- 投稿日:2020-10-17T22:49:40+09:00
Amazon Linux 2をVirtualBoxで実行する
何番煎じかわかりませんが、Amazon Linux 2をVirtualBoxで実行しました。
公式ドキュメントはこちらです。
https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/amazon-linux-2-virtual-machine.html公式ドキュメントでは、カスタマイズしたseed.isoを作る手順が載っていますが、サンプルのseed.isoも用意されておりますので、こちらを使って起動してみます。
準備
ディスクイメージ(vdi)
https://cdn.amazonlinux.com/os-images/latest/virtualbox/サンプルseed.iso
https://cdn.amazonlinux.com/os-images/latest/2020/10/17時点では、
latestは2.0.20200917.0にリダイレクトされます。サンプルseed.isoの内容
サンプルseed.isoでは、以下の設定がされています。
ホスト名 amazonlinux.onprem
ユーザー
user1(パスワードamazon)
user2(パスワードamazon)?
user3(パスワード設定無し、sshのキー指定あり)
ec2-user(パスワードamazon)とりあえずseed.isoで起動して、後で設定を変えればいいような気もします。
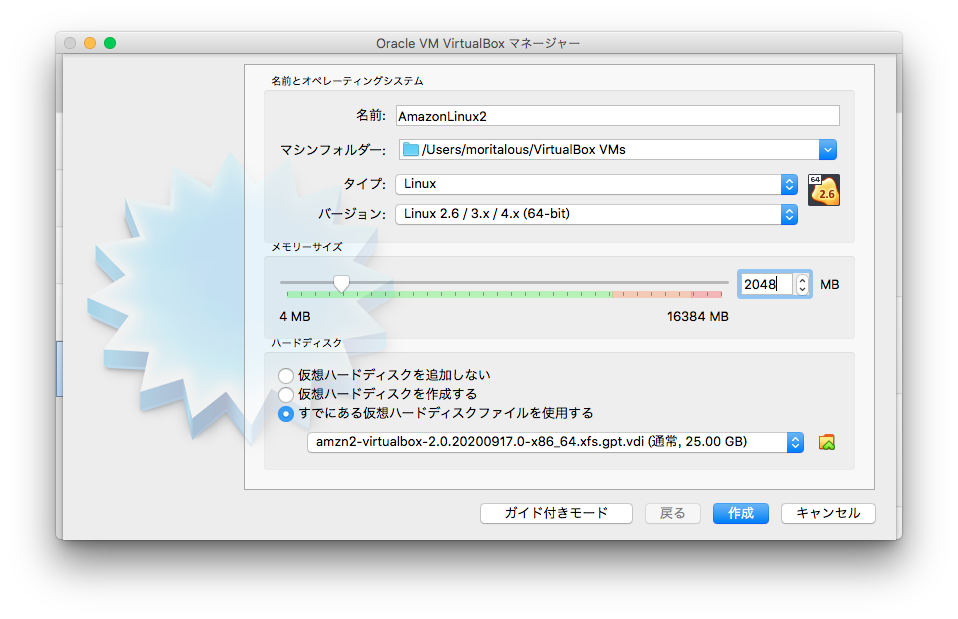
仮想マシンの作成
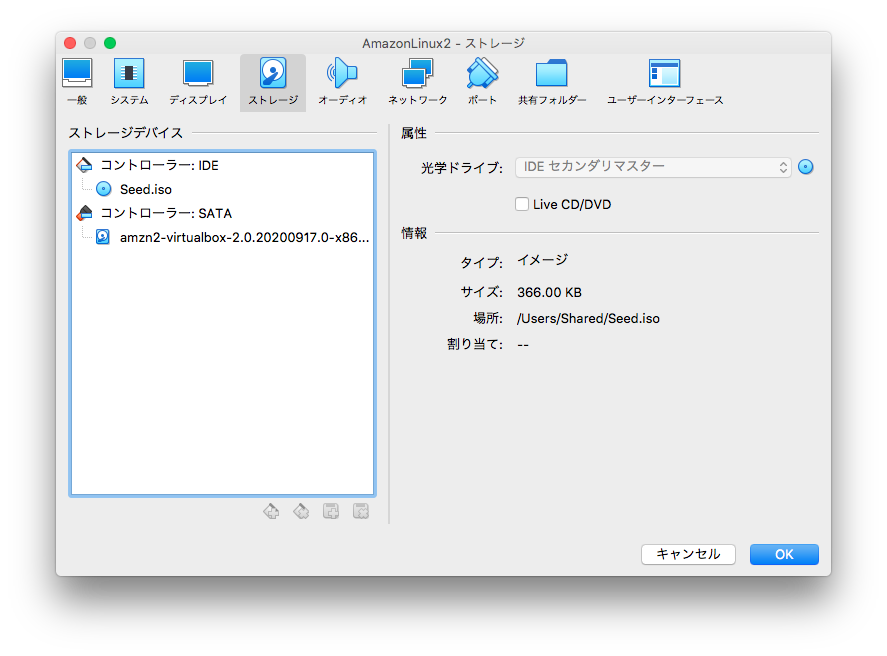
入手したvdiファイルをハードディスクとして設定し、seed.isoを光学ドライブとして設定するだけです。
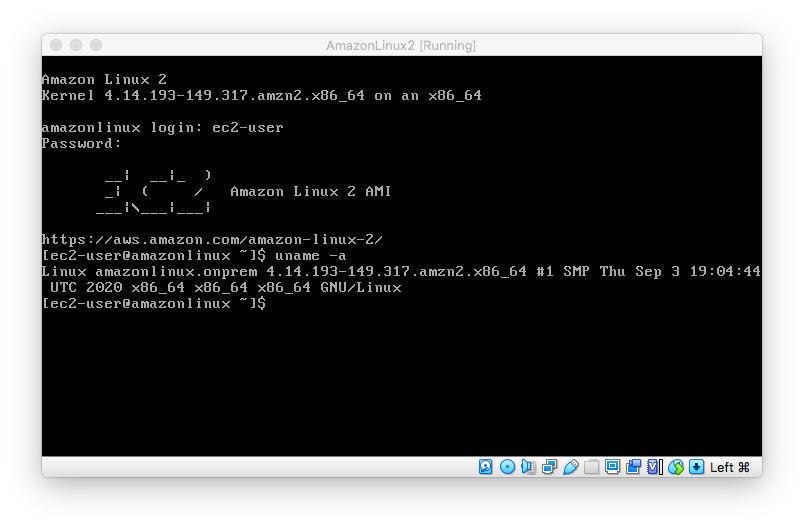
起動
ec2-user(パスワードamazon)でログインできます。
おまけ GUIとVNCをインストールする
https://aws.amazon.com/jp/premiumsupport/knowledge-center/ec2-linux-2-install-gui/
に従い、mateデスクトップとTigerVNCをインストールし、GUIでアクセスしてみます。sudo amazon-linux-extras install mate-desktop1.x sudo bash -c 'echo PREFERRED=/usr/bin/mate-session > /etc/sysconfig/desktop' sudo yum install tigervnc-server vncpasswd sudo cp /lib/systemd/system/vncserver@.service /etc/systemd/system/vncserver@.service sudo sed -i 's/<USER>/ec2-user/' /etc/systemd/system/vncserver@.service sudo systemctl daemon-reload sudo systemctl enable vncserver@:1 sudo systemctl start vncserver@:1かなり味気ない見た目ですが、VNCでアクセスできました。
- 投稿日:2020-10-17T22:13:45+09:00
AWS lightsail+お名前ドットコム、で30分でWordPress立ち上げ:チュートリURLと注意点メモ
注意点
・SSH接続するまでに、5分くらい待つ必要あり
・ドメインを買うのは、amazon routeからだと高いから、お名前ドットコムとかが良いと思う。
(amazon route→11ドル、お名前ドットコム→セールで140円)
・静的IPに紐付けした後は、WordPress管理画面のドメインもそっちになるから注意
・最初、英語表記になる(設定で変えられそうだけど、別に不便がないからこのまま)
- 投稿日:2020-10-17T21:31:24+09:00
EC2にRAILSをデプロイ
- 投稿日:2020-10-17T20:45:43+09:00
AWS Lambdaからツイートする
はじめに
引き続き、退社情報自動通知機能を作っていきます。
前回の記事で、スマホからAWSに位置情報を送信することができました。
次は、AWS Lambdaを使って、Twitterと接続します。通知手段について
前提として、通知先は妻のiPhoneを想定しているので、特殊な設定はしたくありません。
簡単にAWSから第三者のスマホに通知するには以下の方法があげられます。
・LineBot
・TwitterBot
・メール
この中で、一番実装が早そうなTwitterを用いて、通知します。
(もっと簡単な方法があったら教えてください。)Twitter APIの利用登録
Botのように、プログラムを用いてツイートするためには、「Twitter API」の利用登録をする必要があります。
利用登録の前に、まだTwitterのアカウント登録をしていない方は、しておいてください。
なお、アカウントにメールアドレスも登録しておかないと、「Twitter API」の使用登録はできません。下記サイトにアクセスし、TwitterAPIの利用登録を行います。
https://developer.twitter.com/en/apps
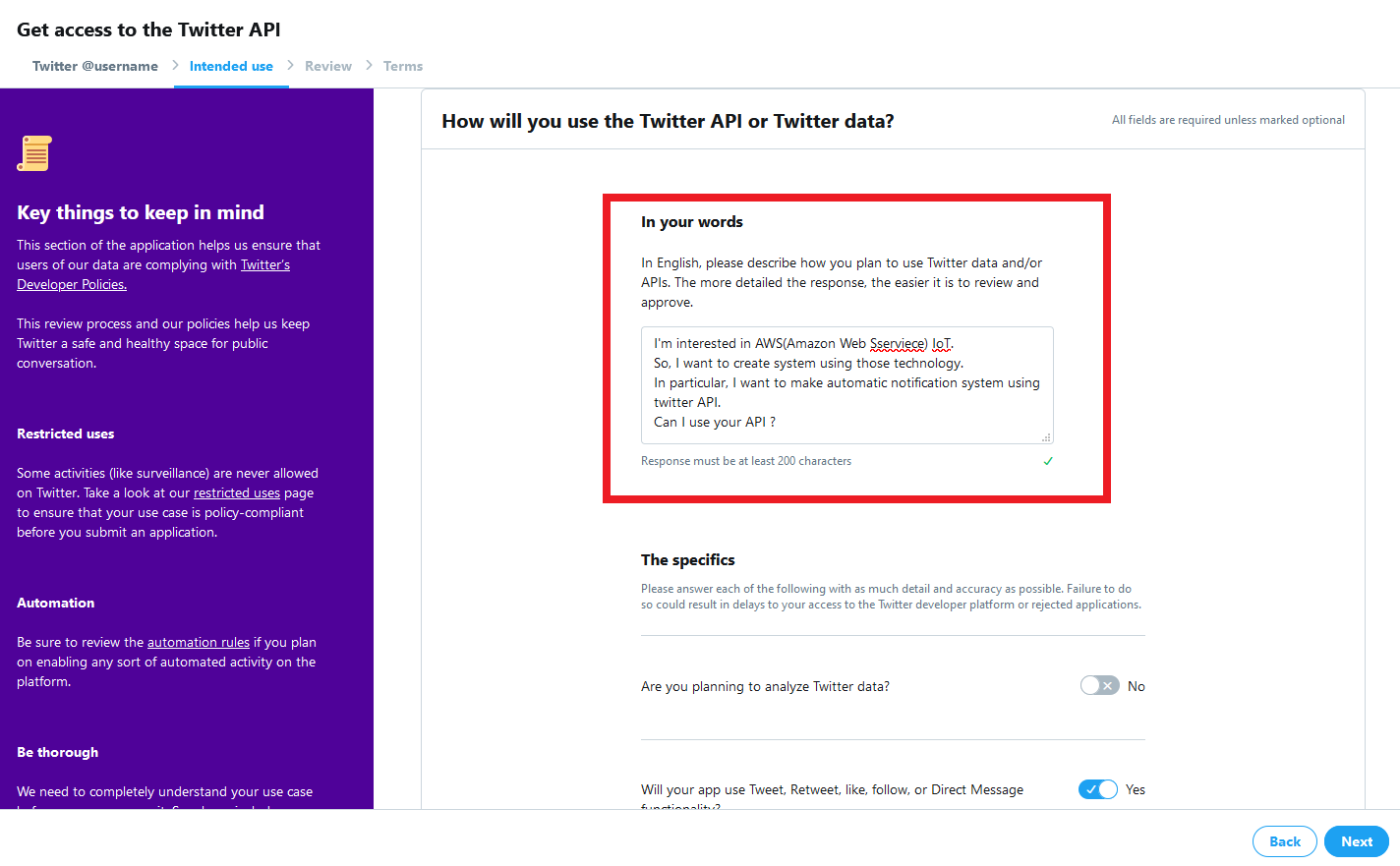
利用用途が問われます。
今回は趣味(Hobbyist)でBotを作成するので「Making a Bot」を選択します
以後は質問に淡々と答えていきます。
英語で答える必要があるので、人によっては時間がかかるかもしれません。
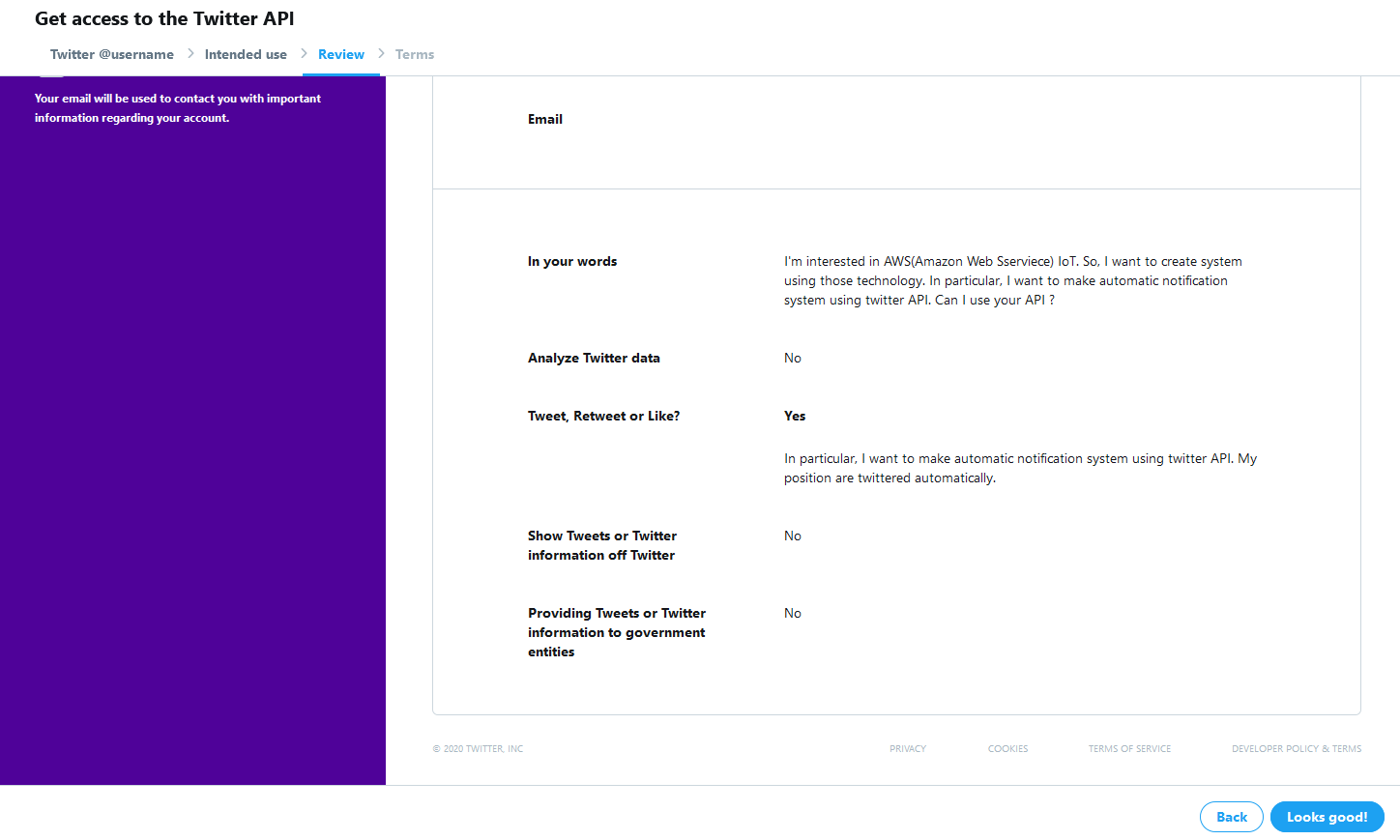
最後に確認画面が出るので、「Looks good!」をクリックします。
利用条約に目を通します。
この画面が出ればOKです。
登録したメールアドレスに確認用メールが届いているので、そちらを開いて登録します。
Twitter APIの初期設定
Twitterの開発者用画面にログインすると、アプリの名前を聞いてくるので、適当に答えます。
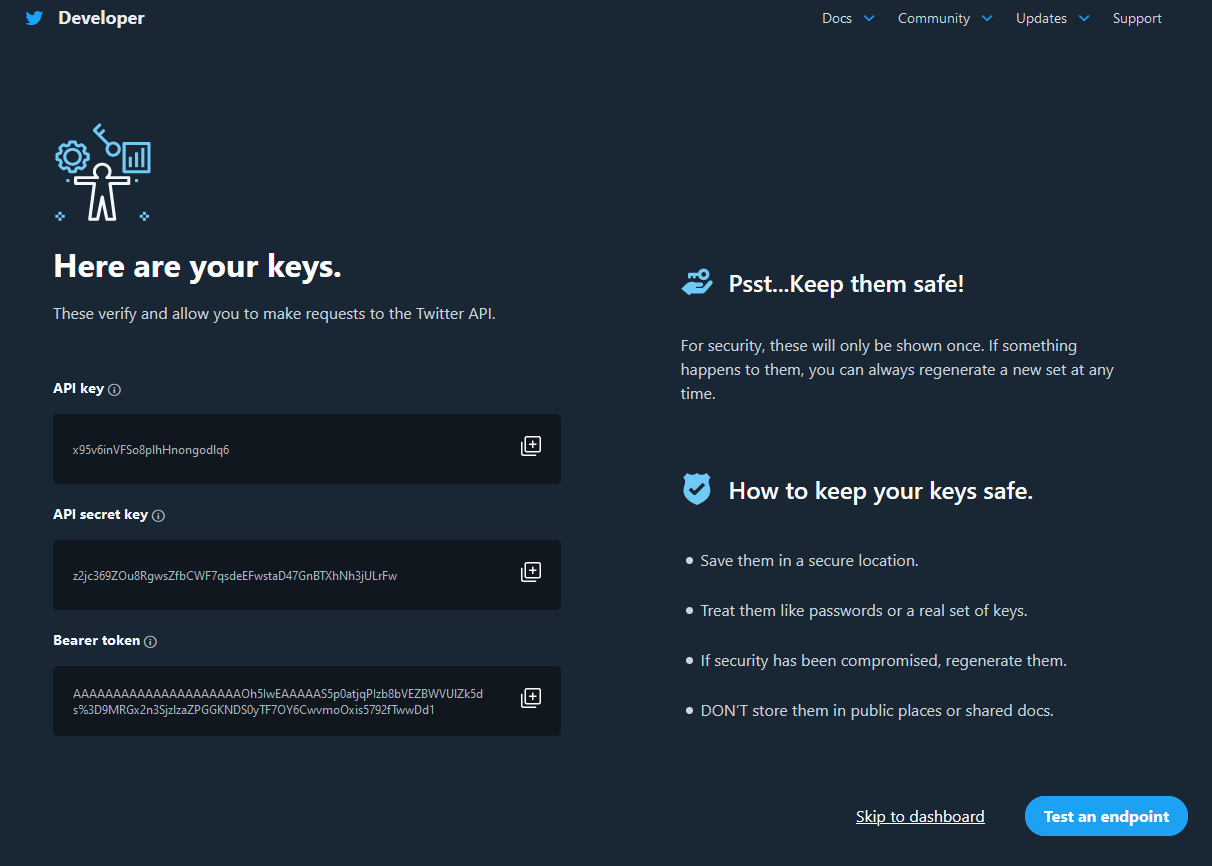
ここで、プログラムからツイートするための鍵が表示されますが、あとで再発行するので、無視して大丈夫です。
「Test an endpoint」をクリックします。
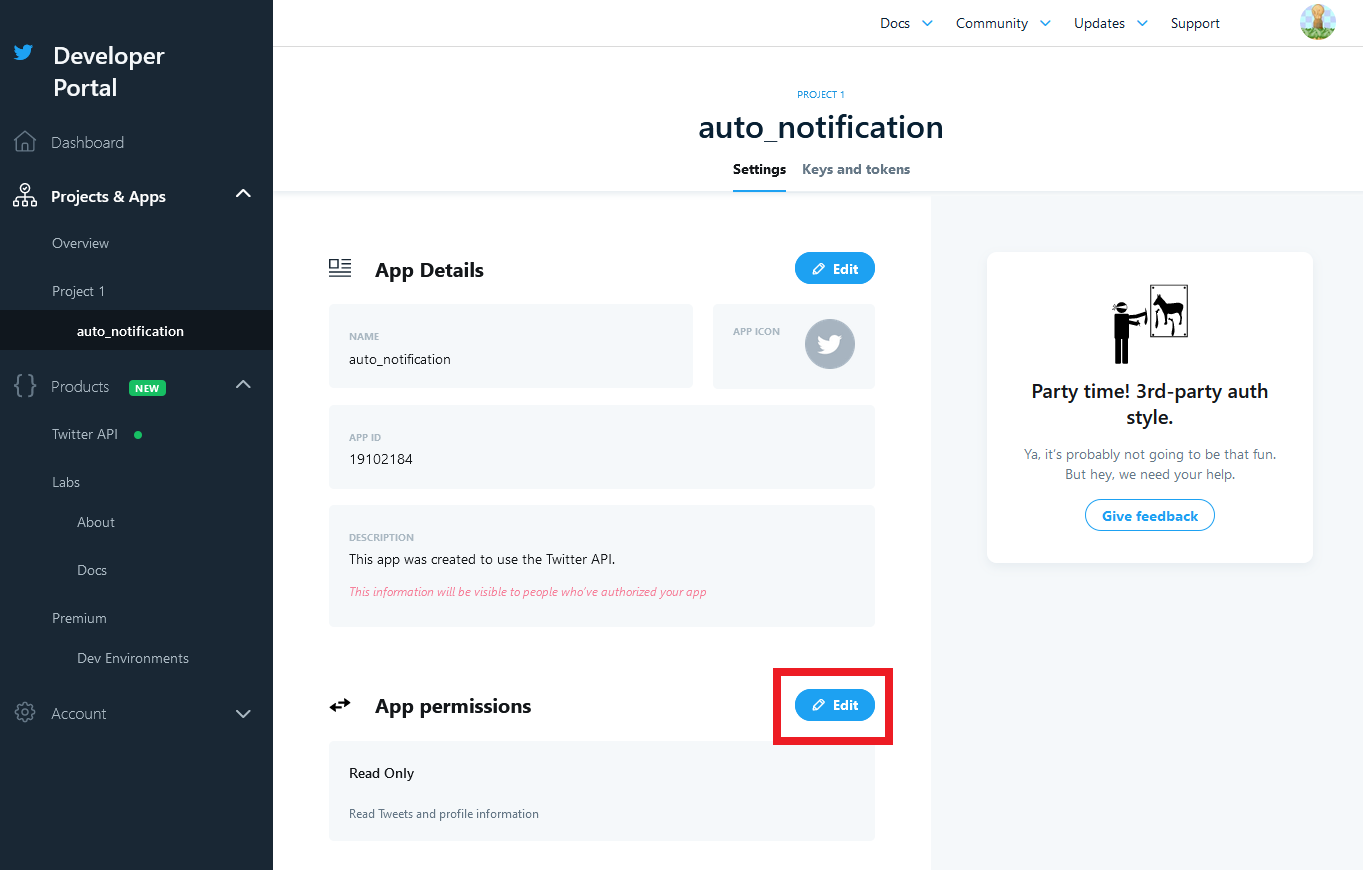
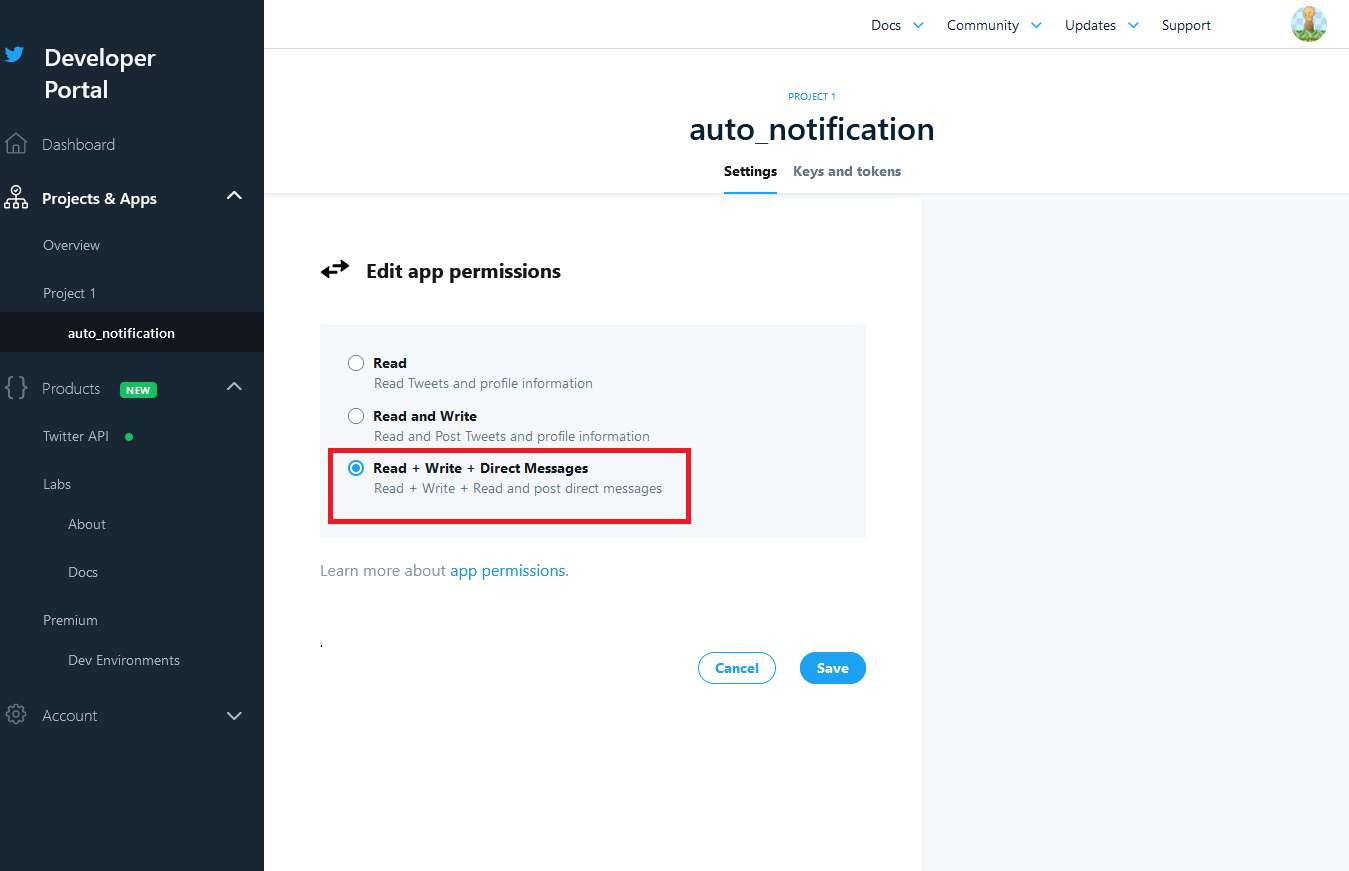
アプリの登録がおわったら、権限の設定を行います。
初期状態だとツイートの読み込みしかできません。
この権限の設定をしないと、プログラムからツイートできないため、後々エラーが発生します。画面右上の「Developer Portal」を開きます。
画面左のタブの「Project & Apps」から先ほど名前を付けたアプリ名を選択します。
すると、アプリの設定画面が出るので、「App Permissions」の「Edit」をクリックします。
Read(読み込みのみ)になっているので、「Read + Write + Direct Message」に変更します。
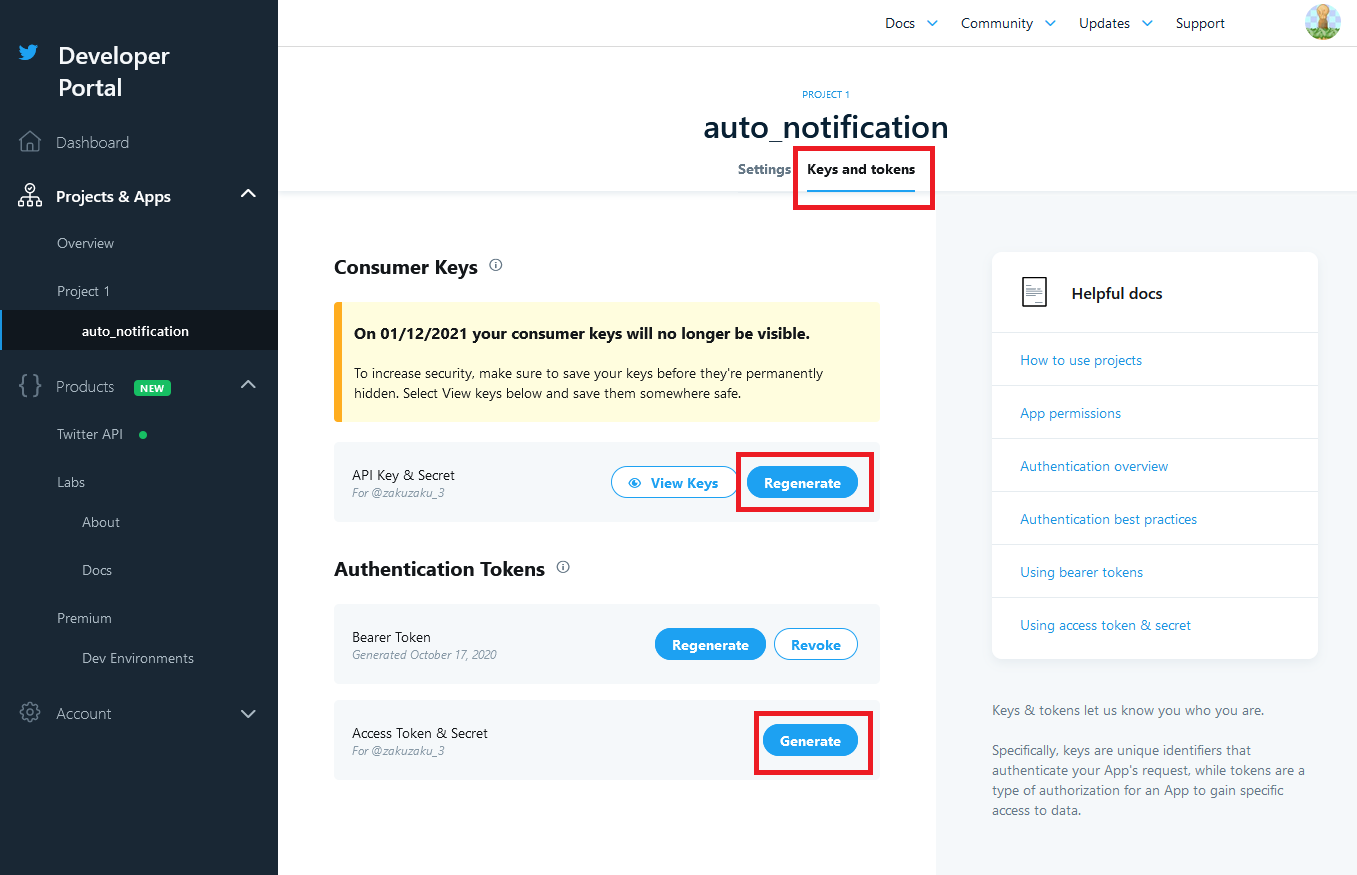
次に、APIを利用するため、KeyとTokenを確認します。
「API Key & Secret」をRegenerateし、①API keyと②API key secretをメモしてください。
また、「Access Token & Secret」をGenerateし、③Access tokenとAccessと④token secretをメモしてください。
後にAWS Lamdaにこの4つの情報を入力します。
これでTwitter APIの設定は終わりです。
AWS Lambdaの構築
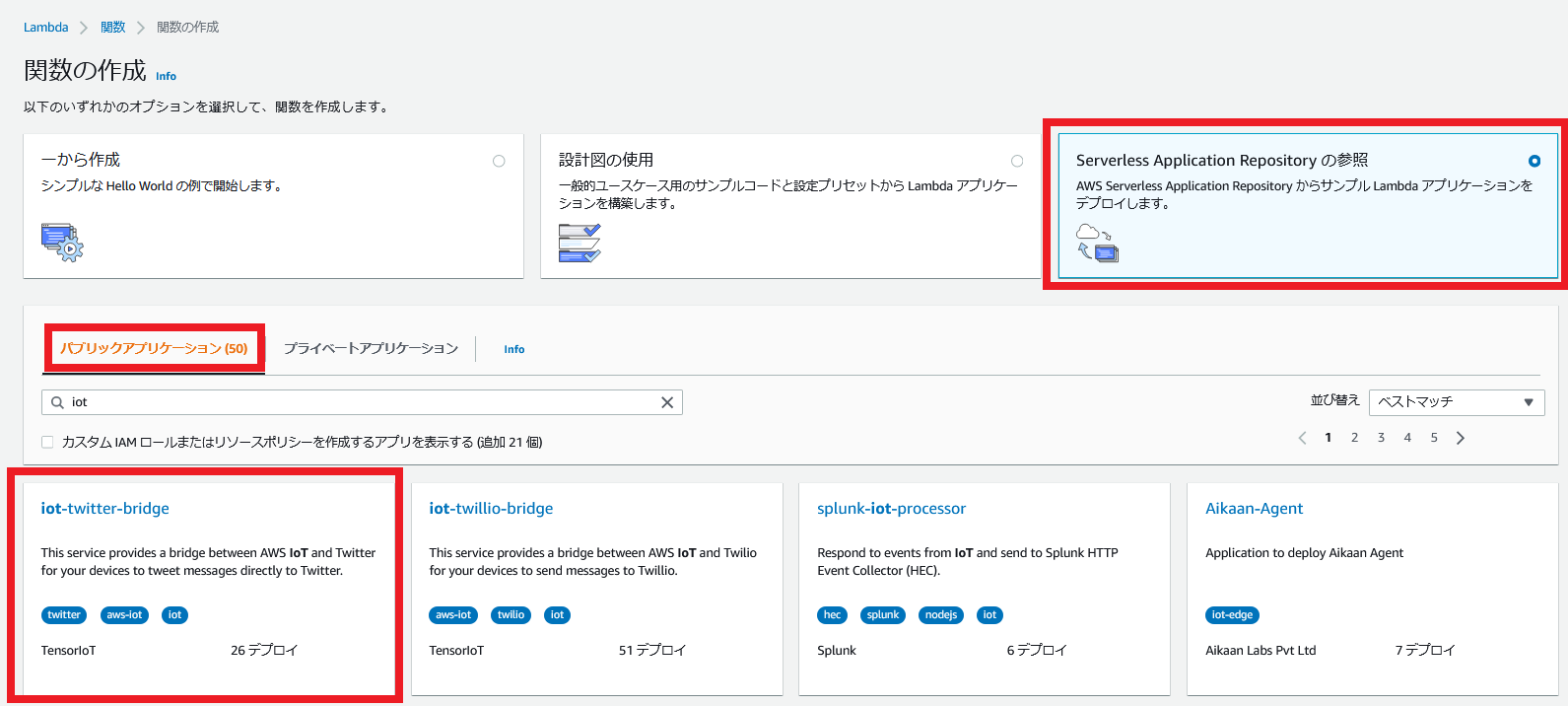
「Lambda>関数」から、関数の作成を行います。
Serverless Application Repository>パブリックアプリケーションを選択して、「iot」で検索し、iot-twitter-bridgeを選択します。
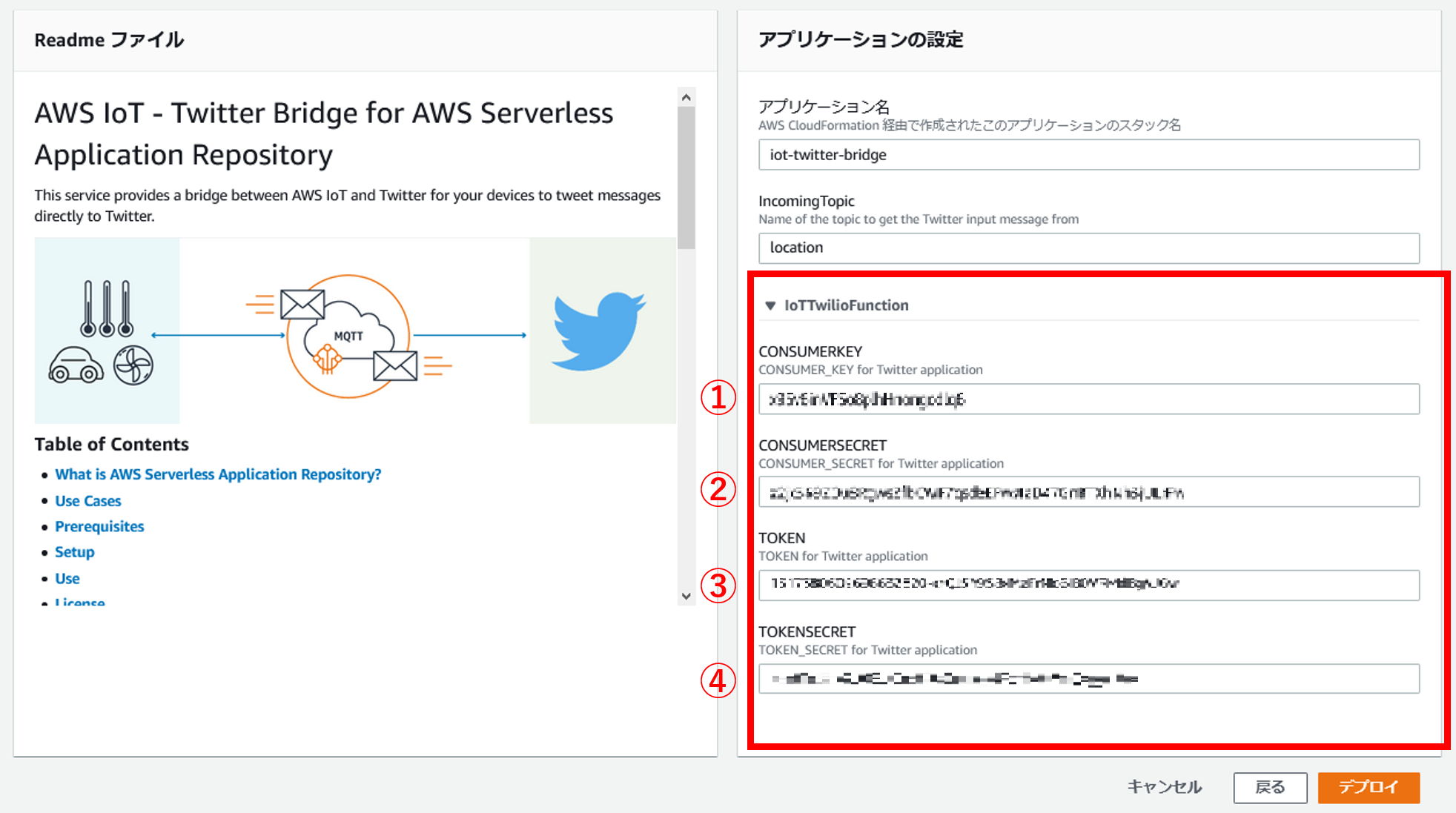
アプリケーションの設定で、先ほどTwitterAPIでメモした4つの情報を入力します。
用語が統一されていないのですが、CONSUMER_KEYがAPI keyです。
これでLambda関数が作成できました。
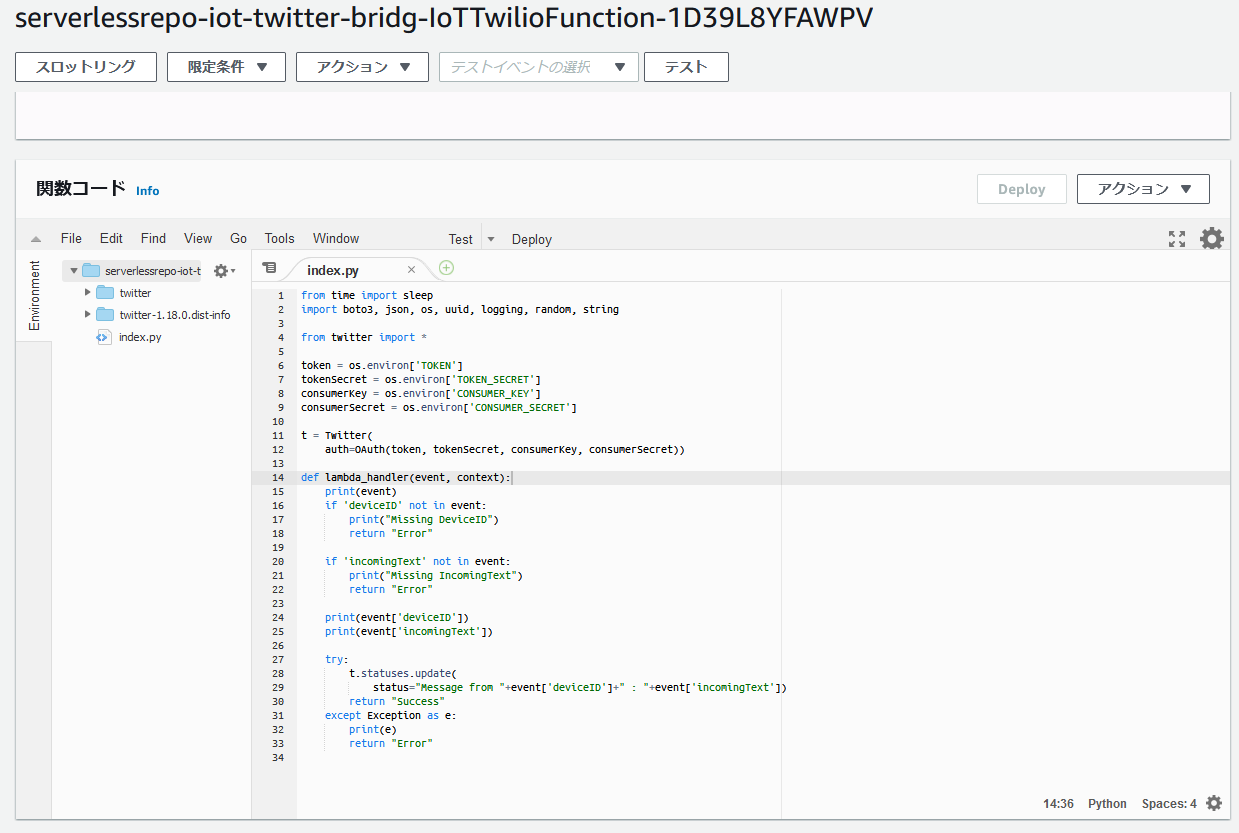
デフォルトの関数コードを確認しましょう。
json形式で、deviceIDとincomingTextがトリガーから入力され、その情報をツイートする仕組みみたいです。
とりあえず、関数はそのままにしてTwitterAPIと接続テストします。
テスト
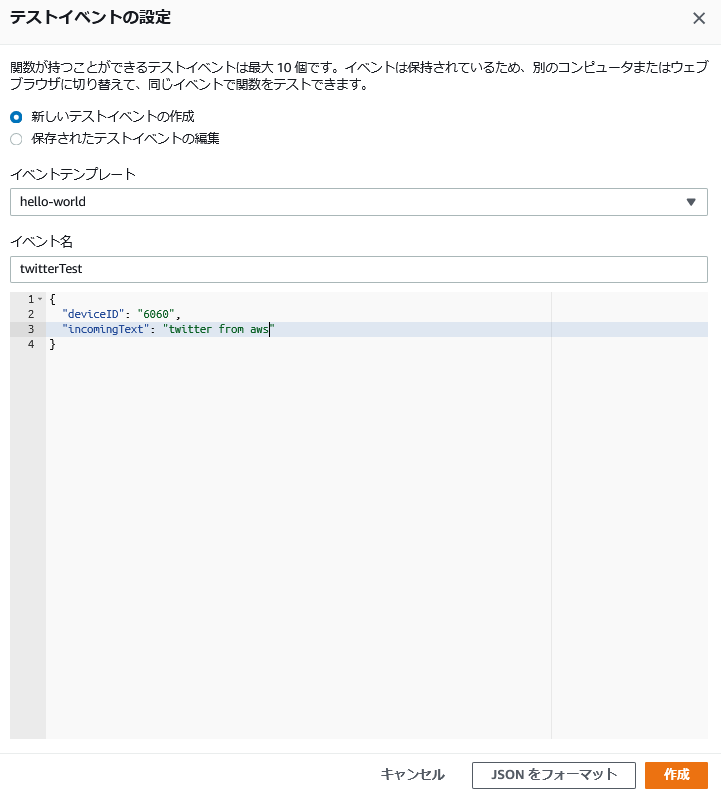
テストイベントを作成します。
下記画像のようにhello-worrldテンプレートを使用し、twitterTestイベントを作成します。
一応、中身を貼り付けておきます。
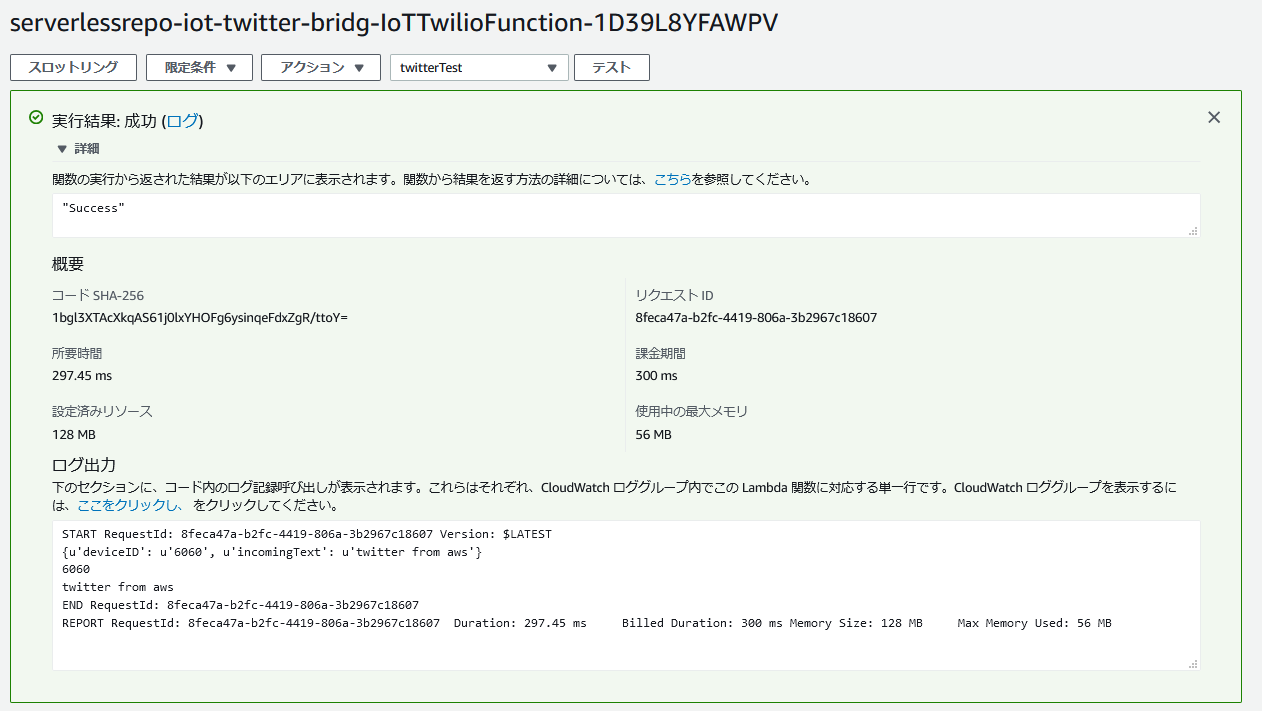
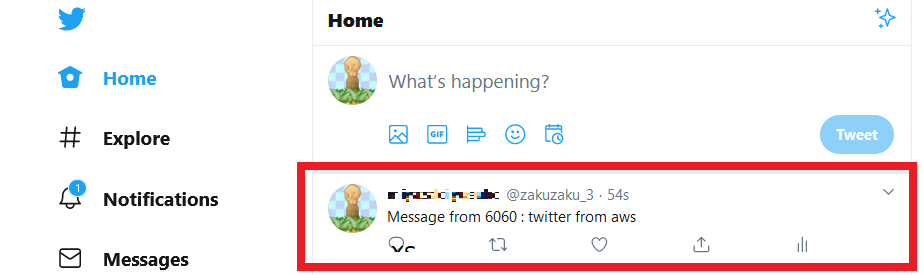
{ "deviceID": "6060", "incomingText": "twitter from aws" }テストします。
下記画像のようにSuccessが表示されたら成功です。
Twitter側も確認します。
おつかれさまでした。ちなみに、同じ内容でテストするとエラーが帰ってきます。
同じ内容で連続投稿させないためのTwitterの仕様だそうです。details: {u'errors': [{u'message': u'Status is a duplicate.', u'code': 187}]}おわりに
退社自動通知機能の作成を目的とし、AWSからツイートするところまでできました。
あとはIotとLambdaを接続し、関数を少しいじくればできそうですね。参考URL
いつも感謝しています。
twitterアプリの作成
https://yosiakatsuki.net/blog/create-twitter-application/
- 投稿日:2020-10-17T19:22:20+09:00
Golangはじめて物語(第4話: ローカルリポジトリで共通モジュール管理編)
はじめに
Golangシリーズ4回目。
過去の3回はこちら。
- Golangはじめて物語(APIGateway+Lambdaといっしょ編)
- Golangはじめて物語(第2話: Gin+ECS+Fargateといっしょ編)
- Golangはじめて物語(第3話: CodePipeline+SAM+LambdaでCI/CD編)
さて、Golangの公開ライブラリは
importで GitHub から持ってくるのが一般的だが、開発をしていると当然「共通のモジュールを作らないといけないけど、GitHubには社内規約上ソース置いちゃいけないし……」と悩むことが出てくる。色々とツッコみたくなるかもしれないが、出てくると言ったら出てくるのである。Javaであれば、CodeArtifactとかを使ってローカルリポジトリをAWSに任せることもできるが、Golangには対応していない。というか対応する必要がない。Golangであれば、CodeCommitをそのまま使えば良いのである。
共通モジュール側
CodeCommitで以下のようなディレクトリ構成のモジュールを作る。
今回は、簡単な標準出力するだけのオレオレロガーを作ってみよう。. ├── mylogger │ ├── go.mod │ └── mylogger.go └── README.mdmylogger.gopackage mylogger import ( "log" ) func OutputLog(str string) { log.Printf(str) }go.modmodule git-codecommit.[リージョン名].amazonaws.com/v1/repos/[リポジトリ名].git/mylogger go 1.13 require ( )ポイントは、
moduleのリポジトリ名の後ろに.gitを付けておくことだ。
これを忘れると上手く動かない。呼び出し側
呼び出し側では、以下のように
importをする。main.goなどimport ( "git-codecommit.[リージョン名].amazonaws.com/v1/repos/[リポジトリ名].git/mylogger" )go.mod を使っていれば、ビルド時に
go.modrequire ( git-codecommit.[リージョン名].amazonaws.com/v1/repos/[リポジトリ名].git/mylogger v0.0.0-20201011112107-e103759ebd6b )な感じで良い感じにバージョンを埋めてくれる。
※もちろん、必要に応じてバージョン指定する。ビルド時は
$ export GOPRIVATE=git-codecommit.[リージョン名].amazonaws.com,directとしておこう。こうしないと、プライベートリポジトリをうまく見に行ってくれなくてビルドが失敗する。
CodePipeline(CodeBuild)に組み込む場合
これも基本はローカルビルドと変わらない。
Buildspecの環境変数で、プライベートリポジトリを設定してあげる。
buildspec.yml(抜粋)env: variables: GOPRIVATE: git-codecommit.[リージョン名].amazonaws.com,directまた、CodeBuildではCodeCommitに対してIAMロールで認証をするので、
pre-buildで以下の設定をしておこう。buildspec.yml(抜粋)pre_build: commands: - git config --global credential.helper '!aws codecommit credential-helper $@' - git config --global credential.UseHttpPath trueCodePipelineを使う場合、ソースコードの取得はCodePipeline側で行ってS3バケットに格納したものをCodeBuildに連携してくるため、通常はCodeCommitにアクセスする権限は不要だが、この方法を使う場合は、CodeBuildが直接CodeCommitを見に行くため、Readアクセス権が必要になる。CodeBuildのサービスロールに
AWSCodeCommitReadOnly相当の権限を付与しておこう(絞ろうと思えばもっと絞れると思うが、力尽きた……)余談ではあるが、CodeBuildのローカルキャッシュを扱う場合、Go言語の場合はデフォルトでは以下のパスになるので設定しておくと良い。
buildspec.yml(抜粋)cache: paths: - '/go/pkg/mod/**/*'これで、共通ライブラリも制約なく自由に作れるようになったぞ!
- 投稿日:2020-10-17T15:25:16+09:00
Pivotal Cloud Foundry (PCF) on the AWS Cloud
前書き
PCF, AWSと興味のある部分を色々調べていたところ AWS での Pivotal Cloud Foundry – クイックスタート というのを見つけたので試してみました。興味ある方は非常に少ないとは思いますが、多くの知識を得られたので是非試していただきたいと思っています。
手順に関しては
https://qiita.com/shuichirock/items/0fd7d8740a07523af4fd
こちらにまとめて下さった方がいらっしゃっるので躓いた部分のみ補足となります。事前にEC2 vCPU 制限を引き上げる
上限が32だったため制限を解除するようにというメッセージのエラーが発生し失敗しました。
32 -> 61 に申請し承認後実施したところ解決しました。
https://aws.amazon.com/jp/premiumsupport/knowledge-center/ec2-on-demand-instance-vcpu-increase/Route 53 で PCF ドメイン用のホストゾーンを作成
Route 53でホストゾーン作成だけでは名前解決ができずうまくいきません。
とりあえずAWSでドメインを登録して自動的に作成されるホストゾーンを利用したところ解決しました。SSL証明書を生成
無料なのでオレオレではなくAWSから発行してもらうのもいいかと思います。
https://qiita.com/yokohama4580/items/f1074e40aaa94361b7d3まとめ
Forward Log Outputの項目をtrueにしログを取りCloudWatchでsyslogを確認するようにすれば他の問題が起きても解決できると思います。
- 投稿日:2020-10-17T14:48:50+09:00
AWS API Gateway基本知識まとめ、Lambda連携手順
記事について
Amazon API Gatewayの基本情報まとめ
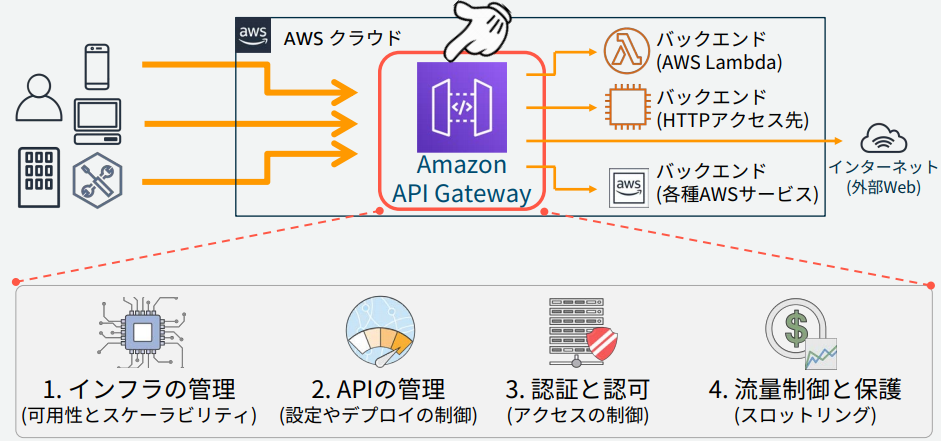
Amazon API Gatewayの位置づけについて
さまざまな機能、処理をWeb APIとして提供
実際に処理を行うバックエンドとしてはLambda関数、各種AWSサービス、インターネット経由で呼び出し可能なURL+メソッド等
Amazon API Gatewayの概要について
APIの種類
API作成時に以下2つから選択
REST
扱うリソースをURIとして定義し、それらをHTTPメソッド(PUT, GET, POST, DELETE, ... )の表現で操作
主なHTTPメソッド
- GET : 取得
- POST : 追加
- PUT : 更新
- DELETE : 削除
WebSocket
HTTPの上で、クライアントとサーバー間の双⽅向通信を実現するための通信仕様
1つのコネクション上で継続的なデータ送受信を行う(1通信毎にWebSocketは切断しない)エンドポイントタイプ
APIを使用するクライアントの場所に応じて決定
API作成時に以下3つから選択エッジ最適化
一旦CloudFrontにルーティング
APIクライアントが地理的に分散している場合に最適リージョン
リージョンに直接ルーティング
APIクライアントが同じリージョンに固まっている場合に最適
クライアントが同じリージョンの場合にレイテンシ削減に有効
APIを作成したリージョンにAPIがデプロイされるプライベート
インターネットからのアクセス不可
デプロイとステージ
APIはステージにデプロイすることで呼び出し可能になる
ステージ
デプロイされる環境
製品向けのデプロイ環境をprod、開発向けのデプロイ環境をdev等で分けることが可能
ステージ名はURLの一部として使用される、以下ステージ名をprodにした場合の例
https://<api-id>.execute-api.<region-id>.amazonaws.com/prod/API作成方式
手動作成
既存APIのクローン
API仕様を記載したSwaggerファイル(JSON, YAML)のインポート
料金
API Gateway
条件:REST API、東京リージョン、キャッシュなし
リクエスト数 (月間) 価格 (100万 APIコールあたり) 最初の 3 億 3,300 万 4.25 USD 次の 6 億 6,700 万 3.53 USD 次の 190 億 3.00 USD 200 億以上 1.91 USD 月に1万回APIコールした場合、
4.25 USD / 100 = 0.0425 USDデータ転送
インバウンドデータ転送は無料
アウトバウンドデータ転送が発生する場合は別途料金が発生
基本的に1GB/月あたり0.9 USDAPI設定(REST)について
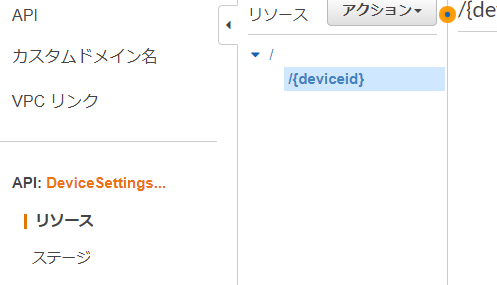
「/」を最上位としてツリー構造で「リソース」を定義する
「/」リソース配下にリソースを複数構成可能、配下のリソース名はURLの一部になる
"{}"でパスパラメータを指定可能
各リソースに受け付けるHTTPメソッド(GET, PUT, POST, DELETE...)を指定、複数指定可能
HTTPメソッドによって呼び出される処理を区別可能、区別したくない場合は"ANY"を選択API例
用途:デバイスの設定取得、更新
API名:DeviceSettingsOperations
URI メソッド / GET 全デバイスの設定取得 /{deviceId} GET 指定したIDのデバイス設定取得 /{deviceId} PUT 指定したIDのデバイス設定更新 メソッド設定
リソースに設定した各メソッドに対して、
一連のフロー(クライアントからのリクエスト → バックエンドでの処理 → クライアントへのレスポンス)を設定する
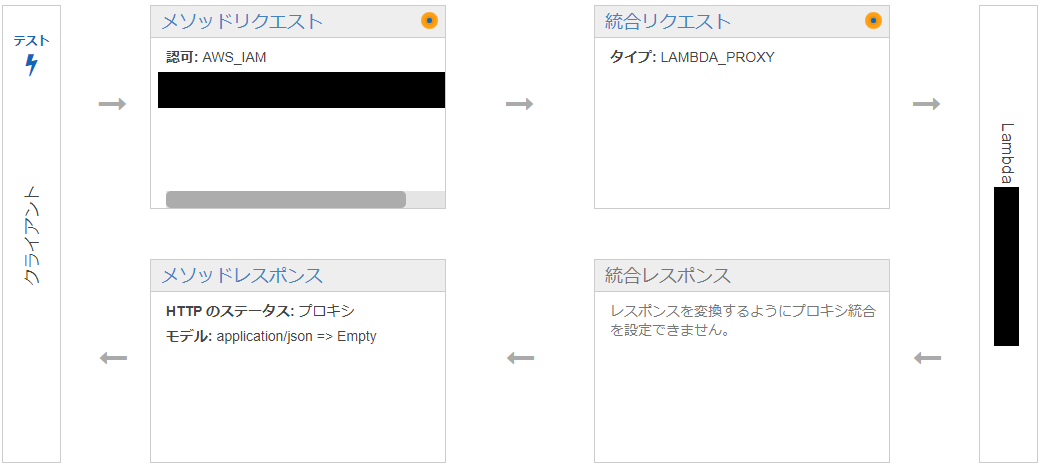
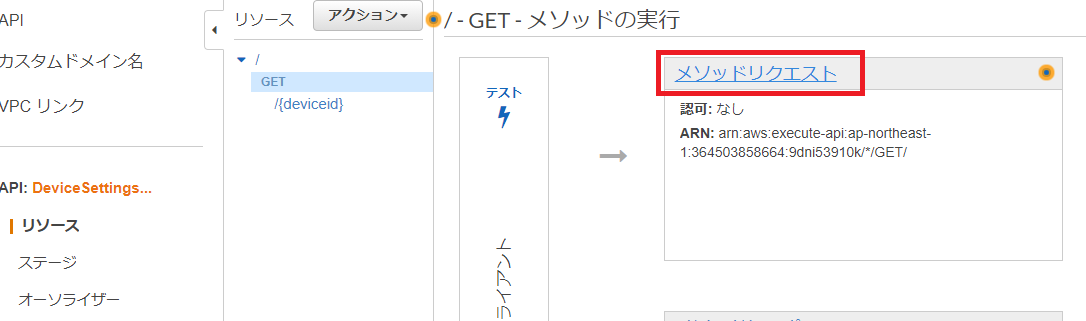
以下のようにメソッドリクエスト、統合リクエスト、統合レスポンス、メソッドレスポンスの設定を行う
メソッドリクエスト
クライアントからのリクエスト受付に関する設定
以下のような設定を行う
- メソッドをコールするための認証(権限を持ったIAMユーザのみコール可能等)
- 受け付けるクエリパラメータ
- 必須とするHTTPヘッダ
※パスパラメータ:一意のリソース特定に使用するパラメータ、ID等
※クエリパラメータ:省略可能なパラメータ統合リクエスト
バックエンドへのリクエストに関する設定
以下のような設定を行う
- リクエストの変換
- バックエンドの種類(Lambda, AWSサービス, HTTP, Mock, VPCリンク)
統合レスポンス
バックエンドからのレスポンスに関する設定
レスポンス内容の変換等メソッドレスポンス
リクエストに対する最終的なAPI Gatewayとしてのレスポンスに関する設定
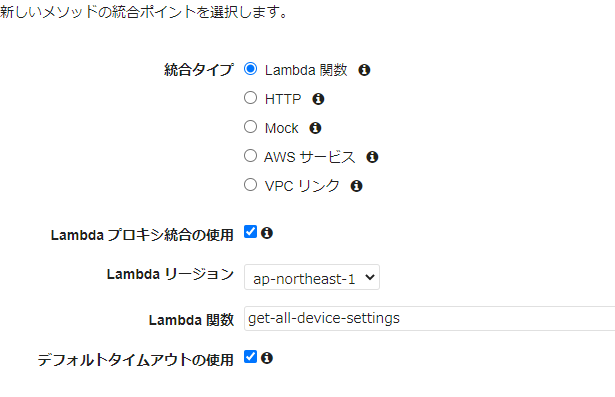
レスポンス内のステータスコードや、レスポンスヘッダ等の設定プロキシ統合の使用(リクエスト、レスポンスの変換を必要としない場合)
リクエスト、レスポンスの変換を必要としない場合、プロキシ統合を使用すると、設定項目を大幅に減らすことが可能
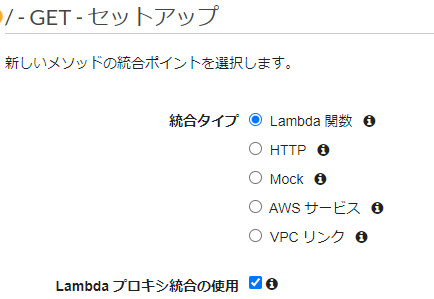
バックエンドがLambda関数の場合、以下のようにLambdaプロキシ統合の使用にチェックを入れる
Lambdaプロキシ統合を使用した場合、
LambdaにInputされるデータ(Lambda関数のパラメータeventに入る値)が決まった形式になり、
LambdaからOutputするデータも決まった形式する必要がある{ "resource": "Resource path", "path": "Path parameter", "httpMethod": "Incoming request's method name" "headers": {String containing incoming request headers} "multiValueHeaders": {List of strings containing incoming request headers} "queryStringParameters": {query string parameters } "multiValueQueryStringParameters": {List of query string parameters} "pathParameters": {path parameters} "stageVariables": {Applicable stage variables} "requestContext": {Request context, including authorizer-returned key-value pairs} "body": "A JSON string of the request payload." "isBase64Encoded": "A boolean flag to indicate if the applicable request payload is Base64-encoded" }{ "isBase64Encoded": true|false, "statusCode": httpStatusCode, "headers": { "headerName": "headerValue", ... }, "multiValueHeaders": { "headerName": ["headerValue", "headerValue2", ...], ... }, "body": "..." }実際のAPI作成手順について
前提条件
API設定
- APIタイプ:REST API
- エンドポイントタイプ:リージョン
作成API
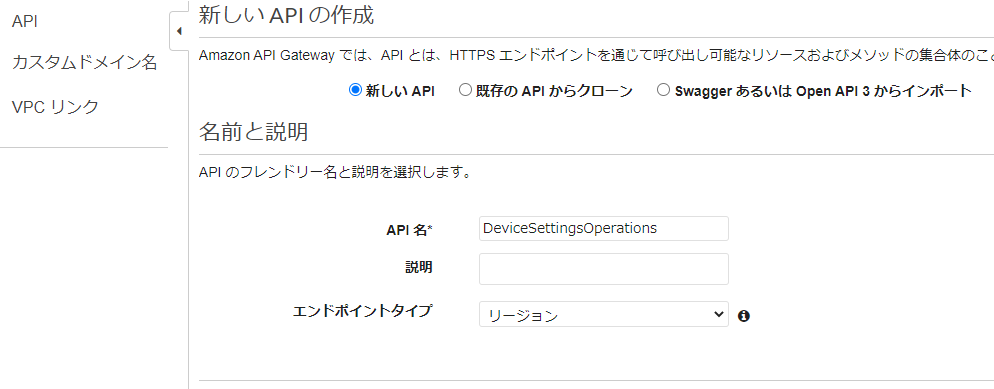
API名:DeviceSettingsOperations
URI メソッド / GET 全デバイスの設定取得 /{deviceId} GET 指定したIDのデバイス設定取得 /{deviceId} PUT 指定したIDのデバイス設定更新 メソッドリクエスト設定
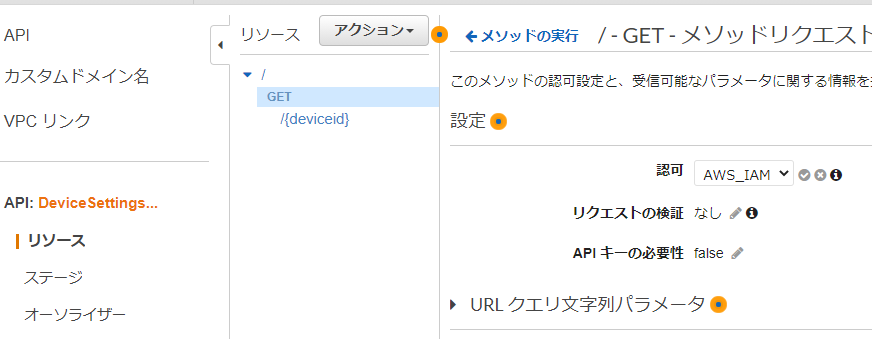
- APIコール時の認証にAWS_IAMを使用
統合リクエスト設定
- バックエンドタイプとしてLambda関数を使用
- Lambdaプロキシ統合を使用
クライアント
- Postmanを使用
※認証にAWS_IAMを使用する場合、署名バージョン 4 の署名をHTTPリクエストヘッダに乗せる必要がある
※バージョン 4 の署名はPostmanの機能で対応可能、またはSDKを使用して署名を作成可能AWSマネジメントコンソールでのAPI作成手順
API作成
1.REST APIの構築をクリック
2.API名を入力、エンドポイントはリージョンを選択
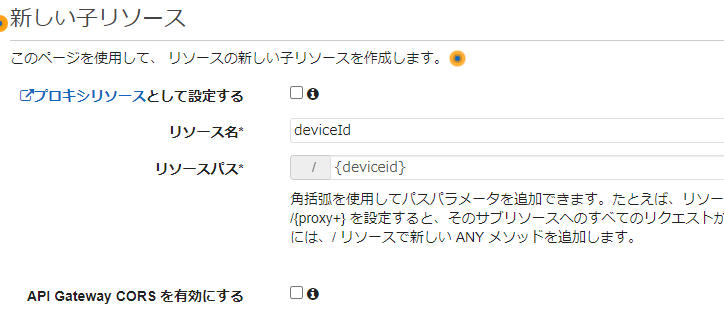
リソースの作成
1.アクションからリソースの作成をクリック
2.リソース名を入力、パスパラメータとして設定する場合はリソースパス欄の値を"{}"で囲む
3.以下のようにリソースが追加される
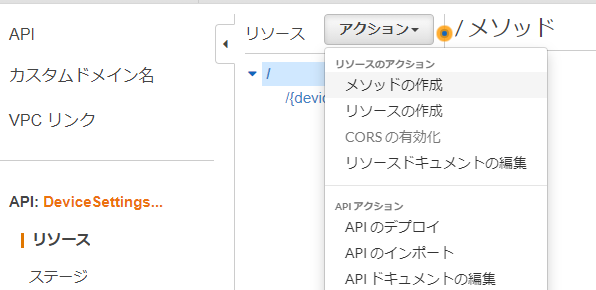
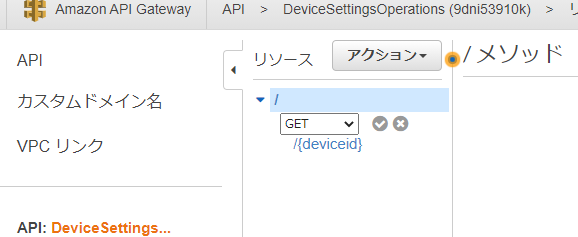
メソッドの追加
1.メソッドの作成をクリック
2.メソッドを選択し☑をクリック
3.統合タイプをLambda関数、Lambdaプロキシ統合を使用をチェック、実行するLambda関数名を入力
4.各リソース、各メソッドについて同様にメソッドを作成
メソッドリクエスト設定
1.メソッドリクエストのリンクをクリック
2.許可欄でAWS_IAMを選択し☑をクリック
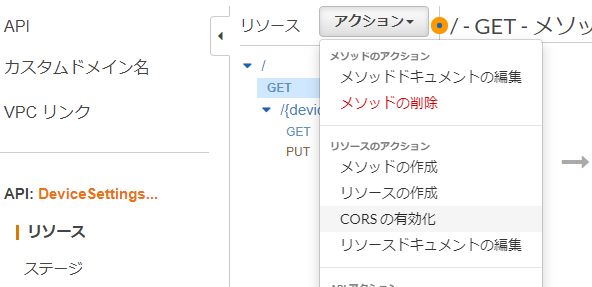
CORS(Cross-Origin Resource Sharing)
ブラウザがオリジン(HTMLを読み込んだサーバのこと)以外のサーバからデータを取得する仕組み
Webアプリケーション等からAPI Gatewayにアクセスする場合、HTMLの読み込み先と、API Gatewayではオリジンが異なるためアクセスができない
その場合は、以下のCORSの有効化を行う
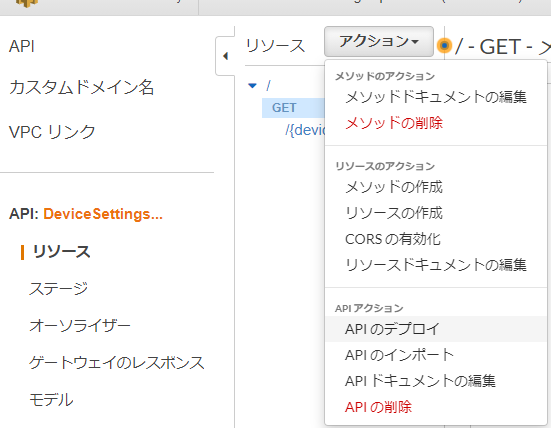
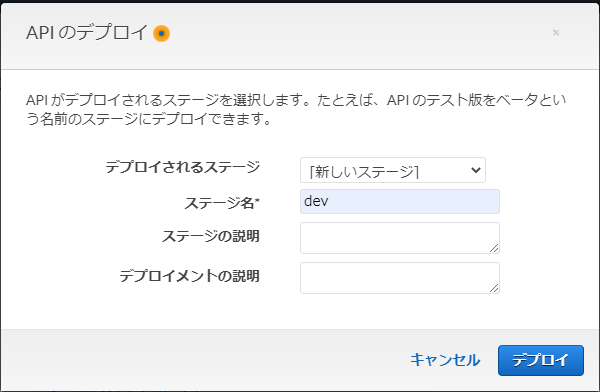
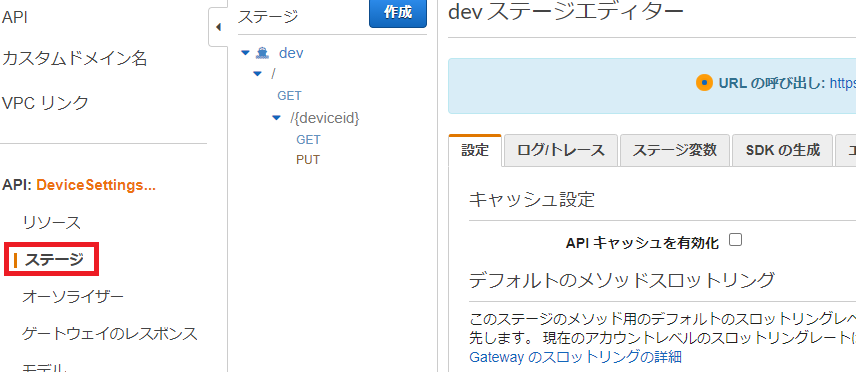
APIのデプロイ
1.APIのデプロイをクリック
2.任意のステージ名を指定してデプロイ
3.ステージを選択、URLを確認
バックエンドとして動作するLambdaサンプル
- デバイス設定情報
# device settings deviceSettings = [ { 'deviceId': 1, 'power': 'ON', 'torque': 20, 'angle': 45 }, { 'deviceId': 2, 'power': 'OFF', 'torque': 12, 'angle': 30 }, { 'deviceId': 3, 'power': 'ON', 'torque': 90, 'angle': 70 } ]1.全デバイスの設定取得
import json def lambda_handler(event, context): return { 'statusCode': 200, 'body': json.dumps(deviceSettings) }2.指定したIDのデバイス設定取得
import json def getSettings(id, items): for item in items: if item['deviceId'] == id: return item return None def lambda_handler(event, context): id = int(event['pathParameters']['deviceid']) item = getSettings(id, deviceSettings) return { 'statusCode': 200, 'body': json.dumps(item) }以下Lambda単体でのテスト用データ
{ "pathParameters": { "deviceid": 1 } }3.指定したIDのデバイス設定更新
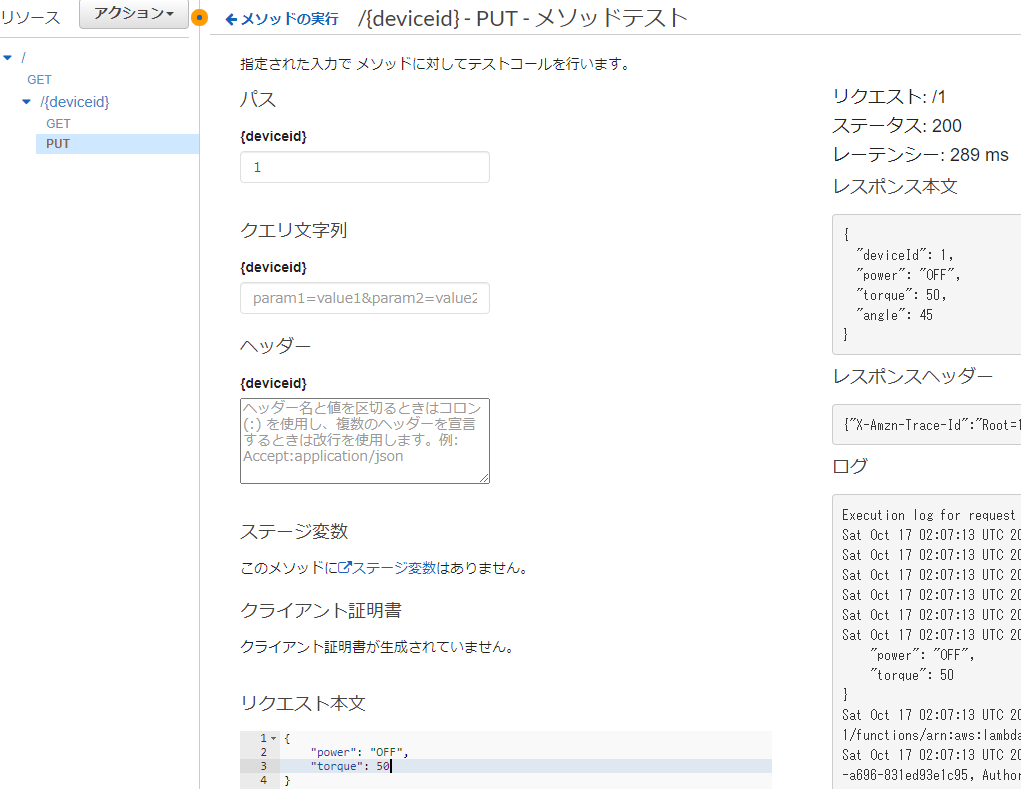
import json def getSettings(id, items): for item in items: if item['deviceId'] == id: print(f'item : {item}') return item return None def lambda_handler(event, context): id = int(event['pathParameters']['deviceid']) settings = json.loads(event['body']) item = getSettings(id, deviceSettings) for key in settings.keys(): if key in item: item[key] = settings[key] return { 'statusCode': 200, 'body': json.dumps(item) }以下Lambda単体でのテスト用データ
{ "pathParameters": {"deviceid": 1}, "body": "{\"power\":\"OFF\",\"torque\": 50}" }API Gattewayテスト
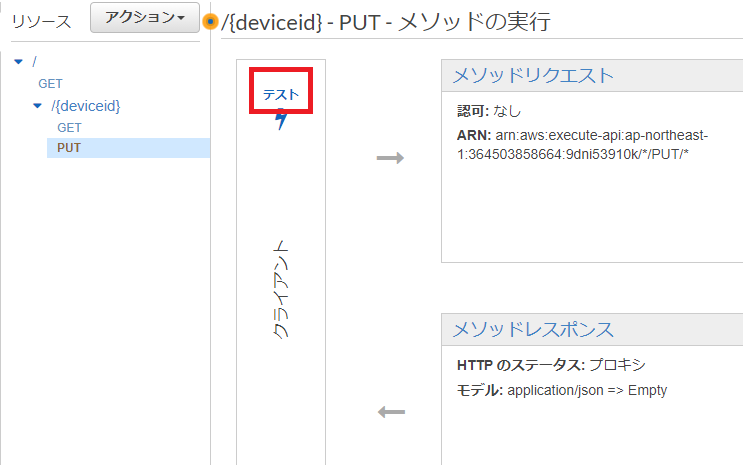
1.テストをクリック
2.パスパラメータ、リクエスト本文を入力してテストボタンをクリック、右側に結果が表示される
3.動作に不具合がある場合、Lambda単体でのテストや、CloudWatchで動作を確認する
Postmanからのアクセス
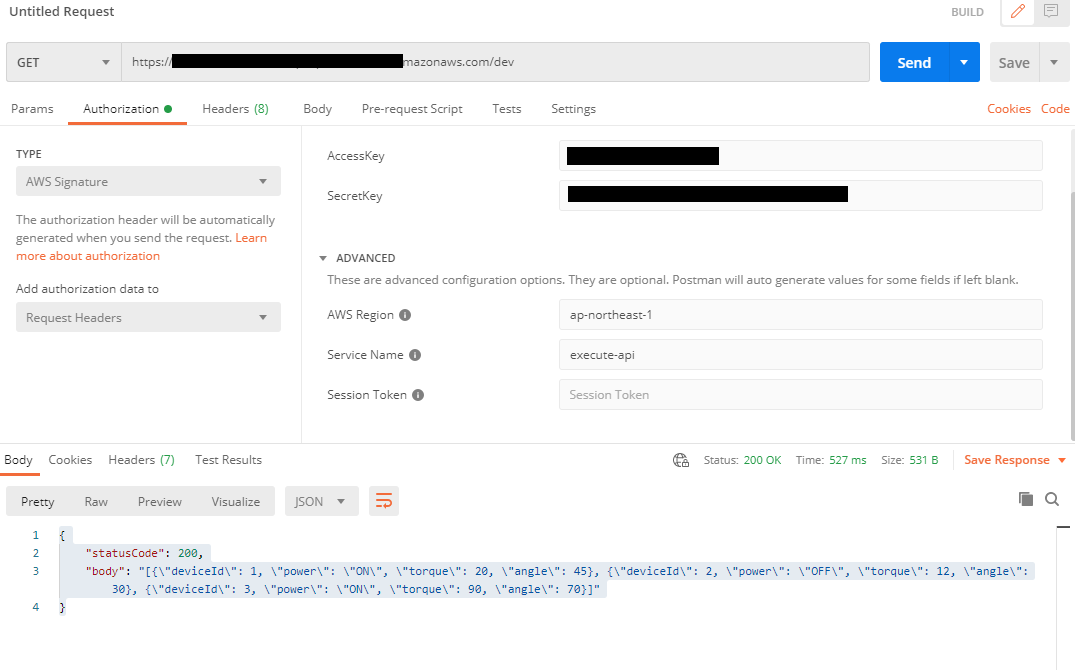
1.Authorizationタブから、TYPEにAWS Signatureを選択、API Gatewayにアクセス可能なIAMユーザのアクセスキー、シークレットキーと、リージョン、サービス名を入力
2.メソッドを選択、URIを入力し、Sendをクリックし、正常に動作するとレスポンスが受信される
参考
- 投稿日:2020-10-17T14:34:47+09:00
AWS EC2本番環境にデプロイしたのに変更が反映されない...の対処法を写真つきで解説
概要
AWSでEC2にデプロイした際に、「ローカルでは変更が反映されているのに本番環境で変更が反映されない...!!」となってしまい詰んだので解決した方法をメモ書きとして共有します。
ローカルでは正しく変更が反映されている前提になります。
何か間違いなどありましたらご指摘いただけますと幸いです。環境
AWS EC2
Ruby 2.6.5
Rails 6.0.3.3
capistranoで自動デプロイ済み解決した方法
EC2インスタンスを再起動複数回の自動デプロイ【bundle exec cap production deploy】を行なっていると、EC2側で変更が反映されないことがあるらしいです、、(今後も頻繁に起こりそう)
なのでEC2インスタンスを再起動する手順を写真つきで以下にメモとして残します。1.AWSマネジメントコンソールにログインしてEC2にいく。
2.インスタンスをクリック
3.該当インスタンスをクリック
4.アクションからインスタンスを再起動する
5.ターミナルからEC2にログイン
ssh -i ~/.ssh/(pemファイル名) ec2-user@(EC2のElastic IP)6.nginxと使用DB(今回はmariadb)を立ち上げる
sudo service nginx start
sudo service mariadb start6.ローカルで自動デプロイのコマンドを実行(bundle exec cap production deploy)
→アプリケーションサーバのunicornが立ち上がる
→本番環境に変更が反映される。終わり
以上です。

- 投稿日:2020-10-17T13:51:23+09:00
AWS Global Accelerator 詳細
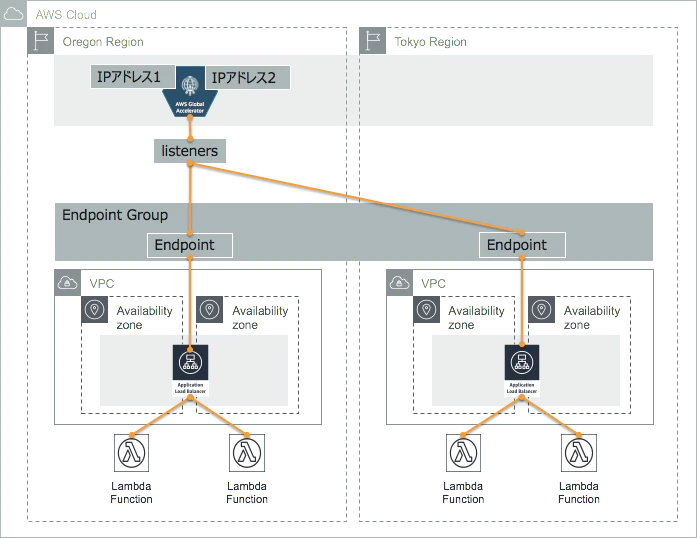
AWS Global Acceleratorとは、「グローバルネットワークインフラストラクチャを介して、ユーザーのトラフィックを送信するネットワークサービス」である。IPアドレスの固定化にも使用される。(下記参照)
https://aws.amazon.com/jp/global-accelerator/
下図が一番わかりやすいので、引用させていただく。
https://qiita.com/atsumjp/items/69917755467173e36f43特徴を挙げていく。
1.IPアドレス固定化
先ほども申し上げた。ロードバランサー等はIPが固定ではない。GlobalAcceleratorを使って、専用のエンドポイントを作ることが可能である。
2.アプリケーション高速化
TCP接続が、ユーザーに最も近いエッジロケーションで終了するため、データ転送がグローバルで加速する。
3.回復性と可用性
アプリケーションオリジン間のフェイルオーバーは自動的に数秒以内に行われる。また、アプリケーションエンドポイントの障害を検出した場合、別の AZ または AWS リージョンで次に利用可能な最も近いエンドポイントへのトラフィック再ルーティングを即座にトリガーする。
エッジロケーションを介することがポイント。
主要なパラメータ
Listener 1 |-Ports |-Protocol |-Client Affinity |-endpoint groups |-region |-traffic dial |-weight Listener 2 . . . Listener 3 . . .1.リスナー
指定したポートとプロトコルに基づいてクライアントからのインバウンド接続を処理する、一般的にELBやALBを選択する
2.Client Affinity
NoneまたはSource IPのどちらかを選択する。
ステートフルアプリケーションの際に、特定のソース(クライアント)IPアドレスのユーザーからのリクエストを同じエンドポイント・リソースに送信するかどうかを定める。Noneを指定するとしない、Source IP を指定するとする。3.traffic dial
どのRegion にどのくらいTrafficを割り当てるか、合計が100になるように定める、デフォルトは100
4.weight
Rigeon内で、どのエンドポイントにどのくらい割り当てるかの比率。1~255の範囲内で定める。全部の合計値から比率を算出する。デフォルトは128
ロードバランサーを使用する際に、Global Acceleratorの使用を選択できるようになった。この記事がGlobal Acceleratorの使用のきっかけになることを願う。
- 投稿日:2020-10-17T13:24:58+09:00
【AWS初学者用】 AWSのストレージサービスについて
本記事について
本記事はAWS初学者の私が学習していく中でわからない単語や概要をなるべくわかりやすい様にまとめたものです。
もし誤りなどありましたらコメントにてお知らせいただけるとありがたいです。AWSのストレージサービス
AWSにはS3やEBSといった代表的な物を始め、たくさんのストレージサービスがあります。
そんなたくさんのストレージサービスを学習したので書き留めたいと思います。S3
まずは有名なS3からです。S3は高耐久で大容量なオブジェクトストレージサービス。
データをオブジェクトとして扱いIDとメタデータによって管理します。
S3つぎはS3の機能を見ていみましょう。耐久性
S3のデータの耐久性は99.999999999%という高耐久性を誇っています。また、保存されたデータは同一リージョン内の3箇所のAZへ自動で複製されます。
容量
S3は容量に制限というものはありません。しかし1ファイルに対する容量の制限はあります。
利用した容量の分だけ料金が発生します。バージョニング
オブジェクトの世代管理をしてくれる機能。S3は通常同名のオブジェクトをアップロードすると上書きされます。上書きされても前のオブジェクトのバージョンを管理してくれます。また誤って更新や削除をしてしまっても前のバージョンに戻す事ができます。
静的WEBサイトホスティング
S3はデータストレージとしての機能だけではなく、Webサイトのホスティング機能もあります。静的なコンテンツを配信するサイトであれば、新たにサーバーを構築せずともWebサイトを公開できます。
アクセス制御
S3はアクセス制御が可能で以下3つの制御の方法があります。
1. IAMポリシーを用いた制御
2. バケットポリシーを用いた制御
3. ACLを用いた制御暗号化
S3はサーバーサイドの暗号化機能があり、AES-256の方式で暗号化します。
※AES-256 : AESという暗号化方式で暗号化鍵に256ビット長を用いる方式。ストレージクラス
S3にはストレージクラスと呼ばれる利用形態がいくつかあり、選択する事ができます。
1. スタンダード
デフォルトのクラスになります。公式で推奨されているクラスです。
2. 低冗長化ストレージ (RRS)
通常3つのAZでレプリケーションされるところを2箇所にする事で、冗長性は下がるがコストを抑える事ができます。
3. スタンダード-IA
スタンダードと同じ耐久性があり、低コストで利用可能です。正しデータ読み取り時に料金が発生することと、オブジェクトが123KB以下でも123KB相当の請求がされます。
4. One Zone-IA
スタンダード-IAよりも耐久性は落ちるが、その分スタンダード-IAよりも低コストで利用できる。(AZは1箇所にみに保管)
5. Glacier
アーカイブを目的としたストレージクラス。たくさんのデータを安価で保管できますが、データの取り出しに時間がかかります。
6. Intelligent-Tiering
データをコスト効率の良いアクセス階層に自動的に移動させて、ストレージコストを最小限に抑えてくれます。公式のページにストレージクラスの比較表がありますので気になる方はご覧ください。(見づらいですが...)
https://docs.aws.amazon.com/ja_jp/AmazonS3/latest/dev/storage-class-intro.htmlライクサイクル
ライフサイクルを設定することで設定した期間が経過したらオブジェクトを削除したり、他の安価なストレージにオブジェクト移動できたりします。
ログ保管
オブジェクトに対するログを保管する機能です。
マルチパートアップロード
大容量のオブジェクトを複数のパートに分割してアップロードする仕組みです。効率よくアップロードできます。
分割されたオブジェクトはS3で再構築されます。クロスリージョンレプリケーション
通常S3に保存したオブジェクトは同一リージョン内の3箇所のAZに保管されますが、クロスリージョンレプリケーションを使用すれば異なるリージョンS3バケットに自動的に複製してくれます。
また、複製先には別のAWSアカウントも指定できるみたいです。EBS
EBSは主にEC2インスタンスにアタッチすることで利用できる永続的なブロックストレージです。
ブロックストレージとはデータをブロックという細かい単位で保管する方式です。
以下、EBSの機能をまとめていきます。ストレージタイプ
EBSにはいくつかのストレージタイプがあり、選択する事ができます。
凡用SSD(gp2)
gp2はSSDを安価に利用できるデフォルトのサービスです。容量に応じてIOPSが設定されているようです。プロビジョンドIOPS SSD (io1)
io1は高パフォーマンスなストレージタイプでユーザーが自由にIOPSを設定できます。設定したIOPSに対しても課金対象となるのでコストは高めです。スループット最適化 HDD (st1)
HDDタイプのストレージタイプです。大容量のストレージを安価で利用でき、アクセス頻度が高いシステムに適しています。Cold HDD (sc1)
st1と同じくHDDタイプの低コストなストレージタイプです。バックアップなどのアクセス頻度は少ないけど大容量なデータを保管するのに適しています。
EC2インスタンスのブートボリュームには使用できないみたいです。高可用性
EBSは99.999%の高い可用性を維持するよう設計されているみたいです。また、S3の時は3箇所のAZに自動的にに複製をしていましたが、EBSはAZ内で自動的に複製されます。
バックアップ
EBSはスナップショットを用いてバックアップを取得する事ができます。スナップショットは自動的にS3に保存されるので高い耐久性があります。
初回はフルバックアップを行うが、そのあとは都度増えた分だけ取得します。インスタンスストア
EC2のインスタンスに利用できるブロックレベルの一時ストレージを提供するサービスです。
揮発性のためインスタンスを停止すると、データは消失してしまうので重要なデータを扱うには向いていません。(エフェメラルディスクと呼ばれることもあります)EFS
EFSはファイルストレージタイプのストレージです。保存されるファイルのサイズによって伸縮するので、予めストレージ容量を決める必要がありません。
EC2インスタンス以外にもオンプレミスサーバーからも利用できます。Storage Gateway (SGW)
SGWはオンプレミスと連携したバックアップストレージサービスです。オンプレミスのストレージとS3のストレージを連携させて高可用性で堅牢なストレージを構築可能。
S3へNFS,SMB,iSCSIといった標準プロトコルでアクセスできます。
SGWには以下の種類があります。
キャッシュ型ボリュームゲートウェイ
基本S3へデータを格納しますが、アクセス頻度の高いデータはローカルにキャッシュすることでアクセスの高速化を実現できます。
キャッシュからデータを探して、無ければS3に探しに行く流れです。保管型ボリュームゲートウェイ
データをスナップショットとして非同期的にS3へ格納します。テープゲートウェイ
物理テープ装置の代替としてS3、Glacierに格納できます。ファイルゲートウェイ
オブジェクトを直接S3に格納できるサービス。AWS Import/Export Snowball
ペタバイト規模の大容量データをAWSのストレージへ転送できるサービスです。
まとめ
後半は駆け足気味となってしまいましたが、まとめてみました。
AWSはストレージサービスだけでたくさんの種類がありますね。詳細を書いていくとキリがなさそうです...
今後はストレージサービスと連携して使用するサービスについてもまとめていきたいと思います。
- 投稿日:2020-10-17T13:24:58+09:00
【AWS初学者用】 AWSの色んなストレージサービス
本記事について
本記事はAWS初学者の私が学習していく中でわからない単語や概要をなるべくわかりやすい様にまとめたものです。
もし誤りなどありましたらコメントにてお知らせいただけるとありがたいです。AWSのストレージサービス
AWSにはS3やEBSといった代表的な物を始め、たくさんのストレージサービスがあります。
そんなたくさんのストレージサービスを学習したので書き留めたいと思います。S3
まずは有名なS3からです。S3は高耐久で大容量なオブジェクトストレージサービス。
データをオブジェクトとして扱いIDとメタデータによって管理します。
S3つぎはS3の機能を見ていみましょう。耐久性
S3のデータの耐久性は99.999999999%という高耐久性を誇っています。また、保存されたデータは同一リージョン内の3箇所のAZへ自動で複製されます。
容量
S3は容量に制限というものはありません。しかし1ファイルに対する容量の制限はあります。
利用した容量の分だけ料金が発生します。バージョニング
オブジェクトの世代管理をしてくれる機能。S3は通常同名のオブジェクトをアップロードすると上書きされます。上書きされても前のオブジェクトのバージョンを管理してくれます。また誤って更新や削除をしてしまっても前のバージョンに戻す事ができます。
静的WEBサイトホスティング
S3はデータストレージとしての機能だけではなく、Webサイトのホスティング機能もあります。静的なコンテンツを配信するサイトであれば、新たにサーバーを構築せずともWebサイトを公開できます。
アクセス制御
S3はアクセス制御が可能で以下3つの制御の方法があります。
1. IAMポリシーを用いた制御
2. バケットポリシーを用いた制御
3. ACLを用いた制御暗号化
S3はサーバーサイドの暗号化機能があり、AES-256の方式で暗号化します。
※AES-256 : AESという暗号化方式で暗号化鍵に256ビット長を用いる方式。ストレージクラス
S3にはストレージクラスと呼ばれる利用形態がいくつかあり、選択する事ができます。
1. スタンダード
デフォルトのクラスになります。公式で推奨されているクラスです。
2. 低冗長化ストレージ (RRS)
通常3つのAZでレプリケーションされるところを2箇所にする事で、冗長性は下がるがコストを抑える事ができます。
3. スタンダード-IA
スタンダードと同じ耐久性があり、低コストで利用可能です。正しデータ読み取り時に料金が発生することと、オブジェクトが123KB以下でも123KB相当の請求がされます。
4. One Zone-IA
スタンダード-IAよりも耐久性は落ちるが、その分スタンダード-IAよりも低コストで利用できる。(AZは1箇所にみに保管)
5. Glacier
アーカイブを目的としたストレージクラス。たくさんのデータを安価で保管できますが、データの取り出しに時間がかかります。
6. Intelligent-Tiering
データをコスト効率の良いアクセス階層に自動的に移動させて、ストレージコストを最小限に抑えてくれます。公式のページにストレージクラスの比較表がありますので気になる方はご覧ください。(見づらいですが...)
https://docs.aws.amazon.com/ja_jp/AmazonS3/latest/dev/storage-class-intro.htmlライクサイクル
ライフサイクルを設定することで設定した期間が経過したらオブジェクトを削除したり、他の安価なストレージにオブジェクト移動できたりします。
ログ保管
オブジェクトに対するログを保管する機能です。
マルチパートアップロード
大容量のオブジェクトを複数のパートに分割してアップロードする仕組みです。効率よくアップロードできます。
分割されたオブジェクトはS3で再構築されます。クロスリージョンレプリケーション
通常S3に保存したオブジェクトは同一リージョン内の3箇所のAZに保管されますが、クロスリージョンレプリケーションを使用すれば異なるリージョンS3バケットに自動的に複製してくれます。
また、複製先には別のAWSアカウントも指定できるみたいです。EBS
EBSは主にEC2インスタンスにアタッチすることで利用できる永続的なブロックストレージです。
ブロックストレージとはデータをブロックという細かい単位で保管する方式です。
以下、EBSの機能をまとめていきます。ストレージタイプ
EBSにはいくつかのストレージタイプがあり、選択する事ができます。
凡用SSD(gp2)
gp2はSSDを安価に利用できるデフォルトのサービスです。容量に応じてIOPSが設定されているようです。プロビジョンドIOPS SSD (io1)
io1は高パフォーマンスなストレージタイプでユーザーが自由にIOPSを設定できます。設定したIOPSに対しても課金対象となるのでコストは高めです。スループット最適化 HDD (st1)
HDDタイプのストレージタイプです。大容量のストレージを安価で利用でき、アクセス頻度が高いシステムに適しています。Cold HDD (sc1)
st1と同じくHDDタイプの低コストなストレージタイプです。バックアップなどのアクセス頻度は少ないけど大容量なデータを保管するのに適しています。
EC2インスタンスのブートボリュームには使用できないみたいです。高可用性
EBSは99.999%の高い可用性を維持するよう設計されているみたいです。また、S3の時は3箇所のAZに自動的にに複製をしていましたが、EBSはAZ内で自動的に複製されます。
バックアップ
EBSはスナップショットを用いてバックアップを取得する事ができます。スナップショットは自動的にS3に保存されるので高い耐久性があります。
初回はフルバックアップを行うが、そのあとは都度増えた分だけ取得します。インスタンスストア
EC2のインスタンスに利用できるブロックレベルの一時ストレージを提供するサービスです。
揮発性のためインスタンスを停止すると、データは消失してしまうので重要なデータを扱うには向いていません。(エフェメラルディスクと呼ばれることもあります)EFS
EFSはファイルストレージタイプのストレージです。保存されるファイルのサイズによって伸縮するので、予めストレージ容量を決める必要がありません。
EC2インスタンス以外にもオンプレミスサーバーからも利用できます。Storage Gateway (SGW)
SGWはオンプレミスと連携したバックアップストレージサービスです。オンプレミスのストレージとS3のストレージを連携させて高可用性で堅牢なストレージを構築可能。
S3へNFS,SMB,iSCSIといった標準プロトコルでアクセスできます。
SGWには以下の種類があります。
キャッシュ型ボリュームゲートウェイ
基本S3へデータを格納しますが、アクセス頻度の高いデータはローカルにキャッシュすることでアクセスの高速化を実現できます。
キャッシュからデータを探して、無ければS3に探しに行く流れです。保管型ボリュームゲートウェイ
データをスナップショットとして非同期的にS3へ格納します。テープゲートウェイ
物理テープ装置の代替としてS3、Glacierに格納できます。ファイルゲートウェイ
オブジェクトを直接S3に格納できるサービス。AWS Import/Export Snowball
ペタバイト規模の大容量データをAWSのストレージへ転送できるサービスです。
まとめ
後半は駆け足気味となってしまいましたが、まとめてみました。
AWSはストレージサービスだけでたくさんの種類がありますね。詳細を書いていくとキリがなさそうです...
今後はストレージサービスと連携して使用するサービスについてもまとめていきたいと思います。
- 投稿日:2020-10-17T12:22:31+09:00
AWS OpsWorksの備忘録
はじめに
AWS認定資格にてAWS OpsWorksについて度々出題されますが、いまいちどういったサービスわかってないので、本稿で整理したいと思います。
OpsWorksとは
ChefまたはPuppetを使用して、アプリケーションを設定および運用するための設定管理サービス。
ChefやPuppetとは「構成管理ツール」の一種。構成管理ツールとは、複数のサーバーに対してアプリケーションを一括でデプロイしたり、構成を流し込んだり、管理したりするツールのこと。ChefやPuppetを使用して、運用を自動化(EC2インスタンスやオンプレミスのコンピューティング環境でのサーバーの設定、デプロイ、管理の自動化)することができる。まとめると...
・ChefやPuppetによってサーバー設定や反復動作を自動的に行ってくれるのを助けてくれる。
・EC2やオンプレミスのVM上で使用可能。
・AWS OpsWorks = マネージドなChef&Puppet
・ChefやPuppetはSSM/CloudFormation/Beanstalkに似ているが、クロスクラウドで動作するオープンソースである。※特にAWS SAA・SOA等を取得するにあたって、ハンズオンまでする必要はない。
https://docs.aws.amazon.com/ja_jp/opsworks/latest/userguide/welcome.html
https://www.ossnews.jp/compare/Chef/Puppet
https://macruby.info/windows/ansible-chef-puppet-compare.html
- 投稿日:2020-10-17T12:00:05+09:00
Djangoチュートリアル(ブログアプリ作成)③ - 記事一覧表示編
前回、Djangoチュートリアル(ブログアプリ作成)② - model 作成、管理サイト準備編では管理サイトで記事を作成するところまで確認できました。
今回は、管理サイトで作成した記事の一覧を表示できるようにしていきます。
template 準備(ファイル作成)
最初に template を作成しましょう。
templates/blog 配下に post_list.html を作成します。└── templates └── blog ├── index.html └── post_list.htmlview の準備
ここで少し重要な説明をします。
Django ではクラスベース汎用ビュー という仕組みを使うと、簡単に model を引っ張ってきて記事を表示させたり、
テンプレートを表示させたりすることが出来、アプリ作成をグンと効率的に行うことができるようになります。
ちなみに前々回、views.py をいじったときに generic という表記がありました、これもクラスベース汎用ビューを使う準備として必要な宣言です。view.pyfrom django.views.generic import TemplateView汎用クラスビューには様々な種類があり、その中でも単純に template を表示させるためだけに使われるのが
index.html の表示に使っていた TemplateView です。
index.html の表示のために、呼び出す template を views.py の中で指定していたことになります。view.pyclass IndexView(TemplateView): template_name = 'blog/index.html'また、これまではわかりやすいように genetic で宣言してから使うクラスを指定して import していましたが
generic.xxxView の形で呼び出すこともできるので views.py を少し書き換えてあげましょう。views.py(書き換え後)from django.views import generic class IndexView(genetic.TemplateView): template_name = 'blog/index.html'これからたくさんのクラスベース汎用ビューを呼び出すことになるので、最初の宣言をスッキリとさせました。
さて、今回は template を単純に表示させるだけでなく、データベースから記事の情報モデルも呼び出してあげる必要があります。
そのため、別の ListView というクラスベース汎用ビューを使うのですが、使い方は TemplateView のときと似ています。最初に使うモデルを宣言し、クラスを記述し、呼び出すモデルを指定してあげるだけです。
views.py(ListViewを追加)from django.views import generic from .models import Post # Postモデルをimport class IndexView(genetic.TemplateView): template_name = 'blog/index.html' class PostListView(generic.ListView): # generic の ListViewクラスを継承 model = Post # 一覧表示させたいモデルを呼び出しmodel = Post という記述を入れてあげることで、記事一覧が post_list という変数でリスト型として template に渡すことができます。
ここで TemplateView を使ったときのことを思い出して「templateを指定してあげるのでは?」と考えた方は鋭いです。
もちろん指定してもよいのですが、実は generic.ListView では template のファイル名をルールに沿った形にしてあげることで、明示しなくても呼び出してくれる便利機能があります。
(ただし、明示した方が第三者にとって分かりやすいので、敢えて記述する場合もあるかと思います。)ルールとしては「post_list.html」のように、model名を小文字にしたものと、ListViewならば"list"という文字列をアンダースコアで区切った文字列をファイル名にすることです。
(使うクラスによって異なってくるため、後ほど説明します)これで template である post_list.html を表示させ、同時に template に記事一覧を渡すための view の準備が整いました。
template 側で記事一覧の受け取り
post_list.html に渡されたモデルを受け取るには、Django ならではの記述方法があります。
Django の template では {% %} で囲むことで Python コードを記述でき、さらに html としてブラウザに値を表示させるには {{ }} と、中括弧を重ねたもので記述します。
今回、記事一覧は post_list というリスト型で変数が template で渡されているので for ループで展開し、それぞれの記事タイトルと日付を取り出していきます。
(各カラムのデータは、変数名にドット付きでカラム名を指定する形で取り出せます)post_list.html<h1>記事一覧</h1> <table class="table"> <thead> <tr> <th>タイトル</th> <th>日付</th> </tr> </thead> <tbody> {% for post in post_list %} <tr> <td>{{ post.title }}</td> <td>{{ post.date }}</td> </tr> {% endfor %} </tbody> </table>ルーティング設定
最後に記事一覧を表示させるための URL へアクセスした時に ListView を呼び出すよう、blog/urls.py を編集します。
blog/urls.pyfrom django.urls import path from . import views app_name = 'blog' urlpatterns = [ path('', views.IndexView.as_view(), name='index'), path('list', views.PostListView.as_view(), name='list'), # ここを追加 ]今回のように、何かを表示させるときには View, Template, URL がそれぞれ絡むことを覚えておいてください。
記事一覧表示の確認
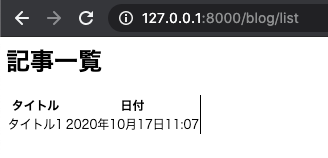
これで model を表示させる準備が整ったので runserver を実行して url にアクセスしましょう。
blogアプリの中の list という URL パスを先ほど設定したので、
127.0.0.1:8000/blog/list という URL で表示できます。
表は格好よくないですが、管理サイトから登録した記事が表示されていることが分かるかと思います。
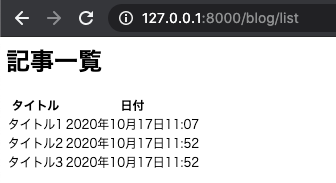
※見た目は後で BootStrap を使って整えますが、まずは Django の基礎を理解するためにベースだけ作ってしまいます。一つだけだと分かりづらいので、ついでに記事を2つぐらい、管理サイトから追加してから再度確認してみましょう。
タイトルと日付がそれぞれ取り出せていることが分かりますね。次回は、テストを自動化するユニットテストを作成していきます。
- 投稿日:2020-10-17T11:12:06+09:00
Djangoチュートリアル(ブログアプリ作成)② - model 作成、管理サイト準備編
前回 はブログアプリの基礎となる部分を作成し、動作確認まで行うことができました。
今回は、実際に記事を登録するための準備をし、記事の作成を行いましょう。記事 model の作成
ブログで記事を管理するためには model を作成します。
model はデータベースと Django の橋渡しの役割を持っており、これのおかげで我々は SQL といったデータベース構文を意識することなくデータベースにデータを登録することができます。最初に設定する models.py では、どのようなデータを登録していくのかを定義します。
Excelの表でいうと、表の各カラムのカラム名を定義したり、各カラムに入るデータがどのようなもの(文字列や数値など)を定義するところです。今回はブログアプリであり、記事 (Post) を修正していくので Post モデルを作成します。
タイトル、本文、日付が入ればとりあえず十分です。blog/models.pyfrom django.db import models from django.utils import timezone # django で日付を管理するためのモジュール class Post(models.Model): title = models.CharField('タイトル', max_length=200) text = models.TextField('本文') date = models.DateTimeField('日付', default=timezone.now) def __str__(self): # Post モデルが直接呼び出された時に返す値を定義 return self.title # 記事タイトルを返す次に、データベースに models.py で定義した情報を反映させます。
このままデータベースに対する処理を行うわけではなく、models.py の内容を反映させるためのワンクッションとなるファイルを作成します。
ファイルの作成を自動的に Django にやってもらうことができ、次のコマンドを実行することでファイルが作成されます。python3 manage.py makemigrationsすると /blog/migrations 配下に番号付きのファイルが作成されます。
. ├── blog │ ├── __init__.py │ ├── admin.py │ ├── apps.py │ ├── migrations │ │ ├── 0001_initial.py # これが追加される │ │ └── __init__.py │ ├── models.py │ ├── tests.py │ ├── urls.py │ └── views.py ├── db.sqlite3 ├── manage.py ├── mysite │ ├── __init__.py │ ├── settings.py │ ├── urls.py │ └── wsgi.py └── templates └── blog └── index.htmlDjango アプリ作成の中でこのファイルを直接いじることはありませんが、中身はこのようになっており、これのおかげでカラムの作成などを Django が一気にやってくれます。
0001_initial.py# Generated by Django 3.1 on 2020-10-17 01:13 from django.db import migrations, models import django.utils.timezone class Migration(migrations.Migration): initial = True dependencies = [ ] operations = [ migrations.CreateModel( name='Post', fields=[ ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')), ('title', models.CharField(max_length=200, verbose_name='タイトル')), ('text', models.TextField(verbose_name='本文')), ('date', models.DateTimeField(default=django.utils.timezone.now, verbose_name='日付')), ], ), ]さて、この migration ファイルを使ってデータベースにテーブルを作成することになりますが
反映もコマンド一発で Django が勝手にやってくれます。
以下のコマンドを実行しましょう。(blog) bash-3.2$ python3 manage.py migrate成功すると、一発目は大量の OK 表示とともに通常のコマンドラインに戻るかと思います。
Operations to perform: Apply all migrations: admin, auth, blog, contenttypes, sessions Running migrations: Applying contenttypes.0001_initial... OK Applying auth.0001_initial... OK Applying admin.0001_initial... OK Applying admin.0002_logentry_remove_auto_add... OK Applying admin.0003_logentry_add_action_flag_choices... OK Applying contenttypes.0002_remove_content_type_name... OK Applying auth.0002_alter_permission_name_max_length... OK Applying auth.0003_alter_user_email_max_length... OK Applying auth.0004_alter_user_username_opts... OK Applying auth.0005_alter_user_last_login_null... OK Applying auth.0006_require_contenttypes_0002... OK Applying auth.0007_alter_validators_add_error_messages... OK Applying auth.0008_alter_user_username_max_length... OK Applying auth.0009_alter_user_last_name_max_length... OK Applying auth.0010_alter_group_name_max_length... OK Applying auth.0011_update_proxy_permissions... OK Applying auth.0012_alter_user_first_name_max_length... OK Applying blog.0001_initial... OK Applying sessions.0001_initial... OK管理サイトでテーブルを確認
いきなり記事を作成していってもよいですが、まずはちゃんとテーブルを作成されているかを UI で確認すると安心かと思います。
Django では特別用意しなくても管理サイトの UI が自動で作られ、その中で作られたテーブルを確認したり、はたまた手動で作成、編集、削除なんかもできたりします。
そのための準備をここでは行っていきます。modelを管理サイトに反映
blogディレクトリ配下に admin.py というファイルが最初から作成されていますが、ここに先程作成した model の情報を記述することで管理サイトでこねくり回すことができるようになります。
blog/admin.pyfrom django.contrib import admin from .models import Post # 追加 admin.site.register(Post) # 追加管理ユーザを作成
管理サイトを使うためには、それ相応の権限を持ったユーザ(アカウント)、つまり superuser を作成してあげる必要があります。
これも Django のコマンドでサクッと作ることができます。python3 manage.py createsuperuser実行するとユーザ名、メールアドレス、パスワードを聞かれるのでそれぞれ入力しましょう。
※開発環境であれば、メールアドレスは適当なものでも問題ありません。作成が完了すると以下のような表示がコマンドライン上に出ます。
Superuser created successfully.管理サイトにログイン
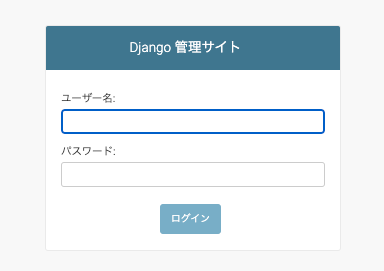
さて、それでは Django の管理サイトに実際にアクセスしてみましょう。
まずはサーバを起動します。
python3 manage.py runserver次にブラウザのアドレスバーに管理サイトのアドレスを入力しますが、
プロジェクトの urls.py に以下の記述があったことはお気づきでしょうか。mysite/ursl.pyurlpatterns = [ path('blog/', include('blog.urls')), path('admin/', admin.site.urls), # ここ ]この記述は最初から存在しており、デフォルトでは "127.0.0.1:8000/admin" で管理サイトにアクセスすることができます。
(通常はあまり変更することはありませんが、本番環境ではセキュリティ上、アドレスを変更しておく場合もあります)それでは Chrome 等で 127.0.0.1:8000/admin にアクセスします。
このようにログイン画面が表示されたら成功です。
先ほど superuser を作成したときの情報を入力し、ログインを選択します。
ログインに成功すると、管理画面が表示されます。
このような管理サイトを作成するには通常のフレームワークだと結構な準備が必要になりますが、デフォルトで用意されているのが Django の用意されているのがよいところです。また、BLOG というアプリ欄の中で Posts という model が反映されていることも分かりますね。
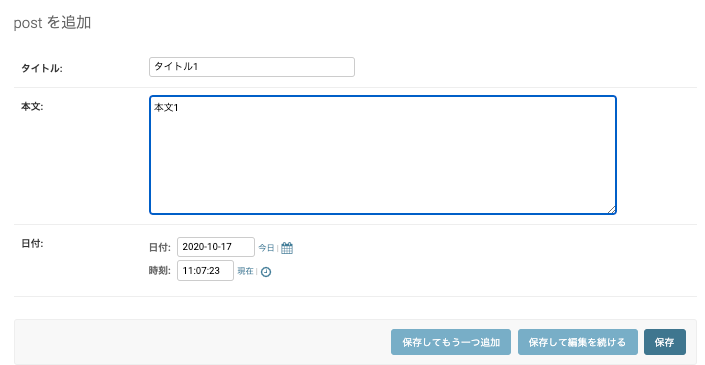
(Postが複数存在することになるので、Postsという表記になっていることもポイントです)ここで 追加 ボタンから記事を手動で作成することも出来ます。
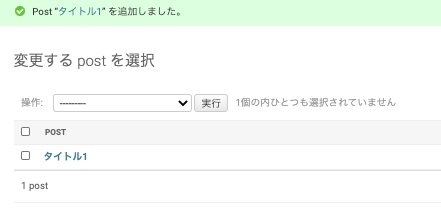
保存を選択すると、実際に記事を作成することもできます。
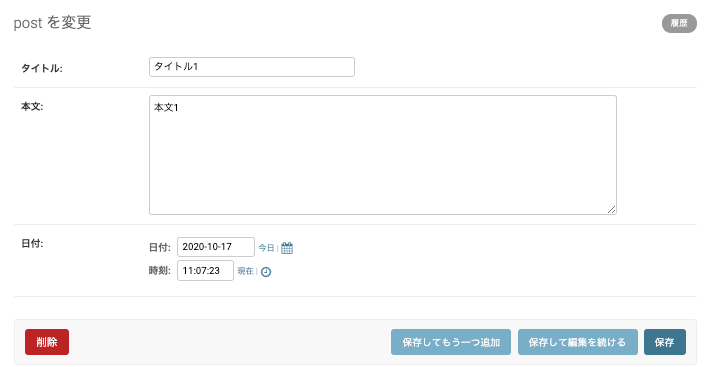
更には作成した記事を編集したり、削除したりすることもできます。便利ですね。
次回は、記事をアプリ上で表示(htmlとして表示)させるようにしていきます。
- 投稿日:2020-10-17T10:54:21+09:00
CloudFormationをゼロから勉強する。(その7:変更セットとドリフト検出)
はじめに
今回はスタック実行前に事前に変更箇所を確認できる
変更セットと、スタック実行後に手動操作などで変更されたリソースを確認できるドリフト検出を試してみようと思います。変更セットについて
前述の通り、スタック実行前に変更箇所を確認することができる機能です。
スタック実行前に変更されるリソースやパラメータを確認できるので、スタック実行することによって意図せずリソースが削除されたりする事故が防げます。
テスト環境ならともかく、サービスが動作している本番環境でスタックを実行する際には必須の機能かと思います。
ドリフト検出について
これも前述の通り、スタック実行後に手動操作などで変更されたリソースを確認できる機能です。
本来は環境を
CloudFormationで管理しているのであればスタックで作成したリソースや設定に対して手動で操作することは極力避けるべきですが、何かしらの理由で手動操作した場合でも変更箇所を検出することができます。例えば障害対応などで手動で変更した設定を、後日ドリフト検出で確認して
CloudFormationテンプレートに落とし込む場合に便利です。今回のシナリオ
変更セットとドリフト検出を試すため、1つのVPCと2つのサブネットリソースのみのシンプルな構成とし、サブネットリソースだけタグ付けした構成をベースとして以下を実施します。
- サブネットのタグを修正して変更セットを作成する。
- 手動で1つのサブネットの削除、VPCのタグの追加とサブネットのタグを修正してドリフト検出する。
- テンプレートからサブネットの削除とタグの追加・修正を行い、再度変更セットを作成する。
また、コンソールやコマンドで実行する際のスタック名等は以下で行うため、適宜読み替えるようにして下さい。
項目 名前 スタック名 stack-test 変更セット名 change-set-test テンプレートファイルパス /home/ec2-user/cf.yaml パラメータファイルパス /home/ec2-user/param.yaml ベーステンプレートの作成
今回は
VPCとサブネットのみのテンプレートとパラメータファイルを新たに作成します。
Metadataや不要な設定は削除して極力シンプルにしました。
ベーステンプレートの作成(展開して下さい)
/home/ec2-user/cf.yamlAWSTemplateFormatVersion: 2010-09-09 Resources: EC2VPC1: Type: 'AWS::EC2::VPC' Properties: CidrBlock: !Ref VPCRange EC2Subnet1: Type: 'AWS::EC2::Subnet' Properties: VpcId: !Ref EC2VPC1 CidrBlock: !Ref SubnetRange1 Tags: - Key: "Name" Value: "CloudFormation" EC2Subnet2: Type: 'AWS::EC2::Subnet' Properties: VpcId: !Ref EC2VPC1 CidrBlock: !Ref SubnetRange2 Tags: - Key: "Name" Value: "CloudFormation" Parameters: VPCRange: Type: String Description: "VPC Subnet Range" SubnetRange1: Type: String Description: "Subnet Range1" SubnetRange2: Type: String Description: "Subnet Range2"
ベースパラメータファイルの作成(展開して下さい)
/home/ec2-user/param.json[ { "ParameterKey" : "VPCRange", "ParameterValue" : "172.24.0.0/16" }, { "ParameterKey" : "SubnetRange1", "ParameterValue" : "172.24.0.0/24" }, { "ParameterKey" : "SubnetRange2", "ParameterValue" : "172.24.1.0/24" } ]テンプレートの作成aws cloudformation create-stack --template-body file:///home/ec2-user/cf.yaml --stack-name stack-test --parameters file:///home/ec2-user/param.jsonベーステンプレートの修正
前準備として作成したベーステンプレートを以下の内容に修正します。
- サブネットリソースのタグを
cf_Subnetという名前に修正する。変更セットの作成
変更セットは作成済みスタックのテンプレートと修正したテンプレートの差分をチェックして変更となる項目を確認することができます。
AWSマネジメントコンソールから操作する場合は作成したスタックを選択し、変更セット→変更セットの作成から修正したテンプレートをアップロードするか、直接編集を行います。
AWS CLIで実行する場合は以下コマンドを実行します。変更セットの作成aws cloudformation create-change-set --change-set-name change-set-test --template-body file:///home/ec2-user/cf.yaml --stack-name stack-test --parameters file:///home/ec2-user/param.json
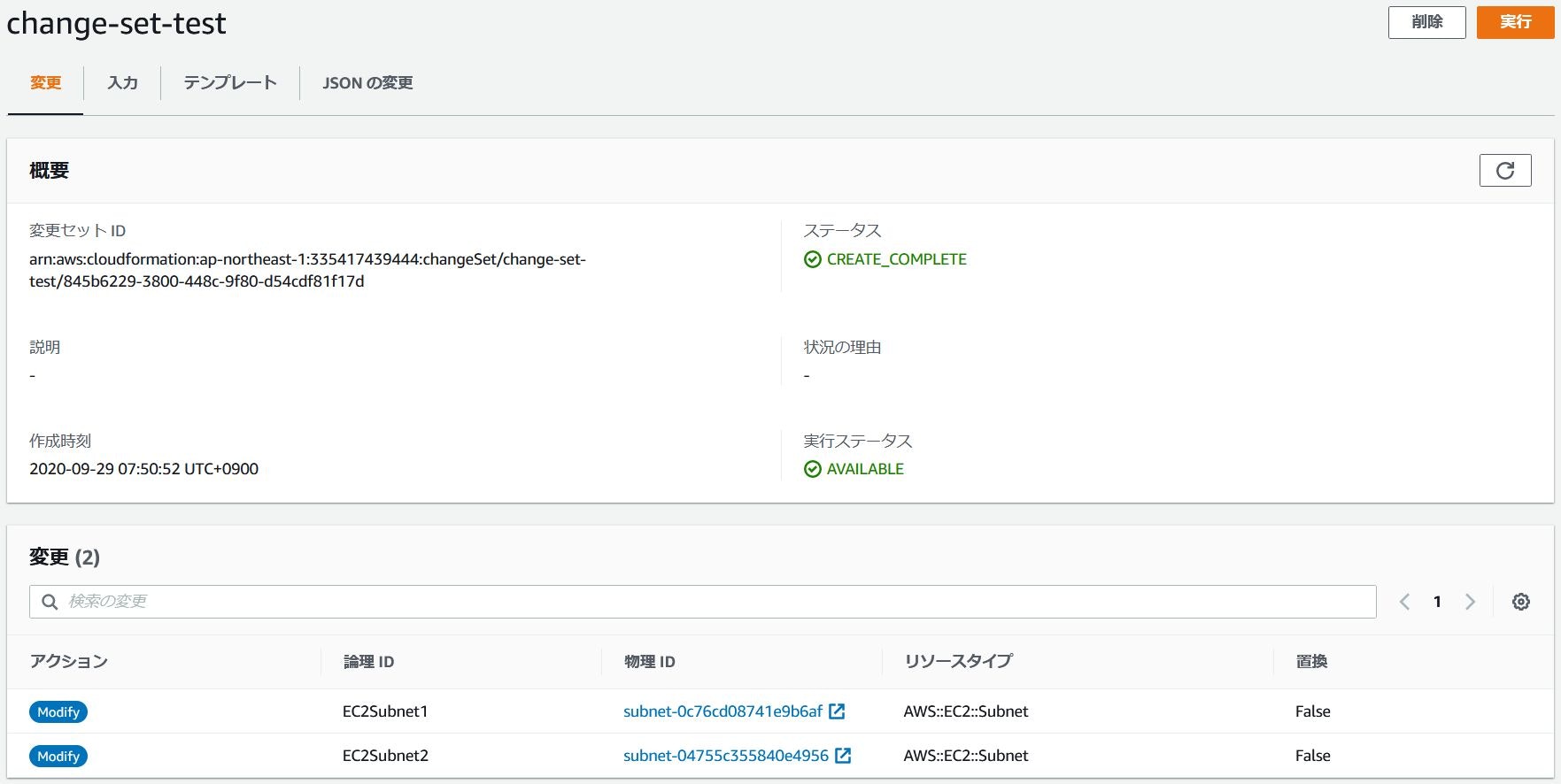
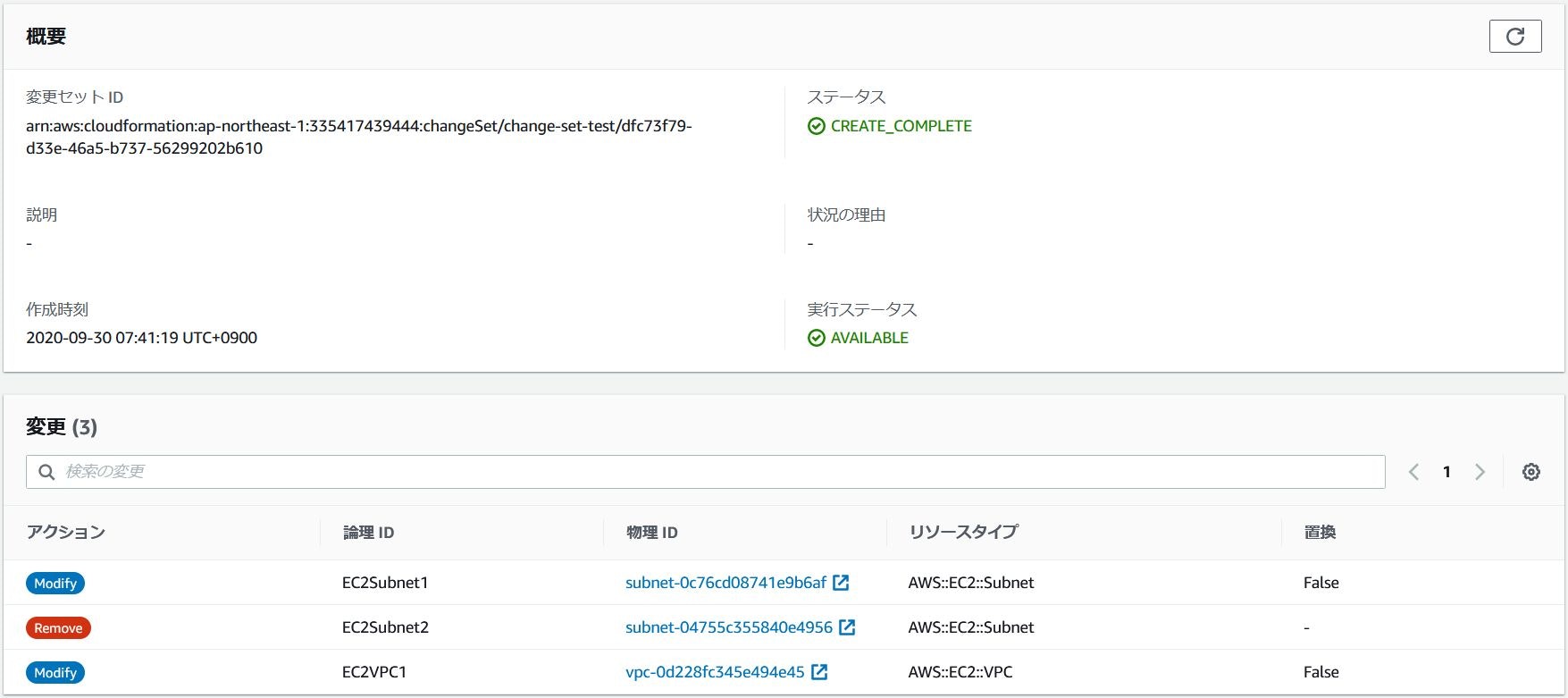
変更セットを作成すると以下画面のような比較結果が表示され、どのリソースが変更されるかが確認できます。
コマンドの場合は以下。
変更セットの確認aws cloudformation describe-change-set --change-set-name change-set-test --stack-name stack-test
コマンド実行結果(展開して下さい)
コマンド実行結果{ "StackId": "arn:aws:cloudformation:ap-northeast-1:335417439444:stack/stack-test/d5249730-01dc-11eb-8e2a-0af1581a9dde", "Status": "CREATE_COMPLETE", "ChangeSetName": "change-set-test", "Parameters": [ { "ParameterValue": "172.24.0.0/24", "ParameterKey": "SubnetRange1" }, { "ParameterValue": "172.24.1.0/24", "ParameterKey": "SubnetRange2" }, { "ParameterValue": "172.24.0.0/16", "ParameterKey": "VPCRange" } ], "Changes": [ { "ResourceChange": { "ResourceType": "AWS::EC2::Subnet", "PhysicalResourceId": "subnet-0c76cd08741e9b6af", "Details": [ { "ChangeSource": "DirectModification", "Evaluation": "Static", "Target": { "Attribute": "Tags", "RequiresRecreation": "Never" } } ], "Action": "Modify", "Scope": [ "Tags" ], "LogicalResourceId": "EC2Subnet1", "Replacement": "False" }, "Type": "Resource" }, { "ResourceChange": { "ResourceType": "AWS::EC2::Subnet", "PhysicalResourceId": "subnet-04755c355840e4956", "Details": [ { "ChangeSource": "DirectModification", "Evaluation": "Static", "Target": { "Attribute": "Tags", "RequiresRecreation": "Never" } } ], "Action": "Modify", "Scope": [ "Tags" ], "LogicalResourceId": "EC2Subnet2", "Replacement": "False" }, "Type": "Resource" } ], "CreationTime": "2020-09-28T22:50:52.425Z", "Capabilities": [], "StackName": "stack-test", "NotificationARNs": [], "ExecutionStatus": "AVAILABLE", "ChangeSetId": "arn:aws:cloudformation:ap-northeast-1:335417439444:changeSet/change-set-test/845b6229-3800-448c-9f80-d54cdf81f17d", "RollbackConfiguration": {} }変更セットの実行
変更セットは作成しただけでは差分結果を表示するだけなので、差分結果に問題が無ければ実際に修正したテンプレートを反映させるため変更セットを実行します。修正したテンプレートを実行するためには、コンソールからなら
実行ボタン、コマンドからならexecute-change-setを実行します。変更セットの実行aws cloudformation execute-change-set --change-set-name change-set-test --stack-name stack-test変更セット実行後は以下の様にタグが追加、修正されているのが確認できます。
サブネットリソースの手動削除とタグ追加・修正
ドリフト検出を試すため、SubnetRange2で作成したサブネットを手動で削除してみます。コマンドで実行する場合は事前に
サブネットIDを調べておいて下さい。サブネットの削除aws ec2 delete-subnet --subnet-id [サブネットID]VPC、サブネットのタグ追加・修正aws ec2 create-tags --resources [VPC ID] --tags Key=Name,Value=cf_VPC1 aws ec2 create-tags --resources [サブネットID] --tags Key=Name,Value=cf_Subnet1ドリフト検出の実行
スタック一覧画面でスタックを選択し、
スタックアクションからドリフトの検出を選択することで最新のテンプレートと異なる設定をチェックできます。
コマンドの場合は以下。
ドリフト検出の実行aws cloudformation detect-stack-drift --stack-name stack-testドリフト結果の確認
スタック一覧画面でスタックを選択し、
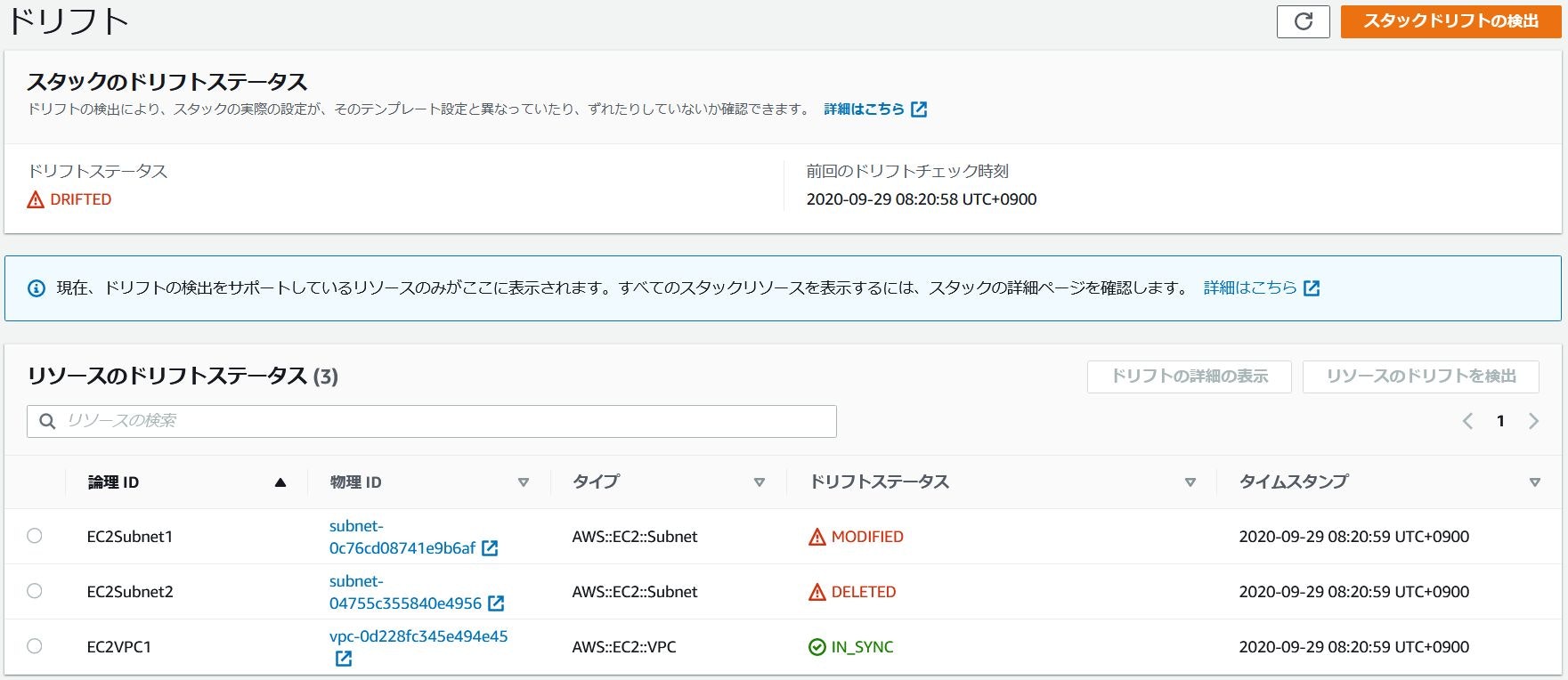
スタックアクションからドリフト結果を表示を選択することで先ほど実行したドリフト検出の結果を確認できます。今回は
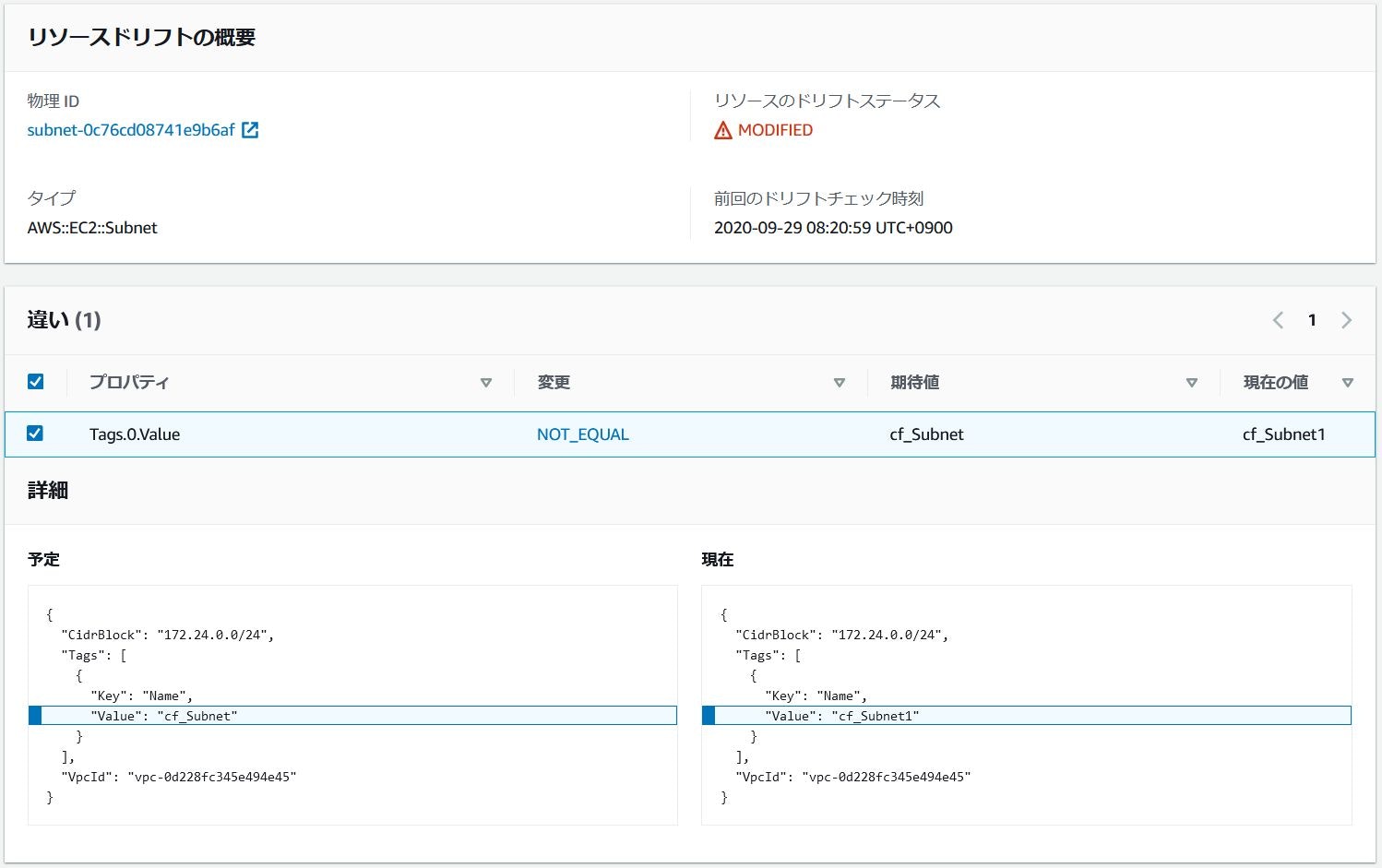
EC2Subnet1のタグの修正とEC2Subnet2リソースを手動で削除しているので、それぞれMODIFIED、DELETEDと検出されていることが確認できます。
コマンドの場合は以下。
ドリフト結果の表示aws cloudformation describe-stack-resource-drifts --stack-name stack-test
コマンド実行結果(展開して下さい)
コマンド実行結果{ "StackResourceDrifts": [ { "StackId": "arn:aws:cloudformation:ap-northeast-1:335417439444:stack/stack-test/d5249730-01dc-11eb-8e2a-0af1581a9dde", "ActualProperties": "{\"CidrBlock\":\"172.24.0.0/24\",\"Tags\":[{\"Key\":\"Name\",\"Value\":\"cf_Subnet1\"}],\"VpcId\":\"vpc-0d228fc345e494e45\"}", "ResourceType": "AWS::EC2::Subnet", "Timestamp": "2020-09-28T23:20:59.182Z", "PhysicalResourceId": "subnet-0c76cd08741e9b6af", "StackResourceDriftStatus": "MODIFIED", "ExpectedProperties": "{\"CidrBlock\":\"172.24.0.0/24\",\"Tags\":[{\"Key\":\"Name\",\"Value\":\"cf_Subnet\"}],\"VpcId\":\"vpc-0d228fc345e494e45\"}", "PropertyDifferences": [ { "PropertyPath": "/Tags/0/Value", "ActualValue": "cf_Subnet1", "ExpectedValue": "cf_Subnet", "DifferenceType": "NOT_EQUAL" } ], "LogicalResourceId": "EC2Subnet1" }, { "StackId": "arn:aws:cloudformation:ap-northeast-1:335417439444:stack/stack-test/d5249730-01dc-11eb-8e2a-0af1581a9dde", "ResourceType": "AWS::EC2::Subnet", "Timestamp": "2020-09-28T23:20:59.746Z", "PhysicalResourceId": "subnet-04755c355840e4956", "StackResourceDriftStatus": "DELETED", "LogicalResourceId": "EC2Subnet2" }, { "StackId": "arn:aws:cloudformation:ap-northeast-1:335417439444:stack/stack-test/d5249730-01dc-11eb-8e2a-0af1581a9dde", "ActualProperties": "{\"CidrBlock\":\"172.24.0.0/16\"}", "ResourceType": "AWS::EC2::VPC", "Timestamp": "2020-09-29T22:21:03.431Z", "PhysicalResourceId": "vpc-0d228fc345e494e45", "StackResourceDriftStatus": "IN_SYNC", "ExpectedProperties": "{\"CidrBlock\":\"172.24.0.0/16\"}", "PropertyDifferences": [], "LogicalResourceId": "EC2VPC1" } ] }また、上記ドリフトの画面からリソースを選択し、
ドリフトの詳細の表示をクリックするとJSON形式ですがテンプレートとの差分を確認することができるので、実際にテンプレートを修正する場合に便利です。
ドリフト検出の注意点
今回、手動修正した個所は
EC2Subnet1のタグ修正、EC2Subnet2のリソース削除、EC2VPC1のタグ追加ですが、上記の画像を見るとEC2VPC1のタグ追加が検出されておりません。はっきり調べていませんが、
ドリフト検出はテンプレートにもともと記載されている設定に対する検出なので、記載されていた設定値の変更は検出できても、そもそも記載されていなかった設定を検出することはできないようです。そのような設定変更を検出するためには
AWS Configで検出する必要があるのかな?変更セットの更新
テンプレートとパラメータファイルからも
EC2VPC1とEC2Subnet1のタグ追加・修正とEC2Subnet2リソースを削除して先ほどと同様変更セットを実行します。
コマンドから実行する場合も、先ほどと同様のコマンドで実行できます。
変更セットの作成aws cloudformation create-change-set --change-set-name change-set-test --template-body file:///home/ec2-user/cf.yaml --stack-name stack-test --parameters file:///home/ec2-user/param.json変更セットの実行aws cloudformation execute-change-set --change-set-name change-set-test --stack-name stack-testおわりに
変更セット、ドリフト検出をこまめに行うことでシステムを運用していると常に付きまとう設計書と実機の差分を減らすことができるのは非常にありがたいですね。
※CloudFormationで管理されていない設定については検出できませんが。次回は
スタックのネストを試してみようと思います。

- 投稿日:2020-10-17T10:06:55+09:00
Djangoチュートリアル(ブログアプリ作成)① - 準備、トップページ作成編
今回は Django を使って、記事を投稿できるブログアプリを作成していきます。
シリーズに分けて紹介していきますが、まずはローカルで作成した上で Docker 構成にしたり、AWS にデプロイしたり、CircleCI で自動テスト・デプロイまでをシリーズ化していきます。
Django とは?
Djangoは Python で実装できる Web アプリケーションフレームワークです。
フレームワークとは、アプリケーションを開発する際に使われる機能がまとまったソフトウェアです。
フレームワークを導入することで、効率よく Web アプリを進めることができます。今回は Blog アプリを作っていきますが、Django を使えばデータベースを用いた、コンテンツ管理システムやWikiからソーシャルネットワーク、ニュースサイトなど、高品質なWebアプリケーションを簡単に、少ないコードで作成できます。シンプルなWebアプリケーションであれば、数分間で作れてしまう場合もあります。もちろん、機能を拡張して複雑なWebアプリケーションを作成することもできます。
また、Djangoは、Instagram など、有名な Webアプリでも使われており、Ruby でいう Ruby on Rails に相当する注目のフレームワークとなっています。
環境構築
まずは作業用のディレクトリを作成します。
ここでの名前はなんでもよいですが、とりあえず blog としておきます。mkdir blog cd blogpipenv のインストール
ベースとなる環境は汚さない方が他のモジュールなどの影響を排除できるため、pipenv を使って仮想環境を構築しましょう。
pip install pipenv # 環境によっては直接 pip を使えない場合もあるので、python3 -m pip install pipenv でインストールしますインストールできたら、作業用フォルダの中で下記のコマンドを実行します。
pipenv shell実行後、仮想環境に入ることが出来るとディレクトリ名に従った文字列がコマンドラインの冒頭に表示されるようになります。
(blog)bash-3.2$Django をインストール
直接 pipenv install django とでも実行して Django をインストールしてもよいですが、
後々 Docker を使うことを考えて、requirements.txt というファイルを作業用ディレクトリ直下に作成して
必要となるモジュールを記述していくことにします。いまは Django だけが必要なので、バージョン情報とともに以下のように記載します。
requirements.txtDjango==3.1.0※今回は Django 3.1.0 で作っていきますが Django 2.2 あたりでも問題なく動くとは思います
モジュールのインストール
下記のコマンドを実行することで、requirements.txt に基づきモジュールをインストールします。
ここでは Django だけがインストールされるはずです。pipenv install -r requirements.txtDjango プロジェクトの作成
blog ディレクトリ直下で実行
django-admin startproject mysite親プロジェクト直下でのファイル構成はこのようになっているかと思います。
├── Pipfile ├── Pipfile.lock ├── mysite │ ├── manage.py │ └── mysite │ ├── __init__.py │ ├── settings.py │ ├── urls.py │ └── wsgi.py └── requirements.txtDjango サーバのテスト起動
開発用サーバを起動する機能がついています。
(Ruby on Rails をやったことがある人は rails -s というと分かりやすいかと思います)これを実行するには manage.py ファイルが置いてあるディレクトリに移動する方が便利なので、mysite/mysite ディレクトリに移動してから実行します
cd mysite python3 manage.py runserver正常に実行できると下記のような出力が出ます。
October 16, 2020 - 21:30:23 Django version 3.1, using settings 'mysite.settings' Starting development server at http://127.0.0.1:8000/ Quit the server with CONTROL-C.なお、この部分は migrate というデータベースへの統合処理が済んでいないために出力されるメッセージですが、いまのところ気にしないで大丈夫です。
You have 18 unapplied migration(s). Your project may not work properly until you apply the migrations for app(s): admin, auth, contenttypes, sessions. Run 'python manage.py migrate' to apply them.さて、これで Django の開発用サーバが起動したのでブラウザから確認します。
Chrome などのブラウザのアドレスバーに「127.0.0.1:8000」と入力して Enter を押下します。
これがすべての始まりです。この画面が出ていれば、最初のステップは完了しています!おめでとうございます。
プロジェクトの設定
さて、先ほどテストサーバへアクセスした時に英語での表記になっていましたね。
こういった設定は mysite/settings.py で設定することができ、デフォルトでは英語圏に合わせた言語表示、およびタイムゾーンになっています。mysite/settings.py(before)LANGUAGE_CODE = 'en-us' TIME_ZONE = 'UTC'これを次のように変更してあげます。
mysite/settings.py(after)LANGUAGE_CODE = 'ja' TIME_ZONE = 'Asia/Tokyo'もう一度テストサーバへアクセスすると、日本語表記になっていることが分かるかと思います。
(また、この画面からでは確認できませんがタイムゾーンも東京設定になっています)
Django アプリの作成
先程 start-project コマンドでプロジェクトを作成しましたが、次はアプリケーションを作っていきます。
混乱しがちですが、ベースとなるプロジェクトと個別のアプリは別物です。公式ページではこのような説明です。
プロジェクトとアプリの違いは何でしょうか? アプリとは、ウェブログシステム、公的記録のデータベース、小規模な投票アプリなど、何かを行う Web アプリケーションです。プロジェクトは、特定のウェブサイトの構成とアプリのコレクションです。プロジェクトには複数のアプリを含めることができます。 アプリは複数のプロジェクトに存在できます。
では、blog アプリを作っていきましょう。mysite プロジェクトリ (manage.py ファイルがある場所) の直下で下記コマンドを実行します。
python3 manage.py startapp blog現在のディレクトリ構成はこのようになっています。
. ├── db.sqlite3 ├── manage.py ├── mysite │ ├── __init__.py │ ├── settings.py │ ├── urls.py │ └── wsgi.py └── blog ├── __init__.py ├── admin.py ├── apps.py ├── migrations │ └── __init__.py ├── models.py ├── tests.py └── views.pyblog 配下に様々なファイルが作成されていることが分かるかと思います。
ここで、このアプリが作成されたことをプロジェクトに教えてあげる必要があります。
mysite/setting.py の中に "INSTALLED_APPS" という欄がありますので、その中で blog アプリの存在を教えてあげましょう。
mysite/settings.pyINSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'blog.apps.BlogConfig', # ここを追加 ]template, view, url の設定
まずは「 template をそれぞれ変更していきます。
template は見た目を作るための部分であり、html ファイルに相当します。
mysite プロジェクト直下に templates フォルダ、その下に blogフォルダ、さらにその下に index.html を作成します。
. ├── blog │ ├── __init__.py │ ├── admin.py │ ├── apps.py │ ├── migrations │ │ └── __init__.py │ ├── models.py │ ├── tests.py │ └── views.py ├── db.sqlite3 ├── manage.py ├── mysite │ ├── __init__.py │ ├── settings.py │ ├── urls.py │ └── wsgi.py └── templates └── blog └── index.html ←ここに作成index.html の中身はとりあえず適当で大丈夫です。
index.html<h1>Hello, from Django!</h1>また、templates フォルダをどこに作ったかをプロジェクトに教えて上げる必要があります。
INSTALLED_APPS を設定したときと同様に、settings.py に下記の記述を入れます。settings.pyTEMPLATES = [ { 'BACKEND': 'django.template.backends.django.DjangoTemplates', 'DIRS': [os.path.join(BASE_DIR, 'templates')], # ここを修正 'APP_DIRS': True,次に views.py を修正していきます。
先ほど作った template である index.html を呼び出します。blog/views.pyfrom django.views.generic import TemplateView class IndexView(TemplateView): template_name = 'blog/index.html'URL の設計
次に、blog アプリ専用のルーティング設定を作成します。
ルーティング設定は「urls.py」というファイルで設定していきます。まずはじめに説明をしますと、プロジェクト全体のルーティングを司る urls.py と、アプリ内の urls.py それぞれでルーティングを設定します。
最初に mysite 直下の urls.py から編集します。
mysite/urls.pyfrom django.contrib import admin from django.urls import include, path urlpatterns = [ path('blog/', include('blog.urls')), path('admin/', admin.site.urls), ]後に作成する blog アプリ用の urls を、urlpatterns 内で読み込むことになります。
では mysite 直下にのみ urls.py が作成されていますが、blog 直下にも自分で「urls.py」を作成します。
エディタでもよいですし、アプリの blog ディレクトリ内で下記コマンドを実行してもよいでしょう。/blogtouch urls.pyblog 配下はこのようなファイル構成です。
. ├── __init__.py ├── admin.py ├── apps.py ├── migrations │ └── __init__.py ├── models.py ├── tests.py ├── urls.py └── views.py作成した urls.py の中身はこのように変更することで、先程 views.py で作成した関数(=index.htmlを呼び出す処理)のルーティングを設定します。
blog/urls.pyfrom django.urls import path from . import views app_name = 'blog' urlpatterns = [ path('', views.IndexView.as_view(), name='index'), ]ちなみに name='index' を設定しておくことで「blog:index」という名前を使ってこの url を逆引きで呼び出すことができるようになります。
この時点で index.html を呼び出せるかの確認を行います。
manage.py が置いてあるディレクトリで runserver を実行します。
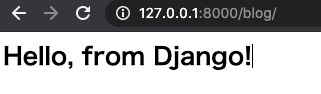
python3 manage.py runserver無事に通ったら、今度はブラウザで 127.0.0.1:8000/blog へアクセスします。
これは先程 mysite/urls.py で blog 付きのアドレスでアクセスされたときに、blog アプリ内に記述した内容を動作させるようにしているためです。アクセスし、index.html の中身が表示されれば成功です。
次回は models を作成し、実際に記事を登録するための準備をします。

- 投稿日:2020-10-17T00:41:15+09:00
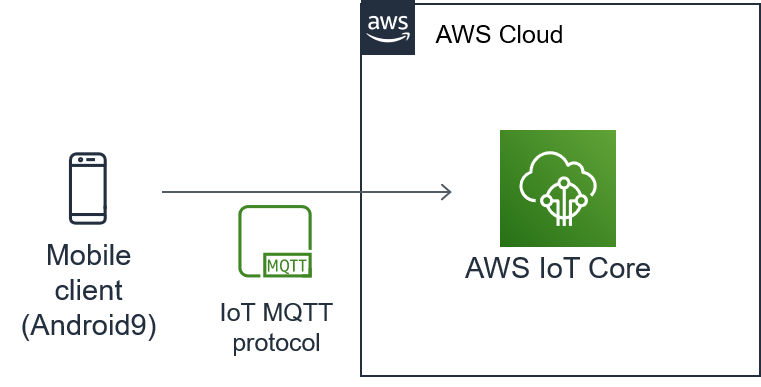
termux×AWS IoT でスマホ位置情報をAWSに送信
はじめに
妻に、「職場を出たらラインしろ」と言われているのですが、正直面倒です。
自分が職場を出たことを自動で通知できないかなと思い、とりあえず位置情報をAWSに送ってみました。
環境
スマホ:京セラ(KTV44)
OS:Android 9スマホ(termux)側
AndroidにGoogle Playを利用して、termuxをインストールします。
https://play.google.com/store/apps/details?id=com.termux&hl=jaスマホだとキーボード入力しづらいため、
インストール後に下記コマンドを入力し、ssh用の環境を構築します。$ termux-setup-storage #termuxにandroidストレージの使用を許可する。 $ pkg install openssh #ssh(サ-バ、クライアント両方)をインストール $ sshd #sshサーバを起動 $ passwd #パスワードの設定 $ whoami #ユーザ名の確認(メモしてください。) $ ifconfig #スマホのIPアドレスの確認(メモしてください。)ちなみに、termuxで表示されるIPアドレスはスマホ自体のIPアドレスと一緒なので、あらかじめ分かっていればifconfigしなくても大丈夫です。
次に作業しやすいようにPCからsshでスマホに接続します。
ここで注意です.
sshのデフォルトのTCPポート番号は22ですが、termuxの場合は8022が指定されています。
そこで-pオプションでポート番号を指定します。
PC(Ubuntu)側$ ssh -p 8022 (ユーザ名)@(スマホのIPアドレス)最初にsshをした場合、
Are you sure you want to continue connecting (yes/no)?
と出るので、yesと回答。
その後、スマホで設定したパスワードを入力します。初期状態ではバックグラウンド処理が禁止されているため、スマホがスリープ状態になるとsshの接続がその都度中断されててしまいます。
スマホで「RELEASE WAKELOCK」を選択することで、バックグラウンド処理が行われるようになる。
sshで入れるようになったら、引き続き環境を構築していきます。
$ pkg install git #後に使用するAWS IoT Core用にgitをインストールしておく。 $ pkg install python #Pythonもインストールしておく。 $ pkg install vim-python #ファイル編集用にvimもインストールしておく。 $ pkg install termux-api #termux-apiもインストールしておく。GPS情報を取得するために必要。インストール系が終了したら、次はAWS Iot Coreを設定します。
この↓記事を参考に「android01」なるモノを登録し、スマホからAWSへの接続テストまで行います。
https://qiita.com/zakuzakuzaki/items/e30d63598ca1d6c0f2a9意外とそのままできたのでびっくりです。
termuxすごい。「termux-api」の中の、termux-locationコマンドで、位置情報を取得します。
https://wiki.termux.com/wiki/Termux-location$ termux-location -p network #スマホが観測している現在位置を出力 { "latitude": 35.6359322, "longitude": 139.8786311, "altitude": 43.5, "accuracy": 23.26799964904785, "vertical_accuracy": 3.299999237060547, "bearing": 0.0, "speed": 0.0, "elapsedMs": 97, "provider": "network" }-pは、位置情報の取得手段を選択するオプションで[gps/network/passive]の中から選択します。
デフォルトだとgpsですが、なぜか自分のスマホではできませんでしたので、networkを選択しました。
(エラーも出ず、ずっと待ち状態になる。)
ちなみにスマホをWi-Fi接続から3G接続に変えても、networkを選択しないと位置情報を取得できません。おそらくtermuxアプリの権限の問題だと思いますが、解決できなかったので放置しました。
通常、androidはアプリの設定画面でアプリ毎にフォルダ、カメラ、GPSなどの利用権限が付与できるのですが、
termuxはそもそも権限の選択肢が出てこないので、付与のしようがありません。位置情報が取得できることが確認できたら、処理しやすいようにしてjson形式で保存します。
$ termux-location -p network |sed -e "4,10d"|tr -d '\n'|tr -d ' '| sed -s s/,}/}/g > location.json $ cat location.json {"latitude":35.6359322,"longitude":139.8786311}#いい感じに整形されたことを確認やっていることは、
・位置情報を取得
・4~10行目(緯度経度以外)を削除
・改行を削除
・スペースを削除
・最後の” , ”(カンマ)を削除
です。
全部の情報をそのまま送ってもいいと思うのですが、少しでも通信量を下げるために、余計なデータをカットしました。次に、位置情報をパブリッシュするためのプログラムを作成します。
aws-iot-device-sdk-python内のサンプルファイル、「basicPubSub.py」の最後の部分を改造した、「jsonPub.py」を作成します。
位置情報が入っている、location.jsonを読み込みパブリッシュするようにします。編集前
basicPubSub.py(112行目以降)# Publish to the same topic in a loop forever loopCount = 0 while True: if args.mode == 'both' or args.mode == 'publish': message = {} message['message'] = args.message message['sequence'] = loopCount messageJson = json.dumps(message) myAWSIoTMQTTClient.publish(topic, messageJson, 1) if args.mode == 'publish': print('Published topic %s: %s\n' % (topic, messageJson)) loopCount += 1 time.sleep(1)編集後
jsonPub.py(112行目以降)# Publish to the same topic in a loop forever with open("location.json", "rb") as load_file:#位置情報ファイルの読み込み location = bytearray(load_file.read())#MQTT送信用にbytearray型に変換 loopCount = 0 while True: if args.mode == 'both' or args.mode == 'publish': myAWSIoTMQTTClient.publish(topic, location, 1)#位置情報をパブリッシュ if args.mode == 'publish': print('Published topic %s: %s\n' % (topic, location))#確認用 loopCount += 1 time.sleep(1)これでスマホ側の構築は終わりです。
AWS側の設定
次にクラウド側の設定を行います。
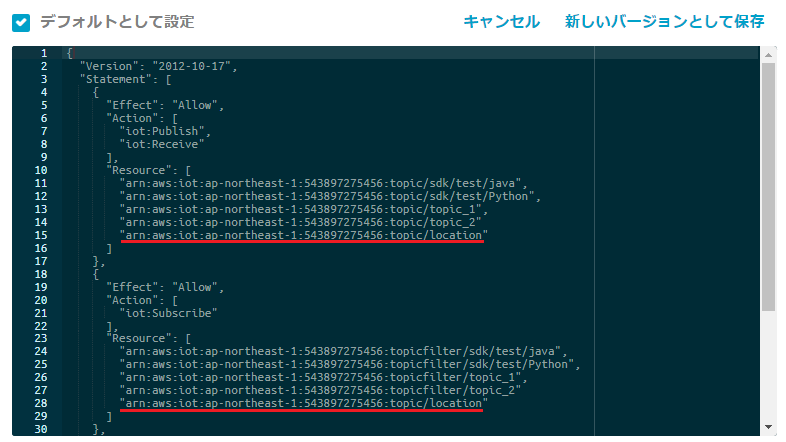
といってもポリシーを変えるだけです。AWS IoT>ポリシーから、パブリッシュ、サブスクライブしてもいいトピックを追加します。
今回は「location」という名前のトピックを追加しました。
編集が終わったら、「新しいバージョンとして保存」します。
これをしないと接続エラーが発生します。
テスト
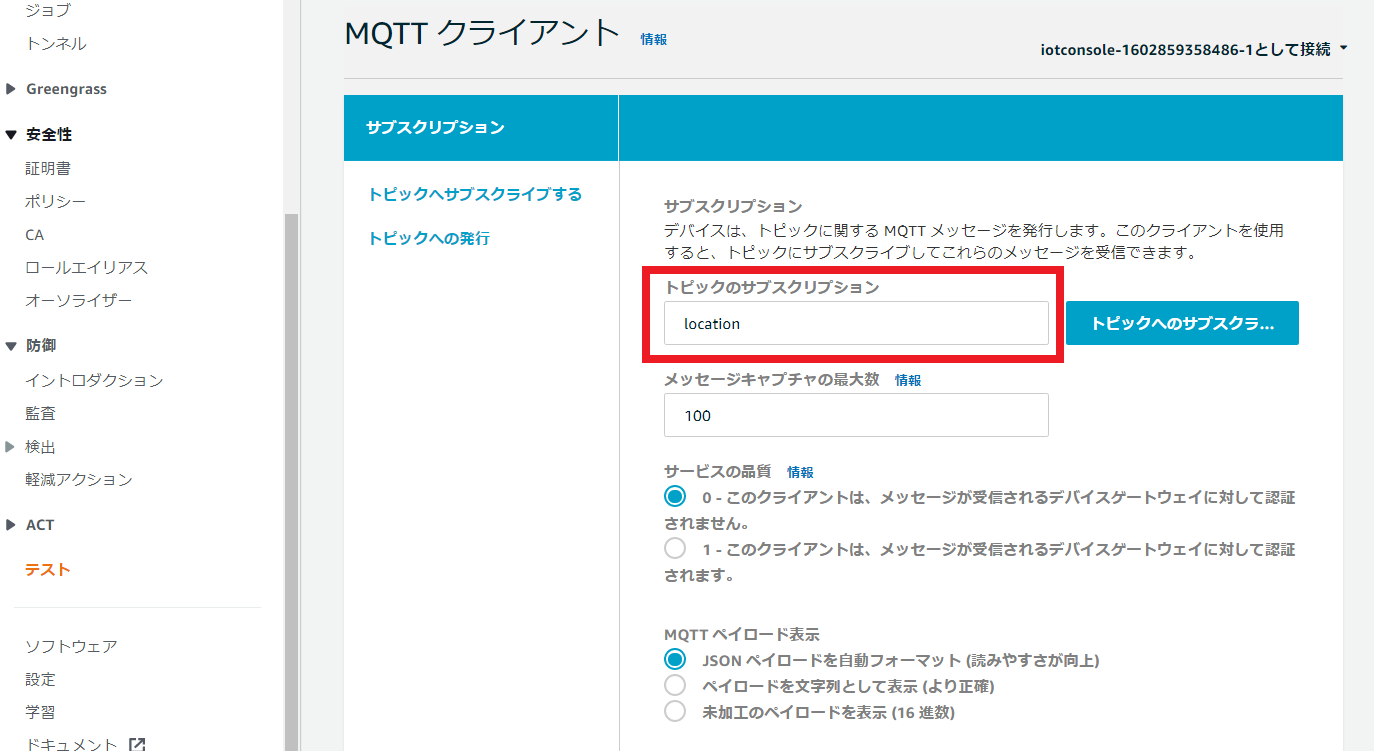
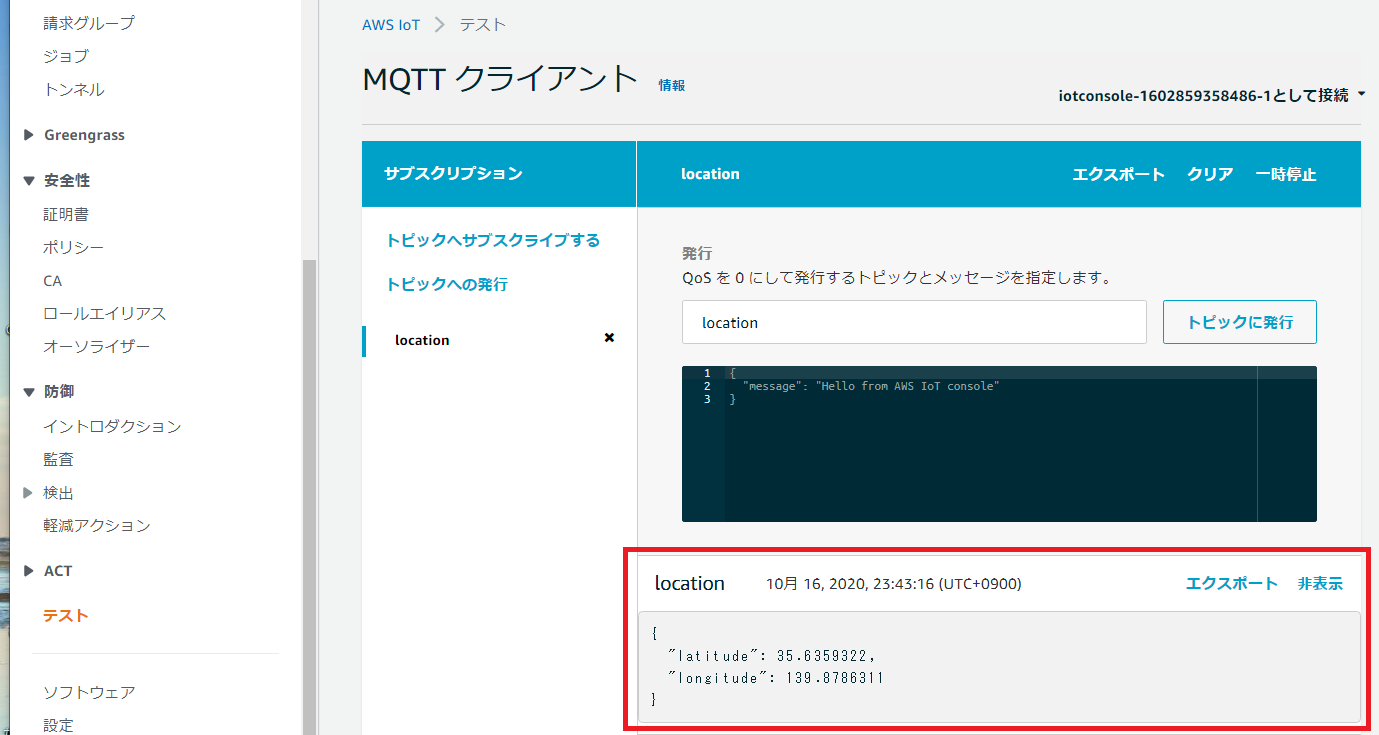
AWS IoT >テストにアクセスし、トピック名(location)を入力したのち、「トピックへのサブスクライブ」をクリックします。
ターミナルでjsonPub.pyを実行します。
コマンドの最後に-tオプションでトピック名を指定します。python jsonPub.py -e (自分のARNに合わせてください)-ats.iot.ap-northeast-1.amazonaws.com -r root-CA.crt -c android01.cert.pem -k android01.private.key -t locationターミナルに下記メッセージが出力されることを確認します。
スマホがAWSにパブリッシュした位置情報をAWSからサブスクライブできました。Received a new message: b'{"latitude":35.6359322,"longitude":139.8786311}' from topic: location --------------さらにAWS側で、locationトピックをサブスクライブしていることを確認します。
おつかれさまでした。
おわりに
スマホの位置情報をAWSに送信する環境を構築しました。
次は、lamda等を利用して退社自動通知や、帰りの電車の発車時刻を調べてくれたらいいですね。
ちなみに、本ページで表示している位置情報は私の家ではありませんので、ご安心ください。今回作成したファイルは、githubにあげました。
https://github.com/zakuzakuzaki/zaki-aws/tree/main/iot参考URL
ご協力ありがとうございました。
Android 端末上で開発環境を整えてみた
https://qiita.com/leosuke/items/b83425d5a6730aa4cf94Termux で持ち運べるモバイルリポジトリを作る
https://wlog.flatlib.jp/item/1859PythonでJSON 読み込み
https://qiita.com/kikuchiTakuya/items/53990fca06fb9ba1d8a7
- 投稿日:2020-10-17T00:26:32+09:00
第六章: 最後に
最後に
全ての章が終わりました。お疲れ様です。
余計なコストをかけない様に作ったサービスは全て削除しておくことをお勧めします。
- Elastic IPアドレスの関連付けの解除+解放
- Ec2のsnapshotを削除
- Ec2のボリュームを削除
- IAMを削除
- RDSのDBインスタンス終了
- RDSのスナップショットを削除
- ELBを終了
- ネットワークインターフェースを削除
- セキュリティーグループを削除
- CloudWatchのログを削除
- ルートテーブルを削除
- インターネットゲートウェイを削除
- サブネットを削除
- VPCを削除
- ACMを削除
- Route53のホストを削除
前へ: 第五章: EC2からRDSに接続してみよう
最初へ: AWSのELBとEC2を使ってwebアーキテクチャを構築しよう
- 投稿日:2020-10-17T00:22:56+09:00
第四章: ELBとRoute53を使って独自ドメインををSSL化してHello worldを表示させよう
ACMで無料のSSL証明書を発行しよう
- awsコンソールからACMと検索してください。Certificate Managerというのがヒットすると思います
- 証明書のプロビジョニングの「今すぐ始める」ボタン押下
- [パブリック証明書のリクエスト]を選択して、「証明書のリクエスト」ボタン押下
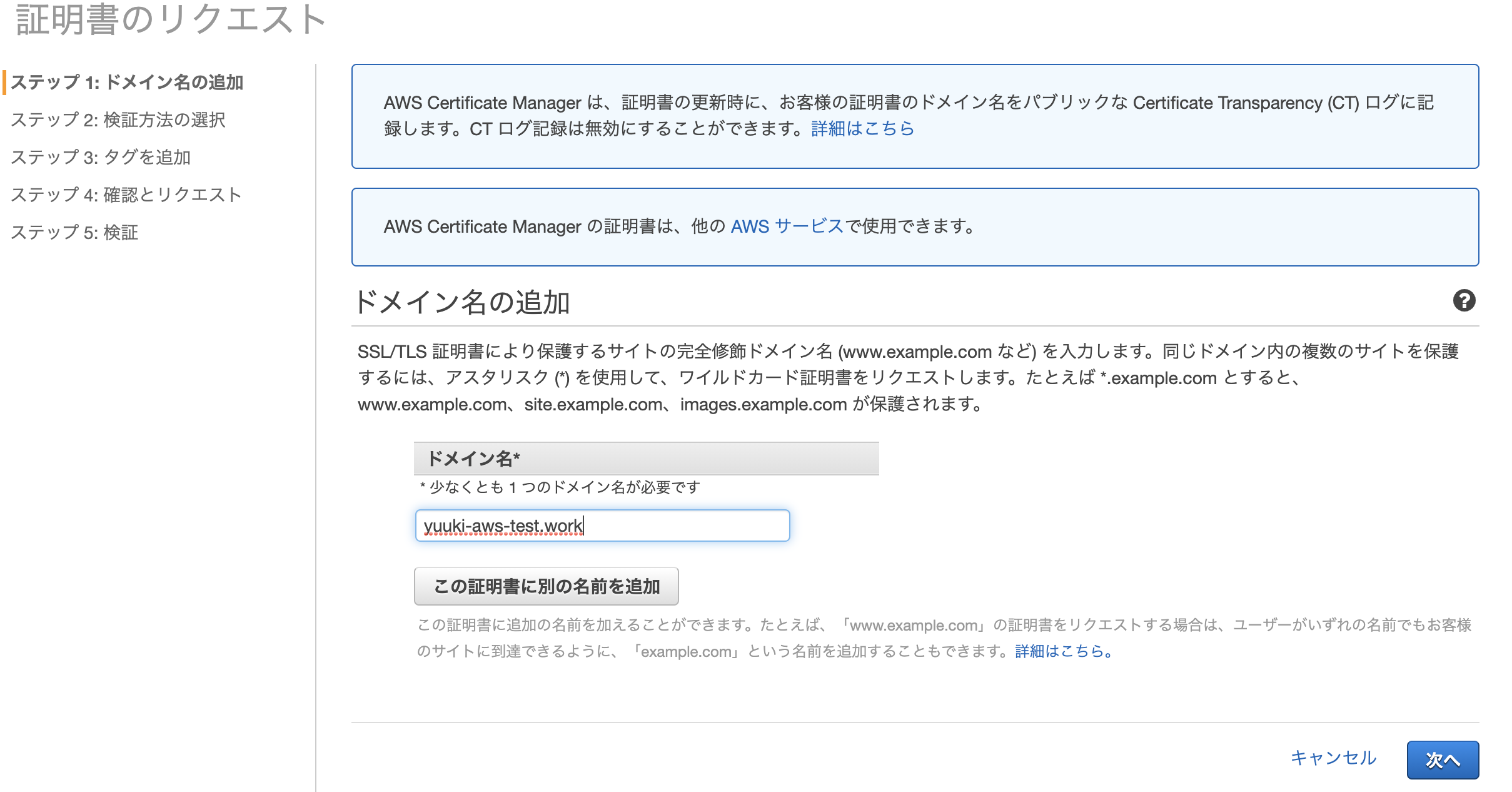
- ステップ1でドメイン名を入力し、次へ
- DNSの検証を選択して「次へ」
- タグの追加ではタグと値にName, my-best-acmを入力して「確認」
- 次の画面で「確認とリクエスト」ボタン押下
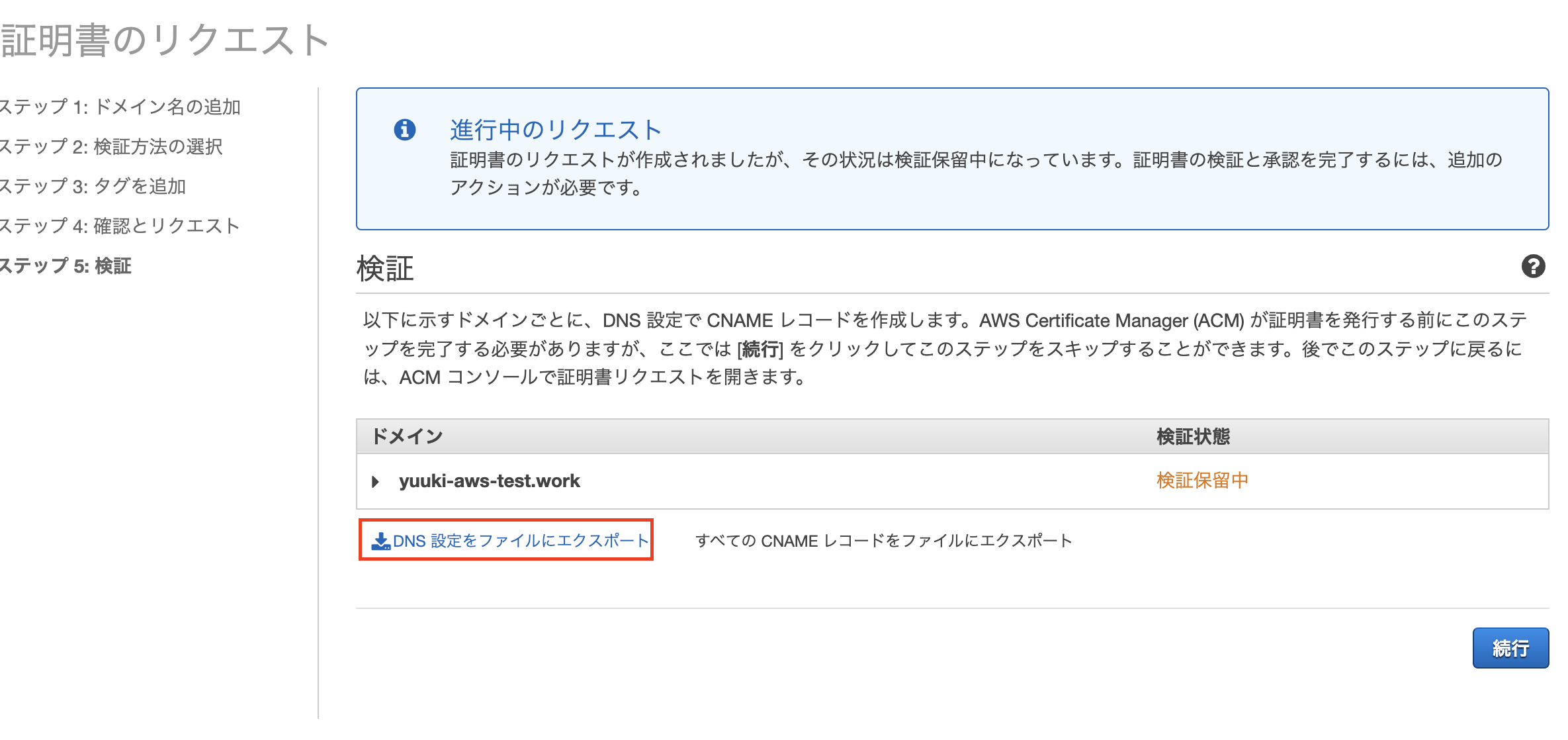
- この画面になったら赤枠の箇所を押してcsvをダウンロードして「続行」ボタンを押下
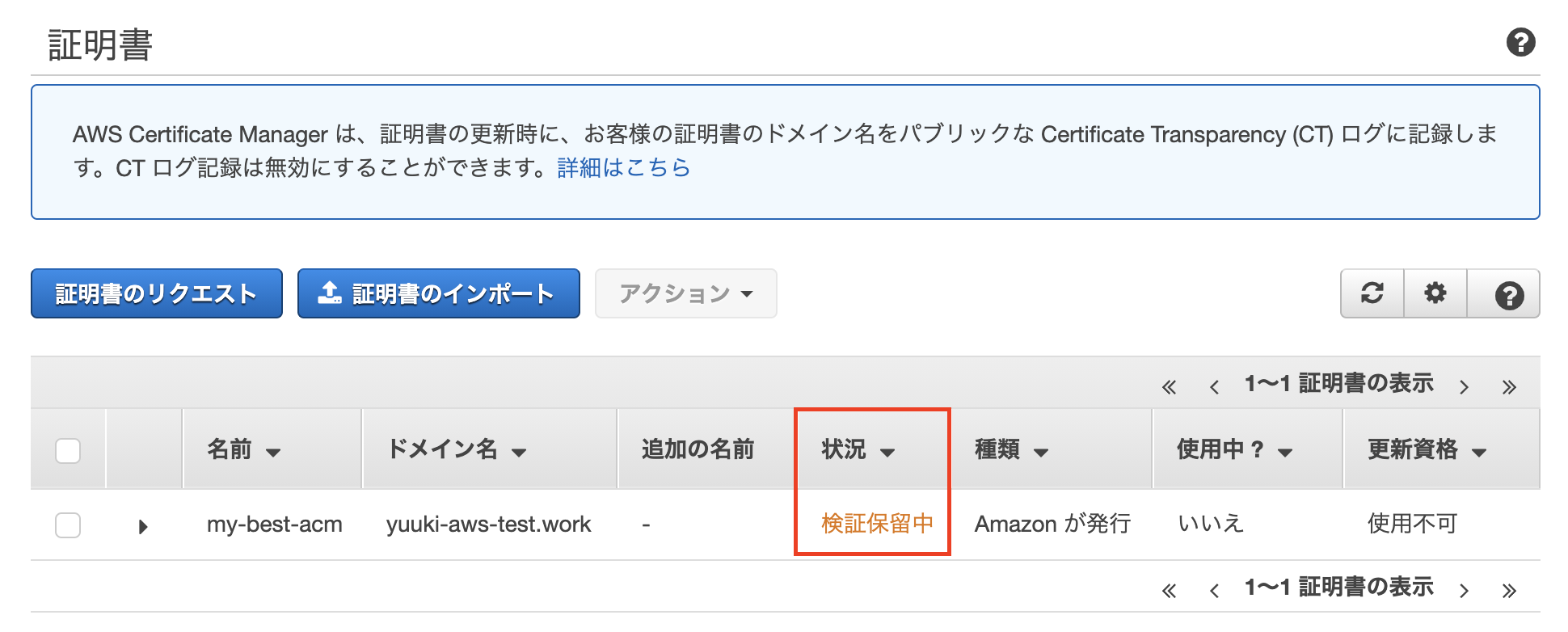
- 状況が検証保留中になってることを確認してください。Route 53で次の設定をするとしばらくしてここが「発行済み」に変わります。
ACMをRoute53に登録しましょう
- awsコンソールからRoute53に行き、ホストゾーンから自分のドメインを選択しましょう
- その画面で「レコードを作成」ボタンを選択します
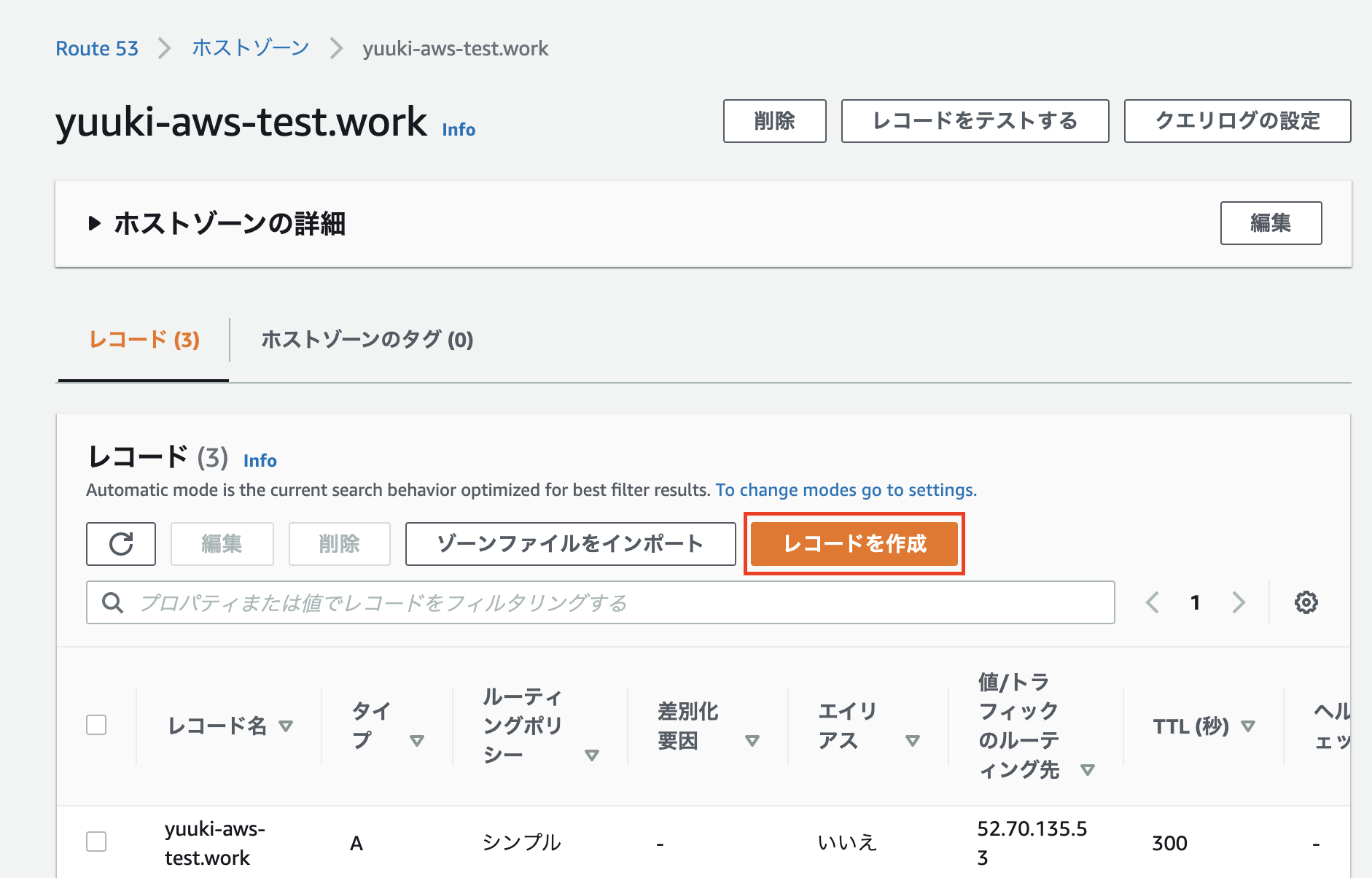
- シンプルルーティングのまま「次へ」
- 「シンプルなレコードを定義」を選択します
- 先ほどダウンロードしたcsvを開いてRecord Name, Valueを画像の様にコピペします。レコードタイプはCNAMEを選択します
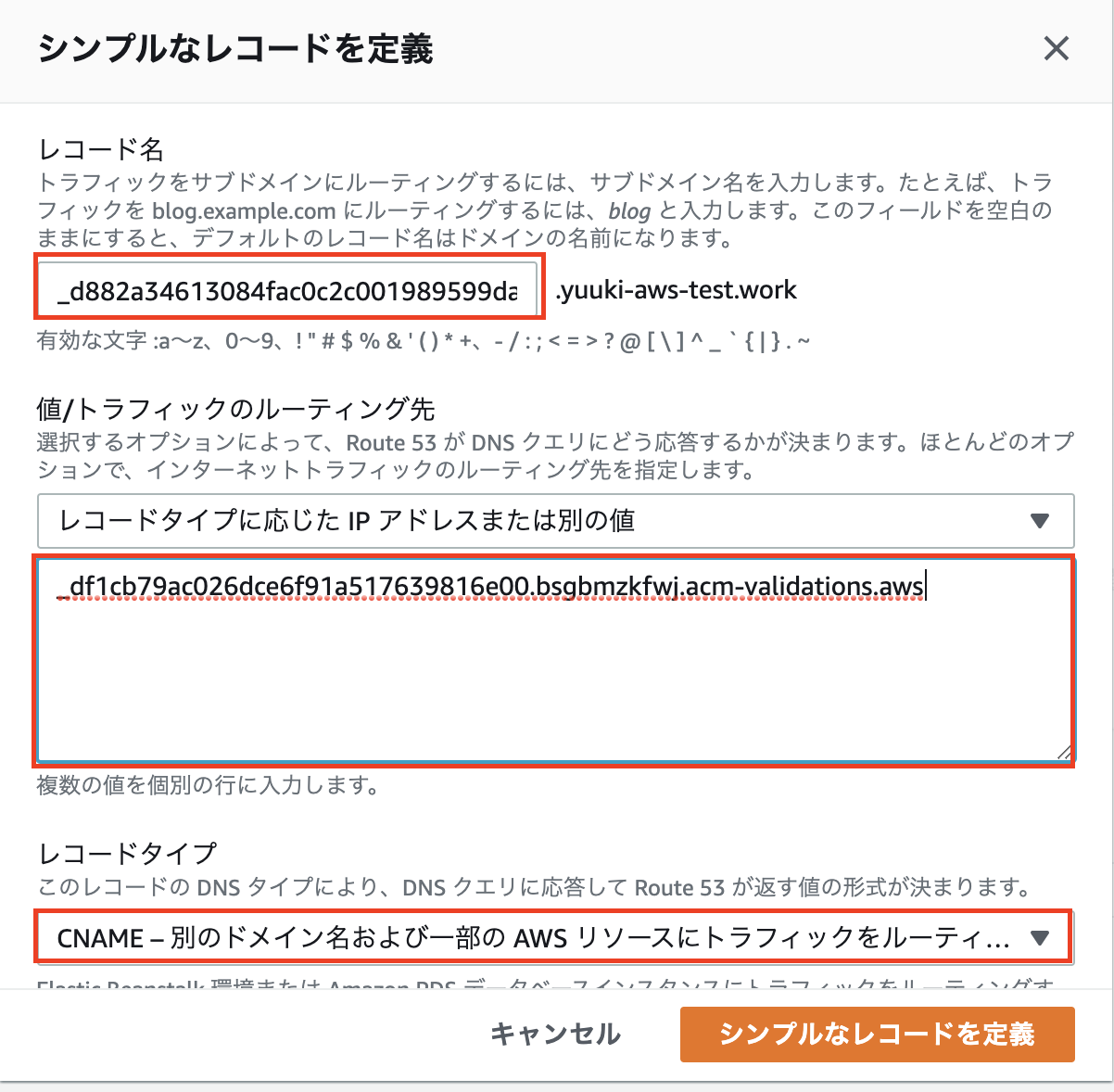
- 「選択できたらシンプルなレコードを定義」ボタンを押して、次の画面で「レコードを作成」を押します
- レコードを作成してしばらく経ったらACMの状況が「発行済み」になれば完了です。
ELBのセキュリティーグループを作成する
- awsのEC2コンソールからセキュリティーグループタブを選択してください
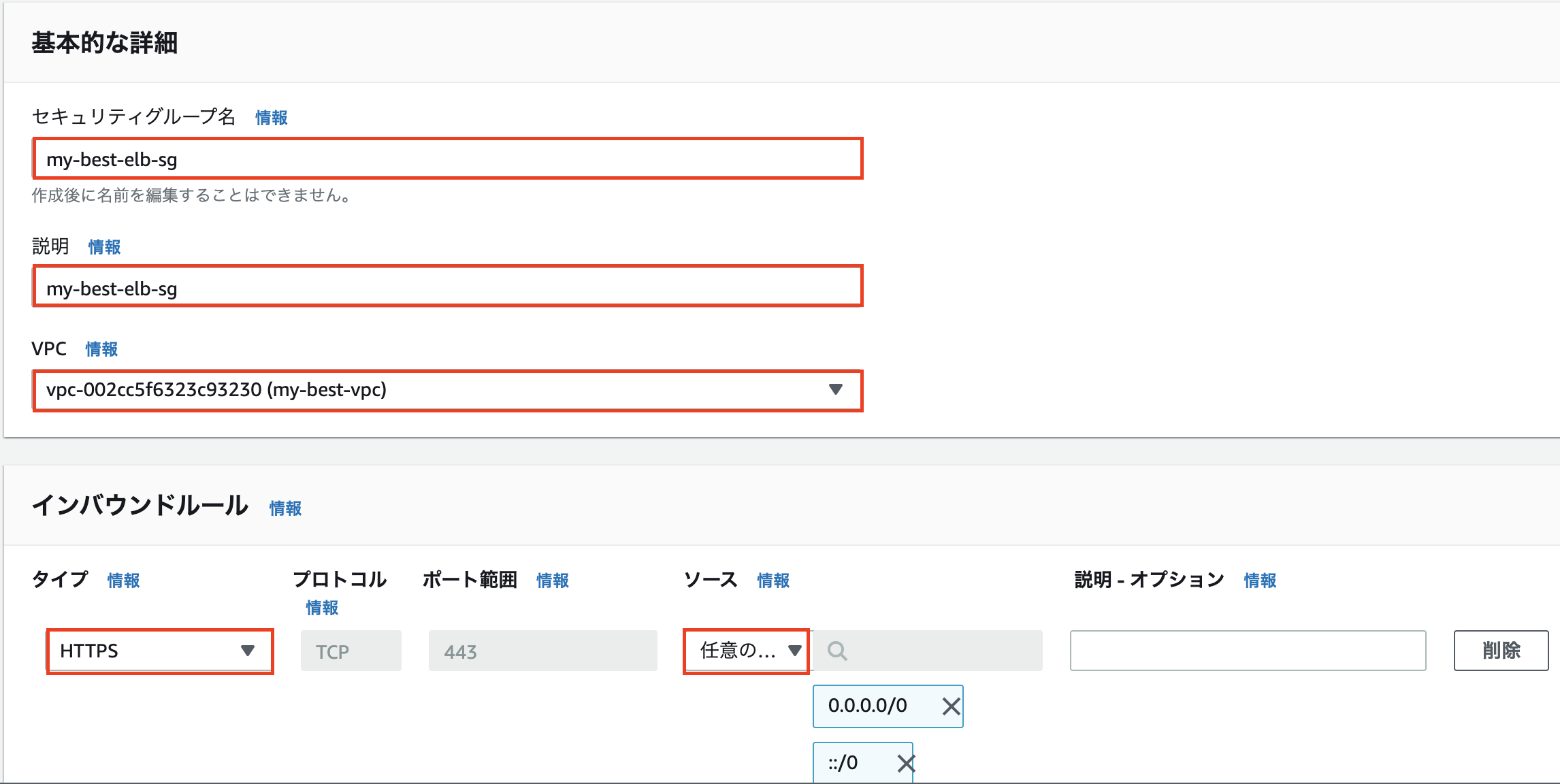
- 前回EC2のセキュリティーグループを作成した要領で「セキュリティーグループを作成」ボタンを押します。
- VPCは今回作成したVPCを選択し、インバウンドルールをHTTPSに設定します。下の画像の様に入力をしたら「セキュリティーグループを作成」
EC2のセキュリティーグループを編集する
- EC2のセキュリティーグループたぶからmy-best-sgを選択し、「インバウンドルールを編集」を選択します。
- 下の画像の様にhttpとhttpsのソースの部分を先ほど作ったmy-best-elb-sgに設定して「ルールを保存」を押してください。
ELBを作成します
- EC2のコンソール画面からロードバランサータブに移動し「ロードバランサーの作成」を押します。
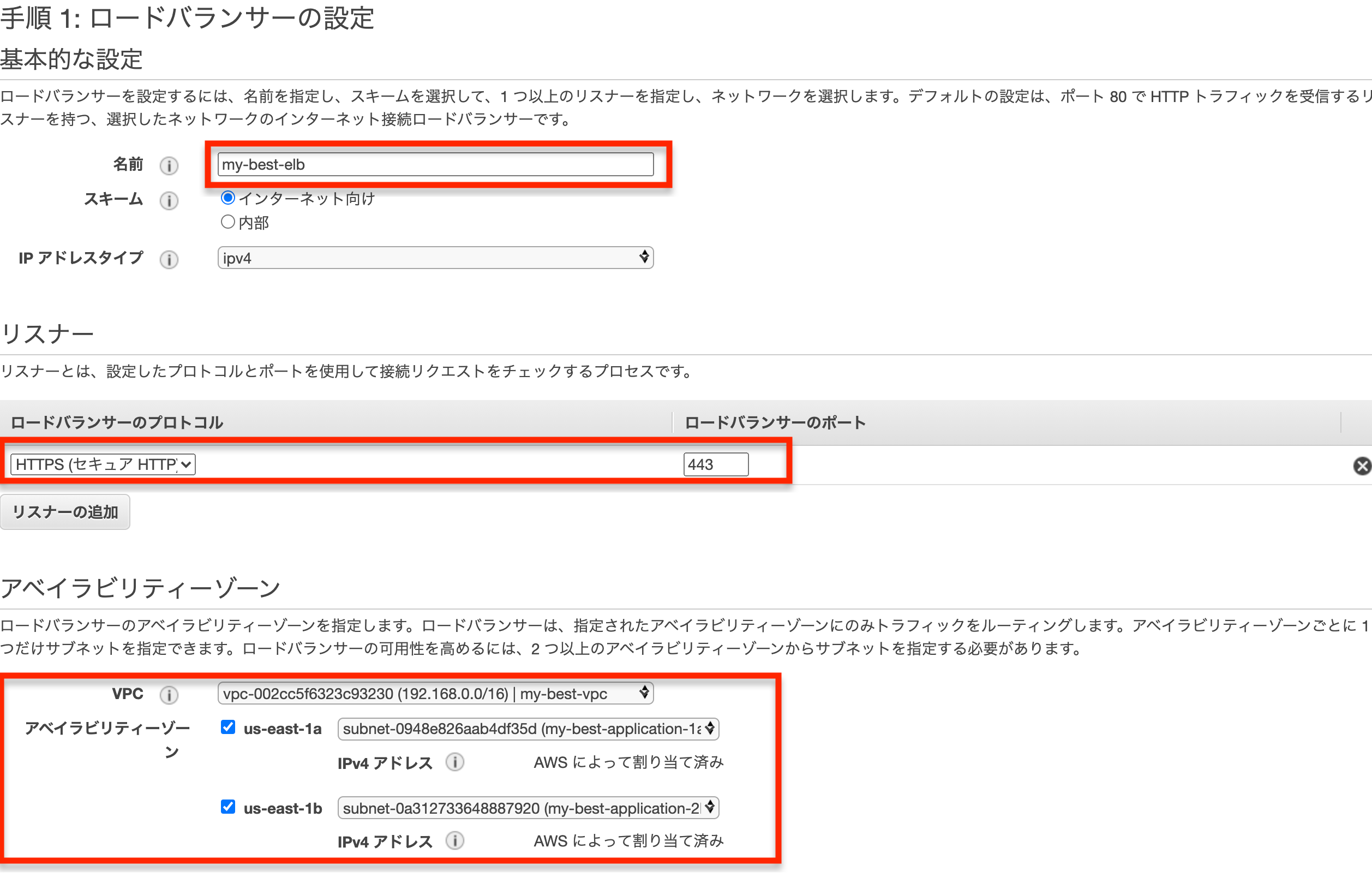
- ロードバランサーの種類はApplication Load Balancerを選択して「作成」
- 画像の様に入力します。名前はmy-best-elb、アベイラビリティーゾーンはmy-best-application-1a, my-best-application-2bを選択します
- 入力が完了したら「セキュリティー設定の構成」
- 証明タイプはACMから証明書を選択するにし、証明書のなまえが先ほど取得したドメインになっていることを確認。したら「セキュリティーグループの設定」
- セキュリティーグループはmy-best-elb-sgを選択し、「ルーティングの設定」
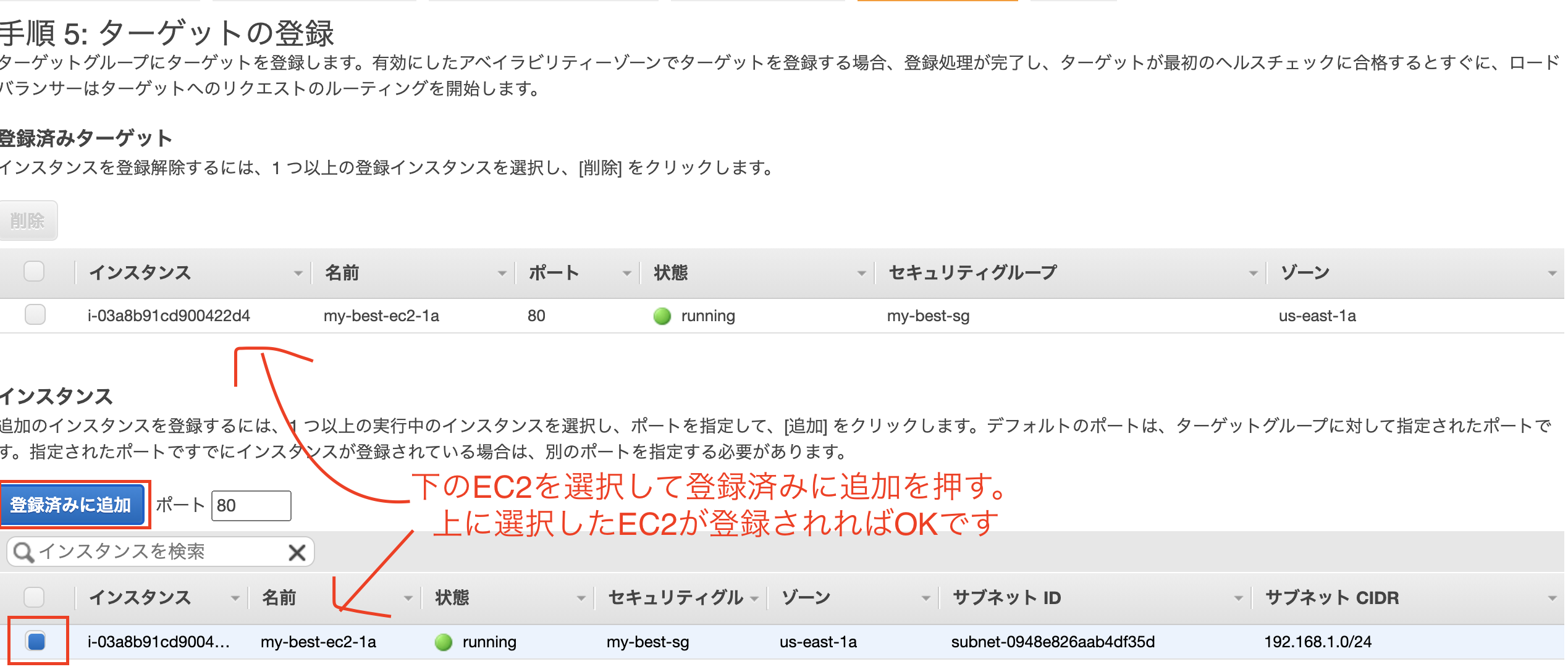
- 画像の様にルーティングを設定したらターゲットの登録
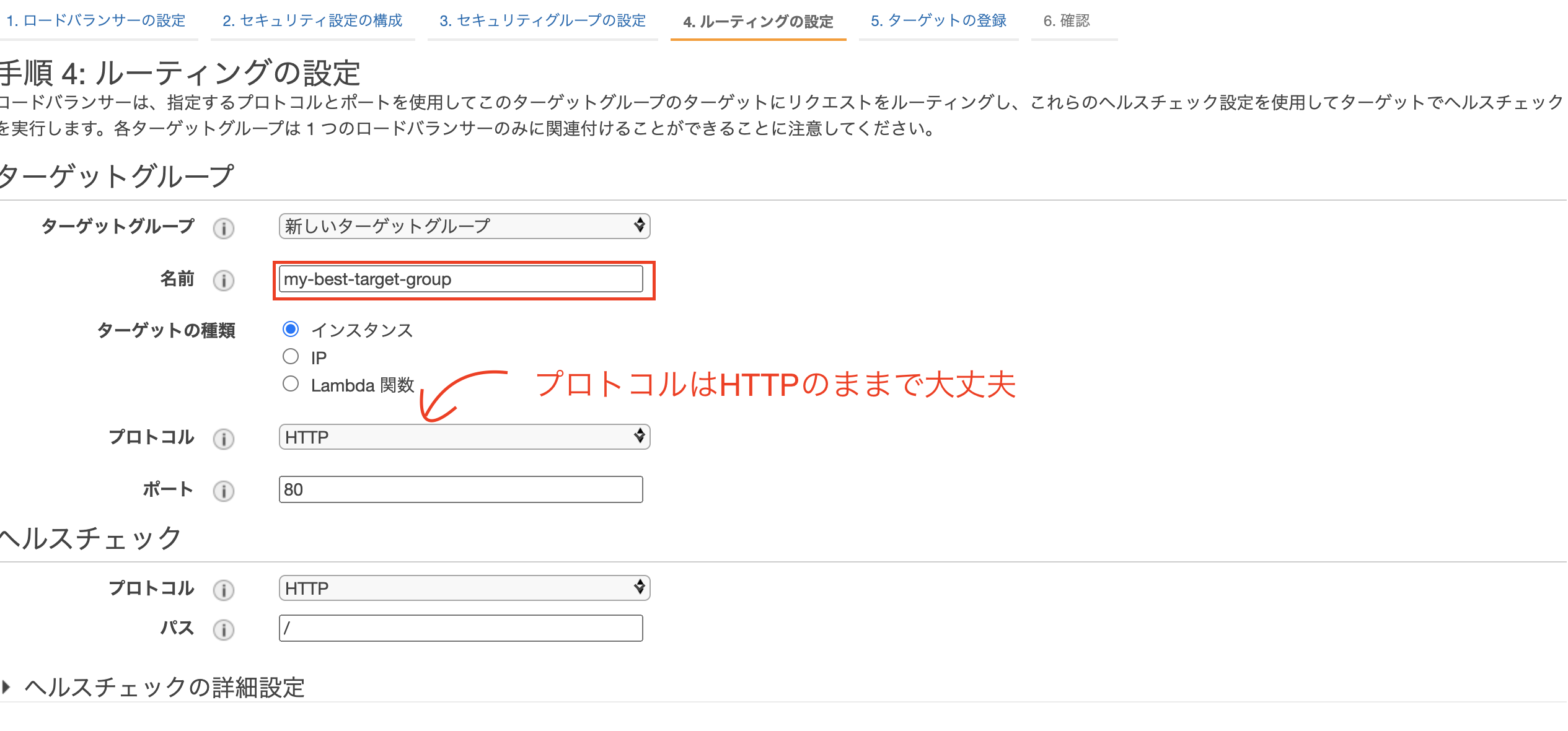
- 画像の様にターゲットを登録したら「次の手順:確認」
- 確認したら「作成」で完了です
https://elbのDNS名をブラウザに貼り付けるとhello world!と確認ができると思いいます。独自ドメインをSSL化する
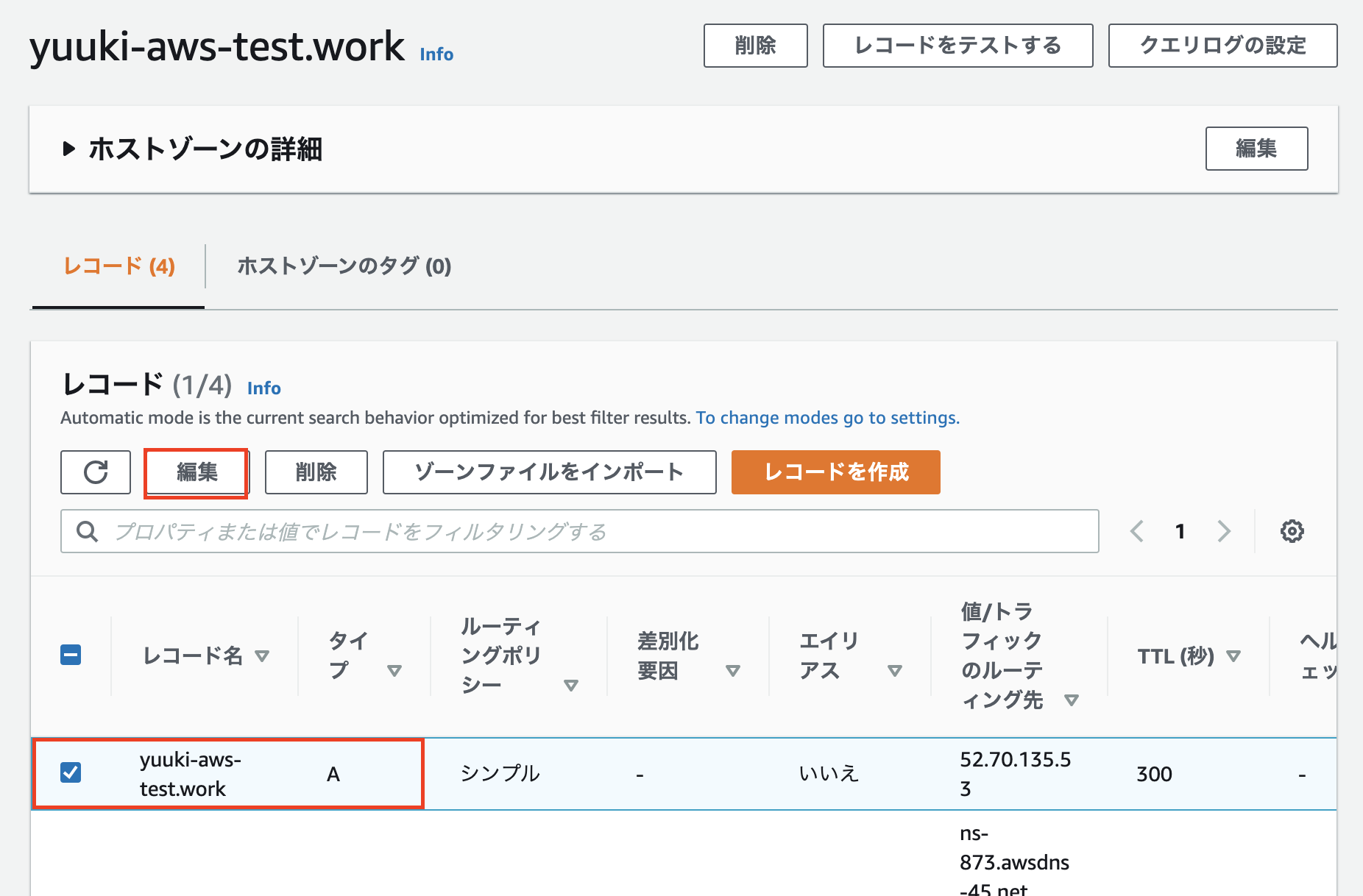
- Route 53のコンソール画面からホストゾーンを選択し、自分のドメインを選択してください
- タイプがAのものを選択して編集を押します
- トラフィックのルーティング先をApplication Load Balancer, リージョンを選択バージニア北部に設定すると自動で先ほど作ったelbが出てくると思いますので「編集を保存」
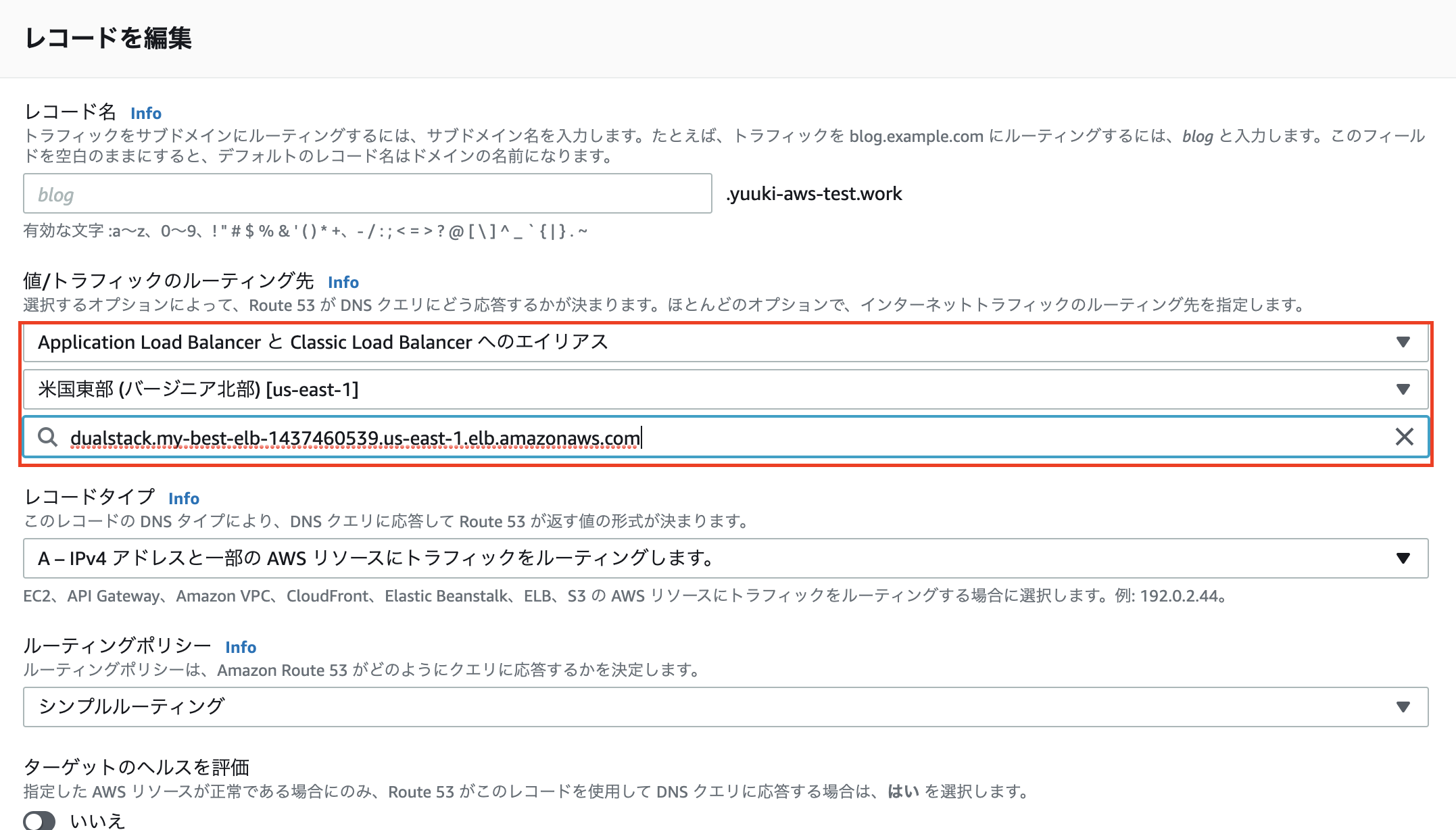
- これで
https://独自ドメインでhello world!が出力されましたでしょうか?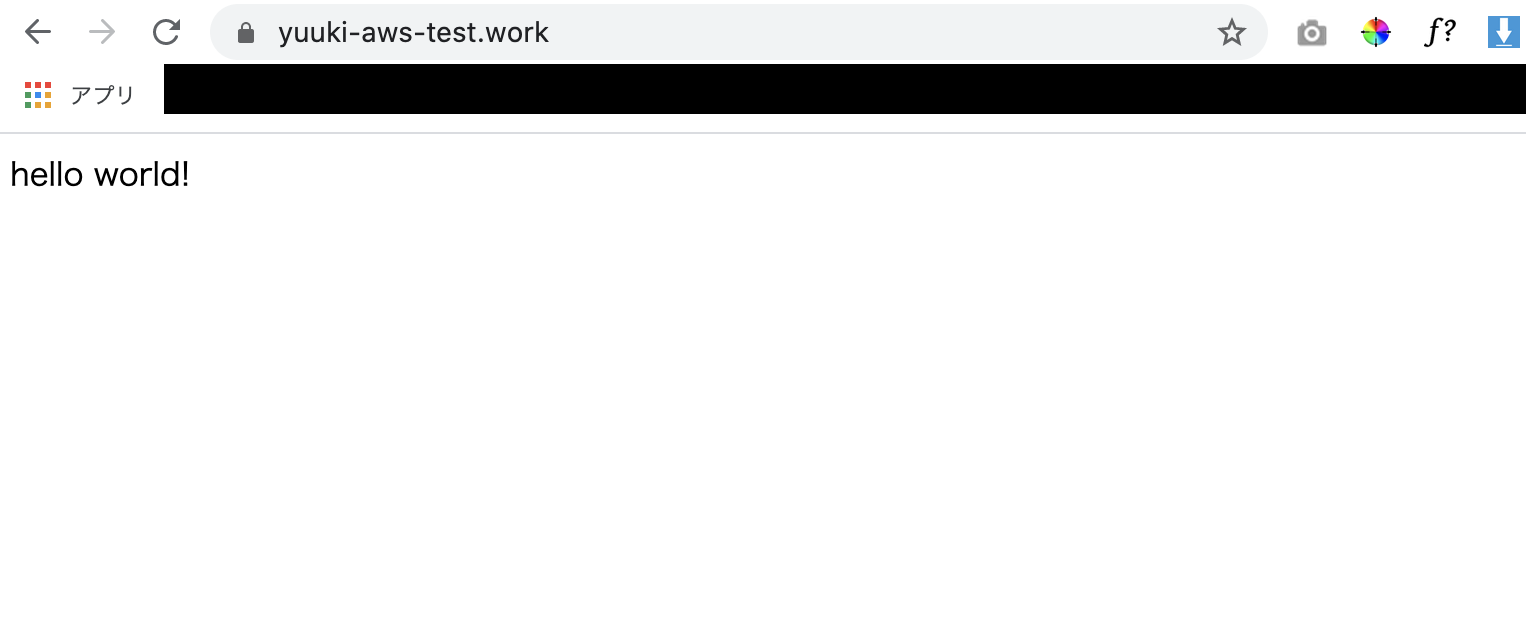
前へ: 第三章: EC2とRoute53を使って独自ドメインでHello world!を表示させよう
次へ: 第五章: EC2からRDSに接続してみよう
- 投稿日:2020-10-17T00:12:46+09:00
第一章: ドメインを取得してRoute53に登録する
スムーズに終わらせるために一番時間のかかるドメインの取得から取り掛かりましょう。
流れの説明
- お名前.comでドメインを取得
- ドメインの自動更新を解除する
- Route53に取得したドメインを登録
- このドメインのネームサーバーをお名前.comからRoute53のネームサーバーに変更する
一番時間のかかるドメインの設定から始める
お名前.comにログイン
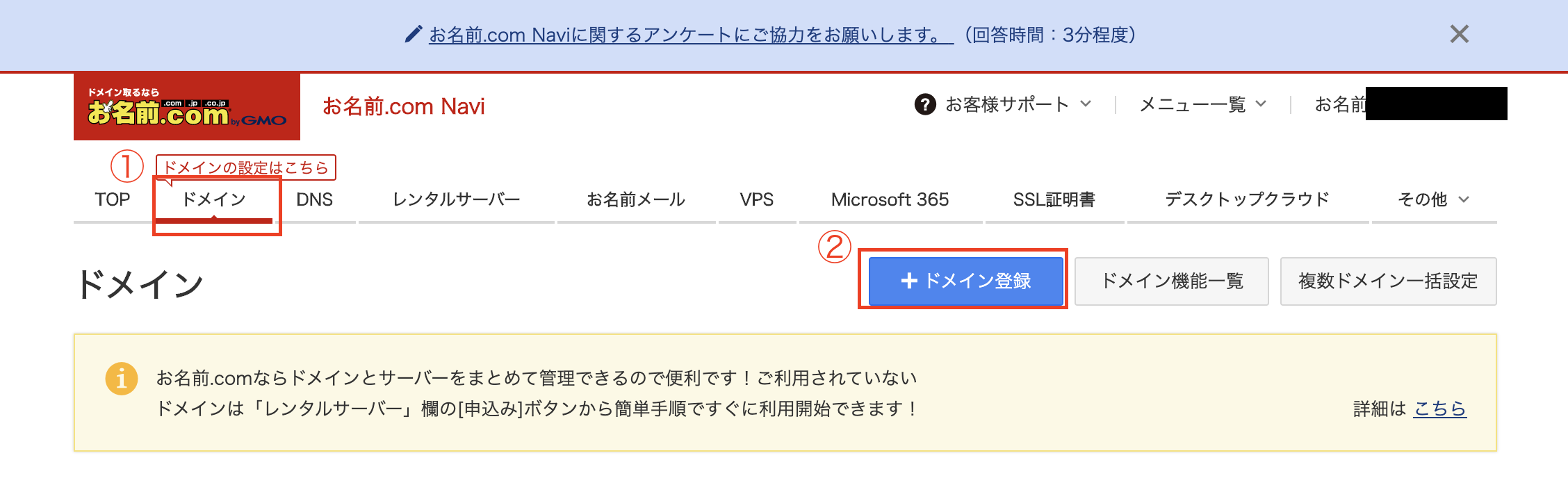
ドメイン→ドメインの登録を押す
次の画面で独自のドメイン名を入力して検索する。僕は[yuuki-aws-test]と入力しました
一番安い[.work]にチェックを入れ、「お申し込みへ進む」ボタン押下
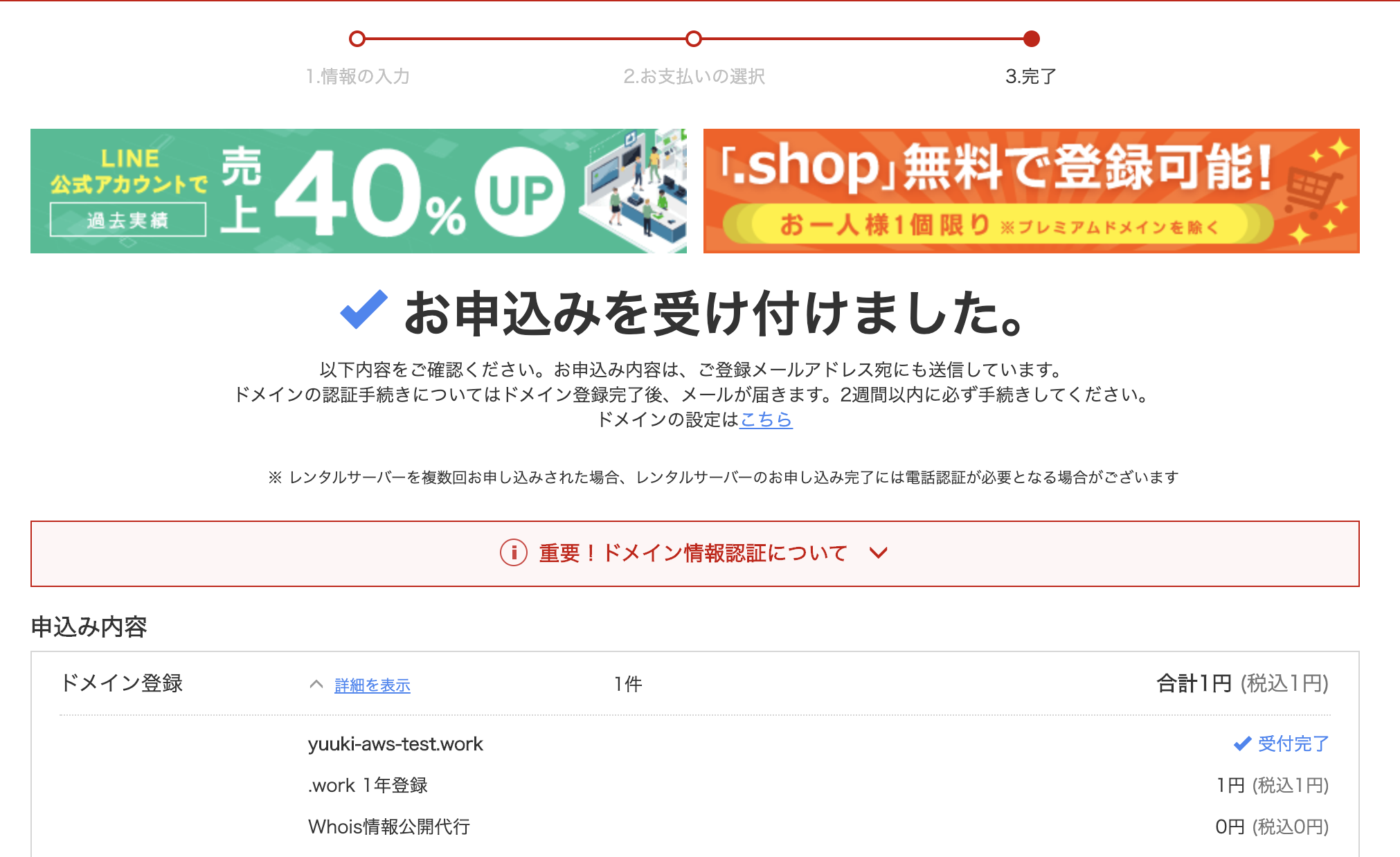
サーバーを勧められますが「利用しない」を選択し、合計金額が1円であることを確認して次へ
お支払いの選択画面で初めて利用される方はクレジットカードの登録を済まし、「申し込む」
完了画面に遷移したらドメインの取得成功です
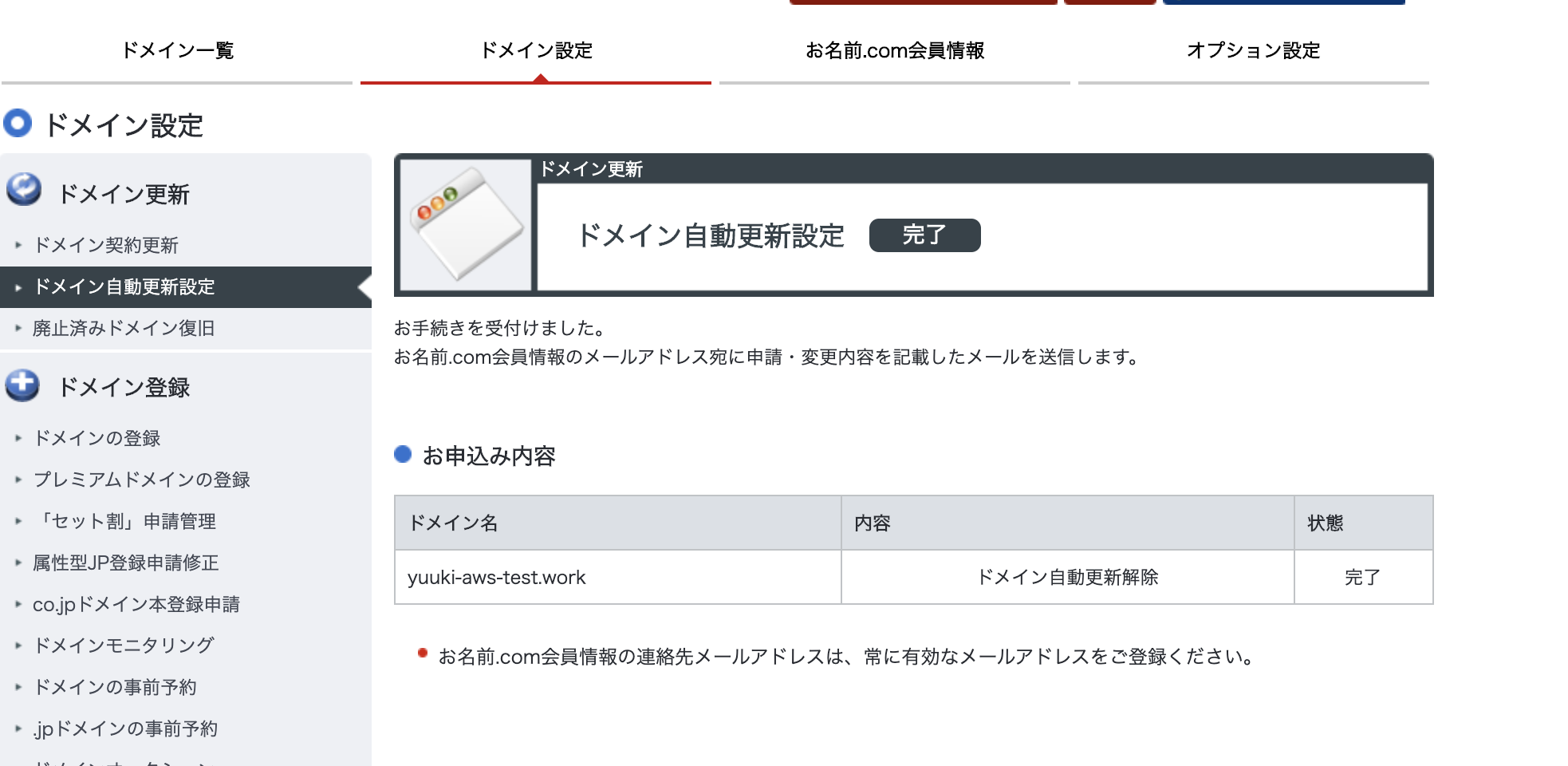
ですが現在の設定だと一年間でドメインが自動更新され、一年後に更新料の980円が自動で引き出されてしまいます。(.workの場合)。ですので試したいだけの場合は自動更新の設定を解除しておくことをお勧めします。
その方法
前回の2の画面から今度はドメイン→ドメイン機能一覧を押す
次の画面で「ドメイン自動更新設定」を選択します
作成したドメインを選択して、「管理画面へ進む」を選択
「規約に同意し、上記内容に申し込む」を選択
出てきたモーダルで解除するを選択します。
最後にこの画面が出てきたら完了です。
Route53に取得したドメインを登録する
先ほど取得したドメインをawsのroute53に登録しましょう
Route53というのはawsのDNSサービスです。
ホスト名をIPアドレスに変換してくれるものですね。例:ヤフーのドメインをIPアドレスに変換する
www.yahoo.co.jp->182.22.25.252に変換
- awsのマネージメントコンソールからのサービスからRoute53を選択します
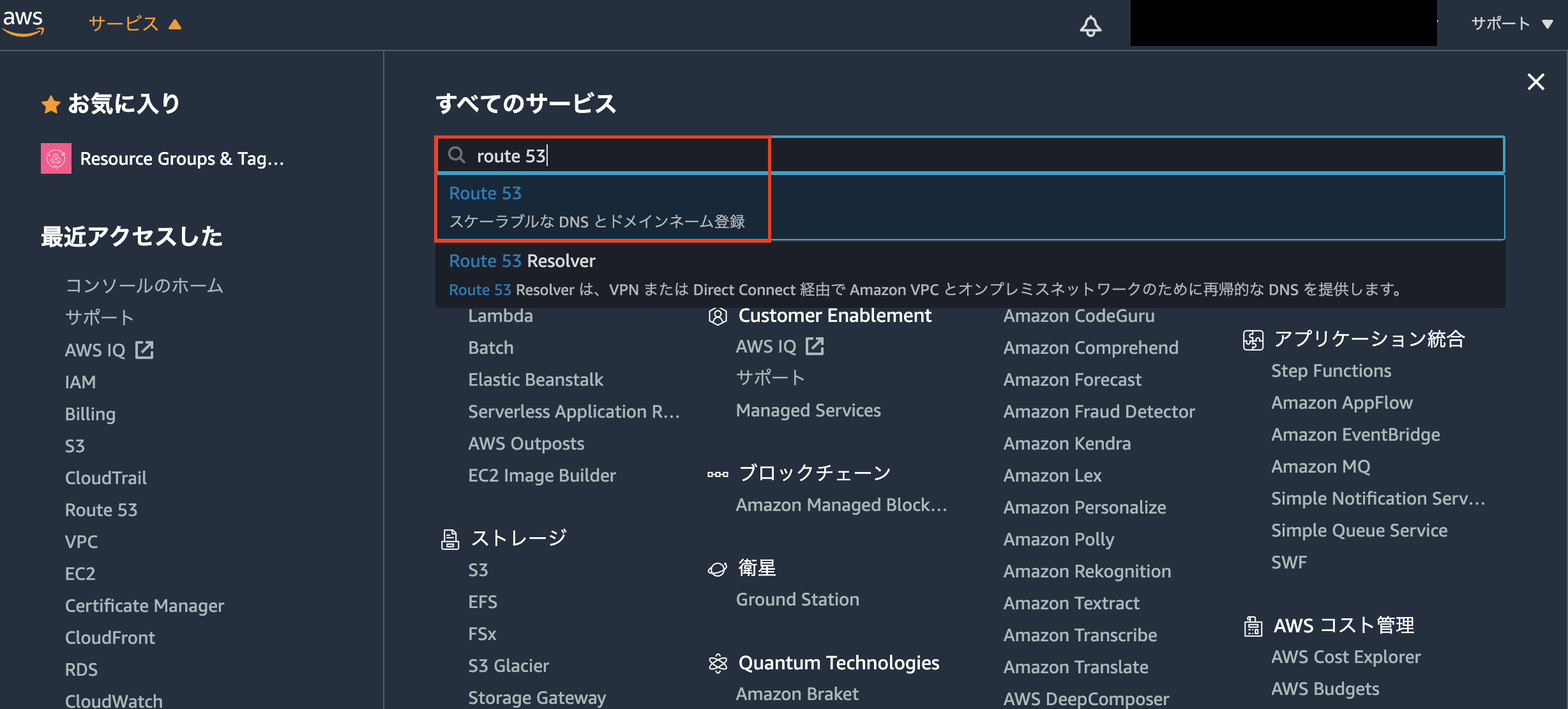
- ホストゾーン→「ホストゾーンの作成」ボタンを選択
- 先ほど取得したドメイン名を入力し、画面下の「ホストゾーンの作成」を押下
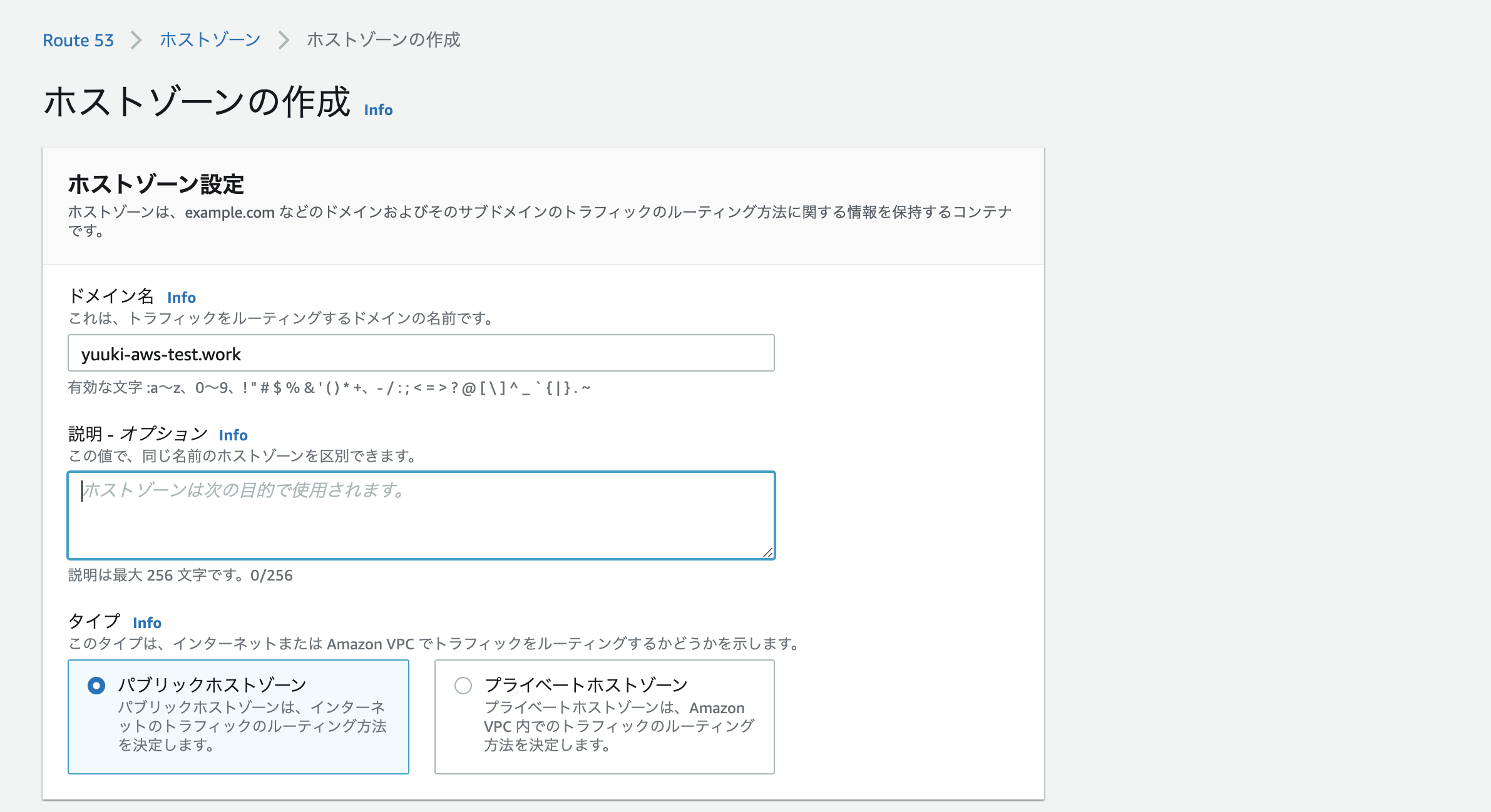
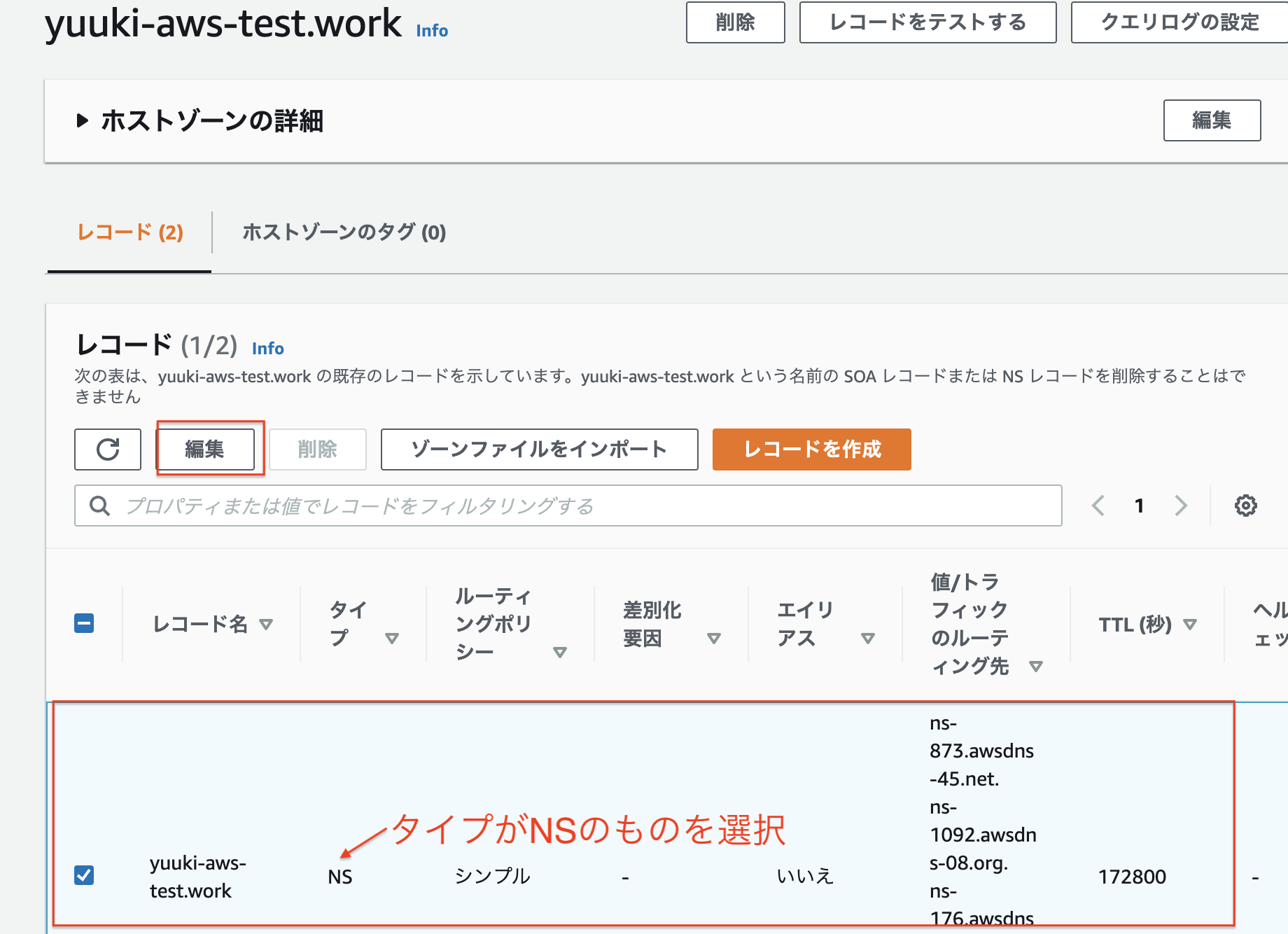
- タイプがNSのものを選択して編集を押下
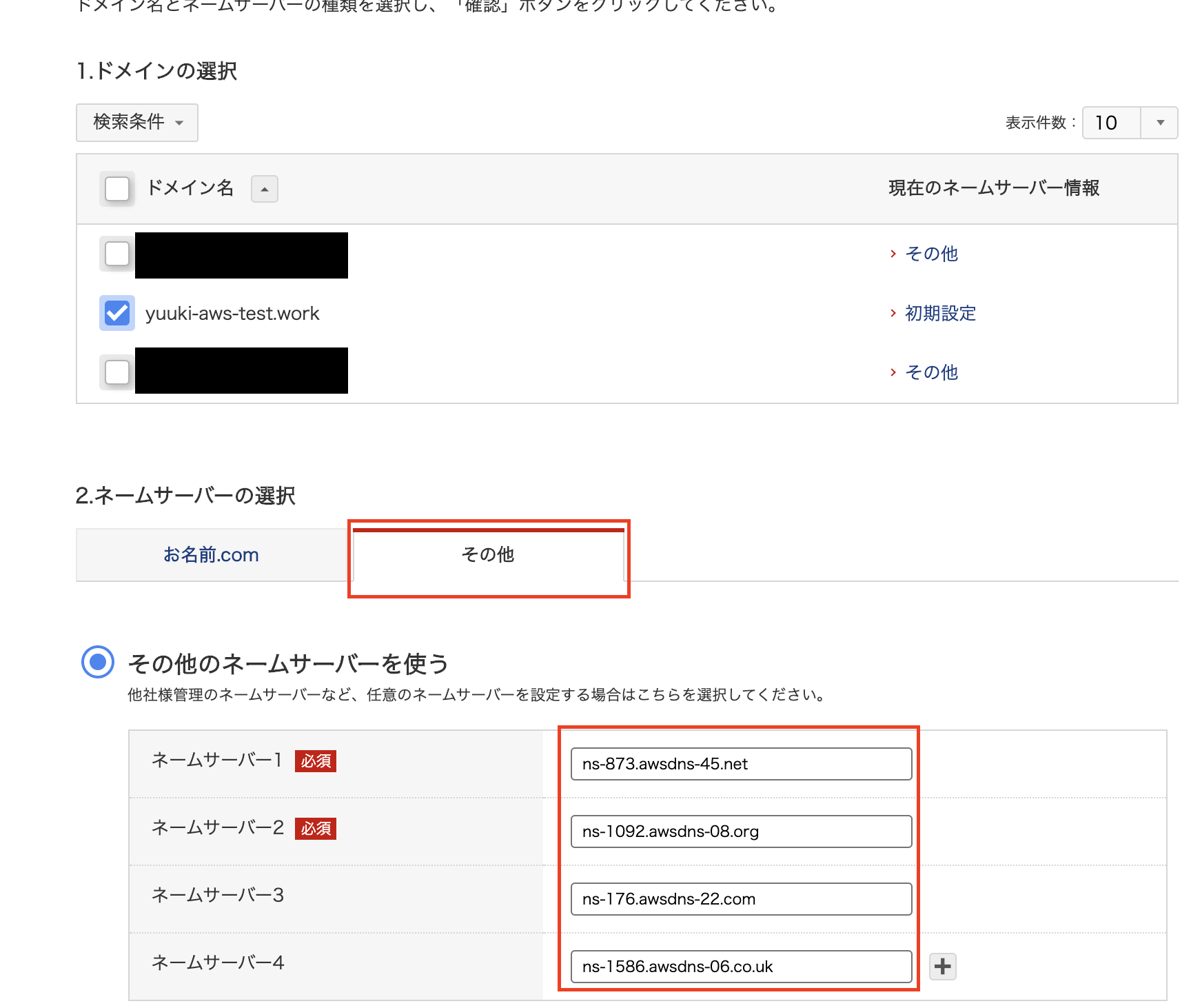
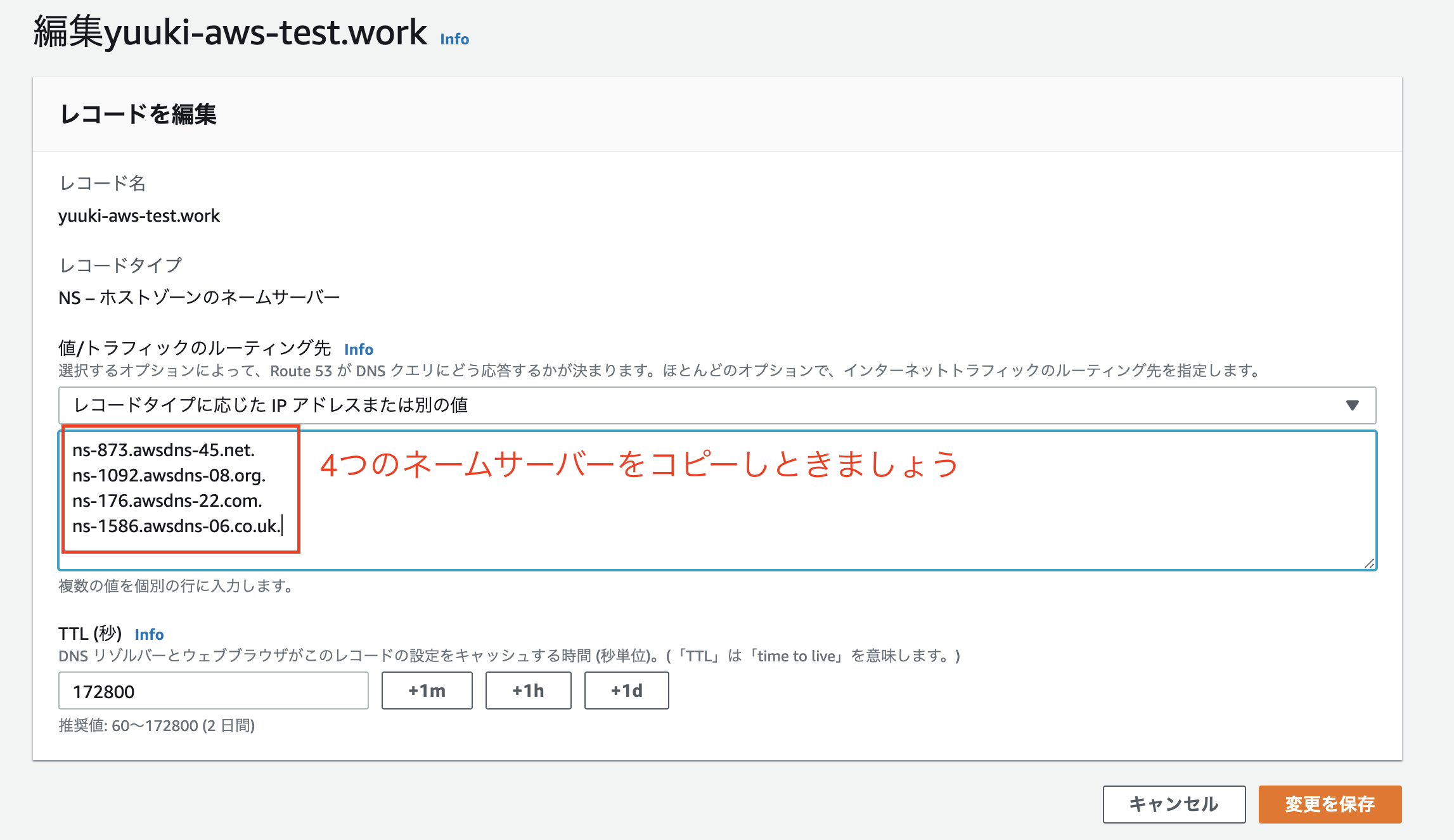
5. 4つのネームサーバーをコピーしておく
ドメインのネームサーバーをawsのネームサーバーに変更する
- お名前.comにログイン
- ドメイン→ドメイン機能一覧を選択
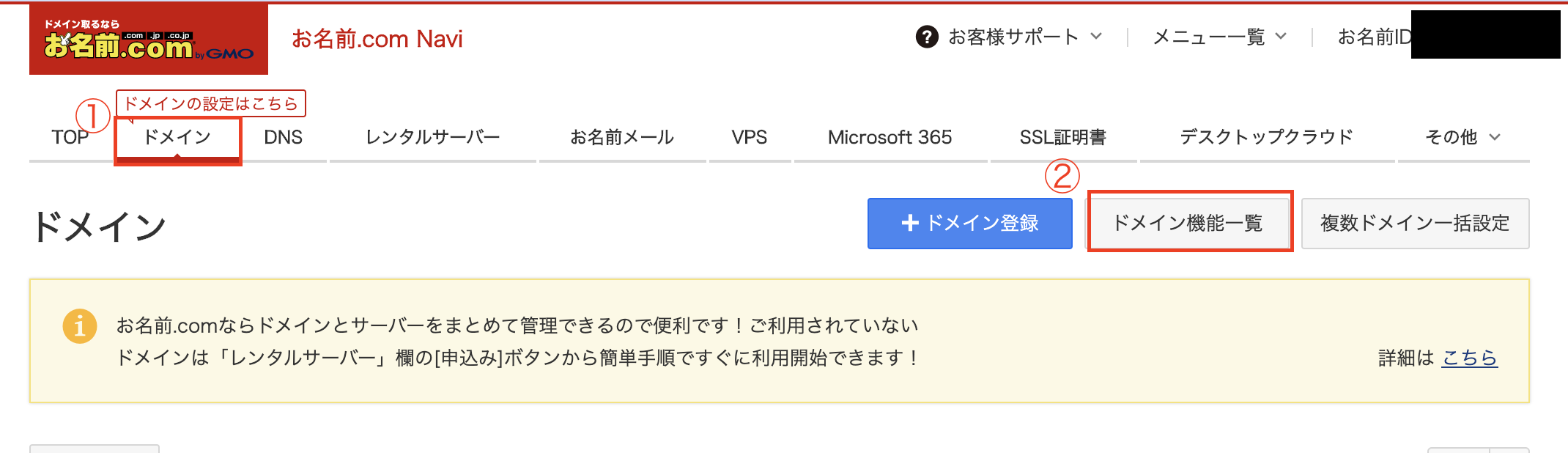
- ネームサーバーの変更を選択
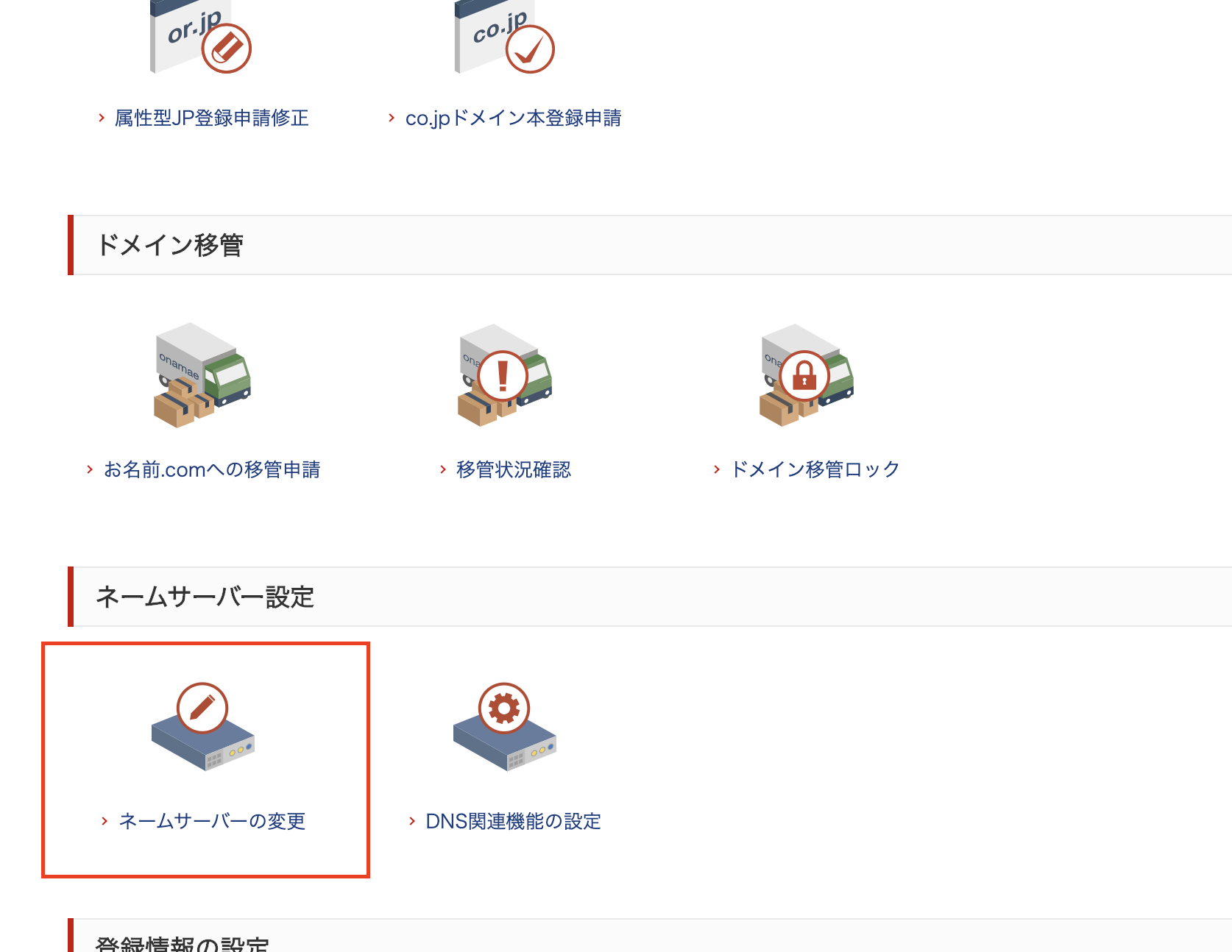
- ドメインを選択して先ほどコピーしたネームサーバーを入力して確認ボタンを押す(最後のドットはコピーしなくて大丈夫です)
- モーダルが出てきたらOKを押す
- 次の画面で完了しましたと出てきたら完了です。この設定が反映されるまで最長で72時間かかるみたいです。
前へ: AWSのELBとEC2を使ってwebアーキテクチャを構築しよう
次へ: 第二章: VPCやサブネット等の設定をしよう
- 投稿日:2020-10-17T00:09:51+09:00
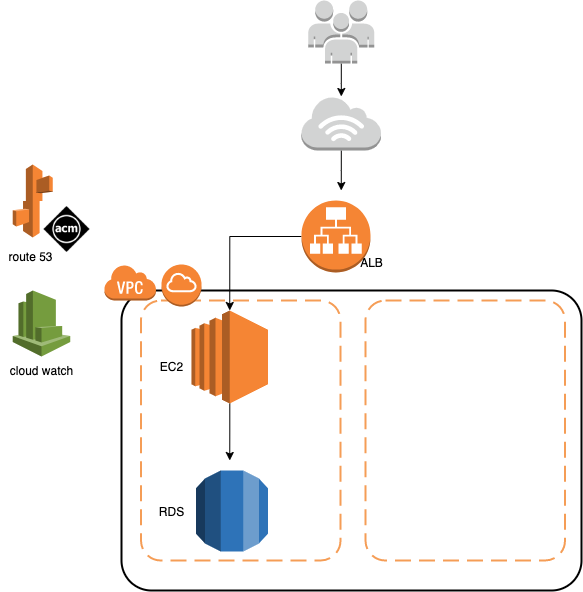
AWSのELBとEC2を使ってwebアーキテクチャを構築しよう
今回使う環境としてPCはmacを使います。windowsの方は適宜読み替えて読み進めてください。
この記事のゴール
以下の画像の様な基本的なwebアーキテクチャを設計すること
第一章: ドメインを取得してRoute53に登録する
第二章: VPCやサブネット等の設定をしよう
第三章: EC2とRoute53を使って独自ドメインでHello world!を表示させよう
第四章: ELBとRoute53を使って独自ドメインををSSL化してHello worldを表示させよう
第五章: EC2からRDSに接続してみよう
第六章: 最後に