- 投稿日:2020-09-14T22:12:20+09:00
【Spring Data JPA】deleteの自動実装されるメソッドでAnd条件は使えるか
概要
【Spring Data JPA】自動実装されるメソッドの命名ルールの記事にある通り、JPAではrepositoryの命名規則に合うメソッでを定義することで、クエリを自動生成してくれる機能があります。今回はその自動生成でdeleteの時にAnd条件を使えるかという話です。
deleteについて
- 公式ドキュメントに記載の通り、deleteでもrepositoryにdeleteByメソッドを定義し条件に使用するプロパティ名を指定することで、クエリを自動生成してくれます。Spring Data JPA – Derived Delete Methodsに実装の詳細が解説してあります。
- [Java][Spring Boot][JPA] データベースを使う - NetBeansで始めるSpring Boot (6)の記事にある通り、deleteでもfindと同じような条件式が使えそうな雰囲気はあります。
結論
And条件は使えました。試してはいませんが、おそらく他の条件も使えると思います。
ただ、複雑な条件はNativeQueryとかで実装した方が良いと思います。。実装サンプル
Entity
UserPost.java@Entity @Table(name = "user_posts") public class UserPost { @Id private long id; private long userId; private String contents; public long getId() { return this.id; } public void setId(long id) { this.id = id; } public long getUserId() { return this.userId; } public void setUserId(long userId) { this.userId = userId; } public String getContents() { return this.contents; } public void setContents(String contents) { this.contents = contents; } }Repository
UserPostRepository.java@Repository public interface UserPostRepository extends JpaRepository<UserPost, String> { // idとuserIdをAnd条件で指定してレコード削除 void deleteByIdAndUserId(long id, long userId); }
- 投稿日:2020-09-14T19:09:50+09:00
Python基礎備忘録その3~オブジェクト指向について~
記事概要
Pythonを少しでも読めるようになってみようと思い、参考書に沿って学習した備忘録になります。
Javaと比較して自身が気になった点、便利と感じた点をまとめております。
その1はこちら
その2はこちら
※かなり基礎的な内容になります。クラス
クラスの概念自体はそこまで大きく違わない認識です。
クラス定義方法については、例を下記に記載してみます。例
javaclass SampleClass { //クラス処理 }pythonclass SampleClass: #クラス処理インスタンス化
クラスをインスタンス化する。
扱いはJavaとほとんど変わらない。はずjavaSampleClass sClass = new SampleClass();pythonsClass = SampleClass()アトリビュート
Javaで言うインスタンス変数のようなもの(?)。
インスタンスに対してアトリビュートを追加できる。pythonsClass.attr = "あとりびゅーと" print(sClass.attr) >>あとりびゅーとクラスのメソッド定義
クラスメソッドに引数を追加する場合には、第一引数にselfを追加する。
selfを使うとインスタンス自体を操作できる
例
javaclass SampleClass { int counter = 0; int count(int a) { counter += a; } }pythonclass SampleClass: counter = 0; def count(self, a): self.counter += a初期化メソッド
初期化メソッドは
__init__(特殊メソッド)を使用する。例
javapubliv class Human { String name; String birthday; public Human(String name, String birthday) { this.name = name; this.birthday = birthday; } }pythonclass Human: def __init__(self, name = None, birthday = None): self.__name = name self.__birthday = birthdayカプセル化
カプセル化を行うにはメソッドやアトリビュートの前に
__(アンダースコア2つ)をつける。
__を付けることで外部からのアクセスを禁止することが出来る。
メソッドやアトリビュートの前に_(アンダースコア1つ)を付けた場合には慣習として、
「クラス内部でのみ使用するので、外部からアクセスしないでね」といった意味を持つ(らしい)。※調べていたらアンダースコアは色々意味があるそうです。参考文献に調べた際の記事などリンク載せています。
追記
Pythonではgetter,setterを定義しないらしいです。
Pythonではget〇〇,set〇〇といったメソッドを定義することは非推奨のようです。
(属性へのアクセス方法はまた別にまとめるかもしれません)
今回の記事ではJavaと比較して、自分が理解しやすくするために、上記のような書き方でgetter,setterを定義しています。
ご了承ください。
アンダースコアの付け方、getter,setterを定義しない場合については、別途学習してまとめようかと考えています。例
javapubliv class Human { private String name; private String birthday; public Human(String name, String birthday) { this.name = name; this.birthday = birthday; } public getName() { return this.name; } public getBirthday() { return this.birthday; } public setName(String name) { this.name = name; } public setBirthday(String birthday) { this.birthday = birthday; } }pythonclass Human: def __init__(self, name = None, birthday = None): self.__name = name self.__birthday = birthday def getName(self): return self.__name def getBirthday(self): return self.__birthday def setName(self, name): self.__name = name def setBirthday(self, birthday): self.__birthday = birthday継承
Pythonは多重継承が可能。
多重継承する場合には、,で区切ってクラス名を指定する。例
javapublic class SuperMan extends Human { private String ability; public getAbility() { return this.age; } public setAbility(String ability) { this.ability = ability; }pythonclass SuperMan(Human): #多重継承の場合SuperMan(Human, Man)のような感じで定義する def getAbility(self): return self.__ability def setAbility(self, ability = None): self.__ability = abilityスロット
アトリビュートの追加を制限することが出来る特殊メソッド
__slots__ = [アトリビュート名1, アトリビュート名2, ...]メモリの使用効率をよくする
pythonclass Profile: __slots__ = ['height', 'weight', 'bloodType'] def __init__(self, bloodType = None): self.bloodType = bloodType a = Profile('A') print(a.bloodType) >>A #slotsに定義されているアトリビュート a.height = 170 a.weight = 60 a.constellation = 'Aries' >>エラーが発生するプロパティ
getter,setterを簡単に定義するための組み込み関数。
非公開のアトリビュートへのアクセス制御を簡単に行う。
property(getterメソッド名, [setterメソッド名])pythonclass Human: def __init__(self, name = None): self.__name = name def getName(self): return self.__name def setName(self, name): self.__name = name propName = property(getName, setName) #代入を行うと、propertyで設定したsetterが動作する propName = 'takeshi' #取り出しを行うと、propertyで設定したsetterが動作する print(propName) >>takeshiあとがき
Pythonのデメリットについて調べると、実行速度の遅さが出てきました。
今回まとめた__slots__はそのデメリットを改善するために必要なことだと感じました。
Pythonらしい機能を適切に使えるよう理解を進めていきたいと思います。参考文献
参考書
柴田淳(2016)「みんなのPython 第4版」SBクリエイティブ株式会社公式リファレンス
Python公式リファレンスデータ型について
Pythonの組み込みデータ型の分類表(ミュータブル等)アンダースコアについて
初学者のためのPython講座 オブジェクト指向編7 カプセル化
Lesson 12 クラスの定義 ― Python基礎文法入門
pythonのアンダーバーこれなんやねん
- 投稿日:2020-09-14T19:04:46+09:00
Javaでページングしてるときのページの総数の求め方
たまに使うのでメモ。
全体の件数 / ページあたりの件数 を、小数点以下切り上げで、ページの総数が得られます。
やり方自体は色々ありますが、上のをそのまま実装するとこんな感じです。
int totalSize = 30; double pageSize = 10.0; int totalPage = (int) Math.ceil(totalSize / pageSize); System.out.println(totalPage); >> 3int totalSize = 35; double pageSize = 10.0; int totalPage = (int) Math.ceil(totalSize / pageSize); System.out.println(totalPage); >> 4int totalSize = 40; double pageSize = 10.0; int totalPage = (int) Math.ceil(totalSize / pageSize); System.out.println(totalPage); >> 4int totalSize = 41; double pageSize = 10.0; int totalPage = (int) Math.ceil(totalSize / pageSize); System.out.println(totalPage); >> 5
Math#ceilが切り上げなのですが、割ったときに少数点がでるように、ページあたりの件数をdoubleで定義します。返り値がdoubleですが、小数点以下はいらないので、intにキャストにします。
primitive型だと、non-nullが担保されますが、「Doubleの整数部分だけ取り出す」みたいなことはオブジェクトになっていないと、やや不自然になる印象。
- 投稿日:2020-09-14T17:06:51+09:00
スクラッチからApache Flinkアプリケーションを5分で構築する方法
このチュートリアルでは、Apache Flink アプリケーションをゼロから数分で構築する方法を簡単に説明します。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
開発環境の準備
Apache FlinkはLinux、Max OS X、Windowsで動作し、互換性があります。Flinkアプリケーションを開発するには、コンピュータ上でJavaバージョン8.0以降かMaven環境のいずれかを実行する必要があります。Java環境を使用している場合は、
$java Cversionコマンドを実行すると、使用しているバージョン情報が以下のように出力されます。java version "1.8.0_65" Java(TM) SE Runtime Environment (build 1.8.0_65-b17) Java HotSpot(TM) 64-Bit Server VM (build 25.65-b01, mixed mode)Maven環境を使用している場合、$ mvn -versionコマンドを実行すると、以下のようなバージョン情報が出力されます。
Apache Maven 3.5.4 (1edded0938998edf8bf061f1ceb3cfdeccf443fe; 2018-06-18T02:33:14+08:00) Maven home: /Users/wuchong/dev/maven Java version: 1.8.0_65, vendor: Oracle Corporation, runtime: /Library/Java/JavaVirtualMachines/jdk1.8.0_65.jdk/Contents/Home/jre Default locale: zh_CN, platform encoding: UTF-8 OS name: "mac os x", version: "10.13.6", arch: "x86_64", family: "mac"さらに、FlinkアプリケーションのIDEとしてIntelliJ IDEA(このチュートリアルではコミュニティフリー版で十分です)を使用することをお勧めします。Eclipseもこの目的で動作しますが、Eclipseは過去にScalaとJavaのハイブリッドプロジェクトに問題があったため、Eclipseを選択することはお勧めしません。
Mavenプロジェクトを作成する
このセクションの手順に従って、Flinkプロジェクトを作成し、IntelliJ IDEAにインポートすることができます。Flink Maven Archetypeを使用して、プロジェクト構造といくつかの初期デフォルトの依存関係を作成します。作業ディレクトリで、
mvn archetype:generateコマンドを実行してプロジェクトを作成します。-DarchetypeGroupId=org.apache.flink \ -DarchetypeArtifactId=flink-quickstart-java \ -DarchetypeVersion=1.6.1 \ -DgroupId=my-flink-project \ -DartifactId=my-flink-project \ -Dversion=0.1 \ -Dpackage=myflink \ -DinteractiveMode=false上記の groupId、artifactId、および package は、任意のパスに編集することができます。上記のパラメータを使用して、Mavenは以下のようなプロジェクト構造を自動的に作成します。
$ tree my-flink-project my-flink-project ├── pom.xml └── src └── main ├── java │ └── myflink │ ├── BatchJob.java │ └── StreamingJob.java └── resources └── log4j.propertiespom.xml ファイルには、必要な Flink の依存関係がすでに含まれており、いくつかのサンプルプログラムフレームワークが
src/main/javaに用意されています。Flink プログラムをコンパイル
では、以下の手順に従って、独自のFlinkプログラムを作成してください。これを行うには、IntelliJ IDEAを起動し、Import Projectを選択し、my-link-projectのルートディレクトリの下にあるpom.xmlを選択します。その後、指示された通りにプロジェクトをインポートします。
src/main/java/myflinkの下にSocketWindowWordCount.javaファイルを作成します。package myflink; public class SocketWindowWordCount { public static void main(String[] args) throws Exception { } }今のところ、このプログラムは基本的なフレームワークだけなので、一歩一歩コードを埋めていきます。なお、インポート文はIDEが自動的に追加してくれるので、以下では書かないことに注意してください。このセクションの最後に、完成したコードを表示します。以下のステップをスキップしたい場合は、最終的な完全なコードをエディタに直接貼り付けます。
Flinkプログラムの最初のステップは
StreamExecutionEnvironmentの作成です。これは、パラメータの設定やデータソースの作成、タスクの投入などに使えるエントリークラスです。それでは、メイン関数に追加してみましょう。StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();次に、ローカルポート 9000 のソケットからデータを読み込むデータソースを作成します。
DataStream text = env.socketTextStream("localhost", 9000, "\n");これにより、文字列型の
DataStreamが作成されます。DataStreamはFlinkのストリーム処理のコアAPIです。多くの一般的な操作(フィルタリング、変換、集約、ウィンドウ、アソシエーションなど)を定義しています。この例では、特定の時間ウィンドウ、例えば5秒のウィンドウ内での各単語の出現回数に興味があります。この目的のために、文字列データは、最初に単語とその出現回数(Tuple2<String, Integer>で表される)に解析され、最初のフィールドが単語、2番目のフィールドが単語の出現回数となります。発生回数の初期値は1に設定されています。1つのデータ行には複数の単語が存在する可能性があるため、解析を行うためにflatmapが実装されています。DataStream> wordCounts = text .flatMap(new FlatMapFunction>() { @Override public void flatMap(String value, Collector> out) { for (String word : value.split("\\s")) { out.collect(Tuple2.of(word, 1)); } } });次に、ワードフィールド(つまりインデックスフィールド0)に基づいてデータストリームをグループ化します。ここでは、
keyBy(int index)メソッドを使用して、ワードをキーとするTuple2<String, Integer>データストリームを取得します。そして、ストリーム上で任意のウィンドウを指定し、ウィンドウ内のデータに基づいて結果を計算します。この例では、5 秒ごとに単語の出現を集約し、各ウィンドウはゼロからカウントされます。DataStream> windowCounts = wordCounts .keyBy(0) .timeWindow(Time.seconds(5)) .sum(1);2 番目の
.timeWindow()は、5 秒間のタンブル・ウィンドウを指定します。3番目の呼び出しは、各キーと各ウィンドウの合計集計関数を指定します。この例では、これは occurrences フィールド (つまり、インデックス・フィールド 1) によって追加されます。結果として得られるデータ・ストリームは、各単語の出現回数を5秒ごとに出力します。最後に、データストリームをコンソールに出力し、実行を開始します。
windowCounts.print().setParallelism(1); env.execute("Socket Window WordCount");実際のFlinkジョブを開始するには、最後の
env.execute呼び出しが必要です。すべてのOperator操作(ソース作成、集約、印刷など)は、内部のOperator操作のグラフを構築するだけです。execute()が呼び出されたときのみ、それらは実行のためにクラスタまたはローカルコンピュータに送信されます。package myflink; import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.windowing.time.Time; import org.apache.flink.util.Collector; public class SocketWindowWordCount { public static void main(String[] args) throws Exception { // Create the execution environment final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // Obtain the input data by connecting to the socket. Here you want to connect to the local 9000 port. If 9000 port is not available, you'll need to change the port. DataStream text = env.socketTextStream("localhost", 9000, "\n"); // Parse the data, group by word, and perform the window and aggregation operations. DataStream> windowCounts = text .flatMap(new FlatMapFunction>() { @Override public void flatMap(String value, Collector> out) { for (String word : value.split("\\s")) { out.collect(Tuple2.of(word, 1)); } } }) .keyBy(0) .timeWindow(Time.seconds(5)) .sum(1); // Print the results to the console. Note that here single-threaded printed is used, rather than multi-threading. windowCounts.print().setParallelism(1); env.execute("Socket Window WordCount"); } }プログラムの実行
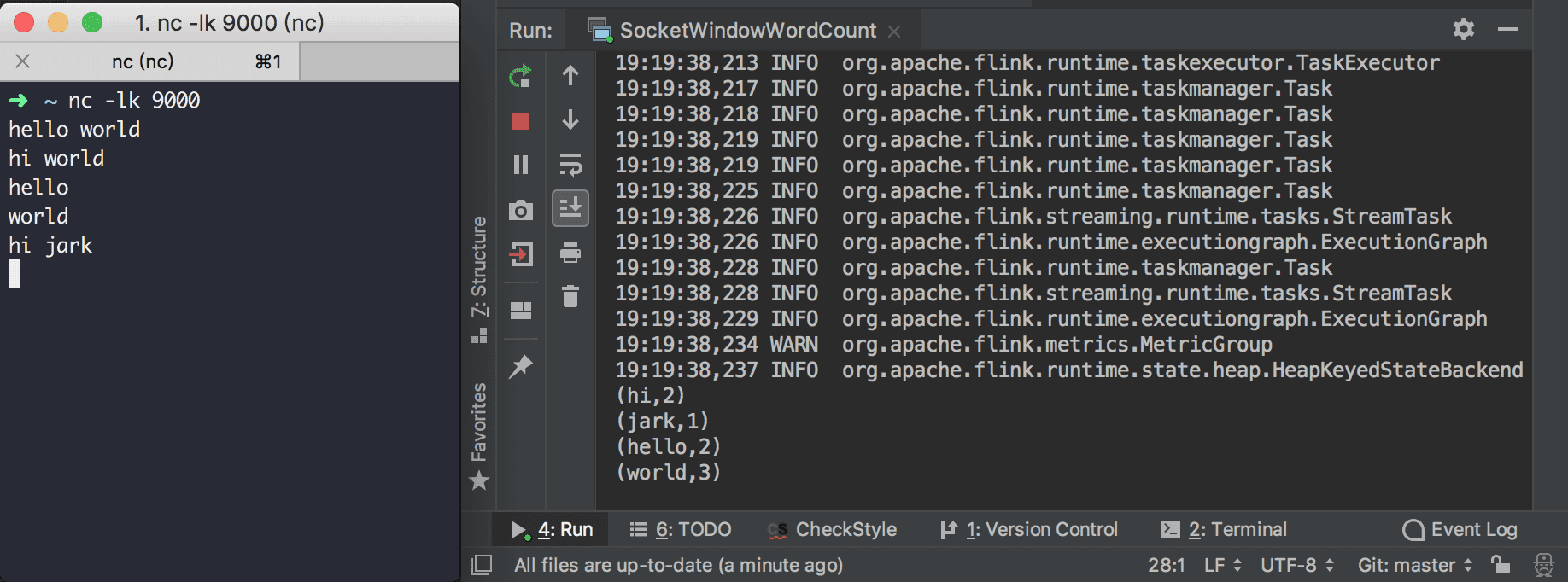
サンプルプログラムを実行するには、端末上でNetCatを起動して入力ストリームを取得します。
nc -lk 9000Windowsの場合は、NMAPを介してNcatをインストールし、実行することができます。
ncat -lk 9000そして、
SocketWindowWordCountのメインメソッドを直接実行します。NetCatのコンソールに単語を入力するだけで、
SocketWindowWordCountの出力コンソールに各単語の出現頻度の統計が表示されます。1以上のカウントを見たい場合は、5秒以内に同じ単語を繰り返し入力してください。
アリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ
- 投稿日:2020-09-14T16:13:28+09:00
S3からオブジェクトを取得したときは解放を忘れずに!
環境
- Java8
- AWS SDK for Java 1.11
現象
S3からオブジェクト取得時に、以下のようなエラーが発生した。
org.apache.http.conn.ConnectionPoolTimeoutException: Timeout waiting for connection from pool問題のコード
public InputStream getFile(String bucketName,String prefix){ try{ GetObjectRequest request = new GetObjectRequest(bucketName, prefix); S3Object object = s3client.getObject(request); // s3clientはシングルトンインスタンス変数として生成済み return object.getObjectContent(); } catch(AmazonServiceException e){ throw e; } }原因
S3Objectを取得した際に、解放処理が行われていないため。
S3内部でHTTPコネクションプールサイズを持っており、デフォルトで50となっている。
これを越えると上記のエラーが発生。解決方法
その1 S3クライアントのラッパークラスなどで行う場合
public InputStream getFile(String bucketName,String prefix){ GetObjectRequest request = new GetObjectRequest(bucketName, prefix); try(S3Object object = s3client.getObject(request)){ // メモリに展開。ここでS3Objectの参照をなくす byte[] file = IOUtils.toByteArray(object.getObjectContent()); // byte[]からInputStreamにして返却 return new ByteArrayInputStream(file); } catch(AmazonServiceException e){ throw e; } catch(IOException e){ throw new RuntimeException(e); } }一時的にメモリに展開しているので注意が必要。
解放処理を行う関係で、InputStreamをそのまま返却できない。その2 呼び出し側で解放する場合
public static main(String[] args){ try(S3Object object = getFile("hoge","fuga")){ 〜処理〜 }catch (IOException e) { throw new RuntimeException(e); } } public S3Object getFile(String bucketName,String prefix){ try{ GetObjectRequest request = new GetObjectRequest(bucketName, prefix); return s3client.getObject(request); } catch(AmazonServiceException e){ throw e; } }解放処理を呼び出しごとに行う必要があるが、
InputStreamを扱える。
- 投稿日:2020-09-14T14:12:41+09:00
環境変数「JAVA_HOME」パス設定手順の備忘録
環境変数「JAVA_HOME」のパス設定手順の備忘録
「JAVA_HOME」の設定手順を良く忘れがちなので、備忘録として示す。
環境
$ cat /etc/redhat-release CentOS Linux release 8.1.1911 (Core)設定手順
JDKのパスを確認する。インストールされていなければ、JDKを適宜インストールしてください。
$ dirname $(readlink $(readlink $(which java))) /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.252.b09-2.el8_1.x86_64/jre/binJAVA_HOMEのパスを設定する。
$ cp -pi /etc/profile{,.org} $ vi /etc/profile $ diff /etc/profile{,.org} 86,90d85 < < export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.252.b09-2.el8_1.x86_64 < export PATH=$PATH:$JAVA_HOME/bin < export CLASSPATH=.:$JAVA_HOME/jre/lib:$JAVA_HOME/lib:$JAVA_HOME/lib/tools.jar < $ source /etc/profile $ echo $JAVA_HOME /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.252.b09-2.el8_1.x86_64以上
- 投稿日:2020-09-14T13:28:55+09:00
try-catch 自分用
◎try-catchメソッド
package trycatch; import java.io.FileWriter; import java.io.IOException; public class trycatch1 { public void test() { FileWriter fw=null; /*入出力処理で、自分で何らかのファイルを開くコードを書いたなら、 必ずファイルを閉じるコードも書く。=closeメソッド*/ /*closeメゾットをtry-catchメソッドの外に書くために、 * ここでFileWriterを登場させる。 * なぜtrycatchメソッドの外にcloseメソッドを書くのか? * =tryメソッドでエラーを発見すると、ただちにcatchメソッドに移動してしまうので、 * closeメソッドが実行されない可能性があるから*/ try { fw=new FileWriter("data.txt"); /*ここで"data.txt"という新しいテキストファイルを このプロジェクト下につくってくれる。 そのファイルをプロジェクトをWindowエクスプローラーで開くと直接見れる*/ fw.write("hello"); /*実行してもdata.txtに文字が入っていないのは * close()メソッドが動いていないから。 * write()メソッドでテキスト挿入の指示をだしても、 * それをJVMが実際に書いてくれるのはclose()するまえだったりする。タイムラグ*/ }catch(IOException ioe){ System.out.println("入出のエラーが発生しました"); System.out.println(ioe); }catch(Exception e){ System.out.println("なんらかのエラーが発生しました"); /*↑なぜここでIOEceptionを先に書くのか?= *javaでは、複数のエラー処理を設定してある場合は、 うえから順に確認していく。ひとつのエラー処理をすると try-catchメソッドの外に出る。*/ System.out.println(e); }finally{ //fw.close(); //finallyメソッドは、例外が起きても起きなくても実行してくれる //ここはまだ難しいので取り掛かり中 } } public static void main(String[] args) { } }◎mainメソッド
package trycatch; public class main { public static void main(String[] args) { //インスタンス生成 trycatch1 t=new trycatch1(); //実行 t.test(); } }
- 投稿日:2020-09-14T12:52:16+09:00
Spring Cloudでマイクロサービスを構成する(4):API Gateway編
Spring Cloudシリーズの第4回です。
概要
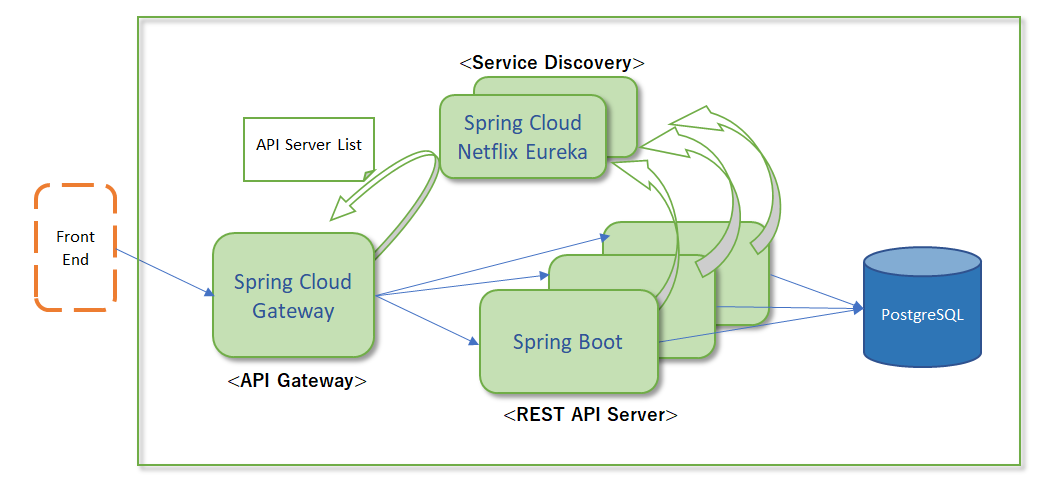
今回は「Spring Cloud Gateway」を使ってAPI Gatewayを立てることにします。
Spring Cloundファミリーでは従来、「Zuul」が使われていましたが、Zuulはメンテナンスモードとなり、「WebFlux&Nettyベースの」「Spring Gloud Gateway」が代替プロダクトとなっています。
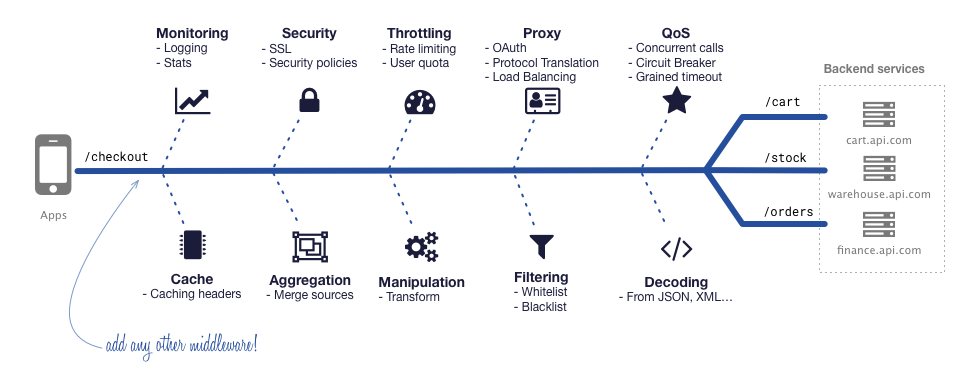
API GatewayはAPIの前段に建てるリバースプロキシとして働きます。
API Gatewayの役割としては、クライアントとAPIの間に入り、API側に持ち込みたくない関心事を前段でさばくことにあります。下の図は、API Gateway向けの別プロダクト「KrakenD」のドキュメントから拝借しています。
フィルタリング、入出力の返還、APIの集約、ログや統計情報取得、認証回り(SSLを解いたり、トークンをチェックしたり付加したり)、Throtting(流量制御でいいのかな?)といったところが代表例です。
個人的には2つを重要視していて、SpirngベースのSpring Cloud Gatewayには期待しています。
- APIの前段に構えるので、パフォーマンスが良いこと。
- 並行してアクセス数を多くさばける必要あり。
- カスタマイズ性に富んでいること。
- API Gatewayに機能追加がしやすいこと。(やりたいことがシンプルにできる)
環境
以下が動く環境を前提とします。
- docker & docker-compose
- JDK11
前回までの投稿の続きですので、前回のゴール地点のソースを手元に用意し、それをベースとします。
作業ステップ
本記事では以下のステップで進めていきます。
- API Gatewayのひな型作成
- 実装(アノテーションの付加と設定ファイルの記述)
- Dockerイメージ化とdocker-componentへの追加
ステップ1:API Gatewayのひな型作成
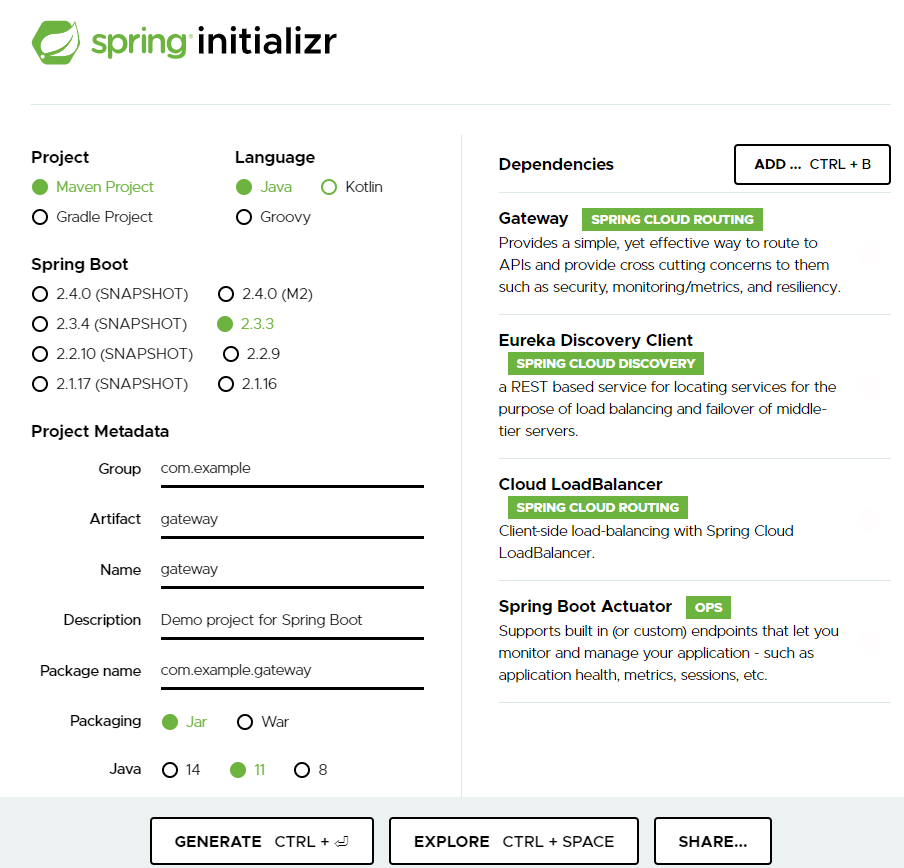
Spring Initializr の出番です。
Artifact と Name だけ
gatewayに指定し、あとは
Dependencies にGatewayとEureka Client、Spring Cloud LoadBalancer、SpringBoot Actuatorを追加しましょう。
ActuatorはGatewayに必須ではありませんが、何かと必要になるものなので追加しておきます。
Dependencies 説明 Gateway Spring Cloud Gateway を導入するために追加 Eureka Discovery Client Eurekaからサービスのリストを取得するために追加 Spring Cloud Loadbalancer クライアントサイド・ロードバランスのライブラリを追加 Spring Boot Actuator Spring Boot の内部情報を参照するために追加
あとは
GENERATEするとスケルトンのgateway.zipがダウンロードできます。
ステップ2:実装(アノテーションの付加と設定ファイルの記述)
今回もあまりやることがありません。2つだけ。
まず1つ目。
Applicationクラスにアノテーションを1つ付けます。
これでService Discoveryを参照できるようになります。gateway/src/main/java/com/example/gateway/GatewayApplication.javapackage com.example.gateway; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; import org.springframework.cloud.client.discovery.EnableDiscoveryClient; // ★追加する @SpringBootApplication @EnableDiscoveryClient // ★追加する public class GatewayApplication { public static void main(String[] args) { SpringApplication.run(GatewayApplication.class, args); } }やること2つ目。設定ファイル「application.yml」を書きます。
※src/main/resources/application.propertiesは不要になるので、削除してください。gateway/src/main/resources/application.ymlserver: port: ${PORT:5000} spring: main: banner-mode: "off" application: name: gateway cloud: gateway: routes: - id: account uri: lb://ACCOUNT-API predicates: - Path=/api/** filters: - RewritePath=/api(?<segment>/?.*), $\{segment} loadbalancer: ribbon: enabled: false management: endpoints: web: exposure: include: "*" eureka: instance: prefer-ip-address: false client: registerWithEureka: false serviceUrl: defaultZone: ${DISCOVERY:http://localhost:8761/eureka}
Routesの箇所がルーティングの定義です。
今回は1つだけRouteの定義をしており、以下を指定しています。
- ServiceDiscoveryから「ACCOUNT-API」サービスのインスタンスリストを取得し、負荷分散してリクエストする。(uri)
- リクエストされたパス「/api/xxx」 に対し、アクセス先パスを「/xxx」に書き換えてサービスへリクエストする。(predicates/filters)
また、
eureka.client.serviceUrl.defaultZoneには、Service Discovery(Eurekaサーバ)のURLを指定します。ステップ3:Dockerイメージ化とdocker-componentへの追加
Dockerイメージを作成してdocker-composeで操れるようにしましょう。
前回のディレクトリ構造に以下のようにgatewayディレクトリを配置します。その上で、Dockerfileを作成し、とdocker-compose.ymlに追記します。
spring-msa ├── account │ └── ・・・ ├── db │ └── init ├── docker-compose.yml <-- ★追記する ├── gateyway <-- ★配置する │ └── Dockerfile <-- ★作成する └── sd └── ・・・discovery/DockerfileFROM openjdk:11-jdk-slim ADD target/gateway-*.jar /gateway.jar ENV CONTAINER_NAME=localhost \ PORT=5000 \ OPTS_ARGS='' ENTRYPOINT ["java", "-jar", "/gateway.jar", "${OPTS_ARGS}"]docker-compose.ymlversion: '3' ・・・ services: db: ・・・ adminer: ・・・ gateway: image: spring-msa/gateway container_name: gw build: context: ./gateway dockerfile: Dockerfile environment: - CONTAINER_NAME=gw - PORT=5000 - DISCOVERY=http://sd:3001/eureka/,http://sd2:3002/eureka/ ports: - "5000:5000" sd: ・・・ account: ・・・これで準備OK.
mvn wrapperでJARを作ったあとに、Dockerイメージを作成します。$ cd discovery $ .mvnw clean package $ cd .. $ docker-compose build gwこれでdocker-composeでgwを起動・停止できるようになりました。
(全サービスを起動) $ docker-compose up -d (GWの停止) $ docker-compose stop gw (全サービスの停止と破棄) $ docker-compose down (全サービスの停止とVolumeを含めた破棄) $ docker-compose down -vコンテナの5000ポートをホストの5000ポートにbindしているので、
http://localhost:5000/api/info でアクセスできます。下記のように繰り返し/api/infoを呼ぶと、Service Discoveryが返すサービスインスタンスのリストを使って
呼び先のACCOUNT-APIが負荷分散されているのがわかると思います。
組み込まれているロードバランサのデフォルトのアルゴリズムがRoundRobinなため、順番にリクエスト先が振られている状態です。$ curl localhost:5000/api/info {"containerName":"account","port":"9001","hostAddress":"172.18.0.9","hostName":"c1f0f98a3859"} $ curl localhost:5000/api/info {"containerName":"account2","port":"9002","hostAddress":"172.18.0.7","hostName":"27d40318d8bc"} $ curl localhost:5000/api/info {"containerName":"account3","port":"9003","hostAddress":"172.18.0.8","hostName":"7c2abf523dcf"} $ curl localhost:5000/api/info {"containerName":"account","port":"9001","hostAddress":"172.18.0.9","hostName":"c1f0f98a3859"} $ curl localhost:5000/api/info {"containerName":"account2","port":"9002","hostAddress":"172.18.0.7","hostName":"27d40318d8bc"} $ curl localhost:5000/api/info {"containerName":"account3","port":"9003","hostAddress":"172.18.0.8","hostName":"7c2abf523dcf"}何かがおかしければdokerのログをみてください。
$ docker-compose logs -f gwさいごに
ここまでのソースを以下に置いています。
https://github.com/SHIRAKI-Takayoshi/spring-msa/tree/add_gateway
ここまで来てようやく土台ができつつあります。
これからやってみたいこととしては、API Gatewayに機能追加を試すことです。
ロードバランスのアルゴリズムをカスタマイズしたり、APIに負荷をかけすぎないようにアクセス流量制御を追加してみたいところです。と、なると、
その前にもう少し準備をしておく必要があります。
- どこのAPIサービスにリクエストが行って1リクエストの中でどこにどれだけ時間がかかっているのか。
- リクエスト数はそれぞれのサービスでどれだけさばけているのか。
- そもそも負荷をかけたときにサービスはどのくらい余裕があるのか。
などなど、アクセスのトレースや、コンテナ/サービスのモニタリングをができる状態で負荷テストツールで負荷をかけられるようにしておきたいところです。
次回からはその辺を進めていきたいと思います。
ではでは。
- 投稿日:2020-09-14T12:17:37+09:00
スクラッチからApache Flinkアプリケーションを5分で構築する方法
このチュートリアルでは、Apache Flink アプリケーションをゼロから数分で構築する方法を簡単に説明します。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
この記事では、Alibaba Cloud Toolkitプラグインを使用して以下のアプリケーションをデプロイする際のコマンドの書き方のベストプラクティスを紹介します。
- スタンダードな Java Web Tomcat アプリケーション
- スタンダードなJava Fatjarアプリケーション
- スタンダードなSpring Bootアプリケーション
- スタンダードなGo アプリケーション
スタンダードなJava Web Tomcatアプリケーション
上図のように,Linux システムの
/root/tomcat/が Tomcat アプリケーションのルートディレクトリであるとします.この/root/tomcat/webappsディレクトリにJava WebアプリケーションのWARパッケージ(javademo.war)をデプロイする必要があります.対応するコマンド構成は以下の通りです。
sh /root/sh/restart-tomcat.shrestart-tomcat.shスクリプトの内容は以下の通りです。
source /etc/profile killall java rm -rf /root/tomcat/webapps/javademo sh /root/tomcat/bin/startup.sh/ect/profile ファイルは環境変数を設定するために使用され、以下のような内容が含まれています。
# Get the aliases and functions if [ -f ~/.bashrc ]; then . ~/.bashrc fi export JAVA_HOME=/usr/share/jdk1.8.0_14 export PATH=$JAVA_HOME/bin:.....スタンダードなJava Fatjarアプリケーション
Linux システムの
/root/javademoディレクトリが Java アプリケーションのルートディレクトリとして使用されているとします。Javaアプリケーションのjarパッケージを/root/javademoディレクトリにデプロイする必要があります.対応するコマンド設定は以下の通りです.
sh /root/sh/restart-java.shrestart-java.shスクリプトの内容は以下の通りです。
source /etc/profile killall java nohup java -jar /root/javademo/javademo-0.0.1-SNAPSHOT.jar > nohup.log 2>&1 &スタンダードなSpring Bootアプリケーション
Linuxシステムの
/root/springbootdemoディレクトリがSpring Bootアプリケーションのルートディレクトリとして使用されているとします。Spring Bootアプリケーションのjarパッケージ(springbootdemo-0.0.1-SNAPSHOT.jar)を/root/springbootdemoディレクトリにデプロイします。対応するコマンド設定は以下の通りです。
sh /root/sh/restart-springboot.shrestart-springboot.shスクリプトの内容は以下の通りです。
source /etc/profile killall java nohup java -jar /root/springbootdemo/springbootdemo-0.0.1-SNAPSHOT.jar > nohup.log 2>&1 &スタンダードなGoアプリケーション
Linux システムの
/root/godemoディレクトリが Go アプリケーションのルート ディレクトリとして使用されているとします。Goアプリケーションの実行ファイル(godemo)を/root/godemoディレクトリにデプロイする必要があります。対応するコマンド構成は以下の通りです。
sh /root/sh/restart-go.shrestart-go.shスクリプトの内容は以下の通りです。
source /etc/profile pkill -f 'godemo' chmod 755 /root/godemo/godemo; sh -c /root/godemo/godemoアリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ

- 投稿日:2020-09-14T12:17:37+09:00
ガイド:Alibaba Cloud Toolkitプラグインを使用してアプリケーションをデプロイ
この記事では、Alibaba Cloud Toolkitプラグインを使用してアプリケーションをデプロイする際のコマンドの書き方のベストプラクティスを紹介します。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
この記事では、Alibaba Cloud Toolkitプラグインを使用して以下のアプリケーションをデプロイする際のコマンドの書き方のベストプラクティスを紹介します。
- スタンダードな Java Web Tomcat アプリケーション
- スタンダードなJava Fatjarアプリケーション
- スタンダードなSpring Bootアプリケーション
- スタンダードなGo アプリケーション
スタンダードなJava Web Tomcatアプリケーション
上図のように,Linux システムの
/root/tomcat/が Tomcat アプリケーションのルートディレクトリであるとします.この/root/tomcat/webappsディレクトリにJava WebアプリケーションのWARパッケージ(javademo.war)をデプロイする必要があります.対応するコマンド構成は以下の通りです。
sh /root/sh/restart-tomcat.shrestart-tomcat.shスクリプトの内容は以下の通りです。
source /etc/profile killall java rm -rf /root/tomcat/webapps/javademo sh /root/tomcat/bin/startup.sh/ect/profile ファイルは環境変数を設定するために使用され、以下のような内容が含まれています。
# Get the aliases and functions if [ -f ~/.bashrc ]; then . ~/.bashrc fi export JAVA_HOME=/usr/share/jdk1.8.0_14 export PATH=$JAVA_HOME/bin:.....スタンダードなJava Fatjarアプリケーション
Linux システムの
/root/javademoディレクトリが Java アプリケーションのルートディレクトリとして使用されているとします。Javaアプリケーションのjarパッケージを/root/javademoディレクトリにデプロイする必要があります.対応するコマンド設定は以下の通りです.
sh /root/sh/restart-java.shrestart-java.shスクリプトの内容は以下の通りです。
source /etc/profile killall java nohup java -jar /root/javademo/javademo-0.0.1-SNAPSHOT.jar > nohup.log 2>&1 &スタンダードなSpring Bootアプリケーション
Linuxシステムの
/root/springbootdemoディレクトリがSpring Bootアプリケーションのルートディレクトリとして使用されているとします。Spring Bootアプリケーションのjarパッケージ(springbootdemo-0.0.1-SNAPSHOT.jar)を/root/springbootdemoディレクトリにデプロイします。対応するコマンド設定は以下の通りです。
sh /root/sh/restart-springboot.shrestart-springboot.shスクリプトの内容は以下の通りです。
source /etc/profile killall java nohup java -jar /root/springbootdemo/springbootdemo-0.0.1-SNAPSHOT.jar > nohup.log 2>&1 &スタンダードなGoアプリケーション
Linux システムの
/root/godemoディレクトリが Go アプリケーションのルート ディレクトリとして使用されているとします。Goアプリケーションの実行ファイル(godemo)を/root/godemoディレクトリにデプロイする必要があります。対応するコマンド構成は以下の通りです。
sh /root/sh/restart-go.shrestart-go.shスクリプトの内容は以下の通りです。
source /etc/profile pkill -f 'godemo' chmod 755 /root/godemo/godemo; sh -c /root/godemo/godemoアリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ
- 投稿日:2020-09-14T11:42:04+09:00
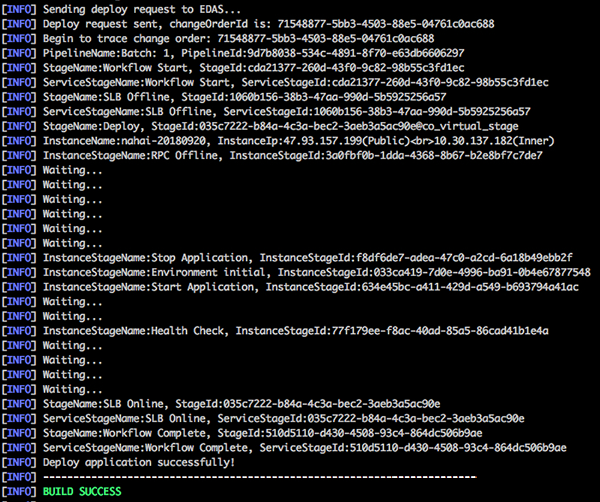
Cloud Toolkit Mavenプラグインを使用してEDASにアプリケーションをデプロイ
この記事では、Cloud Toolkit Mavenプラグインを使用してAlibaba Cloud EDASにアプリケーションをデプロイする方法を紹介します。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
EDAS開発者の場合、アプリケーションのデプロイにWARまたはJARパッケージを使用している場合は、Cloud Toolkit Mavenプラグインを使用して、アプリケーションをAlibaba Cloud EDASにデプロイすることができます。
ステップ1: Maven依存関係を追加
プロジェクトの pom.xml ファイルに、以下の
<build>依存関係を追加します。<build> <plugins> <plugin> <groupId>com.alibaba.cloud</groupId> <artifactId>toolkit-maven-plugin</artifactId> <version>1.0.0</version> </plugin> </plugins> </build>Mavenの公式セントラルリポジトリから最新バージョンを更新します。
ステップ2:Yamlファイルを設定
プロジェクトのルートディレクトリの下にedas_config.yamlファイルを作成します。パッケージ化されたプロジェクトがMavenサブモジュールの場合は、サブモジュールディレクトリにファイルを作成します。ファイルには以下の内容が含まれています。
env: region_id: cn-beijing app: app_id: eb20dc8a-0000-567-1234-5f6a54550453前述の設定項目のうち、region_idはアプリケーションインスタンスのリージョンID、app_idはアプリケーションIDを示します。前述の設定項目の値は一例です。実際のアプリケーションの値に置き換えてください。その他の設定項目については、「その他の設定項目」を参照してください。
ステップ3:EDASアカウントと連携
アカウントファイルを作成し、アクセスキーIDとアクセスキーシークレットをyaml形式で設定します。Access Key IDとAccess Key Secretを表示するには、Alibaba Cloudのユーザー情報管理システムにログオンします。以下に設定例を示します。
access_key_id: 123456 access_key_secret: 7891011ステップ4: 配置の完了
ルートディレクトリ(複数のMavenモジュールを使用している場合はサブモジュールディレクトリ)に移動し、このパッケージングコマンドを実行します。
mvn package toolkit:deploy --proudct=edas -Daccess_key_file= {Account file path}
本コマンドを実行すると、以下のメッセージが表示され、EDASにアプリケーションが正常にデプロイされたことを示します。
その他の設定項目
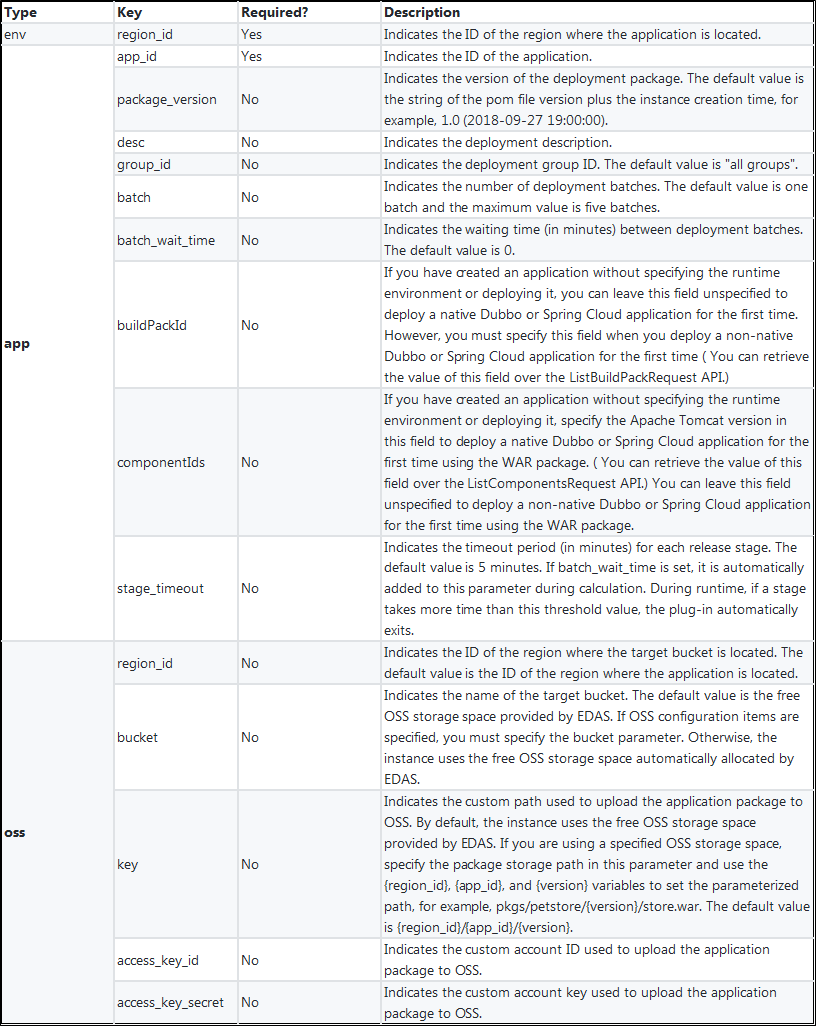
アプリケーションを展開するための設定項目は、以下のように分類されます。
- 基本環境(env)
- アプリケーション構成(アプリ)
- ストレージ構成(OSS) 現在サポートされている設定項目を以下の表に示します。
設定例1:グループと配置パッケージのバージョンを指定
例えば、ID が eb20dc8a-e6ee-4f6d-a36f-5f6a54550453 のアプリケーションが北京にデプロイされています。グループ ID は 06923bb9-8c5f-4508-94d8-517b692f30b9 で、デプロイメント パッケージのバージョンは 1.2 です。この場合の設定は以下のようになります。
env: region_id: cn-beijing app: app_id: eb20dc8a-e6ee-4f6d-a36f-5f6a54550453 package_version: 1.2 group_id: 06923bb9-8c5f-4508-94d8-517b692f30b9設定例2:OSSストレージスペースの指定
例えば、ID が eb20dc8a-e6ee-4f6d-a36f-5f6a54550453 のアプリケーションをデプロイし、デプロイパッケージを北京の release-pkg という名前の自分のバケットにアップロードしたいとします。ファイルオブジェクト名はmy.war、OSSアカウントIDはABC、OSSアカウントキーは1234567890です。この場合の設定は以下のようになります。
env: region_id: cn-beijing app: app_id: eb20dc8a-e6ee-4f6d-a36f-5f6a54550453 oss: region_id: cn-beijing bucket: release-pkg key: my.war access_key_id: ABC access_key_secret: 1234567890設定ファイルの指定
- 設定ファイルが指定されていない場合、このプラグインはパッケージプロジェクトのルートディレクトリにある
.edas_config.yamlファイルを設定ファイルとして使用します。パッケージ化されたプロジェクトがMavenプロジェクトのサブモジュールである場合、設定ファイルはデフォルトでサブモジュールのルートディレクトリの下にありますが、Mavenプロジェクト全体のルートディレクトリの下にはありません。- また、
-Dedas_config=xxxパラメータを設定することで設定ファイルを指定することもできます。- 別の設定ファイルが指定されている間にデフォルトの設定ファイルが存在する場合、プラグインは後者の設定ファイルを使用します。
アカウント設定と優先順位の説明
このプラグインを使用してアプリケーションをデプロイする際には、アプリケーションデプロイ用のAlibaba Cloud Access Keyを提供する必要があります。現在、プラグインは複数の構成方法をサポートしています。構成方法が重複している場合は、優先度の高い構成方法が優先度の低い構成方法よりも優先されます。優先度の高い順に構成方法を示します。
- コマンドラインで指定したAK/SKパラメータ。access_key_idとaccess_key_secretは、以下のいずれかの方法で指定できます。
- Mavenコマンドを実行してプロジェクトをパッケージ化する場合は、
-Daccess_key_id=xx -Daccess_key_secret=xxで両方のパラメータを指定します。- pomファイルでこのプラグインを設定する場合は、以下のようにAKとSKのパラメータを設定します。
<plugin> <groupId>com.aliyun</groupId> <artifactId>edas-maven-plugin</artifactId> <version>2.30.0</version> <configuration> <accessKeyId>abc</accessKeyId> <accessKeySecret>1234567890</accessKeySecret> </configuration> </plugin>
- コマンドラインでアカウントファイルを指定します(推奨)。Mavenコマンドを実行してプロジェクトをパッケージ化する場合、-Daccess_key_file={アカウントファイルのパス}でアカウントファイルをyaml形式で指定します。例: `Daccess_key_file={account file path=
access_key_id: abc access_key_secret: 1234567890
- デフォルトのAlibaba Cloudアカウントファイルを使用します。前述の方法のいずれかでアカウントを指定しないことを選択した場合、プラグインは構成されたAlibaba Cloudアカウントを使用してアプリケーションをデプロイします。
- aliyuncli: 最新の
aliyuncliツールを使用してAlibaba Cloudアカウントを設定した場合、Alibaba Cloudは現在のホームディレクトリの下に.aliyuncliサブディレクトリを生成し、アカウント情報を保存するために.aliyuncliサブディレクトリに資格情報ファイルを作成します。ここでは、Macシステムを例に、システムユーザを "jack "と仮定して、/Users/jack/.aliyuncli/credentialsファイルに以下の情報を格納します。[default] aliyun_access_key_secret = 1234567890 aliyun_access_key_id = abcプラグインは、このアカウントファイルをアプリケーションをデプロイするためのアカウントとして使用します。
- aliyun: レガシーのAliyunツールを使用してAlibaba Cloudのアカウントを設定した場合、Aliyunツールはカレントホームディレクトリの下に.aliyunサブディレクトリを生成し、その
.aliyunサブディレクトリにconfig.jsonファイルを作成します。ここではMacシステムを例に挙げ、システムユーザーを「jack」と仮定しているので、アカウント情報は/Users/jack/.aliyun/config.jsonに格納されています。{ "current": "", "profiles": [{ "name": "default", "mode": "AK", "access_key_id": "", "access_key_secret": "", "sts_token": "", "ram_role_name": "", "ram_role_arn": "", "ram_session_name": "", "private_key": "", "key_pair_name": "", "expired_seconds": 0, "verified": "", "region_id": "", "output_format": "json", "language": "en", "site": "", "retry_timeout": 0, "retry_count": 0 }, { "name": "", "mode": "AK", "access_key_id": "abc", "access_key_secret": "xxx", "sts_token": "", "ram_role_name": "", "ram_role_arn": "", "ram_session_name": "", "private_key": "", "key_pair_name": "", "expired_seconds": 0, "verified": "", "region_id": "cn-hangzhou", "output_format": "json", "language": "en", "site": "", "retry_timeout": 0, "retry_count": 0 }], "meta_path": "" }
- システム環境変数:最後に、プラグインはシステム環境変数からaccess_key_idとaccess_key_secretの値を取得しようとします。つまり、プラグインはJavaコードの
System.getenv("access_key_id”)とSystem.getenv("access_key_secret”)からこれらの値を取得します。アリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ