- 投稿日:2020-09-14T23:59:29+09:00
instagramのクローンアプリを作る②
はじめに
タイトルの通り、簡易版instagramのアプリを作っていきます。
下記の工程に分けて記事を執筆していきますので、順を追って読んでいただけたらなと思います。①アプリ作成〜ログイン機能の実装
②写真投稿機能の実装 ←イマココ
③ユーザーページの実装
④いいね機能の実装
⑤投稿削除機能の実装Active Storageの導入
Active Storageとは...
ファイルアップロードを行うための機能で、
これを使えばフォームで画像の投稿機能などが簡単に作れます。
※以下、アプリケーションのディレクトリでターミナルrails active_storage:install続けてphotoモデルを作成します。
photoはuserに紐づいているのでuser:belongs_to
caption:textとすることで、text型のカラムも作成ターミナルrails g model photo user:belongs_to caption:textそして
ターミナルrails db:migrate最後にコントローラの作成を行います。
ターミナルrails g controller photos下準備完了です。
写真投稿ページへのリンクを作成
まず、ルーティングの設定を行います。
routes.rbRails.application.routes.draw do root 'homes#index' devise_for :users resources :photos # ←ここ end次にホーム画面を編集していきます。
index.html.erb<h3>home</h3> <div> <%= link_to 'logout', destroy_user_session_path, method: :delete %> </div> <div> <%= link_to '写真投稿', new_photo_path %> </div>
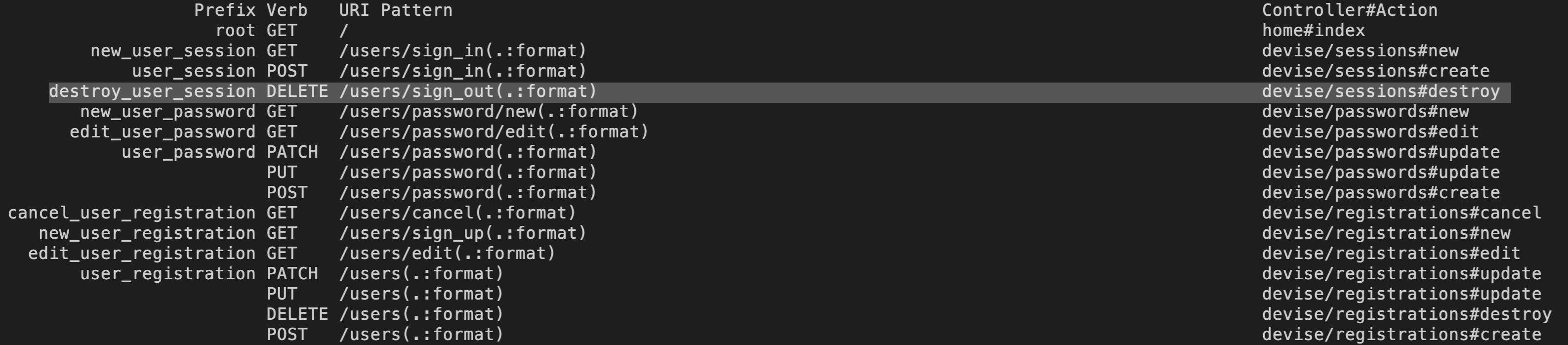
new_photo_pathはrails routesのPrefixで確認
photosモデルに
new.html.erbを作成し、確認用に下記のように記述してみます。app/views/photos/new.html.erb<h3>写真投稿</h3>下記のように、ホーム画面から写真投稿のページに遷移できていれば成功です。
コントローラの設定
rails g controller photosで作成したコントローラに記述していきます。photos_controller.rbclass PhotosController < ApplicationController before_action :authenticate_user! def new @photo = current_user.photos.new end def create @photo = current_user.photos.new(photo_params) if @photo.save redirect_to :root else render :new end end private def photo_params params.require(:photo).permit(:caption, :image) end end
before_action :authenticate_user!で、
ログインユーザーのみ投稿できるように設定しています。
createアクションで引数(photo_params)とし、
private以下で(photo_params)を定義しています。また
createアクションで
保存に成功すればホーム画面に、
失敗すれば新規投稿画面に戻る(留まる)よう設定しています。新規投稿画面のviewを編集
その前に、
userモデルとphotosモデルのアソシエーションを確認します。
userとphotosは1対多の関係なので、以下のように編集します。user.rbclass User < ApplicationRecord # Include default devise modules. Others available are: # :confirmable, :lockable, :timeoutable, :trackable and :omniauthable devise :database_authenticatable, :registerable, :recoverable, :rememberable, :validatable has_many :photos # ←ここ endphoto.rbclass Photo < ApplicationRecord belongs_to :user # ←前回記述した箇所 has_one_attached :image # ←ここ end
has_one_attached :カラム名はモデルに1つの画像を紐づける場合に使います。
複数の画像を紐づけるときはhas_many_attached :カラム名です。今回は1つの画像なので
has_one_attachedとしています。
ちなみにoneとmanyで、画像を表示させる際の記述の仕方が異なります。has_one_attached<%= image_tag(@photo.image) %>has_many_attached<% images.count.times do |i| %> <%= image_tag(@photo.image[i]) %> <% end %>
has_many_attached :カラム名だと、
imageは配列として格納されるので上記のようになります。前置きが長くなりましたが、新規投稿画面のviewを編集していきます。
app/views/photos/new.html.erb<h3>写真投稿</h3> <%= form_with model: @photo, local: true do |f| %> <div> <%= f.file_field :image %> </div> <div> <%= f.text_area :caption %> </div> <%= f.submit %> <% end %>投稿された画像をホーム画面に表示させるようにします。
※とりあえずの確認用なので、後々修正していきます。index.html.erb<h3>home</h3> <div> <%= link_to 'logout', destroy_user_session_path, method: :delete %> </div> <div> <%= link_to '写真投稿', new_photo_path %> </div> <% current_user.photos.each do |photo| %> <div> <p><%= photo.caption %></p> <%= image_tag photo.image %> </div>each文で全ての投稿を表示させるようにしています。
新規投稿ページから
ファイル選択、caption入力、Create Photoをクリックで、
以下のように投稿できていればとりあえずはカタチになっているかと思います。
以上です。お疲れ様でした。



- 投稿日:2020-09-14T23:08:28+09:00
Ruby/Rust 連携 (6) 形態素の抽出
連記事目次
- Ruby/Rust 連携 (1) 目的
- Ruby/Rust 連携 (2) 手段
- Ruby/Rust 連携 (3) FFI で数値計算
- Ruby/Rust 連携 (4) Rutie で数値計算①
- Ruby/Rust 連携 (5) Rutie で数値計算② ベジエ - Qiita
- Ruby/Rust 連携 (6) 形態素の抽出
はじめに
Ruby と Rust を連携させるやり方がだんだん分かり,面白くなってきた。
これまで((3)〜(5))は数値計算をやらせてみたので,こんどはテキスト処理をやってみよう。
よし,いきなりだが,Rust の形態素解析ライブラリーを使って,テキストから固有名詞だけとか,名詞全部とか,形容詞と副詞,とかといったように,特定の品詞の形態素だけを抜き出す,ということをやるぞ。なお筆者は細く長い Ruby 人生を送ってきたが,Rust はド素人であり,形態素解析といえば Ruby で MeCab を扱う遊びをちょっとやった程度。難しいことは分からない。
方針
Rust 製の形態素解析ライブラリーとして, Lindera というものを使う。
これは実験的に作られた kuromoji-rs というライブラリーの @mosuka さんによるフォーク。フォークの形を取っているが,別名で開発を引き継いだというもの。
経緯などは @mosuka さんの下記の記事を参照。
Rust初心者がRust製の日本語形態素解析器の開発を引き継いでみた - QiitaRuby と Rust の連携の仕組みは (4),(5) と同様,Rutie を使う。
Ruby と Rust の役割分担はこんなふうに考えている。
Rust で,形態素抽出器とでもいうような Ruby のクラスを作る(Rutie は Rust で Ruby のクラスが書ける)。初期化のときに,どんな品詞を拾うかをリストで与える(リストにあるすべての品詞を拾う)。
形態素抽出器のインスタンスを作り,それにテキストを与えると,該当する形態素を文字列の配列として返す(出現順に,重複ありで)。Ruby 側のサンプルプログラムでは,返ってきた形態素のリストから頻度表を作り,頻度の高いものから順に表示する。
Lindera の特徴
Lindera の概要はリンク先を見ていただくとして,ここでは以下の点だけ指摘しておきたい。
- IPADIC が最初から入っている
- IPADIC-NEologd など他の辞書も容易に利用できる
- ユーザー単語の追加が容易
辞書が最初から入っているというのはありがたい。ちょっと試してみるだけなのに,まず辞書をどこそこからダウンロードし,なんちゃらコマンドを打って,そのファイルをどこそこに配置し,というのはややつらい。
また,SNS などさまざまなメディアを飛び交う文を扱うのに IPADIC では語数が圧倒的に足りないが,IPADIC-NEologd のような大きな辞書が容易に使えるのもありがたい。
ユーザー単語の追加は CSV ファイルを置いてそのパスを指定するだけ,という容易さ。
動機
この記事では,他の方が参考にしやすいよう,「実用性は低いが,実用的なコードへの道筋が想像できる程度に単純なコード」を提示したい。
Ruby では,形態素解析器 MeCab,JUMAN++ を使うための gem として natto,jumanpp_ruby といったものがそれぞれある1。
それなのになぜ Ruby から Rust を呼ぶようなコードをわざわざ書くのか?
それには,GC を避けたい で書いたような仮説が背景にある。MeCab などを Ruby から利用する場合,形態素ごとに Ruby 側に大量の文字列データが持ち込まれる。その大半はガーベジ(ゴミ)となって,ある程度たまるとガーベジコレクションの対象になる。どうも効率が悪いのではないか2。
名詞抽出のような課題では,Rust 側で名詞だけを抜き出し,Ruby 側が欲する文字列だけを返してやれば効率が良いのではないか。
Rust 側ではガーベジコレクションは起こらない。スコープを外れた変数はその瞬間に消えるのだ。実装:Rust 側
Cargo.toml 編集まで
まず
cargo new phoneme_extractor --libとする。
phoneme というのは形態素という意味。
形態素抽出器という日本語が妥当かどうかしらないし,その英語が果たして phoneme extractor でよいのかどうか,私は知らん。でもって,Cargo.toml に
Cargo.toml[dependencies] lindera = "0.5.1" lazy_static = "1.4.0" rutie = "0.7.0" serde = "1.0.115" serde_json = "1.0.57" [lib] crate-type = ["cdylib"]と書く。
lindera は今回の課題の要となる形態素解析のクレート。
rutie は Ruby と Rust を繋ぐクレート。
lazy_static は,Rutie でクラスを作る際に必要なクレート。どんな品詞を抽出するか,といった情報を Ruby から Rust に伝えるうまい方法が私には分からなかったので,JSON 形式の文字列で伝えることにした。
そのために,serde と serde_json を使う。コード
Rust 側のコードの全体がこれ。
src/lib.rs#[macro_use] extern crate rutie; #[macro_use] extern crate lazy_static; use serde::{Deserialize}; use rutie::{Object, Class, RString, Array}; use lindera::tokenizer::Tokenizer; #[derive(Deserialize)] pub struct RustPhonemeExtractor { mode: String, allowed_poss: Vec<String>, } wrappable_struct!(RustPhonemeExtractor, PhonemeExtractorWrapper, PHONEME_EXTRACTOR_WRAPPER); class!(PhonemeExtractor); methods!( PhonemeExtractor, rtself, fn phoneme_extractor_new(params: RString) -> PhonemeExtractor { let params = params.unwrap().to_string(); let rpe: RustPhonemeExtractor = serde_json::from_str(¶ms).unwrap(); Class::from_existing("PhonemeExtractor").wrap_data(rpe, &*PHONEME_EXTRACTOR_WRAPPER) } fn extract(input: RString) -> Array { let extractor = rtself.get_data(&*PHONEME_EXTRACTOR_WRAPPER); let input = input.unwrap(); let mut tokenizer = Tokenizer::new(&extractor.mode, ""); let tokens = tokenizer.tokenize(input.to_str()); let mut result = Array::new(); for token in tokens { let detail = token.detail; let pos: String = detail.join(","); if extractor.allowed_poss.iter().any(|s| pos.starts_with(s)) { result.push(RString::new_utf8(&token.text)); } } result } ); #[allow(non_snake_case)] #[no_mangle] pub extern "C" fn Init_phoneme_extractor() { Class::new("PhonemeExtractor", None).define(|klass| { klass.def_self("new", phoneme_extractor_new); klass.def("extract", extract); }); }以下,少々解説を加えていく。
RustPhoneneExtractor
Rutie を使って,Ruby の PhonemeExtractor というクラスを作る。
まず RustPhonemeExtractor という構造体を作り,それを wrap して PhonemeExtractor を作ることにする。RustPhonemeExtractor の定義がこれ。
#[derive(Deserialize)] pub struct RustPhonemeExtractor { mode: String, allowed_poss: Vec<String>, }あ,言ってなかったけど,Lindera には
normalとdecomposeという二つの「モード」がある。大雑把にいうと,decomposeは複合語を分解するモード。つまり,normalよりdecomposeのほうがより細かくなる。
これをmodeで指定できるようにする。
一方,allowed_possは,拾うべき品詞をのリストをベクターの形で持つ。
possというのはずいぶん適当なネーミングなのだが,「品詞」の英語が「part of speech」なので,略してpos。それを複数形(?)でpossとした(poses だと pose の三人称単数現在形と紛らわしいし)。PhonenemeExtractor
次に,Ruby のクラス PhonenemeExtractor を作る。
RustPhonemeExtractor を wrap して PhonemeExtractor を作るため,
wrappable_struct!(RustPhonemeExtractor, PhonemeExtractorWrapper, PHONEME_EXTRACTOR_WRAPPER);と書く。
説明は前回の
Ruby/Rust 連携 (5) Rutie で数値計算② ベジエ - Qiita
を見てほしい。そしてクラスを作るのに
class!(PhonemeExtractor);と書く。
PhonenemeExtractor のメソッド
つぎに,PhonenemeExtractor のメソッドを
methods!マクロで書く。
以下の二つのメソッドを記述した。
phoneme_extractor_new(インスタンスを作る)extract(形態素を抽出する)phoneme_extractor_new メソッド
定義はこれ。
fn phoneme_extractor_new(params: RString) -> PhonemeExtractor { let params = params.unwrap().to_string(); let rpe: RustPhonemeExtractor = serde_json::from_str(¶ms).unwrap(); Class::from_existing("PhonemeExtractor").wrap_data(rpe, &*PHONEME_EXTRACTOR_WRAPPER) }
RStringは Ruby の String クラスに対応する Rust の型(Rutie で定義されている)。
paramsは,初期化に Lindera のモードや,拾い上げる品詞リストを JSON 形式で表した文字列。で,ここが面白いところなのだが,
paramsに入っている JSON 文字列を元にして RustPhonemeExtractor 構造体の値を作る,という処理がserde_json::from_str(¶ms).unwrap()だけでできちゃっている。
これが Serde というクレートのスゴイところ(知らんけど)。
構造体の定義に合わせて JSON を解釈してくれる。構造体の定義に合わない JSON 文字列が与えられたときはunwrap()の際にプログラムが落ちる。実用的なライブラリーを作る場合は,ちゃんとエラーの処理をやったほうがいいね。ちなみに,こんな JSON 文字列が与えられることを期待している。
{ "mode": "normal", "allowed_poss": [ "名詞,一般", "名詞,固有名詞", "名詞,副詞可能", "名詞,サ変接続", "名詞,形容動詞語幹", "名詞,ナイ形容詞語幹" ] }品詞については後ほど別の節を設けて述べる。
extract メソッド
こちらは PhonemeExtractor クラスのインスタンスメソッドになる。
定義を抜き出すとこうなっている。
fn extract(input: RString) -> Array { let extractor = rtself.get_data(&*PHONEME_EXTRACTOR_WRAPPER); let input = input.unwrap(); let mut tokenizer = Tokenizer::new(&extractor.mode, ""); let tokens = tokenizer.tokenize(input.to_str()); let mut result = Array::new(); for token in tokens { let detail = token.detail; let pos: String = detail.join(","); if extractor.allowed_poss.iter().any(|s| pos.starts_with(s)) { result.push(RString::new_utf8(&token.text)); } } result }入力テキストを RString(Ruby の String に対応するもの)で与えると,形態素のリストが Array of String の形で返る。
rtselfはmethods!マクロの第二引数に与えたもので,Ruby のクラス PhonemeExtractor のインスタンスに対応する(?)ようだ。
変数extractorはRustPhonemeExtractorのインスタンス。ユーザー辞書の追加をしないときは,トークナイザーを
Tokenizer::newで生成する。第一引数は先述のモードの文字列で,第二引数は使う辞書のディレクトリーパスを与える。第二引数に空文字列を与えると,デフォルトである IPADIC が使われる。ユーザー辞書を使うときは
Tokenizer::new_with_userdicを使い,第三引数にユーザー辞書(CSV 形式)のパスを与える。トークナイザーの
tokenizeメソッドにテキストを与えるとトークン列がベクターで返る。一つの形態素が一つのトークンに対応する。トークンは
#[derive(Serialize, Clone)] pub struct Token<'a> { pub text: &'a str, pub detail: Vec<String>, }という定義になっている。
textは分解された形態素そのもの。「コードを書こう」の場合,「コード」「を」「書こ」「う」の四つが該当する。
detailは取り出した一つの形態素についての情報をまとめて格納する String のベクター。どんな情報がどんな順に入っているかは使う辞書によって異なる。
デフォルトの IPADIC の場合,インデックス 0〜3 が品詞情報で,そのほかに活用型・活用形だの原型だの読みだのといった情報が入っている。この関数の肝は,取り出した形態素が指定した品詞のどれかに当てはまっているかどうかを確認するところだが,品詞体系の説明を先にする必要があるので,いったん棚上げする。
ともかく,Ruby の配列resultに,該当する形態素のtextを放り込んで行き,最後のそのresultを返す。Ruby のクラスとメソッドの割り当て
残る部分は
#[allow(non_snake_case)] #[no_mangle] pub extern "C" fn Init_phoneme_extractor() { Class::new("PhonemeExtractor", None).define(|klass| { klass.def_self("new", phoneme_extractor_new); klass.def("extract", extract); }); }のみ。
Ruby の PhonemeExtractor クラスと,その特異メソッドnewおよびインスタンスメソッドextractを,methods!マクロで定義したメソッドに割り当てている。
前回の記事を参照。品詞体系
品詞は,IPADIC の場合,四階層からなる「IPA 品詞体系」というものに従っているらしい。
この体系の一次情報がどこにあるのかさっぱり分からなかったが,以下のページにとりあえず書かれている。
形態素解析ツールの品詞体系これによると例えば,以下のようになるようだ。
"花子"→["名詞", "固有名詞", "人名", "名"]"玉ねぎ"→["名詞", "一般", "", ""](トークンの
detailの先頭 4 要素を抜き出したイメージ)注意すべきは,
detailの長さ(要素数)は IPADIC では基本的に 9 なのだが,「未知語」と判定される形態素に限ってはdetailが["UNK"]という長さ 1 のベクターになるということ。品詞の指定と判定
さて,用途によって,品詞情報の第 0 要素が
名詞のものをすべてに拾いたいこともあれば,第 0,第 1 要素がそれぞれ名詞,固有名詞のもの(第 3,第 4 要素は問わない)といった場合もあろう。
つまり,どこまで細かく指定したいかは場合によりけり。これをどのように指定させて,どのように判定すればいいか。
なるべく単純にやりたいので,以下のようにすることにした。指定は
"名詞"とか"名詞,固有名詞"といったように,必要な深さまでの品詞情報をカンマで区切った文字列とする。また,見出された形態素については,
detailをカンマで区切った文字列(つまりjoin(",")したもの)とする。そして,後者の先頭に前者が存在するかを,
Stringの starts_with メソッドで判定する。ただし,品詞の指定は複数与えられるようにし,そのうちのどれかに当てはまっていればよいことにする。
それがこの部分:for token in tokens { let detail = token.detail; let pos: String = detail.join(","); if extractor.allowed_poss.iter().any(|s| pos.starts_with(s)) { result.push(RString::new_utf8(&token.text)); } }
anyなんて,Ruby の Enumerable#any? そっくり。なお,
RString::new_utf8は Rust の文字列から Ruby の String を作るもの。コンパイル
例によって
cargo build --releaseとする。
成果物がtarget/release/libmy_rutie_math.dylibというパスに出来る(拡張子はターゲットによる)。実装:Ruby 側
Ruby スクリプトはこれだけ。
例によって,このスクリプトが Rust のプロジェクトのルートディレクトリーに存在するとして,Rust のライブラリーのパスを記述している。# encoding: utf-8 require "rutie" Rutie.new(:phoneme_extractor, lib_path: "target/release").init "Init_phoneme_extractor", __dir__ pe = PhonemeExtractor.new <<JSON { "mode": "normal", "allowed_poss": [ "名詞,一般", "名詞,固有名詞", "名詞,副詞可能", "名詞,サ変接続", "名詞,形容動詞語幹", "名詞,ナイ形容詞語幹" ] } JSON text = <<EOT 「道程」 高村光太郎 僕の前に道はない 僕の後ろに道はできる ああ、自然よ 父よ 僕を一人立ちにさせた広大な父よ 僕から目を離さないで守る事をせよ 常に父の気魄を僕に充たせよ この遠い道程のため この遠い道程のため EOT pe.extract(text).tally .sort_by{ |word, freq| -freq } .each{ |word, freq| puts "%4d %s" % [freq, word] }結果:
3 父 3 道程 2 道 1 前 1 後ろ 1 自然 1 立ち 1 広大 1 目 1 気魄 1 高村 1 光太郎ふう,疲れた。
おわりに
説明を加えようとするとどんどん長くなるし,推敲を重ねるといつまでも書き終わらない。
申し訳ないけど,記事の品質はイマイチかも。
質問は歓迎なので,どんなことでも訊いてください。私に分かることなら答えます。
- 投稿日:2020-09-14T22:42:46+09:00
《未経験→webエンジニア》実務1日目
この記事の目的
自分がやったこと、知らなかったこと、やるべきことを明確にし
1日あたりの成長速度を速める。「エンジニアになって、実務始まるとこんな感じなんだー」という
参考にも!【今日やったこと】
・オリエンテーション
・PCの環境設定
・入社後の書類もろもろ【知らなかったこと】
・APIテストってなに?
https://qiita.com/k-penguin-sato/items/defdb828bd54729272ad・AWSの資格について(知ってたけど、きちんと調べていなかった)
https://proengineer.internous.co.jp/content/columnfeature/13442【明日】やるべきこと
・railsの環境構築
・テストのコードが読めるよう、手を動かす
- 投稿日:2020-09-14T22:18:13+09:00
Rubyメソッド学習1
ArrayクラスとStringクラスのメソッド色々
現在、Ruby技術者認定試験silverを取得するべく勉強中です。
言語に対する理解がまだまだなので、基本的な事からアウトプットしていきます。chopメソッド
文字列の最後尾1文字を削除するメソッド。
str = "abeshi".chop p str => "abesh"ただし、最後尾が\r\nの場合は、2文字とも削除される。Windows環境のみ、改行文字は\rと\n両方が必要だから、だと思います。
str = "tawaba\r\n".chop p str => "tawaba"sliceメソッド
整数の引数を指定し、配列(Array)、または文字列(String)から、指定した引数のインデックスに相当する値を返す。
array = ["abeshi", "tawaba", "uwaraba", "howatya"] p array.slice(2) => "uwaraba"引数をカンマで区切る事で、範囲内の値を返す。
array = ["abeshi", "tawaba", "uwaraba", "howatya"] p array.slice(1,3) => ["tawaba", "uwaraba", "howatya"]sortメソッド
配列の中身を順番に並び替えるメソッド。
num = [2, 1, 4, 8, 9, 7, 6, 3, 5] p num.sort => [1, 2, 3, 4, 5, 6, 7, 8, 9]sort!にする事で、破壊的にソートする事が出来る。
補足 破壊的メソッドとは
オブジェクトそのものを変更するメソッド
破壊的でないメソッド
numの中身がそのままのパターン。
num = [2, 1, 4 ,8 , 9, 7, 6, 3, 5] num.sort p num => [2, 1, 4 ,8 , 9, 7, 6, 3, 5]破壊的メソッド
numの中身が変更されたパターン。
num = [2, 1, 4 ,8 , 9, 7, 6, 3, 5] num.sort! p num => [1, 2, 3, 4, 5, 6, 7, 8, 9]
- 投稿日:2020-09-14T22:18:13+09:00
Ruby学習1
メソッドとか色々1
現在、Ruby技術者認定試験silverを取得するべく勉強中です。
言語に対する理解がまだまだなので、基本的な事からアウトプットしていきます。chopメソッド
文字列の最後尾1文字を削除するメソッド。
str = "abeshi".chop p str => "abesh"ただし、最後尾が\r\nの場合は、2文字とも削除される。Windows環境のみ、改行文字は\rと\n両方が必要だから、だと思います。
str = "tawaba\r\n".chop p str => "tawaba"sliceメソッド
整数の引数を指定し、配列(Array)、または文字列(String)から、指定した引数のインデックスに相当する値を返す。
array = ["abeshi", "tawaba", "uwaraba", "howatya"] p array.slice(2) => "uwaraba"引数をカンマで区切る事で、範囲内の値を返す。
array = ["abeshi", "tawaba", "uwaraba", "howatya"] p array.slice(1,3) => ["tawaba", "uwaraba", "howatya"]sortメソッド
配列の中身を順番に並び替えるメソッド。
num = [2, 1, 4, 8, 9, 7, 6, 3, 5] p num.sort => [1, 2, 3, 4, 5, 6, 7, 8, 9]sort!にする事で、破壊的にソートする事が出来る。
補足 破壊的メソッドとは
オブジェクトそのものを変更するメソッド
破壊的でないメソッド
numの中身がそのままのパターン。
num = [2, 1, 4 ,8 , 9, 7, 6, 3, 5] num.sort p num => [2, 1, 4 ,8 , 9, 7, 6, 3, 5]破壊的メソッド
numの中身が変更されたパターン。
num = [2, 1, 4 ,8 , 9, 7, 6, 3, 5] num.sort! p num => [1, 2, 3, 4, 5, 6, 7, 8, 9]
- 投稿日:2020-09-14T22:10:53+09:00
(Ruby on Rails6) データーベースの作成とビューへの表示
マシンスペック/バージョン
・バージョン 10.15.3
・Ruby ruby 2.6.3p62
・Rails 6.0.3.2まえがき
こちらの記事では、Ruby on Rails6 でのデーターベースの作成とビューへの表示を忘却録として記録します。もしも、データーベース の作成などで困っている方がいればお役に立てると嬉しいです。
準備
こちらでは、ディレクトリの作成から行います。
データーベースの作成は、後ほど記述しますので、ご存知の方は読み飛ばしても大丈夫です!ディレクトリの作成
以下のコマンドを任意のディレクトリ先で入力してください。
また、herokuにデプロイを想定しているのでデーターベース(postgresql)を設定しています。terminalrails new ディレクトリ名 -TB --database=postgresql (例)↓ rails new form_test -TB --database=postgresql設定するデーターベース がなければ以下のコマンドでも問題ありません。
terminalrails new ディレクトリ名 (例)↓ rails new form_test※postgresql で設定すると、ブラウザ表示時にエラーになります。その処理は後ほど記述します。
ページの作成
先ほど生成したディレクトリ先に移動しページを作成しましょう。
terminalcd ディレクトリ名 (例↓) cd form_testterminalrails generate controller 任意の名前 index (例)↓ rails generate controller Forms index"index" は、作成意図で入力名を変更してください。
generate→g の省略コマンドでも問題ありません。
また、ディレクトリ名前は "Forms" のような複数形にすると後に管理しやすいです。terminalrails g controller 任意の名前 index (例)↓ rails g controller Forms indexroutesの設定
以下をroutesに設定すると http://localhost:3000/forms 設定されます。
config/routesRails.application.routes.draw do # get "任意名" => "任意の値#index" get "forms" => "forms#index" # For details on the DSL available within this file, see https://guides.rubyonrails.org/routing.html endブラウザで確認
一度ブラウザで確認してみます。
ブラウザへの表示をコマンドを入力してください。terminalrails s or rails server表示されましたか?
また、postgresql のディレクトリ作成で記述しましたが、エラーが出るかもしれません(私はエラーしました)
その際は以下のコマンドを入力してください。terminalrails db:createエラーの原因は別記事で説明します。
データーベースを準備
ここからは、データベースの作成を行います。
データーベースを作成
terminalrails g model データベース名 content:text (例)↓ rails g model Forms content:textデーターベース名は、頭文字を "大文字" にすることと "複数形" にすると管理しやすいです。
省略をしていない↓でもOKterminalrails generate model データベース名 content:text (例)↓ rails generate model Forms content:textデーターベースのマイグレーション
データベースの作成後は、マイグレーションをしてください。
忘れてしまうと、ブラウザで確認する際にエラーが発生します。terminalrails db:migrateデーターベースの投稿を追加
インスタンス化を行います。
この処理を行うには rails console と先に、コマンドに入力してください。terminalrails console 任意名 = データベース名.new(content: "今日からProgateでRailsの勉強するよー!") 任意名.save (例)↓ form1 = Form.new(content: "test") form1.save余談ですが、ディレクトリ作成時に↓と入力した場合は "forms(formの複数形)" なので、データーベースの追加時には "form(単数形)" にすると良いです。
terminalrails generate controller forms indexデーターベースの投稿を保存
投稿を追加後は、saveをしてください。
これを行うことにより、投稿が保存されます。terminal任意名.save (例)↓ form1.save quitquit は rails console を終了するコマンドです。
この処理を2~‥繰り返すと、複数の投稿を保存できます。データーベースの投稿を取得
terminal今回私は "ディレクトリ名 = データベース名.all" を使います。 ディレクトリ名 = データベース名.all forms = Form.all →全ての値を取得 ディレクトリ名[0] forms[0] →初めの値を取得 ディレクトリ名[0].content forms[0].content →初めの値(content)を取得以上が、データベースの作成でした。次はビューに表示する作業を行います。
データベースの内容をビューに保存
コントロールの設定
controllerに、データベースの取り出しで使用した "ディレクトリ名 = データベース名.all" を設定することにより全ての投稿内容を取得できます。
また、Rubyでは "form" は "@form" のように @ を付けないといけません。
app/controllers/任意_controller.rbclass PostsController < ApplicationController def index # @ディレクトリ名 = データベース名.all @forms = Form.all end endビューの設定とEach配列
app/views/任意/index.html.erb<h1>Forms#index</h1> <p>Find me in app/views/forms/index.html.erb</p> <% @ディレクトリ名.each do |form| %> <div> <%= ディレクトリ名の単数形.content %> </div> <% end %>例↓
app/views/任意/index.html.erb<h1>Forms#index</h1> <p>Find me in app/views/forms/index.html.erb</p> <% @forms.each do |form| %> <div> <%= form.content %> </div> <% end %>Eachによる繰り返し処理
app/views/任意/index.html.erb<% @forms.each do |form| %> 処理 <% end %>each を使うことにより、繰り返しの処理を行うことができます。
またapp/views/任意/index.html.erb<%= form.content %>は、データーベースの "content" を表示させています。
そして、Rubyでは↓の表記の違いで異なる挙動が起こるので注意してください。
ここでは、データベースのcontentを表示させたいので <%= form.content %> と入力します。app/views/任意/index.html.erb<%= form.content %> →文字列をビューへ表示(=が重要) <% form.content %> →文字列の結果をビュー表示しないブラウザで確認
問題がなければ routes 先で、確認できます。
私はテストで test1 と test2 を表示させてみました。以上のテストは、Githubで公開しています。
試してみたい方はダウンロードをしてみてください。あとがき
ここまで読んでいただき、ありがとうございます。
以上が、Ruby on Rails6 での データーベース作成とビューへの表示でした。
routesやcontrollerの設定が、複雑で少し疲れますがビューで表示されると嬉しいです。参考リンク
書籍: たのしいRuby 第6版
私のリンク
また、Twitter・ポートフォリオのリンクがありますので、気になった方は
ぜひ繋がってください。プログラミング学習を共有できるフレンドが出来るととても嬉しいです。

- 投稿日:2020-09-14T21:57:40+09:00
Rubyのmatch / scan の違いをメモ
※いくつか類似のページ見つかりますがメモで残しておきます。
実際に書いてみる
# irb a = "barfoobazfoobaofoo" # matchの場合 a.match(/ba./) => #<MatchData "bar"> # scanの場合 a.scan(/ba./) => ["bar", "baz", "bao"]matchは、
MatchDataオブジェクトが返ってきて
scanは、配列で返ってくる。正規表現でマッチしない場合
#irb # match a.match(/baa./) => nil # scan a.scan(/baa./) => []matchは、nilが返ってきて、
scanは空の配列が返ってくる。考察
考察1
matchは配列を返さないので、結果をループ処理しようとするとエラーになる。
scanは配列を返すので、ループ処理できる。
(と言うかscanはそのままブロックを渡して処理できるからこんなことできる↓)# irb a.scan(/ba./) {|s| p s*2} "barbar" "bazbaz" "baobao"考察2
matchはnilを返すので、条件分岐の時falseになる。
scanは[]なので、条件分岐でtrueになってしまうから注意。参考
https://docs.ruby-lang.org/ja/latest/method/String/i/match.html
https://docs.ruby-lang.org/ja/latest/method/String/i/scan.html
- 投稿日:2020-09-14T20:54:28+09:00
【Rails】オブジェクトの中身を確かめる
オブジェクトとは?
オブジェクトは「箱」のようなもの。
そこで、存在チェックをするときには、
- その箱の中身があるのか?
- そもそも箱そのものがあるのか
という観点で見ていく。
箱そのものは存在していないのか? nil?
obj.nil?箱の中身は空なのか? empty?
obj.empty?箱そのものは存在していないのか?してても中身は空なのか? blank?
「箱が存在していないか、または中身が存在していない状態」
ちなみに、Railsのみのメソッドobj.blank? # 同義 obj.nil? || obj.empty?箱そのものは存在しているし、かつ中身も空ではないか? present?
「箱もある、かつ中身もある状態」
ちなみに、Railsのみのメソッドobj.present? #同義 !obj.nil? && !obj.empty? obj.blank?
- 投稿日:2020-09-14T18:20:04+09:00
Rubyの便利だと思ったメソッド
やっていて便利だと思ったメソッドをメモ書き。
※ 本当にただのメモです。文字列の出現回数を数える
一文字
str = "aaabbbcccabc"
str.count("a")
=> 4複数文字
str = "aaabbbcccabc"
str.scan("ab")
=> [ab, ab]
str.scan("ab").length
=> 2絶対値を取得
num = 5
num.abs
=> 5
num = (-5)
num.abs
=> 5文字列の一部を置き換え
str = "aabbcc"
str.gsub("aa", "")
=> str = bbccaaを空文字に置き換え
文字列の一部を削除
末尾から削除
str = "aabbcc"
str.chomp("cc")
=> aabbどこでも削除
str = "aabbcc"
str.delete("bb")
=> aacc大文字 ⇄ 小文字
str = "abc"
str.upcase
=> ABC
str.downcase
=> abc配列
生成
(1..5).to_a
=> [1, 2, 3, 4, 5]追加
末尾
array = ["a", "b", "c"]
array.push("e");
array = ["a", "b", "c", "e"]先頭
array = ["a", "b", "c"]
array.unshif("e");
array = ["e", "a", "b", "c"]削除
array = ["a", "b", "c", "e"]
array.delete("e")
array = ["a", "b", "c"]
array[0,2] = []
array = ["c"]添字0から2つ削除
置き換え
array = ["a", "b", "c"]
array.map!{|x| x=="a" ? "z" : x}
=> ["z", "b", "c"]二つの配列の結合
arrayX = [1, 2, 3]
arrayY = ["a", "b", "c"]
arrayX.concat(arrayY)
arrayX = [1, 2, 3, "a", "b", "c"]重複を削除
array = [1, 1, 2, 2, 3, 3]
array.uniq
=> [1, 2, 3]反転
`array = ["a", "b", "c"]
array.reverse!
=> ["c", "b", "a"]文字列を一文字ずつ分割
str = "abc"
str.chars
=> ["a", "b", "c"]
num = 12345
num.chars
=> [1, 2, 3, 4, 5]結合した文字列の作成
array = ["a", "b", "c"]
array.join
=> "abc"
- 投稿日:2020-09-14T14:52:03+09:00
特定のページでJavaScriptを動作させる方法
動作環境
Ruby 2.6.5
Rails 6.0.3.2基本的にJavaScriptは全てのページで発生しているため、JavaScriptを使用していないページでも検証ツールのconsole内でJavaScriptのエラーが発生してしまいます。それが、ようやく解決できたので、投稿してみました。
実装に必要なコード
hoge.jsif (location.pathname.match("hoge")){ //ここからJavaScriptを書き始める。 }これでhogeというパスでのみhoge.jsは動作します。
一応解説を入れておくと、location.pathnameにより現在のパスを取得しmatchでhogeと合っているのかを確認しています。
個人的にconsole内のJavaScriptのエラーが気になっていたので、これですっきりしました。
- 投稿日:2020-09-14T14:09:25+09:00
【文字列の頭文字を削除】Ruby
Rubyで文字列の頭文字を削除する方法
sample.rbstr = "あいうえお" str[1..-1] # => "いうえお"シンプルでした!
ーーーーーーーーーーーーーーーーーーーーーーーー
引用元
https://myridia.com/dev_posts/view/93
ーーーーーーーーーーーーーーーーーーーーーーーー
- 投稿日:2020-09-14T12:34:52+09:00
【Ruby on Rails】Googlemapの複数ピン立て、吹き出し、リンク
目標
開発環境
ruby 2.5.7
Rails 5.2.4.3
OS: macOS Catalina前提
※ ▶◯◯ を選択すると、説明等が出てきますので、
よくわからない場合の参考にしていただければと思います。
- 【Ruby on Rails】郵便番号から住所を自動入力
- GoogleAPIキー発行済(GeocodingAPI MapsJavaScriptAPI)
- こちらで分かりやすく説明してくれていました
- Rails5でGoogleMapを表示してみるまで
- 【Ruby on Rails】Google API を使ったGoolgeMAPの表示とピン立て
既に1件は表示はできている前提で進めていきます。
1 gemの導入
下記をGemfileに追加。
Gemfilegem "gon"ターミナル$ bundle install
補足
gonはcontroller内の変数をJavascript内で使う事が出来るgemです。2 controllerの編集
gon.users を定義する。
app/controllers/users_controller.erbclass UsersController < ApplicationController def show @user = User.find(params[:id]) end def index @users = User.all gon.users = User.all end end3 viewの編集
<%= include_gon %>を記述することで、Javascript内で使用可能にする。
app/views/layouts/application.html.erb<head> ... <%= include_gon %> <%= javascript_include_tag 'application', 'data-turbolinks-track': 'reload' %> ... <head>今回は下記ページに記載。
app/views/users/index.html.erb<div id='map'></div> <style> #map{ height: 500px; width: 530px; } </style> <script> let map let geocoder let marker = []; // マーカーを複数表示させたいので、配列化 let infoWindow = []; // 吹き出しを複数表示させたいので、配列化 const users = gon.users; // コントローラーで定義したインスタンス変数を変数に代入 function initMap(){ // geocoderを初期化 geocoder = new google.maps.Geocoder() // mapの初期位置設定 map = new google.maps.Map(document.getElementById('map'), { center: {lat: -35.6809591, lng: 139.7673068}, zoom: 14 }); // forは繰り返し処理 // 変数iを0と定義し、 // その後gonで定義したusers分繰り返し加える処理を行う for (let i = 0; i < users.length; i++) { // geocoderで addressの経緯緯度取得 // users[i]は変数iのユーザーを取得している geocoder.geocode( { 'address': users[i].prefecture_code + users[i].city + users[i].street }, function(results, status) { // statusがOKであれば if (status == 'OK') { // map.setCenterで地図が移動 map.setCenter(results[0].geometry.location); marker[i] = new google.maps.Marker({ map: map, position: results[0].geometry.location }); // 変数iを変数idに代入 let id = users[i]['id'] // infoWindowは吹き出し infoWindow[i] = new google.maps.InfoWindow({ // contentで中身を指定 // 今回は文字にリンクを貼り付けた形で表示 content: `<a href='/users/${id}'>${users[i].email}</a>` }); // markerがクリックされた時、 marker[i].addListener("click", function(){ // infoWindowを表示 infoWindow[i].open(map, marker[i]); }); } else { alert('Geocode was not successful for the following reason: ' + status); } }); } } function codeAddress(){ // 入力を取得 let inputAddress = document.getElementById('address').value; // geocodingしたあとmapを移動 } </script> <script src="https://maps.googleapis.com/maps/api/js?key=<%= ENV['SECRET_KEY'] %>&callback=initMap" async defer></script>

- 投稿日:2020-09-14T11:19:32+09:00
任意の文字列が左から何文字目に出てくるかを出力したい
【概要】
1.結論
2.どのように使うか
3.ここから学んだこと
1.結論
indexメソッドと、putsを使う!
2.どのように使うか
def search(str) puts(str.index("検索したい任意の文字列")+1) endとなります!
こうすることで(str)が仮引数になっており任意の文字列(実引数)を取ってくる形になり戻り値(putsの中身 )が出力されます。str.index("検索したい任意の文字列",[検索したい開始位置])
が型になります。ここで気をつけてほしいことが2点あります。
1点目に"+1"としている部分です。配列と同じようにカウントが"0"から始まります。
2点目に最初の文字しか反応しないことです。ex) ohmygoodness,oh!
であれば"oh"を検索した際に”0”と出力されてしまう(1点目)。そして2つ目の"oh"は認識されません(2点目)。
3.ここから学んだこと
”左から”があれば右からもあるわけでその場合は”rindex”を使用します。注意したいことが2点あります。1点目は[検索したい開始位置]は負の数が入ることです。"-1""-2"と記載します。
2点目は出力される値は先頭から数えた値になります。
また、こちらも最初の文字しか反応しない(今度は末尾のohのみ)ことです。参考にしたサイト:
Rubyで文字列の検索をする方法:index, rindex
- 投稿日:2020-09-14T11:00:42+09:00
RubyのHTTPClientでクエリに配列を渡してリクエストする方法
https://httpbin.org/get?params[]=a¶ms[]=b¶ms[]=cこのようなURLでリクエストしたい場合は以下のようにする
sample.rb#!/usr/bin/env ruby require 'httpclient' url = 'https://httpbin.org/get' query = { 'params[]' => ['a', 'b', 'c'] } puts HTTPClient.get(url, query).bodytest$ ./sample.rb | jq '.args' { "params[]": [ "a", "b", "c" ] }
- 投稿日:2020-09-14T10:49:29+09:00
RailsにDevise+OmniAuthでユーザ認証したい
今回やりたいこと
Deviseを使った基本的なユーザー認証機能
SNS認証には仮登録メールを介さずにワンクリック登録となるようにしたい
Deviseの初期設定でユーザー情報の編集をする際に逐一パスワードを求められるが、ユーザーフレンドリーではないのでパスワードを入力せずにユーザー情報を編集したい
この記事の個人的目的
備忘録。GitHubにこのプロジェクトのソースコードを残しておきます。
https://github.com/zizynonno/devise_omniauth
1 deviseの導入
1.1 プロジェクトの作成
新しいプロジェクトを作ります。
$ rails new devise_omniauth $ cd devise_omniauth1.2 Gemfileの追加とインストール
Gemfileに以下のgemを追加する。
Gemfilesource 'https://rubygems.org' (省略)... # Devise gem 'devise' gem 'devise-i18n' gem 'omniauth-twitter' gem 'omniauth-facebook' gem 'dotenv-rails'Gemfilegem 'devise' #ユーザー認証 gem 'devise-i18n' #deviseのi18n gem 'omniauth-twitter' #twitter認証 gem 'omniauth-facebook' #facebook認証 gem 'dotenv-rails' #環境変数の設定gemをインストール。
$ bundle install2 deviseの設定
devise関連ファイルを追加。
$ rails g devise:installこのコマンドを実行すると、ターミナルに英文でdeviseの設定について記載されています。
それでは1〜4まで実行していきましょう。2.1 デフォルトURLの指定
config/environments/development.rbRails.application.configure do # Settings specified here will take precedence over those in config/application.rb. (省略)... # mailer setting config.action_mailer.default_url_options = { host: 'localhost', port: 3000 } end2.2 root_urlの指定
1番で指定したhttp://localhost:3000/にアクセスした際に表示されるページを指定します。
このプロジェクトではページを1つも作っていないため、先に追加します。Pagesコントローラーと、indexページとshowページを追加してみます。
$ rails g controller Pages index showroutes.rbに以下を指定します。
config/routes.rbRails.application.routes.draw do root 'pages#index' get 'pages/show' (省略)... end2.3 フラッシュメッセージの追加
ログインした時などに上の方に「ログインしました」みたいなメッセージが出るようにします。
以下のファイルの<body>タグのすぐ下に指定されたタグを挿入します。app/views/layouts/application.html.erb<!DOCTYPE html> <html> <head> <title>DeviseRails5</title> <%= csrf_meta_tags %> <%= stylesheet_link_tag 'application', media: 'all', 'data-turbolinks-track': 'reload' %> <%= javascript_include_tag 'application', 'data-turbolinks-track': 'reload' %> </head> <body> <%# ここから %> <p class="notice"><%= notice %></p> <p class="alert"><%= alert %></p> <%# ここまで %> <%= yield %> </body> </html>2.4 DeviseのViewを生成
$ rails g devise:viewsすると以下の様なファイルが生成されます。
app/views/devise/shared/_links.html.erb (リンク用パーシャル) app/views/devise/confirmations/new.html.erb (認証メールの再送信画面) app/views/devise/passwords/edit.html.erb (パスワード変更画面) app/views/devise/passwords/new.html.erb (パスワードを忘れた際、メールを送る画面) app/views/devise/registrations/edit.html.erb (ユーザー情報変更画面) app/views/devise/registrations/new.html.erb (ユーザー登録画面) app/views/devise/sessions/new.html.erb (ログイン画面) app/views/devise/unlocks/new.html.erb (ロック解除メール再送信画面) app/views/devise/mailer/confirmation_instructions.html.erb (メール用アカウント認証文) app/views/devise/mailer/password_change.html.erb (メール用パスワード変更完了文) app/views/devise/mailer/reset_password_instructions.html.erb (メール用パスワードリセット文) app/views/devise/mailer/unlock_instructions.html.erb (メール用ロック解除文)3 Userモデルの設定
3.1 Userモデルの作成
$ rails g devise Userを実行するとmigrationファイルとuserファイルが出来上がります。
db/migrate/20200912194315_devise_create_users.rbclass DeviseCreateUsers < ActiveRecord::Migration[5.2] def change create_table :users do |t| ## Database authenticatable t.string :email, null: false, default: "" t.string :encrypted_password, null: false, default: "" ## Recoverable t.string :reset_password_token t.datetime :reset_password_sent_at ## Rememberable t.datetime :remember_created_at # ## Trackable # t.integer :sign_in_count, default: 0, null: false # t.datetime :current_sign_in_at # t.datetime :last_sign_in_at # t.string :current_sign_in_ip # t.string :last_sign_in_ip # ## Confirmable # t.string :confirmation_token # t.datetime :confirmed_at # t.datetime :confirmation_sent_at # t.string :unconfirmed_email # Only if using reconfirmable # ## Lockable # t.integer :failed_attempts, default: 0, null: false # Only if lock strategy is :failed_attempts # t.string :unlock_token # Only if unlock strategy is :email or :both # t.datetime :locked_at t.timestamps null: false end end endapp/models/user.rbclass User < ApplicationRecord # Include default devise modules. Others available are: # :confirmable, :lockable, :timeoutable and :omniauthable devise :database_authenticatable, :registerable, :recoverable, :rememberable, :trackable, :validatable end3.2 マイグレーションファイル、Userモデルの編集
これを使うものだけコメントアウトしていきます。
db/migrate/20200912194315_devise_create_users.rbclass DeviseCreateUsers < ActiveRecord::Migration[5.2] def change create_table :users do |t| ## Database authenticatable t.string :email, null: false, default: "" t.string :encrypted_password, null: false, default: "" ## Recoverable t.string :reset_password_token t.datetime :reset_password_sent_at ## Rememberable t.datetime :remember_created_at ## Trackable t.integer :sign_in_count, default: 0, null: false t.datetime :current_sign_in_at t.datetime :last_sign_in_at t.string :current_sign_in_ip t.string :last_sign_in_ip ## Confirmable t.string :confirmation_token t.datetime :confirmed_at t.datetime :confirmation_sent_at t.string :unconfirmed_email # Only if using reconfirmable ## Lockable t.integer :failed_attempts, default: 0, null: false # Only if lock strategy is :failed_attempts t.string :unlock_token # Only if unlock strategy is :email or :both t.datetime :locked_at t.timestamps null: false end add_index :users, :email, unique: true add_index :users, :reset_password_token, unique: true add_index :users, :confirmation_token, unique: true add_index :users, :unlock_token, unique: true end endマイグレーションファイルで入れるものに加え、OAuth認証をするので
omniauth_providers: [:twitter,:facebook]を追加します。app/models/user.rbclass User < ApplicationRecord # Include default devise modules. Others available are: # :confirmable, :lockable, :timeoutable and :omniauthable devise :database_authenticatable, :registerable, :recoverable, :rememberable, :trackable, :validatable, :confirmable, :lockable, :timeoutable, :omniauthable, omniauth_providers: [:twitter,:facebook] end3.3 omniauth用カラムの追加
ついでにomniauth-twitter,omniauth-facebookで使う
provider、uid、usernameをUserテーブルに追加します。$ rails g migration add_columns_to_users provider uid username以下のようなマイグレーションファイルができます。
db/migrate/20200912194427_add_columns_to_users.rbclass AddColumnsToUsers < ActiveRecord::Migration[5.2] def change add_column :users, :provider, :string add_column :users, :uid, :string add_column :users, :username, :string end endここまで出来たら以下を実行します。
$ rake db:migrate4 Twitter,facebookで認証する
4.1 Twitter認証,Facebook認証をするためのそれぞれのAPIキー、シークレットキーを取得する
以下よりアプリケーションを作成する。
作成が完了したら、設定より「Add Platform」→「Website」を選択する。
サイトURLにURLを入力する(例:http://localhost:3000)。以下よりアプリケーションを作成する。
作成が完了したら、「Settings」より以下の設定を行なう。
- Callback URL
- 例:
http://〜/users/auth/twitter- 以下にチェックを入れる:
- Allow this application to be used to Sign in with Twitter
4.2 設定ファイルの編集
それぞれのAPIキー、シークレットキーを以下の該当箇所にコピーして貼り付けます。
config/initializers/devise.rbDevise.setup do |config| # The secret key used by Devise. Devise uses this key to generate (省略)... config.omniauth :facebook, 'App IDを入力', 'App Secretを入力' #すぐに訂正します config.omniauth :twitter, 'API keyを入力', 'API secretを入力' #すぐに訂正するのでGitHubにコミットしないでください end4.3 Userコントローラにコールバック処理を実装
providerと同じ名前のメソッドを定義する必要がある。
ただ、基本的に各プロバイダでのコールバック処理は共通しているので、callback_fromメソッドに統一している。$ rails generate devise:controllers usersapp/controllers/users/omniauth_callbacks_controller.rbclass Users::OmniauthCallbacksController < Devise::OmniauthCallbacksController def facebook callback_from :facebook end def twitter callback_from :twitter end private def callback_from(provider) provider = provider.to_s @user = User.find_for_oauth(request.env['omniauth.auth']) if @user.persisted? flash[:notice] = I18n.t('devise.omniauth_callbacks.success', kind: provider.capitalize) sign_in_and_redirect @user, event: :authentication else session["devise.#{provider}_data"] = request.env['omniauth.auth'] redirect_to new_user_registration_url end end end4.4 ルーティング処理
以下のように、OAuthのコールバック用のルーティングを設定する。
config/routes.rbRails.application.routes.draw do devise_for :users, controllers: { omniauth_callbacks: 'users/omniauth_callbacks' } # ... end5 APIキー,シークレットキーの非公開
Twitter認証,Facebook認証をするためのそれぞれのAPIキー、シークレットキーを取得しました、この情報は非常に機密性が高く決して外部に漏らしてはいけない情報です。悪用される恐れがあるため、GitHubのリモートリポジトリや本番環境でAPIキー,シークレットキーが間違って一般公開されないような処理を施す必要があります。
最初の方で環境変数を設定するための
gem 'dotenv-rails'をbundle installしているので、dotenv-railsを使ったAPIキー、シークレットキーの方法を学んでいきます。5.1 .envファイルの設置
次に、環境変数を定義する.envファイルをアプリのプロジェクトルート直下に設置します。
.envファイルはdotenv-railsをbundle installしても自動生成されない為、下記の様にtouchコマンドを使って手動でファイルを作成する必要があります。$ touch .env5.2 .envファイルに以下を記載する
TWITTER_API_KEY="取得したTwitterAPIキー" TWITTER_SECRET_KEY="取得したTwitterシークレットキー" FACEBOOK_API_ID="取得したFacebookAPIキー" FACEBOOK_API_SECRET="取得したFacebookシークレットキー"5.3 環境変数を使う
ENV['SECRET_KEY']のような記載方法で、ハードコーディングしているファイルに環境変数を代入していきます。config/initializers/devise.rbDevise.setup do |config| # The secret key used by Devise. Devise uses this key to generate (省略)... config.omniauth :twitter, ENV['TWITTER_API_KEY'], ENV['TWITTER_API_SECRET_KEY'] config.omniauth :facebook, ENV['FACEBOOK_API_ID'], ENV['FACEBOOK_API_SECRET'] end6 ユーザーモデルにメソッドを追加する
Userモデルにself.from_omniauthとself.new_with_sessionを作ります。
self.from_omniauthではuidとproviderで検索してあったらそれを、無かったらレコードを作ります。
self.new_with_sessionについては、もしこのメソッドを追加しておかなければ、Twitter認証後サインアップページで登録を行っても、認証情報として取ってきたuidやproviderなどが登録されません。それらが登録されないのでTwitterで認証しても登録されてないユーザーとして毎回サインアップページに飛ばされます。app/models/user.rbclass User < ApplicationRecord # Include default devise modules. Others available are: # :confirmable, :lockable, :timeoutable and :omniauthable devise :database_authenticatable, :registerable, :recoverable, :rememberable, :trackable, :validatable, :confirmable, :lockable, :timeoutable, :omniauthable, omniauth_providers: [:twitter] def self.from_omniauth(auth) find_or_create_by(provider: auth["provider"], uid: auth["uid"]) do |user| user.provider = auth["provider"] user.uid = auth["uid"] user.username = auth["info"]["nickname"] end end def self.new_with_session(params, session) if session["devise.user_attributes"] new(session["devise.user_attributes"]) do |user| user.attributes = params end else super end end end6.1 Userモデルにfindメソッドを実装
uidとproviderの組み合わせは一意であり、これによりユーザを取得する。
レコードに存在しない場合は作成する。app/models/user.rbclass User < ActiveRecord::Base # ... def self.find_for_oauth(auth) user = User.where(uid: auth.uid, provider: auth.provider).first unless user user = User.create( uid: auth.uid, provider: auth.provider, email: User.dummy_email(auth), password: Devise.friendly_token[0, 20] ) end user.skip_confirmation! #仮登録メールを介さずに即時登録 user end private def self.dummy_email(auth) "#{auth.uid}-#{auth.provider}@example.com" end endメールアドレスでの認証も実装している場合、OAuthでの認証時もメールアドレスを保存する必要がある。
ここでは、uidとproviderの組み合わせが一意なことを利用して、self.dummy_emailのように生成している。以下ファイルを編集して、コールバック用のコントローラーとしてさっき作ったコントローラーが呼ばれるようにします。これを書かないとdevise側のコントローラーが呼ばれます。
config/routes.rbRails.application.routes.draw do devise_for :users, controllers: { omniauth_callbacks: 'users/omniauth_callbacks' } root 'pages#index' get 'pages/show' (省略)... endこれでTwitter認証ができるようになりました。
初回、Twitter認証を行うと、サインアップページに飛ばされ、そこでメールアドレスやパスワードを入力して登録するとユーザー情報が登録されます。
今回はcomfirmable機能を入れているので、登録したら確認メッセージを送ったとのメッセージが出て、そのままログインすることはできません。
この機能を入れてなかった場合、登録すると即ログインします。7 SNS認証には仮登録メールを介さずに即時登録となるようにしたい
app/model/user.rbclass User < ActiveRecord::Base # ... def self.find_for_oauth(auth) user = User.where(uid: auth.uid, provider: auth.provider).first unless user user = User.create( uid: auth.uid, provider: auth.provider, email: User.dummy_email(auth), password: Devise.friendly_token[0, 20] ) end ######これを追記!###### user.skip_confirmation! ####################### user end private def self.dummy_email(auth) "#{auth.uid}-#{auth.provider}@example.com" end end8 ユーザー情報の編集で逐一パスワードを求められるのがだるい
8.1 routes.rbを修正する
routes.rbdevise_for :users, controllers: { } Rails.application.routes.draw do devise_for :users, controllers: { omniauth_callbacks: 'users/omniauth_callbacks', registrations: 'users/registrations' } root 'pages#index' get 'pages/show' (省略)... end8.2 update_resourceメソッドをオーバーライドする
registrations_controller.rbclass RegistrationsController < Devise::RegistrationsController protected # 追記する def update_resource(resource, params) resource.update_without_password(params) end end8.3 current_passwordフォームを削除する
views/devise/registrations/edit.html.erb<div class="field"> <%= f.label :current_password %> <i>(we need your current password to confirm your changes)</i><br /> <%= f.password_field :current_password, autocomplete: "current-password" %> </div>こちらのフォームを削除しましょう。
これで、パスワードを入力しなくてもユーザーの登録情報を
編集することが可能になりました!9 やりたいことの文献一覧
基本的なユーザー認証機能に加え、SNS認証でワンクリック登録できる仕組みの構築。
[Rails] deviseの使い方(rails5版)
RailsにDevise+OmniAuthでユーザ認証を実装する手順環境変数を使用し、APIキーを隠してリモートにpushしたい(App Secretなどをハードコーディングしているのはよろしくない)
【Rails】dotenv-railsの導入方法と使い方を理解して環境変数を管理しよう!
環境変数の設定ダミーではなく、twitterやfacebookに登録されたemailをDBを持っていきたい(3日くらいかかる)
omniauth-twitterでemail情報を取得する
twitterのoauthを使ってみる(emailも取得)
facebookのoauthを使ってみる(emailも取得)
2015年7月9日以降にFacebook認証でメールアドレスが取れない問題とその対策
TwitterやGoogle,Githubなどの外部サイトを用いた認証には仮登録メールを介さずに即時登録となるようにしたい
Devise内でomniauthのtwitter認証が完了してもレコードが格納されない
deviseのTwitterログイン時はメール認証とメール送信をスキップする
【Rails5】SNS認証でメールアドレス介さず登録・ログインできるようにする実装deviseをi18nで日本語にしたい
i18nで日本語化ユーザー情報の編集で逐一パスワードを求められるのがだるい
[Devise] パスワードを入力せずにユーザー情報を編集するメールアドレスのみでユーザー登録を行う。
devise でメールアドレスのみでユーザー登録を行い、パスワードを後から設定する方法
How To: Email only sign upサインインする際にメールアドレス以外でサインインする方法
How To: Allow users to sign in with something other than their email address
メールアドレスのアップデートをする際に確認を必要としない方法(スキップしたい)
deviseでメールアドレスのアップデートを確認する必要はありませんか?
Deviseでメールアドレスの確認をスキップするその他
【Rails】deviseのTwitter認証で「Unauthorized 403 Forbidden」が出てしまう場合の対処法
deviseのドキュメント(英語)
- 投稿日:2020-09-14T10:41:54+09:00
instagramのクローンアプリを作る①
はじめに
タイトルの通り、簡易版instagramのアプリを作っていきます。
下記の工程に分けて記事を執筆していきますので、順を追って読んでいただけたらなと思います。①アプリ作成〜ログイン機能の実装 ←イマココ
②写真投稿機能の実装
③ユーザーページの実装
④いいね機能の実装
⑤投稿削除機能の実装まずはアプリケーションを作成
ターミナルを開いて下記コマンドを打ち込みます。
データベースはmysqlを使用していきますので、
オプションで「 -d mysql 」としています。ターミナルrails new instaclone -d mysql作成できたらエディターを立ち上げて、「 datebase.yml 」を編集します。
encodingをutf8に修正します。datebase.ymldefault: &default adapter: mysql2 encoding: utf8 # ←修正箇所 pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %> username: root password: socket: /tmp/mysql.sock修正できたらターミナルに戻り、
instacloneのディレクトリに移動してから
rails db:createを実行します。ターミナルinstaclone % rails db:create下準備が整いましたので、次からログイン機能の実装を行います。
deviseの導入
deviseとは...
Railsで作成したアプリケーションに、
簡単に認証機能を実装することができるgemのひとつです。
ログイン、サインアップなどのログイン機能が作成出来ます。Gemfileに下記のgemを追加します。(最下部)
その後、ターミナルでbundle installを行います。Gemfilegem 'devise'ターミナルinstaclone % bundle installgemの追加が完了したら、deviseの設定ファイルを作成します。
ターミナルinstaclone % rails g devise:install続いて、Userモデルを作成します。
ターミナルinstaclone % rails g devise Userマイグレーションファイルも作成されるので
rails db:migrateを実行します。ターミナルinstaclone % rails db:migrateこれでログイン機能はできたので、確認用にホーム画面を作ります。
ターミナルで下記コマンドを実行し、ホーム画面用のコントローラを作成します。ターミナルinstaclone % rails g controller homes作成できたら、
homes_controllerにindexメソッドを追加し、
routes.rbにルートの設定を記述します。homes_controller.rbclass HomesController < ApplicationController def index end endroutes.rbRails.application.routes.draw do root 'homes#index' # ←ここ devise_for :users end先ほどコントーローラを作成した時に、一緒にviewファイルも作成されています。
場所はapp/views/homesです。
こちらに、ホーム画面用のviewファイルを作成し、表示用の文字を記述します。app/views/homes/index.html.erb<h3>home</h3>ターミナルで
rails sを実行し、ローカルサーバーを立ち上げ、
http://localhost:3000/ で確認します。
homeと表示できていれば成功です。before_actionでログイン画面に誘導
ここまでの状態では、誰もがホーム画面にアクセスできてしまいますので、
コントローラにbefore_actionを追記します。
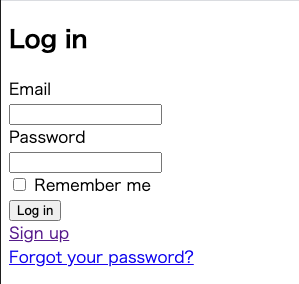
これで、ログイン(もしくは登録)していないユーザーは、自動的にログイン画面に飛ばされます。homes_controller.rbclass HomesController < ApplicationController before_action :authenticate_user! #←ここ def index end endこれで画面を更新すると下記のような画面に遷移するはずです。
この画面で、EmailとPasswordを入力してSign upをクリックすると、
先ほどhomeと表示された画面に遷移することができます。これでほぼほぼ完成ですが、最後にログアウトするボタンを作成する必要があります。
ログアウトの実装
link_toメソッドを使って、ホーム画面からログアウトできるリンクを作成します。
app/views/homes/index.html.erb<h3>home</h3> <div> <%= link_to 'logout', destroy_user_session_path, method: :delete %> </div>
destroy_user_session_pathは、ターミナルのrails routesで確認できます。
devise/sessions#destroy(sign_out)のPrefixが
destroy_user_sessionになっているのが確認できると思います。
Prefixの後に_pathをつけて記述します。続いて、
methodをdeleteとして完成です。このようになっていたら成功です。
logoutをクリックすると、ログイン画面に遷移しますので、これで完成です。
以上です。お疲れ様でした。

- 投稿日:2020-09-14T10:37:17+09:00
Github DependabotでライブラリアップデートPRを自動作成した際の動作確認をなるべく楽にした話
そもそもDependabotとは
GithubにDependabotという機能があるのはご存知でしょうか?
リポジトリ内で使用している依存関係(ライブラリ)で古いものがあれば更新をかけたPullRequestを自動発行してくれる機能です。
パブリックなリポジトリで以下のようなPRを見たことがある方も多いと思います。
もともとは独立したサービスでしたが、Githubに買収されてネイティブ機能として取り込まれたので導入がしやすくなりました。
.github/dependabot.yml配下に設定ファイルを配置するだけでライブラリアップデートPR自動作成を有効に出来ます。今回Dependabot自体の解説は省きますが私の携わるプロジェクトでは以下のような設定ファイルで月曜日の9時にチェックがかかるように運用を始めています。
version: 2 updates: - package-ecosystem: "gradle" directory: "/" target-branch: "develop" schedule: interval: "weekly" day: "monday" time: "09:00" timezone: "Asia/Tokyo" reviewers: - "ignis-ltd/with-android"まずはGithub Dependabotについて詳しく知りたいという方は以下の公式ドキュメントや記事が参考になると思います
※現状「Dependabot」でググると買収される前の独立したサービスだった時代のマーケットプレイス版の記事がたくさん出てきますが、そちらはいずれ廃止されてネイティブ機能に統合される可能性が高いのでご注意下さい
Dependabotの運用課題
Dependabotは1ライブラリのアップデートにつき1つのPRを発行されます。
一部のライブラリアップデートが問題を起こす可能性もあるので問題を切り分けるためにも個別になっている事自体は正しい形だと思っているのですが、いくつもアップデートがある場合やや課題が残ります。
サーバーサイドでも似たような課題は発生しうると思いますが、私の扱うプロジェクトではAndroidアプリなので上記のように5つのPRが一度に発行された場合5回ブランチをcheckoutしてビルドしてインストールして動作確認をする必要がありました。
もちろんCI上でテストを組んで自動化すればリスクを減らすことも出来ますが、やはりアプリの場合はUIの崩れ等が心配なのでマージ前に目視での動作確認は1度はしておきたいところです。
あるいはCIでブランチごとにデプロイまで行えばチェックアウトまではしなくても良いですが、それでも5回ダウンロードしてインストールして起動するだけでもちょっと大変ですよね。解決策
そこで考えたアプローチとして、dependabotが発行したそれぞれのPRのブランチを一つのブランチへマージしてCIからビルドを行い、各PRにコメントとしてバイナリへのリンクを残すという手法を検討しました。
以下で実際のやり方をご紹介致します。Dependabotが発行したブランチを統合する
まずアップデートがかかったGitブランチをすべて抽出して統合するRubyスクリプトを組んでみます。
dependabot/の文字列から始まるブランチ一覧を取得する- 現在のブランチ(develop)からアップデートcommitのパッチファイルを作成する
- 2.で取得したパッチファイルをすべて適用する
(Ruby力は底辺なのでそのあたりは見逃してください
)
Gemfilesource 'https://rubygems.org' gem 'git'merge_dependabot_branchs.rbrequire "git" dependabotBranchs = [] git_client = Git.open(Dir.pwd) git_client.fetch git_client.branches.each do |branch| if branch.name.start_with?('dependabot/') dependabotBranchs.append(branch) end end return if dependabotBranchs.size <= 0 dependabotBranchs.each do |dependabotBranch| system("git format-patch -1 #{dependabotBranch.gcommit} --unified=0") end system("git apply 0001-*.patch --unidiff-zero")ちょっとした解説
ここで肝となるのがパッチファイルの作成と適用方法です。
git format-patchでパッチファイルを生成していますが、通常では前後3行の変更もDiffに含まれています。
つまりアップデートがかかったライブラリの行が隣り合っているときなど、前後3行以内に変更がすでにある場合コンフリクトとして判断されてしまい自動での統合がされません。
Dependabotによるバージョンアップの変更だけを抽出すればコンフリクトは起こり得ないはずなので、近い行で変更があってもコンフリクトとみなさず統合してほしいものです。
そこで--unified=0パラメータを付与することで前後の行をDiffに含めないように調整しています。(参考)また、
git applyでパッチファイルを適用する際にも小技を使っていて、通常では前後の行が含まれていない(--unified=0を指定した)パッチファイルでは適用が失敗してしまうので--unidiff-zeroパラメータを付与して前後の行を無視して適用されるようにしています。(参考)この辺の処理は当初使っていたruby-gitだと機能不足だったのでsystemコールに頼っています。
ここまででライブラリアップデートが統合されたブランチが出来上がっているはずなので、この状態でビルドすれば統合されたバイナリを生成できます。
Dependabotが発行したPRに統合したバイナリへのリンクを貼る
CI上でバイナリを生成してリンクURLも発行したと仮定して、もともとのDependabotが生成したPRにコメントを残すRubyスクリプトを組んでみます。
今度はGitではなくGithub APIを使って抽出します。
- 現在開かれているPullRequestで
dependabot/の文字列から始まるブランチを抽出する- 抽出したPullRequestに対してバイナリへのリンクと統合したPullRequest一覧をコメントとして貼る
(Ruby力底辺コード)
comment_dependabot_prs.rubyrequire 'net/http' require 'uri' require 'json' uri = URI.parse("https://api.github.com/repos/ignis-ltd/with_android/pulls") request = Net::HTTP::Get.new(uri) request["Accept"] = "application/vnd.github.v3+json" request["Authorization"] = "token #{ENV['GITHUB_API_TOKEN']}" req_options = { use_ssl: uri.scheme == "https", } response = Net::HTTP.start(uri.hostname, uri.port, req_options) do |http| http.request(request) end dependabotPullRequests = [] responseBodyJson = JSON.parse(response.body, symbolize_names: true) responseBodyJson.each do |pull| if pull[:head][:ref].start_with?('dependabot/') dependabotPullRequests.append(pull) end end dependabotPullRequests.each do |pull| uri = URI.parse("https://api.github.com/repos/ignis-ltd/with_android/issues/#{pull[:number]}/comments") request = Net::HTTP::Post.new(uri) request.body = JSON.dump({ "body" => "Deployed a binary that merged the following branches\n" + dependabotPullRequests.map { |pull| pull[:html_url] }.join(" ") + "\n\n#{ENV['INSTALL_PAGE_URL']}" }) request["Accept"] = "application/vnd.github.v3+json" request["Authorization"] = "token #{ENV['GITHUB_API_TOKEN']}" req_options = { use_ssl: uri.scheme == "https", } response = Net::HTTP.start(uri.hostname, uri.port, req_options) do |http| http.request(request) end endちょっとした解説
基本的にはGithub APIを使って愚直に実装しているだけです。
上記のRubyスクリプトの実行には以下の環境変数とが必要となります。Github API用のURLも適宜変更して下さい
Githubのトークン情報は直接含めず、CIのシークレット環境変数などを使って下さい。
- GITHUB_API_TOKEN ... GithubへのコメントするためのTokenを指定して下さい
- 個人アクセストークンを使用する - GitHub Docsを参照して取得してください
- INSTALL_PAGE_URL ... 生成したバイナリへのリンクURLを指定して下さい
- 今回はCIでのビルドやデプロイまでは言及しないので省略しますが、アプリのCIは個人的にはBitrise推しです。
ここまで組むことができればDependabotが発行したPullRequestに以下のようなコメントを残すことが出来ます。
どのブランチを統合したのかと統合されたバイナリをどのPullRequestからも参照することが出来るようになります。
Dependabotの実行後にCIでスクリプトとビルドを定時実行させる
私のプロジェクトではDependabotの実行を月曜9:00に行っているため、このスクリプトを含んだCIの実行は月曜10:00に行うように調整しています。
以下はBitriseでの設定例です。このあたりはお好みで調整して下さい。
補足というか注意点
最初のDependabotのブランチを統合するスクリプトはGitのブランチ情報を基準にしてますが、後のコメントする際のスクリプトはPullRequest基準で検索をかけるので、(基本的にはないと思いますが)PullRequestが発行されていないDependabotブランチが存在する場合や、ビルド中にブランチやPRに変更を加えた場合はコメントの内容とバイナリの実態にズレが生じます。
また、
dependabot/という文字列でブランチ名を前方一致検索しているので、これに該当するブランチを手動で作った際に誤作動を起こすのでもう少し厳密な判定ロジックを設けるべきかもしれないです(横着感)おわり
結構力技でしたが、ここまでやることで毎週の動作確認が1度で済ませられるのでコスト削減につながるかと思います。
小さなプログラムではそこまでライブラリが多くないと思うのでここまでする必要性も感じないかもしれませんが、10万行を超えてくる規模だと導入されているライブラリの数も膨大になり動作確認コストも馬鹿にできないので、このような対策を講じることでDependabotを最大限有効活用することが出来るようになりました。また、今回DependabotをCI上で統合するお話ですが、スクリプトを書いて気合で統合してなんとかするという部分の話だけでCI側の話がほとんど出来ていないのでどこかでお話できたらと思います。


- 投稿日:2020-09-14T09:08:23+09:00
Rails 6で認証認可入り掲示板APIを構築する #9 serializer導入
←Rails 6で認証認可入り掲示板APIを構築する #8 seed実装
ActiveModelSerializerの導入
serializerを入れることで、jsonで返されるデータを簡単に整形できます。
Gemfile... + # serializer + gem "active_model_serializers"$ bundle設定ファイルとserializerの編集
導入できたらpostモデルのserializerと、ActiveModelSerializerの設定ファイルも作ります。
$ rails g serializer post $ touch config/initializers/active_model_serializer.rbapp/serializers/post_serializer.rb# frozen_string_literal: true # # post serializer # class PostSerializer < ActiveModel::Serializer attributes :id endconfig/initializers/active_model_serializer.rb# frozen_string_literal: true ActiveModelSerializers.config.adapter = :jsonapp/controllers/v1/posts_controller.rbdef index posts = Post.order(created_at: :desc).limit(20) - render json: { posts: posts } + render json: posts end def show - render json: { post: @post } + render json: @post end def create post = Post.new(post_params) if post.save - render json: { post: post } + render json: post else render json: { errors: post.errors } end @@ -27,7 +27,7 @@ module V1 def update if @post.update(post_params) - render json: { post: @post } + render json: @post else render json: { errors: @post.errors } end @@ -35,7 +35,7 @@ module V1 def destroy @post.destroy - render json: { post: @post } + render json: @post end一旦ここまでやったら
rails sを止めて、再起動しましょう。curlで確認
$ curl localhost:8080/v1/posts {"posts":[{"id":20},{"id":19},{"id":18},{"id":17},{"id":16},{"id":15},{"id":14},{"id":13},{"id":12},{"id":11},{"id":10},{"id":9},{"id":8},{"id":7},{"id":6},{"id":5},{"id":4},{"id":3},{"id":2},{"id":1}]} $ curl localhost:8080/v1/posts/1 {"post":{"id":1}}serializerでidのみにしているので、idの一覧が取得できました。
それではsubject, bodyを追加してみます。app/serializers/post_serializer.rb# frozen_string_literal: true # # post serializer # class PostSerializer < ActiveModel::Serializer - attributes :id + attributes :id, :subject, :body end$ curl localhost:8080/v1/posts {"posts":[{"id":20,"subject":"無駄","body":"ハチのすさいぼうかっこう。暴力血液恨み。秘めるちゅうもんする廃墟。"},... curl localhost:8080/v1/posts/1 {"post":{"id":1,"subject":"hello","body":"警官総括大尉。めいしぼきんかたみち。伝統徳川超〜。正常に動いていそうですね。
rubocopとrspecも動かして、問題なければcommitしておきましょう。続き
- 投稿日:2020-09-14T08:37:57+09:00
paiza Ruby Bランクになるために実施したこと(現在Aランクに向けて勉強中)
はじめに
30代半ば(IT業界未経験)で、就職活動を行うにあたり、自分のスキルレベルを示す必要があると考え、paizaのスキルチェックを活用することにしました。Rubyについては、プログラミングスクールで、少し触ったことがありました(Ruby on Railsを使うための最低限のレベル程度)。
paizaのランキングについて
paizaでは、EからSの6つのランクに分けられています(Eからスタート)。Sランクは上位2%、Aランクは上位8%、Bランクは上位30%、Cランクは上位60%と公式に記載されております。
paiza転職では、取得ランク毎に応募できる企業が異なっており、2020年9月10日時点では、Cランク132件、Bランク638件、Aランク326件、Sランク48件あり、詳細等は不明ではありますが、Bランク程度以上のスキルが求められていると考えました。
その中で、現在の自分のスキル、企業のニーズを鑑み、Bランクは必要と考え、一つの目標としてBランク取得としました。D→Cランクのステップアップについて
D→Cランクについては、Rubyの入門動画を見て勉強しました。
入門動画については、基礎、条件分岐、配列、ハッシュ、2次元配列、クラスについてのチャプターが用意されています。動画を見た後に、演習問題があり、それをひたすら解いて行きました。演習については、動画の内容をトレースする内容で、知識を定着することができます。
問題集が用意されており、Cランクの問題を解くヒントとなるような、Dランクの問題を解いていき、Cランクの問題を解くといった流れで進みました。Cランクの問題が複雑だなと感じましたが、解法がイメージできるようになったので、Cランクのスキルチェックを受け、合格することができました。C→Bランクのステップアップについて
問題集をひたすら解き、勉強しました。Bランクについては、Cランクの問題をより複雑にした内容となっています。問題の内容を理解するのが、難しい、条件分岐の方法が複雑になる、コードが増えるなど、D→Cのランクアップに比べ、数段難しくなりました。
ただ、新しくメソッドを勉強しないといけないというものではないといったものではありませんでした。参考記事
https://programming-beginner-zeroichi.jp/articles/305
https://paiza.jp/challenges/info
- 投稿日:2020-09-14T08:37:57+09:00
paiza Ruby Bランクになるために実施したこと
はじめに
30代半ば(IT業界未経験)で、就職活動を行うにあたり、自分のスキルレベルを示す必要があると考え、paizaのスキルチェックを活用することにしました。Rubyについては、プログラミングスクールで、少し触ったことがありました(Ruby on Railsを使うための最低限のレベル程度)。
paizaのランキングについて
paizaでは、EからSの6つのランクに分けられています(Eからスタート)。Sランクは上位2%、Aランクは上位8%、Bランクは上位30%、Cランクは上位60%と公式に記載されております。
paiza転職では、取得ランク毎に応募できる企業が異なっており、2020年9月10日時点では、Cランク132件、Bランク638件、Aランク326件、Sランク48件あり、詳細等は不明ではありますが、Bランク程度以上のスキルが求められていると考えました。
その中で、現在の自分のスキル、企業のニーズを鑑み、Bランクは必要と考え、一つの目標としてBランク取得としました。D→Cランクのステップアップについて
D→Cランクについては、Rubyの入門動画を見て勉強しました。
入門動画については、基礎、条件分岐、配列、ハッシュ、2次元配列、クラスについてのチャプターが用意されています。動画を見た後に、演習問題があり、それをひたすら解いて行きました。演習については、動画の内容をトレースする内容で、知識を定着することができます。
問題集が用意されており、Cランクの問題を解くヒントとなるような、Dランクの問題を解いていき、Cランクの問題を解くといった流れで進みました。Cランクの問題が複雑だなと感じましたが、解法がイメージできるようになったので、Cランクのスキルチェックを受け、合格することができました。C→Bランクのステップアップについて
問題集をひたすら解き、勉強しました。Bランクについては、Cランクの問題をより複雑にした内容となっています。問題の内容を理解するのが、難しい、条件分岐の方法が複雑になる、コードが増えるなど、D→Cのランクアップに比べ、数段難しくなりました。
ただ、新しくメソッドを勉強しないといけないというものではないといったものではありませんでした。参考記事
https://programming-beginner-zeroichi.jp/articles/305
https://paiza.jp/challenges/info
- 投稿日:2020-09-14T01:46:01+09:00
Railsで.scssをコントローラごとに分ける方法
アプリケーションの規模が大きくなるに連れてapplication.scssファイルの記述が長くなってきたので、今回コントローラーごとにファイルを分けることにしました。
ちょっと苦戦したり、勉強になったことが多かったので、忘れないために記事にすることにしました。環境
Ruby 2.5.7
Rails 5.2.4答え
先に答えだけ書いておきます。
application.scss// require_tree . // require_selfapplication.html.erb<head> ... <%= stylesheet_link_tag 'application' %> ... </head>この記述と各コントローラー名の.scssファイルをapp/assets/stylesheet/の中に作れば大丈夫です!
ここから少し中身を解説していきます。
経緯
//require_tree . って必要?
最初は、application.scssを共通のスタイルファイルとし、各ページのコントローラー名.scssの2ファイルで全てのページに対応しようとしました。
その時の記述は下記のようになります。application.scss// require_selfapplication.html.erb<head> ... <%# application.scssの読み込み %> <%= stylesheet_link_tag 'application' %> <%# コントローラー名.scssの読み込み %> <%= stylesheet_link_tag params[:controller] %> ... </head>application.scssファイルの
// require_tree .はapp/assets/stylesheet内の全ての.scssファイルを読み込む記述なので、一旦削除します。
その代わりに、application.html.erbのstylesheet_link_tagでparams[:controller]と書くと、ディレクトリを含めたコントローラーのパスを取得できるので、コントローラーをディレクトリ分けしている場合もこの書き方で対応できます。しかし、実はこのやり方は.cssファイルならこれで大丈夫なのですが、.scssではエラーになってしまいます。
プリコンパイルで失敗する
.scssは.css形式にコンパイルすることで初めてブラウザに対応できます。
つまり、通常は.scss形式のままでは表示ができないということです。そして、プリコンパイルされた.scssファイル(.cssファイル)は本番環境ではapp/public/assets下に格納され、ファイル名はハッシュ形式に変更されてしまいます。
つまり、application.html.erbに記述した<%= stylesheet_link_tag params[:controller] %>ではcssファイルが拾えなくなるということになります。
ハッシュ形式に変更されたファイル名でも、そのハッシュをそのままstylesheet_link_tagの中で指定したら動作はしますが、このハッシュはファイルが更新されるごとに変更されてしまうので現実的ではありません。私は当初やりたかった.scssファイルを真にコントローラーごとに分割するというやり方にたどり着くことはできなかったので、冒頭の記述に切り替えました。
// require_tree . の有無の違いについて
application.scssに
// require_tree .がある場合はassets/stylesheet下にある全ての.scssファイルが読み込まれるということになります。これはあまりあってはならない事なのですが、仮にcssセレクタのクラス名が被った状態でスタイル指定をすると、後に記述している方が優先されてしまうため、思い通り変更ができないなどの、思わぬところで依存関係ができてしまう恐れがあります。
.css(.scss)ファイル読み込みの順番
application.scss// require_tree . // require_self冒頭のように記述した場合は、全ての.scssファイルが読み込まれた後にapplication.scssが読み込まれます。
また// require_tree .の中身の順番については辞書順となっており、ファイル名a→zの順番で読み込まれます。
必然的にtree .の中ではファイル名のイニシャルがzに近いほど後から読み込まれるため、優先度が高くなる傾向にあります。変数用に用意した.scssファイルの扱い
その前に.scssの変数について少しだけ確認しておきます。
scssではプロパティや値を変数にして使い回すことができます。
私の場合は今のところ
*ハンバーガーメニューのtransition
*サイト全体のカラーリング3パターンほど
*メディアクエリのwidth
をそれぞれ変数化して一つのファイルにまとめ、各ファイルでそのファイルを呼び出す記述をしています。
参考までに記載しておきます。_variables.scss// ハンバーガーアニメーション $hamburger-transition: 0.3s; // テーマカラー $thema-color1: #fff9f9; $thema-color2: #ffefef; $thema-color-font: #555; // メディアクエリ $media-sp-max: 450px; $media-pc-min: 1024px; $media-tb-min: $media-sp-max + 1px; $media-tb-max: $media-pc-min - 1px; //例 セレクタ名 { background: $thema-color1; }これでテーマカラーの変更や、メディアクエリのwidth、ハンバーガーメニューのtransitionなどを各ファイル一括で変更できるようにしています。
変数の定義は$から変数名を書き始め、その後に値を入れることで、定義できます。
呼び出すときはその変数名を値のところにそのまま書くだけです。しかし、このままでは各ファイルで変数が定義されていないので、この変数のみを記載したファイルを各コントローラー名の.scssファイルにインポートする必要があります。
コントローラー名.scss@import "variables"; ...
@import "ファイル名"を記述することで、今回の場合だと、_variablesに書かれた変数が使用できるようになります。ここで疑問が生まれました。
「application.scssで// require_tree .を記載している。各.scssファイルには変数ファイルのインポートを記載していているので、コンパイルの時に各ファイルが読み込まれるたびに変数ファイルも都度都度.cssファイルとして読み込まれるのでは?」と。
読み込まれたとしても問題ないと言えば無いのですが、やっぱり無駄が多いと思ったので、さらに調べました。結果から言うと、知らず知らずのうちにそれを回避していました。笑
共通ファイルをコンパイルから除外する"partial"
どこかの記事をみて変数ファイルの作り方を参考にファイル名を作ったのですが、そのファイル名の先頭に"_"アンダースコアをつけることで、コンパイルはされなくなるようです笑
つまり、今回使っている_variables.scssはアンダースコアから始まるファイル名のため、プリコンパイルからは除外されます。
よく考えてみると確かに変数しか書いていないファイルは直接スタイリングをしないので.cssに変換しても何も意味がないですし、他のファイルを.cssに変換する時に変数部分を中身に置き換えることが出来れば変数ファイルはそれだけ用が済む話だなと、変に納得しました笑まとめ
ここで冒頭の実装方法に戻りますが、とりあえずはこのやり方で運用してみようかと思っています。
application.scss// require_tree . // require_self ..._variables.scss$変数名: 値; ...各コントローラー名.scss@import "variables"; ...application.html.erb<head> ... <%= stylesheet_link_tag 'application' %> ... </head>これまではapplication.scssにしかスタイルを書いておらず、コメントを駆使してコントローラー名を書いてブロックを作ったりしていましたが、コントローラーごとにファイルが分けられるだけでもメンテナンスがやりやすくなるかなと思っています。
もし万が一どうしてもクラス名が被ってしまう場合については.scssの特徴でもあるセレクタのネストを用いて視覚的にもわかりやすく記述していきます。(使い回し用のclass名(flexやgrid、btnなど)は別途application.scssファイルに記述しています。)
// require_tree .を使わずに各コントローラーごとの.scssファイルをプリコンパイルする方法があればご教授いただけると幸いです!
また、質問や解釈の違い、記述方法にも違和感などありましたら、コメント等でご指摘いただけると幸いです。最後まで読んでいただきありがとうございました!
参考サイト
Railsガイド - アセットパイプライン
Web Design Leaves - SASS
CSS HappyLife - Sassを覚えよう!Vol.7】ファイルを分割して管理を楽に(partialについて)
HACK NOTE - Sass:変数を別ファイルで管理しよう
- 投稿日:2020-09-14T01:02:55+09:00
�市のプレミアム商品券の案内があんまりだったので、勝手にLINEBotで使いやすくしてみた
はじめに
私は埼玉県川口市に住んでいるのだが、最近「プレミアム付き商品券」を発行するとのチラシをもらった。
ざっくり説明すると、2万円で商品券を買うと、地元のお店で2万4千円分のお買い物ができるようだ。これはなかなか便利だと思い、どんなお店で使えるのか調べようとホームページへアクセスしたが、、、なんとお店一覧が存在せず、お店の情報をまとめたPDFへの直リンクがおいてあるのみだった。。。
これでは検索も大変だ。。。
ということで、勝手にLINEBot化し、
・キーワードでの検索
・位置情報から最寄りの使えるお店を検索
ができるように実装をしてみた。この記事で説明すること
Railsアプリケーションの作成
Herokuへのデプロイ
LIENBotの準備
LIENBotの実装(オウム返しBOT)
CSVファイルの読み込み
簡単な検索機能の実装詳細な実装は後編にわけます。
環境
Ruby 2.6.6
Rails 6.0.3.3事前準備
rbenvのインストール
gitのインストール
herokuのアカウント登録
PDFをCSVに変換できるなんらかのツール(私はAdobe Acrobatでやりました)Railsアプリケーションの作成
まずはアプリ用のディレクトリを作成します(この記事のやり方だとそのままアプリケーション名になるので考えてから作りましょう)
$ mkdir kawaguchi_ticketl_inebot $ cd kawaguchi_ticketl_inebotruby のバージョンはよほど古くなければなんでもいいと思いますが、ここではとりあえず2.6.6を指定してみます
$ rbenv install 2.6.6 $ rbenv local 2.6.6bundle init を実行しGemfileを作成しましょう
$ bundle init作成されたGemfileのRailsのコメントアウトを削除し、bundle install
$ bundle install --path=vendor/bundle用途がLINEBotだけなので、apiモードでRailsアプリケーションを作成します。
herokuにスムーズにあげる関係で、postgreqlで作っておきます。
Gemfileの上書きをするか尋ねられると思いますが、上書きしちゃって大丈夫です。$ bundle exec rails new . --api -d postgresql $ bundle exec rails db:createここまでできたらサーバーを起動し、アクセスできるかだけ確認します
http://localhost:3000/ にアクセスして確認$ bundle exec rails s
できてますね
(参考)
こちらの記事が大変わかりやすかったです
初心者がRubyで自作したLINE botを公開するまで
rbenvでrubyのバージョンを管理するHerokuへのデプロイ
後からでもいいですが、いったんherokuへpushしておきます。
herokubへの登録や設定がまだでしたら先にそちらを済ませておいてください$ heroku create Creating app... done, ⬢ young-temple-xxxxxx https://young-temple-xxxxxx.herokuapp.com/ | https://git.heroku.com/young-temple-xxxxxx.git $ git add . $ git commit -m 'first commit' $ git push heroku masterheroku create したときに表示されるURLはあとで使うのでメモっておきます
(ここでいう、 https://young-temple-xxxxxx.herokuapp.com/ )githubなどにあげてもいいですが、とりあえずスキップします
(参考)
github にpushしてherokuにあげるまでの流れLINEBotの準備
チャネルの登録
こちらを参考に
https://developers.line.biz/ja/docs/messaging-api/getting-started/#using-consoleBotの登録
こちらを参考に
https://developers.line.biz/ja/docs/messaging-api/building-bot/Webhook URLはまだ設定できないので、このあとで設定をします。
チャネルアクセストークンとチャンネルシークレットをherokuの環境変数に設定します
$ heroku config:set LINE_CHANNEL_SECRET=xxxxxxxxxxxxxxxxxx $ heroku config:set LINE_CHANNEL_TOKEN=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxLINEBotの実装
Gemfileに以下を追加
gem 'line-bot-api'$ bundle installroutes追加
routes.rbRails.application.routes.draw do # For details on the DSL available within this file, see https://guides.rubyonrails.org/routing.html post '/callback' => 'webhook#callback' endコントローラーを作成
$ rails g controller webhookまずは https://github.com/line/line-bot-sdk-ruby のサンプル通りに作ってみましょう
app/controllers/webhook_controller.rbclass WebhookController < ApplicationController require 'line/bot' def client @client ||= Line::Bot::Client.new { |config| config.channel_secret = ENV["LINE_CHANNEL_SECRET"] config.channel_token = ENV["LINE_CHANNEL_TOKEN"] } end def callback body = request.body.read signature = request.env['HTTP_X_LINE_SIGNATURE'] unless client.validate_signature(body, signature) error 400 do 'Bad Request' end end events = client.parse_events_from(body) events.each do |event| case event when Line::Bot::Event::Message case event.type when Line::Bot::Event::MessageType::Text message = { type: 'text', text: event.message['text'] } client.reply_message(event['replyToken'], message) when Line::Bot::Event::MessageType::Image, Line::Bot::Event::MessageType::Video response = client.get_message_content(event.message['id']) tf = Tempfile.open("content") tf.write(response.body) end end # Don't forget to return a successful response "OK" end end endherokuにあげます
$ git add . $ git commit -m 'add controller' $ git push heroku masterこちらを参考にheroku createを行った時に表示されたURLをWebhook URLに設定します
https://developers.line.biz/ja/docs/messaging-api/building-bot/
ここまでで「オウム返しBot」が完成
CSVファイルの読み込み
ここまでで作ったBotはただのオウム返しBotなので、データを読み込み、検索ができるようにします。
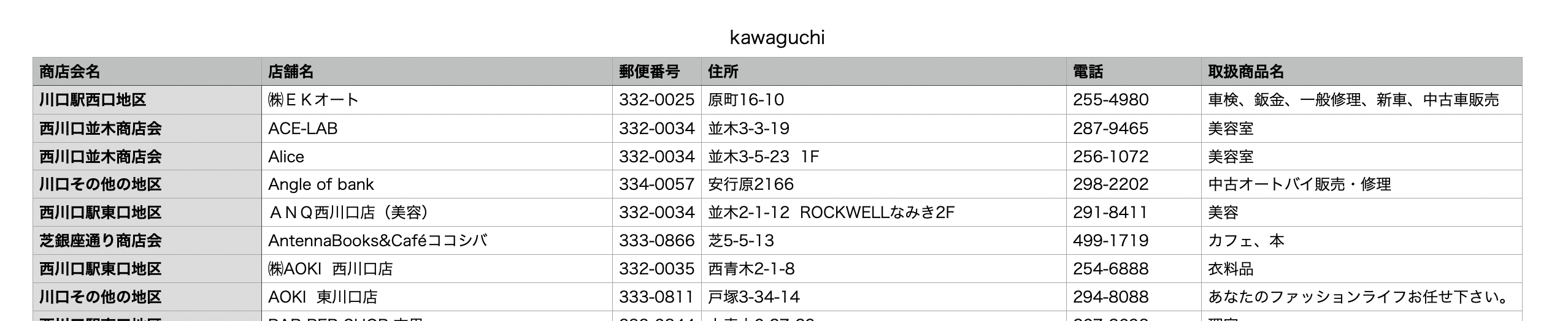
今回はこういったCSVを読み込みます
ここから入手したPDFをCSVにしたもの読み込むCSV用のモデルを作成します
$ bundle exec rails g model store Running via Spring preloader in process 76501 invoke active_record create db/migrate/20200911182431_create_stores.rb create app/models/store.rb invoke test_unit create test/models/store_test.rb create test/fixtures/stores.ymlマイグレーションファイルを編集
db/migrate/20200911182431_create_stores.rbclass CreateStores < ActiveRecord::Migration[6.0] def change create_table :stores do |t| t.string :store_association_name, comment: '商店会名' t.string :store_name, comment: '店舗名' t.string :postal_code, comment: '郵便番号' t.string :address, comment: '住所' t.string :tel, comment: '電話' t.string :lineup, comment: '取扱商品名' t.timestamps end end endマイグレーションを実行
$ bundle exec rake db:migratここまででデータを入れるところはできたので、CSVを取り込むプログラムを作成します
$ bundle exec rails g task import_csv Running via Spring preloader in process 76763 create lib/tasks/import_csv.rakelib/tasks/import_csv.rakerequire 'csv' namespace :import_csv do desc '川口市商店街の発行しているPDFをCSVにしたものを取り込み' task :store, ['file_name'] => :environment do |_, args| # インポートするファイルのパスを取得。 # ファイル名は複数ありそうなのでタスク実行時にファイル名を指定 path = Rails.root.to_s + '/db/csv/' + args.file_name # インポートするデータを格納するための配列 list = [] CSV.foreach(path, headers: true) do |row| list << { # 取り込むCSVのヘッダーにあわせて調整してください store_association_name: row['商店会名'], store_name: row['店舗名'], postal_code: row['郵便番号'], address: row['住所'], tel: row['電話'], lineup: row['取扱商品名'] } end puts 'インポート処理を開始' begin Store.create!(list) puts 'インポート完了' rescue => exception puts 'インポート失敗' puts exception end end endタスクが登録されているか確認
$ bundle exec rake -T rake about # List versions of all Rails frameworks and the environment rake action_mailbox:ingress:exim # Relay an inbound email from Exim to Action Mailbox (URL and INGRESS_PASSWO... rake action_mailbox:ingress:postfix # Relay an inbound email from Postfix to Action Mailbox (URL and INGRESS_PAS... rake action_mailbox:ingress:qmail # Relay an inbound email from Qmail to Action Mailbox (URL and INGRESS_PASSW... rake action_mailbox:install # Copy over the migration rake action_text:install # Copy over the migration, stylesheet, and JavaScript files rake active_storage:install # Copy over the migration needed to the application rake app:template # Applies the template supplied by LOCATION=(/path/to/template) or URL rake app:update # Update configs and some other initially generated files (or use just updat... rake db:create # Creates the database from DATABASE_URL or config/database.yml for the curr... rake db:drop # Drops the database from DATABASE_URL or config/database.yml for the curren... rake db:environment:set # Set the environment value for the database rake db:fixtures:load # Loads fixtures into the current environment's database rake db:migrate # Migrate the database (options: VERSION=x, VERBOSE=false, SCOPE=blog) rake db:migrate:status # Display status of migrations rake db:prepare # Runs setup if database does not exist, or runs migrations if it does rake db:rollback # Rolls the schema back to the previous version (specify steps w/ STEP=n) rake db:schema:cache:clear # Clears a db/schema_cache.yml file rake db:schema:cache:dump # Creates a db/schema_cache.yml file rake db:schema:dump # Creates a db/schema.rb file that is portable against any DB supported by A... rake db:schema:load # Loads a schema.rb file into the database rake db:seed # Loads the seed data from db/seeds.rb rake db:seed:replant # Truncates tables of each database for current environment and loads the seeds rake db:setup # Creates the database, loads the schema, and initializes with the seed data... rake db:structure:dump # Dumps the database structure to db/structure.sql rake db:structure:load # Recreates the databases from the structure.sql file rake db:version # Retrieves the current schema version number rake import_csv:store[file_name] # 川口市商店街の発行しているPDFをCSVにしたものを取り込み rake log:clear # Truncates all/specified *.log files in log/ to zero bytes (specify which l... rake middleware # Prints out your Rack middleware stack rake restart # Restart app by touching tmp/restart.txt rake secret # Generate a cryptographically secure secret key (this is typically used to ... rake stats # Report code statistics (KLOCs, etc) from the application or engine rake test # Runs all tests in test folder except system ones rake test:db # Run tests quickly, but also reset db rake test:system # Run system tests only rake time:zones[country_or_offset] # List all time zones, list by two-letter country code (`rails time:zones[US... rake tmp:clear # Clear cache, socket and screenshot files from tmp/ (narrow w/ tmp:cache:cl... rake tmp:create # Creates tmp directories for cache, sockets, and pids rake yarn:install # Install all JavaScript dependencies as specified via Yarn rake zeitwerk:check # Checks project structure for Zeitwerk compatibilityタスクが登録されているようです。
次に取り込むCSVファイルを設置します。
dbの下にcsvというディレクトリを作成し、そこにCSVファイルを置きます
準備するのが面倒でしたら、ここから取得してください
CSV取り込み用のrakeコマンドを実行します
$ bundle exec rake import_csv:store['kawaguchi.csv'] インポート処理を開始 インポート完了本当にデータが入っているか確認します
$ bundle exec rails c Running via Spring preloader in process 77369 Loading development environment (Rails 6.0.3.3) irb(main):001:0> Store.all Store Load (0.7ms) SELECT "stores".* FROM "stores" LIMIT $1 [["LIMIT", 11]] => #<ActiveRecord::Relation [#<Store id: 1, store_association_name: nil, store_name: "㈱EKオート", postal_code: "332-0025", address: "原町16-10", tel: "255-4980", lineup: "車検、鈑金、一般修理、新車、中古車販売", created_at: "2020-09-11 18:37:12", updated_at: "2020-09-11 18:37:12">, #<Store id: 2, store_association_name: nil, store_name: "ACE-LAB", postal_code: "332-0034", address: "並木3-3-19", tel: "287-9465", lineup: "美容室", created_at: "2020-09-11 18:37:12", updated_at: "2020-09-11 18:37:12">...入っているようです。
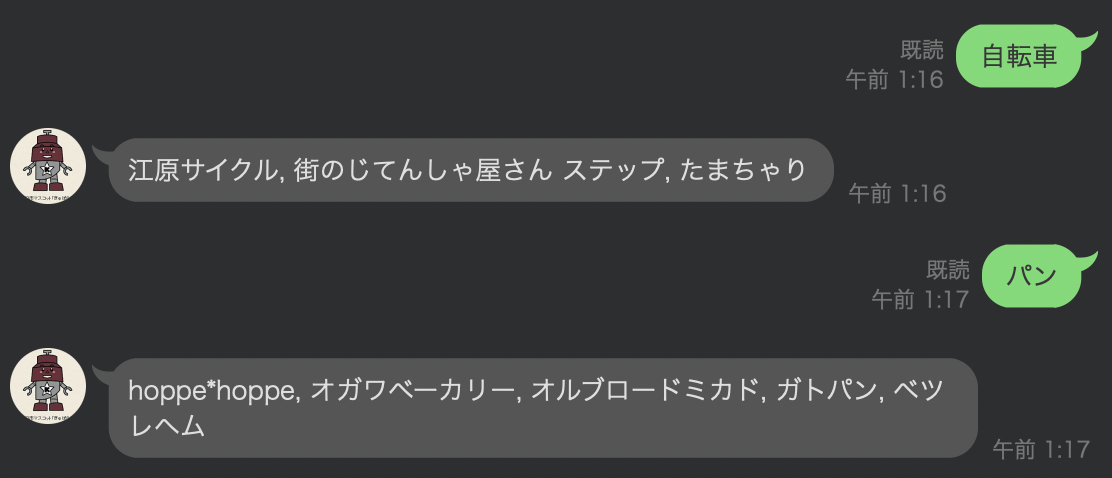
Storeに簡単な検索機能を追加
app/models/store.rbclass Store < ApplicationRecord def self.search(txt) Store.where(lineup: txt) .or(Store.where(store_association_name: txt)) .or(Store.where(store_name: txt)).limit(5) end def self.get_search_message(txt) stores = Store.search(txt) message = [] stores.each do |s| message << s.store_name end message << '検索結果がありませんでした' if message.blank? message.join(', ') end endapp/controllers/webhook_controller.rbclass WebhookController < ApplicationController require 'line/bot' def client @client ||= Line::Bot::Client.new { |config| config.channel_secret = ENV["LINE_CHANNEL_SECRET"] config.channel_token = ENV["LINE_CHANNEL_TOKEN"] } end def callback body = request.body.read signature = request.env['HTTP_X_LINE_SIGNATURE'] unless client.validate_signature(body, signature) error 400 do 'Bad Request' end end events = client.parse_events_from(body) events.each do |event| case event when Line::Bot::Event::Message case event.type when Line::Bot::Event::MessageType::Text message = { type: 'text', # ↓を修正 text: Store.get_search_message(event.message['text']) } client.reply_message(event['replyToken'], message) when Line::Bot::Event::MessageType::Image, Line::Bot::Event::MessageType::Video response = client.get_message_content(event.message['id']) tf = Tempfile.open("content") tf.write(response.body) end end # Don't forget to return a successful response "OK" end end end簡単すぎますが、詳細は後編で詰めるとしていったんherokuにあげましょう
$ git add . $ git commit -m 'easy search' $ git push heroku master自分の手元の環境で行ったことをherokuの環境でも行う必要があります。
$ heroku run rake db:migrate $ heroku run rake import_csv:store['kawaguchi.csv']これで検索結果を返すBotになりました




- 投稿日:2020-09-14T00:45:23+09:00
エラーPG::UndefinedTable: ERROR: relation "XXXXXX" does not existについて
エラーの詳細
herokuへのデプロイのため「% git push heroku master」を実行し、
下記のコマンドを実行した際のエラー
※自分が実際に行った過程はデプロイのリンク先ページにのっています。
ターミナル% heroku run rake db:migrate上記のコマンドを実行した後のエラーが以下
ターミナル(エラー文の一部分)PG::UndefinedTable: ERROR: relation "XXXXXX" does not exist #"XXXXXX"にはテーブル名 以下省略エラー文の解釈
中間テーブル名がエラー文に入っていたことから、
テーブル関係のエラーだとわかる。ローカルでは正常に作動していたため、
本番環境でしか出会わないエラーがあるというのが今回だと思う。
原因
マイグレーションファイルの作成する順番を間違えていたから。(herokの場合の現象)
解説
herokでのマイグレート(% heroku run rake db:migrate)は
作成した日付順に行われる。<例>「20200912095202_create_song_discs.rb」
マイグレーションファイルの頭の文字は作成された年月日で決められる。
(この部分をバージョンとするらしい。)今回は先に中間テーブル(song_discsテーブル)に関するファイルを作成し、
後にそのテーブルに関するテーブル(discsテーブル)に関するファイルを作成した。
その為に起きたエラーでになる。
要するに、中間テーブルは後で作れってことだと思う。※マイグレーションファイルの作成優先順位がどうあるべきなのかまた詳しく調べたい。
対処方法
①中間テーブルの作成日を後にする為、一旦中間テーブルに関するマイグレーションファイルを削除
②中間テーブルに関する他のテーブルの作成日が削除によって先になったところで、改めて中間テーブルを作成
③改めてローカルでマイグレーション % rails db:migrate
④再度デプロイまでの工程をして完成!!
対処の流れ(コマンド)
前提
中間テーブルのマイグレーションファイル内に記述してしまっている。
そのファイルを触って作業する為、内容がなくなっても困らないように別場所にコピー(バックアップ)をしている。
❗️必ず読んでください❗️
ファイルの作成順を変える為の工程として、
ファイルを削除します!中身も消えます!
「ファイル内の記述をそのまま使用したい!」
「内容は変更したくない!」
という人はこの時点でどこかにファイル内の記述をコピー(バックアップ用)してください。
ファイルの削除を実行した時点で内容は破棄されますので御注意ください。
マイグレーションファイルの作成された順番を確認
このコマンドで履歴を確認する事ができる
ターミナル% bundle exec rake db:migrate:statusMigration ID を確認するとバージョンが分かり、
作成された順番で並んでいる。例database: アプリ名_development Status Migration ID Migration Name -------------------------------------------------- up 20200723033017 Devise create users up 20200727050028 Create songs up 20200731024511 Create user songs up 20200801063906 Create songcolors down 20200821150924 Create song discs ←中間テーブルが先に作成されてる。 up 20200821160923 Create discs
不要なマイグレーションファイルを削除
今回song_discsという中間テーブルを先に作成してしまったので
そのファイルを作り直す為に削除。マイグレーションファイルを削除する前に確認事項
削除したいファイルStatusが「down」になっている必要がある。
例database: アプリ名_development Status Migration ID Migration Name -------------------------------------------------- up 20200723033017 Devise create users up 20200727050028 Create songs up 20200731024511 Create user songs up 20200801063906 Create songcolors down 20200821150924 Create song discs up 20200821160923 Create discs上記の例のこうに「down」であればこのまま削除作業へ進み
「up」であれば「down」に変更してから削除する。
(「VERSION=削除したいファイルのマイグレーションID」削除可)Statusをdownするコマンドの例% rails db:migrate:down VERSION=20200821150924
マイグレーションファイルの削除の実行
マイグレーションファイルの名前そのままコピーしてきた方が確実かもしれないです。
ターミナル% rm -rf db/migrate/削除したいファイル名例% rm -rf db/migrate/20200821150924_create_song_discs.rb
削除されているか確認
再度「% bundle exec rake db:migrate:status」
消えていれば削除成功例database: アプリ名_development Status Migration ID Migration Name -------------------------------------------------- up 20200723033017 Devise create users up 20200727050028 Create songs up 20200731024511 Create user songs up 20200801063906 Create songcolors up 20200821160923 Create discs
改めて削除したマイグレーションを作成
マイグレーションファイルのみを作成するコマンドを実行する。
ターミナル% rails g migration 作成したいマイグレーションファイルの名前例% rails g migration create_song_discs出来上がるファイル例は「20200912095202_create_song_discs.rb」
createの入れ忘れに注意!ここで「% bundle exec rake db:migrate:status」で履歴確認しておくと安心です。
作成したマイグレーションファイル内を編集
データベースマイグレーションの前に必要な内容があれば編集
(前提で記載しておいた内容です。)今回の私の場合は内容は削除したファイル内と変わらない為、
あらかじめコピーし保存しておいたものをそのまま貼り付けました。
データベースにマイグレーション
Statusが「down」のままではいけないので以下のコマンドをして
「up」に変えます。% rails db:migrate※マイグレーションファイル内の書き換えだけだと「% rake db:rollback」を実行して
以下のコマンドで更新してあげるだけ。今回は削除が必要だったことを理解しておこう。
気になる方は「% bundle exec rake db:migrate:status」で「up」になっているか
確認してみてください。
あと、私はここでローカル環境でちゃんと動くか確認します!
ファイル触っているので、おかしくなってないか見て次の工程へ進みます。
再度herokuへデプロイする
ここまでくれば対処は完了していますので、
デプロイしてみてください!!もし、どうやるんだっけ?という方がいれば是非こちらから!
お疲れさまでした!!
デプロイ出来ましたでしょうか?
エラーの解決はとても嬉しいですよね!
ポイント
herokuのデプロイの場合、
マイグレーションファイルの作成順を気をつけること!
ひとことMemo
今回はとても勉強になりました。
何気なく作っていると「ここ理解してないままでしょあなた!」と言わんばかりにつまづきますね。
エラーってありがたいです。
記事を書いていると、新たに理解不十分が見つかりました。①マイグレーションファイルの履歴で出てくる、「up」「down」について
②マイグレーションファイルの作成順の決まりについて(herokuに限るのか)これについても気になるのでまた記事にしたいと考えてここに記録しておきます。
また、他にも解決方法を思いついて、
マイグレーションファイルを作成するさいのモデルを作成するコマンド(%rails g model モデル名)の逆で削除してやり直そうと思ったのですが必要以上に削除されるファイルがあって大変そうだったのでやめました!
削除コマンドって何が削除されるのか知らないといけないですよね〜
(当たり前か…笑)
では最後まで読んでいただき、
ありがとうございました!
また、お会いしましよう