- 投稿日:2020-10-17T23:50:45+09:00
PySimpleGUI + OpenCVで動画プレイヤーを作る
はじめに
OpenCV(Open Source Computer Vision Library)はBSDライセンスのオープンソース映像/画像処理ライブラリ集です。画像・動画を対象とした、各種フィルタ処理、テンプレートマッチング、物体認識、機械学習などの各種ライブラリが用意されています。
動画の解析時に、画像を確認しながらROI、マスクなどの設定ができるように、PySimpleGUIを使用して動画プレイヤーを作成していきます。
この記事について
1回目として、GUIを作成し、動画の再生・停止、開始・終了フレームの設定ができるようにします。
操作画面
ファイルの読み込み
PySimpleGUIを使用してファイルの読み込みGUIを作成します。
import numpy as np import PySimpleGUI as sg import cv2 from pathlib import Path def file_read(): ''' ファイルを選択して読み込む ''' fp = "" # GUIのレイアウト layout = [ [ sg.FileBrowse(key="file"), sg.Text("ファイル"), sg.InputText() ], [sg.Submit(key="submit"), sg.Cancel("Exit")] ] # WINDOWの生成 window = sg.Window("ファイル選択", layout) # イベントループ while True: event, values = window.read(timeout=100) if event == 'Exit' or event == sg.WIN_CLOSED: break elif event == 'submit': if values[0] == "": sg.popup("ファイルが入力されていません。") event = "" else: fp = values[0] break window.close() return Path(fp)class Main: def __init__(self): self.fp = file_read() self.cap = cv2.VideoCapture(str(self.fp)) # 1フレーム目の取得 # 取得可能かの確認 self.ret, self.f_frame = self.cap.read() if self.ret: self.cap.set(cv2.CAP_PROP_POS_FRAMES, 0) # 動画情報の取得 self.fps = self.cap.get(cv2.CAP_PROP_FPS) self.width = int(self.cap.get(cv2.CAP_PROP_FRAME_WIDTH)) self.height = int(self.cap.get(cv2.CAP_PROP_FRAME_HEIGHT)) self.total_count = self.cap.get(cv2.CAP_PROP_FRAME_COUNT) # フレーム関係 self.frame_count = 0 self.s_frame = 0 self.e_frame = self.total_count # 再生の一時停止フラグ self.stop_flg = False cv2.namedWindow("Movie") else: sg.Popup("ファイルの読込に失敗しました。") return def run(self): # GUI ####################################################### # GUIのレイアウト layout = [ [ sg.Text("Start", size=(8, 1)), sg.Slider( (0, self.total_count - 1), 0, 1, orientation='h', size=(45, 15), key='-START FRAME SLIDER-', enable_events=True ) ], [ sg.Text("End ", size=(8, 1)), sg.Slider( (0, self.total_count - 1), self.total_count - 1, 1, orientation='h', size=(45, 15), key='-END FRAME SLIDER-', enable_events=True ) ], [sg.Slider( (0, self.total_count - 1), 0, 1, orientation='h', size=(50, 15), key='-PROGRESS SLIDER-', enable_events=True )], [ sg.Button('<<<', size=(5, 1)), sg.Button('<<', size=(5, 1)), sg.Button('<', size=(5, 1)), sg.Button('Play / Stop', size=(9, 1)), sg.Button('Reset', size=(7, 1)), sg.Button('>', size=(5, 1)), sg.Button('>>', size=(5, 1)), sg.Button('>>>', size=(5, 1)) ], [ sg.Text("Speed", size=(6, 1)), sg.Slider( (0, 240), 10, 10, orientation='h', size=(19.4, 15), key='-SPEED SLIDER-', enable_events=True ), sg.Text("Skip", size=(6, 1)), sg.Slider( (0, 300), 0, 1, orientation='h', size=(19.4, 15), key='-SKIP SLIDER-', enable_events=True ) ], [sg.Output(size=(65, 5), key='-OUTPUT-')], [sg.Button('Clear')] ] # Windowを生成 window = sg.Window('OpenCV Integration', layout, location=(0, 0)) # 動画情報の表示 self.event, values = window.read(timeout=0) print("ファイルが読み込まれました。") print("File Path: " + str(self.fp)) print("fps: " + str(int(self.fps))) print("width: " + str(self.width)) print("height: " + str(self.height)) print("frame count: " + str(int(self.total_count))) # メインループ ######################################################### try: while True: self.event, values = window.read( timeout=values["-SPEED SLIDER-"] ) if self.event == "Clear": pass if self.event != "__TIMEOUT__": print(self.event) # Exitボタンが押されたら、またはウィンドウの閉じるボタンが押されたら終了 if self.event in ('Exit', sg.WIN_CLOSED, None): break # 動画の再読み込み # スタートフレームを設定していると動く if self.event == 'Reset': self.cap.set(cv2.CAP_PROP_POS_FRAMES, self.s_frame) self.frame_count = self.s_frame window['-PROGRESS SLIDER-'].update(self.frame_count) window['-ROTATE-'].update(False) window['-ROTATE SLIDER-'].update(0) window['-ROTATE-'].update(False) window['-ROTATE SLIDER-'].update(0) self.video_stabilization_flg = False self.stab_prepare_flg = False # Progress sliderへの変更を反映させるためにcontinue continue # フレーム操作 ################################################ # スライダを直接変更した場合は優先する if self.event == '-PROGRESS SLIDER-': # フレームカウントをプログレスバーに合わせる self.frame_count = int(values['-PROGRESS SLIDER-']) self.cap.set(cv2.CAP_PROP_POS_FRAMES, self.frame_count) if values['-PROGRESS SLIDER-'] > values['-END FRAME SLIDER-']: window['-END FRAME SLIDER-'].update( values['-PROGRESS SLIDER-']) # スタートフレームを変更した場合 if self.event == '-START FRAME SLIDER-': self.s_frame = int(values['-START FRAME SLIDER-']) self.cap.set(cv2.CAP_PROP_POS_FRAMES, self.s_frame) self.frame_count = self.s_frame window['-PROGRESS SLIDER-'].update(self.frame_count) if values['-START FRAME SLIDER-'] > values['-END FRAME SLIDER-']: window['-END FRAME SLIDER-'].update( values['-START FRAME SLIDER-']) self.e_frame = self.s_frame # エンドフレームを変更した場合 if self.event == '-END FRAME SLIDER-': if values['-END FRAME SLIDER-'] < values['-START FRAME SLIDER-']: window['-START FRAME SLIDER-'].update( values['-END FRAME SLIDER-']) self.s_frame = self.e_frame # エンドフレームの設定 self.e_frame = int(values['-END FRAME SLIDER-']) if self.event == '<<<': self.frame_count = np.maximum(0, self.frame_count - 150) window['-PROGRESS SLIDER-'].update(self.frame_count) self.cap.set(cv2.CAP_PROP_POS_FRAMES, self.frame_count) if self.event == '<<': self.frame_count = np.maximum(0, self.frame_count - 30) window['-PROGRESS SLIDER-'].update(self.frame_count) self.cap.set(cv2.CAP_PROP_POS_FRAMES, self.frame_count) if self.event == '<': self.frame_count = np.maximum(0, self.frame_count - 1) window['-PROGRESS SLIDER-'].update(self.frame_count) self.cap.set(cv2.CAP_PROP_POS_FRAMES, self.frame_count) if self.event == '>': self.frame_count = self.frame_count + 1 window['-PROGRESS SLIDER-'].update(self.frame_count) self.cap.set(cv2.CAP_PROP_POS_FRAMES, self.frame_count) if self.event == '>>': self.frame_count = self.frame_count + 30 window['-PROGRESS SLIDER-'].update(self.frame_count) self.cap.set(cv2.CAP_PROP_POS_FRAMES, self.frame_count) if self.event == '>>>': self.frame_count = self.frame_count + 150 window['-PROGRESS SLIDER-'].update(self.frame_count) self.cap.set(cv2.CAP_PROP_POS_FRAMES, self.frame_count) # カウンタがエンドフレーム以上になった場合、スタートフレームから再開 if self.frame_count >= self.e_frame: self.cap.set(cv2.CAP_PROP_POS_FRAMES, self.s_frame) self.frame_count = self.s_frame window['-PROGRESS SLIDER-'].update(self.frame_count) continue # ストップボタンで動画の読込を一時停止 if self.event == 'Play / Stop': self.stop_flg = not self.stop_flg # ストップフラグが立っており、eventが発生した場合以外はcountinueで # 操作を停止しておく # ストップボタンが押された場合は動画の処理を止めるが、何らかの # eventが発生した場合は画像の更新のみ行う # mouse操作を行っている場合も同様 if( ( self.stop_flg and self.event == "__TIMEOUT__" ) ): window['-PROGRESS SLIDER-'].update(self.frame_count) continue # スキップフレーム分とばす if not self.stop_flg and values['-SKIP SLIDER-'] != 0: self.frame_count += values["-SKIP SLIDER-"] self.cap.set(cv2.CAP_PROP_POS_FRAMES, self.frame_count) # フレームの読込 ############################################## self.ret, self.frame = self.cap.read() self.valid_frame = int(self.frame_count - self.s_frame) # 最後のフレームが終わった場合self.s_frameから再開 if not self.ret: self.cap.set(cv2.CAP_PROP_POS_FRAMES, self.s_frame) self.frame_count = self.s_frame continue # 以降にフレームに対する処理を記述 ################################## # frame全体に対する処理をはじめに実施 ############################## # フレーム数と経過秒数の表示 cv2.putText( self.frame, str("framecount: {0:.0f}".format(self.frame_count)), ( 15, 20), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (240, 230, 0), 1, cv2.LINE_AA ) cv2.putText( self.frame, str("time: {0:.1f} sec".format( self.frame_count / self.fps)), (15, 40), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (240, 230, 0), 1, cv2.LINE_AA ) # 画像を表示 cv2.imshow("Movie", self.frame) if self.stop_flg: self.cap.set(cv2.CAP_PROP_POS_FRAMES, self.frame_count) else: self.frame_count += 1 window['-PROGRESS SLIDER-'].update(self.frame_count + 1) finally: cv2.destroyWindow("Movie") self.cap.release() window.close() if __name__ == '__main__': Main().run()環境
Windows10(64bit)
python 3.5.2
OpenCV 4.1.0参考リンク
PySimpleGUI
PySimpleGUI: popup_get_text
PySimpleGUIの基本的な使用方法
PySimpleGUIで画像処理ビューアーを作るOpenCV
- 投稿日:2020-10-17T23:46:32+09:00
Python備忘録[自分用]
Anaconda
- Anacondaで仮想環境を作る方法 https://starpentagon.net/analytics/conda_env_jupyter_notebook/
- pythonを3.7から3.6にダウングレードする方法 https://www.it-swarm-ja.tech/ja/python/python%E3%82%9237%E3%81%8B%E3%82%8936%E3%81%AB%E3%83%80%E3%82%A6%E3%83%B3%E3%82%B0%E3%83%AC%E3%83%BC%E3%83%89%E3%81%99%E3%82%8B%E6%96%B9%E6%B3%95/806822115/
- Anaconda仮想環境の名前を変更する方法 https://qiita.com/TyaoiB/items/b858430c289767cb04be
標準ライブラリ
numpy
matplotlib
pandas
PyTorch
Tesnorflow
- 投稿日:2020-10-17T23:46:32+09:00
Python備忘録[リンク集]
Anaconda
- Anacondaで仮想環境を作る方法 https://starpentagon.net/analytics/conda_env_jupyter_notebook/
- pythonを3.7から3.6にダウングレードする方法 https://www.it-swarm-ja.tech/ja/python/python%E3%82%9237%E3%81%8B%E3%82%8936%E3%81%AB%E3%83%80%E3%82%A6%E3%83%B3%E3%82%B0%E3%83%AC%E3%83%BC%E3%83%89%E3%81%99%E3%82%8B%E6%96%B9%E6%B3%95/806822115/
- Anaconda仮想環境の名前を変更する方法 https://qiita.com/TyaoiB/items/b858430c289767cb04be
標準ライブラリ
numpy
matplotlib
pandas
PyTorch
Tesnorflow
- 投稿日:2020-10-17T23:41:21+09:00
避けて通りたかった Hash chain その(2)
こんばんは。
いつも応援有難う御座います。m(_ _)m前回の続きです。
サラっと書いておいた
dump について補足します。test.pydef dump(self): # i は table[*] のポインタなので table[i] for i in range(self.capacity): # table[i] に格納されている key,value,np を呼び出す p = self.table[i] # end=""は、次の print と繋げる記述 print(i,end="") while p is not None: #前述 i のすぐ後に以下の記述を表示 # p.key , p.value を続けて表示 print(f"=>{p.key}({p.value})",end="") # p に np を代入して次の key,value,np に繋げる p = p.np #改行 print()前回書いた数珠つなぎでデータを格納するイメージがあれば
何となくイメージしやすいと思います。今まで、Hash chain を使って、
データを格納してきました。
格納したのだから、その中からデータを探すアプローチにもチャレンジしましょう。
基本的には既に格納されている Node の中の key に紐づけてデータを探します。test.pydef search(self,key): # key から table のポインタを割り出します。 Vhash = key % self.capacity p = self.table[Vhash] while p is not None: # 格納された key と入力 key が一致した場合。。 if p.key == key: # データを print で表示 return print(f"searched value is {p.value}") p = p.np # while で最後まで該当データを探しても何もない場合、faile print("faile to search")用意した配列に追加して、探したのであれば、
不要項目を削除することも出来ますよね?
チャレンジしてみましょう。
search と同じで、基本的には key で該当 Node を見つけます。
そのあとに、Node から Node の接続点を変えれば削除完了です。
そう、Node 中にある np を編集していきます。test.pydef remove(self,key): Vhash = key % self.capacity p = self.table[Vhash] pp = None # 初期値 None while p is not None: if p.key == key #最初のデータを削除する場合の記述 if pp is None: self.table[Vhash] = self.table[Vhash].np #最初の項目以外の接続点 np を編集 else: # pp は後述するがイメージはkey が該当する前の Node # p は key が該当した Node。 # pp.np に key が該当した Node の np を代入することで # データの繋ぎから key 該当 Node を削除 pp.np = p.np # 冒頭の if p.key != key だった場合に pp には p を代入してバッファ pp = p # while で先端 Node まで進むために p の値を p.np で更新 p = p.npHash とは何ぞや?? っという説明をちゃんとしていませんでした。
私の理解では、key を設けることで、該当する配列のポインタを一発で
見つけることができ、そのあとは、線形探索で該当値を探すことができる
面白い探索方法でした。
上記を実現するために勿論、その規則に沿って格納しなければならないです。今までの記事は与えられた配列を整頓したり、そのままの並びから
探索するアプローチが基本でした。今回はそうではなく、格納方法そのものを見直して
探索しやすくしている興味深いアルゴリズムでした。( `ー´)ノ全体像を載せておきます。
最適案があったり、
問題があれば御教示よろしくお願い致しますm(_ _)m。Chained_hash.pyclass Node: def __init__(self,key,value,np): self.key = key self.value = value self.np = np class ChainedHash: def __init__(self,capacity): self.capacity = capacity self.table = [None]*self.capacity def add(self,key,value): Vhash = key % self.capacity p = self.table[Vhash] while p is not None: if p.key == key: return False p = p.np temp = Node(key,value,self.table[Vhash]) self.table[Vhash] = temp def dump(self): for i in range(self.capacity): p = self.table[i] print(i,end="") while p is not None: print(f"=>{p.key}({p.value})",end="") p = p.np print() def search(self,key): Vhash = key % self.capacity p = self.table[Vhash] while p is not None: if p.key == key: return print(f"searched value is {p.value}") p = p.np print("faile to search") def remove(self,key): Vhash = key % self.capacity p = self.table[Vhash] pp = None while p is not None: if p.key == key: if pp is None: self.table[Vhash] = self.table[Vhash].np else: pp.np = p.np pp = p p = p.np test = ChainedHash(7) while True: num = int(input("select 1.add, 2.dump, 3.search, 4.remove : ")) if num == 1: key = int(input("key: ")) val = int(input("val: ")) test.add(key,val) elif num == 2: test.dump() elif num == 3: key = int(input("key: ")) test.search(key) elif num == 4: key = int(input("key: ")) test.remove(key) else: break
- 投稿日:2020-10-17T22:35:33+09:00
【画像処理】ポスタリゼーション
1. 概要
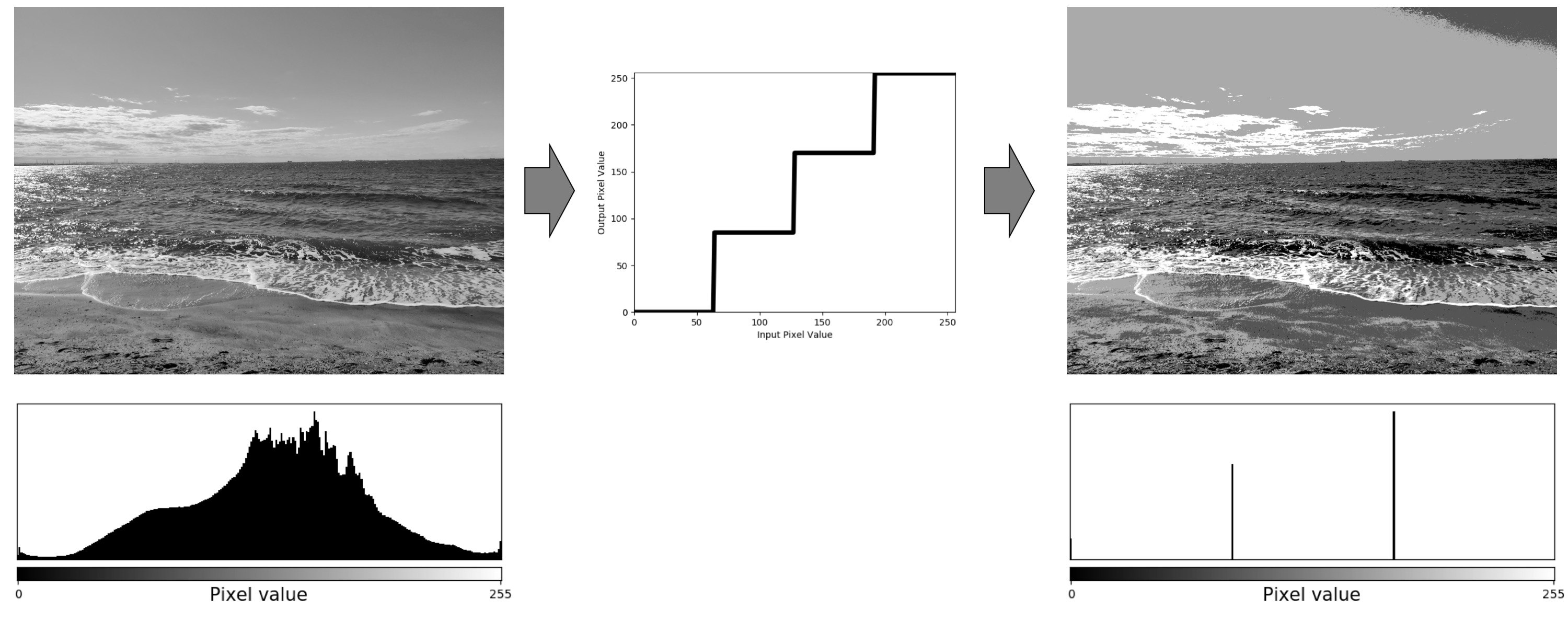
画像処理の基本的な技術、「ポスタリゼーション」を紹介します。ポスタリゼーションとは、階段上のトーンカーブによる変換で、出力画素値を数段階に制限する手法です。
下図のように入力画像の画素値をn段階(下図は4段階)にして、出力画像の画素値を制限します。そうすることで境界線が鮮明になり、アートのような色合いを表現することが出来ます。
ポスタリゼーションは書籍「ディジタル画像処理」に記載されている処理方法を踏襲しています。処理後の画像に画素値0、255を残すようなトーンカーブを使用するのでコントラストのはっきりとした画像となっています。
2. 環境
ポスタリゼーション処理を試した環境は以下となっています。
Python 3.6.8
numpy 1.18.1
matplotlib 3.1.2
opencv-python 4.1.2.30ライブラリでOpenCVを使用するので事前にインストールをお願いします。
pip install opencv-python3. コード
ポスタリゼーションについていろいろなサイトを見てところ、多くのサイトでは画素値255のホワイトは出力画像に反映しないLUTを使用していました。
今回の処理は画素値255「ホワイト」も出力画像に反映しているので、LUT作りを工夫しました。
binsのインプットとアウトプットを分けたりしていますが、詳細はコードのコメント欄を参考にしてくださいね。posterization.py#coding: utf-8 import cv2 import numpy as np import matplotlib.pyplot as plt def main(): img = cv2.imread('image.jpg') #画像の読み込み gray = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY) #グレースケール化 n = 4 # 画素値の分割数 pos = posterization(gray, n) cv2.imwrite('pos.jpg', pos) #ポスタリゼーションした画像の出力 def posterization(img, n): x = np.arange(256) #0,1,2...255までの整数が並んだ配列 ibins = np.linspace(0, 255, n+1) #LUTより入力は255/(n+1)で分割 obins = np.linspace(0,255, n) #LUTより出力は255/nで分割 num=np.digitize(x, ibins)-1 #インプットの画素値をポスタリゼーションするために番号付けを行う num[255] = n-1 #digitize処理で外れてしまう画素値255の番号を修正する y = np.array(obins[num], dtype=int) #ポスタリゼーションするLUTを作成する pos_LUT(n, y) #LUTの図を作成 pos = cv2.LUT(img, y) #ポスタリゼーションを行う return pos #ポスタリゼーションのLUT図作成 def pos_LUT(n, y): x = np.arange(0,256,1) plt.plot(x,y) plt.savefig("pos_LUT.png") if __name__=='__main__': main()4. 参考文献
★書籍
・ディジタル画像処理[改訂第二版] (公益財団法人 画像情報教育振興協会(CG-ARTS))
- 投稿日:2020-10-17T22:23:43+09:00
Pylintを実行して結果を読む
以下のソースコードに対してPylintをかけてみる。
A = 10 print(A)実行コマンドは以下です。-rnをつけると余計なログを出力しないようにできるらしい。
pylint -rn test.py実行結果は以下です。
************* Module test test.py:1:0: C0111: Missing module docstring (missing-docstring) ------------------------------------------------------------------- Your code has been rated at 5.00/10 (previous run: 10.00/10, -5.00)5.00/10 点でした。docstringがないと怒られました。
ソースコード品質の根拠にするためには信頼できそうですが、100点を目指すのは難しそうです。。。
- 投稿日:2020-10-17T22:08:46+09:00
.pyファイルの実行方法
.pyファイルの実行
Windows環境でのラッパーファイル作成方法を書く
Linuxなら.pyファイルそのまま実行できるのに、Windowsではそれができない。普通ならコマンドプロンプト等からこうするはずだ。C:\Users\testuser> python C:\Users\testUser\pyruntest.py →pyruntest.pyの実行結果が出る関連付けしてれば行けるけれども他人の環境でも同じように.pyにpython.exeが関連付けられているとは限らない。
1. batファイル or cmdファイルを作る
@echo off %PYTHONPATH%\python.exe %~dp0\%~n0.py %*例えばpyruntest.batというファイル名で上記を保存しておいたら
pyruntest.batと同じディレクトリにあるpyruntest.pyを次のように実行できる。C:> pyruntest.bat →pyruntest.pyの実行結果が出るPathを通しておけばどこからでも行ける
.batと打つのも面倒ならば拡張子を.cmdに変えればよい。C:> pyruntest →pyruntest.pyの実行結果が出る2. C#でexeを作る。
pyruntest.cs
using System; using System.Diagnostics; class Program { static void Main(string[] args) { // Python Program Path var pythonScriptPath = System.Reflection.Assembly.GetExecutingAssembly().Location.Replace(".exe", "") + ".py"; var startInfo = new ProcessStartInfo() { FileName = @"python.exe", UseShellExecute = false, Arguments = pythonScriptPath + " " + string.Join(" ", args), }; using (var process = Process.Start(startInfo)) { process.WaitForExit(); } } }csc.exeでコンパイルするとpyruntest.exeができる
C:\Users\testuser> C:\Windows\Microsoft.NET\Framework\v4.0.30319\csc.exe pyruntest.cs C:\Users\testuser> pyruntest.exe →pyruntest.pyの実行結果が出るこのpyruntest.exeも1.のbat同様に実行したときのファイル名を動的に取得するようにしてるため、
exeファイル名を変えることで同じ名前の.pyを探して実行できる。
一度コンパイルしておけば後はexeの前のファイル名を変えるだけで良い。
Windows10からは標準でcsc.exeが入ってるようなのでどの環境でもコンパイルできるのがよい。
- 投稿日:2020-10-17T22:08:46+09:00
Windowsでの.pyファイルの実行方法色々
.pyファイルの実行
Windows環境でのラッパーファイル作成方法を書く。
普通ならコマンドプロンプト等から実行する場合こうするはずだ。(python.exeのあるディレクトリのPATHが通ってる前提)C:\Users\testuser> python C:\Users\testUser\pyruntest.py →pyruntest.pyの実行結果が出る関連付けしてれば行けるけれども他人の環境でも同じように.pyにpython.exeが関連付けられているとは限らない。
1. batファイル or cmdファイルを作る
@echo off %PYTHONPATH%\python.exe %~dp0\%~n0.py %*例えばpyruntest.batというファイル名で上記を保存しておいたら
pyruntest.batと同じディレクトリにあるpyruntest.pyを次のように実行できる。C:> pyruntest.bat →pyruntest.pyの実行結果が出るPathを通しておけばどこからでも行ける
.batと打つのも面倒ならば拡張子を.cmdに変えればよい。C:> pyruntest →pyruntest.pyの実行結果が出る2. C#でexeを作る。
pyruntest.cs
using System; using System.Diagnostics; class Program { static void Main(string[] args) { // Python Program Path var pythonScriptPath = System.Reflection.Assembly.GetExecutingAssembly().Location.Replace(".exe", "") + ".py"; var startInfo = new ProcessStartInfo() { FileName = @"python.exe", UseShellExecute = false, Arguments = pythonScriptPath + " " + string.Join(" ", args), }; using (var process = Process.Start(startInfo)) { process.WaitForExit(); } } }csc.exeでコンパイルするとpyruntest.exeができる
C:\Users\testuser> C:\Windows\Microsoft.NET\Framework\v4.0.30319\csc.exe pyruntest.cs C:\Users\testuser> pyruntest.exe →pyruntest.pyの実行結果が出るこのpyruntest.exeも1.のbat同様に実行したときのファイル名を動的に取得するようにしてるため、
exeファイル名を変えることで同じ名前の.pyを探して実行できる。
一度コンパイルしておけば後はexeの前のファイル名を変えるだけで良い。
Windows10からは標準でcsc.exeが入ってるようなのでどの環境でもコンパイルできるのがよい。
- 投稿日:2020-10-17T22:08:46+09:00
Windowsでの.pyファイルの実行方法いろいろ
普通の.pyファイルの実行方法
Windows環境でのラッパーファイル作成方法を書く。
普通ならコマンドプロンプト等から実行する場合こうするはずだ。(python.exeのあるディレクトリのPATHが通ってる前提)C:\Users\testuser> python C:\Users\testUser\pyruntest.py →pyruntest.pyの実行結果が出るしかし.pyファイルにpython.exeを関連付けされてなければ、こうはできない。
C:\Users\testuser> pyruntest.py →エラー1. batファイル or cmdファイルでラッパー作る
@echo off %PYTHONPATH%\python.exe %~dp0\%~n0.py %*例えばpyruntest.batというファイル名で上記を保存しておいたら
pyruntest.batと同じディレクトリにあるpyruntest.pyを次のように実行できる。C:> pyruntest.bat →pyruntest.pyの実行結果が出るPathを通しておけばどこからでも行ける
.batと打つのも面倒ならば拡張子を.cmdに変えればよい。C:> pyruntest →pyruntest.pyの実行結果が出る2. C#でexeを作る。
1.の方法で大抵は問題ないのだが、処理させたい複数のファイルを引数として処理させるために
.cmdへドラッグアンドドロップさせたりしたときに割とこんなエラーが出る。コマンドに指定したコマンドライン引数が多すぎます。正しい値を指定して、再度実行して下さい。原因はcmd.exeの制限? 2047文字 or 8191文字(WinXP以降)が最大のようです。
powershellならこの上限はないのだが、.ps1をダブルクリックで実行させるには更にいばらの道。。
なんとお粗末なターミナルなのだろうか、、コマンドプロンプトだのPowershellなんてこの世から無くなってくれれば良いのにと思う。
exe化してしまえば解決できるはず。そんな時に多分使える手段としてはもう、exe実行形式にするしかないだろう。
どうやってexe化するか色々手段があるのだが、
- pyInstallerやpy2exeで作る -> ファイルサイズがMB単位にバカデカいexeになってしまう。
- C言語で書く -> 開発環境構築が大変 eclipseやVisual Studioなんて入れたくない
- C# & csc -> Windows10からは標準でcsc.exeが入ってる
- JavaScript & jsc -> Windows10からは標準でjsc.exeが入ってる
結局Javascriptで作ろうと思ったが挫折、C#で作ることになった。
pyruntest.cs
C#初心者でよくわからないことが沢山あるがとりあえず動いたので晒す。
using System; using System.Diagnostics; using System.ComponentModel; class Program { static void Main(string[] args) { // Python Program Path var pythonScriptPath = System.Reflection.Assembly.GetExecutingAssembly().Location.Replace(".exe", "") + ".py"; try { var startInfo = new ProcessStartInfo() { FileName = @"python.exe", UseShellExecute = false, Arguments = "\"" + pythonScriptPath + "\" \"" + string.Join("\" \"", args), }; using (var process = Process.Start(startInfo)) { process.WaitForExit(); } } catch (Win32Exception) { Console.WriteLine("python.exeが見つかりませんでした。環境変数PATHに追加してください"); } } }csc.exeでコンパイルするとpyruntest.exeができる
C:\Users\testuser> C:\Windows\Microsoft.NET\Framework\v4.0.30319\csc.exe pyruntest.cs C:\Users\testuser> pyruntest.exe →pyruntest.pyの実行結果が出る C:\Users\testuser> pyruntest →もちろんこれでもpyruntest.pyの実行結果が出るちゃんと環境変数パスを通してあげとけばカレントディレクトリ関係なく実行できる
C:\Users\testuser> set PATH=%PATH%;%CD% C:\Users\testuser> setx PATH %PATH% C:\Users\testuser> cd \ C:> pyruntest →pyruntest.pyの実行結果が出る方法1も方法2も共通の仕組みで、
上記実行方法共通的な仕様:[実行させたい].pyと同じディレクトリに[実行させたい].bat or [実行させたい].cmd or [実行させたい].exeを置く。(ラッパーのソースを毎回修正する必要はないようにした)余談)なぜこんなことをしてるかというと自宅PCなら関連付け設定すれば終わりだが、
仕事用のシンクライアント環境だと権限がなく設定変更できなかったので、
こういった回りくどいラッパーが必要になってしまうのである。不便な世の中になってしまった。
- 投稿日:2020-10-17T21:42:45+09:00
Linux: 強制ロック(mandatory lock)
Linuxでファイルの強制ロック(mandatory lock)をする方法です。
強制ロックとは
- アドバイザリロックとは異なり、Linux固有の機能。POSIXやUNIXにはない。
- ロックを掛けたプロセス以外からの、read()やwrite()をできなくする。
- race conditionが発生する可能性があったりして、ロックの信頼性は高くない。ロックと同時にreadやwriteが獲得されると、ロック中なのに読み書きできてしまうらしい。
強制ロックが有効になる環境を作る
強制ロックを有効にするには、2つの条件を満たす必要があります。
- ロックされるファイルは
-o mandでマウントされたファイルシステムでないとならない。- ロックされるファイルは、set-group-IDビットがOnで、group-executeビットがOffでないとならない。
mkdir dir mount -t tmpfs -o mand,size=1m tmpfs ./dir chmod g+s,g-x dir/lockfile echo hello > dir/lockfile強制ロックを発動する
強制ロックを発動するために、システムコールを呼び出すPythonスクリプトを作ります。
lock.py#!/usr/bin/env python import fcntl, os, time, sys f = open(sys.argv[1], "r+") fcntl.lockf(f, fcntl.LOCK_EX) print(f.readlines()) time.sleep(10)このlock.pyは、10秒間dir/lockfileを排他的強制ロックします。lock.pyを実行している10秒間の間に、他のプロセスからdir/lockfileを読み込もうとすると、pythonのプロセスが終了するまで待たされます。
# ロックする ./lock.py # 別ターミナルで cat dir/lockfile # 10秒程度待たされるこの10秒間に、
lslocksや/proc/locksを確認すると、ロックが掛かっている事がわかります。root@vagrant:~/dir# lslocks COMMAND PID TYPE SIZE MODE M START END PATH lvmetad 463 POSIX 4B WRITE 0 0 0 /run/lvmetad.pid cron 866 FLOCK 4B WRITE 0 0 0 /run/crond.pid atd 848 POSIX 4B WRITE 0 0 0 /run/atd.pid lxcfs 849 POSIX 4B WRITE 0 0 0 /run/lxcfs.pid iscsid 1135 POSIX 5B WRITE 0 0 0 /run/iscsid.pid python 1818 POSIX 0B WRITE 1 0 0 /dev/pts/0 ☝?ここ root@vagrant:~/dir# cat /proc/locks 1: POSIX MANDATORY WRITE 1818 00:2c:3 0 EOF ??ここ 2: POSIX ADVISORY WRITE 1135 00:13:1503 0 EOF 3: POSIX ADVISORY WRITE 849 00:13:1498 0 EOF 4: POSIX ADVISORY WRITE 848 00:13:1487 0 EOF 5: FLOCK ADVISORY WRITE 866 00:13:1485 0 EOF 6: POSIX ADVISORY WRITE 463 00:13:1258 0 EOF参考
- 投稿日:2020-10-17T21:41:13+09:00
AtCoder Beginner Contest 180 参戦記
AtCoder Beginner Contest 180 参戦記
ABC180A - box
1分で突破. 書くだけ.
N, A, B = map(int, input().split()) print(N - A + B)ABC180B - Various distances
3分で突破. 書くだけ.
N, *x = map(int, open(0).read().split()) print(sum(abs(a) for a in x)) print(sum(a * a for a in x) ** 0.5) print(max(abs(a) for a in x))ABC180C - Cream puff
3分で突破. 書くだけ. Nの二乗根まで回すと分かっていれば難しいことはないんじゃないかな.
N = int(input()) result = set() for i in range(1, int(N ** 0.5) + 1): if N % i == 0: result.add(i) result.add(N // i) print(*sorted(result), sep='\n')ABC180D - Takahashi Unevolved
14分で突破. 時間かかりすぎ. 素直にシミュレートするナイーブなコードだと B が小さい場合に TLE になることは火を見るよりも明らか. となると、
+ Bより* Aのほうが増分が小さいうちは* Aをして、残りはまとめて足せば良いんじゃないのという結論に落ち着く. A は少なくとも2なので、素直にシミュレートしても O(logN) なので問題ない.X, Y, A, B = map(int, input().split()) result = 0 while X * A < Y and X * A < X + B: X *= A result += 1 result += ((Y - 1) - X) // B print(result)追記: どうにもD問題でペナ食らった人が多いなあと思っていたが、工夫せずに書くと
X * Aが int64 でもオーバーフローするせいなのね. なるほど.package main import ( "bufio" "fmt" "os" "strconv" ) func main() { defer flush() X := readInt() Y := readInt() A := readInt() B := readInt() result := 0 for X <= (Y-1)/A && X*A < X+B { X *= A result++ } result += ((Y - 1) - X) / B println(result) } const ( ioBufferSize = 1 * 1024 * 1024 // 1 MB ) var stdinScanner = func() *bufio.Scanner { result := bufio.NewScanner(os.Stdin) result.Buffer(make([]byte, ioBufferSize), ioBufferSize) result.Split(bufio.ScanWords) return result }() func readString() string { stdinScanner.Scan() return stdinScanner.Text() } func readInt() int { result, err := strconv.Atoi(readString()) if err != nil { panic(err) } return result } var stdoutWriter = bufio.NewWriter(os.Stdout) func flush() { stdoutWriter.Flush() } func println(args ...interface{}) (int, error) { return fmt.Fprintln(stdoutWriter, args...) }ABC180E - Traveling Salesman among Aerial Cities
39分半で突破. 蟻本のコードを写経して解いた. 写経してあれば黄色パフォとか取れたかな、くそー.
#include <bits/stdc++.h> #define rep(i, a) for (int i = (int)0; i < (int)a; ++i) using ll = long long; using namespace std; #define MAX_N 17 #define INF 2147483647 ll N; ll dp[1 << MAX_N][MAX_N]; ll d[MAX_N][MAX_N]; void solve() { rep(i, 1 << N) rep(j, N) dp[i][j] = INF; dp[(1 << N) - 1][0] = 0; for (int S = (1 << N) - 2; S >= 0; S--) { for (int v = 0; v < N; v++) { for (int u = 0; u < N; u++) { dp[S][v] = min(dp[S][v], dp[S | 1 << u][u] + d[v][u]); } } } cout << dp[0][0] << endl; } int main() { ios_base::sync_with_stdio(false); cin.tie(NULL); cout.tie(NULL); cin >> N; vector<ll> X(N), Y(N), Z(N); rep(i, N) { cin >> X[i] >> Y[i] >> Z[i]; } rep(i, N) { rep(j, N) { d[i][j] = abs(X[i] - X[j]) + abs(Y[i] - Y[j]) + max(0ll, Z[i] - Z[j]); } } solve(); return 0; }
- 投稿日:2020-10-17T20:45:43+09:00
AWS Lambdaからツイートする
はじめに
引き続き、退社情報自動通知機能を作っていきます。
前回の記事で、スマホからAWSに位置情報を送信することができました。
次は、AWS Lambdaを使って、Twitterと接続します。通知手段について
前提として、通知先は妻のiPhoneを想定しているので、特殊な設定はしたくありません。
簡単にAWSから第三者のスマホに通知するには以下の方法があげられます。
・LineBot
・TwitterBot
・メール
この中で、一番実装が早そうなTwitterを用いて、通知します。
(もっと簡単な方法があったら教えてください。)Twitter APIの利用登録
Botのように、プログラムを用いてツイートするためには、「Twitter API」の利用登録をする必要があります。
利用登録の前に、まだTwitterのアカウント登録をしていない方は、しておいてください。
なお、アカウントにメールアドレスも登録しておかないと、「Twitter API」の使用登録はできません。下記サイトにアクセスし、TwitterAPIの利用登録を行います。
https://developer.twitter.com/en/apps
利用用途が問われます。
今回は趣味(Hobbyist)でBotを作成するので「Making a Bot」を選択します
以後は質問に淡々と答えていきます。
英語で答える必要があるので、人によっては時間がかかるかもしれません。
最後に確認画面が出るので、「Looks good!」をクリックします。
利用条約に目を通します。
この画面が出ればOKです。
登録したメールアドレスに確認用メールが届いているので、そちらを開いて登録します。
Twitter APIの初期設定
Twitterの開発者用画面にログインすると、アプリの名前を聞いてくるので、適当に答えます。
ここで、プログラムからツイートするための鍵が表示されますが、あとで再発行するので、無視して大丈夫です。
「Test an endpoint」をクリックします。
アプリの登録がおわったら、権限の設定を行います。
初期状態だとツイートの読み込みしかできません。
この権限の設定をしないと、プログラムからツイートできないため、後々エラーが発生します。画面右上の「Developer Portal」を開きます。
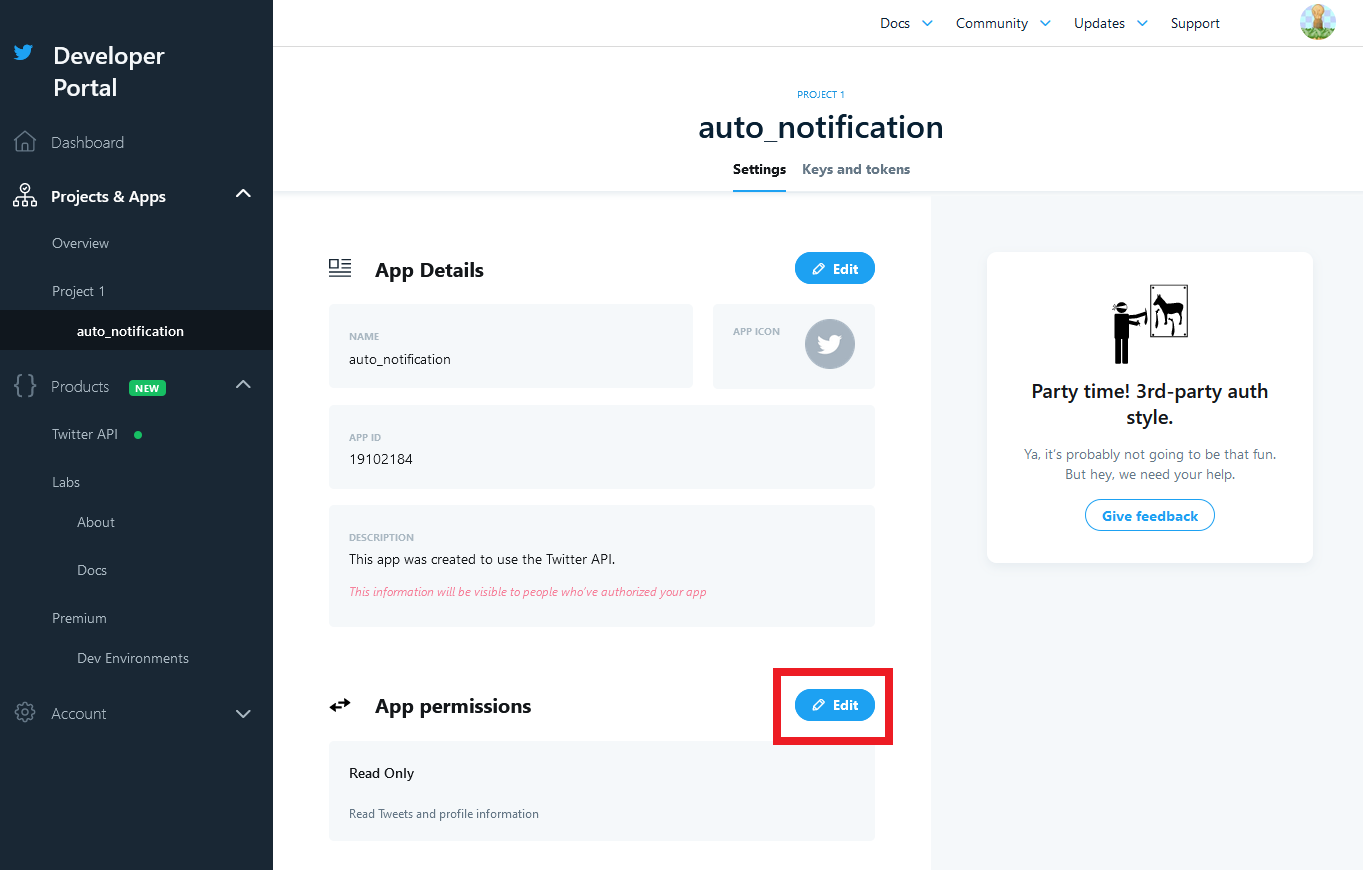
画面左のタブの「Project & Apps」から先ほど名前を付けたアプリ名を選択します。
すると、アプリの設定画面が出るので、「App Permissions」の「Edit」をクリックします。
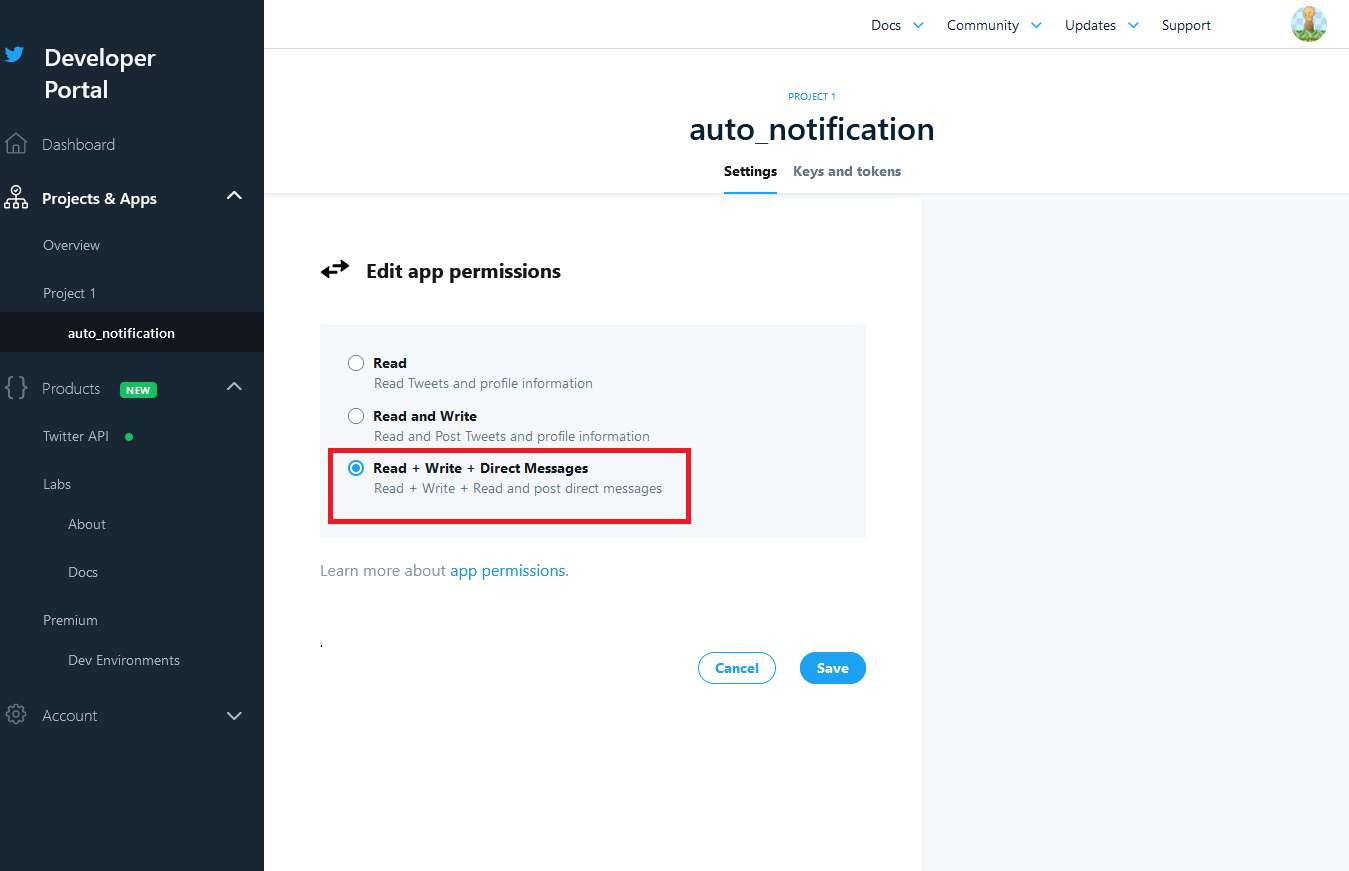
Read(読み込みのみ)になっているので、「Read + Write + Direct Message」に変更します。
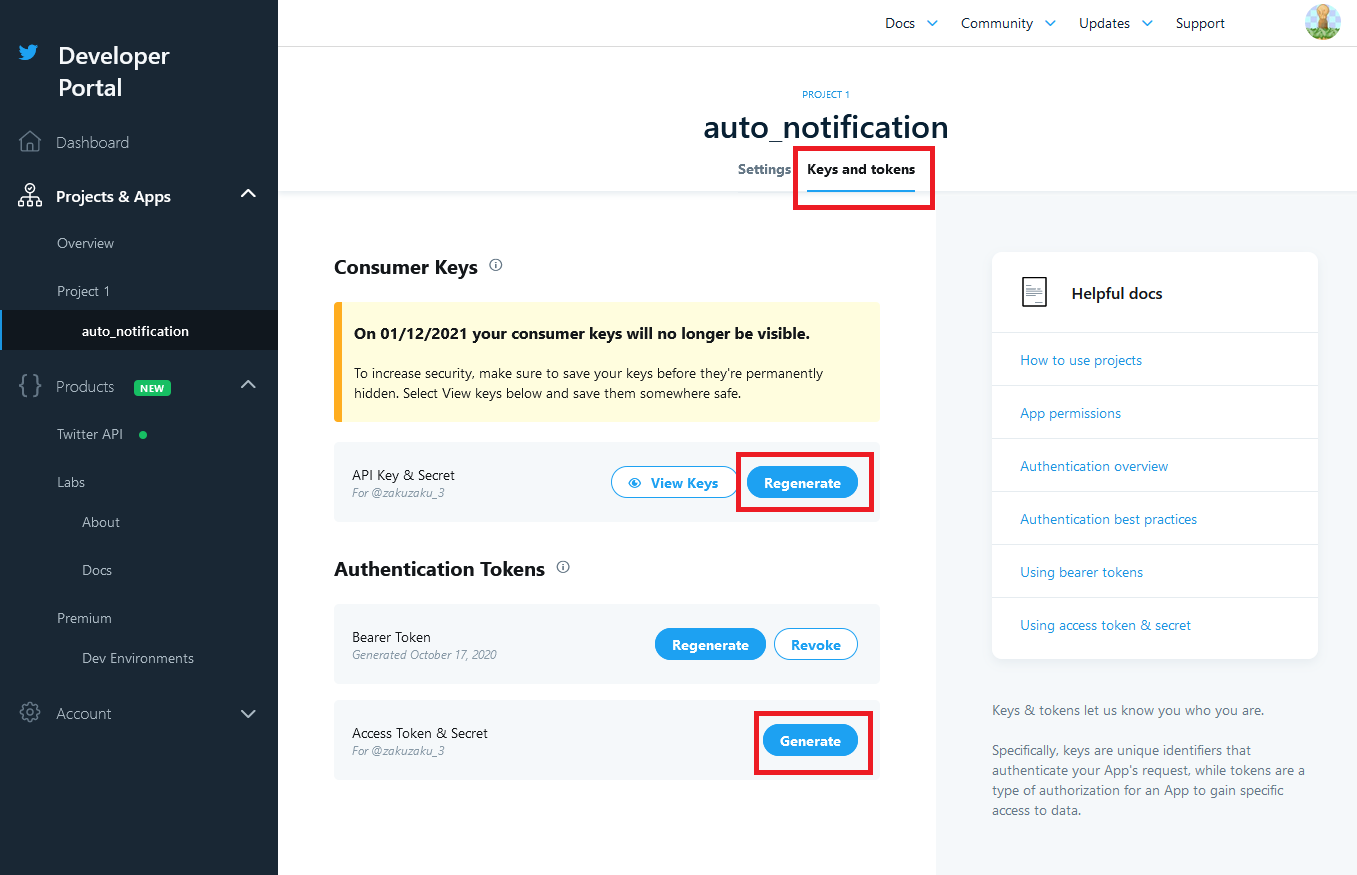
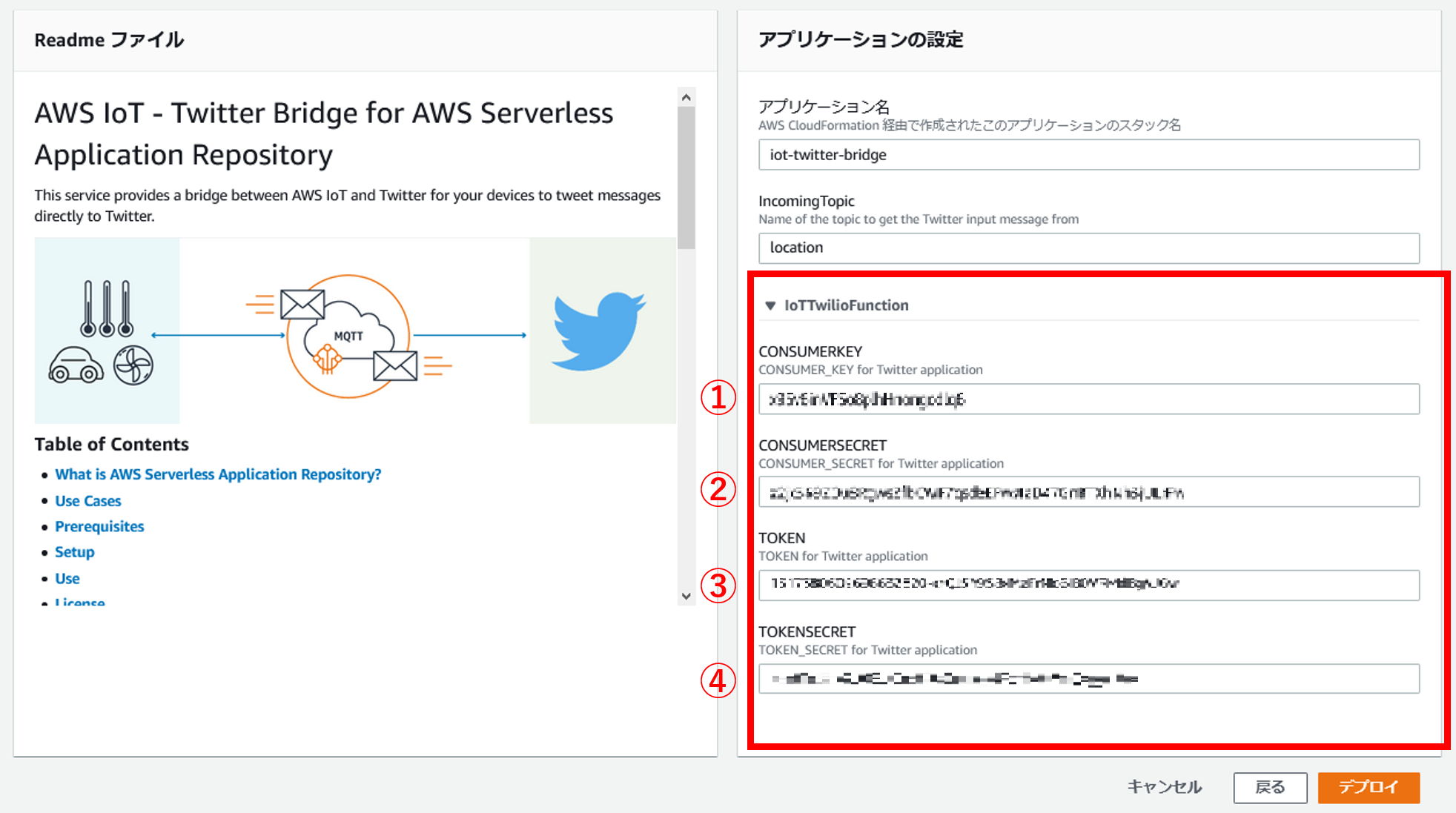
次に、APIを利用するため、KeyとTokenを確認します。
「API Key & Secret」をRegenerateし、①API keyと②API key secretをメモしてください。
また、「Access Token & Secret」をGenerateし、③Access tokenとAccessと④token secretをメモしてください。
後にAWS Lamdaにこの4つの情報を入力します。
これでTwitter APIの設定は終わりです。
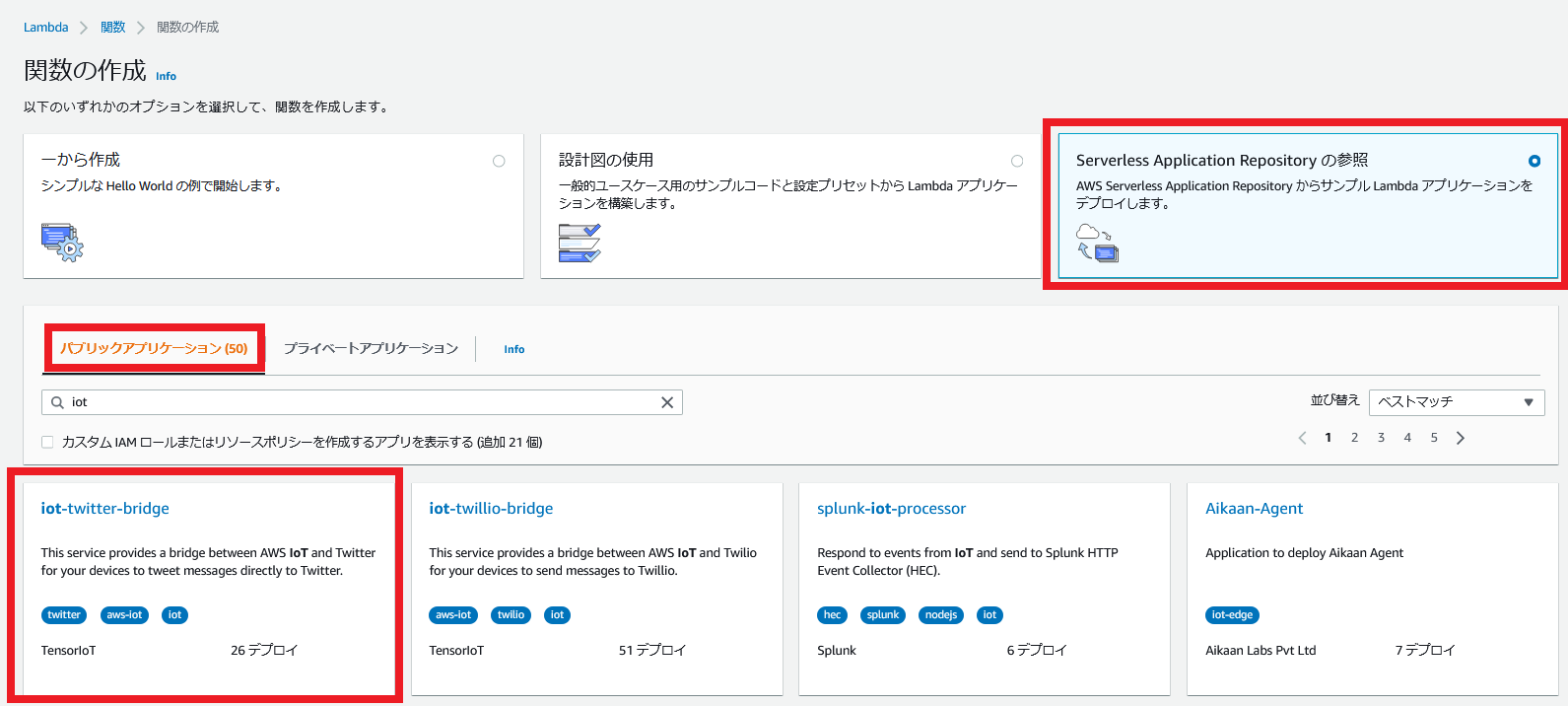
AWS Lambdaの構築
「Lambda>関数」から、関数の作成を行います。
Serverless Application Repository>パブリックアプリケーションを選択して、「iot」で検索し、iot-twitter-bridgeを選択します。
アプリケーションの設定で、先ほどTwitterAPIでメモした4つの情報を入力します。
用語が統一されていないのですが、CONSUMER_KEYがAPI keyです。
これでLambda関数が作成できました。
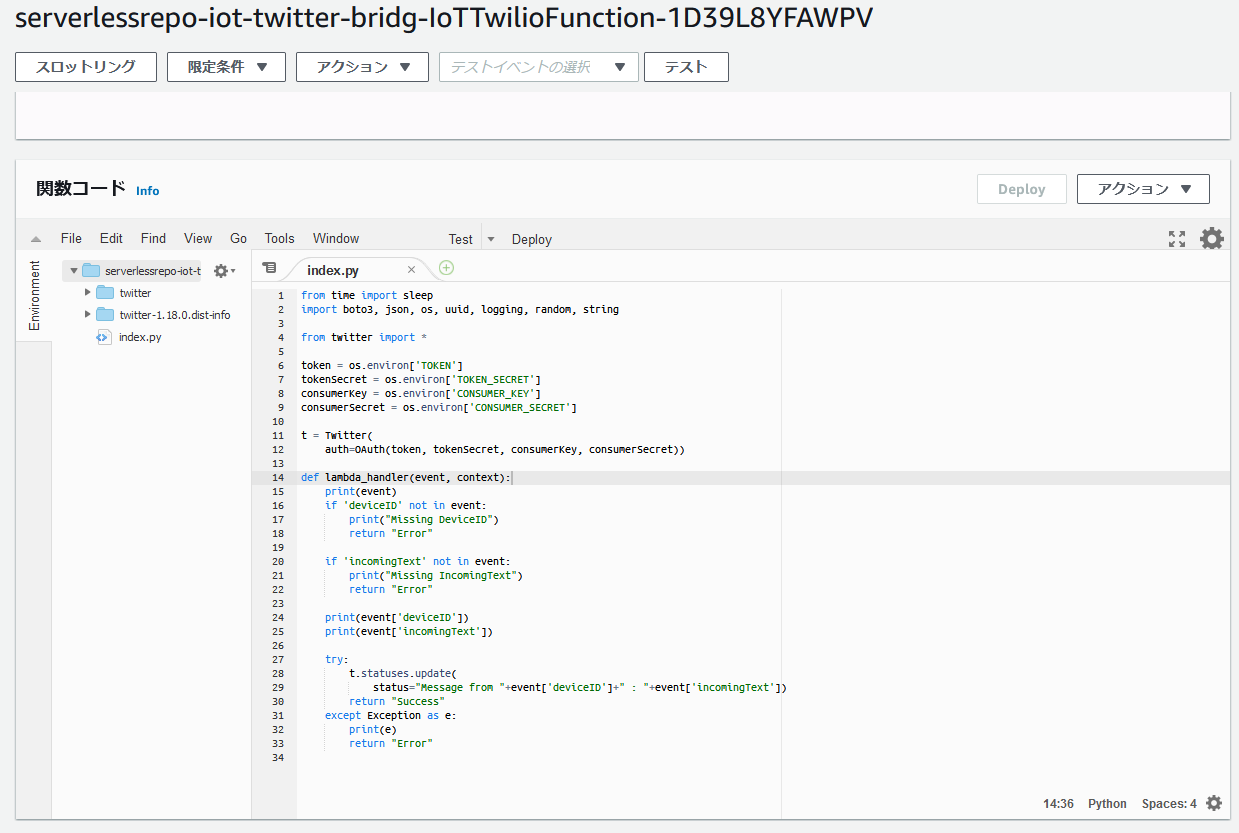
デフォルトの関数コードを確認しましょう。
json形式で、deviceIDとincomingTextがトリガーから入力され、その情報をツイートする仕組みみたいです。
とりあえず、関数はそのままにしてTwitterAPIと接続テストします。
テスト
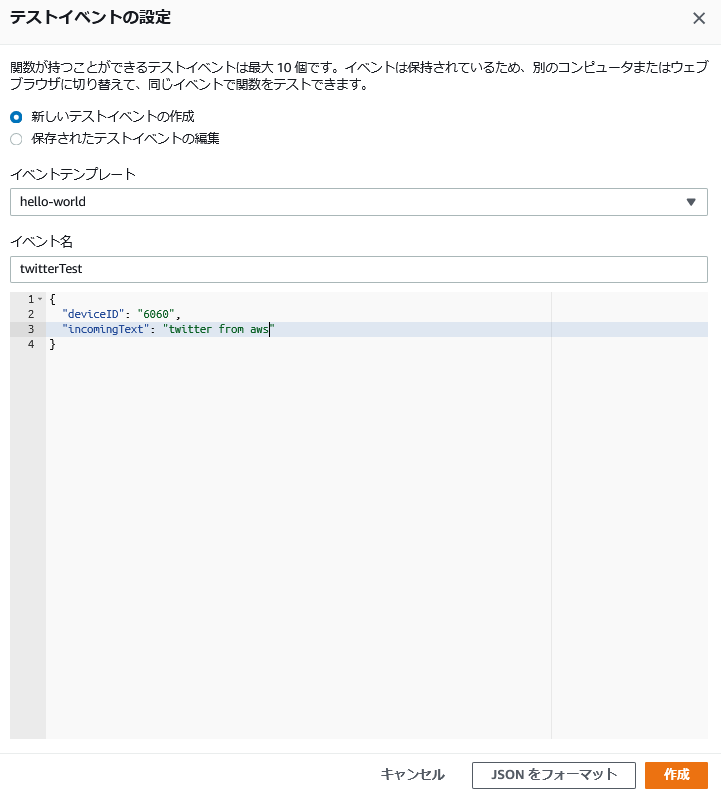
テストイベントを作成します。
下記画像のようにhello-worrldテンプレートを使用し、twitterTestイベントを作成します。
一応、中身を貼り付けておきます。
{ "deviceID": "6060", "incomingText": "twitter from aws" }テストします。
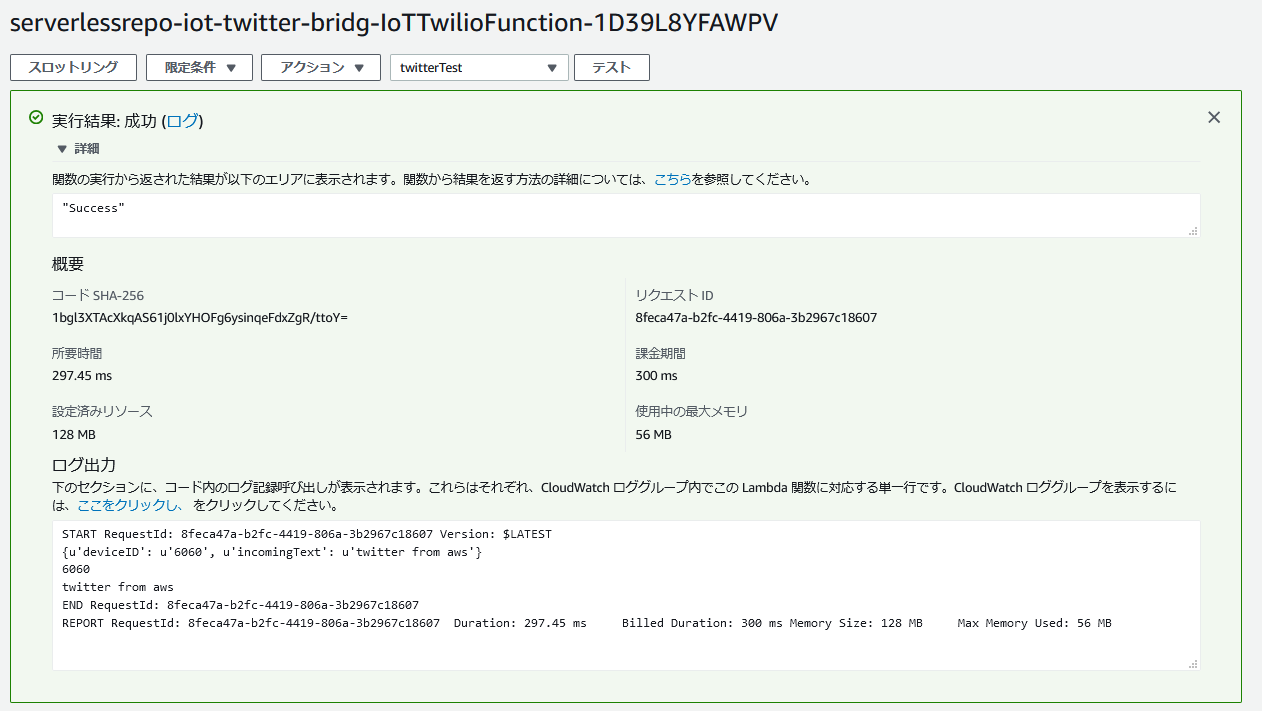
下記画像のようにSuccessが表示されたら成功です。
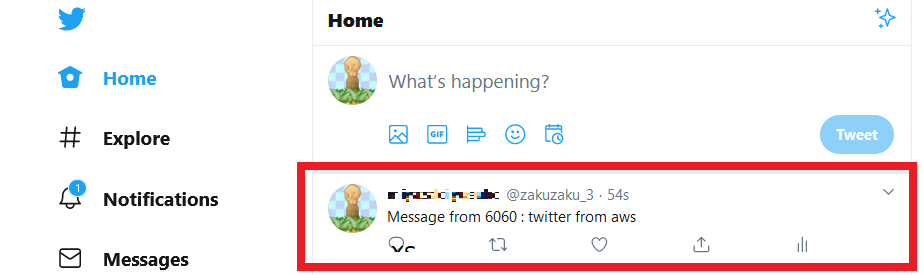
Twitter側も確認します。
おつかれさまでした。ちなみに、同じ内容でテストするとエラーが帰ってきます。
同じ内容で連続投稿させないためのTwitterの仕様だそうです。details: {u'errors': [{u'message': u'Status is a duplicate.', u'code': 187}]}おわりに
退社自動通知機能の作成を目的とし、AWSからツイートするところまでできました。
あとはIotとLambdaを接続し、関数を少しいじくればできそうですね。参考URL
いつも感謝しています。
twitterアプリの作成
https://yosiakatsuki.net/blog/create-twitter-application/
- 投稿日:2020-10-17T20:34:47+09:00
python実行時にオプションを指定する
python実行時にオプションを指定するには、ArgumentParserを使う
option_argparser.pyfrom argparse import ArgumentParser def get_option(level): argparser = ArgumentParser() argparser.add_argument('-l', '--level', type=int, default=level, help='Specify level') return argparser.parse_args() level=1 args = get_option(level) print('level : ' + str(args.level))実行結果
$ python3 option_argparser.py level : 1 $ python3 option_argparser.py -l 3 level : 3 $ python3 option_argparser.py --level 3 level : 3 $ python3 option_argparser.py --help usage: option_argparser.py [-h] [-l LEVEL] optional arguments: -h, --help show this help message and exit -l LEVEL, --level LEVEL Specify level参考
argparse --- コマンドラインオプション、引数、サブコマンドのパーサー
ArgumentParserの使い方を簡単にまとめた
- 投稿日:2020-10-17T20:30:41+09:00
module に依存性を注入する
python の場合、module ごとでよければ、簡単に依存性を逆転できる。
person.pyはAbstractPersonの実装に依存しない。person.pyclass AbstractPerson: def say(self): raise NotImplementedError() def talk_each(): person_a = AbstractPerson() person_b = AbstractPerson() print(person_a.say()) print(person_b.say())
personmodule に依存性を注入する場合は、以下のように書ける。main.pyimport person class JapanesePerson: def say(self): return "こんにちは" class EnglishPerson: def say(self): return "Hi" sample.AbstractPerson = JapanesePerson sample.talk_each() # こんにちは # こんにちは sample.AbstractPerson = EnglishPerson sample.talk_each() # Hi # Hiいかにも
pythonという感じがする。
- 投稿日:2020-10-17T19:50:18+09:00
将棋AIで学ぶディープラーニング on Mac and Google Colab 第12章3~5
モンテカルロ木探索の全体像
mcts_player.pyのgo()関数がやっていること
mcts_player.py
実際にプログラムを動作させる前に下記の修正を実施。
モデルロードの引数を追加
モデルをロードするPolicyValueResnet()に引数blocksを入れないとエラーが出るためPolicyValueResnet(blocks=5)に修正。5はこのモデルを学習したときと同じブロック数。
pydlshogi/player/mcts_player.pydef isready(self): # モデルをロード if self.model is None: self.model = PolicyValueResnet(blocks=5)CPU/GPU自動切り替え
IPアドレスでどのPCで動いているか判断させる。GPU使用するかどうかをフラグgpu_enで切り替える。ついでにモデルファイルのパスもフラグenvで切り替える。
pydlshogi/player/mcts_player.py# 環境設定 #----------------------------- import socket host = socket.gethostname() # IPアドレスを取得 # google colab : ランダム # iMac : xxxxxxxx # Lenovo : yyyyyyyy # env # 0: google colab # 1: iMac (no GPU) # 2: Lenovo (no GPU) # gpu_en # 0: disable # 1: enable if host == 'xxxxxxxx': env = 1 gpu_en = 0 elif host == 'yyyyyyyy': env = 2 gpu_en = 0 else: env = 0 gpu_en = 1 #-----------------------------importのところ
pydlshogi/player/mcts_player.pyif gpu_en == 1: from chainer import cuda, Variabledef init(self):
pydlshogi/player/mcts_player.py# モデルファイルのパス if env == 0: self.modelfile = '/content/drive/My Drive/・・・/python-dlshogi/model/model_policy_value_resnet' elif env == 1: self.modelfile = r'/Users/・・・/python-dlshogi/model/model_policy_value_resnet' elif env == 2: self.modelfile = r"C:\Users\・・・\python-dlshogi\model\model_policy_value_resnet" self.model = None # モデルdef eval_node()
pydlshogi/player/mcts_player.pyif gpu_en == 1: x = Variable(cuda.to_gpu(np.array(eval_features, dtype=np.float32))) elif gpu_en == 0: x = np.array(eval_features, dtype=np.float32) with chainer.no_backprop_mode(): y1, y2 = self.model(x) if gpu_en == 1: logits = cuda.to_cpu(y1.data)[0] value = cuda.to_cpu(F.sigmoid(y2).data)[0] elif gpu_en == 0: logits = y1.data[0] value = F.sigmoid(y2).data[0]def isready()
pydlshogi/player/mcts_player.py# モデルをロード if self.model is None: self.model = PolicyValueResnet(blocks=5) if gpu_en == 1: self.model.to_gpu()コマンドラインからテスト
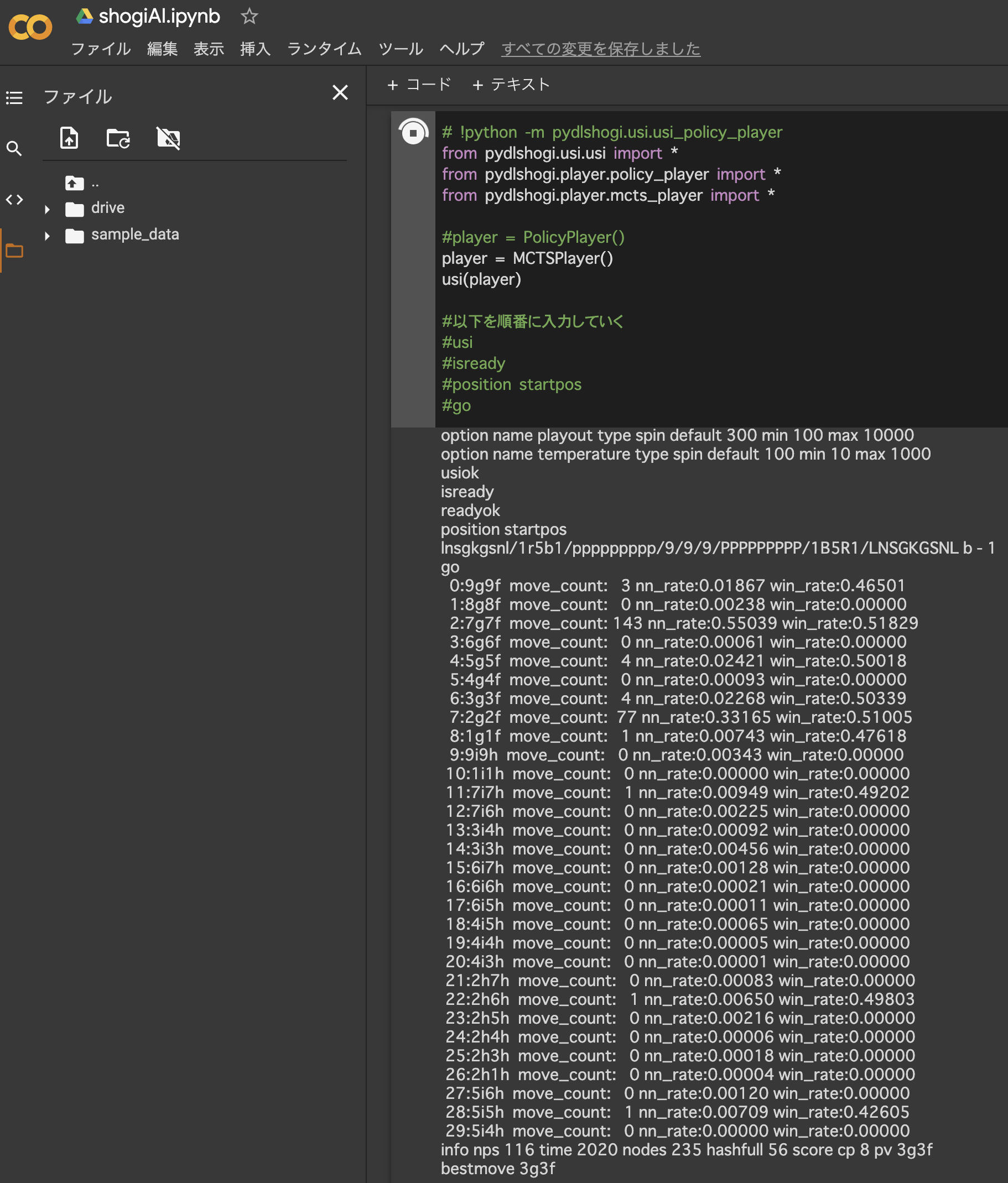
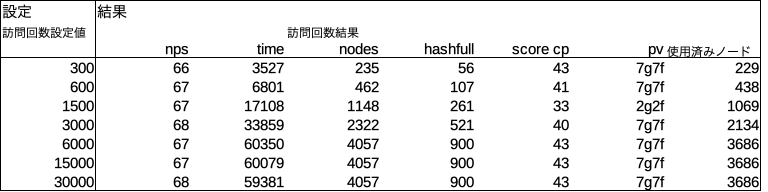
開始局面でプログラムを実行してみた。7六歩が143回訪問、2六歩が77回訪問という結果。とりあえずよさそうである。
Google Colabでも実行できた。
move_count : その指し手ノードの訪問回数
nnrate : 方策ネットワークの予測確率
win_rate : 指し手の平均勝率(=合計勝率/訪問回数)
nps : node/time
time : 1回のgo()に要した時間
nodes : 現ノードの訪問回数(current_node.move_count)
hashfull : node_hash配列とuct_node配列の占有率。4096要素中何要素使ったかを示す。100%占有していた場合を1000として表した数値。
score cp : 評価値
pv : 指し手の座標GPUはCPUの2倍高速
上記結果より1回の実行あたりの所要時間はCPUは3524 ms、GPUは2020 msであった。よってGPU/CPU速度比は3524/2020=1.7。約2倍高速である。
現ノードの訪問回数(nodes)はGPUもCPUも235回と変わらない。単純に訪問1回あたりの速度がGPUの方が速いということがわかる。
探索打ち切りの効果
探索ごとにinterruption_check()という関数で探索を途中で打ち切るか判定している。探索回数は300回に設定しているが、残りの探索を全て次善手に費やしても最善手を超えられない場合は300回に達していなくても探索を打ち切るというものである。上記結果はnodes 235となっているので235回で打ち切られていることがわかる。
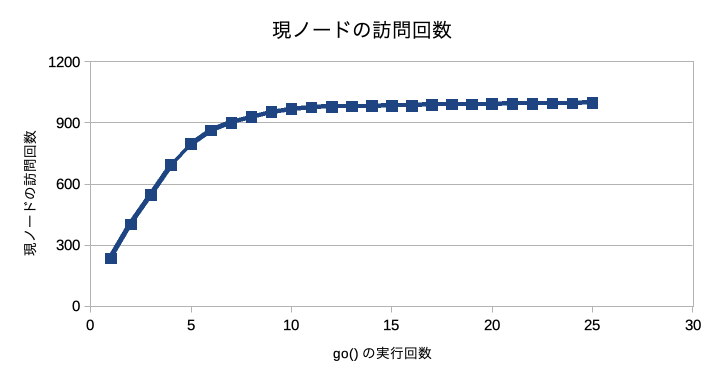
参考までにgo()を連続で実行して現ノードの訪問回数をプロットしてみた。go()の実行回数が増えるにつれ現ノードの訪問回数が増えなくなっていくことがわかる。go()の実行回数が増えるにつれ子ノードの訪問回数も増えていくから探索を打ち切るのが早くなっているのであろう。
探索回数
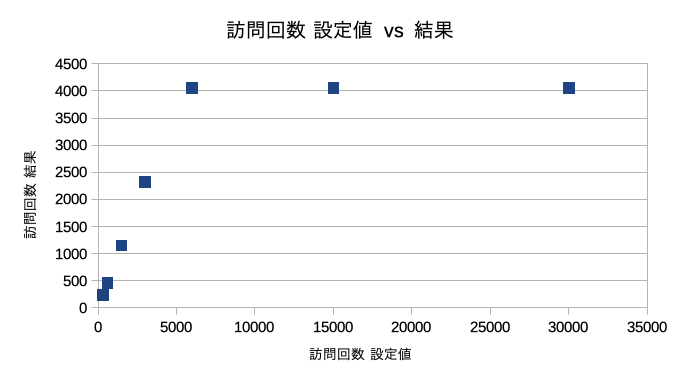
探索回数によって現ノードの訪問回数がどうなるかを把握してみた。訪問回数設定値6000回以上で結果が4057回から増えなくなる。これはあくまで開始局面での結果である。局面によって結果は異なるであろう。
対局
対局動画
https://youtu.be/H0jD76R2PAM
自分(アマ初段) 対 第12章5のAI
方策ネットワーク&価値ネットワーク&モンテカルロ木探索。並列化は無し。変な手を打つことが多く想像していたよりも弱かった。終局図


- 投稿日:2020-10-17T19:00:35+09:00
Pythonモジュールの自動更新
前置き
Pythonのモジュールは、納品時のままにしていると納品物が動かなくなることがあります。
今回は、chromedriver-binaryというモジュールを例に話を進めます。
chromedriver-binaryの役割はPython経由でchromeブラウザを操作できうようにすることです。
chromedriver-binaryはchromeブラウザに対応したものをインストールしておく必要があります。
chromeブラウザは、勝手にアップデートしますので何もしないと
そのうちchromedriver-binaryが対応しなくなり納品物が止まるようになります。
こういうところにモジュールの自動更新が使えます。仕掛け①
以前は、pipの__init__.pyのコードを流用する方法が使えていたのですが
pipのバージョンが新しくなってからは使えなくなりました。
新しいやり方に関しては、Pycharmのコンソールなどを眺めてみると案内が出ていると思います。訳して見ると
「pipコマンドを直接実行してください」
みたいな話だったと思います。簡単に仕掛けを肝をまとめますと
subprocess辺りに「pip install ***」を実行させればよいということになります。
venvを利用していてもこの方法で使えるを確認済みです。以上のことを関数にまとめてみるとこんな感じ。
installer.pyimport sys import subprocess def install_module(module: str, ver: str = None): """ 指定したモジュール(バージョン指定可)をインストールする :param module: モジュール名 :param ver: モジュールのバージョン :return: """ # バージョンの指定がある場合はオプションを付け足す if ver is not None: ver = f"=={ver}" else: ver = "" # インストール作業を行う try: command = f"pip install {module}{ver}" subprocess.call(command, shell=True) except Exception: sys.exit(-1)仕掛け②
上記のコードをプログラムの中に仕込めば完成!!
・・・といえるほど単純じゃないです。
見出しが「仕掛け①」なので②、③もまだあります。以下のような使い方をします。
sample_1.pytry: driver = webdriver.Chrome() except: install_module("chromedriver-binary", "86.0.4240.22.0")exceptに流れたときに指定したモジュールをインストールをしてはくれますが・・・
driver変数の中身はまだ未設定のままです。sample_2.pytry: driver = webdriver.Chrome() except: install_module("chromedriver-binary", "86.0.4240.22.0") driver = webdriver.Chrome()とすればコード上は問題なさそうですが・・・
driver = webdriver.Chrome()このコードは、
どのchromedriver-binaryに基づいて実行されるのでしょうか?
・import chromedriver-binaryを宣言したタイミングのchromedriver-binaryなのか?
・新たにインストールしたchromedriver-binaryなのか?
実装方法にもよるのでしょうが、私が検証した限りは前者で動いてるようです。importlib.reload(モジュール名)などを使えばリロードできますし、
pyファイルそのものを再起動させるみたいな方法もあるのですが、
プログラムの本筋と関係ない部分がやたらと面倒になります。
pyファイルを再起動させるということは一度pyファイルのプロセスが終了することになりますので
プロセスの終了を待つ系の何かがあると
pyファイルのプロセスが終わってないのに次の処理を始めるなど面倒なことがいろいろと発生します。いろいろと考えた中で一番単純に落ち着いたのは、以下のようなバッチを作ること
run.batpy モジュールの確認用.py py メイン処理用.pyバッチファイルを活用すると
①処理の終了を待って次に進むような場合、バッチファイルの終了を待ってから次に進んでくれます
②モジュールの確認とメインの処理を別々のpyファイルにすることにより、メイン処理がスリム化できます
③モジュールの確認用.pyでインストールを実行すると
メイン処理用.pyを実行するときにはモジュールを最新の状態にできます仕掛け③
仕掛け①と仕掛け②が実践できていればモジュールをインストール/アップデートするという用途には使えます。
残念ながらchromedriver-binaryの更新に利用するにはまだ不十分です。
私が2018年辺りで検証した限り、chromedriver-binaryは最新をインストールしても動きません。
どのバージョンをインストールするのかを調べて、引数に与えてあげる必要があります。対応するchromedriver-binaryのバージョンの調べ方
↓のURLにchromeブラウザのメジャーバージョンを与えてURLを開くとわかります
https://chromedriver.storage.googleapis.com/LATEST_RELEASE_{chromeブラウザのメジャーバージョン}
例:
https://chromedriver.storage.googleapis.com/LATEST_RELEASE_86ではバージョンをどうやってchromeブラウザのバージョンを調べるのか?
C:\Program Files (x86)\Google\Chrome\Application
もしくは、
C:\Program Files\Google\Chrome\Application
をのぞいてみるとバージョン番号の書かれたフォルダが見つかるかと
これをうまいこと切り出せばバージョン番号を取得できます。ただ必要なのはメジャーバージョンなので文字列操作でうまいことメジャーバージョンだけを取り出す必要があります
まとめるとこんな感じ。installer.pyimport sys import re import requests import subprocess def get_lastrelease_chromedriver(): """ chromeブラウザに合う最新のchromedriverのバージョンを得る :return: """ # インストール済みのchromeブラウザのバージョンを得る try: res = subprocess.Popen('dir /B /O-N "C:\Program Files (x86)\Google\Chrome\Application" | findstr "^[0-9].*\>"', stdout=subprocess.PIPE, shell=True).communicate() target = str(res[0]) pattern = r'[0-9]+\.' match = re.search(pattern, target) if match is None: # [32bit用] res = subprocess.Popen('dir /B /O-N "C:\Program Files\Google\Chrome\Application" | findstr "^[0-9].*\>"', stdout=subprocess.PIPE, shell=True).communicate() if len(res) < 1: raise Exception("chromeブラウザのバージョン確認のコマンドが失敗しました") target = str(res[0]) pattern = r'[0-9]+\.' match = re.search(pattern, target) if match is None: sys.exit(-1) chrome_ver = match.group(0).replace('.', '') except: return None # WEBサービスにchromedriverのバージョンを問い合わせする try: api = "https://chromedriver.storage.googleapis.com/LATEST_RELEASE_{}" ver = requests.get(api.format(chrome_ver)).text except: return None return verそれをモジュールの確認用.pyに組み込むと↓のようになります
モジュールの確認用.pytry: driver = webdriver.Chrome() except: ver = get_lastrelease_chromedriver() install_module("chromedriver-binary", ver)これでchromedriver-binaryの自動更新もできるはず。
- 投稿日:2020-10-17T18:32:45+09:00
ルービックキューブロボットのソフトウェアをアップデートした 4. 状態認識
この記事はなに?
私は現在2x2x2ルービックキューブを解くロボットを開発中です。これはそのロボットのプログラムの解説記事集です。
かつてこちらの記事に代表される記事集を書きましたが、この時からソフトウェアが大幅にアップデートされたので新しいプログラムについて紹介しようと思います。該当するコードはこちらで公開しています。
関連する記事集
「ルービックキューブを解くロボットを作ろう!」
1. 概要編
2. アルゴリズム編
3. ソフトウェア編
4. ハードウェア編ルービックキューブロボットのソフトウェアをアップデートした
1. 基本関数
2. 事前計算
3. 解法探索
4. 状態認識(本記事)
5. 機械操作(Python)
6. 機械操作(Arduino)
7. 主要処理今回は状態認識編として、
detector.pyを紹介します。使うモジュールのインポート
使うモジュールをインポートします。
import cv2 from time import sleep from basic_functions import * from controller import move_actuatorここで、
controllerは次回解説するプログラムですが、この中のmove_actuator関数は、その名の通りアクチュエータ(ここではモーター)を動かすコマンドを送る関数です。パズル4面の情報から6面の情報を作る
2x2x2ルービックキューブは4面の色を見るだけで全面の色が推測できます。この性質を利用するため、埋まっている色の情報から埋まっていない色を推測する関数が必要です。その関数を紹介します。
先に謝らせてください。こちらの関数、元々手動で色を入力する時代(数ヶ月前)に勢いで作った関数でして、今となってはなにをやっているのかあまりわかりません!そして今は特定の4面の色を見ることで残りの2面の色を推測するので、こんなに汎用性の高い関数である必要はありません。つまりここで紹介する関数は、少し冗長かつ何をやっているのかよくわからないがなんか動いている関数です。ごめんなさい。昔の自分に「せめてコメントをつけろ」とよく注意しておきます。
余談ですが今回こんな記事を書いているのは未来の自分のためでもあります。未来の自分がこのコードを読んで途方に暮れないように、今のうちにコメントを書いて、解説記事も残しておくようにしました。
''' 埋まっていないところで色が確定するところを埋める ''' ''' Fill boxes if the color can be decided ''' def fill(colors): for i in range(6): for j in range(8): if (1 < i < 4 or 1 < j < 4) and colors[i][j] == '': done = False for k in range(8): if [i, j] in parts_place[k]: for strt in range(3): if parts_place[k][strt] == [i, j]: idx = [colors[parts_place[k][l % 3][0]][parts_place[k][l % 3][1]] for l in range(strt + 1, strt + 3)] for strt2 in range(3): idx1 = strt2 idx2 = (strt2 + 1) % 3 idx3 = (strt2 + 2) % 3 for l in range(8): if parts_color[l][idx1] == idx[0] and parts_color[l][idx2] == idx[1]: colors[i][j] = parts_color[l][idx3] done = True break if done: break break if done: break return colors推測で解説を一応します。
最初の2つの
i, jを回すfor文は、単に色の格納された以下のような配列を一つずつ見ています。colors = [ ['', '', 'w', 'o', '', '', '', ''], ['', '', 'w', 'g', '', '', '', ''], ['b', 'o', 'g', 'y', 'r', 'w', 'b', 'r'], ['o', 'o', 'g', 'g', 'w', 'r', 'b', 'b'], ['', '', 'y', 'r', '', '', '', ''], ['', '', 'y', 'y', '', '', '', ''] ]ここで、
w, y, g, b, o, rはそれぞれ白、黄、緑、青、橙、赤を表します。なおこの配列の持ち方は過去に作ったプログラムの伝統を悪い方向に引き継いでいて、無駄が多いです。いつか直したいです。その後の
if (1 < i < 4 or 1 < j < 4) and colors[i][j] == '':で、色の情報が本来含まれているところかそうでないところかを分けます。
for k in range(8):で考えうる全てのパーツの候補を回し、if [i, j] in parts_place[k]:で2色の色が一致したら、for strt in range(3):でパーツの向き3通りを全部チェックします。このような流れで処理をしているのだと思います。
カメラを使った状態認識
パズルの状態を認識するにはカメラを使います。今回はOpenCVというライブラリを使って色を認識します。
''' パズルの状態の取得 ''' ''' Get colors of stickers ''' def detector(): colors = [['' for _ in range(8)] for _ in range(6)] # パズルを掴む for i in range(2): move_actuator(i, 0, 1000) for i in range(2): move_actuator(i, 1, 2000) sleep(0.3) rpm = 200 capture = cv2.VideoCapture(0) # 各色(HSV)の範囲 #color: g, b, r, o, y, w color_low = [[40, 50, 50], [90, 50, 70], [160, 50, 50], [170, 50, 50], [20, 50, 30], [0, 0, 50]] color_hgh = [[90, 255, 255], [140, 255, 200], [170, 255, 255], [10, 255, 255], [40, 255, 255], [179, 50, 255]] # 各パーツのcolors配列上での位置 surfacenum = [[[4, 2], [4, 3], [5, 2], [5, 3]], [[2, 2], [2, 3], [3, 2], [3, 3]], [[0, 2], [0, 3], [1, 2], [1, 3]], [[3, 7], [3, 6], [2, 7], [2, 6]]] # その他定数 d = 10 size_x = 130 size_y = 100 center = [size_x // 2, size_y // 2] dx = [-1, -1, 1, 1] dy = [-1, 1, -1, 1] # パズルの4つの面を読み込む for idx in range(4): # 読み込みがうまくいかない時があるので5回ダミーを読み込ませておく for _ in range(5): ret, frame = capture.read() tmp_colors = [['' for _ in range(8)] for _ in range(6)] loopflag = [1 for _ in range(4)] # 1面にある4枚のステッカーの色が全て読み込まれるまでwhile while sum(loopflag): ret, show_frame = capture.read() show_frame = cv2.resize(show_frame, (size_x, size_y)) hsv = cv2.cvtColor(show_frame,cv2.COLOR_BGR2HSV) # 4枚のステッカーを順番に調べる for i in range(4): y = center[0] + dy[i] * d x = center[1] + dx[i] * d val = hsv[x, y] # 6色のうちどれかを調べる for j in range(6): flag = True for k in range(3): if not ((color_low[j][k] < color_hgh[j][k] and color_low[j][k] <= val[k] <= color_hgh[j][k]) or (color_low[j][k] > color_hgh[j][k] and (color_low[j][k] <= val[k] or val[k] <= color_hgh[j][k]))): flag = False if flag: tmp_colors[surfacenum[idx][i][0]][surfacenum[idx][i][1]] = j2color[j] loopflag[i] = 0 break # colors配列に値を格納 for i in range(4): colors[surfacenum[idx][i][0]][surfacenum[idx][i][1]] = tmp_colors[surfacenum[idx][i][0]][surfacenum[idx][i][1]] # 次の面を見るためにモーターを回す move_actuator(0, 0, -90, rpm) move_actuator(1, 0, 90, rpm) sleep(0.2) capture.release() colors = fill(colors) return colorsここで少し問題なのが、色の範囲が決め打ちなことです。これでは外乱によって色の認識がうまくいかなくなる可能性があります。実際にMaker Faire Tokyo 2020の会場では光の環境によってうまく動きませんでした(値を微修正して乗り切りました)。
まとめ
今回はカメラで状態を認識し、見ていない面を復元するパートを紹介しました。次回は実際にロボットを動かすところです。

- 投稿日:2020-10-17T17:53:17+09:00
この世から一匹残らずヤードポンド法を駆逐してやる!
はじめに
こんな経験をしたことはないだろうか。
何回計算しなおしても、ありえない結果しか出てこない。もう諦めて課題を提出して解説授業を聞いていると、なんのことはない、長さの単位がヤードだったため、計算には単位換算が必要だったのだ、と。
世の中には他にも、ポンド、オンス、グレン、フィート、ガロン、クォート....など大量の単位であふれている。有り余るならロマンスか、せめて大学の単位にしてくれ。
数多の単位に翻弄された傷だらけの無力な手を握り締めながら私は夕日にこう叫んだ。
「ヤードポンド法……駆逐してやる!この世から……一匹残らず!」本編
改めまして、こんにちは。美味しいしです。
今回は、上記のような動機で作った、勝手に単位を変換してくれる、単位付き計算用のライブラリの紹介記事になります。
課題お助けツールとして使ってみてくださると嬉しいです!!
プルリクやissueも立ててくれると滂沱の涙を流して喜びます。
実際に動かしたデモはこちら!githubのコードはこちら!
できたもの
インストール方法
pip install ChemNote使い方
このライブラリはjupyter notebook上で動かすことを推奨します!
import ChemNote as cn基本的な使い方
x=cn.define(数値,単位)で定義。四則演算と累乗が扱える。
x.convertUnits({旧単位:(互換したときの係数,(新単位,新単位の次元)})で単位の変換
x.show(有効数字)で数式として表示。ただし、jupyter notebook上では、最終行に
xとあるだけで数式として表示される。
print(x)とした場合、コピーしやすいtexのテキストとして表示される。(両端を\$で囲うとマークダウンセルの中で数式表示される。)
以下サンプルはjupyter notebook上で動かした場合のデモになります。
sample1
1辺の長さが10 inch の立方体の中に入った水の重さを計算してみる。
l=cn.define(10,"inch") water=cn.define(1,{"g":1,"mL":-1}) l**3*water$1.639\times 10^{1}\, kg$
sample2
sample1の容器の重さが1ポンドだった場合、容器と水の重さの合計を有効数字2桁で表示する。
m1=cn.define(100,"lb") m=l**3*water+m1 m.show(2)$6.17\times 10^{1}\, kg$
sample3
異なる単位系での足し算や引き算をしている場合、気づかせてくれる。
m+lTypeError:units or their dimention are not same
sample4
正確な数字が欲しい場合やマークダウンとして別の場所にコピーしたい場合は以下のようにする。
float(m)61.746301
print(m)6.175\times 10^{1}\, kg
終わりに
pypiに初めてライブラリを登録してみました。
自分で作ったものを公開できるって何かいいなぁなんて思いました。
いろいろ至らぬ点等盛りだくさんだとは思うので、コメントなどなどよろしくお願いしますorz
- 投稿日:2020-10-17T17:06:49+09:00
日向坂46の歌詞をベクトル化してみた!
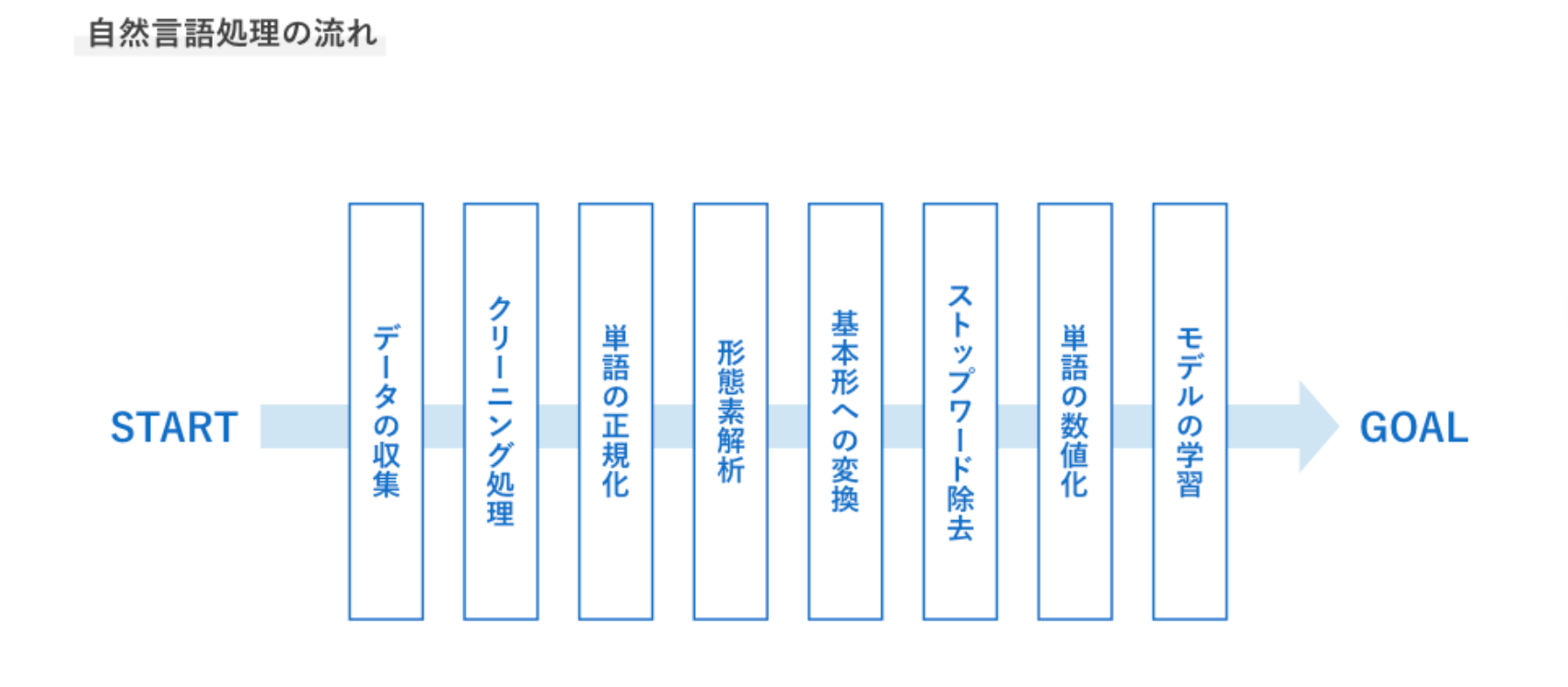
0:やりたいこと
日向坂46の全曲の歌詞データを元にword2vecを用いて、
自然言語⇒数値
に変換して遊んでみたいと思います。
1:データの収集
解決したいタスクに応じてデータを収集する
2:クリーニング処理
HTMLのタグなど意味を持たないノイズを削除する
・Beautiful Soup
・標準ライブラリ re モジュール1,2:データの収集&クリーニング処理
#1.スクレイピング import requests from bs4 import BeautifulSoup import warnings warnings.filterwarnings('ignore')target_url = "https://www.uta-net.com/search/?Aselect=1&Keyword=%E6%97%A5%E5%90%91%E5%9D%82&Bselect=3&x=0&y=0" r = requests.get(target_url) soup = BeautifulSoup(r.text,"html.parser")music_list = soup.find_all('td', class_='side td1') url_list = [] #曲一覧から各曲名のURLを取り出してリストに入れる for elem in music_list: a = elem.find("a") b = a.attrs['href'] url_list.append(b) #<td class="side td1"> # <a href="/song/291307/">アザトカワイイ</a> #</td> #<td class="side td1"> # <a href="/song/250797/">居心地悪く、大人になった</a> #</td>
hinataza_kashi = "" #曲ごとにRequrestを送り歌詞を抽出する base_url = "https://www.uta-net.com" for i in range(len(url_list)): target_url = base_url + url_list[i] r = requests.get(target_url) soup = BeautifulSoup(r.text,"html.parser") div_list = soup.find_all("div", id = "kashi_area") for i in div_list: tmp = i.text hinatazaka_kashi += tmp #<div id="kashi_area" itemprop="text"> #釣られてしまいました (一目でYeah, Yeah, Yeah) #<br> #僕が勝手に恋をしてしまったんです #<br> #君のせいじゃない
#前処理(英語や記号を正規表現で削除) import re kashi=re.sub("[a-xA-Z0-9_]","",hinatazaka_kashi)#英数字の削除 kashi=re.sub("[!-/:-@[-`{-~]","",kashi)#記号の削除 kashi=re.sub(u"\n\n","\n",kashi)#改行の削除 kashi=re.sub(u"\r","",kashi)#空白の削除 kashi=re.sub(u"\u3000","",kashi)#全角の空白を削除kashi=kashi.replace(' ','') kashi=kashi.replace(' ','') kashi=kashi.replace('?','') kashi=kashi.replace('。','') kashi=kashi.replace('…','') kashi=kashi.replace('!','') kashi=kashi.replace('!','') kashi=kashi.replace('「','') kashi=kashi.replace('」','') kashi=kashi.replace('y','') kashi=kashi.replace('“','') kashi=kashi.replace('”','') kashi=kashi.replace('、','') kashi=kashi.replace('・','') kashi=kashi.replace('\u3000','')
with open("hinatazaka_kashi_1.txt",mode="w",encoding="utf-8") as fw: fw.write(kashi)3:単語の正規化
半角や全角、小文字大文字などを統一する
・送り仮名によるもの
「行う」と「行なう」
「受付」と「受け付け」・文字の種類
「りんご」と「リンゴ」
「犬」と「いぬ」と「イヌ」・大文字と小文字
Apple と apple※今回は無視する
4:形態素解析(単語分割)
文章を単語ごと分割する
・MeCab
・Janome
・JUMAN++5:基本形への変換
語幹(活用しない部分)への統一を行う
例:学ん(だ)→学ぶ
昨今の実装では基本形へ変換しない場合もある4,5:形態素解析(単語分割)&基本形への変換
path="hinatazaka_kashi_1.txt" f = open(path,encoding="utf-8") data = f.read() # ファイル終端まで全て読んだデータを返す f.close()#3.形態素解析 import MeCab text = data m = MeCab.Tagger("-Ochasen")#テキストをパースするためのTaggerインスタンス生成 nouns = [line for line in m.parse(text).splitlines()#Taggerクラスのparseメソッドを使うと、テキストを形態素解析した結果が返る if "名詞" or "形容動詞" or "形容詞" or"形容動詞" or "動詞" or "固有名詞" in line.split()[-1]]
nouns = [line.split()[0] for line in m.parse(text).splitlines() if "名詞" or "形容動詞" or "形容詞" or "形容動詞" or "動詞" or "固有名詞" in line.split()[-1]]
6:ストップワード除去
出現回数の多すぎる単語など、役に立たない単語を除去する
昨今の実装では除去しない場合もあるmy_stop_word=["する","てる","なる","いる","こと","の","ん","y","一","さ","そう","れる","いい","ある","よう","もの","ない","しまう", "られる","くれる","から","だろ","その","けど","だけ","つ","て","まで","つて","じゃ","たい","なら","たら","なく","られ","まま","たく"] nouns_new=[] for i in nouns: if i in my_stop_word: continue else: nouns_new.append(i)
import codecs with codecs.open("hinatazaka_kashi_2.txt", "w", "utf-8") as f: f.write("\n".join(nouns_new))7:単語の数値化
機械学習で扱えるよう文字列から数値へ変換を行う
8:モデルの学習
タスクに合わせ、古典的な機械学習~ニューラルネットワーク選択する
それでは、この流れのうち前処理にあたるものを把握する。7,8:単語の数値化&モデルの学習
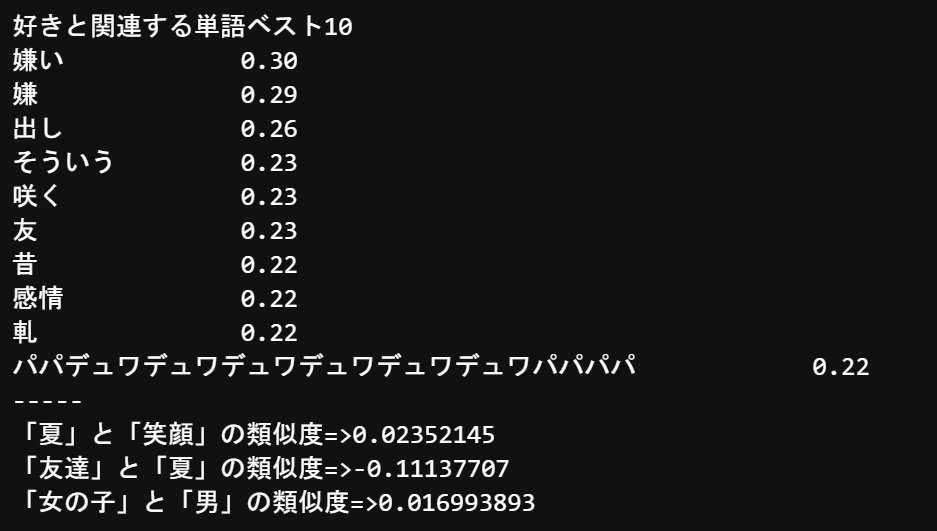
from gensim.models import word2vec corpus = word2vec.LineSentence("hinatazaka_kashi_2.txt") model = word2vec.Word2Vec(corpus, size=100 ,min_count=3,window=5,iter=30) model.save("hinatazaka.model")model = word2vec.Word2Vec.load("hinatazaka.model") # ドライバーと類似している単語を見る print('好きと関連する単語ベスト10') similar_words = model.wv.most_similar(positive=[u"海"], topn=10) for key,value in similar_words: print('{}\t\t{:.2f}'.format(key, value)) print('-----') # # 2つの単語の類似度を計算 similarity = model.wv.similarity(w1=u"笑顔", w2=u"夏") print('「夏」と「笑顔」の類似度=>' + str(similarity)) similarity = model.wv.similarity(w1=u"友達", w2=u"夏") print("「友達」と「夏」の類似度=>" + str(similarity)) similarity = model.wv.similarity(w1=u"女の子", w2=u"男") print('「女の子」と「男」の類似度=>' + str(similarity))
【総評】
「パパデュワデュワデュワデュワデュワデュワパパパパ」ってなんやねん。
歌詞じゃなくてメンバーのブログからデータを取得するとメンバーの仲良し度も分かるんじゃないかな。(次回やってみようかな…)参考文献



- 投稿日:2020-10-17T16:50:59+09:00
CTスキャンの断面再構成アルゴリズム ML-EM法の実装
はじめに
健康診断などでCTスキャンを受ける機会がありました。
どうやって断層の画像を再構成しているのか気になったので、調べて実装してみようと思います。X線CTの画像再構成アルゴリズムは、従来はフィルタ補正逆投影法(FBP)が用いられていましたが、X線量を減らした場合には得られる画質に限界があるそうです。
そこで、計算時間はFBPより増えるものの、明瞭な画像が得られる統計的手法の一つ、ML-EM法をここでは試していきたいと思います。参考
以下を参考にしました。
篠原 広行, 断層映像法の基礎 第32回 ML-EM法とOS-EM法
田中敏幸, 解説:特集 電磁界モデリングを用いる計測技術の基礎と新展開 X線CTの原理・現状とさらなる画像の高品質化
アルゴリズム
まず始めに、アルゴリズムの流れを書きます。その後に、言葉の意味の説明などをします。
- k番目の画像からk番目の投影を作成する。最初の画像は、値が全て1の画像を使う
- k番目の投影と実測した投影データの比を求める 実測した投影データ/(1)の投影データ
- その比を逆投影する
- k番目の画像に逆投影した画像をかけて、k+1番目の画像に更新する
投影、逆投影について説明し、その後にML-EM法の実装を行います。
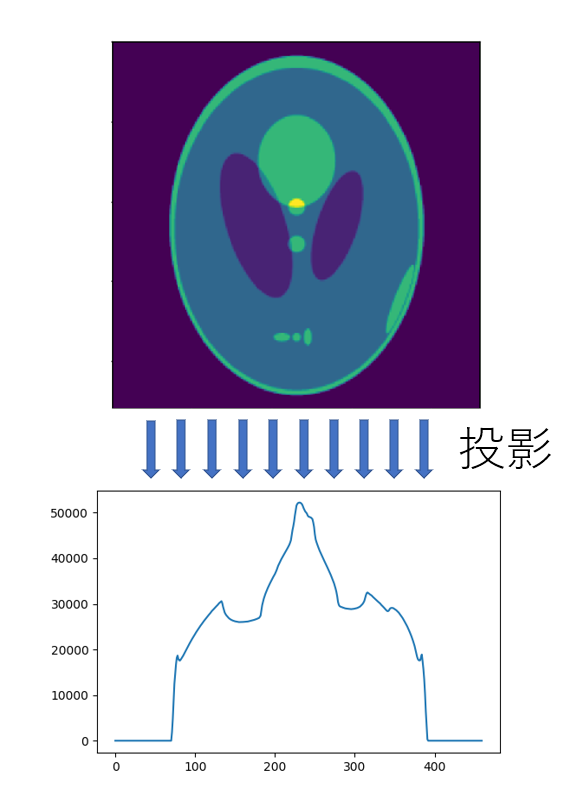
計測データ 投影
計測データは、一方向からX線を照射して、光の一部が人体に吸収された影です。
CTスキャンでは、この投影をいろいろな角度から行います。
ここでは、360度を200分割(1.8度刻み)で撮影したデータを作成しました。
計測データを用意したプログラムは以下の通りです。
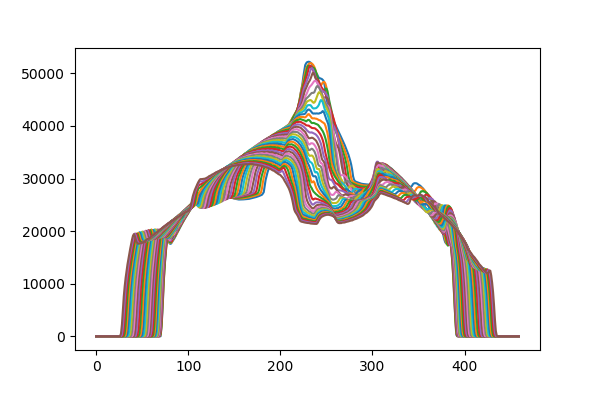
import numpy as np import matplotlib.pyplot as plt from pathlib import Path import cv2 def rotate_center(image, angle): """ 画像の真ん中を中心にして,回転させる image : 画像 angle : 回転させる角度[deg] """ h, w = image.shape[:2] affine = cv2.getRotationMatrix2D((w/2.0, h/2.0), angle, 1.0) #画像の中心の座標,回転させたい角度,拡大比率 return cv2.warpAffine(image, affine, (w, h)) def circle_mask(img): """ 内接円の領域を残して,他を0でマスクする """ x = np.linspace(-1.0,1.0,img.shape[0]) X,Y = np.meshgrid(x,x) distance_map = np.sqrt(X**2+Y**2) #中心からの距離 img[distance_map>=1.0] = 0.0 return img def forward_projection(img,theta): rot_img = rotate_center(img, theta) return np.sum(rot_img,axis=0) theta_array = np.linspace(0.0,360.0,200,endpoint=False) true_img = cv2.imread("CT_img.png",cv2.IMREAD_GRAYSCALE) #CT画像 これをもとに戻すのが目標 true_img = circle_mask(true_img) #円形マスク forward_projection_array_meas = [] for theta in theta_array: forward_projection_array_meas.append(forward_projection(true_img,theta)) forward_projection_array_meas = np.asarray(forward_projection_array_meas) fig,axes = plt.subplots() for i in range(36): axes.plot(forward_projection_array_meas[i]) #参考にしたPDFでは画像にしてありました fig,axes = plt.subplots() axes.imshow(forward_projection_array_meas,aspect=3)参考にした論文では、投影データを並べて画像化してありましたので、ここでもそれと比較するために掲載しておきます。
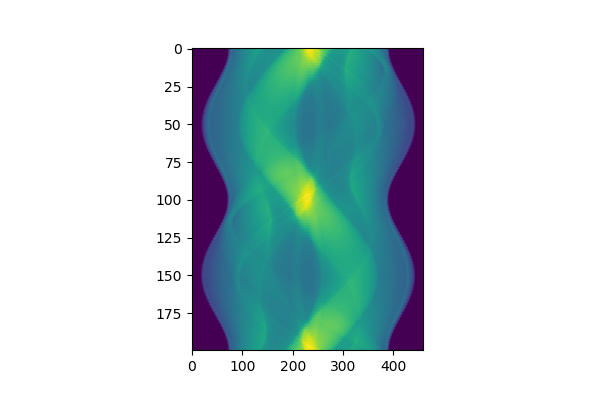
逆投影
逆投影は、投影データをもとの画像と同じ次元になるようタイル状に敷き詰め、足し合わせる操作です。
ML-EM法の実装
ML-EM法のアルゴリズムの則って実装します。
def rotate_center(img, angle): """ 画像の真ん中を中心にして,回転させる image : 画像 angle : 回転させる角度[deg] """ h, w = img.shape[:2] affine = cv2.getRotationMatrix2D((w/2.0, h/2.0), angle, 1.0) #画像の中心の座標,回転させたい角度,拡大比率 rot_img = cv2.warpAffine(img, affine, (w, h)) return rot_img def circle_mask(img): """ 内接円の領域を残して,他を0でマスクする """ x = np.linspace(-1.0,1.0,img.shape[0]) X,Y = np.meshgrid(x,x) distance_map = np.sqrt(X**2+Y**2) #中心からの距離 img[distance_map>=1.0] = 0.0 return img def forward_projection(img, theta_array): """ k番目の画像に回転を加えて投影する操作を繰り返す """ img = circle_mask(img) forward_projection_array = [] for theta in theta_array: rot_img_sum = np.sum(rotate_center(img, theta),axis=0) forward_projection_array.append(rot_img_sum) forward_projection_array = np.asarray(forward_projection_array) return forward_projection_array def back_projection(img_shape, theta_array, forward_projection_array): """ 逆投影する img_shape : 画像サイズ theta_array : 角度データ forward_projection_array : 計測データ """ back_pro_img = np.zeros(img_shape,dtype=np.float64) for i,theta in enumerate(theta_array): tile_img = np.tile(forward_projection_array[i],[460,1]) #axis=0方向に敷き詰める tile_img = rotate_center(tile_img, -theta) #回転 back_pro_img += tile_img back_pro_img /= theta_array.shape[0] #重ね合わせた回数で割る return back_pro_img本来であれば、k-1番目とk番目の画像の差がいくら以下になったら反復をやめるなどとしますが、ここでは簡単のために適当に60回くらいにしました。
init_img = np.ones_like(true_img) forward_projection_array_k = forward_projection(init_img, theta_array)+1.0e-12 # 1.k番目の画像からk番目の投影を作成する 0divを避けるため,1.0e-12を足した forward_pro_ratio = forward_projection_array_meas/forward_projection_array_k # 2.k番目の投影と実測した投影データの比を求める 実測した投影データ/(1)の投影データ back_pro_img = back_projection(true_img.shape, theta_array, forward_pro_ratio) #3. その比を逆投影する k_img = init_img * back_pro_img #4. k番目の画像に逆投影した画像をかけて,k+1番目の画像に更新する for i in range(60): forward_projection_array_k = forward_projection(k_img, theta_array)+1.0e-12 forward_pro_ratio = forward_projection_array_meas / forward_projection_array_k back_pro_img = back_projection(true_img.shape, theta_array, forward_pro_ratio) k_img *= back_pro_img結果
もとの画像
反復1回目
反復60回目
もとの画像より若干ぼやけるものの、よく再現されています。
まとめ
CT画像の再構成手法の一つであるML-EM法を実装し、サンプル画像から計測データを作成し、再構成を行いました。
本来であれば、回転したあとの座標が非整数値であるとき、輝度を複数のピクセルに分割する操作が必要です。参考文献では、EM-ML法の定式化で変数Cにあたります。openCVの画像の回転はバイリニア法で補間されるので、変換前と後で画像の輝度の総和が保たれません。
ただ、趣味でやってみる分には大した問題ではないかなと思います。実際のデータで試してみたいですが、X線CT装置はとても買えません。
寒天に少し小麦粉でも混ぜて、バックライトで照らしながら撮影したら、X線CT画像のような投影データが得られるかなと思います。
機会があったらやります。
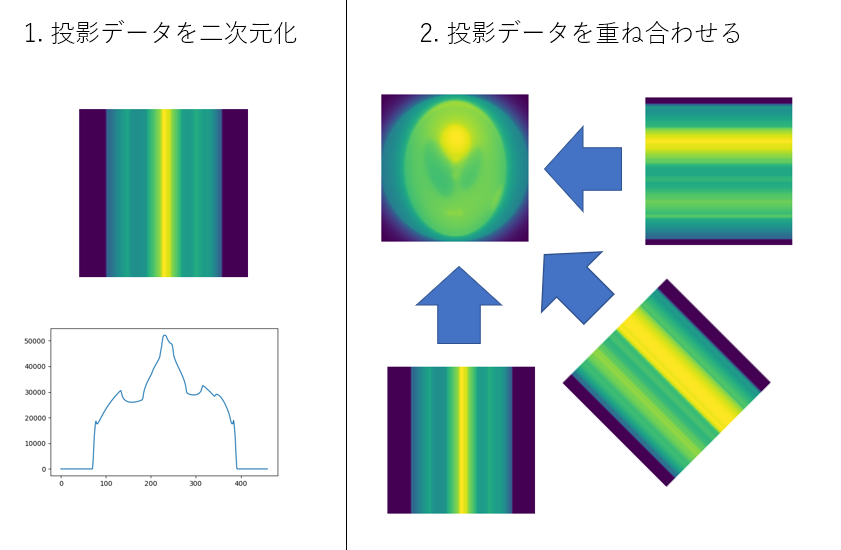

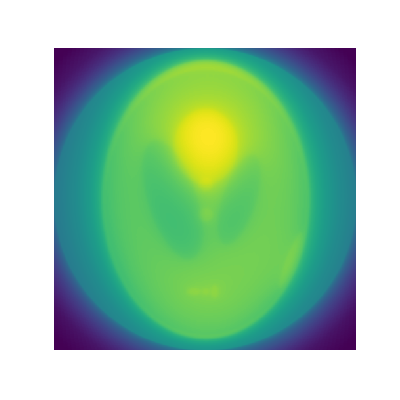
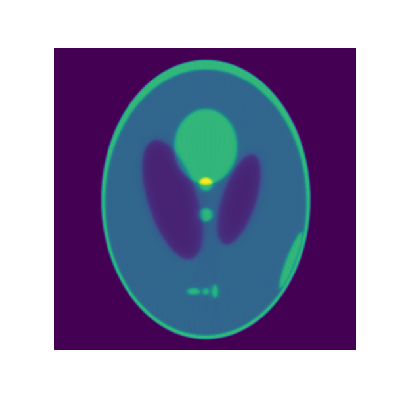
- 投稿日:2020-10-17T15:49:49+09:00
競プロ精進記録 1~3日目(10/14,15,17)
蟻本(けんちょんさんの記事の問題を中心に)とAtCoderの上埋めの精進の復習の記録用の記事を上げていこうと思います。1ヶ月くらいは少なくとも頑張りたいです。また、大量に問題を一記事に載せる可能性があるので、コードはリンクを貼るだけにしておきます。
1日目
蟻本精進
JOIのダーツ,AGC033-Aも解きましたが、簡単なので今回は省きます。
ARC037B - バウムテスト
$N$頂点の閉路を持たない連結なグラフ
$\leftrightarrow$$N$頂点の木
$\leftrightarrow$$N$頂点で連結な$N-1$本の辺を持つグラフ上記の言い換えをたまに忘れるので心に刻みます。
この問題では木になる連結成分を数えれば良く、それはUnionFindで連結成分同士に分解してそれぞれにいくつだけ辺が含まれるかを求めるだけです。
提出→リンク
AtCoder精進
ARC069E - Frequency
diff:1831
結果:合計1.5時間くらいでAC?(パソコン触れない時間が長くて正確な時間がわかりません)
考察
辞書順最小にしたいので、まずはそのために最適な山の減らし方を考えます。初めは$i \in [0,n-1]$で最大の山で最小のインデックス$k$の要素になります。この山を徐々に減らすことで次に最大の山となるインデックスで最小のものを探します。すると、$i \in [0,k-1]$で最大の山で最小のインデックス$l$の要素になります。これを再帰的に繰り返すので、(インデックス付きの)累積最大値を求めておくことでどの山が途中で最大の山になるかは$O(n)$で求まります。
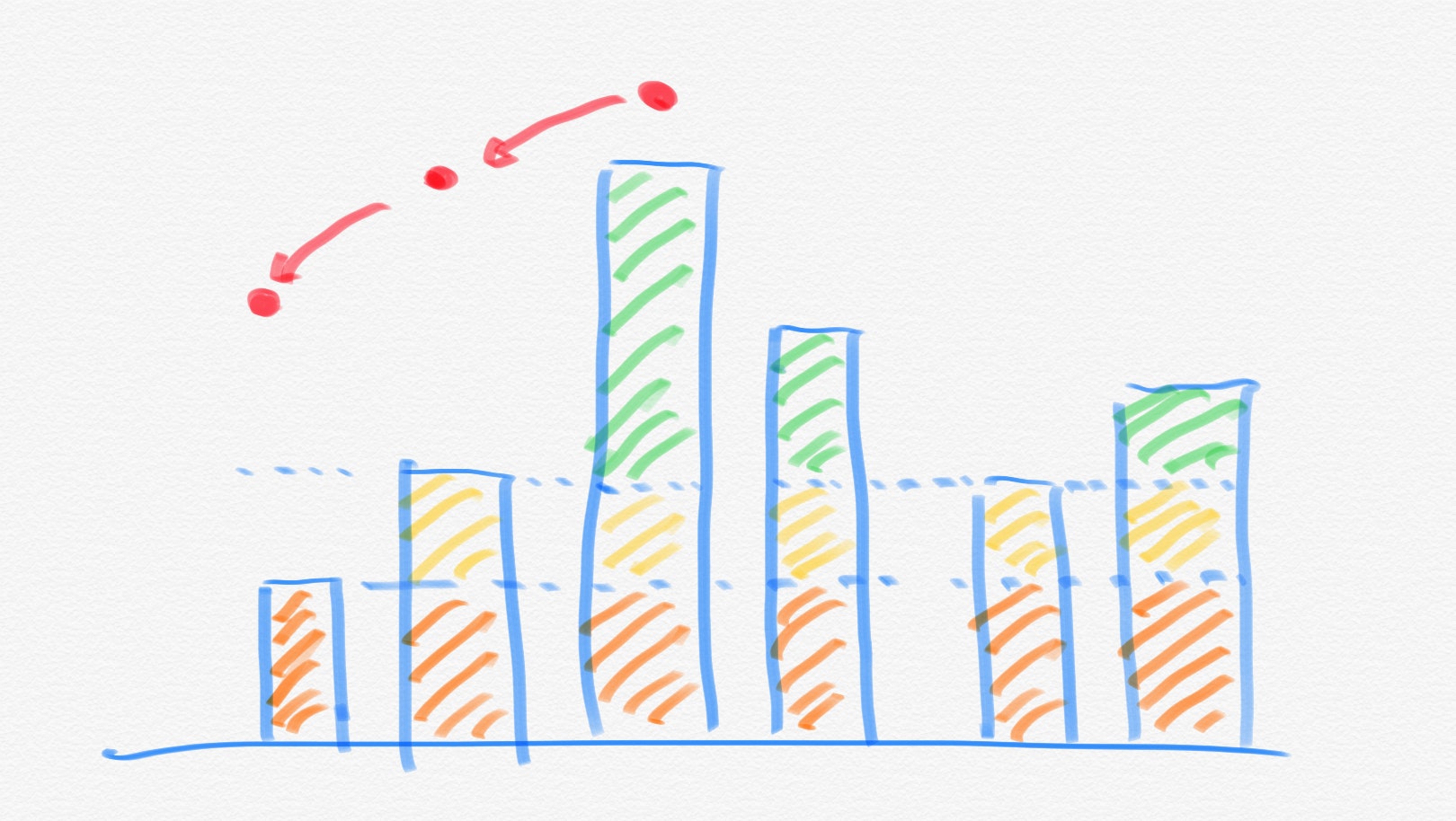
上記の考察により最大のインデックスの移動の仕方は求まりましたが、何回ずつそれぞれのインデックスが現れるかを求める必要があります。この時、下図を考えれば良いです(赤丸の部分が移動で経由するインデックスの場所です。)。
つまり、ある山$i$のインデックスの現れる回数は(次の山$j$の高さまでそれぞれの山を減らした高さの合計)なので、(山$i$以上の山の数)$\times$(山$i$の高さ-山$j$の高さ)+$\sum_{k}${(山$i$より低く山$j$より高い山$k$の高さ)-(山$j$の高さ)}が答えとなります。これは山を昇順に並べて山$i$以上の高さの山の個数を保存することで、$O(n)$で考えることができます。
よって、それぞれのインデックスの現れる回数を保存する配列に回数を記録して最終的にまとめて出力することで答えとなります。また、ボトルネックはソートで全体の計算量は$O(n \log{n})$となります。
提出→リンク
2日目
AtCoder精進
ARC071E - TrBBnsformBBtion
diff:1740
結果:20分ほどでAC(ただしエスパー)
考察
勘で解いていましたが、答えを見ても間違いのない勘であったようです。ただ、最近BITで殴りがちなので$O(N)$解法で解けるようにしていきたいです。
操作が可逆であることに注目しました(✳︎)。また、可逆でありかつ$A$または$B$のみに統一することができるので、ここでは任意の文字を$B$に統一することにしました。すると、任意の文字列は(空文字列,$B,BB$)のいずれかへと変形することができます。また、(空文字列,$B,BB$)の間で変換可能かも証明する必要がありますが、これはeditorialに示されているように変形することができません。
また、$B$に統一すればその文字列の長さを3で割った余りにより(空文字列,$B,BB$)のいずれになるかが決まります。つまり、選んだ$S,T$の部分連続文字列で$A,B$の個数がそれぞれ$(xs,ys),(xt,yt)$として、$(xs \times 2+xt)\%2=(ys \times 2+yt)\%2$が成り立てば同じ文字列にできます。よって、$A,B$の個数で累積和をとっておけばある区間の$A,B$の個数は$O(1)$で求めることができます。よって、最大$10^5$回のクエリに高速に答えることができます。
コンテスト中の自分はそれぞれのインデックスで$A$の場合は1,$B$の場合は0としてBITに$S,T$の情報を保存してクエリがきたら総和を$A$の個数として求めていましたが、累積和の方が実装も簡単で高速です。
(✳︎)…コンテスト中はなんとなくで済ませましたがちゃんと証明してから解きたかったです
提出→リンク
ARC064E - Cosmic Rays
diff:1831
結果:1時間ほどでAC(大量のペナを吐いた)
考察
二次元の座標系上なのでかなり苦手な問題でしたが解けました。これを機に苦手意識を払拭したいです。
まず、図を書いて考えたところ、二つの円の間で宇宙線を浴びる時間が最小となるのは、中心同士を結んだ線分上を動く時です。つまり、ある2円間を移動する際に宇宙線を浴びる時間はmax(0,(2円の中心間距離)-(2円の半径の和))となります。円同士が重なったり包含したりする場合は0となるので、その2円間を移動しても宇宙線を浴びないという条件を満たします。
つまり、任意の2円間での宇宙線を浴びる最小時間が求まります。また、始点及び終点は半径が0の円と捉えれば良いです。したがって、宇宙線を浴びる最小時間を距離と見ることで、$N+2$頂点のグラフにおける始点から終点まの最短距離問題を解けば良いことになります。また、距離は非負なのでダイクストラ法を用いて解けば良く、計算量は$O(N \log{N})$です。
そして、距離が小数になるのでdoubleにするので、以下のような気をつけるポイントがあります。
①doubleをllとしてtypedefしているので整数の際の型指定に気を付ける。
②小数どうしの距離の更新を最小限に抑えるように許容誤差よりも少し小さい値(ここでは$10^{-11}$)を大きい方に加えて判定する。
③小数以下$10$桁で出力する指定を行う。
(✳︎)ダイクストラ法でのINFによる初期化を忘れない。
以上の気を付けるポイントを抑えてダイクストラ法を実装します。コードはこちらの記事のものを使いました。
提出→リンク
3日目
AtCoder精進
ARC075E - Meaningful Mean
diff:1987
結果:40分ほどでAC
考察
まず、平均が$k$以上という条件を任意の要素を$k$でマイナスすることで、平均が0以上($\leftrightarrow$和が0以上)の場合を考えれば良く、要素数の情報を考えなくて済みます。したがって、まずは全ての要素を$-k$しておきます。
また、連続部分列なので初めはDPを考えましたが、その個数を聞かれているので難しいです。ここで、連続部分列を区間と見れば累積和の差分を考える問題に帰着することができます。つまり、$S[i]:=i+1$番目の要素までの和($i=0$のときは$S[i]=-k$)とすることで、ある区間$[l,r]$の和が0以上の条件は$S[r]-S[l-1] \geqq 0 \leftrightarrow S[r] \geqq S[l-1]$となります。
$S[r]=S[l-1]$のパターンの問題の場合はmapを使って管理しますが、今回は転倒数を求めるイメージでBITにより実装します。つまり、大きい$i$から順に$S[i]$の個数をBITに記録していけば(✳︎)、ある$i$においてはそれよりもインデックスの大きい要素のそれぞれの値の個数がすでにメモされていることになります。よって、$r>l-1$の条件を満たすので、このもとで$S[i]$以上となる値の個数を求めれば良くBITにより対数時間で求めることができます。
また、$S[i]$の値は大きい値や負の値になる必要があるので、座標圧縮(参考)を行って$1→x$の番号をつけて考えれば良いです。また、$x$は高々$n+1$にしかなりません。
(✳︎)…小さい方からの実装の方が楽ですが、本質ではないので説明などは省略します。
提出→リンク
- 投稿日:2020-10-17T15:47:18+09:00
APIを使わずにPythonでGmailを作成
概要
- APIを使わずにVBAでGmailを作成 のPython版になります。
- Excelでメール本文書くなんてやりづらいと思う人(自分もそう思いました)の為の別の提案
PythonでGmailのメール作成画面表示
今回のやり方としては、テキストファイルに本文を書き、
そのテキストファイルを取得して、URLを作成する、というやり方になります。
最近日報ではもうこのやり方でやってます。
本記事では、日報を想定とした書き方の上で、前回の流れ通り書いていきます。URL作成
URLやパラメータは前回の記事にも書いてありますが、以下の通りです。
https://mail.google.com/mail/?view=cmこのURLに、パラメータを連結させます。
パラメータは以下の通り(ほぼまんまです)
パラメータ 意味 to= To cc= Cc bcc= Bcc su= 件名 body= 本文 URL作成from datetime import datetime import urllib.parse def getUrl(body: str) -> str: url = "https://mail.google.com/mail/?view=cm" url += "&to=to@hoge.co.jp" url += "&cc=cc@hoge.co.jp" url += "&bcc=bcc@hoge.co.jp" today = datetime.now() url += f"&su=日報 {today.month}/{today.strftime('%d')} 日報太郎" url += f"&body={strenc(body)}" return url def strenc(txt: str) -> str : lst = list("#'|^<>{};?@&$" + '"') for v in lst: txt = txt.replace(v, urllib.parse.quote(v)) txt = urllib.parse.quote(txt) return txtここらへんは前回とほぼ同じです。
URLを開く
こちらも前回と同じで、コマンドを実行していきます。
Pythonなので、VBAと違って書きやすいです。PythonからstartコマンドでURLを開くimport subprocess def openUrl(url: str): subprocess.call(f'cmd /c start "" "{url}"', shell=True)メール作成
関数ができたので、テキストファイルの内容を取得して、メールを作成していきます。
デスクトップに、メール.txtというファイルがあったとします。import os desktop = os.path.join(os.path.join(os.environ['USERPROFILE']), 'Desktop/') fileName = "メール.txt" def main(): with open(f"{desktop}{fileName}", mode="r", encoding="UTF-8") as f: url = getUrl(f.read()) openUrl(url)バッチ作成
これで実行すれば、ブラウザが開き、Gmailが開かれるのですが、
いちいちコマンドプロンプトで、Pythonを実行っていうのはめんどくさいので、バッチを書いていきます。
Pythonファイルは、デスクトップに置いておく必要はないので、
例として、ユーザーフォルダの中に、/work/python/DailyReport/DailyReport.pyとしておきます。@echo off cd ../work/python/DailyReport python DailyReport.pyこのバッチを、デスクトップに保存します。
これにより、メール.txtに本文を書いて、バッチを実行すれば、
ブラウザで開かれ、メール作成画面が表示されたかと思います。
(今回実行結果は割愛します。内容一緒なので・・・)
outlookに関しても、前回のおまけにある、getUrl()を真似すればできるかと思います。全体のソースコード
DailyReport.pyfrom datetime import datetime import os import urllib.parse import subprocess desktop = os.path.join(os.path.join(os.environ['USERPROFILE']), 'Desktop/') fileName = "メール.txt" def main(): with open(f"{desktop}{fileName}", mode="r", encoding="UTF-8") as f: url = getUrl(f.read()) openUrl(url) def getUrl(body: str) -> str: url = "https://mail.google.com/mail/?view=cm" url += "&to=to@hoge.co.jp" url += "&cc=cc@hoge.co.jp" url += "&bcc=bcc@hoge.co.jp" today = datetime.now() url += f"&su=日報 {today.month}/{today.strftime('%d')} 日報太郎" url += f"&body={strenc(body)}" return url def strenc(txt: str) -> str : lst = list("#'|^<>{};?@&$" + '"') for v in lst: txt = txt.replace(v, urllib.parse.quote(v)) txt = urllib.parse.quote(txt) return txt def openUrl(url: str): subprocess.call(f'cmd /c start "" "{url}"', shell=True) if __name__ == "__main__": main()mail.bat@echo off cd ../work/python/DailyReport python DailyReport.py参考サイト
- 投稿日:2020-10-17T13:56:58+09:00
Djangoでstaticフォルダから画像を読み込めなかった時の解決策
結論から言うと、再起動しただけです。
わざわざ投稿するほどのことでもないかもしれませんが、案外こういうところでハマることも多いのではないかと思ったので。状況
djangoで、
myblogappというプロジェクト内でpostsというアプリを作っていました。
この時にstaticファイルを新しく追加して、画像を読み込ませようとしたときのことです。myblogapp
└posts
├ templates
| └ posts
| └ index.html
|
├ static ⏋
| └ posts |←ここを作って
| └ home.html ⏌
|
|
(views.py などその他は省略)
index.htmlの中で{% load static %} <img src="{% static 'posts/home.jpg' %}" alt="home image">と記述して画像を表示しようとした時のことです。
起こった問題
正しく指定したにも関わらず、画像が表示されずに
画像がないことを表すマークと「home image」という文字が表示されるだけで、
正しく画像が読み込まれませんでした。djangoを起動しているシェル上の表示を見ると
[(日時)] "GET /static/posts/home.jpg HTTP/1.1" 404 1668と表示されており、404を返していることから
ファイルの存在が認識されていないことが分かります。解決策
一度djangoのサーバーを止めてから、再度
python manage.py runserverを実行したら普通に読み込めました。
(正しくは、一度サーバーを止めてpython manage.py findstatic .を実行し
staticディレクトリがちゃんと認識されているかを確認してから
python manage.py runserverを実行しました。)どんなプログラムでも、
うまく動かないときはとりあえず再起動した方が良いということを
改めて実感しました...
- 投稿日:2020-10-17T13:05:37+09:00
Twitter 誹謗中傷撃退マシン(最強版)
前にQiitaに書いた「Twitter 誹謗中傷撃退マシン」の記事は出来が良かったのにLGTMが伸び悩んでたため、疑問に思っておりましたところ。いちいち誹謗中傷ワードを配列に入れるのを面倒くさがられたのではと思いDeep Learningの力を借りました。
本記事の目的は前回同様SNSの誹謗中傷をテクノロジーの力で救うこと
です
では、行ってみましょう!!!事前知識
前回の記事で事前知識を学習して進めてください
Twitter 誹謗中傷撃退マシン誹謗中傷識別AIを作ろう
word2vec, RNN(LSTM)を使ってモデルを作ります。データは"umich-sentiment-train.txt"という評判分析によく使われるデータセットを使います。
word2vecモデル
Kerasを使って作成します。word2vecとは一言で言うと人間の言葉をベクトル(数字)におくアルゴリズムです。
word2vec_model = Sequential() word2vec_model.add(Embedding(input_dim=vocab_size, output_dim=EMBEDDING_SIZE, embeddings_initializer='glorot_uniform', input_length=WINDOW_SIZE * 2)) word2vec_model.add(Lambda(lambda x: K.mean(x, axis=1), output_shape=(EMBEDDING_SIZE,))) word2vec_model.add(Dense(vocab_size, kernel_initializer='glorot_uniform', activation='softmax')) word2vec_model.compile(loss='categorical_crossentropy', optimizer="adam", metrics=["accuracy"]) word2vec_model.fit(Xtrain, ytrain, batch_size=BATCH_SIZE, epochs=NUM_EPOCHS, validation_data=(Xtest, ytest)) # evaluate word2vec_score, word2vec_acc = word2vec_model.evaluate(Xtest, ytest, batch_size=BATCH_SIZE) print("word2vec Test score: {:.3f}, accuracy: {:.3f}".format(word2vec_score, word2vec_acc)) # get embedding_weights embedding_weights = word2vec_model.layers[0].get_weights()[0]RNN(LSTM)モデル
RNN(LSTM)とは時系列データを扱うのに特化したAIモデルです。株価予測・機械翻訳とかにも応用されてます。
rnn_model = Sequential() rnn_model.add(Embedding(vocab_size, EMBEDDING_SIZE, input_length=MAX_SENTENCE_LENGTH, weights=[embedding_weights], trainable=True)) rnn_model.add(Dropout(0.5)) rnn_model.add(LSTM(HIDDEN_LAYER_SIZE, dropout=0.5, recurrent_dropout=0.5)) rnn_model.add(Dense(1)) rnn_model.add(Activation("sigmoid")) rnn_model.compile(loss="binary_crossentropy", optimizer="adam", metrics=["accuracy"]) rnn_model.fit(Xtrain, ytrain, batch_size=BATCH_SIZE, epochs=NUM_EPOCHS, validation_data=(Xtest, ytest)) # evaluate rnn_score, rnn_acc = rnn_model.evaluate(Xtest, ytest, batch_size=BATCH_SIZE) print("rnn Test score: {:.3f}, accuracy: {:.3f}".format(rnn_score, rnn_acc)) # save model rnn_model.save(os.path.join(DATA_DIR, "sentence_analyzing_rnn.hdf5"))rnn_model.add(Embedding(vocab_size, EMBEDDING_SIZE, input_length=MAX_SENTENCE_LENGTH, weights=[embedding_weights], trainable=True))ここで先ほどのword2vecで取得した重りを使い学習を進め"sentence_analyzing_rnn.hdf5"として保存します。
「Twitter API + 誹謗中傷識別AI」合体
これらを前回記事にした誹謗中傷撃退マシンと合体させます。
# coding=utf-8 import collections import os import json import nltk import codecs from requests_oauthlib import OAuth1Session from keras.models import Sequential, load_model from keras.preprocessing import sequence # 認証処理 CK = 'YOUR OWN' CS = 'YOUR OWN' AT = 'YOUR OWN' ATS = 'YOUR OWN' twitter = OAuth1Session(CK, CS, AT, ATS) # ツイート検索エンドポイント url = 'https://api.twitter.com/1.1/search/tweets.json' # ユーザーブロックエンドポイント url2 = 'https://api.twitter.com/1.1/blocks/create.json' # Setting parameter DATA_DIR = "./data" MAX_FEATURES = 2000 MAX_SENTENCE_LENGTH = 40 if os.path.exists(os.path.join(DATA_DIR, "sentence_analyzing_rnn.hdf5")): # Read training data and generate word2index maxlen = 0 word_freqs = collections.Counter() with codecs.open(os.path.join(DATA_DIR, "umich-sentiment-train.txt"), "r", 'utf-8') as ftrain: for line in ftrain: label, sentence = line.strip().split("\t") try: words = nltk.word_tokenize(sentence.lower()) except LookupError: print("Englisth tokenize does not downloaded. So download it.") nltk.download("punkt") words = nltk.word_tokenize(sentence.lower()) maxlen = max(maxlen, len(words)) for word in words: word_freqs[word] += 1 vocab_size = min(MAX_FEATURES, len(word_freqs)) + 2 word2index = {x[0]: i + 2 for i, x in enumerate(word_freqs.most_common(MAX_FEATURES))} word2index["PAD"] = 0 word2index["UNK"] = 1 # load model model = load_model(os.path.join(DATA_DIR, "sentence_analyzing_rnn.hdf5")) # エンドポイントへ渡すパラメーター target_account = '@hoge ' # リプライされたアカウント keyword = '@' + target_account + 'exclude:retweets' # RTは除外 params = { 'count': 50, # 取得するtweet数 'q': keyword, # 検索キーワード } req = twitter.get(url, params=params) if req.status_code == 200: res = json.loads(req.text) for line in res['statuses']: target_text = line['text'].replace(target_account, "") test_words = nltk.word_tokenize(target_text.lower()) test_seqs = [] for test_word in test_words: if test_word in word2index: test_seqs.append(word2index[test_word]) else: test_seqs.append(word2index["UNK"]) Xsent = sequence.pad_sequences([test_seqs], maxlen=MAX_SENTENCE_LENGTH) ypred = model.predict(Xsent)[0][0] if ypred < 0.5: params2 = {'user_id': line['user']['id']} # ブロックするユーザー req2 = twitter.post(url2, params=params2) if req2.status_code == 200: print("Blocked !!") else: print("Failed2: %d" % req2.status_code) else: print("Failed: %d" % req.status_code) else: print ("AI model doesn't exist") # 注意:Twitter APIは1週間以上前のリプを検索ヒットさせることができない # 注意:明らかな攻撃的なリプはそもそもヒットしないまずモデルを走らせるために単語をIDにおく必要があるのでword2indexを作成する。
リプライされたアカウントを指定してメッセージを受け取りAIに通す。
悪口だと0,褒め言葉だと1に近くなるよう分類される。
そして、閾値0.5未満だと悪口としてそのアカウントをブロックする。総括
日本語は単語ID化も難しい上に良質なデータセットもないため、本プログラムは英語のみの対応となっています。
このプログラムが少しでも世の中に役立つことを切に祈ってます。ちなみにこれが私のTwitter垢です。気軽にメッセージどうぞ!
https://twitter.com/downtownakasiya
- 投稿日:2020-10-17T13:01:29+09:00
Git hub でcloneしようとすると「fatal: destination path ' ' already exists and is not an empty directory.」際の対応方法
% git clone git@github.com:ochun0116/saku202010.gitでcloneしようとしたところ、
fatal: destination path 'saku202010' already exists and is not an empty directory.
と表記が出てしまいました。
「cloneするときは空っぽのフォルダにしてくれ!」ってことらしく、対応はチェンジディレクトリして、そのフォルダがあるところでやるらしいです。
すなわち
% cd ../% rm -fr saku202010% git clone git@github.com:ochun0116/saku202010.gitです。
できました!

- 投稿日:2020-10-17T12:25:02+09:00
scikit-learn を用いたロバスト線形回帰
概要
Python の機械学習ライブラリー sckit-learn を用いた、ロバスト線形回帰の描画方法を紹介する。本稿では、python の描画ライブラリ altair でチャートオブジェクトを作成し、Streamlit というアプリケーションフレームワークを使ってブラウザに表示させる。
ロバスト線形回帰の特徴
最小二乗法による線形回帰に比べて、外れ値に影響を受けにくい。
ロバスト線形回帰の作成
HuberRegressor を用いて、ロバスト回帰直線を作成する。
streamlit は、streamlit run ファイル名.pyで実行することに注意streamlit_robust_linear.pyimport streamlit as st import numpy as np import pandas as pd import altair as alt from sklearn.linear_model import HuberRegressor from sklearn.datasets import make_regression # デモデータの生成 rng = np.random.RandomState(0) x, y, coef = make_regression( n_samples=200, n_features=1, noise=4.0, coef=True, random_state=0) x[:4] = rng.uniform(10, 20, (4, 1)) y[:4] = rng.uniform(10, 20, 4) df = pd.DataFrame({ 'x_axis': x.reshape(-1,), 'y_axis': y }) # ロバスト回帰のパラメータを設定 epsilon = st.slider('Select epsilon', min_value=1.00, max_value=10.00, step=0.01, value=1.35) # ロバスト回帰実行 huber = HuberRegressor(epsilon=epsilon ).fit( df['x_axis'].values.reshape(-1,1), df['y_axis'].values.reshape(-1,1) ) # 散布図の生成 plot = alt.Chart(df).mark_circle(size=40).encode( x='x_axis', y='y_axis', tooltip=['x_axis', 'y_axis'] ).properties( width=500, height=500 ).interactive() # ロバスト線形回帰の係数を取得 a1 = huber.coef_[0] b1 = huber.intercept_ # 回帰直線の定義域を指定 x_min = df['x_axis'].min() x_max = df['x_axis'].max() # 回帰直線の作成 points = pd.DataFrame({ 'x_axis': [x_min, x_max], 'y_axis': [a1*x_min+b1, a1*x_max+b1], }) line = alt.Chart(points).mark_line(color='steelblue').encode( x='x_axis', y='y_axis' ).properties( width=500, height=500 ).interactive() # グラフの表示 st.write(plot+line)パラメータについて
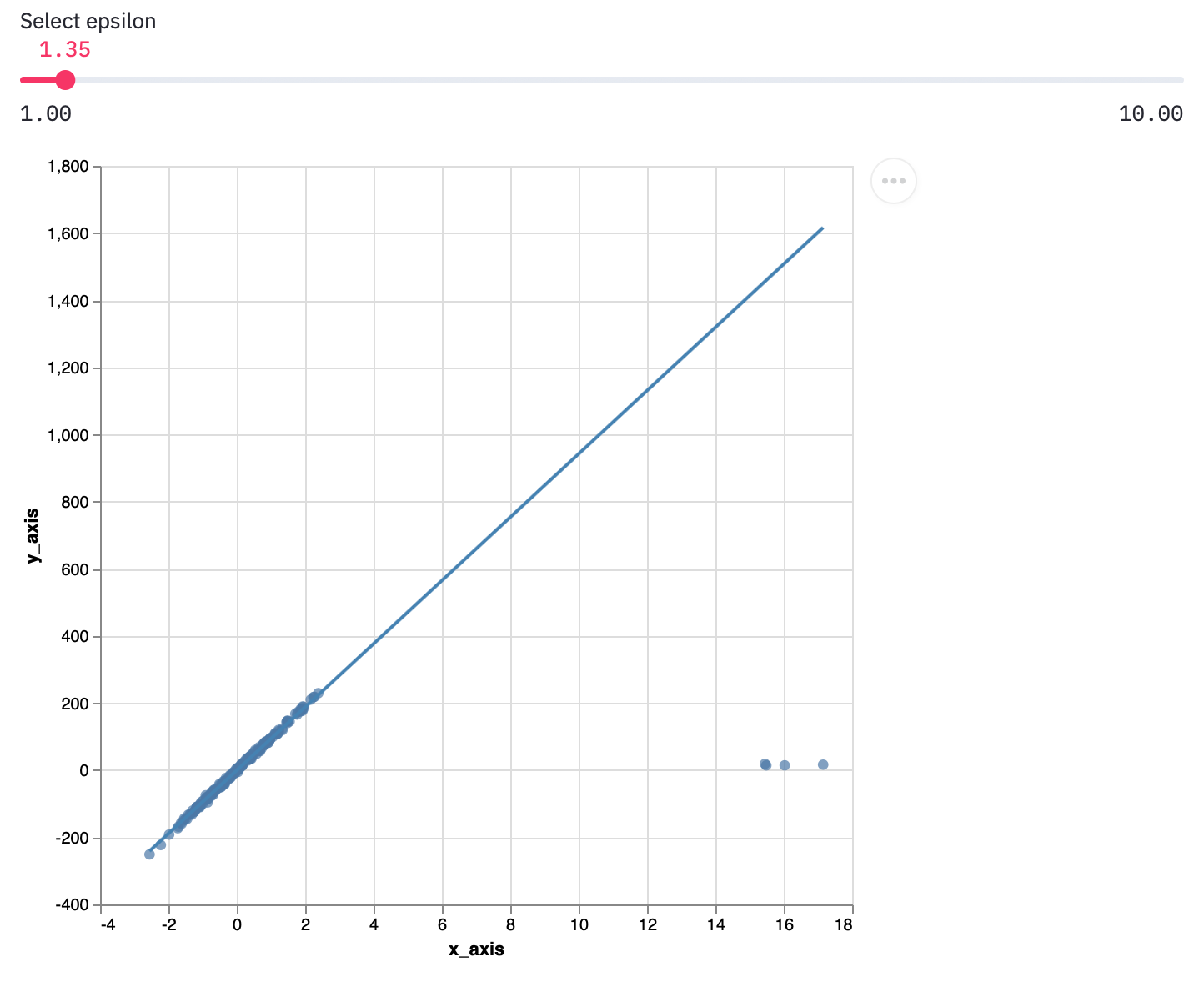
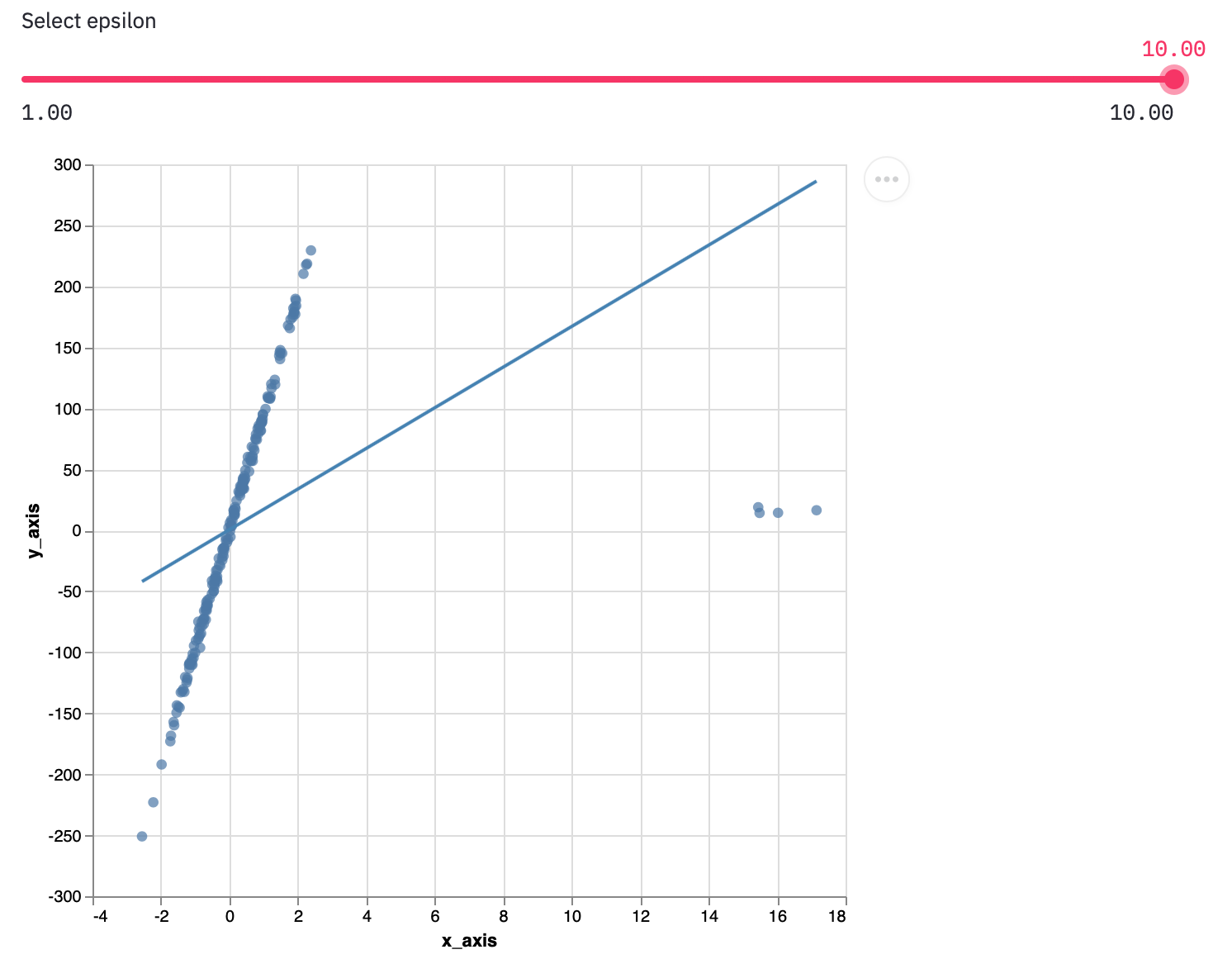
Epsilon は 1 以上の実数で、外れ値の影響度を表す。Default は 1.35 に設定されている。
Epsilon を大きくするほど、外れ値による影響を大きく受ける。(画像は
epsilon=10)
最小二乗法による線形回帰直線の作成
HuberRegressor を LinearRegression に置換すると、最小二乗法による線形回帰直線を作成できる。
- 投稿日:2020-10-17T12:00:05+09:00
Djangoチュートリアル(ブログアプリ作成)③ - 記事一覧表示編
前回、Djangoチュートリアル(ブログアプリ作成)② - model 作成、管理サイト準備編では管理サイトで記事を作成するところまで確認できました。
今回は、管理サイトで作成した記事の一覧を表示できるようにしていきます。
template 準備(ファイル作成)
最初に template を作成しましょう。
templates/blog 配下に post_list.html を作成します。└── templates └── blog ├── index.html └── post_list.htmlview の準備
ここで少し重要な説明をします。
Django ではクラスベース汎用ビュー という仕組みを使うと、簡単に model を引っ張ってきて記事を表示させたり、
テンプレートを表示させたりすることが出来、アプリ作成をグンと効率的に行うことができるようになります。
ちなみに前々回、views.py をいじったときに generic という表記がありました、これもクラスベース汎用ビューを使う準備として必要な宣言です。view.pyfrom django.views.generic import TemplateView汎用クラスビューには様々な種類があり、その中でも単純に template を表示させるためだけに使われるのが
index.html の表示に使っていた TemplateView です。
index.html の表示のために、呼び出す template を views.py の中で指定していたことになります。view.pyclass IndexView(TemplateView): template_name = 'blog/index.html'また、これまではわかりやすいように genetic で宣言してから使うクラスを指定して import していましたが
generic.xxxView の形で呼び出すこともできるので views.py を少し書き換えてあげましょう。views.py(書き換え後)from django.views import generic class IndexView(genetic.TemplateView): template_name = 'blog/index.html'これからたくさんのクラスベース汎用ビューを呼び出すことになるので、最初の宣言をスッキリとさせました。
さて、今回は template を単純に表示させるだけでなく、データベースから記事の情報モデルも呼び出してあげる必要があります。
そのため、別の ListView というクラスベース汎用ビューを使うのですが、使い方は TemplateView のときと似ています。最初に使うモデルを宣言し、クラスを記述し、呼び出すモデルを指定してあげるだけです。
views.py(ListViewを追加)from django.views import generic from .models import Post # Postモデルをimport class IndexView(genetic.TemplateView): template_name = 'blog/index.html' class ListView(generic.ListView): # generic の ListViewクラスを継承 model = Post # 一覧表示させたいモデルを呼び出しmodel = Post という記述を入れてあげることで、記事一覧が post_list という変数でリスト型として template に渡すことができます。
ここで TemplateView を使ったときのことを思い出して「templateを指定してあげるのでは?」と考えた方は鋭いです。
もちろん指定してもよいのですが、実は generic.ListView では template のファイル名をルールに沿った形にしてあげることで、明示しなくても呼び出してくれる便利機能があります。
(ただし、明示した方が第三者にとって分かりやすいので、敢えて記述する場合もあるかと思います。)ルールとしては「post_list.html」のように、model名を小文字にしたものと、ListViewならば"list"という文字列をアンダースコアで区切った文字列をファイル名にすることです。
(使うクラスによって異なってくるため、後ほど説明します)これで template である post_list.html を表示させ、同時に template に記事一覧を渡すための view の準備が整いました。
template 側で記事一覧の受け取り
post_list.html に渡されたモデルを受け取るには、Django ならではの記述方法があります。
Django の template では {% %} で囲むことで Python コードを記述でき、さらに html としてブラウザに値を表示させるには {{ }} と、中括弧を重ねたもので記述します。
今回、記事一覧は post_list というリスト型で変数が template で渡されているので for ループで展開し、それぞれの記事タイトルと日付を取り出していきます。
(各カラムのデータは、変数名にドット付きでカラム名を指定する形で取り出せます)post_list.html<h1>記事一覧</h1> <table class="table"> <thead> <tr> <th>タイトル</th> <th>日付</th> </tr> </thead> <tbody> {% for post in post_list %} <tr> <td>{{ post.title }}</td> <td>{{ post.date }}</td> </tr> {% endfor %} </tbody> </table>ルーティング設定
最後に記事一覧を表示させるための URL へアクセスした時に ListView を呼び出すよう、blog/urls.py を編集します。
blog/urls.pyfrom django.urls import path from . import views app_name = 'blog' urlpatterns = [ path('', views.IndexView.as_view(), name='index'), path('list', views.ListView.as_view(), name='list'), # ここを追加 ]今回のように、何かを表示させるときには View, Template, URL がそれぞれ絡むことを覚えておいてください。
記事一覧表示の確認
これで model を表示させる準備が整ったので runserver を実行して url にアクセスしましょう。
blogアプリの中の list という URL パスを先ほど設定したので、
127.0.0.1:8000/blog/list という URL で表示できます。
表は格好よくないですが、管理サイトから登録した記事が表示されていることが分かるかと思います。
※見た目は後で BootStrap を使って整えますが、まずは Django の基礎を理解するためにベースだけ作ってしまいます。一つだけだと分かりづらいので、ついでに記事を2つぐらい、管理サイトから追加してから再度確認してみましょう。
タイトルと日付がそれぞれ取り出せていることが分かりますね。次回は、Django アプリ上で記事を作成できるようにしていきます。
- 投稿日:2020-10-17T11:50:30+09:00
playwright-pythonで日経平均をスクレイピング
インストール
sudo apt update sudo apt install -y libwoff1 libopus0 libwebp6 libwebpdemux2 libenchant1c2a libgudev-1.0-0 libsecret-1-0 libhyphen0 libgdk-pixbuf2.0-0 libegl1 libnotify4 libxslt1.1 libevent-2.1-7 libgles2 libxcomposite1 libatk1.0-0 libatk-bridge2.0-0 libepoxy0 libgtk-3-0 libharfbuzz-icu0 libgstreamer-gl1.0-0 libgstreamer-plugins-bad1.0-0 gstreamer1.0-plugins-good gstreamer1.0-libav libnss3 libxss1 libasound2 fonts-noto-color-emoji libxtst6 libdbus-glib-1-2 libxt6 ffmpeg xvfb日本語フォントをインストール
sudo apt install fonts-ipafont-gothic fonts-ipafont-minchoplaywrightをインストール
sudo apt install python3-pip pip3 install playwright # chromium・Firefox・WebKitをインストール python3 -m playwright installスクリーンショット
from playwright import sync_playwright with sync_playwright() as p: for browser_type in [p.chromium, p.firefox, p.webkit]: browser = browser_type.launch() page = browser.newPage() page.goto("http://whatsmyuseragent.org/") page.screenshot(path=f"example-{browser_type.name}.png") browser.close()日経平均をスクレイピング
from playwright import sync_playwright with sync_playwright() as p: browser = p.chromium.launch() page = browser.newPage() page.goto("http://www.nikkei.com/markets/kabu/") # html = page.content() print(page.innerText("span.mkc-stock_prices")) browser.close()
- 投稿日:2020-10-17T11:12:06+09:00
Djangoチュートリアル(ブログアプリ作成)② - model 作成、管理サイト準備編
前回 はブログアプリの基礎となる部分を作成し、動作確認まで行うことができました。
今回は、実際に記事を登録するための準備をし、記事の作成を行いましょう。記事 model の作成
ブログで記事を管理するためには model を作成します。
model はデータベースと Django の橋渡しの役割を持っており、これのおかげで我々は SQL といったデータベース構文を意識することなくデータベースにデータを登録することができます。最初に設定する models.py では、どのようなデータを登録していくのかを定義します。
Excelの表でいうと、表の各カラムのカラム名を定義したり、各カラムに入るデータがどのようなもの(文字列や数値など)を定義するところです。今回はブログアプリであり、記事 (Post) を修正していくので Post モデルを作成します。
タイトル、本文、日付が入ればとりあえず十分です。blog/models.pyfrom django.db import models from django.utils import timezone # django で日付を管理するためのモジュール class Post(models.Model): title = models.CharField('タイトル', max_length=200) text = models.TextField('本文') date = models.DateTimeField('日付', default=timezone.now) def __str__(self): # Post モデルが直接呼び出された時に返す値を定義 return self.title # 記事タイトルを返す次に、データベースに models.py で定義した情報を反映させます。
このままデータベースに対する処理を行うわけではなく、models.py の内容を反映させるためのワンクッションとなるファイルを作成します。
ファイルの作成を自動的に Django にやってもらうことができ、次のコマンドを実行することでファイルが作成されます。python3 manage.py makemigrationsすると /blog/migrations 配下に番号付きのファイルが作成されます。
. ├── blog │ ├── __init__.py │ ├── admin.py │ ├── apps.py │ ├── migrations │ │ ├── 0001_initial.py # これが追加される │ │ └── __init__.py │ ├── models.py │ ├── tests.py │ ├── urls.py │ └── views.py ├── db.sqlite3 ├── manage.py ├── mysite │ ├── __init__.py │ ├── settings.py │ ├── urls.py │ └── wsgi.py └── templates └── blog └── index.htmlDjango アプリ作成の中でこのファイルを直接いじることはありませんが、中身はこのようになっており、これのおかげでカラムの作成などを Django が一気にやってくれます。
0001_initial.py# Generated by Django 3.1 on 2020-10-17 01:13 from django.db import migrations, models import django.utils.timezone class Migration(migrations.Migration): initial = True dependencies = [ ] operations = [ migrations.CreateModel( name='Post', fields=[ ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')), ('title', models.CharField(max_length=200, verbose_name='タイトル')), ('text', models.TextField(verbose_name='本文')), ('date', models.DateTimeField(default=django.utils.timezone.now, verbose_name='日付')), ], ), ]さて、この migration ファイルを使ってデータベースにテーブルを作成することになりますが
反映もコマンド一発で Django が勝手にやってくれます。
以下のコマンドを実行しましょう。(blog) bash-3.2$ python3 manage.py migrate成功すると、一発目は大量の OK 表示とともに通常のコマンドラインに戻るかと思います。
Operations to perform: Apply all migrations: admin, auth, blog, contenttypes, sessions Running migrations: Applying contenttypes.0001_initial... OK Applying auth.0001_initial... OK Applying admin.0001_initial... OK Applying admin.0002_logentry_remove_auto_add... OK Applying admin.0003_logentry_add_action_flag_choices... OK Applying contenttypes.0002_remove_content_type_name... OK Applying auth.0002_alter_permission_name_max_length... OK Applying auth.0003_alter_user_email_max_length... OK Applying auth.0004_alter_user_username_opts... OK Applying auth.0005_alter_user_last_login_null... OK Applying auth.0006_require_contenttypes_0002... OK Applying auth.0007_alter_validators_add_error_messages... OK Applying auth.0008_alter_user_username_max_length... OK Applying auth.0009_alter_user_last_name_max_length... OK Applying auth.0010_alter_group_name_max_length... OK Applying auth.0011_update_proxy_permissions... OK Applying auth.0012_alter_user_first_name_max_length... OK Applying blog.0001_initial... OK Applying sessions.0001_initial... OK管理サイトでテーブルを確認
いきなり記事を作成していってもよいですが、まずはちゃんとテーブルを作成されているかを UI で確認すると安心かと思います。
Django では特別用意しなくても管理サイトの UI が自動で作られ、その中で作られたテーブルを確認したり、はたまた手動で作成、編集、削除なんかもできたりします。
そのための準備をここでは行っていきます。modelを管理サイトに反映
blogディレクトリ配下に admin.py というファイルが最初から作成されていますが、ここに先程作成した model の情報を記述することで管理サイトでこねくり回すことができるようになります。
blog/admin.pyfrom django.contrib import admin from .models import Post # 追加 admin.site.register(Post) # 追加管理ユーザを作成
管理サイトを使うためには、それ相応の権限を持ったユーザ(アカウント)、つまり superuser を作成してあげる必要があります。
これも Django のコマンドでサクッと作ることができます。python3 manage.py createsuperuser実行するとユーザ名、メールアドレス、パスワードを聞かれるのでそれぞれ入力しましょう。
※開発環境であれば、メールアドレスは適当なものでも問題ありません。作成が完了すると以下のような表示がコマンドライン上に出ます。
Superuser created successfully.管理サイトにログイン
さて、それでは Django の管理サイトに実際にアクセスしてみましょう。
まずはサーバを起動します。
python3 manage.py runserver次にブラウザのアドレスバーに管理サイトのアドレスを入力しますが、
プロジェクトの urls.py に以下の記述があったことはお気づきでしょうか。mysite/ursl.pyurlpatterns = [ path('blog/', include('blog.urls')), path('admin/', admin.site.urls), # ここ ]この記述は最初から存在しており、デフォルトでは "127.0.0.1:8000/admin" で管理サイトにアクセスすることができます。
(通常はあまり変更することはありませんが、本番環境ではセキュリティ上、アドレスを変更しておく場合もあります)それでは Chrome 等で 127.0.0.1:8000/admin にアクセスします。
このようにログイン画面が表示されたら成功です。
先ほど superuser を作成したときの情報を入力し、ログインを選択します。
ログインに成功すると、管理画面が表示されます。
このような管理サイトを作成するには通常のフレームワークだと結構な準備が必要になりますが、デフォルトで用意されているのが Django の用意されているのがよいところです。また、BLOG というアプリ欄の中で Posts という model が反映されていることも分かりますね。
(Postが複数存在することになるので、Postsという表記になっていることもポイントです)ここで 追加 ボタンから記事を手動で作成することも出来ます。
保存を選択すると、実際に記事を作成することもできます。
更には作成した記事を編集したり、削除したりすることもできます。便利ですね。
次回は、記事をアプリ上で表示(htmlとして表示)させるようにしていきます。
- 投稿日:2020-10-17T10:06:55+09:00
Djangoチュートリアル(ブログアプリ作成)① - 準備、トップページ作成編
今回は Django を使って、記事を投稿できるブログアプリを作成していきます。
シリーズに分けて紹介していきますが、まずはローカルで作成した上で Docker 構成にしたり、AWS にデプロイしたり、CircleCI で自動テスト・デプロイまでをシリーズ化していきます。
Django とは?
Djangoは Python で実装できる Web アプリケーションフレームワークです。
フレームワークとは、アプリケーションを開発する際に使われる機能がまとまったソフトウェアです。
フレームワークを導入することで、効率よく Web アプリを進めることができます。今回は Blog アプリを作っていきますが、Django を使えばデータベースを用いた、コンテンツ管理システムやWikiからソーシャルネットワーク、ニュースサイトなど、高品質なWebアプリケーションを簡単に、少ないコードで作成できます。シンプルなWebアプリケーションであれば、数分間で作れてしまう場合もあります。もちろん、機能を拡張して複雑なWebアプリケーションを作成することもできます。
また、Djangoは、Instagram など、有名な Webアプリでも使われており、Ruby でいう Ruby on Rails に相当する注目のフレームワークとなっています。
環境構築
まずは作業用のディレクトリを作成します。
ここでの名前はなんでもよいですが、とりあえず blog としておきます。mkdir blog cd blogpipenv のインストール
ベースとなる環境は汚さない方が他のモジュールなどの影響を排除できるため、pipenv を使って仮想環境を構築しましょう。
pip install pipenv # 環境によっては直接 pip を使えない場合もあるので、python3 -m pip install pipenv でインストールしますインストールできたら、作業用フォルダの中で下記のコマンドを実行します。
pipenv shell実行後、仮想環境に入ることが出来るとディレクトリ名に従った文字列がコマンドラインの冒頭に表示されるようになります。
(blog)bash-3.2$Django をインストール
直接 pipenv install django とでも実行して Django をインストールしてもよいですが、
後々 Docker を使うことを考えて、requirements.txt というファイルを作業用ディレクトリ直下に作成して
必要となるモジュールを記述していくことにします。いまは Django だけが必要なので、バージョン情報とともに以下のように記載します。
requirements.txtDjango==3.1.0※今回は Django 3.1.0 で作っていきますが Django 2.2 あたりでも問題なく動くとは思います
モジュールのインストール
下記のコマンドを実行することで、requirements.txt に基づきモジュールをインストールします。
ここでは Django だけがインストールされるはずです。pipenv install -r requirements.txtDjango プロジェクトの作成
blog ディレクトリ直下で実行
django-admin startproject mysite親プロジェクト直下でのファイル構成はこのようになっているかと思います。
├── Pipfile ├── Pipfile.lock ├── mysite │ ├── manage.py │ └── mysite │ ├── __init__.py │ ├── settings.py │ ├── urls.py │ └── wsgi.py └── requirements.txtDjango サーバのテスト起動
開発用サーバを起動する機能がついています。
(Ruby on Rails をやったことがある人は rails -s というと分かりやすいかと思います)これを実行するには manage.py ファイルが置いてあるディレクトリに移動する方が便利なので、mysite/mysite ディレクトリに移動してから実行します
cd mysite python3 manage.py runserver正常に実行できると下記のような出力が出ます。
October 16, 2020 - 21:30:23 Django version 3.1, using settings 'mysite.settings' Starting development server at http://127.0.0.1:8000/ Quit the server with CONTROL-C.なお、この部分は migrate というデータベースへの統合処理が済んでいないために出力されるメッセージですが、いまのところ気にしないで大丈夫です。
You have 18 unapplied migration(s). Your project may not work properly until you apply the migrations for app(s): admin, auth, contenttypes, sessions. Run 'python manage.py migrate' to apply them.さて、これで Django の開発用サーバが起動したのでブラウザから確認します。
Chrome などのブラウザのアドレスバーに「127.0.0.1:8000」と入力して Enter を押下します。
これがすべての始まりです。この画面が出ていれば、最初のステップは完了しています!おめでとうございます。
プロジェクトの設定
さて、先ほどテストサーバへアクセスした時に英語での表記になっていましたね。
こういった設定は mysite/settings.py で設定することができ、デフォルトでは英語圏に合わせた言語表示、およびタイムゾーンになっています。mysite/settings.py(before)LANGUAGE_CODE = 'en-us' TIME_ZONE = 'UTC'これを次のように変更してあげます。
mysite/settings.py(after)LANGUAGE_CODE = 'ja' TIME_ZONE = 'Asia/Tokyo'もう一度テストサーバへアクセスすると、日本語表記になっていることが分かるかと思います。
(また、この画面からでは確認できませんがタイムゾーンも東京設定になっています)
Django アプリの作成
先程 start-project コマンドでプロジェクトを作成しましたが、次はアプリケーションを作っていきます。
混乱しがちですが、ベースとなるプロジェクトと個別のアプリは別物です。公式ページではこのような説明です。
プロジェクトとアプリの違いは何でしょうか? アプリとは、ウェブログシステム、公的記録のデータベース、小規模な投票アプリなど、何かを行う Web アプリケーションです。プロジェクトは、特定のウェブサイトの構成とアプリのコレクションです。プロジェクトには複数のアプリを含めることができます。 アプリは複数のプロジェクトに存在できます。
では、blog アプリを作っていきましょう。mysite プロジェクトリ (manage.py ファイルがある場所) の直下で下記コマンドを実行します。
python3 manage.py startapp blog現在のディレクトリ構成はこのようになっています。
. ├── db.sqlite3 ├── manage.py ├── mysite │ ├── __init__.py │ ├── settings.py │ ├── urls.py │ └── wsgi.py └── blog ├── __init__.py ├── admin.py ├── apps.py ├── migrations │ └── __init__.py ├── models.py ├── tests.py └── views.pyblog 配下に様々なファイルが作成されていることが分かるかと思います。
ここで、このアプリが作成されたことをプロジェクトに教えてあげる必要があります。
mysite/setting.py の中に "INSTALLED_APPS" という欄がありますので、その中で blog アプリの存在を教えてあげましょう。
mysite/settings.pyINSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'blog.apps.BlogConfig', # ここを追加 ]template, view, url の設定
まずは「 template をそれぞれ変更していきます。
template は見た目を作るための部分であり、html ファイルに相当します。
mysite プロジェクト直下に templates フォルダ、その下に blogフォルダ、さらにその下に index.html を作成します。
. ├── blog │ ├── __init__.py │ ├── admin.py │ ├── apps.py │ ├── migrations │ │ └── __init__.py │ ├── models.py │ ├── tests.py │ └── views.py ├── db.sqlite3 ├── manage.py ├── mysite │ ├── __init__.py │ ├── settings.py │ ├── urls.py │ └── wsgi.py └── templates └── blog └── index.html ←ここに作成index.html の中身はとりあえず適当で大丈夫です。
index.html<h1>Hello, from Django!</h1>また、templates フォルダをどこに作ったかをプロジェクトに教えて上げる必要があります。
INSTALLED_APPS を設定したときと同様に、settings.py に下記の記述を入れます。settings.pyTEMPLATES = [ { 'BACKEND': 'django.template.backends.django.DjangoTemplates', 'DIRS': [os.path.join(BASE_DIR, 'templates')], # ここを修正 'APP_DIRS': True,次に views.py を修正していきます。
先ほど作った template である index.html を呼び出します。blog/views.pyfrom django.views.generic import TemplateView class IndexView(TemplateView): template_name = 'blog/index.html'URL の設計
次に、blog アプリ専用のルーティング設定を作成します。
ルーティング設定は「urls.py」というファイルで設定していきます。まずはじめに説明をしますと、プロジェクト全体のルーティングを司る urls.py と、アプリ内の urls.py それぞれでルーティングを設定します。
最初に mysite 直下の urls.py から編集します。
mysite/urls.pyfrom django.contrib import admin from django.urls import include, path urlpatterns = [ path('blog/', include('blog.urls')), path('admin/', admin.site.urls), ]後に作成する blog アプリ用の urls を、urlpatterns 内で読み込むことになります。
では mysite 直下にのみ urls.py が作成されていますが、blog 直下にも自分で「urls.py」を作成します。
エディタでもよいですし、アプリの blog ディレクトリ内で下記コマンドを実行してもよいでしょう。/blogtouch urls.pyblog 配下はこのようなファイル構成です。
. ├── __init__.py ├── admin.py ├── apps.py ├── migrations │ └── __init__.py ├── models.py ├── tests.py ├── urls.py └── views.py作成した urls.py の中身はこのように変更することで、先程 views.py で作成した関数(=index.htmlを呼び出す処理)のルーティングを設定します。
blog/urls.pyfrom django.urls import path from . import views app_name = 'blog' urlpatterns = [ path('', views.IndexView.as_view(), name='index'), ]ちなみに name='index' を設定しておくことで「blog:index」という名前を使ってこの url を逆引きで呼び出すことができるようになります。
この時点で index.html を呼び出せるかの確認を行います。
manage.py が置いてあるディレクトリで runserver を実行します。
python3 manage.py runserver無事に通ったら、今度はブラウザで 127.0.0.1:8000/blog へアクセスします。
これは先程 mysite/urls.py で blog 付きのアドレスでアクセスされたときに、blog アプリ内に記述した内容を動作させるようにしているためです。アクセスし、index.html の中身が表示されれば成功です。
次回は models を作成し、実際に記事を登録するための準備をします。