- 投稿日:2020-09-12T23:58:31+09:00
Codeforces Round #668 (Div. 2) バチャ復習(9/7)
今回の成績
今回の感想
今回は悪くない集中力でバチャコンに臨めていたと思います。
しかし、D問題は自分の持ってない知識が問われましたが、知っておくべき知識であったので反省しています。
また、バチャコン中に検索していればわかっていた問題でもあるので、時には検索を活用するのも良いかもしれません。A問題
ギャグだった。気づかんかったら発狂する気がします。変に実験はせずに$p_1,p_2,…,p_n$のまま考えると良いです。
$p_1+p_2,p_2+p_3,…,p_{n-1}+p_n$なので、逆にすれば$p_n+p_{n-1},…,p_3+p_2,p_2+p_1$となり、出てくる数は全く同じになります。
よって、逆順にしたものを出力すれば良いです。
A.pyfor _ in range(int(input())): n=int(input()) p=list(map(int,input().split())) print(" ".join(map(str,p[::-1])))B問題
計算量がギリギリの解法を出したら通らずに焦ってしまいましたが、立て直せて良かったです。
$i,j$を選択して$a_i-1,a_j+1$へと変化させることを考えます。この際に、$i<j$の場合はコインが必要なく,$i>j$の場合はコインが一枚必要で、全てを0にするのに必要な最小の枚数のコインを考えます。
サンプルで実験を行うと、$a_i>0,a_j<0$となる$i,j$を選択すればコインを使わずに0へと近づける変化を行うことができます。また、この変化を行うことで最終的に左側に-,右側に+が残り、この時コインを使った操作を行うしかありません。例えば、一つ目のサンプルでは、
-3 2 -3 4から-3 0 -1 4へコインを使わない操作を行ってその状態からコインを4枚使うことで全ての要素を0にすることができます。また、初めのコインを使わない操作は$a[i]>0$を満たす要素を小さい$i$から順に見ていき、$a[j]<0$を満たす$j(>i)$で小さい$j$から順に操作を行うという貪欲法で行うことができます($\because$小さい$j$の方が選択肢が少ないというイメージ!)。また、$a[j]<0$を満たす$j(>i)$で小さい$j$をset構造で管理しようとしましたが、この場合はsetへの挿入,削除,参照において対数時間かかるのでTLEになります。
ここで、$j$は$i<j,a[j]<0$を満たす中で最小のインデックスであり、$i$を1ずつ増やした時に$j$は単調に増加するので、$j$をそのインデックス単体で持って尺取法のような実装を考えれば良いです。したがって、$O(N)$の計算量での実装が可能となります。
B.pyfor _ in range(int(input())): n=int(input()) a=list(map(int,input().split())) for j in range(n): if a[j]<0: break for i in range(n): if a[i]>0: j=max(i+1,j) while True: if j==n: break if a[j]<0: m=min(a[i],-a[j]) a[i]-=m a[j]+=m if a[i]==0: break j+=1 if j==n: break ans=0 #print(a) for i in range(n): if a[i]>0: ans+=a[i] print(ans)C問題
部分列が連続であることに注意が必要です。自分はそれに気づかずにキレてました。
連続する長さ$k$の部分列であり、差分を見たいので下図を書きました。
すると、インデックスが$0$と$k$の要素は等しいことに気づきました。また、これを一般化すればインデックスが$i$と$i+k$の要素は等しいので、インデックスを$k$で割った余り同士が等しい場合はそれらの要素は等しいと言えます。したがって、まずはインデックスの余りごとに分けてそれぞれで要素が等しいか(0と1が同時に含まれていないか)をチェックします。この時点で等しくないものがある場合はNOを出力します。
また、それぞれの余りのインデックスについて全ての要素が等しいのは必要条件で、十分条件として長さ$k$の連続部分に出てくる0と1の数が等しくなければなりません。よって、余りが$l$の時の要素を任意の$l$について求めます。また、$0$と$1$だけでなく?の場合もあることに注意が必要で、0の数を$ans0$,1の数を$ans1$,?の数を$ex$とします。
この下で十分条件を考えますが、$ex=0$のときは$ans0=ans1$であれば条件を満たすのでYES,そうでない場合はNOを出力します。次に、$ex \neq 0$のときは?の数で調整ができるので、$ans0+ex \geq [\frac{k}{2}]$かつ$ans1+ex \geq [\frac{k}{2}]$であれば条件を満たすのでYES,そうでない場合はNOを出力します。
C.pyfor _ in range(int(input())): n,k=map(int,input().split()) s=input() t=[[] for i in range(k)] for i in range(n): t[i%k].append(s[i]) #違うものあったらその時点でだめ ans0,ans1=0,0 ex=0 for i in range(k): if t[i].count("0")>0 and t[i].count("1")>0: print("NO") break elif t[i].count("0")>0: ans0+=1 elif t[i].count("1")>0: ans1+=1 else: ex+=1 else: if ex==0: if ans0==ans1: print("YES") else: print("NO") else: if ans0+ex>=k//2 and ans1+ex>=k//2: print("YES") else: print("NO")D問題
以下では、AliceをA,BobをBとして略記します。また、Aの一回で進める距離を$da$,Bの一回で進める距離を$db$とします。
BはAから逃げます。Aが先攻なので、一回目でBにたどり着ける場合はAが勝利します。したがって、Aが一回目でBにたどり着けない中でそれぞれの最適な移動を考えます。最初にBの最適な移動を考えます。BはAがギリギリに近づいてくるまで移動する必要はありません。Aがギリギリまで近づいた時、Aから離れる方向に頂点がある場合はそちらに移動するのが良いですが、そのような頂点がない場合はAを跨いで遠くの頂点へ移動する必要があります。それに対し、Aの最適な移動はBにできるだけ近づくことではなく、Bとの距離が$da$になるように移動することです。なぜなら、それよりも近づくとBがAを跨いで逃げる時に逃げやすくなるからです。
上記の考察より、Aが捕まえられるのは$db \leqq 2 \times da$で、Bが逃げ続けられるのは$db > 2 \times da$と考えられます。しかし、Bはここまで逃げられない可能性があります。なぜなら$db$は最大で$n-1$となりますが、木上で頂点間の距離が$n-1$より小さい可能性があるからです(e.g.スターグラフ)。つまり、$db$は$min(db,$木上での二頂点間の最大距離)と置き換える必要があります。ここで、木上での二頂点間の最大距離をどうやって求めるかがバチャコン中にはわかりませんでしたが、調べたところ木の直径というのがこれに当たるようです。よって、$db=min(db,$木の直径)とすれば良いです。
木の直径はこちらの記事を参照すれば以下のアルゴリズムに従うことで求めることができるそうです。
BFS(またはDFS)を二回行うだけで簡単なのでライブラリにはしませんが、今後は見たら解けるようにしたいです。また、証明についても先ほどの記事に簡単なものが書いてあります。
よって、以上よりAとBのいずれが勝つかの判定を任意の場合について行うことができました。
D.cc//デバッグ用オプション:-fsanitize=undefined,address //コンパイラ最適化 #pragma GCC optimize("Ofast") //インクルードなど #include<bits/stdc++.h> using namespace std; typedef long long ll; //マクロ //forループ //引数は、(ループ内変数,動く範囲)か(ループ内変数,始めの数,終わりの数)、のどちらか //Dがついてないものはループ変数は1ずつインクリメントされ、Dがついてるものはループ変数は1ずつデクリメントされる //FORAは範囲for文(使いにくかったら消す) #define REP(i,n) for(ll i=0;i<ll(n);i++) #define REPD(i,n) for(ll i=n-1;i>=0;i--) #define FOR(i,a,b) for(ll i=a;i<=ll(b);i++) #define FORD(i,a,b) for(ll i=a;i>=ll(b);i--) #define FORA(i,I) for(const auto& i:I) //xにはvectorなどのコンテナ #define ALL(x) x.begin(),x.end() #define SIZE(x) ll(x.size()) //定数 #define INF 1000000000000 //10^12:∞ #define MOD 1000000007 //10^9+7:合同式の法 #define MAXR 100000 //10^5:配列の最大のrange //略記 #define PB push_back //挿入 #define MP make_pair //pairのコンストラクタ #define F first //pairの一つ目の要素 #define S second //pairの二つ目の要素 ll n,a,b,da,db; vector<vector<ll>> tree; vector<ll> check; vector<ll> check2; signed main(){ //入力の高速化用のコード //ios::sync_with_stdio(false); //cin.tie(nullptr); ll t;cin>>t; REP(_,t){ cin>>n>>a>>b>>da>>db; tree=vector<vector<ll>>(n); REP(i,n-1){ ll u,v;cin>>u>>v; tree[u-1].PB(v-1); tree[v-1].PB(u-1); } check=vector<ll>(n,INF); deque<ll> d={a-1}; ll dep=0; while(SIZE(d)){ ll l=SIZE(d); REP(i,l){ ll now=d.front(); check[now]=dep; FORA(j,tree[now]){ if(check[j]==INF)d.PB(j); } d.pop_front(); } dep++; } check2=vector<ll>(n,INF); d={ll(distance(check.begin(),max_element(ALL(check))))}; dep=0; while(SIZE(d)){ ll l=SIZE(d); REP(i,l){ ll now=d.front(); check2[now]=dep; FORA(j,tree[now]){ if(check2[j]==INF)d.PB(j); } d.pop_front(); } dep++; } //cout<<check[b-1]<<" "<<da<<endl; if(check[b-1]<=da){ cout<<"Alice"<<endl; //cout<<1<<endl; continue; } if(min(db,*max_element(ALL(check2)))<=2*da){ cout<<"Alice"<<endl; }else{ cout<<"Bob"<<endl; } } }E問題以降
今回は飛ばします


- 投稿日:2020-09-12T23:41:09+09:00
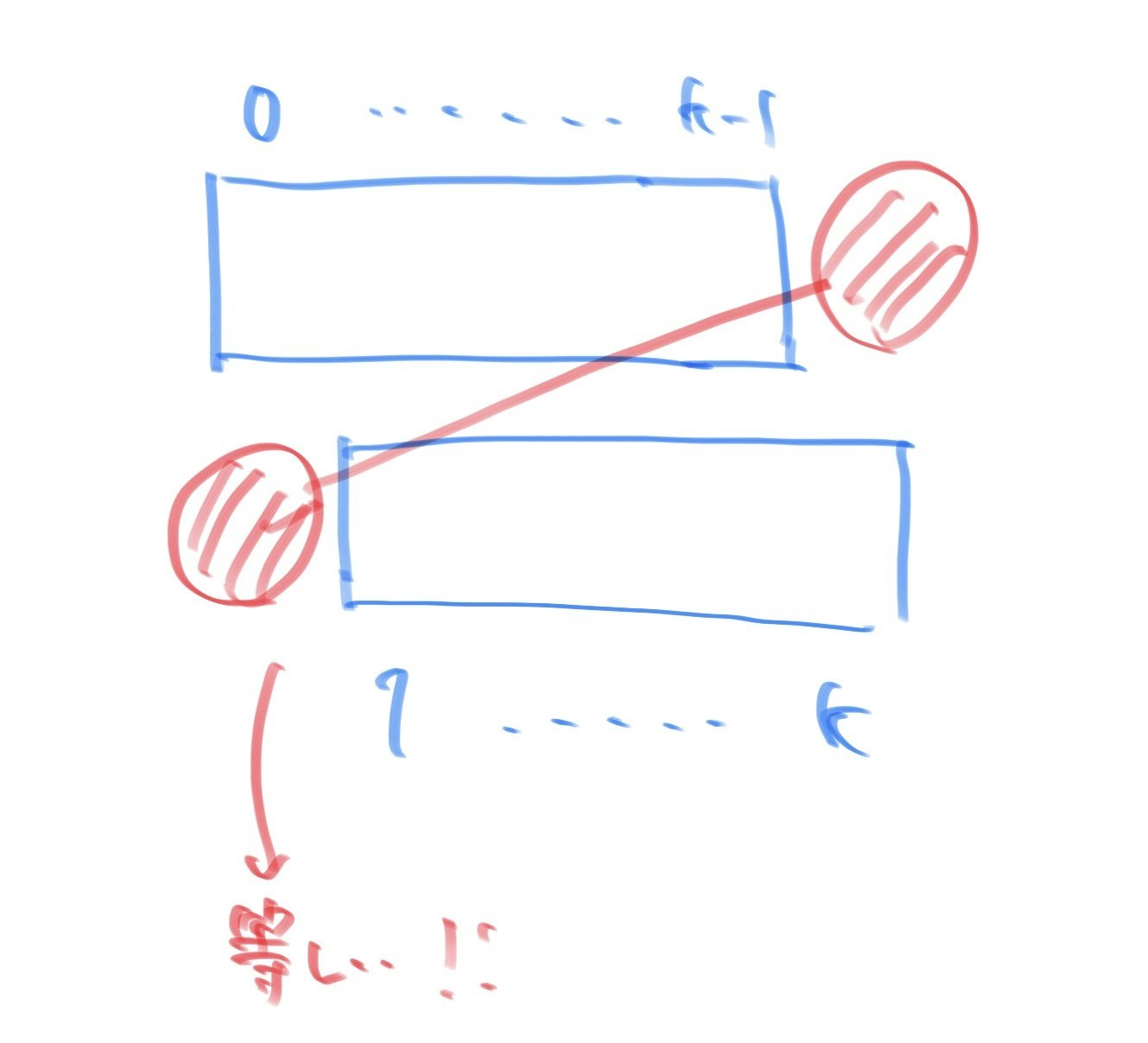
【Python】Openpyxlで書き込んだ値が指数表示(E)にされた
発生した問題
Pythonのライブラリopenpyxlで書き込んだ値がEを用いた指数表示の表示形式にされた
sample_code.pyimport openpyxl wb = openpyxl.open('./Book1.xlsx') sh = wb['Sheet1'] sh.cell(row=1, column=1).value = 308985489249593041 wb.save('./result.xlsx')結果
指数関数を取り除いた表示にしても末尾がいくつか0に置き換えられてて困る原因
openpyxlでなくExcelの仕様上の問題
Excel のセルに15桁を超える数字を入力すると、15桁を超える数字はすべて0に変更されます。
Excel のセルに長い数値を入力すると、最後の数字が0に変更されるより
数値計算ならこんくらいの桁数なら少しくらい精度が落とされても問題ではなさそうですが,
なんかのidだとかクレカの番号だとか1ケタでも違うと困るのを書き込んでる場合は困りますね解決策
文字列として数値を書き込んであげればよい
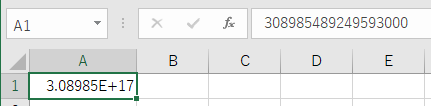
sample_code.pyimport openpyxl wb = openpyxl.open('./Book1.xlsx') sh = wb['Sheet1'] #ここで書き込む数値をstr型にしてあげる sh.cell(row=1, column=1).value = str(308985489249593041) wb.save('./result.xlsx')
これ文字列かアポストロフィで始まってる数値だよって怒られるけど書き込めた
ちなみにExcel内での計算はこのエラー出てても正常に行えるopenpyxlでは文字列として書き込んだ値はどんな感じで取得できるか
sample_code.pyimport openpyxl wb = openpyxl.open('./result.xlsx') sh = wb['Sheet1'] A1_value = sh.cell(row=1, column=1).value print(A1_value) print(type(A1_value)) ''' > 308985489249593041 > <class 'str'>文字列として取得されるみたいですね
intでまた置き換えてあげないといけないですね追記:フォーマットを指定してあげる
コメントで以下の記事を紹介して頂きました.
openpyxlで数値の表示フォーマットを指定するってことで
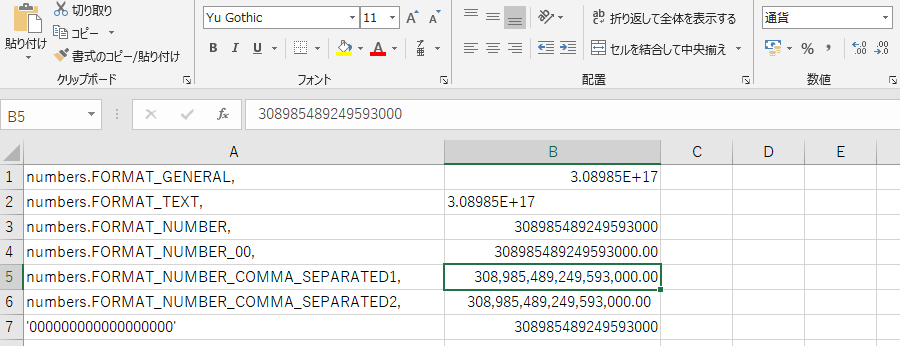
sh.cell(row= , colum=).number_format =に何個かフォーマットを渡してみました.
書き込む数値は上と同じ308985489249593041
A列が与えたフォーマットで,B列が結果
おー,すごい.ちゃんとフォーマットが変わってますね.
けど残念なことにやっぱり末尾の方は0に変えられちゃいますね….
B2とか文字列フォーマットなんだけど書き込む時点でint型だと多分無理っぽいですね….あとがき
もっとかしこい回避策あるんですかね
Excelのプラグインで上限解放できるとかw
知っている方いたら教えてください
- 投稿日:2020-09-12T22:53:42+09:00
TrelloAPIをpythonで使う
TrelloAPIをpythonで使う機会があったので、まとめておきます。
準備
from trello import TrelloClient import requests key = '***********' token = '***********' trello = TrelloClient(key, token)ボード(名前、ID、URL)を取得
boards=trello.list_boards() for board in boards: print(board.name) print(board.id) print(board.url) print("---------------")特定のボードの情報を取得
#知りたいボードのIDを以下に代入 BOARD_ID="***********" board=trello.get_board(BOARD_ID) #リスト一覧取得 lists = board.all_lists() #リスト名、リストID for list_ in lists: print(list_.name) print(list_.id) #カード一覧取得 cards=board.get_cards() #カード名、説明、ID、URL for card in cards: print(card.name) print(card.desc) print(card.id) print(card.url) print("------------------")カードを特定のリストに追加
BOARD_ID="***********" LIST_ID="***********" board = client.get_board(BOARD_ID) target_list = board.get_list(LIST_ID) #カード追加(カード名,説明) created_card = target_list.add_card("card_name","card_desc")説明、コメントを追加
CARD_ID="***********" #カードを選択 card=trello.get_card(CARD_ID) #説明を追加 card.set_description("~~~~~~~~") #コメントを追加 card.comment("~~~~~~~~")カードにファイルを添付
CARD_ID="***********" #カードを選択 card=trello.get_card(CARD_ID) file_path= "***********" file = open(file_path, 'rb') card.attach(name="~~~~~~~~",file=file)参考
Simple python script to upload a file to Trello.
Python + py-trelloで、Trello APIを使ってみた
- 投稿日:2020-09-12T22:25:58+09:00
xserverにpythonをインストールしてpipを使えるようにする
目的
Xserverは管理者権限がないので
- Python2.7.x /usr/bin/python
- Python3.4.x /usr/bin/python3.4
- Python3.6.x /usr/bin/python3.6
が入っているが、パッケージ管理のpipがない&インストールできない
やったこと
Linuxbrewをインストールしてbrewでpythonを入れる
Linuxbrewをインストール
適当なディレクトリで
sh -c "$(curl -fsSL https://raw.githubusercontent.com/Linuxbrew/install/master/install.sh)"以降 XXXXX は Xserverでの自アカウントと置き換えてください
... ==> Select the Homebrew installation directory - Enter your password to install to /home/linuxbrew/.linuxbrew (recommended) - Press Control-D to install to /home/XXXXX/.linuxbrew - Press Control-C to cancel installation [sudo] XXXXX のパスワード:と聞かれるので、
Control-Dでアカウント配下のディレクトリにインストールするしばらくダウンロード、インストールが動く...
インストールが完了すると以下のように
Next stepsとアドバイスされるのでそのとおり実行していく==> Next steps: - Run `brew help` to get started - Further documentation: https://docs.brew.sh - Install the Homebrew dependencies if you have sudo access: sudo yum groupinstall 'Development Tools' See https://docs.brew.sh/linux for more information - Add Homebrew to your PATH in /home/XXXXX/.bash_profile: echo 'eval $(/home/XXXXX/.linuxbrew/bin/brew shellenv)' >> /home/XXXXX/.bash_profile eval $(/home/XXXXX/.linuxbrew/bin/brew shellenv) - We recommend that you install GCC: brew install gcc以下コマンドを実行。
gccはlinuxbrew入れるときに入っているがrecommendしてくれてるので念の為。echo 'eval $(/home/XXXXX/.linuxbrew/bin/brew shellenv)' >> /home/XXXXX/.bash_profile eval $(/home/XXXXX/.linuxbrew/bin/brew shellenv) brew install gccPython3系を入れる(マイナーバージョンは今回指定しなかった)
brew install python3インストールしたら3.8.5が入りました。
$ python3 --version Python 3.8.5 $ pip3 --version pip 20.1.1 from /home/XXXXX/.linuxbrew/opt/python@3.8/lib/python3.8/site-packages/pip (python 3.8)↑
python --versionでは /usr/bin/pythonのパスに通されるので2.7.x系が表示されます注意点
.bash_profileを確認すると
PATH=$PATH:$HOME/bin export PATHeval $(/home/XXXXX/.linuxbrew/bin/brew shellenv)と PATHとevalに改行がなく次回ログイン時にPATHが効かない状態になる
改行いれてなおしておく
↓PATH=$PATH:$HOME/bin export PATH eval $(/home/XXXXX/.linuxbrew/bin/brew shellenv)
- 投稿日:2020-09-12T22:04:19+09:00
Python - pyautoguiによるマウス、キーボード操作
はじめに
皆さんは、マウスやキーボードを自動で操作できることを知っていますか?
pyautoguiを使えば、簡単にマウスやキーボードを操作することができます。pyautoguiの基礎
moveTo
moveTo関数はマウスのポインターを動かすための関数です。
sample.pypyautogui.moveTo(x座標, y座標)click
click関数はPCの画面の特定の位置をクリックさせるための関数です。
sample.pypyautogui.click(x座標, y座標)rightClick
rightClick関数はPCの特定の位置を右クリックさせるための関数です。
sample.pypyautogui.rightClick(x座標, y座標)position
position関数は現在のマウスの位置を取得するための関数です。
sample.pyplace=pyautogui.position() print("x座標", place.x) print("y座標", place.y)typewrite
typewrite関数は渡された文字列を一文字ずつ入力する関数です。
sample.pypyautogui.typewrite("hello")hotkey
hotkey関数はEnterキー(Returnキー)やAltキーなどのキーを入力するための関数です。
sample.pypyautogui.hotkey("Return") pyautogui.hotkey("Alt")最後に
皆さんは、pyautoguiを使いこなせるようになりましたか?
そうだと良いなと思っています。
これからも、沢山のPythonについての記事を書いていきます。
この記事を読んで、何か思ったことがあったら、コメントで教えてください。
- 投稿日:2020-09-12T22:02:18+09:00
お仕事の備忘録(pymongo) その1. 基本操作編
この記事について
仕事でpymongoを使ったので備忘録としてこの記事を作成しました。
下記に分けて書いていこうと思います。
- 基本操作編(このページ)
- 割と便利な操作編(そのうち書く)
- bulk_write
参照:pymongo ドキュメント Bulk_Write- あまり使わなかったけど調べ直したくないからメモしとくやつ編(そのうち書く)
- aggregate
参照:MongoDB ドキュメントaggregate pipeline動作環境
OS: Mac OS MongoDB: 4.2 Python 3.6.8 :: Anaconda, Inc. pymongo: 3.9.0
MongoDBとは?
- MongoDBの特徴として下記が挙げられる。
- NoSQL
- JSON形式のデータであればスキーマの設定なしに登録できる。
Rest APIのレスポンスをそのままインサートしたりできたり、スキーマが異なっていてもDBに登録できて便利です。- DBへの書き込みなどが早い
- 集計などの処理が独特
jsonのデータを格納できるため、配列の集計などもできますが、SQLよりわかりにくいです...- トランザクションなどが弱いRDBに慣れた方には異色な感じのDBかもしれません
pymongoとは?
名前から推測できるかと思いますが、pythonで動かすMongoDBのライブラリです。
pymongoの操作方法
基本的に下記を参考にざっくりとしたメモを作成していきます。
参考:pymongo ドキュメントMongoDBとの接続
main.pyimport pymongo from pymongo import MongoClient # デフォルト値のパラメータでの接続 (host=localhost,port = 27017) # 実際は接続できるかどうかは保証できない # findなどのDB読み書きでエラーが発生するっぽい client = MongoClient() # DBの接続() db = client.DB名 # DBの取得 collection = db.コレクション名 # コレクション(tableみたいなもの)の取得
挿入方法
- json形式のデータを挿入を行う
- 挿入されるデータは,_idが追加されてコレクションに追加される。
main.py# コレクションへの挿入(引数にjson形式のデータを渡すだけ) コレクション名.insert(json) #document or documentsの挿入(非推奨らしい) コレクション名.insert_one(json) # 1つのドキュメントだけ挿入 コレクション名.insert_many(jsons) # 複数のドキュメントの挿入検索方法
main.py# 全件検索(filterに何も指定しなければ全件取得できる) data = collection.find(filter={条件式},projection={}, skip=0,limit=0) for i in data: pprint.pprint(i) # 検索(projectionで必要ないカラムを0にセットするだけ # 0,1じゃなくてもTrue or False で表示のオンオフができるらしい data = collection.find(filter={},projection={"_id":0}, skip=0,limit=0) for i in data: pprint.pprint(i)削除方法
条件式のクエリはfindと同じ感じで使えるっぽい
main.py# シンプルに条件式を渡すだけ コレクション名.delete_one({条件式}) # 条件に一致する一件のドキュメントを削除 コレクション名.delete_many({条件式}) # 条件に一致するドキュメントの削除更新方法
- upsertを指定することで、filterの条件に引っかからない場合、ドキュメントを挿入することもできる。
参照:更新のoperationsmain.py# filterで指定した条件に一致する1つのドキュメントをupdateに従って更新する コレクション名.update_many(filter, update, upsert=False ) # filterで指定した条件に一致するドキュメントをupdateに従って更新する コレクション名.update_many(filter, update, upsert=False )
ざっくりした説明ですが、基本的な操作はこんな感じです。
今度、気が向いたらbulk_write,aggregateとかもうちょっと丁寧に書いてみようと思います。
- 投稿日:2020-09-12T21:43:37+09:00
Codeforces Round #639 (Div. 2) バチャ復習(9/4)
今回の成績
今回の感想
A問題
まず、$n$と$m$の小さい方が1である場合は凹と凸の部分を順につなげて作成することがです。また、それ以外の場合は$n=m=2$の時のみ成り立ちます。(適当に考えて1WAしてしまいました。)
これは実験して考えましたが、正確に考察するなら次のようになります。凹の部分は少ないのでできるだけ境目の部分で用いたいです。したがって、境目の数が凹の部分の数以下であれば作ることができます。ここで、境目の部分は$n \times (m-1)+ (n-1) \times m$だけありますが、パズルの数(凹の部分の数)は$n \times m$です。したがって、$n \times (m-1)+ (n-1) \times m \leqq n \times m$が成り立つ必要があります。この時、$(n -1)(m-1) \leqq 1$であり、これは、「$n=1$または$m=1$」または「$n=2$かつ$m=2$」と同値です。このようにして式変形のみで示すことができました。
A.pyfor _ in range(int(input())): x=list(map(int,input().split())) if min(x)==1 or max(x)==2: print("YES") else: print("NO")B問題
まず、それぞれのピラミッドで何枚ずつカードが必要か考えたところ、高さが増えるにつれて$2 \rightarrow 7 \rightarrow 15 \rightarrow 26 \rightarrow$の順に増えることがわかりました。また、再帰的に増えるのは明らかで、カードの枚数は階差数列($a_{i+1}=a_i+3i+5$)にしたがって増えます。
また、クエリで繰り返し問われるので、それぞれのピラミッドを作るのに必要なカードの枚数を先に求めますが、カードの枚数は高々$10^9$枚なのでそれを超える枚数が必要なピラミッドを考える必要はありません。また、$10^9$枚で作ることのできるピラミッドの高さは高々$25820$であることが実験によりわかったので、高さが$1$~$25820$のピラミッドを作るのに必要なカードの枚数を全列挙します(
check)。そして、クエリの処理を考えます。ここで、与えられた$n$枚のカードで作れる一番高いピラミッドを作る必要があるので、
checkの中からbisect_rightで探したピラミッドの一つ高さの低いピラミッドを作れば良いです。余ったカードについても再帰関数で考えればよく、その合計を出力します。B.pycheck=[2] i=0 while check[-1]<=10**9: check.append(check[-1]+3*i+5) i+=1 print(len(check)) from bisect import bisect_right def dfs(x): if x<2: return 0 return dfs(x-check[bisect_right(check,x)-1])+1 for _ in range(int(input())): n=int(input()) print(dfs(n))C問題
この問題は面白いと感じました。
シャッフルした結果として一致する人が存在するかを考えます。まず、このシャッフルを一般化すると、$k \rightarrow k+a_{k \ mod \ n}$となります。この時のシャッフルで重複するかを考えると、$mod \ n$が等しい時は重複しません。例えば、$k$と$k+n$の$mod \ n$は等しいですが、$k+n \rightarrow k+n+a_{k \ mod \ n}$となるので、シャッフルをしても重複しません。
したがって、シャッフルを行った時にそれぞれの$mod \ n$の部屋番号からどの$mod \ n$の部屋番号に移るかを考え、$mod \ n$が一致する場合が存在するかを確かめれば良いです。よって、$i=0$~$n-1$について、$(i+a_{i \ mod \ n}) \ mod \ n $を求めて一致するものがあるかを探します。また、求めた値をset構造に代入すれば、そのset構造のサイズが$n$であるかどうかを判定すれば良いだけになります。
C.pyfor _ in range(int(input())): n=int(input()) a=list(map(int,input().split())) s=set() for i in range(n): s.add((i+a[i%n])%n) #print(s) print("YES" if len(s)==n else "NO")D問題
題意を勘違いしていてミスが多発してしまいました。惜しかったです。
コンテスト直後の解法はバグっているところを少しずつ埋めていったのですが、考察を仕切れていればバグらせず実装も軽いままで解けたと思うので、反省です。まず、southは自分の都合の良いように置くことができます。ここで、それぞれの移動は同じ行または同じ列の中なので、それぞれの行(or列)に注目して考えます。この時、ある行の黒くなっている部分のうち左端と右端にはsouthが存在しないとその行はnorthで辿れません。また、左端と右端にsouthを置いた時はnorthはその間を全て通ることができるので、左端から右端までは全て黒く塗られている必要があります。
上記に加え、ルール1により任意の行及び列に少なくとも一つのsouthマグネットが存在するという条件も必要です。この時、任意の行及び列に黒のマスが存在すれば良いですが、存在しない場合でも他の任意の黒のマスと行及び列を共有していないマスであればsouthを置くことができます。また、マスを行と列の交叉と考えれば、黒のマスが一つもない行と列が少なくとも一つずつ存在する場合であると言い換えることができます。
上記の判定を任意の行と列で行って正しかった場合、題意を満たすことができます。この時、northの必要な個数は黒のマスを頂点と見た時の連結成分の個数と一致します。連結成分の個数はUnionFindでいつも数えていますが、グリッド上なのでBFSを用いてその個数を数えます。そして、その値を出力すれば良いです。
一つ目のコードはコンテスト後のもので、二つ目のコードは復習時のものになります。
D_worse.cc//デバッグ用オプション:-fsanitize=undefined,address //コンパイラ最適化 #pragma GCC optimize("Ofast") //インクルードなど #include<bits/stdc++.h> using namespace std; typedef long long ll; //マクロ //forループ //引数は、(ループ内変数,動く範囲)か(ループ内変数,始めの数,終わりの数)、のどちらか //Dがついてないものはループ変数は1ずつインクリメントされ、Dがついてるものはループ変数は1ずつデクリメントされる //FORAは範囲for文(使いにくかったら消す) #define REP(i,n) for(ll i=0;i<ll(n);i++) #define REPD(i,n) for(ll i=n-1;i>=0;i--) #define FOR(i,a,b) for(ll i=a;i<=ll(b);i++) #define FORD(i,a,b) for(ll i=a;i>=ll(b);i--) #define FORA(i,I) for(const auto& i:I) //xにはvectorなどのコンテナ #define ALL(x) x.begin(),x.end() #define SIZE(x) ll(x.size()) //定数 #define INF 1000000000000 //10^12:∞ #define MOD 1000000007 //10^9+7:合同式の法 #define MAXR 100000 //10^5:配列の最大のrange //略記 #define PB push_back //挿入 #define MP make_pair //pairのコンストラクタ #define F first //pairの一つ目の要素 #define S second //pairの二つ目の要素 deque<pair<ll,ll>> d; vector<vector<bool>> bfs_chk; ll n,m; void bfs(){ while(SIZE(d)){ ll l=SIZE(d); REP(i,l){ ll c0,c1;c0=d.front().F;c1=d.front().S; //cout<<c0<<" "<<c1<<endl; vector<pair<ll,ll>> nex={MP(c0-1,c1),MP(c0+1,c1),MP(c0,c1-1),MP(c0,c1+1)}; FORA(j,nex){ //cout<<1<<endl; if(0<=j.F and j.F<n and 0<=j.S and j.S<m){ //cout<<j.F<<" "<<j.S<<endl; if(!bfs_chk[j.F][j.S]){ bfs_chk[j.F][j.S]=true; d.PB(j); //cout<<1<<endl; } } } d.pop_front(); } } } signed main(){ //入力の高速化用のコード //ios::sync_with_stdio(false); //cin.tie(nullptr); cin>>n>>m; vector<string> s(n);REP(i,n)cin>>s[i]; bfs_chk=vector<vector<bool>>(n,vector<bool>(m,true)); REP(i,n)REP(j,m)bfs_chk[i][j]=(s[i][j]=='.'); ll ans=0; //cout<<1<<endl; REP(i,n){ REP(j,m){ if(bfs_chk[i][j]==false){ bfs_chk[i][j]=true; d.PB(MP(i,j)); bfs(); ans++; } } } //cout<<1<<endl; vector<bool> r(n,false); vector<bool> c(m,false); REP(i,n){ REP(j,m){ if(s[i][j]=='#'){ FOR(k,j,m-1){ if(s[i][k]=='.'){ FOR(l,k,m-1){ if(s[i][l]=='#'){ //cout<<2<<endl; cout<<-1<<endl; return 0; } } break; }else{ c[j]=true; r[i]=true; } } break; } } } REP(i,m){ REP(j,n){ if(s[j][i]=='#'){ FOR(k,j,n-1){ if(s[k][i]=='.'){ FOR(l,k,n-1){ if(s[l][i]=='#'){ //cout<<3<<endl; cout<<-1<<endl; return 0; } } break; }else{ r[j]=true; c[i]=true; } } break; } } } //追加できる場合 pair<vector<ll>,vector<ll>> addition; REP(i,n){ ll co=0; REP(j,m){ co+=ll(s[i][j]=='#'); } if(co==0)addition.F.PB(i); } REP(j,m){ ll co=0; REP(i,n){ co+=ll(s[i][j]=='#'); } if(co==0)addition.S.PB(j); } FORA(i,addition.F){ FORA(j,addition.S){ r[i]=true; c[j]=true; } } //REP(i,n)cout<<r[i]<<endl; //REP(i,m)cout<<c[i]<<endl; if(all_of(ALL(r),[](bool x){return x;}) and all_of(ALL(c),[](bool x){return x;})){ cout<<ans<<endl; }else if(all_of(ALL(r),[](bool x){return !x;}) and all_of(ALL(c),[](bool x){return !x;})){ cout<<ans<<endl; }else{ //cout<<4<<endl; cout<<-1<<endl; } }D_better.cc//デバッグ用オプション:-fsanitize=undefined,address //コンパイラ最適化 #pragma GCC optimize("Ofast") //インクルードなど #include<bits/stdc++.h> using namespace std; typedef long long ll; //マクロ //forループ //引数は、(ループ内変数,動く範囲)か(ループ内変数,始めの数,終わりの数)、のどちらか //Dがついてないものはループ変数は1ずつインクリメントされ、Dがついてるものはループ変数は1ずつデクリメントされる //FORAは範囲for文(使いにくかったら消す) #define REP(i,n) for(ll i=0;i<ll(n);i++) #define REPD(i,n) for(ll i=n-1;i>=0;i--) #define FOR(i,a,b) for(ll i=a;i<=ll(b);i++) #define FORD(i,a,b) for(ll i=a;i>=ll(b);i--) #define FORA(i,I) for(const auto& i:I) //xにはvectorなどのコンテナ #define ALL(x) x.begin(),x.end() #define SIZE(x) ll(x.size()) //定数 #define INF 1000000000000 //10^12:∞ #define MOD 1000000007 //10^9+7:合同式の法 #define MAXR 100000 //10^5:配列の最大のrange //略記 #define PB push_back //挿入 #define MP make_pair //pairのコンストラクタ #define F first //pairの一つ目の要素 #define S second //pairの二つ目の要素 deque<pair<ll,ll>> d; vector<vector<bool>> bfs_chk; ll n,m; void bfs(){ while(SIZE(d)){ ll l=SIZE(d); REP(i,l){ ll c0,c1;c0=d.front().F;c1=d.front().S; //cout<<c0<<" "<<c1<<endl; vector<pair<ll,ll>> nex={MP(c0-1,c1),MP(c0+1,c1),MP(c0,c1-1),MP(c0,c1+1)}; FORA(j,nex){ //cout<<1<<endl; if(0<=j.F and j.F<n and 0<=j.S and j.S<m){ //cout<<j.F<<" "<<j.S<<endl; if(!bfs_chk[j.F][j.S]){ bfs_chk[j.F][j.S]=true; d.PB(j); //cout<<1<<endl; } } } d.pop_front(); } } } signed main(){ //入力の高速化用のコード //ios::sync_with_stdio(false); //cin.tie(nullptr); cin>>n>>m; vector<string> s(n);REP(i,n)cin>>s[i]; //cout<<1<<endl; ll f=0;ll g=0; REP(i,n){ ll li=-1;ll ri=-1; //左端 REP(j,m){ if(s[i][j]=='#'){ li=j; break; } } //右端 REPD(j,m){ if(s[i][j]=='#'){ ri=j; break; } } if(li==-1 and ri==-1){ f++; continue; } FOR(j,li,ri){ if(s[i][j]!='#'){ cout<<-1<<endl; return 0; } } } REP(j,m){ ll ui=-1;ll di=-1; //上端 REP(i,n){ if(s[i][j]=='#'){ ui=i; break; } } //下端 REPD(i,n){ if(s[i][j]=='#'){ di=i; break; } } if(ui==-1 and di==-1){ g++; continue; } FOR(i,ui,di){ if(s[i][j]!='#'){ cout<<-1<<endl; return 0; } } } //いい感じにsouthをおけない時 if((f==0 and g!=0)or(f!=0 and g==0)){ cout<<-1<<endl; return 0; } bfs_chk=vector<vector<bool>>(n,vector<bool>(m,true)); REP(i,n)REP(j,m)bfs_chk[i][j]=(s[i][j]=='.'); ll ans=0; //cout<<1<<endl; REP(i,n){ REP(j,m){ if(bfs_chk[i][j]==false){ bfs_chk[i][j]=true; d.PB(MP(i,j)); bfs(); ans++; } } } cout<<ans<<endl; }E問題以降
今回は飛ばします

- 投稿日:2020-09-12T21:35:07+09:00
django テーブル作成
前回は、アプリの作成までをしました。
今日は、まずは簡単にサーバーを起動させてまずはきちんとサーバーが立ち上がり表示されることをまずは確認しようと思います。まずは、staffアプリのURLにファンクションを呼び出すために、Viewsのインポートと、URLにhello があった時に、hello というファンクションが呼び出されるようにします。
staff.url.pyfrom django.urls import path, include from .views import hello urlpatterns = [ path('hello/', hello, name = "hello"), ]要らないインポートもありますが、とりあえずサーバー起動のために必要なメンテナンスをしています。
そして、呼び出す hello ファンクションをviews.py に加えます。
このhelloに対してリクエストがあったら、httpレスポンスで次の文字を返して という命令を記載しますstaff.views.pyfrom django.shortcuts import render from django.http import HttpResponse def hello(request): return HttpResponse("Hello ようこそ")httpを返すために、httpにあるHttpResponse をインポートを追加しています。
ターミナルでサーバーを起動させます。
ターミナルpython3 manage.py runserverそうすると設定に問題がないとサーバーが起動します
ターミナルSeptember 12, 2020 - 20:52:23 Django version 3.0.8, using settings 'config.settings' Starting development server at http://127.0.0.1:8000/ Quit the server with CONTROL-C.
URLとして、staff/hello で無事にページが返されました
それでは、これからスタッフのテーブルを作成しようと思います。
staff.models.pyclass Staff(models.Model): from django.db import models id = models.AutoField(verbose_name='社員ID',primary_key=True) password = models.CharField(verbose_name='パスワード',max_length=20) name = models.CharField(verbose_name='社員氏名',max_length=20, blank=False, null=True) roll = models.CharField(verbose_name='役職',max_length=10, blank=False, null=True) nyushabi = models.DateField(verbose_name='入社日',blank=False, null=True) taishabi = models.DateField(verbose_name='退社日',blank=False, null=True) hyoujijyun = models.IntegerField(verbose_name='表示順',unique=True) jikyu = models.IntegerField(verbose_name='時給',blank=False, null=True) delete = models.BooleanField(verbose_name='削除フラグ',default=False) create_date = models.DateTimeField(verbose_name='作成日時', auto_now_add=True) create_user = models.IntegerField(verbose_name='作成ユーザ', max_length=50, null=True) update_date = models.DateTimeField(verbose_name='更新日時', auto_now=True) update_user = models.IntegerField(verbose_name='更新ユーザ', max_length=50, null=True) def __str__(self): return self.nameまだ、社員IDは任意で重複なしでもたすことも考えましたが、今回は自動設定のインクリメントで持つことにしました。
verbose_name は、管理画面で見るとこにフィールド名で付けています。まだ考慮不足がありそうな気はしますが、次はデータベースに記載したフィールドを作成していきたいと思います

- 投稿日:2020-09-12T21:31:09+09:00
Python - 演算をするときに使う記号
はじめに
皆さんは、どんな演算子を使ったことがありますか?
この記事では、様々なPythonの演算子について解説します。演算子とは
演算子とは、計算をするための記号です。
+や-、*、÷などもその一つです。Pythonでよく使う演算子
+
+は足し算をするための演算子です。
-
-は引き算をするための演算子です。
*
*は掛け算をするための演算子です。
/
/は割り算をするための演算子です。
日常生活では使いませんね。//
//はあまりを切り捨てで割り算をするための演算子です。
**
**は〇〇の〇〇乗というような計算をするための演算子です。
最後に
この記事を読んで、初めて知った演算子はありましたか?
何かご意見がありましたら、コメントで教えてください。
- 投稿日:2020-09-12T19:57:35+09:00
スプラトゥーン2のプレイ動画から、やられたシーンだけをディープラーニングで自動抽出する
はじめに
スプラトゥーン2を発売日からやりこんで3年になります。2年かけて全ルールがウデマエXに到達しましたが、そこからXパワーが上がらずウデマエX最底辺で停滞しています。最近は自分のプレイ動画を見て対策を立てるのですが、すべての動画を見るのは大変です。そこで敵にやられたシーンは特に修正すべき自分の弱点があると考え、そこだけを自動で抽出するシステムを作ってみました。
画像の引用
この記事では任天堂株式会社のゲーム、スプラトゥーン2のスクリーンショットを引用しています。
システムの概要
分類モデル
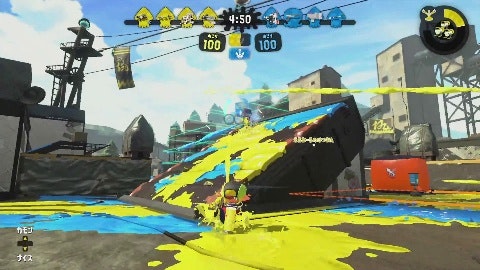
プレイ動画中のやられたシーンの画像とそれ以外のシーンの画像を分類するモデルを作ります。やられたシーンには「○○でやられた!」といった表示が中央上あたりに表示されます。
やられたシーン それ以外のシーン 


動画の切り出し
動画から0.5秒に1回フレームを抽出して前述のモデルで分類します。やられたシーンと分類された場合は、その数秒前から動画を切り出します。
前準備
Python
Pythonをインストールします。
OpenCV Python、TensorFlow、tqdmをインストールします。
この記事では学習をGoogle AutoML Visionで行うのでNVIDIAのGPUが無いPCでも良いです。pip install opencv-python pip install tensorflow pip install tqdmffmpeg
ffmpegをインストールします。
Macの場合はHomebrewでインストール出来ます。brew install ffmpeg学習元動画を準備
まず試合の録画をmp4形式で10時間分用意して、
src_movieディレクトリに格納しました。合計録画時間の確認
OpenCVには動画から合計フレーム数と1秒あたりフレーム数を取る機能があります。それを使って合計録画時間を確認しました。
movie_lengh.pyimport os import cv2 # 合計録画秒数 total_seconds = 0 # 元動画格納ディレクトリ dirname = 'src_movie' # 動画ファイル一覧 for name in os.listdir(dirname): if name.endswith('.mp4'): path = os.path.join(dirname, name) # 動画を読み込む cap = cv2.VideoCapture(path) # フレーム数を取得 frame_count = cap.get(cv2.CAP_PROP_FRAME_COUNT) # 1秒あたりフレーム数を取得 fps = cap.get(cv2.CAP_PROP_FPS) # 秒数を取得 seconds = frame_count / fps # ファイル名と秒数を出力 print("%s %d min" % (path, seconds / 60)) # 合計する total_seconds += seconds # 合計を出力する print(total_seconds/3600)3秒ごとにフレーム画像を切り出す
出力先として
src_imageディレクトリを作ります。
OpenCVには動画からフレーム画像を抽出する機能があります。それを使って3秒ごとにフレーム画像を切り出しました。movie_frame.pyimport os import numpy as np import cv2 # 元動画格納ディレクトリ src_dir = 'src_movie' # フレーム画像格納ディレクトリ dst_dir = 'src_image' # 保存インデックス save_index = 0 # 動画ファイル一覧 for name in os.listdir(src_dir): if name.endswith('.mp4'): path = os.path.join(src_dir, name) # 動画を読み込む cap = cv2.VideoCapture(path) # 1秒あたりフレーム数を取得 fps = cap.get(cv2.CAP_PROP_FPS) # 3秒に1回フレーム画像を取得する skip = fps * 3 # フレームインデックス i = 0 while True: ret, img = cap.read() if ret: if i % skip == 0: # フレームを縮小して保存する shrink = cv2.resize( img, (480, 270), interpolation=cv2.INTER_CUBIC) out_path = os.path.join( dst_dir, "frame%05d.jpg" % save_index) cv2.imwrite(out_path, shrink) print(out_path) save_index += 1 i += 1 else: break12,227枚の画像が出来ました。
やられたシーンとそれ以外のシーンに半自動で分ける
12,227枚の画像を1枚1枚目視して、やられたシーンを拾おうと思いましたが、
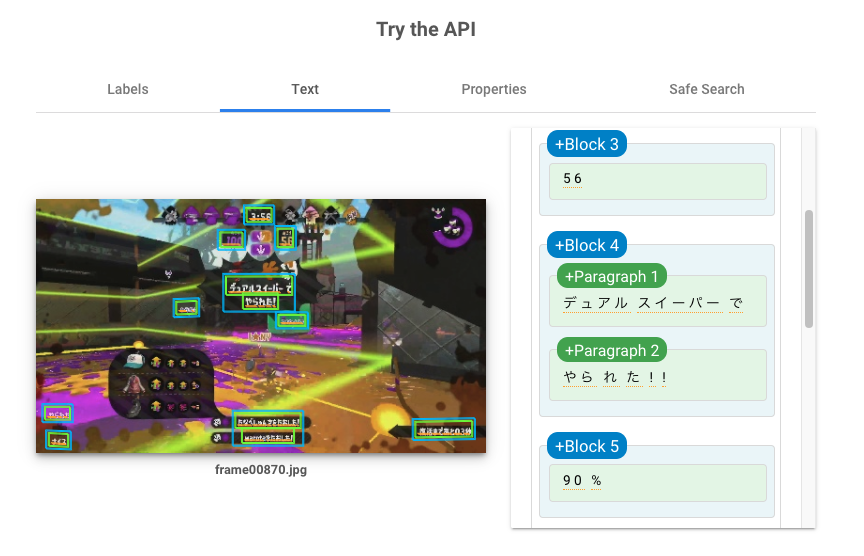
実際やってみると大変だったので、Google Cloud Vision APIのドキュメントテキスト検出を使いました。やられたシーンには「○○でやられた!」という表示があるので、テキスト検出して「で」と「やられた」を含む画像をやられたシーンとして分類します。
「で」をつけた理由はこのように味方から「やられた」シグナルを頂いたシーンを含まないようにするためです。
料金
Google Cloud Vision APIの呼び出しには無視できない金額がかかります。12,227枚の画像からテキスト検出するためには、約2,000円ほどかかります。
テキスト検出による分類を実行する
いったん全ての画像のテキスト検出結果をファイルに保存してから、検出されたテキストを処理して画像分類しています。画像分類は手直しの可能性が高く、Google Cloud Vision API呼び出しにはお金と時間がかかるためです。
すべての画像をテキスト検出結果をファイルに保存する
まず保存先ディレクトリとして
textを作ります。
こちらのPythonスクリプトでAPIのレスポンスをすべて保存します。
認証周りについてはこちらの公式解説を参考にしてください。image_ocr.pyimport os import subprocess import pathlib import base64 import requests # フレーム画像格納ディレクトリ src_dir = 'src_image' # テキスト検出結果格納ディレクトリ dst_dir = 'text' # アクセストークンの取得 access_token = subprocess.check_output( 'gcloud auth application-default print-access-token', shell=True) access_token = access_token.decode('utf-8').rstrip() # フレーム画像一覧 names = [] for name in os.listdir(src_dir): if name.endswith('.jpg'): names.append(name) names.sort() for name in names: print(name) # テキスト検出元画像パス path = os.path.join(src_dir, name) with open(path, 'rb') as f: data = f.read() # 画像データをBase64に変換 b64data = base64.b64encode(data).decode('utf-8') # リクエスト本文の作成 request_body = { 'requests': [ { 'image': { 'content': b64data }, 'features': [ { 'type': 'DOCUMENT_TEXT_DETECTION' } ] } ] } # Cloud Vision API呼び出し r = requests.post('https://vision.googleapis.com/v1/images:annotate', headers={'Authorization': "Bearer %s" % access_token}, json=request_body) # レスポンスを保存する if r.ok: # 出力ファイル名 out_name = pathlib.PurePath(name).stem + '.json' out_path = os.path.join(dst_dir, out_name) with open(out_path, 'w') as f: f.write(r.text) else: raise Exception('Vision API Error: %d' % r.status_code)検出されたテキストを処理して画像分類する
やられたシーン格納ディレクトリとして
train_1、それ以外のシーン格納ディレクトリとしてtrain_0を作ります。textディレクトリにあるjsonファイルを読んで、src_imageディレクトリにある画像をtrain_0train_1に分類します。train_data.pyimport os import pathlib import json import shutil # フレーム画像格納ディレクトリ image_dir = 'src_image' # テキスト検出結果格納ディレクトリ text_dir = 'text' # フレーム画像一覧 names = [] for name in os.listdir(image_dir): if name.endswith('.jpg'): names.append(name) names.sort() for name in names: print(name) # フレーム画像パス image_path = os.path.join(image_dir, name) # テキスト検出結果を取得する json_name = pathlib.PurePath(name).stem + '.json' json_path = os.path.join(text_dir, json_name) with open(json_path) as f: responses = json.loads(f.read()) try: description = responses['responses'][0]['fullTextAnnotation']['text'] except KeyError: description = "" # テキストを見て分類する if 'で' in description and 'やられた' in description: # 「で」「やられた」が含まれていていれば、train_1にコピー train_path = os.path.join('train_1', name) else: # そうでなければ、train_0にコピー train_path = os.path.join('train_0', name) shutil.copy(image_path, train_path)12,227枚中、596枚がやられたシーン、11,631枚がそれ以外のシーンに分類されました。
手動で手直しする
Finderで流すようにすべての画像を見て、誤った分類があれば手動で正しいディレクトリに置きます。
このように、やられたあとマップを見ているシーンもやられたシーン判定になっています。左下の上キーで「やられた」シグナルを出す案内と「復活まであと02秒」に「で」が含まれるためです。このケースは通常のマップを開いたシーンと大きな違いが無いため、それ以外のシーンに分類しました。テキストの位置を見るようにスクリプトを変更しても良かったのですが、手動で分類を直した方が早いと思いました。
「○○でやられた」テキストがあっても検出されなかった画像もありました。
その結果87枚をやられたシーンからそれ以外のシーンに移動して、20枚をそれ以外のシーンからやられたシーンに移動しました。2時間ぐらいかかりました。
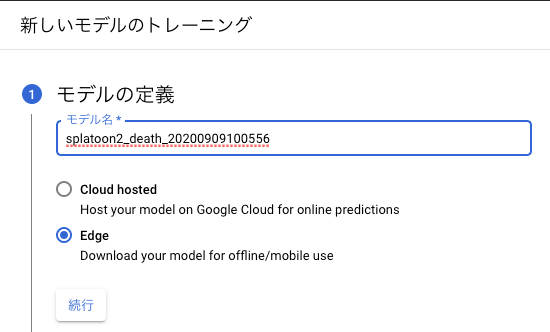
Google AutoML Visionで分類モデルを作成する
Google Cloud Storageに画像とCSVをアップロードする
まずは分類済みの画像ディレクトリ
train_0とtrain_1をGoogle Cloud Storageにアップロードします。
次に各画像のGoogle Cloud StorageのURLと分類ラベルを行にしたCSVファイルを生成します。2列目がdeathだとやられたシーンの画像、otherだとそれ以外のシーンの画像になります。death.csvTRAIN,gs://tfandkusu_spla_cut/death/train_1/frame00029.jpg,death TRAIN,gs://tfandkusu_spla_cut/death/train_1/frame00044.jpg,death TRAIN,gs://tfandkusu_spla_cut/death/train_1/frame00048.jpg,death 略 TRAIN,gs://tfandkusu_spla_cut/death/train_0/frame00000.jpg,other TRAIN,gs://tfandkusu_spla_cut/death/train_0/frame00001.jpg,other TRAIN,gs://tfandkusu_spla_cut/death/train_0/frame00002.jpg,other 略そしてCSVファイルもGoogle Cloud Storageにアップロードします。
最終的にはこのようになりました。
CSV作成スクリプト
CSVを作成するスクリプトはこちらです。
train_csv.pyimport os train_1 = 'train_1' train_0 = 'train_0' train_1_images = [] train_0_images = [] for name in os.listdir(train_1): if name.endswith('.jpg'): train_1_images.append(name) for name in os.listdir(train_0): if name.endswith('.jpg'): train_0_images.append(name) train_1_images.sort() train_0_images.sort() for name in train_1_images: print("TRAIN,gs://tfandkusu_spla_cut/death/train_1/%s,death" % name) for name in train_0_images: print("TRAIN,gs://tfandkusu_spla_cut/death/train_0/%s,other" % name)このように実行します。
python train_csv.py > death.csvGoogle AutoML Visionにインポートする
分類済みの画像を学習して、やられたシーンの画像とそれ以外のシーンの画像を分類するモデルをGoogle AutoML Visionを使って作成します。
Google Cloud Platformの左側のメニューからVision → ダッシュボードを選びます。
AUTOML APIを有効にします。
単一ラベル分類として新しいデータセットを作成します。
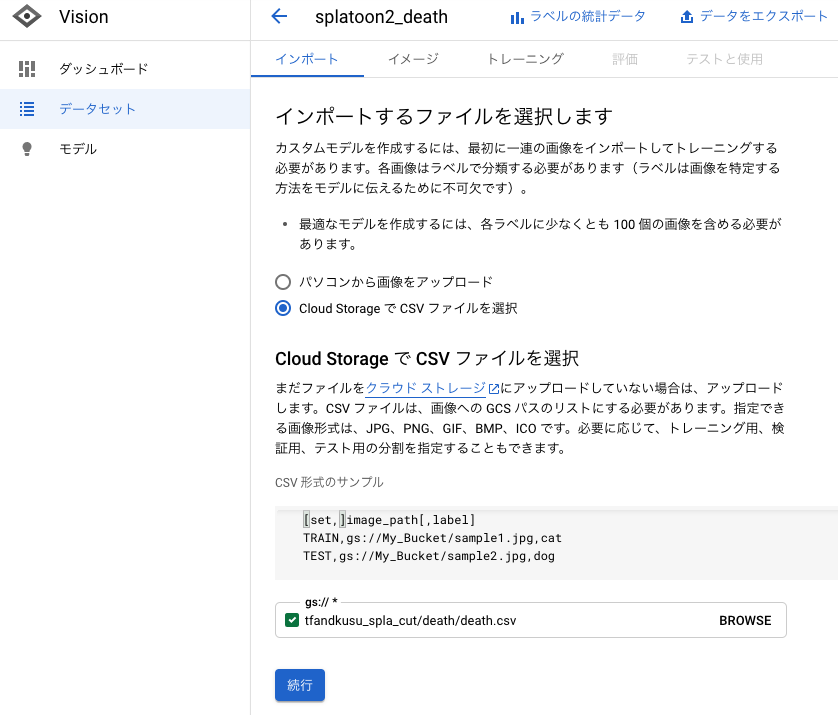
作成したCSVファイルのGoogle Cloud StorageのURLを指定することでインポートします。
インポートには時間がかかるのでしばらく待ちます。
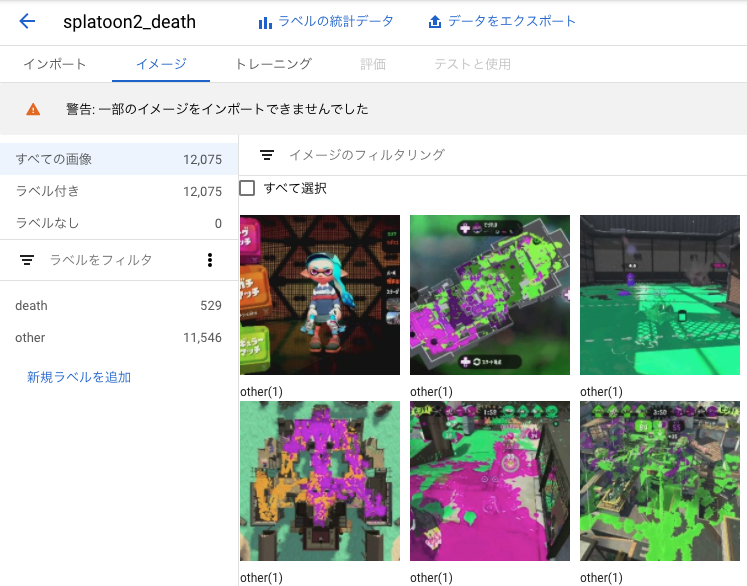
インポートが完了しました。
一部の画像はエラーが発生してしまいインポート出来ませんでした。原因はよく分からないですが、98.7%の画像はインポートに成功したのでそのまま進みます。
学習を行う
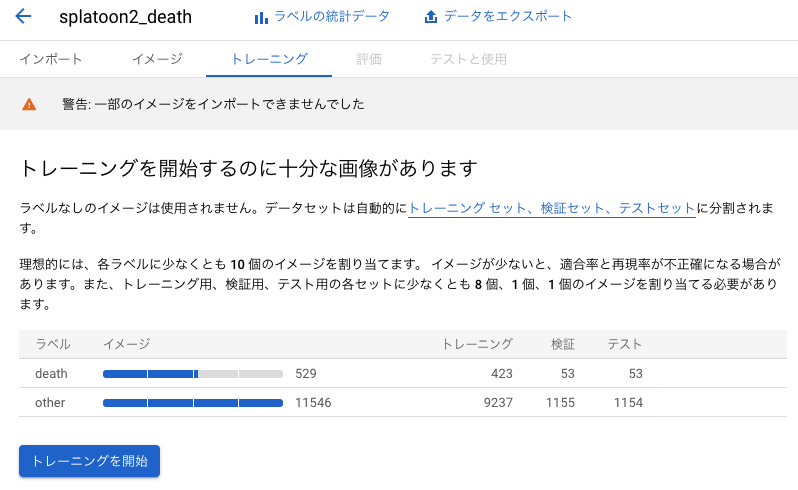
トレーニングタブを開くと、自動で画像がトレーニング用、テスト用、検証用に分けられていることが分かります。その3種類の違いはこちらで解説されていました。トレーニングを開始ボタンを押します。
クラウドかエッジかを聞かれます。今回はあまりお金をかけないように手元のPCで分類したいのでエッジにします。
処理時間を優先するか精度を優先するか聞かれますが、モバイル端末で分類する予定はないので精度重視で行きます。
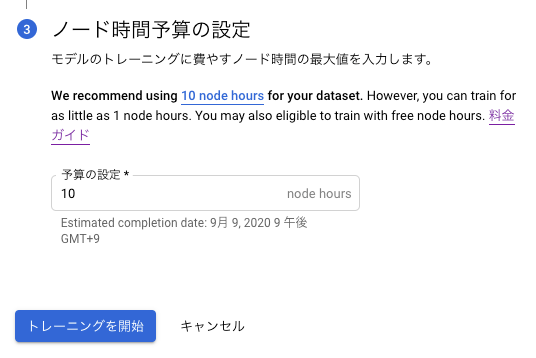
ノード時間予算もおすすめの10 node hoursにします。
料金はこちらです。
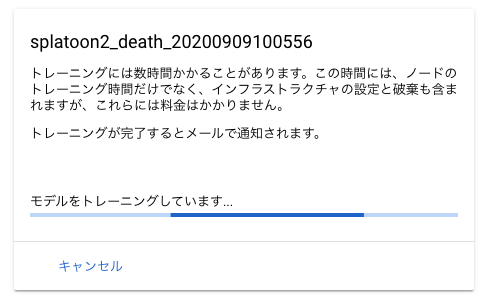
トレーニングを開始ボタンでトレーニングが開始されます。
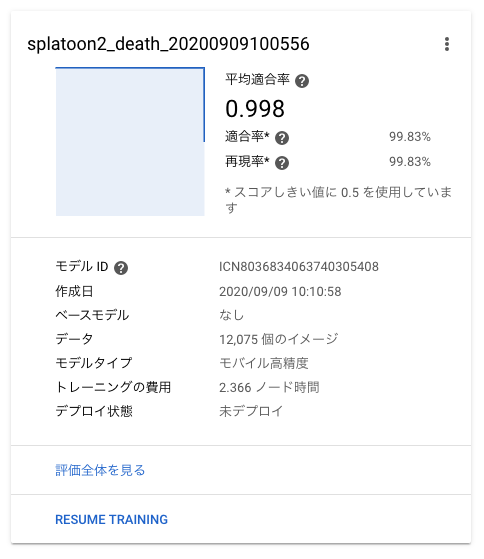
3時間ほどで学習モデルができて評価も出ました。
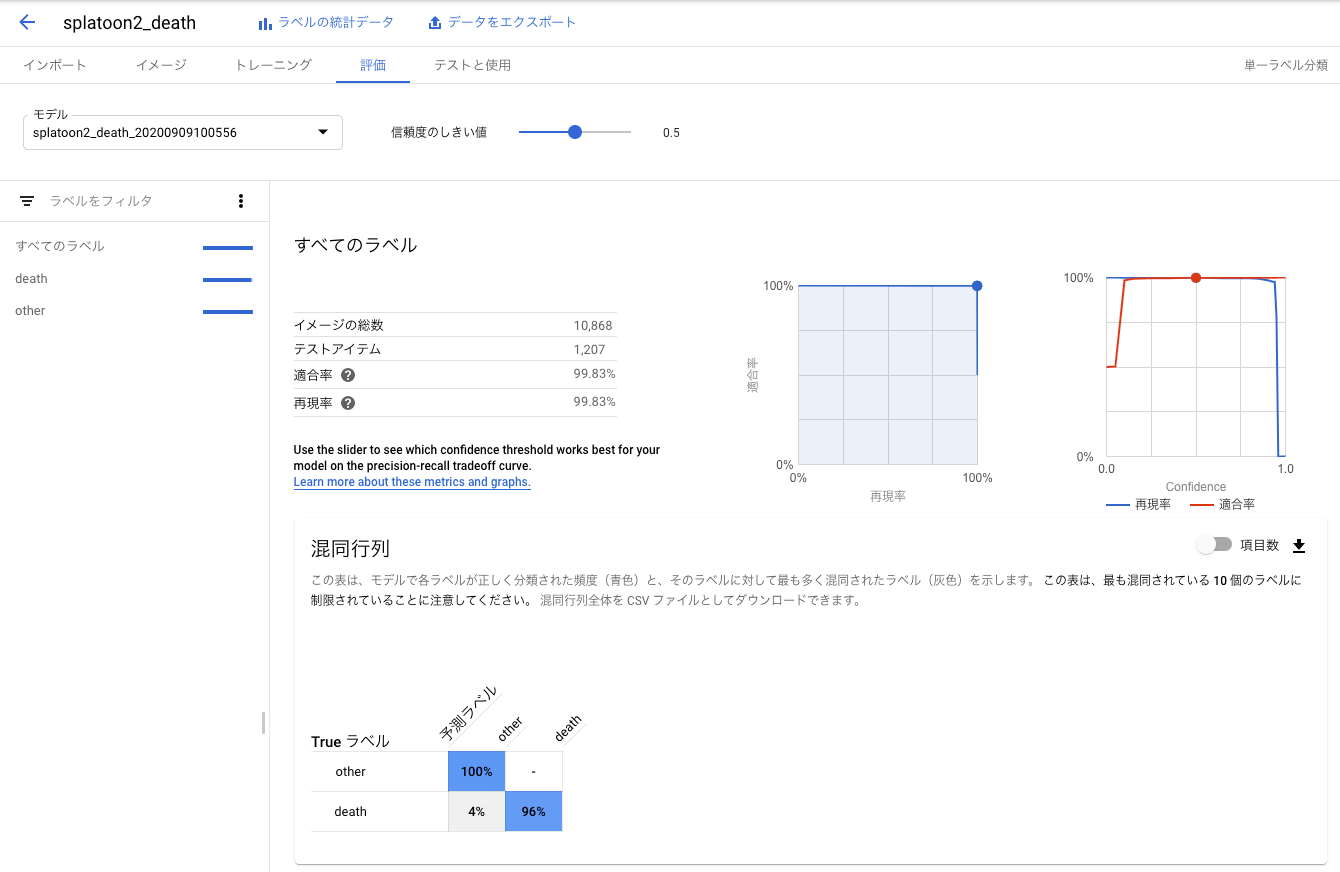
実際かかったノード時間は2.366でした。40までの無料枠があるようなので、その請求は来ませんでした。評価を確認する
混同行列を見ると、やられたシーンは4%の確率でそれ以外のシーンと誤分類されますが、それ以外のシーンがやられたシーンに誤分類されることはないようです。使用目的であるやられたシーンの数秒前からの動画の切り出しに適用すると、25回やられたら24回はやられたシーンの動画を切り出せるので、実用的な精度だと思います。
学習モデルをダウンロードする
テストと使用タブからTF Liteを選びます。
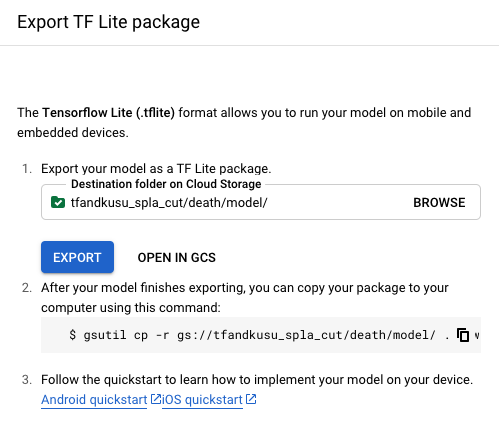
出力先Google Cloud StorageのURLを指定します。
出力先の深めの階層に学習モデルのファイルがあるので、
dict.txtとmodel.tfliteをダウンロードして、modelディレクトリに格納しました。
TensorFlow Liteを使って、やられたシーンを切り出す
入力層、出力層の形を確認する
まずはAutoML Visionによって作られたモデルの入力層、出力層の形を確認します。
TensorFlow Liteの使い方はこちらの記事が参考になりました。初心者に優しくないTensorflow Lite の公式サンプル
まずはモデルを読み込みます。
import tensorflow as tf interpreter = tf.lite.Interpreter(model_path='model/model.tflite')入力層の形を確認します。(ここからJupyter Labを使いました。)
interpreter.get_input_details()[{'name': 'image', 'index': 0, 'shape': array([ 1, 224, 224, 3], dtype=int32), 'shape_signature': array([ 1, 224, 224, 3], dtype=int32), 'dtype': numpy.uint8, 'quantization': (0.007874015718698502, 128), 'quantization_parameters': {'scales': array([0.00787402], dtype=float32), 'zero_points': array([128], dtype=int32), 'quantized_dimension': 0}, 'sparsity_parameters': {}}](1, 224, 224, 3)の4次元配列を入力することが分かりました。学習画像はフルHDの4/1 - 480×270の大きさに縮小しましたが、さらに縮小する必要があるそうです。
出力層の形を確認します。
interpreter.get_output_details()[{'name': 'scores', 'index': 172, 'shape': array([1, 2], dtype=int32), 'shape_signature': array([1, 2], dtype=int32), 'dtype': numpy.uint8, 'quantization': (0.00390625, 0), 'quantization_parameters': {'scales': array([0.00390625], dtype=float32), 'zero_points': array([0], dtype=int32), 'quantized_dimension': 0}, 'sparsity_parameters': {}}](1, 2)の2次元配列を出力することが分かりました。2種類に分類するモデルなので要素数が2になります。
次にdict.txtファイルを見て、やられたシーンとそれ以外のシーンのインデックスを確認します。cat model/dict.txtother deathこのモデルの出力は
[[243, 13]]のように0番目の方が大きいと、それ以外のシーン、
[[ 16, 240]]ように1番目の方が大きいと、やられたシーンになることが分かりました。
やられたシーンを切り出す。
0.5秒に1フレーム推論して、やられたフレームを見つけたら、その8秒前からやられたフレームまで動画を切り出します。切り出し後は8秒間推論をスキップします。動画の切り出しにはffmpegコマンドを使用しました。
ライブラリをインポートします。tqdmはプログレス表示用のライブラリです。
import subprocess import csv import numpy as np import cv2 import tensorflow as tf from tqdm import tqdm動画切り出し設定です。
# 切り出し元動画パス src_movie = 'test.mp4' # 切り出し秒数 cut_duration = 8 # 切り出し終了時間からこの秒数は切り出し開始しない death_duration = 8TensorFlow Liteの初期化を行います。
interpreter = tf.lite.Interpreter(model_path='model/model.tflite') interpreter.allocate_tensors() input_details = interpreter.get_input_details() output_details = interpreter.get_output_details()切り出し開始秒数をCSVファイルに書き出します。
# 書き出しCSVファイル with open('cut_time.csv', 'w') as f: writer = csv.writer(f) # 動画を読み込む cap = cv2.VideoCapture(src_movie) # フレーム数を取得 frame_count = int(cap.get(cv2.CAP_PROP_FRAME_COUNT)) # 1秒あたりフレーム数を取得 fps = cap.get(cv2.CAP_PROP_FPS) # 0.5秒に1回予測する skip = fps / 2 # フレーム i = 0 # 切り出し開始しないカウントダウン no_start = 0 for i in tqdm(range(frame_count)): ret, img = cap.read() if ret: if i % skip == 0 and no_start == 0: # フレームを予測する大きさに縮小 shrink = cv2.resize( img, (224, 224), interpolation=cv2.INTER_CUBIC) # 4次元に変換する input_tensor = shrink.reshape(1, 224, 224, 3) # それをTensorFlow liteに指定する interpreter.set_tensor(input_details[0]['index'], input_tensor) # 推論実行 interpreter.invoke() # 出力層を確認 output_tensor = interpreter.get_tensor(output_details[0]['index']) # やられたシーン判定 scene = np.argmax(output_tensor) if scene == 1: # やられたシーンの時は # 切り出し開始秒数を出力 ss = i - cut_duration * fps if ss < 0: ss = 0 writer.writerow(["%d.%02d" % (ss/fps, 100 * (ss % fps)/fps)]) # シーン判定をしばらく止める no_start = fps * death_duration if no_start >= 1: no_start -= 1 else: breakこのようなCSVファイルができあがります。
cut_time.csvcut_time.csv 511.00 544.50 561.00 // 略CSVファイルを読み込んで切り出し開始時刻配列を作ります。
sss = [] with open('cut_time.csv') as f: reader = csv.reader(f) for row in reader: sss.append(row[0])subprocesモジュールでffmpegコマンドを呼び出して、切り出します。
# ffmpegで切り出す for i in tqdm(range(len(sss))): ss = sss[i] command = "ffmpeg -y -ss %s -i %s -t %d -c copy extract/scene%03d.mp4" % (ss, src_movie, cut_duration, i) subprocess.run(command, shell=True)実用性のある精度か確認する
ガチマッチに2時間潜り録画しました。私は癖としてやられるとすぐにマップを開いてしまうのですが、そうすると「○○でやられた」表示が出なくなります。そこは注意しました。
↑やられたら、この表示を必ず出す。ikaWidget2で合計デス数を計算したところ132回デスしていましたが、このシステムはその132回をすべて正しく切り出していました。十分に実用的な精度です。
学習済みモデルと動画切り出しのJupyter Notebook
学習済みモデルとそれを使って動画を切り出すスクリプトはJupyter Notebook形式でGithubに置きました。
https://github.com/tfandkusu/splatoon2_movie_death










- 投稿日:2020-09-12T19:10:40+09:00
[CovsirPhy] COVID-19データ解析用Pythonパッケージ: S-R trend analysis
Introduction
COVID-19のデータ(PCR陽性者数など)のデータを簡単にダウンロードして解析できるPythonパッケージ CovsirPhyを作成しています。
紹介記事:
今回はS-R trend analysis(感染拡大状況のトレンドの分析法)のご紹介です。
英語版のドキュメントはCovsirPhy: COVID-19 analysis with phase-dependent SIRs, Kaggle: COVID-19 data with SIR modelをご参照ください。
1. 実行環境
CovsirPhyは下記方法でインストールできます!Python 3.7以上, もしくはGoogle Colaboratoryをご使用ください。
- 安定版:
pip install covsirphy --upgrade- 開発版:
pip install "git+https://github.com/lisphilar/covid19-sir.git#egg=covsirphy"import covsirphy as cs cs.__version__ # '2.8.2'
実行環境 OS Windows Subsystem for Linux Python version 3.8.5 本記事の表及びグラフは2020/9/11時点のデータを使用して作成しました。実データをCOVID-19 Data Hub1よりダウンロードするコード2はこちら:
data_loader = cs.DataLoader("input") jhu_data = data_loader.jhu() population_data = data_loader.population()日本の感染者数ですが、厚生労働省HPの値3とは異なる値が出力されるようです。厚生労働省の値を使用したい場合は、次のコードによりCOVID-19 dataset in Japanからデータをダウンロードしてデータを置き換えてください。その際
ImportError/ModuleNotFoundError: requests and aiohttpが発生した場合はpip install requests aiohttpによりインストールをお願いします(原因調査中、requestsは依存パッケージに含めているはずなんですが...)。japan_data = data_loader.japan() jhu_data.replace(japan_data) # Citation -> str print(japan_data.citation)2. データの確認
S-R trend analysisの説明に入る前に、
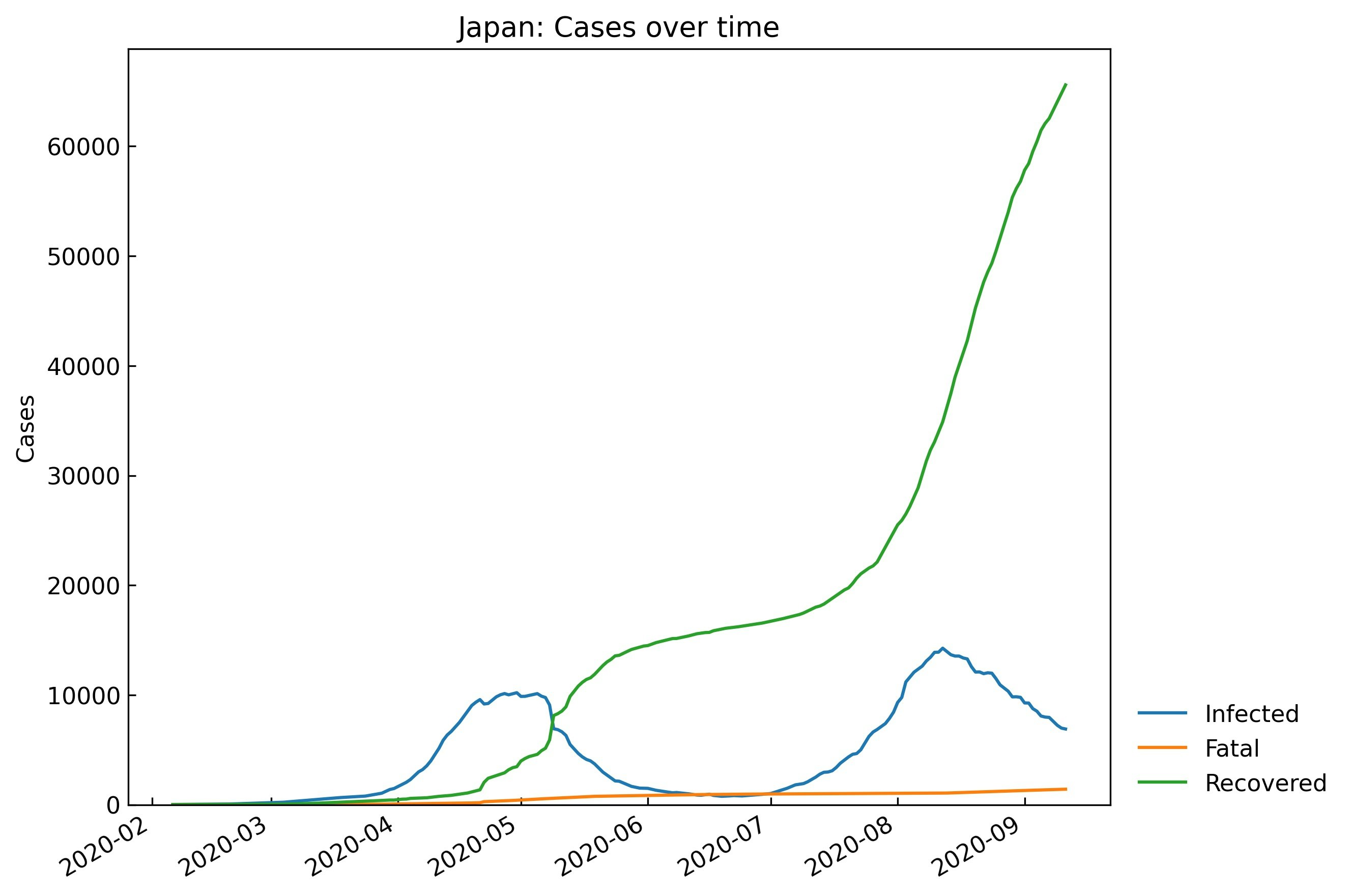
Scenario.records()を使って実データ(例として日本のデータ)を眺めます。snl = cs.Scenario(jhu_data, population_data, country="Japan") # グラフを表示しない場合 snl.records(show_figure=False)
Date Confirmed Infected Fatal Recovered 209 2020-09-07 71856 7957 1363 62536 210 2020-09-08 72234 7575 1377 63282 211 2020-09-09 72726 7233 1393 64100 212 2020-09-10 73221 6980 1406 64835 213 2020-09-11 73901 6899 1412 65590 # グラフを表示する # filename: デフォルト値=None (画像ファイルとして保存しない) _ = snl.records(filename=None)
3. S-R trend analysisの目的
SIR modelなど連立常微分方程式を使って感染症データを扱う場合、次のいずれかの前提の下で解析を行うことが一般的です。
- モデルのパラメータは流行開始から終息まで一定
- モデルのパラメータは毎日変動し、Poisson分布などに従う
しかしCOVID-19の解析を行う場合、どちらか一方を採用するのではなく、カスタマイズする必要があると考えました。
まず今回の流行では、感染が世界に拡大し始めた2020年2月, 3月ごろから各国や各個人が流行を抑えるための何らかの対策を執ってきました。感染率などパラメータは随時変動しており、終息まで一定と仮定することはできません(前述の実データ及びSIR-F modelの波形4より明らか)。
一方でパラメータが毎日変動するとなりますと、取得したデータの値ひとつひとつにかなり依存した解析になってしまいます。特に初期において検査体制が確立されていなかったこと、無症状でも感染力を持つ可能性があることから、COVID-19の場合は1日1日のデータではなく流行の概形を捉えることが必要と考えました。
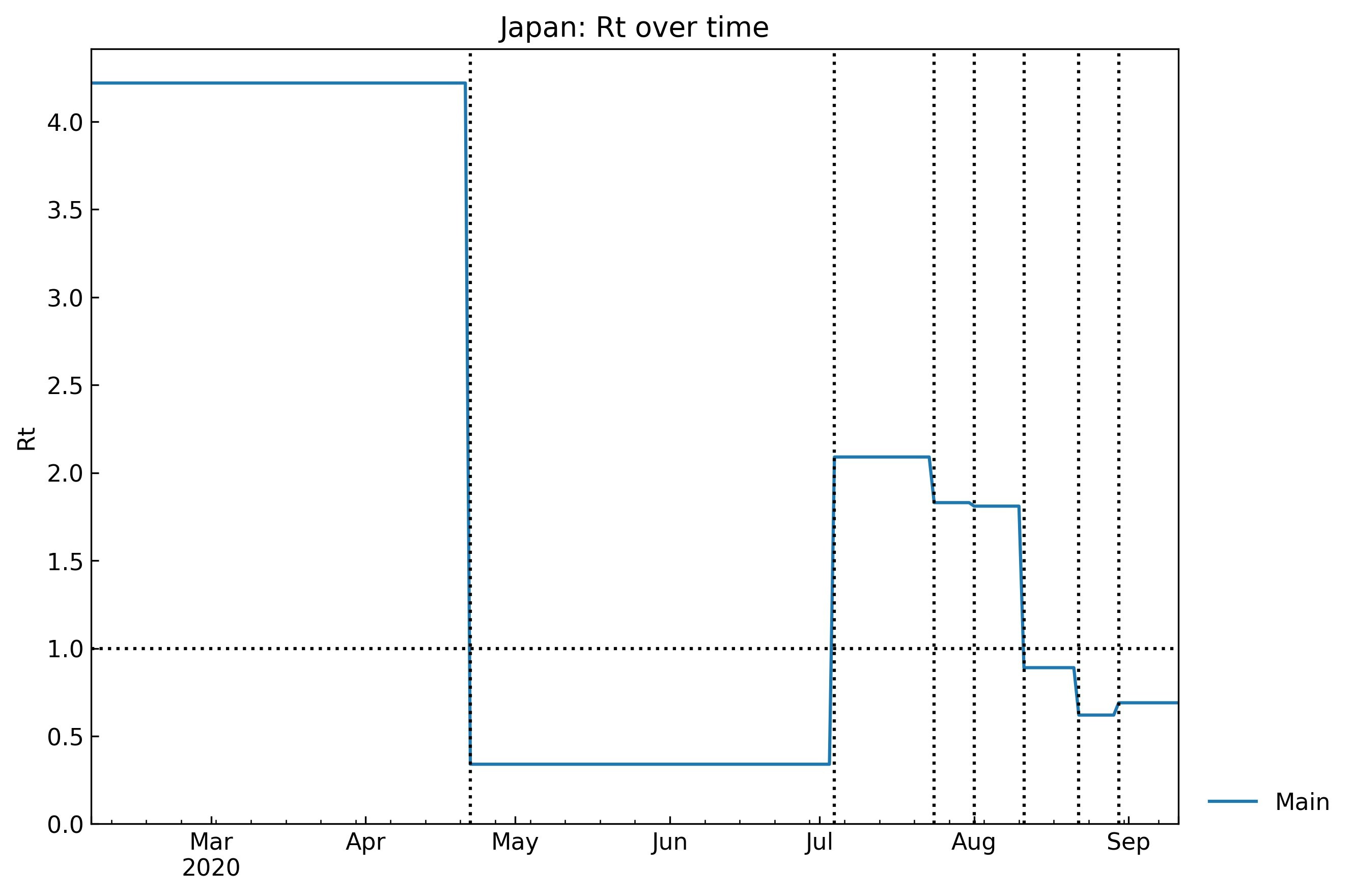
そこでCovsirPhyでは、パラメータが一定と思われる期間に細かく分割することで両者のいいとこ取りをしようと考えました。「パラメータが一定となる期間」を"Phase"と呼んでいます。流行開始から終息まで、パラメータの異なるPhaseが複数連なります。コードは別の記事に記載する予定ですが、たとえばSIR-F modelの実行再生産数$R_{\mathrm{t}}$はグラフのように階段状に変化すると考えます。
ではPhaseはどのようにして設定したら良いのでしょうか?パラメータの計算にはある程度時間がかかるため5、パラメータの計算を行わずにPhaseの分岐点(パラメータの値が変化する日付)を求めたいところです。
4. しくみ
S-R trend analysisを使用すると、感受性保持者数$S$と回復者数$R$の推移からPhaseの分岐点を求めることができます。思いつくまでの過程については長くなるので省略しますが、Kaggle: COVID-19 data with SIR model, S-R trend analysisに記載していますのでぜひご参照ください。
SIR model6, SIR-F model4の連立常微分方程式では、$S$, $R$に関して次のようになっています。
\begin{align*} & \frac{\mathrm{d}S}{\mathrm{d}T}= - N^{-1}\beta S I \\ & \frac{\mathrm{d}R}{\mathrm{d}T}= \gamma I \\ \end{align*}$\frac{\mathrm{d}S}{\mathrm{d}T}$を$\frac{\mathrm{d}R}{\mathrm{d}T}$で割ってみましょう。
\begin{align*} \cfrac{\mathrm{d}S}{\mathrm{d}R} &= - \cfrac{\beta}{N \gamma} S \\ \end{align*}これを積分して$a=\frac{\beta}{N \gamma}$と置けば7、
S_{(R)} = N e^{-a R}両辺を対数で割って、
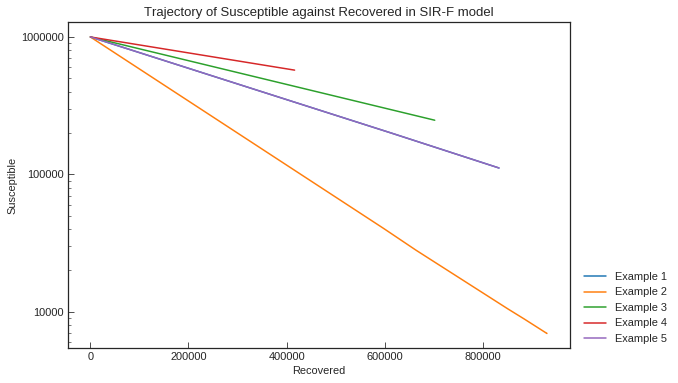
\log S_{(R)} = - a R + \log Nモデルのパラメータが一定のとき、x軸を回復者数$R$, y軸を感受性保持者数$S$として片対数グラフを描くと直線になる!
(グラフ:上述のKaggle Notebookより、パラメータを変えたときの直線の傾きの違い)
5. コード例
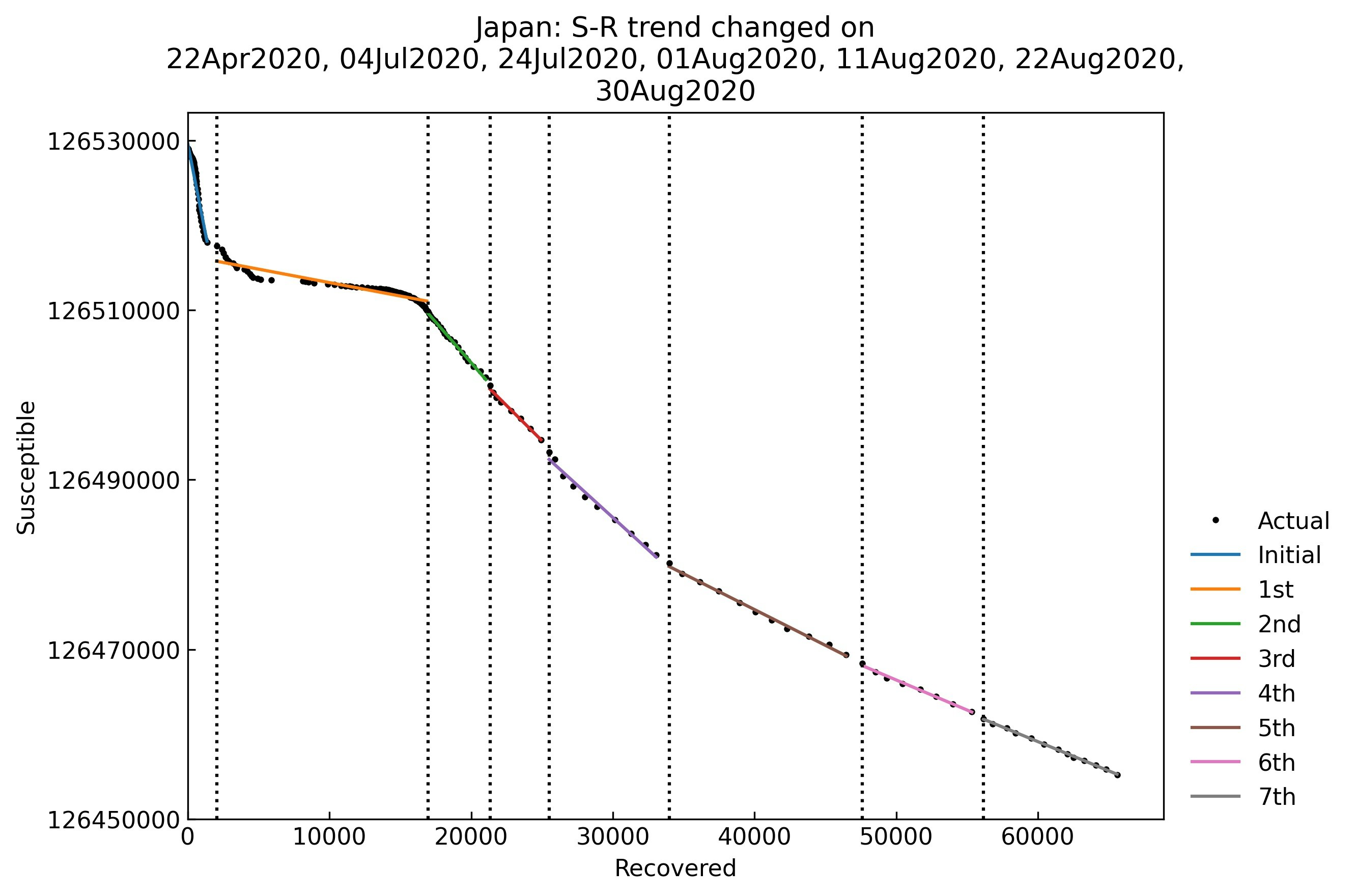
Scenario.trend()メソッドにより1行で実行できます。S-Rの片対数グラフが表示されます。PhaseはInitial (0th) phase, 1st phase, 2nd phase,...と名前をつけています8。# show_figure: グラフを表示する # filename: デフォルト値=None (画像ファイルとして保存しない) snl.trend(show_figure=True, filename=None)
各Phaseの開始日と終了日の一覧は
Scenario.summary()メソッドによってデータフレーム形式で取得できます。snl.summary()
Type Start End Population 0th Past 06Feb2020 21Apr2020 126529100 1st Past 22Apr2020 03Jul2020 126529100 2nd Past 04Jul2020 23Jul2020 126529100 3rd Past 24Jul2020 31Jul2020 126529100 4th Past 01Aug2020 10Aug2020 126529100 5th Past 11Aug2020 21Aug2020 126529100 6th Past 22Aug2020 29Aug2020 126529100 7th Past 30Aug2020 11Sep2020 126529100 総人口の値によって感受性保持者数$S$の値が変化してしまうため、重要な解析条件として一緒に表示するようにしています。また、本記事では出てきませんがパラメータの推測値なども
Scenario.summary()メソッドによって一覧表示できます。実データの登録されていないPhaseがある場合は、該当する行のType欄が"Future"となります。今回は省略しますが、
Scenario.add(),Scenario.combine(),Scenario.delete(),Scenario.separate(),Scenario.clear()によって上記Phase設定を編集することも可能です。6. 実装
Phaseの分岐点の数を求めて分岐点となる回復者数を計算するため、rupturesパッケージを使用しています。時系列解析パッケージとして有名なfbprophetをもともと使用していましたが、分岐点の数を手動で設定しなければならないという問題がありました。ColaboratorのIlyass Tabialさんに教えていただき9、rupturesを使って分岐点の数も自動で推測できるようにしました。
covsirphy.ChangeFinderの実装コードより、主な手順は次の通りです。
- 各日付のS, Rの値を取得する
- log10(S)を計算する
- R=1, 2, 3..についてlog10(S)の値を設定する:データにない場合は前後の値から穴埋めする
- 計算量を抑えるためサンプリングする:サンプリング数 = 元データの個数
- Rupturesパッケージにより、回復者数の変化量に対してlog10(S)が大きく変化する点の集合(R, log10(S))を求める
- 変化点の集合のlog10(S)を元データと照合し、各変化点の日付を求める(元データにない場合は近似値。Rより確定症例数のほうが変動は大きいためlog10(S)を使用した)
- 変化点の日付から各Phaseの開始日と終了日を計算する
あとがき
次回は各Phaseについてパラメータを推測する方法をご説明します。
お疲れさまでした!
Guidotti, E., Ardia, D., (2020), “COVID-19 Data Hub”, Journal of Open Source Software 5(51):2376, doi: 10.21105/joss.02376. ↩
厚生労働省定義の「陽性者数」「退院又は療養解除となった者の数」「死亡者数」を確定症例数Confirmed, 回復者数Recovered, 死亡者数Fatalとして扱った場合。 ↩
10 phases, 8 CPUの並列計算で2分程度かかる。1ヶ国の分析であれば待てるが、データが毎日増えること、多数の国のデータを分析する場合があることを考えると時間がかかって大変。 ↩
SIR modelにおいてS-R平面を解析した先駆者:Balkew, Teshome Mogessie, "The SIR Model When S(t) is a Multi-Exponential Function." (2010).Electronic Theses and Dissertations.Paper 1747. ↩
関連技術:[Python] 自然数を序数に変換する ↩
GitHub issue: How to predict the number of cases accurately #3 ↩
- 投稿日:2020-09-12T18:42:29+09:00
Python関数〜max, min, sum, len, all, any
はじめに
今回の記事では、paizaのスキルチェックでも多用するリストに関する関数を取り上げていきたいと思います。
max, min, sum, len, all, anyの6つを取り上げていきます。
それではいきましょう。max
max関数はリスト内の最大値を取得してくれます。
numbers = [23, 25, 21, 20, 26, 28, 22, 29, 27, 24, 30] print(max(numbers)) # 30一瞬でリスト内の最大値を取得できました。
文字列も見ていきましょう。
names = ["B", "K", "C", "Z", "A"] print(max(names)) # Z文字列の場合max関数を使うとZを取得できました。
アルファベットでは、後ろにあるほど大きいと捉えるとわかりやすいですね。min
min関数はリスト内の最小値を取得してくれます。
numbers = [23, 25, 21, 20, 26, 28, 22, 29, 27, 24, 30] print(min(numbers)) # 20一瞬でリスト内の最小値を取得できました。
文字列も見ていきましょう。
names = ["B", "K", "C", "Z", "A"] print(min(names)) # A文字列の場合max関数を使うとAを取得できました。
アルファベットでは、前にあるほど小さい捉えるとわかりやすいですね。sum
sum関数はリストないの数字の合計を出力してくれます。
numbers = [23, 25, 21, 20, 26, 28, 22, 29, 27, 24, 30] print(sum(numbers)) # 275このようにリストないの数字の合計を出力してくれました。
ここで注意点があります。
リスト内の要素に文字列が一つでもあるとエラーがでます。numbers = ['23', 25, 21, 20, 26, 28, 22, 29, 27, 24, 30] print(sum(numbers)) #TypeError: unsupported operand type(s) for +: 'int' and 'str'リスト内の要素が全部数字であることを確認してから使うようにしましょう。
len
len関数はリストの要素数を出力してくれます。
numbers = [23, 25, 21, 20, 26, 28, 22, 29, 27, 24, 30] print(len(numbers)) # 11このようにリストの要素数を出力してくれました。
all
all関数はリストの要素が全てTrueであればTrueを返し、一つでもFalseがあればFalseを返します。
言葉の説明ではわかりにくいので、コードを見ていきましょう。numbers = [1, 0, 1, 1, 1, 1, 1] print(all(numbers)) # Falsenumbers = [1, 1, 1, 1, 1, 1, 1] print(all(numbers)) # Truewords = ["B", "K", "C", "Z", "A"] print(all(words)) # Trueprint(all([]) # Trueこのように全てがTrue以外の時はFalseを返すことが確認できました。
any
all関数はリストの要素が全てTrueであればTrueを返し、一つでもFalseがあればFalseを返します。
numbers = [0, 1, 0, 0, 0, 0, 0] print(any(numbers)) # Truenumbers = [0, 0, 0, 0, 0, 0, 0] print(any(numbers)) # False1つでもTrueとなるものがあればTrueを返すことを確認できました。
最後に
今回はリストに関する関数を取り上げてきました。
今後paizaのスキルチェックでの活用法などを上げていきたいと思います。
また、Pythonの関数についても今後上げていくので、参考になれば幸いです。
- 投稿日:2020-09-12T18:23:32+09:00
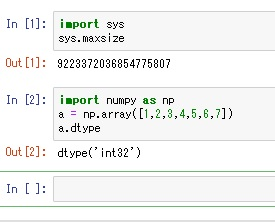
【Python】Numpyにおけるint32の理由(Windows環境)
私がNumpyの勉強を実施している時に気になったことがあります。
例えば以下の通りNumpyの配列を作成して「dtype」でデータ型を確認します。
すると、以下の通り「int32」が返ってきます。
※Windows環境が前提となります。
ここで疑問を感じました。
『なぜデフォルトが int32(32bit)なのか?』
■ OS環境のビット数に依存するのか? ⇒ NO
最初はOSのビット数に依存しているのかと考えました。
しかし私の環境は以下の通り64bitです。
OS環境のビット数には依存していません。
■ Python環境のビット数に依存するのか? ⇒ NO
次にPython環境のビット数に依存しているのかと考えました。
sysモジュールのmaxsizeを利用してPython環境のビット数を調べます。32bit : 2147483647
64bit : 9223372036854775807
結果は上記の通り「9223372036854775807」なので、Python環境は「64bit」となります。
Python環境のビット数には依存していません。■ 結論 ⇒ C言語におけるlong型の仕様です
『なぜデフォルトが int32(32bit)なのか?』
この原因を理解するためには、Numpyの前提を思い出す必要がありました。
『NumPyの内部はC言語 (およびFortran)によって実装されているため非常に高速に動作する』
NumpyはC言語によって実装されており、np.int_はC longで定義されています。
参考:『Numpy データ型』
Microsoftによりデフォルトのlong型は4byte(4*8=32bit)とされています。
そのためWindowsにおいてはOSやpython、numpyのビット数に関わらず、
デフォルトでは np.int_がint32となっているようです。結論は『C言語におけるlong型の仕様』でした。

- 投稿日:2020-09-12T18:23:32+09:00
【Python】Numpyにおけるdtype「int32」の理由(Windows環境)
私がNumpyの勉強を実施している時に気になったことがあります。
例えば以下の通りNumpyの配列を作成して「dtype」でデータ型を確認します。
すると、以下の通り「int32」が返ってきます。
※Windows環境が前提となります。
ここで疑問を感じました。
『なぜデフォルトが int32(32bit)なのか?』
■ OS環境のビット数に依存するのか? ⇒ NO
最初はOSのビット数に依存しているのかと考えました。
しかし私の環境は以下の通り64bitです。
OS環境のビット数には依存していません。
■ Python環境のビット数に依存するのか? ⇒ NO
次にPython環境のビット数に依存しているのかと考えました。
sysモジュールのmaxsizeを利用してPython環境のビット数を調べます。32bit : 2147483647
64bit : 9223372036854775807
結果は上記の通り「9223372036854775807」なので、Python環境は「64bit」となります。
Python環境のビット数には依存していません。■ 結論 ⇒ C言語におけるlong型の仕様です
『なぜデフォルトが int32(32bit)なのか?』
この原因を理解するためには、Numpyの前提を思い出す必要がありました。
『NumPyの内部はC言語 (およびFortran)によって実装されているため非常に高速に動作する』
NumpyはC言語によって実装されており、np.int_はC longで定義されています。
参考:『Numpy データ型』
Microsoftによりデフォルトのlong型は4byte(4*8=32bit)とされています。
そのためWindowsにおいてはOSやpython、numpyのビット数に関わらず、
デフォルトでは np.int_がint32となっているようです。結論は『C言語におけるlong型の仕様』でした。
- 投稿日:2020-09-12T17:53:05+09:00
簡単にできるJenkinsによるtox環境
初めに
みなさん、テストしていますか?
Pythonでの単体テストを複数の環境で実行してくれる「tox」。便利ですよね。
JenkinsでCI環境を作っておけば、一発で複数のバージョンでの動作確認ができちゃいます。けど、pyenvをインストールしたり、複数のpython環境を用意したりと、意外と手間がかかります。
そこで、Jenkinsでtoxを使用する環境を簡単に構築する方法になります。手順としては次の通りです。
- DockerでJenkinsを構築する
- Pyenvをインストールしたコンテナ用のDockerFileを作る
- DockerFileを使用するJenkinsfileを作る
- ユニットテストとカバレッジレポートを取得するtox.iniを作る
- リポジトリのトップにDockerFile,Jenkinsfile,tox.iniを配置する
- JenkinsにPiplineジョブを作る
- ビルド実行
事前準備
今回Jenkisfileを使って、CI環境を動的に生成する部分をメインとして解説します。
ですので、Docker環境の構築、Jenkinsの構築については省略します。
ただ、必ずDocker環境下でJenkinsを構築してください。DockerでJenkinsを構築する
Windows環境の方は下記のページを参考に構築するとよいと思います
https://qiita.com/sh1928kd/items/b248a8d48d16eaab96171点、Ubuntu環境などで、Dockerソケットを共有する際、ホスト側のソケットのソケットの権限を気を付けてください。
Jenkins側からの実行権限がないと、エラーとなります。記事を書いているときのJenkinsのバージョンは「Jenkins 2.255」になります。
プラグイン
お好きなものを入れましょう。
今回はUnittestの結果とカバレッジリポートを表示したいので「JUnit」と「Cobertura」をインストールしておきます。Pyenvをインストールしたコンテナ用のDockerFileを作る
環境構築についてはJenkinsfileだけでも行えるはずなのですが、
複数のPython環境を構築する際にpyenvを使用しようとするとうまくいきませんでした。
そこで、複数のPython環境を構築するところまでDockerFileで行います。FROM python:3.8 USER root ENV HOME /root ENV PYENV_ROOT $HOME/.pyenv ENV PATH $PYENV_ROOT/bin:$PATH # ENV HTTP_PROXY '{プロキシサーバのアドレス}' # ENV HTTPS_PROXY '{プロキシサーバのアドレス' # ENV FTP_PROXY '{プロキシサーバのアドレス}' # RUN echo 'Acquire::http::Proxy "{プロキシサーバのアドレス}";' >> /etc/apt/apt.conf # RUN echo 'Acquire::https::Proxy "{プロキシサーバのアドレス}";' >> /etc/apt/apt.conf RUN apt-get update && apt-get upgrade -y \ && apt-get install -y \ git \ make \ build-essential \ libssl-dev \ zlib1g-dev \ libbz2-dev \ libreadline-dev \ libsqlite3-dev \ wget \ curl \ llvm \ libncurses5-dev \ libncursesw5-dev \ xz-utils \ tk-dev \ libffi-dev \ liblzma-dev \ && git clone https://github.com/pyenv/pyenv.git $PYENV_ROOT RUN echo 'eval "$(pyenv init -)"' >> ~/.bashrc && \ eval "$(pyenv init -)" RUN pyenv install 3.5.9 RUN pyenv install 3.6.2 RUN pyenv install 3.7.2 RUN pyenv install 3.8.2 RUN echo '3.5.9' >> .python-version RUN echo '3.6.2' >> .python-version RUN echo '3.7.2' >> .python-version RUN echo '3.8.2' >> .python-versionDockerfileを使用するJenkinsfileを作る
Dockerfileで環境構築してしまえばJenkinsfileは難しくありません
pipeline { agent { dockerfile { filename 'Dockerfile' args '-u root:sudo' } } stages { stage('setup') { steps { sh 'pip install flake8' sh 'pip install tox' sh 'pip install tox-pyenv' } } stage('test') { steps { sh 'tox' // カバレッジを取得 cobertura coberturaReportFile: 'coverage.xml' // テスト結果を取得 junit 'junit_reports/*.xml' } } } }setupの内容についてもDockerFileに記載してしまってもよかったかもしれません。
ユニットテストとカバレッジレポートを取得するtox.iniを作る
tox.iniを書きます。
今回はテストレポートとカバレッジレポートを取得するので、それぞれのレポートを出力する設定にしてありますtox.ini[tox] envlist = py35, py36, py37, py38, flake8 [travis] python = 3.8: py38 3.7: py37 3.6: py36 3.5: py35 [testenv:flake8] basepython = python deps = flake8 commands = flake8 {解析するモジュール名} tests [flake8] exclude = tests/* [testenv] setenv = PYTHONPATH = {toxinidir} deps = coverage unittest-xml-reporting commands = rm -rf junit_reports python -m xmlrunner discover -o junit_reports coverage erase coverage run --append setup.py test coverage report --omit='.tox/*' coverage xml --omit='.tox/*'リポジトリのトップにDockerFile,Jenkinsfile,tox.iniを配置する
基本的にはPYPI形式のプロジェクトであれば次のような構成になると思います。
-project |-module_dir/ |-main.py |-tests/ |-test_main.py |-setup.py |-Dockerfile |-Jenkinsfile |-tox.iniJenkinsにPiplineジョブを作る
出来上がったスクリプトをGithubなどにPushします。
新規ジョブの作成を選択し、
1. item nameにジョブ名を入力
2. パイプラインを選択
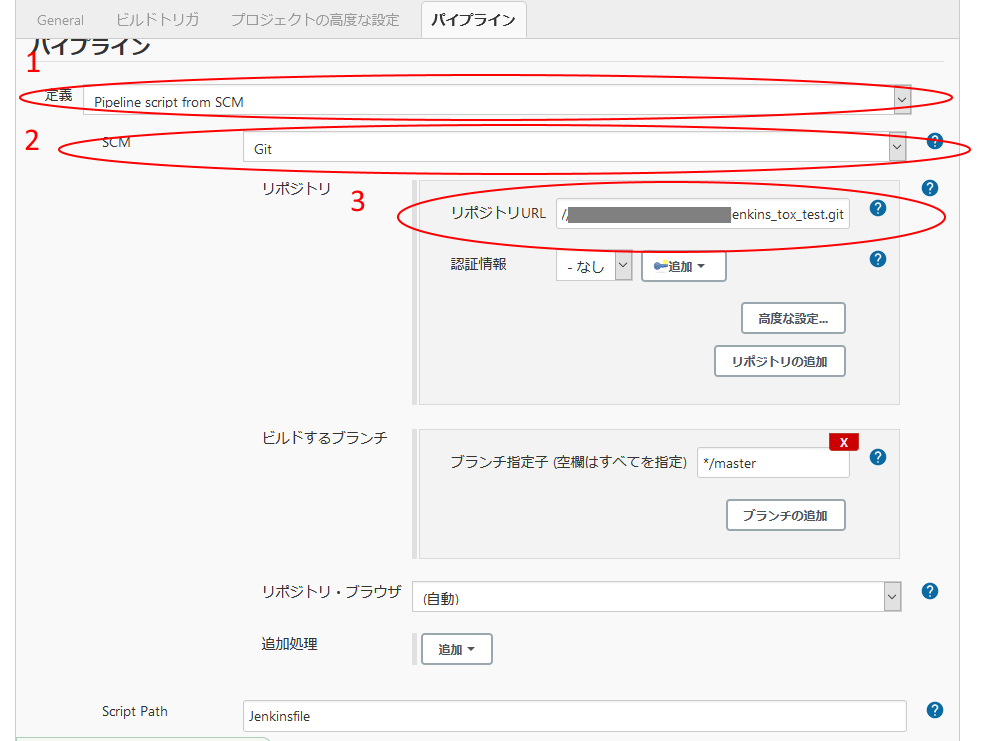
設定画面で
1. 定義に「Pipline script from SCM」を選択
2. SCMに「Git」を選択
3. リポジトリURLにリポジトリのパスを入力ビルド実行
Jenkinsのジョブ画面から、「ビルド実行」をすれば、Dockerfileから環境を構築して、
toxを実行した結果をJenkinsが取得してくれます。まとめ
Jenkinsで簡単にtoxを実行する環境について紹介しました。
本当はJenkinsfileだけで構築したかったのですが、PATH周りの挙動が良くわからなかったので、
Dockerfileを使いました。PyPI形式のプロジェクト構成であれば、この方法でほぼほぼ使いまわせるので、テスト環境構築がらくちんになりました。
また、素の環境が出来上がりますので、モジュールの登録漏れや依存ライブラリに気が付けるという利点があります。
- 投稿日:2020-09-12T17:45:48+09:00
[Python学習その3]pandasのDataFrameとSeries、標準のListを相互に変換する
始めに
- pandasで使われるDataFrameとSeries,標準のlistを相互に変換したい
- pandasで加工したデータを他ライブラリで使う時、listしか対応していないことがあるので、困らないように
作業環境
- OS:macOS Catalina ver10.15.6
- コードエディター:jupyter lab
- 言語:python3
参考サイト
- pandas.DataFrame, SeriesとPython標準のリストを相互に変換
- Pandasユーザーガイド「データの索引と選択」(公式ドキュメント日本語訳)
- pandas documentation
実際にやってみる
- listからdataframe,seriesに変換する
- seriesからlistに変換する
- dataframeからlist,seriesに変換する
listからdataframe,seriesに変換する
list→series
#pandasをインポートしてpdに名前変更 import pandas as pd #標準ライブラリのリストを作成からの表示 l_1d = [0, 1, 2] l_1d #[0, 1, 2]#次はlistをseriesに型変換する s = pd.Series(l_1d) s #0 0 #1 1 #2 2 #dtype: int64 #何も指定しないとindexは0から自動で決まる#次はindexを指定しながらlistからseries型に変換する s = pd.Series(l_1d, index=['row1', 'row2', 'row3']) s #row1 0 #row2 1 #row3 2 #dtype: int64#一気にindexまで指定することもできる #今回の記事とは関係ないけど、以外と使うかも s = pd.Series({"row1":0,"row2":1,"row3":2}) s #row1 0 #row2 1 #row3 2 #dtype: int64list→dataframe
#データーフレームに変換するので2次元配列を用意する l_2d = [[0, 1, 2], [3, 4, 5]] df = pd.DataFrame(l_2d) df # 1 2 #0 0 1 2 #1 3 4 5#index,columnの両方を指定してdataframeを作成することも可能 df = pd.DataFrame(l_2d, index=['row1', 'row2'], columns=['col1', 'col2', 'col3']) df # col1 col2 col3 #row1 0 1 2 #row2 3 4 5#一気にindex,columnまで指定することもできる #今回の記事とは関係ないけど、以外と使うかも df = pd.DataFrame([[1,2,3],[4,5,6]],["row1","row2"],["col1","col2","col3"]) df # col1 col2 col3 #row1 1 2 3 #row2 4 5 6seriesからlistに変換する
series→list
#まずはseriesを作成する s = pd.Series([0, 1, 2]) print(s) # 0 0 # 1 1 # 2 2 # dtype: int64#seriesの値だけlist型で取得する l_1d = s.values.tolist() print(l_1d) #[0, 1, 2]dataframeからlist,seriesに変換する
dataframe→list
#dataframeを作成 df = pd.DataFrame([[0, 1, 2], [3, 4, 5]]) print(df) # 0 1 2 #0 0 1 2 #1 3 4 5#dataframeの値だけをlist型で取得する #indexやcolumnsは無視される l_2d = df.values.tolist() print(l_2d) #[[0, 1, 2], [3, 4, 5]]#dataframeをlist型で取得すると2次元配列になる #2次元を1次元配列に変換する方法 #関係ないけどあったらいつか使うかも? #numpyを使うのでインポートします import numpy as np #標準ライブラリのlist型からarray型に変換 #どちらも配列です arr_list = np.array(l_2d) arr_list.flatten().tolist() #[0, 1, 2, 3, 4, 5]dataframe→series
#dataframeを作成する df = pd.DataFrame([[0, 1, 2], [3, 4, 5]],["row1","row2"],["col1","col2","col3"]) print(df) # col1 col2 col3 #row1 0 1 2 #row2 3 4 5#columnをseriesとして取得する df_toSer = df["col1"] df_toSer #row1 0 #row2 3 #Name: col1, dtype: int64#indexをseriesとして取得する df_toSer2 = df.iloc[0] df_toSer2 #col1 0 #col2 1 #col3 2 #Name: row1, dtype: int64終わりに
今回参考にしたサイトになります。
- pandas.DataFrame, SeriesとPython標準のリストを相互に変換
- Pandasユーザーガイド「データの索引と選択」(公式ドキュメント日本語訳)
- pandas documentation
- 投稿日:2020-09-12T17:29:12+09:00
xgboostで桜開花予想をしてみる
xgboostで桜開花予想をしてみる
昨年の3月から今年の2月までのデータを利用
Python
初心者
機械学習1.目的
AIさくら予想というのがあり、xgboostを使っているという記事があったので、xgboostでさくら開花予想をしてみた。
https://www.businessinsider.jp/post-1865282.結論
微妙な結果でした。上記AIさくら予想が優秀なことがわかりました。
開花時期に影響が大きい要素として、年間平均気温、7月の日照時間、8月の雨量、10月の最低気温とされました。
年間平均気温はわかりますが、7月の日照時間、8月の雨量、10月の最低気温あたりは意外でした。3.データソース
https://www.data.jma.go.jp/gmd/risk/obsdl/index.php
上記気象庁のデータを加工のうえ利用しました。4.コード解説
import numpy as np import pandas as pd import matplotlib.pyplot as plt from xgboost import XGBRegressor, plot_importance from sklearn.model_selection import GridSearchCV, KFold from tqdm import tqdm_notebook path="./" train = pd.read_csv(path+"kikou5train.csv") x_test = pd.read_csv(path+"kikou5test.csv") y_train = train.kaika.copy() x_train = train.drop("kaika", axis=1) train_id = x_train.Id x_train.head() date avtmp3 maxtmp3 mintmp3 ame3 nisho3 joki3 kumo3 avtmp4 maxtmp4 ... kumo13 avtmp14 maxtmp14 mintmp14 ame14 nisho14 joki14 kumo14 kaika TotalInc Id 1 1961 8.2 21.9 -0.4 106.6 181.1 6.7 6.3 14.9 26.0 ... 3.8 5.9 24.5 -2.6 13.5 195.0 4.5 4.1 NaN 193.6 2 1962 8.2 18.8 -0.8 65.5 189.8 6.3 4.7 14.1 24.5 ... 2.0 4.8 15.3 -4.1 21.3 199.9 4.1 4.9 NaN 182.3結合
df = pd.concat([x_train, x_test]) df.head()特徴量エンジニアリング 年平均気温を追加
df["TotalInc"] = df.avtmp3 + df.avtmp4 + df.avtmp5 + df.avtmp6 + df.avtmp7 + df.avtmp8 + df.avtmp9 + df.avtmp10 + df.avtmp11 + df.avtmp12 + df.avtmp13 + df.avtmp14 #平均温度のdf.head() date avtmp3 maxtmp3 mintmp3 ame3 nisho3 joki3 kumo3 avtmp4 maxtmp4 ... kumo13 avtmp14 maxtmp14 mintmp14 ame14 nisho14 joki14 kumo14 kaika TotalInc 0 1980 8.2 21.2 1.3 173.5 157.5 6 6.2 13.6 24 ... 2.9 5.3 17.2 -3.5 38 157.3 4.6 5.5 NaN 183.4 1 rows × 87 columnsx_train = df[df.Id.isin(train_id)].set_index("Id") x_test = df[~df.Id.isin(train_id)].set_index("Id")最適なハイパーパラメータ探索
random_state = 0 params = { "learning_rate": [0.01, 0.05, 0.1], "min_child_weight": [0.1], "gamma": [0], "reg_alpha": [0], "reg_lambda": [1], "max_depth": [3, 5, 7], "max_delta_step": [0], "random_state": [random_state], "n_estimators": [50, 100, 200], } reg = XGBRegressor() cv = KFold(n_splits=3, shuffle=True, random_state=random_state) reg_gs = GridSearchCV(reg, params, cv=cv) reg_gs.fit(x_train, y_train) GridSearchCV(cv=KFold(n_splits=3, random_state=0, shuffle=True), estimator=XGBRegressor(base_score=None, booster=None, colsample_bylevel=None, colsample_bynode=None, colsample_bytree=None, gamma=None, gpu_id=None, importance_type='gain', interaction_constraints=None, learning_rate=None, max_delta_step=None, max_depth=None, min_child_weight=None, missing=nan, monoto... num_parallel_tree=None, random_state=None, reg_alpha=None, reg_lambda=None, scale_pos_weight=None, subsample=None, tree_method=None, validate_parameters=None, verbosity=None), param_grid={'gamma': [0], 'learning_rate': [0.01, 0.05, 0.1], 'max_delta_step': [0], 'max_depth': [3, 5, 7], 'min_child_weight': [0.1], 'n_estimators': [50, 100, 200], 'random_state': [0], 'reg_alpha': [0], 'reg_lambda': [1]}) display(reg_gs.best_params_) display(reg_gs.best_score_) ax = plot_importance(reg_gs.best_estimator_, importance_type="gain") fig = ax.figure fig.set_size_inches(250, 250) ax.figure.set_size_inches(18,18) {'gamma': 0, 'learning_rate': 0.1, 'max_delta_step': 0, 'max_depth': 5, 'min_child_weight': 0.1, 'n_estimators': 50, 'random_state': 0, 'reg_alpha': 0, 'reg_lambda': 1} 0.36250088820449333予測
y_pred3 = reg_gs.predict(x_test)正解ラベルとの誤差を評価
y_true = pd.read_csv(path+"kikou5test.csv") preds = pd.DataFrame({"pred3": y_pred3}) df_out = pd.concat([y_true, preds], axis=1) df_out.head() Id date avtmp3 maxtmp3 mintmp3 ame3 nisho3 joki3 kumo3 avtmp4 ... avtmp14 maxtmp14 mintmp14 ame14 nisho14 joki14 kumo14 kaika pred3 loss3 0 100 1966 9.6 21.6 1.2 99.9 150.4 7.0 6.6 13.6 ... 4.9 19.1 -4.0 43.8 162.6 5.1 5.0 30 29.816103 0.033818RMSE
df_out["loss3"] = (df_out.kaika - df_out.pred3)**2 df_out.iloc[:, -3:].mean() kaika 24.909091 pred3 26.849123 loss3 23.966188 dtype: float64 from sklearn.metrics import mean_squared_error, mean_absolute_error #RMSE rmse_kaika = np.sqrt(mean_squared_error(df_out.kaika, df_out.pred3)) rmse_kaika 4.895527368155607さくらの開花の予測精度が、5日弱。意外と予測できているが、微妙でした。

- 投稿日:2020-09-12T17:25:17+09:00
PythonでSwitchBotから電池残量を取得する
はじめに
SwitchBotを使っていて困るのが電池切れ。
公式アプリを開けば電池残量を確認できるけど、日常的には見ないし、使いたい時に電池が切れてるでおなじみですよね。
私はオートロックの解錠に使っているので死活問題です。SwitchBotの公式が公開しているPythonにはPressなどのコマンドはありますが、電池残量を取得するものはないです。
アプリで取れるんだから、そんなわけないだろと調べていると、やっぱりありました。
https://github.com/RoButton/switchbotpy一旦これを使って満足してたんですけど、なんか安定して取れない時があるので安定してる公式のPythonにコマンド追加することにしました。
公式Pythonの修正
設定情報取得コマンドを追加しました。
公式からForkした私のリポジトリに公開しています。
https://github.com/kanon700/python-host/tree/feature/add_get_settings修正内容は以下
switchbot_py3.pyclass Driver(object): handle = 0x16 notif_handle = 0x13 commands = { 'press' : '\x57\x01\x00', 'on' : '\x57\x01\x01', 'off' : '\x57\x01\x02', 'settings' : '\x57\x02', } def run_and_res_command(self, command): self.req.write_by_handle(self.handle, self.commands[command]) return self.req.read_by_handle(self.notif_handle) def get_settings_value(self, value): value = struct.unpack('B' * len(value[0]), value[0]) settings = {} settings["battery"] = value[1] settings["firmware"] = value[2] / 10.0 settings["n_timers"] = value[8] settings["dual_state_mode"] = bool(value[9] & 16) settings["inverse_direction"] = bool(value[9] & 1) settings["hold_seconds"] = value[10] return settings電池残量取得スクリプト
こんな感じのスクリプトでバッテリ残量を取得できます。
SwitchBot_Battery_Get.py#!/usr/bin/python3 # -*- coding: utf-8 -*- from switchbot_py3 import Driver switchbot = 'xx:xx:xx:xx:xx:xx' #switchbotのMACアドレス def main(): bot = Driver(device=switchbot) bot.connect() value = bot.run_and_res_command('settings') settings = bot.get_settings_value(value) print("battery:" + str(settings["battery"])) if __name__ == '__main__': main()以上
- 投稿日:2020-09-12T17:01:34+09:00
PyInstallerでPythonがないWindows環境で動作するexeファイルを作成する
作成した機械学習のプログラムをPythonがインストールされていないWindows環境で動作させるために試行錯誤したメモ。
環境は以下の通り
- Python 3.6.8
- PyInstaller 4.0
- Windows 10 x64
PyInstallerの基本的な使い方
インストール
$ pip install pyinstallerexeファイル作成
$ pyinstaller main.py --onefileこれで、Pythonの実行環境や関連ライブラリもまとめて1つのexeファイルにまとめてくれる。
ただし、PyInstallerが解決できない依存関係があったりすると、作ったexeファイルがエラーを吐く。
その場合は、
--onefileオプションを使わずにビルドして、以下の2点を1つずつ解消していくとよい。Pyinstallerでうまくexe化できないとき
*.so not foundが出る依存している外部ライブラリのバイナリを取り込めていない。直接参照しているものはPyInstallerが自動で取り込んでくれるようだが、間接的に参照しているものは考慮してくれない様子。
--add-binaryオプションで明示的に取り込むように指定すればよい。
Pathの指定の仕方が特殊なので注意--add-binary "<取り込み元のSOファイルの相対パス>;<配置先のディレクトリの実行時相対パス>"パスの指定の仕方が正しく記述できているはずなのにうまく配置されない
キャッシュが残っていて悪さをしているようだったので、
--cleanオプションをつけると指定した通りに配置されるようになった。
ModuleNotFoundErrorが出るこちらも同様に外部ライブラリが取り込めていない。Pythonのライブラリ系で間接的に参照しているものが該当する様子。
pyinstaller実行時にhidden-importで指定すればよい。
追加しながら、exe化を繰り返して、ModuleNotFoundErrorがなくなるまで続ける。例えば、tensorflowを使ったテキスト分類プログラムを作った場合はこんな感じになった。
$ pyinstaller main.py ¥ --hidden-import=tensorflow.python.keras.engine.base_layer_v1 ¥ --hidden-import=tensorflow.python.ops.while_v2 ¥ --hidden-import=tensorflow.python.ops.numpy_ops最終的なpyinstallerの実行時オプション
例えばこんな感じになる。
$ pyinstaller main.py --onefile -y --clean \ --hidden-import=tensorflow.python.keras.engine.base_layer_v1 \ --hidden-import=tensorflow.python.ops.while_v2 \ --hidden-import=tensorflow.python.ops.numpy_ops \ --add-binary "../../../../AppData/Local/Programs/Python/Python36/lib/site-packages/tensorflow/lite/experimental/microfrontend/python/ops/_audio_microfrontend_op.so;tensorflow/lite/experimental/microfrontend/python/ops"
- 投稿日:2020-09-12T16:31:59+09:00
AtCoder Beginners Contest 過去問チャレンジ 10
AtCoder Beginners Contest 過去問チャレンジ 10
ABC087D - People on a Line
情報により関連付けられているどれかの人の位置を0とおいて、DFS で矛盾がないかを確認すればいいだけ. もちろん1グループとなっているとは限らないことに注意.
from sys import stdin N, M = map(int, stdin.readline().split()) links = [[] for _ in range(N + 1)] for _ in range(M): L, R, D = map(int, stdin.readline().split()) links[L].append((R, D)) links[R].append((L, -D)) t = [None] * (N + 1) for i in range(1, N + 1): if t[i] is not None: continue t[i] = 0 s = [i] while s: j = s.pop() for k, l in links[j]: if t[k] is None: t[k] = t[j] + l s.append(k) else: if t[k] != t[j] + l: print('No') exit() print('Yes')重み付き Union Find 木でも解ける.
from sys import setrecursionlimit, stdin def find(parent, diff_weight, i): t = parent[i] if t < 0: return i t = find(parent, diff_weight, t) diff_weight[i] += diff_weight[parent[i]] parent[i] = t return t def weight(parent, diff_weight, i): find(parent, diff_weight, i) return diff_weight[i] def unite(parent, diff_weight, i, j, d): d -= weight(parent, diff_weight, j) d += weight(parent, diff_weight, i) i = find(parent, diff_weight, i) j = find(parent, diff_weight, j) if i == j: return diff_weight[j] = d parent[i] += parent[j] parent[j] = i setrecursionlimit(10 ** 6) N, M = map(int, stdin.readline().split()) LRD = [tuple(map(int, stdin.readline().split())) for _ in range(M)] parent = [-1] * (N + 1) diff_weight = [0] * (N + 1) for L, R, D in LRD: i = find(parent, diff_weight, L) j = find(parent, diff_weight, R) if i != j: unite(parent, diff_weight, L, R, D) else: if weight(parent, diff_weight, L) + D != weight(parent, diff_weight, R): print('No') exit() print('Yes')ABC136E - Max GCD
どれだけ操作をしても合計は変わらないので、答えの候補は合計の約数のみ. 後は K 回の操作でその約数の倍数に揃えれるかだが、その約数で割った余りをソートすれば引いたほうがいいのが前に、足したほうがいいのが後ろに来るので、前後から順番に数えていけば操作の必要回数の最小が計算できる.
def make_divisor_list(n): result = [] for i in range(1, int(n ** 0.5) + 1): if n % i == 0: result.append(i) result.append(n // i) return result def calc_min_ops(r, d): i, j = 0, len(r) while i < j and r[i] == 0: i += 1 i -= 1 a, b = 0, 0 while j - i != 1: if a <= b: i += 1 a += r[i] else: j -= 1 b += d - r[j] return a N, K, *A = map(int, open(0).read().split()) c = sum(A) divisors = make_divisor_list(c) divisors.sort(reverse=True) r = [None] * N for d in divisors: for i in range(N): r[i] = A[i] % d r.sort() if calc_min_ops(r, d) <= K: print(d) breakABC063D - Widespread
少なくとも ceil(max(h) / b) 以下なんだろうが、A と B の差分を体力の大きい方から順に割り当てるのを計算してしまうと間に合わない(heapq を使って確認済). にぶたんですと言われてみると、確かにそれで解けるって一瞬ででなったけどぱっと思いつきはしない不思議.
from bisect import bisect_right N, A, B, *h = map(int, open(0).read().split()) h.sort() d = A - B ng = (h[-1] + (A - 1)) // A - 1 ok = (h[-1] + (B - 1)) // B while ok - ng > 1: m = (ok + ng) // 2 b = B * m if m >= sum((h[i] - b + (d - 1)) // d for i in range(bisect_right(h, b), N)): ok = m else: ng = m print(ok)ABC060D - Simple Knapsack
ナップサック=DPだろと思ってその方向で考えてみたが全然思いつかない. そもそも N≦100 で w1≦wi≦w1+3 なので、全探索しても (100/4+1)4≒4.6×105 にしからならず、全探索で大丈夫だった.
from sys import stdin from itertools import accumulate readline = stdin.readline N, W = map(int, input().split()) vs = [[] for _ in range(4)] w, v = map(int, input().split()) w1 = w vs[0].append(v) for _ in range(N - 1): w, v = map(int, input().split()) vs[w - w1].append(v) for i in range(4): vs[i].sort(reverse=True) vs[i] = [0] + list(accumulate(vs[i])) result = 0 for i in range(len(vs[0])): a = W - w1 * i if a < 0: break for j in range(len(vs[1])): b = a - (w1 + 1) * j if b < 0: break for k in range(len(vs[2])): c = b - (w1 + 2) * k if c < 0: break t = vs[0][i] + vs[1][j] + vs[2][k] for l in range(len(vs[3])): d = c - (w1 + 3) * l if d < 0: break result = max(result, t + vs[3][l]) print(result)ABC122D - We Like AGC
要するに AGC、ACG、GAC、A?GC、AG?C が駄目なんだから、せいぜい末尾3文字だけ保持すれば良い. 43-3 種類だけ保持すればよく、そこからざっくり4倍に派生するので、計算量はざっくり 250×100=2.5×104 で余裕の範囲だった. という訳で DP で解けた.
def is_ok(s): if s[1:] in ['AGC', 'ACG', 'GAC']: return False if s[0] == 'A' and s[2:] == 'GC': return False if s[:2] == 'AG' and s[3] == 'C': return False return True m = 1000000007 N = int(input()) d = {} for i in 'ACGT': for j in 'ACGT': for k in 'ACGT': d[i + j + k] = 1 for k in ['AGC', 'ACG', 'GAC']: del d[k] for i in range(N - 3): t = {} for k in d: for i in 'ACGT': s = k + i if is_ok(s): t.setdefault(s[1:], 0) t[s[1:]] += d[k] t[s[1:]] %= m d = t print(sum(d.values()) % m)ABC100D - Patisserie ABC
絶対値がなければ簡単なのになあと思った. だったらそれぞれプラスとマイナスの最大値を求めればいいのかなあと思った. それくらいなら23回、絶対値がない場合のをするのと同じなので計算量的には問題ない. 本当にそれで最大値になるという確信はなかったが AC したので考え方としてあっていたようだ.
from itertools import product from sys import stdin readline = stdin.readline N, M = map(int, readline().split()) xyz = [tuple(map(int, readline().split())) for _ in range(N)] result = 0 for s in product([1, -1], repeat=3): xyz.sort(reverse=True, key=lambda e: s[0] * e[0] + s[1] * e[1] + s[2] * e[2]) cx, cy, cz = 0, 0, 0 for x, y, z in xyz[:M]: cx += x cy += y cz += z result = max(result, abs(cx) + abs(cy) + abs(cz)) print(result)
- 投稿日:2020-09-12T15:37:57+09:00
Python初心者によるPython3エンジニア認定データ分析試験の勉強方法(2020年9月合格)
今回は「Python3エンジニア認定データ分析試験」に合格したため、その学習方法を記載します。
■筆者情報(2020年8月時点)
・インフラエンジニア。
・AWS資格はプロフェッショナルまで取得済み。
・「G検定」は合格済み(2020年7月4日受験)。
※詳細は「★G検定合格者による受験時の心構えについて(2020年7月合格)」参照。
・プログラミング経験は新人研修のみ。
・Pythonは7月から勉強し始めて8月に「Python3 エンジニア認定基礎試験」に合格済み(2020年8月1日受験)。
※詳細は「Python初心者によるPython3エンジニア認定基礎試験の勉強方法(2020年8月合格)」参照。
・今年度の目標は「クラウド」&「AI」の知識スキル強化。■受験動機
ことの始まりは今年度の最初にAWSの専門知識資格を取得しようとしたことでした。
今後業務にも影響しそうなAI関連がよいと思い「AWS認定機械学習」を目標にしたのですが、AWSの知識はあってもAIや機械学習の知識が全くない状況でした。その為、まずはG検定を取得したのですが、その中で機械学習の中での「Python」の重要性を知り「Python3 エンジニア認定基礎試験」を取得。今回の「Python3エンジニア認定データ分析試験」受験となりました。
■試験内容
試験内容は以下の通りです。
受験費用:一般:10,000円(税抜)
教材名 区分 情報 Python 3 エンジニア認定データ分析試験(公式) Web(無料) まずは公式サイトで試験内容を確認しました。この試験の特徴はテスト範囲が「Pythonによるあたらしいデータ分析の教科書」(翔泳社)から出題されることが明確になっている点です。どの章から何問出題されるか、まで明確になっています。例えば5章からは1問も出題されません。
■勉強方法と活用した教材
勉強方法と活用した教材は以下の通りです。
教材名 区分 勉強方法 【公式テキスト】
Pythonによるあたらしいデータ分析の教科書(公式)
kindle(有料) すべての出題がここからされる前提となっている公式テキストです。
「教科書」と記載されているので、初心者が読んだら解るかと勘違いしそうですが、実際は全く初心者向けの記載はされていません。書籍の最初に「教科書としてデータ分析に必要な必要な情報を提示し、簡潔に説明しています」と記載がありますが、簡潔に説明が記載されすぎて、初心者が読んでも説明不足で理解できないためです。
内容を理解するためには書籍内のキーワードをネットで調べたり、他の教材で補完する必要があります。「勉強するための本」と言うよりは「テスト範囲を明示するための本」という位置付けだと感じます。
【1日で習得】技術者のためのPythonデータ分析 Web(有料) Udemyの講座です。普段は10,800円しますが、3か月1回くらいで実施しているタイムセール期間中は90%近い値引きとなって1,400円くらいで購入可能です。私自身もタイムセールで購入しました。
動画でAnacondaのインストールやSpyder、Jupyter notobookの使い方、Pythonの基本的な操作方法に触れており、非常に解りやすかった。Numpyより前の章に関しては、「Python3 エンジニア認定基礎試験」を受験する人にもおススメできる内容です。ただし、後の章は「Matplotlib」や「scipy」辺りはいきなり難しくなるので、そこら辺と演習問題は最初は流し見でよいかと思います。
データ分析試験の試験範囲から考えると「数学の基礎」と「scikit-learn」が不足しているので、そこは他の方法で補う必要があります。
やはり動画の解りやすさは最高です。
予備校のノリで学ぶ Web(無料) 「数学の基礎」の部分はWebで調べるより動画で勉強した方が理解しやすいことを「G検定」の学習の中で学びました。「予備校のノリで学ぶ」はその中でも特におすすめの動画になります。もちろん他の講師の方の動画もYoutubeに多数アップされているので、自分が理解しやすい動画を探すことが大事です。
■PRIME STUDY模擬試験 Web(無料) この問題集がこの試験合格の鍵になります。公式テキストは範囲が広いので、私はこの3回の模擬試験に出てくる内容やキーワードについて、100%理解することを重視しました。私の勉強方法だと公式テキストに掲載されているが、模擬試験にキーワードが出てこない問題は解けないことになりますが、そこは割り切って、模擬問題集に賭けました。
■PRIME STUDY模擬試験実施内容(参考)
模擬問題集は最初の1回目で徹底的に内容を理解し、その後はひたすら繰り返しました。最後の1週間の勉強は、1日1回、この模擬試験を解く形となりました。以下が実行結果となります。
模擬試験名 点数 合否 実施日 結果 第1回 模擬試験 047.5点 不合格 2020年08月30日 教科書1周終了後。全然解らない状況。全部の問題を完全に理解できるように学習する。 第1回 模擬試験 100.0点 合格 2020年09月06日 模擬試験内容復習実施後、再受験。 第2回 模擬試験 080.0点 合格 2020年09月06日 なんとか初回で合格点超える。全部の問題を完全に理解できるように学習する。 第2回 模擬試験 100.0点 合格 2020年09月06日 模擬試験内容復習実施後、再受験。 第3回 模擬試験 085.0点 合格 2020年09月06日 初回で合格点超える。全部の問題を完全に理解できるように学習する。 第3回 模擬試験 100.0点 合格 2020年09月06日 模擬試験内容復習実施後、再受験。 第1回 模擬試験 100.0点 合格 2020年09月07日 1日1回目標に実施。 第2回 模擬試験 100.0点 合格 2020年09月08日 1日1回目標に実施。 第3回 模擬試験 100.0点 合格 2020年09月09日 1日1回目標に実施。 第1回 模擬試験 100.0点 合格 2020年09月10日 1日1回目標に実施。 第2回 模擬試験 100.0点 合格 2020年09月11日 1日1回目標に実施。 第3回 模擬試験 097.5点 合格 2020年09月12日 凡ミスで1問間違える。 利用規約に以下の記載があるので、内容については触れられません。また、メールアドレスに関しては、メール配信されても問題のないアドレスにした方が無難です。
<第7条(権利帰属)>
2.当社によって本ウェブサイトに掲載された情報、写真その他の著作物(以下「著作物等」といいます。)は、当社若しくは著作物等を創作した著作者または著作権者に帰属するものとします。3.利用者は、当社著作物について、複製、公衆送信、譲渡、翻案及び翻訳等の著作権を侵害する又は侵害する可能性のある行為を行ってはならないものとします。
<第8条(個人情報等の取扱い)>
2.利用者は、本サービスに広告等が掲載されることおよび広告等が掲載されたメールマガジンが配信されることに同意します。当社は、本サービスまたはメールマガジンに掲載されている広告等によって行われる取引に起因する損害および広告が掲載されたこと自体に起因する損害については一切責任を負いません。3.利用者は、当社より採用に関するメールが配信されることに同意します。採用に関連したメール配信に対する基準等に関しましては一切公開いたしません。
■試験(9月12日受験:合格)
ポイント 内容 試験会場 「OddesseyID&パスワード」と「指定の身分証明書」だけは忘れてはいけません。[OddesseyID&パスワード]を覚えれないなら、係員に言うと記載する付箋の持ち込みを許可してくれます。私以外の他の受験者も付箋を貰っていました。
他の試験の際には途中でトイレに行くことも許されたのですが、この試験は体調が悪かろうが外に出たら終了、の前提でした。テストが始まる前にも何度も事前にトイレに行くように促され、逆にそれがプレッシャーになりました。途中で腹が痛くなったら、と緊張しながら受験しました。
また、今回はPayPalで事前に受験料を支払いしたのですが、私の試験会場では当日に会社宛ての領収書を発行してもらえました。これがないと会社の事務処理が面倒くさいので助かりました。
所感 問題の内容は規約によって記載できません。40問の問題を解くのに30分くらいで終わりました。ただし、40問中12問程度の答えを悩む状況であり、危なかったです。700点以上で合格のなので28問(28×25点=700点)は正解する必要があり、間違えることができるギリギリのラインでした。しかしながら、解らないところが暗記系の問題ばかりであり、時間をかけても仕方ないので諦めてテストを終了しました。
結果 テストが終了した後はアンケート画面に遷移します。アンケートの回答が完了すると合否が表示されます。私は「合格」で、正解率は725点でした。あと2問間違っていたら、不合格になるところでした。久々に薄氷の結果です。
帰りに「試験結果レポート」の印刷物を渡してくれます。他にレポートが発行される訳ではないので、失くしたら困るレポートです。後日に認定証が郵送されてくるので、一緒に保管しておく必要があります。
■Python初心者の理想的な勉強方法
私と同じPython初心者を前提としたポイントになります。
(1)事前に取得した方がよい資格
事前に取得した方がよい資格が2つあります。以下の2つです。この2つを取得できるレベルに達していると、データ分析の資格勉強の理解が早いと思います。
資格 理由 G検定 機械学習のことや手法などが学べます。公式テキストには、さらっと回帰・分類、クラスタリングといった用語が出てくるのですが、G検定を取得していたおかげで、すんなり受け理れることができました。
「G検定合格者による受験に向けた心構えについて(2020年7月合格)」に記事を記載しましたが、1か月くらいの学習期間で取得できる資格です。
Python 3 エンジニア認定基礎試験 こちらはPython初心者なら必ず通る道かと思います。データ分析の試験はPythonの基本が分かっていることが前提なので、必須と思います。
「Python初心者によるPython3エンジニア認定基礎試験の勉強方法(2020年8月合格)」に記事を記載しましたが、1か月くらいの学習期間で取得できる資格です。
(2)公式テキストによる勉強方法
先にも記載した通り「Pythonによるあたらしいデータ分析の教科書(公式)」という公式テキストは初心者が最初に勉強するには難しい教材となります。その為、この教材の内容が頭に入るように事前学習するのが効率的だと思います。
私が学習に利用したUdemy「【1日で習得】技術者のためのPythonデータ分析」は非常に有効だったので、おススメしておきます。動画でAnacondaのインストールやSpyder、Jupyter notobookの使い方、Pythonの基本的な操作方法、Numpy等のライブラリの利用方法まで解りやすく教えてくれます。これを学習したあとに公式テキストを読むと、ある程度すんなり理解することができました。学習の効率化・時間短縮にもつながると思います。この事前学習の教材に関しては、個人ごとに合う教材も異なると思いますので、合わない場合は自分に合った教材を探してみてください。★「Udemy」での教材購入のポイント
①「Udemy)」で教材を購入する時は3か月に1度くらいで開催されるタイムセールの際に購入するようにしてください。この教材は普段は10,800円しますが、タイムセールの期間だけ1,400円くらいまで値段が下がります。
②教材の中の「コースの内容」という部分で幾つかの動画がサンプルとして公開されています。この内容を閲覧して、自分に合いそうだと思ったら購入してください。もし、自分に合わなさそうなら、他の教材を探した方がよいかと思います。(3)本番試験に向けた準備方法
本番試験に向けた準備方法としては「■PRIME STUDY模擬試験」を徹底的に理解するまで実施することが有効だと思います。正解が解るだけでなく、それ以外の選択肢がなぜ間違いなのかを理解するまで勉強することが重要です。
また、勉強するに際して模擬問題に関する補足ですが、模擬問題は全3回すべてが以下の通りの区分になっています。例えば1.データエンジニアの役割に関する問題は必ず1,2となります。この前提が分かっていれば、各模擬問題の内容を比較したり、公式テキストのどこを調べれば記載が載っているか学習を進めやすいかと思います。
章番号 タイトル 問題数 問題割合 模擬問題の問題番号 1 データエンジニアの役割 2 5.00% 1,2 2.1 実行環境構築 1 2.50% 3 2.2 Pythonの基礎 3 7.50% 4,5,6 2.3 Jupyter Notebook 1 2.50% 7 3.1 数式を読むための基礎知識 1 2.50% 8 3.2 線形代数 2 5.00% 9,10 3.3 基礎解析 1 2.50% 11 3.4 確率と統計 2 5.00% 12,13 4.1 NumPy 6 15.00% 14,15,16,17,18,19 4.2 pandas 7 17.50% 20,21,22,23,24,25,26 4.3 Matplotlib 6 15.00% 27,28,29,30,31,32 4.4 scikit-learn 8 20.00% 33,34,35,36,37,38,39,40 5 応用: データ収集と加工 0 0.00% ただ、私の試験結果に記載した通り、それだけだとギリギリの点数での合格になる可能性があります。私の反省から言うと、関数やメソッド類はEXCELか何かに整理して、ある程度理解した方がよいと思います。覚えている内容が多ければ多いほど、点数が向上し、余裕をもって合格できるようになると思います。
■「Pythonによるあたらしいデータ分析の教科書(公式)」の補足事項
公式テキストを実施していて気になったことを記載します。
(1)Anacondaが事前にインストールされている場合の注意点
「2.1 実行環境構築」でPythonをインストールする手順があります。
ただし、Anaondaを既にインストール済みの場合は、インストールする必要はありません。
「Anaconda環境では、pipも利用できますので、こうしたパッケージの追加にpipを利用することは可能です。ただこの場合、稀にcondaコマンドで構築された環境が壊されてしまう可能性があります。」と記載もあり、最悪Anaconda環境が壊れるので、やめておきましょう。
Anacondaのままでも、テスト範囲の4章までの範囲で困ることはありません。(2)公式テキストに記載されている構文実行について
kindle版を購入して構文を張り付けてpythonで実行しようとすると、すぐに以下のメッセージが出ます。
しかし手で例文を転記すると膨大な時間がかかります。
ここで見逃してはいけないのが、テキスト内でダウンロードサイトの記載があるサンプルデータです。
ここでダウンロードした「notobooks」というフォルダを「jupyter」の指定フォルダの直下においてあげると、4章の構文が記載済みのページを開くことができます。その為、即実行して動作確認ができます。
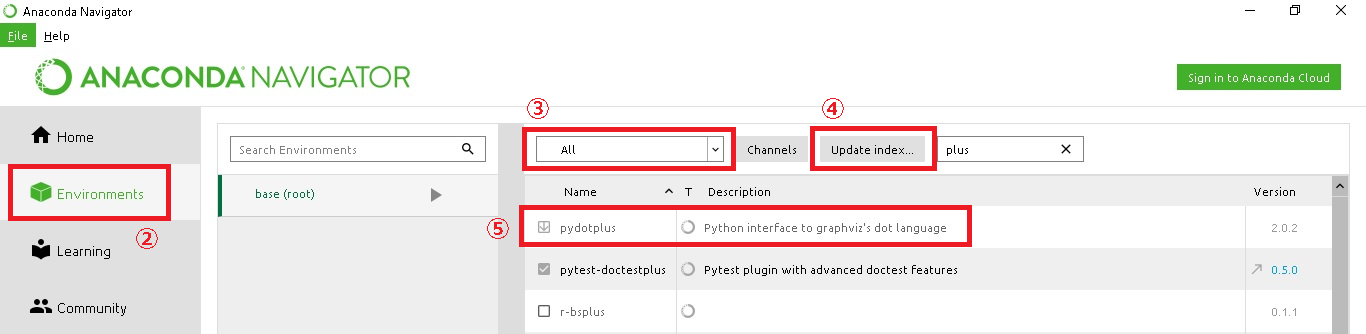
(3)「pydotplus」モジュールのインストール方法
「4.4.2 分類」の「●決定木」のところで「pydotplus」というモジュールのインストールが必要になります。Anacondaによるインストール手順の記載が無かったので、記載しておきます。なお、これを実行する前に、「Jupyter」は一度停止しておきましょう。インストール環境後に「Jupyter」を起動すると、「pydotplus」モジュールが利用可能になっています。
①Wincowsの「スタート」ボタン>Anaconda3(64-bit)>Anaconda Navigator(anaconda3)を起動する。
②「Environments」を選択する。
③「All」を選択する。
④「Update index」を選択してインデックスを更新する。
※これを一度実施しておかないと「pydotplus」が一覧に表示されない。
⑤「pydotplus」モジュールを選択して「Apply」を選択する。
(4)scikit-learnのワーニングについて
「scikit-learn」で構文通りに記載してもエラーとなります。
これは一部のクラスが廃止されているため、エラーとなっています。
私も困りましたが「写経中に遭遇したscikit-learnのワーニングに対応してみた」というページに対策方法が記載されていて、助かりました。■感想
Pythonを利用したNumpy、Pandas、Matplotlib、scikit-learnといったライブラリの具体的な動きが勉強できたことは非常に良かったです。G検定ではライブラリ名は勉強しても、実際にどのような処理をしているかといった具体的な部分は解りませんでした。その疑問がこの資格勉強を通して解消できました。
■次回に向けて
「G検定」⇒「Python基礎」⇒「Pythonデータ分析」と資格取得を進めてきましたが、次は「E資格」及び「AWS認定機械学習」の取得を目指したいと思います。
この記事がこれから「Python3エンジニア認定データ分析試験」を受験される方の参考に少しでもなれば嬉しいです。
以 上

- 投稿日:2020-09-12T14:50:31+09:00
Pythonで解く【初中級者が解くべき過去問精選 100 問】(028 - 033 幅優先探索)
1. 目的
初中級者が解くべき過去問精選 100 問をPythonで解きます。
すべて解き終わるころに水色になっていることが目標です。本記事は「028 - 033 幅優先探索」です。
2. 総括
DFSができればBFSはほぼ同じです。
違いはdeque()からポップする箇所でDFSではpop()を、BFSではpopleft()を使います。3. 本編
028 - 033 幅優先探索
028. ALDS_11_C - 幅優先探索
回答
from collections import deque n = int(input()) graph = [[] for _ in range(n+1)] for _ in range(n): i, num, *nodes = map(int, input().split()) # *で余分を回収 graph[i] = nodes # 有向グラフ visited = [-1] * (n+1) q = deque() q.append(1) visited[1] = 0 while q: node = q.popleft() for next in graph[node]: if visited[next] != -1: continue q.append(next) visited[next] = visited[node] + 1 for i, num in enumerate(visited[1:]): print(i+1, num)これは基礎問題。
ここで自分の型を作っておけば、あとは少しいじるだけで他の問題を解くことができると思われます。
BFSの流れをざっくり示すと、
1.visitedで探索先の記録ようのリストをつくる
2.deque()をとりあえず準備して、初期値をいれる
3.deque()が空になるまでwhileを回す
4.popleft()で先入れ先出しで値を取り出す
5. 取り出した値からgraphを調べて行先を調べる
6. 行先が探索済みか否かを判定
7. 探索してない場合はappendしてvisitedを更新です。
029. AtCoder Beginner Contest 007 C - 幅優先探索
回答
from collections import deque R, C = map(int, input().split()) sy, sx = map(int, input().split()) sy -= 1 # 0インデックスに修正 sx -= 1 gy, gx = map(int, input().split()) gy -= 1 # 0インデックスに修正 gx -= 1 grid = [list(input()) for _ in range(R)] visited = [[-1] * C for _ in range(R)] moves = [(1, 0), (0, 1), (-1, 0), (0, -1)] q = deque() q.append((sy, sx)) visited[sy][sx] = 0 while q: start_y, start_x = q.popleft() for dy, dx in moves: moved_y = start_y + dy moved_x = start_x + dx if grid[moved_y][moved_x] == '#': continue if visited[moved_y][moved_x] != -1: continue visited[moved_y][moved_x] = visited[start_y][start_x] + 1 q.append((moved_y, moved_x)) print(visited[gy][gx])これは典型中の典型です。
とりあえず覚える、です。
030. JOI 2011 予選 5 - チーズ
回答
from collections import deque def bfs(start_y, start_x, target_cheese, H, W, grid): visited = [[-1] * W for _ in range(H)] moves = [(1, 0), (0, 1), (-1, 0), (0, -1)] q = deque() q.append((start_y, start_x)) visited[start_y][start_x] = 0 while q: y, x = q.popleft() for dy, dx in moves: moved_y = y + dy moved_x = x + dx if moved_y < 0 or H - 1 < moved_y or moved_x < 0 or W -1 < moved_x: continue if grid[moved_y][moved_x] == 'X': continue if visited[moved_y][moved_x] != -1: continue if grid[moved_y][moved_x] == target_cheese: visited[moved_y][moved_x] = visited[y][x] + 1 return visited[moved_y][moved_x] visited[moved_y][moved_x] = visited[y][x] + 1 q.append((moved_y, moved_x)) if __name__ == "__main__": H, W, N = map(int, input().split()) grid = [list(input()) for _ in range(H)] # Sは巣でスタート、数字はチーズの硬さ、Xは障害物、.は空き地 # ネズミは数字の順番にチーズを食べる # 各数字から次の数字へのBFSを考える # スタートと各数字の位置を先に把握する start_y, start_x = 0, 0 cheese = [(0, 0) for _ in range(10)] # 初期値を(0, 0)にしておく count = 0 # countにチーズの数をいれておく for row in range(H): for col in range(W): if grid[row][col] == '.' or grid[row][col] == 'X': continue elif grid[row][col] == 'S': start_y, start_x = row, col else: grid[row][col] = int(grid[row][col]) # グリッドの中身を数字に変えておく cheese[int(grid[row][col])] = (row, col) count += 1 # ------- [すべての点を探索] ---------- target_cheese = 1 time_count = 0 while target_cheese <= count: time_count += bfs(start_y, start_x, target_cheese, H, W, grid) start_y, start_x = cheese[target_cheese] target_cheese += 1 print(time_count)やや実装が重いです。
問題文より、ネズミは数字の小さいチーズから大きいチーズへと順番に食べていきますので、各数字から次の数字へのBFSを行ってやればよさそうです。
なので、スタート位置とゴール位置が決まっているBFSを、チーズの数字の順番に設定してやり、
S→1のBFS、1→2のBFS、2→3のBFS・・・と行っていき、合計の最短距離が答えとなります。
031. JOI 2012 予選 5 - イルミネーション
回答
# girdの上下左右に0ますを全て付け加えて、 # 座標(0,0)から行ける各0点が接する1の数を足しあげる from collections import deque # ---------- [建物がない場所が隣接している建物の数を数える] -------------- def check_walls(y, x, grid, W, H, even_moves, add_moves): count = 0 if y % 2 == 0: moves = even_moves else: moves = add_moves for dy, dx in moves: moved_y = y + dy moved_x = x + dx if moved_y < 0 or H + 1 < moved_y or moved_x < 0 or W + 1 < moved_x: continue if grid[moved_y][moved_x] == 1: count += 1 return count if __name__ == "__main__": # ---------- [入力受取] -------------- W, H = map(int, input().split()) grid = [] grid.append([0] * (W+2)) for _ in range(H): temp = list(map(int, input().split())) temp = [0] + temp + [0] grid.append(temp) grid.append([0] * (W+2)) visited = [[-1] * (W+2) for _ in range(H+2)] answer_count = 0 # ---------- [偶数と奇数で動ける方向が異なる] -------------- even_moves = [(-1, -1), (-1, 0), (0, 1), (1, 0), (1, -1), (0, -1)] # 左上から時計回り add_moves = [(-1, 0), (-1, 1), (0, 1), (1, 1), (1, 0), (0, -1)] # 左上から時計回り # ---------- [初期値設定] -------------- q = deque() q.append((0, 0)) # (0, 0)から行ける建物がない場所についてBFSを実施する count = check_walls(0, 0, grid, W, H, even_moves, add_moves) # 隣接する建物数をカウント visited[0][0] = count answer_count += count # ---------- [BFS開始] -------------- while q: y, x = q.popleft() if y % 2 == 0: moves = even_moves else: moves = add_moves for dy, dx in moves: moved_y = y + dy moved_x = x + dx if moved_y < 0 or H + 1 < moved_y or moved_x < 0 or W + 1 < moved_x: continue if grid[moved_y][moved_x] == 1: continue if visited[moved_y][moved_x] != -1: continue q.append((moved_y, moved_x)) count = check_walls(moved_y, moved_x, grid, W, H, even_moves, add_moves) visited[moved_y][moved_x] = count answer_count += count print(answer_count)多くの問題は碁盤目状をベースとしたものですが、本問題は1つのマスが6角形であり若干異なります。
しかし、考え方も解き方も大きくは変わらず、変更するところは、BFSの移動の座標の設定方法です。
具体的には、僕の場合movesで定義している部分です。本問題では
y座標が偶数と奇数の場合で、各マスから動ける先が異なってきます。
したがってそれぞれ下記のように定義をしてやりますeven_moves = [(-1, -1), (-1, 0), (0, 1), (1, 0), (1, -1), (0, -1)] # 左上から時計回り add_moves = [(-1, 0), (-1, 1), (0, 1), (1, 1), (1, 0), (0, -1)] # 左上から時計回り通常の碁盤目状であれば上下左右、または、上下左右+斜めの移動成分を下記のように定義しますので、ここだけが違います。
moves = [(1, 0), (0, 1), (-1, 0), (0, -1)] # 上下左右のみの場合 moves = [(1, 0), (0, 1), (-1, 0), (0, -1), (1, 1), (-1, -1), (1, -1), (-1, 1)] # 上下左右+斜めの場合ここさえ押さえればあとは下記方針として解いていきます
1. 大きな方針は、「建物がない箇所」をBFSで探索し、各箇所で隣接する建物を数えてその合計が答え
2. そのために、まずはデフォルトで受け取るgridの上下左右に追加で「建物がない箇所」を追加する
3. gridの左上(0, 0)からBFSを実施
4. その際にvisitedに記録するのは通常の0, 1ではなく、隣接する建物の数
5. そのため隣接する建物の数を数えるための関数であるcheck_wallsを作成しておく
6.BFSを行うにあたってはyが偶数の場合と奇数の場合で動き方違うので注意する
7.BFSを一通りおこなって、check_wallsで返ってきた数を合計したものが答えです。
032. AOJ 1166 - 迷図と命ず
回答
from collections import deque def main(w, h): tatebou = [] yokobou = [[0] * w] for _ in range(h-1): tate = [0] + list(map(int, input().split())) yoko = list(map(int, input().split())) tatebou.append(tate) yokobou.append(yoko) tate = [0] + list(map(int, input().split())) tatebou.append(tate) visited = [[0] * w for _ in range(h)] moves = [(1, 0), (-1, 0), (0, 1), (0, -1)] q = deque() q.append((0, 0)) visited[0][0] = 1 while q: y, x = q.popleft() for dy, dx in moves: moved_y = y + dy moved_x = x + dx if dy == 1 and dx == 0: if moved_y < 0 or h-1 < moved_y or moved_x < 0 or w-1 < moved_x: # 迷路外 continue if visited[moved_y][moved_x] != 0: continue if yokobou[moved_y][moved_x] == 1: # 下に行くときは動く先が1のときだめ continue visited[moved_y][moved_x] = visited[y][x] + 1 q.append((moved_y, moved_x)) elif dy == -1 and dx == 0: if moved_y < 0 or h-1 < moved_y or moved_x < 0 or w-1 < moved_x: # 迷路外 continue if visited[moved_y][moved_x] != 0: continue if yokobou[y][moved_x] == 1: # 上に行くときは自分が1のときだめ continue visited[moved_y][moved_x] = visited[y][x] + 1 q.append((moved_y, moved_x)) elif dy == 0 and dx == 1: if moved_y < 0 or h-1 < moved_y or moved_x < 0 or w-1 < moved_x: # 迷路外 continue if visited[moved_y][moved_x] != 0: continue if tatebou[moved_y][moved_x] == 1: # 右に行くときは動く先が1のときだめ continue visited[moved_y][moved_x] = visited[y][x] + 1 q.append((moved_y, moved_x)) else: # dy == 0 and dx == -1 if moved_y < 0 or h-1 < moved_y or moved_x < 0 or w-1 < moved_x: # 迷路外 continue if visited[moved_y][moved_x] != 0: continue if tatebou[moved_y][x] == 1: # 左に行くときは自分が1のときだめ continue visited[moved_y][moved_x] = visited[y][x] + 1 q.append((moved_y, moved_x)) return visited[h-1][w-1] if __name__ == "__main__": answer_list = [] while True: w, h = map(int, input().split()) if w == 0 and h == 0: break answer = main(w, h) answer_list.append(answer) for answer in answer_list: print(answer)基本的に問題29とやることは同じです。
異なる点は、当たり判定です。問題29は「マスそれ自体に行けない」という当たり判定でしたので簡単ですが、この問題は、「マス」ではなく「壁」です。
なので、通常のBFSでは必要ない場合分けを行う必要があります。
具体的には、上下左右の動き方それぞれで、下記のように当たり判定を変える必要があります。if dy == 1 and dx == 0: if yokobou[moved_y][moved_x] == 1: # 下に行くときは動く先が1のときだめ continue elif dy == -1 and dx == 0: if yokobou[y][moved_x] == 1: # 上に行くときは自分が1のときだめ continue elif dy == 0 and dx == 1: if tatebou[moved_y][moved_x] == 1: # 右に行くときは動く先が1のときだめ continue else: # dy == 0 and dx == -1 if tatebou[moved_y][x] == 1: # 左に行くときは自分が1のときだめ continueこの当たり判定以外は普通に書くだけです。
033. AtCoder Beginner Contest 088 D - Grid Repainting
回答
# 白だけ動いて(0,0)から(H-1, W-1)に行く # その際にできるだけ黒を増やす # 全体の白から最短距離を除いたものが答え from collections import deque H, W = map(int, input().split()) grid = [list(input()) for _ in range(H)] # .は白、#は黒 visited = [[-1] * W for _ in range(H)] moves = [(1, 0), (0, 1), (-1, 0), (0, -1)] q = deque() q.append((0, 0)) visited[0][0] = 0 while q: y, x = q.popleft() for dy, dx in moves: moved_y = y + dy moved_x = x + dx if moved_y < 0 or H-1 < moved_y or moved_x < 0 or W-1 < moved_x: continue if grid[moved_y][moved_x] == '#': continue if visited[moved_y][moved_x] != -1: continue visited[moved_y][moved_x] = visited[y][x] + 1 q.append((moved_y, moved_x)) min_route = visited[H-1][W-1] if min_route == -1: answer = -1 else: total_white = 0 for row in grid: total_white += row.count('.') answer = total_white - min_route - 1 print(answer)ほかの問題を解けたのであれば、これは結構簡単です。
問題をかみ砕いて解釈すると「できるだけ黒に塗って左上から右下に移動するときの黒に塗った数」が回答になります。
これをもう少し解きやすいように解釈すると「左上から右下に最短距離で移動したときに、その他通っていないところの数」となります。
これがわかれば、普通にBFSで最短距離を算定して、全体のから引けばよいとわかります。なので、方針は
1.(0,0)スタート、(H-1, W-1)ゴールで最短距離min_routeを算出
2. 全体の白の数total_whiteを算出
3.total_whiteからmin_routeを引いたものが答え(min_routeはゼロスタートなので-1を追加でする)です。





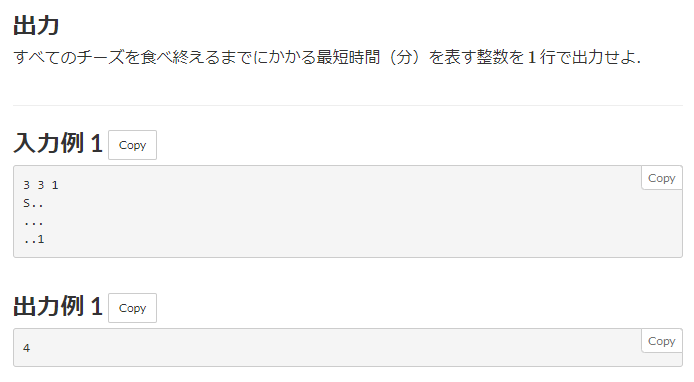
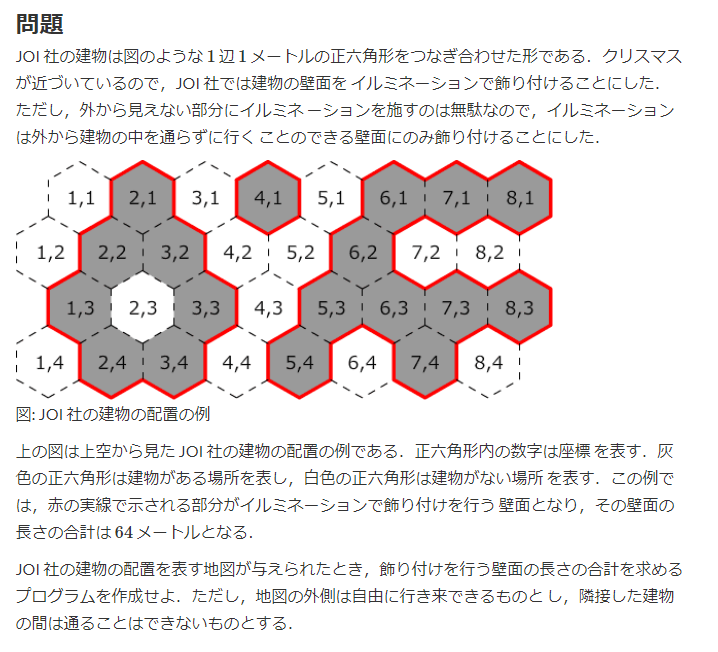



- 投稿日:2020-09-12T12:48:27+09:00
Pythonでデスクトップのパスを得る
PythonでmacOSとWindows共通でデスクトップのパスを得る方法。
いろいろありますが、os.path.expanduserを使うのが簡単です。
get_desktop.pyimport os desktop_dir = os.path.expanduser('~/Desktop') print(desktop_dir)環境変数から取得するのも良い方法ですが、その場合、OS判定が必要です。
get_desktop2.pyimport os if os.name == 'nt': home = os.getenv('USERPROFILE') else: home = os.getenv('HOME') desktop_dir = os.path.join(home, 'Desktop') print(desktop_dir)以上、簡単な紹介でした。
- 投稿日:2020-09-12T12:12:14+09:00
[django] modelのmodifiedが更新される場合と更新されない場合について
はじめに
modelのmodifiedが更新される場合と更新されない場合があるって知ってました?
自分は知りませんでした
ということで調べましたmodifiedが更新される場合
user = User.objects.get(pk=1) user.name = 'hoge' user.save()まあ、よくあるやつです
modifiedが更新されない場合
User.objects.filter(prefecture_id=1).update(prefecture_name='北海道')
updateメソッドを使うと更新されません!modifiedが更新するには
User.objects.filter(prefecture_id=1).update(prefecture_name='北海道', modified=datetime.datetime.now())このように明示的に指定する必要があります
users = [] for user in User.objects.filter(prefecture_id=1): user.prefecture_name ='北海道' user.modified = datetime.datetime.now() users.append(user) User.objects.bulk_update(users, fields=['prefecture_name', 'modified'])bulk_updateも同様に更新されないので、明示的に指定する必要があります
- 投稿日:2020-09-12T11:53:01+09:00
[DRF]PrimaryKeyRelatedFieldを高速化するスニペット
はじめに
シリアライザで
PrimaryKeyRelatedFieldをmany=Trueにすると、pkの配列をリクエストパラメータで渡せますが、pkが大量にあるとめちゃくちゃ遅くなります
そのため原因の調査と高速化方法を考えました原因
結論これです
ManyRelatedField.pydef to_internal_value(self, data): if isinstance(data, str) or not hasattr(data, '__iter__'): self.fail('not_a_list', input_type=type(data).__name__) if not self.allow_empty and len(data) == 0: self.fail('empty') return [ self.child_relation.to_internal_value(item) for item in data ]配列分
self.child_relation.to_internal_value(item)が呼ばれてるため(to_internal_valueの中でpkをgetしている)遅くなっていました高速化するスニペット
from rest_framework import serializers from rest_framework.relations import MANY_RELATION_KWARGS, ManyRelatedField class PrimaryKeyRelatedFieldEx(serializers.PrimaryKeyRelatedField): def __init__(self, **kwargs): self.queryset_response = kwargs.pop('queryset_response', False) super().__init__(**kwargs) class _ManyRelatedFieldEx(ManyRelatedField): def to_internal_value(self, data): if isinstance(data, str) or not hasattr(data, '__iter__'): self.fail('not_a_list', input_type=type(data).__name__) if not self.allow_empty and len(data) == 0: self.fail('empty') return self.child_relation.to_internal_value(data) @classmethod def many_init(cls, *args, **kwargs): list_kwargs = {'child_relation': cls(*args, **kwargs)} for key in kwargs: if key in MANY_RELATION_KWARGS: list_kwargs[key] = kwargs[key] return cls._ManyRelatedFieldEx(**list_kwargs) def to_internal_value(self, data): if isinstance(data, list): if self.pk_field is not None: data = self.pk_field.to_internal_value(data) results = self.get_queryset().filter(pk__in=data) # 全てのデータがあるかチェックする pk_list = results.values_list('pk', flat=True) pk_list = [str(n) for n in pk_list] data_list = [str(n) for n in data] diff = list(set(data_list) - set(list(pk_list))) if len(diff) > 0: pk_value = ', '.join(map(str, diff)) self.fail('does_not_exist', pk_value=pk_value) if self.queryset_response: return results else: return list(results) else: return super().to_internal_value(data)解説
- 一つずつgetしていたのをfilterのinで取得するように変更
- 存在しないpkが含まれていた場合のエラーメッセージは一つしか表示されなかったのを、カンマ区切りで全て表示するように変更
queryset_responseのパラメータを追加しています。queryset_response=Trueにするとレスポンスがquerysetになります(今まではquerysetの配列。個人的にはquerysetになってた方が使いやすいんじゃないかなと思う)
- 投稿日:2020-09-12T10:56:00+09:00
PythonでDICOM画像を扱う
きっかけ
Kaggleコンペで胸部のCTスキャン画像、DICOM画像が出てきてどのように扱えばいいか分からなかったから。
何ができるようになるか
・DICOM画像とは何か
・DICOM画像の表示、データの扱い方DICOM画像とは何か?
DICOM(ダイコム)とは、CTやMRI、CRなどで撮影した医用画像のフォーマットと、それらを扱う医用画像機器間の通信プロトコルを定義した標準規格である。
wiki使用例
インストール
qiita.rb%pip install pydicomdatasetにはメタデータが入っている
qiita.rbimport pydicom import matplotlib.pyplot as plt from pydicom.data import get_testdata_files filename = get_testdata_files('CT_small.dcm')[0] dataset = pydicom.dcmread(filename) print(dataset)
値の表示はキー名(.Rows)や番号(0x0010,0x0010)で表示,アクセスできる。
qiita.rbdataset[0x0010, 0x0010] dataset.Rows
画像の表示まで
qiita.rbpat_name = dataset.PatientName display_name = pat_name.family_name + ", " + pat_name.given_name print("Patient's name...:", display_name) print("Patient id.......:", dataset.PatientID) print("Modality.........:", dataset.Modality) print("Study Date.......:", dataset.StudyDate) print(dataset[0x0018, 0x0050]) if 'PixelData' in dataset: rows = int(dataset.Rows) cols = int(dataset.Columns) print("Image size.......: {rows:d} x {cols:d}, {size:d} bytes".format( rows=rows, cols=cols, size=len(dataset.PixelData))) if 'PixelSpacing' in dataset: print("Pixel spacing....:", dataset.PixelSpacing) # use .get() if not sure the item exists, and want a default value if missing print("Slice location...:", dataset.get('SliceLocation', "(missing)")) # plot the image using matplotlib plt.imshow(dataset.pixel_array, cmap=plt.cm.bone) plt.show()
参考
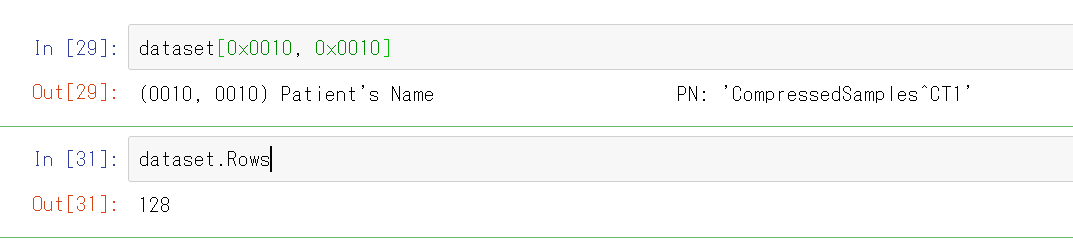
- 投稿日:2020-09-12T09:55:48+09:00
Pythonのbuilt in method
- 投稿日:2020-09-12T09:55:48+09:00
Pythonでlistに連続でappendするときに便利な書き方
下記のように何度もappendを書かずに書けるようです。
>>> v = [] >>> a = v.append >>> a('aaa') >>> a('bbb') >>> v ['aaa', 'bbb']
- 投稿日:2020-09-12T09:37:04+09:00
Python3.8から始めるモダン型付けvol.1 (without class)
イントロダクション
最近オライリーの『プログラミングTypeScript』を読み、非常に感銘を受けました。
ジェネリクスの奥深さ面白さ、型がある事による関数やオブジェクト情報の増加、そして生まれる安心感……。型無しでは不安で昼寝できない身体になってきました。そんな折『飛騨高山Pythonモクモク会』で今月も発表することになり、大概ネタ切れ状態だった私は思いました。そうだ、めっちゃ感銘を受けたTypeScriptを絡めれば楽しく発表できるぞ、と。
幸いPythonにも型ヒントがあります。Pythonの型システムはTypeScriptに比べれは少々貧弱だと思っていたのですが、調べてみたらなかなかどうして! これは便利という機能が揃っていました(特に3.8以降)
この記事ではシリーズを通して型システムの奥深さ面白さ便利さを少しでもお伝えできればと思っています。
完全にネタかぶりしました
途中まで書いた時、ふとPyConJP2020の演目を見ていたら『Python 3.9 時代の型安全な Pythonの極め方 by.小笠原みつき』というのがあるではありませんか。しまったなぁと思ったのですが、まぁ書いちゃったのでそのまま行くことにしました。
皆が皆同じ事書くわけじゃないしね。
3.9以降の記法など一部参考にして、今回の内容に反映しています。対象読者
- JavaScript/Python等、型の無い言語の方々
これらの方々の中には、型と言われるとこういうのをイメージする人がいるかもしれません。
型の存在は筋力(性能)を上げるけど、その分堅苦しくって動きを制約されたプログラミングを強いられる。
しかし、実際はそうではありません。型はプログラマブルで、しかも生産性を上げるものです。
最後まで読んで頂ければ、それがきっと理解できるはず。いや、理解できる。できるんじゃないかな。……理解して頂けるよう、頑張って書きます。
- CとかJavaとかなんでもいいけど古典的型を使った事がある方々
これらの方々にも新しい発見があると思います。
動的言語に後付で型を付けると意外と面白い事になった。それがTypeScriptや型ヒントです。ガチガチに型のある言語経験者にも、Union型やLiteral型の興味深い仕組みには驚きと発見があるのではないでしょうか?Pythonタイプヒントの特性
ここではPythonタイプヒントの特性とその特性から見えてくる、用途について述べます。
型情報は実行時には完全に無視される
型情報は実行時には無視されます。ですので
- 型を書いたところで普通にpythonコマンドで実行しても意味がない
- 実行時の型エラーは防げない
- 速度向上も見込めない
というなんだか一見微妙な代物、言ってしまえばタイプヒントはただのコメントです。……みなさんのモチベーションがダウンしてきているのが見えます。
しかし、逆にタイプヒントをコメントとして見ると、その強烈さが浮かび上がってきます。
- タイプヒントは型についてのコメントである
- タイプヒントはmypyや各種IDEとの組み合わせで、コード内に各種制約を課す事ができる
- 型の合成等の型演算ができる。つまり、コメントなのに関数が使える
いかがでしょう、そう考えるとなんだか面白くありませんか? そしてとても強力に見えるでしょう。実際、強力なのです。
さて、皆さんのモチベーションが少しは回復してきたかと思います。そろそろ実践へと入っていきましょう。
VSCodeで事前準備
今回はVSCodeとPyrightで実験しました。VSCodeにpyrightを入れて設定するには、以下を参照してください。
https://qiita.com/simonritchie/items/33ca57cdb5cb2a12ae16入れるとこんな感じになります。うっとおしい波線が出てきます。
極論を言うとこのうっとおしい波線こそが型ヒントを使う、究極のメリットです。型の書き方
変数名: 型 = 値基本的な型
int:整数型
i: int = 2 i = 1.1 ##type error! # 1.1はfloatなのでエラー型を決めた変数に型違いのものを入れると、うっとおしい感じの波線が出ます。うっとおしいので直しましょう。
float:浮動小数点
f: float = 1.0 f = 1 # 1はint型ですが、キャスト(型変換)が入りエラーになりませんcomplex:複素数型
c: complex = 1 + 2jstr:文字列型
s: str = 'hoge'byte:バイト配列
byte: bytes = b'test'bool:真偽値
b: bool = True型引数を取る型
ここから紹介する型は他の型を型引数(引数のようなもの)に取るすげー型です。いわば型の抽象化とプログラミングです。
typingを利用して記載します。import typing記法としては以下のようになります。
変数名: 型名[型引数] = 値list:リスト
lst: typing.List[int] = [1, 2, 3] lst2: list[int] = [0,1,2] # Python3.9以降で使える記法もうちょい自由の効くリストは作れんのかと思った方、後で出てきます。
set:重複なしのリスト
st: typing.Set[int] = {1, 2, 3}tuple:型、長さ指定の固定長配列
全ての型を記載します。
tpp: typing.Tuple[int, bool, str] = (1, True, 'test')dict:辞書
Dict[キーの型, 値の型]
dic: typing.Dict[str, int] = {'name': 1, 'age': 2} dic1: dict[str, int] = {'test': 1} # Python3.9以降で使える記法これじゃ複雑な辞書使えないじゃんと思った方に朗報です。後でもっときめ細かい指定のできる方法が出てきます。
型エイリアス
型情報ってなんか長げーなと思ってきたころかと思います。
そんなせっかちな貴方や、せっかく作った型には名前を付けてわかりやすく管理したいという実利的な貴方、そんな方々の為に型の変数版とでも言うべき型エイリアスはあります。TupleIBS = typing.Tuple[int, bool, str]選択できる型
Union:列挙型
Union[型1, 型2, 型3 ...]
型引数に列挙した型のどれになっても良い型です。uni: typing.Union[int, bool] = 1 uni = False uni3: int | bool = 1 # Python3.10から使えるようになる記法型は組み合わせる事でさらなる効果を発揮します。
先程、より柔軟なリストについて言及しました。それをそれをここで実現しましょう。list_ib: typing.List[typing.Union[int, bool]] = [1, True, 2, False]Literal:リテラル型 (※Python3.8以降)
神機能です。
なぜ日本語圏での言及が少ないのかわからないほど神機能です。舐めてんのか。PyConJP2020の公演で言及がありました。
一言で言えば、定数の型化です。より限定的な型表現ができます。おまけに列挙機能まであります。強い。li1: typing.Literal[1] = 1 # 実質定数 li2: typing.Literal['hoge', 'fuga'] = 'fuga' # 複数記載可能 li2 = 'hoge'Final (※Python3.8以降)
イミュータブル(普遍)を表現できます。が、ちょっとした落とし穴あり。
c: typing.Final[str] = 'c' c = 'a' ##type error! lis: typing.Final[typing.List[int]] = [1,2,3] lis[1] = 1 # エラー出ずまぁこういうケースは素直にtuple使いましょう。
TypedDict:型付の辞書 (※Python3.8以降)
よりきめ細かく辞書を型指定できます。
そしてこれをじっくり読み、そして実際に書いてみれば、型システムの便利さが感じられるはずです。# クラスの記法を使って辞書の型情報を記載します class UserDict (typing.TypedDict): # TypedDictを継承する name: str age: Optional[int] # None可能にする ≒ Union[int, None] sex: typing.Literal['men', 'women', 'other'] users: typing.List[UserDict] = [ { 'name': 'noji', # 文字列のみ 'age': 33, # 数値かNoneのみ 'sex': 'men' #「漢」とかは入れられません。入力補助も効きます。 }, { 'name': 'superwomen', 'age': None, 'sex': 'women' } ]まとめ:型で楽をしよう
今回は基本的な(ほぼクラスを含まない)基本的な型について解説しました。
型はプログラム可能で、IDEにも作用する有用なコメント、と言った意味が見えてきたのでは無いかと思います。
ぱっと思いつくだけでも、辞書型や引数の選択肢を狭めるという用途が考えられます。オプションを文字列で指定する場合等に、Literal型がとても役に立ちます。
形態の解っているJSONを拾って利用する時に、悩みを減らす事にもなります。
型がわかっていればインテリセンスも効くので、慣れないクラスを使うときもバッチリです。
元々型の無い言語に型を付けたので、型の付け方も柔軟に行なえる点も嬉しいです。型を使うとちょっとの手間で大きな楽ができるのです。プログラマ三大美徳のうちの怠惰を極める為の大いなる助けとなります。
さぁ、型を使って楽で楽しいプログラミングをしましょう。付録:型で苦しんだ時は
でもまぁぶっちゃけ。型で苦しむときもあります。
俺はロジックを書きたいだけなのに、なんでこんな型エラーと戦ってんだ? みたいな。そんな時はまぁ、妥協しちゃってもいいさと考えましょう。
型の推論
一度も変数を書き換えない限りにおいては、型推論が有効に働くので実はわざわざ型は書かなくても良いです。
実際のところ、僕も型情報は以下のものしか書きません。
- 関数の引数
- 関数の戻り値(推論に任せる事もある)
- 再代入がありえる変数
boo = True # IDEが自動的にbool型であると推論し、それに剃った動作をする boo = 1 # しかし書き換えた瞬間に型が変わる(もしくはAnyになる)cast:型の変換
型情報が無かったり困った時は使ってみよう。なかなかどうして役立ちます。強引な変換ができるので、乱用厳禁です。
※実行時には何もしませんi3: int = typing.cast(int, 1.0)Any:なんでもあり型
これ即ち型ヒントの無いPythonの世界です。なかなかの劇薬です。
ani: typing.Any = 1 ani = 'hoge' ani = ['fuga', 129999, True]



- 投稿日:2020-09-12T07:53:41+09:00
Rotrics DexArmを使ってみた #2
Rotrics DexArmを使ってみた #1の続きです。SDKが出てくる気配がないので、シリアル通信でGCodeを送ってなんとかします。意外と応答が素直だから、これで良いのかという気もしてきました。
#!/usr/bin/env python3 import serial, time #Serial setting s = serial.Serial("/dev/ttyACM0",115200) def w(gcode): ''' Send GCode to Dexarm and wait for the response. ''' print(gcode) s.write(gcode.encode('utf-8')+b'\r\n') r = None while r == None or "echo:" in r: r = s.readline().decode('utf-8').strip() print(r) # "ok", "echo:busy" or "beyond limit.." def wait(ms): w('G4 P'+str(ms)) def move(x,y,z): cood = "" if x != None: cood += "X"+str(x) if y != None: cood += "Y"+str(y) if z != None: cood += "Z"+str(z) w('G0 '+cood) z1 = 0 z2 = 30 def pick(): move(None,None,z1) w('G0 Z0') w('M1000') wait(500) move(None,None,z2) def drop(): move(None,None,z1) w('M1001') move(None,None,z2) wait(500) w('M1003') # Main def main(): # Initialize w("M1111") time.sleep(1) move(100,0,30) # Pick and move objects in different speeds. w("G0 F3000") move(100,200,z2) pick() move(0,-200,z2) drop() w("G0 F6000") move(50,200,z2) pick() move(50,-200,z2) drop() w("G0 F8000") move(0,200,z2) pick() move(100,-200,z2) drop() # back to center move(200,0,0) s.close() print("Fin.") #Main loop if __name__ == '__main__': main()よく考えたらPythonに固執する必要もないので、Rubyで書き直し始めています。続きは実機が手に入ったら書きます。基本的な操作をgemとかにまとめても良いかもしれませんね。
#!/usr/bin/env ruby # sudo apt install ruby-dev -y # sudo gem install serialport require 'serialport' s = SerialPort.new('/dev/ttyACM0', 115200, 8, 1, 0) # device, rate, data, stop, parity def w(gcode) puts gcode s.puts gcode + '\r\n' r = nil while r == nil || r.start_with?("echo:") do # "ok", "echo:busy" or "beyond limit.." r = s.readline.chomp.strip puts r end end w("M1111") sleep(1) s.close puts "fin"