- 投稿日:2020-09-14T23:52:21+09:00
AWS SAA学習ノート:暗記すべき数値一覧
AWSソリューションアーキテクトの勉強ノート。
暗記すべき数値の一覧を自分なりにまとめてみた。
カテゴリ 内容 数値 VPC リージョン辺りのMaxVPC数 デフォルト5(100まで緩和可) VPC毎のMaxSubnet数 200 VPCに設定可能なCIDR範囲 /16~/28 ストレージ 以下のスループット(秒)・IOPS
a.汎用SSD
b.スループット最適化HDD
c.プロビジョンドIOPS
d.Amazon FSx
e.EFS
a. 250MB/16000
b. 500MB/500
c. 1GB/64000
d. 2GB/数百万
e. 10GB/50万RDS 自動バックアップの保持期間 35日 S3 STANDARDの可用性・耐久性 99.99%・99.999999999% STANDARD-IAの可用性・耐久性 99.9%・99.999999999% ONEZONE-IAの可用性・耐久性 99.5%・99.999999999% 最大ファイルサイズ 5TB 1回のPUTでの最大サイズ 5GB S3 Glacier 最小保存期間 90日 「迅速」の取得時間 1~5分 「標準」の取得時間 3~5時間 「大容量」の取得時間 5~12時間 最大ファイルサイズ 40TB S3 Glacier Deep Archive 最小保存期間 180日 「標準」の取得時間 12時間以内 「大容量」の取得時間 48時間以内 ELB デフォルトのヘルスチェック間隔 30秒 デフォルトのアイドルタイムアウト 60秒 AutoScalingのデフォルトクールダウン期間 300秒 Route53 デフォルトのヘルスチェック間隔 30秒 IAM 1アカウントで作成できるMAXユーザー数 5000 1アカウントで作成できるMAXグループ数 300 1ユーザーが所属可能なMAXグループ数 10 Lambda 一時ボリュームの最大サイズ 512MB 最大同時実行数 1000 最大実行時間 15分 関数レイヤストレージ最大サイズ 72GB DynamoDB 1RCUの性能 4KBを1秒間に2回読み込み可 1RCUの性能(強力な整合性) 4KBを1秒間に1回読み込み可 1WCUの性能 1KBを1秒間に1回書き込み可 SQS キューの最大サイズ 256KB(緩和して2GBまで増やせる) キューのデフォルト保持期間 4日間 キューの最大・最小保持期間 60秒~14日 1APIあたりの最大メッセージ数 10 可視性タイムアウトデフォルト値 30秒 CloudWatch メトリクスの間隔(通常) 5分間 メトリクスの間隔(詳細) 1分間(有料) Kinesis ストリームのアクセス可能時間 デフォルト24時間・最長7日間 ※他に覚えていたほうが良い数値があればコメント欲しいです!
- 投稿日:2020-09-14T23:52:21+09:00
AWS SAAテスト対策ノート:暗記すべき数値一覧
AWSソリューションアーキテクトの勉強ノート。
暗記すべき数値の一覧を自分なりにまとめてみた。
カテゴリ 内容 数値 VPC リージョン辺りのMaxVPC数 デフォルト5(100まで緩和可) VPC毎のMaxSubnet数 200 VPCに設定可能なCIDR範囲 /16~/28 ストレージ 以下のスループット(秒)・IOPS
a.汎用SSD
b.スループット最適化HDD
c.プロビジョンドIOPS
d.Amazon FSx
e.EFS
a. 250MB/16000
b. 500MB/500
c. 1GB/64000
d. 2GB/数百万
e. 10GB/50万RDS 自動バックアップの保持期間 35日 S3 STANDARDの可用性・耐久性 99.99%・99.999999999% STANDARD-IAの可用性・耐久性 99.9%・99.999999999% ONEZONE-IAの可用性・耐久性 99.5%・99.999999999% 最大ファイルサイズ 5TB 1回のPUTでの最大サイズ 5GB S3 Glacier 最小保存期間 90日 「迅速」の取得時間 1~5分 「標準」の取得時間 3~5時間 「大容量」の取得時間 5~12時間 最大ファイルサイズ 40TB S3 Glacier Deep Archive 最小保存期間 180日 「標準」の取得時間 12時間以内 「大容量」の取得時間 48時間以内 ELB デフォルトのヘルスチェック間隔 30秒 デフォルトのアイドルタイムアウト 60秒 AutoScalingのデフォルトクールダウン期間 300秒 Route53 デフォルトのヘルスチェック間隔 30秒 IAM 1アカウントで作成できるMAXユーザー数 5000 1アカウントで作成できるMAXグループ数 300 1ユーザーが所属可能なMAXグループ数 10 Lambda 一時ボリュームの最大サイズ 512MB 最大同時実行数 1000 最大実行時間 15分 関数レイヤストレージ最大サイズ 72GB DynamoDB 1RCUの性能 4KBを1秒間に2回読み込み可 1RCUの性能(強力な整合性) 4KBを1秒間に1回読み込み可 1WCUの性能 1KBを1秒間に1回書き込み可 SQS キューの最大サイズ 256KB(緩和して2GBまで増やせる) キューのデフォルト保持期間 4日間 キューの最大・最小保持期間 60秒~14日 1APIあたりの最大メッセージ数 10 可視性タイムアウトデフォルト値 30秒 CloudWatch メトリクスの間隔(通常) 5分間 メトリクスの間隔(詳細) 1分間(有料) Kinesis ストリームのアクセス可能時間 デフォルト24時間・最長7日間 ※他に覚えていたほうが良い数値があればコメント欲しいです!
- 投稿日:2020-09-14T23:14:37+09:00
クラウドRDBの初期化(DB・テーブル作成)を考える
背景
RDS(AWS)やCloud SQL(GCP)を利用する際に、どのようにデータベースやテーブルを作成するかを纏めてみる
初期化方法
(1)DBインスタンスにログインして初期化する
ローカルのDBの初期化をSQLで行う場合はこちらを利用することを考える
- アプリでORMを使わない場合
- docker-entrypoint-initdb.dを使う場合
RDS(AWS)
以下の条件を満たすように設定すればインターネットからアクセス可能になる(ただし初期化後は安全のためアクセスを塞いでおくべきである)
- RDSがパブリックサブネットに配置されていること
- VPCのセキュリティグループにmysqlのインバウンドルールが追加されていること
- パブリックアクセシビリティが許可されていること
あるいは同じVPC内に踏み台サーバを起動し、踏み台サーバ経由でアクセスする方法もある。
- サーバレスAuroraではインターネットアクセスができないため、この方法か、次節の方法で初期化する。
- 踏み台サーバは必要な時だけ起動したり、IP制限するとセキュアである
Cloud SQL(GCP)
Cloud Shellからアクセスして初期化する
(2)DB初期化アプリケーションを作成して初期化する
アプリケーションで利用しているライブラリとシステムを用いたDB初期化用のアプリケーションを作成・実行する。
例: SQLAlchemyを利用したCloud Runで動くアプリであれば、SQLAlchemyを利用したDB初期化アプリを作成し、Cloud Runで実行する
大抵のORMにはテーブルを作成する機能があるので利用する。
(3)[Kubernetesの場合]Kubernetesの機能を利用する
アプリケーションがKubernetesで動作している場合は、Kubenetesの機能を用いてデータベースの初期化をすることもできる。
Init Containerを利用
ネットワーク・ボリュームが初期化された後、アプリケーションコンテナが起動する前に実行されるコンテナ。
起動コマンドとしてSQLコマンドを実行させたり、ライブラリを利用したアプリケーションを実行させたりできる。
https://kubernetes.io/ja/docs/concepts/workloads/pods/init-containers/
ConfigMapで記述(できないかも)
ConfigMapにSQLをベタ書きして docker-entrypoint-initdb.d にマウントする方法
Cloud SQLを利用していて、cloudsql-proxyを利用している場合に利用できるかは未確認。
参考記事:
[Kubernetes] ConfigMapでコンテナの設定ファイルをVolumeに配置する
https://a-records.info/kubernetes-configmap-for-container-settings/まとめ
- 簡単にやるならDBインスタンスにログインして初期化する
- 丁寧にやるならアプリやインフラなどからよしなに初期化方法を採用する
- Kubernetesを利用しているならInitContainerを利用する
- 投稿日:2020-09-14T20:28:37+09:00
AWS ルートテーブルについて
AWS基礎_2
基礎_1に戻るルートテーブル
・サブネットに関連づけて使用
・サブネットから外に出る通信を
どこに向けて発信するかルール、定義
・ルートと呼ばれるルールで構成される
・もっとも明確なルールが優先されて適用
送信先 ターゲット 10.0.0.0/21 local ※上記localルートはルートテーブルにデフォルトに設定せれており削除できない。
送信先 ターゲット 10.0.0.0/21 local 0.0.0.0/0 インターネット ※上記はインターネットに向かうルートを設定した場合
ルートテーブルはどのIPアドレスの範囲をどの方向に向けるかは設定するもの
Internet gateway
VP内のAWSリソースとインターネットを繋げる
自働でスケールし、可用性が高い
サブネットのルートテーブルを設定し使用するEC2インスタンスをインターネットと繋ぐにはルートテーブルに設定を追加する
送信先 ターゲット 10.0.0.0/21 local 0.0.0.0/0 Internet gateway サブネット内にあるAWSリソースはEC2インスタンスのVPC内部の通信はlocalルートによってVPC内部に通信が飛び、それ以外の通信はinternetgatewayに向く。
Private subnetからネットワークに繋ぐにはどうするのか?
NAT gateway
Privatesubnetからインターネット接続を可能する
アウトバウンドはできるが、インバウンドはできない発信はできるが、外からの受信はできない。
PrivatesubnetのEC2にログインするにはPublicsubnetにログインしそこからPrivatesubnetにログインしなければならない。ENI(Elastic network interface)
仮想ネットワークインターフェース
EC2インスタンスのIPアドレスはENIに付与される
同じAZ内のインスタンスにアタッチ/デタッチできる
インスタンスに複数のENIをアタッチできるこのENIとインターネットゲートウェイが繋がる事によってインターネット接続する
外部IPアドレスが必要になってくる。
Public IP address
AWSのIPアドレスプールより割り当てられる
インスタンスが再起動、停止、終了した場合このアドレスは解放される。
Elastic IP address
インスタンスにアタッチ/デタッチ可能で静的なパブリックIPアドレス
インスタンスが再起動、停止、終了しても同じアドレス
セキュリティグループ
AWSの仮想ファイアーウォールサービス
IPアドレスの範囲または、セキュリティグループとどのポートを許可するのかを設定する。
インバウンドルール(受信)とアウトバウンドルール(送信)が設定できる。
セキュリティーグループ単位で設定可能。Network ACL
サブネット単位で設定するファイアーウォール
セキュリティグループで対策し、対策仕切れない所を補助する感じ。許可するIPアドレスの範囲とポートのみを指定する。
サブネットはNetwrokACLを一つしか持つ事が出来ません。
サブネットに所属するインスタンス、コンポーネント全てにルールが適応される。
- 投稿日:2020-09-14T19:02:33+09:00
AWSによるLinux最速学習
Linuxとは
LinuxはMacOSやWindowsと同じようなOSです。
UbuntuやCentOSなどが有名で無料です。Red Hatなど有料のものもあります。MacOSやWindowsなど直感的な操作が可能なものはGUI、
Linuxはコマンドラインで操作されCUIと呼ばれます。Linuxはハードウェアにインストールして使う場合もありますが、
今回はAWSを使用します。
AWSにはLinuxがあらかじめインストールされています。動作環境
MacOS Catalina、Amazon EC2
コマンド
LinuxはCUIなのでコマンドラインに命令を打ち込み操作します。
例えば、$ dateと打ち込みEnterを押すと、
$ date 2020年 9月 14日 月曜日 10:00:29 UTCのように、現在の日時が表示されます。
シェル
Linuxはカーネルとシェルのセットです。
カーネルがOSの本体、シェルはユーザーが本体を操作するためのコマンド機能です。
主に、sh、bash、tcsh などがありますが、一番有名な bash を使用します。
以下のコマンドを打ち込むと bash に切り替わります。$ bashシェルを終了したいときは、
$ exitのように入力しEnterを押します。
コマンドライン操作
よく使うコマンド操作は以下の通りです。
コマンド 動作 Ctrl + b 左に1文字移動 Ctrl + f 右に1文字移動 Ctrl + b 一番右に移動 Ctrl + b 一番左に移動 Esc, b 左に1単語移動 Esc, f 右に1単語移動 BackSpace カーソルの左の文字を削除 fn + BackSpace カーソルの位置の文字を削除 Ctrl + w 単語削除
(左の次のスペース区切りまで削除)Ctrl + k カーソルの位置から一番右まで削除 Ctrl + u カーソルの位置から一番左まで削除 あとがき
お読みいただき、ありがとうございました。
- 投稿日:2020-09-14T17:33:42+09:00
JAWS SONIC 2020 & MIDNIGHT JAWS 2020 登壇資料まとめ
JAWS SONIC 2020 & MIDNIGHT JAWS 2020 の登壇資料をTwitterからまとめました。
公開したことをTweetしていただけたもののみです。
登壇資料以外のも一部あります。
もし他にもあったら教えてください。
ECSとGitLabでCI環境構築 JAWS-UG 磐田支部 伊藤秀樹
初心者が避けがちなAWS Well-Architectedフレームワークを使ってWordPressサイトを評価してみた - Speaker Deck JAWS-UG初心者支部 山原崇史
MediaServicesを使って動画配信サービスを構築しよう! Media-JAWS 三浦一樹
Alexaで作る夏の思い出 - Speaker Deck JAWS-UG 神戸支部 Tomoharu Ito、Atushi Ando、Kazuto Takeshita
長く使えるAWSスキルを効率良く身に付けよう /20200912-jaws-sonic-awscli - Speaker Deck JAWS-UG CLI専門支部 波田野 裕一
AWSの研修環境構築のためにAWS CDKとAmplify Console使った話 / jaws sonic 2020 - Speaker Deck JAWS-UG 新潟支部 笠原宏
週末趣味のAWS NAT配下のCGWからIKEv2でサイト間VPN接続 Private Link を添えて JAWS-UG 岡山 難波 和生
20200912 昔、オンプレミスでやっていたことを AWS でやるとどうなるか JAWS-UG札幌 小倉大
ちょっと大きくなりつつある会社で、新規事業系インフラを作ってます (JAWS SONIC 2020) JAWS-UG 京王線 間瀬 哲也
監視論 ~SREと次世代MSP~ - Speaker Deck OpsJAWS 九龍真乙(伊藤覚宏)
AWSコミュニティマネージャーからみたJAWS-UGとは JAWS SONIC 2020 実行委員会沼口 繁
DeepComposerの響きで さわやかな目覚めを JAWS-UG横浜支部 新居田晃史
Copilotによるお手軽3分ECSクッキング / The Cooking of AWS Copilot - Speaker Deck JAWS-UG コンテナ支部 新井雅也、濱田孝治
ParallelClusterを使い倒してみる JAWS-UG HPC専門支部 小林広志
200913 #jawssonic2020 人を育てるということ ~自己の成長を他人の成長に連鎖させる~ #jawsug @applebe… JAWS-UGクラウド女子会 多田 歩美
テレワーク率98%を支えるネットワーク環境構築のお話 JAWS-UG 上越妙高支部 植木和樹
AWSをMotoでmockしてユニットテスト! - Speaker Deck JAWS-UG Nagano 知野雄二, 寺田 怜真, 春原 宏保
JAWS-UG千葉・金沢・初心者支部合同WorkSpacesオンラインハンズオンハンズオン資料 JAWS-UG 千葉 山口正徳、加藤雅之、和田健一郎、北原雅人
"JAWS SONIC 2020 & MIDNIGHT JAWS 2020" と "デザイン" - Speaker Deck JAWS SONIC 2020 実行委員会 Ikuko Eshima、吉江瞬、山口正徳、榎本航介、武田可帆里、織田繁
絶対にLoungeに入るためにAWS認定取得を頑張った話 / Try to AWS Certification for lounge - Speaker Deck MIDNIGHT JAWS 2020で話題になったんですかね。@miu_crescent さんがTweetしていました。
JAWS-UG金沢 AWS Community Day 振り返り - Speaker Deck JAWS-UG 金沢 松田 康宏、ふぁらお加藤
20200912 JAWS SONIC 2020 Opening JAWS SONIC 2020 実行委員会 吉江 瞬
20200912 JAWS SONIC 2020 one-third LookBack JAWS SONIC 2020 実行委員会 吉江 瞬
AWS CDK 勝手に Deep Dive - Speaker Deck JAWS-UG アーキテクチャ専門支部 かれー
Moto で CDK プロジェクト内の Lambda 関数をテストする #jawssonic2020 - michimani.net
JAWS SONICをほぼ参加してみた感想を | Motsu Log
ASCII.jp:24時間開催の「JAWS SONIC 2020&MIDNIGHT JAWS 2020」を楽しむ(シゲモリ編) (1/6)
#JAWSSONIC2020 JAWS SONIC 2020 MIDNIGHT JAWS 2020のOPとJINGLE MOVIEを作成しました! | Developers.IO
jawssonic2020_AWSサービスで_JAMStackの構築をしてみた.pdf - Speaker Deck JAWS-UG名古屋 森 久由生
以下の登壇者(&参加者)の皆様のTweetを参考にさせていただきました。
皆様貴重な情報ありがとうございました!@khe02043
@shonansurvivors
@miu_crescent
@haruharuharuby
@tcsh
@kasacchiful
@kazu_0
@MasaruOgura
@matetsu
@qryuu
@numaguchi
@nid777
@msy78
@applebear_ayu
@czkuk
@chinoppy0727
@Keni_W
@OutputSeq
@PharaohKJ
@Typhon666_death
@curry9999
@michimani210
@ad_motsu
@asciijpeditors
@hisayuki_mori
@nun_is_tiger
(順不同)
- 投稿日:2020-09-14T17:15:36+09:00
クラウドストレージにデータをバックアップするやり方も色々・・ NetBackupの重複排除技術との組み合わせでクラウドストレージの消費量は本当に減るのか試してみた!
はじめに
流行のクラウドストレージをバックアップ先に利用してみたい
今回は、クラウドストレージをどれぐらい無駄なく、企業のデータ保管先に使うことができそうか、というお話です。
総務省の動向調査 (*1) の結果にもありましたが、クラウドストレージ(オブジェクトストレージを含む)にバックアップデータを保管するケースは、安価で高可用性・使い勝手の良さから、今後も増加傾向にあるようですね。
(*1) 令和元年通信利用動向調査の結果
https://www.soumu.go.jp/menu_news/s-news/01tsushin02_02000148.html一方で、企業がビジネスで利用する ITサービスの情報は、豊富でリッチになっています。 「量」「サイズ」ともに肥大化し、運用で維持しなければならないデータ量は予想を上回る勢いで増えていませんか!?
※「ウチはクラウドに移行したから大丈夫かな・・」という方も、クラウドに行っても自分のデータは自分で守らないといけないのでご注意ください有事(故障・災害・セキュリティ被害・人災など)の復旧目的や長期保管用としても、爆発的に増え続ける非構造化データを維持管理することは避けられません。 安価なクラウドストレージを利用した場合でも、数十TB ~ 数PB クラスを保有する企業レベルのデータ量となるとどうでしょうか。 それでもかなりのコスト負担になりそうですね。 今現在だと、標準タイプで 1TB のデータを 5年間保管したら 10万円切るのはさすがに厳しいでしょうか・・
NetBackupのクラウドストレージ対応
Veritas NetBackup では、2010年のバージョン 7.0からデータ保管先としてクラウド/オブジェクトストレージをサポートしてきました。 その後、永久増分バックアップを実現する技術として登場したアクセラレータ(Accelerator)も保管先としてクラウドストレージをサポートしました。
更に世の中の様々なクラウドストレージやオブジェクトストレージを広くサポートし続けながら、バージョン 8.1 では仮想的に重複排除ストレージのように扱える技術 CloudCatalyst が登場しました。 これにより、クラウド/オブジェクトストレージの消費は飛躍的に改善されて、バックアップやリストアの時間も短縮できるようになりましたね。
What is CloudCatalyst に関しては、過去のQiita投稿 ↓ をご参考ください。
NetBackup CloudCatalyst for AWS入門 まとめ
NetBackup CloudCatalyst for AWS入門 その1
NetBackup CloudCatalyst for AWS入門 その2
NetBackup CloudCatalyst for AWS入門 その3
時短ワザ!保存データ量を最小にしてIBM Cloud Object Storageへバックアップデータを保管してみようこのように NetBackup でもクラウドストレージへのデータ保管には幾つか選択肢がありますが、重複排除しながらクラウドストレージが使える技術がどのくらい効果があるのか、非常に興味があるポイントではないでしょうか。
そこで今回はそれぞれのバックアップ方法を試して、クラウド上のストレージ消費量にどのぐらい差が出るのかを実測してみました。 合わせて、オンプレにあるNetBackupオリジナルの重複排除ディスク上のサイズとも比較してみました。
ストレージ消費量を比較する各バックアップ内容は?
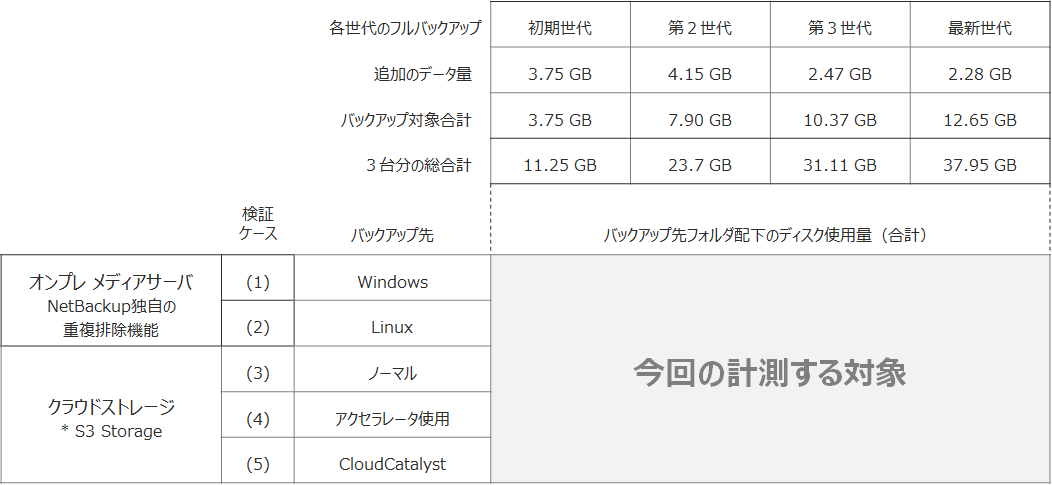
データをバックアップして保管するまでの方法ですが、今回は5つのケースで実測しています。
(1) NetBackupメディアサーバのディスクに重複排除機能(MSDP)で保管します(Windows使用)
(2) NetBackupメディアサーバのディスクに重複排除機能(MSDP)で保管します(Linux使用)
(3) バックアップデータを直接 S3ストレージに保管します(メディアサーバからの複製でも同等)
(4) バックアップデータを直接 S3ストレージに保管しますが、オプションに Acceleratorを指定して永久増分バックアップ方式を使用します
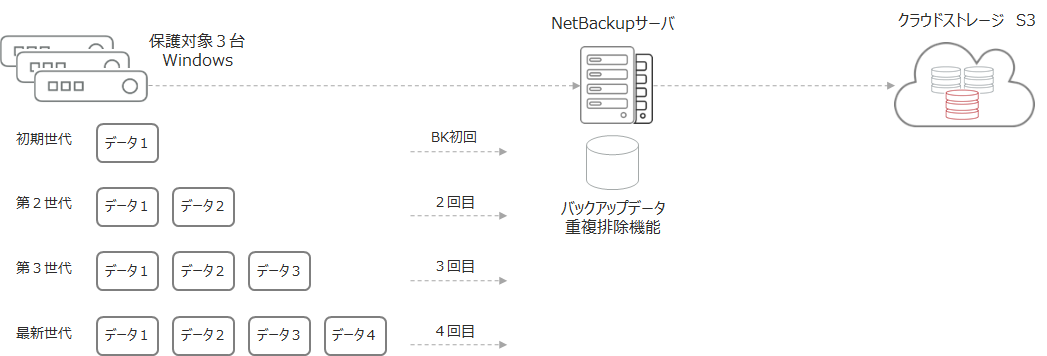
(5) CloudCatalyst を使います。 メディアサーバから CloudCatalyst へ複製、もしくは CloudCatalyst に直接バックアップどちらでもOK図1. ファイルバックアップの検証5パターン
バックアップ対象のデータですが、毎回新しいデータを追加して、世代毎にフルバックアップし、4世代分保管します。 バックアップ対象は3台用意しましたが、グローバル重複排除が本当に効くのかも確認したかったので、今回はどのバックアップ対象にも同じデータを置くことにしました。
図2. 初期世代 ~ 最新世代まで、4世代分のデータを順次フルバックアップ
バックアップ対象のデータは、筆者のパソコンにある普通のオフィス系ファイルやPDFファイル、ZIPファイル、画像や動画ファイルなど使いました。 最近のファイルはかなり最適化されているので、ファイル単体の重複排除効果はあまり期待できないかもしれませんが、リアリティのあるデータにしてみました。
表1. 検証で使用するテストデータ
このような方法で実測しますが、結果は下記のように整理することにします。
表2. 検証結果のまとめ方
さてどんな結果になるんでしょうか・・予想と実測結果
重複排除機能はクラウドストレージにも効くのか?
予想
実は、検証前こんな予想(期待)をしてました。
- (1)と(2) は、プラットフォームが違うけど結果はほぼ同じだろう
- (1)と(2) は、そこそこ重複排除は効くはずなので、元のデータよりは減るだろう
- (1)と(2) は、3台に同じデータがあるので、3台総合計の1/3以下にはなるだろう
- (3)は、毎回バックアップ対象の合計分だけクラウドストレージを消費するだろう
- (3)は、3台分別々にクラウドストレージを消費するだろう
- (4)は、毎回バックアップ対象の追加分だけクラウドストレージを消費するだろう
- (4)は、3台分別々にクラウドストレージを消費するだろう
- (5) CloudCatalyst は、(1)と(2)とほぼ変わらない結果になることを期待!実測結果
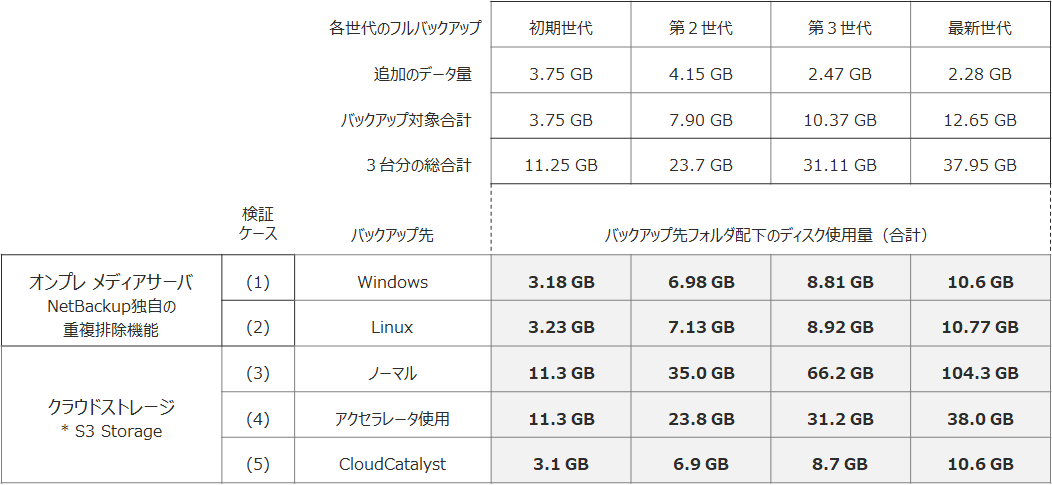
結果はどうなったでしょうか・・ その実測値は次の通りでした!
表3. 検証結果(対象3台、データ4世代)
おぉ!! CloudCatalystの重複排除効果ですが、期待を裏切らない結果になったようですね。
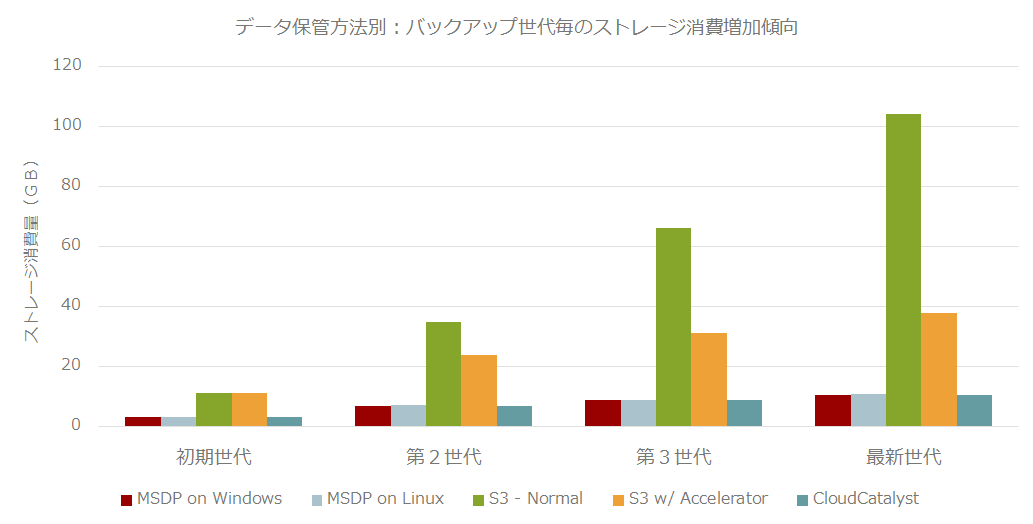
もう少し判りやすくグラフにしてみましょう。グラフ1. データ保管方法別:バックアップ世代毎のストレージ消費増加傾向
(1) (2) (5) の方法でバックアップすれば、グローバル重複排除が効いて必要最小限のディスク領域しか使わないと言えます。 毎回、フルイメージをそのままクラウドストレージに置いていると、あっという間に 10倍ぐらい違う使用量になってしまうんですね。
企業クラスのデータを保護するとなるとバカにならないコストになりそうです。 ここまで違いが出ると、安易にクラウドに同じようなデータをたくさん置いておくのも考え直した方がいいかもしれないと思ってしまいますね。
まとめ
期待を裏切らない結果となりましたが、最後にまとめてみます。
・クラウドストレージも安いからと言って安易に使うと、予想以上に費用がかかるかもしれない
・何世代分も長期間、大量に保存する必要がある企業にとって、重複排除技術の利用は非常に重要
・クラウドストレージをあたかも重複排除ディスクのように見立てる CloudCatalyst は非常に有用
・クラウドストレージと重複排除の組み合わせは、Tape運用と比べて大きなアドバンテージになるということで、一般のバックアップソフトやコピーベースの方法でクラウドストレージにそのままバックアップしている状況であれば、一度見直してみる価値はありそうですね ☺
最後に、2020年7月末に提供開始された NetBackup 最新バージョン 8.3 では、独自の重複排除機能(MSDP)とクラウドストレージを共有化させるような技術 MSDP cloud が登場しました。 ストレージ消費についても CloudCatalystと同等の削減効果が期待できますが、この新機能の嬉しい点は、CloudCatalystの専用サーバを構築しなくても済むようになったことです。
詳しくは今後の投稿にてご紹介します。
いかがでしたでしょうか。 NetBackupの重複排除技術は、クラウドストレージにも広がりましたし、NFS/CIFSのファイル共有サービスにも利用できるようになっていて、常に進化し続けていますね。 この先もさらに便利になることを期待しています。商談のご相談はこちら
本稿からのお問合せをご記入の際には「コメント/通信欄」に#GWCのタグを必ずご記入ください。
ご記入いただきました内容はベリタスのプライバシーポリシーに従って管理されます。その他のリンク
【まとめ記事】ベリタステクノロジーズ 全記事へのリンク集もよろしくお願い致します!
ありがとうございました。


- 投稿日:2020-09-14T15:34:26+09:00
Let's EncryptをCloudFrontに導入する
はじめに
httpsでWebサービスを利用するために必要なSSL証明書ですが、最近は、Let's Encryptという無料で利用できるものが存在します。
これを利用して、CloudFrontに設定するための手順を記載します。
導入までの流れ
以下の通りです。
- certbotのインストール
- 証明書の発行
- IAMへ登録
- CloudFrontへ設定
certbotのインストールや証明書の発行などは、Amazon Linux2上で行なっております。
certbotのインストール
最初に、SSL証明書に発行に必要な鍵などを作成してくれる、certbotというツールをインストールします。
これは、わかりやすくまとめてある記事がありますので、そちらを参照ください。
Amazon Linux2とLet's EncryptでSSL対応サーバを0から爆速構築
証明書の発行
以下のようなコマンドを発行します。
sudo certbot certonly --manual --domain subroq.comコマンドの
--manualの部分を--nginxに変更すると、勝手にnginx.confにSSLの記述を追記してくれてます。もし、nginxにSSL証明書を設定する場合は、変更してみてください。
また、
--domain subroq.comの部分は、複数指定することが可能です。例えば、
sudo certbot certonly --manual --domain subroq.com --domain console.subroq.comのように、サブドメインなしとサブドメイン付きの証明書を一度に発行することが可能です。
IAMへ登録
certbotのコマンドを実行すると、
/etc/letsencrypt/live/というフォルダが作成され、その配下に指定したドメイン毎にフォルダと必要な鍵等々が作成されます。今回だと、
/etc/letsencrypt/live/subroq.comというフォルダが作成されました。次にこれらをIAMに登録します。
コマンドは、以下の通りです。
sudo aws iam upload-server-certificate --server-certificate-name subroq.com-ssl \ --certificate-body file:///etc/letsencrypt/live/subroq.com/cert.pem \ --private-key file:///etc/letsencrypt/live/subroq.com/privkey.pem \ --certificate-chain file:///etc/letsencrypt/live/subroq.com/chain.pem \ --path /cloudfront/subroq/
awsを利用するので、必ずインストールしておいてください。CloudFrontへ設定
最後にアップロードした証明書をCloudFrontに設定します。
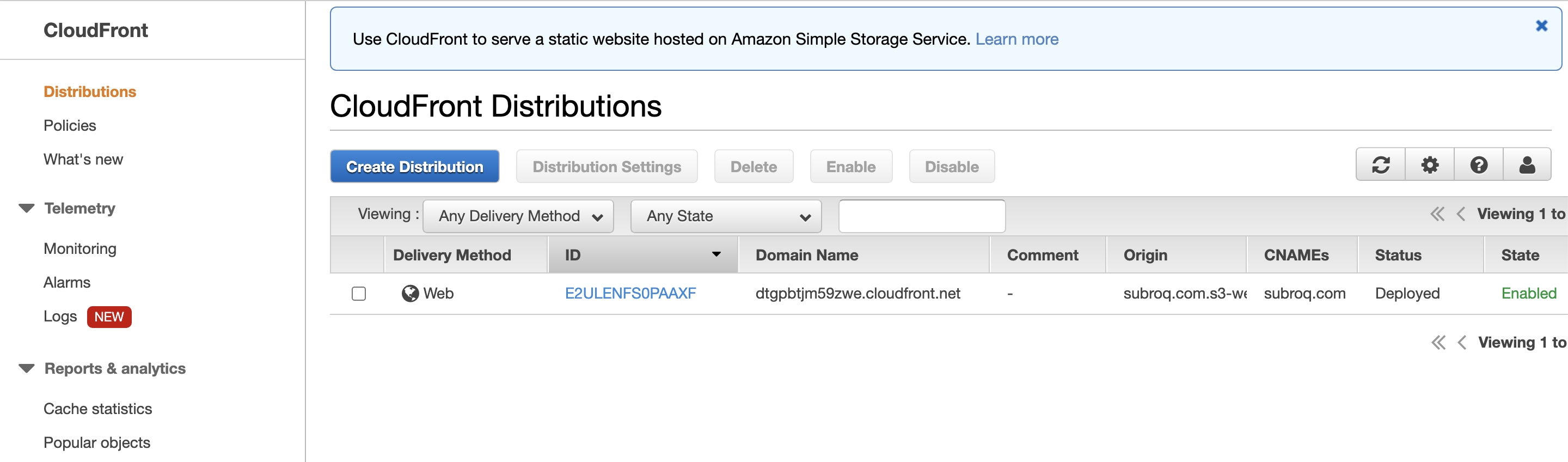
まずは、対象のDistributionsを選択します。
次に、そのDistributionsを編集します。
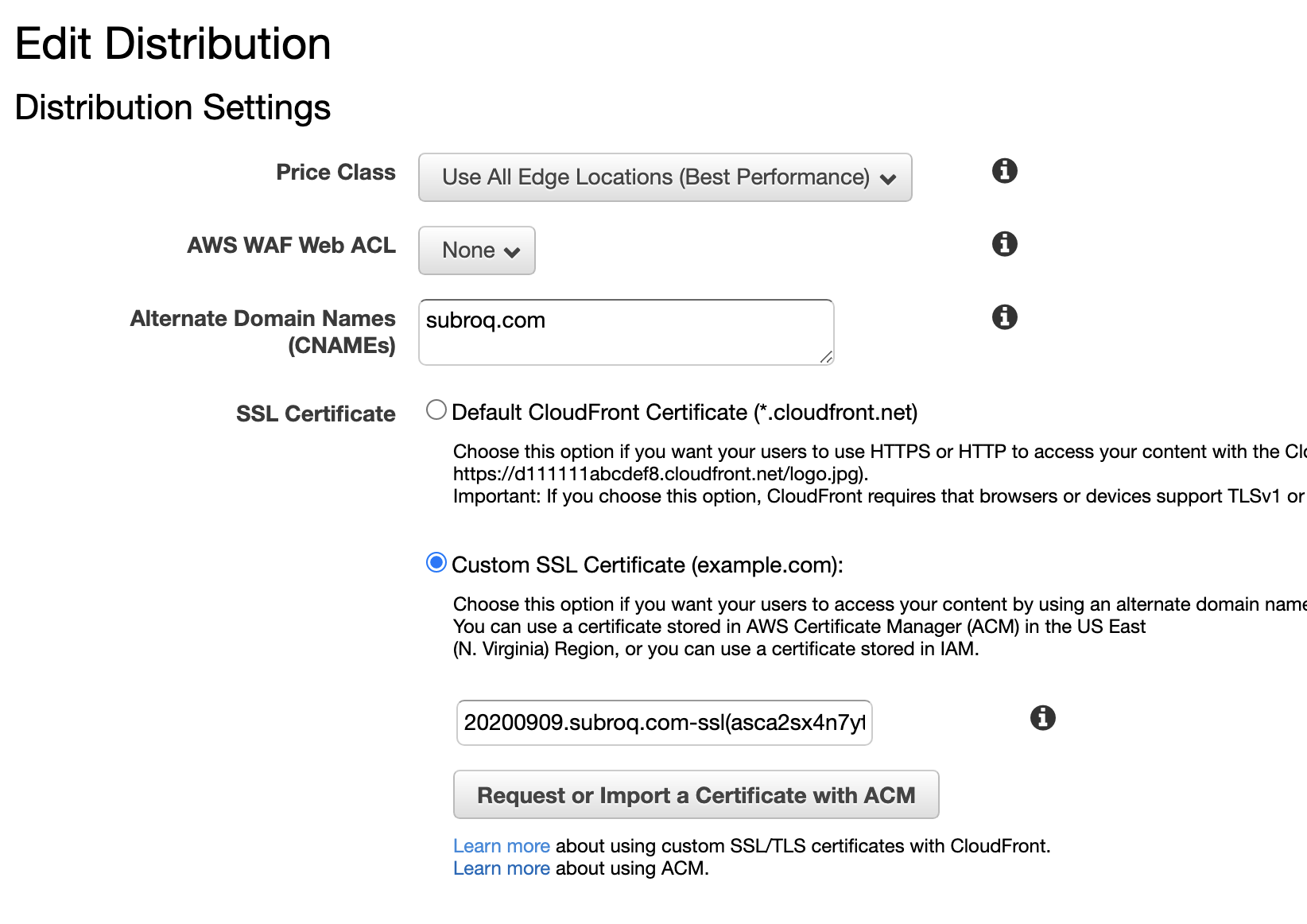
上記、画像のCustom SSL Certificate (example.com)を選択すると、今回追加した証明書が表示されます。
ここに表示される名前は、先ほどawsコマンド実行時に、指定した
--server-certificate-nameの値です。それを選択することで無事設定が完了です。
設定が反映されるまでに10分程度?かかるらしいです。
最後に
昔は、SSL証明書にお金がかかっていましたが、このようなサービスが登場し、気軽にhttps化できるようになりました。
Chromeブラウザなどでは、httpsでなければCookieなどの制御がうまくいかないこともあり、httpsの利用は必須になっているため、ありがたいです。
Subroqは、企業のフリーランスエンジニアの採用や活用を支援するサービスを提供しております。また、フリーランスエンジニア向けの記事も書いておりますので、興味ある方は是非、ご一読いただければと思います。
- 投稿日:2020-09-14T15:17:02+09:00
ローカルのdocker環境で作ったWebアプリをAWSに移行する方法
背景
ローカル環境でWebアプリを作っていたのでAWS上のサーバへ移行した。AWSでサーバを立てたことなかったので有識者に教えてもらいながらやってみた。忘れそうなので今後の自分のためにサーバ上でdockerを動かすところまでの手順を残しておく。
本編
大まかな作業手順はこう。
1. AWSにEC2インスタンスを立てる
2. 立てたサーバの中でdockerをインストールする
3. gitlabからアプリケーションをクローンする実際に行った手順
実際の手順は以下のようにした。ただし今回、EC2インスタンスの作り方は割愛する。
サーバに入るまで
- AWSのEC2インスタンスを作る(詳細は今後書くかもしれない)
- 1ができると
.pemがついたファイルができるのでこれは~/.ssh/大切に保存しておく。- AWSのEC2のページにipアドレスがあるのでsshする。
ssh xx.xxx.xx.xxxやってみたけどできなかった。- ユーザ名をつけてやってみた。
ssh ubuntu@xx.xxx.xx.xxxやってみたけどできなかった。- エラーログがみたい時
ssh -v ubuntu@xx.xxx.xx.xxxssh -i ~/.ssh/xxx.pem ubuntu@xx.xxx.xx.xxxでxxx.pemコマンドで入れた。xxx.pemというキーを使ってubuntuに入りますよコマンドらしい。サーバにて
- gitlabにあるリポジトリをサーバ側にsshでクローンしたい。いきなりクローンができないので、まずは
ssh-keygenでキーペアを作る。3回質問されるが特に何もなければEnterを3回押すだけ。.ssh/id_rsa.pubというキーができているはずなのでその中身をコピーしてgitlab上で公開鍵を記入するところ(設定とかからいけたはず)にペーストする。- サーバ上でdockerをインストールする。
sudo apt updateをまずやってsudo apt install docker.ioする。docker psできるか確認。権限がなかったのでsudo usermod -aG docker $USERという呪文を唱えた。- ログアウトしてもう一度ログインして
docker psしたら確認できた。sudo apt install docker-composeでdocker-composeをインストール。docker-compose upすれば起動するはず。落としたい時はdocker-compose downまたはdocker-compose stopすれば良い。ちなみに、バックグラウンド実行したい時はdocker-compose up -dでできる。まとめ
ローカルのdocker環境で動かしているWebアプリをAWSに移行した。AWSのサーバ内に入るまでの内容とサーバに入ってdockerを動かすまでの内容の話をした。おそらく他のやり方もあるので参考に。
- 投稿日:2020-09-14T12:50:46+09:00
AWS認定クラウドプラクティショナーの勉強法について
はじめに
この記事では、AWS認定資格であるAWS認定クラウドプラクティショナー試験の勉強法について記載します。
資格取得に特化した内容について作成しているので、AWSのサービスの内容についてはほとんど記載するつもりはないです。
対象者としては、AWSサービスに触れたことがなく、一からAWSについて勉強する方を対象としています。
また、受けた感想と受験したからこそ、このように勉強すればもっと効率よく合格できたのでは?と思った部分があったため、共有します。
(もちろん人それぞれ、最適な勉強の仕方は違うため、以下に記載する勉強法が全ての人にあてはまるわけでないということはご理解ください。)結論から言うと、
模擬試験の使い方で、合否が決まる。
ということです。
使用した教材について
AWS認定クラウドプラクティショナー試験の勉強に使用した教材は、以下の二つになります。
テキスト
・AWS認定資格試験テキスト AWS認定クラウドプラクティショナー模擬試験
・https://www.udemy.com/course/aws-4260/
「この問題だけで合格可能!AWS 認定クラウドプラクティショナー 模擬試験問題集(7回分455問)」まずテキストに関してですが、他のAWS試験対策のものを完読したことがないので、比較というものはできませんが、資格取得に関してはこの本で必要十分だと感じます。
Udemyの模擬試験に関しては、全7回分(基本レベル2回、応用レベル3回、難易度高レベル2回)あります。
難易度高レベルは、クラウドプラクティショナーというよりアソシエイトを目指している方向けだと感じました。※Udemyについて、セール中に購入すると安く購入することが可能なので、セール時に購入することを強くおすすめします。(セール外で買うととても高いので要注意です。)
行った勉強法について
私がクラウドプラクティショナー取得までに行った勉強法について簡単に書きます。
ここはあんまり重要ではないので見なくてもいいです。【行った勉強法】
テキストを読む
↓
模擬試験(基礎レベル1週目&間違えたところの見直し)
↓
間違えたところに関する部分をテキストで読む
↓
模擬試験(基礎レベル2週目、応用レベル1週目&間違えたところの見直し)
↓
苦手なところに関する部分をテキストで読む
↓
模擬試験(基礎レベル3週目、応用レベル2週目、難易度高1周目&間違えたところの見直し)
↓
適当にテキストを読む
↓
本番こんな感じだったと思います。
今思うことは、オーバーワークだったなーという感じがあります。
(これも、自分の勉強の仕方が悪かったためにこれだけやってしまったという結果ですが。)おすすめの勉強法について
ここがみなさんに一番見てほしい部分になります。
まず、勉強の進め方に関しては、人それぞれどのくらいの期限があるのか、どのくらい時間を割けるのかなどによって変わってきます。
なので、どの方にも当てはまる勉強の仕方(勉強をする上での意識)についてお伝えしたいと思います。
1. AWSの各サービスの特徴や似たようなサービスの違いに着目して進めていく
AWSの知見がなく、一から取得を目指している方にとっては、似たように見えるサービスが多くでてくると思います。
そのような場合でも、それぞれのサービスのどこかに有用性があるから別々のサービスとして成り立っているということを踏まえ、調べる、考えることを意識するとよいと思います。ほんの例ですが、
・AWSのサービスの中でサーバレスのアーキテクチャにはなにがあるのか?
・ストレージ形式でブロック、ファイル、オブジェクトがあるが、それぞれどのような特徴でどのような違いがあるのか?(また、どのストレージ形式がどのAWSサービスで使われているのか)などそれぞれを単体で頭に入れるのではなく、全てを一つの繋がりとしてみるようにするのも勉強をしていく中で必要な考え方なのかなと思います。
2. 模擬試験のあとの間違えた問題の見直しに一番時間を費やすべき
模擬試験の見直しの際にどこをどう間違えたのかを見ると思います。
正しい回答を見て、「ああ、こっちだったのか、解説を見て納得した」という風に思い込んでるパターンがほとんどです。(私もこのパターンです。)納得したと思っているようで納得したと思い込んでいるだけのパターンだと効率が悪くなってしまいます。
そのため、ここの質を上げましょう。
(資格対策で他のことに時間をかける暇があったら、その分をここにかけるべきです。)当たり前ですが、模擬試験の問題には正しい答えと間違わせるために、私たちが間違いやすいような不正解の選択肢を入れています。
(つまり、解説には、似たようなものでもこういう風に違うから不正解だよと書いてくれているということです。)そこのポイントに着目する意識をつけるだけで、理解度も知識の定着度もはるかに向上すると思います。
これは余談ですが、
模擬試験をやっていると、クラウドプラクティショナーの資格取得を目指している人に対して、AWS側がどのレベルを求めているのかが少しずつ見えてくると思います。
私は、各AWSのサービスの概要(特徴)、基本的な機能としてなにができてなにができないのかなどのレベルを理解するべきだなと感じました。
アソシエイトまで取得を考えている人であれば、お客様からの要望、実際のユースケースなども自分の頭でイメージしてサービスの構成をしたりできるレベルまで最終的には持っていく必要があるのではないかなと考えています。
受験した感想
私が想像しているよりも難しかったです。
そう思う理由は一つで、模擬試験への信頼度が高すぎたことにあります。
模擬試験の問題にように単純に聞いてくる問題はなかなかありません。
例えば、
Q.地域全体が自然災害によって影響を受けたときのためのアプリケーションサービスの可用性にはどれが適しているか?
という問題です。
(私の記憶の中から出してきたので雰囲気レベルですが、ご容赦ください。)選択肢は完璧に覚えていませんが、回答として複数のAZか複数のリージョンの二択に絞りました。
さらに最初に問題を見たときには、自然災害によって影響を受けた場合にも複数AZに配置することによって可用性は向上するという認識があったため、複数AZかな?と思いながら考えていました。
しかし、各AZはそれぞれ他のAZから数km離れているところに配置をしていて、トータルで見ても100km以内には配置しているので、地域全体(そもそもこの地域全体がどのくらいの規模を指しているのか自体が曖昧なのでよくわかりませんが、、、)に自然災害が影響を与えた場合で考えると、リージョンレベルでの可用性が必要なのではないか?と考えて最終的には複数のリージョンを選択しました。
この回答が合っているのか、正しい回答はどれだったのか、細かい結果は返ってこないためわかりませんが、このような曖昧な問題が多々あります。
(細かい部分まで知らないと二択までは絞れるけど、どっちなんだろうと迷ってしまう可能性が高くなります。)そのためにも、模擬試験の問題がすらすら解けて大丈夫ではなく、テキストにかかれている細かい部分に着目できる脳を養うべきだと感じました。
さいごに
私は模擬試験に信頼を置きすぎて、本試験が模擬試験とは結構違うことに焦りました。
(全て解き終わるまでに50分ほどは使ったと思います。)問題の言い回し(ひっかけてくるようなイメージ)や難易度に関しては模擬試験を鵜呑みにしないように気をつけてください。
模擬試験の使い方によって効率、定着度、理解度の全てが変わり、AWS認定試験では、そこの使い方が上手であるかを試されているような気がしました。
(AWSのサービスがとても多く、それぞれ意味を成し、細かく分けられているからこそ問題の解説が大事になってくると感じました。)これを見て、勉強の仕方(意識する部分)など、少しでも使えそうな部分を参考にしていただけたら嬉しいです。
最後まで読んでいただき、ありがとうございました。
- 投稿日:2020-09-14T12:48:35+09:00
テキスト分析API比較調査~Entity抽出~
概要
テキスト分析をおこなうAI系のAPIをいくつか触ってみたので、ざっくりとした比較をまとめておきます。
分類として、今回はEntity分析を対象として大手ベンダー三社の出力結果を比較しました。
Entity分析とは?
エンティティ分析は、指定されたテキストに既知のエンティティ(著名人、ランドマークなどの固有名詞)が含まれていないかどうかを調べて、それらのエンティティに関する情報を返します。
GCP (https://cloud.google.com/natural-language/docs/analyzing-entities?hl=ja)出力結果に対して、後述する使用例(要件)に沿った解釈をおこなっていくので、似たよう用途での使用を検討している方にとって参考になれば幸いです。
比較API
使用例
活用シーン
メールの署名から個人情報を構造化して抜き出し、顧客データベースなどを作成するのに役立てたい
欲を言えば、、
出力された抽出結果に出来るだけ手を加えず、その後の工数を減らして楽をしたい署名から抽出する主な項目と対応する各社APIのEntityタイプ
抽出項目 Natural Language Text Analytics AWS Comprehend 社名 ORGANIZATION Organization ORGANIZATION 名前 PERSON Person PERSON 住所 ADDRESS(LOCATION) Location LOCATION 電話番号 PHONE_NUMBER Phone Number (OTHER) メールアドレス (OTHER) (OTHER) その他Entityタイプなどの詳細は下記のリンクから
署名サンプル
下記の署名サンプルを各社が提供するAPIでEntityを抽出する
※住所はダミーで生成したものであり、実在する住所ではありません株式会社Sample apple ダミーテキスト部 山田 太郎 / Taro Yamada 〒039-2403 青森県上北郡東北町新舘1-12-16新舘ビル19F TEL: 012-3456-7890 MAIL: hoge@example.com WEB: http://example.com抽出結果
Natural Language
Type Text ORGANIZATION 株式会社Sample apple ダミーテキスト部 PERSON 山田 太郎 OTHER Taro Yamada LOCATION 新舘1-12-16新舘ビル19F TEL: 012-3456-7890 MAIL OTHER hoge@example.com LOCATION 〒039-2403 青森県 LOCATION 上北郡 LOCATION 東北町 OTHER WEB DATE 1-12-16 ADDRESS 039-2403 青森県上北郡東北町 NUMBER 039 NUMBER 2403 NUMBER 1 NUMBER 12 NUMBER 16 NUMBER 19 NUMBER 012 NUMBER 3456 NUMBER 7890 後述する2社に比べると抽出結果が多く、抽出の粒度が細かいことが分かる。
この要因は入力されたテキストに対しての重複がいくつか存在するため。(「ADDRESS」のEntityタイプは「LOCATION」で検出されたものが合わさったもの)文字列が中途半端なところで区切れてしまう問題が見られるなど、今回の使用例においての抽出の精度は高いとは言えないため、ここから更に何か手を加える必要がありそう。
(出力結果の粒度の細かさを活かした使用方法が向いているのでは)
※サンプルで使用した電話番号をより現実的な値に変更してみたところ、ハイフンの有無に限らず「PHONE_NUMBER」のEntityタイプとして検出された。結果は
012-3456-7890のように帰ってくる。Text Analytics
(ja)
Type Text Organization Sample apple Person 山田 太郎 Person Taro Yamada Organization 青森県 Location 上北郡 Location 東北町 Microsoftの Text Analytics APIが識別できるEntityタイプは、今回抽出したい項目を全て対応していた。
しかし、抽出結果を見ると求めたいEntityタイプの情報が全く抜き出せていないのが分かる。
特に英数字を殆ど抽出しておらず、個人情報として重要な「メールアドレス」と「電話番号」が無いのが致命的。こちらの問題はオプションの言語を指定することで抽出できる。
(代償に日本語は全く検知されない、、)
一般的に日本語よりも英語の精度の方が高いと言われているので、英語のみのテキストを分析する際には TextAnalytics を使ってみても良いかもしれない。(en)
Type Text Phone Number 039-2403 Quantity 12 Phone Number 012-3456-7890 hoge@example.com Skill WEB URL http://example.com ※電話番号はハイフン無しの場合、「Phone Number」で
01234567890のように返される。AWS Comprehend
Type Text ORGANIZATION Sample apple ダミーテキスト部 PERSON 山田 太郎 PERSON Taro Yamada OTHER 039-2403 LOCATION 青森県上北郡東北町新舘1-12-16 LOCATION 新舘ビル19F OTHER 012-3456-7890 OTHER hoge@example.com OTHER http://example.com 前述の2社に比べるとまとまった抽出結果が返されたように思える。
懸念点としては、AWS Comprehendには電話番号とメールアドレスに対応するEntityタイプが無く、「OTHER」として一括りにされてしまうところ。しかし、電話番号とメールアドレスどちらの抽出もまとまった形で返されているので、この問題は正規表現などでそれぞれを識別できれば解決できそう。
※電話番号はハイフン無しの場合、「OTHER」で01234567890のように返される。まとめ
活用シーンに沿った結論を出すならば、「AWS Comprehendが一番良さそう」と言えそうですが、全てのシーンでAWSを活用できるかと言えば現段階では断言できず、想定される活用シーンごとにまた調査が必要になると感じました。
しかし、今回の比較で対応するEntityタイプなど各社の特徴が少し垣間見えたような気もするので、この比較調査が何かしらの参考になれば嬉しいです。
- 投稿日:2020-09-14T12:29:20+09:00
テキスト分析API比較調査 ~Entity抽出~
概要
テキスト分析をおこなうAI系のAPIをいくつか触ってみたので、ざっくりとした比較をまとめておきます。
分類として、今回はEntity分析を対象として大手ベンダー三社の出力結果を比較しました。
Entity分析とは?
エンティティ分析は、指定されたテキストに既知のエンティティ(著名人、ランドマークなどの固有名詞)が含まれていないかどうかを調べて、それらのエンティティに関する情報を返します。
GCP (https://cloud.google.com/natural-language/docs/analyzing-entities?hl=ja)出力結果に対して、後述する使用例(要件)に沿った解釈をおこなっていくので、似たよう用途での使用を検討している方にとって参考になれば幸いです。
比較API
使用例
活用シーン
メールの署名から個人情報を構造化して抜き出し、顧客データベースなどを作成するのに役立てたい
欲を言えば、、
出力された抽出結果に出来るだけ手を加えず、その後の工数を減らして楽をしたい署名から抽出する主な項目と対応する各社APIのEntityタイプ
抽出項目 Natural Language Text Analytics AWS Comprehend 社名 ORGANIZATION Organization ORGANIZATION 名前 PERSON Person PERSON 住所 ADDRESS(LOCATION) Location LOCATION 電話番号 PHONE_NUMBER Phone Number (OTHER) メールアドレス (OTHER) (OTHER) その他Entityタイプなどの詳細は下記のリンクから
署名サンプル
下記の署名サンプルを各社が提供するAPIでEntityを抽出する
※住所はダミーで生成したものであり、実在する住所ではありません株式会社Sample apple ダミーテキスト部 山田 太郎 / Taro Yamada 〒039-2403 青森県上北郡東北町新舘1-12-16新舘ビル19F TEL: 012-3456-7890 MAIL: hoge@example.com WEB: http://example.com抽出結果
Natural Language
Type Text ORGANIZATION 株式会社Sample apple ダミーテキスト部 PERSON 山田 太郎 OTHER Taro Yamada LOCATION 新舘1-12-16新舘ビル19F TEL: 012-3456-7890 MAIL OTHER hoge@example.com LOCATION 〒039-2403 青森県 LOCATION 上北郡 LOCATION 東北町 OTHER WEB DATE 1-12-16 ADDRESS 039-2403 青森県上北郡東北町 NUMBER 039 NUMBER 2403 NUMBER 1 NUMBER 12 NUMBER 16 NUMBER 19 NUMBER 012 NUMBER 3456 NUMBER 7890 後述する2社に比べると抽出結果が多く、抽出の粒度が細かいことが分かる。
この要因は入力されたテキストに対しての重複がいくつか存在するため。(「ADDRESS」のEntityタイプは「LOCATION」で検出されたものが合わさったもの)文字列が中途半端なところで区切れてしまう問題が見られるなど、今回の使用例においての抽出の精度は高いとは言えないため、ここから更に何か手を加える必要がありそう。
(出力結果の粒度の細かさを活かした使用方法が向いているのでは)
※サンプルで使用した電話番号をより現実的な値に変更してみたところ、ハイフンの有無に限らず「PHONE_NUMBER」のEntityタイプとして検出された。
Text Analytics
(ja)
Type Text Organization Sample apple Person 山田 太郎 Person Taro Yamada Organization 青森県 Location 上北郡 Location 東北町 Microsoftの Text Analytics APIが識別できるEntityタイプは、今回抽出したい項目を全て対応していた。
しかし、抽出結果を見ると求めたいEntityタイプの情報が全く抜き出せていないのが分かる。
特に英数字を殆ど抽出しておらず、個人情報として重要な「メールアドレス」と「電話番号」が無いのが致命的。こちらの問題はオプションの言語を指定することで抽出できる。
(代償に日本語は全く検知されない、、)
一般的に日本語よりも英語の精度の方が高いと言われているので、英語のみのテキストを分析する際には TextAnalytics を使ってみても良いかもしれない。(en)
Type Text Phone Number 039-2403 Quantity 12 Phone Number 012-3456-7890 hoge@example.com Skill WEB URL http://example.com ※電話番号はハイフン無しの場合、「Phone Number」で
01234567890のように返される。AWS Comprehend
Type Text ORGANIZATION Sample apple ダミーテキスト部 PERSON 山田 太郎 PERSON Taro Yamada OTHER 039-2403 LOCATION 青森県上北郡東北町新舘1-12-16 LOCATION 新舘ビル19F OTHER 012-3456-7890 OTHER hoge@example.com OTHER http://example.com 前述の2社に比べるとまとまった抽出結果が返されたように思える。
懸念点としては、AWS Comprehendには電話番号とメールアドレスに対応するEntityタイプが無く、「OTHER」として一括りにされてしまうところ。しかし、電話番号とメールアドレスどちら抽出のまとまった形で返されているので、この問題は正規表現などでそれぞれを識別できれば解決できそう。
※電話番号はハイフン無しの場合、「OTHER」で01234567890のように返される。まとめ
活用シーンに沿った結論を出すならば、「AWS Comprehendが一番良さそう」と言えそうですが、全てのシーンでAWSを活用できるかと言えば現段階では断言できず、想定される活用シーンごとにまた調査が必要になると感じました。
しかし、今回の比較で対応するEntityタイプなど各社の特徴が少し垣間見えたような気もするので、この比較調査が何かしらの参考になれば嬉しいです。
- 投稿日:2020-09-14T10:38:52+09:00
Serverless+Nuxt.jsのプロジェクトを軽くしてLambdaの上限を守る
Nuxt.jsをUniversalモードで利用するためにAWS&Serverlessフレームワークを活用している方向けです。
Serverlessフレームワークを活用するときに使われるAWSLambdaはアップロードできるファイルサイズに上限があります。Lambdaにアップロードできるファイルのサイズは圧縮前で250MB、圧縮後で50MBです。
Nuxt.js+TypeScript+Serverlessの構成ではこれを余裕で超えてしまいます。
実際、Lambdaは250MBまでと言いながら350MBくらいまで上げられるのでしばらく放置していたのですが、ついにそれすら超えてしまうようになりアップロード出来なくなってしまったので対策を打つことにしました。
対策方法
対策方法はズバリ「lamndaで使うやつ以外アップロードしない」です。当たり前の話なのですが、serverless.ymlの
excludeDevDependenciesをtrueにしても、どうやら全てが正しくexcludeされているようには見えなかったので、いっそのこと自分たちで全て選ぶようにしてexcludeDevDependenciesをfalseにしました。package.jsonのdependenciesにはlambda上のnuxtで利用するもののみを入れ、それ以外は全てdevDependenciesに移動させました。
ブラウザ側で本番環境で使われる
- vee-validate
- vue-lazyload
- hooperなどをも使っており、通常はdependenciesに入れるものではありますが、ここらへんも割り切ってdevDependenciesに移動させました。
リリースコマンドも
rm -rf node_modules npm i --production sls deploy --stage prodというように変更し、dependencies以外のライブラリーが絶対にserverlessのpackageに入らないようにしました。
結果
ファイルサイズを60MBほど少なくすることが出来、
excludeDevDependenciesをfalseにしたことで、リリースにかかる時間が6分から1分半へと劇的に改善しました。
- 投稿日:2020-09-14T08:43:38+09:00
AWSのリソース一覧を出力できるツール AWSets を試してみた
AWSets とは
AWSets は AWS アカウント内をクロールし、対応するリソースの一覧を json 形式で
出力可能な Go 製のコマンドラインツールです。
北米のプレミアコンサルティングパートナーである Trek10 社が開発、OSS として公開しています。https://github.com/trek10inc/awsets
現時点ではすべての AWS リソースに対応しているわけではありませんが、
2020/9/13 時点で 200 以上のリソースに対応しています。https://github.com/trek10inc/awsets/blob/master/supported_resources.md
複数のリージョンに同時にクエリを実行しつつ、リージョンやサービスでフィルタリングが
可能であったり、リソース間の依存関係を保持した情報を出力してくれるのが特徴です。インストール
GitHub のリリースページからバイナリファイルをダウンロード可能です。
https://github.com/trek10inc/awsets/releases
以降では、2020/9/13 時点の最新バージョンである、v0.2.4 で確認しています。
$ awsets version awsets - version: 0.2.4 commit: b5be906179904d9d412a70332d9d33b06fdd84df date: 2020-09-09T19:58:18使用方法
認証情報は .credentials ファイルの情報を読み取ってくれるようです。
使用するプロファイルを切り替えたい場合は、AWS_RROFILE環境変数で指定すれば OK です。awsets list
リソース情報を取得します。単に list コマンドを実行した場合、全リージョン、全対応リソースの
情報を取得しますが、--regionオプションでリージョン、--include,--excludeで
対象のサービスをフィルタリングすることができます。以下の例は、東京リージョンの EC2 に関連するリソースを取得します。
$ awsets list --regions ap-northeast-1 -o ec2.json --include ec2ツールで取得された情報は 以下のような json 形式で保存されます。
jq コマンドや jmespath などでで処理することを前提にしているようです。
以下の例では Relations という形で EC2 インスタンスに紐づくリソースを確認できます。ec2.json[ { "Account": "123456789012", "Region": "ap-northeast-1", "Id": "i-xxxxxxxxxxxxxxxxx", "Version": "", "Type": "ec2/instance", "Name": "i-xxxxxxxxxxxxxxxxx", "Attributes": { "AmiLaunchIndex": 0, "Architecture": "x86_64", "BlockDeviceMappings": [ { "DeviceName": "/dev/xvda", "Ebs": { "AttachTime": "2020-09-13T03:03:57Z", "DeleteOnTermination": true, "Status": "attached", "VolumeId": "vol-xxxxxxxxxxxxxxxxx" } } ] ~~省略~~ } "Tags": { "Name": "test-instance" }, "Relations": [ { "Account": "123456789012", "Region": "ap-northeast-1", "Id": "subnet-xxxxxxxxxxxxxxxxx", "Version": "", "Type": "ec2/subnet" }, { "Account": "123456789012", "Region": "ap-northeast-1", "Id": "vpc-xxxxxxxxxxxxxxxxx", "Version": "", "Type": "ec2/vpc" }, { "Account": "123456789012", "Region": "ap-northeast-1", "Id": "sg-xxxxxxxxxxxxxxxxx", "Version": "", "Type": "ec2/securitygroup" }, { "Account": "123456789012", "Region": "ap-northeast-1", "Id": "eni-xxxxxxxxxxxxxxxxx", "Version": "", "Type": "ec2/networkinterface" }, { "Account": "123456789012", "Region": "ap-northeast-1", "Id": "vol-xxxxxxxxxxxx", "Version": "", "Type": "ec2/volume" } ] }, ~~省略~~ ]awsets process
実験的な機能として出力した json ファイルを加工するため機能が用意されています。
v0.2.4 時点では process bot コマンドが使用可能です。
json ファイルのデータ構造をグラフとして表現する DOT 言語形式のファイルに変換することができます。$ awsets process dot -i ec2.json -o ec2.dotDOT ファイルは Graphviz などの描画ツールを使用することで
グラフを SVG や PNG など任意のイメージ形式で出力することができます。$ dot ec2.dot -T svg -o ec2.svg変換後のイメージの一部ですが、以下のように描写されます。
多くのリソースがある環境では複雑なグラフになってしまいますが
削除されて既に存在しないリソースは赤、関係性を持たないリソースは黄色で表示されるため、
孤立したリソースや使用されていないリソースをすぐに判別することができます。
複数リージョンの情報をもつファイルを変換した場合、リージョン毎にグラフが描写されます。
awsets region
region コマンドは 使用している認証情報に紐づくアカウントで有効になっている
リージョンの一覧が表示されます。awsets types
サポートしているリソースのタイプを表示します。
表示される内容は、以下の内容と同じです。https://github.com/trek10inc/awsets/blob/master/supported_resources.md
以上です。
参考になれば幸いです。

- 投稿日:2020-09-14T04:41:01+09:00
[AWS]CloudSearchの"Invalid codepoint" エラーの対応方法
この記事では、[AWS]CloudSearchの"Invalid codepoin xx" エラーの対応方法についてまとめています。
Pythonでコードを書きましたが、ポイントについてはどの言語についても共通だと思います。"Invalid codepoint xx" エラーとは?
CloudSearchの検索ドメインのインデックスフィールドにtextまたはtext-array型を設定し、そのフィールドが受け付けることの出来ない文字のアップロードを試みた場合に発生します。例えばtitleというtext型のフィールドに置換文字(SUB: substitute character)が含まれている場合には次のようなエラーメッセージが返されます。
Validation error for field 'title': Invalid codepoint 1A1Aは置換文字という制御文字の一種で、text型のフィールドには不正なコードポイントです。私は扱っていたデータが
1Aや08といったコードポイントの文字を含んでいたためにこのエラーに遭いました。シンプルな対応方法
不正な文字を取り除いてくれる関数がこちらです。
def remove_invalid_code2(text: str) -> str: RE_ILLEGAL = u"[^\u0009\u000a\u000d\u0020-\uD7FF\uE000-\uFFFD]" return re.sub(RE_ILLEGAL, "", text)text, text-arrayとして型を指定したフィールドの文字列は、この関数を使って不正な文字を取り除きましょう。
ポイントは文字列1つ1つに関数を適用してあげるということです。「
json.dumpsでシリアライズしちゃえば、一発で不正な文字コード除去出来るじゃん」などと考えるのはやめましょう。苦い思いをすることなります。以下はUserクラスのデータを検索ドメインにアップロードするサンプルコードです。私は型が大好きなのでmypyで型チェックしながらコーディングしています。
import json import re from dataclasses import asdict, dataclass from typing import Any, ClassVar, Dict, List, Literal, TypedDict from uuid import uuid4 import boto3 from mypy_boto3_cloudsearchdomain import CloudSearchDomainClient def remove_invalid_code(text: str) -> str: RE_ILLEGAL = u"[^\u0009\u000a\u000d\u0020-\uD7FF\uE000-\uFFFD]" return re.sub(RE_ILLEGAL, "", text) class AddBatchItem(TypedDict): type: Literal["add"] id: str fields: Dict[str, Any] class DeleteBatchItem(TypedDict): type: Literal["delete"] id: str BatchItem = Union[AddBatchItem, DeleteBatchItem] Type = Literal["add", "delete"] @dataclass class User: id: str name: str age: int short_description: str description: str _text_fields: ClassVar[List[str]] = ["short_description", "description"] def get_batch_item(self, operation_type: Type) -> BatchItem: if operation_type == "delete": return {"id": self.id, "type": "delete"} fields = asdict(self) del fields["id"] # ポイント:値1つ1つに関数を適用すること!! fields = { k: remove_invalid_code(v) if k in self._text_fields else v for k, v in fields.items() } return {"id": self.id, "type": "add", "fields": fields} if __name__ == "__main__": SEARCH_ENDPOINT = "http://xxxx.com" client: CloudSearchDomainClient = boto3.client( "cloudsearchdomain", endpoint_url=SEARCH_ENDPOINT ) user = User( id=str(uuid4()), name="ジョン", age=18, short_description="元気です", description="元気です!!" + u"\b" + "よろしくね!", ) batch_items = [user.get_batch_item("add")] docs = json.dumps(batch_items).encode("utf-8") client.upload_documents(documents=docs, contentType="application/json")今回の記事は以上です。
ここで紹介したシンプルな対応方法に辿り着くまでに、私はかなり苦戦しました。そこから学んだこと別の記事にする予定です。
今でこそ「...制御文字の一種で...コードポイントです(えっ、知ってるよね?)」なんて書けますが、エラーに遭遇したときは文字コードに詳しくなかったのでデバックに大変苦労しました。その辺り曖昧な理解で今ドキドキしてるあなた、是非次の記事も読んでください。お楽しみに。
- 投稿日:2020-09-14T00:39:27+09:00
既に作成されてるAWSリソースをterraformのコードに落とし込む
はじめに
awsのterraformテンプレートをを0から書いていくのはなんとなく面倒だったので、既に作成されているawsリソースから作成できないかと調べていたのですが、
terraform importと言うコマンドで似たようなことができそうだったのでまとめます。今回のゴール
今回は既存のVPCをterraformのコードに起こしていきます
ディレクトリ構成
. ├── config.tf ├── terraform.tfstate ├── vpc.tf └── .gitignore下準備
1, 初期設定ファイルを作成
awsの初期設定をするファイル
config.tfvariable "aws_access_key" {} variable "aws_secret_key" {} provider "aws" { version = "~> 3.0" access_key = var.aws_access_key secret_key = var.aws_secret_key region = "ap-northeast-1" }秘匿情報を代入するファイル
terraform.tfvarsaws_access_key = "各種取得したaccess_key" aws_secret_key = "各自取得したsecret_key"vpcの情報を記入するための空ファイル
resource "aws_vpc" "test-tf-vpc" { # (resource arguments) }ignoreファイル
.gitignore# Local .terraform directories **/.terraform/* # .tfstate files *.tfstate *.tfstate.* # .tfvars files *.tfvars2, 既存のvpcをimport
terraform import リソース名.リソースname リソースID
と言う構文を用いることでデータをimportすることができます
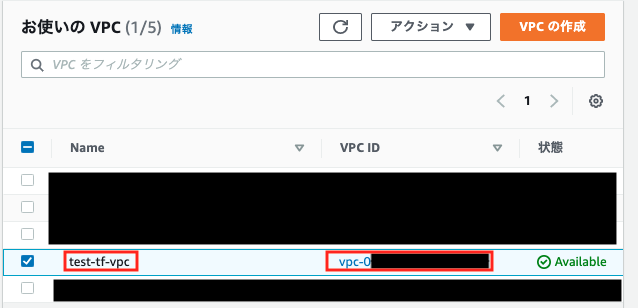
$ terraform state show aws_vpc.test-tf-vpc vpc-xxxxxxxx3, importした内容を確認
terraform import リソース名.リソースname
と言う構文を用いることでimportしたデータを確認することができます$ terraform state show aws_vpc.test-tf-vpc resource "aws_vpc" "test-tf-vpc" { arn = "xxxxxxxxxxxxx" assign_generated_ipv6_cidr_block = false cidr_block = "10.0.0.0/16" default_network_acl_id = "acl-xxxxxxxxxxx" default_route_table_id = "rtb-xxxxxxxxxxx" default_security_group_id = "sg-xxxxxxxxxxx" dhcp_options_id = "dopt-xxxxxxxxxxx" enable_classiclink = false enable_classiclink_dns_support = false enable_dns_hostnames = true enable_dns_support = true id = "vpc-xxxxxxxxxxx" instance_tenancy = "default" main_route_table_id = "rtb-xxxxxxxxxxx" owner_id = "xxxxxxxxxxxxx" tags = { "Name" = "test-tf-vpc" } }vpc.ftにハードコーディング
importを行ったら公式ドキュメントをみたり、
terraform planを叩いたりしながらtfファイルを完成させていきますそして最終的に
$ terraform plan Refreshing Terraform state in-memory prior to plan... The refreshed state will be used to calculate this plan, but will not be persisted to local or remote state storage. aws_vpc.test-tf-vpc: Refreshing state... [id=vpc-xxxxxxxxxxxxx] ------------------------------------------------------------------------ No changes. Infrastructure is up-to-date. This means that Terraform did not detect any differences between your configuration and real physical resources that exist. As a result, no actions need to be performed.と言う文字列が出現すれば完了です
最後に
本当は1コマンドだけで全てのリソースをterraformのファイルに落としてきてもらう物があれば一番良かったのですが、それは難しそうだったので今回は割と頑張るタイプのものになってしまいました汗
ただ、1つ自分専用のterraformテンプレートを持っていれば何かと楽できる場面は多いと思うので1つは所持しておくのがいいのではないかと思います。