- 投稿日:2020-10-12T23:56:06+09:00
今回使ったlink_toのいろいろ、まとめてみた
はじめに
今回のカリキュラムで一番躓いたのが、
link_toメソッドだった。もちろん基本的な使い方は理解しているつもりだが、どうもpathの引数がしっくりときていない。今回の投稿は何かを説明する目的ではなく、自分がコードを読むための記録である。
以下、今回作成したアプリの全link_toを余計な記述はカットして引数の読み方とともに載せる。全link_toメソッド
①
application.html.erb<%= link_to "ログアウト", destroy_user_session_path, method: :delete %> <%= link_to "新規投稿", new_prototype_path %>サインイン状態で表示させている「ログアウト」と「新規投稿」どちらも誰もが共通するページや処理のため、( )で引数を渡す必要がない。
ユーザーによってログアウトページが違うことはないし、ユーザーによって新規投稿ページが違うことはない。
link_toメソッドはデフォルトでHTTPメソッドがGETのため、ログアウトのときは、第三引数にメソッドを指定する。②
application.html.erb<%= link_to "ログイン", new_user_session_path %> <%= link_to "新規登録", new_user_registration_path %>①と考え方は同じ。今度は非ログイン状態のときの表示。ログイン画面も新規登録もユーザーによって変わることはないから、引数がなくてよい。
③
application.html.erb<%= link_to image_tag("logo.png"), root_path %>root_pathは引数がなくてもいける!
④
prototypes/show.html.erb<%= link_to "編集する", edit_prototype_path(@prototype) %> <%= link_to "削除する", prototype_path(@prototype), method: :delete %>投稿したものの詳細ページから、編集したり、削除したりする部分。
showアクションの中で、@prototype = Prototype.find(params[:id])と一つのレコードを選び出しているため、どのprototypeを編集・削除するか判断ができる。⑤
prototypes/_prototype.html.erb<%= link_to prototype.title, prototype_path(prototype.id) %> <%= link_to image_tag(prototype.image), prototype_path(prototype.id) %>user_pathシリーズ
user_pathはユーザーのマイページに飛ぶ。誰のマイページなのか明らかにするため、引数が必要になる。
prototypes/index.html.erb<%= link_to current_user.name + "さん", user_path(current_user) %>ログイン中のユーザー名をクリックするとそのユーザーのマイページに飛ぶ。
deviseのGemを用いることによって使えるcurrent_user。prototypes/_prototype.html.erb<%= link_to "by " + prototype.user.name, user_path(prototype.user.id) %>prototypeとアソシエーションしているuserのidを取得。
prototypes/show.html.erb<%= link_to "by " + @prototype.user.name, user_path(@prototype.user.id) %>誰による投稿か、名前が表示されている部分のコード。
showアクションの中で、@prototype = Prototype.find(params[:id])と一つのレコードを選び出しているため、prototypeとアソシエーションしているuserのidを取得できる。prototypes/show.html.erb<%= link_to comment.user.name, user_path(comment.user.id) %>誰のコメントか表示されているところのコード。each文で|ブロックパラメーター(変数)に
comment|が入り、commentとアソシエーションしているuserのidを取得。
- 投稿日:2020-10-12T23:52:58+09:00
Ruby 標準入力と様々なメソッド
はいじめに
これは学習用のメモになります。
標準入力とは?
もともとはLINUXなどのUnix系OSで用意されていた仕組みです。
標準入力に対応するようにプログラムを作っておけば、プログラム実行時に、ファイルを読み込んだり、キーボードからデータを読み込んだり、パラメータを指定したりというように、入力先を切り替えることができます。getsメソッド
標準入力から一行入力
line = gets puts lineto_iメソッド
標準入力から一行読み込み、整数に変換
line = gets.to.i puts line //入力された数字が出力される例題) 標準入力で2つの整数が2行で与えられます。 1つ目の数値から2つ目の数値までを、1ずつ増加させながら、1行ずつ順番に出力するプログラムを作成してください。たとえば、3と5という数値が与えられた場合、次のように出力します。 3 4 5num1 = gets.to_i num2 = gets.to_i for i in num1..num2 puts i end* to_sメソッド
データを文字列に変換する
* to_fメソッド
データを小数点付きに変換すること
chompメソッド
文字列の末尾の改行コードを取り除きます
line = gets.chomp puts = "#{line}は、スライムを攻撃した" //改行コードを取り除いた状態で出力されるsplitメソッド
splitメソッドとは簡単に言うと
文字列を分割して配列にするためのメソッドです。str = "samurai engineer blog" array = str.split p array[実行結果]
["samurai", "engineer", "blog"]区切り文字を指定して分割する方法
文字列.split(区切り文字) str = "samurai,engineer,blog" array = str.split(",") p array[実行結果]
["samurai", "engineer", "blog"]最後に
この他にも様々なメソッドあると思います。
日々更新していこうと思います。
また、間違っているところがあればご指摘していただけると幸いです。
- 投稿日:2020-10-12T23:10:03+09:00
Sikuli (SikuliX) + RubyでRPAことはじめ(何度もつまづいたけどちゃんとできたよ)
Rubyでもできると聞きまして
SikuliXというフリーのRPAツールがあります。(公式、ドキュメント)
Sikuliの後継にあたるものらしいのですが、上記公式にSikuliX supports as scripting languages
Python language level 2.7 (supported by Jython)
running RobotFramework text-scripts is supported (see docs)
Ruby language level 1.9 and 2.0 (supported by JRuby)
JavaScript (supported by the Java Scripting Engine)と、「Rubyでもコマンドが書けるぜ!」的なことが書いてあり、じゃあちょっとこれで遊んでみようかな、と思いました。1
しかし、Ruby+SikuliXの導入記事って少ないこともあり、やってみると結構最初の設定段階ではまりました。そこでこの記事では同じようなことをやってみたい方のために、この方法でできたよ!というご報告をさせていただきます。
(特に日本語の記事が少ないですね。この界隈、Pythonに比べて多勢に無勢と言った感じなので、もっと増えてー!)
なお、筆者の環境はWindows 10です。
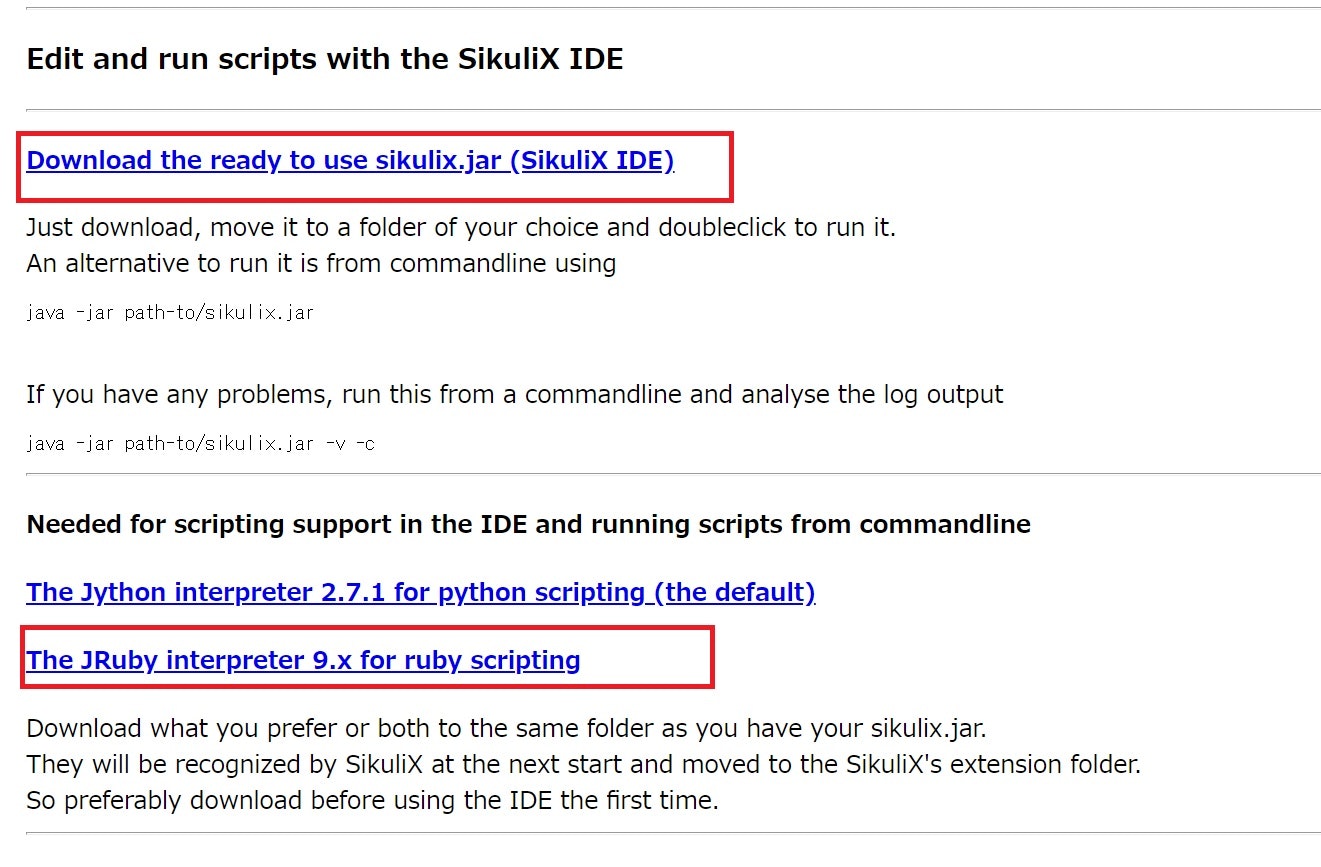
まずはSikuliXのダウンロード
https://raiman.github.io/SikuliX1/downloads.html
にアクセスし、以下赤囲みにしてあるリンクから2つの.jarファイルをダウンロードします。2
SikuliX用の好きなフォルダを作って、2つを同じところに保存しましょう。
SikuliXが動くバージョンのJava (Open JDK)をダウンロード
Javaを既にインストールしている人はsikulixide-2.0.4.jarを動かしたくなるところですが、一旦我慢してください。2020年10月現在、最新のJavaではエラーになり、JRuby Interpreterだけ別の場所に移動するだけされてしまうようです(多分、移動すること自体は問題なく、以下の作業を続ければいいだけだとは思いますが、不安ならJRuby Interpreterをもう一度ダウンロードしてください)。
ここで、少し古いJavaをダウンロードしてきましょう。
https://jdk.java.net/archive/
SikuliXにはバージョン11.0.2がおすすめのようですので、探してダウンロードします。
zipは展開し、できたフォルダは自分のわかるところに置いておきます。私はCドライブ直下にしました。とりあえず起動してみる
コマンドプロンプトでSikuliXをダウンロードしたフォルダに移動し、以下のコマンドを入力します。※但し、これは私のようにCドライブ直下にOpenJDKフォルダを配置した場合です。別の場所に置いた方は、それに従ってjavaのパスを指定してください。
C:\openjdk-11.0.2_windows-x64_bin\jdk-11.0.2\bin\java -jar sikulixide-2.0.4.jarこうすると、先ほどのようにJRuby Interpreterがどこかに移動するのは同じ事ですが、今度はエラーが出ずにIDEが立ち上がってくれます。
しかし、これではまだRubyスクリプトは動きません。正確に言えばputs "Hello"ぐらいは動いてくれるのですが、肝心のSikulix用gemがJRubyにインストールできていないため、RPAらしいことはこのままではできないのです。
gem "sikuli"をJRubyにインストール
そこで、JRubyインタプリタにgemをインストールしたくなるわけですが、そもそも、先ほどダウンロードしたJRubyインタプリタはどこに行ってしまったのでしょう?探してみたところ、以下に移動されていました。
C:\Users\(ユーザー名)\AppData\Roaming\Sikulix\Extensions
jruby-complete-9.2.0.0.jarが発見できると思います(バージョン番号は多少違うかもしれません。)
あとはこれにgemをインストールすればいいことになります。私はJRubyのgemというのがよくわかっていないのですが、こちらのQ&Aを参考に、以下のようにしました。
- まず、JRubyのjarと同じ場所に適当なフォルダを作ります(私は上記参考と同じbiojrubyという名前にしましたが、どんな名でも構わないと思います)。
- そして、コマンドプロンプトでjrubyのjarと同じフォルダに入り、以下を実行ください。※jarのバージョンと作成したフォルダ名は適宜読み替えてください。
java -jar jruby-complete-9.2.0.0.jar -S gem install -i ./biojruby sikuli jar uf jruby-complete-9.2.0.0.jar -C biojruby .gem installで警告がいくつか出ますが、気にしなくてOKです。
確認してみましょう。
$ java -jar jruby-complete-9.2.9.9.jar -S gem list sikuliこれもいくつか警告が出ますが、バージョン番号とともにsikuliが表示されればOKです。
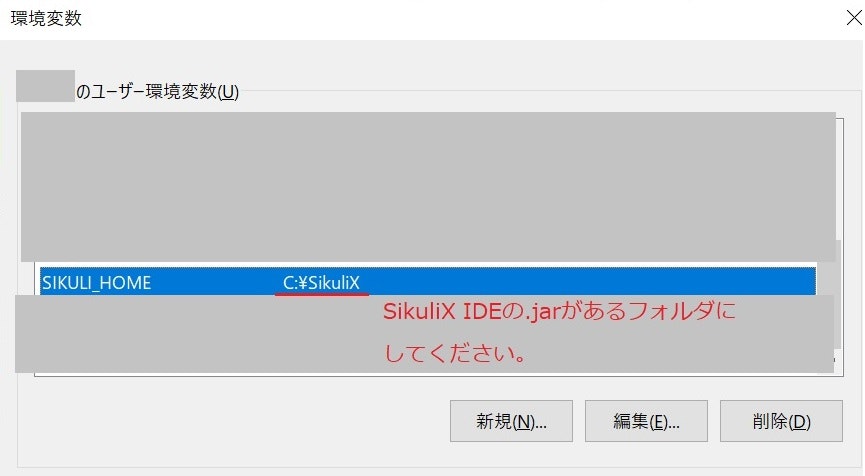
環境変数にSIKULI_HOME
最後の仕上げです!
Windowsの環境変数の設定で、SIKULI_HOMEを加えてあげます。
(どうやらgem sikuli側がSIKULIの.jarを認識するのに必要らしい?これもStack Overflowの受け売りです…ごめんなさい)
RPA実行
お待たせしました!いよいよ実行です。
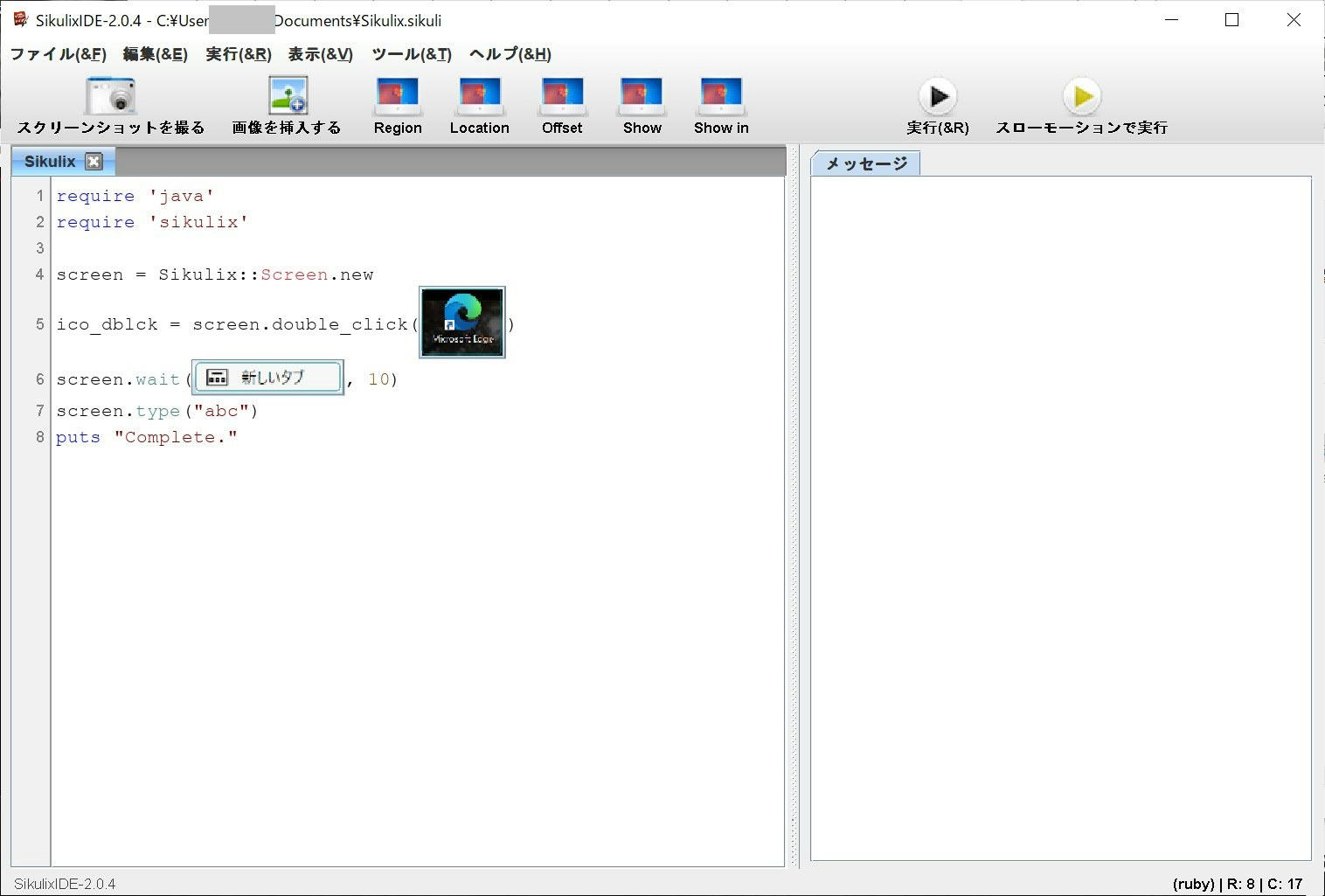
コマンドプロンプトは開き直し、再度SikuliX側の.jarをOpenJDKで開きましょう。C:\openjdk-11.0.2_windows-x64_bin\jdk-11.0.2\bin\java -jar sikulixide-2.0.4.jar以下、画像で恐縮ですがスクリプト例を示します。この場合、
- デスクトップ上のEdgeブラウザのアイコンをダブルクリック
- 「新しいタブ」と同じ画像が表示された場合に、「abc」とキー入力する
という命令になっています。
アイコンなどはメニューの「スクリーンショットを撮る」などで簡単に挿入することができます。お好きなアイコンでお試しください。
完成したら、任意の場所に保存した後(.sikuliと付記されたフォルダが作られます)、実行ボタンをクリックすると…、
どうでしょう?ちゃんと動いたという方、おめでとうございます!
あとは
https://sikulix-2014.readthedocs.io/en/latest/toc.html
あたりを参考にしながら、適宜Rubyに読み替えをどうするか調べていくことになると思う…のですが、やっぱり情報が少ない…。
というわけで、役に立ちそうなトピックがあったら、私自身これからもQiitaで取り上げていこうと思います。感想
今回、フリーのRPAとしてSikuliXを取り上げてみました。Rubyでできるというのがきっかけでしたが、結構環境構築だけで手間取ってしまいました。
参考にできる記事が少ないというのは置いておくとしても、仕事効率化のためのRPAにおいてこれはネックになるかもなあ、というのが正直のところです。今回は自宅で遊んでただけなのでいいですが、数十のPCに導入するだけでも結構手間になりそう。Jythonだとそんなこともないんでしょうか。
RubyでできるRPAなら、有償ですがRobowareといったものがあるらしく(いや、回し者じゃないですよ)、しっかり安定した動作を期待するならサポート面とか考えてもこういうところを検討したほうがいいってことになるかもですね。
むしろ、小さなチームでできることを考える場合はSikuliXが有効になってくるかもしれません。そこでJRubyが選択肢とする人が増えて、公式もドキュメントなどに力を入れてくれるようになるといいなあ、と、結局そこに行きつくのでした、
正確にはJRubyという、RubyスクリプトをJavaに変換して動作する環境を利用しています。SikuliXそのものはJavaで動いていますので。 ↩
Jython interpreterと両方ダウンロードしてもいいというようなことが書いてありますが、これをやるとJythonのほうが優先されてJRubyが動かせませんでした。この際は結局一度アンインストールしてやり直すしかありませんでした。なお、アンインストールについては https://auto-worker.com/blog/?p=473 を参照下さい。 ↩

- 投稿日:2020-10-12T22:28:16+09:00
クラウドIDE:Ruby on RailsチュートリアルでHerokuがインストールできなかった件
Ruby on Railsのチュートリアルで、Herokuをインストールしようとしたら、以下のエラーが出て進まなかった件。
調べても何が悪いのかよくわからなかった(゚∀゚)。
bash: /home/ec2-user/.profile: Permission denied実行コマンドはチュートリアルに記載してあった下記の通り。
source <(curl -sL https://cdn.learnenough.com/heroku_install)環境
・AWS,Cloud9の統合環境(クラウド統合環境)
対処
解決方法をググっても特に見つからなかった\(^o^)/。
Heroku CLIをインストールするらしいので、Heroku CLIのインストール方法を確認した。
書いてあるコマンドで、チュートリアル以外のコマンドでインストールできないか調べた。
https://devcenter.heroku.com/articles/heroku-cli下の方にnpmコマンドを使ってもインストールできることが書いてある。
インストールの注意文を見ると、「npm」と「node」が入っているのが前提のインストール方法なのだそうだ。This installation method is required for users on ARM and BSD. You must have node and npm installed already.
npm install -g herokuというわけでクラウドIDEに入っているかを確認した。
どちらも入っているらしいので、ダメ元で記載されていたコマンドを使ったらインストールができた。
もし詰まっていたら、一度この方法を試してみてください。(役に立つかはわからないけど)


- 投稿日:2020-10-12T22:27:12+09:00
【Rails6】主なGemについて
はじめに
Railsを使うにあたり、当たり前のように
pumaとかwebpackerとかlistenを使用していますが、正直あまり意味がわからずに使っていました。ここいらで主なGemについてまとめたいと思います。Railsデフォルトの主なGem
下記がRails6で生成されるデフォルトGemです。
Gemfile# Bundle edge Rails instead: gem 'rails', github: 'rails/rails' gem 'rails', '~> 6.0.3' # Use sqlite3 as the database for Active Record gem 'sqlite3', '~> 1.4' # Use Puma as the app server gem 'puma', '~> 4.1' # Use SCSS for stylesheets gem 'sass-rails', '>= 6' # Transpile app-like JavaScript. Read more: https://github.com/rails/webpacker gem 'webpacker', '~> 4.0' # Turbolinks makes navigating your web application faster. Read more: https://github.com/turbolinks/turbolinks gem 'turbolinks', '~> 5' # Build JSON APIs with ease. Read more: https://github.com/rails/jbuilder gem 'jbuilder', '~> 2.7' # Use Redis adapter to run Action Cable in production # gem 'redis', '~> 4.0' # Use Active Model has_secure_password # gem 'bcrypt', '~> 3.1.7' # Use Active Storage variant # gem 'image_processing', '~> 1.2' # Reduces boot times through caching; required in config/boot.rb gem 'bootsnap', '>= 1.4.2', require: false group :development, :test do # Call 'byebug' anywhere in the code to stop execution and get a debugger console gem 'byebug', platforms: [:mri, :mingw, :x64_mingw] end group :development do # Access an interactive console on exception pages or by calling 'console' anywhere in the code. gem 'web-console', '>= 3.3.0' gem 'listen', '~> 3.2' # Spring speeds up development by keeping your application running in the background. Read more: https://github.com/rails/spring gem 'spring' gem 'spring-watcher-listen', '~> 2.0.0' end group :test do # Adds support for Capybara system testing and selenium driver gem 'capybara', '>= 2.15' gem 'selenium-webdriver' # Easy installation and use of web drivers to run system tests with browsers gem 'webdrivers' end # Windows does not include zoneinfo files, so bundle the tzinfo-data gem gem 'tzinfo-data', platforms: [:mingw, :mswin, :x64_mingw, :jruby]それぞれ説明していきます。
sqlite3
SQLデータベースエンジンを実装するC言語ライブラリ。
パスワード設定がない等のセキュリティ機能がないため、基本的に開発環境、テスト環境で使用し、本番環境では別のデーターベースエンジンを使用する。https://www.sqlite.org/index.html
puma
RubyWebアプリケーション用のHTTP1.1サーバー構築に使用する。スレッドプールを使用してリクエストを処理する。
https://puma.io/
https://github.com/puma/pumasass-rails
RailsでSass(SCSS)使用できる。
https://github.com/rails/sass-rails
webpacker
Webアプリケーションで一般的に良く使われるメジャーな設定を、標準で実装してくれるwebpackのラッパー。webpackは、最新のJavaScriptアプリケーション用の静的モジュールバンドラー1。
【主な機能】
・webpack 4.x.x
・複数のエントリポイント2を使用した自動コード分割
・新しいJavaScript構文(ES6)をブラウザで動くように変換
・React、Vue.js、PostCSSなどのモダンなフレームワークに対する豊富な実績https://github.com/rails/webpacker
Jbuilder
Jbuilderは、JSON構造を宣言するためのシンプルなDSL(ドメイン特化言語)を提供。
https://github.com/rails/jbuilderturbolinks
Webアプリケーションでのリンクの追跡が高速になる。
https://github.com/turbolinks/turbolinks-classicbootsnap
railsの起動時の処理を最適化する(パスとrubyのコンパイル結果をキャッシュ)ことで起動時間を短縮してくれる。
ActiveSupport や YAML もサポートしている。https://github.com/Shopify/bootsnap/blob/master/README.jp.md
byebug
デバッグツール。
https://github.com/deivid-rodriguez/byebug
web-console
View 内でコンソールを立ち上げて、変数や parameter などの状態を見る事の出来るデバック用のライブラリ。エラー箇所のデバッグがしやすくなる。
https://github.com/rails/web-console
listen
ファイルの変更を検知してそれをフックに何か処理ができる。
【主な機能】
・ファイルの変更、追加、削除を検出
・複数のディレクトリを監視https://github.com/guard/listen
spring
Railsアプリケーションのプリローダー3。アプリケーションをバックグラウンドで実行し続けることで開発をスピードアップするため、テスト、移行を実行するたびにアプリケーションを起動する必要がなくなる。
https://github.com/rails/spring
spring-watcher-listen
Springはファイルシステムをポーリング4するのではなく、Listenを使用してファイルシステムの変更を監視します。
https://github.com/jonleighton/spring-watcher-listen/
capybara
実際のユーザーがアプリをどのように操作するかをシミュレートすることにより、Webアプリケーションのテストを支援する。
https://github.com/teamcapybara/capybara
https://en.wikipedia.org/wiki/Capybara_(software)selenium-webdriver
capybaraではJavaScriptをサポートしていないため、selenium-webdriverでシュミレートする。
https://github.com/SeleniumHQ/selenium/tree/trunk/rb
webdrivers
webブラウザを外部のソフトウェアから操作したり情報を取得したりできるようにするためのものです。
https://github.com/titusfortner/webdrivers
tzinfo-data
Windows ではタイムゾーン情報用に使用する。UnixベースのOSではtzinfoからシステムのタイムゾーン情報に直接アクセスできるので使用する必要はない。
https://github.com/tzinfo/tzinfo-data
それ以外の主なGem
bcrypt
パスワードを暗号化できる。
https://github.com/codahale/bcrypt-ruby
devise
Webアプリケーションには必須の、ユーザー認証機能を作ることができる。会員登録用フォームを作成や、メールやFacebook等での認証も実装できる。
https://github.com/heartcombo/devise
kaminari
ページネーション機能を簡単に追加できる。
https://github.com/kaminari/kaminari
carrierwave
画像のアップロード機能。
https://github.com/carrierwaveuploader/carrierwave
active admin
CRUD系の管理画面を作成することができる。
https://github.com/activeadmin/activeadmin
ruboCop
コーディング規約どおりに書かれているかをチェックする静的コード解析ツール。
https://github.com/rubocop-hq/rubocop
pry-rails
Rubyのirbのようにrailsのコンソールでメソッドなどを使えることができるようになる。
https://github.com/rweng/pry-rails
faker
偽のデータを生成する。
https://github.com/faker-ruby/faker
capistrano
自動デプロイツール。
https://github.com/capistrano/capistrano
まとめ
Railsは歴史が長い分、Gemは数が多いですね。初学者だと選定が難しそうです。まずは開発前にどんな機能がどこまで必要なのかピックアップしてGemを選定する必要がありそうです。Gemを選定の参考になりそうなサイトを張っておきます。この記事も有用なGemがあればどんどん更新していこうと思います。
Gemの探しツール
Gemのランキングサイト
モジュールごとに分割され、別々になったJavaScriptファイルの依存関係を解決して、1つのファイルにまとめるツール。 ↩
プログラムを実行を開始する場所のこと。(エントリーポイント - wiki) ↩
主に通信などの競合を回避するために、ホスト側が各機器に対して定期的に問い合わせを行い、条件を満たした場合に送受信や各種処理を行うこと。(ポーリング - wiki) ↩
- 投稿日:2020-10-12T21:50:26+09:00
動画を挿入する方法
トップページなどに動画を挿入する方法
GIF
https://gyazo.com/3015a8b1f689153dcfe7fcb308d483bb
下記コード
index.html<div class="bg-video-wrap"> <p>Brilliant Blue</p> <video src="images/foreign.mp4" autoplay loop muted> </video> </div>css.bg-video-wrap { position: relative; } p { font-family: serif; color: #fff; font-size: 400%; position: absolute; left: 30%; top: 100px; z-index: 1; }以上です!
状況に応じてCSSは各自変更して使って下さい!
foreign.mp4の部分は各々、ダウンロードや作った動画の名前を決めると思うのでそれを当てはめて下さい!おそらく末尾はmp4でもmovでもどちらでも挿入できます!
現場からは以上です!
- 投稿日:2020-10-12T21:37:13+09:00
RubyでDIしてみた
DIとは
dependency injection (依存性注入)のこと
外からconstractorにobject渡せるようにすることで依存を避けようっていうもの
実装
Interactorを例に書いていく
dry-containerとdry-auto_injectを使ってDIしてみたDIしてない版
not_di.rbmodule Interactor class FindUser def initialize(params) @params = params end def call user_repo = UserRepository.new user_repo.by_pk(@params[:id]) end end endUserRepositoryに依存しているのがわかる
dry-container使わない版
pure-di.rbmodule Interactor class FindUser def initialize(params: {}, user_repo: UserRepository.new) @params = params @user_repo = user_repo end def call @user_repo.by_pk(@params[:id]) end end endinitializdの引数がでっかくなってみづらいコードになりがち
これありますねぇdry-container版
dry-di.rbmodule Container module FindUser extend Dry::Container::Mixin # 注入するobjectを登録していく # blockでdefaultのobjectを宣言できる register "params" register "user_repo" do UserRepository.new end end end module Interactor class FindUser Import = Dry::AutoInject(Container::FindUser) # includeしたものをmethodで呼び出せるようになる include Import["params", "user_repo"] def call user_repo.by_pk(params[:id]) end end endコードは増えたけど責務を切り分けることで見通しがよくなった
InteractorがContainerに依存していて、呼び出す人(Controllerとか)もContainerに依存しているので
いい感じに依存性を逆転させることができたbefore: controller -> interactor
after: controller -> container <- interactor何が嬉しいのか
- コードがスッキリする
initializeをcontainerに委託することでinteractorの責務が減った
classあたりの責務は減らしていきたい
- 単体テストが簡単にできる
InteractorのテストをDB用意しないでできる
上の例だとby_pk(id)に反応するobject渡せば良いtest.rbUser = Struct.new(:id, :name, :age) class TestUserRepo def by_pk(id) User.new(id, "tarou", 20) end end params = { id: 1 } user_repo = TestUserRepo.new input = { params: params, user_repo: user_repo } Interactor::FindUser.new(input).callみたいにできる
- 投稿日:2020-10-12T20:34:22+09:00
ターミナルって何?
ターミナル説明
ターミナルは、PCに命令をすることができるツールですね。
環境構築を実行するには コマンドラインというツールが必要となります。
Macにデフォルトでインストールされているコマンドラインがターミナルです。コマンドライン説明
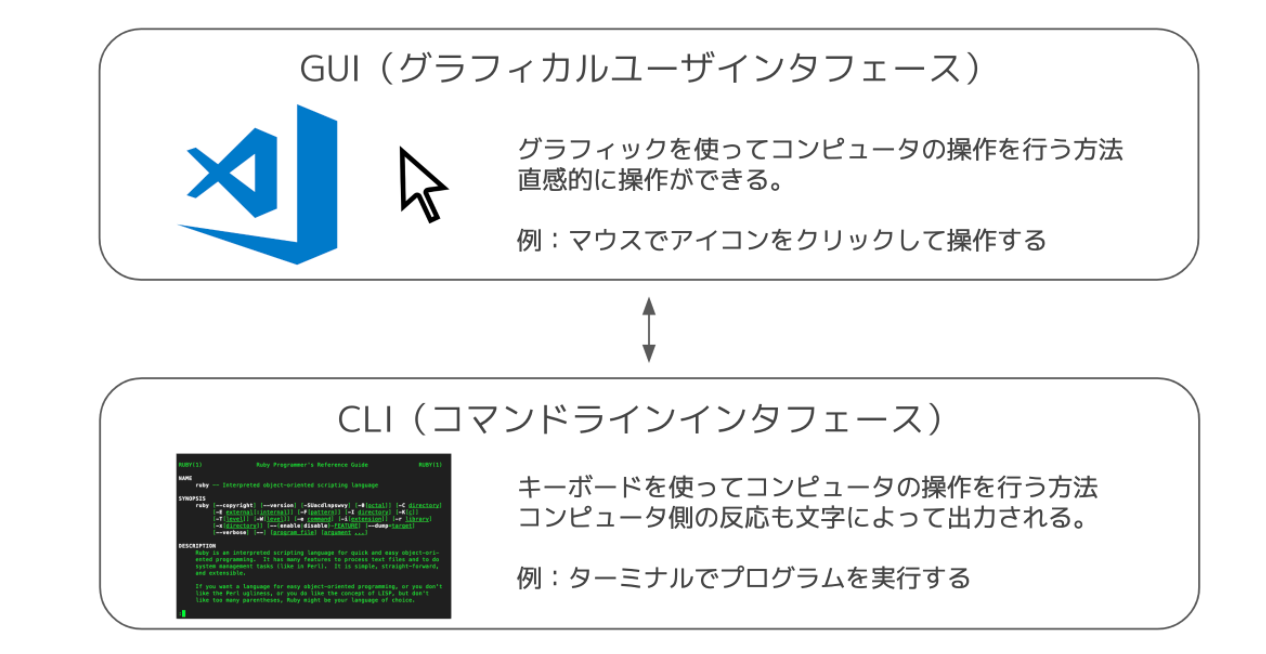
コマンドライン(または コマンドラインインタフェース:CLI )とは、コンピュータに対してキーボードからコマンドという文字を打ち込んで操作を行うツールになります。
GUI(グラフィカルユーザインターフェース)
コマンドラインとは対照的に、グラフィックを用いて操作を行う仕組みを グラフィカルユーザインタフェース(GUI) と言います。
例えば、「マウスでファイルをダブルクリックして開く」という操作など、普段PCで行う操作のほとんどはGUIで行なっていることが多いです。
ターミナルを使う理由を学ぼう
先程、マウスなどを使った直感的に操作をすることができるGUIと、ターミナルのようにコマンドを使用して操作するCLIがあることを説明させて頂きました。
直感的に操作ができて普段から使い慣れたGUIではなく、なぜわざわざターミナルの操作に慣れ、それを使用しなければならないのでしょう?
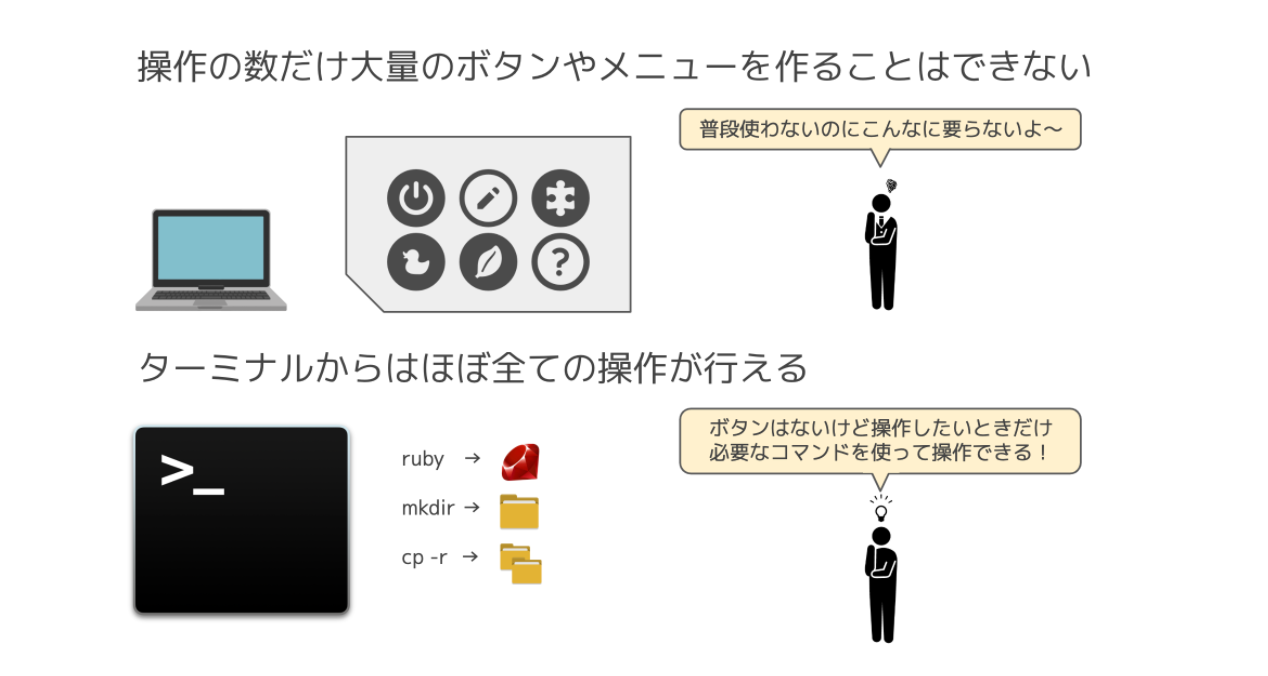
その理由は、GUIとCLIでは CLIの方が行える操作の数が圧倒的に多いためです。
GUIのように全ての操作をグラフィカルに表現していては画面がメニューやボタンで溢りかえってしまって、分かりづらくなってしまうためです。
普段行わない操作についてはボタンが無かったり、そもそも簡単に操作できては危険なものであれば操作できないものである場合が多いです。
CLIでは、PCに対しての操作のほとんどが行えると言って良いほどに、
様々な操作を行うことができます。「Rubyプログラムの実行」もCLIが行える操作の1つです。
そのため、 ターミナルの操作は必須スキルだと思います。ターミナルの見方説明
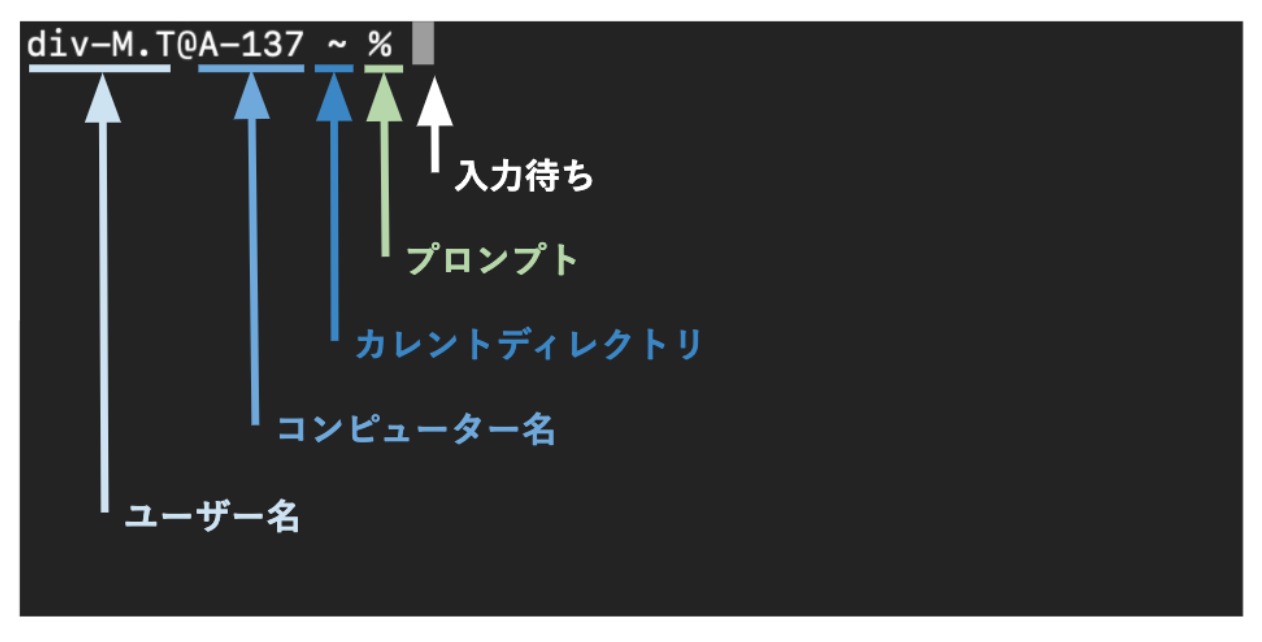
まずは、ターミナルを開いて表示画面を見てみましょう!!
コンピュータ名は自分のコンピュータの名前ですね。
ここでは「A-137」となっています。ユーザ名は自分の名前です。
ここでは「div-M.T」となっています。このあとに続く「$」または「%」は プロンプト といい、 コンピュータが命令を受け付けられる状態であることを示します 。つまり今は、命令待ちの状態です。まとめ
・ターミナルとは、PCに命令をすることができるツールのこと
・「〜」には、カレントディレクトリが入ります。
「%」は、プロンプトを言います。プログラミングは、膨大な量の情報があるので、
基本から徐々に焦らずに理解していきましょう!!
できるようになるまで時間は、かかります。
でも、毎日継続して行えばだんだんとできるようになるので
一緒に頑張りましょう!!以上。
- 投稿日:2020-10-12T19:25:55+09:00
マイグレーションファイルから Model を直接触るのはやめて欲しい
何が起こったのか
開発環境で新たにDBを作成。
お約束通り、
$ rails db:create $ rails db:migrate大量のマイグレーションファイルを一気に migrate しようとしたその時、事件は起こった。
PG undefined column hogehoge ...的な感じで、スッと通らない?
嫌な予感がする。なになに。。。。
マイグレーションファイルから直接 Model にアクセスしていたんです。
migartion_file... Hoge.delete_all ...みたいな感じでモデルに対して直接操作を行う処理が書かれていた?
そのマイグレーションファイルは過去のものであり、その当時はそのモデルがあったのだろうが、今現在のソースコードには存在しない。
当然、そんなモデルは無いよと怒られたりする。こんな感じで直接 Model に対して処理を行っているマイグレーションファイルが散見された。
結果 migrate を通すのにものすごく苦労し、過去のマイグレーションファイルにも手を入れなくてはいけなくなった。マイグレーションファイルってそういうものなのでしょうか?
いいえ、違うはずです。どうすれば良いのか
マイグレーションファイルは、後々どんな人が開発に入ってきてもしっかり
rails db:migrateが通るように積み上げていきましょう。ファイル数が増えるのは仕方ありません。大事なのはしっかり通るかどうかです。
おそらく当時の開発者もモデルに対して処理を書いているのは分かっていたはずで、データメンテナンスがしたかったのだと思います。既存データのメンテナンスはマイグレーションファイルでやらないで、rake task を作成するとか他にもやり方があったはずです。
自戒も込めて、マイグレーションファイルに関して気をつけるべきことを書いておきます
- マイグレーションファイルを追加した時には、
rails db:migrate:redoを習慣づけて redo が通ることを確認する- 古いマイグレーションファイルを後から書き換えない(見栄えは悪いが単純に積み上げていくのがベストプラクティス)
- データメンテナンスはマイグレーションファイルの中で行わない(rake task を作ったり rails console から手動やったり他の方法がある)
Model は単なる ruby のクラスに過ぎません。
それは今後名前が変わるかもしれませんし、データの持ち方も変わるかもしれません。マイグレーションファイルの中からモデルを直接触るのはやめましょう?
どなたかの役に立てば幸いです。
- 投稿日:2020-10-12T18:01:13+09:00
deviseのコントローラー初期状態まとめ
deviseのコントローラーの初期状態が気になったことがあり、一度サンプルを作る羽目になったのでメモとしてQIITAに残しとく。
confirmations_controller.rbclass Sample::ConfirmationsController < Devise::ConfirmationsController # GET /resource/confirmation/new # def new # super # end # POST /resource/confirmation # def create # super # end # GET /resource/confirmation?confirmation_token=abcdef # def show # super # end # protected # The path used after resending confirmation instructions. # def after_resending_confirmation_instructions_path_for(resource_name) # super(resource_name) # end # The path used after confirmation. # def after_confirmation_path_for(resource_name, resource) # super(resource_name, resource) # end endomniauth_callbacks_controller.rbclass Sample::OmniauthCallbacksController < Devise::OmniauthCallbacksController # You should configure your model like this: # devise :omniauthable, omniauth_providers: [:twitter] # You should also create an action method in this controller like this: # def twitter # end # More info at: # https://github.com/heartcombo/devise#omniauth # GET|POST /resource/auth/twitter # def passthru # super # end # GET|POST /users/auth/twitter/callback # def failure # super # end # protected # The path used when OmniAuth fails # def after_omniauth_failure_path_for(scope) # super(scope) # end endpasswords_controller.rbclass Sample::PasswordsController < Devise::PasswordsController # GET /resource/password/new # def new # super # end # POST /resource/password # def create # super # end # GET /resource/password/edit?reset_password_token=abcdef # def edit # super # end # PUT /resource/password # def update # super # end # protected # def after_resetting_password_path_for(resource) # super(resource) # end # The path used after sending reset password instructions # def after_sending_reset_password_instructions_path_for(resource_name) # super(resource_name) # end endregistrations_controller.rbclass Sample::RegistrationsController < Devise::RegistrationsController # before_action :configure_sign_up_params, only: [:create] # before_action :configure_account_update_params, only: [:update] # GET /resource/sign_up # def new # super # end # POST /resource # def create # super # end # GET /resource/edit # def edit # super # end # PUT /resource # def update # super # end # DELETE /resource # def destroy # super # end # GET /resource/cancel # Forces the session data which is usually expired after sign # in to be expired now. This is useful if the user wants to # cancel oauth signing in/up in the middle of the process, # removing all OAuth session data. # def cancel # super # end # protected # If you have extra params to permit, append them to the sanitizer. # def configure_sign_up_params # devise_parameter_sanitizer.permit(:sign_up, keys: [:attribute]) # end # If you have extra params to permit, append them to the sanitizer. # def configure_account_update_params # devise_parameter_sanitizer.permit(:account_update, keys: [:attribute]) # end # The path used after sign up. # def after_sign_up_path_for(resource) # super(resource) # end # The path used after sign up for inactive accounts. # def after_inactive_sign_up_path_for(resource) # super(resource) # end endsessions_controller.rbclass Sample::SessionsController < Devise::SessionsController # before_action :configure_sign_in_params, only: [:create] # GET /resource/sign_in # def new # super # end # POST /resource/sign_in # def create # super # end # DELETE /resource/sign_out # def destroy # super # end # protected # If you have extra params to permit, append them to the sanitizer. # def configure_sign_in_params # devise_parameter_sanitizer.permit(:sign_in, keys: [:attribute]) # end endunlocks_controller.rbclass Sample::UnlocksController < Devise::UnlocksController # GET /resource/unlock/new # def new # super # end # POST /resource/unlock # def create # super # end # GET /resource/unlock?unlock_token=abcdef # def show # super # end # protected # The path used after sending unlock password instructions # def after_sending_unlock_instructions_path_for(resource) # super(resource) # end # The path used after unlocking the resource # def after_unlock_path_for(resource) # super(resource) # end end
- 投稿日:2020-10-12T17:57:40+09:00
Ruby on Rails 教わった事 その2
この記事の目的
プログラミングスクールで私が約3ヶ月で教わった事を転職活動に生かすためにまとめました。
私による私のためだけの記事です。この講義で印象に残った一言は、
RSpecは絶対に身に付けなければいけない必須の技術。Hamlで書く
Hamlを使うと閉じタグがいらなくなり、コードを減らせる。
Hamlの書き方モデルメソッド
何回も使うロジックはモデルメソッドにする、DRYにする↓
example.html.haml- - if current_user.id == post.user_id #直書き + - post.created_user?(current_user) %p あなたは投稿した人ですpost.rbdef created_user?(user) self.user_id == user.id endモデルメソッドをRSpecでテスト
本来はテストを書き、失敗を確認しながらメソッドを書く(TDD、テスト駆動開発)
post_spec.rbdescribe "#created_user?" do let(:user) { FactoryBot.create(:user) } #本人 let(:other_user) { FactoryBot.create(:user) } #他人 let(:post) { FactoryBot.create(:post, user: user) } #本人の投稿 context "ログインユーザーと同じユーザーの場合" do it "trueを返すこと" do expect(post.created_user?(user)).to eq true end end context "ログインユーザーと同じユーザーではない場合" do it "falseを返すこと" do expect(post.created_user?(other_user)).to eq false end end end参考書
Everyday Rails - RSpecによるRailsテスト入門
とにかく手を動かして少しだけできるようになりました。
個人的にsystemスペックのajax関連のテストがトラウマです。
おすすめされた動画
TDD Boot Camp 2020 Online #1 基調講演/ライブコーディング感想
今回は主にRSpecのライブコーディングを見せてもらった。
当時、あまりテストの必要性を感じなかったが、今回過去の動画を見返しながら気になったコードをリファクタリングしようとしたところ無意識に、RSpecを動かしていたので少しずつ慣れてきているのだと思う。
- 投稿日:2020-10-12T17:52:33+09:00
gemfile書き換えによるBundler::Dsl::DSLErrorの対処法
gemfileを書き換えた際のエラー対処法について後発者のためにメモを残しておく。
開発環境
windows 10 home
ubuntu 20.04 LTS
ruby 2.7.1
Rails 6.0.3
postgresql 11エラー文
$ bundle ~~~~~中略~~~~~ Permission denied @ rb_sysopen - /home/admin0/taskleaf2/Gemfile (Errno::EACCES) ~~~~~中略~~~~~ was an error while trying to read from `/home/admin0/taskleaf2/Gemfile`. It is likely that you need to grant read permissions for that path. (Bundler::PermissionError) ~~~~~中略~~~~~ Bundler::Dsl::DSLError今回は特に理由はないが3つ目のエラー文着目に着目して検索したところ以下のサイトに良さげな解決方法が記載されていたので実行してみる
https://stackoverflow.com/questions/57926553/bundle-install-gives-bundlerdsldslerror$ chmod 644 Gemfileこれでエラーが発生しなくなったため、問題解決したと判断する。
- 投稿日:2020-10-12T17:29:19+09:00
並列処理入門 + Rubyでの新しい並列実行単位Ractor
この記事では、並列処理に関する入門的知識を解説する。
さらに、Rubyで開発されている新しい並列実行単位Ractorにも言及する。まず、この話題をする上で混同しがちな用語についてまとめる。
並列処理(parallel)と並行処理(concurrent)について
並列処理 では、ある瞬間に複数の処理が同時に走る。
並行処理 では、複数の処理を時分割で順に処理する。並列処理とは異なり、ある瞬間に同時に走る処理は1つだけ。ある複数の処理が実行されているタイミングを時系列で示すと、下図のようなイメージになる。
(青い線がある部分のみ処理が実行される)
この記事では並列処理の動作について扱うが、並列処理のコードを書いても結局並行処理のように動いている場合もあることには注意。
(例えば、1コアのCPUでは2つ以上の処理を並列に動作させることはできない、など。)
この辺りはOSやVMなどが良い感じにスケジューリングしてくれている。マルチプロセスとマルチスレッド
一般に並列処理を実現するための主な方法として、 マルチプロセス と マルチスレッド の2つがある。
マルチプロセスは、複数のプロセスを作成し、それぞれのプロセスで1つずつ処理を実行させる方法。
マルチスレッドは、1つのプロセス内に複数のスレッドを作成し、それぞれのスレッドで1つずつ処理を実行させる方法。マルチプロセスの場合は、メモリ空間が各プロセスで分離されている。
このため、プロセス間で変数の受け渡しなどは基本的にできない。
また、それが故にプロセス間でメモリを介した意図しない相互作用は起こり得ないので、安全性は高い。
デメリットとしては、プロセスごとにメモリ空間を持つので、合計のメモリ使用量は増大しがち。(ただし、linuxではCopy on writeという仕組みにより、プロセス間のメモリを可能な限り共有してくれる。)マルチスレッドの場合は、1つのプロセスが複数のスレッドを持つため、メモリ空間はスレッド間で共有される。
そのため、メモリ使用量は抑えられる上、実装によってはスレッドの作成や切り替えが、プロセスの作成や切り替えよりも軽いというメリットもある。
ただし、メモリを介してスレッド間が影響を及ぼしあうことができるため、データ競合などのバグは発生しがち。
一般に、マルチスレッドプログラミングは考慮すべきことが多く、正しく実装するのが難しいとされている。なお、並列処理において1つの処理が実行される単位を 並列実行単位 と呼ぶ。
マルチプロセスの場合は並列実行単位はプロセスであり、マルチスレッドの場合はスレッドである。(補足) スレッド処理の実現方法について
スレッド処理の主な実現方法として、 ネイティブスレッド と グリーンスレッド の2種類がある。
ネイティブスレッドは、OSの実装をそのまま利用して、マルチスレッド処理を実現する方法。
スレッドのスケジューリング(今どのスレッドの処理を実行するか決めること)をOSに任せられるので処理系の実装は単純になる。
一方で、スレッドの作成や切り替え(いわゆるコンテキストスイッチ)の処理が重いというデメリットもある。
(ちなみにネイティブスレッドは、正確にはカーネルスレッドと軽量プロセスを合わせた概念とのことだが、詳細は割愛。ネイティブスレッドとカーネルスレッドが混用されることも多々ある気がする。)グリーンスレッドは、言語処理系の仮想マシン(たとえば、crubyのyarv、javaのjvmなど)で独自に実装したスレッドで、マルチスレッド処理を実現する方法である。
golangのgoroutineもグリーンスレッドの一種で、その動作の軽快さはあまりにも有名。
crubyでは、1.9以前はグリーンスレッドにより実装されていたが、今はネイティブスレッドを利用する形に変更された。
グリーンスレッドはユーザースレッドとも呼ばれる。マルチスレッド・マルチプロセスのコード例
一例として、Rubyにおける並列処理の実装を示す。
RubyではParallelというgemを用いることで、容易に並列処理を記述することが可能。マルチプロセスのコードは下記のようになる。
multi_process.rbrequire 'parallel' Parallel.each(1..10, in_processes: 10) do |i| sleep 10 puts i endこのコードを実行して、プロセスリストを見ると、下記のようになる。
1個のメインプロセスと、10個の子プロセスが生じていることが分かる。$ ps aux | grep ruby PID %CPU %MEM VSZ RSS TT STAT STARTED TIME COMMAND PRI STIME UTIME 79050 9.7 0.1 4355568 14056 s005 S+ 2:39PM 0:00.28 ruby mp.rb 79072 0.0 0.0 4334968 1228 s005 S+ 2:39PM 0:00.00 ruby mp.rb 79071 0.0 0.0 4334968 1220 s005 S+ 2:39PM 0:00.00 ruby mp.rb 79070 0.0 0.0 4334968 1244 s005 S+ 2:39PM 0:00.00 ruby mp.rb 79069 0.0 0.0 4334968 1244 s005 S+ 2:39PM 0:00.00 ruby mp.rb 79068 0.0 0.0 4334968 1172 s005 S+ 2:39PM 0:00.00 ruby mp.rb 79067 0.0 0.0 4334968 1180 s005 S+ 2:39PM 0:00.00 ruby mp.rb 79066 0.0 0.0 4334968 1208 s005 S+ 2:39PM 0:00.00 ruby mp.rb 79065 0.0 0.0 4334968 1252 s005 S+ 2:39PM 0:00.00 ruby mp.rb 79064 0.0 0.0 4334968 1168 s005 S+ 2:39PM 0:00.00 ruby mp.rb 79063 0.0 0.0 4334968 1168 s005 S+ 2:39PM 0:00.00 ruby mp.rbマルチスレッドのコードは下記のようになる。
multi_threads.rbrequire 'parallel' Parallel.each(1..10, in_threads: 10) do |i| sleep 10 puts i endこちらも同様にスレッド一覧を見てみる。
psコマンドに-Lをつけると、スレッドがプロセスのように表示される。
-Lなしではプロセスが1個なのに対し、-Lをつけると11行表示される。
また、NLWPカラムはプロセスのスレッド数を示すが、これが11(メインスレッドx1 + ワーカースレッドx10)となっていることからも、マルチスレッド処理になっていることが分かる。$ ps aux | grep mt.rb 4419 1.0 0.6 850176 12384 pts/1 Sl+ 15:41 0:00 ruby mt.rb $ ps aux -L | grep mt.rb PID LWP %CPU NLWP %MEM VSZ RSS TTY STAT START TIME COMMAND 4419 4419 6.0 11 0.6 850176 12384 pts/1 Sl+ 15:41 0:00 ruby mt.rb 4419 4453 0.0 11 0.6 850176 12384 pts/1 Sl+ 15:41 0:00 ruby mt.rb 4419 4454 0.0 11 0.6 850176 12384 pts/1 Sl+ 15:41 0:00 ruby mt.rb 4419 4455 0.0 11 0.6 850176 12384 pts/1 Sl+ 15:41 0:00 ruby mt.rb 4419 4456 0.0 11 0.6 850176 12384 pts/1 Sl+ 15:41 0:00 ruby mt.rb 4419 4457 0.0 11 0.6 850176 12384 pts/1 Sl+ 15:41 0:00 ruby mt.rb 4419 4458 0.0 11 0.6 850176 12384 pts/1 Sl+ 15:41 0:00 ruby mt.rb 4419 4460 0.0 11 0.6 850176 12384 pts/1 Sl+ 15:41 0:00 ruby mt.rb 4419 4461 0.0 11 0.6 850176 12384 pts/1 Sl+ 15:41 0:00 ruby mt.rb 4419 4462 0.0 11 0.6 850176 12384 pts/1 Sl+ 15:41 0:00 ruby mt.rb 4419 4463 0.0 11 0.6 850176 12384 pts/1 Sl+ 15:41 0:00 ruby mt.rbマルチスレッドプログラミングの難しさ
マルチスレッド処理においては、複数のスレッドがメモリを共有した状態で処理が並列に実行されるため、様々な問題が発生しうる。
主な問題の一つがデータレースである。データレースは、下記のようなコードで発生する可能性がある。
このコードは 1~10までの整数の和を求めようとしたものであるが、データレースの問題があるために、正しく和を求められない可能性がある。require 'parallel' sum = 0; Parallel.each(1..10, in_threads: 10) do |i| add = sum + i sum = add end puts sumこのコードにおいて、各スレッドは変数
sumを共有しており、各スレッドがsumの読み込みや書き込みを同時に行う。
この結果、あるスレッドで書き込まれた内容が、別のスレッドにより上書きされる可能性がある。
このため、上記のコードは正常に和を計算できない可能性があるという問題がある。データレースの問題を解決する一般的な方法は、スレッド間で排他ロックを取る方法である。
require 'parallel' sum = 0; m = Mutex.new Parallel.each(1..10, in_threads: 10) do |i| m.lock add = sum + i sum = add m.unlock end puts sumこれにより、ロックを取っている間の処理は同時に1スレッドしか実行されなくなり、データレースは解消される。
これらの問題が正しく考慮され、マルチスレッドにおいても正常に動作するコードを、スレッドセーフと呼ぶ。
Global Interpreter Lockについて
軽量言語(ruby, python等)でのマルチスレッド処理においてしばしば話題に上がるのが GIL である。
ちなみにRubyにおいてはGVL(Giant VM Lock)と呼ばれている。GILは、スレッド同士の排他制御を行うことで、複数のスレッドが同時に実行されることを防ぐ。
つまり、一つのインタープリタ、VM内では同時に一つのスレッドしか実行されないようにする。
これが必要な理由やメリットとして、下記が挙げられる:
- マルチスレッドプログラミングをする際、個々のデータ構造ごとに排他処理を記述する必要がなくなる
- 処理が高速化する
- アプリ開発者のコーディングは簡単になる(データレースについて考えることが減る)
- ネイティブプラグインの実装がスレッドセーフでないことが多々あるが、それらの実装を変えずに安全に実行するため
- VMの実装自体がスレッドセーフではない
GILのおかげで、実は先程例示したマルチスレッドプログラミングのRubyコードは、Mutexを利用しない場合でも正常に動作する。
この挙動は、プログラミングを楽にするというRubyの根本思想に違わないものと言える。しかしながら、同時に1つのスレッドしか実行できないということは、本来の並列処理が不可能であることを意味する。
RubyやPythonが並列計算に適していないとしばしば言及されるのは、このためである。なお、例外的にI/Oの待機時はスレッドはGILを解除するため、実質的に複数のスレッドが同時に処理を実行できる。
このため、I/O待ちが多いような処理(ウェブサーバーなど)では、GILのある処理系においても実用的にマルチスレッドが利用される。実装の例
HTTPサーバーは通常リクエストごとに同時に処理する必要があるため、並列処理の実装がなされていることが多い。
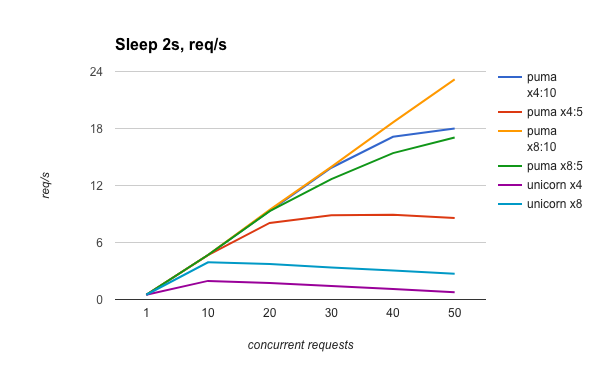
Rubyにおける代表的なHTTPサーバーとしてunicornとpumaがあり、前者はマルチプロセスの実装、後者はマルチスレッドの実装である。unicornとpumaはこちらのブログで性能が比較されている。
このブログの結論は、下記のようなものである:
- CPU boundな処理においては、unicornがやや優れたパフォーマンスを発揮する
- I/O boundな処理においては、pumaのほうが圧倒的に優れたパフォーマンスを発揮する
これは、上記の仕組みを考えても、納得のいく結果である。
Ractorについて
ここまで並列処理の実現方法について説明し、Rubyでの実装やその性能を示した。
Rubyにおけるマルチスレッド処理は、GVLによって、本来のパフォーマンスを発揮することができないという問題がある。
Ractor(旧称: Guild)は、この問題を解決するために生まれた新しいRubyの並列処理機構である。Ractorは従来のGVLによるマルチスレッドプログラミングが扱いやすくなるという利点を保ちながら、本来のマルチスレッドのパフォーマンスを実現できる。
その仕組みを解説する。
Ractorの思想
データレースが生じるのは、スレッド間がメモリを共有しているために、複数のスレッドが一つの変数に対して読み書き可能なためである。
これを解決する方法としては、
- 全ての変数を読み取り専用(Immutable)にする
- スレッド間で共有する変数は型で明示し、スレッドセーフでない処理に対してコンパイル時に検知する
- 並列実行単位ごとにメモリを独立させる
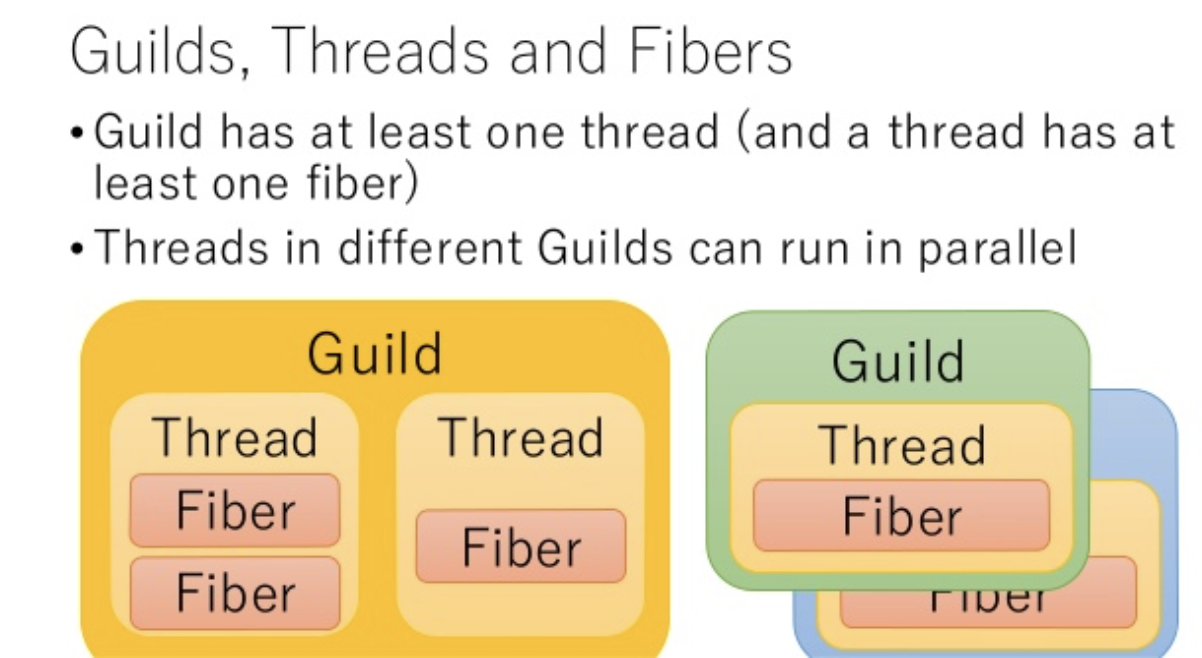
Ractorでは3の方法が採られた。この新しい並列実行単位がRactorと呼ばれている。
1つのRubyプロセスは1つ以上のRactorを持ち、1つのRactorは1つ以上のスレッドを持つ。
Ractorはそれぞれ個別のメモリ空間上で動作するため、従来のスレッドのようにメモリを共有することによる問題は生じない。
出典: https://www.slideshare.net/KoichiSasada/guild-prototypeまた、Ractor導入以前のRubyコードは、1つのRactor内で動かすことにより後方互換性を保つことができる。
Ractor間でのデータ共有の方法
Ractor同士はメモリを共有しないため、情報の受け渡しが面倒になると思うかもしれない。
これを解決するため、Ractor間の通信を実現するchannelという機能も用意されている。
共有したいオブジェクトはchannelを経由してのみ受け渡すことができる。オブジェクトは 共有可能オブジェクト と 共有不可オブジェクト に分類される。
共有可能オブジェクトは、読み取り専用の定数など、Ractor間で共有してもデータレースの発生し得ないオブジェクトを指す。
共有可能オブジェクトは、 channel を通じて自由に共有できる。共有不可オブジェクトは、一般のミュータブルなオブジェクトを指す。
このオブジェクトを channel に通すと、ディープコピーまたはムーブセマンティクスが発生する。
ディープコピーの場合は、コピーの処理コストやメモリ使用量の増大が発生するが、マルチプロセスと同様の安全さ・わかりやすさがある。
ムーブセマンティクスの場合は、オブジェクトの所有権が別のRactorに譲渡される形になる。
このため、元のRactorからはそのオブジェクトを参照できなくなるが、ディープコピーとは異なりコピーほどの処理コストはメモリ使用量も増大しない。まとめると:
- 基本的にRactor間でメモリを共有しない
- 必要なオブジェクトのみを開発者が明示的に指定して共有する
- 共有する場合は、オブジェクトに応じて最適な方法を選択する
ことで、Ractorはスレッドセーフ性を保ちながらも容易なマルチスレッドプログラミングを実現する。
Ractorはプロセスとスレッドの中間に位置する並列実行単位である。
開発者がRactor間で共有したい情報を適切に選択することで、マルチプロセスほどRAM使用量を増やさず、またマルチスレッドのようにGILによるパフォーマンス低下がなく、並列処理を実現できる。Ractorの現在
RactorはRuby 3の新機能として注目を浴びている。
Ractor自体は今も開発が進んでいるようで、一般Rubyユーザーの手に届くのはもう少し先になるだろう。
今後はRubyのマルチスレッド処理をするライブラリがRactorで再実装されることも期待される。
Pumaに代わるHTTPサーバーが主流になる時代も近い、かもしれない。参考文献
- https://github.com/ko1/ruby/blob/ractor/ractor.ja.md
- http://www.atdot.net/~ko1/activities/sasada_ipsj_pro_120.pdf
- https://qiita.com/Kohei909Otsuka/items/26be74de803d195b37bd
- https://qiita.com/yohhoy/items/00c6911aa045ef5729c6
- https://zenn.dev/yohhoy/articles/multithreading-toolbox
勉強のためまとめた文章です。間違いがあればご指摘いただければ幸いです!


- 投稿日:2020-10-12T17:08:30+09:00
【Rails】SessionsHelperを使ってコントローラー間でパラメータを受け継ぐ
はじめに
某プログラミングスクールでフリマアプリを作成中、購入内容の確認ページからクレジットカード登録ページに遷移。カード登録後、購入内容の確認ページに遷移することが出来なくなった。
原因:コントローラーがitems_controller.rbからcredit_cards_controller.rbに変わった時点でパラメータの:item_idが0になっていた。
詳細
- ユーザーログイン後、routingでトップページ(items#index)へ遷移。
- 他ユーザーの出品商品(items#create)の詳細ページ(items#show)へ遷移。
- 詳細ページ(items#show)の購入ボタンより商品購入ページ(items#purchase)へ遷移。
- クレジットカード情報の登録・変更するために、登録・変更ボタンより(credit_cards#index)へ遷移。
- 遷移したが変更がなければ、もどるボタンで商品購入ページ(items#purchase)へ遷移。
- 変更・未登録ならカード登録ページ(credit_cards#new,create)に遷移後,(credit_cards#show)に遷移。その後カード決定・もどるボタンより商品購入ページ(items#purchase)へ遷移。
resources :items, only: [:index, :new, :create, :show, :edit, :destroy] do get '/purchase/:id', to: 'items#purchase', as: :purchase end resources :credit_cards, only: [:index, :new, :create, :show, :destroy]
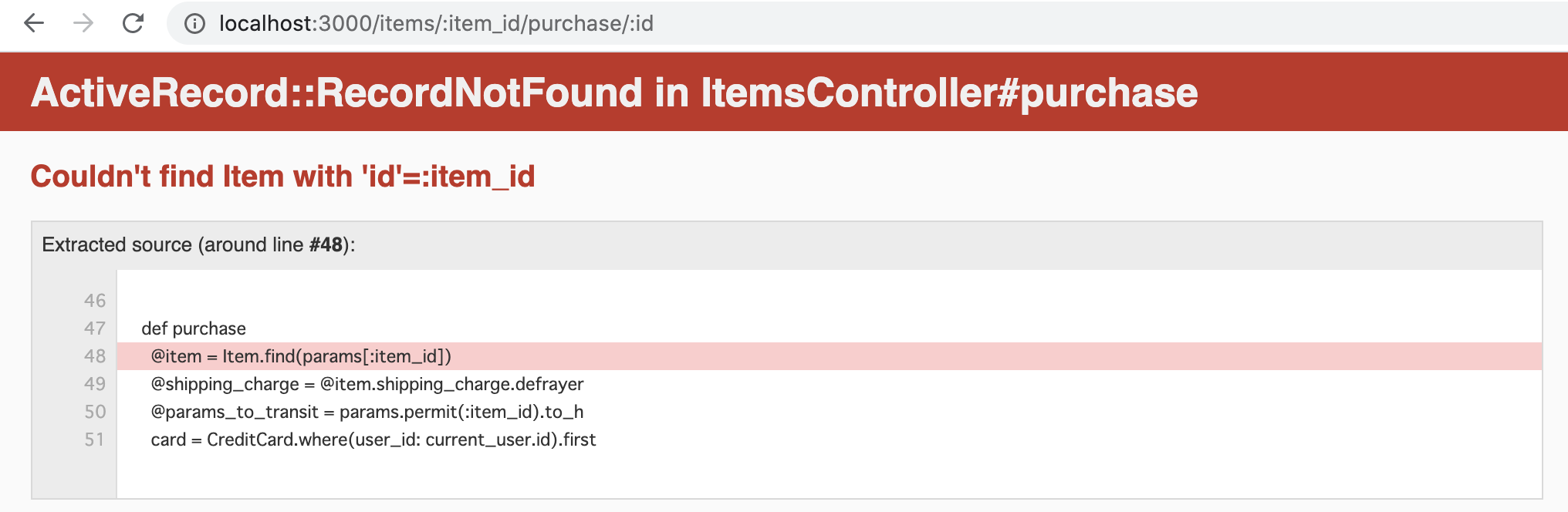
5. 4-1,4-2にてitem_idがないというErrorが発生した
ターミナルで確認するとitem_idがcontrollerを跨ぐタイミングで消えている。
Processing by ItemsController#purchase as HTML Parameters: {"item_id"=>"2"} Item Load (0.3ms) SELECT `items`.* FROM `items` WHERE `items`.`id` = 2 LIMIT 1Processing by CreditCardsController#show as HTML実装内容
item_idを引き継ぐ方法を検索していたところ...
sessionが使えそうだと判断。
はじめにapplication_controller.rbにinclude SessionHelperを追加。application_controller.rbclass ApplicationController < ActionController::Base include SessionsHelper #左記を追加 end/app/helpersに/sessions_helper.rbを作成し、下記コードでSessionsHelperを呼び出し
/app/helpers/sessions_helper.rbmodule SessionsHelper end参考記事
「初期化されていない定数ApplicationController :: SessionsHelper(NameError)」が表示されるのはなぜですか?これでsessionの準備が完了
まず、sessionにitem_idを保存する。
app/controllers/items_controller.rbdef purchase @item = Item.find(params[:item_id]) #paramsからitem_idを取り出し session[:item_id] = @item #取り出したitem_idをsessionに保存 end次に、credit_card登録先のcontroller(credit_cards#index,credit_cards#show)でsessionに保存していたパラメータを取り出す。
binding.pryで確認したところ配列になっていたので、valuesで取り出す。app/controllers/credit_cards_controller.rb#session[:item_id]で先ほどのsessionデータを取り出せる。 def index @item_id = session[:item_id].values.first end def show @item_id = session[:item_id].values.first endcontrollerで作成したインスタンス変数(@item_id)をviewで取り出し
app/views/credit_cards/index.html.haml= link_to "もどる", "/items/#{@item_id}/purchase", class:'return'app/views/credit_cards/show.html.haml%button.enter__permit__box.btn(onclick="location.href='/items/#{@item_id}/purchase'")選択した支払い方法を使う = link_to "もどる", "/items/#{@item_id}/purchase", class:'return'これで items#purchase ⇄ credit_cards#show,index において item_idのやりとりが出来るようになった。
最後に商品購入をした際に、sessionの削除をするapp/controllers/items_controller.rbdef pay session[:item_id] = nil end今回はsessionを使ってパラメータのやりとりを行なったがURLを使用してパラメータをやりとりできるみたいなので、今度試してみたい。
なお、sessionを使用する際は、それなりにリスクを伴うので、使用する際は下記のリンク先も合わせて読んでおきたい。
合わせて読みたい記事(セッションを取り扱う際の注意点)

- 投稿日:2020-10-12T16:53:26+09:00
【Rails】Viewの共有
Viewの共有
editとnewなど、同じ入力内容を伴うviewをまとめて設定する。
今回用意するのは以下の3ファイル、editとnewは共通する入力フォームを有するものとする。
_form.html.erb
edit.html.erb
new.html.erb共有フォームにて
form_for(@profile)と記述するれば、ルーティングも自動で行う。
また、submitボタンの表記も自動化されており、日本語化していれば登録する、更新すると表記される。_form.html.erb
共有するフォームを記述する。
_form.html.erb<%= form_for(@profile) do |f| %> <div class="field"> <%= f.label :img %><br /> <%= f.file_field :img %> <%# 以下で赤文字でエラー内容を表示 %> <% if @profile.errors.include?(:img) %> <p style="color: red;"><%= @profile.errors.full_messages_for(:img).first %> <% end %> <div class="field"> <%= f.label :name %><br /> <%= f.text_field :name, autofocus: true, autocomplete: "name" %> <%# 以下で赤文字でエラー内容を表示 %> <% if @profile.errors.include?(:name) %> <p style="color: red;"><%= @profile.errors.full_messages_for(:name).first %> <% end %> </div> <div class="field"> <%= f.label :age %><br /> <%= f.number_field :age, autofocus: true, autocomplete: "age" %> <%# 以下で赤文字でエラー内容を表示 %> <% if @profile.errors.include?(:age) %> <p style="color: red;"><%= @profile.errors.full_messages_for(:age).first %> <% end %> </div> <div class="field"> <%= f.label :男性 %><%= f.radio_button :sex, :男性 %> <%= f.label :女性 %><%= f.radio_button :sex, :女性 %> <%# 以下で赤文字でエラー内容を表示 %> <% if @profile.errors.include?(:sex) %> <p style="color: red;"><%= @profile.errors.full_messages_for(:sex).first %> <% end %> </div> <div class="field"> <%= f.label :description %><br /> <%= f.text_area :description, autofocus: true, autocomplete: "description" %> <%# 以下で赤文字でエラー内容を表示 %> <% if @profile.errors.include?(:description) %> <p style="color: red;"><%= @profile.errors.full_messages_for(:description).first %> <% end %> </div> <div class="field"> <%= f.label :qualify %><br /> <%= f.text_area :qualify, autofocus: true, autocomplete: "qualify" %> <%# 以下で赤文字でエラー内容を表示 %> <% if @profile.errors.include?(:qualify) %> <p style="color: red;"><%= @profile.errors.full_messages_for(:qualify).first %> <% end %> </div> <div class="field"> <%= f.label :impression %><br /> <%= f.text_area :impression, autofocus: true, autocomplete: "impression" %> <%# 以下で赤文字でエラー内容を表示 %> <% if @profile.errors.include?(:impression) %> <p style="color: red;"><%= @profile.errors.full_messages_for(:impression).first %> <% end %> </div> <div class="actions"> <%= f.submit %> </div> <% end %>edit.html.erb
renderで共有するフォームを呼び出し、
profile: @profileでコントローラーから変数を受け取る。edit.html.erb<h1>プロフィール編集</h1> <%= render 'form', profile: @profile %>new.html.erb
renderで共有するフォームを呼び出す。
new.html.erb<h1>プロフィール登録</h1> <%= render 'form' %>
- 投稿日:2020-10-12T16:37:28+09:00
Ruby on Rails 教わった事 その1
この記事の目的
プログラミングスクールで私が約3ヶ月で教わった事を転職活動に生かすためにまとめました。
私による私のためだけの記事です。この講義で印象に残った一言は、
Rails書けると出来るにはレベルに隔たりがある。
コードレビュー
メンターさんにとってすごい人だそうです!
Railsのコードレビューをするときに確認する観点をまとめてみた
コントローラーについて
スコープ
コントローラーの中で、モデルから直接メソッドを呼び出すことはセキュリティーホールに繋がりやすい。基本的に全体対象はイレギュラーであり、ほぼないものとする。↓
example_controller.rbdef new - @post = Post.new #間違ったIDが入る可能性がある + @post = current_user.posts.build #current_userの範囲(スコープ) endBefore_Action
コントローラー内での共通部分はprivateメソッドにして、before_actionでDRYに保つ↓
example_controller.rbbefore_action :set_post #省略 private def set_post @post = current_user.posts.find(params[:id]) endSave,Destroyメソッド
サーバートラブルなどネット環境の要因以外で、ほぼ失敗しないsave、destroyメソッドには!をつける↓
example_controller.rbdef create @post = current_user.posts.build(post_params) if @post.save! flash[:notice] = "投稿しました" redirect_to posts_path else render :new end end定数を使う
全体の人に分かりやすくするよう定数にする。モデルで定数を定義し、コントローラーで呼び出す。↓
example_controller.rb#ex_model.rb PER_COMMENT = 5 #example_controller.rb @comments = @post.comments.page(params[:page]).per(Ex_model::PER_COMMENT).order(created_at: :desc) #モデル名::定数名ルーティングについて
URLの意味を通す
resourcesをネストすると、URLの意味が分かりやすくなる。↓
routes.rb#Post(投稿)が親、Comment(コメント)とLike(いいね)が子。 resources :posts do resources :comments, only: [:create, :destroy] resources :likes, only: [:show,:create, :destroy] endしかも、URLから2つ、IDを持ってくる事ができる!↓
post_comments POST /posts/:post_id/comments(.:format) comments#create post_comment DELETE /posts/:post_id/comments/:id(.:format) comments#destroy post_likes POST /posts/:post_id/likes(.:format) likes#create post_like GET /posts/:post_id/likes/:id(.:format) likes#show DELETE /posts/:post_id/likes/:id(.:format) likes#destroy講義の感想
私よりも若い先生でしたが、とても立派な人です。
ZOOMで録画したものを、見返していますが当時よりはっきりと内容や意味を理解する事が出来ています。
その2へ続きます。
- 投稿日:2020-10-12T16:16:09+09:00
Rspecのファイルアップロードテスト時にcommitteeでCommittee::InvalidRequestが発生する事象への対処方法
発生しているエラー
Committee::InvalidRequest: #/paths/~1contracts/post/requestBody/content/multipart~1form-data/schema/properties/original_file expected string, but received ActionDispatch::Http::UploadedFile: #<ActionDispatch::Http::UploadedFile:0x00007fa77e1f36a0>何がしたいのか
multipart/form-data形式でファイルアップロードを受け取るようなAPIを定義している。
APIはOpenAPI3.0の仕様に基づいて設計していて、例えば以下のようになる。requestBody: original_file: image/png: schema: type: string format: binarySwaggerのドキュメントにもある。
このAPIに対して
committeegem を使ってRspecを書きたい。テストの内容
some_controller_spec.rb# formのパラメータ let(:file_upload_form) { { article_id: 1_000, name: 'This is good article', # set real existing file original_file: fixture_file_upload( Rails.root.join('sample_files/sample.docx'), 'application/vnd.openxmlformats-officedocument.wordprocessingml.document' ) } }Requestとして使うパラメータは上記のように定義していて、アップロードするファイルはテスト用に用意したDocxファイル。
これを以下のようにPOSTしてAPIのフォーマットをassert_schema_conformメソッドで検証している。some_controller_spec.rbit 'uploads file' do post api_v1_images_path, headers: authenticated_header(user), params: file_upload_form expect(response).to have_http_status(:success) assert_schema_conform endエラーの原因
APIのRequestの仕様が
type: stringなのに、テストではActionDispatchのオブジェクトが設定されているので、期待しているのと違う、っていうエラーが発生している。
しかし、ファイルアップロードのテストなのでStringでは内部の処理がうごかないので、変えることもできない。これは困った。という状況
エラーの発生箇所
エラーは以下の
OpenAPIParserの処理で発生していう。
lib/openapi_parser/schema_validators/string_validator.rb#L11lib/openapi_parser/schema_validators/string_validator.rbdef coerce_and_validate(value, schema, **_keyword_args) return OpenAPIParser::ValidateError.build_error_result(value, schema) unless value.kind_of?(String) # ... 以下省略 ... end単純に
valueがStringクラスかどうかをみていて、Stringじゃない場合はErrorになっている。今回はここがActionDispatchのオブジェクトなのでvalue.kind_of?(String)が偽となりエラーが発生してしまう。
type: stringであってもformat: binaryの場合はStringクラス以外も許すファイルのように、
format: binayの場合はエラーをRaiseしないように条件を変えてやれば良い。そのためのパッチを作成する。
バッチとして該当のメソッドcoerce_and_validate(value, schema, **_keyword_args)を定義した任意のModuleを作成する。module StringValidatorPatch def coerce_and_validate(value, schema, **keyword_args) # この処理を変更 # https://github.com/ota42y/openapi_parser/blob/61874f0190a86c09bdfb78de5f51cfb6ae16068b/lib/openapi_parser/schema_validators/string_validator.rb#L11 if !value.is_a?(String) && schema.format != 'binary' return OpenAPIParser::ValidateError.build_error_result(value, schema) end # --- ここまで value, err = check_enum_include(value, schema) return [nil, err] if err value, err = pattern_validate(value, schema) return [nil, err] if err unless @datetime_coerce_class.nil? value, err = coerce_date_time(value, schema) return [nil, err] if err end value, err = validate_max_min_length(value, schema) return [nil, err] if err value, err = validate_email_format(value, schema) return [nil, err] if err value, err = validate_uuid_format(value, schema) return [nil, err] if err [value, nil] end endこのように、変更したいメソッドだけを再定義したModuleを定義する。このModuleをパッチを当てたいクラス、今回は
OpenAPIParser::SchemaValidator::StringValidatorクラスを再オープンし、Module#prependを使ってメソッドを上書きする。
Module#prependのリファレンスclass OpenAPIParser::SchemaValidator::StringValidator prepend StringValidatorPatch endこれで
Committee::InvalidRequestエラーが発生しなくなる影響を最低限に抑える
パッチを当てることで
Committee::InvalidRequestエラーを回避することはできるが、グローバルなスコープでパッチを当ててしまうと全体に影響が出てしまう。
この変更はファイルアップロードを伴うテストの時だけ有効にしたい。
そのためRspecの必要なコンテキストでだけ反映されるようにcontext 'some context' do ... endの中で定義することを考える。some_controller_spec.rbRSpec.describe SomeController, type: :request do context 'some context' do # context内でパッチを当てる module StringValidatorPatch def coerce_and_validate(value, schema, **keyword_args) if !value.is_a?(String) && schema.format != 'binary' return OpenAPIParser::ValidateError.build_error_result(value, schema) end # (以下略) end end class OpenAPIParser::SchemaValidator::StringValidator prepend StringValidatorPatch end # ここまでパッチ it 'uploads file' do post api_v1_images_path, headers: authenticated_header(user), params: file_upload_form expect(response).to have_http_status(:success) assert_schema_conform end end endしかし、ブロックのスコープは定数を分離したり名前空間を設定したりしないので、ブロック内でクラス定義などの処理は避けたい
Rubocopの Lint/ConstantDefinitionInBlockにもひっかかってしまう。
Rspecで同様の定数定義を行う場合は、stub_const()を使って定義する。
stub_const()を使って必要な箇所にパッチを適用するクラスの再オープンを
classキーワードを使わずに行うには Class.newを使う。
ブロックを渡すことで、クラス定義も行えるFoo = Class.new {|c| def hello; 'hello'; end } puts Foo.new.hello # => 'hello'これを使って、パッチを当てたクラスを定義する。パッチ用の
StringValidatorPatchmoduleはspec/supportディレクトリにstring_validator_patch.rbとして保存し、読み込まれるようにしておく。patched = Class.new(OpenAPIParser::SchemaValidator::StringValidator) do |klass| klass.prepend StringValidatorPatch end stub_const('OpenAPIParser::SchemaValidator::StringValidator', patched)
Class.new()の引数にクラスを渡すと親クラスとして扱われるので、上記の場合はpatchedがOpenAPIParser::SchemaValidator::StringValidatorの子クラスとなる。
それをstub_const()を使って定数定義をしてやれば、パッチを当てたクラスを利用することができる。この処理を必要に応じて
beforeやletで実装する。まとめ
Committee::InvalidRequestエラーを解消するには、Validatorクラスにパッチを当てる- パッチを当てるには当該メソッドだけを実装したModuleを定義し、
prependを使って反映する- RSpecでは
Class.new()とstub_const()を使って局所的にパッチをあてるspec/support/string_validator_patch.rbmodule StringValidatorPatch def coerce_and_validate(value, schema, **keyword_args) # この処理を変更 # https://github.com/ota42y/openapi_parser/blob/61874f0190a86c09bdfb78de5f51cfb6ae16068b/lib/openapi_parser/schema_validators/string_validator.rb#L11 if !value.is_a?(String) && schema.format != 'binary' return OpenAPIParser::ValidateError.build_error_result(value, schema) end # --- ここまで value, err = check_enum_include(value, schema) return [nil, err] if err value, err = pattern_validate(value, schema) return [nil, err] if err unless @datetime_coerce_class.nil? value, err = coerce_date_time(value, schema) return [nil, err] if err end value, err = validate_max_min_length(value, schema) return [nil, err] if err value, err = validate_email_format(value, schema) return [nil, err] if err value, err = validate_uuid_format(value, schema) return [nil, err] if err [value, nil] end endsome_controller_spec.rbRSpec.describe SomeController, type: :request do context 'some context' do let(:file_upload_form) { { article_id: 1_000, name: 'This is good article', original_file: fixture_file_upload( Rails.root.join('sample_files/sample.docx'), 'application/vnd.openxmlformats-officedocument.wordprocessingml.document' ) } } before do # context内でパッチを当てる patched = Class.new(OpenAPIParser::SchemaValidator::StringValidator) do |klass| klass.prepend StringValidatorPatch end stub_const('OpenAPIParser::SchemaValidator::StringValidator', patched) end it 'uploads file' do post api_v1_images_path, headers: authenticated_header(user), params: file_upload_form expect(response).to have_http_status(:success) assert_schema_conform end end end
- 投稿日:2020-10-12T16:05:09+09:00
railsでformをdisableして送信すると値が送信されてない場合の解消法
- 投稿日:2020-10-12T15:39:44+09:00
[Rails] 最小限の労力でrubocopの恩恵を受ける
はじめに
「railsプロジェクトやるときには、rubocop入れましょう」と呪文のように刷り込まれてきましたが、実は、rubocopで何ができるのか、どんなメリットが有るのかきちんと理解していなかったのでまとめました。
この手の「いろいろできるツール」の使う際の大事な心がけとしては、提供される機能をくまなく把握して全部使いこなすことではなく、導入の目的を満たす8割ぐらいのことを、最小限の労力でできるようにすることが大事なんじゃないかとつくづく思います。
この記事を読んで、rubocopを導入することだけでなく、労力を取られずに(=本来書くべきロジックやテストに集中できるように)コードの品質を高めるという成果が得られてもらえれば、何よりです。
rubocopとは?
一言でいうと、ruby(.rbファイル)のコードを検査して、定められた規約に違反している箇所を検出してくれるツールです。
「コードが長すぎる」「インデンが適切でない」とかコードの可読性を高めるものだけでなく、「明確にすべきオプションがされていない」「DBとmodelで整合性があっていない」などバグにつながるような規約違反も検出してくれます。そして多くの場合、自動的に修正もしてくれます。
また、railsを使用している場合には、rubocop-railsを同時利用することで、rails特有のファイル(ex. マイグレーションファイル、設定ファイル)も検査してくれます。
メリット
rubocopを導入することで受けられるメリット(恩恵)は以下のものだと思います。
- バグにつながるような規約違反だったり、コードの読みやすさを阻害するような規約違反を自動検出してくれる
- チーム開発の場合は、チームで定めた同じ設定ファイルを使用することで、各自が書いたコードを同一ルールに基づいた一定の品質に保つことの助けになる
- 単純な規約違反(余計な余白がある、インデントが適切ではない)を自動的に修正してくれる
- 自動実行ツール(pre-commit 後述)と組み合わせることで、意識せずにcommitのタイミングで自動実行して、規約違反を検出してくれる。(そもそもの実行し忘れるということを防げる)
- コードレビューを機械的に行ってくれるので、規約違反の内容を理解し修正することで、自分のコードの品質を高めることができる
rubocopの使い方
railsを使用している場合の導入〜使い方を記載してきます。
試した環境は以下です。
- OS : macOS Catalina(10.15.7)
- ruby : 2.6.6
- rails : 6.0.3.3
また、私の場合まずは作るの優先でやったrailsアプリがあり、model,contorllerともに5,6個程度作成した状態で導入しました。
なお、私は導入に当たり以下のことを心がけました。なので、他の方が記載された導入の仕方や、設定内容とは異なる部分、相容れない部分があると思います。
- いきなり100%を目指さない
- ツールがやってくれることは、ツールに任せ、自分がやらなきゃいけないことに注力する
- 継続的に使えるようにする
インストール&設定
Gemfileに以下の記載を行い、bundle install
group :development do gem 'rubocop', require: false gem 'rubocop-rails' endとりあえずチェックする
$ rubocop Inspecting 57 files CCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCC Offenses: 57 files inspected, 292 offenses detected, 260 offenses auto-correctable292個って、、めちゃくちゃ出ましたね・・・ しかもスクロースしてもすべては表示しきれずorz
これを、一個一個確認して、修正。なんてことをやってくと。もうrubocopなんてしない!と投げ出してしまうので、継続的に使える有用なツールにしましょう。
というわけで、次の「設定ファイルの作成」と「自動修正」を行っています。
設定ファイルの作成
以下のコマンドを実行すると、設定ファイル(
.rubocop.yml)を作成してくれ、かつ検出された規約違反を読み飛ばすための設定を(.rubocop_todo.yml)に記載してくれます。$ rubocop --auto-gen-config適用する(しない)規約・範囲を設定ファイルに書いてあげます。
私は、とりあえず「チェック対象を自分で書いたコードに限定する」という考えで、以下の設定を入れてみました。
- コマンドで自動生成されたファイルや、初期ファイルはチェック対象外にする
AllCops: TargetRubyVersion: 2.6 NewCops: enable # ← 新しい規約が登録された場合に、適用するかどうかの判定 Exclude: - 'bin/**' - 'node_modules/**/*' - 'config/**/*' - 'config.ru' - 'db/schema.rb' - 'db/seeds.rb' - 'Gemfile'
- 自分のコード記載方法にそぐわない、エラー検出が必要ない規約を無効or変更
# 日本語でのコメントを許可 Style/AsciiComments: Enabled: false # クラスのコメント必須を無視 Style/Documentation: Enabled: false # 「frozen_string_literal: true」を追加しない Style/FrozenStringLiteralComment: Enabled: false # メソッドの行数が 10 行までは厳しすぎるので,20行までに変更 Metrics/MethodLength: Max: 20 # private/protected は一段深くインデントする Style/IndentationConsistency: EnforcedStyle: indented_internal_methodsこれらの設定ファイルを記載したうえで、規約違反を退避したファイル(
.rubocop_todo.yml)の中身をコメントアウトして、再度rubocopを実行します。私の場合50個くらいまで減りました。ここまで来てもまだすべてを一つづつ直す気にはなれないので、次の自動修正を実行しします。
自動修正
冒頭にも記載したとおり、簡単な(かつ対処法が明確な)規約違反はrubocop -aコマンドで自動的に修正してくれます。
※ここは、一つ一つ規約違反の内容確認した上で、自動修正するべきという意見もありますが、私は「自動修正してくれるものは任せよう」と割り切って、規約違反はサーと見て自動修正しました。
実行すると、こんな感じで、自動修正された規約違反は
[Corrected]が付与され、最後に、規約違反の総件数に対して、何件自動修正されたか表示されます。$ rubocop -a .rubocop.yml: Style/IndentationConsistency has the wrong namespace - should be Layout Inspecting 29 files ....................CC.CCCCCC Offenses: db/migrate/20200928124523_devise_create_users.rb:6:59: C: [Corrected] Style/StringLiterals: Prefer single-quoted strings when you don't need string interpolation or special symbols. t.string :nickname, null: false, default: "" ^^ ~ 途中略 〜 29 files inspected, 24 offenses detected, 22 offenses corrected手動修正
そして、自動修正しても残ってしまった規約違反が、自分で対応しなきゃいけない(=本来やりたかった、時間をかけて、内容理解し、あるべきコードに修正する作業)ものです。
私の場合は、以下の2つが残りました。こちらはバグに繋がる可能性のある規約違反だと思うので、エラーの内容を確認して(ex.
Rails/HasManyOrHasOneDependentというキーワードでググれば、公式サイトの内容or丁寧解説記事にありつけます)、修正方法を検討して修正し、再度rubocopを実行して、無事に規約違反なしとなりました。# has_manyアソシエーションにたいして、dependentオプション(親レコード削除時に、同時に消す? 残す? エラーにする? 警告出す?)が未設定 app/models/category.rb:3:3: C: Rails/HasManyOrHasOneDependent: Specify a :dependent option. has_many :estimate_details ^^^^^^^^ # modelでuniqueバリデーションを定義しているのに、DB定義にはunique定義がされていない app/models/category.rb:6:3: C: Rails/UniqueValidationWithoutIndex: Uniqueness validation should be with a unique index. validates :user_id, uniqueness: { scope: :category_name }自動実行
便利なツールですが、そもそも実行することを忘れないために、何かを契機に自動的に実行するようにしましょう。一番良いタイミングがcommitのタイミングだと思うので、pre-commitというgemを導入して、git commitコマンド発行したタイミングで自動実行するようにします。
- pre-commitのインストール
gem pre-commitをGemfileに設定して、bundle installしたあとに、以下のコマンドでpre-commitのファイルを生成します。$ pre-commit install Installed /Users/hiro/.rbenv/versions/2.6.6/lib/ruby/gems/2.6.0/gems/pre-commit-0.39.0/templates/hooks/automatic to .git/hooks/pre-commit
- pre-commitの設定
commit時にrubocopを自動実行するために、以下コマンドで設定を行います。
# 設定前の状態を確認 $ pre-commit list Available providers: default(0) git(10) git_old(11) yaml(20) env(30) Available checks : before_all ci coffeelint common console_log csslint debugger gemfile_path go go_build go_fmt jshint jslint json local merge_conflict migration nb_space pry rails rspec_focus rubocop ruby ruby_symbol_hashrockets scss_lint tabs whitespace yaml Default checks : common rails Enabled checks : common rails Evaluated checks : tabs nb_space whitespace merge_conflict debugger pry local jshint console_log migration Default warnings : Enabled warnings : Evaluated warnings : # git commitのタイミングで、rubocopを実行するように設定 $ git config pre-commit.checks rubocop # 設定後の状態を確認 $ pre-commit list Available providers: default(0) git(10) git_old(11) yaml(20) env(30) Available checks : before_all ci coffeelint common console_log csslint debugger gemfile_path go go_build go_fmt jshint jslint json local merge_conflict migration nb_space pry rails rspec_focus rubocop ruby ruby_symbol_hashrockets scss_lint tabs whitespace yaml Default checks : rubocop # ← rubocopが設定された Enabled checks : rubocop # ← rubocopが設定された Evaluated checks : rubocop # ← rubocopが設定された Default warnings : Enabled warnings : Evaluated warnings :また、bundle経由で、pre-commtiを使用する場合には.git配下の設定ファイル(
.git/hooks/pre-commit)を以下のように修正する必要があります。#!/usr/bin/env sh 〜 中略 〜 PATH=$PATH:/usr/local/bin:/usr/local/sbin cmd=`git config pre-commit.ruby 2>/dev/null` if test -n "${cmd}" then true elif which rvm >/dev/null 2>/dev/null then cmd="rvm default do ruby" elif which rbenv >/dev/null 2>/dev/null then cmd="rbenv exec ruby" #← 修正前 then cmd="rbenv exec bundle exec ruby" #← 修正後 else cmd="ruby" fi 〜 中略 〜設定完了後に、git commitコマンドを実行して、rubocopが自動実行されるか確認します。
(規約違反が出るように事前に行末余白を仕込んでおきました)
$ git commit pre-commit: Stopping commit because of errors. Inspecting 1 file C Offenses: app/controllers/home_controller.rb:4:1: C: Layout/TrailingWhitespace: Trailing whitespace detected. 1 file inspected, 1 offense detected, 1 offense auto-correctable .rubocop.yml: Style/IndentationConsistency has the wrong namespace - should be Layout pre-commit: You can bypass this check using `git commit -n`commit時にrubocopが自動実行されることが確認できました。違反が検出されると、commit処理は中断されます。
検出後の流れとしては、「違反内容確認」→(修正すべき場合は)「マニュアル or 自動修正(
rubocop -a)」→ 「ステージング環境へ登録」→「commit」の流れになるかと思います。おわりに
今後、commitのために自動的にrubocopが走り、チェックが行われる設定ができ継続的に使えるようになりました。
コードを書いて、新たな規約違反が出たときに、設定ファイルを見直したり、内容を確認して書き方を改めることができていければ、よりよいツールを育てていけると思いますし、自分のコード品質を高めることにもつながるのではないかと、考えております。参考にさせていただいた記事
使い方に関して、完全に無知でしたのでとても参考になりました。
記事の著者の方にはこの場を借りて、感謝のお礼をさせていただきます。
- 投稿日:2020-10-12T15:38:15+09:00
【Ruby on Rails】MySQL構築からデータベース変更まで
はじめに
様々な記事を参考にしながらなんとか導入できたので、
備忘録として残します。
もしおかしな点や、こうした方がいいなどありましたら
ご教授頂けますと幸いです。開発環境
ruby 2.5.7
Rails 5.2.4.3
Vagrant 2.2.4
VirtualBox 6.0.14
OS: macOS Catalina
centos 7流れ
1 vagrant上にMySQLを構築
2 既存アプリをSqliteからMySQLに変更
3 新規アプリをMySQLに設定
※基本的にはvagrant上で行うため、ssh接続しておいてください。vagrant上にMySQLを構築
CentOS確認
まずは現在のCentOSを確認します。
確認方法はvagrantファイルにあるVagrantfileを確認します。VagrantfileVagrant.configure("2") do |config| GUEST_RUBY_VERSION = '2.5.7' config.vm.box = "centos/7" ...今回はCentOSが7である前提で話を進めます。
CentOSとは仮想環境構築に使用する代表的なLinux系OSです。MySQLのインストール(CentOS7用)
Vagrant+Rails6+MySQL 開発環境構築
こちらの記事を参考にまずはvagrant上にMySQLを構築します。ターミナル$ vagrant ssh $ sudo yum -y install http://dev.mysql.com/get/mysql-community-release-el7-5.noarch.rpm $ sudo yum -y install mysql-community-server $ mysqld --versionバーションが表示されればOKです。
自動起動設定後、MySQL起動
vagrant起動時に自動で起動するように設定します。
2行目はmysqld.service enabledになっていればOKです。ターミナル$ sudo systemctl enable mysqld.service $ sudo systemctl list-unit-files -t service | grep mysqld $ sudo systemctl start mysqld.serviceMySQL初期設定(任意)
https://style.potepan.com/articles/19020.html
こちらの記事がわかりやすかったので、
$ mysql_secure_installation を実行後、
この記事のMySQLの初期設定を実施しよう!から設定してください。# rootユーザーにパスワードを設定(今回はrootパスワードを設定) $ /usr/bin/mysqladmin -u root password 'root' # セキュリティー関連の初期設定(ここでパスワードを聞かれると'root'とする) $ mysql_secure_installation設定後、下記を実行しパスワードを入力後、
mysql>
この表示になればOKです。ターミナル$ mysql -u root -p既存アプリをSqliteからMySQLに変更
Railsでmysql2をインストールするときにハマったところ
[初学者]既存アプリのDBをMySQLに変更する方法
上記記事を参考に導入していきます。railsアプリの作成、データベース確認
試しにscaffoldでpostテーブルを作成します。
ターミナル$ rails new sam $ cd sam $ rails g scaffold post name:stringcongig/database.ymlがこのような表記になっているかと思います。
初期設定ではsqlite3のデータベースをしようしています。congig/database.ymldefault: &default adapter: sqlite3 pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %> timeout: 5000 development: <<: *default database: db/development.sqlite3 # Warning: The database defined as "test" will be erased and # re-generated from your development database when you run "rake". # Do not set this db to the same as development or production. test: <<: *default database: db/test.sqlite3 production: <<: *default database: db/production.sqlite3gemの導入
Gemfile# Use sqlite3 as the database for Active Record gem 'sqlite3' ↓ gem 'mysql2'ターミナル$ bundle installエラーが出る場合は下記を実行するか、
Gemfileのgem 'mysql2'のバージョンを
gem 'mysql2', '~> 0.4.4'
に変更してみてください。ターミナル$ sudo yum install -y mysql-develデータベース設定をMySQLに変更
congig/database.ymldefault: &default adapter: mysql2 encoding: utf8 pool: 5 username: root password: 初期設定をした場合はパスワードを記述 host: localhost development: <<: *default database: sam_development # samはアプリ名です。 # Warning: The database defined as "test" will be erased and # re-generated from your development database when you run "rake". # Do not set this db to the same as development or production. test: <<: *default database: sam_test # samはアプリ名です。 production: <<: *default database: sample_production username: sample_app password: <%= ENV['SAMPLE_DATABASE_PASSWORD'] %>下記でデータベースを作成。
ターミナル$ bundle exec rake db:create $ rails db:migrateターミナル$ mysql -u root -p $ show tables from sam_development; +---------------------------+ | Tables_in_sam_development | +---------------------------+ | ar_internal_metadata | | posts | | schema_migrations | +---------------------------+ 3 rows in set (0.00 sec)このようになっていたら設定完了です。
新規アプリをMySQLに設定
こちらは既存アプリの変更より簡単に出来ます。
ターミナル$ rails new sample -d mysql $ cd sample $ rails g scaffold post name:stringcongig/database.ymldefault: &default adapter: mysql2 encoding: utf8 pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %> username: root password: 初期設定をした場合はパスワードを記述 socket: /var/lib/mysql/mysql.sock development: <<: *default database: sample_development # Warning: The database defined as "test" will be erased and # re-generated from your development database when you run "rake". # Do not set this db to the same as development or production. test: <<: *default database: sample_test # As with config/secrets.yml, you never want to store sensitive information, # like your database password, in your source code. If your source code is # ever seen by anyone, they now have access to your database. # # Instead, provide the password as a unix environment variable when you boot # the app. Read http://guides.rubyonrails.org/configuring.html#configuring-a-database # for a full rundown on how to provide these environment variables in a # production deployment. # # On Heroku and other platform providers, you may have a full connection URL # available as an environment variable. For example: # # DATABASE_URL="mysql2://myuser:mypass@localhost/somedatabase" # # You can use this database configuration with: # # production: # url: <%= ENV['DATABASE_URL'] %> # production: <<: *default database: sample_production username: sample password: <%= ENV['SAMPLE_DATABASE_PASSWORD'] %>Gemfile# Use mysql as the database for Active Record gem 'mysql2', '>= 0.4.4', '< 0.6.0'ターミナル$ bundle exec rake db:create $ rails db:migrateもしAccess deniedのエラーが出た場合は、
下記のように一度ログイン後、再度上記を実行してください。ターミナル$ mysql -u root -p exitまとめ
初期設定を行うことによってAccess deniedで弾かれるこtがありますが、
セキュリティー上仕方がないことかもしれません。
間違っている記述や方法がございましたらご教授頂けますと幸いです。またtwitterではQiitaにはアップしていない技術や考え方もアップしていますので、
よければフォローして頂けると嬉しいです。
詳しくはこちら https://twitter.com/japwork
- 投稿日:2020-10-12T13:46:58+09:00
【Rails】バリデーションの設定と日本語化
バリデーションの設定
modelファイルに記述します。
presence: true によって入力必須となります。
そのほかにもいろいろな設定が可能です。詳細は公式ドキュメント等を参照願います。profile.rbclass Profile < ApplicationRecord belongs_to :user validates :name, presence: true validates :age, presence: true validates :sex, presence: true validates :description, presence: true validates :qualify, presence: true validates :impression, presence: true endエラーメッセージの表示
いろいろな方法がありますが、今回はヘルパー
if @変数名.errors.include?を使用して以下のようにしました。
nameについてのみ記述しておりますが、nameを別のカラム名に変更することでメッセージの表示が可能です。new.html.erb<div class="field"> <%= f.label :name %><br /> <%= f.text_field :name, autofocus: true, autocomplete: "name" %> <%# 以下で赤文字でエラー内容を表示 %> <% if @profile.errors.include?(:name) %> <p style="color: red;"><%= @profile.errors.full_messages_for(:name).first %> <% end %>表示すると以下のような感じになります。
※現段階では日本語化していないので、表示される赤文字は英語のはずです。日本語化については後段で触れます。
エラーメッセージの日本語化 :1(メッセージ)
今回はgemを使いますが、日本語の言語ファイルをGit経由で入手可能です。
興味がある方はrails-i18nで検索してください。
また、この作業ではカラム名が英語のままです。カラム名日本語化は次の段落で行います。gem 'rails-i18n'bundel installエラーメッセージの日本語化 :2(カラム名)
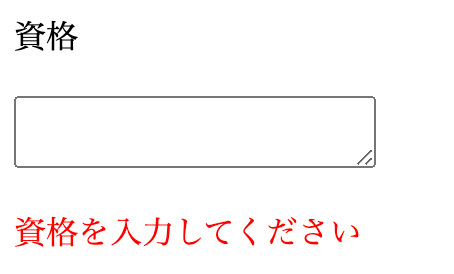
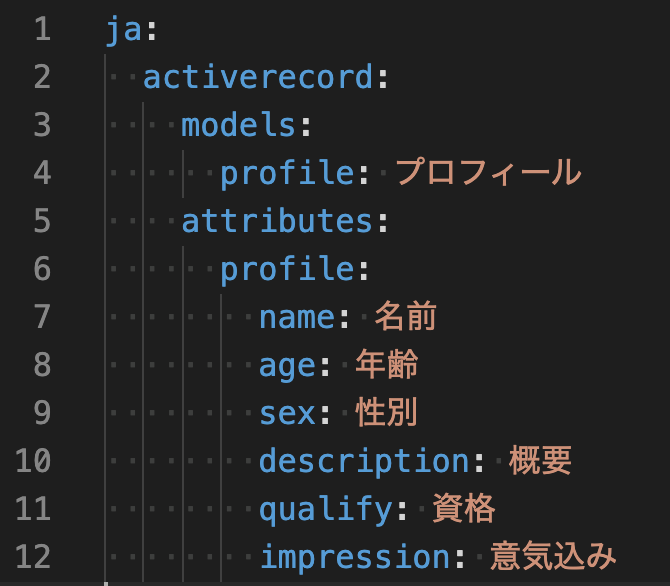
config/locales/modelsディレクトリにja.ymlファイルを作成します。
インデントがずれると正しく動作しないので、画像も参考にしてください(点の数=インデント幅)。ja.ymlja: activerecord: models: profile: プロフィール #日本語化したいカラムがあるmodel名 attributes: profile: name: 名前 age: 年齢 sex: 性別 description: 概要 qualify: 資格 impression: 意気込み
参考に、バリデーションの内容を再度掲載します。
profile.rbclass Profile < ApplicationRecord belongs_to :user validates :name, presence: true validates :age, presence: true validates :sex, presence: true validates :description, presence: true validates :qualify, presence: true validates :impression, presence: true endエラーメッセージの日本語化 :3(読み込み)
最後に、当該ymlファイルを読み込ませる必要があります。
config/application.rbに以下の通り一文を追記してください。
これにより、ディレクトリ内のすべてのymlファイルを読み込むことができます。application.rbmodule Association03 class Application < Rails::Application config.load_defaults 5.1 config.i18n.load_path += Dir[Rails.root.join('config', 'locales', '**', '*.yml').to_s] #追記した一文 end end
- 投稿日:2020-10-12T13:19:05+09:00
[Rails] Herokuデプロイの流れ
備忘録
Herokuを使ったデプロイよく忘れてしまうので記録用
初学者のため間違っていたらご指摘お願いします。
尚本環境ではRails、MySQLを使っています。
プログラミング初心者の方に役立てばと思います!手順1 Heroku CLIをインストール
こちら最初のデプロイのみです。
2回目以降の方は手順2からご覧下さいターミナル
使用するディレクトリ内で以下のコマンドを入力 % brew tap heroku/brew && brew install herokuこのコマンドでherokuコマンドが使用できるようになり、ターミナルからHerokuにログインできるようになります。
手順2 Herokuにログインしましょう
ターミナルで以下を入力 % heroku login --interactive => Enter your Heroku credentials. # メールアドレスを入力し、エンターキーを押す => Email: # パスワードを入力して、エンターキーを押す => Password:これでHerokuにログインできました!
手順3 rails_12factorを導入
Railsアプリケーションを本番環境などのサーバ上で動かすためのアセットがまとまったGem
# Gemfileに追加 group :production do gem 'rails_12factor' endgemインストール % bundle install編集したのでコミット % git add . % git commit -m "gem rails_12factorの追加"デプロイはリモートリポジトリ上のデータを使うので変更の都度コミットしてプッシュを行うことを忘れないで下さい。
手順4 Herokuにアプリを作成
heroku createコマンドでheroku上にアプリを作成します。
heroku create 作成したいアプリ名ターミナルにて入力 例 % heroku create heroku-test01手順5 HerokuでMySQLを使えるようにする
ClearDBアドオンを追加する事でHeroku内でMySQLを使用できるようになります。
ターミナルで以下コマンドを実行 heroku addons:add cleardbターミナルで以下入力 # ClearDBデータベースのURLを変数heroku_cleardb % heroku_cleardb=`heroku config:get CLEARDB_DATABASE_URL` # データベースのURLを再設定 % heroku config:set DATABASE_URL=mysql2${heroku_cleardb:5}ここまででMySQLを使えるようになりました。
手順4に進む前にcredentials.yml.encファイルとmaster.keyファイルについて軽く説明します。credentials.yml.encファイルはrailsで外部に漏らしたくない情報を扱うファイルのこと。
master.keyファイルファイルはcredentials.yml.encの暗号文を複号するためのファイルのことです。
master.keyは重要なファイルのためデフォルトでGitで扱われないようになっています。手順5.5 credentials.yml.encをmaster.keyで複号
以下コマンドでcredentials.yml.encをmaster.keyによって復号し、中身を確認できた状態です
# ターミナルで以下コマンドを実行 % EDITOR="vi" bin/rails credentials:edit手順6 Heroku上にmaster.keyを設置
先ほども説明しましたが、master.keyはGitで扱えないため環境変数を設定する必要があります。
heroku config:set 環境変数名="値"
これにより、Heroku上で環境変数を設定でき、master.keyを使えるようになります。ターミナルで以下入力 heroku config:set RAILS_MASTER_KEY=`cat config/master.key`以下コマンドで環境変数の設定を確認 % heroku config手順7 アプリをプッシュ
git push heroku masterコマンドでheroku上のアプリにリモートリポジトリの内容をプッシュしています。
以下ターミナルで実行 % git push heroku masterここまででHeroku上にアプリケーションを反映する事ができました!
ですがマイグレーション情報が反映されていません、、、手順8 Herokuでマイグレーションを実行
heroku run rails db:migrateコマンドでHerokuのDB上にマイグレーション情報を反映させています。
ターミナルで以下コマンド実行 % heroku run rails db:migrate# 以下コマンドでHeroku上にデプロイしたアプリの情報確認できます % heroku apps:info追記
今後追加機能などを本番環境にデプロイする際には、コミット→プッシュ→手順7で簡単にデプロイする事ができます。
まとめ
お疲れ様です!
ここまでで一通りのデプロイ作業が終了しました!
実際の現場ではHerokuを使う事はほとんど無いと思いますが、私を含め初学者にとっては簡単にデプロイできるツールなのでデプロイの入門としてとても便利ですね!
誰かの助けになれば幸いです。
- 投稿日:2020-10-12T13:12:04+09:00
かるく投稿してみる
- 投稿日:2020-10-12T12:44:36+09:00
Ruby on Rails ログイン機能のバリデーション設定② メールの正規表現
前回の記事の続きになります。
name、emailカラムにバリデーションを設置した後、有効なメールアドレス(sample@sample.comなど)かどうかを判別するために正規表現を使おうと思いますが、Rubyのリファレンスを見ても膨大な情報に溺れてしまいそう。。。そこで今回はemailが有効かどうかを判別するのに必要な分だけを調べて使ってみることにしました。
結論からいいますと、今回使った正規表現はこちら。
/\A[\w+\-.]+@[a-z\d\-.]+\.[a-z]+\z/i正規表現についてはRubyのリファレンスよりもRailsチュートリアルの方が分かりやすく説明されていました。下記はRailsチュートリアルよりの抜粋ですが、これを見ながらだと理解できそうです。
正規表現 意味 /\A[\w+-.]+@[a-z\d-.]+.[a-z]+\z/i (完全な正規表現) / 正規表現の開始を示す \A 文字列の先頭 [\w+-.]+ 英数字、アンダースコア (_)、プラス (+)、ハイフン (-)、ドット (.) のいずれかを少なくとも1文字以上繰り返す @ アットマーク [a-z\d-.]+ 英小文字、数字、ハイフン、ドットのいずれかを少なくとも1文字以上繰り返す . ドット [a-z]+ 英小文字を少なくとも1文字以上繰り返す \z 文字列の末尾 / 正規表現の終わりを示す i 大文字小文字を無視するオプション さらにRubularを使えば正規表現を簡単にチェックできるようです。これは便利!
・・・で、この正規表現を前回の記事で作成したバリデーションに追加します。フォーマットを検証するためには。。。
validates :email, format: { with: /<regular expression>/ }このような形でformatオプションを使用するとのことなので、"regular expression"の箇所に正規表現を追加。
app/models/user.rbclass User < ApplicationRecord validates :name, presence: true, length: { maximum: 20 } validates :email, presence: true, length: { maximum: 300 }, format: { with: /\A[\w+\-.]+@[a-z\d\-.]+\.[a-z]+\z/i } endRails consoleで確認してみると、sample@sample.comのような形でないので、エラーになっていました。
> user = User.create(name: "ruby", email: "ruby") (0.2ms) BEGIN (0.3ms) ROLLBACK => #<User id: nil, name: "ruby", email: "ruby", created_at: nil, updated_at: nil> > user.errors.messages => {:email=>["is invalid"]}
- 投稿日:2020-10-12T12:44:36+09:00
Rails:メールの正規表現を攻略する!
前回の記事の続きになります。
name、emailカラムにバリデーションを設置した後、有効なメールアドレス(sample@sample.comなど)かどうかを判別するために正規表現を使おうと思いますが、Rubyのリファレンスを見ても膨大な情報に溺れてしまいそう。。。そこで今回はemailが有効かどうかを判別するのに必要な分だけを調べて使ってみることにしました。
結論からいいますと、今回使った正規表現はこちら。
/\A[\w+\-.]+@[a-z\d\-.]+\.[a-z]+\z/i正規表現についてはRubyのリファレンスよりもRailsチュートリアルの方が分かりやすく説明されていました。下記はRailsチュートリアルよりの抜粋ですが、これを見ながらだと理解できそうです。
正規表現 意味 /\A[\w+-.]+@[a-z\d-.]+.[a-z]+\z/i (完全な正規表現) / 正規表現の開始を示す \A 文字列の先頭 [\w+-.]+ 英数字、アンダースコア (_)、プラス (+)、ハイフン (-)、ドット (.) のいずれかを少なくとも1文字以上繰り返す @ アットマーク [a-z\d-.]+ 英小文字、数字、ハイフン、ドットのいずれかを少なくとも1文字以上繰り返す . ドット [a-z]+ 英小文字を少なくとも1文字以上繰り返す \z 文字列の末尾 / 正規表現の終わりを示す i 大文字小文字を無視するオプション さらにRubularを使えば正規表現を簡単にチェックできるようです。これは便利!
・・・で、この正規表現を前回の記事で作成したバリデーションに追加します。フォーマットを検証するためには。。。
validates :email, format: { with: /<regular expression>/ }このような形でformatオプションを使用するとのことなので、"regular expression"の箇所に正規表現を追加。
app/models/user.rbclass User < ApplicationRecord validates :name, presence: true, length: { maximum: 20 } validates :email, presence: true, length: { maximum: 300 }, format: { with: /\A[\w+\-.]+@[a-z\d\-.]+\.[a-z]+\z/i } endRails consoleで確認してみると、sample@sample.comのような形でないので、エラーになっていました。
> user = User.create(name: "ruby", email: "ruby") (0.2ms) BEGIN (0.3ms) ROLLBACK => #<User id: nil, name: "ruby", email: "ruby", created_at: nil, updated_at: nil> > user.errors.messages => {:email=>["is invalid"]}
- 投稿日:2020-10-12T11:13:19+09:00
mysql2のbundle installエラー解消
- macOS Catalina
- zsh
rubyのプロジェクトの環境構築にて
1. mysqlないよ
% bundle install怒られる
An error occurred while installing mysql2 (0.5.3), and Bundler cannot continue. Make sure that `gem install mysql2 -v '0.5.3' --source 'https://rubygems.org/'` succeeds before bundling.2. mysql2こける(ライブラリないよ)
言われたとおりに
% gem install mysql2 -v '0.5.3' --source 'https://rubygems.org/'怒られる
ld: library not found for -lssl対処
/usr/local/opt/opensslにopenssl入ってるか確認。わたしの場合は、homebrewでopenssl@1.1をインストール済で、.zshrcにはパス通してたんだけど、
.zshrcexport PATH="/usr/local/opt/openssl@1.1/bin:$PATH"どうやらmysql2が使いたいのはこちらの(最新の)パスのほうではなくて下記のパスのほうだそうなので、ローカルパスを通す。
% export LDFLAGS="-L/usr/local/opt/openssl/lib" % export CPPFLAGS="-I/usr/local/opt/openssl/include"ローカルオプションを設定
% bundle config --local build.mysql2 "--with-cppflags=-I/usr/local/opt/openssl/include" % bundle config --local build.mysql2 "--with-ldflags=-L/usr/local/opt/openssl/lib"2. Pumaでこける
再度
bundle install怒られる
An error occurred while installing puma (4.3.1), and Bundler cannot continue. Make sure that `gem install puma -v '4.3.1' --source 'https://rubygems.org/'` succeeds before bundling.言われたとおりに
% gem install puma -v '4.3.1' --source 'https://rubygems.org/'怒られる
puma_http11.c:203:22: error: implicitly declaring library function 'isspace' with type 'int (int)' [-Werror,-Wimplicit-function-declaration] while (vlen > 0 && isspace(value[vlen - 1])) vlen--; ^ puma_http11.c:203:22: note: include the header <ctype.h> or explicitly provide a declaration for 'isspace' 1 error generated. make: *** [puma_http11.o] Error 1 make failed, exit code 2対処
インストールオプションつける
% gem install puma:4.3.1 -- --with-cflags="-Wno-error=implicit-function-declaration"成功
Successfully installed puma-4.3.1 Parsing documentation for puma-4.3.1 Installing ri documentation for puma-4.3.1 Done installing documentation for puma after 0 seconds 1 gem installedようやく
次こそ・・
% bundle installBundle complete! 24 Gemfile dependencies, 90 gems now installed. Use `bundle info [gemname]` to see where a bundled gem is installed.ホっ?
(最近環境構築しすぎて、このへんの解消に僧侶モードはいってきました)
▶https://qiita.com/mksm_wrk/items/69f6c2fc396dc0abf954さあ仕事しよ。
- 投稿日:2020-10-12T10:00:54+09:00
【ざっくり解説】ActiveHashモデルからnameが取得できない原因と対処法
「ActiveHashのモデルからnameを取得したいんだけど、undefinedエラーが出て取得できない…」
そんな方向けに、ActiveHashのnameを多少強引に取得する方法と、そもそもnameが取得できない理由について解説していきます。
プログラミング初心者の方は参考にしていただけると幸いです。
(なぜエラーが出るかご存知の方にとっては、この記事は無益です。ごめんなさい。)この記事の目的
・ActiveHashを使った正常な値の取得方法を復習する
・ActiveHashモデルからfindメソッドで値を取得する方法を学習する
・なぜundefindエラーが発生するのかを理解する【前提】 ActiveHash 正常な値の取得
sushi.rbclass Sushi < ActiveHash::Base self.data = [ { id: 1, name: '大トロ' }, { id: 2, name: '中トロ' }, { id: 3, name: 'いくら' }, { id: 4, name: '穴子' }, { id: 5, name: 'えんがわ' }, { id: 6, name: '雲丹' }, { id: 7, name: 'いか' } ] endlunch.html.erb<%= @shari.sushi.name %> <!-- @shariのsushi_idが「4」 の場合、「穴子」が表示される-->このような記述で、ActiveHashのモデルから、@shari.sushi_idに紐づくnameの値を取得することができます。(今回モデルの記述は割愛します。)
しかし、ある条件下では、ActiveHashのname要素を取得することができず
undefined method '〇〇' for …のように、エラーとなってしまう場合があります。
そんな時に、無理やりActiveHashのモデルから値を取得する方法をお伝えします。
その①:findを使って取得・表示する
lunch.html.erb<%= Sushi.find(@shari.neta_id).name %>「エラーは起きたけど、せっかくActiveHashモデル書いたし使いたいな…」
という方にオススメなのは、findメソッドを使って無理やり取得する方法です。
①findメソッドの引数に取得したいidを渡し、Sushiモデル(ActiveHash)から@shari.neta_idを探します。
②取得したidのnameが欲しいため、末尾に.nameをつけてあげます。
③Sushiモデルから、@shari.neta_idに合わせたname要素が取得できます。多少強引な方法ではありますが、この方法を使えば指定のname要素を取得することができます。ただし、コードが冗長になりやすいので、使うときは注意が必要です。
その②:form.select と Caseで取得・表示する
new.html.erb<%= form.select :neta_id,[["アジ",1],["コハダ",2],["赤むつ",3],["アマダイ",4]] %>lunch.html.erb<% case @shari.neta_id %> <% when 1 then %> <p>アジ</p> <% when 2 then %> <p>コハダ</p> <% when 3 then %> <p>赤むつ</p> <% when 4 then %> <p>アマダイ</p> <% end %>「記述量は少ないし、ActiveHashじゃなくてもいいかな…」
という方は、プルダウン部分をform.selectに、表示部分をcase文で記述することで、擬似的にActiveHashのような表現をすることができます。
ただし、この方法は選択肢が増えると記述量が膨大になり、コードの可読性を下げる可能性があるので、選択肢が少ない場合のみ使用することをオススメします。
そもそもなぜ取得できないの?
結論、「ActiveHashモデルのモデル名とカラム名が合っていない」場合、name要素を正規の方法で取得することができません。
カラム名がsushi_id(integer型)であった場合、ActiveHashのモデル名もSushi.rbである必要があります。前述その①の場合、Sushi.rbからneta.nameのような形で値を取得しようとしても、取得できません。
ActiveHashモデルを作成してプルダウンやチェックボックスを作る際は、モデルの名前とカラムの名前を揃えるようにしましょう。
まとめ
①ActiveHashはモデル名とカラム名があっていないと、.nameでname要素を取得することができない。
②別名のモデルから値を取得する場合は、findを使うことでname要素を取得することができる。
③記述そのもの(選択肢)が少ない場合は、form.selectとwhenを使うことで表現する方法もある。最後までご覧いただきありがとうございました。
引き続き、学習を頑張っていきましょう!
- 投稿日:2020-10-12T09:30:20+09:00
AWS Cloud9 でRuby on Rails の開発環境を構築する
はじめに
ふとRuby on Railsの勉強をはじめようと思い、環境構築をすることにしました。
せっかくなので、AWS Cloud9で環境構築をしようと思います。やること
この記事では、以下のことを実施します。
- AWS Cloud9環境構築
- Ruby 環境構築
- rvmを使用したruby version 2.5.1のインストールと切り替え
- Rails 環境構築
- gemを使用したrails version 5.2.1のインストール
AWS Cloud9環境構築
Cloud9は、クラウド環境でIDE(統合開発環境)を利用できるサービスです。
ブラウザ上で動くため、OSやその他環境が異なるPCでも同じ手順で開発環境を準備することができます。
特徴 - AWS Cloud9 | AWSCloud9環境作成
AWS マネジメントコンソールからCloud9の画面に遷移します。
Create enviroimentをクリックします。
環境設定
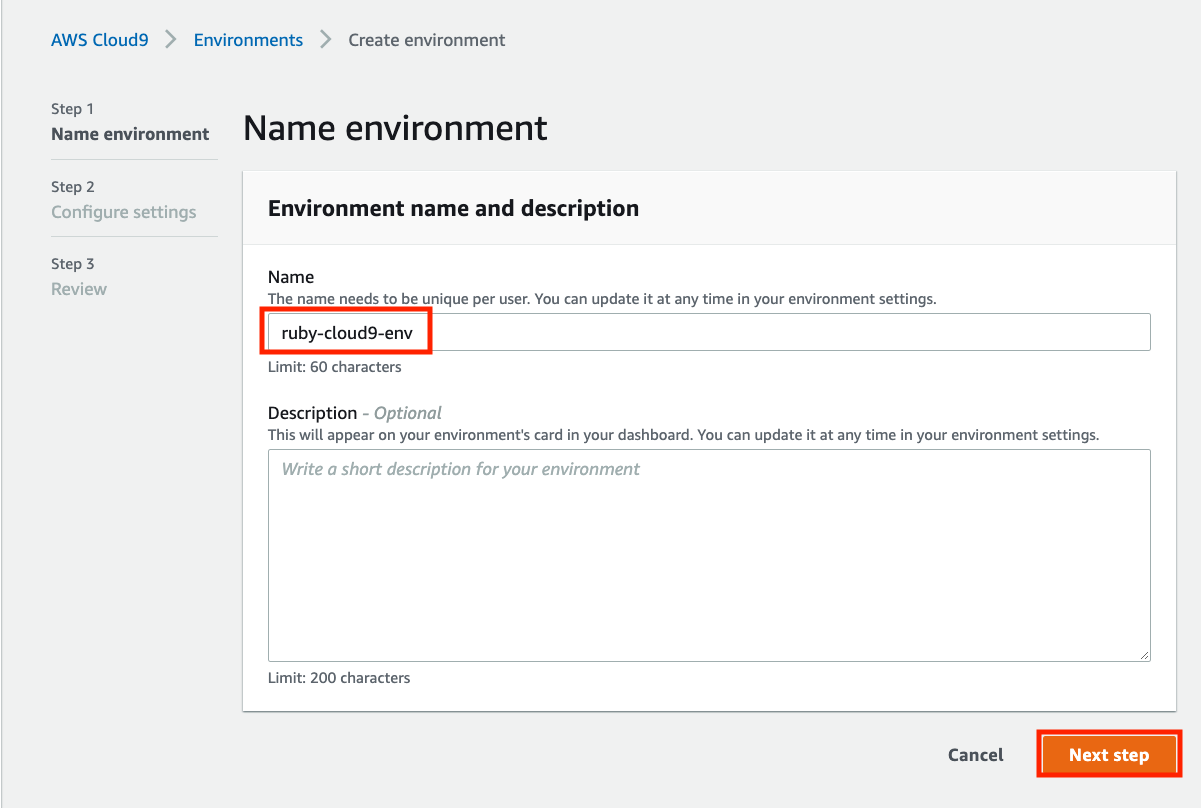
作成するCloud9環境の設定をしていきます。
NameにCloud9環境の名前をつけます。
自由に決定できるようですが、今回はruby-cloud9-envにします。入力できたらNext stepをクリックします。
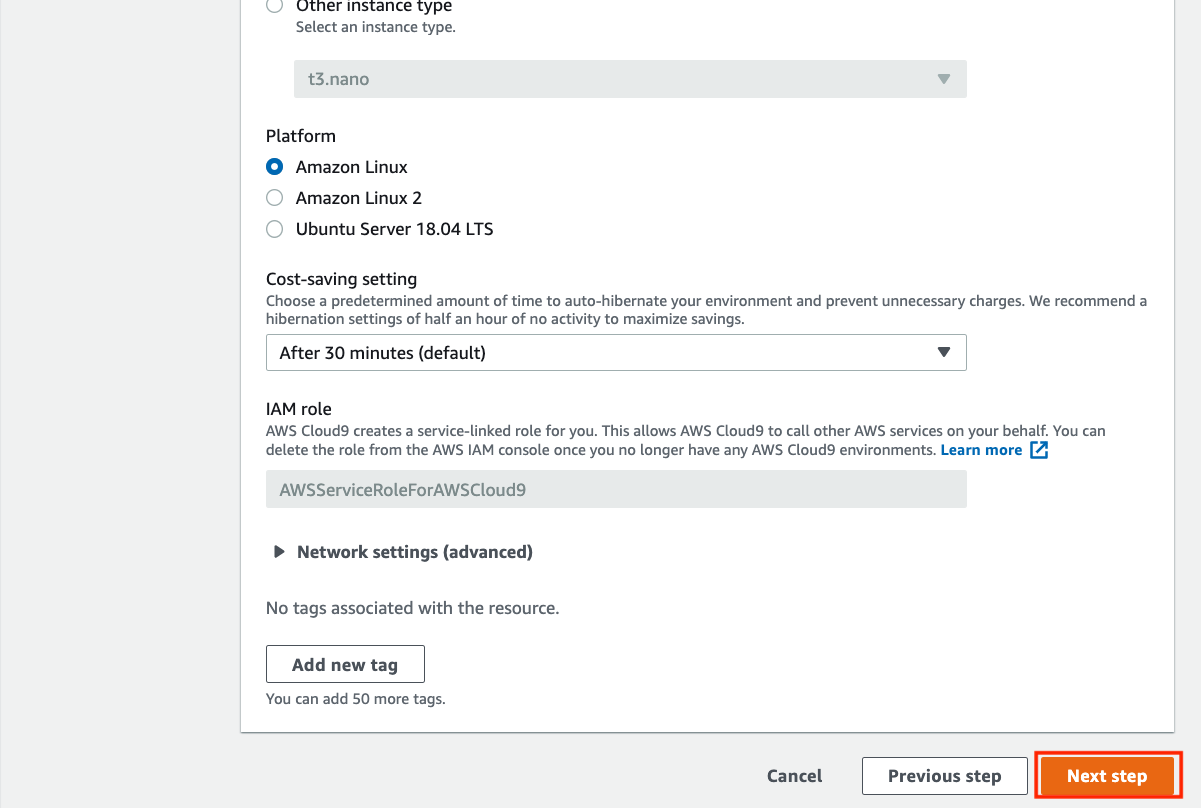
Cloud9環境に使用するEC2インスタンス(仮想マシン)の設定をします。
全てデフォルトで大丈夫です。Next stepをクリックします。
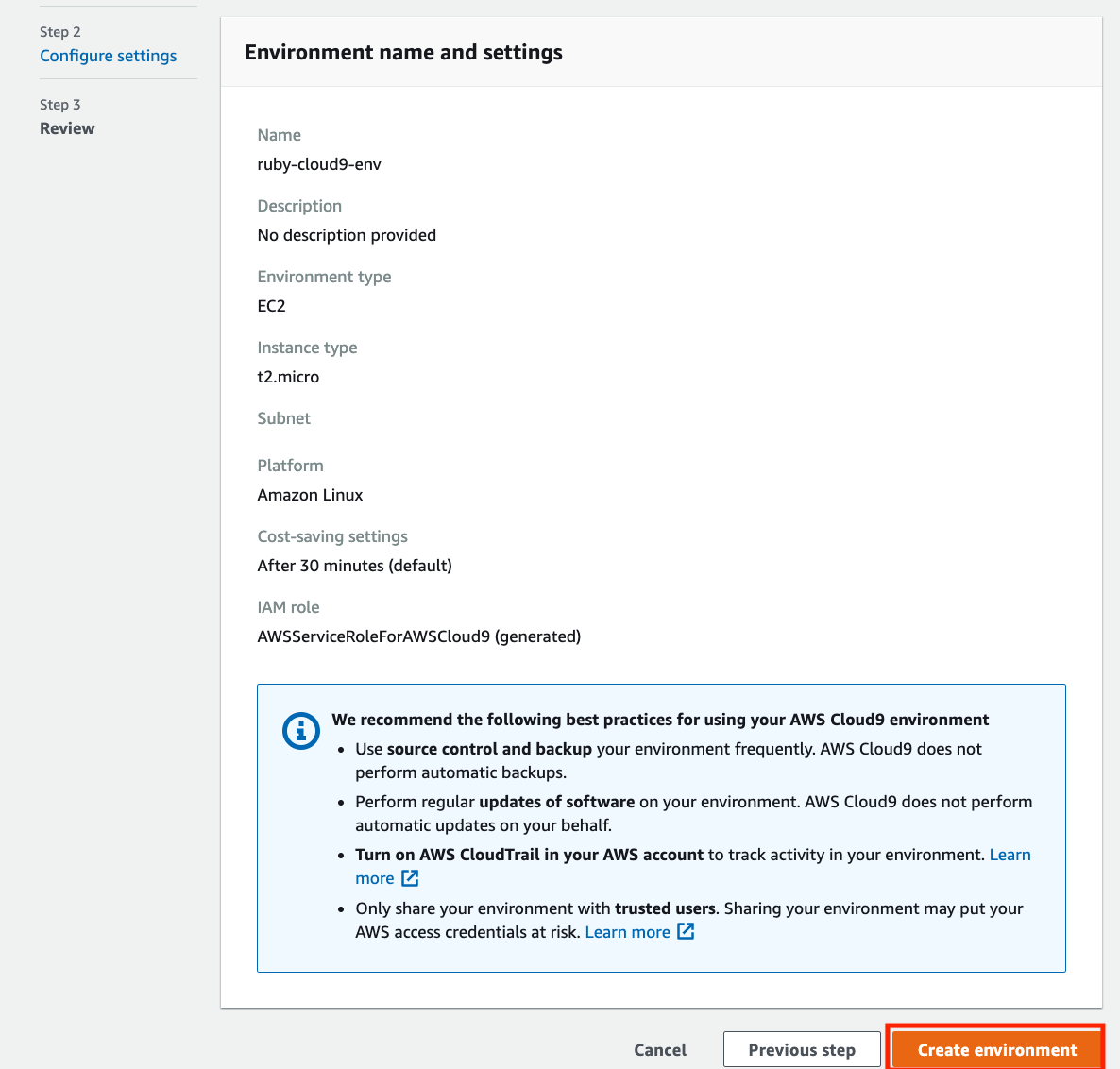
設定確認
構築する環境の設定を確認できます。
確認したらCreate enviroimentをクリックします。
Cloud9のIDE画面に遷移します。
少し待つと操作できるようになります。これでCloud9環境の構築は完了です。
次はCloud9での開発に適した設定変更をします。
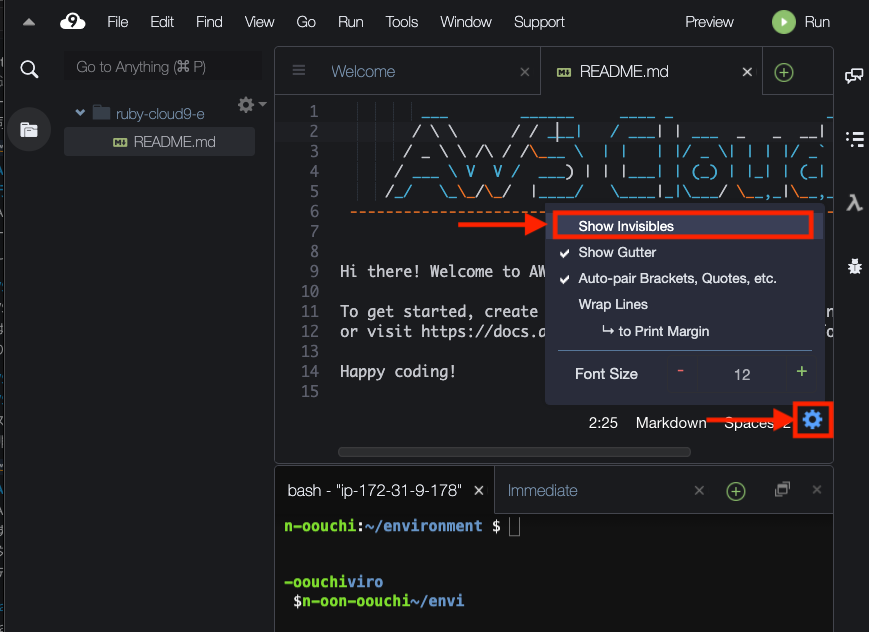
スペース可視化
スペース記号の可視化を行います。
テキストエディタの右下にある⚙歯車マークをクリックします。
設定が表示されるのでShow Invisiblesをクリックします。
Ruby 環境構築
ここからはRubyの環境構築をしていきます。
Cloud9画面下部にターミナルが表示されています。
ここでコマンドを実行していきます。
まずはOSにプリインストールされているライブラリを最新化します。
基本的にアップデートされるものは無いと思います。sudo yum update
rvmを使用してrubyのバージョンを切り替える
今回はRVM(Ruby Version Manager)を使用して複数VersionのRubyを管理したいと思います。
rvmインストール
Clooud9にはrvmがプリインストールされています。
念のためrvmがインストールされていることを確認します。rvm -v
ruby-2.5.1インストール
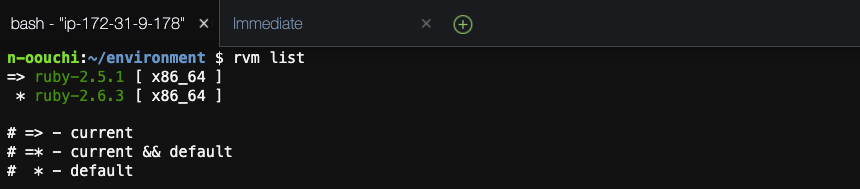
現段階でrvmで切り替えできるRubyのバージョンを確認します。
rvm list
ruby-2.6.3が使用できるようです。
今回はruby-2.5.1を使用したいのでrvmを使ってインストールします。rvm install 2.5.1
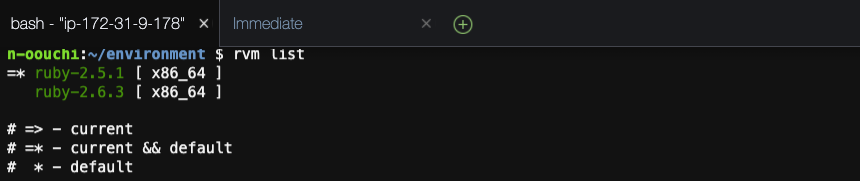
インストールが完了したらもう一度切り替えできるRubyのバージョンを確認します。
rvm list
ruby-2.5.1が追加され、currentとなっていることが確認できます。
念のため、Rubyコマンドでも確認します。
ruby -v
rvmデフォルトバージョン変更
これでRVMを使用したRubyのバージョン切り替えができました。
ただ、今の設定ではターミナルを再起動した時にはrubyバージョンが2.6.3に戻ってしまいます。そのため、RVMでのデフォルトバージョンを2.5.1に変更します。
rvm --default use 2.5.1
切り替えできるRubyのバージョンを確認します。
rvm list
ruby-2.5.1がcurrent && defaultとなっていることが確認できます。
以上でrubyの環境構築は完了です。
Rails 環境構築
ここからはRailsの環境構築をしていきます。
railsインストール確認
まずはrailsコマンドがインストールされているかを確認します。
rails -v
インストールされていないことが確認できます。
gemインストール
Railsはgemというコマンドを使用してインストールします。
gemとはRuby applicationやライブラリーのパッケージです。gemがインストールされているか確認します。
rubyがインストールされていれば使用できます。gem -v
インストールされていることが確認できます。
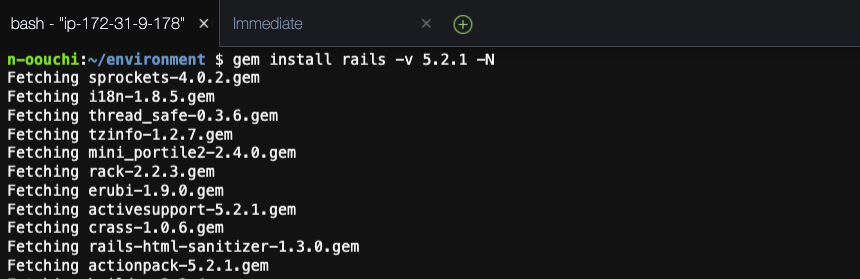
railsインストール
それでは、gemを使用してrailsをインストールします。
gem install rails -v 5.2.1 -N-Nオプションを使用すると、諸々のドキュメントのインストールをスキップできます。(インストールが早くなる)
インストールが完了したらrailsのバージョンを確認します。
rails -v
インストールされていることが確認できました。
Railsの環境構築は以上です。
最後に
Ruby on Railsの環境構築って割と面倒臭いイメージがありましたが、(特にWindows)Cloud9を使用すると簡単に環境構築ができますね。
これからRuby on Railsを使っていくつか簡単なシステムを構築してみようと思います。









- 投稿日:2020-10-12T06:21:35+09:00
DBをSQLiteからMySQLに変更する
はじめに
モデル作ってマイグレートして、シークエルプロでDB確認したら
作ったつもりのデータベースがない!となったので、備忘録として対処法を載せときます。
解決法
こちらの記事を参考に対処したところ、解決に至りました。
やったこと
gemfileの修正
初歩的ミスですが、下画像の選択部分(gemfileのSQLite3)をコメントアウトします。
ターミナルにて
bundle install --without productionDBを作る必要があるので
bundle exec rake db:createそして、これは必要あったのかな?既にやっていたので不要だったかも
rails db:migrateできた
シークエルプロにて、データベースが確認できるようになりました。
- 投稿日:2020-10-12T04:15:05+09:00
rails db:create実行時のFATAL: role "admin0" does not existとPG::ConnectionBad: FATAL: role "admin0" does not existの対処方
rails db:create実行時にエラーが出た際の解決方法について後発者のために解決方法のまとめを書いておく。
実行環境
windows 10 home
ubuntu 20.04 LTS
ruby 2.7.1
Rails 6.0.3
postgresql 11
エラー文
$ rails db:create FATAL: role "admin0" does not exist Couldn't create 'taskleaf2_development' database. Please check your configuration. rails aborted! PG::ConnectionBad: FATAL: role "admin0" does not exist /home/admin0/taskleaf2/bin/rails:9:in `<top (required)>' /home/admin0/taskleaf2/bin/spring:15:in `<top (required)>' bin/rails:3:in `load' bin/rails:3:in `<main>' Tasks: TOP => db:create (See full trace by running task with --trace)今回要所となるのは上から5行目まであたりだろうか。
エラー解決順序
以前私は同じようなエラーに出会っていて既に解決したことがあったので同じ方法をとってみた。
https://teratail.com/questions/297341$ yarn installだがこれでも解決できなかった。
エラーがPG::ConnectionBad:である点に着目してみることにする。
だが以下のコマンドのようにDBは起動しているはずだし、、、?$ sudo service postgresql start [sudo] admin0 のパスワード: * Starting PostgreSQL 11 database server [ OK ] * Starting PostgreSQL 13 database server [ OK ]別(下)の手段で起動にチャレンジしてみることにした。
$ sudo su - postgres \q再度
rails db:createを実行したところエラー文に変化が現れた。$ rails db:create WARNING: could not flush dirty data: Function not implemented Created database 'taskleaf2_development' WARNING: could not flush dirty data: Function not implemented Created database 'taskleaf2_test'あとはこのエラー文で検索したところ
https://stackoverflow.com/questions/45437824/postgresql-warning-could-not-flush-dirty-data-function-not-implemented
こちらが有力そうだったので
/etc/postgresql/11/main/postgresql.confの内容の一部を以下のように書き換えたfsync = off data_sync_retry = true再度
rails db:createを実行してみるrails db:create Database 'taskleaf2_development' already exists Database 'taskleaf2_test' already existsどうやら成功したようだ。
サーバーも起動できたので今回はこれで問題解決したと判断する。