- 投稿日:2020-09-14T23:15:51+09:00
ESP32をGoogle Homeデバイスにする
GoogleのスマートスピーカであるGoogle Home Miniに「OK Google、スイッチをオンにして」というと、M5StickCのLEDが点灯するようにします。(要は、Lチカです)
いまさら感はあるのですが、なんでも最新のAndroid 11になって、電源長押しで、Google Homeデバイスを手軽に操作できるようになったのです。
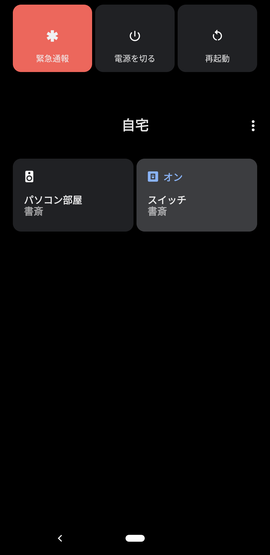
Androidスマホから、電源長押しでこんな感じの画面がすぐ出せるので、いろいろ使えそうです。
ソースコードをGitHubに上げておきました。
poruruba/GoogleHomeDevice
https://github.com/poruruba/GoogleHomeDevice構成
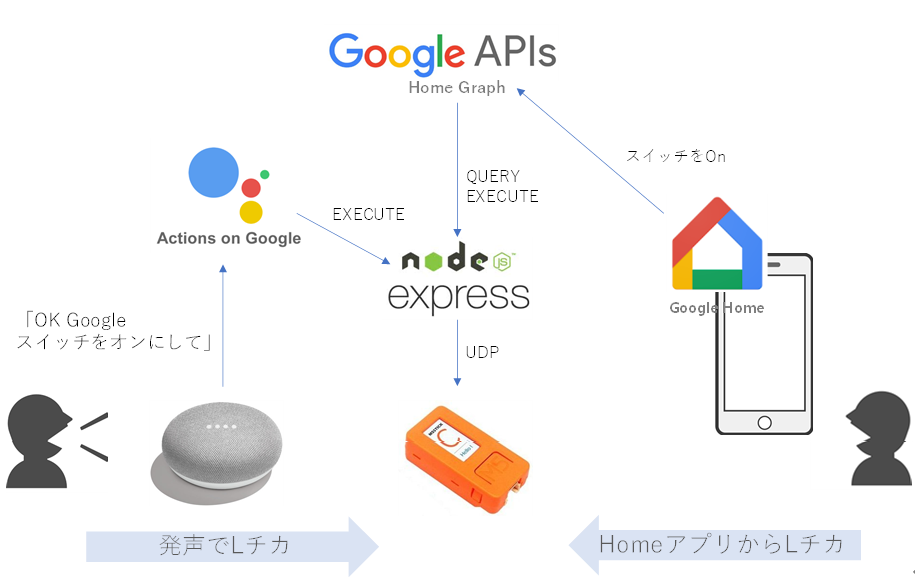
まずは、一般ユーザがM5StickCを使うときの構成です。
自宅のGoogle Home Miniスピーカに、「OK Google スイッチをオンにして」と言うと、今回立ち上げるNode.jsサーバが呼び出され、その中でM5StickCと通信して、M5StickCについているLEDを点灯させます。
M5StickCがGoogleHomeデバイスとして認識されるように、Node.jsサーバがActions on Googleに登録しているためです。今回、M5StickCをGoogleHomeデバイスのスイッチとして認識させます。
同様に、手持ちのAndroidスマホからGoogle Homeアプリを立ち上げ、スイッチを選択して、OnさせたりOffさせたりすることもできます。さらに、Android 11であれば、電源長押しで表示される画面からも操作できます。<準備>
上記の動作となるためには、あらかじめNode.jsサーバがGoogle Homeデバイスを扱えるサーバであることをActions on Google登録する必要があります。これは、GoogleHomeデバイス管理会社としての作業です。
一方、ユーザの方です。
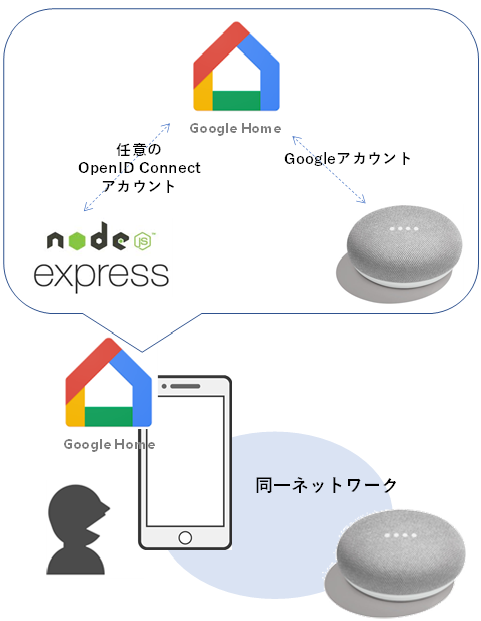
Google HomeとGoogle Home Miniスピーカは、すでにGoogle Homeアプリを使って、Googleアカウントとつながっているのではないでしょうか。そして、Google HomeとGoogle Home Miniスピーカとnode.jsサーバを紐づければ、すべてがつながります。
これらは、Google Home Miniを所有している一般ユーザの作業です。一般ユーザが、自身が持っているGoogle Home Miniに、GoogleHomeデバイス管理会社を登録することになります。
ちょっとわかりにくいかもしれませんが、順を追って説明します。
必要なもの
<一般ユーザとして>
・Google Home Miniスマートスピーカ
・Google Homeアプリ(スマホ)
・Googleアカウント<GoogleHomeデバイス管理会社として>
・Node.jsサーバとそれが動くハードウェア
・LED付きESP32
・GoogleアカウントGoogleアカウントとして、一般ユーザのものとGoogleHomeデバイス管理会社としてのものの2つがあります。
今回は、開発用に作成し、一般には公開しないため、同一アカウントである必要があります。参考となるサンプルコード
以下に、参考となるサンプルコードがあります。
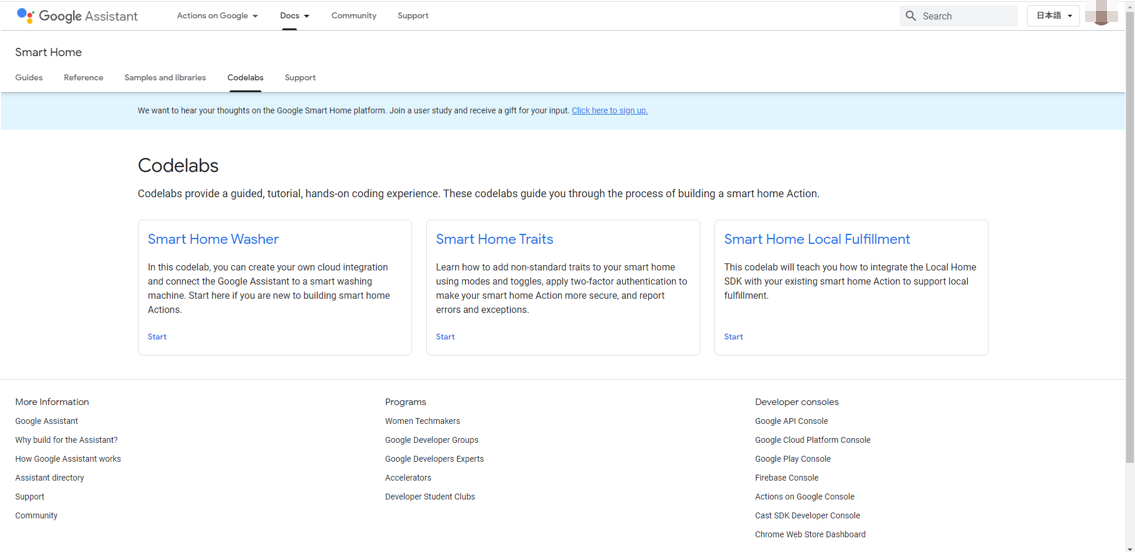
Codelabs
https://developers.google.com/assistant/smarthome/codelabs?hl=ja
このうち、Smart Home Washerがわかりやすく、これをベースに進めていきます。
が、Firebaseを使っていて、何が必須かわけわからなくなりそうなので、Firebaseを使わない方法で進めます。〇Googleアカウントのアクティビティの確認
Googleアカウントは必須なのですが、以下のアクティビティが有効となっている必要があるそうです。
アクティビティの管理
https://myaccount.google.com/activitycontrols・Web & App Activity
・Device Information
・Voice & Audio Activity〇GoogleHomeデバイス管理会社としてプロジェクトを作成する
Actions on Google Developer Consoleより、プロジェクトを作成します。
Actions on Google Developer Console
http://console.actions.google.com/
適当なプロジェクト名を入力し、言語をJapanese、国をJapanにします。例えば、MySmartHomeとか。
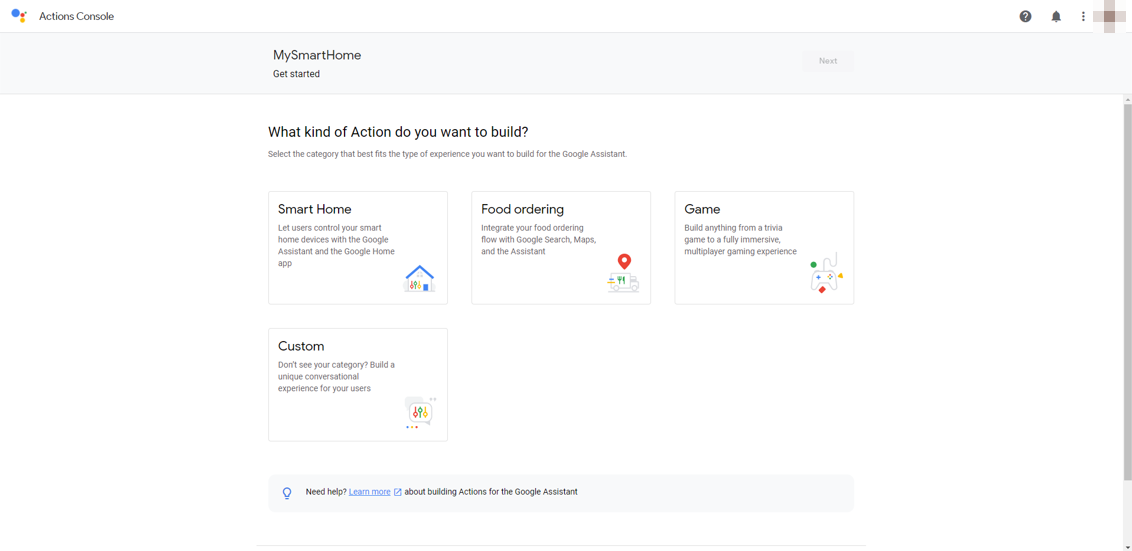
次に、アクションの種類を選ぶのですが、Smart Homeを選択します。
次に、OverviewのQuick setupのName your Smart Home actionを選択し、適当なDisplay nameを入力します。例えば、マイスマートホームとか。
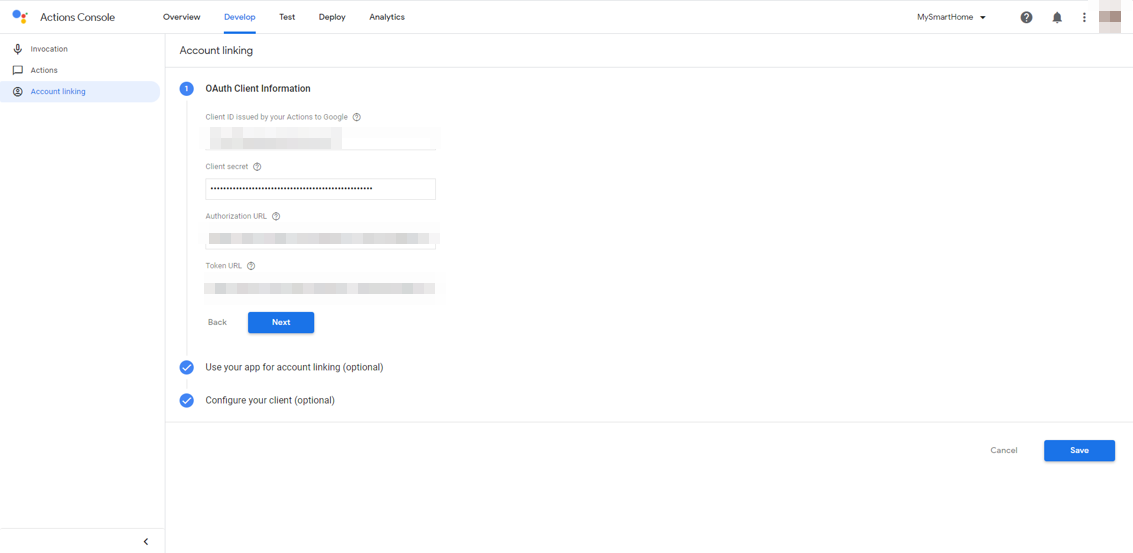
次に、Developタブを選択し、左側のナビゲーションから、Account linkingを選択します。
ここがちょっとわかりにくいかもしれません。OpenID Connectの設定なのですが、今回はCognitoを使います。Google HomeとNode.jsサーバをつなぐときに使います。
Cognitoのユーザプールを作成し、アプリクライアントを作成し、そのアプリクライアントIDとアプリクライアントのシークレットをそれぞれ入力します。手抜きですみませんが、詳細はこちらが参考になるかと思います。
AWS CognitoにGoogleとYahooとLINEアカウントを連携させるAuthorization URLは、以下のようになります。
https://[ドメイン名].auth.ap-northeast-1.amazoncognito.com/oauth2/authorizeToken URLは以下のようになります。
https://[ドメイン名].auth.ap-northeast-1.amazoncognito.com/oauth2/tokenscopeを指定したい場合は、Configure your client (optional)を選択すると、scopeを入力できます。
アプリクライアントの設定において、コールバックURLとして以下を追加しておきます。これはAWS Cognito側の作業です。
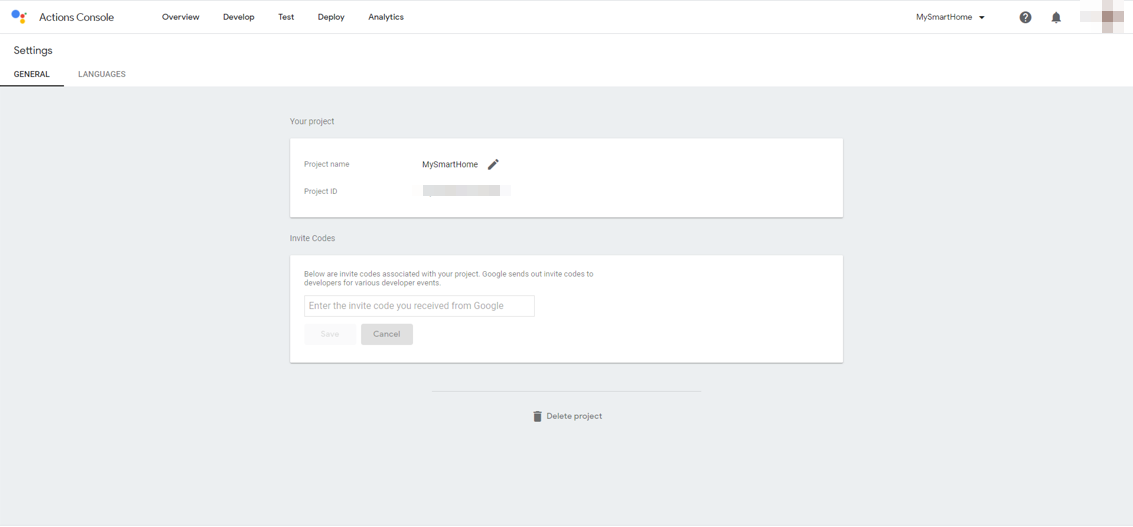
https://oauth-redirect.googleusercontent.com/r/[プロジェクトID]プロジェクト名は、Actions on Googleのプロジェクト名で、右上のメニューアイコンから、Project settingsを選択すると表示されるProject IDです。
次に、同じくDevelopタブで、左側のナビゲーションからActionsを選択します。
Fulfillment URLにはこれから立ち上げるサーバのURLを入力します。HTTPSである必要があります。https://【Node.jsサーバのホスト名】/smarthome
以上で、GoogleHomeデバイスを管理するサーバの設定が完了しました。
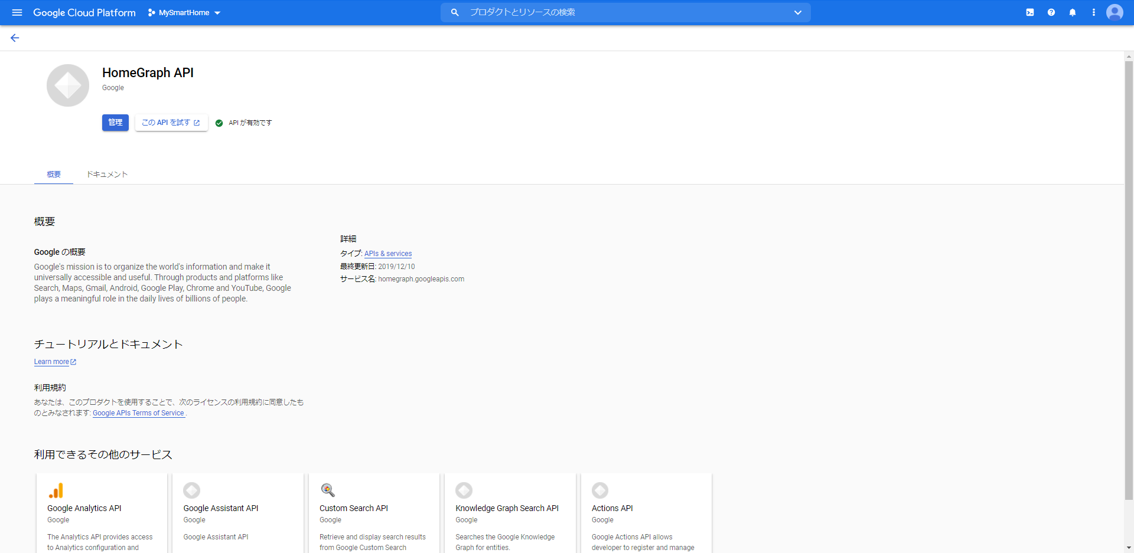
GoogleHomeAPIの有効化
さきに、GoogleHomeデバイス管理会社は、GoogleHomeと連携するためにGoogleHome APIを実行できるようにしておく必要があります。
GoogleHome API
https://console.cloud.google.com/apis/library/homegraph.googleapis.comここで、「有効にする」ボタンを押下します。
(絵ではすでに有効化されていますが)
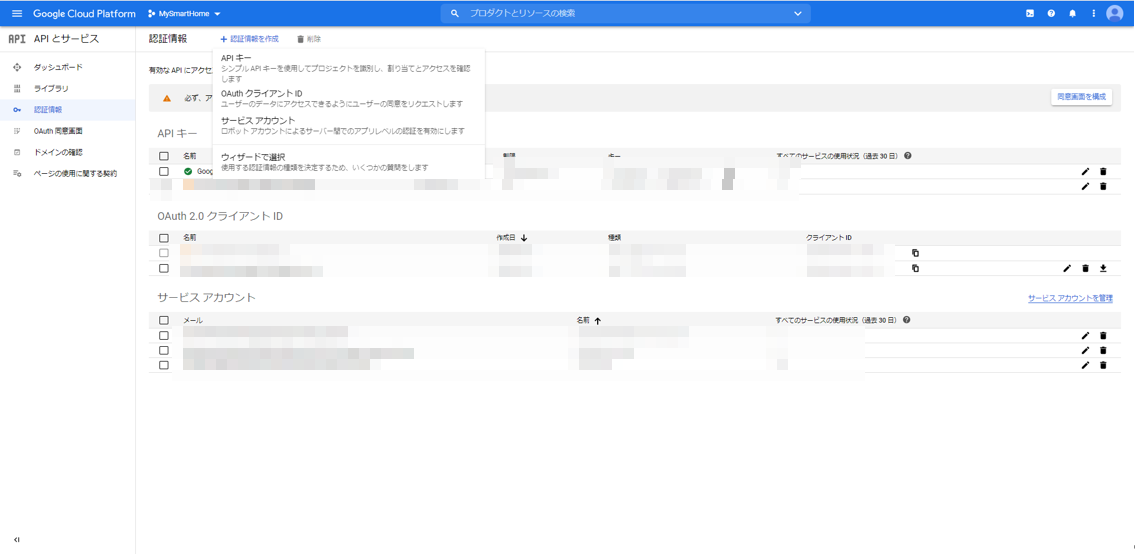
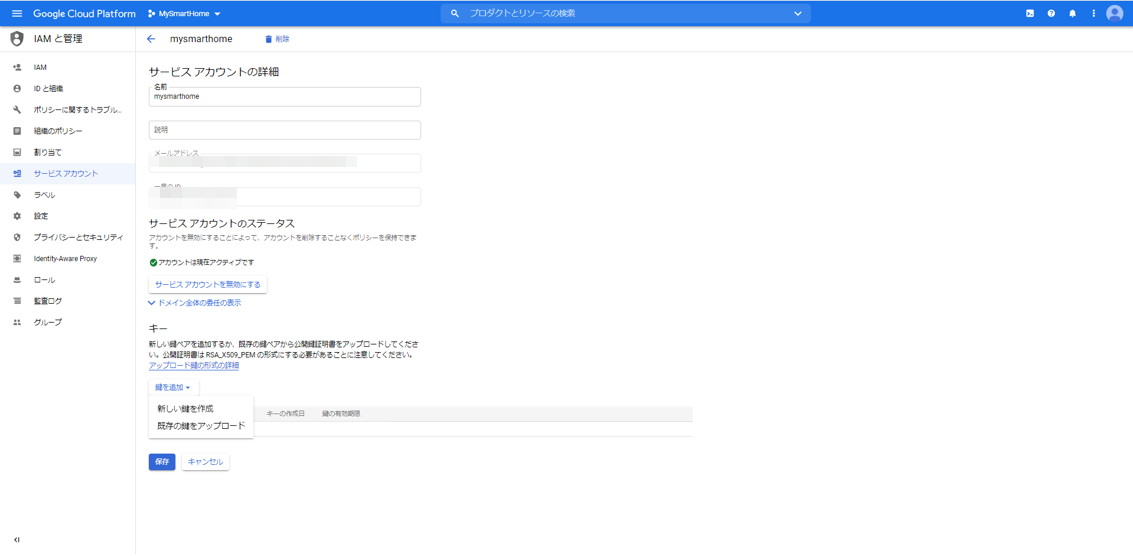
次に、Node.jsサーバからHomeGraphAPIを呼び出せるように、サービスアカウントキーを作成します。
プロジェクトの認証情報のページに行きます。APIとサービス:認証情報
https://console.cloud.google.com/apis/credentials
上の方にある「+認証情報の作成」をクリックし、「サービスアカウント」を選択します。
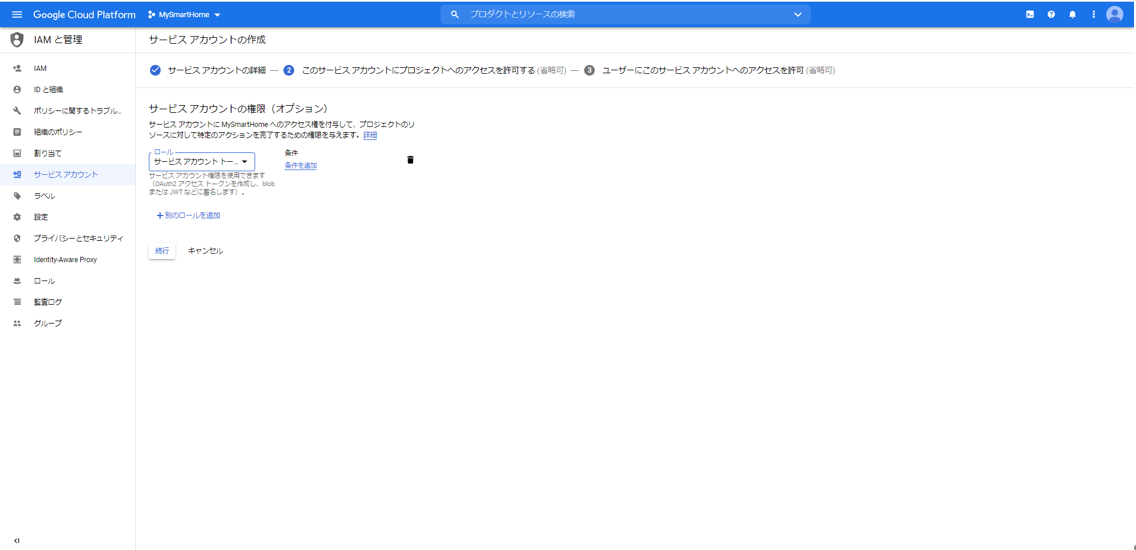
適当なサービスアカウント名を入力し、「作成」ボタンを押下します。例えば、smarthomeとか。
ここで、ロールとして、「Service Accounts」の「サービスアカウント トークン作成者」を選択します。「続行」ボタンを押下します。
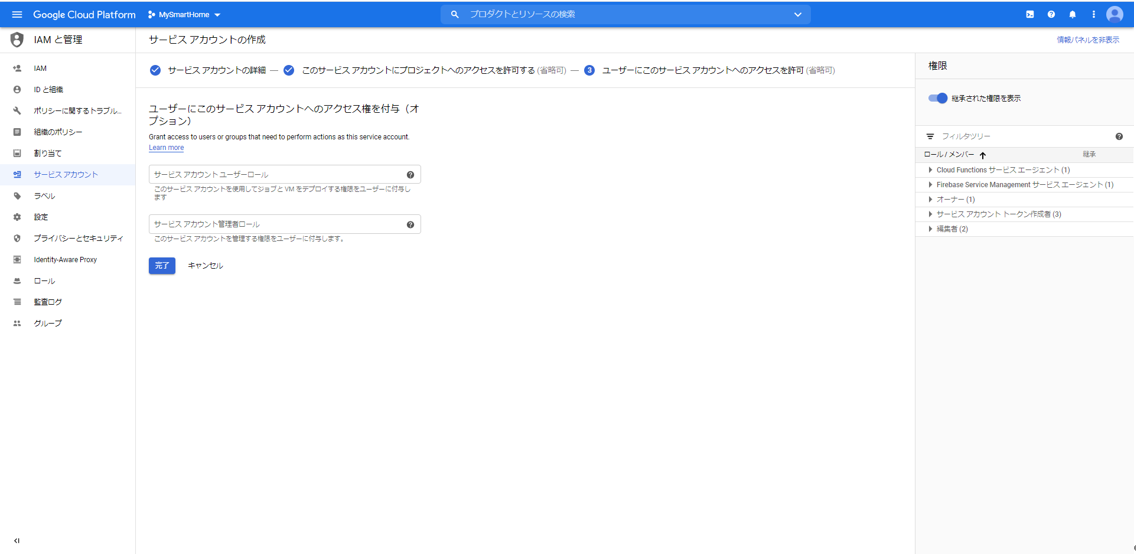
「完了」ボタンを押下します。
最初の画面に戻って、もう一度今作成したサービスアカウントを選択します。
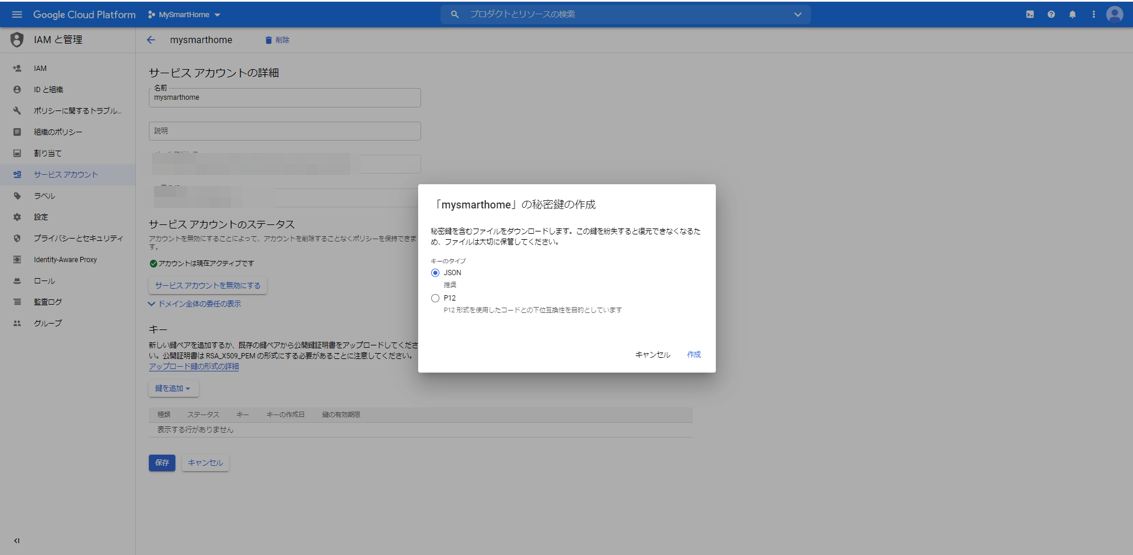
「鍵を追加」から「新しい鍵を作成」を選択します。
キーのタイプとしてJSONを選択します。ファイルが生成されますので、ローカルPCにダウンロードしておきます。
〇Node.jsサーバの立ち上げ
それでは、GoogleHomeデバイスを管理するNode.jsサーバを立ち上げます。
Googleが便利なnpmモジュールを提供してくれていますので、それを使います。
actions-on-google/actions-on-google-nodejs
https://github.com/actions-on-google/actions-on-google-nodejsNode.jsのexpressを使っているのであれば、すぐにつなげることができます。
こんな感じだそうです。const express = require('express') const bodyParser = require('body-parser') // ... app code here const expressApp = express().use(bodyParser.json()) expressApp.post('/fulfillment', app) expressApp.listen(3000)原理がわかったところで、私がいつも使っているswagger-nodeを使います。
内部のフレームワークとしてexpressを選択すればつながります。
具体的には、以下のページで示している、私がいつも使っているものを使って説明します。(GitHub)https://github.com/poruruba/swagger_template
(参考)SwaggerでLambdaのデバッグ環境を作る(1)具体的には、GitHubサイトを開いて、CodeをZIPダウンロードします。
どこかに展開します。
まずは、以下でnpmモジュールを準備します。
また、さきほどのActions on Googleのnpmモジュールを使うので以下を実行します。npm install -g swagger-node npm install npm install actions-on-googleapi/swagger/swagger.yamlに以下を追加します。path: のところです。
api/swagger/swagger.yaml/smarthome: post: x-swagger-router-controller: routing operationId: smarthome parameters: - in: body name: body schema: $ref: "#/definitions/CommonRequest" responses: 200: description: Success schema: $ref: "#/definitions/CommonResponse" /reportstate: post: x-swagger-router-controller: routing operationId: smarthome_reportstate parameters: - in: body name: body schema: $ref: "#/definitions/CommonRequest" responses: 200: description: Success schema: $ref: "#/definitions/CommonResponse"そして、api/controllers/functions.jsのfunc_tableとexpress_tableのところに、以下のように追記します。
api/controllers/functions.jsconst func_table = { // "test-func" : require('./test_func').handler, // "test-dialogflow" : require('./test_dialogflow').fulfillment, "smarthome_reportstate" : require('./smarthome').handler, }; ・・・ const express_table = { // "test-express": require('./test-express').handler, "smarthome": require('./smarthome').fulfillment, };次に、api/controllers/smarthomeフォルダを作成します。
そこに、keysフォルダを作成し、さきほどダウンロードしたサービスアカウントキーのJSONファイルを置きます。
さらに、以下のindex.jsを作成します。api/controllers/smarthome/index.js'use strict'; const HELPER_BASE = process.env.HELPER_BASE || '../../helpers/'; const Response = require(HELPER_BASE + 'response'); const JWT_FILE_PATH = process.env.JWT_FILE_PATH || '【サービスアカウントキーファイル名】'; const DEVICE_ADDRESS = '【ESP32のIPアドレス】'; const DEVICE_PORT = 3333; // UDP受信するポート番号 const dgram = require('dgram'); const udp = dgram.createSocket('udp4'); const jwt_decode = require('jwt-decode'); const {smarthome} = require('actions-on-google'); const jwt = require(JWT_FILE_PATH); const app = smarthome({ jwt: jwt }); var states_switch = { on: false }; var requestId = 0; const DEFAULT_USER_ID = process.env.DEFAULT_USER_ID || "user01"; var agentUserId = DEFAULT_USER_ID; executeDevice('query'); app.onSync((body, headers) => { console.info('onSync'); console.log('onSync body', body); var decoded = jwt_decode(headers.authorization); console.log(decoded); var result = { requestId: body.requestId, payload: { agentUserId: agentUserId, devices: [ { id: 'switch', type: 'action.devices.types.SWITCH', traits: [ 'action.devices.traits.OnOff', ], name: { defaultNames: ['MyHome Switch'], name: 'スイッチ', }, deviceInfo: { manufacturer: 'MyHome Devices', }, willReportState: true, }, ], }, }; executeDevice('query'); console.log("onSync result", result); return result; }); app.onQuery(async (body, headers) => { console.info('onQuery'); console.log('onQuery body', body); var decoded = jwt_decode(headers.authorization); console.log(decoded); const {requestId} = body; const payload = { devices: {} }; for( var i = 0 ; i < body.inputs.length ; i++ ){ if( body.inputs[i].intent == 'action.devices.QUERY' ){ for( var j = 0 ; j < body.inputs[i].payload.devices.length ; j++ ){ var device = body.inputs[i].payload.devices[j]; if( device.id == 'switch' ){ payload.devices.switch = { on: states_switch.on, online: true, status: "SUCCESS" }; }else { console.log('not supported'); } } } } var result = { requestId: requestId, payload: payload, }; console.log("onQuery result", result); return result; }); app.onExecute(async (body, headers) => { console.info('onExecute'); console.log('onExecute body', body); var decoded = jwt_decode(headers.authorization); console.log(decoded); const {requestId} = body; // Execution results are grouped by status var ret = { requestId: requestId, payload: { commands: [], }, }; for( var i = 0 ; i < body.inputs.length ; i++ ){ if( body.inputs[i].intent == "action.devices.EXECUTE" ){ for( var j = 0 ; j < body.inputs[i].payload.commands.length ; j++ ){ var result = { ids:[], status: 'SUCCESS', }; ret.payload.commands.push(result); var devices = body.inputs[i].payload.commands[j].devices; var execution = body.inputs[i].payload.commands[j].execution; for( var k = 0 ; k < execution.length ; k++ ){ if( execution[k].command == "action.devices.commands.OnOff" ){ for( var l = 0 ; l < devices.length ; l++ ){ if( devices[l].id == "switch"){ result.ids.push(devices[l].id); states_switch.on = execution[k].params.on; await executeDevice(devices[l].id); await reportState(devices[l].id); } } } } } } } console.log("onExecute result", ret); return ret; }); app.onDisconnect((body, headers) => { console.info('onDisconnect'); console.log('body', body); var decoded = jwt_decode(headers.authorization); console.log(decoded); // Return empty response return {}; }); exports.fulfillment = app; async function executeDevice(id){ var message; if( id == 'switch' ){ message = { id: id, onoff: states_switch.on, }; }else if( id == 'query' ){ message = { id: 'query' }; }else{ throw 'unknown id'; } var data = Buffer.from(JSON.stringify(message)); return new Promise((resolve, reject) =>{ udp.send(data, 0, data.length, DEVICE_PORT, DEVICE_ADDRESS, (error, bytes) =>{ if( error ){ console.error(error); return reject(error); } resolve(bytes); }); }); } async function reportState(id){ var state; if( id == 'switch'){ state = { requestId: String(++requestId), agentUserId: agentUserId, payload: { devices: { states:{ [id]: { on: states_switch.on } } } } }; }else{ throw 'unknown id'; } console.log("reportstate", state); await app.reportState(state); return state; } exports.handler = async (event, context, callback) => { var body = JSON.parse(event.body); console.log(body); if( event.path == '/reportstate'){ try{ if( body.id == 'switch'){ states_switch.on = body.onoff; } var res = await reportState(body.id); console.log(res); return new Response({ message: 'OK' }); }catch(error){ console.error(error); var response = new Response(); response.set_error(error); return response; } } };環境に合わせて以下の部分を修正します。
【ESP32のIPアドレス】
【サービスアカウントキーファイル名】
※サービスアカウントキーファイルは、keysフォルダに置いたのであれば、「./keys/***-**.json」という感じになります。また、HTTPSで立ち上げる必要があるため、フロントにHTTPSのサーバを立ち上げてProxyしてもらうか、certフォルダを作成してそこにSSL証明書を配置して、app.jsを書き換えることでHTTPSとして立ち上がります。
以下の辺りです。app.jsvar https = require('https'); try{ var options = { key: fs.readFileSync('./cert/privkey.pem'), cert: fs.readFileSync('./cert/cert.pem'), ca: fs.readFileSync('./cert/chain.pem') };ポート番号を変えたい場合は、.envファイルを作成して、以下のように指定してください。
PORT=10080 SPORT=10443以下のようにして立ち上げます。
> node app.jsNode.jsサーバのソースコード解説
Node.jsサーバには、実装するべきIntentが複数あります。
Intent fulfillment
https://developers.google.com/assistant/smarthome/develop/process-intents
- SYNC:Node.jsサーバが管理するGoogle Homeデバイスの情報を返します。複数のデバイスを返すことができます。ユーザがNode.jsサーバが管理するGoogle Homeデバイスを利用登録すると呼ばれます。
- QUERY:Node.jsサーバが管理するGoogle Homeデバイスの状態を返します。ユーザがGoogle Homeアプリを使ってGoogle Homeデバイスを表示されている間定期的に状態を得るためにQUERYが呼ばれてきます。
- EXECUTE:Node.jsサーバが管理するGoogle Homeデバイスに対する変更要求です。Google Home Miniスピーカから、「OK Google、スイッチをオンにして」と言われて、Node.jsが管理するGoogle Homeデバイスの状態の変更要求が来た時に呼ばれます。また、AndroidのGoogle Homeアプリから、Google Homeデバイスを操作したときにも呼ばれます。
- DISCONNECT:Google Homeデバイスがユーザから管理対象から外されたときに呼ばれます。
具体的な入出力電文のJSONフォーマットは以下を参照してください。
- https://developers.google.com/assistant/smarthome/reference/intent/sync
- https://developers.google.com/assistant/smarthome/reference/intent/query
- https://developers.google.com/assistant/smarthome/reference/intent/execute
- https://developers.google.com/assistant/smarthome/reference/intent/disconnect
受信時に呼ばれる関数は、それぞれ以下が対応します。
- app.onSync(function(body, headers));
- app.onQuery(function(body, headers));
- app.onExecute(function(body, headers));
- app.onDisconnect(function(body, headers));
外部から受け付けるエンドポイントは「/smarthome」としており、それを、functions.jsで指定したフォルダに転送し、
exports.fulfillment = app;として受け取っています。
SYNC IntentでGoogle Homeデバイスの定義
Google Homeデバイスの定義は、SYNCに対する応答として返しています。
まず決めるのがTypeです。
Typeは、デバイスの種類を示します。機能は後ほど示すTraitsであり、それらを束ねるものと思ってもよいです。
例えば、エアコンとか、洗濯機とか、照明とか。Smart Home Device Types
https://developers.google.com/assistant/smarthome/guides今回は、単純にLEDの点灯だけなので、
action.devices.types.SWITCH
を選択しました。Smart Home Switch Guide
https://developers.google.com/assistant/smarthome/guides/switch次が、Traitsです。
GoogleHomeデバイスが持っている機能です。Smart Home Device Traits
https://developers.google.com/assistant/smarthome/traits今回は、点灯と消灯の2種類なので、action.devices.traits.OnOff をもっていることとしました。ちなみに、このTraitsは電源のOn/Offとして、いろんなデバイスで共通でもっている機能(Traits)です。
Smart Home OnOff Trait Schema
https://developers.google.com/assistant/smarthome/traits/onoff上記のページに、SYNCの応答として、どのようなAttributesを返すべきかなどが記されています。
ちなみに、その他SYNC Intentで共通で返すべき情報は以下に記載されています。
action.devices.SYNC
https://developers.google.com/assistant/smarthome/reference/intent/sync以下がその部分の抜粋です。
index.jsvar result = { requestId: body.requestId, payload: { agentUserId: agentUserId, devices: [ { id: 'switch', type: 'action.devices.types.SWITCH', traits: [ 'action.devices.traits.OnOff', ], name: { defaultNames: ['MyHome Switch'], name: 'スイッチ', }, deviceInfo: { manufacturer: 'MyHome Devices', }, willReportState: true, }, ], }, };agentUserIdは、接続してきたユーザのIdを指定します。本来であれば、ユニークなIDとしてユーザを区別するべきなのですが、自分しか使わないので固定にしています。
たとえば、headersに、OpenID Connectで認証したユーザのアクセストークンが入っていますので、例えばトークンの中のnameをそれに使うのがよいかと思います。index.jsvar decoded = jwt_decode(headers.authorization); console.log(decoded);QUERY IntentでGoogle Homeデバイスの状態を返す
M5StickCのLEDの点灯状態を返します。
とはいっても、M5StickCとどうやって通信するかというと、今回はUDPを使いました。今回の実装では、QUERY Intentが来てからGoogle HomeデバイスのM5StickCに問い合わせるのではなく、LEDの点灯状態を変更したタイミングあるいは変更されたタイミングでUDPパケットを受け取るようにしておき、QUERY Intentが来たら覚えておいた状態を返すようにしています。
以下が、M5StickCから状態を取得する部分の抜粋です。
index.jsexports.handler = async (event, context, callback) => { var body = JSON.parse(event.body); console.log(body); if( event.path == '/reportstate'){ try{ if( body.id == 'switch'){ states_switch.on = body.onoff; } var res = await reportState(body.id); console.log(res); return new Response({ message: 'OK' }); }catch(error){ console.error(error); var response = new Response(); response.set_error(error); return response; } } };外部から受け取るエンドポイントは、「/reportstate」で、functions.jsで指定されたフォルダに転送して受け取っています。
M5StickC→Node.jsの方向の通信です。一方、Node.jsからLED点灯したり状態取得を要求したりするNode.js→M5StickC方向の通信として以下の関数を作成しています。UDP送信です。index.jsasync function executeDevice(id){ var message; if( id == 'switch' ){ message = { id: id, onoff: states_switch.on, }; }else if( id == 'query' ){ message = { id: 'query' }; }else{ throw 'unknown id'; } var data = Buffer.from(JSON.stringify(message)); return new Promise((resolve, reject) =>{ udp.send(data, 0, data.length, DEVICE_PORT, DEVICE_ADDRESS, (error, bytes) =>{ if( error ){ console.error(error); return reject(error); } resolve(bytes); }); }); }idとして"switch"を指定すると、M5StickCのLEDを点灯させたり消灯させたりします。一方で、"query"を指定すると、今のM5StickCのLEDの状態の取得を要求します。その応答が、さきほどの、/reqportstateのエンドポイントです。実はこの受け口はHTTP Postでして、別途もう一つ立ち上げるNode.jsサーバ(UDP)で、UDP受信・HTTP Post送信をして仲介しています。
(なぜ、UDPにこだわるかというと、Google Homeデバイスには、Local Fulfillmentという機能があるそうで、UDPが対応しているためです。次回頑張ろうと思います)
このエンドポイントには2つの意味があります。
1つ目は、先ほどのお伝えした通り、今のLEDの状態を取得するためのものです。
もう一つは、M5StickCのボタン押下でLEDを変更したときに状態変化通知を取得するためのものです。今回、OK GoogleやGoogleHomeアプリからのLED点灯・消灯に加えて、M5StickC本体でもボタンの押下で点灯・消灯を切り替え、その状態をGoogle Homeアプリに反映するようにしました。
EXECUTE IntentでGoogle Homeデバイスの状態を変更
「OK Google、スイッチをオンにして」、と変更のリクエストを受け取るのがこのEXECUTEです。
抜粋しておきます。
index.jsapp.onExecute(async (body, headers) => { console.info('onExecute'); console.log('onExecute body', body); var decoded = jwt_decode(headers.authorization); console.log(decoded); const {requestId} = body; // Execution results are grouped by status var ret = { requestId: requestId, payload: { commands: [], }, }; for( var i = 0 ; i < body.inputs.length ; i++ ){ if( body.inputs[i].intent == "action.devices.EXECUTE" ){ for( var j = 0 ; j < body.inputs[i].payload.commands.length ; j++ ){ var result = { ids:[], status: 'SUCCESS', }; ret.payload.commands.push(result); var devices = body.inputs[i].payload.commands[j].devices; var execution = body.inputs[i].payload.commands[j].execution; for( var k = 0 ; k < execution.length ; k++ ){ if( execution[k].command == "action.devices.commands.OnOff" ){ for( var l = 0 ; l < devices.length ; l++ ){ if( devices[l].id == "switch"){ result.ids.push(devices[l].id); states_switch.on = execution[k].params.on; await executeDevice(devices[l].id); await reportState(devices[l].id); } } } } } } } console.log("onExecute result", ret); return ret; });さきほどお伝えした、executeDevice()を呼び出しているのがわかります。
ここで、関数reportState()も呼んでいます。実はさっきの/reportstateでも出てきていました。index.jsasync function reportState(id){ var state; if( id == 'switch'){ state = { requestId: String(++requestId), agentUserId: agentUserId, payload: { devices: { states:{ [id]: { on: states_switch.on } } } } }; }else{ throw 'unknown id'; } console.log("reportstate", state); await app.reportState(state); return state; }これは、Google Homeに状態が変わったことを伝えるためのものです。
直接Google Homeデバイスを操作して、M5StickCのLED状態を変えたときには、この関数を呼び出して、Google Homeに新しい状態を伝える必要があります。ESP32からのUDP受信を待ち受けるNode.jsサーバ(UDP)
npmモジュールのnode-fetchを使っています。
index.js'use strict'; var dgram = require('dgram'); const { URL, URLSearchParams } = require('url'); const fetch = require('node-fetch'); const Headers = fetch.Headers; const base_url = "【Node.jsサーバのURL】"; var UDP_HOST = '【自身のIPアドレス】'; var UDP_PORT = 3333; //ESP32からのUDP受信を待ち受けるポート番号 var server = dgram.createSocket('udp4'); server.on('listening', function () { var address = server.address(); console.log('UDP Server listening on ' + address.address + ":" + address.port); }); server.on('message', async (message, remote) => { console.log(remote.address + ':' + remote.port +' - ' + message); var body = JSON.parse(message); var json = await do_post(base_url + '/reportstate', body); console.log(json); }); server.bind(UDP_PORT, UDP_HOST); function do_post(url, body) { const headers = new Headers({ "Content-Type": "application/json; charset=utf-8" }); return fetch(new URL(url).toString(), { method: 'POST', body: JSON.stringify(body), headers: headers }) .then((response) => { if (!response.ok) throw 'status is not 200'; return response.json(); }); }以下の部分を環境に合わせて変更してください。
【Node.jsサーバのURL】
【自身のIPアドレス】以下のようにして立ち上げます。
> node index.jsESP32のソースコード
最後に、GoogleHomeデバイスであるM5StickCのソースコードです。
いきなりですが、こんな感じです。main.cpp#include <M5StickC.h> #include <WiFi.h> #include <ArduinoJson.h> const char* wifi_ssid = "【WiFiアクセスポイントのSSID】"; const char* wifi_password = "【WiFiアクセスポイントのパスワード】"; const char *udp_report_host = "【Node.jsサーバ(UDP)のIPアドレス】"; #define UDP_REQUEST_PORT 3333 //Node.jsサーバからのUDP受信を待ち受けるポート番号 #define UDP_REPORT_PORT 3333 //Node.jsサーバ(UDP)へUDP送信する先のポート番号 #define LED_PIN GPIO_NUM_10 const int capacity_request = JSON_OBJECT_SIZE(3); const int capacity_report = JSON_OBJECT_SIZE(3); StaticJsonDocument<capacity_request> json_request; StaticJsonDocument<capacity_report> json_report; #define BUFFER_SIZE 255 char buffer_request[BUFFER_SIZE]; char buffer_report[BUFFER_SIZE]; bool led_status = false; bool isPressed = false; WiFiUDP udp; void wifi_connect(void){ Serial.println(""); Serial.print("WiFi Connenting"); WiFi.begin(wifi_ssid, wifi_password); while (WiFi.status() != WL_CONNECTED) { Serial.print("."); delay(1000); } Serial.println(""); Serial.print("Connected : "); Serial.println(WiFi.localIP()); M5.Lcd.println(WiFi.localIP()); } void setup() { M5.begin(); M5.Lcd.setRotation(3); M5.Lcd.fillScreen(BLACK); M5.Lcd.setTextColor(WHITE, BLACK); M5.Lcd.println("[M5StickC]"); Serial.begin(9600); Serial.println("setup"); pinMode(LED_PIN, OUTPUT); digitalWrite(LED_PIN, HIGH); wifi_connect(); Serial.println("server stated"); udp.begin(UDP_REQUEST_PORT); } void reportState(){ json_report.clear(); json_report["id"] = "switch"; json_report["onoff"] = led_status; serializeJson(json_report, buffer_report, sizeof(buffer_report)); udp.beginPacket(udp_report_host, UDP_REPORT_PORT); udp.write((uint8_t*)buffer_report, strlen(buffer_report)); udp.endPacket(); } void loop() { M5.update(); int packetSize = udp.parsePacket(); if( packetSize > 0){ Serial.println("UDP received"); int len = udp.read(buffer_request, packetSize); DeserializationError err = deserializeJson(json_request, buffer_request, len); if( err ){ Serial.println("Deserialize error"); Serial.println(err.c_str()); return; } const char* id = json_request["id"]; if( strcmp(id, "query") == 0 ){ reportState(); }else if( strcmp(id, "switch") == 0 ){ led_status = json_request["onoff"]; digitalWrite(LED_PIN, led_status ? LOW : HIGH); } } if( M5.BtnA.isPressed() ){ if( !isPressed ){ isPressed = true; Serial.println("BtnA.Released"); led_status = !led_status; digitalWrite(LED_PIN, led_status ? LOW : HIGH); reportState(); delay(100); } }else if( M5.BtnA.isReleased() ){ isPressed = false; } delay(10); }以下の部分は環境に合わせて変更してください。
【WiFiアクセスポイントのSSID】
【WiFiアクセスポイントのパスワード】
【Node.jsサーバ(UDP)のIPアドレス】UDP受信したら、その内容をJSONパースして、idがswitchだったらLEDを点灯したり、消灯したりし、queryだったら状態をUDPで返しています。
また、ボタンの押下を検出したら、JSON文字列化して、状態をUDP送信します。
JSONパースおよび文字列化には、ArduinoJsonを利用しています。使ってみる
それではさっそく、一般ユーザとして、使ってみましょう。
さきほどのNode.jsサーバやNode.jsサーバ(UDP)を立ち上げておきましょう。まずは、AndroidからGoogle Homeアプリを立ち上げます。
Google Home MiniスマートスピーカはすでにGoogle Homeアプリで登録されている前提です。
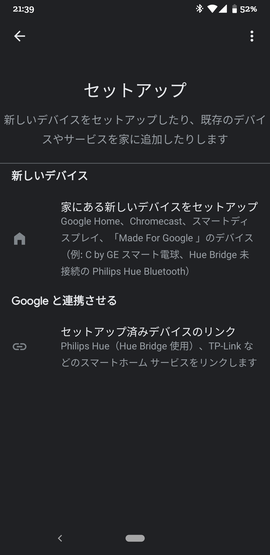
左上の「+」ボタンを押下し、次に、「デバイスのセットアップ」を選択します。
さらに、「Googleと連携させる」を選択します。
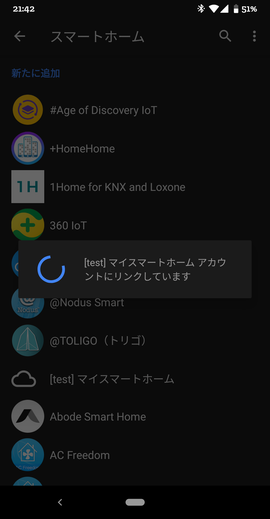
そうすると、[test]と接頭辞が付いたものが見つかります。例:[test]マイスマートホーム。
さっそくそれを選択します。
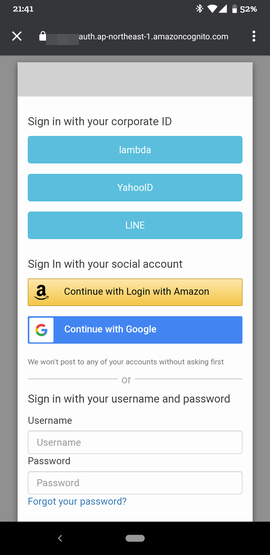
そうすると、ログイン画面が表示されます。
これは、Actions on GoogleのAccount Linkingで設定したauthorizeエンドポイントが呼び出された結果です。OpenID ConnectとしてCognitoを使ったのでCognitoのログイン画面が出ています。Cognitoの設定内容によって見え方は変わります。
アカウントログインが完了すると、
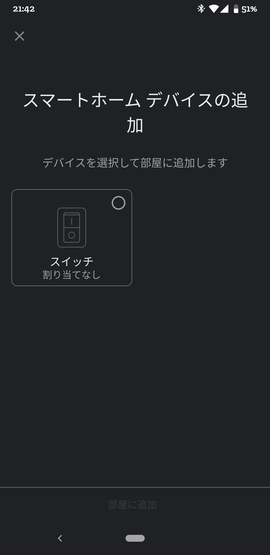
めでたく、以下のようなGoogle Homeデバイス選択画面が現れます。
選択して、部屋に追加しましょう。
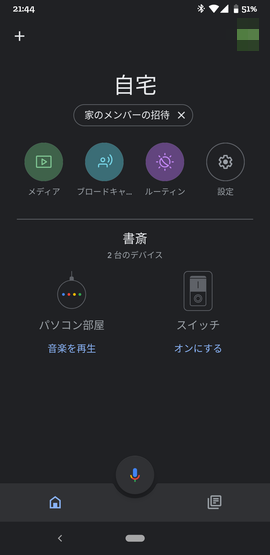
最後に完了ボタンを押すと、以下のように登録されます。
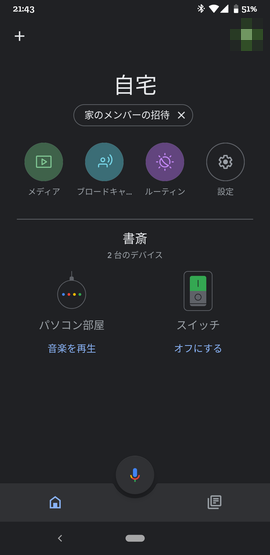
さっそく、オンにする をタップしてみましょう。
M5StickCのLEDがOnになり、画面上も緑色が付いたかと思います。Offもできます。
次は、音声で。「OK Google、スイッチをオンにして」と話してみましょう。LEDがOnになり、画面上も変わりましたでしょうか。
最後に、Android 11だけですが、電源ボタンを長押しします。
メニューボタンからコントロールを追加を選択します。
そこでスイッチのチェックボックスをOn状態にして、「保存」ボタンを押下します。
これで、ワンタッチで、M5StickCのLEDを点灯したり消灯できるようになりました!
最後に
以前、Alexaのスマートホームで、黒豆の学習リモコンを制御しました。今度はこれをGoogleHomeデバイス対応しようと思います。
スマートホームスキルを作る(1):黒豆を操作するRESTful API環境を構築するLocal Fulfillmentというのがあって、GoogleHomeでJavascriptを動かして直接GoogleHomeデバイスを制御するとか。今度調べてみようと思います。
https://developers.google.com/assistant/smarthome/concepts/localこちらを参考にさせていただきました。ありがとうございました。
"○○のアプリにつないで"不要の Google Home 対応スマートホームアプリの実装以上







- 投稿日:2020-09-14T20:58:20+09:00
Instagramにアップロードされた写真を埋め込みHTML形式で取得してみた
はじめに
Instagramにアップロードされた写真を埋め込みHTML形式で取得してみました。
APIを使うために、Facebook developer にアプリを登録したり、Facebookページを作成したり、Instagramのアカウントをビジネスアカウントに切り替えたりと色々事前準備が必要でした。
トークンの取得方法は下記サイトがすごく丁寧に解説してくれていて、参考にさせていただきました。
https://navymobile.co.jp/instagram-graph-api今回は、Graph API用のアプリ(開発モード)とoEmbed用のアプリ(ライブモード)2つ作りました。
Facebookにレビューが通ればアプリは一つで実現できると思います。環境は下記になります。
macOS Catalina 10.15.6
Node.js v14.8.0
(Node.js Library)request 6.14.7コード
下記、コードになります。
(1) Graph API でアカウントに紐付く投稿のURLを取得
(2) oEmbedでURLを埋め込みHTMLに変換
の流れになります。APIの仕様は下記を参照しました。
・Graph API
https://developers.facebook.com/docs/instagram-basic-display-api/reference/user・oEmbed
https://developers.facebook.com/docs/instagram/oembedbatch_instagram.jsconst request = require('request'); const URL_INSTAGRAM_API='https://graph.facebook.com/v8.0/'; const INSTAGRAM_USERID=process.env.INSTAGRAM_USERID; const INSTAGRAM_APP_TOKEN=process.env.INSTAGRAM_APP_TOKEN; const INSTAGRAM_APP_OEMBED_TOKEN=process.env.INSTAGRAM_APP_OEMBED_TOKEN; const URL_INSTAGRAM_POSTS=URL_INSTAGRAM_API + INSTAGRAM_USERID + '?fields=name,media.limit(99){caption,like_count,media_url,permalink,timestamp,username,comments_count}&access_token=' + INSTAGRAM_APP_TOKEN; const URL_INSTAGRAM_OEMBED=URL_INSTAGRAM_API + 'instagram_oembed?fields=html,thumbnail_width,type,width&access_token=' + INSTAGRAM_APP_OEMBED_TOKEN + '&url='; var get_instagram_options_base = { url: '', method: 'GET', json: true }; var html_data = []; var get_instagram_options_1 = get_instagram_options_base; get_instagram_options_1.url = URL_INSTAGRAM_POSTS; request(get_instagram_options_1, function (error, response, posts) { var url_list = []; posts.media.data.forEach(data => { url_list.push(data.permalink); }); // console.log(url_list); urlToHtml_OEmbed( url_list, function() { console.log(html_data); return; } ); }); function urlToHtml_OEmbed(urls, callback) { if (urls.length == 0) { return callback(); } else { let url = urls.shift(); var get_instagram_options_2 = get_instagram_options_base; get_instagram_options_2.url = URL_INSTAGRAM_OEMBED + url; request(get_instagram_options_2, function (error, response, oembed) { html_data.push(oembed.html); // console.log(urls.length); urlToHtml_OEmbed( urls, callback ); }); } }実行結果は下記になります。
XXXXXXXXは各自の環境で置き換えて下さい。% export INSTAGRAM_USERID=XXXXXXXX % export INSTAGRAM_APP_TOKEN=XXXXXXXX % export INSTAGRAM_APP_OEMBED_TOKEN=XXXXXXXX % node batch_instagram.js [ '<blockquote class="instagram-media" data-instgrm-captioned data-instgrm-permalink="https://www.instagram.com/p/CEhFobmnEnM/?utm_source=ig_embed&utm_campaign=loading" data-instgrm-version="12" style=" background:#FFF; border:0; border-radius:3px; box-shadow:0 0 1px 0 rgba(0,0,0,0.5),0 1px 10px 0 rgba(0,0,0,0.15); margin: 1px; max-width:658px; min-width:326px; padding:0; width:99.375%; width:-webkit-calc(100% - 2px); width:calc(100% - 2px);"><div style="padding:16px;"> <a href="https://www.instagram.com/p/CEhFobmnEnM/?utm_source=ig_embed&utm_campaign=loading" style=" background:#FFFFFF; line-height:0; padding:0 0; text-align:center; text-decoration:none; width:100%;" target="_blank"> <div style=" display: flex; flex-direction: row; align-items: center;"> <div style="background-color: #F4F4F4; border-radius: 50%; flex-grow: 0; height: 40px; margin-right: 14px; width: 40px;"></div> <div style="display: flex; flex-direction: column; flex-grow: 1; justify-content: center;"> <div style=" background-color: #F4F4F4; border-radius: 4px; flex-grow: 0; height: 14px; margin-bottom: 6px; width: 100px;"></div> <div style=" background-color: #F4F4F4; border-radius: 4px; flex-grow: 0; height: 14px; width: 60px;"></div></div></div><div style="padding: 19% 0;"></div> <div style="display:block; height:50px; margin:0 auto 12px; width:50px;"><svg width="50px" height="50px" viewBox="0 0 60 60" version="1.1" xmlns="https://www.w3.org/2000/svg" xmlns:xlink="https://www.w3.org/1999/xlink"><g stroke="none" stroke-width="1" fill="none" fill-rule="evenodd"><g transform="translate(-511.000000, -20.000000)" fill="#000000"><g><path d="M556.869,30.41 C554.814,30.41 553.148,32.076 553.148,34.131 C553.148,36.186 554.814,37.852 556.869,37.852 C558.924,37.852 560.59,36.186 560.59,34.131 C560.59,32.076 558.924,30.41 556.869,30.41 M541,60.657 C535.114,60.657 530.342,55.887 530.342,50 C530.342,44.114 535.114,39.342 541,39.342 C546.887,39.342 551.658,44.114 551.658,50 C551.658,55.887 546.887,60.657 541,60.657 M541,33.886 C532.1,33.886 524.886,41.1 524.886,50 C524.886,58.899 532.1,66.113 541,66.113 C549.9,66.113 557.115,58.899 557.115,50 C557.115,41.1 549.9,33.886 541,33.886 M565.378,62.101 C565.244,65.022 564.756,66.606 564.346,67.663 C563.803,69.06 〜(中略)〜 utm_source=ig_embed&utm_campaign=loading" style=" color:#c9c8cd; font-family:Arial,sans-serif; font-size:14px; font-style:normal; font-weight:normal; line-height:17px;" target="_blank"> ma sa</a> (@mamemame_s) on <time style=" font-family:Arial,sans-serif; font-size:14px; line-height:17px;" datetime="2016-08-13T10:54:00+00:00">Aug 13, 2016 at 3:54am PDT</time></p></div></blockquote>\n' + '<script async src="//platform.instagram.com/en_US/embeds.js"></script>' ]以上です。
- 投稿日:2020-09-14T19:48:53+09:00
IMI住所変換コンポーネントを魔改造して昔の地名を検索できるようにしてみた
今回は、IMI住所変換コンポーネントをさらに改造して、昔の地名も検索できるようにしました。
imi-enrichment-address-plus
https://github.com/uedayou/imi-enrichment-address-plus昔の地名の検索
昔の地名のデータソースとして、大学共同利用機関法人 人間文化研究機構が公開する歴史地名データを利用利用しました。
現在の住所と同じくLevelDBに格納し、緯度経度による逆ジオコーディング検索にも対応しました。
これで、imi-enrichment-address-plusは
- 現在の住所
- 正規化
- 緯度経度で検索(逆ジオコーディング)
- 昔の地名
- 部分一致検索
- 緯度経度で検索(逆ジオコーディング)
の4つの検索が可能になりました。
検索方法
この記事では上記4つの検索のうち、昔の地名の部分一致検索と逆ジオコーディング検索の利用方法を紹介します。
現在の住所の正規化については
IMI住所変換コンポーネントでいろんな住所を正規化してみた現在の住所の逆ジオコーディングは
IMI住所変換コンポーネントを改造してリバースジオコーディングに対応してみたもしくはimi-enrichment-address-plusのREADME.mdを見てください。
部分一致検索
最も簡単に試す方法はコマンドラインインタフェースでの検索です。
まず、imi-enrichment-address-plusをグローバルにインストールします。
インストールコマンド$ npm install -g https://github.com/uedayou/imi-enrichment-address-plus/releases/download/v1.1.2/imi-enrichment-address-plus-1.1.2.tgzこれで
imi-enrichment-address-plusコマンドが使えるようになるはずです。
通常の住所正規化は-sオプションを使います。住所正規化コマンド$ imi-enrichment-address-plus -s 永田町昔の地名を検索するときは、
-sとともに--oldオプションをつけてください。
住所正規化は該当する1件を返しますが、この検索では文字数が近い最大10件が出力されます。昔の地名の部分一致コマンド$ imi-enrichment-address-plus -s 永田町 --old例えば、上記を実行すると、以下のような結果が出力されます。
昔の地名での検索結果{ "@context": "https://imi.go.jp/ns/core/context.jsonld", "場所": [ { "@type": "場所型", "住所": [ { "@type": "住所型", "種別": "歴史地名データ", "ID": "10033625", "町名": "永田町", "説明": "「大日本地名辞書」6巻 274頁", "都道府県": "武蔵", "都道府県コード": "594", "市区町村": "麹町区", "市区町村コード": "797" }, { "@type": "住所型", "表記": "東京都千代田区永田町一丁目", "都道府県": "東京都", "都道府県コード": "http://data.e-stat.go.jp/lod/sac/C13000", "市区町村": "千代田区", "市区町村コード": "http://data.e-stat.go.jp/lod/sac/C13101", "町名": "永田町", "丁目": "1", "種別": "位置参照情報" } ], "地理座標": [ { "@type": "座標型", "緯度": "35.676388", "経度": "139.746388" } ] }, ... ] }検索結果には、住所オブジェクトが2つあり、
"種別": "歴史地名データ"であるほうが昔の地名、"種別": "位置参照情報"のほうが逆ジオコーディングにより検索された最も近い現在の住所となります。
地理座標からは緯度経度も得られます。緯度経度で検索(逆ジオコーディング検索)
部分一致と同じく、通常の逆ジオコーディング検索に
--oldつけることで検索対象が昔の地名になります。現在の住所の逆ジオコーディング検索$ imi-enrichment-address-plus --lat 35.675551 --lng 139.750413昔の地名の逆ジオコーディング検索$ imi-enrichment-address-plus --lat 35.675551 --lng 139.750413 --oldコマンドラインインタフェース以外の使い方
上記で説明したコマンドラインインタフェース以外の使い方として、Web APIとしての利用と、Nodeプログラム上で利用できます。
それぞれの使い方については、imi-enrichment-address-plusのREADME.mdを参照してください。
昔の地名のデータの中身
歴史地名データによると以下の資料をもとに作成されたデータだそうです。
資料名 説明 大日本地名辞書 大日本地名辞書は、吉田東伍(1864~1918)が編纂した日本で最初の本格的な地名辞書で、明治33年に初版が発行されました。「歴史地名辞書データ」には、北海道から沖縄(琉球)の53,528件の地名が収録されています。 延喜式神名帳 延喜式神名帳は、「官社」に指定された神社の一覧であり、延長5年(927年)に編纂されました。これに記載されている神社(式内社)全2,861社のうち、2,842社の位置情報が「歴史地名辞書データ」に収録されました。なお、比定された位置は、必ずしも編纂当時の位置とは限りません。 旧5万分の1地形図 日本ではじめて精密測量に基づいて作製された5万分の1地形図に含まれる地名252,544件とその緯度・経度が「歴史地名辞書データ」に収録されました。本データの作成に当たっては、国土地理院長の承認を得ています(承認番号 平成30情使、第12号)。対象となった図幅は1,343枚で、明治29年から昭和10年に測量されたものです(一部、例外あり)。なお、緯度・経度は、当時の測地系から世界測地系に変換されています。 これによれば、明治時代以前の地名であることがわかります。
上記でも説明しましたが、これら昔の地名に該当する現在の住所があらかじめ割り振っていますので、過去と現在を地理的につなげるような使い方ができると思います。本モジュールと同じような機能を提供するWebサービスも公開されています。
歴史地名辞書の検索
http://www.eri.u-tokyo.ac.jp/people/ykano/gazetteer/こちらは今昔マップなどの複数の外部サービスと連携してますし、いくつかの地名や位置を検索したい場合はこちらを利用したほうが良いと思います。
本モジュールはすべてローカル環境で検索を行うので、大量の検索したいデータがある場合、高速に処理が行えることが利点の一つで、自身のサービスに組み込みたい場合にも利用しやすいと思います。
住所・地名周りではかなり便利なツールになったと思いますので、是非活用してもらえればと思います。
- 投稿日:2020-09-14T18:42:04+09:00
togglとExmentをAPI連携させて、簡易原価計算的なことをやってみる
どうも、業務改善が趣味な筆者です。
これまでに、MFクラウド請求書APIとExmentを組み合わせて、簡易SFA/CRM的なことをやってみました。
今回は、さらに発展させて、簡易原価計算的なことをやってみたいと思います。
今回の記事で想定する原価計算
- 筆者の業務はサービス業(人件費=原価)
- 時給×3を原価とする
- 受注した見積書の金額が、業務にかけた時間×時給×3を超えると赤字
- 超えなければ黒字
非常にシンプルですが、サービス業なんてどこもこんな感じではないでしょうか。
これをベースに、各案件が赤字になっていないかどうか、黒字であれば、粗利率はどうなのか、というのがわかる原価計算システムを作ってみたいと思います。
toggl is 何?
togglは、工数管理のSaaSサービスです。Qiitaにもタグがあるぐらいには、日本のIT業界で知名度があると思います。
筆者が以前勤めていた企業では、togglを日報の代わりに利用しており、togglさえつけていれば、手書き(やメール・チャット等の)日報報告は不要とされていました。
togglには日報以外の側面もあり、部署やプロジェクト単位での総勤務時間が明らかになります。また、課金プランのみですが、各ユーザーごとに給与単価を設定することもできます。したがって、togglのダッシュボードを見ているだけで、どのプロジェクトがどれぐらい原価使っているかがひと目で分かるわけです。
余談ですが、筆者はこのtogglの各作業に対してタグづけ(企画立案・進行管理・デザイン・静的コーディング・システム組み込み)をし、各工程がどれぐらい時間をとっているのか、どれぐらい給与もらっている人がどれぐらいの時間で仕事を片付けているのかを見る業務をしていました。
ただ、その時はダッシュボードの内容をCSVで書き出してスプレッドシートで加工するという、完全には自動化されていない作業でした。また、会計システムとも連動していないため、最終的には会計システムから抽出した見積書データを手で入力するという残念なものでもありました。
今回は、APIとtogglの対となる集計システムにExmentを採用し、さらにその先にはMFクラウド請求書があるという前提で、原価計算をしてみたいと思います。
Exmentで下準備をする
まず、自分の給与単価を決めます。筆者は副業をしているので、そのプロジェクトを前提に考えますが、もし複数の社員がいても応用できる仕組みを前提として説明します。
自分(社員)の給与単価を設定する
今回はtoggl無課金で利用することを前提としますので、給与単価はExment側に持たせます。どこに持たせようかという話ですが、取りあえずユーザーカスタムテーブルに「給与単価」という列を追加しました。
ここで入力する値は、給与の時給単価×3の値としています。給与額そのまま入れるか、今回のように係数をかけた値を入れるのかどうかは、各自の判断で決めてください。
工数(タイムレコード)が入るカスタムテーブルを作成する
今回は「工数管理」という名前でカスタムテーブルを作成しました。
列名 列のタイプ 作業者 ユーザー 作業開始時刻 日付と時刻 作業終了時刻 日付と時刻 作業時間 整数 案件名 選択肢 (他のテーブルの値一覧から選択) クライアント 選択肢 (他のテーブルの値一覧から選択) 案件名とクライアントは、それぞれ別のカスタムテーブルから選択することとし、リレーションを結んでおきます。
まっさらなtogglアカウントを用意する
今回は記事を書く上でわかりやすいように、新しいtogglアカウントを取得するところから始めます。
togglに初回ログインするとこんな感じです。
ここから、APIの設定を行います。
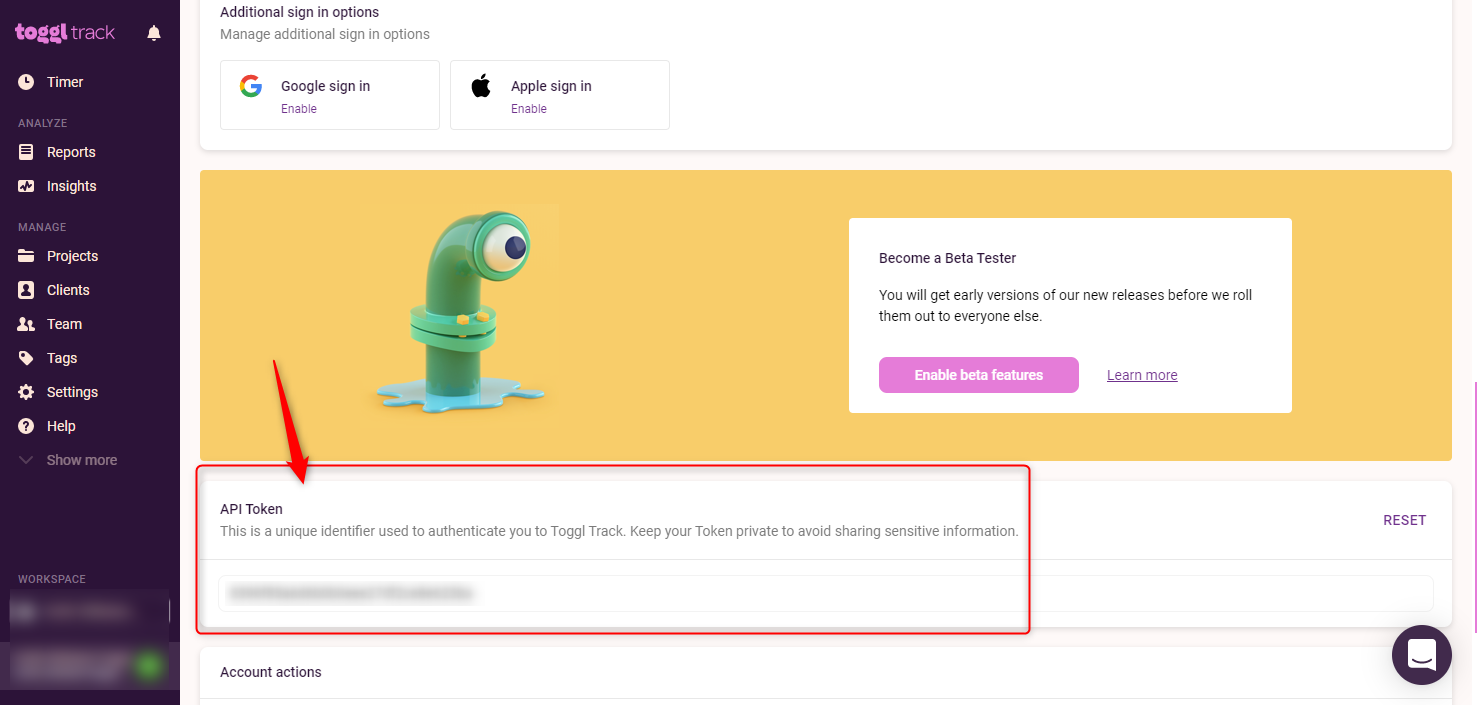
画面左下にある自分のプロフィール画面にアクセスします。開いた画面の下のほうに、APIトークンが表示されているはずです。
このAPIトークンを控えておきます。
API経由でのアクセスをテストしておく
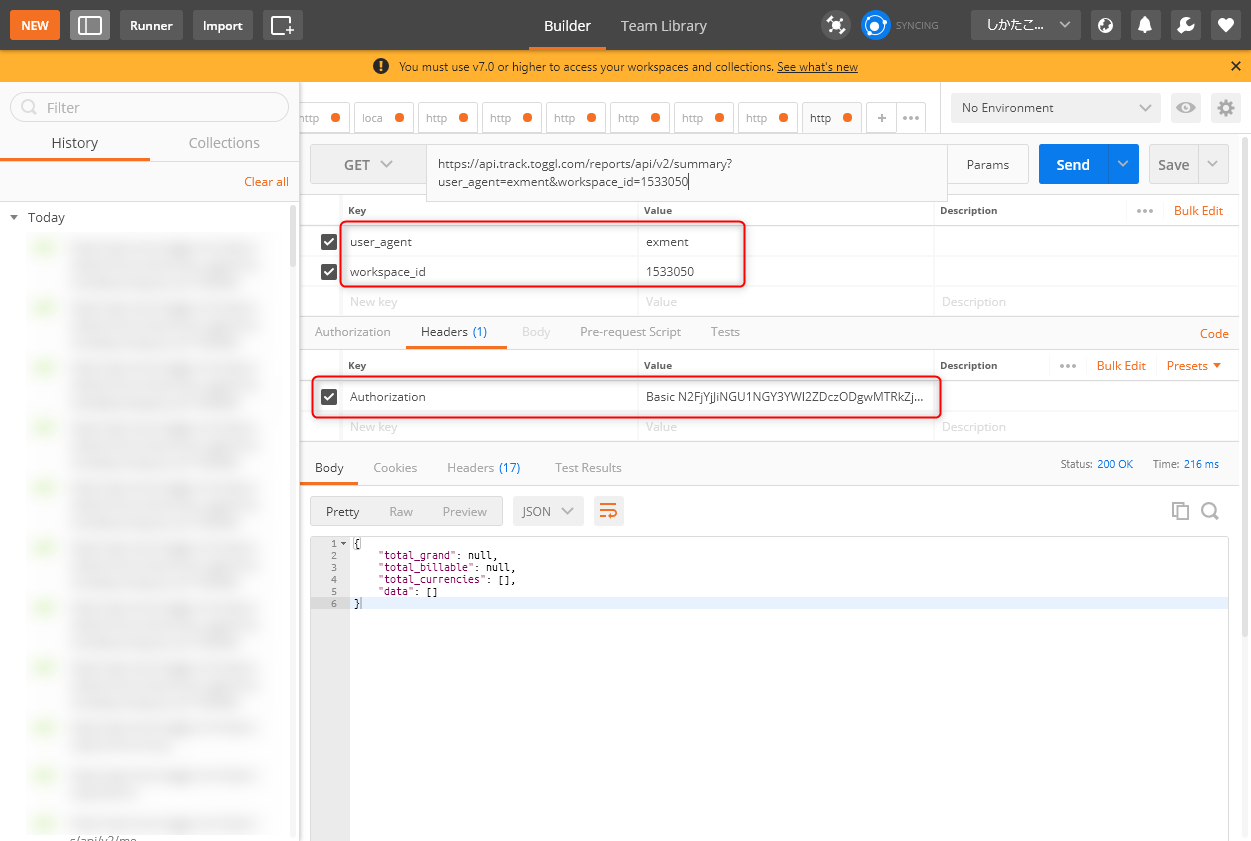
togglはcurlが好きなのか、APIドキュメントでやたらcurlの例を出してくるのですが、個人的にはcurlのオプションが覚えきれないので、Postmanを使用します。
toggl APIの認証はちょっと変わっていて、Basic認証です。HeaderのAuthorizationに、Basic "base64エンコーディングされたtoken文字列:api_token"というヘンテコな認証を掛ける必要があります。そのトークンの使い方合ってんの? っていう。
まあ、いいです。base64エンコーディングが必要なので、こちらのサービスなどを利用して、エンコーディングしましょう。
再度言いますが、「xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx:api_token」(xはトークン文字列)で、base64エンコーディングです。
エンコーディングができたら、Postmanに設定してテストします。
togglのAPIは2系統に分かれていて、データのCRUDをするToggl APIと、Readを中心にするReport APIに分かれています。今回はとりあえず、Read APIのエンドポイントを叩いています。エンドポイントは、こちらのドキュメントを参照してください。
また、パラメータは2つ必須になっています。
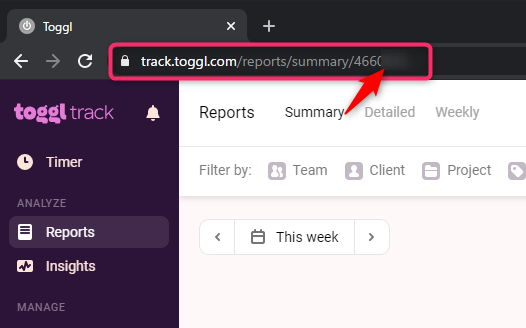
user_agentは、今回作るアプリの名前です。適当につけてOKです。workspace_idは、Togglにログインして設定するWorkspaceの番号です。URLから採取できます。
とりあえず上図のように設定して、レスポンスが以下のように帰ってこれば成功です。
{ "total_grand": null, "total_billable": null, "total_currencies": [], "data": [] }Toggl API経由で、顧客情報をExmentから登録する
まず、まっさらのTogglに顧客情報を登録します。Togglで登録できるか、一度テストしておきましょう。Postmanもいいですが、実際にコードを書いてテストします。筆者はJavaScriptに慣れ親しんでいるため、今回もNode.jsで書きます。
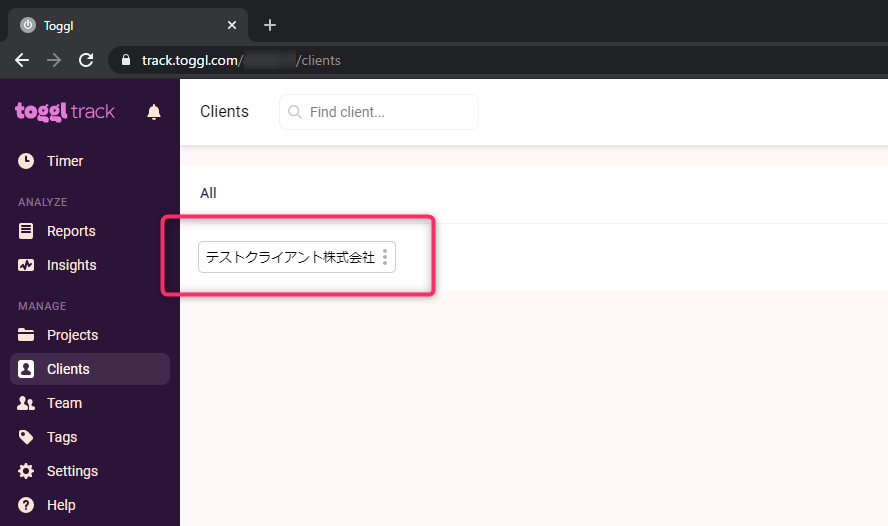
set-clients.jsconst axios = require('axios') //create clients createClientsEndpoint = 'https://api.track.toggl.com/api/v8/clients' const payload = { client: { name: 'テストクライアント株式会社', wid: '00000000' //自分のworkspaceidを設定 } } axios.post(createClientsEndpoint, payload, { headers: { 'Authorization': 'Basic xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx' //base64エンコーディングされたAPIトークン } }) .then(res => { console.log(res) }) .catch(err => { console.log(err) })上記node.jsファイルを実行して、以下のレスポンスが帰ってこれば成功です。
{ "id":00000000, "wid":0000000, "name":"テストクライアント株式会社" }また、togglのClientsページを確認して、クライアントが登録されていることを確認しましょう。
それでは、いよいよ、Exmentから顧客データを全部引っ張り出して、togglに突っ込むプログラムを書きます。
set-clients-toggl.jsconst axios = require('axios') const fs = require('fs') const _ = require('lodash') // get clients data clientDataEndpoint = 'https://example.com/api/data/clients' const exmentToken = fs.readFileSync('./exment_tokens.txt') ;(async () => { let clients = await axios.get(clientDataEndpoint, { headers: { 'Authorization': 'Bearer ' + JSON.parse(exmentToken).access_token } }) .then(res => { // console.log(res.data.data) return res.data.data }) .catch(err => { console.log(err) }) clients = _.map(clients, 'value') clients = _.map(clients, 'name') //create clients createClientsEndpoint = 'https://api.track.toggl.com/api/v8/clients' clients.forEach(item => { const payload = { client: { name: item, wid: '4660619' } } axios.post(createClientsEndpoint, payload, { headers: { 'Authorization': 'Basic xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx' } }) .then(res => { console.log(res) }) .catch(err => { console.log(err) }) }) })()Exmentのトークンは、外部ファイルから引っ張ってきています。多少冗長な感じもしますが、一旦1回きりの処理ということでお許しください。
無事に、全クライアントが挿入されました。
取引停止はいらなさそうですね。後で削除しておきます。
Toggl API経由で、プロジェクト(案件)情報をExmentから登録する
似た要領で、今度はExmentから案件の情報を抽出してTogglに登録します。受注した案件のみ登録するようにしましょう。
取りあえず、抽出までのロジックはこんな感じです。
set-projects-toggl.jsconst axios = require('axios') const fs = require('fs') const projectsDataEndpoint = 'https://example.com/api/data/projects' const exmentToken = fs.readFileSync('./exment_tokens.txt') ;(async () => { let clients = await axios.get(projectsDataEndpoint, { headers: { 'Authorization': 'Bearer ' + JSON.parse(exmentToken).access_token } }) .then(res => { console.log(res.data.data) return res.data.data }) .catch(err => { console.log(err) }) })()とりあえず一旦は案件情報全部取れましたね。
後考えないといけないことは、ここから
- Togglに登録する形にオブジェクトを整形する
- Togglのクライアント番号と、Exmentのクライアント番号を紐付ける
の2つのロジックが必要です。
以下、双方のクライアント番号紐づけのロジックです
set-projects-toggl.jslet exmentClientsArray = [] exmentClients.forEach(item => { exmentClientsArray.push({ id: item.id, name: item.value.name }) }) // console.log(exmentClientsArray) let togglClients = await axios.get(clientsDataTogglEndpoint, { headers: { 'Authorization': 'Basic xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx' } }) .then(res => { return res.data }) let togglClientsArray = [] togglClients.forEach(item => { togglClientsArray.push({ id: item.id, name: item.name }) }) // console.log(togglClientsArray) let symmetricClientsId = [] for(item of togglClientsArray) { const exmentId = _.find(exmentClientsArray, { name: item.name }).id // console.log(exmentId) symmetricClientsId.push({ togglId: item.id, exmentId: exmentId }) } console.log(symmetricClientsId)それぞれ、名前とidのオブジェクトが入った配列を作成し、lodashのfindメソッドで名前を検索して、相対するid同士をオブジェクトにし、さらに配列にしています。(エンドポイント等は冒頭で変数宣言していますので、省略しています。適宜読み替えてください)
console.logの結果はこうです。
[ { togglId: 49984659, exmentId: 7 }, { togglId: 49984658, exmentId: 8 }, { togglId: 49984657, exmentId: 6 }, { togglId: 49984656, exmentId: 3 }, { togglId: 49984655, exmentId: 5 }, { togglId: 49984654, exmentId: 4 }, { togglId: 49984653, exmentId: 2 }, { togglId: 49984652, exmentId: 1 } ]次に、Togglへ突っ込む用の成形です。
set-projects-toggl.jsprojects = _.map(projects, 'value') projects = _.filter(projects, { reliability: '6' }) // フラグ6、つまり受注のみ抽出 let projectsArray = [] projects.forEach(item => { const name = item.name const exmentClientId = item.client projectsArray.push({ name: name, client: exmentClientId }) }) let payload = [] projectsArray.forEach(item => { const name = item.name const cid = _.find(symmetricClientsId, { exmentId: Number(item.client) }).togglId payload.push({ project: { name: name, cid: cid, wid: 0000000 } }) }) console.log(payload)これで、console.logの結果は
[ { name: 'xxxxxx 特設ページ、製品ページ制作', cid: 49984654, wid: 0000000 }, { name: 'xxxxx 公式サイト制作', cid: 49984659, wid: '4660619' }, { name: 'xxxxxx コーディングデザイン', cid: 49984659, wid: 0000000 }, ]こんな感じです。
後は回しておしまいなので、ここでいったん全部の処理を張り付けておきます。
set-projects-toggl.jsconst axios = require('axios') const fs = require('fs') const _ = require('lodash') const clientsDataEndpoint = 'https://example.com/api/data/clients' const clientsDataTogglEndpoint = 'https://api.track.toggl.com/api/v8/workspaces/0000000/clients' const projectsDataEndpoint = 'https://example.com/api/data/projects' const projectsCreateEndpoint = 'https://api.track.toggl.com/api/v8/projects' const exmentToken = fs.readFileSync('./exment_tokens.txt') ;(async () => { let projects = await axios.get(projectsDataEndpoint, { headers: { 'Authorization': 'Bearer ' + JSON.parse(exmentToken).access_token } }) .then(res => { // console.log(res.data.data) return res.data.data }) .catch(err => { console.log(err) }) let exmentClients = await axios.get(clientsDataEndpoint, { headers: { 'Authorization': 'Bearer ' + JSON.parse(exmentToken).access_token } }) .then(res => { return res.data.data }) let exmentClientsArray = [] exmentClients.forEach(item => { exmentClientsArray.push({ id: item.id, name: item.value.name }) }) // console.log(exmentClientsArray) let togglClients = await axios.get(clientsDataTogglEndpoint, { headers: { 'Authorization': 'Basic xxxxxxxxxxxxxxxxx' } }) .then(res => { return res.data }) let togglClientsArray = [] togglClients.forEach(item => { togglClientsArray.push({ id: item.id, name: item.name }) }) // console.log(togglClientsArray) let symmetricClientsId = [] for(item of togglClientsArray) { const exmentId = _.find(exmentClientsArray, { name: item.name }).id // console.log(exmentId) symmetricClientsId.push({ togglId: item.id, exmentId: exmentId }) } // console.log(symmetricClientsId) projects = _.map(projects, 'value') projects = _.filter(projects, { reliability: '6' }) // フラグ6、つまり受注のみ抽出 let projectsArray = [] projects.forEach(item => { const name = item.name const exmentClientId = item.client projectsArray.push({ name: name, client: exmentClientId }) }) let payload = [] projectsArray.forEach(item => { const name = item.name const cid = _.find(symmetricClientsId, { exmentId: Number(item.client) }).togglId payload.push({ project: { name: name, cid: cid, wid: 0000000 } }) }) // console.log(payload) payload.forEach(item => { axios.post(projectsCreateEndpoint, item, { headers: { 'Authorization': 'Basic xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx' } }) .then(res => { console.log(res) }) .catch(err => { console.log(err) }) }) })()TogglのProjectsのページを確認して、プロジェクト(案件)情報がきちんと差し込まれたことを確認します。
はい、案件が全部挿入され、クライアントとも紐づいていますね。筆者は副業なのでプロジェクト数もささやかなものですが、実際の企業では大量のデータが挿入され、プログラムで挿入するメリットが生かせると思います。
Togglをつけることを習慣化する
さて、今回はまっさらなTogglからスタートしているので、Togglをつけることを習慣化しないといけませんね。
Togglには、Chrome拡張やGmailとの連動拡張、スマホアプリにデスクトップアプリと、入力の選択肢はたくさんあります。15分以上かかる作業は、必ずTogglにつけるクセをつけるといいでしょう。
Togglは作業開始時にスタートボタンを押し、終了時にストップボタンを押す方式と、後からまとめて作業時間を登録する2方式でデータを登録できます。お好みのほうでどうぞ(筆者は、作業ごとにボタンを押す方式が好きでした)
Togglに工数データ挿入する
とはいえ、この記事も進めないといけないので、Togglにデータを挿入します。覚えている範囲で、過去、何月何日の何時ぐらいから作業したかなあ、ということを思い出しながら入力しましょう。この作業はToggl管理画面から行います。
一般の企業では、複数人で入力することになりますから、一気にデータが溜まっていきます。みんなの作業が一旦可視化されるので、面白いですよ。
ここまでくれば、利益判断できるフェーズまであと1歩です!
Togglに入力した工数データをAPI経由で取得し、ExmentにAPI経由で突っ込む
Togglに管理画面から工数データの入力が出来たら、今度はAPI経由で取得できるか確認してみましょう。
ソースコードは以下です。
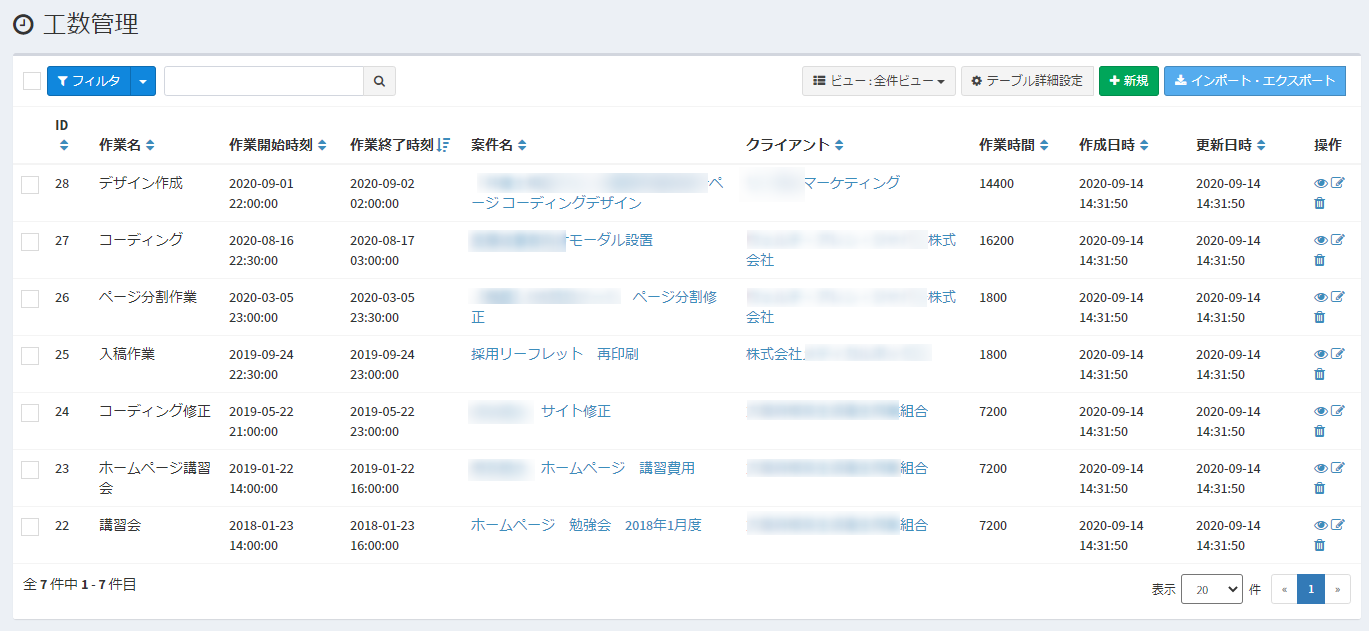
set-toggl-to-exment.jsconst axios = require('axios') //工数データを取得 const endpoint = 'https://api.track.toggl.com/api/v8/time_entries' const start_date_param = encodeURIComponent('2017-01-01T00:00:00+09:00') const end_date_param = encodeURIComponent('2020-09-14T00:00:00+09:00') const query = `?start_date=${start_date_param}&end_date=${end_date_param}` axios.get(endpoint + query, { headers: { 'Authorization': 'Basic xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx' } }) .then(res => { console.log(res.data) }) .catch(err => { console.error(err) })正しく取得できれば、レスポンスは以下のような感じになっているはずです。
[ { id: 1688770474, guid: '15300aa902507be5d98a685ea9b9c121', wid: xxxxxxx, pid: 163437641, billable: false, start: '2019-01-22T05:00:00+00:00', stop: '2019-01-22T07:00:00+00:00', duration: 7200, description: 'ホームページ講習会', duronly: false, at: '2020-09-11T09:56:05+00:00', uid: 6121167 }, { id: 1688769563, guid: '21ff64bea50aeb0f7c12b4d5178c4ba2', wid: xxxxxxx, pid: 163437643, billable: false, start: '2019-05-22T12:00:00+00:00', stop: '2019-05-22T14:00:00+00:00', duration: 7200, description: 'コーディング修正', duronly: false, at: '2020-09-11T09:55:24+00:00', uid: 6121167 }, { id: 1690456743, guid: '3b297fdb6d01b00efd13ee46306b5121', wid: xxxxxxx, pid: 163437646, billable: false, start: '2019-09-24T13:30:00+00:00', stop: '2019-09-24T14:00:00+00:00', duration: 1800, description: '入稿作業', duronly: false, at: '2020-09-14T02:10:27+00:00', uid: 6121167 }, ]実際にはもっと工数データが続きましたが、とりあえず3件だけ紹介しました。
このデータをExmentのAPI形式に整形して、登録します。
最終的なソースコードは以下です。
set-toggl-to-exment.jsconst fs = require('fs') const axios = require('axios') const _ = require('lodash') const moment = require('moment') //工数データを取得 const exmentToken = JSON.parse(fs.readFileSync('./exment_tokens.txt')).access_token const togglEndpoint = 'https://api.track.toggl.com/api/v8/time_entries' const start_date_param = encodeURIComponent('2017-01-01T00:00:00+09:00') const end_date_param = encodeURIComponent('2020-09-14T00:00:00+09:00') const query = `?start_date=${start_date_param}&end_date=${end_date_param}` const exmentEndpoit = 'https://example.com/api/data/manhours' const togglClientsEndpoint = 'https://api.track.toggl.com/api/v8/workspaces/4660619/clients' const exmentClientsEndpoint = 'https://example.com/api/data/clients' const togglProjectsEndpoint = 'https://api.track.toggl.com/api/v8/workspaces/4660619/projects' const exmentProjectsEndpoint = 'https://example.com/api/data/projects/query-column?q=reliability eq 6' const exmentManhoursEndpoint = 'https://example.com/api/data/manhours/' ;(async() => { let manhours = await axios.get(togglEndpoint + query, { headers: { 'Authorization': 'Basic xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx' } }) .then(res => { console.log(res.data) return res.data }) .catch(err => { console.error(err) }) let togglClients = await axios.get(togglClientsEndpoint, { headers: { 'Authorization': 'Basic xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx' } }) .then(res => { // console.log(res.data) return res.data }) .catch(err => { console.err(err) }) let exmentClients = await axios.get(exmentClientsEndpoint, { headers: { 'Authorization': 'Bearer ' + exmentToken } }) .then(res => { // console.log(res.data) return res.data.data }) .catch(err => { console.err(err) }) let clientsArray = [] for(item of exmentClients) { const name = item.value.name const exmentId = item.id clientsArray.push({ name: name, exmentId: exmentId }) } for(item of clientsArray) { _.remove(clientsArray, obj => obj.name === '取引停止') const togglId = _.find(togglClients, { name: item.name }).id // console.log(togglId) if(togglId) { item.togglId = togglId } } // TogglとExmentの案件情報を取得 let togglProjects = await axios.get(togglProjectsEndpoint, { headers: { 'Authorization': 'Basic xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx' } }) .then(res => { // console.log(res.data) return res.data }) .catch(err => { console.error(err) }) let exmentProjects = await axios.get(exmentProjectsEndpoint, { headers: { 'Authorization': 'Bearer ' + exmentToken } }) .then(res => { // console.log(res.data.data) return res.data.data }) .catch(err => { console.error(err) }) let projectsArray = [] for(item of exmentProjects) { const name = item.value.name const exmentId = item.id const togglId = _.find(togglProjects, { name: item.value.name }).id projectsArray.push({ name: name, exmentId: exmentId, togglId: togglId, exmentClientId: Number(item.value.client) }) } let payload = [] manhours.forEach(item => { payload.push({ value: { work_title: item.description, user: 1, // 今回は自分なのでハードコーディング。複数名いる場合は、ユーザーの紐づけデータも作ってください start_at: String(moment(item.start).format('YYYY-MM-DD HH:mm:ss')), end_at: String(moment(item.stop).format('YYYY-MM-DD HH:mm:ss')), duration: item.duration, project: String(_.find(projectsArray, { togglId: item.pid }).exmentId), client: String(_.find(projectsArray, { togglId: item.pid }).exmentClientId) } }) }) // console.log(payload) await axios.post(exmentManhoursEndpoint, { data: payload }, { headers: { 'Authorization': 'Bearer ' + exmentToken } }) .then(res => { // console.log(res.data) }) .catch(err => { console.error(err.response.data.errors) }) })()これで、無事データを投入することができました。
以下のようになっていれば成功です。
ExmentのAPIからデータを引き出し、フロントでグラフ化する
Exmentの計算機能で予実管理できればいいのですが、残念ながらそこまで高度な計算式はExmentで作れません。
そこで、フロントからAPIを読み出し、各データからグラフ化してみます。
本来であれば、何がしかのフロントフレームワークを使うところで、筆者はVueに慣れているので、Vue-Cliで環境を作ろうかとも思ったのですが、Qiitaの記事のためだけにVueSFCの環境を作るのも負荷大きいなと思ったので、今回はミニマムで行きます。
npm i express pugHTTPサーバーを立ててHTMLをサーブするために、Expressをインストールします。筆者はpugに慣れていて、viewはpugを使いたいので、pugもインストールします。
フロントをレンダリングするNode.jsは以下です。
app.jsconst express = require('express') const app = express() const fs = require('fs') const axios = require('axios') const _ = require('lodash') const moment = require('moment') require('moment-duration-format') app.set('view engine', 'pug') // Pugの設定 let graph = '' ;(async () => { const exmentToken = JSON.parse(await fs.readFileSync('./exment_tokens.txt')).access_token let projectsData = await axios.get('https://example.com/api/data/projects/query-column?q=reliability eq 6', { headers: { 'Authorization': 'Bearer ' + exmentToken } }) .then(res => { return res.data.data }) .catch(err => { console.error(err) }) let clientsData = await axios.get('https://example.com/api/data/clients', { headers: { 'Authorization': 'Bearer ' + exmentToken } }) .then(res => { return res.data.data }) .catch(err => { console.error(err) }) let clientsArray = [] clientsData.forEach(item => { clientsArray.push({ id: item.id, name: item.value.name }) }) let manhoursData = await axios.get('https://example.com/api/data/manhours', { headers: { 'Authorization': 'Bearer ' + exmentToken } }) .then(res => { return res.data.data }) .catch(err => { console.error(err) }) const user = await axios.get('https://example.com/api/data/user/query-column?q=id eq 1', { // 自分の給与単価を抽出するため、IDはハードコーディング // 複数ユーザーがいる場合は、別途給与テーブルのオブジェクトを作る必要あり headers: { 'Authorization': 'Bearer ' + exmentToken } }) .then(res => { return res.data.data }) .catch(err => { console.error(err) }) const saraly = user[0].value.saraly // console.log(saraly) let projectsArray = [] projectsData.forEach(item => { const id = item.id const title = item.value.name const amount = item.value.amount const client = _.find(clientsArray, { id: Number(item.value.client) }).name const manhour = () => { let total = _.filter(_.map(manhoursData, 'value'), { project: String(item.id) }) // console.log(total) total = _.sumBy(total, 'duration') return moment.duration(total, 's').asHours() * saraly } projectsArray.push({ id: id, title: title, client: client, amount: Number(amount), manhourTotal: manhour() }) }) // console.log(manhoursData) // console.log(projectsArray) let graphProjectName = ['案件名'] for(item of projectsArray) { graphProjectName.push(item.title + '/' + item.client) } let graphAmounts = ['受注金額'] for(item of projectsArray) { graphAmounts.push(item.amount) } let graphManhours = ['制作原価'] for(item of projectsArray) { graphManhours.push(item.manhourTotal) } const graphData = { types: { '受注金額': 'bar', '制作原価': 'bar' }, columns: [ graphAmounts, graphManhours, graphProjectName, ], colors: { '受注金額': '#f44336', '制作原価': '#03a9f4' }, x: '案件名' } console.log(graphData) graph = JSON.stringify(graphData) })() app.get('/', (req, res) => { res.render('index', { graph }) }) app.listen(3000);案件、クライアント、工数、ユーザーをそれぞれAPIから取得してコネコネしています。フロントでグラフライブラリをc3.jsを使う前提にしているので、c3.jsのデータフォーマットに整形しています。
最後に、フロントのコードです。なんてことはないですね。Expressで、バックエンドでコネコネしたデータを露出させて、c3.jsで読み込んでいます。d3.jsとc3.jsは、ご覧の通りCDNから読み込んでいます。
ちなみに、c3のバージョンが0.7.20は、d3.jsのバージョンが5系でないと通りませんでした。バージョンの相性が悪く、小1位時間ぐらいハマりました… 他のグラフライブラリのほうが良かったかも…
index.pug<!DOCTYPE html> html(lang="ja") head meta(charset="UTF-8") meta(name="viewport", content="width=device-width, initial-scale=1.0") title 制作原価採算分岐 . <link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/c3/0.7.20/c3.min.css" integrity="sha512-cznfNokevSG7QPA5dZepud8taylLdvgr0lDqw/FEZIhluFsSwyvS81CMnRdrNSKwbsmc43LtRd2/WMQV+Z85AQ==" crossorigin="anonymous" /> body h1 制作原価採算分岐 p: strong 赤字に注意! #chart . <script src="https://cdnjs.cloudflare.com/ajax/libs/d3/5.15.1/d3.min.js" integrity="sha512-VcfmBa1zrzVT5htmBM63lMjDtqe4SAcxAlVLpQmBpUoO9beX5iNTKLGRWDuJ5F37jJZotqq65u00EZSVhJuikw==" crossorigin="anonymous"></script> <script src="https://cdnjs.cloudflare.com/ajax/libs/c3/0.7.20/c3.min.js" integrity="sha512-+IpCthlNahOuERYUSnKFjzjdKXIbJ/7Dd6xvUp+7bEw0Jp2dg6tluyxLs+zq9BMzZgrLv8886T4cBSqnKiVgUw==" crossorigin="anonymous"></script> script. var chart = c3.generate({ bindto: '#chart', size: { height: 800, width: 1200, }, padding: { top: 20, right: 50, bottom: 20, left: 70 }, data: !{ graph }, axis: { rotated: true, x: { type: 'category', }, y: { tick: { format: function (d) { return new Intl.NumberFormat("ja").format(d); }書式 }, } }, legend: { position: 'right' }, });結果、このようになりました。
X軸のラベルが不自然ですが、まあ、マウスオーバーすれば案件名が分かるということで、ここはひとつ次回以降の課題としておきます。
このグラフでは、3つ目の案件だけ、わずかに赤字になっています。たかだか500円程度の売上ではありますが、気を付けないといけないですね。
また、これが企業であれば、案件担当者に対してアラートをかけたりすることもできます。日ごろからこのグラフを見て、チームの進捗と予算の進捗が見合っているかを睨めっこすることも大切ですね。
まとめ
いかがでしたでしょうか。Togglの使い方と、Exmentの連携をご理解いただけたかと思います。
APIを叩くので、どうしてもSQLを発行したりする直感的な操作にはならず、lodashのお世話になることも多いのですが、力業でねじ伏せる感じになるのがAPIマッシュアップ流ですね。
今回、最終的なグラフデータを出力するまでNode.jsでやりましたが、React/Vue/Angularなどのフレームワークから直接APIを叩いてグラフを生成するのもいいかもしれません。
また、今回Exmentにインポートをしましたが、この処理だけするのであれば、NoSQLなデータストアを使ったり、Google スプレッドシート + GASでもいいかもしれません。筆者はExmentを採算管理だけでなく、中小企業の基幹システムちっくに使えないかと考えているので、あえてExmentを選びました。もう少しExment側で計算の仕組みがリッチになると良いのですが…
とはいえ、これは試験的なものなので、今回は1回きりのデータインポート前提となりました。これをブラッシュアップして、定期的にデータを取り込んでアップデートしたり新規追加をする前提の処理にすれば、リアルタイムに採算分岐点を追うこともできます。
PMやディレクターから「こんな安い案件に、どんだけ時間かけとるんや!」って怒られる前に、これを見てテキパキ仕事を終わらせたいものですね。


- 投稿日:2020-09-14T18:36:25+09:00
さくらvpsでnode.jsでSocket.ioする
Node.jsインストール
さくらVPSでNode.jsが動く環境を作ってみた - Qiita
curl -L git.io/nodebrew | perl - setup echo 'export PATH=$HOME/.nodebrew/current/bin:$PATH' >> ~/.bash_profile source ~/.bash_profile nodebrew install-binary stable nodebrew use stable node -v v14.10.1Socket.ioインストール
npm install socket.io npm -v 6.14.8Node.jsでHTTPSサーバ(https://〜)
node.jsによるHTTPSサーバの作り方 - Node.js/JavaScript入門
var https = require('https'); var fs = require('fs'); var ssl_server_key = 'server_key.pem'; var ssl_server_crt = 'server_crt.pem'; var port = 8443; var options = { key: fs.readFileSync(ssl_server_key), cert: fs.readFileSync(ssl_server_crt) };Let's EncryptのSSL証明書などの場所 - nwtgck / Ryo Ota
証明書: /etc/letsencrypt/live/ドメイン名/fullchain.pem 秘密鍵: /etc/letsencrypt/live/ドメイン名/privkey.pem※サーバを立ち上げるときは
sudo node saverとしないと証明書等が読み込めないので注意
テスト用のコンテンツ
Node.jsとSocket.IOによるPCとスマホブラウザのペアリングデモ - ICS MEDIA
ここのソースを丸ごといただいてごにょごにょと・・・サーバとクライントでポートが違う場合
<script src="https://planet-ape.net:5000/socket.io/socket.io.js"></script>socket.io.jsを読み込むときにポート指定
// サーバーに接続 //var socket = io.connect(location.origin); var socket = io.connect("https://planet-ape.net:5000");connectするときもポート指定
- 投稿日:2020-09-14T15:57:54+09:00
Sequelizeでdevelopment/production用のseedを分けたい
はじめに
node.jsでサーバサイドの処理を作成するときにORMとして、Sequelizeを利用しています。
その際に、開発用と本番用でseedを分けて管理したくなったので、それについて書かせていただきます。
どのようなケースか?
例えば、以下のようなテーブルがあった場合、
id, request_url開発用にseedで作成するデータは、このようになります。
1, http://localhost:3000/user 2, http://localhost:3000/login 3, http://localhost:3000/companyしかし、これは開発用のデータのため、本番でこのseedを実行しても、うまくアプリケーションが動かないです。
そのため、本番用のseedでは、ドメインを指定して、データを作成したい。
1, https://api.subroq.com/user 2, https://api.subroq.com/login 3, https://api.subroq.com/companyこのようなケースです。
どのように対応するのか?
対応方法としては、seedを分けて、実行時にフォルダを指定します。
フォルダ構成としては、こんな感じ。
seeders/ ├── development │ ├── 20200808080637-users.js │ ├── 20200808101006-categories.js │ ├── 20200808101050-questions.js │ └── 20200911180200-validations.js └── production ├── 20200808101006-categories.js ├── 20200808101050-questions.js └── 20200911180200-validations.jsseedを実行する際にフォルダの指定をすれば、うまいこと動きます。
開発用
NODE_ENV="development" node_modules/.bin/sequelize db:seed:all --seeders-path "seeders/production"本番用
NODE_ENV="production" node_modules/.bin/sequelize db:seed:all --seeders-path "seeders/production"最後に
seedの管理は非常に大事で、これを怠ったことで、環境構築ができなくなったり、難しくなったりすることが多々あります。
それを防ぐためにも、利用しているORMを理解して、それに合わせた管理をするのが大事だと思います。Subroqは、企業のフリーランスエンジニアの採用や活用を支援するサービスを提供しております。また、フリーランスエンジニア向けの記事も書いておりますので、興味ある方は是非、ご一読いただければと思います。
- 投稿日:2020-09-14T15:53:06+09:00
MongoDBを扱うExpressアプリをAWS Lambdaに乗せてサーバーレスにする
はじめに
AWS Lambdaによってバックエンドアプリをサーバーレスにすると、可用性やコスト、スケーリングの面で利点があります。
DBとやり取りするバックエンドアプリの場合、かつてはDBコネクションの所要時間が懸念されたり、またそもそもLambda全般に言えるコールドスタートの遅さが課題でした。しかし最近(2020年頃)ではこれらの課題はかなり解消しており、バックエンドアプリをサーバーレスにすることが随分と現実的になっています。
この記事では、DBがMongoDBであり、Expressで書かれたバックエンドアプリについて、Lambdaによるサーバーレス化の流れを紹介します。作成したLambda関数は、API Gatewayを通して公開する想定とします。
MongoDBへのコネクションを再利用する
DBコネクションの課題への対処法は、MongoDBの公式ドキュメントにポイントがまとめられています。
Best Practices Connecting from AWS Lambda
ポイントは2つです。
DBコネクションの変数をLambdaのハンドラの外側に置く
1つ目のポイントは、DBコネクション(を含んだ)部分の変数を、Lambdaのハンドラ関数の外側に定義することです。ハンドラの外側で定義した変数は、同一コンテナ上で実行される複数回のLambda呼び出しに渡って再利用されます。キャッシュみたいなものです。そのため、コネクションを使い回すことができます。
MongoDBのドキュメントに詳しいサンプルコードが載っていますが、概念的には以下のような要領です。
こんな感じlet cachedDb = null; // handlerの外側に定義しておく。 module.exports.handler = (event, context, callback) => { if (!cachedDb) { cachedDb = // ここでDBコネクションを作る。 } // 以下略 };上記の例ではDBコネクションそのもの(
cachedDb)を変数としましたが、実際にはDBコネクションを内包したExpressのappを変数にすることになるかもしれません。その方が、appを作る処理を毎回しなくて済むはずです(コネクション作成の所要時間に比べれば微々たる節約になりそうですが)。ただし、この再利用が効くのは同一コンテナ上でLambda関数が実行された場合だけです。同時にたくさんのLambda呼び出しが来ると、それに対応するために新たなコンテナの作成などが行われます(コールドスタート)。新しく作られたコンテナの初回呼び出しにおいては再利用が効かず、新たなDBコネクション作成が必要となります。
callbackWaitsForEmptyEventLoopをfalseにする
2つ目のポイントは、ハンドラ関数の中で
context.callbackWaitsForEmptyEventLoopという設定をfalseにすることです。これの詳しい説明はMongoDBのドキュメントに載っているのですが、ともかく素直に従ってfalseにしておきます。こんな感じ// 前略 module.exports.handler = (event, context, callback) => { context.callbackWaitsForEmptyEventLoop = false; // これ // 以下略 };AWS Serverless Expressを使って、ExpressアプリをAPI Gatewayに「Lambdaプロキシ統合」する
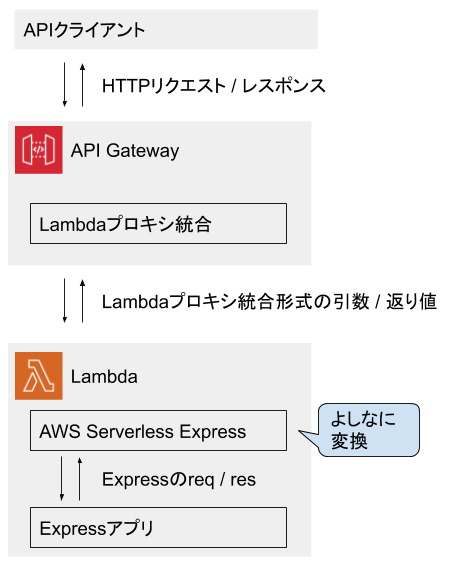
Lambdaの前段にAPI Gatewayを置いて公開する形は定番パターンの一つです。ここで、LambdaとAPI Gatewayを繋げる際のシンプルな手段が「Lambdaプロキシ統合」です。これは平たく言うと、API GatewayがLambda関数に要求するI/F仕様みたいなものです。
Lambdaプロキシ統合は手段の一つですので必ずしもこれを使う必要はないのですが、便利なのでおすすめです。詳しくは、以下の記事が参考になります。
API Gateway + Lambda プロキシ結合の使用有無による違い
Expressアプリを扱う際には、ここでAWS Serverless Expressというライブラリが使えます。このライブラリを使うと、Lambda上で動かすExpressアプリをよしなにLambdaプロキシ統合のルールに合わせてくれます。イメージとしては、下図のような変換役です。
AWS Serverless Expressのおかげで、Expressアプリ開発者はLambda統合プロキシの仕様を意識する必要がなくなります。普段扱っている
appを、Lambdaにぽんと載せられるようになります。AWS Serverless Expressの使い方は、GitHubにあるREADMEに従えばよいだけです。ただし注意点として、Lambdaのハンドラ関数をasyncにしたい場合は、こちらの使い方を参照してください。
ここまでを踏まえたハンドラ関数の実装例
MongoDBのコネクション再利用のテクニックと、AWS Serverless Expressを交えて、ハンドラ関数実装の具体例を載せておきます。TypeScriptで書いた例です。
import { Handler } from "aws-lambda"; import * as awsServerlessExpress from "aws-serverless-express"; // これは何らかの自前の実装。 // この中で、MongoDBへのコネクション作成なども行っているという想定。よってasync関数。 import { createAppAsync } from "./app"; // createServerを呼んだ最終結果を代入しておくための変数を、handlerの外側で定義しておく。 let server: ReturnType<typeof awsServerlessExpress.createServer>; export const handler: Handler = async (event, context) => { // handlerをasyncにした例 context.callbackWaitsForEmptyEventLoop = false; // セオリー通りにfalse if (!server) { // Lambdaがコールドスタートしたときは、このif文の中に入る。 const app = await createAppAsync(); // MongoDBに接続しつつ、Expressのappを作って・・・ server = awsServerlessExpress.createServer(app); // AWS Serverless Expressに渡す。 } // appをAWS Serverless Expressに渡したので、あとはよしなにやってもらうだけ。 return awsServerlessExpress.proxy(server, event, context, "PROMISE").promise; // 上記は、handlerがasyncの場合の呼び方。 // 4番目の引数 "PROMISE" をつけたり、末尾に .promise をつけたりする。 };実装ができたら、コードをLambdaにデプロイしたり、API GatewayのLambdaプロキシ統合の設定をしたりして、APIとして公開しましょう。このあたりの詳細は、この記事では割愛します。
コールドスタートの問題も、最近は許容範囲内になってきた
ここまで、MongoDBへのコネクションを再利用したりして、Lambda関数を実行するコンテナが再利用されるとき(ウォームスタート)のパフォーマンス効率化が図れました。
とはいえ、少なくとも初回の呼び出し時はコールドスタートになります。コールドスタートの方が遅くなりますが、Lambdaそのものの進歩によって、最近(2020年)ではかなり改善されているようです。
試しに自分で作ったLambda関数を実行したところ、コールドスタートとウォームスタートの差は1〜2秒くらいで、現実的に十分許容できる印象です。先ほどのMongoDBの公式ドキュメントにおいても、通常1秒以内と言われていました(参照)。
コールドスタートに関する近況については、以下の記事が参考になります。VPC Lambda(通常と違って、自分のVPC内で実行するLambda)の場合のオーバーヘッドも改善されていることや、Provisioned Concurrencyによってお金の力でコールドスタート頻度を下げられること(自前の暖機運転が不要になること)も触れられています。
まとめ
MongoDBにアクセスするExpressアプリを、LambdaとAPI Gatewayによってサーバーレスにする流れを紹介しました。ポイントは以下の通りです。
- ウォームスタート時に再利用したい変数をハンドラ関数の外側に定義したり、callbackWaitsForEmptyEventLoopをfalseにすることで、DBコネクションを再利用する。
- AWS Serverless Expressを使うと、ExpressアプリをLambdaプロキシ統合の仕組みに簡単に従わせられる。LambdaとAPI Gatewayを簡単に繋げられる。
- 2019年頃からLambdaが根本的に進歩しており、コールドスタートの問題も許容範囲内になっている。
- 投稿日:2020-09-14T10:48:10+09:00
【nvm-windows】ディレクトリ毎に Node.js のバージョンを自動で切り替える
functions などを書いていると、Node.js のバージョンを切り替えたいことがありますよね。手動で
nvm useするのも面倒なので自動化しましょう。nvm のインストールについては割愛します。
環境
- Windows 10 Pro
- Git Bash
- nvm 1.1.7
.nvmrc
バージョンを切り替えたいディレクトリに
.nvmrcを作成し、nvm にインストール済みの Node.js のバージョンを記述します。14.10.1~/.bashrc
以下を追記。ディレクトリを移動した際、
.nvmrcが存在すれば、.nvmrcに記述されている Node.js のバージョンを変数に格納し、nvm use [変数]を実行しています。enter_directory() { if [[ $PWD == $PREV_PWD ]]; then return fi PREV_PWD=$PWD [[ -f ".nvmrc" ]] && current_node_ver=`cat .nvmrc` && nvm use $current_node_ver } export PROMPT_COMMAND=enter_directoryやってみる
$ cd ~/project $ echo "14.10.1" > .nvmrc$ cd ~ $ nvm use 10.22.0 Now using node v10.22.0 (64-bit) $ cd ~/project Now using node v14.10.1 (64-bit)自動で
nvm use 14.10.1が実行されました。
- 投稿日:2020-09-14T08:03:56+09:00
Typeorm でマイグレーションをしよう
はじめに
Typescript 用の OR マッパー Typeorm を使用して、環境設定からマイグレーションをする方法まで紹介します。
前提
$ node -v v14.9.0 $ yarn -v 1.22.4 $ mysql --version mysql Ver 8.0.19 for Linux on x86_64 (MySQL Community Server - GPL)環境構築
まず、Typescript 環境を構築するところから始めます。この記事ではパッケージマネージャに yarn 使用しますが、NPM や他のものをお使いの方は、適宜読み替えてください。
yarn init -yこれで package.json が作成されました。続いて、Typescript 関連のツールと Typeorm をインストールします。その他 Linter や Formatter などはお好きな物をお使いください。
yarn add typeorm yarn add -D typescript ts-nodeまた、今回は DB として MySQL を利用するので、それ用のドライバも合わせてインストールします。
yarn add mysqlMySQL 以外の DB を使う場合は、以下を参考に適宜ドライバをインストールしてください。
# PostgreSQL yarn add pg # SQLite yarn add sqlite3 # Microsoft SQL Server yarn add sql.js # Oracle yarn add oracledb # MongoDB yarn add mongodb # Aurora Data API yarn add typeorm-aurora-data-api-driverさて、ドライバもインストールできたところで、TypeORM のプロジェクトを作成します。
手動でやってもいいのですが、TypeORM の CLI にはテンプレート作成機能があるので、それを利用します。yarn typeorm initコマンドを実行すると以下のようなファイルが生成されたのが確認できます。
~ ├── src │ ├── entity │ │ └── User.ts // サンプルエンティティ │ ├── migration // マイグレーションファイルを置くところ │ └── index.ts ├── .gitignore ├── ormconfig.json // TypeORMの設定情報 ├── package.json ├── README.md └── tsconfig.jsonormconfig.json というファイルは、TypeORM 用の設定ファイルです。
軽く設定項目について見てみましょう。js[ormconfig.json]{ "type": "mysql", "host": "localhost", "port": 3306, "username": "test", "password": "test", "database": "test", "synchronize": false, // コネクションを生成時にエンティティを自動でマイグレーションするかどうか。 "logging": false, // Trueにすると発行したSQLのログが見れます。パフォーマンスが若干悪くなるため、開発環境での利用を推奨します。 "entities": [ "src/entity/**/*.ts" ], "migrations": [ "src/migration/**/*.ts" ], "subscribers": [ "src/subscriber/**/*.ts" ], "cli": { "entitiesDir": "src/entity", "migrationsDir": "src/migration", "subscribersDir": "src/subscriber" } }type や host、port などはお使いの DB に合わせて変更してください。
synchronizeについては、false に設定してください。true にするとコネクション生成時に自動的にマイグレーションが実行されます。この挙動は開発時には便利ですが、プロダクション環境では推奨されない使い方です。今回は手動でマイグレーションをするため false に設定します。ちなみに ormconfig は json 形式以外にも、以下の形式や環境変数からの読み込みもサポートしています。詳細はこちらを確認してください。
- .js
- .yml
- .xml
環境構築は以上となります。次は実際にエンティティを触ってマイグレーションをしていきます。
エンティティを定義してテーブルを作ろう
TypeORM のテンプレートを利用したでは既に
User.tsというファイルが生成されているかと思います。こちらはサンプルのエンティティですが、今回はこのエンティティを使って説明をしていきます。js[src/User.ts]import { Entity, PrimaryGeneratedColumn, Column } from "typeorm"; @Entity() export class User { @PrimaryGeneratedColumn() id: number; @Column() firstName: string; @Column() lastName: string; @Column() age: number; }ormconfig の
synchronizeを false にした場合は、エンティティの追加やカラムの追加など、DB のスキーマの変更に関する変更を行う場合は、マイグレーションをする必要があります。マイグレーションの流れとしては、
- マイグレーションファイルを生成する。
- マイグレーションを実行する。
という流れになります。他の ORM と同様シンプルですね。
1.マイグレーションファイルを生成する
マイグレーションファイルの生成には主に3つの方法があります。
- TypeORM CLI によるエンティティを参照した自動生成
- TypeORM CLI によるマイグレーションファイルテンプレートの自動生成
- スクラッチによるマイグレーションファイルの生成
今回は一番ラクな 1 を行います。
まずは、DB への接続ができるかの確認の意味を含めて、以下のコマンドを実行します。
ts-node の引数として Typeorm の実行ファイルを指定する必要があることに注意してください。yarn ts-node node_modules/.bin/typeorm migration:showこのコマンド自体は、マイグレーションの履歴を出力するコマンドですが、実際に DB に接続して情報を取得するため、接続確認用として使用できます。
ここで MySQL の場合、
ER_NOT_SUPPORTED_AUTH_MODEのようなエラーを受け取ることがあります。
これは、mysql ドライバが古いことが起因しているようです。
MySQL Client から DB に対して、古い認証方式も受け入れるように設定しましょう。mysql> ALTER USER 'root' IDENTIFIED WITH mysql_native_password '<your-password>'; mysql> FLUSH PRIVILEGES;その後、もう一度 TypeORM のコマンドを実行すると、次のような SQL のログを出すことが確認できます。それでもエラーが出る場合は、ormconfig の port や password を見直してみてください。
query: SELECT * FROM `INFORMATION_SCHEMA`.`COLUMNS` WHERE `TABLE_SCHEMA` = 'test' AND `TABLE_NAME` = 'migrations' query: SELECT * FROM `test`.`migrations` `migrations` ORDER BY `id` DESC今は特にマイグレーションファイルなどを生成してないため、結果は何も出力されませんが、DB との接続が確認できました。
では、実際にマイグレーションファイルを生成しましょう。以下のコマンドを実行します。
yarn ts-node node_modules/.bin/typeorm migration:generate -n Test-n は必須のパラメータでファイル名を指定します。コマンドの結果として migration というディレクトリに
タイムスタンプ + -n で指定した名前(ここでは Test) + .tsというファイルが生成されています。js[~/src/migration/timestamp-Test.ts]import {MigrationInterface, QueryRunner} from "typeorm"; export class Test1599199531504 implements MigrationInterface { name = 'Test1599199531504' public async up(queryRunner: QueryRunner): Promise<void> { await queryRunner.query("CREATE TABLE `user` (`id` int NOT NULL AUTO_INCREMENT, `firstName` varchar(255) NOT NULL, `lastName` varchar(255) NOT NULL, `age` int NOT NULL, PRIMARY KEY (`id`)) ENGINE=InnoDB"); } public async down(queryRunner: QueryRunner): Promise<void> { await queryRunner.query("DROP TABLE `user`"); } }このファイルを簡単に説明すると、class の up というメソッドは、実際にマイグレーションの際に実行されるクエリです。queryRunner の query というメソッドには、生の SQL を書くことができます。また、down には up の対のクエリとして、 マイグレーションのロールバックの際に利用されるクエリが生成されます。
このマイグレーションファイルですが、もちろん手動で書き換えることができます。また、queryRunnser には query メソッド以外にも、addColumn や createIndex といったメソッドを持っており、生の SQL だけでなく、構造化されたデータを引数にとってクエリを生成することもできます。
2.マイグレーションを実行する
マイグレーションファイルが生成されたので、あとは実行するだけです。
実行は以下のコマンドです。$ yarn ts-node node_modules/.bin/typeorm migration:run --- 一部抜粋 0 migrations are already loaded in the database. 1 migrations were found in the source code. 1 migrations are new migrations that needs to be executed.これでマイグレーションが実行され、新しいテーブルが作成されました。
一応、現在のマイグレーションの状況も確認しておきましょう。$ yarn ts-node node_modules/.bin/typeorm migration:show --- 一部抜粋 [X] Test1599199531504すると、チェックマークとともに、現在適応されたマイグレーションの一覧を取得できます。ちなみに、マイグレーションの実行履歴は、DB の migrations というテーブルが自動的に生成され、そこに記録されていきます。
また、マイグレーションファイルが複数ある場合にマイグレーションを実行すると、タイムスタンプ順に未適応のマイグレーションが全て実行されます。
一方、マイグレーションをロールバックのしたい場合は、
yarn ts-node node_modules/.bin/typeorm migration:revertによって、直近のマイグレーションを1つがロールバックされます。複数個ロールバックしたい場合は複数回このコマンドを叩く必要があります。
以上がマイグレーションの一連の流れになります。
今回は何もない状態から、テーブルの作成を行うという例でしたが、エンティティを変更した場合などは同じようにマイグレーションファイルの生成 → 実行という手順でマイグレーションを行うことができます。それでは。
*本記事は @qualitia_cdevの中の一人、宮内さんに書いていただきました。
- 投稿日:2020-09-14T05:44:28+09:00
Twitter広告APIを利用してキャンペーンを作ってみる その1~TwitterAPI申請編~
経緯
私が所属している会社では待ラノという小説投稿サイトを運営しています。
待ラノではオススメ小説のランキング上位5作を定期的にTwitterの公式アカウントで紹介しています。
紹介された小説をTwitter広告のキャンペーンを利用してプロモーションをしようってなりました。そもそもTwitter広告のキャンペーンって何?
Twitter広告のキャンペーンですが、簡単いうと1日にかける予算や期間内にかける総予算を指定して、Twitterに広告を出す機能です。
Twitter広告APIでキャンペーンを作る理由
1つのキャンペーンで複数のツイートをプロモーションする場合、1日にかける予算を一気に消化されてしまいます。
しかもどのツイートにどれだけ予算が消化されているかがわかりません。
そのため、1つのツイートに1キャンペーンを紐付けることで消化される予算の見える化を行うことになりました。ただ手動でTwitterの広告コンソールから、1ツイートに1キャンペーンを毎回作ることになると結構手間です。
というわけで、Twitter広告APIを利用して動的にキャンペーンを作成することになりました。Twitter広告APIでキャンペーンを作成するためには
以下の手順が必要です。
- Tiwtterアカウントを作成する(省略)
- Tiwtterアカウントにメールアドレスと電話番号を設定する(省略)
- TiwtterAPIの利用申請をする
- TiwtterAPIのAPIキーとトークンを取得する
- TiwtterAPIを利用してツイートをする
- Tiwtter広告APIの利用申請をする
- Tiwtter広告APIでを利用してツイートを使ったキャンペーンを作る
今回は3の【TiwtterAPIの利用申請をする】について説明していきます。
1.Twitter Developerのページにアクセス
まずはTwitterにログインした状態で、Deeloperサイトへアクセスします。
2.「Create an app」ボタンをクリックします。
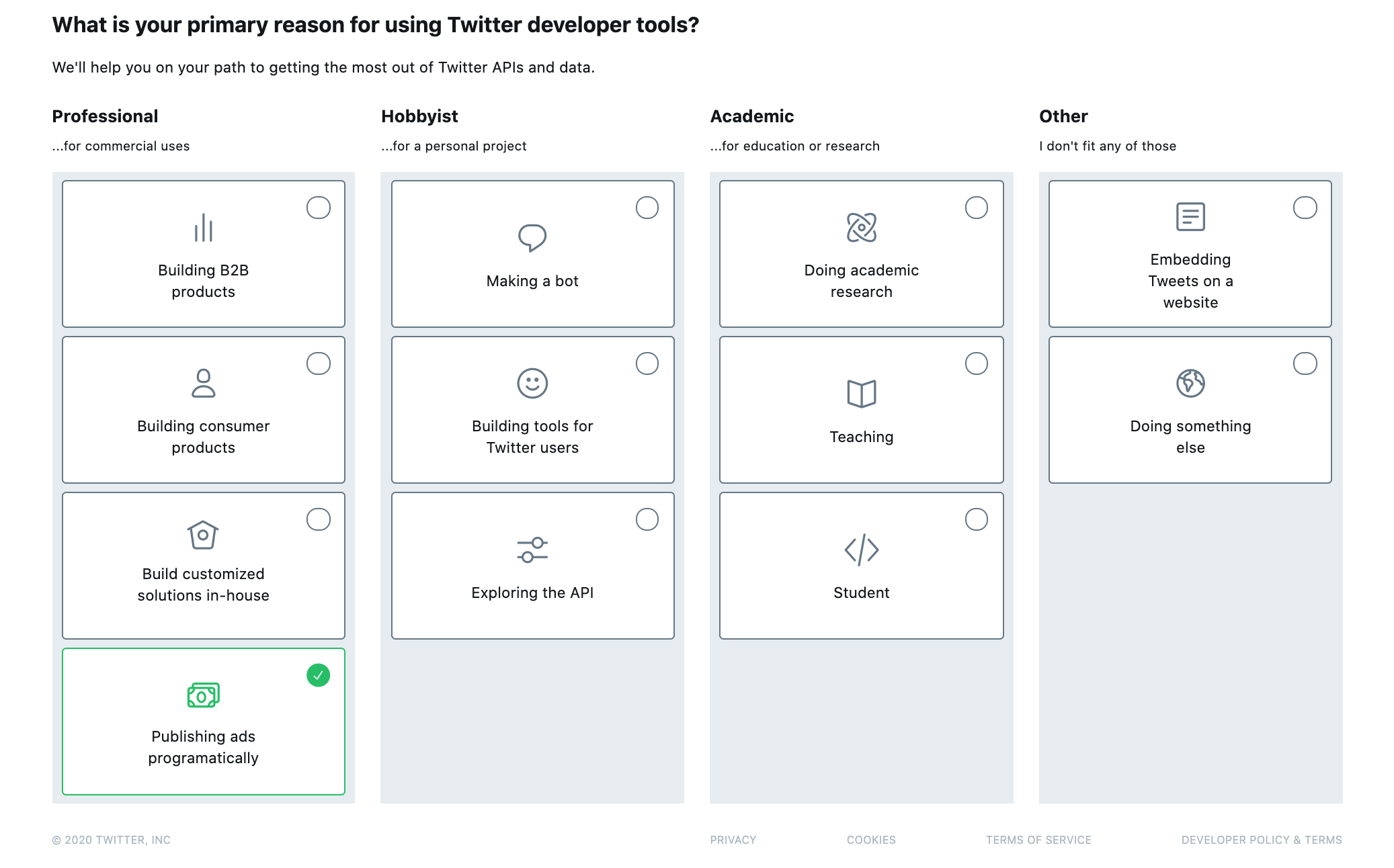
3.デベロッパーツールの利用目的を選択します。
今回はTwitter広告APIを利用するため「Publishing ads programatically」を選択します。
「Doing sometihg else」でもOK。
ここは厳密に回答しなくても問題はありません。
4.内容を確認して次へ進みます。
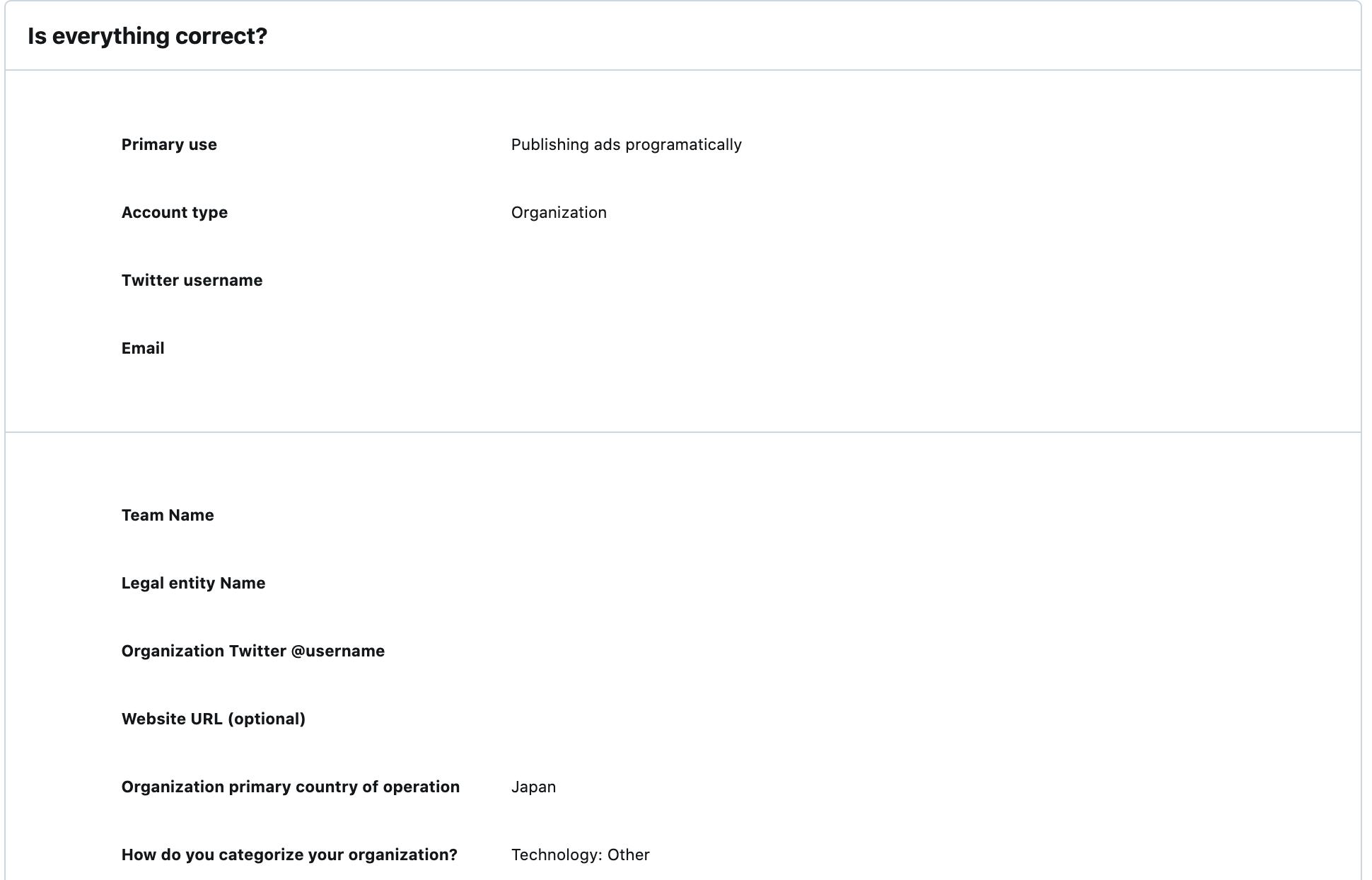
5.所属組織について記入します。
以下の項目を入力していきます。
- 「Team name(TwitterAPIのアカウント名)」
- 「Legal entity name(所属している企業名)」
- 「Organization Twitter @ username(TwitterのアカウントID)」
- 「Organization primary country of operation(所属している企業の主な国)」
- 「How do you categorize your organization?(所属している企業の業種)」
- 「What industries do you / will you serve?(自分が関わっている業種)」
6.英文でTwitterAPIの利用目的を回答していきます。
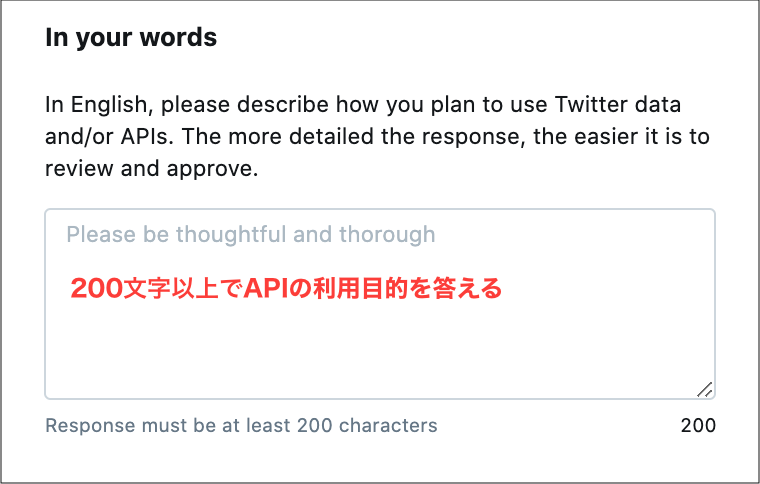
まずは「In English, please describe how you plan to use Twitter data and/or APIs. The more detailed the response, the easier it is to review and approve.(Twitter APIまたはTwitterデータの利用方法を教えて下さい)」
今回、下記のように回答しました。
1.私のウェブサイトに投稿した記事をTwitterのAPIを利用して、Twitterのタイムラインにも自動的に表示されるようにしたい。 2.Twitterのタイムラインに自動的に表示させるのは1日に1回程度です。 3.Twitter APIを利用しTwitterからのコンテンツを取得して、Twitter以外で表示させることはありません。これを英文にすると下記になります。
1.I want to make sure that articles posted on my website are automatically displayed on Twitter's timeline as well, using Twitter's API. 2.I would like to have an article automatically displayed on my Twitter timeline about once a day. 3. We do not use the Twitter API to retrieve content from Twitter and display it outside of Twitter.
「Are you planning to analyze Twitter data?(ツイッターのデータを利用しますか?)」
今回は利用しないので「No」にします。
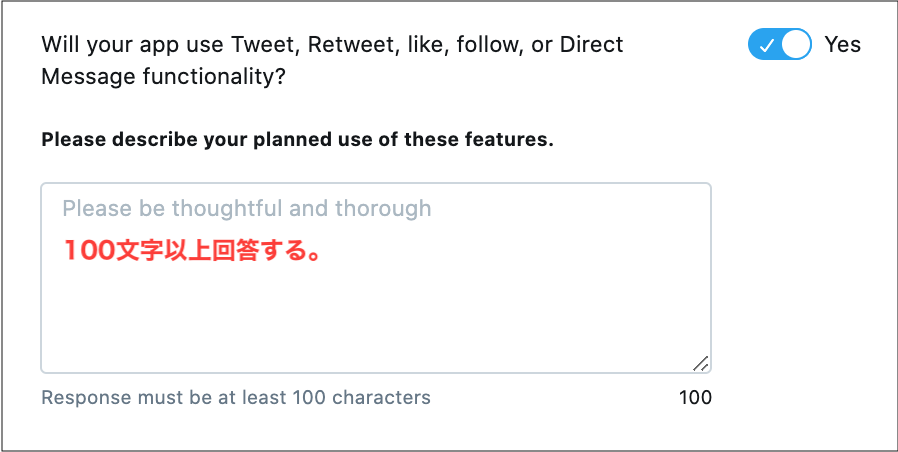
「Will your app use Tweet, Retweet, like, follow, or Direct Message functionality?(アプリはツイート、リツイート、お気に入り、フォロー、ダイレクトメッセージを利用するか?)」
今回は下記のように回答しました。
1.私のウェブサイトに投稿した記事をTwitterのAPIを利用して、Twitterのタイムラインにも自動的に表示されるようにしたい。 2.Twitterのタイムラインに自動的に表示させるのは1日に1回程度です。これを英文にすると下記になります。
1.I want to make sure that articles posted on my website are automatically displayed on Twitter's timeline as well, using Twitter's API. 2.I would like to have an article automatically displayed on my Twitter timeline about once a day.
「Do you plan to display Tweets or aggregate data about Twitter content outside of Twitter?(Twitter以外のTwitterコンテンツに関するツイートを表示したり集計データを表示するか?)」
今回は利用しないので「No」にします。
「Will your product, service or analysis make Twitter content or derived information available to a government entity?(あなたの製品・サービス,または分析によって,Twitterコンテンツまたは派生情報が政府機関が利用可能になりますか?)」
該当しないため「No」にします。
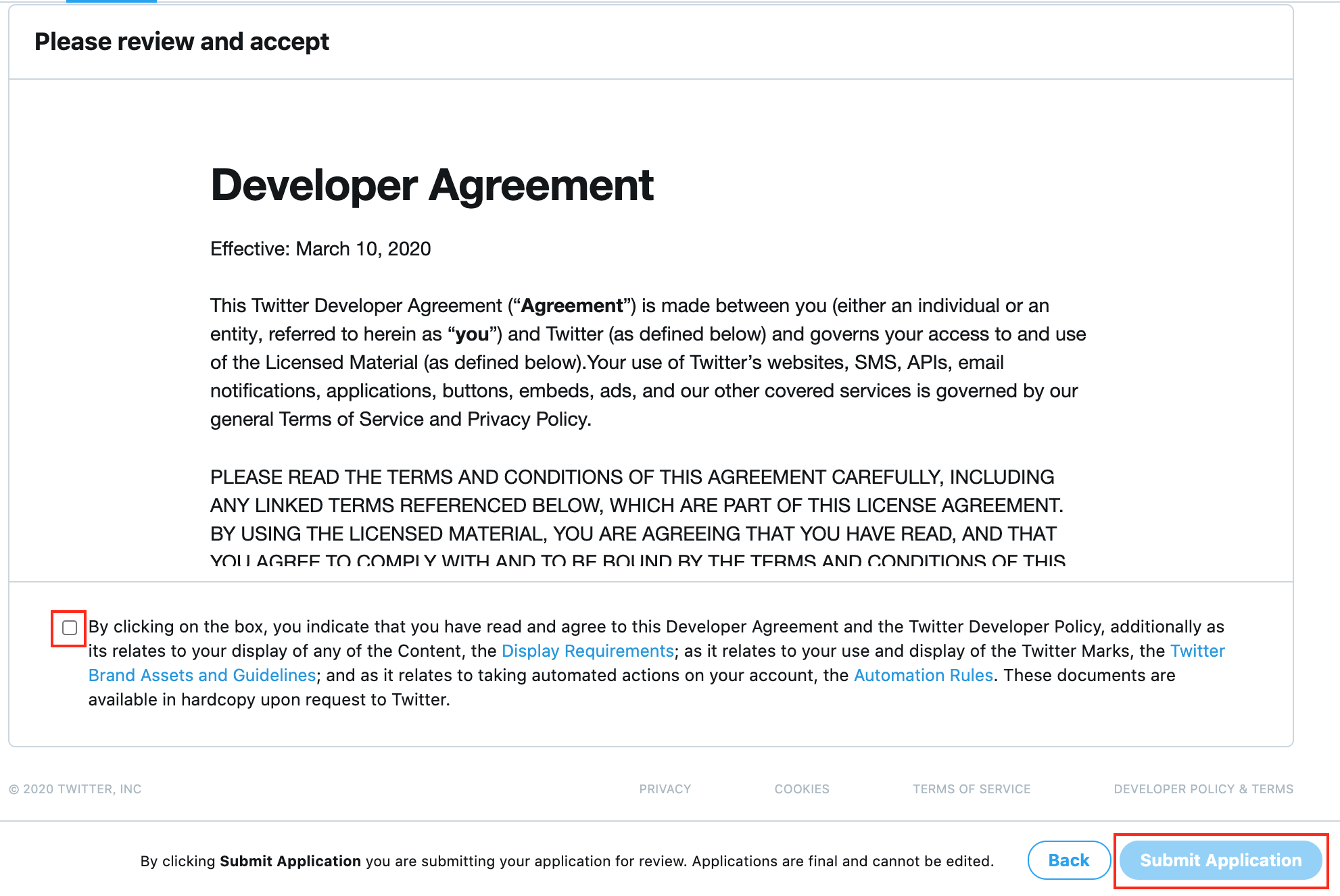
7.内容を確認して次へ進みます。
8.利用規約に同意して申請します。
9.メールアドレスの認証メールが届きます。
以下のようなメールが届き、メールに記載されている「Confirm your email」押して認証を完了します。
10.Twitter社からTwitterAPIの使用目的についての確認メールが届きます。
以下のようなメールが届き、こちらのメールに使用目的を記載して返信します。
11.Twitterからの申請の承認メールが届きます。
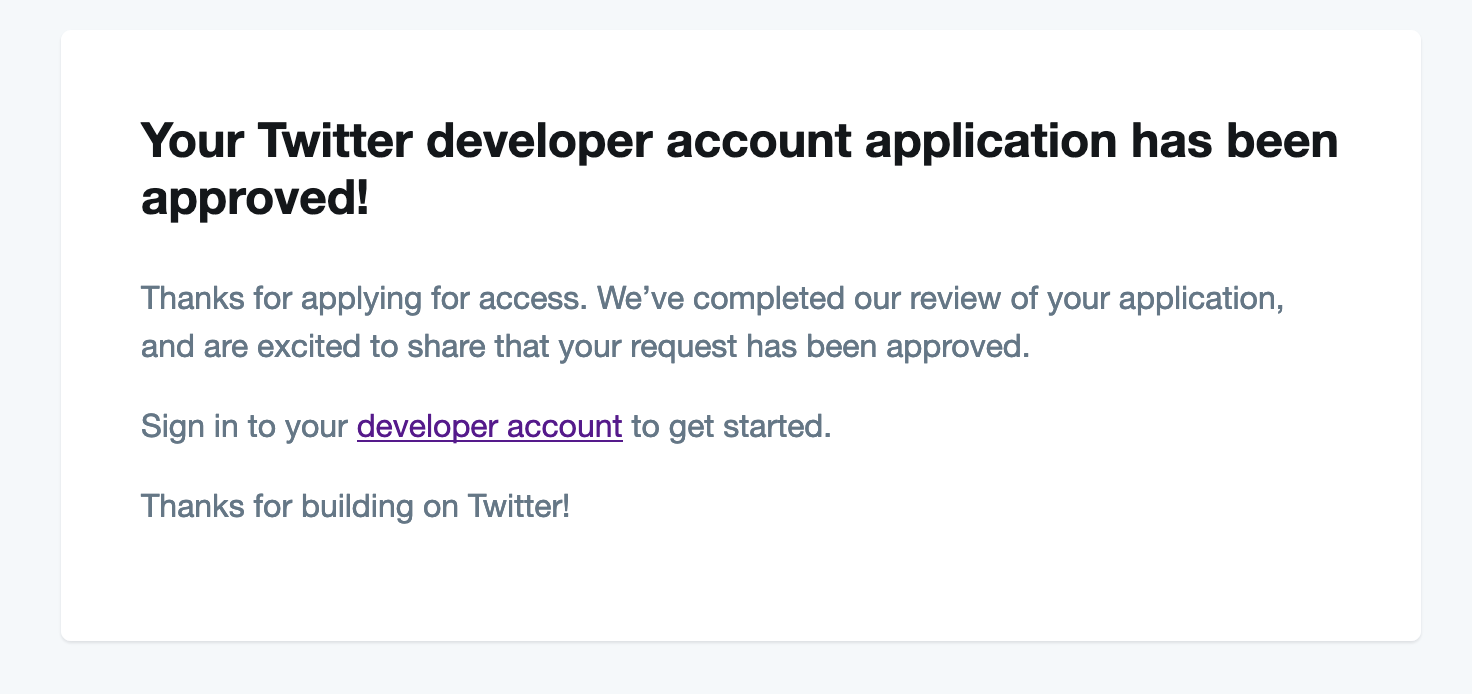
以下のようなメールが届いたら承認が完了です。





- 投稿日:2020-09-14T00:24:25+09:00
VSCodeでDocker入門
対象
Dockerインストール済み
初めてDockerを使用する。前提
コマンドラインは使える
VSCode インストール済み本記事について
一般的なDockerの学習フローではdockerコマンドを学びつつ、イメージやコンテナの概念について理解し、その後docker-composeへと進んでいくと考える。
本記事ではイメージやコンテナ等の概念の説明は大きく省き、コマンドもvscodeの拡張機能で代用する。それによってdocker-composeのコマンドを最小限学んでさくっと動かすことで実践的にDockerについて理解していく。
本記事のゴール
docker-composeコマンドがいくつかつかえるようになる。
nodejsの実行環境が作れる様になる。VSCode環境構築
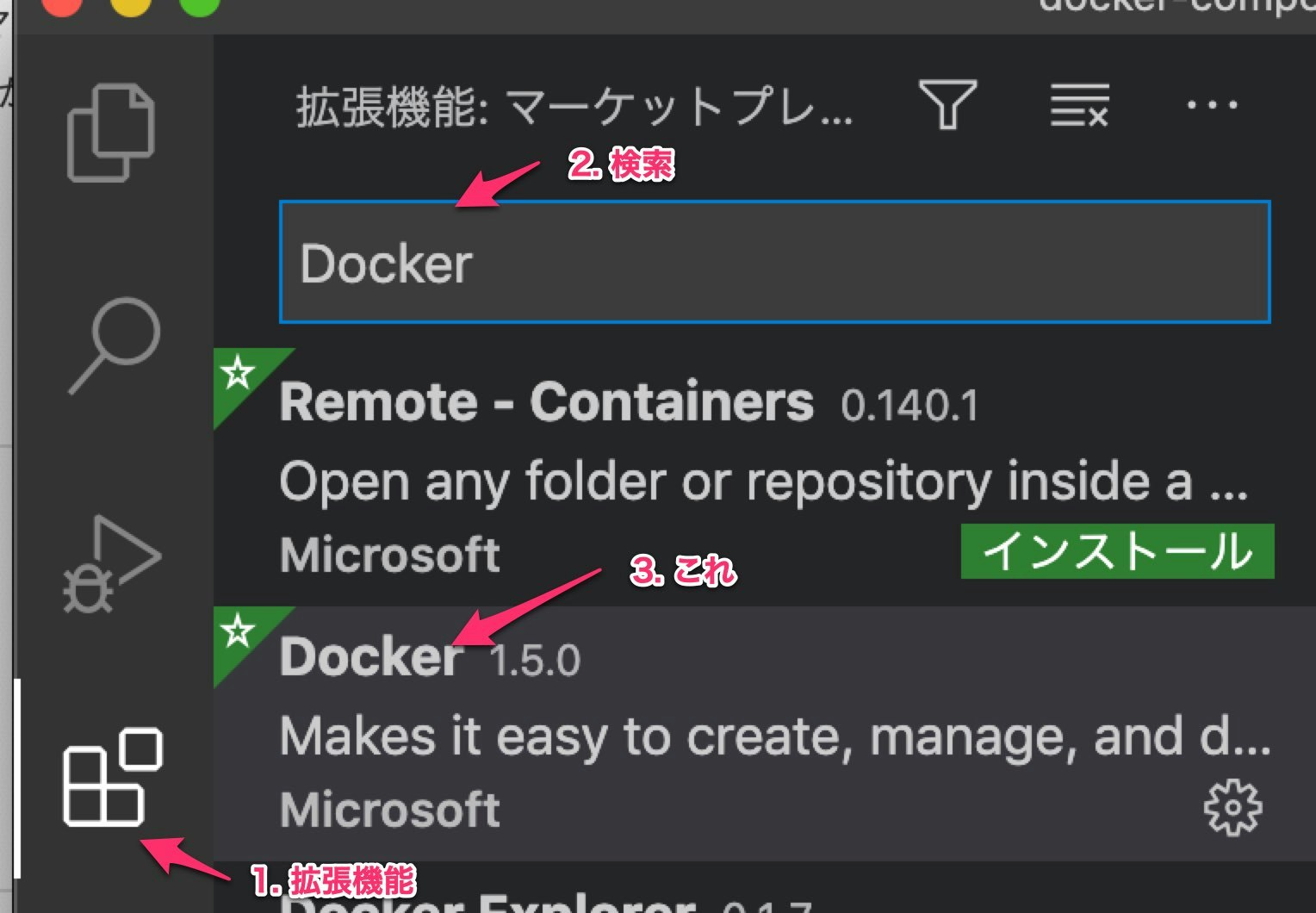
これをあらかじめインストールしておく。
nodejs環境を作る
まずは適当な場所に
nodejssampleというフォルダを作る。この名前は適当。そしてそのフォルダ直下に以下のように
docker-compose.ymlというファイルを作る。docker-compose.ymlversion: "3" services: node: image: node:14.10 volumes: - .:/project tty: true working_dir: /project command: bashこの内容については後ほど解説する。
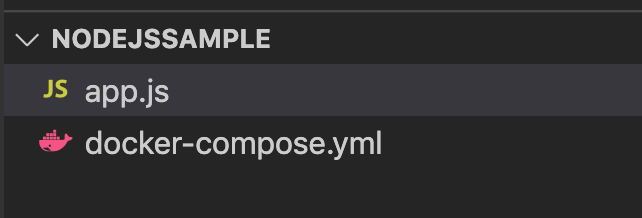
そして、同階層に
app.jsを作成app.jsconst main = () => { console.log("hello node!"); } main();
こうなっていればOK
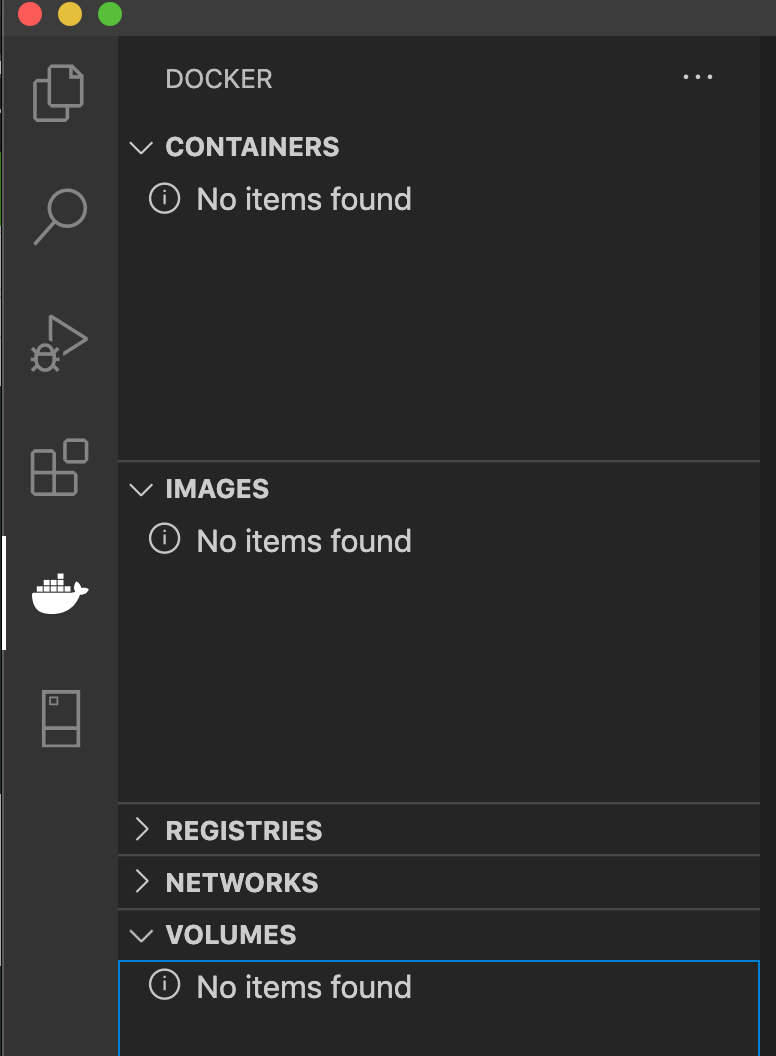
そうしたら一度Dockerの現在の状態を確認しておく。
VSCode左からDockerマークを選択すると以下のような画面になってると思う。
Dockerが起動していなかったり、すでに何かしらDockerを動かしていたらこの画面にならないかもしれない。
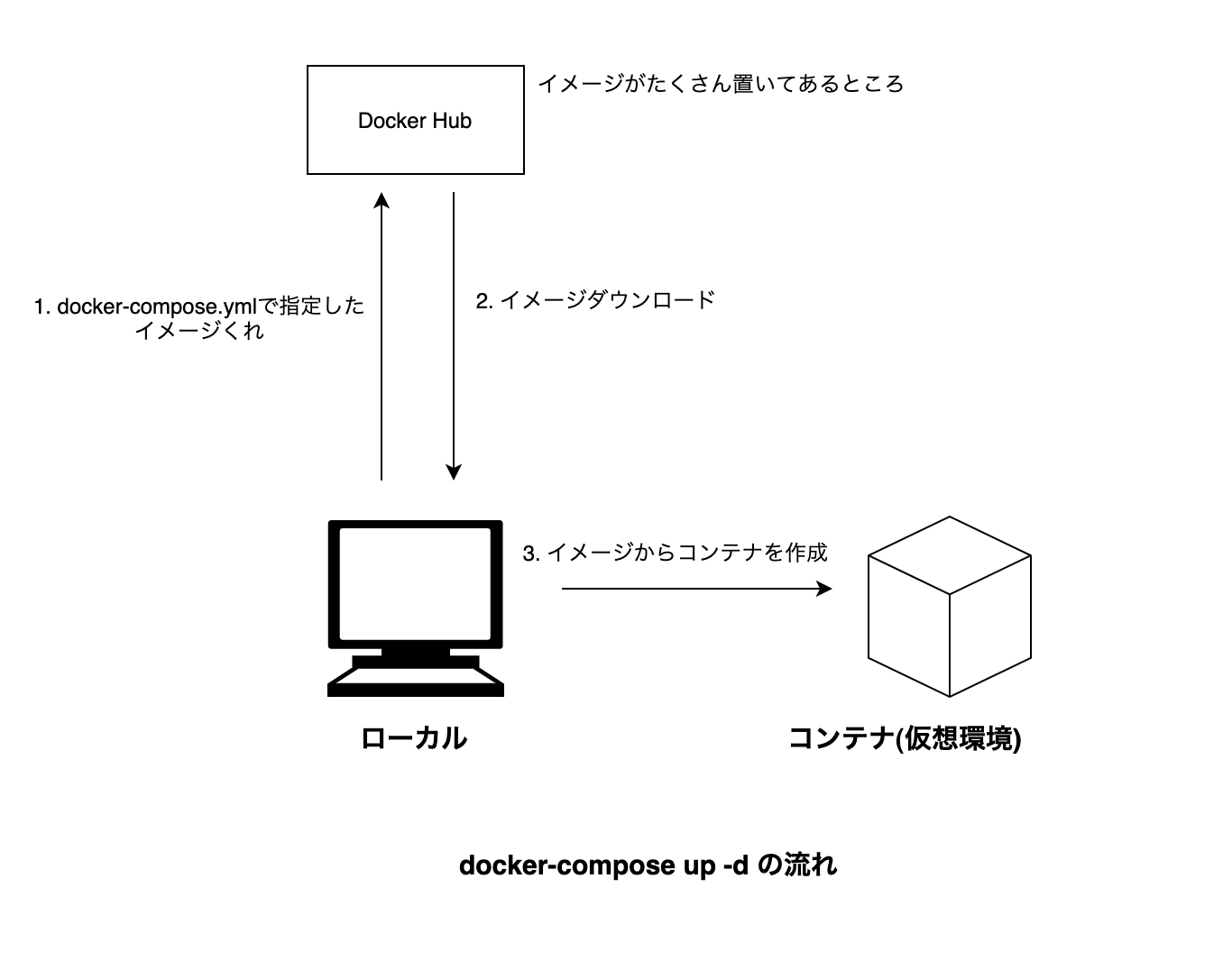
確認できたら、コマンドラインでdocker-compose.ymlのある場所で以下のようにコマンドをうつ。
仮装環境を起動するコマンド
docker-compose up -dするとダウンロードが始まって以下のような画面になる
nodejssample $ docker-compose up -d Creating network "nodejssample_default" with the default driver 4f250268ed6a: Pull complete1b49aa113642: Pull complete c159512f4cc2: Pull complete8439168fd8dc: Pull complete55abbc6cc158: Pull completee5c5821cd889: Pull complete5a7679f70bad: Pull completed827e86d1182: Pull complete2484b06a6da1: Pull complete Digest: sha256:21658666c0eabc9006b279e826e540d20e2c835507347d9c2f3f7dd5820ec9e3 Status: Downloaded newer image for node:14.10 Creating nodejssample_node_1 ... doneそして、Dockerのタブの画面が以下のようになる。
Dockerで作った仮想環境のことをコンテナと呼ぶ。
イメージはコンテナ作るためのもの。
仮想環境が起動できたので、次はその仮想環境でnodejsを動かす。
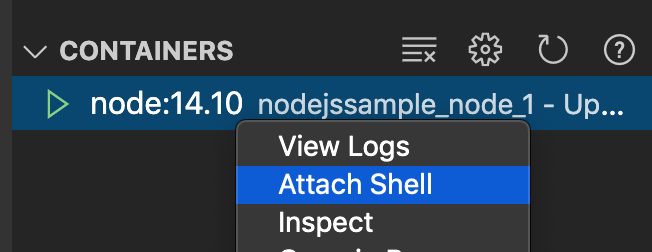
対象のコンテナを右クリック > Attack Shellを押す。
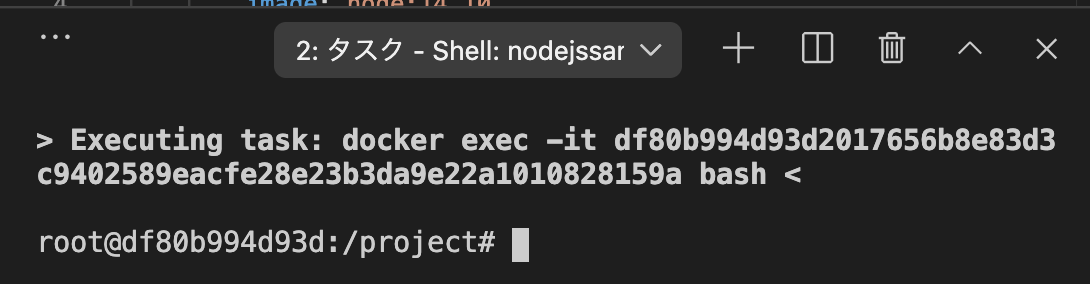
すると以下の様な画面がでる。
これがコンテナの中に入った状態。root@df80b994d93d:/project# ls app.js docker-compose.yml root@df80b994d93d:/project#lsコマンドをうつと中にVSCodeのプロジェクトと同じファイルが表示される。
そして、ここはnodejs環境のコンテナなのでnodejsが使えるかどうか確かめる。root@df80b994d93d:/project# node -v v14.10.1これが出たらOK
あらかじめ用意しておいた
app.jsを実行する。root@df80b994d93d:/project# node app.js hello node!実行できた。
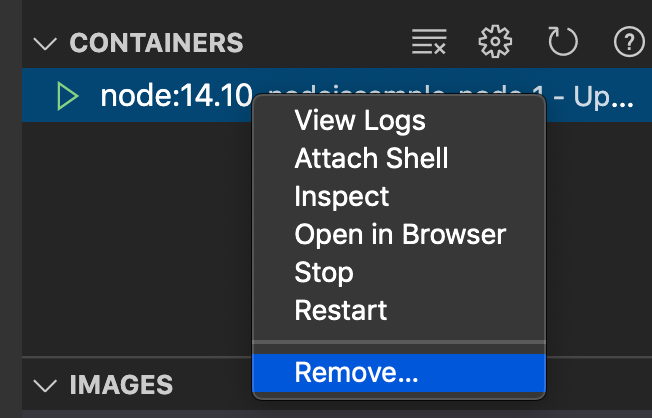
仮想環境を消す。
仮想環境は放置しておくと重いので、作業が終わったら消す。
イメージを消す。
イメージの方は、これがあることによって
docker-compose up -dが早くなるため、頻繁に使うなら残しておいてもOK.しばらく使わないなら消す。
これで仮想環境の構築、仮想環境でのプログラムの実行、仮想環境の削除が一通りできた。
解説
docker-compose.ymlについて
docker-composeの基本的な構文は以下
docker-composeの構文version: バージョン番号。 services: サービス名: サービスの設定...versionは最新版が3
サービス名は自分でつける。なんでもOK。docker-compose.ymlversion: "3" # 最新版は3 services: # ここは固定 node: # なんでも良いが、nodeのイメージを使ってるのでそのままnodeというサービス名に。 image: node:14.10 volumes: - .:/project tty: true working_dir: /project command: bashサービスの設定は多くあるが、詳しく知るためには公式ドキュメントを読むのが一番良い。
今回使った設定項目について1つずつ解説していく。
image
コンテナを作るためのイメージを記載。image: イメージ名:タグ名タグ名はバージョンととらえてOK
Dockerで使うイメージはDocker Hubというサイトにいろいろある。
nodeイメージ
本記事で使ったタグはこれ
volumes
ローカルのフォルダとコンテナのフォルダをリンクさせる。volumes: - ローカルのフォルダのパス:コンテナのフォルダのパスこれを設定しておかないと、コンテナから
app.js等のローカルに配置されたファイルをみることができない。tty
tty: truecommandで指定した処理を行なった後すぐコンテナが停止しないようにする。
Attach Shellでコンテナに入る時は必須。working_dir
そのまんまだが、コマンドを実行するときの場所。Attach Shellを行ったときもここで指定したフォルダに入る。command
コンテナ起動時に実行する処理。
今回はbashを指定してるので、ターミナル開いて待っててっていう感じ。他にもいろんな設定があるので別のDockerの記事をみて知らない項目があったらリファレンスを読むと良いと思う。
docker-compose up -dについて
docker-compose.ymlを読んで、必要であればイメージをダウンロードしてコンテナを作成するコマンド。-dはバックグラウンドで起動するためのオプション。