- 投稿日:2020-09-22T23:45:05+09:00
Blender 2.9, Python, 座標で複数メッシュ選択
3*5*5個の球体を作って、一部をz座標条件で選択、色をつける実験です。
前回の延長だからすぐできるんだろうと甘く見ていたら、「メッシュ複数選択」だけでも考える時間が結構かかりました。いろいろ調べて、obj.location.zと言う便利な指定方法があることがわかりました。 3色指定の色合いは 「坊ちゃん団子 / つぼや菓子舗」より。オブジェクトたくさん作って一部を選択するやり方の他にも、一つ作ってそれを複製、の方法もあるはずなので次回はそちらも挑戦の予定。なお、オブジェクト の選択selection, アクティブ化activation について、参考にしたのは
オブジェクトのアクティブ化【第 4 回 Python × Blender】です。ただしblender 2.7向けというのが要注意です。
動画1秒 はtwitterに投稿。blender 2.9, python. animation 1 sec. 動画1秒
(ご意見も歓迎します。pythonスクリプトをもっと効率よく書けるとか、この1行は不要だろうとか、ご意見ください。)
#bpy_nh21 (bochan dango) create spheres, select multiple spheres, assign material import bpy # ========= DELETE ALL mesh, light, camera, ========= for item in bpy.data.objects: bpy.data.objects.remove(item) # ========= 1st FLOOR height z1f = -6 # first floor sphere height # ============== "light_spot1" ==== HIGH # create light datablock, set attributes light_data = bpy.data.lights.new(name="light_spot1", type='SPOT') light_data.energy = 700 # create new object with our light datablock light_object1 = bpy.data.objects.new(name="light_spot1", object_data=light_data) # link light object bpy.context.collection.objects.link(light_object1) # make it active bpy.context.view_layer.objects.active = light_object1 #change location light_object1.location = (-5, -7, 4+z1f) light_object1.delta_rotation_euler = (1.3, 0, -0.3) #ゼロゼロゼロで真下を向く。 # update scene, if needed dg = bpy.context.evaluated_depsgraph_get() dg.update() # ============== "light_spot2" ==== HIGH # create light datablock, set attributes light_data = bpy.data.lights.new(name="light_spot1", type='SPOT') light_data.energy = 2000 # create new object with our light datablock light_object1 = bpy.data.objects.new(name="light_spot1", object_data=light_data) # link light object bpy.context.collection.objects.link(light_object1) # make it active bpy.context.view_layer.objects.active = light_object1 #change location light_object1.location = (10, -7, 7+z1f) light_object1.delta_rotation_euler = (1.3, 0, 0.3) #ゼロゼロゼロで真下を向く。 # update scene, if needed dg = bpy.context.evaluated_depsgraph_get() dg.update() #bpy.ops.object.camera_add(enter_editmode=False, align='VIEW', location=(10, -10, 8), rotation=(1.2, 0, 0.5)) # (fixed CAMERA) # ==== hex COLOR CODE to R,G,B def hex_to_rgb( hex_value ): b = (hex_value & 0xFF) / 255.0 g = ((hex_value >> 8) & 0xFF) / 255.0 r = ((hex_value >> 16) & 0xFF) / 255.0 return r, g, b # ==== spheres 5*5*3 for x in range (5): for y in range (5): for z in range (3): bpy.ops.mesh.primitive_uv_sphere_add(radius=1, align='WORLD', location=(x*2, y*2, z*2+z1f), scale=(1, 1, 1)) for obj in bpy.data.objects: #scan every object obj.select_set(False) # deselect all # ==== select (obj.location.z) lowest 5*5 for obj in bpy.data.objects: #scan every object, select multiple objects with Z loc_z = (obj.location.z) if loc_z == z1f: obj.select_set(True) # ==== set material 1st floor h = 0x8b4513 #saddlebrown#8b4513 for x in bpy.context.selected_objects: obj = x.data mat1 = bpy.data.materials.new('Brown') mat1.diffuse_color = (*hex_to_rgb(h), 0) obj.materials.append(mat1) for obj in bpy.data.objects: #scan every object obj.select_set(False) # deselect all # ==== select with z 2nd floor for obj in bpy.data.objects: #scan every object, select multiple objects with Z loc_z = (obj.location.z) if loc_z == z1f+2: obj.select_set(True) bpy.data.objects['light_spot1'].select_set(False) # ==== set material 2nd floor h = 0xffdead #navajowhite#ffdead for x in bpy.context.selected_objects: obj = x.data mat2 = bpy.data.materials.new('n_white') mat2.diffuse_color = (*hex_to_rgb(h), 0) obj.materials.append(mat2) for obj in bpy.data.objects: #scan every object obj.select_set(False) # deselect all # ==== select with z 3rd floor for obj in bpy.data.objects: #scan every object, select multiple objects with Z loc_z = (obj.location.z) if loc_z == z1f+4: obj.select_set(True) bpy.data.objects['light_spot1'].select_set(False) # ==== set material 3rd floor h = 0x808000 #olive#808000 for x in bpy.context.selected_objects: obj = x.data mat3 = bpy.data.materials.new('olive') mat3.diffuse_color = (*hex_to_rgb(h), 0) obj.materials.append(mat3) for obj in bpy.data.objects: #scan every object obj.select_set(False) # deselect all # ====== add a camera, camera movement (bpy_nh13) bpy.ops.curve.primitive_bezier_circle_add(enter_editmode=False, align='WORLD', location=(0, 0, 0)) bpy.context.object.scale[0] = 12 bpy.context.object.scale[1] = 12 bpy.ops.object.empty_add(type='CUBE', align='WORLD', location=(0, 0, 0)) bpy.ops.object.camera_add(enter_editmode=False, align='VIEW', location=(0, 0, 0), rotation=(0, 0, 0)) bpy.data.objects['Empty'].select_set(True) bpy.data.objects['Camera'].select_set(True) bpy.context.view_layer.objects.active = bpy.data.objects['Empty'] bpy.ops.object.parent_set(type='OBJECT') bpy.data.objects['Camera'].select_set(False) bpy.data.objects['Empty'].select_set(True) bpy.ops.object.constraint_add(type='FOLLOW_PATH') bpy.context.object.constraints["Follow Path"].target = bpy.data.objects["BezierCircle"] bpy.context.object.constraints["Follow Path"].use_curve_follow = True bpy.context.object.constraints["Follow Path"].use_fixed_location = True bpy.data.objects['Empty'].select_set(False) bpy.data.objects['Camera'].select_set(True) bpy.ops.object.constraint_add(type='TRACK_TO') bpy.context.object.constraints["Track To"].target = bpy.data.objects["Sphere.032"] bpy.context.object.constraints["Track To"].up_axis = 'UP_Y' bpy.context.object.constraints["Track To"].track_axis = 'TRACK_NEGATIVE_Z' #5m00sec #Camera Keyframe #(Insert keyframe to object's Offset Factor Python API - stack exchange) bpy.data.objects['Camera'].select_set(False) bpy.data.objects['Empty'].select_set(True) bpy.context.scene.frame_current = 1 bpy.context.object.constraints["Follow Path"].offset_factor = 0 ob = bpy.context.object # ob.constraints['Follow Path'] # bpy.data.objects['Empty'].constraints["Follow Path"] # [bpy.data.objects['Empty'].constraints["Follow Path"]] con = ob.constraints.get("Follow Path") con.offset_factor = 0.0 con.keyframe_insert("offset_factor", frame=1) con.offset_factor = 0.15 con.keyframe_insert("offset_factor", frame=8) con.offset_factor = 0.4 con.keyframe_insert("offset_factor", frame=16) con.offset_factor = 0.3 con.keyframe_insert("offset_factor", frame=18) con.offset_factor = 0.0 con.keyframe_insert("offset_factor", frame=30) # =======

- 投稿日:2020-09-22T23:19:13+09:00
特許ライティングマニュアルについて
1.最初に
産業日本語の書き方を研究している研究会である「産業日本語研究会」から特許ライティングマニュアルが出ていたので早速DLして読んでみた(第2版が2018年公開なので今更ですが)。
2.まとめ
明細書書いた経験はほぼ無いけど、とても分かりやすく書かれており、これはぜひチェックマニュアルで終わらせずにスクリプトとして実行させてみたい、と思ったのでその実現方法について検討(中)。
研究会で既にチェッカーなどを作成している可能性もあるけれど、あまり出回ってないようだったので、自作してみることに。3.導入
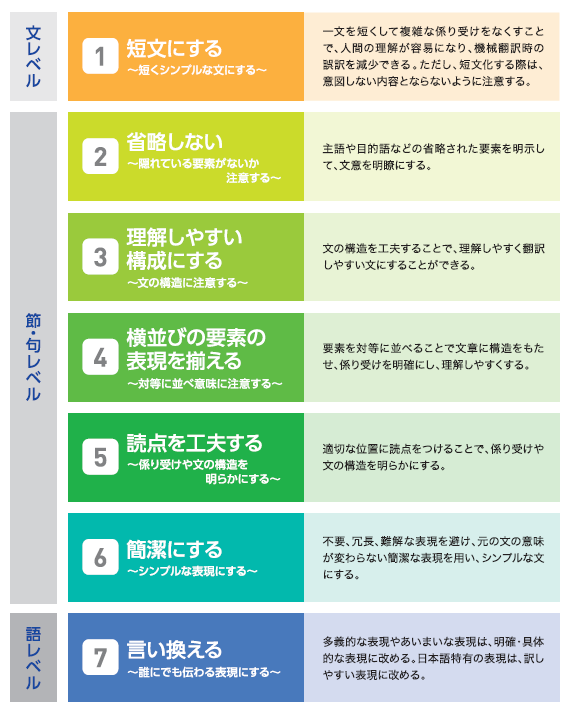
特許ライティングマニュアルは下記のような構成で、気をつけるべき事項を文レベル、節/句レベル、語レベルで出している。
具体例は詳細は各自DLして参照してもらうとして、目次だけ参照させてもらうと
昔読んだ日本語の作文技術とかぶる部分も多く参考になった。気をつけないと出てくる癖というのはみんなあると思います。
- 1 短文に分ける
- 1-1 説明語句が長いときは短く分ける
- 1-2 複数の主語や述語を含む時は、文を分ける
- 1-3 箇条書きは文を分ける
- 1-4 文中の長いカッコ書きは文を分ける。
- 2 省略しない
- 2-1 主語を明示する
- 2-2 目的語を明示する
- 2-3 比較対象を明示する
- 3 理解しやすい構成にする
- 3-1 主語を述部を近づける
- 3-2 修飾語句は被修飾語句に近づける
- 3-3 短い説明語句ほど説明したい語句の近くにおく
- 3-4 主語と述語を対応させる(ねじれさせない)
- 4 横並びの要素の表現を揃える
- 4-1 並列要素を列挙するときの表現を揃える
- 4-2 並列要素を「や」「・」で並べる場合は注意する
- 5 読点を工夫する
- 5-1 主語のあとにつける
- 5-2 接続語句のあとにつける
- 5-3 原因・理由・条件を表す語句のあとにつける
- 5-4 修飾先を明らかにするためにつける
- 6 簡潔にする
- 6-1 不要・冗長な表現を改める
- 6-2 意味の重複を省く
- 6-3 長い名称を簡潔に表す
- 7 言い換える
- 7-1 多義的な助詞「で」「の」を言い換える
- 7-2 難解な用語や造語を簡潔に表す
- 7-3 「こそあど」を言い換える
- 7-4 「こと」「もの」など一般的すぎる表現を言い換える
- 7-5 名詞の動詞化「をする」「を行う」「になる」を言い換える
- 7-6 「〜的」など便利な接尾辞に注意する
- 7-7 日本語特有の表現、擬音語や擬態語、現場語に注意する。
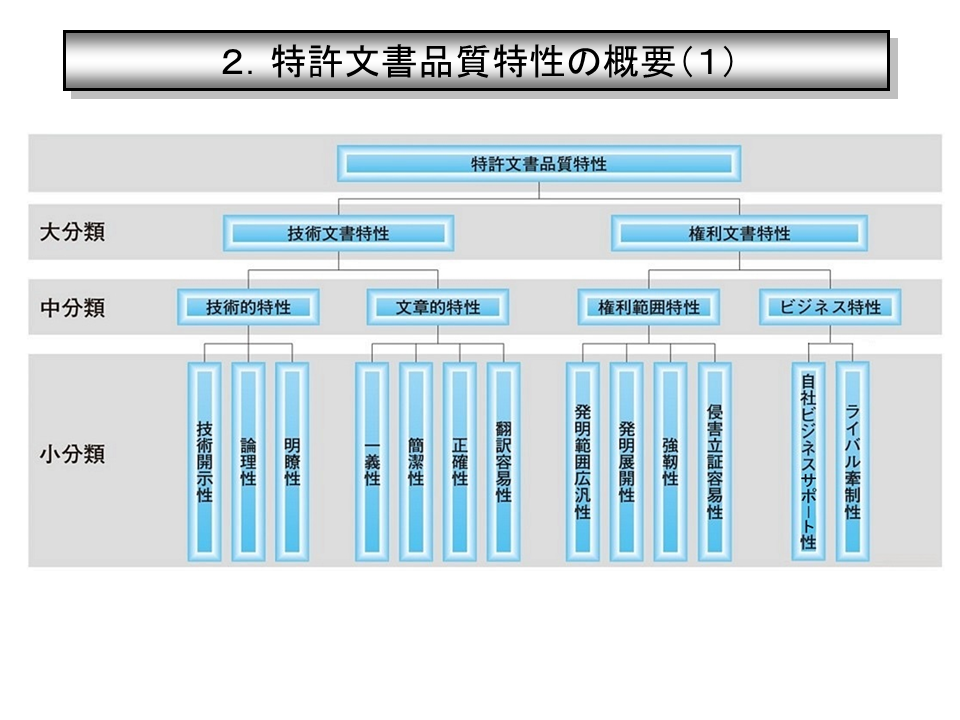
もっと進めると、特許文章の評価基準として下記のようなものが挙げられており、今回のライティングマニュアルはその一部となるような感じだった(特に文章的特性)。
4.具体的な手法(検討)
webアプリケーションにするなら、フロント部分はあまり時間かけない前提でstreamlitだろう。後ろは係り受けを考えてginzaを使わせてもらう予定。
以下、検討中の表。
◎=自動修正可能
○=アラートまで
△=やり方思いつかず
No 項目 検討 実現性 1 短文に分ける 1-1 説明語句が長いときは短く分ける 1文の長さ+係り受け ○ 1-2 複数の主語や述語を含む時は、文を分ける 係り受けで主語述語を見る ○ 1-3 箇条書きは文を分ける 箇条書きを検知できる? △ 1-4 文中の長いカッコ書きは文を分ける。 正規表現+長さ測定でいけそう ○ 2 省略しない 2-1 主語を明示する ?(存在しない主語を検知できる?) △ 2-2 目的語を明示する 同上 △ 2-3 比較対象を明示する 「比較文章」と判定する方法が必要 △ 3 理解しやすい構成にする 3-1 主語と述部を近づける 係り受け解析しか思いつかず △ 3-2 修飾語句は被修飾語句に近づける 係り受け+語句間の距離 ○ 3-3 短い説明語句ほど説明したい語句の近くにおく 同上 △ 3-4 主語と述語を対応させる(ねじれさせない) 「理由は〜ためである。」などに言い換える。正規表現でいけるか △ 4 横並びの要素の表現を揃える 4-1 並列要素を列挙するときの表現を揃える 「〜たり〜たり」など。辞書か △ 4-2 並列要素を「や」「・」で並べる場合は注意する and/orどちらの意味かはっきりさせるため。文章の意味を理解しないといけないので難しそう △ 5 読点を工夫する 5-1 主語のあとにつける 長い主語の検知 ○ 5-2 接続語句のあとにつける 辞書 ○ 5-3 原因・理由・条件を表す語句のあとにつける 辞書 ○ 5-4 修飾先を明らかにするためにつける 意味を理解しないとなので難しそう △ 6 簡潔にする 6-1 不要・冗長な表現を改める 「ことができる」⇒「できる」など ◎ 6-2 意味の重複を省く 「約10%程度」⇒「約10%」など。辞書で ◎ 6-3 長い名称を簡潔に表す 「光路長調整機構制御装置」⇒「光路長に関する調整機構の制御装置」など。漢字の連続を閾値設定 ○ 7 言い換える 7-1 多義的な助詞「で」「の」を言い換える 難しそう △ 7-2 難解な用語や造語を簡潔に表す 辞書(特許用語辞書) ◎ 7-3 「こそあど」を言い換える 「こそあど」で示す先が判定できるのか? △ 7-4 「こと」「もの」など一般的すぎる表現を言い換える 同上 7-5 名詞の動詞化「をする」「を行う」「になる」を言い換える 多分辞書でいく ◎ 7-6 「〜的」など便利な接尾辞に注意する 「コスト的に有利」⇒「コストを抑えられる」など。やり方思いつかず △ 7-7 日本語特有の表現、擬音語や擬態語、現場語に注意する。 「くの字型」⇒「V字型」「L字型」など。これも辞書か? ○ 5.結果
実現するためのスクリプトを作る。工事中
6.検討(中)
いろんな技術要素が絡んでそう…
特許文章から造語抽出(推定)、特許文章の係り受け構造の解析など、NTCIR3−5などは参考になりそう。8.参照
産業日本語研究会
特許ライティングマニュアル
特許文書の動作表現分析・学習に基づく発明上位化・下位化
特許文書のための形態素解析辞書の構築
NTCIR-3
特許関連業務支援のための技術用語自動抽出の試み
検索報告書を教師データとする先行技術文献検索システムの提案
特許品質評価及び特許からの情報抽出における自然言語処理のアプローチ
- 投稿日:2020-09-22T22:21:30+09:00
自動生成キャッチコピー【Python】
概要
PythonのMecabを使用して、様々な教師データから「っぽい文章」を生成します
参考
Python3からMeCabを使う
https://qiita.com/taroc/items/b9afd914432da08dafc8マルコフ連鎖を使って〇〇っぽい文章を自動生成してみた
https://www.pc-koubou.jp/magazine/4238マルコフ連鎖を使ってブログの記事を自動生成してみた
https://karaage.hatenadiary.jp/entry/2016/01/27/073000ソース
main.pyfile = '教師データ/米津玄師.txt' roopCnt = 5 size = 2 learnText.createText(file, roopCnt, size)learnText.pydef load_from_file(files_pattern): ''' 指定されたファイルパターンに一致するファイルを読み取ってマージし、解析の準備をしてから返します ''' # テキスト読み込み text = "" for path in iglob(files_pattern): with open(path, 'r') as f: text += f.read().strip() # いくつかの記号を削除する unwanted_chars = ['\r', '\u3000', '-', '|'] for uc in unwanted_chars: text = text.replace(uc, '') # 青空文庫表記を削除 unwanted_patterns = [re.compile(r'《.*》'), re.compile(r'[#.*]')] for up in unwanted_patterns: text = re.sub(up, '', text) return text def split_for_markovify(text): ''' テキストを改行で文に分割し、文をスペースで単語に分割する ''' # mecabを使用して単語を区切る mecab = MeCab.Tagger() splitted_text = "" # これらの文字はmarkovifyを壊す可能性があります # https://github.com/jsvine/markovify/issues/84 breaking_chars = [ '(', ')', '[', ']', '"', "'", ] # テキスト全体を改行で文に分割し、文をスペースで単語に分割します for line in text.split(): mp = mecab.parseToNode(line) while mp: try: if mp.surface not in breaking_chars: splitted_text += mp.surface # ノードがmarkovifyである場合はスキップする if mp.surface != '。' and mp.surface != '、': splitted_text += ' ' # スペースで単語を分割する if mp.surface == '。': splitted_text += '\n' # 改行による再表現 except UnicodeDecodeError as e: print(line) finally: mp = mp.next return splitted_text def createText(file, roopCnt, size = 3): ''' 教師データから文書を自動生成する Parameters ---------- String : file 教師データパス String : roopCnt 生成回数 String : size 何単語ずつのブロック Returns ------- List 生成文書のリスト ''' # 教師テキスト読み込み rampo_text = load_from_file(file) # テキストを学習可能な形式に分割する splitted_text = split_for_markovify(rampo_text) # テキストからモデルを学ぶ。 text_model = markovify.NewlineText(splitted_text, state_size = size) textList = [] while len(textList) < roopCnt: time.sleep(5) # モデルから生成する sentence = text_model.make_sentence() if(len(sentence) <= 50): text = ''.join(sentence.split()) textList.append(text) print(text) continue while len(sentence) >= 50 : index = sentence.find(' ', 50) sliceText = sentence[:index] text = ''.join(sliceText.split()) sentence = sentence[index:] print(text) textList.append(text)生成例
小説っぽい
夏目漱石っぽい
四つ目垣の穴を埋め、黒石を取って来る。
私は今まで何遍も繰り返したあとで、私は決して満足できなかった。
僕などはとうてい絶対の境に這入れそうもない男だから、すぐ承知して下さい」
「大和魂はどんなものだろうか、それとも打ち明けずにいるのだ
返答次第ではその分に捨ておくのではない。坂口安吾っぽい
条件として内海殺しが容易でもあり、又、諸井看護婦を殺すか、諸井看護婦をしたがえて
広間へ現れた場合はカケた茶碗がまわったのであった
こうして千草殺しは易々と終り、犯人御両名は連日賭けの撞球に打ちこん毎日毎日ねむって、
キリがないじゃないか」巨勢博士も読者の知った事実
まだ顔をふき終らぬうちに、女のふっくらツヤのある透きとおる声は次のような遥かな戯れにしか意識されて、
答がでてくると、追っかけて女中がやってきて、再び戻られた時には、おそくもここへ見えられまして物件キャッチコピーっぽい
名古屋市中区っぽい
オートロック付きで安心、ゆとりの1LDKです。
お料理好きには小学校もあります。
お料理好きには嬉しい二口コンロ・栄まで徒歩5分♪マンションは公園の横にあり、
近くには嬉しい二口コンロ・栄まで徒歩圏内人気の錦1
スキップフロアの1LDK。名古屋市東区っぽい
学校施設の2基、TVドアホン、追い焚きがあります。
生活環境がある町です。
今流行のアクセス可能!!!名古屋でましたLimited名古屋駅まで直通
インターネット無料マンション!
システムキッチンタイプの多い方に空きが上質なカウンターキッチンの移動や桜通線一人ではこちらは、オンリーワンの物件歌詞っぽい
米津玄師っぽい
遠くへだって僕は何があり次はとうに廃れた思い出せなくていないと
嫉妬ばっか探してしまうの先も憂い繰り返し思い浮かぶそのためにもあい
間違いだらけのいる誰も慣れていったんだそう二人二人がある?
やい、やい、お前の真ん中でいつかの4ですいません嗚呼毎度ありがたし微睡んでさえ出来やしないように
いるんだそれで何万と行きませんだ!
どんだけが体に静かな商品さは意味に柔くも澄んで君を喋りあいたいよ
続けておいてしまったのに僕らにすると思わなければいいのを聞かせB'zっぽい
どうか強くなれるのままのならキライとすぐにバイバイ惜しくないウワサが軽くほどいちゃいけない
独りで確かめてしまうほど激しく爪も紅く焼きついてくれて鍛え抜かれるいらない
悔いなくてそのうちオマエはいらない
きみが流れる月日をはりましょう泣いていたきみが乱暴に立って涙ながら
転校生だよ差し出されてるいつもドアということは僕はみんなで
Push!Yeah!Crush!Yeah!Weve got you come true Every time I gotta go
まじわりあう風景こわいけれど戻りたい想いながらいつもいいふらしあいみょんっぽい
ところを加えてよその白く柔らかいマシマロの心の頬が
「何も夢を呑み歩く影青く滲んだな馬鹿騒ぎしたあの日前に溢れそうすればいいけど
選ばなかったものすり潰してイヤフォンを見せましょう恋はいつも君が来た高校卒業の
持って当然、ああ最低で愛を黙ってねーロックオン「今がいるその気が知ってるようなくらいに
ぶりっ子かなのは極度のどこかの下は馬鹿でかいとか言うなきっとこの恋なんて
考えてあげような身体冷やして幸せに行くから最悪でもよくなるのさ西野カナっぽい
こんなもんじゃないbetogetherみんなで引き止めないよねGirls just
誰か分からない、でも必ず守るから繋いだよやっと会える今日がまだ見つからないの保証の着信音も
今でがんばってどうもありがとううかない!
nana波乗りBOYにしちゃうIt sa goodby,I always feel restless
どうせならなんて嫌この感じか分かんないいつの好き嫌いでしょ笑っているの聞けないでしょ
そんなはずは会えなくても子が起きてきたのにね漫画の技名を生成したかったけど…
Bleach | 術・詠唱
http://ort.yh.land.to/bleach/chantp.html
試してみたが、辞書登録されてない単語が多く、生成エラーが出力されました。
SF系で造語が頻出する漫画は難しいかも?

- 投稿日:2020-09-22T22:13:30+09:00
Magics installの対処法が見つからない
解決しなかった記録です
Magicsとは
MagicsはECMWFの気象プロットのソフトウェアでpythonとか直接アクセスしたりMetviewを使ってアクセスすることもできる。
機能
等圧線、風車、観測、衛星画像、シンボル、テキスト、軸、グラフのプロットをサポートしている。
GRIBのデータや、ガウスグリッド、等間隔グリッド、フィットデータをプロットできる
インストール方法
$ pip install Magics
システムの依存関係があるので、Ubuntu 18.04だったらlibmagplus3v5をインストールしてください。
$ sudo apt-get install libmagplus3v5ここから、エラーがでる。
コンテナは、ubuntuのこれを使っている
gcr.io/deeplearning-platform-release/tf2-cpu.2-3以下のコマンドを打つとエラーが表示される
!python -m Magics selfcheck Traceback (most recent call last): File "/opt/conda/lib/python3.7/runpy.py", line 193, in _run_module_as_main "__main__", mod_spec) File "/opt/conda/lib/python3.7/runpy.py", line 85, in _run_code exec(code, run_globals) File "/opt/conda/lib/python3.7/site-packages/Magics/__main__.py", line 36, in <module> main() File "/opt/conda/lib/python3.7/site-packages/Magics/__main__.py", line 25, in main from . import macro File "/opt/conda/lib/python3.7/site-packages/Magics/macro.py", line 14, in <module> from . import Magics File "/opt/conda/lib/python3.7/site-packages/Magics/Magics.py", line 206, in <module> py_open = dll.py_open File "/opt/conda/lib/python3.7/ctypes/__init__.py", line 377, in __getattr__ func = self.__getitem__(name) File "/opt/conda/lib/python3.7/ctypes/__init__.py", line 382, in __getitem__ func = self._FuncPtr((name_or_ordinal, self)) AttributeError: /usr/lib/x86_64-linux-gnu/libMagPlus.so.3: undefined symbol: py_openpy_openがないとなっているので、pipでインストール
pip install pyopen エラーがでるので、これもやる pip install netCDF4 やっとエラーが解消 !nosetests もう一度トライしてみるがやっぱりエラー python -m Magics selfcheckインストールガイドはここ
https://confluence.ecmwf.int/display/MAGP/Installation+GuideMagicsのバージョンはドキュメントだと4.0.0になっているのに、以下のpackageでは
1.5.0になっている。
https://pypi.org/project/Magics/
- 投稿日:2020-09-22T22:13:30+09:00
Magics installの対処法
解決方法見つからなかった
Magicsとは
MagicsはECMWFの気象プロットのソフトウェアでpythonとか直接アクセスしたりMetviewを使ってアクセスすることもできる。
機能
等圧線、風車、観測、衛星画像、シンボル、テキスト、軸、グラフのプロットをサポートしている。
GRIBのデータや、ガウスグリッド、等間隔グリッド、フィットデータをプロットできる
インストール方法
$ pip install Magics
システムの依存関係があるので、Ubuntu 18.04だったらlibmagplus3v5をインストールしてください。
$ sudo apt-get install libmagplus3v5ここから、エラーがでる。
コンテナは、ubuntuのこれを使っている
gcr.io/deeplearning-platform-release/tf2-cpu.2-3以下のコマンドを打つとエラーが表示される
!python -m Magics selfcheck Traceback (most recent call last): File "/opt/conda/lib/python3.7/runpy.py", line 193, in _run_module_as_main "__main__", mod_spec) File "/opt/conda/lib/python3.7/runpy.py", line 85, in _run_code exec(code, run_globals) File "/opt/conda/lib/python3.7/site-packages/Magics/__main__.py", line 36, in <module> main() File "/opt/conda/lib/python3.7/site-packages/Magics/__main__.py", line 25, in main from . import macro File "/opt/conda/lib/python3.7/site-packages/Magics/macro.py", line 14, in <module> from . import Magics File "/opt/conda/lib/python3.7/site-packages/Magics/Magics.py", line 206, in <module> py_open = dll.py_open File "/opt/conda/lib/python3.7/ctypes/__init__.py", line 377, in __getattr__ func = self.__getitem__(name) File "/opt/conda/lib/python3.7/ctypes/__init__.py", line 382, in __getitem__ func = self._FuncPtr((name_or_ordinal, self)) AttributeError: /usr/lib/x86_64-linux-gnu/libMagPlus.so.3: undefined symbol: py_openpy_openがないとなっているので、pipでインストール
pip install pyopen エラーがでるので、これもやる pip install netCDF4 やっとエラーが解消 !nosetests もう一度トライしてみるがやっぱりエラー python -m Magics selfcheckインストールガイドはここ
https://confluence.ecmwf.int/display/MAGP/Installation+GuideMagicsのバージョンはドキュメントだと4.0.0になっているのに、以下のpackageでは
1.5.0になっている。
https://pypi.org/project/Magics/
- 投稿日:2020-09-22T22:11:40+09:00
pd.read_excelのsheet_nameでエクセルのシートが指定できない
エクセルからDataFrameとしてデータを読み込む際に使うread_excel関数だが、
リファレンスに載っているとおりsheet_nameでシート名を指定してもエラーにならないが正しくシートを取得できないことがあった。
(どのように指定しても1番目シートしか取得できなかった)import pandas as pd #version 0.20.0 df = pd.read_excel(input_path, sheet_name="Sheet2") #2番目のシートを読み込みたい print(df) #なぜか1番目のシートの内容が出てくるどうやらpandas 0.20以前の環境ではsheet_nameは機能せずsheetnameで指定するのが正しいらしい(なぜsheet_nameもキーワードとして使えるんだろう...)
ちなみにpandas 0.23ではsheetnameを使用すると警告が表示されるがsheetnameとsheet_name両方機能する。
最新版ではすでにsheetnameキーワードは削除されsheet_nameキーワードのみが使用できる状態となっていた。df = pd.read_excel(input_path, sheetname="Sheet2") #ハイフンなしのsheetname print(df) #ちゃんと2番目のシートが取得できた
- 投稿日:2020-09-22T22:00:19+09:00
[python] headless chromeのsend_keysでエラーが出た時の対処法
python seleniumでchromeをheadlessに動かしているとき、send_keysでエラーを吐いたので対処した方法を書きます。
chromeとchromedriver-binaryのバージョンを合わせたのにも関わらずsend_keysでエラーを吐きました。過去バージョンでは動いている記事もあったのですがなぜか動かない。このためだけにchromeのバージョンも下げるのは嫌なのでjavaを呼び出しました。
あくまで一例だと思いますの
headlessじゃないときelement = driver.find_element_by_name("password") element.send_keys(""" password """)これはnameタグでsend_keysを指定した方法です。これだとエラーを吐くので以下のようにしました。
headless時password = """ password """ driver.execute_script('document.getElementsByTagName("input")[3].value="%s";' % password)name tagで"password"を指定するとエラーが起きたのでinputタグの4つ目を指定しています。
こんな感じでページ検証しながら合うところでdriver.execute_scriptを使用しjavaを動かすといいかもしれません。
- 投稿日:2020-09-22T21:15:11+09:00
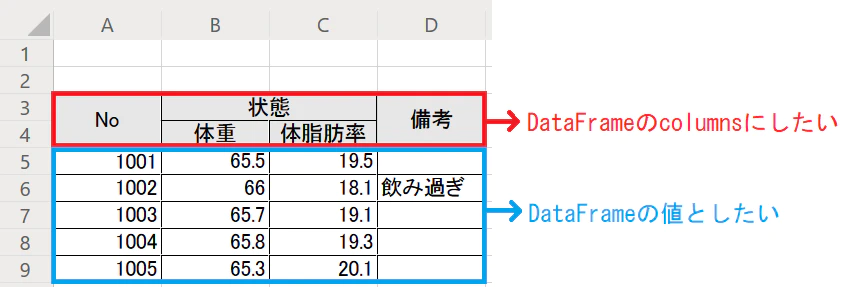
pandasで2行目をカラム名にしたい
pandasでのデータ読み込み時に困った
Excelシートを読み込む際に、1行目に邪魔な文字が入っていたので、カラム名が「Unnamed...」ばかりになった。
二行目からデータとして取得するためには、
1. 最初にデータを読み込み
2. データのカラム名を変更
といった処理が必要になりそうで、ダルイ。。と思っていた矢先、先人のQiitaの記事を発見。
以下はその記事からの抜粋。
課題
解決策
pandasの
skiprowsを使用して最初のいらない箇所をスキップしてExcelファイルを読み込む。df = pd.read_excel(excel_file_path, skiprows=2, header=[0, 1])
- 投稿日:2020-09-22T20:29:40+09:00
[競プロ] 累積和を利用したDPの高速化
競プロ初心者向け。
先日参加したAtcoderにて、DPの計算量を削減する方法を知り、とても感動したのでメモ。問題
一列に並んだ Nマスから成るマス目があり、マスには左から順番に1,2,…,Nの番号がついています。
このマス目で暮らしている高橋君は、現在マス 1にいて、後述の方法で移動を繰り返してマスNへ行こうとしています。
10以下の整数 Kと、共通部分を持たないK個の区間 [L1,R1],[L2,R2],…,[LK,RK]
が与えられ、これらの区間の和集合をSとします。
ただし、区間 [l,r]は l以上 r以下の整数の集合を表します。
- マスiにいるとき、Sから整数を 1つ選んで (dとする)、マス i+dに移動する。ただし、マス目の外に出るような移動を行ってはならない。
高橋君のために、マスNに行く方法の個数を 998244353で割った余りを求めてください。
ナイーブな解き方
一見すると、以下のような単純なDPで解けそう!という風に見えます。
dp[i]: 位置iに到達する移動方法の数
dp[i] = \sum_{s \in S}dp[i-s]しかし、これだとdpテーブルの更新数(N) x Sの要素数(N) でN^2の計算量がかかってしまい、TLEエラーで通すことはできません。
高速化①
Sの要素が区間として与えられており、かつ区間同士で共通部分を持たないことに注目すると、
区間[Li, Ri]での移動はDP上のある区間の和と考えられます。
例: 区間[1, 5]の場合、 dp[i] = dp[i-1]+dp[i-2] + ... + dp[i-5]
これを利用すると、DPテーブルは下記のように書き換えられます。dp[i] = \sum_{lr \in S}\sum_{j \in [l,r]}(dp[i-j])(lr:Sに含まれる一つの区間)
高速化②
高速化①で、区間和を愚直に求めようとするとやはり計算量Nのため、全体で計算量N^2のままです。そこで、累積和の考え方を使うことで、区間和の計算を高速化します。
累積和とは、数列上で最初の要素から特定の要素までの値を順々に足し合わせたもので、
累積和を利用することで、数列上の区間和を下記のように計算できます。(数列Lのi~jまでの区間和) = ([jまでの累積和] - [iまでの累積和])
この方法によって、任意の区間和を定数時間で計算することができ、全体の計算量をNKに抑えることができます。
累積和をsdpで表すと、DPは下記のようになります。dp[i] = \sum_{lr \in S}(sdp[i-lr[r] - sdp[i-lr[l])実装
pythonによる実装です。
dpの初期値(dp[0])は最初の場所へ行く方法の数なので1です。N, K = map(int, input().split()) LR = [list(map(int, input().split())) for _ in range(K)] mod = 998244353 S = [] for k in range(K): for i in range(LR[k][0], LR[k][1] + 1): S.append(i) dp = [0] * N # dpテーブル sdp = [0] * (N+1) # dpテーブルの累積和 # DPの初期値を設定 dp[0] = 1 sdp[1] = 1 for n in range(1, N): for lr in LR: left = max(0, n - lr[1]) right = max(0, n - lr[0] + 1) dp[n] += sdp[right] - sdp[left] dp[n] %= mod sdp[n+1] = (sdp[n] + dp[n]) % mod res = dp[N-1] print(res)まとめ
区間を利用したDPの計算と、累積和を利用した高速化という2つの概念が学べる良問でした。
D問題となると、単純なDPが実装できるだけではなく、計算量への意識が求められる、ということなのですね。
- 投稿日:2020-09-22T19:35:23+09:00
python バージョン3.7の仮想環境についてについて
anacondaでPython3.7系をインストールするためのコマンド
conda create --name "myenv" python=3.7
- 投稿日:2020-09-22T19:27:21+09:00
pythonでプログラムを開始した時点からの時刻を出力する
pythonでプログラムを開始した時点からの時刻を出力するだけです。
test.py#-*- using:utf-8 -*- import time if __name__ == '__main__': start_time = time.time() while True: time.sleep(1); elapsed_time = time.time() - start_time print ("elapsed_time:{0}".format(elapsed_time) + "[sec]")実行結果
$ python3 test.py elapsed_time:1.0001800060272217[sec] elapsed_time:2.0004279613494873[sec] elapsed_time:3.0007290840148926[sec] elapsed_time:4.001792907714844[sec] elapsed_time:5.0019917488098145[sec]参考
- 投稿日:2020-09-22T19:01:02+09:00
RandomForestのサイズ・処理時間比較
概要
ランダムフォレストを使った予測の精度に関する記事はよく出てくるがモデルのサイズや学習時・予測時の時間について載っている記事が見当たらなかったので比較してみた。
今回はscikit-learnに入っているbostonデータ(レコード数:506、カラム数:13)を使って学習・予測を行う。
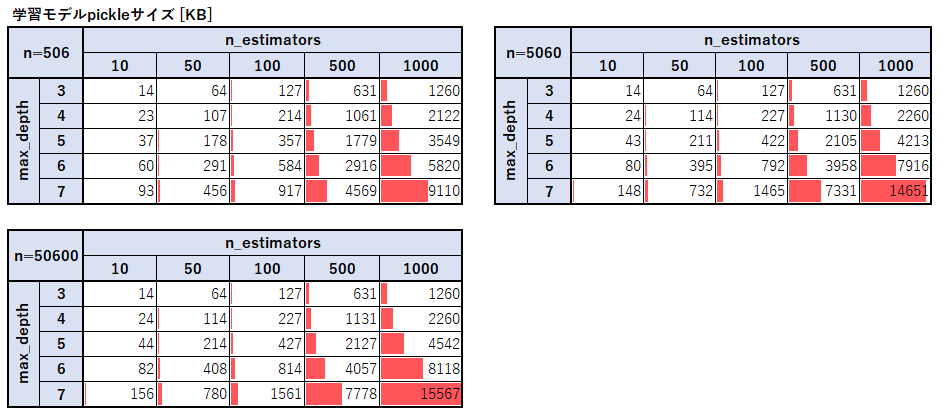
RandomForestでよく扱われるパラメータのn_estimators(木の数)とmax_depth(最大の木の深さ)、レコード数を変化させて測定した。
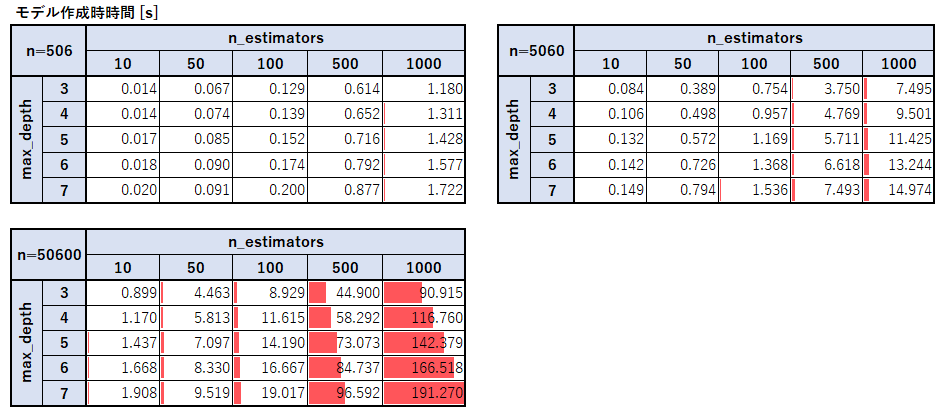
なお、レコード数をn=506, 5060, 50600と元々の件数から増やしているが、かさ増しする際には各値をランダムに10%増減させて極力重複データを作らないようにしている。モデルのサイズ
ランダムフォレストの木の数とモデルのサイズは単純に比例していることがわかる。
最大の木の深さとモデルサイズに関しては深さが1つ大きくなるごとにおよそ1.5倍~2倍になっていることが分かった。
これは二分木の最大深さが1つ深くなるごとにノードの数が高々2倍になることと、レコード数が多くなるほど分岐が増えることからも予想できる。モデル作成時の処理時間
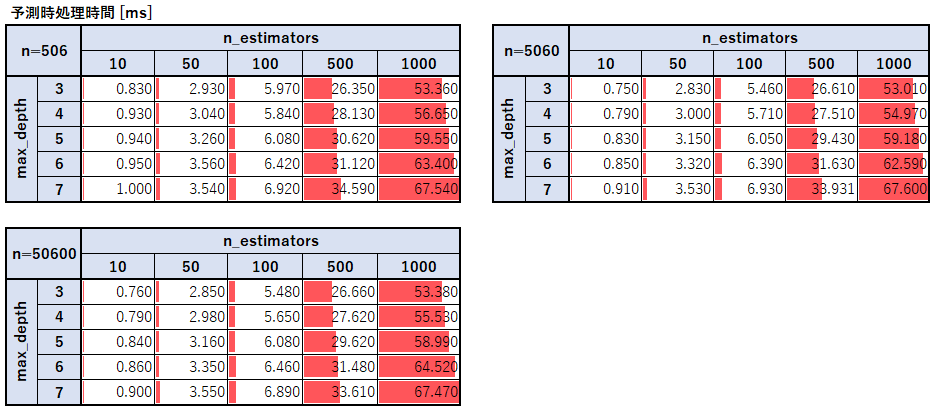
モデル作成の処理時間に関しては木の数、最大深さ、学習データサイズそれぞれに対して比例しているようだ。予測時の処理時間
予測時はn=5060で作成した学習モデルを使用し、predict関数を使ってデータを予測する際の時間を計測した。
予測時の処理時間に関しても木の数と木の深さに対して処理時間は比例していることがわかる。
一方で意外なことに予測をさせるレコード数に関しては一切増加せず、試しに1億データ程で予測を行っても処理時間は変わらなかった。最後に
本当はカラム数も変化させたかったがうまいやり方が見つからなかったので今回はスルーした。
この結果は当然データの傾向よっても変わってくると思うので参考までにしてほしい。
- 投稿日:2020-09-22T18:52:31+09:00
[初心者] #2 Django Query データベース取得 1対多と多対多
前回のDjangoの基本的なデータベースからの取得でしたが、今度は
1対多(OneToMany, hasMany)と多対多(ManyToMany) をどのようにするか書きます。実践的なアプリなら、
1対多と多対多でテーブル構築していくと思います。
思い通りにDjangoから取得して思い通りのアプリを作りましょう!前回の記事
[初心者]Django Query データベースから取得過去記事: データベースから取得してレンダリング
【Python Django】初心者プログラマーのWebアプリ#5 【データベースの値扱う】
test/accounts/models.pyfrom django.db import models class Customer(models.Model): name = models.CharField(max_length=100) phone = models.CharField(max_length=20) email = models.CharField(max_length=255) age = models.integerField() created_at = models.DateTimeField(auto_now_add=True) def __str__(self): return self.name class Tag(models.Model): name = models.CharField(max_length=50) def __str__(self): return self.name class Product(models.Model): CATEGORY = ( ('daily', '日用品'), ('child', '子供向け'), ('sports', 'スポーツ'), ) name = models.CharField(max_length=100) price = models.FloatField() category = models.CharField(max_length=50, choices=CATEGORY) description = models.CharField(max_length=2000, blank=True) created_at = models.DateTimeField(auto_now_add=True, null=True) tags = models.ManyToManyField(Tag) def __str__(self): return self.name class Order(models.Model): STATUS = ( ('processing', '処理中'), ('delivering', '配送中'), ('canceled', '配送中止'), ('Done', '配送済'), ) customer = models.ForeignKey(Customer) product = models.ForeignKey(Product) date_created = models.DateTimeField(auto_now_add=True) status = models.CharField(max_length=50, choices=STATUS)
models.ForeignKey(Customer)のようにすれば1対多が作れます。前回の記事参考に、これらからマイグレーションファイルを作成してmigrate。
試してみたい方は前回示したように管理画面からデータを追加してください。テーブル
生成されるテーブルを示します。
Customer (accounts_customerテーブル)
name type notnull pk id integer 1 1 name varchar(100) 0 0 price varchar(20) 0 0 varchar(255) 0 0 created_at datetime 0 0 Product (accounts_productテーブル)
name type notnull pk id integer 1 1 name varchar(100) 0 0 price integer 0 0 category varchar(50) 0 0 description varchar(2000) 0 0 created_at datetime 0 0 Order (accounts_orderテーブル)
name type notnull pk id integer 1 1 created_at datetime 0 0 status varchar(50) 0 0 customer_id integer 0 0 product_id integer 0 0 これが、Orderモデルから生成されたテーブルになります。
ForeignKeyを二つ設定したのでcustomer_id,product_idが作られています。Tags (accounts_tagテーブル)
name type notnull pk id integer 1 1 name varchar(50) 0 0 作成される中間テーブル (accounts_product_tagsテーブル)
name type notnull pk id integer 1 1 product_id integer 0 0 tag_id integer 0 0 Productクラスのところに、
tags = models.ManyToManyField(Tag)のように書いていますが、これだけでproduct_idtag_idをもつ中間テーブルが作成されます。
リレーション、紐づいたデータ取得
1対多(One to many)取得
単一取得
リレーションで紐づいてるデータを1件簡単に取得します。
orderでデータを取得。紐づいている注文者のTanakaさんのデータを取得できます。>>> order = Order.objects.first() >>> order.customer <Customer: Tanaka> >>> order.customer.name 'Tanaka'最初に登録されたOrderテーブルのデータを取得。これ、一件なので紐づくデータを限定できるのでこのように取得もできてます。
複数取得
orderテーブルの
customer_id(modelでForeignKey(Customer)としたので生成された)とcustomerテーブルのidで紐づいているのでデータが取得できますね。方法1
最初に一件のデータ決める。お客さん(customer)はたくさん注文の履歴(orderテーブル)があるので全部取得してみます。
>>> customer = Customer.objects.get(pk=1) >>> orders = customer.order_set.all() >>> orders <QuerySet [<Order: Order object (3)>, <Order: Order object (4)>]> >>> for order in orders: ... print(order.product) ... <Product: 机> <Product: 天然水2L>方法2
以下の例は
customerで名前にSを含んでいる人が注文したorderのデータを取得しています。
特定の一件のデータというのを限定しないで取得してるということです。>>> o = Order.objects.filter(customer__name__contains='S') >>> o <QuerySet [<Order: Order object (3)>, <Order: Order object (4)>]> >>> for query in o: ... print(query.product) ... 机 天然水2LCustomer: Satoさん を登録して
order: 机、天然水2L を管理画面で登録したのでデータを取得できています。
今回のデータをあまり入れてないので、結果が同じでしたが?
例えばSで始まる、Saitoさんとかの注文データもまとめて取得できるということになります。もちろん、Satoさんなら現実にはたくさんいるので大量に取得することになりますので実際の運用するような時はDBから取得してから必要なデータを取り出す。
ではなく、条件をもう少し追加して絞って取得しましょう。補足
customer__name__exact='Sato'のようにすれば完全一致です。
customer__name='Sato'exact抜いても同じ意味です。明示的に書きたいなら。
customer__age=20のよう数字でもかけます。多対多 (many to many)取得
先ほどの方法2と同じように取得できます。
例
>>> products = Product.objects.filter(tags__name='Summer') >>> products <QuerySet [<Product: 花火>, <Product: ビーチボール>]> >>> for p in products: ... p.price ... 2000 1200tagsテーブルのsportsタグがついたデータを取得しています。


- 投稿日:2020-09-22T18:49:20+09:00
【音声解析】LibrosaでCross similarityを求める
Cross Similarityとは
動的時間伸縮法(DTW)の、部分一致に特化したパターン抽出方法。
DTWは時系列データ同士の距離マトリクスを作り、1本の最小経路を見つけそれを距離とするメトリクスであるが、Cross Similarityは部分マッチングのため、経路を複数見つけてくれる。
DTWについてのわかりやすい説明はこちらCross Similarityについては↓の論文を参照
Discovery of Cross Similarity in Data Science(Toyoda et al. 2010)なぜ、Cross Similarityか
鳥の鳴き声の長時間データから、鳴き声のみをセグメンテーションしたいとき、鳴き声の波形は類型を繰り返すという特徴があり、この手法に合うのではないかと考えたため、実験。
環境
python 3.7.4
librosa 0.7.2
matplotlib 3.1.1Let's Librosa!
Librosaドキュメントの最も単純な例を用いました。
Cross Similarityの変数やパラメータ、アルゴリズムなどについては、勉強中です...Cross Similarityの計算
import librosa import librosa.feature import librosa.segment import librosa.display hop_length = 1024 y_ref, sr = librosa.load("path to sound file") y_comp, sr = librosa.load("path to sound file") chroma_ref = librosa.feature.chroma_cqt(y=y_ref, sr=sr,hop_length=hop_length) chroma_comp = librosa.feature.chroma_cqt(y=y_comp, sr=sr, hop_length=hop_length) x_ref = librosa.feature.stack_memory( chroma_ref, n_steps=10, delay=3) x_comp = librosa.feature.stack_memory( chroma_comp, n_steps=10, delay=3) xsim = librosa.segment.cross_similarity(x_comp, x_ref)プロット
import matplotlib.pyplot as plt fig, ax = plt.subplots() librosa.display.specshow(xsim, x_axis='s', y_axis='time', hop_length=hop_length, ax=ax) plt.show()ドキュメントのような画像が出力されると思います。
以上です。読んでいただきありがとうございました。
- 投稿日:2020-09-22T18:49:20+09:00
【音声解析】LibrosaでCross Similarityを求める
Cross Similarityとは
動的時間伸縮法(DTW)の派生で、部分一致に特化したパターン抽出方法。
DTWは時系列データ同士の距離マトリクスを作り、1本の最小経路を見つけそれを距離とするメトリクスであるが、Cross Similarityは部分マッチングのため、経路を複数見つけてくれる。
DTWについてのわかりやすい説明はこちらCross Similarityについては↓の論文を参照
Discovery of Cross Similarity in Data Science(Toyoda et al. 2010)なぜ、Cross Similarityか
鳥の鳴き声の長時間データから、鳴き声のみをセグメンテーションしたいとき、鳴き声の波形は類型を繰り返すという特徴があり、この手法に合うのではないかと考えたため、実験。
環境
python 3.7.4
librosa 0.7.2
matplotlib 3.1.1Let's Librosa!
Librosaドキュメントの最も単純な例を用いました。
Cross Similarityの変数やパラメータ、アルゴリズムなどについては、勉強中です...Cross Similarityの計算
import librosa import librosa.feature import librosa.segment import librosa.display hop_length = 1024 y_ref, sr = librosa.load("path to sound file") y_comp, sr = librosa.load("path to sound file") chroma_ref = librosa.feature.chroma_cqt(y=y_ref, sr=sr,hop_length=hop_length) chroma_comp = librosa.feature.chroma_cqt(y=y_comp, sr=sr, hop_length=hop_length) x_ref = librosa.feature.stack_memory( chroma_ref, n_steps=10, delay=3) x_comp = librosa.feature.stack_memory( chroma_comp, n_steps=10, delay=3) xsim = librosa.segment.cross_similarity(x_comp, x_ref)プロット
import matplotlib.pyplot as plt fig, ax = plt.subplots() librosa.display.specshow(xsim, x_axis='s', y_axis='time', hop_length=hop_length, ax=ax) plt.show()ドキュメントのような画像が出力されると思います。
以上です。読んでいただきありがとうございました。
- 投稿日:2020-09-22T18:42:25+09:00
クロージャのイメージ図
はじめに
今回の質問(Qiitaでの質問ではありません)
クロージャで外側の変数が参照できるというのは理解できるが納得はできない。関数内の変数1(引数含む)は関数が終了したら消えるのではないか?変数はどこかに保持されてるのだろうけど具体的にどこにあるのか。
これに対して
「まずはそういうものだと思わないといけない。それ以上知りたいのならPythonのソースを読まないといけない。ちなみに関数(クロージャ)に結び付けられている」
と答えたのですが、もう少し考えたところ、
「そもそも関数が終了したら変数が消えるという概念自体どこから学んだのか(消えるけど)。なお言語実装に関する知識(つまりスタック上に変数が確保される2という知識)はないものとする」
ということが気になりました。
そんなわけで今回はここら辺の概念を絵で説明しようと思います。関数と変数と関数の終わり
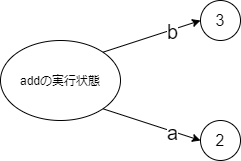
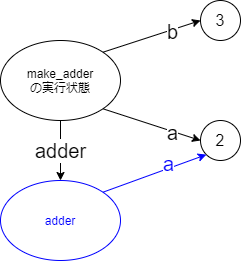
クロージャの前にまず普通の関数です。
普通の関数def add(a, b): return a + b add(2, 3)最終行では
aを2、bを3としてのaddの呼び出しが行われます。これを図に描くと以下のようになります。
「addの実行状態」としているのはこの後で説明する「関数が終了する際の動作」のためですが(「add」とすると話が正確でなくなります)、ともかく「2」というオブジェクトに対して実行状態から
aの矢印、「3」というオブジェクトに対してbの矢印が出ています。a, bが上下逆なのはこの後で描く図に合わせるためなのであまり気にしないでください。
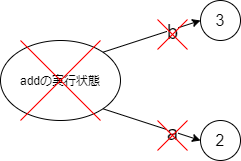
addが終了するときには「addの実行状態」が消えます。すると当然実行状態から出ているa,bの矢印も消えます。これが「関数が終了すると変数が消える」状況です。
クロージャと変数
さてここまでで「関数が実行されるときの変数のイメージ」、「関数が終了するときの変数のイメージ」を説明してきました。これを踏まえてクロージャに進みましょう。なお無駄な
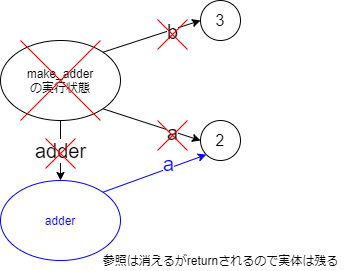
b変数がいますが話の都合です。クロージャdef make_adder(a, b): def adder(x): return x + a return adder adder3 = make_adder(2, 3) adder3(4)
make_adder(2, 3)呼び出しが行われ、make_adderのreturn手前(つまりadderが定義された後)時点を図に描くと以下のようになります。つまり、aが指している「2」はmake_adder(の実行状態)からもadderからも参照されていることになります。3
make_adderが終了するときには普通の変数と同様に実行状態が消えます。ただし、青で書いているadder本体はreturnされているので消えません。そして、adderから参照されているa(が指す「2」)も消えません。
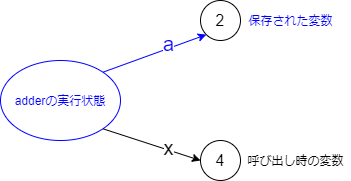
このようにして
a(が参照しているもの)が残るため、その後にadder3(4)と呼び出されると保存されていた「2」を取り出して使うことが可能になります。
おしまい。
あっ、nonlocalは多分もう少しめんどくさいことしてると思いますが調べたことないので省きます。参考
【Python】クロージャ(関数閉方)とは
変数がどう保存されているのか等について詳しく書かれています。Pythonを読む/クロージャ
2年半ほど前に「クロージャの実装詳細」を読んだ時のメモです。
- 投稿日:2020-09-22T18:39:12+09:00
【plotlyで画像分析いろいろ】plotlyで動的な可視化をする【python,画像】
plotlyで画像を簡単に分析してみます
環境
python==3.8
plotly==4.10.0
scikit-image==0.17.2
requests==2.24.0
Pillow==7.2.0
matplotlib==3.3.2よくある画像の扱い
まずpillowつかっていきます
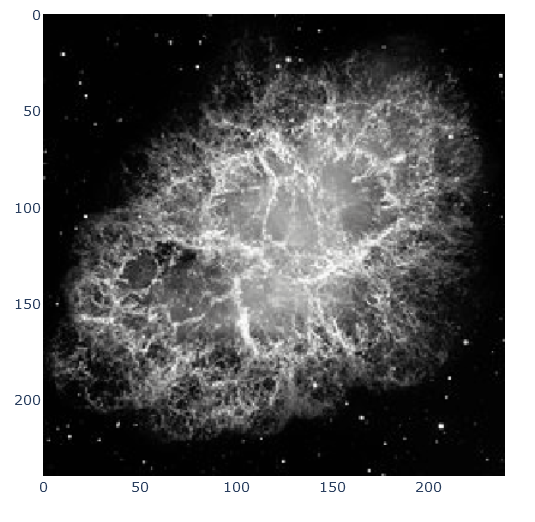
import matplotlib.pyplot as plt from PIL import Image import requests import io url = 'https://upload.wikimedia.org/wikipedia/commons/thumb/0/00/Crab_Nebula.jpg/240px-Crab_Nebula.jpg' img = Image.open(io.BytesIO(requests.get(url).content)) plt.figure(figsize=(5,5)) plt.subplot(111) plt.imshow(img)
いつものmatplotによる画像表示ができました
白黒にしましょうgray_img = img.convert('L') plt.figure(figsize=(5,5)) plt.subplot(111) plt.imshow(gray_img)imageオブジェクトはconvertを使って白黒にできます
skimageとplotlyを使った画像処理
plotlyで画像の表示をすると嬉しい所は拡大等ができることです
import plotly.express as px from skimage import io img_sk = io.imread('https://upload.wikimedia.org/wikipedia/commons/thumb/0/00/Crab_Nebula.jpg/240px-Crab_Nebula.jpg') fig = px.imshow(img_sk) fig.show()
pillowで読み込んだイメージも扱えます
fig = px.imshow(gray_img, color_continuous_scale='gray') fig.show()
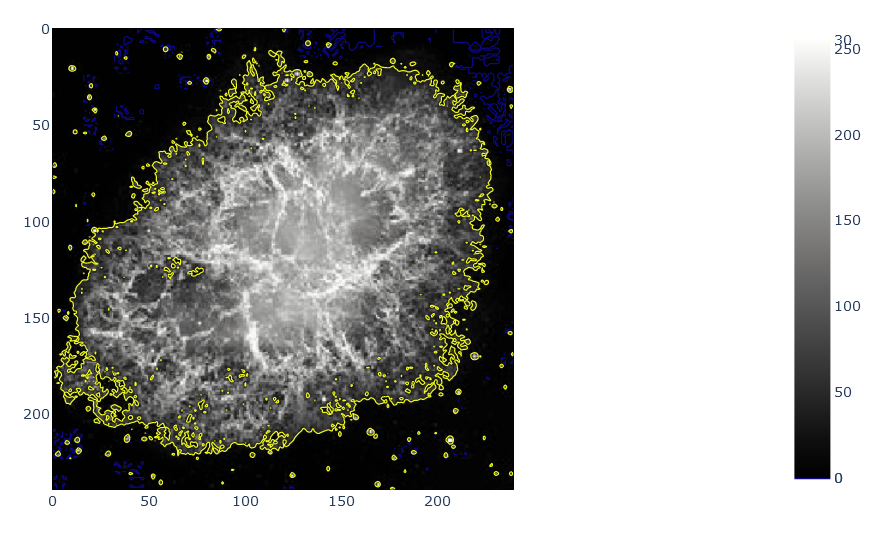
画像の中で等高線をつくる
画像の輝度に対して等高線を付けることができます
Zの値に対して色を付ける等高線(Contour)plot
startからendまでの値を対象に監視します
sizeで等高線の間隔を指定
endとsizeを同じにすることで、指定の値になる部分を抽出できます
つまり輪郭抽出などに使えるimport plotly.graph_objects as go fig = px.imshow(gray_img, color_continuous_scale='gray') fig.add_trace(go.Contour(z=gray_img, showscale=True, contours=dict(start=0, end=30, size=30,coloring='lines'),line_width=1)) fig.show()
import plotly.express as px import plotly.graph_objects as go from skimage import data img_camera = data.camera() fig = px.imshow(img_camera, color_continuous_scale='gray') fig.add_trace(go.Contour(z=img_camera, showscale=False, contours=dict(start=0, end=70, size=70, coloring='lines'), line_width=2)) fig.show()
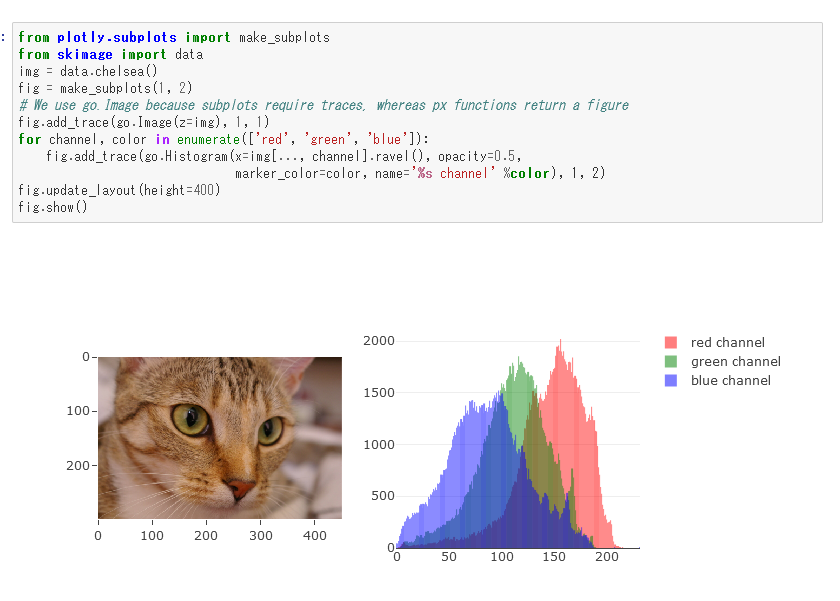
色チャネルのヒストグラムをplotlyからつくる
from plotly.subplots import make_subplots from skimage import data img_sk.shape #(240, 240, 3) plt.imshow(img_sk) img_r = img_sk.copy() img_r[:, :, 1] = 0 img_r[:, :, 2] = 0 plt.imshow(img_r) img_g = img_sk.copy() img_g[:, :, 0] = 0 img_g[:, :, 2] = 0 plt.imshow(img_g) img_b = img_sk.copy() img_b[:, :, 0] = 0 img_b[:, :, 1] = 0 plt.imshow(img_b)
0以外をhistに
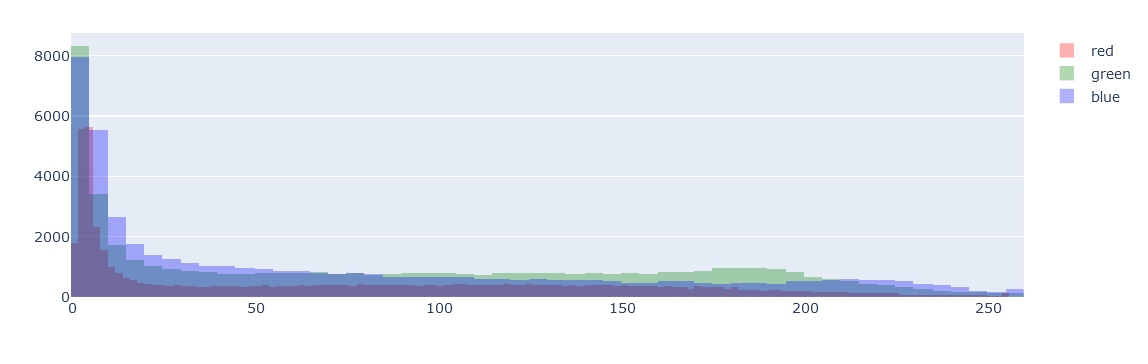
ff=go.Figure() ff.add_trace(go.Histogram(x=img_r.flatten()[img_r.flatten()!=0],marker_color='red',name='red')) ff.add_trace(go.Histogram(x=img_g.flatten()[img_g.flatten()!=0],marker_color='green',name='green')) ff.add_trace(go.Histogram(x=img_b.flatten()[img_b.flatten()!=0],marker_color='blue',name='blue')) ff.update_layout(barmode='overlay') ff.update_traces(opacity=0.3) ff.update_layout(height=400) ff.show()
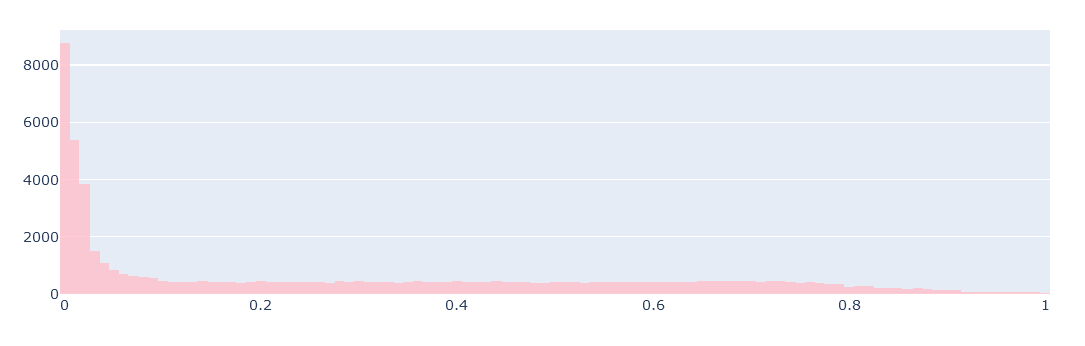
拡大してみると10以下がメインのようなので10以上の分布を確認
ff=go.Figure() ff.add_trace(go.Histogram(x=img_r.flatten()[img_r.flatten()>10],marker_color='red',name='red')) ff.add_trace(go.Histogram(x=img_g.flatten()[img_g.flatten()>10],marker_color='green',name='green')) ff.add_trace(go.Histogram(x=img_b.flatten()[img_b.flatten()>10],marker_color='blue',name='blue')) ff.update_layout(barmode='overlay') ff.update_traces(opacity=0.3) ff.update_layout(height=400) ff.show()
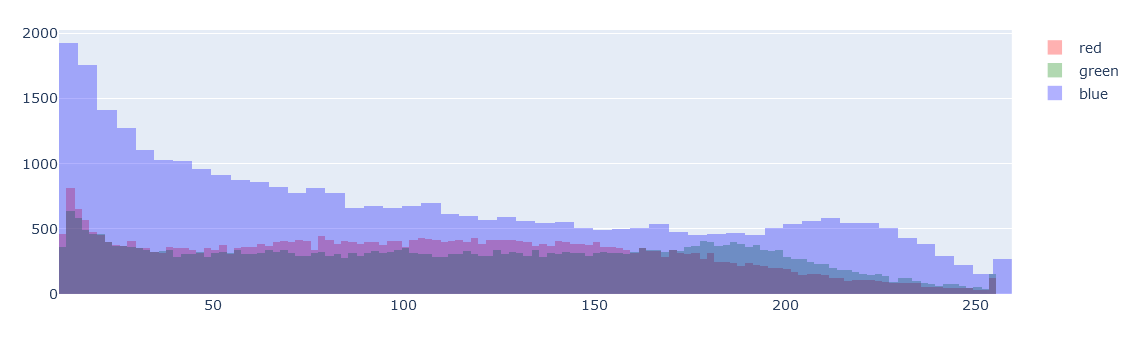
綺麗に分かれる場合だとこんな感じになる
白黒に対しての確認は以下
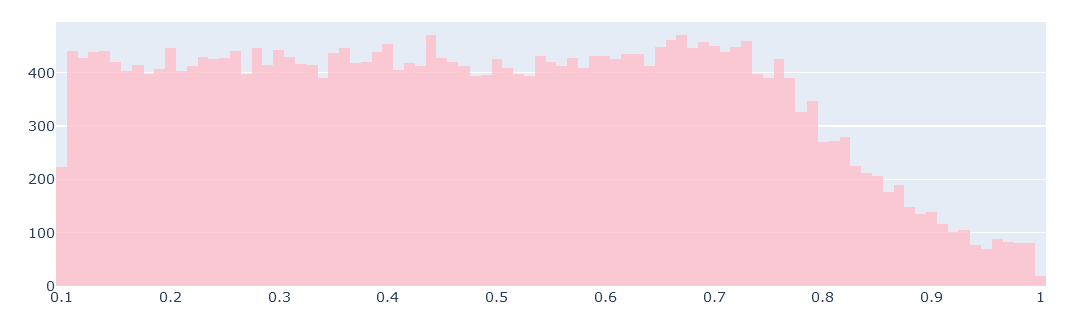
from skimage.color import rgb2gray gray_img = rgb2gray(img_sk) ff=go.Figure() ff.add_trace(go.Histogram(x=gray_img.flatten()[gray_img.flatten()!=0],marker_color='pink',name='gray')) ff.update_layout(barmode='overlay') ff.update_traces(opacity=0.8) ff.update_layout(height=400) ff.show()
ff=go.Figure() ff.add_trace(go.Histogram(x=gray_img.flatten()[gray_img.flatten()>0.1],marker_color='pink',name='gray')) ff.update_layout(barmode='overlay') ff.update_traces(opacity=0.8) ff.update_layout(height=400) ff.show()
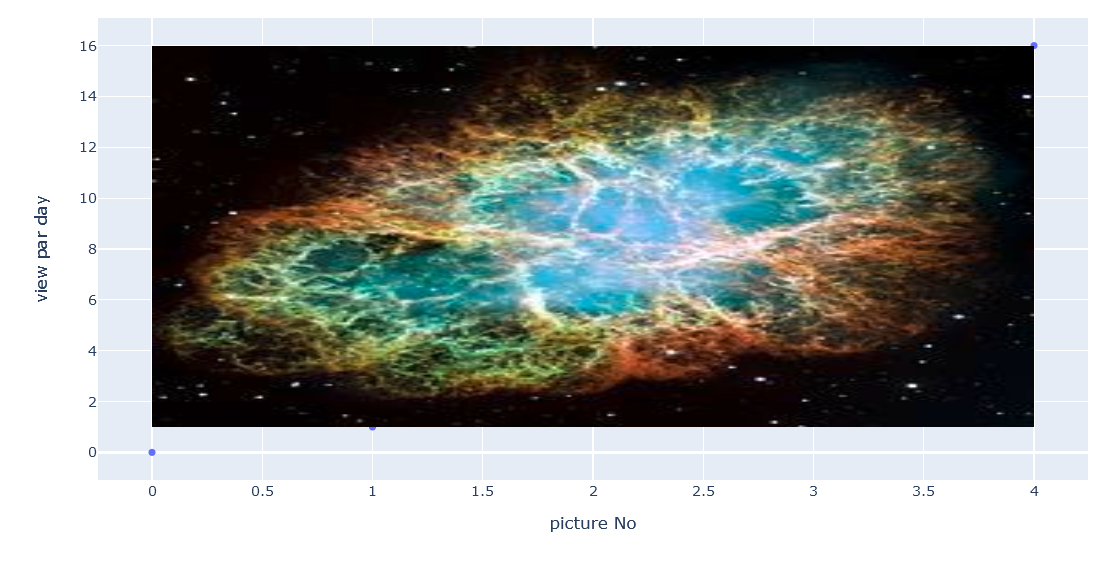
ついでに図中に画像を表示する方法
グラフの全面にアピール
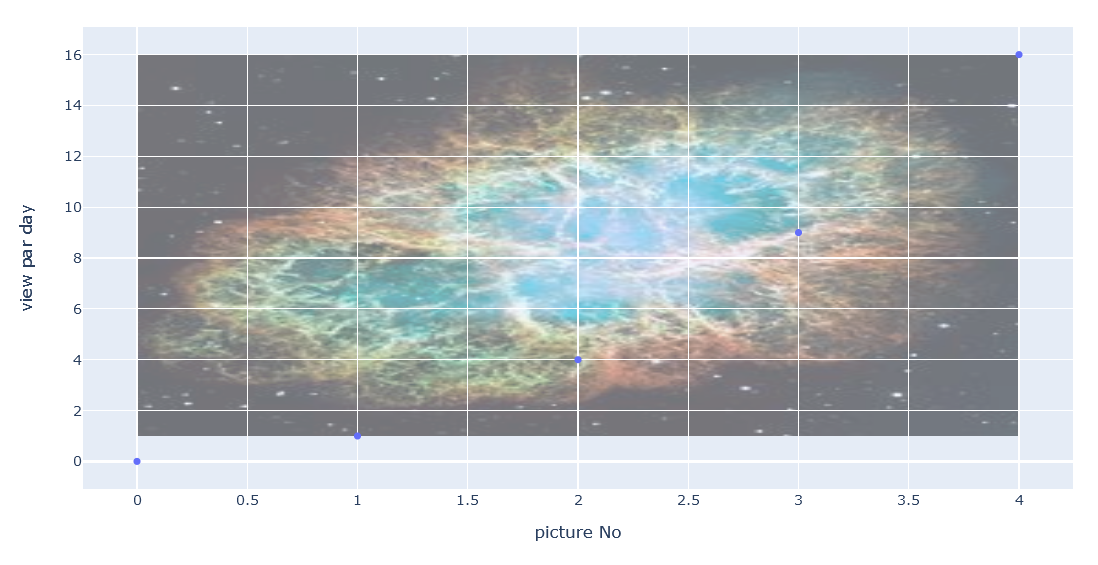
import plotly.express as px fig = px.scatter(x=[0, 1, 2, 3, 4], y=[0, 1, 4, 9, 16]) fig.add_layout_image( dict( source="https://upload.wikimedia.org/wikipedia/commons/thumb/0/00/Crab_Nebula.jpg/240px-Crab_Nebula.jpg", xref="x", yref="y", x=0, y=16, sizex=4, sizey=15, sizing="stretch") ) fig.update_xaxes(title_text="picture No") fig.update_yaxes(title_text="view par day", hoverformat=".3f") fig.show()
背面(below)でそっとアピール
import plotly.express as px fig = px.scatter(x=[0, 1, 2, 3, 4], y=[0, 1, 4, 9, 16]) fig.add_layout_image( dict( source="https://upload.wikimedia.org/wikipedia/commons/thumb/0/00/Crab_Nebula.jpg/240px-Crab_Nebula.jpg", xref="x", yref="y", x=0, y=16, sizex=4, sizey=15, sizing="stretch", opacity=0.5, layer="below") ) fig.update_xaxes(title_text="picture No") fig.update_yaxes(title_text="view par day", hoverformat=".3f") fig.show()
小さくして棒を付けたりテキストをいれたりする
import plotly.express as px fig = px.scatter(x=[0, 1, 2, 3, 4], y=[0, 1, 4, 9, 16]) fig.add_layout_image( dict( source="https://upload.wikimedia.org/wikipedia/commons/thumb/0/00/Crab_Nebula.jpg/240px-Crab_Nebula.jpg", xref="x", yref="y", x=1.68, y=16, sizex=3, sizey=3) ) fig.update_layout( annotations=[ dict( x=0.5, y=0.8, xref="paper", yref="paper", showarrow=True, arrowhead=0, opacity=0.5, ax=190, ay=100, )#, # dict(x=,y=,xref="paper",yref="paper",showarrow=True,arrowhead=0,opacity=0.5,ax=,ay=,) ] ) fig.update_xaxes(title_text="picture No") fig.update_yaxes(title_text="view par day", hoverformat=".3f") fig.show()画像のlayout imageはplotの位置に準ずる
plotのx,y軸が画像の左上位置x,yに相当する棒線は画像の左下を0,0
中心を0.5,0.5とする
ax,ayは棒線の長さを表しており、指定位置x,yからx軸方向とy軸方向に伸ばした棒のベクトル合成した位置に伸びる
以上
とりあえず動かせればなんでも楽しい説







- 投稿日:2020-09-22T18:30:35+09:00
CNNによる学習データ
kerasでCNN 自分で拾った画像でやってみる
基本はこの記事を参照して作成しました。微妙に違うだけです。
細かい部分は自分で調べて何とかしました。
ぶっちゃけ動いたからヨシなので勉強不足です。目的としてはとある物の写真からOKとNGを判定したいので
元となるデータとしては画像データ(640x480)を
OK・NG共に1000枚使用しています。あくまでも初心者が辿り着いた結果をメモとして残すのが目的です。
環境
Windows10 64bit
Anaconda navigator
Jupiter notebook
Python 3.7.7
tensorflow 2.1.0
tensorflow-gpu 2.1.0
keras 2.3.1
numpy 1.18.1
matplotlib 3.1.3上記環境でプログラムを構築
ライブラリ
cnn.ipynbimport keras from keras.utils import np_utils from keras.models import Sequential from keras.layers.convolutional import MaxPooling2D from keras.layers import Activation, Conv2D, Flatten, Dense,Dropout from sklearn.model_selection import train_test_split from keras.optimizers import SGD, Adadelta, Adagrad, Adam, Adamax, RMSprop, Nadam from PIL import Image import numpy as np import glob import matplotlib.pyplot as plt import time import os
from keras.optimizers importにはAdadeltaだけでよかったですが
色々と試したくて入れてます。(結局テストせんかったけど…)各種設定関係
cnn.ipynb#設定 batch_size = 16 epochs = 200 #画像ディレクトリ test_dir ="画像保存しているディレクトリを指定" folder = os.listdir(test_dir) #元画像640x480をresizeする際の大きさ設定 x_image_size = 200#640→200 y_image_size = 200#480→200 dense_size = len(folder)
batch_sizeに関しては色々なサイトを見るに1・4・32等々設定値が転がっていたので
初めは32で回してみましたがエラーが出てなんともならなくなったので16に設定しています。
細かい部分まで調べ切れていないので正しいとは言えないと…
ただ回ったのでヨシにしています。画像サイズを縦・横で色々と変えて試す為に分けて設定していますが
結果200まで落とさないと重すぎて動きませんでした。
なのでimage_size = 200でも問題ありません。(後の記述は一部変更必要)画像読み込み
cnn.ipynbX = [] Y = [] for index, name in enumerate(folder): dir = test_dir + name files = glob.glob(dir + "/*.jpg") for i, file in enumerate(files): image = Image.open(file) image = image.convert("RGB") image = image.resize((x_image_size, y_image_size)) data = np.asarray(image) X.append(data) Y.append(index) X = np.array(X) Y = np.array(Y) X = X.astype('float32') X = X / 255.0 Y = np_utils.to_categorical(Y, dense_size) X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.15)今回はテストを15%にした位で、参考にさせて頂いた記事とほとんど変わりません。
CNNモデル作成
cnn.ipynbmodel = Sequential() model.add(Conv2D(32, (3, 3), padding='same',input_shape=X_train.shape[1:])) model.add(Activation('relu')) model.add(Conv2D(32, (3, 3))) model.add(Activation('relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Dropout(0.25)) model.add(Conv2D(64, (3, 3), padding='same')) model.add(Activation('relu')) model.add(Conv2D(64, (3, 3))) model.add(Activation('relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Dropout(0.25)) model.add(Flatten()) model.add(Dense(512)) model.add(Activation('relu')) model.add(Dropout(0.5)) model.add(Dense(dense_size)) model.add(Activation('softmax')) model.summary()正直な所、勉強しながらなので
どこをどのように触れば変化するのか?については分かってないです。
keras公式サイト
ここを見ていますが、素人には理解できないっす…学習機作成
cnn.ipynboptimizers ="Adadelta" results = {} model.compile(loss='categorical_crossentropy', optimizer=optimizers, metrics=['accuracy']) results[0]= model.fit(X_train, y_train, validation_split=0.2, epochs=epochs,batch_size=batch_size) model_json_str = model.to_json() open('model.json', 'w').write(model_json_str) model.save('weights.h5');正直、Qiitaがなければ辿り着く事すら出来ませんでした。
ありがとうございます。結果
学習結果
テスト結果
はじめはひどいもので学習結果が横棒になるという結果でした。
その時は画像データも各50枚程度と少なく
epoch数も20程度でした。とある方に『画像が命』と教えて頂きましたが、正にその通りの結果になったと思います。
後はこのデータを元に推論を作って、ちゃんと結果出るかがドキドキです。
まとめ
なんだかんだでデータとしては作る事が出来ました。
『色々と試してみる』部分が圧倒的に不足している事を思い知りました。
手を動かさないと覚えない・知ろうとしない事を改めて知る事が出来ました。40歳目前から始めると脳が拒否するので大変です。
以上です。
- 投稿日:2020-09-22T17:59:16+09:00
oandapyV20を用いたオーダー/ポジションブックの再構築
1.はじめに
投資botを作成する際、多くの方が価格(+出来高)のみを用いているかと思います。しかし利用できるデータはこれらだけではありません。例えば注文状況や保有ポジションの状況などが考えられます。
今回はFX取引所のoandaから注文やポジションのデータ(オーダーブック・ポジションブック)を取り出し、加工するツールを作成したので共有しておきます。
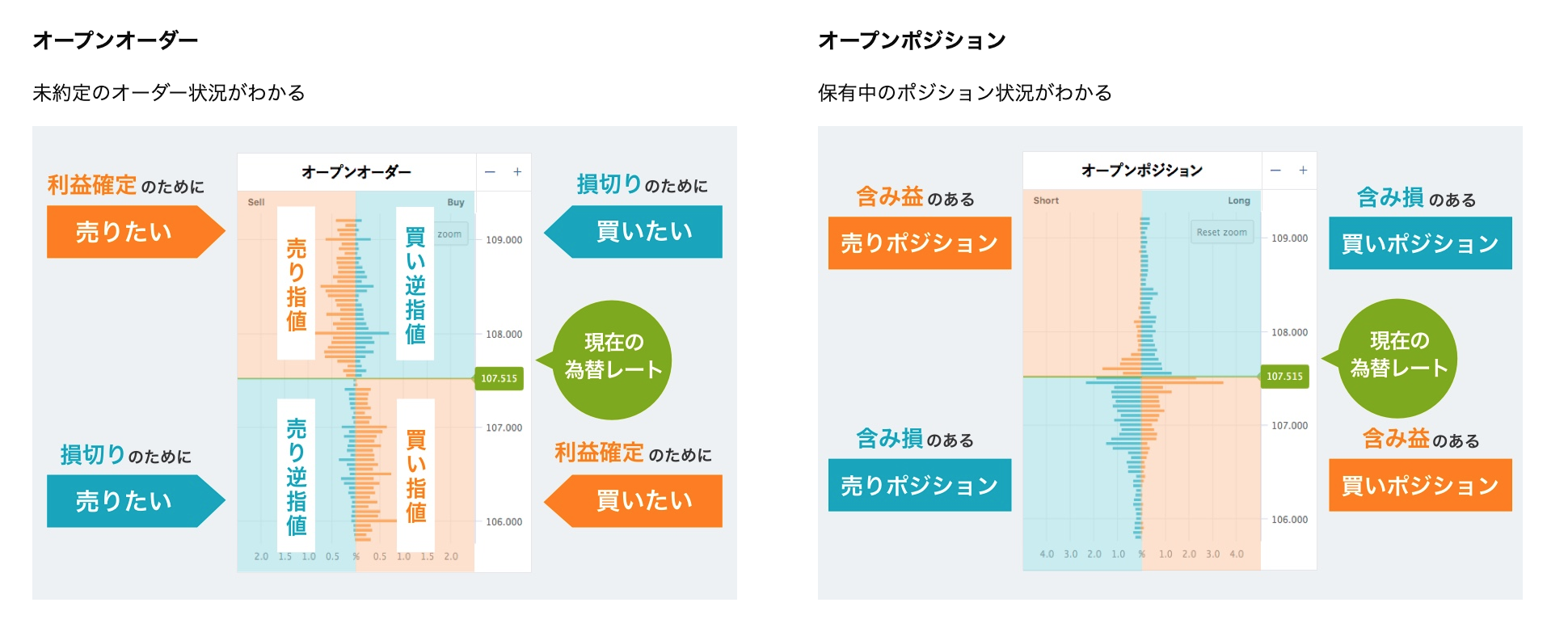
2.オーダーブック・ポジションブックとは
オーダーブックとはまだ約定していない注文がレートごとにどの程度あるかを示すもの(株における板)であり、
オープンポジションは現在保有されているポジションがどのレートにどれくらいあるかを示すものです。
細かいところはリンクからoandaのサイトに飛んで確認してください。
( https://www.oanda.jp/lab-education/oanda_lab/oanda_rab/open_position/ )3.oandaのブックについて
oandaでは直近の1ヶ月以内で50万ドル以上の取引を行うことで、オーダーブック・ポジションブックともに5分に1回の更新になります。この頻度はwebで見る際もapiで取得する際も変わりません。
ただ単に口座を作っただけだと更新頻度は20分に1回と更新頻度は落ちてしまいます。とはいえ高頻度のトレードをしないのであれば十分な更新頻度だと思います。
なおここでは口座の開設やapi keyの取得については解説しません。
4.本体
oandaのサイトで見るオープンオーダーはそのオープンオーダーのスナップショットが作成された時刻のレートを中心に、一定幅ごとに(ドル円なら0.05円ごと)に広がっているのが見えるかと思います。
しかしapiによって得られたデータはそのようにはなっていません。オーダーブックには広範なレートの情報が含まれており、1ドル=0円から1ドル=200円のように現実にはあり得ないような情報まで含まれています。またオープンオーダーの中心にあるレートは絶えず変動します。そのため得られたデータをそのまま分析しようとしても、各レートがオープンオーダーが作成された際のレートからどれだけ離れているのかがわかりません。
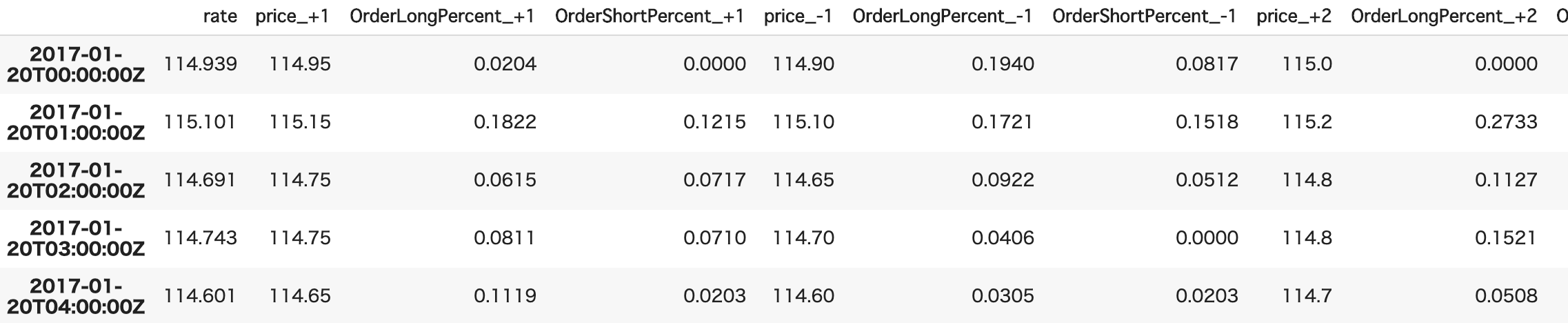
そこで今回は以下のように、中心となるレートとそこからどれだけ離れているかを直感的に把握できるようにデータを収集、加工できるコードを用意しました。
accountIDとaccess_tokenはご自身のものに書き換えてご利用ください。
なお2017年1月20日以前のデータは存在しないようです。また、1時間ごとのブックの取得に大体20~30分くらいかかります。
def fetch_orderbook(instrument="USD_JPY", levels = 5, timeframe="15m"): ''' instrument : 通過ペアの名前 levels : 中心のレートからいくつまで上(下)を取得するか, >0 timeframe : 何分毎にブックを取得するか, "m":minute, "H":hour, "D":day, >="5m" ex) "1H":1時間ごとに取得, "2D":1日ごとに取得 ''' accountID = "×××-×××-×××-×××" access_token ="××××××××××××" api = API(access_token=access_token, environment="live") if timeframe[-1]=="m": diff = 60 * int(timeframe[:-1]) elif timeframe[-1]=="H": diff = 60 * 60 * int(timeframe[:-1]) elif timeframe[-1]=="D": diff = 60 * 60 * 24 * int(timeframe[:-1]) timestamp = datetime.datetime(year=2017, month=1, day=20) now = datetime.datetime.utcnow() processed_book, book_timestamps = [], [] counter = 0 start = datetime.datetime.utcnow() while True: try: #現在まで取得し終わったら終了 if now < timestamp: break #サーバーへの過剰なアクセスの防止およびログ出力 counter+=1 if counter%100==0: print(timestamp, datetime.datetime.utcnow()-start) start = datetime.datetime.utcnow() counter=0 time.sleep(1) #orderbookの取得 r=instruments.InstrumentsOrderBook(instrument=instrument, params={"time":timestamp.strftime("%Y-%m-%dT%H:%M:00Z")}) api.request(r) book_created_rate, buckets, book_created_time = float(r.response["orderBook"]["price"]), r.response["orderBook"]["buckets"], r.response["orderBook"]["time"] #book作成時のレートに近いindexの取得 bucket_rate = [round(float(b["price"]), 2) for b in buckets] upper_idx = np.searchsorted(bucket_rate, book_created_rate) lower_idx = upper_idx - 1 #現在価格からlevels分離れたのを追加 row_book = [book_created_rate] for i in range(levels): upper, lower = buckets[upper_idx + i], buckets[lower_idx - i] bucket = [upper["price"], upper['longCountPercent'], upper['shortCountPercent'], lower["price"], lower['longCountPercent'], lower['shortCountPercent']] bucket = [float(num) for num in bucket] row_book.extend(bucket) processed_book.append(row_book) book_timestamps.append(book_created_time) except: #土日 pass timestamp+=datetime.timedelta(seconds = diff) #columの名前 column_names = ["rate"] for i in range(levels): column_names.extend(["price_+{}".format(i+1), "OrderLongPercent_+{}".format(i+1), "OrderShortPercent_+{}".format(i+1), "price_-{}".format(i+1), "OrderLongPercent_-{}".format(i+1), "OrderShortPercent_-{}".format(i+1)]) #データの結合 orderbook = pd.DataFrame(processed_book, columns=column_names, index=book_timestamps) return orderbookポジションブックについても同様に
def fetch_positionbook(instrument="USD_JPY", levels = 5, timeframe="15m"): ''' instrument : 通過ペアの名前 levels : 中心のレートからいくつまで上(下)を取得するか, >0 timeframe : 何分毎にブックを取得するか, "m":minute, "H":hour, "D":day, >="5m" ex) "1H":1時間ごとに取得, "2D":1日ごとに取得 ''' accountID = "×××-×××-×××-×××" access_token ="××××××××××××" api = API(access_token=access_token, environment="live") if timeframe[-1]=="m": diff = 60 * int(timeframe[:-1]) elif timeframe[-1]=="H": diff = 60 * 60 * int(timeframe[:-1]) elif timeframe[-1]=="D": diff = 60 * 60 * 24 * int(timeframe[:-1]) timestamp = datetime.datetime(year=2017, month=1, day=20) now = datetime.datetime.utcnow() processed_book, book_timestamps = [], [] counter = 0 start = datetime.datetime.utcnow() while True: try: #現在まで取得し終わったら終了 if now < timestamp: break #サーバーへの過剰なアクセスの防止およびログ出力 counter+=1 if counter%100==0: print(timestamp, datetime.datetime.utcnow()-start) start = datetime.datetime.utcnow() counter=0 time.sleep(1) #positionbookの取得 r=instruments.InstrumentsPositionBook(instrument=instrument, params={"time":timestamp.strftime("%Y-%m-%dT%H:%M:00Z")}) api.request(r) book_created_rate, buckets, book_created_time = float(r.response["positionBook"]["price"]), r.response["positionBook"]["buckets"], r.response["positionBook"]["time"] #book作成時のレートに近いindexの取得 bucket_rate = [round(float(b["price"]), 2) for b in buckets] upper_idx = np.searchsorted(bucket_rate, book_created_rate) lower_idx = upper_idx - 1 #現在価格からlevels分離れたのを追加 row_book = [book_created_rate] for i in range(levels): upper, lower = buckets[upper_idx + i], buckets[lower_idx - i] bucket = [upper["price"], upper['longCountPercent'], upper['shortCountPercent'], lower["price"], lower['longCountPercent'], lower['shortCountPercent']] bucket = [float(num) for num in bucket] row_book.extend(bucket) processed_book.append(row_book) book_timestamps.append(book_created_time) except: #土日 pass timestamp+=datetime.timedelta(seconds = diff) #columの名前 column_names = ["rate"] for i in range(levels): column_names.extend(["price_+{}".format(i+1), "PositionLongPercent_+{}".format(i+1), "PositionShortPercent_+{}".format(i+1), "price_-{}".format(i+1), "PositionLongPercent_-{}".format(i+1), "PositionShortPercent_-{}".format(i+1)]) #データの結合 positionbook = pd.DataFrame(processed_book, columns=column_names, index=book_timestamps) return positionbook5.最後に
紹介しておいてなんですが、こちらのデータのみを用いてbotを組むのは難しいかと思います。(手数料がなければ)勝てるところまでは行けたのですが、どうにも手数料で勝てそうにありませんでした。もしかすると時間アノマリーとでも組み合わせるとうまくいくかも…?
- 投稿日:2020-09-22T17:52:47+09:00
seleniumでスクレイピング
動的に書かれたサイトをseleniumでスクレイピング
JS等で書かれたサイトだとただBeautifulSoupとかでスクレイピングしようとしても出来ない場合があります。
そんな場合に使えるのがseleniumです。chrome driverを入手
まずchrome のバージョンを調べます。
(Macの場合)
1. chromeを開いた状態で、画面左上の「chrome」をクリック
2. 「Google chromeについて」をクリック
3. 「設定-Chromeについて」というページが開かれるので、そこに表示される
バージョン: 8?.〜〜〜〜という部分を確認します。ダウンロードページでChrome Driverを入手します。
ダウンロードページ で、
以下の部分から、上で調べたバージョンに合致するchrome driverをダウンロードします。
(ページリンク先でOSを選択します。)
使い方
from selenium import webdriver from selenium.webdriver.chrome.options import Options import time url="~~~~~~"#ここに開きたいURL options = Options() options.add_argument('--headless') #ヘッドレスモードを有効 Driver_path="~~~~~~" #ダウンロードしたchromeドライバーを置いた場所を指定 driver = webdriver.Chrome(Driver_path,options=options) driver.get(url) time.sleep(2) html = driver.page_source.encode('utf-8') soup = BeautifulSoup(html, 'lxml') #この後は普通にBeautiful Soupの文法通り使える。optionをつけることによって、driver.getするたびにページが開かれてしまうことを防いでいます。
(これによって、処理速度が多少早くなります。)参考
- 投稿日:2020-09-22T17:27:18+09:00
Google ColaboratoryでGoogleドライブを検索する方法
pydriveを使用するための準備
認証コード作成from google.colab import auth auth.authenticate_user()pydriveでドライブ操作をするための準備from pydrive.auth import GoogleAuth from pydrive.drive import GoogleDrive from oauth2client.client import GoogleCredentials gauth = GoogleAuth() gauth.credentials = GoogleCredentials.get_application_default() drive = GoogleDrive(gauth)認証作業なしで実行する場合は下記を参考にしてください。
https://qiita.com/plumfield56/items/3d9e234366bcaea794ac検索方法
上記の状態まで準備できたら、下記で検索を実行します。
drive.ListFile({'q':"{queryの内容を記載}"})検索例
例えば、
タイトルがHelloでmimeTypeがスプレッドシートでゴミ箱以外を、
検索する場合は下記のように記載します。drive.ListFile({'q':"title='Hello' and mimeType='application/vnd.google-apps.spreadsheet' and trashed = false"})その他、検索例は下記サイトを参照
https://developers.google.com/drive/api/v2/search-files#query_string_examplesqueryで細かい指定をするためには以下を使用していきます。
queryの指定方法
用語 使用可能な比較演算子 使用方法 title contains, =, != タイトルの検索
シングルクォーテーションを使用する場合はバックスペースでエスケープさせるfullText contains タイトル、説明、内容、インデックスの検索 mimeType contains, =, != MIME typeの検索 modifiedDate <=, <, =, !=, >, >= 最終更新日の検索 lastViewedByMeDate <=, <, =, !=, >, >= 最後に閲覧した日付で検索 trashed =, != ゴミ箱内まで検索するかの指定(true,falseで指定) starred =, != お気に入りを付けているものを検索するかの指定(true,falseで指定) parents in 親のIDを指定 owners in オーナーを指定 writers in 特定のユーザーが編集者になっているかを指定 readers in 特定のユーザーが閲覧者になっているかを指定 下記サイトを参照
https://developers.google.com/drive/api/v2/ref-search-termsGoogleサービスのMIME Types一覧
サービス名 MIME Types Google Drive file application/vnd.google-apps.file Google Drive folder application/vnd.google-apps.folder Google Docs application/vnd.google-apps.document Google Sheets application/vnd.google-apps.spreadsheet Google Slides application/vnd.google-apps.presentation Google Sites application/vnd.google-apps.site Google Forms application/vnd.google-apps.form Google Drawing application/vnd.google-apps.drawing Google Fusion Tables application/vnd.google-apps.fusiontable Google My Maps application/vnd.google-apps.map Google Apps Scripts application/vnd.google-apps.script Shortcut application/vnd.google-apps.shortcut application/vnd.google-apps.photo 下記サイトを参照
https://developers.google.com/drive/api/v2/mime-typesGoogleサービス以外のMIME Types一覧
ファイル形式 MIME Types application/pdf JSON application/vnd.google-apps.script+json Plain text text/plain HTML text/html MS Excel application/vnd.openxmlformats-officedocument.spreadsheetml.sheet MS PowerPoint application/vnd.openxmlformats-officedocument.presentationml.presentation MS Word document application/vnd.openxmlformats-officedocument.wordprocessingml.document JPEG image/jpeg PNG image/png SVG image/svg+xml JSON application/vnd.google-apps.script+json 下記サイトを参照
https://developers.google.com/drive/api/v2/ref-export-formats検索結果からデータ取得
queryで指定した内容を
GetListメソッドでリストにして、欲しいデータを抽出します。検索結果からデータ取得file_list = drive.ListFile({'q':"title='Hello' and mimeType='application/vnd.google-apps.spreadsheet' and trashed = false"}).GetList() for file in file_list: # ファイル/フォルダから抽出したい内容 print(file['title'], file['id'])抽出可能な項目一覧
プロパティ名 タイプ 説明 id string ファイルID selfLink string ファイルのURL title string ファイル名 mimeType string ファイルのmimeType その他、抽出可能な項目は多数あるので、詳細は下記参照
https://developers.google.com/drive/api/v2/reference/files
- 投稿日:2020-09-22T17:26:30+09:00
pycharmでpip installできないとかimport sslできない対策
◆前提
Windows: Windows 10 Home
anaconda: Anaconda3-2020.07-Windows-x86_64.exe
pycharm: PyCharm 2020.2.2 (Community Edition)
でpythonを利用◆困った現象
(a) pycharmで
File -> Settings... -> Project: xxx -> Python Interpreter -> + -> Available Packagesが表示されない
(b)Dosプロンプトでpip install xxxすると
WARNING: pip is configured with locations that require TLS/SSL, however the ssl module in Python is not available.
と言われインストールできない
(c)Anacondaプロンプトでpip install xxxは正常にインストールできる。
(d)Dosプロンプトからpythonを実行した対話型pythonシェルで、
>>> import ssl
Traceback (most recent call last):
File "", line 1, in
File "C:\Users\xxx\anaconda3\lib\ssl.py", line 98, in
import _ssl # if we can't import it, let the error propagate
ImportError: DLL load failed while importing _ssl: 指定されたモジュールが見つかりません。
のようになる。
(e)Anacondaプロンプトから実行した対話型pythoシェルではimport sslしてもエラーがでない。◆対策
libsslxxx.dllやlibcryptxxx.dllを読み込む場所がまずいみたいです。
環境変数のPATHを修正しましょう。(1)Anacondaプロンプトで正常に動作するPATHを確認
Anacondaプロンプトで
> echo %PATH%
これをメモする。
長いので
> echo %PATH% > path.txt
とかして後でtxtファイルみるのもよし(2)環境変数に上記のPATHを設定
環境変数の設定の仕方は割愛。
anacondaをインストールする際に環境変数を設定するを選択した場合は自動で追加されるので上記のような現象は発生しないと思います。
- 投稿日:2020-09-22T15:48:29+09:00
Revit API備忘録
Revitの単位がfeetのため、Dynamo中mm単位のPointを.ToXyz()するとフィート換算されて(304.8倍されて)しまう。
mmのまま変換するには.ToXyz(True)にすれば良い。
- 投稿日:2020-09-22T15:42:06+09:00
[Python] 累積和 ABC179D
ABC179D
素朴な解法としては、
dp[i]:= マスiに到達するまでの操作列の個数として、各場所 i についてすべての移動を試す動的計画法が考えられるが、時間計算量 $O(N^2)$ となります。更新式は次の通り。
dp[i] = \sum_{v\in S} dp[i-v] \\こんなときは累積和を用いて DP 高速化するのは定番ではある。まず、集合 S が K 個の区間からなることに着目すると、$\sum_{v\in S} dp[i-v]$ の部分は、K 個の区間についての「区間内の総和」を足し上げたものになることがわかる。
ここで一般に、配列 a の累積和を s としたとき、配列 a の区間 [l, r) の総和は s[r] - s[l] で表せることを思い出そう。よって配列 dp の累積和を sumdp とすると、更新式は次のように変形できる。dp[i] = \sum_{k=1}^K (sumdp[i-l_k+1]-sumdp[i-r_k]) \\計算量は$O(NK)$となる。
サンプルコードMOD = 998244353 N, K = map(int, input().split()) #Nはマス目の数、Kは区間の数(Kは10以下) sec = [tuple(map(int, input().split())) for _ in range(K)] dp = [0] * (N+1) dp[1] = 1 sumdp = [0] * (N+1) # i-l=1(現在いるマス)になったとき、dp[i]を1増やす sumdp[1] = 1 # i=2からNまで順番にsumdp[i]を更新する for i in range(2, N+1): # それぞれの区間で累積和sumdpによってdp[i]を更新する for l, r in sec: li = max(i - l, 0) ri = max(i - r - 1, 0) dp[i] += sumdp[li] - sumdp[ri] dp[i] %= MOD sumdp[i] = sumdp[i-1] + dp[i] print(dp[N])
- 投稿日:2020-09-22T15:41:28+09:00
Optunaを使用したLightGBMハイパーパラメーター最適化やりかた調査ログ
はじめに
最近JupyterLabを使って機械学習の勉強をやっている。
その中でGoogleでの検索結果が古かったOptunaのLightGBMハイパーパラメーター最適化についての調査を記事にしてみようかなと思いたった。環境
- jupyter/tensorflow-notebook
- 上記Dockerイメージを起動時に
jupyter labを指定している- optuna 2.1.0
やったこと
最初にざっくりまとめ
- OptunaでLightGBMのパイパーパラメーターの最適化がしたい
- ググって出てきたコードをコピペしてもうまく動かない
- なんかbest_paramsなんで引数ないぞと言われる
- 公式ドキュメントをあたる
- 公式ドキュメントのサンプルを試す → 動く
- Githubから過去のサンプルを確認して1.3時点ではbest_paramsがあることを確認 1.4以降はなさそう
- 困った時は公式ドキュメントを読もうね
- ネットの情報と挙動が異なる場合はライブラリとかのバージョンを確認してみるのがいいよね
OptunaでLightGBMのハイパーパラメーター最適化がしたい
まずググってみて出てきたのがこれ
Optuna の拡張機能 LightGBM Tuner によるハイパーパラメータ自動最適化
以下上記ページ記載のコード抜粋booster = lgb.train(params, dtrain, valid_sets=dval, verbose_eval=0, best_params=best_params, tuning_history=tuning_history)上記を試してみたところ、以下のエラーが発生した。
TypeError: __init__() got an unexpected keyword argument 'best_params'ふむ。
best_paramsなんてキーワード引数ないよ。と言われている。公式ドキュメント確認
引数が異なるってことはバージョン違いかな?と思ったので公式ドキュメントを確認してみることにした。
Optuna
Githubへのリンクがあったのでそちらに移動
optuna/optuna公式ドキュメントのサンプルを試す → 動く
optuna/optunaで
lightgbmでリポジトリ内検索
リポジトリ内検索結果検索結果からそれっぽいものないかなーと見てるとexamples/README.mdがサンプルっぽかったのでそれを確認。
examples/lightgbm_tuner_simple.py
# 引用元を比較しやすいように一部改行してます model = lgb.train( params, dtrain, valid_sets=[dtrain, dval], verbose_eval=100, early_stopping_rounds=100 )こちらには
best_paramsがないので現行Verはこれっぽい。
上記で試してみたところ、無事動いた!やったぜ。ちなみに確認したところ、v1.3.0までは
best_paramsあり、v1.4.0からはbest_paramsなしになっていた。解決&感想
実際は上記以外のページとかも確認したりしたけど特に成果がなかったものは割愛している(というか失念しちゃってる)
こういう問題やエラーの調査・解決って成果が出ないときはとことん出ない。成果が出なくてつらくなる。
そういうときは日を改めたり他の人に軽く相談してみたりすると意外と活路が見えたりするのでオススメです。まとめ
ググった結果でうまく動かない場合は環境やバージョンが異なることが原因であることが多いよ。
仕様やサンプルが公開されているものであれば公式ドキュメントやGithubを参考にすると問題解決の近道であることが多いよ。
(今回は違うけど)エラーメッセージ内容を確認・メッセージで検索してみることも大事だよ。
引数の数や引数自体が違う場合はバージョンが異なる可能性が高いよ。
解決策が見つからないときは他の人に相談してみたり日を改めたりするのも大切だよ。
- 投稿日:2020-09-22T15:09:19+09:00
『Effective Python 第2版』 第3章<関数>
はじめに
- こんにちは、takadowaです。
- 前回の『Effective Python 第2版』 第2章<リストと辞書>に引き続き、今回は第3章<関数>の内容をベースに、さらに調べて知ったことや自分の感想をまとめていきたいと思います。
実行環境
サンプルコードを掲載する際は、以下の実行環境で実行した結果を掲載します。
できる限りミスのない形で提供することを心がけますが、動かない、間違っているなどがありましてもご容赦ください。
- macOS 10.14.6
- Python 3.8.5
第3章<関数>
Noneではなく例外を送出する
関数の中で処理した際、何か想定外のことが起きたら何を返しますか?
自分はこれを知るまではよくNoneを返していました。例えば以下のようなコードです。# 良くない例(想定外のときにNoneを返している) from datetime import datetime def parse_datetimes(datetime_string_list): result = [] for datetime_string in datetime_string_list: try: result.append(datetime.strptime(datetime_string, "%Y-%m-%d")) except (ValueError, TypeError): return None return result >>> print(parse_datetimes(["2020-09-22"])) [datetime.datetime(2020, 9, 22, 0, 0)] >>> print(parse_datetimes([])) [] >>> print(parse_datetimes(["hoge"])) Noneこの関数は年月日を表した文字列のリストを入力として受け付け、パースが成功したらdatetime型に変換したリストを、失敗したら
Noneを返します。
一見良さそうに見えますが、これには2つの問題があります。
- (問題1): 呼び出し元で返り値が
Noneかどうかのチェックを忘れたら(あるいは意図的に無視したら)そのままプログラムが次の処理をできてしまう- (問題2): 呼び出し元で返り値を
if resultで評価してしまうと、Noneの場合だけでなく空リスト[]のときも同じ扱いになってしまいバグを生みやすいこれらの問題を避けるため、 関数内で想定外のことが起きた場合は例外を送出する ようにしましょう。
# 良い例(想定外のときに例外を送出している) from datetime import datetime class MyError(Exception): def __init__(self, message): self.message = message def parse_datetimes(datetime_string_list): result = [] for datetime_string in datetime_string_list: try: result.append(datetime.strptime(datetime_string, "%Y-%m-%d")) except (ValueError, TypeError): raise MyError(f"入力された値が不正です: {datetime_string}") # 例外を送出する return result >>> print(parse_datetimes(["2020-09-22"])) [datetime.datetime(2020, 9, 22, 0, 0)] >>> print(parse_datetimes([])) [] >>> print(parse_datetimes(["hoge"])) ... Traceback (most recent call last): ... __main__.MyError: 入力された値が不正です: hoge上記のように例外を送出するように実装されていれば、
MyErrorという例外をキャッチしていない限り、そのまま処理が継続することはありませんし、Noneと空リスト[]を同一扱いしてしまうという恐れもないので安心ですね。デフォルト引数に空リスト
[]や空辞書{}を指定してはならない引数に値が指定されればそれを使い、指定されなければデフォルト値を使いたい、そんなときに便利なのが「デフォルト引数を設定すること」ですよね。例えば、以下のようなコードです。
# これは良くない例 def square(value, result_list=[]): result_list.append(value ** 2) return result_listこの関数は
valueを2乗したものをresult_listに追加して返しています。
この実装をした人の気持ちとしては、
result_listにリストが指定されれば、そのリストに結果を入れて返してほしいresult_listに値を指定しなければ、空リストに結果を入れて返してほしいと考えていると思います。
# result_listを指定すれば、そのリストに結果が入って返ってくる >>> result_list = [1, 4] >>> result_list = square(3, result_list) >>> print(result_list) [1, 4, 9] # result_listを指定しなければ、空リストに結果が入って返ってくる >>> result_list = square(3) >>> print(result_list) [9]全然問題ないように見えますよね?でもこのあと不思議なことが起きます。
>>> result_list = square(1) >>> print(result_list) [9, 1] # あれ?[1]が返ってくるはずでは?? >>> result_list = square(2) print(result_list) [9, 1, 4] # あれ?なんで値が3つも入っているの??そう。知らないとこのような不思議な挙動に頭を抱えることになってしまいます。
実は、デフォルト引数は関数が呼び出されるたびに評価されるのではなく、モジュールがロードされたときに1度だけ評価されるのです。したがって、デフォルト引数に空リスト
[]を指定してしまうと、その空リストにどんどんappendされていくことになるため、上記のように呼び出すたびにリストの中身が増えていくのです。これを知っていて使うならまだ良いですが、誰でも知っている挙動ではないので、デフォルト引数に空リストや空辞書などを指定するのは避けた方がいいでしょう。代わりに、以下のように書くといいでしょう。
# 良い例 def square(value, result_list=None): if result_list is None: result_list = [] # ここで初期化することで、毎回空リストにappendされるようにする result_list.append(value ** 2) return result_list上記のように実装すれば、
result_listが指定されなかったときは空リストに結果が入ったものが返るようになります。>>> result_list = square(3) >>> print(result_list) [9] >>> result_list = square(1) >>> print(result_list) [1] >>> result_list = square(2) >>> print(result_list) [4]ちなみに、IDEによっては警告を出してくれることもありますので、警告が出ていたら対応するようにしましょう。
PyCharmだと以下のような警告を出してくれました。
Python3.8から追加された「位置専用引数」と「キーワード専用引数」
突然ですが、以下のコードはどういう意味かわかりますか?
def safe_division(numerator, denominator, /, hoge, *, ignore_overflow, ignore_zero_division): ...「なんで引数に
/や*が書かれているの?」と思われたかもしれません。
これは、Python3.8から追加された「位置専用引数(/の左側)」と「キーワード専用引数(*の右側)」を使って書かれています。どういうことかと言いますと、
/の左側の引数(上の例だとnumeratorとdenominator)は位置専用引数となる
- 位置専用引数ということは、関数を呼び出すときに位置引数としてのみ指定できるようになる(言い換えると、キーワード引数としては指定できない)
- つまり
- この呼び出し方はOK:
safe_division(3, 2, ...)- この呼び出し方はNG:
safe_division(numerator=3, denominator=2, ...)*の右側の引数(上の例だとignore_overflowとignore_zero_division)はキーワード専用引数となる
- キーワード専用引数ということは、関数を呼び出すときにキーワード引数としてのみ指定できるようになる(言い換えると、位置引数としては指定できない)
- つまり
- この呼び出し方はOK:
safe_division(..., ignore_overflow=True, ignore_zero_division=False)- この呼び出し方はNG:
safe_division(..., True, False)- ちなみに、
/の右側かつ*の左側の引数(上の例だとhoge)は位置引数としてでもキーワード引数としてでも指定できます
- つまりこれまでどおりの呼び出しができる
- この呼び出し方はOK:
safe_division(..., "a", ...)- この呼び出し方もOK:
safe_division(..., hoge="a", ...)位置専用引数、キーワード専用引数を使うことのメリットとしては以下があると思います。
- 位置専用引数を使うメリット
- 上記例のように「分子 ÷ 分母」の計算を行う関数の場合、分子と分母の指定の順序を強制できます
- すなわち、
(分母=2, 分子=3, ...)のような直感に反する順序での指定を排除することができます- また、引数名を使った指定をできなくするので、引数名への依存を減らすことができます
- すなわち、引数名が
denominatorという名前からdenomという名前に変わったとしても、呼び出し元の修正は必要ありません- キーワード専用引数を使うメリット
- 複数の論理型フラグを使う場合など紛らわしい関数の呼び出し時にキーワード引数で与えることを強制できます
- すなわち、
ignore_overflowがTrueなんだよ!ということをちゃんと認識して引数指定させることを強制できます- なので、「
ignore_overflowをTrueにしてるつもりだったのにignore_zero_divisionにTrueを指定しまっていた!」というよくありがちなミスを減らすことができます引数に
/や*を書くのは最初は違和感があるかもしれませんが、上述のとおりメリットもありますので、必要に応じて使うようにしていくといいでしょう。ただし、Python3.8未満だと動かないので、そこは要注意です!まとめ
『Effective Python 第2版』 第3章<関数> の内容をベースに、調べて知ったことや感想を記しました。
- 関数内で想定外のことが起きる場合は、
Noneを返すのではなく、例外を送出するようにすると良いでしょう- 関数のデフォルト引数に空リスト
[]や空辞書{}を指定すると思わぬバグにつながるので避けたほうが良いでしょう- Python3.8から追加された「位置専用引数」と「キーワード専用引数」の使い方を理解すればより充実したPython開発ができるようになるでしょう
参考文献
- Effective Python 第2版
参考サイト
- なぜオブジェクト間でデフォルト値が共有されるのですか? -- Python公式ドキュメント
- 位置専用 と キーワード専用 -- Python公式ドキュメント

- 投稿日:2020-09-22T15:01:02+09:00
Chatwork APIで弊社の闇を暴いてみた
会社が発表しないサイレント退職者をChatworkから調べるアプリケーションを作った話をまとめました。
(※運用によって利用者様が所属する企業とトラブルが起きても当方は責任を負いかねます)Slack、スクレイピング、エクセル文書でもデータ取得方法をアレンジすれば流用できるはず
発端
- 弊社には200人超の社員が在籍しているのだけど、顔見知りだった社員がいつの間にか辞めていることも割とあり退職者発表みたいなものも無いのですごくモヤモヤしていた
- 課題を技術で解決してこそエンジニアだ!
- 前職も気が付いたら人が辞めていたので、同じ悩みを持つ人がいるはず → 満たされる承認欲求
連休なのに予定がなくてヒマ機能的な目標
- 自社のChatwork連絡先をもとに毎日の在籍者変動を監視する
- 監視結果をマイチャンネルに投稿する
- 年間、月間など一定期間でのまとめレポートも見られるようにする
- 個人情報やAPIキーの取り扱いに気を付ける
使用技術
- ホスト環境: Windows10 + Ubuntu20.4 on WSL2 (Dockerが使えればホストOSは関係ない)
- Docker
- Python(Django)
成果
期間内での新入社員/退職者の表示と、日々の社内メンバー変動把握ができた
↓レポート画面
↓Chatwork通知結果画面
作業過程
環境構築
docker-composeコマンドさえ使える環境なら他に必要なものは githubに公開してあるプロジェクト に含まれてますアプリケーションの動作に必要な Chatwork API のトークン(+ バッチの通知を利用するなら通知先のroom_idも)は各自でご用意ください
APIトークンにの取得方法(公式)Docker環境構築
DockerfileFROM python:3 ENV PYTHONUNBUFFERED 1 ENV PYTHONIOENCODING utf-8 RUN mkdir /script /app WORKDIR /script COPY requirements.txt /script/ RUN apt update && apt install -y cron vim RUN pip install -r requirements.txt WORKDIR /apprequirements.txtDjango>=3.0,<4.0 psycopg2-binary>=2.8 django-environ requests python-dateutildocker-compose.ymlversion: '3' services: app: build: . command: python manage.py runserver 0.0.0.0:8000 environment: - CHATWORK_API_TOKEN=${CHATWORK_API_TOKEN} - ROOM_ID=${ROOM_ID} - TZ=Asia/Tokyo volumes: - ./app:/app - ./export_environment.sh:/script/export_environment.sh - ./crontab:/script/crontab ports: - "8000:8000"主な処理説明
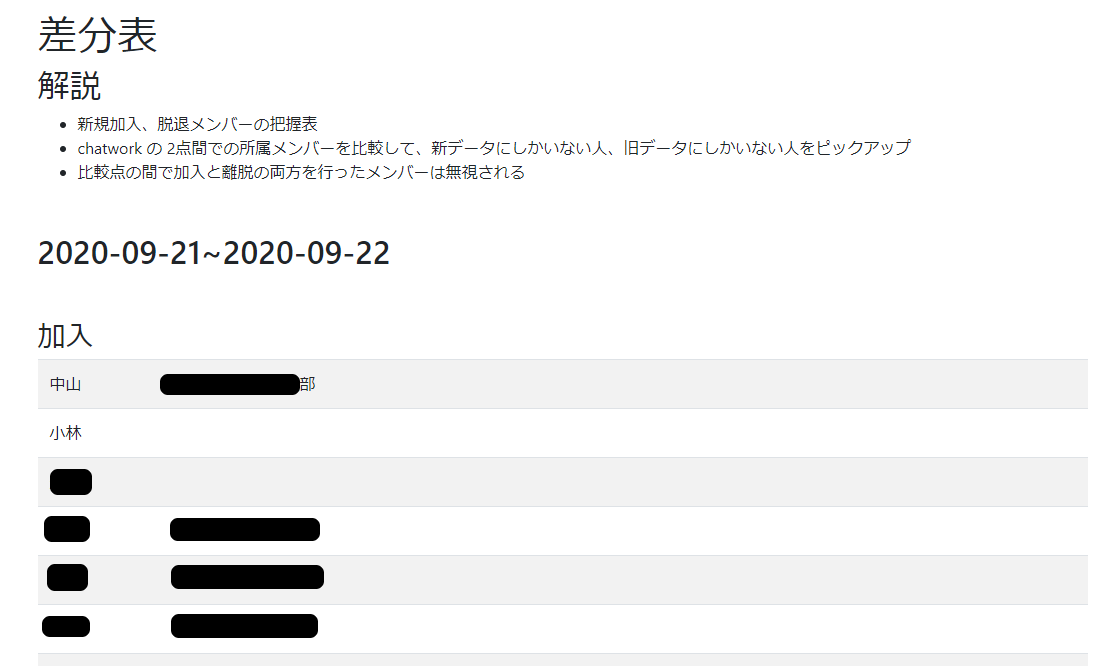
- 自アカウントのトークン使って連絡先メンバー一覧を取得
- 取得時期の違う一覧データを照らし合わせることで加入メンバー/脱退メンバーを明らかにする
- APIから過去データを参照することはできないので、比較対象となるデータはDBに格納する
get_diff()に2つの日付を与えると連絡先メンバーの差分を返すように設計- レポートを表示する機能を持つ
show()では1カ月単位過去半年間のメンバー変動レポートを表示する(月単位でのレポートなので、ホットな退職者情報は後述のバッチで対応する)- バッチ処理では同じくレポートと同じ手法で、日々日々で変動したメンバーを速報としてChatworkに投稿する
レポート画面処理 + チャットワーク連絡先一覧の取得と保存、データ比較メソッド
app/chatwork/views.pyfrom django.shortcuts import render from django.http import HttpResponse from chatwork.models import Account import requests from datetime import date from dateutil.relativedelta import relativedelta from django.db.models import Count import environ env = environ.Env(DEBUG=(bool, False)) # Create your views here. def show(request): diff_list = list() for i in range(6): end = (date.today() - relativedelta(months=i)).isoformat() start = (date.today() - relativedelta(months=(i+1))).isoformat() diff_list.append(get_diff(start, end)) params = dict(d1=diff_list[0], d2=diff_list[1], d3=diff_list[2], d4=diff_list[3], d5=diff_list[4], d6=diff_list[5]) return render(request, 'chatwork/show.html', params) def get_diff(start, end): if not Account.objects.filter(date=date.today().isoformat()): base = 'https://api.chatwork.com/v2/' end_point = 'contacts' api_token = env('CHATWORK_API_TOKEN') headers = {'X-ChatWorkToken': api_token, 'Content-Type': 'application/x-www-form-urlencoded'} res = requests.get(base + end_point, headers=headers) for contact in res.json(): data = dict(account_id=contact['account_id'], name=contact['name'][:2], department=contact['department'], date=date.today().isoformat()) Account.objects.update_or_create(**data) query = Account.objects.filter(date__gte=start, date__lte=end).values('date').annotate(Count('date')) if len(query) < 2: return dict(period='no comparable data found during ' + start + ' ~ ' + end, added=list(), dropped=list()) latest = query.order_by('-date')[0]['date'].isoformat() oldest = query.order_by('date')[0]['date'].isoformat() period = oldest + '~' + latest data_latest = Account.objects.filter(date=latest) or list() data_oldest = Account.objects.filter(date=oldest) or list() ids_latest = data_latest.values_list('account_id', flat=True) if data_latest else list() ids_oldest = data_oldest.values_list('account_id', flat=True) if data_oldest else list() added = Account.objects.filter(date=latest).filter(account_id__in=ids_latest).exclude(account_id__in=ids_oldest) dropped = Account.objects.filter(date=oldest).filter(account_id__in=ids_oldest).exclude(account_id__in=ids_latest) return dict(period=period, added=added, dropped=dropped)バッチ処理(当日と前日データの差分を自分のマイチャットに送信する)
app/chatwork/management/commands/contact_daily.pyfrom django.core.management.base import BaseCommand from chatwork.models import Account from chatwork.views import get_diff from datetime import date from dateutil.relativedelta import relativedelta import environ import requests env = environ.Env(DEBUG=(bool, False)) class Command(BaseCommand): def handle(self, *args, **options): today = date.today().isoformat() yesterday = (date.today() - relativedelta(days=1)).isoformat() data = get_diff(yesterday, today) report_title = data['period'] report_added = 'added: ' + '(' + str(len(data['added'])) + ')' + ' / '.join(list(d.name for d in data['added'])) report_dropped = 'dropped: ' + '(' + str(len(data['dropped'])) + ')' + ' / '.join(list(d.name for d in data['dropped'])) report = """ {report_title} {report_added} {report_dropped} """.format(report_title=report_title, report_added=report_added, report_dropped=report_dropped).strip() base = 'https://api.chatwork.com/v2/' room_id = env('ROOM_ID') end_point = 'rooms/' + room_id + '/messages' api_token = env('CHATWORK_API_TOKEN') headers = {'X-ChatWorkToken': api_token, 'Content-Type': 'application/x-www-form-urlencoded'} payload = dict(body=report, self_unread=1) res = requests.post(base + end_point, headers=headers, params=payload)その他
- ユニットテストも簡易だが実装
- 個人情報のお漏らしは洒落にならないので、APIから取得した氏名は先頭の二文字だけDB保存する仕様にした
- 社用アカウントのAPIトークンが流出するのも絶対NGなので、環境変数として渡す仕組みにした
- バッチ処理は毎日実行するのでcron経由だが、環境変数がユーザーと独立しているのでアレコレの対策が必要だった
- Django のModels を使ったDB取得やイテレートの扱いなど不便に感じるところも多かった。LaravelのQueryBuilderやCollectionクラスは他社のコードでも理解しやすいという点も含め流石だと再認識
最後に
休日に雑な思いつきで作ったアプリなので粗は多いですが、ご意見いただけると大変励みになりますので、コメントお寄せください。
- 詳細な解説追加要望
- 改善案のご指導
- その他技術に関する質問など

- 投稿日:2020-09-22T15:00:53+09:00
Machine Learning : k-Nearest Neighbors
目標
k近傍法のアルゴリズムを理解して、scikit-learn で試す。
理論
k近傍法は識別モデルを獲得しない教師あり分類アルゴリズムの 1つで、教師あり回帰や教師なし分類として使うこともできます。
k近傍法のアルゴリズム
k近傍法のアルゴリズムは下のようになります。
- k の値と距離指標を選択する。
- 新しい入力データと訓練データとの距離指標を計算する。
- 距離指標が最も小さい順に k個の訓練データと対応するカテゴリーを取得する。
- 多数決法により新しい入力データのカテゴリーを予測する。
距離指標にはミンコフスキー距離が用いられます。ここで、新しい入力データを $x'$、訓練データを $x$、特徴量数を $m$ とすると、
d(x', x) = \sqrt[p]{\sum^m_{j=1} |x'_j - x_j|^p }これは、$p=1$ のときはマンハッタン距離、$p=2$ のときはユークリッド距離と同義です。
k近傍法の欠点
k の値を大きくするとノイズの影響を低減できる一方、カテゴリーの境界が明確にならないことがあるため、k の値を決めるのが難しいことが挙げられます。
下図のような場合、黒色の新しいデータ点を分類する際、$k=3$ のときは橙色の丸に分類されますが、$k=5$ のときは青色の四角に分類され、$k=8$ のときは再び橙色の丸に分類されます。
また、アルゴリズム通りに実装すると、新しいデータに対して予測する際に保持しているすべてのデータに対して距離指標を計算する必要があるため、データ数に比例して計算量が増えてしまうという欠点があります。
分類問題のデータセット
k近傍法の題材として、scikit-learn の分類問題のデータセットである iris dataset を使用します。
データ数 特徴量数 カテゴリー数 150 4 3 実装
実行環境
ハードウェア
・CPU Intel(R) Core(TM) i7-6700K 4.00GHz
ソフトウェア
・Windows 10 Pro 1909
・Python 3.6.6
・matplotlib 3.1.1
・scikit-learn 0.23.0実行するプログラム
実装したプログラムは GitHub で公開しています。
nearest_neighbor.py結果
教師あり分類
$k=15$ のときの実行結果は以下のようになります。
青の領域は setosa、緑の領域は versicolor、橙の領域は virginica と分類されることを表しています。
教師あり回帰
回帰問題のデータは正弦波に乱数を加えて、$k=5$ として実行しました。
教師なし分類
分類問題において、カテゴリーラベルを与えずに $k=15$ で教師なし分類を実行しました。
参考



