raise 'still sleeping' # 例外を発生させるとメッセージは未処理のまま残る end end puts 'awake' end def sleeping?(imsi:, token:) now = Time.now from = Time.mktime(now.year, now.mon, now.day) data = get_harvest_data(imsi: imsi, from: from.to_i * 1000, token: token) data.length == 0 end def get_soracom_token uri = URI.parse("https://api.soracom.io/v1/auth") request = Net::HTTP::Post.new(uri) request.content_type = "application/json" request["Accept"] = "application/json" request.body = JSON.generate({ "authKeyId" => ENV['SORACOM_AUTH_KEY_ID'], "authKey" => ENV['SORACOM_AUTH_KEY_SECRET'] }) response = Net::HTTP.start(uri.hostname, uri.port, { use_ssl: true } ) do |http| http.request(request) end raise "fail to get soracom token" if response.code != '200' JSON.parse(response.body) end def get_harvest_data(imsi:, from:, token:) uri = URI.parse("https://api.soracom.io/v1/data/Subscriber/#{imsi}?from=#{from}") request = Net::HTTP::Get.new(uri) request["Accept"] = "application/json" request["X-Soracom-Api-Key"] = token['apiKey'] request["X-Soracom-Token"] = token['token'] response = Net::HTTP.start(uri.hostname, uri.port, { use_ssl: true } ) do |http| http.request(request) end raise "fail to get harvest data" if response.code != '200' JSON.parse(response.body) end def call(call_to:, message:) client = Aws::Connect::Client.new client.start_outbound_voice_contact({ destination_phone_number: call_to, contact_flow_id: ENV['CONNECT_CONTACT_FLOW_ID'], instance_id: ENV['CONNECT_INSTANCE_ID'], source_phone_number: ENV['CONNECT_SOURCE_PHONE_NUMBER'], attributes: { "message" => message } }) end簡単にプログラムの説明をします。
- まだ寝ているかどうかを判定し、寝ていれば電話をしてエラー終了、起きていれば正常終了します。
- LambdaとSQSを組み合わせて使用した場合、キューの内容はeventに渡され、正常終了するとメッセージが削除される、という動作になります。プログラム内でSQSを使う必要はありません。
- 異常終了するとメッセージは削除されずに残り、可視性タイムアウト時間経過後、再実行されます。このプログラムでは通常のプログラムのエラーのほか、SORACOMへのアクセス結果が異常であったり、時間になったのに僕が寝たままであったりしたことを異常と判断して異常終了します。
- SORACOM HarvestからLTE-MボタンのIMSIに関する今日のデータを取得し、今日のデータがなければ寝ている、あれば起きていると判定します。
- SORACOM Harvestからデータを取得するため、認証してトークンを取得しています。
- 電話発信はAmazon ConnectのSDKにて呼び出しています。
- システム全体に関わるパラメータは環境変数から、個別の電話内容は入力から取得しています。これにより他のボタン、他の電話番号を追加することが簡単になっています。
3. 環境変数の設定
Lambdaで実行するプログラムの環境変数を設定します。
環境変数のエリアにある「編集」ボタンをクリックします。
「環境変数の追加」ボタンをクリックし、以下の環境変数を追加して、「保存」ボタンをクリックします。
キー 設定値 備考 CONNECT_CONTACT_FLOW_ID Amazon Connectの問い合わせフローID CONNECT_INSTANCE_ID Amazon ConnectのインスタンスID CONNECT_SOURCE_PHONE_NUMBER Amazon Connectの電話番号 ハイフンおよびスペースは取り除く。
例:電話番号が+1 123-456-7890であれば、+11234567890と入力SORACOM_AUTH_KEY_ID SORACOMのSAMユーザーの認証キーID SORACOM_AUTH_KEY_SECRET SORACOMのSAMユーザーの認証キーシークレット TZ Asia/Tokyo 使用する場所でのタイムゾーン
4. アクセス権限の設定
このプログラムにはAmazon SQSのキューをポーリングする権限と、Amazon Connectから電話を発信する権限が必要です。SQSへの権限は作成時に付与しましたので、Amazon Connectの権限を追加します。
アクセス権限のタブをクリックし、ロール名のリンクをクリックします。IAMのコンソールがブラウザの別タブで開きます。
「ポリシーをアタッチします」をクリックします
ポリシーのフィルタに「AmazonConnect」と入力し、表示された「AmazonConnect_FullAccess」にチェックを入れ、「ポリシーのアタッチ」をクリックします。(ここでは簡単にするためのFullAccess権限をつけていますが、もし業務で使うのであれば権限を狭くした方がいいでしょう)
成功した旨が表示されればOKです。
5. トリガーの設定
SQSにメッセージが入ればこのLambda関数が実行されるよう、トリガーを設定します。
設定タブを開き、デザイナーエリアの「トリガーを追加」をクリックします。
以下の情報で項目を設定し、「追加」をクリックします。
項目 設定値 備考 トリガー種類 SQS SQSキュー 作成したSQSキューを選択 バッチサイズ 1 実行ごとにメッセージを消すか残すかを決めるため、1つのメッセージしか処理しないよう1とします。 トリガーの有効化 ON テスト後ONにしても良い
Amazon EventBridgeの設定
最後にAmazon EventBridgeにて、指定した時間にSQSキューにメッセージを送信するイベントを登録します。
1. イベントを作成
サービス一覧からAmazon EventBridgeを選択します。
ルールのメニューから「ルールを作成」ボタンをクリックします。
以下の内容で項目を入力し、「作成」をクリックします。
項目 設定値 / 例 備考 名前 GoodMorningRule 使用可能文字: 半角英数.,-_
文字数制限: 1文字以上64文字以下パターン スケジュール 定時に実行するためスケジュールを選択します スケジュール cron式 決まった時間に入力するためcron式を使います cron 式 30 21 * * ? * 分 時 日 月 曜日 年をスペース区切りで入力します。「時」はUTCで入力することに注意します。はすべての値を含むワイルドカードです。日がであれば何日でも、月がであれば何月でも、年がであれば何年でも、を意味します。?は任意を意味します。日と曜日は両方を*にできず、いずれかを?にする必要があります。例は毎日6:30を意味します ターゲット SQSキュー キュー 作成したキューを選択 入力の設定 定数(JSONテキスト) 定数(JSONテキスト) テストにてSQSに送信したメッセージと同じ
これですべての設定が終わりました。明日の6時半までにLTM-Mボタンを押さなければ、電話がかかってくるはずです。
動作確認
ちゃんと動作するかを各段階で確認しておきましょう。
1. Lambda コンソールでの動作確認
テストイベントを設定します。
以下のように項目を入力します。テスト内容には下のJSONテキストをペーストし、bodyの中にある各項目を設定します。
項目 設定値 / 例 備考 作成/編集 新しいテストイベントの作成 イベント名 GoodMorningTest 入力可能文字:半角英数
文字数制限:1文字以上25文字以下imsi LTE-MボタンのIMSI callTo 通話先の電話番号 通常の電話番号の先頭の0を+81と変更し、ハイフンを取り除く。
例:電話番号が090-1234-5678であれば、+819012345678と入力message おはようございます 電話を取った時に自動音声で話される内容。任意に入力可能 bodyの中にある設定値を以下のように設定します。
{ "Records": [ { "messageId": "19dd0b57-b21e-4ac1-bd88-01bbb068cb78", "receiptHandle": "MessageReceiptHandle", "body": "{\"imsi\":\"440************\",\"callTo\":\"+8190********\",\"message\":\"おはようございます\"}", "attributes": { "ApproximateReceiveCount": "1", "SentTimestamp": "1523232000000", "SenderId": "123456789012", "ApproximateFirstReceiveTimestamp": "1523232000001" }, "messageAttributes": {}, "md5OfBody": "{{{md5_of_body}}}", "eventSource": "aws:sqs", "eventSourceARN": "arn:aws:sqs:ap-northeast-1:123456789012:MyQueue", "awsRegion": "ap-northeast-1" } ] }
画面右上の「テスト」ボタンをクリックするとテストが実行されます。
ここまでLTE-Mボタンを押していなければ、実行結果は失敗になり、errorMessageに"still sleeping"と表示され、電話がかかってくるはずです。他のエラーが出ていたり、電話がかかってこなかった場合は、コードや環境変数、テストの入力を見直しましょう。
ここで成功してしまう場合は、すでにボタンをクリックしてSORACOM Harvestに保存されていると考えられます。この場合は、SORACOMコンソールにてデータを削除しましょう。
データ削除は、SORACOMコンソールのSIM管理にて、対象のLTE-MボタンのSIMをチェックし、[操作] > [データを確認]をクリックします。
今日のデータにチェックを入れ、「削除」ボタンをクリックします。
確認ダイアログにて「削除する」をクリックします。
今日のデータが全て削除されれば、Lambdaのテスト結果は失敗になるはずです。
次にLTE-Mボタンをクリックしていて、実行結果が成功になる場合をテストします。LTE-Mボタンをクリックし、LEDが緑点灯することを確認します。その後再度テストボタンをクリックすると、今度は成功になるはずです。
ここで失敗する場合は、IMSIが間違えている可能性があります。Harvest Dataを取得するAPIでは存在しないIMSIを指定した場合応答がステータスコード200、レスポンスが[]となり、IMSIを間違えた場合と正しいIMSIでデータがない場合が区別できないためです。成功になることもテストしておいた方が良いでしょう。
当日中にLTE-Mボタンがクリックされていなければ電話がかかってきて処理が失敗し、LTE-Mボタンがクリックされていれば電話はかかってこず処理は正常終了することが確認できました。
2. SQS にメッセージを送信して動作確認
SQS経由でのLambda実行が動作するかを確認しましょう。
まずSORACOM Harvestの当日のデータを削除します。SQSのコンソールにて、作成したキュー名のリンクをクリックします。
画面右上の「メッセージを送受信」ボタンをクリックします。
メッセージ本文に以下のようなJSONテキストを入力します。「メッセージ送信」をクリックします。テストイベントではJSONをエスケープしていましたが、こちらではエスケープせず入力します。imsiとcallToは実際使用するものを入力してください。
{"imsi":"440************","callTo":"+8190********","message":"おはようございます"}
送信してしばらくしたら電話がかかってくるはずです。電話を取っても取らなくても、時間が経つとまたかかってきます。LTE-Mボタンをクリックして、Harvestにデータが届くと電話がかかってこなくなるはずです。
電話がかかってこない場合はcallToが、電話が止まらない場合はimsiが間違っている可能性が高いです。電話が止まらない場合は、まずはLambdaのトリガーのSQSを無効化しましょう。
その後SQSコンソールにてメッセージをポーリングし、受信したメッセージを削除すればよいです。
3. スケジュール実行の動作確認
指定した時間に電話がかかってくることを確認しましょう。
取得した電話番号の他に、非通知でかかってくることもあるようです。
SQS -> Lambda起動がうまくいっているのに電話がかかってこない場合、イベントルールが間違っている可能性が高いです。ルールのcron式やテキスト内容を見直しましょう。
あとかたづけと注意事項
本レシピでは費用がかかるサービスを利用しています。
必要であれば解除作業を行い、想定外の費用がかからないようにしてください。
以下に料金をまとめました。金額は2020/11/22時点、SORACOMは日本カバレッジ、AWSは東京リージョンでの金額としております。
サービス / 機能 料金 解除方法 LTE-M Button SIM (plan-KM1) 基本料金: 100円/ 月、通信料金: 約0.3円 /回 利用開始待ちに変更すれば基本料金を0円 /月にできる。再開には200円かかる SORACOM Harvest Data 5円 /日 /SIM SIMグループを解除するか、グループ設定でHarvest Dataをオフにするかいずれかを設定する Amazon Connect 電話番号(US): \$0.06 /日
発信通話(日本): \$0.0844 /分電話番号を解約する AWS Lambda 呼び出し: \$0.0000002 /回
実行時間(128MBにて):
\$0.000002083 /秒Lambda 関数を削除する Amazon SQS \$0.0000004 /回 キューを削除する Amazon EventBridge \$0.000001 /回 イベントルールを削除する AWS Lambda、Amazon SQS、Amazon EventBridgeの料金は実行されなければ課金されないため、EventBridgeのルールを削除すれば料金はかかりません。
一方電話番号の保持やSORACOM Harvestには基本料金がかかるため、必要なければ解除しておいた方が良いでしょう。次のステップ
本レシピでは、「ボタンを押したら通知する」ではなく、「ボタンを押されるまで通知し続ける」という通知の形を取りました。今回はワンパターンな通知をし続ける構成でしたが、就業時間に間に合わない時間であることを検知したら自動的に会社に通知を送る、などのエスカレーションを考えた方が良いでしょう。指定回数失敗したらメッセージを別のキューに移すSQSのデッドレターキュー機能が使えます。
起こす方法を電話としましたが、電話番号の維持にはお金がかかるので、より費用のかからない起こし方を考えてもいいかもしれません。スマートスピーカーやマイコンボードのブザーなどが使えるかと思います。何か問題があった時に現場にどうやって伝えるか、という方法のアイディアになります。
SORACOM Harvest Dataは簡単に使えますが、1日1回クリックされるボタンのストレージとしてはちょっともったいないです。(5円 /日には2000回分の送信費用が含まれています。)AWSのデータストアが使えるのであれば、S3やDynamoDB、TimestreamなどとSORACOM Funnel、Funkを組み合わせることでより費用を抑えることができます。
また、外部のアプリケーションからHarvest Dataのデータを取り出す方法を実践しました。IoTのデータをどこに保存して、どうやってデータを入れて、どうやってデータを閲覧、解析するか、はIoTの大事なテーマです。今回は起きた時間がHarvest Dataにたまるので、それを分析することを考えてもいいかもしれません。(ただしデータの保持期間は40日間なので注意しましょう)
身近な課題をIoTで解決していきましょう!

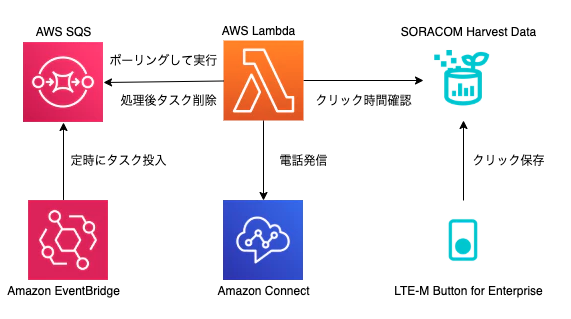
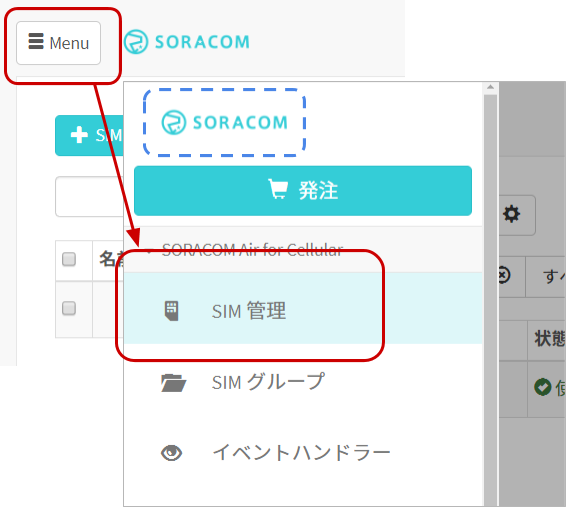
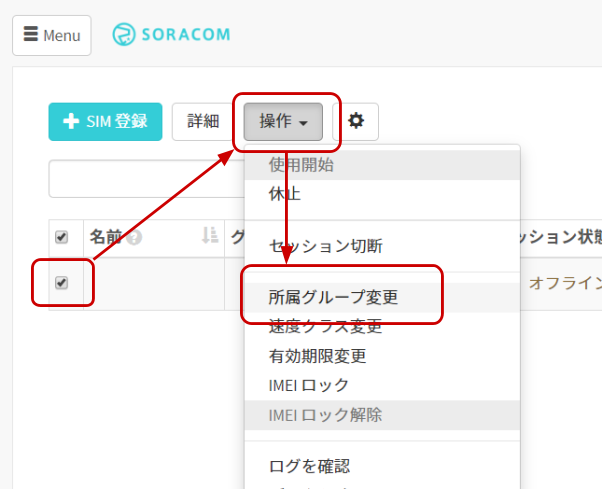

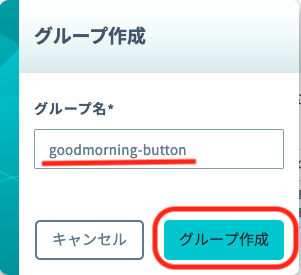
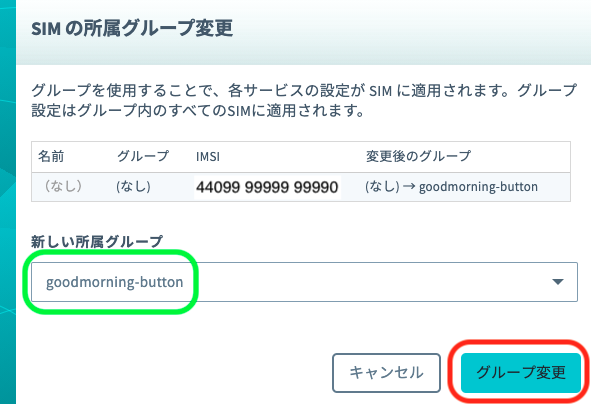


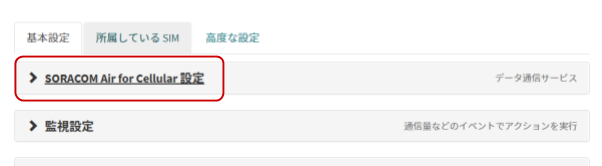
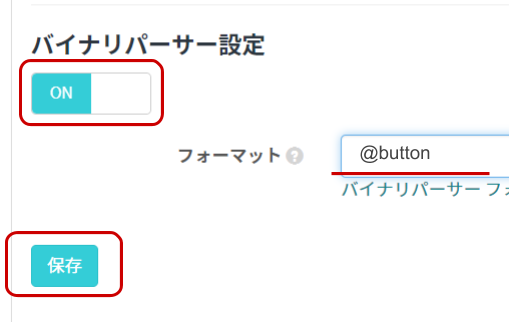



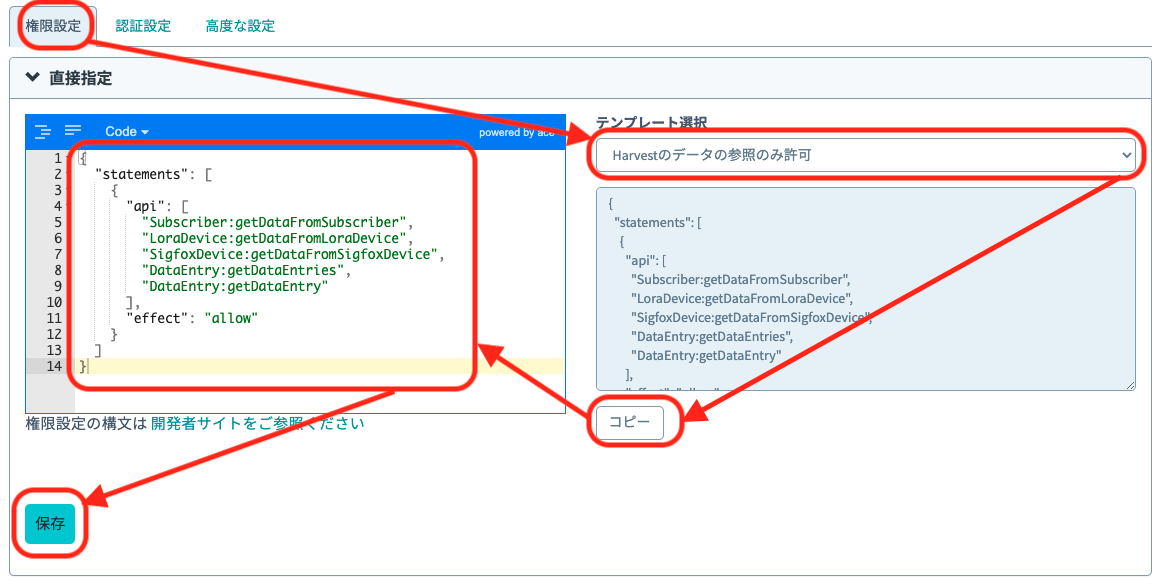
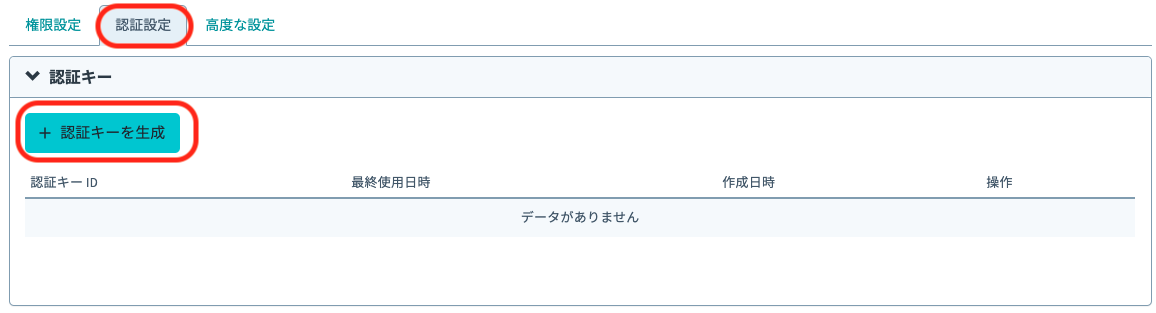
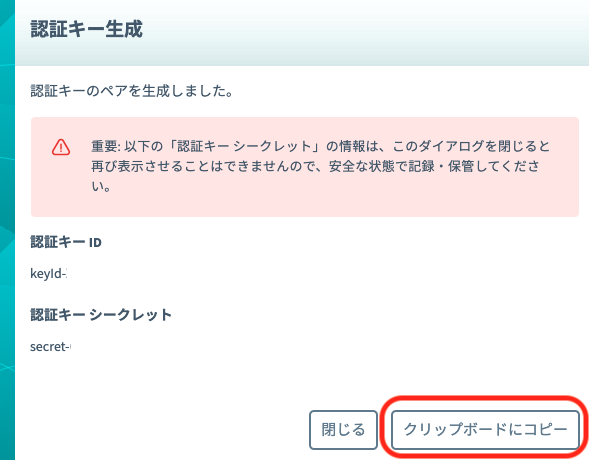
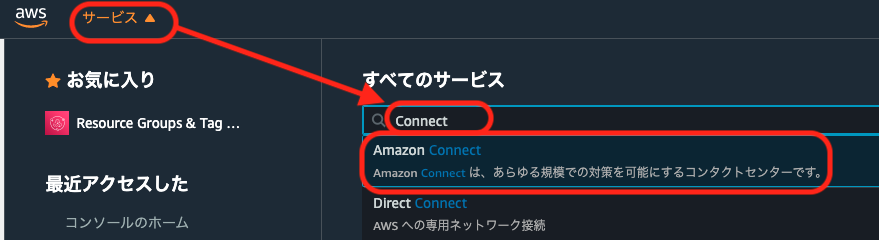

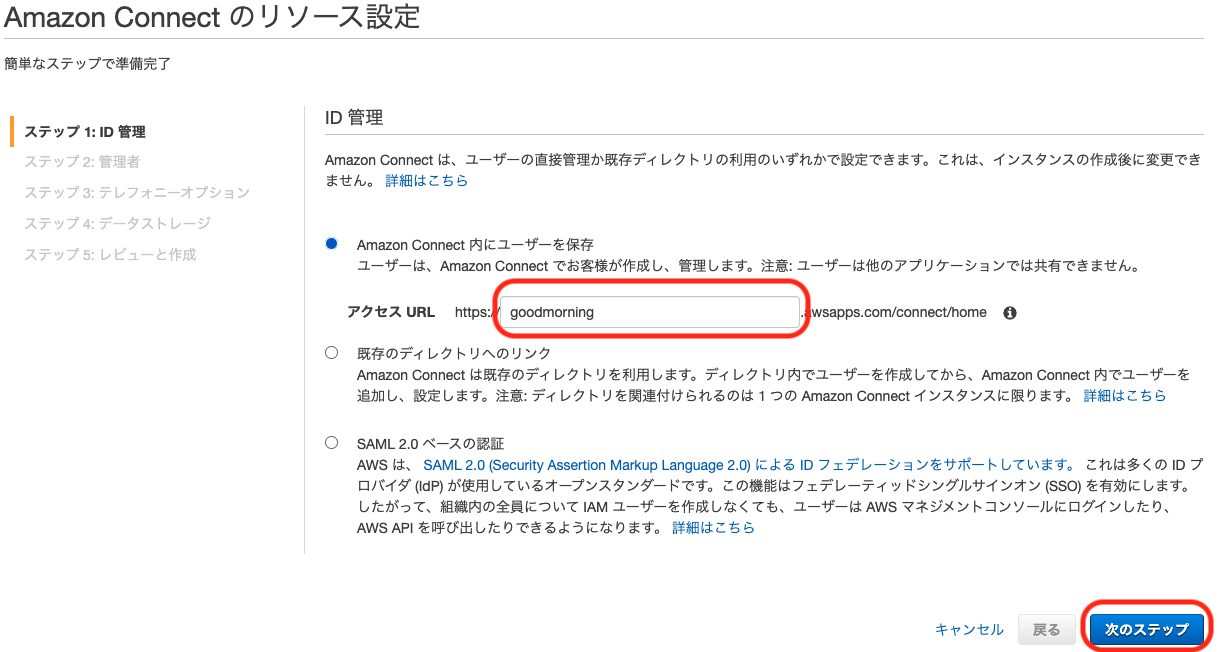


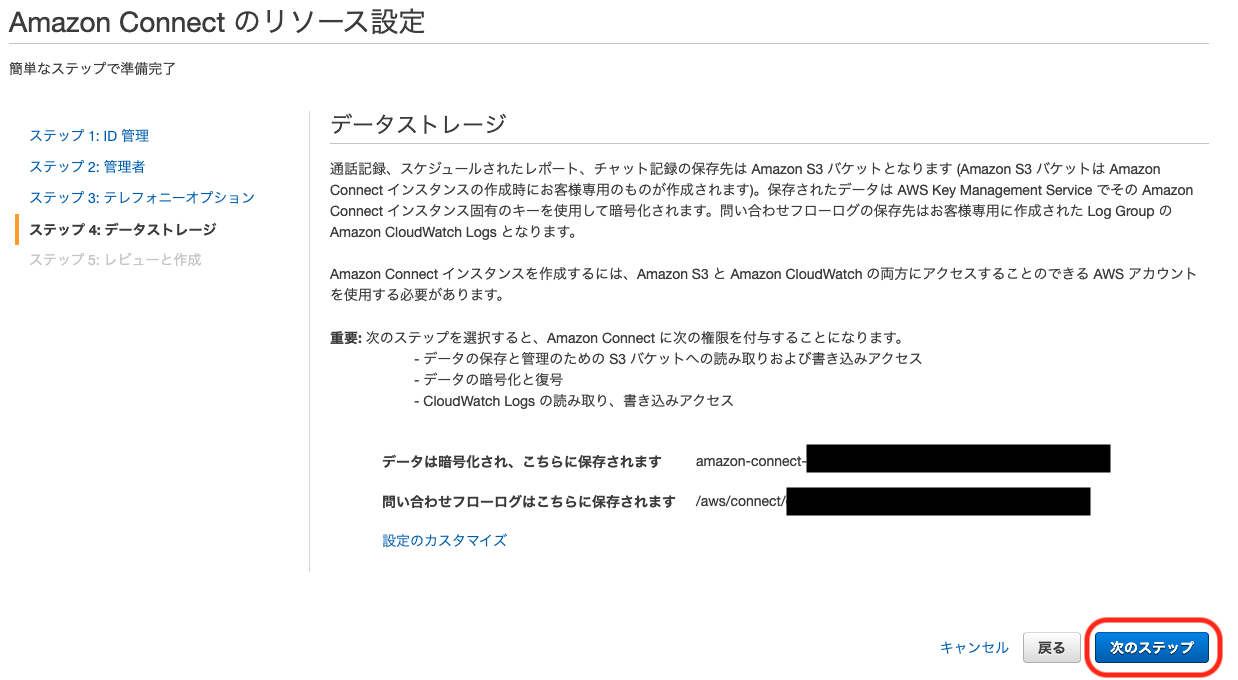

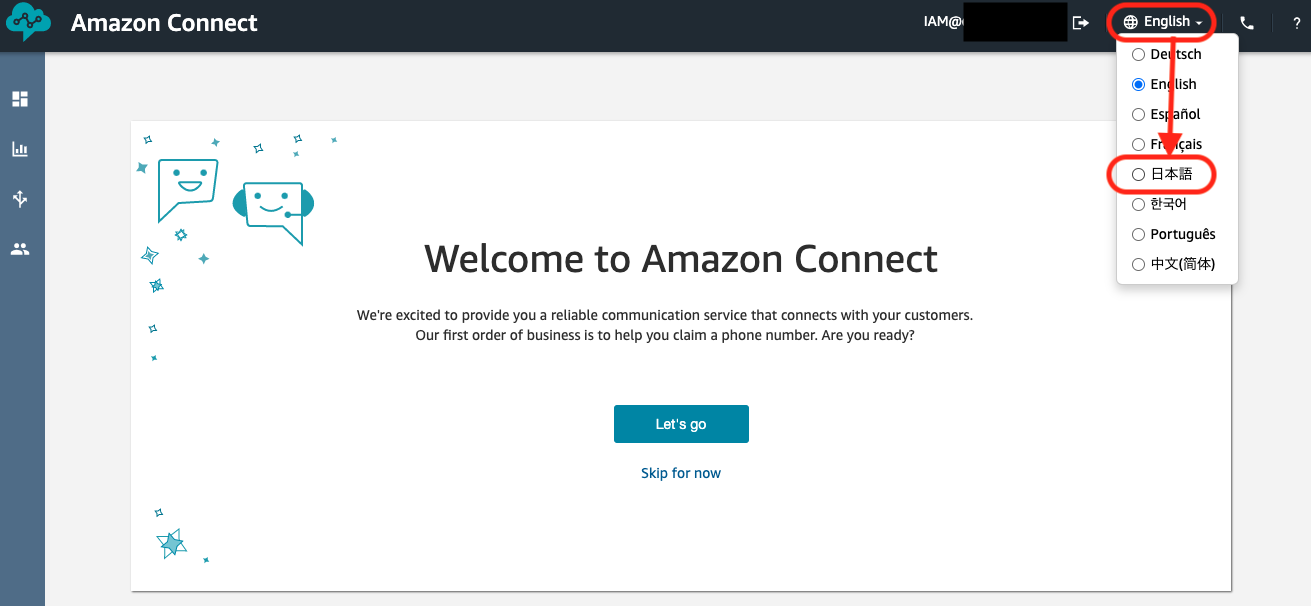

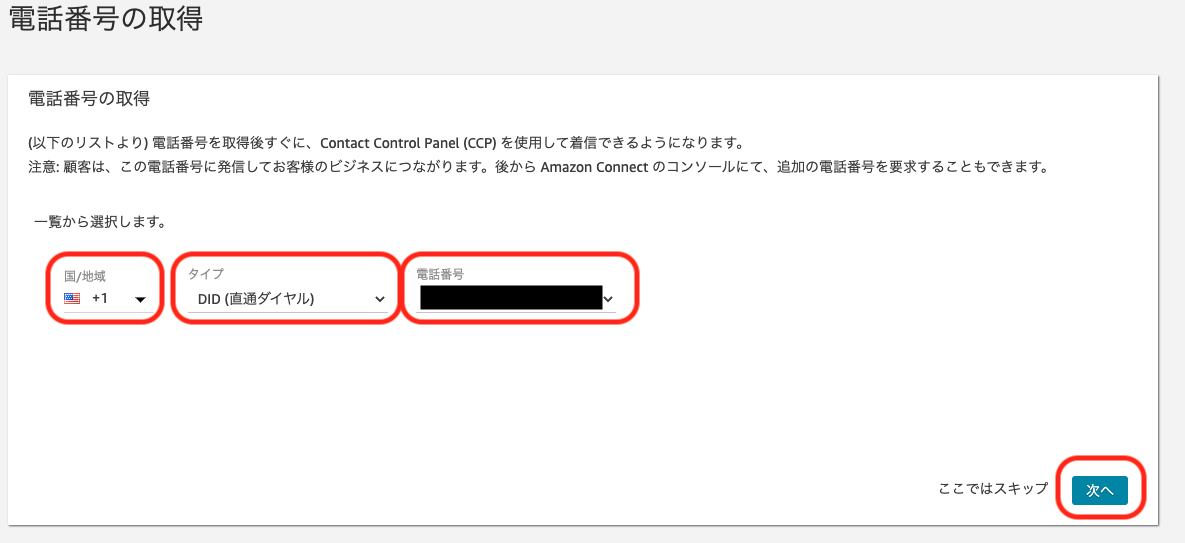
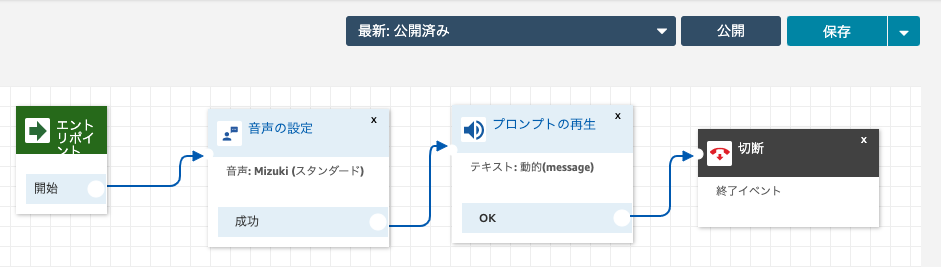


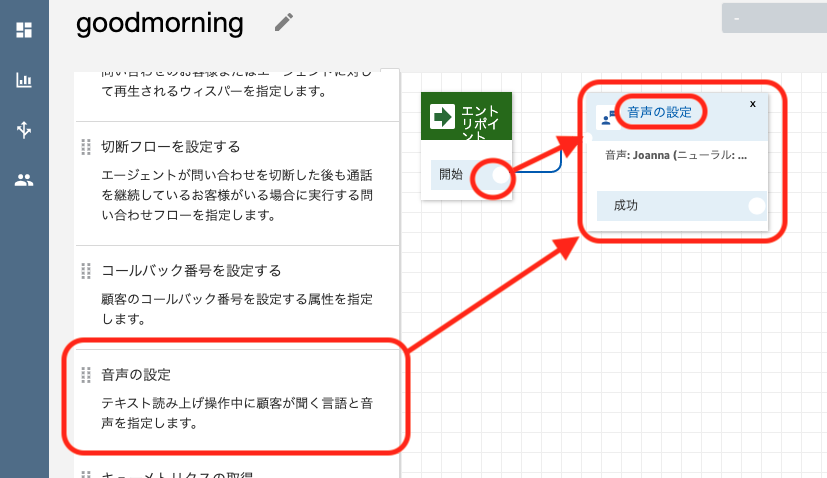

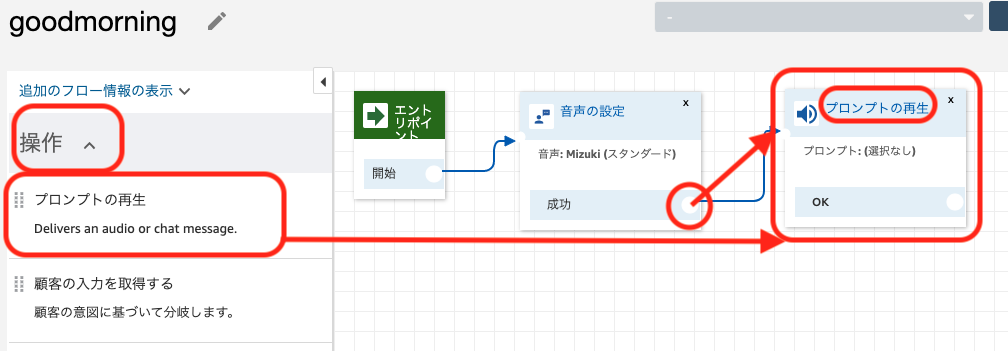
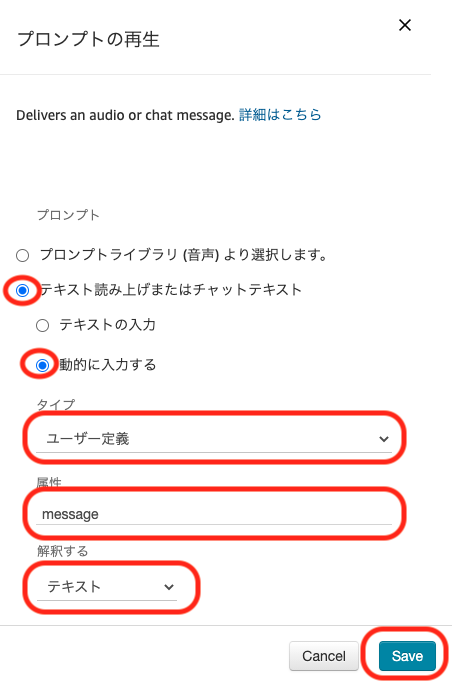

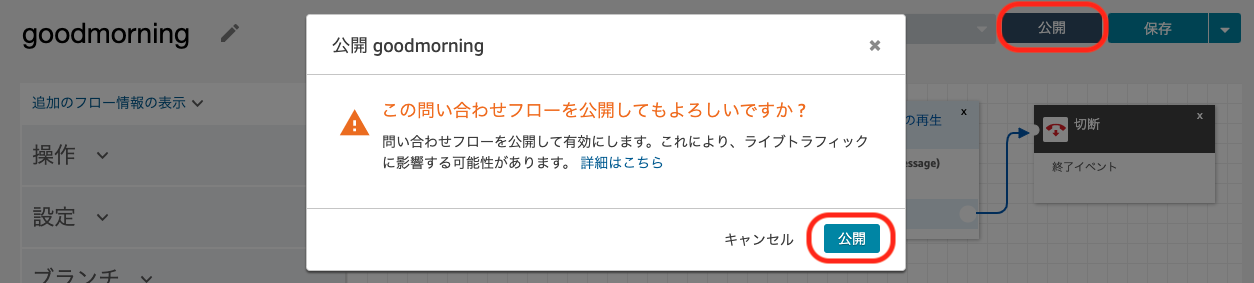
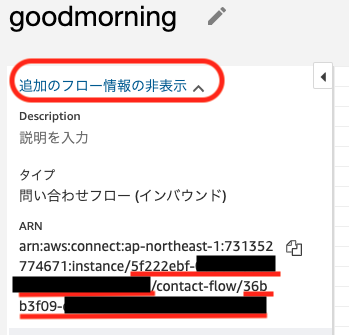

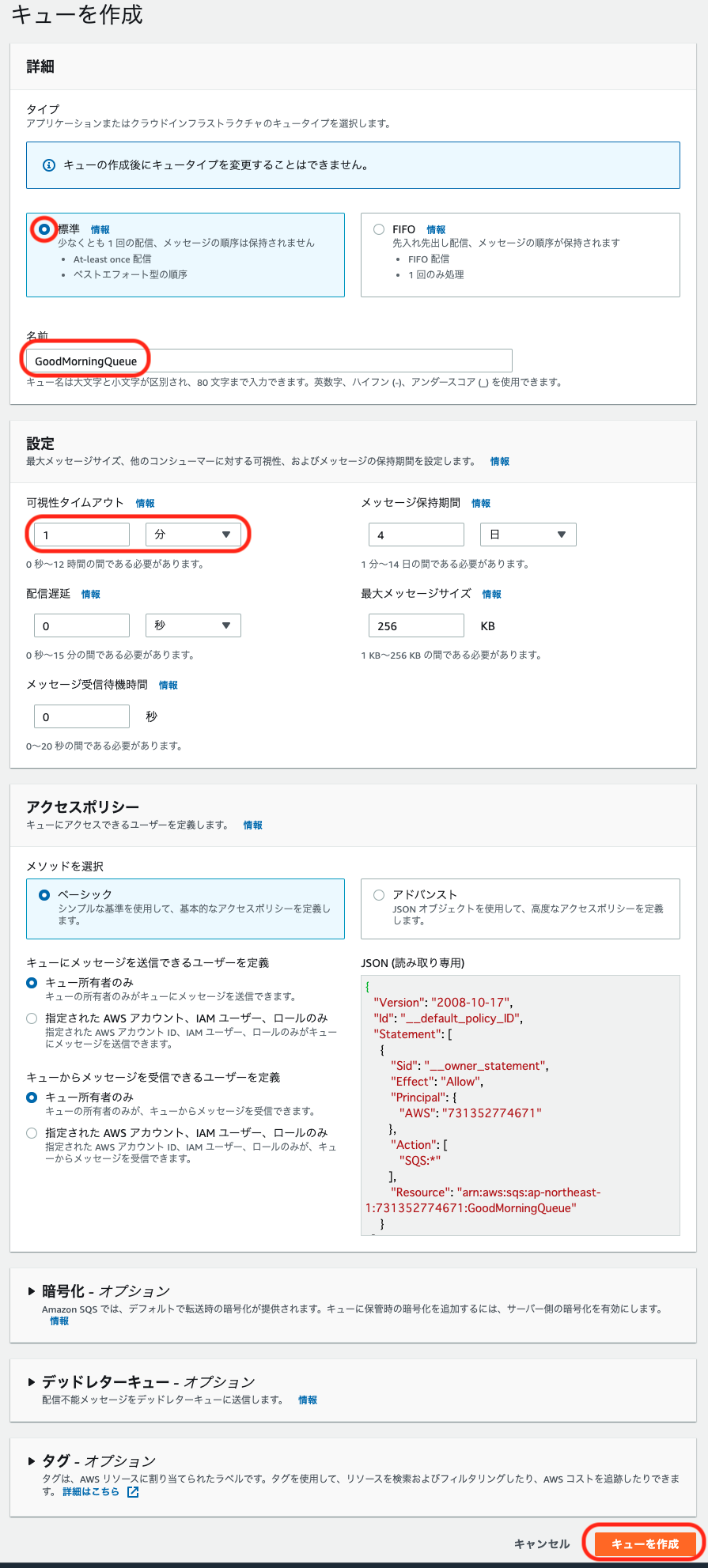


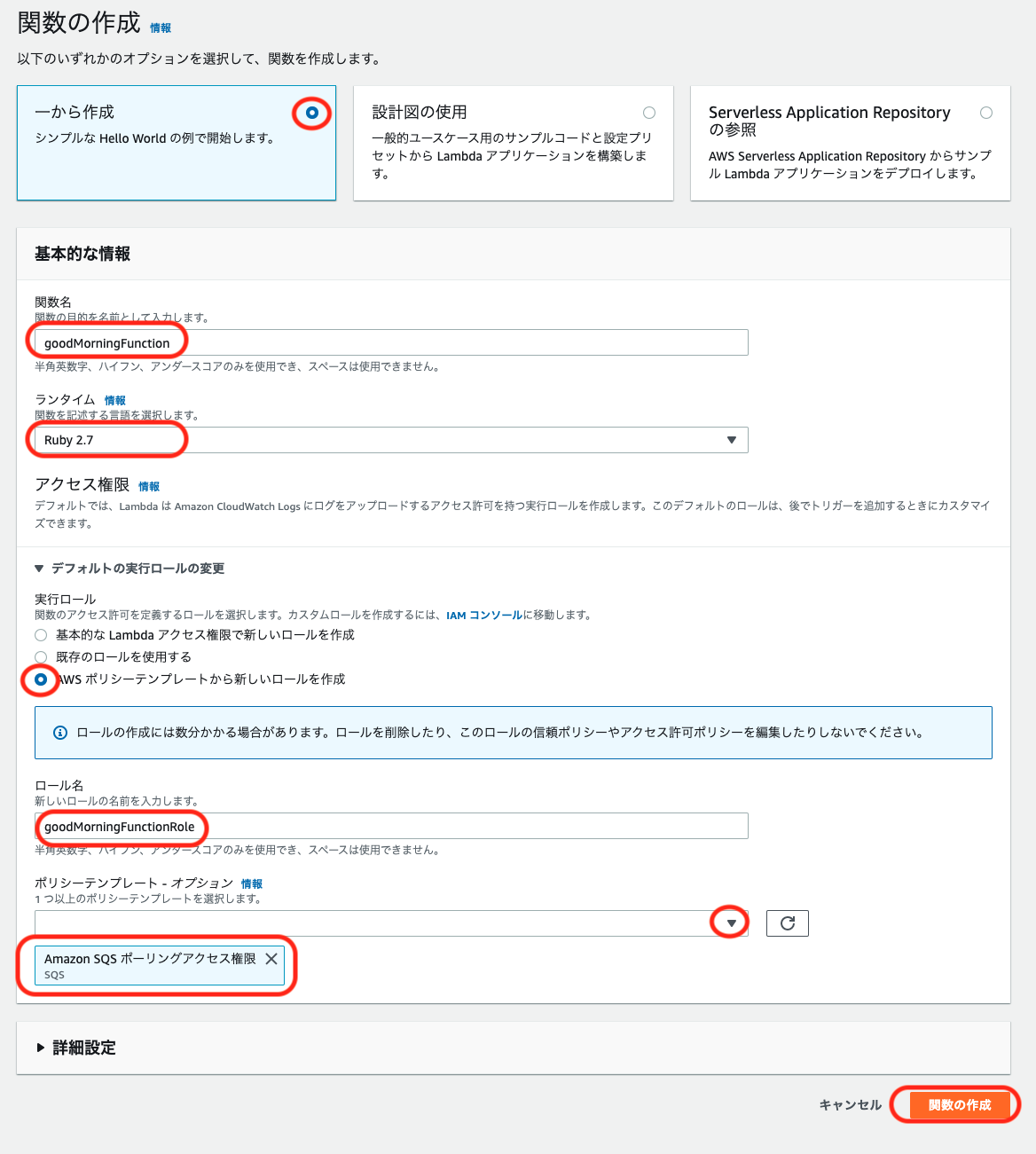
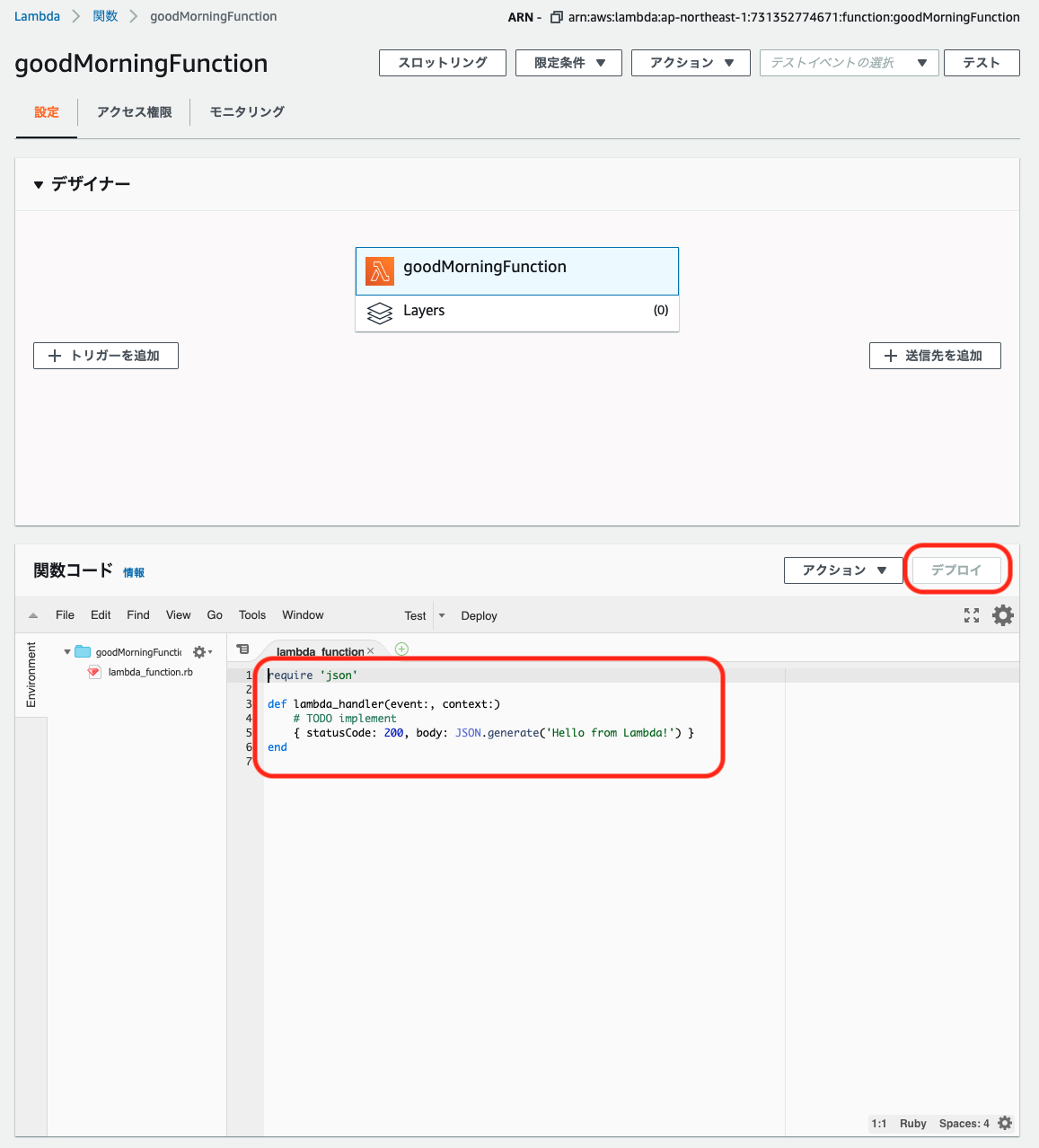

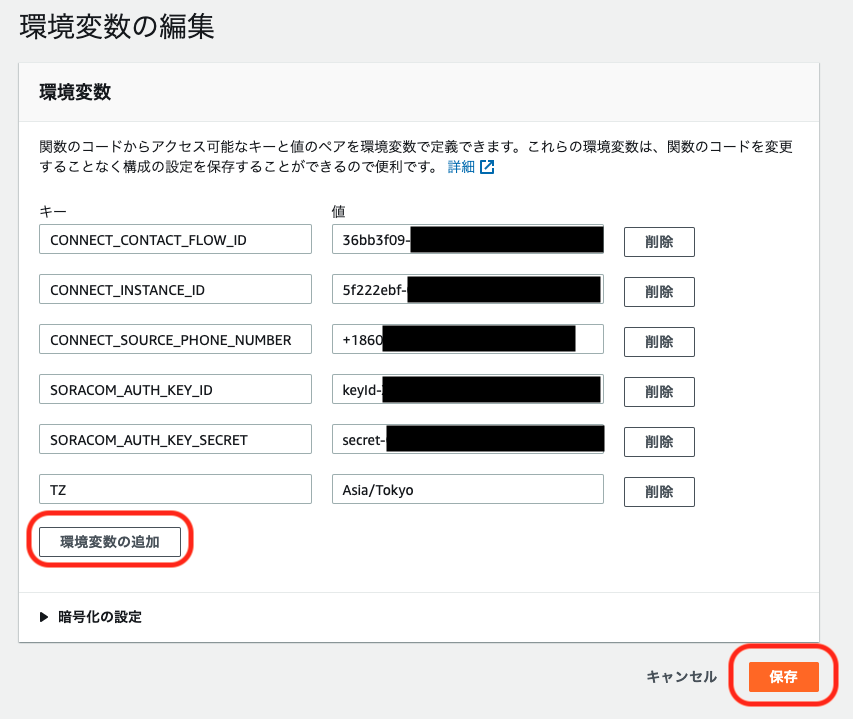




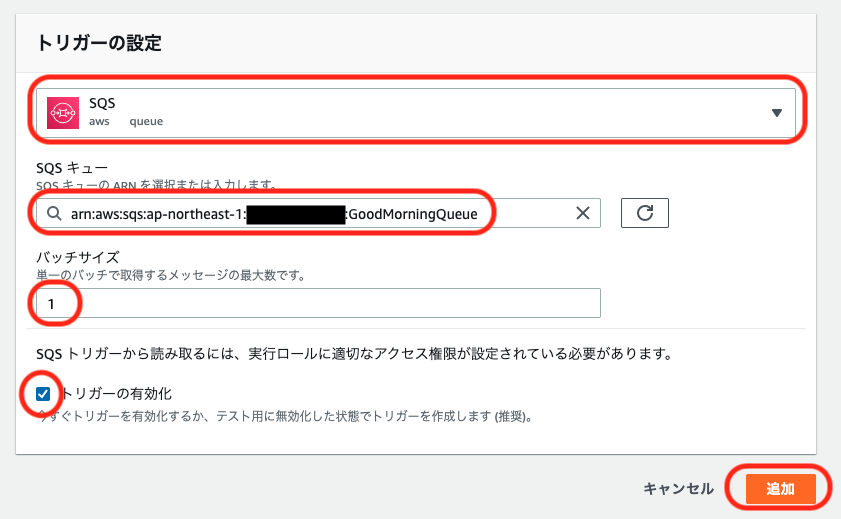

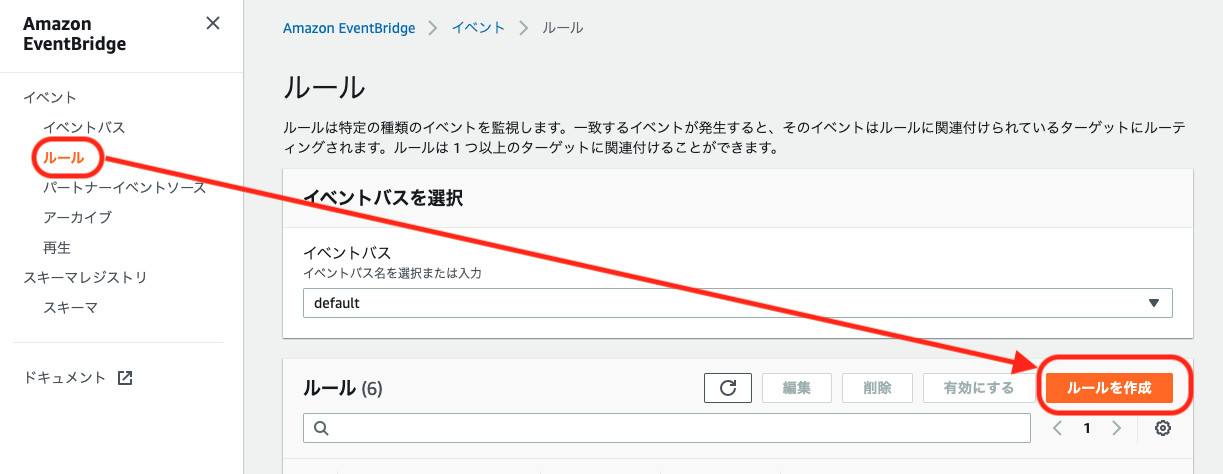
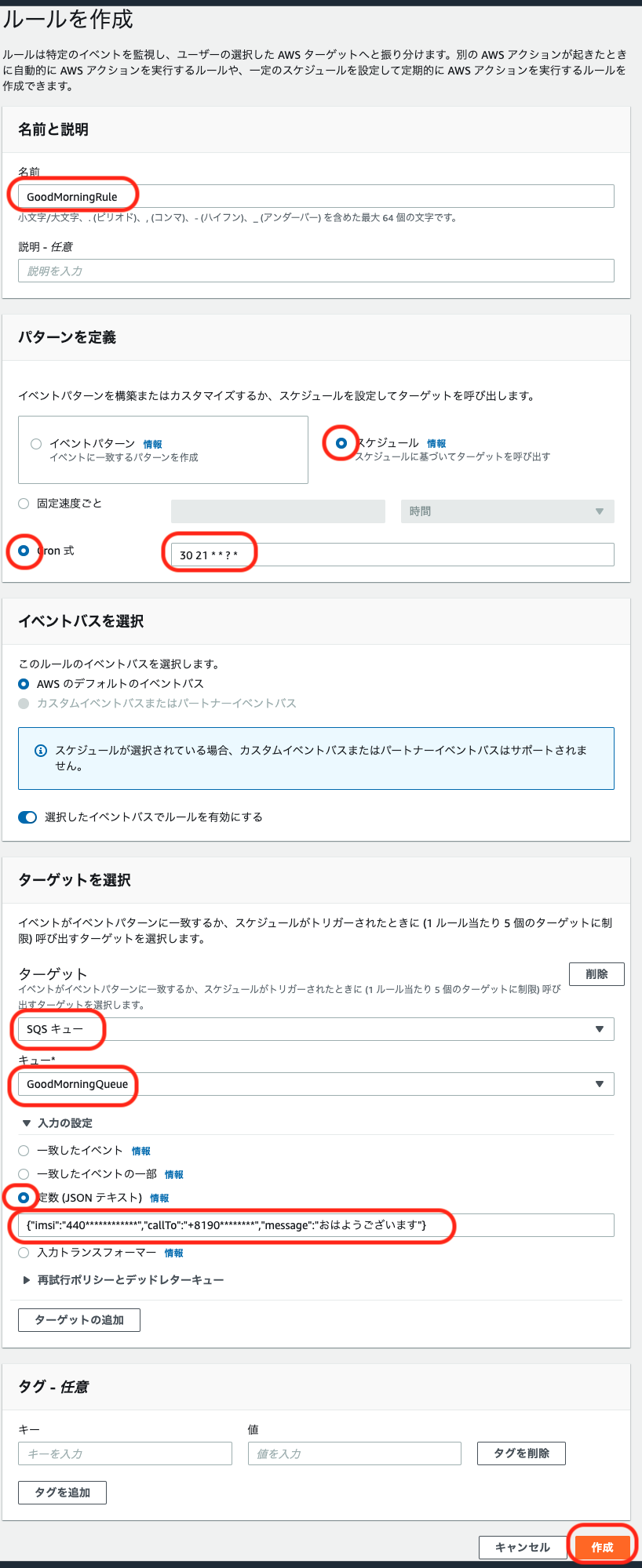

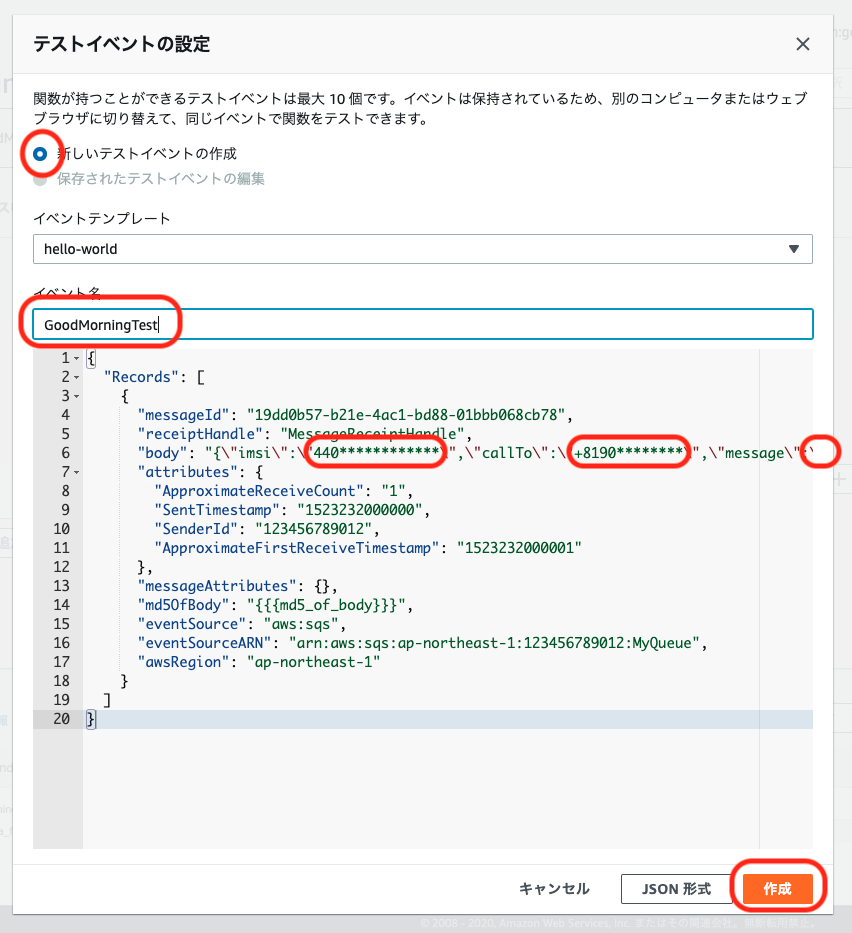
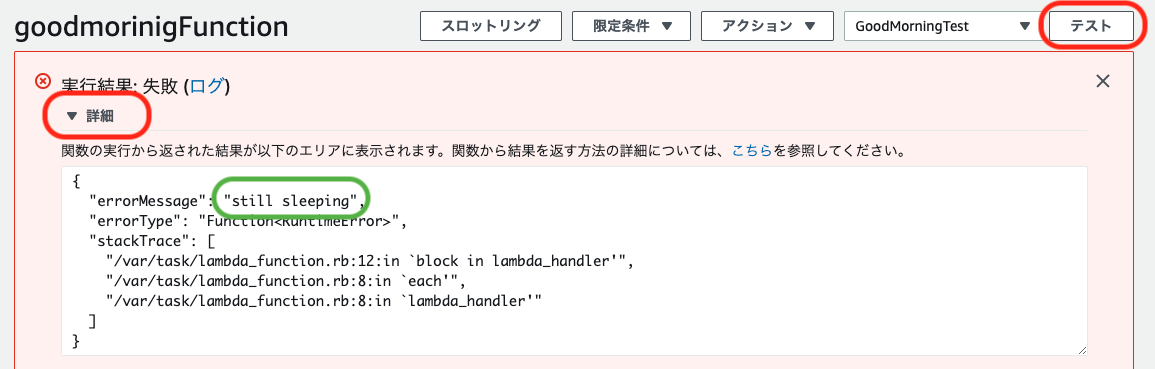
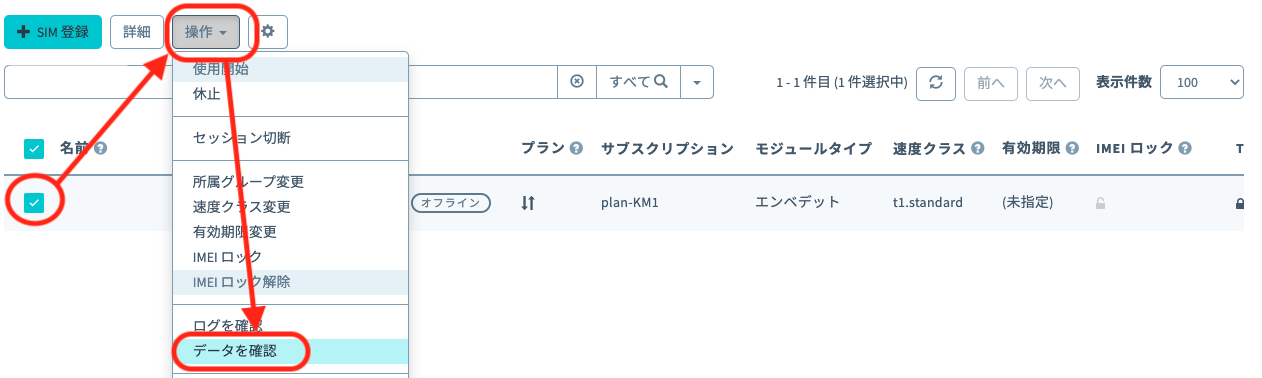



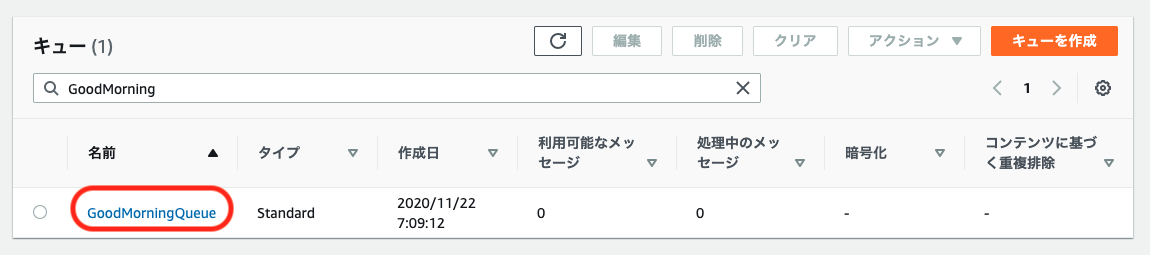

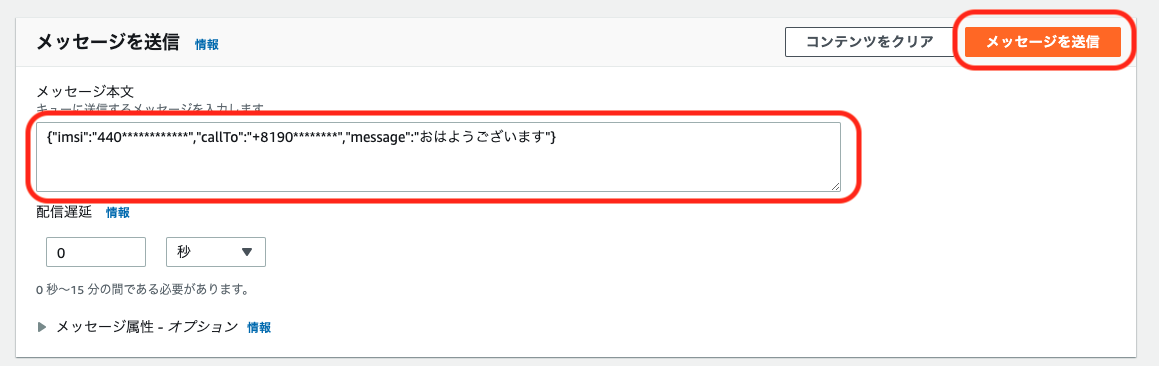

- 投稿日:2020-11-23T03:13:01+09:00
Lambdaで日付を扱うときにはまった話
タイトルの結論
LambdaのtimezoneはUTC(協定世界時)がデフォルトなので、時間を扱うときに時がずれていました。
なので、timezoneをasia/tokyoにする必要がありました。Lambdaでtimezoneをasia/tokyoにする方法
Lambdaの環境変数に、
変数名にTZをセットします。その値にAsia/Tokyoを設定します。Lambdaで環境変数を使う方法は以下のURLを参照ください。
https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/configuration-envvars.html
- 投稿日:2020-11-23T02:41:13+09:00
【クソアプリ】老舗ゲームメーカーになろう
老舗ゲームメーカーになりたい
ファミコン時代からシリーズもののゲームを出し続けている老舗メーカーって憧れますよね。
なりたいですよね。
なりましょう。完成イメージ
「4」くらいまで出しておけば十分老舗でしょう。
キャラ画像1枚と、シリーズタイトルだけ決めて実行すればこのような画像を生成してくれるイメージでいきます。
素材だけ用意して単純な画像加工部分だけサービス化してもよいですが、
今回はクソアプリなので、技術の無駄遣いをしてよりクソ感を出していこうかと思っています。素材を買う
早速ですが、モデリングはできないのでモデルは買ってきます。
いきなりクソ発想ですね。
モデリングする
Blenderの勉強がてら、買ってきたモデルを配置したりUVいじったりしていきます。
Label画像だけあとで差し替えたいため、Label画像だけパックから外し、それ以外のテクスチャ類はパックしてしまう。
ロゴを作る
適当につくります。
どうせ潰れて見えないので適当に。
雰囲気大事。
ビルドコマンドを作成
MakefileTITLE=${T} TITLECOLOR=OrangeRed help: render: gb sw sfc fc /Applications/Blender.app/Contents/MacOS/Blender -b shinise.blend -o //output# -F PNG -x 1 -f 1 gb: convert -define png:size=500x500 input.png -thumbnail 350x350^ -gravity center -extent 500x500 -flatten -depth 4 gb001.png convert -pointsize 40 -font Helvetica -draw "text 130,450 'MADE IN JAPAN'" -fill black gb001.png gb002.png convert gb002.png -stroke lightgray -strokewidth 60 -draw "line 30,0 30,500" gb003.png convert gb003.png -stroke lightgray -strokewidth 60 -draw "line 470,0 470,500" gb004.png convert -pointsize 60 -font fonts/impact/impact.ttf -draw "text 80,100 '${TITLE}'" -fill ${TITLECOLOR} gb004.png gb005.png convert -pointsize 200 -font fonts/designer-2/Designer2.ttf -draw "text 320,200 '2'" -fill ${TITLECOLOR} gb005.png gb006.png mv gb006.png Label2.png sw: convert material/soft.png input.png -gravity center -geometry 140x140+0+30 -compose over -composite sw001.png convert -pointsize 30 -font fonts/impact/impact.ttf -draw "text 40,125 '${TITLE}'" -fill ${TITLECOLOR} sw001.png sw002.png convert -pointsize 80 -font fonts/designer-2/Designer2.ttf -draw "text 170,180 '4'" -fill ${TITLECOLOR} sw002.png sw003.png mv sw003.png soft.png sfc: convert -size 1128x508 canvas:FloralWhite sfc001.png convert sfc001.png input.png -gravity southwest -geometry 450x450+40+0 -compose over -composite -flatten -depth 4 sfc002.png convert sfc002.png material/sfc_logo.png -gravity northeast -geometry 321x37+60+60 -compose over -composite sfc003.png convert sfc003.png material/sfc_mark.png -gravity southeast -geometry 140x120+80+40 -compose over -composite sfc004.png convert -pointsize 80 -font fonts/impact/impact.ttf -draw "text 500,240 '${TITLE}'" -fill ${TITLECOLOR} sfc004.png sfc005.png convert -pointsize 200 -font fonts/designer-2/Designer2.ttf -draw "text 920,280 '3'" -fill ${TITLECOLOR} sfc005.png sfc006.png mv sfc006.png Label3.png fc: convert -size 1128x508 canvas:lightgray fc001.png convert fc001.png -stroke black -strokewidth 80 -draw "line 0,40 240,40" fc002.png convert fc002.png -stroke skyblue -strokewidth 390 -draw "line 400,280 1050,280" fc003.png convert fc003.png material/fc_logo.png -gravity north -geometry +15+20 -compose over -composite fc004.png convert fc004.png input.png -gravity center -geometry 380x380+180+40 -compose over -composite fc005.png convert -pointsize 50 -font Helvetica -draw "text 40,60 'HVC-AA'" -fill white fc005.png fc006.png convert -pointsize 20 -font Helvetica -draw "text 200,470 'MADE IN JAPAN'" -fill black fc006.png fc007.png convert -pointsize 30 -font Helvetica -draw "text 60,440 '(c) N i n t e n d o 1 9 9 4'" -fill black fc007.png fc008.png convert -pointsize 80 -font fonts/impact/impact.ttf -draw "text 40,240 '${TITLE}'" -fill ${TITLECOLOR} fc008.png fc009.png mv fc009.png Label.png clean: rm -rf gb*.png sw*.png soft.png sfc*.png fc*.png output1.png作った素材とフリーのフォントを使い、Imagemagickでガチャガチャしていく。
試しに実行
キャラ画像も適当に用意。
今回はこちらをお借りしました。
https://illustrain.com/?p=30579
実行します。
$ make render T=BraveCats
いい感じですね。
レイアウトが甘いところがクソ感出てていいですね。WEBサービス化していく
しかしながら、
間に合わなかったです。ごめんなさい。以下メモです。
bpy_lambdaをビルドしてLambda Layerに登録する
bpy_lambda
https://github.com/bcongdon/bpy_lambdaAWS CodeBuildでビルドする。
(ローカルでもよいが、結構時間かかるのでCodeBuildさんにお任せする)buildspec.ymlversion: 0.2 phases: build: commands: - sh ./build.sh - sh ./lambda_layer.sh artifacts: files: # - python/**/* - bpy_lambda_layer.zip
Lambdaで実行テスト
WIP
WEBサービスを作成
WIP
Nuxtで作ってNetlifyかAmplifyあたりかなと考えている。
LambdaはSDK使って直接叩いてしまう予定。まとめ
AdventCalendar初めて参加しました。
クソアプリすら完成させられないのかと反省しております。でもまあ。
久しぶりに個人サービスの作業して楽しかったです。また普通に何か作りたいなという気になってきました。





- 投稿日:2020-11-23T01:33:06+09:00
【初心者用】AWSで練習・検証用のWordPress環境を構築する
はじめに
AWS初心者が練習・検証用にWordPress環境を立てた手順を、後から同じことがしたいと思った人向けにまとめた物です。
筆者が色々と失敗した際の経験も記載しておきます。想定読者
・AWSでEC2のインスタンスを立てて接続した事がある程度の初心者
・Linuxの基本操作はわかる人
・ある程度意図が説明された記事が読みたい人目的
・ちょっと知識がある人が、WordPress環境を実際に構築してその感覚を掴む。
・別の練習のために環境を構築する際に手順を理解・覚えておく。構成環境
・EC2(WEB・DB)1台 OS:Amazon Linux2 ※無料枠
実際に公開して運用する際は冗長性のためにEC2(WEBサーバ)とRDS(DBサーバ)に分けるのが鉄板構成のようですが、練習のため同居させます。全体の流れ
- 構築に必要なものを把握する
- EC2インスタンスの起動、SSHで接続
- Apache・PHP・MariaDBをインストール
- MariaDBの初期設定
- WordPressをダウンロード
- Apacheの設定変更
- WordPressの初期設定
1.構築に必要なものを把握する
WordPressは簡単にサイトを構築できる物ですが、それだけがあれば良い訳ではありません。
- WEBサーバ化させるミドルウェア「Apache」
- PHPで出来たWordPressを動かすための「PHP」
- WordPressのデータを保存するSQLデータベース
- WordPress本体
この4つがあることでWordPressでのWEBサイト構築・公開が可能になっています。
そもそも、自前で作った静的なサイトを公開するだけならば、Apacheをインストールするだけで可能です。
WordPressを稼働させるためにPHPとDB(データベース)を入れている訳です。2.EC2インスタンスの起動、SSHで接続
EC2インスタンスを起動
練習・検証用なので無料枠で十分です。
OSはAmazon Linux2にしておきましょう。
それ以外は特に必要はないですが、ポートの開放は必要です。セキュリティグループの設定
・タイプ:SSH ポート範囲:22 ソース:マイIP
・タイプ:HTTP ポート番号:80 ソース:マイIP (こっちは別にフルオープンでも良い)作業をするためにEC2にSSHでアクセスするために22を、WEBサイトとしてアクセスできるようHTTPの80を開放します。
開放先のIPは「0.0.0.0/0」とすると全世界からのフルアクセスとなり、悪意ある攻撃を受ける可能性もありますので、オススメはしません。
「マイIP」を選択すると自宅のIPだけに開放されるので安心です。注意
通常家庭のIPは一定期間やルーターの再起動等で変わります。
なので、後日接続できない事態が起こった場合はまずこの「マイIP」の部分を疑いましょう。
変更していた場合、もう一度「マイIP」と選択し直すと現在のIPに書き換えられるはずです。EC2にSSHで接続
EC2にSSHでアクセスして下さい。
sudo su -練習環境ですので、sudoコマンドでrootに移行して作業をする形にします。
3.Apache・PHP・mariaDBをインストール
それでは、各種必要な物をインストールしていきます。
Apacheをインストール
Apacheをまずインストールさせ、systemctlコマンドで起動後、以降も自動的に起動するように設定します。
yum install httpd -y systemctl start httpd systemctl enable httpd重要:ブラウザからアクセスが出来るか確認する事
Apacheがインストール出来た段階で、Apacheのテストページにアクセスする事ができます。
念の為、ブラウザからパブリックIPを入力してテストページが開くかどうか確認しておきましょう。
全て導入してからアクセス出来なかった場合、「原因は?」となりApacheも含めて全て確認するハメになります。
そのため、まずはここでアクセスできていればポートの「80」が空いていること・Apacheは稼働できている事が確認できます。余談
筆者はとある事情により、ポートが確認できない状況で一気にWordPress環境を構築した事があります。
しかし、アクセスできず、設定等を全て確認した後「ポートが空いてない事しか考えられない」と結論付けました。
この段階で、テストページの確認をしていれば「高確率でポートが空いていない」事に直ぐに気がつけた訳です。PHPをインストール
「Amazon Linux Extras」はAmazonがAmazon Linux2用に提供してくれているシステムで、対応が確認されている主要なパッケージを楽にインストールさせてくれるとても便利な物です。
その中で、今回はphp7.3のバージョンを適用化させるコマンドを入力します。amazon-linux-extras enable php7.3そして、PHP以外にWordPressに必要な3つのPHPの拡張パッケージをまとめてインストールします。
3つの拡張パッケージはインストールしなくてもWordPressは起動はできるようですが、必要な物を入れない理由はないので素直に入れましょう。yum install php php-gd php-mysqlnd php-xmlrpc -yMariaDBをインストール
MySQLでも良いのですが、以前に最新バージョンによって旧来のコマンドで出来たことが出来なくなり、そこで詰まって何時間も時間を消費した経験があるため、MariaDBにしました。
yum install mariadb mariadb-server -y systemctl enable mariadb systemctl start mariadbApacheと同様にインストールをした後、起動させてから以降も自動起動するようにします。
4.MariaDBの初期設定
MariaDBのセキュリティ設定とWordPress用のデータベースを作成します。
セキュリティ設定
まず、最低限のセキュリティ設定を行います。
mysql_secure_installationmysql_secure_installationコマンドは、rootのパスワードの変更や初期設定に存在するセキュリティ的に不用心な匿名ユーザーや初期DBを削除してくれるコマンドです。
練習のためにも、実際の運用で行うであろう設定は行っておきます。
解説すると長くなるので、細かな事はググった方が早いです。Enter current password for root (enter for none) // エンターを入力 Set root password [Y/n] // Yを入力 ※rootのパスワードを設定 New password: // 設定したいパスワードを入力してエンター、入力しても何も表示されないが正常。 Re-enter new password: // 再度同じパスワードを入力してエンター、このときも何も表示されないが正常。 Password updated successfully! // パスワードが設定されました。 Remove anonymous users? [Y/n] // Yを入力 ※匿名ユーザーの削除 Disallow root login remotely? [Y/n] // Yを入力 ※リモートrootのログインの拒否 Remove test database and access to it? [Y/n] // Yを入力 ※テストDBの削除 Reload privilege tables now? [Y/n] // Yを入力 ※権限テーブルをリロード Cleaning up... All done! If you've completed all of the above steps, your MariaDB installation should now be secure. Thanks for using MariaDB! // 無事設定完了です。これらはコマンド入力ではなく、対話的に行う設定です。
データベース作成
WordPress用のデータベースを作成します。
そのために、mysqlにアクセスします。rootのパスワードは先程設定した物を入力しましょう。mysql -u root -pここからはDBの操作になり、コマンド形式がLinuxと違いますので「;」を忘れないようにしましょう。
ユーザーを作成
ユーザー名は「wordpress-user」とパスワードは「test-pass」とします。※名前は各々ご自由に
CREATE USER 'wordpress-user'@'localhost' IDENTIFIED BY 'test-pass';データベースを作成
「test-db」という名前にしておきます。※名前は各々ご自由に
CREATE DATABASE `test-db`;権限付与
GRANTで「ALL PRIVILEGES」(検眼の付与以外の全ての権限)を「test-db」(DB)に対して「wordpress-user」(ユーザー)に付与します。
GRANT ALL PRIVILEGES ON `test-db`.* TO "wordpress-user"@"localhost";下記は権限の設定をリロードするためのコマンドです。
FLUSH PRIVILEGES;DBの操作を終了します。
exit;5.WordPressをインストール
まず、インストール先はWEBの公開ファイルなどを置くドキュメントルート下にしたいので、そこに移動します。
cd /var/www/html/圧縮されたWordPressをダウンロード
wget https://ja.wordpress.org/latest-ja.tar.gz展開します。これで「WordPress」フォルダが出てきているはずです。
tar -xzvf latest-ja.tar.gz展開したので、不要になった圧縮ファイルを削除
削除する時に「本当に削除するの?」と聞いてきますがyを入力すれば消してくれます。rm latest-ja.tar.gz rm: remove regular file ‘latest-ja.tar.gz’? :ylsコマンドを使って、その場に「wordpress」があれば問題ありません。
6. Apacheの設定変更
Apacheの設定と権限を変更します。
Apacheの設定変更
WordPressはイントールできましたが、Apacheの設定変更をしなければ現状テストページにしかアクセスできません。
まず、Apacheの公開先(ドキュメントルート)を変更します。設定を間違ってしまい、Apacheが動かなくなる事がありますのでバックアップを取っておくのをオススメします。
cp /etc/httpd/conf/httpd.conf /etc/httpd/conf/httpd-Backup.conf //バックアップの名前はご自由にvimでApacheの設定ファイルである「httpd.conf」を編集します。
vim /etc/httpd/conf/httpd.conf公開先であるドキュメントルートを「 "/var/www/html/wordpress」に設定します。
元の設定は「"/var/www/html"」になっていると思います。httpd.confDocumentRoot "/var/www/html/wordpress"また、続けてAllwOverrideをnoneからALLにします。
外部ファイルによってApacheの設定を変更可能にするかを設定するオプションで、これを設定しないとWordPressを使っているときに意図した動作が実行できない事が発生するようです。httpd.conf<Directory "/var/www/html"> ~~省略~~ AllowOverride All権限の変更
chownコマンドによって「Apache」ユーザーと「Apache」グループに「/var/www」の所有者権限を与えます。
-Rオプションによって「再帰的」つまり、その中に存在しているもの全ての所有権をまるごと変えます。「Apache」ユーザーは初期設定されているApacheの実行ユーザーで、これに権限を与えないとWordPressがDBに接続する事が出来なくなります。
chown -R apache:apache /var/www【重要】Apacheの再起動
最後に、Apacheを再起動させましょう。
これをしないと設定が反映されないため、Apacheのテストページにしかアクセスできないままになります。systemctl restart httpd余談
筆者は最後の「再起動」をしなかったために、設定が反映されずテストページにアクセスしてWordPressが起動せず、
「Apacheはちゃんと動いているのになぜ?」→「設定がおかしいはず」と無駄な設定確認に時間を費やしてしまった事があります。7.WordPress初期設定
ここまでくればWordPressの初期設定画面にアクセスできるはずです。
データベースの設定
「MariaDBの初期設定」で設定した。
・データベース名
・ユーザー名
・パスワード(rootではなくユーザーのパスワードです)
この3つを入力しましょう。
データベースのホスト名とテーブル接頭辞はそのままで大丈夫です。
インストールを押せば、サイトの設定画面に移行します。
手順にあった「chmod」で権限を変更していない場合、WordPressがDBに関する内容を設定ファイルを書き込む事が出来ないため、エラーとなりこの画面にたどり着けません。
サイトの設定
あとは適当にサイトの名前やログインに必要なユーザー名・パスワード・メールアドレスを設定していきましょう。
外部に公開しない練習・検証環境であれば、「検索エンジンがサイトをインデックスしないようする」にチェックを入れておくと良いでしょう。
これは、Googleなどの検索エンジンからこのサイトに辿り着けないようにするための設定項目です。
WordPressサイトの完成
これでサイトが完成しました。
先程設定したユーザー・パスワードでログインすれば管理画面でサイトを操作できます。
データベース設定の別のやり方
wp-config.php
「/var/www/html/wordpress/wp-config.php」を編集することでここで入力した内容を変更する事もできます。
そもそも最初からこの方法でデータベース情報を入力しておけば、上記のブラウザでデータベースの設定を入力する必要はありません。ただ、私個人的には「初回設定はブラウザで設定する方が短時間で済む上にミスが起きにくい」と思っています。
vimを使って編集して打ち間違いをした場合、ブラウザより修正の時間がかかるからです。参考URL
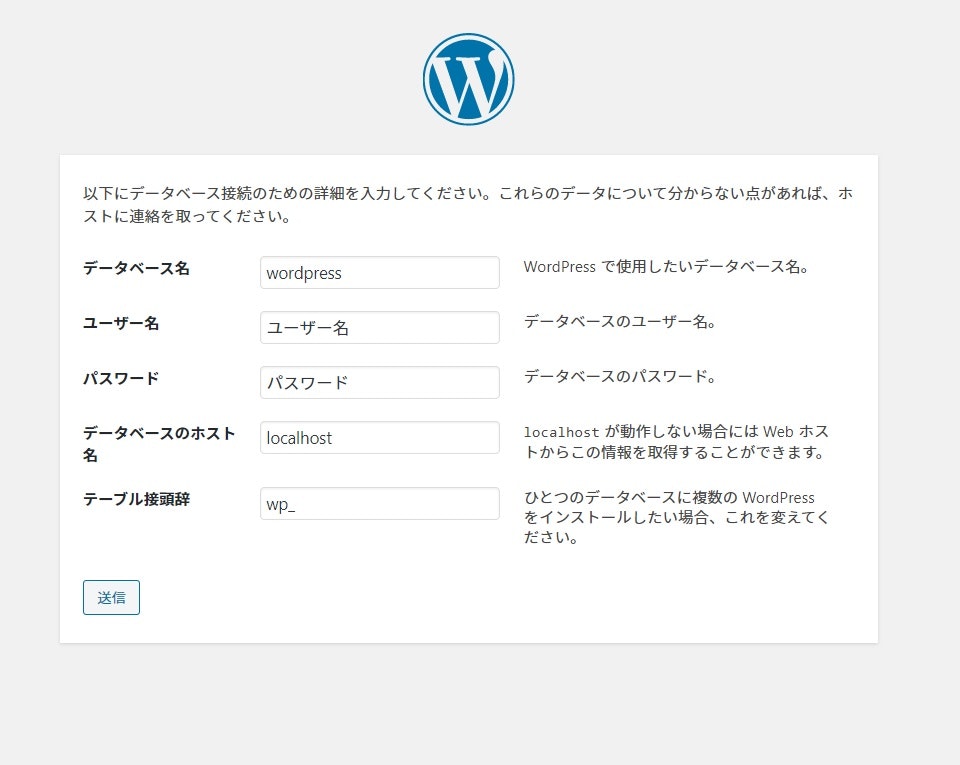
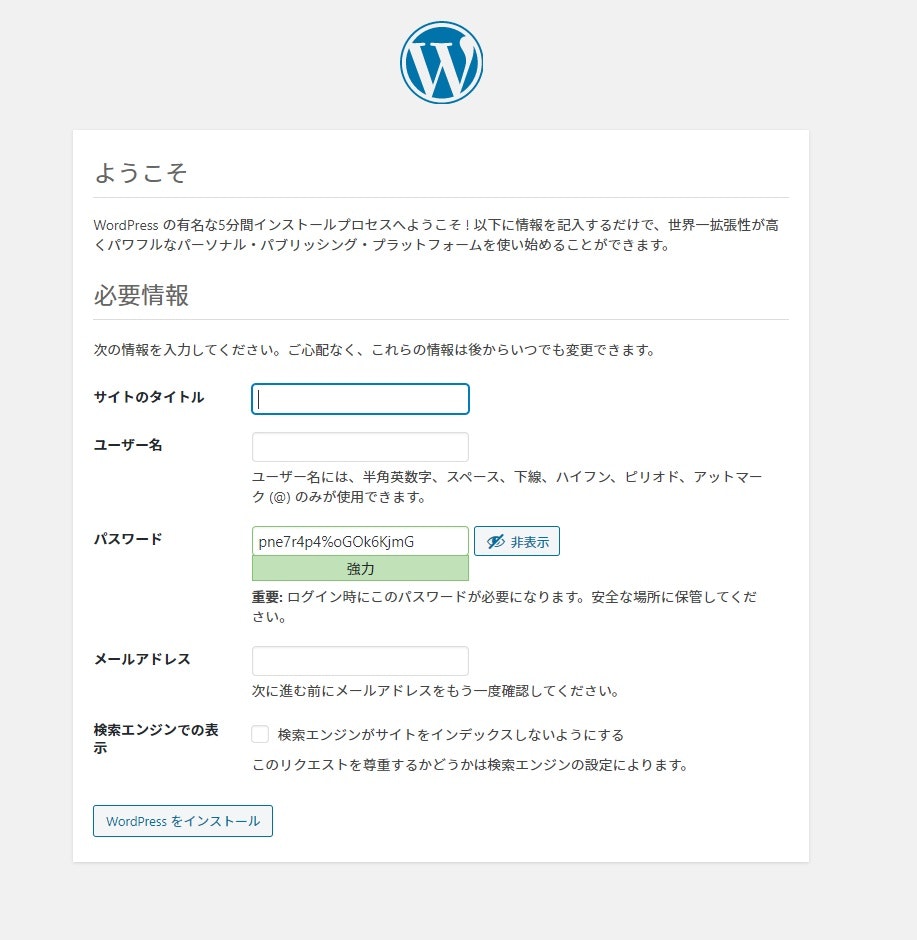
- 投稿日:2020-11-23T00:40:51+09:00