- 投稿日:2020-10-15T23:21:21+09:00
【AWS初学者用】AWS Auto Scalingとは
本記事について
本記事はAWS初学者の私が学習していく中でわからない単語や概要をなるべくわかりやすい様にまとめたものです。
もし誤りなどありましたらコメントにてお知らせいただけるとありがたいです。Auto Scalingとは
AWS Auto ScalingとはAWSが提供するリソースの使用状況に応じてインスタンスを自動的に増減させる事(スケールアウト・スケールイン)ができるサービス。なお、異常なインスタンスやAZを切り離すことも可能とのことです。
Auto Scalingの対象となるリソースはいくつかあるみたいですが,今回はEC2にAuto Scaling(EC2 Auto Scaling)を使用することを前提として進めます。
補足としてAuto ScalingはAMIからEC2インスタンスを起動するので、AMIは常時最新の状態にしておきましょう。以下はAuto Scalingを実行するにあたっての3つの設定です。
スケーリングプラン
Auto Scalingを実行するためにどんな条件・タイミングで実行するかを設定します。
- Cloud Watchのメトリクス(CPUの使用率など)に応じて実行する
アクセスの増減が予測できない時に有効- スケジュールを指定して実行する
決まった時間にアクセスが集中するとわかってる場合に有効- 手動でスケーリングを実行する 高負荷バッチ処理の予定がある時に有効。
起動設定
Auto Scaling実行時にどのようなEC2インスタンスを起動するかを定義します。
定義する項目としては
- AMI
- インスタンスタイプ
- セキュリティグループ
- キーペア
- IAMロールがあります
Auto Scalingグループ
EC2のインスタンスの管理を行う範囲のこと。インスタンス数の最小限・最大限を定義します。
要するにインスタンス数のコントロールができる感じですね。メリット
Auto Svalingはリソースの使用状況をモニタリングし、その使用状況に応じてEC2インスタンスを自動で増減するので常に理想のパフォーマンスを維持してくれる便利なサービス。
しかも従量制なのでコストも無駄なく利用できます。まとめ
ELBと連携して利用することでセキュリティもパフォーマンスも向上する優れもの!
- 投稿日:2020-10-15T22:24:35+09:00
俺でもわかるAurora PostgreSQLバージョンアップの実ダウンタイム雑メモ
俺です。
Aurora PostgreSQLのバージョンアップをいくつかやったのでメモを残します。Aurora PostgreSQL バージョンアップ・パッチ適用の全体時間はだいたい20min~30minぐらいです(Event logより)
バージョンアップ中にDB Instanceの再起動が行われ、一時的に全ての接続が失われます。この一時的にっていうのは一体どれぐらいの期間なのか、数秒なのかそれとも自分が定年退職するまでの期間なのか実際のダウンタイムがきになったので
バージョンアップ中にpsql -c SELECT NOW();をwhile : sleep 1でぶん回して接続が復帰するまでの脳筋的体感時間を計測した結果をざっくりメモで残しておきます。
no verup前 verup後 クラスタ・インスタンスパラメータグループの変更、要不要 再起動対象 脳筋体感的ダウンタイム 備考 1 9.6 10.12 クラスタパラメータグループ・インスタンスパラメータグループ共に変更必要 writer/readerが同時に再起動される 10min ~ 20min パラメータグループの変更が必要なのでクラスタ全体が一回shutdownされてるかんじ 2 10.7 10.12 パラメータグループ変更無し writer/readerが同時に再起動される 30sec ~1min writer/readerエンドポイントが返すAレコードは、一番早く復帰するwriterインスタンスになるが、readerインスタンス復帰後にreaderエンドポイントはreaderインスタンスのAレコードが返される
- メジャーバージョンアップはサービスの適切なメンテナンスウインドウを設定すること。メンテナンスウインドウに重なる、もしくは前後の時間帯で走るバッチ処理調整とか考慮しないとつらいかもって気持ちになりました。
- マイナーバージョンアップであればメンテなしでもぶっこんでよい規模のサービスは多々ありそうって気持ちになりました。
おわり
- 投稿日:2020-10-15T21:42:02+09:00
AWSソリューションアーキテクト(SAA)試験対策関連用語
はじめに
AWSSAA試験対策でUdemyの模擬試験を学習する中で出てきた用語をA~Z、あ~んの並びで記載しました。
79個の用語があります。
ごく簡単な説明ではありますが、これを知っているだけでも、問題の理解度がかなり変わり、意味が分かっているだけで解ける問題がかなり多い印象でした。
仮にこれをカンペに模擬試験を1回行うと、7割は取れる感触です。
あとはハンズオンなどで、具体的なイメージをつかむため、いくつかのサービスで体験すると合格できそうです。
今後学習を続けながら、まずは自分自身が合格し、これを見ながら解いたら合格できるというものに仕上げていき、今後受験される方の補助になればと思います。模擬試験を理解するにあたって出てきた用語
●ALB(Application Load Balancer)
Webサービスに発生する負荷を分散するロードバランシングサービス
https://docs.aws.amazon.com/ja_jp/elasticloadbalancing/latest/application/introduction.html●Amazon API Gateway
開発者は規模にかかわらず簡単に API の作成、公開、保守、モニタリング、保護を行える。API は、アプリケーションがバックエンドサービスからのデータ、ビジネスロジック、機能にアクセスするための「フロントドア」として機能する。
https://aws.amazon.com/jp/api-gateway/●Amazon Aurora
MySQL および PostgreSQL と互換性のあるクラウド向けのリレーショナルデータベースであり、従来のエンタープライズデータベースのパフォーマンスと可用性に加え、オープンソースデータベースのシンプルさとコスト効率性も兼ね備えている。Amazon Aurora は、標準的な MySQL データベースと比べて最大で 5 倍、標準的な PostgreSQL データベースと比べて最大で 3 倍高速。
https://aws.amazon.com/jp/rds/aurora/●Amazon Aurora MySQL
フルマネージド型の MySQL と互換性のあるリレーショナルデータベースエンジンであり、ハイエンドな商用データベースのスピードと信頼性、オープンソースデータベースの簡素性とコスト効率性を兼ね備えている。Aurora MySQL は MySQL のドロップインリプレースメントで、新規および既存の MySQL のデプロイを簡単に、コスト効率よく設定、操作、スケーリングできる。
https://aws.amazon.com/jp/rds/aurora/mysql-features/
https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/AuroraUserGuide/Aurora.AuroraMySQL.html●Amazon CloudFront
データ、動画、アプリケーション、および API をすべてデベロッパーにとって使いやすい環境で、低レイテンシーの高速転送により世界中の視聴者に安全に配信する高速コンテンツ配信ネットワーク (CDN) サービス。S3に保存している画像データを配信するときに併用するという使い方がある。
https://aws.amazon.com/jp/cloudfront/●Amazon EBS(Elastic Block Store)
https://aws.amazon.com/jp/ebs/
●Amazon EC2(Elastic Compute Cloud)
安全でサイズ変更可能なコンピューティング性能をクラウド内で提供するウェブサービス。
リザーブドインスタンス、オンデマンドインスタンス、スポットインスタンス、専有インスタンスがある。
インターネットからのアクセス可能にするためには、セキュリティグループとネットワークACLが適切な許可設定にされていること、および設置されているサブネットのルートテーブルにインターネットゲートウェイへのエントリがあることが必要となる。
https://aws.amazon.com/jp/ec2/●Amazon EC2 インスタンスストア
インスタンス用のブロックレベルの一時ストレージ。長期的に使用する重要なデータがある場合は、Amazon S3、Amazon EBS、または Amazon EFS などのより堅牢なデータストレージを使用する。
https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/InstanceStorage.html●Amazon Elastic File System(EFS)
AWS クラウドサービスおよびオンプレミスリソースで使用するための、シンプルでスケーラブル、かつ伸縮自在な完全マネージド型の NFS ファイルシステム。インスタンス間のデータ共有が可能となるが、インターネットを通じた第三者からのアクセスはできない。ファイルシステムインターフェイスとファイルシステムのアクセスセマンティクス (強い整合性やファイルのロックなど) が用意されており、最大数千の Amazon EC2 インスタンスからの同時アクセスが可能。
https://aws.amazon.com/jp/efs/●Amazon Elastic Transcoder
クラウドのメディア変換サービス。高度なスケーラビリティ、使いやすさ、高い費用効率性を実現する設計で、開発者や企業は、メディアファイルをその元のソース形式からスマートフォン、タブレット、PC などのデバイスで再生可能できるバージョンに変換 (または「トランスコード」) できる。
https://aws.amazon.com/jp/elastictranscoder/●Amazon FSx
SMB プロトコルに基づいて最大数千台のコンピューティングインスタンスからアクセス可能となるNTFS ファイルシステム。フルマネージド型のネイティブ Microsoft Windows ファイルシステムを提供するAWSサービス。
https://aws.amazon.com/jp/fsx/
EFSと似ているが、EFSはLinuxで利用されるNFSv4プロトコルに対応したサーバー。
https://aws.amazon.com/jp/fsx/windows/faqs/●Amazon Kinesis
ストリーミングデータをリアルタイムで収集、処理、分析することが簡単になるため、インサイトを適時に取得して新しい情報に迅速に対応できる。
機械学習、分析、その他のアプリケーションに用いる動画、音声、アプリケーションログ、ウェブサイトのクリックストリーム、IoT テレメトリーデータをリアルタイムで取り込める。
https://aws.amazon.com/jp/kinesis/●Amazon Route 53
可用性と拡張性に優れたクラウドのドメインネームシステム (DNS) ウェブサービス。www.example.com のような名前を、コンピュータが互いに接続するための数字の IP アドレス (192.0.2.1 など) に変換する。IPv6 にも完全準拠。
通常のRoute 53レコードは標準のDNSレコードを使用。CloudFrontなどのAWSリソースを構成する場合はALIASレコードを利用する。
・CNAME
別名を定義するレコード。特定のホスト(FQDN)を別のホスト(FQDN)に転送する時などに利用する。例えば、www.example.com でも example.comでも同じサイトにアクセスさせたい場合に有効。
・ホストレコード
(未確認)
・ALIASレコード
DNS機能に対するRoute 53固有の拡張機能。 IPアドレスまたはドメイン名の代わりに、ALIASレコードにはCloudFront、Elastic Beanstalk環境、ELB 、静的Webサイトとして設定されているAmazon S3バケットへのポインタ、または 同じホストゾーン内の別のRoute 53レコードを設定することができる。
・NSレコード
ゾーン情報を管理するネームサーバーのサーバー名を定義するレコード。※NSレコードのホスト名はAレコードが登録されている必要がある。
・DNSレコード
(未確認)
・Aレコード
アドレス(Address)の頭文字からきており、ドメインをIPアドレスに置き換えるレコード。
など、たくさんのレコードの種類がある。
https://aws.amazon.com/jp/route53/
https://hosting.z.com/jp/support/domains/faq_each-record/●Amazon SNS(Simple Notification Service)
システム間通信とアプリ対個人 (A2P) 通信の両方に向けてフルマネージド型メッセージングサービスを提供。メッセージングが主要な役割。
https://aws.amazon.com/jp/sns/●Amazon SQS(Simple Queue Service)
システムの分散処理化に使用される。完全マネージド型のメッセージキューイングサービスで、マイクロサービス、分散システム、およびサーバーレスアプリケーションの切り離しとスケーリングが可能。あらゆる量のソフトウェアコンポーネント間でメッセージを送信、保存、受信できる。
「保留中のデータベースへの書き込みリクエスト」を、SQSキューに格納して非同期に処理することができる。
キューに対して優先度を設定することができ、優先的に処理されるキューとそうではないキューとに振り分けることが可能
。
FIFOキューを利用することで高スループット、ベストエフォート型の順序付け、少なくとも1回の配信を可能にする。 FIFOキューはメッセージ順序を保証し、少なくとも1回のメッセージ配信をサポートしている。
https://aws.amazon.com/jp/sqs/●AmazonS3(Simple Storage Service )
スケーラビリティ、データ可用性、セキュリティ、およびパフォーマンスを提供するオブジェクトストレージサービス。あらゆる規模や業界のお客様が、データレイク、ウェブサイト、モバイルアプリケーション、バックアップおよび復元、アーカイブ、エンタープライズアプリケーション、IoT デバイス、ビッグデータ分析など、広範にわたるユースケースのデータを容量に関係なく、保存して保護できる。
スナップショットの機能はない。
https://aws.amazon.com/jp/s3/●Amazon S3 standard
アクセス頻度の高いデータ向けに高い耐久性、可用性、パフォーマンスのオブジェクトストレージ
●Amazon S3 One Zone-IA
アクセスが頻繁ではないデータをレジリエンスが低い単一アベイラビリティーゾーンに保存することによってコストを節約。
●Amazon S3 Glacier、Amazon S3 Glacier deep archive
Amazon S3 Glacier ではアーカイブへのアクセスについて、数分から数時間までの 3 つのオプション、また、S3 Glacier Deep Archive には、12 時間から 48 時間までの 2 つのアクセスオプションがある。
Glacierの設定で迅速取り出しでアクセスしたデータは通常 1〜5 分以内、標準取り出しでは、 3〜5 時間以内、大容量取り出しはGlacier の最も安価な取り出しオプションであり、これを使用して大量のデータ (ペタバイトのデータを含む) を 5〜12 時間必要。
ボールトロックはボールトロックポリシーで「write once read many」(WORM) などのコントロールを指定して、ポリシーをロックし、今後編集できないようにする。
https://aws.amazon.com/jp/glacier/●Amazon S3 Standard-IA
低頻度アクセス用ですが、読み込みはすぐにできるため、突然の利用にも対応できるが、 Glacier Deep Archive ストレージクラスの方がStandard-IA よりもコストが安い。
●Amazon S3 RRS(低冗長化ストレージ)
Amazon S3 のストレージオプションの 1 つ。Amazon S3 の標準ストレージと比べて、冗長性レベルを下げることで、重要性の低い、再生可能なデータを保存するのに適している。
https://aws.amazon.com/jp/s3/reduced-redundancy/●API ゲートウェイ
APIの管理や実行を容易にするしくみ。APIを介してバックエンドサービスへのHTTPからのアクセスできるようにする。Lambdaと一体となって利用できるサービスであり、APIゲートウェイをLambdaファンクションと統合する設定を実施することで、HTTPからLambdaファンクションへのアクセスが可能となる。
https://www.wafcharm.com/blog/api-gateway-for-beginners/●AWS Config
AWS リソースの設定を評価、監査、審査できるサービス。AWS リソースの設定が継続的にモニタリングおよび記録され、望まれる設定に対する記録された設定の評価を自動的に実行できる。
https://aws.amazon.com/jp/config/●AWS Direct Connect
オンプレミスから AWS への専用ネットワーク接続の構築をシンプルにするクラウドサービスソリューション。AWS Direct Connect を使用すると、AWS とデータセンター、オフィス、またはコロケーション環境との間にプライベート接続を確立することができる。ただし、AWS側との調整のため、数日ではできない。
https://aws.amazon.com/jp/directconnect/●AWS Fargate
コンテナ向けサーバーレスコンピューティングエンジン。
ECS(Amazon Elastic Container Service)とEKS(Amazon Elastic KubernetesService)の両方で動作する。
サーバーのプロビジョンと管理が不要となり、設計段階からのアプリケーション分離によりセキュリティを強化する。
EC2にDockerインストールするだけで利用可能。
https://aws.amazon.com/jp/fargate/
https://dev.classmethod.jp/articles/developers-io-2020-connect-kaji-ecs-fargate/●AWS IAM(Identity and Access Management)
AWS Identity and Access Management
アクセス権限の認証の実施
アクセスポリシーの設定
ユーザー、グループに設定rootユーザーにしかできない。
CloudFrontのキーペアの作成などあるので、要確認。
https://aws.amazon.com/jp/iam/・IAMロール
AWSリソースに対してアクセス権限をロールとして付与できる
特定のインスタンスだけ別の機能に対してアクセスできるという設定●AWS Import/Export
ポータブルストレージデバイスを使用して AWS に大量のデータを移動し、転送することが可能
AWS クラウドから大量のデータを転送する場合、特にインターネット経由でデータを転送するのが遅すぎる (1週間以上) またはコストがかかりすぎる場合に最適。
https://stay-ko.be/aws/solutionarchitect-pro-aws-importexport●AWS OpsWorks Stacks
Chef(構成管理ツール) を使用してクラウドエンタープライズのアプリケーションを構成および運用するための構成管理サービス。
Chef の自動設定と AWS opsworks による自動化により、Chef クックブックと構成管理ソリューションを使用できる。
OpsWorksスタックおよびChef Automate用OpsWorksを使用すると、構成管理にChefクックブックおよびソリューションを使用できる。
https://docs.aws.amazon.com/ja_jp/opsworks/latest/userguide/welcome_classic.html
https://stay-ko.be/aws/solutionarchitect-pro-aws-opsworks●AWS STS(Security Token Service)
動的にIAMユーザーを作り、一時的に利用するトークンを発行するサービス
アクセス権限を最小限にしてセキュリティを高める。
https://docs.aws.amazon.com/ja_jp/IAM/latest/UserGuide/id_credentials_temp.html●Amazon SES(Simple Email Service)
Eメール機能を実装することができる。デベロッパーが任意のアプリケーションでメールを送信できるようにする。
https://aws.amazon.com/jp/ses/●AWS Snowball
AWS Snow ファミリーの一部で、エッジコンピューティング、データ移行、エッジストレージデバイス。ローカルストレージや大規模データ転送に最適。
Snowball Edge を使用すると、テラバイト規模のデータを 1 週間程度で移動できる。
https://aws.amazon.com/jp/snowball/●AWS Strage Gateway
オンプレミスから実質無制限のクラウドストレージへのアクセスを提供するハイブリッドクラウドストレージサービス。
https://aws.amazon.com/jp/storagegateway/?whats-new-cards.sort-by=item.additionalFields.postDateTime&whats-new-cards.sort-order=desc●AWS WAF(ウェブアプリケーションファイアウォール)
可用性、セキュリティ侵害、リソースの過剰消費といった一般的なウェブの脆弱性からウェブアプリケーションまたは API を保護するウェブアプリケーションファイアウォール。
SQL インジェクションやクロスサイトスクリプティングなどの一般的な攻撃パターンをブロックするセキュリティルールと、定義した特定のトラフィックパターンを除外するルールを作成できるため、トラフィックがアプリケーションに到達する方法を制御できる。CDN ソリューションの一部として Amazon CloudFront にデプロイでき、EC2 上で動作するウェブサーバーやオリジンサーバーの手前に配置した Application Load Balancer や、API を使用するための Amazon API Gateway にデプロイできる。
https://aws.amazon.com/jp/waf/●Chef
同名の企業によって開発されるRubyとErlangで記述された構成管理ツール。
ファイルに記述した設定内容に応じて自動的にユーザーの作成やパッケージのインストール、設定ファイルの編集などを行うツール。
https://ja.wikipedia.org/wiki/Chef_(ソフトウェア)/
https://knowledge.sakura.ad.jp/867●Classic Load Balancer
受信アプリケーショントラフィックを複数のアベイラビリティーゾーンの複数の EC2 インスタンス間で分散。これにより、アプリケーションの耐障害性が高まる。Elastic Load Balancing は異常なインスタンスを検出し、正常なインスタンスにのみトラフィックをルーティングする。
https://docs.aws.amazon.com/ja_jp/elasticloadbalancing/latest/classic/introduction.html●CI/CD
Continuous Integration(継続的インテグレーション)
Continuous Delivery(継続的デリバリー)またはContinuous Deployment(継続的デプロイ)
テスト自動化することで品質を高めるだけではなく、その後のリリース作業も自動化することで、よりアジャイルな開発ができるようになる。テスト自動化といっても、テストの作成は人が行う必要があり、それを任意のタイミングで実施することを自動で行ってくれるということ。●CloudFormation
Amazon Web Services リソースのモデル化およびセットアップに役立つサービス。
AWSで環境を構築するときに、リソースの設定やプロビジョニングをコード化したテンプレートを作成できる。
それをもとにすれば、次に新しい環境を構築するとき、時間や手間を大きく削減できる。
https://aws.amazon.com/jp/cloudformation/●CodePipeline
完全マネージド型の継続的デリバリーサービス。お客様が定義したリリースモデルに基づき、コードチェンジがあった場合のフェーズの構築、テスト、デプロイを自動化する。
https://aws.amazon.com/jp/codepipeline/●DynamoDB(Amazon DynamoDB)
規模に関係なく数ミリ秒台のパフォーマンスを実現する、key-value およびドキュメントデータベースです。完全マネージド型マルチリージョン、マルチマスターで耐久性があるデータベースで、セキュリティ、バックアップおよび復元と、インターネット規模のアプリケーション用のメモリ内キャッシュが組み込まれている。小規模データを保存・処理するためにはNoSQLデータベースを利用するのがよい。
https://aws.amazon.com/jp/dynamodb/●DevOps(デブオプス)
「開発チーム(Development)と運用チーム(Operations)がお互いに協調し合うことで、開発・運用するソフトウェア/システムによってビジネスの価値をより高めるだけでなく、そのビジネスの価値をより確実かつ迅速にエンドユーザーに届け続ける」という概念。より早くビジネスの価値を高め、エンドユーザーに届け続けるためには、ツールと組織文化の両面からカイゼンしていく必要があり、このようなカイゼン活動を指す。
https://www.buildinsider.net/enterprise/devops/01●ECR(Amazon Elastic Container Registry)
完全マネージド型の Docker コンテナレジストリ。このレジストリを使うと、開発者は Docker コンテナイメージを簡単に保存、管理、デプロイできる。Amazon ECR は Amazon Elastic Container Service (ECS) に統合されているため、開発から本稼働までのワークフローを簡略化できる。Dockerイメージファイルを保存するサービス。
https://aws.amazon.com/jp/ecr/●ECS(Elastic Container Searvice)
フルマネージド型のコンテナオーケストレーションサービス
VPCでコンテナを起動するので、セキュリティグループ、ネットワークACLを適用できる
EC2インスタンスを用いてクラスター構成を行うことでdockerコンテナをラッピングして実行できる
単一または複数のコンテナをtaskと呼ばれる形で管理している。
https://aws.amazon.com/jp/ecs/●EC2ワーカープロセス
EC2で実行されるプロセス。
「ワーカープロセス」というのは、そのウェブアプリケーションが実行されるプロセスのこと。●Elastic Beanstalk
Java、.NET、PHP、Node.js、Python、Ruby、Go および Docker を使用して開発されたウェブアプリケーションやサービスを、Apache、Nginx、Passenger、IIS など使い慣れたサーバーでデプロイおよびスケーリングするためのサービス。コードをアップロードするだけで、Elastic Beanstalk が、キャパシティのプロビジョニング、ロードバランシング、Auto Scaling からアプリケーションのヘルスモニタリングまで、デプロイを自動的に処理する。
これ自体は無料。利用しているインスタンスの費用でOK。
https://aws.amazon.com/jp/elasticbeanstalk/●ELB(Elastic Load Balancing)
アプリケーションへのトラフィックを複数のターゲット (Amazon EC2 インスタンス、コンテナ、IP アドレス、Lambda 関数など) に自動的に分散する。変動するアプリケーショントラフィックの負荷を、1 つのアベイラビリティーゾーンまたは複数のアベイラビリティーゾーンで処理する。Elastic Load Balancing では、3 種類のロードバランサーが用意されている。
・Application Load Balancer
・Network Load Balancer
・Classic Load Balancer
https://aws.amazon.com/jp/elasticloadbalancing/● iSCSI (Internet Small Computer System Interface)
SANストレージとの接続方式。
SAN(Storage Area Netawork)というネットワークでサーバと接続するSANストレージ。
ストレージ専用ネットワーク。NAS(Network Attached Storage)に比べてパフォーマンスがよい。●Lambda
サーバーをプロビジョニングしたり管理する必要なくコードを実行できるコンピューティングサービス。
Amazon S3 バケットまたは Amazon DynamoDB テーブル内のデータの変更などのイベントに応答してコードを実行、Amazon API Gateway を使用して HTTP リクエストに応答してコードを実行、AWS SDK を使用して作成された API コールを使用してコードを呼び出しといったことができる。
https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/welcome.html●MFA(多要素認証)(Multi Factor Authrication)
本人確認のための要素を複数、ユーザーに要求する認証方式。
AWSではrootユーザーへの設定を推奨。その他アドミン権限を持つIAMユーザーにもMFAを設定することが望ましいとされている。●NATインスタンス
Network Address Translator
プライベートIPアドレスをグローバルIPアドレスに変換すること。似た機能にNATゲートウェイがある。
https://docs.aws.amazon.com/ja_jp/vpc/latest/userguide/vpc-nat-comparison.html●NATゲートウェイ
NATインスタンスの代わりに使用できるマネージド型サービス。ネットワークアドレス変換 (NAT) ゲートウェイを使用して、プライベートサブネットのインスタンスからはインターネットや他の AWS サービスに接続できるが、インターネットからはこれらのインスタンスとの接続を開始できないようにする。
https://docs.aws.amazon.com/ja_jp/vpc/latest/userguide/vpc-nat-gateway.html●Network Load Balancer
開放型システム間相互接続 (OSI) モデルの第 4 層で機能する。ロードバランサーは、接続リクエストを受信すると、デフォルトルールのターゲットグループからターゲットを選択。リスナー構成で指定されたポート上の選択したターゲットへの TCP 接続を開こうとする。
https://docs.aws.amazon.com/ja_jp/elasticloadbalancing/latest/network/introduction.html●NFSv4プロトコル
NFSとは、LinuxなどUNIX系のOSで利用されるファイル共有システムである。NFSでは、データの実体はNFSサーバと呼ばれるファイルサーバに存在する。NFSクライアントは、NFSサーバの公開されたディレクトリをネットワーク越しにマウントする。この機能を使うと、複数のホストから同じファイルを共有することができる。
●NLB(Network Load Balancer)
ELBの機能の一つ。レイヤー 4に対応、TCP/UDPトラフィックの負荷を分散する。
https://docs.aws.amazon.com/ja_jp/elasticloadbalancing/latest/network/introduction.html●RDS(Amazon Relational Database Service)
クラウド上のリレーショナルデータベースのセットアップ、オペレーション、スケールが簡単になります。ハードウェアのプロビジョニング、データベースのセットアップ、パッチ適用、バックアップなどの時間がかかる管理タスクを自動化しながら、コスト効率とサイズ変更可能なキャパシティーを得られる。
https://aws.amazon.com/jp/rds/●Redshift
クラウド内で完全に管理されたペタバイト規模のリレーショナルデータベース型のデータウェアハウスサービス。業務解析システム用のデータベースに適している。大量データの保存や並列処理によるパフォーマンス向上が可能。データ解析に用いられる。
速い。リザーブドインスタンスの契約をすると75%オフ。
https://aws.amazon.com/jp/redshift/features/●SFA(Sales Force Automation)
営業支援システム。企業の営業部の情報や業務の自動化や分析をして、ボトルネックの発見や効率化を図るシステム。
https://www.e-sales.jp/sfa/about/●SLA(Service Level Agreement)
サービスを提供事業者とその利用者の間で結ばれるサービスのレベル(定義、範囲、内容、達成目標等)に関する合意サービス水準、サービス品質保証などと訳される。
●S3 プレフィックス
パフォーマンス向上のために設定する。
●Temporary Security Credentioals
AWSに対して一時的な認証情報を作成する仕組み
●VM Import/Export
仮想マシンイメージを既存の環境から Amazon EC2 インスタンスにインポートすることや、元のオンプレミス環境にエクスポートすることが簡単にできる。
https://aws.amazon.com/jp/ec2/vm-import/●VPCエンドポイント
VPC内のAWSリソースがVPC外のAWSサービスへのアクセスを可能にする仕組み。
AWS PrivateLink を使用する、サポートされている AWS サービスや VPC エンドポイントサービスに VPC をプライベートに接続できる。インターネットゲートウェイ、NAT デバイス、VPN 接続、または AWS Direct Connect 接続は必要ない。VPC のインスタンスは、サービスのリソースと通信するためにパブリック IP アドレスを必要ない。VPC と他のサービス間のトラフィックは、Amazon ネットワークを離れない。
https://docs.aws.amazon.com/ja_jp/vpc/latest/userguide/vpc-endpoints.html●VPCピアリング
2 つの VPC 間でプライベートなトラフィックのルーティングを可能にするネットワーキング接続。どちらの VPC のインスタンスも、同じネットワーク内に存在しているかのように、相互に通信できる。VPC ピアリング接続は、自分の VPC 間、別の AWS アカウントの VPC との間、または別の AWS リージョンの VPC との間に作成できる。
https://docs.aws.amazon.com/ja_jp/vpc/latest/userguide/vpc-peering.html●管理オーバーヘッド
オーバーヘッドとは仕方ないけどできればやりたくない処理のこと。
管理上は仕方ないけどやらざるを得ない管理のこと。
「処理」や「負荷」と同じだが、意味合い的には負荷のような負のイメージを持つ。●キャッシュ型ボリューム
Storage Gatewayの機能の一つで頻繁にアクセスされるデータはローカルのストレージゲートウェイに保持しながらAmazon S3をプライマリデータストレージとして使用できる。オンプレミスのストレージインフラストラクチャをスケールする必要性を最小限に抑え、アプリケーションからのアクセスが低レイテンシー(速いってこと)となる。
https://docs.aws.amazon.com/ja_jp/storagegateway/latest/userguide/StorageGatewayConcepts.html●結果整合性モデル
S3が採用しているモデル。更新はそのうち全体に反映される。最後に更新した処理が終わると、時間が経てば必ず全てのストレージに最新情報が反映されるというタイムラグがある。
https://dev.classmethod.jp/articles/amazon-s3-eventually-consistent-and-consistent-read/●スナップショット
ある時点でのソースコードや、ファイル、ディレクトリ、データベースファイルなどの状態を抜き出したもの。
記録するのはあくまで「ポインタ」であって「データ自体」ではない。
スナップショットはある瞬間の情報。リードレプリカは元のデータに対して刻々と変化するコピー。
https://www.idcf.jp/words/snapshot.html
https://wa3.i-3-i.info/word14388.html
https://www.storage-channel.jp/blog/snapshot-replication.html
EBS スナップショットは増分バックアップなので、スナップショットの作成に必要な時間が最小限になり、ストレージコストを節約できる。●スケーリングポリシー
EC2 Auto Scalingに対する場合、スケールを大きくするアクションをどのタイミングにするかを定義する。
https://docs.aws.amazon.com/ja_jp/autoscaling/ec2/userguide/as-scale-based-on-demand.html●静的ホスティング
静的ウェブサイトをホスティング(公開するということ)。
https://docs.aws.amazon.com/ja_jp/AmazonS3/latest/dev/WebsiteHosting.html●低レイテンシー
レイテンシとはデータ転送における指標のひとつで、転送要求を出してから実際にデータが送られてくるまでに生じる、通信の遅延時間のこと。
要は速いってこと。●ネットワークACL(アクセスコントロールリスト)
サブネット内外のトラフィックを制御するファイアウォールとして任意のセキュリティを提供する。
セキュリティグループと似ているが、使用方法は異なるので、十分な理解が必要。
https://dev.classmethod.jp/articles/amazon-vpc-acl/
ネットワークACLはサブネットに対して設定し、セキュリティグループはインスタンスに対して設定する。●踏み台サーバー
最もセキュリティが強化される構成はWebサーバーとデータベースサーバーのどちらもプライベートサブネットに移行して、NATゲートウェイをパブリックサブネットに設置する構成です。パブリックサブネットの踏み台サーバーもしくはELBを介してWEBサーバーへのアクセスを可能にする。
●プロビジョニング
必要に応じてネットワークやコンピューターの設備などのリソースを提供できるよう予測し、準備しておくこと。
顧客の需要を予測して設備を事前に準備すること。
供給や設備等の意味を表すプロビジョン(provision)という単語がもととなって派生した言葉。●プロビジョンドIOPS SSD
Amazon EBSボリュームの一つ。EC2インスタンスを作成するときに選択する。
高性能。(ミッションクリティカルな低レイテンシーまたは高スループットワークロードに適した、最高パフォーマンスの SSD ボリューム)
価格と性能に応じて選択する。
IOPSとは、 Input/Output Per Secondの略で、ハードディスクやSSDなどのストレージ(外部記憶装置)の性能指標の一つで、ある条件の元で1秒間に読み込み・書き込みできる回数のこと。
https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/ebs-volume-types.html●保管型ボリューム
Storage Gatewayの機能の一つで、プライマリデータをローカルに保存する一方で、そのデータを非同期にAWSにバックアップする。オンプレミスのアプリケーションがデータセット全体に低レイテンシーでアクセスでき、同時に、耐久性のあるオフサイトのバックアップが提供される。
https://docs.aws.amazon.com/ja_jp/storagegateway/latest/userguide/StorageGatewayConcepts.html●ポリシー
・管理ポリシー
AWS管理ポリシー(初期設定で用意されているポリシー)
カスタマー管理ポリシー(ユーザーが好きなように設定できる)
・インラインポリシー
固有のポリシー(余り使うことはない)
・JSONで設定されている●ポーリング
「サーバーとクライアント」や「主システムと周辺機器」といった複数の機器を円滑に連携させる方法のひとつ。主に通信などの競合を回避するために、ホスト側が各機器に対して定期的に問い合わせを行い、条件を満たした場合に送受信や各種処理を行う。
https://blogs.manageengine.jp/itom_what_is_polling/●マルチパートアップロード
S3に大きなファイルをアップロードする際に利用する機能
●リードレプリカ
データベースの負荷分散のために作成される、参照専用の複製。あるデータベースの内容を複製したもので、データの追加や更新はできず検索や読み込みのみを行うことができる。
参照の要求をリードレプリカに流すことで、全体の性能を向上させることができる。
DBインスタンスに昇格させることもできる。
スナップショットとは違い「データ自体」を保存し、ある時点、またはリアルタイムでストレージとまったく同じ状態を別のストレージに複製する。
http://e-words.jp/w/リードレプリカ.html
https://aws.amazon.com/jp/rds/features/read-replicas/●レプリケーションラグ
リードレプリカは非同期的にレプリケートされる個別のデータベースインスタンスであるため、 レプリケーションデータが遅れることが多く、最新のトランザクションのいくつかを表示できないこと。
おわりに
最後までスクロールしていただきありがとうございます。
2020年内にSAAは合格できるよう仕事の合間をぬって学習中。
- 投稿日:2020-10-15T19:47:18+09:00
RDS for Postgresql での ERROR: canceling statement due to statement timeout の対処法
embulk-input-postgresql を用いたデータ吸い出しを行うときに
ERROR: canceling statement due to statement timeoutというエラーが発生することがあります。org.embulk.exec.PartialExecutionException: java.lang.RuntimeException: org.postgresql.util.PSQLException: ERROR: canceling statement due to statement timeout at org.embulk.exec.BulkLoader$LoaderState.buildPartialExecuteException(BulkLoader.java:340)psqlにて再現してみましょう。embulk経由と同様に、1分経ったところでクエリが中断されました。
何らかのサーバ側のタイムアウト処理で止められています。> psql psql (10.14 (Ubuntu 10.14-0ubuntu0.18.04.1), server 11.1) WARNING: psql major version 10, server major version 11. Some psql features might not work. SSL connection (protocol: TLSv1.2, cipher: ECDHE-RSA-AES256-GCM-SHA384, bits: 256, compression: off) Type "help" for help. test_server=> SELECT test_server-> ...snip... test_server-> FROM test_server-> foo_bar test_server-> WHERE test_server-> ...何か重たいクエリ... ERROR: canceling statement due to statement timeoutstatement_timeout の値を見てみましょう。やはり、1分でした。15分に今回は伸ばしてみます。
マイクロ秒で指定すると読みづらいので、文字列で指定すると楽です。test_server=> SHOW statement_timeout; statement_timeout ------------------- 1min (1 row) test_server=> SET statement_timeout to '15min'; SET test_server=> SHOW statement_timeout; statement_timeout ------------------- 15min (1 row)この設定はembulkには次のように記述します。
before_selectを使うことで、SELECT句と同じトランザクションで実行されます。in: type: postgresql host: {{ env.DB_HOST }} user: {{ env.DB_USER }} password: {{ env.DB_PASSWORD }} ssl: true database: {{ env.DB_DATABASE }} default_timezone: UTC query: | SELECT ... before_select: SET statement_timeout to '15min';私の場合はリードレプリカにてこの現象を見ました。
何かお役に立てると幸いです。
- 投稿日:2020-10-15T19:04:39+09:00
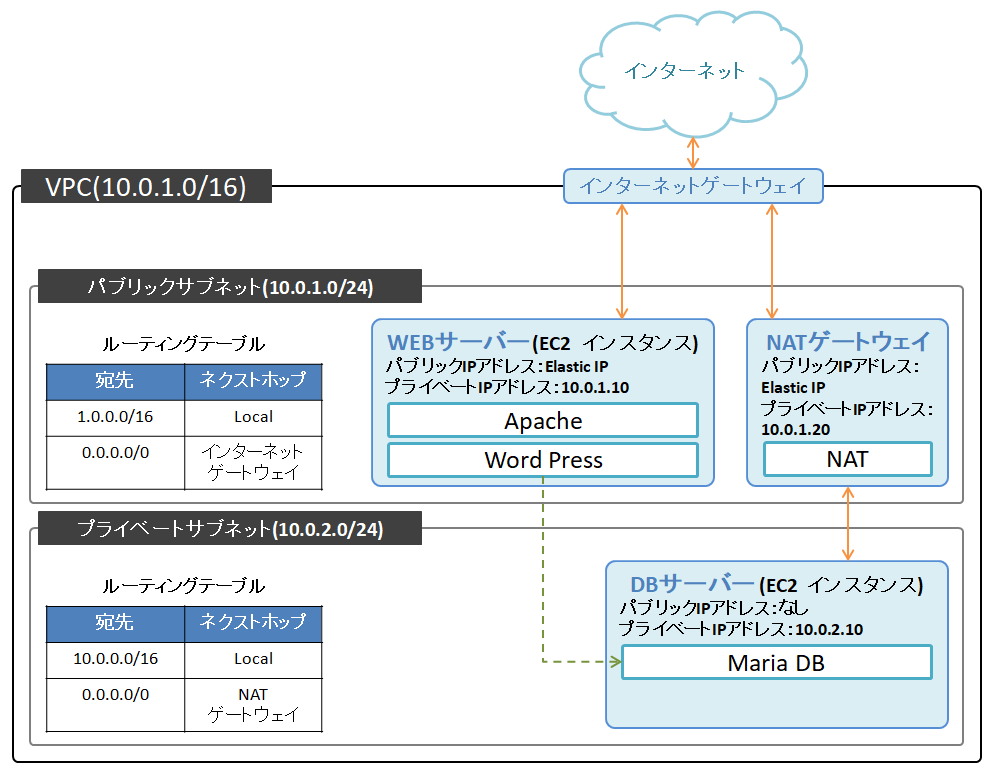
Amazon VPCを使ったネットワーク構築の学習
前置き
今回は初めて学習内容を記事としてアウトプットします。
何か問題などあった場合には教えていただけますと幸いです。使用した学習教材
今回読んだ本はこちらです。こちらの内容に沿って学習した知識をアウトプットします。
Amazon Web Services 基礎からのネットワーク&サーバー構築本学習での目標
AWS上でWordPressによるブログシステムを構築できるようになる。
これを通じて、ネットワークやサーバーを含めたシステム構築への理解を深める。学習内容のまとめ
1. ネットワークの構築
Amazon VPCの使用
今回初めて使ってみます。隔離したネットワークを作れるようです。
ルーターなどの仮想機器も配置したりできるみたいです。クラウド技術って本当にすごいですね。
(どうやって実現してるんだろう? 気になるので調べてみようかな)今回は学習教材に倣って、10.0.0.0/16でネットワークを作成することにします。
サブネットの作成
サブネットの概念は知っていましたが、分ける理由や効果などは理解していませんでした。
物理的な隔離やセキュリティ上の理由など、実際構築する際にはありそうな理由でした。
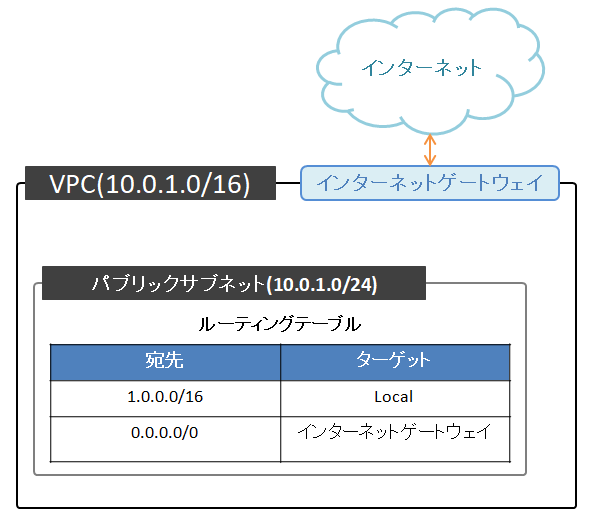
本書には、実務で役立ちそうなTIPS等もたくさん書かれていて勉強になりました。今回は、パブリックサブネット(10.0.1.0/24)とプライベートサブネット(10.0.2.0/24)に分割します。
パブリックサブネットには、インターネットから接続できるWEBサーバーを設置します。
プライベートサブネットには、インターネットから隔離したDBサーバーを設置します。インターネットゲートウェイの作成
初めて触りました。AWS上だと簡単な作業なのでびっくりしました。
やっぱり、クラウド技術ってすごいですね。先ほど作成したVPC領域にアタッチしました。
ルーティング情報の設定(ルーティングテーブル)
パケットを次にどこに転送するかというイメージで行いました。
Amazon VPCの場合は、サブネットとゲートウェイの間にルーターの役割を果たすソフトウェアが動いているようです。
なので、今回はそのルートテーブルを設定しました。新たにルートテーブルを作成して、パブリックサブネットに割り当てます。
デフォルトゲートウェイを先ほど作成したインターネットゲートウェイに設定します。
これにより、10.0.0.0/16以外の宛先のパケットをインターネットゲートウェイに転送するようにできました。この時点では、下図のようなネットワーク構成になっています。
2. サーバーの構築
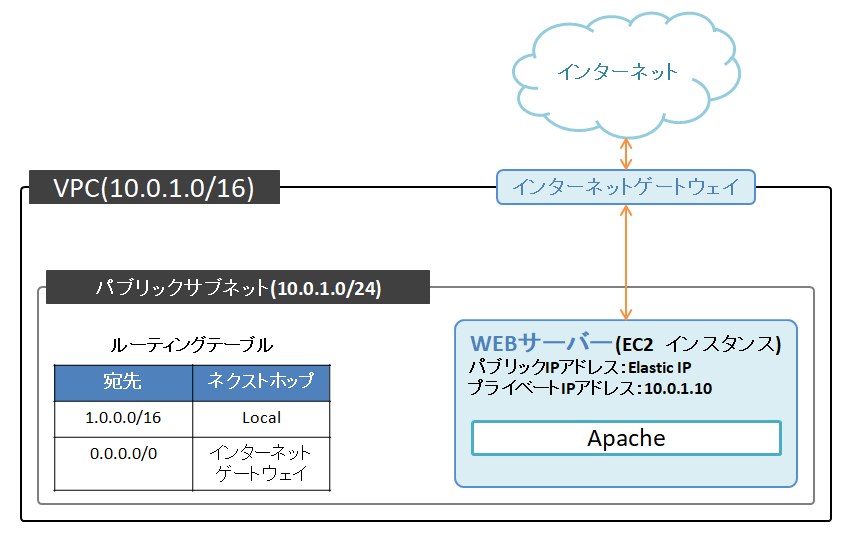
EC2インスタンスの作成
EC2サービスは、以前の自己学習でも使用したことがあります。(業務でも少し触りました)
今回は、作成したVPCのパブリックサブネット上にインスタンスを作成します。
インスタンスのプライベートIPアドレスをパブリックサブネットの範囲内で設定すればOKです。
(キーペアを保存して、SSHでのログインも確認しておきました)Elastic IPの使用
インスタンスに割り当てられるパブリックIPアドレスは、デフォルトではインスタンスが停止→起動する度に別のものが割り当てられます。
学習レベルでは必要ないかもしれないですが、SSHログインの際に都度変更するのも面倒なのでElastic IPを使用して固定化しました。3. サーバーソフトの設定
Apacheのインストール
SSHでインスタンスにログインして、コマンド操作でApacheをインストールします。
インストールしたら、Apacheを起動します。あと、サーバーが再起動しても自動起動するように設定しておきます。セキュリティグループの設定
現時点では、SSH用のポート22以外のポートはブロックされるようになっています。
そのため、HTTP用のポート80をインスタンスのセキュリティグループに追加することで通信を許可します。
これで、ブラウザにインスタンスのIPアドレスを入力すると、Apacheのデフォルトページが表示されるようになりました。DNSサーバーの構成
Amazon VPCには、VPC内の名前解決をするオプション機能があるようです。
VPC->アクション->DNSホスト名の編集で「有効化」にチェックすると、インスタンスに自動でパブリックDNSとプライベートDNSが設定されます。
AWSのRoute53というサービスを用いてDNSサーバーを構築することもできるらしいですが、今回は学習レベルなのでスルーしました。この時点では、下図のようなネットワーク構成になっています。
4. プライべートサブネットとNATを構築
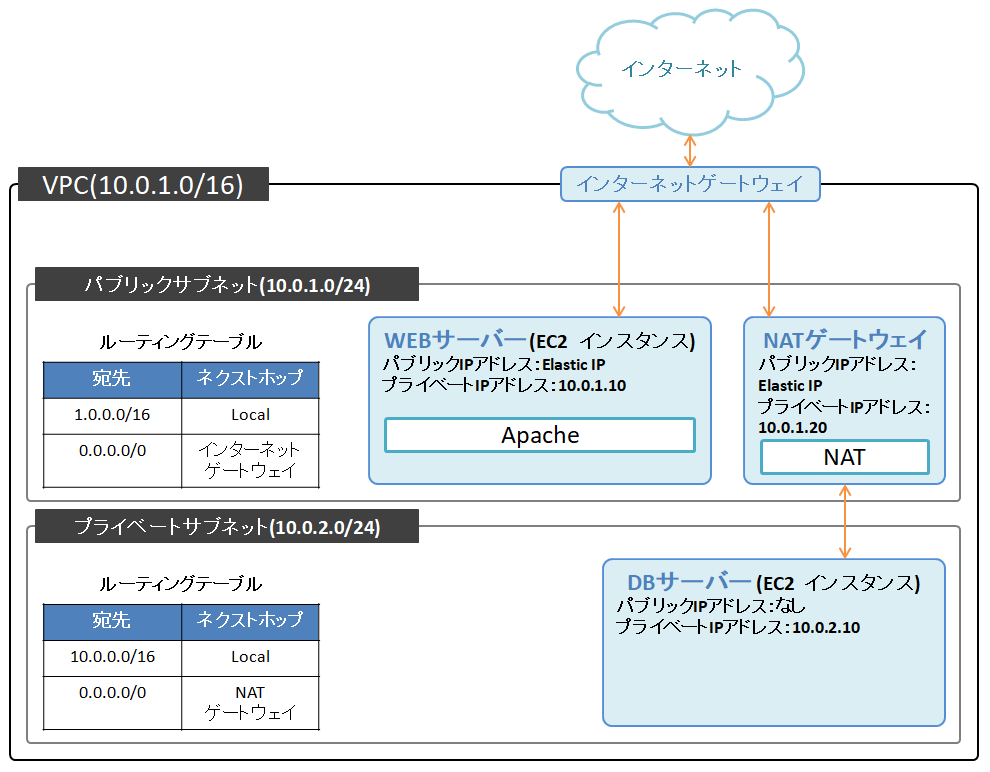
プライベートサブネットの構築
インターネットから接続できるパブリックサブネット領域と、インターネットから接続できないプライベートサブネット領域に分けることで、セキュリティ性能を高められます。
今回は、DBサーバーをプライベートサブネット領域に配置します。
また、今回は耐障害性などは考えないため、パブリックサブネットと同一のアベイラビリティゾーンで新たにプライベートサブネットを構築しました。
(耐障害性などを考慮して、別のアベイラビリティゾーンで構築することもあるみたいです)プライベートサブネットのルーティングテーブルは、VPCネットワーク内に対してのみ設定しておきます。
プライベートサブネットにサーバーを構築
EC2で新しいインスタンスを作成します。
インターネットから隔離するために、プライベートサブネット上に配置して、自動割り当てパブリックIPは無効化しておきます。また、セキュリティグループでDBの通信ポート用に3306を許可しておきます。
一応ですが、WEBサーバーからpingによる通信確認を行いました。
(pingで確認するために、該当するセキュリティグループにICMPを許可するように設定しておきました)踏み台サーバーの設定
このインスタンスはインターネットと接続されていないため、ローカル環境から直接SSHで接続することはできません。
そこで、ローカル→WEBサーバー→DBサーバーとSSHでアクセスできるようにします。
インスタンスにSSHで接続するためには秘密鍵が必要なため、WEBサーバーに秘密鍵を設置しました。実務でも「踏み台サーバー」は存在していたのですが、本学習で色々理解できてすっきりしました。
NATの構築
現在の状態では、DBサーバーはインターネットから隔離されているため、必要なソフトウェアのインストールやOSのアップデートなどが出来ません。
そこで、プライベートサブネット→インターネットの向きだけ通信を許可するようにします。
今回はAWSのNATゲートウェイという機能を利用します。(他にもNATインスタンスという方法もあるらしい)NATはパブリックサブネット内に配置して、Elastic IPも取得します。
プライベートサブネットのデフォルトゲートウェイをNATゲートウェイに向けます。
最後に、DBサーバーからcurlコマンドなどでHTTP通信ができることが確認できればOK。この時点では、下図のようなネットワーク構成になっています。(ほぼ完成に近いです)
5. ブログシステムの構築
DBサーバーにMariaDBをインストール、各種設定
DBサーバー上でコマンドでMariaDBをインストールします。
NATゲートウェイを経由してダウンロード、インストールが完了します。インストールしたらMariaDBを起動して、管理者パスワードも設定しておきます。
さらに、今回使用するDBを作成します。作成はMariaDBのコマンドプロンプトから行いました。
(CREATE文やGRANT文など、はじめて使いました)完了したら、DBサーバーが再起動したときにMariaDBを自動的に起動するようにしておきます。
WEBサーバーにWordPressをインストール、各種設定
WordPressはPHP5.6.20以降でしか動かないようなので、php7.3にアップデートします。
また、必要なライブラリ群もインストールする。WEBサーバーにもMariaDBをインストールして、WEBサーバーからDBサーバー上のMariaDBへの疎通確認をします。
先ほどDBサーバーにて設定したユーザー名とパスワードで接続できればOK。WordPressのダウンロード、初期設定
WordPressはソースファイルを提供サイトからダウンロードする必要があるみたいです。
WEBサーバー上でコマンドを使ってダウンロードしました。ダウンロードしたものは、Apacheから見える位置に配置します。(デフォルトでは/var/www/html)
一応、Apacheを再起動します。この時点で、ブラウザからWEBサーバーに接続した際のTOPページがWordPressの初期設定画面になりました。
あとは、ブラウザ上でWordPressの初期設定を行っていきます。もろもろの設定が完了すれば、ブラウザからWEBサーバーのパブリックDNSアドレスに接続すると作成したWordPressのページが開くようになります。
これで今回の学習は達成です!
まとめ
これで、AWS上にWordPressによるブログシステムを構築できました。
最終的にできたネットワークは下図のような構成になりました。
感想
とても面白かったです。
本書には、より細かく手順まで書かれていたのでテキパキと学習を進めることが出来ました。また、実務や他の学習で「手順」として扱っていたことに対しても、「何故そうするのか」「そうすると何が良いのか」なども書かれていたので、「手順」から「知識」へと昇華するキッカケとなったと思います。
ネットワークやサーバー構築に対して、さらに興味が湧きました。
「もっと〇〇するには、どう構築すればよいか」などの視点から、学習を継続していきたいと思います。補足
今回、はじめて書籍からの学習をアウトプットしてみました。
内容を書きすぎると著作権などに問題が発生すると思うので、概要と感想のみにしました。
文字だけだと記事として稚拙すぎたので、簡単な図も自作して載せました。興味を持った方は是非、購入してみる事をオススメします。
問題が無ければ、このような形で他の学習もアウトプットしてみようと思います。今回使用した学習教材はコチラ
Amazon Web Services 基礎からのネットワーク&サーバー構築
- 投稿日:2020-10-15T19:04:39+09:00
【学習】Amazon VPCを使ったネットワーク構築
前置き
今回は初めて学習内容を記事としてアウトプットします。
何か問題などあった場合には教えていただけますと幸いです。使用した学習教材
今回読んだ本はこちらです。こちらの内容に沿って学習した知識をアウトプットします。
Amazon Web Services 基礎からのネットワーク&サーバー構築本学習での目標
AWS上でWordPressによるブログシステムを構築できるようになる。
これを通じて、ネットワークやサーバーを含めたシステム構築への理解を深める。学習内容のまとめ
1. ネットワークの構築
Amazon VPCの使用
今回初めて使ってみます。隔離したネットワークを作れるようです。
ルーターなどの仮想機器も配置したりできるみたいです。クラウド技術って本当にすごいですね。
(どうやって実現してるんだろう? 気になるので調べてみようかな)今回は学習教材に倣って、10.0.0.0/16でネットワークを作成することにします。
サブネットの作成
サブネットの概念は知っていましたが、分ける理由や効果などは理解していませんでした。
物理的な隔離やセキュリティ上の理由など、実際構築する際にはありそうな理由でした。
本書には、実務で役立ちそうなTIPS等もたくさん書かれていて勉強になりました。今回は、パブリックサブネット(10.0.1.0/24)とプライベートサブネット(10.0.2.0/24)に分割します。
パブリックサブネットには、インターネットから接続できるWEBサーバーを設置します。
プライベートサブネットには、インターネットから隔離したDBサーバーを設置します。インターネットゲートウェイの作成
初めて触りました。AWS上だと簡単な作業なのでびっくりしました。
やっぱり、クラウド技術ってすごいですね。先ほど作成したVPC領域にアタッチしました。
ルーティング情報の設定(ルーティングテーブル)
パケットを次にどこに転送するかというイメージで行いました。
Amazon VPCの場合は、サブネットとゲートウェイの間にルーターの役割を果たすソフトウェアが動いているようです。
なので、今回はそのルートテーブルを設定しました。新たにルートテーブルを作成して、パブリックサブネットに割り当てます。
デフォルトゲートウェイを先ほど作成したインターネットゲートウェイに設定します。
これにより、10.0.0.0/16以外の宛先のパケットをインターネットゲートウェイに転送するようにできました。この時点では、下図のようなネットワーク構成になっています。
2. サーバーの構築
EC2インスタンスの作成
EC2サービスは、以前の自己学習でも使用したことがあります。(業務でも少し触りました)
今回は、作成したVPCのパブリックサブネット上にインスタンスを作成します。
インスタンスのプライベートIPアドレスをパブリックサブネットの範囲内で設定すればOKです。
(キーペアを保存して、SSHでのログインも確認しておきました)Elastic IPの使用
インスタンスに割り当てられるパブリックIPアドレスは、デフォルトではインスタンスが停止→起動する度に別のものが割り当てられます。
学習レベルでは必要ないかもしれないですが、SSHログインの際に都度変更するのも面倒なのでElastic IPを使用して固定化しました。3. サーバーソフトの設定
Apacheのインストール
SSHでインスタンスにログインして、コマンド操作でApacheをインストールします。
インストールしたら、Apacheを起動します。あと、サーバーが再起動しても自動起動するように設定しておきます。セキュリティグループの設定
現時点では、SSH用のポート22以外のポートはブロックされるようになっています。
そのため、HTTP用のポート80をインスタンスのセキュリティグループに追加することで通信を許可します。
これで、ブラウザにインスタンスのIPアドレスを入力すると、Apacheのデフォルトページが表示されるようになりました。DNSサーバーの構成
Amazon VPCには、VPC内の名前解決をするオプション機能があるようです。
VPC->アクション->DNSホスト名の編集で「有効化」にチェックすると、インスタンスに自動でパブリックDNSとプライベートDNSが設定されます。
AWSのRoute53というサービスを用いてDNSサーバーを構築することもできるらしいですが、今回は学習レベルなのでスルーしました。この時点では、下図のようなネットワーク構成になっています。
4. プライべートサブネットとNATを構築
プライベートサブネットの構築
インターネットから接続できるパブリックサブネット領域と、インターネットから接続できないプライベートサブネット領域に分けることで、セキュリティ性能を高められます。
今回は、DBサーバーをプライベートサブネット領域に配置します。
また、今回は耐障害性などは考えないため、パブリックサブネットと同一のアベイラビリティゾーンで新たにプライベートサブネットを構築しました。
(耐障害性などを考慮して、別のアベイラビリティゾーンで構築することもあるみたいです)プライベートサブネットのルーティングテーブルは、VPCネットワーク内に対してのみ設定しておきます。
プライベートサブネットにサーバーを構築
EC2で新しいインスタンスを作成します。
インターネットから隔離するために、プライベートサブネット上に配置して、自動割り当てパブリックIPは無効化しておきます。また、セキュリティグループでDBの通信ポート用に3306を許可しておきます。
一応ですが、WEBサーバーからpingによる通信確認を行いました。
(pingで確認するために、該当するセキュリティグループにICMPを許可するように設定しておきました)踏み台サーバーの設定
このインスタンスはインターネットと接続されていないため、ローカル環境から直接SSHで接続することはできません。
そこで、ローカル→WEBサーバー→DBサーバーとSSHでアクセスできるようにします。
インスタンスにSSHで接続するためには秘密鍵が必要なため、WEBサーバーに秘密鍵を設置しました。実務でも「踏み台サーバー」は存在していたのですが、本学習で色々理解できてすっきりしました。
NATの構築
現在の状態では、DBサーバーはインターネットから隔離されているため、必要なソフトウェアのインストールやOSのアップデートなどが出来ません。
そこで、プライベートサブネット→インターネットの向きだけ通信を許可するようにします。
今回はAWSのNATゲートウェイという機能を利用します。(他にもNATインスタンスという方法もあるらしい)NATはパブリックサブネット内に配置して、Elastic IPも取得します。
プライベートサブネットのデフォルトゲートウェイをNATゲートウェイに向けます。
最後に、DBサーバーからcurlコマンドなどでHTTP通信ができることが確認できればOK。この時点では、下図のようなネットワーク構成になっています。(ほぼ完成に近いです)
5. ブログシステムの構築
DBサーバーにMariaDBをインストール、各種設定
DBサーバー上でコマンドでMariaDBをインストールします。
NATゲートウェイを経由してダウンロード、インストールが完了します。インストールしたらMariaDBを起動して、管理者パスワードも設定しておきます。
さらに、今回使用するDBを作成します。作成はMariaDBのコマンドプロンプトから行いました。
(CREATE文やGRANT文など、はじめて使いました)完了したら、DBサーバーが再起動したときにMariaDBを自動的に起動するようにしておきます。
WEBサーバーにWordPressをインストール、各種設定
WordPressはPHP5.6.20以降でしか動かないようなので、php7.3にアップデートします。
また、必要なライブラリ群もインストールする。WEBサーバーにもMariaDBをインストールして、WEBサーバーからDBサーバー上のMariaDBへの疎通確認をします。
先ほどDBサーバーにて設定したユーザー名とパスワードで接続できればOK。WordPressのダウンロード、初期設定
WordPressはソースファイルを提供サイトからダウンロードする必要があるみたいです。
WEBサーバー上でコマンドを使ってダウンロードしました。ダウンロードしたものは、Apacheから見える位置に配置します。(デフォルトでは/var/www/html)
一応、Apacheを再起動します。この時点で、ブラウザからWEBサーバーに接続した際のTOPページがWordPressの初期設定画面になりました。
あとは、ブラウザ上でWordPressの初期設定を行っていきます。もろもろの設定が完了すれば、ブラウザからWEBサーバーのパブリックDNSアドレスに接続すると作成したWordPressのページが開くようになります。
これで今回の学習は達成です!
まとめ
これで、AWS上にWordPressによるブログシステムを構築できました。
最終的にできたネットワークは下図のような構成になりました。
感想
とても面白かったです。
本書には、より細かく手順まで書かれていたのでテキパキと学習を進めることが出来ました。また、実務や他の学習で「手順」として扱っていたことに対しても、「何故そうするのか」「そうすると何が良いのか」なども書かれていたので、「手順」から「知識」へと昇華するキッカケとなったと思います。
ネットワークやサーバー構築に対して、さらに興味が湧きました。
「もっと〇〇するには、どう構築すればよいか」などの視点から、学習を継続していきたいと思います。補足
今回、はじめて書籍からの学習をアウトプットしてみました。
内容を書きすぎると著作権などに問題が発生すると思うので、概要と感想のみにしました。
文字だけだと記事として稚拙すぎたので、簡単な図も自作して載せました。興味を持った方は是非、購入してみる事をオススメします。
問題が無ければ、このような形で他の学習もアウトプットしてみようと思います。今回使用した学習教材はコチラ
Amazon Web Services 基礎からのネットワーク&サーバー構築
- 投稿日:2020-10-15T18:27:08+09:00
AWS IoT CoreとAWS IoT Device Management基礎知識まとめ
記事について
AWS IoT Device Managementについての自分用まとめ
今後実際にいくつか使用予定があるため、その際にアップデート予定IoTでよく出てくる課題、要件
初期化時
- クラウド接続するための個別の認証情報をどうするか
- デバイスの情報をどう登録するか
動作時
- デバイスの設定変更したい
- デバイスの状態を可視化したい
- デバイスで発生している問題を調べたい
更新時
- FW更新をどうするか
AWS IoT Device Management
IoT Coreに統合されている
※サービス一覧からIoT Device Managementを検索してジャンプするとIoT Coreが開く大量のデバイス向けにデバイスの登録、グルーピング、OTA等のJob、queryベースの検索を提供する管理機能群
主な機能
デバイス登録
膨大な数のIoTデバイスの登録において個別の証明書を発行、デバイスへの埋め込み作業を排除する
以前記事にしたフリートプロビジョニングや、JITR、JITP等のプロビジョニング方式
https://qiita.com/takmot/items/eda7c2f519581b40ec3fデバイスのグループ化
静的グループ
例えばビル内システムでは、
ビル単位、フロア単位、部屋単位のグループや、機種、機能、セキュリティ要件単位のグループ等
以下想像されるユースケース
- グループ単位のアクセスポリシー管理
- グループ単位のアクション実行(再起動、アップデート等)
動的グループ
指定されたグループ条件を満たすデバイスの追加、条件を満たさなくなったデバイスの削除を自動的に実行
動的グループを作る場合は後述するフリートインデックスを使用する必要がある
以下想像されるユースケース
- ステータスがエラーとなったデバイスをグルーピングして情報の確認、ログの収集
- 旧バージョンのファームウェアを持つ、バッテリー残量80%以上のデバイスをグルーピングしてアップデートを実行
- 料金プランでグルーピングして機能制限等の設定変更
フリートインデックスを使用したデバイス検索
デバイスを指定した条件で絞込検索できる
特定のデバイス情報可視化や、絞り込んだデバイスを動的グループとして前述した動的グループに対する処理が実行できる
以下フリートインデックス作成方法
以下、検索条件として設定できる項目
- モノの名前、説明、属性
- デバイスシャドウで管理されているデバイスのステータスや設定
- モノの接続状態
- グループ名、説明、属性
動的グループ作成
フリートインデックスを有効にすると動的グループ作成が可能
以下のようにクエリ条件を指定し、条件を満たしたデバイスをグルーピング
Job
クラウドからJobとしてJSON形式データを送信しデバイスはJob内容に応じた処理を行う
Jobの状態、結果を通知機能で確認が可能
Jobはジョブドキュメント(JSON形式)で定義
ターゲットは、モノ、モノのグループ
Jobの種類は以下の2つ
Snapshot
1回限り実行
Job作成時に存在するモノが対象
ユースケース:
- ビル、フロア等グループに対する一括設定変更
- 異常が発生しているデバイスのグループに対する再起動
Continuouus
特定の条件に一致した場合に実行
Job作成時、作成後の対象グループに存在するモノが対象
タイムアウト設定可能
ユースケース:
- 期間内に接続中かつ、アイドル状態かつ、バッテリー残量80%以上になったデバイスのアップデート
セキュアトンネリング
ファイアウォール内のIoTデバイスに対するリモートアクセスを可能にする
用途としては、デバイスに異常が発生し、デバイスのステータスやログでは原因がわからないような場合に
一時的にトンネルを作成、SSH等でアクセスしデバッグに使用する
デバイス側にLocalproxyアプリケーションをインストールしておく必要あり参考

- 投稿日:2020-10-15T17:22:03+09:00
初学者がAWSにwebアプリケーションをホストする方法について考えてみた
はじめに
30代未経験からエンジニア転職を目指して勉強中のYNと申します。お読みいただきありがとうございます。
一番最初にwebアプリケーションをデプロイしたとき、Herokuを選んだ方が多いと思います。
でも、どうせならAWSを使ってみたいという方もいるでしょう。
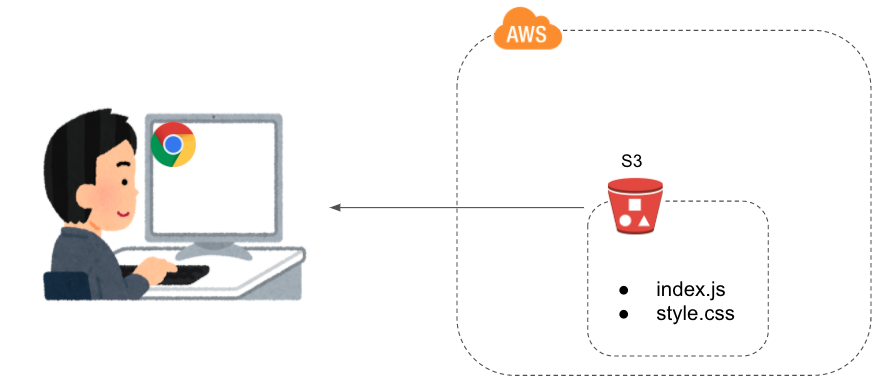
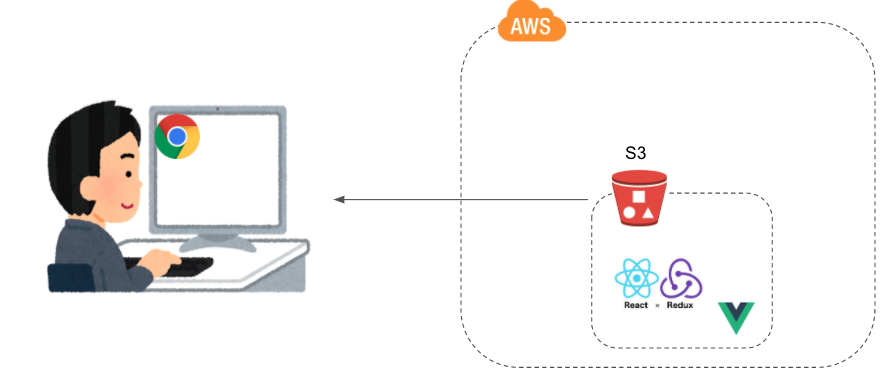
自分もそんな一人だったので、エンジニアを目指して勉強中の方向けに、AWSを使ったwebアプリのホスト方法についてまとめてみました。パターン1:S3で静的ホスティングする
S3を使えば簡単にホスティングできます。
メリット
- とても手軽。S3バケットにビルド済のindex.jsを置いて静的ホスティングの設定をするだけ。
- ほぼタダで利用できる。(S3は無料枠が12カ月間、5GB、20000リクエストまで使える)
- 無料枠期間を過ぎたとしても、使わなければ課金額は微小
デメリット
- S3にサーバとしての機能はないので、バックエンド機能を持つことができない。
- 機能の動作や描画はブラウザ頼み。処理が重いと低スペPCやスマホではヌルヌル動く。
パターン2:S3で静的ホスティングしつつ、モダンなフレームワークを使う
パターン1の発展版です。基本的にビルドしたコードをブラウザに動かしてもらうだけなので、当然ReactやVueも使えます。
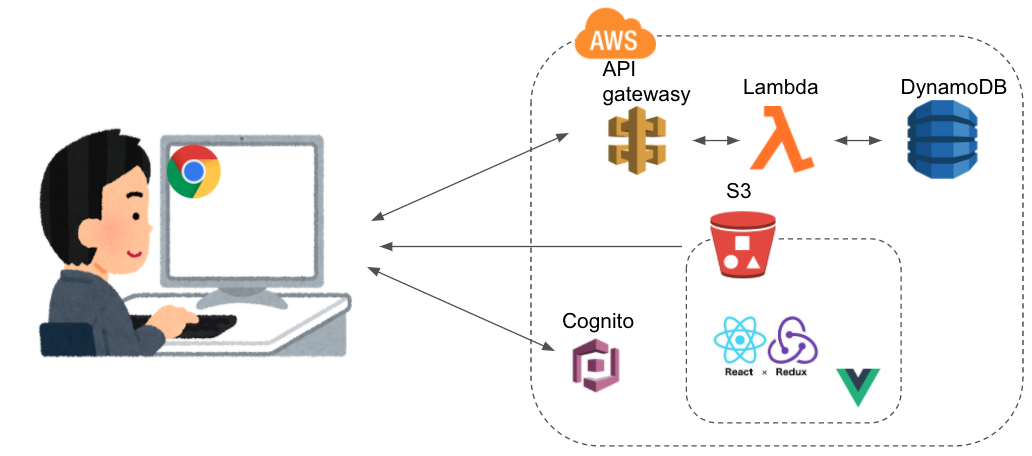
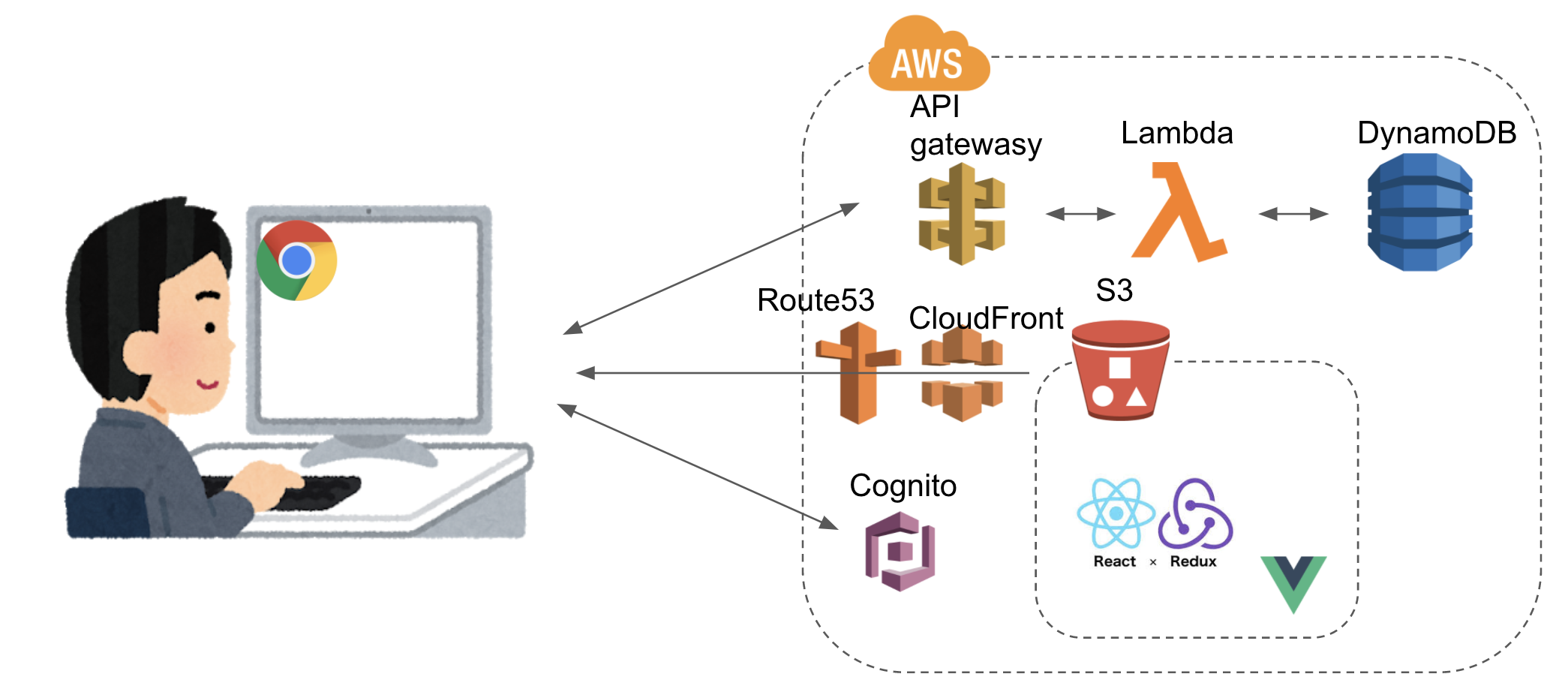
パターン3:S3で静的ホスティングしつつ、バックエンド機能をサーバレスで実装する
これが初心者的に一番オススメです。Lambdaを使えば大抵のバックエンド処理は実装できると思います。
- APIgateway:HTTPリクエストをAPIとして捌くことができます。Lambdaと組み合わせればサーバレスのバックエンド処理ができます。
- Lambda:15分以内の処理なら何でもしてくれます。高可用でスケーラブルな神のサービス。
- DynamoDB:noSQLのデータベースです。そして高可用でスケーラブル。
- Cognito:ユーザー認証してくれます。
また、CloudFrontを使えば画像の読み込みなどを高速化できますし、Route53を使えば簡単に独自ドメインを設定することもできます。
メリット
- まぁまぁ手軽にバックエンドを実装できる。AWS初心者を泣かせるIAMやVPCの面倒な設定も基本不要。
- ほぼタダで利用できる。(無料枠がある)
- 無料枠期間を過ぎたとしても、使わなければ課金額は微小
デメリット
- めちゃくちゃ重い処理はLambdaにはできない。
- リレーショナルデータベースの実装はできない。(可能だがオススメしない)
- 機能の動作や描画はブラウザ頼み。処理が重いと低スペPCやスマホではヌルヌル動く。
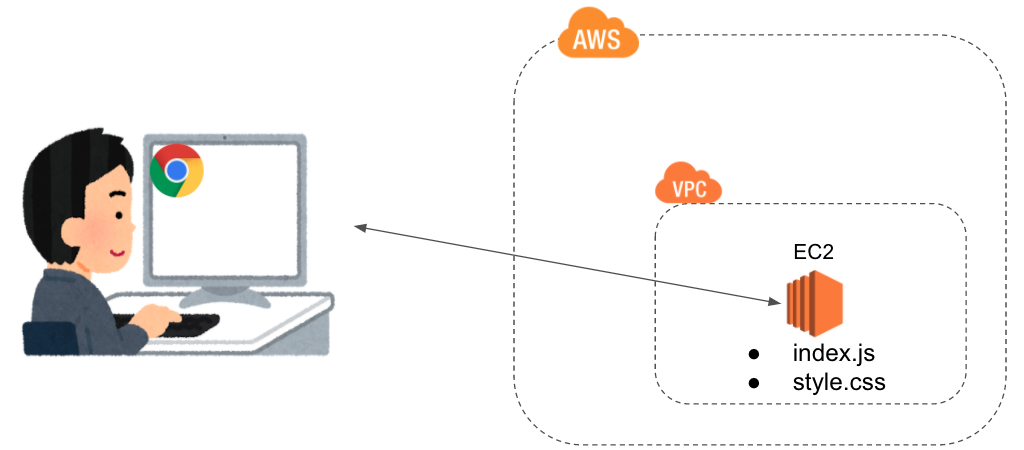
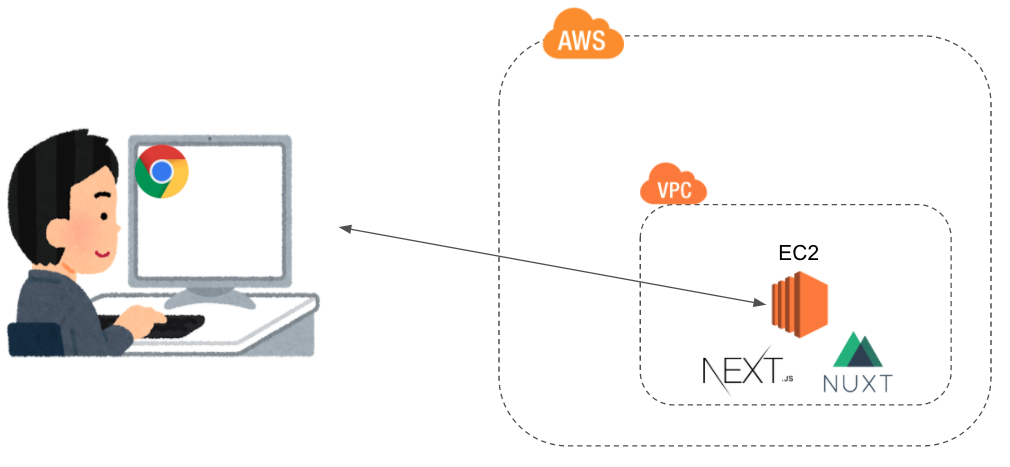
パターン4:EC2を使って静的ホスティングする
EC2はAWSの最も基本的なコンピューティングリソースです。要するにPCを時間貸ししてくれる感じです。PCなので、自由度が高く何でもできます。
FF10で言えばキマリ的な感じでしょうか
これをwebサーバーとして使い、webアプリケーションをデプロイします。
メリット
- 自由度が高く、何でもできる。
- AWSの基本サービスの使い方が勉強になる。
- Herokuの内部処理の勉強にもなる。そしてHerokuのありがたみが分かる(笑)
デメリット
- 無料枠で使えるリソースの性能は結構ショボい。
- EC2は12カ月の無料枠を過ぎると課金される。使わなくても課金される。結構高い。
- EC2の設定の他に、IAMやVPCの設定も必要でAWS初心者には敷居が高い。
- EC2を単なる静的webホスティングに使うのはリソースのムダ
パターン5:EC2でSSRする
EC2をただ静的ホスティングとして使うのはもったいないので、NextやNuxtなどのSSRフレームワークを用いてwebアプリケーションのパフォーマンスを向上させましょう。うまく実装できれば低スペPCやスマホでもサクサク動きます。
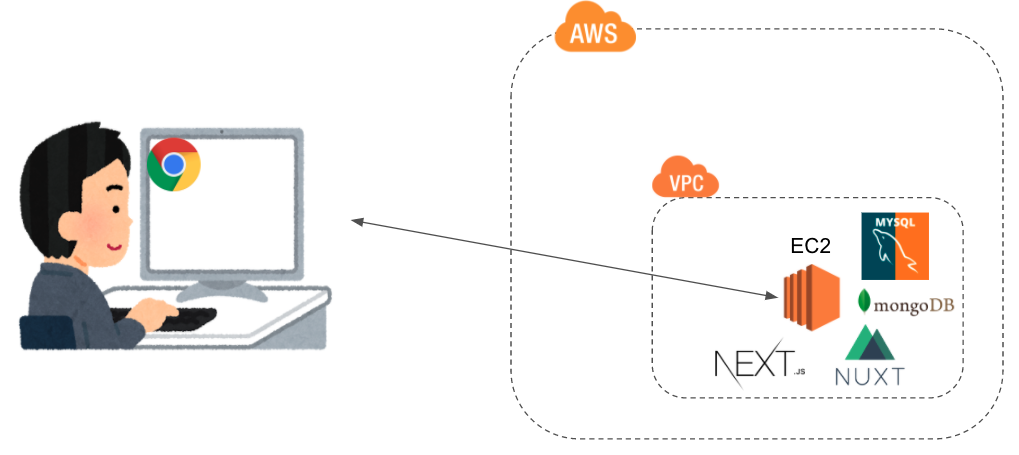
また、当然、EC2の中にデータベースを実装することもできます。
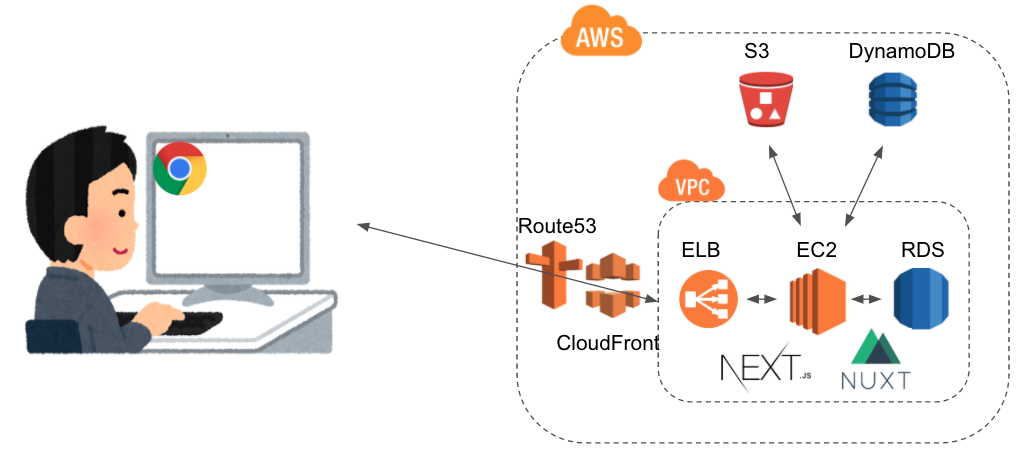
パターン6:EC2でSSRしつつ、AWSのマネージドサービスと連携させる
webアプリケーションの可用性を高めるために、AWSのマネージドサービスを使うことができます。
これらの連携方法を学べば、AWSについての知見も高まるのではないでしょうか。
- RDS:リレーショナルデータベースのマネージドサービス。EC2と同様、時間課金なので注意。
- ELB:ロードバランスによる可用性の担保をしてくれる。個人の作品レベルでは不要かと思う。EC2同様に課金される。
その他
例えばDockerを使ったマイクロサービスの開発など、実際の開発シーンを意識する場合には、ECSやEKSを使ってwebアプリケーションをデプロイしてみるのもいかがでしょうか。自分もいま、kubernetesやOpenShiftの勉強をしている最中なので、EKSでアプリケーションをデプロイできたらカッコいいな、と思っています。(結構お金かかるんですけどね。。。)
また、Heroku同様のPaaSであるElasticBeanstalkっていうのもあります。あえて選ぶならHerokuでいい気がしますが。最後に
いかがでしょうか。自分も引き続きAWSを勉強していきたいと思います。
お読みいただきありがとうございました。
- 投稿日:2020-10-15T17:05:39+09:00
【AWS - RDS】MySQLに特定のDBのみのアクセスユーザー作成
1つのDBサーバーを使用して、複数のDBを管理している場合、
特定のDBへのみアクセス出来るユーザーを作成したい。RDSにアクセス
アクセス権のあるEC2から下記を実行。
※ RDSへアクセス権があることを確認。セキュリティグループ等$ mysql -h RDS_ENDPOINT -u root -p Enter password: パスワードを入力ユーザーの作成
ALLで、全ての権限を付与。
DATABASE_NAME.*で、全てのテーブルを対象とする。
USERNAME@%で、全てのホストを対象とする。$ GRANT ALL ON DATABASE_NAME.* TO 'USERNAME'@'%' IDENTIFIED BY 'YOUR_PASSWORD';※
USERNAMEが存在しない場合は、新規でユーザーを作成
- 投稿日:2020-10-15T16:08:17+09:00
AWS IAMで学習用のユーザーを作成してみる
概要
AWSリソースをセキュアに操作するための認証・認可の仕組みを提供するマネージドサービス。
IAM自体の利用は無料となる。機能
- 各AWSリソースに対して別々のアクセス権限をユーザーごとに付与
- 他要素認証によるセキュリティ強化
- 一時的な認証トークンを用いた権限の委任
- 他のIDプロバイダーで認証されたユーザーにAWSリソースの一時的なアクセス
- 世界中のリージョンで同じアイデンティティと権限の利用
4つの概念
- IAMユーザー:AWSを操作する人やサービス
- IAMグループ:IAMユーザーの集合体
- IAMポリシー:AWSへのアクセス許可の定義
- IAMロール:IAMユーザーやサービスに対して権限の譲渡 (IAMロールにアタッチされたIAMポリシーを他のIAMユーザーに委譲できる)
管理者のIAMユーザーは全操作許可のIAMポリシーをアタッチされることで管理者として全操作を行うことができる。
アカウントを作成したユーザーはルートユーザーであるが、日常的なタスクはルートユーザーを使用しないのがベストプラクティス。とりあえず管理者権限を付与したユーザーを作成
IAMのコンソールから[ユーザー]→[ユーザーを追加]でキャプチャ画像通りに選択し、ユーザー名とパスワードを入力後次のステップへ
[既存のポリシーを直接アタッチ]→[AdministratorAccess]にチェックを入れて次のステップへ
次の画面では何もせずさらに次のステップへ
確認画面が表示されるので、[ユーザーの作成]で作成
作成したユーザーでログインするための12桁のアカウントIDを含むURLが表示されるので保存しておき以後の操作(AWS勉強用)は作成したユーザーで進める!
- 投稿日:2020-10-15T16:08:17+09:00
AWS IAMで学習用のIAMユーザーを作成してみる
参考
AWSではじめるデータレイク: クラウドによる統合型データリポジトリ構築入門
AWS IAMとは
AWSリソースをセキュアに操作するための認証・認可の仕組みを提供するマネージドサービス。
IAM自体の利用は無料となる。機能
- 各AWSリソースに対して別々のアクセス権限をユーザーごとに付与
- 他要素認証によるセキュリティ強化
- 一時的な認証トークンを用いた権限の委任
- 他のIDプロバイダーで認証されたユーザーにAWSリソースの一時的なアクセス
- 世界中のリージョンで同じアイデンティティと権限の利用
4つの概念
- IAMユーザー:AWSを操作する人やサービス
- IAMグループ:IAMユーザーの集合体
- IAMポリシー:AWSへのアクセス許可の定義
- IAMロール:IAMユーザーやサービスに対して権限の譲渡 (IAMロールにアタッチされたIAMポリシーを他のIAMユーザーに委譲できる)
管理者のIAMユーザーは全操作許可のIAMポリシーをアタッチされることで管理者として全操作を行うことができる。
アカウントを作成したユーザーはルートユーザーであるが、日常的なタスクはルートユーザーを使用しないのがベストプラクティス。とりあえず管理者権限を付与したユーザーを作成してみる
IAMのコンソールから[ユーザー]→[ユーザーを追加]でキャプチャ画像通りに選択し、ユーザー名とパスワードを入力後次のステップへ
[既存のポリシーを直接アタッチ]→[AdministratorAccess]にチェックを入れて次のステップへ
次の画面では何もせずさらに次のステップへ
確認画面が表示されるので、[ユーザーの作成]で作成
作成したユーザーでログインするための12桁のアカウントIDを含むURLが表示されるので保存しておき以後の操作(AWS勉強用)は作成したユーザーで進める!
- 投稿日:2020-10-15T14:05:44+09:00
CloudFormation EFSテンプレートサンプル
AWSTemplateFormatVersion: 2010-09-09 Parameters: EFSName: Type: String Default: hoge SecurityGroups: Type: List<AWS::EC2::SecurityGroup::Id> Subnets: Type: List<AWS::EC2::Subnet::Id> Resources: FileSystem: Type: AWS::EFS::FileSystem Properties: FileSystemTags: - Key: Name Value: !Ref EFSName Encrypted: true MountTarget1: Type: AWS::EFS::MountTarget Properties: FileSystemId: !Ref FileSystem SecurityGroups: !Ref SecurityGroups SubnetId: !Select - '0' - !Ref Subnets MountTarget2: Type: AWS::EFS::MountTarget Properties: FileSystemId: !Ref FileSystem SecurityGroups: !Ref SecurityGroups SubnetId: !Select - '1' - !Ref Subnets MountTarget3: Type: AWS::EFS::MountTarget Properties: FileSystemId: !Ref FileSystem SecurityGroups: !Ref SecurityGroups SubnetId: !Select - '2' - !Ref Subnets
- 投稿日:2020-10-15T12:28:32+09:00
量子コンピュータ?5G通信網? 世界を変える先進的AWSサービス5選
はじめに
今回はAWSの先進的なサービスについて、5つほど紹介します!
【YouTube動画】 意外と知らない! AWS の世界を変える可能性をもつ5つのサービス!!
AWS Ground Station
これは、人工衛星と通信する基地局をクラウド化したサービスです。
ただ登録するには、人工衛星のカタログ番号やアマチュア無線のライセンスが必要です。人工衛星を使って、災害状況の確認をしたり、正確な地理情報を取得したりが簡単にできそうですね。
デモ動画はこちらです。
https://www.youtube.com/watch?v=KRWZA00skXoAWS RoboMaker
ROS用アプリケーションの開発環境やシュミレートができるサービスです。
C++やPythonでプログラムできるそうです。
AWS IoT Greengrassと連携すると、実機へのデプロイもできます。もし始めるなら、以下のQiita記事とかわかりやすかったです!
https://qiita.com/nmatsui/items/6721c820000cf5115bdcAmazon Braket
Braketはbra-ket記法のBraketです。
予約制ですが、D-Wave, IonQ, Rigettiの3種の量子コンピュータを利用できるようです。
ローカルで実験する際は、Amazon Braket Python SDKなどが使えます。Amazon Connect
これはクラウド上にコールセンターを構築できるサービスです。
電話番号の取得やコールフローもGUIで簡単にできます。Amazon Wavelength
ボストン、サンフランシスコなどの一部地域でしか利用できませんが、5Gを利用できるサービスです。
リアルタイム性の高いコンテンツと相性が良いです。まとめ
今回はAWSの先進的なサービスについて紹介しました!
他にも面白いサービスがあるので、ぜひ遊んでみてください!

- 投稿日:2020-10-15T10:44:59+09:00
SQSのよくある監視項目をterraformで設定する
IaCの恩恵をわかりやすくすぐに受けやすいのは、Cloudwatch Alarmなどの監視項目だと思っています。
特にSQSキューなどは基本的に監視項目が似通っているため、似たようなものを大量に登録、管理する事が多いでしょう。
今回は、よくあるアラートの設定項目をterraformでさっと量産する方法を覚書として記載しておきます。よくある監視項目
毎回、SQSキューを作った後にとりあえず設定しておきたい監視項目は以下のようなものがあるかと思います。
- デッドレターキューなどにメッセージが入った
- キューされたメッセージがxxx件を超えた
- 未処理のメッセージが放置されたままxxx日が過ぎた
このへんにフォーカスした設定を書いてみます。
terrafromの設定
今回、通知に使っている AWS SNS Topic は別途定義されているものとします。
(もちろんEventBridgeなどSNS以外の方法でaction eventを受け取ってもいいでしょう)module化を避け、1ファイルで完結させます。
sqs_alert.tflocals { queues = [ { queue_name : "sample-A-queue", // SQSキュー名 alert_queue_count = [200], // 何個メッセージがたまったらアラートを出すか alert_oldest_message_day = [5, 7, 10, 13], // 一番古いメッセージがこの日数を検知したらアラート }, { queue_name : "sample-B-queue-dead" alert_queue_count = [1, 10, 20, 30, 100], alert_oldest_message_day = [5, 7, 10, 13], }, { queue_name : "sample-C-queue.fifo", alert_queue_count = [200], alert_oldest_message_day = [5, 7, 10, 13], }, ] } // 使いやすいようにデータ変換処理 locals { queue_count_alert_source = flatten([for q in local.queues : [for c in q.alert_queue_count : { queue_name = q.queue_name count = c }]]) oldest_message_alert_source = flatten([for q in local.queues : [for day in q.alert_oldest_message_day : { queue_name = q.queue_name day = day seconds = day * 24 * 3600 }]]) } // キュー数監視アラート resource aws_cloudwatch_metric_alarm queue_count_alarm { count = length(local.queue_count_alert_source) alarm_name = "sqs_count_${local.queue_count_alert_source[count.index]["queue_name"]}_over_${local.queue_count_alert_source[count.index]["count"]}" alarm_description = "message detected: SQS ${local.queue_count_alert_source[count.index]["queue_name"]} > ${local.queue_count_alert_source[count.index]["count"]} " comparison_operator = "GreaterThanOrEqualToThreshold" evaluation_periods = 1 metric_name = "ApproximateNumberOfMessagesVisible" namespace = "AWS/SQS" period = 300 statistic = "Minimum" threshold = local.queue_count_alert_source[count.index]["count"] alarm_actions = [aws_sns_topic.fatal.arn] ok_actions = [aws_sns_topic.fatal.arn] insufficient_data_actions = [] treat_missing_data = "ignore" //欠落データを無視 dimensions = { QueueName = local.queue_count_alert_source[count.index]["queue_name"] } } // 放置メッセージ監視アラート resource aws_cloudwatch_metric_alarm oldest_message_days { count = length(local.oldest_message_alert_source) alarm_name = "sqs_old_${local.oldest_message_alert_source[count.index]["queue_name"]}_day_${local.oldest_message_alert_source[count.index]["day"]}" alarm_description = "oldest meessage alarm: SQS ${local.oldest_message_alert_source[count.index]["queue_name"]} > ${local.oldest_message_alert_source[count.index]["day"]} day " comparison_operator = "GreaterThanOrEqualToThreshold" evaluation_periods = 1 metric_name = "ApproximateAgeOfOldestMessage" namespace = "AWS/SQS" period = 300 statistic = "Minimum" threshold = local.oldest_message_alert_source[count.index]["seconds"] alarm_actions = [aws_sns_topic.fatal.arn] ok_actions = [aws_sns_topic.fatal.arn] insufficient_data_actions = [] treat_missing_data = "ignore" //欠落データを無視 dimensions = { QueueName = local.oldest_message_alert_source[count.index]["queue_name"] } }
aws_cloudwatch_metric_alarm.queue_count_alarmでは「キュー数監視」
aws_cloudwatch_metric_alarm oldest_message_daysでは「放置されたメッセージの日数」を監視しています。
これで最低限のものは設定できるかと思います。何度も同じlocal変数へのアクセスや[count.index]が出てきてしまうのが少し悩みどころですね。
このへんはCDKやら使っていると、「もうすこし素直にデータ変換やループ定義したいなあ」と思ってしまいます。
tfでももうすこしスマートになら無いかと思うので、綺麗なやり方募集です。
- 投稿日:2020-10-15T09:35:27+09:00
【AWSインフラ運用担当者向け】リリース自動化導入の全体像把握と始め方
こんにちは。
今回はAWSで動くアプリケーションのリリース自動化について書きます。想定読者
①AWS運用(インフラ)しているが、リリースは手動で行っていて、面倒に感じている
②リリース自動化担当になったが、自動化するメリットやどの範囲まで自動化できるのか分かっていない
※①は今の、②は過去の自分です。
記事のテーマ
・【AWS運用担当者向け】リリース自動化導入の全体像把握と始め方
リリース自動化の威力
リリース自動化の導入可能な範囲
リリース自動化導入後のつまずきポイント
まずは何を学ぶか、どう学んでいけばよいか秒間数百アクセスの大規模ECサイトのリリース自動化を設計した経験で得た知見を纏めます。
なぜ自動化するのかという点については下記も参考にしてみてください。
(クラウドのベストプラクティス集に自動化必須の旨が記載されています)
AWS Well-Architected 5本の柱を要約する(運用上の優秀性)リリース自動化の威力
自動化というと面倒なことを自動化して運用が楽になるというイメージが先に来ると思うのですが、それだけではなく、システムの品質があがるという効果があります。
物事が簡単にできるということで劇的に変わることの例えです。
EX.水道が無かったら
⇒体を洗うのに川に水を浴びに行かないといけない
⇒体を洗う頻度は下がる
⇒健康を害したり、体臭を気にするようになる
⇒生活の品質が下がるEx.リリースに置き換えると
⇒リリースが自動化されて簡単にできるようになったら
⇒リリースの頻度が変わる
⇒細かくリリースするようになる
⇒細かいリリースは品質を上げるリリース自動化の導入範囲
リリースフローの中でどの部分が自動化可能か、その中でどれを自動化するべきかを考えます。
案件毎に違うかもしれませんが、リリースの一般的な流れは下記の通りだと思ってます。
○開発
・自分の開発端末での開発(コード修正、試験)
・バージョン管理ツール(CodeCommitやGITやSVNなど)へのアップ
・コードレビュー
○検証
・バージョン管理ツールから検証環境へコピー
・検証環境固有の情報の注入
・(必要な言語なら)ビルド
・新機能の検証、試験の実施
・既存機能の検証、試験の実施
○リリース準備
・有識者のリリース判定会(検証結果を基に)○リリース(サービスイン)
・バージョン管理ツールから本番環境へコピー
・本番環境固有の情報の注入
・(必要な言語なら)ビルド
・サービスイン
・(可能なら)簡易動作確認上記の流れの中で自動化できることは
○検証
と
○リリース(サービスイン)
です。
その中でも自動化が困難、不可な部分は諦めます。リリース自動化導入後のつまずきポイント
・自動化処理がエラーとなり、手動リリースが行われ、自動化環境のメンテもされず、徐々に自動化が使われなくなる
⇒自動化の設計時に自動化環境の維持をどうするか検討した方が良いです。・パラメータ変更時に自動テスト用のコードも修正しないといけなくなる。(2重管理状態になる)
⇒何をテストするべきか検討した方が良いです。(多少のリスクはとっても)パラメータの自動試験は行わず、サイトの動作についてのみ自動試験を行うようにした方が良いと考えています。
※テスト自動化は自分でも最適解が分っていないです。ここはもう少し勉強します。データベース変更のようなサービス停止が必要なリリースでは自動化使えない?
⇒画像だけが変わる、アプリケーションコードが変わる、サーバ設定が変わる、データベースのテーブル列が増える、色々なリリースパターンを考えてそれぞれの自動化設計を行うようにします。
頻度が少ないリリースパターンなら自動化しないという選択もあるかと思います。
まずは何を学ぶか、どう学んでいくか
Codeシリーズでスクリプト(シェル)をデプロイしてみるのが良いと思っています。
バージョン管理ツール、AWSのCodeシリーズの理解につながります。
色々なツールがありますが、AWSであればまずはGit(or CodeCommit)、CodePipeline、CodeDeployを利用してみてください。
環境固有の情報はSystemsManagerのパラメータストアで管理するようにします。全体像のイメージは下記のくろかわさんの動画が分かりやすいです。
【はじめてのCI/CD】AWSでやってみるDevOps最初の一歩、CodeDeploy、CodePipelineを使った自動デプロイのハンズオンIaCを利用して自動化環境を構築する場合は、下記が大変参考になります。
aws-samples/aws-cdk-examples/python/codepipeline-docker-build/IaCについては下記に記事を書いていますのでご参考ください。
AWS自動化の心得(IaC編)


- 投稿日:2020-10-15T02:04:56+09:00
unicorn立ち上げ時にmaster failed to start, check stderr log for detailsがでて弾かれる
今回はアプリケーションサーバーであるunicornを起動した時に見たことないエラーに直面したので解決法を残します
[ec2-user@ip-172-31-23-189 アプリ名]$ RAILS_SERVE_STATIC_FILES=1 unicorn_rails -c config/unicorn.rb -E production -D master failed to start, check stderr log for detmaster failed to start, check stderr log for det ??
見たことないエラー。ログを見にいくことに自身のアプリケーションのディレクトリに移動 [ec2-user@ip-172-31-23-189~]$ cd /var/www/アプリケーション名 currentディレクトリに移動 [ec2-user@ip-172-31-23-189 <リポジトリ名>]$ cd current logディレクトリに移動 [ec2-user@ip-172-31-23-189 current]$ cd log logの中に入っているファイルの情報を表示 [ec2-user@ip-172-31-23-189 log]$ ls production.log unicorn.stderr.log unicorn.stdout.log今回はunicornの問題なので
tail -f unicorn.stderr.log(最新のログを10行分表示) もしくは cat log/unicorn.stderr.log(全てのログ表示)僕の場合はtailの方の10行では確認しきれなかったので、catの方でもログを確認。すると
SQLで何か言われている。SQLに接続してみることに
$ mysql -u root -p ERROR 2002 (HY000): Can't connect to local MySQL server through socket '/var/lib/mysql/mysql.sock' (2)ソケットファイルがないですというエラー文。なのでソケットファイルを作ってあげます。
sudo touch /var/lib/mysql/mysql.sockてことでもう一度接続
$ mysql -u root -p ERROR 2002 (HY000): Can't connect to local MySQL server through socket '/var/lib/mysql/mysql.sock' (13)かっこの中の数字が2から13に変わっただけやん。/var/lib/mysql/mysql.sock というファイルを開く権限がないですてことらしいです。
てことでmysql.sockに権限を付与するコマンド$ sudo chmod 777 /var/lib/mysql/mysql.sockもう一度接続
$ mysql -u root ERROR 2002 (HY000): Can't connect to local MySQL server through socket '/var/lib/mysql/mysql.sock' (111)こんどは111に変わったけど、これは接続対象が起動していない or 存在しないということらしい
ステータスコマンドで状況を確認$ sudo systemctl status mariadbここでactiveと表示されていれば接続されている。僕の場合表示されておらず、つまりMariaDBの再起動ができていなかったということがここで判明
$ sudo systemctl restart mariadb
active!これで無事、unicornを立ち上げることができました。今回はEC2のインスタンス再起動時にサーバーの再起動をしていないことが原因でした。