- 投稿日:2020-09-28T23:26:36+09:00
再帰で階乗に挑戦してみる
こんばんは。
初心者なりに挑んでみたので
皆様の参考になれば幸いです。例えばですが、3!(=3 * 2 * 1) を実現するにはどうすれば良いでしょうか。
print(3*2*1)出来ました(笑)!
じゃあ、def を使って、こんな風に書いてみたらどうでしょうか。test.pydef test(n:int=3): if n>1: return n * test(n-1) else: return 1 print(test())取り急ぎ初期値 3 でやってみました。
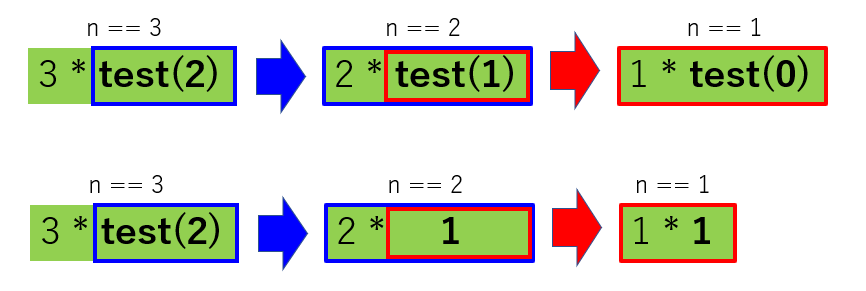
取りあえず、一個一個代入してみてみましょう。
まずは n == 3 の時です。test.py# n == 3 のとき def test(n:int=3): #n == 3 なので、if の中に入ります if n>1: #return 3 * test(3-1) return n * test(n-1) else: return 1 print(test())やった。return が来たから抜けられる!! っと思いきや、
3 * test(2) !?
test(2) が分からないと終われないですね。
仕方ありません。
良くわからないですが、n == 2、つまり test(2) を考えてみましょう。test.py# n == 2 のとき def test(n:int=2): #n == 2 なので、if の中に入ります if n>1: #return 2 * test(2-1) return n * test(n-1) else: return 1 print(test())ん!? return 2 * test(1) !?
またもや test() が現れましたが、今度は test(1) です。
仕方ない、test(1) もやってみましょう。test.py# n == 1 のとき def test(n:int=1): if n>1: return n * test(n-1) #n == 1 なので、else の中に入ります else: # 1 を返します return 1 print(test())取りあえず、n==1 の時は return 1 なので、
答えが 1 であることがわかりました。
よかった、やっと整数に会えた(笑)一旦整理しましょう。
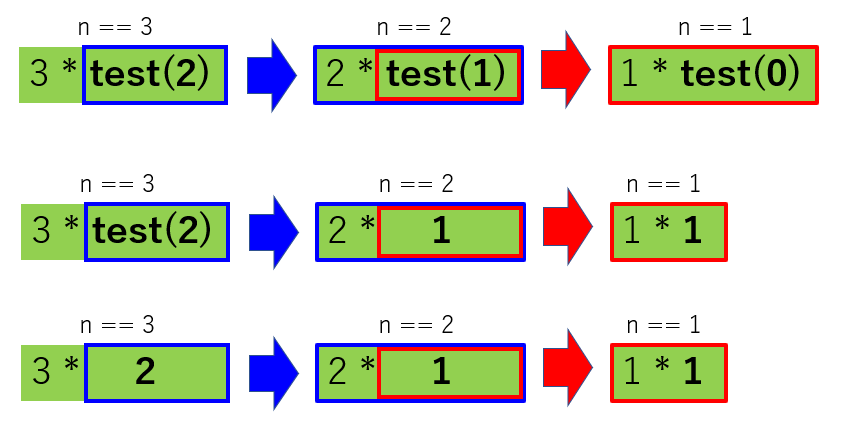
図にあるように n==3 を実行したら、n==2 が現れて、更に n==1 が現れました。
イメージとしては test(2) の中に 2 * test(1) が埋め込まれていて、
test(1) の中に 1 * test(0) が埋め込まれているようです。今分かっているのは、1 * test(0) が 1 * 1 、
つまり 1 であることだけです。よし、3 * test(2) は一旦、無視し、
下図中央の 2 * test(1) の test(1) に 1 * test(0) を代入してみましょう。
2 * test(1) == 2 * {1 * test(0)} なので、2 * 1 = 2 であることが分かります。
ってことは。。。
3 * test(2) == 3 * {2 * test(1)} == 3 * {2 * 1} になりましたね。
これで何とか 3! を表現することが出来ました。以上のように、ある事象に、自身を含んでいた場合、
再帰的であるというそうです。この考え方を使うと 3! だけでなく、n の階乗も勿論、表現できます。
シンプルな記述ですが、ちゃんと考えると複雑だったりして
中々、面白かったです、お疲れ様でした(≧▽≦)。
その他の記事 スタックをPythonで書いてみた 1つの配列に 2 つのスタックを Python で実装してみる Python で作ったスタックに最小値(min) を返す機能を追加するが push/pop/min は基本 O(1) !!

- 投稿日:2020-09-28T22:56:24+09:00
【メモ】BeautifulSoup4の使い方(1) htmlを表示
jupyternotebook上でBeautifulSoupを用いてスクレイピングする。
In[1]BeautifulSoupをimportする
In[1]from bs4 import BeautifulSoupIn[2]スクレイピングしたい記事のhtmlを変数kijiに格納する
In[2]kiji = """<html> <head> <title>Qiitaに投稿してみた</title> </head> <body> <p class="title"> <b>アウトプットのためQiitaに挑戦。</b> </p> <p class="article"> <b>頑張って記事を書きます。</b> </p> </body> </html>"""格納したいhtmlは"""と"""の間に書く。
In[3]先ほど変数kijiに格納したhtmlをBeautifulSoupに読み込ませる。
In[3]soup = BeautifulSoup(kiji,"html.parser")BeautifulSoup(格納したhtmlの入っている変数,"使いたいパーサー(解析器)")と書く。今回は(kiji,"html.parser")である。パーサーは""で囲むことやhtmlparserというように.を書き忘れないことに気を付ける。
In[4]soupをprettifyと一緒に使うことで見やすく表示させる。
In[4]print(soup.prettify())prettify()を使うことで階層化されて見やすくなる。
In[4]出力結果
In[4]<html> <head> <title> Qiitaに投稿してみた </title> </head> <body> <p class="title"> <b> アウトプットのためQiitaに挑戦。 </b> </p> <p class="article"> <b> 頑張って記事を書きます。 </b> </p> </body> </html>In[5]タイトルを表示させる
In[5]print(soup.html.head.title)In[5]出力結果<title>Qiitaに投稿してみた</title>
- 投稿日:2020-09-28T22:19:30+09:00
将棋AIで学ぶディープラーニング on Mac and Google Colab 3
第7章 方策ネットワーク
7.1~7.4
policy.py
python-dlshogi\pydlshogi\network\policy.py#!/usr/bin/env python3 # -*- coding: utf-8 -*- from chainer import Chain import chainer.functions as F import chainer.links as L from pydlshogi.common import * ch = 192 class PolicyNetwork(Chain): # 入力104ch # 入力は9x9の局面図が104個。 # フィルター数194。 # 入力chそれぞれに対してフィルターをかけた9x9の値を入力ch分加算して1chとして出力、 # それをフィルター数194個行うので出力ch数が194chになる。 def __init__(self): super(PolicyNetwork, self).__init__() with self.init_scope(): self.l1 = L.Convolution2D(in_channels = 104, out_channels = ch, ksize = 3, pad = 1) self.l2 = L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1) self.l3 = L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1) self.l4 = L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1) self.l5 = L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1) self.l6 = L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1) self.l7 = L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1) self.l8 = L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1) self.l9 = L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1) self.l10 = L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1) self.l11 = L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1) self.l12 = L.Convolution2D(in_channels = ch, out_channels = ch, ksize = 3, pad = 1) self.l13 = L.Convolution2D(in_channels = ch, out_channels = MOVE_DIRECTION_LABEL_NUM, ksize = 1, nobias = True) # フィルターサイズ1x1(ksize=1)の意味 # 入力:1~192chそれぞれのchのとある1画素、出力:1つの画素値 # これを全画素について実施して1画面の画像を得る。 # それをパラメータを変えて出力ch回数分実施する。 # 出力ch数分の出力画像を得る。 self.l13_bias = L.Bias(shape=(9*9*MOVE_DIRECTION_LABEL_NUM)) # MOVE_DIRECTION_LABEL_NUM=27。移動方向20個と持ち駒7個を示す。 def __call__(self, x): h1 = F.relu(self.l1(x)) h2 = F.relu(self.l2(h1)) h3 = F.relu(self.l3(h2)) h4 = F.relu(self.l4(h3)) h5 = F.relu(self.l5(h4)) h6 = F.relu(self.l6(h5)) h7 = F.relu(self.l7(h6)) h8 = F.relu(self.l8(h7)) h9 = F.relu(self.l9(h8)) h10 = F.relu(self.l10(h9)) h11 = F.relu(self.l11(h10)) h12 = F.relu(self.l12(h11)) h13 = self.l13(h12) return self.l13_bias(F.reshape(h13,(-1, 9*9*MOVE_DIRECTION_LABEL_NUM))) # 出力にソフトマックス関数を記述していない理由は、 # 学習するときにF.softmax_cross_entropy関数を使うため。 # この関数はソフトマックス関数と交差エントロピー誤差の計算を同時に行う。common.py
python-dlshogi\pydlshogi\common.py#!/usr/bin/env python3 # -*- coding: utf-8 -*- import shogi # 移動の定数 # UP=0、UP_LEFT=1、、、、UP_RIGHT_PROMOTE=19と定義している。 # 使うときは、例えば〇〇 = UPとすると〇〇という変数に0が代入される。 MOVE_DIRECTION = [ UP, UP_LEFT, UP_RIGHT, LEFT, RIGHT, DOWN, DOWN_LEFT, DOWN_RIGHT, UP2_LEFT, UP2_RIGHT, UP_PROMOTE, UP_LEFT_PROMOTE, UP_RIGHT_PROMOTE, LEFT_PROMOTE, RIGHT_PROMOTE, DOWN_PROMOTE, DOWN_LEFT_PROMOTE, DOWN_RIGHT_PROMOTE, UP2_LEFT_PROMOTE, UP2_RIGHT_PROMOTE ] = range(20) # 成り変換テーブル # **_PROMOTEという名前の変数はMOVE_DIRECTIONで定義済み。 # UP_PROMOTE=10,・・・,UP_RIGHT_PROMOTE=19と定義されている。 MOVE_DIRECTION_PROMOTED = [ UP_PROMOTE, UP_LEFT_PROMOTE, UP_RIGHT_PROMOTE, LEFT_PROMOTE, RIGHT_PROMOTE, DOWN_PROMOTE, DOWN_LEFT_PROMOTE, DOWN_RIGHT_PROMOTE, UP2_LEFT_PROMOTE, UP2_RIGHT_PROMOTE ] # 指し手を表すラベルの数 MOVE_DIRECTION_LABEL_NUM = len(MOVE_DIRECTION) + 7 # 7は持ち駒の種類 # rotate 180degree # shogi.I1は80、・・・、shogi.A9は0。つまりSQUARES_R180 = [80, 79, ・・・, 1, 0] SQUARES_R180 = [ shogi.I1, shogi.I2, shogi.I3, shogi.I4, shogi.I5, shogi.I6, shogi.I7, shogi.I8, shogi.I9, shogi.H1, shogi.H2, shogi.H3, shogi.H4, shogi.H5, shogi.H6, shogi.H7, shogi.H8, shogi.H9, shogi.G1, shogi.G2, shogi.G3, shogi.G4, shogi.G5, shogi.G6, shogi.G7, shogi.G8, shogi.G9, shogi.F1, shogi.F2, shogi.F3, shogi.F4, shogi.F5, shogi.F6, shogi.F7, shogi.F8, shogi.F9, shogi.E1, shogi.E2, shogi.E3, shogi.E4, shogi.E5, shogi.E6, shogi.E7, shogi.E8, shogi.E9, shogi.D1, shogi.D2, shogi.D3, shogi.D4, shogi.D5, shogi.D6, shogi.D7, shogi.D8, shogi.D9, shogi.C1, shogi.C2, shogi.C3, shogi.C4, shogi.C5, shogi.C6, shogi.C7, shogi.C8, shogi.C9, shogi.B1, shogi.B2, shogi.B3, shogi.B4, shogi.B5, shogi.B6, shogi.B7, shogi.B8, shogi.B9, shogi.A1, shogi.A2, shogi.A3, shogi.A4, shogi.A5, shogi.A6, shogi.A7, shogi.A8, shogi.A9, ] def bb_rotate_180(bb): # bbに入るのはpiece_bbの1要素やoccupiedの1要素。つまり81桁の2進数。 bb_r180 = 0 for pos in shogi.SQUARES: #SQUARESはrange(0, 81)のこと if bb & shogi.BB_SQUARES[pos] > 0: # BB_SQUARESは[0b1, 0b10, 0b100, ・・・, 0b1・・・0]。要素81個。 # &はビット演算子のAND。 bb_r180 += 1 << SQUARES_R180[pos] # a<<bはaのビットを左側にb桁シフトする演算子。 return bb_r180features.py
python-dlshogi\pydlshogi\features.py#!/usr/bin/env python3 # -*- coding: utf-8 -*- import numpy as np import shogi import copy from pydlshogi.common import * def make_input_features(piece_bb, occupied, pieces_in_hand): features = [] for color in shogi.COLORS: # board pieces for piece_type in shogi.PIECE_TYPES_WITH_NONE[1:]: #PIECE_TYPES_WITH_NONEはrange(0, 16)のこと bb = piece_bb[piece_type] & occupied[color] #手番の側の駒の位置を駒ごとに取得(&はビット演算子) feature = np.zeros(9*9) for pos in shogi.SQUARES: #SQUARESはrange(0, 81)のこと if bb & shogi.BB_SQUARES[pos] > 0: #BB_SQUARESは[0b1, 0b10, 0b100, ・・・, 0b1・・・0]。要素81個。 feature[pos] = 1 #bit boardの各bitを要素に分解。例えば1010・・・だったら[1,0,1,0,・・・]に分解。 features.append(feature.reshape((9, 9))) #bit boardの各bitを要素に分解したものを9x9の行列にして返す。 # pieces in hand for piece_type in range(1, 8): for n in range(shogi.MAX_PIECES_IN_HAND[piece_type]): #shogi.MAX_PIECES_IN_HANDは持ち駒の数 #shogi.MAX_PIECES_IN_HAND[1] = 18 :歩 #shogi.MAX_PIECES_IN_HAND[2] = 4 :香車 #shogi.MAX_PIECES_IN_HAND[3] = 4 :桂馬 #shogi.MAX_PIECES_IN_HAND[4] = 4 :銀 #shogi.MAX_PIECES_IN_HAND[5] = 4 :金 #shogi.MAX_PIECES_IN_HAND[6] = 2 :角 #shogi.MAX_PIECES_IN_HAND[7] = 2 :飛車 if piece_type in pieces_in_hand[color] and n < pieces_in_hand[color][piece_type]: feature = np.ones(9*9) else: feature = np.zeros(9*9) features.append(feature.reshape((9, 9))) return features def make_input_features_from_board(board): # boardを引数としてmake_input_featuresを行う。 if board.turn == shogi.BLACK: piece_bb = board.piece_bb occupied = (board.occupied[shogi.BLACK], board.occupied[shogi.WHITE]) pieces_in_hand = (board.pieces_in_hand[shogi.BLACK], board.pieces_in_hand[shogi.WHITE]) else: piece_bb = [bb_rotate_180(bb) for bb in board.piece_bb] occupied = (bb_rotate_180(board.occupied[shogi.WHITE]), bb_rotate_180(board.occupied[shogi.BLACK])) pieces_in_hand = (board.pieces_in_hand[shogi.WHITE], board.pieces_in_hand[shogi.BLACK]) return make_input_features(piece_bb, occupied, pieces_in_hand) def make_output_label(move, color): move_to = move.to_square move_from = move.from_square # ■ Moveクラス # from_squareメソッド :盤面を0~80の数値で表したときの移動元の値を返す。 # 9で割ったときの商がy座標、余りがx座標となる。xy座標は0オリジン。 # to_squareメソッド :同上(移動先)。 # # x座標 # 0 1 2 3 4 5 6 7 8 # # 0 1 2 3 4 5 6 7 8 0 y座標 # 9 10 11 12 13 14 15 16 17 1 # 18 19 20 21 22 23 24 25 26 2 # 27 28 29 30 31 32 33 34 35 3 # 36 37 38 39 40 41 42 43 44 4 # 45 46 47 48 49 50 51 52 53 5 # 54 55 56 57 58 59 60 61 62 6 # 63 64 65 66 67 68 69 70 71 7 # 72 73 74 75 76 77 78 79 80 8 # 白の場合盤を回転 if color == shogi.WHITE: move_to = SQUARES_R180[move_to] if move_from is not None: # 持ち駒ではなく盤上の駒を動かした場合 move_from = SQUARES_R180[move_from] # move direction if move_from is not None: # 持ち駒ではなく盤上の駒を動かした場合 to_y, to_x = divmod(move_to, 9) from_y, from_x = divmod(move_from, 9) dir_x = to_x - from_x dir_y = to_y - from_y if dir_y < 0 and dir_x == 0: move_direction = UP elif dir_y == -2 and dir_x == -1: move_direction = UP2_LEFT elif dir_y == -2 and dir_x == 1: move_direction = UP2_RIGHT elif dir_y < 0 and dir_x < 0: move_direction = UP_LEFT elif dir_y < 0 and dir_x > 0: move_direction = UP_RIGHT elif dir_y == 0 and dir_x < 0: move_direction = LEFT elif dir_y == 0 and dir_x > 0: move_direction = RIGHT elif dir_y > 0 and dir_x == 0: move_direction = DOWN elif dir_y > 0 and dir_x < 0: move_direction = DOWN_LEFT elif dir_y > 0 and dir_x > 0: move_direction = DOWN_RIGHT # promote if move.promotion: move_direction = MOVE_DIRECTION_PROMOTED[move_direction] else: # 持ち駒 # len(MOVE_DIRECTION) は20 # move.drop_piece_typeは置いた持ち駒の種類? # -1は数合わせ? move_direction = len(MOVE_DIRECTION) + move.drop_piece_type - 1 move_label = 9 * 9 * move_direction + move_to # 81進数のイメージ。move_directionが81の桁、move_toが1の桁。 # 81の桁・・・27個 # 1の桁・・・9x9個 return move_label def make_features(position): piece_bb, occupied, pieces_in_hand, move, win = position features = make_input_features(piece_bb, occupied, pieces_in_hand) # 先手の駒が有る場所、先手の持ち駒、後手の駒が有る場所、後手の持ち駒 # [(9x9), (9x9x38x7), (9x9), (9x9x38x7)] return(features, move, win)次\
pickle
chmod 755 policy_player.shshc -f /Users/・・・・/python-dlshogi/bat/policy_player.sh
policy_player.sh.x
sh.xを削除
execファイルができる
- 投稿日:2020-09-28T21:42:31+09:00
将棋AIで学ぶディープラーニング on Mac and Google Colab 1

- 投稿日:2020-09-28T21:34:39+09:00
Qiita Job 求人を分析してみた件
目次
- 背景
- データ取得
- データを見てみた
- 所感と今後の予定
背景
転職活動をしている中、「転職お祝い金30万円プレゼントキャンペーン」という言葉に引っかかり、Qiita Jobsに登録しましたが、いざ使ってみたら、機能が少し足りないと思いました。
勤務地の絞り込みできなかったり、ページ数を分からなかったりなどがありました。
幸いのことで、求人の一覧のところで必要が情報が大体揃えているし、全ページ数が20ほどしかないし(手作業で取得)、Pythonで取得することにしました。
データの取得
大体の流れはこうです。
- Pythonで求人一覧のURLで内容をHTMLとして取得します
- 取得したHTMLで、beautiful soupを作り、タグなどを解析して必要な部分を切り取ります。
- 切り取った部分をJSONにして、Firebase cloud firestore に格納。
- 一方で、引継ぎの解析のためにローカルでcsvファイルとして保存。
合わせて294件の求人を取得しました。(これはおそらく全部?)
データを見てみた
利用したツールは、Pandas、Tableauです。
1点だけ先に言いたいのは、これからの内容はあくまでもQiita jobsの求人内容に基づき作成したものなので、IT業界全体の求人の反映は到底至りませんが、ご参考まで。
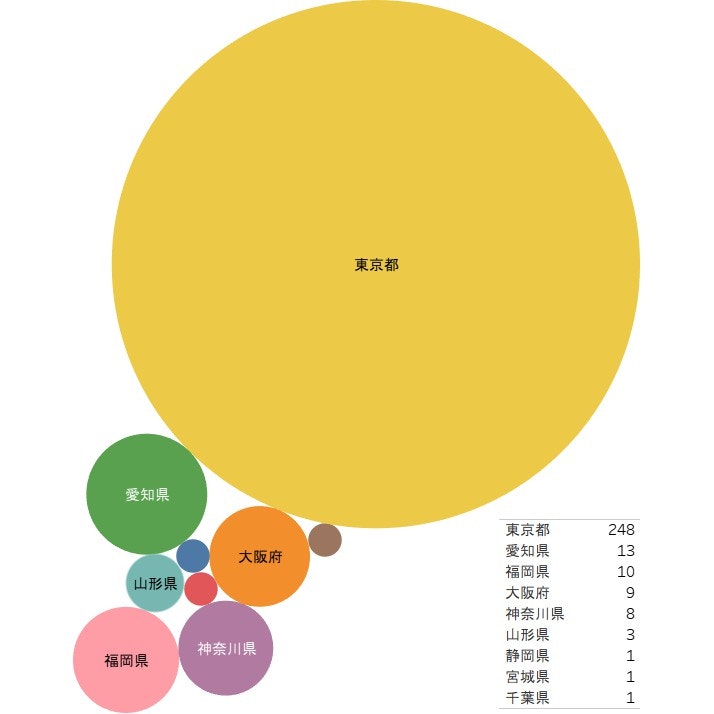
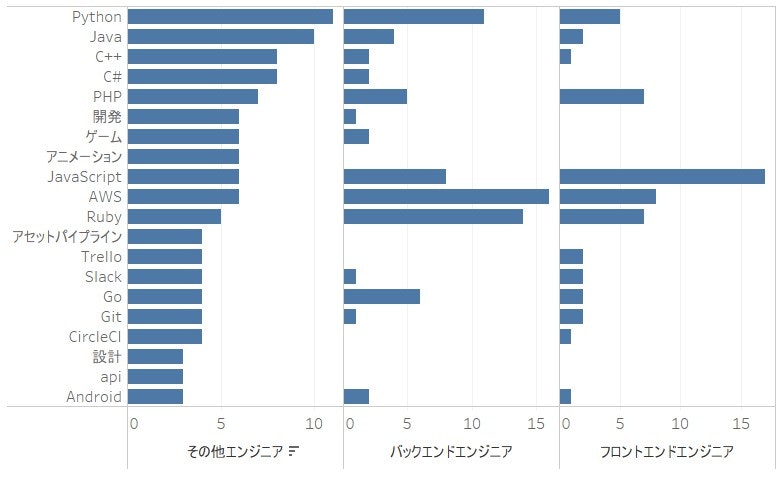
まず一番気になったのは、勤務地別の求人数です。
なるほど、東京都の求人数が圧勝したね。それで勤務地の絞り込みが必要ないわけかな?けど、U・Iターンやの地方求職する者たちには少し不便のような感じはあります。
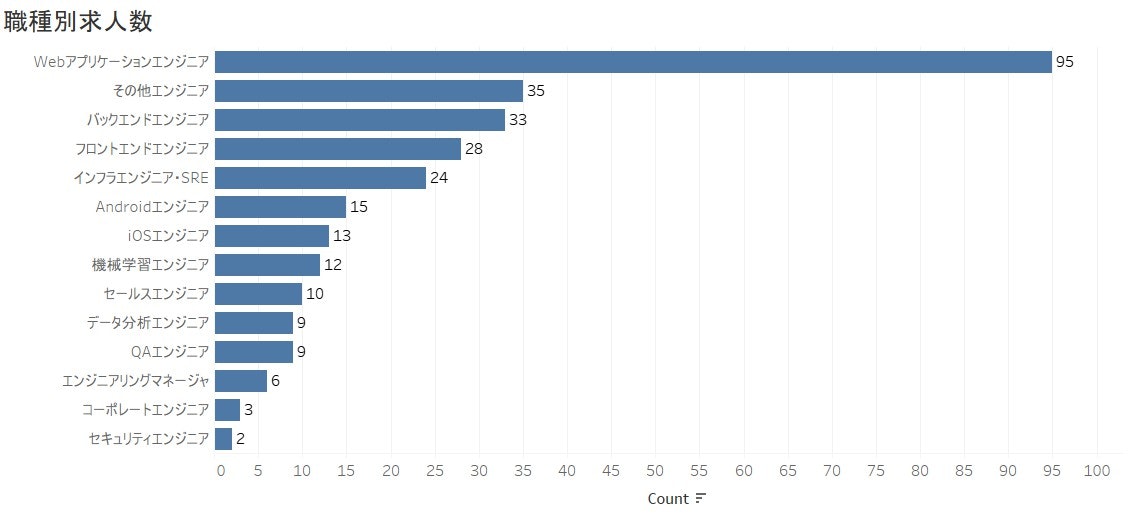
次に、職種別の求人を見てみましょう。
TOP5には、Webアプリケーション、その他エンジニア、バックエンド、フロントエンド、インフラエンジニアでありました。Web系の仕事量がスマホ開発の仕事より人の需要が多く感じられます。
また、その他エンジニアとは何を求められているのかを見るために、その他エンジニア向けの求人にあるタッグと求人数の近いバックエンドエンジニアとフロントエンドエンジニアと比べてみました。
その結果、その他エンジニアにとって、JAVA、C++、C#、ゲーム、アニメーションなど技術タグ量が多いで、おそらく組み込み系、ゲーム開発などでしょうね。
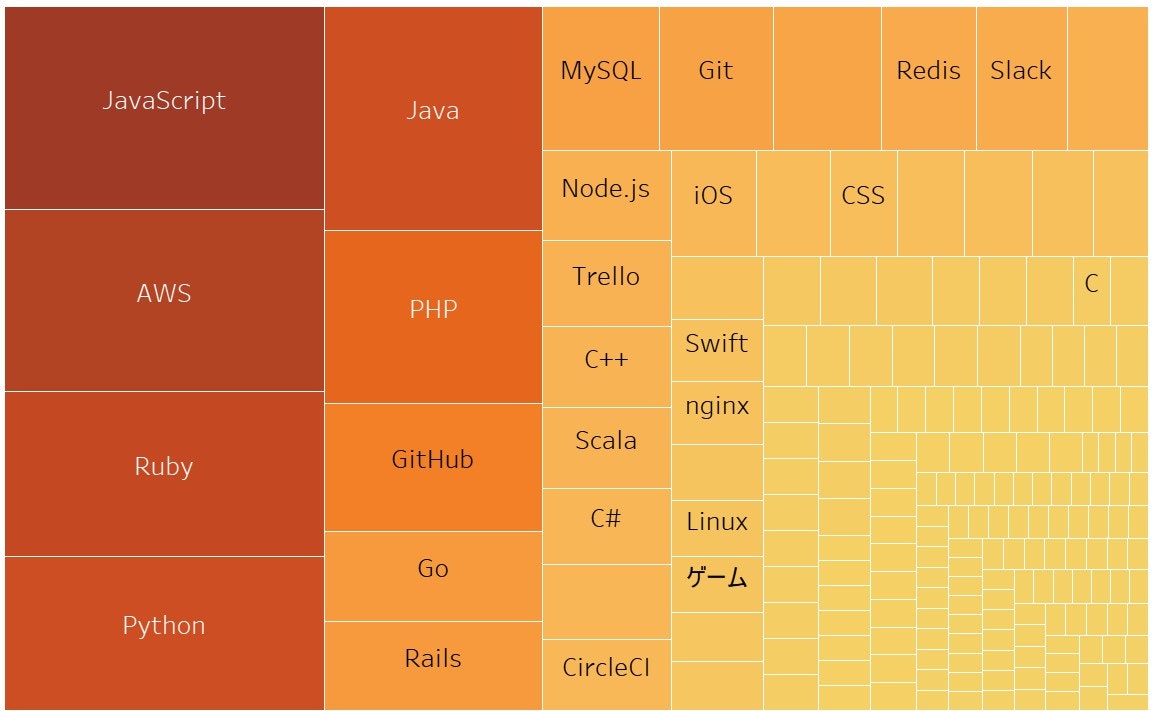
ついでに、全求人の利用技術をまとめたところ、以下のようなヒットマップが得られます。
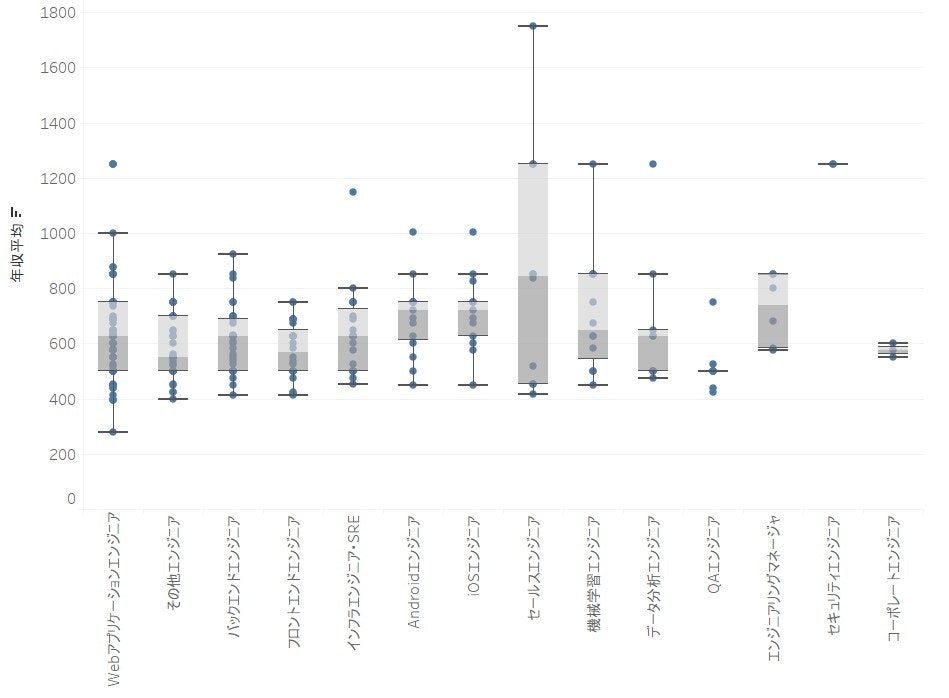
最後に、職種別の年収平均を確認していきますが、ここで注意したいのは、「年収平均」というのは単に年収上限と年収下限を平均で取ったものとします。
こちらの図で見ると、Webアプリケーションエンジニアの給料の範囲が大きいのが分かります。
また、フロントエンドとバックエンドと比べるとバックエンドエンジニアの方が年収平均が高いことが分かります。
所感と今後の予定
今回は初めてTableauを使用したことで、まだまだ可視化の図の作成に慣れないところが多いかもしれませんが、また機会がありましたら使いたいと思います。
Qiita Jobsから取得したデータでできることはまだまだあると確信しています。今日のところはデータの中身を探っただけだが、将来は
- AWS サービスを使用し、指定した職種に新しい求人が来ているかを見てくれるものを作ってみたいです。
- 今回は一覧で得られる情報しか使っていませんが、それぞれお求人詳細には必須スキルや、労働条件など、更なる情報がたくさんあるので、機械学習にも使えると思います。
また、今回の図面は以下のURLにて確認できます。
Tableau Public最後までご覧いただきありがとうございました。
- 投稿日:2020-09-28T21:28:39+09:00
【超初歩】AnacondaのGDALインストール
GDALとは?
Metashape(旧Photoscan)で作成したモザイク画像(Geotiff画像)を読み込んで、Pythonで画像処理したいと思ったので、
GDALというラスターとベクターをいじれるライブラリのインストールに挑戦しました。
インストールに一日かかってしまったので、備忘録も兼ねて書き残しておきます。参考:https://gdal.org/
「GDAL documentation」インストールエラーが発生
「GDAL Python インストール」などで調べると、anaconda promptで以下のコマンドを打つことでインストールできるようです。
参考:https://anaconda.org/conda-forge/gdal
「conda-forge/packages/gdal」conda install -c conda-forge gdalしかし、このコマンドを実行すると、Solving Environment...で止まってしまうエラーが発生します。
参考:https://teratail.com/questions/262267
「AnacondaでGdalをインストールしたい」エラー解決方法
まず、以下のサイトを参考にしてGDALのバージョンが違うのではないか?と思いました。
参考:https://sites.google.com/view/takagilab/manual/program-%E7%92%B0%E5%A2%83%E3%81%AE%E6%A7%8B%E7%AF%89
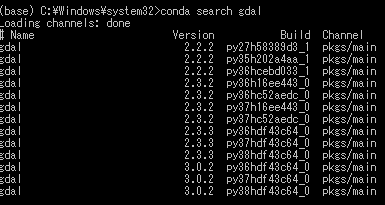
「国土情報処理工学研究室 Program 環境の構築」バージョンの確認は以下のコマンドで可能です。
conda search gdal
バージョン検索の結果、conda install conda-forge gdalだとver3.1.2になってしまう一方で、ver3.0.2が最新?適切?になることが分かりました。
バージョンを指定して以下のようにコマンドを実行します。
conda install gdal==3.0.2これを実行すると先ほどのSolving Environmentエラーは解消された一方で、今度はConflictエラーが生じてしまいました。
参考:https://teratail.com/questions/262267
「AnacondaでGdalをインストールしたい」このConflictエラーは見た感じ、永遠に続きそうなので一旦インストールは終了して、ライブラリのバージョンをアップデートすることにしました。
conda update --allこれでconda内の全てのライブラリを最新バージョンにアップデートすることができました。
最後にもう一度バージョン指定したGDALをインストールします。conda install gdal==3.0.2インストール成功!なぜ、ライブラリをアップデートするとGDALもインストールできるのか不明ですが、良しとしましょう。
動作確認
しっかりimportされました!根本的な解決にはなっていないかもですが、一件落着ですね~
このライブラリを使って、以下の記事を参考にしながらGeotiffの読み込み+画像処理をしていきます。https://qiita.com/HidKamiya/items/d5e69fda61703abe1a58
「PythonによるGeoTiff画像の読み込みと書き出し」参考になったら、LGTMしてください!

- 投稿日:2020-09-28T21:28:39+09:00
【超初歩】AnacondaにGDALをインストールしてみた
GDALとは?
Metashape(旧Photoscan)で作成したモザイク画像(Geotiff画像)を読み込んで、Pythonで画像処理したいと思ったので、
GDALというラスターとベクターをいじれるライブラリのインストールに挑戦しました。
インストールに苦労して今日一日かかってしまったので、備忘録も兼ねて書き残しておきます。参考:https://gdal.org/
「GDAL documentation」インストールエラーが発生
「GDAL Python インストール」などで調べると、anaconda promptで以下のコマンドを打つことでインストールできるようです。
参考:https://anaconda.org/conda-forge/gdal
「conda-forge/packages/gdal」conda install -c conda-forge gdalしかし、このコマンドを実行すると、Solving Environment...で止まってしまうエラーが発生します。
参考:https://teratail.com/questions/262267
「AnacondaでGdalをインストールしたい」エラー解決方法
まず、以下のサイトを参考にしてGDALのバージョンが違うのではないか?と思いました。
参考:https://sites.google.com/view/takagilab/manual/program-%E7%92%B0%E5%A2%83%E3%81%AE%E6%A7%8B%E7%AF%89
「国土情報処理工学研究室 Program 環境の構築」バージョンの確認は以下のコマンドで可能です。
conda search gdal
バージョン検索の結果、conda install conda-forge gdalだとver3.1.2になってしまう一方で、ver3.0.2が最新?適切?になることが分かりました。
バージョンを指定して以下のようにコマンドを実行します。
conda install gdal==3.0.2これを実行すると先ほどのSolving Environmentエラーは解消された一方で、今度はConflictエラーが生じてしまいました。
参考:https://teratail.com/questions/262267
「AnacondaでGdalをインストールしたい」このConflictエラーは見た感じ、永遠に続きそうなので一旦インストールは終了して、ライブラリのバージョンをアップデートすることにしました。
conda update --allこれでconda内の全てのライブラリを最新バージョンにアップデートすることができました。
最後にもう一度バージョン指定したGDALをインストールします。conda install gdal==3.0.2インストール成功!なぜ、ライブラリをアップデートするとGDALもインストールできるのか不明ですが、良しとしましょう。
動作確認
しっかりimportされました!根本的な解決にはなっていないかもですが、一件落着ですね~
このライブラリを使って、以下の記事を参考にしながらGeotiffの読み込み+画像処理をしていきます。https://qiita.com/HidKamiya/items/d5e69fda61703abe1a58
「PythonによるGeoTiff画像の読み込みと書き出し」参考になったら、LGTMしてください!
- 投稿日:2020-09-28T20:47:21+09:00
Djangoを使ったWEBアプリケーションの開発【モデル定義編】
モデルの定義
現在作成しているpostsという機能は、ブログなどの記事を入力するための機能をイメージしているため、タイトル・記事・日時・画像を格納するデータベースが必要になります。
これをmodels.pyに追記していきます。models.pyfrom django.db import models #Postというクラスとして定義していきます。 class Post(models.Model): #タイトルについての定義、文字列型のためCharFieldを使用 #max_lengthで文字数制限をすることが可能 title = models.CharField(max_length=100) #日時についての定義、日付データのためDateTimeFieldを使用 published = models.DateTimeField() #画像データについての定義、画像データのためImageFieldを使用 #引数として画像データの保存先を指定できる(今回は、mediaフォルダを指定) image = models.ImageField(upload_to='media/') #文章についての定義、テキスト型のためTextFieldを使用 #長い文章のときに使用 body = models.TextField()次に、models.pyを基にデータベースのテーブルを作成するコマンドを実行する。
$ python3.6 manage.py makemigrations Migrations for 'posts': posts/migrations/0001_initial.py - Create model Post新しい定義ファイルが有った場合、データベースに投入するためのファイルを作成してくれる。
続いて新しくできたファイルを読み込みテーブルを作成する。
$ python3.6 manage.py migrate Operations to perform: Apply all migrations: admin, auth, contenttypes, posts, sessions Running migrations: Applying posts.0001_initial... OKデータベースにアクセスしてテーブルが存在するかを確認する。
$ sqlite3 db.sqlite3 SQLite version 3.31.1 2020-01-27 19:55:54 Enter ".help" for usage hints. sqlite> .tables auth_group django_admin_log auth_group_permissions django_content_type auth_permission django_migrations auth_user django_session auth_user_groups posts_post #新しく作成されたテーブル auth_user_user_permissions「posts_post」というテーブルが作成されたことがわかる。
- 投稿日:2020-09-28T19:47:56+09:00
Pythonに疲れたのでnehanでデータ分析してみた(コロナ関連、あのワードは今?)
ご挨拶
こんにちは、マンボウです。
昨今盛り上がっているPythonによるデータ分析ですが、使いこなすのは大変です。
ついついPythonと格闘することが目的になり、本来達成したいビジネス改善はいずこへ。。。
そういった悩みを解決するためのGUIツール「nehan」を使って、データを分析する例をご紹介したいと思います。Twitterのデータから、特定単語の出現数を振り返る
コロナウイルスが社会問題になってから半年以上が経過しました。
ここ約2ヶ月のtweetデータから、あの単語の出現数を追ってみます。データ
nehanはTwitterのデータをダイレクトに取り込むことができ、今回はその機能を使いました。
ご紹介はまた後日。
2020/7/27から毎日「コロナ」をtweet本文に含む3,000tweetを蓄積し、約2ヶ月分のデータを準備。
データの詳細はこちらから
前処理
1.使用するText,Created_Atだけ、列選択
port_2 = port_1[['Created_At', 'Text']]
2.Created_Atを日付型に変更
※一部のCreated_Atがおかしなデータになっておりエラーを吐くので、無視
※時:分:秒まで入っているので、年-月-日のみを取得port_3 = port_2.copy() port_3['Created_At'] = pd.to_datetime( port_3['Created_At'], errors='coerce', foramt=None) port_3['Created_At'] = port_3['Created_At'].map(lambda x: x.date())
3.日付型に変更不能なCreated_Atが欠損値になっているので、行ごと削除
port_4 = port_3.copy() port_4 = port_4.dropna(subset=None, how='any')
日別の単語数を集計
4.特定単語を含むtweetにフィルタ
port_5 = port_4[(port_4['Text'].str.contains('クラスター', na=False, regex=False))]
5.日毎に集計
port_9 = port_5.copy() port_9 = port_9.groupby(['Created_At']).agg( {'Created_At': ['size']}).reset_index() port_9.columns = ['Created_At', '行数カウント']
可視化して考察
クラスター
爆発的感染の象徴として「クラスター」という単語は広く認知されたと言えます。
8/9にぶっ飛んでるのは、おそらく渋谷で行われたクラスターフェスが要因でしょう。アベノマスク
もう懐かしい感じになったこの単語も、見てみました。自粛
新しい生活様式が定着しつつあありますが、自粛ムードが完全に終わった訳ではなさそうです。
徐々に減少しているようには見えます。まとめ
厳密な結果を得るためには、本当はもっと前処理をしないといけないのですが、ざっくりとした観察、およびnehanのご紹介を兼ねてシンプルにデータを処理してみました。
分析を実施したnehanの画面はこちらから見れます。
なお、上記のソースコードはnehanのpythonエクスポート機能で出力したコードをコピペしました。※分析ツールnehanのご紹介はこちらから。









- 投稿日:2020-09-28T19:07:01+09:00
Machine Learning : Supervised - Support Vector Machine
目標
サポートベクターマシンを数式で理解して、scikit-learn で試す。
微分積分、線形代数が既習であることを前提としています。
理論
サポートベクターマシンは、サポートベクトルと呼ばれる識別境界を決める少数のデータを基にしてサポートベクトルと識別境界とのマージンが最大となるように学習を行います。
サポートベクターマシンは線形識別モデルですが、カーネルトリックによる非線形識別問題への拡張性も高いため、優秀な分類モデルとして広く利用されています。
本来は 2値分類モデルですが、多クラス分類や回帰、異常検知にも使用されます。
サポートベクターマシンによる分類
サポートベクターマシンの導出
まず、2値の線形分類問題で考えます。ここで、訓練データを $x = (x_1, ..., x_n)$、目標値を $t = (t_1, ..., t_n)$ ただし、$t \in \{ -1, 1 \}$、パラメータを $w$ とすると、識別モデルの出力 $y$ の線形モデルは、
y(x) = w^T x + bのように表せます。ここではバイアス $b$ を明示的に書き表すことにします。線形分離可能であると仮定すると、$t_i = 1$ のとき $y(x_i) = 1$、$t_i = -1$ のとき $y(x_i) = -1$ となるので、すべての訓練データについて $t_n y(x_n) > 0$ が成り立ちます。
サポートベクターマシンは、下図のように識別境界 $y=w^Tx + b$ から最も近い訓練データとの距離であるマージンを最大化することを目指します。
点と平面の距離の公式より、訓練データの点と識別境界面との距離は以下の式で表せます。
\frac{|w^Tx + b|}{||w||}さらに、正しく分類できている訓練データ $t_i y(x_i) > 0$ についてのみ考えると、
\frac{t_i ( w^Tx_i + b )}{||w||}となります。マージンは識別境界から最も近い訓練データとの距離であり、そのマージンを最大化するようなパラメータ $w, b$ を求めることになるので、以下のような式が定義できます。
\newcommand{\argmax}{\mathop{\rm argmax}\limits} \argmax_{w, b} \frac{1}{||w||} \min_i \{ t_i (w^Tx_i + b) \}ここで、$t_i(w^Tx + b) = 1$ となるように $w, b$ をスケーリングするとすべての訓練データは以下の制約を満たすようになります。
t(w^Tx + b) \geq 1さらに、$||w||^{-1}$ の最大化問題を $||w||^2$ の最小化問題に置き換えると、サポートベクターマシンの解くべき式は以下のような制約付き最小化問題となり、これは主問題と呼ばれます。
\newcommand{\argmin}{\mathop{\rm argmin}\limits} \argmin_{w, b} = \frac{1}{2}||w^2|| \\ t_i(w^Tx_i + b) \geq 1サポートベクターマシンの学習
サポートベクターマシンのパラメータを求めるには制約付き最適化問題を解く必要があります。そこで、$a \geq 0$ であるラグランジュ乗数 $a = (a_1, ..., a_n)$ を導入すると、
L(w, b, a) = \frac{1}{2} ||w^2|| - \sum^n_{i=1} a_i \{ t_i(w^Tx_i + b) - 1 \}となります。この $L$ をパラメータ $w, b$ について微分して 0 として解くと、
\begin{align} \frac{\partial L}{\partial w} &= w - \sum^n_{i=1}a_i t_i x_i = 0\\ w &= \sum^n_{i=1}a_i t_i x_i \\ \frac{\partial L}{\partial b} &= \sum^n_{i=1}a_i t_i = 0 \\ 0 &= \sum^n_{i=1}a_i t_i \end{align}これらを $L(w, b, a)$ に代入して $w, b$ を消去すると、
\begin{align} L(a) &= \frac{1}{2} w^T w - \sum^n_{i=1} a_i t_i w^T x_i - b \sum^n_{i=1} a_i t_i + \sum^n_{i=1} a_i \\ &= \frac{1}{2} w^T w - w^T w + \sum^n_{i=1} a_i \\ &= \sum^n_{i=1} a_i - \frac{1}{2} w^T w \\ &= \sum^n_{i=1} a_i - \frac{1}{2} \sum^n_{i,j=1} a_i a_j t_i t_j x^T_i x_j \end{align}したがって、以下の制約付きの 2次計画問題を解くことになり、これは主問題に対して双対問題と呼ばれます。主問題と双対問題は一対一対応なので、主問題の代わりに双対問題を解けばよいことになります。
L(a) = \sum^n_{i=1} a_i - \frac{1}{2} \sum^n_{i,j = 1} a_i a_j t_i t_j k(x_i, x_j) \\ a_i \geq 0 \\ \sum^n_{i=1} a_n t_n = 0上の式において、$k(x_i, x_j) = x^T_i x_j$ はカーネル関数を表しており、ここでは線形カーネルとなっています。これを解くと、サポートベクトルに対応する少数のデータのみ $a_i \neq 0$、それ以外は $a_i = 0$ となるような疎な解が得られます。
双対問題の制約条件を満たすようにハイパーパラメータを $\lambda$ としてペナルティ項 $\frac{1}{2} \lambda \sum^n_{i,j = 1} a_i a_j t_i t_j $ を加えると、
L(a) = \sum^n_{i=1} a_i - \frac{1}{2} \sum^n_{i,j = 1} a_i a_j t_i t_j k(x_i, x_j) - \frac{1}{2} \lambda \sum^n_{i,j = 1} a_i a_j t_i t_jとなります。$L(a)$ を $a_i$ について微分すると、
\frac{\partial L}{\partial a_i} = 1 - \sum^n_{j=1} a_j t_i t_j k(x_i, x_j) - \lambda \sum^n_{j=1} a_j t_i t_jとなります。学習率 $\eta$ として最大化問題を勾配法で解くとすると、
\begin{align} \hat{a_i} &= a_i + \eta \frac{\partial L}{\partial \alpha_i} \\ &= a_i + \eta \left( 1 - \sum^n_{j=1} a_j t_i t_j k(x_i, x_j) - \lambda \sum^n_{j=1} a_j t_i t_j \right) \end{align}となります。この問題は凸2次最適化問題なので収束が保証されます。また、サポートベクターマシンでは $n$ 個のサポートベクターとなるデータを保存しており、予測時にはそのサポートベクターに基づいて分類を行います。
パラメータ $w$ は $a$ から求まるので、最後にバイアス $b$ を導出します。新しいデータ $x_j$ が与えられたとき、以下の式を用いて分類します。
y(x) = \sum^m_{j=1} a_j t_j k(x_i, x_j) + b正しく分類できた場合、$t_i y(x_i) = 1$ を満たすので、
t_i \left( \sum^m_{j=1} a_it_ik(x_i, x_j) + b \right) = 1となります。ここで、$t^2_i = 1$ より、
\begin{align} t_i \left( \sum^m_{j=1} a_j t_j k(x_i, x_j) + b \right) &= t^2_i \\ \sum^m_{j=1} a_j t_j k(x_i, x_j) + b &= t_i \\ \end{align}よって、バイアス $b$ は、
b = \frac{1}{n} \sum^n_{i=1} \left( t_i - \sum^m_{j=1} a_j t_j k(x_i, x_j) \right)となります。なお、データ数が 10万件以上ある場合は SGDClassifier の引数 loss を 'hinge' に設定し、確率的勾配降下法によるサポートベクターマシンを推奨しています。
ソフトマージン
前節のサポートベクターマシンはハードマージンと呼ばれており、それに対して少数の誤分類を許容するソフトマージンが提案されています。ソフトマージンでは、スラック変数 $\xi$ とハイパーパラメータ $C$ を導入して以下の式を解くことになります。
\argmin_{w, b, \xi} \frac{1}{2} ||w||^2 + C \sum^n_{i=1} \xi_i \\ \xi_i \geq 0 \\ t_i (w^T x_i + b) \geq 1 - \xi_i \\カーネルトリック
前節までは線形識別可能な場合を考えていました。しかし現実の問題では線形識別可能な問題はほとんどありません。サポートベクターマシンでは非線形識別を実行したい場合も、カーネル関数 $K(x_i, x_j)$ より線形識別問題のときと全く同じ最適化問題を解けばよいです。このような非線形変換を回避はカーネルトリックと呼ばれています。
サポートベクターマシンで使用可能なカーネル関数は、次のような正定値関数であるという条件を満たしている必要があります。
\sum_{i,j} a_i a_j K(x_i, x_j) > 0以下に代表的なカーネル関数を挙げます。
線形カーネル
線形カーネルは前節までの線形サポートベクターマシンのことです。
k(x_i, x_j) = x_i \cdot x_j多項式カーネル
多項式カーネルは次数 $p$ の高次元に変換します。ハイパーパラメータとして、$p, \gamma, c$ が増えます。
k(x_i, x_j) = (\gamma x_i \cdot x_j + c)^pRadial Basis Function (RBF) カーネル
放射基底関数カーネルは理論上は無限次元に変換します。非線形カーネルとして最もよく使用されます。ハイパーパラメータ $\gamma$ を調整する必要があります。
k(x_i, x_j) = \exp \left( -\gamma || x_i - x_j ||^2 \right)シグモイドカーネル
シグモイドカーネルは正定値関数ではなく半正定値関数ですが、ニューラルネットワークと類似性があります。
k(x_i, x_j) = \tanh (\gamma x_i \cdot x_j + c)実装
実行環境
ハードウェア
・CPU Intel(R) Core(TM) i7-6700K 4.00GHz
ソフトウェア
・Windows 10 Pro 1909
・Python 3.6.6
・matplotlib 3.1.1
・numpy 1.19.2
・scikit-learn 0.23.2実行するプログラム
実装したプログラムは GitHub で公開しています。
svm_classification.pysvm_regression.pysvm_anomaly.py結果
サポートベクターマシンによる分類
LinearSVC による分類
ロジスティック回帰 でも使用した breast cancer dataset を使用しました。
Accuracy 94.74% Precision, Positive predictive value(PPV) 96.92% Recall, Sensitivity, True positive rate(TPR) 94.03% Specificity, True negative rate(TNR) 95.74% Negative predictive value(NPV) 91.84% F-Score 95.45%ハイパーパラメータ C の比較
ハイパーパラメータ $C$ を小さくすると識別境界からのマージンが広くなり、大きくするとマージンは狭くなります。
カーネル関数の比較
線形カーネルでは識別境界は直線ですが、多項式カーネルでは円、シグモイドカーネルでは曲線、RBFカーネルではより複雑な識別境界となっています。
RBFカーネルにおけるハイパーパラメータ γ の比較
非線形識別を実行する際によく使用される RBFカーネルのハイパーパラメータ $\gamma$ を小さくすると識別境界は緩くなり、大きくすると厳しくなります。ハイパーパラメータ $\gamma$ は分散の逆数と見なせるので納得のいく結果です。
多クラス分類
多クラス分類のデータには iris dataset を使用しました。
サポートベクターマシンによる回帰
回帰問題のデータは正弦波に乱数を加えて、$k=5$ として実行しました。
サポートベクターマシンによる異常検知
異常検知では 1クラスサポートベクターマシンを使用します。下図では青色の領域以外を異常値として扱います。
参考
Christpher M. Bishop, "Pattern Recognition and Machine Learning", Springer, 2006.







- 投稿日:2020-09-28T18:37:37+09:00
Functional API で多入力・多出力モデル
はじめに
Keras の Functional API を使った基本的なモデルの実装と多入力・多出力モデルを実装する方法について紹介します。
環境
今回は Tensorflow に統合された Keras を利用しています。
tensorflow==2.3.0ゴール
- Functional API が使える
- 多入力・多出力モデルを実装できる
Functional API とは
Sequential モデルより柔軟なモデルを実装できるものになります。
今回は、Sequential モデルでは表現できないモデルの中から多入力・多出力モデルを実装していきます。基本的な使い方
まずは、Functional API の基本的な使い方を説明していきます。
Functional API はモデルを定義する方法なので、学習・評価・予測は Sequential モデルと同じになります。入力層
まずは、
keras.Inputで入力層を定義します。inputs = keras.Input(shape=(128,))中間層・出力層
以下のように層を追加していくことができ、最後の層が出力層になります。
x = layers.Dense(64, activation="relu")(inputs) outputs = layers.Dense(10)(x)モデル作成
層の定義が完了したら、入力層と出力層を指定して、モデルを作成します。
model = keras.Model(inputs=inputs, outputs=outputs, name="model")Sequential モデルとの比較
Sequential モデルと Functional API で同じモデルを実装してみます。
実装するモデルは以下の通りです。
Sequential モデル
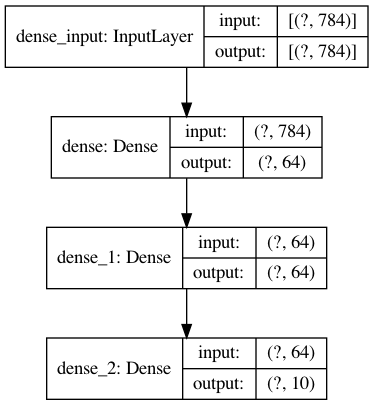
from tensorflow import keras from tensorflow.keras import layers from tensorflow.keras.models import Sequential model = Sequential() model.add(layers.Dense(64, activation='relu', input_shape=(784,))) model.add(layers.Dense(64, activation='relu')) model.add(layers.Dense(10, activation='softmax'))Functional API
from tensorflow import keras from tensorflow.keras import layers inputs = keras.Input(shape=(784,)) x = layers.Dense(64, activation='relu')(inputs) x = layers.Dense(64, activation='relu')(x) outputs = layers.Dense(10, activation='softmax')(x) model = keras.Model(inputs=inputs, outputs=outputs)多入力・多出力モデル
Functional API で多入力・多出力モデルを実装していきます。
多入力
入力層を複数定義することで、多入力にすることができます。
複数の層をまとめるときは、layers.concatenateを利用します。inputs1 = keras.Input(shape=(64,), name="inputs1_name") inputs2 = keras.Input(shape=(32,), name="inputs2_name") x = layers.concatenate([inputs1, inputs2])多出力
中間層を複数に渡すことで、層を分岐させることができます。
終点となる層が複数になることで、多出力になります。outputs1 = layers.Dense(64, name="outputs1_name")(x) outputs2 = layers.Dense(32, name="outputs2_name")(X)コンパイル
複数の出力層がある場合は、それぞれに損失関数と重みを指定できます。
model.compile( optimizer=keras.optimizers.RMSprop(1e-3), loss={ "outputs1_name": keras.losses.BinaryCrossentropy(from_logits=True), "outputs2_name": keras.losses.CategoricalCrossentropy(from_logits=True), }, loss_weights=[1.0, 0.5], )学習
層につけた名前で入力データと出力データ(ターゲット)を指定して、学習させることができます。
model.fit( {"inputs1_name": inputs1_data, "inputs2_name": inputs2_data}, {"outputs1_name": outputs1_targets, "outputs2_name": outputs2_targets}, epochs=2, batch_size=32, )具体例
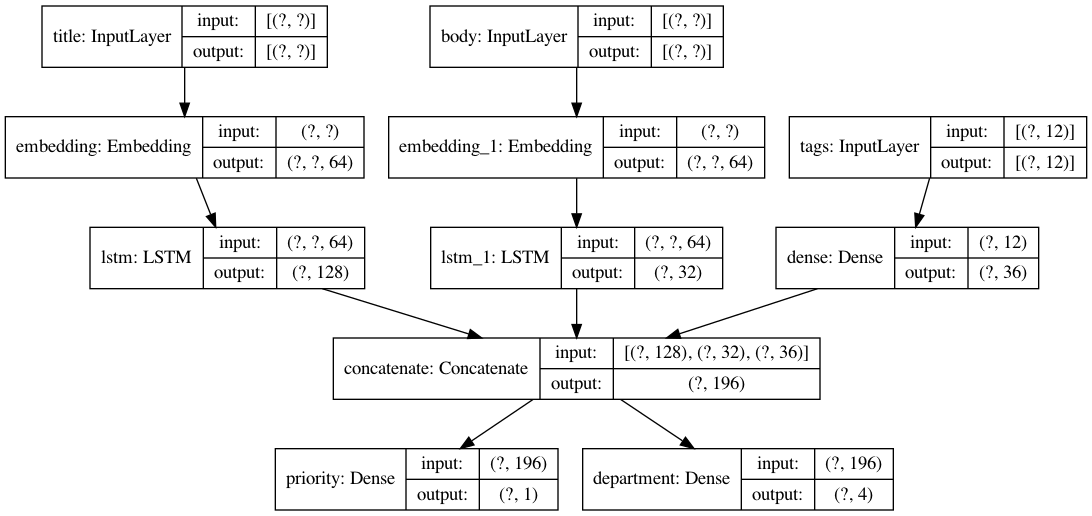
具体的な例を用いて実装してきます。
ここでは、顧客からの問い合わせのタイトルと本文とタグから、その問い合わせの優先度と対応部門を予測します。
入力
- タイトル
- 本文
- タグ
出力
- 優先度
- 対応部門
from tensorflow import keras from tensorflow.keras import layers import numpy as np num_tags = 12 num_words = 10000 num_departments = 4 # ダミーデータの作成 title_data = np.random.randint(num_words, size=(1280, 10)) body_data = np.random.randint(num_words, size=(1280, 100)) tags_data = np.random.randint(2, size=(1280, num_tags)).astype("float32") priority_targets = np.random.random(size=(1280, 1)) dept_targets = np.random.randint(2, size=(1280, num_departments)) # タイトルの層 title_input = keras.Input( shape=(None,), name="title" ) title_features = layers.Embedding(num_words, 64)(title_input) title_features = layers.LSTM(128)(title_features) # 本文の層 body_input = keras.Input(shape=(None,), name="body") body_features = layers.Embedding(num_words, 64)(body_input) body_features = layers.LSTM(32)(body_features) # タグの層 tags_input = keras.Input( shape=(num_tags,), name="tags" ) tags_features = layers.Dense(36, activation='relu')(tags_input) # 層を結合 x = layers.concatenate([title_features, body_features, tags_features]) # 出力層 priority_output = layers.Dense(1, name="priority")(x) department_output = layers.Dense(num_departments, name="department")(x) model = keras.Model( inputs=[title_input, body_input, tags_input], outputs=[priority_output, department_output], ) # モデルをコンパイル model.compile( optimizer=keras.optimizers.RMSprop(1e-3), loss={ "priority": keras.losses.BinaryCrossentropy(from_logits=True), "department": keras.losses.CategoricalCrossentropy(from_logits=True), }, loss_weights=[1.0, 0.5], ) # 学習 model.fit( {"title": title_data, "body": body_data, "tags": tags_data}, {"priority": priority_targets, "department": dept_targets}, epochs=2, batch_size=32, )まとめ
- Functional API を使うと多入力・多出力のモデルを実装できる
参考文献
- 投稿日:2020-09-28T18:22:44+09:00
Python + Janomeでマルコフ連鎖人工無脳(1)Janome入門
前書き
Pythonでマルコフ連鎖人工無脳を実装しようと思いました。
さて、形態素解析はなにに投げますかなと調べたところ、
Janomeというのが他のライブラリとの依存関係もなく、
pip一発でさくっとインストールできるそうです。ためしちゃお!環境
Python 3.8.5
Janome 0.4.1使い方
from janome.tokenizer import Tokenizer t = Tokenizer() s = "草わかば色鉛筆の赤き粉の散るがいとしく寝てけずるなり" for token in t.tokenize(s): print(token)Tokenizerクラスを使います。
t = Tokenizer()Tokenizerインスタンスを作って、
for token in t.tokenize(s): print(token)解析したい文章をtokenizeメソッドに渡します。
上のように中身を一つ一つ表示させると、こんな感じです。python analysis.py 草 名詞,一般,*,*,*,*,草,クサ,クサ わかば 名詞,固有名詞,組織,*,*,*,わかば,ワカバ,ワカバ 色鉛筆 名詞,一般,*,*,*,*,色鉛筆,イロエンピツ,イロエンピツ の 助詞,連体化,*,*,*,*,の,ノ,ノ 赤き 形容詞,自立,*,*,形容詞・アウオ段,体言接続,赤い,アカキ,アカキ 粉 名詞,一般,*,*,*,*,粉,コナ,コナ の 助詞,格助詞,一般,*,*,*,の,ノ,ノ 散る 動詞,自立,*,*,五段・ラ行,基本形,散る,チル,チル が 助詞,接続助詞,*,*,*,*,が,ガ,ガ いとしく 形容詞,自立,*,*,形容詞・イ段,連用テ接続,いとしい,イトシク,イトシク 寝 動詞,自立,*,*,一段,連用形,寝る,ネ,ネ て 助詞,接続助詞,*,*,*,*,て,テ,テ けずる 動詞,自立,*,*,五段・ラ行,基本形,けずる,ケズル,ケズル なり 助詞,接続助詞,*,*,*,*,なり,ナリ,ナリ要素を一つ一つ取り出してやることもできます。
ためしに表層形と基本形、品詞を出力してみました。from janome.tokenizer import Tokenizer t = Tokenizer() s = "寝てけずるなり" for token in t.tokenize(s): print("==========") print(token.surface + " (表層形)") print(token.base_form + " (基本形)") print(token.part_of_speech + " (品詞)")実行結果
python analysis.py ========== 寝 (表層形) 寝る (基本形) 動詞,自立,*,* (品詞) ========== て (表層形) て (基本形) 助詞,接続助詞,*,* (品詞) ========== けずる (表層形) けずる (基本形) 動詞,自立,*,* (品詞) ========== なり (表層形) なり (基本形) 助詞,接続助詞,*,* (品詞)次章で文章生成を実装していきます。
- 投稿日:2020-09-28T18:17:32+09:00
将棋AIで学ぶディープラーニング on Mac and Google Colab 第1章~第6章
第1章〜第5章
特記事項無し。
第6章 ディープラーニングフレームワーク
chainerとnumpyのWarning
iMacでChainerとNumpyをimportすると
import numpy import chainerWarningが出る。
numpyでOpenBLASのような他のBLASを使うことを推奨される。/Users/xxx/Library/Python/3.8/lib/python/site-packages/chainer/_environment_check.py:33: UserWarning: Accelerate has been detected as a NumPy backend library. vecLib, which is a part of Accelerate, is known not to work correctly with Chainer. We recommend using other BLAS libraries such as OpenBLAS. For details of the issue, please see https://docs.chainer.org/en/stable/tips.html#mnist-example-does-not-converge-in-cpu-mode-on-mac-os-x. Please be aware that Mac OS X is not an officially supported OS. warnings.warn('''\公式ページの通りにOpenBLASを入れていく。
https://docs.chainer.org/en/stable/tips.html#mnist-example-does-not-converge-in-cpu-mode-on-mac-os-x.
Use Homebrew to install OpenBLAS.
$ brew install openblasUninstall existing NumPy installation
$ pip uninstall numpyYou’ll to create a file called .numpy-site.cfg in your home (~/) directory with the following:
[openblas] libraries = openblas library_dirs = /usr/local/opt/openblas/lib include_dirs = /usr/local/opt/openblas/includeInstall NumPy from the source code
pip install --no-binary :all: numpyConfirm NumPy has been installed with OpenBLAS by running this command:
$ python -c "import numpy; print(numpy.show_config())"You should see the following information:
blas_mkl_info: NOT AVAILABLE blis_info: NOT AVAILABLE openblas_info: libraries = ['openblas', 'openblas'] library_dirs = ['/usr/local/opt/openblas/lib'] language = c define_macros = [('HAVE_CBLAS', None)] runtime_library_dirs = ['/usr/local/opt/openblas/lib'] ...Once this is done, you should be able to import chainer without OpenBLAS errors.
結果
blas_mkl_info: NOT AVAILABLE blis_info: NOT AVAILABLE openblas_info: libraries = ['openblas', 'openblas'] library_dirs = ['/usr/local/opt/openblas/lib'] language = c define_macros = [('HAVE_CBLAS', None)] blas_opt_info: libraries = ['openblas', 'openblas'] library_dirs = ['/usr/local/opt/openblas/lib'] language = c define_macros = [('HAVE_CBLAS', None)] lapack_mkl_info: NOT AVAILABLE openblas_lapack_info: libraries = ['openblas', 'openblas'] library_dirs = ['/usr/local/opt/openblas/lib'] language = c define_macros = [('HAVE_CBLAS', None)] lapack_opt_info: libraries = ['openblas', 'openblas'] library_dirs = ['/usr/local/opt/openblas/lib'] language = c define_macros = [('HAVE_CBLAS', None)]これでimport chainerとimport numpyしてもエラーが出なくなった。
補足
.numpy-site.cfgは公式に書いてある通りの4行を記載したテキストファイルを作成して.numpy-site.cfgの名前でホームディレクトリに保存するだけ。「.」で始まるファイルは隠しファイル。command + shift + . で表示/非表示を切り替えられる。このファイルを消してしまうとまたエラーが出るようになるので注意。
- 投稿日:2020-09-28T18:12:05+09:00
【Python3】画像のリサイズをフォルダー単位で行いたいときに使えるコード
備忘録やOUTPUT的な意味での蓄積(一気に作った系はこれで終わり)
作成目的
作業用のサイズをすべて変換したいときが定期的に起こったので、作業簡略化のために作成
作成環境
・windows10
・Anaconda3
・python3.7
・Jupyter Notebookドキュメント
①resizeしたいフォルダー名を入力(png_folderの一つ上のディレクトリ)
②folderがなければcurrent_folder内に、resize_folder を作成する
③幅と高さを指定し、画像をリサイズ(入力をしなかった場合Errorになる)
④すでに同じフォルダー名がある場合、誤操作を防ぐためにErrorになるライブラリの読み込み
All Necessary Libraries.pyimport numpy as np import os import pathlib from pathlib import Path from glob import glob from PIL import Image from tqdm import tqdmPG
image_resize_code# フォルダ名を入力 folder_name = input('Enter the folder name :') # pathを取得 p = Path('C:/Users/H3051411/OUT/' + folder_name + '/_png_folder') new_folder_name = '_resize_folder' new_folder_path = os.path.join(p, new_folder_name) # 新しいpathを取得 new_p = Path(new_folder_path) # フォルダーが存在しない場合リサイズ処理を行う if not os.path.exists(new_folder_path): # 新規フォルダーの作成 os.makedirs(new_folder_path) # 幅と高さの指定 width = int(input('withsize_input: ')) height = int(input('height_size_input: ')) # ファイルをリストで取得 files = list(p.glob('*.*')) # リサイズ処理 for f in tqdm(files): # 画像ファイルを取得 img = Image.open(f) # 最高品質でリサイズ処理 img_resize = img.resize((width, height), Image.LANCZOS) # ファイル名を取得 imgname = os.path.basename(f) # print(imgname) # 確認用 # 新規ファイル名を設定 newfname ='resize_' + imgname # print(newfname) # 確認用 # ファイルを保存する(path指定) img_resize.save(new_p/newfname) else: # ファイルが存在する場合Errorを返す print('Error:resize_folderはすでに存在しています.')課題
・関数化していない
・画像数が増えると時間かかりそう(未テスト)まとめ
作業時間が1時間から1分になりました。
あと、もっといい書き方がある気がする。
- 投稿日:2020-09-28T16:46:33+09:00
【形態素解析してみた アウトプット】
Word2vecを使ってみる
・word2vecを使うためにgensimのインストールをする。
・文字処理をするためにjanomeをインストールする。pip install gensim pip install janome・word2vecで青空文庫を読み込むためのコード
//必要なライブラリのインポート from janome.tokenizer import Tokenizer from gensim.models import word2vec import re //txtファイルをopenした後読む binarydata = open("kazeno_matasaburo.txt).read() ーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーー //ちなみにprintして一つ一つ確かめたやつ binarydata = open("kazeno_matasaburo.txt) print(type(binarydata)) 実行結果 <class '_io.BufferedReader'> binarydata = open("kazeno_matasaburo.txt).read() print(type(binarydata)) 実行結果 <class 'bytes'> ーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーー //データ型を文字列型に変換(pythonの書き方) text = binarydata.decode('shift_jis') //いらないデータを削ぎ落とす text = re.split(r'\-{5,}',text)[2] text = re.split(r'底本:',text)[0] text = text.strip() //形態素解析を行う t = Tokenizer() results = [] lines = text.split("\r\n") //行ごとに分けられている for line in lines: s = line s = s.replace('|','') s = re.sub(r'《.+?》','',s) s = re.sub(r'[#.+?]','',s) tokens = t.tokenize(s) //解析したやつが入っている r = [] //一つずつ取り出して、.base_formとか.surfaceとかでアクセスできる for token in tokens: if token.base_form == "*": w = token.surface else: w = token.base_form ps = token.part_of_speech hinshi = ps.split(',')[0] if hinshi in ['名詞','形容詞','動詞','記号']: r.append(w) rl = (" ".join(r)).strip() results.append(rl) print(rl) //解析したやつを書き込むファイルの生成と同時に書き込む wakachigaki_file = "matasaburo.wakati" with open(wakachigaki_file,'w', encoding='utf-8') as fp: fp.write('\n'.join(results)) //解析スタート data = word2vec.LineSentence(wakachigaki_file) model = word2.Word2Vec(data,size=200,window=10,hs=1,min_count=2,sg=1) model.save('matasaburo.model') //model使ってみる model.most_similar(positive=['学校'])まとめ
①解析したい文章を取ってくる。
②文章だけになるように加工する。最後の参考文献みたいなやつとか取り除く
③for文で1行ずつ取り出して、いらない部分を取り除く。
④tokenizerで形態素解析をする。リストに入れる。
⑤作ったリストをファイルに書き込む
⑥形態素解析したファイルを使ってmodelを作る
- 投稿日:2020-09-28T16:46:33+09:00
【形態素解析と単語のベクトル化してみた アウトプット】
Word2vecを使ってみる
・word2vecを使うためにgensimのインストールをする。
・文字処理をするためにjanomeをインストールする。pip install gensim pip install janome・word2vecで青空文庫を読み込むためのコード
//必要なライブラリのインポート from janome.tokenizer import Tokenizer from gensim.models import word2vec import re //txtファイルをopenした後読む binarydata = open("kazeno_matasaburo.txt).read() ーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーー //ちなみにprintして一つ一つ確かめたやつ binarydata = open("kazeno_matasaburo.txt) print(type(binarydata)) 実行結果 <class '_io.BufferedReader'> binarydata = open("kazeno_matasaburo.txt).read() print(type(binarydata)) 実行結果 <class 'bytes'> ーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーー //データ型を文字列型に変換(pythonの書き方) text = binarydata.decode('shift_jis') //いらないデータを削ぎ落とす text = re.split(r'\-{5,}',text)[2] text = re.split(r'底本:',text)[0] text = text.strip() //形態素解析を行う t = Tokenizer() results = [] lines = text.split("\r\n") //行ごとに分けられている for line in lines: s = line s = s.replace('|','') s = re.sub(r'《.+?》','',s) s = re.sub(r'[#.+?]','',s) tokens = t.tokenize(s) //解析したやつが入っている r = [] //一つずつ取り出して、.base_formとか.surfaceとかでアクセスできる for token in tokens: if token.base_form == "*": w = token.surface else: w = token.base_form ps = token.part_of_speech hinshi = ps.split(',')[0] if hinshi in ['名詞','形容詞','動詞','記号']: r.append(w) rl = (" ".join(r)).strip() results.append(rl) print(rl) //解析したやつを書き込むファイルの生成と同時に書き込む wakachigaki_file = "matasaburo.wakati" with open(wakachigaki_file,'w', encoding='utf-8') as fp: fp.write('\n'.join(results)) //解析スタート data = word2vec.LineSentence(wakachigaki_file) model = word2.Word2Vec(data,size=200,window=10,hs=1,min_count=2,sg=1) model.save('matasaburo.model') //model使ってみる model.most_similar(positive=['学校'])まとめ
①解析したい文章を取ってくる。
②文章だけになるように加工する。最後の参考文献みたいなやつとか取り除く
③for文で1行ずつ取り出して、いらない部分を取り除く。
④tokenizerで形態素解析をする。リストに入れる。
⑤作ったリストをファイルに書き込む
⑥形態素解析したファイルを使ってmodelを作る
- 投稿日:2020-09-28T16:46:33+09:00
形態素解析と単語のベクトル化してみた
Word2vecを使ってみる
- word2vecを使うためにgensimのインストールをする。
- 文字処理をするためにjanomeをインストールする。
pip install gensim pip install janome
- word2vecで青空文庫を読み込むためのコード
# 必要なライブラリのインポート from janome.tokenizer import Tokenizer from gensim.models import word2vec import re # txtファイルをopenした後読む binarydata = open("kazeno_matasaburo.txt").read()
# ちなみにprintして一つ一つ確かめたやつ binarydata = open("kazeno_matasaburo.txt") print(type(binarydata))実行結果
<class '_io.BufferedReader'>binarydata = open("kazeno_matasaburo.txt").read() print(type(binarydata))実行結果
<class 'bytes'>
# データ型を文字列型に変換(pythonの書き方) text = binarydata.decode('shift_jis') # いらないデータを削ぎ落とす text = re.split(r'\-{5,}',text)[2] text = re.split(r'底本:',text)[0] text = text.strip() # 形態素解析を行う t = Tokenizer() results = [] lines = text.split("\r\n") # 行ごとに分けられている for line in lines: s = line s = s.replace('|','') s = re.sub(r'《.+?》','',s) s = re.sub(r'[#.+?]','',s) tokens = t.tokenize(s) # 解析したやつが入っている r = [] # 一つずつ取り出して、.base_formとか.surfaceとかでアクセスできる for token in tokens: if token.base_form == "*": w = token.surface else: w = token.base_form ps = token.part_of_speech hinshi = ps.split(',')[0] if hinshi in ['名詞','形容詞','動詞','記号']: r.append(w) rl = (" ".join(r)).strip() results.append(rl) print(rl) # 解析したやつを書き込むファイルの生成と同時に書き込む wakachigaki_file = "matasaburo.wakati" with open(wakachigaki_file,'w', encoding='utf-8') as fp: fp.write('\n'.join(results)) # 解析スタート data = word2vec.LineSentence(wakachigaki_file) model = word2.Word2Vec(data,size=200,window=10,hs=1,min_count=2,sg=1) model.save('matasaburo.model') # model使ってみる model.most_similar(positive=['学校'])まとめ
①解析したい文章を取ってくる。
②文章だけになるように加工する。最後の参考文献みたいなやつとか取り除く
③for文で1行ずつ取り出して、いらない部分を取り除く。
④tokenizerで形態素解析をする。リストに入れる。
⑤作ったリストをファイルに書き込む
⑥形態素解析したファイルを使ってmodelを作る
- 投稿日:2020-09-28T16:39:11+09:00
schemdrawで回路図を
公式には回路例はあるものの
コメントが少なくて読みづらい感じ。
ネットには落ちているけど、トランジスタとかダイオードとか使ってないし微妙。
と思って、じゃあ作ろうと思いました。
お急ぎの方向けの全部ね。細部の説明は近日公開。
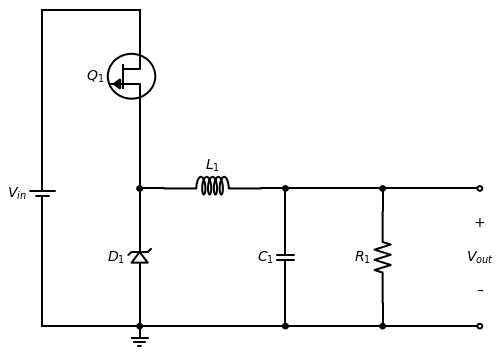
Buck_Switcher.pyimport schemdraw import schemdraw.elements as elm d = schemdraw.Drawing() # 電源からスタート Vin = d.add(elm.BatteryCell('up',reverse=True,label = '$V_{in}$')) d.add(elm.Line('u',l=1.5*d.unit)) #線 d.add(elm.Line('r',l=1*d.unit)) d.add(elm.Line('d',l=0.5*d.unit)) # FETまわり Q1 = d.add(elm.JFetN('right' , anchor='drain', #アンカー(来た線をどこに接続するか) circle = True, reverse=True , #左右反転 label='$Q_1$') ) d.add(elm.Line('d', xy=Q1.source)) d.add(elm.Dot) #点 d.push() #セーブ点 # ツェナーまわり d.add(elm.Line('d', l=d.unit/4)) D1 = d.add(elm.Zener,reverse=True ,label='$D_1$') d.add(elm.Line('d', l=d.unit/4)) G = d.add(elm.Ground()) d.pop() #セーブ点に戻る # コイルまわり d.add(elm.Line('r', l=d.unit/4)) L1 = d.add(elm.Inductor2, label='$L_1$') d.add(elm.Line('r', l=d.unit/4)) d.add(elm.Dot) d.push() #セーブ点 # コンデンサまわり d.add(elm.Line('d', l=d.unit/4)) C1 = d.add(elm.Capacitor, label='$C_1$') d.add(elm.Line('d', l=d.unit/4)) d.pop() #セーブ点に戻る d.add(elm.Line('r', l=d.unit)) d.add(elm.Dot) d.push() #セーブ点 # 抵抗まわり d.add(elm.Line('d', l=d.unit/4)) R1 = d.add(elm.Resistor,label='$R_1$') d.add(elm.Line('d', l=d.unit/4)) d.add(elm.Dot) d.pop() #セーブ点に戻る # 出力まわり d.add(elm.Line('r', l=d.unit)) d.add(elm.Dot(open=True)) Vout = d.add(elm.Gap('down', toy=G.start, label=['+', '$V_{out}$', '–'])) d.add(elm.Dot(open=True)) d.add(elm.Line('l', l=d.unit)) d.pop() #セーブ点に戻る # 帰路 # C1のところまでもどる d.add(elm.Line('l', l=d.unit)) d.add(elm.Dot) d.add(elm.Line('l', l=1.5*d.unit)) d.add(elm.Dot) d.add(elm.Line('l', l=d.unit)) d.add(elm.Line('u', l=d.unit)) d.pop() #セーブ点に戻る # d.save('Buck Switcher.png') #png出力 d.draw()
細部説明
近日公開
以上。
- 投稿日:2020-09-28T16:04:37+09:00
ABC129 A,B,C解説
A問題
https://atcoder.jp/contests/abc129/tasks/abc129_a
p,q,r = map(int,input().split()) print(min(p+q,q+r,p+r))p,q,r の内の2つを選び(3通り)合計の最小のものを選ぶ。
B問題
https://atcoder.jp/contests/abc129/tasks/abc129_b
n = int(input()) w = list(map(int,input().split())) ans = [] for i in range(1,n): ans.append(abs(sum(w[:i])-sum(w[i:]))) print(min(ans))全探索します。リストの間ごとのiまでの合計、iからの合計の差を記録していき
最小値を出力する。C問題
https://atcoder.jp/contests/abc129/tasks/abc129_c
n,m = map(int,input().split()) a = set([int(input())for _ in range(m)]) dp = [0]*(n+1) dp[0] = 1 if 1 in a : dp[1] = 0 else: dp[1] = 1 for i in range(2,n+1): if i in a: continue dp[i] = (dp[i-1]+dp[i-2])%1000000007 print(dp[n])0段目は 1通り
1段目は0段目から1つ登りと言う 1通り
2段目は0段目から1通り
1段目から1通り 合計2通り
3段目は1段目から 1通り
2段目から 2通り 合計3通りつまり n[i] = n[i-1]+n[i-2]
これを実装。
aに該当する場合は計算をスルー。
- 投稿日:2020-09-28T15:30:11+09:00
[python] データ読み込み
pythonで使えるファイル読み込み方法をいくつかあげました。
どんな関数があったっけ、となった時用なので、各関数の詳しい説明は省いてます。open()
ファイルとモードを指定。
モードのデフォルトは'r'(読み込み専用)main.py#一行ずつ読み込んで表示する場合 data = open('/path/to/data', 'r') for line in data: print line data.close() #すべての内容を読み込んで表示する場合 data = open('/path/to/data', 'r') all_data = data.read() print all_data data.close()read_csv(), read_table()
pandas
カンマ区切りならread_csv(), タブ区切りならread_table()
読み込んだものはデータフレームとして返されるmain.pyimport pandas as pd data_csv = pd.read_csv('/path/to/data.csv') data_tsv = pd.read_table('/path/to/data.tsv')loadtxt()
numpy
区切り文字と型も指定する(デフォルトはスペース区切りとfloat)
読み込んだものは配列(array)として返されるmain.pyimport numpy as np data = np.loadtxt('/path/to/data', delimiter=' ', dtype = 'float')
- 投稿日:2020-09-28T15:25:01+09:00
【Python3】画像の拡張子を一気に変更したいときに使えるコード
備忘録やOUTPUT的な意味での蓄積
作成目的
作業用の拡張子をすべて変換したいときが定期的に起こったので、作業簡略化のために作成
作成環境
・windows10
・Anaconda3
・python3.7
・Jupyter Notebookドキュメント
①拡張子を変更したいフォルダ名を入力
②folderがなければcurrent_folder内に、[拡張子]_folderを作成する
③すでに同じフォルダ名がある場合、誤操作を防ぐためにErrorになる※今回はpngに変換するコードを記載する
ライブラリの読み込み
All Necessary Libraries.pyimport pathlib import os import shutil import pprint import numpy as np from glob import glob from PIL import Image from tqdm import tqdm from pathlib import PathPG
change_pngextension_code# フォルダ名を入力 folder_name = input('Enter the folder name :') p, new_folder_name = Path('C:/Users/H3051411/OUT/' + folder_name), '_png_folder' # 現在のpathから新しいpng_folderを作成 new_folder_path = os.path.join(p, new_folder_name) #print(new_folder_path)(必要があれば確認) # フォルダがなければコピーして作成 if not os.path.exists(new_folder_path): # ディレクトリ内のファイルを取得 shutil.copytree(p, new_folder_path) # 新たなpathの拡張子をpngファイルに変換 new_p = Path(new_folder_path) files = list(new_p.glob('*.*')) for i,f in tqdm(enumerate(files)): print('画像変換数:{0}/{1}'.format(i+1,len(files)) shutil.move(f, f.with_name(f.stem + ".png")) else: print('すでにfolderが存在します.')課題
・関数化していない
・画像数が増えると時間かかりそう(未テスト)まとめ
作業時間が1時間から1分になりました。
あと、もっといい書き方がある気がする。
- 投稿日:2020-09-28T15:23:06+09:00
超解像アルゴリズム「PULSE」をWindows環境で試してみた
今年のCVPRで発表された、高性能の超解像アルゴリズム「PULSE:Self-Supervised Photo Upsampling via Latent Space Exploration of Generative Models」を試してみました。
流行りの「自己教師あり学習」です。※論文の内容に関しては省略(いつか解説記事を書くかも?!)
「PULSE」のポイント
- 今までとは評価ポイントが違う
- 超解像した後の画像じゃなくて、超解像した後にダウンスケールした画像で比較
- 今までの手法よりも超解像可能
- 超解像自体はStyleGANを使用(CelebA-HQで学習済み)
このGIFがイメージをつかみやすいです。
ソースコード
ソースコードはGithubにて公開されています。
今回はこれをそのまま使います。インストール
Python 3.7上で、以下のモジュールをインストールしました。
- Anaconda NavigatorのGUIからインストール
- matplotlib
- numpy
- pandas
- pillow
- scipy
- requests
- コマンドラインからインストール
- pytorch
- torchvision
- cudatoolkit(今回は10.2を使用)
環境構築
超解像したい画像を入れておくフォルダを用意します。
ここではとりあえず「input」とします。そこに超解像したい画像を入れます。(複数入れてもOK)
画像にはいくつか制限があります。
- 縦横のサイズは同じ
- サイズは1,024の約数
- フォーマットはPNG(RGB)
実行
> python run.pyで実行します。
エラー対応
ほとんどの画像で、以下のようなエラーになります。
Loading Synthesis Network Optimizing BEST (100) | L2: 0.0058 | GEOCROSS: 4.3057 | TOTAL: 0.7981 | time: 10.0 | it/s: 9.98 | batchsize: 1 Could not find a face that downscales correctly within epsilon上記の例の場合、L2の最小値が「0.0058」なのですが、デフォルトの閾値が「0.002」になっており、それより近づかないとエラーになります。
対応方法としては、引数「eps」で閾値の値を変更します。
> python run.py -eps 0.005実行結果
実行結果は「runs」フォルダに保存されます。
出力される超解像画像は1,024x1,024のpngになります。
外国人バイアスがむごい...
あと、正面顔じゃないとダメそう。感想
実行は簡単ですが、実際に使おうと思うと、いろいろとやらなくてはいけないことがいっぱいありそうです。
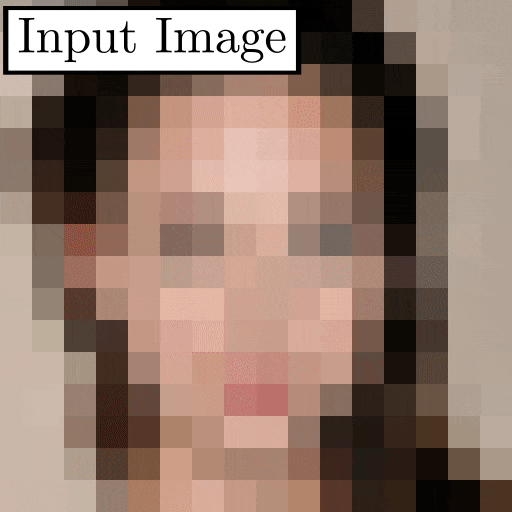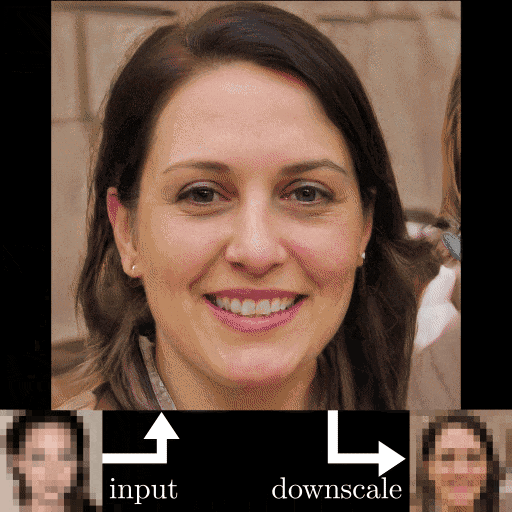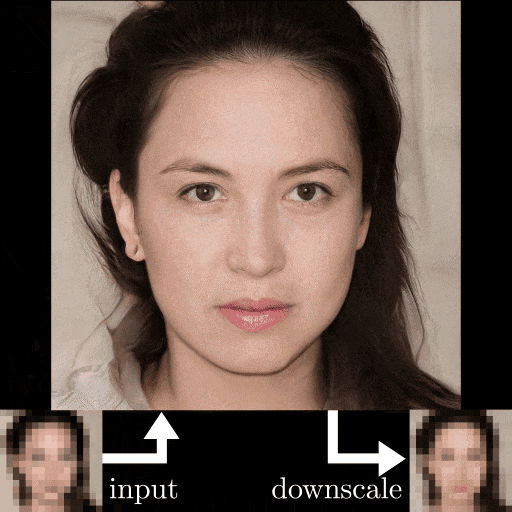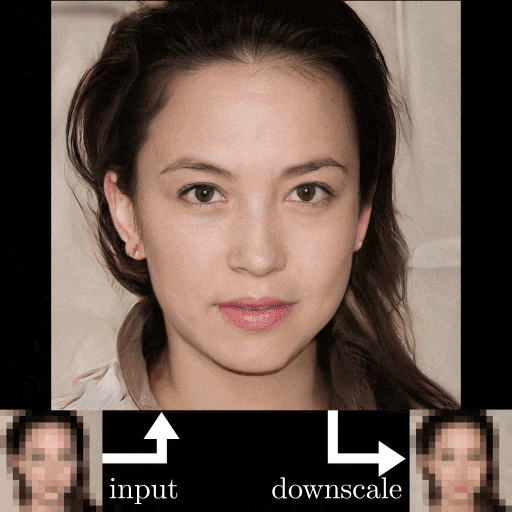


- 投稿日:2020-09-28T15:11:05+09:00
【Python】関数をlambda関数にする
前提
引数に0が来たら「hoge」を返し
それ以外が来たら、入力値を返すだけの関数。
下に細かい手順も書きました。よく迷うため、備忘録的に。
結論
def x(value): if value == 0: return "hoge" else: return valueこれが
y = lambda value : "hoge" if value == 0 else valueこうなる。
文字で表すとこう。
(関数名) = lambda (引数) : (条件がTrueなら返す値) if (条件) else (条件がFalseなら返す値)初見でこれだけ見ると、訳わからなくなります。
手順
lambda関数は
変更したい関数が1行の関数である必要があるため、
まず下記のif文を1行にする。# 再記 def x(value): if value == 0: return "hoge" else: return value①まずTrueになる条件を記述。(if value == 0)
def x(value): if value == 0②Trueになったら返したい値を【先頭】に書く。("hoge")
def x(value): "hoge" if value == 0③Falseのときに返す値を入れる(else value)
def x(value): "hoge" if value == 0 else valueこれでif文を1文にすることが成功しました。
次に、関数を一行にします。④いらない部分を消す。
↓いらない3つのもの
1, def
2, 関数名→ x
3, 引数を囲っているカッコ→()value : "hoge" if value == 0 else value行を揃えると
value : "hoge" if value == 0 else valueこう出来ます。だんだん近づいて来ました。
⑤先頭に「lambda」と書き、値に代入する。
lambda関数にしていきます。
先頭にlambdaを書きlambda value : "hoge" if value == 0 else valuexに代入する。(xは関数名になります)
x = lambda value : "hoge" if value == 0 else valueこれで完成です。
実行
x(0) >>> 'hoge' x(100) >>> 100以上です。
- 投稿日:2020-09-28T14:31:02+09:00
備忘録(「ユーザー定義」された時刻の取得・換算、クロス集計)
はじめに
構想設計の第1ステップである『生データに対し、「社員名と作業時間以外が同じ値ならば作業時間を統合する」処理をかける』が実装できたので取りまとめる。
https://qiita.com/wellwell3176/items/7dba981b479c5933bf5f
図:生データの抜粋
社員名はデータとして不要なので、社員名を削除し、なおかつ社員名以外の情報が全部同じなら作業時間を合算したい完成したプログラム
programimport pandas as pd df=pd.read_excel('/content/drive/My Drive/Colab Notebooks/data2.xlsx') df["区分"]=df["区分"]+df["業務"] #後工程で必要なので区分と業務は一括表示にする df=df.rename(columns = {'区分':'業務区分'} #行の見出しも変更しておく df["作業時間"] = pd.to_datetime(df["作業時間"],format="%H:%M:%S") #作業時間が生データだとエクセルのユーザー定義で入力されていたので、フォーマット指定で文字列からdatetimeに変換 df["作業時間"] = df["作業時間"].dt.minute #数値は[~~分][~~時間]で表示するとの要求があるので、datetimeを[分]に換算したint型にする df2=df.groupby(["テーマ","月日","国名","業務区分"],as_index=False).sum() #社員名以外で集約する。df.groupbyの結果は代入しないと保存されないので注意する df2.to_excel('/content/drive/My Drive/Colab Notebooks/data5.xlsx')
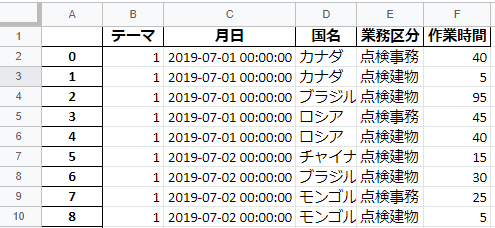
図:プログラムの出力結果
業務区分の文字列結合、社員名の削除、時間の集計が実現しているのでOKとするプログラム中に発生したエラーや失敗」とその概要
1. to_datetimeで文字列から時刻に換算できない
df["作業時間"] = pd.to_datetime(df["作業時間"]) -->TypeError: <class 'datetime.time> is not convertible to datetime #エクセルの「表示形式」に問題が在った。ユーザー定義の「hh:mm」を使っており、デフォルトのto_datetimeではこれが読めなかった #formatオプションを使い、該当列の記述方式を指定することで解決 df["作業時間"] = pd.to_datetime(df["作業時間"],format="%H:%M:%S") #これでOK2. 作業時間がgroupbyで集計されない
失敗バージョンdf["作業時間"] = pd.to_datetime(df["作業時間"],format="%H:%M:%S") df.groupby("国名").mean() ValueError: No axis named テーマ for object type <class 'pandas.core.frame.DataFrame'>
上図のように出力されてしまい、「作業時間」での集計が発生しなかった。
原因はdatetime形式がgroupby関数の集計値として認識されなかった為と思われる。
完成品のようにdatetimeをint型に変更して解決。成功バージョンdf["作業時間"] = pd.to_datetime(df["作業時間"],format="%H:%M:%S") df["作業時間"] = df["作業時間"].dt.minute df.groupby("国名").mean()
これで作業時間が集計側に~~[分]の形で取り込めた。3. AttributeError: 'Series' object has no attribute 'minute'
df["作業時間"] = df["作業時間"].minute #これを使ってエラーが発生 --> AttributeError: 'Series' object has no attribute 'minute' #.dtが抜けていたので、df["作業時間"]という一連の配列を対象とした処理が行えなかった df["作業時間"] = df["作業時間"].dt.minute #これが正解4. ValueError: No axis named HOGE for object type class'pandas.core.frame.DataFrame'
df.groupby("国名","テーマ").sum() #これを使ってエラーが発生 -->ValueError: No axis named テーマ for object type <class 'pandas.core.frame.DataFrame> #groupby関数で複数のインデックスを使用するときの記述ミス。[]が足りなかった。 df.groupby(["テーマ","国名"]).sum() #これでOK参考にしたページ/サイト
rename()でcolumn名の変更ができない https://teratail.com/questions/291634
Pandas の groupby の使い方 https://qiita.com/propella/items/a9a32b878c77222630ae
PandasでSeries.dt()を使って日付を変換する方法 https://qiita.com/Takemura-T/items/79b16313e45576bb6492
- 投稿日:2020-09-28T14:12:55+09:00
Python3ではじめるシステムトレード:投資とリスク
投資の経験が少ない時は
- リスクの取りすぎ
- 高い収益率を求めすぎ
のために、株式を購入し価格が下がると、すぐに売ってしまう傾向があります。そして、この間違いを何度も繰り返すために、損失が膨れ上がってしまいます。経験が少ないとなんど銘柄を選び売買のタイミングを図っても株価はすぎに下がってしまいす。ときたま最初からうまくいくこともありますが、それは運がいいだけで長続きはしません。
そこで株価のデータ分析が重要になります。そして、世界のいろいろな株式市場のデータをもとに分析した結果は単純なものです。
- 長期投資が基本
- 長期に上昇している市場に投資
- 下落相場でドキドキしない程度にリスクを取る
- 利益が出るまで売らない
買った株の価格の下落でドキドキしない人はいません。そのような時はだれでもつらいものです。したがって損をしてでも売ってしまいがちです。このような経験がある人はリスクのとりかたを考え直してみる必要があります。リスクを減らしましょう。より価格変動の少ない株式に投資すべきです。それでも同じ経験を繰り返すようであれば、株式を買うことが適切でないかもしれません。より価格変動の少ない債券などに投資しる方がいいかもしれません。もちろん債券も下落しますから、同じような経験があるかもしれません。そのようなときには、より価格変動の少ない債券を選ぶか、現金預金の方が適しているかもしれません。人のもつこの傾向は、経験や知識の習得で克服できるものではありません。まずは自分を知ることから始まります。
もしある株式の価格が下落しても、そしてドキドキしてもその株を保有し続けられたなら、その株の性質をよく調べて見る必要があります。それがあなたのリスク(どきどき)の許容範囲だからです。その際の目安の一つが収益率と価格変動性です。収益率は株式の価格が過去にどの程度上がったのかを測る目安です。価格変動性は株価がどの程度上下動するかを測る目安です。
では実際にデータ分析の方法を学んでいきましょう。データ分析にはpythonが便利です。その際にJupyter notebookをインストールすることをお勧めします。本記事はJupyter notebookで書かれています。また、プログラムのコードはJupyter notebookを前提に書かれています。また、pandas-datareaderも必要です。jupyter notebookのインストールについてはPython3ではじめるシステムトレード:Jupyter notebookのインストールを参考にしてください。ここにpandas-datareaderのインストールの説明もあります。
pandas-datareaderの使い方はYahoo Finance USから株価をダウンロードしてみたを参考にしてください。
投資対象
初心者にとって株式の銘柄選択は大変に難しことです。ときには買った会社が倒産してしまうこともあります。ですからまずはいろいろな株式で構成される株価指数を見てみましょう。長期の株価を分析する際には株価の対数を取ることが基本です。詳しくはPython3ではじめるシステムトレード: システムトレードにおける対数の役割を参考にしてください。
ETF(上場投資信託)
株価指数に投資する際には手数料の面といつでも売買可能で価格の透明性の高いETF(上場投資信託)が基本です。
ダウジョーンズ
最も長い歴史を持つ米国を代表する株価指数ダウ平均株価のETFは"DIA"はです。
%matplotlib inline import matplotlib.pyplot as plt #描画ライブラリ import pandas_datareader.data as web #データのダウンロードライブラリ import numpy as np import pandas as pd import seaborn as sns tsd = web.DataReader("dia","yahoo","1980/1/1").dropna()#jpy np.log(tsd.loc[:,'Adj Close']).plot()
ナスダック100
米国の経済成長を実現させてきた新興株式市場のナスダックを対象とした株価指数のETFは"QQQ"です。
tsd = web.DataReader("qqq","yahoo","1980/1/1").dropna()#jpy np.log(tsd.loc[:,'Adj Close']).plot()
S&P500
米国の年金基金がベンチマークとする株価指数がS&P500でそのETFは"SPY"です。
tsd = web.DataReader("spy","yahoo","1980/1/1").dropna()#jpy np.log(tsd.loc[:,'Adj Close']).plot()
どれも長期的には、上昇しているのが分かります。
その他のETF
ETF=['DIA','SPY','QQQ','IBB','XLV','IWM','EEM','EFA','XLP','XLY','ITB','XLU','XLF', 'VGT','VT','FDN','IWO','IWN','IYF','XLK','XOP','USMV'] #株式指数のETF ETF2=['BAB','GLD','VNQ','SCHH','IYR','AGG','BND','LQD','VCSH','VCIT','JNK'] #株式指数以外のETFドキドキの度合いをリスクとリターンの比率で把握
株価がどのような動きをするときにドキドキハラハラするのでしょうか。その自分のパターンを知っておくことは大事なことです。それを知ることが株式投資の出発点になります。このパターンを他の人に教えてもらうことはできません。自分で探し当てるしかありません。そして、そのパターンを見つけるまでは、投資は極力少額で行うべきです。
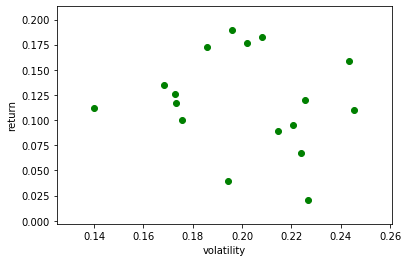
ではそのパターンを見つける一つの道具を紹介します。それがリスクとリターンの比率です。年率換算したリターンを年率換算した標準偏差(ボラティリティ)で割ります。実際にリーマンショック後の動きを見てみましょう。
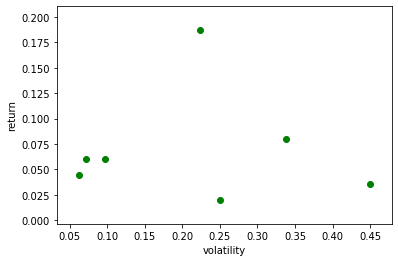
m=[]#それぞれの株価の年率換算平均のデータを保存 v=[]#それぞれの株価の年率換算した標準偏差を保存 PORT=ETF j=0 for i in range(len(PORT)): tsd=web.DataReader(PORT[i], "yahoo",'1980/1/1')#株価データのダウンロード tsd2=tsd.loc['2010/1/1':]#リーマンショック以後 tsd3=tsd.loc['1980/1/1':'2009/12/31']#リーマンショック前 if len(tsd3)>1000: lntsd=np.log(tsd2.iloc[:,5])#データの自然対数を取る m.append((lntsd.diff().dropna().mean()+1)**250-1) v.append(lntsd.diff().dropna().std()*np.sqrt(250)) print('{0: 03d}'.format(j+1),'{0:7s}'.format(PORT[i]),'平均{0:5.2f}'.format(m[j]), 'ボラティリティ {0:5.2f}'.format(v[j]),'m/v {0:5.2f}'.format(m[j]/v[j]), ' データ数{0:10d}'.format(len(tsd))) j+=1 v_m=pd.DataFrame({'v':v,'m':m}) plt.scatter(v_m.v,v_m.m,color="g") plt.ylabel('return') plt.xlabel('volatility')01 DIA 平均 0.12 ボラティリティ 0.17 m/v 0.68 データ数 5710 02 SPY 平均 0.13 ボラティリティ 0.17 m/v 0.73 データ数 6966 03 QQQ 平均 0.19 ボラティリティ 0.20 m/v 0.97 データ数 5424 04 IBB 平均 0.16 ボラティリティ 0.24 m/v 0.65 データ数 4937 05 XLV 平均 0.14 ボラティリティ 0.17 m/v 0.80 データ数 5476 06 IWM 平均 0.10 ボラティリティ 0.22 m/v 0.43 データ数 5116 07 EEM 平均 0.02 ボラティリティ 0.23 m/v 0.09 データ数 4395 08 EFA 平均 0.04 ボラティリティ 0.19 m/v 0.20 データ数 4801 09 XLP 平均 0.11 ボラティリティ 0.14 m/v 0.80 データ数 5476 10 XLY 平均 0.17 ボラティリティ 0.19 m/v 0.93 データ数 5476 11 XLU 平均 0.10 ボラティリティ 0.18 m/v 0.57 データ数 5476 12 XLF 平均 0.11 ボラティリティ 0.25 m/v 0.45 データ数 5476 13 VGT 平均 0.18 ボラティリティ 0.21 m/v 0.88 データ数 4194 14 IWO 平均 0.12 ボラティリティ 0.23 m/v 0.53 データ数 5073 15 IWN 平均 0.07 ボラティリティ 0.22 m/v 0.30 データ数 5073 16 IYF 平均 0.09 ボラティリティ 0.21 m/v 0.42 データ数 5116 17 XLK 平均 0.18 ボラティリティ 0.20 m/v 0.88 データ数 5476
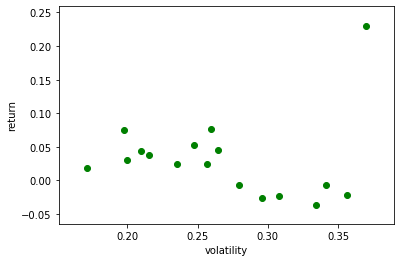
つぎにリーマンショック前を見てみます。
m2=[]#それぞれの株価の年率換算平均のデータを保存 v2=[]#それぞれの株価の年率換算した標準偏差を保存 PORT=ETF j=0 for i in range(len(PORT)): tsd=web.DataReader(PORT[i], "yahoo",'1980/1/1')#株価データのダウンロード tsd2=tsd.loc['1980/1/1':'2009/12/31']#株価データのダウンロード if len(tsd2)>1000: lntsd=np.log(tsd2.iloc[:,5])#データの自然対数を取る m2.append((lntsd.diff().dropna().mean()+1)**250-1) v2.append(lntsd.diff().dropna().std()*np.sqrt(250)) print('{0: 03d}'.format(j+1),'{0:7s}'.format(PORT[i]),'平均{0:5.2f}'.format(m2[j]), 'ボラティリティ {0:5.2f}'.format(v2[j]),'m/v {0:5.2f}'.format(m2[j]/v2[j]), ' データ数{0:10d}'.format(len(tsd2))) j+=1 v_m2=pd.DataFrame({'v2':v2,'m2':m2}) plt.scatter(v_m2.v2,v_m2.m2,color="g") plt.ylabel('return') plt.xlabel('volatility')01 DIA 平均 0.04 ボラティリティ 0.21 m/v 0.21 データ数 3008 02 SPY 平均 0.08 ボラティリティ 0.20 m/v 0.38 データ数 4264 03 QQQ 平均-0.01 ボラティリティ 0.34 m/v -0.02 データ数 2722 04 IBB 平均-0.03 ボラティリティ 0.30 m/v -0.09 データ数 2235 05 XLV 平均 0.03 ボラティリティ 0.20 m/v 0.16 データ数 2774 06 IWM 平均 0.05 ボラティリティ 0.26 m/v 0.17 データ数 2414 07 EEM 平均 0.23 ボラティリティ 0.37 m/v 0.62 データ数 1693 08 EFA 平均 0.05 ボラティリティ 0.25 m/v 0.21 データ数 2099 09 XLP 平均 0.02 ボラティリティ 0.17 m/v 0.11 データ数 2774 10 XLY 平均 0.02 ボラティリティ 0.26 m/v 0.09 データ数 2774 11 XLU 平均 0.04 ボラティリティ 0.22 m/v 0.18 データ数 2774 12 XLF 平均-0.02 ボラティリティ 0.36 m/v -0.06 データ数 2774 13 VGT 平均 0.02 ボラティリティ 0.24 m/v 0.11 データ数 1492 14 IWO 平均-0.01 ボラティリティ 0.28 m/v -0.02 データ数 2371 15 IWN 平均 0.08 ボラティリティ 0.26 m/v 0.30 データ数 2371 16 IYF 平均-0.04 ボラティリティ 0.33 m/v -0.11 データ数 2414 17 XLK 平均-0.02 ボラティリティ 0.31 m/v -0.07 データ数 2774
比率は相対的にリーマンショック後の方が高い傾向にあります。
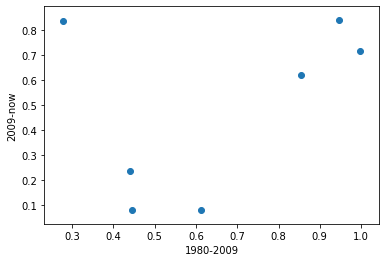
つぎに2つの期間を比べてみましょう。
plt.scatter(v_m.m/v_m.v,v_m2.m2/v_m2.v2) plt.ylabel('2009-now') plt.xlabel('1980-2009')
本当は右肩上がりの直線を引けるような関係にあればよいのですが、残念ながらそのような関係はなさそうです。これは2000年のインターネットバブル崩壊の影響を株価指数が大きく受けているからです。バブルの崩壊は投資の効率を大きく損ないます。しかし、避けることはできません。常に株式投資には予測不可能なリスクがあることを忘れてはなりません。
つぎに株価指数以外のETFについても分析していきましょう。金(ゴールド)や不動産リート(RIET)や債券指数です。
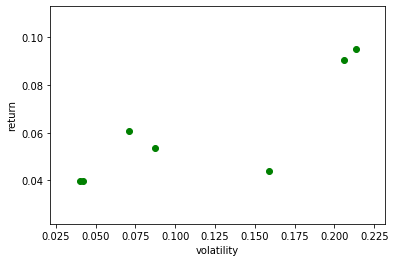
m=[]#それぞれの株価の年率換算平均のデータを保存 v=[]#それぞれの株価の年率換算した標準偏差を保存 PORT=ETF2 j=0 for i in range(len(PORT)): tsd=web.DataReader(PORT[i], "yahoo",'1980/1/1')#データのダウンロード tsd2=tsd.loc['2010/1/1':] tsd3=tsd.loc['1980/1/1':'2009/12/31'] if len(tsd3)>100: lntsd=np.log(tsd2.iloc[:,5])#データの自然対数を取る m.append((lntsd.diff().dropna().mean()+1)**250-1) v.append(lntsd.diff().dropna().std()*np.sqrt(250)) print('{0: 03d}'.format(j+1),'{0:7s}'.format(PORT[i]),'平均{0:5.2f}'.format(m[j]), 'ボラティリティ {0:5.2f}'.format(v[j]),'m/v {0:5.2f}'.format(m[j]/v[j]), ' データ数{0:10d}'.format(len(tsd))) j+=1 v_m=pd.DataFrame({'v':v,'m':m}) plt.scatter(v_m.v,v_m.m,color="g") plt.ylabel('return') plt.xlabel('volatility')01 GLD 平均 0.04 ボラティリティ 0.16 m/v 0.28 データ数 3991
02 VNQ 平均 0.10 ボラティリティ 0.21 m/v 0.45 データ数 4027
03 IYR 平均 0.09 ボラティリティ 0.21 m/v 0.44 データ数 5101
04 AGG 平均 0.04 ボラティリティ 0.04 m/v 1.00 データ数 4279
05 BND 平均 0.04 ボラティリティ 0.04 m/v 0.95 データ数 3392
06 LQD 平均 0.06 ボラティリティ 0.07 m/v 0.85 データ数 4573
07 JNK 平均 0.05 ボラティリティ 0.09 m/v 0.61 データ数 3226
```
右肩上がりの直線で全体の傾向がとらえられそうです。大きなリスクを取れば大きなリターンが得られそうです。
m2=[]#それぞれの株価の年率換算平均のデータを保存 v2=[]#それぞれの株価の年率換算した標準偏差を保存 PORT=ETF2 j=0 for i in range(len(PORT)): tsd=web.DataReader(PORT[i], "yahoo",'1980/1/1')#データのダウンロード tsd2=tsd.loc['1980/1/1':'2009/12/31'] if len(tsd2)>100: lntsd=np.log(tsd2.iloc[:,5])#データの自然対数を取る m2.append((lntsd.diff().dropna().mean()+1)**250-1) v2.append(lntsd.diff().dropna().std()*np.sqrt(250)) print('{0: 03d}'.format(j+1),'{0:7s}'.format(PORT[i]),'平均{0:5.2f}'.format(m2[j]), 'ボラティリティ {0:5.2f}'.format(v2[j]),'m/v {0:5.2f}'.format(m2[j]/v2[j]), ' データ数{0:10d}'.format(len(tsd2))) j+=1 v_m2=pd.DataFrame({'v2':v2,'m2':m2}) plt.scatter(v_m2.v2,v_m2.m2,color="g") plt.ylabel('return') plt.xlabel('volatility')01 GLD 平均 0.19 ボラティリティ 0.22 m/v 0.84 データ数 1289 02 VNQ 平均 0.04 ボラティリティ 0.45 m/v 0.08 データ数 1325 03 IYR 平均 0.08 ボラティリティ 0.34 m/v 0.24 データ数 2399 04 AGG 平均 0.04 ボラティリティ 0.06 m/v 0.72 データ数 1577 05 BND 平均 0.06 ボラティリティ 0.07 m/v 0.84 データ数 690 06 LQD 平均 0.06 ボラティリティ 0.10 m/v 0.62 データ数 1871 07 JNK 平均 0.02 ボラティリティ 0.25 m/v 0.08 データ数 524
リーマンショック後と同じような傾向があります。
つぎに2つの期間を比べてみましょう。
plt.scatter(v_m.m/v_m.v,v_m2.m2/v_m2.v2) plt.ylabel('2009-now') plt.xlabel('1980-2009')
多くの場合、リスクを多くとればリターンも高くなるという傾向はリーマンショックの前と後で同じのようです。これで株式運用よりも債券運用の方が値動きのパターンは予測しやすいようだということが分かります。
そうすると冒頭の注意書き
- 長期投資が基本
- 長期に上昇した市場に投資
- 下落相場でドキドキしない程度にリスクを取る
- 利益が出るまで売らない
- 株式市場が自分にはリスクが高いと思えば、債券市場に投資し、それでもリスクが高いと思えば銀行預金
という結論が得られそうです。しかし、この結論は人それぞれなので、自分で自分のものを得てください。


- 投稿日:2020-09-28T13:23:00+09:00
discord.pyにおける更新型メッセージ
botでテキストを出力する時、前回の投稿を削除して新しくポストすると、
最新の投稿メッセージと表示されるので便利です。ただ、投稿が短時間で行われると、二重に投稿が表示されたりします。
基本的にマルチスレッドにおけるロッキング処理ですが、
今のところうまく行っているのでソースを置いておきます。class RenewalMessage(): def __init__(self, channel): self.lastmessage = None self.outputlock = 0 self.channel = channel async def SendMessage(self, message): if self.outputlock == 1: return try: while self.outputlock != 0: await asyncio.sleep(1) if self.lastmessage is not None: self.outputlock = 1 try: await self.lastmessage.delete() except discord.errors.NotFound: pass self.lastmessage = None try: self.outputlock = 2 self.lastmessage = await self.channel.send(message) except discord.errors.Forbidden: pass finally: self.outputlock = 0
- 投稿日:2020-09-28T12:57:38+09:00
スクレイピング1
Aidemy https:// aidemy.net 2020/9/21
はじめに
こんにちは、んがょぺです!文系大学生ですが、AI分野に興味が湧いたのでAI特化型スクール「Aidemy」に通い、勉強しています。以前のまとめ記事も多くの方に読んでいただけてとても嬉しいです。ありがとうございます!
今回は、スクレイピングの一つめの投稿になります。どうぞよろしくお願いします。*本記事は「Aidemy」での学習内容を「自分の言葉で」まとめたものになります。表現の間違いや勘違いを含む可能性があります。ご了承ください。
今回学ぶこと
・スクレイピングとは
・Webページを取得する(クローリング)スクレイピングとは
スクレイピングについて
・スクレイピングとは、Webページから必要な情報を自動で抜き出す作業のことである。
・スクレイピングを使うことで、機械学習で必要な大量のデータを集めることができる。
・ただし、Web上にあるデータは自由に利用が認められているデータ(オープンデータ)出ない場合もあるので、注意が必要。スクレイピングの流れ
・スクレイピングして良いか確認する。また、データを取得できるAPIが提供されていればそちらを利用する。
・データを得られるWebページを取得する。これをクローリングと言う。
・Webページの中から必要な情報を入手する。(スクレイピング)スクレイピングの主な手法3つ
・wgetコマンド:wgetコマンドを使ってWebページをダウンロードし、unixコマンドや正規表現を使ってスクレイピングを行う。単純で手軽だが機能不足。
・Webスクレイピングツール:Chromeの拡張機能やスプレッドシートその他スクレイピングが可能なツールを使う。機能に制限がある、有料の場合があるなどの点もあるので注意。
・プログラミング:自分でスクレイピングの機能をプログラミングする。複雑なデータも扱える。今回はこの方法でスクレイピングする。エンコードとデコード
・エンコードとは、データを符号化して別の形式にすることである。
・デコードとは、エンコードされたデータを元の形式に戻すことである。
・スクレイピングでは、一度エンコードして仮のデータを取得し、その仮データをデコードすることでデータを取得することができる。Webページを取得する(クローリング)
Webページの取得
・Webページの取得にはurllib.requestモジュールをインポートして使えるようになるurlopen("URL")で行う。
・取得したWebページはread()メソッドで参照できるが、デコードされていないので、文字列(str型)ではないことに注意。(デコードの仕方は次項以降で確認)from urllib.request import urlopen #GoogleのURLを取得 url=urlopen("https://www.google.co.jp")取得したWebページをデコードする
・デコードには、そのWebページに使われている「文字コード」の情報が必要なので、まずはこれを取得する。文字コードはinfo().get_content_charset(failobj="utf-8")メソッドを使うことで取得できる。
・上記メソッドの(failobj="utf-8")とは、文字コード(charset)がWebページ側で指定されていないときに、自動で文字コードを"utf-8"にしてくれると言う意味である。日本語のページは基本的に"utf-8"なのでこのように指定されている。url = urlopen("https://www.google.co.jp") #文字コードの取得and表示 encode = url.info().get_content_charset(failobj="utf-8") print(encode) #shift_jis・文字コードが取得できたら、その文字コードに対応したデコードを行い、
部分をstr型のHTMLコードとして取得。
・デコードはurl.decode(文字コード)で行う。内容はread()で確認できる。#すでにエンコードしたurlを、取得した文字コード(encode)でデコード url_decoded = url.decode(encode) print(url_decoded.read()) #略(HTMLのコードが出力される)もっと簡単にWebページを取得
・requestモジュールをインポートして使えば、urllibよりも簡単にWebページを取得できる。ただし、複雑な操作をする場合には、前処理が大変になってしまう。
requests.get("URL")でURLの取得、取得したURLに対し、encodingを使えば文字コードが取得でき、textを使えばデコードされた状態のHTMLコードが取得できる。import requests url=requests.get("https://www.google.co.jp") print(url.encoding) #shift_jis print(url.text) #略まとめ
・スクレイピングとは、Webページを取得し、そこから必要なデータを抜き出すことである。機械学習では、学習に必要なデータを収集するときに使う。
・Webページを取得(クローリング)するときにはurllib.requestモジュールのurlopen()関数を使うが、デコードしなければデータとしては扱えない。
・デコードするには、まずWebページの文字コードを取得し、その文字コードに合わせてdecode()メソッドを使わなければならない。
・requestsモジュールを使えば、requests.get()でURLが取得でき、それに対しencodingを使えば文字コードが取得でき、textを使えばデコードされた状態のHTMLコードが取得できるため非常に簡単である。今回は以上です。ここまで読んでくださりありがとうございました。
- 投稿日:2020-09-28T12:51:43+09:00
簡単なパスワード保護付き検索サービスを5分で立ち上げる
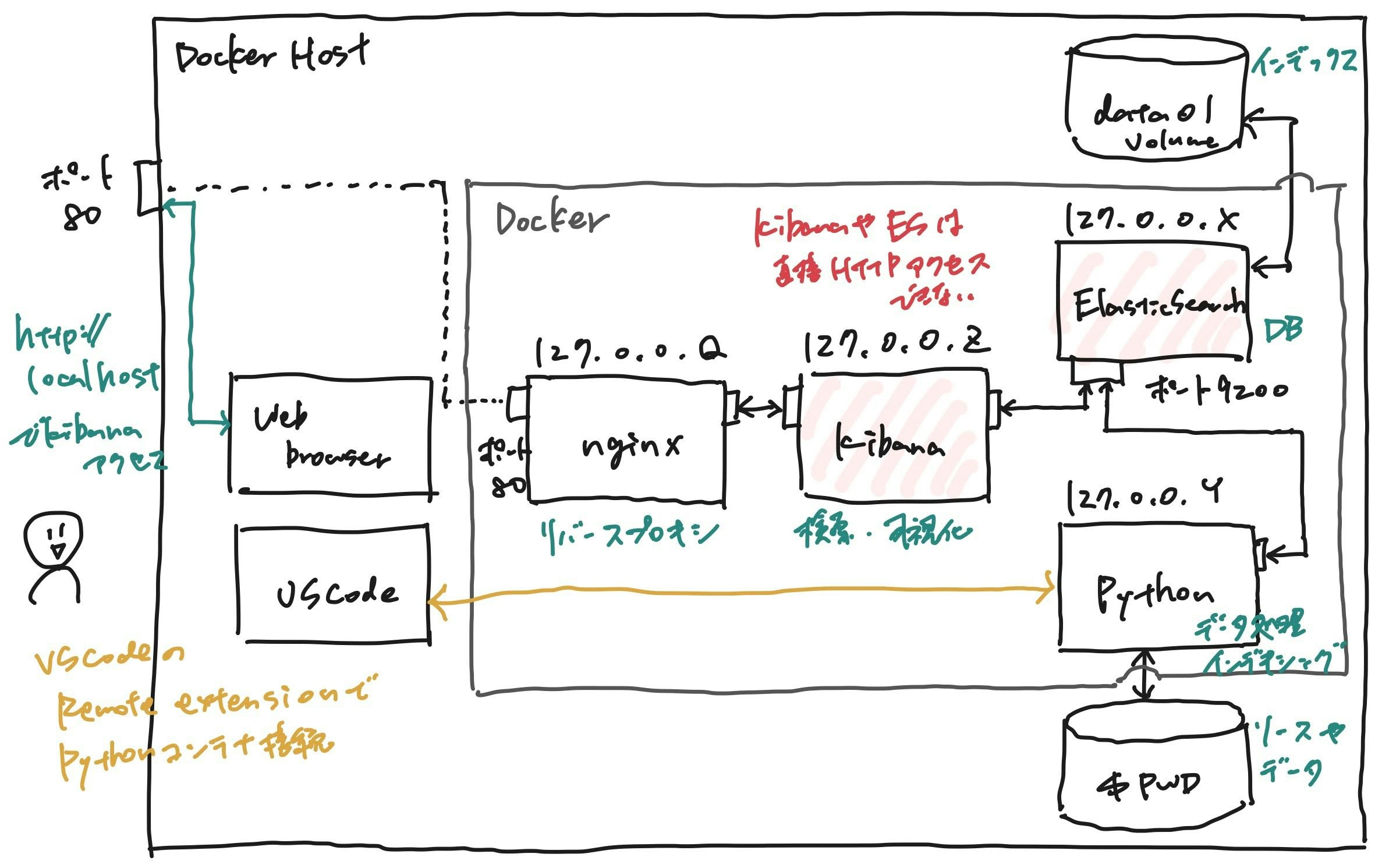
TL;DR (経験者向けまとめ)
下記のコンテナをまとめたdocker-compose.yml を作りました:
- Elasticsearch: 検索エンジン
- Kibana: 簡単な検索画面
- nginx: リバースプロキシ(ID/PWによる軽いユーザー認証)
- Python3: データを加工したりインデックスしたりする作業用
背景
みなさんのご家庭にあるテキストデータをちょっと検索してみたくなることってありますよね?
検索の機能自体はElasticsearchで提供できるのですが
- Non programmerでも使えるように、簡単な検索画面が欲しい(Kibana)
- 秘密のデータなのでパスワード認証かけたい(nginxによるベーシック認証)
- 手軽にデータを追加できるようにしたい
・・・といった要求も一緒に上がってくることが多いです。
以上の要求をかなえるための環境を作りました。1
作ったもの
このリポジトリに全部載せてあります: https://github.com/chopstickexe/es-kibana-nginx-python
主な内容は下記の通りです:
- docker-compose.yml: Elasticsearch, Kibana, nginx, Python3の4つのコンテナをまとめて立ち上げて連携させるための設定ファイル
- index.py: Python3コンテナの中でElasticsearchへのデータの登録(インデキシング)を行うためのサンプルコード
- data/sample.csv: index.pyで登録しているサンプルデータ(ご覧の通り、ノーラン監督作品の個人的な感想文4件です)
Docker Compose概要
このdocker-composeを使うと、下記のような環境が立ち上がります:
- Elasticsearch, Kibana, nginx, Pythonの4つのコンテナが立ち上がるが、ホストにポートがマップされている(ホスト外からHTTPアクセス可能な)コンテナはnginxだけ。そのため、ElasticsearchやKibanaにはnginxで設定したID/PWを知ってる人しかアクセスできない
- Elasticsearchのインデックスデータはホストのどこかのディレクトリに保存される(local volume)。そのため、コンテナを終了・再起動しても、また同じインデックスにアクセスできる。
http://ホストアドレスのような簡単なアドレスでKibanaにアクセス可能。- Pythonコンテナにソースコードやデータをマウントしているため、
docker execでこのコンテナに入って、データの加工やインデキシングを行うPythonコードを実行することが可能。2動かし方
以下、Ubuntu18.04を前提として説明しますが、docker-composeやApache HTTPサーバー(より具体的にはhtpasswdコマンド)が動く環境であれば、CentOSやMac, Windowsでも動くと思います。
事前準備1. docker-composeのインストール
まず、docker-composeがインストールされた環境を用意します。参考
事前準備2. Apache HTTPサーバーのインストール
まず、apache2-utils(HTTPサーバーが入っているパッケージ)をインストールします。
$ sudo apt -y install apache2-utils1. Gitリポジトリのclone
上記リポジトリchopstickexe/es-kibana-nginx-pythonをcloneします。
2. ログインID・パスワードの準備
そして、この後立ち上げるKibana(検索画面)にログインするためのIDとパスワードを何か考えます。
(以下の例ではID=adminでログインします)htpasswdコマンドを以下のように実行し、パスワードを設定したファイル
(cloneしたディレクトリ)/htpasswd/localhostを作成してください。$ cd /path/to/repo $ mkdir htpasswd && cd htpasswd $ htpasswd -c localhost admin # ここにパスワードを入力※ このファイル名(localhost)はdocker-compose.ymlのKibanaコンテナに設定した環境変数VIRTUAL_HOSTと同じ文字列にする必要があります。詳しくはjwilder/nginx-proxyのREADMEを見てください。
3. (オプショナル) docker-compose.ymlの編集
Kibanaにホスト以外のマシンからWebブラウザ経由でアクセスしたい場合
cloneしてきたディレクトリのdocker-compose.ymlを開き、KibanaコンテナのVIRTUAL_HOSTの設定値を
localhostからホストのIPアドレスか、またはfoo.bar.comのようなFQDNに変更してください。すでにホストの80番ポートで別のサービスが立ち上がっている場合
nginxコンテナのポートマッピングを
80:80からホストの空いているポート:80に変更してください。4. Dockerコンテナの起動
下記のdocker-composeコマンドでコンテナを起動します。
$ cd /path/to/this/directory $ docker-compose up5. WebブラウザからKibanaにアクセスできることを確認
docker-compose.ymlを変更していない場合はホストのブラウザから
http://localhost、
変更した場合はお手元の環境のブラウザからhttp://ホストアドレスを開き、設定したIDとパスワードでログインして、Kibanaの画面が見えることを確認してください。6. Elasticsearchにサンプルデータ登録
ホストマシンのターミナルに戻り、下記のコマンドでPythonコンテナに入ってください:
$ docker exec -it python bashPythonコンテナに入ったあとは、下記のコマンドで仮想環境(venv)を作り、そこに必要パッケージをpip installします:
# python -m venv .venv # source .venv/bin/activate (.venv) # pip install -r requirements.txtパッケージのインストールが終わったら、下記のコマンドでサンプルデータをElasticsearchの
nolanインデックスに登録してください:(.venv) # python index.py Finished indexingここで実行しているPythonスクリプトindex.pyはこちらです。
下記でRELEASE_DATEという列のデータ型をdate(日付型)、フォーマットをyyyyMMddに設定しています。es.indices.create( index, body={ "mappings": { "properties": {"RELEASE_DATE": {"type": "date", "format": "yyyyMMdd"}} } }, )7. Kibana上で検索できることを確認
Webブラウザから再びKibanaにアクセスし、下記を設定する:
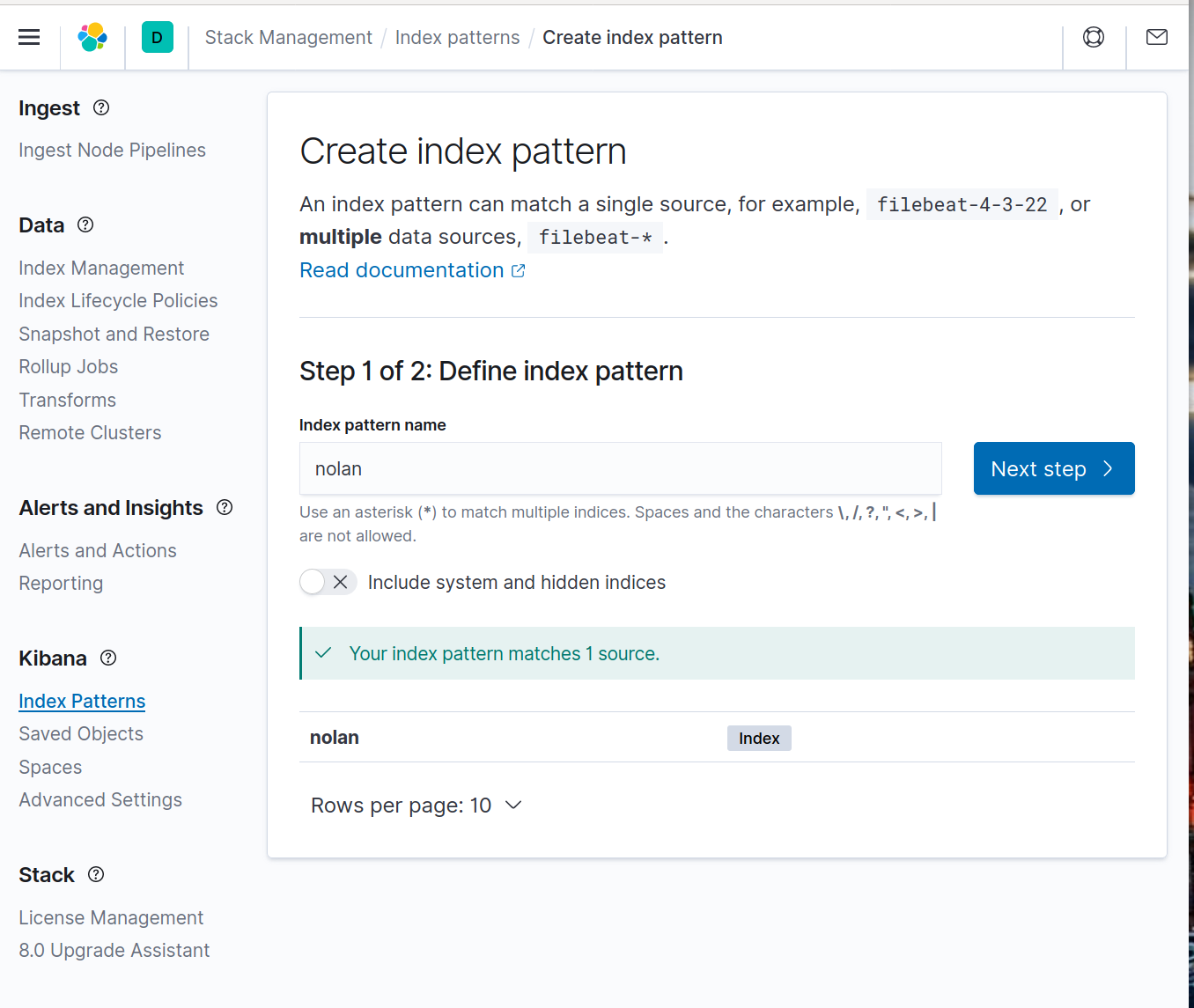
Index Patternを作成
画面左側のメニュー(表示されていない場合は左上の三をクリック)
から Kibana > Index Patterns を選択し、index pattern nameにnolanを入力する。上記のPythonコードが問題なく実行できていればYour index pattern matches 1 sourceというメッセージが出るのでNext stepをクリック:
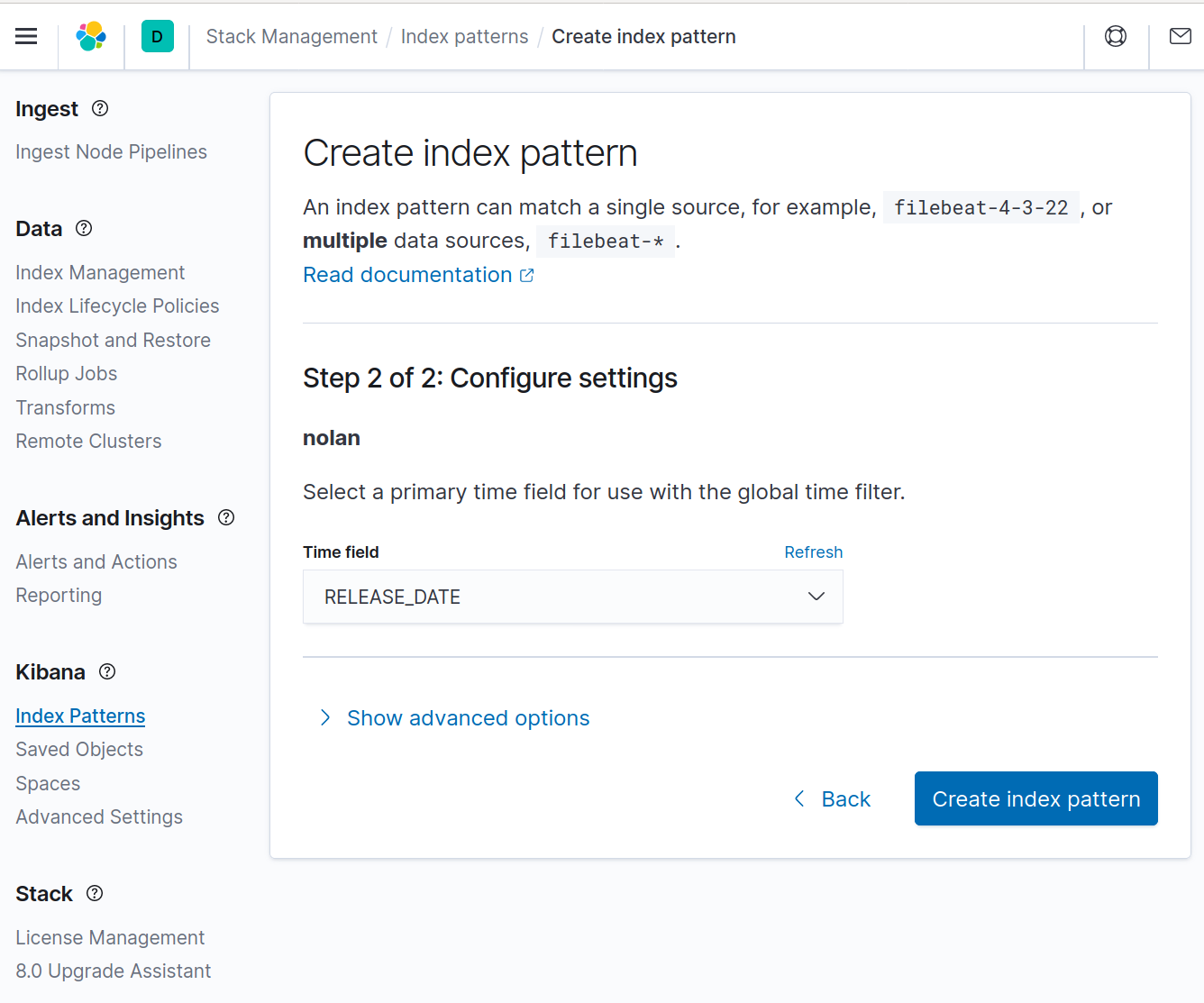
Time fieldに
RELEASE_DATE列を設定し、Create index patternをクリックする。
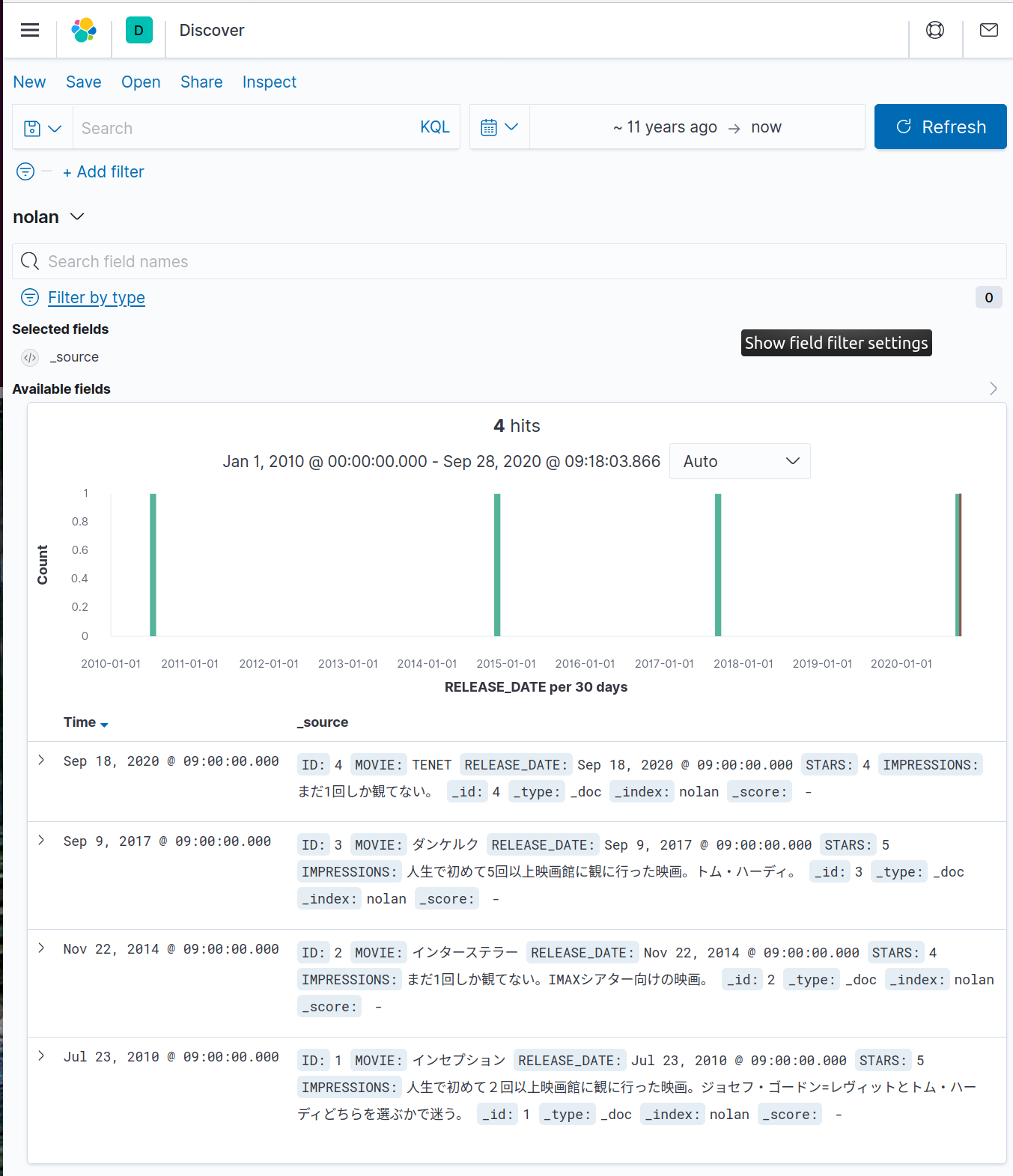
Discover画面上でTime rangeを~11 years ago -> nowに設定
画面左側のメニューからDiscoverを選択し、画面中程のカレンダーアイコンをクリックして、Time rangeをRelative > 11 years agoに設定する。
(結構古いRELEASE_DATEのレビューが入っているので、このようにしないと検索にヒットしません)正しく設定できると、以下のように4件のレビューが表示されます:
このDiscover画面上から「トム・ハーディ」を含むレビューを検索することも可能です:
参考資料
kibanaの使い方はこちらも参考にしてください: https://qiita.com/namutaka/items/b67290e75cbd74cd9a2f
ベーシック認証はもしかしたらElasticsearch Securityを使うと、もう少し気の利いたものができるのかもしれません。また、本記事で紹介する方法はhttp接続を利用していて、セキュリティ的にはガバガバなのでこちらの記事を参考にhttps化することもご検討ください: https://qiita.com/hsano/items/3b4fb372c4dec0cabc08 ↩
また、例えばVSCodeのRemote Containers extensionを利用してコンテナに接続し、コードを編集・実行することも可能。 ↩

- 投稿日:2020-09-28T12:37:22+09:00
ワンクリックでたくさんの写真を切り抜けるノートブック
データセットづくりに
フォルダ内の画像を一気に切り抜けるノートブックをつくりました。
TensorFlow公式のDeepLabのノートブックが元になっています。使い方
2,ご自身のGoogle Driveに切り抜きたい画像のフォルダをアップロード。保存先フォルダも作る。
3,ノートブックからGoogle Driveをマウント
4,右側のメニューで、切り抜きたいオブジェクト、使用したいモデル、画像フォルダのパス、保存先フォルダのパス、画像拡張子を選択。
5,ノートブックを実行
画像フォルダ内のすべての画像が切り抜かれ、保存フォルダに保存されます。
?
お仕事のご相談こちらまで
rockyshikoku@gmail.comCore MLを使ったアプリを作っています。
機械学習関連の情報を発信しています。
- 投稿日:2020-09-28T10:26:56+09:00
Python学習 自分用メモ
はじめに
本記事はProgate Python学習コースでの内容を箇条書きしていたものを記事化したものとなります。
ここ違うよ、とか間違ってるよ、などありましたらお気軽に編集リクエストください、泣いて喜びます。
基本的なやつ、プログラム学習で一番最初に学ぶアレ
print("hello Python")変数の宣言
Pythonでは「name = 文字列」と表記する
型の宣言は特になさそう、stringもintも入る
変数名をつけるとき、わかりやすい方が良い(基本だが)
りんごの値段ならapple_priceのように命名すると良い感じ?
applePriceじゃないデータ型の扱い
Pythonでは異なるデータ型を連結することができないため、型変換を行う必要がある
数値型を文字列型に変換する時は「str(変数名)」と記述する
逆に数値型に変換する時は「int(変数名)」と書く条件分岐
Pythonではif{}といった書き方をせずコロンを使う
スペースで条件式の中を書いていくhoge = 80 if hoge == 100: print("TRUE") print("FALSE")真偽値の出力はprint(変数名 == 100)のように書く
elseを書く時はインデントの必要なし、:だけつけとこうelif
Pythonではelse ifをelifと書く、この記法は他で見たことない
使い方は一緒だから安心しよう!and,or,not
&&,||のような記号では書かない、これもあんまり見ない気がする
使い方は同じinput
コンソールに入力された内容を受け取れる
input("個数を入力してください")とか書くとそれだけで動く、便利
なお受け取った内容は文字列型なので型変換してやらないといけないリスト
Pythonでは数値と文字列を同時に扱うリストを作れる
["hoge1","hoge2",10,100]と記述する
変数に代入することもできる
リストの要素は0スタートで、変数名[0]とすればリスト0に該当するデータを取り出せる
リストの更新は以下の通りbighoge = ["hoge1","hoge2","hoge3"] bighoge[2] = "hogehoge"リストに要素を追加する(増やす)時はappendを使う
bighoge.append("hoge")for文
Pythonのfor文はめちゃくちゃ楽に見えた
for 変数名 in リスト: print("なんか適当に" + 変数名)で宣言してやるとリストの中身全部出してくれる
辞書
なんとリストで辞書を作れるらしい、どういうことだ
作り方は変数名 = {"キー名": "要素"}って感じ
取り出す時は変数名["キー名"]を使う
辞書にデータを追加する際は、appendは使わず、辞書に存在しない文字列を入れればおkbighoge[hoge5] = "hoge10"辞書の更新はリストの更新と同様で、変数名["キー名"] = 更新 でできる
辞書の要素をすべて出力するには、上記のforと同じことをやればおk
辞書が入った変数名を指定してあげようfor 変数名 in 辞書名 print(変数名 + "は" + 辞書名[変数名] + "です")while文
お馴染みwhile文、書き方は以下の通り
while x <= 10 print(x) x++無限ループを防ぐためにカウンタ変数の処理は必ずwhile文中に入れよう
break、continue
ループや処理を抜けるためのbreak、処理をやり直すcontinue
知ってる人の方が多いと思うので割愛関数について
Pythonで関数を作る時はdefを使う、Railsみたい
def 関数名(): print("値")呼び出す時は関数名()だけで良い
()内には仮引数を設定でき、関数を呼び出す際の()に文字列を入れることで関数の結果が変化する
仮関数は複数もたせることができ、,で分ければおk
また、仮引数に初期値をもたせることもでき、「仮引数 = 初期値」と書く戻り値
いつも通りのreturn
真偽値を返す場合は「return True/False」だけでいいモジュール化
長くて冗長なコードはすぐバグの原因になるので分けましょう
分けたコードはimportを使って呼び出すことができる
モジュールの使い方は、「モジュール名.関数名()」で使用することができる
なお、importする際に.pyをつける必要はないライブラリ
Pythonにもいろんなライブラリが存在する
乱数用のrandomとか日付を扱うdatetimeとか
使っていくうちに覚えようクラス
Javaやってるなら分かりやすい
要は弁当箱を作っておかずは各々で決めてねってやつ
定義は簡単で「class クラス名:」としてやれば良い
クラスの中身は記述する必要があるが、処理がない場合はpassとだけ書いとけばおkインスタンス
クラスがあるならインスタンスがあるということ、常識だね(?)
「変数名 = クラス名()」とすることでインスタンスを生成できる
インスタンスを生成した変数に対して、「変数名.インスタンス変数(任意) = 任意」とするとそこに格納されるクラス内ではdefでメソッドを作れる、ただし第一引数は必ず「(self)」とつけること、お約束らしい
メソッドの呼び出し方はインスタンスと同じ「変数名.メソッド名()」init
Pythonでしか見たことない、メソッドが呼び出された時点で実行されるメソッド
hogeが呼び出されました。のような使い方ができる
使い方は以下の通りdef __init__(self):initも第2引数以降をもたせることができる
完走して思ったこと
基本的にコードがシンプルなため可読性がとにかく高く、変数の処理なども見やすいため楽しく学習できたと思う
以前Javaをやっていたため、クラスなどの概念はスムーズに理解することができた
そのうちPythonを使ったツールか何かを作ってGithubにあげてみようと思う