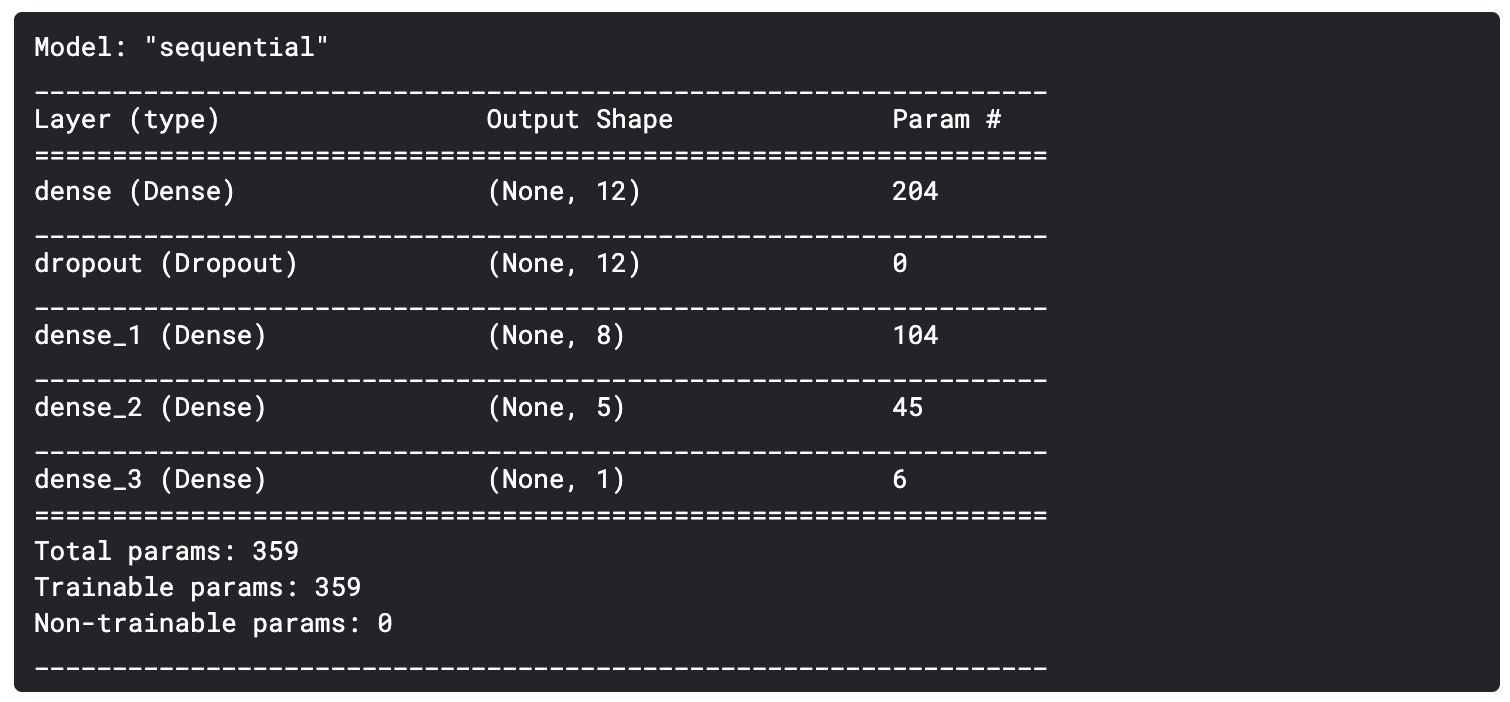
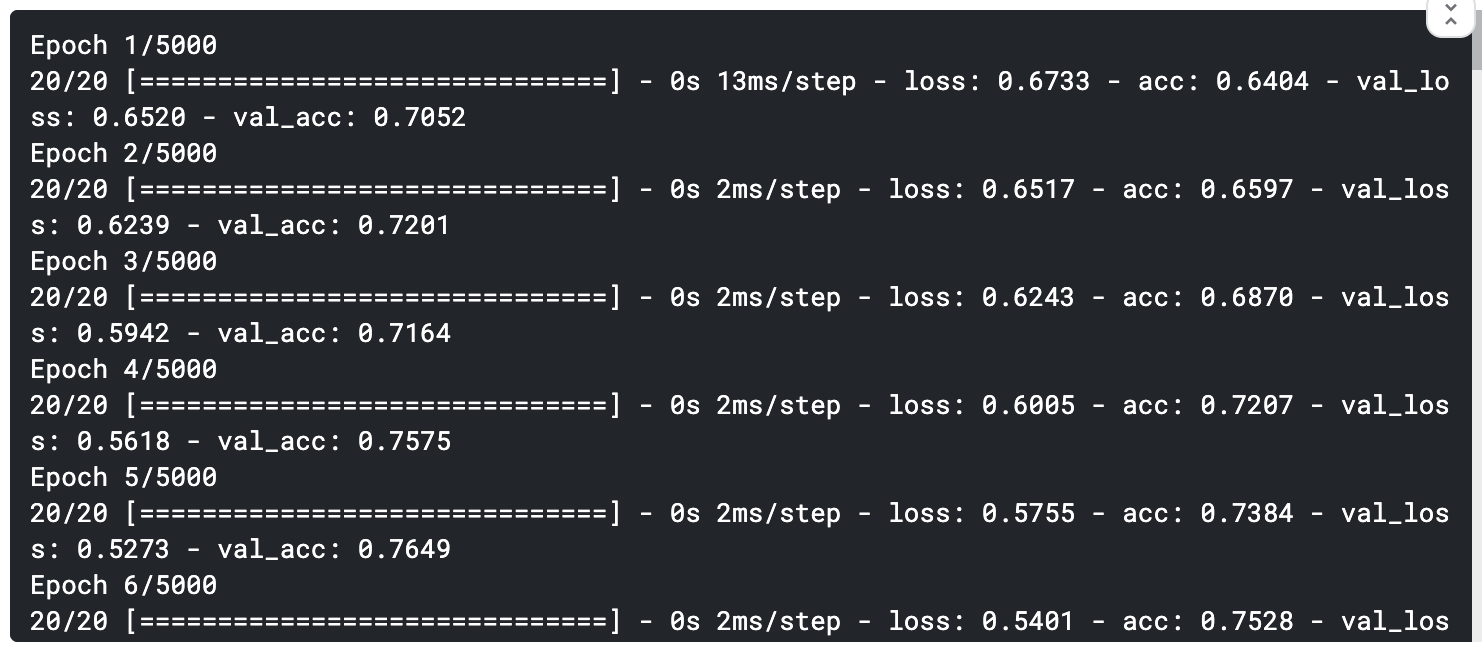
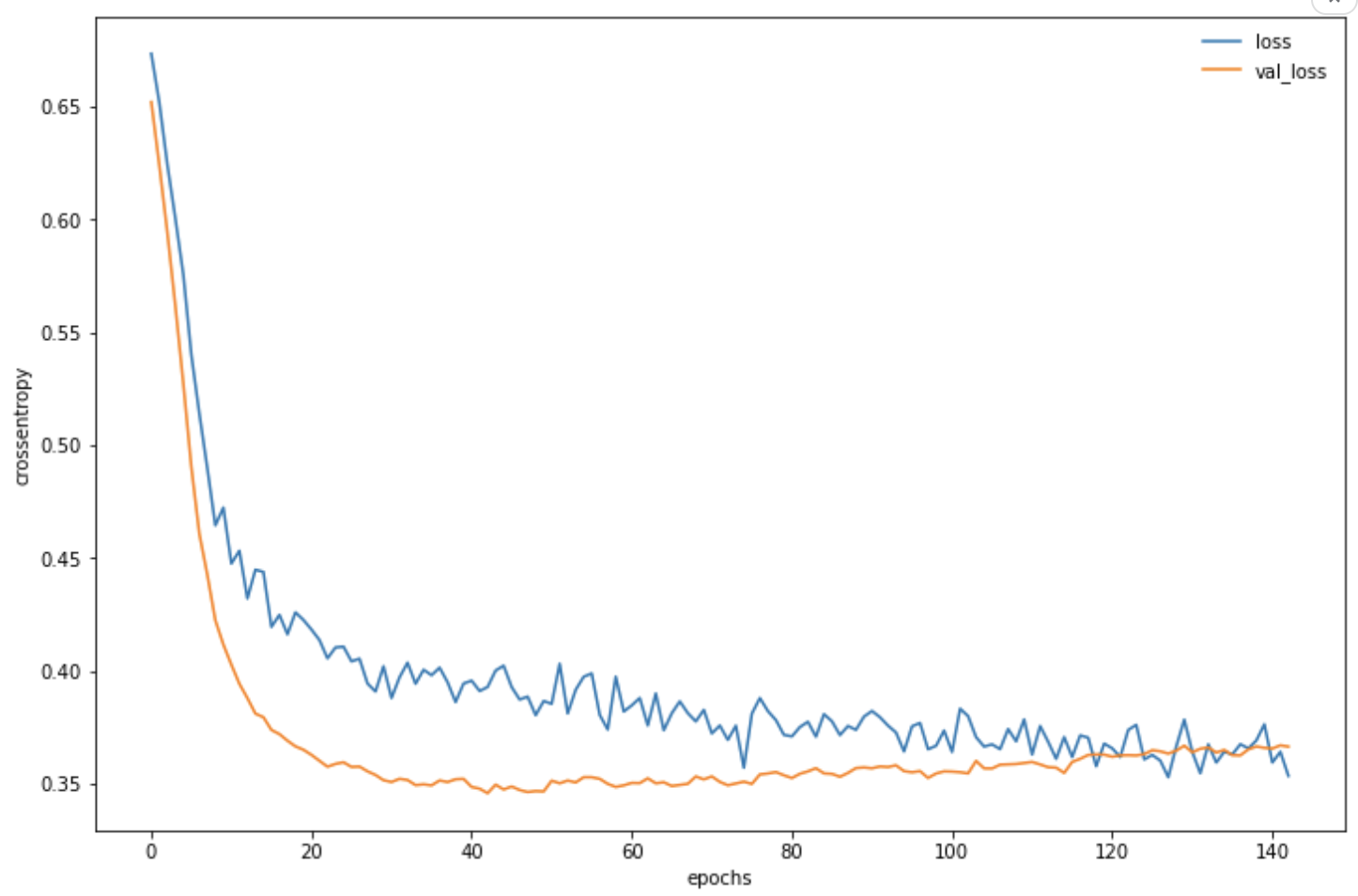
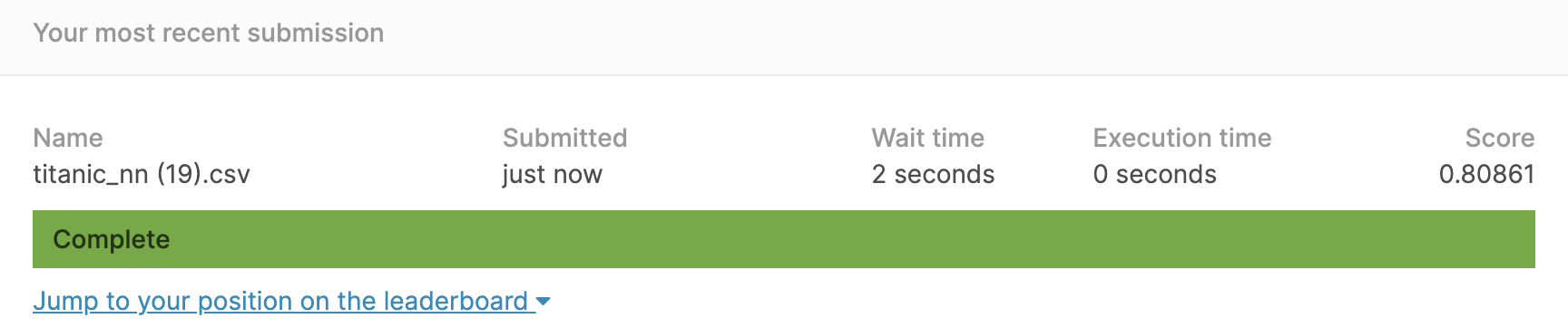
- 投稿日:2020-10-15T23:56:10+09:00
停まれ標識検知 可視化部分の開発part5 物体を検知した時に検知したものを検知したものを表示する
前回まで
前回実装した機能は以下のものになります.
Yolov5上で物体を検知した時➡ソケット通信をする.➡ソケット通信を受けたときに音声を再生する.(複数)今回実装する機能
今までの実装で,音での可視化は可能でしたが実際のものを可視化することはできませんでした.
逆にカメラ映像を見ていればわかるだろという話もありますが...なので今回はあまり意味がないと思われる方もいる機能かもしれませんが,認識したものを可視化するプログラムについて述べていきたいと考えています.なぜこの機能を実現するのか
これは後々web上での可視化を行いたいと考えているので,その時にソケットで飛ばせるようにこの機能を実現しました.
実装について
今回はソケット通信の部分を関数化したのでそこについてもちらっと載せていきます.内容はpart3とかpart4とかで書いています.
socket部分
クライアント部分
detect.pydef socket1(): with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s2: s2.connect(('127.0.0.1', 50007)) BUFFER_SIZE=1024 data1='1' s2.send(data1.encode()) print(s2.recv(BUFFER_SIZE).decode())ここの関数は認識するものが増えたらsocketの後の数字だけ増やしてdata='1'の部分の数字を変えることで認識するものが増えても対応できます.
server.py# socket サーバを作成 from playsound import playsound import socket cont=1 # AF = IPv4 という意味 # TCP/IP の場合は、SOCK_STREAM を使う with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s: # IPアドレスとポートを指定 s.bind(('', 50007)) # 1 接続 s.listen(1) # connection するまで待つ while True: # 誰かがアクセスしてきたら、コネクションとアドレスを入れる conn, addr = s.accept() with conn: while True: # データを受け取る data = conn.recv(1024) if not data: break else: data2=str(data) data3=(data2.replace('b', '')) conn.sendall(b'Received: ' + data) if data3 == "'1'": playsound('2.wav') if data3 == "'2'": playsound('3.wav')認識部分
detect.pyif label1=="cell phone": print("スマホを発見しました") cv2.imwrite('sumaho.jpg',im0) img = cv2.imread('sumaho.jpg') cv2.imshow('sumaho', img) socket1() with open('daystext/'+str(d_today)+'.txt', 'a') as f: dt_now = datetime.datetime.now() f.write(str(dt_now)+"スマホを発見しました"+"\n") if label1=="book": print("本を発見しました") cv2.imwrite('book.jpg',im0) img = cv2.imread('book.jpg') cv2.imshow('book', img) socket2() with open('daystext/'+str(d_today)+'.txt', 'a') as f: dt_now = datetime.datetime.now() f.write(str(dt_now)+"本を発見しました"+"\n")サーバ部分はdata3="'1'"の数字の部分を変えてif文を増やすことで対応できます.
可視化部分
img = cv2.imread('sumaho.jpg') cv2.imshow('sumaho', img)このコードをif label1=="":後に埋め込むことで実現できます.
最後に
今までpart5まで書いてきて録画機能以外はyolov5で実現したい機能をほぼ実現してきましたのでとりあえずyolov5部分を終了にしたいと思います.次は可視化web部分を作っていけたらいいなと思っています.
もしなんか実現できそうな機能を思いついたらこの記事を書きますので連続投稿はこれで終了になります.
- 投稿日:2020-10-15T23:26:14+09:00
swagger.yamlからAPIリスト.csvをpythonで抽出してみました
環境構築
ついでに、初めてQiitaで記事を書いてみました。
前提
MacBook Pro
macOS Catalina 10.15.7導入
下記をインストールしました。
- Docker
- Visual Studio Code
- Visual Studio Code 拡張機能
- Japanese Language Pack
- Docker 1.6.0
- Remote - Containers 0.145.0
- Python
- PyLint
- Rainbow CSV 1.7.1
- YAML 0.11.1
- Swagger Viewer 3.0.1
- OpenAPI (Swagger) Editor 3.7.0
参考:
設定
- VS Code 同期設定の有効化
- 作業フォルダ作成 (dropbox内に作成しました)
- VS Code で作業フォルダを開く
作業
- Github でレポジトリ作成
- 手元で、microsoft/vscode-remote-try-pythonをコピー(git clone)
- フォルダ名と、git remote set-urlでremote 宛先を自分のレポジトリに変更
エラー対応
ライブラリのインストールや、Jupiterの利用で、エラーが出たため、
ひとまず、ユーザーをrootのままとするようなコメントアウトを行いました。ライブラリインストール
PyYAMLライブラリ,CSVライブラリを使います。
requirements.txtに書いて、Rebuild And Rerunするだけなのでとても簡単で素晴らしいです。requirements.txtflask pyyaml csv ipykernelコーディング
yamlを開いて、
順繰りにCSVに書き込みたい内容を収集し、
CSV保存して
完了です。yamlが辞書型というもので読み込まれるので、
欲しい条件に合致するようにループと変数取得を記述する所がポイントでした。open-api-yaml-to-csv.pyimport yaml import csv # yamlファイルのコンテンツを、辞書型の変数に格納 with open("oidc-swagger.yaml", "r") as yf: data = yaml.safe_load(yf) # 辞書内から、必要な情報を抽出し、配列として格納 api_list_array = [] i = 0 api_list_array.append(["#", "operationId", "METHOD", "PATH"]) for path in data['paths'].keys(): if path != "/swagger": for verb in data['paths'][path].keys(): # if 'operationId' in data['paths'][path][verb]: name = data['paths'][path][verb]['operationId'] i = i+1 # print(i,name, verb, path) api_list_array.append([i, name, verb, path]) # 配列をCSVとして保存 with open('list.csv', 'w') as csvfile: writer = csv.writer(csvfile) writer.writerows(api_list_array)以上、初投稿でした。環境構築部分は苦労したので、もう少し書き足そうと思います。
- 投稿日:2020-10-15T23:26:14+09:00
swagger.yamlから、Pythonで、APIリスト.csvを作成してみました
環境構築
ついでに、初めてQiitaで記事を書いてみました。
前提
MacBook Pro
macOS Catalina 10.15.7導入
下記をインストールしました。
- Docker
- Visual Studio Code
- Visual Studio Code 拡張機能
- Japanese Language Pack
- Docker 1.6.0
- Remote - Containers 0.145.0
- Python
- PyLint
- Rainbow CSV 1.7.1
- YAML 0.11.1
- Swagger Viewer 3.0.1
- OpenAPI (Swagger) Editor 3.7.0
参考:
設定
- VS Code 同期設定の有効化
- 作業フォルダ作成 (dropbox内に作成しました)
- VS Code で作業フォルダを開く
作業
- Github でレポジトリ作成
- 手元で、microsoft/vscode-remote-try-pythonをコピー(git clone)
- フォルダ名と、git remote set-urlでremote 宛先を自分のレポジトリに変更
エラー対応
ライブラリのインストールや、Jupiterの利用で、エラーが出たため、
ひとまず、ユーザーをrootのままとするようなコメントアウトを行いました。ライブラリインストール
PyYAMLライブラリ,CSVライブラリを使います。
requirements.txtに書いて、Rebuild And Rerunするだけなのでとても簡単で素晴らしいです。requirements.txtflask pyyaml csv ipykernelコーディング
yamlを開いて、
順繰りにCSVに書き込みたい内容を収集し、
CSV保存して
完了です。yamlが辞書型というもので読み込まれるので、
欲しい条件に合致するようにループと変数取得を記述する所がポイントでした。open-api-yaml-to-csv.pyimport yaml import csv # yamlファイルのコンテンツを、辞書型の変数に格納 with open("oidc-swagger.yaml", "r") as yf: data = yaml.safe_load(yf) # 辞書内から、必要な情報を抽出し、配列として格納 api_list_array = [] i = 0 api_list_array.append(["#", "operationId", "METHOD", "PATH"]) for path in data['paths'].keys(): if path != "/swagger": for verb in data['paths'][path].keys(): # if 'operationId' in data['paths'][path][verb]: name = data['paths'][path][verb]['operationId'] i = i+1 # print(i,name, verb, path) api_list_array.append([i, name, verb, path]) # 配列をCSVとして保存 with open('list.csv', 'w') as csvfile: writer = csv.writer(csvfile) writer.writerows(api_list_array)以上、初投稿でした。環境構築部分は苦労したので、もう少し書き足そうと思います。
- 投稿日:2020-10-15T23:16:06+09:00
ある地域のIPアドレス割り振り・割り当て一覧を作る
はじめに
インターネットサービスをやっていると、アクセスしてくるホストの地域1を判別したいってことが時折あります。
たとえば日本では「IPアドレス逆引きすると
*.hkd.mesh.ad.jpだったので北海道からのアクセスっぽい」という判別ができたりします2が、今回はそこまで細かいことはしません。地域という表現ですが国ぐらいの粒度3で考えます。IPアドレスと地域の関連付け
IPアドレスはIANAから各RIRに割り振られ、それを受けたRIRが各地域に割り振り・割り当てています。
なので、各RIRが提供する「どの地域へ分配したか」リストを処理すれば、各地域への分配IPアドレス一覧をつくることができます。
割り振りと割り当てについて
記事タイトルに「割り振り・割り当て」と書いたように、分配には2つの表現があります。また、RIRの出しているリストにも「allocated」と「assigned」のふたつが存在しています。
これはJPNICが出しているドキュメント割り振り(Allocation)、割り当て(Assignment)とはにある通りなのですが、分配されたアドレス領域を受け取った側が自分で使うかどうかの違いがあります。
- allocate(割り振り)
- 管理組織へ分配(傘下メンバーに分配するところに配る)
- assign(割り当て)
- エンドユーザへの分配(分配されたアドレス領域を実際に使うところに配る)
この記事では、これら2つを区別せずに使うとき「分配」と書いています。
先達
このニーズは昔から存在するので、インターネットには既に上記の考えのもと作成されたリストがいくつか存在します。
IPv4
IPv6
せっかくなので自分で作りたい
リストあるやん、で終わったら面白くないので、自分でも作ることにしました。ネットに正解とみなせるデータが存在しているので、生成結果をそれと比較すれば正しさの評価ができそう。
リストを作る上での問題
※この項は先達の記事を適当にサマライズしています。
RIRのリストフォーマットはAPNICなどが公開しています。これを読んで作れば良いのですが、いくつか問題があります。
IPv4のときCIDR表記じゃない
IPv4は「開始アドレス+個数」という表記4をしています。プログラムでIPアドレスから地域判定するときはCIDRで考えることが多いのでCIDRに変換した方が便利です。また、1レコードにCIDR表記1つで表記しきれないブロック5も存在します6。
IPv6の場合はCIDR表記7なので、この問題はありません。
CIDRにしてもブロックが小分けのときがある
これはRIRのドキュメントには書いてありません。先達の記事にはその旨記述があるし自分で実装しても確かにリストが縮みます6。
リストが冗長になって良いことは特にないので、短くできるに越したことはない。
CIDRの結合についてはCIDR+CIDRはどんな処理をするの?という記事がおすすめ。
Pythonで作ってみる
CIDRの生成と結合をやるわけですが、PythonでCIDR結合などの操作はライブラリnetaddrがあります。
CIDRレコードの生成
from netaddr import IPRange,IPAddress # `start`と`value` は RIRのレコード情報 start_ip = IPAddress(start, version = 4) end_ip = IPAddress(int(start_ip) + value - 1) # `value` は個数なので-1する cidr_list = IPRange(start, end_ip).cidrs()CIDRブロックの結合
- IP Set
- CIDR情報(
IPNetworkオブジェクト)のリストを食わせると、適当に結合してくれます。- 結合されたCIDRはiter_cidrs()で取り出せます。
from netaddr import IPSet v4set = IPSet(v4_cider_list) for cidr in v4set.iter_cidrs(): print(cidr)つくってみたもの
色々書いてきましたが、シュッと書けてしまいました。ライブラリすごい。
大したものでは有りませんが、Gistに放り込んでおきました。
https://gist.github.com/walkure/d1d87d8b4aad3c692edef1cce0f69aab
他言語ではどうなのか
Perlの場合はNet::CIDR::Liteライブラリ9でCIDR結合ができそうです。実際に書いてみようと思ったんですが、
cpan叩いたら「Free to wrong pool 1f7d20 not 89034600d957d249 at C:\Perl64\site\lib/IO/Socket/SSL.pm line 2739.」とか言って落ちてしまう。調べると、Windowsでのみ生じる既知かつ未解決のの問題10の模様で断念。Goの場合はcidrmanというnetaddrにインスパイアされた11ライブラリがありますが、現状IPv4のみ実装されています12。
PHPの場合は、自前の国別IPv6、IPv4アドレス割当リストを作成しようという記事が存在します。
本当に欲しいのはアクセスしてくるユーザの居住地域とかな気もしますが、アクセスしてくるホストのIPアドレスしか分からないという前提。現実問題としてアクセス元のIPアドレスから分かるのは分配された組織の所在する地域でしかなく実際にホストやユーザがどこにいるかは別の話になります(VPNありますし)。 ↩
雑に国って言うと、「アメリカとは別にグアムへの割り振りがあるやん」とかなってくる。 ↩
原文では
valueの項に「In the case of IPv4 address the count of hosts for this range. This count does not have to represent a CIDR range.」と書かれています。CIDRじゃないよって書いてありますね。 ↩例えば、US割り当てのレコード「ripencc|US|ipv4|13.116.0.0|524288|19860425|assigned|61f026d4-8289-4155-b117-b70688eb33ff」を見ると、プレフィクス長は/13(=32-log2(524288))っぽく見えます。だけど、実際に13.116.0.0/13するとホストアドレスが0になりません。例えばネットワーク計算ツールで確認できます。 ↩
CIDRの概念が発生する前から存在するフォーマットだろうからなぁ。 ↩
原文では「In the case of an IPv6 address the value will be the CIDR prefix length from the ‘first address’ value of .」とあります。 ↩
これは前述したとおり、IPアドレスレンジが1つのCIDRで表せるとは限らないからです。 ↩
Merging IPv6 CIDR ranges unimplementedというissueが経っていますが、1年ほど動きがない。 ↩
- 投稿日:2020-10-15T22:54:56+09:00
避けて通りたかった Hash chain その(1)
こんばんは(*´ω`)
題名には、思わず心の声が入っちゃいました(笑)
初めて勉強する人は私を含めイメージが難しかったのではないでしょうか?
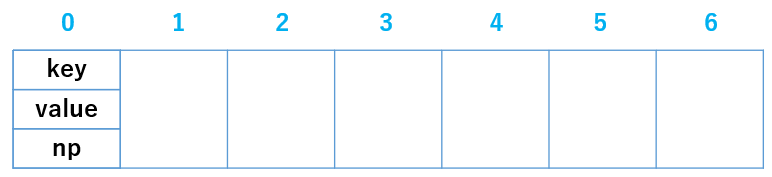
なるべく分かりやすく、さぁ、飛び込んでみましょう。取り急ぎ、適当な配列を用意しました。
これから適当なデータを以下の配列に格納していきます。
普通ならポインタ 0(=x[0]) から順にデータを格納するのですが、今回は趣向を変えましょう。
今回挑戦する Hash chain は
1つのアドレスには 1つのデータしか格納できませんでしたが、
もっと沢山詰め込めないか !! っていうアプローチです。(ちょっと乱暴ですかね。。)
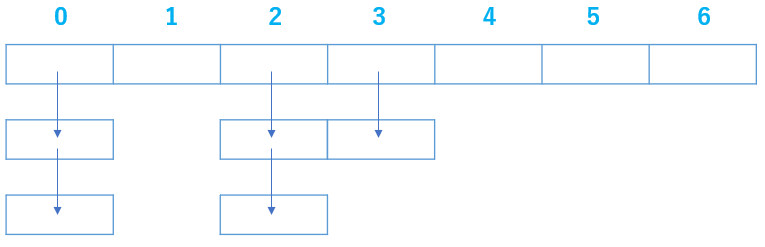
有識者の方の資料を拝見すると以下のような図をよく見かけます。
x[0]であれば、データが紐づいて合計 3 つ鎖で繋がっているように見えます。
初めて見た時、とっても素敵だと思いました、こんなこと出来るって凄い!!
でも、どうやって書くんだ、それ?(;´・ω・)まずは、Hash の基本的な定義から行きます。
格納先のポインタはどうやって決めますか?
はい、これです。"ユーザが任意に指定する整数" % 配列長
例えば14を入力すると今回用意した配列長は 7 なので 0 が出てきます。
OK, じゃあ、x[0] に何を格納しますか?取りあえず 1 でも入れておきましょう。
いやいや stop!! x[0]格納するのは 1 だけじゃないんです、14も一緒に格納するんです!疑問が死ぬほど出てきますが、このまま行きましょう。
表題にある通り chain(鎖) なので繋がり先のアドレスも入れておきましょう!!
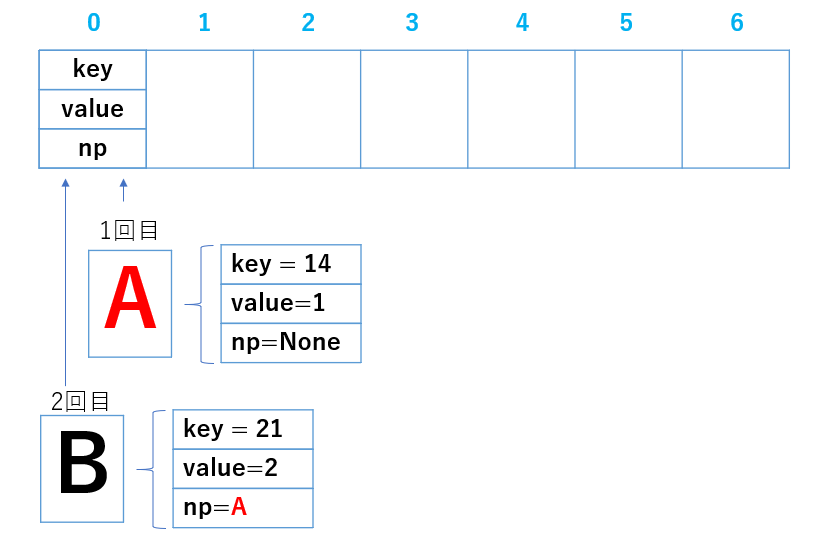
key = 14 , value = 1 , np(next pointer) = none とすると以下の図になります。
では、次の入力で key = 21 としたら、どうなりますか?
21%7 = 0
また 0 だ ('Д')
どうしよう。。。困ったときは取りあえず書いてみると気分転換になります。
test.pyclass Node: def __init__(self,key,value,next): self.key = key # ユーザ入力の任意の整数 self.value = value # 格納したい値 self.np = np # next pointerNode と定義して、その中には 3 つの引数が用意されています。
この Node を格納する配列を用意しましょう。test.pyclass ChainedHash: def __init__(self,capacity): self.capacity = capacity # 配列長なので、あとで 7 を代入します self.table = [None]*self.capacity # Nodeを格納する配列を tableと命名例えば、key = 14,value = 1,np = None を適当に Node に代入し、
更にそれを table[0] に代入し print してみます。
すると、ビックリ以下のようになった。test.py[<__main__.Node object at 0x00000282E2DA9D60>, None, None, None, None, None, None]なんだこれ、Node を table[0] に代入したら大変なことになった。
最初見た時は、思わず倒れそうになりました(笑)
でも今思うと、これも chain 方を構成するための 1 つのミソなのではないかと思います。例えばですが、こんな記述を目にしたら、どう思いますか?
test.pytemp = Node(key,value,self.table[Vhash]) self.table[Vhash] = temp冒頭に用意した Node に key, value, self.table[Vhash] の 3 つを
代入し、temp に代入しています。
key , value は、これから入力しようとしている値です。
でも self.table[Vhash], これは何でしょうか?
そう、これは、もともと table[0] に格納されていた値です。
もともと格納されていた table[0] の値には勿論、key , value, self.table[Vhash] が
格納されています(table[0] の初期値は None です。)。これは、何を意味するのでしょうか。。
ボキャ貧な説明を補うために、イメージを作ってみました。
最初に書き込んだのはデータ(key,value,np)は長いので A とします。
その後 B 同様に x[0] へデータを書き込みましたが、図にあるBの np を見てください。
A のデータそのものが埋め込まれていませんか??
よって、最後に table[0] に格納された値 B の中身を把握した時には、次の A の値も見えるわけです。
このように、データの中にデータを埋め込む処理を続けると、いくつもデータが繋がって見えませんか?
念のため、もう一度前述の説明を念頭にもう一度記述を眺めてみてください。test.py# ↓ Data A = self.table[0] temp = Node(key,value,self.table[Vhash]) #self.table[0] に 新たに用意した key + value + Data A をワンパッケージ化し代入 self.table[Vhash] = temp #以上から table[0] の値は A から B へ更新されますね?(笑)
1つのアドレスに書き込むデータは 1 つだけど、
データの中にデータを埋め込んでるから、チェーンのように
繋がって見えるんです。
面白いですね(≧▽≦)このイメージがあると、次が楽です。データの埋め込み作業の前に
もともと table[0] には重複データが無いか確認する記述が必要ですよね?
多分、このようになると思います。test.pydef add(self,key,value): Vhash = key % self.capacity # table のどのポインタを指定するか算出 p = self.table[Vhash] # 0 だったとすると table[0] の値を p に代入 # ここで p には key,value,np が入っています while p is not None: #p.key は p の中にある key だけを抜き出しています #p.key が今回入力した key と同等の場合は #重複するので使えませんので False を返します if p.key == key: return False #p の中にある np を呼び出し、 #埋め込まれたデータ key, value, np を p に代入しなおします。 p = p.np #冒頭の while に戻って、none になるまで続けて #重複する key が使われていないかを確認します。 temp = Node(key,value,self.table[Vhash]) self.table[Vhash] = tempさぁ、やっとここまで来ました。
ザクっと全体像をまとめておきます。test.pyclass Node: def __init__(self,key,value,np): self.key = key self.value = value self.np = np class ChainedHash: def __init__(self,capacity): self.capacity = capacity self.table = [None]*self.capacity def add(self,key,value): Vhash = key % self.capacity p = self.table[Vhash] while p is not None: if p.key == key: return False p = p.np temp = Node(key,value,self.table[Vhash]) self.table[Vhash] = temp def dump(self): for i in range(self.capacity): p = self.table[i] print(i,end="") while p is not None: print(f"=>{p.key}({p.value})",end="") p = p.np print() test = ChainedHash(7) while True: num = int(input("select 1.add, 2.dump ")) if num == 1: key = int(input("key: ")) val = int(input("val: ")) test.add(key,val) elif num == 2: test.dump() else: break実行結果.pyselect 1.add, 2.dump 1# 1.add を選択 key: 7 val: 1 select 1.add, 2.dump 1 # 1.add を選択 key: 14 val: 2 select 1.add, 2.dump 2# 2.dump を選択 0=>14(2)=>7(1) # chain の完成 ('Д')!! 1 2 3 4 5 6うーん、説明が長くて、申し訳ないです。
続きは、その(2)へ続く...

- 投稿日:2020-10-15T22:45:56+09:00
鹿児島県の Go To EATの利用可能店舗のPDFをCSVに変換
鹿児島商工会議所の利用可能店舗のPDFからCSVに変換
エリアごとにPDFファイルが分かれているのでひとつにまとめる
スクレイピング
import requests from bs4 import BeautifulSoup url = "http://www.kagoshima-cci.or.jp/?p=20375" r = requests.get(url) r.raise_for_status() soup = BeautifulSoup(r.content, "html.parser") result = [] for a in soup.select("#contents_layer > span > p > a"): s = a.get_text(strip=True).replace("全域", "").lstrip("〇") # 地区は除外 if not s.endswith("地区"): result.append({"area": s, "link": a.get("href")})データラングリング
import camelot import pandas as pd dfs = [] for data in result: tables = camelot.read_pdf( data["link"], pages="all", flavor="lattice", split_text=True, strip_text=" \n" ) for table in tables: df_tmp = table.df.iloc[1:].set_axis(["五十音", "店舗名", "所在地"], axis=1) df_tmp["地域"] = data["area"] dfs.append(df_tmp) df = pd.concat(dfs) df.to_csv("kagoshima.csv", encoding="utf_8_sig")
- 投稿日:2020-10-15T22:36:06+09:00
Julia早引きノート[06]ループ処理
ループ処理(書き方例)
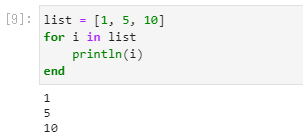
note06◆while~end文 i = 0 # iの初期化 while i <= 10 println(i) global i += 1 # グローバル変数化 end ◆for~end文(=イコール使用の場合) for i = 1:10 println(i) end ◆for~end文(in使用の場合) list = [1, 5, 10] for i in list println(i) end解説
・Juliaでは、ループ処理としてwhilte~end文とfor~end文が使用できます。whilte、forともendまでの間の部分で繰返し処理が実行されます。
・Pythonと大きく異なる点は、endがあることです。
・while、forなどのブロック内で使用される変数はローカル変数のため、ブロック外で使用できません。(1)while~end文の実行結果は以下です。
4行目で変数iにglobalを付加しています。変数iをループ処理内部(whileとendの間)だけでなく外部でも使用する場合、このようにglobalを付加します。また、globalを付加しないとループ処理内部で値の変更はできません。
反対に、変数iを変更しない場合は、globalの付加は不要です。
ループ処理内部では読み取りのみ可能です。(2)for~end文(=イコール使用の場合)の実行結果は以下です。
変数iは1から10まで繰返し実行されます。
Juliaではスライス1:10のうち、最後尾10まで実行されますのでご注意下さい。
(Pythonは1~9までしか実行されません)(3)for~end文(in使用の場合)の実行結果は以下です。
2行目のlist部分にリスト型変数を設定することで、in演算子でもループすることができます。もくじ
Julia早引きノート[01]変数・定数の使い方
Julia早引きノート[02]算術式、演算子
Julia早引きノート[03]複素数
Julia早引きノート[04]正規表現
Julia早引きノート[05]if文
Julia早引きノート[06]ループ処理(※引き続きコンテンツを増やしていきます)
関連情報
Julia - 公式ページ
https://julialang.org/
https://julia-doc-ja.readthedocs.io/ja/latest/index.html
https://qiita.com/ttlabo/items/b05bb43d06239f968035
https://docs.julialang.org/en/v1/base/math/ご意見など
ご意見、間違い訂正などございましたらお寄せ下さい。

- 投稿日:2020-10-15T22:32:24+09:00
【50歳過ぎたオッサンが】生まれて初めてWEBアプリを作製するまで。(deep learning編)
はじめまして。
50過ぎたオッサンです!
プログラミングスキルはゼロです!!
プログラミング経験がないので、ただ漠然とした「WEBアプリ」を作製したい!
そんな思いがありました。
アイデアもなく、ただ何かを作りたい!そう思ってました。
【ヒントの種は?】
***まずプログラミング言語を決めるところからのスタートでした。***
どんな言語が良いのか?
どんな言語が簡単か?
色々と検索をしたら「python」が簡単ということがわかりました。
pythonを調べまくりました。
pythonならWEB系も人工知能系もいけるということで
本を買いました!
この本は初学者にも優しい本で、分かりやすかったです。
やりたいこと(スキルが伴う)がまだ見つからないので
困ってました。
言語はパイソン、やりたいことはまだない!何を始めようか?
よし、米国株のディープラーニングでいこう!!
何故、米国株なのかというと日本株は「ストップ安、ストップ高」で取引ができませんが
米国株なら可能だということで、米国株の未来予測に挑戦してみました。
(この未来予測については、現在作成中です。)
おススメのサイトは以下。
https://qiita.com/innovation1005/items/5be026cf7e1d459e9562
https://econ-blog.com/risk-and-return-plot-with-python/
https://katsuhiroblog.com/python-get-google-stock/
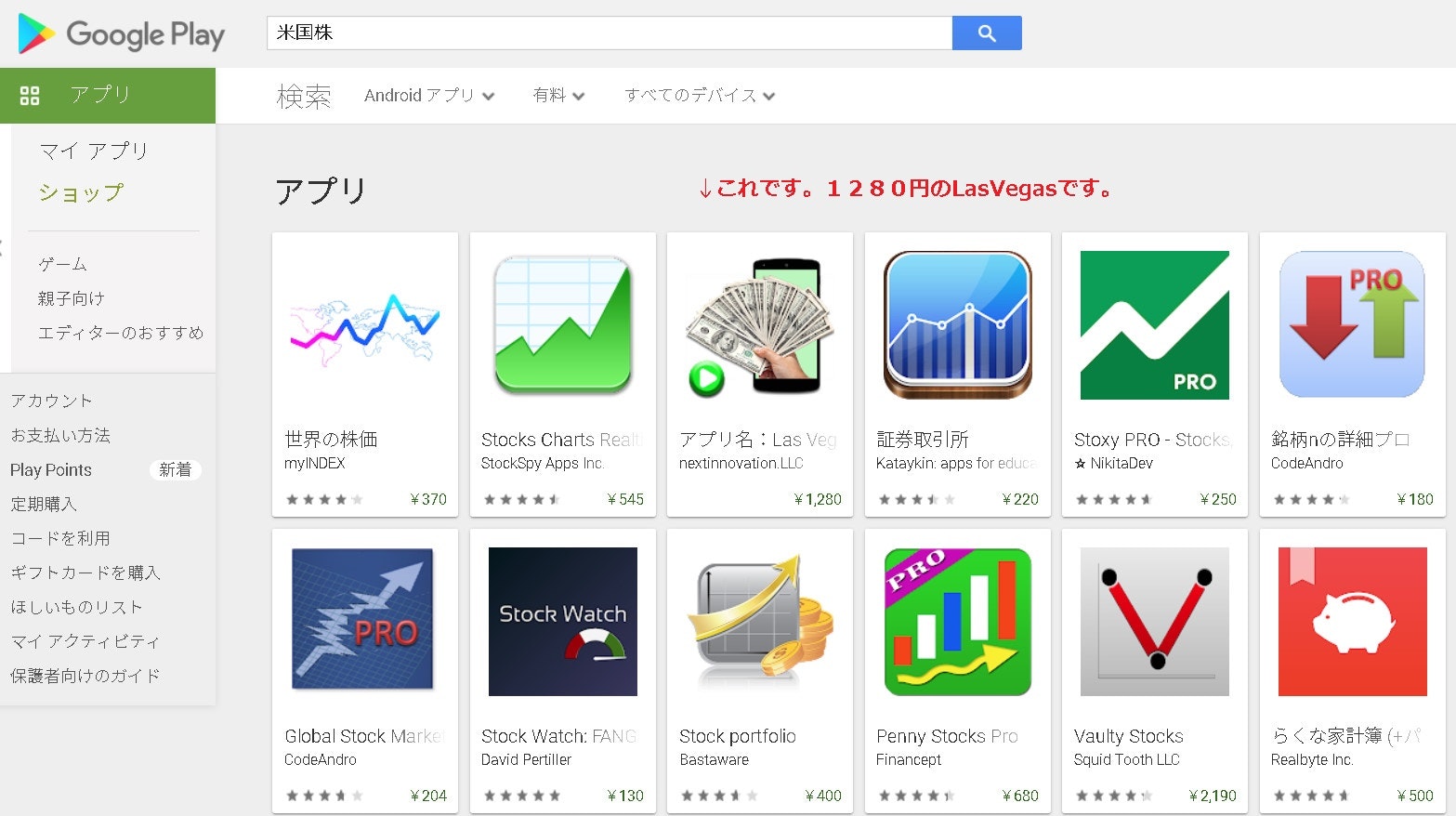
こちらの画像をどうぞ!
16冊の本を読み漁り、ネットでも読み漁り。
【google play】で公開できました。(***ver1.0はDLを使ってません***)
公開画像はコチラ
米国株のチャート分析するアプリを作製しました。
まだまだ戦いは続きます。
DLを用いた株価予測を完成するまでは・・・・。


- 投稿日:2020-10-15T22:30:23+09:00
Python基礎
Pythonの基礎知識です。
自分の勉強メモです。
過度な期待はしないでください。基礎知識
・Pythonのプログラムファイルの拡張子は
py
例:××××.pyIDLEを使った場合
・シェルウィンドウ
IDLEを起動した状態・エディタウィンドウ
-プログラムを入力するものをテキストエディタと言う
-ファイルの新規作成→IDLEのシェルウィンドウのメニューバーにある「File」→「New File」
-保存→エディタウィンドウにプログラムを記述をしファイルを保存する時は、エディタウィンドウのメニューバーにある「File」→「Save as...」
-ファイルを開く→エディタウィンドウのメニューバーにある「File」→「Open」
-プログラムの実行→エディタウィンドウのメニューバーにある「Run」→「Run Module F5」命令
・出力を行う
print()
全角、半角に関わらず文字列を出力するにはprint()と言う命令を使う
また、文字列を扱うにはダブルクォテーション("")また、シングルクォテーション('')で前後をくくる
例:print("おはよう") → おはよう・入力を行う
input()
変数 = input('コンソールに表示したい文字列')のように使うとコンソールに入力された値が変数に代入されます。
また、inputで受け取った値は文字列型になるので数値型に変換する必要がある(「int」を用いる)変数
・変数名の付け方
-1、英単語を用いる、変数名の頭文字を数字にする事は出来ない
例:date
-2、2語以上の変数名を使うときは、単語と単語の間を_ (アンダーバー)で区切る
例:user_name・変数の値を取り出す
name = "Jhon" print(name) # → Jhon print("name") # → name #ダブルクォテーション等を付けると文字列して認識されてしまう・変数の値を更新
基本形 省力形 X = X + 100 X += 100 X = X - 100 X -= 100 X = X * 100 X *= 100 X = X / 100 X /= 100 X = X % 100 X %= 100 型変換
・数値型を文字列型に変換するには
「str」を用いる例price = 200 # 数値型 print("りんごの価格は"+ str(price) + "円です")・文字列型を数値型に変換するには
「int」を用いる例count = "3" price = 100 total_price = price * int(count)if文
書き方
××××.pyscore = 50 if score ==100: #行末にコロンは必須 print("等しい数値です") #インデントを揃える(半角スペース4つ分)××××.pyscore = 50 if score ==100: #行末にコロンは必須 print("等しい数値です") #インデントを揃える(半角スペース4つ分) else: #行末にコロンは必須 print("異なる数値です") #インデントを揃える(半角スペース4つ分)××××.pyscore = 80 if score ==100: #行末にコロンは必須 print("等しい数値です") #インデントを揃える(半角スペース4つ分) elif score >=70: #行末にコロンは必須 print("70よりは大きです") else: #行末にコロンは必須 print("異なる数値です") #インデントを揃える(半角スペース4つ分)××××.py# and - 「条件1も条件2も成り立つというような場合」 x = 20 if x>=10 and x<=30: print("xは10以上30以下です") # or - 「条件1か条件2が成り立つというような場合」 y = 60 if y<10 or y>30: print("yは10未満または30より大きいです") # not - 「条件式がFalseであればTrueになる」 z = 55 if not z== 77: print("zは77ではありません")
式 意味 == 右辺と左辺が等しい時 != 右辺と左辺が等しくない時 < 右辺の時が大きい時 <= 右辺の時が大きいまたは等しい時 > 左辺の時が大きい時 >= 左辺の時が大きいまたは等しい時
- 投稿日:2020-10-15T22:23:39+09:00
KivyでYes No Popupを作る
概要
はい・いいえを聞くダイアログが欲しかったので、使いまわしやすいような形で作りました。
コード
gitにも置きました。
__init__.py''' a simple Yes/No Popup LICENSE : MIT ''' from kivy.uix.popup import Popup from kivy.properties import StringProperty from kivy.lang.builder import Builder Builder.load_string(''' #<KvLang> <YesNoPopup>: FloatLayout: Label: size_hint: 0.8, 0.6 pos_hint: {'x': 0.1, 'y':0.4} text: root.message Button: size_hint: 0.4, 0.35 pos_hint: {'x':0.1, 'y':0.05} text: 'Yes' on_release: root.dispatch('on_yes') Button: size_hint: 0.4, 0.35 pos_hint: {'x':0.5, 'y':0.05} text: 'No' on_release: root.dispatch('on_no') #</KvLang> ''') class YesNoPopup(Popup): __events__ = ('on_yes', 'on_no') message = StringProperty('') def __init__(self, **kwargs) -> None: super(YesNoPopup, self).__init__(**kwargs) self.auto_dismiss = False def on_yes(self): pass def on_no(self): pass if __name__ == '__main__': from kivy.app import App from kivy.uix.boxlayout import BoxLayout from kivy.uix.button import Button class TestApp(App): def __init__(self, **kwargs): super(TestApp, self).__init__(**kwargs) def build(self): self.pop = pop = YesNoPopup( title='Popup !', message='OK ?', size_hint=(0.4, 0.3), pos_hint={'x':0.3, 'y':0.35} ) pop.bind( on_yes=self._popup_yes, on_no=self._popup_no ) root = BoxLayout() btn = Button(text='open') root.add_widget(btn) btn.bind(on_release=lambda btn: self.pop.open()) return root def _popup_yes(self, instance): print(f'{instance} on_yes') self.pop.dismiss() def _popup_no(self, instance): print(f'{instance} on_no') self.pop.dismiss() TestApp().run()結構シンプルです。on_yesとon_noイベントにそれぞれの場合の処理を行うコールバック関数を渡せばよいでしょう。
カスタマイズも容易なので、いろいろな場面で使えそう、、かも?

- 投稿日:2020-10-15T22:12:43+09:00
文春オンラインの記事をスクレイピングして、ネガポジ分析を行います
スクレイピングとは
スクレイピングを利用することでネット上の様々な情報を取得することができます。
今回はPythonのコードを利用して記事を取得しています。
BeautifulSoupなどを利用して、HTMLやCSSの情報を指定して情報を抽出します。ネガポジ分析について
記事の内容がネガティブなのかポジティブなのかを単語感情極性対応表を基準にして数値化してみようと思います。
単語感情極性対応表は単語に対してネガポジ度を-1〜1で定義してあります。喜び:よろこび:名詞:0.998861
厳しい:きびしい:形容詞:-0.999755などです。
参考文献
スクレイピングはudemy講座を利用しました。
ネガポジ分析はこちらの記事を参考にさせていただきました。
また、今回分析対象としたのは文春オンラインです。では作業に取り掛かりましょう。
まずは必要なライブラリをインポートします。import requests from bs4 import BeautifulSoup import re import itertools import pandas as pd, numpy as np import os import glob import pathlib import re import janome import jaconv from janome.tokenizer import Tokenizer from janome.analyzer import Analyzer from janome.charfilter import *まずはスクレイピングの準備です。
URLを取得して
requestsとBeautifulSoupを適用します。url = "https://bunshun.jp/" # urlに文春オンラインのリンクを格納 res = requests.get(url) # requests.get()を用いてurlをresに格納 soup = BeautifulSoup(res.text, "html.parser") # ここでBeautifulSoupを用いてスクレイピングの準備ができました。記事一覧を取得して、タイトルとURLを取得
基本的には記事が
li要素として並んでおり、その親要素はulであるというパターンが多いです。
for文を使って記事一覧からタイトルとURLを取得しています。elems = soup.select("ul") # 記事のリストがli要素として並んでいたので、その親要素であるulを指定しています。 title_list = [] # 記事のタイトルを格納するリスト url_list = [] # 記事のURLを格納するリスト for sibling in elems[3]: # elems[3]に欲しいリストがありました。このfor分により記事のリストから記事のタイトルとURLを取得し、それぞれリストに格納します。 if sibling != "\n": # 改行が含まれていたので除外 print(sibling.h3.string) # タイトルはh3タグに入っていました。 title_list.append(sibling.h3.string.replace('\u3000', ' ')) # \u3000が入っている部分があったので空白に変換 print(url + sibling.h3.a["href"]) # aタグのhref属性にリンクが格納されていました。 url_list.append(url + sibling.h3.a["href"]) # 上記で取得したurl以下の部分が格納されていたので足しています。ジャニーズ元MADEリーダー・稲葉光(29)が元Berryz工房アイドルと“渋谷ホテルデート”《スクープ撮》 https://bunshun.jp//articles/-/40869 「駅近、約1,200㎡の広大な敷地」「自宅の建て替えと地域貢献を両立する土地活用」プロが出した答えとは? https://bunshun.jp//articles/-/40010 「365日24時間働こう」……ワタミの“思想教育”はいまも続いていた https://bunshun.jp//articles/-/40843 “縦割り行政”の弊害だ! 橋下徹が語る「Go Toキャンペーンは何が間違っているのか」 https://bunshun.jp//articles/-/40877 警察官に唾吐き公務執行妨害で逮捕 読売新聞がソウル支局記者を懲戒処分 https://bunshun.jp//articles/-/40868 同性愛差別の足立区議宛てに「とんでもない思い違いです」…81歳祖母の手紙が教えてくれたこと https://bunshun.jp//articles/-/40826 家系ラーメン“のれん分け戦争”「吉村家vs.六角家」裏切りと屈服の黒歴史〈六角家破産〉 https://bunshun.jp//articles/-/40752 《平手派また卒業》欅坂46・佐藤詩織が書いた「活動のなかで悲しかったこと」 櫻坂46の“急勾配”を運営も懸念 https://bunshun.jp//articles/-/40862 安倍政権最大の功績は“アイヌ博物館”だった? 200億円をブチ込んだ「ウポポイ」の虚実 https://bunshun.jp//articles/-/40841 「長さ」ではなく…美容師が教える、髪を切るときに言うといい「意外な言葉」 https://bunshun.jp//articles/-/40694記事は1ページでは終わらない場合があります。1ページずつ遷移してリンクを取得します。
リンク一覧を作成するために、while文を作って次のページが表示されていればそのURLを取得してページに遷移し、遷移したページにも次のページへのリンクがあれば取得して遷移するというループを回します。
こうすることにより、1タイトルのニュースに関する全てのページに関するリンク一覧を作成できます。news_list = [] # 全てのニュース記事のリンクをここに格納します。 for pickup_link in url_list: # このfor文でURLリストからURLを取り出します。 news = [] # ニュース記事はページごとに分かれているため、このリストに各ページのリンクを格納します。 news.append(pickup_link) # 最初のリンクを格納 pickup_res = requests.get(pickup_link) # requests.get()を用いてリンクからページを取得 pickup_soup = BeautifulSoup(pickup_res.text, "html.parser") # BeautifulSoupを適用 while True: # このwhile文では次のページへのリンクがあればそのリンクを取得し、そのページへ遷移するというループを回します。 try: # 遷移した先で次のページへのリンクがあれば永遠にこのループを繰り返します。 next_link = pickup_soup.find("a", class_="next menu-link ga_tracking")["href"] # next menu-link ga_trackingというクラスを持つaタグのhref属性が次のページへのリンクでした。 next_link = url + next_link next_res = requests.get(next_link) # requests.get()とBeautifulSoupを用いて遷移先のページ情報を取得します。 pickup_soup = BeautifulSoup(next_res.text, "html.parser") news.append(next_link) # newsに各ページ情報を追加します。 except Exception: # 次のページへのリンクが無ければここの処理が行われます。 news_list.append(news) # タイトル内の全ての記事をURLがnewsに格納されたのでそれをnews_listに格納します。 break display(news_list) # 作成したURLリストを表示します。[['https://bunshun.jp//articles/-/40869', 'https://bunshun.jp//articles/-/40869?page=2', 'https://bunshun.jp//articles/-/40869?page=3', 'https://bunshun.jp//articles/-/40869?page=4'], ['https://bunshun.jp//articles/-/40010', 'https://bunshun.jp//articles/-/40010?page=2'], ['https://bunshun.jp//articles/-/40843', 'https://bunshun.jp//articles/-/40843?page=2', 'https://bunshun.jp//articles/-/40843?page=3', 'https://bunshun.jp//articles/-/40843?page=4'], ['https://bunshun.jp//articles/-/40877', 'https://bunshun.jp//articles/-/40877?page=2'], ['https://bunshun.jp//articles/-/40868', 'https://bunshun.jp//articles/-/40868?page=2'], ['https://bunshun.jp//articles/-/40826', 'https://bunshun.jp//articles/-/40826?page=2', 'https://bunshun.jp//articles/-/40826?page=3', 'https://bunshun.jp//articles/-/40826?page=4'], ['https://bunshun.jp//articles/-/40752', 'https://bunshun.jp//articles/-/40752?page=2', 'https://bunshun.jp//articles/-/40752?page=3', 'https://bunshun.jp//articles/-/40752?page=4'], ['https://bunshun.jp//articles/-/40862', 'https://bunshun.jp//articles/-/40862?page=2', 'https://bunshun.jp//articles/-/40862?page=3'], ['https://bunshun.jp//articles/-/40841', 'https://bunshun.jp//articles/-/40841?page=2', 'https://bunshun.jp//articles/-/40841?page=3', 'https://bunshun.jp//articles/-/40841?page=4', 'https://bunshun.jp//articles/-/40841?page=5'], ['https://bunshun.jp//articles/-/40694', 'https://bunshun.jp//articles/-/40694?page=2', 'https://bunshun.jp//articles/-/40694?page=3', 'https://bunshun.jp//articles/-/40694?page=4']]先ほどのコードでURLリストを作成できたので、そのリンクを辿って記事本文を取得していきます。
.textを適用することで本文のみを取得できるのですが、細かくfor文を回して.textを適用しています。
そのためいくつかの空文字(or空リスト)を作成して格納しながら本文を格納したリストを作成していきました。news_page_list = [] # ここに全ての記事の本文を格納します。 for news_links in news_list: # このfor文でURLのリストからあるタイトルのリンクリストを取り出します。 news_page = '' # ここに各ページから取得した本文を追加していきます。 for news_link in news_links: # タイトルのリンクリストからリンクを一つずつ取り出します。 news_res = requests.get(news_link) # requests.get()とBeautifulSoupを利用して記事の情報を取得します。 news_soup = BeautifulSoup(news_res.text, "html.parser") news_soup = news_soup.find(class_=re.compile("article-body")).find_all("p") # article-bodyというidを持つタグの直下のpタグに本文が格納されていました。 news_phrase = '' # そのページの本文のフレーズを格納 for news in news_soup: # for文で回すことでtextを適用して本文フレーズのみを取得できました。 news_phrase += news.text.replace('\u3000', ' ') # 取得したフレーズを追加。文字列なので+で追加できました。 news_page += news_phrase # 1ページ分のフレーズが取得できらたらnew_pageに追加 news_page_list.append(news_page) # 一つのタイトルに対する全ての本文がnew_pageに格納されたらnews_page_listに追加。これはリスト型なのでappendを使用。for i in range(1, 4): # 取得した本文の一部を表示してみます。うまく取得できたようです。 print("<%s>" % i, news_page_list[i][:500], end="\n\n")<1> 多くの土地オーナーから「土地活用のパートナー」として選ばれ続けている三井ホーム。土地活用のプロフェッショナルである同社営業担当者へのインタビューを通じ、三井ホームがパートナーとして選ばれる理由をひも解く本企画。今回は、東京都府中市にある約1,200㎡にも及ぶ広大な自宅敷地を、医院+賃貸住宅+自宅と保育所の計2棟に建て替えた事例を紹介する。本件を担当した東京コンサルティング営業部 東京西エリア 営業グループ長の西嶋俊人氏に話を聞いた。 都心から西に延びる京王線の最寄駅から徒歩約5分の場所に、戦前から続く大地主の自宅があった。敷地面積は約1,200㎡。築約50年の自宅は老朽化が進み、建て替えを検討する必要があった。 70代のオーナーさまは、この地に代々続く地主のご一族で、自宅周辺にも複数の賃貸マンションを所有されている方です。老朽化した築約50年の自宅などの建て替えを機に、約1,200㎡にも及ぶ広大な敷地を有効活用しようというのが今回のプロジェクトの発端です。 銀行から弊社に相談が持ち込まれたのが2018年初め。まず自宅+賃貸住宅というプランを持ってオーナーさまにお会いしました。するとオー <2> ワタミ株式会社の労働問題に関する告発が続いている。10月2日、「ワタミの宅食」営業所の所長が、労働基準監督署からの残業代未払いの是正勧告、月175時間を超える長時間労働、上司によるタイムカードの改ざんを次々と公表したのだ。「ホワイト企業」宣伝のワタミで月175時間の残業 残業代未払いで労基署から是正勧告ワタミがホワイト企業になれなかった理由は? 勝手に勤怠「改ざん」システムも Aさんは長時間労働の末、昼夜の感覚がなくなり、「このまま寝たら、もう目が覚めないのではないか」と恐怖を抱きながら生活するほどだった。「あのまま働いていたら、死んでいた」とAさんは断言する。現在は、精神疾患を発症し、労災申請をしながら休業中だ。 しかし、Aさんは命の危険を感じていながら、なぜ過酷な仕事を続けてしまったのだろうか。その背景には、労働者の意識に働きかけ、過酷な労働を受け入れさせてしまう、ワタミによる「思想教育」のシステムがあった。「こんなにいい仕事をしているんだから、苦しくても頑張ろう」「苦しいことも、苦しくない。むしろ自分の力になる」 Aさんは過重労働の最中、そう自分に言い聞かせていた。 実際、Aさ <3> 「規制改革」「行政改革」「縦割り打破」。 菅義偉政権発足後、「改革」という言葉がよく聞こえてくるようになった。菅首相は9月16日の就任記者会見でも「規制改革を政権のど真ん中に置く」と宣言している。この「改革」によって、日本はどのように変わるのだろうか――。 菅首相と親交の深い橋下徹氏が、「文藝春秋」11月号のインタビューで菅政権の「改革」が目指すところを語った。 橋下氏は自身の経験から、「改革」を進めていくためには「おかしい」と言える感覚を持つことが重要だと語る。「“改革力”というのは、常に身の回りのことにアンテナを張って、『これはおかしい』と感じたら、すぐに口に出すことがものすごく重要です。そうしてその都度直していく。その繰り返しです。 僕が知事・市長だった時も、そのような作業の連続でした。 例えば、公用車に乗ったらマガジンラックに新聞5紙がバサッと差し込まれているんですよ。庁舎に着くまでにニュースをチェックできるからいいんですけど、知事室に入ったら机の上に5紙が、知事応接室に行ったらまた5紙……。『公用車の新聞をそのまま知事室に持っていけばいいじゃないか』『どうなってるんや、この新スクレイピングによって得た、今までの情報を一つのDataFrameに格納します。
こうすることでデータが見やすくなるだけでなく、扱いやすくなります。
ここまでできればあとはデータを加工してネガポジ分析をするだけです!new_no_list = [x for x in range(len(title_list))] # あとで使うのでニュースNo.を作成 newslist = np.array([new_no_list, title_list, url_list, news_page_list]).T # DataFrameに格納する準備として、np.arrayのリストに格納して転置しておく。 newslist = pd.DataFrame(newslist, columns=['ニュースNo.', 'title', 'url', 'news_page_list']) # カラム名を指定してDataFrameに格納 newslist = newslist.astype({'ニュースNo.':'int64'}) # あとでテーブルを結合するためにニュースNo.をint64型に変換 display(newslist)
ニュースNo. title url news_page_list 0 0 ジャニーズ元MADEリーダー・稲葉光(29)が元Berryz工房アイドルと“渋谷ホテルデート... https://bunshun.jp//articles/-/40869 ジャニーズJr.内の人気ユニット「宇宙Six」の山本亮太(30)が違法な闇スロット店に通っ... 1 1 「駅近、約1,200㎡の広大な敷地」「自宅の建て替えと地域貢献を両立する土地活用」プロが出し... https://bunshun.jp//articles/-/40010 多くの土地オーナーから「土地活用のパートナー」として選ばれ続けている三井ホーム。土地活用のプ... 2 2 「365日24時間働こう」……ワタミの“思想教育”はいまも続いていた https://bunshun.jp//articles/-/40843 ワタミ株式会社の労働問題に関する告発が続いている。10月2日、「ワタミの宅食」営業所の所長... 3 3 “縦割り行政”の弊害だ! 橋下徹が語る「Go Toキャンペーンは何が間違っているのか」 https://bunshun.jp//articles/-/40877 「規制改革」「行政改革」「縦割り打破」。 菅義偉政権発足後、「改革」という言葉がよく聞こえて... 4 4 警察官に唾吐き公務執行妨害で逮捕 読売新聞がソウル支局記者を懲戒処分 https://bunshun.jp//articles/-/40868 読売新聞ソウル支局の記者(34)が7月中旬、公務執行妨害の容疑で韓国当局に逮捕されていたこ... 5 5 同性愛差別の足立区議宛てに「とんでもない思い違いです」…81歳祖母の手紙が教えてくれたこと https://bunshun.jp//articles/-/40826 「おばあちゃんが足立区議の件で怒っていて、手紙を書くらしい」 母からこんなLINEが来たの... 6 6 家系ラーメン“のれん分け戦争”「吉村家vs.六角家」裏切りと屈服の黒歴史〈六角家破産〉 https://bunshun.jp//articles/-/40752 「『六角家』は破産しましたが、ジャンルとしての『家系ラーメン』は、年々店舗数が拡大しており、... 7 7 《平手派また卒業》欅坂46・佐藤詩織が書いた「活動のなかで悲しかったこと」 櫻坂46の“急勾... https://bunshun.jp//articles/-/40862 《皆さんこんばんは。今日はいつも応援して頂いている皆様にお伝えしたいことがあります。私、佐藤... 8 8 安倍政権最大の功績は“アイヌ博物館”だった? 200億円をブチ込んだ「ウポポイ」の虚実 https://bunshun.jp//articles/-/40841 ──本当にあれでいいんだろうか? 帰路、雨の道央道をレンタカーでひた走りながら、そんな思いが... 9 9 「長さ」ではなく…美容師が教える、髪を切るときに言うといい「意外な言葉」 https://bunshun.jp//articles/-/40694 掛け布団がだんだん心地よくなってきた、今日この頃。朝夜の急激な気温差に、薄めの上着を羽織っ... ネガポジの判断基準には「単語感情極性対応表」を使用します。
この「単語感情極性対応表」を分析で使用するための形に整えます。
p_dic = pathlib.Path('/work/dic') # workディレクトリのdicフォルダにパスを通します。ここに「単語感情極性対応表」のファイルを置いています。 for i in p_dic.glob('*.txt'): # 該当のファイルを見つけます。 with open (i, 'r', encoding='utf-8') as f: x = [i.replace('\n', '').split(':') for i in f.readlines()] # 1行ずつ読み込みます。 posi_nega_df = pd.DataFrame(x, columns = ['基本形', '読み', '品詞', 'スコア']) # 読み込んだデータをDataFrameに格納します。 posi_nega_df['読み'] = posi_nega_df['読み'].apply(lambda x : jaconv.hira2kata(x)) # 平仮名をカタカナに変換(同じ読みのものが含まれており、重複を無くす為のようです。) posi_nega_df = posi_nega_df[~posi_nega_df[['基本形', '読み', '品詞']].duplicated()] # 重複を削除します。 posi_nega_df.head()
基本形 読み 品詞 スコア 0 優れる スグレル 動詞 1 1 良い ヨイ 形容詞 0.999995 2 喜ぶ ヨロコブ 動詞 0.999979 3 褒める ホメル 動詞 0.999979 4 めでたい メデタイ 形容詞 0.999645 記事本文を形態素解析して分析に利用できる形にします。
形態素解析には
Tokenizer()とUnicodeNormalizeCharFilter()を利用します。
単語、基本形、品詞、読みを取り出してDataFrameに格納します。
そして、記事のDataFrameと「単語感情極性対応表」をマージして、記事に含まれるワードをスコア化します。
下記にその表を示しています。
「人気」という単語が高いスコアを示していますのでポジティブな単語だと判断されました。
他の単語はなぜそのスコアになったんだ?というものもありますが、気にせず進みましょう。i = 0 # このiはニュースNo.を取得する際に利用します。 t = Tokenizer() char_filters = [UnicodeNormalizeCharFilter()] analyzer = Analyzer(char_filters=char_filters, tokenizer=t) word_lists = [] for i, row in newslist.iterrows(): # iを一つずつ増やしていきニュースNo.とします。 for t in analyzer.analyze(row[3]): # 取り出したレーベルの3カラム目に本文が格納されています。 surf = t.surface # 単語 base = t.base_form # 基本形 pos = t.part_of_speech # 品詞 reading = t.reading # 読み word_lists.append([i, surf, base, pos, reading]) # word_listsに追加 word_df = pd.DataFrame(word_lists, columns=['ニュースNo.', '単語', '基本形', '品詞', '読み']) word_df['品詞'] = word_df['品詞'].apply(lambda x : x.split(',')[0]) # 品詞は複数格納されるが最初の1つのみ利用 display(word_df.head(10)) # 作成した本文のテーブルを表示 print("↓↓↓↓↓↓↓単語感情極性対応表とマージ↓↓↓↓↓↓↓") score_result = pd.merge(word_df, posi_nega_df, on=['基本形', '品詞', '読み'], how='left') # 本文のテーブルと単語感情極性対応表をマージ display(score_result.head(10)) # 作成したスコアテーブルを表示。「人気」という単語のスコアが高いのは分かるが他は微妙、、、
ニュースNo. 単語 基本形 品詞 読み 0 0 ジャ ジャ 名詞 ジャ 1 0 ニーズ ニーズ 名詞 ニーズ 2 0 Jr Jr 名詞 * 3 0 . . 名詞 * 4 0 内 内 名詞 ナイ 5 0 の の 助詞 ノ 6 0 人気 人気 名詞 ニンキ 7 0 ユニット ユニット 名詞 ユニット 8 0 「 「 記号 「 9 0 宇宙 宇宙 名詞 ウチュウ ↓↓↓↓↓↓↓単語感情極性対応表とマージ↓↓↓↓↓↓↓
ニュースNo. 単語 基本形 品詞 読み スコア 0 0 ジャ ジャ 名詞 ジャ NaN 1 0 ニーズ ニーズ 名詞 ニーズ -0.163536 2 0 Jr Jr 名詞 * NaN 3 0 . . 名詞 * NaN 4 0 内 内 名詞 ナイ -0.74522 5 0 の の 助詞 ノ NaN 6 0 人気 人気 名詞 ニンキ 0.96765 7 0 ユニット ユニット 名詞 ユニット -0.155284 8 0 「 「 記号 「 NaN 9 0 宇宙 宇宙 名詞 ウチュウ -0.515475 result = [] for i in range(len(score_result['ニュースNo.'].unique())): # ニュースNo.を利用してfor文を回します。 temp_df = score_result[score_result['ニュースNo.']== i] text = ''.join(list(temp_df['単語'])) # 1タイトル無いの全ての単語をつなげる。 score = temp_df['スコア'].astype(float).sum() # 1タイトル内のスコアを全て足し合わせる。➡︎累計スコア score_r = score/temp_df['スコア'].astype(float).count() # 本文の長さに影響されないように単語数で割り算する。➡︎標準化スコア result.append([i, text, score, score_r]) ranking = pd.DataFrame(result, columns=['ニュースNo.', 'テキスト', '累計スコア', '標準化スコア']).sort_values(by='標準化スコア', ascending=False).reset_index(drop=True) # 標準化スコアで並び替えてDataFrameに格納 ranking = pd.merge(ranking, newslist[['ニュースNo.', 'title', 'url']], on='ニュースNo.', how='left') # ニュースNo.基準でマージする。タイトルとURLを追加する。 ranking = ranking.reindex(columns=['ニュースNo.', 'title', 'url', 'テキスト', '累計スコア', '標準化スコア']) # カラムを並び替え display(ranking)
ニュースNo. title url テキスト 累計スコア 標準化スコア 0 6 家系ラーメン“のれん分け戦争”「吉村家vs.六角家」裏切りと屈服の黒歴史〈六角家破産〉 https://bunshun.jp//articles/-/40752 「『六角家』は破産しましたが、ジャンルとしての『家系ラーメン』は、年々店舗数が拡大しており、... -238.437124 -0.408983 1 1 「駅近、約1,200㎡の広大な敷地」「自宅の建て替えと地域貢献を両立する土地活用」プロが出し... https://bunshun.jp//articles/-/40010 多くの土地オーナーから「土地活用のパートナー」として選ばれ続けている三井ホーム。土地活用のプ... -315.299051 -0.438524 2 7 《平手派また卒業》欅坂46・佐藤詩織が書いた「活動のなかで悲しかったこと」 櫻坂46の“急勾... https://bunshun.jp//articles/-/40862 《皆さんこんばんは。今日はいつも応援して頂いている皆様にお伝えしたいことがあります。私、佐藤... -136.887378 -0.447344 3 5 同性愛差別の足立区議宛てに「とんでもない思い違いです」…81歳祖母の手紙が教えてくれたこと https://bunshun.jp//articles/-/40826 「おばあちゃんが足立区議の件で怒っていて、手紙を書くらしい」 母からこんなLINEが来たの... -213.244051 -0.460570 4 9 「長さ」ではなく…美容師が教える、髪を切るときに言うといい「意外な言葉」 https://bunshun.jp//articles/-/40694 掛け布団がだんだん心地よくなってきた、今日この頃。朝夜の急激な気温差に、薄めの上着を羽織った... -192.702889 -0.475810 5 8 安倍政権最大の功績は“アイヌ博物館”だった? 200億円をブチ込んだ「ウポポイ」の虚実 https://bunshun.jp//articles/-/40841 ──本当にあれでいいんだろうか? 帰路、雨の道央道をレンタカーでひた走りながら、そんな思いが... -483.393151 -0.476719 6 0 ジャニーズ元MADEリーダー・稲葉光(29)が元Berryz工房アイドルと“渋谷ホテルデート... https://bunshun.jp//articles/-/40869 ジャニーズJr.内の人気ユニット「宇宙Six」の山本亮太(30)が違法な闇スロット店に通って... -196.888853 -0.479048 7 3 “縦割り行政”の弊害だ! 橋下徹が語る「Go Toキャンペーンは何が間違っているのか」 https://bunshun.jp//articles/-/40877 「規制改革」「行政改革」「縦割り打破」。 菅義偉政権発足後、「改革」という言葉がよく聞こえて... -94.718989 -0.480807 8 4 警察官に唾吐き公務執行妨害で逮捕 読売新聞がソウル支局記者を懲戒処分 https://bunshun.jp//articles/-/40868 読売新聞ソウル支局の記者(34)が7月中旬、公務執行妨害の容疑で韓国当局に逮捕されていたこと... -144.916148 -0.489582 9 2 「365日24時間働こう」……ワタミの“思想教育”はいまも続いていた https://bunshun.jp//articles/-/40843 ワタミ株式会社の労働問題に関する告発が続いている。10月2日、「ワタミの宅食」営業所の所長が... -321.838102 -0.528470 print("<<ポジティブ1位>>", end="\n\n") for i in range(1, 4): print(ranking.iloc[0, i])<<ポジティブ1位>> 家系ラーメン“のれん分け戦争”「吉村家vs.六角家」裏切りと屈服の黒歴史〈六角家破産〉 https://bunshun.jp//articles/-/40752 「『六角家』は破産しましたが、ジャンルとしての『家系ラーメン』は、年々店舗数が拡大しており、今が最盛期です。その背景には“資本系”の台頭があります。でもね、確かに資本系も美味しいんですが、かつて『六角家』や『吉村家』の職人たちが日々、味の改良に挑み、切磋琢磨して、互いに覇を競っていたあの時代が、倒産のニュースを聞いた今、妙に懐かしく輝いて見えるんです」(ラーメン評論家・山本剛志氏)(前編「家系ラーメン・名門『六角家』はなぜ破産したか」を読む) 2020年9月4日、かつて家系ラーメンの「代名詞」とまで呼ばれ、一世を風靡した老舗の名店「六角家」が、横浜地裁より破産手続き開始決定を受けていると報じられた。2017年に「六角家」の本店が閉じられ、倒産は時間の問題だったとみるファンも多かったが、いざこのニュースが流れると「マジか」「もう一度食べたかった」など、その倒産を惜しむ声がネット上などで多く上がった。そして、冒頭の山本氏のように、「六角家」がこれまで「家系ラーメン」業界の隆盛にはたした役割について、再評価する声も上がってきている。「そもそも、家系ラーメンが誕生したのは1974年。長距離トラックの運転手だった吉村実氏が仕事の合間に趣味で密かに研究を重ねていた九州の豚骨ベースと東京の醤油ベースを組み合わせたスープを開発したことに端を発しています。この味ならいける! と判断した吉村氏はその後会社を辞め、『吉村家』というラーメン店を横浜の磯子区新杉田に開店。豚骨醤油ベースの風味豊かなスープと、モッチリとした『酒井製麺』の太麺を合わせた1杯は、本人の読みどおり大きな人気を集め、店は日々、大勢のお客さんで賑わいました。 評判を集めた「吉村家」には、多くの才能が集まりました。そして、吉村氏の元で修業をした弟子たちは、吉村氏直々に教わり技術を身に着けると“暖簾分け”という形で自分の店を持つようになり、弟子たちの店もそれぞれのエリアで大人気店となりました。独立した弟子たちが店名に『~家』とつけることが多かったため、ファンの間で、『吉村家』とそこから独立した店は『家系』と呼ばれるようになりました。現在は、“家系皆伝”という証書を吉村氏からもらった店舗のみが吉村家の“直系店舗”として認められています」(ラーメン探究家・田中一明氏) 直系店舗にはいくつか特徴がある。まずは、麺は、酒井製麺所という製麺所から卸している麺でなければならない。『家系といえば酒井製麺』と言われるほどその結びつきは固く、酒井製麺の麺は中太でモチモチした独特の食感があるという。また、麺は寸胴で茹で、テボザルではなく平ザルですくい上げるのも特徴だ。 その直系店鋪以外で、酒井製麺所の麺を使っていたのが今回倒産した「六角家」と、「本牧家」だった。「『六角家』は、吉村氏の一番弟子である神藤隆氏が独立して横浜市神奈川区六角橋で始めた店です。一時は本家『吉村家』や吉村氏が横浜市中区に出したのれん分け1号店である『本牧家』とともに家系御三家と言われたほどの超有名店です。ただ、『六角家』は吉村氏の一番弟子が始めた店にもかかわらず、開店当初から今日まで、一度も吉村氏から吉村家の“直系店舗”として認められたことはありません。『吉村家』と『六角家』はずっとぎくしゃくした関係が続いていたのです」(食ジャーナリスト・小林孝充氏) 一体なぜなのか。ラーメン探究家の田中一明氏が解説する。「吉村氏は1974年に横浜市磯子区新杉田に『吉村家』1号店を開いた後、12年間は支店をつくりませんでしたが、1986年満を持して横浜市中区本牧に2号店である『本牧家』をオープンさせました。この店を弟子の神藤隆氏に任せ、吉村氏はオーナーとして、いよいよ店舗の拡大へと乗り出したかのように見えました。ところがその2年後、店主の神藤氏が従業員を引き連れ、本牧家を出て行ってしまったのです。さらにその後、神藤氏は神奈川区六角橋に自ら『六角家』を開店しました。一方、神藤氏という主を失った『本牧家』は一時期休業を余儀なくされてしまったのです。 なぜ神藤氏は独立したのかについては、当時様々な憶測が飛び交いましたが、私は目指す味の方向性が違っていたことが大きな理由だと思っています。『吉村家』が醤油ダレをガツンと効かせたパンチのあるタイプであるのに対し、『六角家』は豚骨と醤油ダレをバランス良く効かせた食べ手を選ばないタイプであるのが特徴。神藤さんは自ら信じる味を追求したかったということではないでしょうか」 「吉村家」と袂を分かって誕生した「六角家」は、独自路線で成長していった。「六角家」の転機になったのは1994年、新横浜駅近くに誕生した「新横浜ラーメン博物館」に横浜代表として出店したことだった。これにより、全国的な知名度を得た「六角家」は本家の「吉村家」や、吉村氏とは別の経営者を迎えた「本牧家」とともに「家系御三家」とファンの間で呼ばれるようになる。この三店は、次々弟子をとり、彼らを独立させることで、直系店を増やしていった。今でも、この時期の御三家による「争い」はファンの間で語り草となっている。 特に有名なのは、94年に起きた「環2ラーメン戦争」だろう。事の発端は94年、「本牧家」が環状2号線に面した土地に移転したことに始まる。移転から1年も経たずして、「本牧家」の店舗からわずか徒歩1分の位置に、吉村「吉村家」の直系店舗「環2家」がオープンしたのだ。「ちょうどこの頃は横浜各地に吉村家の直系店舗が広がり始めた時期。環状2号線はもともとロードサイドのラーメン激戦区でしたから、偶然、出店が近くになってしまうことはありうる。しかし、『本牧家』と『環2家』はそれにしても近すぎる距離でした。家系ファンの間では『吉村家が直弟子を使って、本牧家をつぶしにきた』と囁かれることもありました」(前出・山本氏) しかし、この戦争は「本牧家」と「環2家」両方が客を離さぬために、職人たちが味の改良を進めたという側面もある。「環2ラーメン戦争」の決着はいまだについておらず、今も両店は行列の絶えない人気店であり、徒歩1分の距離で互いに火花を散らしている。 2000年代初頭になって、吉村家は「杉田家」(横浜市磯子区)、「はじめ家」(富山県魚津市)、「王道家」(千葉県柏市)、「横横家」(横浜市金沢区)などの直系店舗を次々と増やしていった。「『六角家』の多店舗展開や、『吉村家』で修業した人たちの独立開業によって、家系ラーメンの認知度は上がっていきました。1990年代に入ると、『吉村家』や『六角家』の出身者が出した店で修業し、独立開業する者が目立つようになりました。『吉村家』、『六角家』からすれば、孫、曾孫にあたる店になりますね。やがて、家系ラーメンを出す店舗は、発祥の地である横浜を飛び出し、全国各地に広がっていきました。大手飲食企業が、家系ラーメンの人気に商機を見出したのもこの頃だと思います。2010年代に入ると、いよいよ、それらの企業が業界に本格参入してきます。これらの大手飲食企業が各店舗で提供するラーメンが、いわゆる“資本系”と呼ばれるものです」(前出・田中氏) 資本系が徐々に勢力を伸ばす一方、職人たちの技に支えられる「家系御三家」の系列のラーメン店同士でも、競争が激化していった。その最たるものは2013年に起きた「三つ巴の乱戦」(山本氏)である。「『吉村家』の直系店『末廣家』と『六角家』がある県道12号沿いに、元は『吉村家』直系店だった『王道家』の系列である『とらきち家』が開店したのです。『とらきち家』と『六角家』はわずか2軒隣りの距離。ラーメン店の激戦区として知られている地域ですが、『環2ラーメン戦争』を知っている人たちからしたら、またかと思わざるを得ない出来事でした。 もう家系ファンたちは沸き上がりましてね。そもそも『末廣家』が2012年に開店したときに『吉村家がとうとう六角家を潰しに来た』と話題になったのに、その翌年には王道家の系列店がすぐそばに建ったわけです。『吉村家と王道家がタッグを組んで六角家を標的にしたのか』という憶測まで飛び交ったほどです」(同前) しかし、この「三つ巴の乱戦」は4年後に「六角家」の店主である神藤氏が体調不良で店に出ることが困難になり、同店を閉めたことで唐突に決着がついた。「もともと『吉村家』という元祖から派生していった『家系』には、細かな系図があります。あの店は『吉村家』の直系、こっちは『六角家』系列と、ファンは味とともに、“出自”もすごく気にしていました。お店側も、職人のプライドを持って、俺たちの『家系』を見せてやるという気概に溢れて、日々味の改良に明け暮れていた。たしかに『戦争』と呼ばれるほど、競争が激化した地域もありましたけど、それもまた味の新陳代謝を生むプラスの側面があった。あれは家系が進化するための『スパイス』になった部分があるんです」(同前) かつては「家系」の代名詞ともなり、「吉村家」らと“頂上決戦”を行った「六角家」本店の跡地は雑草が伸び放題の空き地になっている。一方の吉村家は、現在は家系総本山だと看板に掲げており、その勢いはますます盛んだ。開店から50年近く経つ現在も長蛇の列ができる人気店である。 ラーメン職人たちの戦いと資本系の台頭。「六角家」の倒産は、家系ラーメンの一つの時代の終焉を意味しているのである。(前編「家系ラーメン・名門『六角家』はなぜ破産したか」を読む)この記事の写真(14枚)print("<<ネガティブ1位>>", end="\n\n") for i in range(1, 4): print(ranking.iloc[-1, i])<<ネガティブ1位>> 「365日24時間働こう」……ワタミの“思想教育”はいまも続いていた https://bunshun.jp//articles/-/40843 ワタミ株式会社の労働問題に関する告発が続いている。10月2日、「ワタミの宅食」営業所の所長が、労働基準監督署からの残業代未払いの是正勧告、月175時間を超える長時間労働、上司によるタイムカードの改ざんを次々と公表したのだ。「ホワイト企業」宣伝のワタミで月175時間の残業 残業代未払いで労基署から是正勧告ワタミがホワイト企業になれなかった理由は? 勝手に勤怠「改ざん」システムも Aさんは長時間労働の末、昼夜の感覚がなくなり、「このまま寝たら、もう目が覚めないのではないか」と恐怖を抱きながら生活するほどだった。「あのまま働いていたら、死んでいた」とAさんは断言する。現在は、精神疾患を発症し、労災申請をしながら休業中だ。 しかし、Aさんは命の危険を感じていながら、なぜ過酷な仕事を続けてしまったのだろうか。その背景には、労働者の意識に働きかけ、過酷な労働を受け入れさせてしまう、ワタミによる「思想教育」のシステムがあった。「こんなにいい仕事をしているんだから、苦しくても頑張ろう」「苦しいことも、苦しくない。むしろ自分の力になる」 Aさんは過重労働の最中、そう自分に言い聞かせていた。 実際、Aさんはワタミの宅食の仕事に「誇り」を感じていたという。確かにワタミの「宅食」に「社会貢献」と言える部分がある。ワタミの宅食には、食事の調達が難しい高齢者に、定期的に安く食事を届けるというコンセプトがある。Aさんの営業所の届け先も、そうした人たちばかりだった。 隔日でデイサービスに通い、隔日で家にいるときの食事に困る一人暮らしの高齢者。毎日昼食用と夕食用の2食を頼んで、ワタミの宅食しか食べていない高齢者、障がい者や、親を介護している人......。 苦しい生活の事情によって、食事に手間や時間、お金をかけられず、ワタミに頼らざるを得ない様々な利用者がいた。それまで介護や教育現場で働いてきたAさんにとって、社会や地域のためになる宅食の仕事は、非常にやりがいの感じられるものだった。 だがそれらの「支援」を通じて無理やり利益をあげようとすれば、長時間労働や低賃金による労働者の犠牲によって支えられることになってしまう。いわば「貧困・ブラック企業ビジネス」とでもいえようか。 Aさんも当初、仕事のやりがいと過酷な労働とは分けるべきものだと冷静に考え、業務のつらさについてはワタミに不満を抱いていた。 しかし、劣悪な労働条件は、Aさんの頭の中ではいつしか問題とはならなくなっていた。その変化をもたらしたのが、ワタミによる「思想教育」だったと、Aさんは振り返っている。「365日24時間、死ぬまで働け」 この言葉をご存知の方も多いだろう。渡邉美樹氏の過去の30年以上に渡る文章を抜粋して編集した400ページにも及ぶ「理念集」という書物に記載されていた言葉である。Aさんは入社直後に会社から「理念集」を渡され、肌身離さず持っているよう言われた。 現在は批判を受けて、「死ぬまで働け」などの極端な表現は削除されている。それでもAさんが手渡された「理念集」(2016年度版)に削除されずに残っていた、印象的な表現の一部を引用しよう。〈私は、仕事はお金を得る為だけの手段とは考えていません。仕事とはその人の「生き方」そのものであり、「自己実現の唯一の手段」であると信じています。だから新卒のセミナーでも、時代遅れはなはだしいと言われつつ、「365日24時間働こう」と言うのです〉〈私も会社説明会で、「仕事とは生きることそのものなんだ。仕事を、お金を得るための手段なんかにしてはいけないんだ。仕事を通して人間性を高めよう」と訴えています〉〈ワタミタクショクの最大の商品は「人」と知れ。まごころさん(注:宅食の配達員)とは、お弁当に「心」を乗せて運び、「ありがとう」をいただく仕事をする人のこと。考え違いをして「お弁当」を運び「お金」をいただく仕事と思う人が出てこないことを祈る〉 このように、同書には、客からの「ありがとう」という感謝のために働くことを奨励して、賃金のために働くことを批判し、ワタミの利益のために自分を犠牲にすることを正当化する内容が、随所に記されていた。 ワタミに入社したAさんは、何かトラブルがあると、支社長から「理念集の第×章をちゃんと読んだ?」と問われ、渡邉美樹氏の「思想」を十分に理解していないせいだと注意されていた。 さらに、エリアマネージャーによる毎月のカウンセリングがあり、そこでは当月の「社内報」(毎月発行され、理念集の文章の多くがここからの抜粋である)の感想と、理念集の任意の箇所の感想を書かされるようになっていた。 加えて、4ヶ月に1回のレポートが課せられた。理念集から指定された章の範囲と、直近4ヶ月分の社内報に掲載される渡邉氏直筆の言葉に対する二つの感想が強制されていた。 Aさんはもともと、これらの感想文提出を「気持ち悪い」と感じていた。しかし、嫌々ながら、継続的に書かされているうちに「どこかで渡邉美樹さんの考えを植え付けられていく感じがあった」という。 それをさらに深化させたのが、「ビデオレター」の存在だった。 毎月、営業所には渡邉美樹氏が出演する「ビデオレター」が提供された。人気テレビ番組「情熱大陸」のナレーターが起用され、渡邉美樹氏が毎回出演し、ワタミの事業の素晴らしさを説く30分間の映像である。 この映像についても、毎月の感想が義務付けられていた。しかも書くのは所長だけではない。個人事業主であるはずの配達員までも、毎月ビデオレターを視聴して感想を書くことが契約に盛り込まれていた。 配達員たちは、営業所でこの映像を見せられると、所長と配達員の名前が羅列されたシートの自分の感想欄(60字ほどは書けるスペースがある)に、手書きで感想を書かされる。なお、配達員は配達先1軒あたりの報酬が百数十円しかないが、この映像視聴や感想を書くことによる新たな報酬は一切ない。 さらに配達員の感想に、ワタミに対する批判や仕事への不満などがある場合は、所長がその箇所に印をして、コメントを書き加えるようにと指示されていた。Aさんは独自の工夫として、すべての配達員の感想に対して、その配達員の感想を超えるほどの字数で、丁寧にコメントをするようにした。 そして、この「コメント」こそが、Aさんの「思想形成」に大きな役割を果たしていたという。 Aさんは、上司のエリアマネージャーから、「配達員たちに、ワタミを称賛するような感想を書くよう“もっていく”ことも所長の仕事だ」と言われていた。配達員の感想を「コントロール」するようにというのだ。 とはいえ、Aさんは配達員の感想の「改ざん」をしたわけではない。まず、Aさんは所長として、配達員に先立って自分の感想欄で、ワタミの事業やワタミで働くことの素晴らしさを説いた。すると、後から書く配達員たちは、おのずと所長の「模範解答」を意識して、否定的な感想を書きづらくなる。 それでも配達員の感想に、ワタミに疑問を呈するような箇所でもあれば、コメント欄でそこを指摘し、「意義を改めて私と共有しましょう」などと食い下がった。やがて、数ヶ月をかけて配達員たちのコメントから否定的な文章は消え、少なくとも表向きは、ワタミを褒め称える感想一色になっていった。 ワタミの素晴らしさをひたすら繰り返す、この毎月のコメントは「思想形成」に着実に影響をもたらした。ただし、本当に変わったのは、配達員ではなく、所長であるAさんの方だったのである。 ワタミに対する「称賛」を業務の必要上、あえて続けていたはずのAさんは、徐々にワタミの事業や労働を無条件に賛美し、労働問題の不満を感じなくなる意識が本当に芽生えてきたという。配達員の感想を何度も指導するという行為を通じて、Aさん自身の意識こそが「教育」されてしまったのだ。 ここで、Aさんが配達員に見せるために書いた、ビデオレターの感想文を引用してみよう。ワタミのSDGsの取り組みや、ワタミが行っているカンボジアの学校支援の取り組みの映像をみた感想だ。〈SDGsという言葉が社会に広く知れわたる前からワタミは取り組みを継続してきました。私はそのような会社で仕事させていただき、本当に感謝致します。自分のすぐ近くにも、社会の役に立つことができることは多くあります。いつも勇気と誇りを胸に笑顔を持って努めて参ります〉〈自分もキラキラした笑顔、そしてまごころさんがキラキラした笑顔でいられる様、前進していきます〉〈ここ(注:Aさんの営業所)を輝かせることこそ私の仕事です。精一杯、努めて参ります!!〉 ワタミの事業に対する絶賛と、ワタミで働かせてもらっていることの感謝。スペースをはみ出るほどの分量と、異様なほどに高揚した表現。当時のAさんが本当にワタミを「信奉」する気持ちがなければ、ここまで書くことは難しいだろう。 現在、精神疾患で休業中のAさんは、この自分の感想文を改めて見返し、こう呟いた。「気持ち悪いですね、いま読むと」 月の残業時間が150時間を超えたころ、Aさんは長時間労働について「私が悪い」と思い詰めていた。多すぎる業務量はワタミの責任なのに、そこは「思想教育」のために受け入れてしまい、むしろ仕事が遅いせいだと自分を責めるようになっていたのだ。 そんなとき、新しく入った配達員の一人が、深夜まで働くAさんを見て心配し、単刀直入に指摘してくれた。「Aさん、『洗脳』されてるんじゃないの?」 当初、「失礼な人だ」と憤ったが、何度もこの配達員が親身になって指摘してくれるうちに、「私、おかしいのかも」と思い始めるようになっていた。 また、単身赴任中だった配偶者が、コロナ禍によってテレワークで自宅勤務をするようになっていた影響も大きかった。Aさんが深夜や休日も延々と働く姿を見て、目を覚ますよう何度も説得したという。 最後に、Aさんは筆者が代表を務めるNPO法人POSSE、そして個人加盟の労働組合のブラック企業ユニオンに辿り着き、ワタミの労働問題を大々的に告発することを決意した。こうして、周囲の人たちに恵まれ、支援者に出会えたことで、Aさんはワタミの「洗脳」を脱し、これまでの労働問題を直視できるようになったのだ。 Aさんはいま、自分がワタミの労働問題に加担したのではという自責の念を抱いている。「ひとつ間違えば、私も上司と同じことをやったと思います」。自分の責任を果たすべく、これからもAさんは、ワタミの告発を続けていくつもりだという。この記事の写真(8枚)最もポジティブな記事と最もネガティブな記事を表示させてみました。
なんとなく正しく評価できている気がしますね!説明は以上です。読んでいただいてありがとうございます。
- 投稿日:2020-10-15T22:12:43+09:00
文春オンラインの記事をスクレイピング&ネガポジ分析
スクレイピングとは
スクレイピングを利用することでネット上の様々な情報を取得することができます。
今回はPythonのコードを利用して記事を取得しています。
BeautifulSoupなどを利用して、HTMLやCSSの情報を指定して情報を抽出します。ネガポジ分析について
記事の内容がネガティブなのかポジティブなのかを単語感情極性対応表を基準にして数値化してみようと思います。
単語感情極性対応表は単語に対してネガポジ度を-1〜1で定義してあります。喜び:よろこび:名詞:0.998861
厳しい:きびしい:形容詞:-0.999755などです。
参考文献
スクレイピングはudemy講座を利用しました。
ネガポジ分析はこちらの記事を参考にさせていただきました。
また、今回分析対象としたのは文春オンラインです。では作業に取り掛かりましょう。
まずは必要なライブラリをインポートします。import requests from bs4 import BeautifulSoup import re import itertools import pandas as pd, numpy as np import os import glob import pathlib import re import janome import jaconv from janome.tokenizer import Tokenizer from janome.analyzer import Analyzer from janome.charfilter import *まずはスクレイピングの準備です。
URLを取得して
requestsとBeautifulSoupを適用します。url = "https://bunshun.jp/" # urlに文春オンラインのリンクを格納 res = requests.get(url) # requests.get()を用いてurlをresに格納 soup = BeautifulSoup(res.text, "html.parser") # ここでBeautifulSoupを用いてスクレイピングの準備ができました。記事一覧を取得して、タイトルとURLを取得
基本的には記事が
li要素として並んでおり、その親要素はulであるというパターンが多いです。
for文を使って記事一覧からタイトルとURLを取得しています。elems = soup.select("ul") # 記事のリストがli要素として並んでいたので、その親要素であるulを指定しています。 title_list = [] # 記事のタイトルを格納するリスト url_list = [] # 記事のURLを格納するリスト for sibling in elems[3]: # elems[3]に欲しいリストがありました。このfor分により記事のリストから記事のタイトルとURLを取得し、それぞれリストに格納します。 if sibling != "\n": # 改行が含まれていたので除外 print(sibling.h3.string) # タイトルはh3タグに入っていました。 title_list.append(sibling.h3.string.replace('\u3000', ' ')) # \u3000が入っている部分があったので空白に変換 print(url + sibling.h3.a["href"]) # aタグのhref属性にリンクが格納されていました。 url_list.append(url + sibling.h3.a["href"]) # 上記で取得したurl以下の部分が格納されていたので足しています。ジャニーズ元MADEリーダー・稲葉光(29)が元Berryz工房アイドルと“渋谷ホテルデート”《スクープ撮》 https://bunshun.jp//articles/-/40869 「駅近、約1,200㎡の広大な敷地」「自宅の建て替えと地域貢献を両立する土地活用」プロが出した答えとは? https://bunshun.jp//articles/-/40010 「365日24時間働こう」……ワタミの“思想教育”はいまも続いていた https://bunshun.jp//articles/-/40843 “縦割り行政”の弊害だ! 橋下徹が語る「Go Toキャンペーンは何が間違っているのか」 https://bunshun.jp//articles/-/40877 警察官に唾吐き公務執行妨害で逮捕 読売新聞がソウル支局記者を懲戒処分 https://bunshun.jp//articles/-/40868 同性愛差別の足立区議宛てに「とんでもない思い違いです」…81歳祖母の手紙が教えてくれたこと https://bunshun.jp//articles/-/40826 家系ラーメン“のれん分け戦争”「吉村家vs.六角家」裏切りと屈服の黒歴史〈六角家破産〉 https://bunshun.jp//articles/-/40752 《平手派また卒業》欅坂46・佐藤詩織が書いた「活動のなかで悲しかったこと」 櫻坂46の“急勾配”を運営も懸念 https://bunshun.jp//articles/-/40862 安倍政権最大の功績は“アイヌ博物館”だった? 200億円をブチ込んだ「ウポポイ」の虚実 https://bunshun.jp//articles/-/40841 「長さ」ではなく…美容師が教える、髪を切るときに言うといい「意外な言葉」 https://bunshun.jp//articles/-/40694記事は1ページでは終わらない場合があります。1ページずつ遷移してリンクを取得します。
リンク一覧を作成するために、while文を作って次のページが表示されていればそのURLを取得してページに遷移し、遷移したページにも次のページへのリンクがあれば取得して遷移するというループを回します。
こうすることにより、1タイトルのニュースに関する全てのページに関するリンク一覧を作成できます。news_list = [] # 全てのニュース記事のリンクをここに格納します。 for pickup_link in url_list: # このfor文でURLリストからURLを取り出します。 news = [] # ニュース記事はページごとに分かれているため、このリストに各ページのリンクを格納します。 news.append(pickup_link) # 最初のリンクを格納 pickup_res = requests.get(pickup_link) # requests.get()を用いてリンクからページを取得 pickup_soup = BeautifulSoup(pickup_res.text, "html.parser") # BeautifulSoupを適用 while True: # このwhile文では次のページへのリンクがあればそのリンクを取得し、そのページへ遷移するというループを回します。 try: # 遷移した先で次のページへのリンクがあれば永遠にこのループを繰り返します。 next_link = pickup_soup.find("a", class_="next menu-link ga_tracking")["href"] # next menu-link ga_trackingというクラスを持つaタグのhref属性が次のページへのリンクでした。 next_link = url + next_link next_res = requests.get(next_link) # requests.get()とBeautifulSoupを用いて遷移先のページ情報を取得します。 pickup_soup = BeautifulSoup(next_res.text, "html.parser") news.append(next_link) # newsに各ページ情報を追加します。 except Exception: # 次のページへのリンクが無ければここの処理が行われます。 news_list.append(news) # タイトル内の全ての記事をURLがnewsに格納されたのでそれをnews_listに格納します。 break display(news_list) # 作成したURLリストを表示します。[['https://bunshun.jp//articles/-/40869', 'https://bunshun.jp//articles/-/40869?page=2', 'https://bunshun.jp//articles/-/40869?page=3', 'https://bunshun.jp//articles/-/40869?page=4'], ['https://bunshun.jp//articles/-/40010', 'https://bunshun.jp//articles/-/40010?page=2'], ['https://bunshun.jp//articles/-/40843', 'https://bunshun.jp//articles/-/40843?page=2', 'https://bunshun.jp//articles/-/40843?page=3', 'https://bunshun.jp//articles/-/40843?page=4'], ['https://bunshun.jp//articles/-/40877', 'https://bunshun.jp//articles/-/40877?page=2'], ['https://bunshun.jp//articles/-/40868', 'https://bunshun.jp//articles/-/40868?page=2'], ['https://bunshun.jp//articles/-/40826', 'https://bunshun.jp//articles/-/40826?page=2', 'https://bunshun.jp//articles/-/40826?page=3', 'https://bunshun.jp//articles/-/40826?page=4'], ['https://bunshun.jp//articles/-/40752', 'https://bunshun.jp//articles/-/40752?page=2', 'https://bunshun.jp//articles/-/40752?page=3', 'https://bunshun.jp//articles/-/40752?page=4'], ['https://bunshun.jp//articles/-/40862', 'https://bunshun.jp//articles/-/40862?page=2', 'https://bunshun.jp//articles/-/40862?page=3'], ['https://bunshun.jp//articles/-/40841', 'https://bunshun.jp//articles/-/40841?page=2', 'https://bunshun.jp//articles/-/40841?page=3', 'https://bunshun.jp//articles/-/40841?page=4', 'https://bunshun.jp//articles/-/40841?page=5'], ['https://bunshun.jp//articles/-/40694', 'https://bunshun.jp//articles/-/40694?page=2', 'https://bunshun.jp//articles/-/40694?page=3', 'https://bunshun.jp//articles/-/40694?page=4']]先ほどのコードでURLリストを作成できたので、そのリンクを辿って記事本文を取得していきます。
.textを適用することで本文のみを取得できるのですが、細かくfor文を回して.textを適用しています。
そのためいくつかの空文字(or空リスト)を作成して格納しながら本文を格納したリストを作成していきました。news_page_list = [] # ここに全ての記事の本文を格納します。 for news_links in news_list: # このfor文でURLのリストからあるタイトルのリンクリストを取り出します。 news_page = '' # ここに各ページから取得した本文を追加していきます。 for news_link in news_links: # タイトルのリンクリストからリンクを一つずつ取り出します。 news_res = requests.get(news_link) # requests.get()とBeautifulSoupを利用して記事の情報を取得します。 news_soup = BeautifulSoup(news_res.text, "html.parser") news_soup = news_soup.find(class_=re.compile("article-body")).find_all("p") # article-bodyというidを持つタグの直下のpタグに本文が格納されていました。 news_phrase = '' # そのページの本文のフレーズを格納 for news in news_soup: # for文で回すことでtextを適用して本文フレーズのみを取得できました。 news_phrase += news.text.replace('\u3000', ' ') # 取得したフレーズを追加。文字列なので+で追加できました。 news_page += news_phrase # 1ページ分のフレーズが取得できらたらnew_pageに追加 news_page_list.append(news_page) # 一つのタイトルに対する全ての本文がnew_pageに格納されたらnews_page_listに追加。これはリスト型なのでappendを使用。for i in range(1, 4): # 取得した本文の一部を表示してみます。うまく取得できたようです。 print("<%s>" % i, news_page_list[i][:500], end="\n\n")<1> 多くの土地オーナーから「土地活用のパートナー」として選ばれ続けている三井ホーム。土地活用のプロフェッショナルである同社営業担当者へのインタビューを通じ、三井ホームがパートナーとして選ばれる理由をひも解く本企画。今回は、東京都府中市にある約1,200㎡にも及ぶ広大な自宅敷地を、医院+賃貸住宅+自宅と保育所の計2棟に建て替えた事例を紹介する。本件を担当した東京コンサルティング営業部 東京西エリア 営業グループ長の西嶋俊人氏に話を聞いた。 都心から西に延びる京王線の最寄駅から徒歩約5分の場所に、戦前から続く大地主の自宅があった。敷地面積は約1,200㎡。築約50年の自宅は老朽化が進み、建て替えを検討する必要があった。 70代のオーナーさまは、この地に代々続く地主のご一族で、自宅周辺にも複数の賃貸マンションを所有されている方です。老朽化した築約50年の自宅などの建て替えを機に、約1,200㎡にも及ぶ広大な敷地を有効活用しようというのが今回のプロジェクトの発端です。 銀行から弊社に相談が持ち込まれたのが2018年初め。まず自宅+賃貸住宅というプランを持ってオーナーさまにお会いしました。するとオー <2> ワタミ株式会社の労働問題に関する告発が続いている。10月2日、「ワタミの宅食」営業所の所長が、労働基準監督署からの残業代未払いの是正勧告、月175時間を超える長時間労働、上司によるタイムカードの改ざんを次々と公表したのだ。「ホワイト企業」宣伝のワタミで月175時間の残業 残業代未払いで労基署から是正勧告ワタミがホワイト企業になれなかった理由は? 勝手に勤怠「改ざん」システムも Aさんは長時間労働の末、昼夜の感覚がなくなり、「このまま寝たら、もう目が覚めないのではないか」と恐怖を抱きながら生活するほどだった。「あのまま働いていたら、死んでいた」とAさんは断言する。現在は、精神疾患を発症し、労災申請をしながら休業中だ。 しかし、Aさんは命の危険を感じていながら、なぜ過酷な仕事を続けてしまったのだろうか。その背景には、労働者の意識に働きかけ、過酷な労働を受け入れさせてしまう、ワタミによる「思想教育」のシステムがあった。「こんなにいい仕事をしているんだから、苦しくても頑張ろう」「苦しいことも、苦しくない。むしろ自分の力になる」 Aさんは過重労働の最中、そう自分に言い聞かせていた。 実際、Aさ <3> 「規制改革」「行政改革」「縦割り打破」。 菅義偉政権発足後、「改革」という言葉がよく聞こえてくるようになった。菅首相は9月16日の就任記者会見でも「規制改革を政権のど真ん中に置く」と宣言している。この「改革」によって、日本はどのように変わるのだろうか――。 菅首相と親交の深い橋下徹氏が、「文藝春秋」11月号のインタビューで菅政権の「改革」が目指すところを語った。 橋下氏は自身の経験から、「改革」を進めていくためには「おかしい」と言える感覚を持つことが重要だと語る。「“改革力”というのは、常に身の回りのことにアンテナを張って、『これはおかしい』と感じたら、すぐに口に出すことがものすごく重要です。そうしてその都度直していく。その繰り返しです。 僕が知事・市長だった時も、そのような作業の連続でした。 例えば、公用車に乗ったらマガジンラックに新聞5紙がバサッと差し込まれているんですよ。庁舎に着くまでにニュースをチェックできるからいいんですけど、知事室に入ったら机の上に5紙が、知事応接室に行ったらまた5紙……。『公用車の新聞をそのまま知事室に持っていけばいいじゃないか』『どうなってるんや、この新スクレイピングによって得た、今までの情報を一つのDataFrameに格納します。
こうすることでデータが見やすくなるだけでなく、扱いやすくなります。
ここまでできればあとはデータを加工してネガポジ分析をするだけです!new_no_list = [x for x in range(len(title_list))] # あとで使うのでニュースNo.を作成 newslist = np.array([new_no_list, title_list, url_list, news_page_list]).T # DataFrameに格納する準備として、np.arrayのリストに格納して転置しておく。 newslist = pd.DataFrame(newslist, columns=['ニュースNo.', 'title', 'url', 'news_page_list']) # カラム名を指定してDataFrameに格納 newslist = newslist.astype({'ニュースNo.':'int64'}) # あとでテーブルを結合するためにニュースNo.をint64型に変換 display(newslist)
ニュースNo. title url news_page_list 0 0 ジャニーズ元MADEリーダー・稲葉光(29)が元Berryz工房アイドルと“渋谷ホテルデート... https://bunshun.jp//articles/-/40869 ジャニーズJr.内の人気ユニット「宇宙Six」の山本亮太(30)が違法な闇スロット店に通っ... 1 1 「駅近、約1,200㎡の広大な敷地」「自宅の建て替えと地域貢献を両立する土地活用」プロが出し... https://bunshun.jp//articles/-/40010 多くの土地オーナーから「土地活用のパートナー」として選ばれ続けている三井ホーム。土地活用のプ... 2 2 「365日24時間働こう」……ワタミの“思想教育”はいまも続いていた https://bunshun.jp//articles/-/40843 ワタミ株式会社の労働問題に関する告発が続いている。10月2日、「ワタミの宅食」営業所の所長... 3 3 “縦割り行政”の弊害だ! 橋下徹が語る「Go Toキャンペーンは何が間違っているのか」 https://bunshun.jp//articles/-/40877 「規制改革」「行政改革」「縦割り打破」。 菅義偉政権発足後、「改革」という言葉がよく聞こえて... 4 4 警察官に唾吐き公務執行妨害で逮捕 読売新聞がソウル支局記者を懲戒処分 https://bunshun.jp//articles/-/40868 読売新聞ソウル支局の記者(34)が7月中旬、公務執行妨害の容疑で韓国当局に逮捕されていたこ... 5 5 同性愛差別の足立区議宛てに「とんでもない思い違いです」…81歳祖母の手紙が教えてくれたこと https://bunshun.jp//articles/-/40826 「おばあちゃんが足立区議の件で怒っていて、手紙を書くらしい」 母からこんなLINEが来たの... 6 6 家系ラーメン“のれん分け戦争”「吉村家vs.六角家」裏切りと屈服の黒歴史〈六角家破産〉 https://bunshun.jp//articles/-/40752 「『六角家』は破産しましたが、ジャンルとしての『家系ラーメン』は、年々店舗数が拡大しており、... 7 7 《平手派また卒業》欅坂46・佐藤詩織が書いた「活動のなかで悲しかったこと」 櫻坂46の“急勾... https://bunshun.jp//articles/-/40862 《皆さんこんばんは。今日はいつも応援して頂いている皆様にお伝えしたいことがあります。私、佐藤... 8 8 安倍政権最大の功績は“アイヌ博物館”だった? 200億円をブチ込んだ「ウポポイ」の虚実 https://bunshun.jp//articles/-/40841 ──本当にあれでいいんだろうか? 帰路、雨の道央道をレンタカーでひた走りながら、そんな思いが... 9 9 「長さ」ではなく…美容師が教える、髪を切るときに言うといい「意外な言葉」 https://bunshun.jp//articles/-/40694 掛け布団がだんだん心地よくなってきた、今日この頃。朝夜の急激な気温差に、薄めの上着を羽織っ... ネガポジの判断基準には「単語感情極性対応表」を使用します。
この「単語感情極性対応表」を分析で使用するための形に整えます。
p_dic = pathlib.Path('/work/dic') # workディレクトリのdicフォルダにパスを通します。ここに「単語感情極性対応表」のファイルを置いています。 for i in p_dic.glob('*.txt'): # 該当のファイルを見つけます。 with open (i, 'r', encoding='utf-8') as f: x = [i.replace('\n', '').split(':') for i in f.readlines()] # 1行ずつ読み込みます。 posi_nega_df = pd.DataFrame(x, columns = ['基本形', '読み', '品詞', 'スコア']) # 読み込んだデータをDataFrameに格納します。 posi_nega_df['読み'] = posi_nega_df['読み'].apply(lambda x : jaconv.hira2kata(x)) # 平仮名をカタカナに変換(同じ読みのものが含まれており、重複を無くす為のようです。) posi_nega_df = posi_nega_df[~posi_nega_df[['基本形', '読み', '品詞']].duplicated()] # 重複を削除します。 posi_nega_df.head()
基本形 読み 品詞 スコア 0 優れる スグレル 動詞 1 1 良い ヨイ 形容詞 0.999995 2 喜ぶ ヨロコブ 動詞 0.999979 3 褒める ホメル 動詞 0.999979 4 めでたい メデタイ 形容詞 0.999645 記事本文を形態素解析して分析に利用できる形にします。
形態素解析には
Tokenizer()とUnicodeNormalizeCharFilter()を利用します。
単語、基本形、品詞、読みを取り出してDataFrameに格納します。
そして、記事のDataFrameと「単語感情極性対応表」をマージして、記事に含まれるワードをスコア化します。
下記にその表を示しています。
「人気」という単語が高いスコアを示していますのでポジティブな単語だと判断されました。
他の単語はなぜそのスコアになったんだ?というものもありますが、気にせず進みましょう。i = 0 # このiはニュースNo.を取得する際に利用します。 t = Tokenizer() char_filters = [UnicodeNormalizeCharFilter()] analyzer = Analyzer(char_filters=char_filters, tokenizer=t) word_lists = [] for i, row in newslist.iterrows(): # iを一つずつ増やしていきニュースNo.とします。 for t in analyzer.analyze(row[3]): # 取り出したレーベルの3カラム目に本文が格納されています。 surf = t.surface # 単語 base = t.base_form # 基本形 pos = t.part_of_speech # 品詞 reading = t.reading # 読み word_lists.append([i, surf, base, pos, reading]) # word_listsに追加 word_df = pd.DataFrame(word_lists, columns=['ニュースNo.', '単語', '基本形', '品詞', '読み']) word_df['品詞'] = word_df['品詞'].apply(lambda x : x.split(',')[0]) # 品詞は複数格納されるが最初の1つのみ利用 display(word_df.head(10)) # 作成した本文のテーブルを表示 print("↓↓↓↓↓↓↓単語感情極性対応表とマージ↓↓↓↓↓↓↓") score_result = pd.merge(word_df, posi_nega_df, on=['基本形', '品詞', '読み'], how='left') # 本文のテーブルと単語感情極性対応表をマージ display(score_result.head(10)) # 作成したスコアテーブルを表示。「人気」という単語のスコアが高いのは分かるが他は微妙、、、
ニュースNo. 単語 基本形 品詞 読み 0 0 ジャ ジャ 名詞 ジャ 1 0 ニーズ ニーズ 名詞 ニーズ 2 0 Jr Jr 名詞 * 3 0 . . 名詞 * 4 0 内 内 名詞 ナイ 5 0 の の 助詞 ノ 6 0 人気 人気 名詞 ニンキ 7 0 ユニット ユニット 名詞 ユニット 8 0 「 「 記号 「 9 0 宇宙 宇宙 名詞 ウチュウ ↓↓↓↓↓↓↓単語感情極性対応表とマージ↓↓↓↓↓↓↓
ニュースNo. 単語 基本形 品詞 読み スコア 0 0 ジャ ジャ 名詞 ジャ NaN 1 0 ニーズ ニーズ 名詞 ニーズ -0.163536 2 0 Jr Jr 名詞 * NaN 3 0 . . 名詞 * NaN 4 0 内 内 名詞 ナイ -0.74522 5 0 の の 助詞 ノ NaN 6 0 人気 人気 名詞 ニンキ 0.96765 7 0 ユニット ユニット 名詞 ユニット -0.155284 8 0 「 「 記号 「 NaN 9 0 宇宙 宇宙 名詞 ウチュウ -0.515475 result = [] for i in range(len(score_result['ニュースNo.'].unique())): # ニュースNo.を利用してfor文を回します。 temp_df = score_result[score_result['ニュースNo.']== i] text = ''.join(list(temp_df['単語'])) # 1タイトル内の全ての単語をつなげる。 score = temp_df['スコア'].astype(float).sum() # 1タイトル内のスコアを全て足し合わせる。➡︎累計スコア score_r = score/temp_df['スコア'].astype(float).count() # 本文の長さに影響されないように単語数で割り算する。➡︎標準化スコア result.append([i, text, score, score_r]) ranking = pd.DataFrame(result, columns=['ニュースNo.', 'テキスト', '累計スコア', '標準化スコア']).sort_values(by='標準化スコア', ascending=False).reset_index(drop=True) # 標準化スコアで並び替えてDataFrameに格納 ranking = pd.merge(ranking, newslist[['ニュースNo.', 'title', 'url']], on='ニュースNo.', how='left') # ニュースNo.基準でマージする。タイトルとURLを追加する。 ranking = ranking.reindex(columns=['ニュースNo.', 'title', 'url', 'テキスト', '累計スコア', '標準化スコア']) # カラムを並び替え display(ranking)
ニュースNo. title url テキスト 累計スコア 標準化スコア 0 6 家系ラーメン“のれん分け戦争”「吉村家vs.六角家」裏切りと屈服の黒歴史〈六角家破産〉 https://bunshun.jp//articles/-/40752 「『六角家』は破産しましたが、ジャンルとしての『家系ラーメン』は、年々店舗数が拡大しており、... -238.437124 -0.408983 1 1 「駅近、約1,200㎡の広大な敷地」「自宅の建て替えと地域貢献を両立する土地活用」プロが出し... https://bunshun.jp//articles/-/40010 多くの土地オーナーから「土地活用のパートナー」として選ばれ続けている三井ホーム。土地活用のプ... -315.299051 -0.438524 2 7 《平手派また卒業》欅坂46・佐藤詩織が書いた「活動のなかで悲しかったこと」 櫻坂46の“急勾... https://bunshun.jp//articles/-/40862 《皆さんこんばんは。今日はいつも応援して頂いている皆様にお伝えしたいことがあります。私、佐藤... -136.887378 -0.447344 3 5 同性愛差別の足立区議宛てに「とんでもない思い違いです」…81歳祖母の手紙が教えてくれたこと https://bunshun.jp//articles/-/40826 「おばあちゃんが足立区議の件で怒っていて、手紙を書くらしい」 母からこんなLINEが来たの... -213.244051 -0.460570 4 9 「長さ」ではなく…美容師が教える、髪を切るときに言うといい「意外な言葉」 https://bunshun.jp//articles/-/40694 掛け布団がだんだん心地よくなってきた、今日この頃。朝夜の急激な気温差に、薄めの上着を羽織った... -192.702889 -0.475810 5 8 安倍政権最大の功績は“アイヌ博物館”だった? 200億円をブチ込んだ「ウポポイ」の虚実 https://bunshun.jp//articles/-/40841 ──本当にあれでいいんだろうか? 帰路、雨の道央道をレンタカーでひた走りながら、そんな思いが... -483.393151 -0.476719 6 0 ジャニーズ元MADEリーダー・稲葉光(29)が元Berryz工房アイドルと“渋谷ホテルデート... https://bunshun.jp//articles/-/40869 ジャニーズJr.内の人気ユニット「宇宙Six」の山本亮太(30)が違法な闇スロット店に通って... -196.888853 -0.479048 7 3 “縦割り行政”の弊害だ! 橋下徹が語る「Go Toキャンペーンは何が間違っているのか」 https://bunshun.jp//articles/-/40877 「規制改革」「行政改革」「縦割り打破」。 菅義偉政権発足後、「改革」という言葉がよく聞こえて... -94.718989 -0.480807 8 4 警察官に唾吐き公務執行妨害で逮捕 読売新聞がソウル支局記者を懲戒処分 https://bunshun.jp//articles/-/40868 読売新聞ソウル支局の記者(34)が7月中旬、公務執行妨害の容疑で韓国当局に逮捕されていたこと... -144.916148 -0.489582 9 2 「365日24時間働こう」……ワタミの“思想教育”はいまも続いていた https://bunshun.jp//articles/-/40843 ワタミ株式会社の労働問題に関する告発が続いている。10月2日、「ワタミの宅食」営業所の所長が... -321.838102 -0.528470 print("<<ポジティブ1位>>", end="\n\n") for i in range(1, 4): print(ranking.iloc[0, i])<<ポジティブ1位>> 家系ラーメン“のれん分け戦争”「吉村家vs.六角家」裏切りと屈服の黒歴史〈六角家破産〉 https://bunshun.jp//articles/-/40752 「『六角家』は破産しましたが、ジャンルとしての『家系ラーメン』は、年々店舗数が拡大しており、今が最盛期です。その背景には“資本系”の台頭があります。でもね、確かに資本系も美味しいんですが、かつて『六角家』や『吉村家』の職人たちが日々、味の改良に挑み、切磋琢磨して、互いに覇を競っていたあの時代が、倒産のニュースを聞いた今、妙に懐かしく輝いて見えるんです」(ラーメン評論家・山本剛志氏)(前編「家系ラーメン・名門『六角家』はなぜ破産したか」を読む) 2020年9月4日、かつて家系ラーメンの「代名詞」とまで呼ばれ、一世を風靡した老舗の名店「六角家」が、横浜地裁より破産手続き開始決定を受けていると報じられた。2017年に「六角家」の本店が閉じられ、倒産は時間の問題だったとみるファンも多かったが、いざこのニュースが流れると「マジか」「もう一度食べたかった」など、その倒産を惜しむ声がネット上などで多く上がった。そして、冒頭の山本氏のように、「六角家」がこれまで「家系ラーメン」業界の隆盛にはたした役割について、再評価する声も上がってきている。「そもそも、家系ラーメンが誕生したのは1974年。長距離トラックの運転手だった吉村実氏が仕事の合間に趣味で密かに研究を重ねていた九州の豚骨ベースと東京の醤油ベースを組み合わせたスープを開発したことに端を発しています。この味ならいける! と判断した吉村氏はその後会社を辞め、『吉村家』というラーメン店を横浜の磯子区新杉田に開店。豚骨醤油ベースの風味豊かなスープと、モッチリとした『酒井製麺』の太麺を合わせた1杯は、本人の読みどおり大きな人気を集め、店は日々、大勢のお客さんで賑わいました。 評判を集めた「吉村家」には、多くの才能が集まりました。そして、吉村氏の元で修業をした弟子たちは、吉村氏直々に教わり技術を身に着けると“暖簾分け”という形で自分の店を持つようになり、弟子たちの店もそれぞれのエリアで大人気店となりました。独立した弟子たちが店名に『~家』とつけることが多かったため、ファンの間で、『吉村家』とそこから独立した店は『家系』と呼ばれるようになりました。現在は、“家系皆伝”という証書を吉村氏からもらった店舗のみが吉村家の“直系店舗”として認められています」(ラーメン探究家・田中一明氏) 直系店舗にはいくつか特徴がある。まずは、麺は、酒井製麺所という製麺所から卸している麺でなければならない。『家系といえば酒井製麺』と言われるほどその結びつきは固く、酒井製麺の麺は中太でモチモチした独特の食感があるという。また、麺は寸胴で茹で、テボザルではなく平ザルですくい上げるのも特徴だ。 その直系店鋪以外で、酒井製麺所の麺を使っていたのが今回倒産した「六角家」と、「本牧家」だった。「『六角家』は、吉村氏の一番弟子である神藤隆氏が独立して横浜市神奈川区六角橋で始めた店です。一時は本家『吉村家』や吉村氏が横浜市中区に出したのれん分け1号店である『本牧家』とともに家系御三家と言われたほどの超有名店です。ただ、『六角家』は吉村氏の一番弟子が始めた店にもかかわらず、開店当初から今日まで、一度も吉村氏から吉村家の“直系店舗”として認められたことはありません。『吉村家』と『六角家』はずっとぎくしゃくした関係が続いていたのです」(食ジャーナリスト・小林孝充氏) 一体なぜなのか。ラーメン探究家の田中一明氏が解説する。「吉村氏は1974年に横浜市磯子区新杉田に『吉村家』1号店を開いた後、12年間は支店をつくりませんでしたが、1986年満を持して横浜市中区本牧に2号店である『本牧家』をオープンさせました。この店を弟子の神藤隆氏に任せ、吉村氏はオーナーとして、いよいよ店舗の拡大へと乗り出したかのように見えました。ところがその2年後、店主の神藤氏が従業員を引き連れ、本牧家を出て行ってしまったのです。さらにその後、神藤氏は神奈川区六角橋に自ら『六角家』を開店しました。一方、神藤氏という主を失った『本牧家』は一時期休業を余儀なくされてしまったのです。 なぜ神藤氏は独立したのかについては、当時様々な憶測が飛び交いましたが、私は目指す味の方向性が違っていたことが大きな理由だと思っています。『吉村家』が醤油ダレをガツンと効かせたパンチのあるタイプであるのに対し、『六角家』は豚骨と醤油ダレをバランス良く効かせた食べ手を選ばないタイプであるのが特徴。神藤さんは自ら信じる味を追求したかったということではないでしょうか」 「吉村家」と袂を分かって誕生した「六角家」は、独自路線で成長していった。「六角家」の転機になったのは1994年、新横浜駅近くに誕生した「新横浜ラーメン博物館」に横浜代表として出店したことだった。これにより、全国的な知名度を得た「六角家」は本家の「吉村家」や、吉村氏とは別の経営者を迎えた「本牧家」とともに「家系御三家」とファンの間で呼ばれるようになる。この三店は、次々弟子をとり、彼らを独立させることで、直系店を増やしていった。今でも、この時期の御三家による「争い」はファンの間で語り草となっている。 特に有名なのは、94年に起きた「環2ラーメン戦争」だろう。事の発端は94年、「本牧家」が環状2号線に面した土地に移転したことに始まる。移転から1年も経たずして、「本牧家」の店舗からわずか徒歩1分の位置に、吉村「吉村家」の直系店舗「環2家」がオープンしたのだ。「ちょうどこの頃は横浜各地に吉村家の直系店舗が広がり始めた時期。環状2号線はもともとロードサイドのラーメン激戦区でしたから、偶然、出店が近くになってしまうことはありうる。しかし、『本牧家』と『環2家』はそれにしても近すぎる距離でした。家系ファンの間では『吉村家が直弟子を使って、本牧家をつぶしにきた』と囁かれることもありました」(前出・山本氏) しかし、この戦争は「本牧家」と「環2家」両方が客を離さぬために、職人たちが味の改良を進めたという側面もある。「環2ラーメン戦争」の決着はいまだについておらず、今も両店は行列の絶えない人気店であり、徒歩1分の距離で互いに火花を散らしている。 2000年代初頭になって、吉村家は「杉田家」(横浜市磯子区)、「はじめ家」(富山県魚津市)、「王道家」(千葉県柏市)、「横横家」(横浜市金沢区)などの直系店舗を次々と増やしていった。「『六角家』の多店舗展開や、『吉村家』で修業した人たちの独立開業によって、家系ラーメンの認知度は上がっていきました。1990年代に入ると、『吉村家』や『六角家』の出身者が出した店で修業し、独立開業する者が目立つようになりました。『吉村家』、『六角家』からすれば、孫、曾孫にあたる店になりますね。やがて、家系ラーメンを出す店舗は、発祥の地である横浜を飛び出し、全国各地に広がっていきました。大手飲食企業が、家系ラーメンの人気に商機を見出したのもこの頃だと思います。2010年代に入ると、いよいよ、それらの企業が業界に本格参入してきます。これらの大手飲食企業が各店舗で提供するラーメンが、いわゆる“資本系”と呼ばれるものです」(前出・田中氏) 資本系が徐々に勢力を伸ばす一方、職人たちの技に支えられる「家系御三家」の系列のラーメン店同士でも、競争が激化していった。その最たるものは2013年に起きた「三つ巴の乱戦」(山本氏)である。「『吉村家』の直系店『末廣家』と『六角家』がある県道12号沿いに、元は『吉村家』直系店だった『王道家』の系列である『とらきち家』が開店したのです。『とらきち家』と『六角家』はわずか2軒隣りの距離。ラーメン店の激戦区として知られている地域ですが、『環2ラーメン戦争』を知っている人たちからしたら、またかと思わざるを得ない出来事でした。 もう家系ファンたちは沸き上がりましてね。そもそも『末廣家』が2012年に開店したときに『吉村家がとうとう六角家を潰しに来た』と話題になったのに、その翌年には王道家の系列店がすぐそばに建ったわけです。『吉村家と王道家がタッグを組んで六角家を標的にしたのか』という憶測まで飛び交ったほどです」(同前) しかし、この「三つ巴の乱戦」は4年後に「六角家」の店主である神藤氏が体調不良で店に出ることが困難になり、同店を閉めたことで唐突に決着がついた。「もともと『吉村家』という元祖から派生していった『家系』には、細かな系図があります。あの店は『吉村家』の直系、こっちは『六角家』系列と、ファンは味とともに、“出自”もすごく気にしていました。お店側も、職人のプライドを持って、俺たちの『家系』を見せてやるという気概に溢れて、日々味の改良に明け暮れていた。たしかに『戦争』と呼ばれるほど、競争が激化した地域もありましたけど、それもまた味の新陳代謝を生むプラスの側面があった。あれは家系が進化するための『スパイス』になった部分があるんです」(同前) かつては「家系」の代名詞ともなり、「吉村家」らと“頂上決戦”を行った「六角家」本店の跡地は雑草が伸び放題の空き地になっている。一方の吉村家は、現在は家系総本山だと看板に掲げており、その勢いはますます盛んだ。開店から50年近く経つ現在も長蛇の列ができる人気店である。 ラーメン職人たちの戦いと資本系の台頭。「六角家」の倒産は、家系ラーメンの一つの時代の終焉を意味しているのである。(前編「家系ラーメン・名門『六角家』はなぜ破産したか」を読む)この記事の写真(14枚)print("<<ネガティブ1位>>", end="\n\n") for i in range(1, 4): print(ranking.iloc[-1, i])<<ネガティブ1位>> 「365日24時間働こう」……ワタミの“思想教育”はいまも続いていた https://bunshun.jp//articles/-/40843 ワタミ株式会社の労働問題に関する告発が続いている。10月2日、「ワタミの宅食」営業所の所長が、労働基準監督署からの残業代未払いの是正勧告、月175時間を超える長時間労働、上司によるタイムカードの改ざんを次々と公表したのだ。「ホワイト企業」宣伝のワタミで月175時間の残業 残業代未払いで労基署から是正勧告ワタミがホワイト企業になれなかった理由は? 勝手に勤怠「改ざん」システムも Aさんは長時間労働の末、昼夜の感覚がなくなり、「このまま寝たら、もう目が覚めないのではないか」と恐怖を抱きながら生活するほどだった。「あのまま働いていたら、死んでいた」とAさんは断言する。現在は、精神疾患を発症し、労災申請をしながら休業中だ。 しかし、Aさんは命の危険を感じていながら、なぜ過酷な仕事を続けてしまったのだろうか。その背景には、労働者の意識に働きかけ、過酷な労働を受け入れさせてしまう、ワタミによる「思想教育」のシステムがあった。「こんなにいい仕事をしているんだから、苦しくても頑張ろう」「苦しいことも、苦しくない。むしろ自分の力になる」 Aさんは過重労働の最中、そう自分に言い聞かせていた。 実際、Aさんはワタミの宅食の仕事に「誇り」を感じていたという。確かにワタミの「宅食」に「社会貢献」と言える部分がある。ワタミの宅食には、食事の調達が難しい高齢者に、定期的に安く食事を届けるというコンセプトがある。Aさんの営業所の届け先も、そうした人たちばかりだった。 隔日でデイサービスに通い、隔日で家にいるときの食事に困る一人暮らしの高齢者。毎日昼食用と夕食用の2食を頼んで、ワタミの宅食しか食べていない高齢者、障がい者や、親を介護している人......。 苦しい生活の事情によって、食事に手間や時間、お金をかけられず、ワタミに頼らざるを得ない様々な利用者がいた。それまで介護や教育現場で働いてきたAさんにとって、社会や地域のためになる宅食の仕事は、非常にやりがいの感じられるものだった。 だがそれらの「支援」を通じて無理やり利益をあげようとすれば、長時間労働や低賃金による労働者の犠牲によって支えられることになってしまう。いわば「貧困・ブラック企業ビジネス」とでもいえようか。 Aさんも当初、仕事のやりがいと過酷な労働とは分けるべきものだと冷静に考え、業務のつらさについてはワタミに不満を抱いていた。 しかし、劣悪な労働条件は、Aさんの頭の中ではいつしか問題とはならなくなっていた。その変化をもたらしたのが、ワタミによる「思想教育」だったと、Aさんは振り返っている。「365日24時間、死ぬまで働け」 この言葉をご存知の方も多いだろう。渡邉美樹氏の過去の30年以上に渡る文章を抜粋して編集した400ページにも及ぶ「理念集」という書物に記載されていた言葉である。Aさんは入社直後に会社から「理念集」を渡され、肌身離さず持っているよう言われた。 現在は批判を受けて、「死ぬまで働け」などの極端な表現は削除されている。それでもAさんが手渡された「理念集」(2016年度版)に削除されずに残っていた、印象的な表現の一部を引用しよう。〈私は、仕事はお金を得る為だけの手段とは考えていません。仕事とはその人の「生き方」そのものであり、「自己実現の唯一の手段」であると信じています。だから新卒のセミナーでも、時代遅れはなはだしいと言われつつ、「365日24時間働こう」と言うのです〉〈私も会社説明会で、「仕事とは生きることそのものなんだ。仕事を、お金を得るための手段なんかにしてはいけないんだ。仕事を通して人間性を高めよう」と訴えています〉〈ワタミタクショクの最大の商品は「人」と知れ。まごころさん(注:宅食の配達員)とは、お弁当に「心」を乗せて運び、「ありがとう」をいただく仕事をする人のこと。考え違いをして「お弁当」を運び「お金」をいただく仕事と思う人が出てこないことを祈る〉 このように、同書には、客からの「ありがとう」という感謝のために働くことを奨励して、賃金のために働くことを批判し、ワタミの利益のために自分を犠牲にすることを正当化する内容が、随所に記されていた。 ワタミに入社したAさんは、何かトラブルがあると、支社長から「理念集の第×章をちゃんと読んだ?」と問われ、渡邉美樹氏の「思想」を十分に理解していないせいだと注意されていた。 さらに、エリアマネージャーによる毎月のカウンセリングがあり、そこでは当月の「社内報」(毎月発行され、理念集の文章の多くがここからの抜粋である)の感想と、理念集の任意の箇所の感想を書かされるようになっていた。 加えて、4ヶ月に1回のレポートが課せられた。理念集から指定された章の範囲と、直近4ヶ月分の社内報に掲載される渡邉氏直筆の言葉に対する二つの感想が強制されていた。 Aさんはもともと、これらの感想文提出を「気持ち悪い」と感じていた。しかし、嫌々ながら、継続的に書かされているうちに「どこかで渡邉美樹さんの考えを植え付けられていく感じがあった」という。 それをさらに深化させたのが、「ビデオレター」の存在だった。 毎月、営業所には渡邉美樹氏が出演する「ビデオレター」が提供された。人気テレビ番組「情熱大陸」のナレーターが起用され、渡邉美樹氏が毎回出演し、ワタミの事業の素晴らしさを説く30分間の映像である。 この映像についても、毎月の感想が義務付けられていた。しかも書くのは所長だけではない。個人事業主であるはずの配達員までも、毎月ビデオレターを視聴して感想を書くことが契約に盛り込まれていた。 配達員たちは、営業所でこの映像を見せられると、所長と配達員の名前が羅列されたシートの自分の感想欄(60字ほどは書けるスペースがある)に、手書きで感想を書かされる。なお、配達員は配達先1軒あたりの報酬が百数十円しかないが、この映像視聴や感想を書くことによる新たな報酬は一切ない。 さらに配達員の感想に、ワタミに対する批判や仕事への不満などがある場合は、所長がその箇所に印をして、コメントを書き加えるようにと指示されていた。Aさんは独自の工夫として、すべての配達員の感想に対して、その配達員の感想を超えるほどの字数で、丁寧にコメントをするようにした。 そして、この「コメント」こそが、Aさんの「思想形成」に大きな役割を果たしていたという。 Aさんは、上司のエリアマネージャーから、「配達員たちに、ワタミを称賛するような感想を書くよう“もっていく”ことも所長の仕事だ」と言われていた。配達員の感想を「コントロール」するようにというのだ。 とはいえ、Aさんは配達員の感想の「改ざん」をしたわけではない。まず、Aさんは所長として、配達員に先立って自分の感想欄で、ワタミの事業やワタミで働くことの素晴らしさを説いた。すると、後から書く配達員たちは、おのずと所長の「模範解答」を意識して、否定的な感想を書きづらくなる。 それでも配達員の感想に、ワタミに疑問を呈するような箇所でもあれば、コメント欄でそこを指摘し、「意義を改めて私と共有しましょう」などと食い下がった。やがて、数ヶ月をかけて配達員たちのコメントから否定的な文章は消え、少なくとも表向きは、ワタミを褒め称える感想一色になっていった。 ワタミの素晴らしさをひたすら繰り返す、この毎月のコメントは「思想形成」に着実に影響をもたらした。ただし、本当に変わったのは、配達員ではなく、所長であるAさんの方だったのである。 ワタミに対する「称賛」を業務の必要上、あえて続けていたはずのAさんは、徐々にワタミの事業や労働を無条件に賛美し、労働問題の不満を感じなくなる意識が本当に芽生えてきたという。配達員の感想を何度も指導するという行為を通じて、Aさん自身の意識こそが「教育」されてしまったのだ。 ここで、Aさんが配達員に見せるために書いた、ビデオレターの感想文を引用してみよう。ワタミのSDGsの取り組みや、ワタミが行っているカンボジアの学校支援の取り組みの映像をみた感想だ。〈SDGsという言葉が社会に広く知れわたる前からワタミは取り組みを継続してきました。私はそのような会社で仕事させていただき、本当に感謝致します。自分のすぐ近くにも、社会の役に立つことができることは多くあります。いつも勇気と誇りを胸に笑顔を持って努めて参ります〉〈自分もキラキラした笑顔、そしてまごころさんがキラキラした笑顔でいられる様、前進していきます〉〈ここ(注:Aさんの営業所)を輝かせることこそ私の仕事です。精一杯、努めて参ります!!〉 ワタミの事業に対する絶賛と、ワタミで働かせてもらっていることの感謝。スペースをはみ出るほどの分量と、異様なほどに高揚した表現。当時のAさんが本当にワタミを「信奉」する気持ちがなければ、ここまで書くことは難しいだろう。 現在、精神疾患で休業中のAさんは、この自分の感想文を改めて見返し、こう呟いた。「気持ち悪いですね、いま読むと」 月の残業時間が150時間を超えたころ、Aさんは長時間労働について「私が悪い」と思い詰めていた。多すぎる業務量はワタミの責任なのに、そこは「思想教育」のために受け入れてしまい、むしろ仕事が遅いせいだと自分を責めるようになっていたのだ。 そんなとき、新しく入った配達員の一人が、深夜まで働くAさんを見て心配し、単刀直入に指摘してくれた。「Aさん、『洗脳』されてるんじゃないの?」 当初、「失礼な人だ」と憤ったが、何度もこの配達員が親身になって指摘してくれるうちに、「私、おかしいのかも」と思い始めるようになっていた。 また、単身赴任中だった配偶者が、コロナ禍によってテレワークで自宅勤務をするようになっていた影響も大きかった。Aさんが深夜や休日も延々と働く姿を見て、目を覚ますよう何度も説得したという。 最後に、Aさんは筆者が代表を務めるNPO法人POSSE、そして個人加盟の労働組合のブラック企業ユニオンに辿り着き、ワタミの労働問題を大々的に告発することを決意した。こうして、周囲の人たちに恵まれ、支援者に出会えたことで、Aさんはワタミの「洗脳」を脱し、これまでの労働問題を直視できるようになったのだ。 Aさんはいま、自分がワタミの労働問題に加担したのではという自責の念を抱いている。「ひとつ間違えば、私も上司と同じことをやったと思います」。自分の責任を果たすべく、これからもAさんは、ワタミの告発を続けていくつもりだという。この記事の写真(8枚)最もポジティブな記事と最もネガティブな記事を表示させてみました。
なんとなく正しく評価できている気がしますね!説明は以上です。読んでいただいてありがとうございます。
- 投稿日:2020-10-15T21:41:57+09:00
GCPコンソールのpythonアップデートで詰まっている①
立ち上がった問題
webサーバーでAPIを使ってみたい
↓
GCPのVMインスタンスが放置されてるので、それにNginxを入れてみよう↓
pipを入れる→詰まる
pyenvでpythonをアップデートしようとする→詰まる解決した問題
aptを他のプロセスが使っているよ!というエラー
- $ sudo apt autoremove
pyenvが無いよ!と言われたので、
インストールしてみると、pyenvの設定ファイルがあるよ!と言われた。
- パスが通ってなかった。
参考にしたサイト
「PythonかければWebアプリぐらい作れる」
https://qiita.com/cabernet_rock/items/852fc7c5d382fdc422a3「GCPのCloud Shellのpythonバージョンの更新方法」
https://qiita.com/greenteabiscuit/items/cbecdf4f84f0b73ff96e「ubuntu 20.04 に pyenv をインストールする話【2020/07/18更新】」
https://qiita.com/neruoneru/items/1107bcdca7fa43de673d環境
Ubuntu 16.04.7 LTS (GNU/Linux 4.15.0-1080-gcp x86_64)
実際に行った手順
$ pip The program 'pip' is currently not installed. To run 'pip' please ask your administrator to install the package 'python-pip' $ sudo apt-get update $ sudo apt install python-pip E: Could not get lock /var/lib/dpkg/lock-frontend - open (11: Resource temporarily unavailable) E: Unable to acquire the dpkg frontend lock (/var/lib/dpkg/lock-frontend), is another process using it?エラー発生。
どうもよくあるエラーらしい。ほかのプロセスが使ってるんじゃないの?とのこと。$ rm -rf ~/.pyenv上手くいかなかった。というかここで消してるはずなのにあとで出てきてないか?
$ ps aux | grep apt | grep -v 'grep' root 2035 0.0 0.1 4504 708 ? Ss 11:37 0:00 /bin/sh /usr/lib/apt/apt.systemd.daily install root 2050 0.0 0.2 4504 1684 ? S 11:37 0:00 /bin/sh /usr/lib/apt/apt.systemd.daily lock_is_hel d install root 2610 0.7 3.1 39640 18884 pts/1 Ss+ 11:39 0:00 /usr/bin/dpkg --status-fd 12 --unpack --auto-decon figure /var/cache/apt/archives/libx11-data_2%3a1.6.3-1ubuntu2.2_all.deb調べたら出てきた方法だけど、kill PID と言われてもどれがPIDか分からない。
$ sudo apt autoremoveこれで行けた。
よく分からんけど上手い事忖度して余計なものを消してくれたのだろう。pyenvのインストール
$ sudo apt-get install -y git $ git clone https://github.com/pyenv/pyenv.git ~/.pyenv fatal: destination path '/home/【user名】/.pyenv' already exists and is not an empty directory.どうもインストールはできているようなので、パスが通っていないのでは?と推測。
参考にしたサイトでは、以下のコマンドでパスを通しているはず。
# add to path echo 'export PATH="$HOME/.pyenv/bin:$PATH"' >> ~/.bashrc echo 'eval "$(pyenv init -)"' >> ~/.bashrc echo 'eval "$(pyenv virtualenv-init -)"' >> ~/.bashrc他のサイトを参照すると、
# .bashrcの更新 echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.bashrc echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.bashrc echo 'eval "$(pyenv init -)"' >> ~/.bashrc source ~/.bashrcとなっている。足りない部分を詠唱する。
$ source ~/.bashrc $ pyenv -v pyenv 1.2.21出来たー!
その後
早速pythonをアップデートしよう。
$ pyenv install 3.7.4 Downloading Python-3.7.4.tar.xz... -> https://www.python.org/ftp/python/3.7.4/Python-3.7.4.tar.xz Installing Python-3.7.4... BUILD FAILED (Ubuntu 16.04 using python-build 1.2.21) Inspect or clean up the working tree at /tmp/python-build.20201015120257.27370 Results logged to /tmp/python-build.20201015120257.27370.log Last 10 log lines: sys.exit(ensurepip._main()) File "/tmp/python-build.20201015120257.27370/Python-3.7.4/Lib/ensurepip/__init__.py", line 204, in _main default_pip=args.default_pip, File "/tmp/python-build.20201015120257.27370/Python-3.7.4/Lib/ensurepip/__init__.py", line 117, in _bootstrap return _run_pip(args + [p[0] for p in _PROJECTS], additional_paths) File "/tmp/python-build.20201015120257.27370/Python-3.7.4/Lib/ensurepip/__init__.py", line 27, in _run_pip import pip._internal zipimport.ZipImportError: can't decompress data; zlib not available Makefile:1132: recipe for target 'install' failed make: *** [install] Error 1なんかまた新しいエラー出てきた…
とりあえず一歩進んだので、ここまでにする。
- 投稿日:2020-10-15T21:41:38+09:00
【PyTorchチュートリアル⑦】Visualizing Models, Data, And Training With Tensorboard
はじめに
前回に引き続き、PyTorch 公式チュートリアル の第7弾です。
今回は Visualizing Models, Data, and Training with TensorBoard を進めます。Visualizing Models, Data, And Training With Tensorboard
60 Minute Blitz では、基本的なニューラルネットワークを構築し、学習データを利用してトレーニングする方法を見てきました。
今回はトレーニングの状況を可視化し、トレーニングが進行しているかどうかを確認する方法を見ていきましょう。
可視化は TensorBoard を利用します。PyTorchは、ニューラルネットワークのトレーニングと結果を視覚化するためのツール「TensorBoard」を利用することができます。このチュートリアルでは、torchvision.datasets の Fashion-MNIST データを使用して、その機能の一部を説明します。
次の方法を学びます。
- データを読み込み、適切な変換を行います。(前のチュートリアルとほぼ同じです)
- TensorBoardをセットアップします。
- TensorBoardに書き込みます。
- TensorBoardを使用してモデルアーキテクチャを可視化します。
- TensorBoardを使用してトレーニング途中の予測や精度を可視化します。
具体的には、上記の5点で次のことがわかります。
- トレーニングデータを検査する方法
- モデルのトレーニング中にモデルのパフォーマンスを追跡する方法
- トレーニング後のモデルのパフォーマンスを評価する方法。
CIFAR-10 チュートリアルと同様のコードから始めます。
%matplotlib inline# imports import matplotlib.pyplot as plt import numpy as np import torch import torchvision import torchvision.transforms as transforms import torch.nn as nn import torch.nn.functional as F import torch.optim as optim # transform の定義 transform = transforms.Compose( [transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))]) # データセット trainset = torchvision.datasets.FashionMNIST('./data', download=True, train=True, transform=transform) testset = torchvision.datasets.FashionMNIST('./data', download=True, train=False, transform=transform) # データローダ trainloader = torch.utils.data.DataLoader(trainset, batch_size=4, shuffle=True, num_workers=2) testloader = torch.utils.data.DataLoader(testset, batch_size=4, shuffle=False, num_workers=2) # クラス分類の定数 classes = ('T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle Boot') # 画像表示のヘルパー関数 # (以下の `plot_classes_preds` 関数で使用されます) def matplotlib_imshow(img, one_channel=False): if one_channel: img = img.mean(dim=0) img = img / 2 + 0.5 # 非正規化 npimg = img.numpy() if one_channel: plt.imshow(npimg, cmap="Greys") else: plt.imshow(np.transpose(npimg, (1, 2, 0)))CIFAR-10 チュートリアルと同様のモデルを定義しますが、画像が3つではなく1つのチャネルになり、32x32ではなく28x28になるようにするため、少し変更します。
class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = nn.Conv2d(1, 6, 5) self.pool = nn.MaxPool2d(2, 2) self.conv2 = nn.Conv2d(6, 16, 5) self.fc1 = nn.Linear(16 * 4 * 4, 120) self.fc2 = nn.Linear(120, 84) self.fc3 = nn.Linear(84, 10) def forward(self, x): x = self.pool(F.relu(self.conv1(x))) x = self.pool(F.relu(self.conv2(x))) x = x.view(-1, 16 * 4 * 4) x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) x = self.fc3(x) return x net = Net()以前と同じオプティマイザと損失関数を定義します。
criterion = nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)1.TensorBoard setup
次に、TensorBoardをセットアップします。
torch.utilsから TensorBoard をインポートし、TensorBoard に書き込むためのオブジェクトである SummaryWriter を定義します。from torch.utils.tensorboard import SummaryWriter # デフォルトのログディレクトリは "runs" ですが、こので指定できます。 writer = SummaryWriter('runs/fashion_mnist_experiment_1')この行を実行するだけで、「runs/fashion_mnist_experiment_1」ディレクトリが作成されます。
2.Writing to TensorBoard
次に、make_grid を使用して TensorBoard に画像を書き込みます。
# ランダムなトレーニング画像を取得します dataiter = iter(trainloader) images, labels = dataiter.next() # 画像のグリッドを作成します img_grid = torchvision.utils.make_grid(images) # 画像を表示します matplotlib_imshow(img_grid, one_channel=True) # テンソルボードに書き込みます writer.add_image('four_fashion_mnist_images', img_grid)(このチュートリアルには記載がありませんが、Google Colaboratory で Tensorboard を利用する場合、TensorBoardノートブック拡張機能を読み込みます。)
%load_ext tensorboard#Google Colaboratory で Tensorboard を利用する場合、マジックコマンドで Tensorboard を実行します #tensorboard --logdir=runs %tensorboard --logdir=runsローカル環境で実行した場合、
https://localhost:6006
で以下の tensorboard の画面が閲覧できます。
TensorBoard を実行することができました。
以降で TensorBoard の機能を見ていきます。3.Inspect the model using TensorBoard
TensorBoard の長所の1つは、複雑なモデル構造を視覚化できることです。作成したモデルを視覚化してみましょう。
writer.add_graph(net, images) writer.close()TensorBoardを更新すると、次のような「GRAPHS」タブが表示されます。
「Net」をダブルクリックして展開し、モデルを構成する個々を確認できます。
TensorBoard には、画像データなどの高次元データを低次元空間で視覚化するための非常に便利な機能があります。以降で説明します。4.Adding a “Projector” to TensorBoard
add_embeddingメソッドを介して、高次元データの低次元表現を視覚化できます。
import tensorflow as tf import tensorboard as tb tf.io.gfile = tb.compat.tensorflow_stub.io.gfile# ヘルパー関数 def select_n_random(data, labels, n=100): ''' データセットからn個のランダムなデータポイントとそれに対応するラベルを選択します ''' assert len(data) == len(labels) perm = torch.randperm(len(data)) return data[perm][:n], labels[perm][:n] # ランダムな画像とそのターゲットインデックスを選択します images, labels = select_n_random(trainset.data, trainset.targets) # 各画像のクラスラベルを取得します class_labels = [classes[lab] for lab in labels] # ログの埋め込み features = images.view(-1, 28 * 28) writer.add_embedding(features, metadata=class_labels, label_img=images.unsqueeze(1)) writer.close()
TensorBoard の [PROJECTOR] タブに、これらの100枚の画像が表示されます。
それぞれの画像は784次元ですが、3次元空間に投影されています。
ドラッグすると、3次元の投影を回転できます。
左上にある「色:ラベル」を選択し、「夜間モード」を有効にすると、背景が黒くなり画像が見やすくなります。ここまでで、TensorBoard を利用してデータを可視化する方法が分かりました。
次に、TensorBoard でトレーニングと評価を可視化する方法を見てみましょう。5.Tracking model training with TensorBoard
前回のチュートリアルでは、2000回の反復ごとにモデルの損失値を単に出力しました。このチュートリアルでは損失値を TensorBoard に記録し、plot_classes_preds 関数で予測値を表示します。
# ヘルパー関数 def images_to_probs(net, images): ''' 学習したモデルと画像を引数に、予測値とその確率を返却します ''' output = net(images) # 出力された確率を予測クラスに変換します _, preds_tensor = torch.max(output, 1) preds = np.squeeze(preds_tensor.numpy()) return preds, [F.softmax(el, dim=0)[i].item() for i, el in zip(preds, output)] def plot_classes_preds(net, images, labels): ''' 学習したモデルと画像、教師データを引数に、matplotlib の図を生成します。 これは、モデルが予測した最も確率の高いラベルを表示し、予測が正しいかどうかを 色付けします。 「images_to_probs」関数を使用します。 ''' preds, probs = images_to_probs(net, images) # 予測されたラベルと実際のラベルとともに、画像をバッチでプロットします。 fig = plt.figure(figsize=(12, 48)) for idx in np.arange(4): ax = fig.add_subplot(1, 4, idx+1, xticks=[], yticks=[]) matplotlib_imshow(images[idx], one_channel=True) ax.set_title("{0}, {1:.1f}%\n(label: {2})".format( classes[preds[idx]], probs[idx] * 100.0, classes[labels[idx]]), color=("green" if preds[idx]==labels[idx].item() else "red")) return fig前回のチュートリアルと同じモデル使用して学習しますが、コンソールに出力するのではなく、1000バッチごとに TensorBoard に書き込みます。(add_scalar関数)
さらに、トレーニング中の予測値と、予測した画像を出力します。(add_figure関数)running_loss = 0.0 for epoch in range(1): # データセットを複数回ループします for i, data in enumerate(trainloader, 0): # 入力を取得します。データは[inputs, labels]のリストです inputs, labels = data # 勾配を初期化します optimizer.zero_grad() # 順伝播 + 逆伝播 + 最適化 outputs = net(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() running_loss += loss.item() if i % 1000 == 999: # 1000バッチごと # ...1000バッチごとに loss 値を記録する writer.add_scalar('training loss', running_loss / 1000, epoch * len(trainloader) + i) # ...ランダムなミニバッチで、モデルの予測をMatplotlib図をログに記録します writer.add_figure('predictions vs. actuals', plot_classes_preds(net, inputs, labels), global_step=epoch * len(trainloader) + i) running_loss = 0.0 print('Finished Training')outFinished Training「SCALARS」タブで、トレーニング中の loss 値を確認できます。
さらに、1000バッチごとに行ったモデルの予測を確認できます。「IMAGES」タブを表示し、「predictions vs. actuals」ビジュアライゼーションの下にスクロールしてください。
見てみると、トレーニングを3,000回繰り返しただけで、モデルはすでにシャツ、スニーカー、コートなどを分類できています。ただし、トレーニングの後半ほどは確率は高くありません。
前回のチュートリアルでは、トレーニング後にラベルごとの正解率を確認しました。ここでは、TensorBoardを使用して、各クラスのPR曲線をプロットします。6.Assessing trained models with TensorBoard
# 1. test_size x num_classes の Tensor で確率予測を取得します # 2. test_size の Tensor で preds を取得します # 実行に最大10秒かかります class_probs = [] class_preds = [] with torch.no_grad(): for data in testloader: images, labels = data output = net(images) class_probs_batch = [F.softmax(el, dim=0) for el in output] _, class_preds_batch = torch.max(output, 1) class_probs.append(class_probs_batch) class_preds.append(class_preds_batch) test_probs = torch.cat([torch.stack(batch) for batch in class_probs]) test_preds = torch.cat(class_preds) # ヘルパー関数 def add_pr_curve_tensorboard(class_index, test_probs, test_preds, global_step=0): ''' 0 から 9 までの「class_index」を取り込み、対応するPR曲線をプロットします ''' tensorboard_preds = test_preds == class_index tensorboard_probs = test_probs[:, class_index] writer.add_pr_curve(classes[class_index], tensorboard_preds, tensorboard_probs, global_step=global_step) writer.close() # PR曲線をプロットします for i in range(len(classes)): add_pr_curve_tensorboard(i, test_probs, test_preds)「PR CURVES」タブが表示されます。各ラベルのPR曲線を開いて確認してみましょう。一部のラベルでは「曲線の下の領域」がほぼ100%であるのに対し、いくつかのラベルではこの領域が少ないことがわかります。
このチュートリアルでは、TensorBoard と PyTorch との統合の紹介しました。もちろん、Jupyter Notebook だけでも TensorBoard と同様なことが実現できますが、TensorBoardを使用すると、視覚的に確認することができます。7. 最後に
以上が「Visualizing Models, Data, And Training With Tensorboard」です。
PyTorch で Tensorboard の使い方が分かりました。
次回は「VTorchVision Object Detection Finetuning Tutorial」を進めたいと思います。履歴
2020/10/15 初版公開
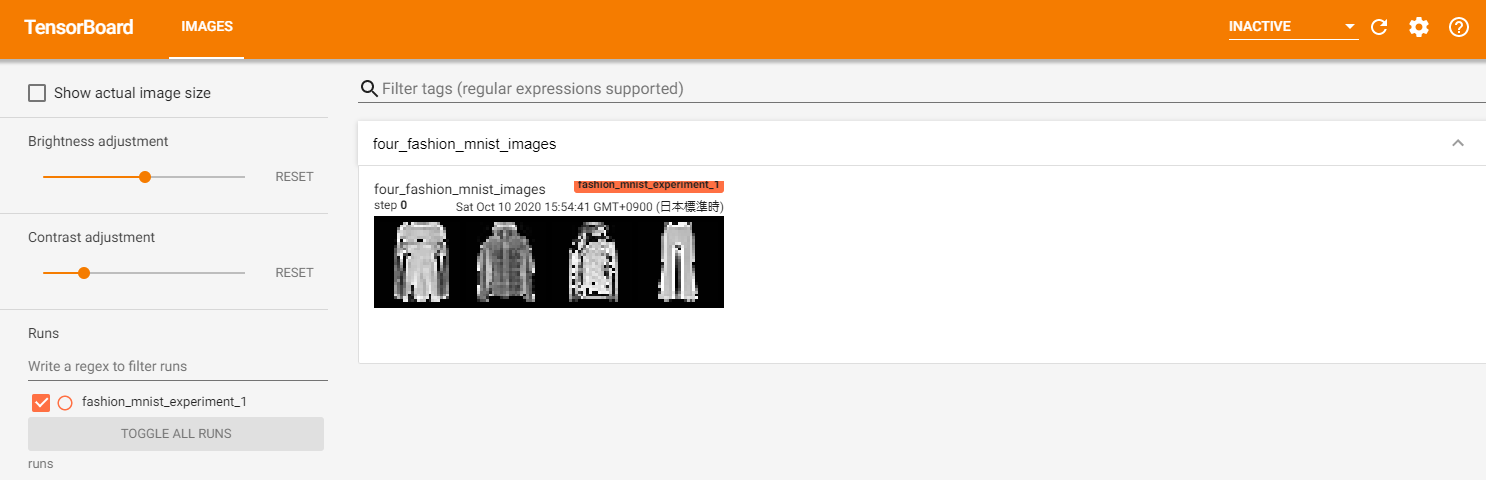
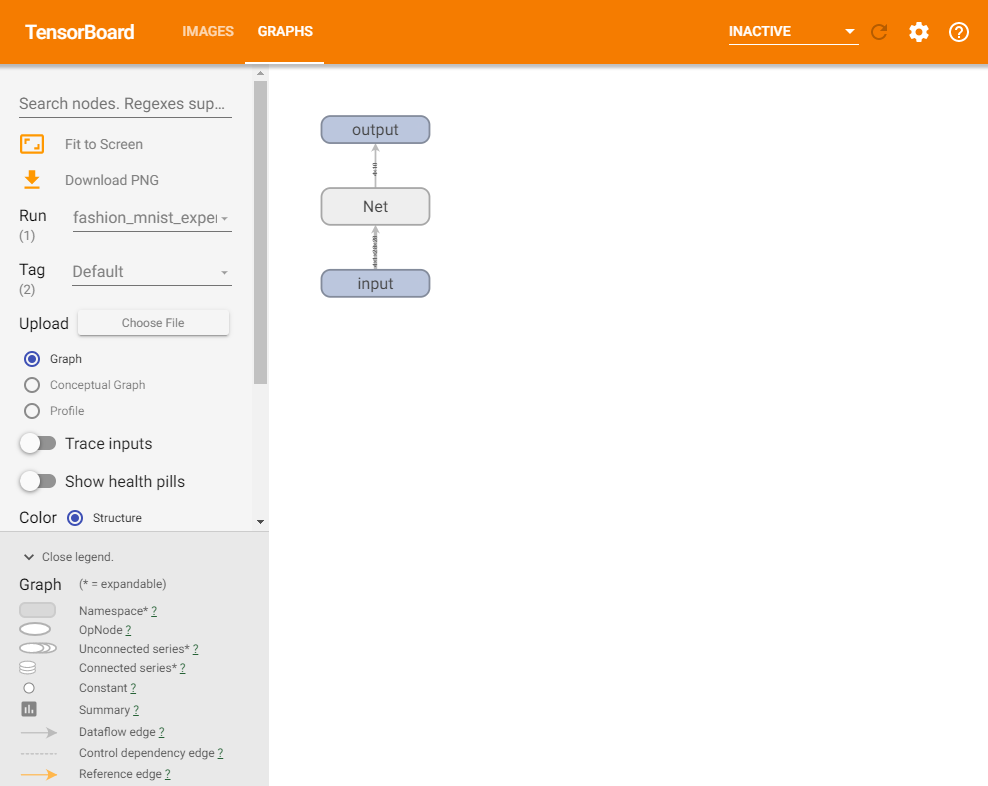
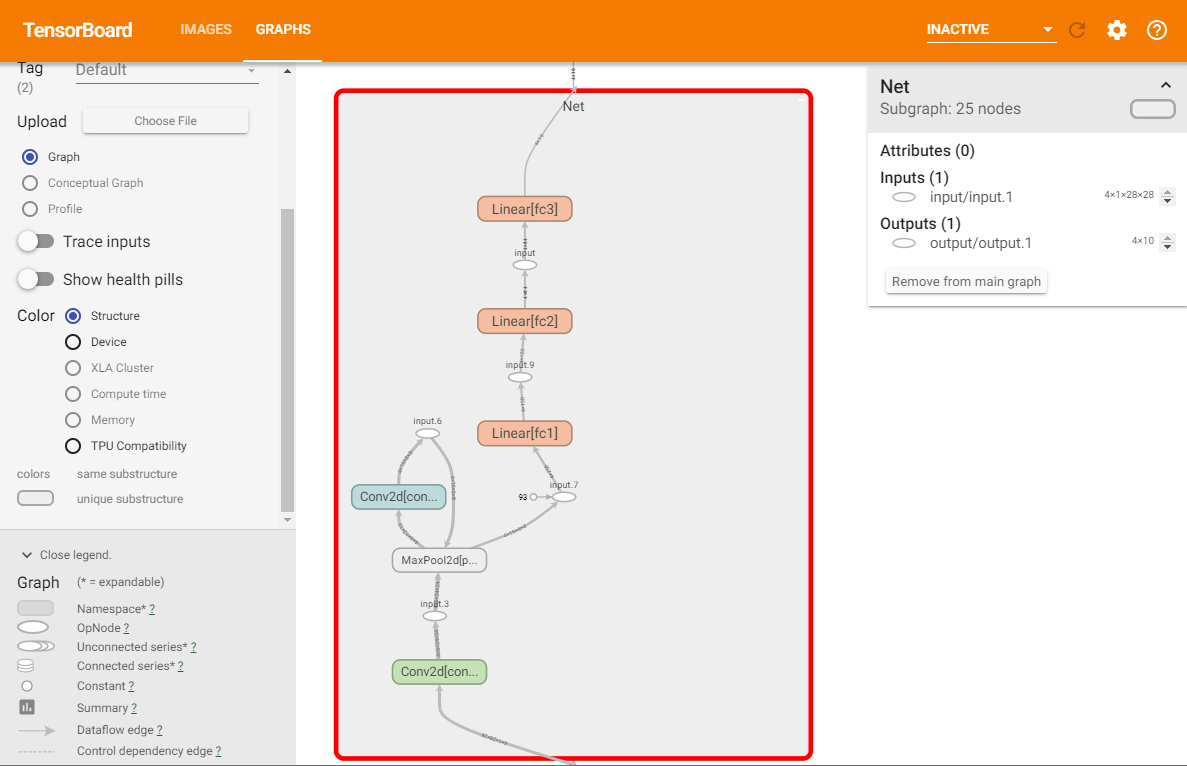
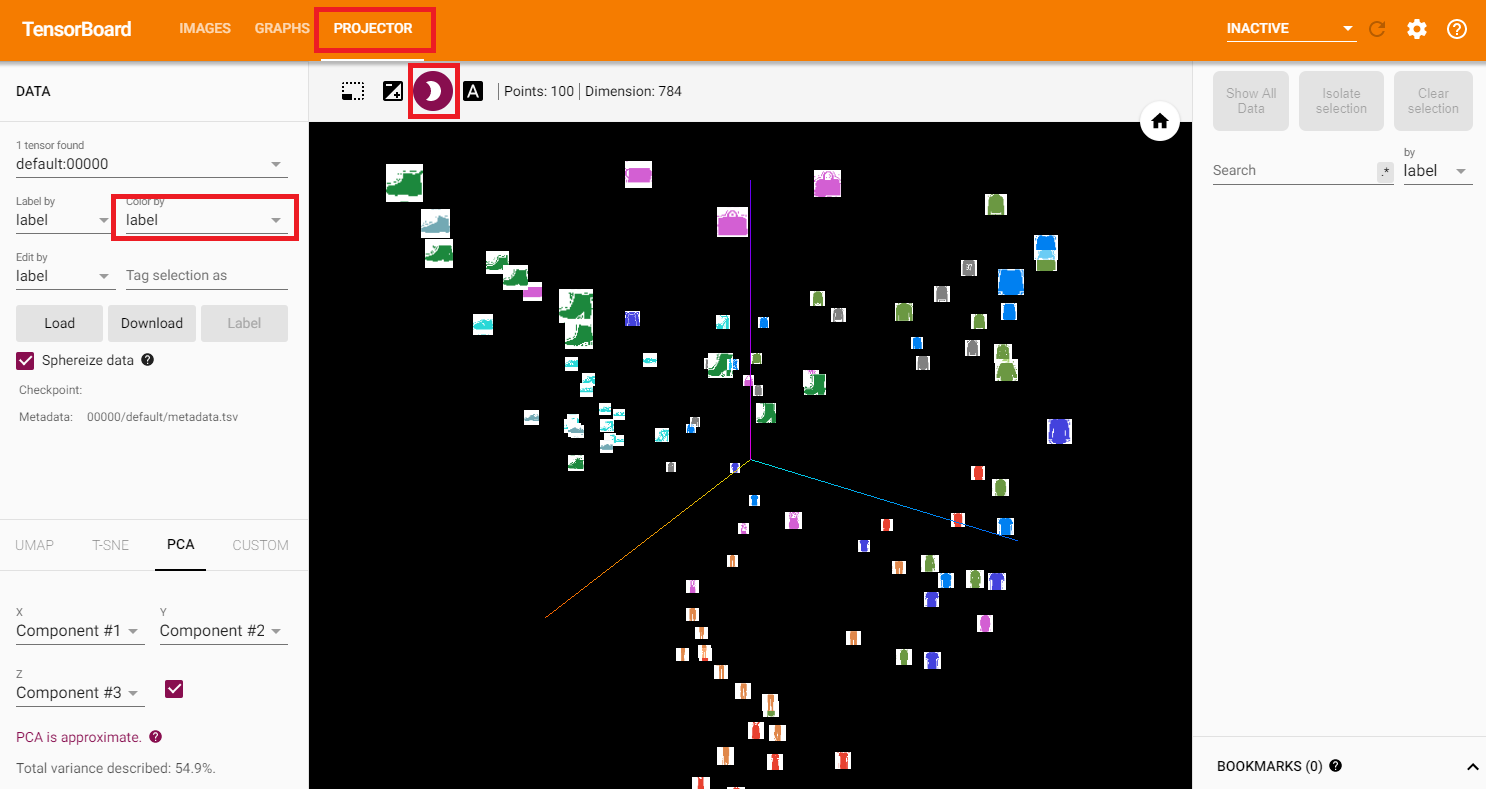
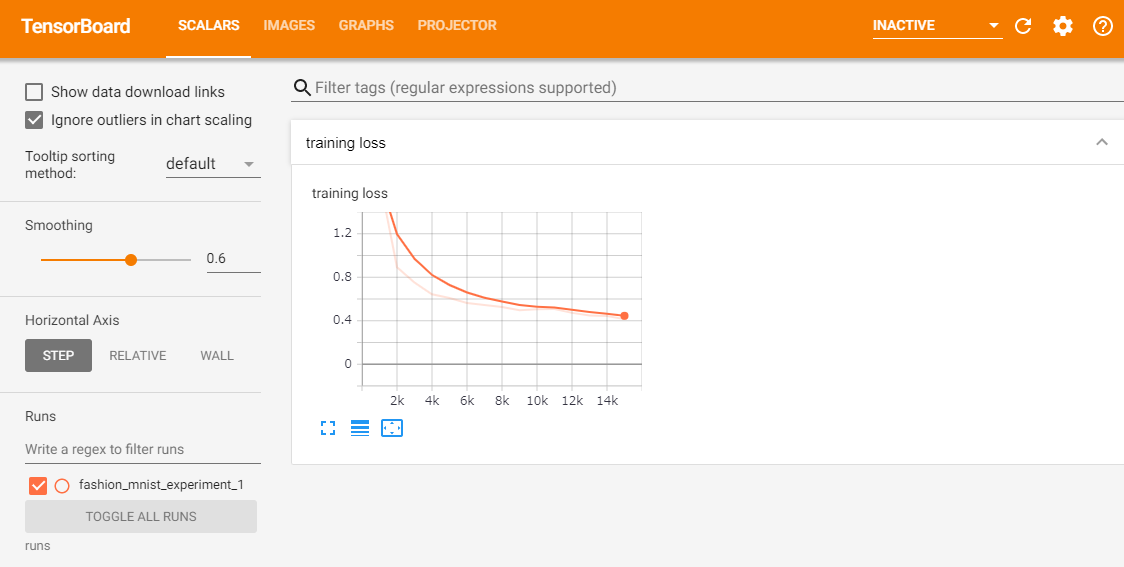
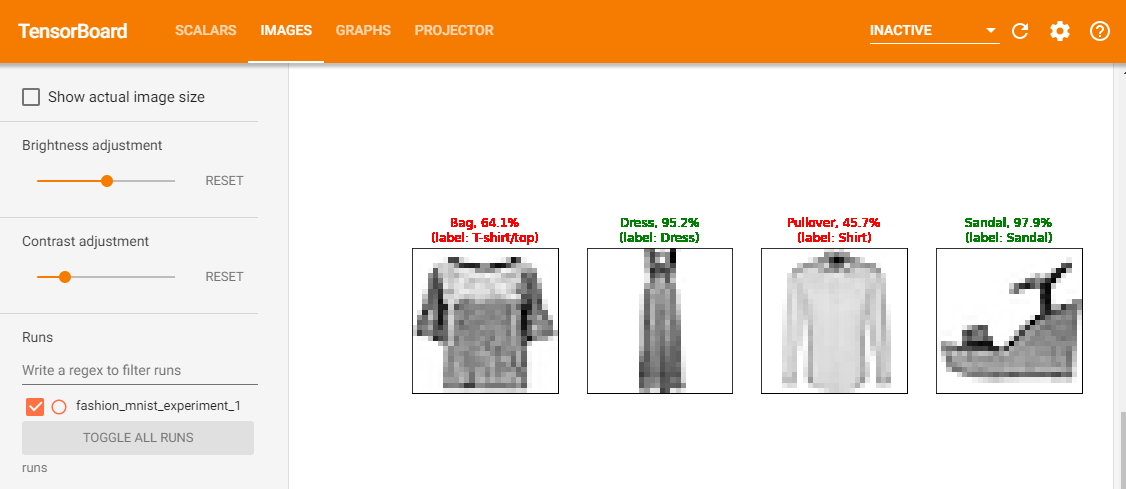
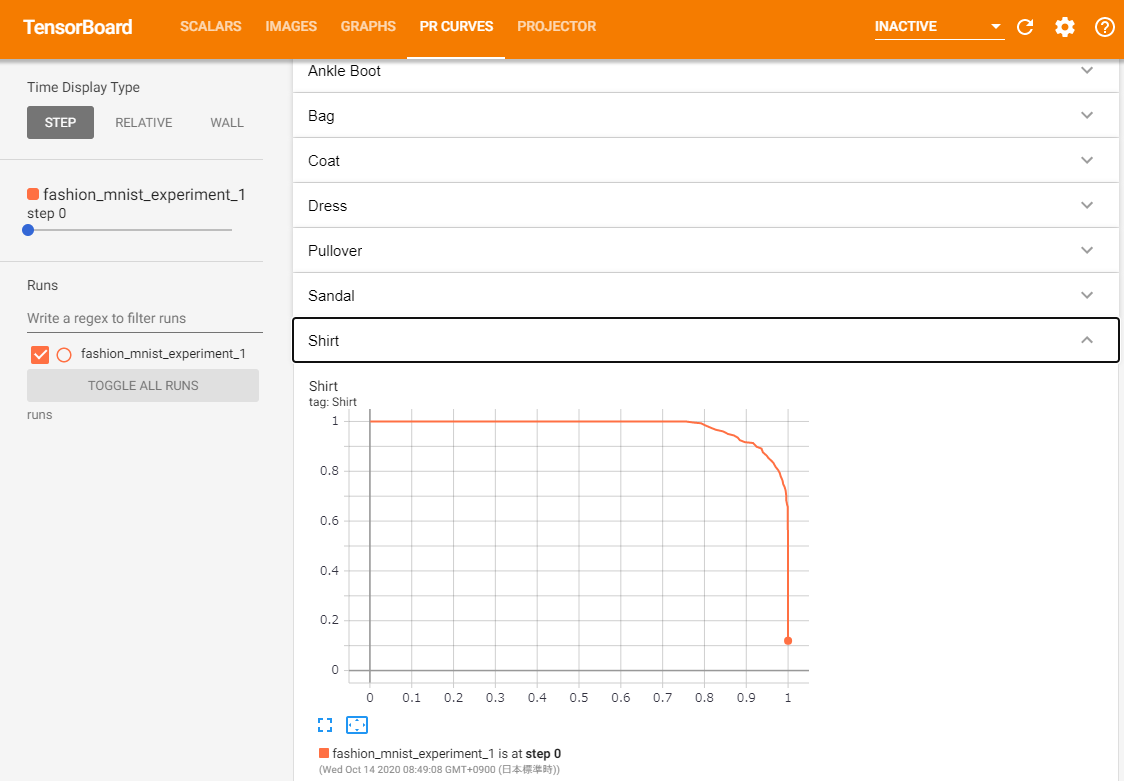
- 投稿日:2020-10-15T21:25:23+09:00
python-pptxでA4サイズ
pythonでパワポ報告書を(自動)生成するための小技
python-pptxではインチで扱うのが便利。
なので、A4サイズ==11.69 inch x 8.27 inchを使う。(python-pptxは長さにEnglish Metric Units (EMU)という単位を使っている。これをインチ変換するメソッドが、pptx.util.Inchesである。)
from pptx import Presentation from pptx.util import Inches prs = Presentation() prs.slide_height=Inches(11.69) prs.slide_width=Inches(8.27) prs.save("./hoge.pptx")これで、一応作れる。
ここに、タイトルのスライドレイアウトと白紙のスライドレイアウトを貼り付けるなら、
from pptx import Presentation from pptx.util import Inches prs = Presentation() prs.slide_height=Inches(11.69) prs.slide_width=Inches(8.27) # タイトルスライド title_slide_layout = prs.slide_layouts[0] slide = prs.slides.add_slide(title_slide_layout) title = slide.shapes.title subtitle = slide.placeholders[1] title.text = "Hello, World!" subtitle.text = "python-pptx was here!" # 白紙のスライド blank_slide_layout = prs.slide_layouts[6] slide = prs.slides.add_slide(blank_slide_layout) prs.save("./hoge.pptx")
となる。
参考
- 投稿日:2020-10-15T21:10:39+09:00
"cannot import name xxx"の時の対処法【Python】
はじめに
なぜかimportの段階で以下のようにコケるバグ(
ImportError: cannot import name 'convert')があったため、その対処法を紹介します。
この記事では、docx2pdfというパッケージについて話していますが、他のパッケージでも同様のバグが生じるため、そのような方々のためにもなったら、幸いです。Traceback (most recent call last): File "docx2pdf.py", line 5, in <module> from docx2pdf import convert File "/Users/xxx.py", line 5, in <module> from docx2pdf import convert ImportError: cannot import name 'convert'対処法
結論から言うと、docx2pdfというパッケージをインポートしようとしているのに、Pythonのスクリプト名を
docx2pdf.pyという名前にしていたのが原因でした。予約語は変数として使えないのと似たバグで、用いるパッケージ名は、ファイル名としては使えないということです。そのため、ファイル名を
docx2pdf.pyからmain.pyに変更したら、無事実行することができました。
- 投稿日:2020-10-15T20:11:02+09:00
ユークリッドの互除法と拡張ユークリッドの互除法
ユークリッドの互除法
整数$a,b(a>b)$が与えられた時,$a$を$b$で割った余り$r$とすると,
$a$と$b$の最大公約数と$b$と$r$の最大公約数は等しいこと(除法の原理)を利用し,割り算を繰り返すことによって$a,b$の最大公約数を求める方法.アルゴリズム
入力 整数$a,b$
出力 最大公約数 $d$
1. $a_0 = a$,$a_1 = b$
2. $a_i=0$のとき,$d=a_{i-1}$とし終了
3. $a_{i-1}=a_iq_i+a_{i+1}$として2に戻るコード
euclid.pydef euclid(a,b): a_list = [] if a < b: a_list.append(b) a_list.append(a) if a >= b: a_list.append(a) a_list.append(b) i = 0 while(a_list[-1]!=0): a_list.append(a_list[i]%a_list[i+1]) i +=1 return a_list[-2]拡張ユークリッドの互除法
以下の仕組みを用いて一次不定方程式の一つの解を求める方法.
$ax+by=d$を求める場合$a_0=a,a_1=b$とおく.$[\begin{array}{cc}
a_{i-1} \
a_i
\end{array}]=
[\begin{array}{cc}
a_iq_i+a_{i+1} \
a_i
\end{array}]$
とすると,
$[\begin{array}{cc}
a_{i-1} \
a_i
\end{array}]=
[\begin{array}{cc}
q_i & 1 \
1 & 0
\end{array}]
[\begin{array}{cc}
a_i \
a_{i+1}
\end{array}]
$
とかける.
$[\begin{array}{cc}
q_i & 1 \
1 & 0
\end{array}]$の逆行列を,$L_i$とする.
$[\begin{array}{cc}
a_i \
a_{i+1}
\end{array}]=L_i
[\begin{array}{cc}
a_{i-1} \
a_i
\end{array}]
$
これを繰り返すと,
$[\begin{array}{cc}
d \
0
\end{array}]=L_i,\dots,L_2
[\begin{array}{cc}
a \
b
\end{array}]
$
となる.アルゴリズム
入力 整数$a,b$
出力 最大公約数$d$ と $ax+by=d$となる整数$x, y$
1. $a_0 =a$, $a_1 =b$ とする.
2. $x_0 =1$, $x_1 =0$,$y_0 =0$, $y_1 =1$ とする.
3. $a_i=0$のとき,$d=a_i−1$,$x=x_{i−1}$,$y=y_{i−1}$とし終了.
4. $a_{i−1} = a_iq_i + a_{i+1}$により,$a_{i+1}$と$q_i$を定める.
$x_{i+1} = x_{i−1} − q_ix_i$
$y_i+1=y_i−1−q_iy_i$
として3に戻る.コード
exEuclid.pydef exEuclid(a,b): a_list = [] if a < b: a_list.append(b) a_list.append(a) if a >= b: a_list.append(a) a_list.append(b) q = [] x = [] x.append(1) x.append(0) y = [] y.append(0) y.append(1) i = 0 while(a_list[-1]!=0): a_list.append(a_list[i]%a_list[i+1]) q.append(a_list[i]//a_list[i+1]) x.append(x[-2]-q[-1]*x[-1]) y.append(y[-2]-q[-1]*y[-1]) i +=1 return x[-2],y[-2],a_list[-2]
- 投稿日:2020-10-15T19:27:32+09:00
[基本情報技術者試験]ユークリッドの互除法のアルゴリズムをPythonで書いてみた。
概要
基本情報技術者試験の午後の試験でアルゴリズムがあります。過去問を解いても理解ができません…。実際にアルゴリズムをPythonで書いて、理解を深めていきたいと思います。
まず最初はユークリッドの互除法のアルゴリズムから書いてみます。
ユークリッドの互除法
アルゴリズム
- 二つの整数の大きい方から小さい方を引くことを、両者が等しくなるまで繰り返す。等しくなった値が最大公約数である。
- GCMはGreatest Common Measure(最大公約数)
コード
# ユークリッドの互除法で最大公約数を求めるGCM関数 def GCM(A,B): # 繰り返し処理 while A != B: # AとBが等しくなるまで繰り返す print("A=",A,"B=",B) # 途中の結果 # 分岐処理 if A > B: # AがBより大きいなら A = A - B # AにA-Bを格納する else: B = B - A # BにB-Aを格納する return A print("実行結果:",GCM(84,60))実行結果
A= 84 B= 60 A= 24 B= 60 A= 24 B= 36 A= 24 B= 12 実行結果: 12まとめ
- 頭で考えるだけよりも、実際にプログラムを書いたほうが理解が深まった。
- 次回はうるう年のアルゴリズムを書こうかな
参考
- こちらの本のCHAPTER3 01ユークリッドの互除法を引用または参考にしました。 情報処理教科書 基本情報技術者試験のアルゴリズム問題がちゃんと解ける本 第2版
- 投稿日:2020-10-15T18:21:42+09:00
ルービックキューブロボットのソフトウェアをアップデートした 1. 事前計算
この記事はなに?
私は現在2x2x2ルービックキューブを解くロボットを開発中です。これはそのロボットのプログラムの解説記事集です。
かつてこちらの記事に代表される記事集を書きましたが、この時からソフトウェアが大幅にアップデートされたので新しいプログラムについて紹介しようと思います。該当するコードはこちらで公開しています。
関連する記事集
「ルービックキューブを解くロボットを作ろう!」
1. 概要編
2. アルゴリズム編
3. ソフトウェア編
4. ハードウェア編ルービックキューブロボットのソフトウェアをアップデートした
1. 基本関数
2. 事前計算(本記事)
3. 解法探索
4. 状態認識
5. 機械操作(Python)
6. 機械操作(Arduino)
7. 主要処理今回は事前計算編として、
create_array.pyを紹介します。ライブラリ等のインポート
ライブラリと基本関数をインポートします
from collections import deque import csv from basic_functions import *状態の遷移テーブルを作る
前回の記事で作った、状態を遷移させる関数は少し遅いです。今後何十万回、何百万回と状態を遷移させるのにいちいちこの関数を使っていては時間がかかってしまいます。そこで、状態の遷移を即座に(計算量$O(1)$で)済ませるために、状態の遷移配列を作ります。
遷移配列[回転前の状態番号][回転番号] = 回転後の状態番号となるような遷移配列を作ります。
''' 状態の遷移テーブルを作る ''' ''' Create state transition tables ''' def create_cp_trans(): # CPの遷移配列 # 8!個の状態それぞれに対して12種類の回転でどう遷移するかを記述 cp_trans = [[-1 for _ in range(12)] for _ in range(fac[8])] # 遷移前の状態を表す番号idxを回す for idx in range(fac[8]): if idx % 1000 == 0: print(idx / fac[8]) # idxからCP配列を作り、実際に回す cp = idx2cp(idx) for i, twist in enumerate(twist_lst): twisted_cp = [j for j in cp] for each_twist in twist: twisted_cp = move_cp(twisted_cp, each_twist) # CP配列を固有の番号に変換 twisted_idx = cp2idx(twisted_cp) cp_trans[idx][i] = twisted_idx # CSVファイルに保存 with open('cp_trans.csv', mode='w') as f: writer = csv.writer(f, lineterminator='\n') for line in cp_trans: writer.writerow(line) print('cp trans done') def create_co_trans(): # 処理の内容はcreate_cp_transのCPがCOになったのみ co_trans = [[-1 for _ in range(12)] for _ in range(3 ** 7)] for idx in range(3 ** 7): if idx % 1000 == 0: print(idx / 3 ** 7) co = idx2co(idx) for i, twist in enumerate(twist_lst): twisted_co = [j for j in co] for each_twist in twist: twisted_co = move_co(twisted_co, each_twist) twisted_idx = co2idx(twisted_co) co_trans[idx][i] = twisted_idx with open('co_trans.csv', mode='w') as f: writer = csv.writer(f, lineterminator='\n') for line in co_trans: writer.writerow(line) print('co trans done')基本関数にある状態配列と状態番号を行き来する関数を使って効率良く配列を埋めていき、そして最後にできた配列をCSVファイルに保存します。
なお、回転に使っている
twist_lstは前回の基本関数編に出てきた配列で、パズルの独自の回転記号をまとめたものです。枝刈り用配列を作る
実際にパズルの解法を探索する時には、「これ以上探索しても絶対に解が見つからない」とわかっている場合の探索を打ち切ります。これを枝刈りと言います。
「これ以上探索しても絶対に解が見つからない」かどうかをチェックするのに使うのがこの枝刈り用配列です。この配列にはCPとCO別々に、各状態についてあとコストいくつで揃うのかを記録しておきます。ちなみにCPとCOが別々なのは、両方を考慮すると状態の数が爆発的に増えてしまいメモリ使用量が膨大になってしまうからです。
''' 枝刈り用配列を作る ''' ''' Create prunning tables ''' def create_cp_cost(): # 状態の遷移配列を読み込む cp_trans = [] with open('cp_trans.csv', mode='r') as f: for line in map(str.strip, f): cp_trans.append([int(i) for i in line.replace('\n', '').split(',')]) # 8!個の各状態に対してコストを計算する cp_cost = [1000 for _ in range(fac[8])] # 幅優先探索をするのでキューに最初の(揃っている)状態を入れておく solved_cp_idx = [cp2idx(i) for i in solved_cp] que = deque([[i, 0] for i in solved_cp_idx]) for i in solved_cp_idx: cp_cost[i] = 0 cnt = 0 # 幅優先探索 while que: cnt += 1 if cnt % 1000 == 0: print(cnt, len(que)) # キューから状態を取得 cp, cost = que.popleft() twists = range(12) # 回転させ、コストを計算する for twist, cost_pls in zip(twists, cost_lst): twisted_idx = cp_trans[cp][twist] n_cost = cost + grip_cost + cost_pls # コストの更新があったら配列を更新し、キューに追加 if cp_cost[twisted_idx] > n_cost: cp_cost[twisted_idx] = n_cost que.append([twisted_idx, n_cost]) # CSVファイルに保存 with open('cp_cost.csv', mode='w') as f: writer = csv.writer(f, lineterminator='\n') writer.writerow(cp_cost) print('cp cost done') def create_co_cost(): # 処理の内容はcreate_cp_transのCPがCOになったのみ co_trans = [] with open('co_trans.csv', mode='r') as f: for line in map(str.strip, f): co_trans.append([int(i) for i in line.replace('\n', '').split(',')]) co_cost = [1000 for _ in range(3 ** 7)] solved_co_idx = list(set([co2idx(i) for i in solved_co])) que = deque([[i, 0] for i in solved_co_idx]) for i in solved_co_idx: co_cost[i] = 0 cnt = 0 while que: cnt += 1 if cnt % 1000 == 0: print(cnt, len(que)) co, cost = que.popleft() twists = range(12) for twist, cost_pls in zip(twists, cost_lst): twisted_idx = co_trans[co][twist] n_cost = cost + grip_cost + cost_pls if co_cost[twisted_idx] > n_cost: co_cost[twisted_idx] = n_cost que.append([twisted_idx, n_cost]) with open('co_cost.csv', mode='w') as f: writer = csv.writer(f, lineterminator='\n') writer.writerow(co_cost) print('co cost done')基本的な処理は幅優先探索によって行います。最初に揃っている状態24種類(同じ揃っているパズルでも見る方向によって状態は24通りになります)をキューに入れておき、
while文の中でキューから状態を取得して順次処理していきます。回転処理には先程作った状態の遷移配列を使います。もちろん使わなくてもできますが、かかる時間が桁違いです。
あと少しで揃う状態を列挙する
解法の探索ではIDA*というルービックキューブの解法探索に最適なアルゴリズムを使うのですが(詳しくは「ルービックキューブを解くロボットを作ろう!」のアルゴリズム編参照)、今回のプログラムではコスト: パズルが解けるまでにかかる時間に近い値を最小化するように解法を探索します。これを使うと手数など他の指標を使うよりも探索が重くなります。そこで、パズルが解けた状態まで一定コスト以上近かったらそこで探索を終了し、事前計算しておいた解をくっつけて全体の解とするようにしました。どれくらい「あと少しで解ける状態」を列挙するかはメモリや計算時間によって決める必要があります。
この状態列挙はパズルが揃っている状態から逆回転を使って作っていく必要があります。そこでまずは逆回転用の状態遷移配列を作ります。その後が本編です。
前編 逆回転による状態の遷移配列を作る
前述の通り、パズルの手順の逆回転に関する状態遷移配列を作ります。ここで、「前に作った遷移配列を使い回せないのか」と思う方がいらっしゃるかもしれませんが、ロボットの構造上、逆回転は前に作った配列に含まれていません。これはロボットがパズルを必ず反時計回りにしか回せない構造をしていることによります。詳しい話は「ルービックキューブを解くロボットを作ろう!」のハードウェア編をご覧ください。
''' 逆手順を回した際の状態遷移配列を作る ''' ''' Create state transition tables for reverse twists''' def create_cp_trans_rev(): # 基本的な処理はcreate_cp_transと同じ cp_trans_rev = [[-1 for _ in range(12)] for _ in range(fac[8])] for idx in range(fac[8]): if idx % 1000 == 0: print(idx / fac[8]) cp = idx2cp(idx) for i, twist in enumerate(twist_lst): twisted_cp = [j for j in cp] for each_twist in twist: twisted_cp = move_cp(twisted_cp, each_twist) twisted_idx = cp2idx(twisted_cp) # create_cp_transと違いcp_trans_rev[twisted_idx][i]を更新する cp_trans_rev[twisted_idx][i] = idx with open('cp_trans_rev.csv', mode='w') as f: writer = csv.writer(f, lineterminator='\n') for line in cp_trans_rev: writer.writerow(line) print('cp trans rev done') def create_co_trans_rev(): # 基本的な処理はcreate_co_transと同じ co_trans_rev = [[-1 for _ in range(12)] for _ in range(3 ** 7)] for idx in range(3 ** 7): if idx % 1000 == 0: print(idx / 3 ** 7) co = idx2co(idx) for i, twist in enumerate(twist_lst): twisted_co = [j for j in co] for each_twist in twist: twisted_co = move_co(twisted_co, each_twist) twisted_idx = co2idx(twisted_co) # create_co_transと違いco_trans_rev[twisted_idx][i]を更新する co_trans_rev[twisted_idx][i] = idx with open('co_trans_rev.csv', mode='w') as f: writer = csv.writer(f, lineterminator='\n') for line in co_trans_rev: writer.writerow(line) print('co trans rev done')前の状態繊維配列を作ったときのプログラムにとても近いですが、一箇所違うところがあります。
逆回転の状態遷移配列[回転後の番号][回転番号] = 回転前の番号としなくてはならないところです。
後編 あと少しで揃う状態を列挙する
状態の列挙には幅優先探索を使います。しかし、
- 状態の番号
- その状態から完成までのコスト
- その状態から完成までの手順
と、たくさんのパラメータを保持しておく必要があるので少し面倒です。
また、すでに訪れた状態でも、前に訪れた時よりもコストが小さく完成できる場合があることがあります。その場合の計算量を減らすため、(この方法は少し冗長でもう少し良い方法がある気がしますが)
neary_solved_idx, neary_solved_cost_dic, neary_solved_idx_dicを使います。実際の解法探索では、CPとCOの番号の組み合わせを使って二分探索を用いてこの配列にある要素を取得します。そのため、出来上がった配列はソートしてから保存します。
''' あと少しで揃う状態を列挙する ''' ''' Create array of states that can be solved soon ''' def create_neary_solved(): # 逆手順の遷移配列を読み込む cp_trans_rev = [] with open('cp_trans_rev.csv', mode='r') as f: for line in map(str.strip, f): cp_trans_rev.append([int(i) for i in line.replace('\n', '').split(',')]) co_trans_rev = [] with open('co_trans_rev.csv', mode='r') as f: for line in map(str.strip, f): co_trans_rev.append([int(i) for i in line.replace('\n', '').split(',')]) # neary_solved配列を更新していくが、計算を高速にするため他の配列も用意する neary_solved = [] neary_solved_idx = set() neary_solved_cost_dic = {} neary_solved_idx_dic = {} # 幅優先探索のキューを作る solved_cp_idx = [cp2idx(i) for i in solved_cp] solved_co_idx = [co2idx(i) for i in solved_co] que = deque([]) for i in range(24): twisted_idx = solved_cp_idx[i] * 2187 + solved_co_idx[i] neary_solved_idx.add(twisted_idx) neary_solved_cost_dic[twisted_idx] = 0 neary_solved_idx_dic[twisted_idx] = len(neary_solved) neary_solved.append([twisted_idx, 0, []]) que.append([solved_cp_idx[i], solved_co_idx[i], 0, [], 2]) twists = [range(6, 12), range(6), range(12)] cnt = 0 while que: cnt += 1 if cnt % 1000 == 0: print(cnt, len(que)) # キューから状態を取得 cp_idx, co_idx, cost, move, mode = que.popleft() for twist in twists[mode]: # 回転後の状態とコストを取得、手順リストを更新 cost_pls = cost_lst[twist] twisted_cp_idx = cp_trans_rev[cp_idx][twist] twisted_co_idx = co_trans_rev[co_idx][twist] twisted_idx = twisted_cp_idx * 2187 + twisted_co_idx n_cost = cost + grip_cost + cost_pls n_mode = twist // 6 n_move = [i for i in move] n_move.append(twist) if neary_solved_depth >= n_cost and not twisted_idx in neary_solved_idx: # 新しく見た状態だった場合 neary_solved_idx.add(twisted_idx) neary_solved_cost_dic[twisted_idx] = n_cost neary_solved_idx_dic[twisted_idx] = len(neary_solved) neary_solved.append([twisted_idx, n_cost, list(reversed(n_move))]) que.append([twisted_cp_idx, twisted_co_idx, n_cost, n_move, n_mode]) elif neary_solved_depth >= n_cost and neary_solved_cost_dic[twisted_idx] > n_cost: # すでに見た状態だがその時よりも低いコストでその状態に到達できた場合 neary_solved_cost_dic[twisted_idx] = n_cost neary_solved[neary_solved_idx_dic[twisted_idx]] = [twisted_idx, n_cost, list(reversed(n_move))] que.append([twisted_cp_idx, twisted_co_idx, n_cost, n_move, n_mode]) # solverパートでは2分探索を用いるため、予めインデックスでソートしておく neary_solved.sort() # インデックスとコストをCSVに配列を保存 with open('neary_solved_idx.csv', mode='w') as f: writer = csv.writer(f, lineterminator='\n') for line in [i[:2] for i in neary_solved]: writer.writerow(line) # 手順をCSV配列に保存 with open('neary_solved_solution.csv', mode='w') as f: writer = csv.writer(f, lineterminator='\n') for line in [i[2] for i in neary_solved]: writer.writerow(line) print('neary solved done')まとめ
今回はルービックキューブの解法探索に用いる様々な配列を事前計算しました。実際には紹介した関数全てを実行することで目的の配列を作ります。ソルバーはこれらの配列を読み込んで、解法探索の中で使用します。

- 投稿日:2020-10-15T18:21:42+09:00
ルービックキューブロボットのソフトウェアをアップデートした 2. 事前計算
この記事はなに?
私は現在2x2x2ルービックキューブを解くロボットを開発中です。これはそのロボットのプログラムの解説記事集です。
かつてこちらの記事に代表される記事集を書きましたが、この時からソフトウェアが大幅にアップデートされたので新しいプログラムについて紹介しようと思います。該当するコードはこちらで公開しています。
関連する記事集
「ルービックキューブを解くロボットを作ろう!」
1. 概要編
2. アルゴリズム編
3. ソフトウェア編
4. ハードウェア編ルービックキューブロボットのソフトウェアをアップデートした
1. 基本関数
2. 事前計算(本記事)
3. 解法探索
4. 状態認識
5. 機械操作(Python)
6. 機械操作(Arduino)
7. 主要処理今回は事前計算編として、
create_array.pyを紹介します。ライブラリ等のインポート
ライブラリと基本関数をインポートします
from collections import deque import csv from basic_functions import *状態の遷移テーブルを作る
前回の記事で作った、状態を遷移させる関数は少し遅いです。今後何十万回、何百万回と状態を遷移させるのにいちいちこの関数を使っていては時間がかかってしまいます。そこで、状態の遷移を即座に(計算量$O(1)$で)済ませるために、状態の遷移配列を作ります。
遷移配列[回転前の状態番号][回転番号] = 回転後の状態番号となるような遷移配列を作ります。
''' 状態の遷移テーブルを作る ''' ''' Create state transition tables ''' def create_cp_trans(): # CPの遷移配列 # 8!個の状態それぞれに対して12種類の回転でどう遷移するかを記述 cp_trans = [[-1 for _ in range(12)] for _ in range(fac[8])] # 遷移前の状態を表す番号idxを回す for idx in range(fac[8]): if idx % 1000 == 0: print(idx / fac[8]) # idxからCP配列を作り、実際に回す cp = idx2cp(idx) for i, twist in enumerate(twist_lst): twisted_cp = [j for j in cp] for each_twist in twist: twisted_cp = move_cp(twisted_cp, each_twist) # CP配列を固有の番号に変換 twisted_idx = cp2idx(twisted_cp) cp_trans[idx][i] = twisted_idx # CSVファイルに保存 with open('cp_trans.csv', mode='w') as f: writer = csv.writer(f, lineterminator='\n') for line in cp_trans: writer.writerow(line) print('cp trans done') def create_co_trans(): # 処理の内容はcreate_cp_transのCPがCOになったのみ co_trans = [[-1 for _ in range(12)] for _ in range(3 ** 7)] for idx in range(3 ** 7): if idx % 1000 == 0: print(idx / 3 ** 7) co = idx2co(idx) for i, twist in enumerate(twist_lst): twisted_co = [j for j in co] for each_twist in twist: twisted_co = move_co(twisted_co, each_twist) twisted_idx = co2idx(twisted_co) co_trans[idx][i] = twisted_idx with open('co_trans.csv', mode='w') as f: writer = csv.writer(f, lineterminator='\n') for line in co_trans: writer.writerow(line) print('co trans done')基本関数にある状態配列と状態番号を行き来する関数を使って効率良く配列を埋めていき、そして最後にできた配列をCSVファイルに保存します。
なお、回転に使っている
twist_lstは前回の基本関数編に出てきた配列で、パズルの独自の回転記号をまとめたものです。枝刈り用配列を作る
実際にパズルの解法を探索する時には、「これ以上探索しても絶対に解が見つからない」とわかっている場合の探索を打ち切ります。これを枝刈りと言います。
「これ以上探索しても絶対に解が見つからない」かどうかをチェックするのに使うのがこの枝刈り用配列です。この配列にはCPとCO別々に、各状態についてあとコストいくつで揃うのかを記録しておきます。ちなみにCPとCOが別々なのは、両方を考慮すると状態の数が爆発的に増えてしまいメモリ使用量が膨大になってしまうからです。
''' 枝刈り用配列を作る ''' ''' Create prunning tables ''' def create_cp_cost(): # 状態の遷移配列を読み込む cp_trans = [] with open('cp_trans.csv', mode='r') as f: for line in map(str.strip, f): cp_trans.append([int(i) for i in line.replace('\n', '').split(',')]) # 8!個の各状態に対してコストを計算する cp_cost = [1000 for _ in range(fac[8])] # 幅優先探索をするのでキューに最初の(揃っている)状態を入れておく solved_cp_idx = [cp2idx(i) for i in solved_cp] que = deque([[i, 0] for i in solved_cp_idx]) for i in solved_cp_idx: cp_cost[i] = 0 cnt = 0 # 幅優先探索 while que: cnt += 1 if cnt % 1000 == 0: print(cnt, len(que)) # キューから状態を取得 cp, cost = que.popleft() twists = range(12) # 回転させ、コストを計算する for twist, cost_pls in zip(twists, cost_lst): twisted_idx = cp_trans[cp][twist] n_cost = cost + grip_cost + cost_pls # コストの更新があったら配列を更新し、キューに追加 if cp_cost[twisted_idx] > n_cost: cp_cost[twisted_idx] = n_cost que.append([twisted_idx, n_cost]) # CSVファイルに保存 with open('cp_cost.csv', mode='w') as f: writer = csv.writer(f, lineterminator='\n') writer.writerow(cp_cost) print('cp cost done') def create_co_cost(): # 処理の内容はcreate_cp_transのCPがCOになったのみ co_trans = [] with open('co_trans.csv', mode='r') as f: for line in map(str.strip, f): co_trans.append([int(i) for i in line.replace('\n', '').split(',')]) co_cost = [1000 for _ in range(3 ** 7)] solved_co_idx = list(set([co2idx(i) for i in solved_co])) que = deque([[i, 0] for i in solved_co_idx]) for i in solved_co_idx: co_cost[i] = 0 cnt = 0 while que: cnt += 1 if cnt % 1000 == 0: print(cnt, len(que)) co, cost = que.popleft() twists = range(12) for twist, cost_pls in zip(twists, cost_lst): twisted_idx = co_trans[co][twist] n_cost = cost + grip_cost + cost_pls if co_cost[twisted_idx] > n_cost: co_cost[twisted_idx] = n_cost que.append([twisted_idx, n_cost]) with open('co_cost.csv', mode='w') as f: writer = csv.writer(f, lineterminator='\n') writer.writerow(co_cost) print('co cost done')基本的な処理は幅優先探索によって行います。最初に揃っている状態24種類(同じ揃っているパズルでも見る方向によって状態は24通りになります)をキューに入れておき、
while文の中でキューから状態を取得して順次処理していきます。回転処理には先程作った状態の遷移配列を使います。もちろん使わなくてもできますが、かかる時間が桁違いです。
あと少しで揃う状態を列挙する
解法の探索ではIDA*というルービックキューブの解法探索に最適なアルゴリズムを使うのですが(詳しくは「ルービックキューブを解くロボットを作ろう!」のアルゴリズム編参照)、今回のプログラムではコスト: パズルが解けるまでにかかる時間に近い値を最小化するように解法を探索します。これを使うと手数など他の指標を使うよりも探索が重くなります。そこで、パズルが解けた状態まで一定コスト以上近かったらそこで探索を終了し、事前計算しておいた解をくっつけて全体の解とするようにしました。どれくらい「あと少しで解ける状態」を列挙するかはメモリや計算時間によって決める必要があります。
この状態列挙はパズルが揃っている状態から逆回転を使って作っていく必要があります。そこでまずは逆回転用の状態遷移配列を作ります。その後が本編です。
前編 逆回転による状態の遷移配列を作る
前述の通り、パズルの手順の逆回転に関する状態遷移配列を作ります。ここで、「前に作った遷移配列を使い回せないのか」と思う方がいらっしゃるかもしれませんが、ロボットの構造上、逆回転は前に作った配列に含まれていません。これはロボットがパズルを必ず反時計回りにしか回せない構造をしていることによります。詳しい話は「ルービックキューブを解くロボットを作ろう!」のハードウェア編をご覧ください。
''' 逆手順を回した際の状態遷移配列を作る ''' ''' Create state transition tables for reverse twists''' def create_cp_trans_rev(): # 基本的な処理はcreate_cp_transと同じ cp_trans_rev = [[-1 for _ in range(12)] for _ in range(fac[8])] for idx in range(fac[8]): if idx % 1000 == 0: print(idx / fac[8]) cp = idx2cp(idx) for i, twist in enumerate(twist_lst): twisted_cp = [j for j in cp] for each_twist in twist: twisted_cp = move_cp(twisted_cp, each_twist) twisted_idx = cp2idx(twisted_cp) # create_cp_transと違いcp_trans_rev[twisted_idx][i]を更新する cp_trans_rev[twisted_idx][i] = idx with open('cp_trans_rev.csv', mode='w') as f: writer = csv.writer(f, lineterminator='\n') for line in cp_trans_rev: writer.writerow(line) print('cp trans rev done') def create_co_trans_rev(): # 基本的な処理はcreate_co_transと同じ co_trans_rev = [[-1 for _ in range(12)] for _ in range(3 ** 7)] for idx in range(3 ** 7): if idx % 1000 == 0: print(idx / 3 ** 7) co = idx2co(idx) for i, twist in enumerate(twist_lst): twisted_co = [j for j in co] for each_twist in twist: twisted_co = move_co(twisted_co, each_twist) twisted_idx = co2idx(twisted_co) # create_co_transと違いco_trans_rev[twisted_idx][i]を更新する co_trans_rev[twisted_idx][i] = idx with open('co_trans_rev.csv', mode='w') as f: writer = csv.writer(f, lineterminator='\n') for line in co_trans_rev: writer.writerow(line) print('co trans rev done')前の状態繊維配列を作ったときのプログラムにとても近いですが、一箇所違うところがあります。
逆回転の状態遷移配列[回転後の番号][回転番号] = 回転前の番号としなくてはならないところです。
後編 あと少しで揃う状態を列挙する
状態の列挙には幅優先探索を使います。しかし、
- 状態の番号
- その状態から完成までのコスト
- その状態から完成までの手順
と、たくさんのパラメータを保持しておく必要があるので少し面倒です。
また、すでに訪れた状態でも、前に訪れた時よりもコストが小さく完成できる場合があることがあります。その場合の計算量を減らすため、(この方法は少し冗長でもう少し良い方法がある気がしますが)
neary_solved_idx, neary_solved_cost_dic, neary_solved_idx_dicを使います。実際の解法探索では、CPとCOの番号の組み合わせを使って二分探索を用いてこの配列にある要素を取得します。そのため、出来上がった配列はソートしてから保存します。
''' あと少しで揃う状態を列挙する ''' ''' Create array of states that can be solved soon ''' def create_neary_solved(): # 逆手順の遷移配列を読み込む cp_trans_rev = [] with open('cp_trans_rev.csv', mode='r') as f: for line in map(str.strip, f): cp_trans_rev.append([int(i) for i in line.replace('\n', '').split(',')]) co_trans_rev = [] with open('co_trans_rev.csv', mode='r') as f: for line in map(str.strip, f): co_trans_rev.append([int(i) for i in line.replace('\n', '').split(',')]) # neary_solved配列を更新していくが、計算を高速にするため他の配列も用意する neary_solved = [] neary_solved_idx = set() neary_solved_cost_dic = {} neary_solved_idx_dic = {} # 幅優先探索のキューを作る solved_cp_idx = [cp2idx(i) for i in solved_cp] solved_co_idx = [co2idx(i) for i in solved_co] que = deque([]) for i in range(24): twisted_idx = solved_cp_idx[i] * 2187 + solved_co_idx[i] neary_solved_idx.add(twisted_idx) neary_solved_cost_dic[twisted_idx] = 0 neary_solved_idx_dic[twisted_idx] = len(neary_solved) neary_solved.append([twisted_idx, 0, []]) que.append([solved_cp_idx[i], solved_co_idx[i], 0, [], 2]) twists = [range(6, 12), range(6), range(12)] cnt = 0 while que: cnt += 1 if cnt % 1000 == 0: print(cnt, len(que)) # キューから状態を取得 cp_idx, co_idx, cost, move, mode = que.popleft() for twist in twists[mode]: # 回転後の状態とコストを取得、手順リストを更新 cost_pls = cost_lst[twist] twisted_cp_idx = cp_trans_rev[cp_idx][twist] twisted_co_idx = co_trans_rev[co_idx][twist] twisted_idx = twisted_cp_idx * 2187 + twisted_co_idx n_cost = cost + grip_cost + cost_pls n_mode = twist // 6 n_move = [i for i in move] n_move.append(twist) if neary_solved_depth >= n_cost and not twisted_idx in neary_solved_idx: # 新しく見た状態だった場合 neary_solved_idx.add(twisted_idx) neary_solved_cost_dic[twisted_idx] = n_cost neary_solved_idx_dic[twisted_idx] = len(neary_solved) neary_solved.append([twisted_idx, n_cost, list(reversed(n_move))]) que.append([twisted_cp_idx, twisted_co_idx, n_cost, n_move, n_mode]) elif neary_solved_depth >= n_cost and neary_solved_cost_dic[twisted_idx] > n_cost: # すでに見た状態だがその時よりも低いコストでその状態に到達できた場合 neary_solved_cost_dic[twisted_idx] = n_cost neary_solved[neary_solved_idx_dic[twisted_idx]] = [twisted_idx, n_cost, list(reversed(n_move))] que.append([twisted_cp_idx, twisted_co_idx, n_cost, n_move, n_mode]) # solverパートでは2分探索を用いるため、予めインデックスでソートしておく neary_solved.sort() # インデックスとコストをCSVに配列を保存 with open('neary_solved_idx.csv', mode='w') as f: writer = csv.writer(f, lineterminator='\n') for line in [i[:2] for i in neary_solved]: writer.writerow(line) # 手順をCSV配列に保存 with open('neary_solved_solution.csv', mode='w') as f: writer = csv.writer(f, lineterminator='\n') for line in [i[2] for i in neary_solved]: writer.writerow(line) print('neary solved done')まとめ
今回はルービックキューブの解法探索に用いる様々な配列を事前計算しました。実際には紹介した関数全てを実行することで目的の配列を作ります。ソルバーはこれらの配列を読み込んで、解法探索の中で使用します。
- 投稿日:2020-10-15T18:03:11+09:00
railsで使ってたbefore_actionのような機能をdjangoでもやりたかった話【初学者が参考書片手にpython学習】
はじめに
大高隆・著「動かして学ぶ!Python Django開発入門」を使用して
python・Djangoの学習を始めた初学者です。
ruby・railsを使用して4ヶ月ほどプログラミングの勉強をしていましたが、
エンジニア転職にあたり、pythonを使用することになったのでこの本を片手に勉強を始めました。
ド級の素人なので、補足・ご指摘等コメントいただけると大変助かります。概要
railsアプリを作成する際に使っていたbefore_actionのように、
決まった処理を指定した汎用ビューの前に差し込む。これをdjangoでもやりたかった。具体的には、、、、
クラスベース汎用ビューのtemplate表示前に、セッションに特定の値があるか確認。
→あり:そのまま表示
→なし:index画面にリダイレクト
という処理にしたい。考察
@login_requiredでログインしてるか確認できるなら、
自分でも同じようなものが作れるのでは、、、?
いや、できないはずはない。
↓
どうやら「@〜」はデコレータというものらしい。
そしてやはり自作できるっぽい。共通して行いたい処理を記述。
今回は、「セッションの中に特定の値があるかどうか」。
def is_hoge_in_session(func): def hoge_checker(request): if 'hoge' in request.session: return func(request) else: return redirect("hogeApp:index") return hoge_checkerコードの中身については、偉大な先人の方々の解説がわかり易すいかと。
・【Python】初心者向けにデコレータの解説
・DjangoにおけるDecoratorの使い方とその作り方対象のクラスビューの上に載せるだけ。
# method_decoratorをインポート from django.utils.decorators import method_decorator 、、、(中略)、、、 @method_decorator(is_hoge_in_session, name='dispatch') class HogeFugaView(LoginRequiredMixin, generic.ListView): 、、、(以下略)ちなみにクラスベースビューで関数デコレータを扱う方法に関しては
下記サイトより知恵を授けていただきました。
【Django】クラスベースビューで関数のデコレータを使用する方法今回のまとめ
ドブに捨ててしまった時間
→2時間
感想:
→初学者でも、周りに開発中の言語についてのスペシャリストな先輩がいなくても、
大丈夫、私にはgoogle大先生がいる。あとは気合い。偉大な参考記事
・【Django】クラスベースビューで関数のデコレータを使用する方法
・【Python】初心者向けにデコレータの解説
・DjangoにおけるDecoratorの使い方とその作り方
- 投稿日:2020-10-15T17:56:46+09:00
【Python】python非同期処理のプラクティスを検討してみた(multiprocessing, asyncio)
python非同期処理のプラクティスとして以下の要件を満たすものを検討してみました。
- main処理と非同期処理を並列実行させたい。
- main処理内の指定した箇所で非同期処理の実行完了までwaitさせたい。
- 非同期処理の戻り値をfutureで取得したい。
コードはやや冗長ですが、そのままコピペして試せるようにロガー等も含めた全ソースを記載しています。
ケース1 mainスレッドと非同期スレッドを並列で処理(multiprocessing利用)
multiprocessing1.pyfrom multiprocessing.pool import ThreadPool import time import threading as th import logging # ロガーの取得 def get_logger(): logger = logging.getLogger("multiprocesssing_test") logger.setLevel(logging.DEBUG) logger.propagate = False ch = logging.StreamHandler() ch.setLevel(logging.DEBUG) ch_formatter = logging.Formatter('%(asctime)s - %(message)s') ch.setFormatter(ch_formatter) logger.addHandler(ch) return logger logger = get_logger() def async_func(name, sleep_time): # スレッドidを取得 thread_id = th.get_ident() logger.info(f"thread_id:{thread_id} name:{name} async_func開始") time.sleep(sleep_time) logger.info(f"thread_id:{thread_id} name:{name} async_func終了") return f"{thread_id}-{name}" if __name__ == "__main__": # スレッド実行用のスレッドプールを作成 # processesでスレッドの最大同時 pool = ThreadPool(processes=1) # スレッドidを取得 thread_id = th.get_ident() # 非同期処理を実行する。第一引数に関数オブジェクト、第二引数に引数を指定する。 logger.info(f"thread_id:{thread_id} mainから非同期処理をcall") future = pool.apply_async(async_func, ("スレッド1", 10)) # 非同期処理と並行してmainスレッドで実行させたい処理 logger.info(f"thread_id:{thread_id} main非同期処理実行中の処理開始") time.sleep(5) logger.info(f"thread_id:{thread_id} main非同期処理実行中の処理終了") # 非同期処理が終わるのを待って、結果を取得する。 result = future.get() logger.info(f"thread_id:{thread_id} 非同期処理の結果取得:{result}") pool.close()実行結果
2020-10-15 16:43:27,073 - thread_id:18440 mainから非同期処理をcall 2020-10-15 16:43:27,074 - thread_id:18440 main非同期処理実行中の処理開始 2020-10-15 16:43:27,074 - thread_id:18132 name:スレッド1 async_func開始 2020-10-15 16:43:32,074 - thread_id:18440 main非同期処理実行中の処理終了 2020-10-15 16:43:37,075 - thread_id:18132 name:スレッド1 async_func終了 2020-10-15 16:43:37,075 - thread_id:18440 非同期処理の結果取得:18132-スレッド1ログから16:43:27に「main非同期処理実行中の処理」と「async_func開始」の処理が同時に並列で実行されているのが分かります。
ケース2 mainスレッドと複数の非同期スレッドを並列で処理(multiprocessing利用)
multiprocessing2.pyfrom multiprocessing.pool import ThreadPool import time import threading as th import logging # ロガーの取得 def get_logger(): logger = logging.getLogger("multiprocesssing_test") logger.setLevel(logging.DEBUG) logger.propagate = False ch = logging.StreamHandler() ch.setLevel(logging.DEBUG) ch_formatter = logging.Formatter('%(asctime)s - %(message)s') ch.setFormatter(ch_formatter) logger.addHandler(ch) return logger logger = get_logger() def async_func(name, sleep_time): # スレッドidを取得 thread_id = th.get_ident() logger.info(f"thread_id:{thread_id} name:{name} async_func開始") time.sleep(sleep_time) logger.info(f"thread_id:{thread_id} name:{name} async_func終了") return f"{thread_id}-{name}" if __name__ == "__main__": # スレッド実行用のスレッドプールを作成 # processesでスレッドの最大同時 pool = ThreadPool(processes=5) # スレッドidを取得 thread_id = th.get_ident() # 非同期処理を実行する。第一引数に関数オブジェクト、第二引数に引数を指定する。 logger.info(f"thread_id:{thread_id} mainから非同期処理をcall") futures = [] for i in range(5): future = pool.apply_async(async_func, (f"スレッド{i + 1}", 10)) # Tuple of args for foo futures.append(future) # 非同期処理と並行してmainスレッドで実行させたい処理 logger.info(f"thread_id:{thread_id} main非同期処理実行中の処理開始") time.sleep(5) logger.info(f"thread_id:{thread_id} main非同期処理実行中の処理終了") # 非同期処理が終わるのを待って、結果を取得する。 results = [future.get() for future in futures] logger.info(f"thread_id:{thread_id} 非同期処理の結果取得:{results}") pool.close()実行結果
2020-10-15 16:47:41,977 - thread_id:13448 mainから非同期処理をcall 2020-10-15 16:47:41,978 - thread_id:13448 main非同期処理実行中の処理開始 2020-10-15 16:47:41,979 - thread_id:23216 name:スレッド1 async_func開始 2020-10-15 16:47:41,979 - thread_id:21744 name:スレッド2 async_func開始 2020-10-15 16:47:41,979 - thread_id:21708 name:スレッド3 async_func開始 2020-10-15 16:47:41,979 - thread_id:21860 name:スレッド4 async_func開始 2020-10-15 16:47:41,979 - thread_id:22100 name:スレッド5 async_func開始 2020-10-15 16:47:46,980 - thread_id:13448 main非同期処理実行中の処理終了 2020-10-15 16:47:51,982 - thread_id:21744 name:スレッド2 async_func終了 2020-10-15 16:47:51,982 - thread_id:23216 name:スレッド1 async_func終了 2020-10-15 16:47:51,983 - thread_id:21708 name:スレッド3 async_func終了 2020-10-15 16:47:51,984 - thread_id:21860 name:スレッド4 async_func終了 2020-10-15 16:47:51,984 - thread_id:22100 name:スレッド5 async_func終了 2020-10-15 16:47:51,986 - thread_id:13448 非同期処理の結果取得:['23216-スレッド1', '21744-スレッド2', '21708-スレッド3', '21860-ス レッド4', '22100-スレッド5']ログから16:47:41に「main非同期処理実行中の処理」と「async_func開始」の5つの処理が同時に並列で実行されているのが分かります。
またThreadPool(processes=3)などにしてプロセス数を少なくすると、まず3つスレッドが実行されて2つが待ち状態になり完了時に新しいスレッドが実行される挙動になります。ケース3 mainスレッドと複数の非同期スレッドを並列で処理(asyncio利用)
asyncio1.pyimport asyncio import itertools import time import profile import random import time import threading as th import logging # ロガーの取得 def get_logger(): logger = logging.getLogger("asyncio_test") logger.setLevel(logging.DEBUG) logger.propagate = False ch = logging.StreamHandler() ch.setLevel(logging.DEBUG) ch_formatter = logging.Formatter('%(asctime)s - %(message)s') ch.setFormatter(ch_formatter) logger.addHandler(ch) return logger logger = get_logger() # task id的なものを取得 # ※asyncioは内部的にジェネレーターを利用しているので # スレッドIDは同じになり、非同期処理のIDに相当するものの取得方法は以下となる。 _next_id = itertools.count().__next__ def get_task_id(): return _next_id() async def async_func(name, sleep_time): # タスクidを取得 task_id = get_task_id() logger.info(f"task_id:{task_id} name:{name} async_func開始") await asyncio.sleep(sleep_time) logger.info(f"task_id:{task_id} name:{name} async_func終了") return f"{task_id}-{name}" async def async_func_caller(): # タスクidを取得 task_id = get_task_id() # 非同期処理タスクを生成 # ※この時点ではタスクを生成しているだけで実行されず、 # loop.run_until_completeを呼び出した際に実行される。 futures = [asyncio.ensure_future(async_func(f"task{i + 1}", 10)) for i in range(5)] # 非同期処理と並行してmainスレッドで実行させたい処理 logger.info(f"task_id:{task_id} async_func_caller 非同期処理実行中の処理開始") await asyncio.sleep(5) logger.info(f"task_id:{task_id} async_func_caller 非同期処理実行中の処理終了") # 非同期処理が終わるのを待って、結果を取得する。 results = await asyncio.gather(*futures) return results if __name__ == "__main__": # 非同期処理実行用のスレッドプールを作成 loop = asyncio.get_event_loop() logger.info(f"main非同期処理実行中の処理開始") # 非同期処理を実行し、終了までwait ret = loop.run_until_complete(async_func_caller()) logger.info(f"main非同期処理実行中の処理終了 結果:{ret}") loop.close()実行結果
2020-10-15 16:49:40,132 - main非同期処理実行中の処理開始 2020-10-15 16:49:40,134 - task_id:0 async_func_caller 非同期処理実行中の処理開始 2020-10-15 16:49:40,134 - task_id:1 name:task1 async_func開始 2020-10-15 16:49:40,135 - task_id:2 name:task2 async_func開始 2020-10-15 16:49:40,135 - task_id:3 name:task3 async_func開始 2020-10-15 16:49:40,136 - task_id:4 name:task4 async_func開始 2020-10-15 16:49:40,136 - task_id:5 name:task5 async_func開始 2020-10-15 16:49:45,138 - task_id:0 async_func_caller 非同期処理実行中の処理終了 2020-10-15 16:49:50,141 - task_id:2 name:task2 async_func終了 2020-10-15 16:49:50,142 - task_id:5 name:task5 async_func終了 2020-10-15 16:49:50,142 - task_id:4 name:task4 async_func終了 2020-10-15 16:49:50,144 - task_id:1 name:task1 async_func終了 2020-10-15 16:49:50,144 - task_id:3 name:task3 async_func終了 2020-10-15 16:49:50,145 - main非同期処理実行中の処理終了 結果:['1-task1', '2-task2', '3-task3', '4-task4', '5-task5']ログから16:49:40に「main非同期処理実行中の処理」と「async_func開始」の5つの処理が同時に並列で実行されているのが分かります。
非同期処理を実装する際にご参考になれば幸いです。
- 投稿日:2020-10-15T17:39:41+09:00
Alibaba CloudでACMEを暗号化:ACMEリクエストを構築し、JWSペイロードに署名
今回の多部構成の記事では、Pythonを使ったLet's Encrypt ACME version 2 APIをSSL証明書に利用する方法を学びます。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
ACMEリクエスト例
新しいアカウントを作成する例を見てみましょう。この擬似コード例は、HTTP POST、HTTPヘッダ、HTTPボディを示しています。based64_encode」は実際にはHTTPボディの一部ではありませんが、ACMEサーバに送信する前にコードがデータをbase64エンコードする必要があることを示しています。
POST /acme/new-account HTTP/1.1 Host: acme-staging-v02.api.letsencrypt.org Content-Type: application/jose+json { "protected": base64_encode({ "alg": "ES256", "jwk": {...}, "nonce": "6S8IqOGY7eL2lsGoTZYifg", "url": "https://acme-staging-v02.api.letsencrypt.org/acme/new-acct" }), "payload": base64_encode({ "termsOfServiceAgreed": true, "contact": [ "mailto:cert-admin@example.com", "mailto:admin@example.com" ] }), "signature": "RZPOnYoPs1PhjszF...-nh6X1qtOFPB519I" }ACME API HTTPリクエストボディ
ACMEリクエストは、JSON Web Signature(JWS)オブジェクトにカプセル化されます。
JWSオブジェクトは3つの部分で構成されています。JWS Protected Header、APIコマンドパラメータ(ペイロード)、シグネチャです。以下、各部分について説明します。各部分は個別にbase64エンコードされ、1つのJSONオブジェクトにまとめられます。
{ "protected": base64_encode(jws_protected_header), "payload": base64_encode(payload), "signature": based64_encode(signature) }JWS保護されたヘッダー
JWS オブジェクトの中には、JWS Protected Header があります。JWS Protected Headerには以下のフィールドが含まれています。
フィールド 説明 alg アルゴリズム。リクエストの署名に使用されるMACベースのアルゴリズムです。サポートされているアルゴリズムはES256とRS256です。参照 RFC 7518 を参照してください。これらの例では、RS256 (SH-256 を使用した RSASSA-PKCS1-v1_5) を使用します。簡単に説明します。RS256とは、RSA秘密鍵で署名し、対応するRSA公開鍵で検証することを意味します。 jwk JSON Web Key。jwkは、既存のアカウントを使用して署名されていないすべてのリクエストに使用されます。例えば、以下のようになります。"新規アカウント"。jwkは、この記事で後述するJSONオブジェクトです。 kid キー ID。kidは、既存のアカウントを使用して署名されているすべてのリクエストに使用されます。例えば、「アカウント情報の取得」などです。 nonce Nonce。リプレイ攻撃を防ぐために使用される一意の値。この値は、NewNonce APIによって返され、各成功したACME API呼び出しの後の応答ヘッダー「Replay-Nonce」で返されます。 url URL。このヘッダーパラメータは、クライアントがリクエストを指示しているURLをエンコードします。必要な値については、各ACME APIを参照してください。 「jwk」と「kid」フィールドは相互に排他的です。サーバーは両方を含むリクエストを拒否しなければいけません。
ACME APIは、どちらか一方を使用し、指定します。
JWSウェブキー(JWK)
JWK のパラメータは、暗号署名の種類によって異なる。このシリーズの例では、RSA 鍵ペアを使用しています。
フィールド 説明 e 公開指数。これは、RSA 鍵ペアの公開指数。 kty Key Type。JWS の署名に使用される方式です。RSA 鍵ペアを使用する場合は RSA になります。詳細はRFC 7638を参照のこと。 n Modulus(モジュラス)。RSA 鍵ペアからのモジュラスです。2048 ビットの鍵の場合、フィールド「n」の値はデコード時に 256 オクテットの長さになります。 { "e": base64_encode(public_exponent), "kty": "RSA", "n": base64_encode(modulus), }ペイロード
ペイロードにはAPIコールパラメータが含まれます。これらはAPIごとに異なります。ペイロードの json オブジェクトの内容は base64 エンコードされています。次の例は、New Account API のペイロードを示しています。パラメータは2つあります。"termsOfServiceAgreed "と "contact "です。ペイロードは、HTTPボディに含まれるJSON Web Signature(JWS)の一部です。
"payload": base64_encode({ "termsOfServiceAgreed": true, "contact": [ "mailto:cert-admin@example.com", "mailto:admin@example.com" ] })署名
署名は、RSA 秘密鍵を使用した SHA-256 メッセージ・ダイジェストです。ACME サーバは、対応する公開鍵を使用して署名を検証します。
def sign(data, keyfile): """ Create the ACME API Signature """ # Load the RSA Private Key from the file (RSA PKCS #1) pkey = load_private_key(keyfile) # Create the signature sig = crypto.sign(pkey, data, "sha256") return sig概要
以上、ACME APIシステムがどのように動作するかを示しました。
次の最後の部分では、DNS検証の実行方法と、ACME DNS検証をサポートするためのDNSサーバーリソースレコードの作成と修正方法を見ていきます。
アリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ
- 投稿日:2020-10-15T17:24:59+09:00
Pandas の Rolling の使い方
株価や新型コロナウイルス陽性患者数など、細かく数値が上下するデータの大まかな傾向を掴むには、ある時点の前後の数値を含めた平均を取ります。このような操作を行う Pandas の関数である rolling についてメモします。
普通の使い方
import pandas as pdまず rolling の基本動作を確認するために、10 個の 1 が並んだ Series を作り ones と名付けます。
ones = pd.Series([1] * 10) ones0 1 1 1 2 1 3 1 4 1 5 1 6 1 7 1 8 1 9 1 dtype: int64rolling を使って ones を4つずつ足してゆきます。1 の数値を 4 つずつ足してゆくだけなので当然結果は 4 の列になります。ただ、最初にデータが 4 つ揃わない部分の結果は NaN になります。元の列と比較するために、ones と足した結果の sum-4 を並べてみました。
このように window で集計するデータの個数 (window の幅) を指定します。4 つの窓が最初から最後まで移動しながら集計してゆくイメージです。集計結果は window の最後に記録されるので、sum-4 の最初の 3 つの値は NaN になっています。
pd.DataFrame({ 'ones': ones, 'sum-4': ones.rolling(window=4).sum(), })
ones sum-4 0 1 NaN 1 1 NaN 2 1 NaN 3 1 4.0 4 1 4.0 5 1 4.0 6 1 4.0 7 1 4.0 8 1 4.0 9 1 4.0 center=True を指定すると、集計結果を window の最後に記録する代わりに真ん中に記録する事も出来ます。これを sum-center として並べてみます。window が偶数の時は中心の後ろに記録します。今度は最後の要素が NaN になりました。
pd.DataFrame({ 'ones': ones, 'sum-4': ones.rolling(window=4).sum(), 'sum-center': ones.rolling(window=4, center=True).sum(), })
ones sum-4 sum-center 0 1 NaN NaN 1 1 NaN NaN 2 1 NaN 4.0 3 1 4.0 4.0 4 1 4.0 4.0 5 1 4.0 4.0 6 1 4.0 4.0 7 1 4.0 4.0 8 1 4.0 4.0 9 1 4.0 NaN デフォルトではデータの端っこの window の幅が足りない部分の集計は行いません。しかし min_periods を指定すると、最低限 min_periods の分があれば集計します。この例では、min_period=2 を指定していますので2つ目の行から結果が現れます。
pd.DataFrame({ 'ones': ones, 'sum-4': ones.rolling(4).sum(), 'min-periods': ones.rolling(window=4, min_periods=2).sum(), })
ones sum-4 min-periods 0 1 NaN NaN 1 1 NaN 2.0 2 1 NaN 3.0 3 1 4.0 4.0 4 1 4.0 4.0 5 1 4.0 4.0 6 1 4.0 4.0 7 1 4.0 4.0 8 1 4.0 4.0 9 1 4.0 4.0 ここまでは window にかかった部分の要素を全て使って集計していましたが、
win_typeを使うと集計する値の重みを変えられるそうです。scipy のインストールが必要。pd.DataFrame({ 'ones': ones, 'sum-4': ones.rolling(4).sum(), 'win_type': ones.rolling(window=4, win_type='nuttall').sum(), })
ones sum-4 win_type 0 1 NaN NaN 1 1 NaN NaN 2 1 NaN NaN 3 1 4.0 1.059185 4 1 4.0 1.059185 5 1 4.0 1.059185 6 1 4.0 1.059185 7 1 4.0 1.059185 8 1 4.0 1.059185 9 1 4.0 1.059185 インデックスに日付を使う
ここまでは window に要素の個数を指定しました。ここで Series の index が日付や時刻の時だけ時間や日数などの期間を window に指定する事が出来ます。早速サンプルのデータを作ってみます。
date_ones = pd.Series( index=[ pd.Timestamp('2020-01-01'), pd.Timestamp('2020-01-02'), pd.Timestamp('2020-01-07'), pd.Timestamp('2020-01-08'), pd.Timestamp('2020-01-09'), pd.Timestamp('2020-01-16'), ], data=[1,1,1,1,1,1] ) date_ones2020-01-01 1 2020-01-02 1 2020-01-07 1 2020-01-08 1 2020-01-09 1 2020-01-16 1 dtype: int64ここで window='7d' のように指定すると、7日前までの要素を使って集計します。
pd.DataFrame({ 'ones': date_ones, 'rolling-7d': date_ones.rolling('7D').sum(), })
ones rolling-7d 2020-01-01 1 1.0 2020-01-02 1 2.0 2020-01-07 1 3.0 2020-01-08 1 3.0 2020-01-09 1 3.0 2020-01-16 1 1.0 この例では
- 2020-01-01: 前に何もないので 1
- 2020-01-02: 7日前以内に一つ有るので 2
- 2020-01-07: 7日前以内には 2020-01-01, 2020-01-02, 2020-01-07 があるので 3
- 2020-01-08: 7日前以内には 2020-01-02, 2020-01-07, 2020-01-08 があるので 3
- 2020-01-16: 7日前以内には何もないので 1
となります。
この '7D' のような指定方法を offset と呼びます。Offset aliases に説明があります。
window に offset を使うとデータが少なくとも集計が行われるので勝手に NaN が記録される事はありません。逆に min_periods を指定すると、指定した offset 期間に指定した以上のデータが無いと NaN になります。
pd.DataFrame({ 'ones': date_ones, 'rolling-7d': date_ones.rolling('7D').sum(), 'rolling-min-periods': date_ones.rolling('7D', min_periods=3).sum(), })
ones rolling-7d rolling-min-periods 2020-01-01 1 1.0 NaN 2020-01-02 1 2.0 NaN 2020-01-07 1 3.0 3.0 2020-01-08 1 3.0 3.0 2020-01-09 1 3.0 3.0 2020-01-16 1 1.0 NaN 移動平均の例
さて、ここまでの知識を使って東京都の新型コロナウイルス感染者数の移動平均グラフを描いてみます。
データは 東京都 新型コロナウイルス陽性患者発表詳細 から拝借します。
covid_src = pd.read_csv('https://stopcovid19.metro.tokyo.lg.jp/data/130001_tokyo_covid19_patients.csv', parse_dates=['公表_年月日']) covid_src
No 全国地方公共団体コード 都道府県名 市区町村名 公表_年月日 曜日 発症_年月日 患者_居住地 患者_年代 患者_性別 患者_属性 患者_状態 患者_症状 患者_渡航歴の有無フラグ 備考 退院済フラグ 0 1 130001 東京都 NaN 2020-01-24 金 NaN 湖北省武漢市 40代 男性 NaN NaN NaN NaN NaN 1.0 1 2 130001 東京都 NaN 2020-01-25 土 NaN 湖北省武漢市 30代 女性 NaN NaN NaN NaN NaN 1.0 2 3 130001 東京都 NaN 2020-01-30 木 NaN 湖南省長沙市 30代 女性 NaN NaN NaN NaN NaN 1.0 3 4 130001 東京都 NaN 2020-02-13 木 NaN 都内 70代 男性 NaN NaN NaN NaN NaN 1.0 4 5 130001 東京都 NaN 2020-02-14 金 NaN 都内 50代 女性 NaN NaN NaN NaN NaN 1.0 ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... 28131 28031 130001 東京都 NaN 2020-10-14 水 NaN NaN 10歳未満 男性 NaN NaN NaN NaN NaN NaN 28132 28032 130001 東京都 NaN 2020-10-14 水 NaN NaN 20代 男性 NaN NaN NaN NaN NaN NaN 28133 28033 130001 東京都 NaN 2020-10-14 水 NaN NaN 70代 男性 NaN NaN NaN NaN NaN NaN 28134 28034 130001 東京都 NaN 2020-10-14 水 NaN NaN 20代 女性 NaN NaN NaN NaN NaN NaN 28135 28035 130001 東京都 NaN 2020-10-14 水 NaN NaN 40代 女性 NaN NaN NaN NaN NaN NaN 28136 rows × 16 columns
必要なのは人数だけなので、groupby と size で日付ごとの件数を出します。
covid_daily = covid_src.groupby("公表_年月日").size() covid_daily.index.name = 'date' covid_dailydate 2020-01-24 1 2020-01-25 1 2020-01-30 1 2020-02-13 1 2020-02-14 2 ... 2020-10-10 249 2020-10-11 146 2020-10-12 78 2020-10-13 166 2020-10-14 177 Length: 239, dtype: int64単に日付ごとの件数をグラフに描くとこのようにジグザグになります。
covid_daily.plot()
一週間の window を設定して陽性患者の傾向を掴みます。ここで、今までの sum() の代わりに mean() を使うと移動平均になります。
covid_daily.rolling(window='7D').mean().plot()
参考
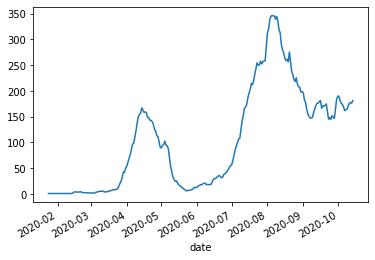
- 投稿日:2020-10-15T17:18:08+09:00
【パス打ちオート】NECLOBOTの導入
必須
事前にこちらに記載された設定を完了させておいてください。
また、当記事に記載された導入方法は私が提供しているパス打ちオート限定のものとなります。オート自体は有料での販売となりますのでご了承ください。
公開中のパス打ちオート → サンプル
ファイルのダウンロード
TwitterのDMにて個別に送られたURLにアクセスします
※TwitterのブラウザではなくSafariで直接開いて下さい右上の
すべてダウンロードをタップします
ダウンロードをタップ
これでファイルのダウンロードは完了ですPythonistaの設定
続いてダウンロードしたファイルをPythonistaアプリ内に移行します
Pythonistaを開き、
OPEN>Folder...をタップ
このiPad内>ダウンロードを選択して右上の完了をタップ
※iCloud Driveにのみダウンロードがある場合はそちらをタップしてください
先程ダウンロードしたzipフォルダを選択して
Extract Archive...をタップ
生成されたフォルダの中にパス打ちオート.GUIがあることを確認します
三本線の左側にある
Editをタップ
パス打ちオート.GUIを選択
画面左下のゴミ箱マークの右隣にあるフォルダマークをタップ
1番上の
Documentsをタップ
※Documentsがない場合は、1番上の項目をタップしてください
パス打ちオート.GUIがスっと消えてなくなりますが、移動しただけなので大丈夫です。
ホームに戻り、
This iPadをタップ
パス打ちオート.GUIをタップ
このような構成になっていれば導入成功です
セットアップ.pyを開き、指示に従って実行してください
セットアップが完了したらオート.pyを開きます
右上の▷を押すとNECLOBOT.GUIが起動しますショートカットの作成
実際にパス打ちオートとして使う際は、プログラムをキーボード上で動かす必要があります。キーボード上にこのプログラムのショートカットを作りましょう。
iOSの設定→一般→キーボードを開きます
キーボード(またはキーボード追加など)をタップします
新しいキーボードを追加より、PyKeysを追加します
iOSの設定→Pythonistaを開きます
キーボードを選択し、PyKeysとフルアクセスを許可を両方オンにしてください
再びPythonistaアプリに戻ります。
オート.pyを開いたまま右上にある?ボタンを押し、Shortcuts...をタップ
Pythonista Keyboardをタップ
右上の
+をタップ
Custom Titleにつけたいショートカット名を入力してください。
Argumentsは空白のままで大丈夫です。
アイコンとアイコンカラーも好みのものにカスタマイズ出来ます。
設定が終わったらAddをタップ
これでキーボードショートカットが作成できました!
DONEを押して終了です。
メモ帳などでPythonistaキーボードを開いて確認してみましょう!
これで導入完了です。お疲れ様でした。
分からないことがあればコメントかTwitter - NECLOMIAまでご連絡ください


























- 投稿日:2020-10-15T16:52:15+09:00
熊本県の Go To EATの加盟店一覧のPDFをCSVに変換
GoToEatキャンペーンくまもとの加盟店一覧のPDFをCSVに変換
コマンド
wget https://gotoeat-kumamoto.jp/pdf/shoplist.pdf -O data.pdf apt install python3-tk ghostscript pip install camelot-py[cv] camelot -p all -o data.csv -f csv -split lattice -scale 40 data.pdfPython
import camelot import pandas as pd tables = camelot.read_pdf("data.pdf", pages="all", split_text=True, strip_text=" \n", line_scale=40) dfs = [table.df for table in tables] df_tmp = pd.concat(dfs) df = df_tmp.iloc[1:].set_axis(df_tmp.iloc[0].to_list(), axis=1).reset_index(drop=True) df.sort_values(by=["郵便番号", "町域、番地"], inplace=True) df.to_csv("kumamoto.csv", encoding="utf_8_sig")
- 投稿日:2020-10-15T16:49:04+09:00
(初心者向け)Pythonでオセロを作ってみよう
こんにちは!かっきーです!!
今回はPythonでオセロを作りたいと思います。
(追記)(1)randomは必要ありませんでした。申し訳ございません。
必要なライブラリは以下の通りです。
(1) random
(2) numpy(1)は標準ライブラリと呼ばれ元々Pythonに組み込まれているので、pip installする必要はありません。
(2)のnumpyはインストールしていなければ、
pip install numpy
とコマンドプロンプトに打ち込み、インストールしてみてください。ライブラリの準備が出来たらメインのオセロプログラムに入りたいと思います。
from numpy import zeros, where, float32 class othello: #定数 (-1をかけることで黒から白、白から黒へのひっくり返しを表現できる) white = 1. black = -1. empty = 0. edge = 8 # 1辺の個数 #初期化 def __init__(self): self.board = zeros(self.edge**2, dtype=float32) # 盤面を0(=self.empty)で初期化 self.board[27] = self.board[36] = self.white # 初期コマ配置 self.board[28] = self.board[35] = self.black # 初期コマ配置 self.turn = True # white:True black:False self.available = [] # ひっくり返せる場所の座標を保持する配列 #ひっくり返す s:置く番号 ex:Trueならひっくり返しを実行, Falseならひっくり返さないで置けるか否か確認するだけ def over(self, s, ex=True): s = int(s) start = s my_color = self.white if self.turn else self.black flag = False # sに置けるか否かフラグ for i in range(-1, 2): for j in range(-1, 2): v = self.edge * i + j # vは8方向(の中のどれか)への移動を表す if v == 0: continue s = start for k in range(self.edge - 1): s += v # 移動量を足す if (s < 0 or s > self.edge**2 - 1 or self.board[s] == self.empty): # 盤面外 or 空きマスならその方向へはひっくり返せない break if self.board[s] == my_color: # 自分の色と一致したら if k > 0: # k=0のときは, 置いた場所(start)と接してるマスなのでひっくり返しは発生しない if ex: self.board[start + v: s : v] *= -1 # ひっくり返しを実行 flag = True # 1枚でもひっくり返せればその場所に置くことができる break if (((s % self.edge == 0 or s % self.edge == self.edge - 1) and abs(v) != self.edge) or ((s // self.edge == 0 or s // self.edge == self.edge - 1) and abs(v) != 1)): break if flag and ex: # 指定した場所にコマを置けるなら置く self.board[start] = my_color return flag #勝敗判定 def judge(self): n_white = len(where(self.board == self.white)[0]) # 白石の個数 n_black = len(where(self.board == self.black)[0]) # 黒石の個数 print("\n", "黒 >> ", n_black, " 白 >> ", n_white, "\n") # 石の個数を出力 if n_white < n_black: print("黒の勝ち") elif n_black < n_white: print("白の勝ち") else: print("引き分け") #アップデート関数 def update(self, end=False): self.turn ^= True self.available = [] # self.availableに置くことのできる座標を入れておく for i in range(self.edge**2): if self.board[i] == self.empty and self.over(i, ex=False): self.available.append(i) if len(self.available) == 0: return False if end else self.master(end=True) # 2回連続置けないならゲーム終了 self._input() return True #入力(CUI) def _input(self): while True: msg = "白のターン" if self.turn else "黒のターン" x, y = map(int, input(msg + " 行列指定 >> ").split()) if 8 * x + y in self.available: # 石が置ける場所が入力されたら self.over(8 * x + y) # ひっくり返す処理 break print("---Invalid Position---") # 石が置けない場所が入力されたら警告メッセージ #盤面描画(CUI) def draw(self): edge = self.edge print("\n 0 1 2 3 4 5 6 7") for i in range(edge): temp = [] temp.append(str(int(i))) for el in self.board[edge * i:edge * (i + 1)]: if el == self.white: temp.append("○") elif el == self.black: temp.append("●") else: temp.append("+") print(" ".join(temp)) #メイン関数 def main(): s = othello() # オセロインスタンス生成 flag = True # ゲームが続いてるか否かのフラグ (True:続行中, False:終了) while flag: s.draw() # 盤面描画 flag = s.update() # アップデート関数 s.judge() #ゲームが終了したら勝敗判定 if __name__ == "__main__": main()(注意点)
(1) overメソッドにおいてキーワード引数exによって、実際にコマをひっくり返すのか否かを判断しています。ひっくり返さなくていいときというのは、事前にどこにコマを置けるのかを探索するときです。(2) overメソッドにおいて盤面の座標は行列形式ではなく、self.board上のインデックスで表現しています。なので行列とインデックスの変換に注意してください。例えば、i行j列のインデックスは、i * self.edge + j となります。
このプログラムをコピペして実行してみてください。
何か不具合等ありましたらお気軽にご連絡ください。
- 投稿日:2020-10-15T16:31:57+09:00
【基本編】集計からダッシュボードの作成まで一本化!PythonとDashによるデータ可視化アプリ開発 〜Dashの概要、環境構築、サンプル実行まで〜
本記事は、2020年10月16日に作成されました。
はじめに
マーケティングリサーチプラットフォームを提供している株式会社マーケティングアプリケーションズの今井です。
弊社では、キリンビール様から発売中の本麒麟がなぜヒットしているのか、その要因を探るため、アンケートでデータ収集→Pythonで集計→Dashでダッシュボードの作成を行い、データを可視化するWebアプリ開発に挑戦しました。
(Twitter公開時にDash操作の動画埋め込み)
(ヒット分析の動画のリンク貼り付け)
弊社では、Dashに関した内容を、基本編、Tips編、活用編の3つに分けてQiitaで投稿していきます。
基本編(本記事)
Dashの概要、環境構築、サンプルを実行してグラフを可視化する方法を紹介します。
YouTubeでも授業形式の解説動画を公開中。本記事を教科書として使いながら、ご視聴ください!Tips編(作成中。記事公開後、リンクいたします)
バブルチャート、複合グラフ、帯グラフ、レーダーチャートなど様々なグラフの可視化や、グラフをより見やすく、かつわかりやすくするための応用的な手法を紹介します。実践編(作成中。記事公開後、リンクいたします)
本麒麟のヒット分析を行うにあたり、Dashを用いてどのようにダッシュボードを作成したか、Tips編の内容を組み合わせた実践的な手法を紹介します。そもそも今回作る「ダッシュボード」とは何か?
Dashによる構築手法を紹介する前に「ダッシュボードとは◯◯である」と皆様と定義を共有しておく必要があります。一つ問いを立ててみましょう。
「Q.ダッシュボードとは何でしょうか?」
この問いに皆様は、何と答えるでしょうか?
「目標達成状況・新規受注状況・売り上げ推移など経営組織全体のKPI進捗サマリー」
「販売している商品の販売実績管理表」
「従業員の仕事のパフォーマンスや満足度をスコア化、勤務の状況も可視化した人事に関したグラフのまとまり」
おそらく、色々な答え方ができると思います。
なぜ違った答え方ができるのかと言うと、ダッシュボードは、色々な立場の人が、色々なデータを可視化し、色々な場面で使っているため、ダッシュボード自体の認識の仕方そのものが千差万別となるのです。そこで本シリーズでは、ダッシュボードの定義をわかりやすく表した、永田ゆかり著 2020年『データ可視化のデザイン』 SBクリエイティブから下記の一文を引用し、ダッシュボードとは、
データを見て理解を促進させる視覚的表現
と定義することにしました。
この定義だと、上記に記載した答え全て含まれると思います。
それでは、皆様とダッシュボードの定義を共有したところで、早速Dashの解説に移ります。Dashとは?
・データ可視化に特化したPythonのWebフレームワークです。
・Flask、Plotly.js、React.jsによって作られています。
・公式サイトでは、「It's particularly suited for anyone who works with data in Python.」とあり、特にPythonでデータを扱う人に向いているとのこと。Pythonで集計・分析したデータを、今度はWebアプリケーションによって可視化するところまで一本でやってみたい!という方には、オススメのフレームワークだと思います。使用環境
使用している環境は、下記の通りです。
・Mac(Windowsでも可)
・Anaconda 4.8.5
・Python 3.8.3
・dash 1.16.3
・dash-core-components 1.12.1
・dash-html-components 1.1.1環境構築
各人ごとに環境構築の方法を記載しています。
自分が該当する項目からお読みください。Anacondaがない方へ ▶︎Anacondaをインストールする
エディタがない方へ ▶︎VisualStudioCode(以下:VSCode)をインストールする
Anacondaとエディタ(VSCode)がある方へ ▶︎Dash用の仮想環境を用意する
※エディタがない方向けにVSCodeを紹介しております。Pythonの開発ができる統合開発環境(PyCharm)、エディタ(Atom,Vim,Sublime Text等)であれば問題ございません。Anacondaがない方へ ▶︎Anacondaをインストールする
「Anaconda」
下記のサイトに遷移して、メニュー内の「Products」→「Individual Edition」をクリック、
https://www.anaconda.com/
ご自身の環境に合ったインストーラーを選んでください。
ダウンロードしたインストーラーパッケージを起動して、最後の「概要」まで進んでいきます。
エディタがない方へ ▶︎VisualStudioCodeをインストールする
「Visual Studio Code」
https://azure.microsoft.com/ja-jp/products/visual-studio-code/「今すぐダウンロード」をクリック。
ご自身の環境に合ったインストーラーを選んでください。
zipファイルを開いたら、アプリケーションが入っていますのでそれが起動できればOKです。
Anacondaとエディタがある方へ ▶︎Dash用の仮想環境を用意する
Anacondaでは複数の仮想環境(conda環境)を構築することができますので、Dash用の仮想環境を用意していきます。
仮想環境を用意することは、「Dashで必要なライブラリをインストールした。すると、他に使用しているライブラリと競合してエラーが出てしまった」というトラブルを回避することができます。Anaconda Navigatorを起動して「Environments」をクリックして、「Create」をクリック。
Nameに「dash」、Pythonは、「3.8」を選択し、「Create」をクリック。
構築が完了しましたら、新しく「dash」という環境が追加されています。
「dash」の環境を起動させます。ターミナルを立ち上げて、下記のコマンドを入力します。
conda activate dash下記のように新しく構築した環境の名前が表示されます。
(dash) L116: (ユーザーの名前等が表示されているかと思います)必要なライブラリをインストールする
実行している現在の環境に、必要なライブラリをcondaコマンドでインストールしていきます。
ライブラリインストール時に、「Proceed ([y]/n)?」と途中に聞かれて「y」と入力しないといけません。
この処理を自動化するために、末尾に「-y」とつけて、インストールしていきます。conda install -c conda-forge dash -yconda install -c anaconda pandas -yconda install -c plotly plotly -y簡単なグラフを可視化する
環境は揃いましたので、次は簡単なグラフを可視化してみます。
作成するのは、下記のグラフです。
デスクトップを作業場所にします。
「dash」フォルダを作成し、その下に「sample」フォルダを作成。
下記のコードをコピペして「app.py」のファイルを作成して、保存します。app.py# -*- coding: utf-8 -*- # Run this app with `python app.py` and # visit http://127.0.0.1:8050/ in your web browser. import dash import dash_core_components as dcc import dash_html_components as html import plotly.express as px import pandas as pd external_stylesheets = ['https://codepen.io/chriddyp/pen/bWLwgP.css'] app = dash.Dash(__name__, external_stylesheets=external_stylesheets) # assume you have a "long-form" data frame # see https://plotly.com/python/px-arguments/ for more options df = pd.DataFrame({ "Fruit": ["Apples", "Oranges", "Bananas", "Apples", "Oranges", "Bananas"], "Amount": [4, 1, 2, 2, 4, 5], "City": ["SF", "SF", "SF", "Montreal", "Montreal", "Montreal"] }) fig = px.bar(df, x="Fruit", y="Amount", color="City", barmode="group") app.layout = html.Div(children=[ html.H1(children='Hello Dash'), html.Div(children=''' Dash: A web application framework for Python. '''), dcc.Graph( id='example-graph', figure=fig ) ]) if __name__ == '__main__': app.run_server(debug=True)「sample」フォルダに「app.py」があることを確認しましょう。
ターミナルを開いて、下記のように進んでいきます。
「dash」の環境を立ち上げる。
conda activate dash「app.py」があるディレクトリに移動。
cd (略)Desktop/dash/sample下記のように入力
python app.pyするとターミナル上で下記のように表示されます。
http://127.0.0.1:8050/
をコピペして、ブラウザのURL入力欄に貼り付けます。
無事に表示されたことが確認できたら、完了です!
Dashの構成とサンプルコードの解説
Dashの構成は、以下の2つです。
「Layout」アプリ内の外観を決める。(例:Divを生成して、その中にH1タグを入れる、グラフを表示させる)
「Callbacks」アプリ内のデータと操作間の連携をさせる。(例:入力した情報に応じてグラフを表示させる)上記の棒グラフを作成するサンプルコードは、下記のような構成をしております。
大まかには、下記のように3工程で完了できるかと思います。準備:必要なライブラリをインポートする、データを作成する、データを使ってグラフを作成する
表示:Layout内で必要な装飾をし、データを流し込む
実行:アプリを実行する
今回シリーズを通して、「Callbacks」は使用せず、ただデータを表示するのみ行っております。
「Callbacks」を使用することで、よりデータを表示させる方法の幅を広げることができると思いますので、興味がある方は、ぜひ「Callbacks」も調べてみてください。その他 エラーが起こったときの対処方法
自分でコードをカスタマイズしていると、下記のようにエラーが起こる場合があります。
その時は、ターミナルを確認します。
するとapp.pyの30行目のfigがうまく読み込めていないことがわかりました。
「app.py」のソースコードを確認すると、figの行がコメントアウトされていました。
再び、実行できるようにコメントアウトを外して保存します。
再度、実行をして、ブラウザを更新します。
python app.py再び画面が表示されました。
次回は、より応用的な手法のTips編です。
今回は、Dashで簡単な棒グラフの可視化までを行いました。
次回は、バブルチャート、複合グラフ、帯グラフ、レーダーチャートなど様々なグラフの可視化や、グラフをより見やすく、かつわかりやすくするための応用的な手法を紹介します。Tips編(作成中。記事公開後、リンクいたします)





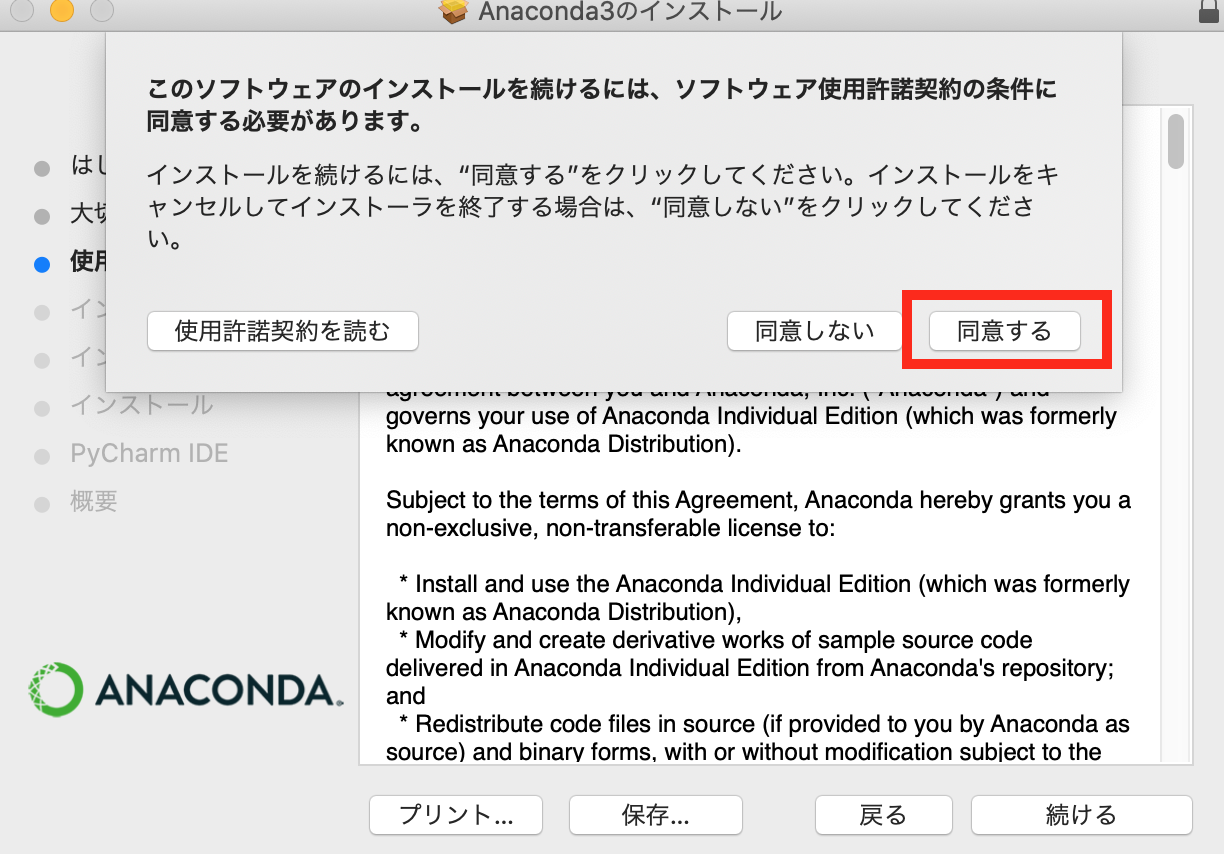
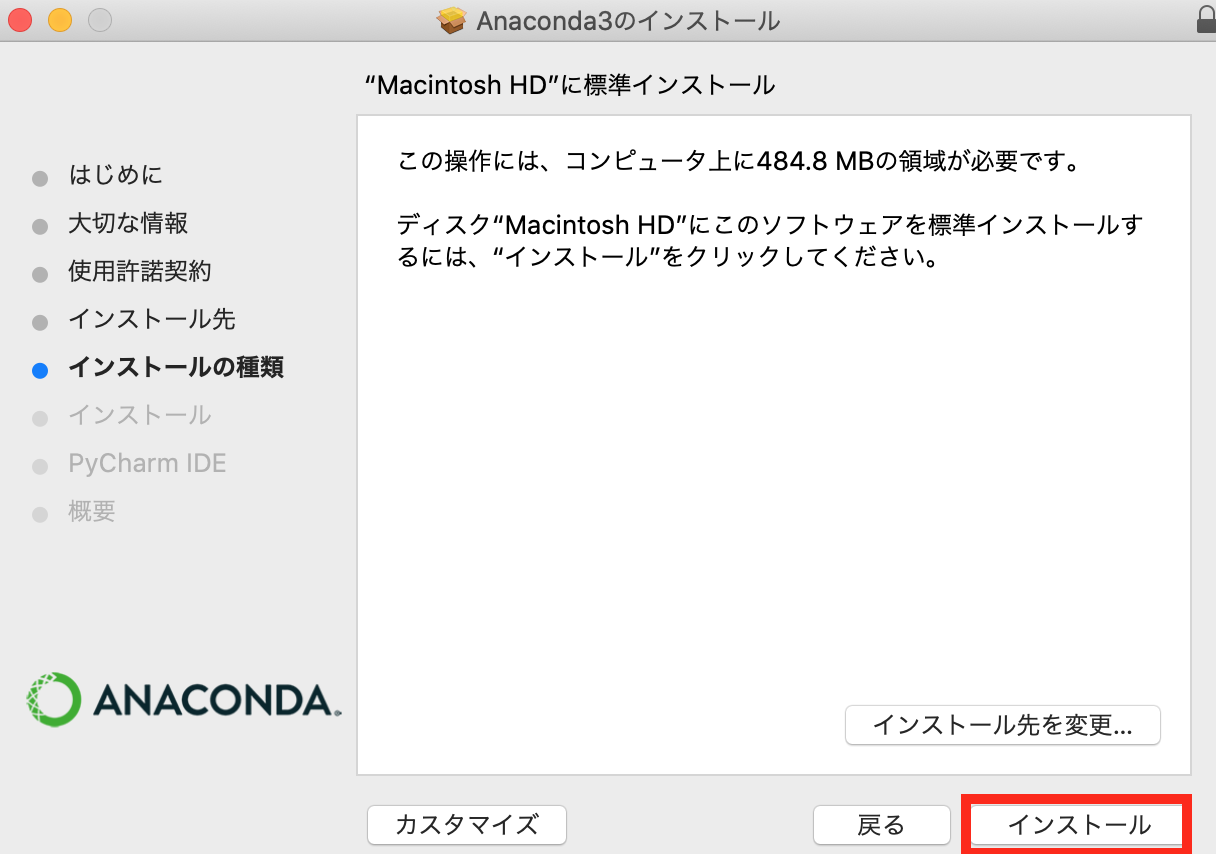
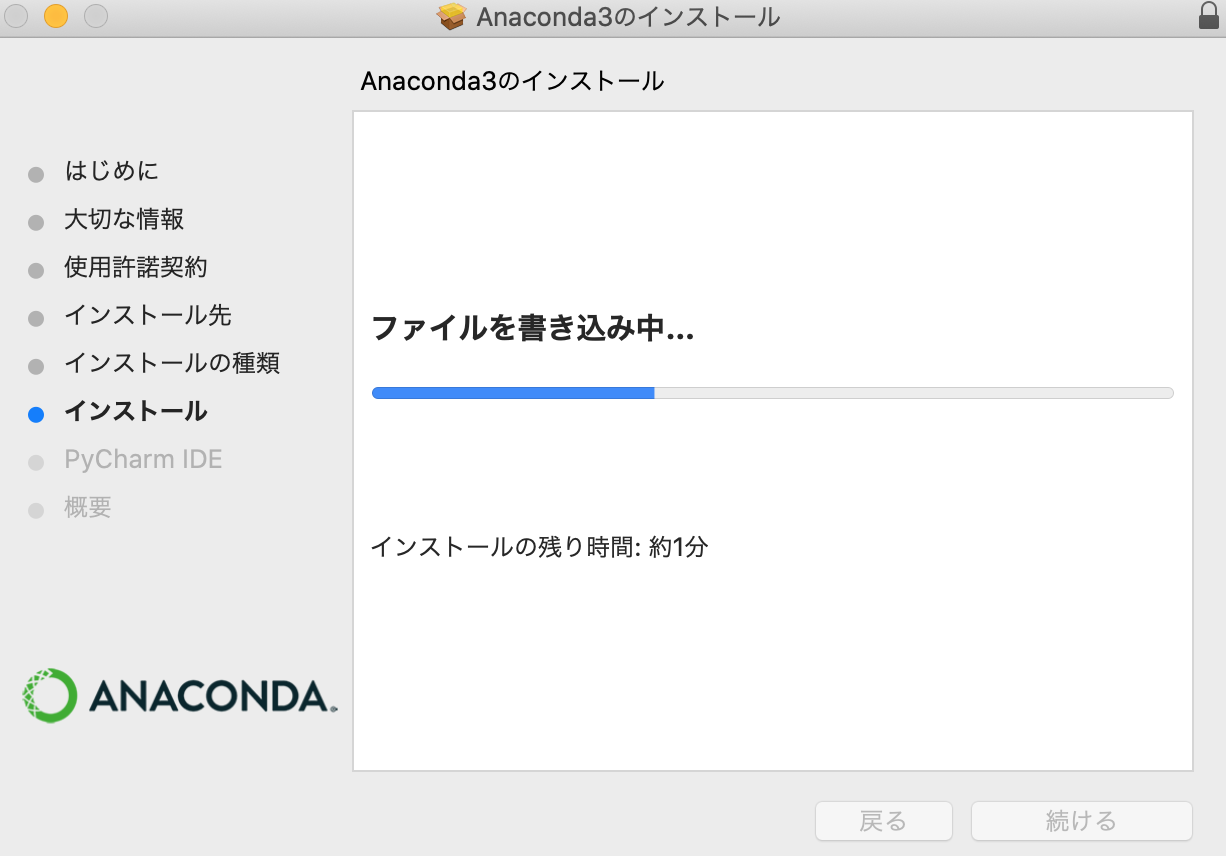
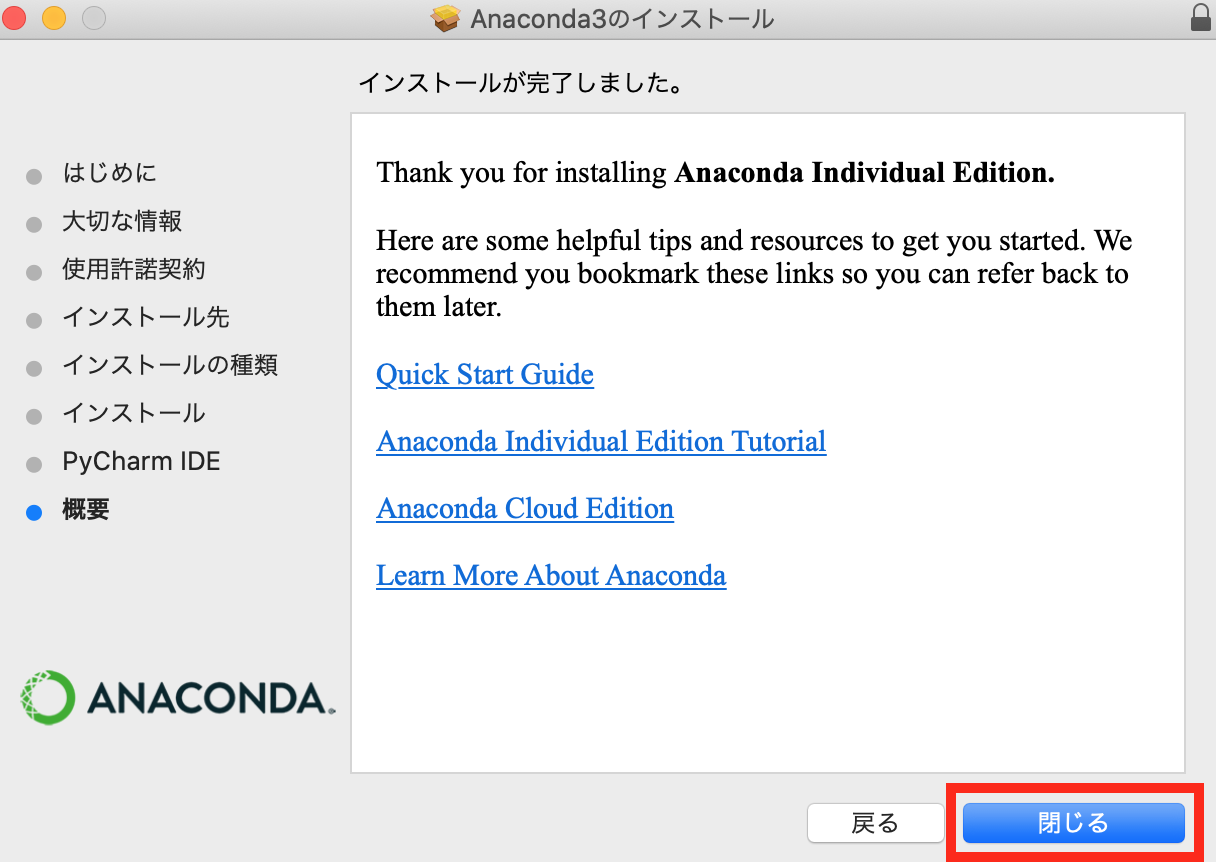
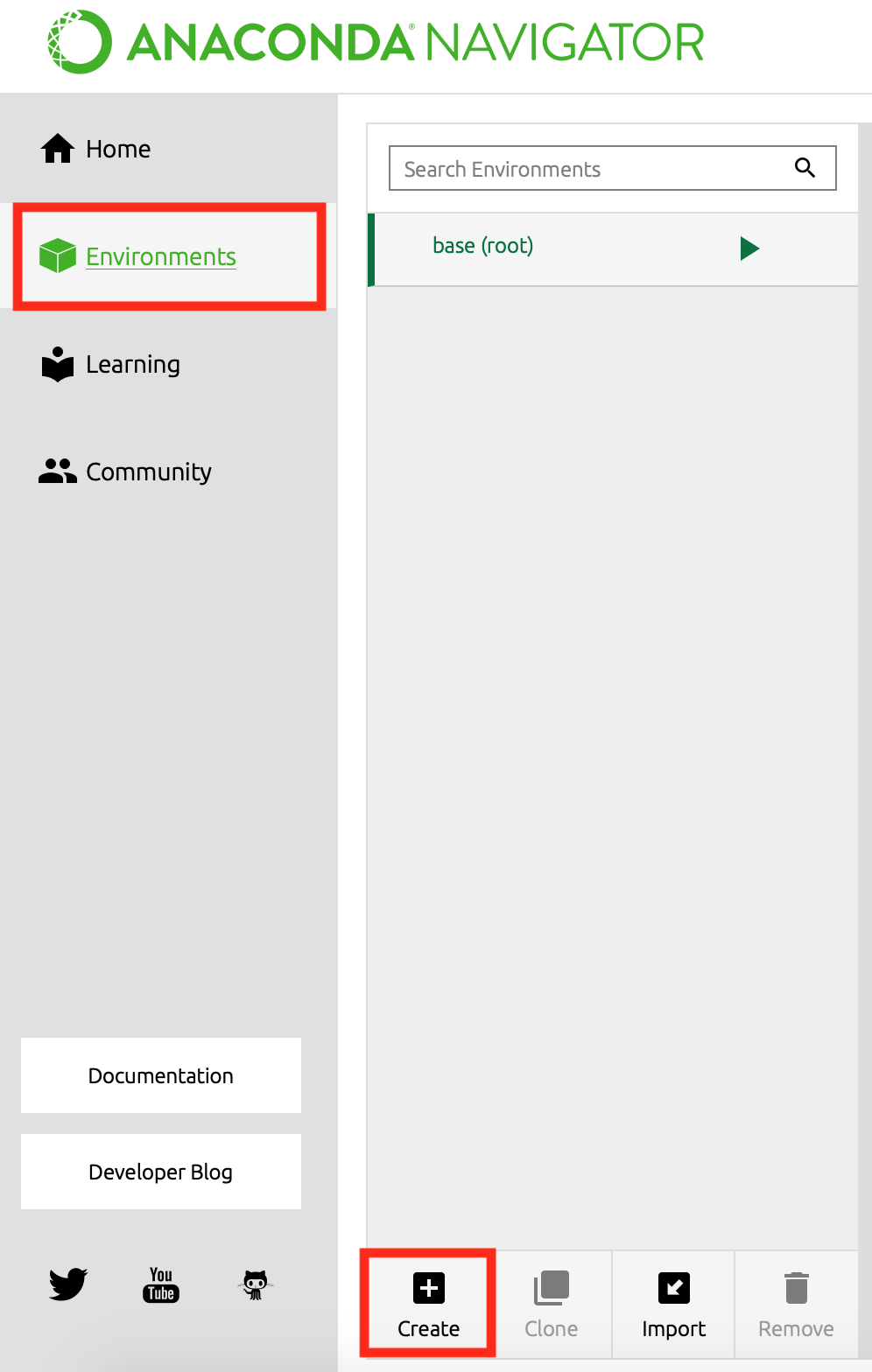

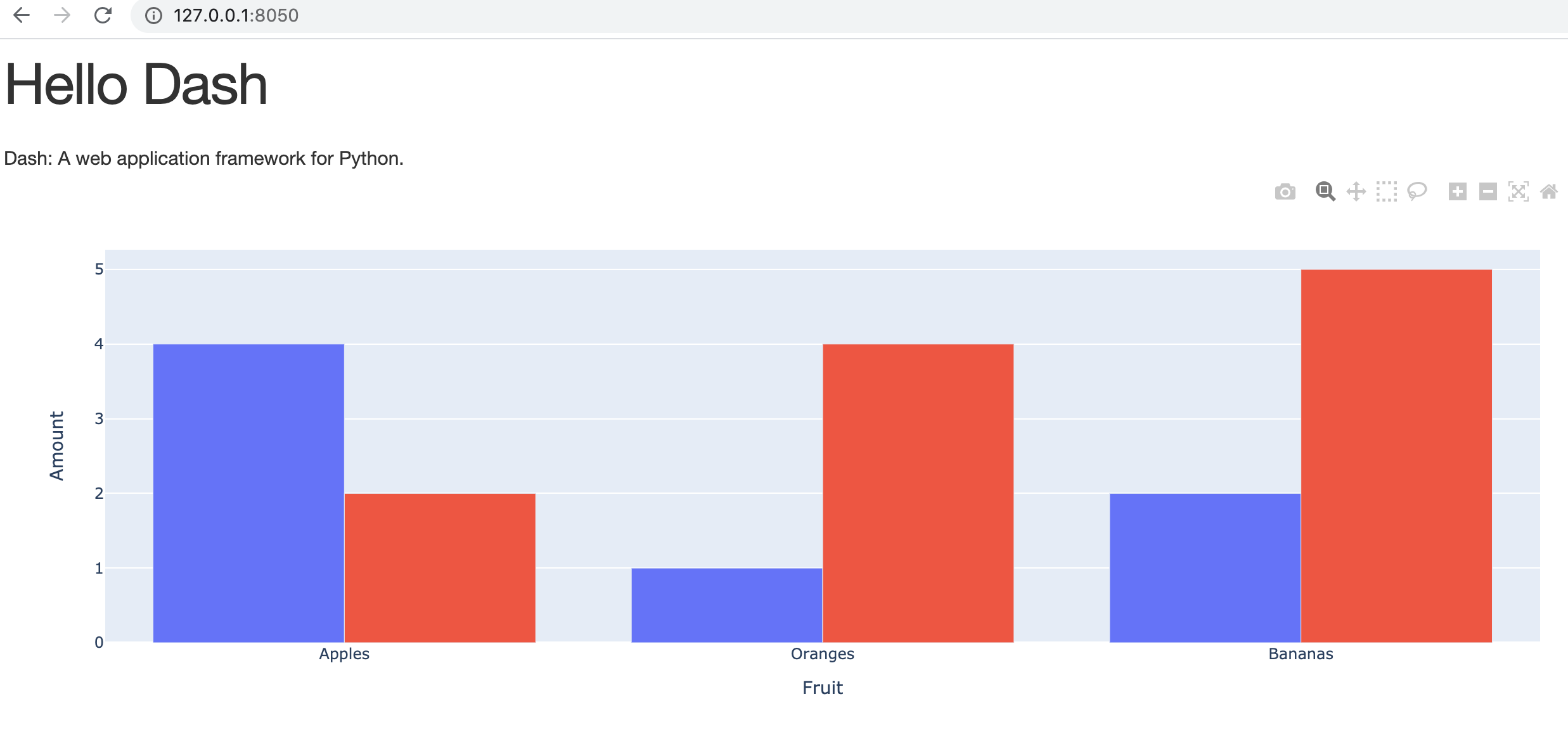


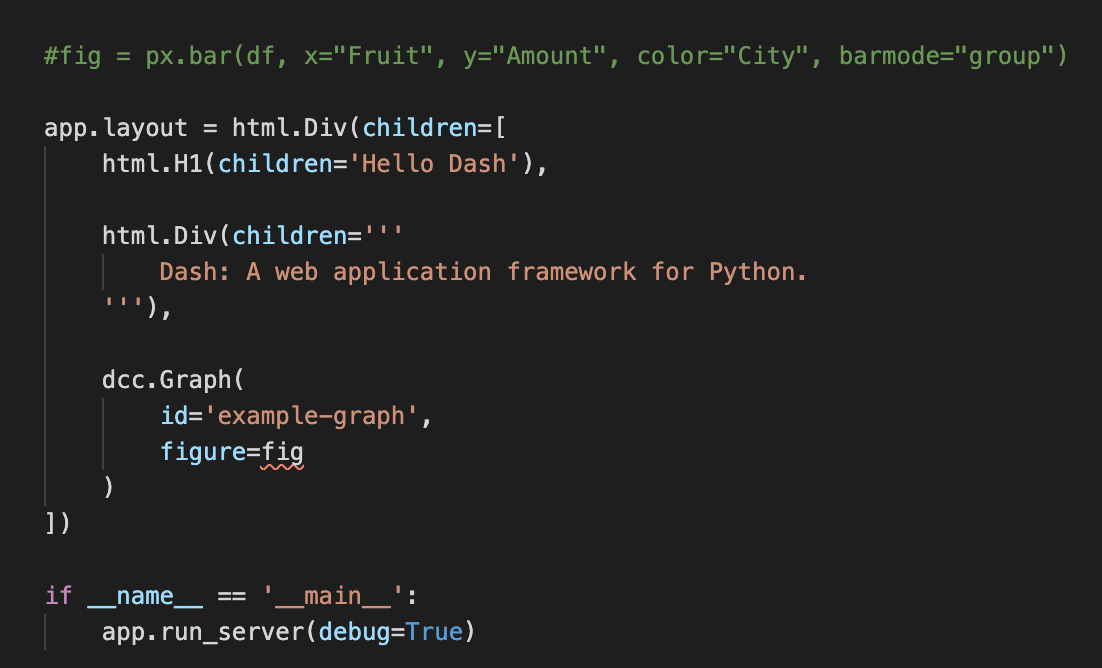
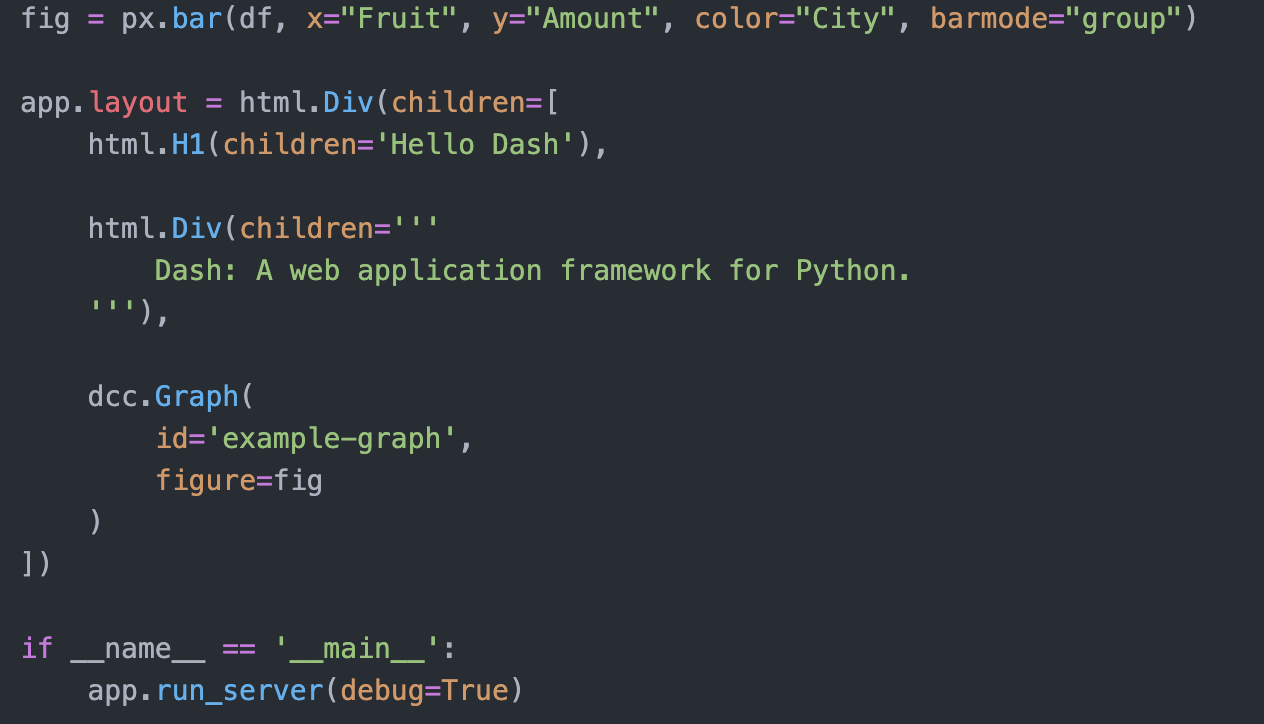
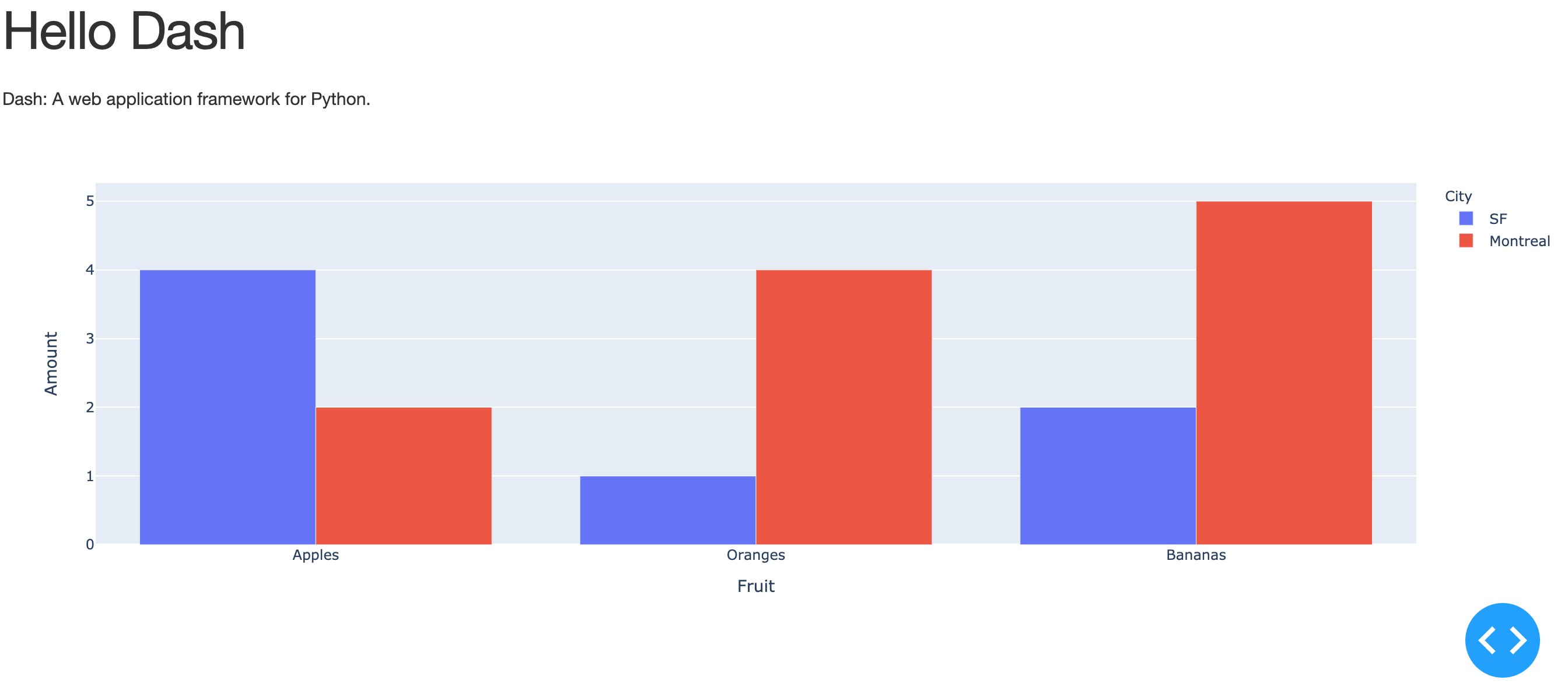
- 投稿日:2020-10-15T15:37:11+09:00
ペンシルパズル「サングラス」用のソルバーを作ったので技術解説をば
概要
「サングラス」、というペンシルパズル(=紙上で鉛筆と消しゴムを使って解くパズル)があります。
この前これの布教ツイートを見かけ、
#ふーのパズル#デレマスパズル部
— ふーなんとかさん(デレマスパズル部 7638パズル課) (@fuwa_lica_chan) October 10, 2020
サングラス(9*10)
10月10日はメガネの日、じゃなかった…
そしてメガネということで比奈(17)&春菜(867)で作ろうとしたら、なぜか日菜子(175)&成宮(7638)に…
ルールは画像1枚目をどうぞ。
想定難易度:3.6/5.0(強めのたいへん)
webで解く→ https://t.co/DQLmPTf7Bq pic.twitter.com/z3sGGMqawUまたネット上で解けるサイトも見つけたので、しばらく自力で遊んでいました。
こんなシンプルな盤面ですら、解答図が想像できないパズル、「サングラス」https://t.co/Dz4algVHKl pic.twitter.com/mWRz9YJo7l
— YSR@LUMIX S5ポチった!!! (@YSRKEN) October 10, 2020サングラス
— YSR@LUMIX S5ポチった!!! (@YSRKEN) October 11, 2020
作: ふーなんとかさん さん
難易度:★4 (アゼン)https://t.co/6WFbARfFO5
さっき解いたので、ペンシルパズル「サングラス」完全に理解した pic.twitter.com/uaIIv9kUgqただ、なんとなくこれ自動で解けないかな?と思ったので、ソルバーをPythonで作成することにしました。
なんでコンパイル言語じゃないかって? C++で書くの辛いんじゃい!作成したソルバー(Python製):
https://github.com/YSRKEN/puzzle_sunglass_solver
基本方針
ソルバーの書き方は色々ありますが、今回は次のようにして解きました。
- 既存の手筋を使い、解けるところまで解く(これをfunc1とする)
- 中身が不定な1マスについて、「塗りつぶす」と仮定した状態でfunc1を走らせ、途中で矛盾が見つかった場合は「空白にする」
- 逆も同様で、「空白にする」と矛盾するなら「塗りつぶす」しかない(これをfunc2とする)
- 中身が不定な1マスについて、「塗りつぶす」と仮定した状態でfunc2を走らせ、途中で矛盾が見つかった場合は「空白にする」
- 逆も同様で、「空白にする」と矛盾するなら「塗りつぶす」しかない(これをfunc3とする)
func1は「手筋を使う方法」、func2は「1マスを仮定した背理法」、func3は「2マスを仮定した背理法」といったところでしょうか。
当初は「いきなり背理法を使い、矛盾が生じれば戻す」といった予定でしたが、計算コストが掛かりすぎるのでセーブした格好。簡単な問題ならfunc1だけで解けるのですが、そうでない問題もままあります。
とりあえず、既存問題の「難易度:アゼン」までならfunc3までで十分かと。使用した手筋
ブリッジの両端は塗りつぶす、その中間は空白にする
これはルールにも書いてあるのですぐ分かると思います。
レンズ同士が接触しないように空白を設置
以下、あるブリッジの両端から生えているレンズを「ブリッジのレンズ」、そうではない(まだどのブリッジから生えているか不定な)レンズを「孤立したレンズ」と呼びます。
ブリッジの両端、または異なるブリッジに属するレンズは、ルール上くっついてはいけません。
つまり、「あるマスが塗りつぶされると2つの(孤立していない、異なった)レンズがくっついてしまう」場合、「そのマス」を空白にする必要があります。そのため、ブリッジのレンズそれぞれについて、その周囲1マス(斜め方向に隣接するものは含まない)に対し、「そこが塗りつぶされると他のレンズとくっついてしまわないか」を調べることで、空白マスに決定できます。
各ブリッジの両端のレンズにおける、塗りつぶし状態・上下左右の空白状態を同期
ルール上、ブリッジの両端のレンズは線対称になりますので、片方で塗りつぶされているマスは、もう一方でも必ず塗りつぶされます。
また、ブリッジのレンズの周囲1マス(上下左右方向のみ)に空白マスがあった場合、その状態も必ずコピーされます。
そうでないと、一方のレンズでそこが塗られた際、もう一方のレンズでも塗る必要があって矛盾してしまいます。
これを実装するためには、「ブリッジを基準にレンズを線対称に反転させたものを用意する」処理が必要ですが、これが非常に難しい。
現状提供されている盤面では、ブリッジの両端のマスの位置関係が「上下方向」「左右方向」「45度の斜め方向(2種)」だけなので、まだ場合分けで解決できますが、それ以外のシチュエーションで実装するのは無理ゲーじゃないのこれ……?※例えば、ペンシルパズル「天体ショー」では、その名の通り点対称の概念が重要となる。だが、点対称の計算は線対称の計算より楽なので、ソルバー開発も比較的簡単と推測される
ヒント数字に従い、ちょうど塗りつぶせるなら塗り潰す
これもすぐ分かると思います。「余ってたら塗りつぶす」ケースと、「余ってたら空白にする」ケースの2種類があるので注意。
どのブリッジからも塗りつぶせない位置のマスは空白マス
一番説明しずらい手筋ですが、同時に最も重要な手筋です。例えば次のような盤面を考えます。
ここで赤色のマス(1列目・4行目)について考えると、いずれの「ブリッジのレンズ」も、このマスを取って「ブリッジのレンズ」の一部にできないだろうなー……というのは少し想像すれば分かるかと思います。
塗りつぶしを増やして強引に取っても、「ブリッジのレンズの両端は線対称で、他の(孤立していない)レンズとくっつけない」ルールに反してしまうからです。その上、ルールから、どの「ブリッジのレンズ」にもくっつくことができない「孤立したレンズ」は盤面に残せませんので、この赤色のマスは必ず空白マスなのです。
このような推論を行うと、他のマスもどんどん空白マスだと確定できます。先ほどの状態から、ここまで盤面を埋めることができました。
さて問題は「どうやって赤色マスなどの『どのブリッジからも塗りつぶせない位置のマス』を決めるのか」です。
思案した結果、次のような作戦を思いつきました。1. それぞれの「ブリッジのレンズ」について、最大限伸ばせる範囲を決める
例えば左上のブリッジにおける、左側の「ブリッジのレンズ」の最大範囲はこんな感じ(橙色で塗ってます)。
また、左上のブリッジにおける、右側の「ブリッジのレンズ」の最大範囲はこんな感じ。
どちらも、「他のレンズとぶつからない」「空白マスの設定は尊重する」「孤立したレンズは飲み込んでOK」という条件下で塗っています。
2. 各ブリッジの両端のレンズについては、「線対称である」条件から、実際に塗れる領域が狭まる
手筋の段では「どちらかでも塗ってたら塗れる」スタンスでしたが、それは確定事項だからであって、今回の場合は「どちらでも塗ってないと塗れない」になります。それぞれ、ここまで塗れる範囲が狭まりました。
3. そもそも、各ブリッジについては、「線対称の軸部分のマス」は塗れない
ブリッジ両端のレンズが線対称になる&くっつけないルール上、その線対称の軸におけるマスは塗れません。
ただ、「線対称の軸」の定義が地味に分かりづらいので、以下に例を示します。
このルールにより、前述のブリッジ両端における、「最大限伸ばせる範囲」はこんな感じになります。
4. 全ての「ブリッジのレンズ」における「最大限伸ばせる範囲」をマージしたものを求め、そこから「どのブリッジからも塗りつぶせないマス」を逆算する
マージしたものがこれで、
そこから逆算したものはこれ。
背理法の「矛盾」判定について
現状の実装では、次の2つだけ実装しています。
- ヒント数字の条件をどうしても満たせない場合は矛盾
- ある列/行について、「塗りつぶした個数」+「未定な個数」<「ヒント数字」なら矛盾
- ある列/行について、「塗りつぶした個数」>「ヒント数字」なら矛盾
- どのブリッジにも属せない「孤立したレンズ」が存在する場合は矛盾
- 言い換えると、盤面内のレンズを全て検索し、その中で「孤立したレンズである」「周囲(上下左右)が全て空白マスである」ものを探す
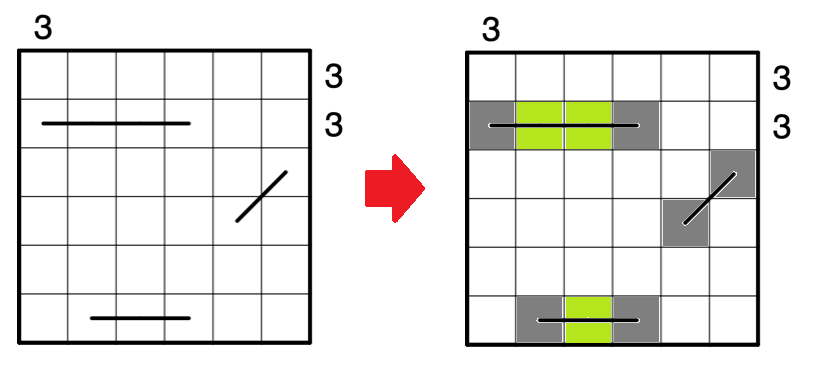
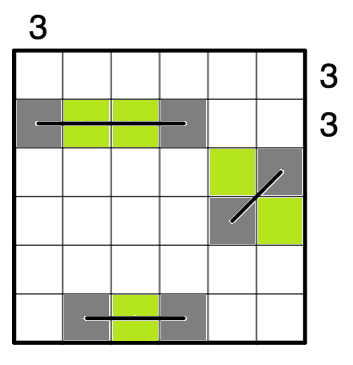
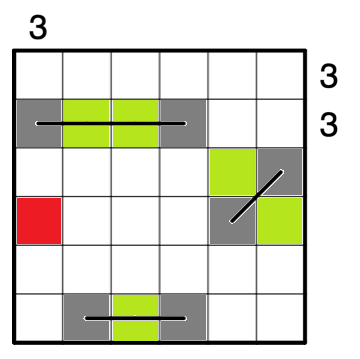
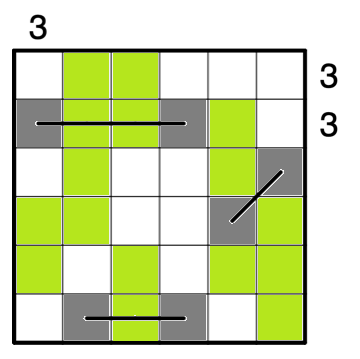
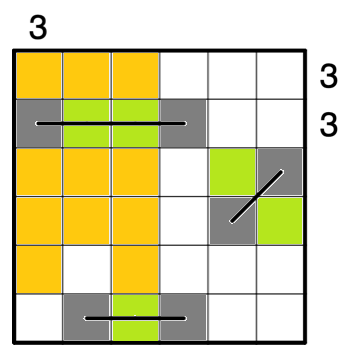
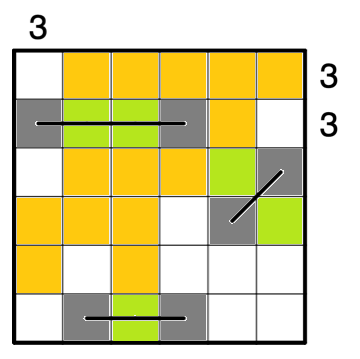
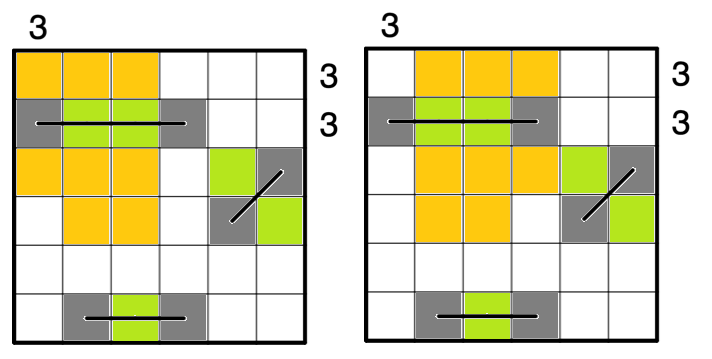
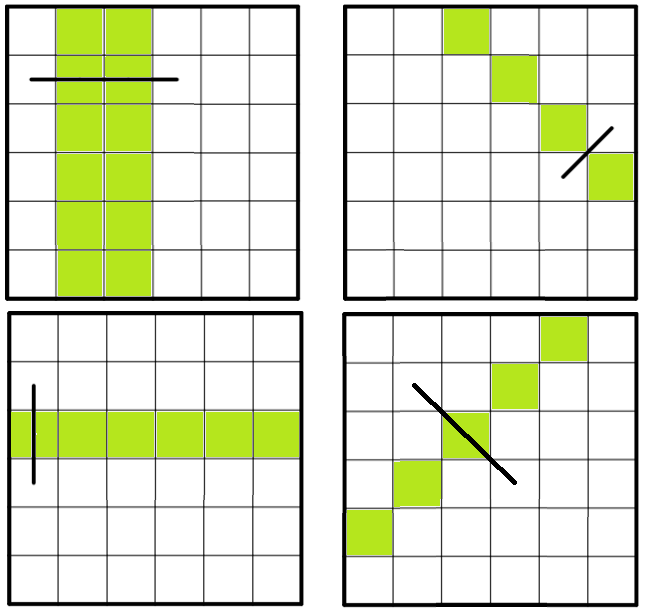
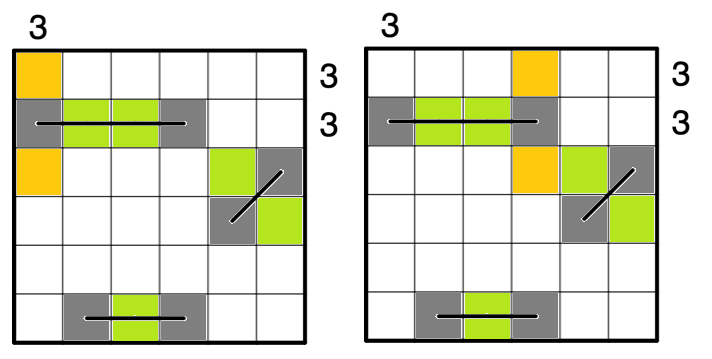
- 投稿日:2020-10-15T14:53:04+09:00
kaggleのtitanic NeuralNetworkを使った生存者予測 [80.8%]
はじめに
前回は決定木ベースのxbgoostを用いた予測を行いました。
前回:kaggleのtitanic 欠損値の補完と特徴量作成今回はkaggleでもよく使われているNeuralNetworkを用いてタイタニックの生存者予測にチャレンジしてみます。
1. データの取得と欠損値の確認
import pandas as pd import numpy as np train = pd.read_csv('/kaggle/input/titanic/train.csv') test = pd.read_csv('/kaggle/input/titanic/test.csv') #trainデータとtestデータを1つにまとめる data = pd.concat([train,test]).reset_index(drop=True) #欠損値が含まれる行数を確認 train.isnull().sum() test.isnull().sum()それぞれの欠損値の数は下のようになりました。
trainデータ testデータ PassengerId 0 0 Survived 0 Pclass 0 0 Name 0 0 Sex 0 0 Age 177 86 SibSp 0 0 Parch 0 0 Ticket 0 0 Fare 0 1 Cabin 687 327 Embarked 2 0 2. 欠損値の補完と特徴量の作成
2.1 Fareの補完
欠損している行のPclassは3でEmbarkedはSでした。
この2つの条件を満たす人の中での中央値で補完します。data['Fare'] = data['Fare'].fillna(data.query('Pclass==3 & Embarked=="S"')['Fare'].median())2.2 グループごとの生死の違い'Family_survival'の作成
Titanic [0.82] - [0.83]こちらのコードで紹介されていた 'Family_survival' という特徴量を作成します。
家族や友人同士だと船内で行動を共にしている可能性が高いので生存できたかどうかもグループ内で同じ結果になりやすいといえます。
そこで名前の名字とチケット番号でグルーピングを行い、そのグループのメンバーが生存しているかどうかで値を決めます。
この特徴量を作成することで予測の正解率が2%ほど向上したのでこのグルーピングはかなり有効です。
#名前の名字を取得して'Last_name'に入れる data['Last_name'] = data['Name'].apply(lambda x: x.split(",")[0]) data['Family_survival'] = 0.5 #デフォルトの値 #Last_nameとFareでグルーピング for grp, grp_df in data.groupby(['Last_name', 'Fare']): if (len(grp_df) != 1): #(名字が同じ)かつ(Fareが同じ)人が2人以上いる場合 for index, row in grp_df.iterrows(): smax = grp_df.drop(index)['Survived'].max() smin = grp_df.drop(index)['Survived'].min() passID = row['PassengerId'] if (smax == 1.0): data.loc[data['PassengerId'] == passID, 'Family_survival'] = 1 elif (smin == 0.0): data.loc[data['PassengerId'] == passID, 'Family_survival'] = 0 #グループ内の自身以外のメンバーについて #1人でも生存している → 1 #生存者がいない(NaNも含む) → 0 #全員NaN → 0.5 #チケット番号でグルーピング for grp, grp_df in data.groupby('Ticket'): if (len(grp_df) != 1): #チケット番号が同じ人が2人以上いる場合 #グループ内で1人でも生存者がいれば'Family_survival'を1にする for ind, row in grp_df.iterrows(): if (row['Family_survival'] == 0) | (row['Family_survival']== 0.5): smax = grp_df.drop(ind)['Survived'].max() smin = grp_df.drop(ind)['Survived'].min() passID = row['PassengerId'] if (smax == 1.0): data.loc[data['PassengerId'] == passID, 'Family_survival'] = 1 elif (smin == 0.0): data.loc[data['PassengerId'] == passID, 'Family_survival'] = 02.3 家族の人数を表す特徴量 'Family_size' の作成と階級分け
SibSpとParchの値を使って何人家族でタイタニックに乗船したかという特徴量'Family_size'をつくり、その人数に応じて階級分けをします。
#Family_sizeの作成 data['Family_size'] = data['SibSp']+data['Parch']+1 #1, 2~4, 5~の3つに分ける data['Family_size_bin'] = 0 data.loc[(data['Family_size']>=2) & (data['Family_size']<=4),'Family_size_bin'] = 1 data.loc[(data['Family_size']>=5) & (data['Family_size']<=7),'Family_size_bin'] = 2 data.loc[(data['Family_size']>=8),'Family_size_bin'] = 32.4 名前の敬称 'Title' の作成
Nameの列から'Mr','Miss'などの敬称を取得します。
数が少ない敬称('Mme','Mlle'など)は同じ意味を表す敬称に統合します。#名前の敬称を取得して'Title'に入れる data['Title'] = data['Name'].map(lambda x: x.split(', ')[1].split('. ')[0]) #数の少ない敬称を統合 data['Title'].replace(['Capt', 'Col', 'Major', 'Dr', 'Rev'], 'Officer', inplace=True) data['Title'].replace(['Don', 'Sir', 'the Countess', 'Lady', 'Dona'], 'Royalty', inplace=True) data['Title'].replace(['Mme', 'Ms'], 'Mrs', inplace=True) data['Title'].replace(['Mlle'], 'Miss', inplace=True) data['Title'].replace(['Jonkheer'], 'Master', inplace=True)2.5 Ageの補完と階級分け
Ageの欠損値の補完には名前の敬称ごとに求めた年齢の平均値を使用します。
そして子供(0~18)、成人(18~60)、高齢者(60~)の3つに階級分けします。#敬称ごとの平均値でAgeの欠損値を補完 title_list = data['Title'].unique().tolist() for t in title_list: index = data[data['Title']==t].index.values.tolist() age = data.iloc[index]['Age'].mean() age = np.round(age,1) data.iloc[index,5] = data.iloc[index,5].fillna(age) #年齢ごとに階級分け data['Age_bin'] = 0 data.loc[(data['Age']>18) & (data['Age']<=60),'Age_bin'] = 1 data.loc[(data['Age']>60),'Age_bin'] = 22.6 Fareの標準化&特徴量のダミー変数化
Fareの値は変数のスケール差が大きいので、ニューラルネットが学習しやすいように標準化(平均値が0、標準偏差を1にする)します。
そして文字列になっている列をget_dummiesでダミー変数化していきます。
Pclassは数値ですが値の大きさそのものに意味はないのでこちらもダミー変数に変換しておきましょう。from sklearn.preprocessing import StandardScaler sc = StandardScaler() #Fareを標準化したものを'Fare_std'に入れる data['Fare_std'] = sc.fit_transform(data[['Fare']]) #ダミー変数に変換 data['Sex'] = data['Sex'].map({'male':0, 'female':1}) data = pd.get_dummies(data=data, columns=['Title','Pclass','Family_survival'])最後に不要な特徴量を落とします。
data = data.drop(['PassengerId','Name','Age','SibSp','Parch','Ticket', 'Fare','Cabin','Embarked','Family_size','Last_name'], axis=1)データフレームはこのような形になりました。
Survived Sex Family_size_bin Age_bin Fare_std Title_Master Title_Miss Title_Mr Title_Mrs Title_Officer Title_Royalty Pclass_1 Pclass_2 Pclass_3 Family_survival_0.0 Family_survival_0.5 Family_survival_1.0 0 0.0 0 1 1 -0.503176 0 0 1 0 0 0 0 0 1 0 1 0 1 1.0 1 1 1 0.734809 0 0 0 1 0 0 1 0 0 0 1 0 2 1.0 1 0 1 -0.490126 0 1 0 0 0 0 0 0 1 0 1 0 3 1.0 1 1 1 0.383263 0 0 0 1 0 0 1 0 0 1 0 0 4 0.0 0 0 1 -0.487709 0 0 1 0 0 0 0 0 1 0 1 0 ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... 1304 NaN 0 0 1 -0.487709 0 0 1 0 0 0 0 0 1 0 1 0 1305 NaN 1 0 1 1.462069 0 0 0 0 0 1 1 0 0 0 0 1 1306 NaN 0 0 1 -0.503176 0 0 1 0 0 0 0 0 1 0 1 0 1307 NaN 0 0 1 -0.487709 0 0 1 0 0 0 0 0 1 0 1 0 1308 NaN 0 1 0 -0.211081 1 0 0 0 0 0 0 0 1 0 0 1 1309 rows × 17 columns
統合させていたデータをtrainデータとtestデータに分けて特徴量の処理は終了です。
model_train = data[:891] model_test = data[891:] x_train = model_train.drop('Survived', axis=1) y_train = pd.DataFrame(model_train['Survived']) x_test = model_test.drop('Survived', axis=1)3. モデルの構築と予測
データフレームが完成したのでニューラルネットのモデルを構築し予測をさせてみます。
from keras.layers import Dense,Dropout from keras.models import Sequential from keras.callbacks import EarlyStopping #モデルの初期化 model = Sequential() #層の構築 model.add(Dense(12, activation='relu', input_dim=16)) model.add(Dropout(0.2)) model.add(Dense(8, activation='relu')) model.add(Dense(5, activation='relu')) model.add(Dense(1, activation='sigmoid')) #モデルの構築 model.compile(optimizer = 'adam', loss='binary_crossentropy', metrics='acc') #モデルの構造を表示 model.summary()
trainデータを渡して学習をさせます。
validation_splitを設定しておけばtrainデータの中からvalidation用のデータを勝手に分けてくれるので楽ですね。log = model.fit(x_train, y_train, epochs=5000, batch_size=32,verbose=1, callbacks=[EarlyStopping(monitor='val_loss',min_delta=0,patience=100,verbose=1)], validation_split=0.3)
学習が進行する様子をグラフで表示させるとこのようになります。
import matplotlib.pyplot as plt plt.plot(log.history['loss'],label='loss') plt.plot(log.history['val_loss'],label='val_loss') plt.legend(frameon=False) plt.xlabel('epochs') plt.ylabel('crossentropy') plt.show()
最後にpredict_classesで予測値を出力させます。
#0と1どちらに分類されるかを予測 y_pred_cls = model.predict_classes(x_test) #kaggleに出すデータフレームを作成 y_pred_cls = y_pred_cls.reshape(-1) submission = pd.DataFrame({'PassengerId':test['PassengerId'], 'Survived':y_pred_cls}) submission.to_csv('titanic_nn.csv', index=False)今回の予測モデルの正解率は80.8%でした。
ニューラルネットはパラメータやモデルの層の数などを自由に決めることができるので作成したこのモデルが最適かどうかはわかりませんが8割を超えればまずまずといったところでしょうか。
ご意見、ご指摘などがございましたらコメント、編集リクエストをしていただけるとありがたいです。
参考にさせていただいたサイト、書籍
Titanic - Neural Networks [KERAS] - 81.8%
Titanic [0.82] - [0.83]
Kaggleで勝つデータ分析の技術
ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装