- 投稿日:2020-10-22T22:36:55+09:00
turbolinksが悪さをして戸惑った話
この記事ではインストールしたRails 6.0.0を使っています
その中のJavaScriptについてです。
Railsでフリマアプリのコピーアプリを作っている中で、販売価格についての実装をJavaScriptで行っていました!
item_price.jswindow.addEventListener('load', () => { const itemPrice = document.getElementById("item-price"); itemPrice.addEventListener("input", () => { const inputValue = itemPrice.value; const addTaxDom = document.getElementById("add-tax-price"); addTaxDom.innerHTML = (Math.floor(inputValue * 0.1)); const saleProfit = document.getElementById("profit"); const value_result = inputValue * 0.1 saleProfit.innerHTML = (Math.floor(inputValue - value_result)); }) });実装には成功し喜んで次の実装に進み、また出品しようと価格をinputするとたまに手数料と利益の計算が作動しない時がありました。
なんでだろう?と感じいろいろ試行錯誤と調べた結果この記述が悪さをしていたみたいです。
require("turbolinks").start()
この記述はapplicaion.jsに定義した記述です。注目して欲しいのはこの中の"turbolinks"です。意味としては『Ajaxによるページ遷移の高速化のためのライブラリ』という感じです。
素晴らしいメリットなのですが、こいつはたまにJava Scriptに悪さをし、小さなバグを発生させたり、readyが呼ばれない、headerが変化しない等というデメリットがあるらしいです。笑
メリットもあるので使いたいですが、どのような時が使いどきなのでしょうか?turbolinksの使いどき
開発コストを上げてでもページのレンダリングを高速化したい場合
Javascriptの記述量が少ないとき
Railsから作られたビューを返す事がメインであるサイトなど逆にページのレンダリングを高速化する必要がない規模のサイトなど
Javascriptの記述量が多い時
ページごとにcssやJavaScriptを分けて記述している場合は使うメリットは減るということです。まとめ
Turbolinks使用の際は挙動をしっかり理解しておく必要がありますね。
メリット、デメリットを十分に考えたうえで使用用途をしっかり考え運用することをおすすめします。

- 投稿日:2020-10-22T22:14:52+09:00
【Ruby on Rails】投稿にタグ付け・インクリメンタルサーチ機能を実装する方法(gemなし)
タグ付けを行う前の前がき
本記事の概要
・投稿にタグ付けをできるようにする。
・文字を入力する度に自動検索を行ってくれる機能(インクリメンタルサーチ)をタグにを実装する開発環境
Mac OS Catalina 10.15.4
ruby 2.6系
rails 6.0系
※rails newでアプリケーションは作成済みであることを前提としています。タグ付け機能の完成形イメージ
上図のGifのように、タグを入力し始めるとDBに保存されているタグを元にオススメタグを表示できるようにしています。
今回の記事を元にタグ付け機能を実装できれば、タグ検索なども容易に実装できるかと思います。タグ付け機能実装の流れ
1. Tag,Post,PostTagRelation、Userモデルを作成
2. 各種モデルのmigrationファイルを編集
3. Formオブジェクトを導入
4. ルーティングの設定
5. postsコントローラーを作成、アクション定義
6. ビューファイルの作成
7. インクリメンタルサーチの実装(JavaScript)上記の手順で実装を行ってきます。
1.Tag,Post,PostTagRelation,Userモデルを作成
まずは、各種モデルを導入しましょう。
% rails g model tag % rails g model post % rails g model post_tag_relation % rails g devise userそのまま、導入した各モデルを関連付け(アソシエーション)してバリデーションを記述しましょう。
post.rbclass Post < ApplicationRecord has_many :post_tag_relations has_many :tags, through: :post_tag_relations belongs_to :user endtag.rbclass Tag < ApplicationRecord has_many :post_tag_relations has_many :posts, through: :post_tag_relations validates :name, uniqueness: true end「through: :中間テーブル」とすることで、多対多の関係であるPostモデルとTagモデルのアソシエーションを組んでいます。
注意点としては、throughによる参照前に中間テーブルの紐付けを行う必要があります。
(コードは上から読み込まれるので、 has_many :posts, through: :post_tag_relations → has_many :post_tag_relationsの順で書いてしまうとエラーになります。)post_tag_relationclass PostTagRelation < ApplicationRecord belongs_to :post belongs_to :tag enduser.rbclass User < ApplicationRecord #<省略> has_many :posts, dependent: :destroy validates :name, presence: trueUserモデルのhas_manyのオプションに、dependent: :destroyと付けているのは、親要素であるユーザー情報が削除された時にそのヒトの投稿も併せて削除されるようにするためです。
なお、PostモデルとTagモデルにて空データを保存させないようにするための記述(validates :〇〇, presence: true)に関しては、後ほど作成するフォームオブジェクトでまとめて指定しますので、今は必要ありません。
2.各種モデルのmigrationファイルを編集
続いて、作成したモデルにカラムを追加していきます。
(最低限必要なのは、tagのnameカラムくらいなので、その他はお好みでアレンジされてください。)postのマイグレーションファイルclass CreatePosts < ActiveRecord::Migration[6.0] def change create_table :posts do |t| t.string :title, null: false t.text :content, null: false t.date :date t.time :time_first t.time :time_end t.integer :people t.references :user, foreign_key: true t.timestamps end end endpostのマイグレーションファイルで外部キーとしてuserを参照しているのは、後ほどuser名を投稿一覧で表示するためです。
tagのマイグレーションファイルclass CreateTags < ActiveRecord::Migration[6.0] def change create_table :tags do |t| t.string :name, null: false, uniqueness: true t.timestamps end end end上記のnameカラムにuniqueness: trueを適用しているのは、タグ名の重複を防ぐために導入しています。
(タグは同じ名前のものが何度も使われることが想定されるので、重複を防いだらタグ付け機能として成り立たなくない?と思われるかもですが、既存のタグを投稿に反映させる方法は後ほど登場します。)post_tag_relationのマイグレーションファイルclass CreatePostTagRelations < ActiveRecord::Migration[6.0] def change create_table :post_tag_relations do |t| t.references :post, foreign_key: true t.references :tag, foreign_key: true t.timestamps end end endこのpost_tag_relationモデルが、多対多の関係であるpostモデルとtagモデルの中間テーブルの役割を担っています。
userのマイグレーションファイルclass DeviseCreateUsers < ActiveRecord::Migration[6.0] def change create_table :users do |t| ## Database authenticatable t.string :name, null: false t.string :email, null: false, default: "" t.string :encrypted_password, null: false, default: "" #<省略>ユーザー名を利用したかったので、nameカラムを追加しました。
カラムの編集が終わったら、忘れずに下記コマンドを実行しましょう。
% rails db:migrate※まだDBを作成していないという方は、先にrails db:createを実行する必要があります。
3.Formオブジェクトを導入
今回の実装では投稿フォームからpostsテーブルとtagsテーブルへ同時に入力値を保存させたいので、Formオブジェクトを利用します。
まず、appディレクトリの中にformsディレクトリを作り、その中にposts_tag.rbファイルを作成しましょう。
そして、下記のようにpostsテーブルとtagsテーブルに同時に値を保存するためのsaveメソッドを定義します。posts_tag.rbclass PostsTag include ActiveModel::Model attr_accessor :title, :content, :date, :time_first, :time_end, :people, :name, :user_id with_options presence: true do validates :title validates :content validates :name end def save post = Post.create(title: title, content: content, date: date, time_first: time_first, time_end: time_end, people: people, user_id: user_id) tag = Tag.where(name: name).first_or_initialize tag.save PostTagRelation.create(post_id: post.id, tag_id: tag.id) end end4. ルーティングの設定
続いて、postsコントローラーのindex・new・createアクションを動かすためのルーティングを設定します。
routes.rbresources :posts, only: [:index, :new, :create] do collection do get 'search' end endcollection内で定義しているsearchアクションへのルーティングは、インクリメンタルサーチ機能で利用します。
5. postsコントローラーを作成、アクション定義
ターミナルでコントローラを生成します。
% rails g controller posts生成されたpostsコントローラファイル内のコードは下記のようになります。
posts_controller.rbclass PostsController < ApplicationController before_action :authenticate_user!, only: [:new] def index @posts = Post.all.order(created_at: :desc) end def new @post = PostsTag.new end def create @post = PostsTag.new(posts_params) if @post.valid? @post.save return redirect_to posts_path else render :new end end def search return nil if params[:input] == "" tag = Tag.where(['name LIKE ?', "%#{params[:input]}%"]) render json: {keyword: tag} end private def posts_params params.require(:post).permit(:title, :content, :date, :time_first, :time_end, :people, :name).merge(user_id: current_user.id) end endcreateアクションでは、先程Formオブジェクトで定義したsaveメソッドを使ってPostsモデルとTagsテーブルへposts_paramsで受け取った値を保存しています。
searchアクションでは、JS側で取得したデータ(タグ入力フォームで打ち込まれた文字列)を元に、 where + LIKE句でtagsテーブルからデータを引っ張り出し、reder jsonでJSに返しています。(JSファイルは後ほど登場。)
そういう訳なので、↑のsearchアクションは、インクリメンタルサーチを実装しないのであれば必要ありません。
6.ビューファイルの作成
new.html.erb<%= form_with model: @post, url: posts_path, class: 'registration-main', local: true do |f| %> <div class='form-wrap'> <div class='form-header'> <h2 class='form-header-text'>タイムライン投稿ページ</h2> </div> <%= render "devise/shared/error_messages", resource: @post %> <div class="post-area"> <div class="form-text-area"> <label class="form-text">タイトル</label><br> <span class="indispensable">必須</span> </div> <%= f.text_field :title, class:"post-box" %> </div> <div class="long-post-area"> <div class="form-text-area"> <label class="form-text">概要</label> <span class="indispensable">必須</span> </div> <%= f.text_area :content, class:"input-text" %> </div> <div class="tag-area"> <div class="form-text-area"> <label class="form-text">タグ</label> <span class="indispensable">必須</span> </div> <%= f.text_field :name, class: "text-box", autocomplete: 'off' %> </div> <div>【おすすめタグ】</div> <div id="search-result"> </div> <div class="long-post-area"> <div class="form-text-area"> <label class="form-text">イベント日程</label> <span class="optional">任意</span> </div> <div class="schedule-area"> <div class="date-area"> <label>日付</label> <%= f.date_field :date %> </div> <div class="time-area"> <label>開始時刻</label> <%= f.time_field :time_first %> <label class="end-time">終了時刻</label> <%= f.time_field :time_end %> </div> </div> </div> <div class="register-btn"> <%= f.submit "投稿する",class:"register-blue-btn" %> </div> </div> <% end %>僕のアプリ実装で使っていたビューファイルをベタ貼りしているため、コードが冗長になっていますが要はフォームの内容を@post等でルーティングに送れていれば問題ありません。
index.html.erb<div class="registration-main"> <div class="form-wrap"> <div class='form-header'> <h2 class='form-header-text'>タイムライン一覧ページ</h2> </div> <div class="register-btn"> <%= link_to "タイムライン投稿ページへ移る", new_post_path, class: :register_blue_btn %> </div> <% @posts.each do |post| %> <div class="post-content"> <div class="post-headline"> <div class="post-title"> <span class="under-line"><%= post.title %></span> </div> <div class="more-list"> <%= link_to '編集', edit_post_path(post.id), class: "edit-btn" %> <%= link_to '削除', post_path(post.id), method: :delete, class: "delete-btn" %> </div> </div> <div class="post-text"> <p>■概要</p> <%= post.content %> </div> <div class="post-detail"> <% if post.time_end != nil && post.time_first != nil %> <p>■日程</p> <div class="post-date"> <%= post.date %> <%= post.time_first.strftime("%H時%M分") %> 〜 <%= post.time_end.strftime("%H時%M分") %> </div> <% end %> <div class="post-user-tag"> <div class="post-user"> <% if post.user_id != nil %> ■投稿者: <%= link_to "#{post.user.name}", user_path(post.user_id), class:'user-name' %> <% end %> </div> <div class="post-tag"> <% post.tags.each do |tag| %> #<%= tag.name %> <% end %> </div> </div> </div> </div> <% end %> </div> </div>こちらも同様に冗長なので、適宜必要なところだけ参照ください...
## 7.インクリメンタルサーチの実装(JavaScript)
こちらは、JSファイルをいじります。
tag.jsif (location.pathname.match("posts/new")){ window.addEventListener("load", (e) => { const inputElement = document.getElementById("post_name"); inputElement.addEventListener('keyup', (e) => { const input = document.getElementById("post_name").value; const xhr = new XMLHttpRequest(); xhr.open("GET", `search/?input=${input}`, true); xhr.responseType = "json"; xhr.send(); xhr.onload = () => { const tagName = xhr.response.keyword; const searchResult = document.getElementById('search-result') searchResult.innerHTML = '' tagName.forEach(function(tag){ const parentsElement = document.createElement('div'); const childElement = document.createElement("div"); parentsElement.setAttribute('id', 'parents') childElement.setAttribute('id', tag.id) childElement.setAttribute('class', 'child') parentsElement.appendChild(childElement) childElement.innerHTML = tag.name searchResult.appendChild(parentsElement) const clickElement = document.getElementById(tag.id); clickElement.addEventListener('click', () => { document.getElementById("post_name").value = clickElement.textContent; clickElement.remove(); }) }) } }); }) };location.pathname.matchを使って、postsコントローラのnewアクションが発火した時に、コードが読み込まれるようにしています。
JS内のおおまかな処理としては、
①keyupでイベント発火させて、タグフォームの入力値をコントローラーへ送る(xhr.〇〇辺り)
②xhr.onload以下でコントローラーから返ってきた情報を元に、予測タグをフロントに表示させる。
③予測タグがクリックされたら、そのタグがフォームに反映される。以上で、タグ付け機能の実装とインクリメンタルサーチの実装ができました。
ざっくりとした記事にはなりますが、最後までお読み頂きありがとうございました!

- 投稿日:2020-10-22T19:59:40+09:00
import * as XX from YYとimport XX from YYの違い
ふと思うとあまり理解していなかったので調べたついでにメモ
間違いあればご指摘ください、、結論
default exportのときはimport XX from YY
named exportのときはimport * as細かい仕様は以下に書いてた
・import
https://developer.mozilla.org/ja/docs/Web/JavaScript/Reference/Statements/import
・export
https://developer.mozilla.org/ja/docs/Web/JavaScript/Reference/Statements/exportdefault exportのとき
export側
defaultExport.jsconst default = () => {......} export default = defaultimport側
import.jsimport hoge from 'defaultExport' // 使うとき hoge()named exportのとき
export側
namedExport.jsexport const named1 = () =>{......} export const named2 = () =>{......}import側
import.jsimport * as hoge from 'namedExport' // 使うとき hoge.named1() hoge.named2() // こちらでも可 import { named1, named2 } from 'namedExport' named1() named2()個人的には
named exportの方が定義側と同じ名前を使えるのでバグとか少なそうで好きかも
- 投稿日:2020-10-22T19:34:26+09:00
Javascript 文字列を降順にしたい sortを使うが思い通りにならない。
降順にしたいデータ
data = ["20[WW]", "25[DDAA]", "19[CCC]", "24[BB]", "18[AA]"]欲しい結果
=> ["25[DDAA]", "24[BB]", "20[WW]", "19[CCC]", "18[AA]"]まずは昇順
data = ["20[WW]", "25[DDAA]", "19[CCC]", "24[BB]", "18[AA]"] data.sort() =>["18[AA]", "19[CCC]", "20[WW]", "24[BB]", "25[DDAA]"]思った通りの動作でいい感じです。
次に降順
data = ["20[WW]", "25[DDAA]", "19[CCC]", "24[BB]", "18[AA]"] data.sort(function(a,b){return(b-a);}) =>["20[WW]", "25[DDAA]", "19[CCC]", "24[BB]", "18[AA]"]どう見てもこれじゃない感
方法1
data = ["20[WW]", "25[DDAA]", "19[CCC]", "24[BB]", "18[AA]"] data.sort((a, b) => a.toLowerCase() < b.toLowerCase() ? 1 : -1) =>["25[DDAA]", "24[BB]", "20[WW]", "19[CCC]", "18[AA]"]期待通りです。全部小文字に変換してから三項演算子で比較してます。
方法2
data = ["20[WW]", "25[DDAA]", "19[CCC]", "24[BB]", "18[AA]"] data.sort().reverse() =>["25[DDAA]", "24[BB]", "20[WW]", "19[CCC]", "18[AA]"]期待通りです。昇順が問題なく動作するならその配列をリバースすれば降順になる。
方法3(推奨)
data = ["20[WW]", "25[DDAA]", "19[CCC]", "24[BB]", "18[AA]"] data.sort((a, b) => parseFloat(b) - parseFloat(a));@il9437 さんよりコメント欄で教えていただきました。感謝です。
整数部の桁数や正負が混在していてもしっかり動作するので一番良い方法かと思います。
※paraseFloatは最初が文字列から始まる場合はうまく動作しません。parseFloat('100[AABB]') => 100 parseFloat('-30example') => -30 parseFloat('0544test') => 544 parseFloat('aaaa1005') => NAN感想
降順が思い通り動作しなくて少しハマりました。
スピード的には方法1と方法2はどっちの方が早いんでしょうか
あまり速度が変わらないor方法2の方が早いなら方法2の方がスッキリしてる気がするのでいいと思いますがもしご存知の方いらっしゃいましたらコメント欄等で教えていただけますと幸いです。(@netebakari さんより参考になるコメントいただいておりますのでぜひ参照くださいませ)
- 投稿日:2020-10-22T19:23:09+09:00
JavaScriptでFizzBuzzを解いてみる
FizzBuzzゲームとは、二人以上のプレイヤーが1から順番に数字を発言し、3で割り切れるときは「Fizz」と答え、5で割り切れるときは「Buzz」と答える。両方割り切れる時は「FizzBuzz」と答え、間違えた人から脱落していくというゲームです。
問題
1から100までを表示させる。ただし、3の倍数では「Fizz」と表示させる。5の倍数では「Buzz」と表示させる。3と5の倍数では「FizzBuzz」と表示させること。
表示させる箇所はコンソールログ内とする。目的
コンソールログ内に次のような表示をさせること。
小さいところから組み立てていこう!
まずは、結果を表示させます。
index.html<script> function fizzbuzz() { console.log(1); } fizzbuzz(); </script>→ログ内に数字の1が表示されます。
次に1から100までを表示します。ここではfor文を使っていきます。
index.html<script> function fizzbuzz() { for(i=1: i<=100; i++) { console.log(i); } } fizzbuzz(); </script>for文の中身を解説します。
i=1で1からスタートすると宣言する。
i<=100で100までと、最終的な数字を決める。
i++で、iが100になるまで1ずつ増やしていく。次に数字で表示させるところ、FizzBuzzなどの文字に置き換えるところをどう分けるかを考える。
数字(すでに出力できている)
Fizz
Buzz
FizzBuzz
→これらが使われる。条件分岐はif文を使っていきます。
まずは、Fizzを表示させてみましょう!index.html<script> function fizzbuzz(){ for(i=1; i<=100; i++){ if(i%3 === 0){ console.log('Fizz'); }else{ console.log(i); } } } fizzbuzz(); </script>i%3 === 0で余りが0かを調べています。
次に、Buzzを表示させてみましょう!
index.html<script> function fizzbuzz(){ for(i=1; i<=100; i++){ if(i%3 === 0){ console.log('Fizz'); }else if(i%5 === 0){ console.log('Buzz'); }else{ console.log(i); } } } fizzbuzz(); </script>else ifをつかうことで、3の倍数でなかったときは〜の処理を書くことができます。i%5 === 0で余りが0かを調べています。
次に、FizzBuzzを表示させてみましょう!
ここから少し難しいですが、頑張りましょう!
今回は2つのやり方を解説します。1つ目
まず、3と5の倍数ということなので最小公倍数を使う方法があります。3の倍数は「3,6,9,12,15」、5の倍数は「5,10,15」です。
3の倍数と5の倍数で共通している数で一番小さい数は15です。それでは、コードに追加していきます。
index.html<script> function fizzbuzz(){ for(i=1; i<=100; i++){ if(i%15 === 0){ console.log('FizzBuzz'); }else if(i%3 === 0){ console.log('Fizz'); }else if(i%5 === 0){ console.log('Buzz'); }else{ console.log(i); } } } fizzbuzz(); </script>書き方は今までと同じですが、一つ重要なポイントがあります。
それは、書く順番が変わっていることです。index.html<script> function fizzbuzz(){ for(i=1; i<=100; i++){ if(i%3 === 0){ console.log('Fizz'); }else if(i%5 === 0){ console.log('Buzz'); }else if(i%15 === 0){ console.log('FizzBuzz'); }else{ console.log(i); } } } fizzbuzz(); </script>このようにFizzBuzzを求めるif文を一番下に書いてしまうと、FizzBuzzとは表示されません。Fizzと表示されてしまいます。理由は、FizzBuzzの分岐に到達する前に条件を満たしてしまっており、下の処理まで行われないからです。なので、書く順番には注意する必要があります。
2つ目
こちらは最小公倍数を使わない方法です。
文字に置き換わる条件は次のようになります。
- 3の倍数の時
- 5の倍数の時
- 3と5の倍数の時
違う言い方をすると次のようになります。
- 3の倍数だけれど、5の倍数ではない時
- 3の倍数ではないけれど、5の倍数である時
- 3と5の倍数の時
それでは書いてみます!
index.html<script> function fizzbuzz(){ for(i=1; i<=100; i++){ if(i%3 === 0 && i%5 !== 0){ console.log('Fizz'); }else if(i%3 !== 0 && i%5 === 0){ console.log('Buzz'); }else if(i%3 === 0 && i%5 === 0){ console.log('FizzBuzz'); }else{ console.log(i); } } } fizzbuzz(); </script>完成です。こちらの長所はFizzBuzzを求めるif文が下になっても大丈夫だということです。
--
コンソールログに文字や数字を表示させる
1から100まで繰り返す命令を書く
3の倍数をFizzに置き換える
5の倍数をBuzzに置き換える3と5の倍数をFizzBuzzに置き換える
このように一つずつ細かくすることで、一つ一つを簡単にすることができました。
今回は以上になります。最後まで読んでいただきありがとうございました!

- 投稿日:2020-10-22T18:48:35+09:00
IE11で使用できないJavaScriptの記法
背景
何も気にせずJavaScriptを書いていたらIEで正しく動作しないものにいくつか当たったので、エラー内容とその修正方法を記録します。
メソッド記法
エラー内容
SCRIPT1002: 構文エラーです。原因
const question = { getAnswer() { console.log('回答だよ'); } }https://developer.mozilla.org/ja/docs/Web/JavaScript/Reference/Functions/Method_definitions
メソッド定義の短い構文はIEでは使えない。解決方法
const question = { getAnswer: function() { console.log('回答だよ'); } }
functionを省略しない。テンプレート文字列
エラー内容
SCRIOPT1014: 文字が正しくありません。原因
const massage = `メッセージは${text}です。`https://developer.mozilla.org/ja/docs/Web/JavaScript/Reference/Template_literals
バッククォートを使用した記法はIEではできない。解決方法
const message = 'メッセージは' + text + 'です。'for...of
エラー内容
SCRIPT1004: ‘:’ がありません。原因
for (let answer of Answers) { console.log(answer); }https://developer.mozilla.org/ja/docs/Web/JavaScript/Reference/Statements/for...of
for...ofを使った配列のループはIEではできない。解決方法
for (let i=0; i < Answers.length; i++) { const answer = Answers[i] console.log(answer); }アロー関数
エラー内容
SCRIPT1002: 構文エラーです。原因
element.addEventListener('click', () => { console.log('クリックされたよ'); };https://developer.mozilla.org/ja/docs/Web/JavaScript/Reference/Functions/Arrow_functions
アロー関数でのfunctionの省略はできない。解決方法
element.addEventListener('click', function() { console.log('クリックされたよ'); };NodeListに対するforEach
エラー内容
SCRIPT438: オブジェクトは 'forEach' プロパティまたはメソッドをサポートしていません。原因
element = document.querySelectorAll('.test'); element.forEach(function (item) { console.log(item); };https://developer.mozilla.org/ja/docs/Web/API/Document/querySelectorAll
querySelectorAll()メソッドはNodeListを返す。https://developer.mozilla.org/ja/docs/Web/API/NodeList/forEach
IEではNodeListに対するforEachはサポートしていないのでエラーになる。解決方法
elementNodeList = document.querySelectorAll('.test'); // Arrayに変換している element = Array.prototype.slice.call(elementNodeList, 0); element.forEach(function (item) { console.log(item); };https://developer.mozilla.org/ja/docs/Web/JavaScript/Reference/Global_Objects/Array/forEach
Arrayに対するforEachはIEでも使用できる。のでArrayに変換してからforEachを使用。他にもいくつかの解決方法があるらしい。
まとめ
解決方法は一例です。
正しく動かない記法はまだまだあると思いますが、自分が使用した段階で追加します。
IEで正しく動かないJavaScriptについてのまとめ記事は探すとたくさん出てくるので、困った際はエラー文でググると、すぐに原因が見つけられると思います。参考記事
- 投稿日:2020-10-22T18:19:51+09:00
slick.jsを使用してページャーに数字を適用する
スライダーを使用したい時、手っ取り早くslickを使っています。便利ですよね。
ある時スライドをポップアップさせて動画を表示させる依頼がありました。
仕様としては
「ページャーには第○章と順に入れてね」
「スマホの時はページャーをドットにしてね」
というもので、やり方を調べて実装しました。以下備忘録です。slickでページャーを変更できる「customPaging」
「customPaging」というオプションで自由に変更できます。
$('.c5-slider').slick({ infinite: true, slidesToShow: 1, slidesToScroll: 1, draggable: false, arrows: true, prevArrow: '<span class="prev-arrow">前</span>', nextArrow: '<span class="next-arrow">次</span>', customPaging: function(slider, i) { return $('<div class="c5-dots__num">').text('第' + (i+1) + '章'); }, dotsClass: 'c5-dots', dots: true, });See the Pen slick__pager__1 by yoshida (@yoshi090) on CodePen.
数字を降順にする
「最新話を一番左にしたいから数字を逆にしてほしい」と言われたら。
<section> <div class="c5-slider_wrap"> <ul class="c5-slider"> <li class="c5-slider_content"> 4章 </li> <li class="c5-slider_content"> 3章 </li> <li class="c5-slider_content"> 2章 </li> <li class="c5-slider_content"> 1章 </li> </ul> <!-- /.c5-slider --> </div> <!-- /.c5-slider_wrap --> </section>customPaging: function(slider, i, j) { j = 5; return $('<div class="c5-dots__num">').text('第' + (j-(i+1)) + '章'); }See the Pen slick__pager__2 by yoshida (@yoshi090) on CodePen.
途中に番外編を入れる
「ごめん、動画で2章番外編があるから4章と3章の間に入れてね」と言われたら。
<section> <div class="c5-slider_wrap"> <ul class="c5-slider"> <li class="c5-slider_content"> 4章 </li> <li class="c5-slider_content"> 2章番外編 </li> <li class="c5-slider_content"> 3章 </li> <li class="c5-slider_content"> 2章 </li> <li class="c5-slider_content"> 1章 </li> </ul> <!-- /.c5-slider --> </div> <!-- /.c5-slider_wrap --> </section>customPaging: function(slider, i, j) { j = 6; if(i >= 0 && i < 1){ return $('<div class="c5-dots__num">').text('第' + (j - (i+2)) + '章'); }else if(i == 1){ return $('<div class="c5-dots__num">').text('第2章番外編'); }else{ return $('<div class="c5-dots__num">').text('第' + (j - (i+1)) + '章'); } }See the Pen slick__pager__3 by yoshida (@yoshi090) on CodePen.
以上です。
参考
- 投稿日:2020-10-22T15:49:23+09:00
next-redux-wrapper のアップデートに見る Universal App の State 管理について思うこと
Next.js で Redux を導入しているプロジェクトで、next-redux-wrapper を使用している方もいるかと思います。
今年に入ってv5からv6にアップデートが行われましたが、だいぶ挙動が変わり Universal App での State 管理をあらためて考えるきっかけになったので、ドキュメントとして残しておきます。細かくなった State 管理
v6のアップデートで特筆すべきはHYDRATEのアクションが追加され、SSR時にサーバサイドで生成された任意の State をクライアント側に移譲する処理を明示的に書く必要が出たことです (React のhydrate()と同じことを Redux で行う感じです)。
v5までは暗黙的に State の状態はサーバ <=> クライアント間で共有されていましたが、今回のアップデートでその処理はなくなりました。本来戻るべき所に戻ってきた感はありますが、暗黙にマージされていた時はそれはそれでコードがスッキリしていたので、個人的には悪くないなって思っていました。Next.js のアップデートのインパクト
Next.js は今まで Universal App を React で比較的容易に構築できるという側面が大きかったですが、近年、静的化 (SSG - Static Site Generation, ISSG - Incremental SSG) に力を入れており、様々なバリエーションに対応するため next-redux-wrapper もそのコンセプトに寄せてきたと解釈しています。
どのみち、Redux を使っている以上 SSR 時の State をクライアントにマージをしなければなりませんが、こうして SSR のバリエーションが増える中、そもそも State をクライアント・サーバサイドで共有すること自体を考えることへのテーゼにも感じます。
煩雑化傾向の処理
今回のアップデートでより強く感じるようになりましたが、コードが煩雑になります。
公式のサンプル にもあるように、今までライブラリがよしなにマージしていた状態を自分たちで抽出する必要が出てきます。また、
HYDRATEには State 全てが渡ってくるので、一部の State のみをサーバサイド・クライアントで共有したいなどある場合、HYDRATEの処理によっては型の定義などに影響が出たりします。下記の例では、ある任意の State ブランチで
HYDRATEを使用する場合の Reducer になります。
※ 全体のソースはこちらで展開していますconst initialCounter: CountState = { count: 0 }; export const counter = ( state = initialCounter, action: CounterActionTypes ): CountState => { switch (action.type) { // サーバサイドの State をクライアントでもつかいたい場合、 // HYDRATE アクションを用いてマージしてあげる必要がある case HYDRATE: return { ...state, count: action.payload.counter.count }; case UPDATE_COUNT: return { ...state, count: action.payload }; default: return state; } };このケースだと、
actionでの型にHYDRATEを考慮せざるおえない処理になり、/** action */ interface HydrateCountAction { type: typeof HYDRATE; payload: RootState; // <= ほしくない箇所に RootState が出てくる } export type CounterActionTypes = | IncrementAction | DecrementAction | UpdateCountAction | HydrateCountAction; /** 参考) redux saga で連携 */ // action type に本来欲しくない RootState がいるため Extract を使用する必要が出てくる const { payload }: Extract<CounterActionTypes, { type: typeof INCREMENT }> = yield take(INCREMENT);State の設計にもよりますが、本来任意の State の型で完結したい所にそれよりも上位の RootState が登場するなど、依存性の逆転が起こってしまうケースも考えられます。
公式のように
combineReducerの前処理で分岐を設けるのも一理ありますが、そこの処理でも「じゃあマージしたい State が増えたら if文 どんどん増やすんですか?」ということは避けて通れません。Next.js (React) での状態管理
今回両者のアップデートで Next.js でのアプリケーションは State の扱いに関して色々と考えなければならない岐路に経っているように思います。
Next.js の API郡や SWR などで見れば、そもそもグローバルオブジェクトに状態を全て突っ込んで管理して欲しいような作りになってないかなと最近は感じており、よりシンプル(ここでのシンプルとは
getserverSidePropsに始まる Data Fetch やStale-While-Revalidateを利用したデータのキャッシュなどを指します)に状態を扱えるように考える方向になっているように思います。つまり、一度取得した情報を一つのオブジェクトに格納して使い回すだけではなく、Data Fetch, キャッシュも含めてより素直な形でUI上で扱う情報を処理して行きましょうということです。
更に、React が Hooks や Context API を提供していることもあり、「React の状態管理するなら Redux」のような脳死に近い形でプロジェクト導入するということは「まった」をかけたほうが良さそうです(Recoil もどこまで伸びるか気になりますね)。
シンプルに考えていきたい
フロントエンド・バックエンドが分離したアプリケーション構成の開発が盛んになってそこそこの年月が経っていますが、フロントエンドは SPA のみならず、Universal App、SSG、JAMStack など多様かつそのプロダクトの特性に於いて適切な実装をしなければならないケースが増えました。
SPA が非常に流行った時期もありますが、最近では SSG + CDN を使用した静的ファイルの配信のほうがやっぱり良いよね。みたいな傾向もあり、開発者はより広域な領域をカバーしないといけない状況が続くかと思います。
ただ一方で、React などの UIライブラリ、Next.js を始めとする Universal App や Data Fetch の技術の進展で先の Redux などの状態管理のように、「難しいことを難しく実装する必要が無くなってきた」 のも事実です。
なにか、今回のことを受けて「Redux を扱うべきケースはこれ」や「Redux 使わないケースはこれ」という解をアウトプットしたかったわけではありませんが、こう状態管理にはおそらく最適解というのはなく、一つ一つプロダクトの仕様と向き合って議論して方針を決めていける開発ができると良いなと思いここに書き残しておきます。
- 投稿日:2020-10-22T15:41:47+09:00
dataTables.js で2回目以降の表示が遅い!!ときに効果があった対処法。
はじめに
dataTables.js(1.10.15)を使用して
6000件~7000件程度のデータでテーブル表示をしていたときのお話。
IE11(なんで今更というツッコミは置いといて)で表示させてみたところ、
うーん。まずまず。
再度検索処理を実行して表示させてみたところ、
…ん?表示されない。
…えっ。。。嘘でしょ。。。
…全然返ってこない。。。
そう。2回目になると1回目に比べて 極端に 遅くなっていました。
IE11でDataTablesの処理開始から終了までを計測したみたところ、
1回目:約6秒
2回目:約153秒という本当に冗談かと思うような(そうあってほしい)結果が出てしまいました。
原因について考えてみる
dataTablesを使用すると決めたときに、
ネットでよく出てくるdataTablesの高速化の方法(※)は既に実装済みだったので
※データはJSON形式にして、DataTablesに直接渡すdataTablesの使い方が原因ではないと考えました。
次に、1回目と2回目で異様に処理時間が変わってしまうこと。
1回目と2回目で何が違うかというと、
間違いなく
膨大な量のHTMLが描画されているか、されていないか
これにつきると考えました。
ということは、その大量のHTMLを一旦削除してしまえばよいのではないか???
解決方法
元々は、サーバ側からjsonデータを取得した後に
$("#result").DataTable({ destroy: true, scrollX: true, data: myData, ~ });というようにdataTablesの描画処理しか行っていませんでした。
それを、
$("#result").empty(); $("#result").DataTable({ destroy: true, scrollX: true, data: myData, ~ });のように、
一旦dataTablesをバインドする要素内のhtmlを全削除
↓
dataTablesの描画処理という処理に変更したところ、
1回目:約6秒
2回目:約6.5秒と劇的(25倍!!)に2回目の処理速度が向上しました。
考えてみたら当たり前なんですが、
意外と気づかないんですよね。。。
おわりに
Chromeでは計測しませんでしたが、体感的には明らかに早くなっていました。
というか、IEは本当に遅い。。。
同じような現象で困っている方、ぜひお試しあれ♪
- 投稿日:2020-10-22T11:26:31+09:00
Nuxtjsでgenerate時に、公開しているページのtitleとurlのリストを作成する
※力技での解決法です。絶対もっと良い方法があるはず。
発端としては、
フロントのNuxt側でデータを受け取るだけでなく、
外部に渡せる形で書き出せないか?と思ったこと。
ググったけど、あまり情報が見当たらず、
「そもそもこの発想自体がズレてるのでは?」と思えてきたが、
とりあえず作ってみた。内容としてはシンプルに、
nuxt generateで生成された
distの中のhtmlファイル群をスクレイピングすること。まずはささっとモジュール作成。
generate-pages-info.jsconst {resolve} = require('path') const {readFileSync, writeFileSync} = require('fs') const requireContext = require('require-context'); module.exports = async function () { const {rootDir, generate: {dir: generateDir}} = this.options const fileName = 'pages.json' this.nuxt.hook('generate:done', async () => { const dir_path = resolve(rootDir, generateDir); const html_files = {}; const page_paths = requireContext(dir_path, true, /\.html$/).keys(); for (const page_path of page_paths) { const name = page_path .split("./") .pop() .split(".") .shift(); html_files[name] = await getPageInfo(dir_path, page_path); } const pages_json = JSON.stringify(html_files); const generate_file_path = resolve(rootDir, generateDir, fileName); writeFileSync(generate_file_path, pages_json); }) } async function getPageInfo(dir_path, page_path) { const file_path = resolve(dir_path, page_path); const content = await readFileSync(file_path, "utf-8"); const page_title = content.match(/<title>(.*?)<\/title>/)[1]; const page_metas = await pageMetas(content); return { "title": page_title, "metas": page_metas, "url": page_path } } async function pageMetas(content) { const regex_text = /<meta[^<>]*?name=\"(.*?)\"[^<>]*?content=\"(.*?)\"/; const metas = content.match(new RegExp(regex_text, 'g')); let result = []; for (const meta of metas) { const match = meta.match(new RegExp(regex_text)); result.push({ "name": match[1], "content": match[2] }) } return result; }nuxt.config.jsにモジュール登録。
nuxt.config.jsmodules: [ '~modules/generate-pages-info.js' ]あとは
nuxt generateして、
公開フォルダ(デフォルトではdist)にpages.jsonが出来ていればOK。パーサー使えばもっと上品にできるかも。
非同期処理関連が結構躓いた。
当たり前だけど、同じサイトだろうが別ファイルの読み込みは時間かかるのね。
- 投稿日:2020-10-22T08:22:10+09:00
Node.jsについて超ミニマムに解説してみる
超ミニマムシリーズとは
様々な事柄に関して超短く解説するシリーズです。
これを読んであなたの興味が沸き、その飽くことのない知識欲を満たすことを願っています。Node.jsとは
「サーバー側で実行されるJavaScript」
プログラミング言語と言語処理系については➡プログラミング言語と言語処理系について超ミニマムに解説してみるchromeの言語処理系とNode.jsの言語処理系は同じ!?
chromeの言語処理系であるJSエンジンはV8です。
ただ実は、Node.jsの言語処理系もV8なんです!あれ?じゃぁブラウザと同じじゃん!と思いますよね?
ただ、前述したように「Node.jsはサーバー側で実行される」というとこがポイントです!
ブラウザはユーザーが立ち上げないとコードが実行されませんが、Node.jsはサーバーに常に存在しているのでコードをいつでも実行できます。おまけ(ブラウザのJSエンジン(言語処理系)との違い)
「ブラウザにはグローバル変数があるが、Node.jsには存在しない」
グローバル変数とは、いわゆるvarで宣言する変数です。
では、なぜNode.jsにはグローバル変数が存在しないのか?
それは、Node.jsには多くのモジュールが存在するため、モジュール間で変数が干渉するのを防ぐためにグローバル変数がないのです。
(※モジュールとは・・・関数などを機能ごとに分けたファイルのこと)
(※変数の干渉とは・・・同じ名前の変数が他のモジュールに存在した場合に、値を上書きしてしまったり予期せぬエラーを生むこと)
- 投稿日:2020-10-22T02:19:35+09:00
ReactからBlocklyを使ってみた
Qiita初投稿です。ReactでBlocklyエディタを表示させるまでの手順を紹介します。
使用環境はこんな感じ。$ npm -v 6.14.8 $ create-react-app --version 3.4.11. create-react-appする
Reactプロジェクトの作成にはcreate-react-appを使用しました。
$ create-react-app blockly-react (省略) Happy hacking!とりあえずちゃんと作成できているかテスト
$ cd blockly-react $ npm start自動的にブラウザが開いて以下の画面が出ていればOKです。
2. Blocklyのインストール
Blockly公式のnpmパッケージを入れます。
$ npm install blockly記事を書いている時点ではこのバージョンが入りました。
package.json{ "dependencies": { ... "blockly": "^3.20200924.3", ... }, }3. App.jsの編集
App.jsに元々入っているコードは使わないので消し、まずは愚直に以下のコードで試してみます。
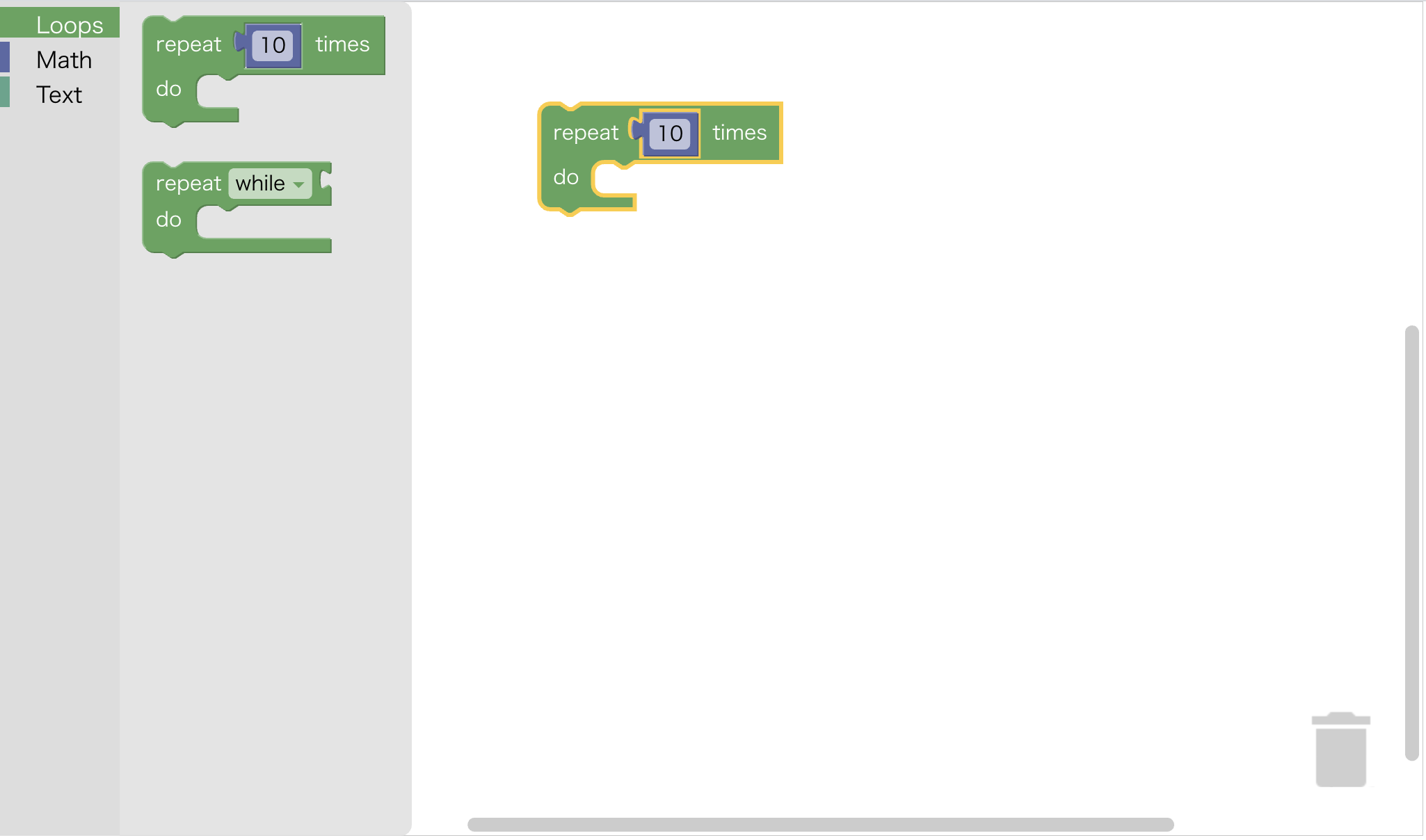
App.jsimport React, { useEffect } from 'react'; import Blockly from "blockly"; function App() { useEffect(() => { Blockly.inject("blocklyDiv", { toolbox: document.getElementById("toolbox") }); }); return ( <div> <div id="blocklyDiv" style={{width: "1024px", height: "600px"}}></div> <xml id="toolbox" style={{display: "none"}}> <category name="Loops" colour="%{BKY_LOOPS_HUE}"> <block type="controls_repeat_ext"> <value name="TIMES"> <block type="math_number"> <field name="NUM">10</field> </block> </value> </block> <block type="controls_whileUntil"></block> </category> <category name="Math" colour="%{BKY_MATH_HUE}"> <block type="math_number"> <field name="NUM">123</field> </block> </category> <category name="Text" colour="%{BKY_TEXTS_HUE}"> <block type="text"></block> <block type="text_print"></block> </category> </xml> </div> ); } export default App;
Blockly.injectはblocklyDivやtoolboxの要素を参照するので、useEffectを使用することでDOMが更新された後に実行するようにしています。
画面は問題なく出ていますが、Chromeのコンソールを見ると大量のWarningが...。
そのうちの1つは、
Warning: The tag <xml> is unrecognized in this browser. If you meant to render a React component, start its name with an uppercase letter.
だそうです。
他のWarningも似たようなもので、xmlやcategory、blockなどのタグを使っているのが理由のようです。4. Warningを消す
App.jsimport React, { useEffect } from 'react'; import Blockly from "blockly"; function App() { const xml = ` <xml id="toolbox"> <category name="Loops" colour="%{BKY_LOOPS_HUE}"> <block type="controls_repeat_ext"> <value name="TIMES"> <block type="math_number"> <field name="NUM">10</field> </block> </value> </block> <block type="controls_whileUntil"></block> </category> <category name="Math" colour="%{BKY_MATH_HUE}"> <block type="math_number"> <field name="NUM">123</field> </block> </category> <category name="Text" colour="%{BKY_TEXTS_HUE}"> <block type="text"></block> <block type="text_print"></block> </category> </xml> `; const xmlParser = new DOMParser(); const xmlDom = xmlParser.parseFromString(xml, "text/xml"); useEffect(() => { Blockly.inject("blocklyDiv", { toolbox: xmlDom.getElementById("toolbox") }); }); return ( <div> <div id="blocklyDiv" style={{width: "1024px", height: "600px"}}></div> </div> ); } export default App;jsx内に直接xmlを書くのではなく、文字列からパースするアプローチで行きました。
これでWarningも出ずにBlocklyエディタの画面も問題なく使えます。

- 投稿日:2020-10-22T00:40:34+09:00
【JavaScript】ドット記法・ブラケット記法について
JavaScriptにはオブジェクトのプロパティにアクセスする方法が2種類あります。
使い方や違いを理解できたのでメモしたいと思います。ドット記法
.(ドット)を使ってプロパティにアクセスする記法です。const obj = {}; obj.name = 'taka'; // objのプロパティをセット obj.hello = function(){ console.log(`Hello,${this.name}`); } console.log(obj.name); // taka obj.hello(); // Hello,takaオブジェクトとプロパティを
.(ドット)で繋げることで、値の取得やメソッド実行ができます。ブラケット記法
[ ](ブラケット)を使ってプロパティにアクセスする方法です。
const obj = {}; obj['name'] = 'taka'; // objのプロパティをセット obj['hello'] = function(){ console.log(`Hello,${this.name}`); } console.log(obj['name']); // taka obj['hello'](); // Hello,takaメソッドも[ ]の後に()を付けて実行できます。
ドット記法とブラケット記法の違い
ブラケット記法は、プロパティ名に変数を与えることができます。ドット記法ではできません。
const propName = 'name'; // 変数を用意 const obj = {}; obj[propName] = 'taka'; // プロパティ名に変数を使う console.log(obj); // {name: "taka"} obj.propName = "taka"; //ドット記法で変数を使ってもプロパティ名になる console.log(obj); // {name: "taka",propName: "taka"}そのため、ブラケット記法はループなど動的にプロパティ名を変更したい場合に便利です。
例えば、配列にキーを格納して、オブジェクトの中身を取得した時など。
const key = ['html','css','javascript']; const obj = { html:'骨組み', css:'装飾', javascript:'動作' } key.forEach(function(key){ let result = key + 'は、Webページの' + obj[key] + 'を作ります。' console.log(result); });まとめ
ドット記法とブラケット記法の特徴、違いを記述しました。
2種類の方法がありますが、可読性の点から不必要に混在して使わない方が良さそうですね。参考
https://ichigo-pantsu.site/javascript-dot-bracket/
https://harakotan.hatenablog.jp/entry/2015/05/17/004707
https://developer.mozilla.org/ja/docs/Web/JavaScript/Reference/Operators/Property_Accessors