- 投稿日:2020-09-28T22:39:14+09:00
Doma入門 - Criteria APIの紹介
はじめに
DomaはJava 8以上で動作するデータベースアクセスフレームワークです。JDBCドライバが提供されるデータベース、主なものでいえば、MySQL、PosgreSQL、Microsoft SQL Sever、H2 Databaseのようなデータベースにアクセスできます。
Domaの最近のバージョンで型安全にSQLを組み立てるための新しいAPI、Criteira APIが追加されました。この記事では、執筆時点で最新のバージョン2.43.0に基づいてCriteria APIを紹介します。
エンティティクラスの定義
次のようなデータベーススキーマがあるとします。
create table employee ( id integer not null primary key, name varchar(255) not null, age integer not null, version integer not null);上記のテーブルに対応するエンティティクラスは次のように定義できます。
@Entity(metamodel = @Metamodel) public class Employee { @Id public Integer id; public String name; public Integer age; @Version public Integer version; }一見、通常のエンティティクラスの定義ですが、
@Entityの宣言にmetamodel = @Metamodelという記述があることに注目してください。この記述がすごく重要で、適切な設定でコンパイルすることでEmployeeクラスと同じパッケージにEmployee_というメタモデルクラスが生成されるようになります。メモモデルクラスの中身
わかりやすさのために少し省略しますが、メタモデルクラスの
Employee_は大体次のようなコードになります。public final class Employee_ implements EntityMetamodel<Employee> { public final PropertyMetamodel<java.lang.Integer> id = ...; public final PropertyMetamodel<java.lang.String> name = ...; public final PropertyMetamodel<java.lang.Integer> age = ...; public final PropertyMetamodel<java.lang.Integer> version = ...; }このメタモデルクラスのポイントは、
id、name、age、versionのようにエンティティクラスのプロパティと同じ名前のプロパティを持っているということです。また、エンティティクラスにおけるプロパティの型情報を持っています。これ以降は、このメタモデルクラスとCriteria APIを使って実際にSQLを組み立てる例を示します。
Criteria APIの利用
Criteria APIはどこでも利用できますが、例えば次のようにxxxRepositoryという名前のクラスを作ってその中で利用するとわかりやすいでしょう。
public class EmployeeRepository { private final Entityql entityql; public EmployeeRepository(Config config) { this.entityql = new Entityql(config); } public Employee selectById(Integer id) { // メタモデルの生成 Employee_ e = new Employee_(); // メタモデルを使ってSQLを組み立て結果を取得 return entityql.from(e).where(c -> c.eq(e.id, id)).fetchOne(); } }上記クラスの
selectByIdメソッドの中身がCriteria APIの利用例です。このメソッドではメタモデルクラスとCriteria APIのエントリーポイントであるEntityqlクラスを使ってSQLを組み立て実行結果を1つのエンティティとして取得しています。組み立てられるSQLは次のようなものになります。
select t0_.id, t0_.name, t0_.age, t0_.version from Employee t0_ where t0_.id = ?型安全の観点で言うと、WHERE句を組み立てる
where(c -> c.eq(e.id, id))の中のeqメソッドがポイントです。このメソッドはジェネリクスを活用し、第1引数の型から第2引数の型をコンパイル時に決定しています。つまり、この例では、
eqメソッドの第1引数にメタモデルクラスのInteger型を表すプロパティを渡すことで第2引数の型をInteger型に決定しています。したがって、例えば、c.eq(e.id, "String value")のように第2引数に誤った型を渡してしまうこと(結果として実行時にエラーを発生させること)を防いでいます。おわりに
エンティティを取得する例を使って、DomaのCriteri APIにより型安全にSQLを組み立てられることを示しました。
ここで示したコードと同等のものは、下記のプロジェクトから入手できます。
- 投稿日:2020-09-28T20:40:40+09:00
【Java】ループ処理と九九の表
forループで九九の表を作る
public class Enshu0112 { public static void main(String[] args) { System.out.println("九九の表"); System.out.println("\t| 1 2 3 4 5 6 7 8 9"); // 最初の見出しの行 System.out.println("----+------------------------------------"); for (int i = 1; i < 10; i++) { // 縦のループ System.out.printf("%3d |", i); for (int j = 1; j < 10; j++) { // 横のループ System.out.printf("%3d", (j*i)); // 表示桁を合わせて縦が揃うようにする } System.out.println(); // 改行を挿入 } } }\tで縦を合わせようとしたら左寄せでになってしまった
見出しの行に\t1\t\2...という形で縦を揃えようとしたら左寄せになったので、半角スペースで調整することにしました。
なんにせよループ処理の練習で九九は基本ですね。
- 投稿日:2020-09-28T19:30:21+09:00
Spring BootでRESTなサービスを作ったときの備忘録
概要
STSを使ってSpring WebでRESTなサービスを使ったときの備忘録を残しておきます。
主に自分用。
Spring Webとは、Spring Frameworkをベースにした
Webアプリケーションフレームワークです。開発環境は次の通りです。
OS : Windows 7 Home Edition 64bit
Java : JavaSE 8 update 181
Spring Boot : 2.3.4
STS : 4.6.1STSのセットアップ
STSのセットアップは自分の備忘録を参考にしました。
プロジェクトの作成
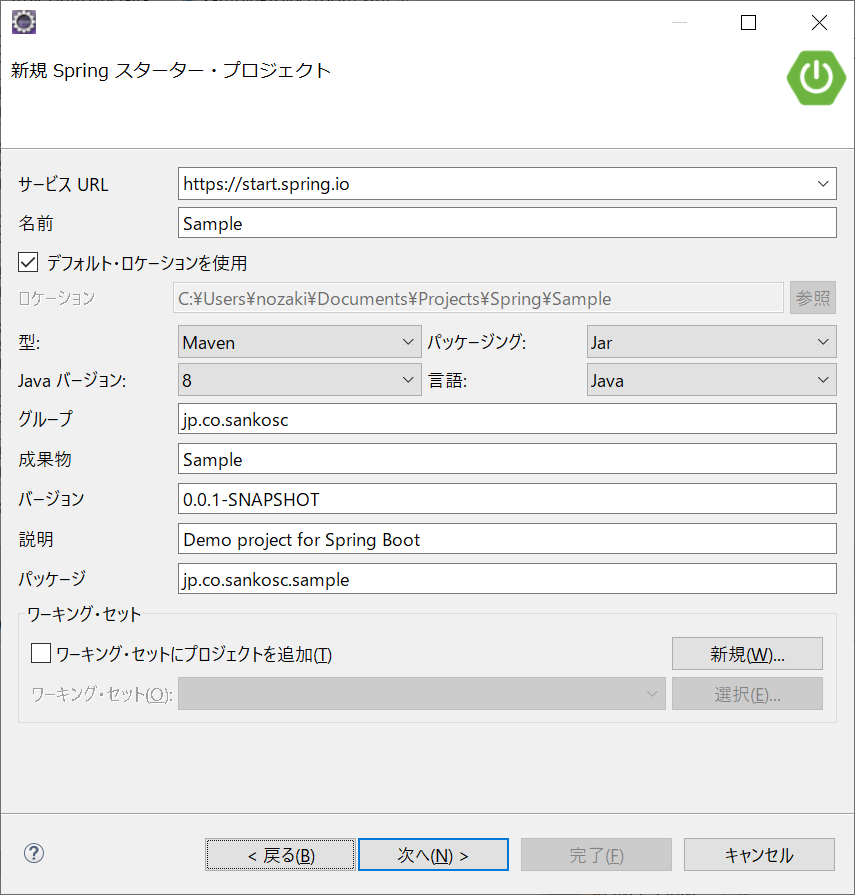
Create new Spring Starter Projectでプロジェクト作成、
参照したライブラリは以下の通りです。
- Spring Web
- Spring Data JPA
- Oracle Driver
- Lombok
アプリケーションの作成
作成したクラス、設定ファイル、用意したデータは次の通りです。
Spring Bootアプリケーション起動時の実行クラスです。
SpringWebSampleApplication.javapackage jp.co.illmatics; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; @SpringBootApplication public class SpringWebSampleApplication { public static void main(String[] args) { SpringApplication.run(SpringWebSampleApplication.class, args); } }REST APIとなるクラスです。
REST APIにするために@RestControllerを、
CORSでアクセス権を付与するために@CrossOriginを
それぞれ付与しました。取得できる値はJSON形式となります。
値の詳細は後程説明します。UsersController.javapackage jp.co.illmatics.controller; import java.util.List; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.web.bind.annotation.CrossOrigin; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RequestMethod; import org.springframework.web.bind.annotation.RestController; import jp.co.illmatics.dao.UserDao; import jp.co.illmatics.model.User; @CrossOrigin @RestController public class UsersController { @Autowired private UserDao userInfoDao; @RequestMapping(method = RequestMethod.GET, value = "/users") public List<User> get() { return userInfoDao.getUserInfoList(); } }Data Access Objectです。
実装時にはインターフェースとその実装クラスの両方が必要です。UserDao.javapackage jp.co.illmatics.dao; import java.util.List; import jp.co.illmatics.model.User; public interface UserDao { public List<User> getUserInfoList(); }UserDaoの実装クラスです。
Userのリストを取得するメソッドを定義します。
IDカラム昇順で全件取得します。UserDaoImpl.javapackage jp.co.illmatics.dao; import java.sql.ResultSet; import java.sql.SQLException; import java.util.List; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.jdbc.core.JdbcTemplate; import org.springframework.jdbc.core.RowMapper; import org.springframework.stereotype.Repository; import jp.co.illmatics.model.User; @Repository public class UserDaoImpl implements UserDao { @Autowired private JdbcTemplate jdbcTemplate; public List<User> getUserInfoList() { List<User> list = jdbcTemplate.query("select * from USER_INFO ORDER BY ID" , new Object[] {}, new RowMapper<User>() { public User mapRow(ResultSet rs, int rowNum) throws SQLException { User user = new User(); user.setId(rs.getString("ID")); user.setName(rs.getString("NAME")); user.setAge(rs.getInt("AGE")); return user; } }); return list; } }USER_INFOテーブルのモデルクラスです。
User.javapackage jp.co.illmatics.model; import javax.persistence.Table; import org.springframework.stereotype.Component; import lombok.Data; @Data @Component @Table(name = "USER_INFO") public class User { private String id; private String name; private Integer age; }テストデータを格納したDB接続情報です。
application.propertiesspring.datasource.driver-class-name=oracle.jdbc.driver.OracleDriver spring.datasource.url=jdbc:oracle:thin:@localhost:1521:XE spring.datasource.username=xxxxxx spring.datasource.password=xxxxxx spring.jpa.database-platform=org.hibernate.dialect.Oracle10gDialect spring.jpa.show-sql=true作成したテーブルです。
※USERというテーブル名は予約語のため作成できず、
このような名前にしています。作成したテーブルcreate table USER_INFO ( "ID" varchar2(20), "NAME" varchar2(20), "AGE" number(3,0), constraint "PK_USER" primary key ("ID") );USER_INFOテーブルに用意したデータです。
ID NAME AGE user001 userName001 35 user002 userName002 30 user003 userName003 25 動作確認
実行してみます。
できました。
以上です。最後までお読みいただき、ありがとうございました。

- 投稿日:2020-09-28T16:17:42+09:00
SpringでJsonデータを送受信するAPI作成
- Java 8
- Eclipse Version: 2020-09
- Windows 10
久しぶりにSpringでのお仕事でした。
Springにて、APIをひとつ作成するというもの。備忘のために、ひな形作成までをまとめます。
ちなみに、Spring Boot は初めてでした。仕様
Jsonでポストされたデータを受け取り、いろいろやってJsonデータを返します。
開発環境
Pleiades All in One Eclipse を選択
https://mergedoc.osdn.jp/#pleiades.html からダウンロード
Eclipse 2020 > Windows 64bit > Java Full Edition を選択7-Zipが必要らしいので、それもダウンロード・インストール
https://sevenzip.osdn.jp/プロジェクト作成
- 「ファイル > 新規 > プロジェクト」で新規プロジェクトウィザーとを開く Spring Boot > Spring スターター・プロジェクトを選択
- Javaバージョンは8に
- 依存関係では、 Web->Spring Webを選択
- 完了
実装:データ定義
- 入力データ、出力データを定義したクラス(InputData, OutputData)を作成
InputDatapackage jp.co.sankosc.sample; public class InputData { public int id; public String value; }OutputDatapackage jp.co.sankosc.sample; import java.util.Date; public class OutputData { public int id; public String value; public Date date; }実装:処理
- ApiControllerクラスを作成
- クラスに@RestControllerアノテーションを定義
- メソッド定義(今回はpostというメソッド)
- メソッドに@RequestMappingアノテーションでuriを定義
- 入力パラメータを@RequestBodyアノテーションで定義
ApiControllerpackage jp.co.sankosc.sample; import java.util.Date; import org.springframework.web.bind.annotation.RequestBody; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RequestMethod; import org.springframework.web.bind.annotation.RestController; @RestController public class ApiController { @RequestMapping(value="/post", method=RequestMethod.POST) public OutputData post(@RequestBody InputData input) { OutputData output = new OutputData(); output.id = input.id; output.value = input.value; output.date = new Date(); return output; } }実行
- プロジェクトを選択して
- 実行 > 実行 > Spring Bootアプリケーション
確認
確認コマンド$postData = @{id=123;value="InputData.Value"} | ConvertTo-Json -Compress Invoke-WebRequest -Method Post -Uri http://localhost:8080/post -Body $postData -ContentType application/json実行結果StatusCode : 200 StatusDescription : Content : {"id":123,"value":"InputData.Value","date":"2020-09-28T06:45:30.925+00:00"}Jarファイル生成
- プロジェクトを選択して
- 実行 > 実行 > Maven Install
- targetの下にjarファイルが作成される
サーバーでの実行
java -jar [.jarファイル]
- これをスクリプトにして、サービス登録する
- 投稿日:2020-09-28T16:16:37+09:00
thymeleafで共通部分のcssが適用されない
はじめに
thymeleaf layout dialect機能を使用したサイトにおいて、共通部分のcssが適用されない事案が発生したので、その対処法について紹介します。
環境
OS: macOS Catalina 10.15.6
JDK:14.0.1
Spring Boot 2.3.3
jquery 3.3.1-1
bootstrap 4.2.1エラー概要
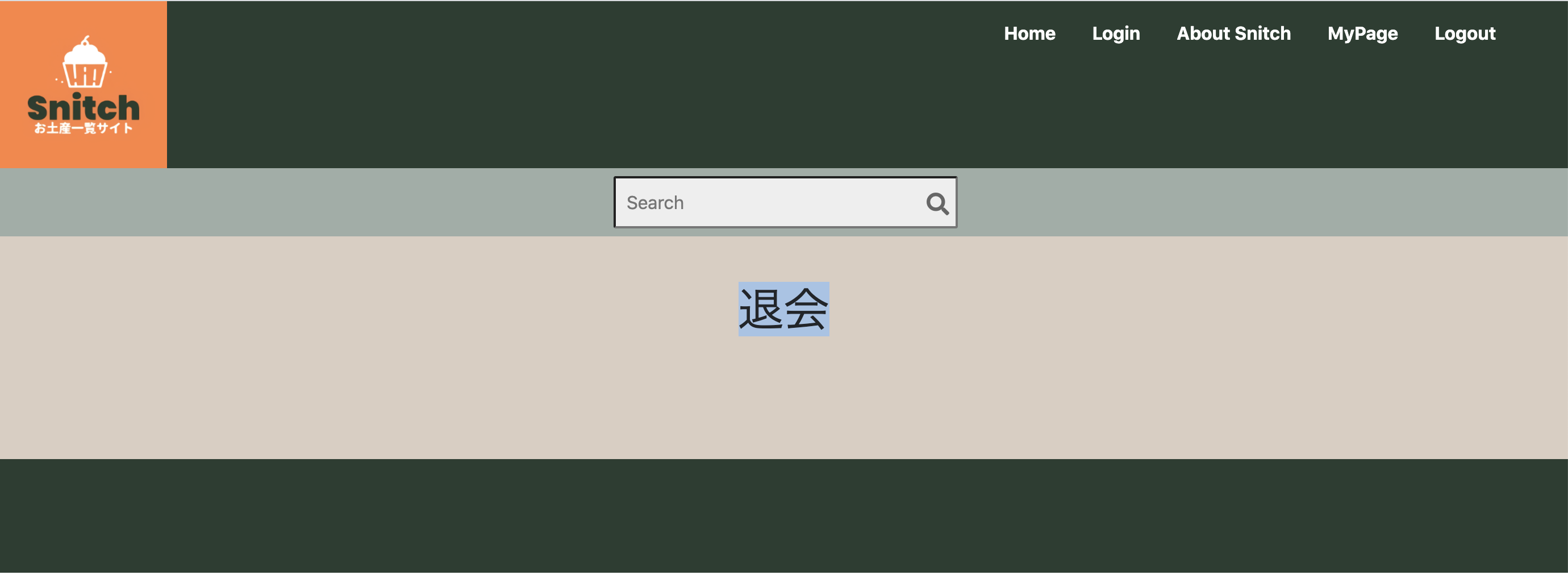
共通部分にcssが正常に適用されると下図のように画面上部に深緑のヘッダー、ロゴ、検索窓が表示されます。
今回、他のページより深い階層にhtmlファイルを作成、格納し実行したところ下記のようになりました。
共通部分に含まれているナビゲーションバー、ロゴ、検索窓は表示されているので、thymeleaf layout dialect機能自体は適用されているようですが、共通部分のcssが適用されておりません。
利用ファイルの階層
今回cssが適用されなかったページは、赤枠のhtmlで作成。
cssが適用されたページとは異なった階層なので、cssへのパスが適切ではない事による事象ではないか?と筆者は仮定いたしました。
デベロッパーツールで適用されているcssのパスを確認
デベロッパーツールでこのページがどういったパスでcssへアクセスしているかを確認します。
htmlファイル上では「css/template.css」とありますが、実際は「http://localhost:8080/mypage/css/template.css」
とcssファイルが格納されていないディレクトリへアクセスを試みています。
共通部分「template.html」の内容を修正
共通部分のhtmlである「template.html」のhead要素の中にある、
<link th:href="@{css/template.css}" rel="stylesheet"></link>の下に下記を追記します。
<link th:href="@{../css/template.css}" rel="stylesheet"></link>「利用ファイルの階層」でも説明したように、「deleteUser.html」はcssが適用されたhtmlよりも1段階下の階層に位置するので、「th:href」に
../ (1階層上の)を加え、「deleteUser.html」からcssへアクセスできるようにしました。template.html<head> <meta charset="UTF-8"></meta> <link th:href="@{/webjars/bootstrap/4.2.1/css/bootstrap.min.css}" rel="stylesheet"></link> <script th:src="@{/webjars/jquery/3.3.1-1/jquery.min.js}"></script> <script th:src="@{/webjars/bootstrap/4.2.1/js/bootstrap.min.js}"></script> <link th:href="@{css/template.css}" rel="stylesheet"></link> <link th:href="@{../css/template.css}" rel="stylesheet"></link> <script src="https://kit.fontawesome.com/665f18a48e.js" crossorigin="anonymous"></script> <title>template</title> </head>保存して実行
cssが適用されました。




- 投稿日:2020-09-28T15:48:39+09:00
【AndroidStudio】SQLiteDatabaseで連続入力できる記述【Java】
はじめに
Android初心者です。
テキストやWebページを見ながら EditText の値をデータベースに登録できるようになったのですが、連続入力しようとすると落ちてしまう。
アプリを1回開く度1回しかデータを登録できない!
これはアプリとして致命的だと思いどうしたら良いのか調べました。
要因は2つあると思います。
➀try-catch-finally 文が書けていない
➁データベースを開く場所が誤っている
もし、同じ状況で悩んでいる方の参考になればと思い記事にすることにしました。➀try-catch-finally 文が書けていない について
この後のコードを見るとわかるかと思いますが、私のコードは必要な try-catch が書けていません、、そもそも catch文を書いていないコードだったのでとても不安定なコードです。try-catch の重要性はわかるのですが、難しい。。まだまだ勉強が必要だと思いました。
複雑な try-catch を考えるより後述の「try-with-resources」を使ったほうがいいと思います。➁データベースを開く場所が誤っている について
落ちるコード
コードの全文はこちら(私の書いた別記事に飛びます)
1回登録するだけなら落ちません。
2回登録しようとすると「java.lang.illegalStateException attempt to re-open an already-closed object」という例外が出ます。
なぜなら、落ちるコードはデータベースを onCreate メソッドで開いているからです。
onCreate メソッドはアプリを起動したら初めに実行されるメソッドです。私はここでデータベースを開き、いろいろ処理をしたのちデータベースを解放しています。それを再び操作しようとしても、 onCreate で閉じてしまったのでアプリが落ちてしまうというわけです。MainActivity.javapublic void insertData(SQLiteDatabase db, String maxBP, String minBP, String pulse){ ContentValues values = new ContentValues(); try { values.put("_maxBP", maxBP); values.put("_minBP", minBP); values.put("_pulse", pulse); db.insert("_BPtable", null, values); } finally { db.close(); } }try-with-resources
try-with-resources の利点は複雑な try-catch 文を書かなくて良いというところだと思います。
try-catch がわからない私には大助かりとはいえ try-catch-finally だけ実装されているプログラムのほうが多いと思うので勉強頑張ります。。
try-with-resources の構文はこちらtry (closeによる後片付けが必要な変数の宣言) { 本来の処理 } catch (例外クラス 変数名) { 例外が発生した場合の処理 }先のコードを try-with-resources を用いて書き直したものがこちら
さらに、データベースをメソッドで開けるようにコードを見直しました。➁解決です。MainActivity.javapublic void insertData(String maxBP, String minBP, String pulse){ ContentValues values = new ContentValues(); DatabaseHelper helper = new DatabaseHelper(MainActivity.this); try (SQLiteDatabase data = helper.getWritableDatabase()){ values.put("_maxBP", maxBP); values.put("_minBP", minBP); values.put("_pulse", pulse); data.insert("_BPtable", null, values); } catch (Exception e){ e.printStackTrace(); } }これで try が終わったあと自動的にデータベース解放処理が行われます.
連続登録落ちしないプログラムができました!参考
WINGSプロジェクト 齊藤新三 著/山田祥寛 監修『Androidアプリ開発の教科書』
中山清喬 著/国本大悟 著/株式会社フレアリンク 監修『スッキリわかるJava入門 第3版』
- 投稿日:2020-09-28T15:24:38+09:00
Red Hat Decision Manager 計画最適化の性能検証
著者: 株式会社 日立ソリューションズ 柳村 明宏
監修: 株式会社 日立製作所はじめに
計画最適化とは、限られたリソースの中で、守るべき制約や効率を考慮しながら、最も良い計画(組合せ計画)を立案することです。
ここで、対象となる計画の規模(例:人員のシフト計画の場合、対象となる人員数や割り当てるシフト枠数)が増加すると、その組合せ数も増加し、良い計画を立案できるまでの時間も増加します。
そのため、計画最適化を行う場合は、以下の内容を検討する必要があります。
- どれくらいの規模の最適化を行うのか
- どれくらいの計算時間をかけられるのか
- どれくらいのマシンスペックが必要か
本稿では、人員の日次シフト計画のモデルケースについてRed Hat Decision Managerを利⽤して計画を最適化する性能検証を紹介します。
本稿が以下のような点でお役に立てれば幸いです。
- 計画最適化が、規模の大きいケースでも現実的な計算時間で対応できることを確認する
- 計算時間やマシンスペックの概算見積時の参考値として利用する
- 設計開発時に調整する最適化アルゴリズムやパラメタのベース値として参照する
なお、Red Hat Decision Managerを利⽤した計画最適化の概要や活用イメージについては、以下の記事を参考にしてください。
結果の理由が分かるAIで計画最適化
結果の理由が分かるAIで計画最適化「活用イメージ」モデルケース
計画の概要
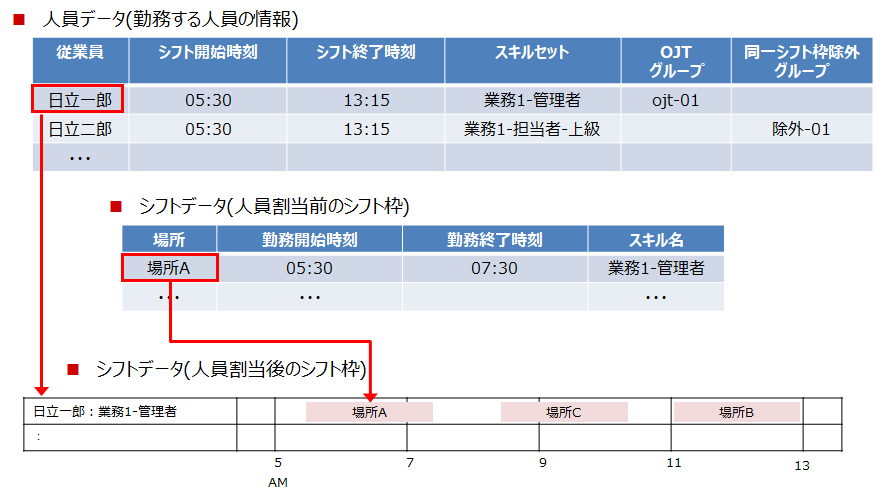
1つの勤務エリアで複数の業務が存在する人員の日次のシフト計画を立案します。具体的には、各シフト枠に対して業務を遂行する人員を、制約や効率を考慮しながら割り当てます。
シフトデータ(⼈員割当後のシフト枠)の作成イメージを以下に示します。
今回のモデルケースでは以下の3パターンの人員数とシフト枠数があるものとします。
# 人員数 シフト枠数 1 1000 4212 2 500 2106 3 250 1053 制約ルール
本モデルケースでは以下の制約ルールを設定しています。
# 制約ルール 制約種別 制約種別説明 レベル 1 シフト枠に必ず人員を割り当てる。 絶対制約 必ず遵守する制約ルール。 Hard 2 同じ人員を、同じ勤務時間帯の複数のシフト枠に割り当てない。 3 各人員の勤務時間帯を遵守する(早出、残業をさせない)。 考慮制約 可能な限り遵守する制約ルール。
ただし、他の制約ルール、評価指標との兼ね合いで遵守しないケースもある。Soft 4 業務に必要なスキルを持つ人員を割り当てる。 5 スキルレベルが低い人員をスキルレベルの高いシフトに割り当てない。 6 OJTグループが同じ人員(指導係と新人)は、同じ勤務時間帯+同じ勤務場所とする。 7 同一シフト枠除外グループが同じ人員(相性が合わない人など)は、同じ勤務時間帯+同じ勤務場所にしない。 8 勤務エリアの移動回数を少なくする。 評価指標 より良い組合せを算出するための制約ルール。 9 人員の作業時間を平準化する。 モデルケースの規模(探索空間のサイズ)と目標スコア
スコアは最適化計算を評価する指標値です。
本モデルケースでは、すべての制約ルールでスコアにペナルティ値(負の値)を付与するため、0(0hard/0soft)が最良のスコアとなります。しかし、限られたリソース(人員数、シフト枠数)や、計画にかけられる時間などの制限がある中で、どこまで最適化できれば良しとするかを目標スコアとして設定します。本モデルケースで設定する規模(探索空間のサイズ)に対する目標スコアは以下の通りです。
# 規模(探索空間のサイズ) 目標スコア 人員数 シフト枠数 1 1000 4212 0hard/-69000soft 2 500 2106 0hard/-34500soft 3 250 1053 0hard/-17250soft 目標スコアの考え方は以下の通りです。
制約種別 目標スコア 目標スコアの計算式 絶対制約 0 ― 考慮制約 0 ― 評価指標 本モデルケースでは、以下の目標で最小化します。
- 勤務エリア移動回数:1人2回以内とする。
- 作業平準化:平均シフト従業率の±7%以内とする。
- 2[回/人] × 人員数 × ペナルティ(重み)値(-10)
- 72[%] × 人員数 × ペナルティ(重み)値(-1)
合計 0hard/-(69 × 人員数)soft 探索空間のサイズ
探索空間のサイズは、計画に対して考えられる組合せ数であり、探索空間のサイズが大きいほど計算時間がかかります。
本モデルケースにおける探索空間のサイズは、「人員数」の「シフト枠数」乗となります。
# 人員数 シフト枠数 探索空間のサイズ 1 250 1053 2501053 ≧ 102525 2 500 2106 5002106 ≧ 105684 3 1000 4212 10004212 ≧ 1012636 Red Hat Decision Managerの探索空間のサイズの仕様は、OptaPlanner User Guide の Search space size に記載されていますので、参考にしてください。
本稿の検証結果を参考値として利用する場合は、この探索空間のサイズを十分に考慮してください。検証環境
本検証では以下のような検証環境を利用して検証を実施しました。
マシン環境
項目 値 OS名 Microsoft Windows10 Pro プロセッサ Intel® Core™ i7-6700 CPU @ 3.40GHz、3408 Mhz、4個のコア、8個のロジカルプロセッサ 物理メモリ 16GB ソフトウェア情報
ソフトウェア名称 バージョン Red Hat Decision Manager 7.6.0 OpenJDK 1.8.0 設定情報
項目 値 Javaの初期ヒープ・サイズ 4096 MB Javaの最大ヒープ・サイズ 4096 MB 利用スレッド数 6 Red Hat Decision Managerの最適化計算では、複数のCPUスレッドを利用して、計算速度を向上できる機能として、Multithreaded incremental solvingという機能があります。moveThreadCountパラメタを追加し、そこに利用したいスレッド数を指定することで利用できます。
本機能を利用した場合、複数のスレッドで分割して最適化計算を行うことができますが、nスレッド使っても単純にn倍の計算速度になるわけではないことに注意してください。Multithreaded incremental solvingの詳細な仕様は、OptaPlanner User Guide の Multithreaded incremental solvingを参照してください。
検証方法
最適化アルゴリズムとチューニングパラメタ
Red Hat Decision Managerは、様々な最適化アルゴリズムをサポートしています。
目標スコアに到達するまでに必要な計算時間は、選択した最適化アルゴリズムとそのアルゴリズムのチューニングパラメタの指定値によって変わります。本検証では、よく利用される以下の3つの最適化アルゴルズムを利用して検証を行います。
- Tabu Search
- Late Acceptance
- Simulated Annealing
アルゴリズムの詳細な仕様や、Red Hat Decision Managerで利用できる他のアリゴリズムに関して知りたい方は、OptaPlanner User Guideを参照してください。
また、Red Hat Decision Managerには、アルゴリズム、パラメタの最適化計算結果をレポートで出力する機能として、ベンチマーク機能があります。ベンチマーク機能を利用し、各アルゴリズム、パラメタの構成を比較することで、パラメタチューニングを効率よく推進することができます。
ベンチマーク機能の詳細な仕様は、OptaPlanner User Guide の Benchmarking and Tweakingを参照してください。最適化計算の終了条件
本検証では、最適化計算の終了条件として、以下の2つのどちらかを満たした場合に終了する設定としています。
- 規定時間到達
- ベストスコアが5分間未更新
「目標スコアに到達」という終了条件も設定できますが、どの程度までスコアが上昇するかも確認したかったため、上記の終了条件としています。実際のシステムでも、目標スコアに到達したらすぐ計算終了させることよりも、許容される時間内でより良い結果を得られるように、上記のような終了条件を設定することも多いと思います。
評価ポイント
本検証では以下の結果をまとめています。
- 目標スコアに到達した時間
- 30分経過後のベストスコア
- 60分経過後のベストスコア(250名規模は30分までしか検証しなかったため、500名規模、1000名規模のみ記載。)
250名規模のような小規模の最適化計算では、可能な限り速く目標スコアに到達することを一番の評価ポイントと考え、1 で評価(順位付け)します。
500名、1000名規模のような大規模の最適化計算では、目標スコアに到達する時間も重要な評価ポイントですが、限られた時間で最適な解を導くことを最も重要な評価ポイントと考え、2 で評価(順位付け)します。検証結果
検証したパターンが非常に多いため、上位の検証結果を抜粋して紹介します。
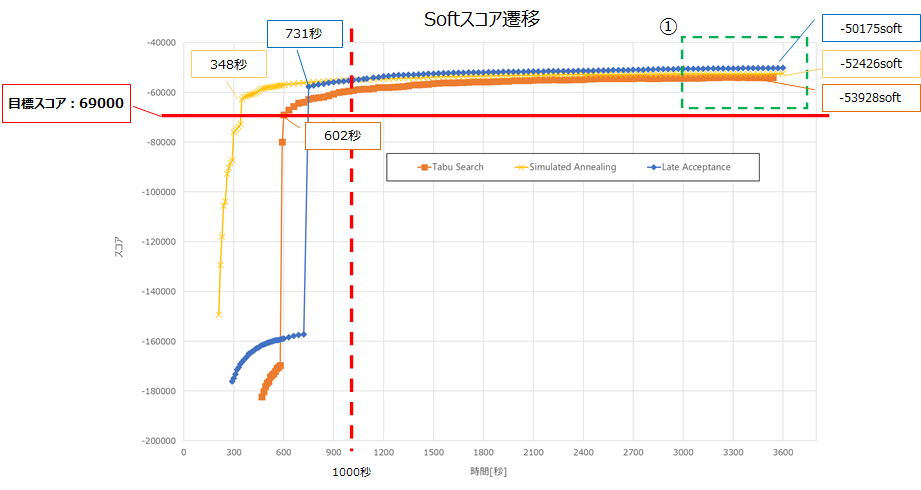
「30分/60分経過後のベストスコア」列の下段の括弧内の数値は、終了条件「ベストスコアが5分間未更新」を満たし、最適化計算が終了した際の時間(秒)を表します。「目標スコアに到達した時間[秒]」列の太字になっている箇所は、各検証パターンで最速で目標スコアに到達した時間です。1000名(目標スコア : 0hard/-69000soft)
Tabu Search
順位 パラメタ 目標スコアに
到達した時間[秒]30分経過後の
ベストスコア60分経過後の
ベストスコアentityTabuSize acceptedCountLimit 1 9 4000 602 0hard/-55780soft 0hard/-53928soft
(3559[秒])2 9 2000 687 0hard/-57125soft 0hard/-56419soft
(2545[秒])3 5 4000 668 0hard/-57476soft 0hard/-55623soft 4 7 2000 1154 0hard/-57586soft 0hard/-57208soft
(2317[秒])Late Acceptance
順位 パラメタ 目標スコアに
到達した時間[秒]30分経過後の
ベストスコア60分経過後の
ベストスコアlateAcceptanceSize acceptedCountLimit 1 3 1 731 0hard/-51909soft 0hard/-50175soft 2 1 1 306 0hard/-53840soft 0hard/-52862soft 3 5 1 1239 0hard/-54752soft 0hard/-51532soft 4 1 4 1270 0hard/-55282soft 0hard/-53976soft Simulated Annealing
順位 パラメタ 目標スコアに
到達した時間[秒]30分経過後の
ベストスコア60分経過後の
ベストスコアsimulatedAnnealing
StartingTemperatureacceptedCountLimit 1 0hard/10soft 4 348 0hard/-53457soft 0hard/-52426soft 2 0hard/5soft 4 1113 0hard/-55198soft 0hard/-53803soft 3 0hard/50soft 4 477 0hard/-55700soft 0hard/-52170soft 4 0hard/100soft 4 1210 0hard/-58192soft 0hard/-51499soft 1000名規模のデータでは、最速306秒で目標スコアに到達しました。
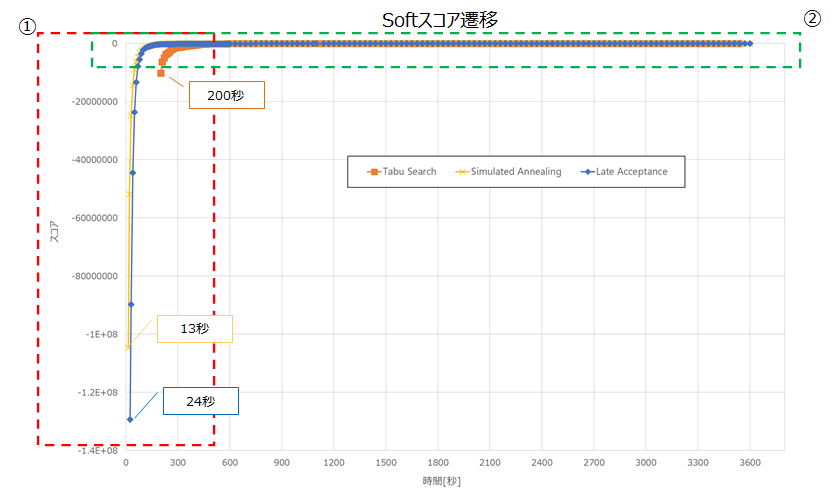
また、目標スコア到達後も最適化計算を行うことで、ベストスコアが更新されました。以下は、前述の表でのアルゴリズムごとのNo1のSoftスコア遷移です。
各アルゴリズムの始点はHardスコアが0hardとなった地点です。
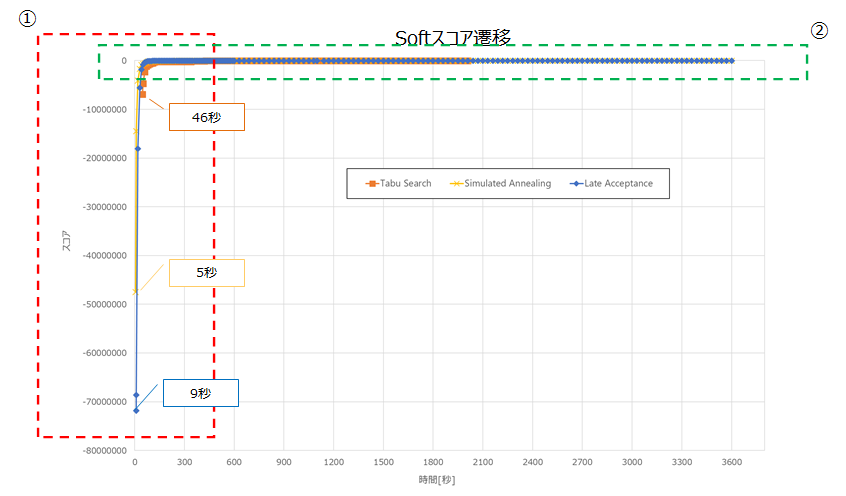
①の吹き出しのとおり、Simulated Annealingが最も速く0hardに収束しました。以下に②を拡大した図を記載します。
目標スコアへの到達が最も速いアルゴリズムは、Simulated Annealingでした。
1000秒程度までは、Simulated Annealingが最も良いスコアですが、以降はLate Acceptanceが最も良いスコアとなりました。
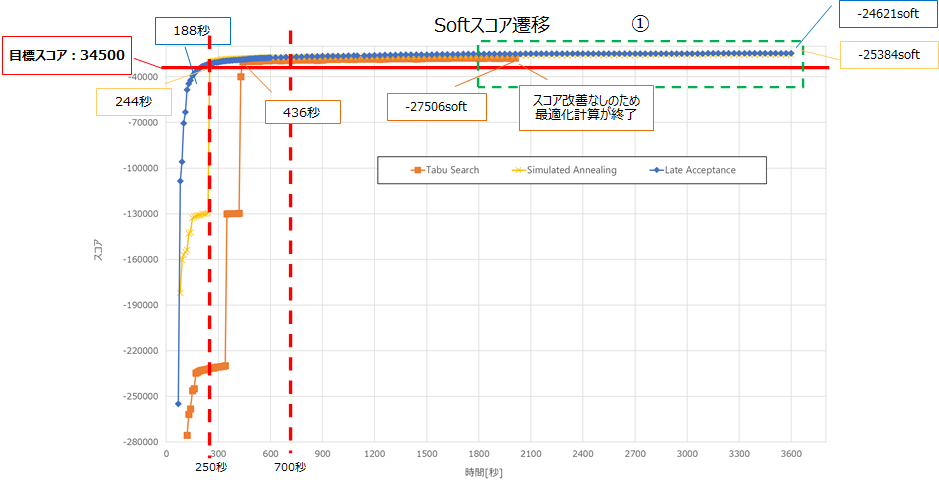
①の3000秒から最適化計算終了までのスコア上昇に関しては、各アルゴリズムで数100程度となっており、これ以上最適化計算を行っても大幅なスコア改善は見込まれないと想定します。500名(目標スコア : 0hard/-34500soft)
Tabu Search
順位 パラメタ 目標スコアに
到達した時間[秒]30分経過後の
ベストスコア60分経過後の
ベストスコアentityTabuSize acceptedCountLimit 1 7 2000 436 0hard/-27506soft 0hard/-27506soft
(2027[秒])2 5 4000 263 0hard/-28082soft 0hard/-27701soft
(2584[秒])3 7 4000 464 0hard/-28222soft 0hard/-27649soft
(3237[秒])4 9 2000 170 0hard/-28585soft
(1129[秒])― Late Acceptance
順位 パラメタ 目標スコアに
到達した時間[秒]30分経過後の
ベストスコア60分経過後の
ベストスコアlateAcceptanceSize acceptedCountLimit 1 5 1 188 0hard/-24991soft 0hard/-24621soft 2 3 1 153 0hard/-25755soft 0hard/-25625soft
(2712[秒])3 100 4 517 0hard/-25983soft 0hard/-25213soft 4 50 4 284 0hard/-26562soft 0hard/-26196soft Simulated Annealing
順位 パラメタ 目標スコアに
到達した時間[秒]30分経過後の
ベストスコア60分経過後の
ベストスコアsimulatedAnnealing
StartingTemperatureacceptedCountLimit 1 0hard/5soft 4 244 0hard/-26071soft 0hard/-25384soft 2 0hard/10soft 4 685 0hard/-26438soft 0hard/-25791soft 3 0hard/5soft 1 468 0hard/-27423soft 0hard/-26365soft 4 0hard/50soft 4 151 0hard/-27932soft 0hard/-26146soft 500名規模のデータでは、最速151秒で目標スコアに到達しました。
また、目標スコア到達後も最適化計算を行うことで、ベストスコアが更新されました。以下は、前述の表でのアルゴリズムごとのNo1のSoftスコア遷移です。
各アルゴリズムの始点はHardスコアが0hardとなった地点です。
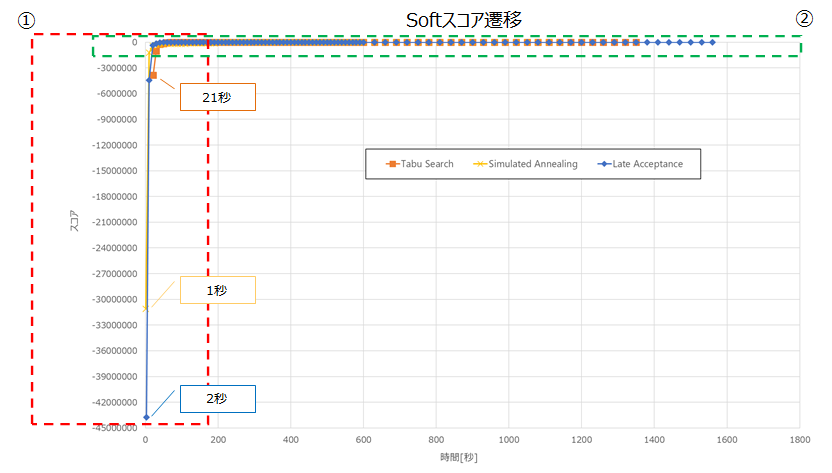
①の吹き出しのとおり、Simulated Annealingが最も速く0hardに収束しました。以下に②を拡大した図を記載します。
目標スコアへの到達が最も速いアルゴリズムは、Late Acceptanceでした。
250秒から700秒程度までは、Simulated Annealingが最も良いスコアですが、以降はLate Acceptanceが最も良いスコアとなりました。
①の1800秒から最適化計算終了までのスコア上昇に関しては、各アルゴリズムで数100程度となっており、これ以上最適化計算を行っても大幅なスコア改善は見込まれないと想定します。また、Tabu Searchに関しては、2000秒程度でスコアの改善が見られず最適化計算が終了しています。250名(目標スコア : 0hard/-17250soft)
Tabu Search
順位 パラメタ 目標スコアに
到達した時間[秒]30分経過後の
ベストスコア60分経過後の
ベストスコアentityTabuSize acceptedCountLimit 1 11 2000 167 0hard/-15400soft
(1378[秒])ー 2 9 2000 224 0hard/-15265soft
(1722[秒])ー 3 5 1000 244 0hard/-16190soft
(686[秒])ー 4 7 4000 262 0hard/-15850soft ― Late Acceptance
順位 パラメタ 目標スコアに
到達した時間[秒]30分経過後の
ベストスコア60分経過後の
ベストスコアlateAcceptanceSize acceptedCountLimit 1 5 1 98 0hard/-14755soft
(1775[秒])ー 2 20 1 182 0hard/-14681soft ー 3 10 1 216 0hard/-14534soft
(1739[秒])ー 4 10 4 248 0hard/-15118soft
(1499[秒])ー Simulated Annealing
順位 パラメタ 目標スコアに
到達した時間[秒]30分経過後の
ベストスコア60分経過後の
ベストスコアsimulatedAnnealing
StartingTemperatureacceptedCountLimit 1 0hard/5soft 4 193 0hard/-15151soft
(1159[秒])ー 2 0hard/100soft 4 325 0hard/-14977soft ー 3 0hard/50soft 1 1215 0hard/-14584soft ー 4 0hard/500soft 4 1355 0hard/-15122soft ー 250名規模のデータでは、最速98秒で目標スコアに到達しました。
また、目標スコア到達後も最適化計算を行うことで、ベストスコアが更新されました。以下は、前述の表でのアルゴリズムごとのNo1のSoftスコア遷移です。
各アルゴリズムの始点はHardスコアが0hardとなった地点です。
①の吹き出しのとおり、Simulated Annealingが最も速く0hardに収束しました。以下に②を拡大した図を記載します。
目標スコアへの到達が最も速いアルゴリズムは、Late Acceptanceでした。
開始から終了までLate Acceptanceが最も良いスコアとなりました。
①の300秒から最適化計算終了までのスコア上昇に関しては、各アルゴリズムで数100程度となっており、これ以上最適化計算を行っても大幅なスコア改善は見込まれないと想定します。考察
今回の検証では、Red Hat Decision Managerで1000名規模の計画最適化を現実的な時間の範囲内で実現できることが確認できました。ここでは、検証から見えてきた内容を考察します。
各アルゴリズムの計算時間とスコアの特性
本検証のモデルケース、規模(探索空間のサイズ)および制約ルールの重み値では、各アルゴリズムの計算時間のスコアの特性(傾向)は見られませんでした。
各アルゴリズムのチューニングのしやすさ
# 最適化アルゴリズム 検証から見られる特性 検証結果からの考察 1 Tabu Search チューニングパラメタの値の範囲が広い。 多くのパラメタを検証してチューニングすれば、最高スコアを出せる可能性は高いと想定します。
ただし、入力データは毎回同じではないため、汎用的な調整は難しいと想定します。2 Late Acceptance チューニングパラメタの値の範囲が比較的狭い。 パラメタの変更に伴うスコアの改善・悪化の傾向が見えやすく、本検証で利用した3つのアルゴリズムの中では、最も調整しやすいと想定します。 3 Simulated Annealing 本検証の検証結果では、チューニングパラメタの値の範囲が比較的狭い。
ただし、チューニングパラメタ「simulatedAnnealingStartingTemperature」で「受け入れを許可するスコア値の初期値」を指定するため、制約ルールの重み値に依存する。規模(探索空間のサイズ)だけでなく、制約ルールの重み値も考慮して調整する必要があり、Late Acceptanceより調整が難しいと想定します。 チューニングパラメタの調整方法
# 最適化
アルゴリズムチューニングパラメタ 指定範囲 1 Tabu Search entityTabuSize 5~12 2 acceptedCountLimit 1000~4000 3 Late Acceptance lateAcceptanceSize 1~600 4 acceptedCountLimit 1 または 4 5 Simulated Annealing simulatedAnnealingStartingTemperature (制約ルールの重み値に依存。) 6 acceptedCountLimit 1 または 4 #3,#5 :
規模(探索空間のサイズ)によって調整するパラメタです。規模(探索空間のサイズ)が大きいほど値を小さくすると良いと想定します。
指定値が大きい場合は、評価対象の組合せ数が多くなり、問題を解く時間が長くなりますが、最高スコアが高くなります。
指定値が小さい場合は、評価対象の組合せ数が少なくなり、問題を解く時間が短くなりますが、最高スコアが低くなります。
#1 :
傾向は明確ではありませんが、7,9が比較的よく、規模(探索空間のサイズ)が小さい場合は、値を大きくすると良いと想定します。
#2,#4,#6 :
傾向が不明なパラメタのため、実測することを推奨します。Tabu Size の entityTabuSize の指定範囲は5~11の範囲で検証しましたが、以下のサイトに「5~12の値が良い」と記載がありました。
https://ja.wikipedia.org/wiki/%E3%82%BF%E3%83%96%E3%83%BC%E3%82%B5%E3%83%BC%E3%83%81どのアルゴリズムでもチューニングパラメタを変更することで結果が大きく変わりますが、調整次第で良い結果を得られることがわかりました。
各アルゴリズムのチューニングパラメタの調整方法を紹介しましたが、Late Acceptance が他のアルゴリズムと比較して調整しやすいと感じました。そのため、実測する時間が十分に確保できない場合は、Late Acceptance から調整してみるのも良いと想定します。規模(探索空間のサイズ)ごとに基礎値として利用できそうなパラメタ
本検証では、各規模で約60パターンの検証を行いました。
同様のモデルケース、規模(探索空間のサイズ)および制約ルールの重み値で最適化計算を行う場合は、以下の最適化アルゴリズム・パラメタの組合せの範囲から、パラメタのチューニングを行うことで、効率よくチューニングを行うことできると想定します。
規模
(探索空間のサイズ)最適化アルゴリズム パラメタ 人員数 シフト
枠数1000 4212 Tabu Search entityTabuSize : 7~9
acceptedCountLimit : 1000~4000Late Acceptance lateAcceptanceSize : 1~10
acceptedCountLimit : 1Simulated Annealing simulatedAnnealingStartingTemperature : 0hard/5soft~0hard/100soft
acceptedCountLimit : 4500 2106 Tabu Search entityTabuSize : 5~9
acceptedCountLimit : 1000~4000Late Acceptance lateAcceptanceSize : 3~10
acceptedCountLimit : 1lateAcceptanceSize : 30~100
acceptedCountLimit : 4Simulated Annealing simulatedAnnealingStartingTemperature : 0hard/5soft~0hard/100soft
acceptedCountLimit : 4250 1053 Tabu Search entityTabuSize : 11
acceptedCountLimit : 1000~4000Late Acceptance lateAcceptanceSize : 5~20
acceptedCountLimit : 1Simulated Annealing simulatedAnnealingStartingTemperature : 0hard/5soft
acceptedCountLimit : 4おわりに
本稿では、250名、500名、1000名規模の計画最適化における性能検証結果を紹介しました。
紹介したチューニングパラメタの調整方法や、基礎値として利用できそうなパラメタを参考にすることで、Red Hat Decision Managerがより使いやすくなると思いますので、是非お試しください。

- 投稿日:2020-09-28T14:06:43+09:00
拡張しやすいStream APIの代替を作ってみる
はじめに
Stream APIとはJava SE 8から追加されたデータの列を処理するAPIです。今までコレクションに対して行っていた煩雑な処理をわかりやすいコードで記述することが可能になります。しかし実際に使ってみるといくつか気になる点があります。
- 終端処理で配列化するときは
.toArray()でいいのに、リスト化するときは.collect(Collectors.toList())とする必要があります。.collect()がわかりにくいです。(特にCollectors.groupingBy()など)終端処理を自分で追加できるように、このような実装になったと思いますが、わかりやすさを犠牲にしていると思います。IntStreamやLongStreamはありますが、ByteStreamやCharStreamはありません。Collection APIにはプリミティブ型を直接格納するコレクションはないのに、なぜStream APIにはそれらを追加したのでしょうか。しかも中途半端に。- 中間処理はすべてインスタンスメソッドなので新たな中間処理を追加できません。
これらを改善する新たなAPIを作ってみたいと思います。方針は以下のとおりです。
- APIの拡張を容易にするためにすべてのAPIをインスタンスメソッドではなく、スタティックメソッドで実装します。
- プリミティブ型を直接操作するAPIは実装しません。
- 簡略化のために並列化はあきらめます。
- FunctionインタフェースやComparatorインタフェースなどは既存のものをできる限り流用します。
この記事で記述したすべてのコードは拡張しやすいStream APIの代替を作ってみるにあります。
Streamに代わるインタフェース
Stream APIの代わりになるものを作るとなると、
Streamインタフェースに相当するものを定義する必要があります。新たなインタフェースを定義することもできますがここではIterableインタフェースを使います。CollectionインタフェースはIterableインタフェースを実装しているので、list.stream()のような操作なしで直接的にIterableを取り出すことができます。中間処理
map
最初に
mapを実装してみます。Iterable<T>を受け取って結果としてIterable<U>を返します。List<U>はIterable<U>を実装しているので、List<U>を返してもよいと考えるとこんな実装ができます。public static <T, U> Iterable<U> map(Function<T, U> mapper, Iterable<T> source) { List<U> result = new ArrayList<>(); for (T element : source) result.add(mapper.apply(element)); return result; }しかし、これでは
sourceに100万の要素があると100万件のArrayListが作成されてしまいます。中間処理では要素が必要になったときにmapperを適用した結果を逐次返すようにする必要があります。そのためには逐次的にmappaerを適用するIterator<U>を実装しなければなりません。Iterator<U>を実装すれば、それを返すIterable<U>を実装するのは簡単です。Iterable<U>はIterator<U> iterator()のみが定義された関数型インタフェースだからです。public static <T, U> Iterable<U> map(Function<T, U> mapper, Iterable<T> source) { return () -> new Iterator<U>() { final Iterator<T> iterator = source.iterator(); @Override public boolean hasNext() { return iterator.hasNext(); } @Override public U next() { return mapper.apply(iterator.next()); } }; }テストする前に終端処理
toListを定義しておきます。Iterable<T>を受け取ってList<T>を返します。拡張for文が使えるので簡単です。public static <T> List<T> toList(Iterable<T> source) { List<T> result = new ArrayList<>(); for (T element : source) result.add(element); return result; }テストはこんな感じになります。比較のためStream APIを使ったコードも記述してみます。
@Test void testMap() { List<String> actual = toList( map(String::toUpperCase, List.of("a", "b", "c"))); List<String> expected = List.of("A", "B", "C"); assertEquals(actual, expected); List<String> stream = List.of("a", "b", "c").stream() .map(String::toUpperCase) .collect(Collectors.toList()); assertEquals(stream, expected); }Stream APIではインスタンスメソッドの連鎖で処理を行うため、上から下に向かって順次処理する感じですが、スタティックメソッドを使っているので、記述の順序が逆になります。少し違和感があるかもしれません。
filter
次に
filterを実装してみます。mapの時と同じように逐次的に処理する必要があるので、Iterator<T>を実装する無名のインナークラスを定義します。mapは入力と出力が1対1に対応するので単純ですが、filter`の場合はそうではないので少しめんどうです。public static <T> Iterable<T> filter(Predicate<T> selector, Iterable<T> source) { return () -> new Iterator<T>() { final Iterator<T> iterator = source.iterator(); boolean hasNext = advance(); T next; boolean advance() { while (iterator.hasNext()) if (selector.test(next = iterator.next())) return true; return false; } @Override public boolean hasNext() { return hasNext; } @Override public T next() { T result = next; hasNext = advance(); return result; } }; }
filterが呼び出された時点でselectorの条件を満たすものがあるかどうかを先読みして調べておく必要があります。満たすものがあれば、それをインスタンス変数nextに保存しておいて、next()が呼ばれた時点でそれを返します。同時に次のselectorを満たす要素を探しておきます。
テストしてみます。整数の列から偶数だけを取り出して10倍したものの数列を求めます。@Test void testFilter() { List<Integer> actual = toList( map(i -> i * 10, filter(i -> i % 2 == 0, List.of(0, 1, 2, 3, 4, 5)))); List<Integer> expected = List.of(0, 20, 40); assertEquals(expected, actual); List<Integer> stream = List.of(0, 1, 2, 3, 4, 5).stream() .filter(i -> i % 2 == 0) .map(i -> i * 10) .collect(Collectors.toList()); assertEquals(stream, actual); }Streamの場合は終端処理を行ってしまうと、そのStreamは再利用できません。Iterableの場合は途中結果を保存しておいて、あとからそれを再利用することもできます。
@Test void testSaveFilter() { Iterable<Integer> saved; List<Integer> actual = toList( map(i -> i * 10, saved = filter(i -> i % 2 == 0, List.of(0, 1, 2, 3, 4, 5)))); List<Integer> expected = List.of(0, 20, 40); assertEquals(expected, actual); assertEquals(List.of(0, 2, 4), toList(saved)); }終端処理
終端処理は前述の
toList()のように、拡張for文を使って結果を保存するだけなので簡単です。toMap
toMap()は要素からキーと値を取り出すFunctionを使ってMapを作るだけです。public static <T, K, V> Map<K, V> toMap(Function<T, K> keyExtractor, Function<T, V> valueExtractor, Iterable<T> source) { Map<K, V> result = new LinkedHashMap<>(); for (T element : source) result.put(keyExtractor.apply(element), valueExtractor.apply(element)); return result; }groupingBy
次に単純な
groupingByを実装してみます。要素からキーを取り出してMapにするだけです。キーが重複する要素はリストに詰め込みます。public static <T, K> Map<K, List<T>> groupingBy(Function<T, K> keyExtractor, Iterable<T> source) { Map<K, List<T>> result = new LinkedHashMap<>(); for (T e : source) result.computeIfAbsent(keyExtractor.apply(e), k -> new ArrayList<>()).add(e); return result; }テストしてみます。文字列の長さでグループ化する例です。
@Test public void testGroupingBy() { Map<Integer, List<String>> actual = groupingBy(String::length, List.of("one", "two", "three", "four", "five")); Map<Integer, List<String>> expected = Map.of( 3, List.of("one", "two"), 5, List.of("three"), 4, List.of("four", "five")); assertEquals(expected, actual); Map<Integer, List<String>> stream = List.of("one", "two", "three", "four", "five").stream() .collect(Collectors.groupingBy(String::length)); assertEquals(stream, actual); }次はキーでグループ化したあと重複した要素を集約する
groupingByです。static <T, K, V> Map<K, V> groupingBy(Function<T, K> keyExtractor, Function<Iterable<T>, V> valueAggregator, Iterable<T> source) { return toMap(Entry::getKey, e -> valueAggregator.apply(e.getValue()), groupingBy(keyExtractor, source).entrySet()); }同一キーを持つ要素を
valueAggregatorで集約します。
テストのために終端処理をもう一つ定義しておきます。public static <T> long count(Iterable<T> source) { long count = 0; for (@SuppressWarnings("unused") T e : source) ++count; return count; }以下は文字列の長さでグループ化して、同一文字列長の文字列の数を数えます。
@Test public void testGroupingByCount() { Map<Integer, Long> actual = groupingBy(String::length, s -> count(s), List.of("one", "two", "three", "four", "five")); Map<Integer, Long> expected = Map.of(3, 2L, 5, 1L, 4, 2L); assertEquals(expected, actual); Map<Integer, Long> stream = List.of("one", "two", "three", "four", "five").stream() .collect(Collectors.groupingBy(String::length, Collectors.counting())); assertEquals(stream, actual); }Stream APIでは実装が難しいもの
最後にStream APIでは実装が難しいものをを実装してみましょう。いずれも中間処理です。Stream APIにおける中間操作はすべてインスタンスメソッドなので、容易に拡張できません。
zip
zipは二つのデータ列の先頭から1件ごとにマッチさせて、一つのデータ列にする処理です。二つの入力列の長さが異なる場合は、短い方に合わせて長い方の残りは無視します。static <T, U, V> Iterable<V> zip(BiFunction<T, U, V> zipper, Iterable<T> source1, Iterable<U> source2) { return () -> new Iterator<V>() { final Iterator<T> iterator1 = source1.iterator(); final Iterator<U> iterator2 = source2.iterator(); @Override public boolean hasNext() { return iterator1.hasNext() && iterator2.hasNext(); } @Override public V next() { return zipper.apply(iterator1.next(), iterator2.next()); } }; }整数と文字列の並びを文字列の並びにするテストです。
@Test void testZip() { List<String> actual = toList( zip((x, y) -> x + "-" + y, List.of(0, 1, 2), List.of("zero", "one", "two"))); List<String> expected = List.of("0-zero", "1-one", "2-two"); assertEquals(expected, actual); }cumulative
要素を累積する中間処理です。
reduce()に似ていますが、reduce()が終端処理で一つの値を返すのに対し、cumulativeは列を返します。public static <T, U> Iterable<U> cumulative(U unit, BiFunction<U, T, U> function, Iterable<T> source) { return () -> new Iterator<U>() { Iterator<T> iterator = source.iterator(); U accumlator = unit; @Override public boolean hasNext() { return iterator.hasNext(); } @Override public U next() { return accumlator = function.apply(accumlator, iterator.next()); } }; }先頭からの部分和を求めるテストです。
@Test public void testCumalative() { List<Integer> actual = toList( cumulative(0, (x, y) -> x + y, List.of(0, 1, 2, 3, 4, 5))); List<Integer> expected = List.of(0, 1, 3, 6, 10, 15); assertEquals(expected, actual); }flatMap
flatMap()はStream APIにもありますが、実装方法がわかりにくいので、ここに載せておきます。public static <T, U> Iterable<U> flatMap(Function<T, Iterable<U>> flatter, Iterable<T> source) { return () -> new Iterator<U>() { final Iterator<T> parent = source.iterator(); Iterator<U> child = null; boolean hasNext = advance(); U next; boolean advance() { while (true) { if (child == null) { if (!parent.hasNext()) return false; child = flatter.apply(parent.next()).iterator(); } if (child.hasNext()) { next = child.next(); return true; } child = null; } } @Override public boolean hasNext() { return hasNext; } @Override public U next() { U result = next; hasNext = advance(); return result; } }; }以下はテストです。各要素を2個ずつの並びにに膨らませます。
@Test public void testFlatMap() { List<Integer> actual = toList( flatMap(i -> List.of(i, i), List.of(0, 1, 2, 3))); List<Integer> expected = List.of(0, 0, 1, 1, 2, 2, 3, 3); assertEquals(expected, actual); List<Integer> stream = List.of(0, 1, 2, 3).stream() .flatMap(i -> Stream.of(i, i)) .collect(Collectors.toList()); assertEquals(stream, actual); }最後に
Stream APIに対応するすべてのAPIを実装したわけではありませんが、意外と簡単に相当品が作れることがわかりました。
- 投稿日:2020-09-28T14:01:09+09:00
【AndroidStudio】EditText に登録する値に制限を設けたい【Java】
はじめに
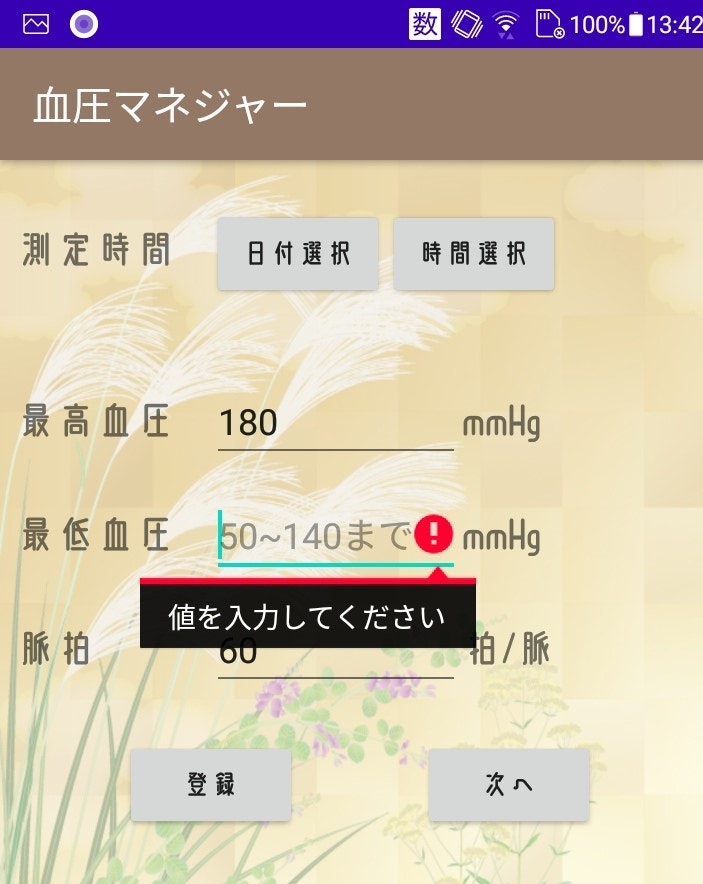
画像3枚は私が作った血圧をメモするアプリです。
EditText に入力した値をデータベースに保存しています。
その際、範囲外の値や null を避けたかったのでいろいろ調べ、if文と論理演算子で書きました。
ちなみにですが、このコードだと連続でデータ登録しようとするとアプリが落ちます。
連続登録落ちについての記事はこちら(私の書いた別記事に飛びます)。


サンプルコード
MainActivity.java
DatePicker と TimePicker、カスタムフォントのコードは省略しています。
DatePicker、TimePicker 導入で参考にしたブログ。
カスタムフォントの記事はこちら(私の書いた別記事に飛びます)。
if文は onClick メソッドの中に書きます。
(コードを載せておいて言うのもあれですが、insertDataメソッドは不安定なコードなのでそっくりそのまま使うことはお控えください)MainActivity.javapublic class MainActivity extends AppCompatActivity { EditText getMaxBP; EditText getMinBP; EditText getPulse; Button btEntry; Button btNext; DatabaseHelper helper; SQLiteDatabase db; @Override protected void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState); setContentView(R.layout.activity_main); helper = new DatabaseHelper(MainActivity.this); db = helper.getWritableDatabase(); btEntry = findViewById(R.id.btEntry); btEntry.setOnClickListener(new View.OnClickListener() { @Override public void onClick(View view) { getMaxBP = findViewById(R.id.etUpperBloodPressure); String maxBP = (getMaxBP.getText().toString()); getMinBP = findViewById(R.id.etLowerBloodPressure); String minBP = (getMinBP.getText().toString()); getPulse = findViewById(R.id.etPulse); String pulse = (getPulse.getText().toString()); String nullMsg = "値を入力してください"; if(maxBP.length()==0){ getMaxBP.setError(nullMsg); return; } else if(minBP.length()==0){ getMinBP.setError(nullMsg); return; } else if(pulse.length()==0){ getPulse.setError(nullMsg); return; } String errorMsg = "この値は入力できません"; if(!(80 <= Integer.parseInt(maxBP) && Integer.parseInt(maxBP) <= 180)){ getMaxBP.setError(errorMsg); return; } else if(!(50 <= Integer.parseInt(minBP) && Integer.parseInt(minBP) <= 140)){ getMinBP.setError(errorMsg); return; } else if(!(40 <= Integer.parseInt(pulse) && Integer.parseInt(pulse) <= 120)){ getPulse.setError(errorMsg); return; } // データベースに値を登録するメソッド insertData(db, maxBP, minBP, pulse); // 登録に成功したらトーストがでる Toast toast = Toast.makeText(BloodPressureAdditionActivity.this, "登録しました", Toast.LENGTH_SHORT); toast.setGravity(Gravity.CENTER, 0, 0); toast.show(); } }); btNext = findViewById(R.id.btNext); btNext.setOnClickListener(new View.OnClickListener() { @Override public void onClick(View view) { Intent intent = new Intent(MainActivity.this, SubActivity.class); startActivity(intent); } }); } public void insertData(SQLiteDatabase db, String maxBP, String minBP, String pulse){ ContentValues values = new ContentValues(); try { values.put("_maxBP", maxBP); values.put("_minBP", minBP); values.put("_pulse", pulse); db.insert("_BPtable", null, values); } finally { db.close(); } }insertDate メソッドの説明ですが、
_maxBP,_minBP,_pulse というカラムに引数の値を渡して insert メソッドで table(ここでは_BPtable) に登録しています。
ContentValues クラスについての説明はこのサイトがわかりやすいと思います。
Let's プログラミング キーと値を追加
insert と close は SQLiteDatabase のメソッドです。
デベロッパー:SQLiteDatabase クラスsetError
setError を使えば自動的に画像のような赤いビックリマークと黒地白文字テキストのスタイルが出力されます。
二つif文を書きましたが、
一つ目はnull
二つ目は範囲外入力
にそれぞれ対応しています。
参考になれば幸いです。
- 投稿日:2020-09-28T06:40:05+09:00
MS932 CP943C 変換問題
Shift_JIS の文字を Unicode に変換する際、文字エンコーディング(=変換テーブル)が異なると問題になることがある。
Shift_JIS
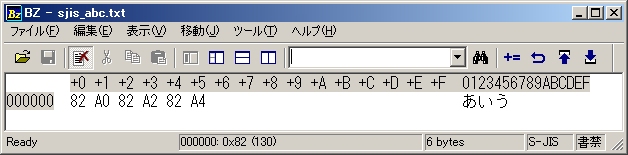
Shift_JIS では「あ」を「0x82A0」、「い」を「0x82A2」、「う」を「0x82A4」で表すように決められている。
Shift_JIS のテキストファイルで「あいう」と書いて、バイナリエディタで開くと確認できる。あ 0x82A0 (Shift_JIS)
い 0x82A2 (Shift_JIS)
う 0x02A4 (Shift_JIS)図.バイナリエディタでShift_JISのテキストファイルを開いたところ
Shift_JIS -> Unicode 変換 (MS932)
Shift_JIS と Unicode では文字(上の例では「あ」)とコード(上の例では「0x82A0」)の割り当てが異なっているので、変換ルール(文字エンコーディング)が決められている。Windows Java での標準文字エンコーディングである MS932 を使うと、Shift_JIS の「あいう」は以下のように変換される。
あ 0x82A0 (Shift_JIS) -> U+3042 (Unicode) MS932で変換した結果
い 0x82A2 (Shift_JIS) -> U+3044 (Unicode) MS932で変換した結果
う 0x02A4 (Shift_JIS) -> U+3046 (Unicode) MS932で変換した結果MS932で変換した結果はJava のツールである native2ascii を使っても確認できる。
native2ascii -encoding MS932 sjis_abc.txt
\u3042\u3044\u3046日本語文字列でよく使われる文字エンコーディングには MS932C だけでなく Cp943C というのも存在する。
Cp943C を使って「あいう」をUnicodeに変換しても結果は同じである。あ 0x82A0 (Shift_JIS) -> U+3042 (Unicode) Cp943Cで変換した結果
い 0x82A2 (Shift_JIS) -> U+3044 (Unicode) Cp943Cで変換した結果
う 0x02A4 (Shift_JIS) -> U+3046 (Unicode) Cp943Cで変換した結果native2ascii でも以下の通り。
native2ascii -encoding Cp943C sjis_abc.txt
\u3042\u3044\u3046ところが一部の文字
- 0x817C (Shift_JIS)
― 0x815C (Shift_JIS)
~ 0x8160 (Shift_JIS)
∥ 0x8161 (Shift_JIS)
¦ 0xFA55 (Shift_JIS)については、MS932とCP943C のそれぞれでUnicodeに変換されたとき、割り当てられるUnicode 文字が異なってしまう。
バグではなく、エンコーディングの仕様
表にすると以下のようになる。
文字 Shift_JIS MS932での変換結果 Cp943Cでの変換結果 - 0x817C u+FF0D u+2212 ― 0x815C u+2015 u+2014 ~ 0x8160 u+FF5E u+301C ∥ 0x8161 u+2225 u+2016 ¦ 0xFA55 u+FFE4 u+00A6 以下は native2ascii での結果。
native2ascii -encoding MS932 sjis.txt
\uff0d\u2015\uff5e\u2225\uffe4native2ascii -encoding Cp943C sjis.txt
\u2212\u2014\u301c\u2016\u00a6
以下リンクからの転載記事です。
https://sites.google.com/site/myitmemo/java-kanren/unicode/ms932-vs-cp943c

- 投稿日:2020-09-28T01:45:45+09:00
開発未経験のエンジニアでも開発業務に就くことができるプロジェクト(つづき)
概要
未経験のエンジニアの方でどうやったら開発に業務に携われることができるかご相談を受けました。相談に対して回答していく中で2人で一緒に何か作っていこうという話になり、それ自体をプロジェクトとして発足しました。
8月度から継続で活動している内容になり、今回の記事は9月の内容をまとめております。8月の活動記録については以下の記事にまとめておりますので、ご興味がありましたらお読みいただければ幸いです。
■開発未経験のエンジニアでも開発業務に就くことができるプロジェクト
https://qiita.com/tamoco/items/cf657ec4d74ccbf4d493今回はこのプロジェクトを行うことで実際に企業に面談に行く機会が増えてきました。実は開発業務に就くことができたのは9月の話で、現場が決まるまでもう少しお話がつづいています。そういった経緯も赤裸々に記事としてまとめてみましたのでぜひお読みいただければ幸いです。
前回(8月)は何をやったか
いろいろと2人で一緒に考えたり作業したりして以下のことができています。
- 簡易なインセプションデッキを作ることで方向性を定める
- 目標設定の洗い出し
- やりたいことの具体化
- 使用する技術の選定
- 開発環境構築
- ペアプロで開発するために環境の差をなくす
- どの環境でも動くようにコンテナで環境の準備を整えた
- アプリケーションの作成
- GitLabによるIssueでのタスク管理
- 開発環境が不便と感じたら改善も行う
- チャットアプリとして完成させることができた
- ポートフォリオの作成
- 作成したのは単純なチャットアプリだが使っている技術は多かった
- ポートフォリオで取り組みの経緯や使用技術に関する情報を記載
- 成果物と併せてエンジニアとしてPRできる資料として準備することができた
9月は何をすることになったのか?
8/23(月)の振り返りの
KPTから「作ったモノをベースに新しいモノを作る」というモノがトライとして挙がりました。そのためポートフォリオが完了したのと同時にチャットアプリはクローズして、開発環境(コンテナの構成)などは引き継いで別のアプリケーションを作ることにしました。そして何をつくるのかこれまでと同じような形で一緒に考えてみました。
とりあえず思いついた機能を書いています。意外と少ない感じで作業に入るとアレもコレも必要だなということが多かったりします。これも1つの経験になるのかなと・・・。
ひたすら作業
GitLabの別のプロジェクトとして作業を続けていきました。https://gitlab.com/vorwort.k/spring-todo
必要な機能を
GitLabのIssueとして作成して実装していきます。8月と同じようにペアプロで一緒に作業しながら1つずつの機能を実現していきます。意外にやることが多くなりそうだったので必要最低限の機能に絞りながら後で拡充できるように取り組みました。企業面談が決まることで割り込むタスク
日々作業を続けている中で未経験のエンジニアの方に企業面談のお話があったようです。企業面談に行くにあたり、会社(企業面談先の企業ではなく所属しているSES)からはコードの開示をお願いされました。単純に
GitLabのプロジェクトをパブリックにして公開するだけだとPRにつながらない可能性も考えられます。実際に未経験のエンジニアの方もコードを公開するに対して不安があるようだったので効果的にPRする方法を整理していみました。
現状の課題として未経験エンジニアの方の不安を、現状の課題として書いてもらいました。結構不安に思われていることが出てくるモノですね。
現状の課題に対して解消できそうな解決案を一緒に考えていきました。単純にコードを公開して説明できるかどうかという不安が大きいようなので、そこをフォローする解決案を選択しました。
そして実際に取ったアクションは
GitLabのWikiを作成していただきました。Wikiにはこれまで行ってきたインセプションデッキや振り返りの内容などを記述したり、継続して行っているプロジェクトについても記述しています。こういった成果物に対する解説があるだけで印象が大きく変わると思われます。余談
会社(企業面談先の企業ではなく所属しているSES)からはコード量が少ないのでコードの一部だけ見せればよいのではというお話もあったようで解決案として追加しています。複雑なアルゴリズムなどが書いてあればそういった解決案も有効そうです。ただし、今回の場合はコード量も少なく一部だけみせた場合の効果は薄いと考えて採用を見送りました。
企業面談に行った結果
未経験エンジニアの方に話を伺うと成果物に対するリアクションはそこまでなく感触が微妙とのことでした。設計書や定義所を作成した経験を問われた際に回答にするのに困ったとのことです。9/13(日)の振り返りでも
Probremとして挙がりました。
企業面談を踏まえてこれからやること(Tryの設定)
企業面談での課題も改善活動して取り込みつつチャレンジすることにしました。具体的には「仕様書を作ってみる」ということですが、単純に仕様書を作ってみるだけだと面白味がなかったので
SwaggerによるAPI定義やSchemaspyによるER図を自動生成することをTryとして設定しました。継続的にチャレンジし続けた結果、
schemaspyでER図を作成し.gitlab.ciでpagesに公開することができました。本音をいうとパイプラインの処理のdind(docker-in-docker)でER図を作成してそれをpagesにデプロイしたいところですが一旦は公開して閲覧できるようにしています。実際にはすでに内定はいただいていた・・・
1週間後にわかったことですがこの企業面談で内定をいただくことができました。結果的には無事に開発業務に就けることになりましたが、上記のTryは継続的に続けていくことにしました。内定をいただいたことによって一旦このプロジェクトは完了することにしました。
このプロジェクトを振り返って
たった2人のプロジェクトとして始まりましたがチームとして考えながら進めてこれました。少しずつ有効だと思える成果物を作っていくことで、「開発業務に就く」という目標を達成することができました。
開発未経験のエンジニアの方でも一緒になって考えて進めていけばエンジニアの技術や考え方は成長し評価されるようになりました。技術力やPR方法がわからず不安なエンジニアの方もいらっしゃると思いますが、今回のようなアプローチを少しでもお役に立てれば幸いです。




- 投稿日:2020-09-28T01:08:52+09:00
super-csvを使用したcsv出力処理
1.目的
scheduleの内容をCSV出力したい
Top画面で表示しているscheduleテーブルの内容を結果DLボタンを押下してCSV出力
2.事前準備
build.gradleにsuper-csvを追加
build.gradleplugins { id 'org.springframework.boot' version '2.3.3.RELEASE' id 'io.spring.dependency-management' version '1.0.10.RELEASE' id 'java' } group = 'com.example' version = '0.0.1-SNAPSHOT' sourceCompatibility = '11' configurations { compileOnly { extendsFrom annotationProcessor } } repositories { mavenCentral() } dependencies { implementation 'org.springframework.boot:spring-boot-starter-thymeleaf' implementation 'org.springframework.boot:spring-boot-starter-web' implementation 'org.mybatis.spring.boot:mybatis-spring-boot-starter:2.1.3' compileOnly 'org.projectlombok:lombok' developmentOnly 'org.springframework.boot:spring-boot-devtools' runtimeOnly 'mysql:mysql-connector-java' annotationProcessor 'org.springframework.boot:spring-boot-configuration-processor' annotationProcessor 'org.projectlombok:lombok' testImplementation('org.springframework.boot:spring-boot-starter-test') { exclude group: 'org.junit.vintage', module: 'junit-vintage-engine' } implementation 'javax.validation:validation-api:2.0.1.Final' // https://mvnrepository.com/artifact/javax.validation/validation-api implementation 'javax.validation:validation-api:2.0.1.Final' // https://mvnrepository.com/artifact/org.hibernate.validator/hibernate-validator runtimeOnly 'org.hibernate.validator:hibernate-validator:6.0.17.Final' // https://mvnrepository.com/artifact/org.glassfish/javax.el runtimeOnly 'org.glassfish:javax.el:3.0.1-b11' // https://mvnrepository.com/artifact/org.webjars/fullcalendar compile group: 'org.webjars.bower', name: 'fullcalendar', version: '3.5.1' // https://mvnrepository.com/artifact/org.webjars.bower/moment compile group: 'org.webjars.bower', name: 'moment', version: '2.19.1' // https://mvnrepository.com/artifact/org.webjars/jquery compile group: 'org.webjars', name: 'jquery', version: '2.0.3' // https://mvnrepository.com/artifact/com.github.mygreen/super-csv-annotation compile group: 'com.github.mygreen', name: 'super-csv-annotation', version: '2.2' } test { useJUnitPlatform() }3.Controller
HttpServletResponseにヘッダー情報を設定し、Controller内でCSV出力処理メソッドを呼び出す
service処理内でファイル書き込み関連の例外がraiseされる可能性があるため、IOExceptionをthrow宣言しておくTopController.java...中略 //CSV出力リクエストの受付 @RequestMapping(value = "/top/csv", method = RequestMethod.GET) public String csvDownload(HttpServletResponse response) throws IOException { String header = String.format("attachment; filename=\"%s\";", UriUtils.encode("result.csv", StandardCharsets.UTF_8.name())); response.setHeader(HttpHeaders.CONTENT_TYPE, MediaType.APPLICATION_OCTET_STREAM_VALUE); response.setHeader(HttpHeaders.CONTENT_DISPOSITION, header); topService.csvDownload(response); return "/top"; }4.Service
org.supercsv.io.CsvMapWriterクラスのインスタンスをOutputStreamWriter及びエクセル形式可のコンストラクタで生成する
DBからスケジュールの情報を取得したBeanをフォーマット化しつつwriteHeader / writeCommentメソッドで書き込むTopService.javapackage com.example.alhproject.service; import java.io.IOException; import java.io.OutputStreamWriter; import java.nio.charset.Charset; import java.util.List; import javax.servlet.http.HttpServletResponse; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.stereotype.Service; import org.supercsv.io.CsvMapWriter; import org.supercsv.prefs.CsvPreference; import com.example.alhproject.entity.Schedule; import com.example.alhproject.mapper.ScheduleMapper; @Service public class TopService { @Autowired private ScheduleMapper scheduleMapper; private static final String OUTPUT_SCHEDULE_FORMAT = "%s,%s,%s,%s,%s,%s"; private static final String SJIS = "SJIS"; private static final String TITLE = "title"; private static final String CONTEXT = "context"; private static final String USER_ID= "user_id"; private static final String CREATED_DATE = "created_date"; private static final String SCHEDULE_START_TIME = "schedule_start_time"; private static final String SCHEDULE_END_TIME = "schedule_end_time"; //scheduleテーブル内容取得 public List<Schedule> getAllSchedule() { return scheduleMapper.selectAll(); } //CSV出力処理 public void csvDownload(HttpServletResponse response) throws IOException { try (OutputStreamWriter osw = new OutputStreamWriter(response.getOutputStream(), Charset.forName(SJIS)); CsvMapWriter wr = new CsvMapWriter(osw, CsvPreference.EXCEL_NORTH_EUROPE_PREFERENCE)) { wr.writeHeader(String.format(OUTPUT_SCHEDULE_FORMAT, TITLE, CONTEXT, USER_ID, CREATED_DATE, SCHEDULE_START_TIME, SCHEDULE_END_TIME )); getAllSchedule().forEach(dbsc -> { String scheduleResult = String.format(OUTPUT_SCHEDULE_FORMAT, dbsc.getTitle(), dbsc.getContext(), dbsc.getUserId().toString(), dbsc.getCreatedDate().toString(), dbsc.getScheduleStartTime().toString(), dbsc.getScheduleEndTime().toString()); try { wr.writeComment(scheduleResult); } catch (IOException e) { e.printStackTrace(); } }); } } }(参)レコード名と完全一致する場合は,LazyCsvAnnotationBeanWriterが使いやすそう
https://mygreen.github.io/super-csv-annotation/sphinx/labelledcolumn.htmlSample.java// 全レコードを一度に書き込む場合 public void sampleWriteAll() { ... LazyCsvAnnotationBeanWriter<UserCsv> csvWriter = new LazyCsvAnnotationBeanWriter<>( SampleCsv.class, Files.newBufferedWriter(new File("sample.csv").toPath(), Charset.forName("Windows-31j")), CsvPreference.STANDARD_PREFERENCE); ...5.結果

- 投稿日:2020-09-28T00:30:29+09:00
Spring Batchを試してみた
概要
STSを使ってSpring Batchを使ったときの備忘録を残しておきます。
主に自分用。
Spring Batchとは、Spring Frameworkをベースにしたバッチアプリケーションフレームワークです。開発環境は次の通りです。
OS : Windows 7 Home Edition 64bit
Java : JavaSE 8 update 181
Spring Boot : 2.3.4
STS : 4.6.1STSのセットアップ
STSのセットアップは自分の備忘録を参考にしました。
プロジェクトの作成
下記のCreate new Spring Starter Projectをクリックします。
プロジェクトの設定をします。
ライブラリ参照を設定します。
site infoを設定、変更無しです。
プロジェクトができました。
注意事項
Lombokについて
Lombokだけはjarをダウンロードして、
インストーラーで使っているSTSを選択、インストールしてください。
インストーラーはLombok公式からダウンロード可能です。
Lombokはプロジェクト参照させているため、
アノテーションを使ってもコンパイルエラーになりませんが、
getter/setter、コンストラクタが自動生成されず、
これらを呼び出そうとするとコンパイルエラーになります。
getter/setter等はIDEに自動生成させる必要があるため、
STSへのインストールも必要です。Oracle Driverのインストール
本記事ではDBを用いていませんが、
Spring Boot+Spring Batchの構成ではDB利用を前提としています。
そのため、application.propertiesやapplication.ymlに
DB接続情報を記載していなかったり、
そもそもOracle Driverが無いといった構成で
アプリケーションを実行すると
datasourceが必要というエラーで実行できません。
そのため、動作確認したPCにセットアップしていたOracleに
接続できるよう、ライブラリ参照しています。
また、実行時にDBを起動しなくても実行可能です。
ライブラリがあって、DBスキーマに接続しようとする構成、設定なら
OKということです。バッチアプリケーションの作成
Spring Batch公式のget startedはこちらです。
上記の場合、作ったjarを実行してcsvデータをDBのテーブルにロードする仕様です。この記事では、cronを使わずにバッチ処理をスケジューリングしてみます。
参考にしたのはSpring Batch scheduling tasksと
@Scheduledのドキュメントです。例としてBeanを作成し、その内容をログ出力する処理を実装してみます。
ログ出力用の変数宣言やBeanクラスのボイラープレートを省略するため、Lombokを参照します。実装したクラスは次の通りです。
まず、@SpringBootApplicationを付与したクラス、
実行時に指定するクラスです。BatchSampleApplication.javapackage jp.co.illmatics; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; @SpringBootApplication public class BatchSampleApplication { public static void main(String[] args) { SpringApplication.run(BatchSampleApplication.class, args); } }バッチ処理のメインルーチンです。
@EnableSchedulingを指定することで
バッチのスケジューリングが可能になり、
@Scheduledを指定したメソッドが
cron = "${cron.pattern1}"
で指定したタイミングで実行されます。Batch.javapackage jp.co.illmatics; import org.springframework.context.annotation.Configuration; import org.springframework.scheduling.annotation.EnableScheduling; import org.springframework.scheduling.annotation.Scheduled; import jp.co.illmatics.bean.Member; import jp.co.illmatics.enumeration.VoicePart; import lombok.extern.slf4j.Slf4j; @Configuration @EnableScheduling @Slf4j public class Batch { private String firstName = "Dummy"; private String familyName = "Family"; private String part = VoicePart.LEAD_VOCAL.toString(); private String birthday = "1991/01/01"; @Scheduled(cron = "${cron.pattern1}") public void execute() { Member member = new Member(firstName, familyName, part, birthday); log.info("member = " + member.toString()); } }リソースファイルです。
キーcron.pattern1でバッチ処理の実行タイミングを
毎分0秒ごとに指定しています。
書式については公式APIドキュメントをご確認ください。application.propertiesspring.datasource.driver-class-name=oracle.jdbc.driver.OracleDriver spring.datasource.url=jdbc:oracle:thin:@localhost:1521:XE spring.datasource.username=xxxxxx spring.datasource.password=xxxxxx spring.jpa.database-platform=org.hibernate.dialect.Oracle10gDialect spring.jpa.show-sql=true cron.pattern1: 0 * * * * *テストデータ用のBeanです。
Bean Validationを使ってバリデーションしています。
その中でも、カスタムバリデーションとして@ExistsInVoicePratを実装しました。Member.javapackage jp.co.illmatics.bean; import javax.validation.constraints.NotEmpty; import org.springframework.format.annotation.DateTimeFormat; import jp.co.illmatics.validator.annotation.ExistsInVoicePart; import lombok.AllArgsConstructor; import lombok.Data; import lombok.extern.slf4j.Slf4j; @Data @AllArgsConstructor public class Member { @NotEmpty(message = "Input first name.") private String firstName; @NotEmpty(message = "Input family name.") private String familyName; @ExistsInVoicePart private String part; @DateTimeFormat(pattern = "yyyy/MM/dd") private String birthday; }カスタムバリデーション用のアノテーションです。
ExistsInVoicePart.javapackage jp.co.illmatics.validator.annotation; import static java.lang.annotation.ElementType.FIELD; import static java.lang.annotation.RetentionPolicy.RUNTIME; import java.lang.annotation.Retention; import java.lang.annotation.Target; import javax.validation.Constraint; import javax.validation.Payload; import jp.co.illmatics.validator.VoicePartValidator; @Constraint(validatedBy = {VoicePartValidator.class}) @Target({FIELD}) @Retention(RUNTIME) public @interface ExistsInVoicePart { String message() default "Input voice part."; Class<?>[] groups() default {}; Class<? extends Payload>[] payload() default {}; @Target({FIELD}) @Retention(RUNTIME) public @interface List { ExistsInVoicePart[] value(); } }カスタムバリデータ用のEnumです。
VoicePart.javapackage jp.co.illmatics.enumeration; public enum VoicePart { LEAD_VOCAL("lead vocal"), BEATBOXER("beatboxer"), BASS("bass"), OTHERS("others"); @SuppressWarnings("unused") private final String name; private VoicePart(String name) { this.name = name; } }カスタムバリデータです。
VoicePartValidator.javapackage jp.co.illmatics.validator; import java.util.Arrays; import javax.validation.ConstraintValidator; import javax.validation.ConstraintValidatorContext; import jp.co.illmatics.enumeration.VoicePart; import jp.co.illmatics.validator.annotation.ExistsInVoicePart; public class VoicePartValidator implements ConstraintValidator<ExistsInVoicePart, String> { public void initialize(ExistsInVoicePart annotation) { } @Override public boolean isValid(String value, ConstraintValidatorContext context) { return Arrays.stream(VoicePart.values()).filter(part -> part.name().equals(value)).findFirst().isPresent(); } }動作確認
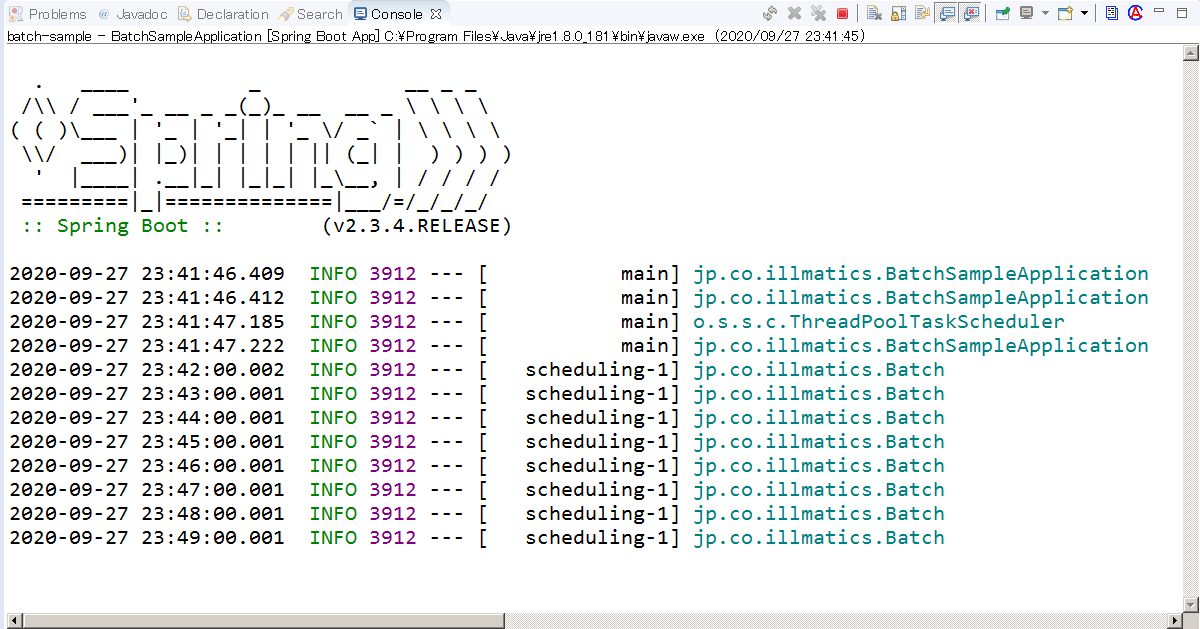
BatchSampleApplication.javaを右クリック、
Spring Boot Applicationとして実行します。毎分0秒ごとに実行されています。
以上です。最後までお読みいただき、ありがとうございました。




- 投稿日:2020-09-28T00:04:30+09:00
Javaラムダ式についてまとめてみた
ラムダ式とは
Java8で導入された新しい文法。
ローカルクラスと無名クラスを利用して記述する内容を省略して処理記述を簡潔にする。
代表的な例としてCollections.sortやStreamAPIのメソッドが恩恵を受けた。ラムダ式について分解
ラムダ式はローカルクラスと無名クラスという仕組みを利用しています。
1.ローカルクラス
ローカルクラスとはメソッドの処理中でクラスを宣言して利用できる仕組みです。
public static void main(String[] args) { class Local { public void sayHello() { System.out.println("Hello!"); } } Local local = new Local(); local.sayHello(); // Hello! }インターフェースを実装したローカルクラスを定義することもできます。
public static void main(String[] args) { class Local implements Runnable { @Override public void run() { System.out.println("Hello Lambda!"); } } Runnable runner = new Local(); runner.run(); // Hello Lambda! }次に無名クラスを見てみましょう。
2.無名クラス
無名クラスとはインターフェースを実装したローカルクラスの宣言を省略する仕組みです。
Runnableインターフェースを実装した無名クラスの例を記述します。public static void main(String[] args) { Runnable runner = new Runnable() { @Override public void run() { System.out.println("Hello Lambda!"); } }; runner.run(); //Hello Lambda! }あたかもRannableインターフェースのインスタンスを生成しているように見えると思いますが、実際にはRannableインターフェースを実装した無名クラスのインスタンスを生成しています。
最後にラムダ式を見てみましょう。3.ラムダ式
無名クラスから更に「new Runnable(){}」と「public void run」を省略してラムダ式となります。
public static void main(String[] args) { Runnable runner = () -> { System.out.println("Hello Lambda!"); }; runner.run(); //Hello Lambda! }最初の()はrunメソッドの引数を表し、->{}の中身はrunメソッドの実装内容になります。
runner変数にはRunnableを実装した無名クラスのインスタンスが代入されます。
つまり、ラムダ式とはインターフェースを実装したインスタンスを生成する式といえます。ところで「new Runnable(){}」を省略したら、何型のインスタンスを生成するのかわかりません。
Javaでは代入される変数の型によって自動的に推論する仕組みになっています。
この仕組みを型推論と呼びます。また、「public void run」を省略すると、複数メソッドが定義されているインターフェースの場合、どのメソッドをオーバーライドするのかわかりません。
そのため、ラムダ式で使用できるのは抽象メソッドが一つのインターフェースのみとなります。Rannableインターフェースだけでは引数なし、戻り値なしのラムダ式しか作れません。
他の形で作成したい場合は、関数型インターフェースというものが追加されたのでそちらを利用します。関数型インターフェース
関数型インターフェースは、ラムダ式やメソッド参照の代入先になれるインターフェースのこと。
関数型インターフェースの条件は、大雑把に言って、定義されている抽象メソッドが1つだけあるインターフェース。
staticメソッドやデフォルトメソッドは含まれていても構わない(関数型インターフェースの条件としては無視される)。
また、Objectクラスにあるpublicメソッドがインターフェース内に抽象メソッドとして定義されている場合、そのメソッドも無視される。
(この条件を満たすインターフェースを、JDK1.8で「関数型インターフェース」と呼ぶようになった)SE8から新しくjava.util.functionパッケージ配下にインターフェースがたくさん追加されました。
https://docs.oracle.com/javase/jp/8/docs/api/java/util/function/package-summary.html今回はその中でもよく使うインターフェースを紹介します。
2-1. Function<T, R>
Functionは、値を変換する為の関数型インターフェース。
Function<T, R>のTはメソッドの引数の型、Rは戻り値の型を指定します。
引数を受け取り、変換(演算)して別の値を返す。
メソッドは R apply(T) です。Function<Integer, String> asterisker = (i) -> { return "*"+ i; }; String result = asterisker.apply(10); System.out.println(result); // *102-2. Consumer<T>
Consumerは、引数を受け取り、それを使って処理を行う為の関数型インターフェース。
Consumer<T>のTはメソッドの引数の型を指定します。
値を返さないので、基本的に副作用を起こす目的で使用する。
メソッドは void accept(T) です。Consumer<String> buyer = (goods) -> { System.out.println(goods + "を購入しました"); }; buyer.accept("おにぎり"); // おにぎりを購入しました。2-3. Predicate<T>
Predicateは判定を行う為の関数型インターフェース。
Predicate<T>のTはメソッドの引数の型を指定します。
引数を受け取り、判定を行い、真偽値(判定結果)を返す。
メソッドは boolean test(T) です。Predicate<String> checker = (s)-> { return s.equals("Java"); }; boolean result = checker.test("Java"); System.out.println(result); //trueラムダ式を利用する意図
次のコードは、Stream APIをラムダ式を用いて記述したものです。
List<Integer> numbers = List.of(3, 1, -4, 1, -5, 9, -2, 6, 5, 3, 5); numbers.stream() .filter(number -> Math.abs(number) >= 5) .forEach(System.out::println);出力結果は次のようになります。
-5 9 6 5 5次にラムダ式を利用しないで記述したコードを見てみます。
List<Integer> numbers = List.of(3, 1, -4, 1, -5, 9, -2, 6, 5, 3, 5); numbers.stream() .filter(new Predicate<Integer>() { @Override public boolean test(Integer number) { return Math.abs(number) >= 5; } }) .forEach(new Consumer<Integer>() { @Override public void accept(Integer number) { System.out.println(number); } });ラムダ式の分解で紹介したようにインターフェースの生成、実行するメソッド記述が増えているため、
コードの記述量が多くなり処理の見通しがとても悪くなりました。
このように処理記述を簡潔でわかりやすくするために利用します。ラムダ式の文法
ラムダ式の文法を説明します。以下がラムダ式の基本文法です。
(引数) -> { 処理; }この文法に従って書いたのが以下になります。
// (1) 引数と戻り値がある場合 (Integer number) -> { return Math.abs(number) >= 5; } // (2) 戻り値がない場合 (Integer number) -> { System.out.println(number); } // (3) 引数も戻り値もない場合 () -> { System.out.println("Hello!"); }(1)は、Predicateのように引数と戻り値がある例です。引数で指定されたnumberを用いて処理を行い、戻り値をreturnしています。
(2)は、Consumerのように戻り値がない例です。その場合はreturn文を書く必要はありません。
(3)のように、引数がない処理は引数部分を( )で記載します。java.lang.Runnableなどがこれに該当します。また、ラムダ式では引数の型を省略することができます。
そして、引数が1つしかない場合に限り、引数を囲む小括弧( )を省略することができます。引数がない場合や、2つ以上ある場合は省略できません。このルールを(1)と(3)に当てはめると、次のようになります。// (1) 引数が1つなので ( ) を省略できる number -> { return Math.abs(number) >= 5; } // (3) 引数がないため ( ) を省略できない () -> { System.out.println("Hello!"); }さらに、処理が1行しかない場合は、中括弧{ }と、returnと、文末のセミコロンを省略することもできます。(1)~(3)について省略した形で記述すると次のようになります。
// (1) 引数と戻り値がある場合 number -> Math.abs(number) >= 5 // (2) 戻り値がない場合 number -> System.out.println(number) // (3) 引数も戻り値もない場合 () -> System.out.println("Hello!")最後に、処理内容がメソッド呼び出し1つの場合、かつ、引数が一意に決まる場合に限り、メソッド参照を利用して、引数そのものを省略することができます。メソッド参照は次のような文法になります。
クラス名::メソッド名このメソッド参照を適用できるのは(2)だけとなります。(2)をメソッド参照を用いて記載すると次のようになります。
System.out::printlnSystem.out.printlnメソッドは引数を1つだけ取るメソッドであり、引数であるIntegerの値が渡されることが明らかであるため、メソッド参照が利用できるのです。一方、(1)はメソッド呼び出しの後に>= 5という大小判定があるため、メソッド参照が使えません。また、(3)は引数に"Hello!"という値を指定しているため引数が一意には決まるとは言えず、これもメソッド参照は使えません。
これを踏まえた上で先ほどのstream処理を見てみましょう
List<Integer> numbers = List.of(3, 1, -4, 1, -5, 9, -2, 6, 5, 3, 5); numbers.stream() .filter(number -> Math.abs(number) >= 5) .forEach(System.out::println);streamAPIの中に(1),(2)で学習したラムダ式が組み込まれていることがわかります。
※streamAPIについては後日記事を書きます。参考記事
Java8のラムダ式を理解する
ラムダ式とStream APIで学ぶモダンJava ― 関数型を取り入れて変化するJava言語の現在