- 投稿日:2020-10-22T21:03:20+09:00
AWS SAM Lambda関数からS3アクセス
- AWS SAM概要、Hello World
- AWS SAM Lambda関数からS3アクセス (※本記事)
Lambda関数からS3にアクセスする
変更必要点
- Lambda関数にS3アクセス権限を与える
- Lambda関数から参照するバケット名を環境変数に追加する
変更後テンプレートは以下のようになる
Parameters: DataBucketName: Type: String Default: 'for-dev-bucket' Resources: GetAllDataFunction: Type: AWS::Serverless::Function Properties: CodeUri: get-all-data/ Handler: function.lambda_handler Runtime: python3.8 Environment: Variables: BUCKET_NAME: !Ref DataBucketName Events: getAllPermission: Type: Api Properties: Path: /api/devices Method: get Policies: - S3ReadPolicy: BucketName: !Ref DataBucketNameテンプレート変更点
- Parametersセクションにバケット名を定義
- PoliciesにS3のバケットを指定してリード権限を追加
- EnvironmentにLambda関数から参照できるようにバケット名を設定
その他定義可能なセクションは公式ドキュメント参照
その他ポリシーに関しては公式ドキュメント参照
S3ReadPolicyのようにプレースホルダー値("Ref": "BucketName")があるものは指定が必要Lambda関数からの環境変数アクセス
Lambda関数(Python)からは以下のようにアクセス可能
import os BUCKET_NAME = os.getenv('BUCKET_NAME')Lambda関数で外部ライブラリの使用
変更必要点
- Layerの追加
Parameters: DataBucketName: Type: String Default: 'for-dev-bucket' PandasLayerArn: Type: String Default: 'arn:aws:lambda:ap-northeast-1:770693421928:layer:Klayers-python38-pandas:18' Resources: GetAllDataFunction: Type: AWS::Serverless::Function Properties: CodeUri: get-all-data/ Handler: function.lambda_handler Runtime: python3.8 Layers: - !Ref PandasLayerArn Environment: Variables: BUCKET_NAME: !Ref DataBucketName Events: getAllPermission: Type: Api Properties: Path: /api/devices Method: get Policies: - S3ReadPolicy: BucketName: !Ref DataBucketNameテンプレート変更点
- ParametersセクションにLayerのARN追加
- Layersを追加
外部ライブラリのLayer ARNについては以前の記事で記載しているのでそちらを参照
- 投稿日:2020-10-22T21:03:20+09:00
[AWS SAM] Lambda関数からS3アクセス
- [AWS SAM] 概要、Hello World
- [AWS SAM] Lambda関数からS3アクセス (※本記事)
Lambda関数からS3にアクセスする
変更必要点
- Lambda関数にS3アクセス権限を与える
- Lambda関数から参照するバケット名を環境変数に追加する
変更後テンプレートは以下のようになる
Parameters: DataBucketName: Type: String Default: 'for-dev-bucket' Resources: GetAllDataFunction: # リソース名 Type: AWS::Serverless::Function # Lambda Properties: CodeUri: get-all-data/ # Lambdaソースコード格納パス Handler: function.lambda_handler # 関数実体:ファイル名function.pyの関数名lambda_handler Runtime: python3.8 Environment: Variables: BUCKET_NAME: !Ref DataBucketName # Lambda関数から参照する環境変数 Events: # Lambdaをキックするイベント設定 getAllData: Type: Api Properties: Path: /api/devices Method: get Policies: - S3ReadPolicy: # S3リードポリシー設定 BucketName: !Ref DataBucketName # Parametersで定義した値を参照テンプレート変更点
- Parametersセクションにバケット名を定義
- PoliciesにS3のバケットを指定してリード権限を追加
- EnvironmentにLambda関数から参照できるようにバケット名を設定
その他定義可能なセクションは公式ドキュメント参照
その他ポリシーに関しては公式ドキュメント参照
S3ReadPolicyのようにプレースホルダー値("Ref": "BucketName")があるものは指定が必要Lambda関数からの環境変数アクセス
Lambda関数(Python)からは以下のようにアクセス可能
import os BUCKET_NAME = os.getenv('BUCKET_NAME')Lambda関数で外部ライブラリの使用
変更必要点
- Layerの追加
Parameters: DataBucketName: Type: String Default: 'for-dev-bucket' PandasLayerArn: Type: String Default: 'arn:aws:lambda:ap-northeast-1:770693421928:layer:Klayers-python38-pandas:18' Resources: GetAllDataFunction: Type: AWS::Serverless::Function Properties: CodeUri: get-all-data/ Handler: function.lambda_handler Runtime: python3.8 Layers: # Layer追加 - !Ref PandasLayerArn Environment: Variables: BUCKET_NAME: !Ref DataBucketName Events: getAllData: Type: Api Properties: Path: /api/devices Method: get Policies: - S3ReadPolicy: BucketName: !Ref DataBucketNameテンプレート変更点
- ParametersセクションにLayerのARN追加
- Layersを追加
外部ライブラリのLayer ARNについては以前の記事で記載しているのでそちらを参照
- 投稿日:2020-10-22T21:01:25+09:00
AWS SAM概要、Hello World
- AWS SAM概要、Hello World (※本記事)
- AWS SAM Lambda関数からS3アクセス
AWS SAM(AWS Serverless Application Model)
サーバレスアプリケーション
Lambda関数、トリガとなるイベントリソース、およびLambda関数から操作するリソース等を組み合わせたもの
AWS SAM
サーバレスアプリケーションのデプロイに特化したAWS CloudFormationの拡張機能
CloudFormationと比べて簡潔にテンプレートを記述可能
SAMはCloudFormationの拡張機能のため、CloudFormationの文法と共存可能
SAMでサポートしていないサービスについてはCloudFormationの文法で対応CloudFormationと同様にYAMLまたはJSONでSAMテンプレートを記述する
デプロイ時にCloudFormationによってSAMテンプレートはCloudFormationテンプレートに変換される
テンプレート内のTransform: AWS::Serverless-2016-10-31で変換方式を指定しているAWS SAM CLIのインストール
公式ドキュメントを参考にAWS SAM CLIをインストール
Hello Worldアプリケーションの導入
公式ドキュメントを参考に
sam initでアプリケーションを作成、
今回はRuntimeにpython3.8、アプリケーションテンプレートにhello-worldを選択
python3.8をインストールしておく必要あり、バージョン違いも不可----------------------- Generating application: ----------------------- Name: sam-app Runtime: python3.8 Dependency Manager: pip Application Template: hello-world Output Directory: .デプロイは、
aws cloudformation package、aws cloudformation deployを使用
パッケージのアップロード先S3バケットは事前に作成しておく必要あり$ aws cloudformation package \ --template-file ./template.yaml \ --s3-bucket ${YOUR_BUCKET_NAME} \ --output-template-file ./packaged_template.yaml $ aws cloudformation deploy \ --template-file ./packaged_template.yaml \ --stack-name ${YOUR_STACK_NAME} \ --capabilities CAPABILITY_IAM \ --region ${YOUR_REGION}
aws cloudformation packageで実装ファイルをzip圧縮し、S3の指定バケットにアップロード、
aws cloudformation deployでCloudFormationのスタックとして、指定された名前でデプロイスタックはデプロイされるリソース一式で、スタックを削除すると紐づいているリソースすべてが削除される、
存在しないスタック名でデプロイすると新規作成、すでに存在するスタック名の場合は更新される
デプロイしたLambda関数、API GatewayのAPI名に指定したスタック名で含まれる(明示的にFunctionName, Nameを指定しなかった場合)hello-worldアプリケーションをデプロイすると、
API Gateway にスタック名でAPIが生成、
Lambdaに${YOUR_STACK_NAME}-HelloWorldFunction-XXXXXXのような名前で関数が生成されるテンプレート内容
Resources: HelloWorldFunction: Type: AWS::Serverless::Function Properties: CodeUri: hello_world/ # Lambda関数ファイルの場所、※packageコマンドで実際のS3パスに置き換えれる Handler: app.lambda_handler # Lambda関数実体(ファイル名app、関数名lambda_handler) Runtime: python3.8 Events: # Lambdaのトリガとなるイベント HelloWorld: Type: Api # API Gatewayの以下パス、メソッドコール時にLambdaをキック Properties: Path: /hello Method: get
- 投稿日:2020-10-22T21:01:25+09:00
[AWS SAM] 概要、Hello World
- [AWS SAM] 概要、Hello World (※本記事)
- [AWS SAM] Lambda関数からS3アクセス
AWS SAM(AWS Serverless Application Model)
サーバレスアプリケーション
Lambda関数、トリガとなるイベントリソース、およびLambda関数から操作するリソース等を組み合わせたもの
AWS SAM
サーバレスアプリケーションのデプロイに特化したAWS CloudFormationの拡張機能
CloudFormationと比べて簡潔にテンプレートを記述可能
SAMはCloudFormationの拡張機能のため、CloudFormationの文法と共存可能
SAMでサポートしていないサービスについてはCloudFormationの文法で対応CloudFormationと同様にYAMLまたはJSONでSAMテンプレートを記述する
デプロイ時にCloudFormationによってSAMテンプレートはCloudFormationテンプレートに変換される
テンプレート内のTransform: AWS::Serverless-2016-10-31で変換方式を指定しているAWS SAM CLIのインストール
公式ドキュメントを参考にAWS SAM CLIをインストール
Hello Worldアプリケーションの導入
公式ドキュメントを参考に
sam initでアプリケーションを作成、
今回はRuntimeにpython3.8、アプリケーションテンプレートにhello-worldを選択
python3.8をインストールしておく必要あり、バージョン違いも不可----------------------- Generating application: ----------------------- Name: sam-app Runtime: python3.8 Dependency Manager: pip Application Template: hello-world Output Directory: .デプロイは、
aws cloudformation package、aws cloudformation deployを使用
パッケージのアップロード先S3バケットは事前に作成しておく必要あり$ aws cloudformation package \ --template-file ./template.yaml \ --s3-bucket ${YOUR_BUCKET_NAME} \ --output-template-file ./packaged_template.yaml $ aws cloudformation deploy \ --template-file ./packaged_template.yaml \ --stack-name ${YOUR_STACK_NAME} \ --capabilities CAPABILITY_IAM \ --region ${YOUR_REGION}
aws cloudformation packageで実装ファイルをzip圧縮し、S3の指定バケットにアップロード、
aws cloudformation deployでCloudFormationのスタックとして、指定された名前でデプロイスタックはデプロイされるリソース一式で、スタックを削除すると紐づいているリソースすべてが削除される、
存在しないスタック名でデプロイすると新規作成、すでに存在するスタック名の場合は更新される
デプロイしたLambda関数、API GatewayのAPI名に指定したスタック名で含まれる(明示的にFunctionName, Nameを指定しなかった場合)hello-worldアプリケーションをデプロイすると、
API Gateway にスタック名でAPIが生成、
Lambdaに${YOUR_STACK_NAME}-HelloWorldFunction-XXXXXXのような名前で関数が生成されるテンプレート内容
Resources: HelloWorldFunction: Type: AWS::Serverless::Function Properties: CodeUri: hello_world/ # Lambda関数ファイルの場所、※packageコマンドで実際のS3パスに置き換えれる Handler: app.lambda_handler # Lambda関数実体(ファイル名app、関数名lambda_handler) Runtime: python3.8 Events: # Lambdaのトリガとなるイベント HelloWorld: Type: Api # API Gatewayの以下パス、メソッドコール時にLambdaをキック Properties: Path: /hello Method: get
- 投稿日:2020-10-22T19:59:58+09:00
Amazon Elasticsearch Serviceを最小構成で作ってみた
※最小構成(コスト的に)で構築する手順を書いていますが、注意が必要なので前置きが長いです。まずは作ってから考えたい人はスクロールして前置きを読み飛ばしてください
※構造を理解するために書いたものです。一部予想図で書いています
※Elasticsearchの具体的な操作方法は知りません。環境構築するためのお話ですAmazon Elasticsearch Service(AmazonES)の位置づけ
Elasticsearch は、Elastic社が中心となって開発しているオープンソース製品名。
AmazonESは、このオープンソースをSaaSとして利用できるようにしたもの。AWSの他のサービスと比べて、癖が強い感じがするので、癖の部分を”ポイント”としてまとめますた。
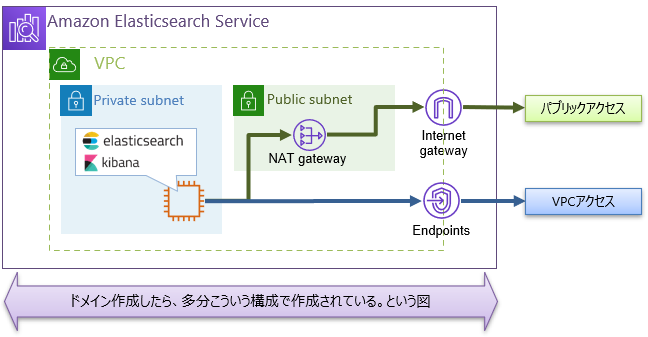
そのうえで、最小構成でAmazonESドメインを構築する手順を記載します。ポイント1:通信経路について
管理コンソールのドメイン作成ウィザードで、以下の選択があります。
”VPCアクセス”とは、自分が作成したVPC内にインスタンスが作成されるわけではなく、VPCピアリングによって、Saas環境とプライベートIPで接続できる。という意味っぽい。
見えないところに↓のような環境が構築されるのだと思われる(あくまでも予想図)
※VPCアクセスで設定したときは、自AWSアカウント側にはプライベートIPをもつネットワークインターフェイスのみができている。VPCエンドポイントオブジェクトはできていない(隠している??(陰謀論))
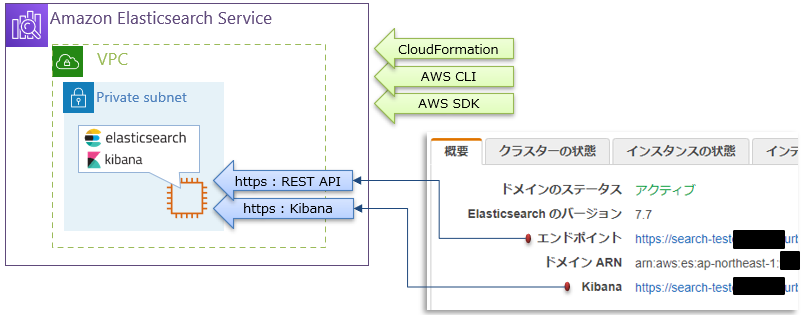
ポイント2:ツールごとの操作範疇
CloudFormation / AWSCLI / AWSSDK は、AmazonESドメイン構築等、環境に関する部分のみ操作できる
Elasticsearch本体に対してのデータ操作関連は、HTTPSで行う。ポイント1の通信経路を経由して利用できるということになる。
なお、REST APIを使う場合は
接続先ホストは、”エンドポイント”
利用可能なAPIは Open Distro for Elasticsearchを使う事になる(多分、本家Elasticsearch APIからの派生したもの)ポイント3:インスタンスタイプと機能制限
サポートされるインスタンスタイプ
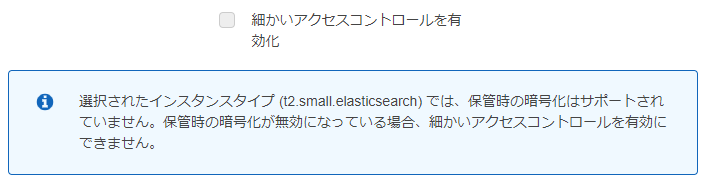
とりあえずお試しで使ってみたくて、インスタンスタイプを最弱である t2.small.elasticsearch を 選択した場合は、「きめ細かい」と言われるアクセス方法が使えないので注意Kibanaで使える機能も変わってくる様子
きめ細かい無 きめ細かい有 ポイント4:アクセス権限について
AmazonESドメインに対するアクセス制限は、以下のように3段階で考えるのが吉
(まくまでも予想図です)
- 通信経路による制限 → VPCの中・外の2択。
- 利用許可制限 → Elasticsearch側で許可するユーザ・ロール・IPアドレスが指定できる
- きめ細やかな設定 → Kibanaにより指定可能
1.通信経路
ポイント1の通り
VPC経由の方が安全ですわな2.利用許可
IAMでポリシーを決定する必要はない
ポイント2の通り、環境構築の場合はAWS側で。データ操作はElasticsearchで。という分類となる。
つまり、データ操作を行う場合は、IAMでポリシーを設定する必要はない。(というかできない)
Elasticsearchにとっては、”誰が(IAMuser)・何か(IAMrole)”が判ればよい程度となる。Elasticsearch側の認可(利用許可)
ここ
・誰、もしくはどのリソースからのアクセスを許可するか→IAMリソースのARNによって指定
・どこからのアクセスを許可するか→IPアドレスで指定
・誰なら何が使えるとかも設定可能ドメイン新規作成時の「アクセスポリシー」か、ドメイン作成後の「アクセスポリシーの変更」で設定できる
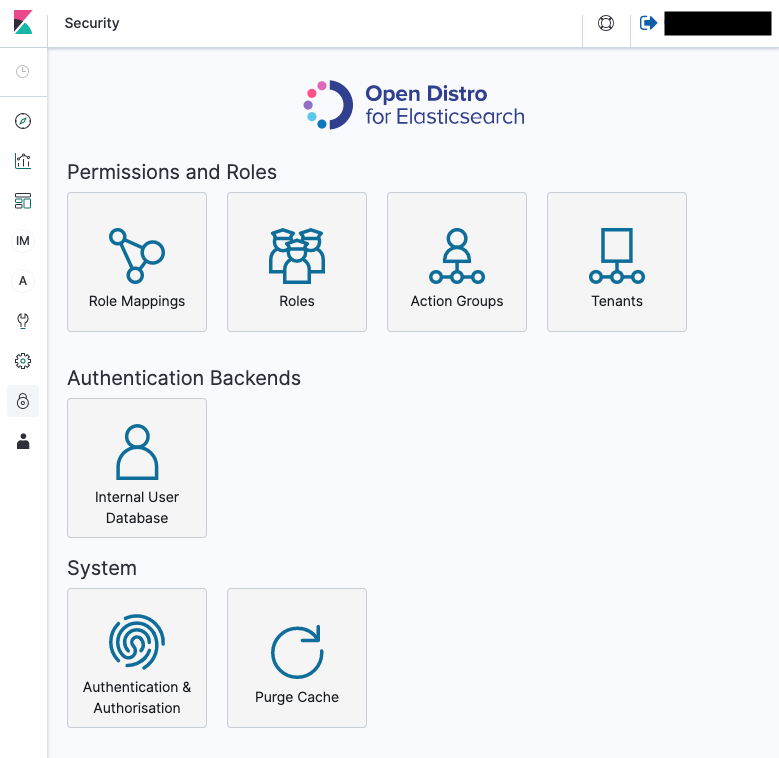
3.きめ細かな
ここに記載されている通り、要するにKibana内でARNごとに、具体的な操作まで指定できる。
Role MappingsにIAM User・RoleのARNを指定する事で接続許可される。
ここから先は、Kibana側の範疇になるので略最小構成でのドメイン作成
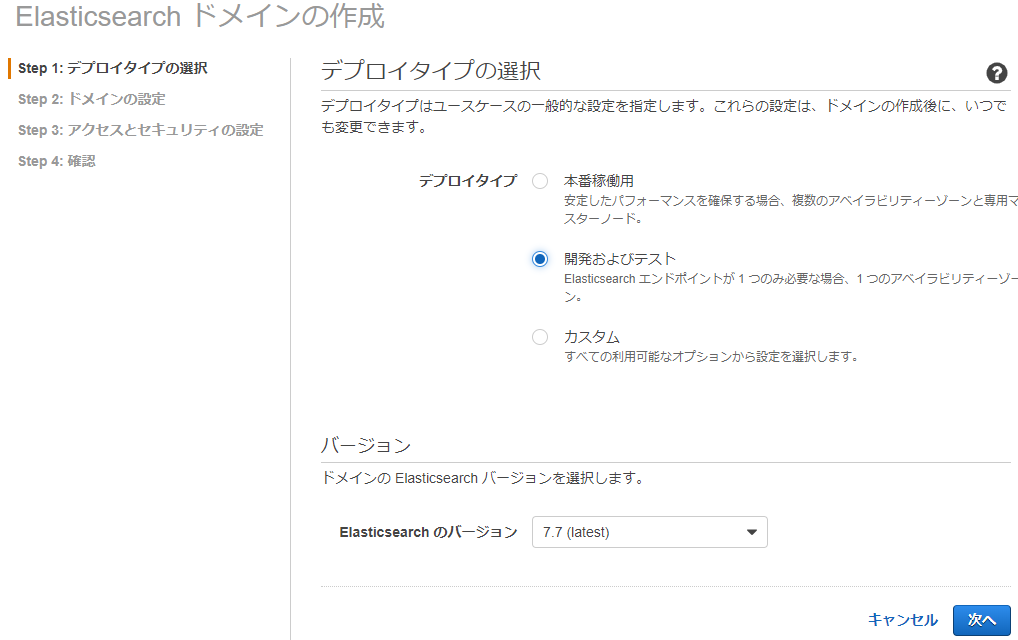
ゴール:最小構成(コストが安い。という意味で)ドメインを作成し、自分のPCからKibanaが操作できること。
Step 1
デプロイタイプ:開発およびテスト
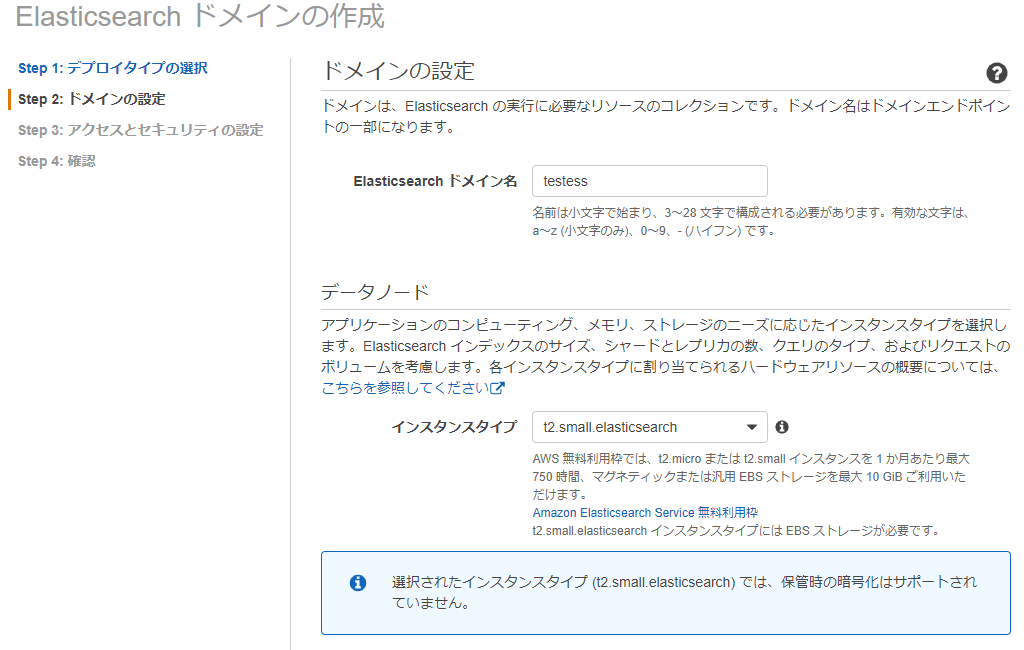
Step 2
ドメイン名とインスタンスタイプを指定します。
ドメイン名は適当に。インスタンスタイプは最安のt2.small.elasticsearch
以下、デフォルトStep 3
パブリックアクセスを指定します。インターネット経由でElasticsearchとKibanaにアクセスするという意味です。
インターネット経由なので、何らかの制限をしておく必要があります→ドメインアクセスポリシーで縛ります
(ちなみにVPC内からアクセスできるのなら、ドメインアクセスポリシー設定は不要です。この例では”自分のPCでアクセスできること”をゴールとしているので。。)
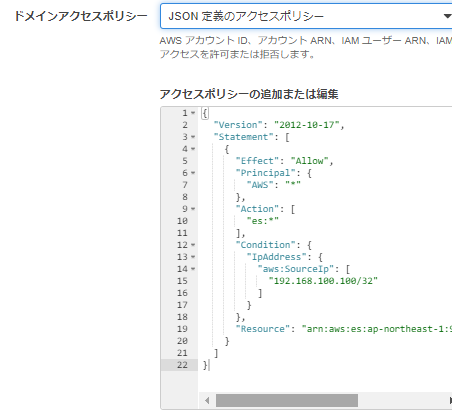
t系のインスタンスタイプだと、「細かい…」が有効化できないので、ドメインアクセスポリシーで個別指定します。
ドメインアクセスポリシーで、アクセス許可するIPアドレスを指定します。
例として、192.168.100.100/32としていますが、グローバルIPを指定しないといけないです。
もしくは、JSONで定義できるのなら、ここを参考に設定します。
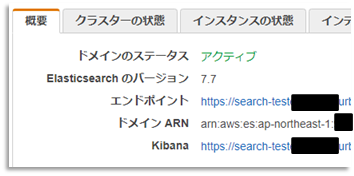
完成後
管理コンソールに、出力されている Kibana のURLにブラウザでアクセスしてみます。
Kibanaのログイン画面なしで、直接ログイン後画面になります。(IPアドレスでしか制限していないからですね)(怖)
試していないが、RESTAPIもパスワード無でいけてしまう気がする。。
接続できない場合は、ドメインアクセスポリシーで設定したIPアドレスが間違っているとか。まとめ
という事で、最小構成だとセキュリティ面がかなり心配。少なくともKibanaログインにユーザアカウントくらいは使いたい。
となるので、
t2.small.elasticsearchを使ってテストする場合は、あくまでも機能面の調査となると思われます。





- 投稿日:2020-10-22T19:53:15+09:00
最初のStackを騙せ!cdk deployを騙せ!
はじめに
タイトルの元ネタは特に説明しません。今回はAWS CDKで複数のStackを作った時に発生するdeployエラーの回避方法について書きます。
発生しうるdeployエラー
CDKを実装する時に、設計思想的な観点からもリソース数制限の観点からもStackを分ける実装をおそらくすることは結構あると思います。この時、
cdk deploy時に以下のようなエラーが発生することが度々ありました。Export Stack:XXXX cannot be deleted as it is in use by StackXXXXこれが起こってしまうのは大体以下のようなStackを実装した場合だと思います(コード全体)。
sampleStack/lib/stackA.tsimport * as cdk from '@aws-cdk/core' import * as lambda from '@aws-cdk/aws-lambda' export class StackA extends cdk.Stack { public readonly handler: lambda.Function constructor(scope: cdk.Construct, id: string, props?: cdk.StackProps) { super(scope, id, props) this.handler = new lambda.Function(this, `${id}Handler`, { runtime: lambda.Runtime.NODEJS_12_X, code: lambda.Code.fromAsset('lambda'), handler: 'index.handler', }) } }sampleStack/lib/stackB.tsimport * as cdk from '@aws-cdk/core' import * as lambda from '@aws-cdk/aws-lambda'; import * as apigateway from '@aws-cdk/aws-apigateway' interface StackBProps extends cdk.StackProps { handler: lambda.Function } export class StackB extends cdk.Stack { constructor(scope: cdk.Construct, id: string, props: StackBProps) { super(scope, id, props) new apigateway.LambdaRestApi(this, `${id}Endpoint`, { handler: props.handler, }) } }sampleStack/bin/sample_stack.tsimport * as cdk from '@aws-cdk/core' import { StackA } from '../lib/stackA' import { StackB } from '../lib/stackB' const app = new cdk.App() const { handler } = new StackA(app, 'StackA') new StackB(app, 'StackB', { handler })このスタックではlambdaのリソースを
StackAに実装して、API GatewayのリソースをStackBに実装しています。そしてStackAで定義したリソースをStackBで呼び出しています(実際はこの程度であれば同じスタックで定義すると思いますが一応例として、、)。
このときStackBをデプロイすると必ずStackAもデプロイされるはずです。StackBはStackAに依存する形になっています。StackAがデプロイされると以下のようなOutputsが表示されるはずです。StackA.ExportsOutputFnGetAttStackAHandlerxxx = arn:aws:lambda:region:xxxxx:function:StackA-StackAHandlerxxxxxCDKではStack間の変数やインスタンスの受け渡しを行うと、それをCloudFormationに変換した時にOutputsの機能を利用して内部的に処理しているようです。
これはCDKを実装しているときには特に意識することはないのですが、例えばStackAを以下のように変更したときに面倒なことになります。sampleStack/lib/stackA.ts... this.handler = new lambda.Function(this, `${id}Lambda`, { // IDを変更 runtime: lambda.Runtime.NODEJS_12_X, code: lambda.Code.fromAsset('lambda'), handler: 'index.handler', }) ...変更したのは単に
lambda.Functionの第2引数のIDの文字列だけなのですが、このIDはOutputsのキー名に関係します。おそらくOutputsが以下のように変わるはずです(単にHadlerがLambdaに変わるだけです)。StackA.ExportsOutputFnGetAttStackALambdaxxx = arn:aws:lambda:region:xxxxx:function:StackA-StackALambdaxxxxxこのこと自体は特に大した問題ではありませんが、デプロイ時には必ず
StackA->StackBという順番でのデプロイになってしまうので、「StackBで使うはずのOutputsの値がなくなっている」と勝手にCloudFormationが判断してしまってデプロイを失敗させてしまいます。考えた解決方法
本当はCDKのデプロイについての設定(順番とか)が充実していたらこんな面倒な対処は必要ないのですが、現状その機能はなさそうなのでこちらでなんとかするしかありません。
一番手っ取り早いのはStackAを一旦destroyすることなのですが、あまりやりたくない場合もあると思います(CloudFrontとか使い出すと削除とデプロイにものすごく時間がかかります)。
CDKにはCfnOutputというClassが存在します。これはCloudFormationのOutputsが使える機能です。つまりこれで擬似的にOutputsを生成すればデプロイエラーを回避できるのではと思ってStackAに以下を加えました。sampleStack/bin/sample_stack.tsimport * as cdk from '@aws-cdk/core' import * as lambda from '@aws-cdk/aws-lambda' export class StackA extends cdk.Stack { public readonly handler: lambda.Function constructor(scope: cdk.Construct, id: string, props?: cdk.StackProps) { super(scope, id, props) this.handler = new lambda.Function(this, `${id}Lambda`, { runtime: lambda.Runtime.NODEJS_12_X, code: lambda.Code.fromAsset('lambda'), handler: 'index.handler', }) // 擬似的なOutputsの作成 new cdk.CfnOutput(this, 'handlerOutput', { exportName: 'tackA.ExportsOutputFnGetAttStackAHandlerxxx', value: 'arn:aws:lambda:region:xxxxx:function:StackA-StackAHandlerxxxxx', }) } }この
CfnOutputはexportNameをキー名に、valueをその値にあてはめます(どちらも変更前のOutputsの値と完全に一致させることが重要です)。
すると案の定ビンゴで、StackAの変更のデプロイを無事に行うことができました。この追加実装はデプロイの一時回避用なので、デプロイ後は消しても問題ありません。さいごに
完全にこのタイトルで書きたいがために書いた記事です。一応このタイトルの元ネタ通り、過去(変更前のStack)と未来(変更後のStack)の辻褄を合わせることで悲しい悲劇を回避することができるので同じ問題に困った時はぜひ試してみてください!
- 投稿日:2020-10-22T19:18:12+09:00
【AWS】QuickSightのダッシュボードで直近10日間のデータをデフォルト表示する
はじめに
フィルタの相対日付を使うのではなく、パラメータとコントロールを使った動的デフォルト設定をやろうと思ったら、ちょっとトリッキーな対応が必要だったので共有します。
やりたいこと
パラメータの動的デフォルト値を使って、ダッシュボードで常に直近10日間のデータをデフォルト表示するようにしたい。
(貼り付けたコントロールのデフォルトのフィルタ条件を「FROM日付=9日前」~「TO日付=本日」にしたい)手順
AthenaにQuickSightのユーザーテーブルを作成する(カラムはuserのみでOK)
CREATE EXTERNAL TABLE IF NOT EXISTS db_name.user ( user string ) LOCATION 's3://XXXXXXXX/USER/' TBLPROPERTIES ('classification'='csv')上記のS3上にQuickSightのユーザー名のみを記載したcsvファイルを配置する
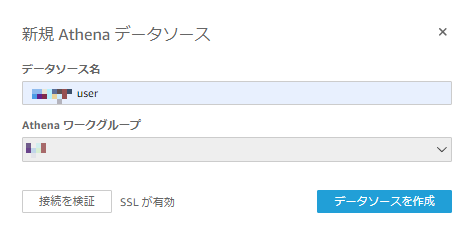
(例) user.csvYuto.Yamada Anne.Tanaka Gaku.SuzukiQuickSightのデータセットにて【新しいデータセット】からAthenaデータソースを作成する
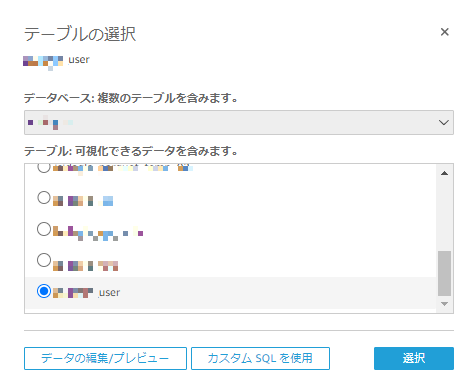
テーブルには先程作成したユーザーテーブルを選択する
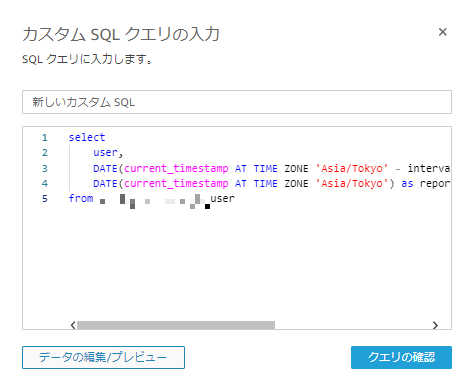
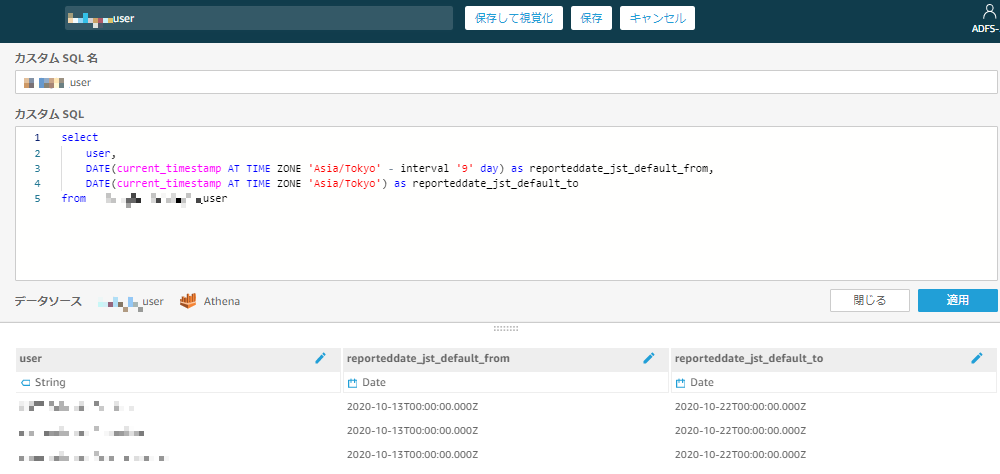
【カスタムSQLを使用】からカスタムSQLクエリを以下のように入力する
select user, DATE(current_timestamp AT TIME ZONE 'Asia/Tokyo' - interval '9' day) as reporteddate_jst_default_from, DATE(current_timestamp AT TIME ZONE 'Asia/Tokyo') as reporteddate_jst_default_to from db_name.user
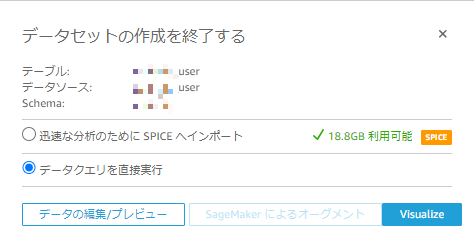
今回はSPICEは使わない方針だったので「データクエリを直接実行」を選択
【データの編集/プレビュー】からカスタムSQLクエリと実行結果を確認したらuserデータセットを保存する
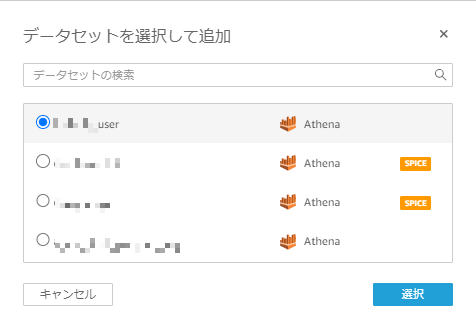
次に、予め作成していた分析の画面に移動し、先程作成したuserデータセットを分析に追加する
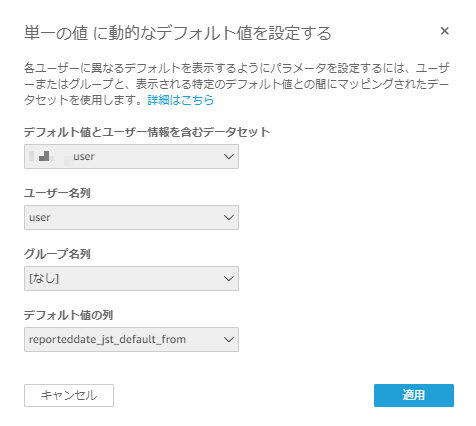
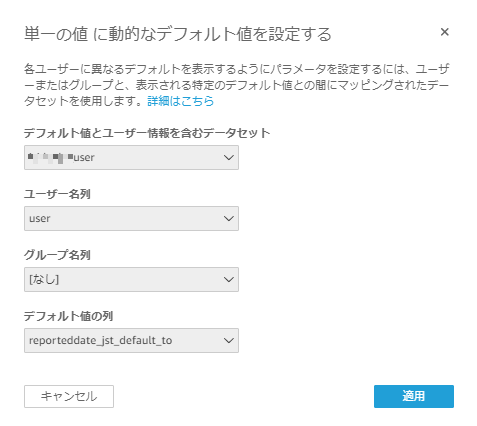
FROM日付のパラメータを追加して【動的デフォルトを設定】へ進み、「デフォルト値とユーザー情報を含むデータセット」に先程作成したuserデータセットを選択し、「ユーザー名列」には
user、「デフォルト値の列」にはreporteddate_jst_default_fromを選択する(静的デフォルト値は使わないため適当な値を設定しておく)
同様に、TO日付のパラメータを追加して【動的デフォルトを設定】へ進み、「デフォルト値とユーザー情報を含むデータセット」に先程作成したuserデータセットを選択し、「ユーザー名列」には
user、「デフォルト値の列」にはreporteddate_jst_default_toを選択する(静的デフォルト値は使わないため適当な値を設定しておく)
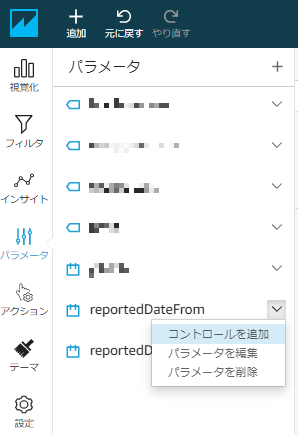
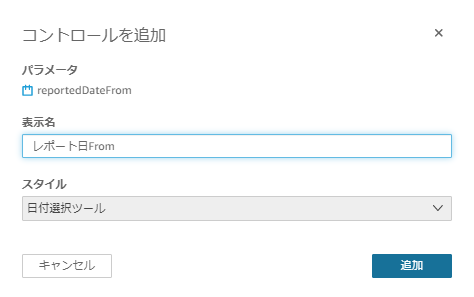
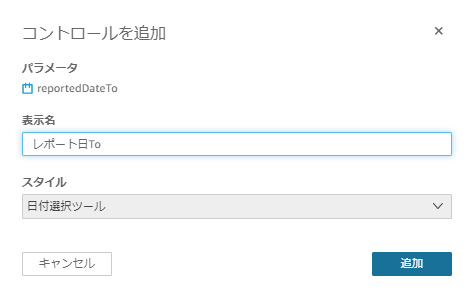
作成したFROM日付のパラメータをコントロールに追加する
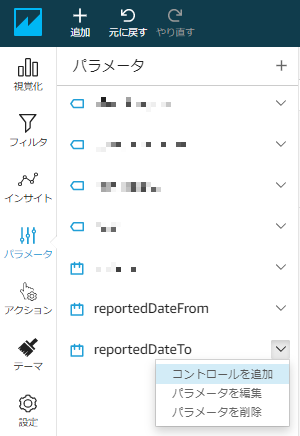
同様に、TO日付のパラメータをコントロールに追加する
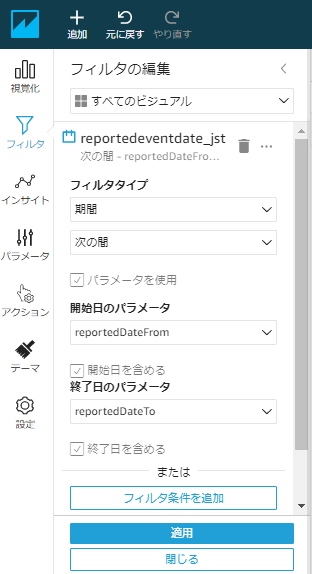
フィルタにてフィルタ対象項目を追加し、「フィルタタイプ」、「開始日のパラメータ」、「終了日のパラメータ」を以下のように設定する
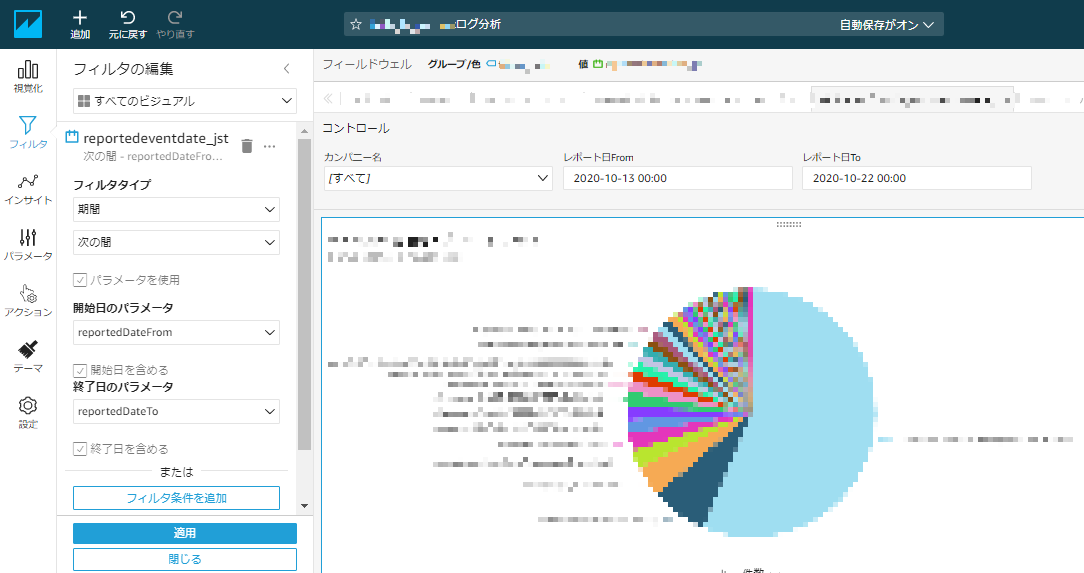
コントロールの「レポート日From」と「レポート日To」に自動的に直近10日間の期間が設定され、この条件で分析結果が表示される
この分析をダッシュボードとして公開すれば完了です
最後に
今回はuserデータセットにAthenaを利用しましたが、上記のようなuserデータセットはRedshiftなど他のデータソースから作成して、各データソースに応じたSQL関数を用いたカスタムSQLクエリを組むことでも同様に実現できるようです


- 投稿日:2020-10-22T16:33:10+09:00
AWSからのアカウント停止メール!?
休み明けの月曜日
メールを開くとAWSから以下のようなメールが届いていたDear Amazon Web Services Customer,
Your AWS Account is about to be suspended. There is still an outstanding payment problem with your account, as our previous communications did not lead to successful payment of your past due AWS charges.
~以下略~英語はもっぱら駄目なのでGoogle先生に翻訳してもらうと
アマゾンウェブサービスのお客様へ、
AWSアカウントが停止されようとしています。以前の連絡ではAWSの延滞料金の支払いが成功しなかったため、アカウントには未解決の支払いの問題がまだあります。
~The following is omitted~朝っぱらから背筋が凍るメール
(以前からメールは来ていたが埋もれて気づけなかった。。。)AWSサポートセンターに電話していつ頃に停止するか確認したところ、滞納月の翌月中旬から下旬の間に停止しますとの事。
期限はあったが、重大なトラブルの為、コンソール画面から支払いカードを確認し、総務に問い合わせると引き落とし先の口座に残金が無いかもしれないとのこと。
あまりの事態に前任者に連絡したところ、よくあることだから別のカードで対応していたと・・・
そんな管理で大丈夫かと思いながらも、口座への入金と別のカード情報を貰い、別のパターンで支払いができるかを調べてみて以下のことが分かった。AWSの支払い方法
▼引き落とせるカードは『VISAカード』か『Masterカード』
別のカードでの支払いをした際に、VISAでもMasterでもないカードで支払いをしようとしていた為、引き落としのエラーメールが届いてしまった。
▼振り込みはできないが、『海外送金』は可能
AWSはAmazonの会社の為、振り込みは海外送金での対応となる。
また以下の条件を満たした状態でAWSサポートセンター連絡すると送金先の口座情報を教えてもらえるらしい。
・今までのAWSの使用料金が2000$を超えていること
・支払い滞納ではないこと
・送金はUS$で送金すること
今回の問題は、支払い滞納の為『海外送金』ができない。
詰んだと思っていたところ、口座へ入金したとの連絡がきたので支払いをしたところ無事に支払えた!
※午前中に入金し、すぐに支払いしてもエラーになる。
数時間経ち午後に支払いができたので気を付けておくこと。まとめ
・支払い滞納によるアカウント停止は翌月の中旬から下旬にかけて停止される。
・引き落とせるカードは『VISAカード』か『Masterカード』
・『海外送金』はできるが、条件がある。
・カードに入金してもすぐに反映しない
- 投稿日:2020-10-22T16:03:40+09:00
実践編!Amazon S3/Google Cloud Storage エンタープライズデータ保護のテクニック 中編
はじめに
前回は 実践編!Amazon S3/Google Cloud Storage エンタープライズデータ保護のテクニック 前編 としてデータ保護が必要な理由や実装のために必要なモジュール、検証環境を説明してきました。今回は続編として、アクセラレーターやリカバリにおける注意事項について解説していきます!
3-2-1 ルール
みなさんはデータ保護の実装で必須と言われている 3-2-1 ルールをご存知でしょうか。3-2-1 ルールとは
- 3つのコピー
- 2つのメディア
- 1つの異なるロケーション
を意味します。データ被災に対する基本的な考え方で、これに加えて保持期限ベースの世代管理あるいはシングルクラウド非依存といった実装をします。商用レベルの実装です。例えば以下のように設計します。
- MSDP on EBS & S3 & Glacier
- EBS & S3
- Tokyo & North Virginia
これに加えて保持期限やシングルクラウド非依存という要件を考慮していくと S3 Sync やCCR だけではどうにもなりません。また、これらをスクリプトだけ実装していくとなるとメンテナンスや突然のエンジニアの退職など匠の技への依存がITリスクになります。大規模クラウドでは商用ソフトウェアでなければ、長期間の運用シナリオに堪えるのはなかなかに困難です。
S3やGCS が強固なので保護しないという考え方は、3-2-1ルールに則らないため、データ被災の可能性が高まります。これらの考え方はRAIDなので保護しない、スナップショットがあるので保護しない、というのと同様であり、企業や政府のデータでは絶対に避けるべきアプローチです。
s3fs の制約
以下の制約を考慮する必要があります。
• ファイルの内容のみがオブジェクトの階層と共にバックアップされます。s3fs は S3 ストレージを NFS 共有として公開するため、オブジェクトのメタデータ属性の一部は失われます。これにはアクセス許可、ACL、タグなどが含まれます。
• ホットストレージのみがサポートされます。このソリューションは、NFS マウントができないため、Amazon Glacier などのコールドストレージには適用されません。
• s3fs のインストールは、原則、NetBackup アプライアンスのメディアサーバーではサポートされていません。アプライアンス以外のメディアサーバーに s3fs をインストールします。NetBackup アプライアンスのメディアサーバーのみがある場合は、s3fs を別の Linux クライアントにインストールし、NetBackup アプライアンス のメディアサーバーにバックアップします。
• s3fs は、S3 ないしその互換ストレージから何らかの機能が欠損していることを自動検出できません。たとえば、Google Cloud ではマルチパートアップロード(復元)はサポートされていません。ただし、s3fs は Google クラウドでマルチパートアップロードを使用しようと試みて失敗します。そのような場合にはs3fsのオプションである-nomultipartを使用してください。
• s3fs は結果整合性 (Eventual Consistency) を保証しています。このため、復元中に間欠的な問題が発生する可能性があります。詳細はこちらを確認してください。
• s3fs マウントポイントへの直接復元は部分的に成功します。宛先マウントポイント (バケット) のアクセス時間および変更時刻を変更できないという警告が記録されます。この場合、データが失われるわけではありません。この警告を回避するにはマウントポイント内のディレクトリに復元します。次の警告がログに記録されます。
Warning bpbrm (pid=26322) from client <hostname>: WRN - Couldn't change access and modification times of /mnt/restore_full2/0/000/001/337.txt: Input/output error Warning bpbrm (pid=26322) from client <hostname>: WRN - Couldn't change access and modification times of /mnt/restore_full2/0/000/009/101.txt:ジョブは、次のようなエラーと共に部分的な成功を返しますが、リストアは成功します。
Error bpbrm (pid=26322) client restore EXIT STATUS 5: the restore failed to recover the requested files Standard policy restore error (2800)• s3fs は Linux プラットフォームでのみサポートされています。
既知の事象
s3fs では次の点に配慮する必要があります。
s3fs データキャッシュを使用しない場合、または、新しいオブジェクトの追加または古いオブジェクトの削除のみを行う場合は s3fs バージョン 1.85 を使用します。データキャッシュを使用し、オブジェクトが更新される場合は、こちらの問題が修正されたバージョンを使用します。
https://github.com/s3fs-fuse/s3fs-fuse/issues/1047
修正プログラムを適用せずにキャッシュを有効にした場合は、バックアップ対象のオブジェクトが更新されるとデータが破損する可能性があります。s3fs マウントされたバケット上の多数の小さなファイルの復元中にいくつかのエラーが発生する場合があります。問題が報告されたファイルの復元を再試行して対応します。詳細は以下を確認してください。
https://github.com/s3fs-fuse/s3fs-fuse/issues/1086
おわりに
どこがハードボイルドや!きちんと制約が出ているというのは真面目にみなさんのお役に立つために検証した結果です!ぜひ、オブジェクトストレージに格納されたデータも 3-2-1 ルールを守り、データ被災のリスクを減らしていきましょう!次回は後編としてベストプラクティスと検証結果を公開します!
商談のご相談はこちら
本稿からのお問合せをご記入の際には「コメント/通信欄」に#GWCのタグを必ずご記入ください。ご記入いただきました内容はベリタスのプライバシーポリシーに従って管理されます。
その他のリンク
【まとめ記事】ベリタステクノロジーズ 全記事へのリンク集もよろしくお願い致します!
- 投稿日:2020-10-22T15:32:57+09:00
CodePipelineを「例え話」で説明してみた話
はじめに
自社内で開催しているAWS勉強会にてCodePipelineについて説明する機会があり、そのまま説明しても理解が難しいだろうと思って「例え話」で説明してみたのですが、
「なんとなくだけど分かった!」風なリアクションをもらえたので公開したいと思います。前提
勉強会の受講者の知識レベルは以下の通りです。
- そもそも、CI/CDが分からないし聞いたこともない。ピンとこない。
例え話
色々と考えた挙句、辿り着いたのが以下の例えです。
「コンビニのバックヤードに置かれている段ボールに入ったペットボトルを冷蔵ケースに品出しするバイト」
をテーマにして、
- 店舗に新しいペットボトルが届く
- ペットボトルをバックヤードに運ぶ
- ペットボトルに破損が無いかチェックする
- 問題なければ冷蔵ケースに並べる
- お客様が購入する
という一連の流れがあった場合に、
「届いたペットボトルをバックヤードに運べば、あとは、CodePipelineが自動的に破損チェックをやって、冷蔵ケースに並べてくれるんですよ。すごいですよね?便利ですよね?楽ですよね?
これを開発現場に置き換えると、皆さんがGitリポジトリにPushすると、CodePipelineがビルドとテストを実行して、デプロイまで自動的にやってくれる、ということなんですよ」とやや強引に説明したら、みんなそれとなく理解してくれたみたいでした。
きちんとCodePipeline以外のCodeシリーズの説明もした方がよかったという後悔はありますが、ひとまずは、これで良かったとも思います。
同じような境遇の方の助けになれば幸いです。
- 投稿日:2020-10-22T11:48:08+09:00
CognitoにGoogleでサインインしたときメアド以外のGoogleの情報を取得したい
ほぼ自分用メモ。
前提
CognitoにGoogleでサインインするとこまではできる。
GoogleのトークンをCognitoのカスタム属性に入れるなりして参照可能な形にできる。やりたいこと
https://www.googleapis.com/admin/directory/v1/users/
このAPIを叩いてログインユーザーのGoogleアカウントの情報を引っ張りたい。
(他のGoogle APIでも大体やり方は同じじゃないかと思います)やりかた
APIの仕様を調べる
目的のAPIを探す。
今回使うのはAdminSDKのAPIなのでここから探します。
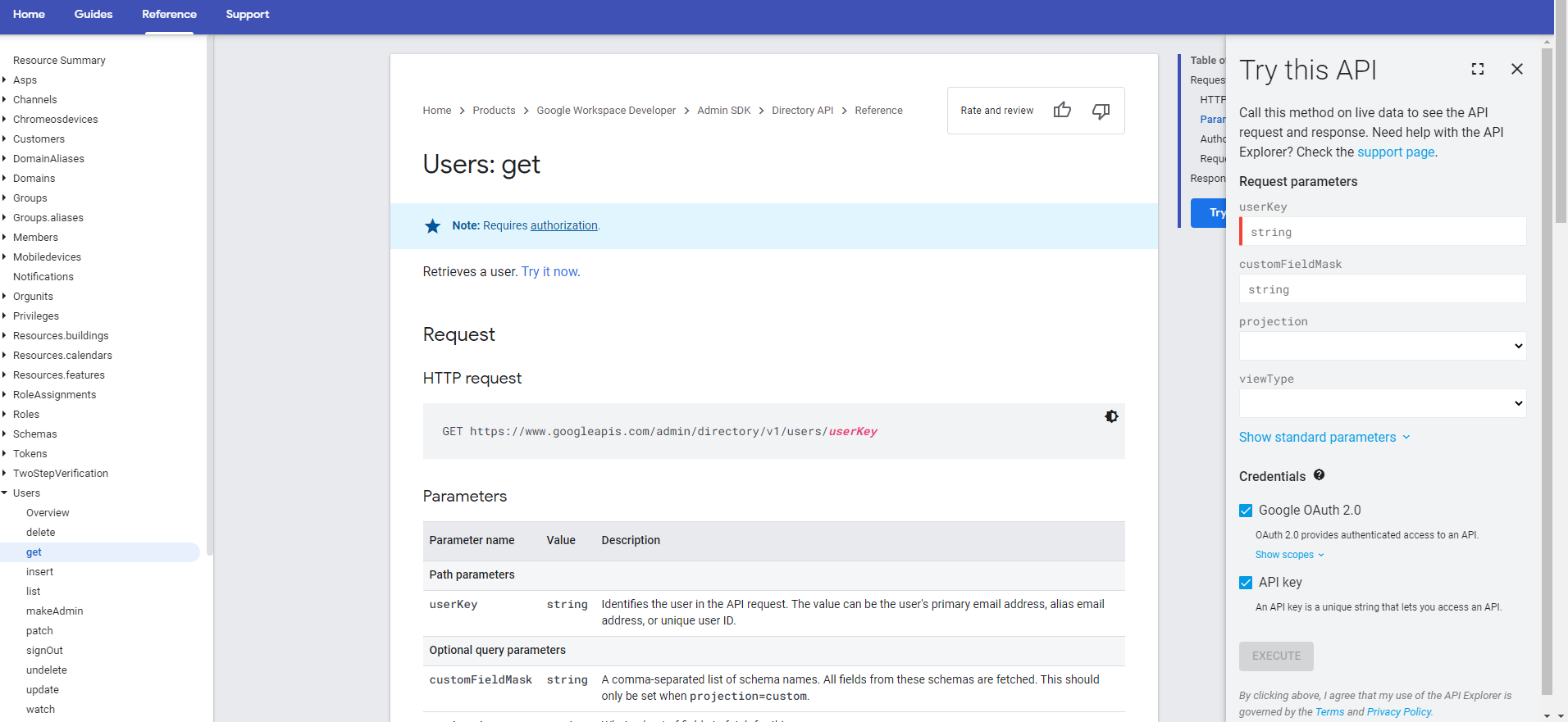
Google API Reference使いたいAPIはこちら。
Users: get
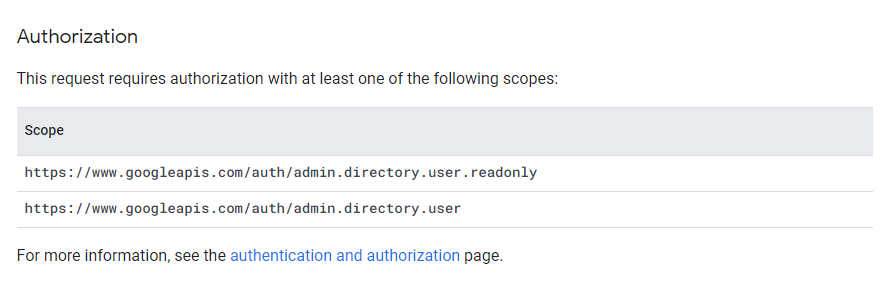
※右側の「Try this API」で欲しい情報を取得できるか試しておくとよい。このAPIを使用するために必要なスコープを確認する
ちょっと下にスクロールするとこれがあるので、ScopeのURLをメモる。
今回は情報を取得するだけなのでreadonlyだけでよい。
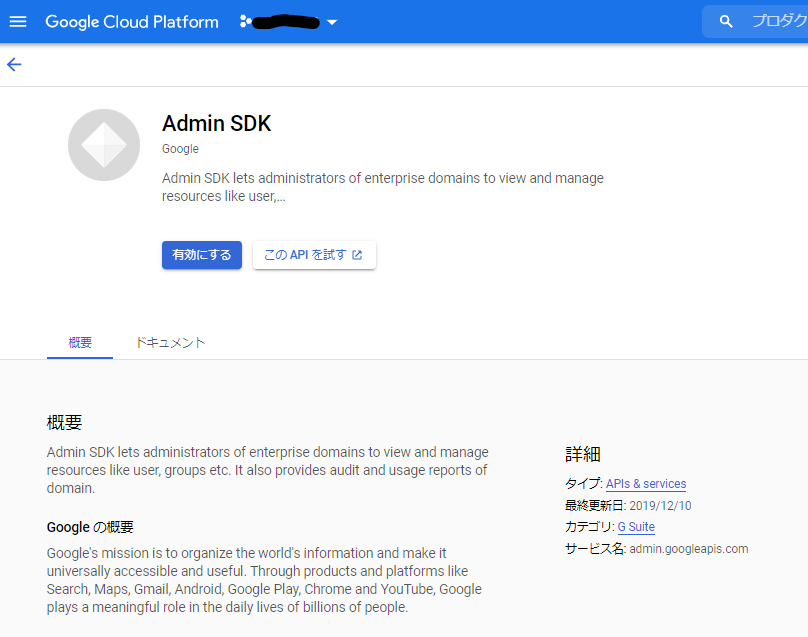
GCPでAPIを使えるように設定する
ライブラリからAPIを有効にする
AdminSDKを使うので有効にします。
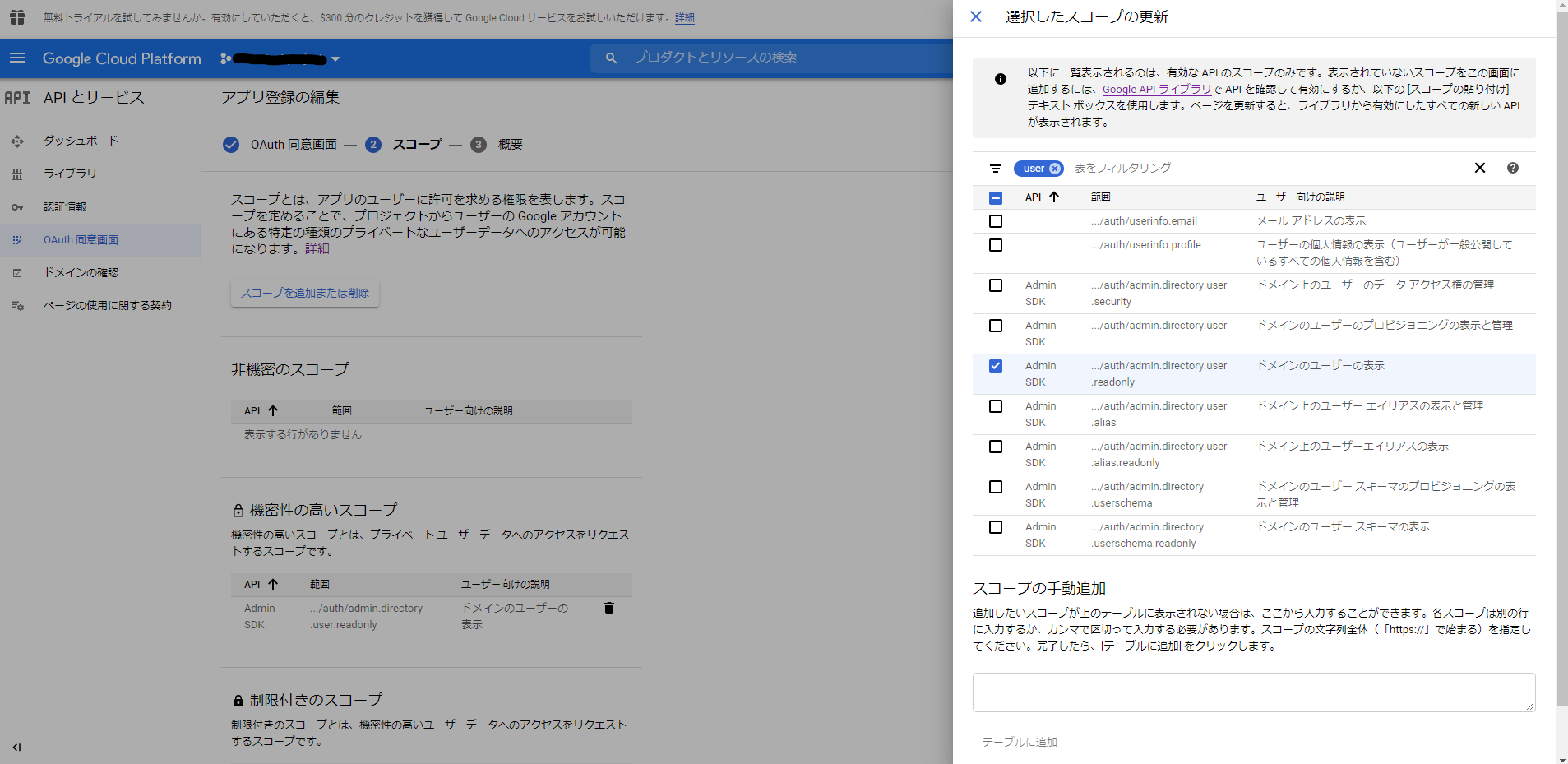
OAuth同意画面にスコープを追加する
必要なスコープのみチェックを入れる
Cognito IDプロバイダーの承認スコープに追記する
API仕様書からメモったスコープのURLをそのままぺたっと貼るだけ。
複数指定する場合は半角スペース区切りで貼っていく。
おわり
あとはトークンを使ってLambdaなり何なりでAPIを叩いて情報を引っ張ってよしなに使うとよい。

- 投稿日:2020-10-22T11:16:28+09:00
Elastic File Systemをざっくり知る。
この記事について
Elastic File Syestemについてざっくり説明する営業資料記事的な感じ。
まだEFSを触ったこと無い人、調べてる途中の人、良さがわからんって人向けです。「今からNFSインスタンスを構築するって?ならElastic File Systemを試してみない?」
Elastic File Systemってなぁに
Amazon Web Services社が提供するフルマネージド型のファイルシステム。
・容量の心配無し(サイジング不要の従量課金)。
・メンテナンスの心配無し。
・EFSへのファイル伝送時は暗号化されてて高セキュア。という、最強のファイルシステム。
EBSと比べると費用が3倍だったり、IOPS速度は汎用SSDと比べてちょっと遅かったり、
バックアップにはAmazon Backupの設定が必要だったりするけど、
そんなデメリット消し飛ばすくらいメリットや構成案の幅が増えるサービスである。長年の課題だったAutoscaling時の先祖返り対策がこれ一発で解決した。
(今までは別途NFSインスタンス立てて、それのマネージドどうするねんとかサイジングどうするねんとかやらないといけなくて辛かった)そもそもファイルシステムってなによ
調べた中で一番分かりやすかったのは以下記事。
【ざっくり概要】Linuxファイルシステムの種類や作成方法まとめ!
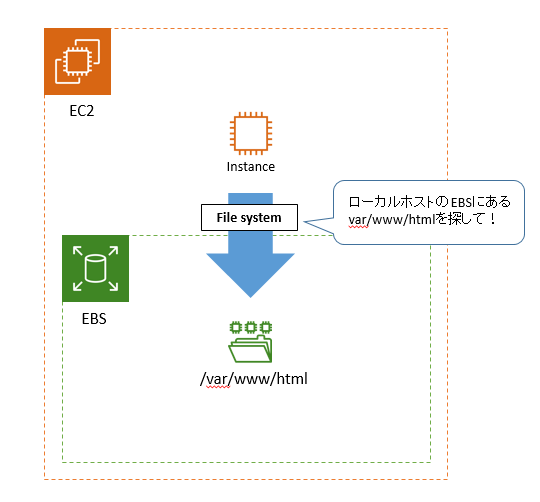
その上で、さらに自分でまとめた図解が以下。
このファイルシステムは通常サーバー起動時に自動でマウントされているので、
普段は意識することが無い。
このファイルシステムが無いと、「ディレクトリどこ?」「ファイルどこ?」って状態になっちゃう。
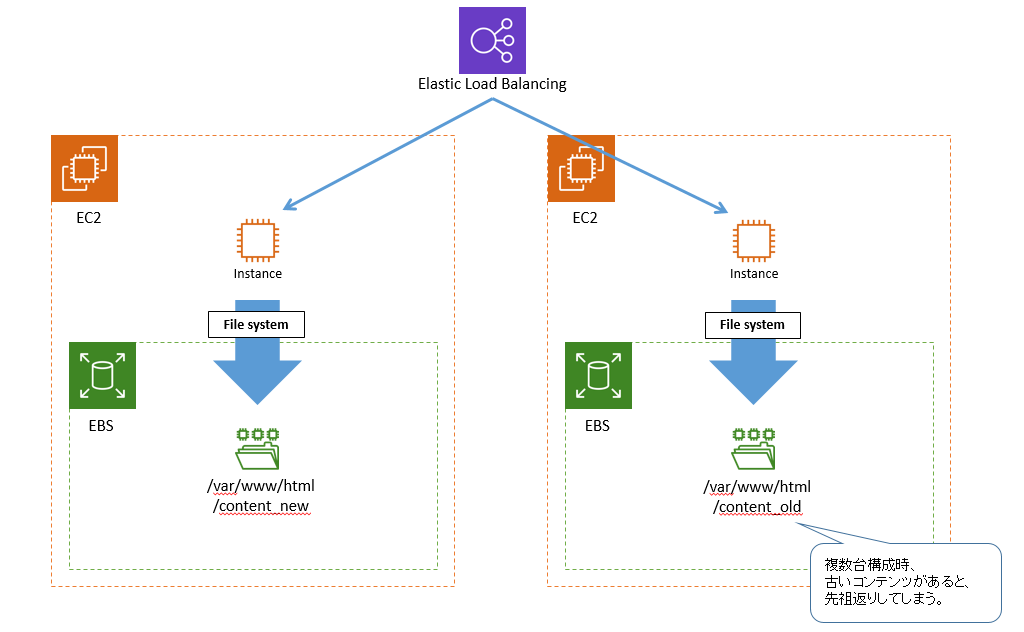
その上で、Autoscalingの先祖返りっていうのがどういう状態かっていうと以下。
折角負荷分散でELBをかましているのに、その下のコンテンツが古いっていう状態。
それぞれのファイルシステムは各々のローカルホストEBSを見にいってる状態なので、
見る人によってコンテンツが新しかったり古かったりするのはとてもマズイ。
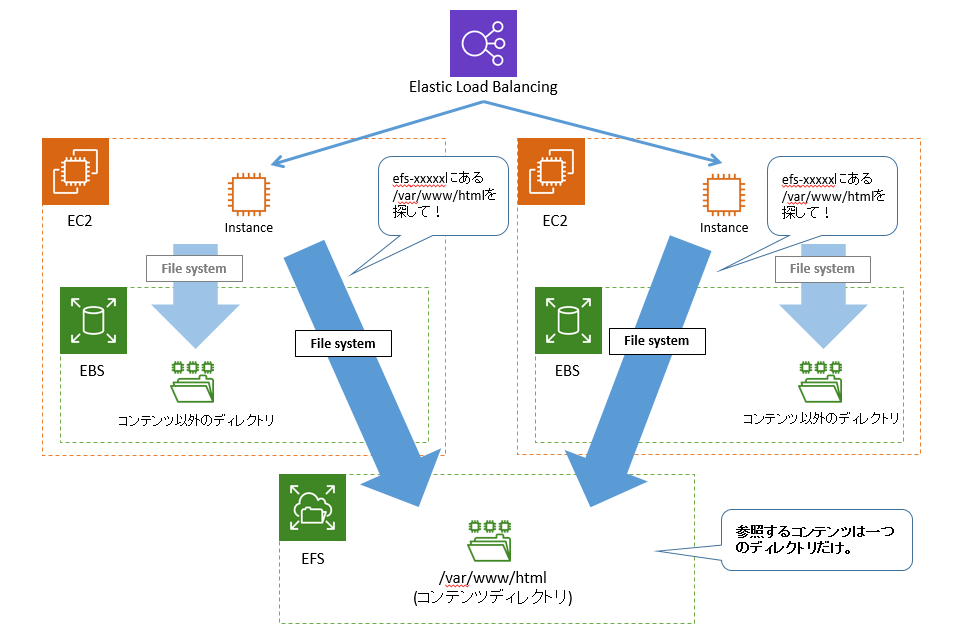
そんな時の救世主がElastic File System
これであれば、見にいくディレクトリは1つだけになり、左右どちらのインスタンスでコンテンツを更新したとしても左右のインスタンスは同じものを返す。
インスタンスがいくつ増えようとも、いつ増えようともEFSにマウントさえしていれば先祖返りは発生しない。
勿論、fstabとかで起動時にマウントする設定とかが必要になってくるんだけど、そこは誰かの記事見て実際に作ってみて欲しい。まとめ
Elastic File Systemは可能性の塊のようなサービスなので、まだ触ったこと無い人、提案したことが無い人は是非とも触れてみて欲しいな。
ownCloudとかオンラインストレージをこれで構築できないか検討中。
- 投稿日:2020-10-22T08:32:12+09:00
MacのターミナルでAWSのS3に接続してバケットの一覧を表示する
目的
- MacのターミナルでAWSのS3に接続してバケットの一覧を表示する方法をまとめる
実施環境
- ハードウェア環境
項目 情報 OS macOS Catalina(10.15.5) ハードウェア MacBook Pro (13-inch, 2020, Four Thunderbolt 3 ports) プロセッサ 2 GHz クアッドコアIntel Core i5 メモリ 32 GB 3733 MHz LPDDR4 グラフィックス Intel Iris Plus Graphics 1536 MB
- S3
- 下記の方法でバケットを作成した。
必要なもの
- バケット作成をしたAWSアカウントのアクセスキーとシークレットアクセスキー(AWSのユーザアカウント登録時にダウンロードされたCSVに記載されている、シークレットアクセスキーは再確認方法がなかったはずなのでCSVを紛失したなら新たにアカウント作成したほうが早いかもしれない。)
前提情報
- 本説明で実行するコマンドはMacのターミナルで実行するものとする。
詳細
下記コマンドを実行してs3cmdをインストールする。
$ brew install s3cmd下記コマンドを実行してc3cmdの設定を行う。
$ s3cmd --configure下記のように設定内容を入力してEnterを押下する。
> Access Key: AWSアカウントのアクセスキーを入力する > Secret Key: AWSアカウントのシークレットアクセスキーを入力する > Default Region [US]: ap-northeast-1と入力する > S3 Endpoint [s3.amazonaws.com]: 何も入力しない > DNS-style bucket+hostname:port template for accessing a bucket [%(bucket)s.s3.amazonaws.com]: 何も入力しない > Encryption password: 何も入力しない > Path to GPG program: Noneと入力する > Use HTTPS protocol [Yes]: Trueと入力する > HTTP Proxy server name: 何も入力しない > Test access with supplied credentials? [Y/n] Yを入力してEnterを押下すると接続テストが実施される下記のような警告が出たがアクセスキーの確認は無事通ったらしいので「Save Settings?」はyを入力してEnterを押下する。
Please wait, attempting to list all buckets... WARNING: Retrying failed request: /?delimiter=%2F (Remote end closed connection without response) WARNING: Waiting 3 sec... Success. Your access key and secret key worked fine :-) Now verifying that encryption works... Not configured. Never mind. Save settings? [y/N]設定ファイルはデフォルトで下記に保存されている。
/Users/Macのユーザ名/.s3cfg下記コマンドを実行してS3のバケットが表示されることを確認する。
$ c3cmd ls下記のように現在存在するバケットの一覧が表示される。
> 2020-08-17 06:41 s3://バケット名
- 投稿日:2020-10-22T01:55:29+09:00
Heroku上の画像をAWSのS3へ保存する方法
はじめに
AWSはAmazon Web Servisesの略で、Amazonが提供しているクラウドサーバーのサービスです。
多くの人や企業で使用されているサービスであり、使う容量や期間によっては完全に無料で使うことができます。Heroku上の画像をAWSに保存する理由
Herokuに保存した画像は24時間に一度リセットされる仕様になっています。
画像を外部のサーバーに保存することで、画像が消えてしまうという現象を防ぐことができるため、今回は外部サーバーとしてAWSを利用します。S3とは
AWSのサービスの一つで、12ヶ月間、5GBまでのストレージを無料で利用することができるサービスで、画像などを保存しておくことができます。
今回の手順
AWSへの登録はできている前提で進めます。(登録していない方はAWSで検索して、新規登録してください。)
- IAMユーザーを作成する
- S3に画像の保存先を用意する
- ローカル環境で画像の保存先をS3に変更する
- 本番環境で画像の保存先をS3に変更する
IAMユーザーを作成する
IAMとは
IAMとはAWSのサービスの一つです。
AWSで作成したアカウントはすべての権限を持つルートユーザーとなり、万が一、情報漏洩してしまうと悪用されてしまうリスクがあります。
そのため、使える権限を制限したユーザーを作成し、通常の作業はそのユーザーで行うようにします。
その制限された権限を持つユーザーを作成する機能を持つのがIAMです。IAMユーザーの作成
IAMで作成されるユーザーをIAMユーザーと呼びます。
まず、AWSのサービス検索でIAMを検索し、IAMページへ遷移します。
サイドバーのユーザーから「ユーザーを追加」をクリックします。
そして、任意のユーザー名を入力し、プログラムによるアクセスにチェックを入れ、「次のステップ」をクリックします。
既存のポリシーを直接アタッチを選択し、ポリシーのフィルタにamazons3と入力し、、「AmazonS3FullAccess」にチェックを入れ、「次のステップ」をクリックします。
タグの追加はやりたい人のみやって、「次のステップ」をクリックします。
設定の確認画面が出るので、問題なければ「ユーザーの作成」をクリックします。
この時に出てくる「.csvのダウンロード」は忘れずに、行います。(後々、使うため。)IAMユーザーのパスワードを設定
上で作成したAWS上のIAMユーザーの中で、認証情報のタブをクリックすると、コンソールのパスワード欄があります。
ここの管理をクリックした後に出てくるページで、コンソールへのアクセスは有効化、パスワードの設定は自動生成パスワードを選択し、適用します。
そうすると、パスワードが生成されます。
この時に出てくる「.csvのダウンロード」は忘れずに、行います。(後々、使うため。)S3に画像の保存先を用意する
バケットの作成
S3で実際にデータが格納される場所のことをバケットと呼びます。
AWSにログイン後、サービス検索でS3のページに遷移すると、バケットという文字が出てきます。
サイドバーのバケットという項目の中には「バケットを作成する」というボタンが存在するので、そのボタンをクリックします。バケット名とリージョンの設定
バケット名とリージョンの入力画面に遷移するため、自身で考えたバケット名を入力します。
※バケット名はAWSを使う誰かのバケットと同じ名前はつけられません。リージョンは地域という意味ですが、ここではサーバーの場所を表します。
日本人ならアジアパシフィック(東京)を選択で良いと思います。オプションの設定
オプションを設定したい方はここで設定します。
設定が終われば、次へをクリックします。アクセス許可の設定
デフォルトでは「パブリックアクセスをすべてブロック」にチェックが入っています。
このチェックを外すと、パブリックアクセスのお好みの設定ができます。
設定が終われば、次へをクリックします。確認
確認ページではこれまで行った設定の一覧が表示されるので、問題なければ、「バケットを作成」をクリックします。
バケットポリシーの設定
バケットポリシーとは、どのようなアクセスに対してS3への保存やデータの読み取りを許可するか決められる仕組みです。
今回は先ほど作成したIAMユーザーからのアクセスを許可します。まず、IAMユーザーのARNをコピーして、どこかにメモしておきます。
作成したバケットから、アクセス権限をクリックし、バケットポリシーをクリックし、以下を記述します。
{ "Version": "2012-10-17", "Id": "Policy1544152951996", "Statement": [ { "Sid": "Stmt1544152948221", "Effect": "Allow", "Principal": { "AWS": "コピーしたIAMユーザーのARN" }, "Action": "s3:*", "Resource": "arn:aws:s3:::バケット名" } ] }保存すれば、完了です。
ローカル環境で画像の保存先をS3に変更する
Gemのインストール
rubyでS3を使用するためにaws-sdk-smというGemをインストールします。
Gemfile一番下に下記を追記 gem "aws-sdk-s3", require: falseその後、ターミナルでbundle installを入力します。
保存先を指定する
config/environments/development.rbconfig.active_storage.service = :local 上の記述を以下に変更 config.active_storage.service = :amazonconfig/storage.yml以下のコードを追記 amazon: service: S3 access_key_id: <%= ENV['AWS_ACCESS_KEY_ID'] %> secret_access_key: <%= ENV['AWS_SECRET_ACCESS_KEY'] %> region: ap-northeast-1 bucket: ご自身のバケット名※regionのap-northease-1はアジアパシフィック(東京)の番号
環境変数の設定
ターミナル% vim ~/.zshrc iを押して、以下を追記 export AWS_ACCESS_KEY_ID="ここにCSVファイルのAccess key IDの値をコピー" export AWS_SECRET_ACCESS_KEY="ここにCSVファイルのSecret access keyの値をコピー" (CSVファイルはIAMユーザー作成時にダウンロードしたファイルのこと。) :wqで保存するローカル環境で、アプリケーションから画像を投稿し、問題なくS3に保存されていることが確認できたら、本番環境でも画像の保存先をS3に変更します。
本番環境で画像の保存先をS3に変更する
保存先を指定する
ローカル環境と同様の作業を行います。
config/environments/production.rbconfig.active_storage.service = :local 上の記述を以下に変更 config.active_storage.service = :amazon環境変数の設定
本番環境にはHerokuを用いるため、Heroku上で環境変数を設定します。
heroku config:setコマンドで環境変数の設定をすることができます。ターミナル% heroku config:set AWS_ACCESS_KEY_ID="ここにCSVファイルの「Access key ID」の値をコピー" % heroku config:set AWS_SECRET_ACCESS_KEY="ここにCSVファイルの「Secret access key」の値をコピー" 環境変数が設定できたか確認するときは % heroku config編集内容をHerokuに反映させる
ターミナル% git push heroku master参考
テックキャンプのカリキュラム
「AWSに画像をアップロードする」最後に
本投稿が初学者の復習の一助となればと幸いです。
- 投稿日:2020-10-22T00:34:23+09:00
Djangoチュートリアル(ブログアプリ作成)⑦ - フロントエンド完成編
前回、Djangoチュートリアル(ブログアプリ作成)⑥ - 記事詳細・編集・削除機能編では記事個別の詳細、編集、削除画面を作成しました。
今回は template を大幅に調整していきますが、大きく分けると以下のことをやっていきます。
全ページ共通画面の作成
ナビゲーションバーの作成
各templateの修正
不要なtemplateや処理の削除
全ページ共通画面の作成
Django に限らず、ホームページには画面遷移しても共通的に表示される箇所ってありますよね。
Qiita でいえば上部に表示されている、緑色のナビゲーションバーなんかが良い例ですね。↓これ
ただ、これをすべての template に毎回書くなんてのは大変ですよね。
一回コードを書いて終わりならまだしも、修正が入ったときのことを考えるともう…。そこで、Django の便利な機能として共通テンプレートを使います。
簡単にいうと、共通的な部分は一つのファイルにまとめて、
画面ごとに異なる部分は別の template を呼び出して使うということです。そのために、まずは template フォルダ直下にはじめてファイルを作成します。
今回は /template/base.html というファイルを作成しましょう。└── templates ├── base.html # 追加 └── blog ├── index.html ├── post_confirm_delete.html ├── post_detail.html ├── post_form.html └── post_list.htmlこのファイルに共通の処理を書き、画面ごとに異なる部分は
post_detail.html などのファイルを呼び出していくことにします。base.html の修正
中身はこのようにしていきます。
base.html<!doctype html> <html lang="ja"> <head> <title>tmasuyama のブログ</title> <!-- Required meta tags --> <meta charset="utf-8"> <meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no"> <!-- Bootstrap CSS --> <link rel="stylesheet" href="https://maxcdn.bootstrapcdn.com/bootstrap/4.0.0-beta.2/css/bootstrap.min.css" integrity="sha384-PsH8R72JQ3SOdhVi3uxftmaW6Vc51MKb0q5P2rRUpPvrszuE4W1povHYgTpBfshb" crossorigin="anonymous"> </head> <body> <div class="container"> <nav class="navbar navbar-expand-lg navbar-light bg-light"> <a class="navbar-brand" href="{% url 'blog:post_list' %}">トップ</a> <button class="navbar-toggler" type="button" data-toggle="collapse" data-target="#navbarSupportedContent" aria-controls="navbarSupportedContent" aria-expanded="false" aria-label="Toggle navigation"> <span class="navbar-toggler-icon"></span> </button> <div class="collapse navbar-collapse" id="navbarSupportedContent"> <ul class="navbar-nav mr-auto"> <li class="nav-item"> <a class="nav-link" href="{% url 'blog:post_create' %}">投稿</a> </li> </ul> </div> </nav> <!-- このblockの中で各templateの記載内容が呼び出される --> {% block content %} # 注目! {% endblock %} # 注目! </div> <!-- Optional JavaScript --> <!-- jQuery first, then Popper.js, then Bootstrap JS --> <script src="https://maxcdn.bootstrapcdn.com/bootstrap/4.0.0-beta.2/js/bootstrap.min.js" integrity="sha384-alpBpkh1PFOepccYVYDB4do5UnbKysX5WZXm3XxPqe5iKTfUKjNkCk9SaVuEZflJ" crossorigin="anonymous"></script> </body> </html>このチュートリアルはフロントエンドについて詳細な解説はしませんが、
Bootstrap を使って見た目を整えるために CDN から Bootstrap を呼び出して使えるようにしたり、
ナビゲーションバーを 内で表させるようにしています。
このようにどの画面でも使いたいものは base.html で書くようにします。注目してほしいのは 「# 注目!」 とメモをした部分です。
<!-- このblockの中で各templateの記載内容が呼び出される --> {% block content %} # 注目! {% endblock %} # 注目!View に従って template を呼び出す際、各 template はここに格納されていくことになります。
逆にいうと、各 template は各ページに特徴的な部分だけを書いておけばよいのです。また、呼び出される側の template では親となる template (base.html) を明示してあげる必要があります。
基本的な書き方は次の通りです。各template{% extends 'base.html' %} # 親 template の指定 {% block content %} # 中身の記述開始 ...各 template 固有の記述... {% endblock %} # 中身の記述終了これで親templateと子templateの役割を明確に分けることが出来るようになりました。
次は親templateで用意するナビゲーションバーについて解説します。ナビゲーションバーの説明
上述の base.html を使うと以下のようなナビゲーションバーが表示されるようになります。
なお、今回は Bootstrap4 の Cheat Sheat を参考にしています。
https://hackerthemes.com/bootstrap-cheatsheet/#navbar
トップ を選択すると post_list.html の画面へ遷移し、
投稿 を選択すると post_form.html の画面(新規投稿画面)へ遷移するようにしています。base.html のうち、ナビゲーションバーを表示させるための部分はここでした。
base.html<nav class="navbar navbar-expand-lg navbar-dark bg-dark"> <a class="navbar-brand" href="{% url 'blog:post_list' %}">トップ</a> <button class="navbar-toggler" type="button" data-toggle="collapse" data-target="#navbarSupportedContent" aria-controls="navbarSupportedContent" aria-expanded="false" aria-label="Toggle navigation"> <span class="navbar-toggler-icon"></span> </button> <div class="collapse navbar-collapse" id="navbarSupportedContent"> <ul class="navbar-nav mr-auto"> <li class="nav-item"> <a class="nav-link" href="{% url 'blog:post_create' %}">投稿</a> </li> </ul> </div> </nav>ここで大事なのは「href="{% url 'blog:post_list' %}"」という部分です。
これまで template ではリンクを記述してきませんでしたが、
上記のようなフォーマットで逆引き用の URL を記述すると
に相当する URL へリダイレクトされるようになります。※urls.py でいうとこの部分です。
python:urls.py
...
path('post_list', views.PostListView.as_view(), name='post_list'),
...
ここで name='post_list' というように、各URLに名前をつけていたおかげで
template側ではその名前を指定することで、自動でルーティングしてくれるようになります。各templateの修正
さて、各 template で親 template の指定をしつつ、Bootstrapで見た目の調整をしていきましょう。
完成形を載せていきます。post_detail.html{% extends 'base.html' %} {% block content %} <table class="table"> <tr> <th>タイトル</th> <td>{{ post.title }}</td> </tr> <tr> <th>本文</th> <!-- linebreaksbk を入れると改行タグでちゃんと改行して表示されるようになる --> <td>{{ post.text | linebreaksbr}}</td> </tr> <tr> <th>日付</th> <td>{{ post.date }}</td> </tr> </table> {% endblock %}post_form.html{% extends 'base.html' %} {% block content %} <p>{{ post.title }}</p> <!-- actionにはサーバのどのURLに対して情報を送信する --> <!-- actionを空欄にすると現在開いている URL = /blog/post_create に値を返すので、views.py の PostCreateView が再度呼び出されることになる --> <form action="" method="POST"> <table class="table"> <tr> <th>タイトル</th> <td>{{ form.title }}</td> </tr> <tr> <th>本文</th> <td>{{ form.text }}</td> </tr> </table> <button type="submit" class="btn btn-primary">送信</button> {% csrf_token %} </form> {% endblock %}post_confirm_delete.html{% extends 'base.html' %} {% block content %} <form action="" method="POST"> <table class="table"> <tr> <th>タイトル</th> <td>{{ post.title }}</td> </tr> <tr> <th>本文</th> <td>{{ post.text }}</td> </tr> <tr> <th>日付</th> <td>{{ post.date }}</td> </tr> </table> <p>こちらのデータを削除します。</p> <button type="submit">送信</button> {% csrf_token %} </form> {% endblock %}post_list.html{% extends 'base.html' %} {% block content %} <table class="table"> <thead> <tr> <th>タイトル</th> <th>日付</th> <th></th> <th></th> </tr> </thead> <tbody> {% for post in post_list %} <tr> <!-- 「url 'アプリ名:逆引きURL' 渡されるモデル.pk」 という描き方 --> <td><a href="{% url 'blog:post_detail' post.pk %}">{{ post.title }}</a></td> <td>{{ post.date }}</td> <td> <!-- superuserでログインしている時にのみ表示 --> {% if user.is_superuser %} <!-- HTMLを アプリ名_モデル名_change にすると admin でそのまま編集できる --> <a href="{% url 'blog:post_update' post.pk %}">編集</a> {% endif %} </td> <td> {% if user.is_superuser %} <a href="{% url 'blog:post_delete' post.pk %}">削除</a> {% endif %} </td> </tr> {% endfor %} </tbody> </table> {% endblock %}なお、最後の post_list.html はいくつか変更を追加で加えました。
ひとつは、一覧に表示させる各記事ごとに詳細、編集、削除のリンクをつけるようにしました。
プライマリキーに基づきリンク先が決まるような場合は 変数名.pk の形でプライマリキーを指定できます。
※templateがviewから変数を受け取る時の名前は post_list となっていますが、
for文で回しているので post という変数で展開しています。
そのため post.pk と指定しています。逆引きする用URLの名前で指定する形は、決まった書き方なので覚えてしまいいましょう。
<a href="{% url 'blog:post_detail' post.pk %}">...また、今回のチュートリアルではユーザ登録機能を実装していませんが、
誰でも記事の編集や削除をできてしまわないようにぐらいの制限はかけておきましょう。今回はユーザは superuser しか存在していませんので、
superuser で管理画面 (127.0.0.1:8000/admin) からログインしている場合にのみ
記事の編集および削除のリンクを表示させるようにします。
※厳密にいえば、この状態でもアドレスから直接アクセスすると編集・削除画面には飛べてしまいます。
この制限も Django で実装することはできます。念の為。{% if user.is_superuser %} # superuser でログインしているときのみ、if文の中身を表示 <a href="{% url 'blog:post_update' post.pk %}">編集</a> {% endif %}上記では superuser の時でしたが、他にも何かしらのユーザでログインしている時の表示や、
特定のユーザでログインしている時にのみ表示させるということも出来たりします。不要なtemplateや処理の削除
さて、これまで Hello を表示させるためだけの index.html ページを練習用に残しておきましたが、
これ以上残しておくと管理の手間が増えるため、このタイミングで削除しておきましょう。└── templates ├── base.html └── blog ├── index.html # これを削除する ├── post_confirm_delete.html ├── post_detail.html ├── post_form.html └── post_list.htmlurls.py test_urls.py、、views.py、test_views.py も忘れずに編集しておきます。
urls.py... urlpatterns = [ path('', views.IndexView.as_view(), name='index'), # ここを削除 ...test_urls.py... class TestUrls(TestCase): """index ページへのURLでアクセスする時のリダイレクトをテスト""" def test_post_index_url(self): # このメソッドを丸々削除 view = resolve('/blog/') self.assertEqual(view.func.view_class, IndexView) class TestUrls(TestCase): """index ページへのURLでアクセスする時のリダイレクトをテスト""" def test_post_index_url(self): # このメソッドを削除 view = resolve('/blog/') self.assertEqual(view.func.view_class, IndexView) ...views.py... class IndexView(generic.TemplateView): # この汎用ビューを削除 template_name = 'blog/index.html' ...test_views.py... class IndexTests(TestCase): # このテストクラスごと削除 """IndexViewのテストクラス""" def test_get(self): """GET メソッドでアクセスしてステータスコード200を返されることを確認""" response = self.client.get(reverse('blog:index')) self.assertEqual(response.status_code, 200) ...一気に変更を行ったので、最後にユニットテストを実行してエラーが出ないかを確認しておきましょう。
(blog) bash-3.2$ python3 manage.py test Creating test database for alias 'default'... System check identified no issues (0 silenced). ..............E ====================================================================== ERROR: blog.tests.test_urls (unittest.loader._FailedTest) ---------------------------------------------------------------------- ImportError: Failed to import test module: blog.tests.test_urls Traceback (most recent call last): File "/usr/local/Cellar/python@3.8/3.8.5/Frameworks/Python.framework/Versions/3.8/lib/python3.8/unittest/loader.py", line 436, in _find_test_path module = self._get_module_from_name(name) File "/usr/local/Cellar/python@3.8/3.8.5/Frameworks/Python.framework/Versions/3.8/lib/python3.8/unittest/loader.py", line 377, in _get_module_from_name __import__(name) File "/Users/masuyama/workspace/MyPython/MyDjango/blog/mysite/blog/tests/test_urls.py", line 3, in <module> from ..views import IndexView, PostListView ImportError: cannot import name 'IndexView' from 'blog.views' (/Users/masuyama/workspace/MyPython/MyDjango/blog/mysite/blog/views.py) ---------------------------------------------------------------------- Ran 15 tests in 0.283s FAILED (errors=1) Destroying test database for alias 'default'...エラーが確認されました。
エラーメッセージは区切り文字などを使って表示されているので、どこでエラーが起きているかも置いやすいようになっています。エラーメッセージを追っていくと、test_urls.pyで import できないものがあり、エラーが起きていることが分かります。
ImportError: cannot import name 'IndexView' from 'blog.views'もう一度 test_urls.py を読んでみると、たしかに冒頭で IndexView の読み込みを残してしまっていることが分かりました。
test_urls.pyfrom django.test import TestCase from django.urls import reverse, resolve from ..views import IndexView, PostListView # この行これを消して、次のようにしてあげます。
test_urls.pyfrom django.test import TestCase from django.urls import reverse, resolve from ..views import PostListViewこれでユニットテストをもう一度実行しましょう。
(blog) bash-3.2$ python3 manage.py test Creating test database for alias 'default'... System check identified no issues (0 silenced). ............... ---------------------------------------------------------------------- Ran 15 tests in 0.223s OK Destroying test database for alias 'default'...今度はエラーなくテストが完了しました。
また、テストの数は 15 となっており、前回は 17 だったテストから2つのテストメソッドを減らしたこととも一致していますね。これまではユニットテストが通るようにした結果しかお見せしませんでしたが、
今回のように一気に複数のファイルで変更を起きたときでも
予めユニットテストを用意しておくと、コマンド一つで問題箇所を特定することができると分かっていただけたかと思います。これで無事にローカルの Django アプリとしては完成しました!
次回はいよいよ環境の整備というところで、今回作ったアプリを Docker 化していきましょう。

