- 投稿日:2020-10-12T21:32:05+09:00
AWS触ったことがなかった新卒のワイがSAA-C02に合格するまでの道のり
概要
さんざんいろんな人が書いてるけど・・・
2020/10/11、SAA-C02版のAWS認定ソリューションアーキテクトアソシエイトに合格したので、どういう勉強をしたのか、どういう問題が出たのかお伝えしていきたいと思います。
結果は769点でした。
8割くらいはいってるかなと思いましたが、そう甘くなかったですね。
でも、一発で合格できたので良かったです。受けるきっかけ
私は20年卒の新入社員で都内の某IT企業で働いております。
私の会社では、数年前から自社のシステムをAWSに移行するプロジェクトが開始しており、社内でもAWS勉強会や資格試験に挑戦する流れが活発になってます。会社に入る前の学生のときは、勉強したいとは思っていたものの、知らぬ間に数千円も課金されていたらヤダな・・・と思いAWSに触れたことはありませんでした。
会社では、エンジニアだけの共通研修があるのですが、そこで上司の方に「挑戦してみよう」と言われたことがきっかけで勉強することになりました。
受ける前の知識
EC2・・・きいたことはある
VPC・・・知らん
AZ ・・・知らん
RDS・・・知らんザコですねw
勉強内容
勉強期間
6月下旬くらいから初めて、受かったのは10月初旬なので約3ヶ月程ということになります。
新人だからといって資格を勉強する時間は与えられなかったので、仕事が終わって、ほぼ毎日30分~1時間くらいは勉強していたと思います。
私が所属する部署が管轄しているシステムは、現状AWSに移行していないので、業務で触れる経験はまったくありませんでした><
なので、社内で定期的に開催されるAWSハンズオンに参加して基本的なS3やLambda、EC2なんかは社内のアカウントを使用して実際に触れることはできました。
(途中で仕事が忙しくなって全く参加できなくなりましたw)教材
1.黒本
最初はこの本をじっくり読むことから始めました。
少し古い本なので、正直試験に大きく役に立つことはなかったですが、基本的なAWSサービスの解説やアーキテクチャのイメージが掲載されていたので基礎を固める上では非常に役に立ちました。
模擬テストが1回分ついてくるのですが、私の感覚では本番の難易度に結構近いと思いました。2.模擬試験(udemy)
6回分390問ついてます。
最初にやったときはどれも40%前後しか取れなかったので、高難易度とはいうもののこんなに難しいのかと思いました。
この模擬試験6回分をだいたい5~6周くらいはしたと思います。(問題をある程度覚えてしまって、あまり効果がなかったかも)
この模擬試験のいいところは問題料が多いところと解説が丁寧なところです。
解説をよく読んだ上で、よくわからなかったところを調べたりすれば合格できる知識が自然と身につくと思います。いざ本試験
テストセンターで受験しました。
始まる前は落ちたらヤダな~、怖いな~と思って少し緊張しましたが、最初の問題が自信を持って回答できたので緊張がほぐれました。問題の内容としては、コスト最適化を考えたときのインスタンスの選択やAutoScaling、リードレプリカが答えになるような問題が10問前後くらい出たと思います。
Udemyの6回目の模擬試験はC02を考慮した問題なので、似たような問題がいくつかでました。(Transit GatewayやFSxなど)
FSxが答えになりそうな問題が4問出たのは少し驚きましたw先程も書きましたが、黒本の模擬試験やUdemyの基本問題に近い難易度の問題が多かったように感じます。
しっかり知識をつけていれば消去法で解ける問題が多いので、Udemyの高難易度の問題よりは細かい知識はいらないかなと思いました。
まとめ
コツコツ勉強したかいがあって、合格できました。嬉しいです。
実際にAWSを触らなくても合格できると思いますが、勉強したあとでAWSを触ってみると覚えやすかったですし、理解が深まったのでできればやっておいたほうがいいと思います。難易度の感覚としては、基本情報 <= AWS SAA < 応用情報 といった感じでしょうか。
いろいろ攻略方法はあると思いますが、Udemyの模擬試験 これが無難かと思います。
現状、仕事ではAWSを使えていませんが、近いうちに使う予定なので貢献できるように頑張りたいと思います。
実務経験が何よりも大事だと思うので・・・
以上、ありがとうございました。

- 投稿日:2020-10-12T20:57:44+09:00
【AWS初学者用】IAMとは?
本記事について
本記事はAWS初学者の私が学習していく中でわからない単語や概要をなるべくわかりやすい様にまとめたものです。
もし誤りなどありましたらコメントにてお知らせいただけるとありがたいです。IAMサービスとは
IAM(Identity and Access Management)サービスとはAWSを利用するユーザーのアクセスを安全に制御するサービス。正しいユーザーがアクセスし、ユーザーが持ってるアクセス権のサービスのみ操作できる仕組みです。
初めてAWSを利用する際にユーザーはメールアドレスやクレジットカード情報などを登録することでAWSアカウントを取得できます。そして取得したAWSアカウントの情報でAWSマネジメントコンソールにログインできます。このAWSマネジメントコンソールにログインしたユーザーをルートユーザーと呼び、AWSアカウントの全ての管理権限を持っています。
ルートユーザーは全ての管理権限を持っているので「アカウント情報の漏洩」や「誤操作」などが起きるとアカウントを乗っ取られてしまったりして大変危険です。なので通常AWSのサービスを操作する際は、操作する用のユーザー(グループ)を作成して操作します。この操作する用のユーザー(グループ) = IAMユーザー(グループ)といいますIAMユーザー(グループ)
IAMユーザーはAWSサービスを利用するためのアカウントです。ログインIDを決めてIAMユーザーを作成します。 ※作成した際にcsvでIDとパスワードがダウンロードできるかと思うので、ダウンロードしてください。今後ログインする上で必要になりますので。
IAMグループは会社などが複数のIAMユーザーをまとめて管理するときに使います。
IAMポリシー
IAMユーザーを作成した段階では何も権限を持っていません。なのでIAMポリシーによって権限を付与してあげることでAWSの各サービスなどのアクセスの制御ができます。
IAMポリシーはIAMユーザーにアタッチすることができて、操作権限を付与(適用)する機能です。
例えばIAMユーザーにIAMポリシーでS3へのアクセス権限を付与します。そうすることでS3へのみの操作が許可されたIAMユーザーが作成されたことになり、もしこのアカウントを乗っ取られたりしたとしても被害を最小限に抑えることができます。IAMロール
先ほどIAMポリシーはIAMユーザーに権限を適用するといいましたが、IAMロールにも適用することができます。
IAMロールとはAWSのサービスや他のアカウントに対して権限を付与するためのものです。IAMポリシーによってアクセス権限を付与されたIAMロールをEC2などのawsサービスにアタッチすることで権限を付与できます。まとめ
IAMサービスはAWSを安全に利用する上でとても重要なサービスです。
二段階認証アプリなどと併用することでより強固なセキュリティで保護できるかと思います。
- 投稿日:2020-10-12T20:39:18+09:00
AWS 自然言語処理 - demo
利用するサービス 説明 Amazon Translate 機械翻訳 Amazon Polly テキスト読み上げサービス Amazon Transcribe 音声をテキストに変換する Amazon Comprehend 文書解析サービス 1.IAM ロールの設定
Lambda 関数が他のサービスの実行に必要となる権限を作成する。
アタッチするポリシーは次の4つ。
- TranslateFullAccess
- AmazonPollyFullAccess
- AmazonTranscribeFullAccess
- ComprehendFullAccess
2.Amazon Translate
Amazon Translateは世界中の言語のユーザー向けにウェブサイトやアプリケーションなどのコンテンツをローカライズし、大量のテキストを効率的に簡単に翻訳できます。
lambdaからTranslateを呼び出して、英語'en'を日本語'ja'に機械翻訳していきます。
python3.8、IAMロールで作成した【1.IAM ロールの設定】をアタッチし、関数は以下の通り。
python3.8import boto3 import os def lambda_handler(event, context): SRC_LANG = 'en' TRG_LANG = 'ja' translate = boto3.client('translate') response = translate.translate_text(Text=event["text"], SourceLanguageCode=SRC_LANG, TargetLanguageCode=TRG_LANG) return (response['TranslatedText'])次の内容でテストする。
{ "text": "Thank you for calling" }結果は以下の通り。
3.Amazon Polly
Amazon Polly は、高度なディープラーニング技術を使用したテキスト読み上げサービスで、人間の声のような音声を合成します。
【2.Amazon Translate】で翻訳された言葉をプレーンテキストに入力する。
「▶︎音声を聴く」で音声を確認し、「ダウンロードMP3」でダウンロードしておく。
4.Transcribe
【3.Amazon Polly】の音声ファイルをlambdaで、Transcribeを使って文字に起こしS3バケットに保存します。
S3に【3.Amazon Polly】でダウンロードしたMP3ファイルをアップロードする。
次に【1.IAM ロールの設定】で作成したものにS3のアクセス権限を追加します。
- AmazonS3FullAccess
【2.Amazon Translat】と同じ要領でLambda関数を作成する。今度は、Node.js 12.x を利用します。
const FilePath = "s3://transcribecomprehendtest/speech_20200108084356790.mp3"
の部分を先程作成したS3バケットのMP3ファイルのURLに置き換えて関数を作成する。node.jsconst AWS = require('aws-sdk'); const transcribeservice = new AWS.TranscribeService({apiVersion: '2017-10-26'}); exports.handler = async (event, context) => { const FilePath = "s3://transcribecomprehendtest/speech_20200108084356790.mp3" const jobName = context.awsRequestId console.log('FilePath : ' + FilePath); const params = { LanguageCode: "ja-JP", Media: { MediaFileUri: FilePath }, TranscriptionJobName: jobName, MediaFormat: "mp3", }; try{ const response = await transcribeservice.startTranscriptionJob(params).promise() console.log(response) return response }catch(error){ console.log(error) } };この関数では外部インプトは必要ありませんので、文字列はデフォルトのままダミーのテストイベントを作成し、テストします。
"TranscriptionJobStatus": "IN_PROGRESS",が表示されていれば成功です。Transcribe の画面にいき、[Download full transcript]を押すと json がダウンロードされ、文字お起しされた文字列が格納されています。
5.Comprehend
Amazon Comprehend は、機械学習を使用してテキスト内でインサイトや関係性を検出する自然言語処理 (NLP) サービスです。
【2.Amazon Translat】と同じ要領でLambda関数を作成する。今度は、python 3.8 を利用します。
python3.8import os, boto3 ESCALATION_INTENT_MESSAGE="エスカレーションをしてください" FULFILMENT_CLOSURE_MESSAGE="エスカレーションをしてください" escalation_intent_name = os.getenv('ESCALATION_INTENT_NAME', None) client = boto3.client('comprehend') def lambda_handler(event, context): sentiment=client.detect_sentiment(Text=event['inputTranscript'],LanguageCode='ja')['Sentiment'] if sentiment=='NEGATIVE': if escalation_intent_name: result = { "sessionAttributes": { "sentiment": sentiment }, "dialogAction": { "type": "ConfirmIntent", "message": { "contentType": "PlainText", "content": ESCALATION_INTENT_MESSAGE }, "intentName": escalation_intent_name } } else: result = { "sessionAttributes": { "sentiment": sentiment }, "dialogAction": { "type": "Close", "fulfillmentState": "Failed", "message": { "contentType": "PlainText", "content": FULFILMENT_CLOSURE_MESSAGE } } } else: result ={ "sessionAttributes": { "sentiment": sentiment }, "dialogAction": { "type": "Delegate", "slots" : event["currentIntent"]["slots"] } } return resultネカティブな情報でテスト
{ "messageVersion": "1.0", "invocationSource": "DialogCodeHook", "userId": "1234567890", "sessionAttributes": {}, "bot": { "name": "BookSomething", "alias": "None", "version": "$LATEST" }, "outputDialogMode": "Text", "currentIntent": { "name": "BookSomething", "slots": { "slot1": "None", "slot2": "None" }, "confirmationStatus": "None" }, "inputTranscript": "あなたが嫌いです" }ネカティブな情報の結果
{ "sessionAttributes": { "sentiment": "NEGATIVE" }, "dialogAction": { "type": "Close", "fulfillmentState": "Failed", "message": { "contentType": "PlainText", "content": "エスカレーションをしてください" } } }ポジティブな情報でテスト
{ "messageVersion": "1.0", "invocationSource": "DialogCodeHook", "userId": "1234567890", "sessionAttributes": {}, "bot": { "name": "BookSomething", "alias": "None", "version": "$LATEST" }, "outputDialogMode": "Text", "currentIntent": { "name": "BookSomething", "slots": { "slot1": "None", "slot2": "None" }, "confirmationStatus": "None" }, "inputTranscript": "あなたが好きです" }ポジティブな情報の結果
{ "sessionAttributes": { "sentiment": "POSITIVE" }, "dialogAction": { "type": "Delegate", "slots": { "slot1": "None", "slot2": "None" } } }


- 投稿日:2020-10-12T20:39:18+09:00
AWS 自然言語処理 ~ demo
利用するサービス 説明 Amazon Translate 機械翻訳 Amazon Polly テキスト読み上げサービス Amazon Transcribe 音声をテキストに変換する Amazon Comprehend 文書解析サービス 1.IAM ロールの設定
Lambda 関数が他のサービスの実行に必要となる権限を作成する。
アタッチするポリシーは次の4つ。
- TranslateFullAccess
- AmazonPollyFullAccess
- AmazonTranscribeFullAccess
- ComprehendFullAccess
2.Amazon Translate
Amazon Translateは世界中の言語のユーザー向けにウェブサイトやアプリケーションなどのコンテンツをローカライズし、大量のテキストを効率的に簡単に翻訳できます。
lambdaからTranslateを呼び出して、英語'en'を日本語'ja'に機械翻訳していきます。
python3.8、IAMロールで作成した【1.IAM ロールの設定】をアタッチし、関数は以下の通り。
python3.8import boto3 import os def lambda_handler(event, context): SRC_LANG = 'en' TRG_LANG = 'ja' translate = boto3.client('translate') response = translate.translate_text(Text=event["text"], SourceLanguageCode=SRC_LANG, TargetLanguageCode=TRG_LANG) return (response['TranslatedText'])次の内容でテストする。
{ "text": "Thank you for calling" }結果は以下の通り。
3.Amazon Polly
Amazon Polly は、高度なディープラーニング技術を使用したテキスト読み上げサービスで、人間の声のような音声を合成します。
【2.Amazon Translate】で翻訳された言葉をプレーンテキストに入力する。
「▶︎音声を聴く」で音声を確認し、「ダウンロードMP3」でダウンロードしておく。
4.Transcribe
【3.Amazon Polly】の音声ファイルをlambdaで、Transcribeを使って文字に起こしS3バケットに保存します。
S3に【3.Amazon Polly】でダウンロードしたMP3ファイルをアップロードする。
次に【1.IAM ロールの設定】で作成したものにS3のアクセス権限を追加します。
- AmazonS3FullAccess
【2.Amazon Translat】と同じ要領でLambda関数を作成する。今度は、Node.js 12.x を利用します。
const FilePath = "s3://transcribecomprehendtest/speech_20200108084356790.mp3"
の部分を先程作成したS3バケットのMP3ファイルのURLに置き換えて関数を作成する。node.jsconst AWS = require('aws-sdk'); const transcribeservice = new AWS.TranscribeService({apiVersion: '2017-10-26'}); exports.handler = async (event, context) => { const FilePath = "s3://transcribecomprehendtest/speech_20200108084356790.mp3" const jobName = context.awsRequestId console.log('FilePath : ' + FilePath); const params = { LanguageCode: "ja-JP", Media: { MediaFileUri: FilePath }, TranscriptionJobName: jobName, MediaFormat: "mp3", }; try{ const response = await transcribeservice.startTranscriptionJob(params).promise() console.log(response) return response }catch(error){ console.log(error) } };この関数では外部インプトは必要ありませんので、文字列はデフォルトのままダミーのテストイベントを作成し、テストします。
"TranscriptionJobStatus": "IN_PROGRESS",が表示されていれば成功です。Transcribe の画面にいき、[Download full transcript]を押すと json がダウンロードされ、文字お起しされた文字列が格納されています。
5.Comprehend
Amazon Comprehend は、機械学習を使用してテキスト内でインサイトや関係性を検出する自然言語処理 (NLP) サービスです。
【2.Amazon Translat】と同じ要領でLambda関数を作成する。今度は、python 3.8 を利用します。
python3.8import os, boto3 ESCALATION_INTENT_MESSAGE="エスカレーションをしてください" FULFILMENT_CLOSURE_MESSAGE="エスカレーションをしてください" escalation_intent_name = os.getenv('ESCALATION_INTENT_NAME', None) client = boto3.client('comprehend') def lambda_handler(event, context): sentiment=client.detect_sentiment(Text=event['inputTranscript'],LanguageCode='ja')['Sentiment'] if sentiment=='NEGATIVE': if escalation_intent_name: result = { "sessionAttributes": { "sentiment": sentiment }, "dialogAction": { "type": "ConfirmIntent", "message": { "contentType": "PlainText", "content": ESCALATION_INTENT_MESSAGE }, "intentName": escalation_intent_name } } else: result = { "sessionAttributes": { "sentiment": sentiment }, "dialogAction": { "type": "Close", "fulfillmentState": "Failed", "message": { "contentType": "PlainText", "content": FULFILMENT_CLOSURE_MESSAGE } } } else: result ={ "sessionAttributes": { "sentiment": sentiment }, "dialogAction": { "type": "Delegate", "slots" : event["currentIntent"]["slots"] } } return resultネカティブな情報でテスト
{ "messageVersion": "1.0", "invocationSource": "DialogCodeHook", "userId": "1234567890", "sessionAttributes": {}, "bot": { "name": "BookSomething", "alias": "None", "version": "$LATEST" }, "outputDialogMode": "Text", "currentIntent": { "name": "BookSomething", "slots": { "slot1": "None", "slot2": "None" }, "confirmationStatus": "None" }, "inputTranscript": "あなたが嫌いです" }ネカティブな情報の結果
{ "sessionAttributes": { "sentiment": "NEGATIVE" }, "dialogAction": { "type": "Close", "fulfillmentState": "Failed", "message": { "contentType": "PlainText", "content": "エスカレーションをしてください" } } }ポジティブな情報でテスト
{ "messageVersion": "1.0", "invocationSource": "DialogCodeHook", "userId": "1234567890", "sessionAttributes": {}, "bot": { "name": "BookSomething", "alias": "None", "version": "$LATEST" }, "outputDialogMode": "Text", "currentIntent": { "name": "BookSomething", "slots": { "slot1": "None", "slot2": "None" }, "confirmationStatus": "None" }, "inputTranscript": "あなたが好きです" }ポジティブな情報の結果
{ "sessionAttributes": { "sentiment": "POSITIVE" }, "dialogAction": { "type": "Delegate", "slots": { "slot1": "None", "slot2": "None" } } }
- 投稿日:2020-10-12T18:41:17+09:00
OODAループ+メタ認知 =フロントエンドのビジネスロジック
今回の記事では、前回の記事「OOUI(オブジェクト指向ユーザーインターフェース)のビジネスロジックにOODAループを適用する」で紹介したフロントエンドのビジネスロジックにOODAループを適用する手法に「メタ認知」を組み合わせフロントエンドにおけるデータ検索処理の質を向上させる手法を紹介したいと思う。
前回の記事は下記のURL参照
https://qiita.com/aLtrh3IpQEnXKN7/items/aa440e8b143dca0004e9メタ認知
メタ認知とは
メタ認知に関しては以下のような様々な定義が存在している。
自分自身の思考プロセスと戦略に関する知識、それらを意識的に反映し、この知識に基づいて行動を変更および実施する能力。
思考プロセスを理解することを目的とした精神活動
認知は、感覚データの取得、それらの削減、処理、蓄積、複製、および使用を含む、段階的な情報処理の連続プロセス。メタ認知とは認知プロセスを改善する活動。メタ認知の活動内容
基本的に以下の3つの活動で構成されている。
・メタ認知的モニタリング・・・認知に関する知識-認知行動と能力に関する意識的な反省を含む一連の活動。
・メタ認知的コントロール・・・認知の調節-学習または問題解決中に自己調節メカニズムを必要とする一連の活動
・メタ認知体験・・・メタ認知的モニタリングとメタ認知的コントロールによって発生する相互作用メタ認知的モニタリングの機能一覧
1.宣言的知識・・・学習者としての自分自身と、自分のパフォーマンスに影響を与える可能性のある要因についての知識。宣言的知識は、「世界知識」と呼ばれることもある。
2.手続き的知識・・・物事を行うことについての知識。高度な手続き的知識により、個人はより自動的にタスクを実行できる。
3.条件付き知識・・・宣言的および手続き的知識をいつ、なぜ使用するかを知ることを指す。メタ認知的コントロールの機能一覧
1.計画・・・戦略の適切な選択と、タスクのパフォーマンスに影響を与えるリソースの正しい割り当て。
2.モニタリング・・・理解とタスクのパフォーマンスに対する意識。
3.評価・・・タスクの最終製品とタスクが実行された効率を評価する。使用された戦略の再評価も含まれる。メタコグノロジスト
最終的目標、自分の長所と短所、目前のタスクの性質、および利用可能な「ツール」またはスキルを認識し、戦略の計画、開発、実行、評価までのプロセス過程を作成できる人物。
メタ認知はメタコグノロジストを実践できる自己組織化された人物の育成を最終的な目標とする。
メタ認知の実施によって以下のようなスキルを見つけた人物をメタコグノロジストと認定する。
・主導権
・認知活動
・活発な認知活動
・創造的思考
・知識の検索
・獲得
・統合
・深化に関連するスキルメタ認知における活動内容、機能概要、最終目的の一覧
1.認知スタイルが提供する非自発的な知的制御
2.自分の学習のための戦略を選択して変更する能力
3.必要に応じて、自身の知的活動を停止または減速する機能
4.オープンな認知的位置-イベントの知覚と理解の主観的な方法の変動性
5.メタ認知的認識-「個々の知的資源に関する個人の内省的アイデアのレベルとタイプ」
6.恣意的な知的制御-目標の設定、目標を達成するための手段の決定、一連の行動、結果の制御を目的とした能力。
7.知的活動の個々のステップの質、および彼ら自身の知識を評価する能力
8.行われた決定の結果および状況の起こり得る変化を予測し、考慮に入れる能力
9.自分の知的活動の目標とサブ目標を計画し、それらの実施手段と一連の行動を決定する能力メタ認知の設計モデル
メタ認知の設計モデルはマーヴィン・ミンスキーの「A脳B脳C脳」をモデルを採用する。
マービン・ミンスキーは、マサチューセッツ工科大学の人工知能研究所の創設者の1人で「人工知能の父」と呼ばれている。
マーヴィン・ミンスキーは「AIの機能設計」を行う際に以下のような「A脳B脳C脳」モデルを提唱。
「A脳B脳C脳」モデルは「世界」->「A脳」->「B脳」->「C脳」の流れで情報が処理される。
メタ認知とは「A脳」に対する「B脳」「C脳」の活動を明確にし、「A脳」の活動のパフォーマンス向上を目的としている。
すなわち、OODAループの観察(Observe)- 情勢への適応(Orient)- 意思決定(Decide)- 行動(Act)のループにおける情勢への適応(Orient)をコントロールし、判断の質を向上させることを目的としている。
A脳の機能
目、耳、鼻、皮膚などの器官から流れる信号を受信する。次に、これらの信号を使用して、外界で発生するいくつかのイベントを識別する。
筋肉を動かす信号を送信することで、これらのイベントに反応する。
これにより、世界の状態に影響を与えることができる。B脳の機能
A脳の思考を実際に「理解」することなく、A脳の動作を「修正」する。
B脳はA脳を監視しており、適切であると判断したときに介入または拒否する。
B脳は信念、イデオロギー、将来のイメージ、反省、内省などを形成し、A脳の実際に行おうとしている動作に介入し、修正を託す。C脳の機能
社会組織の「集合的思考」を追加の層。組織は、高レベルのコマンドがCEOから発せられ、組織全体に浸透している。
しかし、行動が上から始まったトップダウンの組織は、官僚主義になる。
よりダイナミックな組織は、ボトムアップの原則に基づいて組織された組織になる。
組織の低レベルは、独自の意思決定を行うための「権限」を与えられているが、場合によってはより高いレベルが介入して行動を拒否する必要がある。
C脳は社会全体のイメージ、コミュニティなど外部から影響力が反映される。
C脳はB脳が行う行動を監視し、B脳によって行われる行動がコミュニティ内に対して悪影響を与える場合、動作に介入し、修正を託す。メタ認知能力を向上させるためのアプローチ
メタ認知能力を向上させるためにアプローチとして以下の4つの手法が提唱されている。
・「活動感知」のアプローチ
・「スタイル分化」のアプローチ
・「反射層化」のアプローチ
・「因子分解」のアプローチ・「活動感知」のアプローチ・・・OODAループの観察(Observe)- 情勢への適応(Orient)- 意思決定(Decide)- 行動(Act)のループにおける観察(Observe)の能力を拡張し、メタ認知能力を向上させるアプローチ。
・「スタイル分化」のアプローチ・・・メタ認知能力における戦略のスタイルを複数のパターンに分類し、最適な戦略パターンを選定するアプローチ。
・「反射層化」のアプローチ・・・メタ認知において反省とは反射(リフレクション)行動として定義している。「反射」は出来事や物に精神的に戻った後になされる声明。リフレクションは、思考を明確にする手段として、また経験を再フォーマットする方法としての発展の手段として機能する。
・「因子分解」のアプローチ・・・メタ認知における外部からの情報処理に数式モデルを採用する。現実世界で観察したデータを数式モデルによって特定の意味に解釈し、概念と紐づけるアプローチ。
メタ認知におけるビジネスロジックの流れ
メタ認知には以下の4つの要素で構成されている。
・知識
・経験
・目標
・戦略
目標に基づいた戦略を選択し、外部から取得する情報を知識と紐付けることで創造的行動に繋げる。
知識に紐づく行動を実行する際に経験によって得られたデータをフィードバックし、より適切な行動選択に繋げる。
上記のビジネスロジックをフロントエンドの設計に採用するとして、以下のようなクラスが必要になると思われる。戦略クラス・・・「A脳B脳C脳」モデルのB脳のビジネスロジックを実装するクラス。知識、経験のクラスを呼び出し相互作用が発生する。
目標クラス・・・戦略クラスを包み込む文脈クラス。メタ認知におけるFacadeクラス。ここから戦略クラスのメソッドを呼び出す。
知識クラス・・・フロントエンドの「A脳B脳C脳」モデルのC脳のビジネスロジックを実装するクラス。バックエンドで取得したドメインオブジェクトとC脳の集合的無意識が結びつく。セマンティックウェブのオントロジー技術が活用されると思われる。
経験クラス・・・「A脳B脳C脳」モデルのB脳の反省に該当する。活動を実施後、活動の見直しによって生じするフィードバックを発生させるクラス。戦略クラス内部で判定や判断を行う際に呼び出される。メタ認知をフロントエンドのビジネスロジックに採用するための環境と条件
メタ認知をフロントエンドのビジネスロジックに組み込むには、以下の環境と条件を整えなければならない。
1.フロントエンドのビジネスロジックにOODAループとマービン・ミンスキーの「A脳B脳C脳」モデルを採用する
2.数学、物理学、心理学、生物学、制御工学など理系の知識を持った高学歴なフロントエンドエンジニアを採用する
3.フロントエンド側のアプリを使用して行う活動内容を特定の戦略モデルごとに分類し、戦略モデルの行動内容をイメージできるプロモーションビデオを作成し、顧客のB脳に戦略モデルのイメージを投射する。
4.フロントエンド側のユーザー設定機能に戦略モデルを選択することができる機能を追加する。
5.ロントエンド側のユーザー設定機能にアクションに対する反省機能を追加し、フィードバックが発生する環境を作成する。
6.データから顧客の活動内容を分析し、戦略モデルのビジネスロジックに反映を行う。
7.セマンティックウェブのオントロジー技術を活用し、バックエンドから取得したドメインモデルのオブジェクトと集合知が結びつく環境を構築する。結論
フロントエンドの設計でメタ認知を採用する意義とは、顧客を消費的行動パターンから生産的行動パターンへ移行させることを目的としている。
従来のフロントエンドの設計は、UI/UI設計を採用することで顧客の5感を刺激し、消費的行動パターンを強要することを目的としてきた。
この手法は、技術が発展していなかった2000年初期の頃は有効であったが、技術の発展とSNSの登場によってユーザーの行動が生産的行動パターンへ移行している2020年において有効な手法ではない。
企業は、顧客の教育を目的としたフロントエンドのアプリ開発へ経済活動を移行させ、新しい価値観の創造に寄与すべき。

- 投稿日:2020-10-12T18:16:30+09:00
AWSアカウントを作成したらやっておくことメモ
- 投稿日:2020-10-12T18:13:25+09:00
【AWS】マネコンの新しいEC2管理画面ではCloudWatchアラーム設定出来ない
ことわり
これは2020年10月時点でのAWSマネジメントコンソールの操作画面に関する話であり、
将来的に改変されている可能性があります。EC2 > ターゲットグループ > モニタリング
ALBからのヘルスチェックでインスタンスの死活監視をCloudWatchアラームで行うのは定番方法であるが、
マネジメントコンソールのEC2のページで、ターゲットグループからモニタリングタグを選択すると、
旧管理画面ではCloudWatch アラームの作成・設定が行えるが、
新しい管理画面では行えなくなっている。◼︎旧管理画面
◼︎新管理画面(CloudWatchアラームに関するリンクが存在しない)
旧管理画面に変更する方法
ページ左上にて新・旧 画面の切り替えスイッチがあるので、そこから旧画面へ切り替える。
おまけ
実はマネコンのCloudWatchのページからCloudWatchアラームを作成可能であるのだが、
そこから作成すると(個人的に)凄い煩わしかったりする。
(ターゲットグループから設定出来た方が直感的に楽である)



- 投稿日:2020-10-12T17:48:41+09:00
ChaliceでLINE chatbotを実装するまで
前提
なんでもいいからAWS上に乗せて動かしてみたかった。
LINE chatbotをHeroku上にデプロイしたことはあったので、
とりあえずこれを乗せてみることにしました。Chaliceとは
Chalice は、 Amazon API Gateway と AWS Lambda for Python による API 環境を実現してくれる、 AWS 製のアプリケーションフレームワークです。(AWS公式より)
コマンドラインでアプリケーションの構築やデプロイができるほか、
Lambdaに付与するIAMロールのポリシーを自動で付与してくれたり、
APIを自動で払い出してくれたりと、かなり便利でした。Chalice導入まで
前準備
・AWSアカウントの取得
・AWS CLIのインストール
AWS CLIを始めてインストールする場合は、インストール後にaws configureコマンドをたたいて、アカウントのアクセスキーやシークレットアクセスキー、
リージョンや出力形式を登録しておきましょう。
認証情報はホームディレクトリ配下の.awsフォルダに格納されます。
ルートユーザーのアクセスキーの発行は推奨されないので、IAMユーザーを作成してその認証情報を登録しておきます。Chaliceは
pip install chaliceでインストールできます。
プロジェクトの作成からデプロイまで
chalice new-project hello-worldコマンドでプロジェクトファイルが生成されます。
ディレクトリ構造はこちら。│ .gitignore │ app.py │ requirements.txt │ └─.chalice config.jsonapp.pyを編集していきます。
デフォルトではこうなっています。app.pyfrom chalice import Chalice app = Chalice(app_name='hello-world') @app.route('/') def index(): return {'hello': 'world'} # The view function above will return {"hello": "world"} # whenever you make an HTTP GET request to '/'. # # Here are a few more examples: # # @app.route('/hello/{name}') # def hello_name(name): # # '/hello/james' -> {"hello": "james"} # return {'hello': name} # # @app.route('/users', methods=['POST']) # def create_user(): # # This is the JSON body the user sent in their POST request. # user_as_json = app.current_request.json_body # # We'll echo the json body back to the user in a 'user' key. # return {'user': user_as_json} # # See the README documentation for more examples. #以下コマンドで、ローカルでの動作確認ができます。
chalice local
デプロイはこちら。
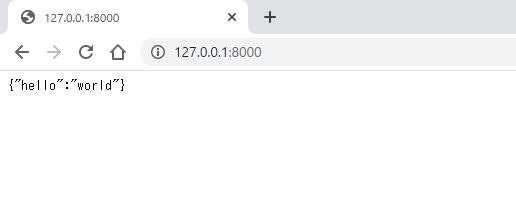
chalice deploy
払い出されたAPI URLにアクセスして{'hello': 'world'}が返ってきているのを確認しましょう。
お片づけはこちらです。chalice deleteLINE chatbotを実装する
LINE developersに登録する
適当にアプリ名等を設定し、オウム返し用のチャネルを作ります。
Messaging API設定からWebhookの利用をオンにし、
Messaging API設定のチャネルアクセストークン(長期)、
チャネル基本設定のチャネルシークレットを控えておきます。line-bot-sdkをインストールする
ローカルでは
pip install line-bot-sdkでOK。
Lambdaにデプロイするとき用に、PyPIからwhl形式のファイルを落としておきます。
Lambdaで外部ライブラリを使うときはプロジェクト名のフォルダにvendorフォルダを作り、そこにwhl形式で格納します。さらにrequirements.txtを作成し、使用するバージョンを指定します。requirements.txtline-bot-sdk==1.17.0環境変数を登録する
環境変数は.chaliceディレクトリ内のconfig.jsonに書き加えます。
先ほど控えたチャネルシークレットとチャネルアクセストークンを以下のように登録しましょう。config.json{ "version": "2.0", "app_name": "line-bot", "stages": { "dev": { "api_gateway_stage": "api", "environment_variables": { "LINE_CHANNEL_SECRET": "チャネルシークレット", "LINE_CHANNEL_ACCESS_TOKEN": "チャネルアクセストークン" } } } }app.pyの編集
Chalice を使って AWS Lambda 上に LINE Bot 用の Webhook を作成する
こちらを参考にしました。デプロイ~結果
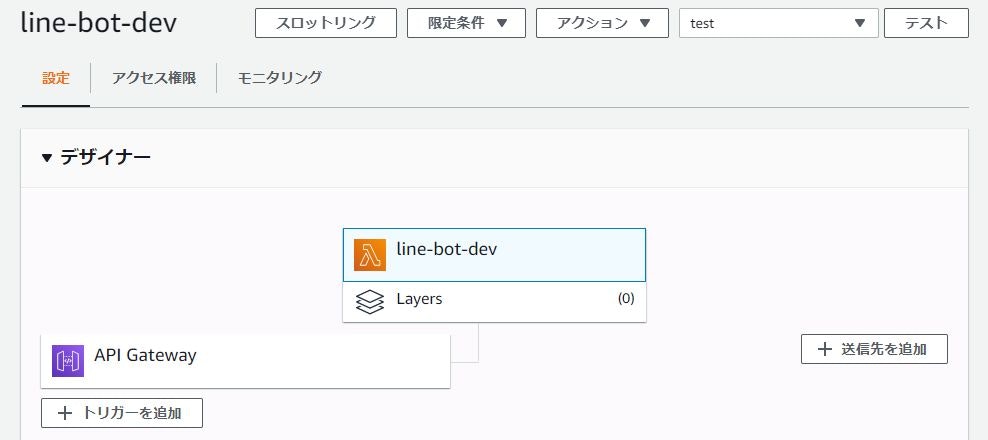
デプロイします。
コンソールを確認すると、LambdaとAPI gatewayが作成されています。
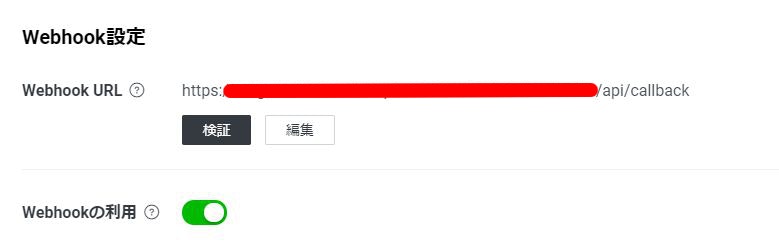
払い出されたAPI URLに/callbackを足したものをLINE developersのWebhookに登録します。検証を押して問題なければOKです。
あとはbotに話しかけて、オウム返しが作動するか確認しましょう。
実装までのトラブルシューティング
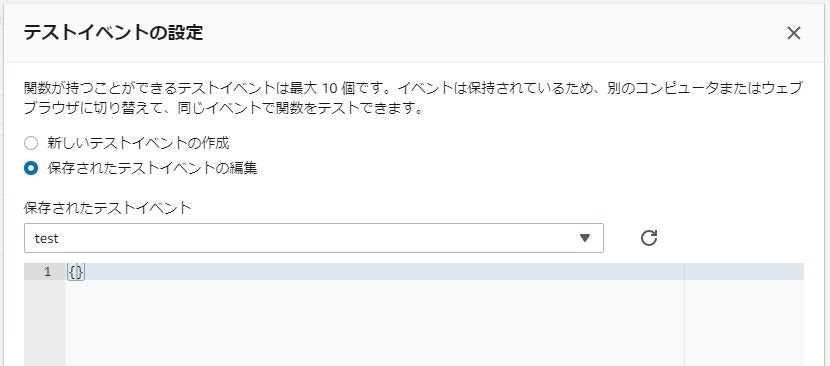
最初、オウムがうんともすんとも言わないのでLambdaをテストしに行きました。
テスト関数はここでは空のjsonで十分です。
失敗が確認されたので、CloudWatchを見に行きました。
エラーログはCloudWatch>CloudWatch Logs>Log groupsに格納されます。line-botのログストリームを開けていくと……
line-botモジュールがないよと言われています。
確認したところ、vendorにライブラリを格納したまでは良いものの、requirements.txtファイルを編集するのを忘れていました。注意点・未解決事項
・deploy後に数分コンソールが動かなくて慌てましたが、line-bot-sdkをインストールするのに時間がかかっていただけのようです。気長に待ちましょう。
・ブラウザでapi/callbackに接続すると、{"message":"Missing Authentication Token"}になってしまいます。オウム返し自体は機能しているのですが……
・ChaliceはLambdaに付与するIAMロールのポリシーは自動でいい感じに付与してくれますが、AWSにアクセスするアクセスキーを持ったIAMユーザーのポリシーはこちらで与えないといけません。
それらしいポリシーを与えても権限がありませんよエラーではじかれてしまい、今回は結局AdministratorAccessポリシーを当ててごり押ししてしまいました(IAMユーザーを作った意味がない……)。




- 投稿日:2020-10-12T17:30:26+09:00
AWS Glueの概要ついてまとめ
はじめに
DWHとかデータレイクとか扱うお仕事でGlueを使うことになったので勉強もかねてまとめ。
※実装とかには触れないので、概念とかこんなもんか~を知りたい方向けですGlueとは
データの分類、クリーニング、加工を優れたコスト効果で容易に行い、さまざまなデータストア間およびデータストリーム間でデータを確実に移動するための、完全マネージド型ETL (Extract/Transform/Load、抽出/変換/ロード) サービス
※参照:https://docs.aws.amazon.com/ja_jp/glue/latest/dg/what-is-glue.html例えば、IFされるJSONデータをDBに入れたいんだけど、そのままの形式ではDBに入れられないからDBに入れるように加工してあげてロードまでやっちゃおうね、というイメージ。(ETL読んで字の如くではあるが)
S3、DynamoDB、Redshift、RDS等と連携可能で、用途としては、データウェアハウス・データレイク構築に向いている。稼働イメージ
■図の用語について
・データストア:データを永続的に保存するリポジトリ(S3、RDBなど)
・クローラ:データストアに接続し、データカタログにメタデータテーブルを作成するプログラム
・データカタログ:テーブル定義、ジョブ定義などのメタデータが集約されたもの
・ジョブ:ETL作業のビジネスロジック。オンデマンド、スケジュール、イベントトリガーで実行可能。
・データソース:インプット(加工対象データ)
・データターゲット:アウトプット(データのロード先)クローラって、データカタログって、結局何なの、、、というのが初見での感想
(技術系公式ドキュメント読むとだいたいこうなる)
先ほどの例で考えてみると、JSONを加工する用のジョブのスクリプトだったり、加工したあとにアウトプットになるDBの情報(テーブル、カラム、型など)だったり、要するに処理に必要な情報をため込んでいる箱のようなものかなと。で、クローラは、そのDBのテーブル情報を作ってくれる担当というイメージ。
なんとなく、わかった気がする、、、!まとめ
Glueの基礎の基礎くらいは認識できた気がしています。
実装部分については、まだ触っていないのでよくわからないですが、また知識が増えたら投稿しようかなあと思います。

- 投稿日:2020-10-12T16:35:44+09:00
AWS CloudWatchEventsの時間指定をCDKでラクにする。
いっっっっつも失敗するのでJSTで指定してCDKでUTCに変換することにした。
CDKでCloudWatchEventsを定義する
取り敢えずCloudWatchEventsの定義のとこだけ。
これをよしなにStepFunctionsとかと組み合わせるなり何なりする。# バッチスケジュールをJSTで定義する(cron式で * にする所は空でよい) props['schedule'] = { 'minute': 40, 'hour': 9, 'week_day': 'MON-FRI' } # JSTをUTCに変換する if props['schedule'].get('hour') is not None: props['schedule']['hour'] = props['schedule']['hour'] - 9 if props['schedule']['hour'] < 0: props['schedule']['hour'] += 24 if props['schedule'].get('day') is not None: props['schedule']['day'] = props['schedule']['day'] - 1 # JST 月初の朝9時までに動作する場合は、月末っぽい日付で動作させてLambda等で判定する if props['schedule'].get('day') == 0: props['schedule']['day'] = '28-31' # props['schedule']の中身をstrに変換する for key in props['schedule'].keys(): props['schedule'][key] = str(props['schedule'][key]) # Cloud Watch Events Rule = events.Rule( app, f"Batch-{id}", schedule=events.Schedule.cron(**props['schedule']) )月初の9:00より前(UTC月末)の判定Lambda
今がJSTの月初(1日)かどうかだけ判定してTrueかFalseが返る。
StepFunctionsに組み込むならこれの返り値を判定して次に流すか終わるかすればよいし、単純な処理ならこのLambda内にてif result:で続けて処理してしまってもよいかと思います。import datetime import calendar def lambda_handler(event, context): print('===Start Lambda===') print(event) dt_now = datetime.datetime.now() monthrange = calendar.monthrange(dt_now.year, dt_now.month)[1] result = dt_now.day == monthrange print(result) return result※printは動作確認のためだけに書いてるので要らなければ消してよい。
おわり
何かもっといい方法とかご存知の賢者様はご指摘いただけると嬉しいです。
- 投稿日:2020-10-12T16:22:59+09:00
EC2のキーペアを紛失した時の簡単な対処法
EC2のキーペアを無くしてしまった時、既存のインスタンスに別のキーペアを登録できます。
新しいインスタンスを作成する必要はありません。例としてlinux/MacOSの場合の手順を示します。
新しいキーペアを作成する
新しいキーペアの作成は必須ではありません。
既存の別のキーペアを使用する場合はスキップしてください。
- AWSマネジメントコンソールにアクセス
EC2>ネットワーク&セキュリティ>キーペアへ移動- 「キーペアを作成」をクリック
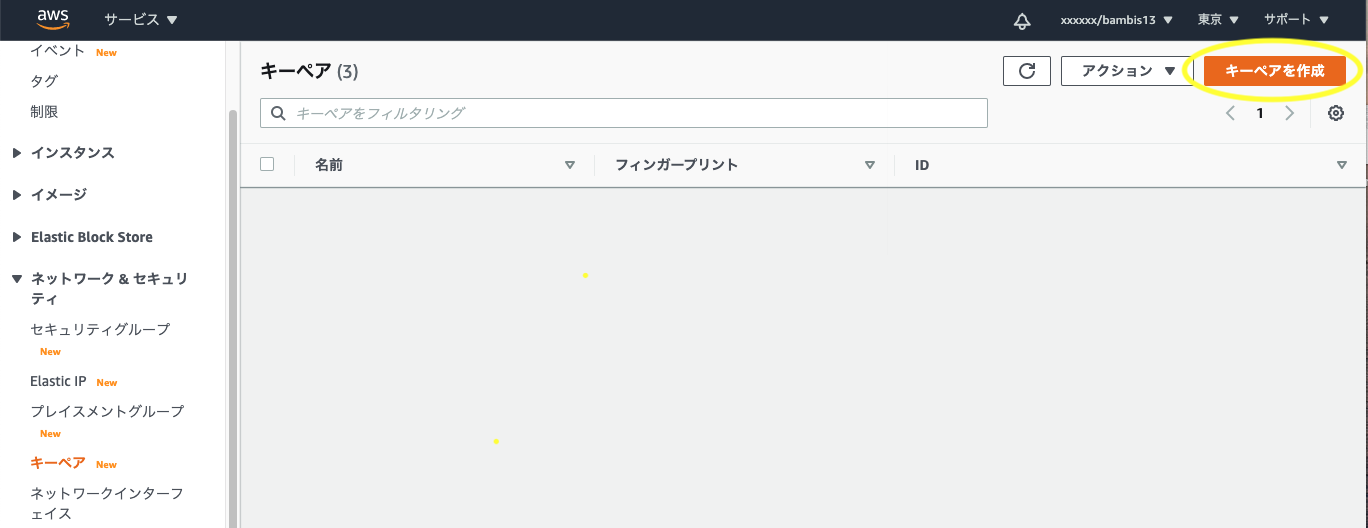
- キーペア名を入力して「キーペアを作成」をクリック
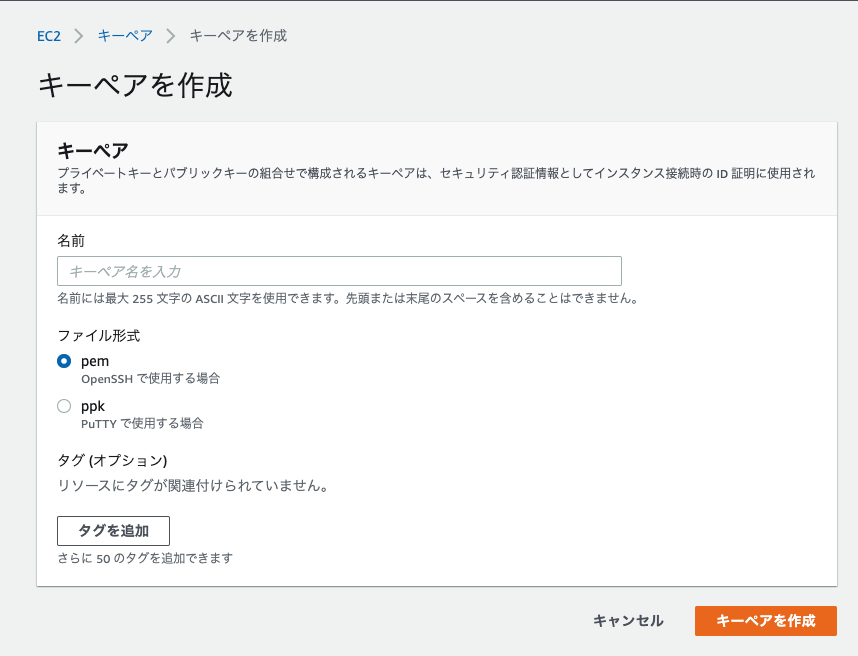
- pemファイルがダウンロードされる
- pemファイルを適当なディレクトリに移動し、適切な権限を設定する
$ mv xxxxx.pem ~/.ssh/ $ chmod 400 ~/.ssh/xxxxx.pemWindowsの場合
公開キーを作成する
$ ssh-keygen -y -f ~/.ssh/xxxxx.pem- 出力された公開キーを「ssh-rsa 」も含めて全てコピーしておく
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQClKsfkNkuSevGj3eYhCe53pcjqP3maAhDFcvBS7O6V hz2ItxCih+PnDSUaw+WNQn/mZphTk/a/gU8jEzoOWbkM4yxyb/wB96xbiFveSFJuOp/d6RJhJOI0iBXr lsLnBItntckiJ7FbtxJMXLvvwJryDUilBMTjYtwB+QhYXUMOzce5Pjz5/i8SeJtjnV3iAoG/cQk+0FzZ qaeJAAHco+CY/5WrUBkrHmFJr6HcXkvJdWPkYQS3xqC0+FmUZofz221CBt5IMucxXPkX4rWi+z7wB3Rb BQoQzd8v7yeb7OzlPnWOyN0qFU0XA246RA8QFYiCNYwI3f05p6KLxEXAMPLEWindowsの場合
EC2インスタンスのユーザーデータを変更する
- EC2インスタンスを停止
アクション>インスタンスの設定>Edit user dataをクリック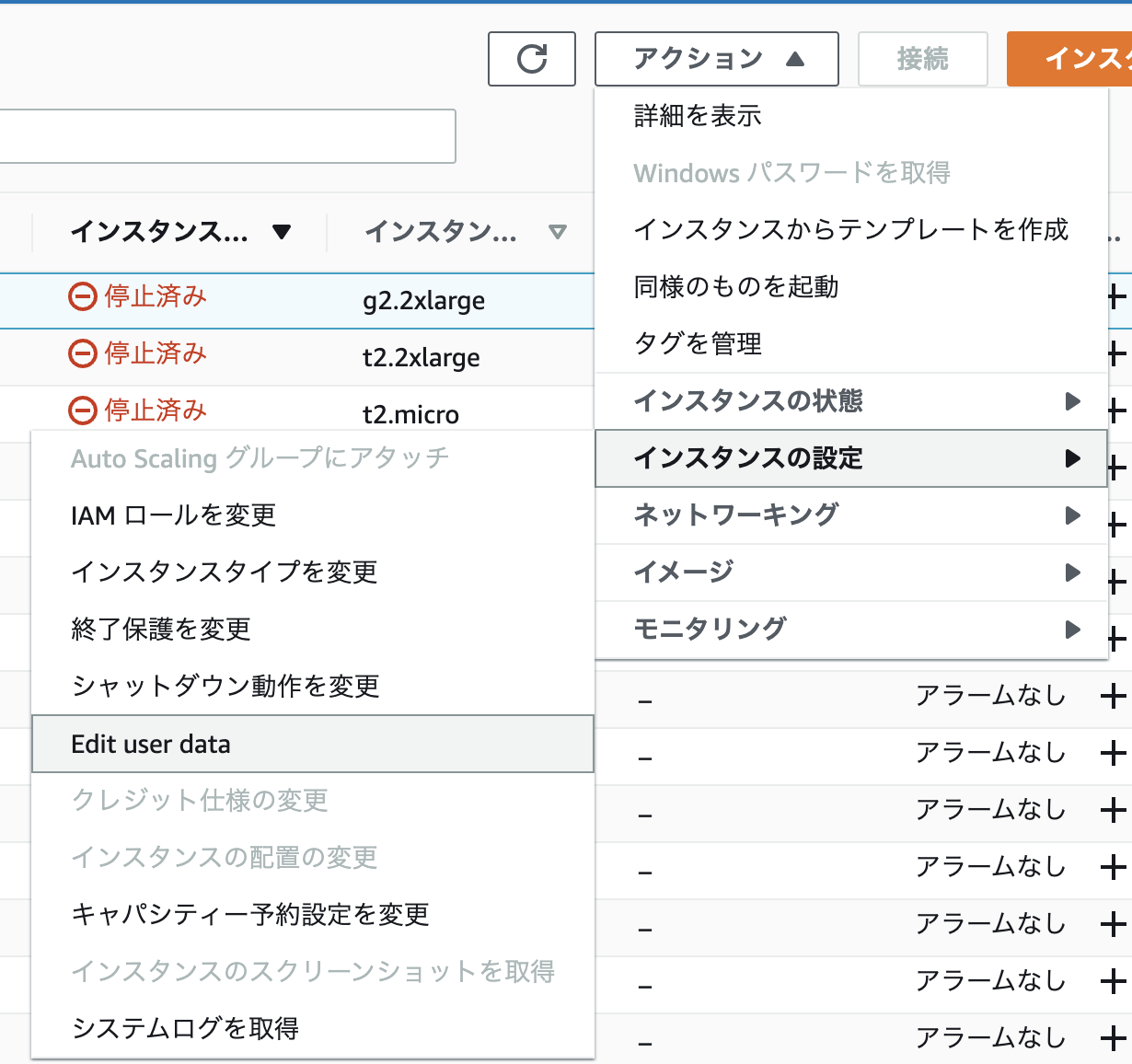
- すでに定義されたユーザーデータがある場合は、一旦どこかへ退避しておく
- ユーザーデータに下記のスクリプトを貼り付ける
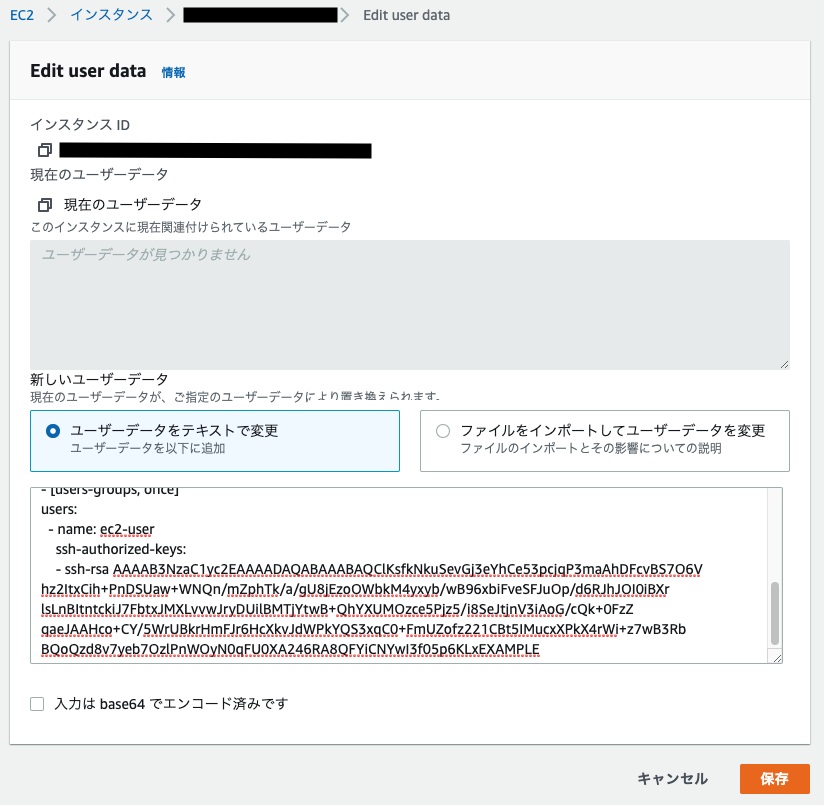
Content-Type: multipart/mixed; boundary="//" MIME-Version: 1.0 --// Content-Type: text/cloud-config; charset="us-ascii" MIME-Version: 1.0 Content-Transfer-Encoding: 7bit Content-Disposition: attachment; filename="cloud-config.txt" #cloud-config cloud_final_modules: - [users-groups, once] users: - name: username ssh-authorized-keys: - PublicKeypair
users.name と PublicKeypair を修正して「保存」をクリック
- users.name ... ec2-user など
- PublicKeypair ... 先ほど作成した公開キー
インスタンスを起動
起動後、ダウンロードしたpemファイルを使用してssh接続出来ることを確認する
ssh -i ~/.ssh/xxxxx.pem ec2-user@xxx.xxx.xxx.xxxインスタンスを停止
先ほど貼り付けたスクリプトを公開キーを含め全て削除する
- 退避したユーザーデータがある場合は貼り付ける
「保存」をクリック
インスタンスを起動する
参考
- 投稿日:2020-10-12T16:20:14+09:00
AWS CDKで暗黙の依存関係が削除できないとき
CDKでクロススタック参照するリソースを作成したとき
CDKで複数スタックを定義して、スタック間でリソースを共有したいケースはよくあると思います。
スタックAで定義したLambda関数をスタックBでも使いたい、とかそういう感じのやつです。基本的にCDKは頭がいいので、渡したいリソースを適当に変数にでも入れて別のスタックに引き渡してやれば、明示的にアウトプットを定義してやらなくても勝手に依存関係を理解していい感じにしてくれますよね。
しかし、いざクロススタック参照していたリソースを削除しようとすると、CloudForamtionがこんな感じにエラーを出してきます。
Export StackA:ExportsOutputFnGetAttLambdaFnstacka07BAF5DArn93F62DF0 cannot be deleted as it is in use by StackBどうしてですか?
CDKは賢いので、StackAで作成したLambdaがStackBで使われなくなった事に気付いてアウトプットを削除します。
そしてcdk deployを走らせると、StackBはStackAに依存しているため、先にStackAのデプロイが走ります。そう!!StackBより先に!!StackAを更新しようとするのである!!!
そうすると、LambdaがStackBで使われているためアウトプットの削除が出来ないのです。
解決方法
先にStackBだけ単体で更新する
まあ、当然といえば当然なのですが、StackBを先に単体で更新してからStackAを更新するとうまくいきます。
cdk deploy -e StackBデプロイ時にオプション
-eをつけると、指定したスタックのみ更新してくれます。これでStackBからStackAのLambdaを参照しなくなり、依存関係がなくなったため、以降は前述のエラーなくStackA、StackB共にデプロイできるようになるはずです。
めでたし!!!!!!!!!!
知らなかったの私だけかもしれないですけどね!!
なかなか-eオプションにたどり着けなかったので……。
ちゃんとドキュメントを読みましょうというお話でした。ドキュメントを読もう:AWS CDK Toolkit (cdk command)
- 投稿日:2020-10-12T16:17:19+09:00
Amazon Elastic Transcoder概要とLambdaからのJob実行
Amazon Elastic Transcoder
映像・音声をユーザーが再生可能なフォーマットに変換するクラウドサービス
用語
Pipeline
動画を通してトランスコードを行うパイプライン
Pipeline ID が割り当てられ、Lambda 等から使用する際に指定
以下主な設定項目
- 変換元/先の S3 バケット
- 変換完了 SNS 通知
Job
Pipeline 内で実行するトランスコード処理
Lambda 連携する場合は Lambda から生成、実行する
以下主な設定項目
- 変換元/先ファイル名
- Preset
- サムネイル生成等のオプション
Preset
トランスコード内容をまとめた設定
Job にてトランスコード内容として指定
AWS で用意されているものかカスタムで生成したものを使用
Preset ID が割り当てられ、Lambda 等から使用する際に指定
Preset一覧:https://docs.aws.amazon.com/ja_jp/elastictranscoder/latest/developerguide/system-presets.htmlアーキテクチャ例
1. 動画が S3 にアップロードされたことをトリガに Lambda を実行
2. Lambda で Amazon Elastic Transcoder の Job を実行
3. Amazon Elastic Transcoder が S3 内の元動画からトランスコードしmp4 動画を S3 に出力トランスコード時間
元動画の 50 ~ 100%程度
料金試算
無料枠
- SD: 20 分
- HD: 10 分
1 日 1 時間分の動画をトランスコードした場合
SD(480p)の場合
(1 時間 ×30 日 ×60 分 - 20 分)×0.017USD = 30.26USD = 3177 円HD(720p)の場合
(1 時間 ×30 日 ×60 分 - 10 分)×0.034USD = 60.86USD = 6390 円Amazon Elastic Transcoder + Lambda 例
AWS マネジメントコンソールから Pipeline の作成
Pipeline の名前、変換元/先の S3 バケット、サムネイルの出力先 S3 バケット等を指定
Job は Lambda から生成するため不要、Preset は用意されたものを使用するため不要
S3 を以下構成で用意
入力用:
- bucket : elastic-transcoder-dev-input
- key : input/
出力用:
- bucket : elastic-transcoder-dev-output
- key : output/
Lambdaトリガ設定
- トリガとするサービス:S3
- バケット:elastic-transcoder-dev-input
- イベントタイプ:すべてのオブジェクト生成イベント
- プレフィックス:input/
- サフィックス:.webm
Lambdaロール設定
Elastic TranscoderにJobをSubmitできるポリシー「AmazonElasticTranscoder_JobsSubmitter」を追加しますLambda実装
以下サンプルlet aws = require('aws-sdk'); let s3 = new aws.S3({apiVersion: '2006-03-01'}); let ets = new aws.ElasticTranscoder({apiVersion: '2012-09-25', region: 'ap-northeast-1'}); exports.handler = function(event, context) { let pipelineId = 'xxxxxxxxxxxxx-xxxxx'; let presetId = '1351620000001-000030'; let bucket = event.Records[0].s3.bucket.name; let key = event.Records[0].s3.object.key; let fileName = (key.split('/')[1]).split('.')[0]; ets.createJob({ PipelineId: pipelineId, OutputKeyPrefix: 'output/', Input: { Key: key, FrameRate: 'auto', Resolution: 'auto', AspectRatio: 'auto', Interlaced: 'auto', Container: 'auto', }, Output: { Key: fileName + '.mp4', ThumbnailPattern: fileName + '-thumbs-{count}', PresetId: presetId, Rotate: 'auto' } }, function(error, data) { if(error) { console.log(error); context.done('error',error); } else { console.log('Job submitted'); context.done(null,'') } }); }
ets.createJob:Jobを生成しています
PipelineId、presetId:AWSマネジメントコンソールで確認して指定
OutputKeyPrefix:出力先フォルダ
出力されるファイルは、OutputKeyPrefix+Output['key']になります参考記事


- 投稿日:2020-10-12T15:50:08+09:00
Lambda_備忘録
備忘録用
(notice_unhealthy_to_slack)
import boto3 import json import logging import os from base64 import b64decode from urllib.request import Request, urlopen from urllib.error import URLError, HTTPError # The Slack channel to send a message to stored in the slackChannel environment variable SLACK_CHANNEL = os.environ['slackChannel'] HOOK_URL = os.environ['hook_URL'] logger = logging.getLogger() logger.setLevel(logging.INFO) def handler(event, context): logger.info("Event: " + str(event)) message = json.loads(event['Records'][0]['Sns']['Message']) logger.info("Message: " + str(message)) alarm_name = message['AlarmName'] #old_state = message['OldStateValue'] new_state = message['NewStateValue'] #reason = message['NewStateReason'] slack_message = { 'channel': SLACK_CHANNEL, # 'text': "<@UL0TNE657> 【ENV: dev/stg】 %s // state is now %s" % (alarm_name, new_state) 'text': "<@UL0TNE657> 【ENV: dev/stg】 %s // state is now %s" % (alarm_name, new_state) } req = Request(HOOK_URL, json.dumps(slack_message).encode('utf-8')) try: response = urlopen(req) response.read() logger.info("Message posted to %s", slack_message['channel']) except HTTPError as e: logger.error("Request failed: %d %s", e.code, e.reason) except URLError as e: logger.error("Server connection failed: %s", e.reason)
- 投稿日:2020-10-12T15:09:03+09:00
AWSデプロイ後、画像が表記されない問題について
本番環境にアクセスしたらCSSがかかっていない。。。そんな時に解消した自分の解決法を備忘録に残します。画像の場所はapp/assets/imagesです
解決策1 CSSファイルの拡張子の後ろに.SCSSを付け足す
しかしこれでも解決しませんでした。人によってはこれだけいけたという人も聞きます。
解決策2 CSS.SCSSの表記を見直す
僕の場合、表記が
background-image: url(/assets/画像名);
だったのを
background-image: image-url("画像名");
に変更後$ git pull origin masterで反映させる。しかしこれでも適用されず
解決策3 コンパイルし直す
https://qiita.com/yoheism42/items/dcf71691ca3e8dfc26c5
ここの記事を参考に$ find app/assets/ -type f -exec touch {} \; $ rake assets:clobber assets:precompile $ RAILS_ENV=production rake assets:precompileを試す。そうすると2行目のコマンドで
======================================== Your Yarn packages are out of date! Please run `yarn install --check-files` to update. ========================================こんなエラー。これに対しては
$ yarn upgrade
その後またさっきの3行のコマンドを初めから試す。そうすると今回は弾かれずにすんなりいった。最後に
$ sudo systemctl start nginx $ sudo systemctl reload nginxの順に実行してエンジンエックス再起動
その後
$ ps aux | grep unicorn $ kill 1376 ←unicorn masterの行の一番左端の数字 $ RAILS_SERVE_STATIC_FILES=1 unicorn_rails -c config/unicorn.rb -E production -Dこれでなんとか画像を表示させることに成功しました。
長かった・・・
- 投稿日:2020-10-12T13:54:48+09:00
TableauのMongoDB BI コネクタを使ってドキュメント指向DBがどのように見えるか試してみる
はじめに
ドキュメント指向データベースをBIツールで分析する場合、どのようなテーブルになるのか確認してみます。
BIツールはTableauを使い、ドキュメント指向データベースはMongoDB Atlasを使ってみます。
MongoDB Atlasを選定した理由は、Tableauで接続できる「BI Connector」が手軽に使えるからです。なお私はMongoDBもTableauも全くの素人です。
用語の使い方に間違いがあるかもしれません。(ご指摘いただけると嬉しいです)環境
以下のような構成図になっています。
主目的はBI Connectorの利用なのでMongoDBに接続していますが、ついでに以下もためしました。
- [MongoDB Atlas]と[AWS]とのVPCピアリング
- [Tableau]から[Amazon DocumentDB]への接続
バージョンは以下のとおりです。
対象 バージョン Tableau Desktop 2020.3.0 MongoDB Atlas 4.2.10 なお、
Tableauは「MongoDB BI Connector」というデータソースがあります。
MongoDB Atlasには「BI Connector」というサービスがあります。
まぎらわしいので以後は後者のほうを 「Atlas BI Connector」と呼ぶことにします。接続先の用意
MongoDB Atlas
アカウントのセットアップ
とりあえずアカウントを作成します。
最初は無料版を選択してみます。
無料版クラスタの作成
AWS上に作成します。無料版なので東京リージョンは選べないため、バージニア北部を選択します。
スクロールしM0クラスタを作成します。
ウィザードが次に何をすべきか指示してくれます。
DBユーザの作成
DBユーザを作成します。
とりあえずパスワード認証で、権限は「Read and write to any database」にしてみます。
ホワイトリストの登録
接続元のIPを登録(自宅と、ピアリング先のAWSのVPCのセグメントを登録しました)
サンプルデータの読み込み
サンプルデータがあるようなので、三点リーダーから取り込んでみます。
Clusterを選択してCollectionsを選択するとデータが確認できます。
クレジットカードの登録
今回は BI Connectorを使うのが目的です。BI Connectorはそれ自体が有料です。さらに利用には有料版のクラスタ(M10以上)が必要です。
有料版を使うため、クレジットカードを登録します。
有料版クラスタの作成
クラスター作成画面より、有料のM10を選択してみます。
Atlas BI Connector の有効化
下にスクロールし、「Advanced Settings」からBI コネクタを有効化してみます。
あまり課金ロジックを理解していませんが、数日間利用したところ、1日あたり $3.64 かかっていました。おそらくBIコネクタを有効化している日数ではなく、使用した日の日数分だけ課金されているような気がします。実際にコネクションを張らなかった日は課金されていないように思えました。
作成後は、この有料版クラスタにもサンプルデータを読み込ませておきます(省略します)
接続文字列の確認
Atlas BI Connectorは通常のクラスタ接続先と異なるようです。
Atlas BI Connectorの接続文字列を見てみます。
ホスト名に「biconnector」という文字列が追加されていますね。それぞれコピーしておきます。
VPC ピアリング
主目的ではありませんが、AWSとのピアリングも試しておきます。
AWSのアカウントID、VPC ID、とそのCIDRを指定します。Atlas側のCIDRは自動入力されていました。
AWS側にピアリング申請がきているので承認しておきます。
接続したいサブネットのルートテーブルにもVPCピアリングを通しておきます。先程確認したAtlas側のCIDRをいれます。
VPC側でDNSホスト名とDNS解決が有効になっていることを確認します。
AWS側からクラスタのドメイン名にpingを通すと、プライベートIPで応答が帰ってきます。
TableauからMongoDB Atlasへ接続
AWSのEC2上にインストールしてあるTableau Desktopから操作します。
tableauからMongoDB BIコネクターを選択すると、まずはドライバダウンロードを求められます。
リンクをクリックするとブラウザが開きます。Windows用のmysql odbcドライバ「mysql-connector-odbc-8.0.21-winx64.msi」を落とします。
インストールしようとすると「this application requires visual studio 2019 x64 redistributable」と警告が出たため、「VC_redist.x64.exe」をインストールし再起動します。再起動したらmysql odbcドライバを改めて入れ(たような気がし)ます。
https://support.microsoft.com/ja-jp/help/2977003/the-latest-supported-visual-c-downloads
tableauから接続してみます。
接続は成功するも、システムDBしか見えません。
MongoDB Atlasのほうで、接続用ユーザの権限を「Read and write to any database」から「Atlas admin」に変更してみます。
反映まで念のため数分待ち、再度接続してみます。今度はデータベース名も指定します。
正常に接続でき、データベースや表もちゃんと見えました。
BI Connectorでどのように見えるか確認する
テーブル構造の確認
"sample_training"データベースの"companies"コレクションの1データをMongoDB Atlasから見てみます。
以下のような構造をしています。例として image は Object型になっていることが確認できます。
tableauからみると、companiesコレクションはオブジェクト単位で分離していることがわかります。
オブジェクトのネストはアンダーバーで表現されています。
imageの実際のJSONデータを抜粋します。
$numberIntで型定義されている配列と、ファイルパスの文字列というデータになっています。"image": { "available_sizes": [ [ [ { "$numberInt": "150" }, { "$numberInt": "75" } ], "assets/images/resized/0000/3604/3604v14-max-150x150.jpg" ], [ [ { "$numberInt": "250" }, { "$numberInt": "125" } ], "assets/images/resized/0000/3604/3604v14-max-250x250.jpg" ],上記のような構造のデータは、tableau側ではこうなります。
今度はオブジェクトのネストが2階層になっているテーブルの元データを見てみます。
"funding_rounds": [ { "id": { "$numberInt": "888" }, "round_code": "a", "source_url": "http://seattlepi.nwsource.com/business/246734_wiki02.html", "source_description": "", "raised_amount": { "$numberInt": "5250000" }, "raised_currency_code": "USD", "funded_year": { "$numberInt": "2005" }, "funded_month": { "$numberInt": "10" }, "funded_day": { "$numberInt": "1" }, "investments": [ { "company": null, "financial_org": { "name": "Frazier Technology Ventures", "permalink": "frazier-technology-ventures" }, "person": null }, { "company": null, "financial_org": { "name": "Trinity Ventures", "permalink": "trinity-ventures" }, "person": null } ] },1階層目。自テーブルのidxカラムが自動追加されています。
2階層目。自テーブルのidxカラムと、親テーブルのidxカラムが自動追加されています。このidxカラムの組み合わせにより、データを一意的に識別できるようになっています。
Tableauのシートに表示してみる
Tableauのデータソースから、2階層にネストしたテーブルをリレーションシップで組み合わせてみます。
まずはrootの companies と companies_acquisitionsをドラッグアンドドロップします。
同名のカラムがあるため、カラム指定せずに自動で紐付けてくれます。
rootの companies と companies_funding_roundsも同じように自動紐付けされます。
companies_funding_rounds と companies_funding_rounds_investmentsは自動紐付けされないようです。同名カラムが複数ある(_IdとFunding Rounds Idx)からですかね?
手動で子にとっての親を指すインデックスカラム(Funding Rounds Idx)を選択します。
リレーションシップができました。
シートに移ります。
業種カテゴリと従業員数でグラフを作ってみました。
所感
- オブジェクト単位でテーブルが分割されるものの、自動で追加されるインデックスカラムによって結びつけができるという点は便利です。ドキュメントDBを表現するにはこういうアプローチしかなさそうですし。
- ただ元データ側は、やはりドキュメント志向なためか文字列型が多く、Tableauで分析するにはメジャーが少ない印象です。
- このサンプルデータはキレイなのでなんとか棒グラフを作ることはできましたが、データによってはTableauの「テキスト表」でしか表現できないケースもあるようです。
- ですのでtableauで表示をするまえに、どのような分析をしたいか、その分析をするためにどのようなデータ型で定義するか、を検討すべきであるという当たり前の事実を再確認しました。
- 必要であれば事前にETL処理などを行うべきですし、ETLを行えば何もBIツールから直接ドキュメント志向データベースに接続する必要もない気がします。
おまけ(TableauからAmazon DocumentDBへの接続試行)
直接アプローチ
Tableauの「MongoDB BI Connector」からAmazon DocumentDBへの接続
ダメ元でやってみたらやはりだめでした。
Tableauの「MongoDB BI Connector」は、Tableau側に DocumentDBのマッピング機能があるわけではなく、あくまで接続機能でしかないようです。マッピング機能は MongoDB側の BI Connector(Atlas BI Connector)にあります。
接続先のサーバをDocumentDBにしてみると、
エラーになります。
Tableauのカスタムコネクタ(JDBC/ODBC)の利用
有償コネクタ(未検証)
- MongoDBへのコネクタは世間にいろいろありますが、試していません。
無償コネクタ
- 以下のようなものを見つけてGradleでビルドし、JDBCドライバを作り、TDCファイルを置いてみたりしましたが接続できず諦めました。
ODBCドライバから Atlas BI Connectorへ接続
これはうまくいきました。接続後、Collectionは検索しないと表示されませんでしたが、それ以外は問題なし。
機能的にはMongoDB側のAtlas BI Connectorがあればクライアント側の機能はさほど問われないということなんでしょう。WindowsにODBCドライバをインストールし、
https://github.com/mongodb/mongo-odbc-driver/releases/
mongodb-connector-odbc-1.4.2-win-64-bit.msiWindowsの標準機能からODBCドライバを作ります。
tableauからはODBCで接続できます。
PowerBIからはODBCを指定して、
さきほどのコネクタを指定し、
改めてユーザ名とパスワードをいれると、
接続ができました。
ODBCドライバから DocumentDBへ接続
MongoDBのODBCドライバの接続先をDocumentDBに変え、Tableauからそれを指定し接続してみましたが、接続できずテスト接続でフリーズしました。アクセス元がBIツールなので仕方ないです。これができればAtlas BI Connectorの存在理由はありませんし。
間接アプローチ
Athenaを経由しAmazon DocumentDBへの接続
AthenaはDocumentDBへの接続機能があるようなので、Athenaを経由すればTableauから見えないか?という案
そもそもTableau側のAthenaコネクタがS3しか想定しない作りになっているので、NG。
Tableauからはだめそうですが、AthenaのFederated Queryそのものについては別の機会で記事にしてみようと思います。
GlueジョブでDocumentDBにETL処理を行うパターン
詳細は省きますが、DocumentDBへの接続はできました。以下のようなデータが、
{ "_id": "01001", "city": "AGAWAM", "loc": [ -72.622739, 42.070206 ], "pop": 15338, "state": "MA" }GlueのDynamicFrameによって以下のように型認識されています。
|-- _id: string |-- city: string |-- loc: array | |-- element: double |-- pop: int |-- state: string型はちゃんと認識できているので、ETL処理を行うことはできると思います。
以上























































- 投稿日:2020-10-12T13:27:23+09:00
AWS 認定 ソリューションアーキテクトアソシエイトサンプル問題を解説します
こんにちは。一気に秋も深まり、赤や黄色で樹々が彩られるようになりましたね。
前回に引き続いて、AWS認定のサンプル問題をもとに、深堀をして解説しようと思います。
今回は、AWS 認定のまずとっておけ!的な資格である「ソリューションアーキテクト アソシエイト」のサンプル問題を取り上げます。
AWS認定とは
AWS 認定は、クラウドの専門知識を検証し、専門家が需要の高いスキルを強調し、組織が AWS を使用してクラウドイニシアチブにおける効果的で革新的なチームを構築するのに役立ちます。個人やチームが独自の目標を達成できるように、役割と専門分野ごとに設計したさまざまな認定試験から選択します。
AWS 認定は領域やレベルごとに分けられ、本校執筆時点(2020/09)では12の認定資格が存在しています。
- レベル
- 基礎
- アソシエイト(中級ととらえてください)
- プロフェッショナル(上級ととらえてください)
- 専門知識(対象分野に特化した高度な認定)
- 領域
- 全般
- ソリューション
- 開発
- 運用
- DBや機械学習といった専門分野
表にまとめると以下の通りです。
# レベル 認定名 1 基礎 クラウドプラクティショナー 2 アソシエイト ソリューションアーキテクトアソシエイト 3 アソシエイト デベロッパー アソシエイト 4 アソシエイト SysOps アドミニストレーター アソシエイト 5 プロフェッショナル ソシューションアーキテクト プロフェッショナル 6 プロフェッショナル DevOps エンジニア プロフェッショナル 7 専門知識 高度なネットワーク 8 専門知識 Alexaスキルビルダー 9 専門知識 セキュリティ 10 専門知識 機械学習 11 専門知識 データ分析 12 専門知識 データベース AWS認定ソリューションアーキテクトアソシエイト
試験の概要や出題割合などは、以下の試験ガイドをご確認ください。
https://d1.awsstatic.com/ja_JP/training-and-certification/docs-sa-assoc/AWS-Certified-Solutions-Architect-Associate_Exam-Guide.pdfサンプル問題を解いてみよう
それでは、サンプル問題を確認していきましょう。
※以降、Markdown記載に合わせて、サンプル問題のABCDを1234と置き換えています。
第1問
問題文
カスタマーリレーションシップマネジメント (CRM) アプリケーションは、アプリケーションロードバランサーの背後にある複数のアベイラビリティーゾーンの Amazon EC2 インスタンスで実行されます。
これらのインスタンスの 1 に障害が発生した場合、どうなりますか?
- ロードバランサーが、障害が発生したインスタンスへのリクエストの送信を停止する。
- ロードバランサーが、障害が発生したインスタンスを終了する。
- ロードバランサーが、障害が発生したインスタンスを自動的に置換する。
- ロードバランサーが、インスタンスが置換されるまで、504 ゲートウェイ タイムアウト エラーを返す。
回答
1
解説
問題文で、「これらのインスタンスの 1 に障害が~」という記載は、「これらのインスタンスの 1つに障害が~」ととらえていただくとよいでしょう。
- ロードバランサーは障害が発生した(ヘルスチェックに失敗した)インスタンスに対してリクエスト送信を停止しますので、適当といえます。
- ロードバランサーは、インスタンスに対してヘルスチェックを行いますが、インスタンスそのものを終了(削除)したりはしないので、不適当です。
- ロードバランサーは、インスタンスに対してヘルスチェックを行いますが、自動的に置き換える(終了(削除)や起動)といったことはしないので、不適当です。
- これらのインスタンスの1(つ)に障害が発生した場合とあるので、この環境はロードバランサーに複数のインスタンスが存在しており1つ以上は正常に稼働している考えられます。
504 エラーが発生する条件はいくつかありますが、1つ以上のインスタンスが稼働している状況では、インスタンスの置き換え完了するまでというのを理由に 504 エラーを返すというのは誤りですので、不適当です。第2問
問題文
企業は非同期処理を実行する必要があり、分離されたアーキテクチャの一部として Amazon SQS を持っています。同社は、ポーリングリクエストからの空の応答件数を最小限に抑えることを望んでいます。
空の応答を減らすために、ソリューションアーキテクトは何をすべきでしょうか?
- キューの最大メッセージ保存期間を増やす。
- キューのリドライブポリシーの最大受信数を増やす。
- キューの既定の可視性タイムアウトを増やす。
- キューの受信メッセージ待機時間を延長する。
回答
4
解説
空の応答を減らすためには、SQS へメッセージを取得するポーリングリクエスト実施時に、空の場合には指定秒数の間、待機するロングポーリング機能(待たない場合は、ショートポーリング)を使用します。
- 「最大メッセージ保存期間」は SQS の設定にある「メッセージ保持期間」のことであると考えます。これは、メッセージがキューに格納されてから削除されるまでの期間の設定です。空の応答を最小限に抑えることにつながりません。そのため、不適当です。
- 「最大受信数」から、デッドレターキュー(DLQ) の最大受信数の設定であると考えます。 DLQ は何かしらの理由で配信されなかった(処理されなかった)メッセージが格納されているキューのことです。空の応答を最小限に抑えることにつながりません。そのため、不適当です。
- 可視性タイムアウトは既に処理などを行っているメッセージを、別のインスタンス(メッセージを取得し処理を行うインスタンス)などから見えなくする期間を設定するものです。そのため空の応答を最小限に抑えることにつながらないので不適当です。
- 受信メッセージ待機時間を設定、延長することでロングポーリングを使用するようになります。メッセージが空の場合の待ち時間が長くなりますので、ポーリングリクエストの実行回数が減ります。結果として空の応答を減らすことにつながるので適当といえます。
第3問
問題文
企業は現在、オンプレミスアプリケーションのデータをローカルドライブに格納しています。最高技術責任者は、データを Amazon S3 に保存してハードウェアコストを削減したいのですが、アプリケーションに変更を加えたくないと考えています。レイテンシーを最小限に抑えるには、頻繁にアクセスするデータをローカルで使用できるようにする必要があります。
ローカルストレージのコストを削減するためにソリューションアーキテクトが実装できる、信頼性の高い耐久性のあるソリューションとは何ですか?
- ローカルサーバーに SFTP クライアントをデプロイし、SFTP 用 AWS 転送を使用してデータを Amazon S3 に転送する。
- キャッシュ型ボリュームモードで設定された AWS Storage Gateway のボリューム型ゲートウェイをデプロイする。
- ローカルサーバーに AWS DataSync エージェントをデプロイし、S3 バケットを転送先として設定する。
- 保管型ボリュームモードで設定された AWS Storage Gateway ボリューム型ゲートウェイをデプロイする。
回答
2
解説
「Amazon S3 に保存してハードウェアコストを削減したい」、「アプリケーションに変更を加えたくない」、「レイテンシーを最小限に抑える」、「頻繁にアクセスするデータをローカルで使用できるようにする」といった要件から、ローカルドライブと同等の方式で読み書きを行いつつ Amazon S3 へのデータ格納をしてもレイテンシーを抑えるソリューションを選択すればよいです。
- アプリから見てデータ(ファイル)へのアクセス方式が変わってしまうため要件を満たせません。そのため不適当です。
- キャッシュ型ボリュームモードの AWS Storage Gateway の場合は、データ自体は S3 に書き込まれます。頻繁にアクセスするデータはキャッシュとしてローカルに保持されます。ストレージ容量については、必要なキャッシュ容量分だけ確保します。アプリ側からはアクセス方式も変わりません。このことから要件を満たせるため、適当といえます。
- 「AWS DataSync エージェント」は Amazon S3 や Amazon EFS に対してデータ転送を行いますが、データ同期を目的とした機能であるので、使用容量分だけローカル側にストレージ容量が必要になってしまい「ハードウェアコストを削減したい」という要件を満たせません。そのため、不適当です。
- 保管型ボリュームモードの AWS Storage Gateway の場合は、ローカル側に必要な分だけストレージ容量を確保し、書き込まれたデータは非同期で Amazon S3 にバックアップされます。アプリからみると iSCSI で接続されたストレージに対して読み書きを行うので、アクセス方式は変わりません。しかし、ローカル側に必要な分だけストレージ容量が必要になってしまい「ハードウェアコストを削減したい」という要件を満たせません。そのため、不適当です。
第4問
問題文
企業は、複数のアベイラビリティーゾーン全体にわたる VPC で、公開されている 3 層 Web アプリケーションを実行します。プライベートサブネットで実行されているアプリケーション層の Amazon EC2 インスタンスでは、インターネットからソフトウェアパッチをダウンロードする必要があります。ただし、インターネットから直接インスタンスにアクセスすることはできません。
インスタンスが必要なパッチをダウンロードできるようにするために実行すべきアクションはどれですか? (2 つ選択してください。)
- パブリックサブネットで NAT ゲートウェイを構成する。
- インターネットトラフィック用の NAT ゲートウェイへのルートがあるカスタムルートテーブルを定義し、それをアプリケーション層のプライベートサブネットに関連付ける。
- Elastic IP アドレスをアプリケーションインスタンスに割り当てる。
- インターネットトラフィック用のインターネットゲートウェイへのルートがあるカスタムルートテーブルを定義し、それをアプリケーション層のプライベートサブネットに関連付ける。
- プライベートサブネットで NAT インスタンスを設定する。
回答
1,2
解説
パッチを当てたい Amazon EC2 インスタンスはプライベートサブネットにいるという情報と、プライベートサブネットにいる Amazon EC2 インスタンスがどのようにすればインターネットに出ていけるか、どんな設定をすればよいのかがわかれば、解ける問題です。
- プライベートサブネットのインスタンスがインターネットと通信するには、 NAT ゲートウェイもしくは NAT インスタンスを経由する必要があるので、この選択肢は適当といえます。
- NAT ゲートウェイや NAT インスタンスを作成・起動させただけでは、プライベートサブネットの Amazon EC2 インスタンスはインターネットと通信できません。ルートテーブルに通信経路の設定を行うことでインターネットと通信できるようになるので、この選択肢は適当といえます。
- プライベートサブネットのインスタンスに Elastic IP アドレスを割り当てることは可能ですが、プライベートサブネットはインターネットゲートウェイへの通信経路設定がルートテーブルにされていません。また、選択肢4と組み合わせてしまうと、プライベートサブネットではなくなってしまうため、不適当です。
- この設定をしていますと、プライベートサブネットがパブリックサブネットになってしまいます。セキュリティなどを考慮してのインスタンス配置、ネットワーク設定といった設計が崩れてしまうため、不適当です。
- NAT インスタンスをプライベートサブネットに設定してもインターネットへの通信設定がルートテーブルにされていないためインターネットと通信できません。そのため、不適当です。
第5問
問題文
ソリューションアーキテクトは、2 週間の会社のシャットダウン中に実行不要の Amazon EC2 インスタンスのコストを節約するためのソリューションを設計したいと考えています。インスタンスで実行されているアプリケーションは、インスタンスが動作を再開するときに必要なデータをインスタンスメモリ (RAM) に格納します。
インスタンスをシャットダウンして再開するために、ソリューションアーキテクトが推奨すべきアプローチはどれですか?
- インスタンスストアボリュームにデータを格納するようにアプリケーションを変更する。ボリュームを再起動中に再接続する。
- インスタンスを停止する前に、インスタンスのスナップショットを作成する。インスタンスの再起動後にスナップショットを復元する。
- 休止状態が有効になっているインスタンスでアプリケーションを実行する。シャットダウンの前にインスタンスを休止状態にする。
- 停止する前に、各インスタンスのアベイラビリティーゾーンをメモしておく。シャットダウン後に、同じアベイラビリティーゾーン内のインスタンスを再起動する。
回答
3
解説
Amazon EC2 インスタンスを再開し、必要なデータをインスタンスメモリ (RAM) に格納するには、「休止状態」をサポートしているインスタンスを使用し、インスタンスの停止時に「休止状態」にする必要があります。
- インスタンスストアボリューム(エフェメラルディスク)に格納したデータは、インスタンスの停止時に消えてしまいます。そのため、不適当です。
- インスタンスのスナップショットを Amazon Machine Image(AMI) と考えますが、AMI にはメモリの状態まで保存しません。そのため、インスタンスが動作を再開するときに必要なデータをインスタンスメモリ (RAM) に格納できません。よって、不適当です。
- 選択肢の記載の通り、休止状態が有効なインスタンスでアプリケーションを実行し、シャットダウンの前にインスタンスを休止状態にすることで、再開時に必要なデータがインスタンスメモリ (RAM) に格納されます。よって、適当といえます。
- アベイラビリティゾーンをメモしておき、再起動時にそのアベイラビリティゾーンで再起動しても、インスタンスメモリ (RAM) にデータを格納できません。そのため、不適当です。
第6問
問題文
企業は、VPC で Amazon EC2 インスタンスでモニタリングアプリケーションを実行する予定です。インスタンスへの接続は、そのプライベート IPv4 アドレスを使用して行われます。ソリューションアーキテクトは、アプリケーションに障害が発生して到達不能になった場合に、トラフィックをスタンバイインスタンスに迅速に送信できるソリューションを設計する必要があります。
これらの要件を満たすアプローチはどれですか?
- プライベート IP アドレスのリスナーで構成されたアプリケーションロード バランサーをデプロイし、ロードバランサーにプライマリインスタンスを登録する。障害発生時に、インスタンスを登録解除してセカンダリインスタンスを登録する。
- カスタム DHCP オプションセットを構成する。プライマリインスタンスで障害が発生したときに、同じプライベート IP アドレスをセカンダリインスタンスに割り当てるように DHCP を設定する。
- プライベート IP アドレスで設定されたインスタンスにセカンダリエラスティックネットワークインターフェイス (ENI) を接続する。プライマリインスタンスが到達不能になった場合は、ENI をスタンバイインスタンスに移動する。
- Elastic IP アドレスをプライマリインスタンスのネットワークインターフェイスに関連付ける。障害発生時にElastic IP とプライマリインスタンスの関連付けを解除し、セカンダリインスタンスに関連付ける。
回答
3
解説
ポイントは Amazon EC2 インスタンスのプライベート IPv4 アドレスを使って通信していること、障害発生時にはトラフィックをスタンバイインスタンスへ迅速に送信できる必要があることです。この点を踏まえると接続元はプライマリインスタンスやセカンダリインスタンスを意識せず接続したい、つまり、プライマリインスタンスからセカンダリインスタンスに切り替わっても、アクセスに使用するプライベート IPv4 は変わらないと思われるので、答えが見えてきます。
- ロードバランサーを使うというのはある意味正しいですが、プライマリインスタンスの登録を解除し、セカンダリインスタンスを登録するというのは試してみるとわかりますが、通信可能な Healthy 状態になるまで思いのほか時間がかかります。
また、要件ではAmazon EC2 インスタンスのプライベート IPv4 アドレスを使うということですが、アプリケーションロードバランサーを使うとアプリケーションロードバランサーの IPv4 アドレスを使うことになり(厳密には、アプリケーションロードバランサーの DNS 名を名前解決して得られる IPv4 アドレス)、選択肢としては不適当と考えます。
また、アプリケーションロードバランサーは負荷に応じて機能を提供するノードが増えたり減ったり切り替わったりするため、その都度、IP アドレスも更新されてしまいます。- DHCP オプションセットで選択肢にあるような プライマリインスタンスで障害発生時にセカンダリインスタンスに同じ IP アドレスを割り当てるような設定はできません。そのため、不適当です。
- セカンダリエラスティックネットワークインターフェイス (ENI) であれば、割り当てるインスタンスを変更するのも迅速に行えるため、使用するローカル IPv4 アドレスを変更することなく、接続することが可能です。よって、適当といえます。
- Elastic IP アドレスはパブリック IP アドレスを固定化して利用するためのサービスです。要件はプライベート IPv4 アドレスとあるため不適当です。
第7問
問題文
分析会社は、ユーザーにサイト分析サービスを提供する予定です。このサービスでは、ユーザーの Web ページに、同社の Amazon S3 バケットに対して認証済み GET リクエストを行う JavaScript スクリプトが含まれている必要があります。
スクリプトを正常に実行するため、ソリューションアーキテクトが行うべきことは何ですか?
- S3 バケットでクロスオリジンリソース共有 (CORS) を有効にする。
- S3 バケットで S3 バージョニングを有効にする。
- ユーザーにスクリプトの署名付き URL を提供する。
- パブリック実行権限を許可するようバケットポリシーを設定する。
回答
1
解説
ユーザーの Web ページ に含まれている JavaScript から Amazon S3 バケットに対して認証済み GET リクエストを行うことが要件になっています。Web ページが格納されているユーザーの Web サーバから分析会社の Amazon S3 バケットへ JavaScript でアクセスできる必要があります。Web ブラウザには HTML ファイルや JavaScript ファイルを読み込んだ Web サーバー(オリジンサーバー)と異なるサーバーからデータを取得すること(クロスドメイン通信)を拒否する仕組みがあります。つまり、CORS(Cross-Origin Resource Sharing)の設定が必要ということです。
- 上記の通り、JavaScript からアクセスするには、 CORS の設定が必要で、 S3 バケットにはその機能があります。よって適当といえます。
- S3 バージョニングの設定は S3 バケット上に格納したオブジェクトのバージョン管理を行い、必要に応じて復元するための機能です。そのため、要件とは関係がないため、不適当です。
- 署名付き URL を利用することで S3 上のオブジェクトにアクセスできるようにはなりますが、その URL は有効期限が定められており、JavaScript に含めるには不適切であると考えます(有効期限が切れるたびに更新しないとならない)。もちろん、異なるサーバーからのアクセスは、やはりCORSの有効化が必要です。そのため、不適当です。
- パブリック実行権限と同じ名前の機能は S3 の設定にはありませんので、パブリック読み取り許可、パブリック書き込み許可のことだと考えてみますが、やはり、JavaScript からのアクセスであれば、 CORS の有効化が必要になるため、不適当です。
第8問
問題文
企業のセキュリティチームは、クラウドに保存されているすべてのデータを、オンプレミスに保存された暗号化キーを使用して保管時に必ず暗号化する必要があります。
これらの要件を満たす暗号化オプションはどれですか。(2 つ選択してください。)
- Amazon S3 管理キー (SSE-S3) でサーバー側の暗号化を使用する。
- AWS KMS 管理キー (SSE-KMS) でサーバー側暗号化を使用する。
- 顧客が提供するキー (SSE-C) でサーバー側暗号化を使用する。
- クライアント側の暗号化を使用して、保存時の暗号化を提供する。
- Amazon S3 イベントによってトリガーされる AWS Lambda 関数を使用し、顧客のキーを使ってデータを暗号化する。
回答
3,4
解説
オンプレミスに保存された暗号化キーを使用するのが要件として記載されています。つまり、クライアント(オンプレミス)側で暗号化キーを管理して暗号化するものが要件を満たす暗号化オプションになります。
- この選択肢では、鍵の生成や管理が、Amazon S3となってしまい、オンプレミス側に保存された暗号化キーを使いません。よって、不適当です。
- この選択肢では、鍵の管理が、Amazon KMS となってしまい、オンプレミス側に保存された暗号化キーを使いません。よって、不適当です。
- 顧客が提供するキー、つまり、今回でいえばオンプレミス側に保存されたキーを使用して、サーバー側暗号化するので,適当です。
- クライアント側(オンプレミス側)の暗号化ということなので、適当といえます
- オンプレミスに保存されたキーで暗号化できないので不適当です。
第9問
問題文
規制要件により、企業はアクセスログを最低 5 年間維持する必要があります。一度保存された後のデータにアクセスすることはほとんどありませんが、必要に応じて 1 日前に通知することでアクセスできなければなりません。
これらの要件を満たす最もコスト効率の高いデータストレージソリューションは何ですか?
- Amazon S3 Glacier ディープアーカイブストレージにデータを保存し、ライフサイクルルールを使用して 5 年後にオブジェクトを削除する。
- データを Amazon S3 標準ストレージに保存し、ライフサイクルルールを使用して 30 日後に Amazon S3 Glacier に移行する。
- Amazon CloudWatch ログを使用してデータをログに保存し、保存期間を 5 年に設定する。
- Amazon S3 標準頻度の低いアクセス (S3 Standard-Ia) ストレージにデータを保存し、ライフサイクルルールを使用して 5 年後にオブジェクトを削除する。
回答
1
解説
5年間保持する必要があり、一度保存されるとほとんどアクセスがない。しかし、依頼などを受けたら1日でデータにアクセスできないとならない。逆に言えば、取り出すまで1日の猶予はあるということです。
これらの要件を満たすものが正解です。
いったん、 Amazon S3 の各ストレージクラスや仕様について、確認しましょう。
Amazon S3 は S3 1ゾーン以外は格納されたオブジェクトを複数のアベイラビリティゾーンに複製し、アベイラビリティゾーンに障害があってもオブジェクト破損にならないように設計されています。
- S3 標準
- 高頻度アクセスの汎用ストレージ用
- S3 Intelligent - Tiering
- 未知のアクセスパターンのデータ、またはアクセスパターンが変化するデータ用
- アクセスパターンに応じて自動的に高頻度アクセス用の階層や低頻度アクセス用の階層にオブジェクトを移動させ、コスト低減が可能
- S3 標準 - 低頻度アクセス
- 長期間使用するが低頻度アクセスのデータ用
- S3 標準と比較してストレージ利用料が安価
- S3 1ゾーン - 低頻度アクセス
- 長期間使用するが低頻度アクセスのデータ用、1つのアベイラビリティゾーンのみ使うため、S3 標準 - 低頻度アクセスと比較すると安価
- オブジェクトが格納されているアベイラビリティゾーンで障害が発生するとデータ破損の可能性がある
- S3 Glacier
- アーカイブ用とのストレージクラスのため、利用料が S3 標準 や 各種低頻度アクセスと比較して安価
- データの取得に時間がかかり、数分から数時間の3種類で設定が可能
- 長さによって取り出しにかかる料金に差がある
- S3 Glacier ディープアーカイブ
- 7~10 年以上といった長期アーカイブおよびデジタル保存用
- 1年に 1~2 回程度しか取り出さないデータ保存用途のため、 S3 Glacier よりもさらに安価
- 取り出し時間は 12 時間以内
その他、各機能の詳細は以下の Web サイトにまとめられています。
https://aws.amazon.com/jp/s3/storage-classes/料金についてはこちら。
https://aws.amazon.com/jp/s3/pricing/
- 選択肢の中で最もコスト効率が高く、要件をすべて満たしているため適当といえます。
- Amazon S3 Glacier へ移すのを30日待つ必要がないこと、5年後に削除するようになっていないなどから、不適当です。
- Amazon Cloudwatch ログにデータを格納すると、検索しやすいといったメリットはありますが、保存量に対する課金額が Amazon S3 や Amazon S3 Glacier と比較して高価なため、コスト効率が低いと言わざるを得ません。そのため、不適当です。
- 一見よさそうですが、Amazon S3 Standard-Ia は Amazon Glacier と比較すると、コスト効率が低いと言わざるを得ません。そのため、不適当です。
第10問
問題文
企業は、データ処理ワークロードを実行するためにリザーブドインスタンスを使用しています。
夜間のジョブは通常、実行に 7 時間かかり、10 時間以内に完了する必要があります。同社は、毎月末に需要が一時的に増加するため、現在のリソースの容量ではジョブが制限時間以内に終わらないと予想しています。
いったん開始された処理ジョブは、完了する前に中断できません。
同社は、できる限りコスト効率の高い容量を提供できるソリューションを実装したいと考えています。ソリューションアーキテクトは、これを達成するために何をすべきでしょうか?
- 需要の高い期間中にオンデマンドインスタンスをデプロイする。
- 追加インスタンス用に 2 つ目の Amazon EC2 予約を作成する。
- 需要が高まる期間中にスポットインスタンスを展開する。
- ワークロードの増加をサポートするために、Amazon EC2 予約のインスタンスのインスタンスサイズを増やす。
回答
1
解説
問題から推察するに、毎晩夜間ジョブが走り、完了まで7時間、長くても10時間以内に完了しないとならないという制限がある。その処理に対しては、リザーブドインスタンス(RI)で処理能力を確保している。しかし、毎月末には需要がひっ迫し、現状の処理能力では、制限時間内に完了しない恐れがあるので、コスト効率が高い方法で対処できるものを選択します。
- 必要な時に必要なだけ利用できるクラウドらしい対処の仕方です。適当といえます。
- 月末のみに必要な処理能力に対して、 リザーブドインスタンスを追加するのはやりすぎです(仮に月末2日だけ処理が重いとしても、年間で24日分であり費用対効果が期待できません)。よって、不適当です。
- オンデマンドインスタンスより安価なため、一見、適当であるように思えますが、問題文の中に「いったん開始された処理ジョブは、完了する前に中断できません」とあるので、落ちてしまう可能性があるスポットインスタンスは適しません。よって、不適当です。
- 現状の処理能力で月末以外は問題がないため、リザーブドインスタンスのインスタンスサイズを大きくする(増やす)のは月末以外に余剰が生まれてしまうため不適当です。
サンプル問題以外の学習リソース
様々な学習リソースが用意されています。
以下はその一例です。
- AWS 公式の模擬問題
- AWS 認定サイトから受験可能です。
- 認定準備ワークショップに参加
- AWS が定期的に開催しているワークショップに参加して学ぶことが可能です
- 試験対策テキスト
まとめ
このソリューションアーキテクトアソシエイトは前回お伝えしたクラウドプラクティショナーがリリースされる前は、AWS エンジニアの入門的資格と捉えている方が多かった印象があります。
AWSを利用するシステムを設計構築している SE の皆様におかれましては、ある程度の経験を積んだら挑戦してみてはいかがでしょうか。記載されている会社名、製品名、サービス名、ロゴ等は各社の商標または登録商標です。
- 投稿日:2020-10-12T12:36:13+09:00
【AWS初学者用】AWS グローバルインフラインストラクチャとは?
本記事について
本記事はAWS初学者が学習していく中でわからない単語や概要をなるべくわかりやすい様にまとめたものです。
私自身もAWS初学者なので、もし誤りなどありましたらコメントにてお知らせいただけるとありがたいです。AWS グローバルインフラインストラクチャとは?
まずはじめにAWS公式サイトの説明を載せておきます。
AWS グローバルクラウドインフラストラクチャは、安全性、広範性、信頼性に最も優れたクラウドプラットフォームであり、世界中のデータセンターから 175 以上の完全な機能を提供しています。一度のクリックで世界中にアプリケーションワークロードをデプロイする必要がある、あるいは 1 桁台のミリ秒のレイテンシーでエンドユーザーにさらに近い特定のアプリケーションを構築しデプロイしたいなど、どんな場合においても AWS は必要なときに必要な場所で、クラウドインフラストラクチャを提供します。
世界中に何百万ものアクティブなお客様と数万のパートナーを有し、AWS は最も動的で最大規模のエコシステムを備えています。スタートアップ企業、エンタープライズ、公共部門の組織など、ほとんどの業界やあらゆる規模のお客様が、考えつく限りのユースケースを AWS で実行しています。予想通り理解が深まりませんでした...
なのでまずは私が調べた上での概要を書いていきます。AWS グローバルインフラインストラクチャの概要
- リージョン リージョンは「地域」のことを指す単語です。AWSは世界中にデータセンターを持っていて、そのまとまりをリージョンと呼びます。(2020年10月12日現在 24のリージョンが存在します)

- アベイラビリティーゾーン(AZ) アベイラビリティーゾーン(AZ)はリージョン内に複数あるデータセンターの集合体を指します。 AZが複数存在する理由はデータセンターに何らかの障害が発生したときに、他のAZでシステムを継続することを可能にするためです。(2020年10月12日現在 77のAZが存在します)
- エッジロケーション エッジロケーションはDNSサービスを提供するためのデータセンターのことです。 ユーザーから最も近いエッジロケーションを利用するので、低いレイテンシでコンテンツを配信できます。
※「ローカルリージョン」というリージョンもあり、広範囲による災害などが起きた際に遠隔地でシステムの復旧・再開を行うためのリージョンです。日本には大阪ローカルリージョンが存在します。
AWSサービスの範囲
AWSのサービスは各サービスのレベルによって以下の3つに分類できます。
1. グローバルサービス
リージョン外、要するにリージョンに縛られないサービスのことです。
例)IAM , CloudFront , Route 53
2.リージョンサービス
リージョン内でのみ利用できるサービスのことです。
例)VPC , DynamoDB , Lambda
3. アベイラビリティーゾーンサービス
AZ内で利用するサービスのことです。
例) EC2 , RDS※S3はグローバルサービスに分類されますが、データはリージョン内に保管されます。
まとめ
AWS グローバルインフラインストラクチャ世界中に存在する「リージョン」、「アベイラビリティーゾーン」、「エッジロケーション」により構成され、安全性、信頼性・セキュリティに優れたクラウドプラットフォームです。
- 投稿日:2020-10-12T11:12:58+09:00
実践編!Amazon S3/Google Cloud Storage エンタープライズデータ保護のテクニック 前編
はじめに
パブリッククラウドで様々なパイプライン処理に使われるクラウドストレージですが、昨今、データレイクや永続データの格納先としての利用も増えています。一方、クラウド環境のオブジェクトストレージは強固な耐久性と可用性で知られています。
データ保護が必要な理由
まずはこちらの動画をご覧ください!
AWSでもGCPでもそのサービスに対して”責任共有モデル”という概念が適用されています。
例)AWS の共有責任モデル
https://aws.amazon.com/jp/compliance/shared-responsibility-model/
こちらのURLにあるようにお客様のデータ、データの整合性、設定内容、暗号化、トラフィックの保護については全てお客様で責任を持つように定義されています。例えばAWSが担保するのはAWSのインフラストラクチャであってそのデータではありません。したがって、これらのデータは自己の責任において保護、担保する必要があります。これはオブジェクトストレージに存在するデータでも同様です。これからそのデータを保護するための仕組みについてご紹介します。
s3fs
s3fs ツールは、S3 ストレージを NFS として公開します。そのファイルシステムが NetBackup ホストにマウントされ、マウントポイントがバックアップセレクションとして設定されている場合、NetBackup でS3ストレージを保護できます。
メモ:s3fs はオープンソースプロジェクト (https://github.com/s3fs-fuse/s3fs-fuse) です。ベリタスはs3fsの開発やサポートには関与していません。s3fs で見つかった問題は、s3fs プロジェクトチームへ直接連絡する必要があります。NetBackup は POSIX 準拠のファイルシステムをサポートしており、これは OSS でも同様です。s3fs がPOSIX 準拠のインターフェースを提供する限りはその属性をサポートします。
検証環境
• s3fs バージョン 1.85
• プラットフォーム- RedHat Linux 7.5 および SuSE Linux 12.3
• Veritas NetBackup 8.2s3fs はネットワークマウントのためにNetBackup メディアサーバーに構築します。
検証シナリオ
検証は 2 つのシナリオで実施しています。
オンプレミス
NetBackup マスターサーバーとメディアサーバーをベリタスのオンプレミスのネットワークに構築しています。バックアップは MSDP または アドバンストディスクのストレージユニットに保存されています。このシナリオでクラウドストレージを利用すると、データがクラウドストレージからダウンロードされ、アップデートやリストアではクラウドストレージにデータが再アップロードされます。パブリッククラウド
NetBackup マスターサーバーとメディアサーバーを EC2 インスタンスに構築しています。バックアップデータは同じリージョンの S3 バケットを使用して CloudCatalyst サーバーに転送されています。これにより、データは S3 バケットで移動しますので、データ転送のコストが削減され、転送速度が向上します。ただし、EC2 インスタンスには追加コストがかかります。クラウドプロバイダー
プライマリの検証プラットフォームとしてAmazon S3 を利用します。また、AWS GovCloud、Google Cloud Platform、HITACHIにおけるサニティチェックを実施しています。
C2S は AWS GovCloud ではサポートされていません。
IAM ロール (s3fs および NetBackup でサポートされています)を利用します。Veritas NetBackupと s3fs を設定する
- s3fs ツールをダウンロードし、メディアサーバーにインストールします。サイトに記載されている手順に従います。
https://github.com/s3fs-fuse/s3fs-fuse- man s3fs で s3fs に渡すことができるオプションのリストを取得します。
- S3 バケットをマウントします。次のコマンドを実行します。
/usr/bin/s3fs <バケット名> <マウントポイント> -O passwd_file=<passwd_file> -o storage_class=<ストレージクラス> -o dbglevel=<デバッグレベル> -o curldbg
- NetBackup のバックアップセレクションとして、マウントポイントまたはそのサブディレクトリとファイルを使用します。ワイルドカードやマルチストリームディレクティブなどの標準的な NetBackup の手法を使用できます。詳細は以下を確認してください。
複数のデータストリームを許可する
https://sort.veritas.com/doc_viewer/#/content?id=49563028-136776245-0%2Fv42177506-136776245
NetBackup でワイルドカードを使用する
https://sort.veritas.com/doc_viewer/#/content?id=49563028-136776245-0%2Fv41588053-136776245なお、s3fs のロギングを有効にするには、syslogd/rsyslogd を設定します。
データを保護するための準備はこれだけです!
おわりに
今回はデータを保護が必要な背景、今回の検証環境やその準備について掲載しました。結構、あっけないですね!次回はアクセラレーターやリカバリにおける注意事項やプラグインの制限や設定なについて、ハードボイルドな感じで公開します!
商談のご相談はこちら
本稿からのお問合せをご記入の際には「コメント/通信欄」に#GWCのタグを必ずご記入ください。ご記入いただきました内容はベリタスのプライバシーポリシーに従って管理されます。
その他のリンク
【まとめ記事】ベリタステクノロジーズ 全記事へのリンク集もよろしくお願い致します!

- 投稿日:2020-10-12T10:53:23+09:00
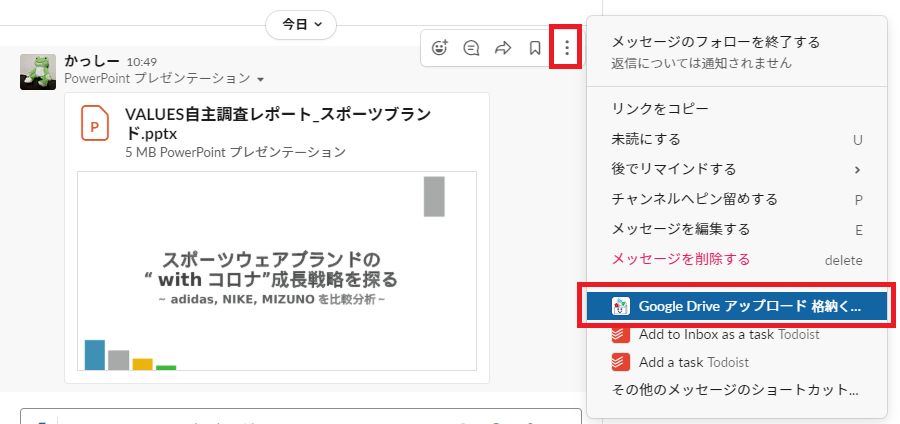
Slackに共有されたファイルをサーバーレスでGoogle Driveにアップロードする仕組みを作るまで
はじめに
社内の要望を受け、Slackに共有されたファイルをGoogleドライブに簡単にアップロードできるSlackアプリを完全サーバーレスで開発した話です。
「要件を整頓する」「アーキテクチャを考える」「Lambdaを利用して開発する」など…
全てが初めてでしたので、どうか温かい目で読んでいただければと思います。作ったもの
格納くん
(弊社の画伯にアイコンを作成いただきました!)
格納くんは社内の資料管理用に作られたSlackアプリによるツールです。使い方
ファイルが添付されたメッセージのメニューから起動します。
開いたフォームでメッセージに添付されたファイルからGoogleドライブにアップロードしたいファイルを選択する。
アップロードしたいファイルのファイル名や格納先のフォルダを選択して、Googleドライブへアップロードする。
Slackの元メッセージのスレッドに格納されたファイルの情報がメッセージで送られてくる。
Googleドライブにアップロードされる。
スプレッドシートにログが出力される。
便利ポイント
Googleドライブへのファイル格納がSlackでの操作のみでできる。
Slackだけの操作でGoogleドライブへのファイル格納が可能。
→時間がないときはとりあえずファイルだけSlackにあげておくだけでもOK。ファイルアップロードした人と資料を格納する人が別の人でもOK。
などなど
開発のキッカケ
とある相談
以前、Slackのワークフローでこんな
くだらないもの(長濱ねるからメッセージが届く申請依頼ワークフロー)を作っていたからでしょうか。社内で相談を受けました。Slackに共有されたファイルをGoogle Driveに簡単にアップロードする仕組みがほしい
- Slackでワークフローのようなフォームに必要事項(アップロード先のフォルダ、ファイル名など)を入力し、送信。
- フォームの入力内容に応じて、ファイルをGoogle Driveにアップロードする。
- 同時にGoogle Driveにアップロードされたファイルをスプレッドシートなどに一覧化する。
こんなものが欲しいとのこと。
なるほど…これは色々と考えることがありそう…
気合を入れ、大事に検討していきました。
使用する技術・機構の検討
まず、ユーザーの操作ごとにポイントとなる検討事項を整頓しました。
1.Slackでワークフローのようなフォームに必要事項(アップロード先のフォルダ、ファイル名など)を入力し、送信。
- トリガーをどうするか
- フォーム表示をどうするか
2.フォームの入力内容に応じて、ファイルをGoogle Driveにアップロードする。
- フォームの入力内容をどう受け取るか
- SlackのファイルをダウンロードしてGoogle Driveにアップロードするのにどの技術や機構を使うか
以上のような点に留意して、使用する技術・機構の検討をしていきました。
トリガー
Event APIを利用して、Slackにファイルがアップロードされたのをトリガーにフォームを表示しようと考えました。
しかし、以下のような懸念が出てきました。
- ファイルアップロードされるたびにフォームが表示されるのは、ユーザーからするとさすがに鬱陶しい
- ファイルアップロードのイベントを感知して動くEvent APIはチャンネルごとに設定する必要があり、チャンネルが増えるごとに設定することになるため、先々の運用がしんどそう
メッセージアクション
どうしよう…と思いつつ調べていたら、この記事を見つけました。
Slack メッセージ・アクション API を使ってディスカバラブルなアプリを作ろう
メッセージアクションといって、メッセージのメニューをクリックすることでそのアクションをトリガーにしたEvent APIのようです。Slackのメッセージ右側から開くことができるメニュー
- ファイルが添付されたメッセージごとにフォームを表示させることができる
- メッセージアクションはチャンネルに対しての設定ではなく、アプリに対しての設定でワークスペース全体で使える
ということで、今回の要件をぴったり満たすのでトリガーはメッセージアクションを採用しました!
Slack API views.openメソッドによるフォーム(モーダル)表示
メッセージアクションをトリガーに表示するSlackでフォーム(モーダル)を表示させる技術として、Slack APIのviews.openメソッドを利用するとフォームが表示できるようなので、こちらを使うことにしました。
(公式ドキュメント上ではフォームのことをモーダルという表現なので、以降モーダルと表現します)Block KitでイケてるUIが作れる!
views.* メソッドで表示することができるモーダルですが、これまでSlack APIで用意されていたフォーム表示のAPIにdialog.openというメソッドがありました。
しかし、2019年から2020年にかけてのSlack APIの仕様変更に伴って、dialog.* メソッドに代わって出てきたメソッドがviews.* メソッドとなります。views.* メソッドは、従来のdialog.* メソッドに比べて入力や表示のバリエーションが増えています。
今回はモーダルで使用しましたが、メッセージやアプリのホームタブの表示などにも活用できます。
詳しくは、Slack APIの公式ドキュメントや参考にさせていただいた記事を是非ご覧ください。今回参考にさせていただいた記事はこちら
Block KitでリッチなSlackアプリを作る -乗換経路案内での実例-
Block Kit Builder を使ってインタラクティブな Slack アプリをプロトタイピングしようSlackとのやり取りとGoogle Driveにアップロードする機構
弊社ではこれまで社内でツールを作るとなるとEC2でたてたサーバーでツールを開発しており、今回もその流れにのって、開発しようと思ったのですが、
サーバーレスに興味があり自身の成長も期待できると思い、
今回は、サーバーレスでの開発に挑戦しました!
※個人的に強めの思いがあり、今回のツールで一番こだわったポイントです。アーキテクチャ
検討を重ね、最終的なアーキテクチャは上のようになりました。
SQS
SQSで処理制御しているのが、今回のアーキテクチャの大きなポイントです。
SQSを通して処理を制御することで、Slack上で複数のユーザーが同時にツールを動かしたときに競合することないようにしました。
そのため、LambdaがSlackとのやり取り用、Google Driveへのアップロード用の2つに分けることにしました。API Gateway/Lambda(Slackとのやり取り)
後述しますが、今回はSlackとインタラクティブなやり取りをすることになり、Slackからのリクエストを受けるエンドポイントが必要となっため、API Gatewayを使用しました。
こちらのLambdaでは、以下のような処理を行っています。
- メッセージアクションを受けて1つ目のモーダル表示
- 1つ目のモーダルでのアクション(block_actions)を受けて、2つ目のモーダルを表示
- モダールの回答を受けて、
- その他、ダイレクトメッセージやファイル添付のないメッセージからのメッセージアクション時のモーダル表示(使用不可の旨)
Lambda(Google Driveへのアップロード)
SQSからのメッセージを受けて、Slackから対象のファイルをダウンロードして、Google Driveへアップロードする部分です。
UXとSlack APIによるモーダル表示
アーキテクチャ以上に躓いたのが、Slack APIでのモーダル表示とUXの部分です。
複数のファイルが添付されたメッセージはどうする?
アーキテクチャを考えていた段階では1つのファイルが添付されたメッセージしか想定してなかったのですが、よくよく考えてみればSlackに複数ファイル添付することありますよね…(気づくの遅いですね)
そこで、モーダル内でファイル選択できるようすることにしました。
モーダルが更新されない…
ユーザーの入力工数を省く観点から実装したかったのが、
ファイル選択されるとデフォルトで元のファイル名がフォームの入力欄に入力されるという仕組みです。views.openメソッドで開いた先に載せた画像のモーダルを、views.updateメソッドでファイル名の入力欄のだけを変えたモーダルに更新しようとしたところ、モーダルにまったく変化がありませんでした。
その後、views.updateメソッドであれこれと試したいたところ、更新される場合とされない場合がありました。
views.updateメソッドで更新されない場合(テキストボックス内のデフォルト文字列追加)
views.updateメソッドで更新される場合(モーダルの項目追加)
views.updateメソッドでモーダルの更新が適用されるのは、「表示されるモーダルのBlockの構成が変わったときのみ」ということがわかりました。。(さあ困った…)
UXを考え直す
views.updateメソッドに代わって、views.openで開いたモーダルの上にもう一つ別のモーダルを載せるviews.pushメソッドの使用を検討し、ファイル選択のモーダルをだけを先に行ってその後にファイル名や格納するフォルダの選択のモーダルを表示させることにしました。
こうすることで、ファイル選択のUXは残しつつ、デフォルトでファイル名が入っている状態のモーダルを表示することができます。
実装
実装したコードの一部です。
Python初心者の拙いコードですので、ある程度目を瞑っていただけると大変ありがたいです。。ファイル選択を受けて、ファイル情報を入力するモーダルを表示する
slack_client = WebClient(token=os.environ['SLACK_TOKEN']) if type == 'block_actions': #views.push # ファイル選択が行われた場合 if body['actions'][0]['action_id'] == 'select_file' and body['actions'][0]['block_id'] == 'upload_file': modal_template_open = open('modal_template.json', 'r') #modal_template.jsonというモーダルのテンプレをLambda内にもっておく modal_template = json.load(modal_template_open) # 受け取ったファイルの情報から元ファイルのファイル名 defalt_file_name = os.path.basename(body['actions'][0]['selected_option']['text']['text']).split('.', 1)[0] # 表示するモダールの構築 view = {} view['type'] = body['view']['type'] view['callback_id'] = body['view']['callback_id'] view['title'] = body['view']['title'] view['submit'] = modal_template['submit'] view['close'] = modal_template['reselectViewClose'] # ...省略(モーダルの中身の構築) data = json.dumps(view, ensure_ascii=False) response = slack_client.views_push( trigger_id=body['trigger_id'], view=data )
- 選択されたファイルの元のファイル名を取得し、pushで表示されるモーダルにデフォルトのファイル名として表示するようにしています。
モーダルの入力内容を受けて、SQSに諸情報を送る
if type == 'view_submission': submission_dict = {} submission_dict['state'] = body['view']['state']['values'] submission_dict['private_metadata'] = body['view']['private_metadata'] private_metadata_dict = json.loads(submission_dict['private_metadata']) private_metadata_dict['user_name']=body['user']['name'] submission_dict['private_metadata'] = json.dumps(private_metadata_dict) # private_metadataを加えた情報をSQSへ submission = json.dumps(submission_dict) sqs = boto3.client('sqs') #SQSへメッセージ送信 response = sqs.send_message(QueueUrl=os.environ['QUEUE_URL'], MessageBody=submission) #response_action clearで開いたmodalを全て閉じる return { 'isBase64Encoded': False, 'statusCode': 200, 'headers': {}, 'body': '{"response_action": "clear"}' }
private_metadataはSlackAPIで用意されているフィールドで、後続の処理で必要になる情報(今回の場合はユーザー情報やファイルの情報など)を裏側でずっと持ちつつ渡していくのに使えます。- views.openとviews.pushで2つ開いたモーダルを閉じるのに、Slackアプリに対して200番ので
{"response_action": "clear"}を返す必要があります。 参考ドキュメントGoogleドライブへのファイルアップロード
SQSからメッセージを受けるLambdaの一部になります。
SlackからLambdaの一時領域(
/tmp)にファイルをダウンロードLambdaには
/tmpディレクトリが用意されています。今回はダウンロードしてアップロードするまでのファイルの一時保存で/tmpディレクトリを使用しています。
公式ドキュメントによると、/tmpディレクトリの容量は512 MBとあるので容量の大きい動画ファイルだと対応しきれないものが出てくるかもしれないですが、大体のファイルは対応できるであろうということで…#download name,ext = ['ファイル名','拡張子'] url_private_download = 'Slackにアップロードされたファイルのダウンロードリンク' save_file_path = "/tmp/" + str(math.floor(time.time())) + name + ext headers = {'Authorization': 'Bearer ' + os.environ['SLACK_OATH_TOKEN'] } response = requests.get( url_private_download, headers=headers )Googleドライブへアップロード
今回は、GCPのサービスアカウントを利用してGoogleドライブへファイルをアップロードしています。
また、今回は仕様としてファイルに「タグ」をつける意味合いでGoogleドライブに格納するファイルの説明にタグとなる文字列をいれていくこととしています。(tag_strがその文字列)from googleapiclient.discovery import build from googleapiclient.http import MediaFileUpload from oauth2client.service_account import ServiceAccountCredentials def uploadFileToGoogleDrive(fileName,ext,localFilePath,drive_folder_id,file_tags): try: mimeType = mimetypes.guess_type(localFilePath)[0] tag_str = "" for tag in file_tags: tag_str += " "+tag service = getGoogleDriveService() file_metadata = {"name": fileName, "mimeType": mimeType, "parents": [drive_folder_id],"description":tag_str } media = MediaFileUpload(localFilePath, mimetype=mimeType , resumable=True) file = service.files().create(body=file_metadata, media_body=media, fields='id').execute() except Exception as e: logger.exception(e) def getGoogleDriveService(): scope = ['https://www.googleapis.com/auth/drive.file'] keyFile = 'utilserviceaccounts-×××××××××.json' # GCPのサービスアカウントのキーとなるJSONをLambda内に置く credentials = ServiceAccountCredentials.from_json_keyfile_name(keyFile, scopes=scope) return build("drive", "v3", credentials=credentials, cache_discovery=False)環境整備とバージョン管理(今後の課題)
格納くんは既に社内で運用をはじめており依頼を受け改修しているのですが、現状だと本番(実際に運用している環境)しか作っておらず、改修中は利用を控えていただくように都度周知して開発した私がタイムアタックのように改修作業をしてリリースしています。そのため、現在は本番と別に開発用の環境を作りつつバージョン管理(特にLambda)を行いスムーズにリリースができるように整備を進めています。整備についても、記事を書いてみたいと思います。
おわりに
完全サーバーレスでここまでできるとは、正直思ってませんでした。。
サーバーレスが世の中的に流行っているのも頷けるなと思いました。
今回の経験を活かし、もっと便利なSlackアプリをサーバーレスで開発していきたいです!使用技術
- AWS: API Gateway、Lambda、SQS
- GCP: Google Drive API、Google Sheets API
- Slack API
- 言語: Python 3.7(Lambdaにて)












- 投稿日:2020-10-12T09:51:20+09:00
INTERNAL ERROR: cannot create temporary directory! : Docker環境
RubyとRspecを学習中のゆーたです!
久しぶりに、自身のポートフォリオサイトを開いてみたら、本番環境で見たくない画面になっていました。
ただ、githubのdockerのissueにこの問題が上がっていたので、割と簡単に問題解決できました。
また、AWSでRDSを使っていたので、データベースは安全でした。
RDSは、コストが高いですが、精神的によろしいですね!!環境
- Docker 19.03.5
- docker-compose 1.25.2
- nginx 1.15.8
解決方法
解決方法は、コンテナのイメージを削除することです。
ただ、コンテナの中身の情報は、消えるかもしれないです...
そこは、情報があいまいでした。$ docker rm $(docker ps -a -q) $ docker rm -f $(docker ps -a -q) $ docker-compose build --no-cache原因
docker-composeのディスクのスペースが少なくなってくるとdocker-composeが起動しなくなるようです。
つまり、docker-composeファイルで、データを維持したり、処理をまとめすぎるとキャッシュが溜まっていき、docker-composeのディスク領域がなくなり、
INTERNAL ERROR: cannot create temporary directory!が起きるみたいです。参照

- 投稿日:2020-10-12T09:30:20+09:00
AWS Cloud9 でRuby on Rails の開発環境を構築する
はじめに
ふとRuby on Railsの勉強をはじめようと思い、環境構築をすることにしました。
せっかくなので、AWS Cloud9で環境構築をしようと思います。やること
この記事では、以下のことを実施します。
- AWS Cloud9環境構築
- Ruby 環境構築
- rvmを使用したruby version 2.5.1のインストールと切り替え
- Rails 環境構築
- gemを使用したrails version 5.2.1のインストール
AWS Cloud9環境構築
Cloud9は、クラウド環境でIDE(統合開発環境)を利用できるサービスです。
ブラウザ上で動くため、OSやその他環境が異なるPCでも同じ手順で開発環境を準備することができます。
特徴 - AWS Cloud9 | AWSCloud9環境作成
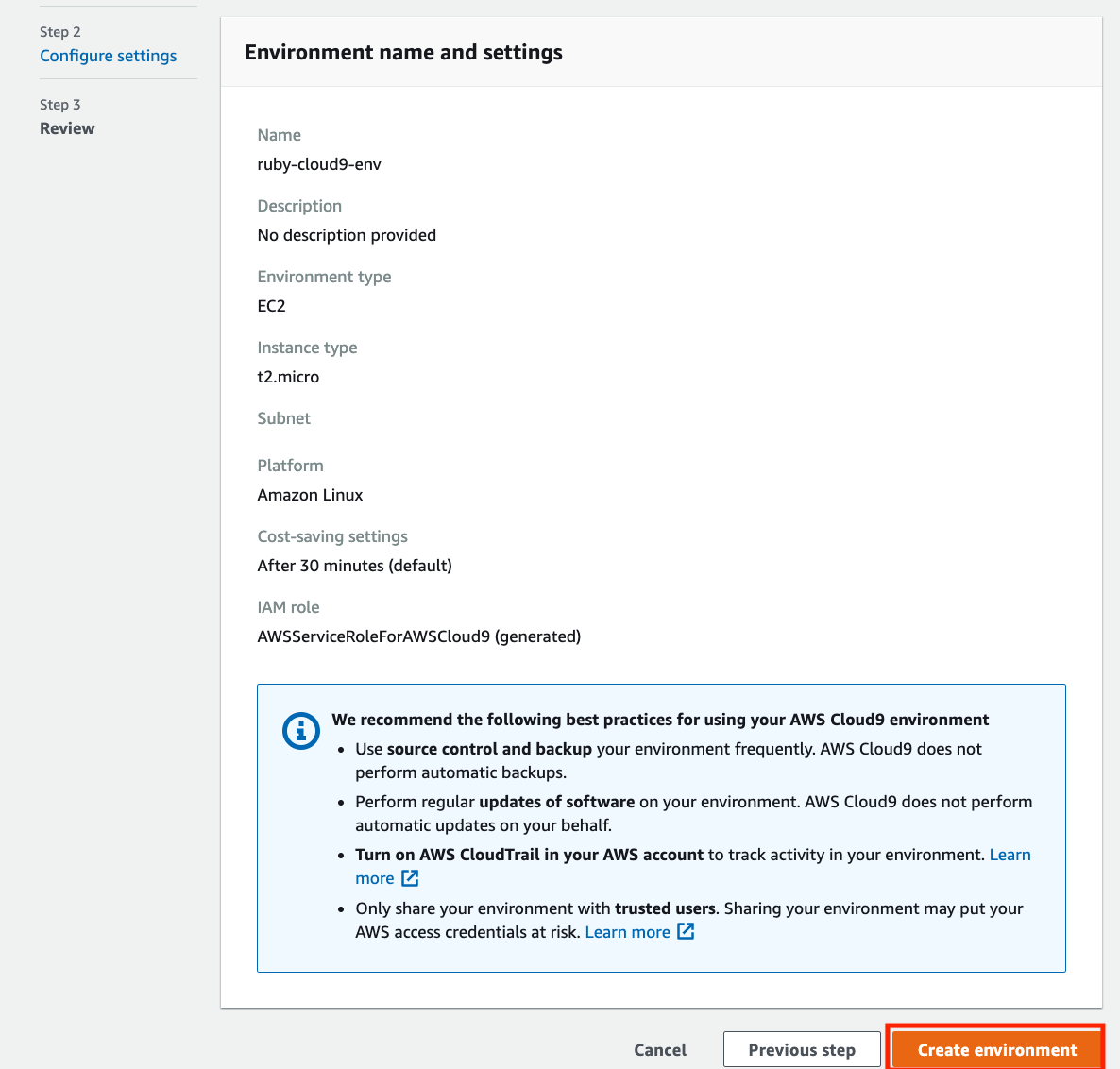
AWS マネジメントコンソールからCloud9の画面に遷移します。
Create enviroimentをクリックします。
環境設定
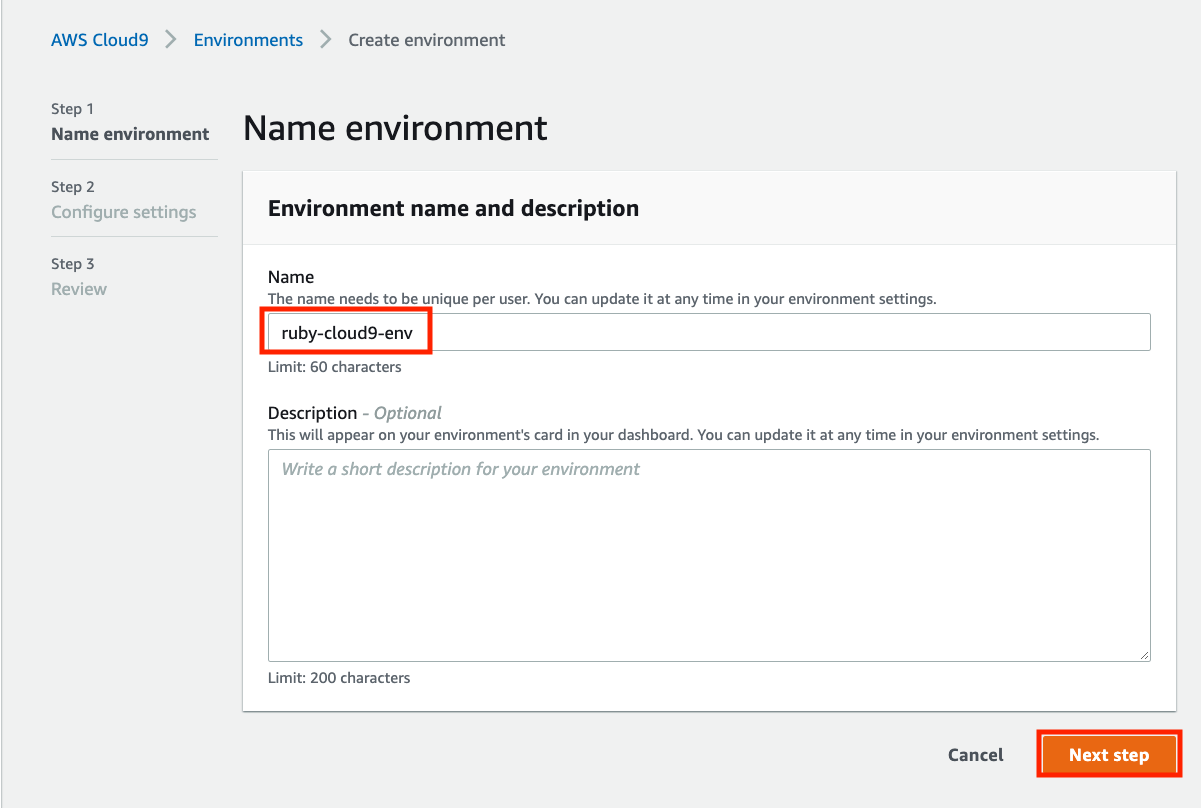
作成するCloud9環境の設定をしていきます。
NameにCloud9環境の名前をつけます。
自由に決定できるようですが、今回はruby-cloud9-envにします。入力できたらNext stepをクリックします。
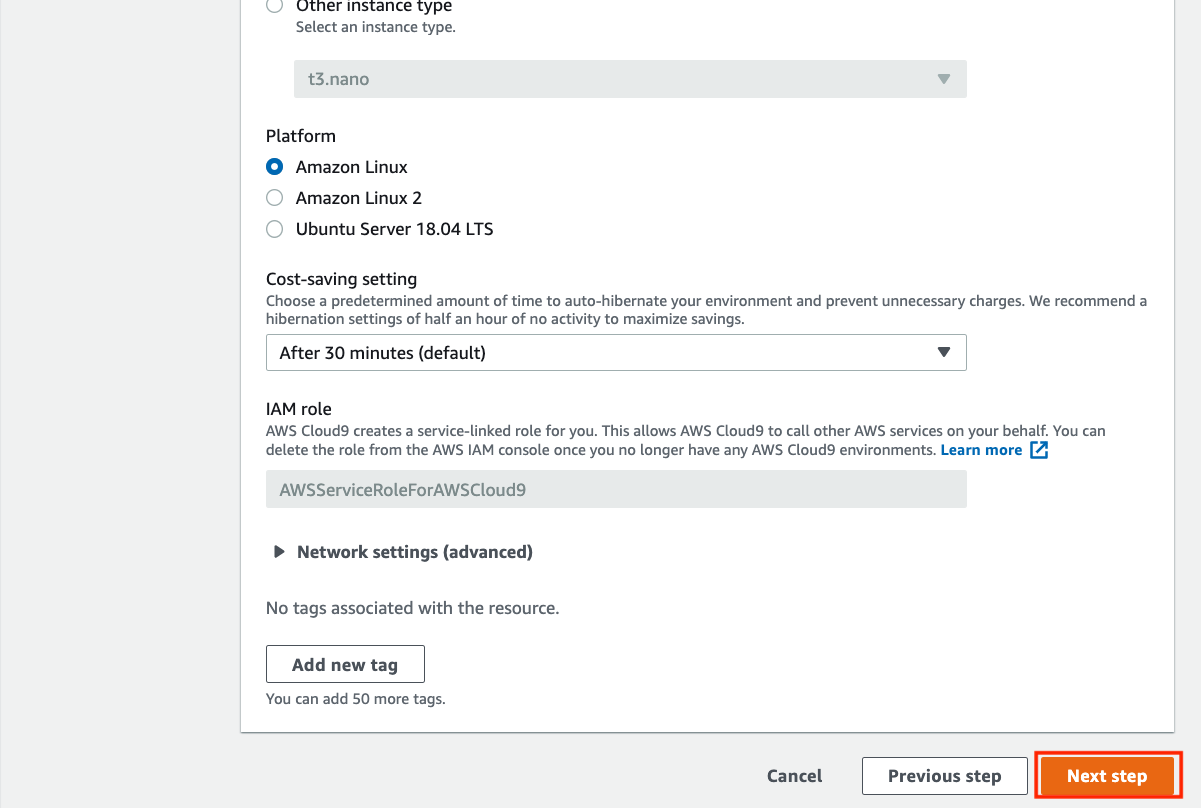
Cloud9環境に使用するEC2インスタンス(仮想マシン)の設定をします。
全てデフォルトで大丈夫です。Next stepをクリックします。
設定確認
構築する環境の設定を確認できます。
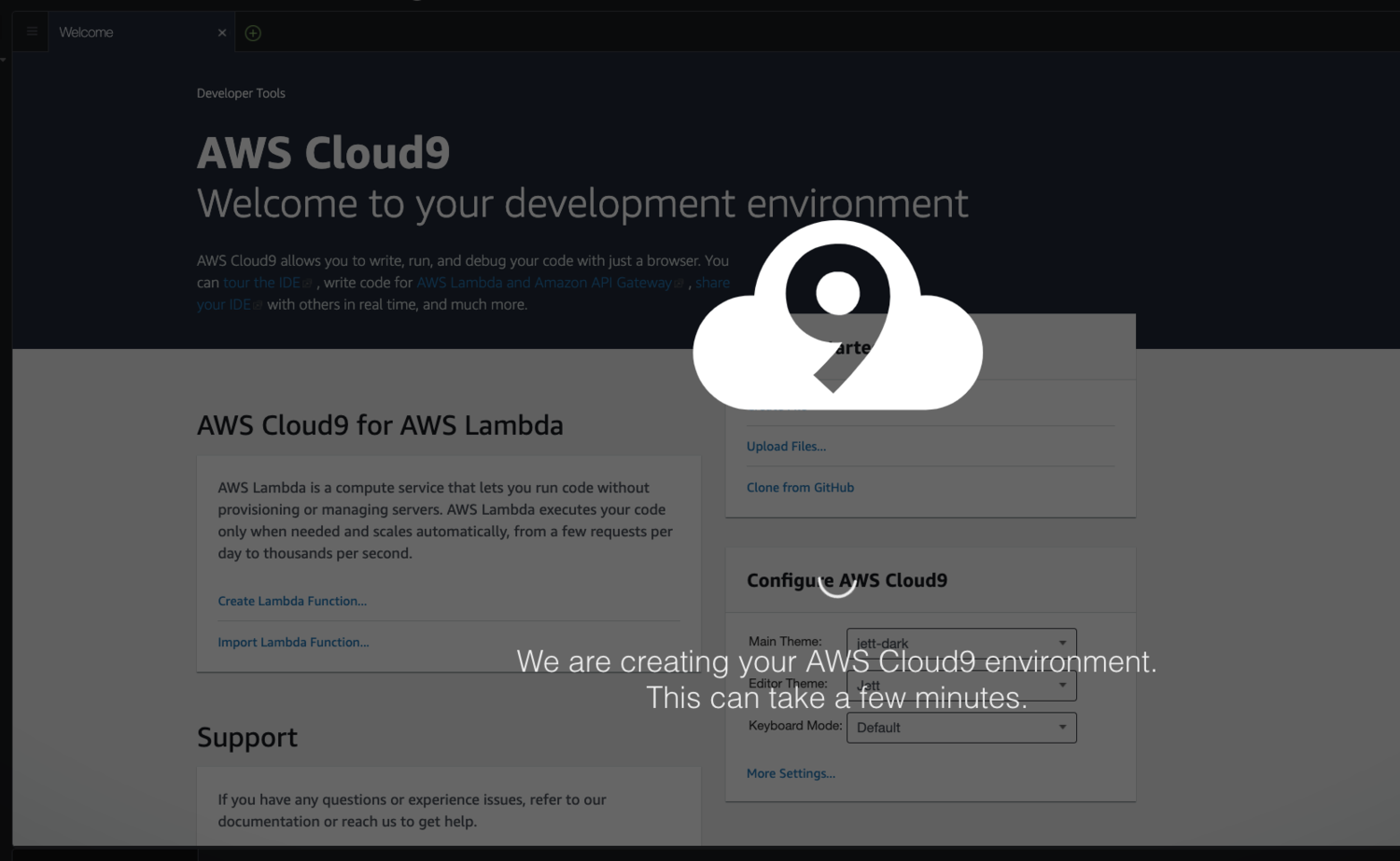
確認したらCreate enviroimentをクリックします。
Cloud9のIDE画面に遷移します。
少し待つと操作できるようになります。これでCloud9環境の構築は完了です。
次はCloud9での開発に適した設定変更をします。
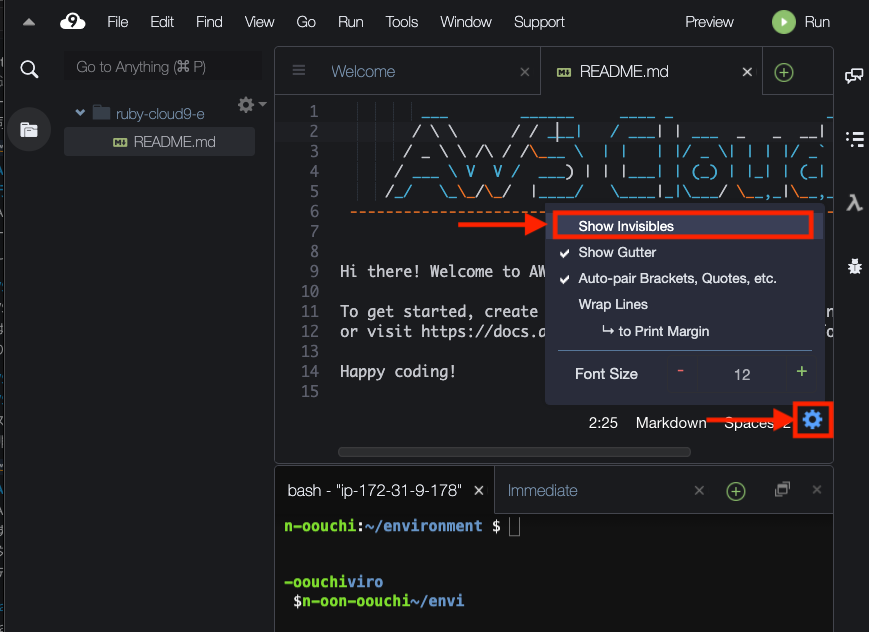
スペース可視化
スペース記号の可視化を行います。
テキストエディタの右下にある⚙歯車マークをクリックします。
設定が表示されるのでShow Invisiblesをクリックします。
Ruby 環境構築
ここからはRubyの環境構築をしていきます。
Cloud9画面下部にターミナルが表示されています。
ここでコマンドを実行していきます。
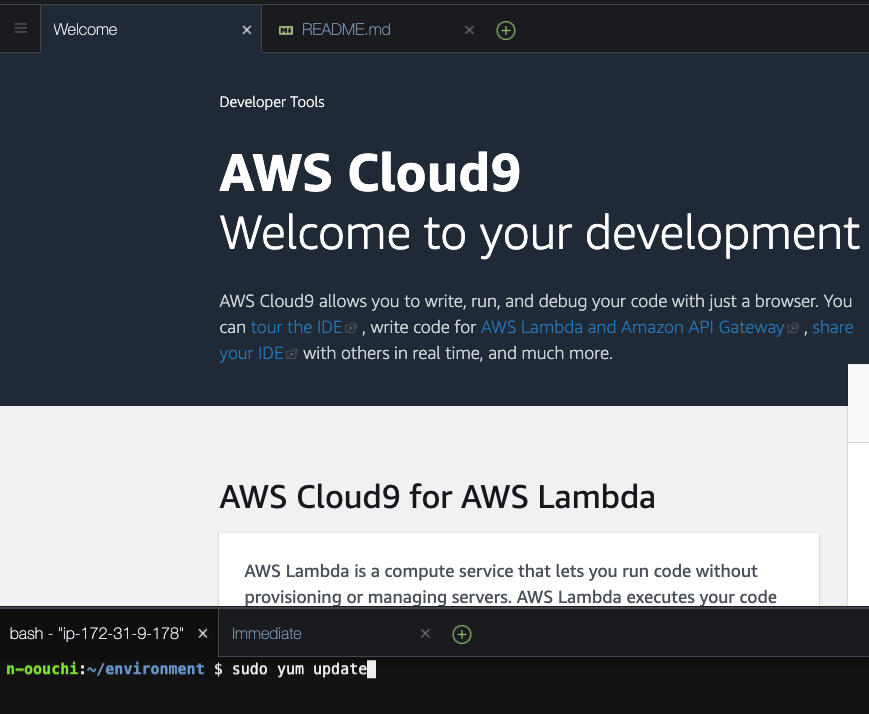
まずはOSにプリインストールされているライブラリを最新化します。
基本的にアップデートされるものは無いと思います。sudo yum update
rvmを使用してrubyのバージョンを切り替える
今回はRVM(Ruby Version Manager)を使用して複数VersionのRubyを管理したいと思います。
rvmインストール
Clooud9にはrvmがプリインストールされています。
念のためrvmがインストールされていることを確認します。rvm -v
ruby-2.5.1インストール
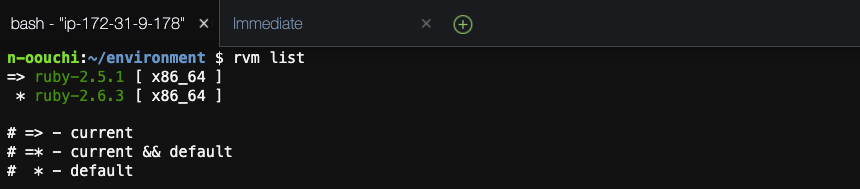
現段階でrvmで切り替えできるRubyのバージョンを確認します。
rvm list
ruby-2.6.3が使用できるようです。
今回はruby-2.5.1を使用したいのでrvmを使ってインストールします。rvm install 2.5.1
インストールが完了したらもう一度切り替えできるRubyのバージョンを確認します。
rvm list
ruby-2.5.1が追加され、currentとなっていることが確認できます。
念のため、Rubyコマンドでも確認します。
ruby -v
rvmデフォルトバージョン変更
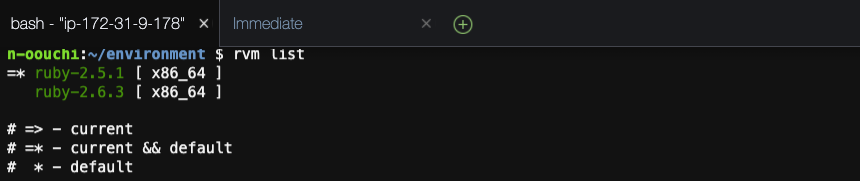
これでRVMを使用したRubyのバージョン切り替えができました。
ただ、今の設定ではターミナルを再起動した時にはrubyバージョンが2.6.3に戻ってしまいます。そのため、RVMでのデフォルトバージョンを2.5.1に変更します。
rvm --default use 2.5.1
切り替えできるRubyのバージョンを確認します。
rvm list
ruby-2.5.1がcurrent && defaultとなっていることが確認できます。
以上でrubyの環境構築は完了です。
Rails 環境構築
ここからはRailsの環境構築をしていきます。
railsインストール確認
まずはrailsコマンドがインストールされているかを確認します。
rails -v
インストールされていないことが確認できます。
gemインストール
Railsはgemというコマンドを使用してインストールします。
gemとはRuby applicationやライブラリーのパッケージです。gemがインストールされているか確認します。
rubyがインストールされていれば使用できます。gem -v
インストールされていることが確認できます。
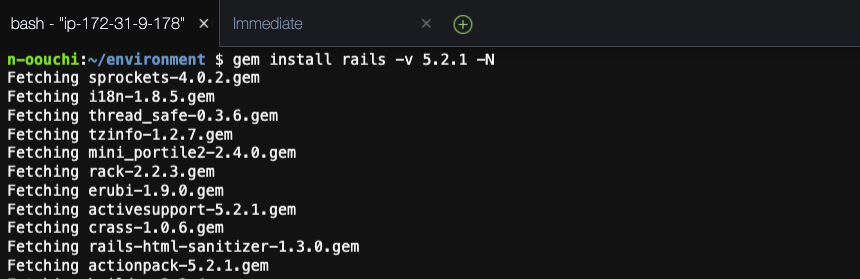
railsインストール
それでは、gemを使用してrailsをインストールします。
gem install rails -v 5.2.1 -N-Nオプションを使用すると、諸々のドキュメントのインストールをスキップできます。(インストールが早くなる)
インストールが完了したらrailsのバージョンを確認します。
rails -v
インストールされていることが確認できました。
Railsの環境構築は以上です。
最後に
Ruby on Railsの環境構築って割と面倒臭いイメージがありましたが、(特にWindows)Cloud9を使用すると簡単に環境構築ができますね。
これからRuby on Railsを使っていくつか簡単なシステムを構築してみようと思います。









- 投稿日:2020-10-12T08:57:05+09:00
Amazon Cognitoカスタム属性の落とし穴
最近Amazon Cognitoでログイン機能を実装して遊んでいたのですが、
ユーザープールにカスタム属性を追加したところ、AWS CLIやマネジメントコンソール上ではカスタム属性情報の取得ができるのに、
Web上でAmazon CognitoのjavaScriptライブラリを使い、getUserAttributes関数で属性情報を取得したところ、何故かカスタム属性だけ取得できないということがありました。なので、getUserAttributes関数でカスタム属性を取得する方法についてメモしておきます。
解決方法だけ見たい方はこちら (アプリクライアントにカスタム属性への読み取り権限を与える)
AWS CLIでカスタム属性を含むユーザーを作成
AWSマネジメントコンソールから以下のようなカスタム属性を追加。
AWS CLIで以下のコマンドを打ち動作確認用のアカウントを作成し、2つ目のコマンドでパスワードを設定しました。・ユーザーを作成
aws cognito-idp admin-create-user --user-pool-id {ユーザープールID} \ --username {ユーザーネーム} --user-attributes Name=email,Value={メールアドレス} \ Name=email_verified,Value=True Name=custom:name_user,Value=テストそら \ --desired-delivery-mediums EMAIL・パスワードを設定
aws cognito-idp --permanent admin-set-user-password \ --user-pool-id {ユーザープールID}--username {ユーザーネーム} --password {パスワード}
作成したユーザーの属性情報を確認
・CLI上で属性情報を確認
・マネジメントコンソール上で属性情報を確認
CLIとマネジメントコンソール上ではしっかりカスタム属性の「custom:name_user テストそら」も表示されているのでうまくいっています。
Web上ではカスタム属性の取得に失敗
Web上でログイン機能はすでに実装してあったので、ログインしたユーザー(CLIで作成したユーザー)の属性情報をgetUserAttributes関数で全て取得し、コンソールに表示してみました。
・コンソールに表示させる部分
cognitoUser.getSession(function(err, session) { if (err) { console.log(err) } else { cognitoUser.getUserAttributes(function(err, result) { if (err) { console.log(err) } console.log(result) }) } })
・コンソールログで属性情報を確認
カスタム属性だけ取得できてないじゃん!!!!
emailやemail_verifiedなどの標準属性のみを取得していてカスタム属性が取得できていません。特になんのエラーも出ていないので結構困ったことになりました。
原因
stackoverflowでのQ&A
AWS公式ドキュメントこれらによるとどうやらアプリクライアントにカスタム属性へのアクセス権限がないことが原因のようです。
解決方法
アプリクライアントにカスタム属性への読み取り権限を与える
・マネジメントコンソールからCognitoのユーザープールを開き、「アプリクライアント」タブの「詳細を表示」をクリック
・次に「属性の読み込みおよび書き込みアクセス権限を設定する」をクリック
・読み取りを許可したいカスタム属性にチェックを入れ、「アプリクライアントの変更を保存」をクリック
これで権限設定は完了です。
あらためて属性情報取得し、コンソールログで見てみると、
カスタム属性を取得することができました。まとめ
答えがわかってしまえば「なんだこれだけか」というようなものでしたが、
標準属性に対するアクセス権限はデフォルトで与えられていて、特に設定した覚えもなかったので、
カスタム属性に対するアクセス権限がないことが原因だとは中々気づくことができませんでした。察しの良い方や、AWSに触りなれている方でしたら、「権限の問題かな」とすぐわかりそうなものですが筆者は完全初心者なので思わぬ落とし穴でした。
エラー文が特に出ていないので原因を探るのも少し大変でした。
困っている方の助けになればうれしいです。
![7fb9b90e1fef0b286fc81e21d2bd0826[1].png](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F693048%2F0054c3a5-d572-026a-08b8-639e7adb773c.png?ixlib=rb-1.2.2&auto=format&gif-q=60&q=75&s=6824b084e6dfae118c686951269e9e19)


![Inked7b85eb2b9f2f04d7b30faeec8cbe4b83[1]_LI.jpg](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F693048%2Ffdb4247f-2161-6712-1b33-7e67419c30c2.jpeg?ixlib=rb-1.2.2&auto=format&gif-q=60&q=75&s=269092b1866ac2847ca9cd1b0542f5b5)




- 投稿日:2020-10-12T08:57:05+09:00
Amazon Cognitoカスタム属性を追加する時に気をつけること
最近Amazon Cognitoでログイン機能を実装して遊んでいたのですが、
ユーザープールにカスタム属性を追加したところ、AWS CLIやマネジメントコンソール上ではカスタム属性情報の取得ができるのに、
Web上でAmazon CognitoのjavaScriptライブラリを使い、getUserAttributes関数で属性情報を取得したところ、何故かカスタム属性だけ取得できないということがありました。なので、getUserAttributes関数でカスタム属性を取得する方法についてメモしておきます。
解決方法だけ見たい方はこちら (アプリクライアントにカスタム属性への読み取り権限を与える)
AWS CLIでカスタム属性を含むユーザーを作成
AWSマネジメントコンソールから以下のようなカスタム属性を追加。
AWS CLIで以下のコマンドを打ち動作確認用のアカウントを作成し、2つ目のコマンドでパスワードを設定しました。・ユーザーを作成
aws cognito-idp admin-create-user --user-pool-id {ユーザープールID} \ --username {ユーザーネーム} --user-attributes Name=email,Value={メールアドレス} \ Name=email_verified,Value=True Name=custom:name_user,Value=テストそら \ --desired-delivery-mediums EMAIL・パスワードを設定
aws cognito-idp --permanent admin-set-user-password \ --user-pool-id {ユーザープールID}--username {ユーザーネーム} --password {パスワード}
作成したユーザーの属性情報を確認
・CLI上で属性情報を確認
・マネジメントコンソール上で属性情報を確認
CLIとマネジメントコンソール上ではしっかりカスタム属性の「custom:name_user テストそら」も表示されているのでうまくいっています。
Web上ではカスタム属性の取得に失敗
Web上でログイン機能はすでに実装してあったので、ログインしたユーザー(CLIで作成したユーザー)の属性情報をgetUserAttributes関数で全て取得し、コンソールに表示してみました。
・コンソールに表示させる部分
cognitoUser.getSession(function(err, session) { if (err) { console.log(err) } else { cognitoUser.getUserAttributes(function(err, result) { if (err) { console.log(err) } console.log(result) }) } })
・コンソールログで属性情報を確認
カスタム属性だけ取得できてないじゃん!!!!
emailやemail_verifiedなどの標準属性のみを取得していてカスタム属性が取得できていません。特になんのエラーも出ていないので結構困ったことになりました。
原因
stackoverflowでのQ&A
AWS公式ドキュメントこれらによるとどうやらアプリクライアントにカスタム属性へのアクセス権限がないことが原因のようです。
解決方法
アプリクライアントにカスタム属性への読み取り権限を与える
・マネジメントコンソールからCognitoのユーザープールを開き、「アプリクライアント」タブの「詳細を表示」をクリック
・次に「属性の読み込みおよび書き込みアクセス権限を設定する」をクリック
・読み取りを許可したいカスタム属性にチェックを入れ、「アプリクライアントの変更を保存」をクリック
これで権限設定は完了です。
あらためて属性情報取得し、コンソールログで見てみると、
カスタム属性を取得することができました。まとめ
答えがわかってしまえば「なんだこれだけか」というようなものでしたが、
標準属性に対するアクセス権限はデフォルトで与えられていて、特に設定した覚えもなかったので、
カスタム属性に対するアクセス権限がないことが原因だとは中々気づくことができませんでした。察しの良い方や、AWSに触りなれている方でしたら、「権限の問題かな」とすぐわかりそうなものですが筆者は完全初心者なので思わぬ落とし穴でした。
エラー文が特に出ていないので原因を探るのも少し大変でした。
困っている方の助けになればうれしいです。
- 投稿日:2020-10-12T00:57:38+09:00
EC2 Redhat Imageに設定すべき初期設定
目的
Redhat AMIイメージを用いたEC2を起動した際に、最初に設定する内容を以下に纏
める。パッケージアップデート
1. Before
Nothing2. Command
yum update3. After
NothingTime_zoneの設定
1. Before
[ec2-user@ip-172-31-48-200 ~]$ sudo timedatectl Local time: Sun 2020-10-11 15:05:46 UTC Universal time: Sun 2020-10-11 15:05:46 UTC RTC time: Sun 2020-10-11 15:05:46 Time zone: UTC (UTC, +0000) NTP enabled: yes NTP synchronized: yes RTC in local TZ: no DST active: n/a2. Command
[ec2-user@ip-172-31-48-200 ~]$ sudo timedatectl set-timezone Asia/Tokyo3. After
[ec2-user@ip-172-31-48-200 ~]$ sudo timedatectl Local time: Mon 2020-10-12 00:07:02 JST Universal time: Sun 2020-10-11 15:07:02 UTC RTC time: Sun 2020-10-11 15:07:02 Time zone: Asia/Tokyo (JST, +0900) NTP enabled: yes NTP synchronized: yes RTC in local TZ: no DST active: n/aAmazon Time Sync Serviceの同期
1. Before
[ec2-user@ip-172-31-48-200 ~]$ chronyc sources -v 210 Number of sources = 4 .-- Source mode '^' = server, '=' = peer, '#' = local clock. / .- Source state '*' = current synced, '+' = combined , '-' = not combined, | / '?' = unreachable, 'x' = time may be in error, '~' = time too variable. || .- xxxx [ yyyy ] +/- zzzz || Reachability register (octal) -. | xxxx = adjusted offset, || Log2(Polling interval) --. | | yyyy = measured offset, || \ | | zzzz = estimated error. || | | \ MS Name/IP address Stratum Poll Reach LastRx Last sample =============================================================================== ^- mail.masters-of-cloud.de 3 6 377 16 -65us[ -65us] +/- 134ms ^- sv1.localdomain1.com 2 6 377 19 +3022us[+3022us] +/- 33ms ^* ntp-b2.nict.go.jp 1 6 377 26 +206us[ +442us] +/- 2481us ^- ntp.nyy.ca 1 6 377 26 +25ms[ +25ms] +/- 95ms2. Command
$ sudo yum erase 'ntp*' $ sudo yum install chrony $ sudo echo '#Add TimeSync' >> /etc/chrony.conf $ sudo echo 'server 169.254.169.123 prefer iburst' >> /etc/chrony.conf $ systemctl restart chronyd3. After
[root@ip-172-31-48-200 ec2-user]# chronyc sources -v 210 Number of sources = 5 .-- Source mode '^' = server, '=' = peer, '#' = local clock. / .- Source state '*' = current synced, '+' = combined , '-' = not combined, | / '?' = unreachable, 'x' = time may be in error, '~' = time too variable. || .- xxxx [ yyyy ] +/- zzzz || Reachability register (octal) -. | xxxx = adjusted offset, || Log2(Polling interval) --. | | yyyy = measured offset, || \ | | zzzz = estimated error. || | | \ MS Name/IP address Stratum Poll Reach LastRx Last sample =============================================================================== ^* 169.254.169.123 3 6 17 31 -60us[ -84us] +/- 501us ^- ntp.nic.kz 1 6 17 31 +9449us[+9449us] +/- 128ms ^- sv1.localdomain1.com 2 6 17 32 +2605us[+2581us] +/- 43ms ^- 153.127.161.248 2 6 17 32 +9404us[+9380us] +/- 99ms ^- ns2.customer-resolver.net 2 6 17 32 +3321us[+3297us] +/- 160ms
- 投稿日:2020-10-12T00:24:42+09:00
awsセルフハンズオン「AWSの基礎サービス ~ Amazon EC2, Amazon RDS, Amazon VPC ~」をやってみた
awsセルフハンズオン「AWSの基礎サービス ~ Amazon EC2, Amazon RDS, Amazon VPC ~」をやってみる。
https://resources.awscloud.com/aws-summit-online-japan-2020-on-demand-self-paced-hands-on-85234ハンズオン資料はここ。
https://github.com/harunobukameda/Amazon-VPC---Amazon-EC2---Amazon-RDS-Handsonハンズオン
ハンズオンはフェーズ1から3、オプションまで段階を踏んで環境構築を進めていきます。
フェーズ1ではWordPressをEC2インスタンス1台構成で構築(WordPress、nginx、MySQLインストール済みAMIを使用)し、
オプションまで完了すると、LB+Webサーバ2台+DBサーバ2台(Multi-AZ)構成ができます。
※フェーズ3までは無料枠で構築できるハンズオンではVPCウィザードを使用しますが、今回は理解のため使わずに進めていきます。
(なので、フェーズ1の範囲は作業が変わります)
図はハンズオン資料を元にdraw.ioで作成。フェーズ1:サーバ1台構成(EC2インスタンス1台)
やること
- VPC作成
- ハンズオンではVPC作成ウィザードを使用しますが、理解のためここでは使いません。
- VPCウィザードを使用すると、サブネット・ルートテーブルやインターネットゲートウェイ等のVPCコンポーネントも一緒に作成される。
- コミュニティAMIからEC2作成
- ElasticIPを割り当て、EC2インスタンスに割当
- WordPress設定
やっていき
VPC作成〜VPCコンポーネント設定
VPC作成
- サービスから「VPC」を選択
- VPC > VPCの作成
- 名前タグ … 自分が認識できるもの。ここでは「vpc-handson」にした
- IPv4 CIDR ブロック … ハンズオン資料と同じく10.0.0.0/16
- IPv6 CIDR ブロック … IPv6 CIDR ブロックなしを選択
サブネット作成
- サブネット > サブネットの作成
- ここでは、AZ 1a、1cにそれぞれパブリックサブネット、プライベートサブネットを作成
- フェーズ1ではAZ 1aに作成したパブリックサブネットのみ使用。残りはフェーズ2、3、オプションで使用
- サブネットの作成
- 名前タグ … 自分が認識できるもの。ここでは「sb-handson-public-1a」「sb-handson-private-1a」といった名前タグを指定
- VPC … 作成したvpc-handsonを指定
- IPv4 CIDR ブロック … 資料と同じく 10.0.0.0/24、10.0.1.0/24、10.0.2.0/24、10.0.3.0/24 をそれぞれ指定
インターネットゲートウェイ作成
- インターネットゲートウェイ > インターネットゲートウェイ作成
- 名前タグ … 自分が認識できるもの。ここでは「igw-handson」
- インターネットゲートウェイ > アクション > VPCにアタッチ
- 作成したインターネットゲートウェイを選択、VPCにアタッチする
ルートテーブル作成&編集
- 作成したインターネットゲートウェイを送信先に追加する
- ひとまず既に作成されているルートテーブルは識別できる名前(ここではrtb-handson-private)に変更
- 作成されたサブネットに関連付け済み。送信先は作成したVPCになっている
- ルートテーブル > ルートテーブルを作成
- インターネットゲートウェイに向けるルートテーブル
- 名前タグ … 自分が認識できるもの。ここでは「rtb-handson-public」
- インターネットゲートウェイを送信先に追加
- 新しく作成したルートテーブルを選択 > ルートの編集
- ルートの追加
- 送信先を0.0.0.0/0(デフォルトルート)、ターゲットをインターネットゲートウェイを選択
- サブネットの関連付け
- サブネットの関連付けの編集
- パブリックサブネット用に作成したサブネットを選択
セキュリティグループ設定
- 後の作業でセキュリティグループを新しく追加するので、既に作成されているセキュリティグループのNameを認識しやすい名称(ここではsg-handson-default)に変更する
EC2インスタンスの作成〜WordPressの構成
コミュニティAMIからEC2インタンスを起動、WordPressの設定をしていきます。
EC2インスタンスの作成
- サービスから「EC2」を選択
- EC2を作成する
- EC2インタンスの起動 > コミュニティAMIを選択
- 資料にあるAMI-IDを検索し、選択
- wordpress, nginx, mysqlが既に設定済みのイメージ
- インスタンスタイプ … t2.microを選択
- インスタンスの詳細 … VPCは作成したVPC、サブネットはパブリックサブネット(AZ az)を選択、自動割当パブリックIPは有効にする
- 高度な詳細 … ユーザーデータに
#!/bin/bashchown apache:apache /var/www/html/を指定- ストレージ … 特に設定せず
- タグの追加 … キーに「Name」を追加。認識しやすい名前を指定(ここではweb-user-1)
- セキュリティグループの設定
- セキュリティグループの割り当て … 新しいセキュリティグループを作成する
- ルールに「SSH」追加 … プロトコルがTCP、ポート範囲が22、ソースは任意の場所(0.0.0.0/0, ::/0)
- ルールに「HTTP」追加 … プロトコルがHTTP、ポート範囲が80、ソースは任意の場所(0.0.0.0/0, ::/0)
- キーペアの作成
- 新規作成した場合はpemファイルを保存する
ElasticIPの割り当て
- Elastic IP > Elastic IPアドレスの割り当て よりElasticIPを作成
- Elastic IP > アクション > Elastic IPの関連付け
- 先程作成したEC2インスタンスを関連付け
WordPressの構成
- ターミナルからssh接続を確認
ssh -i [EC2インスタンス起動時に保存したpemファイル] ec2-user@[作成したElasticIP]- MySQLとnginxが起動していることを確認
sudo service mysqld statussudo service nginx status- http://[作成したElasticIP]/にアクセス、資料通りにWordPressの設定をする
フェーズ2:Web+DB(サーバ2台構成)(EC2インスタンス1台+RDS1台)
やること
- DB用セキュリティグループ作成
- DBサブネットグループを作成(フェーズ1で作成したプライベートサブネットを割り当てる)
- RDSインタンス作成(作成したサブネットグループを割り当てる)
- フェーズ1のEC2インスタンス上のMySQLを停止&RDSに接続設定を変更
やっていき
DB用セキュリティグループ作成
- セキュリティグループを作成
- セキュリティグループ名 … db-user1
- 説明 … RDS for MySQL
- VPC … 作成したVPC
- インバウンドルール
- タイプ … MySQL/Aurora
- ソース … カスタムを選択、webserver用に作成セキュリティグループを選択
DBサブネットグループを作成
- サービスから「RDS」を選択
- サブネットグループ > DBサブネットグループを作成
- 名前 … db subnet user1
- 説明 … RDS for MySQL
- VPC … 作成したVPC
- アベイラビリティゾーン … 1a、1c
- サブネット … AZ 1a、1cに作成したプライベートサブネットを選択
RDSインタンス作成
- データベース > データベースの作成
- データベースの作成方法 … 標準作成
- エンジンのタイプ … MySQL
- テンプレート … 開発/テスト
- DBインスタンスサイズ … バースト可能クラスでdb.t2.microを選択
- VPC … 作成したVPC
- サブネットグループ … 先程作成したサブネットグループを選択
- データベース作成、起動までには数分かかる
wordpressの接続先DBを変更
- 作成したEC2からRDSに接続できることを確認
$ mysql -u admin -p -h [作成したRDSのエンドポイント]- EC2インスタンス上にインストールされているMySQLのデータをエクスポート
mysqldump -u root -p wordpress > export.sql- EC2インスタンス上のMySQLは今後使わないため停止
sudo service mysqld stopsudo chkconfig --level 345 mysqld off- エクスポートしたデータをRDSにインポート
mysql -u admin -p -h [作成したRDSのエンドポイント] wordpress < export.sql- 再設定をWebから行うため、DB接続設定を初期化する
sudo mv /var/www/html/wp-config.php ~/http://[EIP]/に接続、WordPressを再設定- データベースのホスト名をlocalhostからRDSのエンドポイントに変更
http://[EIP]/にアクセスして表示されることを確認フェーズ3:LB + Webx2 + DB構成 (サーバ3台構成)
やること
- フェーズ2までに作成したwebserverを元にAMIを作成する
- 2つ目のEC2インスタンスを作成
- ELBのセキュリティグループを作成
- ELBを作成
- パブリックサブネットに配置
- セキュリティグループを新規に作成
- WordPressが生成するHTMLのホスト名をELBのDNSに変更
- Webサーバ用のセキュリティグループ変更
- WebサーバにELBからのみ許可するよう変更
やっていき
2台目のWebサーバーを作成
- WebサーバのAMIを作成
- インスタンス > アクション > イメージ > イメージを作成
- AMI > 作成したAMIを選択、起動
- ネットワーク … 作成したVPCを選択
- サブネット … AZ 1cに作成したパブリックサブネットを選択
- 自動割り当てパブリックIP … 有効
- タグ … キー「Name」を追加。認識できる名称(ここではwebserver-handson-2)を指定
- セキュリティグループ … 既存のセキュリティグループ(1台目のWebサーバと同じ)を選択
ELBを作成
- ロードバランサー > ロードバランサーの作成
- Application Load Balancer(HTTP、HTTPS)を作成
- 名前 … 認識できる名前(ここではelb-handson)
- アベイラビリティーゾーン … 1a、1cのパブリックサブネットを選択
- セキュリティグループ
- 新しいセキュリティグループを作成
- セキュリティグループ名 … 認識できる名称(elb-user1)
- ルール … HTTP、TCP、80
- ルーティングの設定
- 各ターゲットグループは 1 つのロードバランサーのみに関連付けることができることに注意
- 名前 … 認識できる名前(target-user1)
- ターゲットの登録
- 作成済みのインスタンス2台を登録済みに追加
- 作成したらターゲットグループのStatusがhealthyに変わるのを確認
- WordPressの設定変更
- WordPressの生成するHTML内のホスト名は初期セットアップ時のEIPが指定されているので、ELBのDNSに変更
$ mysql -u admin -p -h [RDSのエンドポイント] wordpress;update wp_options set option_value='[ELBのDNS名]' where option_name='siteurl' or option_name='home';http://[ELBのDNS名]/でWordPressが表示されることを確認ELBのセキュリティグループ設定変更
- WebサーバにはELBからのみアクセスを許可するよう、セキュリティグループを変更
- セキュリティグループでWebサーバーに指定しているものを選択
- インバウンドルールのHTTPのソースを0.0.0.0からELBに変更
http://[EIP]にアクセスできなくなることを確認オプション:LB + Webx2 + DBx2構成(サーバ4台構成)
やること
- RDSのMulti-AZを有効にする
- RDSインタンスのフェイルオーバーを選択、再起動する
やっていき
- データベース > 変更
- 可用性と耐久性の「マルチAZ配置」に変更
- データベース > アクション > 再起動
- フェイルオーバーし再起動する
さらに拡張性、安全性を高める
ハンズオン資料より引用
- さらに拡張性を高める
- Webサーバ
- AutoScalingで負荷調整を自動に
- 静的コンテンツにS3のWebサイト機能を使用する
- CloudFrontでコンテンツキャッシュする
- DBサーバ
- DBのリードレプリカを作成し、読み込み負荷を分散 • DBをシャーディングで分散
- ElastiCacheでセッション情報の保持
- ElastiCacheでデータをキャッシュ
- さらに安全性を高める
- IAMを利用する
- SSH等の管理接続を制限する
- Security Groupで接続元を制限
- VPCのVPN経由のみに限定
- System Manager Run Commandを利用し、SSHを使用しない
- 監視を行う
- CloudWatchで監視
- サードパーティ製品・サービスで監視
- CloudTrailで監査ログを残す
- AWS WAFを利用する
- 前段にELBを配置した場合は、EC2をプライベートサブネットに置く
最後にリソースの削除をする
削除するまでがハンズオン。

- 投稿日:2020-10-12T00:07:10+09:00
【AWS初学者用】AWS Well-Architectedフレームワークとは?
本記事について
本記事はAWS初学者が学習していく中でわからない単語や概要をなるべくわかりやすい様にまとめたものです。
私自身もAWS初学者なので、もし誤りなどありましたらコメントにてお知らせいただけるとありがたいです。AWS Well-Architectedフレームワーク
本記事では「AWS Well-Architectedフレームワーク」について書いていきたいと思います。
まずはじめにAWS公式サイトでの説明をみてみます。AWS Well-Architected フレームワークは、AWSのソリューションアーキテクト(SA)が、AWSのサービス開始から10年以上に渡り、様々な業種業界、数多くのお客様のアーキテクチャ設計および検証をお手伝いしてきた経験から作成したクラウド活用のベストプラクティス集です。具体的には「運用の優秀性」「セキュリティ」「可用性」「パフォーマンス効率」「コスト最適化」の5つの観点について、クラウドをより活用するための設計原則と、お客様システムがベストプラクティスに沿っているかを確認するための質問と回答で構成されています。本ホワイトペーパーは、クラウドにおけるアーキテクチャ設計や運用に携わっているすべての方に読んでいただきたい内容となっています。
一方でお客様のシステムが必ずしもAWSが提唱する全てのベストプラクティスに沿っている必要はありません。ベストプラクティスをご理解いただいた上で、お客様ご自身でのビジネス的なご判断を実施いただくためのアイデアです。AWS初学者の私からするとこの説明でもイマイチ理解が深まりませんでした。(勉強不足でスミマセン...)
なのでこれから理解できる様に説明を書いていきます。AWS Well-Architectedフレームワークの概要(簡単に)
AWS Well-Architectedフレームワーク
Well-ArchitectedフレームワークはAWSが数多くのサービスを提供してきた経験をもとに、最善のやり方や解決・改善策を整理しました!と言う感じです。
ユーザーがクラウド活用のノウハウを効率よく行えるための資料の様なものといった感じかと。そしてこのフレームワークは質問と回答で構成されているということです。Well-Architectedフレームワークの5本の柱
このフレームワークには「運用上の優秀性」、「セキュリティ」、「信頼性」、「パフォーマンス効率」、「コスト最適化」という5つの柱が存在し、これを基本設計に組み込むことで安定した効率の良いシステムが作成できる、といううものです。
それでは5つの柱を順番にみていきます。
運用上の優秀性
運用上の優秀性の柱は、AWS上で構築したシステムでビジネス価値をもたらすために運用面でどんなことを気をつければ良いか記載してあります。セキュリティ
セキュリティの柱は、AWS上で構築したシステムとデータや資産をどの様に保護しセキュリティを向上するかが記載されています。信頼性
信頼性の柱は、AWSでの障害が起きた際の復旧について、どの様に障害を防止するかが記載してあります。パフォーマンス効率
パフォーマンス効率の柱は、コンピューティングリソースを効率的に使用することについて記載されています。コスト最適化
コスト最適化の柱は、無駄なコストは排除し最適化することについて記載してあります。まとめ
AWS Well-Architectedフレームワークは、AWSを利用する上での重要なベストプラクティス(最善の方法)集です。
ベストプラクティスに沿っているかを確認しながらシステムの構築・運用をしましょう。






%0AAWS%20CLI%E3%81%A7%E4%BB%A5%E4%B8%8B%E3%81%AE%E3%82%B3%E3%83%9E%E3%83%B3%E3%83%89%E3%82%92%E6%89%93%E3%81%A1%E3%80%81%E5%8B%95%E4%BD%9C%E7%A2%BA%E8%AA%8D%E3%83%86%E3%82%B9%E3%83%88%E7%94%A8%E3%81%AE%E3%82%A2%E3%82%AB%E3%82%A6%E3%83%B3%E3%83%88%E3%82%92%E4%BD%9C%E6%88%90){kind=link}