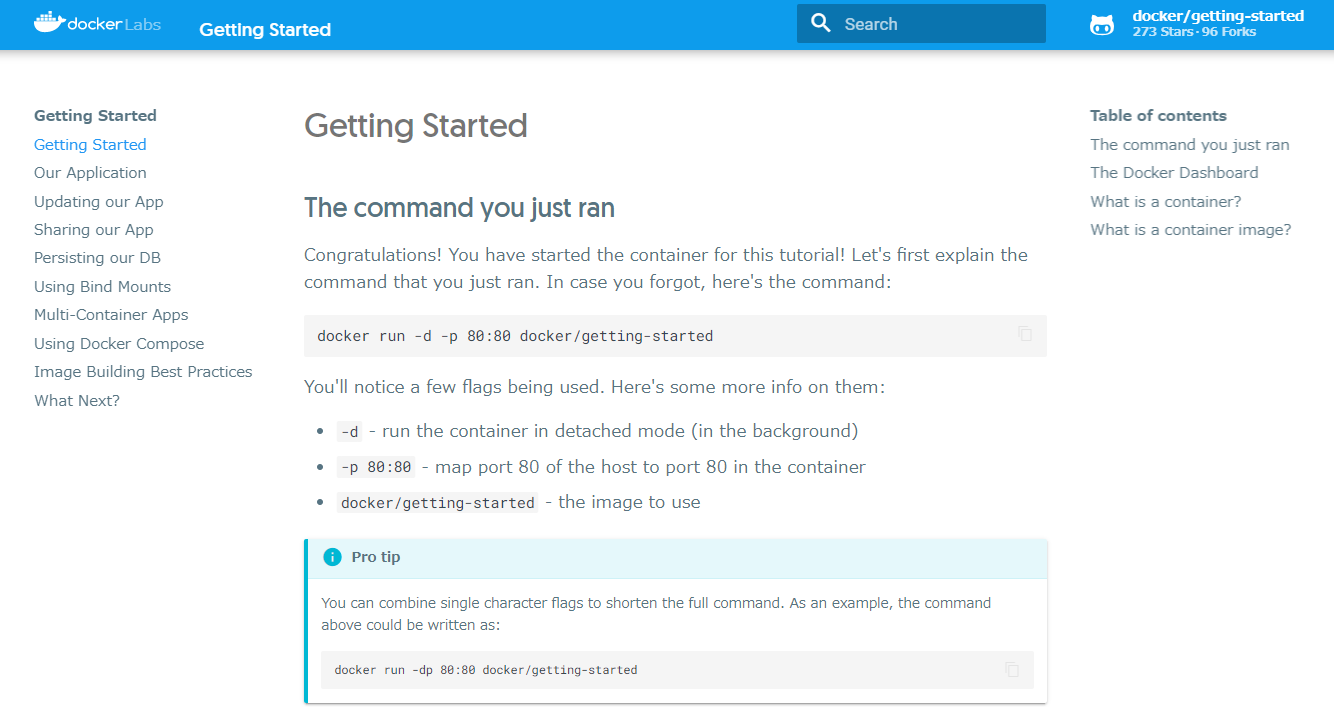
- 投稿日:2020-09-28T23:37:52+09:00
【Docker for Windows】突然Dockerアプリが起動しなくなった、、、
今日、普通にDockerを起動しようとしたらなぜかDocker is starting...のままDockerが起動しない、、突然の出来事だったので焦りました。やはりまだDocker for Windowsは若干不安定なんですかね、、はやくMac買いたい、、w
ちなみにDocker for WindowsはWindows10 Proでしか使えないのでこちらはWindows10 Proで開発している方向けの記事になります。
@userisgod さんよりご指摘のコメントがありました。
Docker for Window はWSL2への対応が行われた際、Window10 Homeもサポートするようになったようです。
参考記事解決策
Dockerアプリをアンインストールして、再インストール。私はこれで治りました。
※注意
大事なデータがコンテナ内にありましたら全部消えてしまうので(当たり前)バックアップデータはしっかりとっておきましょう。その他の解決策①
↑に加えてHyper-Vもアンインストールして、再インストールする
Docker for WindowsではHyper-Vというマイクロソフト社のサーバー仮想化技術を利用して動いています。OSのnative機能を使います。このHyper-VがWindow10 Pro にしかないのでHOMEエディション等では使えないのです。
その他の解決策②
Hyper-Vにおける制御フローガードのチェックをはずず。
【方法】
1.検索窓からWindowsセキュリティと入力しアプリを起動する。
2.アプリとブラウザー コントロール
3.Exploit protection の設定 (かなり下のほうにあります)
4.プログラム設定 タブ
5.C:\WINDOWS\System32\vmcompute.exe > 編集
6.制御フローガード (CFG)の設定の「システムの上書き」 チェックを外して、適用ボタンをクリック最後まで読んでいただきありがとうございます!
以上がとりあえず気軽に出来ることなので、試してみてください。
これでも解決しない場合、こちらの記事の「コマンドで強制的に起動させる」等を参考にしてみてください!
- 投稿日:2020-09-28T22:32:21+09:00
最短工程でubuntuにdockerとdocker-composeをインストールする
$ uname -a Linux geo-functions 5.4.0-1021-gcp #21-Ubuntu SMP Fri Jul 10 06:53:47 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux$sudo apt-get update $sudo apt-get install -y apt-transport-https ca-certificates curl software-properties-common $curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add - $sudo apt-key fingerprint 0EBFCD88 $sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu \ $(lsb_release -cs) \ stable" $sudo apt-get update $sudo apt-get install -y docker-ce $sudo service docker start $sudo systemctl enable docker $sudo curl -L "https://github.com/docker/compose/releases/download/1.24.1/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose $sudo chmod +x /usr/local/bin/docker-compose$ sudo docker version Client: Docker Engine - Community Version: 19.03.12 ... $ sudo docker-compose --version docker-compose version 1.24.1, build 4667896b以上!!!
- 投稿日:2020-09-28T19:15:45+09:00
AWS Fargateで動かしてるコンテナの中に入る方法
はじめに
AWS Fargateの場合、トラブルがあった時に動かしてるコンテナの中に入ってなくて調査できないのが不便なのでコンテナに入る方法を調査した。
- 現時点(2020年9月)でAWS Fargateの独自機能でコンテナの中に入る方法はない
- コンテナにsshdをインストールする方法とssm-agentをインストールする方法がある
ssm-agentを使うとSSHのポートの開放やSSHする公開鍵の管理などをしなくて済むためssm-agentを使う方法で行った。
コンテナにsshdをインストールする方法
- SSHのポートを空けておく
- コンテナの中の~/.ssh/authorzied_keysにsshするユーザーの公開鍵を追加しておく
- コンテナの中にsshdをインストールしておいて、コンテナ起動時にsshdを立ち上げておく
メリット
- セッションマネージャーを使わないため、セッションマネージャーを使う料金はかからない
デメリット
- SSHのポートを開放する必要がある
- SSHするユーザーの公開鍵を管理する必要がある
コンテナにssm-agentをインストールする方法
- コンテナ起動時にハイブリッドアクティベーションでアクティベーションを作成して登録してssm-agentを起動
- セッションマネージャーを使ってコンテナの中に入る
メリット
セッションマネージャーを使うので以下のメリットがある。
- SSHのポートを開放する必要がなくなる
- SSHするユーザーの公開鍵を管理する必要がなくなる
デメリット
- 通常のAmazon EC2に対してセッションマネージャーを使う料金はかからないが、ハイブリッドアクティベーションを使って登録することから、オンプレミスインスタンス管理の扱いになるため利用料金がかかる
https://docs.aws.amazon.com/ja_jp/systems-manager/latest/userguide/activations.html
Amazon EC2 インスタンスへのアクセスは、追加料金なしでご利用いただけます。
ソースコード
https://github.com/f96q/fargate-ssm-sample
DockerfileとAWS Fargateで動かす環境を作るためのTerraform含む
Dockerfile
Alpineで使う場合はssm-agentのパッケージがないのでソースから持ってきてビルドして設置する必要がある。
他のLinuxディストーションの場合はインストールできるssm-agentのパッケージを提供してる場合があるので、その場合はそのパッケージをインストールするだけで済む。
https://docs.aws.amazon.com/ja_jp/systems-manager/latest/userguide/sysman-manual-agent-install.htmlARG GOLANG_TAG=1.14.4-alpine3.12 ARG ALPINE_TAG=3.12 # ssm agenet builder FROM golang:$GOLANG_TAG as ssm-agent-builder ARG SSM_AGENT_VERSION=2.3.1205.0 RUN apk add --no-cache \ 'make~=4.3-r0' \ 'git~=2.26.2-r0' \ 'gcc~=9.3.0-r2' \ 'libc-dev~=0.7.2-r3' \ 'bash~=5.0.17-r0' RUN wget -q https://github.com/aws/amazon-ssm-agent/archive/${SSM_AGENT_VERSION}.tar.gz && \ mkdir -p /go/src/github.com && \ tar xzf ${SSM_AGENT_VERSION}.tar.gz && \ mv amazon-ssm-agent-${SSM_AGENT_VERSION} /go/src/github.com/amazon-ssm-agent && \ echo ${SSM_AGENT_VERSION} > /go/src/github.com/amazon-ssm-agent/VERSION WORKDIR /go/src/github.com/amazon-ssm-agent RUN gofmt -w agent && make checkstyle || ./Tools/bin/goimports -w agent && \ make build-linux # merge image FROM alpine:$ALPINE_TAG RUN apk add --no-cache \ 'jq~=1' \ 'aws-cli~=1.18.55-r0' \ 'sudo~=1.9.0-r0' RUN adduser -D ssm-user && \ echo "Set disable_coredump false" >> /etc/sudo.conf && \ echo "ssm-user ALL=(ALL) NOPASSWD:ALL" > /etc/sudoers.d/ssm-agent-users && \ mkdir -p /etc/amazon/ssm COPY --from=ssm-agent-builder /go/src/github.com/amazon-ssm-agent/bin/linux_amd64/ /usr/bin COPY --from=ssm-agent-builder /go/src/github.com/amazon-ssm-agent/bin/amazon-ssm-agent.json.template /etc/amazon/ssm/amazon-ssm-agent.json COPY --from=ssm-agent-builder /go/src/github.com/amazon-ssm-agent/bin/seelog_unix.xml /etc/amazon/ssm/seelog.xml COPY docker-entrypoint.sh / ENTRYPOINT ["/docker-entrypoint.sh"] CMD ["amazon-ssm-agent"]docker-entrypoint.sh#!/bin/sh set -e AWS_REGION=${AWS_REGION:-} SSM_ACTIVATION=$(aws ssm create-activation --default-instance-name "fargate-ssm" --iam-role "service-role/AmazonEC2RunCommandRoleForManagedInstances" --registration-limit 1 --region $AWS_REGION) export SSM_ACTIVATION_CODE=$(echo $SSM_ACTIVATION | jq -r .ActivationCode) export SSM_ACTIVATION_ID=$(echo $SSM_ACTIVATION | jq -r .ActivationId) amazon-ssm-agent -register -code $SSM_ACTIVATION_CODE -id $SSM_ACTIVATION_ID -region $AWS_REGION exec "$@"使い終わったら手動で行わないといけないこと
https://aws.amazon.com/jp/systems-manager/pricing/#On-Premises_Instance_Management
動かしてる時間課金されてしまうため以下を行う。
- ハイブリッドアクティベーションの削除
- 登録したインスタンスを外す
- 投稿日:2020-09-28T15:15:59+09:00
[Docker 入門] 公式 チュートリアル (和訳)
はじめに
dockerの公式チュートリアルがかなりまとまっていてわかりやすかったので、一通りやってみました。ただ、チュートリアルが英語で躊躇しがちなのかなと思ったので、どなたかの参考になればと和訳してみました。
当方、windows環境なのでwindowsのUIで説明しています。前提
・dockerインストール済
・gitインストール済チュートリアルを開始する
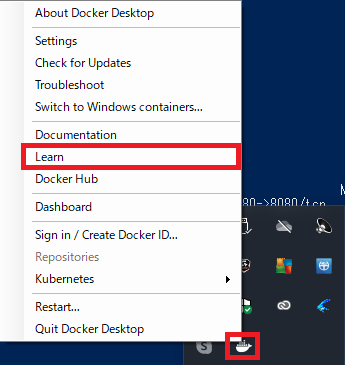
インストール済の状態からチュートリアルを開始する場合は、dockerのアイコンをクリックして、Learnをクリックするとチュートリアルが起動します。インストール前ならインストール完了時に自動でチュートリアルが開始されるはずです。
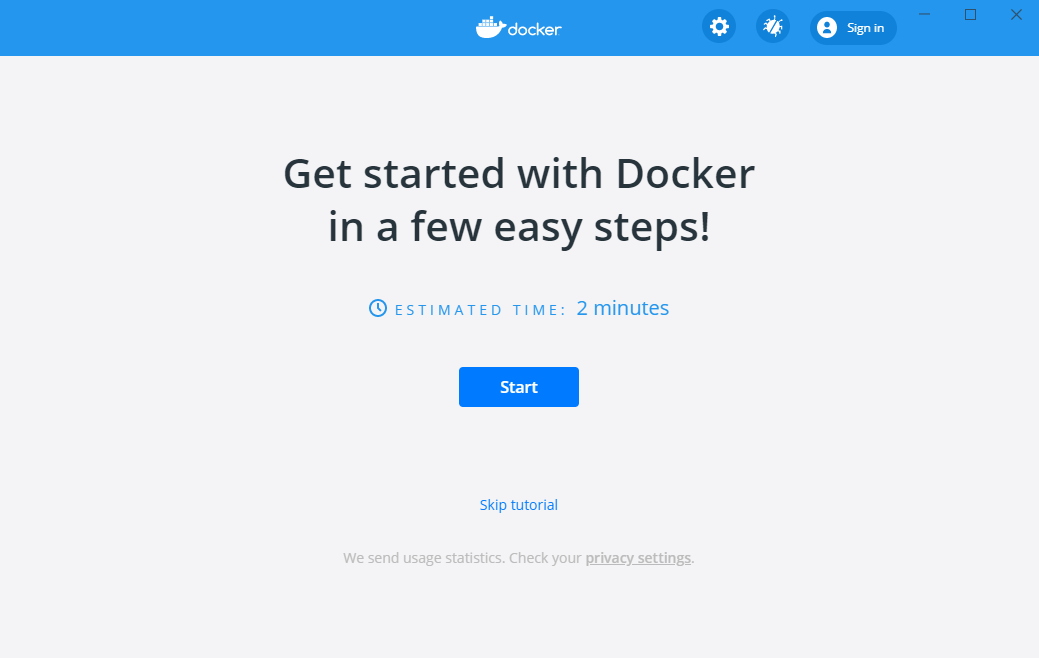
下記の画面が立ち上がるので、Startします。
clone
チュートリアル用のコードをcloneします
git clone https://github.com/docker/getting-started.gitBuild
docker build -t docker101tutorial .
DokerfileからDockerイメージを作成する際はこのbuildコマンドを使用します。-t docker101tutorialはDockerイメージのタグ名を指定しています。tはtagの頭文字です。.はDockerfileがカレントディレクトリにあるということを表しています。
まとめると上記コマンドは、カレントディレクトリにあるDokerfileからdocker101tutorialというタグ名でDockerイメージを作成する、という意味になります。Dockerイメージは、アプリケーションの実行に必要なファイル群が格納されたディレクトリで、コンテナのもとになるものです。Run
docker run -d -p 80:80 --name docker-tutorial docker101tutorial
runコマンドは、Dockerイメージからコンテナを生成し起動するために使用するコマンドで、生成と起動を同時に実行することができます。生成するコマンドdocker createと起動するコマンドdocker startもあり、createしてからstartすることはrunするのと同じ動作になります。
-dはdetachモードで起動することを指定しており、これを指定しておくとバックグラウンド起動できます。これを指定せずに起動するとターミナルに情報が出力されて占有されしまうので、これを避けたい場合は指定します。
上記コマンドは、docker101tutorialというDockerイメージからdocker-tutorialという名前のコンテナを起動します。
このときdockerの起動に失敗した場合は、ホスト側のポートを8080に変更してみてください。1.さぁ、はじめよう
localhost:80にアクセスして下記画面が表示されれば、チュートリアル用のコンテナにアクセスできています。ここからはこのチュートリアルに沿って和訳していきます。ところどころ私のコメントも入れています。
(補足)
このように記載しているところは私のコメント(補足)です。
実行したコマンドについて
コンテナを生成、起動した下記コマンドの説明をします。
docker run -d -p 80:80 docker/getting-started
-d: バックグラウンドモードでコンテナを生成/起動します-p 80:80: ホスト側のポート80をコンテナ側のポート80にマッピングするdocker/getting-started: 使用するイメージこのコマンドは下記のように省略して記載することができます。
docker run -dp 80:80 docker/getting-startedThe Docker Dashboard
ここで一旦、Docker Dashboardについて説明しておきます。Dashboardを起動することで、コンテナログを確認したり、コンテナ内のshellを起動したりできます。このほかにも、ブラウザで開いたり、再起動、削除することができ、いろいろな操作がUIで直感的に操作できます。
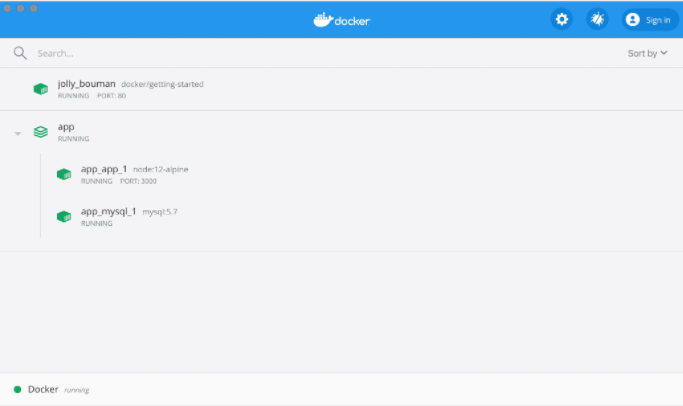
Dashboardにアクセスすると、下記のような画面が開き、コンテナがRUNNINGしていることが確認できます。「jolly_bouman」のところは、ランダムな名前になるので別の名前になっているはずです。
コンテナとは?
コンテナとは何か・・?簡単に言うと、ホストマシン上での、その他プロセスとは隔離されたマシン上のプロセスです。プロセスというのは、マシンで実行されているプログラムのことです。プロセスの隔離は、Linuxのnamespacesとcgroupsという機能を利用しています。
コンテナイメージとは?
コンテナイメージとは・・?イメージは実行環境で動くコンテナのもと(ひな形)です。コンテナイメージの正体は、アプリケーションの実行に必要なファイル群が格納されたディレクトリです。環境変数やデフォルトで実行するコマンド、その他メタデータが含まれています。
2.アプリケーション
このチュートリアルで実行するアプリケーションはNode.jsで動作するtodoアプリです。Node.jsになじみがなくても大丈夫です。
ここでは、todoアプリとして最低限動くものを用意します。下記の手順に沿ってアプリを起動し、動作を確認してください。アプリケーションの取得
http://localhost:80/assets/app.zipからソースコードをダウンロードします。(補足)
上記アドレスをブラウザに入力するとソースコードがダウンロードされます。ポートは適宜変更してください。zipを解凍すると、package.jsonと2つのサブディレクトリ(srcとspec)があります。
コンテナイメージのビルド
アプリケーションをビルドするために、ここでは
Dockerfileを使います。Dockerfileはテキストベースのスクリプトで、コンテナイメージを生成するための指示書のようなものです。
下記の手順にそってDockerイメージを作成しましょう。
package.jsonと同じディレクトリ階層に
Dockerfileを作成し、下記を記載してください。dockerfileには拡張子は必要ありません。FROM node:12-alpine WORKDIR /app COPY . . RUN yarn install --production CMD ["node", "src/index.js"]ターミナル開き、appディレクトリまで移動して下記コマンドを実行してください。
docker build -t getting-started .Dockerfileから新規のコンテナイメージを生成する場合はこのコマンドを使用します。実行後にターミナルを確認すると多数の"レイヤー"をダウンロードしていることがわかります。これは
node:12-alpieイメージをベースイメージとして使用したためで、マシン上にこのイメージがない場合はダウンロードする必要があるからです。
ダウンロードが完了すると、アプリケーション内にコピー(COPY . .)してyarnを使ってアプリケーション依存関係をインストール(RUN yarn install --production)します。依存関係のインストールはRUN yarn install --productionのコマンドで実行され、package.jsonでdevDependenciesに記載されているもの以外をアプリケーション内にインストールします。devDependenciesに記載されているものは開発時に必要となるパッケージであり、製品版(--production)では必要ないので--productionを指定しています。
CMDはコンテナイメージからコンテナを起動したときにデフォルトで実行されるコマンドです。つまり、docker run XXXXを実行したときにnode src/index.jsのコマンドが実行されるということです。
docker buildコマンドの最後の.はDockerfileがカレントディレクトリにあるということを意味しています。(補足)
dockerはDockerfileという名前をデフォルトで探しますが、-fを指定すれば別名も指定できます。Dockerfile.baseという名前にしたい場合は下記のようなコマンドになります
docker build -t sample -f Dockerfile.base .コンテナを開始する
イメージの準備ができたので
docker runコマンドを使用してアプリケーションを実行します。
イメージを指定して
docker runコマンドでコンテナを起動しますdocker run -dp 3000:3000 getting-started
-dはコンテナをバックグラウンドで起動することを意味していて、-pによってホスト側のポート3000とコンテナ側のポート3000をマッピングしています。このポートマッピングがないとアプリケーションにアクセスすることができません。http://localhost:3000にアクセスするとアプリケーションにアクセスできます。
アイテムが想定通り追加されることが確認できるはずです。完了マークをつけることができ、追加したアイテムを削除することもできます。
ここに少し変更を加えてコンテナの管理について学んでいきます。
3.アプリケーションの更新
下記の手順に沿ってアプリケーションを更新してください。
src/static/js/app.jsの56行目を下記のように変更します。
アップデートしたバージョンのイメージをbuildしましょう。下記コマンドを実行します。
docker build -t getting-started .更新したコードを使った新しいコンテナを起動します。
docke run -dp 3000:3000 getting-startedこのコードを実行したとき、次のようなエラーが表示されたはずです。
docker: Error response from daemon: driver failed programming external connectivity on endpoint laughing_burnell
(bb242b2ca4d67eba76e79474fb36bb5125708ebdabd7f45c8eaf16caaabde9dd): Bind for 0.0.0.0:3000 failed: port is already allocated.このエラーの原因は、古いコンテナがまだポート3000で起動したままになっているからです。ホスト側の一つのポートで占有できるプロセスは一つだけです。
これを解決するには、古いコンテナを削除すればよいです。古いコンテナを差し替える
コンテナを削除するために、まず停止します。停止をしないと削除できません。
古いコンテナを削除する方法は2通りあるので好きなほうで削除してください。コンテナの削除(CLIを使う)
docker psコマンドでコンテナIDを取得しますdocker psコンテナを停止するために
docker stopを使います# <the-container-id> のところはdocker ps で取得したコンテナIDと差し替えてください docker stop <the-container-id>停止したコンテナを
docker rmコマンドで削除しますdocker rm <the-container-id>下記コマンドを使用するとコンテナの停止と削除を1行のコマンドで実行することができます。
docker rm -f <the-container-id>コンテナの削除(Docker Dashboardを使う)
Docker dashboardを使うと、2クリックでコンテナを削除することができます。CLIを使う場合と比べて簡単で直感的にコンテナを削除することができます。
- dashboardを開き、削除したいコンテナにマウスオーバーすると右側にアクションボタンが表示されます
- ゴミ箱アイコンをクリックしてコンテナを削除します

- コンテナがなくなったことを確認します
更新したアプリケーションを開始する
更新したアプリケーションを起動します
docker run -dp 3000:3000 getting-startedhttp://localhost:3000にアクセスして、テキストが更新されていることを確認してください
(3章の要約)
アプリケーションの更新をしましたが、下記2点気づいたと思います。
- 初めに登録したアイテムがすべて消えています。これはtodoリストアプリとして良くないので、これについては後の章で触れます
- 小さな変更にしては、アプリを更新するのにたくさんのステップが必要でした。rebuildして新規のコンテナ起動をいちいちしなくてもよい方法を後の章で見ていきます。
アイテムが保持される方法について触れる前に、イメージを共有する方法について簡単に見ていきましょう。
4.アプリケーションの共有
ここまででイメージが完成したので、それをシェアしていきましょう。Dockerイメージをシェアするには、Dockerレポジトリを利用する必要があります。
Docker Hubを使用していきましょう、ここには、私たちが使用するイメージのすべてが入っています。レポジトリの作成
イメージをプッシュするためにDocker Hubにレポジトリを作成していきましょう。
- Docker Hubにログインします
- Create a Repositoryをクリックします
- レポジトリ名は
getting-startedとします。またVisibilityはPublicになっていることを確認します。- Createボタンをクリックします
ページ右側を見ると、Docker commandsセクションがあり、イメージをプッシュするために実行するコマンドサンプルが表示されています。
イメージのプッシュ
コマンドラインを開き、さきほど確認したプッシュ用のコマンドを入力します。このとき、
dockerのところは自分のDocker IDに差し替えてください。$ docker push docker/getting-started The push refers to repository [docker.io/docker/getting-started] An image does not exist locally with the tag: docker/getting-started失敗してしまいました。pushコマンドはdocker/getting-startedという名前のイメージを探したはずです、しかし見つけることができなかったということです。
docker image lsコマンドを実行してREPOSITORYを確認してみてください。確かにそのような名前のイメージはないですね。
これを解決するためには、"tag"でイメージに別名を付与します。Docker Hubにログインします。
docker login -u YOUR-USER-NAME(実行後パスワードを入力してください)
YOUR-USER-NAMEは自分のDocker IDに差し替えてください。docker tag getting-started YOUR-USER-NAME/getting-started再度プッシュコマンドを実行します。コマンドをDocker Hubからコピーしている場合は、
tagnameはなにも記入しないでください。Dockerではtagを指定しなかった場合、latestタグが使われます。docker push YOUR-USER-NAME/getting-started新しいインスタンスでイメージを起動する
ここまでで、イメージのビルドとレジストリへのプッシュが完了しました。プッシュしたイメージを完全に新規の環境で起動させてみたいと思います。ここでは
Play with Dockerを使いましょう。
- Play with Dockerを開きます
- Docker Hubアカウントでログインしましょう
ログインができたら左側のサイドバーにある
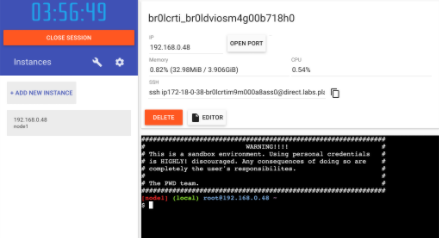
+ ADD NEW INSTANCEをクリックしましょう。(もし表示されていない場合はブラウザのサイズを少し小さくしてみてください)少し待つと、下記のような画面がブラウザ上で表示されます。
ターミナル上で先ほどプッシュしたアプリケーションを起動してみましょう
docker run -dp 3000:3000 YOUR-USER-NAME/getting-started起動すると
3000と書かれたボタンが表示されるのでクリックしてみましょう。Docker Hubにプッシュしたアプリケーションが起動できたのが確認できます。ボタンがない場合は、OPEN PORTをクリックして、3000と入力してください。(4章の要約)
この章では作成したイメージをレジストリにプッシュして共有する方法について解説しました。Play with Dockerを使ってプッシュしたイメージを使って新規にアプリケーションを起動してみました。これはCIパイプラインと呼ばれるものと同じで、イメージを作成、プッシュすることでプロダクション環境で最新のイメージを利用することができるのです。
5.DBの永続化
気づいていないかもしれませんが、TODOアプリはコンテナを起動させるたびにデータが消えてしまいます。なぜこのようなことが起きるのか、コンテナがどのように動いているのかを確認しながら理解していきましょう。
コンテナのファイルシステム
コンテナはイメージの様々なレイヤーを使用して起動します。
(補足)
dockerイメージはdockerfile一つ一つの命令がイメージとして重なった状態で、ここではそれら重なった状態を"レイヤー(層)"と表現しているようです。
dockerはdockerfileの各命令一つ一つをイメージとして保持し、それらイメージを利用して、コンテナを起動します。それぞれのコンテナは独自の"スクラッチスペース"を取得し、その中でファイルの生成、更新、削除を実施します。同じイメージであってもあらゆる変更は他のコンテナからはみることができません。
(補足)
スクラッチスペース:
ここでは他のプロセスから隔離されたメモリ上の空間を想像するとよさそうです実際に手を動かして確認してみよう
上記を確認するために、2つのコンテナを起動して、それぞれでファイルを編集してみましょう。一方のコンテナで編集したファイルは、もう一方のコンテナからは利用できないことがわかると思います。
ubuntuコンテナを起動します。このコンテナでは、1~10000のランダムな数値を/data.txtに出力しますdocker run -d ubuntu bash -c "shuf -i 1-10000 -n 1 -o /data.txt && tail -f /dev/null"このコマンドでは、bash shellを起動して2つのコマンドを呼び出しています(&&で2つのコマンドを繋げている)。最初のコマンドはランダムな数値を/data.txtに書き出しています。2つ目のコマンドは、コンテナを実行し続けるために単にファイルを監視しています.
(補足)
試しに2つ目のコマンドと&&を削除してrunしてみてください、起動したコンテナは直ちに停止してしまい、コンテナ内のファイルを確認することができません。出力された値を確認しましょう。Dashboardを開いて、
ubuntuイメージを起動しているコンテナにマウスオーバーし、一番左のボタン(CLI)をクリックしましょう。
コンテナ内に入ったら、下記コマンドを実行して/data.txtの中身を確認してみましょう。cat /data.txtもしコマンドラインを使いたい場合は、
docker execコマンドで同じことができます。docker psでコンテナIDを取得後、下記コマンドを実行すればよいです。docker exec <container-id> cat /data.txtランダムな数値が表示されているのがわかると思います。
次に、同じ
ubuntuイメージを使って、もう一つコンテナを起動してみましょう。そうすると/data.txtが存在しないことが確認できます。docker run -it ubuntu ls //data.txtが存在しないのは、このファイルがはじめのコンテナのスクラッチスペースに書き出されたからです。
docker rm -fコマンドで不要なコンテナを削除してください。コンテナVolumes
これまで見てきたようにコンテナはそれが起動されたときにイメージの内容に従って起動されるものです。コンテナを生成し、ファイルを更新、削除しても、それらの変更はコンテナが削除されてしまうと消失してしまいます。すべての変更は各コンテナで独立しているということです。
Volumesを使えば、消失しないようにすることができます。Volumesを使えばコンテナの特定のファイルシステムパスをホストマシンに接続することができます。コンテナ側のディレクトリがマウントされていれば、変更はホストマシン側でも確認することができます。もしコンテナを起動したときに、同じディレクトリをマウントしておけば、同じファイルをコンテナ側で確認することができます。つまりデータは消失しないということです。
volumesは2つのタイプがあります。まずは、named volumesから確認してみましょう。
TODOデータを消えないようにする
デフォルトでは、TODOアプリケーションのデータは/etc/todos/todo.dbのSQLite Databaseに保存されます。SQLiteに詳しくなくても大丈夫です。単に関係データベースで、すべてのデータがひとつのファイル内に保存されています。大規模なアプリケーションではこの方法は適さないですが、今回のTODOアプリのような小規模アプリではうまく機能します。あとで、別のデータベースエンジンに切り替える方法についてもみていきます。
データベースが一つのファイルであるならば、そのファイルをホスト側に保持しておき、次回の新規コンテナで使用できるようにすれば、中断したところからコンテナを再開できるはずです。volumeを作成して、データを格納するディレクトリにvolumeをアタッチ(これを"マウント"と呼びます)することにより、データを持続的に利用することができます。コンテナがデータをtodo.dbファイルに書き込むと、それらのデータはホスト側のvolume内で保存されます。
さきほども言った通り、ここではnamed volumeを使います。named volumeは単なるデータのバケツと考えればよいです。これを使う場合、volumeの名前だけを覚えておけば十分で、物理的な記憶領域がどこであるかを意識する必要はなく、volumeの名前と記憶領域の紐づけはDockerが管理します。volumeを利用するたびに、実際のデータの所在をDockerが特定します。
docker volume createコマンドを使ってvolumeを作成します。docker volume create todo-db今回のnamed volumesを利用していないTODOアプリをDashboardで削除します。(あるいは、
docker rm -f <container-id>で削除する)続いてTODOアプリコンテナを起動するのですが、今回は、
-vフラグによりvolume mountを指定してください。これによりnamed volumeが利用され、/etc/todosにマウントされます。これにより/etc/todosのパスに生成されたすべてのファイルをホスト側で保存することができます。docker run -dp 3000:3000 -v todo-db:/etc/todos getting-startedコンテナを起動したらいくつかアイテムを追加してみてください。
TODOアプリのコンテナを削除します。Dashboardを使うか、
docker psでコンテナIDを取得したあと、docker rm -f <id>で削除します。上記で示したのと同じコマンドを再度入力し、実行します
アプリを開き、先ほど追加したアイテムがあることが確認できるはずです
確認ができたらコンテナをさきほどと同様に削除します。
これでデータを保持する方法がわかりましたね。
(補足)
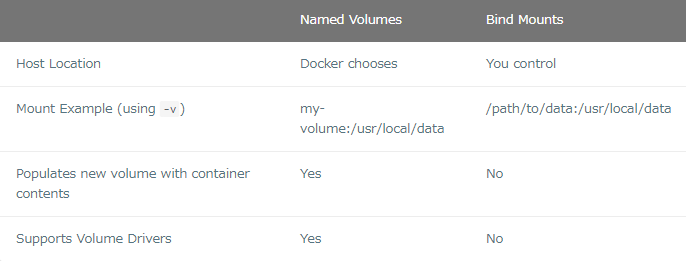
volumesにはnamed volumesとbind mountの2タイプが標準で使用できます。それぞれの主な違いは、ホスト側でのデータ管理場所です。named volumesは上記で見たようにユーザーはvolume名だけ意識すればOKでした。つまりデータの実体をどこに保存するかはdockerにお任せということです。次にbind mountは、ホスト側のどのディレクトリをコンテナ側のどこのディレクトリにマウントするかを指定することができます。つまり、ホスト側でのデータ管理場所を任意に選択可能ということです。
(情報) Pro-tip
named volumesやbind mounts(次章で説明)はDockerエンジンをインストールすると標準でサポートされている2つの主なvolumesなのですが、このほかにもNFS,SFTP,NetApp,そのほかにもたくさん..をサポートしたvolumeドライバープラグインがあります。これは、Swarm, Kubernetesなどのクラスタ環境内のマルチホスト上でコンテナを起動するときに特に重要となる技術です。Volumeの詳細を確認する
"named volumeを使ったとき、保存したデータはいったいどこにあるんだろう"と疑問に思うかもしれません。もしそれが知りたい場合は、下記コマンドを実行すれば解決できます。
docker volume inspect todo-db [ { "CreatedAt": "2019-09-26T02:18:36Z", "Driver": "local", "Labels": {}, "Mountpoint": "/var/lib/docker/volumes/todo-db/_data", "Name": "todo-db", "Options": {}, "Scope": "local" } ]
Mountpointが実際にデータが保存されている場所を示しています。多くのマシンでは、ホストからこのディレクトリにアクセスするためには管理者権限が必要になりますが、確かにデータはそこにあります。(情報) Docker Desktop上で直接Volumeデータにアクセスするには
上記todo-dbのMountpointを見たとき、こんなディレクトリどこにも存在しない、と思ったかもしれません。Docker Desktopを起動している間、Dockerコマンドはマシン上の小さなVM内で実際は動いています。なのでもしMountpointのディレクトリ内のデータを確認したい場合は、VM内部に接続する必要があります。この方法についてはググると方法がたくさんでてきます。(5章の要約)
コンテナを削除して再起動した場合にもデータが保持されているアプリケーションを作成できました。
しかし、前の章で見たとおり、イメージに変更を加えて再度ビルドするためにはいくらかの時間がかかってしまいます。bind mountsを利用すれば、より良い方法でアプリを構築できます。次章ではbind mountsについてみていきます。6.Bind Mountsを使う
前章ではnamed volumeを使ったデータ保持の方法についてみてきました。named volumesはデータの実体がどこに保存されているかを意識しなくてよいので単にデータを保存したい場合にはとても役に立ちます。
bind mountsを使えば、ホスト上のどこにマウントするのかを確実に制御できます。おおよそこれはデータを保持するために使用されますが、新規データをコンテナに追加したい場合にも使用されます。アプリケーションを起動する際にソースコードをコンテナ側にマウントし、ソースコード変更や動作確認をリアルタイムに行うのにbind mountsを利用することができます。
Nodeベースアプリケーションでは、ファイル変更を監視し、変更時にアプリを再起動するといったことを実施するnodemonというツールがあり、他の言語やフレームワークにはこれに相当するツールがあります。
Volumeタイプ比較表
Bind mountsやnamed volumesはDockerエンジンで標準で使用できる主なvolumeなのですが、これに加えて他のユースケース(SFTP,Ceph,NetApp,S3,etc...)をサポートするために様々なvolumeドライバーを利用することができます。
開発モードコンテナを起動する
開発ワークフローをサポートしたコンテナを起動するために、下記を実施します。
- ソースコードをコンテナにマウントする
- すべてのdependenciesをインストールする("dev"dependenciesを含む)
- ファイル変更を監視するためにnodemonを起動する
getting-startedコンテナが起動していないことを確認してください- 下記コマンドを実行してください。コマンドの意味は後ほど説明します
docker run -dp 3000:3000 \ -w /app -v "$(pwd):/app" \ node:12-alpine \ sh -c "yarn install && yarn run dev"もしPowerShellを使っている場合は下記コマンドを使ってください。
docker run -dp 3000:3000 ` -w /app -v "$(pwd):/app" ` node:12-alpine ` sh -c "yarn install && yarn run dev"
-dp 3000:3000:backgroundで起動し、ホスト側のポート3000とコンテナ側のポート3000をマッピングします。-w /app:作業ディレクトリを設定しています。コマンドを実行したとき、ここで指定したディレクトリがカレントディレクトリになります。-v "$(pwd):/app":ホスト側のカレントディレクトリとコンテナ側の/appディレクトリをマウントしますnode:12-plpine:使用するイメージです。これはDockerfileからのアプリケーションベースイメージであることに注意してください。sh -c "yarn install && yarn run dev:shを使ってshellを起動します(alpineではbashはありません)。そしてyarn installをしてすべてのdependenciesをインストールし、yarn run devを走らせます。package.jsonをみればわかりますが、devスクリプトを走らせることでnodemonを起動しています。3.
docker logs -f <container-id>を使ってログを確認します。下記のような表示になっていれば準備OKです。docker logs -f <container-id> $ nodemon src/index.js [nodemon] 1.19.2 [nodemon] to restart at any time, enter `rs` [nodemon] watching dir(s): *.* [nodemon] starting `node src/index.js` Using sqlite database at /etc/todos/todo.db Listening on port 3000ログが確認できたら
Ctrl+Cで終了します。4.それではアプリに修正を加えましょう。
src/static/js/app.jsの109行目を下記のように変更してください。
5.ページを更新(あるいは開く)して変更が即座に反映されていることを確認してください。Nodeサーバーが再起動するまでに数秒かかります。もしエラーとなった場合はリフレッシュしてみてください。
6.自由に変更を加えてみてください。満足したらコンテナを停止し、
docker build -t getting-started .で新しいイメージをビルドしてください。ローカル開発環境構築においてbind mountsはよく利用されます。利点は開発マシンにビルドツールが必要ないことです。単に
docker runするだけで、開発環境はプルされ、準備完了です。今後Docker Composeについて話す予定ですが、これによりコマンドを簡略化することができます。(6章要約)
ここではデータベースを永続化して、さらにニーズや要求に対して迅速に対応する方法についてみてきました。
本番環境に備えるため、データベースをSQLiteから、より簡単にスケールできるものへと移行する必要があります。話を簡単にするためにここではリレーショナルデータベースを使い、アプリケーションでMySQLを利用するように更新します。コンテナが互いに通信を許可する方法などを次章から見ていきます。7.マルチコンテナアプリケーション
ここまではシングルコンテナアプリケーションを扱ってきましたが、次はTODOアプリにMySQLを追加したいと思います。「MySQLはどこで起動させるのか?」「同じコンテナ内にインストールする?それともそれぞれ独立して起動する?」などの疑問があると思います。一般的にはそれぞれのコンテナ内では一つのことを実施すべきです。理由は次の通りです。
- データベースとは関係なく、APIやフロントエンドをスケールさせたいという状況が十分に考えられます
- 各コンテナを独立させることでアップデートやバージョン管理をそれぞれ独立して実施できます
- アプリケーションにデータベースを内蔵する必要がなく、本番環境のデータベースにマネージドサービスを使用したい場合に相性がよいです
- マルチプロセスを起動するにはプロセスマネージャーが別途必要です(コンテナは1つのプロセスしか開始できません)。それにより起動、シャットダウンが複雑になります。
このほかにも理由はたくさんあります。
なのでここではアプリケーションを下記の構成としましょう。
コンテナネットワーキング
コンテナはデフォルトでは他のプロセスとは独立して実行されていて、同じマシン上であっても他のコンテナ/プロセスと繋がることはできません。コンテナを他のコンテナとつなげるためにはどうすればよいでしょうか?答えはネットワーキングです。ネットワークエンジニア並みの知識は必要なく、下記だけ覚えておけば十分です。
2つのコンテナが同じネットワークにあれば互いに繋がることができる
MySqlを起動する
コンテナをネットワーク上に配置する方法は2つあります。1)起動時にネットワークを配置する 2)起動済のコンテナに接続する。ここでは始めにネットワークを作成して、MySQLコンテナ起動時にそれをアタッチします。
ネットワークを作成します
docker network create todo-app ```MySQLを起動してネットワークをアタッチします。データベースの初期設定をするためにいくつか環境変数を設定しています。(詳細を知りたい場合はMuSQL Docker Hub listingを確認してください。)
docker run -d \ --network todo-app --network-alias mysql \ -v todo-mysql-data:/var/lib/mysql \ -e MYSQL_ROOT_PASSWORD=secret \ -e MYSQL_DATABASE=todos \ mysql:5.7もしPowerShellを使っている場合は下記のコマンドを使ってください。
docker run -d ` --network todo-app --network-alias mysql ` -v todo-mysql-data:/var/lib/mysql ` -e MYSQL_ROOT_PASSWORD=secret ` -e MYSQL_DATABASE=todos ` mysql:5.7データベースの初期設定用の環境変数以外にも、
--network-aliasフラグがあることがわかります。これについては後ほど説明します。(Pro-tip)
上記コマンドでは、todo-mysql-dataというnamed volumeを使いMYSQLのデータ保存先である/var/lib/mysqlにマウントしています。しかし、docker volume createコマンドを実行してvolumeを作成していないです。Dockerは、新規のnamed volume名が指定された場合は自動で作成してくれるのです。データベースが起動していることを確認するために接続してみましょう
docker exec -it <mysql-container-id> mysql -pパスワードを聞かれるので
secretと入力します。MySQLシェルに入ったらtodosデータベースを確認してください。mysql> SHOW DATABASES;次のような出力結果が得られるはずです。
+--------------------+ | Database | +--------------------+ | information_schema | | mysql | | performance_schema | | sys | | todos | +--------------------+ 5 rows in set (0.00 sec)todoデータベースの準備が完了していることがわかりましたね。
MySQLに接続する
MySQLが起動していることが確認できたのでそれを使ってみましょう。ただどうやって・・?同じネットワーク上でもう一つのコンテナを起動しているとしても、どうやってそのコンテナを見つければいいんでしょう(それぞれのコンテナにはIPが割りあっているのは覚えているが)?
これを理解するためにnicolaka/netshootコンテナを使いましょう。このコンテナにはネットワークのトラブルシューティングやデバックをするのに便利なツール群がインストールされています。
nicolaka/netshootイメージを使って新しいコンテナを起動します。同じネットワークに接続することを忘れないでください。
docker run -it --network todo-app nicolaka/netshoot上記コマンドを打つとコンテナ内にはるので
digコマンドを実行しましょう(このコマンドは便利なDNSツールです)。ホスト名mysqlのIPアドレスを確認します。dig mysql次の出力が得られます。
; <<>> DiG 9.14.1 <<>> mysql ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 32162 ;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 0 ;; QUESTION SECTION: ;mysql. IN A ;; ANSWER SECTION: mysql. 600 IN A 172.23.0.2 ;; Query time: 0 msec ;; SERVER: 127.0.0.11#53(127.0.0.11) ;; WHEN: Tue Oct 01 23:47:24 UTC 2019 ;; MSG SIZE rcvd: 44"ANSWER SECTION"をみるとIPアドレス172.23.0.2に解決されたホスト名
mysqlのAレコードが確認できます(IPアドレスは環境によって異なります)。通常mysqlは有効なホスト名ではありませんが、Dockerはnetwork aliasを持ったコンテナのIPアドレスを解決することができるのです(--network-aliasフラグを覚えていますよね?)。
これが意味するところは、TODOアプリからホスト名mysqlに接続するだけで、データベースと接続することができるということです。これ以上簡単なことはないですね!TODOアプリをMySQLに接続して起動する
TODOアプリはMySQL接続に関する環境変数の設定をいくつかサポートしています。下記の4つです。
MYSQL_HOST:MySQLサーバーを実行しているホスト名MYSQL_USER:接続に使用するユーザー名MYSQL_PASSWORD:接続に使用するパスワードMYSQL_DB:使用するデータベース名注意!
接続の設定を実施するのに環境変数を使うのは開発環境では問題ないのですが、本番環境でアプリを実行する場合には全く推奨されない方法です。Dockerの前セキュリティリーダーのDiogo Monicaはこの理由についてすばらしいブログ記事に記載してくれています。それでは、開発環境コンテナをを起動しましょう。
上記の環境変数を指定して、MySQLコンテナをTODOアプリネットワークに接続します。
docker run -dp 3000:3000 \ -w /app -v "$(pwd):/app" \ --network todo-app \ -e MYSQL_HOST=mysql \ -e MYSQL_USER=root \ -e MYSQL_PASSWORD=secret \ -e MYSQL_DB=todos \ node:12-alpine \ sh -c "yarn install && yarn run dev"PowerShellを使っている場合は次のコマンドを使用してください。
docker run -dp 3000:3000 ` -w /app -v "$(pwd):/app" ` --network todo-app ` -e MYSQL_HOST=mysql ` -e MYSQL_USER=root ` -e MYSQL_PASSWORD=secret ` -e MYSQL_DB=todos ` node:12-alpine ` sh -c "yarn install && yarn run dev"
docker logs <container-id>コマンドでコンテナのログを確認すると、mysqlデータベースを利用している旨の記載があることがわかります。# Previous log messages omitted $ nodemon src/index.js [nodemon] 1.19.2 [nodemon] to restart at any time, enter `rs` [nodemon] watching dir(s): *.* [nodemon] starting `node src/index.js` Connected to mysql db at host mysql Listening on port 3000 ```ブラウザでTODOアプリを開いて、いくつかアイテムを追加してみてください。
mysqlデータベースに接続して、追加したアイテムが確かにデータベースに追加されていることを確認してみてください。パスワードはsecretです。
docker exec -ti <mysql-container-id> mysql -p todosmysqlシェルに入ったら、下記コマンドを実行します。
mysql> select * from todo_items; +--------------------------------------+--------------------+-----------+ | id | name | completed | +--------------------------------------+--------------------+-----------+ | c906ff08-60e6-44e6-8f49-ed56a0853e85 | Do amazing things! | 0 | | 2912a79e-8486-4bc3-a4c5-460793a575ab | Be awesome! | 0 | +--------------------------------------+--------------------+-----------+追加したアイテムによってnameは変わりますが、確かに保存されていることが確認できました。
Docker Dashboardを確認してみてください。2つのコンテナが起動していることがわかりますが、それらが1つのアプリにグループ化されていないことがわかります。それぞれのコンテナは独立して起動されていますが、TODOアプリはmysqlコンテナに接続しているのです。
(7章要約)
TODOアプリのデータを、独立した外部のmysqlコンテナ内に保存しました。そして、コンテナネットワーキングについても少し学び、サービスディスカバリがどのように実施されるのかをDNSを利用して確認しました。
しかし、アプリケーションを起動するだけなのに、ネットワークを作成したり、コンテナを起動したり、環境変数を指定したり、ポートを開放したり、そのほかにもたくさんのことをやらなければならず、すこし圧倒されたかもしれません。こんなに多くのことは覚えられないですし、誰かに伝えるのも大変です。
次の章では、Docker Composeについて説明します。Docker Composeを使うとはるかに簡単な方法でアプリケーションを他者と共有することができ、また単純なコマンドでこの章で扱ったアプリを起動することができるようになります。8.Docker Composeを使おう
Docker Composeはマルチコンテナアプリケーションを定義したり、共有したりするときの手助けになるようにと開発されたツールです。Docker Composeを使うとYAMLファイルでサービスを定義でき、一つのコマンドでサービスを起動したり破棄したりできます。
Docker Composeを利用する利点は、アプリケーションを一つのファイルに定義することができ(ファイルはプロジェクトのルートディレクトに配置する)、他の誰かが簡単にプロジェクトに参加できるようになる点です。プロジェクトに参加したい場合は、レポジトリをクローンし、アプリケーションをDocker Composeのコマンドで起動するだけでよいです。GithubやGitLabにはこれを使用したプロジェクトがたくさんあります。Docker Composeをインストールする
WindowsあるいはMacでDocker Desktop/Toolboxをインストールしている場合は、すでにDocker Composeがインストールされています。Play-with-Dockerについても同様にDocker Composeがすでにインストールされています。Linuxを利用している場合はこちらの手順に沿ってインストールします。
インストールすると、下記コマンドでバージョン情報が確認できます。
docker-compose versionDocker Composeファイルを作成する
- プロジェクトのルートディレクトリに
docker-compose.ymlファイル(コンポーズファイル)を作成するコンポーズファイルにはまずスキーマバージョンを記載します。ほとのどのケースでは最新のバージョンを利用するとよいです。Compose file referenceに現在のスキーマバージョンと互換性表が記載されています。
version: 3.7次は、アプリケーションとして起動させたいサービス(あるいは、コンテナ)のリストを定義します
version: "3.7" services:次から、コンポーズファイルのサービスについて説明していきます。
アプリのサービスを定義する
アプリのコンテナを定義するために使用した下記コマンドを思い出してください。
docker run -dp 3000:3000 \ -w /app -v "$(pwd):/app" \ --network todo-app \ -e MYSQL_HOST=mysql \ -e MYSQL_USER=root \ -e MYSQL_PASSWORD=secret \ -e MYSQL_DB=todos \ node:12-alpine \ sh -c "yarn install && yarn run dev"PowerShellを使用している場合は下記コマンドでした。
docker run -dp 3000:3000 ` -w /app -v "$(pwd):/app" ` --network todo-app ` -e MYSQL_HOST=mysql ` -e MYSQL_USER=root ` -e MYSQL_PASSWORD=secret ` -e MYSQL_DB=todos ` node:12-alpine ` sh -c "yarn install && yarn run dev"
はじめにサービスを登録し、コンテナイメージを定義しましょう。サービスの名前を任意に設定でき、その名前が自動的にネットワークのエイリアスになります。このエイリアスはMySQLサービスを定義するのに便利です。
version: "3.7" services: app: image: node:12-alpine通常は
imageの定義の近くにcommandを配置しますが、順序に制約はありません。version: "3.7" services: app: image: node:12-alpine command: sh -c "yarn install && yarn run dev"次に、
portsで定義される-p 3000 3000コマンドについてみていきましょう。ここで記載しているのはshort syntaxで、より詳細なlong syntax変数もあります。version: "3.7" services: app: image: node:12-alpine command: sh -c "yarn install && yarn run dev" ports: - 3000:3000次は、
working_dirで定義する作業ディレクトリ(-w /app)と、volumesで定義するボリュームマッピング(-v "$(pwd):/app")です。ボリュームにもショートとロングシンタックスがあります。version: "3.7" services: app: image: node:12-alpine command: sh -c "yarn install && yarn run dev" ports: - 3000:3000 working_dir: /app volumes: - ./:/app最後は、環境変数を定義している
environmentです。version: "3.7" services: app: image: node:12-alpine command: sh -c "yarn install && yarn run dev" ports: - 3000:3000 working_dir: /app volumes: - ./:/app environment: MYSQL_HOST: mysql MYSQL_USER: root MYSQL_PASSWORD: secret MYSQL_DB: todosMySQLサービスの定義
MySQLサービスを定義していきましょう。コンテナを作ったときは下記のコマンドを使用しました。
docker run -d \ --network todo-app --network-alias mysql \ -v todo-mysql-data:/var/lib/mysql \ -e MYSQL_ROOT_PASSWORD=secret \ -e MYSQL_DATABASE=todos \ mysql:5.7PowerShellの場合は下記です。
docker run -d ` --network todo-app --network-alias mysql ` -v todo-mysql-data:/var/lib/mysql ` -e MYSQL_ROOT_PASSWORD=secret ` -e MYSQL_DATABASE=todos ` mysql:5.7
最初は、
mysqlという名前で新規にサービスを定義しましょう。このときmysqlが自動的にネットワークエイリアスになります。appを定義したときと同様にイメージを指定しましょう。version: "3.7" services: app: # The app service definition mysql: image: mysql:5.7次はボリュームマッピングの定義です。
docker runコマンドでコンテナを起動したときは、named volumeは自動的に作成されます。しかし、docker composeの場合は自動的に作成されません。volumes:を定義する必要があり、マウントポイントを指定します。ボリューム名を指定するだけで、デフォルトのオプションが使用されます。ほかにもたくさんのオプションがあります。version: "3.7" services: app: # The app service definition mysql: image: mysql:5.7 volumes: - todo-mysql-data:/var/lib/mysql volumes: todo-mysql-data:最後に環境変数を指定します。
version: "3.7" services: app: # The app service definition mysql: image: mysql:5.7 volumes: - todo-mysql-data:/var/lib/mysql environment: MYSQL_ROOT_PASSWORD: secret MYSQL_DATABASE: todos volumes: todo-mysql-data:ここまでをまとめると、
docker-compose.ymlは下記のようになります。version: "3.7" services: app: image: node:12-alpine command: sh -c "yarn install && yarn run dev" ports: - 3000:3000 working_dir: /app volumes: - ./:/app environment: MYSQL_HOST: mysql MYSQL_USER: root MYSQL_PASSWORD: secret MYSQL_DB: todos mysql: image: mysql:5.7 volumes: - todo-mysql-data:/var/lib/mysql environment: MYSQL_ROOT_PASSWORD: secret MYSQL_DATABASE: todos volumes: todo-mysql-data:アプリケーションを起動しよう
docker-compose.ymlが作成できたので、アプリを起動してみましょう。
- ほかのアプリやデータベースのコピーが起動していないか確認してください。(
docker psでidを調べて、rm if <ids>で削除してください)
docker compose upコマンドを利用してアプリケーションを起動します。このとき-dフラグもつけてバックグラウンドで起動するようにしましょう。docker-compose up -d下記の出力が得られます。
Creating network "app_default" with the default driver Creating volume "app_todo-mysql-data" with default driver Creating app_app_1 ... done Creating app_mysql_1 ... doneネットワークと同様にボリュームも作成されていることがわかると思います。Docker Composeではネットワークがデフォルトで自動的に作成されます。なのでdocker-compose.yml内にネットワーク作成を定義しませんでした。
docker-compose logs -fコマンドでログを確認しましょう。各サービスごとに1行でログが出力されていることがわかります。このログは、時間に関する不具合を監視したいときに役にたちます。-fフラグはログに"フォロー(follow)"するというもので、ログが生成されたときに即座に出力されるようになります。mysql_1 | 2019-10-03T03:07:16.083639Z 0 [Note] mysqld: ready for connections. mysql_1 | Version: '5.7.27' socket: '/var/run/mysqld/mysqld.sock' port: 3306 MySQL Community Server (GPL) app_1 | Connected to mysql db at host mysql app_1 | Listening on port 3000各サービスからのメッセージを区別するためにサービス名が先頭に記載されています。特定のサービスのみログに出力したい場合は、例えば
docker-comopse log -f appのコマンドのようにサービス名を最後に追加します。(お役立ち情報)アプリが起動するまでDBを待つ
アプリケーションが起動しているとき、アプリ側はMySQLが起動して準備完了になるのを待って接続を開始します。Dockerには、別のコンテナが完全に起動し、準備完了になるのを待ってから別のコンテナを開始するための組み込みサポートがありません。Nodeベースのプロジェクトの場合、待機ポート(wait-port)の依存関係(dependency)を利用することができます。他の言語、フレームワークにも同様のプロジェクトが存在します。ここまでくると、アプリケーションが起動していることが確認できます。たった一つのコマンドで実行できることが確認できましたね!
Docker Dashboardでアプリを確認する
Docker Dashboardを開くと、appという名前でグルーピングされたものが確認できます。これは、Docker Composeが割り当てたプロジェクト名で、複数のコンテナが一つにまとめられています。プロジェクト名は、デフォルトでは
docker-compose.ymlが配置されたディレクトリ名になります。
appを展開すると、コンポーズファイル内で定義した2つのコンテナが確認できます。それぞれの名前はわかりやすく表記されていて、
<プロジェクト名>_<サービス名>_<レプリカ番号>の形式になっているので、どれがappのコンテナで、どれがmysqlのデータベースなのかが一目でわかります。
コンテナを停止し、削除する
コンテナを停止して削除したい場合は、
docker-compose downコマンドを使用するか、Docker Dashboardでゴミ箱アイコンをクリックします。コンテナは停止し、ネットワークは削除されます。ボリュームの削除
デフォルトの設定ではdocker-compose downコマンドで停止してもnamed volumeは削除されません。もし削除したい場合は--volumesフラグを追加する必要があります。
Docker Dashboardで削除した場合にもnamed volumeは削除されません。停止して削除してしまえば、
docker-compose upにより別のプロジェクトを開始することができます。(8章の要約)
このセクションではDocker Composeについて学び、それによりマルチサービスアプリケーションを定義したり、共有することが劇的に簡単になることがわかりました。また、適切なコンポーズの形式に則ってコマンドを記載してコンポーズファイルを作成しました。
これでチュートリアルは終わりにしたいと思います。しかし、これまで使用してきたDockerfileは大きな問題を抱えているため、それらについて学ぶためにイメージビルドのベストプラクティスについて次章以降記載していきます。
とりあえず、ここまでです。
次の9、10章は随時加筆していこうと思います。9章:イメージビルドのベストプラクティス
10章:次は何をすればよいか









- 投稿日:2020-09-28T10:53:13+09:00
とりあえずのdocker-compose upから入って、Web server(Nginx)の基礎設計を学びながら、Dockerを学ぶ①
①環境構築〜最もシンプルなWeb server構築編です
分かりづらい点、不正確な点はコメントいただけましたらモチベーションに繋がります
今回こちらに先立ってZennというサービスで記事を書いて見ました
元記事
とりあえずのdocker-compose upから入って、Web serverの基礎設計を学びながらDockerを学ぶ① | Zennはじめに
以下のような方とって有益な内容になればと思っています
- これから初めてのwebアプリを作成する
- webアプリを作成し、これからデプロイする
- 初めてデプロイまで到達したが、Nginxが何をしているかとか、設定内容はコピペでよくわかっていない
私は独学プログラミング5ヶ月目で3の状態に近いかと思います
個人的なメッセージとしては是非1.の状態の方により多く、この記事の内容が届くといいなと思っています
Dockerがなんとなくわかる、便利な気がする!、webアプリが動く仕組みに関心を広げる、そんな気づきを共有できたらいいなと思っていますこの記事と同じ内容は、AWS上のEC2を利用したり、契約したVPSを利用するよることで再現可能ですが、dockerを利用すれば完全無料で挑戦可能です!より手軽で、予定外の課金に怯える必要はありません
この記事で知ることができる内容
ネットワークに視野を広げる
- webアプリが最低限動作するために必要な構成を知る
- Nginx(エンジンエックスと読みます)の3つの重要な役割, webサーバー, ロードバランサー, リバースプロキシの役割に触れる
- Nginxの基本的な設定を知る
Dockerの基本を知る
- 既存の開発環境を簡単に再現できることを知る
- Docker上で開発を行うために最低限必要なコマンドを試すことができる
- docker-compose.ymlに記述された内容や、volumeの仕組みを手を動かして知ることができる
- 複数のdocker-compose.ymlを用意して、異なる環境をシミュレートする (development -> production)
webアプリの開発環境 - 本番環境での違いを知る
- 本番環境でアセットコンパイルが必要な理由を知る
- 開発環境でアセットコンパイルが必要でない理由を知る
よって、この記事の最後ではDocker上で、仮想の本番環境で開発環境との違いに触れながら、アプリをデプロイしてみます
Appendix
appendixは補足的内容となっています
その項で知ることのできる内容を初めに書いておきましたので、
改めて知る必要のない内容でしたら読み飛ばして頂いて結構です
もし知らない内容でしたら、実際に手を動かして頭の片隅に留めておくことで、後々役に立つ物があるかもしれません
必要なもの、スキル
エディタ(VS Codeで検証しています)
Visual Studio Code - Code Editing. RedefinedLinuxの基礎コマンドの知識(cd, ls, vi...くらい、なくてもコピペでなんとかなります)
Docker desktop
Docker Desktop for Mac and Windows | DockerDockerって何?っていう方は以下がおすすめです
【連載】世界一わかりみが深いコンテナ & Docker入門 〜 その1:コンテナってなに? 〜 | SIOS Tech. Lab
概念をさらっと理解していただき、ここでは手を動かしてみるというのがおすすめですアプリの部分はFW(フレームワーク)にRailsを使用しておりますが、
Railsの知識はなくても大丈夫です(私自身Rails以外の開発経験がないため、他のFWにおいて不適切な内容があるかもしれません)
検証環境
macOS Catalina
docker desktop: 2.3.05
(docker engin: 19.03.12, docker-compose: 1.27.2)
Nginx: 1.18
Rails: 6.03
PostgreSQL: 11.0アーキテクチャ(設計)概要
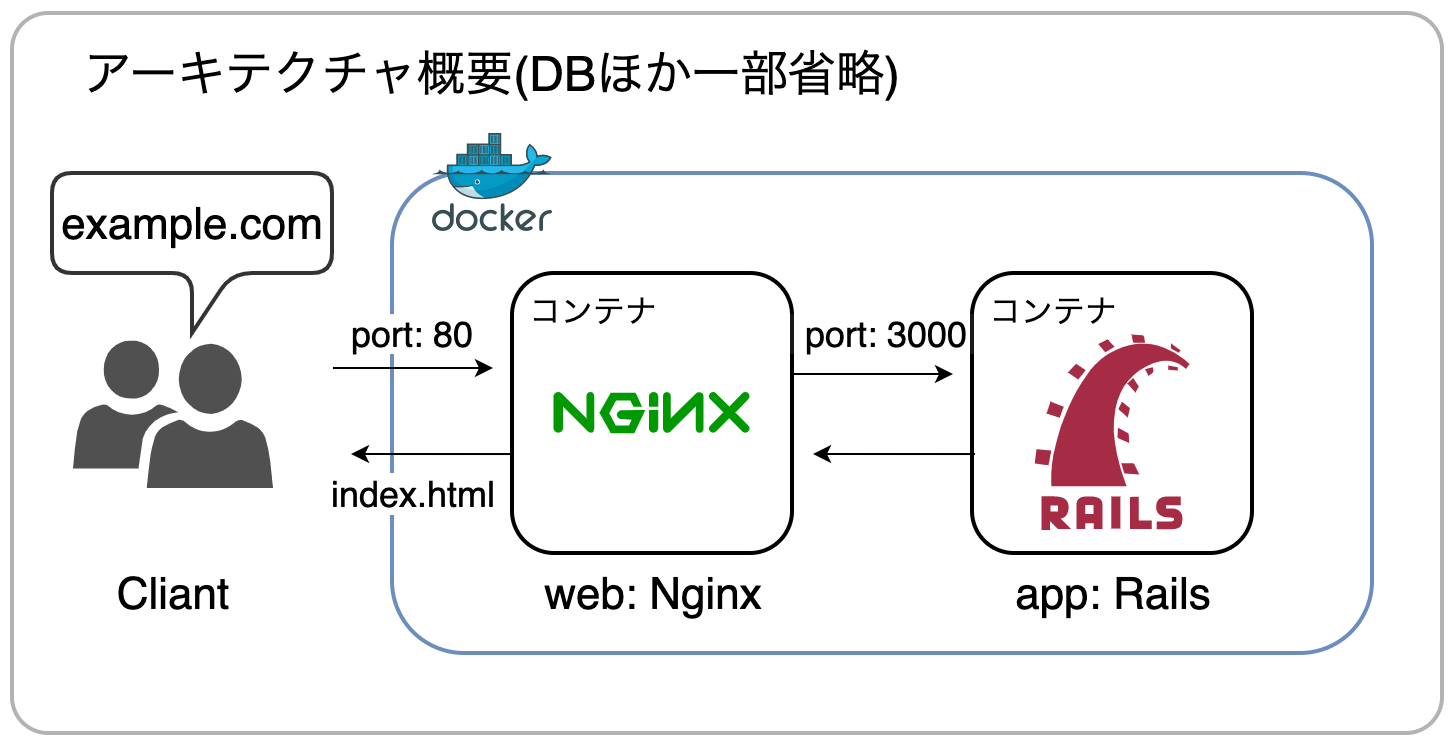
これからDockerで構築する環境では
Nginxはリバースプロキシとして機能していて、静的コンテンツをapp: Railsに代わって代理(=プロキシ)配信しており、動的コンテンツへのリクエストのみapp: Railsに転送するようになっていますというのを少しずつ理解していきたいと思います
よく見る構成です(Databaseほか一部省略)
docker上でweb(Nginx), app(rails)というサービスがそれぞれ独立したコンテナで動いていて
docker-composeによってそれぞれの依存関係等が定義されているような理解です
目標5分、DockerでRailsの環境構築
Nginx - Railsの環境を構築します
以下の素晴らしい記事を参考にします(笑)
Nginx, Rails 6, PostgreSQL環境(おまけにBootstrapまで)がすぐに構築できます!
少しづつ改善していますので、改善コメントもお待ちしております。上記をベースに今回の記事のために用意したソースコード
https://github.com/naokit-dev/try_nginx_on_docker.gitソースコードをgit clone
#アプリを配置するディレクトリを作成(アプリケーションルート) mkdir try_nginx_on_docker #アプリケーションルートへ移動 cd $_ #ソースコード取得 git clone https://github.com/naokit-dev/try_nginx_on_docker.git #アプリケーションルートにソースコードを移動 cp -a try_nginx_on_docker/. . rm -rf try_nginx_on_docker以下のような構成になるかと思います
.(try_nginx_on_docker) ├── Dockerfile ├── Gemfile ├── Gemfile.lock ├── README.md ├── docker │ └── nginx │ ├── default.conf │ ├── load_balancer.conf │ └── static.conf ├── docker-compose.prod.yml ├── docker-compose.yml ├── entrypoint.sh ├── setup.sh └── temp_files ├── copy_application.html.erb ├── copy_database.yml └── copy_environment.jsソースコードの一部
docker-compose.yml
4つのコンテナが定義されていますversion: "3.8" services: web: image: nginx:1.18 ports: - "80:80" volumes: - ./docker/nginx/static.conf:/etc/nginx/conf.d/default.conf - public:/myapp/public - log:/var/log/nginx - /var/www/html depends_on: - app db: image: postgres:11.0-alpine volumes: - postgres:/var/lib/postgresql/data:cached ports: - "5432:5432" environment: PGDATA: /var/lib/postgresql/data/pgdata POSTGRES_USER: ${POSTGRES_USER:-postgres} POSTGRES_PASSWORD: ${POSTGRES_PASSWORD:-password} POSTGRES_INITDB_ARGS: "--encoding=UTF-8 --locale=ja_JP.UTF-8" TZ: Asia/Tokyo app: build: context: . image: rails_app tty: true stdin_open: true command: bash -c "rm -f tmp/pids/server.pid && ./bin/rails s -p 3000 -b '0.0.0.0'" volumes: - .:/myapp:cached - rails_cache:/myapp/tmp/cache:cached - node_modules:/myapp/node_modules:cached - yarn_cache:/usr/local/share/.cache/yarn/v6:cached - bundle:/bundle:cached - public:/myapp/public - log:/myapp/log - /myapp/tmp/pids tmpfs: - /tmp ports: - "3000-3001:3000" environment: RAILS_ENV: ${RAILS_ENV:-development} NODE_ENV: ${NODE_ENV:-development} DATABASE_HOST: db DATABASE_PORT: 5432 DATABASE_USER: ${POSTGRES_USER} DATABASE_PASSWORD: ${POSTGRES_PASSWORD} WEBPACKER_DEV_SERVER_HOST: webpacker depends_on: - db - webpacker webpacker: image: rails_app command: ./bin/webpack-dev-server volumes: - .:/myapp:cached - public:/myapp/public - node_modules:/myapp/node_modules:cached environment: RAILS_ENV: ${RAILS_ENV:-development} NODE_ENV: ${NODE_ENV:-development} WEBPACKER_DEV_SERVER_HOST: 0.0.0.0 tty: false stdin_open: false ports: - "3035:3035" volumes: rails_cache: node_modules: yarn_cache: postgres: bundle: public: log: html:環境構築
source setup.sh正常にセットアップが終われば
アプリケーションルートディレクトリで以下のコマンドでコンテナ立ち上げた後docker-compose up # バックグラウンドで起動させる場合 -dオプション docker-compose up -dブラウザから
localhostもしくはlocalhost:80へアクセスすると
Yay! You’re on Rails!が確認できるかと思います
誰でも簡単に開発環境を構築できます!Dockerのメリット1つ目ここで起動しているコンテナを確認してみます
(-dオプションを付けずにdocker-compose upした場合には新しくターミナルを開きます。VS Codeならcontrol+@*mac環境)docker psweb (Nginx), app(Rails), webpacker(webpack-dev-server), db(PostgreSQL)の4つのコンテナが起動していることだけ確認してください
確認できたら一旦コンテナを終了させておきます
docker-compose down
Nginxで静的コンテンツを配信してみる
まだRailsアプリは使用しません
ここでは以下に挑戦します
Nginxの最小の設定を確認する
Docker-composeを利用しつつ、コンテナを単独 (nginxのみ) で起動してみる
Nginx単独で単純な静的コンテンツ(HTML)を配信してみる
最もシンプルなNginxの設定
Nginxの設定を変更するため
docker-compose.ymlを編集しますservices: web: image: nginx:1.18 ports: - "80:80" volumes: #ここを書き換える./docker/nginx/default.conf... -> ./docker/nginx/static.conf... - ./docker/nginx/static.conf:/etc/nginx/conf.d/default.conf - public:/myapp/public - log:/var/log/nginx depends_on: - app ...Dockerのvolumeについて少し
volumes:の./docker/nginx/static.conf:/etc/nginx/conf.d/default.confは<host側path>:<container側path>になっていて
これによってホスト(ローカル)側のstatic.confをボリュームとしてマウントし、コンテナ内のdefault.confとして扱えるようにしています
ここでは、ホスト側とコンテナ内では、ストレージが独立して存在するように振る舞われるため、このようなvolumeマウントが必要ということだけ心に留めてください
docker/nginx/static.confにはNginxの設定が記述されており、中身は以下のようになっていますserver { #ココから listen 80; # must server_name _; # must root /var/www/html; # must index index.html; access_log /var/log/nginx/access.log; error_log /var/log/nginx/error.log; } #ココまで、一つのserverブロック = Nginxが扱う一つの仮想サーバーの仕様server: "{}"で囲われた内容(serverブロック)をもとに仮想サーバーを定義します
ここでは以下3項目が設定必須です
listen: 待ち受けるIP, portを指定(xxx.xxx.xxx.xxx:80, localhost:80, 80)
server_name: 仮想サーバに割り当てる名前。Nginxはリクエストに含まれるホスト名(example.com)やIP(xxx.xxx.xxx.xxx)に一致する仮想サーバを検索します。("_"はすべての条件で一致させるの意味です。その他、ワイルドカードや正規表現が利用可能)
root: ドキュメントルート、コンテンツが配置されたディレクトリを指定しますちなみにlogについては、
etc/nginx/nginx.confというファイルで上記と同じパスが定義されているので、
ここで記述がなくても、error_logおよびaccess_logともに/var/log/nginx/以下に記録されるはずです
例えばaccess_log /var/log/nginx/static.access.log;とすることで、当該の仮想サーバ(serverブロック)固有のログを記録することもできるようですNginxコンテナ単独で起動
先程の
docker-compose upではnginx, rails, webpack-dev-server, dbのすべてのコンテナが起動していますが、docker-composeのオプションを使用することで特定のコンテナだけを起動することも可能です
--no-deps: コンテナ間の依存関係を無視して起動 (ここではweb: nginxのみ)
-d: バックグラウンドでコンテナを起動、シェルは入力を継続できます
-p: ポートマッピング<host>:<container>
web: composeで定義されたnginxコンテナです以下のコマンドでNginxコンテナを起動します
docker-compose run --no-deps -d -p 80:80 web(ポートマッピングについてはcomposeでも指定しているのですが、改めて指定する必要があり、ホスト側のport 80をwebコンテナのport 80にマッピングしています)
docker-composeをオプション無しで実行したときとの違いを確認します
docker ps先ほどと異なり、nginxのコンテナのみが起動していると思います
HTMLコンテンツを作成
コンテナの中でシェルを呼び出します
docker-compose run --no-deps web bash以下webコンテナ内での作業です
# index.htmlを作成 touch /var/www/html/index.html # index.htmlの中身を追加 echo "<h1>I am Nginx</h1>" > /var/www/html/index.html # index.htmlを確認 cat /var/www/html/index.html <h1>I am Nginx</h1>これでコンテナ内のドキュメントルート直下に
index.htmlが作成できたのでexitでシェルを閉じましょう動作確認
ブラウザからlocalhostにアクセスすると、
以下のようにHTMLとして配信されているのが確認できていると思います
ここでのNginxはリクエストに一致するコンテンツをドキュメントルートから探して、一致するものを返すというシンプルな挙動をしています
確認できたら一旦コンテナを終了させておきます
docker-compose downAppendix - リクエストに一致する仮想サーバがない場合のNginxの挙動
- Nginxのデフォルトサーバーの概念を知る
Nginxはクライアントからのリクエストに含まれるHostフィールドの情報をもとに、どの仮想サーバーにルーティングするかを定義しています
では、いずれの仮想サーバもリクエストと一致しない場合はどのような挙動をするのでしょうか?
設計を考える上で重要そうだったので、ここではそれを確認してみます先の設定ファイルのserverブロックで、いずれのリクエストに対しても該当するように
server nameを定義しましたが、これをリクエストと一致しないデタラメな名前に書き換えてみますserver_name undefined_server;再びNginxコンテナを起動します
docker-compose run --no-deps -p 80:80 webブラウザからlocalhostにアクセスすると、リクエストに一致する仮想サーバが存在しないにもかかわらず
予想に反して先ほどと同じ"I am Nginx"が表示されると思いますdefault server
Nginxはリクエストがいずれの仮想サーバにも該当しなかった場合、default serverで処理する使用になっており、一番最初、一番上に記述された仮想サーバをdefault serverとして扱う仕様になっています
In the configuration above, the default server is the first one — which is nginx’s standard default behaviour. It can also be set explicitly which server should be default, with the default_server parameter in the listen directive:
How nginx processes a requestまたはlistenディレクティブに明示的に
default_serverを指定することも可能ですlisten 80 default_server;今回の実験では"undefined_server"はリクエストに一致しないが、他に一致するものがないので
default serverとしてルーティングされたと考えられますいずれの仮想サーバもリクエストと一致しない場合 => default serverにルーティングされる
うまくバックエンドのサーバーに接続されない場合など、エラーを切り分けるのに役立つ気がします
一旦コンテナも終了させておきましょう
docker-compose downappendix - Dockerのvolumeを少し理解する
- コンテナの独立性について知る
- コンテナ - コンテナ間でストレージを共有する(永続化して共有する)仕組みとしてvolume、ここでは特にnamed volume, anonymous volumeの違いについて知る
そもそもvolumeが必要(= 永続化が必要)な意義について
Dockerではコンテナ内のデータを永続化するためにvolumeを作成し管理しますよくわからないので確認してみます
webコンテナの中でシェルを呼び出します
docker-compose run --no-deps web bash以下webコンテナ内での作業です
# 検証用のディレクトリを作成 mkdir /var/www/test # 検証用のファイルを作成します touch /var/www/test/index.html # 存在確認 ls /var/www/test/これで
/var/www/testはdocker-compose.ymlの中でボリュームとして管理されていないパスであることがポイントです一旦
exitでシェルを閉じましょう(コンテナも終了します)再度webコンテナを起動しシェルを呼び出します
docker-compose run --no-deps web bash先程のファイルを探してみます
cat /var/www/test/index.htmlls /var/wwwいかがでしょうか、
ディレクトリ/var/www/test、ファイル/var/www/test/index.htmlともに見つからないと思いますコンテナを終了すると、コンテナ内のデータは保持されないこれが原則であり
ボリュームはこの仕組を回避するために利用可能です
exitでターミナルを閉じますすべてのコンテナを停止します
docker-compose downvolumeの種類
Dockerにおけるボリュームには以下のタイプがありますが、コンテナ内のデータを永続化するという点では同じです
- host volume ?(ちょっと名前がわからないです)
- anonymous volume (匿名ボリューム?anonymous volumeで通っている気がします)
- named volume (名前付きボリューム)
docker-compose.ymlを見みてみます
version: "3.8" services: web: image: nginx:1.18 ports: - "80:80" volumes: - ./docker/nginx/static.conf:/etc/nginx/conf.d/default.conf #host volume - public:/myapp/public # named volume - log:/var/log/nginx # named volume - html:/var/www/html # named volume ... volumes: # ここで異なるコンテナ間での共有を定義 public: log: html:host volume
nginxの設定のパートで触れました
./docker/nginx/static.conf:/etc/nginx/conf.d/default.confの部分でホスト側のパスをボリュームとしてマウントします
ホスト内のファイルをコンテナ側にコピーしているイメージですnamed volume
html:/var/www/htmlの部分
"html"という名前をつけてボリュームをマウントしています
さらに、"services"ブロックと同列の"volumes"ブロックでこの名前をもって定義することで
複数のコンテナ間でボリュームをシェアすることを可能にしていますそして、このボリュームはホスト側からは独立して永続化されます
最後にanonymous volume
公式docではnamed volumeとの違いは名前があるかないかのみとありますが
実際に名前がないというより、named volumeの名前に相当する部分がコンテナごとにハッシュで与えられているそうです
ちょっとわかりにくいですが、ホスト側をマウントする必要がないが、永続化の必要がある、かつ複数のコンテナでの共有を想定しない場合に利用するケースが考えられます
(まだイメージし難いですが、この後のコンテンツでanonymous volumeでないといけない場面に遭遇します)ここでは少し理解を深めるために検証してみます
もともとnamed volumeとして定義している/var/www/htmlをanonymous volumeに変更して
本項で実施したHTMLファイル作成の手順を繰り返してみます
docker-compose.ymlversion: "3.8" services: web: image: nginx:1.18 ports: - "80:80" volumes: - ./docker/nginx/static.conf:/etc/nginx/conf.d/default.conf - public:/myapp/public - log:/var/log/nginx - /var/www/html # コンテナ側のpathのみ指定しanonymous volumeに変更 ... volumes: public: log: # html: ここをコメントアウトNginxをweb serverとして起動
docker-compose run --no-deps -d -p 80:80 webシェルを呼び出します
docker-compose run --no-deps web bashここが重要なのですが、別のターミナルでいま起動しているコンテナを確認すると
docker ps2つのコンテナが起動しており、シェルが動いているコンテナは、80:80でポートマッピングしているコンテナとは別であることがわかります
このままコンテナ内でHTMLを作成
# index.htmlを作成 touch /var/www/html/index.html # index.htmlの存在を確認 ls /var/www/htmlさきほどと同様にブラウザから
localhostにアクセスしてみましょうするとブラウザは403エラーを示し
Nginxのエラーログを確認するとtail -f 20 /var/log/nginx/error.log...directory index of "/var/www/html/" is forbidden...ディレクトリを見つけられないとエラーが記録されています
named volume -> anonymous volumeに変更したことで
2つのコンテナ間で/var/www/html/以下の内容が共有されなくなり
ローカルからport 80でリクエストを受けたコンテナからはindex.htmlを参照することができなくなったことで
このようなエラーが生じていると考えられます永続化はするが、他のコンテナとボリュームを共有しない、その特性に触れることができたかと思います
確認できたら
exitでシェルを閉じ毎度ですがコンテナを終了させておきましょう
docker-compose down(変更したdocker-compose.ymlの内容はこのままでも構いません)
...
appendixの内容に思ったよりも熱が入ってしまい長くなったので、(私のモチベーション維持のために)一旦ここで区切ります
②に続く

- 投稿日:2020-09-28T08:24:15+09:00
【Docker】マルチステージビルドって言うほど良いか? → 言うほど良いわとなった話
結論
マルチステージビルドを活用することでコンテナイメージのサイズを大幅に抑えられる可能性があります。
以下はNuxt.jsアプリケーションの例です。$ docker images REPOSITORY TAG IMAGE ID CREATED SIZE nuxt single-stage fba421d5de5b About a minute ago 371MB nuxt multi-stage a40d0000d0a8 10 minutes ago 22MB検証手順
環境
- Docker version 19.03.12
- CentOS Linux release 7.8.2003 (Core)
- Node.js v12.18.3
- create-nuxt-app/3.3.0 linux-x64
Nuxtアプリケーションを作成する
npx create-nuxt-app <アプリ名>でNuxt.jsアプリケーションを作成します。構成は自由です。どのように設定しても、多少サイズの違いはあれ同じような結果を得られます。ルートディレクトリに以下のファイルを追加する
Dockerfile-Single
FROM node:lts-alpine WORKDIR /app COPY . ./ RUN npm install -g http-server && \ npm install && \ npm run build EXPOSE 8080 CMD [ "http-server", "dist" ]この記事ではマルチステージじゃないビルドは便宜的にシングルステージビルドと呼んでいます。正しい用語が分からなかったので詳しい方は教えてください!
アプリケーションを動かすためのhttp-serverを持ってきて、ビルドしたファイル群を乗っけています。Dockerfile-Multi
FROM node:lts-alpine AS build-stage WORKDIR /app COPY . ./ RUN npm install && \ npm run build FROM nginx:stable-alpine AS production-stage COPY --from=build-stage /app/dist /usr/share/nginx/html EXPOSE 80 CMD [ "nginx", "-g", "daemon off;" ]ビルドの段階ではnode.jsのイメージを使い、実行段階ではnginxのイメージを使用しています。
asでステージに名前を付けたり、--fromでどのステージのファイルかを指定したりできます。
最終的にビルドステージで生成したディレクトリをnginxのドキュメントルートに置いています。.dockerignore
node_modules dist Dockerfile*Dockerfileは誤差のようなものですが、
node_modulesやdistは使うもの次第で膨らみます。それぞれnpm installとnpm buildによってコンテナ内で実行されるので、イメージ作成段階では除外します。それぞれのイメージをビルドし、動作確認する
シングルステージの場合
$ docker build -t nuxt:single-stage --file Dockerfile-Single . $ docker run -dit -p 8080:8080 --name nuxt-single nuxt:single-stage $ docker exec nuxt-single wget -S -O- localhost:8080 Connecting to localhost:8080 (127.0.0.1:8080) HTTP/1.1 200 OK (以下省略 レスポンスデータとしてHTMLが返ってきていればOK!)マルチステージの場合
$ docker build -t nuxt:multi-stage --file Dockerfile-Multi . $ docker run -dit -p 80:80 --name nuxt-multi nuxt:multi-stage $ docker exec nuxt-multi wget -S -O- localhost:80 Connecting to localhost:80 (127.0.0.1:80) HTTP/1.1 200 OK (以下省略 レスポンスデータとしてHTMLが返ってきていればOK!)この時点でそれぞれのイメージサイズを比較すると、冒頭のような結果を得られます。
マルチステージビルドの使いどころ
今回挙げた例では、アプリケーションのビルドの時は必要だけど実行の時はいらないものを捨てることでイメージのサイズダウンが実現されています。
つまり、マルチステージビルドは実行環境だけあればいいコンテナのイメージを作る際に威力を発揮すると言えます。
例えばCI/CD用のコンテナなんかはビルドの成果物さえあれば良く、むしろビルド時のみに必要なファイルたちは無駄にコンテナサイズを膨らませる原因となってしまいます。マルチステージビルドの使いどころですね。余談
node_modulesを.dockerignoreから外してnpm installを省略することでnpm installにより発生するネットワーク通信を抑えることができます。node_modulesを一度Dockerデーモンに送るのとnpm installを実行するのとでは、ネットワーク環境にもよりますがそれほど時間に差はないです。また、マルチステージビルドを利用すると中間イメージが
<none:none>として残ってしまいます。
これを避けるには以下のいずれかを実施します。
--targetオプションで中間イメージにタグ付けする(もちろんタグが付いたイメージは残ります)- 最後のイメージのビルド成功後、
docker image pruneを実行する関連のGitHub Issue では「仕様です(意訳)」で切り捨てられるも、オプションでどうにかできないか、イメージのビルダーを新しいものにすることで対応できないかといった議論が行われていたようです。現状、新しいビルダー(BuildKit)をデフォルトにすることで対応するというのが本線のようです。(個人的にはBuildKitを使ったとしても、docker image pruneするのとdocker builder prune するのとに如何ほどの違いが...? という疑問あり。。。特定ビルドに対応する中間イメージやキャッシュのみを削除したい)
参考
- 投稿日:2020-09-28T01:45:45+09:00
開発未経験のエンジニアでも開発業務に就くことができるプロジェクト(つづき)
概要
未経験のエンジニアの方でどうやったら開発に業務に携われることができるかご相談を受けました。相談に対して回答していく中で2人で一緒に何か作っていこうという話になり、それ自体をプロジェクトとして発足しました。
8月度から継続で活動している内容になり、今回の記事は9月の内容をまとめております。8月の活動記録については以下の記事にまとめておりますので、ご興味がありましたらお読みいただければ幸いです。
■開発未経験のエンジニアでも開発業務に就くことができるプロジェクト
https://qiita.com/tamoco/items/cf657ec4d74ccbf4d493今回はこのプロジェクトを行うことで実際に企業に面談に行く機会が増えてきました。実は開発業務に就くことができたのは9月の話で、現場が決まるまでもう少しお話がつづいています。そういった経緯も赤裸々に記事としてまとめてみましたのでぜひお読みいただければ幸いです。
前回(8月)は何をやったか
いろいろと2人で一緒に考えたり作業したりして以下のことができています。
- 簡易なインセプションデッキを作ることで方向性を定める
- 目標設定の洗い出し
- やりたいことの具体化
- 使用する技術の選定
- 開発環境構築
- ペアプロで開発するために環境の差をなくす
- どの環境でも動くようにコンテナで環境の準備を整えた
- アプリケーションの作成
- GitLabによるIssueでのタスク管理
- 開発環境が不便と感じたら改善も行う
- チャットアプリとして完成させることができた
- ポートフォリオの作成
- 作成したのは単純なチャットアプリだが使っている技術は多かった
- ポートフォリオで取り組みの経緯や使用技術に関する情報を記載
- 成果物と併せてエンジニアとしてPRできる資料として準備することができた
9月は何をすることになったのか?
8/23(月)の振り返りの
KPTから「作ったモノをベースに新しいモノを作る」というモノがトライとして挙がりました。そのためポートフォリオが完了したのと同時にチャットアプリはクローズして、開発環境(コンテナの構成)などは引き継いで別のアプリケーションを作ることにしました。そして何をつくるのかこれまでと同じような形で一緒に考えてみました。
とりあえず思いついた機能を書いています。意外と少ない感じで作業に入るとアレもコレも必要だなということが多かったりします。これも1つの経験になるのかなと・・・。
ひたすら作業
GitLabの別のプロジェクトとして作業を続けていきました。https://gitlab.com/vorwort.k/spring-todo
必要な機能を
GitLabのIssueとして作成して実装していきます。8月と同じようにペアプロで一緒に作業しながら1つずつの機能を実現していきます。意外にやることが多くなりそうだったので必要最低限の機能に絞りながら後で拡充できるように取り組みました。企業面談が決まることで割り込むタスク
日々作業を続けている中で未経験のエンジニアの方に企業面談のお話があったようです。企業面談に行くにあたり、会社(企業面談先の企業ではなく所属しているSES)からはコードの開示をお願いされました。単純に
GitLabのプロジェクトをパブリックにして公開するだけだとPRにつながらない可能性も考えられます。実際に未経験のエンジニアの方もコードを公開するに対して不安があるようだったので効果的にPRする方法を整理していみました。
現状の課題として未経験エンジニアの方の不安を、現状の課題として書いてもらいました。結構不安に思われていることが出てくるモノですね。
現状の課題に対して解消できそうな解決案を一緒に考えていきました。単純にコードを公開して説明できるかどうかという不安が大きいようなので、そこをフォローする解決案を選択しました。
そして実際に取ったアクションは
GitLabのWikiを作成していただきました。Wikiにはこれまで行ってきたインセプションデッキや振り返りの内容などを記述したり、継続して行っているプロジェクトについても記述しています。こういった成果物に対する解説があるだけで印象が大きく変わると思われます。余談
会社(企業面談先の企業ではなく所属しているSES)からはコード量が少ないのでコードの一部だけ見せればよいのではというお話もあったようで解決案として追加しています。複雑なアルゴリズムなどが書いてあればそういった解決案も有効そうです。ただし、今回の場合はコード量も少なく一部だけみせた場合の効果は薄いと考えて採用を見送りました。
企業面談に行った結果
未経験エンジニアの方に話を伺うと成果物に対するリアクションはそこまでなく感触が微妙とのことでした。設計書や定義所を作成した経験を問われた際に回答にするのに困ったとのことです。9/13(日)の振り返りでも
Probremとして挙がりました。
企業面談を踏まえてこれからやること(Tryの設定)
企業面談での課題も改善活動して取り込みつつチャレンジすることにしました。具体的には「仕様書を作ってみる」ということですが、単純に仕様書を作ってみるだけだと面白味がなかったので
SwaggerによるAPI定義やSchemaspyによるER図を自動生成することをTryとして設定しました。継続的にチャレンジし続けた結果、
schemaspyでER図を作成し.gitlab.ciでpagesに公開することができました。本音をいうとパイプラインの処理のdind(docker-in-docker)でER図を作成してそれをpagesにデプロイしたいところですが一旦は公開して閲覧できるようにしています。実際にはすでに内定はいただいていた・・・
1週間後にわかったことですがこの企業面談で内定をいただくことができました。結果的には無事に開発業務に就けることになりましたが、上記のTryは継続的に続けていくことにしました。内定をいただいたことによって一旦このプロジェクトは完了することにしました。
このプロジェクトを振り返って
たった2人のプロジェクトとして始まりましたがチームとして考えながら進めてこれました。少しずつ有効だと思える成果物を作っていくことで、「開発業務に就く」という目標を達成することができました。
開発未経験のエンジニアの方でも一緒になって考えて進めていけばエンジニアの技術や考え方は成長し評価されるようになりました。技術力やPR方法がわからず不安なエンジニアの方もいらっしゃると思いますが、今回のようなアプローチを少しでもお役に立てれば幸いです。




- 投稿日:2020-09-28T00:56:41+09:00
DockerでSpringBoot-gradle-mysqlの開発環境を作成する
DockerでSpringBoot-gradle-mysqlの開発環境を作成する
Dockerを使用してCentOS用コンテナにgradle環境
DB用コンテナにmysql環境を構築して
仮想環境上でSpringBootが動作できるようにする構成
コンテナ
CentOSコンテナ: java8/gradle/mysql
Mysqlコンテナ : MysqlCentOSコンテナでSpringBootを起動させ、MysqlコンテナのdbにアクセスしてDBデータを取得の後、tomcatポート8080を通してホスト上にDBデータを表示させる
ディレクトリ構成
docker-compose.yml
centos ー Dockerfile
gradle-project ー [project-name] ー gradleプロジェクトファイル群
mysql ー settings ー 空フォルダ
ー sql ー init.sqlディレクトリ/ファイル説明
docker-compose.yml: CentOSとMysqlコンテナを作成するためのdocker-compose記述
centos -> Dockerfile: CentOSコンテナ起動ようのDockerファイル
gradle-project -> [project-name]: SpringBootアプリのGradleプロジェクトファイル群
mysql -> settings: mysqlのDBデータ永続用のvolume(/var/lib/mysql)
-> sql -> init.sql: Mysqlコンテナ起動時の初期化スクリプトdocker-compose.yml
version: "3" services: centos: build: ./centos # centosのDockerfileのビルド設定(後述) container_name: boot-container # centosコンテナ名指定 ports: - "8080:8080" # ホストOSコンテナ間通信のポートフォワード設定 volumes: - ./gradle-project:/gradle-project # gradleプロジェクトの永続化設定 links: - mysql # service[mysql]のコンテナ間通信処理の許可 depends_on: - mysql # mysqlコンテナ起動後にcentosコンテナを作成するよう設定 privileged: true # centos操作で管理者権限付与(コマンド操作等で面倒ごとが発生しないため念のために) tty: true # コンテナ作成後にcentosが起動し続けるよう設定 mysql: image: mysql:5.7 container_name: boot-mysql command: mysqld --character-set-server=utf8mb4 --collation-server=utf8mb4_unicode_ci # mysqlデーモンコマンド 文字コード指定 volumes: - ./mysql/sql:/docker-entrypoint-initdb.d # 初期化スクリプトをコンテナへ配置 - ./mysql/settings:/var/lib/mysql # 永続化したいDBデータ群を格納するディレクトリをマウント environment: # mysqlの各々パラメータ設定 MYSQL_DATABASE: bootdb MYSQL_USER: boot MYSQL_PASSWORD: boot MYSQL_ROOT_PASSWORD: rootcentos ー> Dockerfile
# centos7を取得 FROM centos:7 # コンテナ内で行うコマンドソフトの取得 RUN yum -y update RUN yum -y install wget RUN yum -y install unzip # install mysql5.7 RUN yum localinstall -y https://dev.mysql.com/get/mysql57-community-release-el7-11.noarch.rpm # setting for mysql version 5.6 # mysql5.6の使用する場合は、下記のコメントアウトをはずす # RUN yum-config-manager --disable mysql57-community # RUN yum-config-manager --enable mysql56-community RUN yum install -y mysql mysql-server # install java RUN yum install -y java-1.8.0-openjdk RUN yum install -y java-1.8.0-openjdk-devel # install gradle RUN wget https://services.gradle.org/distributions/gradle-6.4.1-bin.zip RUN unzip -d /opt/gradle /gradle-6.4.1-bin.zip RUN rm -rf /gradle-6.4.1-bin.zip RUN ls /opt/gradle/ # setting path # gradle/javaコマンドを操作できるように事前に環境変数を定義 ENV GRADLE_HOME /opt/gradle/gradle-6.4.1 ENV JAVA_HOME /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.262.b10-0.el7_8.x86_64 ENV PATH ${JAVA_HOME}/bin:${GRADLE_HOME}/bin:${PATH}gradle-project -> [project-name]:
[project-name]ディレクトリ内にgradleプロジェクトファイルを配置する
SpringInitilizerの出力やEclipseのgradleプロジェクトのファイル群を
そのままこのディレクトリに配置する永続化設定を行っているため、ホストコンピュータとコンテナ内のファイル操作は連動して行われる。
したがって、Eclipse等で開発を進めて、そのままコンテナに対してbuild/jar実行操作を行えるmysql -> settings:
mysqlのDBデータ群が格納されるファイル群を格納する
コンテナ作成前は、空ディレクトリだが
コンテナ作成あとのmysql操作にしたがってデータファイル等が追加されるコンテナ内で作成されたデータファイルは、永続化を行えるように
volume定義しておくmysql -> sql -> init.sql
コンテナ起動時の初期化スクリプトを定義
今回はSpringBootから下記のdataレコードの内容を取得して、
表示するようにコードを記述しているCREATE DATABASE IF NOT EXISTS bootdb; CREATE TABLE IF NOT EXISTS test( id int(11) PRIMARY KEY, data varchar(255) NOT NULL ); INSERT INTO test (id, data) VALUES (1, 'welcome to spring boot with docker');コンテナ起動から動作確認まで
cd ./*docker-compose.ymlのカレントディレクトリへ移動 # コンテナをバックグランド起動 docker-compose up -d Creating boot-mysql ... done Creating boot-container ... done # コンテナ起動確認 docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 74f3771fef53 boot_with_docker_centos "/bin/bash" 4 minutes ago Up 4 minutes 0.0.0.0:8080->8080/tcp boot-container 5448c1a111c0 mysql:5.7 "docker-entrypoint.s…" 4 minutes ago Up 4 minutes 3306/tcp, 33060/tcp boot-mysql # gradleでプロジェクトをビルド docker exec -w /gradle-project/docker-app boot-container gradle build # jarファイルが作成されていることを確認 docker exec -w /gradle-project/docker-app/build/libs boot-container ls docker-app-0.0.1-SNAPSHOT.jar # boot起動 docker exec -w /gradle-project/docker-app/build/libs boot-container java -jar docker-app-0.0.1-SNAPSHOT.jar --spring.profiles.active=docker * application.ymlのdockerプレフィックスを使用してローカル環境とコンテナ環境で起動処理を場合分けしている # 動作確認 curl http://localhost:8080/docker/test 結果[welcome to spring boot with docker] # コンテナダウン docker-compose down補足
mysqlはホストOSから直接アクセスできないようにしている。
CentOSコンテナ(サーバ)を踏み台設定(links)として
CentOSコンテナからMysqlコンテナ(サーバ)へアクセスするプライベートネットワークとして起動しているそのため、Mysqlへのデータ操作を行う場合は、CentOSからMysqlにアクセスする必要がある
したがって、CentOSのDockerfile記載の通り、mysqlをcentos側にもインストールしている下記がMysqlアクセスの例
# CentOSコンテナのbashプロセス起動 docker exec -it boot-container /bin/bash # Mysqlログイン mysql -u boot -p -h mysql # データ確認 mysql> use bootdb mysql> select * from test; +----+------------------------------------+ | id | data | +----+------------------------------------+ | 1 | welcome to spring boot with docker | +----+------------------------------------+ 1 row in set (0.00 sec)最後に
SpringBootやMysqlなどのデータベース連携の開発を行い際に、
ローカル環境に各ソフトウェアのインストール等を行う必要があるが、
Dockerでコンテナ管理してしまえば簡単に開発環境が作成されるため、
個人開発用のためにもDockerを使用することを検討しました。DockerのVolume機能を使用して、データベースのデータの永続化や
Springプロジェクトの管理の煩雑さも簡単になるためお勧めです。SpringBootの設定値なども確認したい方がいらっしゃいましたらgithubを参照ください
githubReference
https://blog.tiqwab.com/2017/03/21/docker-java.html
プログラマのためのDocker教科書
- 投稿日:2020-09-28T00:08:47+09:00
【Python】AWS-CDKを利用してBatch環境を作成する
1. はじめに
今回は、AWS Batchの環境をCDKを利用して実装していきます。
よくTypeScriptでの実装例は多いのですが、Pythonはあまりなかったので記事にしました。1.1 実行環境
実行環境は以下の通りです。
特にインストールやaws-cliとaws-cdkの初期設定については触れません。
ただ、注意点としてaws-cdkは非常にバージョンの更新頻度が高く、現在書かれている内容でも動かない可能性があります。
- MacOS: Catarila (10.15.6)
- Python (brew): 3.8
- aws-cli (brew): 2.0.50
- aws-cdk (brew): 1.63.0 (build 7a68125)
- docker: 19.03.12
1.2 料金
気になるのは、料金ですよね。
以下の条件で動かしたところ、課金されたのはEC2の料金のみで0.01 [$/日]程度でした。
(Batchだと、毎回ジョブにキューが追加されてからインスタンスの作成が行われ、ジョブが完了すると削除されるためです。)
- 処理時間:10~15 [min/回]
- 起動したインスタンスタイプ: c4.large (スポット料金)
1.3 手順
Batchの実行環境を整えるのに以下の手順で実装を行います。
- Python scriptの作成
- Dockerfileの作成
- ECRに登録
- CDKにてappを記述
1.4 準備
フォルダ構成は以下の通りです。
ファイル名の右側に付いているのは、上記の手順の番号と対応しています。batch_example └── src ├── docker │ ├── __init__.py (1) │ ├── Dockerfile (2) │ ├── requirements.txt (2) │ └── Makefile (3) └── batch_environment ├── app.py (4) ├── cdk.json └── README.md2. 実装
それでは、上記の手順にしたがって実装を進めていきます。
2.1 Python scriptの作成
Docker内にて実行するscriptの例を以下に示します。
clickはCMDからのコマンドライン引数の受け渡しをするために、
watchtowerはCloudWatch Logsへのログの書き込みをするために利用しています。__init__.py# timeのparse用 from datetime import datetime from logging import getLogger, INFO # インストールライブラリ from boto3.session import Session import click import watchtower # envvarで指定すると環境変数から値を取得する @click.command() @click.option("--time") @click.option("--s3_bucket", envvar='S3_BUCKET') def main(time: str, s3_bucket: str): if time: # CloudWatch Eventから実行することを想定し、時刻のparseをする d = datetime.strptime(time, "%Y-%m-%dT%H:%M:%SZ") # 実行日付を取得 execute_date = d.strftime("%Y-%m-%d") # loggerの設定 # loggerの名前がログストリームの名前になる logger_name = f"{datetime.now().strftime('%Y/%m/%d')}" logger = getLogger(logger_name) logger.setLevel(INFO) # CloudWatch Logsのロググループの名前をここで指定 # Sessionを渡してIAM Role経由でログを送信 handler = watchtower.CloudWatchLogHandler(log_group="/aws/some_project", boto3_session=Session()) logger.addHandler(handler) # 実行予定の処理 # ここでは、CloudWatch Logsに実行日時を書き込むのみ logger.info(f"{execute_date=}") if __name__ == "__main__": """ python __init__.py --time 2020-09-11T12:30:00Z --s3_bucket your-bucket-here """ main()2.2 Dockerfileの作成
次に上記のPython scriptを実行するDockerfileを作成します。
ここを参考にマルチステージでビルドしました。Dockerfile# ここはビルド用のコンテナ FROM python:3.8-buster as builder WORKDIR /opt/app COPY requirements.txt /opt/app RUN pip3 install -r requirements.txt # ここからは実行用コンテナの準備 FROM python:3.8-slim-buster as runner COPY --from=builder /usr/local/lib/python3.8/site-packages /usr/local/lib/python3.8/site-packages COPY src /opt/app/src WORKDIR /opt/app/src CMD ["python3", "__init__.py"]同時にrequirements.txtにも利用するライブラリを入れておきます。
requirements.txtclick watchtower2.3 ECRへの登録
Dockerfileの作成が終わったら、ECRに登録します。
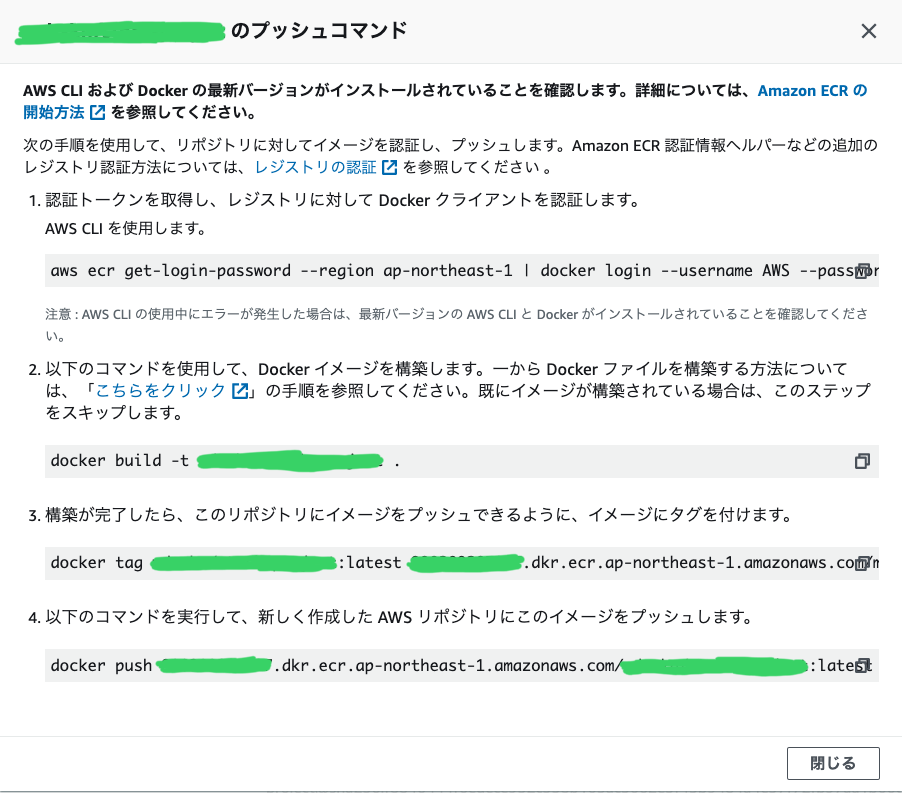
まずは、コンソールからECRに「リポジトリ作成」ボタンを押してrepositoryを作成します。
リポジトリの名前は適当に設定します。
作成したリポジトリを選択して、「プッシュコマンドの表示」ボタンを押します。
すると、プッシュに必要なコマンドが表示されるので、何も考えずにコピーして実行していきます。
ここで、失敗する方はAWS CLIの設定がうまくで来ていないと思うので、AWS CLIの設定を見直してください。
毎回、コマンドを打つのが大変なので、上記のコマンドをコピーしたMakefileを作成します。
(1のコマンドの--username AWSは定数だと思われます。)Makefile.PHONY: help help: @echo " == push docker image to ECR == " @echo "type 'make build tag push' to push docker image to ECR" @echo "" .PHONY: login login: (1のコマンド)aws ecr get-login-password --region ap-northeast-1 | docker login --username AWS --password-stdin {ACCOUNT_NUMBER}.dkr.ecr.ap-northeast-1.amazonaws.com .PHONY: build build: (2のコマンド)docker build -t {REPOSITORY_NAME} . .PHONY: tag tag: (3のコマンド)docker tag {REPOSITORY_NAME}:latest {ACCOUNT_NUMBER}.dkr.ecr.ap-northeast-1.amazonaws.com/{REPOSITORY_NAME}:latest .PHONY: push push: (4のコマンド)docker push {ACCOUNT_NUMBER}.dkr.ecr.ap-northeast-1.amazonaws.com/{REPOSITORY_NAME}:latestこのMakefileを利用することで、以下のように簡単にコマンドを短縮できます。
加えて、上記のMakefileには特に外部にもれても危ない情報はないと思うので、ソースコードも共有できます。# ECRにログイン $ make login # ECRに最新の状態のimageをpush $ make build tag push2.4 CDKの実装
CDKの実装内容はTypeScriptで書かれたこの記事を参考に行いました。
なお、事前にapp.pyを実装するディレクトリにて$ cdk initの実行をした方が良いです。2.4.1 実装に必要なパッケージのインストール
一つ一つのパッケージ名が長いですね・・・。加えて、インストールにかかる時間も結構長いです。
$ pip install aws-cdk-core aws-cdk-aws-stepfunctions aws-cdk-aws-stepfunctions-tasks aws-cdk-aws-events-targets aws-cdk.aws-ec2 aws-cdk.aws-batch aws-cdk.aws-ecr2.4.2 app.pyの実装
まずは、今回構築する環境のクラスを作成します。
BatchEnvironmentクラスの引数として、stack_nameとstack_envを設定しています。
これは、この環境の名前と、実行環境(検証/開発/本番)などと対応しています。
(なお、本当に実行環境を分ける場合は、ECRのリポジトリも変更する必要があるかなと思います。)app.pyfrom aws_cdk import ( core, aws_ec2, aws_batch, aws_ecr, aws_ecs, aws_iam, aws_stepfunctions as aws_sfn, aws_stepfunctions_tasks as aws_sfn_tasks, aws_events, aws_events_targets, ) class BatchEnvironment(core.Stack): """ Batchの環境とそれを実行するStepFunctions + CloudWatch Event環境を作成 """ # 上で作成したECRのリポジトリ名 # Batchで実行する際に、このリポジトリからイメージをpullする ECR_REPOSITORY_ARN = "arn:aws:ecr:ap-northeast-1:{ACCOUNT_NUMBER}:repository/{YOUR_REPOSITORY_NAME}" def __init__(self, app: core.App, stack_name: str, stack_env: str): super().__init__(scope=app, id=f"{stack_name}-{stack_env}") # 以下の実装はここの下に連なるイメージです。2.4.3 app.pyの実装(VPC環境の作成)
app.py# def __init__(...):の中 # CIDRは好きな範囲を cidr = "192.168.0.0/24" # === # # vpc # # === # # VPCはパブリックサブネットしか利用しない場合は、無料で利用可能できる(はずです) vpc = aws_ec2.Vpc( self, id=f"{stack_name}-{stack_env}-vpc", cidr=cidr, subnet_configuration=[ # Public Subnetのnetmaskを定義 aws_ec2.SubnetConfiguration( cidr_mask=28, name=f"{stack_name}-{stack_env}-public", subnet_type=aws_ec2.SubnetType.PUBLIC, ) ], ) security_group = aws_ec2.SecurityGroup( self, id=f'security-group-for-{stack_name}-{stack_env}', vpc=vpc, security_group_name=f'security-group-for-{stack_name}-{stack_env}', allow_all_outbound=True ) batch_role = aws_iam.Role( scope=self, id=f"batch_role_for_{stack_name}-{stack_env}", role_name=f"batch_role_for_{stack_name}-{stack_env}", assumed_by=aws_iam.ServicePrincipal("batch.amazonaws.com") ) batch_role.add_managed_policy( aws_iam.ManagedPolicy.from_managed_policy_arn( scope=self, id=f"AWSBatchServiceRole-{stack_env}", managed_policy_arn="arn:aws:iam::aws:policy/service-role/AWSBatchServiceRole" ) ) batch_role.add_to_policy( aws_iam.PolicyStatement( effect=aws_iam.Effect.ALLOW, resources=[ "arn:aws:logs:*:*:*" ], actions=[ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents", "logs:DescribeLogStreams" ] ) ) # EC2に付与するRole instance_role = aws_iam.Role( scope=self, id=f"instance_role_for_{stack_name}-{stack_env}", role_name=f"instance_role_for_{stack_name}-{stack_env}", assumed_by=aws_iam.ServicePrincipal("ec2.amazonaws.com") ) instance_role.add_managed_policy( aws_iam.ManagedPolicy.from_managed_policy_arn( scope=self, id=f"AmazonEC2ContainerServiceforEC2Role-{stack_env}", managed_policy_arn="arn:aws:iam::aws:policy/service-role/AmazonEC2ContainerServiceforEC2Role" ) ) # S3にアクセスするpolicyの追加 instance_role.add_to_policy( aws_iam.PolicyStatement( effect=aws_iam.Effect.ALLOW, resources=["*"], actions=["s3:*"] ) ) # CloudWatch Logsにアクセスするpolicyの追加 instance_role.add_to_policy( aws_iam.PolicyStatement( effect=aws_iam.Effect.ALLOW, resources=[ "arn:aws:logs:*:*:*" ], actions=[ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents", "logs:DescribeLogStreams" ] ) ) # EC2にロールを付与 instance_profile = aws_iam.CfnInstanceProfile( scope=self, id=f"instance_profile_for_{stack_name}-{stack_env}", instance_profile_name=f"instance_profile_for_{stack_name}-{stack_env}", roles=[instance_role.role_name] )2.4.4 app.pyの実装(Batchの実行環境およびジョブ定義・ジョブキューの作成)
app.py# VPCの続き... # ===== # # batch # # ===== # batch_compute_resources = aws_batch.ComputeResources( vpc=vpc, maxv_cpus=4, minv_cpus=0, security_groups=[security_group], instance_role=instance_profile.attr_arn, type=aws_batch.ComputeResourceType.SPOT ) batch_compute_environment = aws_batch.ComputeEnvironment( scope=self, id=f"ProjectEnvironment-{stack_env}", compute_environment_name=f"ProjectEnvironmentBatch-{stack_env}", compute_resources=batch_compute_resources, service_role=batch_role ) job_role = aws_iam.Role( scope=self, id=f"job_role_{stack_name}-{stack_env}", role_name=f"job_role_{stack_name}-{stack_env}", assumed_by=aws_iam.ServicePrincipal("ecs-tasks.amazonaws.com") ) job_role.add_managed_policy( aws_iam.ManagedPolicy.from_managed_policy_arn( scope=self, id=f"AmazonECSTaskExecutionRolePolicy_{stack_name}-{stack_env}", managed_policy_arn="arn:aws:iam::aws:policy/service-role/AmazonECSTaskExecutionRolePolicy" ) ) job_role.add_managed_policy( aws_iam.ManagedPolicy.from_managed_policy_arn( scope=self, id=f"AmazonS3FullAccess_{stack_name}-{stack_env}", managed_policy_arn="arn:aws:iam::aws:policy/AmazonS3FullAccess" ) ) job_role.add_managed_policy( aws_iam.ManagedPolicy.from_managed_policy_arn( scope=self, id=f"CloudWatchLogsFullAccess_{stack_name}-{stack_env}", managed_policy_arn="arn:aws:iam::aws:policy/CloudWatchLogsFullAccess" ) ) batch_job_queue = aws_batch.JobQueue( scope=self, id=f"job_queue_for_{stack_name}-{stack_env}", job_queue_name=f"job_queue_for_{stack_name}-{stack_env}", compute_environments=[ aws_batch.JobQueueComputeEnvironment( compute_environment=batch_compute_environment, order=1 ) ], priority=1 ) # ECRリポジトリの取得 ecr_repository = aws_ecr.Repository.from_repository_arn( scope=self, id=f"image_for_{stack_name}-{stack_env}", repository_arn=self.ECR_REPOSITORY_ARN ) # ECRからイメージの取得 container_image = aws_ecs.ContainerImage.from_ecr_repository( repository=ecr_repository ) # ジョブ定義 # ここで、Python scriptで利用する`S3_BUCKET`を環境変数として渡す batch_job_definition = aws_batch.JobDefinition( scope=self, id=f"job_definition_for_{stack_env}", job_definition_name=f"job_definition_for_{stack_env}", container=aws_batch.JobDefinitionContainer( image=container_image, environment={ "S3_BUCKET": f"{YOUR_S3_BUCKET}" }, job_role=job_role, vcpus=1, memory_limit_mib=1024 ) )2.4.5 app.pyの実装(StepFunctions + CloudWatch Eventsの作成)
ここからは、必ずしもBatchの環境構築に必要ではありませんが、
定期実行をするためにStepFunctionsとCloudWatch Eventを利用して行います。CloudWatch Eventからも直接Batchを呼べますが、
他サービスとの連携のしやすさやパラメータの受け渡しなどを考えて間にStepFunctionsを挟んでいます。StepFunctionsのステップとして登録する際に、
DockerのCMDコマンドを(=Batchのジョブ定義に設定した状態)上書きして、
CloudWatch Eventからの引数timeを受け取り、Python scriptへ渡しています。app.py# Batchの続き... # ============= # # StepFunctions # # ============= # command_overrides = [ "python", "__init__.py", "--time", "Ref::time" ] batch_task = aws_sfn_tasks.BatchSubmitJob( scope=self, id=f"batch_job_{stack_env}", job_definition=batch_job_definition, job_name=f"batch_job_{stack_env}_today", job_queue=batch_job_queue, container_overrides=aws_sfn_tasks.BatchContainerOverrides( command=command_overrides ), payload=aws_sfn.TaskInput.from_object( { "time.$": "$.time" } ) ) # 今回は1ステップしかないので、単純ですが複数のステップをつなげたい場合は # batch_task.next(aws_sfn_tasks.JOB).next(aws_sfn_tasks.JOB) # のようにチェインメソッドで渡せます。 definition = batch_task sfn_daily_process = aws_sfn.StateMachine( scope=self, id=f"YourProjectSFn-{stack_env}", definition=definition ) # ================ # # CloudWatch Event # # ================ # # Run every day at 21:30 JST # See https://docs.aws.amazon.com/lambda/latest/dg/tutorial-scheduled-events-schedule-expressions.html events_daily_process = aws_events.Rule( scope=self, id=f"DailySFnProcess-{stack_env}", schedule=aws_events.Schedule.cron( minute=31, hour=12, month='*', day="*", year='*'), ) events_daily_process.add_target(aws_events_targets.SfnStateMachine(sfn_daily_process)) # ここまで def __init__(...):2.4.6 app.pyの実装(main関数の実装)
最後に、CDKを実行する処理を書いたら、完了です。
app.py# ここに def __init__(...): def main(): app = core.App() BatchEnvironment(app, "your-project", "feature") BatchEnvironment(app, "your-project", "dev") BatchEnvironment(app, "your-project", "prod") app.synth() if __name__ == "__main__": main()2.5 デプロイ
上記のスクリプトが完成後に、以下のコマンドで正しくCDKの設定ができているか確認の上、デプロイしましょう。
Batchの環境を0から作成する場合でも10分程度で完了します。# 定義の確認 $ cdk synth Successfully synthesized to {path_your_project}/cdk.out Supply a stack id (your-project-dev, your-project-feature, your-project-prod) to display its template. # デプロイできる環境の確認 $ cdk ls your-project-dev your-project-feature your-project-prod $ cdk deploy your-project-feature ...deploying...2.5.1 環境が正しく作られたか確認する
デプロイが完了したら、コンソールから作成したStepFunctionsを選択し、「実行の開始」ボタンを押します。
timeの引数だけ入れてあげて、{ "time": "2020-09-27T12:31:00Z" }
正しく動いたら完了です。
また、CloudWatch Logsへも想定した通りに動いているか確認しましょう。3. おわりに
CDKは、環境の構築と削除がコマンドですぐにできるのでめっちゃ好きです!
あと、コンソールから作成するよりも、プログラムのパラメータで求められているものがわかるので、
知らないサービスでも、どんなパラメータが必須かがわかりやすくて良いなと思いました!(いつか、GitHubのリポジトリにて上記のソースをまとめたものを展開します・・・!)