- 投稿日:2020-10-22T23:28:46+09:00
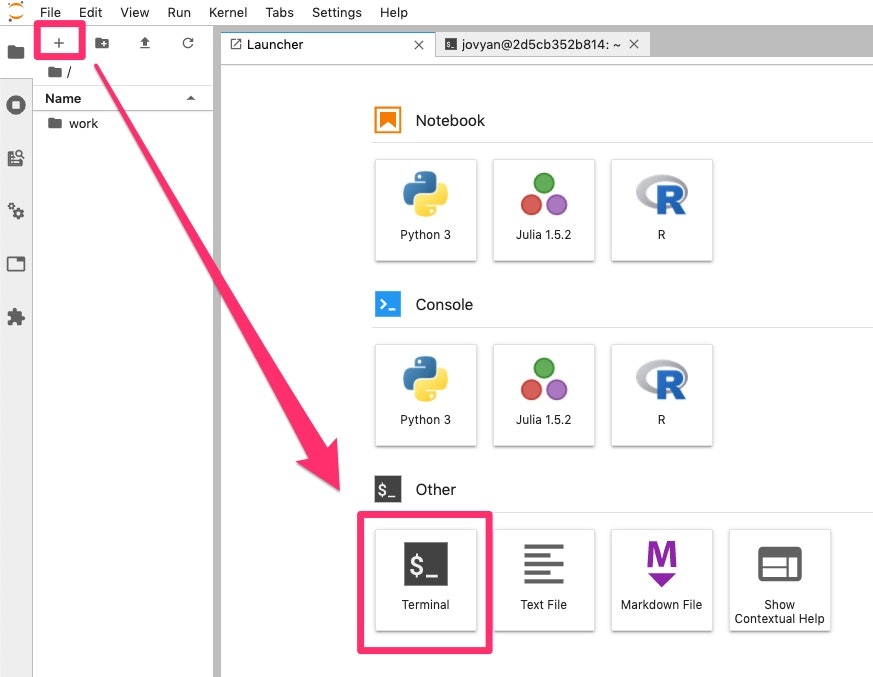
PySimpleGUI + OpenCVで動画プレイヤーを作る2 ROI設定と保存機能の追加(DIVX, MJPG, GIF)
はじめに
前回の記事に加えて、操作の対象として選ぶ領域ROI (Region of Interest)と特定の部分のみを処理対象とする処理(マスク)を付け加えます。
また、フレーム、ROIを切り出した画像を保存する機能を付け加えます。コーデックは種々選択可能ですが、圧縮率の高いDIVX, ImageJで解析可能なMJPG, Qiitaに張り付け可能なGIFで保存できるようにします。前回記事:
PySimpleGUI + OpenCVで動画プレイヤーを作るこの記事でできること
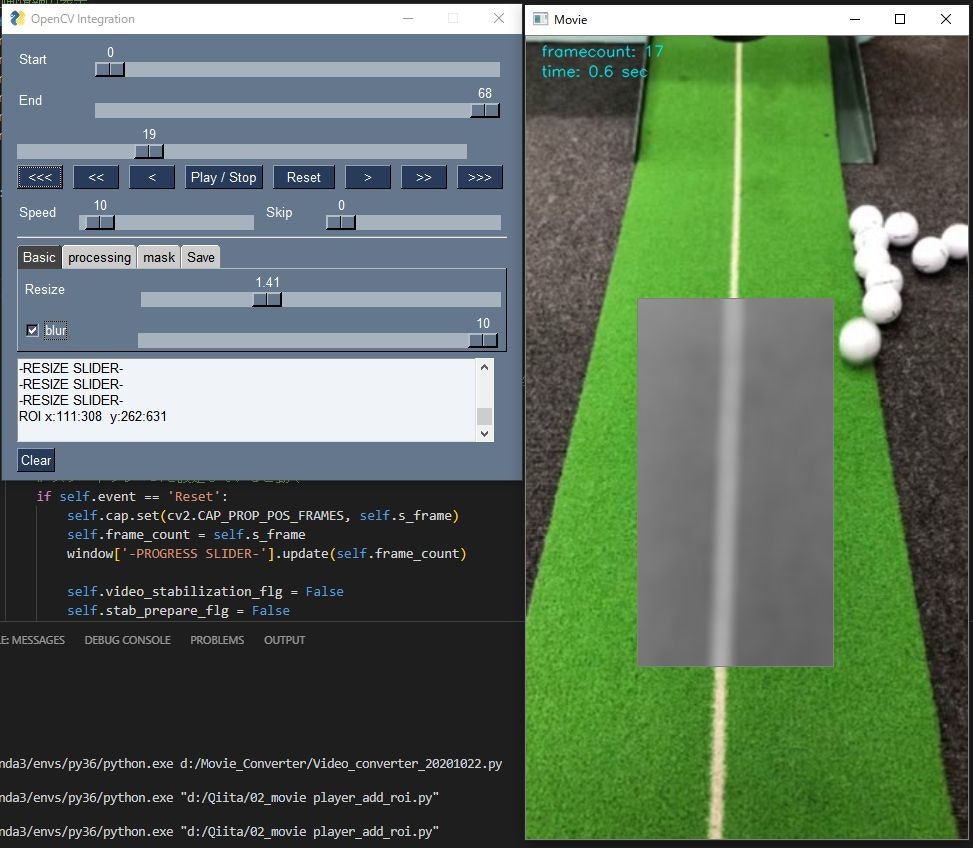
動画のサイズをスライダで変更できます。
マウスで矩形選択した部分に、グレースケール、ぼかしを入れることが出来ます。
選択部分をDIVX, MJPEG, GIFのいずれかで保存することが出来ます。
動画の読込
前回と同様PySimpleGUIを使用してファイルの読込GUIを生成します。
class Main: def __init__(self): self.fp = file_read() self.cap = cv2.VideoCapture(str(self.fp)) # 1フレーム目の取得 # 取得可能かの確認 self.ret, self.f_frame = self.cap.read() if self.ret: self.cap.set(cv2.CAP_PROP_POS_FRAMES, 0) # 動画情報の取得 self.fps = self.cap.get(cv2.CAP_PROP_FPS) self.width = int(self.cap.get(cv2.CAP_PROP_FRAME_WIDTH)) self.height = int(self.cap.get(cv2.CAP_PROP_FRAME_HEIGHT)) self.total_count = self.cap.get(cv2.CAP_PROP_FRAME_COUNT) # フレーム関係 self.frame_count = 0 self.s_frame = 0 self.e_frame = self.total_count # 再生の一時停止フラグ self.stop_flg = False cv2.namedWindow("Movie") else: sg.Popup("ファイルの読込に失敗しました。") return動画の読込
class Main: def __init__(self): self.fp = file_read() self.cap = cv2.VideoCapture(str(self.fp)) # 1フレーム目の取得 # 取得可能かの確認 self.ret, self.f_frame = self.cap.read() self.cap.set(cv2.CAP_PROP_POS_FRAMES, 0) # フレームが取得できた場合、各種パラメータを取得 if self.ret: self.cap.set(cv2.CAP_PROP_POS_FRAMES, 0) # 動画情報の取得 self.fps = self.cap.get(cv2.CAP_PROP_FPS) self.width = int(self.cap.get(cv2.CAP_PROP_FRAME_WIDTH)) self.height = int(self.cap.get(cv2.CAP_PROP_FRAME_HEIGHT)) self.total_count = self.cap.get(cv2.CAP_PROP_FRAME_COUNT)ROIの初期サイズは動画サイズと同じにします。
# ROI self.frames_roi = np.zeros((5, self.height, self.width)) # オリジナルサイズの保存 self.org_width = self.width self.org_height = self.height # フレーム関係 self.frame_count = 0 self.s_frame = 0 self.e_frame = self.total_count # 画像きり抜き位置 self.x1 = 0 self.y1 = 0 self.x2 = self.width self.y2 = self.height # 再生の一時停止フラグ self.stop_flg = False # 動画の保存フラグ self.rec_flg = False # マウスの動きの制御 # マウスのボタンが押されているかどうか self.mouse_flg = False self.event = "" # ROIへの演算を適応するかどうか self.roi_flg = True cv2.namedWindow("Movie")動画ウィンドウの左クリックDOWN → UP で矩形選択できるようコールバック関数を登録します。
# マウスイベントのコールバック登録 cv2.setMouseCallback("Movie", self.onMouse) # フレームを取得出来なかった場合に終了する else: sg.Popup("ファイルの読込に失敗しました。") return # マウスイベント def onMouse(self, event, x, y, flags, param): # 左クリック if event == cv2.EVENT_LBUTTONDOWN: self.x1 = self.x2 = x self.y1 = self.y2 = y # 長方形の描写開始。マウスを一回押すと長方形描写を開始する。 self.mouse_flg = True # ROI部分の演算を一時停止 self.roi_flg = False return elif event == cv2.EVENT_LBUTTONUP: # 長方形の更新を停止 self.mouse_flg = False # ROIへの演算を開始する self.roi_flg = True # ROIの選択で0の場合はリセットし、ROIの演算をストップ if ( x == self.x1 or y == self.y1 or x <= 0 or y <= 0 ): self.x1 = 0 self.y1 = 0 self.x2 = self.width self.y2 = self.height return # x1 < x2になるようにする elif self.x1 < x: self.x2 = x else: self.x2 = self.x1 self.x1 = x if self.y1 < y: self.y2 = y else: self.y2 = self.y1 self.y1 = y # ROI範囲を表示 print( "ROI x:{0}:{1} y:{2}:{3}".format( str(self.x1), str(self.x2), str(self.y1), str(self.y2) ) ) return # マウスが押下されている場合、長方形を表示し続ける if self.mouse_flg: self.x2 = x self.y2 = y returnGUIの生成
ROIに実施する処理として、グレイスケール、ぼかしを追加しています。
画像サイズの変更スライダも追加しています。def run(self): # GUI ####################################################### # GUIのレイアウト T1 = sg.Tab("Basic", [ [ sg.Text("Resize ", size=(13, 1)), sg.Slider( (0.1, 4), 1, 0.01, orientation='h', size=(40, 15), key='-RESIZE SLIDER-', enable_events=True ) ], [ sg.Checkbox( 'blur', size=(10, 1), key='-BLUR-', enable_events=True ), sg.Slider( (1, 10), 1, 1, orientation='h', size=(40, 15), key='-BLUR SLIDER-', enable_events=True ) ], ]) T2 = sg.Tab("processing", [ [ sg.Checkbox( 'gray', size=(10, 1), key='-GRAY-', enable_events=True ) ], ]) T3 = sg.Tab("mask", [ [ sg.Radio( 'Rectangle', "RADIO2", key='-RECTANGLE_MASK-', default=True, size=(8, 1) ), sg.Radio( 'Masking', "RADIO2", key='-MASKING-', size=(8, 1) ) ], ]) T4 = sg.Tab("Save", [ [ sg.Button('Write', size=(10, 1)), sg.Radio( 'DIVX', "RADIO1", key='-DIVX-', default=True, size=(8, 1) ), sg.Radio('MJPG', "RADIO1", key='-MJPG-', size=(8, 1)), sg.Radio('GIF', "RADIO1", key='-GIF-', size=(8, 1)) ], [ sg.Text('Caption', size=(10, 1)), sg.InputText( size=(32, 50), key='-CAPTION-', enable_events=True ) ] ]) layout = [ [ sg.Text("Start", size=(8, 1)), sg.Slider( (0, self.total_count - 1), 0, 1, orientation='h', size=(45, 15), key='-START FRAME SLIDER-', enable_events=True ) ], [ sg.Text("End ", size=(8, 1)), sg.Slider( (0, self.total_count - 1), self.total_count - 1, 1, orientation='h', size=(45, 15), key='-END FRAME SLIDER-', enable_events=True ) ], [sg.Slider( (0, self.total_count - 1), 0, 1, orientation='h', size=(50, 15), key='-PROGRESS SLIDER-', enable_events=True )], [ sg.Button('<<<', size=(5, 1)), sg.Button('<<', size=(5, 1)), sg.Button('<', size=(5, 1)), sg.Button('Play / Stop', size=(9, 1)), sg.Button('Reset', size=(7, 1)), sg.Button('>', size=(5, 1)), sg.Button('>>', size=(5, 1)), sg.Button('>>>', size=(5, 1)) ], [ sg.Text("Speed", size=(6, 1)), sg.Slider( (0, 240), 10, 10, orientation='h', size=(19.4, 15), key='-SPEED SLIDER-', enable_events=True ), sg.Text("Skip", size=(6, 1)), sg.Slider( (0, 300), 0, 1, orientation='h', size=(19.4, 15), key='-SKIP SLIDER-', enable_events=True ) ], [sg.HorizontalSeparator()], [ sg.TabGroup( [[T1, T2, T3, T4]], tab_background_color="#ccc", selected_title_color="#fff", selected_background_color="#444", tab_location="topleft" ) ], [sg.Output(size=(65, 5), key='-OUTPUT-')], [sg.Button('Clear')] ] # Windowを生成 window = sg.Window('OpenCV Integration', layout, location=(0, 0)) # 動画情報の表示 self.event, values = window.read(timeout=0) print("ファイルが読み込まれました。") print("File Path: " + str(self.fp)) print("fps: " + str(int(self.fps))) print("width: " + str(self.width)) print("height: " + str(self.height)) print("frame count: " + str(int(self.total_count))) # メインループ ######################################################### try: while True: # GUIイベントの読込 self.event, values = window.read( timeout=values["-SPEED SLIDER-"] ) # イベントをウィンドウに表示 if self.event != "__TIMEOUT__": print(self.event) # Exitボタンが押されたら、またはウィンドウの閉じるボタンが押されたら終了 if self.event in ('Exit', sg.WIN_CLOSED, None): break # 動画の再読み込み # スタートフレームを設定していると動く if self.event == 'Reset': self.cap.set(cv2.CAP_PROP_POS_FRAMES, self.s_frame) self.frame_count = self.s_frame window['-PROGRESS SLIDER-'].update(self.frame_count) self.video_stabilization_flg = False self.stab_prepare_flg = False # Progress sliderへの変更を反映させるためにcontinue continue動画の保存
動画ファイルとして保存する場合は、cv2.VideoWriter_fourccを使用します。ここでは、圧縮率が高いDIVXとフリーの動画解析ソフトImageJで読み込み可能なMJPEG形式で保存できるように設定しています。
GIFファイルで保存する場合は、Pillowを使用しています。# 動画の書き出し if self.event == 'Write': self.rec_flg = True self.cap.set(cv2.CAP_PROP_POS_FRAMES, self.s_frame) self.frame_count = self.s_frame window['-PROGRESS SLIDER-'].update(self.frame_count) if values["-GIF-"]: images = [] else: # 動画として保存 # コーデックの選択 # DIVXは圧縮率高い # MJEGはImageJで解析可能 if values["-DIVX-"]: codec = "DIVX" elif values["-MJPG-"]: codec = "MJPG" fourcc = cv2.VideoWriter_fourcc(*codec) out = cv2.VideoWriter( str(( self.fp.parent / (self.fp.stem + '_' + codec + '.avi') )), fourcc, self.fps, (int(self.x2 - self.x1), int(self.y2 - self.y1)) ) continue # フレーム操作 ################################################ # スライダを直接変更した場合は優先する if self.event == '-PROGRESS SLIDER-': # フレームカウントをプログレスバーに合わせる self.frame_count = int(values['-PROGRESS SLIDER-']) self.cap.set(cv2.CAP_PROP_POS_FRAMES, self.frame_count) if values['-PROGRESS SLIDER-'] > values['-END FRAME SLIDER-']: window['-END FRAME SLIDER-'].update( values['-PROGRESS SLIDER-']) # スタートフレームを変更した場合 if self.event == '-START FRAME SLIDER-': self.s_frame = int(values['-START FRAME SLIDER-']) self.cap.set(cv2.CAP_PROP_POS_FRAMES, self.s_frame) self.frame_count = self.s_frame window['-PROGRESS SLIDER-'].update(self.frame_count) if values['-START FRAME SLIDER-'] > values['-END FRAME SLIDER-']: window['-END FRAME SLIDER-'].update( values['-START FRAME SLIDER-']) self.e_frame = self.s_frame # エンドフレームを変更した場合 if self.event == '-END FRAME SLIDER-': if values['-END FRAME SLIDER-'] < values['-START FRAME SLIDER-']: window['-START FRAME SLIDER-'].update( values['-END FRAME SLIDER-']) self.s_frame = self.e_frame # エンドフレームの設定 self.e_frame = int(values['-END FRAME SLIDER-']) if self.event == '<<<': self.frame_count = np.maximum(0, self.frame_count - 150) window['-PROGRESS SLIDER-'].update(self.frame_count) self.cap.set(cv2.CAP_PROP_POS_FRAMES, self.frame_count) if self.event == '<<': self.frame_count = np.maximum(0, self.frame_count - 30) window['-PROGRESS SLIDER-'].update(self.frame_count) self.cap.set(cv2.CAP_PROP_POS_FRAMES, self.frame_count) if self.event == '<': self.frame_count = np.maximum(0, self.frame_count - 1) window['-PROGRESS SLIDER-'].update(self.frame_count) self.cap.set(cv2.CAP_PROP_POS_FRAMES, self.frame_count) if self.event == '>': self.frame_count = self.frame_count + 1 window['-PROGRESS SLIDER-'].update(self.frame_count) self.cap.set(cv2.CAP_PROP_POS_FRAMES, self.frame_count) if self.event == '>>': self.frame_count = self.frame_count + 30 window['-PROGRESS SLIDER-'].update(self.frame_count) self.cap.set(cv2.CAP_PROP_POS_FRAMES, self.frame_count) if self.event == '>>>': self.frame_count = self.frame_count + 150 window['-PROGRESS SLIDER-'].update(self.frame_count) self.cap.set(cv2.CAP_PROP_POS_FRAMES, self.frame_count) # カウンタがエンドフレーム以上になった場合、スタートフレームから再開 if self.frame_count >= self.e_frame: self.cap.set(cv2.CAP_PROP_POS_FRAMES, self.s_frame) self.frame_count = self.s_frame window['-PROGRESS SLIDER-'].update(self.frame_count) continue # ストップボタンで動画の読込を一時停止 if self.event == 'Play / Stop': self.stop_flg = not self.stop_flg # ストップフラグが立っており、eventが発生した場合以外はcountinueで # 操作を停止しておく # ストップボタンが押された場合は動画の処理を止めるが、何らかの # eventが発生した場合は画像の更新のみ行う # mouse操作を行っている場合も同様 if( ( self.stop_flg and self.event == "__TIMEOUT__" and self.mouse_flg is False ) ): window['-PROGRESS SLIDER-'].update(self.frame_count) continue # スキップフレーム分とばす if not self.stop_flg and values['-SKIP SLIDER-'] != 0: self.frame_count += values["-SKIP SLIDER-"] self.cap.set(cv2.CAP_PROP_POS_FRAMES, self.frame_count) # フレームの読込 ############################################## self.ret, self.frame = self.cap.read() self.valid_frame = int(self.frame_count - self.s_frame) # 最後のフレームが終わった場合self.s_frameから再開 if not self.ret: self.cap.set(cv2.CAP_PROP_POS_FRAMES, self.s_frame) self.frame_count = self.s_frame continue画像処理の実施
以降に、サイズ変更、グレースケール化、ぼかしなどの処理を記述していきます。
フレーム全体に行う処理であるサイズ変更を行った後、ROIにのみグレースケール化とぼかしの処理を行っています。# 以降にフレームに対する処理を記述 ################################## # frame全体に対する処理をはじめに実施 ############################## # リサイズ self.width = int(self.org_width * values['-RESIZE SLIDER-']) self.height = int(self.org_height * values['-RESIZE SLIDER-']) self.frame = cv2.resize(self.frame, (self.width, self.height)) if self.event == '-RESIZE SLIDER-': self.x1 = self.y1 = 0 self.x2 = self.width self.y2 = self.height # ROIに対して処理を実施 ########################################## if self.roi_flg: self.frame_roi = self.frame[ self.y1:self.y2, self.x1:self.x2, : ] # ぼかし if values['-BLUR-']: self.frame_roi = cv2.GaussianBlur( self.frame_roi, (21, 21), values['-BLUR SLIDER-'] ) if values['-GRAY-']: self.frame_roi = cv2.cvtColor( self.frame_roi, cv2.COLOR_BGR2GRAY ) self.frame_roi = cv2.cvtColor( self.frame_roi, cv2.COLOR_GRAY2BGR )処理したROIはフレームに戻して表示させます。
# 処理したROIをframeに戻す self.frame[self.y1:self.y2, self.x1:self.x2, :] = self.frame_roi # 動画の保存 if self.rec_flg: # 手振れ補正後再度roiを切り抜き self.frame_roi = self.frame[ self.y1:self.y2, self.x1:self.x2, : ] if values["-GIF-"]: images.append( Image.fromarray( cv2.cvtColor( self.frame_roi, cv2.COLOR_BGR2RGB ) ) ) else: out.write(self.frame_roi) # 保存中の表示 cv2.putText( self.frame, str("Now Recording"), (20, 60), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (10, 10, 255), 1, cv2.LINE_AA ) # e_frameになったら終了 if self.frame_count >= self.e_frame - values["-SKIP SLIDER-"] - 1: if values["-GIF-"]: images[0].save( str((self.fp.parent / (self.fp.stem + '.gif'))), save_all=True, append_images=images[1:], optimize=False, duration=1000 // self.fps, loop=0 ) else: out.release() self.rec_flg = False # フレーム数と経過秒数の表示 cv2.putText( self.frame, str("framecount: {0:.0f}".format(self.frame_count)), ( 15, 20), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (240, 230, 0), 1, cv2.LINE_AA ) cv2.putText( self.frame, str("time: {0:.1f} sec".format( self.frame_count / self.fps)), (15, 40), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (240, 230, 0), 1, cv2.LINE_AA ) # ROIへの演算を実施している場合 or マウス左ボタンを押している最中 # 長方形を描写する if self.roi_flg or self.mouse_flg: cv2.rectangle( self.frame, (self.x1, self.y1), (self.x2 - 1, self.y2 - 1), (128, 128, 128) ) # 画像を表示 cv2.imshow("Movie", self.frame) if self.stop_flg: self.cap.set(cv2.CAP_PROP_POS_FRAMES, self.frame_count) else: self.frame_count += 1 window['-PROGRESS SLIDER-'].update(self.frame_count + 1) # その他の処理 ############################################### # ログウィンドウのクリア if self.event == 'Clear': window['-OUTPUT-'].update('') finally: cv2.destroyWindow("Movie") self.cap.release() window.close() if __name__ == '__main__': Main().run()参考リンク

- 投稿日:2020-10-22T23:18:39+09:00
pythonの対話モードで'(Single quote)のエスケープ記号がそのまま表示される場合がある
※BashもPythonもよくわかってない人が書いているので、話半分で見てください…
pythonの対話モードで以下のような入力をすると、
'の前の\まで表示されてしまうという話を聞いた。>>> "\"No, I can\'t\" He said." # '"No, I can\'t" He said.'と表示される >>> print("\"No, I can\'t\" He said.") # "No, I can't" He said. エスケープ記号は入らないなお、print()の引数にすると意図したとおりに出る。
それについての予想を書いてみる。(そのうち根拠を見つけてくるかも)環境
入力値とその結果
"abc" →'abc'
"\"\"" →'""'
"\"\'" →'"\''
"\'\'" → "''"
"a\'" → "a'"上記からわかること
- 'の前に\が付いてしまうのは"と'が混在している時である
- 文字列は'で囲まれて出力されるが、'が含まれる場合は"で囲う
- Bashには'で文字列を囲む場合、'を含めることができないという制限があるらしい
ひょっとして
こんな感じの処理になっているのでは?
1. "\"\'"と入力("'と表示させたい)
2. [1]まで解釈すると'"'という文字列ができる
3. [3]まで解釈すると文字列中に'が含まれることがわかる
4. 2の文字列はそのままで、新たに文字列を生成。'が含まれるので囲み文字は"にする。囲み文字が"なのでエスケープ記号もそのまま含まれてしまう1ため\を取り除くべきだが、うっかりそのまま含めて文字列を作ってしまう
5. '"'の文字列と"\'"の文字列ができたので結合して出力!2
6. '"\'∧∧
ヽ(・ω・)/ ズコー
\(.\ ノ
、ハ,,、  ̄今後
インタプリタの挙動を調べる?どこから調べたらいいものか…
割り込みが来たのでとりあえずここまで
- 投稿日:2020-10-22T23:18:39+09:00
Pythonの対話モードで'(Single quote)のエスケープ記号がそのまま表示される場合がある
※Pythonよくわかってない人が書いているので、話半分で見てください…
pythonの対話モードで以下のような入力をすると、
'の前の\まで表示されてしまうという話を聞いた。>>> "\"No, I can\'t\" He said." # '"No, I can\'t" He said.'と表示される >>> print("\"No, I can\'t\" He said.") # "No, I can't" He said. エスケープ記号は入らないなお、print()の引数にすると意図したとおりに出る。
この動作は仕様です。公式Docに同じような事例が紹介されていますね。お恥ずかしいです…
なぜその仕様なのかは頂いたコメントを元に今後考えていきます。
それについての予想を書いてみる。(そのうち根拠を見つけてくるかも環境
入力値とその結果
"abc" →'abc'
"\"\"" →'""'
"\"\'" →'"\''
"\'\'" → "''"
"a\'" → "a'"上記からわかること
- 'の前に\が付いてしまうのは"と'が混在している時である
- 文字列は'で囲まれて出力されるが、'が含まれる場合は"で囲う(これは仕様)
以下は駄々滑りの考察だったので消しています。
本当に恥ずかしい…ひょっとして
こんな感じの処理になっているのでは?
1. "\"\'"と入力("'と表示させたい)
2. [1]まで解釈すると'"'という文字列ができる
3. [3]まで解釈すると文字列中に'が含まれることがわかる
4. 2の文字列はそのままで、新たに文字列を生成。'が含まれるので囲み文字は"にする。囲み文字が"なので\はエスケープ文字として機能しない1。そのため\を取り除くべきだが、うっかりそのまま含めて文字列を作ってしまう
5. '"'の文字列と"\'"の文字列ができたので結合して出力!2今後
コメントで頂いた通り、str()とrepr()の違いを調べて何故今の出力に落ち着いたかを考えていきたい。
しかしPythonがわかっている人なら即答レベルなのかもしれないので、記事を消すかも。
- 投稿日:2020-10-22T22:56:31+09:00
python + JupyterLab で Web スクレイピング
はじめに
JupyterLabはお手軽にpythonを触ることができる実行環境です。環境構築
git clone https://github.com/takiguchi-yu/python-jupyterLab.git cd python-jupyterLabJupyterLab 起動
docker-compose up -dアクセス
JupyterLab 終了
docker-compose downWeb スクレイピングサンプル
ちょっとした Web スクレイピングを書いてみる。
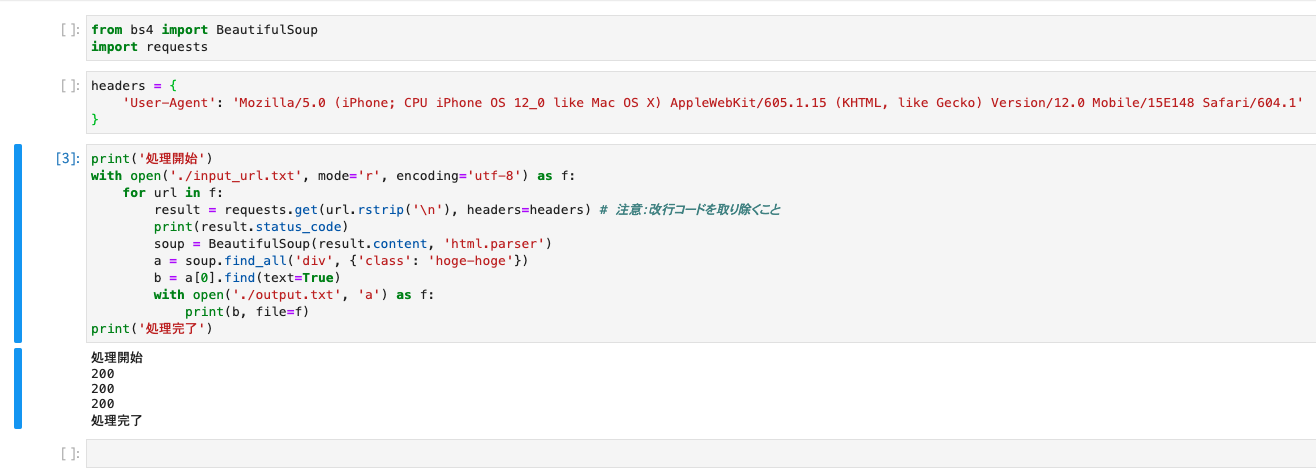
外部ファイルに記載されているURLを読み込んで、それを叩きながら結果を外部ファイルに出力するサンプル。
from bs4 import BeautifulSoup import requests headers = { 'User-Agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 12_0 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/12.0 Mobile/15E148 Safari/604.1' } print('処理開始') with open('./input_url.txt', mode='r', encoding='utf-8') as f: for url in f: result = requests.get(url.rstrip('\n'), headers=headers) # 注意:改行コードを取り除くこと print(result.status_code) soup = BeautifulSoup(result.content, 'html.parser') a = soup.find_all('div', {'class': 'hoge-hoge'}) b = a[0].find(text=True) with open('./output.txt', 'a') as f: print(b, file=f) print('処理完了')ターミナルも使える
好きなライブラリを自由に入れることができる
環境構築は以下を参考
- 投稿日:2020-10-22T19:16:07+09:00
pyenv で特定のバージョンで jupyter を動かす
Overview
- python のバージョンを固定したい(venv含む)
- けど、それぞれのバージョンに jupyter 入れるのは効率が悪い
- ので、どれか1つのバージョンに jupyter を入れて kernel だけ選べるようにしたい
ときってあるじゃないですか。
具体的に
こういう状況で、
bash$ pyenv versions system 3.6.12 * 3.8.6 (set by /Users/kuryu/.pyenv/version)
3.8.6で jupyter を起動して、3.6.12の kernel を動かすのを目指す。まず jupyter を入れる
bash$ python -V Python 3.8.6 $ pip install jupyterpython のバージョンを変更する
bash$ pyenv global 3.6.12 $ python -V Python 3.6.12必要なら venv を作成
pyenv 環境にそのまま構築することも可能だけど、今回は venv 作ります。
bash$ python -m venv .venv $ . .venv/bin/activate (.venv) $ python -V Python 3.6.12 (.venv) $ pip list Package Version ---------- ------- pip 18.1 setuptools 40.6.2 You are using pip version 18.1, however version 20.2.4 is available. You should consider upgrading via the 'pip install --upgrade pip' command.ipykernel を入れる
bash(.venv) $ pip install ipykernel (.venv) $ ipython kernel install --user --name=hoge仮想環境を出て
bash(.venv) $ deactivatepython のバージョンも戻す
bash$ pyenv global 3.8.6 $ python -V Python 3.8.6おもむろに jupyter を起動
bash$ jupyter notebookkernel が追加されているので
実行してバージョンを確認
kernel が不要になったら
bash$ jupyter kernelspec uninstall hogeっていう話なんですけど、まぁまぁややこしいので混乱しないように注意。
cf.


- 投稿日:2020-10-22T17:49:57+09:00
【Python】文字列を一斉置換する正規表現も使える関数を作った。
はじめに
文字列を複数のパターンで置換する場合、↓ のような冗長なコードになりがちですよね。
#例えば # " <-> ' # abc...z -> * # ABC...Z -> AA, BB, CC, ...,ZZ #のような置換がしたい場合 text = "'abc'" + '"ABC"' #パターン1 replaced_text = text.replace('"', '#').replace("'", '"').replace('#', "'").replace("a", "*"). ....... #パターン2 trdict = str.maketrans({'"': "'", "'": '"', "a": "*", "b": "*", .......}) replaces_text = text.translate(trdict) #パターン3 import re replaced_text = re.sub("#", '"', re.sub('"', "'", re.sub("'", '#', re.sub("[a-z], "*", re.sub("[A-Z]", "\\1\\1", text))))) #etc...また、パターン1、3のような置換方法の場合、置換は順を追って行われるため、置換後の文字が更に置換されたりなど予期せぬ置換が行われる可能性も考慮しなければなりません。
しかし、パターン3のように正規表現を使えないと多大で無駄な手間がかかってしまいます。そんな不満を解消するべく、
正規表現も使えて、
置換パターンを辞書でまとめて渡せて、
すべての置換を同時に行える関数を書きました。
出来たもの
import re from typing import Dict def replaces(text: str, trdict: Dict[str, str]) -> str: """ IN: Source text Replacement dictionary OUT: Replaced text NOTE: You can use regular expressions. If more than one pattern is matched, the pattern closest to the front of the dictionary takes precedence. EXAMPLE: text = "'abc'" + '"ABC"' replaces(text, {"'": '"', '"': "'", "[a-z]": "*", "([A-Z])": "\\1\\1"}) ---> "***"'AABBCC' """ return re.sub( "|".join(trdict.keys()), lambda m: next( (re.sub(pattern, trdict[pattern], m.group(0)) for pattern in trdict if re.fullmatch(pattern, m.group(0)))), text)使い方
第1引数:元の文字列
第2引数:置換用辞書{before: after}
返り値 :置換後の文字列text = "'abc'" + '"ABC"' trdict = {"'": '"', '"': "'", "[a-z]": "*", "([A-Z])": "\\1\\1"} replaces(text, trdict) # ---> "***"'AABBCC'辞書内の複数パターンに一致した場合、前方のパターンが優先されます。
- 投稿日:2020-10-22T14:43:57+09:00
Numpyを使用してFFT&トレンド除去
はじめに
Pythonで,Numpyを使って時系列データをFFT(Fast Fourier Transform: 高速フーリエ変換)する方法と,時系列データのトレンドを除去する方法について紹介しようと思います.FFTとは,DFT(Discrete Fourier Transform:離散フーリエ変換)を高速処理する計算方法です.この記事では理論には触れず,FFTを実行する最低限のコードを示します.参考にした文献は「スペクトル解析 著:日野幹雄 (朝倉書店)」.フーリエ解析の基礎からFFTの理論まで,この本1冊で十分です.
目次
1.時系列データ
2.FFT実行
3.トレンド除去
4.フーリエ成分を周波数平滑化(スムージング)
5.Appendix本題
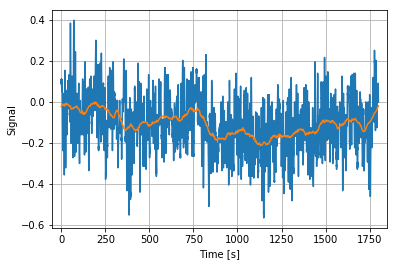
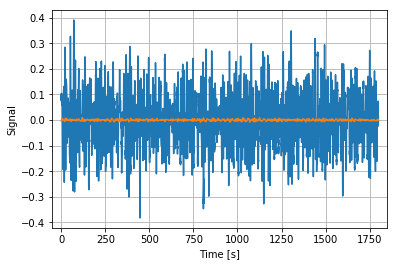
1. 時系列データ
サンプリング周波数10Hzの30分間データ.オレンジの線は移動平均です.トレンドがあるのが分かりますね.
図1.元の時系列データこのデータをFFTしていきます.
2. FFT実行
N =len(X) #データ長 fs=10 #サンプリング周波数 dt =1/fs # サンプリング間隔 t = np.arange(0.0, N*dt, dt) #時間軸 freq = np.linspace(0, fs,N) #周波数軸 fn=1/dt/2 #ナイキスト周波数FFTはデータ長が2のべき乗である場合に最も計算速度が速くなるような計算手法ですが,そうでない場合でも計算は可能です(処理時間が多少長くなりますが).ただし,データ長が素数の場合には,2のべき乗の時に比べて相対的にかなり処理時間がかかるので,2のべき乗になるよう0パディングした方が良さそうです.Appendixにそれを確かめるコードを載せたので是非確かめてみてください.
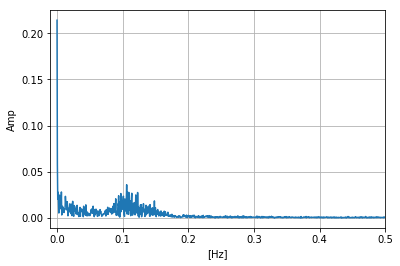
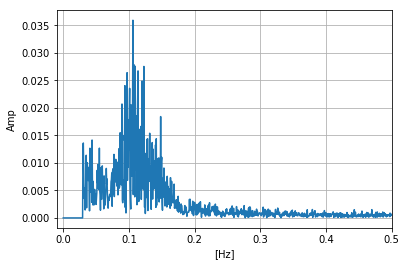
F=np.fft.fft(X)/(N/2) F[(freq>fn)]=0 #ナイキスト周波数以降をカット plt.plot(freq,np.abs(F))# plt.xlabel("[Hz]") plt.ylabel("Amp") plt.xlim(-0.01,0.5) plt.grid() plt.show()np.fft.fftでは複素フーリエ成分で与えられるので,その絶対値をとったものをプロットしたのが下図です.トレンド成分が0Hz付近にありますね.
次節ではトレンド除去してみましょう.
図2.元の時系列データに対してFFT実行3. トレンド除去
図1の移動平均(オレンジ線)を見ると,時系列データの軸がx軸と乖離しており,データにトレンドがあるのが分かります.次の操作で,0.03Hz以下を0にすることでトレンドを除去してみましょう.
F=np.fft.fft(X)/(N/2) F[(freq>fn)]=0 F[(freq<=0.03)]=0 #0.03HZ以下を除去 X_1=np.real(np.fft.ifft(F))*N plt.xlabel("Time [s]") plt.ylabel("Signal") plt.xlim(-50,1850) plt.grid() plt.show()
図3.トレンド除去後の時系列データx軸を起点に周期関数となっていることが分かります.
4. フーリエ成分を周波数平滑化(スムージング)
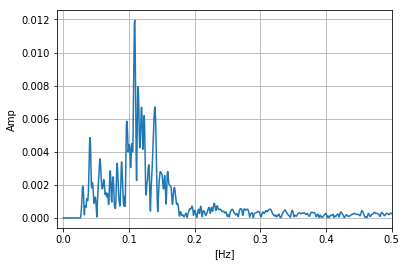
図3のデータをFFTすると図4になります.
図4.トレンド除去後の時系列データに対してFFTガタガタしてるので,平滑化ウィンドーを作用させてスムージングをしてみます.
window=np.ones(5)/5 #平滑化ウィンドー F3=np.convolve(F2,window,mode='same') #畳み込み F3=np.convolve(F3,window,mode='same') #畳み込み F3=np.convolve(F3,window,mode='same') #畳み込み plt.plot(freq,np.abs(F3)) plt.xlabel("[Hz]") plt.ylabel("Amp") plt.xlim(-0.01,0.5) plt.grid() plt.show()
図5.平滑化した5. Appendix
データ長さを3種類用意して計算時間を比較してみます.
①2^19(2のべき乗) ②2^(19)-1 (素数) ③2^(19)-2 (素数でも2のいべき乗でもない)import time if __name__ == '__main__': start = time.time() x2 = np.random.uniform(size=2**19-2)#2**19 , 2**19-1 print(np.fft.fft(x2)) elapsed_time = time.time() - start print ("elapsed_time:{0}".format(elapsed_time) + "[sec]")計算結果
①0.04197[sec]
②0.1679[sec]
③0.05796[sec]データ長が素数の場合には0パディングを行って2のべき乗にした方が良さそうですね.
- 投稿日:2020-10-22T12:19:46+09:00
Speech Recognition : Phoneme Prediction Part2 - Connectionist Temporal Classification RNN
目標
Microsoft Cognitive Toolkit (CNTK) を用いた音素予測の続きです。
Part2 では、Part1 で準備した特徴量と音素ラベルを用いて音素予測を行います。
NVIDIA GPU CUDA がインストールされていることを前提としています。導入
Speech Recognition : Phoneme Prediction Part1 - ATR Speech dataset では、ATR サンプル音声データベース [1] から音素ラベルのリストと HTK フォーマットファイル、フレームと音素ラベルを準備しました。
Part2 では、再帰ニューラルネットワーク (RNN) による音素予測モデルを作成して訓練します。
音声認識における再帰ニューラルネットワーク
今回実装した音素予測の全体像は下図のようになります。再帰ニューラルネットワークの構成要素は、LSTM [2] とし、forward, backward の出力を連結する双方向モデル [3] にしました。
各層では、forward, backward にそれぞれ Layer Normalization [4] を適用してから連結して残差接続 [5] を行い、最後の全結合で音素ラベルを予測します。
訓練における諸設定
各パラメータの初期値は、Glorot の一様分布 [6] を使用しました。
損失関数には Connectionist Temporal Classification [7] を使用しました。
最適化アルゴリズムには Adam [8] を採用しました。Adam のハイパーパラメータ $\beta_1$ は 0.9、$\beta_2$ は CNTK のデフォルト値に設定しました。
学習率には、Cyclical Learning Rate (CLR) [9] を採用して、最大学習率は 1e-3、ベース学習率は 1e-5、ステップサイズはエポック数の 10倍、方策は triangular2 に設定しました。
過学習対策として、残差接続の前に Dropout [10] を 0.1 で適用しました。
モデルの訓練はミニバッチ学習によって 100 Epoch を実行しました。
実装
実行環境
ハードウェア
・CPU Intel(R) Core(TM) i7-7700 3.60GHz
・GPU NVIDIA Quadro P4000 8GBソフトウェア
・Windows 10 Pro 1909
・CUDA 10.0
・cuDNN 7.6
・Python 3.6.6
・cntk-gpu 2.7
・cntkx 0.1.53
・librosa 0.8.0
・numpy 1.19.2
・pandas 1.1.2
・PyAudio 0.2.11
・scipy 1.5.2実行するプログラム
訓練用のプログラムは GitHub で公開しています。
ctcr_training.py解説
今回の実装で要となる内容について補足します。
Connectionist Temporal Classification
音声認識において、音声データのフレーム数と予測したい音素の数は異なっていることが多いです。そのような場合、RNN の出力と正解データが一対一に対応しません。
そこで、空白文字として _ を導入することにより、下図のように正解データ aoi は矢印の経路を辿ることにして、__a_o__i_ のようにフレーム数との長さを合わせます。
Connectionist Temporal Classification (CTC) ではパラメータの学習を最尤推定で行い、上図のような正解データの系列が得られる経路の確率を計算します。入力データの系列を $x$、正解データの系列を $l$ とすると、損失関数は以下の式で定義されます。
Loss = - \log p(l|x)しかし損失関数を計算するための経路の組み合わせは非常に多く存在します。そこで、動的計画法に基づく前向き後ろ向きアルゴリズムを用いて効率良く求めます。
ここで、下図のように時刻 $t$ で系列 $s$ に到達する経路の集合 $\pi$ の確率の総和 $\alpha_t(s)$ を前向き確率と呼び、以下の式で表します。
\alpha_t (s) = \sum_{s \in \pi} \prod^t_{i=1} y^i_s
この前向き確率 $\alpha_t(s)$ は、動的計画法の考え方に基づいて再帰的に効率良く求めることができます。
\left\{ \begin{array}{ll} \alpha_1(1) = y^1_1 \\ \alpha_t(s) = (\alpha_{t-1} (s-1) + \alpha_{t-1} (s)) y^t_s \end{array} \right.同様に、下図のような後ろ向き確率 $\beta_t(i)$ は以下のように定義します。
\beta_t(s) = \sum_{s \in \pi} \prod^T_{i=s} y^i_s
この後ろ向き確率 $\beta$ も前向き確率 $\alpha$ と同様に再帰的に効率良く求めることができます。
\left\{ \begin{array}{ll} \beta_T(S) = 1 \\ \beta_t(s) = (\beta_{t+1} (s+1) + \beta_{t+1} (s)) y^{t+1}_s \end{array} \right.すると、すべての経路における確率は $\alpha_t(s) \beta_t(s)$ となり、損失関数は以下の式になります。
Loss = - \log \sum^S_{s=1} \alpha_t(s)\beta_t(s)編集距離
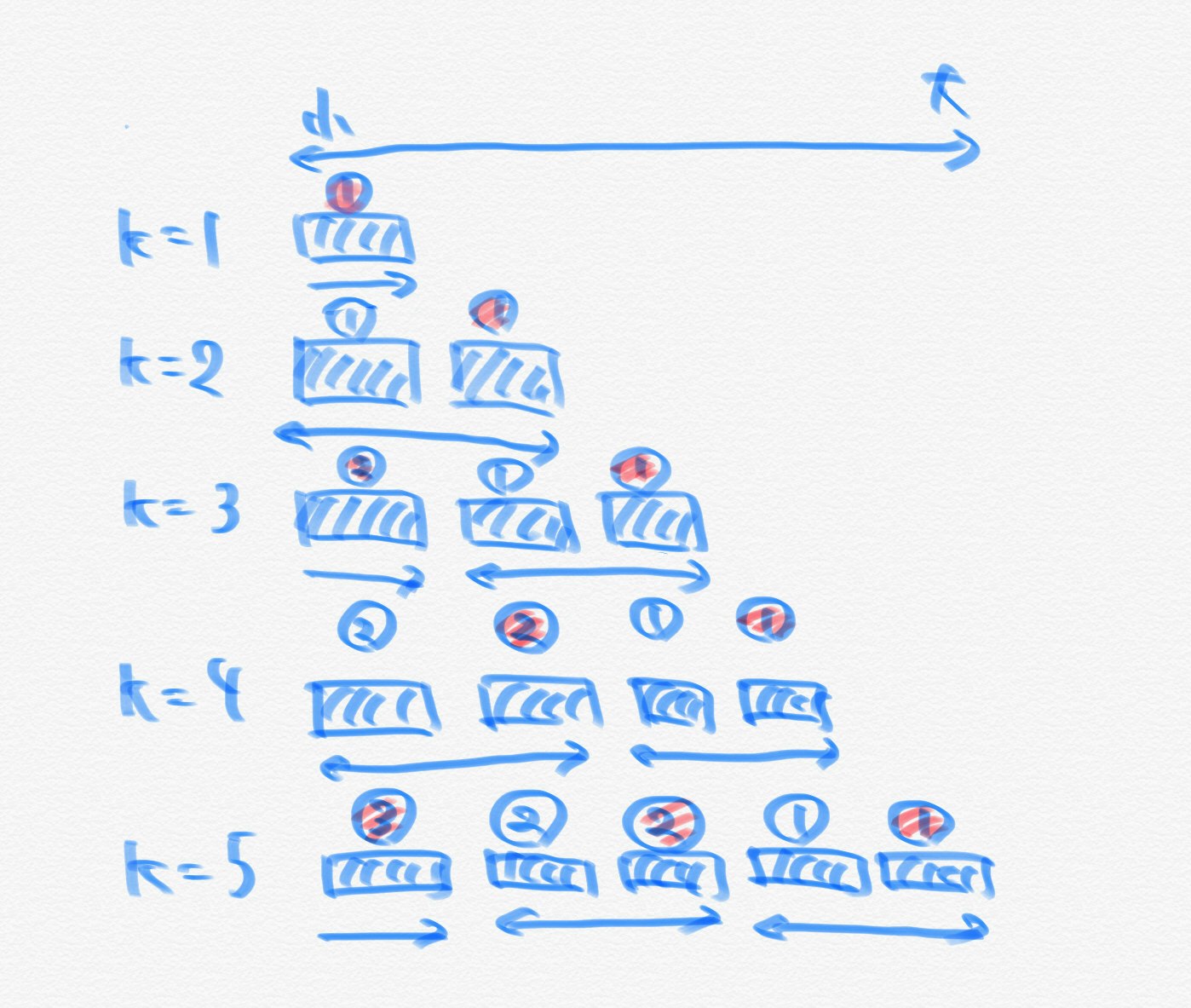
今回はモデルの性能評価指標として編集距離を使用しました。編集距離はレーベンシュタイン距離とも呼ばれており、挿入、削除、置換の操作を行う最小回数のことです。
例として、akai という文字列と aoi という文字列の編集距離は、
・akai の k を削除
・aai の a を o に置換という操作によって 2 と求まります。編集距離は以下のように先頭に空白文字を追加した表を用いて求めることができます。
まず、下図の青矢印のように 1行目と 1列目の編集距離を求めます。これは空白文字 _ と各時点での文字列の長さと同じになります。
次に、緑矢印のように上左から順に、以下のいずれかの中で最も小さい値を入力します。
・1つ上の値に 1を加えたもの
・1つ左の値に 1を加えたもの
・左上の値に 1を加えたもの(ただし、行方向と列方向の文字が同じ場合は 1 は加えない)
そして最後に求まる右下の赤で示した値が求めるべき編集距離になります。
結果
Training loss and error
訓練時の損失関数と誤認識率のログを可視化したものが下図です。左のグラフが損失関数、右のグラフが編集距離になっており、横軸はエポック数、縦軸はそれぞれ損失関数の値と編集距離を表しています。
Validation error
Part1 でデータを準備する際に切り離しておいた検証データで性能評価してみると以下のような結果になりました。
Validation Error 40.31%発話音声データに対する音素予測
自身の発話音声を録音したものに対して音素予測した結果を以下に示します。発話内容は「こんにちは」としました。
Say... Record. ['sil', 'h', 'o', 'h', 'i', 'cl', 'ch', 'i', 'e', 'o', 'a', 'sil']推論時にはフレーム毎に音素を出力するので、連続する音素の冗長性と空白文字である _ を除去したものが音素予測の結果となります。
母音はほぼ正解しているようですが、子音は 'ch' 以外上手くいっていないようです。
参考
CNTK 208: Training Acoustic Model with Connectionist Temporal Classification (CTC) Criteria
Speech Recognition : Phoneme Prediction Part1 - ATR503 Speech dataset
- 吉田芳郎, 袋谷丈夫, 竹沢寿幸. "ATR 音声データベース", 人工知能学会全国大会論文集 0 (2002): pp. 189-189.
- Sepp Hochreiter, and Jürgen Schmidhuber. "Long Short-Term Memory", Neural Computation. 1997, p. 1735-1780.
- Mike Schuster and Luldip K. Paliwal. "Bidirectional Recurrent Neural Networks", IEEE transactions on Signal Processing, 45(11), 1997, p. 2673-2681.
- Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E. Hinton. "Layer Normalization", arXiv preprint arXiv:1607.06450 (2016).
- Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. "Deep Residual Learning for Image Recognition", the IEEE conference on computer vision and pattern recognition. 2016. p. 770-778.
- Xaiver Glorot and Yoshua Bengio. "Understanding the difficulty of training deep feedforward neural networks", Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics. 2010, p. 249-256.
- Alex Graves, Santiago Fernandez, Faustino Gomez, and Jurgen Schmidhuber. "Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Networks", In: Proceedings of the 23rd international conference on Machine learning. 2006. pp. 369-376.
- Diederik P. Kingma and Jimmy Lei Ba. "Adam: A method for stochastic optimization", arXiv preprint arXiv:1412.6980 (2014).
- Leslie N. Smith. "Cyclical Learning Rates for Training Neural Networks", 2017 IEEE Winter Conference on Applications of Computer Vision. 2017, p. 464-472.
- Nitish Srivastava, Geoffrey Hinton, Alex Krizhevshky, Ilya Sutskever, and Ruslan Salakhutdinov. "Dropout: A Simple Way to Prevent Neural Networks from Overfitting", The Journal of Machine Learning Research 15.1 (2014) p. 1929-1958.







- 投稿日:2020-10-22T12:01:09+09:00
Speech Recognition : Phoneme Prediction Part1 - ATR Speech dataset
目標
Microsoft Cognitive Toolkit (CNTK) を用いた音素予測についてまとめました。
Part1 では、音素予測のための準備を行います。
以下の順で紹介します。
- ATR サンプル音声データセットのダウンロード
- 特徴量の作成と HTK フォーマットファイルの保存
- CNTK が提供するビルトインリーダーが読み込むファイルの作成
導入
ATR サンプル音声データセットのダウンロード
ATR サンプル音声データセット [1] は、ATR データベースの音韻で構成された発話データセットです。
上記のリンクから atr_503_v1.0.tar.gz をダウンロードして解凍します。音声データは speech ディレクトリ下の .ad ファイルに存在し、今回使用する音素ラベルは label/monophone 下の old ディレクトリ下の .lab ファイルの方を使用します。
今回のディレクトリ構成は以下のようにしました。
CTCR
|―atr_503
|―label
|―speech
|―...
ctcr_atr503.py
MGCC特徴量の作成と HTK フォーマットファイルの保存
音声データはサンプリング周波数は 16,000 のビッグエンディアンの符号付き整数型 16bit で保存されているので、その最大値 $2^{16}/2-1=32,767$ で割って値の範囲 [-1, 1] に正規化します。
今回は音声データからメル周波数ケプストラム係数 (Mel Frequency Cepstrum Coefficient: MFCC) を求めました。使用する特徴量の数は 13次元としました。
なお、音声データには前処理として高域強調を施します。また、MFCC の 1階微分、2階微分も併せて、合計 39次元の特徴量としました。
作成した特徴量は、HTK (Hidden Markov Toolkit) フォーマットのバイナリファイルとして書き込んで保存します。
CNTK が提供するビルトインリーダーが読み込むファイルの作成
今回訓練時には音声認識に特化したビルトインリーダーの1つである HTKDeserializer と HTKMLFDeserializer を用います。
音素予測のための準備を行うプログラムの大まかな処理の流れは以下のようになります。
- 訓練データと検証データの分割
- 音素ラベルのリストファイルの作成
- 特徴量の生成と HTK フォーマットファイルの保存、フレームと音素ラベルの書き込み
実装
実行環境
ハードウェア
・CPU Intel(R) Core(TM) i7-6700K 4.00GHz
ソフトウェア
・Windows 10 Pro 1909
・Python 3.6.6
・librosa 0.8.0
・numpy 1.19.2
・pandas 1.1.2
・scikit-learn 0.23.2
・scipy 1.5.2実行するプログラム
実装したプログラムは GitHub で公開しています。
ctcr_atr503.py解説
実行するプログラムの要となる内容について補足します。
高域強調フィルタ
音声のパワーは高域になるほど減衰するので、それを補うために高域強調が行われます。周波数を $f$、サンプリング周波数を $f_s$ とすると、高域通過フィルタとして用いられる 1次有限インパルス応答 (Finite Impulse Response: FIR) フィルタ $H(z)$ は以下の式で表されます。
H(z) = 1 - \alpha z^{-1} \\ z = \exp(j \omega), \omega = 2 \pi f / f_s一般的に、$\alpha = 0.97$ が用いられます。
メル周波数ケプストラム
メル周波数ケプストラムは、Speech Recognition : Genre Classification Part1 - GTZAN Genre Collections で使用したメルスペクトログラムのパワースペクトルをデシベルに変換してから離散コサイン変換を適用することによって得られます。
ケプストラム (Cepstrum) [2] はスペクトル (Spectrum) のアナグラムで、スペクトルの細かな変動とスペクトルのなだらかな変動を分離でき、人間の声道の特性を表すことができます。
また特徴量の時間変化を捉えるために、隣接したフレーム間の差分も特徴量として加えます。これは、デルタケプストラム [3] と呼ばれており、今回は 1次微分だけでなく、2次微分も求めて特徴量とします。
HTKDeserializer と HTKMLFDeserializer
CNTK のビルトインリーダーの1つである HTKDeserializer と HTKMLFDeserializer は list ファイル、script ファイル、model label file の 3つのファイルを必要とします。
list ファイルは下記のように使用する音素ラベルがユニークに書き込まれている必要があります。また、空白文字として _ を加えておきます。
atr503_mapping.listA E ... z _script ファイルの中身は以下のようになっており、等号の右側に HTK フォーマットのファイルが保存されているパスを記述し、ブラケット内にフレーム数を書き込んでおきます。なお、フレーム数の開始は 0 で、終端はフレーム数から 1 引いておく必要があります。
train_atr503.scptrain_atr503/00000.mfc=./train_atr503/00000.htk[0,141] train_atr503/00001.mfc=./train_atr503/00001.htk[0,258] ...script ファイルの等号の左側は、model label file と対応しておく必要があります。model label file ファイルの中身は以下のようになっており、2行目からフレームと音素ラベルが始まります。フレームの間隔は 1以上でなければならず、仕様上 0 を 5つ付け加えておく必要があります。ラベル情報はドットで区切られています。
train_atr503.mlf#!MLF!# "train_atr503/00000.lab" 0 1600000 sil 1600000 1800000 h ... 13600000 14200000 sil . "train_atr503/00001.lab" 0 400000 sil 400000 1100000 s ...結果
プログラムを実行すると、特徴量の生成と HTK フォーマットのバイナリファイルが保存されていきます。同時に、フレームと音素ラベルを書き込んでいきます。
Number of labels : 43 Number of samples 452 Number of samples 51これで訓練を行う準備が整ったので、Part2 では音素予測を行います。
参考
CNTK 208: Training Acoustic Model with Connectionist Temporal Classification (CTC) Criteria
Speech Recognition : Genre Classification Part1 - GTZAN Genre Collections
- 吉田芳郎, 袋谷丈夫, and 竹沢寿幸. "ATR 音声データベース", 人工知能学会全国大会論文集 0 (2002): pp. 189-189.
- B.P. Bogert, M. J. R. Healy, and J. W. Tukey. "The quefrency analysis of time series for echoes: cepstrum, pseudo-autocovariance, cross-cepstrum, and saphe cracking", in Proceedings of the Sympsium on Time Series Analysis, Wiley, pp. 209-243(1963).
- S. Furui. "On the role of dynamic characteristics of speech spectra for syllable perception", IEEE Transaction on Acoustics, Speech, and Signal Processing, vol.34, no. 1, pp. 52-59(1986).
- 篠田浩一.『機械学習プロフェッショナルシリーズ 音声認識』,講談社,2017.
- 投稿日:2020-10-22T11:22:47+09:00
「ImportError: No module named requests」の解決方法
- 投稿日:2020-10-22T10:53:36+09:00
AtCoder Grand Contest 048 復習
今回の成績
今回の感想
自明枠の早解きしかできないカスです…。C問題をなんとなくずーっと考えていましたが、全く解けませんでした。
解けないからといってTwitterをしてました。もう少し考察の体力がないとこの先やっていけない気がします…。
A問題
冷静になればWAは回避できたはずで、悔しいです。コドフォで見かけそうな感じで比較的(時間としては)早く解けたのではないでしょうか。
まず、$a$しかない場合は自明に-1です。同様に与えられた文字列がすでに"atcoder"という文字列より大きければ自明に0です。
また、$a$以外の文字があれば最初にその文字を持ってくることで必ず辞書順で大きくすることができます。ここで、前から数えて初めて$a$ではない文字があるインデックスを$x$とすれば、最初にその文字を持ってくるのに必要な最小のswapの回数は$x$となります。これを答えとしたいのですが、$x$に存在する文字が"t"より大きい場合は二番目の文字に持ってくれば辞書順で大きくすることができるので、1回ぶん少ない回数で辞書順にすることができます。逆にこの2パターン以外の場合は"aa…"という文字列となり"atcoder"より辞書順で大きくなることはありません。
A.pyfor _ in range(int(input())): s=input() if all(i=="a" for i in s): print(-1) else: n=len(s) if "atcoder"<s: print(0) continue for i in range(n): if s[i]!="a": if s[i]>"t": print(i-1) else: print(i) breakB問題
いろいろ高速化して最速コードを取りました→提出(自分のコードの高速化を諦めてyosupoさんのコードを高速化しただけです。yosupoさんごめんなさい。)。
DPぽいけど無理だなあという短絡的な思考をし、ずっとC問題を考えていました。冷静に考えてDPは無理なので別の方法を探すだけです。DPや愚直に決める方法では難しそうなので何らかの法則性があるのではと考えて考察をします。また、累積和を扱うのが括弧列の典型解法ですが、パターン数が多すぎてこれも無理そうです。
このような典型解法の当てはまらない問題はとにかく実験をします。また、括弧は開きと閉じの両方があって初めて成り立つので偶奇性にも注目して考察を行うと良いです(この辺の考察はコンテスト中にはせず、後からTLを見ていて気付きました…。)。
さらに気づくべきは$A,B$になるインデックスを選んだ時に(と)及び[と]は自由に選べることができるということです。したがって、インデックスの位置関係が重要であると考えられます。すると、$A$となるインデックスと$B$となるインデックスのいずれも全体の偶数のインデックスと奇数のインデックスの個数が等しければ、( )と[ ]を上手く配置することで必ず題意を満たす括弧列を作ることができます(証明はmaspyさんの記事)。
また、上記はかなり論理があやふやなので(✳︎1)、正確にはeditorialの解法を参考にするのが良いと思います。そのまま書き写すことになるのでここでは省略します。
また、editorial中の[ ]が配置されるインデックスの集合$x_1,x_2,…,x_k$を選んできてその条件を考えるという方法は抽象度が高いですが汎用的な考えと思います。コンテスト中はこのインデックスの集合での考察が完全に抜け落ちていたので反省しています(✳︎2)。
(✳︎1)…実験による考察と抽象化による考察のいずれかが抜け落ちてしまうことが多いので、両立できるようにしたいものです。
(✳︎2)…調子がよければこのような抽象化はできるので、考察の安定化が必要であると感じました。まず、この問題ではインデックスの集合という仮定を置く思考に至れなかったのが本当に謎です。
B.pyn=int(input()) a=list(map(int,input().split())) b=list(map(int,input().split())) s=sum(a) e,o=[b[i]-a[i] for i in range(n) if i%2==0],[b[i]-a[i] for i in range(n) if i%2==1] e.sort(reverse=True) o.sort(reverse=True) for i in range(n//2): if e[i]+o[i]>0: s+=e[i]+o[i] else: break print(s)C問題
他の人の解説なども見ればわかるようにいい感じに尺取法のノリでやればできるっぽいですが、自分は上手い実装が思いつきませんでした。いつか解きに帰ってきます。
C問題以降
今回は飛ばします。

- 投稿日:2020-10-22T10:26:45+09:00
Atomでの"No kernel of grammar Python found"エラーの解決方法
はじめに
昨日まで正常に動いていたatom, Hydrogenが,今日動かしてみると
No kernel of grammar Python foundと真っ赤なエラーメッセージがでたときの対処方法です。解決方法
jupyter kernelspec list --json上記コマンドでkernlspecを表示させます。以下のような回答が得られます。
出力例{ "kernelspecs": { "python3": { "resource_dir": "/Users/taka/Library/Jupyter/kernels/python3", "spec": { "argv": [ "/opt/anaconda3/bin/python", "-m", "ipykernel_launcher", "-f", "{connection_file}" ], "env": {}, "display_name": "Python 3", "language": "python", "interrupt_mode": "signal", "metadata": {} } } } }これをコピーし,atom > Settings > packages > Hydrogen の下にある
Startup Codeの欄にこれを貼り付けます。以上でエラーは解決されます。
最後に
atomからjupyter kernelに正しくアクセスできなかったのが問題だったようです。上記の設定で正しくkernelにアクセスできるようにすれば解決されると思います。
個人的な感想になりますが,atomはちょくちょくこういったエラーが発生するなぁ,と。未だ見ぬ大地・vscodeに移民したほうが良いのかな・・・。
- 投稿日:2020-10-22T09:49:54+09:00
Codeforces Round #600 (Div. 2) バチャ復習(10/21)
今回の成績
今回の感想
今日の卒研発表を直前に準備したせいでバチャの復習が追いついてません。卒研と競プロのバランスを取れる人間になりたいです。
また、復習が追いついてないのでupsolveもしません。明日からは頑張ります。
A問題
問題の詳細は省きますが、操作一回で$a$と$b$を等しくすることを考えます。
ここで、問題を言い換えると、$a$と$b$の等しくない連続部分を取ってきた元で①その部分の個数が二つ以上の場合②その部分の個数が一つかつ(部分内で差分は等しくならない または 部分内での差分が$b_i-a_i<0$)の時にNOで,それ以外の時にYESを出力すれば良いです。
$a$と$b$の等しくない連続部分はgroupby関数により$b_i-a_i=0$かどうかを判定することで簡単に抜きだせます。また、この連続部分さえ抜き出せれば①と②の判定は難しくないです。
A.pyfrom itertools import groupby for _ in range(int(input())): n=int(input()) a=list(map(int,input().split())) b=list(map(int,input().split())) c=[a[i]-b[i] for i in range(n)] d=[[i,list(j)] for i,j in groupby(c,key=lambda x:x==0) if i==False] if len(d)>=2: print("NO") elif len(d)==0: print("YES") else: l=len(d[0][1]) for i in range(l): if d[0][1][i]!=d[0][1][0]: print("NO") break else: if d[0][1][i]>0: print("NO") else: print("YES")B問題
問題を整理しないと危うく$O(n^2)$にしそうなので慎重に実装を行います。また、今回は最大の日数や最小の日数を考える必要はないので、愚直にシミュレーションをするだけです。
また、条件がいくつかあるので、忘れないように書き出しておきましょう。問題文とは多少表現が違いますがお許しください。それぞれの入出力の情報について以下が成り立たなければ日として成り立ちます。
①+,-の一方しか(+しか)出ない場合
②+,-(+)が二回以上出てくる場合
③-が+よりも先に出てくる場合この時、②の条件の二回以上出てくる場合を避けるために日として成り立つ場合はすぐにその日は成り立つものとして決定します。この説明だけだとわかりにくいので、実装を以下では説明します。
$s:$すでに来た人の集合
$b:$来た人のうちまだ帰ってない人の集合
$now:$今見ている与えられた入出力の情報のインデックス($n$より小さい)
$ans:$ある日について与えられた入出力の情報の最後のインデックス上記の四つを用意すれば以下の場合分けをするだけです。
(1)$a[now]>0$の時
[1]$a[now]$が$s$に含まれるとき
+が二回出てくるので②を満たしません。-1を出力します。
[2]含まれないとき
$s$と$b$のいずれもに$a[now]$を加えます。(2)$a[now]<0$の時
[1]$-a[now]$が$b$に含まれないとき
-が先に出ているもしくはすでに+,-が出ているので、②,③のいずれも満たしません。-1を出力します。
[2]含まれるとき
$b$から$-a[now]$を除きます。また、$b$が空の場合は日として成り立つので、$s$の中身を全てclearして$ans$に$now$を追加します。
上記の場合分けを任意の入出力の情報で順に行った後に$b$が空でない場合は①を満たしません。この場合は-1を出力します。
また、出力するのは入出力の情報を分割したときの長さなので、$ans[i]-ans[i-1]$を$i$の昇順で出力すれば良いです。
(長い解説になりましたが、①~③の条件と何が変数として必要かのみを考えるだけです。)
B.pyn=int(input()) a=list(map(int,input().split())) #すでに来た人 s=set() #今解消しなければならない人 b=set() #どの日までみたか now=0 #答えの配列 ans=[] while now<n: if a[now]>0: if a[now] in s: print(-1) exit() else: s.add(a[now]) b.add(a[now]) else: if -a[now] not in b: print(-1) exit() else: b.remove(-a[now]) if len(b)==0: ans.append(now+1) s=set() now+=1 if len(b)!=0: print(-1) exit() for i in range(len(ans)-1,0,-1): ans[i]-=ans[i-1] print(len(ans)) print(" ".join(map(str,ans)))C問題
問題設定で混乱しましたが、落ち着いて考えればかなり自明な部分の多い問題です。
ある$k$個を選ぶことを考えます。このとき、小さい方から$k$個選ぶのが最適です。さらに、$k$個選んだ時にそれぞれの日では甘さの大きいものから順に$m$個ずつ選ぶのが最適です。したがって、$m=2$で考えるなら下図のようになります。(両矢印が$m$個を表し、丸の部分がそれぞれの菓子が選ばれる日です。そして、赤で表示されているところは変化分です。)
上図において$m$の長さの区間の移動を考えれば、$k$を増やすことで合計の甘さの増分は$m$の余りが同じインデックスになります(抽象度の高い言い換え!)。つまり、インデックス(0-indexed)を$m$で割った余りが$(k-1) \ \% \ m$となるインデックスのうち$k$個に含まれるところとなります。また、これはインデックスごとの余りで累積和をとることで簡単に求めることができます。さらに、累積和で求めたのは増分なので、最後にさらに累積和をとることで任意の$k$に対して答えを求めることができます。
(✳︎)…バチャコン中は増分がそれぞれの余りでの累積和なので、添字をガチャガチャしたらいけるだろうと思っていたことをここに記します。
C.pyn,k=map(int,input().split()) a=list(map(int,input().split())) a.sort() tod=[[] for i in range(k)] for i in range(n): tod[i%k].append(a[i]) from itertools import accumulate for i in range(k): tod[i]=list(accumulate(tod[i])) ans=[] now=0 for i in range(n): now+=tod[i%k][i//k] ans.append(now) print(" ".join(map(str,ans)))D問題
UnionFindを使う問題で一番好きな問題かもしれません。
割とやることは見えやすいので、実装を上手くいくように頑張ります。
$(l,r)$がつながっている時$(l,l+1)$、$(l,l+2)$…$(l,r-1)$の間でもつながっている、つまり$[l,r]$に含まれる番号のノードは全て同じ連結成分に含まれる必要があります。サンプル1がわかりやすいので、この場合を考えると以下のようになります。
1-2-5-7 3-4-6-8 9 10 11-12この時、$(1,7)$が繋がるので、$[1,7]$に含まれる番号のノードは同じ連結成分となる必要があります。すなわち、一つ目の連結成分と二つ目の連結成分は同じ連結成分とする必要があり、答えは1です。
1-2-3-4-5-6-7-8 9 10 11-12したがって、まずは連結成分に分けるためにUnionFindを行います。また、UnionFindを行った後に題意を満たすように最小回数だけ連結成分どうしをくっつける必要があります。ここで、$l$と$r$がつながっている場合は$[l,r]$に含まれるノードどうしは全て繋がるので、連結成分の番号が最小のノードと最大のノードのみを保存すれば良いです。
したがって、UnionFindにより、$i$番目の連結成分について$l_i$を最小値で$r_i$を最大値とすれば、$[l_1,r_1],[l_2,r_2],….[l_k,r_k]$という区間を得ることができます。
この区間を$l$の昇順で並べておけば(✳︎)、同じ連結成分とすべき区間の右端を$hashi$とすることで$hashi>l_i$が成り立つ時には$[l_i,r_i]$も同じ連結成分とする必要があり、この時$hashi=max(hashi,r_i)$として更新します。
逆に、$hashi<l_i$のときは更新の必要がなく題意を満たすので、その連結成分に含まれる元の連結成分の個数を$now$に保存しておけば、$now-1$がその連結成分を作り出すのに必要な最小の辺の本数となります。(同時に次の調べたい連結成分のために$hashi$と$now$の値の更新も行います。)
よって、答えとして求めたい最小の追加する辺の本数を$ans$とすれば、任意の区間で調べて$ans$に$now-1$を足していくことで答えは求まり、$ans$を出力すれば良いです。
(✳︎)…区間のマージを考える時に左端or右端でソートするのは一般的
D.cc//デバッグ用オプション:-fsanitize=undefined,address //コンパイラ最適化 #pragma GCC optimize("Ofast") //インクルードなど #include<bits/stdc++.h> using namespace std; typedef long long ll; //マクロ //forループ //引数は、(ループ内変数,動く範囲)か(ループ内変数,始めの数,終わりの数)、のどちらか //Dがついてないものはループ変数は1ずつインクリメントされ、Dがついてるものはループ変数は1ずつデクリメントされる //FORAは範囲for文(使いにくかったら消す) #define REP(i,n) for(ll i=0;i<ll(n);i++) #define REPD(i,n) for(ll i=n-1;i>=0;i--) #define FOR(i,a,b) for(ll i=a;i<=ll(b);i++) #define FORD(i,a,b) for(ll i=a;i>=ll(b);i--) #define FORA(i,I) for(const auto& i:I) //xにはvectorなどのコンテナ #define ALL(x) x.begin(),x.end() #define SIZE(x) ll(x.size()) //定数 #define INF 1000000000000 //10^12:∞ #define MOD 1000000007 //10^9+7:合同式の法 #define MAXR 100000 //10^5:配列の最大のrange //略記 #define PB push_back //挿入 #define MP make_pair //pairのコンストラクタ #define F first //pairの一つ目の要素 #define S second //pairの二つ目の要素 //以下、素集合と木は同じものを表す class UnionFind{ public: vector<ll> parent; //parent[i]はiの親 vector<ll> siz; //素集合のサイズを表す配列(1で初期化) map<ll,set<ll>> group; //集合ごとに管理する(key:集合の代表元、value:集合の要素の配列) ll n; //要素数 //コンストラクタ UnionFind(ll n_):n(n_),parent(n_),siz(n_,1){ //全ての要素の根が自身であるとして初期化 for(ll i=0;i<n;i++){parent[i]=i;} } //データxの属する木の根を取得(経路圧縮も行う) ll root(ll x){ if(parent[x]==x) return x; return parent[x]=root(parent[x]);//代入式の値は代入した変数の値なので、経路圧縮できる } //xとyの木を併合 void unite(ll x,ll y){ ll rx=root(x);//xの根 ll ry=root(y);//yの根 if(rx==ry) return;//同じ木にある時 //小さい集合を大きい集合へと併合(ry→rxへ併合) if(siz[rx]<siz[ry]) swap(rx,ry); siz[rx]+=siz[ry]; parent[ry]=rx;//xとyが同じ木にない時はyの根ryをxの根rxにつける } //xとyが属する木が同じかを判定 bool same(ll x,ll y){ ll rx=root(x); ll ry=root(y); return rx==ry; } //xの素集合のサイズを取得 ll size(ll x){ return siz[root(x)]; } //素集合をそれぞれグループ化 void grouping(){ //経路圧縮を先に行う REP(i,n)root(i); //mapで管理する(デフォルト構築を利用) REP(i,n)group[parent[i]].insert(i); } //素集合系を削除して初期化 void clear(){ REP(i,n){parent[i]=i;} siz=vector<ll>(n,1); group.clear(); } }; signed main(){ //小数の桁数の出力指定 //cout<<fixed<<setprecision(10); //入力の高速化用のコード //ios::sync_with_stdio(false); //cin.tie(nullptr); ll n,m;cin>>n>>m; UnionFind uf(n); REP(i,m){ ll u,v;cin>>u>>v; uf.unite(u-1,v-1); } uf.grouping(); vector<pair<ll,ll>> segments; FORA(i,uf.group){ segments.PB(MP(*i.S.begin(),*--i.S.end())); } sort(ALL(segments)); ll hashi=segments[0].S; ll now=1; ll ans=0; FOR(i,1,SIZE(segments)-1){ if(hashi<segments[i].F){ ans+=(now-1); now=1; hashi=segments[i].S; }else{ hashi=max(hashi,segments[i].S); now++; } } ans+=(now-1); cout<<ans<<endl; }E問題以降
今回は飛ばします。

- 投稿日:2020-10-22T09:08:01+09:00
日付付きcsvファイルを取り込み時間パーティションテーブルとしてBigQueryにインポートするpythonスクリプト
背景
xxxx_20200930.csvのように、ファイル名に日付が入っているcsvファイルをパーティションタイム指定してBigQueryにインポートするpythonスクリプトが欲しい。
今回は、大量のcsvファイルがディレクトリ以下に入っているという前提で作成。サンプルスクリプト
main.pyfrom google.cloud import bigquery import json import glob client = bigquery.Client() job_config = bigquery.LoadJobConfig( source_format=bigquery.SourceFormat.CSV, skip_leading_rows=1, autodetect=True, allow_quoted_newlines=True, time_partitioning=bigquery.TimePartitioning() ) path = "../some/dir/*" files = glob.glob(path + '*') for file_name in files: date = file_name.split('_')[-1][0:8] table_id = 'dataset.table_name$' + date # パーティション指定 with open(file_name, "rb") as source_file: job = client.load_table_from_file( source_file, table_id, job_config=job_config ) job.result() # Waits for the job to complete. table = client.get_table(table_id) # Make an API request. print( "Loaded {} rows and {} columns to {}".format( table.num_rows, len(table.schema), table_id ) )参考
- 投稿日:2020-10-22T08:12:28+09:00
pgmpy:離散ベイジアンネットワークの試用 -推論まで-
きっかけ
メタ学習やグラフニューラルネットワーク、事前知識としての利用を含む知識構造の利用、知識保存に興味あり。
関連し、ベイジアンネットワークを手軽に実装できないかとライブラリを探していた。
pgmpyがよさそうであったので、一通りの流れを記録しておく。pgmpy:pgmpy is a python library for working with Probabilistic Graphical Models.
https://pgmpy.org/参考
Titanicデータでベイジアンネットワークを実装
https://qiita.com/YuyaOmori/items/e051f0360d1f9562620bベイジアンネットワーク:入門からヒューマンモデリングへの応用まで
https://staff.aist.go.jp/y.motomura/paper/BSJ0403.pdf環境
Windows10
Python3.7
Anaconda
pgmpy==0.1.9インストール
pip install pgmpy==0.1.9pytorchを入れておらずnonGPUならば
conda install pytorch torchvision cpuonly -c pytorchデータ
次のデータを使用
import pandas as pd df = pd.DataFrame() df['t'] = [1, 1, 1, 1, 0, 0, 1, 1, 1, 2, 0, 0, 1, 1, 1, 2, 2, 2, 2, 2] df['a'] = [2, 2, 2, 2, 1, 1, 1, 1, 2, 1, 1, 2, 0, 0, 0, 1, 1, 2, 2, 2] df['h'] = [0, 0, 0, 1, 0, 0, 1, 1, 1, 1, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1]実行
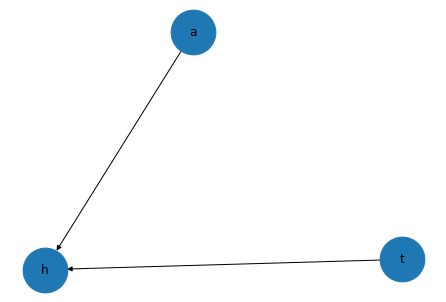
モデル構造の定義
from pgmpy.models import BayesianModel model = BayesianModel([('t','h'),('a','h')])t→h、a→hの有向非巡回グラフとした。
モデル内にCPD作成・確認
model.fit(df) #条件は省略。標準ではオーバーフィットに特に注意 print(model.get_cpds('t')) print(model.get_cpds('a')) print(model.get_cpds('h'))出力+------+-----+ | t(0) | 0.2 | +------+-----+ | t(1) | 0.5 | +------+-----+ | t(2) | 0.3 | +------+-----+ +------+------+ | a(0) | 0.15 | +------+------+ | a(1) | 0.4 | +------+------+ | a(2) | 0.45 | +------+------+ +------+------+--------------------+------+------+------+------+------+------+------+ | a | a(0) | a(0) | a(0) | a(1) | a(1) | a(1) | a(2) | a(2) | a(2) | +------+------+--------------------+------+------+------+------+------+------+------+ | t | t(0) | t(1) | t(2) | t(0) | t(1) | t(2) | t(0) | t(1) | t(2) | +------+------+--------------------+------+------+------+------+------+------+------+ | h(0) | 0.5 | 0.3333333333333333 | 0.5 | 1.0 | 0.0 | 0.0 | 1.0 | 0.6 | 0.0 | +------+------+--------------------+------+------+------+------+------+------+------+ | h(1) | 0.5 | 0.6666666666666666 | 0.5 | 0.0 | 1.0 | 1.0 | 0.0 | 0.4 | 1.0 | +------+------+--------------------+------+------+------+------+------+------+------+推論1
from pgmpy.inference import VariableElimination ve = VariableElimination(model) #t=1,h=1とした場合のaは? print(ve.map_query(variables=['a'], evidence={'t':1, 'h':1}))出力{'a': 1}推論2
#t=0,1,2とした場合のa,hそれぞれの推測値?は? for i in [0,1,2]: print(ve.query(variables=['a', 'h'], evidence={'t':i}))出力Finding Elimination Order: : : 0it [00:00, ?it/s] 0it [00:00, ?it/s] +------+------+------------+ | a | h | phi(a,h) | +======+======+============+ | a(0) | h(0) | 0.0750 | +------+------+------------+ | a(0) | h(1) | 0.0750 | +------+------+------------+ | a(1) | h(0) | 0.4000 | +------+------+------------+ | a(1) | h(1) | 0.0000 | +------+------+------------+ | a(2) | h(0) | 0.4500 | +------+------+------------+ | a(2) | h(1) | 0.0000 | +------+------+------------+ Finding Elimination Order: : : 0it [00:00, ?it/s] 0it [00:00, ?it/s] +------+------+------------+ | h | a | phi(h,a) | +======+======+============+ | h(0) | a(0) | 0.0500 | +------+------+------------+ | h(0) | a(1) | 0.0000 | +------+------+------------+ | h(0) | a(2) | 0.2700 | +------+------+------------+ | h(1) | a(0) | 0.1000 | +------+------+------------+ | h(1) | a(1) | 0.4000 | +------+------+------------+ | h(1) | a(2) | 0.1800 | +------+------+------------+ Finding Elimination Order: : : 0it [00:00, ?it/s] 0it [00:00, ?it/s] +------+------+------------+ | a | h | phi(a,h) | +======+======+============+ | a(0) | h(0) | 0.0750 | +------+------+------------+ | a(0) | h(1) | 0.0750 | +------+------+------------+ | a(1) | h(0) | 0.0000 | +------+------+------------+ | a(1) | h(1) | 0.4000 | +------+------+------------+ | a(2) | h(0) | 0.0000 | +------+------+------------+ | a(2) | h(1) | 0.4500 | +------+------+------------+補足
- model.fit(df) は、例えば、次に分割できる。 分割したほうが扱いやすいこともあろうかとメモ。
#CPD作成部分 from pgmpy.estimators import BayesianEstimator estimator = BayesianEstimator(model, df) cpd_ta = estimator.estimate_cpd('t', prior_type='dirichlet', pseudo_counts=[[0],[0],[0]]) cpd_aa = estimator.estimate_cpd('a', prior_type='dirichlet', pseudo_counts=[[0],[0],[0]]) cpd_h = estimator.estimate_cpd('h', prior_type='dirichlet', pseudo_counts=[[0,0,0,0,0,0,0,0,0],[0,0,0,0,0,0,0,0,0]]) #CPD入力部分 model.add_cpds(cpd_ta, cpd_aa, cpd_h)
- CPDを任意に作成する場合には、例えば、次とする。ベイジアンネットワークには変数を含められないが、個人的には、任意の制約が必要となる場合もあると思う。
from pgmpy.factors.discrete import TabularCPD cpd_h = TabularCPD(variable='h', variable_card=2, values=[[1, 0.3, 0.5, 1, 0, 0, 1, 0.6, 0], [0, 0.7, 0.5, 0, 1, 1, 0, 0.4, 1]], evidence=['t', 'a'], evidence_card=[3, 3])
構造学習については省略する。最初は推論と構造学習がセットとなっていると認識できておらずよくわからなかった・・・
時系を考慮した動的ベイジアンネットワークという手法もあるそうだ。
個の抽出を重視したい。次は以下を進める。
階層ベイズ(「ベイズモデリングの世界」から)
https://recruit.cct-inc.co.jp/tecblog/machine-learning/hierarchical-bayesian/
PyMC3過去、
Pythonで体験するベイズ推論:PyMCによるMCMC入門
https://github.com/CamDavidsonPilon/Probabilistic-Programming-and-Bayesian-Methods-for-Hackers
においてPyMC2を触ったのだが、ほぼ忘れている。
- 投稿日:2020-10-22T08:12:28+09:00
pgmpy:離散ベイジアンネットワークの試用 -推論
きっかけ
メタ学習やグラフニューラルネットワーク、事前知識としての利用を含む知識構造の利用、知識保存に興味あり。
関連し、ベイジアンネットワークを手軽に実装できないかとライブラリを探していた。
pgmpyがよさそうであったので、一通りの流れを記録しておく。pgmpy:pgmpy is a python library for working with Probabilistic Graphical Models.
https://pgmpy.org/参考
Titanicデータでベイジアンネットワークを実装
https://qiita.com/YuyaOmori/items/e051f0360d1f9562620bベイジアンネットワーク:入門からヒューマンモデリングへの応用まで
https://staff.aist.go.jp/y.motomura/paper/BSJ0403.pdf環境
Windows10
Python3.7
Anaconda
pgmpy==0.1.9インストール
pip install pgmpy==0.1.9pytorchを入れておらずnonGPUならば
conda install pytorch torchvision cpuonly -c pytorchデータ
次のデータを使用
import pandas as pd df = pd.DataFrame() df['t'] = [1, 1, 1, 1, 0, 0, 1, 1, 1, 2, 0, 0, 1, 1, 1, 2, 2, 2, 2, 2] df['a'] = [2, 2, 2, 2, 1, 1, 1, 1, 2, 1, 1, 2, 0, 0, 0, 1, 1, 2, 2, 2] df['h'] = [0, 0, 0, 1, 0, 0, 1, 1, 1, 1, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1]実行
モデル構造の定義
from pgmpy.models import BayesianModel model = BayesianModel([('t','h'),('a','h')])t→h、a→hの有向非巡回グラフとした。
モデル内にCPD作成・確認
model.fit(df) #条件は省略。標準ではオーバーフィットに特に注意 print(model.get_cpds('t')) print(model.get_cpds('a')) print(model.get_cpds('h'))出力+------+-----+ | t(0) | 0.2 | +------+-----+ | t(1) | 0.5 | +------+-----+ | t(2) | 0.3 | +------+-----+ +------+------+ | a(0) | 0.15 | +------+------+ | a(1) | 0.4 | +------+------+ | a(2) | 0.45 | +------+------+ +------+------+--------------------+------+------+------+------+------+------+------+ | a | a(0) | a(0) | a(0) | a(1) | a(1) | a(1) | a(2) | a(2) | a(2) | +------+------+--------------------+------+------+------+------+------+------+------+ | t | t(0) | t(1) | t(2) | t(0) | t(1) | t(2) | t(0) | t(1) | t(2) | +------+------+--------------------+------+------+------+------+------+------+------+ | h(0) | 0.5 | 0.3333333333333333 | 0.5 | 1.0 | 0.0 | 0.0 | 1.0 | 0.6 | 0.0 | +------+------+--------------------+------+------+------+------+------+------+------+ | h(1) | 0.5 | 0.6666666666666666 | 0.5 | 0.0 | 1.0 | 1.0 | 0.0 | 0.4 | 1.0 | +------+------+--------------------+------+------+------+------+------+------+------+推論1
from pgmpy.inference import VariableElimination ve = VariableElimination(model) #t=1,h=1とした場合のaは? print(ve.map_query(variables=['a'], evidence={'t':1, 'h':1}))出力{'a': 1}推論2
#t=0,1,2とした場合のa,hそれぞれの推測値?は? for i in [0,1,2]: print(ve.query(variables=['a', 'h'], evidence={'t':i}))出力+------+------+------------+ | a | h | phi(a,h) | +======+======+============+ | a(0) | h(0) | 0.0750 | +------+------+------------+ | a(0) | h(1) | 0.0750 | +------+------+------------+ | a(1) | h(0) | 0.4000 | +------+------+------------+ | a(1) | h(1) | 0.0000 | +------+------+------------+ | a(2) | h(0) | 0.4500 | +------+------+------------+ | a(2) | h(1) | 0.0000 | +------+------+------------+ +------+------+------------+ | h | a | phi(h,a) | +======+======+============+ | h(0) | a(0) | 0.0500 | +------+------+------------+ | h(0) | a(1) | 0.0000 | +------+------+------------+ | h(0) | a(2) | 0.2700 | +------+------+------------+ | h(1) | a(0) | 0.1000 | +------+------+------------+ | h(1) | a(1) | 0.4000 | +------+------+------------+ | h(1) | a(2) | 0.1800 | +------+------+------------+ +------+------+------------+ | a | h | phi(a,h) | +======+======+============+ | a(0) | h(0) | 0.0750 | +------+------+------------+ | a(0) | h(1) | 0.0750 | +------+------+------------+ | a(1) | h(0) | 0.0000 | +------+------+------------+ | a(1) | h(1) | 0.4000 | +------+------+------------+ | a(2) | h(0) | 0.0000 | +------+------+------------+ | a(2) | h(1) | 0.4500 | +------+------+------------+補足
- model.fit(df) は、例えば、次に分割できる。 分割したほうが扱いやすいこともあろうかとメモ。
#CPD作成部分 from pgmpy.estimators import BayesianEstimator estimator = BayesianEstimator(model, df) cpd_ta = estimator.estimate_cpd('t', prior_type='dirichlet', pseudo_counts=[[0],[0],[0]]) cpd_aa = estimator.estimate_cpd('a', prior_type='dirichlet', pseudo_counts=[[0],[0],[0]]) cpd_h = estimator.estimate_cpd('h', prior_type='dirichlet', pseudo_counts=[[0,0,0,0,0,0,0,0,0],[0,0,0,0,0,0,0,0,0]]) #CPD入力部分 model.add_cpds(cpd_ta, cpd_aa, cpd_h)
- CPDを任意に作成する場合には、例えば、次とする。ベイジアンネットワークには変数を含められないが、個人的には、任意の制約が必要となる場合もあると思う。局所的なネットワークを組むだけで十分かもしれないけれど。
from pgmpy.factors.discrete import TabularCPD cpd_h = TabularCPD(variable='h', variable_card=2, values=[[1, 0.3, 0.5, 1, 0, 0, 1, 0.6, 0], [0, 0.7, 0.5, 0, 1, 1, 0, 0.4, 1]], evidence=['t', 'a'], evidence_card=[3, 3])
構造学習については省略する。
multiply connectedに対応したJunction treeのような機能もあるようだ。どこまでできるのか確認中。
時系を考慮した動的ベイジアンネットワークという手法もあるそうだ。
個の抽出を重視したい。次は以下を進める。
階層ベイズ(「ベイズモデリングの世界」から)
https://recruit.cct-inc.co.jp/tecblog/machine-learning/hierarchical-bayesian/
PyMC3過去、
Pythonで体験するベイズ推論:PyMCによるMCMC入門
https://github.com/CamDavidsonPilon/Probabilistic-Programming-and-Bayesian-Methods-for-Hackers
においてPyMC2を触ったのだが、ほぼ忘れている。
- 投稿日:2020-10-22T06:48:04+09:00
Django genericview にテキストを渡す
少しの改善ですが、希望シフトを作成するページにシフト情報が表示されていませんでした。
理由は、genericviewを使った時に、指定したModel以外の情報をどうやってテンプレートに受け渡しできるかがわからなかったからです。4時半に目が覚めたので、2時間格闘し出来上がりました。
2時間で5行ぐらいしか書けていないというなんという生産性(笑)
ググり方がまだわかっていないのとググるためのキーワードが何が適切なのか、まだまだな気がします。きっと、すぐにもっとすらすらかけるようになっているはず!
まずは、Viewで受け渡すコード
schedule/views.pyclass KibouCreate(CreateView): template_name = 'schedule/kiboushift/create.html' model = KibouShift fields = ('user', 'date', 'shift_name_1', 'shisetsu_name_1', 'shift_name_2', 'shisetsu_name_2', 'shift_name_3', 'shisetsu_name_3', 'shift_name_4', 'shisetsu_name_4') success_url = reverse_lazy('schedule:KibouList') def get_context_data(self, **kwargs): context = super().get_context_data(**kwargs) context['shift'] = Shift.objects.all() return context以前、こちらで質問させていただいたkwargsを使っての実装です。
まだkwargs が理解しきれていいないので少しづつでも理解を進めたいですこれだけでテンプレートに受け渡してくれるので、あとは、テンプレートで表示するだけです。
schedule/create.html{% extends 'schedule/kiboushift/base.html' %} {% load static %} {% block customcss %} <link rel="stylesheet" type="text/css" href ="{% static 'schedule/kiboushift/update.css' %}"> {% endblock customcss %} {% block header %} <div class="jumbotron jumbotron-fluid"> <div class="container"> <h1 class="display-4">希望シフト登録</h1> {% for shift in shift %} {% if shift.name != "休" and shift.name != "有" %} {{ shift.name }} : {{ shift.start_time }}~{{ shift.end_time }} {% endif %} {% endfor %} <p class="lead"></p> </div> </div> {% endblock header %} {% block content %} <div class="container"> <form action="" method="POST">{% csrf_token %} <table> {{ form.user.first_name }} {{ form.as_p }} </table> <p><input type="submit" value="作成" class="btn-info btn active"> <a href="{% url 'schedule:KibouList' %}" class="btn-secondary btn active">戻る</a></p> </form> </div> {% endblock content %}これで画面に表示することができました。
これでOK
マスタ関係の登録が画面を作るか、それはDjangoの管理画面でするか考えていこうかと思います。
新機能を作ることも検討しています。その方が楽しいので(笑)

- 投稿日:2020-10-22T04:50:28+09:00
[初心者向け]Pythonで音声認識をしてLineに通知!
はじめに
Googleのspeech-to-text APIとLine Notifyを最近使い始めたのですが、案外簡単に扱えると感じたので、
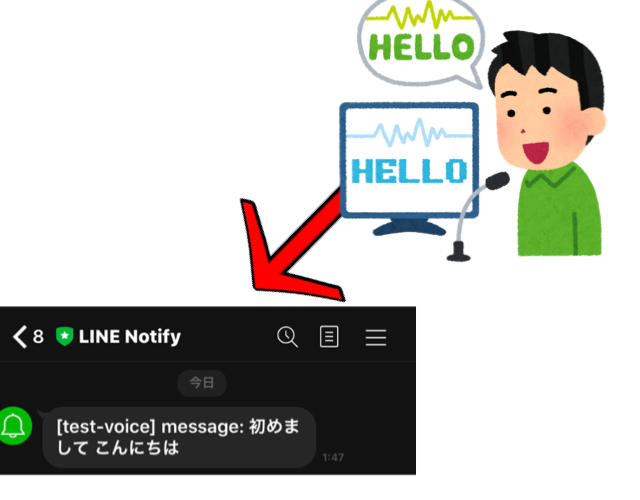
今回はこの2つの技術を使ったボットの作り方を説明します!今回つくるもの
状況が、上記画像のような状況で人が話した内容が文字列となって、それをLine Notifyを使ってLINEに出力するというものを開発します。実際に動いている動画。
Google Speech-to-Text APIを使ってLineNotifyで出力したー pic.twitter.com/NcBgsGd82P
— たーる (@taarusauce) October 21, 2020準備
LINE Notifyからアクセストークンを取得する
- LINE Notifyのサイトにアクセス。 https://notify-bot.line.me/ja
- LINEで登録しているメールアドレスとパスワードを入力してログインする

- トップページからバーを探して、自分の名前をクリックしマイページをクリック。

4. トークンを発行するをクリックし、次にトークン名の入力とトークルームを選択する。
5. 英数字の赤文字で表示されたものがアクセストークンになる。これをコピーする。必要なパッケージのダウンロード
- ターミナルを開いて、下記のコマンドを実行 1回目
pip3 install SpeechRecognition requests python-dotenv numpy
2. コマンド実行 2回目macの場合
pip3 install PyAudioubuntu or debian or Raspberry Piの場合
sudo apt -y upgrade && sudo apt -y update
sudo apt install python3-pyaudio
実装
LINEに通知を行う機能の作成
line_notice.pyimport requests # Lineにメッセージを送信する関数 送信したい文字列を引数に定義 def send(send_message): line_notify_token = <先程作ったアクセストークンをここで指定> line_notify_api = 'https://notify-api.line.me/api/notify' # トークン情報をヘッダーに載せる headers = {'Authorization': f'Bearer {line_notify_token}'} data = {'message': send_message} # 送信 requests.post(line_notify_api, headers = headers, data = data) if __name__ == "__main__": text = "test" send(text)モジュールテスト
下記のコマンドを実行して、正しく準備が出来ていたらtestという文字が通知される。
python3 line_notice.py
音声の録音と音声認識を行う機能の作成
voice.pyimport speech_recognition as sr import numpy as np import pyaudio import wave class voiceFunctionsClass: def __init__(self): self.CHUNK = 1024 self.FORMAT = pyaudio.paInt16 self.CHANNELS = 1 self.RATE = 48000 self.RECORD_SECONDS = 5 self.WAVE_OUTPUT_FILENAME ="recorded.wav" self.p = pyaudio.PyAudio() self.stream = self.p.open(format=self.FORMAT, channels=self.CHANNELS, rate=self.RATE, input=True, frames_per_buffer=self.CHUNK) # 録音処理 def voice_recode(self): print("<<<録音中>>>") frames = [] calc = int(self.RATE / self.CHUNK * self.RECORD_SECONDS) for i in range(0, calc): data = self.stream.read(self.CHUNK) buf = np.frombuffer(data, dtype="int16") frames.append(b''.join(buf[::3])) print("<<<録音終了>>>") # 録音したものを保存 self.voice_save(frames) # 録音保存処理 def voice_save(self, frames): self.stream.stop_stream() self.stream.close() self.p.terminate() wf = wave.open(self.WAVE_OUTPUT_FILENAME, 'wb') wf.setnchannels(self.CHANNELS) wf.setsampwidth(self.p.get_sample_size(self.FORMAT)) wf.setframerate(self.RATE / 3) wf.writeframes(b''.join(frames)) wf.close() # 音声認識 def voice_recognize(self): print("音声認識を開始します") r = sr.Recognizer() with sr.AudioFile(self.WAVE_OUTPUT_FILENAME) as source: audio = r.record(source) result = r.recognize_google(audio, language='ja-JP') return result if __name__ == "__main__": voice = voiceFunctionsClass() voice.voice_recode() print(f"音声認識結果: {voice.voice_recognize()}")モジュールテスト
python3 voice.py
正常に動作していれば、録音され、録音終了後。話した内容が結果として出力される。2つの機能を組み合わせたプログラム
main.pyimport line_notice import voice voice_class = voice.voiceFunctionsClass() voice_class.voice_recode() voice_result = voice_class.voice_recognize() line_notice.send(voice_result)
python3 main.py
を実行すると、音声が録音 -> 音声認識が実行 -> Lineに送信という流れで処理が行われるはずです!github
今回作成したプログラムをGithubに上げました、こちらもぜひご活用ください!
https://github.com/taruscript/speech2Lineまとめ
今回は、2つの技術を使った活用例として作ってみましたが。気軽に割と簡単に作れて初心者にはかなりオススメかと思います!
なにかご不明な点がございましたら僕のTwitterに質問して頂ければ答えられる範囲でお答えしますー!https://twitter.com/taarusauce

- 投稿日:2020-10-22T04:37:03+09:00
Python基礎⑤
Pythonの基礎知識⑤です。
引き続き自分の勉強メモです。
過度な期待はしないでください。過去投稿記事
Python基礎
Python基礎②
Python基礎③
Python基礎④
継承
-既にあるクラスを元にして新たなクラスをつくること
「class 新しいクラス名(元となるクラス名):」とすることで他のクラスを継承して、
新しいクラスを定義することが出来る。
新しいクラスは「子クラス」、元となるクラスは「親クラス」と呼ばれます。menu_item.py# 親クラス class MenuItem: def __init__(self, name, price): self.name = name self.price = price def info(self): return self.name + ': ¥' + str(self.price) def get_total_price(self, count): total_price = self.price * count if count >= 3: total_price *= 0.9 return round(total_price)sweets.py# 子クラス # menu_item.pyからMenuItemクラスを読み込む from menu_item import MenuItem # 他のクラスを継承して、新しいクラスを定義 class Sweets(MenuItem): pass # 何も処理がない事を表す # インデントを揃える(半角スペース4つ分)
-子クラスのインスタンスメソッド
子クラスは「親クラス内に定義されているメソッド」と「独自に定義したメソッド」の両方が使える。
しかし、親クラスでは子クラスのメソッドは使えない。sweets.py# 子クラス from menu_item import MenuItem class Sweets(MenuItem): def calorie_info(self): # メソッドの定義には、第1引数にselfを追加する print(str(self.calorie) + 'kcalです') # str()で数値を文字列に変換 # インデントを揃える(半角スペース4つ分)
-オーバーライド
親クラスにあるメソッドと同じ名前のメソッドを子クラスで定義すると、メソッドが上書きされる。
要は、子クラスで定義したメソッドが優先して呼び出されるようになっている。menu_item.py# 親クラス class MenuItem: def __init__(self, name, price): self.name = name self.price = price def info(self): return self.name + ': ¥' + str(self.price) def get_total_price(self, count): total_price = self.price * count if count >= 3: total_price *= 0.9 return round(total_price)sweets.pyfrom menu_item import MenuItem class Food(MenuItem): # infoメソッドを定義 def info(self): return self.name + ': ¥' + str(self.price) + str(self.calorie) + 'kcal' def calorie_info(self): print(str(self.calorie) + 'kcalです')親クラスにある infoメソッドではなく、子クラスにある infoメソッドが優先されて上書きされる
メソッド内の重複
-
「super().メソッド名()」とすることで、
親クラス内に定義されたインスタンスメソッドをそのまま利用することが出来る。menu_item.py# 親クラス class MenuItem: def __init__(self, name, price): self.name = name self.price = price def info(self): return self.name + ': ¥' + str(self.price) def get_total_price(self, count): total_price = self.price * count if count >= 3: total_price *= 0.9 return round(total_price)sweets.pyfrom menu_item import MenuItem class Food(MenuItem): def __init__(self, name, price): # super()を用いて、親クラスの__init__()を呼び出す super().__init__(name, price) # self.name = name → 重複している部分は削除 # self.price = price → 重複している部分は削除 def info(self): return self.name + ': ¥' + str(self.price) + str(self.calorie) + 'kcal' def calorie_info(self): print(str(self.calorie) + 'kcalです')
- 投稿日:2020-10-22T04:07:41+09:00
Django Serializerを使って関連先のフィールドを取得する
Serializerを簡単にいうと!
モデルオブジェクトをJSONに変換してくれる!
それでは
今回はBookオブジェクトを取得する際に、
ForeignKeyで参照しているAuthorをオブジェクトも含めて取得します!!!!!!!!!!!!modelを定義する
サンプルのモデルです!
BookモデルはAuthorモデルを参照しています!models.pyclass AbstractModel(models.Model): id = models.UUIDField(primary_key=True, default=uuid.uuid4, editable=False) is_deleted = models.CharField(max_length=1, default='0') created_at = models.DateTimeField(auto_now_add=True) updated_at = models.DateTimeField(auto_now=True) class Meta: abstract = True class Author(AbstractModel): first_name = models.CharField(max_length=128) last_name = models.CharField(max_length=128) class Book(AbstractModel): title = models.CharField(max_length=128)] sub_title = models.CharField(max_length=128)] price = models.DecimalField(max_digits=8, decimal_places=2, blank=True, null=True) author = models.ForeignKey(Author, on_delete=models.PROTECT, blank=True, null=True)参照元のモデルも一緒に取得する
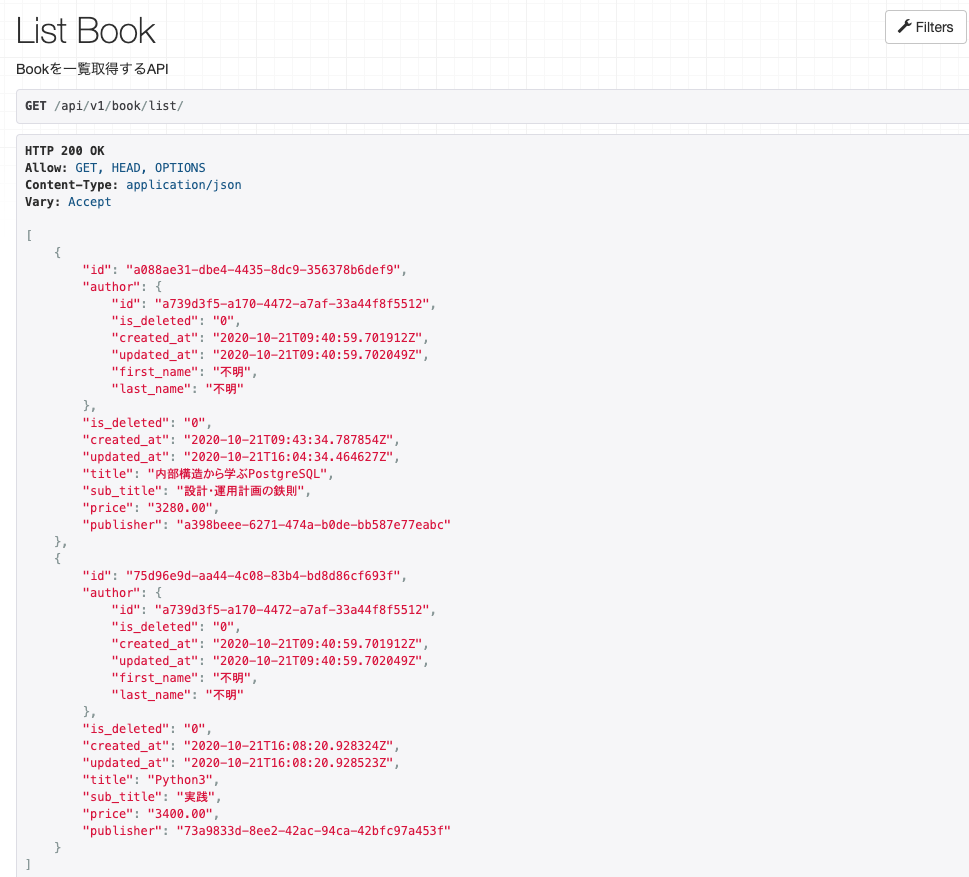
Viewを定義する
genericsのListAPIViewを使って取得APIを作成します!
authorモデルも取得するのでquerysetには
select_relatedでauthorを指定しておきます。
all()なのでも取得することは可能ですが、select_related.('author')を
事前に指定しておくことで、発行するSQLを削減できます!!views.pyfrom django_filters import rest_framework as filters from rest_framework import generics from book.models import Book, Author from book.serializers import BookSerializer class ListBook(generics.ListAPIView): """Bookを一覧取得するAPI""" queryset = Book.objects.select_related('author') serializer_class = BookSerializer filter_backends = [filters.DjangoFilterBackend] filterset_fields = '__all__'Serializerに参照元Serializerを定義する
BookSerializerのフィールドに関連先Serializerを定義することができます!
これで関連先のモデルも取得することができます!!!ただここで一つ注意なのは参照元のserializerを
定義する時にフィールド名がlookupに関係しているので間違えないようにしてください!!serializer.pyclass AuthorSerializer(serializers.ModelSerializer): class Meta: model = Author fields = '__all__' class BookSerializer(serializers.ModelSerializer): author = AuthorSerializer() class Meta: model = Book fields = '__all__'結果がこちらです!!!!
出力結果にはサンプルモデルでは省いたデータも出力されちゃってます!!
飛ばしてください!!
参照先のモデルを取得する
先ほどは、Bookモデルと参照元の
Authorモデルも取得しましたが、
逆に、AuthorからBookを取得したいと思います!!。
方法は簡単です!Viewを定義する
ListAPIViewを使って取得していきたいと思います。
今回は、select_relatedなどせずにそのままall()で問題ありません。views.pyclass ListAuthor(generics.ListAPIView): """Authorを取得する""" queryset = Author.objects.all() serializer_class = AuthorBookSerializer filter_backends = [filters.DjangoFilterBackend] filterset_fields = '__all__'Serializerの定義
参照先のモデルを取得するため、
book_setとなっています!
これでAPIをリクエストするとAuthorとBookが取得することができます。
この時に、BookSerializerにauthor = AuthorSerializer()を残しておくと
book取得した時にさらにauthorを再び取得してしまうので注意。serializers.pyclass BookSerializer(serializers.ModelSerializer): class Meta: model = Book fields = '__all__' class AuthorBookSerializer(serializers.ModelSerializer): book_set = BookSerializer(many=True) class Meta: model = Author fields = '__all__'結果がこちらです!!!!
以上になります!
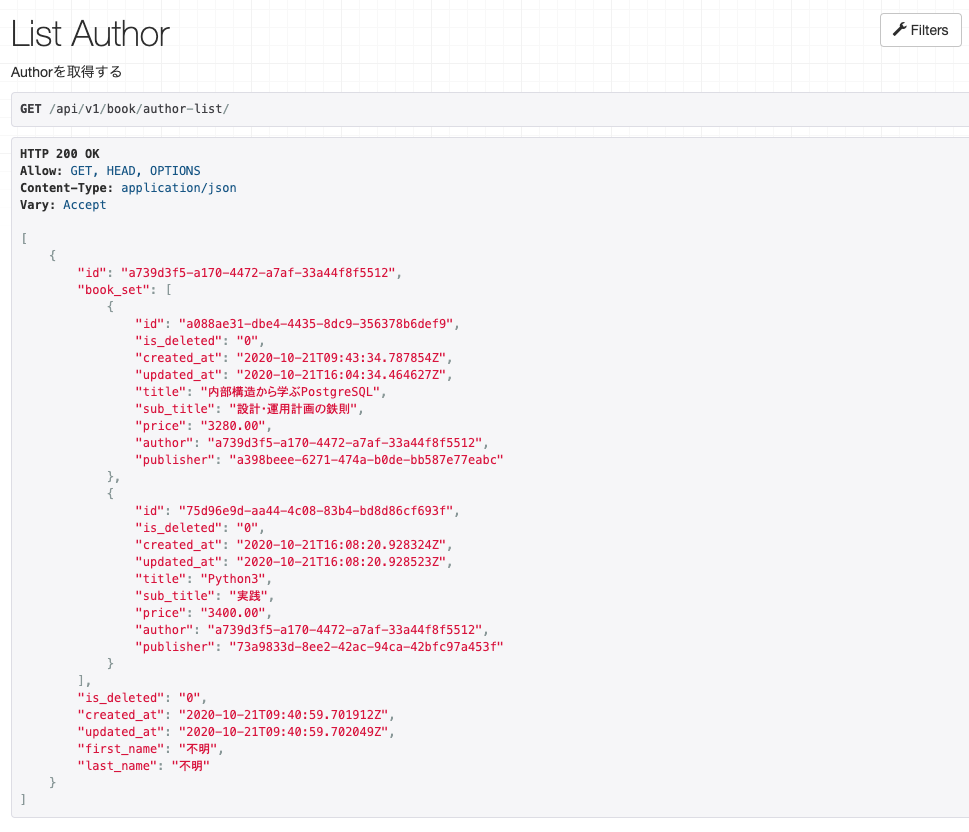
- 投稿日:2020-10-22T04:07:41+09:00
Django Serializerを使って参照モデルを取得する
Serializerを簡単にいうと!
モデルオブジェクトをJSONに変換してくれる!
それでは
今回はBookオブジェクトを取得する際に、
ForeignKeyで参照しているAuthorをオブジェクトも含めて取得します!!!!!!!!!!!!modelを定義する
サンプルのモデルです!
BookモデルはAuthorモデルを参照しています!models.pyclass AbstractModel(models.Model): id = models.UUIDField(primary_key=True, default=uuid.uuid4, editable=False) is_deleted = models.CharField(max_length=1, default='0') created_at = models.DateTimeField(auto_now_add=True) updated_at = models.DateTimeField(auto_now=True) class Meta: abstract = True class Author(AbstractModel): first_name = models.CharField(max_length=128) last_name = models.CharField(max_length=128) class Book(AbstractModel): title = models.CharField(max_length=128)] sub_title = models.CharField(max_length=128)] price = models.DecimalField(max_digits=8, decimal_places=2, blank=True, null=True) author = models.ForeignKey(Author, on_delete=models.PROTECT, blank=True, null=True)参照元のモデルも一緒に取得する
Viewを定義する
genericsのListAPIViewを使って取得APIを作成します!
authorモデルも取得するのでquerysetには
select_relatedでauthorを指定しておきます。
all()なのでも取得することは可能ですが、select_related.('author')を
事前に指定しておくことで、発行するSQLを削減できます!!views.pyfrom django_filters import rest_framework as filters from rest_framework import generics from book.models import Book, Author from book.serializers import BookSerializer class ListBook(generics.ListAPIView): """Bookを一覧取得するAPI""" queryset = Book.objects.select_related('author') serializer_class = BookSerializer filter_backends = [filters.DjangoFilterBackend] filterset_fields = '__all__'Serializerに参照元Serializerを定義する
BookSerializerのフィールドに関連先Serializerを定義することができます!
これで関連先のモデルも取得することができます!!!ただここで一つ注意なのは参照元のserializerを
定義する時にフィールド名がlookupに関係しているので間違えないようにしてください!!serializer.pyclass AuthorSerializer(serializers.ModelSerializer): class Meta: model = Author fields = '__all__' class BookSerializer(serializers.ModelSerializer): author = AuthorSerializer() class Meta: model = Book fields = '__all__'結果がこちらです!!!!
出力結果にはサンプルモデルでは省いたデータも出力されちゃってます!!
飛ばしてください!!
参照先のモデルを取得する
先ほどは、Bookモデルと参照元の
Authorモデルも取得しましたが、
逆に、AuthorからBookを取得したいと思います!!。
方法は簡単です!Viewを定義する
ListAPIViewを使って取得していきたいと思います。
今回は、select_relatedなどせずにそのままall()で問題ありません。views.pyclass ListAuthor(generics.ListAPIView): """Authorを取得する""" queryset = Author.objects.all() serializer_class = AuthorBookSerializer filter_backends = [filters.DjangoFilterBackend] filterset_fields = '__all__'Serializerの定義
参照先のモデルを取得するため、
book_setとなっています!
これでAPIをリクエストするとAuthorとBookが取得することができます。
この時に、BookSerializerにauthor = AuthorSerializer()を残しておくと
book取得した時にさらにauthorを再び取得してしまうので注意。serializers.pyclass BookSerializer(serializers.ModelSerializer): class Meta: model = Book fields = '__all__' class AuthorBookSerializer(serializers.ModelSerializer): book_set = BookSerializer(many=True) class Meta: model = Author fields = '__all__'結果がこちらです!!!!
以上になります!
- 投稿日:2020-10-22T02:22:10+09:00
【Python】50文字でワンライナースターリンソート
はじめに
スターリンソートとは
昇順(降順)になっていない要素を粛清する(取り除く)ことで$O(n)$の計算量を実現したソートアルゴリズム?
去年話題になったらしいが、自分は出会わなかった。
Python3.8以降ならすごくスッキリ書ける。実装
stalin_sort = lambda x:[m:=x[0]] + [m:=i for i in x[1:] if i>=m]動作
arr = [1, 2, 1, 1, 4, 3, 9] print(stalin_sort(arr)) #---> [1, 2, 4, 9]長さ
print(len('lambda x:[m:=x[0]] + [m:=i for i in x[1:] if i>=m]')) #---> 50まとめ
粛清というより存在を無視する感じの実装になったが短くてステキ
- 投稿日:2020-10-22T01:42:08+09:00
WAVファイルをCloud Speech APIで文字起こしする
目的
WAVファイル音声をGoogle Cloud Speech-to-Text APIで文字起こしする方法を説明します.FLACファイルの文字起こし方法の記事を参考にして,WAVファイルの文字起こしを行いました.この方法なら,FLAC形式に変換しなくても文字起こしを行うことができるようになります.
【重要】 WAVファイルの準備
Cloud Speech-to-Text APIはWAVファイルのヘッダ情報から文字起こしに必要な情報を得るため,音声変換したいWAVファイルのヘッダが正常かどうか事前に確認する必要があります.ヘッダ情報の中で確認すべき情報は,PCMかどうか(fmt_wave_format_type)とサンプリング周波数(fmt_samples_per_sec)です.
Cloud Speech-to-Text APIの仕様を確かめたい方は,VSCodeからRecognitionConfigに定義元ジャンプしてください.
WAVファイルヘッダの確認
PythonでWAVEファイルのヘッダ情報の読み取りの記事に書かれているプログラムを動かしてヘッダ情報を確かめます.
正常なWAVファイル
- fmt_samples_per_sec: 8000〜48000(16000が最適)
- fmt_wave_format_type: 1 (PCMを指す)
ダメなWAVファイル例
- fmt_samples_per_sec: 0
- fmt_wave_format_type: 0
ダメな形式のWAVファイルだった場合
こちらを参考にMacのデフォルトの「ミュージック」アプリを使ってWAVファイルを書き出すとうまく動きました!
【注意】 iMovieで書き出したWAVファイルやQuickTimePlayerで編集したWAVファイルはヘッダが正常でないので動かせませんでした!
サービスアカウントキーの作成
基本的にFLACファイルの文字起こし方法の記事を参考にして,jsonキーの作成を行なってください.
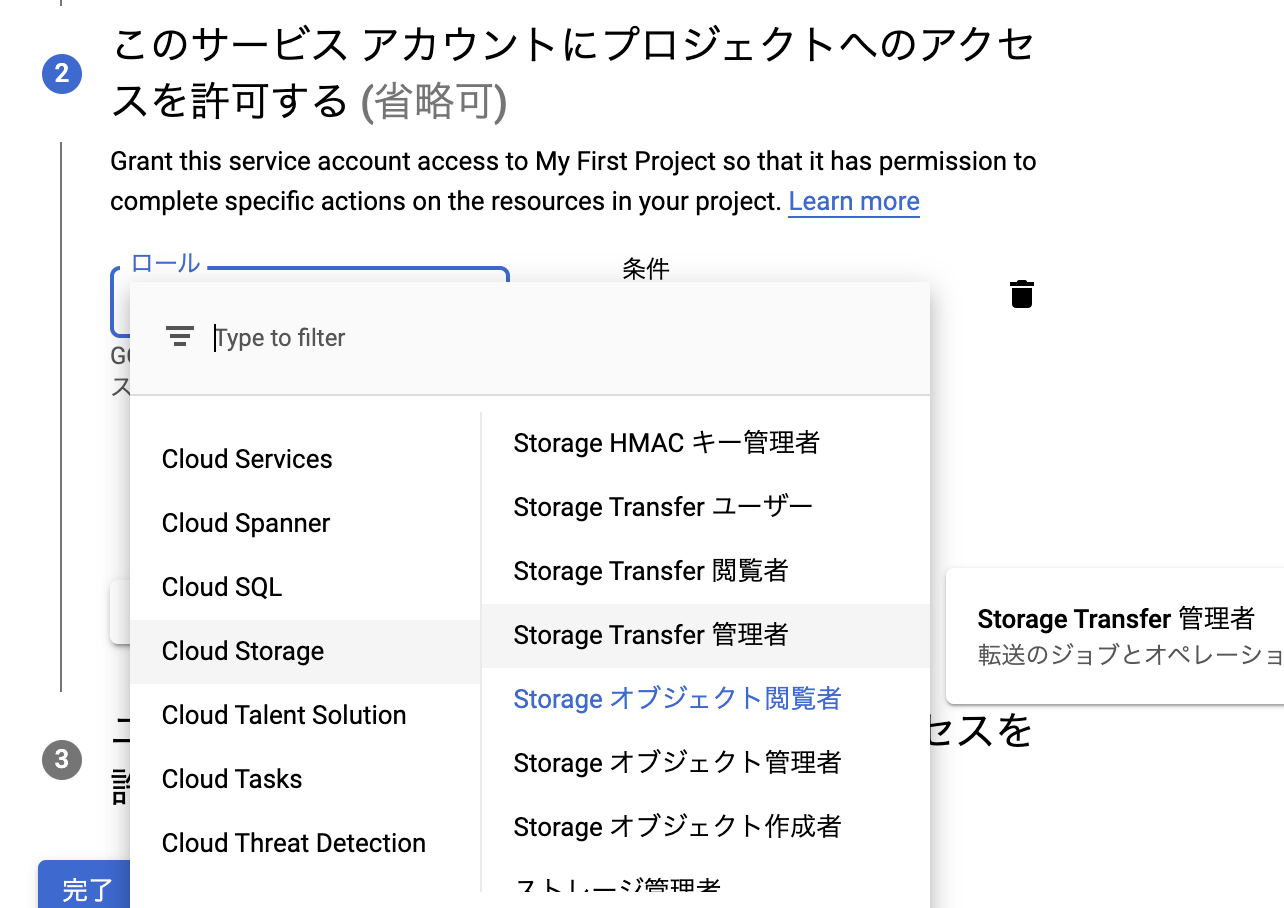
【注意】今回はGoogle Cloud StorageにアップロードしたWAVファイルを文字起こしするので,サービスアカウント にCloud Storageのアクセス権を付与する必要があります.
ロールにStorageオブジェクト閲覧者を追加してください.
Cloud Storageのアクセス権がないサービスアカウントを用いると次のように怒られるはずです.
PermissionDenied: 403 hogehoge does not have storage.objects.get access to the Google Cloud Storage object.サービスアカウントキーのパスを環境変数に設定する
先ほどダウンロードしたjsonファイルのパスを環境変数に設定します.
export GOOGLE_APPLICATION_CREDENTIALS=./hoge.jsonWAVファイルをCloud Storageにアップロード
FLACファイルの文字起こし方法の記事を参考にして,WAVファイルをCloud Storageにアップロードしてください.オブジェクトの詳細画面を見ると,gsから始まるCloud Storage内のリソースへのファイルパスが確認できます.
文字起こしスクリプト
FLACファイルの文字起こし方法の記事を参考にして,作成させていただきました.
transcribe.py# # !/usr/bin/env python # coding: utf-8 import argparse import datetime def transcribe(gcs_uri): from google.cloud import speech_v1 as speech from google.cloud.speech_v1 import types client = speech.SpeechClient() audio = types.RecognitionAudio(uri=gcs_uri) # 音声ファイルのヘッダに書かれているので, サンプリング周波数は指定しなくて良い config = types.RecognitionConfig(language_code='ja-JP') operation = client.long_running_recognize(config, audio) operationResult = operation.result() now = datetime.datetime.now() print('Waiting for operation to complete...') with open('./{}.txt'.format(now.strftime("%Y%m%d-%H%M%S")), mode='w') as f: for result in operationResult.results: print("Transcript: {}".format(result.alternatives[0].transcript)) print("Confidence: {}".format(result.alternatives[0].confidence)) f.write('{}\n'.format(result.alternatives[0].transcript)) if __name__ == '__main__': parser = argparse.ArgumentParser() parser.add_argument( 'path', help='cloud storage path start with gs://') args = parser.parse_args() transcribe(args.path)文字起こしスクリプトの実行
引数にgs://から始まるCloud Storage内のリソースへのファイルパスを指定し,スクリプトを実行してください.
python transcribe.py gs://hogehoge.wav結果
標準出力とテキストファイルとして結果が出てきます.
Transcript: 登録できそうなら Confidence: 0.8765763640403748 Transcript: いた方がいいんじゃないかな Confidence: 0.841985464096069320201022-010101.txt登録できそうなら いた方がいいんじゃないかな参考
- 投稿日:2020-10-22T01:37:23+09:00
WAVファイルをCloud Speech APIで文字起こしする
目的
WAVファイル音声をGoogle Cloud Speech-to-Text APIで文字起こしする方法を説明します.FLACファイルの文字起こし方法の記事を参考にして,WAVファイルの文字起こしを行いました.この方法なら,FLAC形式に変換しなくても文字起こしを行うことができるようになります.
【重要】 WAVファイルの準備
Cloud Speech-to-Text APIはWAVファイルのヘッダ情報から文字起こしに必要な情報を得るため,音声変換したいWAVファイルのヘッダが正常かどうか事前に確認する必要があります.ヘッダ情報の中で確認すべき情報は,PCMかどうか(fmt_wave_format_type)とサンプリング周波数(fmt_samples_per_sec)です.
Cloud Speech-to-Text APIの仕様を確かめたい方は,VSCodeからRecognitionConfigに定義元ジャンプしてください.
WAVファイルヘッダの確認
PythonでWAVEファイルのヘッダ情報の読み取りの記事に書かれているプログラムを動かしてヘッダ情報を確かめます.
正常なWAVファイル
- fmt_samples_per_sec: 8000〜48000(16000が最適)
- fmt_wave_format_type: 1 (PCMを指す)
ダメなWAVファイル例
- fmt_samples_per_sec: 0
- fmt_wave_format_type: 0
ダメな形式のWAVファイルだった場合
こちらを参考にMacのデフォルトの「ミュージック」アプリを使ってWAVファイルを書き出すとうまく動きました!
【注意】 iMovieで書き出したWAVファイルやQuickTimePlayerで編集したWAVファイルはヘッダが正常でないので動かせませんでした!
サービスアカウントキーの作成
基本的にFLACファイルの文字起こし方法の記事を参考にして,jsonキーの作成を行なってください.
【注意】今回はGoogle Cloud StorageにアップロードしたWAVファイルを文字起こしするので,サービスアカウント にCloud Storageのアクセス権を付与する必要があります.
ロールにStorageオブジェクト閲覧者を追加してください.
Cloud Storageのアクセス権がないサービスアカウントを用いると次のように怒られるはずです.
PermissionDenied: 403 hogehoge does not have storage.objects.get access to the Google Cloud Storage object.サービスアカウントキーのパスを環境変数に設定する
先ほどダウンロードしたjsonファイルのパスを環境変数に設定します.
export GOOGLE_APPLICATION_CREDENTIALS=./hoge.jsonWAVファイルをCloud Storageにアップロード
FLACファイルの文字起こし方法の記事を参考にして,WAVファイルをCloud Storageにアップロードしてください.オブジェクトの詳細画面を見ると,gsから始まるCloud Storage内のリソースへのファイルパスが確認できます.
文字起こしスクリプト
FLACファイルの文字起こし方法の記事を参考にして,作成させていただきました.
transcribe.py# # !/usr/bin/env python # coding: utf-8 import argparse import datetime def transcribe(gcs_uri): from google.cloud import speech_v1 as speech from google.cloud.speech_v1 import types client = speech.SpeechClient() audio = types.RecognitionAudio(uri=gcs_uri) # 音声ファイルのヘッダに書かれているので, サンプリング周波数は指定しなくて良い config = types.RecognitionConfig(language_code='ja-JP') operation = client.long_running_recognize(config, audio) operationResult = operation.result() now = datetime.datetime.now() print('Waiting for operation to complete...') with open('./{}.txt'.format(now.strftime("%Y%m%d-%H%M%S")), mode='w') as f: for result in operationResult.results: print("Transcript: {}".format(result.alternatives[0].transcript)) print("Confidence: {}".format(result.alternatives[0].confidence)) f.write('{}\n'.format(result.alternatives[0].transcript)) if __name__ == '__main__': parser = argparse.ArgumentParser() parser.add_argument( 'path', help='cloud storage path start with gs://') args = parser.parse_args() transcribe(args.path)文字起こしスクリプトの実行
引数にgs://から始まるCloud Storage内のリソースへのファイルパスを指定し,スクリプトを実行してください.
python transcribe.py gs://hogehoge結果
標準出力とテキストファイルとして結果が出てきます.
Transcript: 登録できそうなら Confidence: 0.8765763640403748 Transcript: いた方がいいんじゃないかな Confidence: 0.841985464096069320201022-010101.txt登録できそうなら いた方がいいんじゃないかな参考
- 投稿日:2020-10-22T01:23:58+09:00
反実仮想サンプル生成:「DiCE」
はじめに
ML (Machine Learning:機械学習)モデルの解釈は,ビジネスの現場における重要課題です.
推定精度の高いMLモデルを開発し,「出力と特徴量の対応関係」を評価することで,
ビジネス効果のある施策を打ち出すことが可能になります.
ex : 「成功確率」(出力)が高くなる,「プロジェクトリーダーの条件」(特徴量)近年,MLモデル解釈の方法として,「ELI5」「LIME」「SHAP」などの様々なアルゴリズムが開発されています.
これらアルゴリズムの内容は,「出力に対する特徴量の寄与度の計算」というもので,このような「寄与度の評価」では,モデルの解釈が「出力と特徴量の関係性の記述」に留まるため,出力最適化のためのサンプル特徴量の生成が難しい点があります.Microsoft Researchが開発した「DiCE」は,反実仮想を考慮したモデル解釈アルゴリズムであり,目的とする出力を得るための特徴量サンプリングを可能にするアルゴリズムです.「サンプル生成による直接的な材料提供」という点において,他のアルゴリズムとは差別化されています.
本ブログでは,反実仮想を考慮したモデル解釈アルゴリズムである「DiCE」を取り上げ,原著論文の購読によるアルゴリズム理解と,実装による動作確認の概要をまとめます.
出典:https://www.microsoft.com/en-us/research/project/dice/目次
- はじめに
- MLモデルの解釈とは?
- DiCEの概要
- DiCEとは?
- DiCEのコンセプト:「反実仮想サンプル生成」による「MLモデルの解釈」
- DiCEのアルゴリズム説明と実装
- 使用データ
- サンプリングまでのフロー
- アルゴリズムのコンセプト
- 最適化関数の定義
- DiCEを使ってみる
- まとめ
- 参考文献
MLモデルの解釈とは?
教師あり学習では与えられたデータに対して学習モデルが予測したラベルを返します.
このとき、MLでは以下の点が不透明です.・学習モデルを作り、そこから得られた予測結果は正しいか?
・現象の因果関係を正しく学習できているか?「MLの信頼性獲得」および「安全な実用」のためにも,上記疑問を解消するための,特徴量と出力(目的変数)の対応関係の評価が必要となります.本ブログでは,この対応関係の評価を「MLモデルの解釈」と表現します.
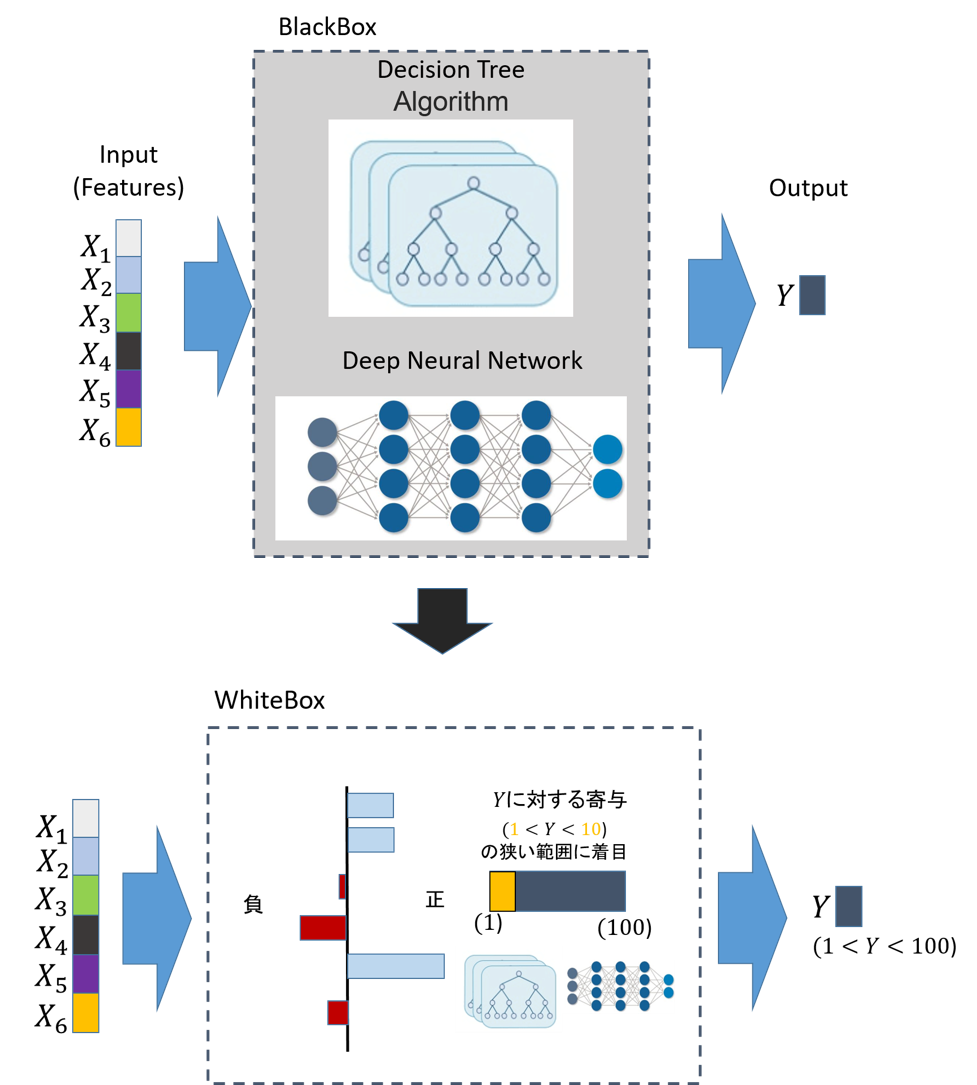
図:MLモデルの解釈とは?
余談ですが,「”MLの解釈性”というトピックを持つ論文数」は,過去20年において約4倍程度に増加しています.MLモデル理論の発展の実用化に伴い,ML人口が単純に増加したことも要因として考えられますが,一定数の興味を獲得するトピックであることは間違いなさそうです.
出典:https://beenkim.github.io/papers/BeenK_FinaleDV_ICML2017_tutorial.pdf「DiCE」の概要
・DiCEとは?
Microsoft Researchの提供する,反実仮想サンプルを列挙するフレームワーク:Python ライブラリー
pip install dice_ml出典:https://www.microsoft.com/en-us/research/project/dice/
・DiCEのコンセプト:「反実仮想サンプル生成」による「MLモデルの解釈」
反実仮想:事実と反対のことを想定すること.「もし~だったら…だろうに」のような言い方
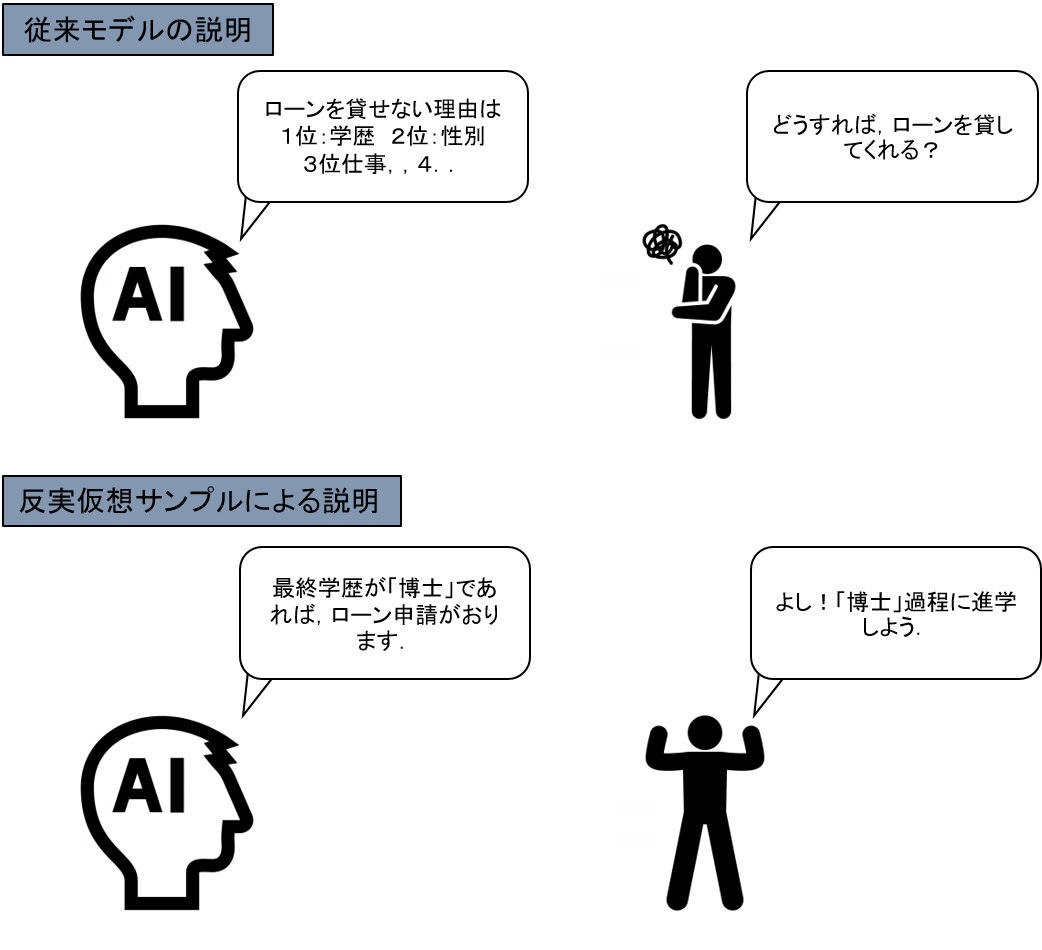
図:反実仮想モデルによるMLモデルの解釈
現在,「ELI5」「LIME」「SHAP」など,「出力と特徴量の関係性」を記述するためのアルゴリズムが開発されています.各アルゴリズムの基本コンセプトは「出力に対する特徴量の寄与度の算出」であり,寄与度の「正負」「大小」から出力との関係性を解釈できます.
しかし,一方で「寄与度」のみが算出される「出力と特徴量の関係性の記述」だけでは,出力最適化のための「最適特徴量」を算出することができません.
例えば,図のような「ローン貸出審査」を行う機械学習モデルが,任意の候補者の貸出判定を実施する場合を考えます.任意の候補者の特性は,「年齢」「学歴」「過去の借入履歴」などの変数で特徴づけられ,機械学習モデルは,事前に学習したパターンにより,その候補者の貸出の判定をします.
そして,仮に,モデルが候補者の貸出を「拒否」と判定したとします.
この場合,従来の解釈アルゴリズムでは,「なぜ候補者が拒否されたか」を説明することができますが,「では,この候補者はどうすれば借入できるか」の具体提案を出すことはできません.
この問題を解決したのが,DiCEの基本コンセプト:「反実仮想サンプル生成」になります.
DiCEでは,既存のMLモデルからは反実仮想に当たるサンプルを生成し,直接的な改善案を提示することができます.
出典:https://qiita.com/OpenJNY/items/ef885c357b4e0a1551c0DiCEのアルゴリズム説明と実装
・使用データ
本ブログでは,DiCEアルゴリズムの説明のため,「Bank Marketing Data Set from UCI Machine Learning Repository」データを使います.
本データは,複数の社会人に関する特徴量とloan貸出判定が記載されているデータで,目的変数 y を loan={0:No, 1:Yes}と設定します.
表:Bank Marketing Data Set:データセット内の一部のカラムのみ表示
出典:http://archive.ics.uci.edu/ml/datasets/Bank+Marketing#・サンプリングまでのフロー
本解説における問題設定とサンプリングの方針を下記に示します.
(問題設定)
1.ローンを借りれない候補者がいる(loan=0:No)
2.loanと特徴量を学習したMLモデルが開発されている.
3.候補者は,に,loan=1:Yes(反実仮想)になるための条件を,モデルよりサンプリングする.(サンプリング方針)
反実仮想サンプル用の格納ベクトルcを用意し,MLモデルより出力f(c)を算出
→そのラベルが望むクラス(loan=1)になった場合に小さくなる損失関数を定義
→極値を取るときのサンプルcを抽出する. = 反実仮想サンプル
図:問題設定とサンプリングフロー・アルゴリズムのコンセプト
DiCEには,上記最適化関数の最小化において,実装されているいくつかの工夫があります.それら7つのコンセプトをここでご説明します.
また,以下に出てくる式は原著論文から引用しております.
出典:https://www.microsoft.com/en-us/research/publication/explaining-machine-learning-classifiers-through-diverse-counterfactual-examples/1.「実現可能性」
事実ベクトル(loan =0:No)に対して離れすぎたものを反実仮想ベクトル(c)としてサンプリングしても,現実味がなく,実現することができません.そのため,DiCEでは,評価関数に,ベクトル(loan =0:No)と反実仮想ベクトル(c)の距離を追加し,距離が遠くなりすぎないような最適化をかけています.
2.「ダイバーシティ」
複数の反実仮想ベクトル(c)をサンプリングする場合,多種な選択パターンがあったほうが嬉しく,類似したベクトルが含まれていて欲しくありません.そのため,複数の反実仮想ベクトル(c_i)間の距離を定義し,その値ができるだけ遠くなるように最適化をかけます.
3.「損失関数にhinge lossを採用」
SVMなどに使用されることのあるhinge関数がlossとして活用されています.
4.「連続変数とカテゴリー変数の区別」
DiCEでは,多次元データ間の距離を算出し,「実現可能性」と「ダイバーシティ」を定義しています(1.2.).
その際,連続的な分布をとる連続変数と,ダミー変数化したカテゴリー変数は,分布の仕方の違いにより,区別して距離を計算しています(おそらくです...間違えているかも)5.「分散を考慮した距離の算出による特徴量の重み調整(連続変数)」
多次元のベクトルの距離を考える場合,平均値(または中央値)だけでは,データ群同士の適切な距離を測ることができません.なぜならば,次元の変数ごとに分散が異なる場合,データの広がりによりデータ群の距離が変化するからです.こういった場合には,マハラビス距離のような分散を考慮した距離を考慮する必要があります.DiCEでは,平均値よりもロバストな「中央値によるばらつき:MAD」を用いて,連続変数に関する距離を分散考慮型へと変換しています.
MAD:median absolute deviation
MADが大きい変数に関して,重み付けを行わない場合には,「より広い範囲での値変動」が起きるため,実現不可能な非現実的な特徴量がサンプリングされることになります.
6.「変化させる特徴量の選択」
反実仮想サンプリングの実問題として,変更できない特徴量が存在します.
※性別や若返りなど
そのため,DiCEでは,変更する特徴量を選択できるようになっています(最適化の際に,可変に設定しなければ良いだけです)7.「実現可能性とダイバーシティのトレードオフ」
DiCEの定義する最適化関数には,「実現可能性」と「ダイバーシティ」の重みを設定するハイパーパラメータが存在します.本値を調整することにより,それぞれの比率を変化させられます.
(また,本レポートでは記述がないが,有益なサンプリングかどうかの評価指標が存在しているらしいため,その指標の活用よりパラメタチューニングができるのだと思っています)
・最適化関数の定義
上記コンセプトを考慮したうえで,最適化する関数を定義します.
反実仮想ベクトル(c_i)のサンプリングロジックと,各コンセプトを考慮したうえで,最適化関数は以下のように記述できます.
λ1とλ2はハイパーパラメータ・DiCEを使ってみる
それでは,DiCEを使って,実際に反実仮想サンプルを生成してみます.
なお,本実装はMicrosoft社ドキュメント(GitHub)を参照しています.
出典:https://www.microsoft.com/en-us/research/project/dice/#Library import import pandas as pd import numpy as np import dice_ml import tensorflow as tf from tensorflow import keras tf.compat.v1.logging.set_verbosity(tf.compat.v1.logging.ERROR)#データの読み込み&目的変数のダミー変数化 data = pd.read_csv('bank-full.csv' ,sep=';' ,usecols=['age', 'job', 'marital', 'education', 'default', 'balance', 'housing','loan']) data['loan'] = pd.get_dummies(data.loan,drop_first=True) data.head()
#DiCE用にデータ構造を定義 d = dice_ml.Data(dataframe=data, continuous_features=['age', 'balance'], outcome_name='loan')#MLモデルの学習 train, _ = d.split_data(d.normalize_data(d.one_hot_encoded_data)) X_train = train.loc[:, train.columns != 'loan'] y_train = train.loc[:, train.columns == 'loan'] model = keras.Sequential() model.add(keras.layers.Dense(20, input_shape=(X_train.shape[1],), kernel_regularizer=keras.regularizers.l1(0.001), activation=tf.nn.relu)) model.add(keras.layers.Dense(1, activation=tf.nn.sigmoid)) model.compile(loss='binary_crossentropy', optimizer=tf.keras.optimizers.Adam(0.01), metrics=['accuracy']) model.fit(X_train, y_train, validation_split=0.20, epochs=100, verbose=0, class_weight={0:1,1:2})#DiCEオブジェクトにMLモデルをprovide backend = 'TF'+tf.__version__[0] # TF1 m = dice_ml.Model(model=model, backend=backend)#反実仮想サンプリングモデル exp = dice_ml.Dice(d, m) #query instanceの設定:反実仮想を求める基準値の設定(であると理解してます) query_instance = {'age':20, 'job':'blue-collar', 'marital':'single', 'education':'secondary', 'default':'no', 'balance': 129, 'housing':'yes'} #反実仮想サンプリングの生成 dice_exp = exp.generate_counterfactuals(query_instance ,total_CFs=4 ,desired_class="opposite") #total_CFs:生成するベクトルの数 #desired_class:生成したいサンプルのクラス:反実仮想の場合にはopposite#サンプル結果の可視化 dice_exp.visualize_as_dataframe()
サンプル結果を見ると,outcome=0に対し,outcome=1のサンプルが4つ生成されていることが分かります.
loanのカラムは,sigmoid関数に対する入力値であり,outcome=0が約0.3に対し,outcome=1が0.5以上になっていることが分かります.
※MLモデルを上手く作れなかったので微妙な結果になりました...特徴量を見ると, age, job, maritalなどが変化していることが分かります.
確かに,設定したquery_instanceとは異なる特徴量が生成されていることが分かります.また,「特徴量に対する重みの変更」や「変化させる特徴量の指定」を行う場合には以下のように設定します.
feature_weights = {'age': 1}#ageの重み→1 features_to_vary = ['age','job']#ageとjobだけ変化させる dice_exp = exp.generate_counterfactuals(query_instance ,total_CFs=4 ,desired_class="opposite" ,feature_weights=feature_weights ,features_to_vary=features_to_vary)まとめ
本ブログでは,反実仮想を考慮したモデル解釈アルゴリズムである「DiCE」を取り上げ,原著論文の購読によるアルゴリズム理解と,実装による動作確認の概要をまとめてみました.DiCEは「サンプル生成による直接的な材料提供」という点において,他のアルゴリズムとは差別化されたものであり,多角的なモデルの解釈に貢献してくれるものかと思います.
原著論文の内容は記載内容だけでなく,まだフォローしていない点がありますし,間違い等あるかと思います.
ご指摘いただけると幸いです.以上です.
参考文献
・Welcome to ELI5’s documentation!(ELI5)
https://eli5.readthedocs.io/en/latest/
・"Why Should I Trust You?": Explaining the Predictions of Any Classifier(LIME)
https://arxiv.org/abs/1602.04938#:~:text=version%2C%20v3)%5D-,%22Why%20Should%20I%20Trust%20You%3F%22%3A%20Explaining,the%20Predictions%20of%20Any%20Classifier&text=In%20this%20work%2C%20we%20propose,model%20locally%20around%20the%20prediction.・LIMEで機械学習の予測結果を解釈してみる
https://qiita.com/fufufukakaka/items/d0081cd38251d22ffebf
・Explainable AI: ELI5,LIME and SHAP(kaggle kernel)
https://www.kaggle.com/kritidoneria/explainable-ai-eli5-lime-and-shap
・DiCE: Diverse Counterfactual Explanations for Machine Learning Classifiers(DiCE)
https://www.microsoft.com/en-us/research/project/dice/
https://arxiv.org/pdf/1905.07697.pdf(転記してある数式はすべてここから)
・DiCE: 反実仮想サンプルによる機械学習モデルの解釈/説明手法
https://qiita.com/OpenJNY/items/ef885c357b4e0a1551c0
・入門統計的因果推論:Judea Pearl (著), Madelyn Glymour (著), Nicholas P. Jewell (著), 落海 浩 (翻訳)
https://www.amazon.co.jp/%E5%85%A5%E9%96%80-%E7%B5%B1%E8%A8%88%E7%9A%84%E5%9B%A0%E6%9E%9C%E6%8E%A8%E8%AB%96-Judea-Pearl/dp/4254122411
・CounterFactual Machine Learningの概要 (反実仮想機械学習)
https://usaito.github.io/files/190729_sonyRD.pdf
・Interpretable Machine Learning: The fuss, the concrete and the questions
https://beenkim.github.io/papers/BeenK_FinaleDV_ICML2017_tutorial.pdf



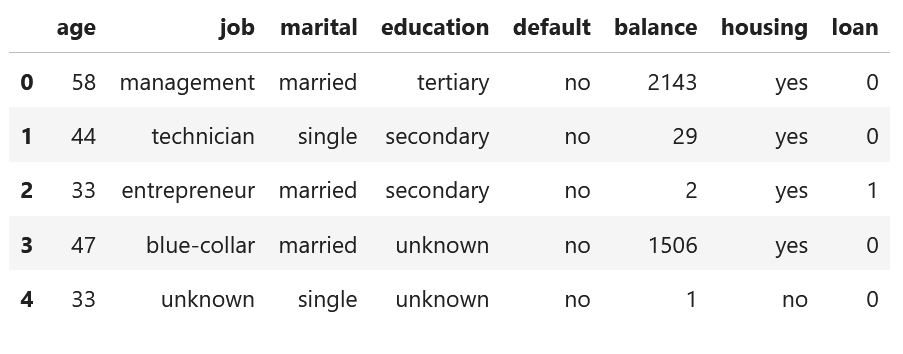


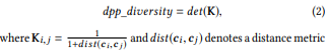
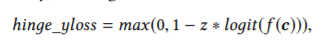
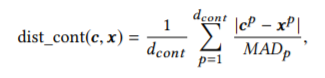
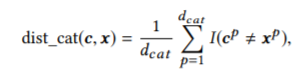
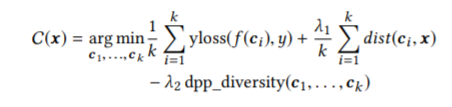
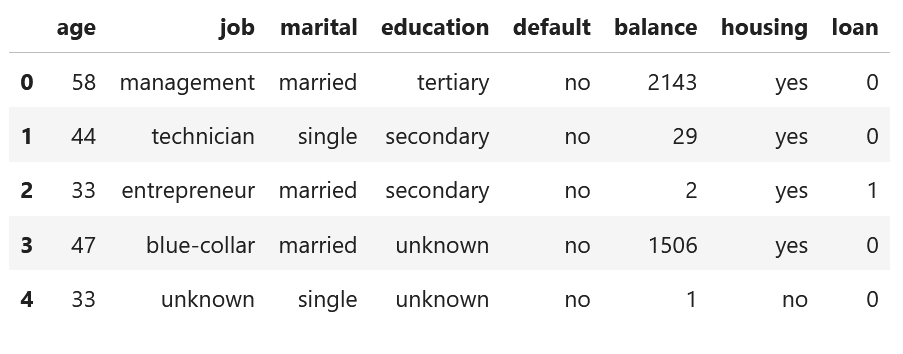

- 投稿日:2020-10-22T00:52:29+09:00
pythonで複数行サイズ指定読み込み
pythonで複数行読み込み
pythonでファイルを複数行に分けて読み込みたくて試してみたので備忘録として残しておきます。
<結果>
サイズ指定は文字数で途中までの文字数を指定するとその行の
最後まで読み込む。
改行はカウントされない。ゼロは全行読み込む
<環境>
バージョン:Python 3.8.5
windows 10<詳細>
ファイルの内容abcdefghijklmnopqrstuvwxyz
12345678901234567890
ABCDEFGHIJKLMNOPQRSTUVWXYZ1行目の途中を指定.pydef readlines( fname ): with open( fname, 'r') as f: readData = f.readlines( 20 ) return readData if __name__ == '__main__': fname = './Dmy.txt' readData = readlines( fname ) print( f' readData = {type(readData)} {readData}')<出力>
readData = <class 'list'> ['abcdefghijklmnopqrstuvwxyz\n']
2行目の途中を指定.pydef readlines( fname ): with open( fname, 'r') as f: readData = f.readlines( 30 ) return readData if __name__ == '__main__': fname = './Dmy.txt' readData = readlines( fname ) print( f' readData = {type(readData)} {readData}')<出力>
readData = <class 'list'> ['abcdefghijklmnopqrstuvwxyz\n', '12345678901234567890\n']
ファイルの内容
あいうえおかきくけこさしすせそ
12345678901234567890
ABCDEFGHIJKLMNOPQRSTUVWXYZ1行目の改行前を指定.pydef readlines( fname ): with open( fname, 'r') as f: readData = f.readlines( 15 ) return readData if __name__ == '__main__': fname = './Dmy.txt' readData = readlines( fname ) print( f' readData = {type(readData)} {readData}')<出力>
readData = <class 'list'> ['あいうえおかきくけこさしすせそ\n']
1行目の改行を指定のつもりだけど2行目の先頭.pydef readlines( fname ): with open( fname, 'r') as f: readData = f.readlines( 16 ) return readData if __name__ == '__main__': fname = './Dmy.txt' readData = readlines( fname ) print( f' readData = {type(readData)} {readData}')<出力>
readData = <class 'list'> ['あいうえおかきくけこさしすせそ\n', '12345678901234567890\n']
0を指定.pydef readlines( fname ): with open( fname, 'r') as f: readData = f.readlines( 0 ) return readData if __name__ == '__main__': fname = './Dmy.txt' readData = readlines( fname ) print( f' readData = {type(readData)} {readData}')<出力>
readData = <class 'list'> ['あいうえおかきくけこさしすせそ\n', '12345678901234567890\n', 'ABCDEFGHIJKLMNOPQRSTUVWXYZ']
- 投稿日:2020-10-22T00:34:23+09:00
Djangoチュートリアル(ブログアプリ作成)⑦ - フロントエンド完成編
前回、Djangoチュートリアル(ブログアプリ作成)⑥ - 記事詳細・編集・削除機能編では記事個別の詳細、編集、削除画面を作成しました。
今回は template を大幅に調整していきますが、大きく分けると以下のことをやっていきます。
全ページ共通画面の作成
ナビゲーションバーの作成
各templateの修正
不要なtemplateや処理の削除
全ページ共通画面の作成
Django に限らず、ホームページには画面遷移しても共通的に表示される箇所ってありますよね。
Qiita でいえば上部に表示されている、緑色のナビゲーションバーなんかが良い例ですね。↓これ
ただ、これをすべての template に毎回書くなんてのは大変ですよね。
一回コードを書いて終わりならまだしも、修正が入ったときのことを考えるともう…。そこで、Django の便利な機能として共通テンプレートを使います。
簡単にいうと、共通的な部分は一つのファイルにまとめて、
画面ごとに異なる部分は別の template を呼び出して使うということです。そのために、まずは template フォルダ直下にはじめてファイルを作成します。
今回は /template/base.html というファイルを作成しましょう。└── templates ├── base.html # 追加 └── blog ├── index.html ├── post_confirm_delete.html ├── post_detail.html ├── post_form.html └── post_list.htmlこのファイルに共通の処理を書き、画面ごとに異なる部分は
post_detail.html などのファイルを呼び出していくことにします。base.html の修正
中身はこのようにしていきます。
base.html<!doctype html> <html lang="ja"> <head> <title>tmasuyama のブログ</title> <!-- Required meta tags --> <meta charset="utf-8"> <meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no"> <!-- Bootstrap CSS --> <link rel="stylesheet" href="https://maxcdn.bootstrapcdn.com/bootstrap/4.0.0-beta.2/css/bootstrap.min.css" integrity="sha384-PsH8R72JQ3SOdhVi3uxftmaW6Vc51MKb0q5P2rRUpPvrszuE4W1povHYgTpBfshb" crossorigin="anonymous"> </head> <body> <div class="container"> <nav class="navbar navbar-expand-lg navbar-light bg-light"> <a class="navbar-brand" href="{% url 'blog:post_list' %}">トップ</a> <button class="navbar-toggler" type="button" data-toggle="collapse" data-target="#navbarSupportedContent" aria-controls="navbarSupportedContent" aria-expanded="false" aria-label="Toggle navigation"> <span class="navbar-toggler-icon"></span> </button> <div class="collapse navbar-collapse" id="navbarSupportedContent"> <ul class="navbar-nav mr-auto"> <li class="nav-item"> <a class="nav-link" href="{% url 'blog:post_create' %}">投稿</a> </li> </ul> </div> </nav> <!-- このblockの中で各templateの記載内容が呼び出される --> {% block content %} # 注目! {% endblock %} # 注目! </div> <!-- Optional JavaScript --> <!-- jQuery first, then Popper.js, then Bootstrap JS --> <script src="https://maxcdn.bootstrapcdn.com/bootstrap/4.0.0-beta.2/js/bootstrap.min.js" integrity="sha384-alpBpkh1PFOepccYVYDB4do5UnbKysX5WZXm3XxPqe5iKTfUKjNkCk9SaVuEZflJ" crossorigin="anonymous"></script> </body> </html>このチュートリアルはフロントエンドについて詳細な解説はしませんが、
Bootstrap を使って見た目を整えるために CDN から Bootstrap を呼び出して使えるようにしたり、
ナビゲーションバーを 内で表させるようにしています。
このようにどの画面でも使いたいものは base.html で書くようにします。注目してほしいのは 「# 注目!」 とメモをした部分です。
<!-- このblockの中で各templateの記載内容が呼び出される --> {% block content %} # 注目! {% endblock %} # 注目!View に従って template を呼び出す際、各 template はここに格納されていくことになります。
逆にいうと、各 template は各ページに特徴的な部分だけを書いておけばよいのです。また、呼び出される側の template では親となる template (base.html) を明示してあげる必要があります。
基本的な書き方は次の通りです。各template{% extends 'base.html' %} # 親 template の指定 {% block content %} # 中身の記述開始 ...各 template 固有の記述... {% endblock %} # 中身の記述終了これで親templateと子templateの役割を明確に分けることが出来るようになりました。
次は親templateで用意するナビゲーションバーについて解説します。ナビゲーションバーの説明
上述の base.html を使うと以下のようなナビゲーションバーが表示されるようになります。
なお、今回は Bootstrap4 の Cheat Sheat を参考にしています。
https://hackerthemes.com/bootstrap-cheatsheet/#navbar
トップ を選択すると post_list.html の画面へ遷移し、
投稿 を選択すると post_form.html の画面(新規投稿画面)へ遷移するようにしています。base.html のうち、ナビゲーションバーを表示させるための部分はここでした。
base.html<nav class="navbar navbar-expand-lg navbar-dark bg-dark"> <a class="navbar-brand" href="{% url 'blog:post_list' %}">トップ</a> <button class="navbar-toggler" type="button" data-toggle="collapse" data-target="#navbarSupportedContent" aria-controls="navbarSupportedContent" aria-expanded="false" aria-label="Toggle navigation"> <span class="navbar-toggler-icon"></span> </button> <div class="collapse navbar-collapse" id="navbarSupportedContent"> <ul class="navbar-nav mr-auto"> <li class="nav-item"> <a class="nav-link" href="{% url 'blog:post_create' %}">投稿</a> </li> </ul> </div> </nav>ここで大事なのは「href="{% url 'blog:post_list' %}"」という部分です。
これまで template ではリンクを記述してきませんでしたが、
上記のようなフォーマットで逆引き用の URL を記述すると
に相当する URL へリダイレクトされるようになります。※urls.py でいうとこの部分です。
python:urls.py
...
path('post_list', views.PostListView.as_view(), name='post_list'),
...
ここで name='post_list' というように、各URLに名前をつけていたおかげで
template側ではその名前を指定することで、自動でルーティングしてくれるようになります。各templateの修正
さて、各 template で親 template の指定をしつつ、Bootstrapで見た目の調整をしていきましょう。
完成形を載せていきます。post_detail.html{% extends 'base.html' %} {% block content %} <table class="table"> <tr> <th>タイトル</th> <td>{{ post.title }}</td> </tr> <tr> <th>本文</th> <!-- linebreaksbk を入れると改行タグでちゃんと改行して表示されるようになる --> <td>{{ post.text | linebreaksbr}}</td> </tr> <tr> <th>日付</th> <td>{{ post.date }}</td> </tr> </table> {% endblock %}post_form.html{% extends 'base.html' %} {% block content %} <p>{{ post.title }}</p> <!-- actionにはサーバのどのURLに対して情報を送信する --> <!-- actionを空欄にすると現在開いている URL = /blog/post_create に値を返すので、views.py の PostCreateView が再度呼び出されることになる --> <form action="" method="POST"> <table class="table"> <tr> <th>タイトル</th> <td>{{ form.title }}</td> </tr> <tr> <th>本文</th> <td>{{ form.text }}</td> </tr> </table> <button type="submit" class="btn btn-primary">送信</button> {% csrf_token %} </form> {% endblock %}post_confirm_delete.html{% extends 'base.html' %} {% block content %} <form action="" method="POST"> <table class="table"> <tr> <th>タイトル</th> <td>{{ post.title }}</td> </tr> <tr> <th>本文</th> <td>{{ post.text }}</td> </tr> <tr> <th>日付</th> <td>{{ post.date }}</td> </tr> </table> <p>こちらのデータを削除します。</p> <button type="submit">送信</button> {% csrf_token %} </form> {% endblock %}post_list.html{% extends 'base.html' %} {% block content %} <table class="table"> <thead> <tr> <th>タイトル</th> <th>日付</th> <th></th> <th></th> </tr> </thead> <tbody> {% for post in post_list %} <tr> <!-- 「url 'アプリ名:逆引きURL' 渡されるモデル.pk」 という描き方 --> <td><a href="{% url 'blog:post_detail' post.pk %}">{{ post.title }}</a></td> <td>{{ post.date }}</td> <td> <!-- superuserでログインしている時にのみ表示 --> {% if user.is_superuser %} <!-- HTMLを アプリ名_モデル名_change にすると admin でそのまま編集できる --> <a href="{% url 'blog:post_update' post.pk %}">編集</a> {% endif %} </td> <td> {% if user.is_superuser %} <a href="{% url 'blog:post_delete' post.pk %}">削除</a> {% endif %} </td> </tr> {% endfor %} </tbody> </table> {% endblock %}なお、最後の post_list.html はいくつか変更を追加で加えました。
ひとつは、一覧に表示させる各記事ごとに詳細、編集、削除のリンクをつけるようにしました。
プライマリキーに基づきリンク先が決まるような場合は 変数名.pk の形でプライマリキーを指定できます。
※templateがviewから変数を受け取る時の名前は post_list となっていますが、
for文で回しているので post という変数で展開しています。
そのため post.pk と指定しています。逆引きする用URLの名前で指定する形は、決まった書き方なので覚えてしまいいましょう。
<a href="{% url 'blog:post_detail' post.pk %}">...また、今回のチュートリアルではユーザ登録機能を実装していませんが、
誰でも記事の編集や削除をできてしまわないようにぐらいの制限はかけておきましょう。今回はユーザは superuser しか存在していませんので、
superuser で管理画面 (127.0.0.1:8000/admin) からログインしている場合にのみ
記事の編集および削除のリンクを表示させるようにします。
※厳密にいえば、この状態でもアドレスから直接アクセスすると編集・削除画面には飛べてしまいます。
この制限も Django で実装することはできます。念の為。{% if user.is_superuser %} # superuser でログインしているときのみ、if文の中身を表示 <a href="{% url 'blog:post_update' post.pk %}">編集</a> {% endif %}上記では superuser の時でしたが、他にも何かしらのユーザでログインしている時の表示や、
特定のユーザでログインしている時にのみ表示させるということも出来たりします。不要なtemplateや処理の削除
さて、これまで Hello を表示させるためだけの index.html ページを練習用に残しておきましたが、
これ以上残しておくと管理の手間が増えるため、このタイミングで削除しておきましょう。└── templates ├── base.html └── blog ├── index.html # これを削除する ├── post_confirm_delete.html ├── post_detail.html ├── post_form.html └── post_list.htmlurls.py test_urls.py、、views.py、test_views.py も忘れずに編集しておきます。
urls.py... urlpatterns = [ path('', views.IndexView.as_view(), name='index'), # ここを削除 ...test_urls.py... class TestUrls(TestCase): """index ページへのURLでアクセスする時のリダイレクトをテスト""" def test_post_index_url(self): # このメソッドを丸々削除 view = resolve('/blog/') self.assertEqual(view.func.view_class, IndexView) class TestUrls(TestCase): """index ページへのURLでアクセスする時のリダイレクトをテスト""" def test_post_index_url(self): # このメソッドを削除 view = resolve('/blog/') self.assertEqual(view.func.view_class, IndexView) ...views.py... class IndexView(generic.TemplateView): # この汎用ビューを削除 template_name = 'blog/index.html' ...test_views.py... class IndexTests(TestCase): # このテストクラスごと削除 """IndexViewのテストクラス""" def test_get(self): """GET メソッドでアクセスしてステータスコード200を返されることを確認""" response = self.client.get(reverse('blog:index')) self.assertEqual(response.status_code, 200) ...一気に変更を行ったので、最後にユニットテストを実行してエラーが出ないかを確認しておきましょう。
(blog) bash-3.2$ python3 manage.py test Creating test database for alias 'default'... System check identified no issues (0 silenced). ..............E ====================================================================== ERROR: blog.tests.test_urls (unittest.loader._FailedTest) ---------------------------------------------------------------------- ImportError: Failed to import test module: blog.tests.test_urls Traceback (most recent call last): File "/usr/local/Cellar/python@3.8/3.8.5/Frameworks/Python.framework/Versions/3.8/lib/python3.8/unittest/loader.py", line 436, in _find_test_path module = self._get_module_from_name(name) File "/usr/local/Cellar/python@3.8/3.8.5/Frameworks/Python.framework/Versions/3.8/lib/python3.8/unittest/loader.py", line 377, in _get_module_from_name __import__(name) File "/Users/masuyama/workspace/MyPython/MyDjango/blog/mysite/blog/tests/test_urls.py", line 3, in <module> from ..views import IndexView, PostListView ImportError: cannot import name 'IndexView' from 'blog.views' (/Users/masuyama/workspace/MyPython/MyDjango/blog/mysite/blog/views.py) ---------------------------------------------------------------------- Ran 15 tests in 0.283s FAILED (errors=1) Destroying test database for alias 'default'...エラーが確認されました。
エラーメッセージは区切り文字などを使って表示されているので、どこでエラーが起きているかも置いやすいようになっています。エラーメッセージを追っていくと、test_urls.pyで import できないものがあり、エラーが起きていることが分かります。
ImportError: cannot import name 'IndexView' from 'blog.views'もう一度 test_urls.py を読んでみると、たしかに冒頭で IndexView の読み込みを残してしまっていることが分かりました。
test_urls.pyfrom django.test import TestCase from django.urls import reverse, resolve from ..views import IndexView, PostListView # この行これを消して、次のようにしてあげます。
test_urls.pyfrom django.test import TestCase from django.urls import reverse, resolve from ..views import PostListViewこれでユニットテストをもう一度実行しましょう。
(blog) bash-3.2$ python3 manage.py test Creating test database for alias 'default'... System check identified no issues (0 silenced). ............... ---------------------------------------------------------------------- Ran 15 tests in 0.223s OK Destroying test database for alias 'default'...今度はエラーなくテストが完了しました。
また、テストの数は 15 となっており、前回は 17 だったテストから2つのテストメソッドを減らしたこととも一致していますね。これまではユニットテストが通るようにした結果しかお見せしませんでしたが、
今回のように一気に複数のファイルで変更を起きたときでも
予めユニットテストを用意しておくと、コマンド一つで問題箇所を特定することができると分かっていただけたかと思います。これで無事にローカルの Django アプリとしては完成しました!
次回はいよいよ環境の整備というところで、今回作ったアプリを Docker 化していきましょう。


- 投稿日:2020-10-22T00:26:10+09:00
OSやPythonのバージョンに関わらずOpenSeesPyを使う
(モチベーション)
OpenSeesPyを利用しようと思ったところ、環境構築方法がOSによって違っていたり、Pythonバージョンによっては使えなかったり、使えるようになったとしても、VSCodeのインタープリターがOpenSeesPyのメソッドを解釈してくれなかったりと始めるまでに苦労しました。そのため、何かそれらに関わらず簡単に環境構築できる方法を考えました。
この記事について
- Dockerを使ってOSに関わらず環境構築
- VSCodeのRemote Developmentを使って、Dockerコマンドとか使わなくても簡単環境構築
- OpenSeesPy?インストールされるようにコード書いといたから、それを使えばOK
OpenSeesPyとは
OpenSeesは、Open System for Earthquake Engineering Simulationの略で、地震時における構造物や地盤の構造解析などで利用されているオープンソースのフレームワークです。OpenSeesPyは、それをPythonで利用するためのインタープリターです。
Dockerとは
Dockerはコンテナ仮想化によって、異なる環境でも同じ環境を構築することができるツールです。構築方法をファイルに記述しておけば、OSはもちろん、指定したバージョンのPythonのインストールやその他のライブラリのインストールなども、それはもうドッカーンと作成して実行してくれます。ドッカーンと。
手順
必要なもの
Docker Desktop
https://www.docker.com/products/docker-desktopVS Code
https://code.visualstudio.com/Remote Development(VS Codeにインストール)
https://marketplace.visualstudio.com/items?itemName=ms-vscode-remote.vscode-remote-extensionpackDockerfileを準備
DockerはDockerfileという名前のファイルを準備しておくとそれを元に環境を構築してくれます。今回は以下のように準備しました。主にやっていることは、
- Pythonインストール(バージョン3.8。linux環境も一緒に入る)
- pipをインストール
- pypiの必要パッケージをインストール
# Dockerfile FROM python:3.8 RUN mkdir -p /usr/src/app WORKDIR /usr/src/app RUN apt-get update RUN apt-get install -y --no-install-recommends \ python3-dev \ python3-pip ADD . /usr/src/app/ RUN pip install -r requirements.txt CMD bashrequirements.txtを準備
Dockerfileに記載した通り、
pip install -r requiremennts.txtしてパッケージをインストールするので、必要なパッケージを予め書いておきます。今回はOpenSeesPyを始めたいので、openseespyをお忘れなく。(てか、もはやOpenSeesPyに限らない方法なんだが)# requrements.txt(例) matplotlib==3.3.2 numpy==1.19.2 openseespy==3.2.2.5 pylint==2.6.0Dockerfileとrequirements.txtは何かフォルダを作って、その中に入れておきます。
ドッカーン
VS Codeで開いて、VS Codeの左下の青いボタン(以下の図参照)を押します。そして、"Remote-Containers: Open Folder in Container..."を選択し、Dockerfileとrequirements.txtを用意したフォルダ選べば環境の構築完了です!
と言いたいところですが、このままだとまだOpenSeesPyのメソッドをVS Codeが理解してくれません。
開いた後に、.devcontainerというフォルダと、その中にdevcontainer.jsonというファイルが入っていると思います。それに、以下のように記述を追加しておけば今度こそ完成です!# devcontainer.json { ... "settings": { ... "python.linting.pylintArgs": ["--extension-pkg-whitelist=openseespy.opensees"] <- 追加 }, "extensions": [ "ms-python.python" <- 追加 ] }完成したコード
できたものをすでに用意してありますので、差し替えます。(料理番組風)
https://github.com/kakemotokeita/openseespy-docker-vscode良かったら使ってください。個人的に好みのものも入れてしまっているので、適宜不要なものは消してください。
間違っている点やうまくいかなかった点などあれば優しく教えてください。
ちなみに、OpenSeesは立体の構造解析が可能ですが、質点系の振動解析のみの場合なら、簡単な設定で使えるパッケージを作成しました。良かったら、こちらも使ってください。
https://github.com/adc21/asvaよろしくお願いします。