- 投稿日:2020-09-12T22:12:06+09:00
ElasticBeanstalk(Amazon Linux2)+RDS(MariaDB)でDjangoアプリをデプロイ
こんにちは
初めて記事を投稿します。
タイトルの方法でWebアプリのデプロイを行ったので,備忘録として残しておきます。
ElasticBeanstalkは長いので以後EBと書きます。環境
windows10(2004)
Python3.8
Django3.1.1この記事を残す意味
公式ガイドの方法に従ってデプロイを進めていくのですが,この通りにやると本番環境ではいくつかの問題が生じます。
問題点
データベースにSQLite3を用いることになる
本番環境で用いるデータベースとしてSQLiteは適切ではありません。
テスト環境においても,ディレクトリごとデプロイする仕様上,sqliteファイルをignoreしない限り,デプロイするたびにローカルのデータに上書きされ,オンラインで追加したデータが消えてしまいます。コンソール操作ができない
SQLiteを使う上では直面しない問題という点で一つ目の問題点と関連しています(ローカルで変更を加えてSQLiteファイルをアップロードすれば一応動く)。
Djangoでは「Python manage.py hoge」というコマンドでデータベースや静的ファイルに対する操作を行うことが多いですがそういった操作に関するサポートが行われていません。.gitignore,.ebignoreを設定していない
多くの方がGitおよびGitHub管理しているアプリケーションをデプロイするのではないでしょうか。
.gitignoreが設定されていると意図しない挙動になり,別に.ebignoreを設定する必要があります。OSが違う
公式ガイドの方法はPython3.6の少し古いプラットフォームを用いており,これはAmazon Linuxです。本ページはPython3.7(Amazon Linux2)を使ったデプロイの方法になります。これらを解決する方法をまとめます。
まだできていないこと
同じところで詰まっている方が読んで,「できてねーのかよ!」となるのを防ぐために先に書いておきます。わかる方がいたらコメントで教えてください。
一通り使える状態までデプロイしましたが,SSHを使ったコンソール操作ができていません。
EBのPythonプラットフォームのAmazon Linux2ではデプロイしたファイルが/var/app/currentに設置されることまでは分かったのですが,そこにあるmanage.pyを叩いても動きません。(ちなみにAmazon Linuxでは/opt/python/current/appです。)
直接コマンドを叩かない,後述する方法でmigrateなどを行っています。実際の手順
大まかな手順はこんな感じです。
- Djangoアプリの作成
- EB CLIのインストールと初期設定&デプロイ
- 外部RDSサーバの設置とセキュリティグループの設定
- DjangoアプリのRDS設定
各手順での細かい操作は省きます。公式ガイドで詰まりそうな部分をかいつまんで書きます。
Djangoアプリの作成
EBでデプロイしようとしてこの記事にたどり着く方は,ここで困ることはそうないと思います。
ここでの注意点は,venvとrequirements.txtを使って環境を構築すべきという点です。
EBでは,アプリケーションとそれに紐づく環境が管理されます。環境の大枠は,次項で説明するプラットフォームの選択(ここではPython3.7)で決まりますが,その場合必要なPythonライブラリはrequirements.txtを参照して環境構築時に自動でインストールされます。
そのため,適切なrequirements.txtが存在しないとデプロイを完了できません。EB CLIのインストールと初期設定&デプロイ
EB CLIはpipを用いてインストールします。
Pythonとpipの環境さえあれば,pip install awsebcli --upgrade --userを実行するだけです。
詳しくは公式ガイドに記載されています。公式の手順にのっとって設定すると,
.gitignoreのファイルに設定されているものが無視してデプロイされます。
Djangoで開発を行っている方で,DEBUGやSECRET_KEYを外部ファイルにして.gitignoreに書いている方は多いと思います。
EBでは.gitignoreを読み込んでファイルを無視する設定になっているので,代わりに.ebignoreを同じディレクトリに作成します。
.ebignoreがあるときは,それに従ってファイルを無視します。(.gitignoreは読まれません。)
venvなど,本当に無視してデプロイを行ってよいファイルを設定しましょう。ここまででSQLiteを使った状態のアプリをデプロイして動作確認することをおすすめします。
外部RDSサーバの設置とセキュリティグループの設定
EBにはRDSサーバーを追加する設定がありますが,この方法はAWS公式からも推奨されていません。
EBによって追加されたRDSインスタンスはEB環境の終了とともに削除されてしまうためです。
ここでは,手動でRDSインスタンスを立てて接続します。公式ガイドも参考にしてください。
手順
AWSマネジメントコンソールで,RDSを開きます。
[データベースの作成]を選択してください。
このデータベースの作成には必ず標準作成を選択してください。
プランはどれでも構いませんが,接続先を変更することは難しくないため,とりあえず無料利用枠をおすすめします。
[Additional configuration (追加の設定)]の[Initial database name (初期データベース名)] に 任意の名前を設定します。ここでは公式ガイドに従って"ebdb"とします。
セキュリティグループは,このインスタンスのために自由に設定が行えるものであればなんでも構いません。不安な方は新規に作成してください。
マスターユーザとそのパスワードはあとで使用しますので覚えておいてください。AWSマネジメントコンソールで,VPCを開きます。
左側のペインからセキュリティグループを選択し,先ほどRDSにアタッチしたものを選択してください。
インバウンドルールで,設定したDBの通信許可を行います(自分の場合はMysqlでポート3306です)。送信元として許可するセキュリティグループは,EBによって生成されたEC2インスタンス用のセキュリティグループです(これはEBによってEC2インスタンスに自動的にアタッチされます)。
awseb-e-から始まって,AWSEBSecurityGroupが含まれるものです。AWSEBLoadBalancerSecurityGroupが含まれているものもEBによて生成されますが,そちらはELB用のものですので間違えないようにします。DjangoアプリのRDS設定
最後にDjangoアプリ側にRDSへの接続設定を行います。
参考になる公式ガイドはこちらです。
Djangoアプリのsettings.pyを開いて,以下を追加してください。私はDEBUGがFalseの時の設定として書きました。[AppName]/settings.pyif 'RDS_HOSTNAME' in os.environ: DATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', 'NAME': os.environ['RDS_DB_NAME'], 'USER': os.environ['RDS_USERNAME'], 'PASSWORD': os.environ['RDS_PASSWORD'], 'HOST': os.environ['RDS_HOSTNAME'], 'PORT': os.environ['RDS_PORT'], } }見ていただいてわかる通り,環境変数を設定する必要があります。
EBのマネジメントコンソールから[環境プロパティ]に以下を追加してください。デフォルトではPYTHONPATHのみが設定されています(下表は公式ガイドから拝借・一部改変)。
プロパティ名 説明 プロパティ値 RDS_HOSTNAME DB インスタンスのホスト名。 Amazon RDS コンソールの [Connectivity & security (接続とセキュリティ)] タブ: [Endpoint (エンドポイント)]。 RDS_PORT DB インスタンスが接続を許可するポート。デフォルト値は DB エンジンによって異なります。(MySQL系は3306) Amazon RDS コンソールの [Connectivity & security (接続とセキュリティ)] タブ: [Port (ポート)]。 RDS_DB_NAME 任意のデータベース名 (今回はebdb) Amazon RDS コンソールの [設定] タブ: [DB 名]。 RDS_USERNAME データベース用に設定したユーザー名。 Amazon RDS コンソールの [設定] タブ: [マスターユーザー名]。 RDS_PASSWORD データベース用に設定したパスワード。 Amazon RDS コンソールでは参照できません。 加えて,公式ガイドにはありませんが,mysqlclient周りの設定を行う必要があります。
requirements.txtにmysqlclientを追加します。バージョンは依存関係によるかもしれませんが,私の場合はmysqlclient==2.0.1で問題なく動いています。
手動でデプロイしたことがある方ならお分かりかと思いますが,mysqlclientのインストールにはmysqlの開発パッケージなどが必要です。
デプロイ時に環境にそういったものを自動でインストールしてもらわなければ,pip install時にエラーが発生してデプロイに失敗します。そこで[ProjectRoot]/.ebextensionsに01_packages.configを以下の内容で追加します。01_packages.configpackages: yum: python3-devel: [] mariadb-devel: []これでEBがデプロイ時にパッケージをインストールしてくれるので,問題なくmysqlclientのインストールが通ります。
これで,RDSには接続できると思いますが,マイグレーションができません。
マイグレーションを行うには,先ほどと同様,デプロイ時にEBにコマンドを実行してもらう必要があります。
[ProjectRoot]/.ebextensionsに02_python.configを以下の内容で追加します。02_python.configcontainer_commands: 01_migrate: command: "source /var/app/venv/[*]/bin/activate && python3 manage.py migrate --noinput" leader_only: true 02_collectstatic: command: "source /var/app/venv/[*]/bin/activate && python3 manage.py collectstatic --noinput"[*]の部分は環境によって変わるようなのでSSHするなりで調べてください。
これで,デプロイ時にコマンドが実行され,マイグレーションと静的ファイルの収集が自動的に行われます。課題点
最初にも書きましたが,手動でmanage.pyを叩けません。
createsuperuserは,create_superuserメソッドを叩くカスタムコマンド(createsu.py)を用意して,02_python.configで叩いています。
同じ方法でやりたい方は,02_python.configを以下のように変更してください。02_python.configcontainer_commands: 01_migrate: command: "source /var/app/venv/staging-LQM1lest/bin/activate && python3 manage.py migrate --noinput" leader_only: true 02_collectstatic: command: "source /var/app/venv/staging-LQM1lest/bin/activate && python3 manage.py collectstatic --noinput" 03_createsu: command: "source /var/app/venv/staging-LQM1lest/bin/activate && python3 manage.py createsu"終わり
以上です。
EBを使うとELBを自動で設定してくれたり,eb deployコマンドでデプロイを更新できたり,過去のバージョンに簡単に戻せるので便利ですね。
できていないことの解決策,質問,間違いの指摘など,コメントをお待ちしています。
- 投稿日:2020-09-12T20:47:11+09:00
AWS考试笔记(CLF-C01)
概要
CLF-C01 - AWS Certified Cloud Practitioner - Chinese Simplified (CHS)
学习: 1.edx上清掉了AWS Developer Series的3个考试; 2.书看掉了《AWS認定クラウドプラクティショナー》
刷题: examtopics常考概念
Amazon Macie
- 一句话:梅西,管理隐私数据
- Which AWS service provides the ability to detect inadvertent data leaks of personally identifiable information (PII) and user credential data?
AWS Trusted Advisor
- 一句话:实时监控,指导你该干啥,功能和sourceclear差不多
- Which tool can be used to monitor AWS service limits?
AWS Artifact
- 一句话:合规情报
- What is the best resource for a user to find compliance-related information and reports about AWS?
Amazon S3
- 一句话:相当于dragon的功能,注意区别三种模式:Standard, One Zone-Infrequent Access, Glacier
- Which Amazon S3 storage class is optimized to provide access to data with lower resiliency requirements, but rapid access when needed such as duplicate backups? → standard
Amazon KMS
- 一句话:相当于CKMS
- A user would like to encrypt data that is received, stored, and managed by AWS CloudTrail. Which AWS service will provide this capability?
AWS OpsWorks
- 一句话:自动化部署,提供 Chef 和 Puppet 的托管实例
- Which AWS service is used to automate configuration management using Chef and Puppet?
AWS Total Cost of Ownership
- 一句话:和自己建立系统做比较,知道自己实惠了多少
- estimate savings when comparing the AWS Cloud to an on-premises environment
- What can assist in evaluating an application for migration to the cloud? (Choose two.) → AWS Professional Services,AWS Partner Network (APN)
Amazon Polly
- 一句话:文字转语音(这都会出题。。)
- Which AWS service can be used to turn text into life-like speech?
Amazon DynamoDB
- 一句话:NOSQL相当于Casssandra, 可以auto-scale
- Which AWS services may be scaled using AWS Auto Scaling? (Choose two.) → EC2、DynamoDB
AWS WAF
- 一句话:防火墙
- Which AWS service or feature can enhance network security by blocking requests from a particular network for a web application on AWS? (Choose two.) → AWS WAF、Network ACLs
Amazon EFS(Elastic File System)
- 一句话:文件系统。题设中出现File System就选它
- An application runs on multiple Amazon EC2 instances that access a shared file system simultaneously. Which AWS storage service should be used?
AWS Snowball
- 一句话:和本地传数据用
- Which AWS services can be used to move data from on-premises data centers to AWS? (Choose two.) → AWS Snowball, AWS Database Migration Service (AWS DMS)
Amazon GuardDuty
- 一句话:保护账户,监控非法访问
- Which AWS service helps identify malicious or unauthorized activities in AWS accounts and workloads?
Amazon QuickSight
- 一句话:GA,YA,AA
AWS CloudHSM
- 一句话:云的硬件安全模块。本地管理密匙
- Which AWS service helps users meet contractual and regulatory compliance requirements for data security by using dedicated hardware appliances within the AWS Cloud?
AWS Elastic Beanstalk
- 一句话:PaaS, 还有一个k8s版本是CaaS
- Which AWS service is suitable for an event-driven workload?
常考英文
- on-premises: 本地的
- compliance: 合规
备注,杂谈
- examtopics之外的刷题网站:acloudguru, udemy
- Practitioner因为太简单没人考,买鸡精都要420(SAA只要200),被卖鸡精的无情鄙视
- 投稿日:2020-09-12T20:43:54+09:00
『AWS初学者向けハンズオン』EC2インスタンスからRDSインスタンスに接続してみる編
初めに
この記事はAWS初学者が書いているAWS初学者の方や未経験の方向けの記事になります。
内容や説明が間違っていた場合はコメントいただけるとありがたいです。投稿者のレベル
AWS CLF持ってるレベル
AWS実務経験無し
AWS使用経験(個人用+会社作成アカウント使用):約2ヶ月
ちょっと触ったことがあるサービス:IAM、EC2、EIP、VPC、RDS、CloudWatch(もしかしたら他にも使ったような気がする...)
最近本格的にAWSの勉強を始めたインフラエンジニアです。前提知識&条件
『AWS初学者向けハンズオン』VPCとEC2を使ってWebサーバの構築編
こちらの記事を事前に読んでいただけると今回行うハンズオンがスムーズに進みます。
またEC2インスタンスをSSHできる状態を作成します。今回の目的
EC2でデータベースサーバを構築することも可能ですが、RDSを使用することでバックアップやデータベースのスケーリングをAWSに任せることができるのでWebアプリケーションの最適化に集中できるようになります。
今回の目的はRDSの基本的な使用方法を学ぶことを目的としています。使用するサービス
・RDS
AWSの提供するリレーショナルデータベースサービスです。
MySQLやOracleといった人気のデータベースを使用することが可能です。・VPC
Virtual Private Cloud の略です。
VPCはAWS内にプライベートなネットワーク環境を作成することが出来ます。
アカウント作成後はデフォルトのVPCが作成されています。・EC2
Elastic Compute Cloud の略です。
AWS上に仮想サーバを構築するサービスです。
仮想サーバの事をEC2インスタンスと言います。
慣れている人なら数分で仮想サーバを作成することが可能です。事前準備
1. VPCの作成
VPCを作成します。
作成方法は過去に書いたこちらの記事をお読みください。
『AWS初学者向けハンズオン』VPCとEC2を使ってWebサーバの構築編2. インターネットゲートウェイの作成
インターネットゲートウェイの作成をします。
作成方法は過去に書いたこちらの記事をお読みください。
『AWS初学者向けハンズオン』VPCとEC2を使ってWebサーバの構築編3. サブネットの作成
RDSはインターネットから接続されたくないのでプライベートサブネットに所属させます。
RDSは作成する際にアベイラビリティーゾーンを二つ指定する必要があります。
なのでサブネットを2つ作成し、その2つがそれぞれ違うアベイラビリティーゾーンに所属している状態を作成します。
またEC2インスタンスからRDSに接続するためにインターネットに接続できるパブリックサブネットを1つ作成します。
サブネットの作成は前回同様の作り方になります。
作成方法は過去に書いたこちらの記事をお読みください。
『AWS初学者向けハンズオン』VPCとEC2を使ってWebサーバの構築編4. ルートテーブルの作成
今回作成するルートテーブルは2つで、一つがインターネットゲートウェイ宛のルートが書いてあるパブリックサブネット用、もう一つがRDS用のインターネットに接続しないプライベートサブネットに関連付けるものです。
作成方法は過去に書いたこちらの記事をお読みください。
『AWS初学者向けハンズオン』VPCとEC2を使ってWebサーバの構築編設定の流れ(今回の本編)
1. RDS用セキュリティグループの作成
AWSマネジメントコンソールの左上にある「サービス」をクリックして「EC2」を検索して開きます。
開いたら左側の欄にある「セキュリティグループ」をクリックします。(少し下の方にスクロールしてください。)
クリックすると以下のページが表示されます。
表示されたら「セキュリティグループを作成」をクリックしてください。
クリックすると以下のページが表示されます。
表示されたら「セキュリティグループ名」「説明」「VPC」を入力していきます。
「セキュリティグループ名」は任意の名前で大丈夫です。自分はAWS_DB_sgにしました。
「説明」も任意で大丈夫です。
「VPC」は作成したVPCを選択してください。
これらの入力が完了したら下にスクロールします。
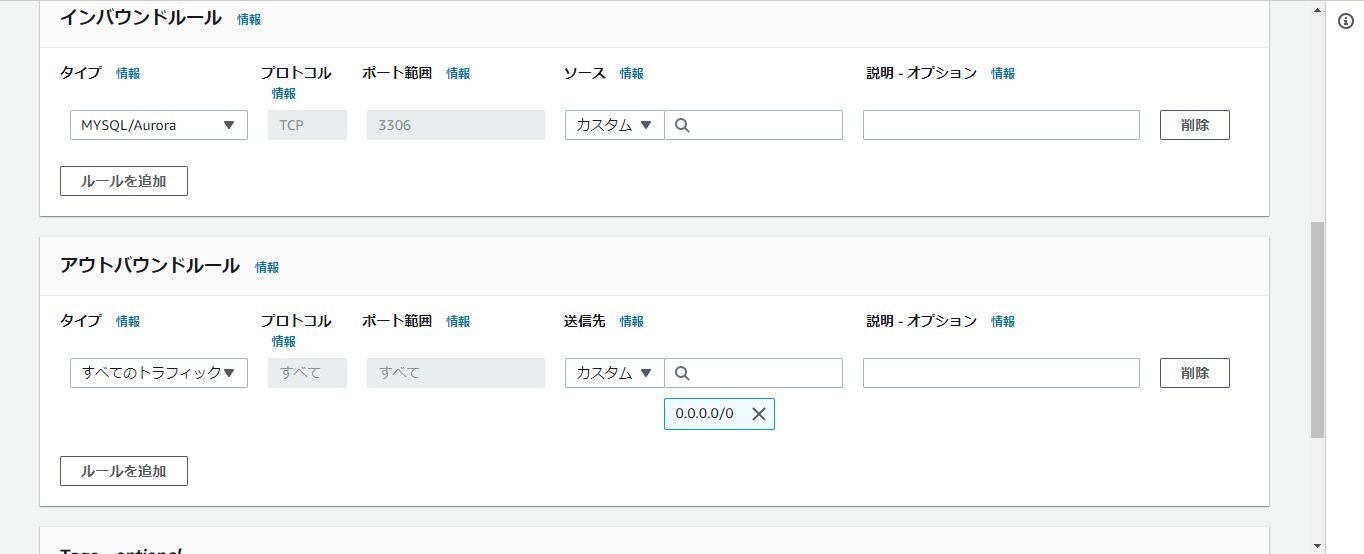
下にスクロールすると「インバウンドのルール」があり、「ルールの追加」をクリックします。
クリックするとルールの追加ができるようになるので追加していきます。
「タイプ」には「MYSQL/Aurora」を選択します。
「ソース」には接続したいEC2インスタンスのIPアドレスかセキュリティグループで指定します。
追加が完了したら下にスクロールして「セキュリティグループを作成」をクリックします。
クリックしたらセキュリティグループ一覧のページに戻って作成されていることを確認してください。2. RDSの設定
確認ができたら左上の「サービス」から「RDS」を検索して開きます。
開くと以下のページが表示されると思います。
表示されたら左側の欄から「サブネットグループ」をクリックします。
クリックすると以下の画面が表示されると思います。
表示されたら「DBサブネットグループを作成」をクリックします。
クリックすると以下のページが表示されると思います。
表示されたら「名前」「説明」「VPC」を入力します。
「名前」は任意のもので大丈夫です。自分はAWS_DB_subnetGにしました。
「説明」も任意のもので大丈夫です。
「VPC」は作成したものを選択してください。
入力が完了したら下にスクロールします。
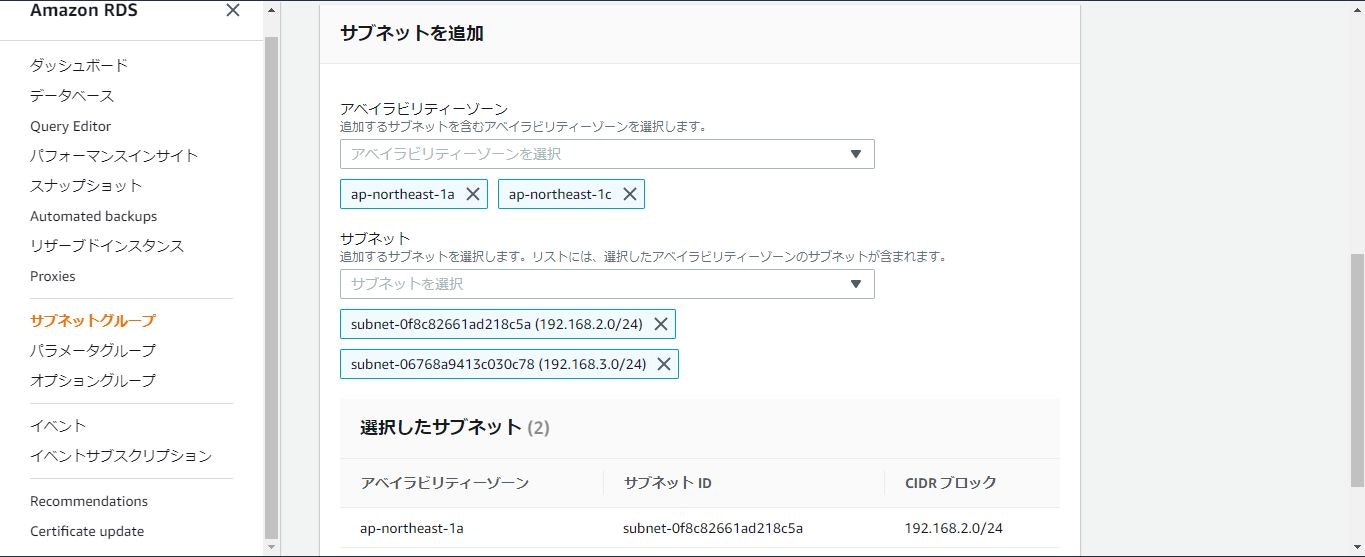
下にスクロールすると「サブネットを追加」という項目があるので追加します。
「アベイラビリティーゾーン」はプライベートサブネットの所属しているものを二つ選択します。
「サブネット」は作成したプライベートサブネットを選択します。
選択すると以下のようになると思います。
このようになったら下にスクロールして「作成」をクリックします。
クリックすると以下の画面のようになります。
サブネットグループが作成されていることを確認します。
確認が出来たら左側の欄にある「データベース」をクリックします。
クリックすると以下のページが表示されます。
表示されたら「データベースの作成」をクリックします。
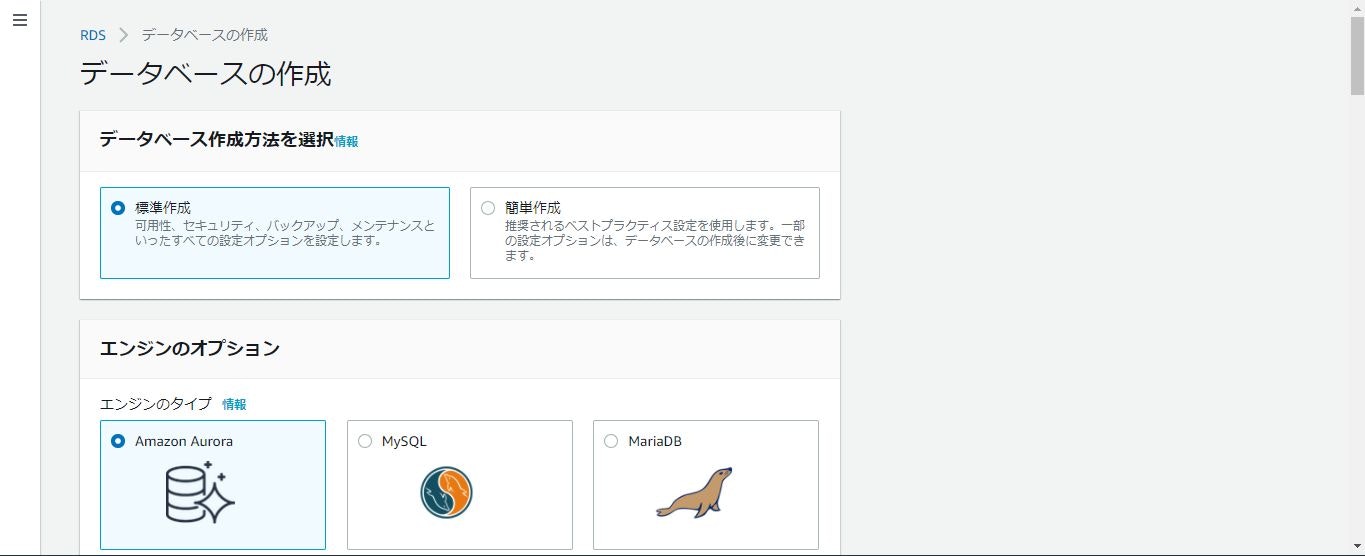
クリックすると以下のページが表示されます。
「データベースの作成方法を選択」「エンジンのオプション」「テンプレート」「設定」「DBインスタンスサイズ」「接続」「追加設定」を変更していきます。
「データベースの作成方法を選択」は「標準作成」を選択します。
「エンジンのオプション」は「MySQL」を選択します。「バージョン」は最新のものを選択します。
「テンプレート」は「無料利用枠」を選択します。
「設定」の「DBインスタンス識別子」は任意の物を入力してください。自分はAWS-DB-MySQLにしました。
「マスターユーザー名」はadminのままです。
「マスターパスワード」任意の物を入力してください。
「DBインスタンスサイズ」は「バースト可能クラス(tクラスを含む)」を選択します。
「ストレージ」は変更無しです。
「接続」の「VPC」は作成したVPCを選択してください。
「サブネットグループ」は上記で作成したものを選択します。
「パブリックアクセス可能」は「なし」を選択します。
「既存のVPCセキュリティグループ」は上記で作成したものを選択します。
「アベイラビリティーゾーン」はおそらく二つ選べるようになっていると思いますのでどちらかを選択します。
「データベースポート」はそのままで大丈夫です。
ここまでの作業が完了したら下にスクロールして「データベースの作成」をクリックします。
クリックすると以下のページが表示されます。
表示されたら作成されていることを確認してください。
(作成には少し時間がかかります。)
3. EC2インスタンスからRDSに接続
まずEC2インスタンスにSSHで接続します。
接続方法は過去に書いたこちらの記事をお読みください。
『AWS初学者向けハンズオン』VPCとEC2を使ってWebサーバの構築編
接続ができたらEC2インスタンスにMySQLをインストールします。
以下のコマンドを実行してください。EC2インスタンス上sudo yum update -y #このコマンドでパッケージを最新版のものにしています。 sudo yum install mysql -y上記コマンドを実行したらRDSに接続するために必要な情報を確認しに行きます。
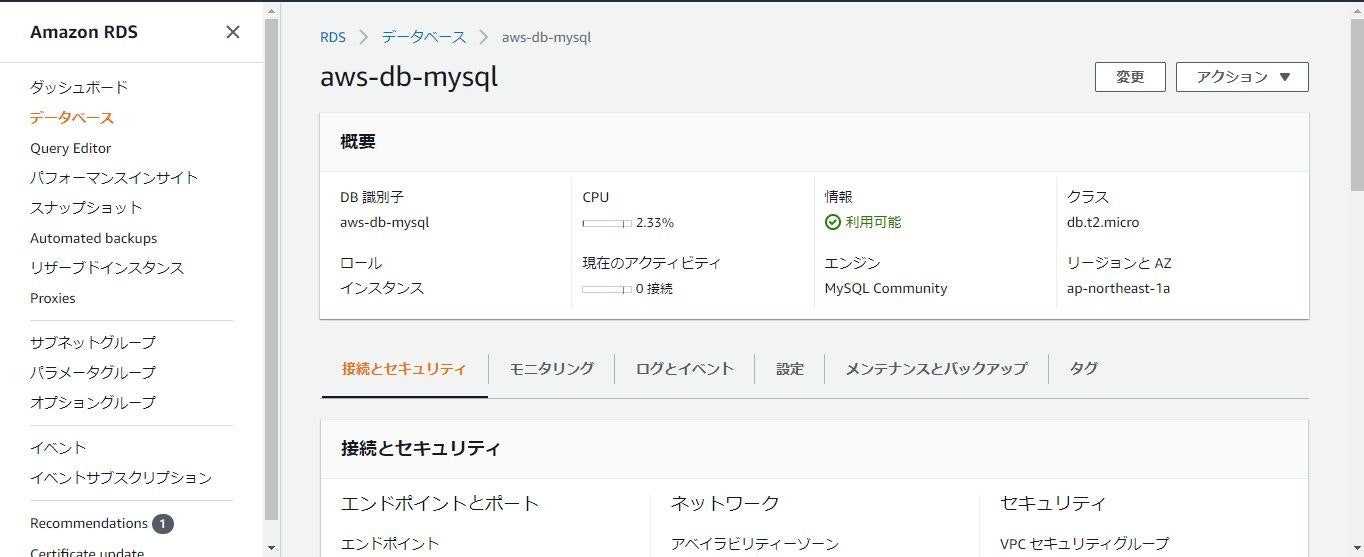
先程のデータベース一覧ページを表示して、データベースの「DB識別子」をクリックします。
クリックすると以下のページが表示されると思います。
表示されたら下にスクロールして「エンドポイント」のところに表示されてるものをコピーします。
コピーができたらEC2インスタンス上で以下のコマンドを実行してください。EC2インスタンス上mysql -h コピーしてきたエンドポイント -P 3306 -u admin -p上記のコマンドを打ち込んだらエンターを押します。
そうするとパスワードが求められるので、RDS作成時に設定したマスターパスワードを入力してください。
(-u の後のadminはRDSの作成の際に指定したマスターユーザーです。)
接続が成功すると以下の画面が表示されます。
以上でEC2インスタンスからRDSインスタンスに接続することが成功しました。4. 片付け
RDSインスタンスやEC2インスタンスは動かしていると料金が発生するので使用後は停止しておきます。
データベース一覧のページを開いて「アクション」をクリックして「停止」をクリック、「今すぐ停止」をクリックすると停止します。EC2インスタンスの一覧ページを開いて「アクション」をクリック、「停止」をクリックすると停止します。
感想
今回の記事はいかがだったでしょうか?
この記事を読んでRDSの基本的な使いかたの参考になっていると幸いです。
今回ハンズオン記事を書きましたが実務で一度もAWSを使用したことが無いので、「実務ではこんな使いかたします!」みたいなコメントを頂けるとありがたいです。
- 投稿日:2020-09-12T20:17:05+09:00
【AWS・Lambda】エラーハンドリングの基礎 ~ Design for Failure ~
はじめに
Lambdaのエラーハンドリングについて、
『AWS Japan Summit Online 2020』のオンラインセッションで学んだ [ Design for Failure ] の考え方をまとめます。Lambdaの実行中には様々なエラーが予想されます。
それらに適切に対応するためのデザインが必要です。Lambda関数でエラーを受け取ったら?
Lambda関数は、エラーを受け取ると基本的に複数回リトライを行います。
不要なリトライは、膨大なログデータを発生させたり、無限にリトライし続けることで膨大な料金になってしまうことも考えられます。そのため、エラーに適切な対処ができるようあらかじめ準備していかなければなりません。
エラーへの対処
エラーへの対処には、主に以下3つの方法が考えられます。
- 不要なリトライの回避
- エラー伝播の回避
- データ整合性の確保
1~3のそれぞれを詳しく見ていきましょう。
1. 不要なリトライの回避
無駄なリトライはトラブルの元です。リトライ設計を適切に考える必要があります。
リトライ設計で考慮するポイントは以下の通りです。
- 誰がリトライを実施するのか
- どれくらいの期間・何回リトライするのか
- イベントデータの行き先(退避先)はあるか
- 退避されたイベントデータのモニタリング・処理
イベントソースごとに異なるリトライ制御を考える
イベントソース(つまりLambdaにイベントを渡す元)によって、制御で考慮するポイントが異なります。
- イベントソースごとに適切なリトライ回数を設定する
- イベントソースごとに適切な失敗時のイベント送信先を設定する
2. エラー伝播の回避
エラーが不要に伝播することも、避けなければなりません。
主に、以下2点に注意して設計を行います。
- エラーを受け取らない
- エラーしか受け取らなくなった場合にそれ以上受け取らないようにする
エラーを受けとならい
以下2点について忘れずに設定を行うことで対策が可能です。
処理結果による分岐が可能になるからです。
- 非同期呼び出しによるLambda関数の起動
- SQSやSNSなどのコンポーネントを関数チェーンの間に差し込む
エラーしか受け取らなくなった場合にそれ以上受け取らないようにする
緊急停止の仕組みをあらかじめ構築しておき対策します。
- CloudWatchメトリクスのErrorsをモニタリングする -> 閾値を超えた場合に緊急停止します。
- 緊急停止後の回復を策定する -> AWS Step Functionsなどで緊急停止後のワークフローを設定する
3. データ整合性の確保
エラー時のデータ不整合への対策を行います。
データの不整合には以下の2つのケースが考えられます。
- 処理済みのリクエストを再度処理したケース
- 1つのプロセス内で複数のリソースを更新するケース
処理済みのリクエストを再度処理したケース
バッチ(複数のレコード処理)を起動中にエラーが発生すると、すでに完了済みのレコードについても再度リトライが発生するなどのケースです。
以下2点について忘れずに設定を行うことで対策が可能です。
- 重複処理を排除する -> 処理ずみの判定チェックをDBで管理するなど
- 重複処理を許容する -> 重複によりエラーやデータ不整合対策をロジックで解消する
1つのプロセス内で複数のリソースを更新するケース
一つのLambdaで複数のリソースを更新する場合があります。
例えば、一つのLambdaでDynamoDBとAuroraの両方を更新するケースなどです。
DynamoDBの更新は成功したが、Auroraの更新が失敗した場合、確定したDynamoDBのデータ変更を取り消してリトライする仕組みが必要です。
反対処理による取り消し(Compensation Transaction)
データ変更の取り消しとは、成功した処理の逆の処理を行うことです。(反対処理)
反対処理の実装を全てのロジックに行うと、膨大な記述が必要です。
そのため、ステートマシンを利用した制御が推奨されています。AWS Step Functionsを活用し、個別の関数を組み合わせたワークフローとして実装します。
まとめ
エラーへの対処として以下3つのポイントがありました。
- 不要なリトライの回避
- エラー伝播の回避
- データ整合性の確保
また、これらを実現するために、
疎結合な小さなコンポーネントの組み合わせで処理を実装することが大切です。
- 投稿日:2020-09-12T19:51:50+09:00
AWS SAMのtipsをひたすら書く
はじめに
タイトルめっちゃ雑ですみません。
筆者は約半年に渡って、aws-samを使ったアプリケーションを作成しています。
たくさんトラブルや学びがあったので、それらをメモしてきたいと思います。トラブルとその解決
開発環境と本番環境を分けたい
パラメータの上書きを使うと良いです。
筆者の場合はこんな感じです。Parameters: AppId: Type: String Environment: Type: Stringリソース数が200を超えてこれ以上デプロイ出来ない
クロススタック参照を使うと良いです。
CodePipelineの画面はこんな感じになっています。
デプロイが遅い
色々試しましたが、どうしようもありませんでした。
なので、sam-local invokeを使って、ローカルで呼び出すしたり、関数のテストコードを書くと良いでしょう。DynamoDBの読み書きテストをしたい
https://jestjs.io/docs/en/dynamodb
出来ます。CORSどうしよう
関数の返り値にCorsの情報を追加してください。
初回起動遅い(コールドスタート)
AutoPublishAlias: live ProvisionedConcurrencyConfig: ProvisionedConcurrentExecutions: 2同時実行の予約をすると良いでしょう。
ただ、デプロイに時間がかかるようになります。。。

- 投稿日:2020-09-12T16:07:47+09:00
ECS Fargateデプロイ用CodePipelineのtaskdef.jsonに変数を持たせる方法
はじめに
CodePipelineによるCI/CDパイプラインは便利なんだけど、せっかくTerraformやCloudFormationであれこれ変数化して自動化しているにもかかわらず、ECS Fargateにデプロイするための taskdef.json と Appspec.yml で変数化できずにハマるケースがあって困る。今回は、これを解決する手段を考えた。
前提条件
初学者向けのパイプライン作成ハンズオンに出てくるアウトプットをごちゃごちゃいじるので、少なくとも、CodePipelineの基礎は抑えていないと厳しい。過去の記事では以下のあたりを読んでおくと分かりやすくなっているはずだ。
なお、この記事ではIaCはTerraformで書いている。
- CloudFormationテンプレートを1からしっかり理解しながらECS on Fargateなアプリを自動構築する(前編)
- CloudFormationテンプレートを1からしっかり理解しながらECS on Fargateなアプリを自動構築する(中編)
- CloudFormationテンプレートを1からしっかり理解しながらECS on Fargateなアプリを自動構築する(後編)
- Terraformの初心者がAmazon EC2に実行環境を作ってECS Fargateなアプリの自動構築をしてみる
方針
CodePipelineの taskdef.json には、プレースホルダ(チュートリアルやハンズオンではという名前で出てくる、コンテナのイメージIDで置換する機能)という強力な機能があるが、これは1つのビルドアーティファクトに対して1つのプレースホルダにしか対応していないし、最大4つまでしか指定できない。
これを駆使して頑張ろうとすると、変なビルドステージを作ったりしなければならずBuildSpecが煩雑化するので没にする。となると、ビルドステージで良い感じに taskdef.json を生成してあげるのが簡単だろう。
IaC見直し箇所
さて、通常のハンズオンやチュートリアルでは、taskdef.json はリポジトリに入っているものをそのままソースステージから引っ張ってくることになるが、今回はビルドステージで編集したものを利用するため、CodePipelineのリソースを以下のように修正する。
stage { name = "Deploy" action { run_order = 3 name = "Deploy" category = "Deploy" owner = "AWS" provider = "CodeDeployToECS" version = "1" input_artifacts = [ "SourceArtifact", "BuildArtifact", ] configuration = { ApplicationName = aws_codedeploy_app.application.name DeploymentGroupName = aws_codedeploy_deployment_group.application.deployment_group_name AppSpecTemplateArtifact = "SourceArtifact" AppSpecTemplatePath = var.appspec_file_name TaskDefinitionTemplateArtifact = "BuildArtifact" # ★ここをSourceArtifactから変更 Image1ArtifactName = "BuildArtifact" Image1ContainerName = "IMAGE1_NAME" } }また、taskdef.json は以下のように修正しておこう。
以下を、外部から指定可能にして置換できるようにする。
- <EXECUTION_ROLE_ARN>
- <TASK_ROLE_ARN>
- <CONTAINER_NAME>
- <LOGGROUP_NAME>
- <TASK_FAMILY>{ "executionRoleArn": "<EXECUTION_ROLE_ARN>", "taskRoleArn": "<TASK_ROLE_ARN>", "containerDefinitions": [ { "name": "<CONTAINER_NAME>", "image": "<IMAGE1_NAME>", "logConfiguration": { "logDriver": "awslogs", "options": { "awslogs-group": "<LOGGROUP_NAME>", "awslogs-region": "ap-northeast-1", "awslogs-stream-prefix": "ecs" } }, "portMappings": [ { "containerPort": 80, "hostPort": 80, "protocol": "tcp" } ], "essential": true, "cpu": 0, "memoryReservation": 256, } ], "requiresCompatibilities": ["FARGATE"], "networkMode": "awsvpc", "cpu": "256", "memory": "512", "family": "<TASK_FAMILY>" }さて、CodeBuildでは、Buildspec の post_build で以下のようにして、上記の置換対象のタグを環境変数で置換する。
sed の置換の区切り文字をスラッシュから変更しているのは、IAMロールのARNやロググループ名にスラッシュが入ってくる可能性があるからだ。Terraformのtfファイル側で上手くエスケープしようと思ったが、面倒なのでBuildspec側で対応した。post_build: commands: - docker push ${REPOSITORY_URI}:${IMAGE_TAG} - docker push ${REPOSITORY_URI}:latest - printf '{"name":"%s","ImageURI":"%s"}' $ECR_REPOSITORY_NAME $REPOSITORY_URI:$IMAGE_TAG > imageDetail.json # ★以下を追加 - sed -i -e "s#<EXECUTION_ROLE_ARN>#${EXECUTION_ROLE_ARN}#" taskdef.json - sed -i -e "s#<TASK_ROLE_ARN>#${TASK_ROLE_ARN}#" taskdef.json - sed -i -e "s#<CONTAINER_NAME>#${CONTAINER_NAME}#" taskdef.json - sed -i -e "s#<LOGGROUP_NAME>#${LOGGROUP_NAME}#" taskdef.json - sed -i -e "s#<TASK_FAMILY>#${TASK_FAMILY}#" taskdef.jsonまた、taskdef.json をアーティファクトに指定することを忘れないように。
artifacts: files: - imageDetail.json - taskdef.jsonで、肝心のCodeBuild側から、良い感じに環境変数を渡してあげれば、taskdef.json も自動化の流れに乗せらえれる。CPUやメモリを検証環境とプロダクション環境で変更する場合も、tfファイル側でmapしてあげれば環境差分も吸収可能だ!
resource "aws_codebuild_project" "application" { (中略) environment { type = "LINUX_CONTAINER" compute_type = "BUILD_GENERAL1_SMALL" image = "aws/codebuild/amazonlinux2-x86_64-standard:3.0" privileged_mode = "true" # 以下を追加 environment_variable { name = "EXECUTION_ROLE_ARN" value = aws_iam_role.ecs_taskexecution.arn } environment_variable { name = "TASK_ROLE_ARN" value = aws_iam_role.ecs.arn } environment_variable { name = "CONTAINER_NAME" value = var.container_name } environment_variable { name = "LOGGROUP_NAME" value = aws_cloudwatch_log_group.ecstask_log_group.name } environment_variable { name = "TASK_FAMILY" value = aws_ecs_task_definition.ecsfargate.family } } (中略) }これでビルドを走らせると、ビルドアーティファクトの taskdef.json が以下のように出力される。
{ "executionRoleArn": "arn:aws:iam::xxxxxxxxxxxx:role/ContainerPipeline-ECSTaskExecutionRole", "taskRoleArn": "arn:aws:iam::xxxxxxxxxxxx:role/ContainerPipeline-ECSTaskRole", "containerDefinitions": [ { "name": "ContainerPipeline-ECSContainer", "image": "<IMAGE1_NAME>", "logConfiguration": { "logDriver": "awslogs", "options": { "awslogs-group": "/ecstask/ContainerPipeline-LogGroup", "awslogs-region": "ap-northeast-1", "awslogs-stream-prefix": "ecs" } }, "portMappings": [ { "containerPort": 80, "hostPort": 80, "protocol": "tcp" } ], "essential": true, "cpu": 0, "memoryReservation": 256, } ], "requiresCompatibilities": ["FARGATE"], "networkMode": "awsvpc", "cpu": "256", "memory": "512", "family": "ContainerPipeline-ECSTaskFamily" }Appspecの
ContainerNameも同じ要領で置換可能なはず。
これで、夢の全自動ビルドに一歩近づいた!
- 投稿日:2020-09-12T15:39:37+09:00
Railsの本番環境でなぜかセッションが保存できない問題を解決した経緯
概要
railsで本番環境にプッシュしたアプリがある日セッションを使った機能の全てが動作しなくなるという絶望的な問題にぶち当たった。めちゃくちゃ苦戦したし記事も全然なかったのでその解決方法を記しておく。
最終的にこの記事から設定しなおして解決しました。
https://www.cotegg.com/blog/?p=1850環境
・EC2にデプロイ
・サーバー環境はWebサーバーにnginx、アプリケーションサーバーにPuma
・AWSのELBにACMのSSL証明書をアタッチしてSSL化↓クライアント→ELB→nginx→puma
セッションが保存されない原因
まず、セッションが保存されない原因
RailsではCSRF(クロスサイトリクエストフォージェリー)という脆弱性からサイトを守るための対策として
protect_from_forgeryというメソッドでサイトを保護している
application.html.erbのheadタグ内にcsrf_meta_tagという記述をしているが
ここで認証用のauthenticate_tokenを生成しておりこの値を使ってサイトを認証している。この辺りの説明は腐る程ググれば出てくるため割愛。
このprotect_from_forgeryメソッドのデフォルトの設定でこのauthenticate_tokenが正しくないと
セッションを空にする。(:null_sessionオプション)が指定されている。
こいつのせいでセッションは空になっている。
※これが原因かどうか一発でわかる方法として、application_controller.rbに
protect_from_forgery with: :exception←CSRFトークンが正しくなければエラーを返す
を記述してサイトにアクセスする
ActionController::InvalidAuthenticityTokenというエラーが出たら原因はそれつまりなんらかの原因でCSRFの認証が通っていない
なぜこんなエラーがでるのか
冒頭に環境を載せておいたが
クライアント→ELB→nginx→puma
という経路でアプリケーションにアクセスするようになっている
ELBにはSSL証明書をアタッチしてあり、自分のこの構成だと
ELBまではhttpsアクセス
ELBとnginxはhttpアクセスになっている。実際にユーザーがアクセスするのはhttpsなのにrailsアプリ側にはhttpでアクセスしていると
情報が伝わってしまい、ここで矛盾が生じるためクロスサイト認定され
エラーが起きてしまっている模様。対策は
nginxなら
/etc/nginx/nginx.confにlocation / { proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; #これ追加 proxy_set_header X-Forwarded-Proto https; #これ追加 proxy_pass http://www.xxxx.com; }としてやるとアクセスするURLと伝わるヘッダー情報が一致してエラーが出なくなる
つまり解決
補足
自分なりの理解で対処した問題の内容をまとめただけのため
間違いがあればご指摘いただけますと幸いです。
Twitterアカウント↓
https://twitter.com/TakeWeb1
- 投稿日:2020-09-12T13:39:20+09:00
【AWS】から学ぶデータベース基礎 [ Purpose Build ] の考え方
はじめに
私のような令和プログラマー*1にとって、圧倒的に不足しがちなのがDB・ネットワーク等のインフラ周りの知識・経験です。
(*1: 令和になってからプログラミングを知った人。初心者のこと。)
しかしながら、AWSやFirebase等のマネージドサービスを活用することで、これまでよりも簡単に、セキュリティ・可用性の高い堅牢なインフラ運用を体験することができるようになっています。
今回は『AWS Japan Summit Online 2020』のオンラインセッションで学んだ
データベース基礎 [ Purpose Build ] の考え方をまとめます。様々なデータベース
私のような初心者にとって『データベース = リレーショナルデータベース』でした。
しかし現代には様々なデータベースが存在し、実際にAWSでは以下の種類のDBサービスを提供しています。
- Relational
- Key-Value
- Document
- In-Memory
- Graph
- Time-Series
- Ledger
要件に合わせた最適なDBを選択する必要があります。すなわち[ Purpose Build ] です。
Relational
リレーショナルデータベースは多くの人に馴染みのあるDBかと思います。
以下のような特徴があります。
- 複数ユーザーからのクエリに対する一貫性
- テーブル同士の関係性
- 柔軟なクエリ
管理しやすく、テーブルの追加や変更が比較的柔軟に行えるため、様々な用途で使われています。
AWSサービスの例
- RDS
- Aurora
NoSQL
Relationalデータベース以外を、広くNoSQLデータベースと言います。
「Not Only SQL」の略語で、Relationalデータベースの課題を解決するために生まれました。Relationalと比較して、以下のような特徴があります.
- シンプルなデータ構造
- 非正規化
- DBによって異なるクエリ方法
- 限定的なトランザクション
- 高いスケーラビリティ
Key-Value
{ key: Value }のシンプルな構造故、高スループット・低レイテンシが特徴です。トラフィックの多いWebサービスやゲームなどに向いています。
AWSサービスの例
- DynamoDB
- Keyspaces(Cassandra)
Document
JSONやXMLなどドキュメントと格納し、クエリに応じて任意のデータを取り出します。
コンテンツ管理、ユーザープロファイルなどに向いています。
JSONをリレーショナルDBのスキーマにマッピングする必要がないため高速・高可用性を実現できます。
AWSサービスの例
- DocumentDB
In-Memory
キャッシュを利用してマイクロ秒のレイテンシでクエリします。
キャッシュ・セッション管理・地理空間アプリケーションに向いています。
AWSサービスの例
- ElastiCache
Graph
データ間を相互に結びつけ、関係性をグラフで表します。
リレーショナルデータベースでは、関係性が複雑になると対応してクエリも複雑になります。
Graphでは初めから関係性への対応に最適化されているので、クエリをシンプルに保ち、高速です。
ソーシャルネットワーク・レコメンデーションエンジンなどに向いています。
AWSサービスの例
- Neptune
Time-Series
特定の間隔で記録され続ける時間の経過にともなう変化を測定します。
時系列のデータ分析・ログに向いています。
ログのデータは大量に発生し、常にデータが挿入され続けるため、こちらもリレーショナルデータベースでの対応が難しい分野です。
AWSサービスの例
- Timestream
Ledger
データの変更履歴がイミュータブル(変更不可)という特徴があります。
ハッシュ関数を利用し、変更されていないことを検証することができます。
改竄・変更の保証をすることが可能です。銀行のトランザクションや記録システムなどに向いています。
AWSサービスの例
- Quantum Ledger Database
まとめ
様々な用途・要件に合わせて最適化されたDBを使用することで高いパフォーマンス・可用性・コスト効率を実現することができます。
適材適所の選択をする [ Purpose Build ] が必要であり、そのためには様々なサービスに触れて知識として持っておくことが重要かと思います。
- 投稿日:2020-09-12T11:26:20+09:00
LambdaとAmazon ConnectでRDS障害時のSlack通知と電話連絡を行う
概要
- RDSで障害が起きた時にSlackに通知すると同時に電話も掛けて欲しかったのでLambdaとConnectを使って実装しました。
- 単純に電話を掛けるだけではなく、複数人に電話をして1人目が対応可能だったら他の人には電話せずということも実現したかったのでそれも実装しました。
- 実際に実装してみて気になる細かい点(後述)はありますが、それは徐々に改善していこうと思っています。
処理の流れ
- RDSのイベントでトリガー
- SNSが受け取ってSlack通知用Lambda(Lambda1)と電話連絡用Lambda(Lambda2)を呼び出す
- Slack通知用LambdaはRDSイベントの内容(どのRDSでどんな障害なのか)をSlackに通知
- 電話連絡用LambdaはConnectを呼び出して電話を掛ける
- 誰が対応可能なのか判定も行ってSlackへ通知
前提
- RDSイベントやSNSやConnectのセットアップなどの設定についてはここでは説明はしません。
- LambdaやConnectの実行権限は適宜付与してください。
- Lambdaのコードが拙い部分があるかと思いますがご容赦ください。
設定の流れ
- Connectのセットアップ(省略)
- Connectの問い合わせフロー設定
- Lambda作成
- SNS作成(省略)
- RDSイベント設定(省略)
Connectの問い合わせフロー
- 下記のように作りました。
ログ記録動作の設定はログを見たかったので有効化音声の設定は適当に(裏ではPolly使ってるみたいですね)プロンプトの再生でLambdaから呼び出される時に渡されるテキストを読むように設定顧客の入力を取得するで番号を入力させて、対応するなら1、対応しないなら2で分岐するよう設定問い合わせ属性の設定で対応するか否かを変数として持たせる
- 後ほどLambdaでこの属性を取得する

Lambda
- 電話連絡用Lambdaだけ記載します。
- ロギングの設定は適宜行うことをおすすめします。
- Pythonで書きました。
import os import json import logging import boto3 from datetime import datetime, timedelta from urllib.request import Request, urlopen from urllib.error import URLError, HTTPError logger = logging.getLogger() logger.setLevel(logging.INFO) # Lambdaの環境変数からConnectで取得した発信元電話番号とインスタンスIDと問い合わせフローIDを取得 SOURCE_PHONE_NUMBER = os.getenv('SOURCE_PHONE_NUMBER') INSTANCE_ID = os.getenv('INSTANCE_ID') CONTACT_FLOW_ID = os.getenv('CONTACT_FLOW_ID') # Lambdaの環境変数からSlack通知用のWebHookURL取得 Slack_Webhook_URL = os.environ['SLACK_WEBHOOK_URL'] # Lambdaの環境変数から電話を掛ける相手の番号と名前を取得 destination_phone_number = [os.getenv('DESTINATION_NUMBER_1'),os.getenv('DESTINATION_NUMBER_2'),os.getenv('DESTINATION_NUMBER_3')] person_name = [os.getenv('NAME_1'),os.getenv('NAME_2'),os.getenv('NAME_3')] def lambda_handler(event, context): # SNSから取得されるRDSイベントの内容 rds_event_message = json.loads(event['Records'][0]['Sns']['Message']) # RDSイベントのメッセージをセット target = (rds_event_message["Source ID"]) event_message = (rds_event_message["Event Message"]) tel_message = "データベースで障害です。" + "対象のデータベースは " + target + "で、" + "障害内容は " + event_message + "です。" # 誰も対応しないということを初期設定 isCorrespond = "false" # ここからConnectの処理 connect = boto3.client('connect' , region_name='ap-northeast-1') for number,name in zip(destination_phone_number,person_name): # connectで電話を掛ける contact = connect.start_outbound_voice_contact( DestinationPhoneNumber=number, ContactFlowId=CONTACT_FLOW_ID, InstanceId=INSTANCE_ID, SourcePhoneNumber=SOURCE_PHONE_NUMBER, Attributes={ 'message': tel_message , 'isCorrespond': 'false' # ここはもしかしたら不要かもしれません } ) # 電話を掛け始めて一旦待つ time.sleep(60) # Connectの結果を取得 contact_id = contact['ContactId'] attributes = connect.get_contact_attributes( InstanceId=INSTANCE_ID, InitialContactId=contact_id) # 対応者がいるかどうかの結果をセット isCorrespond = attributes['Attributes']['isCorrespond'] if (isCorrespond == "true"): # 対応者あり slack_post_correspond("[対応者]" + name) break; else: # 対応者がいない continue; # 全員に電話を掛けても対応者不在 if(isCorrespond == "false"): slack_post_correspond("対応者不在") # Slackに対応者情報投稿 def slack_post_correspond(message): slack_message = { 'text': "*" + message + "*", } req = Request(Slack_Webhook_URL, json.dumps(slack_message).encode('utf-8')) try: response = urlopen(req) response.read() logger.info("Message posted to %s", Slack_Webhook_URL) return { 'statusCode': 200 } except HTTPError as e: logger.error("Request failed: %d %s", e.code, e.reason) except URLError as e: logger.error("Server connection failed: %s", e.reason)気になる細かい点
- 電話連絡先の番号や名前を設定する部分がイマイチな感じはありますが、頻繁に変動するものではないので良しとしています。理想はDBから取得したりしたいところです。
- Connectで電話を掛ける処理の呼び出しはsleepで強制的に待っているので、Connect側で何かいい感じに制御出来るものがあればなと思っています。
- RDSで複数イベントが発生した時に複数電話がかかってきてしまい(Lambdaが複数実行される)、ワチャワチャしてしまうので改善したいところです。
所感
- 色々と改善したいと感じるところはありましたが、Connectを使って障害時の電話連絡が実装出来て良かったです。
- これの応用が出来ればEC2障害時の一次対応が自動化出来たりしそうだなと感じています。
- Connectすごい!
最後に
- 初めてQiitaに記事を投稿したので色々とご容赦ください


- 投稿日:2020-09-12T10:24:09+09:00
これまで書いてきた記事を整理した
記事の本数が50本を超えたので、これまで書いてきた記事をカテゴライズして整理した。
1つの記事が複数のカテゴリに入るので、同じ記事が2度登場したりするが、気にしないでいただきたい。AWSサービス系
ECS
- AWSのアカウント作った直後の状態からECS+FargateでTomcatのDockerコンテナを起動する
- AWSでSpringBootベースのWebアプリを起動してみる(Docker on EC2編/ECS+Fargate編)
- CloudFormationテンプレートを1からしっかり理解しながらECS on Fargateなアプリを自動構築する(前編)
- CloudFormationテンプレートを1からしっかり理解しながらECS on Fargateなアプリを自動構築する(中編)
- CloudFormationテンプレートを1からしっかり理解しながらECS on Fargateなアプリを自動構築する(後編)
- SonarQubeをサーバレスコンテナで起動してみる
- Terraformの初心者がAmazon EC2に実行環境を作ってECS Fargateなアプリの自動構築をしてみる
- TerraformでECS FargateなコンテナにFireLensを適用する
- Golangはじめて物語(第2話: Gin+ECS+Fargateといっしょ編)
- ECSなコンテナにSSM Parameter Storeの値を渡して保持させる
- ECSのデプロイ中の正常性確認を自動化するAppspecのHooks設定
- ECS Fargateデプロイ用CodePipelineのtaskdef.jsonに変数を持たせる方法
API Gateway
- Amazon API Gateway/ALBのバックエンドで動くLambda関数をJava(Eclipse+maven)で実装する
- 複数のバックエンドのリソースをAmazon API Gatewayで統合する
- Amazon APIGatewayでCI/CDパイプラインと親和性を高めてIaC運用するにはどうするべきか
- TerraformでAmazon API Gatewayを構築する(基本編)
- TerraformでAmazon API Gatewayを構築する(ゲートウェイのレスポンス&ステージ詳細編)
- Amazon API GatewayでサクッとCORS対応する
Lambda
- Amazon API Gateway/ALBのバックエンドで動くLambda関数をJava(Eclipse+maven)で実装する
- ALBのバックエンドで動作するJava実装のLambda関数をBlue/GreenデプロイメントするCodePipelineを作zる
- CodeCommitのイベントから自動でSonarQubeのプロジェクトを設定するLambda関数のSAMテンプレート
- Spring Cloud FunctionでAmazon API Gatewayのプロキシ統合なLambda関数をサクッと書いてみる
- LambdaをCanaryリリースするSAMテンプレートに自動ロールバックを組み込む
- Golangはじめて物語(APIGateway+Lambdaといっしょ編)
- Golangはじめて物語(第3話: CodePipeline+SAM+LambdaでCI/CD編)
- Lambda+SAMテンプレートのBlue/Greenデプロイメントで「デプロイの再試行」した際の動作を検証する
CloudFormation
- CloudFormationテンプレートを1からしっかり理解しながらECS on Fargateなアプリを自動構築する(前編)
- CloudFormationテンプレートを1からしっかり理解しながらECS on Fargateなアプリを自動構築する(中編)
- CloudFormationテンプレートを1からしっかり理解しながらECS on Fargateなアプリを自動構築する(後編)
- Lambda関数をBlue/GreenデプロイメントするCodePipelineをCloudFormationで自動構築する
- CodePipelineでSonarQubeの静的解析を自動化するCloudFormationテンプレート
- CodePipelineで承認ステージ付きのパイプラインを作成する(CloudFormationテンプレート付)
- CloudFormationで既存IAMロールのポリシーを自動で追加するにはどうしたら良いかを考えた
- Amazon APIGatewayのSAMテンプレートを更新してcloudformation deployしたときの動作を確認する
- LambdaをCanaryリリースするSAMテンプレートに自動ロールバックを組み込む
- Golangはじめて物語(第3話: CodePipeline+SAM+LambdaでCI/CD編)
S3
- S3で色々お試しして遊んでみる(VPCエンドポイント&静的Webホスティング性能編)
- S3の静的ウェブサイトホスティングをRoute53のプライベートホストゾーンからエイリアスする
- S3の静的WebサイトホスティングをCloudFrontでキャッシュしてみる
DynamoDB
Route53
CloudFront
ELB
- ALBのバックエンドで動作するJava実装のLambda関数をBlue/GreenデプロイメントするCodePipelineを作zる
- Terraformでオレオレ証明書を作ってIaCだけでALBをHTTPS化する
CloudMap
CodeArtifact
X-Ray
Terraform
- Terraformの初心者がAmazon EC2に実行環境を作ってECS Fargateなアプリの自動構築をしてみる
- TerraformでAmazon API Gatewayを構築する(基本編)
- TerraformでAmazon API Gatewayを構築する(ゲートウェイのレスポンス&ステージ詳細編)
- 理想を追い求めたCI/CDパイプラインをTerraformで実装するためのポイント
- TerraformでECS FargateなコンテナにFireLensを適用する
- ステートバケットでtfstateを管理しているときに更新競合したらどうなるか確認した
- Terraformでオレオレ証明書を作ってIaCだけでALBをHTTPS化する
- AWSの内部通信で好きなドメインを使えるようにする
- Gitのサブモジュール機能とTerraformのモジュール機能で実現するCI/CDパイプラインの量産(Lambda編)
- Lambda+SAMテンプレートのBlue/Greenデプロイメントで「デプロイの再試行」した際の動作を検証する
- クロスアカウント・クロスリージョンなCodePipelineを実行する
- 【Tips】TerraformでDynamoDBにそこそこの量のアイテムを初期構築でputしておく方法
- Amazon API GatewayでサクッとCORS対応する
- ECS Fargateデプロイ用CodePipelineのtaskdef.jsonに変数を持たせる方法
CI/CD
- WindowsのEclipseからCodePipelineを起動してEC2にデプロイ&ECS on Fargateにアプリをデプロイする
- ALBのバックエンドで動作するJava実装のLambda関数をBlue/GreenデプロイメントするCodePipelineを作る
- CodePipelineでSonarQubeの静的解析を自動化するCloudFormationテンプレート
- CodePipelineで承認ステージ付きのパイプラインを作成する(CloudFormationテンプレート付)
- CloudFormationで既存IAMロールのポリシーを自動で追加するにはどうしたら良いかを考えた
- Amazon APIGatewayでCI/CDパイプラインと親和性を高めてIaC運用するにはどうするべきか
- Amazon APIGatewayのSAMテンプレートを更新してcloudformation deployしたときの動作を確認する
- AWS CodeArtifactでJavaのライブラリを管理してみる
- 理想を追い求めたCI/CDパイプラインをTerraformで実装するためのポイント
- LambdaをCanaryリリースするSAMテンプレートに自動ロールバックを組み込む
- Gitのサブモジュール機能とTerraformのモジュール機能で実現するCI/CDパイプラインの量産(Lambda編)
- クロスアカウント・クロスリージョンなCodePipelineを実行する
- ECSのデプロイ中の正常性確認を自動化するAppspecのHooks設定
- ECS Fargateデプロイ用CodePipelineのtaskdef.jsonに変数を持たせる方法
開発環境
Eclipse
- WindowsのEclipseからCodePipelineを起動してEC2にデプロイ&ECS on Fargateにアプリをデプロイする
- Amazon API Gateway/ALBのバックエンドで動くLambda関数をJava(Eclipse+maven)で実装する
- GitLabとEclipseのEgitでGitLab Flow運用をやってみよう
SonarQube
- SonarQubeをサーバレスコンテナで起動してみる
- CodeCommitのイベントから自動でSonarQubeのプロジェクトを設定するLambda関数のSAMテンプレート
- CodePipelineでSonarQubeの静的解析を自動化するCloudFormationテンプレート
その他
Golang
- Golangはじめて物語(APIGateway+Lambdaといっしょ編)
- Golangはじめて物語(第2話: Gin+ECS+Fargateといっしょ編)
- Golangはじめて物語(第3話: CodePipeline+SAM+LambdaでCI/CD編)
Git
- GitLabとEclipseのEgitでGitLab Flow運用をやってみよう
- Gitのサブモジュール機能をCodeCommitとEgitで連動させてみる
- Gitのサブモジュール機能とTerraformのモジュール機能で実現するCI/CDパイプラインの量産(Lambda編)
Docker
Locust
Springフレームワーク
- Spring BootのActuatorを使ってバックエンドサービスのサーキットブレーカーを作ってみる(前編)
- Spring Cloud FunctionでAmazon API Gatewayのプロキシ統合なLambda関数をサクッと書いてみる
Tips
- 投稿日:2020-09-12T09:48:44+09:00
AWSクラウドプラクティショナーに合格したのでやって良かったこと&本番トラブルを振り返ってみる
先日オンライン自宅受験でAWSクラウドプラクティショナーに合格しました。直前1週間はかなり焦って無我夢中で対策していたので、一旦落ち着いて振り返ってみたいと思います。
だらだらと書いていますが、受験を考えている方のご参考になれば幸いです。
ちなみに結果は895/1000で、合格ラインの700点と比べると比較的余裕がありました。経歴
- AWSはEC2やVPC、S3などほんの少しだけ触っていました。業務での利用はなし。
- 基本情報技術者(FE)だけ取得済み
- 仕事の一環でクラウド全般やAWSの基礎講座を何回か受けていました。
勉強時間
30~40時間程度。試験のために本腰を入れたのは約1週間前からで、おそらく20時間くらい。 試験関係なく、AWSの勉強自体を始めていたのは2か月前くらいだったと思います。やったこと(◎必須、〇やってよかった、△プラスアルファ)
◎ 公式の試験ガイドを確認する
◎ 公式のサンプル問題(10問)
◎ 各サービスの紹介ページをみて概要を確認する
〇 模擬試験(有料)を解く
〇 公式トレーニング動画を見る(「AWS Cloud Practitioner Essentials(2nd edition)」)
〇 料金系のサービスなどは実際のコンソールを確認
△ Udemy講座「この問題だけで合格可能!クラウドプラクティショナー模擬問題7回分」の最後を除いた6回分。分からなかった問題の解説はスクショして、空き時間に確認してました。まさに詰め込み。
△ Udemy講座「これだけでOK!AWSソリューションアーキテクト-アソシエイト突破講座」のEC2やS3、DBなど、ハンズオン以外。(購入はセール期間中に!)
△ Black Beltでサービスの概要と仕様を確認する
ちなみにこの試験のための書籍は購入せず、主に公式サイトや動画を利用していました。やってよかったこと、感想
- テスト範囲とその配点比重の確認はやはり重要だと思いました。これはサンプル問題10問と公式の試験ガイドで把握できます。プラス2000円で模擬問題も解けば、難易度と本番の試験形式もある程度把握できるかと思います。サンプル問題より本番試験の方が難しく感じたので、注意が必要です。
- ちなみに本番1週間前に解いたこの模擬問題が想像以上に難しく感じ、実際テクノロジーや料金の範囲の正答率がかなり低かったので結構焦りました。そこからSAA向けの講座を聞いたり、black beltをざっと確認したりしていましたが、技術面に関してはそこまでの詳細は聞かれなかったと思います。
- Udemyの模擬問題も、本番試験と比べると比較的難しめに作られている気がしました。確実に合格したい方はきちんと取り組むと良いかもしれませんが、この結果を真に受ける必要はあまりない気がします(半分くらいしか取れませんでした)。
- ただし公式のトレーニング動画よりは試験の方がより広く深く聞かれた体感があります。
重要視されていると感じたこと
- 基本的なサービスの概要や使い方:EC2,NW(VPC,Route53,CloudFront),ストレージ(S3,EBS,EFS,Snowball),DB(RDS,Aurora,Dynamo)など
- 責任共有モデル:AWSとカスタマーの責任範囲の分担。数題出題されてました。
- コスト計算系サービス:Cost Explorer, AWS Budgets, TCOなど。地味に区別がややこしいです
- 管理系サービス:Config, CloudTrail, TrustedAdviser。割と聞かれた気がします。
- クラウドを使うメリット:スケーラビリティや柔軟性など。実際の問題は国語力で解けるかもしれません。
- その他サービス:分析系(Redshift,Kinesis)、コンテナ系(ECS,EKS)など以外と幅広く見かけた気がしました。
当日おきたこと
オンラインで受験中、試験の様子がPCのカメラで常に撮影されてチェックされます。
事前のシステムテストは問題なく通りましたが、途中そのビデオの送信が途切れてしまったみたいで、試験官とチャットやコールで何回かやりとりすることに(ちなみに訛りのある英語でやや聞き取りづらめ)。
wi-fiに特に問題はなさそうで、また代わりのネット接続法はないことを伝えると、いったん試験を中断しPCの再起動を要求されました(ちなみに何回かこのやりとりをしました。再起動中は試験官と電話で会話をしたり、しなかったり)。・・お気づきかもしれませんが、監視がない状態なので、この間しようと思えば離席したりネットに繋いだりできてしまいます(もちろんしませんでしたが!!)。
最終的にはビデオが繋がり無事に試験を終えられましたが、今のオンライン受験の体制の限界を垣間見た気がします..。個人の主観が多分に入っていますので、他の方のご意見も参考にされますとより試験のイメージが深まるかと思います。
- 投稿日:2020-09-12T07:16:48+09:00
AWS AmplifyでS3のBucket名を取得する [メモ]
はじめに
基本は自分のための備忘録だが、誰かの参考になれば幸い。
なお、クイックハックです。正式なやり方ではないと思うのでご注意を。動機
AWSのAmplifyを使ってモバイルアプリを作ることになったが、使いやすい半面、小回りがきかなそうで困ってる。
すごいざっくりのAmplify概要
Amplifyは、CLIから簡単にバックエンドを構築できて、そのバックエンドへのアクセス方法をライブラリが隠蔽するので、開発者はその詳細を知らなくてもアクセス出来るというところがメリット。
また、Dev -> Prodの2Stageで開発するときに、アプリで使うバックエンドを下記のコマンドでDev用、Prod用に切り替えることが出来る。当然、開発者はバックエンドの詳細を知らなくてもよい。
$ amplify env checkout <stage>困ってること
詳細が隠蔽されているので、バックエンドのリソース名が取れない(ようにみえる)。
例えば、バケット名を表示したいと思っても、のバケット名を取得する方法がない(ようにみえる)。
具体的に困っているのは、Amplifyを使ってS3にアップロードしたファイルを、Amplifyで作成したAPI-Gateway -> Lambdaからアクセスしたい。だが、Lambdaが直接Amplifyが作成したS3のBucketの名前を取得する方法がない(こちらも、ようにみえる)。なので、アプリからAPI-Gatewayを叩くときに、バケット名を渡してやる必要がある。必要があるのだが、上記のようにバケット名を取る方法がない。こまるー。
→Lambdaで使う場合、バケットにアクセスすることを明示しておけば、環境変数に入れてくれるようでした。。Amplify ディスってごめんよ。一応、以下、何かのときのために残しておく。方式案
方式案1:設定ファイルから読み込む。
上述した
amplify env checkout <stage>でバックエンドを切り替えると、/res/raw/amplifyconfiguration.jsonの内容が書き換わる。これにより、開発者は詳細を知らずにバックエンドを切り替えてアプリを動かすことが出来る。なので、こいつをパースしてやれば良い。
方式案2:android-amplifyをカスタマイズしちゃう。
https://github.com/aws-amplify/amplify-android からcloneして、ソースコード書き換えちゃおうぜ。という方法。
方式案1 vs 方式案2
どちらも、正式な方法じゃないと思われる。思われるが、おそらく方式案1のほうがよろしかろうと思われる。
でも、どうせ正しくないのだから、敢えて方式案2でやってみる。(^_^:)/
ちなみに、正しい方法は、featureリクエスト/pullリクエストを出して実装してもらうことだ。
手順
githubからクローン
$ git clone https://github.com/aws-amplify/amplify-android.git -b release_v1.3.1 $ git checkout -b release_v1.3.1arrを作成
プロジェクトを開く
プロジェクトをオープンする。モジュールがいろいろ入っているが、トップのプロジェクトをオープンしましょう。
必要なソースコード編集を行う。
今回は、
aws-storage-s3のcom.amplifyframework.storage.s3.AWSS3StoragePlugin.javaをいじります。(ここでは、すごく適当にやってますが、ご参考頂く方々はもう少しマトモに配慮いただけると信じてます。)インスタンス変数に下記を追加。
public String regionStr; public String bucket;
configureメソッドのローカル変数をコメントアウトpublic void configure( JSONObject pluginConfiguration, @NonNull Context context ) throws StorageException { // String regionStr; // String bucket;ビルド
Android Studioの右にGradleのタスク一覧を出せるウィンドウがあるので1、buildを選んで実行しましょう。
なんか、エラーがちらほら出ますが、s3のモジュールには出てないようなので、今回は無視します。
build/outputs/arr/aws-storage-s3-release.aarが作成されていたらOKです。arrをインポート
それでは、作成したarrを自分のアプリにインポートします。
ファイル名に先ほど作成したarrを指定します。
これにより、
Open Modules settingsから依存関係を設定できるようになります。なるはずです、、、なりませんね。おかしい。。。(バグかな? 使っているのはv4.0.1です。)ということで、自力で
build.gradleを書き換えます。dependenciesに下記を追加します。implementation project(path: ':aws-storage-s3-release') implementation 'com.amazonaws:aws-android-sdk-s3:2.18.0' // カスタムのaws-storage-s3-releaseを使うときに必要。理由は不明。以上で、pluginからバケット名にアクセスすることが出来るようになりました。下のような文を追加して、正しく出力されるか確認してみましょう。
val plugin = Amplify.Storage.getPlugin("awsS3StoragePlugin") as AWSS3StoragePlugin Log.e(TAG,"Bucket ${plugin.bucketName} ${plugin.regionStr}")最後に
普通にjsonファイルをパースしたほう(方式案1)が早そうですね。ただ、これまでAmplifyを使った結果、今後もいろいろ小回りがきかなくて困りそうだったので、カスタマイズすることを前提にarrのインポートをするという手段をとってみました。
どなたかのご参考になれば幸いです。(自己責任でお願いします。)
デフォルトでは右端の細長いところにあるのですが、最初これが見つからなくて困りました。AndroidStudioは機能が多すぎて大変です。。。 ↩

- 投稿日:2020-09-12T01:39:59+09:00
AWS EC2 AmazonLinux2に導入したMailCatcherでLaravelのメールの受け取りを行う
目的
- AWS EC2 AmazonLinux2インスタンスに導入したMailCatcherにてLaravelから送られてきたメールを受け取る方法をまとめる
前提条件
- AWS EC2 AmazonLinux2インスタンスにLaravelの動作環境が構築されていること。
前提情報
- 下記の方法で構築したLaravel環境にMailCatcherを導入し作業を行う。
読後感
- AWSのインスタンス内に構築したLaravelアプリから送信されたメールを同じインスタンス内に導入されたMailCatcherで受け取ることができる。
概要
- MailCatcherの導入
- .envファイルの記載
- 確認
詳細
- MailCatcherの導入
- 下記の方法でAWS EC2 AmazonLinux2にMailCatcherを導入する。
.envファイルの記載
.envファイルのMail設定部分を下記の様に修正する。
MAIL_DRIVER=smtp MAIL_HOST=127.0.0.1 MAIL_PORT=1025 MAIL_ENCRYPTION=null MAIL_FROM_ADDRESS=admin@gmail.com MAIL_FROM_NAME=admin MAIL_USERNAME=null MAIL_PASSWORD=null MAIL_PRETEND=false確認
- Laravelアプリからメールを送信する。
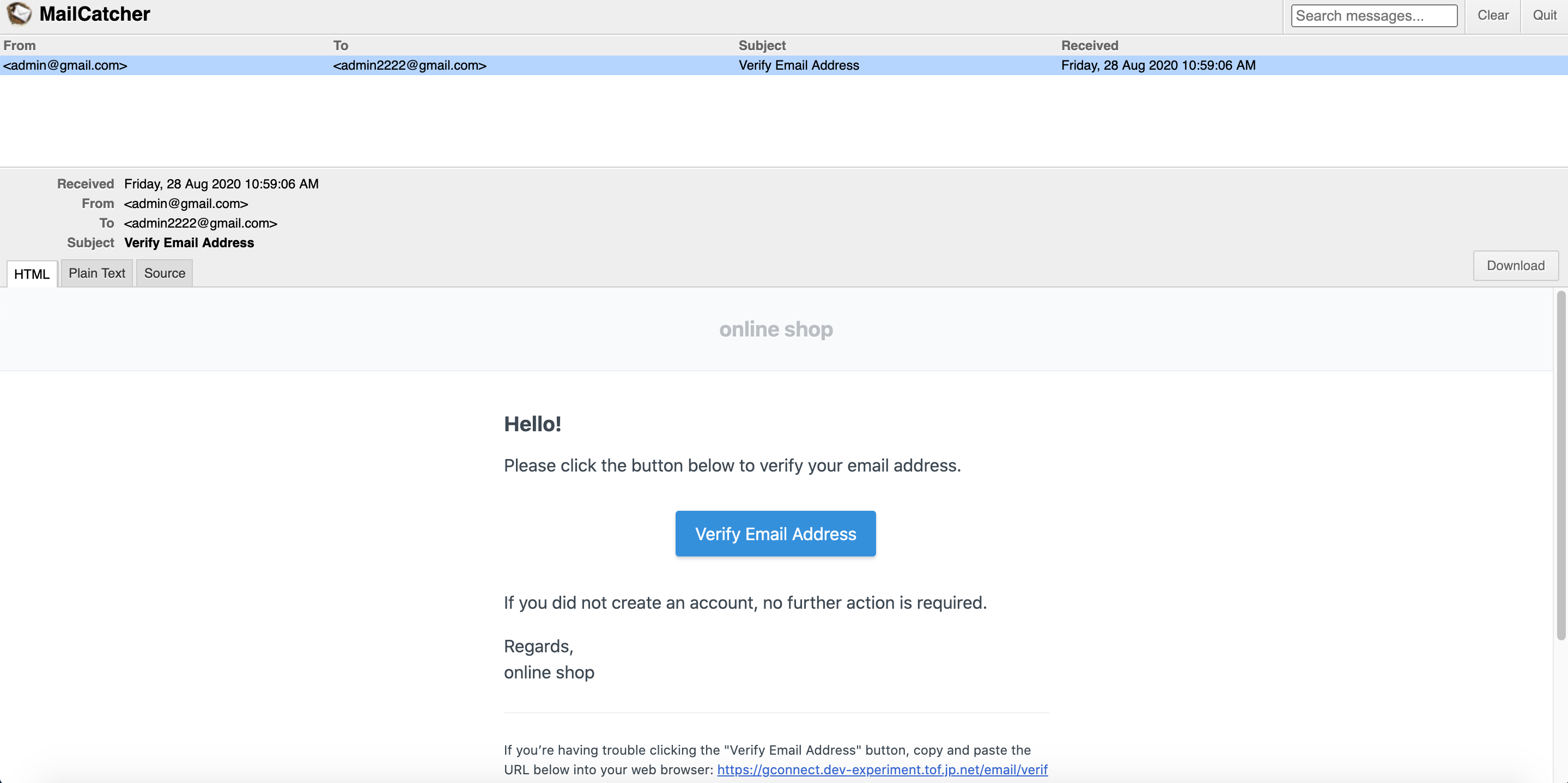
下記の様にブラウザでMailCatcherを表示しメールが受信できていることを確認したら作業完了である。
- 投稿日:2020-09-12T00:07:00+09:00
AWS日記18 (Step Functions)
はじめに
今回は AWS Step Functions を試します。
画像を自動的に変換・サイズ変更するページを作成します。
Lambda関数・SAMテンプレート準備
[AWS SAMの資料]
AWS Step Functions
Create a Step Functions State Machine Using AWS SAMAWS SAM テンプレート作成
AWS SAM テンプレートで API-Gateway , Lambda, Step Functionsの設定をします。
[参考資料]
AWS SAM テンプレートを作成する
template.yml
template.ymlAWSTemplateFormatVersion: '2010-09-09' Transform: AWS::Serverless-2016-10-31 Description: Serverless Application Template for Step Functions Parameters: ApplicationName: Type: String Default: 'ServerlessApplicationCreateThumbnail' FrontApiStageName: Type: String Default: 'ProdStage' Metadata: AWS::ServerlessRepo::Application: Name: Serverless-Application-Step-Functions Description: 'This application convert image and create icon, thumbnail.' Author: tanaka-takurou SpdxLicenseId: MIT LicenseUrl: LICENSE.txt ReadmeUrl: README.md Labels: ['ServerlessRepo'] HomePageUrl: https://github.com/tanaka-takurou/serverless-application-step-functions-page-go SemanticVersion: 0.0.2 SourceCodeUrl: https://github.com/tanaka-takurou/serverless-application-step-functions-page-go Resources: FrontApi: Type: AWS::Serverless::Api Properties: EndpointConfiguration: REGIONAL StageName: !Ref FrontApiStageName ImgBucket: Type: AWS::S3::Bucket Properties: CorsConfiguration: CorsRules: - AllowedHeaders: ['*'] AllowedMethods: [GET, HEAD] AllowedOrigins: ['*'] Id: CORSRuleId1 MaxAge: '3600' FrontFunction: Type: AWS::Serverless::Function Properties: CodeUri: bin/ Handler: main MemorySize: 256 Runtime: go1.x Description: 'Front Function' Policies: - Statement: - Effect: 'Allow' Action: - 'logs:CreateLogGroup' - 'logs:CreateLogStream' - 'logs:PutLogEvents' Resource: '*' Events: FrontApi: Type: Api Properties: Path: '/' Method: get RestApiId: !Ref FrontApi Environment: Variables: REGION: !Ref AWS::Region BUCKET_NAME: !Ref 'ImgBucket' API_PATH: !Join [ '', [ '/', !Ref 'FrontApiStageName', '/api'] ] MainFunction: Type: AWS::Serverless::Function Properties: CodeUri: api/bin/ Handler: main MemorySize: 256 Runtime: go1.x Description: 'API Function' Policies: - S3CrudPolicy: BucketName: !Ref ImgBucket - Statement: - Effect: 'Allow' Action: - 'logs:CreateLogGroup' - 'logs:CreateLogStream' - 'logs:PutLogEvents' Resource: '*' - Effect: 'Allow' Action: - 'states:StartExecution' - 'states:ListExecutions' Resource: '*' Events: FrontApi: Type: Api Properties: Path: '/api' Method: post RestApiId: !Ref FrontApi Environment: Variables: REGION: !Ref AWS::Region BUCKET_NAME: !Ref 'ImgBucket' STATE_MACHINE_ARN: !Ref MainStateMachine StepFunctionsMain: Type: AWS::Serverless::Function Properties: CodeUri: step/bin/ Handler: main MemorySize: 256 Runtime: go1.x Description: 'Step Functions Main' Policies: - S3CrudPolicy: BucketName: !Ref ImgBucket - Statement: - Effect: 'Allow' Action: - 'logs:CreateLogGroup' - 'logs:CreateLogStream' - 'logs:PutLogEvents' Resource: '*' Environment: Variables: REGION: !Ref AWS::Region BUCKET_NAME: !Ref 'ImgBucket' FrontApiPermission: Type: AWS::Lambda::Permission Properties: Action: lambda:InvokeFunction FunctionName: !Ref FrontFunction Principal: apigateway.amazonaws.com MainStateMachine: Type: AWS::Serverless::StateMachine Properties: DefinitionUri: step/statemachine.json DefinitionSubstitutions: LambdaFunction: !GetAtt StepFunctionsMain.Arn Role: !GetAtt StatesExecutionRole.Arn StatesExecutionRole: Type: "AWS::IAM::Role" Properties: AssumeRolePolicyDocument: Version: "2012-10-17" Statement: - Effect: "Allow" Principal: Service: - !Sub states.${AWS::Region}.amazonaws.com Action: "sts:AssumeRole" Path: "/" Policies: - PolicyName: StatesExecutionPolicy PolicyDocument: Version: "2012-10-17" Statement: - Effect: Allow Action: - "lambda:InvokeFunction" Resource: "*" Outputs: APIURI: Value: !Join [ '', [ 'https://', !Ref FrontApi, '.execute-api.',!Ref 'AWS::Region','.amazonaws.com/',!Ref 'FrontApiStageName','/'] ]Step Functionsの設定は以下の部分
MainStateMachine: Type: AWS::Serverless::StateMachine Properties: DefinitionUri: step/statemachine.json DefinitionSubstitutions: LambdaFunction: !GetAtt StepFunctionsMain.Arn Role: !GetAtt StatesExecutionRole.Arn StatesExecutionRole: Type: "AWS::IAM::Role" Properties: AssumeRolePolicyDocument: Version: "2012-10-17" Statement: - Effect: "Allow" Principal: Service: - !Sub states.${AWS::Region}.amazonaws.com Action: "sts:AssumeRole" Path: "/" Policies: - PolicyName: StatesExecutionPolicy PolicyDocument: Version: "2012-10-17" Statement: - Effect: Allow Action: - "lambda:InvokeFunction" Resource: "*"Lambda関数作成
※ Lambda関数は aws-lambda-go を利用し、Step Functionsの周りの処理は aws-sdk-go-v2 を利用しました。
AWS SDK for Go API Reference V2
main.go
main.gopackage main import ( "os" "log" "time" "bytes" "errors" "strings" "context" "net/http" "path/filepath" "encoding/json" "encoding/base64" "github.com/aws/aws-lambda-go/events" "github.com/aws/aws-lambda-go/lambda" "github.com/aws/aws-sdk-go-v2/aws" "github.com/aws/aws-sdk-go-v2/aws/external" "github.com/aws/aws-sdk-go-v2/service/sfn" "github.com/aws/aws-sdk-go-v2/service/s3" "github.com/aws/aws-sdk-go-v2/service/s3/s3manager" ) type APIResponse struct { Message string `json:"message"` } type Response events.APIGatewayProxyResponse var cfg aws.Config var s3Client *s3.Client var sfnClient *sfn.Client const layout string = "2006-01-02-15-04" const layout2 string = "20060102150405.000" func HandleRequest(ctx context.Context, request events.APIGatewayProxyRequest) (Response, error) { var jsonBytes []byte var err error d := make(map[string]string) json.Unmarshal([]byte(request.Body), &d) if v, ok := d["action"]; ok { switch v { case "upload" : if v, ok := d["filename"]; ok { if w, ok := d["filedata"]; ok { if name, key, e := uploadImage(v, w); e == nil { err = startExecution(ctx, name, key) if err == nil { jsonBytes, _ = json.Marshal(APIResponse{Message: name}) } } else { err = e } } } case "checkstatus" : if id, ok := d["id"]; ok { res, e := checkStatus(ctx, id) if e != nil { err = e } else { jsonBytes, _ = json.Marshal(APIResponse{Message: res}) } } } } if err != nil { return Response{ StatusCode: http.StatusInternalServerError, }, err } else { log.Print(request.RequestContext.Identity.SourceIP) } responseBody := "" if len(jsonBytes) > 0 { responseBody = string(jsonBytes) } return Response { StatusCode: http.StatusOK, Body: responseBody, }, nil } func uploadImage(filename string, filedata string)(string, string, error) { t := time.Now() b64data := filedata[strings.IndexByte(filedata, ',')+1:] data, err := base64.StdEncoding.DecodeString(b64data) if err != nil { log.Print(err) return "", "", err } extension := filepath.Ext(filename) var contentType string switch extension { case ".jpg": contentType = "image/jpeg" case ".jpeg": contentType = "image/jpeg" case ".gif": contentType = "image/gif" case ".png": contentType = "image/png" default: return "", "", errors.New("this extension is invalid") } name := strings.Replace(t.Format(layout2), ".", "", 1) key := strings.Replace(t.Format(layout), ".", "", 1) + "/" + name + extension uploader := s3manager.NewUploader(cfg) _, err = uploader.Upload(&s3manager.UploadInput{ ACL: s3.ObjectCannedACLPublicRead, Bucket: aws.String(os.Getenv("BUCKET_NAME")), Key: aws.String(key), Body: bytes.NewReader(data), ContentType: aws.String(contentType), }) if err != nil { log.Print(err) return "", "", err } return name, key, nil } func startExecution(ctx context.Context, name string, key string) error { if sfnClient == nil { sfnClient = sfn.New(cfg) } input := &sfn.StartExecutionInput{ Input: aws.String("{\"Key\" : \"" + key + "\"}"), Name: aws.String(name), StateMachineArn: aws.String(os.Getenv("STATE_MACHINE_ARN")), } req := sfnClient.StartExecutionRequest(input) _, err := req.Send(ctx) if err != nil { log.Print(err) return err } return nil } func checkStatus(ctx context.Context, id string)(string, error) { if sfnClient == nil { sfnClient = sfn.New(cfg) } statusList := []sfn.ExecutionStatus{sfn.ExecutionStatusRunning, sfn.ExecutionStatusSucceeded} for _, v := range statusList { input := &sfn.ListExecutionsInput{ StateMachineArn: aws.String(os.Getenv("STATE_MACHINE_ARN")), StatusFilter: v, } req := sfnClient.ListExecutionsRequest(input) res, err := req.Send(ctx) if err != nil { log.Print(err) return "", err } for _, w := range res.ListExecutionsOutput.Executions { if id == aws.StringValue(w.Name) { return string(v), nil } } } return "Error", nil } func init() { var err error cfg, err = external.LoadDefaultAWSConfig() cfg.Region = os.Getenv("REGION") if err != nil { log.Print(err) } } func main() { lambda.Start(HandleRequest) }ステートマシンの実行を開始するには StartExecutionRequest を使う
func startExecution(ctx context.Context, name string, key string) error { if sfnClient == nil { sfnClient = sfn.New(cfg) } input := &sfn.StartExecutionInput{ Input: aws.String("{\"Key\" : \"" + key + "\"}"), Name: aws.String(name), StateMachineArn: aws.String(os.Getenv("STATE_MACHINE_ARN")), } req := sfnClient.StartExecutionRequest(input) _, err := req.Send(ctx) if err != nil { log.Print(err) return err } return nil }ステートマシンの定義ファイル作成
statemachine.json
statemachine.json{ "StartAt": "Convert jpg image", "States": { "Convert jpg image": { "Type": "Task", "Resource": "${LambdaFunction}", "Parameters": { "action": "convert", "key.$": "$.Key", "type": "jpg" }, "Next": "Convert png image" }, "Convert png image": { "Type": "Task", "Resource": "${LambdaFunction}", "Parameters": { "action": "convert", "key.$": "$.Key", "type": "png" }, "Next": "Create medium icon" }, "Create medium icon": { "Type": "Task", "Resource": "${LambdaFunction}", "Parameters": { "action": "icon", "key.$": "$.Key", "icon": { "diameter": "200", "bgcolor": "f0ff" } }, "Next": "Create large icon" }, "Create large icon": { "Type": "Task", "Resource": "${LambdaFunction}", "Parameters": { "action": "icon", "key.$": "$.Key", "icon": { "diameter": "300", "bgcolor": "f0ff" } }, "Next": "Create medium thumbnail" }, "Create medium thumbnail": { "Type": "Task", "Resource": "${LambdaFunction}", "Parameters": { "action": "thumbnail", "key.$": "$.Key", "thumbnail": { "width": "960", "height": "540", "bgcolor": "f0ff" } }, "Next": "Create large thumbnail" }, "Create large thumbnail": { "Type": "Task", "Resource": "${LambdaFunction}", "Parameters": { "action": "thumbnail", "key.$": "$.Key", "thumbnail": { "width": "1440", "height": "810", "bgcolor": "f0ff" } }, "Next": "Create small thumbnail" }, "Create small thumbnail": { "Type": "Task", "Resource": "${LambdaFunction}", "Parameters": { "action": "thumbnail", "key.$": "$.Key", "thumbnail": { "width": "480", "height": "270", "bgcolor": "f0ff" } }, "End": true } } }ステートマシンの実行開始後、AWSの管理ページから、ステートマシンの進捗を確認できます。
終わりに
連続した処理を行う際には積極的にStep Functionsを利用していきたいと思います。
分岐処理も行えるため、今後試していこうと思います。

- 投稿日:2020-09-12T00:04:17+09:00
Amazon API GatewayでサクッとCORS対応する
はじめに
Amazon API GatewayとS3の静的Webサイトホスティングを組み合わせると、サーバレスで何でもできるようになるのだけど、当然のことながらオリジンが変わってしまうので、CORSの設定が必要。
マネコンからは一発でCORSの設定を入れることができるものの、IaCと組み合わせてると、マネコンからの変更は色々と不都合があるので、ここはTerraform一撃でCORSの設定を入れられるようにしてしまおう。CORSって何?という人はクラメソ先生に教えてもらおう!
簡単なリクエスト編(GETメソッド)
GETについては、レスポンスのheadersでCORSを許容することを示せば良い。
具体的には、
Access-Control-Allow-Headers、Access-Control-Allow-Origin、Access-Control-Allow-Methodsを返す。以下はPython+API Gatewayの統合レスポンスで返す場合の例。
return { 'isBase64Encoded': False, 'statusCode': status_code, 'headers': { "Access-Control-Allow-Headers" : "*", "Access-Control-Allow-Origin": "[許容するオリジン]", "Access-Control-Allow-Methods": "GET" }, 'body': json.dumps(body) }プリフライトリクエスト編(OPTIONメソッド)
プリフライトリクエストについては、Lambdaで実装しても良いが、いちいちLambdaなんて作っていられないので、API Gatewayの統合でMockを使うことにする。
まずは、API GatewayのRESTAPIと、リソースを作成し、
resource "aws_api_gateway_rest_api" "test" { name = local.api_gateway_name description = "テスト用API Gateway" } resource "aws_api_gateway_resource" "test" { rest_api_id = aws_api_gateway_rest_api.test.id parent_id = aws_api_gateway_rest_api.test.root_resource_id path_part = "test" }OPTIONメソッドを定義する。
resource "aws_api_gateway_method" "test_options" { rest_api_id = aws_api_gateway_rest_api.test.id resource_id = aws_api_gateway_resource.test.id http_method = "OPTIONS" authorization = "NONE" }testのOPTIONメソッドに対する統合レスポンスを作りつつ、メソッドレスポンスでCORSのヘッダを透過するよう設定し、
resource "aws_api_gateway_method_response" "test_options_200" { rest_api_id = aws_api_gateway_rest_api.test.id resource_id = aws_api_gateway_resource.test.id http_method = aws_api_gateway_method.test_options.http_method status_code = "200" response_models = { "application/json" = "Empty" } response_parameters = { "method.response.header.Access-Control-Allow-Headers" = true, "method.response.header.Access-Control-Allow-Methods" = true, "method.response.header.Access-Control-Allow-Origin" = true } } resource "aws_api_gateway_integration_response" "test_options" { rest_api_id = aws_api_gateway_rest_api.test.id resource_id = aws_api_gateway_resource.test.id http_method = aws_api_gateway_method.test_options.http_method status_code = aws_api_gateway_method_response.test_options_200.status_code response_parameters = { "method.response.header.Access-Control-Allow-Headers" = "'Content-Type,X-Amz-Date,Authorization,X-Api-Key,X-Amz-Security-Token'", "method.response.header.Access-Control-Allow-Methods" = "'GET,OPTIONS,POST,PUT'", "method.response.header.Access-Control-Allow-Origin" = "'[許容するオリジン]'" } }testパスのOPTIONSメソッドに対して200応答をするモックを作成する。
resource "aws_api_gateway_integration" "test_options_mock" { rest_api_id = aws_api_gateway_rest_api.test.id resource_id = aws_api_gateway_resource.test.id http_method = aws_api_gateway_method.test_options.http_method type = "MOCK" request_templates = { "application/json" = <<EOF { "statusCode": 200 } EOF } }これでOPTIONリクエストに良い感じにCORS許容のレスポンスをしてくれるモックが作れた!
あとは好きなようにPOSTなりPUTのメソッドでCORSな更新系リクエストを作れるぞ!