- 投稿日:2020-09-14T21:07:41+09:00
python ディレクトリ作成 ディレクトリ存在する場合対応
- 投稿日:2020-09-14T20:57:22+09:00
Djangoを使ったWEBアプリケーションの開発【リクエスト処理編】
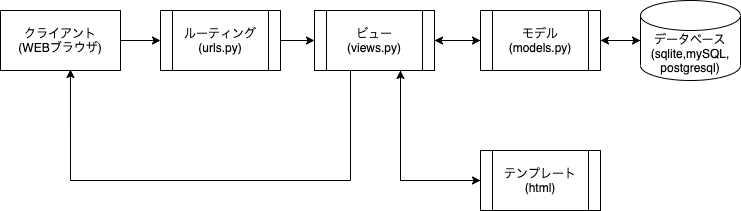
Djangoのリクエスト処理フロー
Djangoのリクエスト処理フローは下記のようになっています。
今回は、ルーティング・ビューだけを使い、ビューの関数に記載した「Hello, World!」を表示する。
フロートしては、ブラウザからのリクエスト→project1.urls→posts.urls→views.indexとなる。
ルーティング(urls.py)
ブラウザからのリクエストを受けたURLパターンとルーティングファイル内に記述されているパターンからどのファイルを呼び出すかを決める。
アプリ内とプロジェクト内でそれぞれ2つのurls.pyが存在し、それぞれがアプリ内とプロジェクト内の動作振り分けを定義している。ビュー(views.py)
ルーティングで呼び出された関数の動作を返す。
データベースからデータを呼び出す必要があればデータベースへアクセスする記述などを記載する。また、そのデータを必要な形に加工しテンプレートに渡す動作を記述する。Hello, World!を表示させてみよう!
今回作成したproject1フォルダ内にあるpostsフォルダの中あるviews.pyにリクエストを受けた際にHello, World!を返す関数を記述する。
views.pyfrom django.shortcuts import render from django.http import HttpResponse #この行を追加 def index(request): #この行を追加 return HttpResponse("Hello, World!") #この行を追加次に、postsフォルダ内にurls.pyを作成し、アプリ(posts)内での定義を行う。
アプリ名/urls.pyfrom django.urls import path from . import views urlpatterns = [ path('', views.index, name='index'), ]最後に、project1フォルダ内のurls.pyを編集していく。
プロジェクト名/urls.pyfrom django.contrib import admin from django.urls import path,include #includeを追加 urlpatterns = [ path('admin/', admin.site.urls), path('posts/', include('posts.urls')), #この行を追加 ]サーバーを起動し、「http://127.0.0.1:8000/アプリ名/」(今回の場合posts)にアクセスし、「Hello, World!」が表示されていれば成功です。

- 投稿日:2020-09-14T20:24:52+09:00
Django + Docker でImageFieldを反映させる方法(pillow)
はじめに
今回の記事では、僕が実際に「ImageField」の反映の際に悩まされたエラーについて解決方法を通して書いていきたいと思います。
kadaikun.Image.image: (fields.E210) Cannot use ImageField because Pillow is not installed.HINT: Get Pillow at https://pypi.org/project/Pillow/ or run command "pip install Pillow"
最初はこのエラーで悩まされていました。
pillowをインストールしたのに、インストールされていないと言われ「?」状態でした。
とりあえず次のコマンドで対処を試みました。terminal$ python3 -m pip uninstall pillow $ python3 -m pip install pillowそしてマイグレイトしました。
terminal$ python manage.py migrate結果...
terminalkadaikun.Image.image: (fields.E210) Cannot use ImageField because Pillow is not installed. HINT: Get Pillow at https://pypi.org/project/Pillow/ or run command "pip install Pillow"ダメでした...。
このときに自分がDockerを使っていることに気がつきました...。
Dockerは今回が使うのは初めてだったので、「Dockerfile」とか「requirementes.txt」あたりを変更させればいいのかなくらいしかわかっていませんでした。
そのためググりにググって出てきたものは片っ端からDockerfileに書き込んで、「docker-compose up」をひたすら繰り返していました。
/bin/sh: 1: apk: not found
繰り返した結果...
terminal/bin/sh: 1: apk: not foundとエラーが出るだけで、全く解決しませんでした。
そんな中ついに解決しそうな記事を見つけました。
それがこの記事です。
Docker+djangoで詰まった所
この記事のようにDockerfileに
DockerfileRUN pip install pillowと記入し、「equirementes.txt」に、
equirementes.txtPillow==7.2.0と記入します。
そしてターミナルに次のように打ち込みます。
terminal$ python manage.py makemigrations $ python manage.py migrate $ docker-compose upこれで完了!と言いたいところなのですが、ブラウザを開いたときにエラーが出ました...。
OperationalError
エラーが出たものの、この対処法は簡単でした。
terminal$ rm -d -r db.sqlite3 $ rm -d -r app/migrations/* $ python manage.py migrateこれでOKです!
最後に
terminal$ docker-compose upと打ち込むときれいに反映されているはずです。
ちなみに参考にした記事はこちらです。
webページを開くと django.db.utils.OperationalError: no such column: app_action.author_idエラー
最後に
今回は僕が体験したエラーについて書いていきました。
Djnagoについての記事もこれから上げていくので、参考になれば幸いです。
- 投稿日:2020-09-14T20:24:52+09:00
Django + Docker でImageFieldを反映させる方法
はじめに
今回の記事では、僕が実際に「ImageField」の反映の際に悩まされたエラーについて解決方法を通して書いていきたいと思います。
kadaikun.Image.image: (fields.E210) Cannot use ImageField because Pillow is not installed.HINT: Get Pillow at https://pypi.org/project/Pillow/ or run command "pip install Pillow"
最初はこのエラーで悩まされていました。
pillowをインストールしたのに、インストールされていないと言われ「?」状態でした。
とりあえず次のコマンドで対処を試みました。terminal$ python3 -m pip uninstall pillow $ python3 -m pip install pillowそしてマイグレイトしました。
terminal$ python manage.py migrate結果...
terminalkadaikun.Image.image: (fields.E210) Cannot use ImageField because Pillow is not installed. HINT: Get Pillow at https://pypi.org/project/Pillow/ or run command "pip install Pillow"ダメでした...。
このときに自分がDockerを使っていることに気がつきました...。
Dockerは今回が使うのは初めてだったので、「Dockerfile」とか「requirementes.txt」あたりを変更させればいいのかなくらいしかわかっていませんでした。
そのためググりにググって出てきたものは片っ端からDockerfileに書き込んで、「docker-compose up」をひたすら繰り返していました。
/bin/sh: 1: apk: not found
繰り返した結果...
terminal/bin/sh: 1: apk: not foundとエラーが出るだけで、全く解決しませんでした。
そんな中ついに解決しそうな記事を見つけました。
それがこの記事です。
Docker+djangoで詰まった所
この記事のようにDockerfileに
DockerfileRUN pip install pillowと記入し、「equirementes.txt」に、
equirementes.txtPillow==7.2.0と記入します。
そしてターミナルに次のように打ち込みます。
terminal$ python manage.py makemigrations $ python manage.py migrate $ docker-compose upこれで完了!と言いたいところなのですが、ブラウザを開いたときにエラーが出ました...。
OperationalError
エラーが出たものの、この対処法は簡単でした。
terminal$ rm -d -r db.sqlite3 $ rm -d -r app/migrations/* $ python manage.py migrateこれでOKです!
最後に
terminal$ docker-compose upと打ち込むときれいに反映されているはずです。
ちなみに参考にした記事はこちらです。
webページを開くと django.db.utils.OperationalError: no such column: app_action.author_idエラー
最後に
今回は僕が体験したエラーについて書いていきました。
Djnagoについての記事もこれから上げていくので、参考になれば幸いです。
- 投稿日:2020-09-14T19:48:42+09:00
【岩手県民向け】地元割+GoTo適用対象のホテルを一覧にして自分に合った一番良いものを探してみる。
地元割+GoTo対象のホテルを探してみる。
完全に岩手県民向けのスクリプト。価格もろもろの情報をCSVに出力します。
goto.pyimport requests from bs4 import BeautifulSoup from selenium import webdriver import chromedriver_binary import time import os from selenium.webdriver.common.by import By from selenium.webdriver.chrome.options import Options def getBFData_onHTML(html): sp=BeautifulSoup(html,'html.parser') return sp def getBFData(ul): html=requests.get(ul) sp=BeautifulSoup(html.content,'html.parser') return sp def getBFData_onSelenium(driver): html = driver.page_source.encode('utf-8') sp = BeautifulSoup(html, 'lxml') return sp urlbase="https://www.jalan.net" urlSearch_Shizukuishi= urlbase + "/030000/LRG_030100/" urlJimoto = "https://jimotowari-iwate.jp/list/#travelagency_morioka" if False == os.path.isfile('jimowari.txt'): f = open('jimowari.csv', 'w') spJimoto = getBFData(urlJimoto) spjimoHotel = spJimoto.find_all('section') strHotels = [] for section in spjimoHotel: hotelsec = section.find('h2', id="hotel") if hotelsec != None: hotels = section.find_all('ruby') for hotel in hotels: for script in hotel(["rt"]): script.decompose() Nm = hotel.get_text().replace("\n", "").replace(" ", "") f.write(Nm + "\n") strHotels.append(Nm) f.close() else: strHotels = [] with open('jimowari.csv') as f: while True: line = f.readline() if line: strHotels.append(line.replace("\n", "").replace("\u3000", " ")) else: break options = Options() options.add_argument('--headless') f = open('data.csv', 'w') f.write("ホテル名(真),ホテル名(検索結果),URL,プラン内容1,プラン内容2,プラン内容3,部屋種類,食事,価格,そのほか") cnt = 0 for hotel in strHotels: time.sleep(7) # driver = webdriver.Chrome(chrome_options=options) driver = webdriver.Chrome() driver.get(urlbase) cnt+=1 # if cnt ==3:break driver.find_element_by_id('searchAreaStn').send_keys(hotel) time.sleep(2) driver.find_element_by_id('image1').click() time.sleep(2) spSerachResult = getBFData(driver.current_url) listres = spSerachResult.find_all('div', class_="p-yadoCassette__body p-searchResultItem__body") if len(listres)==0: print("No Matching Resulr") continue item = listres[0] hotel_res = item.find('h2', class_="p-searchResultItem__facilityName").text Goto = item.find('span', class_="c-label p-searchResultItem__campaignLabelEm") if Goto != None: strGoto = Goto.text else: strGoto="" driver.find_element_by_link_text(hotel_res).click() time.sleep(5) # タブ driver.switch_to.window(driver.window_handles[1]) spSerach = getBFData(driver.current_url) time.sleep(5) driver.find_element_by_class_name('tab_02').click() time.sleep(5) spHotel = getBFData(driver.current_url) syosaiURL = driver.current_url listPlan = spHotel.find_all('li', class_="p-planCassette p-searchResultItem js-searchResultItem") for whole_plan in listPlan: Nmplan = whole_plan.find('p', class_="p-searchResultItem__catchPhrase").text.replace("\n", "") listPlan_Child1 = whole_plan.find('div', class_="p-planCassette__body p-searchResultItem__body") listPlan_Child2 = listPlan_Child1.find_all('td', class_="p-searchResultItem__perPersonCell") listpricestring = [] for price in listPlan_Child2: listpricestring.append(price.text.replace("\n", "").replace(" ", "").replace(",", "")) listplan = whole_plan.find_all('div', class_="p-searchResultItem__planNameAndHorizontalLabels") listPlanString = [] idx = 0 for plan in listplan: stroutputCSV = [] stroutputCSV.append(hotel) stroutputCSV.append(hotel_res) stroutputCSV.append(syosaiURL) stroutputCSV.append(strGoto) stroutputCSV.append(Nmplan) strroom = plan.text.replace("\n", "") stroutputCSV.append(strroom) strroomtype = whole_plan.find('li', class_="c-label--room") if strroomtype!= None: stroutputCSV.append(strroomtype.text.replace("\n", "")) else: stroutputCSV.append("不明") streat = whole_plan.find('dd', class_="c-label c-label--meal p-mealType__value") if streat!= None: stroutputCSV.append(streat.text.replace("\n", "")) else: stroutputCSV.append("飯無し") strNumberPeople = whole_plan.find('th', class_="p-searchResultItem__headCell p-searchResultItem__headCell--numberOfPeople") if strNumberPeople!= None: strNumberPeople.append(strNumberPeople.text.replace("\n", "")) else: stroutputCSV.append("何人単位の金額か不明") stroutputCSV.append(listpricestring[idx]) stroption = plan.find_all('li', class_="c-label p-searchResultItem__horizontalLabel") stropt = "" for opt in stroption: stropt += opt.text.replace("\n", "") + " " stroutputCSV.append(stropt) idx += 1 print(stroutputCSV) f.write(",".join(stroutputCSV) + "\n") driver.quit() f.close()
- 投稿日:2020-09-14T19:48:42+09:00
地元割+GoTo適用対象のホテルを一覧にしてみる。
地元割+GoTo対象のホテルを探してみる。
岩手県民向けスクリプト。価格もろもろの情報をCSVに出力します。
goto.pyimport requests from bs4 import BeautifulSoup from selenium import webdriver import chromedriver_binary import time import os from selenium.webdriver.common.by import By from selenium.webdriver.chrome.options import Options def getBFData_onHTML(html): sp=BeautifulSoup(html,'html.parser') return sp def getBFData(ul): html=requests.get(ul) sp=BeautifulSoup(html.content,'html.parser') return sp def getBFData_onSelenium(driver): html = driver.page_source.encode('utf-8') sp = BeautifulSoup(html, 'lxml') return sp urlbase="https://www.jalan.net" urlSearch_Shizukuishi= urlbase + "/030000/LRG_030100/" urlJimoto = "https://jimotowari-iwate.jp/list/#travelagency_morioka" if False == os.path.isfile('jimowari.txt'): f = open('jimowari.csv', 'w') spJimoto = getBFData(urlJimoto) spjimoHotel = spJimoto.find_all('section') strHotels = [] for section in spjimoHotel: hotelsec = section.find('h2', id="hotel") if hotelsec != None: hotels = section.find_all('ruby') for hotel in hotels: for script in hotel(["rt"]): script.decompose() Nm = hotel.get_text().replace("\n", "").replace(" ", "") f.write(Nm + "\n") strHotels.append(Nm) f.close() else: strHotels = [] with open('jimowari.csv') as f: while True: line = f.readline() if line: strHotels.append(line.replace("\n", "").replace("\u3000", " ")) else: break options = Options() options.add_argument('--headless') f = open('data.csv', 'w') f.write("ホテル名(真),ホテル名(検索結果),URL,プラン内容1,プラン内容2,プラン内容3,部屋種類,食事,価格,そのほか") cnt = 0 for hotel in strHotels: time.sleep(7) # driver = webdriver.Chrome(chrome_options=options) driver = webdriver.Chrome() driver.get(urlbase) cnt+=1 # if cnt ==3:break driver.find_element_by_id('searchAreaStn').send_keys(hotel) time.sleep(2) driver.find_element_by_id('image1').click() time.sleep(2) spSerachResult = getBFData(driver.current_url) listres = spSerachResult.find_all('div', class_="p-yadoCassette__body p-searchResultItem__body") if len(listres)==0: print("No Matching Resulr") continue item = listres[0] hotel_res = item.find('h2', class_="p-searchResultItem__facilityName").text Goto = item.find('span', class_="c-label p-searchResultItem__campaignLabelEm") if Goto != None: strGoto = Goto.text else: strGoto="" driver.find_element_by_link_text(hotel_res).click() time.sleep(5) # タブ driver.switch_to.window(driver.window_handles[1]) spSerach = getBFData(driver.current_url) time.sleep(5) driver.find_element_by_class_name('tab_02').click() time.sleep(5) spHotel = getBFData(driver.current_url) syosaiURL = driver.current_url listPlan = spHotel.find_all('li', class_="p-planCassette p-searchResultItem js-searchResultItem") for whole_plan in listPlan: Nmplan = whole_plan.find('p', class_="p-searchResultItem__catchPhrase").text.replace("\n", "") listPlan_Child1 = whole_plan.find('div', class_="p-planCassette__body p-searchResultItem__body") listPlan_Child2 = listPlan_Child1.find_all('td', class_="p-searchResultItem__perPersonCell") listpricestring = [] for price in listPlan_Child2: listpricestring.append(price.text.replace("\n", "").replace(" ", "").replace(",", "")) listplan = whole_plan.find_all('div', class_="p-searchResultItem__planNameAndHorizontalLabels") listPlanString = [] idx = 0 for plan in listplan: stroutputCSV = [] stroutputCSV.append(hotel) stroutputCSV.append(hotel_res) stroutputCSV.append(syosaiURL) stroutputCSV.append(strGoto) stroutputCSV.append(Nmplan) strroom = plan.text.replace("\n", "") stroutputCSV.append(strroom) strroomtype = whole_plan.find('li', class_="c-label--room") if strroomtype!= None: stroutputCSV.append(strroomtype.text.replace("\n", "")) else: stroutputCSV.append("不明") streat = whole_plan.find('dd', class_="c-label c-label--meal p-mealType__value") if streat!= None: stroutputCSV.append(streat.text.replace("\n", "")) else: stroutputCSV.append("飯無し") strNumberPeople = whole_plan.find('th', class_="p-searchResultItem__headCell p-searchResultItem__headCell--numberOfPeople") if strNumberPeople!= None: strNumberPeople.append(strNumberPeople.text.replace("\n", "")) else: stroutputCSV.append("何人単位の金額か不明") stroutputCSV.append(listpricestring[idx]) stroption = plan.find_all('li', class_="c-label p-searchResultItem__horizontalLabel") stropt = "" for opt in stroption: stropt += opt.text.replace("\n", "") + " " stroutputCSV.append(stropt) idx += 1 print(stroutputCSV) f.write(",".join(stroutputCSV) + "\n") driver.quit() f.close()
- 投稿日:2020-09-14T19:09:50+09:00
Python基礎備忘録その3~オブジェクト指向について~
記事概要
※記載内容についてご指摘いただき、内容を大幅修正中の為注意(2020/09/17 20:30)※
Pythonを少しでも読めるようになってみようと思い、参考書に沿って学習した備忘録になります。
Javaと比較して自身が気になった点、便利と感じた点をまとめております。
その1はこちら
その2はこちら
※かなり基礎的な内容になります。クラス
クラスの概念自体はそこまで大きく違わない認識です。
クラス定義方法については、例を下記に記載してみます。例
javaclass SampleClass { //クラス処理 }pythonclass SampleClass: #クラス処理インスタンス化
クラスをインスタンス化する。
扱いはJavaとほとんど変わらない。はずjavaSampleClass sClass = new SampleClass();pythonsClass = SampleClass()アトリビュート
Javaで言うインスタンス変数のようなもの(?)。
インスタンスに対してアトリビュートを追加できる。pythonsClass.attr = "あとりびゅーと" print(sClass.attr) >>あとりびゅーとクラスのメソッド定義
クラスメソッドに引数を追加する場合には、第一引数にselfを追加する。
selfを使うとインスタンス自体を操作できる
例
javaclass SampleClass { int counter = 0; int count(int a) { counter += a; } }pythonclass SampleClass: counter = 0; def count(self, a): self.counter += a初期化メソッド
初期化メソッドは
__init__(特殊メソッド)を使用する。例
javapubliv class Human { String name; String birthday; public Human(String name, String birthday) { this.name = name; this.birthday = birthday; } }pythonclass Human: name = None birthday = None def __init__(self, name, birthday): self.__name = name self.__birthday = birthdayカプセル化
カプセル化を行うにはメソッドやアトリビュートの前に
__(アンダースコア2つ)をつける。
__を付けることで外部からのアクセスを禁止することが出来る。
メソッドやアトリビュートの前に_(アンダースコア1つ)を付けた場合には慣習として、
「クラス内部でのみ使用するので、外部からアクセスしないでね」といった意味を持つ(らしい)。※調べていたらアンダースコアは色々意味があるそうです。参考文献に調べた際の記事などリンク載せています。
初学者のためのPython講座 オブジェクト指向編7 カプセル化
Lesson 12 クラスの定義 ― Python基礎文法入門
pythonのアンダーバーこれなんやねん例
javapubliv class Human { private String name; private String birthday; public Human(String name, String birthday) { this.name = name; this.birthday = birthday; } public getName() { return this.name; } public getBirthday() { return this.birthday; } public setName(String name) { this.name = name; } public setBirthday(String birthday) { this.birthday = birthday; } }pythonclass Human: __name = None __birthday = None def __init__(self, name, birthday): self.__name = name self.__birthday = birthday def getName(self): return self.__name def getAge(self): return self.__birthday def setName(self, name): self.__name = name def setAge(self, birthday): self.__birthday = birthday継承
Pythonは多重継承が可能。
多重継承する場合には、,で区切ってクラス名を指定する。例
javapublic class SuperMan extends Human { private String ability; public getAbility() { return this.age; } public setAbility(String ability) { this.ability = ability; }pythonclass SuperMan(Human): #多重継承の場合SuperMan(Human, Man)のような感じで定義する __ability = None def getAbility(self): return self.__ability def setAbility(self, ability): self.__ability = abilityスロット
アトリビュートの追加を制限することが出来る特殊メソッド
__slots__ = [アトリビュート名1, アトリビュート名2, ...]メモリの使用効率をよくする
pythonclass Profile: __slots__ = ['height', 'weight', 'bloodType'] def __init__(self, bloodType): self.bloodType = bloodType a = Profile('A') print(a.bloodType) >>A #slotsに定義されているアトリビュート a.height = 170 a.weight = 60 a.constellation = 'Aries' >>エラーが発生するプロパティ
getter,setterを簡単に定義するための組み込み関数。
非公開のアトリビュートへのアクセス制御を簡単に行う。
property(getterメソッド名, [setterメソッド名])pythonclass Human: __name = None def __init__(self, name): self.__name = name def getName(self): return self.__name def setName(self, name): self.__name = name propName = property(getName, setName) #代入を行うと、propertyで設定したsetterが動作する propName = 'takeshi' #取り出しを行うと、propertyで設定したsetterが動作する print(propName) >>takeshiあとがき
Pythonのデメリットについて調べると、実行速度の遅さが出てきました。
今回まとめた__slots__はそのデメリットを改善するために必要なことだと感じました。
Pythonらしい機能を適切に使えるよう理解を進めていきたいと思います。参考文献
参考書
柴田淳(2016)「みんなのPython 第4版」SBクリエイティブ株式会社公式リファレンス
Python公式リファレンスデータ型について
Pythonの組み込みデータ型の分類表(ミュータブル等)アンダースコアについて
初学者のためのPython講座 オブジェクト指向編7 カプセル化
Lesson 12 クラスの定義 ― Python基礎文法入門
pythonのアンダーバーこれなんやねん
- 投稿日:2020-09-14T18:54:13+09:00
時系列データを比較する方法-Derivative DTW, DTW-
要約
- 目的:異なる時系列データの類似度を測る
- キーワード:動的時間伸縮法 / Dynamic Time Warping (以下、DTW),Derivative Dynamic Time Warping (以下、DDTW)
- 参照1.:Derivative DTW ~時系列パターンの類似度計算の手法~ by Tech Blog
- 参照2.:DTW(Dynamic Time Warping)動的時間伸縮法 by S-Analysis
- 参照3.:DTW (動的時間伸縮法)の実装 by ksknw
- 参照4.:fastdtwの使い方
DTW
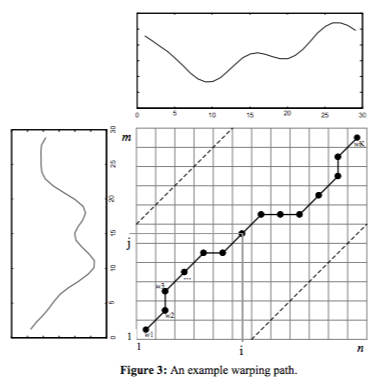
DTWの求め方
2つの時系列の各点の距離(データの次元にもよるが、今回は絶対値)を計算した(コスト)行列を作成
\begin{align} time\ series\ T&:t_0,t_1,...,t_N,\\ time\ series\ S&:s_0,s_1,...,s_M,\\ \boldsymbol{W}&:=(\delta(i,j)) ,\\ where\ \delta(t_i,s_j)&:=|t_i-s_j|,i \in \{0,1,...,N\},j\in\{0,1,...,M\} \end{align}この行列上を(0,0)から(N,M)を通るパスで単調性増加性を満たすものを考える。
\begin{align} path\ \tau :\tau(0)=(0,0),\tau(1),...,\tau(p)=(p_i,p_j),...,\tau(K),\\ where\ p_i \in \{0,1,...,N\},p_j\in\{0,1,...,M\}. \end{align}特に、この$path\ \tau$で単調性増加性を満たすようなものを考える。
\tau(p) \leq \tau(q) \Longleftrightarrow^{def} p_i\leq q_i\ or\ p_j\leq q_j.\\ if\ p\leq q,then\ \tau(p) \leq \tau(q).この$path$が通る行列$\boldsymbol{W}$の要素の和で最少となる値をDTWのコストとする。
\begin{align} cost(\tau)&:=\sum_{p}\delta(p_i,p_j)\\ Dist(T,S)&:=min_{\tau}cost(\tau) \end{align}公式の式とは違うが、こんな感じでしょう。
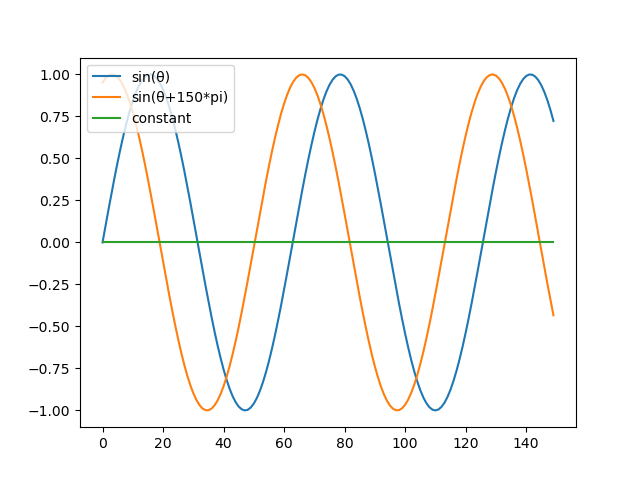
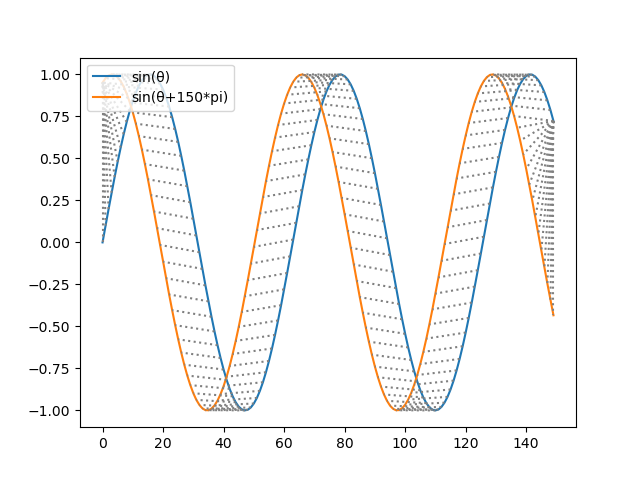
テストコード:参照3# 準備 pip install fastdtw # <= pipは実際こいつだけでよい pip install numpy pip install scipy ##code## import numpy as np from scipy.spatial.distance import euclidean from fastdtw import fastdtw A = np.sin(np.array(range(T)) / 10) B = np.sin((np.array(range(T)) / 10 + t * np.pi)) C = np.zeros((T)) distance, path = fastdtw(A, B, dist=euclidean) print(distance) plt.plot(A) plt.plot(B) for i, j in path: plt.plot([i, j], [A[i], B[j]],color='gray', linestyle='dotted') plt.legend(["sin(θ)", "sin(θ+150*pi)"], fontsize=10, loc=2) plt.show() ##結果## sin(θ)-sin(θ+150*pi): 0.6639470476737607 sin(θ)-constant: 0.5150026855435942 DTW(sin(θ), sin(θ+150*pi)): 16.720461687388624 DTW(sin(θ), constant): 97.26964355198544
DTWのメリット
時系列同士の長さや周期が違っても類似度が求まる
DTWのデメリット
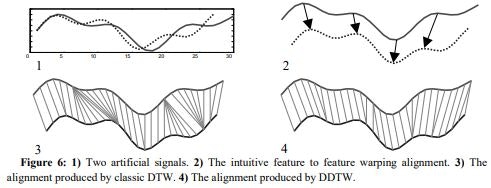
時間軸に関して局所的に加速、減速した部分がある時系列データに対して、直観とは違うアライメントが行われてしまう:
参照:Derivative Dynamic Time Warping by Eamonn等
例えば、一方がs高になった場合、DTWはデータ形状を無視してアライメントするため、s高のデータ点はs高前のデータ点とペアの物と対応付けてしまうのが原因DDTW
DTWを受けて、形状を捉えた情報加味して類似度を測る。
実際には時系列データ$time\ series\ T:t_0,t_1,...,t_N$を以下のように加工した後、DTWする:T^*:t^*_0,t^*_1,...,t^*_N,\\ where\ t^*_i := \frac{t_i-t_{i-1}+\frac{t_{i+1}-t_{i-1}}{2}}{2}= \frac{t_i-t_{i-1}+\frac{(t_{i+1}-t_i)+(t_i-t_{i-1})}{2}}{2}この加工は、注目する点$t_i$に関して、左微分$t_i-t_{i-1}$と右微分$t_{i+1}-t_i$の平均と左微分の平均を出したものである。
この加工をDTWするのがDDTWである。DDTWのメリット
上昇トレンドや下降トレンドなどの形状を考慮した類似度が算出できる
DDTWのデメリット
傾きの平均でよいのだろうか?
code
from concurrent.futures import ProcessPoolExecutor from concurrent.futures import ThreadPoolExecutor import time import numpy as np import pylab as plt import seaborn as sns from fastdtw import fastdtw from scipy.spatial.distance import euclidean def get_test_curves(view=False): T = 150 t = .4 A = np.sin(np.array(range(T)) / 10) B = np.sin((np.array(range(T)) / 10 + t * np.pi)) C = np.zeros((T)) if view: plt.plot(A) plt.plot(B) plt.plot(C) plt.legend(['sin(θ)', 'sin(θ+150*pi)', 'constant'], fontsize=10, loc=2) plt.show() return {'name': 'sin(θ)', 'data': A}, {'name': 'sin(θ+150*pi)', 'data': B}, {'name': 'constant', 'data': C} def mse(a, b): return ((a-b)**2).mean() def get_DWT_results(T, S, skip=1, view=False): T_data, S_data = T['data'], S['data'] T_name, S_name = T['name'], S['name'] distance, path = fastdtw(T_data, S_data, dist=euclidean) print("DTW({}, {}):".format(T_name, S_name), distance) if view: plt.plot(T_data) plt.plot(S_data) k = -1 for i, j in path: k += 1 if k % skip == 0: plt.plot([i, j], [T_data[i], S_data[j]], color='gray', linestyle='dotted') plt.legend([T_name, S_name], fontsize=10, loc=2) plt.title('DWT plot result') plt.show() return distance, path def get_derivative(T): diff = np.diff(T) next_diff = np.append(np.delete(diff, 0), 0) avg = (next_diff + diff) / 2 avg += diff avg /= 2 return np.delete(avg, -1) def get_DDWT_results(T, S, skip=1, view=False): T_data, S_data = T['data'], S['data'] dT_data = get_derivative(T_data) dS_data = get_derivative(S_data) T_name, S_name = T['name'], S['name'] distance, path = fastdtw(dT_data, dS_data, dist=euclidean) print("DDTW({}, {}):".format(T_name, S_name), distance) if view: plt.plot(T_data) plt.plot(S_data) k = -1 for i, j in path: k += 1 if k % skip == 0: plt.plot([i+1, j+1], [T_data[i+1], S_data[j+1]], color='gray', linestyle='dotted') plt.legend([T_name, S_name], fontsize=10, loc=2) plt.title('DDWT plot result') plt.show() return distance, path def get_test_curves_DDTWvsDWT(view=False): T = 150 t = .4 A = np.zeros((T)) B = np.zeros((T)) # A = np.sin(np.array(range(T)) / 10) # B = np.sin(np.array(range(T)) / 10+2)+50 s_i = 50 e_i = 60 for i in range(s_i, e_i, 1): A[i] = np.sin(np.pi*(i-s_i)/(e_i-s_i)) # B[i] = -2.2 if view: plt.plot(A) plt.plot(B) plt.legend(['sin(θ)', 'sin(θ+150*pi)'], fontsize=10, loc=2) plt.show() return {'name': 'down', 'data': A}, {'name': 'up', 'data': B} def main(): print("=== main ===") # A, B, C = get_test_curves() A, B = get_test_curves_DDTWvsDWT() # A["data"] = np.array([2, 0, 1, 1, 2, 4, 2, 1, 2, 0]) # B["data"] = np.array([1, 1, 2, 4, 2, 1, 2, 0]) print("{}-{}:".format(A['name'], B['name']), mse(A['data'], B['data'])) # print("{}-{}:".format(A['name'], C['name']), mse(A['data'], C['data'])) # DTWを計算 get_DWT_results(A, B, skip=5) get_DDWT_results(A, B, skip=5) if __name__ == "__main__": main()応用記事
DTW(Dynamic Time Warping)動的時間伸縮法 by 白浜公章で2,940社の日本企業の株価変動のクラスタリングをDTWとDDTWを使い、結果の違いを比較。使用データは"トムソン・ロイター データストリーム"を使用。DTW+DDTWが株価データを分類・解析するには最適な類似尺度であることを(目視による)定性的評価により結論付けている。
参照3はコードも実験も載っていてかなり参考になる。気温のデータに適用。
また、k-shapeなるものがあるそうです。これは読んでいないが、距離を相互相関とし、k-meansを使いクラスタリングを行う。
感想
実際に時系列データをDTW/DDTWを使ってクラスタリングをしてみたが上手くいかなかった。
あまり、理解ができていないのが原因である。
ご指摘等ありましたらよろしくお願いいたします。

- 投稿日:2020-09-14T18:53:25+09:00
男なら黙って棒でも立てとけと言わんばかりのまなざしでする強化学習
最近強化学習にハマってます。強化学習やってると, やっぱり棒を立てたくなってしまうのが男ってもんですよね。というわけで, 前回に引き続きOpenAIGymのCartPoleをやってみたので紹介します。
前回の記事 強化学習で山を登りたい
SARSA学習法とは
前回の記事で触れたQ学習ですが, 今回はSARSAという手法を用いたいと思います。ではおさらいです。強化学習における状態行動価値Qの更新は,
$$\begin{aligned}Q\left( s_{t},a_{t}\right) \ \leftarrow Q\left( s_{t},a_{t}\right) \ +\alpha \left( G_{t}-Q\left( s_{t},a_{t}\right) \right) \end{aligned}$$
を一回の状態遷移ごとに行います。SARSAとQ学習の違いは, この$G_{t}$の決め方です。
Q学習の場合
$$G_{t}=r_{t+1}+\gamma\max_{a\in At}[Q(s_{t+1},a)]$$SARSAの場合
$$G_{t}=r_{t+1}+\gamma Q(s_{t+1},a_{t+1}^{\pi})$$ここで, $a_{t+1}^{\pi}$とは, 状態$s_{t+1}$において方策に従って次の行動を選んだときの行動を示しています。以上からわかることは, Q学習では値の更新にmaxを使っている, つまり得られるであろう最大の状態価値を用いて更新を行っているいはば楽観的な学習方法であることに対し, SARSAでは, 次の行動を考慮に入れているため, より現実的な方策の決定方法になっています。今回は, これらの比較も行っていきます。
CartPoleルール
この棒を長い間(200step)立て続ければクリアという形式です。与えられる状態は四つで, 台車の位置, 台車の速度, ポールの角度, ポールの角速度が与えられます。行動は, 左に台車を押す:0, 右に押す:1の2つに制限されます。ポールの角度が12度以上傾くか, 200ステップ耐久で終了です。実装
まずはライブラリをインポートします。
import gym from gym import logger as gymlogger gymlogger.set_level(40) #error only import numpy as np import matplotlib import matplotlib.pyplot as plt %matplotlib inline import math import glob import io import base64学習を実装するクラスSARSAを定義します。
class SARSA: def __init__(self, env): self.env = env self.env_low = self.env.observation_space.low # 状態最小値 self.env_high = self.env.observation_space.high # 状態最大値 tmp = [7,7,7,7] #状態を7つの状態に分ける self.env_dx = [0,0,0,0] self.env_dx[0] = (self.env_high[0] - self.env_low[0]) / tmp[0] self.env_dx[1] = (self.env_high[1] - self.env_low[1]) / tmp[1] self.env_dx[2] = (self.env_high[2] - self.env_low[2]) / tmp[2] self.env_dx[3] = (self.env_high[3] - self.env_low[3]) / tmp[3] self.q_table = np.zeros((tmp[0],tmp[1],tmp[2],tmp[3],2)) #状態価値関数の初期化 def get_status(self, _observation): #状態を離散化する s1 = int((_observation[0] - self.env_low[0])/self.env_dx[0]) #7つの状態のいづれかに落とし込む if _observation[1] < -1.5: #自分で分類する s2 = 0 elif -1.5 <= _observation[1] < - 1: s2 = 1 elif -1 <= _observation[1] < -0.5: s2 = 2 elif -0.5 <= _observation[1] < 0.5: s2 = 3 elif 0.5 <= _observation[1] < 1.5: s2 = 4 elif 1.5 <= _observation[1] < 2: s2 = 5 elif 2 <= _observation[1]: s2 = 6 s3 = int((_observation[2] - self.env_low[2])/self.env_dx[2]) #7つの状態のいづれかに落とし込む if _observation[3] < -1: #自分で分類する s4 = 0 elif -1 <= _observation[3] < -0.7: s4 = 1 elif -0.7 <= _observation[3] < -0.6: s4 = 2 elif -0.6 <= _observation[3] < -0.5: s4 = 3 elif -0.5 <= _observation[3] < -0.4: s4 = 4 elif -0.4 <= _observation[3] < -0.4: s4 = 5 else: s4 = 6 return s1, s2, s3, s4 def policy(self, s, epi): #状態sにおける行動を選択する epsilon = 0.5 * (1 / (epi + 1)) if np.random.random() <= epsilon: return np.random.randint(2) #ランダムに選ぶ else: s1, s2, s3, s4 = self.get_status(s) return np.argmax(self.q_table[s1][s2][s3][s4]) #行動価値が最大の行動を選択する def learn(self, time = 200, alpha = 0.5, gamma = 0.99): #time回数だけ学習を行う log = [] #1エピソードごとの合計報酬を記録 t_log = [] #1エピソードごとのステップ数を記録 for j in range(time+1): t = 0 #ステップ数 total = 0 #合計報酬 s = self.env.reset() done = False while not done: t += 1 a = self.policy(s, j) next_s, reward, done, _ = self.env.step(a) reward = t/10 #長い間耐久すればするほど報酬は増える if done: if t < 195: reward -= 1000 #耐久に失敗したら罰則 else: reward = 1000 #成功時はもっと報酬を与える total += reward s1, s2, s3, s4 = self.get_status(next_s) G = reward + gamma * self.q_table[s1][s2][s3][s4][self.policy(next_s, j)] #累積報酬の計算 s1, s2, s3, s4 = self.get_status(s) self.q_table[s1][s2][s3][s4][a] += alpha*(G - self.q_table[s1][s2][s3][s4][a]) #Qの更新 s = next_s t_log.append(t) log.append(total) if j %1000 == 0: print(str(j) + " ===total reward=== : " + str(total)) return plt.plot(t_log) def show(self): #学習結果を表示 s = self.env.reset() img = self.env.render() done = False t = 0 while not done: t += 1 a = self.policy(s, 10000) s, _, done, _ = self.env.step(a) self.env.render() print(t) self.env.reset() self.env.close()困ったポイント
ここで自分がつまずいたところを紹介します。initのところで, env_dxで四つの状態それぞれについて, 離散化するための前準備をしているのですが, ここである問題が生じました. レファレンスをよく見ると,
速度の値の可変領域がinfです。そう, 無限なんです!これでは, env_dxの値も無限になってしまって, 連続値の離散化がうまくいきません。そこで,
from random import random env.step(random.randint(2))を何度も実行して, 台車の速度, それからポールの角速度の変異を観察しました。すると,
if _observation[1] < -1.5: #台車の速度 s2 = 0 elif -1.5 <= _observation[1] < - 1: s2 = 1 elif -1 <= _observation[1] < -0.5: s2 = 2 elif -0.5 <= _observation[1] < 0.5: s2 = 3 elif 0.5 <= _observation[1] < 1.5: s2 = 4 elif 1.5 <= _observation[1] < 2: s2 = 5 elif 2 <= _observation[1]: s2 = 6 if _observation[3] < -1: #ポールの角速度 s4 = 0 elif -1 <= _observation[3] < -0.7: s4 = 1 elif -0.7 <= _observation[3] < -0.6: s4 = 2 elif -0.6 <= _observation[3] < -0.5: s4 = 3 elif -0.5 <= _observation[3] < -0.4: s4 = 4 elif -0.4 <= _observation[3] < -0.4: s4 = 5 else: s4 = 6こんな感じで分類できそうということに気づきました。
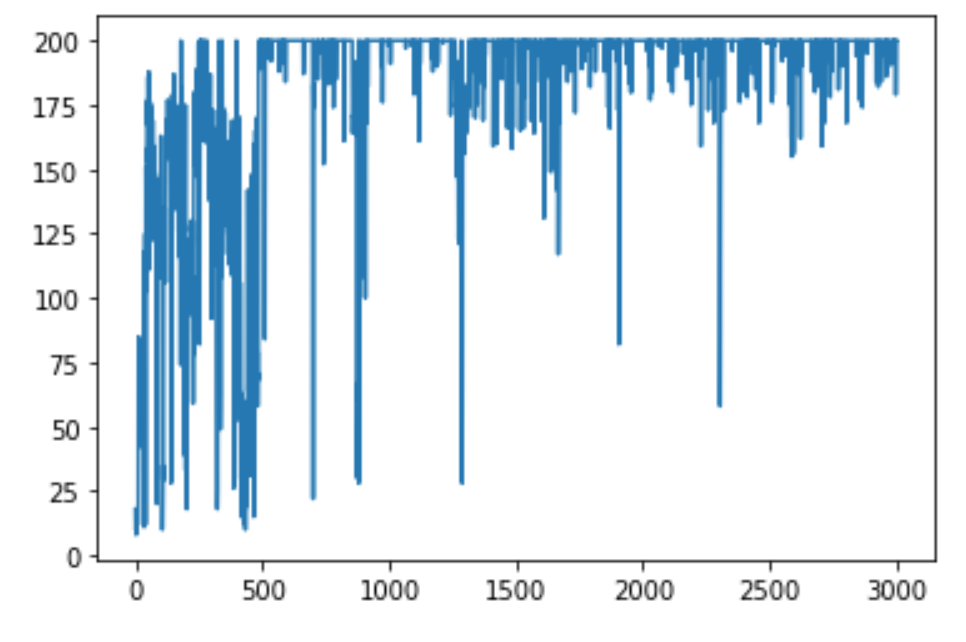
学習
そんなこんなで学習。3000回くらいで余裕っしょってことで。
env = gym.make('CartPole-v0') agent = SARSA(env) agent.learn(time = 3000)ステップ数の変化はこんな感じです。
さて,
agent.show()でアニメーションで確認してみましょう。
かなり安定していて持続力がすごいですね。これでめでたく男になれました。
Q学習vsSARSA
この環境においてQ学習とSARSAを比較してみます。Q学習ではGを
G = reward + gamma * max(self.q_table[s1][s2][s3][s4])のようにします。これで学習してみると,
収束の安定性が, SARSAの方が一枚上手に見えます。男ならSARSAのように現実をみろってことですね。はい。感想
この環境だと, 状態の離散化が一番大変なところなのかなと思いました。そこを解決していくという点でDQNが誕生したみたいですね。次回はDQNを組んでみようかなと思います。ではまた!





- 投稿日:2020-09-14T18:53:25+09:00
男なら黙って棒でも立てとけと言わんばかりのまなざしで強化学習
最近強化学習にハマってます。強化学習やってると, やっぱり棒を立てたくなってしまうのが男ってもんですよね。というわけで, 前回に引き続きOpenAIGymのCartPoleをやってみたので紹介します。
前回の記事 強化学習で山を登りたい
SARSA学習法とは
前回の記事で触れたQ学習ですが, 今回はSARSAという手法を用いたいと思います。ではおさらいです。強化学習における状態行動価値Qの更新は,
$$\begin{aligned}Q\left( s_{t},a_{t}\right) \ \leftarrow Q\left( s_{t},a_{t}\right) \ +\alpha \left( G_{t}-Q\left( s_{t},a_{t}\right) \right) \end{aligned}$$
を一回の状態遷移ごとに行います。SARSAとQ学習の違いは, この$G_{t}$の決め方です。
Q学習の場合
$$G_{t}=r_{t+1}+\gamma\max_{a\in At}[Q(s_{t+1},a)]$$SARSAの場合
$$G_{t}=r_{t+1}+\gamma Q(s_{t+1},a_{t+1}^{\pi})$$ここで, $a_{t+1}^{\pi}$とは, 状態$s_{t+1}$において方策に従って次の行動を選んだときの行動を示しています。以上からわかることは, Q学習では値の更新にmaxを使っている, つまり得られるであろう最大の状態価値を用いて更新を行っているいはば楽観的な学習方法であることに対し, SARSAでは, 次の行動を考慮に入れているため, より現実的な方策の決定方法になっています。今回は, これらの比較も行っていきます。
CartPoleルール
この棒を長い間(200step)立て続ければクリアという形式です。与えられる状態は四つで, 台車の位置, 台車の速度, ポールの角度, ポールの角速度が与えられます。行動は, 左に台車を押す:0, 右に押す:1の2つに制限されます。ポールの角度が12度以上傾くか, 200ステップ耐久で終了です。実装
まずはライブラリをインポートします。
import gym from gym import logger as gymlogger gymlogger.set_level(40) #error only import numpy as np import matplotlib import matplotlib.pyplot as plt %matplotlib inline import math import glob import io import base64学習を実装するクラスSARSAを定義します。
class SARSA: def __init__(self, env): self.env = env self.env_low = self.env.observation_space.low # 状態最小値 self.env_high = self.env.observation_space.high # 状態最大値 tmp = [7,7,7,7] #状態を7つの状態に分ける self.env_dx = [0,0,0,0] self.env_dx[0] = (self.env_high[0] - self.env_low[0]) / tmp[0] self.env_dx[1] = (self.env_high[1] - self.env_low[1]) / tmp[1] self.env_dx[2] = (self.env_high[2] - self.env_low[2]) / tmp[2] self.env_dx[3] = (self.env_high[3] - self.env_low[3]) / tmp[3] self.q_table = np.zeros((tmp[0],tmp[1],tmp[2],tmp[3],2)) #状態価値関数の初期化 def get_status(self, _observation): #状態を離散化する s1 = int((_observation[0] - self.env_low[0])/self.env_dx[0]) #7つの状態のいづれかに落とし込む if _observation[1] < -1.5: #自分で分類する s2 = 0 elif -1.5 <= _observation[1] < - 1: s2 = 1 elif -1 <= _observation[1] < -0.5: s2 = 2 elif -0.5 <= _observation[1] < 0.5: s2 = 3 elif 0.5 <= _observation[1] < 1.5: s2 = 4 elif 1.5 <= _observation[1] < 2: s2 = 5 elif 2 <= _observation[1]: s2 = 6 s3 = int((_observation[2] - self.env_low[2])/self.env_dx[2]) #7つの状態のいづれかに落とし込む if _observation[3] < -1: #自分で分類する s4 = 0 elif -1 <= _observation[3] < -0.7: s4 = 1 elif -0.7 <= _observation[3] < -0.6: s4 = 2 elif -0.6 <= _observation[3] < -0.5: s4 = 3 elif -0.5 <= _observation[3] < -0.4: s4 = 4 elif -0.4 <= _observation[3] < -0.4: s4 = 5 else: s4 = 6 return s1, s2, s3, s4 def policy(self, s, epi): #状態sにおける行動を選択する epsilon = 0.5 * (1 / (epi + 1)) if np.random.random() <= epsilon: return np.random.randint(2) #ランダムに選ぶ else: s1, s2, s3, s4 = self.get_status(s) return np.argmax(self.q_table[s1][s2][s3][s4]) #行動価値が最大の行動を選択する def learn(self, time = 200, alpha = 0.5, gamma = 0.99): #time回数だけ学習を行う log = [] #1エピソードごとの合計報酬を記録 t_log = [] #1エピソードごとのステップ数を記録 for j in range(time+1): t = 0 #ステップ数 total = 0 #合計報酬 s = self.env.reset() done = False while not done: t += 1 a = self.policy(s, j) next_s, reward, done, _ = self.env.step(a) reward = t/10 #長い間耐久すればするほど報酬は増える if done: if t < 195: reward -= 1000 #耐久に失敗したら罰則 else: reward = 1000 #成功時はもっと報酬を与える total += reward s1, s2, s3, s4 = self.get_status(next_s) G = reward + gamma * self.q_table[s1][s2][s3][s4][self.policy(next_s, j)] #累積報酬の計算 s1, s2, s3, s4 = self.get_status(s) self.q_table[s1][s2][s3][s4][a] += alpha*(G - self.q_table[s1][s2][s3][s4][a]) #Qの更新 s = next_s t_log.append(t) log.append(total) if j %1000 == 0: print(str(j) + " ===total reward=== : " + str(total)) return plt.plot(t_log) def show(self): #学習結果を表示 s = self.env.reset() img = self.env.render() done = False t = 0 while not done: t += 1 a = self.policy(s, 10000) s, _, done, _ = self.env.step(a) self.env.render() print(t) self.env.reset() self.env.close()困ったポイント
ここで自分がつまずいたところを紹介します。initのところで, env_dxで四つの状態それぞれについて, 離散化するための前準備をしているのですが, ここである問題が生じました. レファレンスをよく見ると,
速度の値の可変領域がinfです。そう, 無限なんです!これでは, env_dxの値も無限になってしまって, 連続値の離散化がうまくいきません。そこで,
from random import random env.step(random.randint(2))を何度も実行して, 台車の速度, それからポールの角速度の変異を観察しました。すると,
if _observation[1] < -1.5: #台車の速度 s2 = 0 elif -1.5 <= _observation[1] < - 1: s2 = 1 elif -1 <= _observation[1] < -0.5: s2 = 2 elif -0.5 <= _observation[1] < 0.5: s2 = 3 elif 0.5 <= _observation[1] < 1.5: s2 = 4 elif 1.5 <= _observation[1] < 2: s2 = 5 elif 2 <= _observation[1]: s2 = 6 if _observation[3] < -1: #ポールの角速度 s4 = 0 elif -1 <= _observation[3] < -0.7: s4 = 1 elif -0.7 <= _observation[3] < -0.6: s4 = 2 elif -0.6 <= _observation[3] < -0.5: s4 = 3 elif -0.5 <= _observation[3] < -0.4: s4 = 4 elif -0.4 <= _observation[3] < -0.4: s4 = 5 else: s4 = 6こんな感じで分類できそうということに気づきました。
学習
そんなこんなで学習。3000回くらいで余裕っしょってことで。
env = gym.make('CartPole-v0') agent = SARSA(env) agent.learn(time = 3000)ステップ数の変化はこんな感じです。
さて,
agent.show()でアニメーションで確認してみましょう。
かなり安定していて持続力がすごいですね。これでめでたく男になれました。
Q学習vsSARSA
この環境においてQ学習とSARSAを比較してみます。Q学習ではGを
G = reward + gamma * max(self.q_table[s1][s2][s3][s4])のようにします。これで学習してみると,
収束の安定性が, SARSAの方が一枚上手に見えます。男ならSARSAのように現実をみろってことですね。はい。感想
この環境だと, 状態の離散化が一番大変なところなのかなと思いました。そこを解決していくという点でDQNが誕生したみたいですね。次回はDQNを組んでみようかなと思います。ではまた!




- 投稿日:2020-09-14T18:33:39+09:00
Azure Custom Vision で画像分類モデルを爆速構築しFlaskで実装
概要
勉強会にて以下の本を参考に、画像データを用いた教師あり学習Webアプリを構築しました。
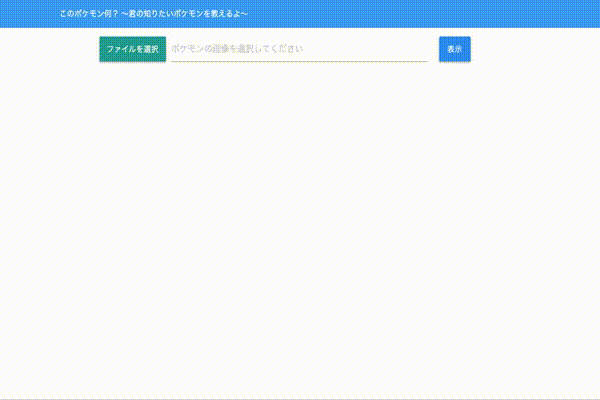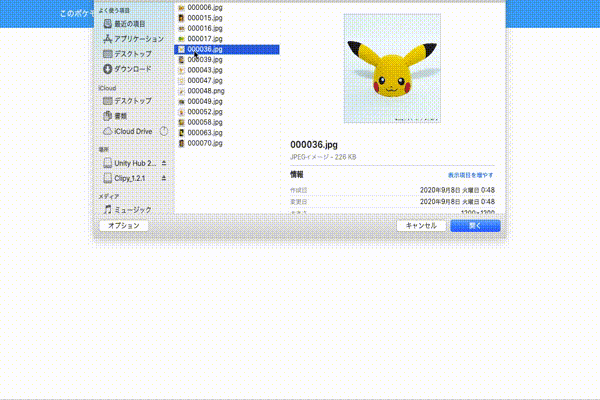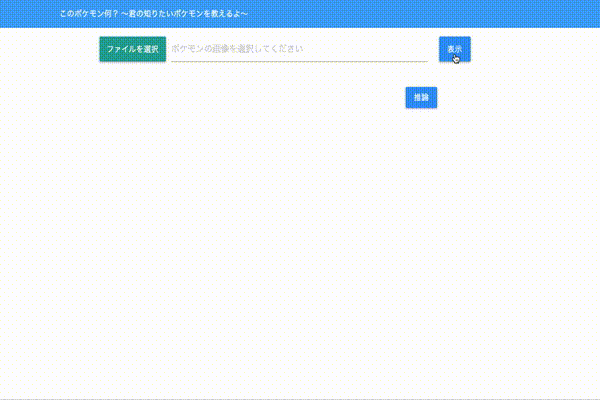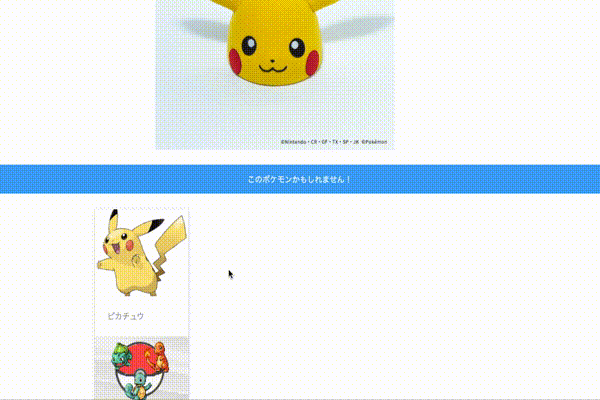
作成したアプリは以下になります。
URL:https://pokemonclassfication.herokuapp.com/
ポケモンの画像をアップロードすると画像を分類し、推測されるポケモンの情報を表示します。分析モデルにAzureのCustom Visionを活用し、WebフレームワークにはFlaskを活用しています。
本記事では主に以下を記載します。
1. GoogleImageCrawlerで画像データ収集スクリプトの作成
2. Custom Visonで分析モデルの構築
3. モデルの検証
4. Custom Vision APIを活用する実装Flaskの実装に関する詳細な解説などは、参考にした本「実践で学ぶ機械学習活用ガイド」や「公式リファレンス」を読むことを推奨します。
Webアプリのコードはこちら:ポケモン画像分類アプリのコード
1. GoogleImageCrawlerで画像データ収集スクリプトの作成
教師あり学習で画像分類モデルを構築するためには、大量の画像が必要です。
やはり画像を手動で集めるのは、工数の無駄なのである程度は自動化したいです。
※自動で収集した画像、モデルに有用ではない画像も含まれてしまうので最終的にはある程度手動で選抜する作業など必要になります。画像収集スクリプトはPythonのパッケージである icrawler を活用します。
ただ収集するのではなく、収集した画像の2割をテストデータとするため、フォルダを分けて収集しています。
活用したコードは以下になります。collect_img_poke.pyimport os import glob import random import shutil from icrawler.builtin import GoogleImageCrawler #画像を保存するルートディレクトリ root_dir = 'pokemon/' #ポケモン画像検索キーワードリスト pokemonnames = ['ピカチュウ','ゼニガメ','ヒトカゲ','フシギダネ','カビゴン'] #収集画像データ数 data_count = 100 for pokemonname in pokemonnames: crawler = GoogleImageCrawler(storage={'root_dir':root_dir + pokemonname + '/train'}) filters = dict( size = 'large', type = 'photo' ) #クローリングの実行 crawler.crawl( keyword=pokemonname, filters=filters, max_num=data_count ) #前回実行時のtestディレクトリが存在する場合、ファイルをすべて削除する if os.path.isdir(root_dir + pokemonname + '/test'): shutil.rmtree(root_dir + pokemonname + '/test') os.makedirs(root_dir + pokemonname + '/test') #ダウンロードファイルのリストを取得 filelist = glob.glob(root_dir + pokemonname + '/train/*') #ダウンロード数の2割をtestデータとして抽出 test_ratio = 0.2 testfiles = random.sample(filelist, int(len(filelist) * test_ratio)) for testfile in testfiles: shutil.move(testfile, root_dir + pokemonname + '/test/')上記は、実践で学ぶ機械学習活用ガイドに記載している内容とほぼ同じです。
しかし、このコードだけでは2020年9月13日時点ではうまくいきません。Google画像検索のAPIが変更されたのが原因だそうです。
この回避策を記載します。参考: Google Crawler is down #65/icrawler/builtin/google.py の parseメソッドを以下のように変更すれば良いそうです。
コメントアウトしている内容が変更前の内容になります。def parse(self, response): soup = BeautifulSoup( response.content.decode('utf-8', 'ignore'), 'lxml') #image_divs = soup.find_all('script') image_divs = soup.find_all(name='script') for div in image_divs: #txt = div.text txt = str(div) #if not txt.startswith('AF_initDataCallback'): if 'AF_initDataCallback' not in txt: continue if 'ds:0' in txt or 'ds:1' not in txt: continue #txt = re.sub(r"^AF_initDataCallback\({.*key: 'ds:(\d)'.+data:function\(\){return (.+)}}\);?$", # "\\2", txt, 0, re.DOTALL) #meta = json.loads(txt) #data = meta[31][0][12][2] #uris = [img[1][3][0] for img in data if img[0] == 1] uris = re.findall(r'http.*?\.(?:jpg|png|bmp)', txt) return [{'file_url': uri} for uri in uris]icrawlerが実際にあるディレクトリは以下の方法などで確認できます。
>>import icrawler >>icrawler.__path__ ['/~~~~~~~~/python3.7/site-packages/icrawler']ちなみに以下のような階層になっているとおもいます。
├── pokemon │ ├── ピカチュウ │ │ ├── test │ │ └── train │ ├── ヒトカゲ │ │ ├── test │ │ └── train │ ├── ゼニガメ │ │ ├── test │ │ └── train │ ├── フシギダネ │ │ ├── test │ │ └── train │ └── カビゴン │ ├── test │ └── train │ └── collect_img_poke.py2. Custom Visonで分析モデルの構築
Custom VisionはAzureサービスの1つで画像分類分析モデルをノンプログラミングで構築することができます。
また、APIとして公開が容易なのも特徴です。
こちら活用する場合、Azureのサブスクリプションを持つ必要があります。一ヶ月は無料で使えます。
Azure 登録
Custom VisionポータルCustom VisionをGUIで構築する手順は以下を参考にしています。
クイック スタート:Custom Vision で分類子を構築する方法以下、Custom VisionポータルにSign IN後の簡単な手順です。
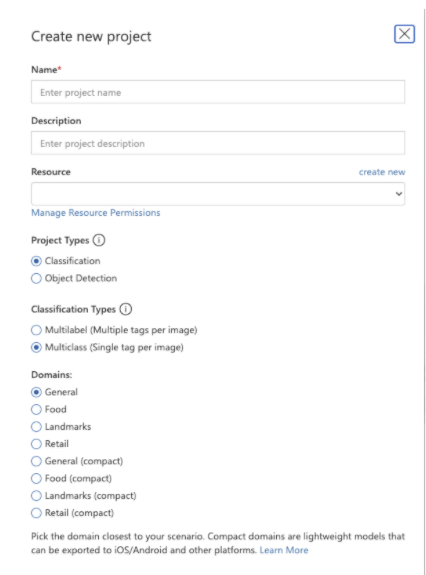
1. 最初のプロジェクトを作成するには、 [新しいプロジェクト] を選択します。 [新しいプロジェクトの作成] ダイアログ ボックスが表示されます。テキストボックスには、任意の設定、チェックボックスは以下の設定を参考にしてください。
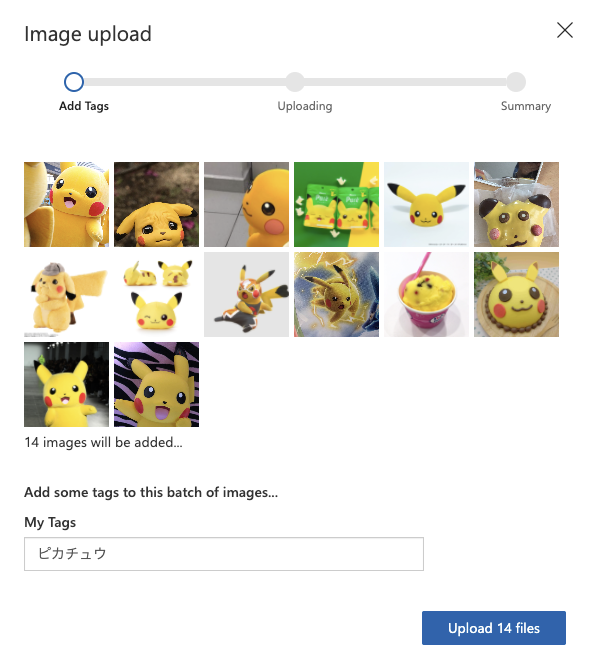
2.Add Imageをクリックします。
- 画像にタグをつけてアップロードします。今回はピカチュウ、ヒトカゲ、ゼニガメ、フシギダネ、カビゴンの画像をアップロードしてます。
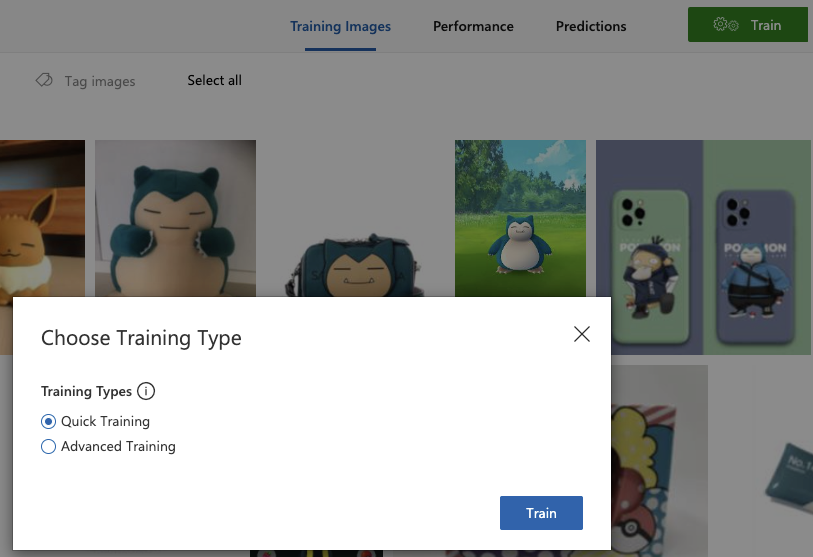
4.右上のTrainをクリックし、Quick Trainingを選択後、モーダルウィンドウのTrainをクリックします。
上記の手順で画像分類アプリが構築されます。
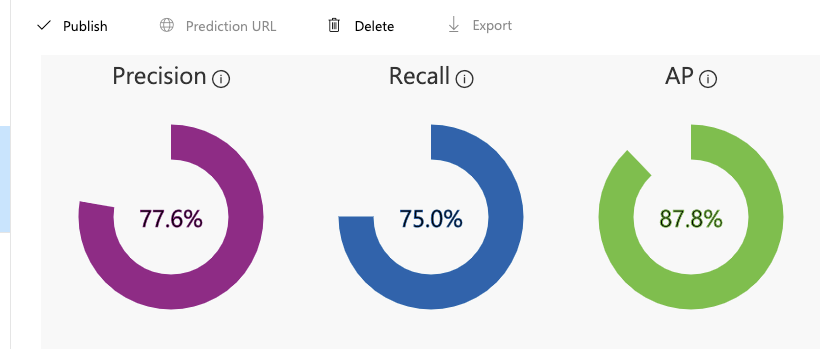
構築モデルの情報は以下になります。
今回精度がガバガバなのは、自動収集した画像を精査せずにアップロードしているからです。
精度をあげたい場合、自動収集した画像を精査してください。多分ピカチュウとかコスプレしている人とかが混じってたりしてます。5.次に左上のPublishボタンをクリックするだけで、この分析モデルはAPIとしてWebで公開されます。
6.Prediction URLをクリックすると、APIと接続するための情報が記載されています。
今回は、画像をアップロードして活用するため、画像における下に記載してあるURLとPrediction-Keyを活用します。
上記の手順で簡単に画像分類モデルを構築することができ、またAPIとしてWebに公開できるのがAzure Custom Visionの特徴です。
3.モデルの検証
テスト用にダウンロードした画像を構築モデルに分析させ、その正解率を調べます。
collect_img_poke.pyと同じ階層に以下のファイルを作成します。
作成したモデルの公開URLとKeyを設定後にファイルを実行します。predictions_poke_test.pyimport glob import requests import json base_url = '<API URL>' prediction_key = '<Key>' poke_root_dir = 'pokemon/' # 検証対象のポケモン名一覧 pokemonnames = ['ピカチュウ','ゼニガメ','ヒトカゲ','フシギダネ','カビゴン'] for pokename in pokemonnames: testfiles = glob.glob(poke_root_dir + pokename + '/test/*') data_count = len(testfiles) true_count = 0 for testfile in testfiles: headers = { 'Content-Type': 'application/json', 'Prediction-Key': prediction_key } params = {} predicts = {} data = open(testfile, 'rb').read() response = requests.post(base_url, headers=headers, params=params, data=data) results = json.loads(response.text) try: # 予測結果のタグの数だけループ for prediction in results['predictions']: # 予測したポケモンとその確率を紐づけて格納 predicts[prediction['tagName']] = prediction['probability'] # 一番確率の高いポケモンを予測結果として選択 prediction_result = max(predicts, key=predicts.get) # 予測結果が合っていれば正解数を増やす if pokename == prediction_result: true_count += 1 #画像サイズ > 6MB だとCustom Vision の制限にひっかりエラーが出るまで握り潰し except KeyError: data_count -= 1 continue # 正解率の算出 accuracy = (true_count / data_count) * 100 print('ポケモン名:' + pokename) print('正解率:' + str(accuracy) + '%')以下のような結果が出力されていればOKです。
モデルの精度は低いですが、おそらく色で大雑把に判断しているんでしょうんね。>>>python predictions_poke_test.py ポケモン名:ピカチュウ 正解率:95.45454545454545% ポケモン名:ゼニガメ 正解率:95.23809523809523% ポケモン名:ヒトカゲ 正解率:81.81818181818183% ポケモン名:フシギダネ 正解率:85.0% ポケモン名:カビゴン 正解率:95.83333333333334%4. Custom Vision APIを活用する実装
このアプリはFlaskで実装しています。
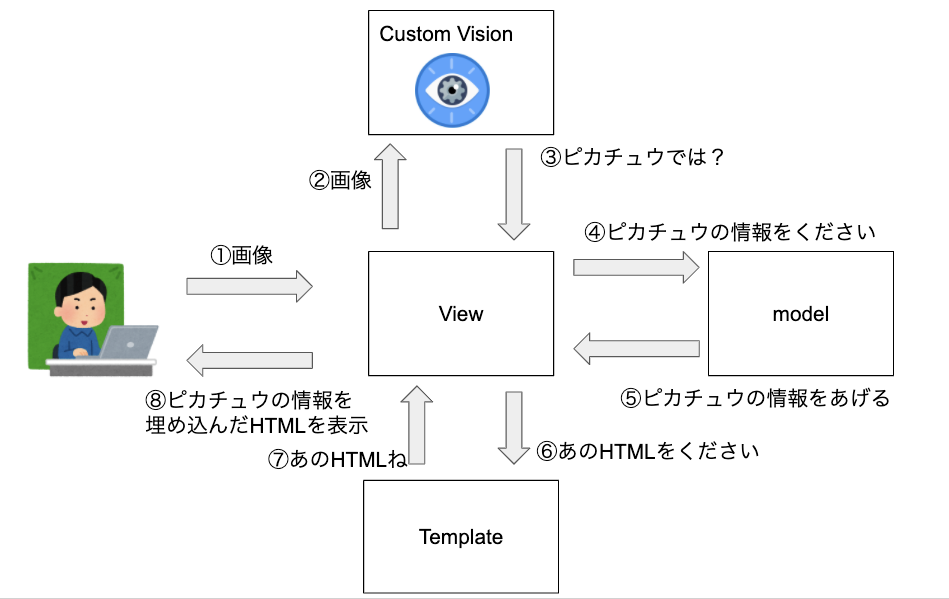
アプリの概要を簡単に図で表すと以下になります。
Webアプリはアップロードされた画像をCustom Visionで分析させ、その分析結果を取得します。
分析結果から、DBにある詳細な情報を取得し、その情報をHTMLに埋め込んで画面に表示しています。
このMTVモデルは、FlaskやDjangoで採用されています。
Flaskの詳細は「実践で学ぶ機械学習活用ガイド」や「公式リファレンス」を確認してください。
ここでは、図の②〜⑤に該当するCusom Visionとの連携からDB情報取得までを記載します。全コードはこちら:ポケモン画像分類アプリのコード
以下、該当コードです。
models.pyimport flaski.database import requests import json import os base_url = '<API URL>' prediction_key = '<Key>' POKEMON_FOLDER = './static/images/pokemon/' # 予測確率のしきい値(パーセント) threshold = 60 # ポケモン情報をDBから取得し辞書型で返す def get_pokemon_data(pokemonname): ses = flaski.database.db_session() pokemon = flaski.database.Pokemon pokemon_data = ses.query(pokemon).filter(pokemon.pokemon_name == pokemonname).first() pokemon_data_dict = {} if not pokemon_data is None: pokemon_data_dict['pokemon_name'] = pokemon_data.pokemon_name pokemon_data_dict['wiki_url'] = pokemon_data.wiki_url pokemon_data_dict['picture_path'] = os.path.join(POKEMON_FOLDER, pokemon_data.pokemon_name + '.png') return pokemon_data_dict # モデルAPIの呼び出し def callAPI(uploadFile): # 予測実行 headers = { 'Content-Type': 'application/json', 'Prediction-Key': prediction_key } params = {} predicts = {} data = open(uploadFile, 'rb').read() response = requests.post(base_url, headers=headers, params=params, data=data) response_list = json.loads(response.text) result = [] try: # 予測結果のタグの数だけループ for prediction in response_list['predictions']: if len(get_pokemon_data(prediction['tagName'])) != 0: # 確率がしきい値より大きいものを採用する if prediction['probability'] * 100 > threshold: result.append(get_pokemon_data(prediction['tagName'])) return result #画像サイズ > 6MB だとCustom Vision の制限にひっりエラーが出るまで握り潰し except KeyError: return resultdef callAPI(uploadFile)はCustom Visionに画像をアップロードし、データを取得する処理になり、3.モデルの検証で記載したスクリプトの内容とほぼ同じです。
異なる点は、予測確率のしきい値(パーセント):threshold を設定しており、これ以上の適合率の情報しか取得しないようにしています。上記のコードの場合、適合率が60%以上のポケモンの情報を取得しています。def get_pokemon_data(pokemonname)は、以下の処理でFlaskで作成したDBのテーブルに接続しています。
そして、filter処理で特定のポケモンの情報を取得しています。ses = flaski.database.db_session() pokemon_data = ses.query(pokemon).filter(pokemon.pokemon_name == pokemonname).first()このようにFlaskではSQLを使わずDBの情報を取得が容易です。
DBテーブルの作成などもコードで実行可能です。上記したコードでCustom Visionから分析結果を取得し活用しています。
このようにCustom Visionを活用したアプリ開発は非常に簡単です。最後に
Azure Custom Visionは簡単に画像分類モデルを構築できるため、機械学習アプリを開発する入門に大変良い題材でした。
参考にした本に詳細な解説があるにも関わらず、記事を書いた理由としましては、去年出版した本のため様々な仕様変更に対応できていない部分があったからです(crawlerなど)。そこで新たに実装にした内容を本記事では書いています。Flaskの実装などに関して、あまり言及していないのは、本を読んでいただければ理解できる内容だからです。本記事で機械学習アプリの作成概要がふわ〜っとでもわかれば幸いです。



- 投稿日:2020-09-14T18:26:17+09:00
【python】listのスライス操作を秒で理解
初めに
僕がスライスをどう読んでるかの解説になると思います。
初心者がサッサとスライス使いたいと思ったら読んで見てください。「python スライス 使い方」でググると、細かく書いてる記事ばっかりだったので、ざっくり書きます。
解説
3点だけおさえれば大丈夫です。
1. インデックスの理解
インデックスが文字と文字の あいだ (between) を指しており、最初の文字の左端が 0 になっていると考えましょう。
+---+---+---+---+---+---+ | P | y | t | h | o | n | +---+---+---+---+---+---+ 0 1 2 3 4 5 6 -6 -5 -4 -3 -2 -12. 指定の仕方 → リスト名[から:まで:間隔]
頭の中で、コメントのようにコードを読めます。
>>> num_list = [1, 5, 2, 3, 4] >>> num_list[1:4:1] #1で紹介したインデックスを指定します。1番目「から」4番目「まで」を1「間隔」で選択 [5, 2, 3]3.「:」が一つのときは「から:まで」の間の「:」
>>> num_list = [1, 5, 2, 3, 4] >>> num_list[-4:] # 後ろ4番目「から」選択 [5, 2, 3]これでざっくりコードを読めます。
練習
あとは、例を二点をおさえながら読んで見てください。
書き方を網羅できるはずです。>>> num_list = [1, 5, 2, 3, 4] >>> num_list[:4:1] # 「から」を省略すると最初の要素から選択 [1, 5, 2, 3] >>> num_list[1::1] # 「まで」を省略すると最後の要素まで選択 [5, 2, 3, 4] >>> num_list[1:4:] # 「間隔」を省略することで1個間隔で選択 [5, 2, 3] >>> num_list[1:4] # 「から:まで」の「:」(「間隔」を省略する場合は2つ目のコロンを省略可能) [5, 2, 3] >>> num_list[-4:] # 後ろ4番目から選択 [5, 2, 3, 4]終わりに
わかりにくかったらすみません。
- 投稿日:2020-09-14T18:00:25+09:00
ディクショナリ型1
ディクショナリ型
ディクショナリ型
ディクショナリ型は、1組のデータを「キー」と呼ばれる識別子とそれに対応する「値」とともに管理するデータ型。
タプルは「 () 」カッコ、リストは「 [] 」大カッコで作成しますが、ディクショナリは「 {} 」波カッコを使用します
オブジェクトを作成するには以下のように記述します。hatamoto = {"kokugo":65,"suugaku":82,"eigo":70"}
次の要素との間は「 , 」で区切ります。
自分はSQLのテーブル操作の様な使い方だと認識しています。dict()
hatamoto = {"kokugo”:65,”suugaku”:82,”eigo”:70}
print( hatamoto)実行結果:
{"kokugo":65,"suugaku":82,"eigo":70"}
dict()を使ってコピーなどもできる。
hatamoto = {"kokugo":65,"suugaku":82,"eigo":70"}
hatamoto2 = dict(hatamoto)
print(hatamoto2){"kokugo”:65,”suugaku”:82,”eigo”:70}
同じキーとバリューのディクショナリが作成される。
len()
Python のディクショナリはリストと同じように len で長さが確認できます。hatamoto = {"kokugo":65,"suugaku":82,"eigo":70"}
len(hatamoto)実行結果:
3
update()
ディクショナリ.update(結合するディクショナリ)
hatamoto = {"kokugo":65,"suugaku":82,"eigo":70"}
hatamoto2 = {"rika":"90", "syakai":"51"}
hatamoto.update(hatamoto2)
print(hatamoto)実行結果:
{'kokugo':'65','suugaku':'82','eigo':70,'rika':'90','syakai':'51'}新規キーを指定した場合は項目が追加され、既存のものを指定すると上書きされる。
キーを指定して要素を削除
hatamoto = {"kokugo":65,"suugaku":82,"eigo":70"}
del hatamoto['kokugo']
print(hatamoto)実行結果:
{'suugaku':'82','eigo':'70'}
存在しないキーを指定すると「KeyError」が発生する。
keys()
すべてのキーを取得するhatamoto = {"kokugo":65,"suugaku":82,"eigo":70"}
print(hatamoto.keys())dict_keys(['kokugo', 'suugaku', 'eigo'])
- 投稿日:2020-09-14T17:18:00+09:00
Python3 | リスト・タプル・辞書
リスト
- 複数の値をまとめることができる
- [ ](ブラケットの角括弧)を使う
- 各要素は , (カンマ)で区切る
a = [apple, banana, orange]各要素の取り出し
変数名の直後に[ ]をつけ、数値を代入すると各要素が取り出せる。
a = ['フシギダネ', 'ヒトカゲ', 'ゼニガメ'] print(a[0]) # フシギダネ print(a[1]) # ヒトカゲ print(a[2]) # ゼニガメ: を使うことでリストのまま取り出せる。
a = ['フシギダネ', 'ヒトカゲ', 'ゼニガメ'] print(a[0:3]) # ['フシギダネ', 'ヒトカゲ', 'ゼニガメ']リストの中のリスト
リストの中にリストを収納できる。このとき、[ ] で取り出せるのは、
リストの中のリストだけであることに注意。a = [['フシギダネ', 'ヒトカゲ', 'ゼニガメ'], ['チコリータ', 'ヒノアラシ', 'ワニノコ']] print(a[0]) # ['フシギダネ', 'ヒトカゲ', 'ゼニガメ'] print(a[1]) # ['チコリータ', 'ヒノアラシ', 'ワニノコ']タプル
- リストと同じく複数の値をまとめることができる ※ただし、各要素の追加や消去、場所の移動などはできない
- ( )(パーレンの丸括弧)を使う
- 各要素は , (カンマ)で区切る
b = {'キモリ', 'アチャモ', 'ミズゴロウ'}リストとタプルの違いは?
リストとタプルの大きな違いはmutable(変更可能)か
ということである。「変更可能のほうが便利じゃないか」と思われるかもしれないが、
タプルにすると変わってほしくないデータに対して便利になる。例えば、地図の緯度経度など半不変的なデータは変更して欲しくないので、
このようなときにタプルが使われる。辞書
- key(キー)とvalue(バリュー)の組合わせで使われる ※これをkey value pair(キーバリューペア)という
- リストと同じくmutable(変更可能)
- { }(ブレースの波括弧)を使う
c = {'ナエトル': 'Grass', 'ヒコザル': 'Fire', 'ポッチャマ': 'Water'} print(c['ナエトル']) # 'Grass' print(c) # {'ナエトル': 'Grass', 'ヒコザル': 'Fire', 'ポッチャマ': 'Water'}要素の入れ替え・追加
キー自体に代入することで、要素の入れ替えができる。
c['ナエトル'] = '草' print(c['ナエトル']) # '草'同様にキーとバリューをセットにすると、要素の追加ができる。
c = {'ナエトル': 'Grass', 'ヒコザル': 'Fire', 'ポッチャマ': 'Water'} c['ピカチュウ'] = 'Electric' print(c) # {'ナエトル': 'Grass', 'ヒコザル': 'Fire', 'ポッチャマ': 'Water', 'ピカチュウ': 'Electric'}
- 投稿日:2020-09-14T15:23:48+09:00
仮想環境の共有をする方法 [requirements.txtについて]
はじめに
仮想環境をGitで共有するについて話が上がったのですが、さっぱりだったので調べてみました。
仮想環境とは
わかっている方は読み飛ばしていただいて結構です。
統合開発環境(IDE) vs. 仮想環境(virtual environment)
具体的方法
仮想環境をGitで共有する具体的な方法について以下に書きます。こちらの記事を参考にしました。
仮想環境をGitで共有するというのは、誰かが仮想環境を作りそれをチームで共有するということではなく、各々がそれぞれのpc内に新規にPython仮想環境を作り、その中でrequirements.txtという、そのプロジェクトで必要なパッケージライブラリを記載したファイルを読み込むということ。つまり、Gitでrequirements.txtを共有すればいいということです。
requirements.txtについて
ここに現在の環境に入っているパッケージライブラリの一覧を取得します。具体的には、ターミナルで以下のコマンドを実行しましょう。
pip freeze > requirements.txtこれでプロジェクト内にrequirements.txtが生成されるはずなので、これをGitHub上に上げます。
一括インストール
requirements.txtが入ったプロジェクトを保存するだけではパッケージライブラリはまだ仮想環境において使える状態にはありません。それをインストールするためには以下のコマンドをターミナルで実行する必要があります。
pip install -r requirements.txtこれで、パッケージライブラリの共有は完了となります。
終わりに
仮想環境の共有という日本語は誤解を生み出してしまいそうで、正しくはパッケージライブラリの共有ですが、日常会話では前者が使われることが多い気がする(?)ので、題名はそのままにしておきます。
参考
- 投稿日:2020-09-14T14:48:21+09:00
ディープラーニングでFX(ドル円)のレート予測正解率が88%を叩き出す聖杯プログラムが作成出来たと思って喜んでいたのに、本番データで予測させたら「分からない」を連発するポンコツだったようです。
本記事について
なろうみたいな記事タイトルですみません。
「ディープラーニング(CNN)で、ドル円の予測プログラムを作って億万長者や!」
と意気込んだ結果、失敗したお話です。反面教師にされたい方のみご参照ください。成果物についての説明
あまり説明したくないですが、成果物について説明します。
CNN(畳み込みニューラルネットワーク)で、大量のチャート画像でレートの予測方法を学習し、
24時間後のレートが「上がる」「下がる」「分からない」の3択を出力するプログラムを作成しました。
推論結果は正解率88%という好成績でした。
しかし、実データで予測させると「分からない」を連発するポンコツっぷり。。
作成期間3日もかけたので、ガックリ具合が半端ないですが、
作成した経過で勉強になることが多かったのでアウトプットとして残しておこうと思います。
構築環境
Google Colaboratory上で構築。
Python 3.6
Tensorflow 1.13.1データの前処理
画像データの準備
CNNは画像分類の深層学習です。
というわけで、大量のチャート画像を用意する必要があります。
以下のような画像データを約8万枚ほど準備しました。
なお、8時間ほどかけて作成した8万枚の画像ですが、後述にある理由で、実際に使ったのは3万枚でした。
チャート画像作成方法については、こちらの記事を参照ください。画像データの配列化とバイナリ形式への保存
学習作業は画像データそのままでは出来ません。
画像データをnumpyのarrayに変換する必要があり、1万枚ごとにnpy形式に保存してみました。import glob import cv2 import numpy as np X=[] #対象の画像をリスト化 img_list = glob.glob('<画像の保存先フォルダ>/*.png') #画像をリサイズ for i in img_list: img = cv2.imread(i) img = cv2.resize(img, dsize=(150, 150)) #リサイズ X.append(img) #リストに追加 #1万枚毎にバイナリ形式で保存する if (i > 0) and (i % 10000 == 0): #numpyに変換して、バイナリ保存 X = np.array(X) npy_name = 'traintest_' + str(i) + '.npy' np.save(npy_name, X) X = []すると、1つあたりのnpyファイルが0.7GBもあり、
8万枚分だと6GB近い大容量になってしまいました。
今回はGoogleDrive上に保存したデータを、
GoogleColobで読み込ませて作業する予定なので、
こんな大容量ファイルをアップするのはよろしくありません。
複数npyファイルを1つに圧縮して、npz形式で纏めます。
※最初からこうすれば配列からnpyに変換して保存する必要は無かったと後で気づく。arr1 = np.load('traintest_10000.npy') arr2 = np.load('traintest_20000.npy') arr3 = np.load('traintest_30000.npy') arr4 = np.load('traintest_40000.npy') arr5 = np.load('traintest_50000.npy') arr6 = np.load('traintest_60000.npy') arr7 = np.load('traintest_70000.npy') arr8 = np.load('traintest_80000.npy') np.savez_compressed('traintest_all.npz', arr1 , arr2, arr3, arr4, arr5, arr6, arr7, arr8)圧縮すると、0.7GB程度になりました。
当初、250*250にリサイズしたのですが、
Google Colabで読み込ませた結果、メモリがクラッシュしてしまい、150*150のサイズに変更しました。
このサイズだとボヤける箇所があり、特徴量を上手く掴めているのか不安な感じです。
今回の予測が失敗した理由の1つかもしれません。GoogleColabで訓練データ、テストデータ、正解ラベルの読み込み
作成したnpzファイルをGoogleDriveにアップし、
GoogleColabを起動して、それを読み込みます。# パッケージのインポート from tensorflow.keras.callbacks import LearningRateScheduler from tensorflow.keras.layers import Activation, Add, BatchNormalization, Conv2D, Dense, GlobalAveragePooling2D, Input from tensorflow.keras.models import Model from tensorflow.keras.optimizers import SGD from tensorflow.keras.preprocessing.image import ImageDataGenerator from tensorflow.keras.regularizers import l2 from tensorflow.keras.utils import to_categorical import numpy as np import matplotlib.pyplot as plt import pandas as pd %matplotlib inline #Google Driveマウント from google.colab import drive drive.mount('/content/drive') # データセットの元となるnpzを読み込む loadnpz = np.load(r'/content/drive/My Drive/traintest_all.npz')ちゃんと8個読み込めていることを確認します。
続いて、訓練用と検証用とで画像を分けます。
それぞれ1万枚を読み込みます。
※これ以上読み込んだら学習中にメモリがクラッシュするため。#訓練とテスト画像データセット train_images = loadnpz['arr_0'] test_images = loadnpz['arr_1']正解ラベルが入ったCSVファイルをDataFrameで読み込んだのちにarrayに変換します。
変換後、訓練用と検証用とで正解ラベルを分けます。#正解ラベルのセット df = pd.read_csv(r'/content/drive/My Drive/Colab Notebooks/npyファイル/tarintest_labels.csv') df['target'] = df['target'].replace('Up', '0') df['target'] = df['target'].replace('Down', '1') df['target'] = df['target'].replace('Flat', '2') df['target'] = df['target'].astype('int') labels_arr = df['target'].to_numpy() #ラベル部分をarraryに変換 #ラベルデータを分ける train_labels = labels_arr[0:10001] #訓練用 test_labels = labels_arr[10001:20001] #検証用ラベルデータはOneHot形式に変換します。
# OneHot形式に変換 train_labels = to_categorical(train_labels) test_labels = to_categorical(test_labels)ここまで出来たら、Shape数を確認しましょう。
モデル作成
続いて、モデルの作成です。
今回、ResNetという構造体で作成します。
ResNetって何だよという方はこちらの記事を参照ください。読み込む画像データ大きすぎると、メモリがクラッシュ連発で全然先に進みません。
その場合は、学習時のbatch_sizeを小さくするか、画像データ自体を小さくする必要があります。
私の場合は、当初画像データ250*250でやってメモリクラッシュ連発で全進めなかったので、150*150にリサイズしました。# 畳み込み層の生成 def conv(filters, kernel_size, strides=1): return Conv2D(filters, kernel_size, strides=strides, padding='same', use_bias=False, kernel_initializer='he_normal', kernel_regularizer=l2(0.0001)) # 残差ブロックAの生成 def first_residual_unit(filters, strides): def f(x): # →BN→ReLU x = BatchNormalization()(x) b = Activation('relu')(x) # 畳み込み層→BN→ReLU x = conv(filters // 4, 1, strides)(b) x = BatchNormalization()(x) x = Activation('relu')(x) # 畳み込み層→BN→ReLU x = conv(filters // 4, 3)(x) x = BatchNormalization()(x) x = Activation('relu')(x) # 畳み込み層→ x = conv(filters, 1)(x) # ショートカットのシェイプサイズを調整 sc = conv(filters, 1, strides)(b) # Add return Add()([x, sc]) return f # 残差ブロックBの生成 def residual_unit(filters): def f(x): sc = x # →BN→ReLU x = BatchNormalization()(x) x = Activation('relu')(x) # 畳み込み層→BN→ReLU x = conv(filters // 4, 1)(x) x = BatchNormalization()(x) x = Activation('relu')(x) # 畳み込み層→BN→ReLU x = conv(filters // 4, 3)(x) x = BatchNormalization()(x) x = Activation('relu')(x) # 畳み込み層→ x = conv(filters, 1)(x) # Add return Add()([x, sc]) return f # 残差ブロックAと残差ブロックB x 17の生成 def residual_block(filters, strides, unit_size): def f(x): x = first_residual_unit(filters, strides)(x) for i in range(unit_size-1): x = residual_unit(filters)(x) return x return f # 入力データのシェイプ input = Input(shape=(150,150, 3)) # 畳み込み層 x = conv(16, 3)(input) # 残差ブロック x 54 x = residual_block(64, 1, 18)(x) x = residual_block(128, 2, 18)(x) x = residual_block(256, 2, 18)(x) # →BN→ReLU x = BatchNormalization()(x) x = Activation('relu')(x) # プーリング層 x = GlobalAveragePooling2D()(x) # 全結合層 output = Dense(3, activation='softmax', kernel_regularizer=l2(0.0001))(x) # モデルの作成 model = Model(inputs=input, outputs=output) # TPUモデルへの変換 import tensorflow as tf import os tpu_model = tf.contrib.tpu.keras_to_tpu_model( model, strategy=tf.contrib.tpu.TPUDistributionStrategy( tf.contrib.cluster_resolver.TPUClusterResolver(tpu='grpc://' + os.environ['COLAB_TPU_ADDR']) ) ) # コンパイル tpu_model.compile(loss='categorical_crossentropy', optimizer=SGD(momentum=0.9), metrics=['acc']) # ImageDataGeneratorの準備 train_gen = ImageDataGenerator( featurewise_center=True, featurewise_std_normalization=True) test_gen = ImageDataGenerator( featurewise_center=True, featurewise_std_normalization=True) # データセット全体の統計量を予め計算 for data in (train_gen, test_gen): data.fit(train_images)学習
学習作業を実施します。
TPUモデルに変換したとはいえ、容量が容量なので5時間近くかかります。# LearningRateSchedulerの準備 def step_decay(epoch): x = 0.1 if epoch >= 80: x = 0.01 if epoch >= 120: x = 0.001 return x lr_decay = LearningRateScheduler(step_decay) # 学習 batch_size = 32 history = tpu_model.fit_generator( train_gen.flow(train_images, train_labels, batch_size=batch_size), epochs=100, steps_per_epoch=train_images.shape[0] // batch_size, validation_data=test_gen.flow(test_images, test_labels, batch_size=batch_size), validation_steps=test_images.shape[0] // batch_size, callbacks=[lr_decay])学習終了後、検証データでの正解率(val_acc)が88%に!
実データでの予測
新規に検証用データをtest_imagesに読み込んで、予測してみます。
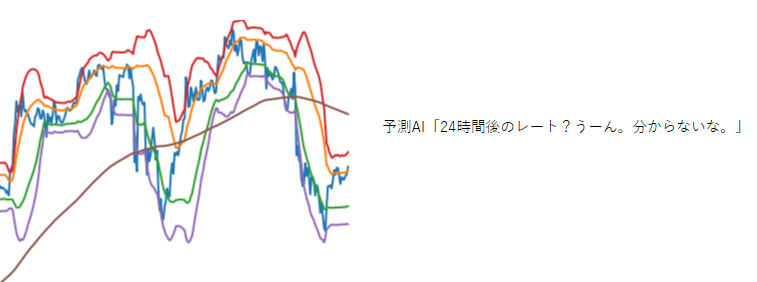
test_predictions = new_model.predict_generator( test_gen.flow(test_images[0:10000], shuffle = False, batch_size=16), steps=16) test_predictions = np.argmax(test_predictions, axis=1)[0:10000]予測結果は、「0:上がる」「1:下がる」「2:分からない」の3択で出力されます。
確認してみましょう。
「2:分からない」を連発してます・・・。
ところどころ「0:上がる」「1:下がる」もありましたが、
正解率は50%を割り込む悲惨な結果でした・・・。なぜ失敗したのか?
以下の2つが大きいのかなと思います。
- リサイズ後の画像サイズが小さすぎて特徴量が大雑把になりすぎた。
- 検証期間の画像が少なすぎる
1は画像のサイズを大きくすれば解決するのですが、
無料のGoogleColab環境だと厳しいです。
月額10ドルの有料会員になると、倍のメモリが利用できるようになるらしいので、解決するかもしれません。2は全画像をシャッフルすれば色々なチャートパターンを学習できるので、ある程度は良くなるかもしれません。
2の対策は簡単に出来るので、暇なときに試してみようと思います。







- 投稿日:2020-09-14T14:48:21+09:00
ディープラーニングでFX(ドル円)のレート予測正解率が88%を叩き出す聖杯プログラムが作成出来たと思って喜んでいたのに、本番データで予測させたら「分からない」を連発するポンコツでした。
本記事について
なろうみたいな記事タイトルですみません。
「ディープラーニング(CNN)で、ドル円の予測プログラムを作って億万長者や!」
と意気込んだ結果、失敗したお話です。反面教師にされたい方のみご参照ください。成果物についての説明
あまり説明したくないですが、成果物について説明します。
CNN(畳み込みニューラルネットワーク)で、大量のチャート画像でレートの予測方法を学習し、
24時間後のレートが「上がる」「下がる」「分からない」の3択を出力するプログラムを作成しました。
推論結果は正解率88%という好成績でした。
しかし、実データで予測させると「分からない」を連発するポンコツっぷり。。
作成期間3日もかけたので、ガックリ具合が半端ないですが、
作成した経過で勉強になることが多かったのでアウトプットとして残しておこうと思います。
構築環境
Google Colaboratory上で構築。
Python 3.6
Tensorflow 1.13.1データの前処理
画像データの準備
CNNは画像分類の深層学習です。
というわけで、大量のチャート画像を用意する必要があります。
以下のような画像データを約8万枚ほど準備しました。
なお、8時間ほどかけて作成した8万枚の画像ですが、後述にある理由で、実際に使ったのは3万枚でした。
チャート画像作成方法については、こちらの記事を参照ください。画像データの配列化とバイナリ形式への保存
学習作業は画像データそのままでは出来ません。
画像データをnumpyのarrayに変換する必要があり、1万枚ごとにnpy形式に保存してみました。import glob import cv2 import numpy as np X=[] #対象の画像をリスト化 img_list = glob.glob('<画像の保存先フォルダ>/*.png') #画像をリサイズ for i in img_list: img = cv2.imread(i) img = cv2.resize(img, dsize=(150, 150)) #リサイズ X.append(img) #リストに追加 #1万枚毎にバイナリ形式で保存する if (i > 0) and (i % 10000 == 0): #numpyに変換して、バイナリ保存 X = np.array(X) npy_name = 'traintest_' + str(i) + '.npy' np.save(npy_name, X) X = []すると、1つあたりのnpyファイルが0.7GBもあり、
8万枚分だと6GB近い大容量になってしまいました。
今回はGoogleDrive上に保存したデータを、
GoogleColobで読み込ませて作業する予定なので、
こんな大容量ファイルをアップするのはよろしくありません。
複数npyファイルを1つに圧縮して、npz形式で纏めます。
※最初からこうすれば配列からnpyに変換して保存する必要は無かったと後で気づく。arr1 = np.load('traintest_10000.npy') arr2 = np.load('traintest_20000.npy') arr3 = np.load('traintest_30000.npy') arr4 = np.load('traintest_40000.npy') arr5 = np.load('traintest_50000.npy') arr6 = np.load('traintest_60000.npy') arr7 = np.load('traintest_70000.npy') arr8 = np.load('traintest_80000.npy') np.savez_compressed('traintest_all.npz', arr1 , arr2, arr3, arr4, arr5, arr6, arr7, arr8)圧縮すると、0.7GB程度になりました。
当初、250*250にリサイズしたのですが、
Google Colabで読み込ませた結果、メモリがクラッシュしてしまい、150*150のサイズに変更しました。
このサイズだとボヤける箇所があり、特徴量を上手く掴めているのか不安な感じです。
今回の予測が失敗した理由の1つかもしれません。GoogleColabで訓練データ、テストデータ、正解ラベルの読み込み
作成したnpzファイルをGoogleDriveにアップし、
GoogleColabを起動して、それを読み込みます。# パッケージのインポート from tensorflow.keras.callbacks import LearningRateScheduler from tensorflow.keras.layers import Activation, Add, BatchNormalization, Conv2D, Dense, GlobalAveragePooling2D, Input from tensorflow.keras.models import Model from tensorflow.keras.optimizers import SGD from tensorflow.keras.preprocessing.image import ImageDataGenerator from tensorflow.keras.regularizers import l2 from tensorflow.keras.utils import to_categorical import numpy as np import matplotlib.pyplot as plt import pandas as pd %matplotlib inline #Google Driveマウント from google.colab import drive drive.mount('/content/drive') # データセットの元となるnpzを読み込む loadnpz = np.load(r'/content/drive/My Drive/traintest_all.npz')ちゃんと8個読み込めていることを確認します。
続いて、訓練用と検証用とで画像を分けます。
それぞれ1万枚を読み込みます。
※これ以上読み込んだら学習中にメモリがクラッシュするため。#訓練とテスト画像データセット train_images = loadnpz['arr_0'] test_images = loadnpz['arr_1']正解ラベルが入ったCSVファイルをDataFrameで読み込んだのちにarrayに変換します。
変換後、訓練用と検証用とで正解ラベルを分けます。#正解ラベルのセット df = pd.read_csv(r'/content/drive/My Drive/Colab Notebooks/npyファイル/tarintest_labels.csv') df['target'] = df['target'].replace('Up', '0') df['target'] = df['target'].replace('Down', '1') df['target'] = df['target'].replace('Flat', '2') df['target'] = df['target'].astype('int') labels_arr = df['target'].to_numpy() #ラベル部分をarraryに変換 #ラベルデータを分ける train_labels = labels_arr[0:10001] #訓練用 test_labels = labels_arr[10001:20001] #検証用ラベルデータはOneHot形式に変換します。
# OneHot形式に変換 train_labels = to_categorical(train_labels) test_labels = to_categorical(test_labels)ここまで出来たら、Shape数を確認しましょう。
モデル作成
続いて、モデルの作成です。
今回、ResNetという構造体で作成します。
ResNetって何だよという方はこちらの記事を参照ください。読み込む画像データ大きすぎると、メモリがクラッシュ連発で全然先に進みません。
その場合は、学習時のbatch_sizeを小さくするか、画像データ自体を小さくする必要があります。
私の場合は、当初画像データ250*250でやってメモリクラッシュ連発で全進めなかったので、150*150にリサイズしました。# 畳み込み層の生成 def conv(filters, kernel_size, strides=1): return Conv2D(filters, kernel_size, strides=strides, padding='same', use_bias=False, kernel_initializer='he_normal', kernel_regularizer=l2(0.0001)) # 残差ブロックAの生成 def first_residual_unit(filters, strides): def f(x): # →BN→ReLU x = BatchNormalization()(x) b = Activation('relu')(x) # 畳み込み層→BN→ReLU x = conv(filters // 4, 1, strides)(b) x = BatchNormalization()(x) x = Activation('relu')(x) # 畳み込み層→BN→ReLU x = conv(filters // 4, 3)(x) x = BatchNormalization()(x) x = Activation('relu')(x) # 畳み込み層→ x = conv(filters, 1)(x) # ショートカットのシェイプサイズを調整 sc = conv(filters, 1, strides)(b) # Add return Add()([x, sc]) return f # 残差ブロックBの生成 def residual_unit(filters): def f(x): sc = x # →BN→ReLU x = BatchNormalization()(x) x = Activation('relu')(x) # 畳み込み層→BN→ReLU x = conv(filters // 4, 1)(x) x = BatchNormalization()(x) x = Activation('relu')(x) # 畳み込み層→BN→ReLU x = conv(filters // 4, 3)(x) x = BatchNormalization()(x) x = Activation('relu')(x) # 畳み込み層→ x = conv(filters, 1)(x) # Add return Add()([x, sc]) return f # 残差ブロックAと残差ブロックB x 17の生成 def residual_block(filters, strides, unit_size): def f(x): x = first_residual_unit(filters, strides)(x) for i in range(unit_size-1): x = residual_unit(filters)(x) return x return f # 入力データのシェイプ input = Input(shape=(150,150, 3)) # 畳み込み層 x = conv(16, 3)(input) # 残差ブロック x 54 x = residual_block(64, 1, 18)(x) x = residual_block(128, 2, 18)(x) x = residual_block(256, 2, 18)(x) # →BN→ReLU x = BatchNormalization()(x) x = Activation('relu')(x) # プーリング層 x = GlobalAveragePooling2D()(x) # 全結合層 output = Dense(3, activation='softmax', kernel_regularizer=l2(0.0001))(x) # モデルの作成 model = Model(inputs=input, outputs=output) # TPUモデルへの変換 import tensorflow as tf import os tpu_model = tf.contrib.tpu.keras_to_tpu_model( model, strategy=tf.contrib.tpu.TPUDistributionStrategy( tf.contrib.cluster_resolver.TPUClusterResolver(tpu='grpc://' + os.environ['COLAB_TPU_ADDR']) ) ) # コンパイル tpu_model.compile(loss='categorical_crossentropy', optimizer=SGD(momentum=0.9), metrics=['acc']) # ImageDataGeneratorの準備 train_gen = ImageDataGenerator( featurewise_center=True, featurewise_std_normalization=True) test_gen = ImageDataGenerator( featurewise_center=True, featurewise_std_normalization=True) # データセット全体の統計量を予め計算 for data in (train_gen, test_gen): data.fit(train_images)学習
学習作業を実施します。
TPUモデルに変換したとはいえ、容量が容量なので5時間近くかかります。# LearningRateSchedulerの準備 def step_decay(epoch): x = 0.1 if epoch >= 80: x = 0.01 if epoch >= 120: x = 0.001 return x lr_decay = LearningRateScheduler(step_decay) # 学習 batch_size = 32 history = tpu_model.fit_generator( train_gen.flow(train_images, train_labels, batch_size=batch_size), epochs=100, steps_per_epoch=train_images.shape[0] // batch_size, validation_data=test_gen.flow(test_images, test_labels, batch_size=batch_size), validation_steps=test_images.shape[0] // batch_size, callbacks=[lr_decay])学習終了後、検証データでの正解率(val_acc)が88%に!
実データでの予測
新規に検証用データをtest_imagesに読み込んで、予測してみます。
test_predictions = new_model.predict_generator( test_gen.flow(test_images[0:10000], shuffle = False, batch_size=16), steps=16) test_predictions = np.argmax(test_predictions, axis=1)[0:10000]予測結果は、「0:上がる」「1:下がる」「2:分からない」の3択で出力されます。
確認してみましょう。
「2:分からない」を連発してます・・・。
ところどころ「0:上がる」「1:下がる」もありましたが、
正解率は50%を割り込む悲惨な結果でした・・・。なぜ失敗したのか?
以下の2つが大きいのかなと思います。
- リサイズ後の画像サイズが小さすぎて特徴量が大雑把になりすぎた。
- 検証期間の画像が少なすぎる
1は画像のサイズを大きくすれば解決するのですが、
無料のGoogleColab環境だと厳しいです。
月額10ドルの有料会員になると、倍のメモリが利用できるようになるらしいので、解決するかもしれません。2は全画像をシャッフルすれば色々なチャートパターンを学習できるので、ある程度は良くなるかもしれません。
2の対策は簡単に出来るので、暇なときに試してみようと思います。
- 投稿日:2020-09-14T14:48:21+09:00
ディープラーニングでFX(ドル円)のレート予測正解率88%を叩き出す聖杯プログラムが作成出来たと思って喜んでいたのに、本番データで予測させたら「分からない」を連発するポンコツでした。
本記事について
なろうみたいな記事タイトルですみません。
「ディープラーニング(CNN)で、ドル円の予測プログラムを作って億万長者や!」
と意気込んだ結果、失敗したお話です。反面教師にされたい方のみご参照ください。成果物についての説明
あまり説明したくないですが、成果物について説明します。
CNN(畳み込みニューラルネットワーク)で、大量のチャート画像でレートの予測方法を学習し、
24時間後のレートが「上がる」「下がる」「分からない」の3択を出力するプログラムを作成しました。
推論結果は正解率88%という好成績でした。
しかし、実データで予測させると「分からない」を連発するポンコツっぷり。。
作成期間3日もかけたので、ガックリ具合が半端ないですが、
作成した経過で勉強になることが多かったのでアウトプットとして残しておこうと思います。
構築環境
Google Colaboratory上で構築。
Python 3.6
Tensorflow 1.13.1データの前処理
画像データの準備
CNNは画像分類の深層学習です。
というわけで、大量のチャート画像を用意する必要があります。
以下のような画像データを約8万枚ほど準備しました。
なお、8時間ほどかけて作成した8万枚の画像ですが、後述にある理由で、実際に使ったのは3万枚でした。
チャート画像作成方法については、こちらの記事を参照ください。画像データの配列化とバイナリ形式への保存
学習作業は画像データそのままでは出来ません。
画像データをnumpyのarrayに変換する必要があり、1万枚ごとにnpy形式に保存してみました。import glob import cv2 import numpy as np X=[] #対象の画像をリスト化 img_list = glob.glob('<画像の保存先フォルダ>/*.png') #画像をリサイズ for i in range(len(file_list)): file_name = '../Make_img/USDJPY/' + str(i) + '.png' img = cv2.imread(file_name) img = cv2.resize(img, dsize=(150, 150)) #リサイズ X.append(img) #リストに追加 #1万枚毎にバイナリ形式で保存する if (i > 0) and (i % 10000 == 0): #numpyに変換して、バイナリ保存 X = np.array(X) npy_name = 'traintest_' + str(i) + '.npy' np.save(npy_name, X) X = []すると、1つあたりのnpyファイルが0.7GBもあり、
8万枚分だと6GB近い大容量になってしまいました。
今回はGoogleDrive上に保存したデータを、
GoogleColobで読み込ませて作業する予定なので、
こんな大容量ファイルをアップするのはよろしくありません。
複数npyファイルを1つに圧縮して、npz形式で纏めます。
※最初からこうすれば配列からnpyに変換して保存する必要は無かったと後で気づく。arr1 = np.load('traintest_10000.npy') arr2 = np.load('traintest_20000.npy') arr3 = np.load('traintest_30000.npy') arr4 = np.load('traintest_40000.npy') arr5 = np.load('traintest_50000.npy') arr6 = np.load('traintest_60000.npy') arr7 = np.load('traintest_70000.npy') arr8 = np.load('traintest_80000.npy') np.savez_compressed('traintest_all.npz', arr1 , arr2, arr3, arr4, arr5, arr6, arr7, arr8)圧縮すると、0.7GB程度になりました。
当初、250*250にリサイズしたのですが、
Google Colabで読み込ませた結果、メモリがクラッシュしてしまい、150*150のサイズに変更しました。
このサイズだとボヤける箇所があり、特徴量を上手く掴めているのか不安な感じです。
今回の予測が失敗した理由の1つかもしれません。GoogleColabで訓練データ、テストデータ、正解ラベルの読み込み
作成したnpzファイルをGoogleDriveにアップし、
GoogleColabを起動して、それを読み込みます。# パッケージのインポート from tensorflow.keras.callbacks import LearningRateScheduler from tensorflow.keras.layers import Activation, Add, BatchNormalization, Conv2D, Dense, GlobalAveragePooling2D, Input from tensorflow.keras.models import Model from tensorflow.keras.optimizers import SGD from tensorflow.keras.preprocessing.image import ImageDataGenerator from tensorflow.keras.regularizers import l2 from tensorflow.keras.utils import to_categorical import numpy as np import matplotlib.pyplot as plt import pandas as pd %matplotlib inline #Google Driveマウント from google.colab import drive drive.mount('/content/drive') # データセットの元となるnpzを読み込む loadnpz = np.load(r'/content/drive/My Drive/traintest_all.npz')ちゃんと8個読み込めていることを確認します。
続いて、訓練用と検証用とで画像を分けます。
それぞれ1万枚を読み込みます。
※これ以上読み込んだら学習中にメモリがクラッシュするため。#訓練とテスト画像データセット train_images = loadnpz['arr_0'] test_images = loadnpz['arr_1']正解ラベルが入ったCSVファイルをDataFrameで読み込んだのちにarrayに変換します。
変換後、訓練用と検証用とで正解ラベルを分けます。#正解ラベルのセット df = pd.read_csv(r'/content/drive/My Drive/Colab Notebooks/npyファイル/tarintest_labels.csv') df['target'] = df['target'].replace('Up', '0') df['target'] = df['target'].replace('Down', '1') df['target'] = df['target'].replace('Flat', '2') df['target'] = df['target'].astype('int') labels_arr = df['target'].to_numpy() #ラベル部分をarraryに変換 #ラベルデータを分ける train_labels = labels_arr[0:10001] #訓練用 test_labels = labels_arr[10001:20001] #検証用ラベルデータはOneHot形式に変換します。
# OneHot形式に変換 train_labels = to_categorical(train_labels) test_labels = to_categorical(test_labels)ここまで出来たら、Shape数を確認しましょう。
モデル作成
続いて、モデルの作成です。
今回、ResNetという構造体で作成します。
ResNetって何だよという方はこちらの記事を参照ください。読み込む画像データ大きすぎると、メモリがクラッシュ連発で全然先に進みません。
その場合は、学習時のbatch_sizeを小さくするか、画像データ自体を小さくする必要があります。
私の場合は、当初画像データ250*250でやってメモリクラッシュ連発で全進めなかったので、150*150にリサイズしました。# 畳み込み層の生成 def conv(filters, kernel_size, strides=1): return Conv2D(filters, kernel_size, strides=strides, padding='same', use_bias=False, kernel_initializer='he_normal', kernel_regularizer=l2(0.0001)) # 残差ブロックAの生成 def first_residual_unit(filters, strides): def f(x): # →BN→ReLU x = BatchNormalization()(x) b = Activation('relu')(x) # 畳み込み層→BN→ReLU x = conv(filters // 4, 1, strides)(b) x = BatchNormalization()(x) x = Activation('relu')(x) # 畳み込み層→BN→ReLU x = conv(filters // 4, 3)(x) x = BatchNormalization()(x) x = Activation('relu')(x) # 畳み込み層→ x = conv(filters, 1)(x) # ショートカットのシェイプサイズを調整 sc = conv(filters, 1, strides)(b) # Add return Add()([x, sc]) return f # 残差ブロックBの生成 def residual_unit(filters): def f(x): sc = x # →BN→ReLU x = BatchNormalization()(x) x = Activation('relu')(x) # 畳み込み層→BN→ReLU x = conv(filters // 4, 1)(x) x = BatchNormalization()(x) x = Activation('relu')(x) # 畳み込み層→BN→ReLU x = conv(filters // 4, 3)(x) x = BatchNormalization()(x) x = Activation('relu')(x) # 畳み込み層→ x = conv(filters, 1)(x) # Add return Add()([x, sc]) return f # 残差ブロックAと残差ブロックB x 17の生成 def residual_block(filters, strides, unit_size): def f(x): x = first_residual_unit(filters, strides)(x) for i in range(unit_size-1): x = residual_unit(filters)(x) return x return f # 入力データのシェイプ input = Input(shape=(150,150, 3)) # 畳み込み層 x = conv(16, 3)(input) # 残差ブロック x 54 x = residual_block(64, 1, 18)(x) x = residual_block(128, 2, 18)(x) x = residual_block(256, 2, 18)(x) # →BN→ReLU x = BatchNormalization()(x) x = Activation('relu')(x) # プーリング層 x = GlobalAveragePooling2D()(x) # 全結合層 output = Dense(3, activation='softmax', kernel_regularizer=l2(0.0001))(x) # モデルの作成 model = Model(inputs=input, outputs=output) # TPUモデルへの変換 import tensorflow as tf import os tpu_model = tf.contrib.tpu.keras_to_tpu_model( model, strategy=tf.contrib.tpu.TPUDistributionStrategy( tf.contrib.cluster_resolver.TPUClusterResolver(tpu='grpc://' + os.environ['COLAB_TPU_ADDR']) ) ) # コンパイル tpu_model.compile(loss='categorical_crossentropy', optimizer=SGD(momentum=0.9), metrics=['acc']) # ImageDataGeneratorの準備 train_gen = ImageDataGenerator( featurewise_center=True, featurewise_std_normalization=True) test_gen = ImageDataGenerator( featurewise_center=True, featurewise_std_normalization=True) # データセット全体の統計量を予め計算 for data in (train_gen, test_gen): data.fit(train_images)学習
学習作業を実施します。
TPUモデルに変換したとはいえ、容量が容量なので5時間近くかかります。# LearningRateSchedulerの準備 def step_decay(epoch): x = 0.1 if epoch >= 80: x = 0.01 if epoch >= 120: x = 0.001 return x lr_decay = LearningRateScheduler(step_decay) # 学習 batch_size = 32 history = tpu_model.fit_generator( train_gen.flow(train_images, train_labels, batch_size=batch_size), epochs=100, steps_per_epoch=train_images.shape[0] // batch_size, validation_data=test_gen.flow(test_images, test_labels, batch_size=batch_size), validation_steps=test_images.shape[0] // batch_size, callbacks=[lr_decay])学習終了後、検証データでの正解率(val_acc)が88%に!
実データでの予測
新規に検証用データをtest_imagesに読み込んで、予測してみます。
test_predictions = new_model.predict_generator( test_gen.flow(test_images[0:10000], shuffle = False, batch_size=16), steps=16) test_predictions = np.argmax(test_predictions, axis=1)[0:10000]予測結果は、「0:上がる」「1:下がる」「2:分からない」の3択で出力されます。
確認してみましょう。
「2:分からない」を連発してます・・・。
ところどころ「0:上がる」「1:下がる」もありましたが、
正解率は50%を割り込む悲惨な結果でした・・・。なぜ失敗したのか?
以下の2つが大きいのかなと思います。
- リサイズ後の画像サイズが小さすぎて特徴量が大雑把になりすぎた。
- 検証期間の画像が少なすぎる
1は画像のサイズを大きくすれば解決するのですが、
無料のGoogleColab環境だと厳しいです。
月額10ドルの有料会員になると、倍のメモリが利用できるようになるらしいので、解決するかもしれません。2は全画像をシャッフルすれば色々なチャートパターンを学習できるので、ある程度は良くなるかもしれません。また、画像自体をあえて簡略化し、似たようなチャートを増やすというのもありかもしれません。記事中ではボリンジャーバンドを利用していますが、外して終値と移動平均線だけのプロットにすることで、改善する可能性もあります。
2の対策は無料で出来るので、暇なときに試してみようと思います。
- 投稿日:2020-09-14T14:07:37+09:00
セグメンテーション用のラベル(マスク)をlabelmeで作成する方法(semantic segmentation mask)
↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
前提知識
以下の知識があることを前提に記事を書いています
- semantic segmentation(#セマンティックセグメンテーション)
- mask(#label)
labelmeはラベル作成用のアプリ
こんな感じのアプリです
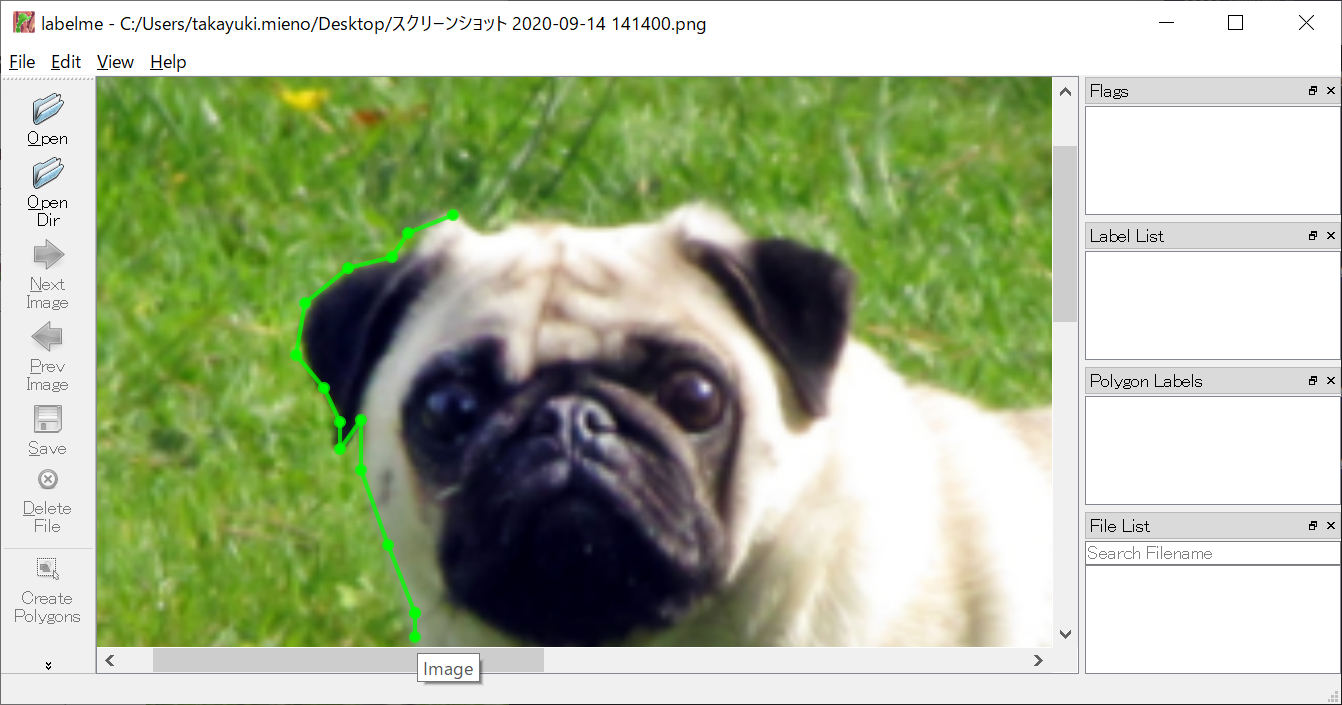
- labelmeはpython製のラベル作成用アプリです。画像に対して複数のラベルを付けることができます。
- 他クラスでも問題ありません。ので、もちろん2クラスのsemantic segmentationでもできます。
- 画像にポイントで線を引き、結果がJSONファイルで出力されます
- JSONファイルが同名で画像と同フォルダに保存されているばあい(デフォルトで同じ名前で保存されます)、画像を読み込んだ時に勝手にJSONもロードされ、アノテーションされた状態で開いてくれる。
- 作成したポイントは再編集可能。
labelmeの使い方詳細
labelmeをダウンロード
windowsの場合
macの場合
labelmeでラベル付け
labelmeを開くと、以下のようなウインドウが開きます。(画像はgoogle検索画面のスクリーンショットです。なんかわかりずらいですね。。。)
拡大しながら、ポイントで線を引いていきます。
拡大と移動は非常に簡単にできます。
この適当な感じで1minくらいかなー。
かなり使いやすい。。
左側のSAVEからJSONを保存します。
こんな感じのデータができます!{ "version": "4.5.6", "flags": {}, "shapes": [ { "label": "dog", "points": [ [ 104.36893203883496, 66.99029126213593 ], [ 93.44660194174757, 71.35922330097087 ], ここは省略 [ 112.13592233009709, 74.27184466019418 ], [ 107.28155339805825, 73.30097087378641 ] ], "group_id": null, "shape_type": "polygon", "flags": {} } ], "imagePath": "スクリーンショット 2020-09-14 141400.png", "imageData": "省略", "imageHeight": 405, "imageWidth": 535 }注意!このJSONポイントは、ポリゴンのポイントなので、そのままマスクには使えません。。なので、このポイントをマスクに変換する必要があります。
labelmeのファイルをJSONからMASKに変換
当初自分で実装しようかと思ってたのですが(くっそ面倒だな)、それ用の関数が用意されていました(そらそうだ)
labelmeにはutilsフォルダにshape.pyというモジュールが用意されており、shape_to_mask関数を使用することでJSONからMASKに変換することができます。ただ、微妙に実装しないといけないので、サンプルのコードを載せておきます。
import json with open(path, "r",encoding="utf-8") as f: dj = json.load(f) # dj['shapes'][0]は今回一つのラベルのため。 mask = shape_to_mask((dj['imageHeight'],dj['imageWidth']), dj['shapes'][0]['points'], shape_type=None,line_width=1, point_size=1)mask_img = mask.astype(np.int)#booleanを0,1に変換 #anacondaを使っています import matplotlib.pyplot as plt %matplotlib inline plt.imshow(mask_img)
うまくラベリングできました。
このくらいのレベルであれば、画像開いてから保存までで2-3minくらいでできるんじゃねーでしょーか。最後に
labelme以外におすすめのラベリングツールあったら教えてください。
結構独自に実装したりしてる人もいるのかな。





- 投稿日:2020-09-14T14:05:14+09:00
AtCoderBeginnerContest178復習&まとめ(後半)
AtCoder ABC178
2020-09-13(日)に行われたAtCoderBeginnerContest178の問題をA問題から順に考察も踏まえてまとめたものとなります.
後半ではDEの問題を扱います.前半はこちら
問題は引用して記載していますが,詳しくはコンテストページの方で確認してください.
コンテストページはこちら
公式解説PDFD問題 Redistribution
問題文
整数$S$が与えられます。 すべての項が$3$以上の整数で、その総和が$S$であるような数列がいくつあるか求めてください。ただし、答えは非常に大きくなる可能性があるので、$10^9+7$で割った余りを出力してください。かなり苦戦しました.
$a_n$を$S=n$のときの答えとすると以下の漸化式が成り立つので,漸化式を順に計算していくことで答えを求めることができます.
$a_n = a_{n-3} + a_{n-1}$abc178d.pys = int(input()) mod = 10**9 + 7 a_list = [0] * (2000 + 1) a_list[0] = 1 a_list[1] = 0 a_list[2] = 0 a_list[3] = 1 for i in range(4, s + 1): a_list[i] = a_list[i - 1] + a_list[i - 3] a_list[i] %= mod print(a_list[s])E問題 Dist Max
問題文
二次元平面上に$N$個の点があり、$i$番目の点の座標は$(x_i,y_i)$です。 同じ座標に複数の点があることもあります。 異なる二点間のマンハッタン距離として考えられる最大の値はいくつでしょうか。
ただし、二点$(x_i,y_i)$と$(x_j,y_j)$のマンハッタン距離は$|x_i−x_j|+|y_i−y_j|$のことをいいます。問題見た当初は,点をいくつか結んで,その内側の点は考えなくて済むなーとか思いつつ,最初に選ぶ点をなるべくはじのものにしたいなと思っていたら,解き方に気づきました.やっぱり図を書くって大事ですね.
$x_i+y_i=k_i$から,$(1,1)$に一番近い点($k_i$が最小となる点)と$(10^9,10^9)$に一番近い点($k_i$が最大となる点)を求める.
$-x_i+y_i=n_i$から,$(10^9,1)$に一番近い点($n_i$が最小となる点)と$(1,10^9)$に一番近い点($n_i$が最大となる点)を求める.$k_{max}$と$k_{min}$のマンハッタン距離か$n_{max}$と$n_{min}$のマンハッタン距離が,考えられるマンハッタン距離の最大となる.
abc178e.pyn = int(input()) point_dict1 = {} point_dict2 = {} for i in range(n): x, y = map(int, input().split()) point_dict1[x + y] = (x, y) point_dict2[y - x] = (x, y) min_point1 = min(point_dict1) max_point1 = max(point_dict1) min_point2 = min(point_dict2) max_point2 = max(point_dict2) print(max(max_point1 - min_point1, max_point2 - min_point2))個人的には普段の問題セットと比べ,E問題までソースコード自体はシンプルで,数学?を使う問題が多かったので,好きな問題セットでした.
後半も最後まで読んでいただきありがとうございました.
- 投稿日:2020-09-14T13:30:34+09:00
Python + Unity 強化学習環境構築
PythonでML-Agentを動かすための環境構築
使用環境
Python 3.7.6
mlagents 0.17.0
ML-Agents Release3
Unity 2019.2.21f1
Pyenv
Poetry前提条件
Unity Hubのダウンロード
1.Unity ML-Agentsのインストール
(1)以下のサイトからUnity ML-Agents Release3をインストールする
https://github.com/Unity-Technologies/ml-agents
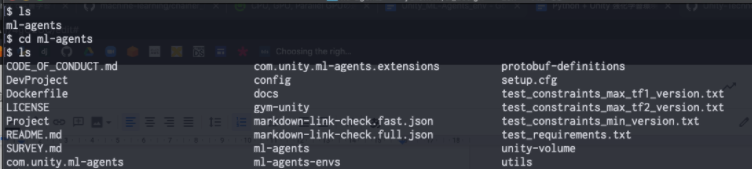
(2)コピーしたURLをGit cloneコマンドの後ろに付けて実行 ファイル一式をダウンロードできる
(※git clone する前に作業をするディレクトリを作成!)terminalmkdir [任意のディレクトリ名] cd [ディレクトリ名] git clone [コピーしたURL](3)ml-agentsディレクトリが作成され、中に以下のようなファイルが入っていることを確認!
2.Python3.7.6の仮想環境の構築!
(1)pyenvをインストール!
terminalbrew install pyenv(2)Python3.7.6のインストール
terminalpyenv install 3.7.6(3)このディレクトリはPython3.7.6で実行することを設定
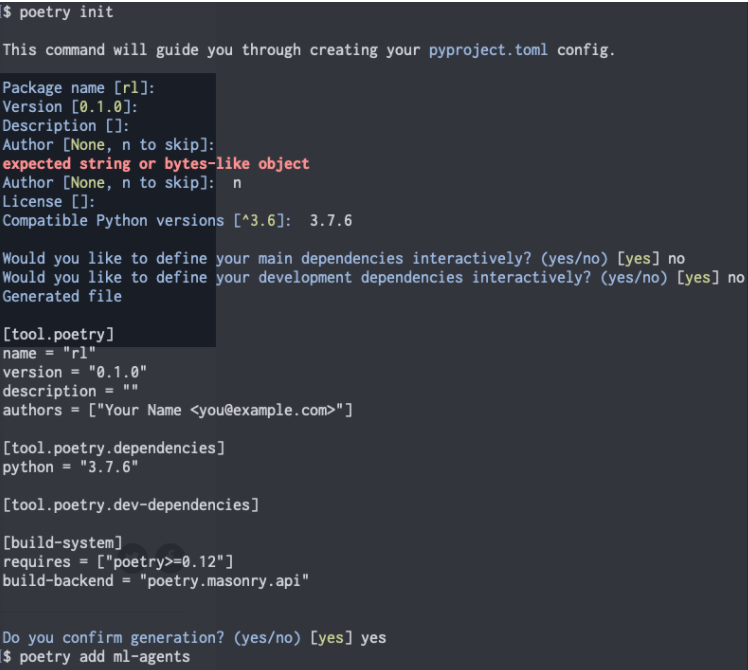
terminalpyenv local 3.7.6(4)Pythonの管理パッケージPoetryをダウンロード&インストール
terminalcurl -sSL https://raw.githubusercontent.com/sdispater/poetry/master/get-poetry.py | python(5)Poetryの仮想環境準備
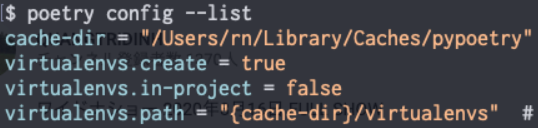
設定を確認
プロジェクト内に仮想環境が作られるように設定し、再び設定状態を確認terminalpoetry config virtualenvs.in-project true(6)Python3.7.6で仮想環境構築
(7)mlagent==0.17.0のインストール!
terminalpoetry add mlagents==0.17.0(7)mlagents-learnコマンドが実行できることを確認
下のコマンド実行後下の画像のようなものが出てくることを確認terminalmlagents-learn

- 投稿日:2020-09-14T13:27:34+09:00
AtCoderBeginnerContest178復習&まとめ(前半)
AtCoder ABC178
2020-09-13(日)に行われたAtCoderBeginnerContest178の問題をA問題から順に考察も踏まえてまとめたものとなります.
前半ではABCまでの問題を扱います.
問題は引用して記載していますが,詳しくはコンテストページの方で確認してください.
コンテストページはこちら
公式解説PDFA問題 Not
問題文
$0$以上$1$以下の整数$x$が与えられます。
$x$が$0$なら$1$を、$1$なら$0$を出力してください。提出したとき,テストケースが複数あってビビりましたが,無事'AC'でした.
case02~09も必要なのだろうか.abc178a.pyx = int(input()) print(1 - x)B問題 Product Max
問題文
整数$a,b,c,d$が与えられます。
$a \leq x \leq b, c \leq y \leq d$を満たす整数$x,y$について、$x×y$の最大値はいくつですか。$x,y$が異符号しかとれない場合,最大値は$a×d$ または $c×b$.
$x,y$が同符号の場合,最大値は$a×c$ または $b×d$.abc178b.pya, b, c, d = map(int, input().split()) print(max(a * c, b * d, a * d, c * b))C問題 Ubiquity
問題文
長さ$N$の整数の列$A_1,A_2,…,A_N$であって以下の条件をすべて満たすものはいくつありますか。
・$0 \leq A_i \leq 9$
・$A_i=0$なる$i$が存在する。
・$A_i=9$なる$i$が存在する。
ただし、答えはとても大きくなる可能性があるので、$10^9+7$で割った余りを出力してください。高校1年生の数Aの問題でした.
$A_i=0$なる$i$が存在する配列の集合を$B$,$A_i=9$なる$i$が存在する配列の集合を$C$とすると,\begin{align} n(B \cap C) = n(B) + n(C) - n(B \cup C) \end{align}で求められますが,このままでは計算が大変なので式変形を行うと,
\begin{align} n(B \cap C) &= n(B) + n(C) - n(B \cup C) \\ &= n(U) - (n(\overline{B}) + n(\overline{C}) - n(\overline{B \cup C})) \\ &= n(U) - n(\overline{B}) - n(\overline{C}) + n(\overline{B} \cap \overline{C}) \\ \end{align}となり,計算が簡単にできます.
$n(U) = 10^N$
$n(\overline{B}) = 9^N$
$n(\overline{C}) = 9^N$
$n(\overline{B} \cap \overline{C}) = 8^N$abc178c.pyn = int(input()) mod = 10**9 + 7 print((10**n - 9**n + 8**n - 9**n) % mod)前半はここまでとなります.
最近は公式の解説がとても丁寧に記述してあったので,詳しい解法はそちらを参考にしてもらえたらと思います.
前半の最後まで読んでいただきありがとうございました.後半はDE問題の解説となります.
後半に続く.
- 投稿日:2020-09-14T12:51:54+09:00
mp3ファイルの再生時間をpythonで計測する方法
mp3ファイルの持続時間を取得する方法は2つあります。
一つは mutagenを使用する方法で、もう一つはpysoxを使用する方法です。
それぞれの方法には長所と短所があります。mutagenを使った方法は、pysoxを使った方法よりも軽量で高速です。
mutagenはmp3ファイルのID3タグをチェックするだけなのはそのためです。一方、pysoxはSox CLIを使ってmp3ファイルのバイナリをチェックするようです。
pysoxの方法では、ID3情報を使わずに持続時間を判定する、つまりID3情報が無効なファイルや、ID3情報がないファイルを認識することができます。pysoxを使うことで、ID3情報を使わずにデュレーションを調べることができる、つまり、ID3情報が無効なファイルや、ID3情報がないファイルのデュレーションを検出することができます。
mutagenを使う方法
from mutagen.mp3 import MP3 def mutagen_length(path): try: audio = MP3(path) length = audio.info.length return length except: return None length = mutagen_length(wav_path) print("duration sec: " + str(length)) print("duration min: " + str(int(length/60)) + ':' + str(int(length%60)))pysox を使う方法
Note: pysox needs SOX cli.
import sox def sox_length(path): try: length = sox.file_info.duration(path) return length except: return None length = sox_length(mp3_path) print("duration sec: " + str(length)) print("duration min: " + str(int(length/60)) + ':' + str(int(length%60)))
- 投稿日:2020-09-14T12:13:01+09:00
AtCoder Beginner Contest 178 復習
今回の成績
今回の感想
今回も悔しい結果に終わってしまいました。E問題は自分の方針にこだわれず時間がかかってしまいました。
F問題はそれなりに時間があったにも関わらずsetを使った嘘貪欲をやろうとして実装に時間がかったので反省しています。貪欲は適当な気持ちでやらないようにします。また、この問題は実はギャグ問題で、まさかこの解法ではないだろと思っていたものが正解でした。悔しすぎます…。
今回も悔しい結果でしたが、徐々に地力がついてきた気もするので、諦めずにがんばりたいです。おそらく黄パフォくらいを出せると波に乗れると思うので精進します。
A問題
簡単に書こうと思って失敗しました。
A.pyprint(1 if int(input())==0 else 0)B問題
端でない部分を選ぶよりも端を選んだ方が値が大きくなることを示せるので、端の掛け算の4通りの最大値を求めます。
B.pya,b,c,d=map(int,input().split()) print(max(a*c,a*d,b*c,b*d))C問題
存在条件は否定を考えて補集合を考えれば良いです。つまり、全体($10^n$)から1~9のみを選んだ時($9^n$)と0~8を選んだ時($9^n$)を除きます。また、1~8を選んだ時($8^n$)が重複するので除きます。よって、$10^n-9^n-9^n+8^n$が答えです。また、$mod \ 10^9+7$で答える必要がありますが、Pythonでは組み込みのpow関数を使う必要があります。
C.pyn=int(input()) mod=10**9+7 print((pow(10,n,mod)-2*pow(9,n,mod)+pow(8,n,mod)+2*mod)%mod)D問題
数列の長ささえわかれば重複組み合わせで決められそうです。ここで、全ての項が3以上という条件から数列の長さは高々$[\frac{n}{3}]$です。また、重複組み合わせは0以上にしたいので、全ての項から3を引きます。したがって、数列の長さを$x$とすれば総和が$s-3x$で全ての数が0以上である場合を考えます。この時、$s-3x$個の球と$x-1$の仕切りを並べる問題と言い換えることができ、組み合わせの総数は$_{s-3x+x-1} C _{s-3x}$となります。また、$10^9+7$の余りを求めたいので、逆元による二項係数の計算を用いました。
D.cc//デバッグ用オプション:-fsanitize=undefined,address //コンパイラ最適化 #pragma GCC optimize("Ofast") //インクルードなど #include<bits/stdc++.h> using namespace std; typedef long long ll; //マクロ //forループ //引数は、(ループ内変数,動く範囲)か(ループ内変数,始めの数,終わりの数)、のどちらか //Dがついてないものはループ変数は1ずつインクリメントされ、Dがついてるものはループ変数は1ずつデクリメントされる //FORAは範囲for文(使いにくかったら消す) #define REP(i,n) for(ll i=0;i<ll(n);i++) #define REPD(i,n) for(ll i=n-1;i>=0;i--) #define FOR(i,a,b) for(ll i=a;i<=ll(b);i++) #define FORD(i,a,b) for(ll i=a;i>=ll(b);i--) #define FORA(i,I) for(const auto& i:I) //xにはvectorなどのコンテナ #define ALL(x) x.begin(),x.end() #define SIZE(x) ll(x.size()) //定数 #define INF 1000000000000 //10^12:∞ #define MOD 1000000007 //10^9+7:合同式の法 #define MAXR 100000 //10^5:配列の最大のrange //略記 #define PB push_back //挿入 #define MP make_pair //pairのコンストラクタ #define F first //pairの一つ目の要素 #define S second //pairの二つ目の要素 ll fac[MAXR+1],finv[MAXR+1],inv[MAXR+1]; //テーブルの作成 void COMinit() { fac[0]=fac[1]=1; finv[0]=finv[1]=1; inv[1]=1; FOR(i,2,MAXR){ fac[i]=fac[i-1]*i%MOD; inv[i]=MOD-inv[MOD%i]*(MOD/i)%MOD; finv[i]=finv[i-1]*inv[i]%MOD; } } // 二項係数の計算 ll COM(ll n,ll k){ if(n<k)return 0; if(n<0 || k<0)return 0; return fac[n]*(finv[k]*finv[n-k]%MOD)%MOD; } signed main(){ //入力の高速化用のコード //ios::sync_with_stdio(false); //cin.tie(nullptr); COMinit(); ll s;cin>>s; ll ans=0; FOR(x,1,ll(s/3)){ ll k=s-3*x; ans+=COM(k+x-1,k); ans%=MOD; } cout<<ans<<endl; }E問題
難しそうに思えてしまい、集中力が切れてしまいました。結果論ではありますが、この問題を高速に通すことができればF問題も解けたので集中力を保てるようにバチャでトレーニングしたいと思います。
また、コンテスト中はググってこの記事を発見したために解くことができました。この問題は簡単ではないので、多くの人がググって正答にたどり着けたのではないでしょうか。
まず、二点のうちを固定したり$x$座標や$y$座標を固定したりしようと思いましたが埒が明きませんでした。したがって、次に考えるべきは絶対値を外すことです。ここで、絶対値を外す際の典型パターンとして$|x|=max(x,-x)$があるようです。これに従うと、二点間$(x_1,y_1),(x_2,y_2)$のマンハッタン距離は$max((x_1+y_1)-(x_2+y_2),(x_1-y_1)-(x_2-y_2),(-x_1+y_1)-(-x_2+y_2),(-x_1-y_1)-(-x_2-y_2))$となります。したがって、任意の二点間で考えれば、それぞれの点$(x,y)$について$x+y,x-y,-x+y,-x-y$ごとに(最大値)-(最小値)を求めてその最大値が答えとなります。
E.pyn=int(input()) xy=[list(map(int,input().split())) for i in range(n)] ans=[] cand=[xy[i][0]+xy[i][1] for i in range(n)] ans.append(max(cand)-min(cand)) cand=[-xy[i][0]+xy[i][1]for i in range(n)] ans.append(max(cand)-min(cand)) cand=[-xy[i][0]-xy[i][1] for i in range(n)] ans.append(max(cand)-min(cand)) cand=[xy[i][0]-xy[i][1] for i in range(n)] ans.append(max(cand)-min(cand)) print(max(ans))F問題
まず、初めに、前の要素から順に一致しないようにswapをする貪欲法を考えましたが、正当性が示なさそうなので却下しました。次に、一致しないようにすれば良いことといずれもソート済なことを利用すれば、逆にすることで一致するのは真ん中だけだと思いました(✳︎)。しかし、この方法ではあまりにも簡単だと考えて却下してしまいました。その後思いついた方法は多いものから順に決めていくというものです。この方法も正当性が示せないのに実装してしまいました。また、実装が少し重く、コンテスト中に解き終わりませんでした。
コンテスト後にTwitterで他の方の解答を見ているうちにコンテスト中の自分の考察の甘さに気づきました。あまりにも簡単なので却下したという点です。自分はある問題の解法が難しすぎたり簡単すぎたりすると考察を止める癖があるのでやめるようにしたいです。ともかく、(✳︎)の考察を進めると以下のようにしてこの問題は解けます。
まず、$A$と$B$で1~$n$が合計でそれぞれ何個ずつあるかを考え、$n$より多くある要素がある場合は題意を満たす数列が作成できないのは鳩の巣原理より明らかなのでNoを出力します。
このもとで、先ほどの方針にしたがってBをまずは逆順にします。この時、$(\forall x \in [l,r])(A_x=B_x=p)$となる$p$が一つのみ存在します。逆に存在しない時はそのまま出力すれば題意を満たします。また、この時、$(\forall x \notin [l,r])(A_x \neq B_x)$も成り立ちます。(証明は省略します)
ここで、$x \in [l,r]$の任意の要素についてスワップを行います。このスワップは$x(\in [l,r])$と$y(\notin [l,r])$の間で行います。また、このスワップは$y(\notin [l,r])$について$A_y \neq p$かつ$B_y \neq p$であれば行うことができ、スワップで選んだ二つの要素はそれぞれのインデックスで一致することはありません。さらに、$A$と$B$に出てくる$p$は$n$個以下なので、任意の$x(\in [l,r])$に対してスワップを行うことが可能です(最大限スワップをした時に全てのインデックスに$p$が存在するようなスワップができると考えると良いです。)。
以上より、逆順にして重なったところのみ重なってないところとのスワップを繰り返す方法の正当性が示されたので、これを実装して以下のようになります。
F.pyn=int(input()) a=list(map(int,input().split())) b=list(map(int,input().split())) from collections import Counter,deque x,y=Counter(a),Counter(b) for i in range(1,n+1): if x[i]+y[i]>n: print("No") exit() ans=b[::-1] change=deque() num=-1 now=deque() for i in range(n): if a[i]==ans[i]: change.append(i) num=ans[i] else: now.append(i) if change==[]: print("Yes") print(" ".join(map(str,ans))) exit() while len(change): q=now.popleft() p=change.popleft() if a[q]!=num and ans[q]!=num: ans[q],ans[p]=ans[p],ans[q] else: change.appendleft(p) print("Yes") print(" ".join(map(str,ans)))

- 投稿日:2020-09-14T10:46:55+09:00
【wandb】AttributeError: module 'wandb' has no attribute 'init'とでたら
AttributeError: module 'wandb' has no attribute 'init'とエラーがでた。前は動いてたはずなのに...
pip install --upgrade wandbしたら動いた
- 投稿日:2020-09-14T10:19:28+09:00
UIDが変更になってpyenvのライブラリのパスが通らなくなった場合の対応
概要
UIDが変更にあり、ホームディレクトリの名前が変更されると、pyenvが動かなくなることがあります。これは、pyenvの環境にあるライブラリが参照しているpythonのパスが通常ホームディレクトリ内にあるのですが、通らなくなることによります。以下の方法で解消可能です。pyenv-virtualenvでも対応は同様です。
環境: Ubuntu 16.04手順
# 環境名取得 $ pyenv versions $ vi ~/.pyenv/versions/環境名/bin/pip一行目は以下のようになっていると思います。
#!/home/旧ID/.pyenv/versions/環境名/bin/python3.*これはインタプリタ言語において、読み込むインタプリタを指定するいわゆるシバンというものです。IDが古いままですので、新しいものに変更します。
#!/home/新ID/.pyenv/versions/環境名/bin/python3.*これでpipが動くようになりました。あとは、他のライブラリも再インストールすれば一律変更できます。
$ pip freeze > requirements.txt $ pip install -r requirements.txt
- 投稿日:2020-09-14T10:19:28+09:00
user名が変更になってpyenvのライブラリのパスが通らなくなった場合の対応
概要
user名が変更になり、ホームディレクトリの名前が変更されると、pyenvが動かなくなることがあります。これは、pyenvの環境にあるライブラリが参照しているpythonのパスが通常ホームディレクトリ内にあるのですが、通らなくなることによります。以下の方法で解消可能です。pyenv-virtualenvでも対応は同様です。
環境: Ubuntu 16.04手順
# 環境名取得 $ pyenv versions $ vi ~/.pyenv/versions/環境名/bin/pip一行目は以下のようになっていると思います。
#!/home/旧user名/.pyenv/versions/環境名/bin/python3.*これはインタプリタ言語において、読み込むインタプリタを指定するいわゆるシバンというものです。IDが古いままですので、新しいものに変更します。
#!/home/新user名/.pyenv/versions/環境名/bin/python3.*これでpipが動くようになりました。あとは、他のライブラリも再インストールすれば一律変更できます。
$ pip freeze > requirements.txt $ pip install -r requirements.txt
- 投稿日:2020-09-14T10:16:36+09:00
python 配列の基礎
python 配列の基礎
複数のデータをまとめて管理するには配列というものを用います。
配列は[要素1, 要素2, ...]のように作ります。リストに入っているそれぞれの値のことを要素と呼びます。
配列を使うと、複数の文字列や複数の数値を1つのものとして管理することができます。変数に、複数の文字列を要素に持つリストを代入してください
fruits = ['apple','banana','orange']配列も1つの値なので変数に代入することができます。
このとき、リストを代入する変数名は慣習上複数形にすることが多いので、覚えておきましょう。インデックス番号が0の要素を出力してください
print(fruits[0])出力結果appleリストの要素には、前から順に「0, 1, 2,・・・」と数字が割り振られています。これをインデックス番号といいます。インデックス番号は0から始まる点に注意してください。
リストの各要素は、リスト[インデックス番号]とすることで取得することができます。インデックス番号が2の要素を文字列と連結して出力してください
print('好きな果物は' + fruits[2] + 'です')出力結果好きな果物はorangeですリストの末尾に文字列「grape」を追加する
リストには、新しく要素を追加することもできます。
「リスト.append(値)」とすることで、すでに定義されているリストの末尾に新たな要素を追加することができます。fruits.append('grape')インデックス番号が0の要素を文字列「strawberry」に更新する
リストの要素を更新することもできます。
「リスト[インデックス番号] = 値」とすることで、リストの指定したインデックス番号の要素を更新することができます。fruits[0] = 'strawberry'
- 投稿日:2020-09-14T09:47:49+09:00
pelicanでmarkdownをブログにする
wordpressの管理が面倒で、
もっとシンプルにgithubにcommit/pushするだけでできないものかと試してみた。
まだ途中だがgithubにUPするところまで書きたい。参考
環境
- Windows10
- Python 3.8.2
インストール
> pip install pelican markdown Collecting pelican Downloading pelican-4.5.0-py2.py3-none-any.whl (673 kB) |████████████████████████████████| 673 kB 2.2 MB/s Collecting markdown Downloading Markdown-3.2.2-py3-none-any.whl (88 kB) |████████████████████████████████| 88 kB 4.0 MB/s Collecting feedgenerator>=1.9 Downloading feedgenerator-1.9.1-py3-none-any.whl (22 kB) Collecting jinja2>=2.11 Downloading Jinja2-2.11.2-py2.py3-none-any.whl (125 kB) |████████████████████████████████| 125 kB 6.8 MB/s Collecting unidecode Downloading Unidecode-1.1.1-py2.py3-none-any.whl (238 kB) |████████████████████████████████| 238 kB 6.4 MB/s Collecting pygments Downloading Pygments-2.7.0-py3-none-any.whl (950 kB) |████████████████████████████████| 950 kB 6.8 MB/s Collecting docutils>=0.15 Downloading docutils-0.16-py2.py3-none-any.whl (548 kB) |████████████████████████████████| 548 kB 6.4 MB/s Collecting python-dateutil Downloading python_dateutil-2.8.1-py2.py3-none-any.whl (227 kB) |████████████████████████████████| 227 kB 6.8 MB/s Collecting blinker Downloading blinker-1.4.tar.gz (111 kB) |████████████████████████████████| 111 kB ... Requirement already satisfied: pytz>=0a in c:\users\username\appdata\local\programs\python\python38\lib\site-packages (from pelican) (2020.1) Collecting six Downloading six-1.15.0-py2.py3-none-any.whl (10 kB) Collecting MarkupSafe>=0.23 Downloading MarkupSafe-1.1.1-cp38-cp38-win_amd64.whl (16 kB) Building wheels for collected packages: blinker Building wheel for blinker (setup.py) ... done Created wheel for blinker: filename=blinker-1.4-py3-none-any.whl size=13455 sha256=57daa4945a8c37e456b038a3022c48e58d2d7f7e1d02cb7efc612448ad4b89ef Stored in directory: c:\users\username\appdata\local\pip\cache\wheels\b7\a5\68\fe632054a5eadd531c7a49d740c50eb6adfbeca822b4eab8d4 Successfully built blinker Installing collected packages: six, feedgenerator, MarkupSafe, jinja2, unidecode, pygments, docutils, python-dateutil, blinker, pelican, markdown Successfully installed MarkupSafe-1.1.1 blinker-1.4 docutils-0.16 feedgenerator-1.9.1 jinja2-2.11.2 markdown-3.2.2 pelican-4.5.0 pygments-2.7.0 python-dateutil-2.8.1 six-1.15.0 unidecode-1.1.1 WARNING: You are using pip version 20.2.2; however, version 20.2.3 is available. You should consider upgrading via the 'c:\users\username\appdata\local\programs\python\python38\python.exe -m pip install --upgrade pip' command.jinja2など、必要なライブラリも色々インストールされる。
プロジェクト作成
ディレクトリ作成
mkdir -p mysite cd mysiteプロジェクト作成
コマンド実行すると色々質問される。
> pelican-quickstart Welcome to pelican-quickstart v4.5.0. This script will help you create a new Pelican-based website. Please answer the following questions so this script can generate the files needed by Pelican. > Where do you want to create your new web site? [.] . > What will be the title of this web site? MyBlog > Who will be the author of this web site? HyunwookPark > What will be the default language of this web site? [Japanese] ja > Do you want to specify a URL prefix? e.g., https://example.com (Y/n) n > Do you want to enable article pagination? (Y/n) n > What is your time zone? [Europe/Paris] Asia/Tokyo > Do you want to generate a tasks.py/Makefile to automate generation and publishing? (Y/n) Y > Do you want to upload your website using FTP? (y/N) N > Do you want to upload your website using SSH? (y/N) N > Do you want to upload your website using Dropbox? (y/N) N > Do you want to upload your website using S3? (y/N) N > Do you want to upload your website using Rackspace Cloud Files? (y/N) N > Do you want to upload your website using GitHub Pages? (y/N) y > Is this your personal page (username.github.io)? (y/N) y Done. Your new project is available at D:\work\mysite作られたディレクトリmysite ├─content └─output作ったmarkdownはこんな感じ↓
Title: My First Review
Date: 2010-12-03 10:20
Category: Review
Tags: テスト, 投稿
Summary: どんな感じに出るのか# テストタイトル
この内容がどのように出力されるのか。
```python
print('HelloWorld')
```### テーブル
|項目|内容|
|---|---|
|python|プログラム言語|### リスト
* リスト
* リスト\1. リスト
\1. リスト
> pelican content WARNING: Watched path does not exist: mysite\content\images Done: Processed 1 article, 0 drafts, 0 pages, 0 hidden pages and 0 draft pages in 0.31 seconds.mysite ├─content ├─output │ ├─author │ ├─category │ ├─tag │ └─theme │ ├─css │ ├─fonts │ └─images │ └─icons └─__pycache__実行
> pelican --listen Serving site at: 127.0.0.1:8000 - Tap CTRL-C to stop
テーマの変更
- 投稿日:2020-09-14T09:43:52+09:00
mutableオブジェクトとimmutableオブジェクトの違い in Python 1
はじめに みなさんはmutable(ミュータブル)オブジェクト、immutable(イミュータブル)オブジェクトの違いについて、理解しているだろうか?大抵の場合「変更できるのがmutable、変更できないのがimmutable」のような答えが返ってくる。もちろん間違いではないのだが、変更できないというのは具体的にどういうことかと聞くと答えに窮する方が多かったので、本記事で整理しておく。 準備知識 id() Pythonのbuilt-in関数であるid()は、メモリ内のオブジェクトのアドレス(位置)のIDを整数で返す。本記事では、メモリアドレスを16進数で表現するためにhex()を併用する。なお、Pythonの比較演算子であるisがTrueになるのは、2つの変数が同じidを返す時である。( = 2つの変数が同一のオブジェクトを参照している) Pythonオブジェクトリファレンス 例えばこのような変数を宣言する >>> x = 10000 >>> hex(id(x)) '0x10088d9d0' 簡単に説明するとPython内では int型の10000というオブジェクトを生成し、 0x10088d9d0 に配置する xをオブジェクトに紐付ける といった動作をする。 ※細かいPython memory managementの動作については、また別の記事で。ここではオブジェクトとアドレスの概念が理解できればOK。 mutableオブジェクト mutableオブジェクトに変更を加えた場合どうなるかをlistを例に見ていく。 >>> x = [1, 2] >>> x [1, 2] >>> hex(id(x)) '0x1008c8f00' このlistオブジェクトを変更するために、appendしてみると下記のようになる。 >>> x.append(3) >>> x [1, 2, 3] >>> hex(id(x)) '0x1008c8f00' 0x1008c8f00 上のlistオブジェクトの値 [1, 2] が [1, 2, 3] になっただけで、xの参照オブジェクトのアドレスに変化はない。 immutableオブジェクト 同じように、ここではintオブジェクトに変更を加えてみる。 >>> x = 10000 >>> x 10000 >>> hex(id(x)) '0x10088da10' >>> x = x + 1 >>> x 10001 >>> hex(id(x)) '0x10088dad0' <---- idの値が変わっている immutableオブジェクトを変更しようとすると、このように新しいオブジェクトが生成され、 x は新しいオブジェクトを参照する。その結果、idの値が元の 0x10088da10 から 0x10088dad0 に変わっている。これがimmutableオブジェクトにおける動作で、冒頭の immutableオブジェクトは変更できない は、既にメモリ上作成されていた元オブジェクトに対して変更することができないということになる。そして、もとよりlistにおけるappendやpopのようなオブジェクトの値を操作するための関数が用意されていない。 x = 10000 の時点ではこのようになっていたのが 元々生成されたいたintオブジェクト10000の値は変更されず、新しいオブジェクト10001が生成され、そちらを参照する。 例外 immutableオブジェクトに関連する全てがimmutableなわけではない。例えばtupleで下記のようなオブジェクトがあったとする。 >>> x = ('hello', [1, 2]) >>> hex(id(x)) '0x1008c8580' >>> hex(id(x[0])), hex(id(x[1])) ('0x1008d11b0', '0x1008b56c0') tupleオブジェクトはimmutableなので、 x[1] のオブジェクトを他のオブジェクトに変更しようとするとexceptionが発生する。 >>> x[1] = 4 Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'tuple' object does not support item assignment しかしながら、実際のところ、tupleの値はオブジェクトへのバインディング(結びつき、紐付き)であり、tuple内のそれぞれのindexがどのアドレスのオブジェクトへ紐付いているという情報を変更することはできないが、バインドされているオブジェクトそのものの値の変更は可能である。 >>> x[1].append(3) >>> x ('hello', [1, 2, 3]) >>> hex(id(x[0])), hex(id(x[1])) ('0x1008d11b0', '0x1008b56c0') <- それぞれのindexの参照先のアドレスは変わっていない このようにtuple内のmutableオブジェクト x[1] の値を変更することは可能であるが、tupleオブジェクト内の x[0] と x[1] の参照先アドレスは 0x1008d11b0 と 0x1008b56c0 から変更されていないことが確認できる。 まとめ 元となるデータを保持しているオブジェクト自体は変更されず、新しいオブジェクトを生成し、そちらを参照するのがimmutableオブジェクト、データを保持しているオブジェクトそのものの値を変更できるのがmutableオブジェクトとなる。ただ、tupleのように複数のオブジェクトによって構成されているようなオブジェクトは、immutableであっても内部のオブジェクトがmutableの場合、そのオブジェクト自体の値の変更は可能。