- 投稿日:2020-10-09T23:15:16+09:00
tkinterを使ってGUIでS3に画像をアップロードする
tkinterでGUIを作成して、ボタンを押すことでS3に画像をアップロードするソースコードです。
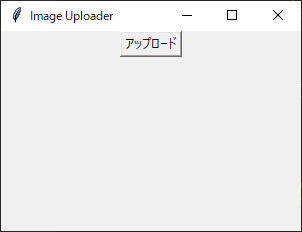
import tkinter from boto3.session import Session session = Session(aws_access_key_id='access_key_id', aws_secret_access_key='secret_access_key_id') s3 = session.resource('s3') bucket = s3.Bucket('bucket-name') def btn_click(): bucket.upload_file('sample.png', 'sample.png') print("uploaded !") root = tkinter.Tk() root.title("Image Uploader") root.geometry("300x200") btn = tkinter.Button(root, text='アップロード', command=btn_click) btn.pack() root.mainloop()スクリプトを実行することで以下のようなGUIが表示されます。
アップロードボタンを押下することで指定された画像がS3にアップロードされます。
最後まで読んでいただきありがとうございました。
またお会いしましょう。ps. ちなみにpyinstallerでexe化する時は以下のコマンドを使いました。
pyinstaller .\uploader.py --onefile --noconsole --hidden-import=configparser
- 投稿日:2020-10-09T22:55:19+09:00
AWSのUbuntuのEC2でEFSのマウント(amazon-efs-utils)
他のQiitaの記事の言っていることだけではだめだったので備忘録.
EFS (Elastic File System)はファイルサーバとして便利で,https://docs.aws.amazon.com/ja_jp/efs/latest/ug/mounting-fs.htmlでいっているようにマウントヘルパーを使うのが便利です.Amazon Linux2のAMIを用いればデフォルトで
sudo mount -t efs fs-12345678:/ /mnt/efsのようにして簡単にできるのですが,Ubuntuベースなど他のディストリビューションを使うとこれが入っていないのでメモ.
amazon-efs-utilsを入れればいいと公式も言っている(https://docs.aws.amazon.com/ja_jp/efs/latest/ug/installing-other-distro.html)わけですが,ちょっとだけトラブったのでメモ.
結論
sudo apt update & sudo apt upgradeが必要.sudo apt update sudo apt upgrade sudo apt install -y stunnel4 git clone https://github.com/aws/efs-utils cd efs-utils sudo apt install -y binutils ./build-deb.sh sudo apt install -y ./build/amazon-efs-utils*deb他の記事で言っていること
sudo apt install -y stunnel4しないとThe following packages have unmet dependencies: amazon-efs-utils : Depends: stunnel4 (>= 4.56) but it is not installable E: Unable to correct problems, you have held broken packages.と怒られる,というのはよく見る.また,エラーをよく見ると
sudo apt install -y binutilsをしなさいというのもわかる.けどこれでもバージョンの依存関係が合わなかった.
ということで,
sudo apt update sudo apt upgradeすればokだった.
あとは
sudo mount -t efs fs-12345678:/ /mnt/efsできる.
- 投稿日:2020-10-09T22:26:25+09:00
【AWS SOA】SystemsManagerでRun Commandしてみよう
はじめに
本稿ではSSMを使用してRun Commandできる所までしてみたい。
ちなみにSSM Agentを用いてEC2インスタンスを作成するまではこちら→https://qiita.com/blackpeach7/items/3d22eecbe7a705a35456
(今回のRun Commandを行う場合、インスタンス数は3つにする。)手順
EC2インスタンスに以下のようにタグ付けする。
SystemsManagerに行って、リソースグループの作成を選択する。
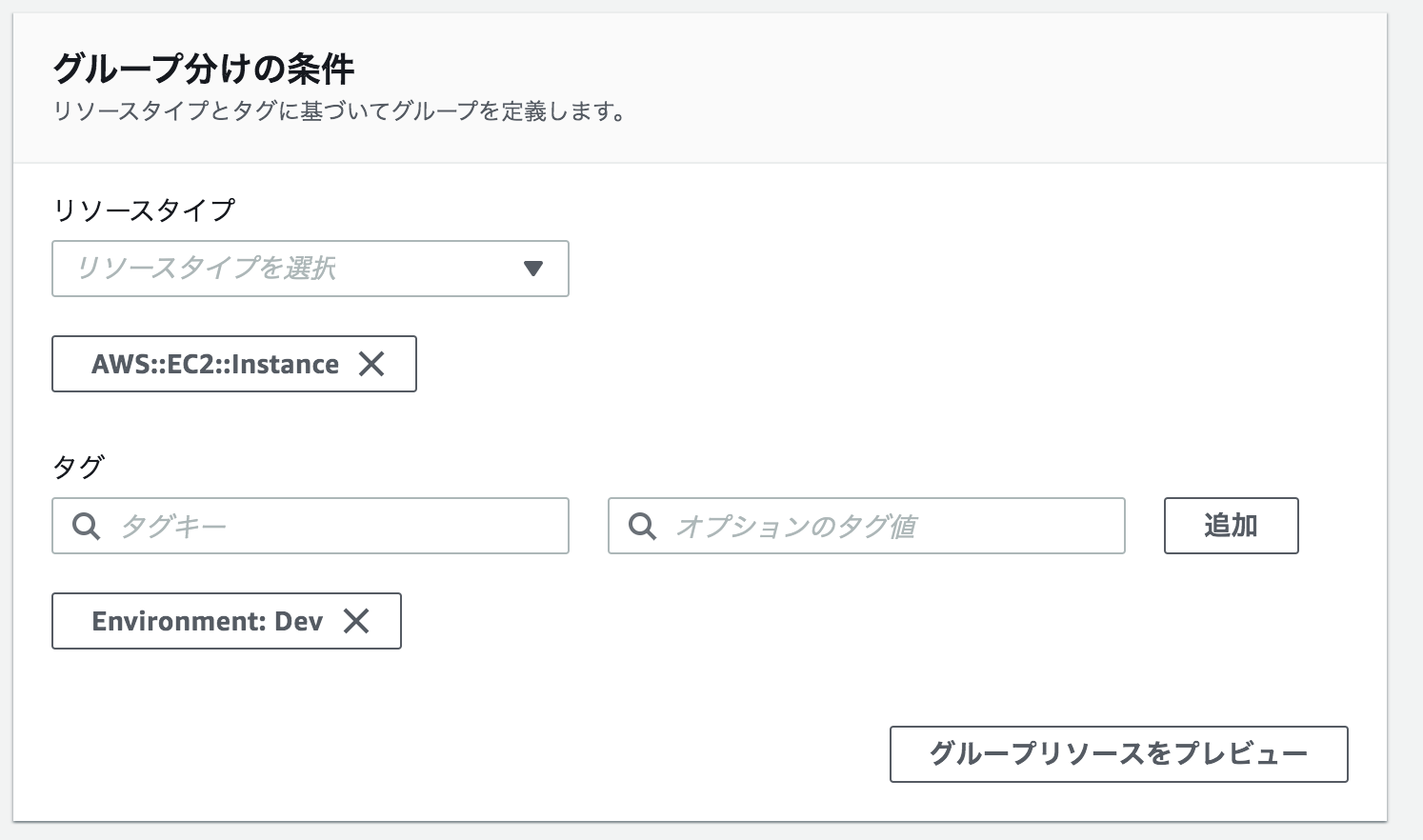
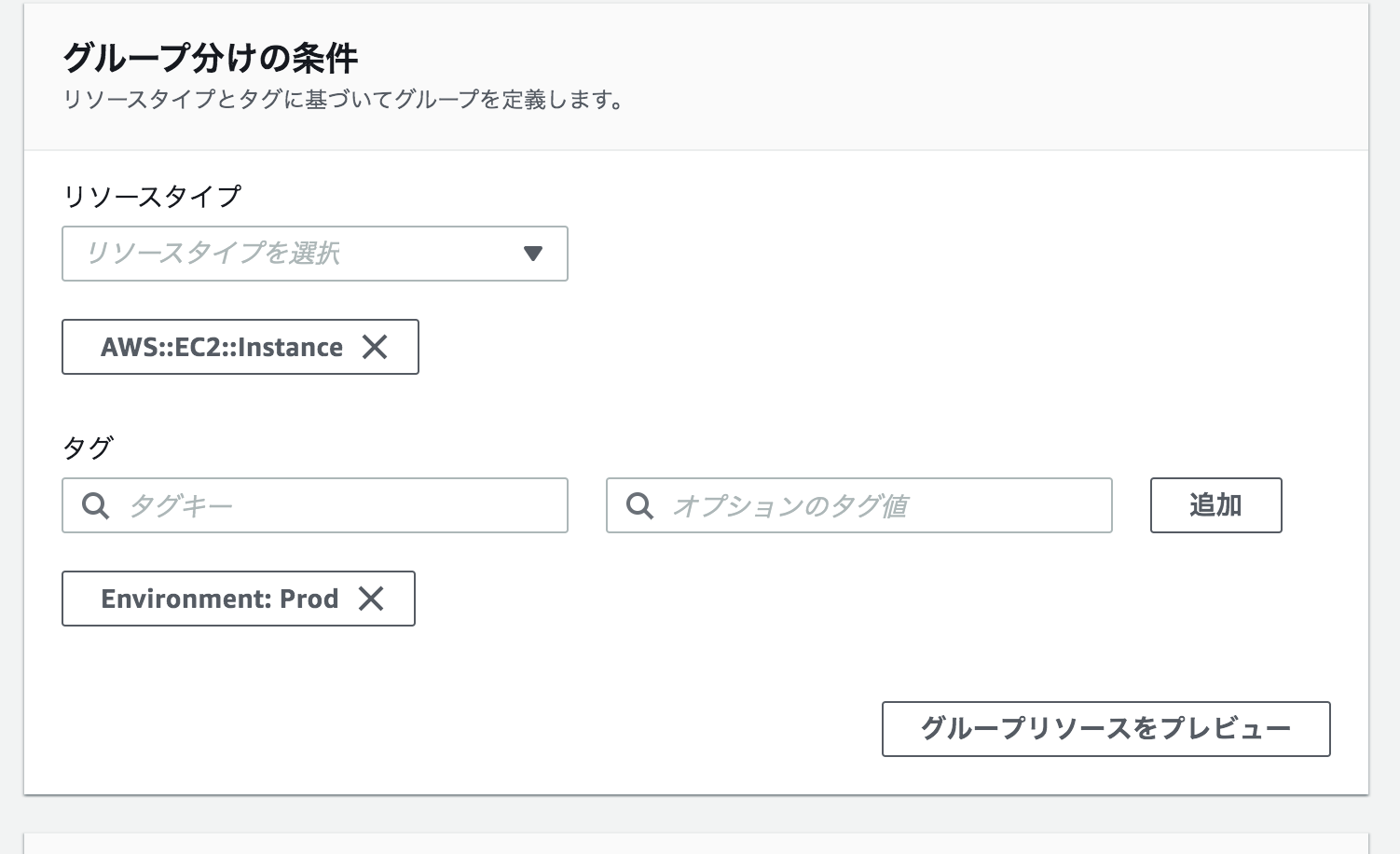
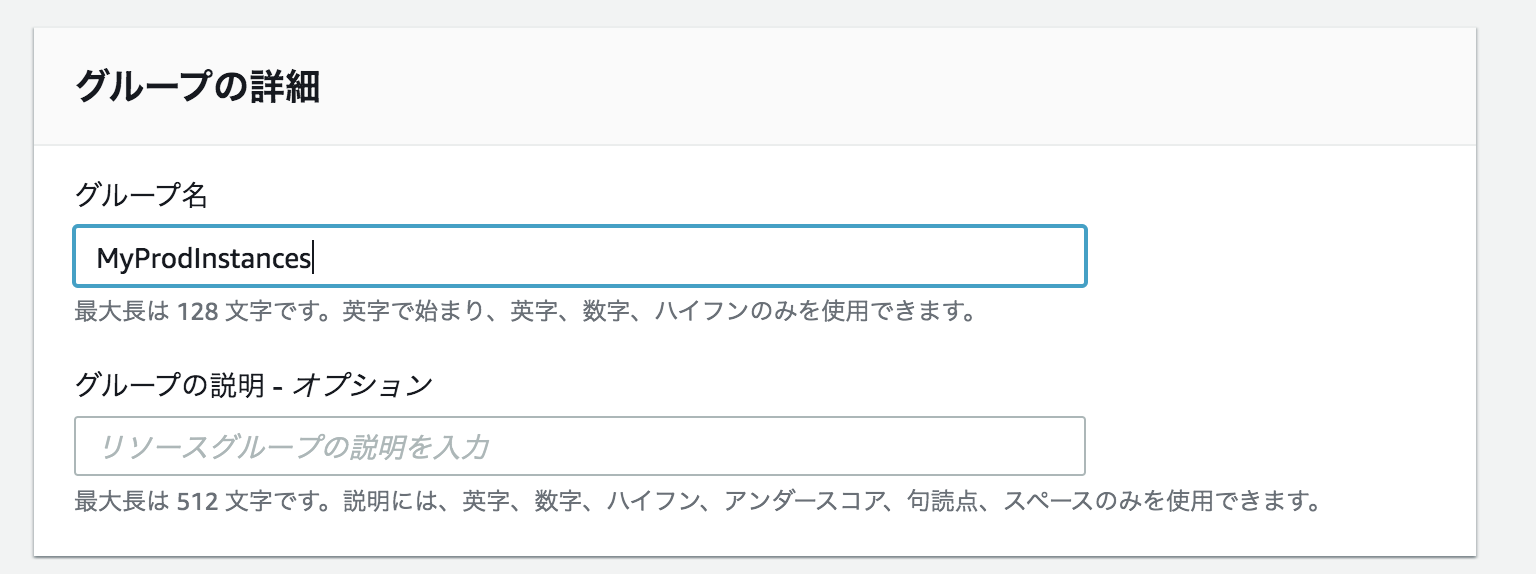
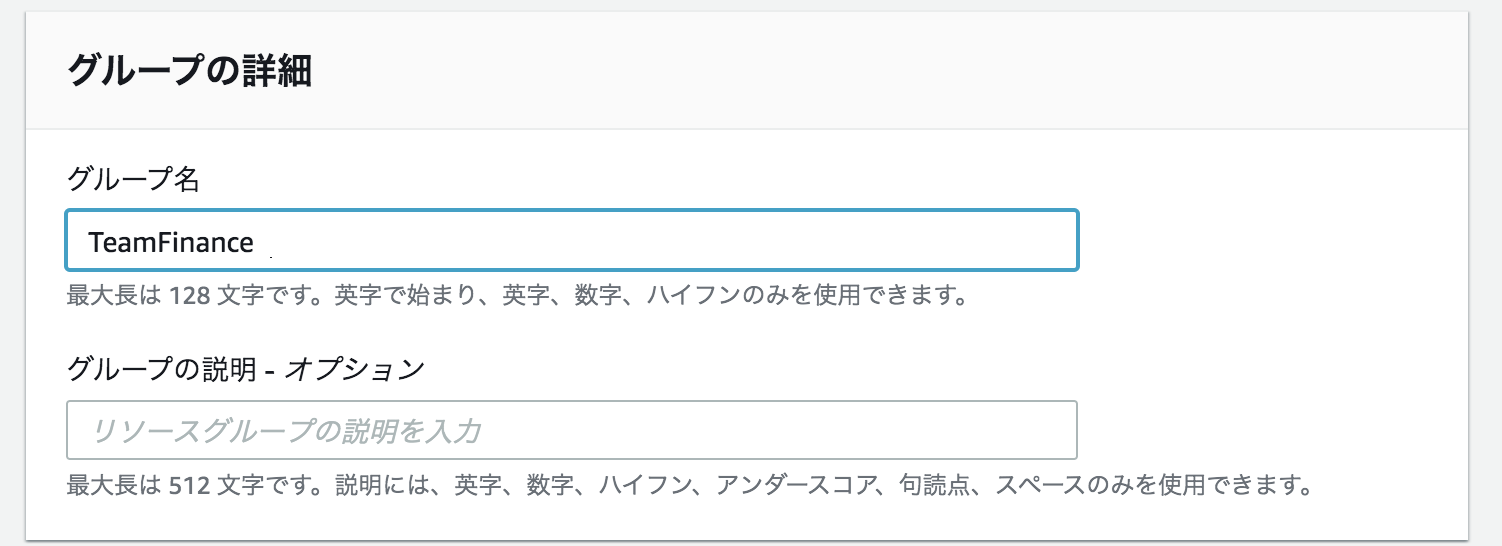
下記のように3つのリソースグループを設定する。
グループ分けの条件とグループの詳細を以下のようにする。
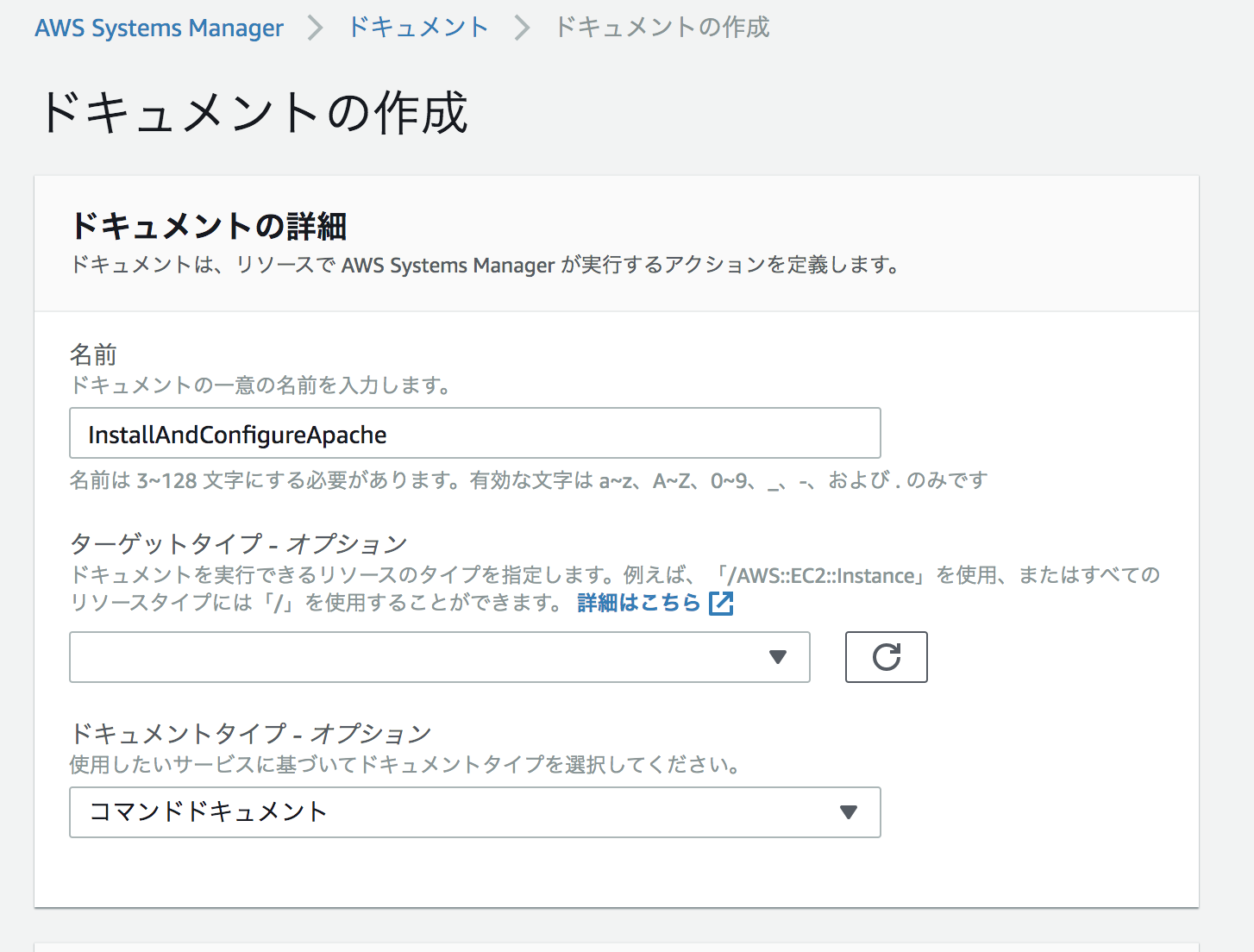
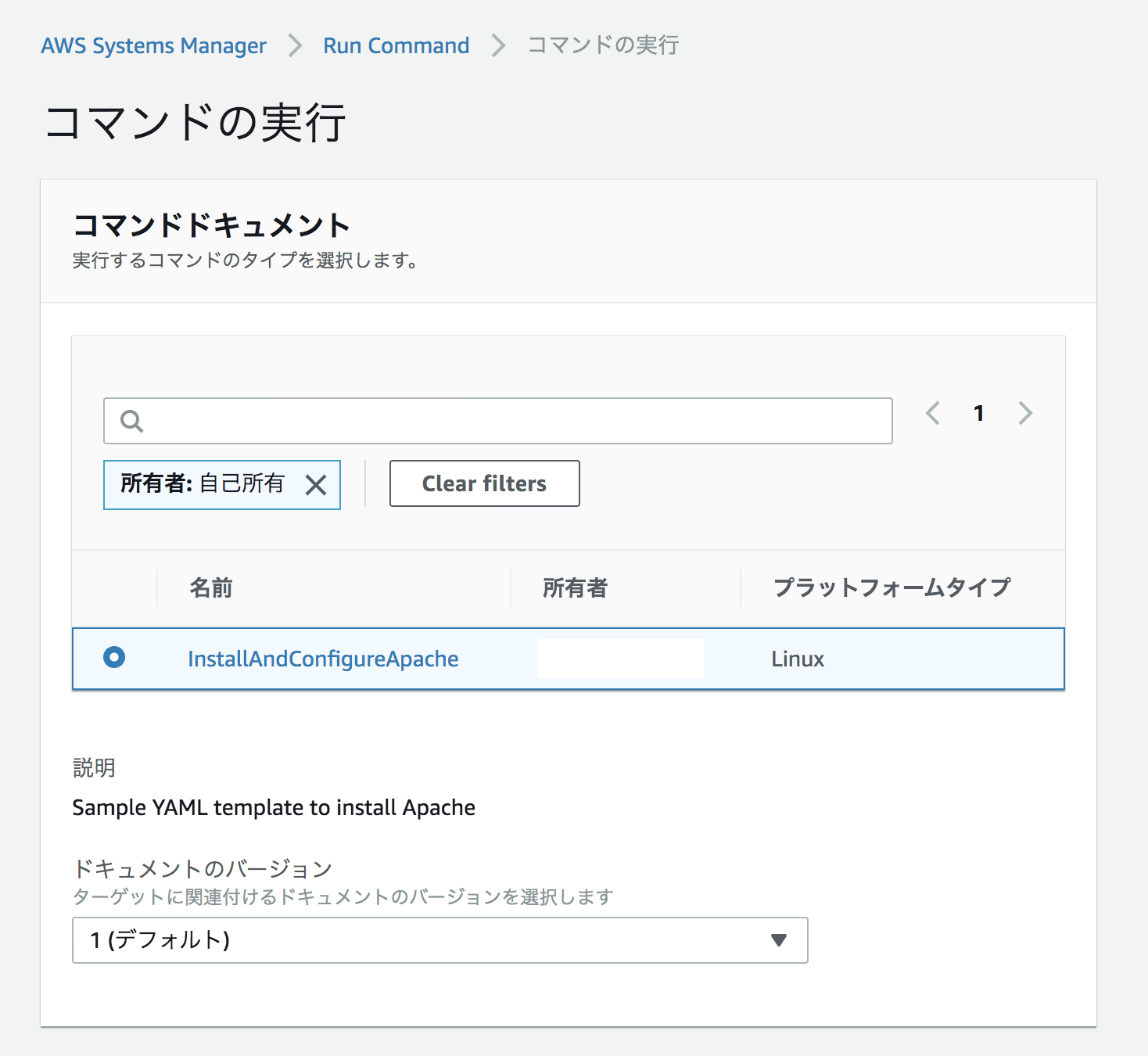
SystemsManager>ドキュメントでドキュメントの作成を選択する。
名前でInstallAndConfigureApacheにする。
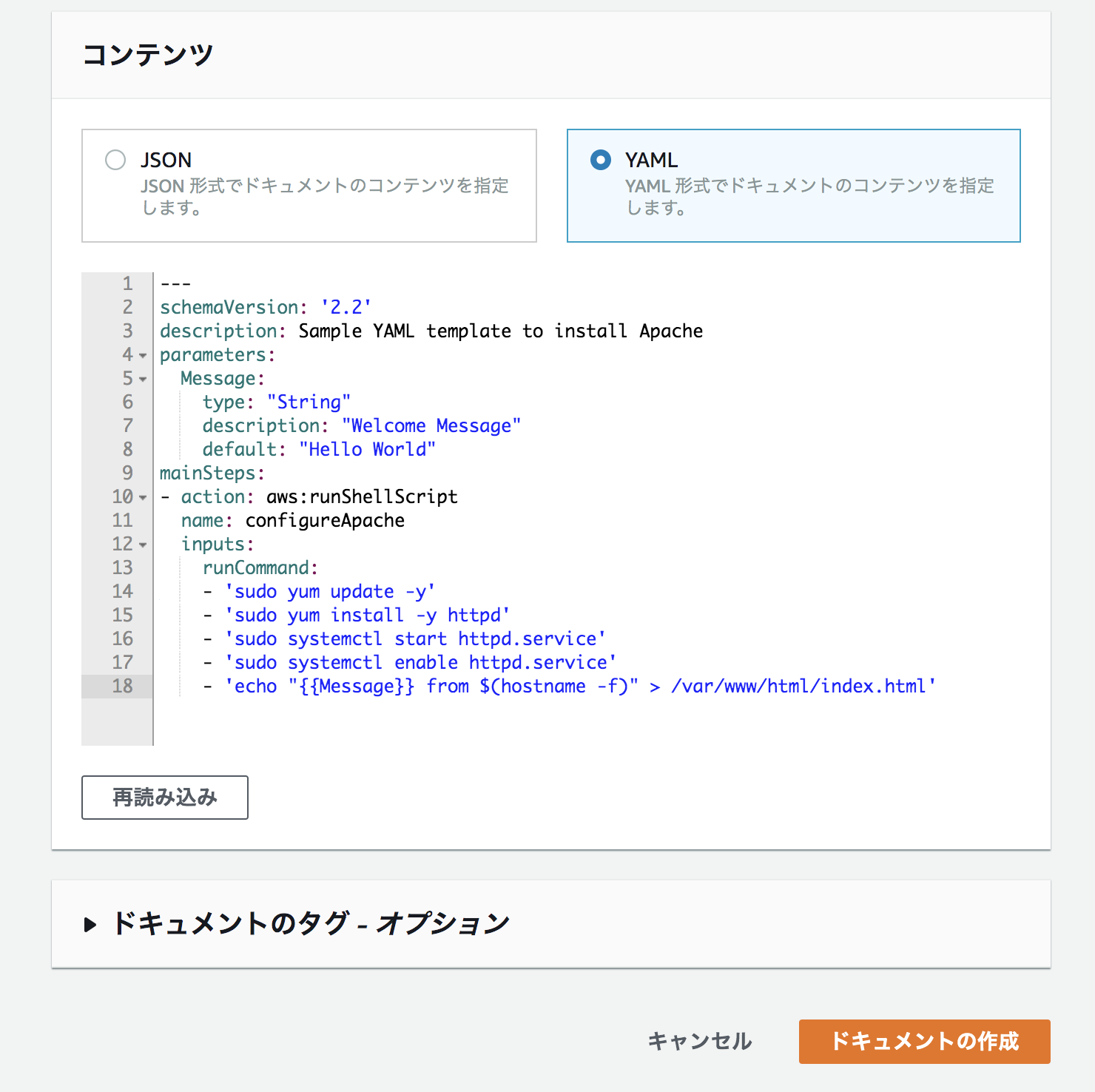
コンテンツではYAMLに変更し、コンテンツを以下のようにする。
設定したら、ドキュメントの作成を選択する。
--- schemaVersion: '2.2' description: Sample YAML template to install Apache parameters: Message: type: "String" description: "Welcome Message" default: "Hello World" mainSteps: - action: aws:runShellScript name: configureApache inputs: runCommand: - 'sudo yum update -y' - 'sudo yum install -y httpd' - 'sudo systemctl start httpd.service' - 'sudo systemctl enable httpd.service' - 'echo "{{Message}} from $(hostname -f)" > /var/www/html/index.html'Systems Manager>Run CommandでRun Commandを選択する。
下記のようにコマンドの設定を行っていく。
ドキュメントを先ほど作成したInstallAndConfigureApacheで選択する。
メッセージをCustom Hello Worldにする。
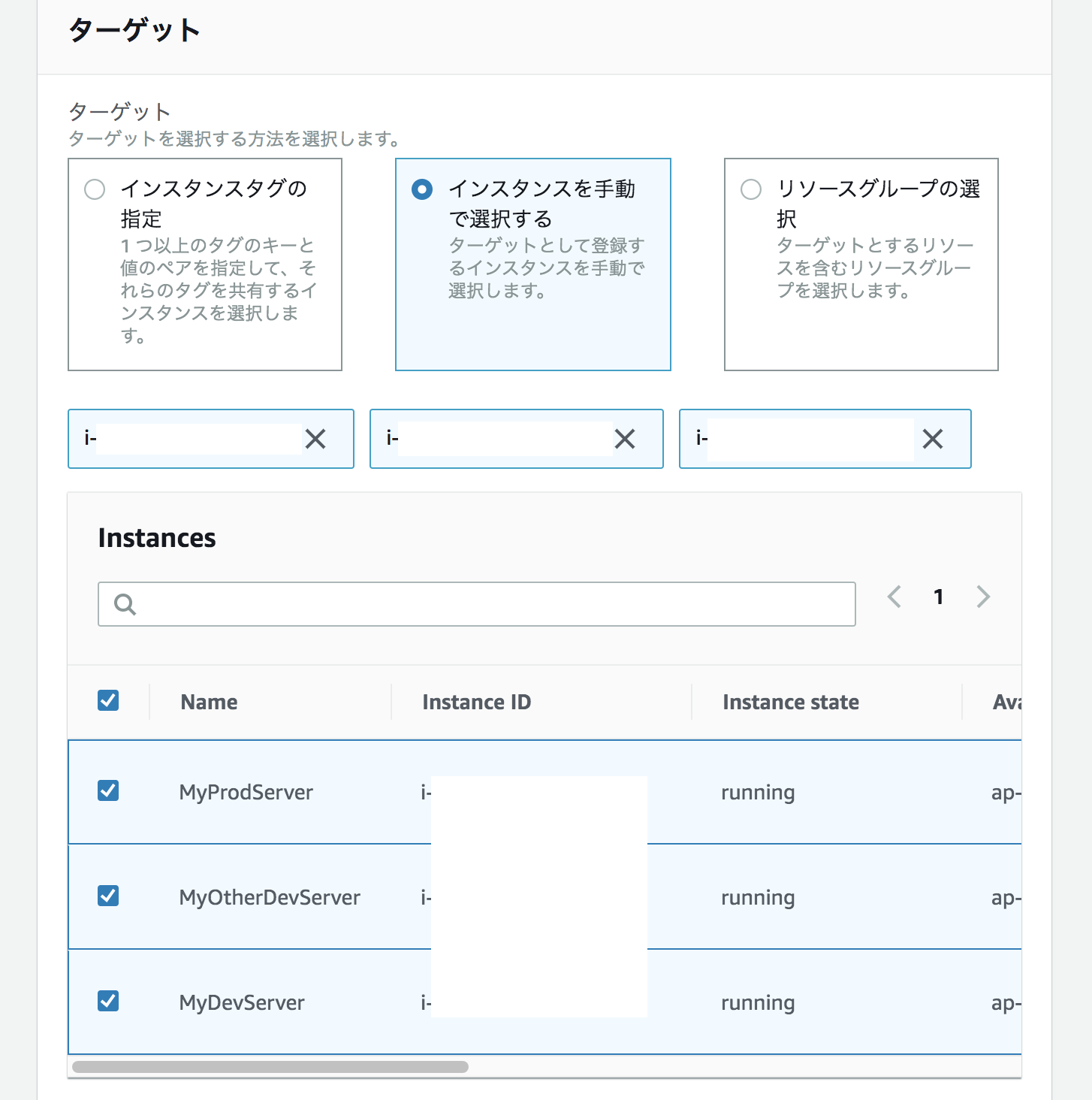
ターゲットを先ほど作成したMyProdServer、MyOtherDevServer、MyDevServerを選択する。
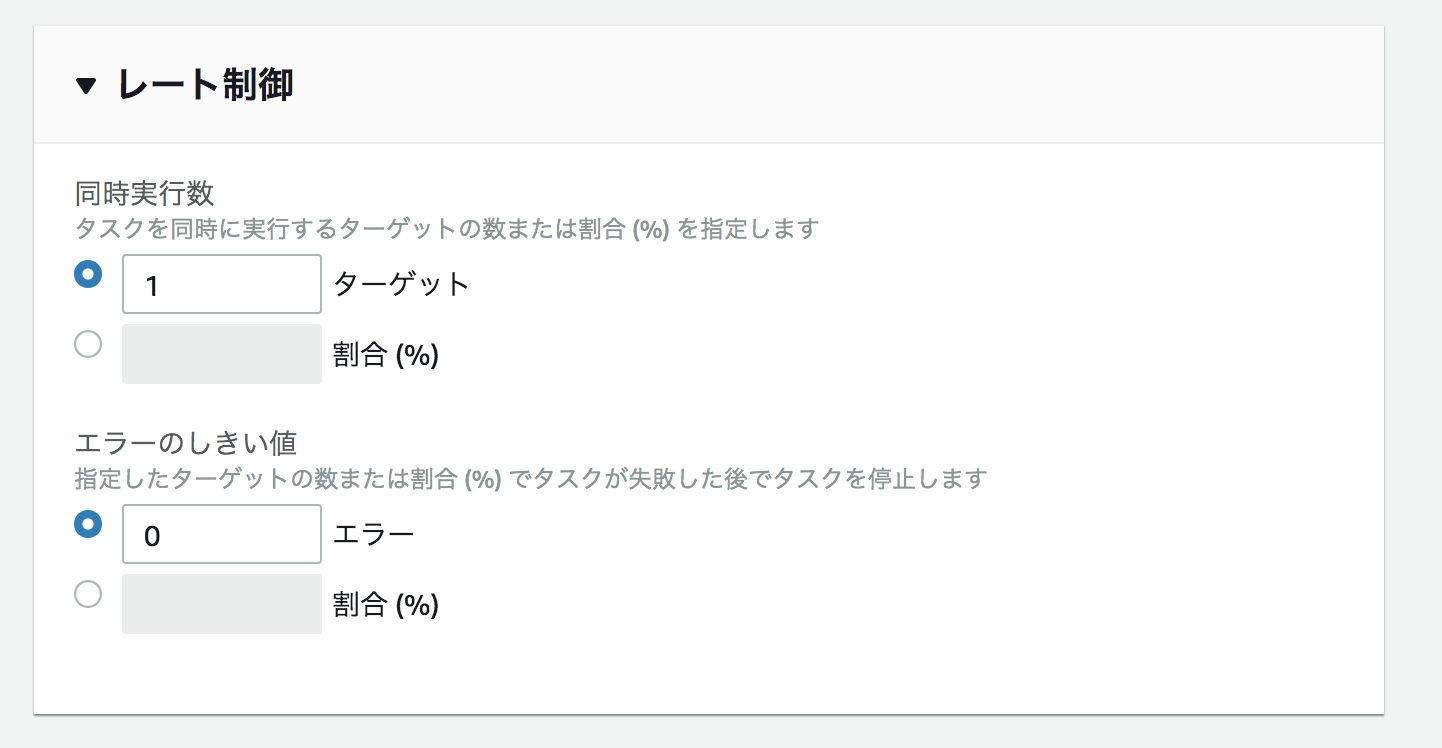
レート制御において1ターゲットにする。
出力オプションをCloudWatch出力を選択し、ロググループ名をCustomRunCommandで選択する。
実行を選択する。
Run Commandでステータスが成功になっているか確認する。
成功していたら、EC2インスタンスでパブリックIPv4アドレスでIPアドレスをURL欄に入力しエンターすると、下記のような画面が表示される。









- 投稿日:2020-10-09T19:47:20+09:00
serverless-s3-removerでオブジェクトが存在するS3もremove
Serverless Framewok便利ですね。
S3を作ったからにはモノを置くと思うんですが、この状態でremoveしようとすると、空じゃないバケットをremoveしてはダメらしくエラーが出ます。
An error occurred: xxxBucket - The bucket you tried to delete is not emptyそこで探し当てたのがserverless-s3-remover
sls remove時に先に指定S3バケットを空っぽにしてくれるという優れもの。
ただちょっと扱いに難ありだったのでここに記録を残します。ずいぶんメンテされてないようですが、十分使えます。
最終的なyaml構成
service: ez-s3-remove provider: name: aws stage: ${opt:stage, 'dev'} region: ${opt:region, 'ap-northeast-1'} profile: ${opt:profile, 'default'} deploymentBucket: 'sls-deploy-bucket' resources: Resources: myBucket: Type: AWS::S3::Bucket Properties: AccessControl: Private BucketName: Fn::Join: - "" - - '${self:service}-${self:provider.stage}-' - Ref: AWS::AccountId Outputs: myBucket: Value: !Ref myBucket plugins: - serverless-s3-remover custom: remover: buckets: - ${cf:${self:service}-${self:provider.stage}.myBucket, ''}ここに至る過程を書きます。
ただの日記です。
過程
ベースとなるyamlファイル
S3だけ作る簡単なものです。
service: ez-s3-remove provider: name: aws stage: ${opt:stage, 'dev'} region: ${opt:region, 'ap-northeast-1'} profile: ${opt:profile, 'default'} deploymentBucket: 'sls-deploy-bucket' resources: Resources: myBucket: Type: AWS::S3::Bucket Properties: AccessControl: Private BucketName: Fn::Join: - "" - - '${self:service}-${self:provider.stage}-' - Ref: AWS::AccountIdこれだけだとremoveするときにファイルがあるとエラーになってしまいます。
serverless-s3-removerを追加
npm i -D serverless-s3-removerプラグインを使うようにyamlを変更。
対象バケット名をRefで参照。service: ez-s3-remove provider: name: aws stage: ${opt:stage, 'dev'} region: ${opt:region, 'ap-northeast-1'} profile: ${opt:profile, 'default'} deploymentBucket: 'sls-deploy-bucket' resources: Resources: myBucket: Type: AWS::S3::Bucket Properties: AccessControl: Private BucketName: Fn::Join: - "" - - '${self:service}-${self:provider.stage}-' - Ref: AWS::AccountId plugins: - serverless-s3-remover custom: remover: buckets: - !Ref myBucketそして最初のremove
S3 Remover: Faild: [object Object] may not be empty. ~略~ An error occurred: myBucket - The bucket you tried to delete is not emptyだめだ…
何かエラーが出ている。
オブジェクトが消せてないためCloudFormationのエラーも変わりません。バケット名の参照の仕方を変えてみる
もともとRefでバケット名がとれるんだっけ?と思い、バケット名と同じ書き方で直接突っ込んでみる
custom: remover: buckets: - Fn::Join: - "" - - '${self:service}-${self:provider.stage}-' - Ref: AWS::AccountIdremove
S3 Remover: Faild: [object Object] may not be empty. ~略~ An error occurred: myBucket - The bucket you tried to delete is not emptyだめ。
どうやらRefとか関数をかますと動かない模様。解決編
いろいろ調べてこのIssueに到達。
https://github.com/sinofseven/serverless-s3-remover/issues/3#issuecomment-621385163CloudFormationのOutputsを参照すればいいとのこと。
Outputs: myBucket: Value: !Ref myBucket plugins: - serverless-s3-remover custom: remover: buckets: - ${cf:${self:service}-${self:provider.stage}.myBucket, ''}そしてremove
S3 Remover: Success: ez-s3-remove-dev-xxxxxxxx is empty. ~略~ Serverless: Stack removal finished...やった!成功です!
CloudFormationのOutputsって使いどころよくわからず使ってこなかったんですが、初めて活躍しました。
書き方も簡単ですね。まとめ
最近はAWS SDKにも興味があります。TypeScript補完がかなり効くらしいので。
CloudFormationのyamlを手で書くのがつらい…
- 投稿日:2020-10-09T19:04:10+09:00
一緒にクラウドを学ぶシリーズの紹介・クラウドコンピューティングについて
長い間大切にしてきた期間を軽て、クラウドについてお教えするシリーズをお書きします。
どうしてクラウドについて書きますか?
数年前、どこに行っても、クラウドコンピューティングテクノロジーについて聞くことができます。テクノロジーの未来などと言われています。
多数に反対するのが好きで、どのテクノロジーが人々から賞賛されているかをみて、まだ学びません(以前はCloud、Angular、React、Blockchain)。
多くの企業で使用され、実用的なメリットがユーザーにもたらされるようになるまで、学び始める前によく待ちます。当時、クラウドコンピューティングサービスを提供していたのはAmazonだけでした。ただし、需要の増加、AmazonWebServiceの収益はますます成長しています。それを見て、Microsoftも飛び込み(Azureを立ち上げた)、Googleは遅くなり、Google Cloud Platformを立ち上げました。競争のおかげで、より手頃なクラウドコスト、より多くのサポートツール、より多くの調査資料があります。
Amazon、Microsoft、Googleがクラウド市場で競争現在、企業がクラウドをますます使用するようになった、プロセスとベストプラクティスは明確です。クラウドは、有用で頻繁に使用され、学ぶする価値のあるテクノロジーであることが証明されています。
だから私は調査に集中して、そして共有します!
プログラマーがクラウドについて知っておく必要があるのはなぜですか。
あなたは疑問に思うかもしれません:
このクラウドの知識は自分にとって役に足りますか?
2、3年間働きましたが、クラウドについては何もありません。実はそれは私自身も過去にも当てはまります。1~2年間働いていますが、クラウドが何であるかまだわかりません。
しかし、最近、ますます多くの企業がクラウドサービスを使用して製品を開発しています。そのため、仕事を探すと、「クラウド体験が有利」という募集が段々と出てきます。
DevOpsになるために、またはSoftware Architectのようなより高い地位にジャンプしたい場合は、Cloudを理解することがさらに必要です。
ますます多くの企業がクラウドコンピューティングを使用しています。また、私たちは単なるコーダーではなく、ソフトウェアエンジニアです。エンジニアとして、コードについてかんえるだけでなく、システムアーキテクチャについても考え、コードがどこで実行されるかについても考える必要があります。
クラウドについて知っていると、システムのアーキテクチャを設計および選択するときに役立ちます。
「一緒にクラウドを学ぶシリーズ」の注目点は何ですか?
タイトルにあるように、一緒にクラウドを学びます。
私自身もクラウドコンピューティングについて1年以上学びましたが、仕事でもかなりの量を使用しましたが、そのレベルはまだ他の人に教えるためマスターのレベルに達していません。しかし、「マスター」レベルを得るまで持つだけながら、どれくらい持つのでしょうか?したがって、調査して書き、それをレビューと見直し、知識を総合できます。
このシリーズでは初心者の視点から、基本的でわかりやすく、アクセスしやうし方法でクラウドの知識を共有します。理解していることが正しくないとか、説明が明確ではない場合は、自由にコメントして改善してください。
シリーズの概要:
・クラウドは何か、クラウドの簡単な歴史
・一部のクラウドモデル:IAAS, PAAS, SAAS
・クラウドにはセルフホストより長所と短所は何か
・主要部分:チュートリアル実装とデモ(AWS、Azure)
シリーズでガイドされている内容:
もちろん、クラウドについて話し、理論についてのみ話すことは退屈で混乱するでしょう!だから、理論に加えて、有名なクラウドサービスの使い方もご案内します。
現在、AWS(Amazon Web Service)とAzureの2つの人気のあるクラウドコンピューティングサービスがあります。格サービスは非常に幅広く、無数のサブサービスが接続されています。Googleの市場シャアは少し小さいので、それを一時てきに言及しません!
シリーズでは、AWSとAzureの概要を説明します。 次に、労力を節約するために、横行するものを紹介するのではなく、使用する必要のあるサブサービスの役割と使用法について説明します。
I. Microsoft Azure
・アカウントを作成するAzure無料12か月
・Azureの概要、基本
・仮想マシンをレンタルする
・安いデータベース
・Storage:ファイルストレージ
・Redisキャッシュ:低価格でのキャッシング
・WebApp:アプリケーションのデプロイ(デプロイするアプリには多くの種類があり、Visual Studioから直接デプロイできます)
・Function・Serverless:サーバーなしでコードを実装
Azureが提供するサービスII. AWS(Amazon Web Service)
AWSとそれぞれのサービスの簡単な紹介
・AWSの概要・基本
・IAM:アカウントを作成してセキュリティを管理する
・AWS EC2:仮想マシンをレンタルする
・AWS S3:ファイルストレージ
・RDS:低価格でデータベースをレンタルする
・ElastiCache:低価格でのキャッシング
・Elastic BeanstalkDeploy:アプリのデプロイは簡単です
・Lambda:小さいけれどとても有利
AWSが提供するサービス結論
最初にフレーム(目次)を書き、後でシリーズ内容を書くことに集中しましょう! あなたが興味を持っていることが合ったら、コメントを残しておいてください。多くの人が興味を持っているなら、もっと書くことに集中します。
また、クラウドについてご不明点がございましたら、コメントを残しておいて、シリーズへの追加をご検討致します。
Noteにフローしてください!!
https://note.com/devstory/n/ne9b008a36134




- 投稿日:2020-10-09T17:39:08+09:00
EC2を複数台立ち上げた後、全てのEC2にSSH接続するためのTeraTermマクロファイルを作成するShellスクリプト
負荷試験を実施するために同じ構成のEC2を15台立ち上げてTeratermでSSH接続負荷試験を実施していたのですが、コスト削減のためにEIPを使用せずに負荷試験を実施しないときは停止することにしました。
そうするともちろんEC2を起動するたびに接続先のIPが変更されるため、毎回15台のIPをTeratermに入力しなければいけません。というわけで、EC2を複数台立ち上げた後、接続先のIPを取得し、立ち上げた全てのEC2にSSH接続を行うTeratermマクロファイルを作成するShellスクリプトを作ることにしました。
事前準備
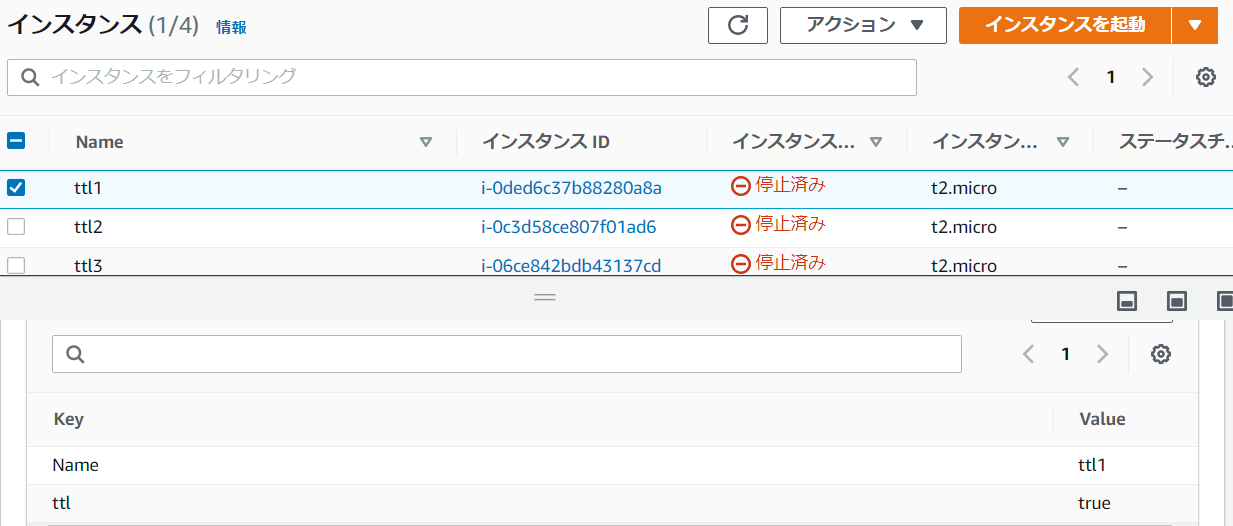
起動したいEC2のタグに
NAME VALUE ttl true を登録しておきます。
本題
Shellスクリプト
※使用する際は
<profile>→AWS-CLIのプロファイル名、
<keypath>→接続に使うSSHKeyのフルパス
に置き換えてください。# aws cliのプロファイル AWS_PROFILE_NAME=<profile> # リージョン REGION=ap-northeast-1 # 起動するEC2インスタンスリストを取得 INSTANCES_ID_LIST=$( aws ec2 describe-instances \ --region $REGION \ --profile $AWS_PROFILE_NAME \ --output text \ --filters "Name=tag:ttl,Values=true" \ --query 'Reservations[*].Instances[*].InstanceId' | sed -e "s/[\r\n]\+//g" ) # EC2インスタンスを起動する INSTANCES=$( aws ec2 start-instances --instance-ids $INSTANCES_ID_LIST \ --region $REGION \ --profile $AWS_PROFILE_NAME \ --output text && aws ec2 wait instance-running --instance-ids $INSTANCES_ID_LIST \ --region $REGION \ --profile $AWS_PROFILE_NAME \ --output text ) # パブリックIPアドレスを取得 INSTANCES_IP=($( aws ec2 describe-instances --instance-ids $INSTANCES_ID_LIST \ --region $REGION \ --profile $AWS_PROFILE_NAME \ --query 'Reservations[*].Instances[*].PublicIpAddress' \ --output text | sed -e "s/[\r\n]\+//g" )) # TeraTermマクロファイル(.ttl)を作成する echo '' >loadtest-connecct.ttl | sed -e "s/[\r\n]\+//g" >loadtest-connecct.ttl cat <<-EOS >>loadtest-connecct.ttl $( echo strdim ip ${#INSTANCES_IP[@]} for ((i = 0; i < ${#INSTANCES_IP[@]}; i++)); do echo "ip[$i] = '${INSTANCES_IP[i]}'" done echo for i 0 $((${#INSTANCES_IP[@]} - 1)) echo username = "'ec2-user'" echo hostname = ip[i] echo keyfile = "'<keypath>'" echo msg = hostname echo strconcat msg "':22 /ssh /auth=publickey /nosecuritywarning /user='" echo strconcat msg username echo strconcat msg "' /keyfile='" echo strconcat msg keyfile echo connect msg echo unlink echo next ) EOSやっていること
やっていることは冒頭で記述した通りです。
- タグにttl = trueが定義されているEC2インスタンスのリストを取得
- 取得したEC2インスタンスを全て起動
- 起動したインスタンスのパブリックIPを取得
- 取得したパブリックIPを使用してSSH接続を実施するTeraTermマクロファイルをヒアドキュメントで作成
動作確認
今回接続したいEC2はこちらです。
ttl1,ttl2,ttl3それぞれにttl = trueタグを定義しています。
shellを実行するとEC2が起動し、ttlファイルが作成されています。
内容を見てみます。
生成されたttlファイルの内容
strdim ip 3 ip[0] = '3.112.15.xxx' ip[1] = '35.72.3.xxx' ip[2] = '18.181.203.xxx' for i 0 2 username = 'ec2-user' hostname = ip[i] keyfile = "'<keypath>'" msg = hostname strconcat msg ':22 /ssh /auth=publickey /nosecuritywarning /user=' strconcat msg username strconcat msg "' /keyfile='" strconcat msg keyfile connect msg unlink next起動したEC2のパブリックIP配列を作成した後、パブリックIP配列に対してループ処理を行い、SSH接続を試みています。
実際にTeraTermマクロを実行すると、起動したEC2台数分のTeraTermが立ち上がってSSH接続してくれます。終わりに
このshellスクリプトを応用すれば複数台サーバーに対して同じファイルを一括でSCP送信するスクリプトなどを簡単に作れると思います。
是非カスタマイズして便利なTeraTermライフを送ると同時に、記事などでアウトプットシェアしてみんなで幸せになりましょう。
- 投稿日:2020-10-09T17:00:37+09:00
新人エンジニアがインフラのコード化(IaC)に3ヶ月取り組んで見えた知見をまとめてみた
はじめに
約3ヶ月間、それなりにボリュームのある新規開発で AWS周りをガッツリやらせてもらいました。
AWS や新規開発について学ぶことが多かったので何回かに分けてまとめてみたいと思います。
これから AWS をガッツリ使っていこうと思っている方の参考になれば幸いです。今回はその第1回、 IaC (Infrastructure as Code)編です?
AWSで使った技術など
- CloudFormation
- Lambda
- DynamoDB
- API Gateway
- CloudWatch
- CloudFront
- X-Ray
- SNS
- S3
などなんかたくさん。
今回 IaC にはCloudFormationを使ったのですが、Terraform など他のツールでも参考になると思います。ある程度の規模になりそうなら SAM はやめておこう
AWS でインフラをコード化するにはいろいろ選択肢がありますが、AWS SAM というものも使えます。
今回使用したのは厳密に言えばこちらの SAM です。【参考】
https://aws.amazon.com/jp/serverless/sam/簡単に言うと、Lambdaを中心としたサーバーレスアプリケーションを構築する人向けに、CloudFormationをより簡単に使えるようにラップしたもの、でしょうか。
何が問題なのか?
CloudFormationをラップしたものなので、CloudFormationで書けるものは基本的には書けるはずです。
では、何が問題なのでしょうか?それは、 CloudFormation なら使える機能の1部が使えない(あるいは使いづらい) からです。
最初はスピード感を重視して SAM で開発を始めたのですが後々、
- Stack の管理外にあるリソースを CloudFormation の管理下におきたい
- リソースを記載したファイルが煩雑になってきたのでリファクタリングしたい
という時に苦労しました。もしかしたら何か別の方法があったかもしれませんが、必須では無かったのでとりあえず諦めました。
サクッとサーバーレスアプリを立ち上げたい時には素晴らしいのですが、ある程度の規模になることが見込まれるのであれば最初から純粋な CloudFormation で良くない?というのが印象です。
あまりメリットを享受できなかった気がする。。。
リソースの命名規則は最初にチームでしっかり決めていく
インフラをコード化する時には論理名(下のサンプルで言うと
HelloBucket)と、そのリソースの名前(バケット名とか)があると思います。Resources: HelloBucket: Type: AWS::S3::Bucket Properties: AccessControl: PublicReadこれらの命名規則をしっかり決めておかないと、後で
何が何だかどこで使っているリソースなんだか分からなくなります。私の失敗談を共有しておくと、それなりに分かりやすい名前を付けて進めていたつもりなんですが、「環境名の prefix」を付けていなかったんですね。
そして開発が進み、必要になりました。はい。環境名の prefix が。
うわあああああああああああああ、めんどくせええええええええ!!!!!!!
本当に後から名前を変える単純作業は苦痛ですし、工数としてもちょっと無駄です。
せっかく効率化のために IaC ツールを使っているのですから、この辺はスマートにやりたいところ。
是非皆さんには私のような間違いは犯して欲しくないなと思っております?命名規則に関しては以下のクラスメソッドさんの記事が非常に参考になります。
https://dev.classmethod.jp/articles/aws-name-rule/ワークフローはしっかりチームで決めよう
もちろんインフラをコード化したらチームメンバーにレビューをお願いすると思います。
しかしまだ経験が少ないなら尚更のこと、 AWS は実際にデプロイしてみないと分からないことが多々あります。
もしかしたら、合っていたと思っていた設定値が間違っていてデプロイに失敗するかもしれません。それにレビューする側もプロパティがツラツラ書いているだけのものを見るより、動いてから見せてもらった方が良いと思います。
なので開発用の環境が用意できるのであればそこで試してからレビュー依頼を出す、とか工夫をした方が良いです。工夫というか、チームで決めるようにできると良いですね!!
他にもワークフローに関してはこんなことを事前に決めておくと良いかもしれません
- 手でデプロイするの? CI/CD ツールを使ってデプロイするの?
- 環境は何を用意してそれぞれがどんな役割なの?
- コードレビューの着眼点
IaC ツールは Terraform を使おう
以上です、何も言うことはありません?
手動を排除しよう
最初は良いんです、最初は。
しかし開発は進み、当初は予期していなかったリソースは増えていくものです。その時、 チームのワークフローはそれに対応できるものでしょうか?
確かにコマンド一発でインフラを構築できる威力は凄いですしシンプルですが、それでも環境が増えたりすると手順ミスは当然起こりえます。
AWS ですし、下手にミスると大事なデータを消してしまったりもします。精神衛生上も良くないです(幸い問題にはなりませんでしたが、私も開発中何度かヒヤッとしました)。めんどくさい気持ちは分かるんです。最初はコマンドラインから普通にデプロイした方が楽ですからね。
しかしこういうのは最初に CI/CD パイプラインを構築するなどして 仕組みに頼る べきです。
間違っても「自分は間違えない」などと過信してはいけません。どんなに優秀な人でも所詮人間です、普通に間違えます。間違えるのは決して悪いことではありません。それに対して策を講じないのが悪いことです。気合で頑張るとかはやめて、仕組みに頼りましょう。
【例】
GitHubにpush → CDで検証環境にデプロイ → 動作確認 → レビュー依頼 → 修正対応 → masterにマージ → 本番環境にデプロイほんの一例ですが、手元からデプロイするよりずっと安全です。
おわりに
まだまだあるのですが、長くなるのでこの辺で切ります。
引き続き、もっと安定して強力なワークフローを考えられるように頑張ります?どなたかの役に立てば幸いです、ありがとうございました。
- 投稿日:2020-10-09T16:52:22+09:00
AWS GlueでRDSにデータを上書き保存する
GlueのジョブでDynamicFrameを使ってデータをRDSに書き込むとき、
追記(Append)で書き込むため、同じジョブを動かすとデータが重複してしまいます。DynamicFrameをDataFrameに変換すると、上書きモードで書き込むことができます。
自動生成されたジョブのコードに以下を追記します。
JDBCの接続定義が用意されてることが前提です。#datasink4 = glueContext.write_dynamic_frame.from_jdbc_conf(frame = dropnullfields3, catalog_connection = "MyConnection", connection_options = {"dbtable": "my_table", "database": "my_database"}, transformation_ctx = "datasink4") # 接続定義からJDBC情報を取得 jdbc_conf = glueContext.extract_jdbc_conf(connection_name='MyConnection') # DynamicFrameをDataFrameに変換 df = dropnullfields3.toDF() # DataFrameをテーブルに書き込み(上書きモード) df.write \ .format("jdbc") \ .option("url", jdbc_conf['url']) \ .option("dbtable", "my_database.my_table") \ .option("user", jdbc_conf['user']) \ .option("password", jdbc_conf['password']) \ .mode("overwrite") \ .save() job.commit()例では、S3のデータをAurora Serverless MySQLに書き込んでいますが上書きできました。
- 投稿日:2020-10-09T12:47:25+09:00
brefphpを使って簡単にLaravelをサーバレス環境で動かす
はじめに
ここではbrefについてと、実際の使い方や使ってみた所感などをまとめてみようと思います。
brefphp とは?
PHPアプリケーションをAWS Lambdaに簡単にデプロイするための Composer パッケージです。
コマンド1つでサーバーからアプリケーションのデプロイまで行えます。
使い方
Step
serverless のインストール
bref は serverless コマンドを使用してAWS環境にデプロイを行います。
以下のコマンドでインストールしましょう。npmの場合
npm install -g serverlessyarnの場合
yarn global add serverless追加したら以下のコマンドでちゃんと実行できるか確認しましょう
$ serverless --version Framework Core: 2.4.0 Plugin: 4.0.4 SDK: 2.3.2 Components: 3.2.1Step
Laravelプロジェクトの作成 [公式]
今回はLaravelで使うため、プロジェクトを作成します。
Laravelインストーラーがない場合はインストールします
composer global require laravel/installerプロジェクトを作成します。
laravel new brefphp-testStep
brefphp パッケージのインストール [公式]
作成したLaravelプロジェクトのディレクトリに移動して、
brefphpをインストールします。composer require bref/bref bref/laravel-bridgeデフォルトのサーバ構成設定ファイルを作成します。
php artisan vendor:publish --tag=serverless-configStep
デプロイの準備
「アクセスキーID」と「シークレットアクセスキー」の作成
デプロイ前に、デプロイ先のサーバ(AWS)のアクセスキーとシークレットキーを使用します。
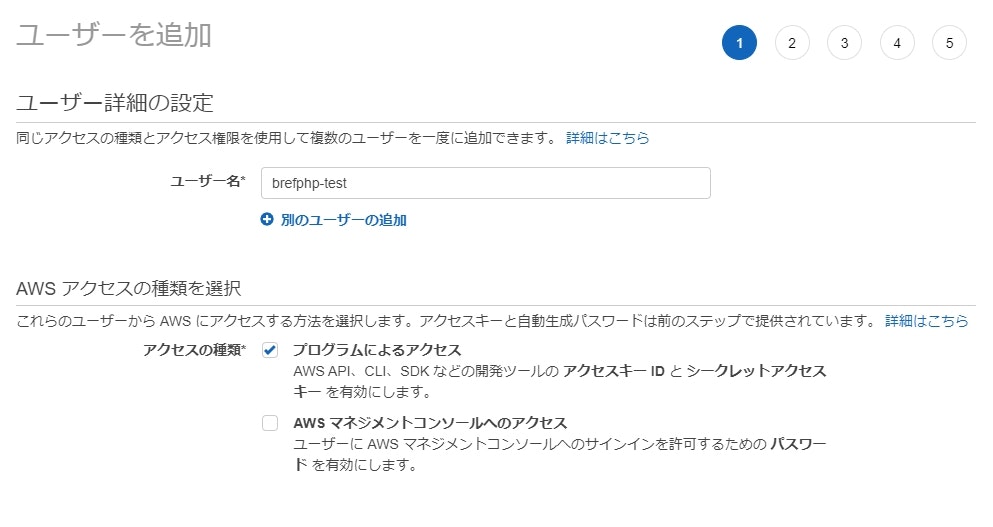
IAMのユーザー追加画面でテスト用ユーザーを作りましょう。
ユーザー名を決めて、アクセスの種類の「プログラムによるアクセス」をチェックします。
アクセス権限の設定です。「既存のポリシーを直接アタッチ」を選択して「AdministratorAccess」を選択します。
名前の通り最強権限なので、発行されるキーは絶対に外部に漏らさないでください!
タグはよしなに追加します。(自分は何もしません)
ユーザーの追加完了です。
「アクセスキーID」と「シークレットアクセスキー」をメモしておいてください。
プロファイルの追加
メモした「アクセスキーID」と「シークレットアクセスキー」をプロファイルに登録します。
$ aws configure --profile <プロファイル名> AWS Access Key ID [None]: <アクセスキーID> AWS Secret Access Key [None]: <シークレットアクセスキー> Default region name [None]: Default output format [None]:すると、
~/.aws/credentials(Windowsの場合は%USERPROFILE%/.aws/credentials) にプロファイルが登録されます。/.aws/credentials[<プロファイル名>] aws_access_key_id = <アクセスキーID> aws_secret_access_key = <シークレットアクセスキー>Step
デプロイ
以下のコマンドでデプロイします。
<プロファイル名>は、先程(Step4)で登録した名前を指定してください。$ serverless deploy -v --aws-profile=<プロファイル名> Serverless: Packaging service... Serverless: Excluding development dependencies... Serverless: Creating Stack... Serverless: Checking Stack create progress... ~~~~~~~[色々ログ出てきて]~~~~~~~ Serverless: Stack update finished... Service Information service: laravel stage: dev region: us-east-1 stack: laravel-dev resources: 15 api keys: None endpoints: ANY - https://xxxxxxxxxx.execute-api.us-east-1.amazonaws.com/dev ANY - https://xxxxxxxxxx.execute-api.us-east-1.amazonaws.com/dev/{proxy+} functions: web: laravel-dev-web artisan: laravel-dev-artisan layers: None Stack Outputs WebLambdaFunctionQualifiedArn: arn:aws:lambda:us-east-1:000000000000:function:laravel-dev-web:2 ArtisanLambdaFunctionQualifiedArn: arn:aws:lambda:us-east-1:000000000000:function:lara vel-dev-artisan:2 ServiceEndpoint: https://xxxxxxxxxx.execute-api.us-east-1.amazonaws.com/dev ServerlessDeploymentBucketName: laravel-dev-serverlessdeploymentbucket-o2rnhi5yd9v6生成されたエンドポイントにアクセスして、LaravelのWelcomeページが出てくれば成功です
AWS Lambdaの関数にも追加されています。
Step
環境の削除
$ serverless removeコマンドで環境を削除できます。$ serverless deploy -v --aws-profile=<プロファイル名> Serverless: Getting all objects in S3 bucket... Serverless: Removing objects in S3 bucket... Serverless: Removing Stack... Serverless: Checking Stack removal progress... ~~~~~~~[色々ログ出てきて]~~~~~~~ Serverless: Stack removal finished... Serverless: Stack removal finished...
ローカル環境の構築
Dockerでローカル環境を構築します。
すでにローカル用のイメージは用意されているので、すぐに立ち上げることができます。Laravelプロジェクトと同じディレクトリに
docker-compose.ymlの作成docker-compose.ymlversion: "3.5" services: web: image: bref/fpm-dev-gateway ports: - '8000:80' volumes: - .:/var/task links: - php environment: HANDLER: public/index.php DOCUMENT_ROOT: public php: image: bref/php-74-fpm-dev volumes: - .:/var/task:ro
docker-compose up -dでコンテナを起動します。1
http://localhost:8000にアクセスするとLaravelのWelcomeページが表示されます。
料金について
ローカル環境には料金はかかりません。
AWSにデプロイした際に以下のサービスを利用するため、料金が発生します。所感
個人開発で使って便利だったので、会社のプロジェクトでも導入してみました。
LambdaやAPI Gatewayによるいろいろな制限があったりして、思うように行かなかった部分もありますが、なんとかサービスもリリースしているような状態です。EC2に比べてLambdaやAPI Gatewayの料金は基本的にトラフィック依存なので、
アクセス数のそんなにないサービスでは、かなりのコスト削減になりました。
発生した問題とその対策
実際にプロジェクトに導入した際に発生した問題と、それについての対策を記述します。
もし似たような問題が発生した場合は参考になればと思います。POSTで10MBを超えるファイルをアップロードできない
API GatewayのPOSTリクエストサイズの最大が10MBのため、大容量のファイルをPOSTできません。
最終的にS3にアップロードする予定だったので、S3でPresigned URL2を発行して、それに対しアップロードするようにしました。6MBを超えるデータを返せない
またもやAPI Gatewayの制約により、レスポンスの最大は6MBです。
(まぁ、6MBなんて超えることなんて稀ですが…)
こちらも一度S3にアップロードしてPresigned URLを生成し、
フロントエンドから直接S3のURLを参照するようにしました。APIのタイムアウトの最長が29秒
API Gatewayの制約上、29秒でタイムアウトしてしまいます。
なので、重い処理はAmazon SQSに投げて処理するようにしました。PR
brefのSlackコミュニティに日本語チャンネルができました。
一緒にbrefについて語りましょう?



- 投稿日:2020-10-09T10:43:43+09:00
フリートプロビジョニング前にフックするLambdaの作成例
https://qiita.com/takmot/items/eda7c2f519581b40ec3f
前回記事の続きとして、フリートプロビジョニング前にフックするLambdaの作成例を記載します。プロビジョニング許可/拒否判定方法
- シリアルナンバーと、プロビジョニング許可/拒否を表す値を記載したCSVファイルをS3に格納
- LambdaからこのCSVファイルを参照し、デバイスから通知されたシリアルナンバーからプロビジョニング許可/拒否判定
以下CSVファイル例
SerialNumber,Effect 1,Allow 2,Deny 3,AllowLambda関数
変更前コード
import json provision_response = {'allowProvisioning': False} def isBlacklisted(serial_number): #check serial against database of blacklisted serials ... def lambda_handler(event, context): # DISPLAY ALL ATTRIBUTES SENT FROM DEVICE print("Received event: " + json.dumps(event, indent=2)) # Assume Device has sent a device_serial attribute device_serial = event["parameters"]["SerialNumber"] # Check serial against an isBlacklisted() function if not isBlacklisted(device_serial): provision_response["allowProvisioning"] = True return provision_responseisBlacklistedで、
引数としてシリアルナンバーを受け取り、
プロビジョニング許可であればFalse、
プロビジョニング拒否であればTrueを返すように変更します。変更後コード
参考記事:
https://qiita.com/asunaro/items/99472b492af387d97b70
https://note.nkmk.me/python-pandas-at-iat-loc-iloc/lambda_function.pyimport json import boto3 import pandas as pd from io import StringIO def isBlacklisted(serial_number): BUCKET_NAME:<バケット名> KEY_NAME:<CSVファイルパス(xxx/yyy.csv)> # S3に格納したCSVファイルからDataFrameを作成 s3 = boto3.resource('s3') s3obj = s3.Object(BUCKET_NAME, KEY_NAME).get() csv_string = s3obj['Body'].read().decode('utf-8') df = pd.read_csv(StringIO(csv_string), index_col=0) try: # 許可/拒否判定 effect = df.at[serial_number, 'Effect'] if effect == 'Allow': return False else: return True except: # 該当serial_numberなし return True def lambda_handler(event, context): # 変更なし外部ライブラリの使用
Lambdaから外部ライブラリ(今回の場合Pandas)を使用する場合、
ライブラリをzipにまとめてアップロードする方法と、
Layerを設定する方法があります。
Layerの作成方法に関しては触れません。
以下記事(2. pandasのLayerのARNを調べ、Layerを追加)を参考にLayerを追加
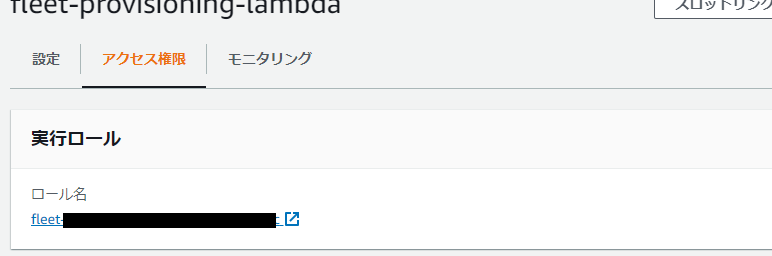
https://qiita.com/polarbear08/items/202752d5ffcb65595bd9実行ロールのポリシー設定
アクセス制限→ ロール名のリンクをクリック
「ポリシーをアタッチします」をクリック
AWS管理ポリシーからs3で検索し、
今回S3に格納したファイルのリードが必要なので、
「AmazonS3ReadOnlyAccess」をチェックし、
「ポリシーのアタッチ」をクリックLambda関数のアップロード
※ローカルでLambda関数を作成してアップロードする場合
ファイル名は
lambda_function.pyにします。
lambda_function.pyをzip圧縮します
アクションから.zipファイルをアップロードを選択し、アップロードします


- 投稿日:2020-10-09T10:35:15+09:00
[Rails]本番環境EC2で"rails db:create"などの実行方法
投稿内容
ローカル環境で行う
rails db:createやrails db:migrateなどを本番環境で実行する方法について投稿します。実行するディレクトリへ移動
まず本番環境で下記コマンドで
currentディレクトリまで移動します。ターミナル.[ec2-user@******* ~]$ cd /var/www/アプリ名/currentコマンド実行
ターミナル.//データベースを削除 [ec2-user@******* current]$ RAILS_ENV=production DISABLE_DATABASE_ENVIRONMENT_CHECK=1 bundle exec rake db:drop //データベース作成 [ec2-user@******* current]$ rails db:create RAILS_ENV=production //テーブル、カラムの作成 [ec2-user@******* current]$ rails db:migrate RAILS_ENV=production //データベースのカラムに情報を送りたい場合 [ec2-user@******* current]$ rails db:seed RAILS_ENV=production最後に
本番環境のコマンドはついつい忘れてしまいそうになるので、是非参考にしてもらえると幸いです!
- 投稿日:2020-10-09T09:54:51+09:00
AWS LightsailにMineCraft(Spigot)サーバーを移行してみた
MineCraft(Spigot)サーバーをAWSに移行しました。
AWS初心者が事始めにちょっとやってみたというノリなので
- これやりゃもっと安く上がる
- これは無駄なことやってる
等のマサカリがあれば随時募集してます。
概要
- 自宅でHamachi使っていた身内向けSpigotサーバーをAWS Lightsailに移行した
- 移行後1日しか経過してないけど報告
- 動作は快適そのもの
- 24時間動かしてたらCPUバースト1日で溶けた
- 月10$(のはず)
手順概略
- AWS Lightsailでインスタンス作成
- 静的IP設定
- FW設定
- インスタンスにssh接続
- scp使って既存サーバーのワールドデータコピー
- BuildTools.jarでspigotをビルド
- サーバー起動・接続
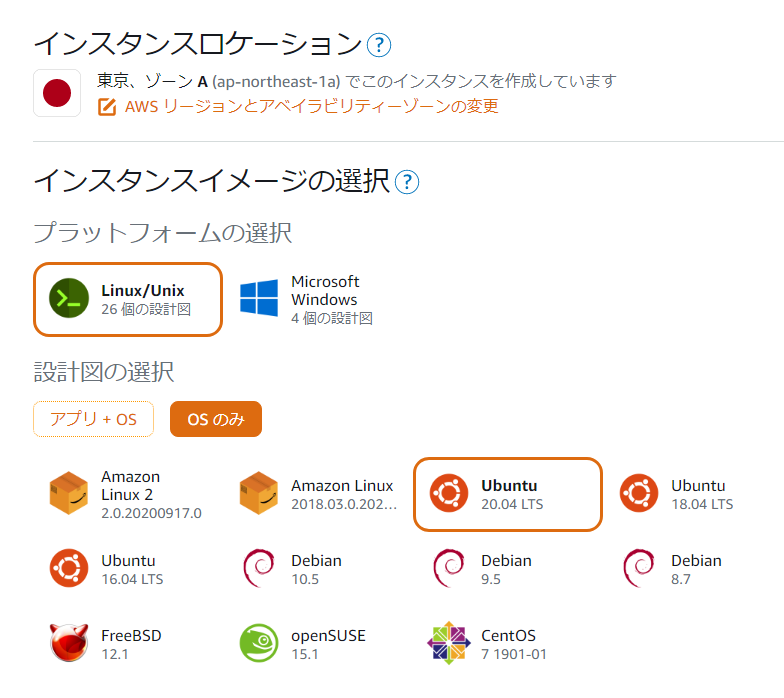
AWS Lightsailでインスタンス作成
インスタンスのディストロ選択
ロケーションは住んでいるところの近くらへんで適当に
Linux選んでディストロは適当に
Ubuntu好きなのでUbuntuにしました
SSHのpemはここで落とします(あとでも落とせます)
プラン選択
この辺は人によりそう
自分のサーバーは同時接続5人行かない上にプラグイン少ない小規模鯖なのでRAM2GBの$10で足りました
RAMは必要に応じて増やしましょう
あとは作るだけ
名前を入れて作成ポチっとするだけです
静的IP設定
から静的IPを作ります
名前とアタッチするインスタンスを設定するだけです
インスタンスはさっき作ったものを指定しますElastic IPのものと同じらしく、アタッチしてない静的IPには課金されます
FW設定
↓から管理
ネットワーキングタブから25565ポートを許可しておきます
インスタンスに接続
上のターミナルのボタンクリックするとブラウザ上でSSH接続始まってコンソールが開きます
パッケージインストールなどは適当にここでscp使ってコピー
前もって
spigot.zipとかにでも圧縮しといたことにしますscp -i xxx.pem spigot.zip <username>@<静的IP>:<path>あとは展開もしときましょう
BuildTools.jarでspigotをビルド
デフォでjava8が入っていたかうろ覚え
入ってなさそうだったら適当にインストールしてください
sudo apt update && sudo apt upgrade -yお忘れなく
BuildTools.jarはwget https://hub.spigotmc.org/jenkins/job/BuildTools/lastSuccessfulBuild/artifact/target/BuildTools.jar落としてきたのを
spigot-<version>.jarがもともとあった場所に動かしたらあとはjava -jar BuildTools.jar --rev <version>サーバー起動・接続
サーバー起動はいつも通り
bash
java -jar -Xmx1024M -Xms1024M spigot-<version>.jar nogui
あとは静的IPをクライアントで入力して接続するだけです
今後解決が必要そうなやつ
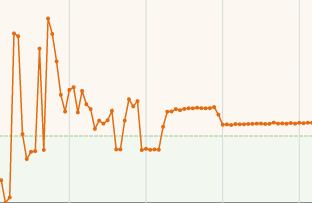
1日でCPUのバーストが溶けました
左側のスパイクは諸々ビルドしたりしてた時のもので、その後は落ち着いているんですが、右端のところはアイアンゴーレムトラップ横で放置していた時のもので、誰かログインしているとクレジットが溶ける、という状態のようです。
しかしこれの為に$20にするのは気が引ける…まとめ
spigotサーバーをAWSに移行しました
少人数・MOD少なめ鯖なら$10で移行可能です



- 投稿日:2020-10-09T09:16:04+09:00
API実行ログをSlackに通知させる
はじめに
前回の記事の続きです。
前回は、WebページのボタンからAPIを実行させるところまでを実装しました。
今回は実行ログの出力について記載します。前回作成したAPIは限定された人しか実行できないようにしている訳ではなく、
Webページにアクセスできる人であれば誰でもボタンを押すことで実行できてしまいます。そのため、どのIPから、どのような端末で、いつ実行したのかが記録として残るように、
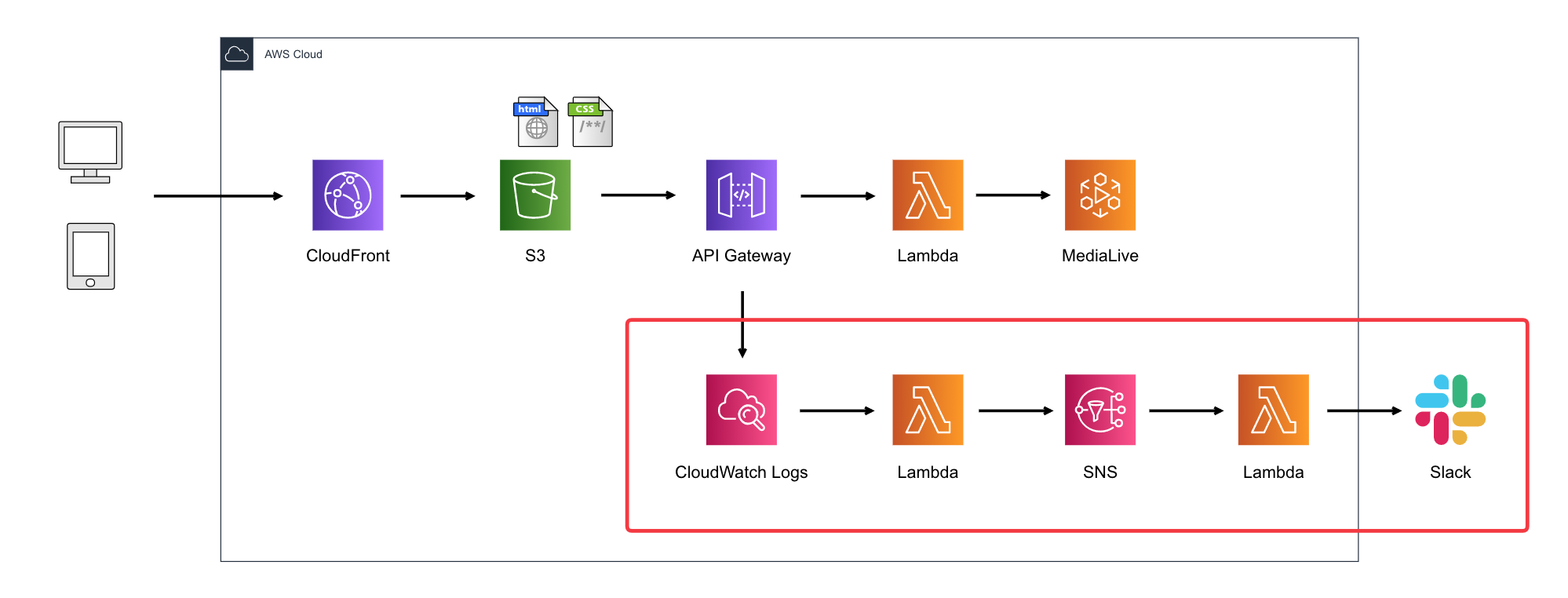
API実行ログを出力させる方法にしました。構成図
赤枠で囲った部分が、今回のログをSlackに出力する構成です。
2つのLambdaを使って、API GatewayからCloudWatch Logsに出力されたログを整形してSNSに送り、
SNSに来たメッセージをSlackに送信してます。
(もっと効率的な方法があるかもしれませんが)
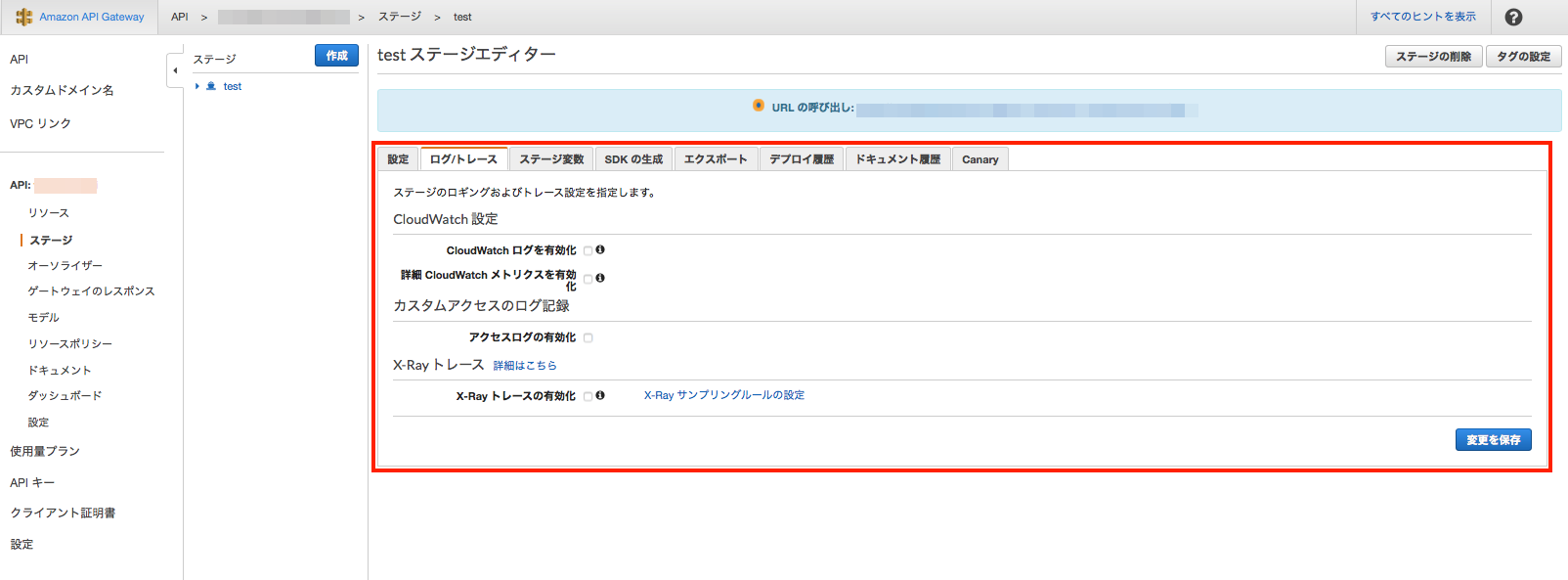
API Gateway
API Gatewayのログはここで設定できます。
デフォルトは無効になっているので、「アクセスログの有効化」にチェックを入れます。
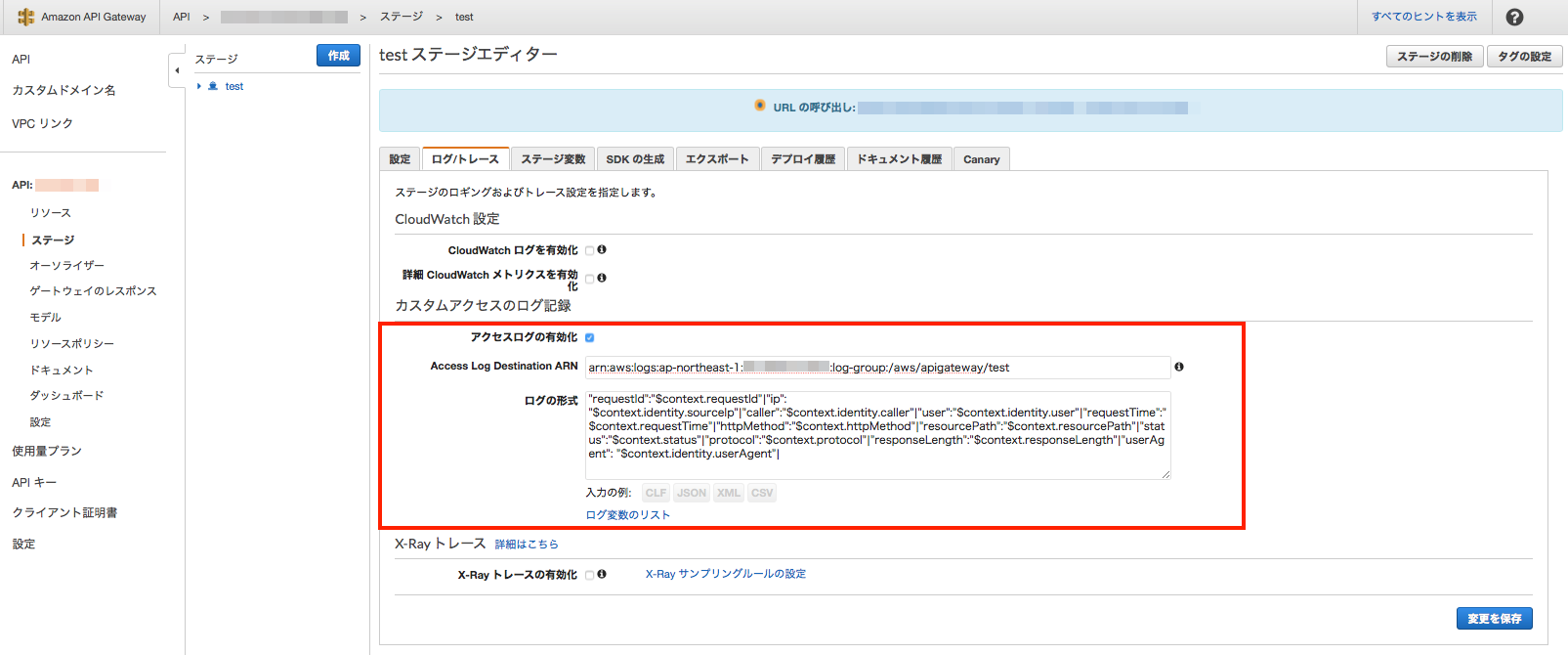
有効化すると画面表示が変わるので、ARNとログ形式を入力します。
ログ形式は下記のように少し変えています。理由は後述。{ "requestId":"$context.requestId"|"ip": "$context.identity.sourceIp"|"caller":"$context.identity.caller"|"user":"$context.identity.user"|"requestTime":"$context.requestTime"|"httpMethod":"$context.httpMethod"|"resourcePath":"$context.resourcePath"|"status":"$context.status"|"protocol":"$context.protocol"|"responseLength":"$context.responseLength"|"userAgent": "$context.identity.userAgent"| }SNS
整形したログの出力先として、トピックを作っておきます。
Lambda(CWLogs → SNS)
1.CloudWatch Logsに出力されたログを整形するためのLambdaを作ります。
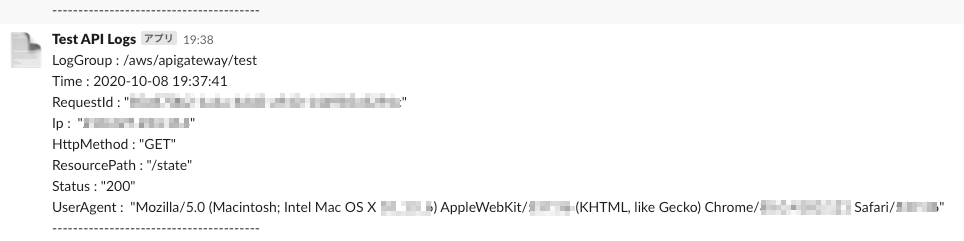
(こちらの記事を参考にさせていただきました)やや無理やりですが、「|」と「:」の記号でメッセージを分割してリスト化しています。
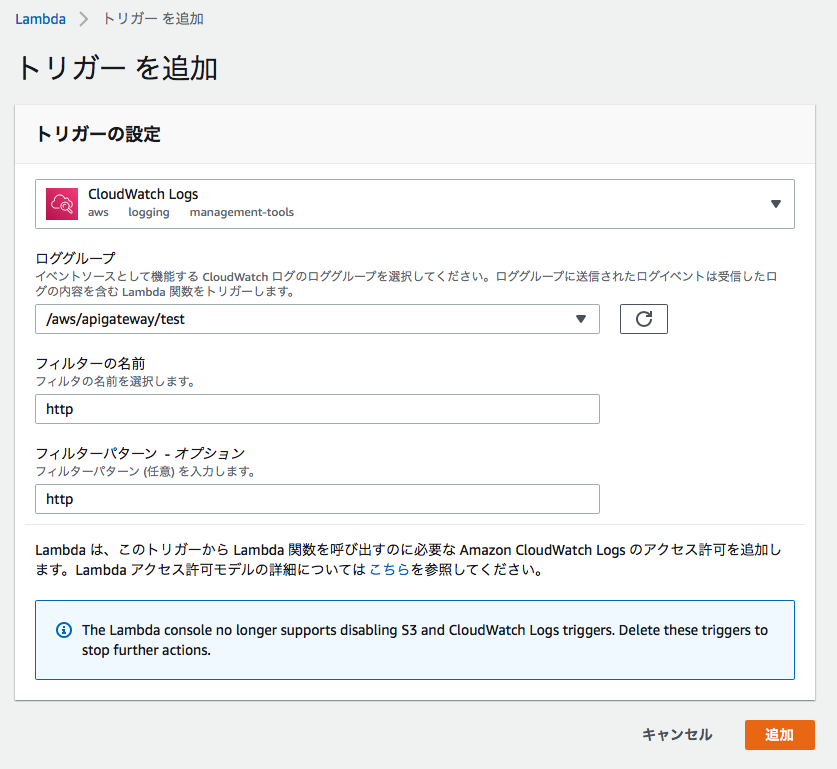
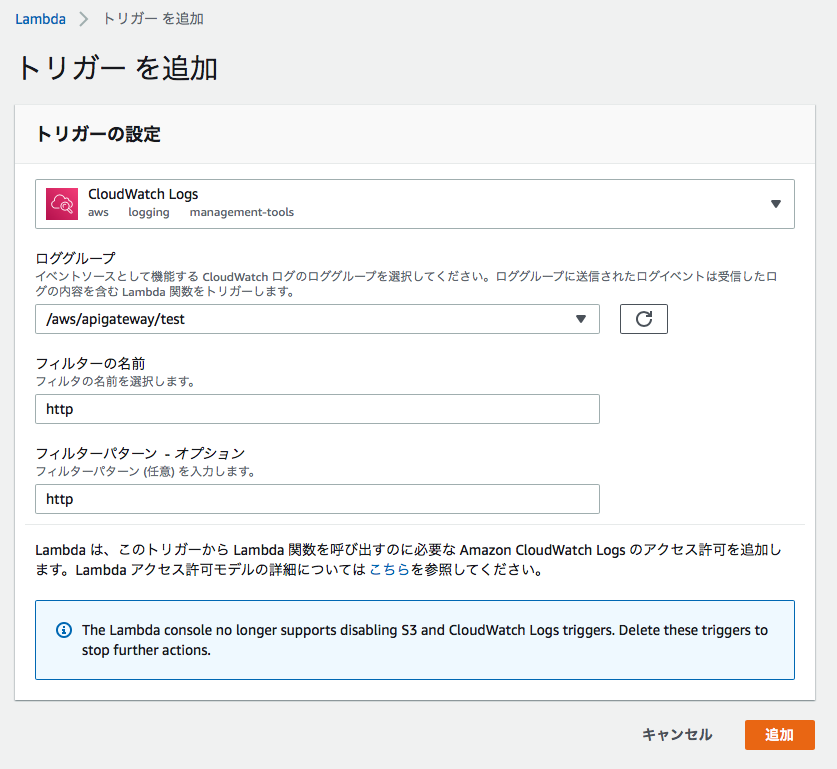
from __future__ import print_function import base64 import json import zlib import datetime import boto3 import re sns = boto3.client('sns') print('Loading function') def lambda_handler(event, context): data = zlib.decompress(base64.b64decode(event['awslogs']['data']), 16+zlib.MAX_WBITS) data_json = json.loads(data) log_json = json.loads(json.dumps(data_json["logEvents"][0], ensure_ascii=False)) if data_json["logGroup"]: date = datetime.datetime.fromtimestamp(int(str(log_json["timestamp"])[:10])) + datetime.timedelta(hours=9) msg = log_json['message'] msg_sp = re.split('[|:]',msg) sns_body = {} sns_body["default"] = "" sns_body["default"] += "LogGroup : " + data_json["logGroup"] + "\n" sns_body["default"] += "Time : " + date.strftime('%Y-%m-%d %H:%M:%S') + "\n" sns_body["default"] += "RequestId : " + msg_sp[1] + "\n" sns_body["default"] += "Ip : " + msg_sp[3] + "\n" sns_body["default"] += "HttpMethod : " + msg_sp[14] + "\n" sns_body["default"] += "ResourcePath : " + msg_sp[16] + "\n" sns_body["default"] += "Status : " + msg_sp[18] + "\n" sns_body["default"] += "UserAgent : " + msg_sp[24] + "\n" sns_body["default"] += "----------------------------------------" + "\n" topic = '<SNSトピックのARN>' subject = 'cloudwatchlogs-to-sns' region = 'ap-northeast-1' response = sns.publish( TopicArn=topic, Message=json.dumps(sns_body, ensure_ascii=False), Subject=subject, MessageStructure='json' ) return 'Successfully processed {} records.'.format(len(event['awslogs']))2.トリガーに「CloudWatch Logs」を選択して、下記のように設定します。
Lambda(SNS → Slack)
1.SNSに届いたメッセージをSlackに送るためのLambdaを作ります。
設定方法は下記のAWSページに載っていましたので、こちらをご参照ください。
https://aws.amazon.com/jp/premiumsupport/knowledge-center/sns-lambda-webhooks-chime-slack-teams/import urllib3 import json http = urllib3.PoolManager() def lambda_handler(event, context): url = "https://hooks.slack.com/services/xxxxxxx" msg = { "channel": "#CHANNEL_NAME", "username": "WEBHOOK_USERNAME", "text": event['Records'][0]['Sns']['Message'], "icon_emoji": "page_facing_up" } encoded_msg = json.dumps(msg).encode('utf-8') resp = http.request('POST',url, body=encoded_msg) print({ "message": event['Records'][0]['Sns']['Message'], "status_code": resp.status, "response": resp.data })2.トリガーには、先程作成したSNSトピックを設定しておきます。
Slack
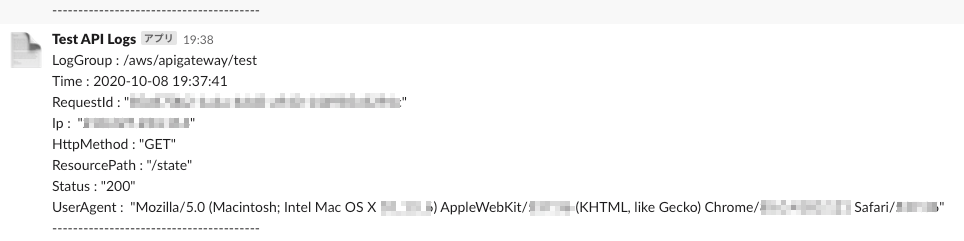
最終的に下記のように出力されます。
おわりに
今回はあまり時間がなく、なるべく手軽な方法で実装したかったので、これで良しとします。
参考
- 投稿日:2020-10-09T09:16:04+09:00
API実行ログをSlackに出力する
はじめに
前回の記事の続きです。
前回は、WebページのボタンからAPIを実行させるところまでを実装しました。
今回は実行ログの出力について記載します。前回作成したAPIは限定された人しか実行できないようにしている訳ではなく、
Webページにアクセスできる人であれば誰でもボタンを押すことで実行できてしまいます。そのため、どのIPから、どのような端末で、いつ実行したのかが記録として残るように、
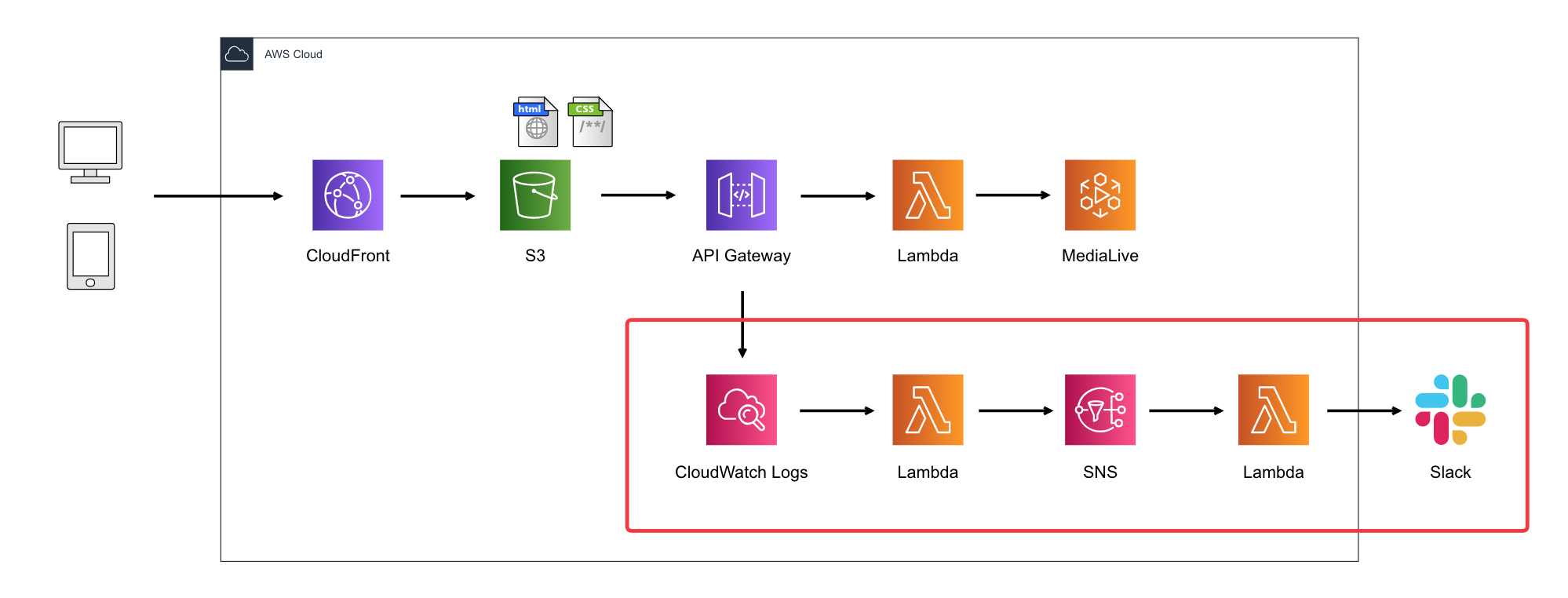
API実行ログを出力させる方法にしました。構成図
赤枠で囲った部分が、今回のログをSlackに出力する構成です。
2つのLambdaを使って、API GatewayからCloudWatch Logsに出力されたログを整形してSNSに送り、
SNSに来たメッセージをSlackに送信してます。
(もっと効率的な方法があるかもしれませんが)
API Gateway
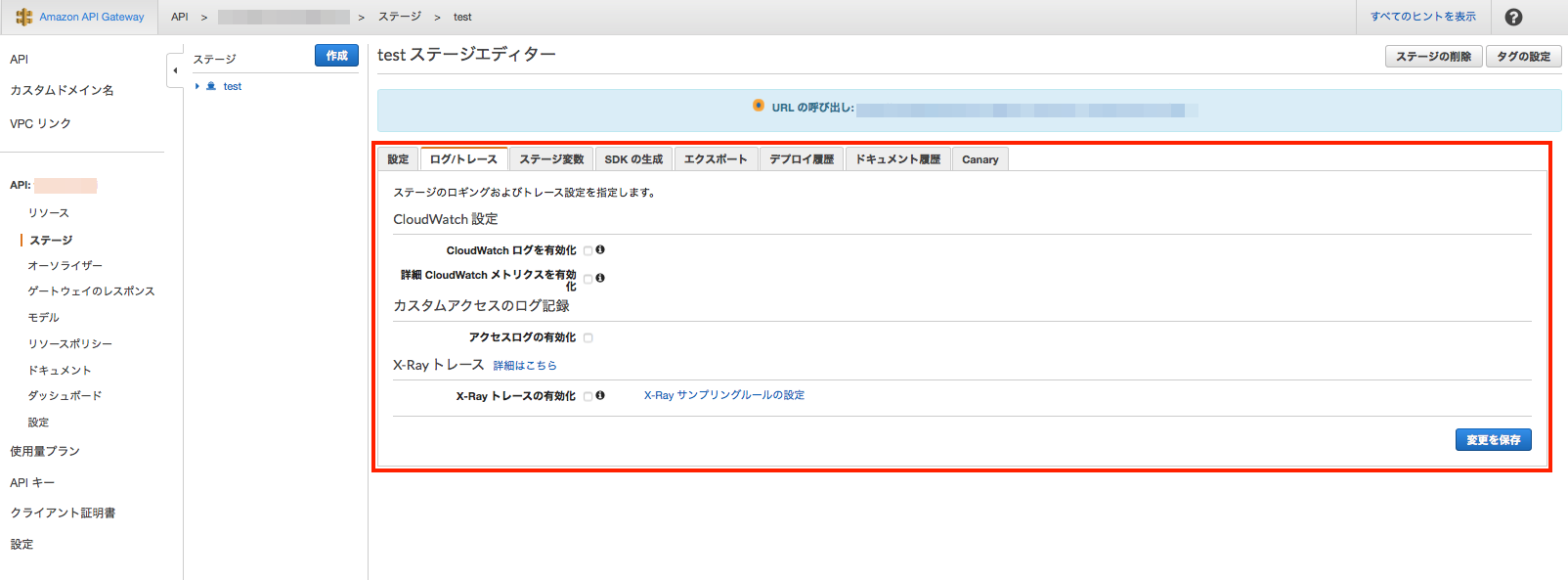
API Gatewayのログはここで設定できます。
デフォルトは無効になっているので、「アクセスログの有効化」にチェックを入れます。
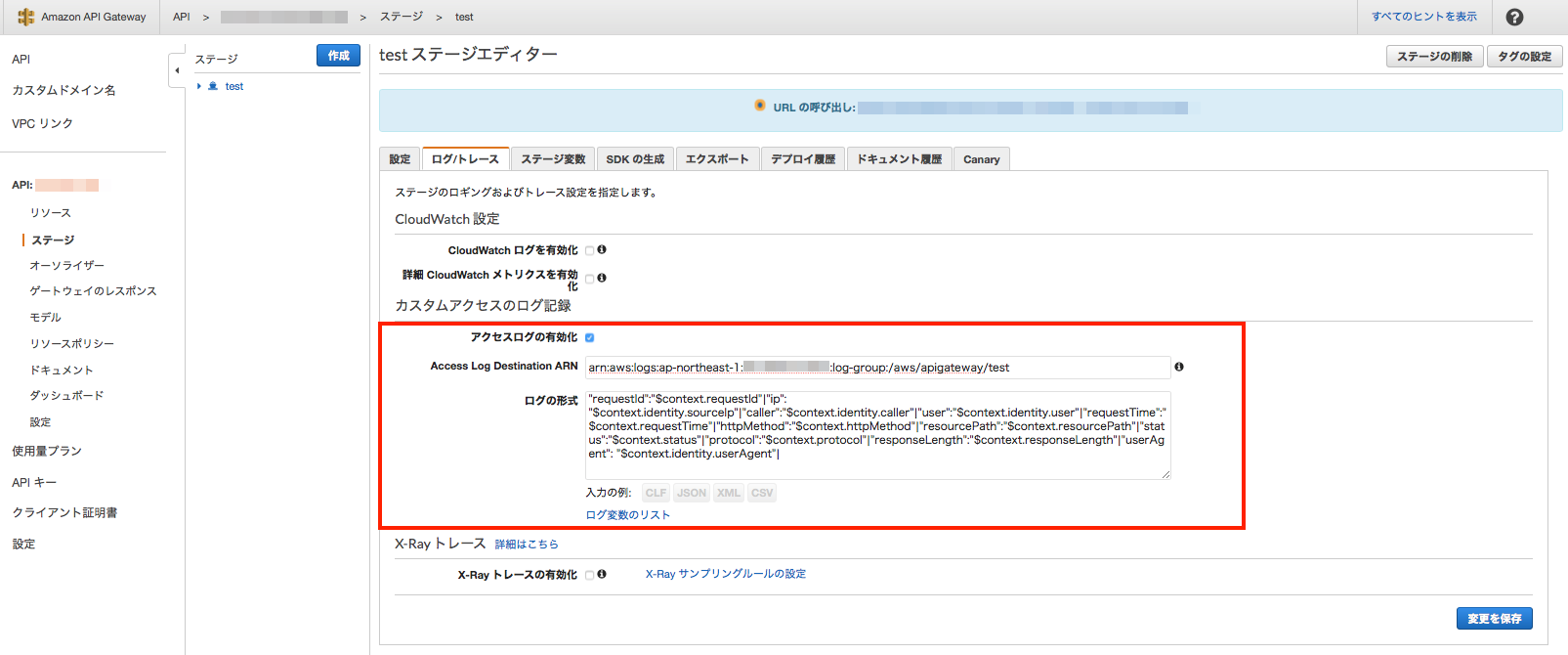
有効化すると画面表示が変わるので、ARNとログ形式を入力します。
ログ形式は下記のように少し変えています。理由は後述。{ "requestId":"$context.requestId"|"ip": "$context.identity.sourceIp"|"caller":"$context.identity.caller"|"user":"$context.identity.user"|"requestTime":"$context.requestTime"|"httpMethod":"$context.httpMethod"|"resourcePath":"$context.resourcePath"|"status":"$context.status"|"protocol":"$context.protocol"|"responseLength":"$context.responseLength"|"userAgent": "$context.identity.userAgent"| }SNS
整形したログの出力先として、トピックを作っておきます。
Lambda(CWLogs → SNS)
1.CloudWatch Logsに出力されたログを整形するためのLambdaを作ります。
(こちらの記事を参考にさせていただきました)やや無理やりですが、「|」と「:」の記号でメッセージを分割してリスト化しています。
from __future__ import print_function import base64 import json import zlib import datetime import boto3 import re sns = boto3.client('sns') print('Loading function') def lambda_handler(event, context): data = zlib.decompress(base64.b64decode(event['awslogs']['data']), 16+zlib.MAX_WBITS) data_json = json.loads(data) log_json = json.loads(json.dumps(data_json["logEvents"][0], ensure_ascii=False)) if data_json["logGroup"]: date = datetime.datetime.fromtimestamp(int(str(log_json["timestamp"])[:10])) + datetime.timedelta(hours=9) msg = log_json['message'] msg_sp = re.split('[|:]',msg) sns_body = {} sns_body["default"] = "" sns_body["default"] += "LogGroup : " + data_json["logGroup"] + "\n" sns_body["default"] += "Time : " + date.strftime('%Y-%m-%d %H:%M:%S') + "\n" sns_body["default"] += "RequestId : " + msg_sp[1] + "\n" sns_body["default"] += "Ip : " + msg_sp[3] + "\n" sns_body["default"] += "HttpMethod : " + msg_sp[14] + "\n" sns_body["default"] += "ResourcePath : " + msg_sp[16] + "\n" sns_body["default"] += "Status : " + msg_sp[18] + "\n" sns_body["default"] += "UserAgent : " + msg_sp[24] + "\n" sns_body["default"] += "----------------------------------------" + "\n" topic = '<SNSトピックのARN>' subject = 'cloudwatchlogs-to-sns' region = 'ap-northeast-1' response = sns.publish( TopicArn=topic, Message=json.dumps(sns_body, ensure_ascii=False), Subject=subject, MessageStructure='json' ) return 'Successfully processed {} records.'.format(len(event['awslogs']))2.トリガーに「CloudWatch Logs」を選択して、下記のように設定します。
Lambda(SNS → Slack)
1.SNSに届いたメッセージをSlackに送るためのLambdaを作ります。
設定方法は下記のAWSページに載っていましたので、こちらをご参照ください。
https://aws.amazon.com/jp/premiumsupport/knowledge-center/sns-lambda-webhooks-chime-slack-teams/import urllib3 import json http = urllib3.PoolManager() def lambda_handler(event, context): url = "https://hooks.slack.com/services/xxxxxxx" msg = { "channel": "#CHANNEL_NAME", "username": "WEBHOOK_USERNAME", "text": event['Records'][0]['Sns']['Message'], "icon_emoji": "page_facing_up" } encoded_msg = json.dumps(msg).encode('utf-8') resp = http.request('POST',url, body=encoded_msg) print({ "message": event['Records'][0]['Sns']['Message'], "status_code": resp.status, "response": resp.data })2.トリガーには、先程作成したSNSトピックを設定しておきます。
Slack
最終的に下記のように出力されます。
おわりに
今回はあまり時間がなく、なるべく手軽な方法で実装したかったので、これで良しとします。
参考
- 投稿日:2020-10-09T09:08:26+09:00
nginxのエラー「413 Request Entity Too Large」の解決方法
前提開発環境
- AWSのEC2インスタンスを使用してデプロイ済み
- Ruby on Rails6で開発
エラー概要
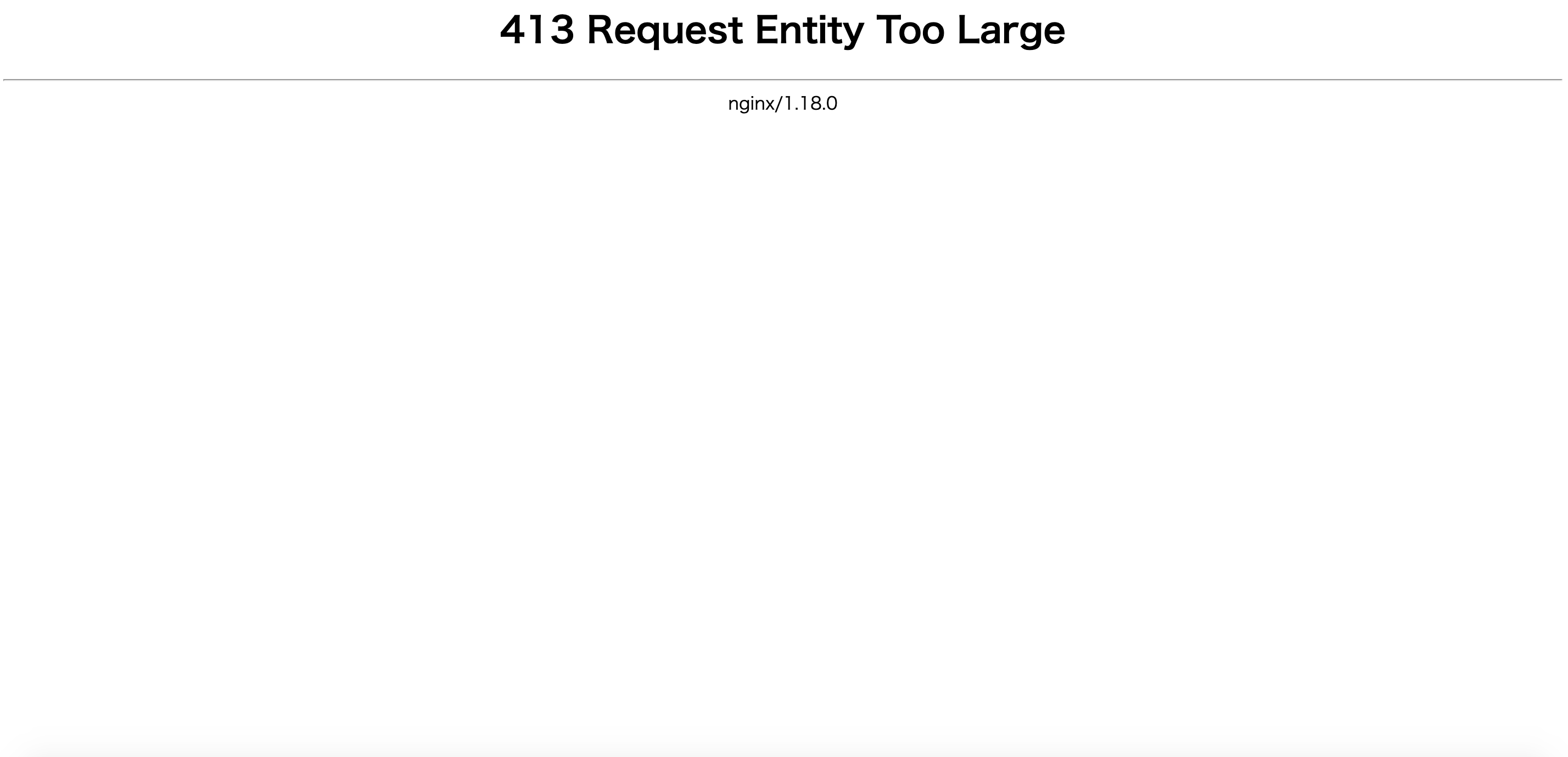
Rails6で投稿アプリを作成し、本番環境で投稿すると下記画像のエラーが発生しました。
画面を無駄に占有して413 Request Entity Too Largeとエラーが発生しました。
もうちょっと控えめな自己主張をして頂きたいものです((((;゚Д゚)))))))投稿した画像サイズが大きすぎると怒られています。
画像サイズの設定を変更する為にEC2へログインします。恒例のコマンドです。 以下を順にローカルのターミナルに入力していく。 ①mkdir ~/.ssh ②cd .ssh/ ③lsコマンドで、EC2で作成済みの<鍵名>.pemが表示される。 ④chmod 600 <鍵名>.pem ⑤ssh -i <鍵名>.pem ec2-user@<EC2で発行したElastic IP> すると、 __| __|_ ) _| ( / Amazon Linux 2 AMI ___|\___|___| と、上記の表示が出てEC2へのログインが完了。viでnginxのファイル編集
今回はnginxの画像投稿許容サイズを引き上げる必要があります。
デフォルトが1MBまでなので、それ以上の容量を送信すると上記のエラーが起きます。エラー解消の為に、Amazon Linuxに標準で装備されているテキストエディタviでファイル編集を行います。
EC2にログインしている状態で下記コマンドを実行する。 $ sudo vi /etc/nginx/nginx.confこれでviが起動して、さらに編集したいファイルが表示されますが、結構長い表記のファイルです。その中でhttp {}の中で追記を行います。
ファイル表示しただけでは編集できないので、「i」を押してinsertモードに切り替えてファイル編集を行いましょう。
# /etc/nginx/nginx.conf ....中略 http { .... .... #中略 sendfile on; tcp_nopush on; tcp_nodelay on; keepalive_timeout 65; types_hash_max_size 4096; client_max_body_size 20M; #この項目を追記します。 .... server { .... .... } ....以下省略 }追記したら「esc」を押してinsertモードを終了し、「:wq」で変更を保存します。
ファイル編集は終わりましたが、あとは更新を反映させる必要があります。
今回のパターンは編集ファイルの反映が目的なので、nginxの再起動でなくリロードを行います。sudo service nginx reloadこれでviファイルへの編集が反映されたので、サイズが大きい画像サイズも送信が可能になります。viにはまだまだ馴染みが薄いので、慣れていきたいところです。
追記 viの操作方法
viエディタで実際の設定ファイルを編集する場合の流れ
1.「通常モード」でファイルを開く 2.「インサートモード」でファイルを編集する 3. 再び「通常モード」へ移行し、「:wq」で保存して終了する通常モード
viエディタには「通常モード」と「インサートモード」があります。
通常モードは、viエディタにコマンドを打つことでファイルを保存したりviコマンドを終了したりできます。「通常モード」のコマンド コマンド 説明 :w 作成・編集したファイルを保存します。 :q viコマンドを終了します。 :q! 編集した内容を保存しないでviコマンドを強制終了します。 :wq 編集した内容を保存してviコマンドを強制終了します。i (インサートモード)
「通常モード」では、文字を入力することができません。文字を入力したい場合は、インサートモードにする必要が有ります。「I」キーを押すとインサートモードになり、文字の入力が可能です。Esc
Escキーを押すと通常モードに戻ります。
- 投稿日:2020-10-09T00:32:24+09:00
AWS香港リージョンをつかってEC2からS3にファイルを送信時にエラーが発生して解消した話
タイトルの通りです。
実行コマンド
aws s3 cp /home/ubuntu/gomi.txt s3://bucket-name/gomi.txtエラー
The ap-east-1 location constraint is incompatible for the region specific endpoint this request was sent to修正内容
sourceとtargetを明示する必要があるようです。
aws s3 cp /home/ubuntu/gomi.txt s3://bucket-name/gomi.txt --region ap-east-1 --source-region ap-east-1参考資料