- 投稿日:2020-09-12T23:34:34+09:00
TensorFlowのOptimizerの違いによる学習推移をアニメーションにした
前回の記事で、Optimizerごとの学習推移の例をグラフにしました。
今回はアニメーションを作ってみました。
これです。
損失関数の設定
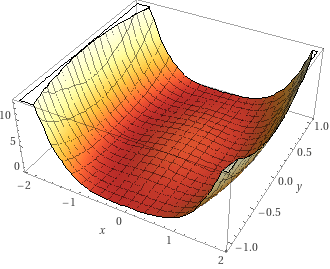
今回の損失関数は $ (x^2+y^2-1)^2 + \frac{1}{8}(x + 1)^2 $ です。グラフにするとこんな感じです。
牛乳ビンの底をちょっと傾けたような形をしています。前回とほぼ同じ形の関数ですが、 $ x=-1, y=0 $ で最小値 $ 0 $ になるように少し変えました。
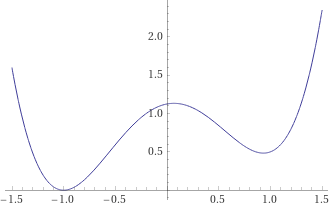
$ y=0 $ での断面はこんな感じです。
勾配降下法のOptimizer
シンプルな勾配降下法、モーメンタム、Adagrad、RMSprop、Adadelta、Adam、自作アルゴリズムを試しました。学習率はそれぞれのOptimizerで最適と思われる値を探しました。
[ (tf.optimizers.SGD(learning_rate=0.1), "sgd"), (tf.optimizers.SGD(learning_rate=0.1, momentum=0.5), "momentum"), (tf.optimizers.Adagrad(learning_rate=2.0), "adagrad"), (tf.optimizers.RMSprop(learning_rate=0.005), "rmsprop"), (tf.optimizers.Adadelta(learning_rate=100), "adadelta"), (tf.optimizers.Adam(learning_rate=0.2), "adam"), (CustomOptimizer(learning_rate=0.1), "custom"), ]グラフ
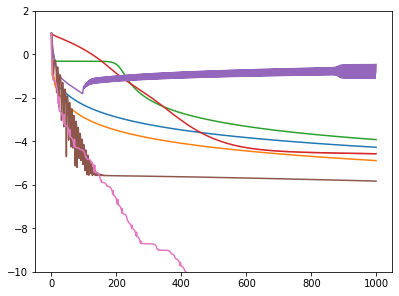
1000ステップ中の損失関数の値推移のグラフです。
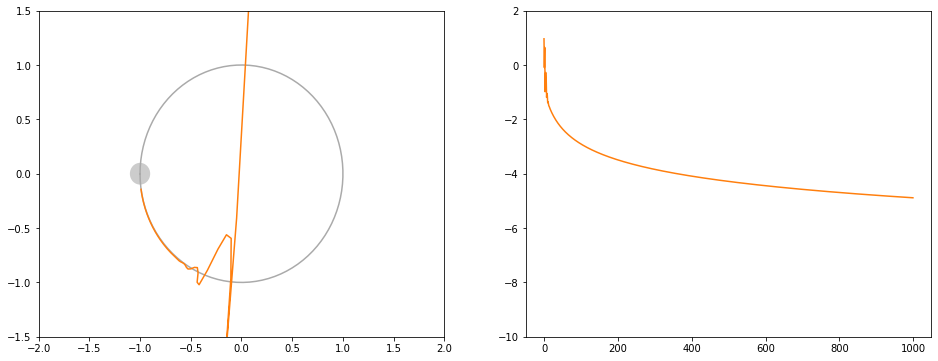
青: シンプルな勾配降下法
橙: モーメンタム
緑: Adagrad
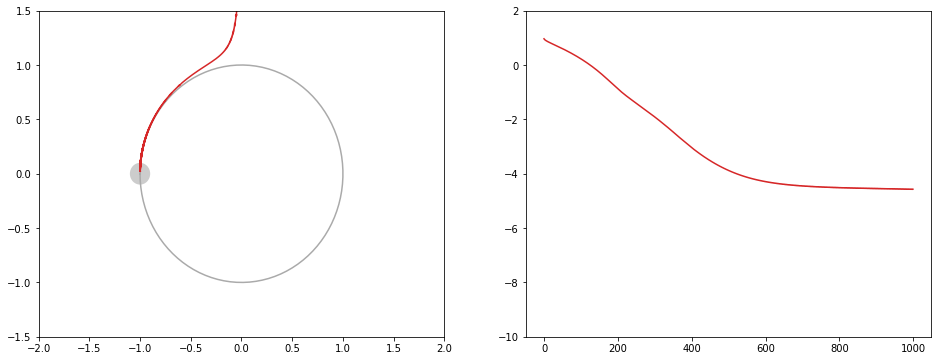
赤: RMSprop。初動が遅い
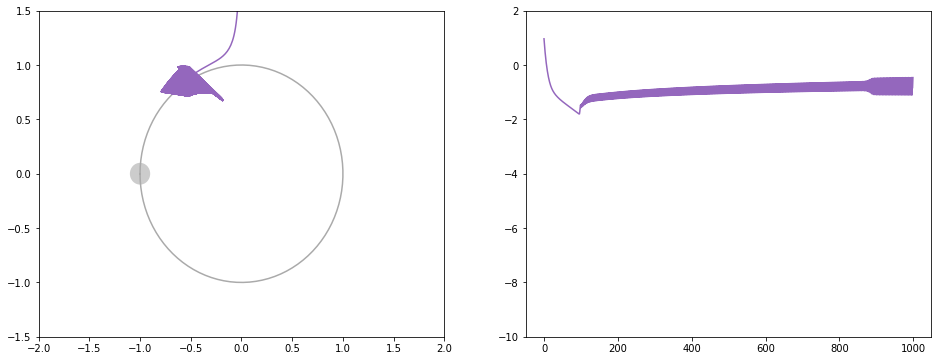
紫: Adadelta。振動してしまって解にたどり着けない
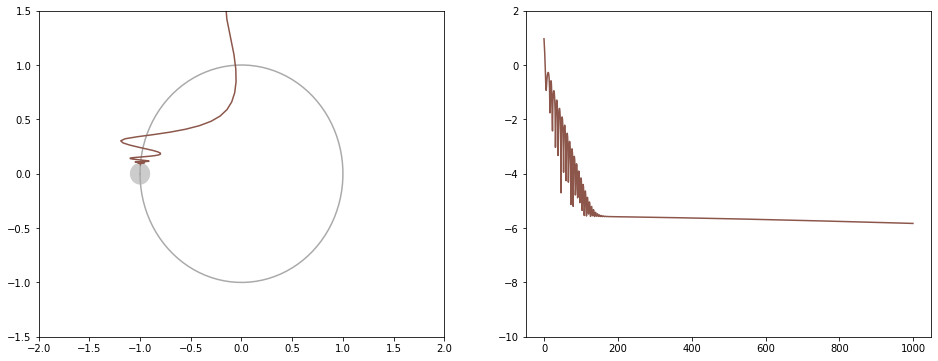
茶: Adam。最初振動しているが、解に近くなると動かなくなる
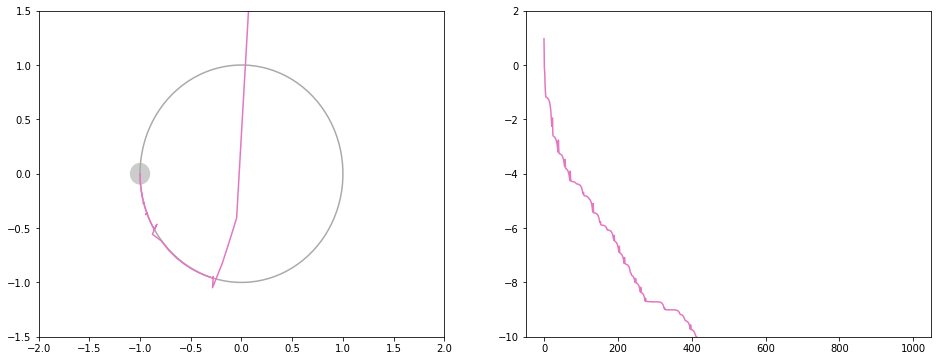
桃: 自作アルゴリズム。Adamと同じくらいの速さで解に近づき、その後も解に限りなく近づくシンプルな勾配降下法
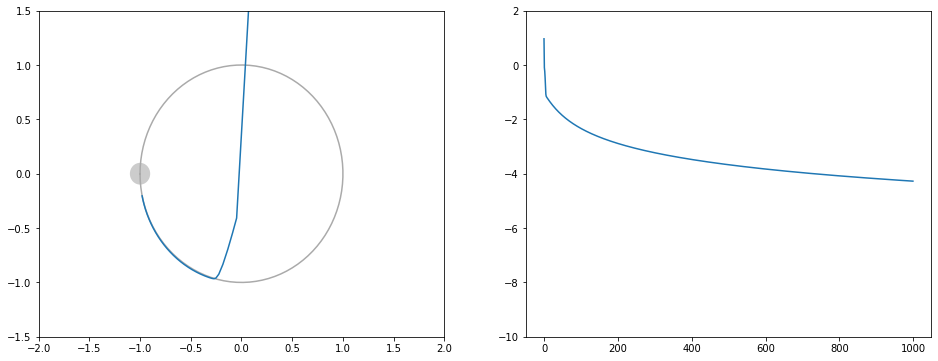
左はxy平面上での移動の様子です。右は損失関数の値推移です。
モーメンタム
シンプルな勾配降下法よりは収束が速いです。
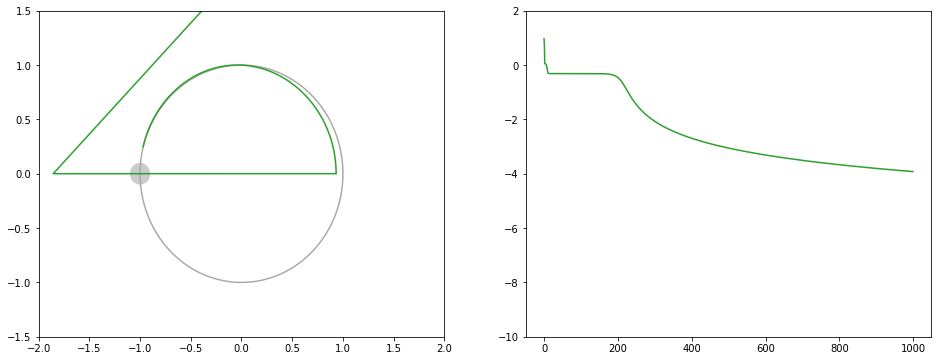
Adagrad
RMSprop
初動が遅いのですが、振動せずにまっすぐに解に近づきます。
Adadelta
学習率を調整したのですが、収束しなかったです。
Adam
ボールが転げ落ちるように解に近づきます。谷で振動はします。
解にある程度近くなると動かなくなってしまうのは、式の分母が0になるのを防ぐための $ \epsilon $ があるためと思われます。
自作アルゴリズム
Adadeltaと違って限りなく解に近づいていきます。
谷を通り過ぎるとすぐに気がついて立ち止まるので振動はほとんどしません。そのかわり直進しやすいため円弧状の谷ではカーブを曲がれずに立ち止まるのを繰り返します。
2020/09/22追記: 自作アルゴリズムのソースコード → TensorFlowでOptimizerを自作する
処理速度と収束までのステップ数
- time: 1000ステップの処理にかかった時間
- counter1: 損失関数が0.0001を初めて下回るまでにかかったステップ数
- counter2: 損失関数が0.0001を安定的に下回るまでにかかったステップ数
- loss: 1000ステップ実行後の損失関数の値
sgd time: 2.369345188140869 counter1: 731 counter2: 731 loss: 5.330099884304218e-05 momentum time: 2.378025770187378 counter1: 361 counter2: 361 loss: 1.3026465239818208e-05 adagrad time: 2.489086627960205 counter1: 1000 counter2: 1000 loss: 0.00011992067447863519 rmsprop time: 3.6131269931793213 counter1: 522 counter2: 522 loss: 2.695291732379701e-05 adadelta time: 2.5074684619903564 counter1: 1000 counter2: 1000 loss: 0.34417498111724854 adam time: 2.8565642833709717 counter1: 46 counter2: 96 loss: 1.4833190107310656e-06 custom time: 3.4037697315216064 counter1: 68 counter2: 72 loss: 1.9912960169676808e-12counter1とcounter2が1000のOptimizerは1000ステップ処理しても0.0001に達しなかったことを示します。counter1とcounter2が1000未満で同じ値のOptimizerは振動せずに解に近づいていることを示します。
Pythonコード
Google Colaboratoryで実行しました。アニメーションを作るために最初にAPNGというパッケージをインストールします。
!pip install APNGimport time import numpy as np import matplotlib.pyplot as plt import math import tensorflow as tf import matplotlib.patches as patches from apng import APNG import IPython opts1 = [(tf.optimizers.SGD(learning_rate=lr), str(lr)) for lr in [0.3, 0.2, 0.1, 0.05]] opts2 = [(tf.optimizers.SGD(learning_rate=lr, momentum=0.5), str(lr)) for lr in [0.3, 0.2, 0.1, 0.05]] opts3 = [(tf.optimizers.Adagrad(learning_rate=lr), str(lr)) for lr in [3.0, 2.0, 1.0, 0.5]] opts4 = [(tf.optimizers.RMSprop(learning_rate=lr), str(lr)) for lr in [0.01, 0.005, 0.003, 0.002]] opts5 = [(tf.optimizers.Adadelta(learning_rate=lr), str(lr)) for lr in [200, 100, 50, 30]] opts6 = [(tf.optimizers.Adam(learning_rate=lr), str(lr)) for lr in [0.5, 0.3, 0.2, 0.1]] opts7 = [(CustomOptimizer(learning_rate=lr), str(lr)) for lr in [0.2, 0.1, 0.05, 0.03]] opts8 = [ (tf.optimizers.SGD(learning_rate=0.1), "sgd"), (tf.optimizers.SGD(learning_rate=0.1, momentum=0.5), "momentum"), (tf.optimizers.Adagrad(learning_rate=2.0), "adagrad"), (tf.optimizers.RMSprop(learning_rate=0.005), "rmsprop"), (tf.optimizers.Adadelta(learning_rate=100), "adadelta"), (tf.optimizers.Adam(learning_rate=0.2), "adam"), (CustomOptimizer(learning_rate=0.1), "custom"), ] opts = opts8 k1x = 1.0 k1y = 1.0 k2 = 1.0 k1x2 = k1x * k1x k1y2 = k1y * k1y # 目的となる損失関数 def loss(i): x2 = k1x2 * x[i] * x[i] y2 = k1y2 * y[i] * y[i] r2 = (x2 + y2 - 1.0) x1 = k1x * x[i] + 1.0 ret = r2 * r2 + 0.125 * x1 * x1 return k2 * ret thres = k2 * 0.0001 # 最適化する変数 x = [] y = [] # グラフにするための配列 xHistory = [] yHistory = [] lossHistory = [] calculationTime = [] convergenceCounter1 = [] convergenceCounter2 = [] maxLoopCount = 1000 maxLoopCountAnimation = 1000 x_ini = 0.1 y_ini = 2.0 for i in range(len(opts)): x.append(tf.Variable(x_ini)) y.append(tf.Variable(y_ini)) xHistory.append([]) yHistory.append([]) lossHistory.append([]) convergenceCounter1.append(maxLoopCount) convergenceCounter2.append(0) start = time.time() for loopCount in range(maxLoopCount): l = float(loss(i)) # グラフにするために記録 xHistory[i].append(float(x[i])) yHistory[i].append(float(y[i])) lossHistory[i].append(l) if (math.isfinite(l) and l < thres and convergenceCounter1[i] >= maxLoopCount): convergenceCounter1[i] = loopCount if (not math.isfinite(l) or l >= thres): convergenceCounter2[i] = loopCount + 1 # 最適化 opts[i][0].minimize(lambda: loss(i), var_list = [x[i], y[i]]) calculationTime.append(time.time() - start) colors = ['#1f77b4', '#ff7f0e', '#2ca02c', '#d62728', '#9467bd', '#8c564b', '#e377c2', '#7f7f7f', '#bcbd22', '#17becf'] # グラフ化1つ目 plt.rcParams['figure.figsize'] = (6.4, 4.8) plt.ylim(-10.0, +2.0) for i in range(len(opts)): plt.plot(range(maxLoopCount), np.log10(lossHistory[i]) - np.log10(k2), color=colors[i % len(colors)]) plt.show() ths = np.linspace(-math.pi, math.pi, 100) thsx = np.cos(ths) / k1x thsy = np.sin(ths) / k1y # グラフ化2つ目以降 plt.rcParams['figure.figsize'] = (16.0, 6.0) for i in range(len(opts)): print(opts[i][1]) print("time: " + str(calculationTime[i])) print("counter1: " + str(convergenceCounter1[i])) print("counter2: " + str(convergenceCounter2[i])) print("loss: " + str(lossHistory[i][-1])) fig, (ax1, ax2) = plt.subplots(ncols=2) ax1.set_xlim(-2 / k1x, +2 / k1x) ax1.set_ylim(-1.5 / k1y, +1.5 / k1y) ax1.plot(thsx, thsy, color="#aaaaaa") ax1.add_patch(patches.Ellipse(xy=(-1.0, 0.0), width=0.2 / k1x, height=0.2 / k1y, fc="#cccccc")) ax1.plot(xHistory[i], yHistory[i], color=colors[i % len(colors)]) ax2.set_ylim(-10.0, +2.0) ax2.plot(range(maxLoopCount), np.log10(lossHistory[i]) - np.log10(k2), color=colors[i % len(colors)]) plt.show() # アニメーション plt.rcParams['figure.figsize'] = (6.4, 9.6) ax = plt.axes() fnames = [] for loopCount in range(maxLoopCountAnimation): if not (loopCount <= 150 or loopCount % 3 == 0): continue plt.cla() plt.xlim(-1.5 / k1x, +1.5 / k1x) plt.ylim(-2.1 / k1y, +2.1 / k1y) plt.text(-1.5 / k1x, -2.1 / k1y, str(loopCount)) plt.plot(thsx, thsy, color="#aaaaaa") ax.add_patch(patches.Ellipse(xy=(-1.0, 0.0), width=0.2 / k1x, height=0.2 / k1y, fc="#cccccc")) for i in range(len(opts)): if math.isfinite(xHistory[i][loopCount]) and math.isfinite(yHistory[i][loopCount]): plt.text(xHistory[i][loopCount], yHistory[i][loopCount], opts[i][1]) ax.add_patch(patches.Ellipse(xy=(xHistory[i][loopCount], yHistory[i][loopCount]), width=0.05 / k1x, height=0.05 / k1y, fc=colors[i % len(colors)])) fname = str(loopCount) + ".png" plt.savefig(fname) fnames.append(fname) if loopCount < 10: fnames.append(fname) if loopCount == 0: fnames.append(fname) fnames.append(fname) plt.cla() APNG.from_files(fnames, delay=200).save("animation.png") IPython.display.Image("animation.png")ステップ150以降のアニメーションは3倍速にしています。
リンク
関連する私の記事

- 投稿日:2020-09-12T19:57:35+09:00
スプラトゥーン2のプレイ動画から、やられたシーンだけをディープラーニングで自動抽出する
手っ取り早く、やられたシーンを切り出したい人向け
こちらでJupyterのノートブックを配布しています。
はじめに
スプラトゥーン2を発売日からやりこんで3年になります。2年かけて全ルールがウデマエXに到達しましたが、そこからXパワーが上がらずウデマエX最底辺で停滞しています。最近は自分のプレイ動画を見て対策を立てるのですが、すべての動画を見るのは大変です。そこで敵にやられたシーンは特に修正すべき自分の弱点があると考え、そこだけを自動で抽出するシステムを作ってみました。
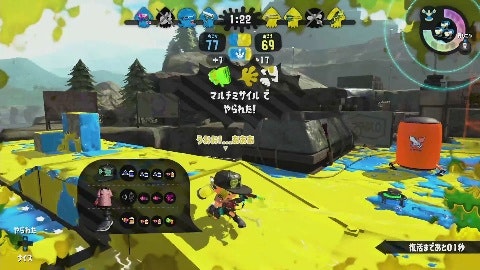
↑このシーンを切り出します。
画像の引用
この記事では任天堂株式会社のゲーム、スプラトゥーン2のスクリーンショットを引用しています。
使用技術
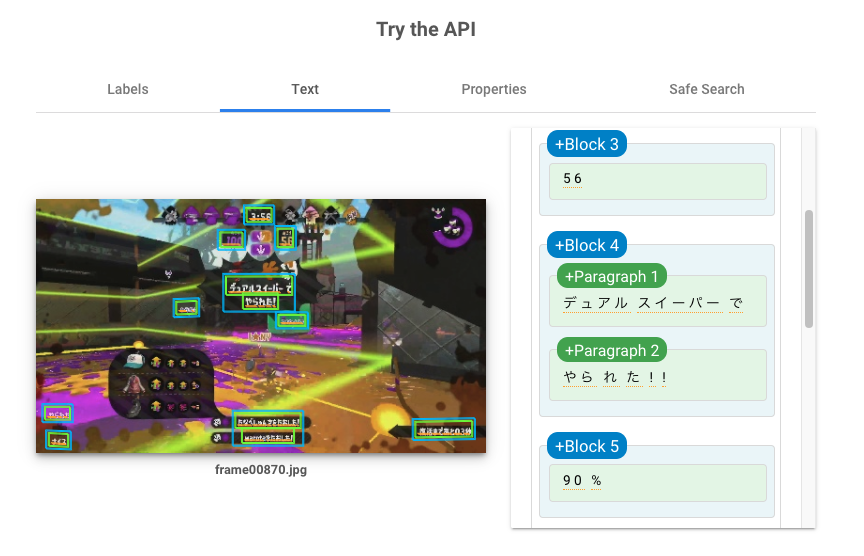
他のスプラトゥーン関連の画像処理を行っている例では、テンプレートマッチングを使用しているものが多いですが、この記事では工数削減と他のシーン検出への発展性を考慮してディープラーニングで処理しています。さらにそのモデルもGoogle AutoML Visionで自分では調整などを全くせずに作っています。学習データはすべての画像を目視して人力で分類して作っていますが、Google Cloud Vision APIのテキスト検出を使い、仮である程度分類したあとに目視で間違いを修正する形で省力化しています。
システムの概要
分類モデル
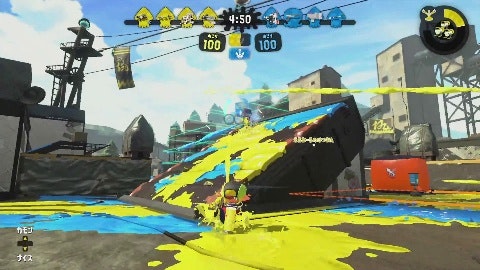
プレイ動画中のやられたシーンの画像とそれ以外のシーンの画像を分類するモデルを作ります。やられたシーンには「○○でやられた!」といった表示が中央上あたりに表示されます。
やられたシーン それ以外のシーン 


動画の切り出し
動画から0.5秒に1回フレームを抽出して前述のモデルで分類します。やられたシーンと分類された場合は、その数秒前から動画を切り出します。
前準備
Python
Pythonをインストールします。
OpenCV Python、TensorFlow、tqdmをインストールします。
この記事では学習をGoogle AutoML Visionで行うのでNVIDIAのGPUが無いPCでも良いです。pip install opencv-python pip install tensorflow pip install tqdmffmpeg
ffmpegをインストールします。
Macの場合はHomebrewでインストール出来ます。brew install ffmpeg学習元動画を準備
まず試合の録画をmp4形式で10時間分用意して、
src_movieディレクトリに格納しました。合計録画時間の確認
OpenCVには動画から合計フレーム数と1秒あたりフレーム数を取る機能があります。それを使って合計録画時間を確認しました。
movie_lengh.pyimport os import cv2 # 合計録画秒数 total_seconds = 0 # 元動画格納ディレクトリ dirname = 'src_movie' # 動画ファイル一覧 for name in os.listdir(dirname): if name.endswith('.mp4'): path = os.path.join(dirname, name) # 動画を読み込む cap = cv2.VideoCapture(path) # フレーム数を取得 frame_count = cap.get(cv2.CAP_PROP_FRAME_COUNT) # 1秒あたりフレーム数を取得 fps = cap.get(cv2.CAP_PROP_FPS) # 秒数を取得 seconds = frame_count / fps # ファイル名と秒数を出力 print("%s %d min" % (path, seconds / 60)) # 合計する total_seconds += seconds # 合計を出力する print(total_seconds/3600)3秒ごとにフレーム画像を切り出す
出力先として
src_imageディレクトリを作ります。
OpenCVには動画からフレーム画像を抽出する機能があります。それを使って3秒ごとにフレーム画像を切り出しました。movie_frame.pyimport os import numpy as np import cv2 # 元動画格納ディレクトリ src_dir = 'src_movie' # フレーム画像格納ディレクトリ dst_dir = 'src_image' # 保存インデックス save_index = 0 # 動画ファイル一覧 for name in os.listdir(src_dir): if name.endswith('.mp4'): path = os.path.join(src_dir, name) # 動画を読み込む cap = cv2.VideoCapture(path) # 1秒あたりフレーム数を取得 fps = cap.get(cv2.CAP_PROP_FPS) # 3秒に1回フレーム画像を取得する skip = fps * 3 # フレームインデックス i = 0 while True: ret, img = cap.read() if ret: if i % skip == 0: # フレームを縮小して保存する shrink = cv2.resize( img, (480, 270), interpolation=cv2.INTER_CUBIC) out_path = os.path.join( dst_dir, "frame%05d.jpg" % save_index) cv2.imwrite(out_path, shrink) print(out_path) save_index += 1 i += 1 else: break12,227枚の画像が出来ました。
やられたシーンとそれ以外のシーンに半自動で分ける
12,227枚の画像を1枚1枚目視して、やられたシーンを拾おうと思いましたが、
実際やってみると大変だったので、Google Cloud Vision APIのドキュメントテキスト検出を使いました。やられたシーンには「○○でやられた!」という表示があるので、テキスト検出して「で」と「やられた」を含む画像をやられたシーンとして分類します。
「で」をつけた理由はこのように味方から「やられた」シグナルを頂いたシーンを含まないようにするためです。
料金
Google Cloud Vision APIの呼び出しには無視できない金額がかかります。12,227枚の画像からテキスト検出するためには、約2,000円ほどかかります。
テキスト検出による分類を実行する
いったん全ての画像のテキスト検出結果をファイルに保存してから、検出されたテキストを処理して画像分類しています。画像分類は手直しの可能性が高く、Google Cloud Vision API呼び出しにはお金と時間がかかるためです。
すべての画像をテキスト検出結果をファイルに保存する
まず保存先ディレクトリとして
textを作ります。
こちらのPythonスクリプトでAPIのレスポンスをすべて保存します。
認証周りについてはこちらの公式解説を参考にしてください。image_ocr.pyimport os import subprocess import pathlib import base64 import requests # フレーム画像格納ディレクトリ src_dir = 'src_image' # テキスト検出結果格納ディレクトリ dst_dir = 'text' # アクセストークンの取得 access_token = subprocess.check_output( 'gcloud auth application-default print-access-token', shell=True) access_token = access_token.decode('utf-8').rstrip() # フレーム画像一覧 names = [] for name in os.listdir(src_dir): if name.endswith('.jpg'): names.append(name) names.sort() for name in names: print(name) # テキスト検出元画像パス path = os.path.join(src_dir, name) with open(path, 'rb') as f: data = f.read() # 画像データをBase64に変換 b64data = base64.b64encode(data).decode('utf-8') # リクエスト本文の作成 request_body = { 'requests': [ { 'image': { 'content': b64data }, 'features': [ { 'type': 'DOCUMENT_TEXT_DETECTION' } ] } ] } # Cloud Vision API呼び出し r = requests.post('https://vision.googleapis.com/v1/images:annotate', headers={'Authorization': "Bearer %s" % access_token}, json=request_body) # レスポンスを保存する if r.ok: # 出力ファイル名 out_name = pathlib.PurePath(name).stem + '.json' out_path = os.path.join(dst_dir, out_name) with open(out_path, 'w') as f: f.write(r.text) else: raise Exception('Vision API Error: %d' % r.status_code)検出されたテキストを処理して画像分類する
やられたシーン格納ディレクトリとして
train_1、それ以外のシーン格納ディレクトリとしてtrain_0を作ります。textディレクトリにあるjsonファイルを読んで、src_imageディレクトリにある画像をtrain_0train_1に分類します。train_data.pyimport os import pathlib import json import shutil # フレーム画像格納ディレクトリ image_dir = 'src_image' # テキスト検出結果格納ディレクトリ text_dir = 'text' # フレーム画像一覧 names = [] for name in os.listdir(image_dir): if name.endswith('.jpg'): names.append(name) names.sort() for name in names: print(name) # フレーム画像パス image_path = os.path.join(image_dir, name) # テキスト検出結果を取得する json_name = pathlib.PurePath(name).stem + '.json' json_path = os.path.join(text_dir, json_name) with open(json_path) as f: responses = json.loads(f.read()) try: description = responses['responses'][0]['fullTextAnnotation']['text'] except KeyError: description = "" # テキストを見て分類する if 'で' in description and 'やられた' in description: # 「で」「やられた」が含まれていていれば、train_1にコピー train_path = os.path.join('train_1', name) else: # そうでなければ、train_0にコピー train_path = os.path.join('train_0', name) shutil.copy(image_path, train_path)12,227枚中、596枚がやられたシーン、11,631枚がそれ以外のシーンに分類されました。
手動で手直しする
Finderで流すようにすべての画像を見て、誤った分類があれば手動で正しいディレクトリに置きます。
このように、やられたあとマップを見ているシーンもやられたシーン判定になっています。左下の上キーで「やられた」シグナルを出す案内と「復活まであと02秒」に「で」が含まれるためです。このケースは通常のマップを開いたシーンと大きな違いが無いため、それ以外のシーンに分類しました。テキストの位置を見るようにスクリプトを変更しても良かったのですが、手動で分類を直した方が早いと思いました。
「○○でやられた」テキストがあっても検出されなかった画像もありました。
その結果87枚をやられたシーンからそれ以外のシーンに移動して、20枚をそれ以外のシーンからやられたシーンに移動しました。2時間ぐらいかかりました。
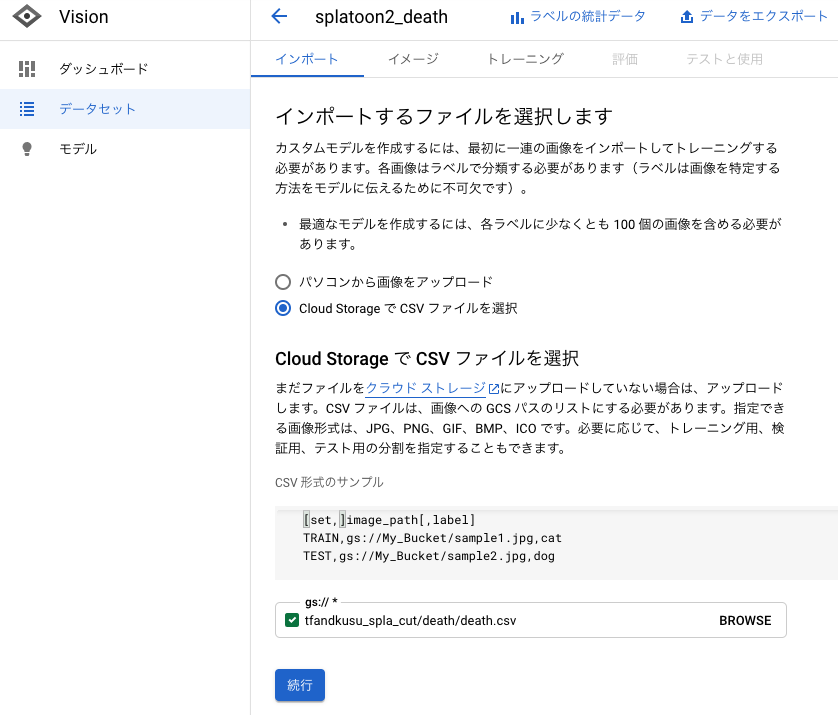
Google AutoML Visionで分類モデルを作成する
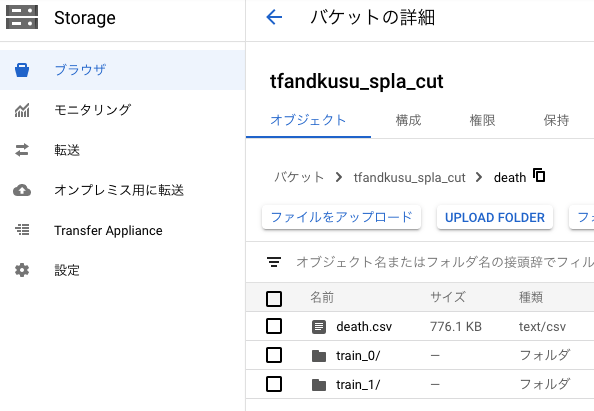
Google Cloud Storageに画像とCSVをアップロードする
まずは分類済みの画像ディレクトリ
train_0とtrain_1をGoogle Cloud Storageにアップロードします。
次に各画像のGoogle Cloud StorageのURLと分類ラベルを行にしたCSVファイルを生成します。2列目がdeathだとやられたシーンの画像、otherだとそれ以外のシーンの画像になります。death.csvgs://tfandkusu_spla_cut/death/train_1/frame00029.jpg,death gs://tfandkusu_spla_cut/death/train_1/frame00044.jpg,death gs://tfandkusu_spla_cut/death/train_1/frame00048.jpg,death 略 gs://tfandkusu_spla_cut/death/train_0/frame00000.jpg,other gs://tfandkusu_spla_cut/death/train_0/frame00001.jpg,other gs://tfandkusu_spla_cut/death/train_0/frame00002.jpg,other 略そしてCSVファイルもGoogle Cloud Storageにアップロードします。
最終的にはこのようになりました。
CSV作成スクリプト
CSVを作成するスクリプトはこちらです。
train_csv.pyimport os train_1 = 'train_1' train_0 = 'train_0' train_1_images = [] train_0_images = [] for name in os.listdir(train_1): if name.endswith('.jpg'): train_1_images.append(name) for name in os.listdir(train_0): if name.endswith('.jpg'): train_0_images.append(name) train_1_images.sort() train_0_images.sort() for name in train_1_images: print("TRAIN,gs://tfandkusu_spla_cut/death/train_1/%s,death" % name) for name in train_0_images: print("TRAIN,gs://tfandkusu_spla_cut/death/train_0/%s,other" % name)このように実行します。
python train_csv.py > death.csvGoogle AutoML Visionにインポートする
分類済みの画像を学習して、やられたシーンの画像とそれ以外のシーンの画像を分類するモデルをGoogle AutoML Visionを使って作成します。
Google Cloud Platformの左側のメニューからVision → ダッシュボードを選びます。
AUTOML APIを有効にします。
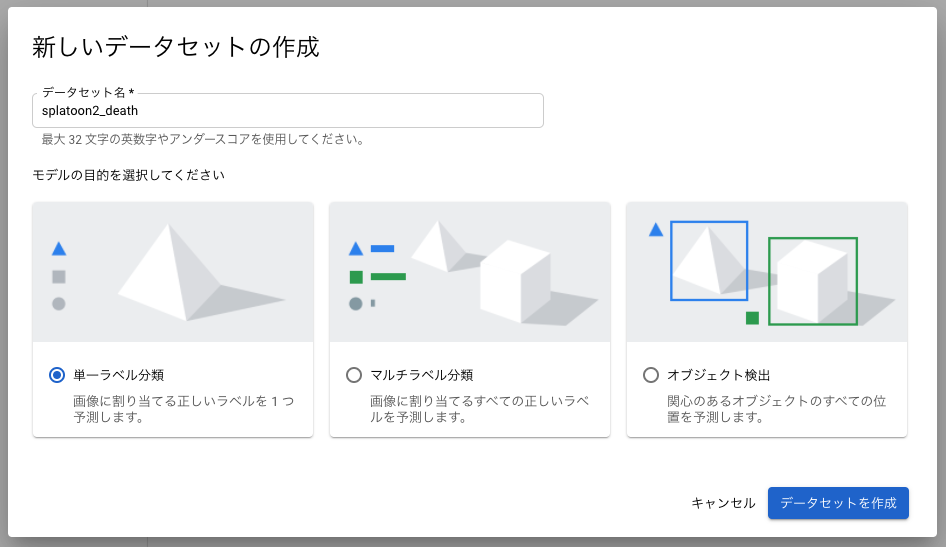
単一ラベル分類として新しいデータセットを作成します。
作成したCSVファイルのGoogle Cloud StorageのURLを指定することでインポートします。
インポートには時間がかかるのでしばらく待ちます。
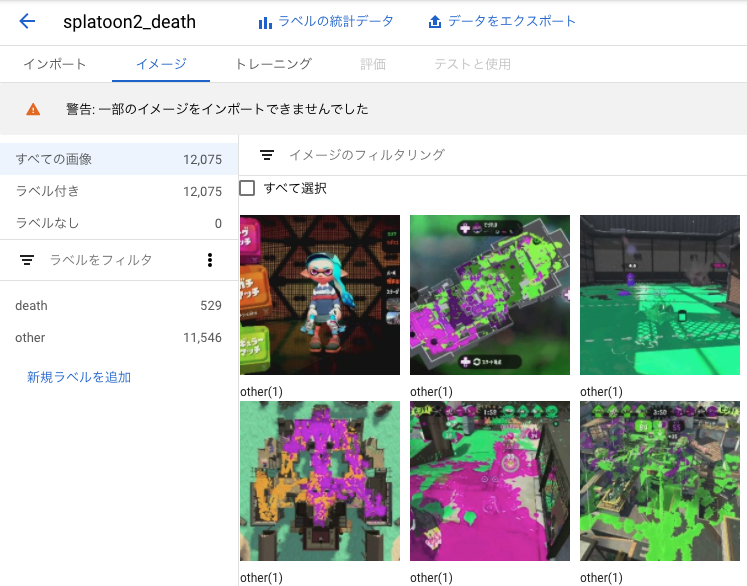
インポートが完了しました。
一部の画像はエラーが発生してしまいインポート出来ませんでした。原因はよく分からないですが、98.7%の画像はインポートに成功したのでそのまま進みます。
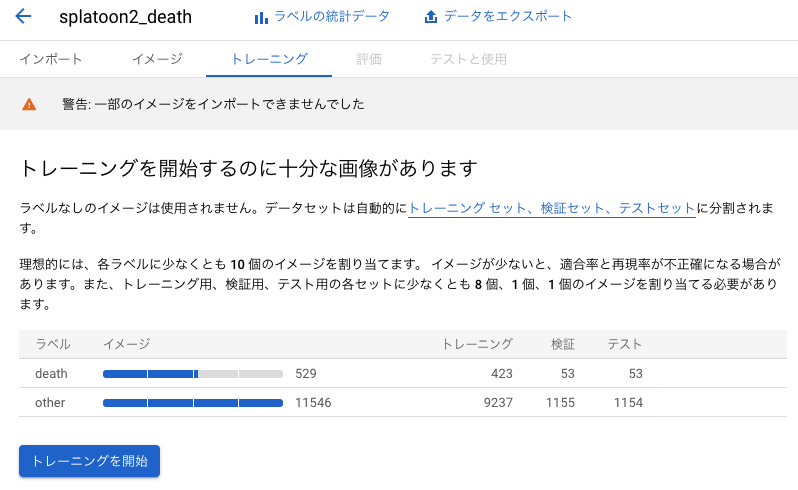
学習を行う
トレーニングタブを開くと、自動で画像がトレーニング用、テスト用、検証用に分けられていることが分かります。その3種類の違いはこちらで解説されていました。トレーニングを開始ボタンを押します。
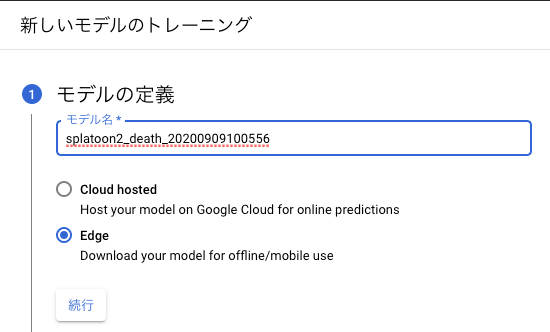
クラウドかエッジかを聞かれます。今回はあまりお金をかけないように手元のPCで分類したいのでエッジにします。
処理時間を優先するか精度を優先するか聞かれますが、モバイル端末で分類する予定はないので精度重視で行きます。
ノード時間予算もおすすめの10 node hoursにします。
料金はこちらです。
トレーニングを開始ボタンでトレーニングが開始されます。
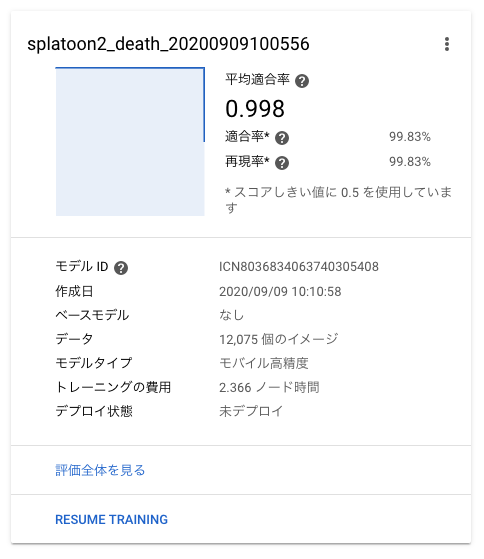
3時間ほどで学習モデルができて評価も出ました。
実際かかったノード時間は2.366でした。40までの無料枠があるようなので、その請求は来ませんでした。評価を確認する
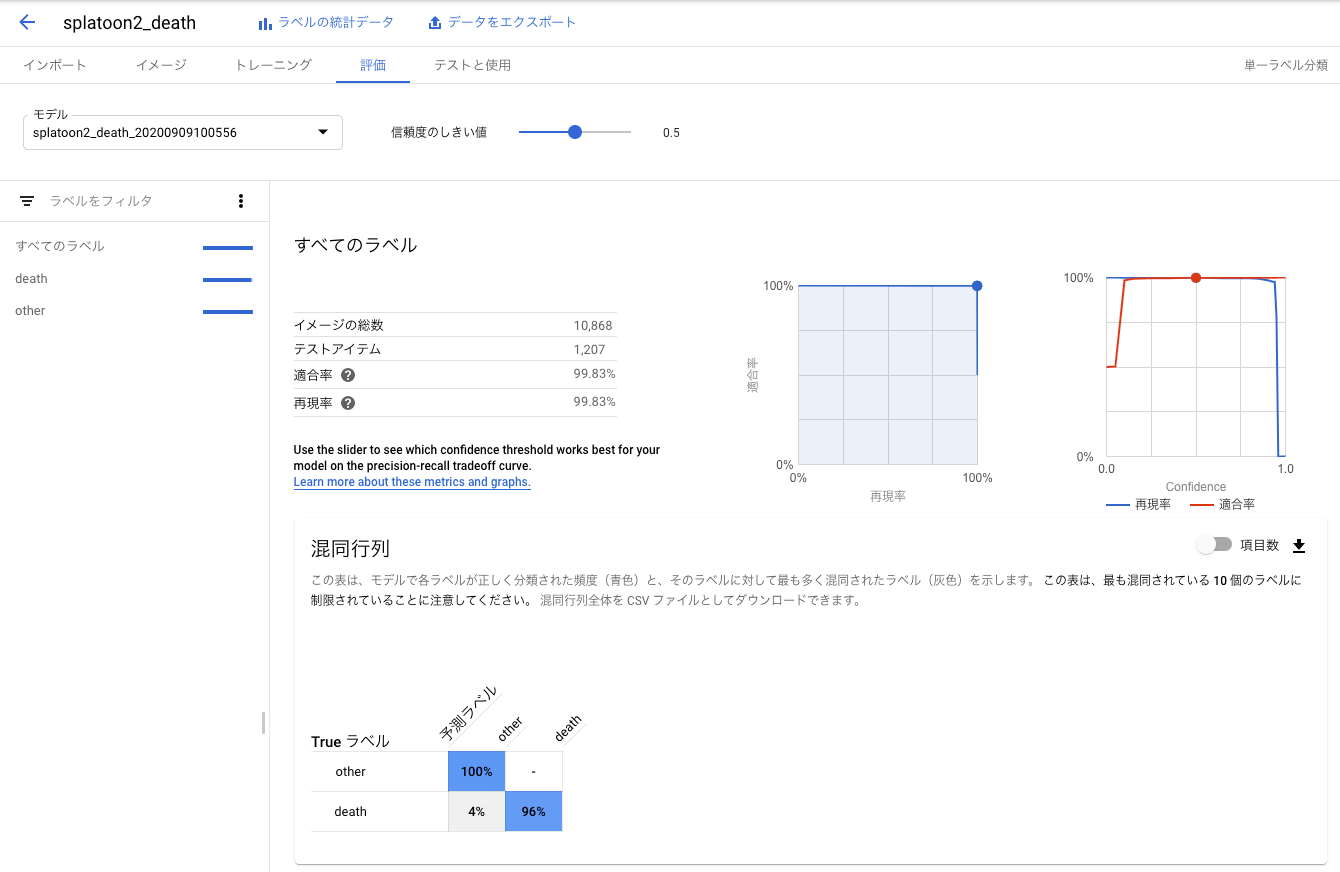
混同行列を見ると、やられたシーンは4%の確率でそれ以外のシーンと誤分類されますが、それ以外のシーンがやられたシーンに誤分類されることはないようです。使用目的であるやられたシーンの数秒前からの動画の切り出しに適用すると、25回やられたら24回はやられたシーンの動画を切り出せるので、実用的な精度だと思います。
学習モデルをダウンロードする
テストと使用タブからTF Liteを選びます。
出力先Google Cloud StorageのURLを指定します。
出力先の深めの階層に学習モデルのファイルがあるので、
dict.txtとmodel.tfliteをダウンロードして、modelディレクトリに格納しました。
TensorFlow Liteを使って、やられたシーンを切り出す
入力層、出力層の形を確認する
まずはAutoML Visionによって作られたモデルの入力層、出力層の形を確認します。
TensorFlow Liteの使い方はこちらの記事が参考になりました。初心者に優しくないTensorflow Lite の公式サンプル
まずはモデルを読み込みます。
import tensorflow as tf interpreter = tf.lite.Interpreter(model_path='model/model.tflite')入力層の形を確認します。(ここからJupyter Labを使いました。)
interpreter.get_input_details()[{'name': 'image', 'index': 0, 'shape': array([ 1, 224, 224, 3], dtype=int32), 'shape_signature': array([ 1, 224, 224, 3], dtype=int32), 'dtype': numpy.uint8, 'quantization': (0.007874015718698502, 128), 'quantization_parameters': {'scales': array([0.00787402], dtype=float32), 'zero_points': array([128], dtype=int32), 'quantized_dimension': 0}, 'sparsity_parameters': {}}](1, 224, 224, 3)の4次元配列を入力することが分かりました。学習画像はフルHDの4/1 - 480×270の大きさに縮小しましたが、さらに縮小する必要があるそうです。
出力層の形を確認します。
interpreter.get_output_details()[{'name': 'scores', 'index': 172, 'shape': array([1, 2], dtype=int32), 'shape_signature': array([1, 2], dtype=int32), 'dtype': numpy.uint8, 'quantization': (0.00390625, 0), 'quantization_parameters': {'scales': array([0.00390625], dtype=float32), 'zero_points': array([0], dtype=int32), 'quantized_dimension': 0}, 'sparsity_parameters': {}}](1, 2)の2次元配列を出力することが分かりました。2種類に分類するモデルなので要素数が2になります。
次にdict.txtファイルを見て、やられたシーンとそれ以外のシーンのインデックスを確認します。cat model/dict.txtother deathこのモデルの出力は
[[243, 13]]のように0番目の方が大きいと、それ以外のシーン、
[[ 16, 240]]ように1番目の方が大きいと、やられたシーンになることが分かりました。
やられたシーンを切り出す。
0.5秒に1フレーム推論して、やられたフレームを見つけたら、その8秒前からやられたフレームまで動画を切り出します。切り出し後は8秒間推論をスキップします。動画の切り出しにはffmpegコマンドを使用しました。
ライブラリをインポートします。tqdmはプログレス表示用のライブラリです。
import subprocess import csv import numpy as np import cv2 import tensorflow as tf from tqdm import tqdm動画切り出し設定です。
# 切り出し元動画パス src_movie = 'test.mp4' # 切り出し秒数 cut_duration = 8 # 切り出し終了時間からこの秒数は切り出し開始しない death_duration = 8TensorFlow Liteの初期化を行います。
interpreter = tf.lite.Interpreter(model_path='model/model.tflite') interpreter.allocate_tensors() input_details = interpreter.get_input_details() output_details = interpreter.get_output_details()切り出し開始秒数をCSVファイルに書き出します。
# 書き出しCSVファイル with open('cut_time.csv', 'w') as f: writer = csv.writer(f) # 動画を読み込む cap = cv2.VideoCapture(src_movie) # フレーム数を取得 frame_count = int(cap.get(cv2.CAP_PROP_FRAME_COUNT)) # 1秒あたりフレーム数を取得 fps = cap.get(cv2.CAP_PROP_FPS) # 0.5秒に1回予測する skip = fps / 2 # フレーム i = 0 # 切り出し開始しないカウントダウン no_start = 0 for i in tqdm(range(frame_count)): ret, img = cap.read() if ret: if i % skip == 0 and no_start == 0: # フレームを予測する大きさに縮小 shrink = cv2.resize( img, (224, 224), interpolation=cv2.INTER_CUBIC) # 4次元に変換する input_tensor = shrink.reshape(1, 224, 224, 3) # それをTensorFlow liteに指定する interpreter.set_tensor(input_details[0]['index'], input_tensor) # 推論実行 interpreter.invoke() # 出力層を確認 output_tensor = interpreter.get_tensor(output_details[0]['index']) # やられたシーン判定 scene = np.argmax(output_tensor) if scene == 1: # やられたシーンの時は # 切り出し開始秒数を出力 ss = i - cut_duration * fps if ss < 0: ss = 0 writer.writerow(["%d.%02d" % (ss/fps, 100 * (ss % fps)/fps)]) # シーン判定をしばらく止める no_start = fps * death_duration if no_start >= 1: no_start -= 1 else: breakこのようなCSVファイルができあがります。
cut_time.csvcut_time.csv 511.00 544.50 561.00 // 略CSVファイルを読み込んで切り出し開始時刻配列を作ります。
sss = [] with open('cut_time.csv') as f: reader = csv.reader(f) for row in reader: sss.append(row[0])subprocesモジュールでffmpegコマンドを呼び出して、切り出します。
for i in tqdm(range(len(sss))): ss = sss[i] command = "ffmpeg -y -ss %s -i %s -t %d -c copy extract/scene%03d.mp4" % (ss, src_movie, cut_duration, i) subprocess.run(command, shell=True)実用性のある精度か確認する
ガチマッチに2時間潜り録画しました。私は癖としてやられるとすぐにマップを開いてしまうのですが、そうすると「○○でやられた」表示が出なくなります。そこは注意しました。
↑やられたら、この表示を必ず出す。ikaWidget2で各試合のデス数を確認して合計してみたところ132回デスしていましたが、このシステムはその132回をすべて正しく切り出していました。十分に実用的な精度です。
学習済みモデルと動画切り出しのJupyter Notebook
学習済みモデルとそれを使って動画を切り出すスクリプトはJupyter Notebook形式でGithubに置きました。
https://github.com/tfandkusu/splatoon2_movie_death補足
ローラーでひかれたケース
ローラーの転がしに巻き込まれてやられたときは「ローラーでひかれた!」という表示になるというご指摘がありました。そのパターンはめったに無いため学習データやテストデータには含まれていませんでした。
「やられた」で検出してるけど「ローラーにひかれた」とかもなかったっけ。 https://t.co/LSWUnuq7zF
— もおあき (@moooaki) September 12, 2020そこでYouTubeから、ななとさんのコロコロ縛りプラベ動画をお借りして検証してみました。
https://youtu.be/FIMpiH9SkBo0.5秒に1回のフレーム画像の予測結果をすべて目視で確認してみたところ、混同行列はこのようになりました。
やられたシーンに予測された それ以外のシーンに予測された 正解はやられたシーン 49 1 正解はそれ以外のシーン 0 2,071 ローラーによくひかれる人にとっても、実用的な精度であることが確認できました。










- 投稿日:2020-09-12T15:36:48+09:00
GPU性能比較 Colabo vs GCP vs GTX1070
概要
仕事やCouseraのコーディング演習のモデルは、Google ColaboratoryやGCP(Google Cloud Platform)のVMでトレーニングしています。
また、Toy datasetを使って、自分のゲーミングPCでモデルの動作確認もやったりします。
でも、どうもGPUの違いでFit()の実行時間が変わる体験ができず、スペックが一番低いゲーミングPCがサクサク動いているように感じる。
いつもハイパパラメータを調整しながらなので、どの環境でもモデルが全く同じだったためしがなく、まぁそのせいだろう、と思っていました。
今日はCNNのモデルとTraining datasetを固定して、環境間でどれほどFit()周りの実行速度が変わるか測ってみます。
YouTubeなんかで、よくグラボ間でゲーム中のTPS比較なんかやっているので、その深層学習版をちょっとやってみようかと。たいしたもんじゃないけど。使用モデル
よくありがちな犬猫Clasification用CNNを使いました。従い、loss='binary_crossentropy'です。
ハイパパラメータは指定していないのでKerasデフォルトです。
下記を参考にColaboではTPUでも測ってみたかったけど、エラーがどうしても取れなかった。
https://www.tensorflow.org/guide/tpu
ImageDataGeneratorでFit()にデータを渡すあたりが、どうもサポートされてないっぽいので諦めた。Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d (Conv2D) (None, 148, 148, 32) 896 _________________________________________________________________ max_pooling2d (MaxPooling2D) (None, 74, 74, 32) 0 _________________________________________________________________ conv2d_1 (Conv2D) (None, 72, 72, 64) 18496 _________________________________________________________________ max_pooling2d_1 (MaxPooling2 (None, 36, 36, 64) 0 _________________________________________________________________ conv2d_2 (Conv2D) (None, 34, 34, 128) 73856 _________________________________________________________________ max_pooling2d_2 (MaxPooling2 (None, 17, 17, 128) 0 _________________________________________________________________ conv2d_3 (Conv2D) (None, 15, 15, 128) 147584 _________________________________________________________________ max_pooling2d_3 (MaxPooling2 (None, 7, 7, 128) 0 _________________________________________________________________ dropout (Dropout) (None, 7, 7, 128) 0 _________________________________________________________________ flatten (Flatten) (None, 6272) 0 _________________________________________________________________ dense (Dense) (None, 512) 3211776 _________________________________________________________________ dense_1 (Dense) (None, 1) 513 ================================================================= Total params: 3,453,121 Trainable params: 3,453,121 Non-trainable params: 0 _________________________________________________________________Training dataset
Kegoleで犬猫を探しましたが枚数が多いものしかなく、以前演習で使用した各1000枚の犬猫を使いました。
データは、
・そのままImageDataGenerator経由でFit()に渡すケース
・Augmentation*をImageDataGeneratorで施したものを渡すケース
の2ケースで計測しています。
ImageDataGeneratorの画像加工処理にはおそらくCPUを使うと思われ、CPUの比較も同時に行えるかと思ったからです。
ファイルはアクセスオーバヘッドを同じにするため、各環境ともroot/tmp直下に置きました。
*Augmentation:元画像を傾けたり、ずらしたり、左右反転させたり、色合いを変えたりしてトレーニングを堅牢にする機能で下記のように書きます。train_datagen = ImageDataGenerator( rescale=1./255, rotation_range=40, width_shift_range=0.2, height_shift_range=0.2, shear_range=0.2, zoom_range=0.2, horizontal_flip=True, fill_mode='nearest')計測方法
epoch=100で、1回実行した時間で比較します。
コード中、モデルを定義するところからFit()が終わるところまで、下記のようにtimeで囲み計測しています。import time start = time.time() ## 比較対象コード end = time.time() print(end-start, 'sec')比較環境
Google Colaboratory Pro
ColaboはProに変更してから、安定してV100が割り当たってます。
!nvidia-smi +-----------------------------------------------------------------------------+ | NVIDIA-SMI 450.66 Driver Version: 418.67 CUDA Version: 10.1 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla V100-SXM2... Off | 00000000:00:04.0 Off | 0 | | N/A 36C P0 24W / 300W | 0MiB / 16130MiB | 0% Default | | | | ERR! | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+ !cat /proc/cpuinfo processor : 0 / 1 (2processorsみたい) vendor_id : GenuineIntel cpu family : 6 model : 85 model name : Intel(R) Xeon(R) CPU @ 2.00GHz stepping : 3 microcode : 0x1 cpu MHz : 2000.136 cache size : 39424 KBGCP
VMのCPUは8core、メモリ30BG、GPUはTesla T4 1個を借りています。
!nvidia-smi +-----------------------------------------------------------------------------+ | NVIDIA-SMI 418.87.01 Driver Version: 418.87.01 CUDA Version: 10.1 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | |===============================+======================+======================| | 0 Tesla T4 Off | 00000000:00:04.0 Off | 0 | | N/A 53C P0 28W / 70W | 0MiB / 15079MiB | 0% Default | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: GPU Memory | | GPU PID Type Process name Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+ !cat /proc/cpuinfo processor : 0 ~ 7 (8processors) vendor_id : GenuineIntel cpu family : 6 model : 79 model name : Intel(R) Xeon(R) CPU @ 2.20GHz stepping : 0 microcode : 0x1 cpu MHz : 2199.998 cache size : 56320 KBゲーミングPC
3,4年前に機械学習勉強用に購入しました。
nvidia-smi +-----------------------------------------------------------------------------+ | NVIDIA-SMI 440.33.01 Driver Version: 440.33.01 CUDA Version: 10.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | |===============================+======================+======================| | 0 GeForce GTX 1070 On | 00000000:01:00.0 On | N/A | | 33% 44C P2 37W / 151W | 7928MiB / 8117MiB | 20% Default | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: GPU Memory | | GPU PID Type Process name Usage | |=============================================================================| | 0 1016 G /usr/lib/xorg/Xorg 122MiB | | 0 1324 G /usr/bin/gnome-shell 97MiB | | 0 17963 G ...AAAAAAAAAAAACAAAAAAAAAA= --shared-files 193MiB | | 0 26359 C ...e/imo/anaconda3/envs/tf-gpu2/bin/python 7509MiB | +-----------------------------------------------------------------------------+ cat /proc/cpuinfo processor : 0 ~ 7 (8processors) vendor_id : GenuineIntel cpu family : 6 model : 158 model name : Intel(R) Core(TM) i7-7700 CPU @ 3.60GHz stepping : 9 microcode : 0xd6 cpu MHz : 800.047 cache size : 8192 KB結果
100epockの実行速度は下表のとおりで、体感してたようにゲーミングPCが速かった。
Augmentation入れるとFit()だけのときと比べてどの環境でも倍の時間がかかるようです。
この結果のみでは何が原因なのか断定できません。
Environment Colaboratory Pro GCP AI Platform Gaming PC GPU Spec Tesla V100-SXM2 16GB Tesla T4 15GB GTX 1070 8GB CNN 900.12 sec 723.94 sec 533.10 sec CNN w/ Augmentation 1838.30 sec 1504.83 sec 1088.91 sec VM上のリソース(GPUとメモリ)はシステムで複数ユーザにアサインされフルに使用できないからしかたない。
Colabo ProのGPUはハイエンドのV100だけど、かなりのユーザでリソースシェアしているんでしょう。
まあ基本タダ(Proは$99/月)で使わせて頂いているので、文句は言えない。
GCPは微妙。100円ちょっと/時間も払っているのに少し納得いかないかな。会社が払うからいいんだけど。結論
使用時間の制約を一切受けないグラボが刺さった手元のPCでモデル開発するのが一番ってことでしょう。
RTX3080が欲しい… 薄給だから値ごろになるまでお金ためよう…
備考
当然ですが、LossもAccuracyも環境間でほぼ同じでした。
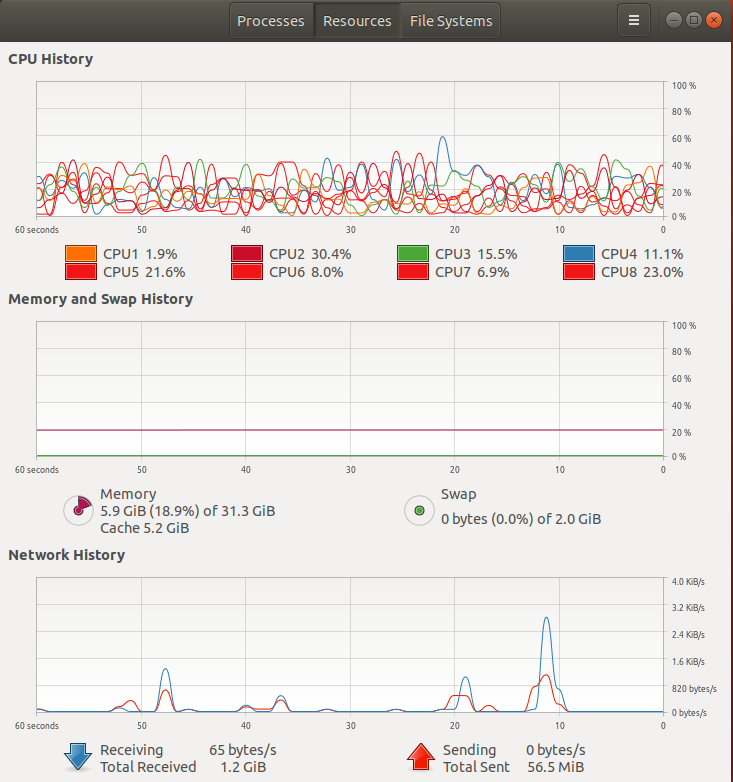
また、ゲーミングPCでFit()中のCPU負荷等は下図です。
今回のCNNはImageDataGeneratorを使ったから、メモリ使用量は抑えられているみたい。
LSTMのトレーニングには時系列データ全部をいっぺんにモデルに晒す必要があるから16GB以上のシステムメモリを使っていたけど。

- 投稿日:2020-09-12T04:46:33+09:00
[TensorFlow 2.x (tf.keras)] 乱数シードを固定して再現性を向上
Tensorflow 2.x(tf.keras)で乱数シードを固定する方法を紹介します。実行環境
- Python: 3.6 | 3.7
- Tensorflow: 2.0 | 2.1 | 2.2 | 2.3
- GitHub Actionsでテスト
テストに使用したコードはこちらにあります。
背景
機械学習の開発において、「学習を再現可能にしたい」や「テスト用に、モデルの初期値を固定したい」などの要求があります。
重みの初期値の違いは学習結果に影響を及ぼすので、初期値を固定できるとこれらの悩みの解消に役立ちそうです。重みの初期値生成は乱数を利用してます。乱数は乱数シードに基づいて生成されています。TensorFlowはデフォルトでは乱数シードは可変です。よって、毎回異なる初期値をもったモデルが生成されてしまいます。
そこで今回は、乱数シードを固定することで再現性の向上を目指します。乱数シードの固定
TensorFlowに加えて、NumPy、Pythonの組み込み関数のシードも固定します。
まとめると以下の様な乱数固定関数が実装できます。import tensorflow as tf import numpy as np import random import os def set_seed(seed=200): tf.random.set_seed(seed) # optional # for numpy.random np.random.seed(seed) # for built-in random random.seed(seed) # for hash seed os.environ["PYTHONHASHSEED"] = str(seed)これは、以下の様に使用します。ただし、TensorFlowの乱数シード固定だけで十分な場合は、
set_seedをtf.random.set_seedに置き換えてください。set_seed(0) toy_model = tf.keras.Sequential( tf.keras.layers.Dense(2, input_shape=(10,)) ) # 何らかの処理... # モデルを再現 set_seed(0) reproduced_toy_model = tf.keras.Sequential( tf.keras.layers.Dense(2, input_shape=(10,)) )
reproduced_toy_modelは先に生成したモデルtoy_modelと同じ初期値 (重みの) を持ちます。つまり、再現されています。
set_seedを使用しなければ、reproducible_toy_modelとtoy_modelは全く異なる初期値をもってしまい、再現性が損なわれてしまいます。
tf.keras.Sequentialだけではなく、Functional APIやSubClassを利用することもできます。乱数シードの固定方法 (
set_seed) をもう少し整理します。
tf.random.set_seedについて
tf.random.set_seedの挙動は少し注意が必要です。まず、
tf.random.set_seedを使用した後で、乱数を使用する関数(tf.random.uniform: 一様分布からランダムに値をサンプリング) を何度か使用してみます。tf.random.set_seed(0) tf.random.uniform([1]) # => [0.29197514] tf.random.uniform([1]) # => [0.5554141] (異なる値!) tf.random.uniform([1]) # => [0.1952138] (異なる値!!) tf.random.uniform([1]) # => [0.17513537] (異なる値!!!)それぞれ異なる値が出力されました。このままでは再現性がなさそうです。
しかし、改めてtf.random.set_seedを以下の様に使います。tf.random.set_seed(0) tf.random.uniform([1]) # => [0.29197514] (A) tf.random.uniform([1]) # => [0.5554141] (B) tf.random.set_seed(0) tf.random.uniform([1]) # => [0.29197514] (Aの再現) tf.random.uniform([1]) # => [0.5554141] (Bの再現)このように
tf.random.set_seedが呼ばれた場所を起点にして出力が再現されます(tf.random.uniformはランダムに値を出力する関数にも関わらず)。なので、例えば、モデルインスタンス生成 (Sequentialやfunctional APIやSubClassの利用) の直前に
tf.random.set_seedを呼ぶようにすると、生成されたモデルは毎回同じ初期値をもってくれます。補足
TensorFlowには引数にseedを渡せるlayerや関数があります。
しかし、layerやlayerに渡すinitializerの引数を明示的に指定するのはモデルが大きくなってくるとあまり現実的な方法ではないと思います。
また、今回紹介した
tf.random.set_seedを併用しないとうまく動作しないものがあります。なので、固定したい箇所が少ない場合でも、まずは
tf.random.set_seedを試してみて下さい。まとめ
TensorFlow 2.x (tf.keras) では、
tf.random.set_seedを使って乱数シードを固定できます。特に重みの初期値が同じモデルを毎回生成できるようになるので、再現性の向上が期待できます。
Ref
- TensorFlow official document: tf.random.set_seed
- keras (tf.kerasじゃない方)の乱数固定: kerasで学習が再現できない人へ