- 投稿日:2020-10-09T23:47:53+09:00
GoToEat 大阪キャンペーンのページをスクレイピングしてcsvファイルに
概要
GoToEat大阪のキャンペーンページには、店舗検索のページはありますがマップ表示ができないんですね。
Google Map APIを使えばマップ表示できますが、その前にまず対象店をテーブル形式で保管する必要があります。
RubyのNokogiriを使ってスクレイピングしました。
コード
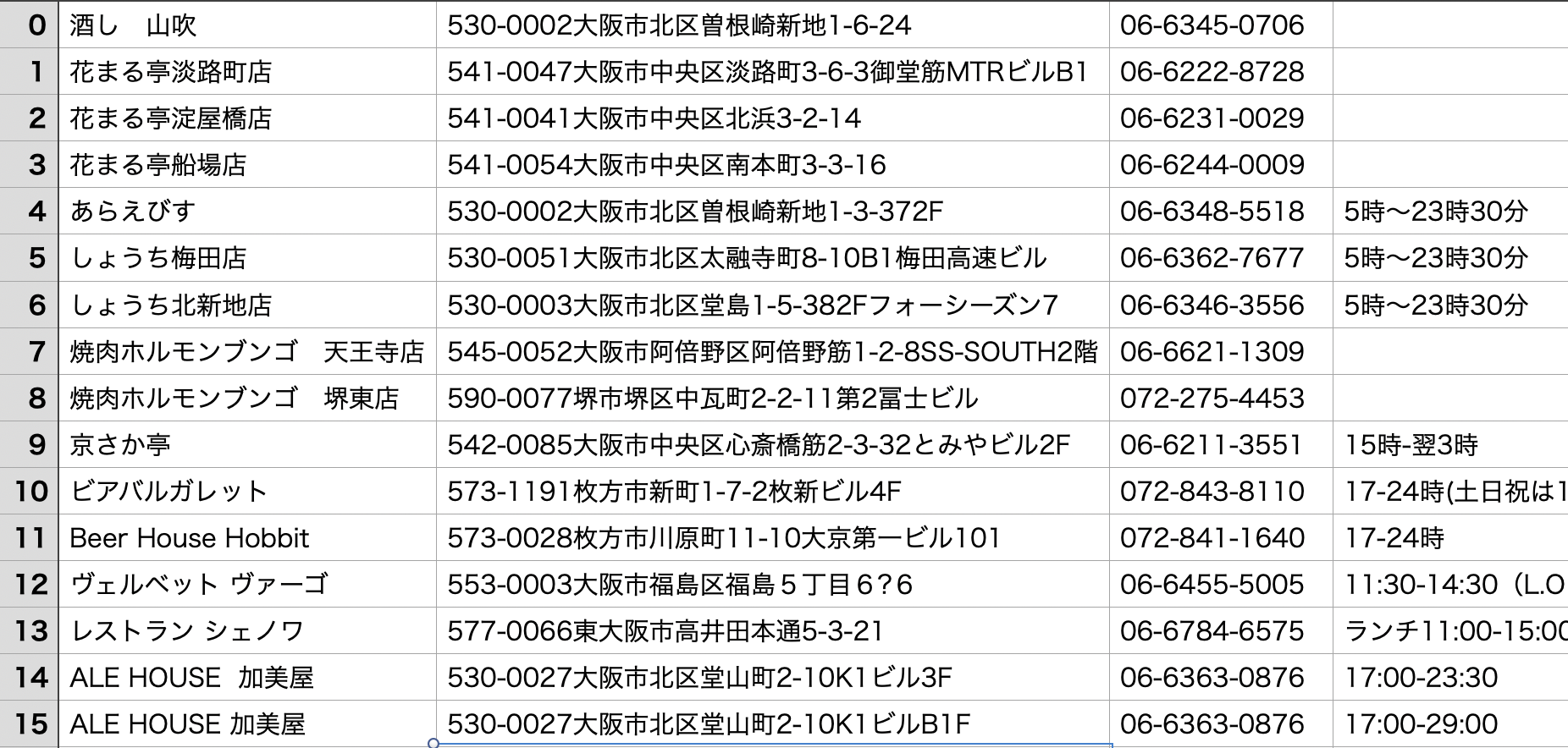
require 'open-uri' require 'nokogiri' require "csv" @id=0 @page=1 @hashes=[] # GoToEat大阪のページ(1ページ目) @url = 'https://goto-eat.weare.osaka-info.jp/?search_element_0_0=2&search_element_0_1=3&search_element_0_2=4&search_element_0_3=5&search_element_0_4=6&search_element_0_5=7&search_element_0_6=8&search_element_0_7=9&search_element_0_8=10&search_element_0_9=11&search_element_0_cnt=10&search_element_1_cnt=18&searchbutton=%E5%8A%A0%E7%9B%9F%E5%BA%97%E8%88%97%E3%82%92%E6%A4%9C%E7%B4%A2%E3%81%99%E3%82%8B&csp=search_add&feadvns_max_line_0=2&fe_form_no=0' def scraping(page) # ページを開き、htmlを読み込んで変数htmlに渡す html = open(@url) {|f| f.read} charset = "utf8" # htmlをパース(解析)してオブジェクトを作成 doc = Nokogiri::HTML.parse(html, nil, charset) doc.xpath('/html/body/div/div[1]/main/section/div/div/ul/li').each { |node| # データ格納庫であるhashを作成 hash=Hash.new(nil) keys=[:id,:name,:address,:tel,:open,:close,:category1,:category2] keys.each {|key| hash.store(key,nil)} hash.store(:id,@id) hash.store(:name,node.xpath("p").inner_text) trs=node.xpath("table").xpath("tr") address=trs[0].xpath("td").inner_text address.gsub!("\r\n","") address.gsub!(/[[:space:]]/,"") hash.store(:address,address) hash.store(:tel,trs[1].xpath("td").inner_text) hash.store(:open,trs[2].xpath("td").inner_text) hash.store(:close,trs[3].xpath("td").inner_text) categories=node.xpath("ul").xpath("li") hash.store(:category1,categories[0].inner_text) if categories[0] hash.store(:category2,categories[1].inner_text) if categories[1] @id+=1 @hashes << hash CSV.open("GoToEatOsaka.csv", "a", headers: hash.keys) {|csv| csv << hash.values } } # 次のページを探します as=doc.xpath("/html/body/div/div[1]/main/section/div/div/div[2]").xpath("a") as.each{|a| content=a.get_attribute("title") if content=="Page #{page}" then puts page @url=a.attribute("href") break end } end (2..221).each{|page| scraping(page) }実行結果
いい感じにcsvとして保存できました。
- 投稿日:2020-10-09T23:46:50+09:00
Ruby print puts p printf 出力メソッド
はじめに
学習用のメモになります。
Rubyにはログやコンソールに何らかの処理の結果を目に見える形で出力するためのメソッドとしてprintメソッドがあります。
そして、Rubyにはprintメソッド以外にも様々な出力系メソッドが存在します
printメソッド
printメソッドは以下のサンプルコードのように、
半角スペースを空けて出力する値を指定するだけで利用できます。printメソッドの特徴は
改行を入れずに引数に指定した値を出力することです。1.print 'こんにちは' 2.print 'hello world'[実行結果]
1. こんにちはhello worldputsメソッド
putsメソッドも同様に出力する値を半角スペース後に指定することで利用できますが、printメソッドとの違いは、
末尾に改行が入る形で出力されることです。1.print 'こんにちは' 2.print 'hello world'[実行結果]
1. こんにちは 2. hello worldpメソッド
pメソッドは
出力する値と共に型情報(文字列や数値型など)を一緒に出力します。p '私の年齢' p 40 p '歳です。'[実行結果]
"私の年齢" 40 "歳です。"文字列はダブルクォーテーションで囲まれ、数字はそのまま出力されていることが確認できるかと思います。
printfメソッド
printfメソッドは書式を指定して出力するためのメソッドとなります。
具体的なサンプルをまずは確認してみましょう。
printf('商品情報: カテゴリー %s 型番 %d', 'bag', 10111)[実行結果]
商品情報: カテゴリー bag 型番 10111これまでの出力メソッドと異なり、カッコで出力内容をくくります。
また、%sや%dはその後のカンマで区切った引数の値が代入されるものとなり、その引数の型(文字列や数値型)によって、%sと%dの指定を使い分けます。
最後に
このほかにも様々なメソッドあるので日々更新していきます。
- 投稿日:2020-10-09T23:19:42+09:00
続・ActiveStorageを使って、画像投稿機能実装までの流れ
はじめに
ActiveStorageを使った画像保存から表示までの説明。前回の投稿で、ActiveStorageの導入方法については説明している。
リンク↓
ActiveStorageを使って、画像投稿機能実装までの流れ画像の保存から表示までの流れ
- アソシエーションの定義
- ストロングパラメーターに画像保存の許可をする
- HTMLのimg要素として生成
- エラーの解消
- 画像の大きさ調整
- バリデーションの設定
1. アソシエーションの定義
has_one_attachedメソッドを用いて、各レコードと画像ファイルを1対1の関係で紐づける。
紐づけたいモデルファイルに記述modelclass モデル < ApplicationRecord has_one_attached :ファイル名 endファイル名には、呼び出す際の名前を設定する。また、パラメーターのキーになる。
ex):image, :file etc
イメージとしては、ファイル名のカラムができて、そこに添付ファイルが入っているような感じ。
このアソシエーションをすることで、
モデル名.ファイル名で添付したファイルにアクセスすることができる。2. ストロングパラメーターに画像保存の許可をする
controllersparams.require(:message).permit(:text, :image)アソシエーションの定義のときにも取り上げたように、パラメーターのキーにファイル名を用いる。このときにも、カラムができているイメージというのは当てはまるだろう。
以上が、保存までの流れ。
以下は、表示するまでの流れ。
3. HTMLのimg要素として生成
image_tagメソッドというヘルパーメソッドを用いて、HTMLにimgタグを生成する。html.erb<%= image_tag モデル名.ファイル名 %> <%= image_tag message.image %> #例アソシエーションしているため、
モデル名.ファイル名だけの記述で画像を表示させられる。基本的にはここまでで、画像を表示できる。しかしこのままでは、画像が必ずなければ、エラーになってしまう。
4. エラーの解消
先の
image_tagメソッドにif文で条件分岐させる。html.erb<%= image_tag message.image, if message.image.attached? %>
attached?メソッドで画像が添付されていると、trueを返し、読み込まれる。画像が添付されていないと、falseを返し、読み込まれず、エラーが起きない。5. 画像の大きさ調整
ActiveStorageを導入していると使えるメソッドの
variantメソッドを使う。
先のコードに付け足すと、html.erb<%= image_tag message.image.variant(resize: '500×500'), if message.image.attached? %>画像の表示サイズを指定すると、それ以上に大きくならない。
6. バリデーションの設定
現状だと、LINEをイメージすると、テキストと画像が必ず両方ないとエラーになる。使い勝手がよくないため、テキストと画像のどちらかが存在すればよい、という仕様にする。
modelvalidates :message, presence: true, unless: :was_attacher? def was_attached? self.image.attached? endメソッドの返り値がfalseならば、バリデーションの検証を行う。(messageが存在しないとダメ)
最後に
アソシエーションするだけで、簡単に画像にアクセスできるのが便利すぎる!!
- 投稿日:2020-10-09T20:34:57+09:00
引数で渡した文字列をsendでメソッドとして発動させる
概要
sendメソッドの使い方で、勉強になったのでメモ。
画像を2枚まで添付できるフォームがあり、どれくらい閾値を超えるサイズで投稿されているか調べたかったので、ログを仕込もうとしていた。
そこで、もともと次のようなコードを書いていた。
リファクタリング前
validate :checking_image_size_over_limit def checking_image_size_over_limit logging_image_size(image_first, 'first') if image_first.present? logging_image_size(image_second, 'second') if image_second.present? end def logging_image_size(image, number) if image&.size >= 5 * 1024 * 1024 Rails.logger.info "[#{self.class.name}] Over 5MB of images (image_#{number})" end end1枚目と2枚目どちらなのかを判別したかったので、第2引数に文字列を渡し、ログのメッセージの中で展開させていた。
しかし、先輩から「それだったら、sendを使えば引数1つでいけるよ」とレビューをもらい書き直した。リファクタリング後
validate :checking_image_size_over_limit def checking_image_size_over_limit logging_image_size('image_first') if image_first.present? logging_image_size('image_second') if image_second.present? end def logging_image_size(image) if send(image)&.size >= 5 * 1024 * 1024 Rails.logger.info "[#{self.class.name}] Over 5MB of images (#{image})" end endsendといえば、動的にメソッドを切り替えるために使うくらいのイメージしか持っていなかったが、このように引数で渡した文字列をまたメソッドとして発動させるという方法でも使えるのだと勉強になった。
- 投稿日:2020-10-09T20:34:57+09:00
引数で渡した文字列をsendでメソッドとして使い直す
概要
sendメソッドの使い方で、勉強になったのでメモ。
画像を2枚まで添付できるフォームがあり、どれくらい閾値を超えるサイズで投稿されているか調べたかったので、ログを仕込もうとしていた。
そこで、もともと次のようなコードを書いていた。リファクタリング前
validate :checking_image_size_over_limit def checking_image_size_over_limit logging_image_size(image_first, 'first') if image_first.present? logging_image_size(image_second, 'second') if image_second.present? end def logging_image_size(image, number) if image&.size >= 5 * 1024 * 1024 Rails.logger.info "[#{self.class.name}] Over 5MB of images (image_#{number})" end endしかし、先輩から「sendを使えば、引数1つでいけるよ」とレビューをもらい、このように書き直した。
リファクタリング後
validate :checking_image_size_over_limit def checking_image_size_over_limit logging_image_size('image_first') if image_first.present? logging_image_size('image_second') if image_second.present? end def logging_image_size(image) if send(image)&.size >= 5 * 1024 * 1024 Rails.logger.info "[#{self.class.name}] Over 5MB of images (#{image})" end endsendといえば、動的にメソッドを切り替えるために使うくらいのイメージしか持っていなかったが、このように引数で渡した文字列をまたメソッドとして使い直すという方法でも使えるのだと勉強になった。
- 投稿日:2020-10-09T19:30:02+09:00
【Ruby on Rails】RSpec実行時にgem 'chromedriver-helper'は非推奨ですよって警告を受ける。
前書き・編集点
この記事は前回の記事
【Ruby on Rails】RSpec実行時にgemのバージョン違いで警告を受ける。
の続きですが、全く別の警告だったので2つに分けました。2020.10.10
コメントで、私の解釈の違いについてご指摘をいただきましたのでその点修正を行いました。環境
Ruby 2.5.7
Rails 5.2.4gem
gem 'rspec-rails', '~> 3.6'
経緯
RSpecを使ってテストコードを記述し、実行すると下記のような警告文が出ました。
$ rspec spec/models/tag_spec.rb 2020-10-09 09:13:13 WARN Selenium [DEPRECATION] Selenium::WebDriver::Chrome#driver_path= is deprecated. Use Selenium::WebDriver::Chrome::Service#driver_path= instead.これはエラーではないのでテストは正常に実行されますが、毎回出るのを放っておくわけにも行かないのでこれも解決していきます。
手順
警告文の内容ですが、
Selenium::WebDriver::Chrome#driver_path= is deprecated.
Chromeクラスのdriver_path=メソッドが非推奨であるため、
Selenium::WebDriver::Chrome::Service#driver_path= instead.
Serviceクラスのdriver_path=メソッドを代わりに使うようにというメッセージです。こちらに書かれている通り、私のGemfileにも
gem 'chromedriver-helper'がありましたので、まずはこれをコメントアウトします。
次に代わりとなる
gem 'webdrivers'を記述します。最後に
$ bundle installで解決することができました。
まとめ
質問や解釈の違い、記述方法に違和感ありましたら、コメント等でご指摘いただけると幸いです。
最後まで読んでいただきありがとうございました。
参考サイト
私のGitHubに実際に使っているファイルを公開しているのでそちらも参考にしていただければと思います!
GitHub - MasaoSasaki/matchiその他
Qiita - サポートが終了したchromedriver-helperからwebdrivers gemに移行する手順
Qiita - rspec-rails 3.7の新機能!System Specを使ってみた
- 投稿日:2020-10-09T19:18:41+09:00
【Rails,JS】コメントの非同期表示を実装する方法
この記事では、コメントを非同期で表示できる実装方法を解説します。
- Rails_6.0.0_ を使用しています。
- 商品が出品・購入できるアプリケーションにコメントをつけます。
- それぞれの商品(item)の詳細ページにコメントをする場所があります。
- コメントの保存や送信に必要なRubyのコーディングと、保存したコメントを即時に表示させるJavaScriptのコーディングを行います。
- すでにコメント投稿機能は完成している体で、非同期機能だけ実装していきます。
実装内容
- channelを用いて実装を行う
- コメントを非同期で表示
- コメントには名前(name)、コメントされた日付(created_at)、コメント内容(text)を表示
channelとは?
channelとは?
チャネルとは、即時更新機能を実現するサーバー側の仕組みのことです。データの経路を設定したり、送られてきたデータをクライアントの画面上に表示させたりします。
channelでどんなことができる?
データの経路を設定したり、送られてきたデータを表示させるJavaScriptを記述すれば、送信したデータが非同期で表示できます。
channelのファイル作成
ターミナルで以下コマンドを実行
% rails g channel comment
(commentには自分が作成するファイルの名前を記述)
いくつかファイルができますが、今回は以下2つのファイルを使用します。app/channel/comment_channel.rb
クライアントとサーバーを結びつけるためのファイルです。
app/javascript/channels/comment_channel.js
サーバーから送られてきたデータをクライアントの画面に表示させるためのファイルです。
comment_channel.rbの記述
class MessageChannel < ApplicationCable::Channel def subscribed stream_from "comment_channel" end def unsubscribed end end
stream_from "comment_channel"を記述することでサーバーとクライアントを結びつけることができます。comments_controller.rbの記述
コントローラーの記述です。
すでに非同期でないコメント実装機能は済んでいる体なので、非同期に関する記述以外の説明は割愛します。データベースからJSに渡したいデータを記述する
今回JSで反映させたいデータは以下の通りです
- ユーザーのニックネーム
- コメントされた時間
- コメントのテキスト
- アイテムのid(どの商品にコメントするかを判断するために必要)
この3つの情報を、コントローラーでJSに渡してあげる必要があります。
class CommentsController < ApplicationController before_action :authenticate_user! def create @comment = Comment.new(comment_params) @item = Item.find(params[:item_id]) @comments = @item.comments.includes(:user).order('created_at DESC') if @comment.valid? @comment.save ActionCable.server.broadcast 'comment_channel', content: @comment, nickname: @comment.user.nickname, time: @comment.created_at.strftime("%Y/%m/%d %H:%M:%S"), id: @item.id else render "items/show" end end private def comment_params params.require(:comment).permit(:text).merge(user_id: current_user.id, item_id: params[:item_id]) end end今回の実装で書き足したのは以下の1文だけです。
ActionCable.server.broadcast 'comment_channel', content: @comment, nickname: @comment.user.nickname, time: @comment.created_at.strftime("%Y/%m/%d %H:%M:%S"), id: @item.id
contentとuserとtimeとidをJSで使用するので、そちらの定義をしてあげました。
content
@commentで定義している:text、Commentテーブルのtextカラム、すなわち入力したコメントのことです。
user
@commentに紐づいているuserのnicknameをとってきています。(commentとuserにアソシエーションを組んでいます。)
time
Commentテーブルのcreated_atカラムです。strftime("%Y/%m/%d %H:%M:%S")と記述することで任意の日付、時刻設定を表示できます。以下の記事を参考にさせていただきました。
strftime を憶えられない (rubyの)
item
自分が今表示しているアイテムのページだけでJSが発火する必要があるので、それを判断するために使用します。comment_channel.rbの記述(JavaScript)
今回は
app/javascript/channels/comment_channel.jsのreceived()部分に記述していきます。app/javascript/channels/comment_channel.jsreceived(data) { }()の中に
dataと記述してあげることで、コントローラーで定義した値がとってこれるようになります。receivedは、受け取るという意味なので、データを受け取ったら、この中に記述しているJSを実行してね!ということになります。
さあ、これからこの中にJSの記述をしていきます!今開いているアイテムページだけでコメント表示できるように、条件分岐分を書きます。
app/javascript/channels/comment_channel.js//現在開いているページのURLをゲット let url = window.location.href //スラッシュ(/)ごとに要素を取り出す let param = url.split('/'); //このアプリの場合、URLの一番最後にアイテムidがきており、それをparamItemとして定義 let paramItem = param[param.length-1] // パラメータid(URLの中に含まれているid)が、コントローラーから送った`data.id`かどうかを判断する if (paramItem == data.id) {}if文で、条件分岐をしてあげます。次は、処理の内容を条件分岐分の中に書いてあげます。
記述する内容は、
- div要素を生成する
- 生成した要素をブラウザに表示させる
- 表示させるテキストを生成する
といった流れです。
表示させるためのdivを作る
app/javascript/channels/comment_channel.js//表示させる場所のdivのIDをとってくる const comments = document.getElementById('comments'); // すでにあるビューファイルと同じになるようにdivを作成 const textElement = document.createElement('div'); textElement.setAttribute('class', "comment-display"); const topElement = document.createElement('div'); topElement.setAttribute('class', "comment-top"); const nameElement = document.createElement('div'); const timeElement = document.createElement('div'); const bottomElement = document.createElement('div'); bottomElement.setAttribute('class', "comment-bottom");createElementメソッドを使用し、div要素を作成、必要なものにはそれぞれsetAttributeメソッドでclass名を与えてあげます。
ちなみに、コメントを表示するビューは以下の通り
<div id='comments'> </div> <% @comments.each do |comment| %> <div class='comment-display'> <div class='comment-top'> <div><%= comment.user.nickname %></div> <div><%= l comment.created_at %></div> </div> <div class='comment-bottom'> <p><%= comment.text %></p> </div> </div> <% end %>div要素を生成しましたが、まだブラウザに表示されていません。ブラウザに表示させ、かつ親子関係を作りましょう。
app/javascript/channels/comment_channel.js// 生成したHTMLの要素をブラウザに表示させる comments.insertBefore(textElement, comments.firstElementChild); textElement.appendChild(topElement); textElement.appendChild(bottomElement); topElement.appendChild(nameElement); topElement.appendChild(timeElement);insertBefireメソッドと、appendChildメソッドを使用します。
親要素.insertBefore(追加する要素, どこに追加するのか)
親要素.appendChild(追加する要素)
で、insertBefireは任意の場所に、appendChildは親クラスの中の最後のに要素を入れることができます。もう少し詳しく見たい方は以下をご覧ください
【JavaScript】appendChildとinsertBeforeの違いdiv要素が作成できたら、次は表示させる情報をとってきましょう。
app/javascript/channels/comment_channel.jsconst name = `${data.nickname}`; nameElement.innerHTML = name; const time = `${data.time}`; timeElement.innerHTML = time; const text = `<p>${data.content.text}</p>`; bottomElement.innerHTML = text;表示させる情報をそれぞれ変数に入れています。dataは、
received(data) {}のdataです。コントローラーで定義した値のことです。それぞれcontent,nickname,time,を定義しましたね。
innerHTMLで、既存の要素にHTMLを上書きをします。ここまでで表示は完了しました!
ですがこのままだと、2つ問題があります。
1. データは表示されたが、コメント入力欄にコメントが残ったままであること
2. HTMLはデフォルトでボタンが1回しか押せない仕様になっていること
これを解決しましょう!データ送信した後にコメント入力欄のコメントを消す
app/javascript/channels/comment_channel.jsconst newComment = document.getElementById('comment_text'); newComment.value='';コメント入力欄のIDをとってきて、そこの値を空にする、という記述です。
何度もコメントボタンを押せるようにする
app/javascript/channels/comment_channel.jsconst inputElement = document.querySelector('input[name="commit"]'); inputElement.disabled = false;"コメントする"ボタンの、name属性をとってきて、そこを
disabled = falseとしてあげることで何度もクリック可能になります。記述をまとめると以下の通りです。
app/javascript/channels/comment_channel.jsimport consumer from "./consumer" consumer.subscriptions.create("CommentChannel", { connected() { }, disconnected() { }, // ↓データを受け取ったら実行してね received(data) { let url = window.location.href let param = url.split('/'); let paramItem = param[param.length-1] if (paramItem == data.id) { const comments = document.getElementById('comments'); const comment = document.getElementsByClassName('comment-display'); //使用する要素の作成 const textElement = document.createElement('div'); textElement.setAttribute('class', "comment-display"); const topElement = document.createElement('div'); topElement.setAttribute('class', "comment-top"); const nameElement = document.createElement('div'); const timeElement = document.createElement('div'); const bottomElement = document.createElement('div'); bottomElement.setAttribute('class', "comment-bottom"); // 生成したHTMLの要素をブラウザに表示させる comments.insertBefore(textElement, comments.firstElementChild); textElement.appendChild(topElement); textElement.appendChild(bottomElement); topElement.appendChild(nameElement); topElement.appendChild(timeElement); // 表示するテキストを生成 const name = `${data.nickname}`; nameElement.innerHTML = name; const time = `${data.time}`; timeElement.innerHTML = time; const text = `<p>${data.content.text}</p>`; bottomElement.innerHTML = text; //コメントを送った後、コメント欄をからにする const newComment = document.getElementById('comment_text'); newComment.value=''; //何度もボタンを押せるようにする const inputElement = document.querySelector('input[name="commit"]'); inputElement.disabled = false; } } });おわりに
完成したと思っていましたが、これを書いている時点でいくつもミスや、ちょっとよくわからない記述を発見しました。
リファクタリングがいかに大切かよく分かりました。
正しく無い記述があるかもしれませんが、誰かのお役に立てれば幸いです。

- 投稿日:2020-10-09T19:16:54+09:00
【Rails】複数モデルのインスタンスを一覧表示する
したいこと
YouTubeやFacebookのタイムラインのように、投稿と広告を作成降順に同じ画面に表示する機能が必要になった(通常なら広告は作成順の表示ではないかもしれないが、話を簡単にするために作成順で並べると仮定する)。
投稿モデル(Post)と広告モデル(Advertisement)をコントローラーでうまいこと取得して、ビューで並列して処理する方法を考える。
前提
バージョン
- Ruby 2.6.3
- Rails 5.2.3
それぞれのモデルのカラム
# 投稿モデルと広告モデルはカラムが異なるとする # 投稿モデル(Post) t.integer "user_id" t.string "content" t.string "image" t.datetime "created_at" t.datetime "updated_at" # 広告モデル(Advertisement) t.integer "company_id" t.string "content" t.string "link_url" t.datetime "expired_date" t.datetime "created_at" t.datetime "updated_at"実装方法
timeline_controller.rbdef index posts = Post.all ads = Advertisement.all # それぞれの複数インスタンスを1つの配列にする @instances = posts | ads # 作成降順に並び替え @instances.sort!{ |a, b| b.created_at <=> a.created_at } endindex.html.erb<% @instances.each do |instance| %> <% if instance.class == "Post" %> <%# Postの表示 %> <%= instance.user_id %> <%= instance.content %> <%= instance.image %> <% else %> <%# Advertisementの表示 %> <%= instance.company_id %> <%= instance.content %> <%= instance.link_url %> <% end %> <% end %>
- 投稿日:2020-10-09T18:47:52+09:00
【Ruby on Rails】RSpec実行時にgemのバージョン違いで警告を受ける。
前書き・編集点
2020.10.10
コメントより環境
Ruby 2.5.7
Rails 5.2.4gem
gem 'rspec-rails', '~> 3.6'
経緯
RSpecでテストコードを書いて、いざ実行すると、次のようなエラーが発生しました。
$ rspec spec/models/tag_spec.rb WARN: Unresolved specs during Gem::Specification.reset: diff-lcs (< 2.0, >= 1.2.0) WARN: Clearing out unresolved specs. Please report a bug if this causes problems.正確にはエラーではなく、同じgemで複数のバージョンがあるからそれの警告を受けているようで、テスト自体は無事に実行されていました。
しかし、放っておくわけにも行かないので、解決していきます。手順
解決策はこちらの記事を参考にさせていただきました。
Qiita - RubygemでWARN: Clearing out unresolved specs.が出た時の対応まずは問題のgemについて確認していきます。
$ diff-lcs (< 2.0, >= 1.2.0)
diff-lcsというgemのバージョンが複数あるという指摘でしたが、このgemは自分でインストールした覚えはないので、当然ながらGemfileには記載がありません。
となると、何らかのgemをインストールした時にbundlerが依存gemとして自動的にインストールした可能性があるので、Gemfile.lockを確認すると、rspecのgemの依存以外のところにもdiff-lcs (1.4.4)がありました。rspecでインストールされている依存gemは2箇所あって、どちらも
diff-lcs (>= 1.2.0, < 2.0)という感じで、バージョンは書かれていないので、このgemのバージョンを次のコマンドで調べていきます。$ gem list -a | grep diff-lcs diff-lcs (1.4.4, 1.4.2, 1.3)調べた結果、どうやら
(1.4.4, 1.4.2, 1.3)3つのバージョンがインストールされているようです。
依存していない方のdiff-lsc (1.4.4)がこの中で一番最新ということで、rspec依存の他二つをこのバージョンに合わせていきます。ここで一つ注意ですが、bundlerで依存しているgemをインストールした場合、依存gemのバージョンを安易に変更してしまうと、依存関係にある他のgemに不具合が起きる可能性があります。
今回の場合だと、rspec依存のdiff-lcs (< 2.0, >= 1.2.0)はバージョンが「1.2.0以上、2.0未満」と書かれてあったので(今回の中で)最新の1.4.4ならバージョンアップしても問題ないという結論に至りました。次に参考サイトにも書かれてあるコマンドを実行していきます。
$ gem cleanupそして
$ bundle installこれで警告文が消えました。
手順(依存関係でgemが複数バージョン必要な場合)
こちらコメントより抜粋させていただきます。
$ bundle exec rspec (実行ファイル指定)を行うと、bundlerがGemfileに記述されている依存関係を自動的に認識してくれます。
依存関係が複雑になって、どうしても複数バージョンが必要な時は、前述した最新バージョンにまとめることはできないので、この方法しかなくなります。
まとめ
私の場合は、これ以外にもう一つ警告文が出ていましたので、それについては次の記事をご覧いただければと思いますヽ(;▽;)ノ
Qiita - 【Ruby on Rails】RSpec実行時にgem 'chromedriver-helper'は非推奨ですよって警告を受ける。質問や解釈の違い、記述方法に違和感ありましたら、コメント等でご指摘いただけると幸いです。
最後まで読んでいただきありがとうございました。
参考サイト
私のGitHubに実際に使っているファイルを公開しているのでそちらも参考にしていただければと思います!
GitHub - MasaoSasaki/matchiその他
Qiita - RubygemでWARN: Clearing out unresolved specs.が出た時の対応
YoheiIsokawa - 【Rails】Gemfileのバージョン指定の書き方
- 投稿日:2020-10-09T18:22:30+09:00
CircleCIのシステムスペックをselenium dockerを利用する
今回が初投稿ですので、ミスや分かりにくいなどは多めに見てください
環境
・Ruby 2.7.1
・Rails 6.0.2.1やりたいこと
・CircleCIでselnium dockerを利用してシステムテストを実行
・system js: trueをCircleCIでも利用できるようにするdocker-compose.yml
システムスペックで利用するseleniumのイメージを取得し、depens_onで連携とportの指定も忘れずに
docker-compose.ymlversion: "3" services: web: build: . volumes: - .:/myapp ports: - "3000:3000" tty: true stdin_open: true depends_on: - db - chrome db: image: mysql:8.0 environment: MYSQL_ROOT_PASSWORD: password MYSQL_DATABE: db ports: - "3306:3306" volumes: - mysql-data:/var/lib/mysql command: --default-authentication-plugin=mysql_native_password chrome: image: selenium/standalone-chrome-debug:latest ports: - "4444:4444" volumes: mysql-data: driver: localdatabase.ymlを修正
このままではデータベースがdbコンテナが利用されないのでdatabase.ymlを修正します。
database.ymldefault: &default adapter: mysql2 encoding: utf8mb4 pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %> username: root password: password host: db development: <<: *default database: myapp_development test: <<: *default database: myapp_test production: <<: *default database: myappp_production username: myapp password: <%= ENV['MYAPP_DATABASE_PASSWORD'] %>$ docker-compose build $ docker-compose up $ docker-compose run web rake db:createspec/rails_helper
テストに必要なGemを追加
Gemfilegroup :test do gem 'capybara' gem 'selenium-webdriver' gem 'rspec-rails' endsystemテストはselenium dockerを使うようにrails_specを変更する
rails_spec.rbCapybara.register_driver :remote_chrome do |app| url = 'http://chrome:4444/wd/hub' caps = ::Selenium::WebDriver::Remote::Capabilities.chrome( 'goog:chromeOptions' => { 'args' => [ 'no-sandbox', 'headless', 'disable-gpu', 'window-size=1680,1050' ] } ) Capybara::Selenium::Driver.new(app, browser: :remote, url: url, desired_capabilities: caps) end RSpec.configure do |config| #省略 config.before(:each, type: :system) do driven_by :rack_test end config.before(:each, type: :system, js: true) do driven_by :remote_chrome Capybara.server_host = IPSocket.getaddress(Socket.gethostname) Capybara.server_port = 4444 Capybara.app_host = "http://#{Capybara.server_host}:#{Capybara.server_port}" end endこれでローカルのシステムスペックは問題なく動くはずです
.circleci/config.yml
CircleCIの設定です
- run: mv ./config/database.yml.ci ./config/database.ymlでCI環境ではデータベースの設定を変更しています。
name: chromeと設定しておかないと
Errno::EADDRINUSE:Address already in use - bind(2) for "172.27.0.3" port 4444のエラーが発生するconfig.ymlversion: 2.1 jobs: build: docker: - image: circleci/ruby:2.7.1-node-browsers RAILS_ENV: test DB_HOST: 127.0.0.1 - image: mysql:8.0 environment: MYSQL_ALLOW_EMPTY_PASSWORD: "true" MYSQL_ROOT_HOST: "127.0.0.1" MYSQL_DATABE: db command: --default-authentication-plugin=mysql_native_password - image: selenium/standalone-chrome-debug:latest name: chrome working_directory: ~/coffee steps: - checkout - run: name: bundleをインストール command: bundle check || bundle install --jobs=4 - run: name: yarnを追加 command: yarn install - run: name: webpackを追加 command: bundle exec bin/webpack - run: name: rubocop command: bundle exec rubocop - run: mv ./config/database.yml.ci ./config/database.yml - run: name: データベースを作成 command: bundle exec rails db:create || bundle exec rails db:migrate - run: name: rspec test command: | mkdir /tmp/test-results TEST_FILES="$(circleci tests glob "spec/**/*_spec.rb" | \ circleci tests split --split-by=timings)" bundle exec rspec \ --format RspecJunitFormatter \ --out /tmp/test-results/rspec.xml \ --format progress \ $TEST_FILES - store_test_results: path: /tmp/test-results - store_artifacts: path: /tmp/test-results destination: test-resultsこれでCircleCIでのrspec systemテストが正常に動くはずです
参考
・Rails on DockerでRSpecのSystem testをSelenium Dockerを使ってやってみた。
・既存のRails6アプリをDocker化しつつCircleCIでシステムスペックも実行できる環境を作る
- 投稿日:2020-10-09T18:13:24+09:00
Ruby On Rails コメント機能の追加
条件
postとcommentはログインユーザーのみが行える。
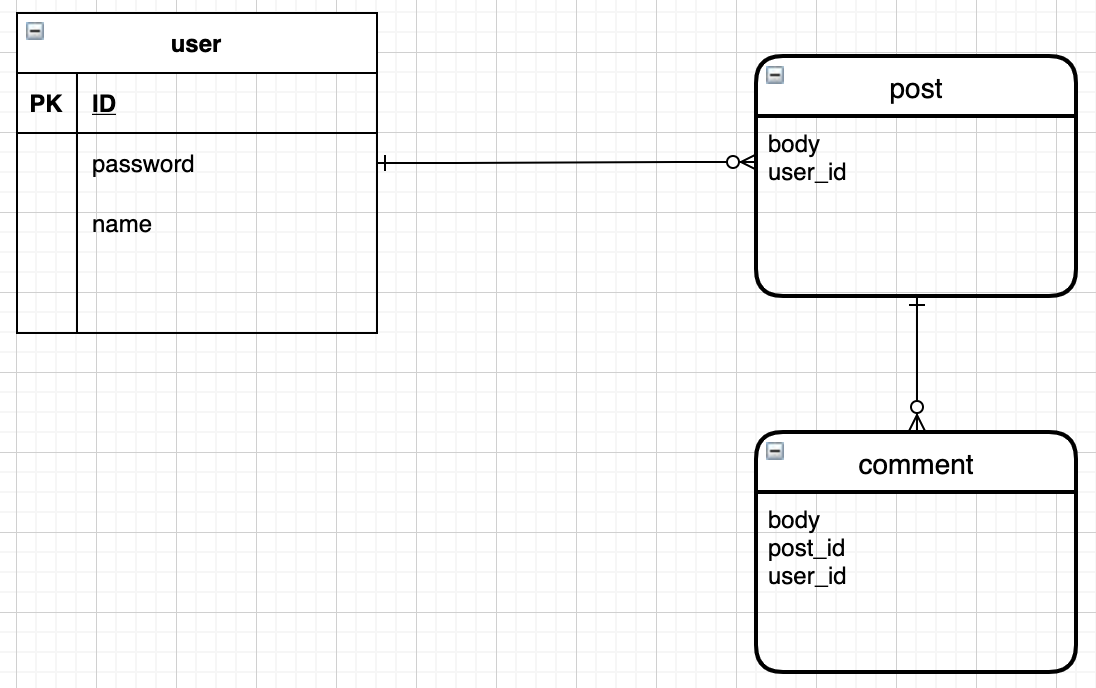
commentの削除は作成者のみが行える。テーブル
モデル
post.rbclass Post < ApplicationRecord belongs_to :user has_many :comments endcomment.rbclass Comment < ApplicationRecord belongs_to :post endルーティング
パラメーターでpost_idと(userの)idが使用できる。
routes.rbRails.application.routes.draw do devise_for :users resources :posts do resources :comments, only: [:create, :destroy] end root "posts#index" endpost_comments POST /posts/:post_id/comments(.:format) comments#create post_comment DELETE /posts/:post_id/comments/:id(.:format) comments#destroyコントローラー
comments_controller.rbdef create @post = Post.find(params[:post_id]) @post.comments.create(comment_params) redirect_to post_path(@post) end def destroy @post = Post.find(params[:post_id]) @comment = @post.comments.find(params[:id]) @comment.destroy redirect_to post_path(@post) end private def comment_params params.require(:comment).permit(:body, :user_id) endビュー
<%= f.hidden_field :user_id, value: current_user.id %>で作成したuserのidを渡している。show.html.erb<p> <strong>Post:</strong> <%= @post.post %> </p> <% if @post.user_id == current_user.id %> <%= link_to 'Edit', edit_post_path(@post) %> | <% end %> <%= link_to 'Back', posts_path %> <h3>Comments</h3> <% @post.comments.each do |comment|%> <ul> <li><%= comment.body %> <span> <% if comment.user_id == current_user.id %> <%= link_to '[X]', post_comment_path(@post, comment), method: :delete %> <% end %> </span> </li> </ul> <% end %> <%= form_for [@post, @post.comments.build] do |f| %> <div class="field"> <%= f.text_field :body, autofocus: true, autocomplete: "body" %> </div> <div class="field"> <%= f.hidden_field :user_id, value: current_user.id %> </div> <div class="actions"> <%= f.submit %> </div> <% end %>
- 投稿日:2020-10-09T16:11:46+09:00
質問箱のクローンをリプレイスする
これはなに?
GMOペパボさんが運営するオートスケール機能がついたコンテナサービスにRails製アプリをデプロイするまでのメモです。
アプリはこちらの質問箱のクローンをさらにクローンさせてもらっています。
作者の方はHerokuで運用されているみたいだったので、他の人が作ったアプリからRailsの組み方を学ばせてもらうとともに、Lolipop!マネージドクラウド(以下マネクラ)へのデプロイの練習を目的として進めてみました。
大元の情報
事前の準備
- ロリポップ!マネージドクラウドの会員登録とssh,各種鍵の登録までしておく
- rbenvを入れていろんなバージョンのrubyを使ったリポジトリを扱えるようにしておく
- git や エディタ を設定しておく
マネージドクラウド側の設定
- プロジェクト(専用コンテナ)をつくる
- コンテナにsshができるか確かめる
なんだかんだ一つのコンテナあたり10日間無料で使えるのは太っ腹です。
難しい設定をしらなくても、チェックツールさえ通って入ればコンテナ上で本番環境に対してdb:migrate かけてくれたりするのも魅力ですね。macに当該リポジトリをcloneしてくる
git clone git@github.com:seiyatakahashi/peing-questionbox-clone.gitローカルリポジトリのRuby および Railsの バージョンをロリポップと揃える
マネージドクラウドではRubyが2.5.8、railsが5.2だったので、ローカルで
ruby -vrails -vしてバージョンを確かめました。
ここでバージョンがあって揃ってなかったため、
rbenv install 2.5.8
および、
rbenv local 2.5.8 && rbenv rehashしてあげてバージョンを揃えてあげました。
(railsは変えた記憶(history)がない...)チェックツール
公式で用意されているチェックツールを入れましょう。(github)
gem install lolipop-mc-starter-railsここでRailsのプロジェクトをマネクラにPushするための必要事項を適宜チェックしてくれる(スゴイ)。
私の場合はここでdatabase.ymlがなんか変だぞと教えたもらったので、
./config/database.yml
の内容をみてみます。
database.tmlの内容
# SQLite version 3.x # gem install sqlite3 # # Ensure the SQLite 3 gem is defined in your Gemfile # gem 'sqlite3' # default: &default adapter: sqlite3 pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %> timeout: 5000 development: <<: *default database: db/development.sqlite3 # Warning: The database defined as "test" will be erased and # re-generated from your development database when you run "rake". # Do not set this db to the same as development or production. test: <<: *default database: db/test.sqlite3 production: database: my_database_production adapter: postgresql encoding: unicode pool: 5ここでRailsの各環境におけるSQLの選択ができます。
クローン元のリポジトリでは、Herokuのproduction環境のPostgreSQLに合わせてあるので、
マネクラの本番環境(production)のMySQLに合わせないといけないですね。というわけでこんな感じで書き換えます。
database.ymlを変更
production: <<: *default adapter: mysql2 encoding: utf8 pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %> username: <%= ENV["MC_DB_USERNAME"] %> password: <%= ENV["MC_DB_PASSWORD"] %> database: <%= ENV["MC_DATABASE"] %> host: <%= ENV["MC_DB_HOSTNAME"] %>
MC_DB_USERNAMEなどなどは、ブラウザからマネクラのコントロール画面を開いて環境変数として設定してあげます。
もちろんそのまま直書きもできますが、危険なのでやめましょう。
(ちなみにローカル環境でも直書きしたくないよ〜ってひとはenvdirとかで設定してあげるといいかも)
gem install mysql2ローカルリポジトリにgemを入れてあげて、
./gemfileにgem mysql2と追記。新たにgemを入れたので
bundle installしてあげて、これでSQL周りは大丈夫なはず。マネクラの環境変数を設定していく。
続いてブラウザでマネクラのコントロールパネルを開きつつ、マネクラ側の環境変数を設定していきます。
上記MC_DB_USERNAMEなどを読み込むようにします。今回は他の人が作成したRailsのプロジェクトを使っているので、
./config/master_keyを作り直しました。
EDITOR="vi" bin/rails credentials:editを打ち込むと上書き作成されます。これを
RAILS_MASTER_KEYとしてマネクラの環境変数に登録。また、ローカルで、
mc-rails databaseしてデータベースのURLを作成します。
データベース名、ユーザ名、パスワードの入力を求められるので、マネクラのコンソールにあるものをそれぞれ入力すると、
URLが表示されるのでこれをDATABASE_URLとして同様に環境変数として設定。また、公式の手順に則り、
RAILS_SERVE_STATIC_FILESも環境変数に入力し、値としてtrueを与えておきましょう。Twitterの各種認可キーを取得する。
Tiwtterのデベロッパー向けサイトにいき、APIキーの発行を行いました。
Developer portal に移動し、会員登録をしていなければ、会員登録およびSign in後、右上のアカウント名のメニューより作成したAPIキー一覧のページに飛びます。
Create an APPs の項目を適宜埋めてAPIキーを作成したら、Details > Keys and tokensより、
- API Key
- API serect key
- Access token
- Access token secret
を手元に控えておきます。これをそれぞれ、
環境変数名 値 API_KEY "API Key" API_SECRET "API serect key" TOKEN "Access token" SECRET "Access token secret" としてマネクラに登録しておきます。
なお、クローン元のアプリではさらに、
- APP_NAME="アプリの名前"
- APP_NAME_EN="アプリの英語の表記名"
- CURRENT="自分ののツイッターのID"
- DESCRIPTION="サイトの情報"
- KEYWORDS="サイトのキーワード"
- GOOGLE_ANALYTICS="Google アナリティクスのID"
といった情報もコンテナの環境変数として登録できるように設定されています。(README.mdより)
マネクラにPush
改めて
git add . git commit mc-rails checkなにも怒られななかったはずなので、これでローカルの
git push lolipop master
してマネクラにpush。無事にデプロイできました?
リモートリポジトリ(コンテナ)からエラーを拾う。
上記で無事に、といってはいますが、実際には当初、Twitterアカウントでの認証画面への遷移の際にエラーが吐かれていました。
そこで、リモートリポジトリの中に何かエラーログはないか探索してみました。リモートリポジトリは以下のようになっていて、
僕のリモートリポジトリのホームディレクトリ:~$ ls -a . .bash_history .cache .ssh .viminfo 1597471676557237 projrepo .. .bundle .lolipop .vim 0000000000000000 current sharedこの
currentの中がPushしたRailsのプロジェクトになっています。
また、currentディレクトリ内にlogディレクトリが存在しており、この中にコンテナのログが蓄積されていくことになります。Haconiwaのログが出るのでこれを掘る
logの中身はgitpush.log production.log {プロジェクト名}.lolipop.io-{ハッシュ値} みたいなディレクトリがたくさんという感じでした。
ややエスパーではありますが、ここで
duして重そうなログが格納してあるディレクトリを探しました。
普通のディレクトリの容量が、4KBのところ、40KBくらいのディレクトリを見つけたのでここをcatしてみると、
Started GET "/auth/twitter"のあとに、...OAuth::Unauthorized (401 Authorization Required)...みたいな怒られが発生しているのを発見。
どうやらTwitter APIの認可がうまくいってないっぽい。参考
なので再度Callback用のURLなどTwitterのDevサイトにバッチリ登録し直してみるとうまく画面遷移するようになりました。
ちなみにHaconiwaはRuby製のコンテナです。
おわりに
VPSとか手持ちのオンプレ環境にRailsを動かしたあとだったこともあって、とても手軽にアプリを作成できるようになるのはめちゃくちゃ体験としてよかったです。
また、他の人の作った質問箱様アプリを触ってみて、「僕だったらこの機能とこの機能に絞って作るかも!」とか、「テーブル構造はどうなってるんだろう」みたいな感想が浮かんだのもいい収穫だった様に思います。
Dockerもですが、デプロイ先としてコンテナを設けて置くのはちょっとしたアプリをシャッと作りたいときに便利そうですよね。
先に触れたHaconiwaに関連する宣伝ではありますが、mRubyの本が2020年11月に刊行されるみたいです。買いましょう。
おわり。
- 投稿日:2020-10-09T15:57:24+09:00
[Rails] Couldn't find with 'id'=:id でupdateアクションが実行されない
- 投稿日:2020-10-09T15:57:16+09:00
Ruby on rails学習記録 -2020.10.09
ログイン時だけの機能を持つ掲示板
1行掲示板の作成
$ cd bbs_users
$ rails g scaffold article user_id:integer content:string
$ rails db:migrate
初期データの投入
db/seeds.rbArticle.create(user_id: 1, content: 'hello world') Article.create(user_id: 1, content: 'hello paiza') Article.create(user_id: 2, content: '世界の皆さん、こんにちは')データベースに反映
$ rails db:seedログイン時に、特定のアクションだけ実行できるようにする
articles_controller.rbbefore_action :authenticate_user!, only: [:new, :create, :edit, :update, :destroy] before_action :set_article, only: [:show, :edit, :update, :destroy]ArticlesモデルとUserモデルの関連付け
model/article.rbclass Article < ApplicationRecord belongs_to :user end投稿者のメールアドレスの表示
views/articles/index.html.erb<table> <thead> <tr> <th>User</th> <th>Content</th> <th colspan="3"></th> </tr> </thead> <tbody> <% @articles.each do |article| %> <tr> <td><%= article.user.email %></td> <td><%= article.content %></td> <td><%= link_to 'Show', article %></td> <td><%= link_to 'Edit', edit_article_path(article) %></td> <td><%= link_to 'Destroy', article, method: :delete, data: { confirm: 'Are you sure?' } %></td> </tr> <% end %> </tbody> </table>ナビゲーションを共通で表示
app/views/layouts/application.html.erb<body> <% if user_signed_in? %> Logged in as <strong><%= current_user.email %></strong>. <%= link_to "Settings", edit_user_registration_path %> | <%= link_to "Logout", destroy_user_session_path, method: :delete %> <% else %> <%= link_to "Sign up", new_user_registration_path, :class => 'navbar-link' %> | <%= link_to "Login", new_user_session_path, :class => 'navbar-link' %> <% end %> <p class="notice"><%= notice %></p> <p class="alert"><%= alert %></p> <%= yield %> </body>Userモデルにカラムを追加
$ rails g migration AddNameToUser name:string
$ rails db:migrate
サインアップ画面に「name」カラムを追加
app/views/devise/registrations/new.html.erb<div class="field"> <%= f.label :name %><br /> <%= f.text_field :name %> </div>ユーザー情報の変更画面に「name」カラムを追加
app/views/devise/registrations/edit.html.erb<div class="field"> <%= f.label :name %><br /> <%= f.text_field :name %> </div>Userモデルのユーザー名の変更
コントーローラで、nameカラムを保存
app/controllers/application_controller.rbbefore_action :configure_permitted_parameters, if: :devise_controller? protected def configure_permitted_parameters devise_parameter_sanitizer.permit(:sign_up, keys: [:name]) devise_parameter_sanitizer.permit(:account_update, keys: [:name]) endナビゲーションのログイン情報に、ユーザー名を表示
app/views/layouts/application.html.erb<% if user_signed_in? %> Logged in as <strong><%= current_user.name %></strong>. <%= link_to "Settings", edit_user_registration_path, :class => "navbar-link" %> | <%= link_to "Logout", destroy_user_session_path, method: :delete, :class => "navbar-link" %> <% else %> <%= link_to "Sign up", new_user_registration_path, :class => 'navbar-link' %> | <%= link_to "Login", new_user_session_path, :class => 'navbar-link' %> <% end %>投稿一覧に、nameカラムを表示
views/articles/index.erb.html<table> <thead> <tr> <th>Name</th> <th>Content</th> <th colspan="3"></th> </tr> </thead> <tbody> <% @articles.each do |article| %> <tr> <td><%= article.user.name %></td> <td><%= article.content %></td> <td><%= link_to 'Show', article %></td> <td><%= link_to 'Edit', edit_article_path(article) %></td> <td><%= link_to 'Destroy', article, method: :delete, data: { confirm: 'Are you sure?' } %></td> </tr> <% end %> </tbody> </table>投稿の詳細画面に、nameカラムを表示
views/articles/show.erb.html<p> <strong>User:</strong> <%= @article.user.name %> </p>新規投稿フォームを修正して、user_idを削除
app/views/articles/_form.html.erb<%= form_with(model: article, local: true) do |form| %> <% if article.errors.any? %> <div id="error_explanation"> <h2><%= pluralize(article.errors.count, "error") %> prohibited this article from being saved:</h2> <ul> <% article.errors.full_messages.each do |message| %> <li><%= message %></li> <% end %> </ul> </div> <% end %> <div class="field"> <%= form.label :content %> <%= form.text_field :content, id: :article_content %> </div> <div class="actions"> <%= form.submit %> </div> <% end %>createメソッドの修正
app/controllers/articles_controller.rb# POST /articles # POST /articles.json def create @article = Article.new(article_params) @article.user_id = current_user.idupdateメソッドの修正
app/controllers/articles_controller.rbdef update if @article.user_id == current_user.id respond_to do |format| if @article.update(article_params) format.html { redirect_to @article, notice: 'Article was successfully updated.' } format.json { render :show, status: :ok, location: @article } else format.html { render :edit } format.json { render json: @article.errors, status: :unprocessable_entity } end end else redirect_to @article, notice: "You don't have permission." end enddestroyメソッドの修正
app/controllers/articles_controller.rbdef destroy if @article.user_id == current_user.id @article.destroy msg = "Article was successfully destroyed." else msg = "You don't have permission." end respond_to do |format| format.html { redirect_to articles_url, notice: msg } format.json { head :no_content } end endupdateアクションの修正
app/controllers/articles_controller.rbdef update if @article.user_id == current_user.id respond_to do |format| if @article.update(article_params) format.html { redirect_to @article, notice: 'Article was successfully updated.' } format.json { render :show, status: :ok, location: @article } else format.html { render :edit } format.json { render json: @article.errors, status: :unprocessable_entity } end end else redirect_to @article, notice: "You don't have permission." end enddestroyアクションを修正する
app/controllers/articles_controller.rbdef destroy if @article.user_id == current_user.id @article.destroy msg = "Article was successfully destroyed." else msg = "You don't have permission." end respond_to do |format| format.html { redirect_to articles_url, notice: msg } format.json { head :no_content } end end投稿一覧の表示
app/views/articles/index.html.erb<% if user_signed_in? && article.user_id == current_user.id %> <td><%= link_to 'Edit', edit_article_path(article) %></td> <td><%= link_to 'Destroy', article, method: :delete, data: { confirm: 'Are you sure?' } %></td> <% end %>詳細画面の修正
app/views/articles/show.html.erb<% if user_signed_in? && @article.user_id == current_user.id %> <%= link_to 'Edit', edit_article_path(@article) %> | <% end %> <%= link_to 'Back', articles_path %>
- 投稿日:2020-10-09T13:12:38+09:00
rails simple formでbooleanのvalueをjQueryでgetする方法
- 投稿日:2020-10-09T13:10:52+09:00
【Ruby on Rails】ページング機能導入
目標
ページング機能を作成し、
一覧表示時の画像読み込み速度低下を防ぐ開発環境
ruby 2.5.7
Rails 5.2.4.3
OS: macOS Catalina前提
※ ▶◯◯ を選択すると、説明等が出てきますので、
よくわからない場合の参考にしていただければと思います。今回はgem 'kaminari'を導入し、ページング機能実装します。
kaminari導入までの流れ
Gemfilegem 'kaminari','~> 1.2.1'ターミナル$ bundle install $ rails g kaminari:config $ rails g kaminari:views defaultこれで導入は完成です。
使い方
個人的によく使うものを紹介します。
https://github.com/kaminari/kaminari
こちらに詳しい使い方が記載されておりますので、
興味のある方はこちらをみてください。
ただし、全て英語です。基本的なページング
ページングしたい場所に以下を設置。
この場所に1ページ目や2ページ、次へリンクも出てきます。app/views/homes/index.html.erb<%= paginate @posts %>コントローラーをこのように記述することでページングが実装できます。
app/controllers/homes_controller.rb@posts = posts.page(params[:page])
補足【page(params[:page])】
page(params[:page]) ≒ all と思って頂いて大丈夫です。ページングの並び替え
コントローラーの記述に書きを追加することで逆の順番にすることが可能。
app/controllers/homes_controller.rb@posts = posts.page(params[:page]).reverse_order1ページあたりの表示件数を指定
config/initializers/kaminari_config.rbKaminari.configure do |config| config.default_per_page = 5 # この数字でkaminariを使用したすべてのページの1ページあたりの表示上限件数を指定 end個別で表示1ページあたりの表示件数を指定する場合
app/controllers/homes_controller.rb@posts = posts.page(params[:page]).per(10)
補足【表示の優先順位】
優先順位はkaminari_config.rbの数字が優先されるため、
kaminari_config.rb >= homes_controller.rb
このような数字の優劣をつけてください。表示を変更する
nextやlastなどを変更したい場合、
1 gem 'rails-i18n'を導入
2 config/locals/ja.ymlファイルを作成
3 ja.ymlを編集上記を行えばOKです。
【ja.yamlの参考】ja.yamlja views: pagination: first: "≪" previous: "<" next: ">" last: "≫"配列に対して適用する場合
上記方法で実装する際に、値が配列の場合は表示されないため、
下記のように記述する必要があります。app/controllers/homes_controller.rb@posts = Kaminari.paginate_array(配列).page(params[:page])実際の記述:【Ruby on Rails】ランキング表示(合計、平均値)
その他機能
【Rails】自動で次のページへ!!jscrollによるページネーションの無限スクロール
他にも多くあるので興味のある方はぜひ調べてみてください。
まとめ
導入自体はそこまで難しくないものの、ページング機能がないと
サイトが成長したときに読み込みが遅く使い物にならないので、
なにかしらのページング機能は必須です。またtwitterではQiitaにはアップしていない技術や考え方もアップしていますので、
よければフォローして頂けると嬉しいです。
詳しくはこちら https://twitter.com/japwork
- 投稿日:2020-10-09T11:20:45+09:00
多重配列から各名前とその中身の合計を出力する
【概要】
1.結論
2.どのようにコーディングするのか
3.ここから学んだこと
1.結論
eachメソッドの入れ子と添字を使用する!
2.どのようにコーディングするのか
vegetables_price = [["tomato", [200, 250, 220]], ["potato", [100, 120, 80]], ["cabbage", [120, 150]]] #---❶ vegetables_price.each do |vegetable| #---❷ sum = 0 fruit[1].each do |price| #---❸ sum += price end puts "#{vegetable[0]}の合計金額は#{sum}円です" #---❹ end❶:vegetables_priceを多重配列にして、トマト・じゃがいも・キャベツの中に3種類の金額を配列にしています。
❷:まず、1段階目の各配列を取り出したいのでvegetables_priceをeachメソッドを使用しvegetableで抜き出しています。(ex:["tomato", [200, 250, 220],["potato", [100, 120, 80]],["cabbage", [1200, 1500]])
❸:さらにeachメソッドを使用し、金額を抜き出しています。出力用に事前にsum = 0にしておき、各野菜に対して合計金額を計算するようにしています。[1]なのは、["tomato", [200, 250, 220]の状態だと配列なのでtomatoは[0]、[200, 250, 220]は[1]になるからです。(ex:tomato➡︎200+250+220,potato➡︎100+120+80,cabbage➡︎120+ 150)
❹:ここで各野菜の名前と各合計金額を出力しています。vegetable[0]で固定しているのも❸と同じ理屈です。3.ここから学んだこと
二重ハッシュにして、目的の名前を入力した金額だけを合計することもできそうだと思いました。なので、キーバリューストアを使用してコーディングしてみます。
- 投稿日:2020-10-09T10:35:15+09:00
[Rails]本番環境EC2で"rails db:create"などの実行方法
投稿内容
ローカル環境で行う
rails db:createやrails db:migrateなどを本番環境で実行する方法について投稿します。実行するディレクトリへ移動
まず本番環境で下記コマンドで
currentディレクトリまで移動します。ターミナル.[ec2-user@******* ~]$ cd /var/www/アプリ名/currentコマンド実行
ターミナル.//データベースを削除 [ec2-user@******* current]$ RAILS_ENV=production DISABLE_DATABASE_ENVIRONMENT_CHECK=1 bundle exec rake db:drop //データベース作成 [ec2-user@******* current]$ rails db:create RAILS_ENV=production //テーブル、カラムの作成 [ec2-user@******* current]$ rails db:migrate RAILS_ENV=production //データベースのカラムに情報を送りたい場合 [ec2-user@******* current]$ rails db:seed RAILS_ENV=production最後に
本番環境のコマンドはついつい忘れてしまいそうになるので、是非参考にしてもらえると幸いです!
- 投稿日:2020-10-09T10:14:01+09:00
Rubyのtest/unitの使い方と、ジャンケンのコードをテストしてみた。
まず初めに
課題で「ジャンケンのプログラムをtest/unitを使ってテストしろ。」と出され、テストコード自体初めて聞いたので、自分用のメモとして記載します。
動作環境は以下の通り。mac
Ruby 2.6.5
test/unit 3.3.6達成したいこと
ジャンケンのプログラムを、「test/unit」を使用して、テストする。
test/unitとは
そもそも、テストコードとは、書いたプログラムのロジックが、想定通りの動きをしているか、確認するためのプログラムです。
test/unitはRuby用のテストフレームワークで、元々は標準搭載されていたらしいです。
tesu/unit自体のインストールはこちらを参照してください。test/unitの基本的な使い方
前提として、ver.によって多少異なるので、ご了承ください。
基本的な構文は以下の通り。require 'test/unit' class [クラス名] < Test::Unit::TestCase endまずはこのフレームワークを使用するために
'test/unit'をrequireします。
つぎに、Test::Unit::TestCaseを継承したclassを作成します。
RubyではTest::Unit::TestCaseを継承することでそのクラスはテスト実行ファイルになります。require 'test/unit' class [クラス名] < Test::Unit::TestCase def test_[メソッド名] foo = "hoge" assert_equal("hoge", foo) end endテストの処理は上記の通りです。
メソッドを作成し、そちらにテストしたいプログラムを書きます。メソッド名はtest_から始めるのがルールです。このメソッド内では、以下の書式でチェックメソッドを書きます。(チェックメソッドは、他にもあります)assert_equal(想定の値, 変数やメソッド等)
assert_equalでは、変数の値やメソッドの返り値が想定のものと一致することを確認します。こちらで簡単なチュートリアルは終わりですが、もっとデフォルトで使用できるメソッドなどあるので、リファレンスを参照してみてください。
解決方法
それでは、達成条件の解決方法を以下に記載します。
まずですが、ジャンケンのプログラムを先に書いてしまいます。
(あまり、スマートなプログラムではないですが、ご容赦ください)
標準入力でgかcかpを入力したら、ジャンケンの結果が出力される仕組みです。player = gets.chomp if player == "g" player = "グー" elsif player == "c" player = "チョキ" elsif player == "p" player = "パー" end com = rand(3) if com == 0 com = "グー" elsif com == 1 com = "チョキ" else com = "パー" end if player == com res = "引き分け" elsif (player == "グー" && com == "チョキ") || (player == "チョキ" && com == "パー") || (player == "パー" && com == "グー") res = "あなたの勝ち" else res = "あなたの負け" end puts "あなたは#{player}、私は#{com}、#{res}です。"今回の場合は、
playerとcomの2つの変数の値が決まったときに正しい結果が表示されるかをテストするので、テストするのは以下の部分です。if player == com res = "引き分け" elsif (player == "グー" && com == "チョキ") || (player == "チョキ" && com == "パー") || (player == "パー" && com == "グー") res = "あなたの勝ち" else res = "あなたの負け" end puts "あなたは#{player}、私は#{com}、#{res}です。"今回は、上記の勝敗を判定する処理をクラスにまとめます。
class Janken def self.judge(player,com) if player == com res = "引き分け" elsif (player == "グー" && com == "チョキ") || (player == "チョキ" && com == "パー") || (player == "パー" && com == "グー") res = "あなたの勝ち" else res = "あなたの負け" end return "あなたは#{player}、私は#{com}、#{res}です。" end endジャンケンの勝敗の処理をクラスにまとめました。
そうしたら、テスト処理の方を書きます。require 'test/unit' class Test_Janken < Test::Unit::TestCase def test_janken assert_equal('あなたはグー、私はグー、引き分けです。', Janken.judge("グー","グー")) assert_equal('あなたはチョキ、私はチョキ、引き分けです。', Janken.judge("チョキ","チョキ")) assert_equal('あなたはパー、私はパー、引き分けです。', Janken.judge("パー","パー")) assert_equal('あなたはグー、私はチョキ、あなたの勝ちです。', Janken.judge("グー","チョキ")) assert_equal('あなたはチョキ、私はパー、あなたの勝ちです。', Janken.judge("チョキ","パー")) assert_equal('あなたはパー、私はグー、あなたの勝ちです。', Janken.judge("パー","グー")) assert_equal('あなたはグー、私はパー、あなたの負けです。', Janken.judge("グー","パー")) assert_equal('あなたはチョキ、私はグー、あなたの負けです。', Janken.judge("チョキ","グー")) assert_equal('あなたはパー、私はチョキ、あなたの負けです。', Janken.judge("パー","チョキ")) end endジャンケンの勝敗のパターンの全9通りを
assert_equalで検証するという感じです。
これをジャンケンの処理を合体させます。
以下のコードが最終的なものになります。require 'test/unit' class Janken def self.judge(player,com) if player == com res = "引き分け" elsif (player == "グー" && com == "チョキ") || (player == "チョキ" && com == "パー") || (player == "パー" && com == "グー") res = "あなたの勝ち" else res = "あなたの負け" end return "あなたは#{player}、私は#{com}、#{res}です。" end end class Test_Janken < Test::Unit::TestCase def test_janken assert_equal('あなたはグー、私はグー、引き分けです。' ,Janken.judge("グー","グー")) assert_equal('あなたはチョキ、私はチョキ、引き分けです。' ,Janken.judge("チョキ","チョキ")) assert_equal('あなたはパー、私はパー、引き分けです。' ,Janken.judge("パー","パー")) assert_equal('あなたはグー、私はチョキ、あなたの勝ちです。' ,Janken.judge("グー","チョキ")) assert_equal('あなたはチョキ、私はパー、あなたの勝ちです。' ,Janken.judge("チョキ","パー")) assert_equal('あなたはパー、私はグー、あなたの勝ちです。' ,Janken.judge("パー","グー")) assert_equal('あなたはグー、私はパー、あなたの負けです。' ,Janken.judge("グー","パー")) assert_equal('あなたはチョキ、私はグー、あなたの負けです。' ,Janken.judge("チョキ","グー")) assert_equal('あなたはパー、私はチョキ、あなたの負けです。' ,Janken.judge("パー","チョキ")) end end結果は、、
Loaded suite test Started . Finished in 0.000811 seconds. -------------------------------------------------------------------------------- 1 tests, 9 assertions, 0 failures, 0 errors, 0 pendings, 0 omissions, 0 notifications 100% passed -------------------------------------------------------------------------------- 1233.05 tests/s, 11097.41 assertions/s問題なく、テストできました。
リファレンス
test/unitライブラリ - doc.ruby-lang.org
- 投稿日:2020-10-09T09:21:38+09:00
「暗記」ダメ!!!! 絶対!!!!それって本当ですか?
暗記ってダメなの?
学習をしていく中で1度は耳にする
「暗記」はダメ
といった論調があると思います
最初に結論を言っておくと私はこの記事で
暗記を全て否定するのではなく、拾ってくる情報リソースの多くで頻出している「単語」や「概念」は暗記しましょうね。と伝えたいです。私の背景
半年前の私は
・HTMLって何
・PHP何それ弱そう
・プログラミング=ホームページを作る事でしょ?といったようにプログラミングに関してほとんど無知の状態でした。
今では半年間毎日1日8時間の学習を継続しているので、そんなふざけた状態ではないですが、当時は間違いなく全くの初学者でした。私は初学者だった当時スクールに通うことはせずネットのPHP教材を購入し独学をはじめました。
少し話がそれますが、この半年でオンラインなどの交流会でスクールを卒業された方の話しを10人前後聞いてきたのですが、その方々の満足度は大変高い印象でした。ただし、接頭辞的な感じで、「挫折しない為には」いいですね。といった言い回しをされる方が多い印象でした笑
私も半年間独学をしてきた経験と周りの卒業された方の意見を合わせて考えると時間効率を求めるならスクールは大いにありだと思います。
スクールを通う段階としてはプロゲートで5つくらいの言語を一通りやってみてからでいいのかな〜といった印象です。
お金に余裕があって少しでも一人でやる自信がないと思っている方は即決でスクールを選んだ方が効率は絶対にいいです(こんな事言ってますがスクールの回し者ではありません笑。なんならエンジニアyoutuerみたいに一回くらい企業案件やってみたいです。この動画はテックアカ、、、、?)さて本題に戻ります。
私はスクールには通いませんでしたがネットで教材を購入しそれを独学しました。その教材の中には「暗記してください」などとは書かれて言いませんでしたが、重要なポイントとして取り上げられているTipsはたくさんありました。
要するに何が言いたいかと言うと
単語レベルの理解はもちろん、多くの人が共通して主立って「重要」と言っている事は四の五の言わず暗記した方が後の開発効率がスムーズになる。
と言うのが私の意見です。
そんなの当たり前だろ。。記事にすることじゃないよね。。と思われるかもしれませんが
初学者の方で
・「暗記」をひとまとめにして「悪」と捉えている
・「暗記」って本当にダメなのか疑心暗鬼になっている方は少なくないと思い、この記事を書きました。
少なからず私が学習初期の段階では色んな情報に触れて
「暗記は効率悪いんだ」と一括りにしてしまっていました。暗記しなくてもいい事
もちろん暗記する方が圧倒的に効率が悪くなることもあると思います。
そこで、大きく分けてみると3つに分類できるかなと思います。
※前提として忘れないで頂きたいのはこれは学習して半年程度且つ実務未経験者の意見です?また、PHPやLaravel以外の言語に関しては詳しくないのでご了承ください。笑
1. コードの書き方を暗記する
私が考えるに暗記してはいけないと情報発信されている方の本質的部分はここだと思います。
ここは私が細かく言うまでもないですが、効率が悪く、キリがないですよね。笑
これをやってしまっている方がいたら今すぐにその習慣を辞めて、コードを書いて覚えましょう!
無心で書き続けていればいつの間にか覚えます。必ずです。
2. 開発環境の構築の仕方
これはキリがないとか効率が悪いとか言うより初学者のうちにここを重点的に覚えようとすると、挫折率が上がってしまうかと思います。
サーバーやネットワークの知識が必要となってくるので初学者の段階は
「そう言うものを使っているんだな」程度の理解でいいのではないでしょうか。
3. 関数を全て覚えようとする
これもコードを暗記するに近いですが、仮に全て覚えても一生使わないものも出てくる可能性があり且つ効率が悪いからです。
経験上、使用頻度の高い関数はコードを書いて入れば勝手に覚えます。つまり使用頻度が高い=重要度の高い関数と言う認識で良いかと。暗記した方がいい事
さて、今度は逆に暗記した方がいい事について少しみていきましょう。
冒頭でも述べましたが、暗記をした方が良い内容は 拾ってくる情報リソースの多くで頻出している「単語」や「概念」の事でしたね。では具体的にはどう言った単語や概念でしょうか。
私の経験から「早めに覚えておいてよかった」「ここは早めに深く覚えておけばよかった」点から解説します。
※ここからはさらに個人的主観が強くなりますでご了承ください
以下の内応は一応、PHPを対象としていますの
if文/繰り返し文/関数/引数/戻り値/変数
と言ったどのプログラミング言語でも共通する基礎の部分は除きますざっくりですが以下2点の理解をまずは「暗記」する事を私はお勧めします。
1.$GETと$POST
2.データベースは何をしているか
詳しくは次の段落で書いていきます。
$GETと$POST
[なぜこれを覚えておいた方が良いのか]
それはPHP言語でCRUDを実装する時に超頻出の概念だからです。
(CRUDとは、システムに必要な4つの主要機能である「Create(生成)」「Read(読み取り)」「Update(更新)」「Delete(削除)」の頭文字を並べた用語です。)
CRUDはWEBアプリ制作する上で基本的な考え方になります。PHPとよく比較されるプログラミング言語が、JavaScriptです。この両者はスクリプト言語でも、動作については全く異なります。
JavaScriptはHTMLやCSS、画像と同じようにブラウザを表示しているPCにファイルをダウンロードしてから実行し動作するのに対し
PHPはWebサーバ上にファイルを置いて、以下の順で実行されます。1.ブラウザを見ているユーザがクリックなど何かの操作をする
2.その動作を受けたプログラムがサーバで動作する
3.動作結果をレスポンスとして、インターネット経由で送り、ブラウザ上にHTMLを表示する
このようにPHPのような言語は、サーバサイドのプログラミング言語と呼ばれ、PHPはサーバー側で動くプログラミング言語でこの全体の処理の中でも、$_GETと$_POSTは超頻出です。つまりこの2つの処理が何をしているのかを「暗記」する事はPHPを早く上達する上では効率が良いと言えます。
GETやPOSTについてもっと詳しく知りたいと言う方はこちらの書籍を読んでみるのもいいかと思います。
HTTP通信についての理解が深まりクライアントとサーバーが裏でどんな事をやっているかのイメージがつくかと思います。
www.amazon.co.jp/dp/4774142042データベースは何をしているか
データベースを扱うアプリケーションでは「CRUD」のアクションが基本となります。
つまり、データベースに対して行うアクションは、・データベースにデータを「新規登録」する、
・そのデータを「読み出す」、
・そのデータを「変更し上書き」登録する、
・そのデータを「削除」する、という、「基本この4つしか無い」ということです。
つまりこの流れのイメージを意識的に暗記する事でコードを書いている時に、今何やっているかの把握ができ結果として開発効率が上がると考えます。
[補足]
個人的にはSQL文法も暗記しておいた方が効率が良いのではと思っています。これも超頻出なので。笑最後に
まとめとして、頻出する単語や概念、その周りの流れは覚えてしまった方が結果的に効率が上がると言う事です。
本記事とは少しずれますが、有名な方の発言を鵜呑みにするのではなく、その意見を一回自分の頭に持ち込んで、処理して自分なりの答えを導き出すと言う事も重要です。この「脳に対する意識的な習慣」ができていると、エラー時にもイライラしなくなると思います。(エラーでイライラしてしまう人は他責思考が強い人だと思う)
この事は自戒を含めて伝えたいなと思いました。
- 投稿日:2020-10-09T09:00:07+09:00
Rubyで「フロイドの循環検出法」を実装
# 漸化式 x_{n+1} = f(x_{n}) で与えられる列が循環を持つとき、 # 循環に入るまでの長さ l と循環の長さ m を測る def find_cycle(x0, limit = nil, &f) # 循環検出の回数制限を設定(終端 nil または Float::INFINITY で無限) seq = 1..limit # step1: 循環を検出する # - x と y は共にスタート地点( x0 )から始める # - x は1つずつ、 y は2つずつ進める # - → 循環に入ればいつか必ず x == y になる # - → この x == y の位置は x0 と並行したところ # (十分大きな n について常に f^{n}(x) == f^{n}(x0) が成り立つ) x = y = x0 k = seq.find { (x = f[x]) == (y = f[f[y]]) } raise "failed to detect a cycle" unless k # step2: 循環に入るまでの長さを測る # - x だけスタート地点に戻し、 y はstep1終了時から続ける # - x も y も1つずつ進める(並行した位置関係を保つ) # - → 循環に入ったところで必ず x == y になる x = x0 l = (x == y) ? 0 : seq.find { (x = f[x]) == (y = f[y]) } # step3: 循環の長さを測る # - x と y は共に循環の中(ここではstep2終了時)から始める # - x は1つずつ、 y は2つずつ進める # - → x がちょうど1周で必ず x == y になる m = seq.find { (x = f[x]) == (y = f[f[y]]) } [l, m] end if $0 == __FILE__ # テスト: x_{n+1} ≡ x_{n} * 2 (mod 360), x_{0} = 133 l, m = find_cycle(133) { |x| x * 2 % 360 } p [l, m] # x_{l} == x_{l+m} (かつ x_{l-1} != x_{l+m-1} )になるはず ary = (l + m).times.inject([133]) { |a, _| a << (a.last * 2 % 360) } ary.each_with_index { |x, i| puts "%3d %4d" % [i, x] } end※「並行」と表現しているのは、グラフ表示した際にノードを揃えて循環節に非循環節が巻き付いている様子をイメージしている。
- 投稿日:2020-10-09T03:18:11+09:00
Railsモデルのメソッドの命名について
はじめに
Railsの命名について、Model, Controllerやテーブルに対する命名のことは数多く書かれているが、メソッド名、変数名、スコープ名についてはあまり書かれていないように見受けられる。
命名の良し悪しはコードの可読性に大きく影響を与えるが、一方で英語が苦手な僕たちは度々血迷ったネーミングをしてしまい、しばしば技術的負債を溜め込む。
そもそもrubyは英語っぽい書き味(あくまで「ぽい」)を意識した言語仕様になっているので、メソッド名、変数名、スコープ名についてもある程度このマナーに則るべきだと思う。そこで改めて、これら命名が従うべきガイドラインを考察してみた。
色々整理しながら書くので小分けにしたく、今回は一旦モデルのメソッド、スコープ、(少しだけ)変数の命名だけ考えたが、後日コントローラーについても考えるつもりでいる。
TL;DR (モデル編)
※ いろいろ考えているうちに頭がこんがらがってきた。後で修正するかもしれません。
命名対象 形式 スコープ 「形容詞(句)」, 「前置詞_名詞」, 「動詞ing」, 「動詞の過去分詞形」 作用を持つメソッド 「他動詞」 → 他動詞の目的語がレシーバーobjectになるように! 判定系メソッド 「形容詞(句)?」, 「前置詞_名詞?」, 「動詞ing?」, 「動詞の過去分詞形?」 作用を持たないメソッド 「名詞(句)」 → プロパティとして使えるように オブジェクトそのものを変換するメソッド 「to_名詞」 変数 「名詞(句)」 変数(例外) 「動詞の過去分詞形_前置詞(_名詞)」 → 避けられるなら避ける 使用する単語の品詞に留意する。そして、読んで意味がわかるのが一番大切。
詳細
スコープ名
形容詞または形容詞句であるべき。
スコープ名がモデル名を後置修飾する。
「どんな〇〇」の「どんな」の部分をスコープ名にする。
〇〇にはモデル名が入る。形容詞句で後置修飾するようにスコープを命名しておくと、スコープチェーンしたときにも英文法的に破綻しない。
Book.in_sale.published_by("O'Reilly")← Book (which is) in sale published by O'Reilly典型例
モデル名.動詞+ing または モデル名.動詞の過去分詞形
Shop.selling_books # 本を売っている店 Task.not_running # 否定形 Book.published # 過去分詞形 Book.published_by("O'Reilly") # 引数も取るスコープBook (which is) published by O'Reilly
の
(which is)が省略された名詞句に見えるのが良い命名です。モデル名.前置詞+名詞
Shop.without_blue_roof Devil.in_the_prada Man.with_the_machine_gunモデル名.形容詞
Mission.impossible Daemon.alive Picture.not_displayable Tower.taller_than(100) Session.expired # 補足) expired は形容詞ともみなせるし、自動詞の過去分詞形ともみなせる(大きな差はない)だめパターン
時々
:filtered_xxxxというスタイルのスコープ名を見かけることがあるけど、そもそもスコープの機能が絞り込みなのでこういう命名は冗長。
:can_xxxxも推奨しない。いい命名かどうかの判定は, 「Model (which is) scope名」というふうに省略していた which is を復活させて文法的に崩壊しないかどうか。メソッド名
作用(変数等の変更)を伴うメソッドか、作用のないメソッドかで考え方が大きく異なってくる。
作用を伴うメソッド
「主語(呼び出し元オブジェクト)」が「目的語(レシーバー)」を「どうするか」。
「どうするか」の部分をメソッド名とする。
どうにかした結果として内部の変数状態を変えたり、外部のオブジェクトに作用したり、外部のサービスにアクセスしたりする。cow.grow # <= I grow up the cow. その結果 cow.age はインクリメントされる、などの作用が起こる。 file.delete # <= I delete the file. その結果、(プログラムにとっては)外部のファイルシステム上でファイルが消える作用を起こす。 job.perform # <= I perform the job.時々、レシーバー(オブジェクト)が主語とされるようなメソッドを見かけるが、良くない。
一瞬良さそうに見えるかもしれないが、長い目で見るとオブジェクト指向じゃなくなってしまい、崩壊し始める。
※ オブジェクトに対してメソッドというインターフェースを通じて作用を加える。この連鎖で作るのがオブジェクト指向開発。# 悪い例 manager.evaluate(member) # <= 語順そのまま A manager evaluates his member.作用を伴わないメソッド
判定系メソッド(Predicate methods)
trueかfalseを返す判定系(作用しない)メソッドは、通常の(作用を起こす)メソッドと明確に命名のアプローチが違う。
この場合に限り、レシーバーは主語扱いする。例えば、
Shopがopen状態かどうかを判定するStatementはshop.open? # <= Is the shop open?他の言語だと、しばしば
shop.is_openというbe動詞付きのノリで判定系メソッドを作るが、
Ruby / Railsの通例ではbe動詞は省略して、末尾に?をつける。?が使えるという言語仕様特有の文化だと思うし、そもそも疑問形だと「S+V+C」は「V+S+C?」になるので、主語と補語の間にはisは入らない。判定系メソッドの場合に限り、メソッド名は「補語句的」である必要がある。(S=object, V=省略, C=メソッド名)
→ スコープの命名と似ていて、「形容詞?」か「前置詞+名詞?」か「動詞+ing?」か「動詞の過去分詞形?」が基本となる。
can_xxx,can_be_yyyは有りか無しか? できるだけ避けたほうが良いとは思う。後で考える。判定系の否定メソッド
shop.not_open?というメソッドは極力作らない。!shop.open?と書けば済む。
判定条件が複雑になると、そのメソッドの可読性も落ちてしまうので、そもそも否定の意味を内包しないように設計するのが吉だと思う。作用は伴わないが判定しないメソッド
true/falseを返すわけではないメソッドは, 外部からプロパティとして利用できるようなものはプロパティとして定義するのが良さそう。
このときの命名は後述の「変数名」と同じスタイル。もしくは、オブジェクトそのものを別の形式に変換するなら
to_xxxという命名にすべき。convert_to_xxxとはしない。例えば
class Sylinder attr_accessor :bore, :stroke def initializer(bore, stroke) @bore = bore @stroke = stroke end def displacement # <= オブジェクトの内部状態に作用しないので :calculate_displacement のようなメソッド名にはしない (@bore/2) * (@bore/2) * Math::PI * @stroke end end変数名
基本的には名詞句を変数名としたい。
変数はオブジェクト(またはクラス)が所有する属性。属性名は名詞。名詞の前に形容詞とか所有格を付けて意味を絞り込んでも良い。user.email user.first_name例外的に、そのオブジェクトに対するアクション(作用)に関する補助的な情報を保持する変数は、動詞の過去分詞形+前置詞(+名詞)という形式の変数名となることがある。
こういう変数名を使わずに表現できるのであれば、避けたほうが後で読みやすい気がする。article.created_at article.published_by article.referenced_in_indices考察
Ruby言語仕様
automator.call bob if not bob.awake?みたいにメソッドの引数を括弧無しで呼び出せるところや、
not,andキーワードが定義されているあたりからも、
もともと記号的記述を少なく押さえて自然言語っぽく書けるようになっている。
呼び出す際に自然言語っぽい表現になるように、スコープやメソッド、変数の命名も工夫してあげるとコードリーディングのストレスが軽くなる。英文法の基本
英文法は基本的に下記の5文型に類型されることが知られている。
- S+V
- S+V+C
- S+V+O
- S+V+O+O
- S+V+O+C
文型の構成要素と、それぞれが対応する Rails プログラミングにおける概念は下記になると思う。
S: 主語(主部) → 呼び出し元(サブジェクト)
V: 動詞 → メソッド
O: 目的語(名詞) → レシーバー(メソッドを生やしているオブジェクト) と, メソッド引数(第4文型の場合)
C: 補語(形容詞/副詞/形容詞句/副詞句) → 代入値S+V+Oの"O"はオブジェクト指向(Object-oriented)の"O"です。
オブジェクト指向的言語がカバーすべき表現力
基本的にメソッド呼び出しは第3文型のセンテンスを表現していると考えて良さそう。それ以外は、代入やプロパティ変更として実装するか、第3文型に変換して実装することになるか。
第1文型: S+V
あんまりない。なぜなら、オブジェクト指向は呼び出し元がレシーバーに対して作用することで処理を実装していくパラダイムだから。
シンプルなfile.delete()とかは、実は第3文型だと思う。file.delete # <= I deletes the file.第2文型: S+V+C
O (Object)が登場しないので、これもメソッドの形としてはあまりないケース。あるとすれば呼び出し元オブジェクトが自分のプロパティに何かを代入するとか、そういう実装になると思う。
この文型をとるV(動詞)のバリエーションは下記のとおり。
状態型: be, look, seem, appear, keep, remain, lie
変化型: become, get, turn, grow, make, come, go, fall
感覚型: smell, taste, feel, sound
出典: https://www.eng-builder.jp/learning/sentence-pattern2/つまり、これらの動詞は変化を伴うか伴わないかなどの違いはあれどどれも結果的にSがCという状態 (
S = C) であることを表現しているわけである。
この表現をプログラミングで記述するにあたり、大概の場合はオブジェクトの状態を表すプロパティに対して値を代入することで実現できそう。alice.health = :fine # <= Alice becomes fine.第3文型: S+V+O
これはわかりやすい。一番多そう。
file.delete # <= I delete the file. window.move_to(100, 300) # <= I move the window to (100, 300).与えられる引数は副詞句として文全体を修飾する役割に使われることが多い気がする。
要するに、引数はオブジェクトに対する作用を調整するパラメータ。
パラメーターは呼び出された側のメソッド内ではconstであるほうがいいような気もするけど、そこまでまだ自分の中で考えられてません。第4文型: S+V+O1+O2
この文型をとるV(動詞)のバリエーションは下記のとおり。
give, show, offer, hand, pass, send, teach, tell, pay, lend, do
傾向として, SがO1にO2を与えるような意味になっていると分かる。
オブジェクト指向的プログラミングで記述する場合、プロパティへの代入/追加などで表現できることが多い気がする。alice.belongings.push book # <= I give Alice a book alice.give book # <= I give Alice a book第5文型: S+V+O+C
この文型をとるV(動詞)のバリエーションは下記のとおり。
make, get, keep, leave, think, believe, find, call, name
どれも O=Cであるという状態を表現する動詞ばかりであることが分かる。
SがOに働きかけるか否かの違いはあるが、結果的に 「Oの何らかの状態がC」になったり、 「Oの何らかの状態がC」であることを認識するという意味の動詞。
これは、オブジェクト指向的に実装しようとするとCとOだけ使ってもっと単純なSVC表現に書き換えることができそう。Room.tidiness = :clean # <= I make the room clean. cat.name = "Tom" # <= I name the cat "Tom."まとめ
ややこしくてもうわからん。なんかまとまりの悪い文章になってしまった。
参考にしたページ
- 投稿日:2020-10-09T02:09:20+09:00
アソシエーション(1対1)!!
アソシエーション?
簡単に説明するとモデルを利用したテーブル同士の関連付けのことですね。
テーブル同士で関連付けておき、一方のモデルからもう一方のモデルに
アクセスできるようにするためということですね。関連付けを行う理由
Railsでは、「関連付け(アソシエーション: association)」とは2つの
Active Recordモデル同士の繋がりのことですね。2つモデルの間には関連付けを行なう必要がありますが、
その理由を知っていますか?それはですね、関連付けを行う事でコードの共通操作をより
シンプルで簡単にできるからなんです。アソシエーション(1対1)定義の際に使用するメソッド
has_oneメソッド
アソシエーションが1対1の時に使われます。
注意点としては、親モデル側に「has_one」の記述を、
子モデル側に「belongs_to」を書きます。「belongs_to」メソッドについては下記のURLに説明がありますので、
そちらを参考にして下さい。今回は説明を省きます。まとめると下記のようになりますね。
今回、説明する上で下記のアソシエーション(関係)で記述例を
載せていきます。userとaddress 1対1アソシエーションの定義記述方法
先にUserモデルの記述例を載せていきます。
/models/user.rbclass User < ApplicationRecord has_one :address end書き方としましては、has_one :モデル名(単数形)
今回は「1対1」のためモデル名は単数形になります。Userモデルの記述は以上です。
次は、addressモデルの記述にいきましょう。
/models/address.rbclass Address < ApplicationRecord belongs_to :user end書き方としましては、 belong_to :モデル名(単数形) になります。
これで、Userモデルとaddressモデル間のアソシエーションができましたね。
まとめ
「1対1」のアソシエーションには、has_oneを用いましょう!!
「1対1」を記述する際は、「1対多」・「多対多」などのように
モデル名が複数形ではなく、単数形で記述するのであまり気を付けなくても
大丈夫ですね笑これまでで、「1対1」・「1対多」の説明をさせて頂いたので残りは
「多対多」になりますね。これで「1対1」のアソシエーションの定義の仕方などわかって頂けたら嬉しいです。
ご覧頂きありがとうございました。以上。

- 投稿日:2020-10-09T01:25:54+09:00
sliceメソッドの使い方のアウトプット
表題の通りsliceメソッドについてアウトプットします。
sliceメソッドとは
配列や文字列から指定した要素を取り出すことができる。
使い方いろいろ
その1 (1つ指定して取り出す)
array = [0,1,2,3,4,5,6] result = array.slice(1) puts result #=> 1 # 配列自体は変わらない puts array #=> [0,1,2,3,4,5,6]その2-1 (複数の要素を取り出す)
複数の要素を取り出すこともできる。
下記は「ここから○つ分を取り出す」方法。
array = [0,1,2,3,4,5,6] # 配列番号1から4つ分の要素をsliceする result = array.slice(1,4) puts result #=> 1 2 3 4この方法を使って下記のようなこともできる。
# 任意の文字列の最後の2文字を3回繰り返して出力するメソッドを作る def extra_end(str) num = str.length right2 = str.slice(num - 2, 2) puts right2 * 3 end extra_end(str)
str.lengthで文字列の文字数を取得。
文字列も配列と同じで先頭は0から数えていくので、
文字列の最後の文字を取得するならstr.slice(num - 1)となる。
今回は文字列の最後の2文字を取得したいので、str.slice(num - 2, 2)にする。その2-2
複数の要素を取り出す方法には他に、
「配列番号○から配列番号Xまでを指定して取り出す」方法もある。array = [0,1,2,3,4,5,6] # 配列番号1から4までの要素をsliceする result = array.slice(1..4) puts result #=> 1 2 3 4こんなこともできる。
# 要素を定義 array = "string" # 配列番号の-3から-1の範囲の文字列を切り取る result = array.slice(-3..-1) puts result #=> "ing"一番右側が-1で、右から左に-1,-2,-3...と配列番号を数える。
その3 slice!
sliceの後ろに!を付けると元の配列や文字列を変化させることができる。
(破壊的メソッド)string = "abcde" result = string.slice!(2) puts result #=> "c" # "c"が取り除かれている puts string #=> "abde"
- 投稿日:2020-10-09T01:14:30+09:00
[rails]タグのランキング機能
今日ポートフォリオにタグ付け機能を追加し、ランキングを作ったので
アウトプットします。タグ付け機能はformオブジェクトを使いました。
まずtweetコントローラーにこのように記述します。tweets_controller.rbdef rank @tag_ranks = TweetTag.find( TweetTagRelation.group(:tweet_tag_id).order('count(tweet_tag_id)desc').limit(4).pluck(:tweet_tag_id)) endpluckって何・・・・って思ったので調べてみると
公式では
pluckは、1つのモデルで使用されているテーブルからカラム (1つでも複数でも可) を取得するクエリを送信するのに使用できます。引数としてカラム名のリストを与えると、指定したカラムの値の配列を、対応するデータ型で返します。だそうです。
pluckの引数にtweet_tag_id(これは中間テーブルのタグのカラム)をとることで中身が取得できます。
次にviewです tweetsの配下にファイルを作ってこのように記述してください
rank.html.erb<div class="rank-tag-all"> <% @tag_ranks.each.with_index(1) do |tag,i| %> <div class="rank-tag-num">第<%= i %>位 </div> <div class="rank-tag"><%= tag.name%></div> <%end%> </div>with_index(1)を書いて第二引数をとることで順位が表示されます。
雑談
かなり眠いので簡素的にかきました。。。
もっと早い時間にqiitaを書く予定を立てようと思います...
- 投稿日:2020-10-09T00:30:21+09:00
Railsで簡単にプルダウンを作る方法
簡単にプルダウンを作る方法
使用するディレクトリ(私の場合)⚠️命名はご自身で
- ビューファイル(new.html.erb)
- コントローラー(mentors.controller.rb)
- モデル(sukill_id.rb)
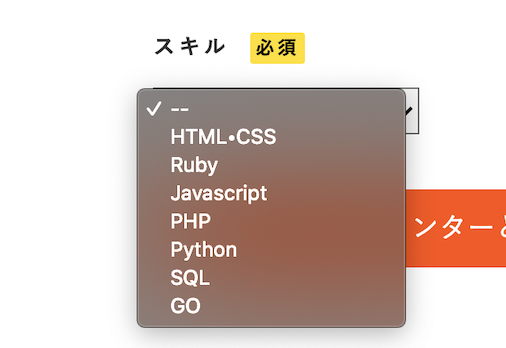
目指す完成形
まずビューファイルから(どこからでもいい)
1.こういうパターンや
new.html.erb<select> <option>チャットするユーザーを選択してください</option> <option>ユーザー1</option> <option>ユーザー2</option> </select>2.こういうパターンもある
new.html.erb<div class="mentors-detail"> <div class="form"> <div class="weight-bold-text"> スキル <span class="indispensable">必須</span> </div> <%= f.collection_select(:skill_id, Skill.all, :id, :name, {}, {class:"select-box", id:"mentor-skill"}) %> </div>今回は2のf.collection_selectを使用してプルダウンを作成します!
6行目で「:skill_id, Skill.all」となっていますがこれは選択したいプルダウンの内容は「skill_idモデル」から選ぶわけなので次はモデルの中身を書いていきます!
モデル作成
skill_id.rbclass Skill < ActiveHash::Base self.data = [ { id: 1, name: '--' }, { id: 2, name: 'HTML•CSS' }, { id: 3, name: 'Ruby' }, { id: 4, name: 'Javascript' }, { id: 5, name: 'PHP' }, { id: 6, name: 'Python' }, { id: 7, name: 'SQL' }, { id: 8, name: 'GO' }, ] endあとはコントローラーにnewアクションやらcreateアクションを記述してルーティングやパスをrails routesで確認しながら記述すれば出来上がり!
まとめ
CSSの部分は省きましたが多分こんな感じ(ここはご自身でやってみてください)
new.css.mentors-detail { display: flex; justify-content: space-between; padding: 2vh 0; } .mentors-detail>.form { width: 300px; padding: 2vh 0; } .select-box { margin: 2vh 0; }現場からは以上です!
- 投稿日:2020-10-09T00:23:42+09:00
Rubyの&って真逆の2つの意味を持つよねって話
ここでの&はビット演算子ではなくProc関連で出てくるアレのことです。
知ってる人にとっては当たり前のことかもしれませんが、自分的にわかりやすい(それでいて他にこういう書き方をしてる記事がなかった)ので書き留めておきます。そもそも&と言えば
ブロックをProcオブジェクトに変換する記法です。最も単純な例で
def test(&fun) fun.call end test { p 1 } #=> 1これは1と表示されます。
・ブロック { p 1 } がfunに渡される
・このfunは&によってProcオブジェクトに変換される。
・そのため、funはProcのメソッドの1つであるcallを用いた呼び出しを受け付けるようになる
という算段ですね。ちなみに本題からは外れますが、Rubyでは
・「yieldとは&引数で生成されたProcを.callする略記法である」
・「yieldに渡す&引数Procはメソッド定義行で省略して構わない」
と定められていますので、上記はdef test yield end test { p 1 } #=> 1でもOKです。しんぷる!
では、次は?
def test(&fun) fun.call end proc = Proc.new { p 1 } test &proc #=> 1これも1と表示されます。
ここで最初私は、
「(この部分は間違いです)&はProcへの変換のおまじないだから、もともとProcのものに&をつけても相変わらずProcのままで、&procでも&funでもProcオブジェクトが渡されてるのかな」
と思いました。上記が正しければ、片方の&を取り払っても問題ないはずですね。ずっとProcが渡されているはずですから。
実際にやってみると…def test(fun) fun.call end proc = Proc.new { p 1 } test &proc #=> wrong number of arguments(given 0, expected 1)あれ?エラーですね。
何が起こったのでしょう。試しに&procのクラスを調べてみましょうか。proc = Proc.new { p 1 } p proc.class #=> Proc # p (&proc).class #=> syntax Errorどうやらprocと&procは別物。&procは.classそのものを受け付けないようです。
それもそのはず。実は、&procはオブジェクトですらないからです。
Ruby公式ドキュメントには、ブロック付きメソッドに対して Proc オブジェクトを `&' を指定して渡すと
呼び出しブロックのように動作します。と、ちゃんと書かれておりました。そして、Rubyでブロックはオブジェクトではありません(逆に言えば、ブロックをオブジェクトとして扱いたいという欲求から出てきたのがProcなのだと思います)。
こうして、&には二つの意味があることがわかります。
・ブロックからProcオブジェクトへの変換
・Procオブジェクトからブロックへの変換
真逆ですね。うーん…正直奇妙に思えましたが、慣れるとこれがむしろしっくりくるのでしょうか。
余談
上でエラーになったコードですが、そもそも&を使わずにProc状態でどんどん受け渡せば問題なく動きます。
def test(fun) fun.call end proc = Proc.new { p 1 } test proc #=> 1随分すっきりしました。
&を使わない引数なら、複数のProcも問題なく受け渡せます(&付き仮引数の場合はメソッドにつき1つだけと決められている)。def test(one, two) one.call two.call end proc1 = Proc.new { p 1 } proc2 = Proc.new { p 2 } test proc1, proc2 #=> 1 # 2こうしてみると、仕様上は、Procでないブロックを定義せずとも十分言語として機能するということになりそうです。
しかし、やっぱりRubyっぽくmapなどには直接ブロックを渡したいですし、先に述べたyield記法は捨てがたい。とすると可読性の上で&は大事ですので、コイツとは末永く付き合っていくことになりそうだな、と思ったのでした。
そこで付き合うコツとして、&の意味が文脈で変わってくるので、(これはすべての型やクラスに言えることかとは思いますが)プログラムの中で「これは今Procとブロックのどちらなのか」を常に把握するのが大事なのかな、というのが今の考えです。参考
大変参考になりました。ありがとうございました。
Ruby block/proc/lambdaの使いどころ
Procを制する者がRubyを制す(嘘)