<divclass="center jumbotron"><h1>WelcometotheSampleApp</h1>
<h2>
This is the home page for the
<a href="https://railstutorial.jp/">Ruby on Rails Tutorial</a>
sample application.
</h2>
<%= link_to "Signupnow!", signup_path, class: "btnbtn-lgbtn-primary" %>
</div>
<%= link_to image_tag("rails.png", alt: "Railslogo"),
'http://rubyonrails.org/' %>
# Use postgresql as the database for Active Record
gem 'pg', '>= 0.18', '< 2.0'
に変更して、bundle installする。
この状態だと、rails db:createできない
bin/rails db:create
rails aborted!
LoadError: Error loading the 'sqlite3' Active Record adapter. Missing a gem it depends on? sqlite3 is not part of the bundle. Add it to your Gemfile.
database.ymlの編集
before
# SQLite version 3.x
# gem install sqlite3
#
# Ensure the SQLite 3 gem is defined in your Gemfile
# gem 'sqlite3'
#
default: &default
adapter: sqlite3
pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %>
timeout: 5000
development:
<<: *default
database: db/development.sqlite3
# Warning: The database defined as "test" will be erased and
# re-generated from your development database when you run "rake".
# Do not set this db to the same as development or production.
test:
<<: *default
database: db/test.sqlite3
production:
<<: *default
database: db/production.sqlite3
Rational に持ち込めば加減乗除で演算誤差は生じない。
こんなふうにしよう。
Rational にしてから取った総和を「真の和」と呼ぶことにする。 sum と inject で作った和と真の和の差の絶対値を「誤差」と呼ぶことにする。
どちらが誤差が小さいか比べるため,sum 版の誤差から inject 版の誤差を引いたものを計算する。これが正なら sum 版の誤差が大きく,負なら inject 版の誤差が大きい。
# 足すべき数x=0.1# 足し合わせる個数n=6# 真の和(Rational)exact_sum=x.to_r*n# n 個の x からなる配列numbers=[x]*n# sum による和(Rational)sum_by_sum=numbers.sum.to_r# その誤差error_by_sum=(exact_sum-sum_by_sum).abs# inject による和(Rational)sum_by_inject=numbers.inject(:+).to_r# その誤差error_by_inject=(exact_sum-sum_by_inject).abs# 比較putssum_by_sum-sum_by_inject# => 1/9007199254740992putserror_by_sum-error_by_inject# => 0/1
あれれ? sum 版の和と inject 版の和は確かに微妙に違っているのだが,それぞれの誤差は完全に一致している?
一見不可解だが,何も不思議なことはない。「誤差」を計算するときに絶対値を取っているからこうなる。 sum 版と inject 版の和は,真の和の左右に同じ距離だけ離れて存在しているのだ。和そのものの値は違っているが真の和とのズレ量は同じだったということ。
-> % rbenv install 2.7.1
rbenv: /Users/(username)/.rbenv/versions/2.7.1 already exists
continue with installation? (y/N) N
でも、プロジェクトは2.6.3になってる。。。
-> % rbenv versions
system
2.3.7
2.3.8
2.5.1
2.5.3
* 2.6.3 (set by /Users/(username)/projects/import_agent_app/.ruby-version)
2.6.5
2.6.6
2.7.1
-> % git checkout -b feature/version_up
Switched to a new branch 'feature/version_up'
-> % rbenv local 2.7.1
[feature/version_up *]
-> % rbenv versions
system
2.3.7
2.3.8
2.5.1
2.5.3
2.6.3
2.6.5
2.6.6
* 2.7.1 (set by /Users/(username)/projects/import_agent_app/.ruby-version)
-> % bundle install
Traceback (most recent call last):
2: from /Users/(username)/.rbenv/versions/2.7.1/bin/bundle:23:in `<main>'
1: from /Users/(username)/.rbenv/versions/2.7.1/lib/ruby/2.7.0/rubygems.rb:294:in `activate_bin_path'
/Users/(username)/.rbenv/versions/2.7.1/lib/ruby/2.7.0/rubygems.rb:275:in `find_spec_for_exe': Could not find 'bundler' (1.17.2) required by your /Users/(username)/projects/import_agent_app/Gemfile.lock. (Gem::GemNotFoundException)
To update to the latest version installed on your system, run `bundle update --bundler`.
To install the missing version, run `gem install bundler:1.17.2`
-> % bundle install
/Users/(username)/.rbenv/versions/2.7.1/lib/ruby/gems/2.7.0/gems/bundler-1.17.2/lib/bundler/rubygems_integration.rb:200: warning: constant Gem::ConfigMap is deprecated
Your Ruby version is 2.7.1, but your Gemfile specified 2.6.3
-> % bundle install
/Users/(username)/.rbenv/versions/2.7.1/lib/ruby/gems/2.7.0/gems/bundler-1.17.2/lib/bundler/rubygems_integration.rb:200: warning: constant Gem::ConfigMap is deprecated
The dependency tzinfo-data (>= 0) will be unused by any of the platforms Bundler is installing for. Bundler is installing for ruby but the dependency is only for x86-mingw32, x86-mswin32, x64-mingw32, java. To add those platforms to the bundle, run `bundle lock --add-platform x86-mingw32 x86-mswin32 x64-mingw32 java`.
Fetching gem metadata from https://rubygems.org/............
Fetching gem metadata from https://rubygems.org/.
Resolving dependencies...
Bundler could not find compatible versions for gem "activesupport":
In snapshot (Gemfile.lock):
activesupport (= 5.2.4.3)
In Gemfile:
rails (~> 6.0.3, >= 6.0.3.3) was resolved to 6.0.3.3, which depends on
activesupport (= 6.0.3.3)
web-console (>= 3.3.0) was resolved to 3.7.0, which depends on
railties (>= 5.0) was resolved to 5.2.4.3, which depends on
activesupport (= 5.2.4.3)
Running `bundle update` will rebuild your snapshot from scratch, using only
the gems in your Gemfile, which may resolve the conflict.
senpai=BreakwaterClub.new(name: 'ohno',grade: 2)senpai[:height]#=>NameError (no member 'height' in struct)senpai.height#=>NoMethodError# Hashだと定義してなくても参照できてしまうsenpai[:height]#=>nil
補足【rails-i18n】
rails g devise:install は deviseの初期設定を行います。
config/application.rbの編集
下記2行を追加。
config/application.rb
classApplication<Rails::Application# Initialize configuration defaults for originally generated Rails version.config.load_defaults5.2config.i18n.default_locale=:ja# ←追加config.i18n.load_path+=Dir[Rails.root.join('my','locales','*.{rb,yml}').to_s]# ←追加# Settings in config/environments/* take precedence over those specified here.# Application configuration can go into files in config/initializers# -- all .rb files in that directory are automatically loaded after loading# the framework and any gems in your application.end
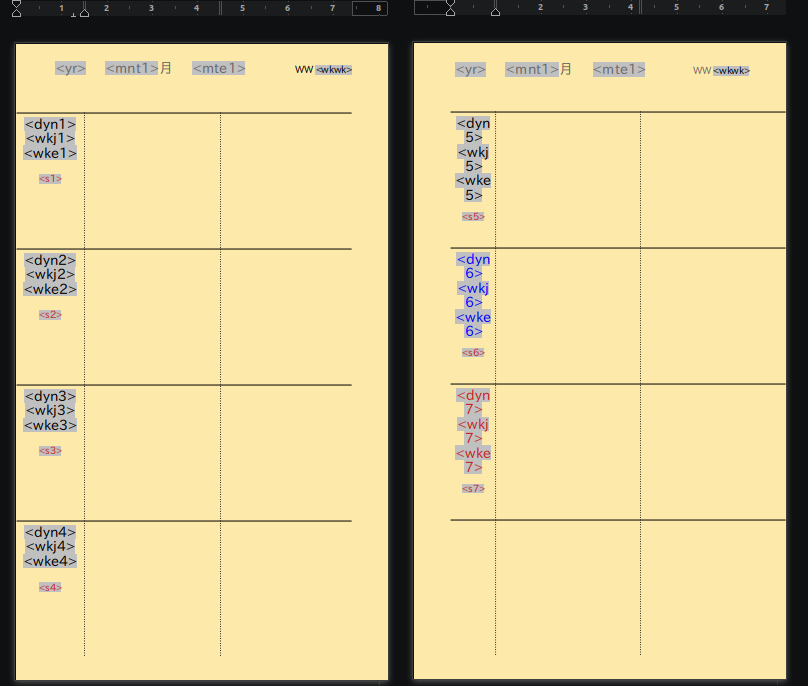
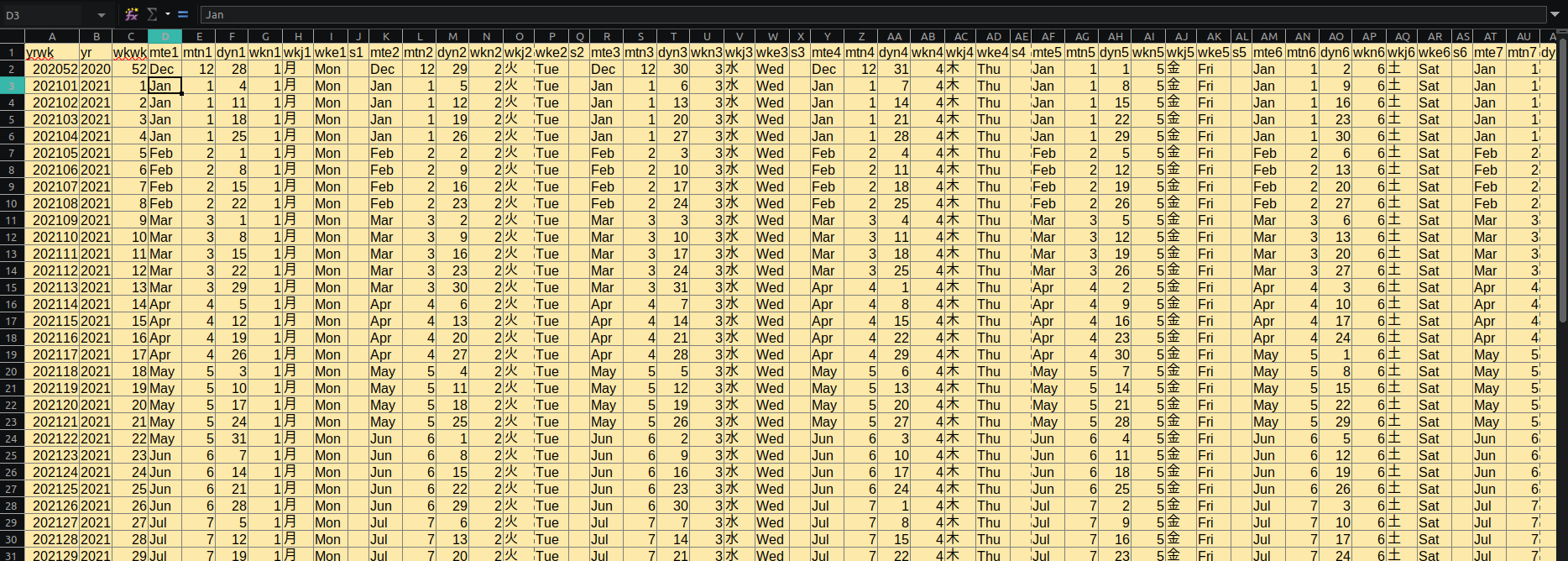
システム手帳のリフィルのサイズ(82mmW x 140mmL)が特殊で、使い始めたものの、入手困難であったため、いっそ手作りしてしまおうと考えたのは過去のことです。その際、リフィル用紙を特注で作ったことがありまして、その時の白紙が余っているので、来年は、久しぶりに手作りしようと考えたこと。
年に一度のことですので、手作りでも良いのですが、せっかくのプログラミング環境があるので、毎年、自動でカレンダーが出力できるような仕組みを作成してみようじゃあないか。という理由で、プログラミングしました。