- 投稿日:2020-09-22T22:53:21+09:00
TensorFlowでmodel.save()ができなかった
TensorFlow: model.save()ができなかった
TensorFlowでVAE(Variational Auto Encoder)を作成したところ、動かすことには成功したもののモデルが保存できないという事態に。
モデル
公式のtutorialConvolutional Variational Autoencoder、およびサブクラス化による新しいレイヤーとモデルの作成を参考にしてMNISTデータ用のVAEを作成した。(モデルの構造は適当に変えてます)
環境はGoogle Colabで、TensorFlowのversionは2.3.0。#tf.__version__ = 2.3.0 import tensorflow as tf from tensorflow.keras import layers #潜在変数のsampling class Sampling(layers.Layer): def call(self,inputs): """ inputs:(batch,hidden_dim)のタプル """ mean,logvar = inputs eps = tf.random.normal(mean.shape) return mean + eps*tf.exp(0.5*logvar) #encoder class Encoder(layers.Layer): def __init__(self,hidden_dim=32,mid_dim=3,name='encoder',**kwargs): super(Encoder,self).__init__(name=name,**kwargs) self.conv1 = layers.Conv2D(filters=mid_dim,kernel_size=3,activation='relu') self.pool = layers.MaxPool2D(2) self.flatten = layers.Flatten() self.dense_mean = layers.Dense(units=hidden_dim) self.dense_sigma = layers.Dense(units=hidden_dim) self.sample = Sampling() #自分でサブクラス化したlayer def call(self,inputs): x = self.conv1(inputs) x = self.pool(x) x = self.flatten(x) mean = self.dense_mean(x) var = self.dense_sigma(x) z_sample = self.sample((mean,var)) return mean,var,z_sample #Decoder class Decoder(layers.Layer): def __init__(self,original_dim=28*28,mid_dim=200,name="decoder",**kwargs): super(Decoder,self).__init__(name=name,**kwargs) self.dense1 = layers.Dense(mid_dim,activation='relu') self.out = layers.Dense(original_dim) def call(self,inputs,apply_sigmoid=False): x = self.dense1(inputs) out = self.out(x) if apply_sigmoid: #訓練時は使わない。 out = tf.nn.sigmoid(out) return out #VAE classを定義する class VAE(tf.keras.Model): def __init__(self,hidden_dim,mid_dim_enc=3,mid_dim_dec=200,original_dim=28*28,name="VAE",**kwargs): super(VAE,self).__init__(name=name,**kwargs) self.encoder = Encoder(hidden_dim=hidden_dim,mid_dim=mid_dim_enc) self.decoder = Decoder(original_dim=original_dim,mid_dim=mid_dim_dec) def call(self,inputs,apply_sigmoid=False): mean,logvar,z_sample = self.encoder(inputs) output = self.decoder(z_sample,apply_sigmoid=apply_sigmoid) #損失計算のためmeanとlogvarも出力する return output,mean,logvar結構長くて読みづらいコードになってしまったが、まとめると
・Encoder Layerで元画像(shape=(batch,28,28,1))を受け取り、潜在変数の事後分布パラメータmean,logvarを出力する
・Sampling Layerで、平均値mean,分散exp(logvar)の正規分布から潜在変数をサンプリングする(shape=(batch,hidden_dim))
・Decoder Layerで、サンプリングされた潜在変数を元に画像を再構成する(shape=(batch,28*28))
という流れ。(EncoderとDecoderの構造が全く対称になっていないがまあそこは適当ということで...)VAEについてはAuto-Encoding Variational Bayesを読んで理解しました。損失関数定義
続いてVAEの損失関数を定義する。この形については上の論文を参照。
#metrics,optimizerを定義 train_loss = tf.keras.metrics.Mean() test_loss = tf.keras.metrics.Mean() optimizer = tf.keras.optimizers.Adam() #損失関数を定義 def compute_loss(model,x): out,mean,logvar = model(x) out = tf.reshape(out,x.shape) #(batch,28,28,1) に変換 cross_ent = tf.nn.sigmoid_cross_entropy_with_logits(labels=x,logits=out) #ベルヌーイ分布の対数損失 kl_loss = -0.5*tf.reduce_sum(1+logvar - mean**2 - tf.exp(logvar),axis=1) #KL divergence loss_ent = tf.reduce_sum(cross_ent,axis=[1,2,3]) return tf.reduce_mean(kl_loss+loss_ent) #訓練 @tf.function def train_step(model,images,optimizer): with tf.GradientTape() as tape: loss = compute_loss(model,images) gradient = tape.gradient(loss,model.trainable_variables) optimizer.apply_gradients(zip(gradient,model.trainable_variables)) train_loss(loss)学習、評価
道具は出揃ったのでいよいよ学習させる。(今回の記事は学習が目的ではないので、テストデータによる評価はしていません)
#data set train_ds = tf.data.Dataset.from_tensor_slices(x_train).shuffle(60000).batch(128) #潜在変数の次元は10 model = VAE(hidden_dim=10) epochs = 2 #2エポックだけ学習する for epoch in range(epochs): for images in train_ds: train_step(model,images,optimizer) print("Epoch:{} Loss:{}".format(epoch+1,train_loss.result()))学習後、テストデータを適当に入力して画像を再構成した。
2エポックしか学習していないのでぼやけた感じだが、ある程度いい感じに再構成できていると思われる。
モデルの保存
随分前置きが長くなってしまったが、ここからが本記事の主題。以上で学習させたモデルをmodel.save(filepath)で保存したい。
model.save('try')すると...
ValueError: Cannot convert a partially known TensorShape to a Tensor: (None, 10)
となって保存できず。色々と見てみたところ、どうやらSamplingの部分が原因のよう。解決策1.model.save_weightsを使う
多分これが一番簡単な策。model.save_weigthts(filepath)とすればそのモデルのパラメータを保存できるので、あとは新しくモデルを作成してloadすればいい。
model.save_weights('try') #これはうまく行く model_new = VAE(hidden_dim=10) #新規モデル作成 model_new.load_weights('try') #学習済みパラメータ読み込み学習済みのモデルを再利用するだけならこれでいいのでは?という感じがする。
解決策2. Sampling Layerの変更
各レイヤの設計はサブクラス化による新しいレイヤーとモデルの作成を参考にしたが、一か所Sampling Layerの中で変更していた点があった。
#チュートリアルの場合 class Sampling(layers.Layer): def call(self,inputs): """ inputs:(batch,hidden_dim)のタプル """ mean,logvar = inputs batch = tf.shape(mean)[0] hid = tf.shape(mean)[1] eps = tf.random.normal(shape=(batch,hid)) return mean + eps*tf.exp(0.5*logvar) #自分で設計した方 class Sampling(layers.Layer): def call(self,inputs): """ inputs:(batch,hidden_dim)のタプル """ mean,logvar = inputs eps = tf.random.normal(shape=mean.shape) return mean + eps*tf.exp(0.5*logvar)チュートリアルではまず目標のテンソルのサイズをbatch,hid という変数に格納してからサンプリングを行っているのに対し、自分はいきなりtf.random.normal(shape=mean.shape)でサンプリングしようとした。実はこの部分が問題であり、チュートリアル通りに変更したところmodel.save()ができるようにできるようになった。
わざわざサイズを取得する必要ないだろ、と思って変えてしまったのが仇となったというわけでした。公式は正義。
よくわからないが、計算グラフの中で新しくテンソルを作る際にはサイズを事前に確保しておかないとダメだということだろうか。まとめ
とりあえずsave()がうまく行かなかったらsave_weights()をすればモデルの再利用はできるのでそれでいい気がする。前者の保存法の方が後者の保存法より優れている点・望ましいケースって何かあるんでしょうか。

- 投稿日:2020-09-22T18:30:35+09:00
CNNによる学習データ
kerasでCNN 自分で拾った画像でやってみる
基本はこの記事を参照して作成しました。微妙に違うだけです。
細かい部分は自分で調べて何とかしました。
ぶっちゃけ動いたからヨシなので勉強不足です。目的としてはとある物の写真からOKとNGを判定したいので
元となるデータとしては画像データ(640x480)を
OK・NG共に1000枚使用しています。あくまでも初心者が辿り着いた結果をメモとして残すのが目的です。
環境
Windows10 64bit
Anaconda navigator
Jupiter notebook
Python 3.7.7
tensorflow 2.1.0
tensorflow-gpu 2.1.0
keras 2.3.1
numpy 1.18.1
matplotlib 3.1.3上記環境でプログラムを構築
ライブラリ
cnn.ipynbimport keras from keras.utils import np_utils from keras.models import Sequential from keras.layers.convolutional import MaxPooling2D from keras.layers import Activation, Conv2D, Flatten, Dense,Dropout from sklearn.model_selection import train_test_split from keras.optimizers import SGD, Adadelta, Adagrad, Adam, Adamax, RMSprop, Nadam from PIL import Image import numpy as np import glob import matplotlib.pyplot as plt import time import os
from keras.optimizers importにはAdadeltaだけでよかったですが
色々と試したくて入れてます。(結局テストせんかったけど…)各種設定関係
cnn.ipynb#設定 batch_size = 16 epochs = 200 #画像ディレクトリ test_dir ="画像保存しているディレクトリを指定" folder = os.listdir(test_dir) #元画像640x480をresizeする際の大きさ設定 x_image_size = 200#640→200 y_image_size = 200#480→200 dense_size = len(folder)
batch_sizeに関しては色々なサイトを見るに1・4・32等々設定値が転がっていたので
初めは32で回してみましたがエラーが出てなんともならなくなったので16に設定しています。
細かい部分まで調べ切れていないので正しいとは言えないと…
ただ回ったのでヨシにしています。画像サイズを縦・横で色々と変えて試す為に分けて設定していますが
結果200まで落とさないと重すぎて動きませんでした。
なのでimage_size = 200でも問題ありません。(後の記述は一部変更必要)画像読み込み
cnn.ipynbX = [] Y = [] for index, name in enumerate(folder): dir = test_dir + name files = glob.glob(dir + "/*.jpg") for i, file in enumerate(files): image = Image.open(file) image = image.convert("RGB") image = image.resize((x_image_size, y_image_size)) data = np.asarray(image) X.append(data) Y.append(index) X = np.array(X) Y = np.array(Y) X = X.astype('float32') X = X / 255.0 Y = np_utils.to_categorical(Y, dense_size) X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.15)今回はテストを15%にした位で、参考にさせて頂いた記事とほとんど変わりません。
CNNモデル作成
cnn.ipynbmodel = Sequential() model.add(Conv2D(32, (3, 3), padding='same',input_shape=X_train.shape[1:])) model.add(Activation('relu')) model.add(Conv2D(32, (3, 3))) model.add(Activation('relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Dropout(0.25)) model.add(Conv2D(64, (3, 3), padding='same')) model.add(Activation('relu')) model.add(Conv2D(64, (3, 3))) model.add(Activation('relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Dropout(0.25)) model.add(Flatten()) model.add(Dense(512)) model.add(Activation('relu')) model.add(Dropout(0.5)) model.add(Dense(dense_size)) model.add(Activation('softmax')) model.summary()正直な所、勉強しながらなので
どこをどのように触れば変化するのか?については分かってないです。
keras公式サイト
ここを見ていますが、素人には理解できないっす…学習機作成
cnn.ipynboptimizers ="Adadelta" results = {} model.compile(loss='categorical_crossentropy', optimizer=optimizers, metrics=['accuracy']) results[0]= model.fit(X_train, y_train, validation_split=0.2, epochs=epochs,batch_size=batch_size) model_json_str = model.to_json() open('model.json', 'w').write(model_json_str) model.save('weights.h5');正直、Qiitaがなければ辿り着く事すら出来ませんでした。
ありがとうございます。結果
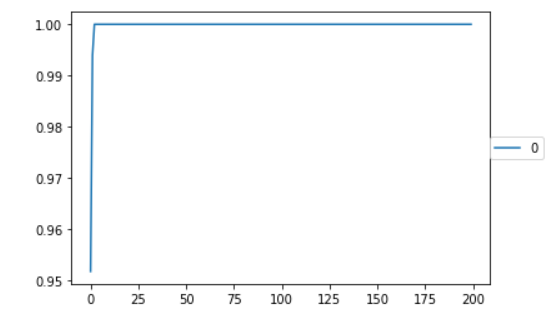
学習結果
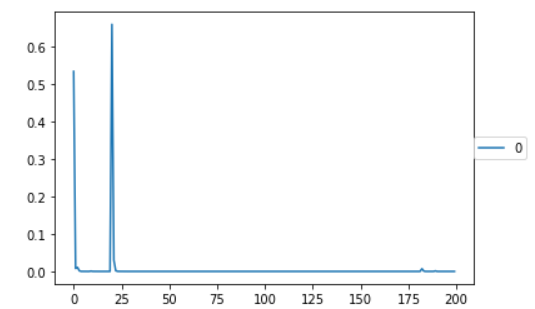
テスト結果
はじめはひどいもので学習結果が横棒になるという結果でした。
その時は画像データも各50枚程度と少なく
epoch数も20程度でした。とある方に『画像が命』と教えて頂きましたが、正にその通りの結果になったと思います。
後はこのデータを元に推論を作って、ちゃんと結果出るかがドキドキです。
まとめ
なんだかんだでデータとしては作る事が出来ました。
『色々と試してみる』部分が圧倒的に不足している事を思い知りました。
手を動かさないと覚えない・知ろうとしない事を改めて知る事が出来ました。40歳目前から始めると脳が拒否するので大変です。
以上です。
- 投稿日:2020-09-22T11:11:59+09:00
kerasで再現性の担保(2020/09/22現在)
導入
kerasで学習の再現をするとき検索して最初に出てくる情報や公式の日本語ドキュメントが古いバージョンのやり方で,現在は方法が変わっているので記録.
バージョン
- Python 3.7.6
- Keras 2.3.1
- tensorflow 2.2.0
再現性の担保
環境変数の設定
python3.2.3以降はPYTHONHASHSEEDの値を固定することでpythonのハッシュベースの操作の再現性を担保できる.
export PYTHONHASHSEED=0また,PYTHONHASHSEEDはコード内ではなくプログラムの実行前に設定する必要がある.
$ python -c 'import os;os.environ["PYTHONHASHSEED"]="0";print(hash("keras"))' 2834998937574676049 $ python -c 'import os;os.environ["PYTHONHASHSEED"]="0";print(hash("keras"))' -1138434705774533911 $ PYTHONHASHSEED=0 python -c 'print(hash("keras"))' 4883664951434749476 $ PYTHONHASHSEED=0 python -c 'print(hash("keras"))' 4883664951434749476他の方の記事では環境変数を設定しなくても再現できたとあるのでもしかしたら必要ないかもいれない.
https://sanshonoki.hatenablog.com/entry/2019/01/15/230054ライブラリのシード値を固定
Kersa公式ドキュメントページから抜粋.このあたりのコードが以前のバージョンと変わっている.
import numpy as np import tensorflow as tf import random as python_random # The below is necessary for starting Numpy generated random numbers # in a well-defined initial state. np.random.seed(123) # The below is necessary for starting core Python generated random numbers # in a well-defined state. python_random.seed(123) # The below set_seed() will make random number generation # in the TensorFlow backend have a well-defined initial state. # For further details, see: # https://www.tensorflow.org/api_docs/python/tf/random/set_seed tf.random.set_seed(1234) # Rest of code follows ...最後に
ちゃんとドキュメントが最新バージョンのものに更新されているか確認する.(戒め)
参考ページ
Keras FAQ: How can I obtain reproducible results using Keras during development?(2020/09/22閲覧)