- 投稿日:2020-10-09T23:17:07+09:00
Chainerによる機械学習のためのPython学習メモ 3章
What
Chainerを利用して機械学習を学ぶにあたり、私自身が、気がついた点、リサーチした内容をまとめる記事になります。今回は、機械学習に必要な数学を抜粋して勉強します。
私の理解に基づいて記述しているため、間違っている場合があります。間違いは都度修正するつもりです、ご容赦ください。
Content
機械学習とは
お決まりのなんぞや?って話ですね。 コンピューターを使ったパターンや規則のを見つけ出すことなんですね。人間では処理しきれない複雑なパターンや、規則についてコンピュータに解かせるという手法です。決して、コンピューターに無鉄砲なアウトプットを求めるわけではないみたいです。
3.1. 機械学習とは
機械学習は、与えられたデータから、未知のデータに対しても当てはまる規則やパターンを抽出したり、それらを元に未知のデータを分類したり、予測したりする手法を研究する学術領域です。 機械学習は様々な技術に応用されており、例えば画像認識、音声認識、文書分類、医療診断、迷惑メール検知、商品推薦など、幅広い分野で重要な役割を果たしています。教師あり学習
機械学習の代表的な問題設定として、教師あり学習 (supervised learning) というものがあります。 これは、問題に対して予め答えを用意しておき、予想された答えと実際の答えの違いが小さくなるように訓練を行う方法です。
教師あり学習では答え合わせが必要なんですね。答えを誰もしらないような問題を解くにはまだ足りないと思っていいのか。
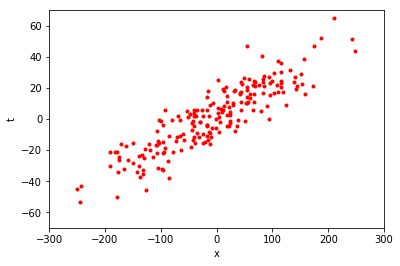
この図は、tとxの関係を示す、データ点の集合を表している。例えば、上の図に対して、近似線を引くとき、その精度が良ければ、予測精度が高いことを機械学習において汎化性能が高いと表現する。また、予測するに使うツール(例では近似線)をモデルと呼ぶ。テキストではパラメータを使って何らかの計算を行うことで、与えられたデータの特徴や関係性を表すもの
と表現している。
目的関数
コンピュータに良いパラメータを自動的に見つけてもらうためには、何が良いパラメータなのかという指標を定義する必要があります。 そのような指標を表す関数を目的関数 (objective function) と呼びます。
変数y,xに対して y = ax + bを計算するとき。機械学習でa, bを精度良く決定したいとする。
ここで、? を入力変数 (input variable)、? を出力変数 (output variable) と呼びます。 今、任意の 1 点の ? 座標の値を式に与えたとします。 このとき、式に与えた具体的な ? の値を、入力値 (input value) と呼びます。 そして、パラメータ a と b を用いて計算を行った結果得られる具体的な y の値を、予測値 (predicted value) と呼びます。 このとき、直線の式ではなく、実際の赤い点の持つ ? の値は、この式が予測したい目標の値なので、目標値 (target value) と呼びます。
目的関数は多くの場合、モデルの予測値と目標値を受け取って、その間の差異を測って返すような関数です。 差異は小さければ小さいほどモデルの予測が当たっていることを意味するため、この場合は目的関数の値を最小にするパラメータを見つけ出すのが目的になります。目的値と予測値の数字の値を小さくするなら目的関数はそんな難しくなさそうだけど、対象が画像とか、音声とか人の感覚で差異を判断するようなデータに対して目的関数を決めろと言われてもパッとイメージできないですね・・・・
ここに機械学習の難しさがありそうです二乗誤差関数
内容読むと、誤差解析で学ぶ最小二乗法の話なので割愛。
目的関数の最適化
目的関数はモデルの精度の良さを数値が小さくなることで計る指標なので、ここでは最適化といえば目的関数を小さくすることだということになります。
目的関数を最適化するために必要な数学
ある関数の最小値を求めるためには、グラフの切片の傾きの傾向を掴む必要があります。
なので、微分が役に立ちますね。逆に最適化が難しい関数って何かあるのかな・・・・?データ点のまとまりを取り扱う数学
関数として取り扱うことができればまだしも、できない時は、行列、線形代数の出番です。
データから特徴を読み取る数学
確率、統計です。
上記が必要最低限のようです。最適化のところ奥が深そうです。。。目的関数の最適化が単純な微分で解けないような問題だったら???
Comment
3章はここで終わっています。大学に入った時、工学では数学を道具として扱うことが多いと教わり。当時は全く意味が分からなかったのですが、こうやってまとめてみると本当に道具のような気がします。実際にいろんなデータを取り扱って覚えていくしかなさそうです。
でもワクワクします。
- 投稿日:2020-10-09T23:16:23+09:00
Kaggle House Prices ③ ~ 予測 ~
以下で作成したモデルを使用してテストデータの予測行います。
Kaggle House Prices ② ~ モデル作成 ~ライブラリの読み込み
import numpy as np from sklearn.externals import joblibデータの読み込み
def load_x_test() -> pd.DataFrame: """事前に作成したテストデータの特徴量を読み込む :return: テストデータの特徴量 """ return joblib.load('test_x.pkl') def load_model(i_fold): """事前に作成したモデルを読み込む :return: 対象foldのモデル """ return joblib.load(f'model-{i_fold}.pkl')テストデータの予測を実行
# クロスバリデーションで学習した各foldのモデルの平均により、テストデータの予測を行う test_x = load_x_test() preds = [] n_fold = 4 # 各foldのモデルで予測を行う for i_fold in range(n_fold): print(f'start prediction fold:{i_fold}') model = load_model(i_fold) pred = model.predict(test_x) preds.append(pred) print(f'end prediction fold:{i_fold}') # 予測の平均値を取得する pred_avg = np.mean(preds, axis=0) # 予測結果の保存 joblib.dump(preds, 'pred-test.pkl')
- 投稿日:2020-10-09T23:16:23+09:00
Kaggle House Prices ③ ~ 予測・提出 ~
以下で作成したモデルを使用してテストデータの予測、及び submission ファイルの提出を行います。
Kaggle House Prices ② ~ モデル作成 ~ライブラリの読み込み
import numpy as np from sklearn.externals import joblibデータの読み込み
def load_x_test() -> pd.DataFrame: """事前に作成したテストデータの特徴量を読み込む :return: テストデータの特徴量 """ return joblib.load('test_x.pkl') def load_model(i_fold): """事前に作成したモデルを読み込む :return: 対象foldのモデル """ return joblib.load(f'model-{i_fold}.pkl') def load_pred_test(): """事前に作成したテストデータの予測結果を読み込む :return: テストデータの予測結果 """ return joblib.load('pred-test.pkl')テストデータの予測を実行
# クロスバリデーションで学習した各foldのモデルの平均により、テストデータの予測を行う test_x = load_x_test() preds = [] n_fold = 4 # 各foldのモデルで予測を行う for i_fold in range(n_fold): print(f'start prediction fold:{i_fold}') model = load_model(i_fold) pred = model.predict(test_x) preds.append(pred) print(f'end prediction fold:{i_fold}') # 予測の平均値を取得する pred_avg = np.mean(preds, axis=0) # 予測結果の保存 joblib.dump(pred_avg, 'pred-test.pkl')提出用の submission ファイルを作成
pred = load_pred_test() print(len(pred)) print(load_x_test()) submission = pd.DataFrame(pd.read_csv('test.csv')['Id']) submission['SalePrice'] = np.exp(pred) submission.to_csv( 'submission.csv', index=False )提出結果
- 投稿日:2020-10-09T23:15:16+09:00
tkinterを使ってGUIでS3に画像をアップロードする
tkinterでGUIを作成して、ボタンを押すことでS3に画像をアップロードするソースコードです。
import tkinter from boto3.session import Session session = Session(aws_access_key_id='access_key_id', aws_secret_access_key='secret_access_key_id') s3 = session.resource('s3') bucket = s3.Bucket('bucket-name') def btn_click(): bucket.upload_file('sample.png', 'sample.png') print("uploaded !") root = tkinter.Tk() root.title("Image Uploader") root.geometry("300x200") btn = tkinter.Button(root, text='upload', command=btn_click) btn.pack() root.mainloop()最後まで読んでいただきありがとうございました。
またお会いしましょう。ps. ちなみにpyinstallerでexe化する時は以下のコマンドを使いました。
pyinstaller .\uploader.py --onefile --noconsole --hidden-import=configparser
- 投稿日:2020-10-09T23:04:29+09:00
千葉県 Go To EATの加盟店一覧のPDFをCSVに変換(コマンド)
千葉県 Go To EAT事業公式サイトの加盟店一覧のPDFをCSVに変換
※文字数オーバーの場合隣のセルと結合されています
wget https://www.chiba-gte.jp/downloads/store_list.pdf -O data.pdf apt install python3-tk ghostscript pip install camelot-py[cv] camelot -p all -o data.csv -f csv -split stream -C 97,116,146,365,500 data.pdf
- 投稿日:2020-10-09T22:50:01+09:00
プログラムでExcelに埋め込んだ関数の結果を読み込めないかったからいろいろ試してみた
- 環境
- macOS Catalina バージョン10.15.7
- Microsoft Excel for Macバージョン16.41
- PyCharm Community 2020.2
- Python 3.8.5
- pandas 1.1.3
- formulas 1.0.0
- openpyxl 3.0.5
- xlrd 1.2.0
- xlwings 0.20.7
PythonのpanadasでとあるExcelファイルを読み込んだらデータが読めなかった。
- 他のプログラムでExcelファイルに関数を入れていた
- ファイルは手動で保存されることなくやってきた
- pandasで読み込んだら関数の結果値を読み込めなかった
- ファイルを手動かVBAで開いて保存した後はpanadasで関数の結果値を読み込めた
調べたら何かプログラム的なものでExcelに関数をいれて手動で保存していないと関数の結果はなかなか読み込むのが大変らしい、が不可能ではないようなので頑張ってみた。
頑張ってみた
if __name__ == '__main__': excel_file = 'Book.xlsx' sheet_name = 'Sheet1' # 1. Excelファイルに関数を入れる write_openpyxl() # 2. Pythonで入れた関数の結果を読み込む print_cell()1. Excelファイルに関数を入れる
- やること :
B4セルに関数=TIMEVALUE("11:45")を入れる本当の時は、Pythonではない何かが使われたが今回はPythonで再現してみた。
panadasでExcelファイルを更新したところ書式が崩れたのでopenpyxlでやってみた。
参考 : 【Python】「OpenPyXL」で「Excel」のセルの値を取得・入力するなどセルを操作してみよう | zak-papadef write_pandas(): # pandasで書き込むと書式が崩れた sheet = pandas.read_excel(excel_file, sheet_name=sheet_name, header=None) sheet.iloc[3, 1] = '=TIMEVALUE("11:00")' sheet.to_excel(excel_file, sheet_name=sheet_name, index=False, header=False) def write_openpyxl(): """`B4`セルに関数`=TIMEVALUE("11:45")`を入れる""" book = openpyxl.load_workbook(excel_file) book[sheet_name]['B4'].value = '=TIMEVALUE("11:45")' book.save(excel_file)2. Pythonで入れた関数の結果を読み込む
- やること :
B4セルを読み込む(関数の結果値がほしい)def print_cell(): update_formulas() read_pandas() read_openpyxl() read_xlrd() read_xlwings()formulasで関数を計算して保存しても読み込めない
- 参考
def update_formulas(): """formulasで関数を計算して保存・・・した後に読み込んでも結果値が取得できない""" model = formulas.ExcelModel().loads(excel_file).finish() model.calculate() model.write()pandasで読み込むと
nanになったdef read_pandas(): """pandasで読み込むと`nan`になった""" sheet = pandas.read_excel(excel_file, sheet_name=sheet_name, header=None) print(sheet.iloc[3, 1]) # >> nanopenpyxlで読み込むと
Noneになったdef read_openpyxl(): """openpyxlで読み込むと`None`になった""" # openpyxlで関数の結果を取得するには「data_only=True」を指定する. book = openpyxl.load_workbook(excel_file, data_only=True) sheet = book[sheet_name] print(sheet['B4'].value) # >> None # 手動保存でできるならopenpyxlで開いて保存したら結果値が読み込めるかと思ったけど、 # 保存するとNoneが保存されて関数が消えてしまうだけだった・・・ # book.save(excel_file) # print(sheet['B4'].value) # >> Nonexlrdで読み込むと
empty:''になったdef read_xlrd(): """xlrdで読み込むと`empty:''`になった""" sheet = xlrd.open_workbook(excel_file).sheet_by_name(sheet_name) print(sheet.cell(3, 1)) # >> empty:''xlwingsで読み込むと結果値が取れた
- 参考
def read_xlwings(): """xlwingsで読み込むと結果値が取れた""" # 非表示でExcelアプリを開く app = xlwings.App(visible=False) book = app.books.open(excel_file) sheet = book.sheets[sheet_name] # 関数の結果値がシリアル値(24h = 1)で取れた print(sheet.range('B4').value) # >> 0.4895833333333333 # シリアル値に24hを乗算して時間にする print(sheet.range('B4').value * 24) # >> 11.75 # Excelファイルを閉じる book.close() # Excelアプリを終了する app.kill()xlwingsはデータが読めたけどExcelが非表示にしたはずなのにぴょこぴょこ表示される・・・処理が重そう・・・ファイル数が多い場合は時間がかかりそう・・・

- 投稿日:2020-10-09T22:48:31+09:00
Start to Selenium using python
知り合いからテストツールの色々聞かれて、
Seleniumへ挑戦することになった。browserの拡張機能を使ってから
Selenium IDE
https://github.com/SeleniumHQ/selenium-ide
Selenium using Python
pip : Virtualenv/VirtualenvWrapper
from selenium import webdriver browser = webdriver.Chrome();selenium.common.exceptions.WebDriverException: Message: 'chromedriver' executable needs to be in PATH. Please see https://sites.google.com/a/chromium.org/chromedriver/home上のサイトでダウンロードしようとしたらVERSIONによって再ダウンロードする必要がある。
pip install webdriver_managerしてダウンロード後
https://github.com/SergeyPirogov/webdriver_manager 参照してfrom selenium import webdriver from webdriver_manager.chrome import ChromeDriverManager browser = webdriver.Chrome();from webdriver_manager.chrome import ChromeDriverManager追加
- 投稿日:2020-10-09T22:15:40+09:00
Ridge回帰(初学者向け)~コード編~
今回は Ridge 回帰の実装(コード)をまとめていきます。
■ Ridge回帰の手順
次の7つのSTEPで進めます。
- モジュールの用意
- データの準備
- パラメータの探索
- モデルの作成
- 予測値の算出
- 残差プロット
- モデルの評価
1. モジュールの用意
最初に、必要なモジュールをインポートしておきます。
import numpy as np import pandas as pd import matplotlib.pyplot as plt # データセットを読み込むモジュール from sklearn.datasets import load_boston # 訓練データとテストデータを分割するモジュール from sklearn.model_selection import train_test_split # 標準化(分散正規化)を行うモジュール from sklearn.preprocessing import StandardScaler # パラメータ(alpha)を探索するモジュール from sklearn.linear_model import RidgeCV # パラメータ(alpha)をプロットするモジュール from yellowbrick.regressor import AlphaSelection # Ridge 回帰を実行するモジュール(最小二乗法+L2正則化項) from sklearn.linear_model import Ridge
2. データの準備
データの取得をした後、処理しやすいように分割を行います。
# Bostonデータセットの読み込み boston = load_boston() # 目的変数と説明変数に分ける X, y = boston.data, boston.target # 標準化(分散正規化) SS = StandardScaler() X = SS.fit_transform(X) # 訓練データとテストデータに分割する X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state=123)標準化は、例えば2桁と4桁の特徴量(説明変数)があった際に、後者の影響が大きくなってしまうため
全ての特徴量に対して平均を0・分散を1にして、スケールを揃えています。random_state では、データの分割結果が毎回同じになるようにシード値を固定しています。
3. パラメータの探索
Ridge 回帰では過学習を避けるために、最小二乗法の式に正則化項が追加されています。
alpha を大きくすると正則化が強くなり、小さくすると弱くなります。最適な alpha を求めるため、訓練データに対してグリッドサーチと交差検証を行います。
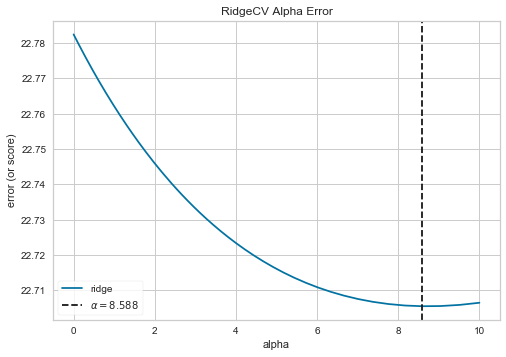
# パラメータ(alpha)の探索区間を設定 alphas = np.logspace(-10, 1, 500) # 訓練データを交差検証し、最適な alpha を求める ridgeCV = RidgeCV(alphas = alphas) # alpha をプロットする visualizer = AlphaSelection(ridgeCV) visualizer.fit(X_train, y_train) visualizer.show() plt.show()<出力結果>
以上より、最適な alpha = 8.588 が求まりました。
4. モデルの作成
先ほど求めたパラメータ(alpha)を用いて、Ridge 回帰のモデルを作成していきます。
# Ridge回帰のインスタンスを作成 ridge = Ridge(alpha = 8.588) # 訓練データからモデルを生成(最小二乗法+正則化項) ridge.fit(X_train, y_train) # 切片を出力 print(ridge.intercept_) # 回帰係数(傾き)を出力 print(ridge.coef_)<出力結果>
lr.intercept_: 22.564747201001634 lr.coef_: [-0.80818323 0.81261982 0.24268597 0.10593523 -1.39093785 3.4266411 -0.23114806 -2.53519513 1.7685398 -1.62416829 -1.99056814 0.57450373 -3.35123162]lr.intercept_:切片(重み $w_0$)
lr.coef_:回帰係数・傾き(重み $w_1$ ~ $w_{13}$)よって、モデル式(回帰式)における具体的な数値が求まりました。
$ y = w_0 + w_1x_1+w_2x_2+ \cdots + w_{12}x_{12} + w_{13}x_{13}$
5. 予測値の算出
作成したモデル式にテストデータ(X_test)を入れ、予測値(y_pred)を求めます。
y_pred = lr.predict(X_test) y_pred<出力結果>
y_pred: [15.25513373 27.80625237 39.25737057 17.59408487 30.55171547 37.48819278 25.35202855 ..... 17.59870574 27.10848827 19.12778747 16.60377079 22.13542152]
6. 残差プロット
モデルの評価をする前に、残差のプロットを見ておきます。
残差:予測値と正解値の差(y_pred - y_test)
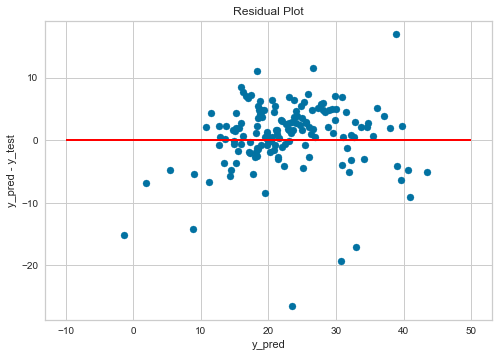
# 描画オブジェクトとサブプロットの作成 fig, ax = plt.subplots() # 残差のプロット ax.scatter(y_pred, y_pred - y_test, marker = 'o') # y = 0 の赤い直線をプロット ax.hlines(y = 0, xmin = -10, xmax = 50, linewidth = 2, color = 'red') # 軸ラベルを設定する ax.set_xlabel('y_pred') ax.set_ylabel('y_pred - y_test') # グラフのタイトルを追加 ax.set_title('Residual Plot') plt.show()<出力結果>
赤い線(y_pred - y_test = 0)の上と下で、バランス良くデータが散らばっているので
予測値の出力に大きな偏りはないことが確認できます。
7. モデルの評価
今回は、決定係数を用いて評価をしていきます。
# 訓練データに対するスコア print(ridge.score(X_train, y_train)) # テストデータに対するスコア print(ridge.score(X_test, y_test))<出力結果>
Train Score: 0.763674626990198 Test Score: 0.6462122981958535
■ 最後に
以上、上記1~7の手順に沿って、Ridge 回帰を行いました。
今回は初学者の方向けに、実装(コード)のみまとめさせていただきましたが
今後タイミングを見て、理論(数式)についても記事を作成していければと思います。ご精読いただき、ありがとうございました。
参考文献:Pythonによるあたらしいデータ分析の教科書
(Python 3 エンジニア認定データ分析試験 主教材)
- 投稿日:2020-10-09T21:17:36+09:00
Pythonのappendメソッドで気をつけること
TL;DR
- リスト末尾に要素を追加するPythonの
appendメソッドで気をつけることについて。実行環境
ハードウェア
項目 情報 OS macOS Catalina(10.15.7) ハードウェア MacBook Pro (13-inch, 2019, Two Thunderbolt 3 ports) プロセッサ 1.4 GHz クアッドコアIntel Core i5 メモリ 16 GB 2133 MHz LPDDR3 ソフトウェア
項目 情報 言語 Python(3.8.5) appendメソッド
使い方については、わざわざ書くまでも無いようなものですが、下記のように使います。
$ Python >> array = [] >> array.append('item') >> print(array) ['item']この
appendメソッドですが、これ自体はリスト返す訳ではなく、Noneが返ってきます。$ Python >> array = [] >> print(array.append('item')) None関数の戻り値や引数に渡す際に、うっかり
Array.append(Item)を指定すると、Noneが渡ってしまいます。
今日はこれに地味に時間を取られてしまったので、備忘録として残しておきます。
- 投稿日:2020-10-09T21:13:58+09:00
【初心者】【Python/Django】駆け出しWebエンジニアがDjangoチュートリアルをやってみた~その3~
はじめに
みなさん、初めまして。
Djangoを用いた投票 (poll) アプリケーションの作成過程を備忘録として公開していこうと思います。
Qiita初心者ですので読みにくい部分もあると思いますがご了承ください。シリーズ
- 【初心者】【Python/Django】駆け出しWebエンジニアがDjangoチュートリアルをやってみた~その0~
- 【初心者】【Python/Django】駆け出しWebエンジニアがDjangoチュートリアルをやってみた~その1~
- 【初心者】【Python/Django】駆け出しWebエンジニアがDjangoチュートリアルをやってみた~その2~
作業開始
オーバービュー
MVCモデルのViewとはユーザーに表示する画面を返すプログラムのことです。
投票アプリケーションでは、以下4つのビューを作成します:
質問 "インデックス" ページ -- 最新の質問をいくつか表示
質問 "詳細" ページ -- 結果を表示せず、質問テキストと投票フォームを表示
質問 "結果" ページ -- 特定の質問の結果を表示
投票ページ -- 特定の質問の選択を投票として受付ちなみに、URLからビューを得るDjango機能をURLconfといいます
もっとビューを書いてみる
以下の動作をURLconfを用いて実装します。
ユーザが「/polls/100/」にアクセス
→config/urls.pyのpath.'polls/'に一致するためpolls/urls.pyを読み込む
→polls/urls.pyのpath.'100/'に一致するためviews.pyのdetail(request=, question_id=100)を返すpolls/views.py# Create your views here. from django.http import HttpResponse def index(request): return HttpResponse("Hello,world.You're at the polls index.") def detail(request, question_id): return HttpResponse("You're looking at question %s." % question_id) def results(request, question_id): response = "You're looking at the results of question %s." return HttpResponse(response % question_id) def vote(request, question_id): return HttpResponse("You're voting on question %s." % question_id)question_id=100は<>で挟んでURLの一部からキャプチャします。
polls/urls.pyfrom django.urls import path from . import views urlpatterns = [ path('', views.index, name='index'), path('<int:question_id>/', views.detail, name='detail'), path('<int:question_id>/results/', views.results, name='results'), path('<int:question_id>/vote/', views.vote, name='vote'), ]実際に動作するビューを書く
いままで動かないもの作っていたのか・・・
違うみたいです。「実際に動作する」とは「HttpRequest処理と例外処理を実装して、実運用に沿った挙動を実現する」ということみたいです。viewに以下を追加します。
polls/views.pyfrom .models import Question from django.template import loader def index(request): latest_question_list = Question.objects.order_by('-pub_date')[:5] template = loader.get_template('polls/index.html') context = { 'latest_question_list': latest_question_list, } return HttpResponse(template.render(context, request))「template.render(context, request)」でlatest_question_listをpolls/index.htmlに渡し、レンダリングします。
Djangoのloader.get_templateの仕様で、レンダリングテンプレートを「.templates/アプリ名(polls)」ディレクトリ配下から検索するようです。polls/templates/polls/index.html{% if latest_question_list %} <ul> {% for question in latest_question_list %} <li><a href="/polls/{{ question.id }}/">{{ question.question_text }}</a></li> {% endfor %} </ul> {% else %} <p>No polls are available.</p> {% endif %}ショートカットすることもできます。
django.shortcutからrenderをインポートします。polls/views.pyfrom .models import Question from django.shortcuts import render def index(request): latest_question_list = Question.objects.order_by('-pub_date')[:5] context = { 'latest_question_list': latest_question_list, } return render(request, 'polls/index.html', context)このような画面が表示されるはずです。
404 エラーの送出
まずはビューを作成します。
polls/views.pyfrom django.http import HttpResponse, Http404 from .models import Question from django.shortcuts import render def detail(request, question_id): try: question = Question.objects.get(pk=question_id) except Question.DoesNotExist: raise Http404("Question dose not exist") return render(request, 'polls/detail.html', {'question': question})続いてHTML
polls/templates/polls/detail.html{{question}}動作確認します。
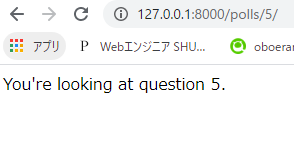
question_id=5は存在するため、「http://127.0.0.1:8000/polls/5/」は以下のように表示されます。
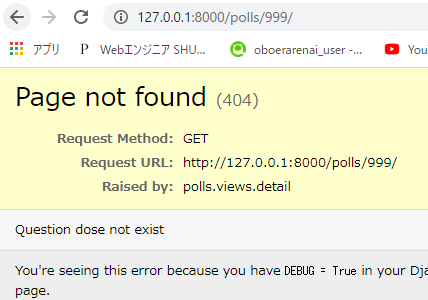
question_id=999は存在しないため、「http://127.0.0.1:8000/polls/999/」は以下のように表示されます。
Exceptionをキャッチして「Question dose not exist」が表示されてます。
テンプレートシステムを使う
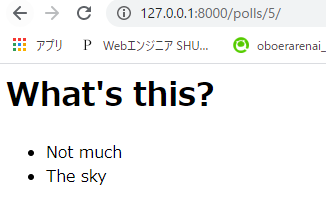
detailページのhtmlをマークアップしていきます。
polls/templates/polls/detail.html<h1>{{ question.question_text }}</h1> <ul> {% for choice in question.choice_set.all %} <li>{{ choice.choice_text }}</li> {% endfor %} </ul>再度、「http://127.0.0.1:8000/polls/5/」を表示します。
テンプレート内のハードコードされたURLを削除
URL部分を変数化します。URLの変更時にテンプレートの修正が必要になるためです。
仕組みとしては、polls/urls.py > urlpatterns > pathで name='detail' を指定しましたね。
これをpolls/templates/polls/index.htmlで読み込みます。するとname='detail'に紐づくURLが読み込まれます。polls/templates/polls/index.html<li><a href="{% url 'detail' question.id %}">{{ question.question_text }}</a></li>polls/urls.pyurlpatterns = [ *** path('<int:question_id>/', views.detail, name='detail'), *** ]表示も問題ないです。
URL 名の名前空間
今回作成したアプリはpollsアプリ1つだけです。
複数アプリを作成した場合、複数アプリがdetailビューを持つ可能性があります。
pollsアプリのdetailビューを飛び出すためには、名前空間を作成・指定します。名前空間の作成は、<アプリ名>/templates/<アプリ名>/index.htmlにapp_name=<アプリ名>を追記します。
polls/urls.pyapp_name = 'polls' urlpatterns = [ *** path('<int:question_id>/', views.detail, name='detail'), *** ]名前空間を指定したURL指定は、<アプリ名>:detailとします。
polls/templates/polls/index.html<li><a href="{% url 'polls:detail' question.id %}">{{ question.question_text }}</a></li>本日はここまでにします。ありがとうございました。


- 投稿日:2020-10-09T18:53:44+09:00
Python辞書
辞書型
python version
Python 3.7.3 (default, Mar 28 2020, 17:59:31) [Clang 9.1.0 (clang-902.0.39.1)] on darwin Type "help", "copyright", "credits" or "license" for more information. >>>用語
keyとvalue
左側にあるのがkeyで、右側にあるのがvalue。
dict = {"key1" : value, "key2": value2 }並び替え
例として、国名と人口を一対一対応させた辞書を考える。
>>> population {'India': 1380004385, 'China': 1439323776, 'Pakistan': 220892340, 'UnitedStates': 331002651, 'Indonesia': 273523615}人口トップ5の国を適当に並べたときに、「アルファベット順に並べ替えたい」「人口トップはどの国だろう?」という、keyやvalueでソートしたいという作業が必要になる。
予備知識
>>> population.items() dict_items([('India', 1380004385), ('China', 1439323776), ('Pakistan', 220892340), ('UnitedStates', 331002651), ('Indonesia', 273523615)])sorted
並び替えには2種類あり、keyで並び替えるか、valueで並び替えるか。
# keyをアルファベット順で並べ替える >>> sorted(population) ['China', 'India', 'Indonesia', 'Pakistan', 'UnitedStates'] # 降順 >>> sorted(population, reverse=True) ['UnitedStates', 'Pakistan', 'Indonesia', 'India', 'China'] # アルファベット順で並べ替え、各リストを返す >>> sorted(population.items()) [('China', 1439323776), ('India', 1380004385), ('Indonesia', 273523615), ('Pakistan', 220892340), ('UnitedStates', 331002651)] # valueだけで並び替える(降順にするときは、後述のreverse=Trueオプションを使用) >>> sorted(population.values()) [220892340, 273523615, 331002651, 1380004385, 1439323776]ラムダ関数を用いる
# 辞書をkeyでソートする >>> sorted(population.items(), key = lambda x : x[0]) [('China', 1439323776), ('India', 1380004385), ('Indonesia', 273523615), ('Pakistan', 220892340), ('UnitedStates', 331002651)] # 辞書のvalueでソートする >>> sorted(population.items(), key = lambda x : x[1]) [('Pakistan', 220892340), ('Indonesia', 273523615), ('UnitedStates', 331002651), ('India', 1380004385), ('China', 1439323776)]二次元辞書
次に、辞書のvalueがさらにリストであるような型を考える(この例の場合、第一成分が総人口、第二成分は年変化率)。
>>> population {'India': [1380004385, 0.99], 'China': [1439323776, 0.39], 'Pakistan': [220892340, 2.0], 'UnitedStates': [331002651, 0.59], 'Indonesia': [273523615, 1.07]}# 辞書keyで並び替え >>> sorted(population.items(), key = lambda x : x[0] ) [('China', [1439323776, 0.39]), ('India', [1380004385, 0.99]), ('Indonesia', [273523615, 1.07]), ('Pakistan', [220892340, 2.0]), ('UnitedStates', [331002651, 0.59])] # 辞書value第一成分で並び替え >>> sorted(population.items(), key = lambda x: x[1][0], reverse=True ) [('China', [1439323776, 0.39]), ('India', [1380004385, 0.99]), ('UnitedStates', [331002651, 0.59]), ('Indonesia', [273523615, 1.07]), ('Pakistan', [220892340, 2.0])] ## --> 中国、インド、アメリカ、インドネシア、パキスタンの順に人口が多いことがわかる # 辞書value第二成分で並び替え >>> sorted(population.items(), key = lambda x: x[1][1], reverse=True ) [('Pakistan', [220892340, 2.0]), ('Indonesia', [273523615, 1.07]), ('India', [1380004385, 0.99]), ('UnitedStates', [331002651, 0.59]), ('China', [1439323776, 0.39])] ## --> パキスタン、インドネシア、インド、アメリカ、中国の順に年増加率が高いことがわかるラムダ式の
x[1][0]やx[1][1]が少しややこしいかもしれない。>>> population.items() dict_items([('India', [1380004385, 0.99]), ('China', [1439323776, 0.39]), ('Pakistan', [220892340, 2.0]), ('UnitedStates', [331002651, 0.59]), ('Indonesia', [273523615, 1.07])])を見ればわかるように、
x[1]で用意した辞書のvalueを表現し、次にx[1][0]でvalueの第0番目の値を使うということを言っているのである。
- 投稿日:2020-10-09T18:37:29+09:00
【Python】xlsbで保存されているEXCELファイルを、xlsxに変える方法
これは何か
なぜかEXCELファイルをxlsbという形式で保存しており(しかも3年分とか!)、その形式ではBIツールに読み込ませられたなかったので、「手で一つ一つ形式変えて保存しないといけないの…?」と絶望したので、Pythonでできるか調べました。Qiitaにはあまり情報なかったので、メモします。
結論
Pyxlsbライブラリで、できました。
スクリプト
import pandas as pd import pyxlsb import_file='sample.xlsb' #読み込みファイルの場所 sheet= 'sheet1' #読み込みファイルのシート名 export_file='sample.xlsx' #ファイルの吐き出し先 df_read = pd.read_excel(import_file,sheet,engine='pyxlsb') #xlsbファイルの読み込み df_read.to_excel(export_file) #xlsxで保存参考
- 投稿日:2020-10-09T17:23:53+09:00
【地図×データ】Pythonで中野区のコロプレス図を描く(プログラミング初心者体験談)
中野区町丁別のコロプレス図を作成したところ
「プログラミング初心者がどうやってこの図を作ったの?」と聞かれましたので、この記事にまとめました。
なお、作成を始めた当初のスキルは、Word、Excel、Powerpoint、昔のhtmlを書ける程度でした。
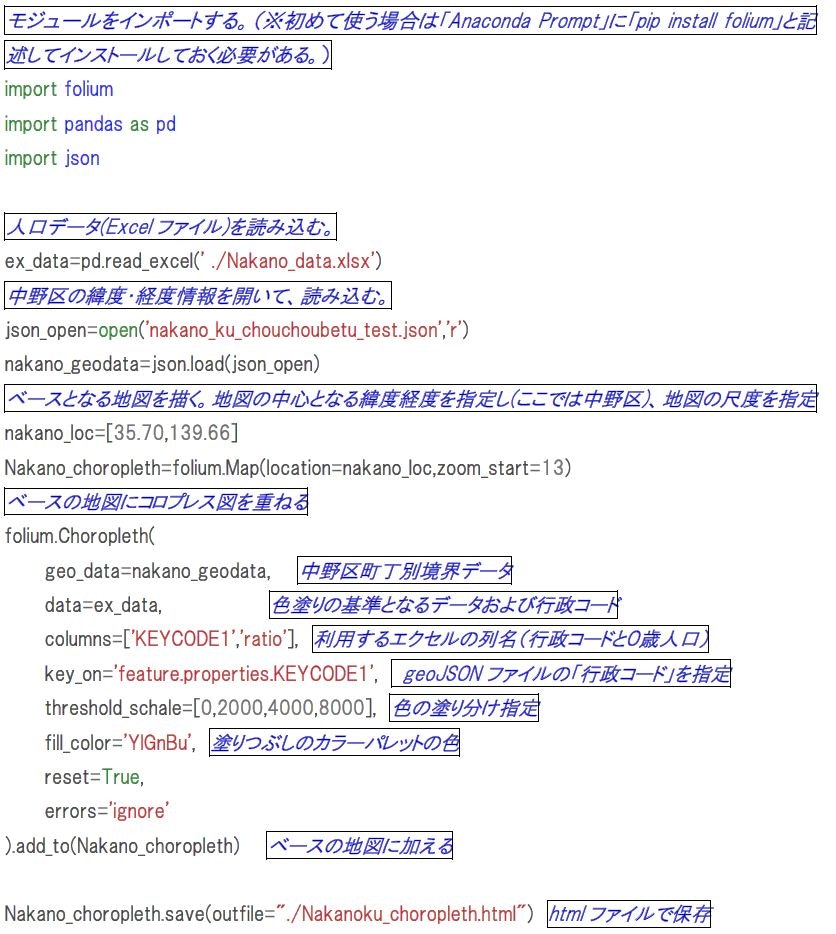
Pythonのコード
まず、最終的に記述したコードです。初心者なので間違いもあるかと思いますがご容赦ください。
※作業環境はWindows7です。
※Anacondaをインストールして、Jyupter Notebook上で作業しました。コードで記述した内容のイメージ
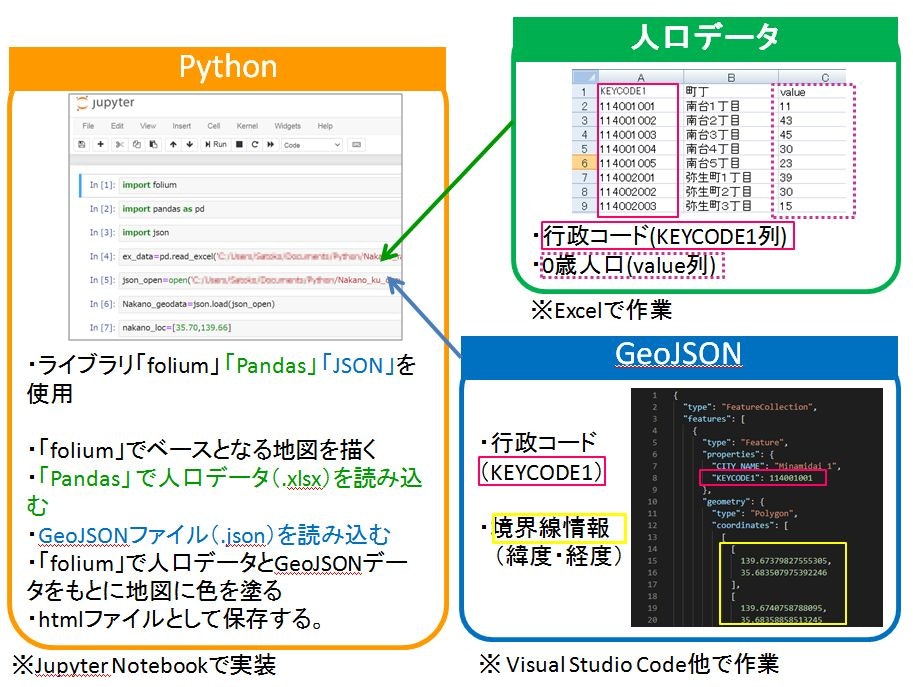
境界データのJSONデータ
中野区町丁別の境界データのファイルはGitHubで公開しましたので、そちらを参照ください。
https://github.com/RefletsDansLeau/GeojsonJSONデータの整形の体験談
JSONファイルが完成するまで長い道のりでした。ご興味がある方はお読みください。
①「地図で見る統計(統計GIS)」でShapeファイルをダウンロード
まず、中野区町丁別の境界データのjsonファイルを「地図で見る統計(統計GIS)」サイトで探しましたが、Shapeファイルしか見つかりませんでした。JeoJSONデータが用意されている場合もありますが、中野区町丁別の境界データのjsonファイルは見つかりませんでした。
Shapeファイルは4つに分かれており、そのままだとPythonでコロプレス図が書けなかったので、自分で整形することにしました。
②phtyonのPyShpライブラリで4つのファイルを一つに統合
PythonのPyShpライブラリでShapeファイルを読み込むことができ、jsonデータ風の文字列が表示されたので、この文字列を保存しました。③細かい整形
しかし、上記の状態ではPythonで読み込めなかったので、知人に相談したところ「文法エラー」とのことでした。そして、括弧の種類を()→[]へ、また余分な,(カンマ)を修正してくださりました。「Code for 中野」の皆様、アドバイスありがとうございました。
この段階でPythonで読み込もうとしたところ、エラー(UnicodeDecodeError)が出てきてしまいました。余分なデータが含まれているのかもしれないと思い「geojson.io」のサイトで不要な列をガンガン削除し、「Right Hand Rule GeoJSON Fixer」というサイトで修正し、Geojson ファイルチェッカーにかけたところ、無事に境界線が描写されました。
しかし、まだPythonでコロプレス図が書けません。そこで「Visual Studio Code」を使って「JSONで保存」としてみたり、町丁名を日本語→英語表記に変えたところ、ついにPythonでコロプレス図が描写できるようになりました。最後に、描写したコロプレス図ですが、なぜか、色が塗れている区画と灰色の区画が混じっていました。そこで、Visual Studio Codeを開いて色が塗れる区画と塗れない区画を比較したところ、行政コードの数字をダブルクオテーションで囲うか囲わないかの違いがあることに気づき、ダブルクオテーション無しで統一しました。すると、すべての区画で無事に色が塗れるようになりました。かくして悲願のJSONファイルが完成しました。
プログラミング初心者の私がつまづいた点
①Anacondaの閉じ方
Anacondaの使い方については色々なサイトで説明をしておりますが、検索してもなかなか分からなかったのが「Anacondaの閉じ方」です。「Ctrl+Cでターミナルを閉じる。」と説明があるのですが、そもそも「ターミナル」が分かりませんでした。
→「ターミナル」とは、どうやら「Anaconda Prompt」と書いてある謎の画面だと気づくまでに何時間もかかりました。
②Pythonライブラリのインストール
始めは、Jupyter Notebookのセルに「import folium」と記述しても何も起こりませんでした。
色々検索すると、ライブラリを使う時に、まずはじめに「pip install folium」などと記述する必要がある、と分かりましたが、どこに記述するのか分かりませんでした。
色々いじってみて「Anaconda Prompt」なるものを発見!ここに記述すると上手くいくことが分かりました。感想
時間はかかりましたが、念願のコロプレス図を作成することができました。今後も色々なオープンデータを可視化したいと思います。応援よろしくお願いします!
- 投稿日:2020-10-09T16:52:22+09:00
AWS GlueでRDSにデータを上書き保存する
GlueのジョブでDynamicFrameを使ってデータをRDSに書き込むとき、
追記(Append)で書き込むため、同じジョブを動かすとデータが重複してしまいます。DynamicFrameをDataFrameに変換すると、上書きモードで書き込むことができます。
自動生成されたジョブのコードに以下を追記します。
JDBCの接続定義が用意されてることが前提です。#datasink4 = glueContext.write_dynamic_frame.from_jdbc_conf(frame = dropnullfields3, catalog_connection = "MyConnection", connection_options = {"dbtable": "my_table", "database": "my_database"}, transformation_ctx = "datasink4") # 接続定義からJDBC情報を取得 jdbc_conf = glueContext.extract_jdbc_conf(connection_name='MyConnection') # DynamicFrameをDataFrameに変換 df = dropnullfields3.toDF() # DataFrameをテーブルに書き込み(上書きモード) df.write \ .format("jdbc") \ .option("url", jdbc_conf['url']) \ .option("dbtable", "my_database.my_table") \ .option("user", jdbc_conf['user']) \ .option("password", jdbc_conf['password']) \ .mode("overwrite") \ .save() job.commit()例では、S3のデータをAurora Serverless MySQLに書き込んでいますが上書きできました。
- 投稿日:2020-10-09T16:29:27+09:00
numpyで文字データのファイルを読み込む
- 投稿日:2020-10-09T16:09:22+09:00
sklearnの中身を見てみたよ(1) ~ CountVectorizer の実装ってどうなってんの?~
はじめに
この記事ではsklearnの中身を見てみようという感じの記事です.最近では,自分で機械学習のアルゴリズムを実装してみよう的な本が多数出版されています.僕自身読んだことはないですが,この本を読まずにsklearnの中身をじっくり見ていくと本を購入しなくても自分で実装することができるぐらいには慣れると信じています.また,sklearnはフリーのパッケージであり多数のユーザによって日々,編集されているためプログラムが素晴らしく最適化されています.なのでとても丁寧なプログラムとなっておりプログラムの勉強をするには使わない手はないのです!!
とは言っても初学者がいきなりsklearnの中身を見ても中々理解できないのげ本音であると思います.僕自身もsklearnの中身を見ても頭の中で整理できずにいました.ですので,誰かがsklearnのパッケージの中身を解説してくれる人いないかな〜〜?と....と思っていたのはいいものの中々現れません.ですので,僕が暇を見つけて中身をちょこちょこ見ていこうかな〜〜と思いました!!そこまで丁寧に解説はしませんがざっくりとだけみていきますね.
その手始めに,最初は簡単なCountVectorizerの中身を見ていこうかな〜と思います.CountVectorizer
CountVectorizerとは単語の出現頻度を数えるアルゴリズムです。単語の出現頻度とは文章中に出てくる単語について何回使用されたかをカウントするもので、sklearnのCountVectorizerを用いて簡単に求めることが出来ます。出現頻度を求める方法は特徴量抽出という手法を用います。特徴量抽出とは、学習データにどのような特徴があるかをベクトル化したもので、今回のケースでは単語の出現頻度がベクトル(数値)にあたります引用.
さて見ていきましょう.
class CountVectorizer(_VectorizerMixin, BaseEstimator): def __init__(self, input='content', encoding='utf-8', decode_error='strict', strip_accents=None, lowercase=True, preprocessor=None, tokenizer=None, stop_words=None, token_pattern=r"(?u)\b\w\w+\b", ngram_range=(1, 1), analyzer='word', max_df=1.0, min_df=1, max_features=None, vocabulary=None, binary=False, dtype=np.int64): self.input = input self.encoding = encoding self.decode_error = decode_error self.strip_accents = strip_accents self.preprocessor = preprocessor self.tokenizer = tokenizer self.analyzer = analyzer self.lowercase = lowercase self.token_pattern = token_pattern self.stop_words = stop_words self.max_df = max_df self.min_df = min_df if max_df < 0 or min_df < 0: raise ValueError("negative value for max_df or min_df") self.max_features = max_features if max_features is not None: if (not isinstance(max_features, numbers.Integral) or max_features <= 0): raise ValueError( "max_features=%r, neither a positive integer nor None" % max_features) self.ngram_range = ngram_range self.vocabulary = vocabulary self.binary = binary self.dtype = dtypeという感じらしいですね.このオブジェクトは二つのクラスを継承しているようですが,基本的にこれを実際に利用するときはfit,fit_transformで十分ですね.また,初期値を見たときも必須となるパラメータは無いようです.
さてまずfitを見ていきましょう.def fit(self, raw_documents, y=None): """Learn a vocabulary dictionary of all tokens in the raw documents. Parameters ---------- raw_documents : iterable An iterable which yields either str, unicode or file objects. Returns ------- self """ self._warn_for_unused_params() ##気になる self.fit_transform(raw_documents) return self面白いことに,fitの中でfit_transformを利用しているようですね.てことは重要なのはfitなどではなく,fit_transformだということがわかります.
また,上の気になるやつを見てみましょう.def _warn_for_unused_params(self): if self.tokenizer is not None and self.token_pattern is not None: warnings.warn("The parameter 'token_pattern' will not be used" " since 'tokenizer' is not None'") if self.preprocessor is not None and callable(self.analyzer): warnings.warn("The parameter 'preprocessor' will not be used" " since 'analyzer' is callable'") if (self.ngram_range != (1, 1) and self.ngram_range is not None and callable(self.analyzer)): warnings.warn("The parameter 'ngram_range' will not be used" " since 'analyzer' is callable'") if self.analyzer != 'word' or callable(self.analyzer): if self.stop_words is not None: warnings.warn("The parameter 'stop_words' will not be used" " since 'analyzer' != 'word'") if self.token_pattern is not None and \ self.token_pattern != r"(?u)\b\w\w+\b": warnings.warn("The parameter 'token_pattern' will not be used" " since 'analyzer' != 'word'") if self.tokenizer is not None: warnings.warn("The parameter 'tokenizer' will not be used" " since 'analyzer' != 'word'")これを見る限り,パラメータが何かしらおかしいものがないかをみて居るようです.ここで重要なのはここのメソッドがCountVectorizerではなく,VectorizerMixinのオブジェクトです.ということはこのオブジェクトはどうやらパラメータ及びその他に関するエラーチェックをしているようです.また,複数のオブジェクトを継承するときは,_VectorizerMixinのように後ろにMixinをよくつけます.これが付与されているオブジェクトは基本的に他のオブジェクトと一緒に併用して利用しますよ!!ということを指しています.
では,重要なfittransformメソッドを確認しましょう.def fit_transform(self, raw_documents, y=None): if isinstance(raw_documents, str): #ここでraw_documentsがリスト型出ない場合を排除.str型ダメ!! raise ValueError( "Iterable over raw text documents expected, " "string object received.") self._validate_params() #n_gramの範囲が適しているかどうか self._validate_vocabulary()#気になる max_df = self.max_df #ここが少しポイント.selfを何度も記述するのが面倒なので,ここで変数として使う. min_df = self.min_df max_features = self.max_features vocabulary, X = self._count_vocab(raw_documents, self.fixed_vocabulary_) #気になる if self.binary: X.data.fill(1) if not self.fixed_vocabulary_: X = self._sort_features(X, vocabulary) n_doc = X.shape[0] max_doc_count = (max_df if isinstance(max_df, numbers.Integral) else max_df * n_doc) min_doc_count = (min_df if isinstance(min_df, numbers.Integral) else min_df * n_doc) if max_doc_count < min_doc_count: raise ValueError( "max_df corresponds to < documents than min_df") X, self.stop_words_ = self._limit_features(X, vocabulary, max_doc_count, min_doc_count, max_features) self.vocabulary_ = vocabulary return X #ベクトルを返す最初のポイントであるself._validate_vocabulary()のメソッドを見てみましょう.
def _validate_vocabulary(self): vocabulary = self.vocabulary #辞書 if vocabulary is not None: #辞書が初期値として入力されているか.#辞書が設定されていないとき.あるいは一度fitさせているときこちらが実行 if isinstance(vocabulary, set): vocabulary = sorted(vocabulary) if not isinstance(vocabulary, Mapping): #vocabularyがちゃんとdict型であるか?を調べている. vocab = {} for i, t in enumerate(vocabulary): if vocab.setdefault(t, i) != i: #ここで辞書の中に重複表現がないかチェック msg = "Duplicate term in vocabulary: %r" % t raise ValueError(msg) vocabulary = vocab else:#あなたの辞書はdict型じゃ無いけど大丈夫?? indices = set(vocabulary.values()) if len(indices) != len(vocabulary): raise ValueError("Vocabulary contains repeated indices.") for i in range(len(vocabulary)): if i not in indices: msg = ("Vocabulary of size %d doesn't contain index " "%d." % (len(vocabulary), i)) raise ValueError(msg) if not vocabulary: raise ValueError("empty vocabulary passed to fit") self.fixed_vocabulary_ = True #ちゃんと辞書が設定 self.vocabulary_ = dict(vocabulary) #辞書を形成. else: #辞書を初期パラメータに入力していないとき. self.fixed_vocabulary_ = False #辞書が設定されていない.このメソッドはvectorizerMixinのメソッドです.このメソッドでは基本的に辞書を形成されているのか??を確かめるためのメソッドのようです.辞書を作成することは,出力結果のカラムに対応する重要な要素です.初期パラメータに辞書を作成していなければ,self.fixedvocabulary_ = False が実行される.二度目,つまりtransformされるときもこのメソッドが実は呼び出されています.そのため,self.fixed_vocabulary_ = True self.vocabulary_ = dict(vocabulary) この二つが実行される.
さて,辞書が作成されているのか確認できたので,self.count_vocab(raw_documents,self.fixed_vocabulary) を確認しましょう.
def _count_vocab(self, raw_documents, fixed_vocab): """Create sparse feature matrix, and vocabulary where fixed_vocab=False """ if fixed_vocab:#辞書が作成されているとき vocabulary = self.vocabulary_ else:#辞書が作成されていないとき # Add a new value when a new vocabulary item is seen vocabulary = defaultdict() vocabulary.default_factory = vocabulary.__len__ #ここらの設定を行うことでvocabulary[単語]とすることでその単語に自動でindexが設定されます.結構役たちます. analyze = self.build_analyzer() #ここでn_gramとかの設定が適応. j_indices = [] indptr = [] values = _make_int_array() indptr.append(0) for doc in raw_documents:#一次元のデータを読み込む. #doc = ["hoge hogeee hogeeeee"] みたいな感じ feature_counter = {} for feature in analyze(doc):#単語 #feature = "hoge" みたいな感じ try: feature_idx = vocabulary[feature] #ここでhoge:1 hogee:2 hogeee:3という感じになる. feature_idxは数値データとなる.hogeだと1がかえる. if feature_idx not in feature_counter: feature_counter[feature_idx] = 1 #feature_counterの辞書に無い場合. else: feature_counter[feature_idx] += 1 #feature_counterの辞書にある場合 +1される except KeyError: # Ignore out-of-vocabulary items for fixed_vocab=True continue j_indices.extend(feature_counter.keys()) #辞書の単語(数値になっている) values.extend(feature_counter.values()) #辞書の単語が何回出現されているか indptr.append(len(j_indices)) #上記三つに関してはスパースモデルを作成するときに登場するやり方です. if not fixed_vocab: #辞書が作成されていないとき,実行 # disable defaultdict behaviour vocabulary = dict(vocabulary) if not vocabulary: raise ValueError("empty vocabulary; perhaps the documents only" " contain stop words") if indptr[-1] > np.iinfo(np.int32).max: # = 2**31 - 1 if _IS_32BIT: raise ValueError(('sparse CSR array has {} non-zero ' 'elements and requires 64 bit indexing, ' 'which is unsupported with 32 bit Python.') .format(indptr[-1])) indices_dtype = np.int64 else: indices_dtype = np.int32 j_indices = np.asarray(j_indices, dtype=indices_dtype) indptr = np.asarray(indptr, dtype=indices_dtype) values = np.frombuffer(values, dtype=np.intc) X = sp.csr_matrix((values, j_indices, indptr), shape=(len(indptr) - 1, len(vocabulary)), dtype=self.dtype) X.sort_indices() return vocabulary, X #辞書とX(スパースのベクトル値)ここらの辞書の作成のアルゴリズムは馴染みがあるひとは多いのでは無いでしょうか?やっていることはそこまで難しくありません.ただし,スパースの値を使っているところは少し複雑です.
さて終盤です.
if not self.fixed_vocabulary_: #Falseのとき実行 X = self._sort_features(X, vocabulary) #辞書を綺麗に並び直す. n_doc = X.shape[0] max_doc_count = (max_df if isinstance(max_df, numbers.Integral) else max_df * n_doc) min_doc_count = (min_df if isinstance(min_df, numbers.Integral) else min_df * n_doc) if max_doc_count < min_doc_count: raise ValueError( "max_df corresponds to < documents than min_df") X, self.stop_words_ = self._limit_features(X, vocabulary, max_doc_count, min_doc_count, max_features) self.vocabulary_ = vocabulary #ここで辞書を設定 return X上記は基本的に,min_doc_count < min_doc_countだとおかしいよ!と言っており,self._limit_features()にて出現頻度に応じて次元を少なくしています.return Xでベクトルがscipyで返却されます.
終わりに
sklearnの中のCountVectorizerの中身を少し見てみました.今回は数式が登場もしないのでそこまでプログラムが複雑でもありませんでした.案外部品に分けていくと一つ一つの処理は単純です.この記事を少しでも見て,自分でどうやって作られているのか確かめてみてください.次はTF-IDFでもみてみようかなと思います.気が向いたら書きます.以上
- 投稿日:2020-10-09T16:09:22+09:00
sklearn(scikit-learn)の中身を見てみたよ(1) ~ CountVectorizer の実装ってどうなってんの?~
はじめに
この記事ではsklearnの中身を見てみようという感じの記事です.最近では,自分で機械学習のアルゴリズムを実装してみよう的な本が多数出版されています.僕自身読んだことはないですが,この本を読まずにsklearnの中身をじっくり見ていくと本を購入しなくても自分で実装することができるぐらいには慣れると信じています.また,sklearnはフリーのパッケージであり多数のユーザによって日々,編集されているためプログラムが素晴らしく最適化されています.なのでとても丁寧なプログラムとなっておりプログラムの勉強をするには使わない手はないのです!!
とは言っても初学者がいきなりsklearnの中身を見ても中々理解できないのげ本音であると思います.僕自身もsklearnの中身を見ても頭の中で整理できずにいました.ですので,誰かがsklearnのパッケージの中身を解説してくれる人いないかな〜〜?と....と思っていたのはいいものの中々現れません.ですので,僕が暇を見つけて中身をちょこちょこ見ていこうかな〜〜と思いました!!そこまで丁寧に解説はしませんがざっくりとだけみていきますね.
その手始めに,最初は簡単なCountVectorizerの中身を見ていこうかな〜と思います.CountVectorizer
CountVectorizerとは単語の出現頻度を数えるアルゴリズムです。単語の出現頻度とは文章中に出てくる単語について何回使用されたかをカウントするもので、sklearnのCountVectorizerを用いて簡単に求めることが出来ます。出現頻度を求める方法は特徴量抽出という手法を用います。特徴量抽出とは、学習データにどのような特徴があるかをベクトル化したもので、今回のケースでは単語の出現頻度がベクトル(数値)にあたります引用.
さて見ていきましょう.
class CountVectorizer(_VectorizerMixin, BaseEstimator): def __init__(self, input='content', encoding='utf-8', decode_error='strict', strip_accents=None, lowercase=True, preprocessor=None, tokenizer=None, stop_words=None, token_pattern=r"(?u)\b\w\w+\b", ngram_range=(1, 1), analyzer='word', max_df=1.0, min_df=1, max_features=None, vocabulary=None, binary=False, dtype=np.int64): self.input = input self.encoding = encoding self.decode_error = decode_error self.strip_accents = strip_accents self.preprocessor = preprocessor self.tokenizer = tokenizer self.analyzer = analyzer self.lowercase = lowercase self.token_pattern = token_pattern self.stop_words = stop_words self.max_df = max_df self.min_df = min_df if max_df < 0 or min_df < 0: raise ValueError("negative value for max_df or min_df") self.max_features = max_features if max_features is not None: if (not isinstance(max_features, numbers.Integral) or max_features <= 0): raise ValueError( "max_features=%r, neither a positive integer nor None" % max_features) self.ngram_range = ngram_range self.vocabulary = vocabulary self.binary = binary self.dtype = dtypeという感じらしいですね.このオブジェクトは二つのクラスを継承しているようですが,基本的にこれを実際に利用するときはfit,fit_transformで十分ですね.また,初期値を見たときも必須となるパラメータは無いようです.
さてまずfitを見ていきましょう.def fit(self, raw_documents, y=None): """Learn a vocabulary dictionary of all tokens in the raw documents. Parameters ---------- raw_documents : iterable An iterable which yields either str, unicode or file objects. Returns ------- self """ self._warn_for_unused_params() ##気になる self.fit_transform(raw_documents) return self面白いことに,fitの中でfit_transformを利用しているようですね.てことは重要なのはfitなどではなく,fit_transformだということがわかります.
また,上の気になるやつを見てみましょう.def _warn_for_unused_params(self): if self.tokenizer is not None and self.token_pattern is not None: warnings.warn("The parameter 'token_pattern' will not be used" " since 'tokenizer' is not None'") if self.preprocessor is not None and callable(self.analyzer): warnings.warn("The parameter 'preprocessor' will not be used" " since 'analyzer' is callable'") if (self.ngram_range != (1, 1) and self.ngram_range is not None and callable(self.analyzer)): warnings.warn("The parameter 'ngram_range' will not be used" " since 'analyzer' is callable'") if self.analyzer != 'word' or callable(self.analyzer): if self.stop_words is not None: warnings.warn("The parameter 'stop_words' will not be used" " since 'analyzer' != 'word'") if self.token_pattern is not None and \ self.token_pattern != r"(?u)\b\w\w+\b": warnings.warn("The parameter 'token_pattern' will not be used" " since 'analyzer' != 'word'") if self.tokenizer is not None: warnings.warn("The parameter 'tokenizer' will not be used" " since 'analyzer' != 'word'")これを見る限り,パラメータが何かしらおかしいものがないかをみて居るようです.ここで重要なのはここのメソッドがCountVectorizerではなく,VectorizerMixinのオブジェクトです.ということはこのオブジェクトはどうやらパラメータ及びその他に関するエラーチェックをしているようです.また,複数のオブジェクトを継承するときは,_VectorizerMixinのように後ろにMixinをよくつけます.これが付与されているオブジェクトは基本的に他のオブジェクトと一緒に併用して利用しますよ!!ということを指しています.
では,重要なfittransformメソッドを確認しましょう.def fit_transform(self, raw_documents, y=None): if isinstance(raw_documents, str): #ここでraw_documentsがリスト型出ない場合を排除.str型ダメ!! raise ValueError( "Iterable over raw text documents expected, " "string object received.") self._validate_params() #n_gramの範囲が適しているかどうか self._validate_vocabulary()#気になる max_df = self.max_df #ここが少しポイント.selfを何度も記述するのが面倒なので,ここで変数として使う. min_df = self.min_df max_features = self.max_features vocabulary, X = self._count_vocab(raw_documents, self.fixed_vocabulary_) #気になる if self.binary: X.data.fill(1) if not self.fixed_vocabulary_: X = self._sort_features(X, vocabulary) n_doc = X.shape[0] max_doc_count = (max_df if isinstance(max_df, numbers.Integral) else max_df * n_doc) min_doc_count = (min_df if isinstance(min_df, numbers.Integral) else min_df * n_doc) if max_doc_count < min_doc_count: raise ValueError( "max_df corresponds to < documents than min_df") X, self.stop_words_ = self._limit_features(X, vocabulary, max_doc_count, min_doc_count, max_features) self.vocabulary_ = vocabulary return X #ベクトルを返す最初のポイントであるself._validate_vocabulary()のメソッドを見てみましょう.
def _validate_vocabulary(self): vocabulary = self.vocabulary #辞書 if vocabulary is not None: #辞書が初期値として入力されているか.#辞書が設定されていないとき.あるいは一度fitさせているときこちらが実行 if isinstance(vocabulary, set): vocabulary = sorted(vocabulary) if not isinstance(vocabulary, Mapping): #vocabularyがちゃんとdict型であるか?を調べている. vocab = {} for i, t in enumerate(vocabulary): if vocab.setdefault(t, i) != i: #ここで辞書の中に重複表現がないかチェック msg = "Duplicate term in vocabulary: %r" % t raise ValueError(msg) vocabulary = vocab else:#あなたの辞書はdict型じゃ無いけど大丈夫?? indices = set(vocabulary.values()) if len(indices) != len(vocabulary): raise ValueError("Vocabulary contains repeated indices.") for i in range(len(vocabulary)): if i not in indices: msg = ("Vocabulary of size %d doesn't contain index " "%d." % (len(vocabulary), i)) raise ValueError(msg) if not vocabulary: raise ValueError("empty vocabulary passed to fit") self.fixed_vocabulary_ = True #ちゃんと辞書が設定 self.vocabulary_ = dict(vocabulary) #辞書を形成. else: #辞書を初期パラメータに入力していないとき. self.fixed_vocabulary_ = False #辞書が設定されていない.このメソッドはvectorizerMixinのメソッドです.このメソッドでは基本的に辞書を形成されているのか??を確かめるためのメソッドのようです.辞書を作成することは,出力結果のカラムに対応する重要な要素です.初期パラメータに辞書を作成していなければ,self.fixedvocabulary_ = False が実行される.二度目,つまりtransformされるときもこのメソッドが実は呼び出されています.そのため,self.fixed_vocabulary_ = True self.vocabulary_ = dict(vocabulary) この二つが実行される.
さて,辞書が作成されているのか確認できたので,self.count_vocab(raw_documents,self.fixed_vocabulary) を確認しましょう.
def _count_vocab(self, raw_documents, fixed_vocab): """Create sparse feature matrix, and vocabulary where fixed_vocab=False """ if fixed_vocab:#辞書が作成されているとき vocabulary = self.vocabulary_ else:#辞書が作成されていないとき # Add a new value when a new vocabulary item is seen vocabulary = defaultdict() vocabulary.default_factory = vocabulary.__len__ #ここらの設定を行うことでvocabulary[単語]とすることでその単語に自動でindexが設定されます.結構役たちます. analyze = self.build_analyzer() #ここでn_gramとかの設定が適応. j_indices = [] indptr = [] values = _make_int_array() indptr.append(0) for doc in raw_documents:#一次元のデータを読み込む. #doc = ["hoge hogeee hogeeeee"] みたいな感じ feature_counter = {} for feature in analyze(doc):#単語 #feature = "hoge" みたいな感じ try: feature_idx = vocabulary[feature] #ここでhoge:1 hogee:2 hogeee:3という感じになる. feature_idxは数値データとなる.hogeだと1がかえる. if feature_idx not in feature_counter: feature_counter[feature_idx] = 1 #feature_counterの辞書に無い場合. else: feature_counter[feature_idx] += 1 #feature_counterの辞書にある場合 +1される except KeyError: # Ignore out-of-vocabulary items for fixed_vocab=True continue j_indices.extend(feature_counter.keys()) #辞書の単語(数値になっている) values.extend(feature_counter.values()) #辞書の単語が何回出現されているか indptr.append(len(j_indices)) #上記三つに関してはスパースモデルを作成するときに登場するやり方です. if not fixed_vocab: #辞書が作成されていないとき,実行 # disable defaultdict behaviour vocabulary = dict(vocabulary) if not vocabulary: raise ValueError("empty vocabulary; perhaps the documents only" " contain stop words") if indptr[-1] > np.iinfo(np.int32).max: # = 2**31 - 1 if _IS_32BIT: raise ValueError(('sparse CSR array has {} non-zero ' 'elements and requires 64 bit indexing, ' 'which is unsupported with 32 bit Python.') .format(indptr[-1])) indices_dtype = np.int64 else: indices_dtype = np.int32 j_indices = np.asarray(j_indices, dtype=indices_dtype) indptr = np.asarray(indptr, dtype=indices_dtype) values = np.frombuffer(values, dtype=np.intc) X = sp.csr_matrix((values, j_indices, indptr), shape=(len(indptr) - 1, len(vocabulary)), dtype=self.dtype) X.sort_indices() return vocabulary, X #辞書とX(スパースのベクトル値)ここらの辞書の作成のアルゴリズムは馴染みがあるひとは多いのでは無いでしょうか?やっていることはそこまで難しくありません.ただし,スパースの値を使っているところは少し複雑です.
さて終盤です.
if not self.fixed_vocabulary_: #Falseのとき実行 X = self._sort_features(X, vocabulary) #辞書を綺麗に並び直す. n_doc = X.shape[0] max_doc_count = (max_df if isinstance(max_df, numbers.Integral) else max_df * n_doc) min_doc_count = (min_df if isinstance(min_df, numbers.Integral) else min_df * n_doc) if max_doc_count < min_doc_count: raise ValueError( "max_df corresponds to < documents than min_df") X, self.stop_words_ = self._limit_features(X, vocabulary, max_doc_count, min_doc_count, max_features) self.vocabulary_ = vocabulary #ここで辞書を設定 return X上記は基本的に,min_doc_count < min_doc_countだとおかしいよ!と言っており,self._limit_features()にて出現頻度に応じて次元を少なくしています.return Xでベクトルがscipyで返却されます.
終わりに
sklearnの中のCountVectorizerの中身を少し見てみました.今回は数式が登場もしないのでそこまでプログラムが複雑でもありませんでした.案外部品に分けていくと一つ一つの処理は単純です.この記事を少しでも見て,自分でどうやって作られているのか確かめてみてください.次はTF-IDFでもみてみようかなと思います.気が向いたら書きます.以上
- 投稿日:2020-10-09T15:21:56+09:00
pystanによる将棋プロ棋士の実力値モデリング【先手と後手での実力差可視化】
こんな人におすすめ
- 将棋が好きな人
- pystanによる統計モデリングに興味がある人
- 藤井聡太二冠の実力がすごいのかを知りたい人
この記事でやったこと
- 棋士ごとに先手、後手で実力値がどの程度違うかを検討
- pystanを用いて将棋のプロ棋士の実力値をモデリング
- 棋士の実力は対局ごとにばらつきのある正規分布としてモデリング
- 将棋レーティングサイトから対局結果をスクレイピングした結果を使用
はじめに
藤井聡太二冠、強いですよね。テレビで取り上げられたりするなど将棋の露出度がましています。
プロの将棋でよく取り上げられる議題は、後手番は本当に不利なのか?というもの。普通に考えたら一手先にさせる分先手が有利そうです。事実としてプロの将棋では先手番の勝率の方がやや高くなっているそうです。(先手番勝率が53%程度)
しかし、それは将棋界全体でみた場合のはなし。実際は、棋士ごとに先手、後手どちらが得意かというのは異なるはず。
一般に棋士の実力値を数値化したものとして棋士のレーティングがあげられます。このレーティングサイトでは、棋士の実力値が数値化されています。しかし、先手後手ごとの数値化はなされていません。また、棋士の実力の安定感もレーティングからのみではわかりません。そこで、本記事ではpystanを用いたベイズ統計モデリングによって
- 棋士ごとに先手、後手でどの程度の実力値の違いがでるか
- 勝負ムラが大きい棋士、小さい棋士は誰か
を検討したいと思います。ちなみに、筆者は振り飛車党で好きな戦型は四間飛車です。
使用したデータ
- レーティングサイトからスクレイピング :http://kishibetsu.com/rating.html
- 2017年1月~2020年9月までの対局結果を使用
- 対局数が先手、後手それぞれ10局以上ある棋士の結果のみを使用(外れ値が生成されるのを防ぐため)
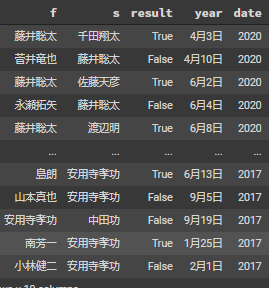
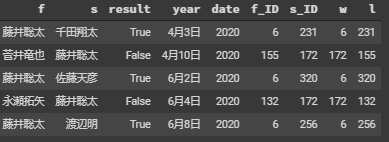
- 使用した対局数は7733局、棋士数は166人
下記の図のように先手(f列)、後手(s列)、対局結果(result列、trueだと先手勝ち)が保存されているdataframeを作成しました。
実力値のモデリング手法
参考文献の「StanとRでベイズ統計モデリング」にのっている手法を参考にしました。詳細は「ベイズモデリングで男子プロテニスの強さを分析してみた」にも記載されています。
概要を記すと
- 棋士の実力値を$\mu$、実力ムラを$\sigma$として、対局時の実力は$normal(\mu,\sigma)$で表される
- 対局時の実力が高いほうが対局に勝利する
とモデリングしています。
つまり棋士の真の実力に対して対局ごとにばらつきがある、とモデリングしているということになります。
このモデリングをすることで、レーティングのみではわからなかった、勝負ムラが明らかになるというメリットもあります。先手、後手の実力をどうやってモデリングするか、ですが今回は先手と後手が全く別人だとしてモデリングを行いました。つまり、先手の実力値は先手の対局結果のみから推定され、後手の実力値は後手の対局結果のみから推定されます。
pystanでは勝者の列、敗者の列の二列を対局結果として与えます。そのため下記のようにwの勝者列、lの敗者列作成しました。
df["w"] = np.where(df["result"],df["f_ID"],df["s_ID"]) df["l"] = np.where(df["result"],df["s_ID"],df["f_ID"])モデリング結果
計算はNUTSで行い1時間程度かかりました。
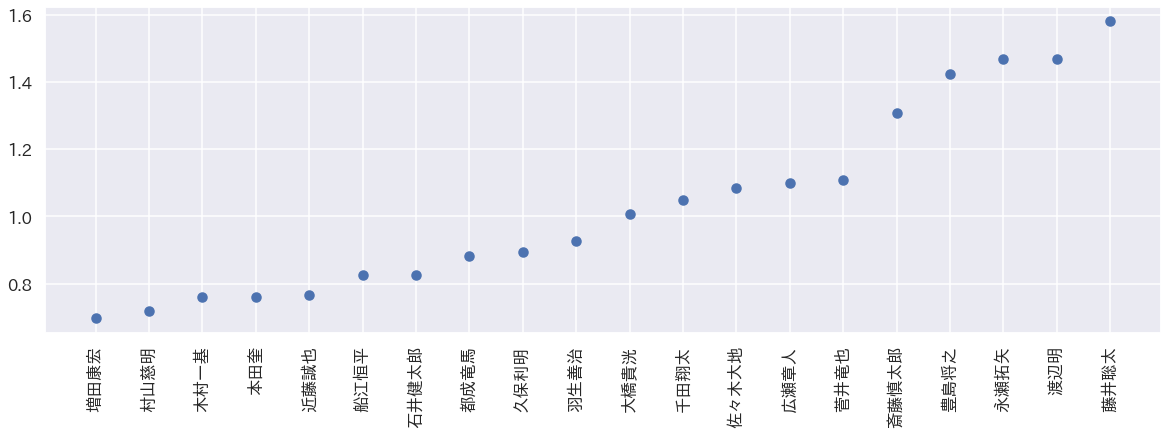
先手実力値が高い棋士TOP20
まずは計算結果の妥当性を確かめる上で先手版での実力値が高い棋士TOP20を抜き出します。
縦軸が実力値となっています。またプロットしているのはモデリングされた実力の平均値を示しています。
この結果をみると、現在四強といわれている「藤井聡太、永瀬拓矢、豊島将之、渡辺明」の4人がtop4人となっており妥当性の高そうな結果が得られています。実力値の4分位点をみても有意性の
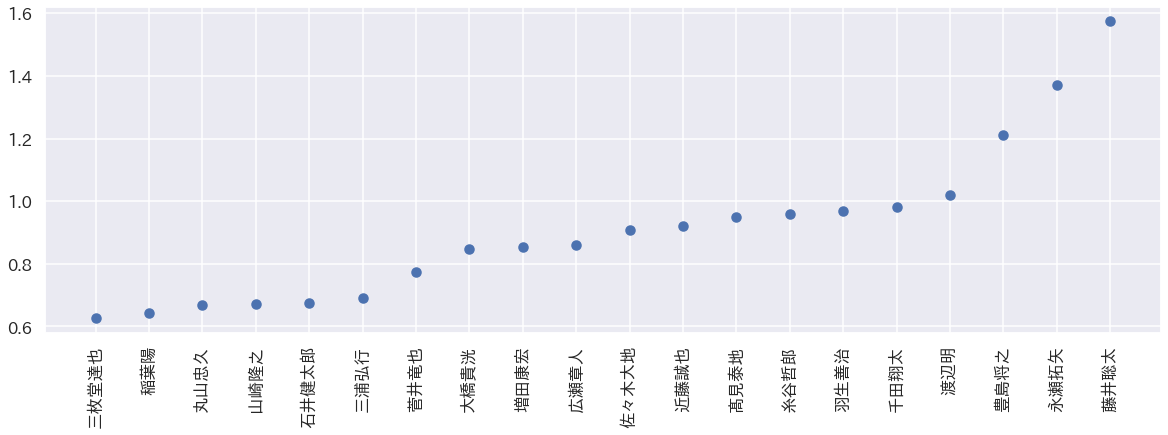
ある結果となっていそうです。次に後手番top20の結果を示します。
やはり、「藤井聡太、永瀬拓矢、豊島将之、渡辺明」の4人がtop4人となっています。ただし、先程と比べるとそれ以外の方は入れ替わりがありますね。このことから先手とは違う実力値がモデリングされていることがわかります。というより後手番藤井聡太圧倒的強さ...
以上の結果、よりモデリングは妥当性の高そうな結果が得られていると考えられます。次に先手番と後手番でどの程度違いがあるかを検討していきます。
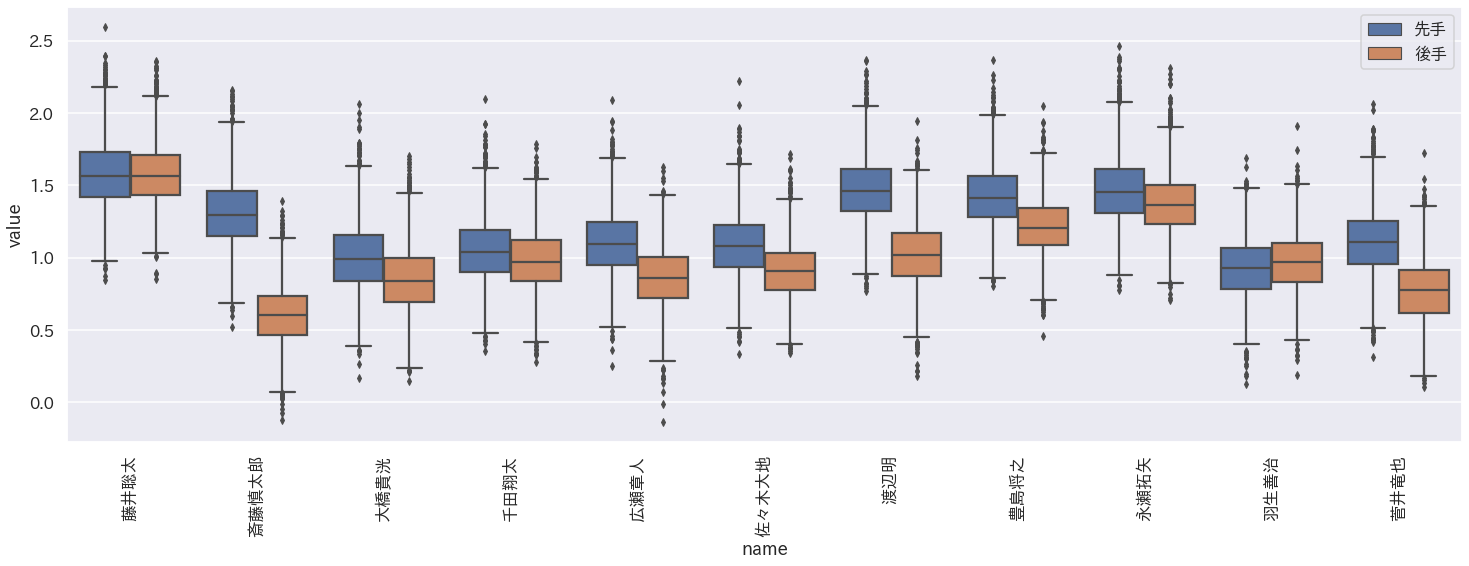
先手と後手番の差
先手番の上位の棋士の実力値を先手後手で比較してみます。下記の図において青が先手、オレンジが後手を表しています。箱ひげ図の箱が4分位点を表しており、この箱が重なってない場合有意差がありそうと考えることができます。
上の図より以下のことがわかります。
- 多くの棋士は後手番のほうがやや実力値が低い
- 特に実力値に違いがあるのが斎藤慎太郎、渡辺明、菅井竜也
- 藤井聡太、羽生善治は後手番と先手番の実力差が少ないこの結果は感覚的にも正しそうです。藤井二冠は後手番でも勝率が高いですし、渡辺二冠は数年前後手番で特に苦戦していた印象があります。
これらのことから、棋士により先手と後手の実力差には大きな違いがあることがわかりました。先手後手の実力差が大きい棋士
次は、先手後手の実力差が大きい/小さい棋士について可視化します。上位棋士39名に絞って実力差の違いを可視化しました。
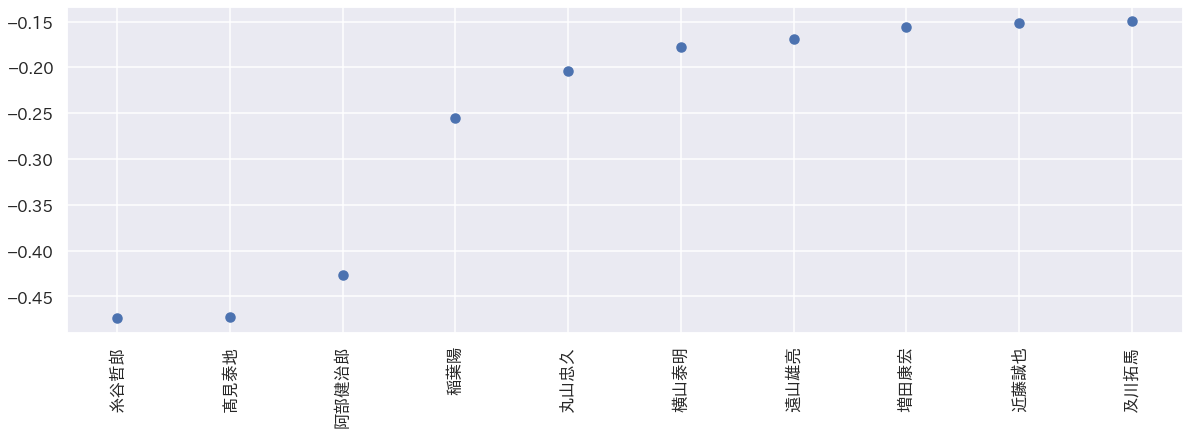
まずは後手番のほうが強い棋士top10。
値が小さいほど、後手番のほうが強いことを示しています。際立っているのは糸谷哲郎、高見泰地、阿部健治郎の三人ですね。
あまり自分的には後手番のほうが強い印象がないので有識者の意見を聞いてみたいところです。
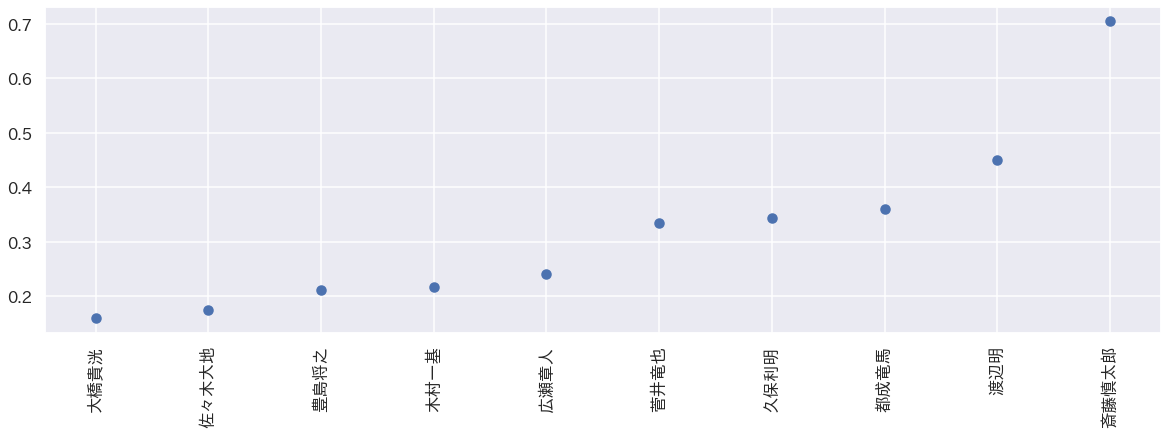
次に先手番のほうが強い棋士10人。値が大きいほど先手のほうが強いことを示しています。
際立っているのは斎藤慎太郎。これもそういう印象はないので意見求む。
勝負ムラの大きい棋士
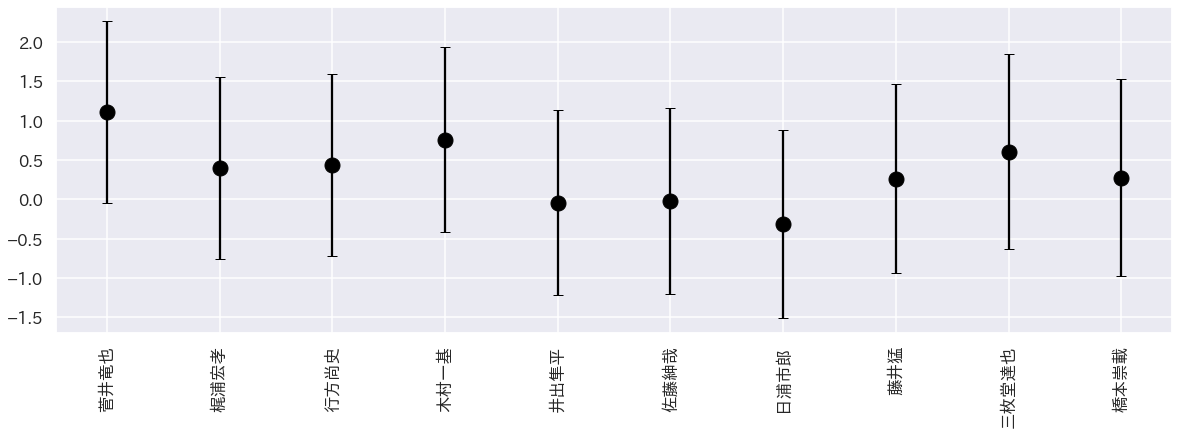
次に勝負ムラの大きい棋士の結果です。分析したところ、勝負ムラは先手、後手で大きな違いがない棋士が多かったのでここでは先手の分析結果のみを使いました。
下記が勝負ムラの大きいとモデリングされた棋士10人です。注目は木村一基や菅井竜也。この二人は2017年から考えるとタイトル獲得歴もある棋士であり、そのときの爆発力が勝負ムラとしてモデリングされたと考えられます。
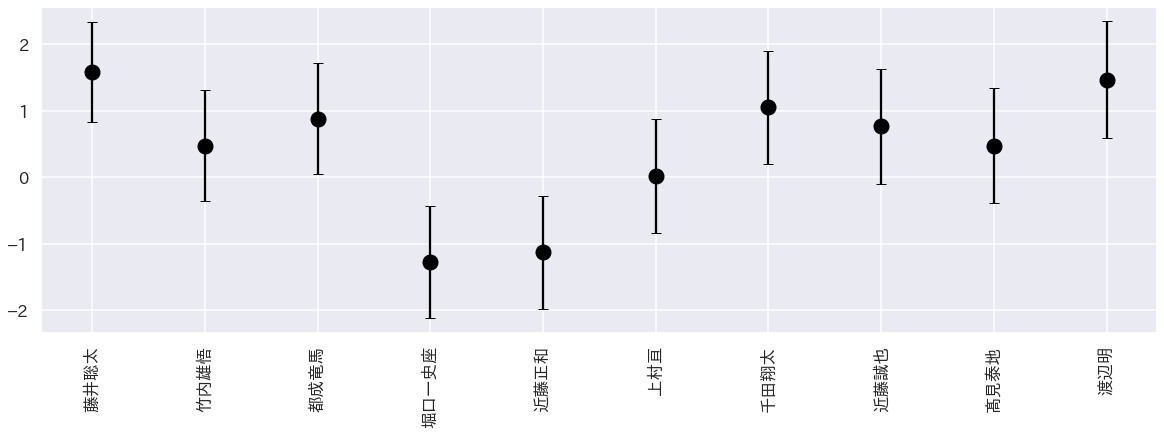
次に勝負ムラの少ない棋士10人。ここで藤井聡太、渡辺明の二名が入っているのが面白いところです。
この二人は実力値が高い上に、勝負ムラも少ない。
なのでこの二名は勝負の取りこぼしが少なく、安定して勝っているといえます。
終わりに
- ベイズ統計モデリングを行って将棋棋士の実力値をモデリング
- 先手、後手の実力差の違いが明らかになった。多くの棋士は後手のほうが実力が低い。
- 後手番のほうが特に強いのは糸谷哲郎、高見泰地、阿部健治郎の三人。
- 先手番のほうが特に強いのは斎藤慎太郎。
- 渡辺明、藤井聡太は実力値が高いうえに勝負ムラも小さい。安定して勝っているといえる。
もし面白いと思ったらLGTMよろしくお願いします。
その他解析したいこと
- 振り飛車党の棋士の後手番解析
参考文献
StanとRでベイズ統計モデリング
https://www.amazon.co.jp/Stan%E3%81%A8R%E3%81%A7%E3%83%99%E3%82%A4%E3%82%BA%E7%B5%B1%E8%A8%88%E3%83%A2%E3%83%87%E3%83%AA%E3%83%B3%E3%82%B0-Wonderful-R-2-%E6%9D%BE%E6%B5%A6-%E5%81%A5%E5%A4%AA%E9%83%8E-ebook/dp/B07M8LWLS1/ref=sr_1_1?__mk_ja_JP=%E3%82%AB%E3%82%BF%E3%82%AB%E3%83%8A&dchild=1&keywords=stan%E3%81%A8R&qid=1602217801&sr=8-1
ベイズモデルで大相撲力士の強さを判定してみた
https://qiita.com/a0082273/items/670ccafff23c3c576371
ベイズモデリングで男子プロテニスの強さを分析してみた
http://www.ie110704.net/2018/05/24/%E3%83%99%E3%82%A4%E3%82%BA%E3%83%A2%E3%83%87%E3%83%AA%E3%83%B3%E3%82%B0%E3%81%A7%E7%94%B7%E5%AD%90%E3%83%97%E3%83%AD%E3%83%86%E3%83%8B%E3%82%B9%E3%81%AE%E5%BC%B7%E3%81%95%E3%82%92%E5%88%86%E6%9E%90/
- 投稿日:2020-10-09T14:58:48+09:00
Dango 権限者によって表示するものを変更する
シフト表を一度、使用してもらう友人に見てもらいました。
いくつか要望がありました。①シフト表 管理者以外は時間の編集はできないようする
②シフト表 シフト作成は曜日でコピーしてほしい
③希望シフト 毎月5日までにシフト希望を聞いて10日までに作成し配布しているので5までに入力させる入力制限
④掲示板 施設ごとにお知らせをする
⑤タスク 何をやらないといけないかを引き継ぎとかできると最高今までは、動くものをとりあえず目標に作成していきました。
ここからは、本当に使ってもらえるための入力制限や権限によるコントロールを学んでいこうと思います。まず、シフト表の労働時間をクリックすると、シフトを登録する画面に遷移するのですが、これをスーパーユーザーのだけができて、他のユーザーにはできないように変更します。
htmlに、
{% if perms.schedule.add_schedule %}
の条件文を追加しました。
perms. が権限設定自体をさしていて、そのなかのscheduleテーブルに追加権限があるかを判断します。
たった1行のことですが、これだけで2時間近くかかりました。
権限設定について、学ぶことがありそうです。htmlはこんな感じ
schedule.month.html{% extends 'accounts/base.html' %} {% load static %} {% block customcss %} <link rel="stylesheet" href="{% static 'schedule/month.css' %}"> {% endblock customcss %} {% block header %} <div class="header"> <div class="cole-md-1"> <a href="{% url 'schedule:KibouList' %}" class="btn-secondary btn active">希望シフト一覧</a></p> {% ifnotequal month 1 %} <a href="{% url 'schedule:monthschedule' year month|add:'-1' %}" class="btn-info btn active">前月</a> {% else %} <a href="{% url 'schedule:monthschedule' year|add:'-1' 12 %}" class="btn-info btn active">前月</a> {% endifnotequal %} {% ifnotequal month 12 %} <a href="{% url 'schedule:monthschedule' year month|add:'1' %}" class="btn-info btn active">次月</a> {% else %} <a href="{% url 'schedule:monthschedule' year|add:'1' 1 %}" class="btn-info btn active">次月</a> {% endifnotequal %} {% if perms.schedule.add_schedule %}<!--権限--> <a href="{% url 'schedule:schedulecreate' year month %}" class="btn-info btn active">シフト作成</a> {% endif %} </div> <div class="cole-md-2"> {% for shift in shift_object %} {% if shift.name != "休" and shift.name != "有" %} {{ shift.name }} : {{ shift.start_time | date:"G"}}~{{ shift.end_time | date:"G"}} {% endif %} {% endfor %} </div> <p> <a href="{% url 'schedule:monthschedule' year month %}" button type="button" class="btn btn-outline-dark">すべて</a> {% for shisetsu in shisetsu_object %} <a href="{% url 'schedule:monthschedulefilter' year month shisetsu.pk %}" button type="button" class="btn btn-outline-dark" span style="background-color:{{ shisetsu.color }}">{{ shisetsu.name }}</span></a> {% endfor %} </p> </div> {% endblock header %} {% block content %} <table class="table"> <thead> <tr> <!--日付--> <th class ="fixed00" rowspan="2">{{ kikan }}</th> {% for item in calender_object %} <th class ="fixed01">{{ item.date | date:"d" }}</th> {% endfor %} <tr> <!--曜日--> {% for item in youbi_object %} <th class ="fixed02">{{ item }}</th> {% endfor %} </tr> </thead> <tbody> {% for profile in profile_list %} {% for staff in user_list %} {% if profile.user_id == staff.id %} <tr align="center"> <th class ="fixed03" >{{ staff.last_name }} {{ staff.first_name }}</th> <!--staff_id要素はjsで使う--> {% for item in object_list %} {% if item.user|stringformat:"s" == staff.username|stringformat:"s" %}<!--usernameが同一なら--> <td class="meisai"> {% if item.shift_name_1 != None %} {% if item.shift_name_1|stringformat:"s" == "有" or item.shift_name_1|stringformat:"s" == "休" %} {{ item.shift_name_1 }} {% else %} {% for shisetsu in shisetsu_object %} {% if item.shisetsu_name_1|stringformat:"s" == shisetsu.name|stringformat:"s" %} <span style="background-color:{{ shisetsu.color }}">{{ item.shift_name_1 }}</span> {% endif %} {% endfor %} {% endif %} {% endif %} {% if item.shift_name_2 != None %} {% if item.shift_name_2|stringformat:"s" == "有" or item.shift_name_2|stringformat:"s" == "休" %} {{ item.shift_name_2 }} {% else %} {% for shisetsu in shisetsu_object %} {% if item.shisetsu_name_2|stringformat:"s" == shisetsu.name|stringformat:"s" %} <span style="background-color:{{ shisetsu.color }}">{{ item.shift_name_2 }}</span> {% endif %} {% endfor %} {% endif %} {% endif %} {% if item.shift_name_3 != None %} {% if item.shift_name_3|stringformat:"s" == "有" or item.shift_name_3|stringformat:"s" == "休" %} {{ item.shift_name_3 }} {% else %} {% for shisetsu in shisetsu_object %} {% if item.shisetsu_name_3|stringformat:"s" == shisetsu.name|stringformat:"s" %} <span style="background-color:{{ shisetsu.color }}">{{ item.shift_name_3 }}</span> {% endif %} {% endfor %} {% endif %} {% endif %} {% if item.shift_name_4 != None %} {% if item.shift_name_4|stringformat:"s" == "有" or item.shift_name_4|stringformat:"s" == "休" %} {{ item.shift_name_4 }} {% else %} {% for shisetsu in shisetsu_object %} {% if item.shisetsu_name_4|stringformat:"s" == shisetsu.name|stringformat:"s" %} <span style="background-color:{{ shisetsu.color }}">{{ item.shift_name_4 }}</span> {% endif %} {% endfor %} {% endif %} {% endif %} {% endif %} {% endfor %} </td> <tr align="center"> {% for month in month_total %} {% if month.user == staff.id %}<!--usernameが同一なら--> <td class="fixed04"><b>{{ month.month_total_worktime }}</b></td> {% endif %} {% endfor %} {% for item in object_list %} {% if item.user|stringformat:"s" == staff.username|stringformat:"s" %}<!--usernameが同一なら--> {% if perms.schedule.add_schedule %}<!--権限--> <td class="meisai" id="s{{ staff.id }}d{{ item.date }}"> <a href="{% url 'schedule:update' item.pk %}">{{ item.day_total_worktime }} </a> </td> {% else %} <td class="meisai" id="s{{ staff.id }}d{{ item.date }}"> {{ item.day_total_worktime }} </td> {% endif %} {% endif %} {% endfor %} </tr> {% endif %} {% endfor %} {% endfor %} </tbody> </table> </div> </div> {% endblock content %}
シフト作成ボタンが権限がないと表示されないくなりました。
そして、時間もクリックできないようになっています。①シフト表 管理者以外は時間の編集はできないようする
これで、解決できました。②シフト表 シフト作成は曜日でコピーしてほしい
⇒曜日でのコピーはどうするのがいいのか考えます。
profileに持たせて、そこからコピーする方が楽なような気がします。③希望シフト 毎月5日までにシフト希望を聞いて10日までに作成し配布しているので5までに入力させる入力制限
⇒こちらは、今2時間ぐらいやりましたが、解決ができていません。
現在のコードはこちらですschedule.viewsclass KibouUpdate(UpdateView): template_name = 'schedule/kiboushift/update.html' model = KibouShift fields = ('user', 'date', 'shift_name_1', 'shisetsu_name_1', 'shift_name_2', 'shisetsu_name_2', 'shift_name_3', 'shisetsu_name_3', 'shift_name_4', 'shisetsu_name_4') def date(self): date = self.cleaned_date.get('date') now = datetime.now() print(now.date) #5日になったら20日以降のみ入力 if now.day > 5: startdate = datetime.date(now.year,now.month,20) if date < startdate: raise ValidationError( "入力できない日付です", params={'value': value}, ) else: startdate = datetime.date(now.year,now.month,20) startdate = enddate + relativedelta(months=1) if date < startdate: raise ValidationError( "入力できない日付です", params={'value': value}, ) return date success_url = reverse_lazy('schedule:KibouList')これで5日を超えると翌月の20日以降しか更新できないようしたのですが、
全然できてしまいます(笑)これは、すぐに解決できないかも
④掲示板 施設ごとにお知らせをする
⇒これは実装できそうなのでやっていこうと思います(⌒∇⌒)⑤タスク 何をやらないといけないかを引き継ぎとかできると最高
⇒redmine かtodoist 等の使い勝手等を研究して定期タスクなどいろいろ作り方を検討しようと思います
これは、ひとつのアプリになると思うので後回しにする予定

- 投稿日:2020-10-09T12:21:24+09:00
ファイル名一覧をテキスト(.txt)ファイルに書き込む【Python】
機械学習のデータセットのためのファイル名一覧などに。
import os path = "./datasets/train" # ファイル名一覧を取得したいディレクトリのパス text_file = open("./datasets/train.txt", "w") # 書き込み先のテキストファイルを作る files = os.listdir(path) # ファイル名一覧を取得 for f in files: basename_without_ext,ext = os.path.splitext(os.path.basename(f)) # 拡張子抜きのファイル名を取得 text_file.write(basename_without_ext + "\n") # テキストファイルに書き込む text_file.close() # テキストファイルを保存image0
image1
image2
image3
・
・
・という感じで書き込まれます。
拡張子も書き込みたい場合は、# basename_without_ext,ext = os.path.splitext(os.path.basename(f)) # 拡張子抜きのファイル名を取得 basename = os.path.basename(f) # 拡張子ありのファイル名を取得image0.jpg
image1.jpg
image2.jpg
image3.jpg
・
・
・?
お仕事のご相談こちらまで
rockyshikoku@gmail.comCore MLを使ったアプリを作っています。
機械学習関連の情報を発信しています。
- 投稿日:2020-10-09T10:41:53+09:00
Seleniumとheadless chromeをAWS lambdaに入れてみました。(Win10環境下の注意点等)
Python でWeb Scraper を作る時に、対象ターゲットのがclient-side javascript で取得している際、単純にurlopenではほしい情報を取得できないことが多いです。そのため、SeleniumかAPI(もしあれば)で取得することが多いと思います。
一方で、定期的に、かつ経済的に何かを実行したい時には、on-demand のAWS lambdaとCloudEvent を使用するのが良いでしょう。
では、スタート
手順
環境構築
Windows環境下でAmazon LinuxをOSにしたAWS lambdaを使うには、Ubuntu on Windows 10 かその他remote linux server の支援が必要です。今回はより経済的な方法として、Ubuntu on Windows 10 を選択。
具体的なインストール方法は以下参照すると良いでしょう。
次に、Pythonを入れておきます。
sudo apt-get update sudo apt-get install python3.6次
環境が整えたら、次にUbuntu 下で以下の操作を行う。
※Windowsで圧縮しても後にLambdaでエラー発生するので要注意。
- 分かりやすい場所に移動する、以下は例
# Cディスクに移動する cd /mnt/c/ mkdir /path/to/folder cd /path/to/folderそれで、File Explorerですぐに生成してファイルを見つけるでしょう。(あとでS3に入れる時が方便になります)
headless chrome と chromedriver を取得
- ここで注意すべきのは、新しいバージョンのheadless-chromiumを使っても、対応するchromedriverでないとエラー発生します。私が使っていたのは、以下の2つ
- https://github.com/adieuadieu/serverless-chrome/releases/tag/v1.0.0-37
stable-headless-chromium-64.0.3282.167-amazonlinux-2017-03.zip- https://chromedriver.storage.googleapis.com/index.html?path=2.37/
chromedriver_linux64.zip次に、それらを解凍して以下のように権限調整(
chmod 777)して、最終的に以下のようにchromeフォルダーに格納し、1つのZIPファイルに圧縮します。chrome.zip chrome ├── chromedriver └── headless-chromium
- Ubuntu にselenium package のZIPファイルを作成する。
mkdir python-selenium cd python-selenium python3 -m pip install --system --target ./ selenium zip -r python-selenium.zip ../python-selenium
chrome.zip&python-selenium.zipをS3に入れて、Object URLをメモしておき、Layer作成しましょう。最後サンプルを動いてみます。
from selenium import webdriver from selenium.webdriver.chrome.options import Options def lambda_handler(event, context): options = Options() # 自分の対応するファイルパスを入れる options.binary_location = '/opt/chrome/headless-chromium' options.add_argument('--headless') options.add_argument('--no-sandbox') options.add_argument('--single-process') options.add_argument('--disable-dev-shm-usage') # 自分の対応するファイルパスを入れる browser = webdriver.Chrome('/opt/chrome/chromedriver', chrome_options=options) browser.get('https://www.google.com') title = browser.title browser.close() browser.quit() return {"title": title}ここで注意するのは、Basic setting of lambda function(基礎設定)のところを、Exampleを動くにはメモリ消耗が256MB以上、Durationがおよそ10秒しました(512MB, timeout:20s設定の場合)、事前に調整して状況を見た方が良いでしょう。
Q&A
もしかすると疑問ある方いるかもしれないので、いくつ自分がやる時に戸惑っていたことを書きます。
Q:なぜchrome フォルダーに入れて圧縮する
A:特に必要ないが、Lambdaにlayerを追加する際に、zipファイルにあるものを、
/optフォルダーにくっつきます。例えば、/opt/chrome/chromedriver&/opt/chrome/headless-chromiumQ:図示のように、Windows持っているzip化の使用はダメですか。
A:実際にそれをLayerにアップロードすると、
Message: 'chromedriver' executable may have wrong permissionsというエラーメッセージが出されるので、調べたところ、どうも権限がうまくつけないらしい。そのため、Ubuntu下でファイルの権限調整し、圧縮しましょう。参考
おわりに
何かエラーを発生しても慌てずに、lambda test実行後のエラーレポートを確認すると良いでしょう。意外に問題点がはっきりと書いてある。
- 投稿日:2020-10-09T09:26:44+09:00
graph-toolでcsv形式のリンクリストを読み込む
やりたいこと
graph-toolで以下のようなリンクリスト
(source,dest,weight)形式のファイルを読み込むことを考える。link_list.csvAlice,Bob,2 Bob,Charlie,5 Charlie,Alice,3コード
このファイルをgrpah-toolで読み込むには以下のようにcsvモジュールを使ってパースする。
load_csv_link_list.pyimport csv import graph_tool.all as gt nodes = set() rows = [] with open('link_list.csv') as f: reader = csv.reader(f) rows = [row for row in reader] for row in rows: nodes.add(row[0]) nodes.add(row[1]) nodes = list(nodes) g = gt.Graph() g.vp['name'] = g.new_vp('string') for n in nodes: v = g.add_vertex() g.vp['name'][v] = n # set edges g.ep['weight'] = g.new_ep('double') for row in rows: s = nodes.index(row[0]) t = nodes.index(row[1]) w = float(row[2]) vs = g.vertex(s) # => get vertex object from the index vt = g.vertex(t) e = g.add_edge(vs, vt) g.ep['weight'][e] = wやっていることは以下の通り
- まずはcsvファイルの内容全てを読み込んでしまい、ノードの一覧
nodesを作る
- ユニークな物だけを取り出したいので、
setに格納し、その後listに変換している- ノード名はgraph に文字列の vertex_property
nameを作成してg.vp['name'] = g.new_vp('string')格納している
g.vpはノードに対する属性(vertex_property)を保持している- エッジの重みは浮動小数点型 edge_property
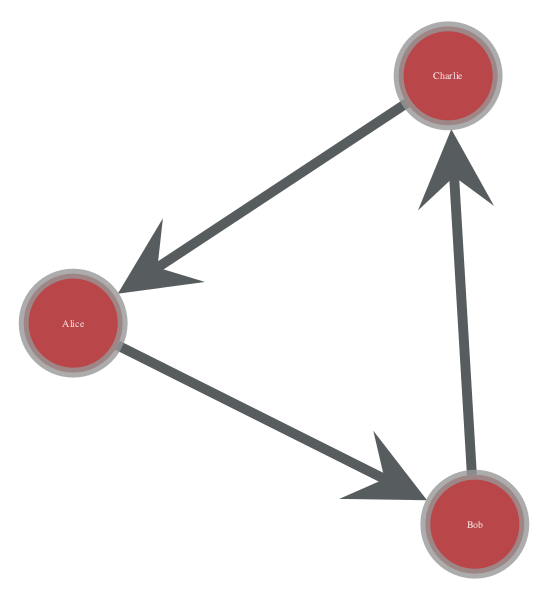
weightを作成して、格納しているグラフを可視化してみるとこのようになる。
結果
ちなみにこのグラフを可視化した結果はこのようになる。
pos = gt.arf_layout(g) gt.graph_draw(g, pos=pos, vertex_text=g.vp.name, vertex_font_size=10)
- 投稿日:2020-10-09T07:55:50+09:00
【Django】PyCharmでDjangoのコンテナ(Docker)開発環境をサクっと構築する
はじめに
普段業務でPyCharmを愛用しているのですが、Djangoコンテナ開発環境の構築について調べるのに少し時間がかかったので、最小構成で構築する手順を投稿します。
※この記事はPyCharm Professional(有料 無料期間30日有り)専用機能の紹介です。
無料でやりたい方は別記事でVSCodeを使ったコンテナ開発環境構築を紹介していますのでそちらをご覧ください。VSCodeには強力な拡張機能が多くあるのでDjangoの開発にも十分使えます。事前準備
1.Djangoプロジェクトの作成
※既に開発中のソースがある方はそれを使ってもOKです
今回はPythonインストール済みの環境で以下コマンドから作成したシンプルなDjangoアプリを使用します。> pip install django > django-admin startproject sampleApp > cd sampleApp sampleApp> python manage.py migrate2.Dockerfileの作成
Djangoアプリを作成したフォルダに以下内容のDockerfileを作成します。
FROM python:3.8 # 必要なパッケージがある場合インストール # RUN apt install ~~~ RUN pip intall django3.docker-compose.ymlの作成
同じくDjangoアプリを作成したフォルダに以下内容で作成します。
docker-compose.ymlversion: '3' services: app: build: . ports: - "8000:8000" volumes: - './:/app/sampleApp' working_dir: '/app/sampleApp' container_name: sampleApp privileged: true tty: true準備は以上です。
ここまでのディレクトリ構成は以下の通りです。Django-docker-sample-pycharm #今回のワークスペースフォルダ | docker-compose.yml | Dockerfile | \---sampleApp | db.sqlite3 | manage.py | \---sampleApp | asgi.py | settings.py | urls.py | wsgi.py | __init__.pyリモートインタープリタの設定
ワークスペースフォルダをPyCharmで開きます。
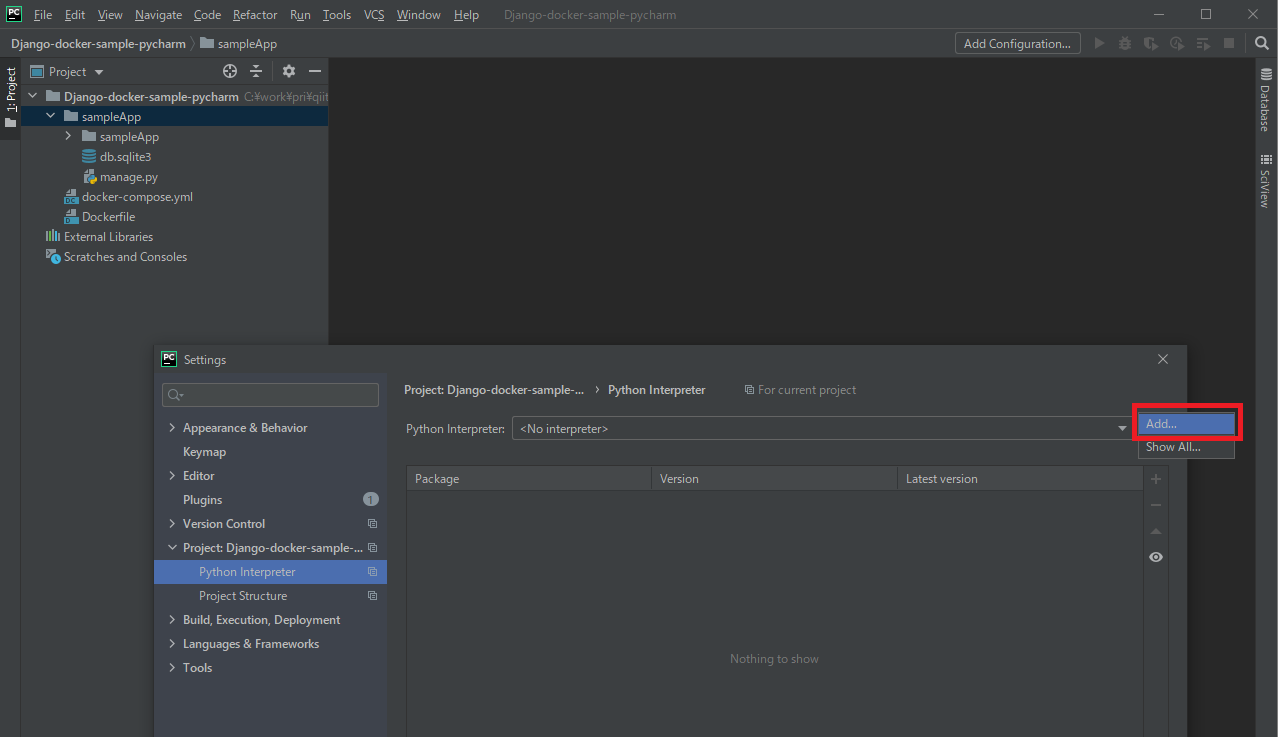
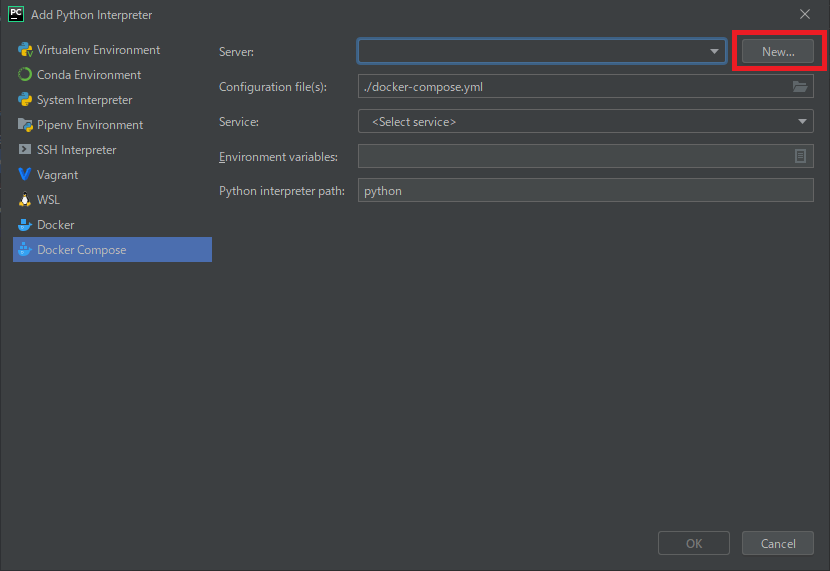
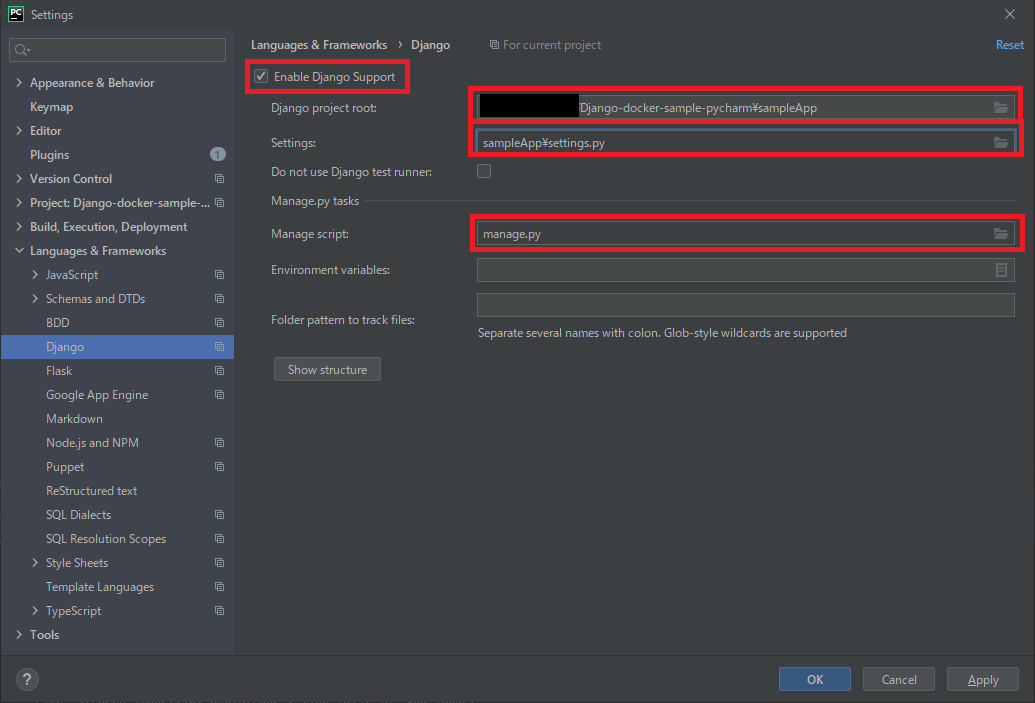
続いて[File]→[Settings]から[Python Interpreter]を選択し、インタープリタの追加画面を開きます。
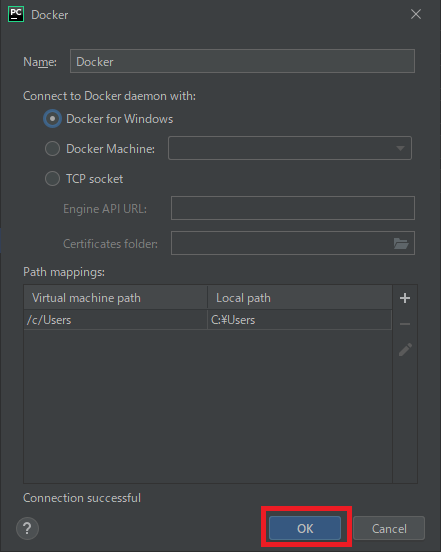
Docker Composeを選択し、[Server]新規作成画面を開きます。
特に何も変更せずOKで作成します。
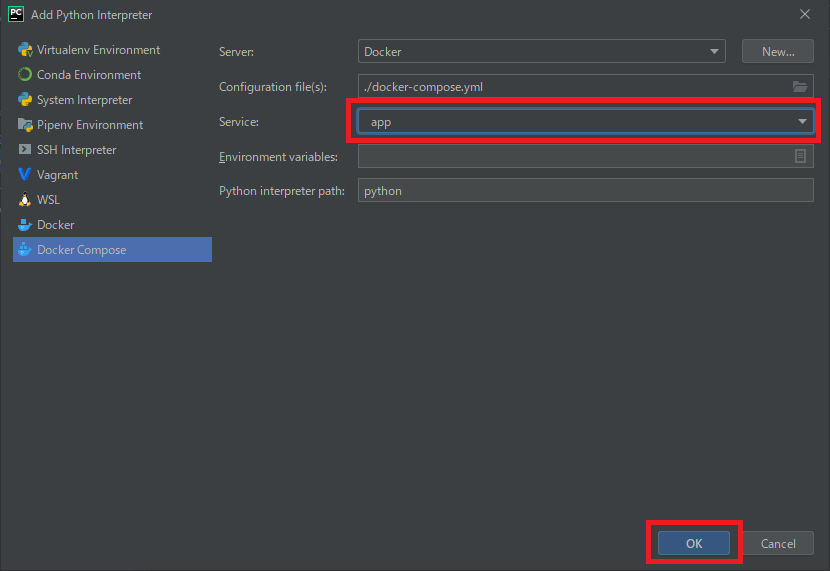
続いて[Service]のプルダウンから[app]を選択し、OKで設定を完了します。
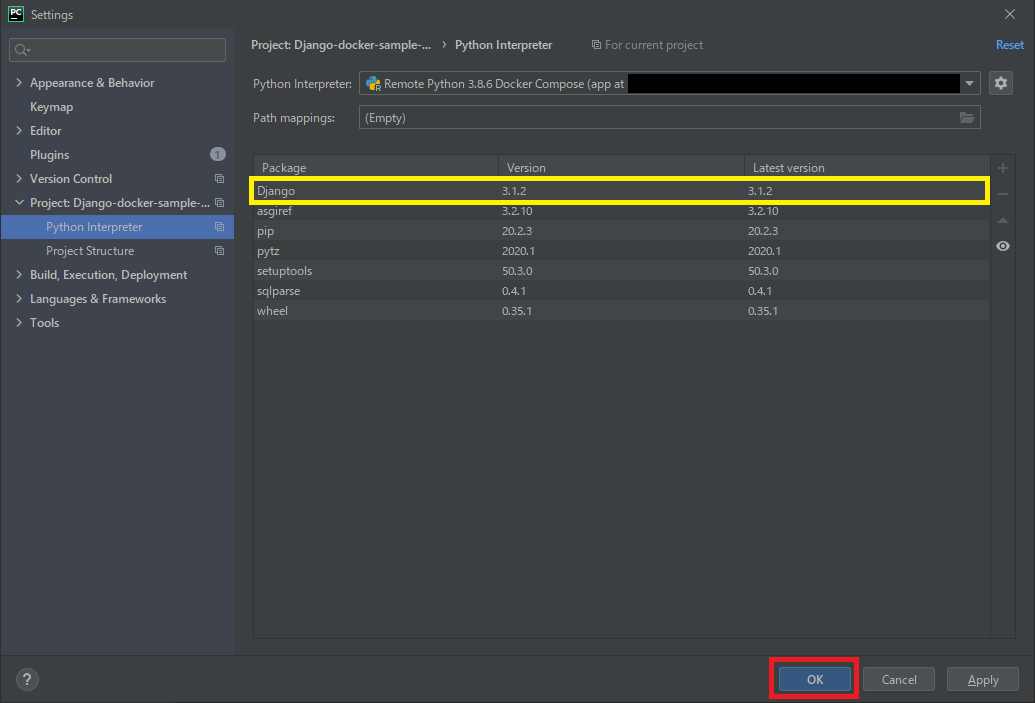
インタープリタの設定画面でリモートインタープリタが表示されていればOKです。
Dockerfileで「pip install django」を実行していたのでパッケージの一覧にDjangoが表示されていますね。
OKで設定を完了させましょう。
これで「このプロジェクトではワークスペースフォルダ直下にあるdocker-compose.ymlから作成されたコンテナのインタープリタを使用する」という設定が完了しました
いざ実行!
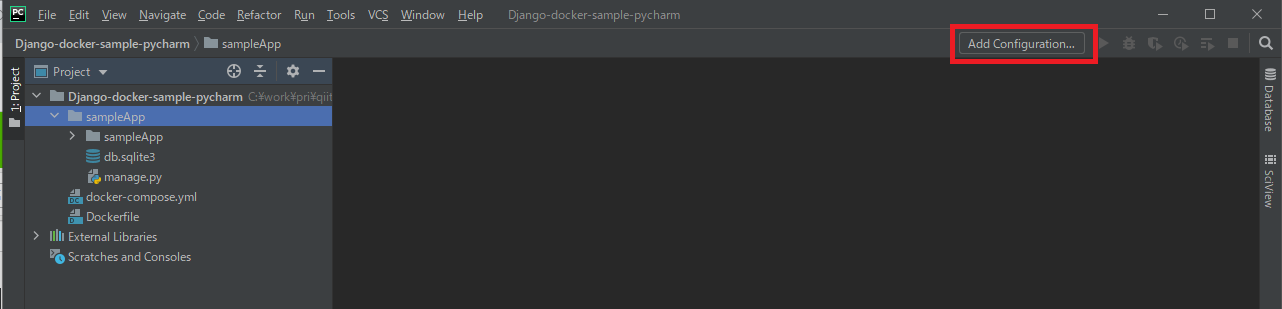
ここからはいつもの手順でrunserverしていきましょう。
[File]→[Settings]からDjangoの設定
[Add Configurations]
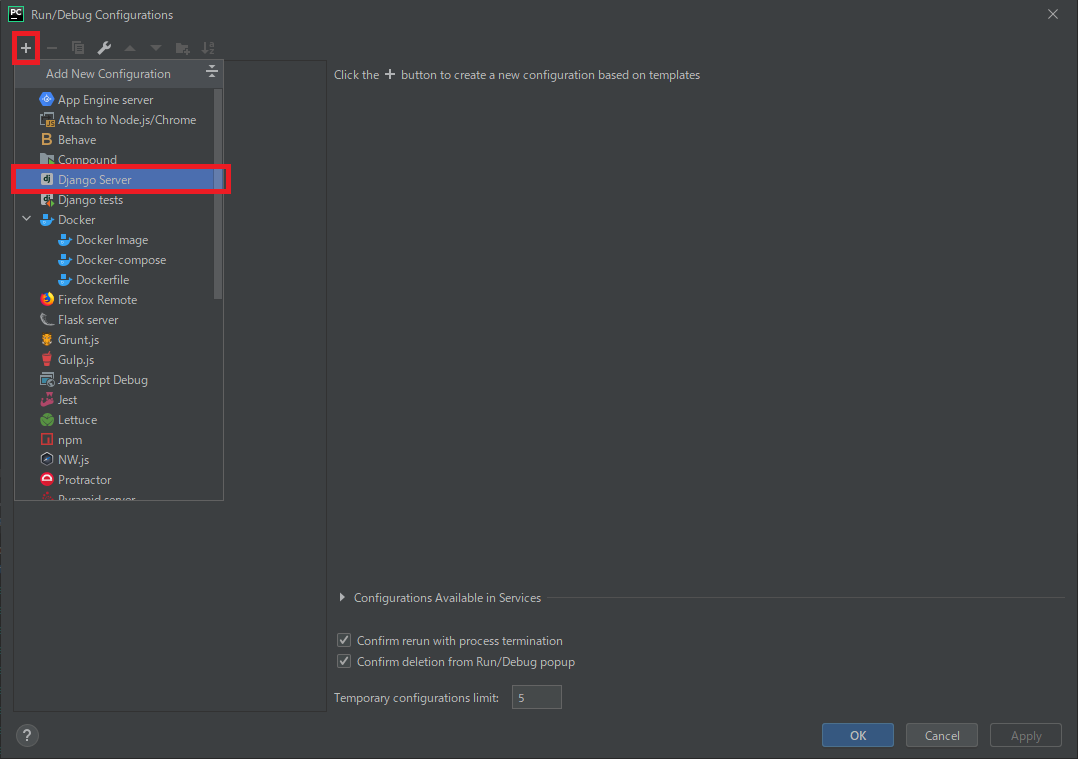
[+]→[Django Server]
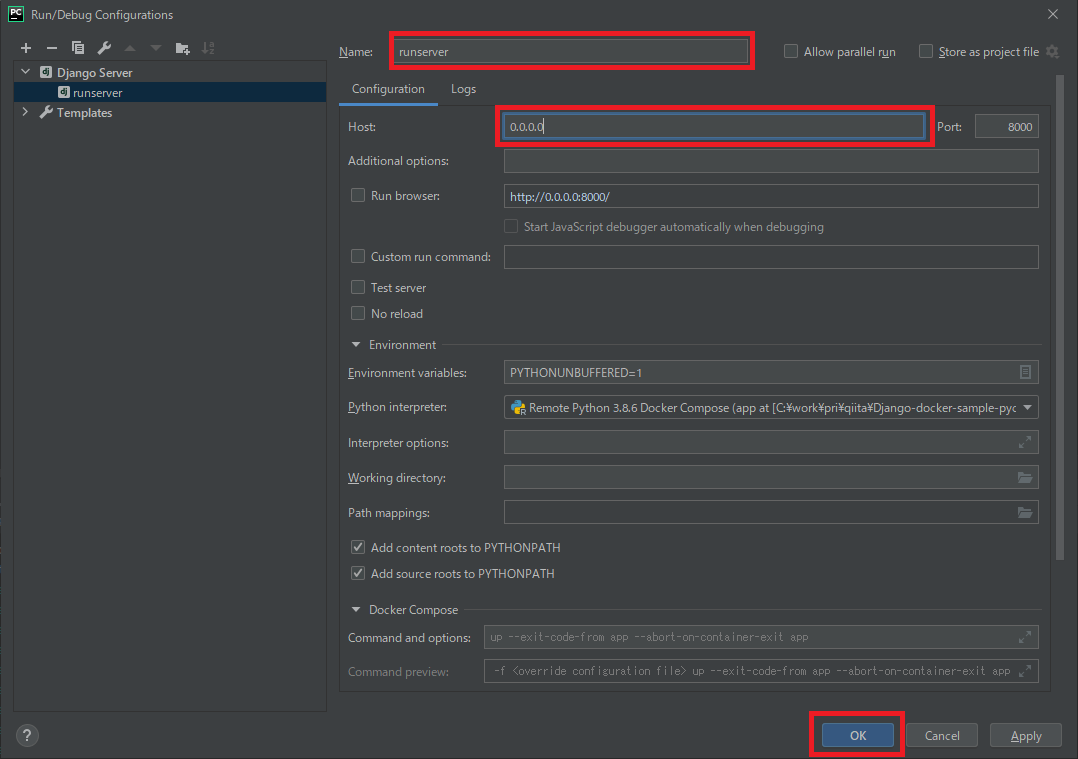
[Name](任意)と[Host](0.0.0.0)を設定してOK
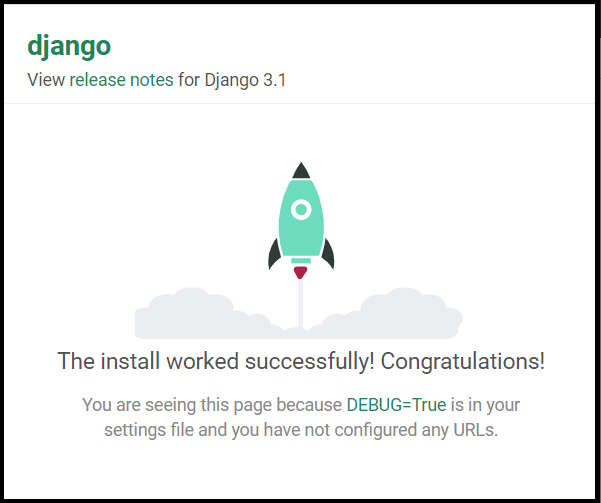
実行!隣の虫マークのボタンからデバッグも可能です。
ブラウザからhttp://localhost:8000にアクセスしてDjangoテストページが表示されればOK!
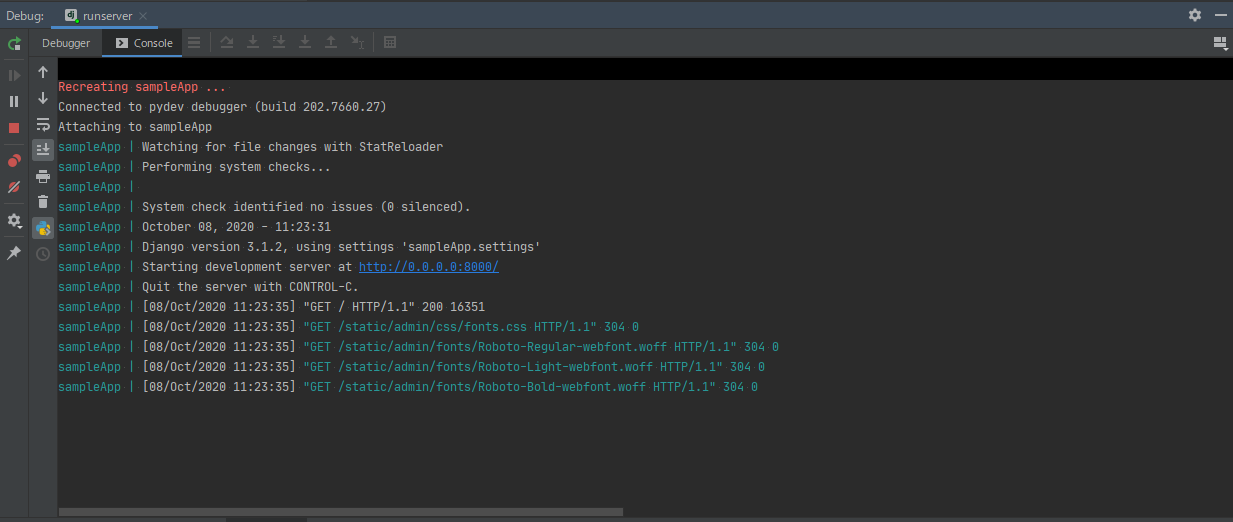
コンソールを見るとsampleAppコンテナ内で実行されていることがわかります。
デバッグモードではもちろんブレークポイントも使えます!
こんなに簡単にリモートインタープリタが使えるなんてさすが有料機能ですね。
これでコンテナを使った開発も捗りそうです

- 投稿日:2020-10-09T05:30:29+09:00
Plotlyで綺麗なグラフを描きたい
これは
Plotlyは少ないコードで綺麗なグラフがかけますが, matplotlibばかり使っていてあまりよく知らなかったので調べながら入門してみた人の備忘録です
環境
Google colaboratory
インストール
colabであればインストールはありませんが、必要な場合はpipでインストールできます
pip install plotlyデータの準備
seabornですぐ使える時系列データがあったのでそれを使ってみます. 以下はデータの準備なので飛ばしてください
import seaborn as sns import pandas as pd from calendar import month_name month_name_mappings = {name[:3]: n for n, name in enumerate(month_name)} # ただのデータの準備 df = sns.load_dataset('flights') df["month"] = df.month.apply(lambda x: month_name_mappings[x]) df["year-month"] = pd.to_datetime(df.year.astype(str) + "-" + df.month.astype(str)) ts_data = df[["passengers", "year-month"]].set_index("year-month")["passengers"] ts_datayear-month 1949-01-01 112 1949-02-01 118 1949-03-01 132 1949-04-01 129 1949-05-01 121 ... 1960-08-01 606 1960-09-01 508 1960-10-01 461 1960-11-01 390 1960-12-01 432 Name: passengers, Length: 144, dtype: int64月ごとの乗客数のシンプルなデータです.
基本操作
グラフを作成してみます
import plotly.graph_objects as go fig = go.Figure() fig.show()
グラフができた. ここに色々追加していくのですね
# 折れ線グラフ fig = go.Figure() fig.add_trace(go.Scatter(x=ts_data.index, y=ts_data.values, name="passengers")) fig.show()
メモリを対数表示にしてみる
# 折れ線グラフ fig = go.Figure() fig.add_trace(go.Scatter(x=ts_data.index, y=ts_data.values, name="passengers")) # 見た目のカスタマイズはlayoutをいじる fig.update_layout(yaxis_type="log") fig.show()
豪華なグラフを描きたい
もっと豪華にしたくなってきたので, 無理やり色々可視化してみます
- 月ごとにデータを分割?して, 各データの変化を折れ線グラフにする
- 年ごとの合計乗客数を棒グラフにしてみる
# 少しデータをこねこねする ts_data_monthly = df.groupby("month")["passengers"].apply(list) ts_sum_yearly = df.groupby("year")["passengers"].sum()# 複数の折れ線グラフにしたい ts_data_monthlymonth 1 [112, 115, 145, 171, 196, 204, 242, 284, 315, ... 2 [118, 126, 150, 180, 196, 188, 233, 277, 301, ... 3 [132, 141, 178, 193, 236, 235, 267, 317, 356, ... 4 [129, 135, 163, 181, 235, 227, 269, 313, 348, ... 5 [121, 125, 172, 183, 229, 234, 270, 318, 355, ... 6 [135, 149, 178, 218, 243, 264, 315, 374, 422, ... 7 [148, 170, 199, 230, 264, 302, 364, 413, 465, ... 8 [148, 170, 199, 242, 272, 293, 347, 405, 467, ... 9 [136, 158, 184, 209, 237, 259, 312, 355, 404, ... 10 [119, 133, 162, 191, 211, 229, 274, 306, 347, ... 11 [104, 114, 146, 172, 180, 203, 237, 271, 305, ... 12 [118, 140, 166, 194, 201, 229, 278, 306, 336, ... Name: passengers, dtype: object# 棒グラフにしたい ts_sum_yearlyyear 1949 1520 1950 1676 1951 2042 1952 2364 1953 2700 1954 2867 1955 3408 1956 3939 1957 4421 1958 4572 1959 5140 1960 5714 Name: passengers, dtype: int64# ラベル(x軸) ts_labels = ts_sum_yearly.index ts_labelsInt64Index([1949, 1950, 1951, 1952, 1953, 1954, 1955, 1956, 1957, 1958, 1959, 1960], dtype='int64', name='year')可視化してみます. layoutを少しいじってみました
fig = go.Figure() # 月ごとの時系列データは折れ線グラフにする for month, passengers in ts_data_monthly.iteritems(): fig.add_trace(go.Scatter(x=ts_labels, y=passengers, name=str(month)+"月", yaxis='y2')) # 年ごとの合計は棒グラフにする fig.add_trace(go.Bar(x=ts_labels, y=ts_sum_yearly.values, name="合計", yaxis="y1")) # 見た目のカスタマイズはlayoutをいじる # 軸が2つあるのでメモリは無しにする fig.update_layout( title={ "text": "乗客数時系列データ", "x":0.5, "y": 0.9 }, legend={ "orientation":"h", "x":0.5, "xanchor":"center" }, yaxis1={ "title": "乗客数(合計)", "side": "left", "showgrid":False }, yaxis2={ "title": "乗客数(月ごと)", "side": "right", "overlaying": "y", "showgrid":False } ) fig.show()
凡例をぽちぽちしたりできます. こんな少ないコードでちょっと動かせるグラフが書けるのは感動です...
その他
ドーナッツ(かわいい)
import numpy as np ts_sum_monthly = df.groupby("month")["passengers"].sum() # 一番乗客が多い月を切ったピザみたいにする pull=[0]*12 pull[np.argmax(ts_sum_monthly.values)] = 0.2 fig = go.Figure() fig.add_trace(go.Pie( labels=[str(month) + "月" for month in ts_sum_monthly.index], values=ts_sum_monthly.values, hole=.3, pull=pull ) ) fig.update_layout( title={ "text": "乗客数の割合(1949~1960年の合計)", "x":0.5, "y": 0.9 } ) fig.show()
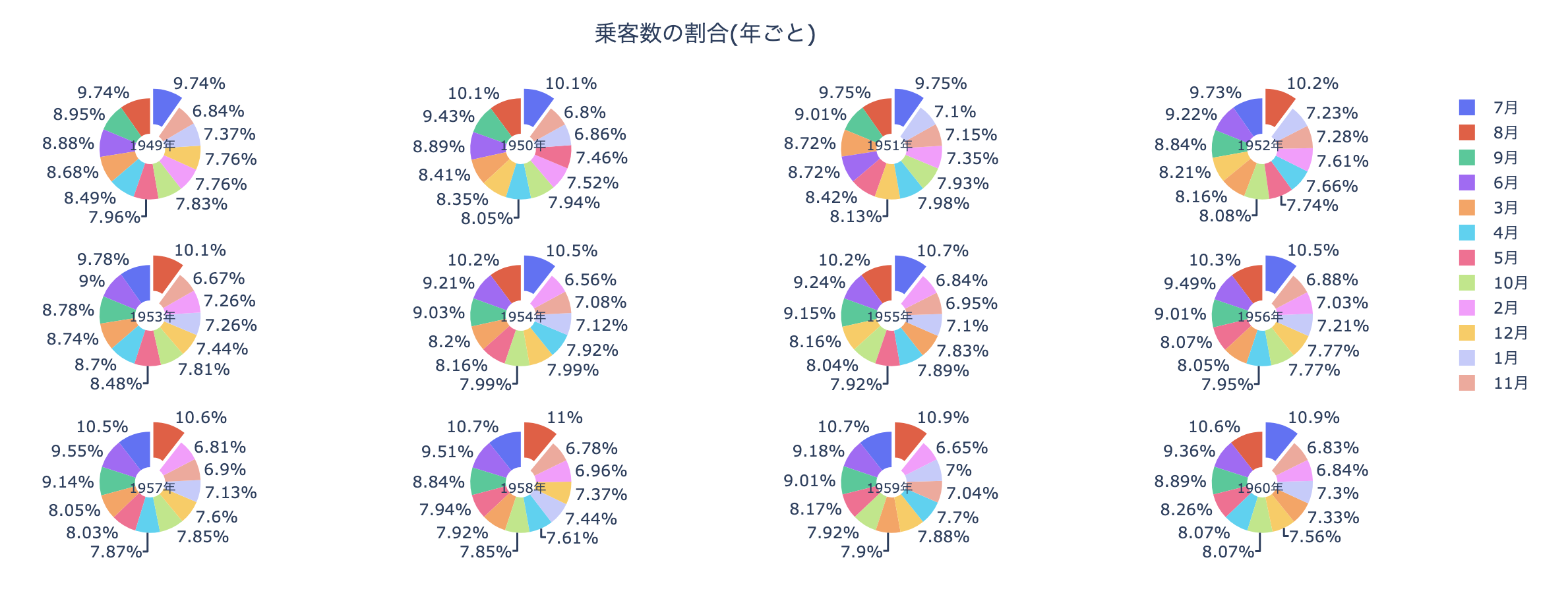
年ごとに合計乗客数求めて円グラフを作成
from plotly.subplots import make_subplots specs = [[{'type':'domain'}, {'type':'domain'}, {'type':'domain'}, {'type':'domain'}] for _ in range(3)] # 3*4のグリッドにグラフを分割する fig = make_subplots(rows=3, cols=4, specs=specs) # ラベルの各円グラフのラベルのタイトルの位置 pos_x = [0.09, 0.37, 0.63, 0.91] pos_y = [0.9, 0.5, 0.1] annotations = [] # (row, col)の位置に円グラフを載せる row = 0 for i, (year, df_yearly) in enumerate(df.groupby(["year"])[["month","passengers"]]): pull=[0]*12 pull[np.argmax(df_yearly.passengers.values)] = 0.2 col = i%4+1 if col == 1: row += 1 annotations.append({ "text": str(year)+"年", "x": pos_x[col-1], "y": pos_y[row-1], "font_size": 10, "showarrow":False }) fig.add_trace(go.Pie( labels=[str(month) + "月" for month in df_yearly.month.values], values=df_yearly.passengers.values, name=str(year)+"年", hole=.3, pull=pull ), row, col ) fig.update_layout( title={ "text": "乗客数の割合(年ごと)", "x":0.5, "y": 0.9 }, annotations=annotations ) fig.show()
終わり
グラフが動くと嬉しいのは私だけでしょうか. 次回はplotlyでダッシュボードが作れるdashというWebフレームワークについてまとめたいと思います.
参考にさせていただいたサイト
- 投稿日:2020-10-09T05:30:29+09:00
Plotlyで綺麗なグラフが描きたい
これは
Plotlyは少ないコードで綺麗なグラフがかけますが, matplotlibばかり使っていてあまりよく知らなかったので調べながら入門してみた人の備忘録です
環境
Google colaboratory
インストール
colabであればインストールはありませんが、必要な場合はpipでインストールできます
pip install plotlyデータの準備
seabornですぐ使える時系列データがあったのでそれを使ってみます. 以下はデータの準備なので飛ばしてください
import seaborn as sns import pandas as pd from calendar import month_name month_name_mappings = {name[:3]: n for n, name in enumerate(month_name)} # ただのデータの準備 df = sns.load_dataset('flights') df["month"] = df.month.apply(lambda x: month_name_mappings[x]) df["year-month"] = pd.to_datetime(df.year.astype(str) + "-" + df.month.astype(str)) ts_data = df[["passengers", "year-month"]].set_index("year-month")["passengers"] ts_datayear-month 1949-01-01 112 1949-02-01 118 1949-03-01 132 1949-04-01 129 1949-05-01 121 ... 1960-08-01 606 1960-09-01 508 1960-10-01 461 1960-11-01 390 1960-12-01 432 Name: passengers, Length: 144, dtype: int64月ごとの乗客数のシンプルなデータです.
基本操作
グラフを作成してみます
import plotly.graph_objects as go fig = go.Figure() fig.show()
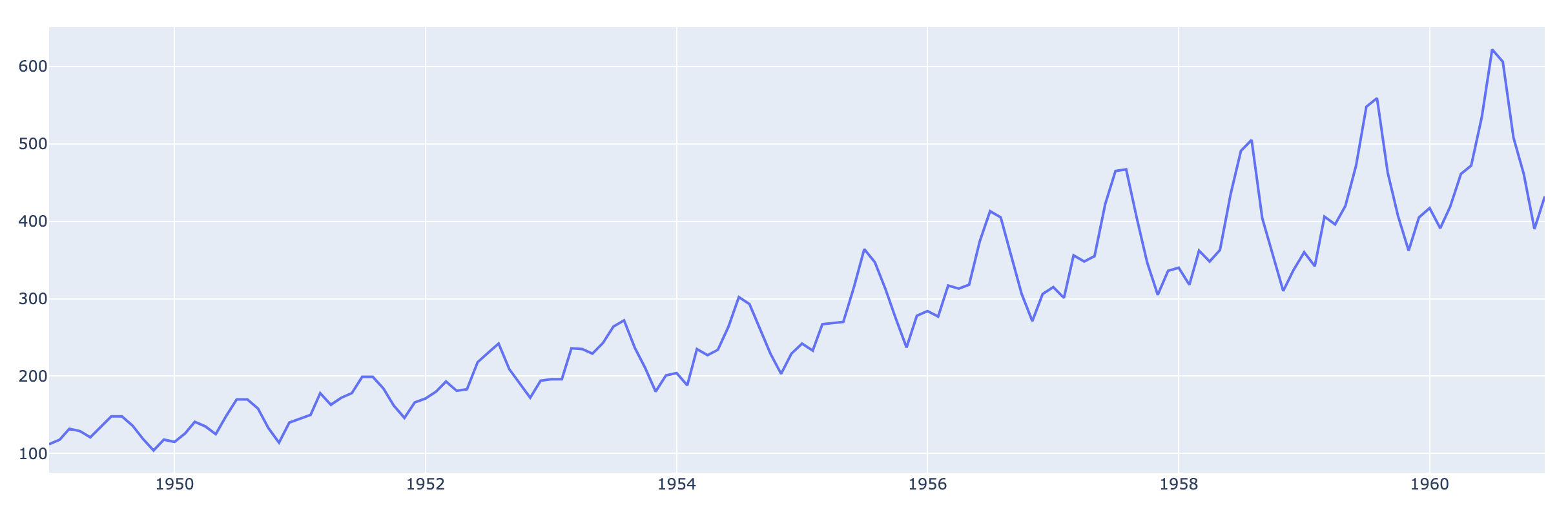
グラフができた. ここに色々追加していくのですね
# 折れ線グラフ fig = go.Figure() fig.add_trace(go.Scatter(x=ts_data.index, y=ts_data.values, name="passengers")) fig.show()
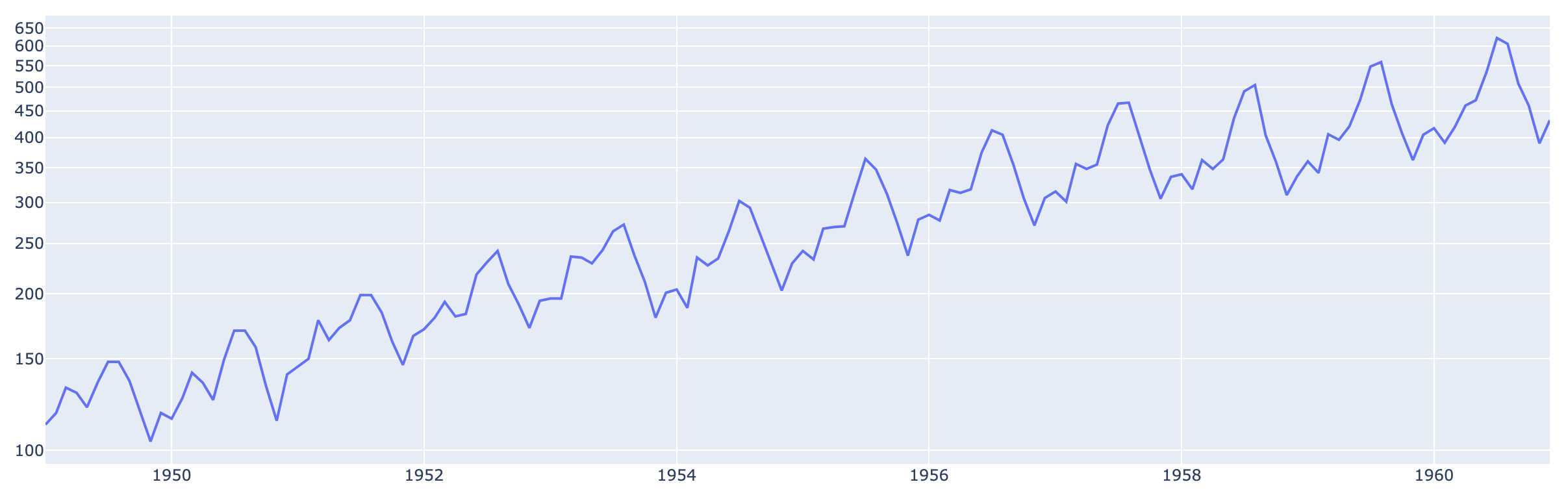
メモリを対数表示にしてみる
# 折れ線グラフ fig = go.Figure() fig.add_trace(go.Scatter(x=ts_data.index, y=ts_data.values, name="passengers")) # 見た目のカスタマイズはlayoutをいじる fig.update_layout(yaxis_type="log") fig.show()
豪華なグラフを描きたい
もっと豪華にしたくなってきたので, 無理やり色々可視化してみます
- 月ごとにデータを分割?して, 各データの変化を折れ線グラフにする
- 年ごとの合計乗客数を棒グラフにしてみる
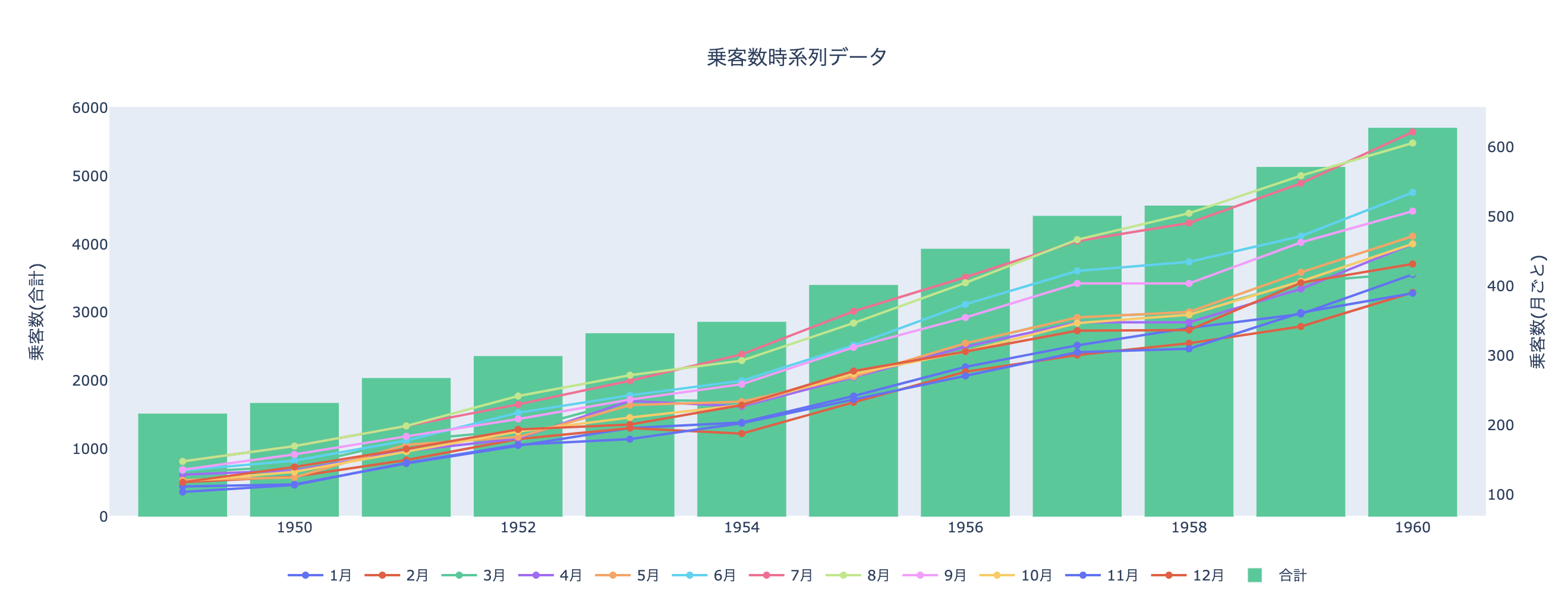
# 少しデータをこねこねする ts_data_monthly = df.groupby("month")["passengers"].apply(list) ts_sum_yearly = df.groupby("year")["passengers"].sum()# 複数の折れ線グラフにしたい ts_data_monthlymonth 1 [112, 115, 145, 171, 196, 204, 242, 284, 315, ... 2 [118, 126, 150, 180, 196, 188, 233, 277, 301, ... 3 [132, 141, 178, 193, 236, 235, 267, 317, 356, ... 4 [129, 135, 163, 181, 235, 227, 269, 313, 348, ... 5 [121, 125, 172, 183, 229, 234, 270, 318, 355, ... 6 [135, 149, 178, 218, 243, 264, 315, 374, 422, ... 7 [148, 170, 199, 230, 264, 302, 364, 413, 465, ... 8 [148, 170, 199, 242, 272, 293, 347, 405, 467, ... 9 [136, 158, 184, 209, 237, 259, 312, 355, 404, ... 10 [119, 133, 162, 191, 211, 229, 274, 306, 347, ... 11 [104, 114, 146, 172, 180, 203, 237, 271, 305, ... 12 [118, 140, 166, 194, 201, 229, 278, 306, 336, ... Name: passengers, dtype: object# 棒グラフにしたい ts_sum_yearlyyear 1949 1520 1950 1676 1951 2042 1952 2364 1953 2700 1954 2867 1955 3408 1956 3939 1957 4421 1958 4572 1959 5140 1960 5714 Name: passengers, dtype: int64# ラベル(x軸) ts_labels = ts_sum_yearly.index ts_labelsInt64Index([1949, 1950, 1951, 1952, 1953, 1954, 1955, 1956, 1957, 1958, 1959, 1960], dtype='int64', name='year')可視化してみます. layoutを少しいじってみました
fig = go.Figure() # 月ごとの時系列データは折れ線グラフにする for month, passengers in ts_data_monthly.iteritems(): fig.add_trace(go.Scatter(x=ts_labels, y=passengers, name=str(month)+"月", yaxis='y2')) # 年ごとの合計は棒グラフにする fig.add_trace(go.Bar(x=ts_labels, y=ts_sum_yearly.values, name="合計", yaxis="y1")) # 見た目のカスタマイズはlayoutをいじる # 軸が2つあるのでメモリは無しにする fig.update_layout( title={ "text": "乗客数時系列データ", "x":0.5, "y": 0.9 }, legend={ "orientation":"h", "x":0.5, "xanchor":"center" }, yaxis1={ "title": "乗客数(合計)", "side": "left", "showgrid":False }, yaxis2={ "title": "乗客数(月ごと)", "side": "right", "overlaying": "y", "showgrid":False } ) fig.show()
凡例をぽちぽちしたりできます. こんな少ないコードでちょっと動かせるグラフが書けるのは感動です...
その他
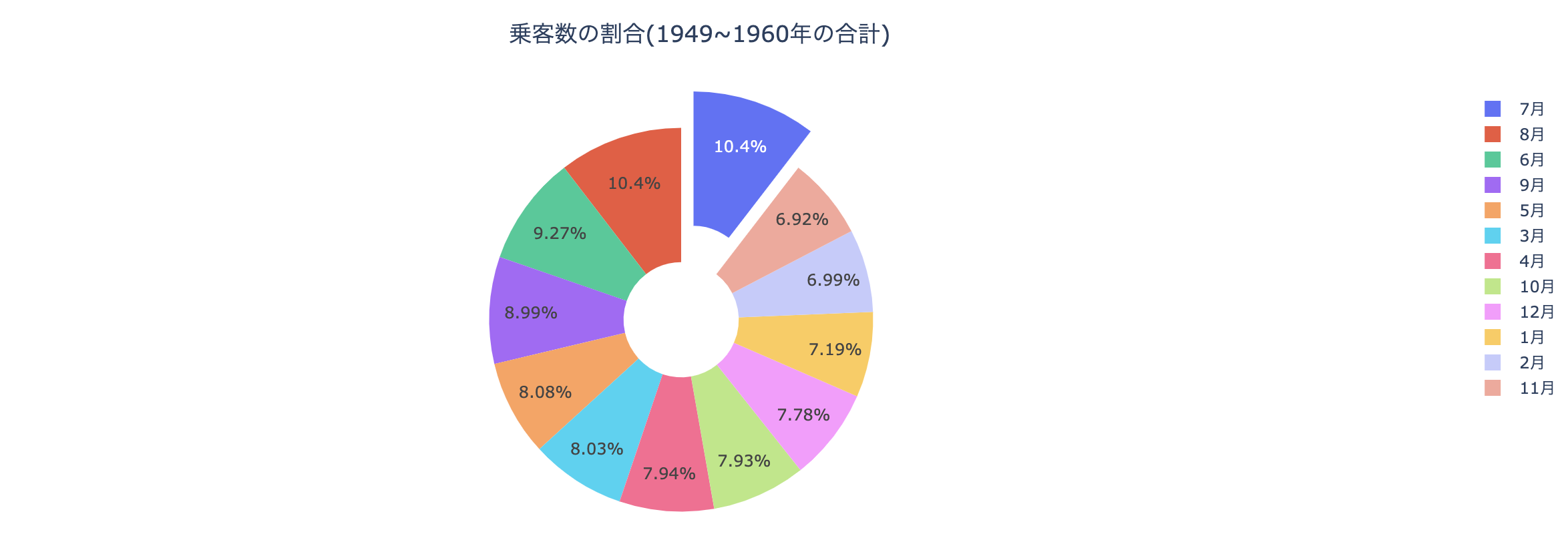
ドーナッツ(かわいい)
import numpy as np ts_sum_monthly = df.groupby("month")["passengers"].sum() # 一番乗客が多い月を切ったピザみたいにする pull=[0]*12 pull[np.argmax(ts_sum_monthly.values)] = 0.2 fig = go.Figure() fig.add_trace(go.Pie( labels=[str(month) + "月" for month in ts_sum_monthly.index], values=ts_sum_monthly.values, hole=.3, pull=pull ) ) fig.update_layout( title={ "text": "乗客数の割合(1949~1960年の合計)", "x":0.5, "y": 0.9 } ) fig.show()
年ごとに合計乗客数求めて円グラフを作成
from plotly.subplots import make_subplots specs = [[{'type':'domain'}, {'type':'domain'}, {'type':'domain'}, {'type':'domain'}] for _ in range(3)] # 3*4のグリッドにグラフを分割する fig = make_subplots(rows=3, cols=4, specs=specs) # ラベルの各円グラフのラベルのタイトルの位置 pos_x = [0.09, 0.37, 0.63, 0.91] pos_y = [0.9, 0.5, 0.1] annotations = [] # (row, col)の位置に円グラフを載せる row = 0 for i, (year, df_yearly) in enumerate(df.groupby(["year"])[["month","passengers"]]): pull=[0]*12 pull[np.argmax(df_yearly.passengers.values)] = 0.2 col = i%4+1 if col == 1: row += 1 annotations.append({ "text": str(year)+"年", "x": pos_x[col-1], "y": pos_y[row-1], "font_size": 10, "showarrow":False }) fig.add_trace(go.Pie( labels=[str(month) + "月" for month in df_yearly.month.values], values=df_yearly.passengers.values, name=str(year)+"年", hole=.3, pull=pull ), row, col ) fig.update_layout( title={ "text": "乗客数の割合(年ごと)", "x":0.5, "y": 0.9 }, annotations=annotations ) fig.show()
終わり
グラフが動くと嬉しいのは私だけでしょうか. 次回はplotlyでダッシュボードが作れるdashというWebフレームワークについてまとめたいと思います.
参考にさせていただいたサイト
- 投稿日:2020-10-09T00:43:54+09:00
【けんちょん本 to Python】-第4章-「問題解決力を鍛える! アルゴリズムとデータ構造」掲載コードをPythonに書き直してみた!
はじめに
この記事は、競技プログラミングの解説を多数書かれているけんちょんさんの書籍、問題解決力を鍛える! アルゴリズムとデータ構造(けんちょんさん本)について、掲載コードをPythonに翻訳したものを、備忘のためまとめたものです。
このページでは、第4章掲載分について紹介します!
バグ等ありましたらご容赦ください。他の章へのリンクは以下のページをご覧ください。
【目次ページ】
https://qiita.com/KevinST/items/002676619a583754bf76code4.1 1からNまでの総和を計算する再帰関数
基本的な再帰です。
code4-1.pydef func(N): if N == 0: return 0 return N + func(n-1)関数部分だけ作ってあるので、入出力はありません。
code4.2 1からNまでの総和を計算する再帰関数
code4.1の使用例です(N=5)
code4-2.py#pythonは再帰が制限されている(1000回等、環境によって異なる) #これを十分大きい値(今回は10の9乗)に変更 import sys sys.setrecursionlimit(10**9) def func(N): #再帰関数を呼び出したことを報告する print("func({})を呼び出しました".format(N)) #ベースケース if N == 0: return 0 #ベースケースでない場合、再帰的に答えを求める result = N + func(N-1) print("{}までの和 = {}".format(N, result)) return result func(5)【出力例】
func(5)を呼び出しました
func(4)を呼び出しました
func(3)を呼び出しました
func(2)を呼び出しました
func(1)を呼び出しました
func(0)を呼び出しました
1までの和 = 1
2までの和 = 3
3までの和 = 6
4までの和 = 10
5までの和 = 15お作法として、再帰上限の回数を増やしています。
Pythonでは再帰上限がデフォルトだと1000回程度にセットされていることが多いので、
競プロ等で再帰を使用する際は変更されるとよいと思います。
(今回のケースでは必要ないが、念のため)
※以降は必要ない場合省略します。code4.3 再帰呼び出しが止まらない再帰関数
code4-3.py#危険! 実行は自己責任でお願いします def func(N): if N == 0: return 0 return N + func(N+1)TLE間違いなし。
code4.4 ユークリッドの互除法によって最大公約数を求める
おなじみのユークリッドの互除法です。
Q: 51と15の最大公約数は?
1. 51÷15 = 3 あまり6
2. 15÷6 = 2あまり3
3. 6÷3 = 2あまり0
A: 3!!
というやつですね。再帰関数で書いてみましょう。
code4-4.pydef GCD(m, n): #ベースケース if n == 0: return m #再帰呼び出し return GCD(n, m % n) print(GCD(51, 15)) #3が出力される print(GCD(15, 51)) #3が出力される【出力例】
3
3ちなみに計算量は$O(log(n))$です。
GCDは高速!!!!code4.5 フィボナッチ数列を求める再帰関数
こちらもおなじみのやつです。
1 1 2 3 5 8 13 21 34 ...code4-5.pydef fibo(N): #ベースケース if N == 0: return 0 elif N == 1: return 1 #再帰呼び出し return fibo(N-1) + fibo(N-2) print(fibo(5))【出力例】
5原本にはありませんが、動作確認のため出力もつけておきました。
詳細な動作は、次のcode4.6で確認しましょう。code4.6 部分和問題に対するビットを用いる全探索手法
code4.5の具体的な使用例です。
内部の状態を確認できるように、出力が付いています。code4-6.pydef fibo(N): #再帰関数を呼び出したことを報告する print("fibo({})を呼び出しました".format(N)) #ベースケース if N == 0: return 0 elif N == 1: return 1 #再帰的に答えを求めて出力する result = fibo(N-1) + fibo(N-2) print("{}項目 = {}".format(N, result)) return result fibo(6)【出力例】
fibo(6)を呼び出しました
fibo(5)を呼び出しました
fibo(4)を呼び出しました
fibo(3)を呼び出しました
fibo(2)を呼び出しました
fibo(1)を呼び出しました
fibo(0)を呼び出しました
2項目 = 1
fibo(1)を呼び出しました
3項目 = 2
fibo(2)を呼び出しました
fibo(1)を呼び出しました
fibo(0)を呼び出しました
2項目 = 1
4項目 = 3
fibo(3)を呼び出しました
fibo(2)を呼び出しました
fibo(1)を呼び出しました
fibo(0)を呼び出しました
2項目 = 1
fibo(1)を呼び出しました
3項目 = 2
5項目 = 5
fibo(4)を呼び出しました
fibo(3)を呼び出しました
fibo(2)を呼び出しました
fibo(1)を呼び出しました
fibo(0)を呼び出しました
2項目 = 1
fibo(1)を呼び出しました
3項目 = 2
fibo(2)を呼び出しました
fibo(1)を呼び出しました
fibo(0)を呼び出しました
2項目 = 1
4項目 = 3
6項目 = 8N=6と比較的小さい数にも関わらず、多数の関数呼び出しがかかっていますね。
次の次のコード(code4.8)では、この改善を試みます。code4.7 フィボナッチ数列をfor文による反復で求める
一度再帰を離れ、for文と配列で実装するとどうなるか、という試みです。
code4-7.pyF = [None] * 50 F[0], F[1] = 0, 1 for N in range(2, 50): F[N] = F[N-1] + F[N-2] print("{}項目 : {}".format(N, F[N]))【出力例】
2項目 : 1
3項目 : 2
4項目 : 3
5項目 : 5
6項目 : 8
7項目 : 13
8項目 : 21
9項目 : 34
10項目 : 55
11項目 : 89
12項目 : 144
13項目 : 233
14項目 : 377
15項目 : 610
16項目 : 987
17項目 : 1597
18項目 : 2584
19項目 : 4181
20項目 : 6765
21項目 : 10946
22項目 : 17711
23項目 : 28657
24項目 : 46368
25項目 : 75025
26項目 : 121393
27項目 : 196418
28項目 : 317811
29項目 : 514229
30項目 : 832040
31項目 : 1346269
32項目 : 2178309
33項目 : 3524578
34項目 : 5702887
35項目 : 9227465
36項目 : 14930352
37項目 : 24157817
38項目 : 39088169
39項目 : 63245986
40項目 : 102334155
41項目 : 165580141
42項目 : 267914296
43項目 : 433494437
44項目 : 701408733
45項目 : 1134903170
46項目 : 1836311903
47項目 : 2971215073
48項目 : 4807526976
49項目 : 7778742049計算量$O(N)$で実装できています。
code4.8 フィボナッチ数列を求める再帰関数をメモ化
配列をうまく使えば、同じ計算を省略して、プログラムを高速化できます。
これを再帰にも取り入れてみましょう(=メモ化)。code4-8.py#fibo[N]の結果をメモする配列 memo = [-1] * 50 def fibo(N): #ベースケース if N == 0: return 0 elif N == 1: return 1 #メモをチェック if memo[N] != -1: return memo[N] #答えをメモ化しながら、再帰呼び出し memo[N] = fibo(N-1) + fibo(N-2) return memo[N] fibo(49) for N in range(2, 50): print("{}項目 : {}".format(N, memo[N]))【出力例】
2項目 : 1
3項目 : 2
4項目 : 3
5項目 : 5
6項目 : 8
7項目 : 13
8項目 : 21
9項目 : 34
10項目 : 55
11項目 : 89
12項目 : 144
13項目 : 233
14項目 : 377
15項目 : 610
16項目 : 987
17項目 : 1597
18項目 : 2584
19項目 : 4181
20項目 : 6765
21項目 : 10946
22項目 : 17711
23項目 : 28657
24項目 : 46368
25項目 : 75025
26項目 : 121393
27項目 : 196418
28項目 : 317811
29項目 : 514229
30項目 : 832040
31項目 : 1346269
32項目 : 2178309
33項目 : 3524578
34項目 : 5702887
35項目 : 9227465
36項目 : 14930352
37項目 : 24157817
38項目 : 39088169
39項目 : 63245986
40項目 : 102334155
41項目 : 165580141
42項目 : 267914296
43項目 : 433494437
44項目 : 701408733
45項目 : 1134903170
46項目 : 1836311903
47項目 : 2971215073
48項目 : 4807526976
49項目 : 7778742049こちらも計算量$O(N)$で実装できました。
code4.9 部分和問題を再帰関数を用いる全探索で解く
前章code3.6と同じ問題を、再帰関数を使って解きます。
一度メモ化は忘れ、シンプルな再帰で実装します。code4-9.pydef func(i, w, a): #ベースケース if i == 0: if w == 0: return True else: return False #a[i-1]を選ばない場合 if func(i-1, w, a): return True #a[i-1]を選ぶ場合 if func(i-1, w-a[i-1], a): return True #どちらもFalseの場合 return False N, W = map(int, input().split()) a = list(map(int, input().split())) if func(N, W, a): print("Yes") else: print("No")【入力例】
4 10
1 9 100 200
【出力例】
Yesこのコードは計算量$O(2^N)$です。
(詳細はけんちょんさん本をご覧ください)興味がある方は、これもメモ化してみましょう!(章末問題4.6)
第5章はこちら
(完成次第追加)
- 投稿日:2020-10-09T00:08:48+09:00
Chainerによる機械学習のためのPython学習メモ 2章終わりまで
What
Chainerを利用して機械学習を学ぶにあたり、私自身が、気がついた点、リサーチした内容をまとめる記事になります。今回は、制御構文
ifとかwhileとか、いろんな言語でよく出てくるやつを勉強します。御礼
自分の振り返りのために書いていましたが、予想外にも見ていただき反応を示しており驚いております。また、時間を割いてまでコメントやご指摘を頂き感謝いたします。とても参考になっております。最後に
私の理解に基づいて記述しているため、間違っている場合があります。間違いは都度修正するつもりです、ご容赦ください。Content
2. Python入門に関するノート 続き
if
お馴染みの条件分岐式。if, elif, else。下記は記述例。
{}もendも不要でみやすい!
ifに関しては特に特筆すべき点はなさそう。条件式がTrueを返すときに実行されるif a > 0: print('0より大きいです') elif a == 0: print('0です') else: print('0より小さいです')while
whileループも特筆すべき点はなし、スッキリした記述でみやすい!
if同様に条件式がTrueを返すときに実行される。count = 0 while count < 3: # 条件式ない not False条件式でもOK print(count) count += 1 break #でループを強制的に抜けることもできる書いてて気になったのですが、1ループってどこからどこまで?調べたらこんな記述が、
Python では特別な文字を使わずに同じインデントがされている文を同じブロックとして扱います。
インテンドの管理には注意したいですね。
もう一つ,True,Flase以外の条件式判定方法はないか調べたところbool型はint型のサブクラス. bool型TrueとFalseは1, 0と等価
とありましたので、数字でもいけるみたいです。サブクラス??
関数
関数の定義もシンプル。下記のように引数を初期化して渡すこともできる。
インテンドがブロックと等価なので定義終了は明記されないdef hello(message='Chainerチュートリアルにようこそ'): print(message) return message # 返り値を明示することもできる変数のスコープ(寿命)
基本的にブロックを抜けると初期化されるよう。確かC言語と同じ。
a = 1 # 関数の内部で a に 2 を代入 def change(): a = 2 change() a # = 1 が出力変数をグローバルに扱うには
globalと書けば良い。以下、サンプルの例文になるが、不明点が・・・a = 1 def change(): global a # a をグローバル変数である宣言 a = 2 # グローバル変数への代入 change() a # = 2 が出力これってはじめに
a = 1でaを定義してからglobal aに再定義しているんですかね?
それともはじめのaとglobal aってプログラム内では区別されているんですかね?
一方以下のように記述したら文法エラーが出たglobal a = 1 def change(): a = 2 # グローバル変数への代入 change() aちょっと原因がイメージできていないですが、
global宣言はローカルブロック内でのみ有効なんですかね?
ローカル変数からグローバル変数に変えますと言った具合。C言語みたいに最初からグローバルに使えるような宣言はできないのかな。
本当に困ったらちゃんと調べよう。Class
オブジェクトの概念はC++, Rubyを通してそれなりにイメージできている。
initはコンストラクタ。selfは生成したインスタンス自身を示す。メソッドは、インスタンスから呼び出されるとき自動的に第一引数にそのインスタンスへの参照を渡します。
とあるので、self自体はポインタだと思って差支えなさそう。ところで、self.name_plateは組み込み関数?(もしくは準ずる変数)
class House: def __init__(self, name): self.name_plate = name my_house = House('Chainer') # 宣言引数は一つ。第一引数はselfと決まったものが与えられるから明示しなくて良い。
initに限らず、selfは呼び出し時に明示する必要はない。継承
C++と同じく継承できます。Chainが子クラスでLinkが親クラス。
ポイントはコンストラクタは記述がなければ親クラスのコンストラクタを呼び出す点。
子クラスから親クラスを参照する場合はsuper()を使う。
親クラスと同名の関数はオーバーライドされる。class Chain(Link): def __init__(self): # 親クラスの `__init__()` メソッドを呼び出す super().__init__() def true(): return True以上で2章Pythonの学習は終了になります長かった・・・w
次回は3章に取り組みます。Comment
最近寒くなってきたので、今年度初の入浴をしました。週末になるにつれ疲れも溜まり、仕事終わりに学習しようとしても眠くなりがちですが、しっかり入浴すると就寝までの集中力くらいは確保できますね。
継続するためには、体のコンディション整えて、無理せず、高い集中力を持って短時間取り組み続けるがベストだと思っているので。