- 投稿日:2020-09-14T20:31:44+09:00
Linuxカーネル、その29年の歴史レポート
2020/08/25、Linux Foundationが2020 Linux Kernel History Reportというレポートを発表しました。
1991年9月17日の最初のリリースから、2020年8月2日にリリースされたLinux5.8まで、29年におよぶLinuxカーネルの歴史をまとめたものです。ということでざっくり斜め読みしてみました。
ていうかコピペできないPDFなのどうにかしてくれ。Linux Kernel History Report
このレポートは、Linuxの全ての歴史を調査したものである。
1991年9月17日に最初のカーネルがリリースされてから、最新の5.8カーネルがリリースされた2020年8月2日までには、BitKeeperとgitに100万件以上のcommit履歴が記録されている。Kernel Archeology
最初のリリースは88ファイル1万行、2964トークンしかなかった。
当初の痕跡はごくわずかしか残っていないが、vsprintf.cには1991/09/17のLinus自身によるファーストコミットが今も存在する。
Linux5.8のカーネルの半分以上はこの7年以内に書かれたコードである。
Impact of Development Process Best Practices
開発のベストプラクティスを推進するため、CIIは2015年にベストプラクティスバッジ制度を作った。
Linuxコアは最初期にこのバッジを取得したプロジェクトのひとつで、2020年6月には最高級称号であるゴールドバッジを取得した。とか書いてあるんだけど、CIIはLinuxFoundation内の組織なのでどうにもマッチポンプ感が拭えない。
Adoption of Maintainer Hierarchy
1996年の1.3.68で初めて
MAINTAINERSファイルがコミットされた。
わずか107行で、メンテナは僅か3人。
Alan Cox、Jon Naylor、そしてLinus Torvalds。MAINTAINERSREST: P: Linus Torvalds S: Buried alive in emailLinuxカーネル開発の初期の議論は複数のMLでなされていたので、1997年以前の議論については断片的にしか存在していない。
集められた一部についてはhttp://lkml.iu.edu/hypermail/linux/で公開されているが、これにも抜けがあるので、当時のログを持っている人がいたら提供してほしい。翻って5.8の
MAINTAINERSは19033行もあり、そして1501人のメンテナがリストされている。MAINTAINERSTHE REST M: Linus Torvalds <torvalds@linux-foundation.org> L: linux-kernel@vger.kernel.org S: Buried alive in reporters Q: http://patchwork.kernel.org/project/LKML/list/ T: git git://git.kernel.org/pub/scm/linux/ kernel/git/torvalds/linux.git F: * F: */Version Control Systems
BitKeeper以前は、誰がどれくらい貢献していたかについてはあまりはっきりとしていない。
きちんとした履歴は2002年ごろにはじまっていて、それ以前については各文献に残された履歴から推測している。2005年に色々あってBitKeeperが使えなくなったので、Linusが一からGitを作ってそっちに移行した。
開発者の確保は永遠の課題であり、Linux FoundationもOutreachyやLKMPプログラムといった支援を続けている。
女性コントリビュータを増やす取り組みも行ってきた。
Removing Unused Code
使用していないコードを削除する取り組みは継続していて、たとえば2018年の4.17では8アーキテクチャ18000行を削除した。
ということらしいのだけど増加量に比べたら微々たる量でしかないな。
Highly Diversified Corporate Contributors
Linuxカーネルは多くの企業から貢献を受けている。
2007年から2019年まで、1730の企業から780048のコミットがあった。
そのうちトップ20企業が68%を占めている。
この10年では、毎年400社程度からのコントリビュートがある。
Release Model with Predictable Release Cycle Cadence
Linuxのリリースモデルは4種類に分類される。
・Prepatch (RC)
・Mainline
・Stable
・Long Term Stable最新のカーネルはhttps://www.kernel.org/で見ることができる。
リリースサイクルについては多くの議論がなされたが、2011年以降概ね機能するリリースモデルが構築された。
まず2週間のmerge windowから始まり、新機能はテストされてgitリポジトリに導入される。
RC1のタグが振られると結合テスト、デバッグ、最適化のサイクルに入り、品質と安定性が確保されるまでRCが毎週更新される。
新機能がリリースされると、ふたたび次のmerge windowが始まる。
Improving Automated Testing the Kernel
カーネルのテストはコミュニティの努力によって成り立っている。
自動テストBOTとしてSparse、Smatch、coccicheck、ファジングテストとしてTrinity、syzbotなどが走っている。
これらによって多くのバグが発見されている。
Stable Release Process
安定版へのリリースはおよそ週1で行われる。
Linux5.7.9を例に取ると、まずリリース候補
RCがMLにメールでアナウンスされる。
このRFには166のパッチがあり、それらは全て個別にMLで通知される。
各開発者および自動テストツールがそれらのリリース工法をテストし、結果をメールに返信する。
RCに問題があればRC2、RC3と後続が作成されるが、RC2が作られることはあまり多くない。自動ビルドBOTは30種以上のアーキテクチャに対してビルドを実行する。
安定版では31アーキテクチャ、56コンフィグに対してビルドが行われる。
そしてLKFT、LTP、Linux Kernel Selftests、Linux Perfなど多くのテストが行われる。
テストが十分に果たされるとリリースされ、その通知がMLに送られる。Longterm Release Kernels
長期サポートを導入したことにより、組込製品などにおいてLinux人気がさらに高まった。
SUSE、Ubuntu、Red Hatなどのディストリビューションが先駆けて導入して有用性を証明したことで、カーネルにもこの概念が導入されることになった。安定版カーネルで発見されたバグはまず安定版に適用されるが、LTSにも適用可能であると判断された場合はバックポートされる。
安定版の修正をLTSも適用可能であるかの判定は、Sasha Levinによる機械学習ツールの開発などによって年々改善されている。
2019年には18668件のバックポートが行われたが、これは15年前の安定版カーネルへの変更より多い件数である。LTSよりさらに長い超長期サポートSLTSを求めている市場もあり、一部の開発者はLinux4.4と4.19をSLTSとしてサポートすることにしている。
Conclusion
現在のLinuxカーネルは、医療機器から宇宙船に至るまで、セキュリティと安全性が必要なあらゆる分野で使用されている。
Linuxを使う前に、適切なセキュリティと安全性を確保できるようインフラを改善していくことが、次の取り組んでいる大きな課題のひとつである。Linuxカーネルには、OSS業界全体を改善していくためのベストプラクティスを作成し、世界をリードし続けるための素晴らしい基盤が存在している。
Thanks
なんか見切れてるんだけど。
感想
もはや世界的に無くてはならない存在であるLinuxですが、その成長の軌跡がざっくりわかる興味深い資料でした。
コミッター数もコミット数もコード量も、近年のその飛躍的な増加も、このプロジェクトの重要性をよく示していますね。ただまあ公的に近い資料だけあって表沙汰にできるような内容しかありません。
裏側の歴史の集まったレポートとかもあると楽しそうです。最近はクラウドだーサーバレスだーと、低レベルOSの存在は裏に隠そう隠そうと躍起になっていますが、何かあるとすぐコマンドとかログとか掘り返さないといけなくなって結局Linuxの知識が必要となるのは今でもあまり変わりません。
OSの存在や種類など気にしなくていいような世界は、本当にいつの日かやってくるのでしょうか。










- 投稿日:2020-09-14T19:40:51+09:00
【macOS】Virtual BoxにCent OSのインストール後、起動させるとクラッシュする問題
仮想環境の構築に死ぬ程ハマったので、備忘録として書きます。
・環境
macOS catalina Ver10.15.6Virtual Box 6.1.14
CentOS-8.2.2004-x86_64-dvd1.isoをインストールしようとした。
・状況
OSインストール後の再起動で、Virtual Box VMがクラッシュ。
その後起動しようとしても同様にクラッシュ。結論:Virtual Boxを6.0.14にダウングレードしたら起動できた
もう怖くないLinuxコマンド。手を動かしながらLinuxコマンドラインを5日間で身に付けよう
山浦先生のLinux講座を学ぶために環境構築しようとしたところ、何をやってもクラッシュした。
ダウングレードしてようやく成功したので、
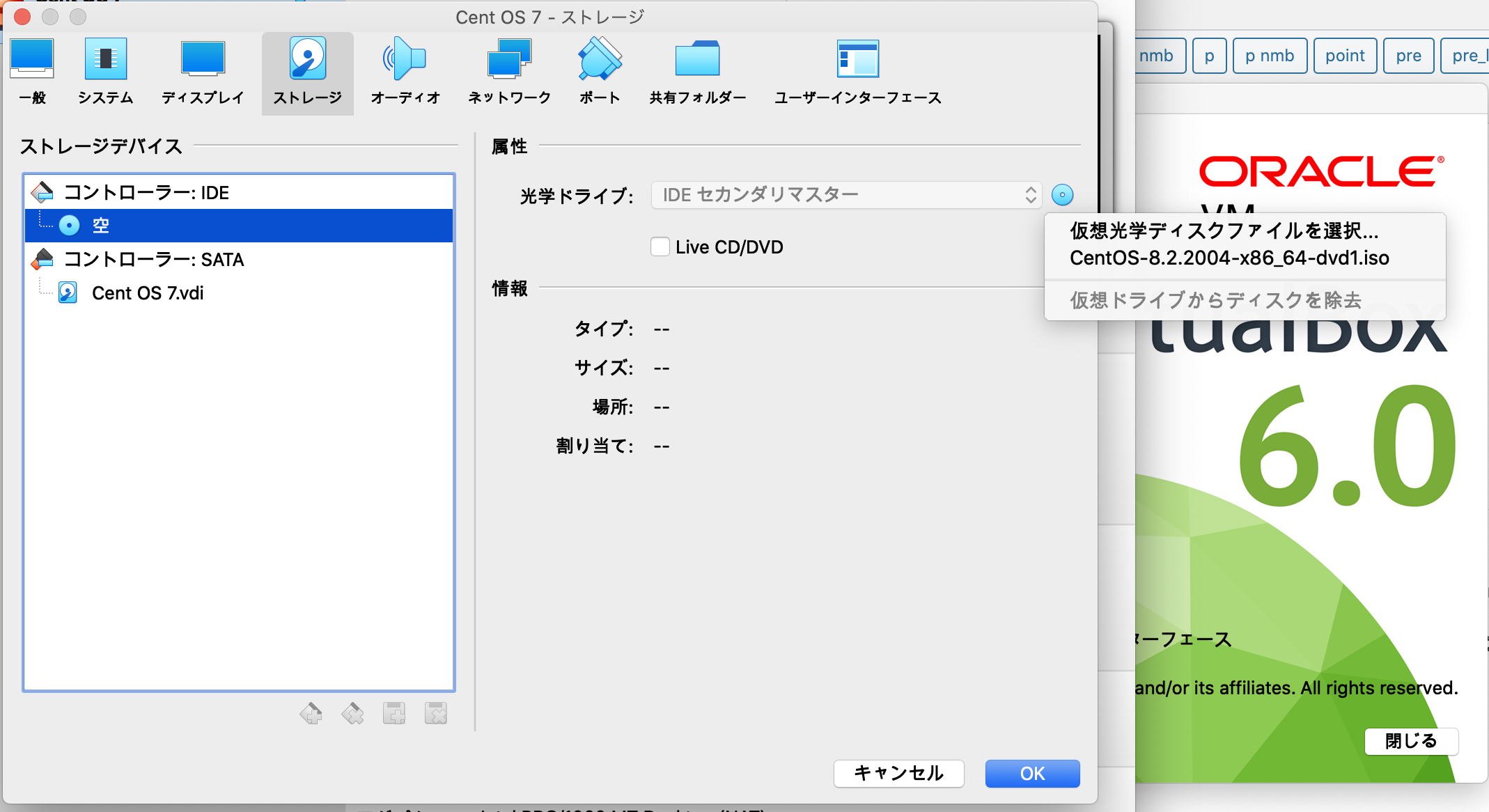
・設定→ディスプレイ→グラフィックコントローラをVboxVGAに
・設定→ストレージ→光学ドライブアイコンクリック→仮想ドライブからディスクを消去
でやっと起動。
・試した事
仮想メモリ1024B→2048B ×
ブートメディアの順番変更 ×
仮想マシンにCentOSをインストールする ×
実機のメモリクリア ×
VirtualBoxへCentOS7をインストール ×
- 投稿日:2020-09-14T19:02:33+09:00
AWSによるLinux最速学習
Linuxとは
LinuxはMacOSやWindowsと同じようなOSです。
UbuntuやCentOSなどが有名で無料です。Red Hatなど有料のものもあります。MacOSやWindowsなど直感的な操作が可能なものはGUI、
Linuxはコマンドラインで操作されCUIと呼ばれます。Linuxはハードウェアにインストールして使う場合もありますが、
今回はAWSを使用します。
AWSにはLinuxがあらかじめインストールされています。動作環境
MacOS Catalina、Amazon EC2
コマンド
LinuxはCUIなのでコマンドラインに命令を打ち込み操作します。
例えば、$ dateと打ち込みEnterを押すと、
$ date 2020年 9月 14日 月曜日 10:00:29 UTCのように、現在の日時が表示されます。
シェル
Linuxはカーネルとシェルのセットです。
カーネルがOSの本体、シェルはユーザーが本体を操作するためのコマンド機能です。
主に、sh、bash、tcsh などがありますが、一番有名な bash を使用します。
以下のコマンドを打ち込むと bash に切り替わります。$ bashシェルを終了したいときは、
$ exitのように入力しEnterを押します。
コマンドライン操作
よく使うコマンド操作は以下の通りです。
コマンド 動作 Ctrl + b 左に1文字移動 Ctrl + f 右に1文字移動 Ctrl + b 一番右に移動 Ctrl + b 一番左に移動 Esc, b 左に1単語移動 Esc, f 右に1単語移動 BackSpace カーソルの左の文字を削除 fn + BackSpace カーソルの位置の文字を削除 Ctrl + w 単語削除
(左の次のスペース区切りまで削除)Ctrl + k カーソルの位置から一番右まで削除 Ctrl + u カーソルの位置から一番左まで削除 あとがき
お読みいただき、ありがとうございました。
- 投稿日:2020-09-14T18:54:41+09:00
Linuxの基礎
仮想環境を作ろう
https://www.sejuku.net/blog/86137
上記を参考にdockerで作れる。
docker exec -it mycentos /bin/bash
で中に入って作業できるよ。
docker stop mycentosでコンテナを停止できるよ。
docker start mycentosで一度作ったコンテナを起動できるよ。
docker ps -aで停止しているコンテナを表示。
docker rm コンテナIDでコンテナのイメージを削除できるよ。
基礎知識
・現在自分が位置しているディレクトリをカレントディレクトリ、またはワーキングディレクトリと呼ぶ。
・ルートディレクトリを起点としてファイルやディレクトリのパスを示すことを絶対パス、もしくはフルパスと呼ぶ。
・逆にカレントディレクトリを起点として表記されるパスを相対パスと呼ぶ。
・ . カレントディレクトリ
・ .. 親ディレクトリ
・ ../.. 親の親ディレクトリ
・ ./home/file-1 カレントディレクトリの下にあるhomeディレクトリの中にあるfile-1を示す
プロセス: Linuxカーネルから見た処理の単位。
ジョブ: シェルから見た処理の単位。
コマンドを3つパイプした場合、プロセスは3つなのに対し、ジョブは1つ。コマンドラインに入力している1つの行が1つのジョブ。/dev/null 入力先として指定しても何も返さない。出力先として指定しても書き込んだデータは消えて無くなる。標準エラーメッセージだけは画面に表示される。コマンドの表示結果が大量にある時に使うと便利。
パイプライン: コマンドの標準出力を別のコマンドの標準入力につなぐ。lsコマンドの表示結果をlessコマンドで見るなど。
複数のファイルやディレクトリをまとめたファイルをアーカイブファイルと呼ぶ。
それを圧縮したものを圧縮ファイルと呼ぶ。便利な操作方法
Ctrl + k カーソル位置から行末までを削除する
Ctrl + u カーソル位置から行頭までを削除する
Ctrl + y 最後に削除した内容を挿入する
Meta + b 一つ前の単語に移動
Meta + f 一つ後の単語に移動
Ctrl + s キー入力を受け付けなくする
Ctrl + q キー入力を再開する
Ctrl + c 実行中のコマンドを強制終了する
Ctrl + l 画面をきれいにする/clearコマンドと同じ
reset Ctrl + lでも文字化けが直らない時にやってみる
tabキーを2回 候補のコマンドを全て表示することができる
Ctrl + r インクリメンタル検索をすることができる
Ctrl + g 検索結果を破棄してプロンプトに戻る
Linuxコマンド集
pwd カレントディレクトリを確認する
ls /usr usrディレクトリ内のファイル一覧を表示する
ls /usr /tmp usrディレクトリとtmpディレクトリ内のファイル一覧を表示する
ls -l ファイル名だけでなくファイル属性などの詳細情報を一緒に表示する
表示された最初の文字がdならディレクトリ、-なら通常ファイルと覚えておこう。ls -a 隠しファイルも含めて表示する。基本的にはlsだけだと.から始まるファイル名は表示されない。
ls -F ファイル種別を含めて表示する。なし:通常ファイル, /:ディレクトリ, *:実行可能ファイル, @:シンボリックリンク
ls -a -F / このようにオプションを2つ重ねて、さらに/という引数を取ることもできる。
ls -w 30 30桁で表示する
ls --quote-name ファイル名を""で囲んで表示する
mkdir work workディレクトリを作成する
mkdir -p report/2014/01 -pオプションをつけることで、一気に階層の深いディレクトリを作成することができる。
touch ファイル名 新しいファイルを作成する。
touch file1 file2 複数のファイルを一度に作成可能
rm ファイル名 ファイルを削除する
rm file1 file2 複数のファイルを一度に削除可能
rm *.html 拡張子.htmlのファイルを一度に削除できる
rm file* fileとつくファイルを一度に削除することができる
rm -r ディレクトリ名 ディレクトリとその下のファイルを全て削除する
rm -i ファイル名 削除確認をしてくれる
rmdir 空のディレクトリを削除する。中身がある場合はエラーになる
cat /etc/hosts /etc/hostname hostsとhostnameというファイルの中身を表示する
cat -n ファイル名 行番号付きでファイルの中身を表示する
catコマンドを引数抜きでenterするとキーボードからの入力を表示するモードに変わる。それを終了させたい時はCtrl + dを押す。
less ファイル名 指定したファイル名を1画面いっぱいに表示することができ、上下にスクロールできる。catコマンドだと1画面に収まり切らなそうな時に使う。
cp file1 file2 file1をfile2という名前でコピー
cp file1 file2 file3 dir2 3つのファイルをコピーしてdir2というディレクトリに入れる
cp *.txt backupdir 拡張子.txtのファイル全てをbackupdirにコピーする
cp -i file1 file2 もしディレクトリ内にfile2が既に存在している場合だけ、上書きしていいか確認してくれる
cp -r dir2 dir3 dir2を中身も含め全てdir3としてコピーする
cp -r dir2 dir3 既にdir3があった場合は、dir2が中身ごとdir3の下に配置される
mv file1 file2 file1をfile2という名前に変える
mv file1 dir1 file1をdir1に移動する
mv file1 file2 file3 dir1 3つのファイルをdir1に移動する
mv -i file1 file2 既にfile2が存在している場合は上書きして良いか確認してくれる
mv dir1 dir2 dir1の中身ごとdir2の中に移動させる
ln file1 file2 ハードリンクを作成する。別のコマンドでfile2を指定するとfile1にアクセスできるようになる。例えばcat file2とするとfile1の中身が表示される。つまりファイルに別名をつけるコマンド。
ln -s file1 file2 シンボリックリンクを作成する。ls -lでファイルにシンボリックリンクがあるかどうか確認できる。
ln -s dir1/dir2 syouryaku このように深い階層にあるディレクトリにシンボリックリンクを付けておくとすぐに移動することができる。
unlink syouryaku シンボリックリンクを消すことができる。syouryaku/では消えないのでご注意。
find . -name file1.txt -print カレントディレクトリの下にあるfile1-txtというファイルのパスを全て表示する。
find . -iname file1.txt -print 大文字小文字の区別なく検索する
find . -name '.txt' -print カレントディレクトリ下にある拡張子が.txtのファイルを全て表示する(必ずか?を使う時は''で囲むこと)
find . -type d -print カレントディレクトリ下にある全てのディレクトリのパスを表示する(d:ディレクトリ, f:通常ファイル, l:シンボリックリンク)
find -type f -a -name 'file*' -print カレントディレクトリ以下の通常ファイルでfileとつく名前のパスを全て表示する。-aはANDを意味し複数の検索条件を指定することができる。
locate 文字列 任意の文字列を含むパス名を全て表示することができる。カレントディレクトリではなく、ルートディレクトリ下から検索される。(locateコマンドをインストールしてupdatedbコマンドを事前に打つ必要がある)
locate -i FiLe1 大文字小文字関係なくfile1とつくパスを全て表示する
locate -b file1 -bとつけるとファイルに絞って検索することができる。ディレクトリは検索されない。
locate file1 file2 file1かfile2どちらかの名前が含まれているパスを全て表示する
locate -A dir2 file1 dir2とfile1どちらの名前も含まれているパスを全て表示する
コマンド --help そのコマンドの使用を表示する
which コマンド コマンドを入力する時、シェルが実際にどのファイルを実行するかを確認する
alias 名前='コマンド' 長いコマンドにエイリアスを設定することができる
type コマンド名 エイリアスの場合どのコマンドのエイリアスなのかを表示してくれる
unalias エイリアス名 エイリアスを削除する
/bin/ls コマンドのフルパスを指定すると、一時的にエイリアスを無効にしてコマンドを実行することができる
command ls 同じくエイリアスを一時的に無効にできる
\ls 上と同じ。バックスラッシュはoption + ¥
set
shopt bashの設定を変更できる。p134var1='test variable' シェル変数を設定。値に空白が入る時は''で囲む必要がある。変数を設定する時に=の左右にスペースをつけてはいけない。
echo $var1 $変数名という形で参照することができる。
PS1='任意の文字列' プロンプトに表示する文字を設定することができる
PS1='[yokotabash] \w \$ ' このようにするとカレントディレクトリを追加で表示してくれる。\wがカレントディレクトリを指す。さらに詳しい設定方法はp137
printenv 現在シェルに設定されている環境変数を表示する
source ~/.bashrc ファイルの内容を読み込んで実行できる。この場合、.bashrcファイルの設定を即座に反映させることができる。
ls -ld dir1 ディレクトリのパーミッションを確認する
chmod [ugoa] [+-=] [rwx] <ファイル名> 権限を与えるコマンド。u:オーナー, g:グループ, o:その他のユーザー, a:ugo全て
chmod 8進数の数値 <ファイル名> 元のパーミッションに関わらず新しいパーミッションの値へと変更する。r:4:読み取り, w:2:書き込み, x:1:実行となる。 p158
su スーパーユーザの略。一般ユーザでログインしてる時に、一時的にスーパーユーザとして作業したい時にsuと打つ。スーパーユーザとして作業を終えたら、exitコマンドで元の一般ユーザに戻ることができる。
su - 環境変数などをスーパーユーザのそれに初期化してユーザを切り替えることができる。
sudo 別のユーザとしてコマンドを実行するために利用される。つまり一般ユーザでログインしてる時に、スーパーユーザでないと実行できないコマンドを実行するために使う。sudoの場合、実行したコマンドが終了すれば元の一般ユーザに自動的に戻る。ちなみにパスワードは今ログインしているユーザのパスワードを入力する。ユーザにsudoコマンドを許可するかは/etc/sudoersファイルに管理されている。(sudoersファイルを編集する時はp163,164を必ず読む)
ps 現在動作しているプロセスを表示する。(プロセスとは実行中のプログラムのこと)
ps xf 現在のユーザが実行中の全てのプロセスを表示
ps ax システムで動作している全てのプログラムを表示する。Linuxはマルチタスク機能で様々なプログラムが同時に動作している。(psコマンドのオプション一覧はp171)
Ctrl + z 起動しているジョブを停止状態にする
jobs 現在のジョブを確認する
jobs -l プロセスIDも一緒に表示する
fg %ジョブ番号 そのジョブを再開する
bg %ジョブ番号 そのジョブをバックグラウンドにする
kill %ジョブ番号 ジョブを終了させる。ジョブが終了すると、Terminatedというメッセージが表示される。
kill PID 同じくプロセスを終了させる。psコマンドでPIDを確認する。
cat < /ect/crontab キーボードの代わりにファイルを標準入力につないでいる。結果はcatコマンドを普通に打った時と同じだが、入力リダイレクトの場合は、標準入力をそのまま標準出力しているのに対し、普通のcatコマンドの場合は「ファイル名が指定された場合はその内容を対象にする」という用意された動作をしている。
ls -l > list.txt 標準出力先を画面ではなくlist.txtというファイルに変更している。
ls /xxxxxx 2> list.txt list.txtに標準エラー出力先を変更している。
ls /xxxxx > list.txt 2> error.txtというように書くことも可能。
ls /xxxx > result.txt 2>&1 標準出力をリダイレクトした後に、2>&1と書くと標準出力と標準エラー出力をまとめて1つのファイルにリダイレクトできる。
echo >> number.txt ファイルを上書きせずに、ファイル末尾に追記するようにする
ls -l | less パイプラインでlsコマンドの表示結果をlessで画面に表示できる
history ~/.bash_historyというファイルに保存されてあるコマンドライン履歴を表示することができる。
histroy | less 上記と同じ。
ls -l | cat -n | less パイプラインで3つのコマンドをつなげている。ただパイプラインは標準出力しか次のコマンドに繋げられないので、ls -l / /eeee 2>&1 | lessこのように書く必要がある。
ちなみに、catコマンドのように標準入力を入力として受け取り、標準出力に出力するコマンドのことをフィルタと呼ぶ。
head ファイルの先頭から10行を表示するコマンド。
head -n 3 ファイルの先頭から3行を表示する。
tail headコマンドの逆で末尾を確認することができる。
du -b ファイルorディレクトリ そのファイルのバイト数を表示する。
sort ABC順に並べ替える。
sort -n 数値順に並べ替える。
tac 入力行の順序を逆にして表示する。
du -b /bin/* | sort -n | tac バイト数が小さい順に並べる。
wc 入力ファイルの行数、単語数、バイト数を表示する。(左から)
wc -l 行だけ
wc -w 単語だけ
wc -c バイト数だけls . | wc -l カレントディレクトリ直下のファイル、ディレクトリ数を数える。
ps | sort -k 4 縦の列の4行目を基準に並び替える
sort -r 逆順に並べる
ls -l . | sort -rn -k 6 カレントディレクトリ直下のファイルとディレクトリを縦6行目の数値を基準にして逆順で表示する。
uniq 同じ内容の行が連続している場合、重複を取り除く。
sort file | uniq 重複している要素が離れている場合は、一旦sortコマンドで調整してからuniqをすれば良い。uniqコマンドを使う時は常にsortコマンドとセットで使うことを念頭に。
sort -u file 重複行を取り除いて順番を揃える。sort file | uniqよりこっちの方が良さそう。
uniq -c 重複行を数えてその数を教えてくれる
sort file1.txt | uniq -c | sort -rn file1の重複行を数えて、重複が多い順に並び替えて表示する。
cut -d : -f 7 /etc/passwd :を区切り文字にして7つ目のフィールドを表示する。
cut -d : -f 1,6,7 /etc/passwd このように複数のフィールドを指定することも可能。
tr abc ABC 文字を置き換える。aはAに。bはBにという感じ。あくまでも1文字単位の文字変換。文字列の置き換えは別のコマンドを利用する。trコマンドはファイル名を指定してもエラーになる。なので、catコマンドを使うか、tr a b < ./file1.txtのようにリダイレクトさせる。
tr -d 消したい文字 -dをつけると指定した文字を削除して表示することができる。消したい文字の部分に\nを指定すると、改行を取り除いて1行で表示することができる。
tail -f ファイル名 ファイルの内容が書き換えられると、追記された内容を表示する
diff 比較元ファイル 比較先ファイル ファイルの差を表示する。
diff -u 比較元ファイル 比較先ファイル ユニファイド形式で表示する。githubみたいな感じ。
grep 検索パターン ファイル名 そのファイルから検索パターンに一致する行を出力する。
grep -n 検索パターン ファイル名 マッチした行の行番号を一緒に表示する
grep -i 検索パターン ファイル名 大文字小文字を区別しないでマッチさせる
grep -v 不要なワード ファイル名 不要なワードを除いてファイルの内容を表示させる
ls / | grep word ファイル名を指定しない場合、標準入力から読み込ませることができる。
ls | grep '^file' fileという文字から始まるディレクトリまたはファイルを表示する。
正規表現を使用する場合は''で囲む必要あり。grep 't.st' example.txt tで始まりstで終わる4文字のワードを検索する。.は任意の1文字という意味がある。
.そのものを検索したい時は、ドットの前に\を付ける。
.ではなく、[]に含まれるいずれかの1文字。
[^文字][]の中に含まれないいずれかの1文字。
grep 'file[1-3]' number.txt file1,file2,file3があれば表示する
grep 'file[^13]' number.txt fileがついて、file1,file3,file13以外を表示する
grep '^txt' file1.txt 先頭がtxtで始める行のみを抜き出す。.txtなどは除外できる。^は行頭を意味する。
grep 'txt$' file1.txt 行末がtxtとつく行のみを抜き出すことができる。$は行末を意味する。また、^$は空行を意味する。-vオプションを使って空行だけを除いて表示することができる。
- 0回以上の繰り返しを表すメタ文字 grep 'be*r' txt.html brやber,beerなどが表示される。 grep 'b[ea]*r' txt.html br,bear,beerなどが表示される。
.* 任意の文字が0回以上繰り返されているという意味。あらゆる文字列にマッチする。
grep '^ex.*txt$' file.txt exで始まってtxtで終わる行を全て表示する。拡張正規表現 基本正規表現よりも使えるメタ文字を増やしたもの。-Eオプションをつけて使う。
- 拡張正規表現のメタ文字。直前の文字の1回以上の繰り返しを意味する。 grep -E 'be+r' txt.html ber,beer,などが表示される。
? 拡張正規表現のメタ文字。直前の文字の0回または1回の繰り返しを意味する。
grep -E 'be?r' txt.html br,berが表示される。{m,n} 拡張正規表現のメタ文字。直前の文字のm回以上n回以下の繰り返しを意味する。
grep -E 'be{1,2}r' txt.html ber,beer,beerbeerなどが表示される。{m} 拡張正規表現のメタ文字。直前の文字のm回の繰り返しを意味する。
grep -E 'be{1}r' txt.html berが表示される。
[0-9]{3}-[0-9]{4}とすると郵便番号の桁のチェックなどができる。{m,} 拡張正規表現のメタ文字。直前の文字のm回以上を意味する。
(文字) 拡張正規表現のメタ文字。単語をグループするためのメタ文字。
grep -E '(wine){2,}' txt.html wineという文字が2回以上繰り返されるものを表示する。abc|xyz 拡張正規表現のメタ文字。複数の単語をOR条件でつなげるメタ文字。多くの場合は()とセットで使われる。
grep -E 'my(water|wine)' txt.html mywater,mywineが表示される。sed 1d txt.html txt.htmlの1行目を削除したものを表示する。sedは元のファイルを上書きすることはない。sedは非対話型エディターである。1の部分をアドレスと呼ぶ。
sed 1,5d txt.html txt.htmlの1~5行目までを削除したものを表示する。
sed '3,$d' txt.html txt.htmlの3~最終行までを削除したものを表示する。アドレスに$を指定すると最終行を意味する。
sed d txt.html txt.htmlの全ての行を削除する。アドレスを省略すると、コマンドは全ての行に作用する。
sed /^b/d txt.html txt.htmlの先頭がbで始まる行を削除したものを表示する。アドレスに正規表現を使う時は/で囲んであげる。
sed 1p txt.html txt.htmlの1行目を表示する。+パターンスペースを表示する。
sed -n 1p txt.html パターンスペースを除いて1行目だけ表示する。
sed 's/beer/whisky/' txt.html txt.htmlのbeerという単語をwhiskyに置換したものを表示する。ただ、beerbeerはwhiskybeerという風にしか変わらない。行頭から探して最初に見つかった文字列だけを置換する。
sed 's/beer/whisky/g' txt.html 見つかった全ての文字列を置換するにはgフラグを付ける。これで、txt.htmlのbeerという単語全てがwhiskyに置換され、それが表示される。
sed 's/b.*r/whisky/g' txt.html txt.htmlのbで始まりrで終わる単語全てをwhiskyに置換したものを表示する。
sed 's/b//g' txt.html 置換後の文字列を指定しないことで、txt.htmlのbを全て削除している。
sed -n 's/b//gp' txt.html 置換が発生した行だけ表示している。-nオプションでパターンスペースを非表示にし、pフラグで置換が発生した部分だけ表示できる。
sed -r 's/be+r/whisky/' txt.html sedで拡張正規表現を使うには-rを指定する。
sed -r 's/my(.*)/--\1--/' txt.html ()でグループ化して\1でそれを参照することができる。この場合、myappleが--apple--と置換される。
sed '1,2s/beer/whisky/g' txt.html txt.htmlの1~2行目の範囲でbeerをwhiskyに置換したものを表示する。
/という文字そのものを指定するには、\/と表記する。もしくは
sed 's!beer!/beer/!g' txt.htmlというように区切り文字を/から!に変えて書く。ls -l | awk '{print $5,$9}' lsコマンドで表示される行の5と9行だけを表示する。ちなみに1~9行目までの全ての列を指定するには$0とする。
ls -l | awk '{print $5$9}' 表示されるレコードが空白で区切られてないものになる。
$NF awkで使う組込変数。$NFをprintすると最後のフィールドが表示される。
ls -l | awk '{print $(NF-1)}' 最後から2番目のフィールドが表示される。
ls -l | awk '$9 ~ /^fi/ {print $5,$9}' 9個目のフィールドで、先頭がfiで始まるレコードに対して、5と9フィールドを表示する。正規表現との比較は~を使用する。正規表現のパターンは//で囲んで指定する。
ls -l | awk '/^d/ {print $5,$9}' 比較対象を指定しないと、レコード全体が比較対象になる。
ls -l | awk '/^d/' アクションを省略すると{print $0}が実行される。この場合、フィールド全体でdから始まる全てのレコードを表示する。
awk -F, '{sum += $NF} END{print "Average:",sum/NR}' score.csv まず、-F,でフィールド全体の区切り文字を空白から,に変更する。次にsumという変数を作成し、そこに全員の点数を足していく。ENDブロックに書かれた処理は最後に実行される。NRは行数を取得できる組込変数。合計点をレコードの行数で割って平均点を出すことができる。
cat average.awk
=> {sum += $NF} END{print "Average:",sum/NR}awk -F, -f average.awk score.csv
=> 平均点上記のように作ったawkスクリプトを.awkファイルに保存して、-fオプションでいつでも再利用することができる。
tar cf dir1.tar dir1 dir1下のディレクトリまたはファイルをdir1.tarというアーカイブファイルにまとめる。cfはcreate fileの略。
tar tf dir1.tar dir1.tarというアーカイブファイルの中身を確認する。tはlistのtらしい。
tar xf dir1.tar dir1.tarファイルを展開して取り出すことができる。xはextractのx。展開されるファイル名と同じファイル名が存在する場合は上書きされてしまうので注意。
tar cvf dir1.tar dir1 cfと一緒に対象になったファイル一覧を表示することができる
tar tvf dir1.tar tfと一緒に、ls -lのようにパーミッションやオーナー、ファイル属性を表示してくれる
注意:rootユーザーではないユーザーがアーカイブを作成すると展開時に読み込み権限がなくファイルを展開できないなどの問題が発生するリスクがある。なのでrootユーザーでやると良い。アーカイブはタイムスタンプなどもそのままコピーするので、バックアップ向き。
gzip ps.txt ps.txtを圧縮する。.gzという拡張子になる。
gzip -d ps.txt.gz 圧縮したファイルを元に戻す。
tar czf dir.tar.gz dir1 これはtarコマンドだけでアーカイブと圧縮を同時に行っている。cfの間にzオプションを挟む。
tar xzf dir.tar.gz 逆にアーカイブされ、圧縮されたファイルを展開して取り出している。
ちなみにbzip2というコマンドでもファイルを圧縮できるらしい。gzipよりも圧縮率が高くデータ量も小さくできるが、圧縮や展開に時間がかかる。xzコマンドはさらに圧縮できる。
zipコマンドはアーカイブと圧縮を同時に行う。多くのディストリビューションにはインストールされていないので、使う場合はzipとunzipコマンドをインストールする必要がある。git log -p コミットごとの差分を含めて履歴を表示することができる。
git diff --cached 次にgit commit したときにリポジトリにコミットされる差分を表示します
https://qiita.com/shibukk/items/8c9362a5bd399b9c56be
上記の記事がgit diffについて詳しく書いてる。
git add -u 変更したファイル全てをindexにあげる。新規作成されて一度もコミットされていないファイルは対象外となる。
git revert コミットid 誤った内容をコミットしたときに、それを打ち消すことができる。ただ、履歴からなくなるわけではなく、打ち消したものをコミットするという流れになる。
git branch -d ブランチ名 ブランチを削除する。
vimの操作
:w ファイルを保存する。新規ファイルの場合はファイルを作成。既存ファイルの場合は上書き保存をする
:w ファイル名 名前をつけて保存する
:q! 上書き保存せずにvimを終了する
h 左に移動
j 下に移動
k 上に移動
l 右に移動
x カーソルより右側の文字を削除する
i insertモードに変える(カーソルの左側に文字)
a insertモードに変える(カーソルの右側に文字)
w 次の単語の先頭に移動する
b 後ろの単語の先頭に移動する
W スペース区切りで次の単語へ
B スペース区切りで後ろの単語へ
0 行の先頭に移動
$ 行の末尾に移動gg ファイルの最初の行に移動
G ファイルの最後の行に移動
20G ファイルの20行目に移動
d$ 行末までをデリート
d0 行頭までをデリート
dl 1文字デリート
dw 単語1つをデリート
dgg 最初の行までデリート
dG 最後の行までデリート
ヤンクの場合はdがyに置き換わる
yy カーソルのある1行をコピーする
dd カーソルのある1行をデリートする
J カーソルのある行と1つ下の行を連結させる
u 直前の編集操作を取り消す(アンドゥ)
Ctrl + r アンドゥを取り消すことができる(リドゥ)
/文字列 任意の文字列を検索してマーカーをつける
n マーカーがついた状態の次の単語に移動する
N マーカーのついた1つ前の単語に移動する
:noh ハイライトを消す
:%s/置換前/置換後/g 文字列の置き換えをするiTerm2の便利コマンド
Command + D→ウインドウを左右に分割する
Command + Shift + D→ウインドウを上下に分割する
Command + n→新しいウインドウを作成
Command + f→検索
Command + t→新しいタブを作成
Command + T→タブを複製する
Command + W→タブを削除する
Command + 矢印キー→タブを移動する
Command + Enter→全画面を表示させる
Command + [→次のウインドウへ移動
Command + ]→前のウインドウへ移動シェルスクリプト
簡単なファイルの作り方
homesize.sh#!/bin/bash du -h ~ | tail -n 1からの
$chmod +x homesize.sh $ ./homesize.shこれでシェルスクリプトを実行することができる
1行目のやつはシバンもしくはシェバンと呼ばれ、/bin/bashで以下のコマンドを実行するよーっていう意味。
また、1行目を書かずに、sourceコマンドや.でファイルの中身を実行することもできる。
シバンをつけるとサブシェルで実行されるので、元のシェルには影響を及ぼさないが、sourceや.コマンドでは元のシェルに影響を及ぼす。また、複数のコマンドを;で区切ることで1行で書くことができる。
rootls.sh#!/bin/bash echo "root directory";cd /;ls -lコマンドが1行に収まらなそうなら、\を使うことで改行できる。
シェルスクリプトではシェル変数というものを使うことができる。
シェル変数を参照するには$変数名とする。
example.sh#!/bin/bash comment="Ruby on Rails" echo $commentこんな感じで変数を参照するよ。
変数に続いて文字列をechoしたいなんて時は
example.sh#!/bin/bash comment=Ruby echo ${comment} on Railsこんな感じで${変数名}とすると良い
また、文字列ないでシェル変数を使うには""で囲まなくてはいけない。Rubyと同じ。
example.sh#!/bin/bash comment=Ruby echo "$comment on Rails"コマンドの結果をシェルスクリプトで使いたい時は、$()の中にコマンドを書く。その結果を文字列として取得することができる。
example.sh#!/bin/bash comment=$(date '+%Y-%m-%d') echo "today is $comment"こんな感じ。
こんな書き方もできる
example.sh#!/bin/bash echo "today is $(date '+%Y-%m-%d')"位置パラメーターを使う
example.sh#!/bin/bash echo $1 echo $2上記のファイルがある状態で、
$ ./example.sh Ruby PHPとすると、
./example.shが$0
Rubyが$1
PHPが$2
となり、Ruby PHPと出力される。
引数の個数を取得するには$#と書けば良い。
example.sh#!/bin/bash echo $1 echo $2 echo "vars $#"引数を分割せずに使うには、$@か$*を使う。
example.sh#!/bin/bash echo $@ echo $*この状態で./example.sh hello worldとするとhello worldと出力される。
$@は一つ一つの引数がそれぞれ展開されていく。
$*は複数の引数を1つの引数ととらえる。if文を使ってみる。
example.sh#!/bin/bash if [ "$1" = "bin" ]; then echo "ok" else echo "ng" fi第一引数がbinという文字列ならokを出力する。
終了ステータスとは、
例えばlsを打って正常に動作した場合は、
$echo $?で終了ステータス 0を取得することができる。
エラーになってしまった場合は、0以外の数値を取得する。
[ 条件式 ]はtestコマンドで代用できる。
example.shif test "$1" = "bin"; then echo "ok" else echo "ng" fiこんな感じ。
評価演算子はp292あたりに。
for文の使い方
for 変数名 in リスト do 繰り返す処理 done詳しくはp300くらい
- 投稿日:2020-09-14T17:31:27+09:00
tar.gzが展開できない
はじめに
tarでtar.gzファイルを展開しようとしたところ、エラーが出てうまくいかないという事象に遭遇したため、トラブルシューティングと解決方法をまとめてみmた。
結論
curlでtar.gzファイルが正しくダウンロードできていなかった。curlコマンドを見直して解決
切り分け
fiileコマンドを使うことでtarファイルであることを確認できる。
正しいtar.gzファイル
[root@redmine: # file ruby-2.6.5.tar.gz ruby-2.6.5.tar.gz: gzip compressed data, was "ruby-2.6.5.tar", from Unix, last modified: Tue Oct 1 20:01:03 2019, max compressioncurlが失敗していたtar.gzファイル
[root@redmine: # file ruby-2.6.5.tar.gz ruby-2.6.5.tar.gz: XML 1.0 documen, ASCII text
- 投稿日:2020-09-14T16:54:27+09:00
Dockerコマンド超省略版
ターミナルからコンテナ作成〜dockerhubリポジトリ作成までの最低限のコマンドをまとめました。
イメージ作成
※ cd でdockerfileのあるディレクトリに予め移動
docker build -t --force-rm=true (イメージ名):(タグ) .--force-rm:ビルド失敗したらイメージ削除
コンテナ作成+起動
/bin/bach は任意の実行コマンドに変更可
docker run --runtime=nvidia --rm -v (マウント先ディレクトリ):(コンテナ内でのディレクトリ名)\\ --name (コンテナ名) -it (イメージ名) /bin/bash--runtime=nvidia:ランタイム指定(たぶん2020年時点で変更されている)
--rm:実行終了時にコンテナ削除
-v:DockerコンテナにホストOSのディレクトリを共有するdockerhubに上げるリポジトリ作成
docker commit (コンテナ名) (リポジトリ名):(タグ)dockerhubにアップする
docker login # ユーザ名とパスワードを求められる docker push (リポジトリ名):(タグ)(おまけ)Docker操作
docker images -a # イメージ一覧 docker rmi (イメージID) # イメージ削除 docker ps -a # コンテナ一覧 docker rm (コンテナID) # コンテナ削除 docker start -i (コンテナID) # コンテナ起動-a:未使用のイメージ、コンテナも表示
- 投稿日:2020-09-14T13:10:23+09:00
Linuxのllist (Lock-less NULL terminated single linked list)について
IntelのHuang Yingさんによって導入された(条件によっては)ロックを使わなくてもよい単方向リストについての分析メモ。
LListとは
リストへの(単一・複数)追加と全削除についてはロックなしに並行してリストの操作が可能。
また、リストからの単一エントリの削除同士が競合しなければ、リストへの追加の操作と並行してもロックは不要。
ただし、複数の並行するスレッドからリストからの単一削除と全削除あるいは単一削除が競合する場合については、ロックが必要になる。
単一削除の操作はリスト先頭からのみをサポート。llist_add()は先頭に追加するだけなので、基本的にはpush/popをリストで実装できるという話。Lockが必要な条件
add del_first del_all add - - - del_first L L del_all - del_firstとdel_allが被る場合はロックしておけ、ということがサマライズされている。
コア部分の実装
lib/llist.cに実装が書かれている。
bool llist_add_batch(struct llist_node *new_first, struct llist_node *new_last, struct llist_head *head) { struct llist_node *first; do { new_last->next = first = READ_ONCE(head->first); } while (cmpxchg(&head->first, first, new_first) != first); return !first; }リストへの追加の実装を見ると、基本的にはspinlockと同じく、リスト先頭へのatomicな挿入が成功するまで繰り返すことになっていて、まあlocklessではあるけど繰り返しは発生する。クリティカルセクションが発生しないというのが重要なポイント、というのは(極端な状況でなければ)大体は1メモリアクセス分の競合で済むからだ。
struct llist_node *llist_del_first(struct llist_head *head) { struct llist_node *entry, *old_entry, *next; entry = smp_load_acquire(&head->first); for (;;) { if (entry == NULL) return NULL; old_entry = entry; next = READ_ONCE(entry->next); entry = cmpxchg(&head->first, old_entry, next); if (entry == old_entry) break; } return entry; }削除も基本的にはspinlockの亜種であり、削除を試したあと、atomicなcmpxchg命令で次のエントリをリストの先頭に登録しようとしてみて、失敗だったら(更新前に他のエントリが追加されたなど)繰り返すようになっている。同じくクリティカルセクションは発生しない。
競合の条件
これだけだとdel同士が競合しても問題なさそうに見えるんだけども。もう一度詳しくヘッダを読んでみよう。
* Cases where locking is needed: * If we have multiple consumers with llist_del_first used in one consumer, and * llist_del_first or llist_del_all used in other consumers, then a lock is * needed. This is because llist_del_first depends on list->first->next not * changing, but without lock protection, there's no way to be sure about that * if a preemption happens in the middle of the delete operation and on being * preempted back, the list->first is the same as before causing the cmpxchg in * llist_del_first to succeed. For example, while a llist_del_first operation * is in progress in one consumer, then a llist_del_first, llist_add, * llist_add (or llist_del_all, llist_add, llist_add) sequence in another * consumer may cause violations.つまりdelがpreemptされている間にdelしてからadd->addのシーケンスが他のCPUで起きると競合する。
こういう風になる。(LLIST)A->B
(cpu1) entry[A] = smp_load_acquire(&head->first);
(cpu1) old_entry[A] = entry; next[B] = READ_ONCE(entry->next);(LLIST)A->B
(cpu0) entry[A] = smp_load_acquire(&head->first);
(cpu0) old_entry[A] = entry; next[B] = READ_ONCE(entry->next);
(cpu0) entry[A] = cmpxchg(&head->first[A], old_entry[A], next[B]);(LLIST)B
(cpuX) new_last->next[B] = first[B] = READ_ONCE(head->first[B]);
(cpuX) } while (cmpxchg(&head->first[B], first[B], new_first[C]) != first);(LLIST)C->B
(cpu0) new_last->next[C] = first[C] = READ_ONCE(head->first[C]);
(cpu0) } while (cmpxchg(&head->first[C], first[C], new_first[A]) != first);(LLIST)A->C->B
(cpu1) entry = cmpxchg(&head->first[A], old_entry[A], next[B]);
(LLIST)B
あれ?Cは何処に行った? となる。
つまり、問題が発生するのは「一度削除したエントリが、処理に失敗するなどして元に戻される」処理が、他に「エントリを追加する」処理と「エントリを削除する」処理が並行している場合に限られそう。注意が必要なのは、「一度エントリを削除してから同じエントリを追加する」処理が複数走っても同じ問題が起きる。
要するにhead->firstのアドレス値をキーにして確認しているため、同じアドレス値が戻ってきた場合には危険であると。その他注意点
* The basic atomic operation of this list is cmpxchg on long. On * architectures that don't have NMI-safe cmpxchg implementation, the * list can NOT be used in NMI handlers. So code that uses the list in * an NMI handler should depend on CONFIG_ARCH_HAVE_NMI_SAFE_CMPXCHG.とあるので、アーキテクチャ的にNMI-safeなcmpxchgがないアーキテクチャではNMIハンドラ内では
これは使ってはならないとのこと。
- 投稿日:2020-09-14T11:12:13+09:00
CentOS7でDRBD+CryptSetup+PaceMakerでACT/SBY
はじめに
サーバをACT/SBYで構築します
環境
version 備考 CentOS 7.4 DRBD 9.0 cryptSetup 2.0.3 paceMaker 1.1.20-5.el7_7.2 corosync 2.4.3 ディスク追加
今回はKVMで行っています。
SERVER-1とSERVER-2というインスタンスがある前提です。
ディスクの追加を行っていく。インスタンス確認
[root@kvm ~]# virsh list Id 名前 状態 ---------------------------------------------------- 126 SERVER-1 実行中 127 SERVER-2 実行中ディスク追加の定義のxml作成
/tmp/server-1-adddisk.xml[root@kvm ~]# vi /tmp/server-1-adddisk.xml <disk type='file' device='disk'> <driver name='qemu' type='qcow2' cache='none' /> <source file='/var/lib/libvirt/images/SERVER-1-vdb.qcow2' /> <target dev='vdb' bus='virtio' /> </disk>/tmp/server-2-adddisk.xml[root@kvm ~]# vi /tmp/server-2-adddisk.xml <disk type='file' device='disk'> <driver name='qemu' type='qcow2' cache='none' /> <source file='/var/lib/libvirt/images/SERVER-2-vdb.qcow2' /> <target dev='vdb' bus='virtio' /> </disk>両方にvdbに16Gで作成
[root@kvm ~]# qemu-img create -f qcow2 /var/lib/libvirt/images/SERVER-1-vdb.qcow2 16G [root@kvm ~]# qemu-img create -f qcow2 /var/lib/libvirt/images/SERVER-2-vdb.qcow2 16G設定を当てる
[root@kvm ~]# virsh attach-device SERVER-1 --file /tmp/server-1-adddisk.xml [root@kvm ~]# virsh attach-device SERVER-2 --file /tmp/server-2-adddisk.xml永続的に設定を反映
[root@kvm ~]# virsh attach-device SERVER-1 --file /tmp/server-1-adddisk.xml --config [root@kvm ~]# virsh attach-device SERVER-2 --file /tmp/server-2-adddisk.xml --configSERVER設定
IPとhost名とドメインを決めておきましょう。
号機 hostname IP 1号機 SERVER-1 192.168.200.10 2号機 SERVER-2 192.168.200.11 hostsにはお互いのIPを書きましょう。
[root@server-1 ~]# cat /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.200.10 SERVER-1 192.168.200.11 SERVER-2[root@server-2 ~]# cat /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.200.10 SERVER-1 192.168.200.11 SERVER-2資材インストール
まずは両系で必要なものをインストールしておく。
[root@server-1 ~]# rpm -Uvh http://www.elrepo.org/elrepo-release-7.0-2.el7.elrepo.noarch.rpm [root@server-1 ~]# yum --enablerepo=extras -y install kmod-drbd90 [root@server-1 ~]# yum -y install cryptsetup cryptsetup-libs [root@server-1 ~]# yum -y install pacemaker [root@server-1 ~]# yum -y install pcs fence-agents-all[root@server-2 ~]# rpm -Uvh http://www.elrepo.org/elrepo-release-7.0-2.el7.elrepo.noarch.rpm [root@server-2 ~]# yum --enablerepo=extras -y install kmod-drbd90 [root@server-2 ~]# yum -y install cryptsetup cryptsetup-libs [root@server-2 ~]# yum -y install pacemaker [root@server-2 ~]# yum -y install pcs fence-agents-all増設ディスク初期化
両方で初期化
[root@server-1 ~]# parted /dev/vdb -s mklabel msdos -s mkpart primary 0% 100%[root@server-2 ~]# parted /dev/vdb -s mklabel msdos -s mkpart primary 0% 100%DRBD設定
/etc/drbd.d/drbd0.resの編集
/etc/drbd.d/drbd0.res[root@server-1 ~]# vi /etc/drbd.d/drbd0.res resource drbd0 { protocol C; volume 0 { device /dev/drbd0; disk /dev/vdb; meta-disk internal; } on SERVER-1 { node-id 0; address 192.168.200.10:7789; } on SERVER-2 { node-id 1; address 192.168.200.11:7789; } }SERVER-2への配布
[root@server-1 ~]# scp -p /etc/drbd.d/drbd0.res root@server-2:/etc/drbd.d/drbd0.resDRBD作成と起動
create-mdしていきます。
[root@server-1 ~]# drbdadm create-md drbd0 md_offset 17179865088 al_offset 17179832320 bm_offset 17179308032 Found some data ==> This might destroy existing data! <== Do you want to proceed? [need to type 'yes' to confirm] yes //入力箇所 initializing activity log initializing bitmap (512 KB) to all zero Writing meta data... New drbd meta data block successfully created.[root@server-2 ~]# drbdadm create-md drbd0 md_offset 17179865088 al_offset 17179832320 bm_offset 17179308032 Found some data ==> This might destroy existing data! <== Do you want to proceed? [need to type 'yes' to confirm] yes //入力箇所 initializing activity log initializing bitmap (512 KB) to all zero Writing meta data... New drbd meta data block successfully created.
起動前の状態をlsblkで確認
1号機[root@server-1 ~]# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sr0 11:0 1 1024M 0 rom vda 252:0 0 16G 0 disk ├─vda1 252:1 0 1G 0 part /boot └─vda2 252:2 0 15G 0 part ├─centos-root 253:0 0 13.4G 0 lvm / └─centos-swap 253:1 0 1.6G 0 lvm [SWAP] vdb 252:16 0 16G 0 disk2号機
[root@server-2 ~]# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sr0 11:0 1 1024M 0 rom vda 252:0 0 16G 0 disk ├─vda1 252:1 0 1G 0 part /boot └─vda2 252:2 0 15G 0 part ├─centos-root 253:0 0 13.4G 0 lvm / └─centos-swap 253:1 0 1.6G 0 lvm [SWAP] vdb 252:16 0 16G 0 disk
DRBDの起動
片方起動させただけだと、終了しない。
待ち合わせをしてるみたいなので、同じタイミングぐらいで。[root@server-1 ~]# systemctl start drbd[root@server-2 ~]# systemctl start drbd起動後をlsblkで確認
1号機
drbd0が増えてますね[root@server-1 ~]# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sr0 11:0 1 1024M 0 rom vda 252:0 0 16G 0 disk ├─vda1 252:1 0 1G 0 part /boot └─vda2 252:2 0 15G 0 part ├─centos-root 253:0 0 13.4G 0 lvm / └─centos-swap 253:1 0 1.6G 0 lvm [SWAP] vdb 252:16 0 16G 0 disk └─drbd0 147:0 0 16G 0 disk2号機も確認
[root@server-2 ~]# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sr0 11:0 1 1024M 0 rom vda 252:0 0 16G 0 disk ├─vda1 252:1 0 1G 0 part /boot └─vda2 252:2 0 15G 0 part ├─centos-root 253:0 0 13.4G 0 lvm / └─centos-swap 253:1 0 1.6G 0 lvm [SWAP] vdb 252:16 0 16G 0 disk └─drbd0 147:0 0 16G 0 disk
SERVER-1を主系にする[root@server-1 ~]# drbdadm primary --force drbd0ファイルシステムをext4にする
[root@server-1 ~]# mkfs.ext4 /dev/drbd0ここで確認の為にマウントしてみます。
両系にマウントするディレクトリを作成しておく。[root@server-1 ~]# mkdir /opt/mntpoint [root@server-1 ~]# mount /dev/drbd0 /opt/mntpoint[root@server-1 ~]# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sr0 11:0 1 1024M 0 rom vda 252:0 0 16G 0 disk ├─vda1 252:1 0 1G 0 part /boot └─vda2 252:2 0 15G 0 part ├─centos-root 253:0 0 13.4G 0 lvm / └─centos-swap 253:1 0 1.6G 0 lvm [SWAP] vdb 252:16 0 16G 0 disk └─drbd0 147:0 0 16G 0 disk /opt/mntpointさらに同期されるかの確認で適当にファイルを作ってみる
[root@server-1 ~]# touch /opt/mntpoint/hoge.txt1号機からアンマウント
[root@server-1 ~]# umount /opt/mntpoint2号機にマウントしてlsblk
[root@server-2 ~]# mkdir /opt/mntpoint [root@server-2 ~]# mount /dev/drbd0 /opt/mntpoint [root@server-2 ~]# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sr0 11:0 1 1024M 0 rom vda 252:0 0 16G 0 disk ├─vda1 252:1 0 1G 0 part /boot └─vda2 252:2 0 15G 0 part ├─centos-root 253:0 0 13.4G 0 lvm / └─centos-swap 253:1 0 1.6G 0 lvm [SWAP] vdb 252:16 0 16G 0 disk └─drbd0 147:0 0 16G 0 disk /opt/mntpointちゃんと同期されてますね。
hoge.txtは削除しておきましょう。[root@server-2 ~]# ll /opt/mntpoint/ -rw-r--r-- 1 root root 0 9月 11 13:07 hoge.txtディスク暗号化
今回はKVMなんであまり意味がないかもしれないですが、暗号化しているということで、だれかが安心してくれる場合もある。
まずdrbdをマウントした状態ならアンマウントしておきます。
[root@server-2 ~]# umount /opt/mntpointフォーマット
[root@server-1 ~]# cryptsetup luksFormat -c aes-cbc-essiv:sha256 -s 256 /dev/drbd0 WARNING! ======== This will overwrite data on /dev/drbd0 irrevocably. Are you sure? (Type uppercase yes): YES //大文字のYESしか認識してくれなかった Enter passphrase for /dev/drbd0: Verify passphrase: //【パスワード】入力 encrypt success //【パスワード】再入力 mke2fs 1.42.9 (28-Dec-2013) Filesystem label= OS type: Linux Block size=4096 (log=2) Fragment size=4096 (log=2) Stride=0 blocks, Stripe width=0 blocks 1048576 inodes, 4193655 blocks 209682 blocks (5.00%) reserved for the super user First data block=0 Maximum filesystem blocks=2151677952 128 block groups 32768 blocks per group, 32768 fragments per group 8192 inodes per group Superblock backups stored on blocks: 32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208, 4096000 Allocating group tables: done Writing inode tables: done Creating journal (32768 blocks): done Writing superblocks and filesystem accounting information: donecryptdirという名前で暗号化ディレクトリを作る
[root@server-1 ~]# echo 【パスワード】 | cryptsetup luksOpen /dev/drbd0 cryptdirそうすると
[root@server-1 ~]# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sr0 11:0 1 1024M 0 rom vda 252:0 0 16G 0 disk ├─vda1 252:1 0 1G 0 part /boot └─vda2 252:2 0 15G 0 part ├─centos-root 253:0 0 13.4G 0 lvm / └─centos-swap 253:1 0 1.6G 0 lvm [SWAP] vdb 252:16 0 16G 0 disk └─drbd0 147:0 0 16G 0 disk └─cryptdir 253:2 0 16G 0 crypt //なんかぽいのができる
/dev/mapper/の下にさっきのcryptdirができているので、ファイルシステムをext4で作成[root@server-1 ~]# mkfs.ext4 /dev/mapper/cryptdirDRBDこみで同期するかを確認します。確認します。
/dev/mapper/cryptdir
こいつをさっきのマウントポイントに。mount /dev/mapper/cryptdir /opt/mntpointマウントされました。
[root@server-1 ~]# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sr0 11:0 1 1024M 0 rom vda 252:0 0 16G 0 disk ├─vda1 252:1 0 1G 0 part /boot └─vda2 252:2 0 15G 0 part ├─centos-root 253:0 0 13.4G 0 lvm / └─centos-swap 253:1 0 1.6G 0 lvm [SWAP] vdb 252:16 0 16G 0 disk └─drbd0 147:0 0 16G 0 disk └─cryptdir 253:2 0 16G 0 crypt /opt/mntpointさきほどのように、適当にファイルを作ってみる
[root@server-1 ~]# touch /opt/mntpoint/hoge.txt1号機からアンマウント
[root@server-1 ~]# umount /opt/mntpoint暗号化解除
[root@server-1 ~]# cryptsetup luksClose cryptdir2号機で暗号化したのちマウント
[root@server-2 ~]# echo 【パスワード】 | cryptsetup luksOpen /dev/drbd0 cryptdir [root@server-2 ~]# mount /dev/mapper/cryptdir /opt/mntpointありますね。
[root@server-2 ~]# ll /opt/mntpoint/ -rw-r--r-- 1 root root 0 9月 11 13:51 hoge.txt2号機からアンマウントと暗号化解除
[root@server-1 ~]# umount /opt/mntpoint [root@server-1 ~]# cryptsetup luksClose cryptdir
ここでのちにpacemakerにリソース管理をさせる為、
systemdのサービスとして、/usr/lib/systemd/system/encrypt.serviceを作成。/usr/lib/systemd/system/encrypt.service[root@server-1 ~]# vi /usr/lib/systemd/system/encrypt.service [Unit] Description=encrypt [Service] ExecStart=/opt/bin/encryptstart.sh ExecStop=/opt/bin/encryptstop.sh Type=oneshot RemainAfterExit=yes [Install] WantedBy=multi-user.targetsystemctl start encryptしたときに実行されるscript
/opt/bin/encryptstart.sh[root@server-1 ~]# mkdir /opt/bin [root@server-1 ~]# vi /opt/bin/encryptstart.sh #!/usr/bin/sh /usr/bin/echo 【パスワード】 | /usr/sbin/cryptsetup luksOpen /dev/drbd0 cryptdirsystemctl stop encryptしたときに実行されるscript
/opt/bin/encryptstop.sh[root@server-1 ~]# vi /opt/bin/encryptstop.sh #!/usr/bin/sh /usr/sbin/cryptsetup luksClose cryptdir2号機にも送っておきましょう。
[root@server-1 ~]# scp -p /usr/lib/systemd/system/encrypt.service root@server-2:/usr/lib/systemd/system/encrypt.service [root@server-1 ~]# scp -rp /opt/bin root@server-2:/opt/binsystemd設定反映
1号機[root@server-1 ~]# systemctl daemon-reload2号機
[root@server-2 ~]# systemctl daemon-reloadpacemakerとcorosyncの設定
一旦まずはDRBD停止します。
[root@server-1 ~]# systemctl stop drbd[root@server-2 ~]# systemctl stop drbd/etc/corosync/corosync.confを編集
/etc/corosync/corosync.conf[root@server-1 ~]# vi /etc/corosync/corosync.conf totem { version: 2 cluster_name: XXX_cluster secauth: off transport: udpu } nodelist { node { ring0_addr: SERVER-1 nodeid: 1 } node { ring0_addr: SERVER-2 nodeid: 2 } } quorum { provider: corosync_votequorum two_node: 1 } logging { to_logfile: yes logfile: /var/log/cluster/corosync.log to_syslog: yes }2号機へ転送
[root@server-1 ~]# scp -p /etc/corosync/corosync.conf 192.168.200.11:/etc/corosync/corosync.conf
/etc/sysconfig/pacemakerの編集/etc/sysconfig/pacemaker[root@server-1 ~]# vi /etc/sysconfig/pacemaker # PCMK_fail_fast=no ↓ PCMK_fail_fast=yes2号機へ転送
[root@server-1 ~]# scp -p /etc/sysconfig/pacemaker 192.168.200.11:/etc/sysconfig/pacemaker中身を変更しているわけではないが、一応/etc/systemd/system/にサービスをコピーしておく
[root@server-1 ~]# cp -p /usr/lib/systemd/system/corosync.service /etc/systemd/system/ [root@server-1 ~]# cp -p /usr/lib/systemd/system/pacemaker.service /etc/systemd/system/ [root@server-1 ~]# scp -p /usr/lib/systemd/system/corosync.service root@192.168.200.11:/usr/lib/systemd/system/corosync.service [root@server-1 ~]# scp -p /usr/lib/systemd/system/pacemaker.service root@192.168.200.11:/usr/lib/systemd/system/pacemaker.serviceもう一度systemd設定反映
1号機[root@server-1 ~]# systemctl daemon-reload2号機
[root@server-2 ~]# systemctl daemon-reloadpacemakerの起動
[root@server-1 ~]# systemctl start pacemaker [root@server-1 ~]# systemctl start pcsd [root@server-1 ~]# systemctl enable pcsdあとhaclusterというユーザにパスワードを付与しておく
1号機[root@server-1 ~]# echo 【haパスワード】 | passwd -f hacluster --stdin2号機
[root@server-2 ~]# echo 【haパスワード】 | passwd -f hacluster --stdin
haclusterユーザ使って認証[root@server-1 ~]# pcs cluster auth SERVER-1 SERVER-2 -u hacluster -p 【haパスワード】clusterの設定
[root@server-1 ~]# pcs cluster setup --name HA_cluster SERVER-1 SERVER-2 --forceクラスタの起動
[root@server-1 ~]# pcs cluster start --all [root@server-1 ~]# pcs cluster enable --allリソース登録
DRBDの登録
[root@server-1 ~]# pcs resource create DRBD ocf:linbit:drbd drbd_resource=drbd0 op monitor interval=10s role=Master monitor interval=30s role=Slave [root@server-1 ~]# pcs resource master MS_DRBD DRBD master-max=1 master-node-max=1 clone-max=2 clone-node-max=1 notify=trueディスク暗号化
[root@server-1 ~]# pcs resource create ENCRYPT systemd:encrypt --group HAファイルシステムのマウント
[root@server-1 ~]# pcs resource create FS ocf:heartbeat:Filesystem device=/dev/mapper/criptdir directory=/opt/mntpoint fstype=ext4 --group HAなんか色々
[root@server-1 ~]# pcs constraint colocation add HA MS_DRBD INFINITY with-rsc-role=Master [root@server-1 ~]# pcs constraint order promote MS_DRBD then start HAリソースのクリーン
[root@server-1 ~]# pcs resource cleanupこういう設定もしたのだけど、なんだったかわすれた・・・
[root@server-1 ~]# pcs property set stonith-enabled=false [root@server-1 ~]# pcs property set no-quorum-policy=ignoreあとVIPもリソースに追加
[root@server-1 ~]# pcs resource create VIP ocf:heartbeat:IPaddr2 ip=192.168.200.12 cidr_netmask=24 --group HA確認
[root@server-1 ~]# pcs status Cluster name: HA_cluster Stack: corosync Current DC: SERVER-2 (version 1.1.20-5.el7_7.2-3c4c782f70) - partition with quorum Last updated: Sun Sep 13 06:57:08 2020 Last change: Thu Sep 10 14:31:58 2020 by root via cibadmin on SERVER-1 2 nodes configured 7 resources configured Online: [ SERVER-1 SERVER-2 ] Full list of resources: Master/Slave Set: MS_DRBD [DRBD] Masters: [ SERVER-1 ] Slaves: [ SERVER-2 ] Resource Group: HA ENCRYPT (systemd:encrypt): Started SERVER-1 FS (ocf::heartbeat:Filesystem): Started SERVER-1 VIP (ocf::heartbeat:IPaddr2): Started SERVER-1 Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled
- 投稿日:2020-09-14T11:05:47+09:00
linuxで音量を指定して、音を鳴らす
amixer -c0 sset PCM 60% && aplay --duration=2 a.wav
amixer -c0 sset PCM 70% && aplay --duration=2 a.wav
amixer -c0 sset PCM 80% && aplay --duration=2 a.wav
amixer -c0 sset PCM 85% && aplay --duration=2 a.wav
amixer -c0 sset PCM 90% && aplay --duration=2 a.wav
- 投稿日:2020-09-14T04:09:34+09:00
TinyEMU をビルドしてEmscripten上でLinuxカーネルを起動するメモ
前回( RISC-V 開発環境をbuildrootとcrosstool-ngで用意する )はカーネルをqemuで起動したので、今度はWebブラウザ上で動作するRISC-VエミュレータであるところのTinyEMU( https://bellard.org/tinyemu/ )で起動してみる。
- https://sophisticated-overjoyed-treatment.glitch.me/run.html
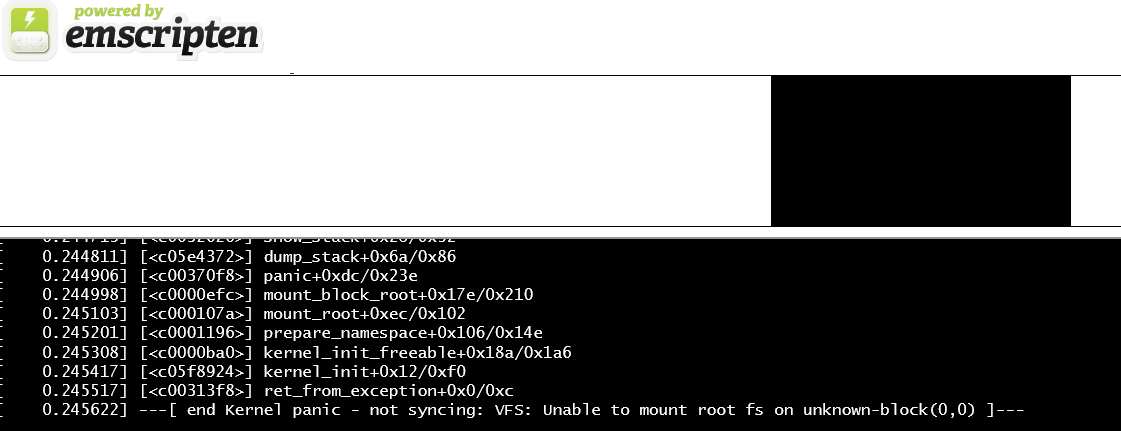
- ビルドしたTinyEMUとLinuxカーネル(rootfsが無いので直ぐpanicする)
- dmesg: https://gist.github.com/okuoku/23c2fbd2400d21949fbb5e80c686149d#file-dmesg-txt
親のカーネルpanicより見た。
tl;dr
今回はTinyEMU標準のI/Oライブラリは一切使用せず、EmscriptenのC言語側からVMを構成して起動する形を取ってみた。
- ブートローダはTinyEMU付属のものを使用する必要がある 。付属のローダには改造が施されていて、普通のローダではコンソールが出ない。
- ビルド自体はEmscripten 2.0.2 の
emccで単にビルドしてEmscripten標準のHTML出力でも動作する。TinyEMU のビルド
ビルド自体は特に難しいところはなく、適当に
*.cをコンパイルして出力すれば動くものができる。emcc jsemu.c softfp.c virtio.c fs.c fs_net.c fs_wget.c fs_utils.c simplefb.c pci.c ^ json.c block_net.c iomem.c cutils.c aes.c sha256.c riscv_cpu.c riscv_machine.c machine.c ^ --llvm-opts 2 -Wall -D_FILE_OFFSET_BITS=64 -D_LARGEFILE_SOURCE -MMD -fno-strict-aliasing ^ -DCONFIG_FS_NET -O3 --memory-init-file 0 --closure 0 -s NO_EXIT_RUNTIME=1 ^ -s "EXPORTED_FUNCTIONS=['_console_queue_char','_vm_start','_fs_import_file','_display_key_event','_display_mouse_event','_display_wheel_event','_net_write_packet','_net_set_carrier','_main']" ^ -s "EXTRA_EXPORTED_RUNTIME_METHODS=[\"ccall\", \"cwrap\"]" ^ --js-library js/lib.js -s WASM=1 -s TOTAL_MEMORY=67108864 -s ALLOW_MEMORY_GROWTH=1 ^ -DMAX_XLEN=32 -DCONFIG_RISCV_MAX_XLEN=32 -s ASSERTIONS=1 --emrun -g4 ^ --source-map-base http://localhost:6931/ --preload-file kernel --preload-file bbl32.bin emmain.c -o run.html初期設定ルーチン(いわゆる
main)通常のTinyEMUでは、VMの設定はJavaScript側から実施するが、ちょっとネイティブ版と統一の上で不便だったので
main関数を用意することにした。
- https://github.com/okuoku/patched-tinyemu-proto/blob/302211483e374b61dd686e1662b59a33eb5fc501/emmain.c
- 作成した
emmain.cブートローダー
bbl32.binと Linuxカーネルkernelは一旦Emscriptenの--preload-fileアプリ側に埋め込み、C言語のファイルI/Oで読み込んでいる。
kernelは前回( https://qiita.com/okuoku/items/3133c75d26c57394fd1a )buildrootでビルドしたものがそのまま使用できるが、ブートローダbbl32.binはTinyEMU付属( https://bellard.org/tinyemu/diskimage-linux-riscv-2018-09-23.tar.gz )のものを使用しなければならない。TinyEMU固有(?)のHTIF実装
TinyEMUはいわゆるUARTデバイスをエミュレートしておらず、Spike(RISC-V公式のエミュレータ)が実装していたHTIF(Host-Target IF)を実装している。
ただ、qemu等の他の実装と異なり、TinyEMUのHTIF実装はアドレスが決め打ちになっており、ブートローダの方をパッチしてアドレスを伝達している。
- https://github.com/okuoku/patched-tinyemu-proto/blob/302211483e374b61dd686e1662b59a33eb5fc501/riscv_machine.c#L69
- TinyEMU内では、物理アドレス
0x40008000にHTIFのレジスタを配置している#define HTIF_BASE_ADDR 0x40008000
- https://gist.github.com/okuoku/23c2fbd2400d21949fbb5e80c686149d#file-riscv-pk-diff-L14-L33
- TinyEMU付属のBBLでは使用されるシンボルを直接パッチしている(TinyEMU付属のパッチ)
diff --git a/bbl/bbl.lds b/bbl/bbl.lds index 26f5816..615c3dc 100644 --- a/bbl/bbl.lds +++ b/bbl/bbl.lds @@ -43,15 +43,10 @@ SECTIONS _etext = .; /*--------------------------------------------------------------------*/ - /* HTIF, isolated onto separate page */ + /* HTIF I/Os */ /*--------------------------------------------------------------------*/ - . = ALIGN(0x1000); - .htif : - { - PROVIDE( __htif_base = .); - *(.htif) - } - . = ALIGN(0x1000); + tohost = 0x40008000; + fromhost = 0x40008008;このリンカスクリプトへのパッチで、
tohostとfromhostのアドレスを固定化している。
- https://github.com/riscv/riscv-pk/blob/ac2c910b18c3e36cfd85080472e78ad2fe484325/machine/htif.c#L11-L12
- ブートローダ内での
tohostfromhostの宣言volatile uint64_t tohost __attribute__((section(".htif"))); volatile uint64_t fromhost __attribute__((section(".htif")));本来、これらのアドレスはエミュレータがロードしたタイミングで取得される。
- https://github.com/qemu/qemu/blob/c47edb8dda0660180f86df4defae2a1f60e345db/hw/riscv/riscv_htif.c#L45-L63
- qemuのSpikeマシンモデルで使用されるパッチコード
そもそもHTIF自体が旧い仕様なので今となってはどうでも良いのかもしれないが、もうちょっと真面目なプロトコルが欲しいところでもある。
HTIFを32bitで使う
HTIFは64bit巾のインターフェースであるため、本来32bitアーキテクチャでは使用できない。(書き込みが2つ以上のCPUで競合すると安全に処理できない)
TinyEMUではマルチプロセッサをサポートしていないためこの辺は特に気にしていないようで、 レジスタを32bit巾で宣言し、上位ワードが書き込まれたタイミングで発動する コードとすることで32bit/64bit両対応としている。
- TinyEmu: https://github.com/okuoku/patched-tinyemu-proto/blob/302211483e374b61dd686e1662b59a33eb5fc501/riscv_machine.c#L163-L166
- qemu: https://github.com/qemu/qemu/blob/c47edb8dda0660180f86df4defae2a1f60e345db/hw/riscv/riscv_htif.c#L210-L214
... qemuはマルチプロセッサをサポートしているので同じ方針ではダメな気もするが。。
かんそう
RISC-V 32bitの環境が揃ったのが最近すぎて64bitに比べて色々遅れているというのは覚悟していたけど、HTIFのような純粋なデバッグ用I/Fが32bit非サポートというのはちょっと予想外だった。
TODO: npmで配る用に
-s SINGLE_FILE=1して、かつ、カーネルやブートローダは外部から与えられるようにしないといけない。