- 投稿日:2020-10-12T23:49:55+09:00
【Python】スプラトゥーン2のリーグマッチデータを相関係数表を使って分析する
【Python】スプラトゥーン2のリーグマッチデータを相関係数表を使って分析する
はじめに
スプラトゥーン2の戦績データは任天堂のサーバーに直近50試合分が保管され、公式アプリ「イカリング2」で確認することが出来る。後述する「ikaWidget2」では、この戦績データをダウンロード・保存し、キルやデスの平均値や、ステージ毎の勝率等の統計データが取得できる。「スプラデータクラブ」等のWebサイトでは、「ikaWidget2」に保存されたデータを用いることで、より詳細な統計データを得ることが出来る。しかし、こういった統計データの多くは各個人の戦績に基づいたものであり、4人用モード「リーグマッチ」における自チーム内の相互作用に着目した解析ツールはほとんどない。本記事では「リーグマッチ」における自チーム内スコアの相関係数表を計算するライブラリを作成し、それを利用して試合の分析を行う。
スプラトゥーン2とは
概要
スプラトゥーン2は任天堂より2017年7月21日に発売されたアクションシューティングゲームである。2020年10月現在1000万本以上が販売されている。発売から3年以上が経過した今でも定期的にアップデートがされる大人気ゲームである。仕様
プレイヤーはイカ(orタコ)に扮したキャラクターとなり、水鉄砲やローラー等の武器でインクを塗りあって戦う。インクを敵に浴びせれば倒すこともできる(キル)。倒されたプレイヤーは約10秒程度で復活する。どのルールも4対4のチーム戦であるため、チーム内の連携が重要になる。ステージを自チームのインクで塗るとスペシャルポイントが溜まり、強力な「スペシャルウェポン」が使えるようになる。ただし、敵に倒されるとスペシャルポイントが半分になってしまう。
ルール
ナワバリバトル
制限時間内に相手より広く地面を塗ったチームが勝利となる。スプラトゥーンにおける基本ルール。
ガチエリア
ステージ内に配置された「ガチエリア」を自陣のインクで占拠した時間を競う。ナワバリバトルを局所化して、占拠時間による勝敗を設けたゲーム。
ガチヤグラ
「ガチヤグラ」に乗り込み、制限時間内に相手チームのゴールまで近づけたチームが勝利となる。上に乗ることで「ガチヤグラ」を進めることが出来るが、敵からは格好の的になってしまう。
ガチホコバトル
「ガチホコ」と呼ばれる巨大な水鉄砲を拾い、制限時間内に相手チームのゴールまで近づけたチームが勝利となる。「ガチホコ」を持ったプレイヤーは強力な「ガチホコショット」を放つことが出来るようになるが、敵チームから位置がバレてしまい、狙われやすくなる。
ガチアサリ
ステージに散らばった「アサリ」を拾い、相手チームのゴールに入れて得点を競う。ゴールは初め、バリアで守られているため、アサリを10個集めて「ガチアサリ」を作りバリアを破壊しなければならない。バリアを破壊すると一定時間相手チームのゴールにアサリを入れられるようになる。
リーグマッチ
フレンドと4人チームを作って他のチームと対戦するモード。リーグマッチでは、「ガチエリア」「ガチヤグラ」「ガチホコバトル」「ガチアサリ」の4つの対戦ルールで遊ぶことが出来る。
相関係数表とは
相関係数
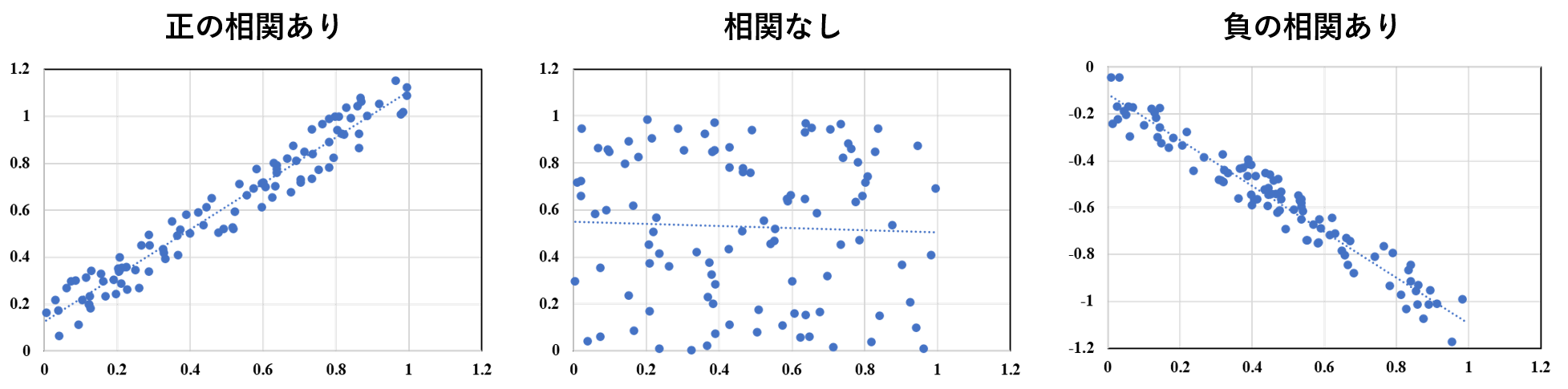
相関係数とは、2つの変数間の関係の強さを表す-1から+1の指標である。相関係数が正の時は「正の相関」が、負の時は「負の相関」があるという。正の相関がある時、2つの変数はいわゆる「正比例」のような関係になり、一方が増加する時もう一方も増加する。負の相関がある時は正の相関とは逆に、一方が増加する時もう一方は減少する。例えば、身長と体重の関係は強い正の相関を示し、国の失業率と経済成長率は負の相関を示す。
相関係数の絶対値とその相関の強さの関係は以下である。
相関係数 abs(r) 相関の強さ 0.7 ≦ abs(r) 強い相関がある 0.4 ≦ abs(r) ≦ 0.7 相関がある 0.2 ≦ abs(r) ≦ 0.4 弱い相関がある 0 ≦ abs(r) ≦ 0.2 ほとんど相関がない
相関係数表
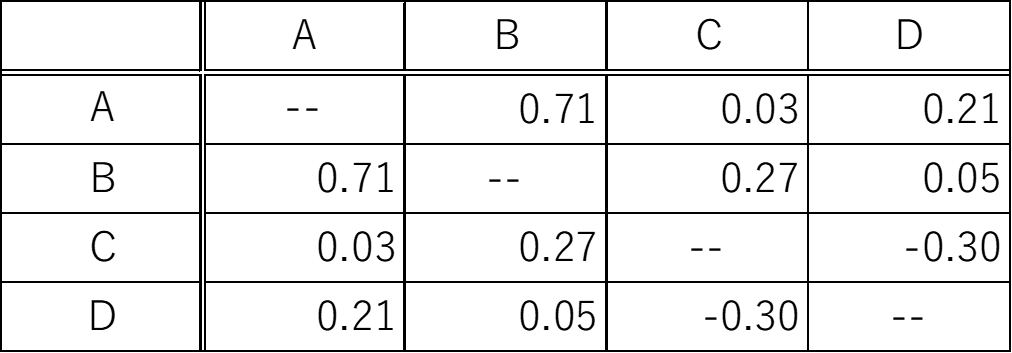
相関係数表は、各2変数間の相関係数をまとめた表である。
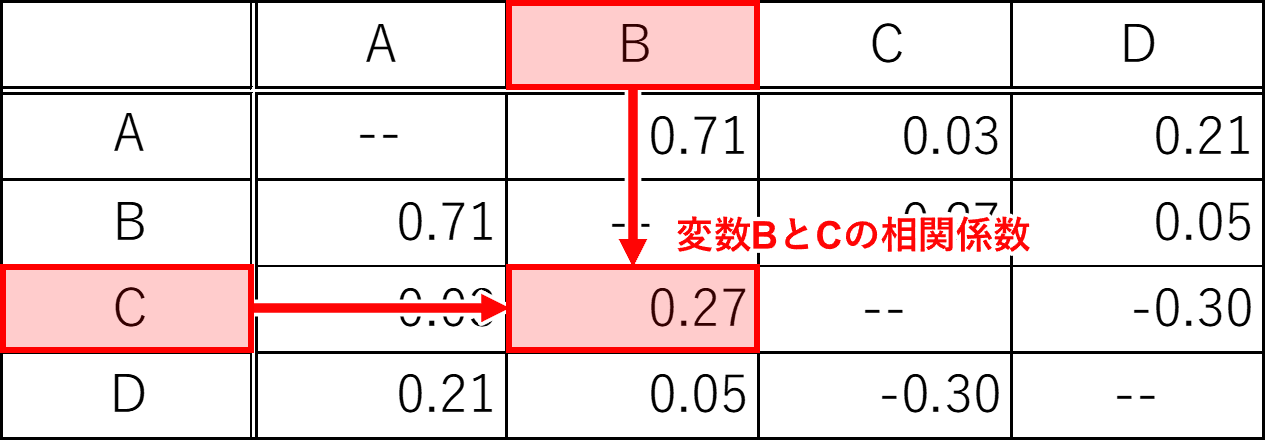
上図は、変数A,B,C,Dの相関係数表である。相関係数表はその特性上、表の左下と右上の値が線対象になる。ある2変数の行と列が交わった位置の値がその2変数の相関係数になる。例えば、変数BとCの相関係数は0.27になる。
このように、取り扱う変数が多い場合には相関係数表を用いることで、各変数間の関係をわかりやすく記述することが出来る。ikaWidget2
ikaWidget2は、任天堂非公式のスプラトゥーン2の分析アプリである。
App Store : https://apps.apple.com/jp/app/ikawidget-2/id1271025591
Google Play : https://play.google.com/store/apps/details?id=com.flapg.ikawidget2&hl=ja任天堂のサーバーに保管された直近50試合をダウンロード・保管し、キルやデスの平均値や、ステージごとの勝率等の統計データが取得できる。下図は、ikaWidget2の実際の画面である。
ikaWidget2はデータの外部出力機能も搭載しており、jsonとcsv(拡張子.tcsv)形式に対応している。今回は、ikaWidget2から出力されたcsvを使って相関係数表の計算を行う。環境
- Python
- pandas
- DateTime
- openpyxl
計算方法
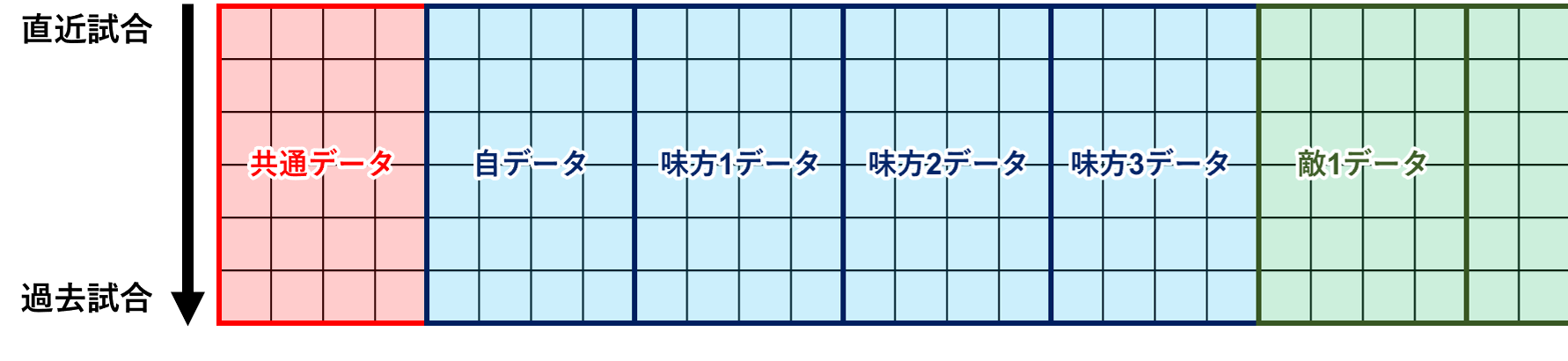
ikaWidget2のcsvファイルの構造を以下に示す。
共通データは試合の開始日時やステージ、ゲームモード等である。共通データ以降はキルやデス数等のプレイヤー情報が自分→味方→敵の順番に並ぶ。味方データの順番は試合ごとにバラバラであるため、このデータ群からリーグマッチの相関係数表を計算する際には、味方データとフレンド個々人の紐づけが必要になる。これをスプラトゥーン2のユーザーネームを用いて行うこともできるが、Nintendo Switchのユーザーネームを変更するとスプラトゥーン2のユーザーネームも変更されてしまうため普遍的でなく、汎用性に乏しい。ここでは「PrincipalID」を使って紐づけを行う。「PrincipalID」はユーザー固有の値であり、ユーザーネームを変更しても変わることはない。この値は内部データであるためゲーム中では確認出来ないが、ikaWidget2から出力されるファイルから取得できる。キルやデス数をフレンド毎に整理することが出来れば、後はpandasの.corr()関数で容易に相関係数表を作成することが出来る。ダウンロード・インストール
今回作成したスプラトゥーン2リーグマッチ相関係数表計算ライブラリ「splatoon_league_corr」はGitHub及びPyPlにアップロード済みである。
GitHub : https://github.com/JmpM-0743/splatoon_league_corr.git
PyPlからインストールする場合はpipでインストールできる。
pip install splatoon_league_corrライブラリの使い方
splatoon_league_corrでは、以下のクラス及び関数を提供する。
class ika_data
プレイヤーデータの格納クラス。
コンストラクタ
def __init__(self,pid,jpname,usname)
メンバ変数 説明 pid プレイヤーのPrincipalID
PrincipalIDは内部データなのでゲーム内では確認できないが、
ikaWidget2から出力されるtcsvファイル等から取得できるjpname 相関係数表出力時に表示される名前 usname 戦績データ一覧出力時に表示される名前 使用例
player = splatoon_league_corr.ika_data('824a58fc35365d11','まるや','maruya')class team_data
4つのika_dataで構成されるチームクラス。
コンストラクタ
def __init__(self,player,friend1,friend2,friend3)
メンバ変数 説明 player tscvファイルを出力した本人のデータ friend1~3 同じチームのフレンドデータ 使用例
myteam = splatoon_league_corr.team_data(player,friend1,friend2,friend3)calc_corr_number_of_games(filename,save_dir,myteam,n)
試合数を引数にして相関係数表のエクセルファイル(result.xlsx)を出力する関数。
引数 説明 型 filename 入力するtcsvファイルのパス str save_dir 出力データを格納するディレクトリ名(自動生成) str myteam team_dataクラス team_data n 相関係数表を計算する際の試合数 int 使用例
splatoon_league_corr.calc_corr_number_of_games('ikaWidgetCSV_20201009231053.tcsv','output',myteam,50)calc_corr_days(filename,save_dir,myteam,datemin,datemax)
試合の期間を引数にして相関係数表のエクセルファイル(result.xlsx)を出力する関数。
引数 説明 型 filename 入力するtcsvファイルのパス str save_dir 出力データを格納するディレクトリ名(自動生成) str myteam team_dataクラス team_data datemin、datemax 相関係数表を計算する際の試合期間(datemin~datemax)
YYMMDDで記述する。str 使用例
splatoon_league_corr.calc_corr_days('ikaWidgetCSV_20201009231053.tcsv','output_date',myteam,'20200901','20201030')分析結果と考察
以下に、筆者のチームのガチエリア50試合分の相関係数表を示す。
この表ではノックアウトによる値のズレを防ぐため、試合中の各変数は分当たりの値としている。
変数名 説明 win 試合の勝敗 勝利が1で敗北が0 EnemyUdemae 敵チームの平均ウデマエ
ウデマエ : 一人用プレイモードにおけるランクのようなものKill/min 分当たりのキル数 Death/min 分当たりのデス数 PaintPoint/min 分当たりの塗りポイント Special/min 分当たりのスペシャルウェポン発動回数 分析の例として、この表からわかること・わかりそうなことを述べていく。
① 相関係数の大きい変数ペア
フレンド2の
PaintPoint/minとSpecial/minの相関係数が0.77と、表中で一番大きい値をとっている。これら2変数の相関係数は、プレイヤーや他のフレンドも同様に高い値をとっている。前述の通り、スペシャルウェポンは塗りポイントが一定量溜まると発動できるため、この結果は妥当といえる。
② 勝利に影響している変数
勝利との相関が最も強い変数は、フレンド1の
Kill/minであるが、他のプレイヤー・フレンドも同様に高く、突出はしていない。「キルが多いと勝ちやすい」ことは自明であるため、この結果も妥当である。逆に、負の相関が最も強いのはプレイヤーのDeath/minで、相関係数-0.61である。この値は他フレンドと比較しても大きく、プレイヤーが頻繁にデスしているときは負けやすい、と言えるだろう。
③ 敵のウデマエに関する相関
敵の強さによって味方の立ち回りがどのように変わるのかを分析する。こちらは、先程までと比べて個々人の特色がよく表れている。例えば、敵のウデマエが高い時は「キルが減ってデスが増える」ことが自然な流れだが、フレンド1は敵のウデマエとデス数の相関がなく、フレンド3はキル数との相関がない。
フレンド1は後衛武器を持つことが多く、前衛の味方がやられた時に自陣に下がり易いためデスが増えないと考えられる。きちんと生存している一方で、キル数の負相関はチームで一番大きく、敵が強いと苦戦している様子も伺える。
プレイヤーは他のフレンドと比較して塗りポイントとスペシャルの相関が少し高い。敵が強いと中々倒せなくなるため、地面を塗ってスペシャルで対抗しようとしていることが見て取れる。
④ チーム内の相関を考える
最後に、チーム内の相関を分析してみる。下図は、キル数のみに着目した相関係数表である。この表を見ると、プレイヤーのみフレンド1以外のフレンドとのキル相関がほとんどないことが確認できる。言い換えると、プレイヤーのキルは他の前衛武器のキル数に何の影響も与えていないと言える(前述の通りフレンド1は後衛武器メイン)。明確な事はこの表からだけではわからないが、プレイヤーが前線から浮いていることや、逆に前線から手前側の位置で戦っていることを示していると考えられる。
まとめ
- ikaWidgetとPythonを用いることで、リーグマッチデータの相関係数表の計算が可能になった。
- 相関係数表の利用により、各個人のキルやデスだけではわからなかったチーム内の相互作用や、個々人のプレイ状況まで可視化できるようになった。






- 投稿日:2020-10-12T23:48:55+09:00
教師なし学習3 主成分分析
Aidemy 2020/10/29
はじめに
こんにちは、んがょぺです!バリバリの文系ですが、AIの可能性に興味を持ったのがきっかけで、AI特化型スクール「Aidemy」に通い、勉強しています。ここで得られた知識を皆さんと共有したいと思い、Qiitaでまとめています。以前のまとめ記事も多くの方に読んでいただけてとても嬉しいです。ありがとうございます!
今回は、教師なし学習の3つ目の投稿になります。どうぞよろしくお願いします。*本記事は「Aidemy」での学習内容を「自分の言葉で」まとめたものになります。表現の間違いや勘違いを含む可能性があります。ご了承ください。
今回学ぶこと
・主成分分析について
・カーネル主成分分析について主成分分析
主成分分析について
・主成分分析は、少ないデータから元のデータを表すこと、すなわちデータの要約(圧縮)を行う手法の一つである。
・主成分分析を行うと、「全てのデータを効率よく説明できる軸(第一主成分軸)」と「それだけでは説明しきれないデータを効率よく説明できる軸(第二主成分軸)」が作成される。
・このうち第一主成分のみを使うことで、余分なデータを捨てられ、データが圧縮できる。
・主成分分析を使えば次元削減も行えるので、データを2、3次元に落として可視化させたり、回帰分析に使えるようにしたりできる。主成分分析の流れ(概要)
①データXを標準化する。
②特徴同士の相関行列を計算する。
③相関行列の固有値と固有ベクトルを求める。
④固有値の大きい方からk個(k=圧縮したい次元数)選び、対応する固有ベクトルを選択する。
⑤選んだk個の固有ベクトルから特徴変換行列Wを作成する。
⑥データXと行列Wの積を計算し、k次元に変換されたデータX'を得る。(終了)主成分分析① 標準化
・標準化とは、データの各特徴を、平均を0分散を1になるように変換することである。
・標準化を行うことで、単位や基準の異なるデータを同じように扱えるようになる。・標準化は以下のように行われる。 (データと平均の差)÷標準偏差
X = (X - X.mean(axis=0))/X.std(axis=0)主成分分析② 相関行列
・相関行列とは、各特徴データ同士の相関係数がk×k個集まった行列のことである。
相関係数は2データ間の直線的な関係性の強さを表し、1に近いほど「aが正の一次関数の傾向が強い」すなわち、正の相関が強いと言え、-1に近いほど「aが負の一次関数の傾向が強い」すなわち、負の相関が強いと言える。
・相関係数が0に近いときは、直線的な傾向があまりないことを示す。・相関行列Rの計算は以下のように行われる。
R = np.corrcoef(X.T)・相関行列を行うnp.corrcoef()に渡すのが、転置を行ったデータX.Tであるのは、Xのまま渡すとデータそのもの(行同士)の相関行列を計算してしまうためである。今回は「特徴データ(列同士)」の相関行列を計算したいので、このような場合は転置すれば良い。
主成分分析③ 固有値と固有ベクトル
・②で求めた相関行列Rは、固有値分解というものを行うと固有値と固有ベクトルに分解される。この二つはそれぞれ行列の次元数と同じ個数で分解される。
・固有ベクトルが示すのは、行列Rにおいてその方向に情報が集中していること、固有値はその集中の度合いを示す。・固有値分解は以下のように取得できる。変数のeigvalsに固有値が、eigvecsに固有ベクトルが昇順で格納される。
eigvals, eigvecs = np.linalg.eigh(R)主成分分析④⑤⑥ 特徴変換
・ここでは、データの次元を任意のk次元に変換する手順を見ていく。
・③で分解した固有値のうち大きいものからk個を使って変換する(④)。具体的には、このk個の固有値にそれぞれ対応する固有ベクトルを連結して特徴変換行列Wを作成する(⑤)。最後に、このWとデータXをかけることで、k次元に変換されたデータX'を取得することができる(⑥)。・変換行列Wの作成方法は以下の通りである。(2次元に変換したい場合)
W = np.c_[eigvecs[:,-1],eigvecs[:,-2]]・XとWの積は「行列積」なのでX.dot(W)で計算する。
主成分分析①〜⑥を簡単に行う
・以上①〜⑥の手順で主成分分析を行うことができるが、PCAというscikit-learnのクラスを使うことで簡単に主成分分析を行うことができる。
・コード
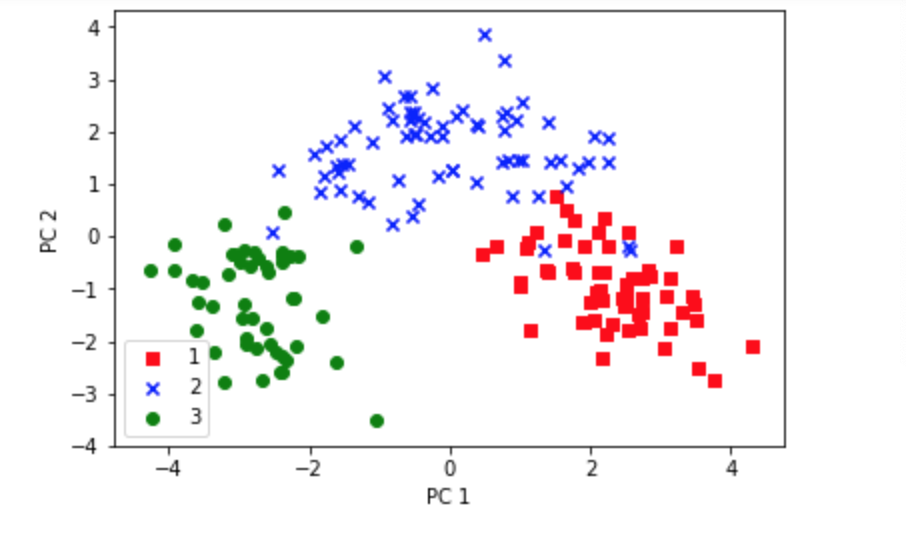
・コードその2(3種類のワインデータを2次元にまとめる)
・結果
回帰分析の前処理としての主成分分析
・LogisticRegression()を使用した回帰分析を実行する前に、主成分分析を行ってデータを圧縮しておくことで、より汎用性の高いモデルを作ることができる。
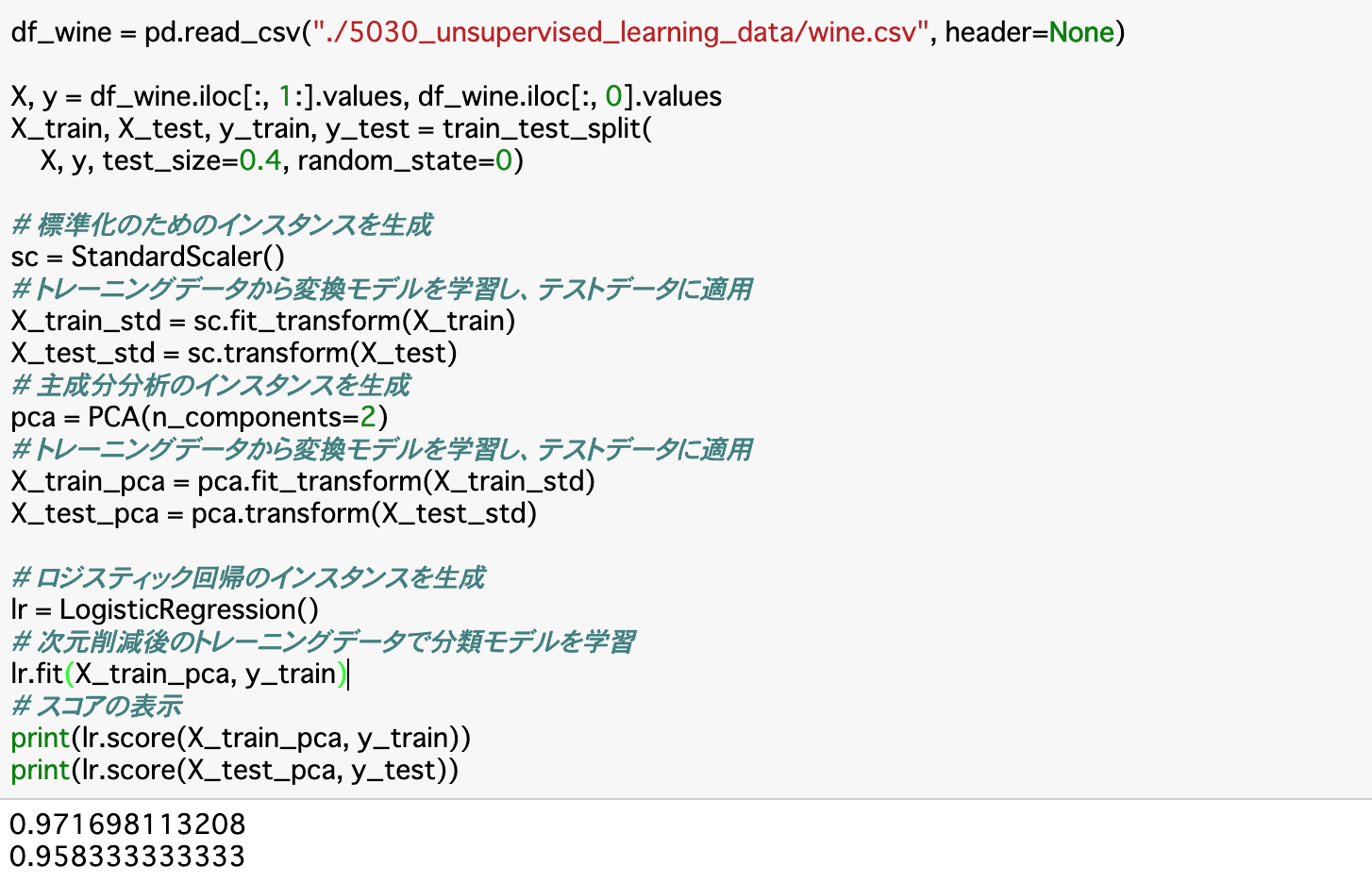
・以下では、データを分割したX_trainとX_testについて、標準化と主成分分析を行う。標準化には「StandardScaler」クラス、主成分分析にはPCAクラスを使うと良い。また、トレーニングデータとテストデータは共通の基準で処理する。
・trainデータは学習させる必要があるので「fit_transform()」を使い、testデータはそのまま「transform()」を使えば良い。・コード
カーネル主成分分析
カーネル主成分分析とは
・回帰分析などの機械学習は線形分離を前提としているため、線形分離不可能な
データは扱うことができないが、非線形分離のデータを線形可能なデータに変換するカーネル主成分分析(カーネルPCA)という物を使えば、そのようなデータも扱うことができるようになる。
・カーネルPCAでは、与えられたN(データ数)×M(特徴)のデータを、新しい特徴M'を持ったN×M'のデータKに作り替えるということを行う。これをカーネルトリックと言い、Kをカーネル行列という。
・このカーネル行列Kは主成分分析をすることが可能となる。カーネルトリックについて
・カーネルトリックを行うには、まずカーネル行列Kを算出する必要がある。元のデータがN(データ数)×M(特徴)ならば、KはN×Nとなる。
・カーネル行列は「データのペアごとの類似度」を計算したカーネル関数を行列にした物である。
・このカーネル関数は数種類あるが、今回はその中の動径基底関数(カーネル)のガウスカーネルについて見ていく。
・カーネル関数の一つガウスカーネルは以下のようにして計算できる。#データ同士の平方ユークリッド距離を計算 M = np.sum((X - X[:,np.newaxis])**2, axis=2) #Mを使ってカーネル行列を計算 K = np.exp(-gamma*M)カーネルトリックしたデータを主成分分析
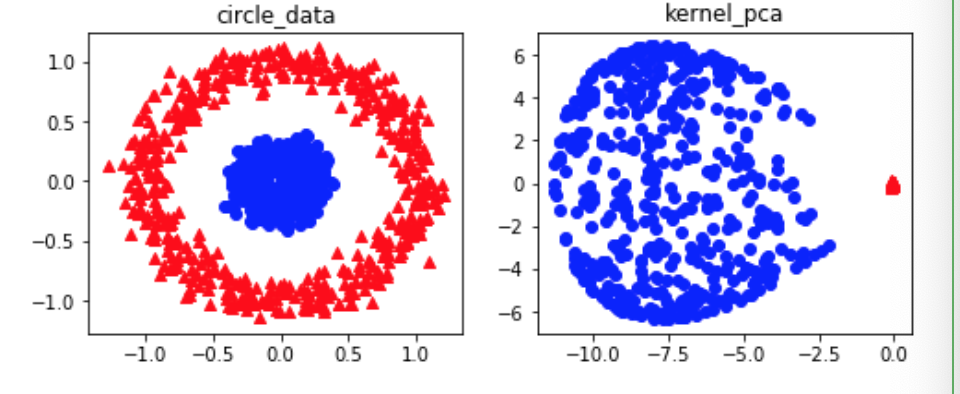
・先述の通り、カーネルトリックを行って取得したカーネル行列Kは、主成分分析を行うことができる。
・主成分分析を行うことで、元は線形分離不可能だったデータXを、線形分離可能なデータX'に変換することができる。・コード
・結果
カーネル主成分分析を簡単に行う
・KernelPCAというscikit-learnのクラスを使うことで簡単にカーネル主成分分析を行うことができる。
・引数については、n_componentsが圧縮後の次元数、kernelが動径基底関数(カーネル)、gammaがカーネル行列の算出に使われる「γ」の値を示す。from sklearn.decomposition import KernelPCA #KernelPCAインスタンスを作成し、主成分分析する kpca = KernelPCA(n_components=2, kernel="rbf", gamma=15) X_kpca = kpca.fit_transform(X)まとめ
・主成分分析によってデータの圧縮(次元削減)を行うことで、平面上に描画したり、回帰分析の精度を上げたりすることができる。
・主成分分析は、PCAクラスを呼び出すことで簡単に行える。
・動径基底関数(カーネル)によってデータを変換することで、線形分離不可能なデータに対して主成分分析を行うことができる。これによって、線形分離不可能なデータが線形分離可能となり、機械学習が可能になる。これをカーネル主成分分析という。
・カーネル主成分分析はKernelPCAクラスを呼び出すことで簡単に行える。今回は以上です。最後まで読んでいただき、ありがとうございました。



- 投稿日:2020-10-12T23:48:30+09:00
教師なし学習2 非階層的クラスタリング
Aidemy 2020/10/29
はじめに
こんにちは、んがょぺです!バリバリの文系ですが、AIの可能性に興味を持ったのがきっかけで、AI特化型スクール「Aidemy」に通い、勉強しています。ここで得られた知識を皆さんと共有したいと思い、Qiitaでまとめています。以前のまとめ記事も多くの方に読んでいただけてとても嬉しいです。ありがとうございます!
今回は、教師なし学習の2つ目の投稿になります。どうぞよろしくお願いします。*本記事は「Aidemy」での学習内容を「自分の言葉で」まとめたものになります。表現の間違いや勘違いを含む可能性があります。ご了承ください。
今回学ぶこと
・クラスタリングの種類
・k-means法
・DBSCAN法クラスタリング
階層的クラスタリング
・階層的クラスタリングとは、データの中から最も似ている(近い)データをクラスター化していく手法である。
・例えば、a=1,b=2,c=10,d=15,e=100のデータがあったとすると
「(a,b),c,d,e」=>「(a,b),(c,d),e」=>「((a,b),(c,d)),e」=>「(((a,b),(c,d)),e)」
のようにクラスター化し、最終的に全データがまとめられたら終了となる。
・この時、まとまりごとに階層を形成するので、階層的クラスタリングという。非階層的クラスタリング
・非階層的クラスタリングも、階層的クラスタリングと同様、最も似ている(近い)データをクラスター化していく手法であるが、階層構造を作らない。
・非階層的クラスタリングでは、人が幾つクラスターを作るかを決め、それに従ってクラスターが生成される。
・非階層的クラスタリングは、階層的クラスタリングよりも計算量が少なくて済むので、データ量が多い時に有効である。クラスタリングに使うデータの構造
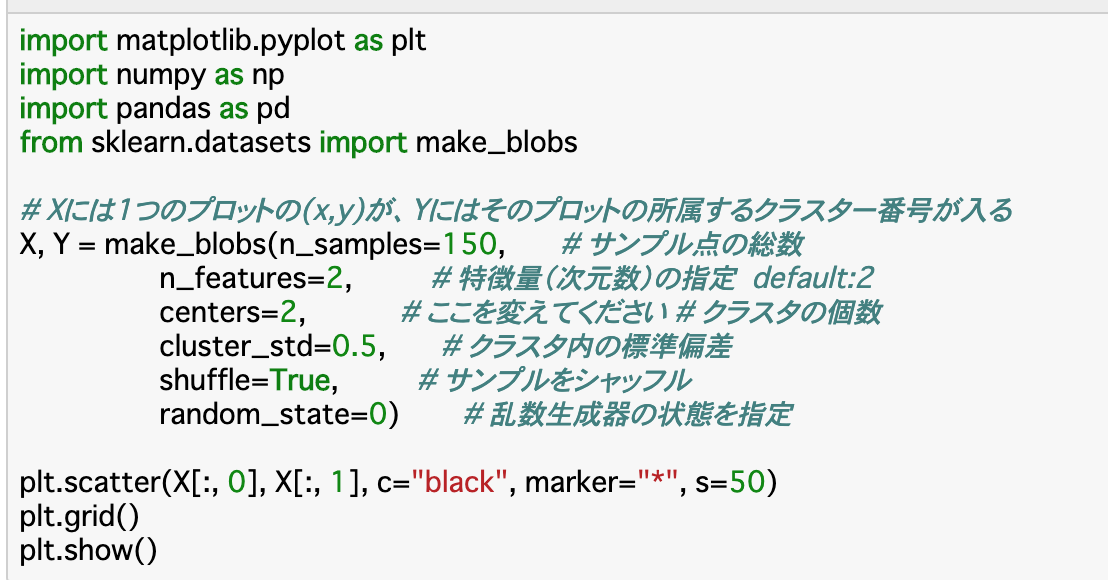
・make_blobs()を使うことで、クラスター数などを指定してデータを生成できる。
・変数のうち、Xにはデータの点(x,y)が、Yにはクラスターのラベルが入る。
・各引数について
n_samples:データの総数
n_features:特徴量(次元数)
centers:クラスター数
cluster_std:クラスター内の標準偏差
shuffle:データをランダムに並べ替えるかどうか
random_state:seed設定
k-means法
・k-means法は非階層的クラスタリングの一つである。クラスタリングの仕方としては、分散の等しいクラスターに分けることで行われる。
・分け方は、SSEと呼ばれる指標を使う。SSEとは、クラスターごとの重心(セントロイド)とデータ点との差の二乗和(=分散)のことである。(詳細は後述)
・そして、この分散(SSE)が最小となるような重心(セントロイド)を学習、選択する。・k_means法の具体的な流れは以下のようになる。
①データの中からk個のデータを抽出し、それらを初期のセントロイドとする。
②全てのデータ点を、最も近いセントロイドに割りふる。
③各セントロイドに集まったデータ群の重心を計算し、その重心を新しいセントロイドとしてセットする。
④元のセントロイドと新しいセントロイドの距離を計算し、近づくまで②③を反復する。
⑤距離が十分近づいたら終了。k-means法の実行
・k-means法を実行するには、KMeans()を使う。引数は以下を参照。
n_clusters:クラスターの個数(make_blobの「centers」に合わせる)
init:初期セントロイドの設定方法("random"でランダムにセットされる)
n_init:上記①を何回行うか
max_iter:上記②③の反復の最大回数
tol:「収束」しているとみなす許容度
random_state:初期seed・コード
・結果
SSEについて
・SSEは「クラスターごとの重心(セントロイド)とデータ点との差の二乗和(=分散)のことである」と説明したが、この指標をクラスタリングの性能評価に使うこともできる。
・SSEからわかるのは「各データと重心がどれだけずれているか」であるため、値が小さいほどクラスターがまとまっている良いモデルと言える。・SSEの値を表示させるには、
print("Distortion: %2f"% km.inertia_)
とすれば良い。(kmは前項で作ったKMeansインスタンス)エルボー法
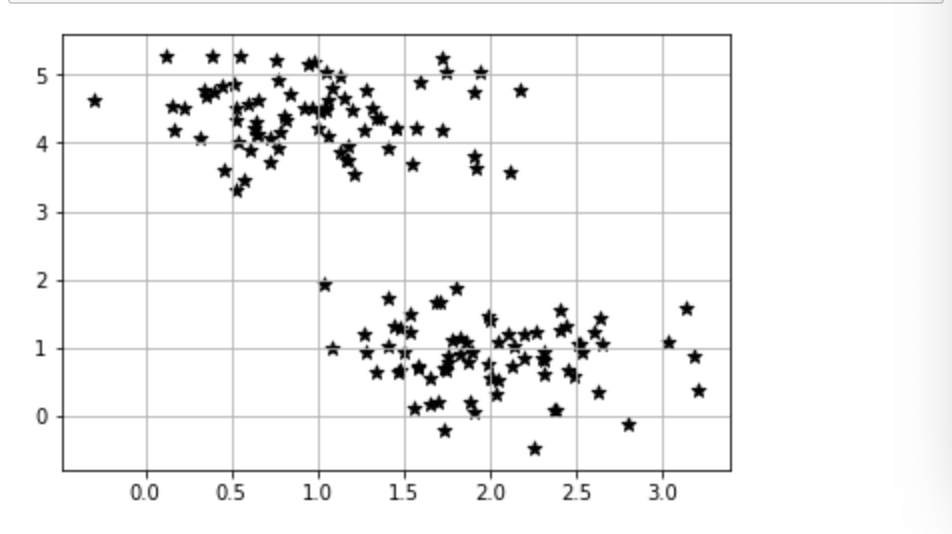
・k-means法ではクラスター数を自分で定める必要があるが、クラスター数決定の際に参考になる手法がある。これがエルボー法と呼ばれるものである。
・エルボー法は、「クラスター数を大きくして行った時のSSEの値」を図式化したものである。
・この図ではSSEの値が折れ曲がる点があり、この点を最適なクラスター数とみなして算出する。この折れ曲がり方が肘のようであることから、エルボー法と呼ばれる。・コード
・結果
その他の非階層的クラスタリング
DBSCAN
・非階層的クラスタリングの一例としてk-means法を見てきたが、特徴としては、各クラスターの重心の周囲にデータが集まってくるので、クラスターは円形に近い形になる。そのため、クラスターの大きさや形に偏りがない時にはクラスタリングの精度が上がりやすいが、そうでないと良いクラスタリングにならない。
・このような時に使えるのが、DBSCANという方法である。
・DBSCANは、データが一定数以上集まっているところを中心とし、その周囲にあるデータとそれ以外のデータで切り分ける手法である。
・具体的には、「min_sample」と「eps」という二つの指標を使って行う。手順は以下のとおり。
①データの半径「eps」内にデータが「min_sample」個以上ある場合は、その点をコア点とみなす。
②コア点から、半径「eps」内にあるデータをボーダー点とみなす。
③コア点でもボーダー点でもない点はノイズ点とみなす。
④コア点の集まりをクラスターとみなし、ボーター点を最も近いクラスターに組み込んで終了。・このように、DBSCANではデータを三種類に分けて分類することから、偏ったデータでも良いクラスタリングが行える。
・DBSCANを実行するにはDBSCAN()を使えば良い。(以下のmetric="euclidean"はユークリッド距離を使うという宣言)
まとめ
・クラスタリングには、階層的クラスタリングと、非階層的クラスタリングがある。アルゴリズム上、非階層的クラスタリングは手動でクラスター数を設定する必要がある。
・非階層的クラスタリングの一つにはk-means法がある。k-means法では重心の設定を反復させることでクラスターを生成する。
・k-means法の性能指標にはSSEが使える。値が小さいほどクラスタリングがうまく行っていると言える。
・クラスター数とSSEの関係をプロットしたエルボー法によって、最適なクラスター数を算出できる。
・非階層的クラスタリングのもう一つの手法として、DBSCANがある。DBSCANはある範囲のデータ数を参考にしてクラスターを生成するので、偏ったデータでもクラスタリングがうまく行きやすい。今回は以上です。最後まで読んでいただき、ありがとうございました。



- 投稿日:2020-10-12T23:48:14+09:00
教師なし学習1 基礎編
Aidemy 2020/10/28
はじめに
こんにちは、んがょぺです!バリバリの文系ですが、AIの可能性に興味を持ったのがきっかけで、AI特化型スクール「Aidemy」に通い、勉強しています。ここで得られた知識を皆さんと共有したいと思い、Qiitaでまとめています。以前のまとめ記事も多くの方に読んでいただけてとても嬉しいです。ありがとうございます!
今回は、教師なし学習の投稿になります。どうぞよろしくお願いします。*本記事は「Aidemy」での学習内容を「自分の言葉で」まとめたものになります。表現の間違いや勘違いを含む可能性があります。ご了承ください。
今回学ぶこと
・教師なし学習について
・教師なし学習の種類
・数学的な事前知識教師なし学習
教師なし学習とは
・教師あり学習は、クラスラベルと呼ばれる「答え」が与えられて学習が行われるが、教師なし学習はこの答えを渡さず、コンピュータ自身が判断して学習するものである。
・今回は、この教師なし学習の中の「クラスタリング」と「主成分分析」という手法について学ぶ。クラスタリング
・クラスタリングとは、データを塊(クラスター)ごとに分割する手法である。
・クラスタリングの一手法である「k-means法」は、人がクラスターの個数を決め、コンピュータがその個数になるようにデータを分割するものである。
・また、k-means法では「重心」と呼ばれる点の位置が適切になるように学習し、これに基づいてクラスタリングを行う。主成分分析
・主成分分析とは、データの次元を減らして(次元削減)一つのグラフに情報を集約させる手法である。
・主成分分析では、データの特徴を特に示す(主成分)軸を学習し、定めるという流れで行われる。
・例えば、「年齢、身長、体重」の3つの異なるデータから軸を定め、「個人データ」という形で2次元のグラフで表すというものが挙げられる。教師なし学習の事前知識
ユークリッド距離
・二次元空間上の二点(x1,x2),(y1,y2)間の座標距離は
$\sqrt{(x_1-y_1)^2+(x_2-y_2)^2}$
で求めることができる。
・同様にn次元空間上の2点(x1,x2...xn),(y1,y2...yn)間の距離は
$\sqrt{(x_1-y_1)^2+(x_2-y_2)^2+...+(x_n-y_n)^2}$
で求められる。この距離のことをユークリッド距離(ノルム)という。・以下のように、NumPyでユークリッド距離を求められる。(np.linalg.norm() は「()内の二乗の和」を表す)
コサイン類似度
・二つのベクトルがどのぐらい似ているかを評価するとき、「長さ」と「方向」の類似性から判断される。
・このうち方向に注目すると、二つのベクトルの作る角度「θ」が小さければ小さいほど類似性が高いと言える。
・θの求め方としては、ベクトルの内積の公式 $\vec{a} \cdot \vec{b} = |\vec{a}|\, |\vec{b}| \, \mathrm{cos}\theta$ を発展させて、cosθを求めることでわかる。この手法のことを「コサイン類似度」という。
・この時のcosθであるが、cosθは値が大きいほどθが小さくなることに注意。
・また、コサイン類似度もn次元のデータに対応している。・コードでは、NumPyで求めることができる。(np.dot()は「各要素の積の総和」を表す(以下で言うと、1*2+2*3+3*4))
まとめ
・教師なし学習は正解ラベルを渡さずにコンピュータ自身が判断し学習する手法である。
・教師なし学習には「クラスタリング」と「主成分分析」がある。前者はデータをクラスターごとに分割する手法であり、後者は、次元削減することで一つのグラフに情報を集約させる手法である。
・教師なし学習では、「ユークリッド距離(ノルム)」や「コサイン類似度」でデータの類似性などを判断することがある。今回は以上です。最後まで読んでいただき、ありがとうございました。


- 投稿日:2020-10-12T23:47:53+09:00
教師あり学習(回帰) 2 応用編
Aidemy 2020/10/28
はじめに
こんにちは、んがょぺです!バリバリの文系ですが、AIの可能性に興味を持ったのがきっかけで、AI特化型スクール「Aidemy」に通い、勉強しています。ここで得られた知識を皆さんと共有したいと思い、Qiitaでまとめています。以前のまとめ記事も多くの方に読んでいただけてとても嬉しいです。ありがとうございます!
今回は、教師あり学習の二つ目の投稿になります。どうぞよろしくお願いします。*本記事は「Aidemy」での学習内容を「自分の言葉で」まとめたものになります。表現の間違いや勘違いを含む可能性があります。ご了承ください。
今回学ぶこと
・モデルの汎化についてモデルの汎化
(復習)汎化とは
・回帰分析での予測は関数に基づいたものであるが、実際の価格変動には幅があり、入力データが同じでも結果が異なることもままある。
・このような前提のもとで、モデルが過去のデータを信頼しすぎると予測が破綻してしまうことになる。これを過学習と言い、過学習を防ぐことを汎化という。正則化
・線形回帰における汎化の手段として、正則化というものが用いられる。正則化とは、モデルの複雑性にペナルティを設け、モデルを一般化しようとすることである。
・正則化には「L1正則化」と「L2正則化」の2種類がある。
・L1正則化とは、予測に対する影響が小さいであろうデータの係数を0に近づけることで、余分な情報を削減して正則化を行う。
・L2正則化とは、係数の大きさに制限を設けることで、過学習を防いで正則化を行う。ラッソ回帰
・ラッソ回帰とは、L1正則化を使う回帰モデルを指す。
・L1正則化は、余分な情報が多い時に高い効果があるので、例えばデータ数(行数)に対するパラメータ数(列数)が多いときなどにラッソ回帰が使われる。
・ラッソ回帰の使い方は、model=Lasso()のようにすれば良い。リッジ回帰
・リッジ回帰とは、L2正則化を使う回帰モデルを指す。
・L2正則化は、係数の範囲に上限ができるため、汎化されやすい。
・リッジ回帰の使い方は、model=Ridge()のようにすれば良い。ElasticNet回帰
・ElasticNet回帰とは、L1正則化とL2正則化を組み合わせて使う回帰モデルを指す。
・L1正則化の情報を取捨選択してくれる点と、L2正則化の汎化されやすい点を持つので、メリットが大きい。
・ElasticNet回帰の使い方は、model=ElasticNet()とすれば良い。
・また、引数に「l1_ratio=0.3」などのように指定すれば、L1正則化とL2正則化の割合を指定できる。・以上3つの回帰モデルを実行
・結果
まとめ
・線形回帰における汎化の手段には、正則化がある。
・正則化にはL1正則化とL2正則化があり、前者を使った回帰がラッソ回帰、後者がリッジ回帰、両方を使った回帰がElasticNet回帰と呼ばれる。今回は以上です。最後まで読んでいただき、ありがとうございました。


- 投稿日:2020-10-12T23:47:36+09:00
教師あり学習(回帰)1 基礎編
Aidemy 2020/10/28
はじめに
こんにちは、んがょぺです!バリバリの文系ですが、AIの可能性に興味を持ったのがきっかけで、AI特化型スクール「Aidemy」に通い、勉強しています。ここで得られた知識を皆さんと共有したいと思い、Qiitaでまとめています。以前のまとめ記事も多くの方に読んでいただけてとても嬉しいです。ありがとうございます!
今回は、教師あり学習(回帰)の一つ目の投稿になります。どうぞよろしくお願いします。*本記事は「Aidemy」での学習内容を「自分の言葉で」まとめたものになります。表現の間違いや勘違いを含む可能性があります。ご了承ください。
今回学ぶこと
・教師あり学習(回帰)について
・線形回帰の方法教師あり学習(回帰)
(復習)機械学習の手法
・機械学習には3つの手法がある。「教師あり学習」「教師なし学習」「強化学習」である。
・このうち、教師あり学習は「分類」「回帰」の二つに分けられる。今回学ぶ回帰は、株価や時価などの連続値を予測する。線形回帰
線形回帰とは
・線形回帰とは、既に分かっているデータの式(グラフ=線形)から、その先のデータの動きを予測するものである。この時のグラフは必ず直線(一次関数)になる。
決定係数
・決定係数とは、線形回帰で予測したデータと実際のデータがどのぐらい一致しているかを示すものである。
・教師あり学習に使われるscikit-learnのおいては決定係数は0〜1の値をとる。数値が大きいほど一致度は高いと言える。
・決定係数を出力するときはprint(model.score(test_X,test_y))のようにすれば良い。線形単回帰
・線形単回帰とは、1つの予測したいデータ(y)を1つのデータ(x)から求める線形回帰のことである。
・すなわち、データが「y=ax+b」で表せると仮定して、aとbを推測することを指す。
・aとbの推測には、一つには、最小二乗法というものが使われる。これは、実際のyと推定するy(つまりax+b)の差の二乗の総和が最小になるようなaとbを設定するというものである。
・この方法で差を二乗するのは、データの正負を考慮しなくて良いからである。・線形(単)回帰を使うには、「model=LinearRegression()」のようにすればよい。
・線形単回帰の実行
線形重回帰
・線形重回帰とは、予測したいデータが1つ(y)に対し、予測に用いるデータが複数個(x1,x2...)となる線形回帰のことである。
・すなわち、データが「y = a1x1 + a2x2... +b」で表せると仮定して、aとbを推測することを指す。
・線形重回帰でも、aとbの予測は最小二乗法で行われる。
・また、使うのも、LinearRegression()で良い。単回帰か重回帰を自動で判断してくれる。・線形重回帰の実行
まとめ
・教師あり学習(回帰)の一つである線形回帰とは、既に分かっているデータの式(グラフ=線形)から、その先のデータの動きを予測するものである。
・線形回帰には、予測するものが一つである「線形単回帰」と複数である「線形重回帰」がある。今回は以上です。最後まで読んでいただき、ありがとうございました。

- 投稿日:2020-10-12T23:40:20+09:00
【Python】自動フォルダ作成ツールを開発してみた!
はじめに
前回の記事で自動でフォルダを作成してくれるコードを書きましたが、GUI化して、操作しやすいようにした方が複数のフォルダを作成するときに、楽だと思ったので作成してみることにしました。
環境
実行は以下の環境で行いました。
Windows 10 version 1903
Python 3.7.6
PyInstaller 3.6完成品
完成したものはこちらになります
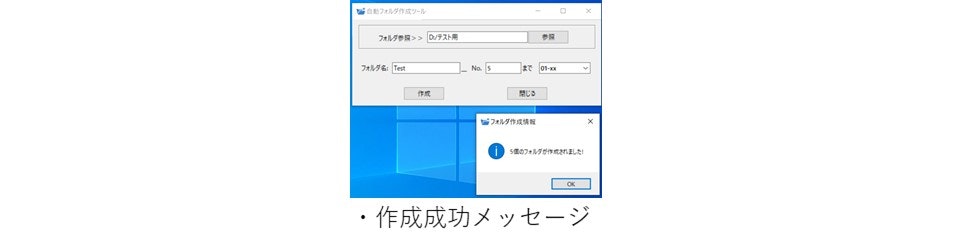
パスを指定して、フォルダ名とフォルダを何個まで作成するかを入力します。
次に、数字の種類を選び、「作成」ボタンを押します。
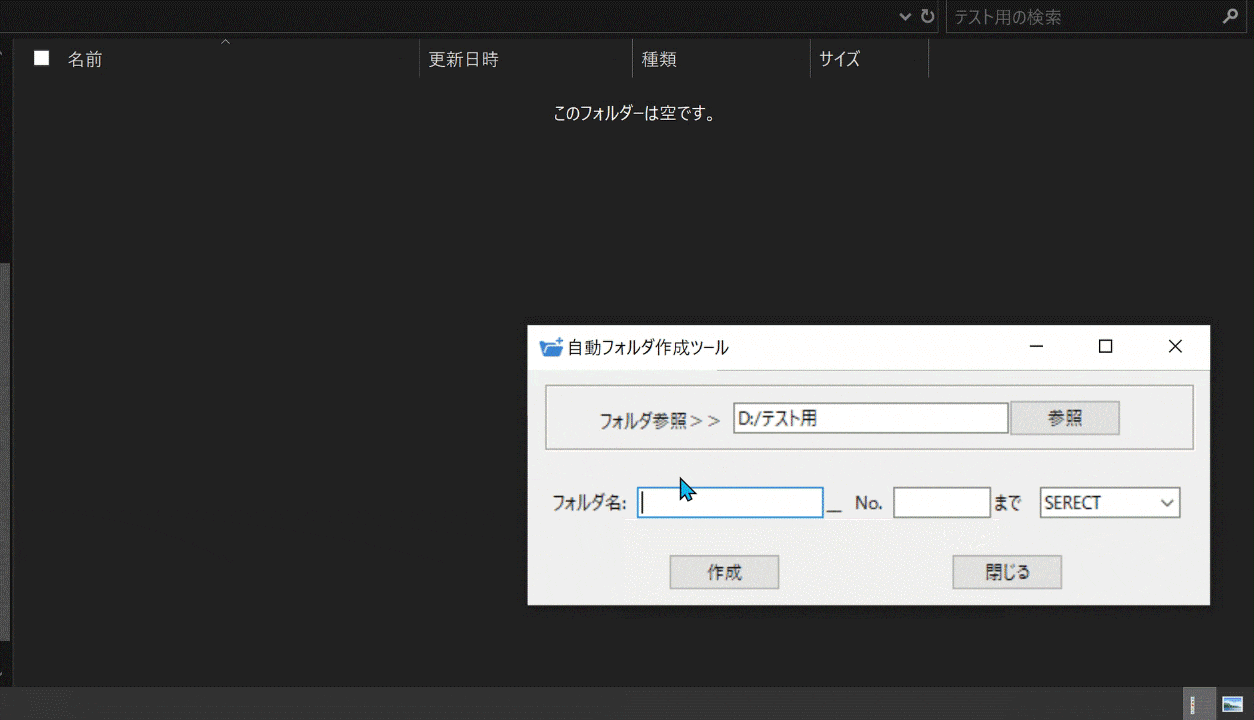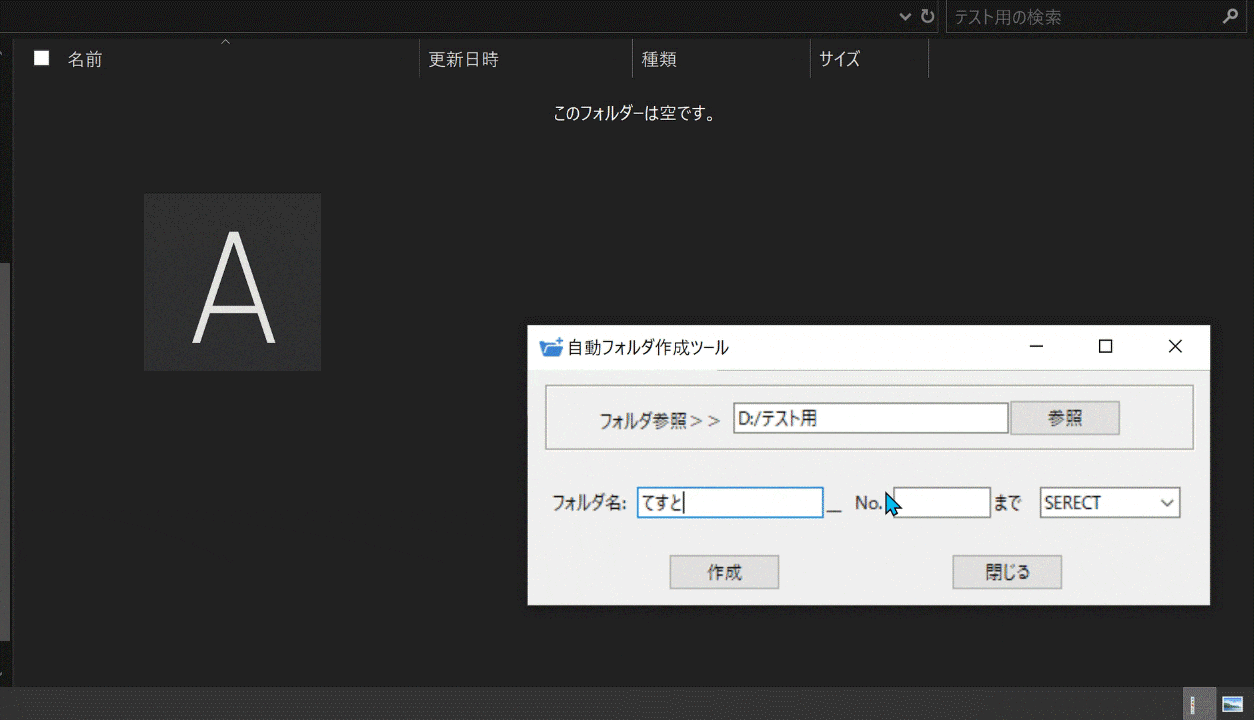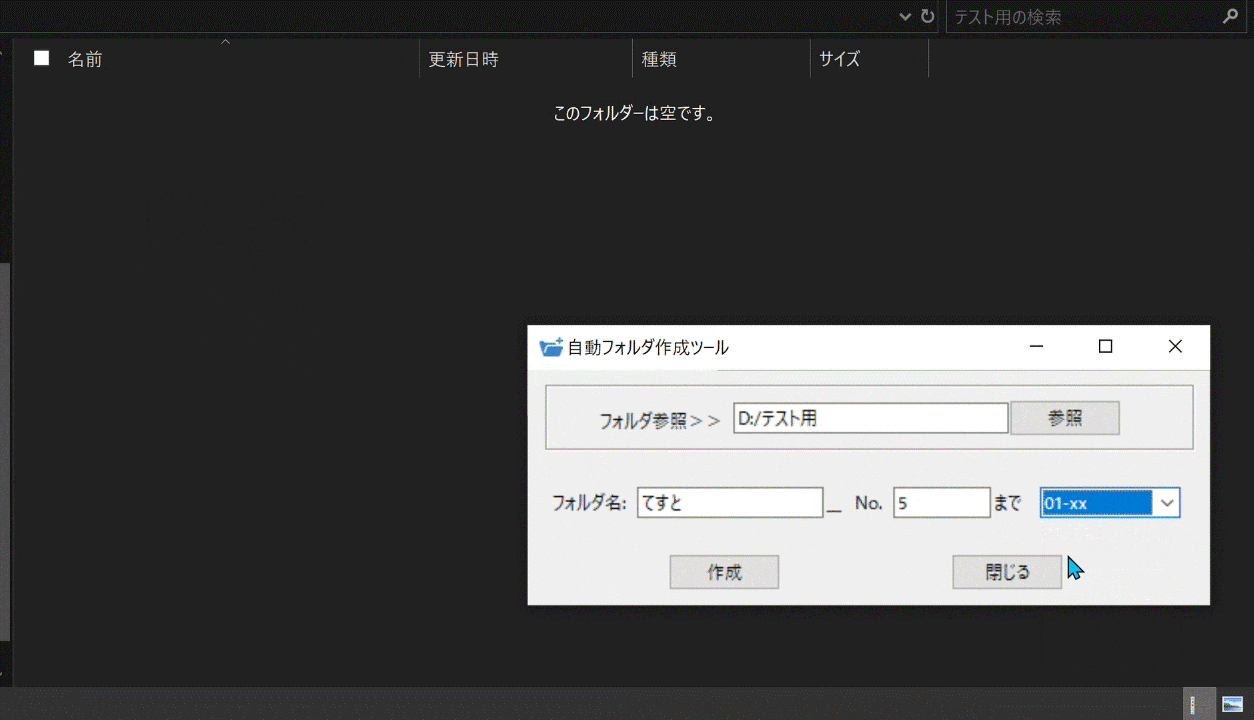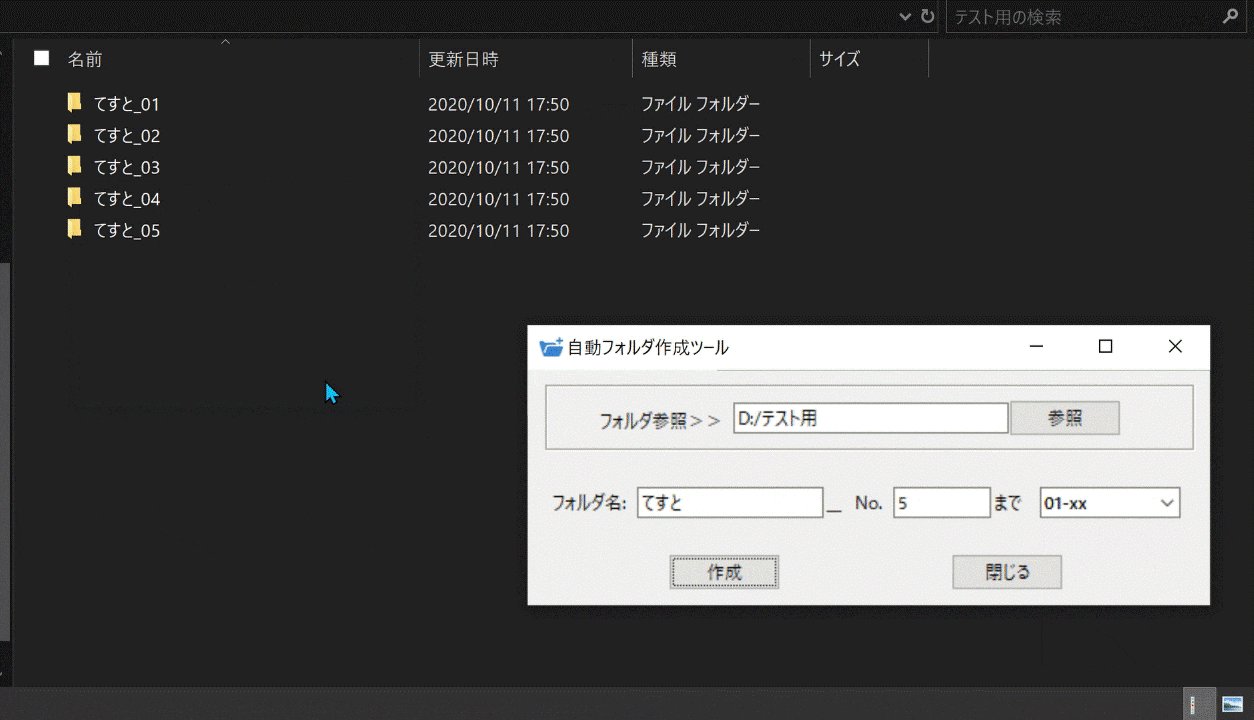
すると、指定した分の数だけフォルダが作成されます。
フォルダ名の表記はex.『No.1~No.100』を選択、フォルダ名[Test]_No.[5]までを指定すると、Test_No.1 Test_No.2 Test_No.3 Test_No.4 Test_No.5のように作成されます。
数字の表記は
- 『01~100』までの数字
- 『No.1~No.100』までの数字
- 『One~One_Hundred』までの英語表記の数字
- 『一~百』までの漢字表記の数字
- 『I~C』のローマ数字
となっております。英語表記と漢字表記の数字は自動ソートがされないので使い勝手が悪いです。
今回、フォルダの個数は誤入力が起こらないように100個までに制限しています。
また、フォルダ名を入力しない場合でも、パスとフォルダの数の指定があれば、作成され、同じフォルダ名があったとき、作成個数が違った場合、作成されないです。※注意点として、何回もフォルダを作成・削除して、デフラグを起こさないように!!
ツールが欲しい方
GitHubにプッシュしたので、下のURLからダウンロードしてください。
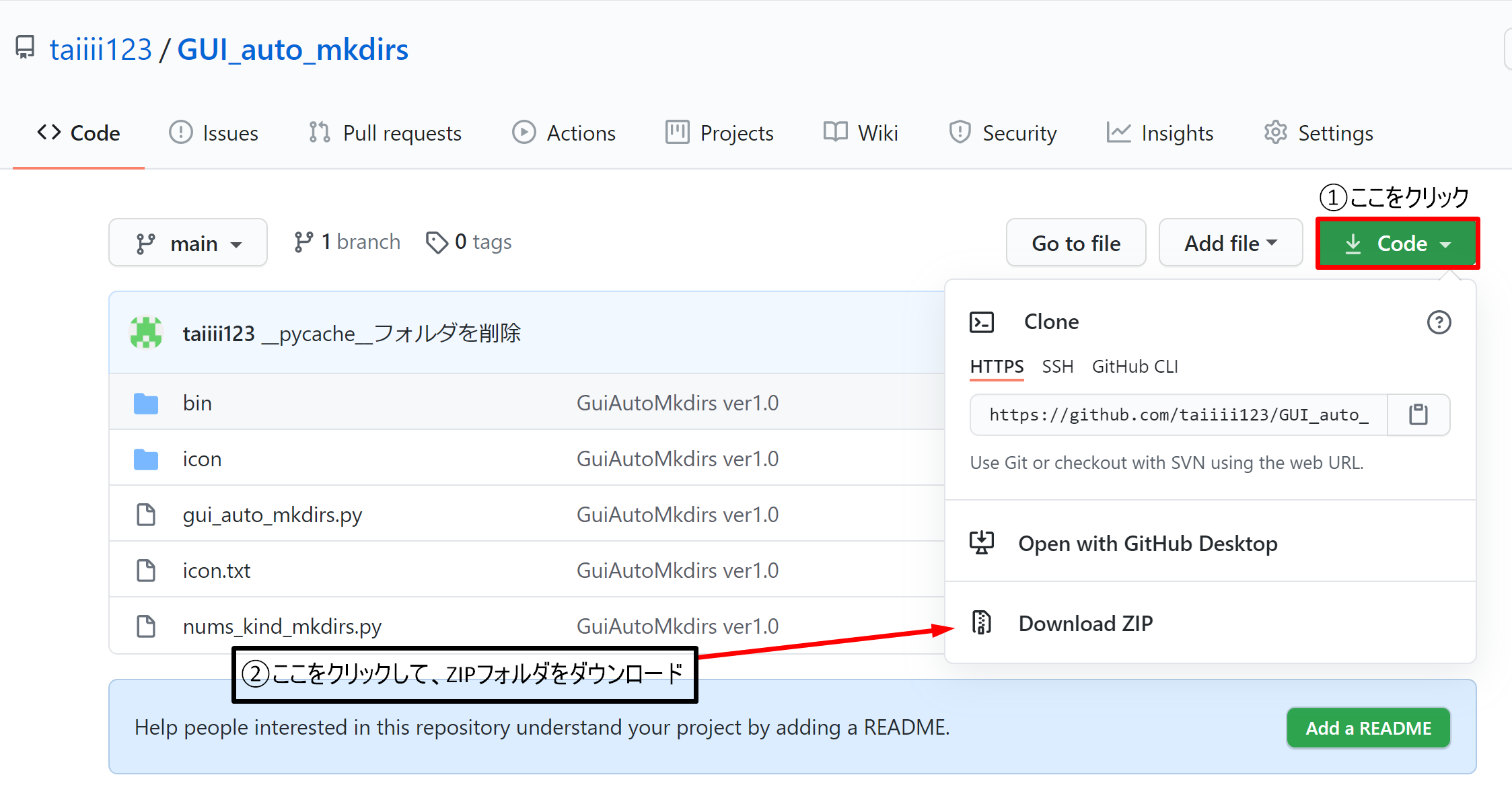
ダウンロード方法
- 上記のURLからGithubにアクセスして頂き、右上のCodeをクリックします。
- 「Download ZIP」という項目が表示されるので、その項目をクリック。クリックすると、ZIPフォルダがダウンロードされます。
- ダウンロードしたZIPフォルダを解凍して頂き、binフォルダにある「gui_auto_mkdirs.exe」の実行ファイルが確認できたら完了です。
- 最後は、実行ファイルを起動することを確認したら、任意の場所にフォルダを作成してみてください。
実装内容
設計
今回、Pythonの標準ライブラリであるTkinterを使いました。サードパーティ製ライブラリであるkivyというライブラリが人気らしいですが、Tkinterの方が参考文献がたくさんあったのでTkinterを選びました。
自動フォルダ作成ツールを考えたときに、まず、設計から考えました。
- デザインやレイアウト等
- 条件処理について
- クリック処理について
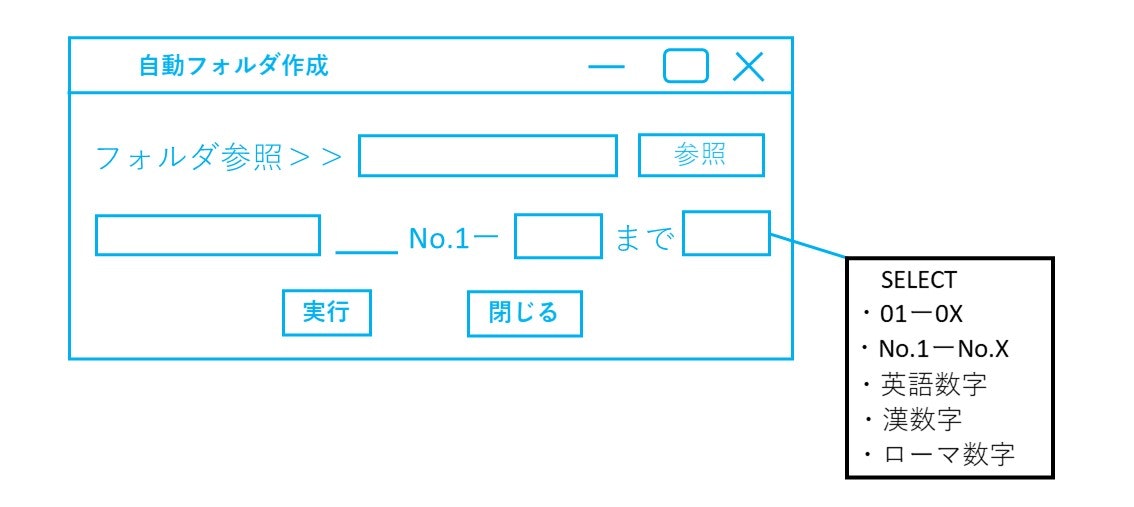
デザインはまず、どうするかを考え、「参考記事【Python】tkinterでファイル&フォルダパス指定画面を作成する」をもとにデザインを考えました。
・考えたデザイン
こんな感じで作っていこうと考えました。
次に、何個まで作成するか等の条件を考えました。入力の桁を打ち間違ったときに、何千個と作成されないように100個までという条件を付けました。また、「SELECT」ボタンですが、本当は実装する予定がなく、ただディレクトリ名と数字だけだと機能が少ないなと思い、「No.1~No.100」以外で選択できるように実装しようと考えました。
最後に、ユーザーが選択して、「作成」ボタンを押したときにフォルダ作成されるように実装していこうと考えました。
コードについて
全コード?Github
まず、Tkinterのレイアウト等を決めるPythonファイルとディレクトリ作成用の関数がもとまったPythonファイルに分けることにしました。
ディレクトリ作成用のPythonファイルから、
『01~100』と『No.1~No.100』は数字の部分でfor文のint型でそれぞれ処理できるのですが、英語表記の数字、漢数字、ローマ数字は文字列として扱うので、それぞれの1から100までのタプル形式で用意しました。リストにしなかったのは、後から変更しないためです。例ENG_NUMS = ( "One", "Two", "Three",‥‥, "One_Hundred")用意した番号の一覧をもとに、ディレクトリを作成する関数を作っていきます。
def mkdir_eng_nums(dirPath, dir_name, dir_count): for count in range(0, int(dir_count)): os.mkdir(dirPath + '/' + '{}_{}'.format(dir_name, ENG_NUMS[count]))引数に、それぞれ、パスを指定した絶対パス、入力したディレクトリ名、入力した作成個数の指定として、
dir_countをint型にキャストし、for文で回しています。for文内の処理は、osモジュールのmkdir関数をつかって、指定した絶対パスとディレクトリ名とタプルの中身を連結することで、1個ずつディレクトリを作成していきます。他の数字や漢数字等は同様な原理で作成しています。続いて、メインとなるレイアウト等のPythonファイルですが、まずは、osやtkinterモジュール等をインポート。
import os,sys from tkinter import * from tkinter import ttk from tkinter import messagebox from tkinter import filedialog from nums_kind_mkdirs import *次に、フォルダ参照ですが、以下のように処理しています。
entry1 = StringVar() IDirEntry = ttk.Entry(frame1, textvariable=entry1, width=30) IDirEntry.pack(side=LEFT) IDirButton = ttk.Button(frame1, text="参照", command=dirdialog_clicked) IDirButton.pack(side=LEFT)ボタンのオブジェクトを設置し、ボタンを押したときに、
dirdialog_clicked関数を呼び出しています。dirdialog_clicked関数内は、ユーザーがディレクトリ指定したときに、絶対パスを取得します。また、取得した絶対パスは変数entry1に代入します。
同様に、ファイル名およびディレクトリ個数入力欄も入力したときに、フォルダ名はentry2に、作成個数はentry3に代入しています。また、ドロップダウンリストでは、以下のように処理しています。
nums_kind = ["SERECT", "01-xx", "No.1-No.xx", "英語表記(One~)", "漢数字(一~)", "ローマ数字(I~)"] co = ttk.Combobox(frame2, state="readonly", values=nums_kind, width=12) co.set(nums_kind[0]) co.pack(side=LEFT, padx=(2, 10))
ttk.Comboboxでコンボボックスを作成し、選択肢はリスト型のnums_kindから選びます。co.set(nums_kind[0])で何もしない処理としてデフォルトでSERECTをセットしています。続いて、ディレクトリを作成する処理やエラー処理についてですが、以下のように処理をしています。
try: if dirPath: if int(input_dir_count) <= 100: if co.get() != 'SERECT': if co.get() == '01-xx': mkdir_nums(dirPath, input_dir_name, input_dir_count) elif co.get() == 'No.1-No.xx': mkdir_numbers(dirPath, input_dir_name, input_dir_count) elif co.get() == '英語表記(One~)': mkdir_eng_nums(dirPath, input_dir_name, input_dir_count) elif co.get() == '漢数字(一~)': mkdir_kansuuji(dirPath, input_dir_name, input_dir_count) elif co.get() == 'ローマ数字(I~)': mkdir_roman_numbers(dirPath, input_dir_name, input_dir_count) else: pass text += dirPath else: messagebox.showwarning("警告", "数字の表記が選択されていません") else: messagebox.showwarning("警告", "最大、100個までのフォルダを作成することが可能です") elif not dirPath and not input_dir_name and not input_dir_count: messagebox.showerror("エラー", "何も入力されていません") else: messagebox.showerror("エラー", "パスの指定がありません。")まず、実行ボタンを押したときに、絶対パスが入力され、ディレクトリ作成個数が100個以下という条件だったときに、それぞれのディレクトリを作成する関数を呼び出して、複数のディレクトリを作成していきます。そのとき、入力したパスは文字列になるので、
text = ""に代入することで、フォルダ作成メッセージを表示させています。if text: messagebox.showinfo("フォルダ作成情報", "{}個のフォルダが作成されました!".format(input_dir_count))
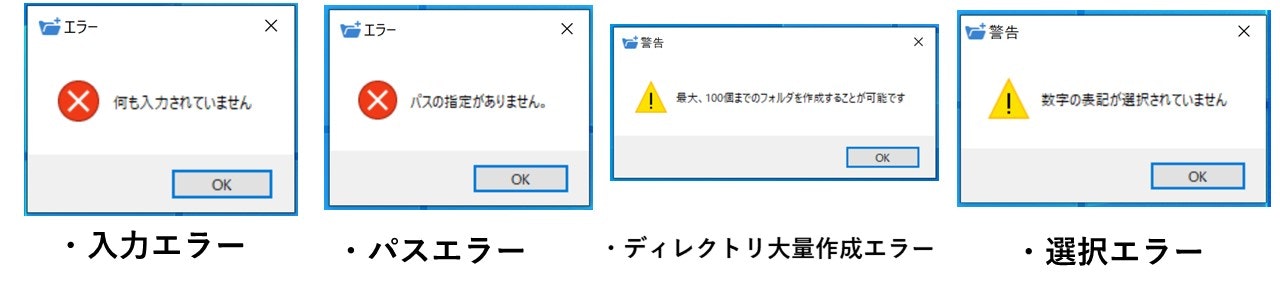
エラー処理については、演算子記号のnotを用いて、3つの入力欄に何も入力していないときの処理として、「入力エラー」を表示させています。また、パスが入力され、フォルダ作成個数が100より大きければ、「ディレクトリ大量作成エラー」を表示させています。さらに、パスが入力され、100個以下の作成条件下でドロップダウンリストが選択されていないとき、「選択エラー」を表示させています。最後に、パス以外の入力がされているとき、「パスエラー」を表示させています。以下にエラー表示パターンを示します。
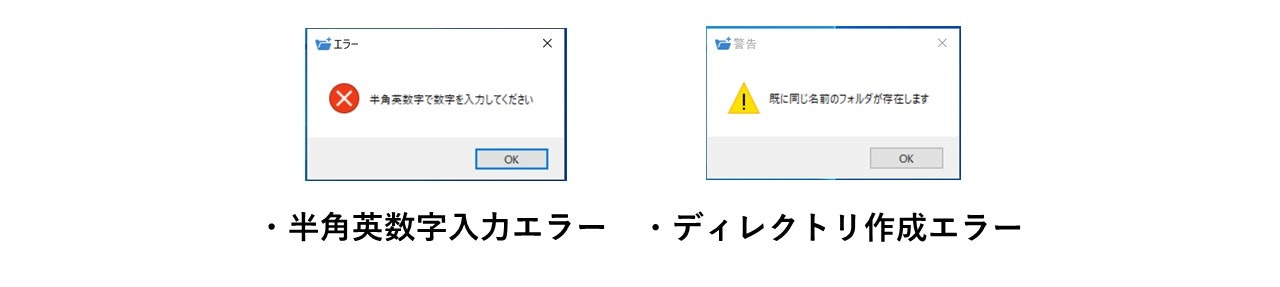
続いて、例外処理ですが、作成個数入力欄に半角英数字の数字以外を入力すると、ValueErrorが返されるので、ValueErrorが発生したときに、「半角英数字入力エラー」を表示させるようにしています。また、ディレクトリが重複した場合、FileExistsErrorが返されるので、FileExistsErrorが発生したときに、「ディレクトリ作成エラー」を表示させるようにしています。
以下にエラー表示パターンを示します。
もっと、エラー処理について、簡単な書き方がある気がする、、、
最後に、作成ボタンやキャンセルボタンについてですが、以下のように処理をしています。
作成ボタンコードbutton1 = ttk.Button(frame3, text="作成", command=conductMain) button1.pack(fill = "x", padx=85, side = "left")キャンセルボタンコードbutton2 = ttk.Button(frame3, text=("閉じる"), command=root.quit) button2.pack(fill = "x", padx=30, side = "left")作成ボタンを押したときに、
command=でイベントを発生させ、conductMain関数を呼び出しています。その後、条件によって、ディレクトリが作成されます。
また、キャンセルについては、ボタンを押したときに、root.quitでウィンドウを閉じています。長くなりましたが、実装内容は以上となります。
説明が必要ないところも説明したかもしれませんがご容赦ください。つまずいたところ
エラーハンドリング
どこを入力して、入力しないかで思いもよらなかった動作をするので、ちょっと大変でした。
エラーするたびに、条件を変えたり、メッセージを表示させたり、トライ&エラーの繰り返しでした。ディレクトリを作成する関数
作成する関数の部分はちょっと間違えばCドライブ直下に大量にディレクトリが作成されるので、気を付けながら条件等を変えていました。
アイコンの設定
tkinterでは
root = tk.Tk() iconfile = 'アイコンのパス' root.iconbitmap(default=iconfile)のように、記述すると、tkinterで表示される画面のアイコンは設定されるのですが、Pyinstallerでexe化したときにスクリプトが実行されず、アイコンも設定されないので、画像ファイルの拡張子をgifにしてBase64のデータを取得する必要がありました。なので、
terminalcertutil -encode icon.gif text.txtでCUI操作をして、iconデータをテキストファイルに書き出しました。Base64データをコピペしてコードに埋め込むことによって解決しました。また、実行ファイルのアイコンは通常のPyinstallerの操作では
terminalpyinstaller ファイル名.py --onefile --noconsoleですが、このままだとPythonの実行ファイルのアイコンが変えられないので、
terminalpyinstaller gui_auto_mkdir.py --onefile --noconsole --icon=favicon.icoのように
--icon=アイコンファイルを付与しました。そうすることで、Tkinterで表示される画面と実行ファイルのアイコンを設定することが出来ました。参考
- 【Python】tkinterでファイル&フォルダパス指定画面を作成する
- tkinter --- Tcl/Tk の Python インタフェース
- Tkinter 入門: 2. Widget を配置しよう
- Tkinter による GUI プログラミング
- 仕事を自動化する!Python入門講座
終わりに
最後まで、見ていただき、ありがとうございます。
皆さんの、作業効率化にお役に立てれば、嬉しいです。
今回、指定した数だけフォルダを作成する機能を実装しましたが、拡張機能としてチェックボックスを利用したフォルダ作成機能もこれから実装する予定です。

- 投稿日:2020-10-12T23:21:47+09:00
Think Python 2E ハック
Think Python 2E ハック
Think Python 2Eを学んでまともなプログラマーになるためのに
モチベーション
NEXT STEP NEXT STEP
概要
think Python 2e を
問題を含めてハックする。
http://facweb.cs.depaul.edu/sjost/it211/documents/think-python-2nd.pdf目次
・エクササイズノート
エクササイズメモ
CHAPTER 2
Exercise 2-1
省略
Exercise 2-2import math
4 / 3 * math.pi (5*5*5)
523.5987755982989
24.95(100-40) + 3 + 24.95*(100-40)* (60-59)+ 59 * 0.75
3041.257:30:06
- 投稿日:2020-10-12T22:57:55+09:00
'pip' は、内部コマンドまたは外部コマンド、 操作可能なプログラムまたはバッチ ファイルとして認識されていません。
- 投稿日:2020-10-12T21:36:55+09:00
数値を線形探索/2分探索で探してみよう
こんにちは。
いつも応援有難うございます m(_ _)m
9/23 から投稿を開始して、そろそろ 3 週間が経とうとしています。
楽しいことは あっ という間ですね(笑)。さて、今回は探索です。
最初は線形探索から行きましょう。
構えなくて大丈夫です。
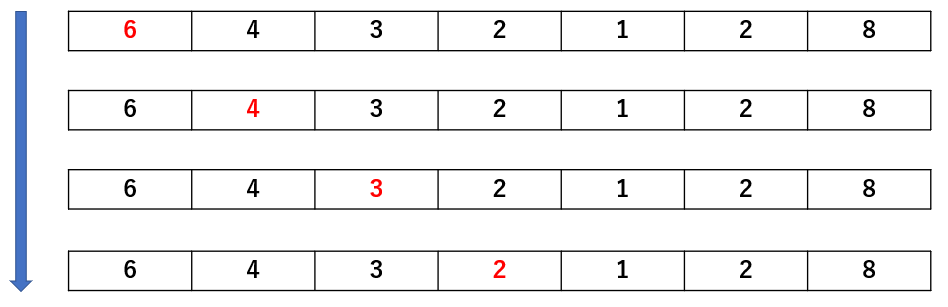
こんな感じで左から順番に、探したい値と赤字が一致しているか確認するだけです。
※すいません、途中で図が切れてて。。
早速、書いてみましょう。linear_search.pydef search(x,key): for i in range(len(x)): if x[i] == key: print(f"value is placed at x[{i}]") break #最終項 x[6] != key の場合、前述の if x[i] == key を pass するので、 #そのまま以下の if 文に入ります。 #i == len(x)-1 なら、fail です。 if i == len(x)-1: print("fail to serch") break if __name__ == "__main__": x = [6,4,3,2,1,2,8] # 配列を指定 key = int(input("enter search value: ")) # 探したい値を入力 search(x,key)では次は、2分探索です。
線形探索との前提条件が大きく異なります。その違いをイメージにしました。
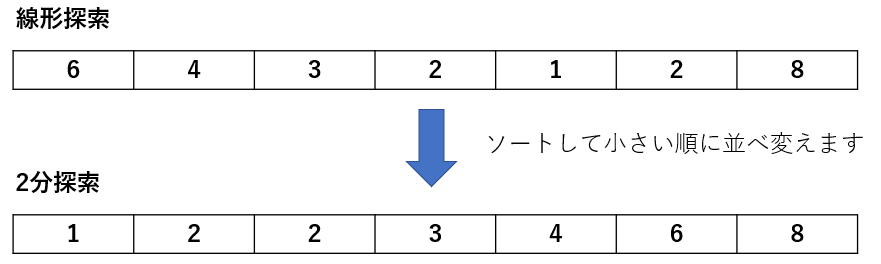
線形探索の場合は、与えられたものを端から比較していくのですが、
2分探索は、そうは行きません。一旦、整列します。出だしが全然違うので注意が必要です。
(? _ ?)(? _ ?)(?_?)
はい、構わず次のステップに行きます。
仮に 3 を探している場合、中央値との比較で一発で発見できます(笑)
では、3 より小さい値を探している場合はどうでしょうか。
探したい値が1の場合どうしましょうか。
[1 , 2 , 2] の中央値 2 でもない場合は、更にそれ以下の
1 が格納されている x[0] を見るだけです。
もし、それでも探している値が無ければ、探し物はそもそも、
用意された配列には存在しない事になります。
一旦、整理しないとイケないメンドイ アルゴですが、なかなか有名らしいです。
今回は再帰で書いてみました。binary_search.pydef binary_search(x,left,right,key): cen = (left + right)//2 if left > right: print(f"left is {left},right is {right}") print("faile to search") return None if x[cen] == key: return print(f"found at x[{cen}]") #中央値 x[cen] が探し物 key より大きい場合 if x[cen] > key: print(f"left is {left},cen is {cen}") binary_search(x,left,cen-1,key)#cen-1 の "-1" がミソです!!! #中央値 x[cen] が探し物 key より小さい場合 if x[cen] < key: print(f"cen is {cen},right is {right}") binary_search(x,cen+1,right,key)#cen+1 の "+1" がミソです!!! if __name__ == "__main__": x =[1,2,2,3,4,6,8] binary_search(x,0,len(x)-1,1)実行結果.pyleft is 0,cen is 3 left is 0,cen is 1 found at x[0]左側を選択し、徐々に狭めていますね。
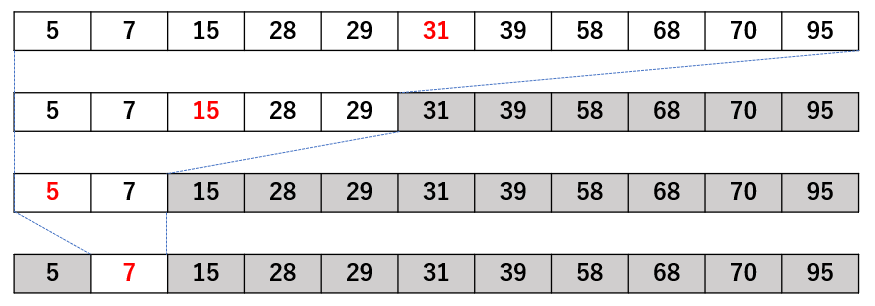
配列長を大きくしてイメージを作り直してみました。
このほうが分かりやすいかもしれません(中央値は赤、探し物が 7 の場合)。
もし、探し物が7じゃなかったらどうしますか?
以下の記述のミソに着目してみてください。miso.py#中央値 x[cen] が探し物 key より大きい場合 if x[cen] > key: print(f"left is {left},cen is {cen}") binary_search(x,left,cen-1,key)#cen-1 の "-1" がミソです!!! #中央値 x[cen] が探し物 key より小さい場合 if x[cen] < key: print(f"cen is {cen},right is {right}") binary_search(x,cen+1,right,key)#cen+1 の "+1" がミソです!!!念のため実行してみると以下のコメントが見えてきます。
実行結果.pyleft is 5,right is 4 faile to searchそうなんです。left > right が実現しています。
どういう事でしょうか?探し物が 6 だった場合、
記述にある if x[cen] > key:に突入します。その結果、binary_search(x,left,cen-1,key) となります。
この時点で、left == right なので、前述の式を考えると
left > right になりますよね!??。
これが逆転の仕組みです。
ここまで来たら、何もないって言えますよね??
※逆のパターン(if x[cen] < key:)もしかりです(≧▽≦)もっとシンプルに書ける方が居たら、
申し訳ありませんが御教示宜しくお願い致します。m(_ _)m


- 投稿日:2020-10-12T21:12:35+09:00
Python3のExecutor.submitを大量に実行するとメモリを多く消費する場合がある
参考にしました: https://www.bettercodebytes.com/theadpoolexecutor-with-a-bounded-queue-in-python/
概要
Executorでmax_workersを指定すると並列度が調整できますが、並列数を上回るペースでsubmitした場合にどうなるかというとブロックは起きません。その代わりメモリにため込むようです。この動きのため、大量に実行するとメモリを多く消費してしまうことがあります。
with ThreadPoolExecutor(max_workers=10) as executor: for i in range(0, 1024*1024): # たくさん executor.submit(fn, i) # つくる # forループはすぐ終わるが、消費メモリがすごいことになっている実際、100万ループするようなコードを書くとメモリを2GBぐらい消費します。なので、対応を考えることにしました。
内部実装と原因
内部実装を確認したところ、ThreadPoolExecutorは内部でキューを持っており、submitするとWorkItemというオブジェクトを作りキューに入れます。この内部のキューには上限が無くブロックすることもないため、際限なくsubmitできてしまいます。
ちなみに、Workerスレッドはキューに詰めたタイミングで作っていて、Workerスレッドはキューからデータを取り出し、実行、というのを無限ループでやっています。
確認コード
実際にその動きを観察してみます。例えば0.01秒かかる関数を5000回実行します。これをmax_workers=10で回してみます。
for文内での進捗としてタイムスタンプとメモリ(今回はmaxrss)を見ます。
https://wandbox.org/permlink/n2P2CQssjhj1eOFw
タイムスタンプからsubmitでブロッキングは起きていないことがわかります(forループのsubmitする処理はすぐに終えてほとんどshutdown待ちになっている)
しかし、処理が進むにつれメモリ消費が増えていることがわかります。対応
案1. キューをサイズ付きにする
最初に考えたのはこの方法です。
ThreadPoolExecutorの内部で使うキューをサイズ付きのキューにします。継承してインスタンス変数をすり替えます。https://wandbox.org/permlink/HJN0lRBR0VBYU0Pv
タイムスタンプからループ中にブロッキングが起きていることがわかります。しかしトータルの時間はさほど変わらずメモリの消費は非常に緩やかです。
コードは単純ですが、内部実装に手を出すのは若干いまいちな感じがしますし、ProcessPoolExecutorではこういったキューは持っていないので、この方法は使えません。
案2. Semaphoreで同時実行数を制御する
案1がいまいちだったのでどうにかできないか探していたところ参考元の記事を見つけました。
https://www.bettercodebytes.com/theadpoolexecutor-with-a-bounded-queue-in-python/
参考元を参考にPoolExecutorをラップしたクラスBoundedExecutorを作成します。API互換(map以外)なので差し替えて使えます。
内部実装はsubmit時にsemaphoreのカウントダウンを行い、ワーカーの処理が完了したときはsemaphoreのカウントアップをすること同時実行を制御します。「ワーカーの処理が完了したとき」というのは「futureのadd_done_callbackで登録した関数が完了時に呼ばれるとき」とします。(ワーカーの処理が完了した時もraise Exceptionした時もコールバックは呼ばれるので辻褄は合うはず)
https://wandbox.org/permlink/jn4nN8leJonLi2ty
こちらも、案1のときと同様な結果になりました。
ちなみに、max_workersよりも多くなるようにキューのサイズを決めたほうが良いです(コードで言えばbounded_ratio=1の箇所がbounded_ratio=2になるように引数を与えるor変える)
「並列数==キューのサイズ」にしてしまうと、キューに空きができてしまうタイミングが発生してしまい、ワーカーが遊んでしまい全体の完了が若干遅くなります。なので、少し多くなるようにするのがよいです。
- 投稿日:2020-10-12T21:02:02+09:00
異常検出の基本的な流れ
1. 前処理
KaggleのCredit Card Fraud Detectionを利用する。
import numpy as np import pandas as pd import os import matplotlib.pyplot as plt import seaborn as sns import matplotlib as mpl from sklearn import preprocessing as pp from scipy.stats import pearsonr from sklearn.model_selection import train_test_split from sklearn.model_selection import StratifiedKFold from sklearn.metrics import log_loss from sklearn.metrics import precision_recall_curve, average_precision_score from sklearn.metrics import roc_curve, auc, roc_auc_score from sklearn.metrics import confusion_matrix, classification_report from sklearn.linear_model import LogisticRegression from sklearn.ensemble import RandomForestClassifier import xgboost as xgb import lightgbm as lgb %matplotlib inline data = pd.read_csv('creditcard.csv') print(data.shape) print(data.columns) print(data.dtypes)(284807, 31) Index(['Time', 'V1', 'V2', 'V3', 'V4', 'V5', 'V6', 'V7', 'V8', 'V9', 'V10', 'V11', 'V12', 'V13', 'V14', 'V15', 'V16', 'V17', 'V18', 'V19', 'V20', 'V21', 'V22', 'V23', 'V24', 'V25', 'V26', 'V27', 'V28', 'Amount', 'Class'], dtype='object') Time float64 V1 float64 V2 float64 V3 float64 V4 float64 V5 float64 V6 float64 V7 float64 V8 float64 V9 float64 V10 float64 V11 float64 V12 float64 V13 float64 V14 float64 V15 float64 V16 float64 V17 float64 V18 float64 V19 float64 V20 float64 V21 float64 V22 float64 V23 float64 V24 float64 V25 float64 V26 float64 V27 float64 V28 float64 Amount float64 Class int64 dtype: objectdata.apply(lambda x: len(x.unique()))Time 124592 V1 275663 V2 275663 V3 275663 V4 275663 V5 275663 V6 275663 V7 275663 V8 275663 V9 275663 V10 275663 V11 275663 V12 275663 V13 275663 V14 275663 V15 275663 V16 275663 V17 275663 V18 275663 V19 275663 V20 275663 V21 275663 V22 275663 V23 275663 V24 275663 V25 275663 V26 275663 V27 275663 V28 275663 Amount 32767 Class 2 dtype: int64284807の取引データのうち、492が不正取引である。
data['Class'].sum()492また、今回は外れ値の処理は省略。
data.isnull().sum()Time 0 V1 0 V2 0 V3 0 V4 0 V5 0 V6 0 V7 0 V8 0 V9 0 V10 0 V11 0 V12 0 V13 0 V14 0 V15 0 V16 0 V17 0 V18 0 V19 0 V20 0 V21 0 V22 0 V23 0 V24 0 V25 0 V26 0 V27 0 V28 0 Amount 0 Class 0 dtype: int64データセットの分割
features_to_scale = data_X.drop(['Time'], axis=1).columns scaler = pp.StandardScaler(copy=True) data_X.loc[:, features_to_scale] = scaler.fit_transform(data_X[features_to_scale]) X_train, X_test, y_train, y_test = train_test_split(data_X, data_y, stratify=data_y)k分割交差検証
k_fold = StratifiedKFold(n_splits=5, shuffle=True, random_state=2018)2. ロジスティック回帰
log_reg = LogisticRegression() model = log_reg training_scores = [] cv_scores = [] predictions_based_on_k_folds = pd.DataFrame(data=[], index=y_train.index, columns=[0,1]) for train_index, cv_index in k_fold.split(np.zeros(len(X_train)), y_train.ravel()): X_train_fold, X_cv_fold = X_train.iloc[train_index,:], X_train.iloc[cv_index,:] y_train_fold, y_cv_fold = y_train.iloc[train_index], y_train.iloc[cv_index] model.fit(X_train_fold, y_train_fold) log_loss_training = log_loss(y_train_fold, model.predict_proba(X_train_fold)[:,1]) training_scores.append(log_loss_training) predictions_based_on_k_folds.loc[X_cv_fold.index,:] = model.predict_proba(X_cv_fold) log_loss_cv = log_loss(y_cv_fold, predictions_based_on_k_folds.loc[X_cv_fold.index,1]) cv_scores.append(log_loss_cv) print('Training Log Loss: ', log_loss_training) print('CV Log Loss: ', log_loss_cv) log_loss_logistic_regression = log_loss(y_train, predictions_based_on_k_folds.loc[:,1]) print('Logistic Regression Log Loss: ', log_loss_logistic_regression)Training Log Loss: 0.005995557191448456 CV Log Loss: 0.005125568292973096 Training Log Loss: 0.006253549879846522 CV Log Loss: 0.00484099351605527 Training Log Loss: 0.005099537613560319 CV Log Loss: 0.007849849024852518 Training Log Loss: 0.006164376210898366 CV Log Loss: 0.004896801432022977 Training Log Loss: 0.005689191528946416 CV Log Loss: 0.0072969772559491235 Logistic Regression Log Loss: 0.006002037904370599適合率・再現率曲線
preds = pd.concat([y_train, predictions_based_on_k_folds.loc[:,1]], axis=1) preds.columns = ['true_label', 'prediction'] predictions_based_on_k_folds_logistic_regression = preds.copy() precision, recall, thresholds = precision_recall_curve(preds['true_label'], preds['prediction']) average_precision = average_precision_score(preds['true_label'], preds['prediction']) plt.step(recall, precision, color='k', alpha=0.7, where='post') plt.fill_between(recall, precision, step='post', alpha=0.3, color='k') plt.xlabel('Recall') plt.ylabel('Precision') plt.xlim([0.0, 1.0]) plt.ylim([0.0, 1.05]) plt.title('Precision-Recall curve: Average Precision = {0:0.2f}'.format(average_precision))
auROC (受信者動作特性曲線下面積)
fqr, tqr, thresholds = roc_curve(preds['true_label'], preds['prediction']) area_under_ROC = auc(fqr, tqr) plt.figure() plt.plot(fqr, tqr, color='r', lw=2, label='ROC curve') plt.plot([0, 1], [0, 1], color='k', lw=2, linestyle='--') plt.xlim([0.0, 1.0]) plt.ylim([0.0, 1.05]) plt.xlabel('False Positive Rate') plt.ylabel('True Positive Rate') plt.title('Receiver Operating Characteristic: Area under the Curve = {0:0.2f}'.format(area_under_ROC)) plt.legend(loc="lower right") plt.show()
3. Random Forest
RFC = RandomForestClassifier(n_estimators=10, class_weight='balanced') model = RFC training_scores = [] cv_scores = [] predictions_based_on_k_folds = pd.DataFrame(data=[], index=y_train.index, columns=[0,1]) for train_index, cv_index in k_fold.split(np.zeros(len(X_train)), y_train.ravel()): X_train_fold, X_cv_fold = X_train.iloc[train_index,:], X_train.iloc[cv_index,:] y_train_fold, y_cv_fold = y_train.iloc[train_index], y_train.iloc[cv_index] model.fit(X_train_fold, y_train_fold) log_loss_training = log_loss(y_train_fold, model.predict_proba(X_train_fold)[:,1]) training_scores.append(log_loss_training) predictions_based_on_k_folds.loc[X_cv_fold.index,:] = model.predict_proba(X_cv_fold) log_loss_cv = log_loss(y_cv_fold, predictions_based_on_k_folds.loc[X_cv_fold.index,1]) cv_scores.append(log_loss_cv) print('Training Log Loss: ', log_loss_training) print('CV Log Loss: ', log_loss_cv) log_loss_random_forest = log_loss(y_train, predictions_based_on_k_folds.loc[:,1]) print('Random Forest Log Loss: ', log_loss_random_forest) preds = pd.concat([y_train, predictions_based_on_k_folds.loc[:,1]], axis=1) preds.columns = ['true_label', 'prediction'] predictions_based_on_k_folds_random_forests = preds.copy() precision, recall, thresholds = precision_recall_curve(preds['true_label'], preds['prediction']) average_precision = average_precision_score(preds['true_label'], preds['prediction']) plt.step(recall, precision, color='k', alpha=0.7, where='post') plt.fill_between(recall, precision, step='post', alpha=0.3, color='k') plt.xlabel('Recall') plt.ylabel('Precision') plt.xlim([0.0, 1.0]) plt.ylim([0.0, 1.05]) plt.title('Precision-Recall curve: Average Precision = {0:0.2f}'.format(average_precision)) preds = pd.concat([y_train, predictions_based_on_k_folds.loc[:,1]], axis=1) preds.columns = ['true_label', 'prediction'] predictions_based_on_k_folds_random_forests = preds.copy() precision, recall, thresholds = precision_recall_curve(preds['true_label'], preds['prediction']) average_precision = average_precision_score(preds['true_label'], preds['prediction']) plt.step(recall, precision, color='k', alpha=0.7, where='post') plt.fill_between(recall, precision, step='post', alpha=0.3, color='k') plt.xlabel('Recall') plt.ylabel('Precision') plt.xlim([0.0, 1.0]) plt.ylim([0.0, 1.05]) plt.title('Precision-Recall curve: Average Precision = {0:0.2f}'.format(average_precision))Training Log Loss: 0.00036571581908744426 CV Log Loss: 0.013690949627129164 Training Log Loss: 0.0004235723689615818 CV Log Loss: 0.00570945955148682 Training Log Loss: 0.00037000075061198505 CV Log Loss: 0.012404725764776376 Training Log Loss: 0.00039448357820150154 CV Log Loss: 0.009696866082135918 Training Log Loss: 0.00039912406259827595 CV Log Loss: 0.008095821155055213 Random Forest Log Loss: 0.009919564436116697
4. XGBoost
params_xGB = { 'objective':'binary:logistic', 'eval_metric':'logloss' } training_scores = [] cv_scores = [] predictions_based_on_k_folds = pd.DataFrame(data=[], index=y_train.index, columns=['prediction']) for train_index, cv_index in k_fold.split(np.zeros(len(X_train)), y_train.ravel()): X_train_fold, X_cv_fold = X_train.iloc[train_index,:], X_train.iloc[cv_index,:] y_train_fold, y_cv_fold = y_train.iloc[train_index], y_train.iloc[cv_index] dtrain = xgb.DMatrix(data=X_train_fold, label=y_train_fold) dCV = xgb.DMatrix(data=X_cv_fold) bst = xgb.cv(params_xGB, dtrain, num_boost_round=2000, nfold=5, early_stopping_rounds=200, verbose_eval=50) best_rounds = np.argmin(bst['test-logloss-mean']) bst = xgb.train(params_xGB, dtrain, best_rounds) log_loss_training = log_loss(y_train_fold, bst.predict(dtrain)) training_scores.append(log_loss_training) predictions_based_on_k_folds.loc[X_cv_fold.index,'prediction'] = bst.predict(dCV) log_loss_cv = log_loss(y_cv_fold, predictions_based_on_k_folds.loc[X_cv_fold.index, 'prediction']) cv_scores.append(log_loss_cv) print('Training Log Loss: ', log_loss_training) print('CV Log Loss: ', log_loss_cv) log_loss_xgboost_gradient_boosting = log_loss(y_train, predictions_based_on_k_folds.loc[:,'prediction']) print('XGBoost Gradient Boosting Log Loss: ', log_loss_xgboost_gradient_boosting) params_xGB = { 'objective':'binary:logistic', 'eval_metric':'logloss' } training_scores = [] cv_scores = [] predictions_based_on_k_folds = pd.DataFrame(data=[], index=y_train.index, columns=['prediction']) for train_index, cv_index in k_fold.split(np.zeros(len(X_train)), y_train.ravel()): X_train_fold, X_cv_fold = X_train.iloc[train_index,:], X_train.iloc[cv_index,:] y_train_fold, y_cv_fold = y_train.iloc[train_index], y_train.iloc[cv_index] dtrain = xgb.DMatrix(data=X_train_fold, label=y_train_fold) dCV = xgb.DMatrix(data=X_cv_fold) bst = xgb.cv(params_xGB, dtrain, num_boost_round=2000, nfold=5, early_stopping_rounds=200, verbose_eval=50) best_rounds = np.argmin(bst['test-logloss-mean']) bst = xgb.train(params_xGB, dtrain, best_rounds) log_loss_training = log_loss(y_train_fold, bst.predict(dtrain)) training_scores.append(log_loss_training) predictions_based_on_k_folds.loc[X_cv_fold.index,'prediction'] = bst.predict(dCV) log_loss_cv = log_loss(y_cv_fold, predictions_based_on_k_folds.loc[X_cv_fold.index, 'prediction']) cv_scores.append(log_loss_cv) print('Training Log Loss: ', log_loss_training) print('CV Log Loss: ', log_loss_cv) log_loss_xgboost_gradient_boosting = log_loss(y_train, predictions_based_on_k_folds.loc[:,'prediction']) print('XGBoost Gradient Boosting Log Loss: ', log_loss_xgboost_gradient_boosting) fqr, tqr, thresholds = roc_curve(preds['true_label'], preds['prediction']) area_under_ROC = auc(fqr, tqr) plt.figure() plt.plot(fqr, tqr, color='r', lw=2, label='ROC curve') plt.plot([0, 1], [0, 1], color='k', lw=2, linestyle='--') plt.xlim([0.0, 1.0]) plt.ylim([0.0, 1.05]) plt.xlabel('False Positive Rate') plt.ylabel('True Positive Rate') plt.title('Receiver Operating Characteristic: Area under the Curve = {0:0.2f}'.format(area_under_ROC)) plt.legend(loc="lower right") plt.show()[0] train-logloss:0.43780+0.00001 test-logloss:0.43797+0.00002 [50] train-logloss:0.00012+0.00000 test-logloss:0.00260+0.00027 [100] train-logloss:0.00005+0.00000 test-logloss:0.00279+0.00026 [150] train-logloss:0.00004+0.00000 test-logloss:0.00288+0.00026 [200] train-logloss:0.00003+0.00000 test-logloss:0.00292+0.00027 Training Log Loss: 0.000792206342624254 CV Log Loss: 0.0029518170688098444 [0] train-logloss:0.43784+0.00002 test-logloss:0.43805+0.00007 [50] train-logloss:0.00013+0.00000 test-logloss:0.00292+0.00084 [100] train-logloss:0.00005+0.00000 test-logloss:0.00319+0.00095 [150] train-logloss:0.00004+0.00000 test-logloss:0.00328+0.00098 [200] train-logloss:0.00003+0.00000 test-logloss:0.00332+0.00099 Training Log Loss: 0.0005385763160533223 CV Log Loss: 0.001907025524733791 [0] train-logloss:0.43780+0.00002 test-logloss:0.43798+0.00009 [50] train-logloss:0.00011+0.00001 test-logloss:0.00278+0.00088 [100] train-logloss:0.00005+0.00000 test-logloss:0.00299+0.00097 [150] train-logloss:0.00004+0.00000 test-logloss:0.00308+0.00102 [200] train-logloss:0.00003+0.00000 test-logloss:0.00314+0.00104 Training Log Loss: 0.0008465584373083585 CV Log Loss: 0.003197665909513871 [0] train-logloss:0.43785+0.00004 test-logloss:0.43802+0.00006 [50] train-logloss:0.00012+0.00001 test-logloss:0.00293+0.00057 [100] train-logloss:0.00005+0.00000 test-logloss:0.00320+0.00063 [150] train-logloss:0.00004+0.00000 test-logloss:0.00329+0.00065 [200] train-logloss:0.00003+0.00000 test-logloss:0.00335+0.00067 Training Log Loss: 0.0005723772843934578 CV Log Loss: 0.001984392100999932 [0] train-logloss:0.43786+0.00003 test-logloss:0.43803+0.00006 [50] train-logloss:0.00013+0.00001 test-logloss:0.00290+0.00095 [100] train-logloss:0.00005+0.00000 test-logloss:0.00310+0.00104 [150] train-logloss:0.00004+0.00000 test-logloss:0.00316+0.00107 [200] train-logloss:0.00003+0.00000 test-logloss:0.00320+0.00108 Training Log Loss: 0.000810889205186624 CV Log Loss: 0.002501448645341887 XGBoost Gradient Boosting Log Loss: 0.002508469849879866
5. LightGBM
params_lightGBM = { 'objective':'binary', 'metric':'binary_logloss', 'max_depth':4, 'learning_rate':0.01 } training_scores = [] cv_scores = [] predictions_based_on_k_folds = pd.DataFrame(data=[], index=y_train.index, columns=['prediction']) for train_index, cv_index in k_fold.split(np.zeros(len(X_train)), y_train.ravel()): X_train_fold, X_cv_fold = X_train.iloc[train_index,:], X_train.iloc[cv_index,:] y_train_fold, y_cv_fold = y_train.iloc[train_index], y_train.iloc[cv_index] lgb_train = lgb.Dataset(X_train_fold, y_train_fold) lgb_eval = lgb.Dataset(X_cv_fold, y_cv_fold, reference=lgb_train) gbm = lgb.train(params_lightGBM, lgb_train, num_boost_round=2000, valid_sets=lgb_eval, early_stopping_rounds=200) log_loss_training = log_loss(y_train_fold, gbm.predict(X_train_fold, num_iteration=gbm.best_iteration)) training_scores.append(log_loss_training) predictions_based_on_k_folds.loc[X_cv_fold.index,'prediction'] = gbm.predict(X_cv_fold, num_iteration=gbm.best_iteration) log_loss_cv = log_loss(y_cv_fold, predictions_based_on_k_folds.loc[X_cv_fold.index,'prediction']) cv_scores.append(log_loss_cv) print('Training Log Loss: ', log_loss_training) print('CV Log Loss: ', log_loss_cv) log_loss_lightgbm_gradient_boosting = log_loss(y_train, predictions_based_on_k_folds.loc[:,'prediction']) print('lightGBM Gradient Boosting Log Loss: ', log_loss_lightgbm_gradient_boosting) params_lightGBM = { 'objective':'binary', 'metric':'binary_logloss', 'max_depth':4, 'learning_rate':0.01 } training_scores = [] cv_scores = [] predictions_based_on_k_folds = pd.DataFrame(data=[], index=y_train.index, columns=['prediction']) for train_index, cv_index in k_fold.split(np.zeros(len(X_train)), y_train.ravel()): X_train_fold, X_cv_fold = X_train.iloc[train_index,:], X_train.iloc[cv_index,:] y_train_fold, y_cv_fold = y_train.iloc[train_index], y_train.iloc[cv_index] lgb_train = lgb.Dataset(X_train_fold, y_train_fold) lgb_eval = lgb.Dataset(X_cv_fold, y_cv_fold, reference=lgb_train) gbm = lgb.train(params_lightGBM, lgb_train, num_boost_round=2000, valid_sets=lgb_eval, early_stopping_rounds=200) log_loss_training = log_loss(y_train_fold, gbm.predict(X_train_fold, num_iteration=gbm.best_iteration)) training_scores.append(log_loss_training) predictions_based_on_k_folds.loc[X_cv_fold.index,'prediction'] = gbm.predict(X_cv_fold, num_iteration=gbm.best_iteration) log_loss_cv = log_loss(y_cv_fold, predictions_based_on_k_folds.loc[X_cv_fold.index,'prediction']) cv_scores.append(log_loss_cv) print('Training Log Loss: ', log_loss_training) print('CV Log Loss: ', log_loss_cv) log_loss_lightgbm_gradient_boosting = log_loss(y_train, predictions_based_on_k_folds.loc[:,'prediction']) print('lightGBM Gradient Boosting Log Loss: ', log_loss_lightgbm_gradient_boosting) fqr, tqr, thresholds = roc_curve(preds['true_label'], preds['prediction']) area_under_ROC = auc(fqr, tqr) plt.figure() plt.plot(fqr, tqr, color='r', lw=2, label='ROC curve') plt.plot([0, 1], [0, 1], color='k', lw=2, linestyle='--') plt.xlim([0.0, 1.0]) plt.ylim([0.0, 1.05]) plt.xlabel('False Positive Rate') plt.ylabel('True Positive Rate') plt.title('Receiver Operating Characteristic: Area under the Curve = {0:0.2f}'.format(area_under_ROC)) plt.legend(loc="lower right") plt.show()
6. スタッキング
predictions_test_set_logistic_regression = pd.DataFrame(data=[], index=y_test.index, columns=['prediction']) predictions_test_set_logistic_regression.loc[:, 'prediction'] = log_reg.predict_proba(X_test)[:,1] log_loss_test_set_logistic_regression = log_loss(y_test, predictions_test_set_logistic_regression) predictions_test_set_random_forests = pd.DataFrame(data=[], index=y_test.index, columns=['prediction']) predictions_test_set_random_forests.loc[:, 'prediction'] = RFC.predict_proba(X_test)[:,1] log_loss_test_set_random_forests = log_loss(y_test, predictions_test_set_random_forests) predictions_test_set_xgboost_gradient_boosting = pd.DataFrame(data=[], index=y_test.index, columns=['prediction']) dtest=xgb.DMatrix(data=X_test) predictions_test_set_xgboost_gradient_boosting.loc[:, 'prediction'] = bst.predict(dtest) log_loss_test_set_xgboost_gradient_boosting = log_loss(y_test, predictions_test_set_xgboost_gradient_boosting) predictions_test_set_light_gbm_gradient_boosting = pd.DataFrame(data=[], index=y_test.index, columns=['prediction']) predictions_test_set_light_gbm_gradient_boosting.loc[:, 'prediction'] = gbm.predict(X_test, num_iteration=gbm.best_iteration) log_loss_test_set_light_gbm_gradient_boosting = log_loss(y_test, predictions_test_set_light_gbm_gradient_boosting) print('Log Loss of Logistic Regression on Test Set: ', log_loss_test_set_logistic_regression) print('Log Loss of Random Forests on Test Set: ', log_loss_test_set_random_forests) print('Log Loss of XGBoost Gradient Boosting on Test Set: ', log_loss_test_set_xgboost_gradient_boosting) print('Log Loss of LightGBM Gradient Boosting on Test Set: ', log_loss_test_set_light_gbm_gradient_boosting)Log Loss of Logistic Regression on Test Set: 0.006119615555779465 Log Loss of Random Forests on Test Set: 0.012553984393960552 Log Loss of XGBoost Gradient Boosting on Test Set: 0.003148207871388518 Log Loss of LightGBM Gradient Boosting on Test Set: 0.00333516364607809prediction_based_on_kfolds_four_models = pd.DataFrame(data=[], index=y_train.index) prediction_based_on_kfolds_four_models = prediction_based_on_kfolds_four_models.join(predictions_based_on_k_folds_logistic_regression['prediction'].astype(float), how='left').join(predictions_based_on_k_folds_random_forests['prediction'].astype(float), how='left', rsuffix="2").join(predictions_based_on_k_folds_xgboost_gradient_boosting['prediction'].astype(float), how='left', rsuffix="3").join(predictions_based_on_k_folds_light_gbm_gradient_boosting['prediction'].astype(float), how='left', rsuffix="4") prediction_based_on_kfolds_four_models.columns = ['predsLR', 'predsRF', 'predsXGB', 'predsLightGBM'] X_train_with_predictions = X_train.merge(prediction_based_on_kfolds_four_models, left_index=True, right_index=True)7. で、もう一回LightGBM
params_lightGBM = { 'objective':'binary', 'metric':'binary_logloss', 'max_depth':4, 'learning_rate':0.01 } training_scores = [] cv_scores = [] predictions_based_on_k_folds = pd.DataFrame(data=[], index=y_train.index, columns=['prediction']) for train_index, cv_index in k_fold.split(np.zeros(len(X_train)), y_train.ravel()): X_train_fold, X_cv_fold = X_train_with_predictions.iloc[train_index, :], X_train_with_predictions.iloc[cv_index, :] y_train_fold, y_cv_fold = y_train.iloc[train_index], y_train.iloc[cv_index] lgb_train = lgb.Dataset(X_train_fold, y_train_fold) lgb_eval = lgb.Dataset(X_cv_fold, y_cv_fold, reference=lgb_train) gbm = lgb.train(params_lightGBM, lgb_train, num_boost_round=2000, valid_sets=lgb_eval, early_stopping_rounds=200) log_loss_training = log_loss(y_train_fold, gbm.predict(X_train_fold, num_iteration=gbm.best_iteration)) training_scores.append(log_loss_training) predictions_based_on_k_folds.loc[X_cv_fold.index,'prediction'] = gbm.predict(X_cv_fold, num_iteration=gbm.best_iteration) log_loss_cv = log_loss(y_cv_fold, predictions_based_on_k_folds.loc[X_cv_fold.index,'prediction']) cv_scores.append(log_loss_cv) print('Training Log Loss: ', log_loss_training) print('CV Log Loss: ', log_loss_cv) log_loss_ensemble = log_loss(y_train, predictions_based_on_k_folds.loc[:,'prediction']) print('lightGBM Gradient Boosting Log Loss: ', log_loss_ensemble) preds = pd.concat([y_train, predictions_based_on_k_folds.loc[:,'prediction']], axis=1) preds.columns = ['true_label', 'prediction'] predictions_based_on_k_folds_ensamble = preds.copy() precision, recall, thresholds = precision_recall_curve(preds['true_label'], preds['prediction']) average_precision = average_precision_score(preds['true_label'], preds['prediction']) plt.step(recall, precision, color='k', alpha=0.7, where='post') plt.fill_between(recall, precision, step='post', alpha=0.3, color='k') plt.xlabel('Recall') plt.ylabel('Precision') plt.xlim([0.0, 1.0]) plt.ylim([0.0, 1.05]) plt.title('Precision-Recall curve: Average Precision = {0:0.2f}'.format(average_precision)) preds = pd.concat([y_train, predictions_based_on_k_folds.loc[:,'prediction']], axis=1) preds.columns = ['true_label', 'prediction'] predictions_based_on_k_folds_ensamble = preds.copy() precision, recall, thresholds = precision_recall_curve(preds['true_label'], preds['prediction']) average_precision = average_precision_score(preds['true_label'], preds['prediction']) plt.step(recall, precision, color='k', alpha=0.7, where='post') plt.fill_between(recall, precision, step='post', alpha=0.3, color='k') plt.xlabel('Recall') plt.ylabel('Precision') plt.xlim([0.0, 1.0]) plt.ylim([0.0, 1.05]) plt.title('Precision-Recall curve: Average Precision = {0:0.2f}'.format(average_precision))
8. 実運用システムパイプライン
new_data = pd.read_cv('') new_feature_to_scale = new_data.drop(['Time'], axis=1).columns new_data.loc[:, new_feature_to_scale] = sX.fit_transform(new_data[new_feature_to_scale]) gbm.predict(new_data, num_iteration=gbm.best_iteration)










- 投稿日:2020-10-12T20:41:07+09:00
PythonでTwitterのツイートをしてみたいけどハマった話
自動でTwitterのツイートをしてみたいという話を聞いて、ちょっと作ってみたがハマった話
CONSUMER_KEYがない
色々なサイトを見て検索するとpythonからツイートをするにあたって必要な項目が4項目あります。
CONSUMER_KEY, CONSUMER_SECRET,
ACCESS_TOKEN, ACCESS_SECRETが必要と出てくるのですがどう見てもCONSUMER_KEYとCONSUMER_SECRETがない!
ただ、どうやっても見つからないので検索すると
CONSUMER_KEYはAPI KEYで
CONSUMER_SECRETはAPI_key_secretでいいそうです。検索すればよく見るコードですが下記のコードに変数を変更しました。
このほうが理解しやすいと思います。twitter.pyimport json from requests_oauthlib import OAuth1Session #ここにKeyとToken API_KEY = 'XXXXXXX' API_KEY_SECRET = 'XXXXXXX' ACCESS_TOKEN = 'XXXXXXX' ACCESS_TOKEN_SECRET = 'XXXXXXX' twitter = OAuth1Session(API_KEY, API_KEY_SECRET, ACCESS_TOKEN, ACCESS_TOKEN_SECRET) url = "https://api.twitter.com/1.1/statuses/update.json" print(twitter) tweet = "Pythonからのテストツイートです\r改行する\r\n改行\n改行" # ツイート内容 params = {"status" : tweet} req = twitter.post(url, params = params) #ここでツイート if req.status_code == 200: #成功 print("Succeed!") else: #エラー print("ERROR : %d"% req.status_code)401エラーでツイートができない
API_KEYを取ったあと上記コードで実行を行っても
ERROR : 401
で全然ツイートができない。このケースは設定漏れでした。401の通り、権限なしでした。
まず、最初の設定は読み込みのみなので書き込みもできるように設定を変更しました。
ただ、401エラーは継続です。
なんで出来なかったか。
多分ですがあとは読み込み & 書き込み設定に変更したあとに
再度ACCESS_KEYを取り直すこと(regenerate)。
再度取得しないと読み込みしか出来ないACCESS_KEYを使用している状態で書き込みができないのだと思われます。
それでも401エラーダメな場合は何度か取得して変数に代入してみてください。
参考資料
- 投稿日:2020-10-12T20:35:53+09:00
Natural Language : GPT - Japanese Generative Pretraining Transformer
目標
Microsoft Cognitive Toolkit (CNTK) を用いて GPT をやってみました。
訓練に使用する日本語のコーパスを用意しておきます。
NVIDIA GPU CUDA がインストールされていることを前提としています。導入
今回は日本語のコーパスを用意して日本語文生成モデルを訓練しました。単語の分割に関しては、sentencepiece [1] を用いたサブワードモデルを作成しておきます。
GPT
Generative Pretraining Transformer (GPT) [2] は Transformer [3] の Decoder 部分だけを使用します。Transformer については Natural Language : Machine Translation Part2 - Neural Machine Translation Transformer で紹介しています。
また今回は Natural Language : BERT Part2 - Unsupervised pretraining ALBERT のときと同様に、Pre-Layer Normalization Transformer [4] で構成しました。層構造の詳細を下図に示します。
また、Factorized embedding parameterization と Cross-layer parameter sharing を用いてモデルを軽量化しました。
GPT の Multi-Head Attention では Masked Self-Attention を使用しており、自己回帰による教師なし学習を行います。
訓練における諸設定
各パラメータの初期値は分散 0.02 の正規分布に設定しました。
損失関数は Cross Entropy Error を使用します。
最適化アルゴリズムには Adam [5] を採用しました。Adam のハイパーパラメータ $β_1$ は 0.9、$β_2$ は CNTK のデフォルト値に設定しました。
学習率は、Cyclical Learning Rate (CLR) [6] を使って、最大学習率は 1e-4、ベース学習率は 1e-8、ステップサイズはエポック数の 10倍、方策は triangular2 に設定しました。
モデルの訓練はミニバッチ学習によって 1,000,000 Iteration を実行しました。
実装
実行環境
ハードウェア
・CPU Intel(R) Core(TM) i7-5820K 3.30GHz
・GPU NVIDIA Quadro RTX 6000 24GBソフトウェア
・Windows 10 Pro 1909
・CUDA 10.0
・cuDNN 7.6
・Python 3.6.6
・cntk-gpu 2.7
・cntkx 0.1.53
・pandas 1.1.2
・sentencenpiece 0.1.91実行するプログラム
訓練用のプログラムは GitHub で公開しています。
jgpt_training.py解説
今回の実装で要となる内容について補足します。
OpenAI GPT
GPT は自然言語処理における事前学習モデルとして提案されました。時刻 $t$ までの入力単語 $w_1, w_2, ..., w_{t}$ からその次の時刻 $t+1$ の単語 $w_{t+1}$ を予測する自己回帰言語モデルです。
p(w) = \prod^T_{t=1} p(w_{t+1} | w_1, w_2, ..., w_t)GPT は BERT と同様に教師なし事前学習をしてから複数のタスクのデータセットでファインチューニングをします。BERT では特別な [MASK] トークンを用いることで教師なし学習を実現していましたが、GPT では下図のように自己回帰を用いることで教師なし事前学習を行います。
下図は BERT と GPT の Multi-Head Attention を表しています。BERT では過去・未来の双方向の情報を使用できますが、GPT では未来の情報がマスクされるため単方向の情報のみを使用します。
GPT-2
GPT-2 [7] では Pre-Layer Normalization で構成され、Transformer Decoder は最大 48層で 15億のパラメータを持ちます。
GPT-2 は WebText と呼ばれる 800万の文章を含む 40GB の巨大なデータセットを使用して事前学習を行うことで、Zero-shot でも複数のタスクで高い性能を示しました。
GPT-3
GPT-3 [8] は GPT-2 のネットワークとデータセットの規模を限界まで巨大にすることで、さらに高精度の言語モデルを獲得しました。
GPT-3 のモデルは GPT-2 と同じ構成になっていますが、Transformer Decoder に Sparse Transformer [9] を導入しており、最大 96層で 175兆のパラメータを持ちます。GPT-3 の学習には約 4億9000万円のコストがかかっているらしく、仮に 1台の GPU で訓練を行った場合は約 355年かかるとのことです。
GPT-3 は人間との文章のやり取りに違和感のないレベルの文章を生成することができるとされていますが、双方向情報を必要とするようなタスクでは BERT系モデルよりも性能が劣るという弱点は顕在のようです。
結果
Training Loss
訓練時の損失関数のログを可視化したものが下図です。横軸は繰り返し回数、縦軸は損失関数の値を表しています。
日本語文生成の例
訓練したモデルによる生成の例を示します。> から始める単語を入力として、その続きを生成します。
>人類は 人類は、この再建されたバイオエンジニアリング子宮を学習した経験のを、経済学の初めてデバイスをデバイスを学習し、その対価を切り替えない。 >魔法が 魔法が、その大きな成功を収める人だ。 >地球 地球は、後者の重要性が強調される。 >葵葉月は、 葵葉月は、その安らかなぶるな、身をかがめた。日本語っぽい文が生成できているように見えますが、意味不明な文章になってしまっています。違和感のないレベルの文章を生成するにはより巨大なモデルと訓練データセット、それを実行できるだけのハードウェアが必要だと実感できます。
参考
Natural Language : Machine Translation Part2 - Neural Machine Translation Transformer
Natural Language : BERT Part2 - Unsupervised pretraining ALBERT
- Taku Kudo and John Richardson. "SentencePiece: A simple and language independent subword tokenizer and detokenizer for Neural Text Processing", arXiv preprint arXiv:1808.06226, (2018).
- Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. "Improving Language Understanding by Generative Pre-Training", (2018): 12.
- Ashish Vaswani, et. al. "Attention Is All You Need", Advances in neural information processing systems. 2017. p. 5998-6008.
- Ruibin Xiong, Yunchang Yang, Di He, Kai Zheng, Shuxin Zheng, Chen Xing, Huishuai Zhang, Yanyan Lan, Liwei Wang, and Tie-Yan Liu . "On Layer Normalization in the Transformer Architecture", arXiv preprint arXiv:2002.04745 (2020).
- Diederik P. Kingma and Jimmy Lei Ba. "Adam: A method for stochastic optimization", arXiv preprint arXiv:1412.6980 (2014).
- Leslie N. Smith. "Cyclical Learning Rates for Training Neural Networks", 2017 IEEE Winter Conference on Applications of Computer Vision. 2017, p. 464-472.
- Alex Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. "Language Models are Unsupervised Multitask Learners", OpenAI blog 1.8 (2019): 9.
- Tom B. Brown, et al. "Language Models are Few-Shot Learners", arXiv preprint arXiv:2005.14165 (2020).
- Rewon Child, Scott Gray, Alec Radford, and Ilya Sutckever. "Generating Long Sequences with Sparse Transformers", arXiv preprint arXiv:1904.10509 (2019).




- 投稿日:2020-10-12T20:02:31+09:00
Pythonに疲れたのでnehanでデータ分析してみた(コロナ禍でもライブに行きたい - 後編)
ご挨拶
こんにちは、マンボウです。
「Twtter×コロナ」引き続き分析していきます。
前編はtweetテキストを形態素解析し、頻出単語の日別出現数を出すところまでやりました。↓選ばれた頻出単語27
Twitterのデータから、上昇・下降トレンドの単語を探してみる
コロナウイルスが社会問題になってから半年以上が経過しました。
人々の中で何が高まり、逆に何が忘れられているのか、つぶやきから追ってみます。
後編では、回帰分析を用いて上昇・下降トレンドの単語を見つけ出します。データ
前編で作成した、日別・単語別出現数のデータを使います。
↓データ
↓可視化すると
回帰分析を行う準備
日が経過するに連れ、出現数が増or減、の単語を見つけたいと思います。
つまりy:特定単語のtweet数=a\times x:経過日数+bこういう回帰式を導き、傾きである
aと、相関係数を観察してみよう、と。
データ操作としては、日付のデータから「経過日数」を算出する必要があります。
アプローチとして、連番を・単語ごとに・日付が若い順から、振ります。from scipy.spatial.distance import cdist import pandas as pd import statsmodels.api as sm port_23 = port_22.copy() model_params = {'method': 'first', 'ascending': True} port_23[['Created_At']] = pd.to_datetime(port_23[['Created_At']]) port_23['index'] = port_23.groupby(['単語'])[['Created_At']].rank(**model_params) port_23[['Created_At']] = port_23[['Created_At']].map(lambda x: x.date())
↓x軸に注目。経過日数が出せ、回帰分析の準備が整いました。
回帰分析を実施。単語ごとに
選定した24単語が経過日数に応じてどう変化しているか、回帰分析結果から観察していきます。
pythonで書こうとすると、単語ごとにループを回したりと、大変です。group_keys = ['単語'] X_columns = ['index'] Y_column = 'カウント' groups = port_23.groupby(group_keys) models = {} summaries = {} def corr_xy(X, y): """目的変数と説明変数の相関係数を求める""" X_label = X.columns.tolist() X = X.T.values y = y.values.reshape(1, -1) corr = 1 - cdist(X, y, metric='correlation') corr = pd.DataFrame(corr, columns=['目的変数との相関係数']) corr['説明変数'] = X_label return corr for i, g in groups: X = g[X_columns] Y = g[Y_column].squeeze() corr = corr_xy(X, Y) try: model = sm.OLS(y, sm.add_constant(X, has_constant='add')).fit() model.X = X.columns models[i] = model summary = pd.DataFrame( { '説明変数': X.columns, '係数': np.round(model.params, 5), '標準偏差': np.round(model.bse, 5), 't値': np.round(model.tvalues, 5), 'Pr(>|t|)': np.round(model.pvalues, 5) }, columns=['説明変数', '係数', '標準偏差', 't値', 'Pr(>|t|)']) summary = summary.merge(corr, on='説明変数', how='left') summaries[i] = summary except: continue res = [] for key, value in summaries.items(): value[group_keys] = key res.append(value) concat_summary = pd.concat(res, ignore_index=True) port_24 = models port_25 = concat_summary↓nehanであれば、
グループごとにモデルを作成するオプションで面倒なループ処理を書かずに済みます。
そして、単語ごとの回帰分析の結果を得られました。
説明変数=const、は切片の情報です。
上昇/下降トレンドの単語に絞る
様々な解釈はありますが、ここでは
- 相関係数が0.4以上
- 相関係数が-0.4以下
に絞り、これを相関がある、として単語を抽出します。
port_27 = port_25[(port_25['目的変数との相関係数'] <= -0.4) | (port_25['目的変数との相関係数'] >= 0.4)]
単語の情報を詳しく見てみます。
結果を観察
上昇トレンドの単語
- イベント
- ライブ
下降トレンドの単語
- 患者
- 政府
- 症状
- 重症
↓ライブ、の出現数日別推移
↓政府、の出現数日別推移
まとめ
コロナの脅威は去ったわけでは有りませんが、危機的な時期にニュースでよく見ていたような単語の出現数は減り、イベントやライブといった、自粛の影響を強く受けた単語の出現数が増えている様子が見て取れます。
もちろん、これだけでは「みんなライブに行きたいんだ!」とは言えませんが、ここまでのデータを見た、いち考察として本テーマを締めさせていただければと思います。前処理したデータから様々な分析、可視化に繋げられるプログラミング不要の分析ツールnehanの魅力が少しでも伝われば幸いです。
※分析ツールnehanのご紹介はこちらから。
※↓今日の内容
なお、上記のソースコードはnehanのpythonエクスポート機能で出力したコードをコピペしました。(一部バグってたので、書き直しました・・・)












- 投稿日:2020-10-12T19:33:53+09:00
ESP32 を Arduino IDE から操作する
ESP32 用の環境構築
ESP32用のプログラムを書けるようにする
まずはここからArduino IDEをダウンロード
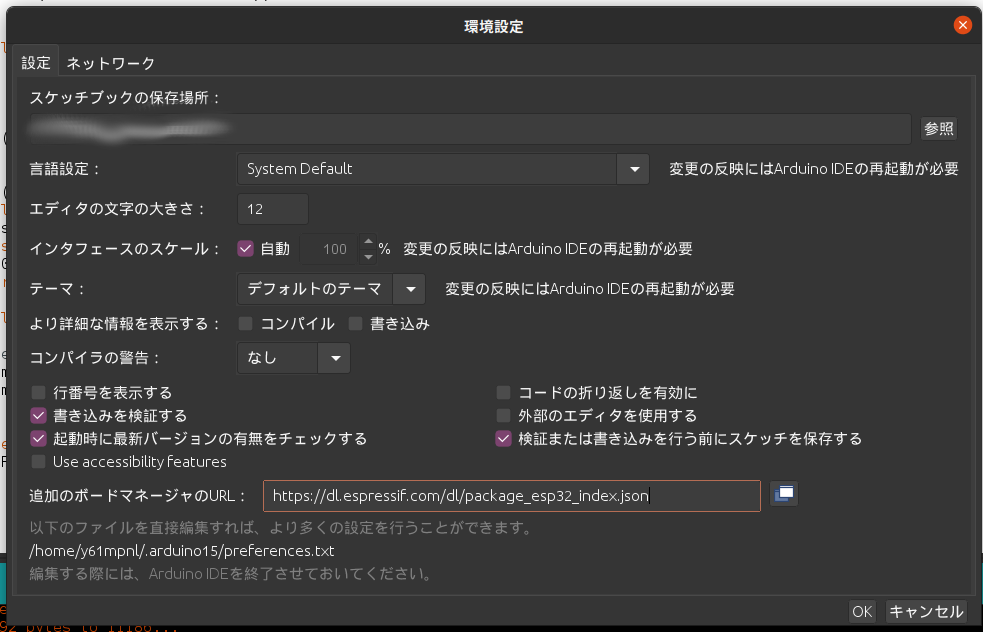
Arduino IDE の初期設定は省略上のバーの
ファイル > 環境設定から追加のボードマネージャーのURLにhttps://dl.espressif.com/dl/package_esp32_index.jsonを追加する。すでに入力がある場合;で区切ってつなげる。
ツール > ボード > ボードマネージャーから右上のテキストボックスにesp32と入力して検索
esp32 by Espressif Systemsを選択してインストール
以降、Arduino IDE を開いて
ツール > ボードを見てみると確かにESP32 Arduinoの枠が追加されている。使い方・文法など
なんと使い方は普段と同様である。特に設定を変更する必要はない。arduino のプログラムを書くときと全く同じように書き、コンパイルし、書き込めばいい。
謎のエラー
最後にボードへの書き込みの際に自分がハマったポイントを書き記しておく
ボードへ書き込もうとするとexec: "python": executable file not found in $PATHといったエラーが出て書き込めなくなることがある。普通に読むとpythonがインストールされていない、あるいはpythonのPATHが通っていない、ということだが自分の環境は確実に整っている。
しかしよく読むと"python"が無いと言っているのであって"python3"あるいは"python2"が無いとは言っていないのである。もしやと思いsudo apt install python-is-python3をしてみた。これで"python"が存在することになった(中身は"python3"だが)。これで書き込んでみると無事完了 しっかり動作した。よくわからない設定ですね。
- 投稿日:2020-10-12T19:13:53+09:00
Pythonの内包表記が好きなのでmapと比較検証してみた
はじめに
こんにちは、麻菜結です。Pythonの内包表記が数多あるプログラミング言語の記法の中でも多機能かつ可読性が高く素晴らしい文法なのは間違いありませんが(個人の意見であり多大に偏見を含んでいる可能性があります)、よく競技プログラミングでは以下の記法が見られます。
l = list(map(int, input().split()))内包表記の敵、
mapですね(偏見を(略)。いちいちlistかまさないといけないmapがなんぼのもんじゃい!ということで速度を比較してみました。環境
wsl1のUbuntuを使います。
$ uname -a Linux LAPTOP-H6KC5C7N 4.4.0-18362-Microsoft #1049-Microsoft Thu Aug 14 12:01:00 PST 2020 x86_64 x86_64 x86_64 GNU/Linux $ py --version Python 3.8.0概要
110000行5列の非負な整数値が並ぶテキストファイルを用意する。先頭に10000と記述しファイルの列の数とする。
2timeモジュールのtime()を用いて始まりの時間を記録する。
3行ごとに内包表記かmapでデータを格納する。
4data.appendを繰り返して終わったらtime()で時間を取得して2の値と差分を出しそれを実行時間として表示する。
55回ほど試しそれの平均を取り比較する。スクリプト
以下のスクリプトを用います。
内包表記import time start = time.time() n = int(input()) data = [] for _ in range(n): data.append([int(e) for e in input().split(" ")]) process_time = time.time() - start print(process_time)mapimport time start = time.time() n = int(input()) data = [] for _ in range(n): data.append(list(map(int, input().split()))) process_time = time.time() - start print(process_time)検証
五回ぐらい実行してみてその平均を考えてみます。
まずは内包表記です。まぁまずまずですね。内包表記$ for((i=0;i<5;i++)); do cat InputText.txt | py time_comp.py; done 0.0833895206451416 0.07289266586303711 0.08693099021911621 0.12533855438232422 0.09039974212646484平均すると0.09541くらいでしょうか。
次にmapです。map$ for((i=0;i<5;i++)); do cat InputText.txt | py time_map.py; done 0.0980367660522461 0.08674144744873047 0.11994338035583496 0.08462047576904297 0.08770060539245605こちらも平均すると0.09541と同じですね。
(いや有意差が無いぞ…内包表記遅いやないかい!で記事書こうと思ったのに)追加検証
ラズパイ4でやりました。
$ uname -a Linux asana 5.4.51-v8+ #1333 SMP PREEMPT Mon Aug 10 16:58:35 BST 2020 aarch64GNU/Linux $ py --version Python 3.7.3 $ for((i=0;i<5;i++)); do cat InputText.txt | py time_comp.py; done 0.12080025672912598 0.10874629020690918 0.1127462387084961 0.1103978157043457 0.15588116645812988 $ for((i=0;i<5;i++)); do cat InputText.txt | py time_map.py; done 0.11949372291564941 0.11281895637512207 0.11392450332641602 0.2708289623260498 0.276080846786499平均を計算すると、内包表記は0.1217、mapは0.1786ぐらいでしょうか。ここでは内包表記が優位になりました。
Windowsでやりました。
> cmd /c ver Microsoft Windows [Version 10.0.18363.1110] > py --version Python 3.8.2 > for($i = 0;$i -le 5; $i++){cat .\InputText.txt | py .\time_comp.py} 1.0488629341125488 0.7845804691314697 1.163966178894043 0.7295846939086914 0.7399096488952637 0.8466687202453613 > for($i = 0;$i -le 5; $i++){cat .\InputText.txt | py .\time_map.py} 0.5758388042449951 0.5823671817779541 0.6683478355407715 0.6919825077056885 0.6597652435302734 0.6140100955963135
Windowsおっそ明らかな有意差が出ましたね、結構OSによる差があるみたいです。結論
結論としては、『環境や状況に左右されやすく、どっちが良いとは断言できない。』という感じでしょうか。自分はmapの方が明らかに早いからよくつかわれていているのだと思い込んでいましたが、そういうわけでは無いみたいですね。それともまた他のアーキテクチャやOSでは差が出るのか…inputをsys.stdinにしたら変わるのか、そもそもリストアペンドが遅くて差が隠れてしまっているのではないか、メモリの効率はいかがなのかなど他にも検証事項はありそうですが、この辺でいったん終わりにしたいと思います。
ここまでお読みいただいてありがとうございました。皆さんはどちら派ですか?
- 投稿日:2020-10-12T18:50:05+09:00
Django シフト表 自分の所属している施設のみを表示する
スタッフ全員で20名を超えるのでシフト表が自分の関係ない施設分まで表示されていると見にくくなるので、修正しました。
この修正にかなりてこずり、Qiitaで質問させていただき実装できましたschedule/views.pyfrom django.shortcuts import render, redirect, HttpResponseRedirect from shisetsu.models import * from accounts.models import * from .models import * import calendar import datetime from datetime import timedelta from datetime import datetime as dt from django.db.models import Sum, Q from django.contrib.auth.models import User from django.views.generic import FormView, UpdateView, ListView, CreateView, DetailView, DeleteView from django.urls import reverse_lazy from .forms import * from dateutil.relativedelta import relativedelta from django.contrib.auth.models import User from django.contrib.auth.mixins import LoginRequiredMixin # Create your views here. def homeschedule(request): from datetime import datetime now = datetime.now() return HttpResponseRedirect('/schedule/monthschedule/%s/%s/' % (now.year,now.month,)) # 自動的に今月のシフト画面にリダイレクト def monthschedulefilterfunc(request,year_num,month_num,shisetsu_num): #user_list = User.objects.all() #profile_list = Profile.objects.select_related().values().order_by('hyoujijyun') #ログインユーザーから所属情報を取得 current_user = request.user UserShozoku_list = UserShozokuModel.objects.filter(user = current_user).values_list("shisetsu_name", flat=True) UserShozoku_list = list(UserShozoku_list) #ログインユーザーと同一の所属情報を取得する Shzoku_list = UserShozokuModel.objects.filter(shisetsu_name__in = UserShozoku_list).values_list("user_id", flat=True).distinct() user_list = User.objects.select_related().all().order_by("profile__hyoujijyun") profile_list = Profile.objects.filter(user_id__in = Shzoku_list).select_related().values().order_by("hyoujijyun") year, month, shisetsu = int(year_num), int(month_num), int(shisetsu_num) shisetsu_object = Shisetsu.objects.filter(id = shisetsu) shisetsu_all_object = Shisetsu.objects.all() shift_object = Shift.objects.all() object_list = Schedule.objects.filter(year = year, month = month).order_by('user', 'date') month_total = Schedule.objects.select_related('User').filter(year = year, month = month).values("user").order_by("user").annotate(month_total_worktime = Sum("day_total_worktime")) #シフト範囲の日数を取得する enddate = datetime.date(year,month,20) startdate = enddate + relativedelta(months=-1) kaisu = enddate - startdate kaisu = int(kaisu.days) kikan = str(startdate) +"~"+ str(enddate) #日付と曜日のリストを作成する hiduke = str(startdate) date_format = "%Y-%m-%d" hiduke = dt.strptime(hiduke, date_format) weekdays = ["月","火","水","木","金","土","日"] calender_object = [] youbi_object = [] for i in range(kaisu): hiduke = hiduke + timedelta(days=1) calender_object.append(hiduke) youbi = weekdays[hiduke.weekday()] youbi_object.append(youbi) kaisu = str(kaisu) context = { 'year': year, 'month': month, 'kikan': kikan, 'object_list': object_list, 'user_list': user_list, 'shift_object': shift_object, 'calender_object': calender_object, 'youbi_object': youbi_object, 'kaisu': kaisu, 'shisetsu_object': shisetsu_object, 'month_total' : month_total, 'profile_list' : profile_list, 'shisetsu_all_object' : shisetsu_all_object, } return render(request,'schedule/monthfilter.html', context) def monthschedulefunc(request,year_num,month_num): #ログインユーザーから所属情報を取得 current_user = request.user UserShozoku_list = UserShozokuModel.objects.filter(user = current_user).values_list("shisetsu_name", flat=True) UserShozoku_list = list(UserShozoku_list) #ログインユーザーと同一の所属情報を取得する Shzoku_list = UserShozokuModel.objects.filter(shisetsu_name__in = UserShozoku_list).values_list("user_id", flat=True).distinct() user_list = User.objects.select_related().all().order_by("profile__hyoujijyun") profile_list = Profile.objects.filter(user_id__in = Shzoku_list).select_related().values().order_by("hyoujijyun") #施設ボタン表示のために再取得 UserShozoku_list = UserShozokuModel.objects.filter(user = current_user) year, month = int(year_num), int(month_num) shisetsu_object = Shisetsu.objects.all() shift_object = Shift.objects.all() object_list = Schedule.objects.filter(year = year, month = month).order_by('user', 'date') month_total = Schedule.objects.select_related('User').filter(year = year, month = month).values("user").order_by("user").annotate(month_total_worktime = Sum("day_total_worktime")) #シフト範囲の日数を取得する enddate = datetime.date(year,month,20) startdate = enddate + relativedelta(months=-1) kaisu = enddate - startdate kaisu = int(kaisu.days) kikan = str(startdate) +"~"+ str(enddate) #日付と曜日のリストを作成する hiduke = str(startdate) date_format = "%Y-%m-%d" hiduke = dt.strptime(hiduke, date_format) weekdays = ["月","火","水","木","金","土","日"] calender_object = [] youbi_object = [] for i in range(kaisu): hiduke = hiduke + timedelta(days=1) calender_object.append(hiduke) youbi = weekdays[hiduke.weekday()] youbi_object.append(youbi) kaisu = str(kaisu) context = { 'year': year, 'month': month, 'kikan': kikan, 'object_list': object_list, 'user_list': user_list, 'shift_object': shift_object, 'calender_object': calender_object, 'youbi_object': youbi_object, 'kaisu': kaisu, 'shisetsu_object': shisetsu_object, 'month_total' : month_total, 'profile_list' : profile_list, 'UserShozoku_list':UserShozoku_list, } return render(request,'schedule/month.html', context) def scheduleUpdatefunc(request,pk): Schedule_list = Schedule.objects.get(pk = int(pk)) User_list = User.objects.get(username = Schedule_list.user) shift_object = Shift.objects.all() if request.method == 'POST': form = ScheduleUpdateForm(data=request.POST) year = Schedule_list.year month = Schedule_list.month #更新ボタン処理 if form.is_valid(): Schedule_list.shift_name_1 = form.cleaned_data['shift_name_1'] Schedule_list.shisetsu_name_1 = form.cleaned_data['shisetsu_name_1'] Schedule_list.shift_name_2 = form.cleaned_data['shift_name_2'] Schedule_list.shisetsu_name_2 = form.cleaned_data['shisetsu_name_2'] Schedule_list.shift_name_3 = form.cleaned_data['shift_name_3'] Schedule_list.shisetsu_name_3 = form.cleaned_data['shisetsu_name_3'] Schedule_list.shift_name_4 = form.cleaned_data['shift_name_4'] Schedule_list.shisetsu_name_4 = form.cleaned_data['shisetsu_name_4'] #更新ボタン if "updatebutton" in request.POST: Schedule_list.day_total_worktime = form.cleaned_data['day_total_worktime'] #シフトから計算して更新ボタン elif "sumupdatebutton" in request.POST: # 日の労働合計時間をシフトから計算 sum_work_time = 0 for shift in shift_object: if str(form.cleaned_data['shift_name_1']) == str(shift.name): sum_work_time = shift.wrok_time + sum_work_time if str(form.cleaned_data['shift_name_2']) == str(shift.name): sum_work_time = shift.wrok_time + sum_work_time if str(form.cleaned_data['shift_name_3']) == str(shift.name): sum_work_time = shift.wrok_time + sum_work_time if str(form.cleaned_data['shift_name_4']) == str(shift.name): sum_work_time = shift.wrok_time + sum_work_time Schedule_list.day_total_worktime = sum_work_time Schedule_list.save() return HttpResponseRedirect('/schedule/monthschedule/%s/%s/' % (year,month,)) else: item = { "shift_name_1":Schedule_list.shift_name_1, "shisetsu_name_1": Schedule_list.shisetsu_name_1, "shift_name_2": Schedule_list.shift_name_2, "shisetsu_name_2": Schedule_list.shisetsu_name_2, "shift_name_3": Schedule_list.shift_name_3, "shisetsu_name_3": Schedule_list.shisetsu_name_3, "shift_name_4": Schedule_list.shift_name_4, "shisetsu_name_4": Schedule_list.shisetsu_name_4, "day_total_worktime": Schedule_list.day_total_worktime, } form = ScheduleUpdateForm(initial=item) context = { 'form' : form, 'Schedule_list': Schedule_list, 'User_list': User_list, 'shift_object': shift_object, } return render(request,'schedule/update.html', context ) def schedulecreatefunc(request,year_num,month_num): year, month = int(year_num), int(month_num) #対象年月のscheduleをすべて削除する Schedule.objects.filter(year = year, month = month).delete() #シフト範囲の日数を取得する enddate = datetime.date(year,month,20) startdate = enddate + relativedelta(months=-1) #希望シフトから対象期間の希望を抽出する kiboushift_list = KibouShift.objects.filter(date__range=[startdate, enddate]) kiboushift_list = list(kiboushift_list) shift_list = Shift.objects.all() #希望シフトを反映 for kibou in kiboushift_list: sum_work_time = 0 for shift in shift_list: if str(kibou.shift_name_1) == str(shift.name): sum_work_time = shift.wrok_time + sum_work_time if str(kibou.shift_name_2) == str(shift.name): sum_work_time = shift.wrok_time + sum_work_time if str(kibou.shift_name_3) == str(shift.name): sum_work_time = shift.wrok_time + sum_work_time if str(kibou.shift_name_4) == str(shift.name): sum_work_time = shift.wrok_time + sum_work_time new_object = Schedule( user = kibou.user, date = kibou.date, year = year, month = month, shift_name_1 = kibou.shift_name_1, shisetsu_name_1 = kibou.shisetsu_name_1, shift_name_2 = kibou.shift_name_2, shisetsu_name_2 = kibou.shisetsu_name_2, shift_name_3 = kibou.shift_name_3, shisetsu_name_3 = kibou.shisetsu_name_3, shift_name_4 = kibou.shift_name_4, shisetsu_name_4 = kibou.shisetsu_name_4, day_total_worktime = sum_work_time, ) new_object.save() #希望シフト以外を作成 user_list = User.objects.all() #シフト範囲の日数を取得する enddate = datetime.date(year,month,20) startdate = enddate + relativedelta(months=-1) kaisu = enddate - startdate kaisu = int(kaisu.days) #前月 if month != 1 : zengetsu = month - 1 else: zengetsu = 12 year = year - 1 #ユーザーごとに処理をする for user in user_list: #base_shiftが登録されている情報から作成 base_shift = BaseShift.objects.filter(user = user.id) kongetsu_list = Schedule.objects.filter(year = year, month = month, user = user.id).order_by('date') zengetsu_list = Schedule.objects.filter(year = year, month = zengetsu, user = user.id).order_by('date') sakusei_date = startdate shift_list = Shift.objects.all() for new_shift in range(kaisu): sakusei_date = sakusei_date + timedelta(days=1) if kongetsu_list.filter(user = user.id, date = sakusei_date).exists(): print("ok") else: weekdays = ["月","火","水","木","金","土","日"] youbi = weekdays[sakusei_date.weekday()] #ベースシフトから取得して取得 if base_shift.filter(user = user.id ).exists(): for base in base_shift: sum_work_time = 0 shift1 = None shisetsu1 = None shift2 = None shisetsu2 = None shift3 = None shisetsu3 = None shift4 = None shisetsu4 = None if youbi == "月": for shift in shift_list: if str(base.getsu_shift_name_1) == str(shift.name): shift1 = base.getsu_shift_name_1 shisetsu1 = base.getsu_shisetsu_name_1 sum_work_time = shift.wrok_time + sum_work_time if str(base.getsu_shift_name_2) == str(shift.name): shift2 = base.getsu_shift_name_2 shisetsu2 = base.getsu_shisetsu_name_2 sum_work_time = shift.wrok_time + sum_work_time if str(base.getsu_shift_name_3) == str(shift.name): shift3 = base.getsu_shift_name_3 shisetsu3 = base.getsu_shisetsu_name_3 sum_work_time = shift.wrok_time + sum_work_time if str(base.getsu_shift_name_4) == str(shift.name): shift4 = base.getsu_shift_name_4 shisetsu4 = base.getsu_shisetsu_name_4 sum_work_time = shift.wrok_time + sum_work_time elif youbi == "火": for shift in shift_list: if str(base.ka_shift_name_1) == str(shift.name): shift1 = base.ka_shift_name_1 shisetsu1 = base.ka_shisetsu_name_1 sum_work_time = shift.wrok_time + sum_work_time if str(base.ka_shift_name_2) == str(shift.name): shift2 = base.ka_shift_name_2 shisetsu2 = base.ka_shisetsu_name_2 sum_work_time = shift.wrok_time + sum_work_time if str(base.ka_shift_name_3) == str(shift.name): shift3 = base.ka_shift_name_3 shisetsu3 = base.ka_shisetsu_name_3 sum_work_time = shift.wrok_time + sum_work_time if str(base.ka_shift_name_4) == str(shift.name): shift4 = base.ka_shift_name_4 shisetsu4 = base.ka_shisetsu_name_4 sum_work_time = shift.wrok_time + sum_work_time elif youbi == "水": for shift in shift_list: if str(base.sui_shift_name_1) == str(shift.name): shift1 = base.sui_shift_name_1 shisetsu1 = base.sui_shisetsu_name_1 sum_work_time = shift.wrok_time + sum_work_time if str(base.sui_shift_name_2) == str(shift.name): shift2 = base.sui_shift_name_2 shisetsu2 = base.sui_shisetsu_name_2 sum_work_time = shift.wrok_time + sum_work_time if str(base.sui_shift_name_3) == str(shift.name): shift3 = base.sui_shift_name_3 shisetsu3 = base.sui_shisetsu_name_3 sum_work_time = shift.wrok_time + sum_work_time if str(base.sui_shift_name_4) == str(shift.name): shift4 = base.sui_shift_name_4 shisetsu4 = base.sui_shisetsu_name_4 sum_work_time = shift.wrok_time + sum_work_time elif youbi == "木": for shift in shift_list: if str(base.moku_shift_name_1) == str(shift.name): shift1 = base.moku_shift_name_1 shisetsu1 = base.moku_shisetsu_name_1 sum_work_time = shift.wrok_time + sum_work_time if str(base.moku_shift_name_2) == str(shift.name): shift2 = base.moku_shift_name_2 shisetsu2 = base.moku_shisetsu_name_2 sum_work_time = shift.wrok_time + sum_work_time if str(base.moku_shift_name_3) == str(shift.name): shift3 = base.moku_shift_name_3 shisetsu3 = base.moku_shisetsu_name_3 sum_work_time = shift.wrok_time + sum_work_time if str(base.moku_shift_name_4) == str(shift.name): shift4 = base.moku_shift_name_4 shisetsu4 = base.moku_shisetsu_name_4 sum_work_time = shift.wrok_time + sum_work_time elif youbi == "金": for shift in shift_list: if str(base.kin_shift_name_1) == str(shift.name): shift1 = base.kin_shift_name_1 shisetsu1 = base.kin_shisetsu_name_1 sum_work_time = shift.wrok_time + sum_work_time if str(base.kin_shift_name_2) == str(shift.name): shift2 = base.kin_shift_name_2 shisetsu2 = base.kin_shisetsu_name_2 sum_work_time = shift.wrok_time + sum_work_time if str(base.kin_shift_name_3) == str(shift.name): shift3 = base.kin_shift_name_3 shisetsu3 = base.kin_shisetsu_name_3 sum_work_time = shift.wrok_time + sum_work_time if str(base.kin_shift_name_4) == str(shift.name): shift4 = base.kin_shift_name_4 shisetsu4 = base.kin_shisetsu_name_4 sum_work_time = shift.wrok_time + sum_work_time elif youbi == "土": for shift in shift_list: if str(base.do_shift_name_1) == str(shift.name): shift1 = base.do_shift_name_1 shisetsu1 = base.do_shisetsu_name_1 sum_work_time = shift.wrok_time + sum_work_time if str(base.do_shift_name_2) == str(shift.name): shift2 = base.do_shift_name_2 shisetsu2 = base.do_shisetsu_name_2 sum_work_time = shift.wrok_time + sum_work_time if str(base.do_shift_name_3) == str(shift.name): shift3 = base.do_shift_name_3 shisetsu3 = base.do_shisetsu_name_3 sum_work_time = shift.wrok_time + sum_work_time if str(base.do_shift_name_4) == str(shift.name): shift4 = base.do_shift_name_4 shisetsu4 = base.do_shisetsu_name_4 sum_work_time = shift.wrok_time + sum_work_time if youbi == "日": for shift in shift_list: if str(base.nichi_shift_name_1) == str(shift.name): shift1 = base.nichi_shift_name_1 shisetsu1 = base.nichi_shisetsu_name_1 sum_work_time = shift.wrok_time + sum_work_time if str(base.nichi_shift_name_2) == str(shift.name): shift2 = base.nichi_shift_name_2 shisetsu2 = base.nichi_shisetsu_name_2 sum_work_time = shift.wrok_time + sum_work_time if str(base.nichi_shift_name_3) == str(shift.name): shift3 = base.nichi_shift_name_3 shisetsu3 = base.nichi_shisetsu_name_3 sum_work_time = shift.wrok_time + sum_work_time if str(base.nichi_shift_name_4) == str(shift.name): shift4 = base.nichi_shift_name_4 shisetsu4 = base.nichi_shisetsu_name_4 sum_work_time = shift.wrok_time + sum_work_time new_object=Schedule( user = base.user, date = sakusei_date, year = year, month = month, shift_name_1 = shift1, shisetsu_name_1 = shisetsu1, shift_name_2 = shift2, shisetsu_name_2 = shisetsu2, shift_name_3 = shift3, shisetsu_name_3 = shisetsu3, shift_name_4 = shift4, shisetsu_name_4 = shisetsu4, day_total_worktime = sum_work_time, ) new_object.save() else: hukushadate = sakusei_date + relativedelta(months=-1) hukusha_list = zengetsu_list.filter(date = hukushadate, user = user.id) if zengetsu_list.filter(date = hukushadate, user = user.id).exists(): for hukusha in hukusha_list: # 日の労働合計時間をシフトから計算 sum_work_time = 0 for shift in shift_list: if str(hukusha.shift_name_1) == str(shift.name): sum_work_time = shift.wrok_time + sum_work_time if str(hukusha.shift_name_2) == str(shift.name): sum_work_time = shift.wrok_time + sum_work_time if str(hukusha.shift_name_3) == str(shift.name): sum_work_time = shift.wrok_time + sum_work_time if str(hukusha.shift_name_4) == str(shift.name): sum_work_time = shift.wrok_time + sum_work_time new_object=Schedule( user = hukusha.user, date = sakusei_date, year = year, month = month, shift_name_1 = hukusha.shift_name_1, shisetsu_name_1 = hukusha.shisetsu_name_1, shift_name_2 = hukusha.shift_name_2, shisetsu_name_2 = hukusha.shisetsu_name_2, shift_name_3 = hukusha.shift_name_3, shisetsu_name_3 = hukusha.shisetsu_name_3, shift_name_4 = hukusha.shift_name_4, shisetsu_name_4 = hukusha.shisetsu_name_4, day_total_worktime = sum_work_time, ) new_object.save() else: useradd = User.objects.get(id=user.id) shiftadd = Shift.objects.get(id=2) new_object=Schedule( user = useradd, date = sakusei_date, year = year, month = month, shift_name_1 = shiftadd, shisetsu_name_1 = None, shift_name_2 = None, shisetsu_name_2 = None, shift_name_3 = None, shisetsu_name_3 = None, shift_name_4 = None, shisetsu_name_4 = None, day_total_worktime = 0, ) new_object.save() return HttpResponseRedirect('/schedule/monthschedule/%s/%s/' % (year,month,)) def kiboulistfunc(request): current_user = request.user if current_user.is_superuser == True: # スーパーユーザの場合、リストにすべてを表示する KibouShift_list = KibouShift.objects.all().order_by('-date') else: # 一般ユーザは自分のレコードのみ表示する。 KibouShift_list = KibouShift.objects.filter(user = current_user.id).order_by('-date') User_list = User.objects.all() shift_object = Shift.objects.all() context = { 'KibouShift_list': KibouShift_list, 'User_list': User_list, 'shift_object': shift_object, } return render(request,'schedule/kiboushift/list.html', context ) class KibouCreate(CreateView): template_name = 'schedule/kiboushift/create.html' model = KibouShift fields = ('user', 'date', 'shift_name_1', 'shisetsu_name_1', 'shift_name_2', 'shisetsu_name_2', 'shift_name_3', 'shisetsu_name_3', 'shift_name_4', 'shisetsu_name_4') success_url = reverse_lazy('schedule:KibouList') def kiboubCreate(request): if request.method == 'POST': if now.day > 5: startdate = datetime.date(now.year,now.month,20) if date < startdate: raise ValidationError( "入力できない日付です", params={'value': value}, ) else: startdate = datetime.date(now.year,now.month,20) startdate = enddate + relativedelta(months=1) if date < startdate: raise ValidationError( "入力できない日付です", params={'value': value}, ) return date class KibouUpdate(UpdateView): template_name = 'schedule/kiboushift/update.html' model = KibouShift fields = ('user', 'date', 'shift_name_1', 'shisetsu_name_1', 'shift_name_2', 'shisetsu_name_2', 'shift_name_3', 'shisetsu_name_3', 'shift_name_4', 'shisetsu_name_4') def date(self): date = self.cleaned_date.get('date') now = datetime.now() print(now.date) #5日になったら20日以降のみ入力 if now.day > 5: startdate = datetime.date(now.year,now.month,20) if date < startdate: raise ValidationError( "入力できない日付です", params={'value': value}, ) else: startdate = datetime.date(now.year,now.month,20) startdate = enddate + relativedelta(months=1) if date < startdate: raise ValidationError( "入力できない日付です", params={'value': value}, ) return date success_url = reverse_lazy('schedule:KibouList') class KibouDelete(DeleteView): template_name = 'schedule/kiboushift/delete.html' model = KibouShift fields = ('user', 'date', 'shift_name_1', 'shisetsu_name_1', 'shift_name_2', 'shisetsu_name_2', 'shift_name_3', 'shisetsu_name_3', 'shift_name_4', 'shisetsu_name_4') success_url = reverse_lazy('schedule:KibouList') def dayschedulefunc(request,date): profile_list = Profile.objects.select_related().values().order_by('hyoujijyun') shisetsu_all_object = Shisetsu.objects.all() date = str(date) tdatetime = datetime.datetime.strptime(date, '%Y-%m-%d') tdate = datetime.date(tdatetime.year, tdatetime.month, tdatetime.day) object_list = Schedule.objects.select_related().filter(date = tdate) shift_object = Shift.objects.all() start_time = datetime.time(15, 00) for object in object_list: print(object.shift_name_1.start_time) context = { 'profile_list': profile_list, 'shisetsu_all_object': shisetsu_all_object, 'object_list': object_list, 'shift_object':shift_object, } return render(request,'schedule/gant.html', context)schedule/month.html{% extends 'accounts/base.html' %} {% load static %} {% block customcss %} <link rel="stylesheet" href="{% static 'schedule/month.css' %}"> {% endblock customcss %} {% block header %} <div class="header"> <div class="cole-md-1"> <a href="{% url 'schedule:KibouList' %}" class="btn-secondary btn active">希望シフト一覧</a></p> {% ifnotequal month 1 %} <a href="{% url 'schedule:monthschedule' year month|add:'-1' %}" class="btn-info btn active">前月</a> {% else %} <a href="{% url 'schedule:monthschedule' year|add:'-1' 12 %}" class="btn-info btn active">前月</a> {% endifnotequal %} {% ifnotequal month 12 %} <a href="{% url 'schedule:monthschedule' year month|add:'1' %}" class="btn-info btn active">次月</a> {% else %} <a href="{% url 'schedule:monthschedule' year|add:'1' 1 %}" class="btn-info btn active">次月</a> {% endifnotequal %} {% if perms.schedule.add_schedule %}<!--権限--> <a href="{% url 'schedule:schedulecreate' year month %}" class="btn-info btn active">シフト作成</a> {% endif %} </div> <div class="cole-md-2"> {% for shift in shift_object %} {% if shift.name != "休" and shift.name != "有" %} {{ shift.name }} : {{ shift.start_time | date:"G"}}~{{ shift.end_time | date:"G"}} {% endif %} {% endfor %} </div> <p> <a href="{% url 'schedule:monthschedule' year month %}" button type="button" class="btn btn-outline-dark">すべて</a> {% for shisetsu in shisetsu_object %} {% for UserShozoku in UserShozoku_list %} {% if shisetsu.name|stringformat:"s" == UserShozoku.shisetsu_name|stringformat:"s" %} <a href="{% url 'schedule:monthschedulefilter' year month shisetsu.pk %}" button type="button" class="btn btn-outline-dark" span style="background-color:{{ shisetsu.color }}">{{ shisetsu.name }}</span></a> {% endif %} {% endfor %} {% endfor %} </p> </div> {% endblock header %} {% block content %} <table class="table"> <thead> <tr> <!--日付--> <th class ="fixed00" rowspan="2">{{ kikan }}</th> {% for item in calender_object %} <th class ="fixed01">{{ item.date | date:"d" }}</th> {% endfor %} <tr> <!--曜日--> {% for item in youbi_object %} <th class ="fixed02">{{ item }}</th> {% endfor %} </tr> </thead> <tbody> {% for profile in profile_list %} {% for staff in user_list %} {% if profile.user_id == staff.id %} <tr align="center"> <th class ="fixed03" >{{ staff.last_name }} {{ staff.first_name }}</th> <!--staff_id要素はjsで使う--> {% for item in object_list %} {% if item.user|stringformat:"s" == staff.username|stringformat:"s" %}<!--usernameが同一なら--> <td class="meisai"> {% if item.shift_name_1 != None %} {% if item.shift_name_1|stringformat:"s" == "有" or item.shift_name_1|stringformat:"s" == "休" %} {{ item.shift_name_1 }} {% else %} {% for shisetsu in shisetsu_object %} {% if item.shisetsu_name_1|stringformat:"s" == shisetsu.name|stringformat:"s" %} <span style="background-color:{{ shisetsu.color }}">{{ item.shift_name_1 }}</span> {% endif %} {% endfor %} {% endif %} {% endif %} {% if item.shift_name_2 != None %} {% if item.shift_name_2|stringformat:"s" == "有" or item.shift_name_2|stringformat:"s" == "休" %} {{ item.shift_name_2 }} {% else %} {% for shisetsu in shisetsu_object %} {% if item.shisetsu_name_2|stringformat:"s" == shisetsu.name|stringformat:"s" %} <span style="background-color:{{ shisetsu.color }}">{{ item.shift_name_2 }}</span> {% endif %} {% endfor %} {% endif %} {% endif %} {% if item.shift_name_3 != None %} {% if item.shift_name_3|stringformat:"s" == "有" or item.shift_name_3|stringformat:"s" == "休" %} {{ item.shift_name_3 }} {% else %} {% for shisetsu in shisetsu_object %} {% if item.shisetsu_name_3|stringformat:"s" == shisetsu.name|stringformat:"s" %} <span style="background-color:{{ shisetsu.color }}">{{ item.shift_name_3 }}</span> {% endif %} {% endfor %} {% endif %} {% endif %} {% if item.shift_name_4 != None %} {% if item.shift_name_4|stringformat:"s" == "有" or item.shift_name_4|stringformat:"s" == "休" %} {{ item.shift_name_4 }} {% else %} {% for shisetsu in shisetsu_object %} {% if item.shisetsu_name_4|stringformat:"s" == shisetsu.name|stringformat:"s" %} <span style="background-color:{{ shisetsu.color }}">{{ item.shift_name_4 }}</span> {% endif %} {% endfor %} {% endif %} {% endif %} {% endif %} {% endfor %} </td> <tr align="center"> {% for month in month_total %} {% if month.user == staff.id %}<!--usernameが同一なら--> <td class="fixed04"><b>{{ month.month_total_worktime }}</b></td> {% endif %} {% endfor %} {% for item in object_list %} {% if item.user|stringformat:"s" == staff.username|stringformat:"s" %}<!--usernameが同一なら--> {% if perms.schedule.add_schedule %}<!--権限--> <td class="meisai" id="s{{ staff.id }}d{{ item.date }}"> <a href="{% url 'schedule:update' item.pk %}">{{ item.day_total_worktime }} </a> </td> {% else %} <td class="meisai" id="s{{ staff.id }}d{{ item.date }}"> {{ item.day_total_worktime }} </td> {% endif %} {% endif %} {% endfor %} </tr> {% endif %} {% endfor %} {% endfor %} </tbody> </table> </div> </div> {% endblock content %}schedule/monthfileter.html{% extends 'accounts/base.html' %} {% load static %} {% block customcss %} <link rel="stylesheet" href="{% static 'schedule/month.css' %}"> {% endblock customcss %} {% block header %} <div class="header"> <div class="cole-md-1"> <a href="{% url 'schedule:KibouList' %}" class="btn-secondary btn active">希望シフト一覧</a></p> {% ifnotequal month 1 %} <a href="{% url 'schedule:monthschedule' year month|add:'-1' %}" class="btn-info btn active">前月</a> {% else %} <a href="{% url 'schedule:monthschedule' year|add:'-1' 12 %}" class="btn-info btn active">前月</a> {% endifnotequal %} {% ifnotequal month 12 %} <a href="{% url 'schedule:monthschedule' year month|add:'1' %}" class="btn-info btn active">次月</a> {% else %} <a href="{% url 'schedule:monthschedule' year|add:'1' 1 %}" class="btn-info btn active">次月</a> {% endifnotequal %} {% if perms.schedule.add_schedule %}<!--権限--> <a href="{% url 'schedule:schedulecreate' year month %}" class="btn-info btn active">シフト作成</a> {% endif %} </div> <div class="cole-md-2"> {% for shift in shift_object %} {% if shift.name != "休" and shift.name != "有" %} {{ shift.name }} : {{ shift.start_time | date:"G"}}~{{ shift.end_time | date:"G"}} {% endif %} {% endfor %} </div> <p> <a href="{% url 'schedule:monthschedule' year month %}" button type="button" class="btn btn-outline-dark">すべて</a> {% for shisetsu in shisetsu_object %} {% for UserShozoku in UserShozoku_list %} {% if shisetsu.name|stringformat:"s" == UserShozoku.shisetsu_name|stringformat:"s" %} <a href="{% url 'schedule:monthschedulefilter' year month shisetsu.pk %}" button type="button" class="btn btn-outline-dark" span style="background-color:{{ shisetsu.color }}">{{ shisetsu.name }}</span></a> {% endif %} {% endfor %} {% endfor %} </p> </div> {% endblock header %} {% block content %} <table class="table"> <thead> <tr> <!--日付--> <th class ="fixed00" rowspan="2">{{ kikan }}</th> {% for item in calender_object %} <th class ="fixed01">{{ item.date | date:"d" }}</th> {% endfor %} <tr> <!--曜日--> {% for item in youbi_object %} <th class ="fixed02">{{ item }}</th> {% endfor %} </tr> </thead> <tbody> {% for profile in profile_list %} {% for staff in user_list %} {% if profile.user_id == staff.id %} <tr align="center"> <th class ="fixed03" >{{ staff.last_name }} {{ staff.first_name }}</th> <!--staff_id要素はjsで使う--> {% for item in object_list %} {% if item.user|stringformat:"s" == staff.username|stringformat:"s" %}<!--usernameが同一なら--> <td class="meisai"> {% if item.shift_name_1 != None %} {% if item.shift_name_1|stringformat:"s" == "有" or item.shift_name_1|stringformat:"s" == "休" %} {{ item.shift_name_1 }} {% else %} {% for shisetsu in shisetsu_object %} {% if item.shisetsu_name_1|stringformat:"s" == shisetsu.name|stringformat:"s" %} <span style="background-color:{{ shisetsu.color }}">{{ item.shift_name_1 }}</span> {% endif %} {% endfor %} {% endif %} {% endif %} {% if item.shift_name_2 != None %} {% if item.shift_name_2|stringformat:"s" == "有" or item.shift_name_2|stringformat:"s" == "休" %} {{ item.shift_name_2 }} {% else %} {% for shisetsu in shisetsu_object %} {% if item.shisetsu_name_2|stringformat:"s" == shisetsu.name|stringformat:"s" %} <span style="background-color:{{ shisetsu.color }}">{{ item.shift_name_2 }}</span> {% endif %} {% endfor %} {% endif %} {% endif %} {% if item.shift_name_3 != None %} {% if item.shift_name_3|stringformat:"s" == "有" or item.shift_name_3|stringformat:"s" == "休" %} {{ item.shift_name_3 }} {% else %} {% for shisetsu in shisetsu_object %} {% if item.shisetsu_name_3|stringformat:"s" == shisetsu.name|stringformat:"s" %} <span style="background-color:{{ shisetsu.color }}">{{ item.shift_name_3 }}</span> {% endif %} {% endfor %} {% endif %} {% endif %} {% if item.shift_name_4 != None %} {% if item.shift_name_4|stringformat:"s" == "有" or item.shift_name_4|stringformat:"s" == "休" %} {{ item.shift_name_4 }} {% else %} {% for shisetsu in shisetsu_object %} {% if item.shisetsu_name_4|stringformat:"s" == shisetsu.name|stringformat:"s" %} <span style="background-color:{{ shisetsu.color }}">{{ item.shift_name_4 }}</span> {% endif %} {% endfor %} {% endif %} {% endif %} {% endif %} {% endfor %} </td> <tr align="center"> {% for month in month_total %} {% if month.user == staff.id %}<!--usernameが同一なら--> <td class="fixed04"><b>{{ month.month_total_worktime }}</b></td> {% endif %} {% endfor %} {% for item in object_list %} {% if item.user|stringformat:"s" == staff.username|stringformat:"s" %}<!--usernameが同一なら--> {% if perms.schedule.add_schedule %}<!--権限--> <td class="meisai" id="s{{ staff.id }}d{{ item.date }}"> <a href="{% url 'schedule:update' item.pk %}">{{ item.day_total_worktime }} </a> </td> {% else %} <td class="meisai" id="s{{ staff.id }}d{{ item.date }}"> {{ item.day_total_worktime }} </td> {% endif %} {% endif %} {% endfor %} </tr> {% endif %} {% endfor %} {% endfor %} </tbody> </table> </div> {% endblock content %}一部の施設に所属している場合
すべての施設に所属している場合
なかなかうまくいきました(⌒∇⌒)
今回思ったことは、データの抽出の条件指定が全然理解できていないことです。SQL文もわかりませんが、SQLで実行してデータ抽出した方が、自分の思っているデータが取得できるのではと考えたほど、Djangoのデータ抽出が理解できていません。
いいサイトも見つけられずまた、壁にぶち当たりそうですが邁進していこうと思います


- 投稿日:2020-10-12T18:08:37+09:00
[Python]アイシャドウのランキング上位10位をグラフにしてみた
概要
化粧サイトLIPSでは化粧品のランキングが見れます。
今回はアイシャドウのランキングを取得し、
縦軸は商品の名前、横軸を星の評価にしてグラフにしたいと思います。
上から下への流れが順位となります。
完成
コード
import requests from bs4 import BeautifulSoup import matplotlib.pyplot as plt # LIPSのサイトをスクレイピング urlName = "https://lipscosme.com/" url = requests.get(urlName) url.raise_for_status() bs = BeautifulSoup(url.text, "html.parser") url_list = [] # url_listにアイシャドウ、ファンデーション、口紅、化粧水のURLが入っている # 今回はアイシャドウのみをグラフにする for i in bs.select('a.ranking-products-list__more-link'): url_list.append(urlName + i.get('href')) url_list.pop() # 化粧水のURLを削除 url_list.pop() # 口紅のURLを削除 url_list.pop() # ファンデーションのURLを削除 name_list = [] start_list = [] for i in url_list: url_temp = requests.get(i) url_temp.raise_for_status() bs_temp = BeautifulSoup(url_temp.text, "html.parser") for j in bs_temp.select('div.ProductListArticle'): for k in j.select('div.ProductListArticle__product'): for k2 in k.select('h2.ProductListArticle__productTitle-productName'): name_list.append(k2.text) for k3 in k.select('span.ratingStar__num'): start_list.append(k3.text) # グラフ作成 # 上位10位 start_list = start_list[:10] name_list = name_list[:10] # 上から下にかけて順位を表示させるため、逆順にする start_list.reverse() name_list.reverse() labels = [float(i) for i in start_list] # 横のラベルに星の評価を入れる height = name_list # 縦のラベルにアイシャドウの名前を入れる fig = plt.figure() ax = fig.add_subplot(1,1,1) ax.barh(height,labels,height = 0.5) plt.xticks(rotation=90) plt.title('アイシャドウのランキング10選', fontsize=15) plt.ylabel("化粧品名", fontsize=15) plt.xlabel("星の評価", fontsize=15) plt.tick_params(labelsize=10) plt.show()まとめ
ランキング1位から下に行くほどに星の評価が下がると思いきや
余り星が変わらない結果となりました。アイシャドウ買う時はこのグラフを参考にしてもらえると嬉しいです!
次回はファンデーションとか他の化粧品のグラフを作ってみよう。

- 投稿日:2020-10-12T17:48:41+09:00
ChaliceでLINE chatbotを実装するまで
前提
なんでもいいからAWS上に乗せて動かしてみたかった。
LINE chatbotをHeroku上にデプロイしたことはあったので、
とりあえずこれを乗せてみることにしました。Chaliceとは
Chalice は、 Amazon API Gateway と AWS Lambda for Python による API 環境を実現してくれる、 AWS 製のアプリケーションフレームワークです。(AWS公式より)
コマンドラインでアプリケーションの構築やデプロイができるほか、
Lambdaに付与するIAMロールのポリシーを自動で付与してくれたり、
APIを自動で払い出してくれたりと、かなり便利でした。Chalice導入まで
前準備
・AWSアカウントの取得
・AWS CLIのインストール
AWS CLIを始めてインストールする場合は、インストール後にaws configureコマンドをたたいて、アカウントのアクセスキーやシークレットアクセスキー、
リージョンや出力形式を登録しておきましょう。
認証情報はホームディレクトリ配下の.awsフォルダに格納されます。
ルートユーザーのアクセスキーの発行は推奨されないので、IAMユーザーを作成してその認証情報を登録しておきます。Chaliceは
pip install chaliceでインストールできます。
プロジェクトの作成からデプロイまで
chalice new-project hello-worldコマンドでプロジェクトファイルが生成されます。
ディレクトリ構造はこちら。│ .gitignore │ app.py │ requirements.txt │ └─.chalice config.jsonapp.pyを編集していきます。
デフォルトではこうなっています。app.pyfrom chalice import Chalice app = Chalice(app_name='hello-world') @app.route('/') def index(): return {'hello': 'world'} # The view function above will return {"hello": "world"} # whenever you make an HTTP GET request to '/'. # # Here are a few more examples: # # @app.route('/hello/{name}') # def hello_name(name): # # '/hello/james' -> {"hello": "james"} # return {'hello': name} # # @app.route('/users', methods=['POST']) # def create_user(): # # This is the JSON body the user sent in their POST request. # user_as_json = app.current_request.json_body # # We'll echo the json body back to the user in a 'user' key. # return {'user': user_as_json} # # See the README documentation for more examples. #以下コマンドで、ローカルでの動作確認ができます。
chalice local
デプロイはこちら。
chalice deploy
払い出されたAPI URLにアクセスして{'hello': 'world'}が返ってきているのを確認しましょう。
お片づけはこちらです。chalice deleteLINE chatbotを実装する
LINE developersに登録する
適当にアプリ名等を設定し、オウム返し用のチャネルを作ります。
Messaging API設定からWebhookの利用をオンにし、
Messaging API設定のチャネルアクセストークン(長期)、
チャネル基本設定のチャネルシークレットを控えておきます。line-bot-sdkをインストールする
ローカルでは
pip install line-bot-sdkでOK。
Lambdaにデプロイするとき用に、PyPIからwhl形式のファイルを落としておきます。
Lambdaで外部ライブラリを使うときはプロジェクト名のフォルダにvendorフォルダを作り、そこにwhl形式で格納します。さらにrequirements.txtを作成し、使用するバージョンを指定します。requirements.txtline-bot-sdk==1.17.0環境変数を登録する
環境変数は.chaliceディレクトリ内のconfig.jsonに書き加えます。
先ほど控えたチャネルシークレットとチャネルアクセストークンを以下のように登録しましょう。config.json{ "version": "2.0", "app_name": "line-bot", "stages": { "dev": { "api_gateway_stage": "api", "environment_variables": { "LINE_CHANNEL_SECRET": "チャネルシークレット", "LINE_CHANNEL_ACCESS_TOKEN": "チャネルアクセストークン" } } } }app.pyの編集
Chalice を使って AWS Lambda 上に LINE Bot 用の Webhook を作成する
こちらを参考にしました。デプロイ~結果
デプロイします。
コンソールを確認すると、LambdaとAPI gatewayが作成されています。
払い出されたAPI URLに/callbackを足したものをLINE developersのWebhookに登録します。検証を押して問題なければOKです。
あとはbotに話しかけて、オウム返しが作動するか確認しましょう。
実装までのトラブルシューティング
最初、オウムがうんともすんとも言わないのでLambdaをテストしに行きました。
テスト関数はここでは空のjsonで十分です。
失敗が確認されたので、CloudWatchを見に行きました。
エラーログはCloudWatch>CloudWatch Logs>Log groupsに格納されます。line-botのログストリームを開けていくと……
line-botモジュールがないよと言われています。
確認したところ、vendorにライブラリを格納したまでは良いものの、requirements.txtファイルを編集するのを忘れていました。注意点・未解決事項
・deploy後に数分コンソールが動かなくて慌てましたが、line-bot-sdkをインストールするのに時間がかかっていただけのようです。気長に待ちましょう。
・ブラウザでapi/callbackに接続すると、{"message":"Missing Authentication Token"}になってしまいます。オウム返し自体は機能しているのですが……
・ChaliceはLambdaに付与するIAMロールのポリシーは自動でいい感じに付与してくれますが、AWSにアクセスするアクセスキーを持ったIAMユーザーのポリシーはこちらで与えないといけません。
それらしいポリシーを与えても権限がありませんよエラーではじかれてしまい、今回は結局AdministratorAccessポリシーを当ててごり押ししてしまいました(IAMユーザーを作った意味がない……)。




- 投稿日:2020-10-12T17:37:23+09:00
停まれ標識検知 可視化部分の開発part1 物体の検知と記録※今回は椅子を検出しています(モデルは自作ではありません)
初めに
前回は,看板検知の学習モデルについて記してきました.今回は,その検知したモデルを使って実際に検知し,それを可視化する為のプログラムを書いていこうと考えています.
実現したい機能
・yolov5で動画を使って推定し推定した動画を保存する.
・検知されたときに別システムに検知を可視化する.
・検知された時間やモノを記録する.
この辺を実際に実現していきたいなと思います.実現したい機能の実現
前置き
実は,似た機能を前にtensorflowとpython,processingを利用して簡易的なものを作ったことがあるのでそのプログラムを流用して書いていきたいと思います.
プログラムはgithubに載せてあります.※学習モデルの作り方やどうそのモデルをlabelプログラムで動かしたかを作った本人は忘れています.
URL https://github.com/S-mishina/Personal-estimation
このプログラムのsketch_190628a/sketch_190628a.pdeが可視化部分です.
システムの全体についてもここに一応載せておきます.
ここから実際にyolov5の改造をしていきます.特定の何かが検知されたときに何かアクションを起こす.
今回は簡単に実装してみたかったので検知したいものが見つかったときにはそれを検知しましたよ
という通知を出すプログラムにした.detect.pylabel1 = str((names[int(c)])) # add to string if label1=="chair": print("椅子を検知しました.")まぁ簡単なコードなので誰でもわかると思いますが,一応説明すると,yoloでオブジェクトを検出するとおそらく検出したものがnames[int(c)]というところで記録されるみたいでした.なのでそれを文字列化して文字列化したものが自分が検出したいものとマッチしているかを見てマッチしていれば検出OK,マッチしていなければ検出NGという具合になっています.
このプログラムの展望
この実装した機能の展望としてはここからソケット通信で検出したかどうかを文字ベースじゃなくて可視化できるシステムにつなげていきたいと考えています.
検知された時間やモノを記録する.
今回は椅子を検出することを目的としているので椅子が検出されたときにログを取るプログラムを書いていきたいと思います.
インポート部分detect.pyimport pathlibファイル作成部分
detect.py#初期化 set_logging() device = select_device(opt.device) if os.path.exists(out): shutil.rmtree(out) #出力フォルダーを削除します os.makedirs(out) #新しい出力フォルダーを作成します d_today = datetime.date.today() f = pathlib.Path('daystext/'+ str(d_today) +'.txt') f.touch()記録部分
detect.pylabel1 = str((names[int(c)])) # add to string if label1=="chair": print("椅子を検知しました.") with open('daystext/'+str(d_today)+'.txt', 'a') as f: dt_now = datetime.datetime.now() f.write(str(dt_now)+"椅子を検知しました."+"\n")記録されたもの
2020-10-12 17:27:42.914446椅子を検知しました. 2020-10-12 17:27:42.941445椅子を検知しました. 2020-10-12 17:27:42.968444椅子を検知しました. 2020-10-12 17:27:42.996444椅子を検知しました. 2020-10-12 17:27:43.024443椅子を検知しました. 2020-10-12 17:27:43.051442椅子を検知しました. 2020-10-12 17:27:43.079441椅子を検知しました. 2020-10-12 17:27:43.108440椅子を検知しました. 2020-10-12 17:27:43.135454椅子を検知しました. 2020-10-12 17:27:43.162439椅子を検知しました. 2020-10-12 17:27:43.190452椅子を検知しました. 2020-10-12 17:27:43.218437椅子を検知しました. 2020-10-12 17:27:43.245436椅子を検知しました. 2020-10-12 17:27:43.274445椅子を検知しました. 2020-10-12 17:27:43.301448椅子を検知しました. 2020-10-12 17:27:43.329434椅子を検知しました. 2020-10-12 17:27:43.357433椅子を検知しました. 2020-10-12 17:27:43.384432椅子を検知しました.こんな感じで記録されていきます.
動画を記録する部分
ここは結構大変そうなのでとりあえず次回に回します.
ごめんなさい.次回へ
主に今回はyolov5のデフォルトプログラムを改良して物体を検知した後に記録するというプログラムを主にして書いて行きました.
次回は可視化する部分を具体的に書いていけたらいいなと考えていますのでよろしくお願いします.
- 投稿日:2020-10-12T17:36:02+09:00
集計したTwitterデータを自動でWordPressにcronで投稿して、最高の自分ログを作成する
しょーもない自分アプリのアイデアを紹介する投稿です。
思いついたことをメモがわりにTwitterに投稿することが多いのですが、内容が細切れなのであとで見返すのに苦労します。かといって都度ブログにまとめて投稿するかといったらしないです。
そこで、Twitterの投稿をAPIで取得して自動でWordPressに投稿すれば、週単位や数日単位の自分ログができるのではないかと考えました。アプリの概要
TwitterのAPIを使って、Pythonでデータを取得します。それをWordPressのxml-rpcのインターフェースでPythonから投稿します。PythonはXserverにファイルを置いて、Cronで実行します。
ツール
TwitterAPI
Python
Xserver流れ
- TwitterのAPIトークンを取得
- Pythonでツイートを取得するプログラムを作成
- WordPressにPythonから自動投稿するプログラムを作成
- XserverにPythonをインストール
- Twitterデータを取得するプログラムとWordPressに投稿するプログラムを合体
- Xserverでcronで動かす
方法
既にきれいにまとめていただいた記事が多くあり、それの劣化版を作成してもしょうがないので参照しつつコメントさせていただく形で説明させていただきます。
TwitterのAPIトークンを取得
Twitterのトークンは結構手間がかかります。Twitter Developerというサイトで申請して待ってから使えるようになります。申請して他をやって待つのがかも
https://www.itti.jp/web-direction/how-to-apply-for-twitter-api/ツイートを取得するプログラムを作成
トークンが発行できたら面白いところです。tweetyみたいなライブラリを使う方法もありますが、この記事が神すぎます。非常にプログラムもきれい。
https://qiita.com/kyohei_ai/items/243b6f98a31433d2faaf
WordPressにPythonから自動投稿するプログラムを作成
これも面白いところです。WordPressは自動で投稿する方法として2つありますが、この記事のように昔からあるxml-rpcを使います。
XserverにPythonをインストール
XserverにもともとあるPythonは権限の関係でpipできません。なので自分用のPythonを導入する必要があります。ついでにSSH接続できるようにもしておきます
Python
https://note.com/coeeff/n/neab8acfde97e
SSH
https://qiita.com/NP_Systems/items/5277827a9ba7805d0811そしたら、あとはwitterデータを取得するプログラムとWordPressに投稿するプログラムを合体させます。
Xserverでcronで動かす
XserverではCronの設定が簡単にできます。結果も自動でメール配信してくれるので重宝します。
https://www.xserver.ne.jp/manual/man_program_cron.phpできるようになったこと
Twitterデータが自動で投稿できるようになりました。
- 投稿日:2020-10-12T16:56:14+09:00
相関関係についての備忘録【Python】
はじめに
この記事は、誤差変数や交絡因子のあるデータの相関関係に対して考察を行う過程で幾つか試みたことを備忘録のために書きおこした記事です。
先ずはこの記事の構成を示します。
- データの因果構造 (Data Generation)
- 相関行列 / 偏相関行列 1(Correlation / Partial Correlation [1])
- スパース推定 (Graphical Lasso)
- 相関行列 / 偏相関行列 2(Correlation / Partial Correlation [2])
- 回帰分析 (回帰分析)
- まとめ (まとめ)
Data Generation
データの尺度に関しましては「名義尺度」「順序尺度」「カテゴリー変数」などは含めず、データの性質や構造に関しましては「バイアス」「未観測交絡因子」「有向巡回」などへのアプローチは行っておりません。
扱う多変量データはすべて連続値でありそれぞれが正規分布に従うとします。データの「粒度」に対しては標準化を行っています。<必要なライブラリの読み込み>
import pandas as pd import numpy as np import math import matplotlib.pyplot as plt %matplotlib inline import seaborn as sns sns.set() import scipy as sp from scipy import linalg from scipy.stats import multivariate_normal from sklearn.linear_model import LinearRegression, HuberRegressor, TheilSenRegressor, RANSACRegressor from sklearn.svm import SVR from sklearn.covariance import GraphicalLasso from sklearn.preprocessing import StandardScaler from sklearn.model_selection import train_test_split from sklearn.metrics import mean_squared_error, mean_squared_log_error<利用するデータの生成>
以下の有向非巡回な因果構造をもつデータの生成を行います。
未観測因子による影響という意味よりも誤差変数としてそれぞれのノードに対し正規分布または一様分布に従う乱数を加えています。
np.random.seed(0) data_ = np.array([[20, 1, 0.3242, 34, 1, 0.10, 52, 5], [52, 0, 0.6134, 63, 1, 0.35, 38, 8], [38, 0, 0.7136, 57, 0, 0.20, 64, 7], [63, 1, 0.4592, 49, 0, 0.80, 95, 2]]) mu = np.mean(data_, axis = 0) cov = np.cov(data_, rowvar = 0, bias = 0) w_9 = np.random.multivariate_normal(mu, cov, 1000)[:, 0][:, np.newaxis] + np.random.uniform(1.3, size = 1000)[:, np.newaxis] w_8 = 0.32 * w_9 + np.random.multivariate_normal(mu, cov, 1000)[:, 3][:, np.newaxis] w_7 = np.random.multivariate_normal(mu, cov, 1000)[:, 1][:, np.newaxis] + np.random.uniform(1.6, size = 1000)[:, np.newaxis] w_6 = 0.50 * w_7 + np.random.multivariate_normal(mu, cov, 1000)[:, 4][:, np.newaxis] w_5 = 0.53 * w_7 + np.random.multivariate_normal(mu, cov, 1000)[:, 5][:, np.newaxis] w_4 = 0.48 * w_5 + 0.40 * w_6 + np.random.uniform(1.5, size = 1000)[:, np.newaxis] w_3 = 0.28 * w_4 + np.random.uniform(1.7, size = 1000)[:, np.newaxis] w_2 = 0.20 * w_5 + np.random.uniform(3.2, size = 1000)[:, np.newaxis] w_1 = 0.31 * w_2 + np.random.uniform(1.5, size = 1000)[:, np.newaxis] w_0 = 0.290 * w_1 + 0.327 * w_4 + 0.491 * w_8 + 0.136 * w_9 + 10.0 + np.random.multivariate_normal(mu, cov, 1000)[:, 2][:, np.newaxis] mu = np.mean(w_0, axis = 0) cov = np.cov(w_0, rowvar = 0, bias = 0) list_ = np.where(w_0 <= 0) for i in list_: normal = np.random.normal(mu, cov) if normal <= 0: w_0[i] = mu elif normal > 0: w_0[i] = normal data_ = pd.DataFrame(np.concatenate([w_0, w_1, w_2, w_3, w_4, w_5, w_6, w_7, w_8, w_9], axis = 1))Correlation / Partial Correlation [1]
相関行列を計算すると
w_7によりw_5とw_6に間に相関があるという結果を出し、偏相関行列を計算するとその相関は擬似相関であるという結果が出れば理想です。
同時に興味のあることはw_0とw_8の相関について相関行列と偏相関行列でどのように結果が変わるのかです。
w_0w_8w_9の関係のような複雑でないデータ構造であれば、交絡因子w_9が存在していてもw_0とw_8に因果関係がなければ偏相関行列を計算することでw_0とw_8に因果関係はないという結果が出されるはずです。
一方で、扱うデータではw_0とw_8に因果関係がありw_0とw_8に対しての交絡因子であるw_9が存在しています。その場合にw_0w_8の相関関係はどのように表されるのかを確認します。
w_0とw_1w_4w_8w_9についてもどの程度の正確さで相関関係が表されるのかを確認します。def partital_corr(data): temp_cov = data.cov() omega = np.linalg.inv(temp_cov) D = np.diag(np.power(np.diag(omega), -0.5)) temp_pcorr = -np.dot(np.dot(D, omega), D) + 2 * np.eye(temp_cov.shape[0]) mtx_pcorr = pd.DataFrame(temp_pcorr, columns = temp_cov.columns, index = temp_cov.index) return mtx_pcorr partial_correlation = partital_corr(data_) fig = plt.subplots(figsize=(9, 9)) heatmap = sns.heatmap(data_.corr(), annot = True, cmap = 'Blues', square = True) heatmap_ = sns.heatmap(partial_correlation, annot = True, cmap = 'Blues', square = True)Correlation(left) VS Partial Correlation(right)
w_0w_8w_0w_9w_0w_1w_0w_4w_5w_6w_8w_9相関 0.96 0.66 -0.031 0.014 0.36 0.43 偏相関 1 1 0.28 0.24 -0.6 -1 1 つの解釈として、 交絡因子
w_7からの影響を受けるw_5とw_6の両方がw_4に影響しているため偏相関行列を計算する過程の分散共分散行列を計算する際に上手く変数間の関係を測れていないと考察できそうです。
別の考察を行うために Correlation / Partial Correlation [2] ではデータにループ構造と外れ値を加えます。Graphical Lasso
グラフィカルラッソはデータが多変量正規分布に従う場合にスパースな分散共分散行列の逆行列を算出するスパース推定です。ガウシアングラフィカルモデルとスパース推定の要素をもちます。
2つの変数間の相関において他の変数との関係の下で条件付き独立性を考えます。
データから算出される分散共分散行列から対数尤度関数を作り、$L1$正則化項を加えた損失関数に対し最小化問題を解くことでスパースな分散共分散行列の逆行列(精度行列)を推定します。
推し測って考えると扱っているデータにグラフィカルラッソは適していませんが試してみます。ss = StandardScaler() data_ss = ss.fit_transform(data_) gl = GraphicalLasso(alpha = 0.1, max_iter = 100, ) gl.fit(data_ss) gl.get_params() # correlation diag = np.zeros(shape = (10, 10)) for i in range(diag.shape[0]): for j in range(diag.shape[1]): if i == j: diag[i,j] = 1 / np.sqrt(gl.covariance_[i,j]) corr = np.dot(np.dot(diag, gl.covariance_), diag) # partial correlation omega = np.linalg.inv(gl.covariance_) diag = np.diag(np.power(np.diag(omega), -0.5)) partial_corr = -np.dot(np.dot(diag, omega), diag) partial_corr += 2 * np.eye(gl.covariance_.shape[0]) heatmap_gl =sns.heatmap(corr, annot = True, cmap = 'Blues', square = True) figure_gl = heatmap_gl.get_figure() figure_gl.savefig('graph_gl_corr') heatmap_gl_ = sns.heatmap(partial_corr, annot = True, cmap = 'Blues', square = True) figure_gl_ = heatmap_gl_.get_figure() figure_gl_.savefig('graph_gl_partial_corr')Correlation(left) VS Partial Correlation(right)
グラフィカルラッソはノイズや交絡に対応したアルゴリズムではないので今回のデータに適した選択ではないと考えられます。Correlation / Partial Correlation [2]
w_0w_4w_6にループ構造を作りw_1w_4w_9を外れ値のあるデータにします。np.random.seed(0) data_ = np.array([[20, 1, 0.3242, 34, 1, 0.10, 52, 5], [52, 0, 0.6134, 63, 1, 0.35, 38, 8], [38, 0, 0.7136, 57, 0, 0.20, 64, 7], [63, 1, 0.4592, 49, 0, 0.80, 95, 2]]) mu = np.mean(data_, axis = 0) cov = np.cov(data_, rowvar = 0, bias = 0) #w_11 = np.random.multivariate_normal(mu, cov, 1000)[:, 6][:, np.newaxis] #w_10 = 0.27 * w_11 + np.random.multivariate_normal(mu, cov, 1000)[:, 7][:, np.newaxis] w_9 = np.random.multivariate_normal(mu, cov, 1000)[:, 0][:, np.newaxis] + np.random.uniform(1.3, size = 1000)[:, np.newaxis] noise_upper = np.random.normal(200, 30, 20) noise_row = np.random.randint(0, 1000, 20) w_9[noise_row] = noise_upper[:, np.newaxis] w_8 = 0.32 * w_9 + np.random.multivariate_normal(mu, cov, 1000)[:, 3][:, np.newaxis] w_7 = np.random.multivariate_normal(mu, cov, 1000)[:, 1][:, np.newaxis] + np.random.uniform(1.6, size = 1000)[:, np.newaxis] w_6 = 0.50 * w_7 + np.random.multivariate_normal(mu, cov, 1000)[:, 4][:, np.newaxis] + 0.53 * w_0 w_5 = 0.53 * w_7 + np.random.multivariate_normal(mu, cov, 1000)[:, 5][:, np.newaxis] w_4 = 0.48 * w_5 + 0.40 * w_6 + np.random.uniform(1.5, size = 1000)[:, np.newaxis] noise_lower = np.random.normal(0.6, 0.2, 10) noise_upper = np.random.normal(30, 2, 30) noise_row = np.random.randint(0, 1000, 40) w_4[noise_row] = np.concatenate([noise_lower, noise_upper])[:, np.newaxis] w_3 = 0.28 * w_4 + np.random.uniform(1.7, size = 1000)[:, np.newaxis] w_2 = 0.20 * w_5 + np.random.uniform(3.2, size = 1000)[:, np.newaxis] w_1 = 0.31 * w_2 + np.random.uniform(1.5, size = 1000)[:, np.newaxis] noise_upper = np.random.normal(30, 4, 20) noise_upper_ = np.random.normal(50, 3, 20) noise_row = np.random.randint(0, 1000, 40) w_1[noise_row] = np.concatenate([noise_upper, noise_upper_])[:, np.newaxis] w_0 = 0.290 * w_1 + 0.327 * w_4 + 0.491 * w_8 + 0.136 * w_9 + 10.0 + np.random.multivariate_normal(mu, cov, 1000)[:, 2][:, np.newaxis] #+ 0.426 * w_11 mu = np.mean(w_0, axis = 0) cov = np.cov(w_0, rowvar = 0, bias = 0) list_ = np.where(w_0 <= 0) for i in list_: normal = np.random.normal(mu, cov) if normal <= 0: w_0[i] = mu elif normal > 0: w_0[i] = normal data_ = pd.DataFrame(np.concatenate([w_0, w_1, w_2, w_3, w_4, w_5, w_6, w_7, w_8, w_9], axis = 1))def partital_corr(data): temp_cov = data.cov() omega = np.linalg.inv(temp_cov) D = np.diag(np.power(np.diag(omega), -0.5)) temp_pcorr = -np.dot(np.dot(D, omega), D) + 2 * np.eye(temp_cov.shape[0]) mtx_pcorr = pd.DataFrame(temp_pcorr, columns = temp_cov.columns, index = temp_cov.index) return mtx_pcorr partial_correlation = partital_corr(data_) fig = plt.subplots(figsize=(9, 9)) heatmap = sns.heatmap(data_.corr(), annot = True, cmap = 'Blues', square = True) heatmap_ = sns.heatmap(partial_correlation, annot = True, cmap = 'Blues', square = True)Correlation(left) VS Partial Correlation(right)
w_0とw_4はループ構造で繋がっているためw_4はw_8とw_9それぞれと相関があるという結果になっています。相関行列では正の相関を示し偏相関行列では負の相関を示しています。
相関行列の結果ではw_3w_4w_9における相関においてw_3に対してw_9は間接的に正の相関を示しています。偏相関行列の結果ではw_3とw_9に相関はなくw_4とw_9は負の相関を示しています。
相関行列は対応できていて偏相関行列が対応できていないところを幾つか確認できます。逆も然りです。相関行列では正の相関を示し偏相関行列では負の相関を示すところも確認できます。十分な考察を行うには根拠が足りていないですが 1 つの解釈として、このセクションのケースからは相関行列と偏相関行列はどちらも「一定以上の大きさの誤差変数」「ある因子(変数)に間接的または直接的に影響を受ける 2 つ以上の変数 $x_1,...,x_n$ が因果もしくは相関の関係にあるまたは $x_1,...,x_n$ の内 2 つ以上が他の同じ変数に影響する場合」「ループ構造」に上手く対応できていないと考察できそうです。
回帰分析
w_0は線形の式で表現できるように作ってあるので回帰分析を行います。
誤差の分布に対して「正規性」「等分散性」「独立性」を仮定でき、目的変数と説明変数の関係に対して「線形性」を仮定できれば回帰分析を行うモチベーションを強く持つことができます。
scikit-learnを用いてHuberRegressorやSVRも試しましたがLinearRegressionで十分に対応できます。
扱うデータにはセレクションバイアスなどのバイアスや未観測交絡因子がないためです。
SVR を行う際には入力ベクトルに対して重みづけを行う線形カーネルを用いています。
複数の素性に対応した多項式カーネルを用いて自由度を調整する方法やガウスカーネルを用いた方法で回帰を行っても精度は出ます。
ロバスト回帰にはフーバー回帰を用いています。今回は誤差の分布に非対称性や大きなノイズはないため適した選択ではないと考えられます。
「目的変数を正規分布に従わせる」「外れ値に対処する」「目的変数と説明変数との関係が指数関数の傾向にある」などのモチベーションはないので対数変換は行っていません。X_train, X_valid, y_train, y_valid = train_test_split(data_.drop(0, axis =1), data_[0], test_size = 0.4, random_state = 0) data_ss = pd.DataFrame(data_ss) X_train_ss, X_valid_ss, y_train_ss, y_valid_ss = train_test_split(data_ss.drop(0, axis =1), data_ss[0], test_size = 0.4, random_state = 0) y_valid = y_valid.sort_index(ascending = True) X_valid = X_valid.sort_index(ascending = True) y_valid_ss = y_valid_ss.sort_index(ascending = True) X_valid_ss = X_valid_ss.sort_index(ascending = True) plt.hist(np.ravel(y_train), label = 'training data', color = 'c') plt.hist(np.ravel(y_valid), label = 'valid data', color = 'k') plt.savefig('graph_hist')
# 非標準化データ linear = LinearRegression() linear.fit(X_train, y_train) # <SVR> # svr_linear = SVR(kernel = 'linear', C = 1.0, epsilon = 0.1, gamma = 'scale') # svr_linear.fit(X_train, np.ravel(y_train)) # scores = svr_linear.score(X_valid, y_valid) # print('R^2 scores : %s' %scores) # <HuberRegressor> # hr = HuberRegressor(alpha = 0.0001, epsilon = 1.35, # fit_intercept = True, max_iter = 100, tol = 1e-05, warm_start = False) # hr.fit(X_train, y_train) pred = linear.predict(X_valid) plt.plot(np.ravel(y_valid), label = 'true valid', color = 'k') plt.plot(np.ravel(pred), label = 'pred valid', color = 'w') diff = np.log1p(pred) - np.log1p(y_valid) diff = np.where(np.isnan(diff) == True, 0, diff) RMSLE = np.sqrt(np.mean(diff ** 2)) # 標準化データ linear_ss = LinearRegression() linear_ss.fit(X_train_ss, y_train_ss) # <SVR> # svr_linear_ss = SVR(kernel = 'linear', C = 1.0, epsilon = 0.1, gamma = 'scale') # svr_linear_ss.fit(X_train_ss, np.ravel(y_train_ss)) # scores = svr_linear_ss.score(X_valid_ss, y_valid_ss) # print('R^2 scores : %s' %scores) # <HuberRegressor> # hr_ss = HuberRegressor(alpha = 0.0001, epsilon = 1.35, # fit_intercept = True, max_iter = 100, tol = 1e-05, warm_start = False) # hr_ss.fit(X_train_ss, y_train_ss) pred_ss = linear_ss.predict(X_valid_ss) plt.plot(np.ravel(y_valid_ss), label = 'true valid', color = 'k') plt.plot(np.ravel(pred_ss), label = 'pred valid', color = 'w') coef = pd.DataFrame(X_train.columns.values, columns = {'feature'}) coef['coef'] = linear.coef_.T coef['coef_ss'] = linear_ss.coef_.T<非標準化データを用いた結果>
print('MSE : %s' %mean_squared_error(y_valid, pred, squared = True)) print('RMSLE : %s' %RMSLE) >> RMSE : 0.02983134938758614 >> RMSLE : 0.03423681936352853 coef.sort_values(by = 'coef', ascending = False) >> feature coef 8 0.480333 4 0.322978 1 0.284168 9 0.133841 6 0.039120 5 0.016435 3 -0.005714 2 -0.009774 7 -0.020549<標準化データを用いた結果>
print('MSE : %s' %mean_squared_error(y_valid_ss, pred_ss, squared = True)) >> MSE : 0.000242675476861591 coef.sort_values(by = 'coef_ss', ascending = False) >> feature coef 8 0.652601 9 0.332685 1 0.194995 4 0.109338 6 0.020749 5 0.000665 3 -0.000551 2 -0.000566 7 -0.001129残差を確認します。
# 非標準化データ plt.scatter(pred, pred - y_valid, color = 'blue') plt.hlines(y = 0, xmin = -10, xmax = 150, color = 'c') plt.xlabel('Prediction') plt.ylabel('Residual error') plt.grid() # 標準化データ plt.scatter(pred_ss, pred_ss - y_valid_ss, color = 'blue') plt.hlines(y = 0, xmin = -10, xmax = 150, color = 'c') plt.xlabel('Prediction') plt.ylabel('Residual error') plt.grid()Non Standardized(left) VS Standardized(right)
# 非標準化データ plt.hist(pred - y_valid) # 標準化データ plt.hist(pred_ss - y_valid_ss)Non Standardized(left) VS Standardized(right)
標準化データと非標準化データの残差はそれぞれ $y = 0$ の $±0.5$ と $±0.05$ の範囲に散らばっており、残差に正規性を確認できます。
残差の散らばり方はどちらも不規則ではなく $y = 0$ を境界として対称性があります。
標準化データは非標準化データと比較して MSE による検証データに対する予測精度は高いですが、目的変数に対しての係数の寄与を降順で確認すると非標準化データの8419の並びは検証データに対する予測精度の高い標準化データよりも正確であることが確認できます。
データに誤差変数や外れ値を加えても、データに複数の尺度や未観測交絡因子がない場合にはそれなりの精度を出しています。
誤差変数や外れ値をよりランダムに多く大きく割り振っても今回のデータでは目的変数に対しての係数の寄与を適切に算出し、未観測変数がある場合にはモデルの精度は安定しないという結果が出ています。因果関係ではなく予測に重きを置く場合に複数の尺度や粒度の違いなどを考慮するデータに対して
statsmodels.formula.apiを用いて回帰分析を行い、多重共線性に対してはCond. No.を確認して条件数が 1 に近ければ多重共線性は弱いと判断しそうでなければstatsmodels.stats.outliers_influenceのvariance_inflation_factorを用いて分散拡大係数を計算するという方法もあります。
例えば 2 つの変数間に多重共線性がある場合には変数が直線状に並ぶ形をとるため回帰平面は直線の上にしか存在せず、分散共分散行列の逆行列は存在しないため 1 次式を解くことが出来ません。結果として「係数の標準偏差が大きくなる」「$t$ 値が小さくなり $p$ 値に影響を及ぼす」「決定係数が大きな値をとる」などのことが考えられます。
statsmodels.formula.apiを用いると「$p$ 値, $z$ 値, 母数の信頼区間を用いて実質的な効果を判断」「共分散の種類(Covariance Type)」「標本データに対する正規性の検定(Omnibus 検定)」なども容易に確認できます。まとめ
誤差変数や交絡因子のあるデータに対して相関関係についての考察と回帰分析を行ってみました。
備忘録とはいえ、記事としては主題に対して内容の一貫性が欠けているように感じます。
記事にするうえで差し支えのないデータを上手く揃えることができれば構造方程式モデリングによる因果の推定などより面白いことができそうです。
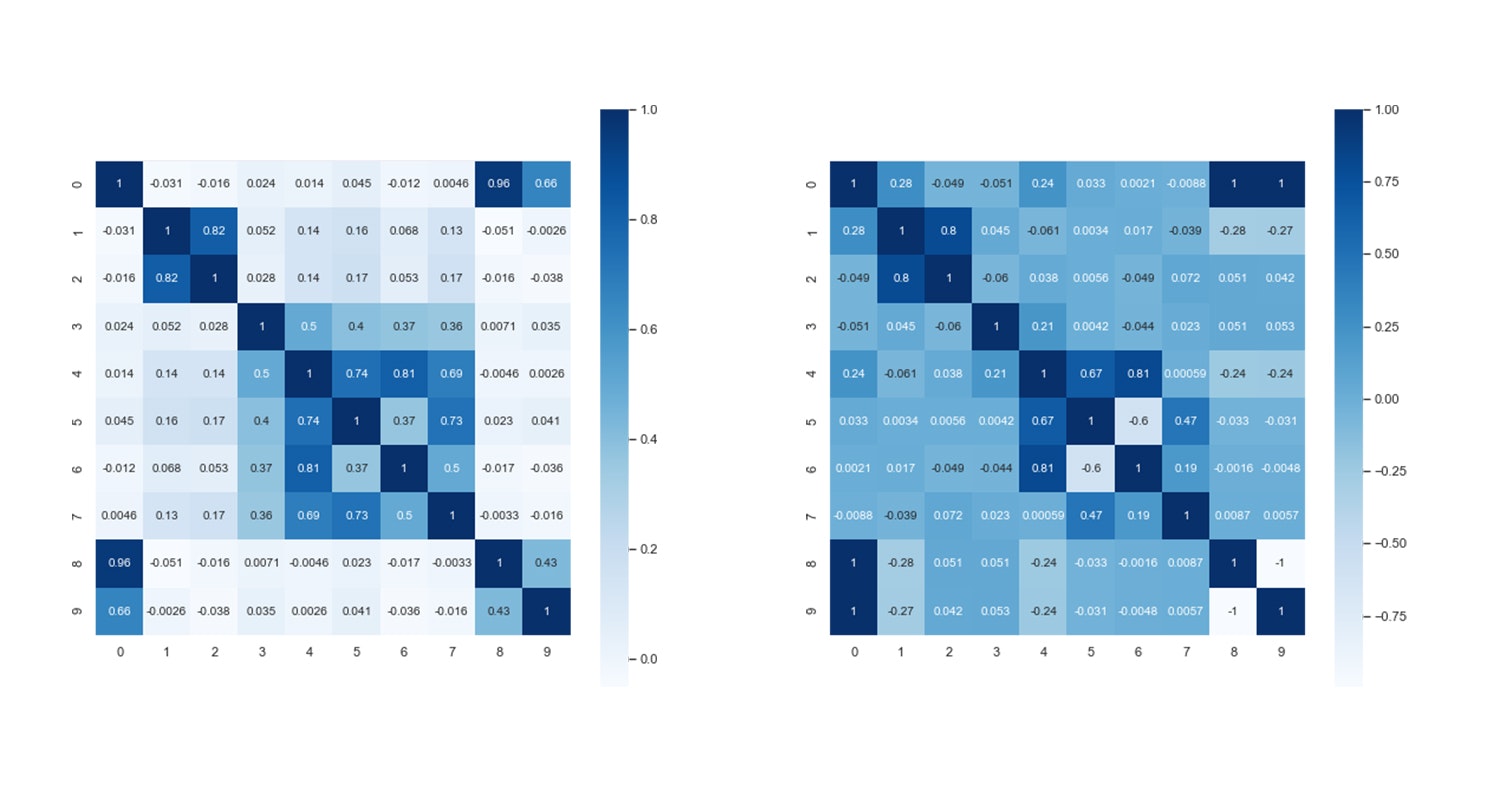
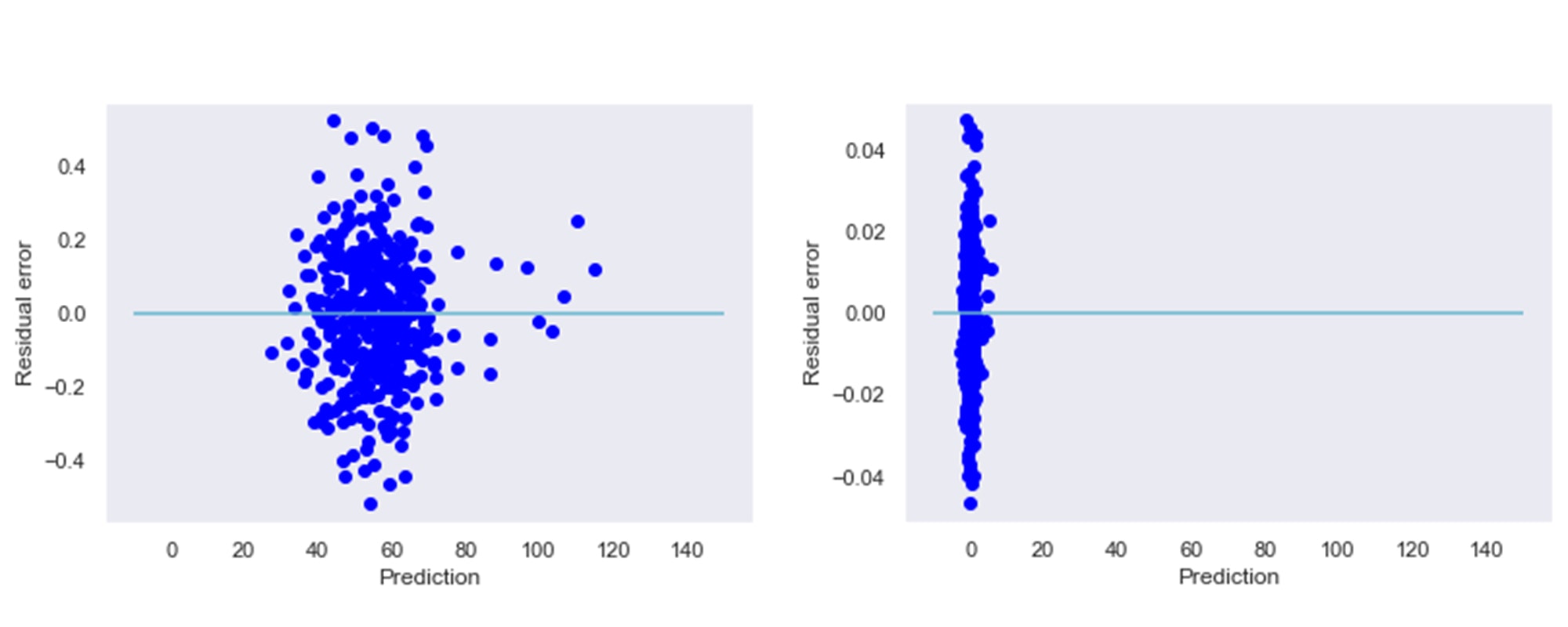
- 投稿日:2020-10-12T16:53:39+09:00
MemSQLの処理能力検証(応用編3)
さて、今回のチャレンジ(?)は・・・・
今回は、連続してデータが挿入されているMemSQLのテーブルに対して、連続して一定間隔の処理を実行して指定された時間範囲に入るデータを抽出・テーブル生成を行ってみたいと思います。時間が押し押しの状況での検証ですので、今少し詰めが甘い感が否めませんが、一方で秒に数個の挿入処理を実行中のMemSQLが、別の処理要求を連続して受けた場合にどのような動きになるかを確認する意味で、とりあえずザクッと実施してみます。
バッチ的な定形処理の間隔を短縮化する
よくある作業としては、纏めてドン!型の世界におけるバッチ処理が有りますが、今回は以前より検証・紹介させて頂いているリアルタイム・ストリーミングをプログラムレスで構築できる、Equalumというソリューションが有りますので、それとの連携を想定した「既存のオリジナル側データシステムに対してトランザクション泥棒と呼ばれずに」「時間を気にしないで」「想いのままに」「創造的なクエリ処理」を実現する為の環境として、MemSQLがどの程度行けるか?を見てみたいと思います。
先ずは、以前のPythonスクリプトを改造して、定期的に実行されるプロセス内で
(1)起動したタイミングの日時情報でテーブル名を生成して新規テーブルを作成
(2)連続挿入されているオリジナル側のテーブルから必要情報を時間範囲指定で抽出
(3)返ってきた情報を(1)で作成した新規テーブルに格納
という処理を入れ込みます。(今回も力業でエイヤー版になる関係上、ツッコミ所満載かもしれませんが、その辺は平にご容赦の程・・・・)検証は今回設定した一連の処理を30秒毎に処理を走らせて、その時点から30秒前までのデータを条件抽出する想定で実施しました。(実際には、その他の影響を受けて微妙にズレたりしていますが・・・(汗))連続挿入しているテーブルに、定期的に割り込みを掛けて条件抽出&新規テーブル作成の負荷を掛けたらどうなるか・・・を検証出来れば、とりあえずOkという事で作業を進めて行きます。
# coding: utf-8 # # Pythonでタスクを一定間隔に実行する (力技バージョン) # Version 2.7版 # import sys stdout = sys.stdout reload(sys) sys.setdefaultencoding('utf-8') sys.stdout = stdout # インポートするモジュール import schedule import time import pymysql.cursors # SQL文で使う情報 SQL1 = "SELECT ts, Category, Product, Price, Units, Card, Payment, Prefecture FROM Qiita_Test " SQL3 = " ORDER BY ts" # スナップショット・テーブルのカラム定義 DC0 = "id BIGINT AUTO_INCREMENT, PRIMARY KEY(id), O_ts DATETIME(6), " DC1 = "Category VARCHAR(20), Product VARCHAR(20), Price INT, Units INT, " DC2 = "Card VARCHAR(40), Payment INT, Prefecture VARCHAR(10)" # SQLで書き込むカラム定義 DL1 = "O_ts, Category, Product, " DL2 = "Price, Units, Card, Payment, " DL3 = "Prefecture" # # 此処に一定間隔で走らせる処理を設定する # def job(): # スナップショットのタイミングから遡る時間設定 Time_Int = 30 Time_Adj = 0 from datetime import datetime, date, time, timedelta # 現在日時情報の取得 now = datetime.now() print ("JOBの開始 : " + now.strftime("%Y/%m/%d %H:%M:%S")) # スナップショット用のテーブル名を生成してSQL文を生成 dt = 'Qiita_' + now.strftime('%Y%m%d_%H%M%S') Table_Make = "CREATE TABLE IF NOT EXISTS " + dt SQL_Head = "INSERT INTO " + dt # SQLで使用する時間設定の終了情報(補正が必要な場合はTime_Adjで調整) pre_sec = now - timedelta(seconds = Time_Int + Time_Adj) from_dt = pre_sec.strftime("%Y/%m/%d %H:%M:%S") # SQLで使用する時間設定の開始情報 (補正が必要な場合はTime_Adjと+-で調整) now_sec = now + timedelta(seconds = Time_Adj) to_dt = now_sec.strftime("%Y/%m/%d %H:%M:%S") # 時間範囲指定のSQL文を生成 SQL2 = "WHERE ts BETWEEN '" + from_dt + ".000000' AND '" + to_dt + ".000000'" SQL_Def = SQL1 + SQL2 + SQL3 # MemSQLとの接続 db = pymysql.connect(host = 'xxx.xxx.xxx.xxx', port=3306, user='qiita', password='adminqiita', db='Test', charset='utf8', cursorclass=pymysql.cursors.DictCursor) with db.cursor() as cursor: cursor.arraysize = 1000 # スナップショット用の新規テーブルを作成 cursor.execute(Table_Make +"("+DC0+DC1+DC2+")" ) db.commit() # 作業用のバッファを初期化 Tmp_Data = [] # クエリ用のSQLを送信してコミット cursor.execute(SQL_Def) db.commit() # クエリの結果を取得 rows = cursor.fetchall() # クエリ結果を取り出す for Query_Data in rows: for item in Query_Data.values(): Tmp_Data.append(item) # 各カラムへ反映 Category = str(Tmp_Data[0]) Product = str(Tmp_Data[1]) Price = str(Tmp_Data[2]) O_ts = str(Tmp_Data[3]) Units = str(Tmp_Data[4]) Prefecture = str(Tmp_Data[5]) Payment = str(Tmp_Data[6]) Card = str(Tmp_Data[7]) # SQLを作ってスナップショットテーブルに格納 DV1 = O_ts + "','" + Category + "','" + Product + "','" DV2 = Price + "','" + Units + "','" + Card + "','" + Payment + "','" DV3 = Prefecture SQL_Data = SQL_Head + "("+DL1+DL2+DL3+") VALUES('"+DV1+DV2+DV3+"')" # スナップショット用のテーブルに挿入 cursor.execute(SQL_Data) db.commit() Tmp_Data = [] #データベース接続を切断 db.close() print ("JOBの終了 : " + datetime.now().strftime("%Y/%m/%d %H:%M:%S")) print ("+++++++++++++++++++++++++++++++") print # # 此処からメイン部分 # def main(): # 使用する変数の設定 Loop_Count = 3 Count = 0 Interval_Time = 30 # 処理全体のスタート時間 from datetime import datetime print ("プログラム開始日時 : " + datetime.now().strftime("%Y/%m/%d %H:%M:%S")) print # 10分ごと # schedule.every(10).minutes.do(job) # 2時間ごと # schedule.every(2).hours.do(job) # 毎日10時 # schedule.every().day.at("10:00").do(job) # 毎週月曜日 # schedule.every().monday.do(job) schedule.every(Interval_Time).seconds.do(job) # 無限ループで処理を実施 while True: schedule.run_pending() # 謎の呪文・・ww time.sleep(Interval_Time) # 規定回数をチェック if (Count >= Loop_Count): break else: Count += 1 print print (str(Count) + "回 : 規定回数のJOBが終了しました!") print from datetime import datetime print ("プログラム終了日時 : " + datetime.now().strftime("%Y/%m/%d %H:%M:%S")) if __name__ == "__main__": main()このスクリプトを動かした結果は以下の通りです。
プログラム開始日時 : 2020/10/12 14:31:35 JOBの開始 : 2020/10/12 14:32:05 JOBの終了 : 2020/10/12 14:32:06 +++++++++++++++++++++++++++++++ JOBの開始 : 2020/10/12 14:32:36 JOBの終了 : 2020/10/12 14:32:37 +++++++++++++++++++++++++++++++ JOBの開始 : 2020/10/12 14:33:07 JOBの終了 : 2020/10/12 14:33:09 +++++++++++++++++++++++++++++++ 3回 : 規定回数のJOBが終了しました! プログラム終了日時 : 2020/10/12 14:33:39想定通り動いていれば、MemSQL上に開始時間情報を持つテーブルが3個出来上がっているはずです。
先ずは毎度お馴染みのDBeaverで確認してみます。
オリジナルテーブルのQiita_Testテーブルと併せて無事に出来上がっている様です。
念のために各テーブルの先頭部分と末端部分を確認してみます。
挿入スクリプトと今回のスクリプトを起動させた順番の関係上、最初のデータ時間が少し遅めになっていますが、とりあえず立ち上がりの抽出は上手く処理されている様です。
次に終端部分を比較してみます。
最後のデータのTIMESTAMP(6)のデータが14:32:04:804694ですので、想定通りに収まっている事が確認できます。
同様に他の2つも確認します。
処理のインターバルに挟まったデータをミスっていますが、定義された時間範囲はカバーされてます。(ロジックを練らねば・・(汗))
無事に範囲に収まっています。
最後のテーブルは・・・
先程と同様に処理過程で時間計算の葉境に嵌った2-3個のデータは収集出来ませんでしたが、SQL文上で定義した時間範囲には収まっている様です。
さて、取り出したテーブルをどうするか・・・・
もう少し気を利かして時間をコントロールできれば、より緻密に短いサイクルでのデータ利活用の精度は上がってくると思いますが、取り急ぎインメモリパワーに助けられて、大きな処理(例えば以前紹介させて頂いたEqualumを使って、今回の検証で行った連続挿入部分を置き換える等)をMemSQLに実行させていても、ミリ秒台の性能で自由にデータの抽出&次工程の作業を行う事が出来る事は極めて現実的であるとご理解頂けたかと思います。
また、大きなポイントは・・・
短時間の処理サイクルでは、基本的に取り扱うデータも少ないので、極めて今に近い状況を自由に想定しながらシュミレーション的にデータの抽出・集計処理等を行う事が可能です。深夜バッチで纏めてドン!ではないので、何時でもその時点までの取り扱い可能な全てのデータを、Equalumを使って上流側のサイロの壁を越えたデータソースから抽出・前処理済みで、MemSQLのメモリ空間上に展開し(この時点で、サイロ内の情報は同一のDBが管理するメモリ空間にフラットに展開されています)、サイロ透過の横串的なデータ利活用も簡単に行えるようになります。
もちろん、MemSQL上に今回のオリジナル側に展開した情報を10万行入れたターブルに対して、幾つかの条件を設定した抽出系クエリ(今回の時間指定も含めて)を仕掛けた際にも、安定してミリ秒台の性能が維持出来ていますので、メモリ展開の空間が大きな状況が想定されるのであれば、必要なIAサーバをクラスタリングして、存分なインメモリ・データ・コンピューティングを実施する事が可能です。
今回バッチ処理的に抽出したテーブルは、以前にご紹介させて頂いたExcelのテーブルとして読み込む事が出来るので、Excel上の機能を活用したBI的活用も可能ですし、MemSQLの高いMySQL互換性を活用した、その他のBI/AI等のソリューションへの元ネタとして即利用する事も可能でしょう。
MemSQLを使ってみようVol.6 : 脱線編が参考になるかと。次回は・・・
次回は、今回抽出されたテーブルを使って、幾つかの外部連携を試してみたいと思います。この作業はMemSQLとは直接関係しませんが、MemSQL社がメッセージとして出している「オペレーショナル・データベース」(リレーショナルではない点が面白いかと・・)の部分を少し深掘りして、最近のモダン・トランザクション系データ・コンピューティングとのコラボを検証し、
既存のデータ・システム >> Equalum >>MemSQL >> BI/AI/ロボットetc..
リレーショナル <<<<<<<<<<<>>>>>>>> オペレーショナルの世界を覗いてみたいと思います。
謝辞
本検証は、MemSQL社の公式Freeバージョン(V6)を利用して実施しています。
この貴重な機会を提供して頂いたMemSQL社に対して感謝の意を表すると共に、本内容とMemSQL社の公式ホームページで公開されている内容等が異なる場合は、MemSQL社の情報が優先する事をご了解ください。












- 投稿日:2020-10-12T16:35:44+09:00
AWS CloudWatchEventsの時間指定をCDKでラクにする。
いっっっっつも失敗するのでJSTで指定してCDKでUTCに変換することにした。
CDKでCloudWatchEventsを定義する
取り敢えずCloudWatchEventsの定義のとこだけ。
これをよしなにStepFunctionsとかと組み合わせるなり何なりする。# バッチスケジュールをJSTで定義する(cron式で * にする所は空でよい) props['schedule'] = { 'minute': 40, 'hour': 9, 'week_day': 'MON-FRI' } # JSTをUTCに変換する if props['schedule'].get('hour') is not None: props['schedule']['hour'] = props['schedule']['hour'] - 9 if props['schedule']['hour'] < 0: props['schedule']['hour'] += 24 if props['schedule'].get('day') is not None: props['schedule']['day'] = props['schedule']['day'] - 1 # JST 月初の朝9時までに動作する場合は、月末っぽい日付で動作させてLambda等で判定する if props['schedule'].get('day') == 0: props['schedule']['day'] = '28-31' # props['schedule']の中身をstrに変換する for key in props['schedule'].keys(): props['schedule'][key] = str(props['schedule'][key]) # Cloud Watch Events Rule = events.Rule( app, f"Batch-{id}", schedule=events.Schedule.cron(**props['schedule']) )月初の9:00より前(UTC月末)の判定Lambda
今がJSTの月初(1日)かどうかだけ判定してTrueかFalseが返る。
StepFunctionsに組み込むならこれの返り値を判定して次に流すか終わるかすればよいし、単純な処理ならこのLambda内にてif result:で続けて処理してしまってもよいかと思います。import datetime import calendar def lambda_handler(event, context): print('===Start Lambda===') print(event) dt_now = datetime.datetime.now() monthrange = calendar.monthrange(dt_now.year, dt_now.month)[1] result = dt_now.day == monthrange print(result) return result※printは動作確認のためだけに書いてるので要らなければ消してよい。
おわり
何かもっといい方法とかご存知の賢者様はご指摘いただけると嬉しいです。
- 投稿日:2020-10-12T16:26:29+09:00
optunaとkerasとtitanic
はじめに
機械学習とベイズ最適化の勉強のためにk、kaggleのチュートリアル的なコンペ「Titanic: Machine Learning from Disaster」をニューラルネットワークでスコアを出してみました。
ハイパラ最適化には、Preferred Networksのoptunaライブラリ(公式サイト)を使っています。結果
Public Score : 0.7655
ノート
kaggleノートのリンクを貼っときます。
kaggleノートコード
前処理
まずは欠損地処理と関係なさそうな特徴量の削除の前処理です。勘で行いました。
train = train.fillna({'Age':train['Age'].mean()}) X_df = train.drop(columns=['PassengerId','Survived', 'Name', 'Ticket', 'Cabin', 'Embarked']) y_df = train['Survived']次は、ダミー変数の取得です。
X_df = X_df.replace('male', 0) X_df = X_df.replace('female', 1)データを訓練用と評価用に分けます。
from sklearn.model_selection import train_test_split X_train, X_val, y_train, y_val = train_test_split(X_df.values, y_df.values, test_size=0.25, shuffle=True, random_state=0)X_trainの中身を見てみます。カラム名は、Pclass,Sex,Age,SibSp,Parch,Fareです。
[[ 3. 0. 28. 0. 0. 7.8958 ] [ 3. 1. 17. 4. 2. 7.925 ] [ 3. 0. 30. 1. 0. 16.1 ] ... [ 3. 0. 29.69911765 0. 0. 7.7333 ] [ 3. 1. 36. 1. 0. 17.4 ] [ 2. 0. 60. 1. 1. 39. ]]ニューラルネットワーク
ニューラルネットワークモデルを組んでいきます。全結合層のみです。隠れ層の数やユニット数の数もoptunaで最適化します。
def create_model(activation, num_hidden_layer, num_hidden_unit): inputs = Input(shape=(X_train.shape[1],)) model = inputs for i in range(1,num_hidden_layer): model = Dense(num_hidden_unit, activation=activation,)(model) model = Dense(1, activation='sigmoid')(model) model = Model(inputs, model) return modeloptunaで最適化するパラメータの範囲を決めます。関数の返り値を最小化もしくは最大化してくれます。デフォルトでは最小化になっています。最大化したい場合は後ほど出てくる、
create_study('direction = maximize)としてやれば良いです。def objective(trial): K.clear_session() activation = trial.suggest_categorical('activation',['relu','tanh','linear']) optimizer = trial.suggest_categorical('optimizer',['adam','rmsprop','adagrad', 'sgd']) num_hidden_layer = trial.suggest_int('num_hidden_layer',1,5,1) num_hidden_unit = trial.suggest_int('num_hidden_unit',10,100,10) learning_rate = trial.suggest_loguniform('learning_rate', 0.00001,0.1) if optimizer == 'adam': optimizer = Adam(learning_rate=learning_rate) elif optimizer == 'adagrad': optimizer = Adagrad(learning_rate=learning_rate) elif optimizer =='rmsprop': optimizer = RMSprop(learning_rate=learning_rate) elif optimizer =='sgd': optimizer = SGD(learning_rate=learning_rate) model = create_model(activation, num_hidden_layer, num_hidden_unit) model_list.append(model) model.compile(optimizer=optimizer, loss='binary_crossentropy', metrics=['acc', 'mape'],) es = EarlyStopping(monitor='val_acc', patience=50) history = model.fit(X_train, y_train, validation_data=(X_val, y_val), verbose=0, epochs=200, batch_size=20, callbacks=[es]) history_list.append(history) val_acc = np.array(history.history['val_acc']) return 1-val_acc[-1]学習と最適化を行います。最適化のあとで、再度学習しやすい用に各モデルをリストに格納しました。約6分12秒かかりました。
model_list=[] history_list=[] study_name = 'titanic_study' study = optuna.create_study(study_name=study_name,storage='sqlite:///../titanic_study.db', load_if_exists=True) study.optimize(objective, n_trials=50, )最適化の結果を見ます。
print(study.best_params) print('') print(study.best_value)最適化の結果です。
雑で申し訳ないです。
上が各ハイパラ、下が正答率です。{'activation': 'relu', 'learning_rate': 0.004568302718922509, 'num_hidden_layer': 5, 'num_hidden_unit': 50, 'optimizer': 'rmsprop'} 0.17937219142913818テストデータを用いて予測します。その前に、ベストパラメータで十分な量の学習を行います。テストデータの前処理は、ほぼ学習用データの同じですが、PassengerIdは、スコア提出用に別データフレームに取っておきます。
model_list[study.best_trial._number-1].compile(optimizer=study.best_trial.params['optimizer'], loss='binary_crossentropy', metrics=['acc', 'mape'],) es = EarlyStopping(monitor='val_acc', patience=100) history = model_list[study.best_trial._number-1].fit(X_train, y_train, validation_data=(X_val, y_val), verbose=1, epochs=400, batch_size=20, callbacks=[es]) predicted = model_list[study.best_trial._number-1].predict(X_test.values) predicted_survived = np.round(predicted).astype(int)予測結果
乗船者と生存予測結果を紐づけて、csvに出力して完了です。
df = pd.concat([test_df_index,pd.DataFrame(predicted_survived, columns=['Survived'])], axis=1) df.to_csv('gender_submission.csv', index=False) df
PassengerId Survived 0 892 0 1 893 0 2 894 0 3 895 0 4 896 0 ... ... ... 413 1305 0 414 1306 1 415 1307 0 416 1308 0 417 1309 0 418 rows × 2 columns
Public Score : 0.7655
感想
微妙な結果でした。でも非常に楽でした。この先ずっと、optunaに頼ってしまいそうで、チューニングの技術力が上がらないことが心配です。すべて、自動最適化してしまっていいんでしょうか。
参考サイト
非常に分かりやすくて参考になりました。
Optuna入門
- 投稿日:2020-10-12T16:25:13+09:00
Python pyxelを使ってシューティングゲーム
はじめに
ゲームを作ったのが初めてなので、参考資料を元に制作しました。
動画
— Janner (@Janner65116061) October 12, 2020ソースコード
from random import random import pyxel #画面の大きさ SCENE_TITLE = 0 SCENE_PLAY = 1 SCENE_GAMEOVER = 2 #星の数、手前の星の色、奥の星の色 STAR_COUNT = 50 STAR_COLOR_HIGH = 10 STAR_COLOR_LOW = 4 # プレイヤーの大きさ、動きの速さ PLAYER_WIDTH = 8 PLAYER_HEIGHT = 8 PLAYER_SPEED = 2 #弾の大きさ、色、速さ BULLET_WIDTH = 2 BULLET_HEIGHT = 5 BULLET_COLOR = 8 BULLET_SPEED = 4 #敵の大きさ、速さ ENEMY_WIDTH = 8 ENEMY_HEIGHT = 8 ENEMY_SPEED = 1.5 #爆発の大きさ BLAST_START_RADIUS = 1 BLAST_END_RADIUS = 8 BLAST_COLOR_IN = 7 BLAST_COLOR_OUT = 10 #敵のリスト enemy_list = [] #弾のリスト bullet_list = [] #爆発のリスト blast_list = [] #更新 def update_list(list): for elem in list: elem.update() #描画 def draw_list(list): for elem in list: elem.draw() #初期化 def cleanup_list(list): i = 0 while i < len(list): elem = list[i] if not elem.alive: list.pop(i) else: i += 1 #背景 class Background: def __init__(self): self.star_list = [] for i in range(STAR_COUNT): self.star_list.append( (random() * pyxel.width, random() * pyxel.height, random() * 1.5 + 1) ) def update(self): for i, (x, y, speed) in enumerate(self.star_list): y += speed if y >= pyxel.height: y -= pyxel.height self.star_list[i] = (x, y, speed) def draw(self): for (x, y, speed) in self.star_list: pyxel.pset(x, y, STAR_COLOR_HIGH if speed > 1.8 else STAR_COLOR_LOW) #プレイヤー class Player: def __init__(self, x, y): self.x = x self.y = y self.w = PLAYER_WIDTH self.h = PLAYER_HEIGHT self.alive = True def update(self): if pyxel.btn(pyxel.KEY_LEFT): self.x -= PLAYER_SPEED if pyxel.btn(pyxel.KEY_RIGHT): self.x += PLAYER_SPEED if pyxel.btn(pyxel.KEY_UP): self.y -= PLAYER_SPEED if pyxel.btn(pyxel.KEY_DOWN): self.y += PLAYER_SPEED self.x = max(self.x, 0) self.x = min(self.x, pyxel.width - self.w) self.y = max(self.y, 0) self.y = min(self.y, pyxel.height - self.h) if pyxel.btnp(pyxel.KEY_SPACE): Bullet( self.x + (PLAYER_WIDTH - BULLET_WIDTH) / 2, self.y - BULLET_HEIGHT / 2 ) pyxel.play(0, 0) def draw(self): pyxel.blt(self.x, self.y, 0, 0, 0, self.w, self.h, 0) #弾 class Bullet: def __init__(self, x, y): self.x = x self.y = y self.w = BULLET_WIDTH self.h = BULLET_HEIGHT self.alive = True bullet_list.append(self) def update(self): self.y -= BULLET_SPEED if self.y + self.h - 1 < 0: self.alive = False def draw(self): pyxel.rect(self.x, self.y, self.w, self.h, BULLET_COLOR) #敵 class Enemy: def __init__(self, x, y): self.x = x self.y = y self.w = ENEMY_WIDTH self.h = ENEMY_HEIGHT self.dir = 1 self.alive = True self.offset = int(random() * 60) enemy_list.append(self) def update(self): if(pyxel.frame_count + self.offset) % 60 < 30: self.x += ENEMY_SPEED self.dir = 1 else: self.x -= ENEMY_SPEED self.dir = -1 self.y += ENEMY_SPEED if self.y > pyxel.height - 1: self.alive = False def draw(self): pyxel.blt(self.x, self.y, 0, 8, 0, self.w * self.dir, self.h, 0) #爆発 class Blast: def __init__(self, x, y): self.x = x self.y = y self.radius = BLAST_START_RADIUS self.alive = True blast_list.append(self) def update(self): self.radius += 1 if self.radius > BLAST_END_RADIUS: self.alive = False def draw(self): pyxel.circ(self.x, self.y, self.radius, BLAST_COLOR_IN) pyxel.circb(self.x, self.y, self.radius, BLAST_COLOR_OUT) class App: def __init__(self): pyxel.init(120, 160, caption="シューティングゲーム") pyxel.image(0).set( 0, 0, [ "00c00c00", "0c7007c0", "0c7007c0", "c703b07c", "77033077", "785cc587", "85c77c58", "0c0880c0", ], ) pyxel.image(0).set( 8, 0, [ "00088000", "00ee1200", "08e2b180", "02882820", "00222200", "00012280", "08208008", "80008000", ], ) pyxel.sound(0).set("a3a2c1a1", "p", "7", "s", 5) pyxel.sound(1).set("a3a2c2c2", "n", "7742", "s", 10) self.scene = SCENE_TITLE self.score = 0 self.background = Background() self.player = Player(pyxel.width / 2, pyxel.height - 20) pyxel.run(self.update, self.draw) def update(self): if pyxel.btnp(pyxel.KEY_Q): pyxel.quit() self.background.update() if self.scene == SCENE_TITLE: self.update_title_scene() elif self.scene == SCENE_PLAY: self.update_play_scene() elif self.scene == SCENE_GAMEOVER: self.update_gameover_scene() def update_title_scene(self): if pyxel.btnp(pyxel.KEY_ENTER): self.scene = SCENE_PLAY def update_play_scene(self): if pyxel.frame_count % 6 == 0: Enemy(random() * (pyxel.width - PLAYER_WIDTH), 0) for a in enemy_list: for b in bullet_list: if ( a.x + a.w > b.x and b.x + b.w > a.x and a.y + a.h > b.y and b.y + b.h > a.y ): a.alive = False b.alive = False # 自機の爆発を生成する blast_list.append( Blast(a.x + ENEMY_WIDTH / 2, a.y + ENEMY_HEIGHT / 2) ) pyxel.play(1, 1) self.score += 10 for enemy in enemy_list: if( self.player.x + self.player.w > enemy.x and enemy.x + enemy.w > self.player.x and self.player.y + self.player.h > enemy.y and enemy.y + enemy.h > self.player.y ): enemy.alive = False blast_list.append( Blast( self.player.x + PLAYER_WIDTH / 2, self.player.y + PLAYER_HEIGHT / 2, ) ) pyxel.play(1, 1) self.scene = SCENE_GAMEOVER self.player.update() update_list(bullet_list) update_list(enemy_list) update_list(blast_list) cleanup_list(enemy_list) cleanup_list(bullet_list) cleanup_list(blast_list) def update_gameover_scene(self): update_list(bullet_list) update_list(enemy_list) update_list(blast_list) cleanup_list(enemy_list) cleanup_list(bullet_list) cleanup_list(blast_list) if pyxel.btnp(pyxel.KEY_ENTER): self.scene = SCENE_PLAY self.player.x = pyxel.width / 2 self.player.y = pyxel.height - 20 self.score = 0 enemy_list.clear() bullet_list.clear() blast_list.clear() def draw(self): pyxel.cls(0) self.background.draw() if self.scene == SCENE_TITLE: self.draw_title_scene() elif self.scene == SCENE_PLAY: self.draw_play_scene() elif self.scene == SCENE_GAMEOVER: self.draw_gameover_scene() pyxel.text(39, 4, "SCORE {:5}".format(self.score), 7) def draw_title_scene(self): pyxel.text(50, 66, "Shooter", pyxel.frame_count % 16) pyxel.text(31, 126, "- PRESS ENTER -", 14) def draw_play_scene(self): self.player.draw() draw_list(bullet_list) draw_list(enemy_list) draw_list(blast_list) def draw_gameover_scene(self): draw_list(bullet_list) draw_list(enemy_list) draw_list(blast_list) pyxel.text(43, 66, "GAMEOVER", 11) pyxel.text(31, 126, "- PRESS ENTER -", 12) App()最後に
初めてのゲーム制作だったので時間がかかりエラーも多く大変でしたが、なんとか動いて良かったです。
詳しく説明はできないのでご了承下さい。
- 投稿日:2020-10-12T15:21:48+09:00
【初心者】【Python/Django】駆け出しWebエンジニアがDjangoチュートリアルをやってみた~その6~
はじめに
みなさん、初めまして。
Djangoを用いた投票 (poll) アプリケーションの作成過程を備忘録として公開していこうと思います。
Qiita初心者ですので読みにくい部分もあると思いますがご了承ください。シリーズ
- 【初心者】【Python/Django】駆け出しWebエンジニアがDjangoチュートリアルをやってみた~その0~
- 【初心者】【Python/Django】駆け出しWebエンジニアがDjangoチュートリアルをやってみた~その1~
- 【初心者】【Python/Django】駆け出しWebエンジニアがDjangoチュートリアルをやってみた~その2~
- 【初心者】【Python/Django】駆け出しWebエンジニアがDjangoチュートリアルをやってみた~その3~
- 【初心者】【Python/Django】駆け出しWebエンジニアがDjangoチュートリアルをやってみた~その4~
作業開始
今回はstaticファイルを操作していきます。staticファイルとはJavaScript、CSS、画像などのことです。
アプリ の構造をカスタマイズする
SCCファイルを作成します。
まずはCSSファイルを格納するディレクトリを作成します。Djangoのデフォルト仕様に則り「polls/static/polls/」ディレクトリを作成します。その配下にstyle.cssファイルを作成しましょう。
CSSを記述します。
polls/static/polls/style.cssli a { color: red; }HTMLにCSSを読み込みます。
この時、{% static %}テンプレートタグを使用するのを忘れないでください。polls/templates/index.html{% load static %} <link rel="stylesheet" type="text/css" href="{% static 'polls/style.css' %}">サーバを起動しSCCが適用されていることを確認します。
(poll-HcNSSqhc) C:\django\poll>python manage.py runserverリンクが赤になりました。
より自然な緑にしておきます。
polls/static/polls/style.cssli a { color: green; }背景画像を追加する
画像フォルダを作成します。
画像もstaticファイルの一種ですので、「polls/static/polls/images」フォルダを作成し、配下にDjangoのロゴを配置します。polls/static/polls/style.cssbody { background-image: url("images/django.png"); background-size: 30%; background-repeat: no-repeat; }背景画像が表示されました。画像読み込みができたので、とりあえずOKとします。
本日はここまでにします。ありがとうございました。
- 投稿日:2020-10-12T15:07:53+09:00
Jリーグのデータを検索できるサービスを作った
概要
記事概要
今回作ったサービスの紹介をしつつ開発の流れやつまずきポイントを紹介します。
アプリ概要
- サッカーJリーグのデータを検索できるサービスをです。
- こちらから検索サイトに飛べます
- JリーグのデータをスクレイピングするWebAPIと検索するフロント画面で構成されます。
- 現在は2017〜2019の連勝記録を調べられます。
- フロントの検索画面
アプリ作成理由
- 川崎フロンターレというサッカーJリーグのチームのサポーターなのだが、2020年に今までの連勝記録を更新(10連勝!)をしたことをきっかけに過去のデータを調べたくなった。
- WebAPIをより理解するために自分で作りたくなった。
全体の構成
フロントとバックのソースコードはGitHubにあげています。
サーバー構成図
ER図
使用技術
- Python (ライブラリにFlask)
- Docker
- MySQL
- Javascript(フロント)
作成の流れ&つまづきポイント
流れ
- Dockerで環境構築
- JリーグのデータサイトをスクレイピングしてDB作成
- Flask APIを使ってデータをWebAPIにする
- AWSにデプロイ
つまづきポイント
設計どうすればいいの・・・
いざWebAPIを開発しようとして、「初めの一歩」の参考になる情報があまり見つからなかったですね。Restfulの原則の解説などはいろいろありますが、じゃあ実際どう作るのがスタンダードなの?ってなってしまいますね。
とりあえず今までWebAPIを利用した経験で設計してみました。DBが保存されてない!?
mysql-connector-pythonというライブラリでMySQLに接続していたのですが、Pythonから操作した時に、DBの追加処理をしても保存されないという問題が発生。ずっと詰まっていたのですが、公式ドキュメントに「デフォルトではConnector / Pythonは自動コミットしないため、トランザクションストレージエンジンを使用するテーブルのデータを変更するすべてのトランザクションの後にこのメソッドを呼び出すことが重要です。」と書いてあった。ドキュメントはちゃんと読まないとね!
AWSむずし
フロント側をGithubPagesで公開すると以下のようなエラーが
index.js:30 Mixed Content: The page at 'https://yuta97.github.io/j-search-front/' was loaded over HTTPS, but requested an insecure XMLHttpRequest endpoint 'http://18.178.166.9:5000/continuous-records/match/win/?yearFrom=2017&yearTo=2019&continuou_recordFrom=2&continuou_recordTo=15'. This request has been blocked; the content must be served over HTTPS.要はhttpsのサイトの中でhttpのAPIサーバを呼び出していることが問題のようです。
このような混合コンテンツは非推奨のようですね。
解決策としてEC2のAPIサーバーをSSL化使用としましたがうまく行かない・・・
苦肉の策としてS3でホスティングし、フロントをhttp通信にすることで対応。感想
感想をだらだらと書きます。
- アジャイル開発みたいに小さく作って改善してくのが自分の精神衛生上大事だな。
- メディアの人は記録更新とかどうやって調べてるんだろう?何かデータベースがあるのかな?
- AWSは使いつつ慣れるしかないな。まだまだ理解が足りん。
- セキュリティももっと知りたいな。どんな攻撃があるか知らないと、対策もわからん。
今後の展望
今後やりたいことをだらだらと列挙していきます。
- ソート機能
- その他のデータ(連敗、負けなしとか)も検索
- セキュリティーの強化(APIkey入れるとか)
- APIテスト
- APIのドキュメント作成(swaggerでできる?)
- AWS(APIGateWay,ECS,RDS)の他のサービス利用
- SSL化
- 最新のデータを自動収集
- UIの改善(Vue.jsとか使いたい)
- CICD
- クイズ作成


- 投稿日:2020-10-12T14:31:52+09:00
「ゼロから作るDeep Learning」自習メモ(その10)MultiLayerNet クラス
「ゼロから作るDeep Learning」(斎藤 康毅 著 オライリー・ジャパン刊)を読んでいる時に、参照したサイト等をメモしていきます。 その9 ←
5章でレイヤでの実装を説明した後、6章以降ではプログラム自体の説明をあまりやらなくなる。
プログラム例は、最初にダウンロードしたファイルにあるから、自分で実行して、内容を確認しなさい、ということなのだろうが、初心者にはけっこう大変。まあ、ぼちぼちいきます。
6章の MultiLayerNet クラスの内容を確認してみる
3章でニューラルネットの基本的な説明があり、4章で2層ニューラルネットワークのクラスTwoLayerNet が実装されました。その後、いろんな説明があって、MultiLayerNetクラスになったわけです。すごく複雑になったように見えますが、基本部分は TwoLayerNet と変わってません。このクラスが参照しているライブラリ layers.py の内容を見ると、TwoLayerNetクラスで使っているものと同じです。
複雑そうに見えるのは、
プログラムの汎用性を高めるためにレイヤ単位の実装にした
活性化関数、パラメータ更新手法、重みの初期値等を選択できるようにした
からのようです。プログラムを理解したいときは、1行ずつ手動トレースしていくのが確実。
というわけで、P192のプログラムをトレースしてみます。
ニューラルネットオブジェクトnetwork を生成する
weight_decay_lambda = 0.1 network = MultiLayerNet(input_size=784, hidden_size_list=[100, 100, 100, 100, 100, 100], output_size=10, weight_decay_lambda=weight_decay_lambda)input_size=784 というのは、要素数784個のMNISTデータを使うということ
output_size=10 というのは、認識した結果は10通りになるということ
で
hidden_size_list=[100, 100, 100, 100, 100, 100]
によって、networkオブジェクトの中が、どのようになるかというとmulti_layer_net.py の MultiLayerNet の定義にある、初期化で
def __init__(self, input_size, hidden_size_list, output_size, activation='relu', weight_init_std='relu', weight_decay_lambda=0): self.input_size = input_size self.output_size = output_size self.hidden_size_list = hidden_size_list self.hidden_layer_num = len(hidden_size_list) self.weight_decay_lambda = weight_decay_lambda self.params = {} # 重みの初期化 self.__init_weight(weight_init_std)オブジェクト生成のところでは省略していたけれど
activation='relu' 活性化関数は relu を使う
weight_init_std='relu' 重みの初期値は relu と相性がいい Heの初期値 を使う
self.hidden_layer_num = len(hidden_size_list) リストhidden_size_listの要素の数だけ隠れ層のレイヤを作る、
ということになっています。レイヤを生成する
ということで、要素の数だけ forループします
# レイヤの生成 activation_layer = {'sigmoid': Sigmoid, 'relu': Relu} self.layers = OrderedDict() for idx in range(1, self.hidden_layer_num+1): self.layers['Affine' + str(idx)] = Affine(self.params['W' + str(idx)], self.params['b' + str(idx)]) self.layers['Activation_function' + str(idx)] = activation_layer[activation]()これの最後に 出力層last_layer として
SoftmaxWithLoss
が付け加わります。idx = self.hidden_layer_num + 1 self.layers['Affine' + str(idx)] = Affine(self.params['W' + str(idx)], self.params['b' + str(idx)]) self.last_layer = SoftmaxWithLoss()つまり、隠れ層が6つ+出力層1つで、7層のネットワークになります。
リスト layers の内容は、次のようになります。OrderedDict([
('Affine1', Affine(params[W1],params[b1])),
('Activation_function1', Relu),
('Affine2', Affine(params[W2],params[b2])),
('Activation_function2', Relu),
('Affine3', Affine(params[W3],params[b3])),
('Activation_function3', Relu),
('Affine4', Affine(params[W4],params[b4])),
('Activation_function4', Relu),
('Affine5', Affine(params[W5],params[b5])),
('Activation_function5', Relu),
('Affine6', Affine(params[W6],params[b6])),
('Activation_function6', Relu),
('Affine7', Affine(params[W7],params[b7]))
])レイヤ単位で実装したことで、hidden_size_listの要素数で、隠れ層の数を指定できるようになっているのがわかります。6層くらいなら、TwoLayerNetクラスのようにプログラム内で層を増やしていくこともできますが、これが100とかになったら、まずムリ。
学習させてみる
このネットワークオブジェクトにMNISTデータを与えて学習させます。
optimizer = SGD(lr=0.01) for i in range(1000000000): batch_mask = np.random.choice(train_size, batch_size) x_batch = x_train[batch_mask] t_batch = t_train[batch_mask] grads = network.gradient(x_batch, t_batch) optimizer.update(network.params, grads)ミニバッチのループの中の
grads = network.gradient(x_batch, t_batch)
で、勾配を求めています
grads の中身は、こんな感じ{
'W1': array([[-0.00240062, -0.01276378, 0.00096349, ..., 0.0054993 ],
[-0.00232299, -0.0022137 , 0.0036697 , ..., -0.00693252],
...,
[-0.00214929, 0.00358515, -0.00982791, ..., 0.00342722]]),
'b1': array([-4.51501921e-03, 5.25825778e-03, ..., -8.60827293e-03]),
'W2': array([[ 0.00394647, -0.01781943, 0.00114132, ..., 0.0029042 ],
[-0.00551014, 0.00238989, 0.01442266, ..., 0.00171659],
...,
[ 0.00279524, 0.01496588, 0.01859664, ..., -0.02194152]]),
'b2': array([ 2.08738753e-03, -8.28071395e-03, ..., 1.22945079e-02]),
'W3': array([[ ..., ]]),
'b3': array([ ..., ]),
'W4': array([[ ..., ]]),
'b4': array([ ..., ]),
'W5': array([[ ..., ]]),
'b5': array([ ..., ]),
'W6': array([[ ..., ]]),
'b6': array([ ..., ]),
'W7': array([
[ 6.72420338e-02,3.36979669e-04,1.26773417e-02,-2.30916938e-03, -4.84414774e-02,
-2.58458587e-02,-5.26754173e-02,3.61136740e-02,-4.29689699e-03, -2.85799599e-02],
[ ...],
[-1.68008362e-02, 6.87882255e-03, -3.15578291e-03, -8.00362948e-04, 8.81555008e-03,
-9.23032804e-03,-1.83337109e-02, 2.17933554e-02, -6.52331525e-03, 1.50930257e-02]
]),
'b7': array([ 0.11697053, -0.02521648, 0.03697393, -0.015763 , -0.0456317 ,
-0.03476072, -0.05961871, 0.0096403 , 0.03581566, -0.01840983])
}最後のgrads['W7']の内容には、softmax関数で出力した数字0 ~ 9 のどれであるかの確率を10個の要素のリストにして、読み込ませた訓練データの行数分並んでいます。
そしてoptimizer.update(network.params, grads)commonフォルダにあるライブラリ optimizer.py の関数SGDのupdateメソッドで、パラメータparamsの内容からgradsの内容を引いて更新します。上の例では、SGD手法で更新しています。ライブラリにはSGDのほかにMomentum、AdaGrad、Adam、RMSpropとかが定義されています。
更新した結果のparamsは、次のバッチ処理に引き継いで使うので、バッチがループする分、学習が進んでいきます。
gradientメソッドは何をしているか
じゃあ、このgradientメソッドは何をしているかというと、重みパラメータの勾配を誤差逆伝播法で求めています。
まず、順方向で損失関数の値を計算し、それから、networkオブジェクトを創生したときに設定したレイヤを、逆方向に辿って勾配を求めます。def gradient(self, x, t): # forward self.loss(x, t) # backward dout = 1 dout = self.last_layer.backward(dout) layers = list(self.layers.values()) layers.reverse() for layer in layers: dout = layer.backward(dout) # 設定 grads = {} for idx in range(1, self.hidden_layer_num+2): grads['W' + str(idx)] = self.layers['Affine' + str(idx)].dW + self.weight_decay_lambda * self.layers['Affine' + str(idx)].W grads['b' + str(idx)] = self.layers['Affine' + str(idx)].db return grads最初に、
self.loss(x, t)
とあるのが、よくわかりませんでした。
関数を実行していますが、その結果を次に利用してるように見えませんから。
なので、その中身をトレースしてみました。
実行しているのは、multi_layer_net.pyで定義している関数 loss です。損失関数lossをトレースしてみた
network.loss(x_batch, t_batch)62.09479496490768
def loss(self, x, t): y = self.predict(x) weight_decay = 0 for idx in range(1, self.hidden_layer_num + 2): W = self.params['W' + str(idx)] weight_decay += 0.5 * self.weight_decay_lambda * np.sum(W ** 2) return self.last_layer.forward(y, t) + weight_decayloss関数の中では、predictで、入力データから結果 y を予測させています。この中で、Affine1からAffine7までのレイヤのforwardメソッドが実行されていきます。
def predict(self, x): for layer in self.layers.values(): x = layer.forward(x) return x過学習を防ぐために重み(params['W1']等)から weight_decay を計算し、これを加えて
出力します。weight_decay59.84568388277881
network.last_layer.forward(y, t_batch)2.2491110821288687
self.last_layer.forward(y, t) は、MultiLayerNetクラスの初期化のところで、
self.last_layer = SoftmaxWithLoss()と定義してあるので、 実際に実行しているのはlayers.pyで定義している SoftmaxWithLoss()のforwardメソッドです。
class SoftmaxWithLoss: def __init__(self): self.loss = None self.y = None # softmaxの出力 self.t = None # 教師データ def forward(self, x, t): self.t = t self.y = softmax(x) self.loss = cross_entropy_error(self.y, self.t) return self.loss def backward(self, dout=1): batch_size = self.t.shape[0] if self.t.size == self.y.size: # 教師データがone-hot-vectorの場合 dx = (self.y - self.t) / batch_size else: dx = self.y.copy() dx[np.arange(batch_size), self.t] -= 1 dx = dx / batch_size return dxで、このforwardメソッドの中で、交差エントロピー誤差(cross entropy error)を計算して返しています。
network.last_layer.loss2.2491110821288687
from common.functions import * cross_entropy_error(network.last_layer.y, network.last_layer.t)2.2491110821288687
と言う事で、self.loss(x, t) で何を参照して、何をやっているかはわかりました。
で、
SoftmaxWithLoss関数は、この後、勾配を求めるために誤差逆伝播法で backwardメソッドを使うことになるわけです。その中で self.y とか self.t とかを参照していますが、これらは forwardメソッドを実行したときにセットされる変数です。
つまり、最初にself.loss(x, t)とあるのは、損失関数を求めているのではなく、誤差逆伝播法で backwardメソッドを使うための準備だった、ということです。後ろに戻るためには、先に前に進んでおかなければいけないと言う、まあ、分かって見れば、当たり前の話なんですが。
backward で勾配を求める
self.loss(x, t) を実行して、入力したデータからの予測値等をセットしたら、誤差逆伝播法で勾配を求めます。
# backward dout = 1 dout = self.last_layer.backward(dout)self.last_layer.backward(dout) はSoftmaxWithLoss.backward()のことです。
doutには、予測値y と、教師ラベルt の差のリストが返されます。
[y1 - t1, y2 - t2, y3 - t3, ・・・ , y100 - t100]layers = list(self.layers.values()) layers.reverse() for layer in layers: dout = layer.backward(dout)layers.reverse()で、積み重ねたレイヤを逆順にして、dout = layer.backward(dout)を繰り返して、勾配を求めています。繰り返しを展開すると、こうなります。
dout = layers[0].backward(dout) #Affine7 dout = layers[1].backward(dout) #Activation_function6 Relu dout = layers[2].backward(dout) #Affine6 dout = layers[3].backward(dout) #Activation_function5 Relu dout = layers[4].backward(dout) #Affine5 dout = layers[5].backward(dout) #Activation_function4 Relu dout = layers[6].backward(dout) #Affine4 dout = layers[7].backward(dout) #Activation_function3 Relu dout = layers[8].backward(dout) #Affine3 dout = layers[9].backward(dout) #Activation_function2 Relu dout = layers[10].backward(dout) #Affine2 dout = layers[11].backward(dout) #Activation_function1 Relu dout = layers[12].backward(dout) #Affine1各Affineレイヤ内で参照する self.x self.W は、forwardメソッドを実行したときにセットされたものを使っています。
class Affine: def __init__(self, W, b): self.W =W self.b = b self.x = None self.original_x_shape = None # 重み・バイアスパラメータの微分 self.dW = None self.db = None def forward(self, x): # テンソル対応 self.original_x_shape = x.shape x = x.reshape(x.shape[0], -1) self.x = x out = np.dot(self.x, self.W) + self.b return out def backward(self, dout): dx = np.dot(dout, self.W.T) self.dW = np.dot(self.x.T, dout) self.db = np.sum(dout, axis=0) dx = dx.reshape(*self.original_x_shape) # 入力データの形状に戻す(テンソル対応) return dx各レイヤで求めたdw、dbを使って、各レイヤの重みとバイアスの勾配をセットして、関数の値として返します。
# 設定 grads = {} for idx in range(1, self.hidden_layer_num+2): grads['W' + str(idx)] = self.layers['Affine' + str(idx)].dW + self.weight_decay_lambda * self.layers['Affine' + str(idx)].W grads['b' + str(idx)] = self.layers['Affine' + str(idx)].db返された勾配で、パラメータを更新して、ミニバッチの処理が1回終わります。
grads = network.gradient(x_batch, t_batch) optimizer.update(network.params, grads)class SGD: def __init__(self, lr=0.01): self.lr = lr def update(self, params, grads): for key in params.keys(): params[key] -= self.lr * grads[key]lr はlearning rate( 学習係数)
この例では、0.01が設定されている。MultiLayerNetExtendクラス
multi_layer_net_extend.py にあるMultiLayerNetExtendクラスは、レイヤ生成のところで Dropout、Batch Normalization に対応していますが、基本的なところはMultiLayerNetと同じです。
その9 ←