- 投稿日:2020-09-10T23:11:52+09:00
Rubyで型宣言っぽくコードを書けるようにしてみた
結論
以下のようなコードが動くようになります。
n = int 42 # => 42が代入される f = int 4.2 # => TypeError!やったこと
以下のように
Kernelモジュールにモンキーパッチしますmodule Kernel module_function def int(var = 0) if var.is_a?(Integer) var else raise TypeError, "#{var} isn't Integer" end end endあとは、
n = int 42のように書くだけで型宣言っぽくRubyの変数を作ることができます。また異なる型(というかクラス)の値を渡した場合は例外としてTypeErrorが発生します。n = int 42 i = int 21 p n # => 42 p i # => 21 n = int 4.2 # => `int': 4.2 isn't Integer (TypeError)影響範囲を狭めるのであれば、
refinementsで以下のように書けばいいかとmodule Type refine Kernel do module_function def int(var = 0) if var.is_a?(Integer) var else raise TypeError, "#{var} isn't Integer" end end end endあとは使いたい箇所で
using TypeとすればOkですおわりに
とりあえず、
IntegerとかStringとかはこんな感じで型宣言っぽく書けそう。ArrayとかHashとかは何かいい書き方ないか考えてみよう
- 投稿日:2020-09-10T22:49:40+09:00
Kinx Tiny Typesetting - LaTeX 派? つか、知ってる?
Kinx Tiny Typesetting
こんにちわ。
今回は組版システムがメインです。TeX や LaTeXを使ってますか?それは良いですね。私はイマイマ 全く使ってません。好きですけど。
学生時代の論文書きには使ったものの、就職したら使わなくなってしまったあの懐かしくも美しいシステム、LaTeX。
この記事はそんな LaTeX に関係しつつ、私たちの Kinx に関連する、そんな内容です。
はじめに
「見た目は JavaScript、頭脳(中身)は Ruby、(安定感は AC/DC)」 でお届けしているスクリプト言語 Kinx。最近はだいぶ記事を書く時間がなく、生存確認的な記事ですが、ご容赦。書きたいことはいっぱいあるのですが。
- 参考
- 最初の動機 ... スクリプト言語 KINX(ご紹介)
- 個別記事へのリンクは全てここに集約してあります。
- リポジトリ ... https://github.com/Kray-G/kinx
- Pull Request 等お待ちしております。
組版?
まずはこちらのPDFファイルからご覧ください。
https://github.com/Kray-G/kinx/blob/master/examples/typesetting/typesetting.pdf
これは Kinx 組版ライブラリによって生成されました。なんだそれ、というのが今回のお話です。
このライブラリはまだ完成しておらず、極めて初期の段階にありますが、割りとイケてる感じに出力できたので、勇み足風に紹介したくなってしまった、という記事でありんす。
なぜ作り始めたか
PDF ライブラリ実装したんですよ。libharu ラップして。でもですね、生の PDF 操作するツール作るのも、まああるとは思いますが、座標計算したり面倒なので、ルールにしたがって組版する仕組みはほしいですよね。
そう思って見渡すと、そういうのって TeX くらいですよね。あと SATySFi とか SILE とか見つけたんですが、SATySFi も SILE も Windows が弱点のご様子(SILE はビルドできたけど出力が正しくなかった…)。まあ、SILE はすごく良さそうでしたが、数式はまだ未対応。数式が必要か?は議論の余地はありますが、TeX っぽい感じ!を意識すると欲しいところ。
というわけで、またしても車輪の再発明に走りました。特長としては「スモールサイズで手軽に組版」。面倒な作業は一切なし。ここだけは守りたい。
LaTeX は不要(使ってない)
ちなみに LaTeX は使っていません。というと語弊があるかもしれませんね。実際、LaTeX 自体はインストールすらしてません。が、数式に関しては KaTeX 内蔵でゴニョゴニョしてます。
LaTeX システムは非常に巨大なので、優れたシステムだとは思いますが、ちょっと PDF 作りたいなー程度の要望にインストールするには本格的すぎる気がして。
Kinx のスモール・パッケージをインストールしたら「なんかそれなりのが付いてた!」、くらいがちょうどいい感じなので、そんな感じを目指してます。
おわりに
これはまだ完成してないシステムの紹介です。やることはまだたくさんあるので、これからです。目次とか Book Style とか。最終的には簡易マークアップからの変換がまず当面のゴール。基本 Markdown からは行ける感じで。
まだまだ発展途上の段階ですが、興味があったり応援してくださる方がいれば、ぜひぜひ Github スターください!やる気出します。(ただ、完成形はリポジトリ独立させるかも…)
同梱するとフォントだけで Kinx 本体のサイズ越えそうなので、別パッケージでアドオンできるようにしたいですね。パッケージ・マネージャーが必要だ。
ではまた次回!
- 投稿日:2020-09-10T22:43:36+09:00
【Ruby on Rails】DM、チャット機能
目標
開発環境
ruby 2.5.7
Rails 5.2.4.3
OS: macOS Catalina前提
※ ▶◯◯ を選択すると、説明等が出てきますので、
よくわからない場合の参考にしていただければと思います。
- deviseでログイン環境構築
- ユーザー詳細画面と一覧と作成済み
流れ
1 modelの作成
2 modelの編集
3 controllerの作成
4 routingの編集
5 viewの編集modelの作成
ターミナル$ rails g model Room $ rails g model Chat user_id:integer room_id:integer message:string $ rails g model UserRoom user_id:integer room_id:integer $ rails db:migrate
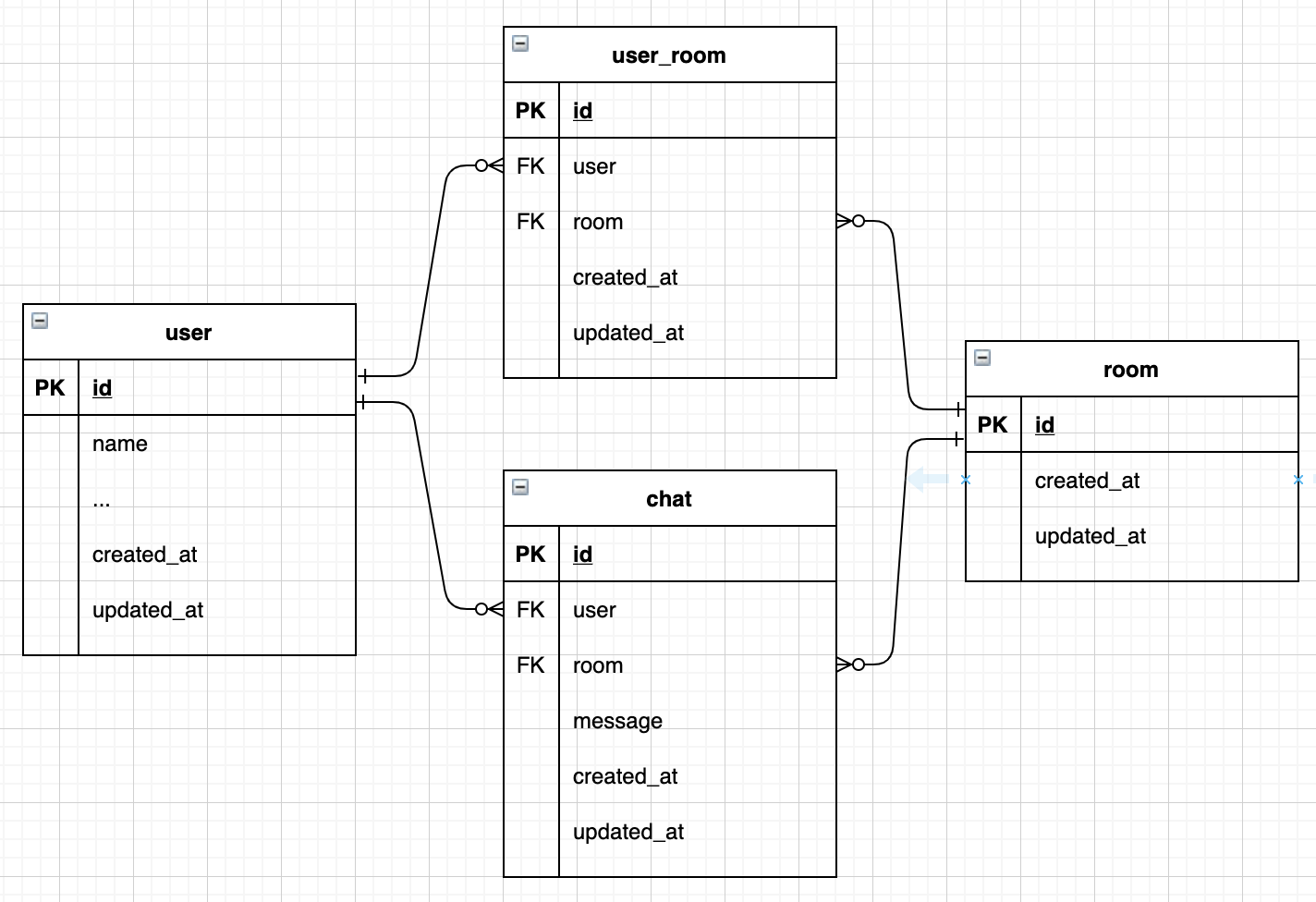
補足1【room】
ユーザー同士が会話をする部屋。
補足2【chat】
ユーザーが発言した内容を保存するテーブル。
補足3【user_room】
userとroomが多対多の関係性のため、中間テーブルとしてこれを管理。modelの編集
下記のようなリレーションにしていきます。
app/models/room.rbhas_many :user_rooms has_many :chats
補足【リレーション】
room内では多くのuser_roomがあるので、1対多。
room内では多くのchatがあるので、1対多。app/chats/room.rbbelongs_to :user belongs_to :roomapp/user_rooms/room.rbbelongs_to :user belongs_to :roomapp/models/user.rbhas_many :user_rooms has_many :chats
補足【リレーション】
1ユーザーが多くのuser_roomを保有しているので、1対多。
1ユーザーが多くのchatを行うので、1対多。controllerの作成
ターミナル$ rails g controller chatsapp/controllers/chats_controller.rbclass ChatsController < ApplicationController def show @user = User.find(params[:id]) rooms = current_user.user_rooms.pluck(:room_id) user_rooms = UserRoom.find_by(user_id: @user.id, room_id: rooms) unless user_rooms.nil? @room = user_rooms.room else @room = Room.new @room.save UserRoom.create(user_id: current_user.id, room_id: @room.id) UserRoom.create(user_id: @user.id, room_id: @room.id) end @chats = @room.chats @chat = Chat.new(room_id: @room.id) end def create @chat = current_user.chats.new(chat_params) @chat.save redirect_to request.referer end private def chat_params params.require(:chat).permit(:message, :room_id) end end下記コメントアウトにて、分かりづらい箇所を補足。
app/controllers/chats_controller.rbdef show # どのユーザーとチャットするかを取得。 @user = User.find(params[:id]) # カレントユーザーのuser_roomにあるroom_idの値の配列をroomsに代入。 rooms = current_user.user_rooms.pluck(:room_id) # user_roomモデルから # user_idがチャット相手のidが一致するものと、 # room_idが上記roomsのどれかに一致するレコードを # user_roomsに代入。 user_rooms = UserRoom.find_by(user_id: @user.id, room_id: rooms) # もしuser_roomが空でないなら unless user_rooms.nil? # @roomに上記user_roomのroomを代入 @room = user_rooms.room else # それ以外は新しくroomを作り、 @room = Room.new @room.save # user_roomをカレントユーザー分とチャット相手分を作る UserRoom.create(user_id: current_user.id, room_id: @room.id) UserRoom.create(user_id: @user.id, room_id: @room.id) end @chats = @room.chats @chat = Chat.new(room_id: @room.id) endroutingの編集
config/routes.rbget 'chat/:id' => 'chats#show', as: 'chat' resources :chats, only: [:create]viewの編集
app/view/users/show.html.erb<% if current_user != @user %> <%= link_to 'chatを始める', chat_path(@user.id)%> <% end %>app/view/chats/show.html.erb<%= form_with model: @chat do |f| %> <%= f.text_field :message %> <%= f.hidden_field :room_id %> <%= f.submit %> <% end %> <table> <thead> <tr> <td>投稿者名</td> <td>投稿内容</td> </tr> </thead> <tbody> <% @chats.each do |chat| %> <tr> <td><%= chat.user.name %></td> <td><%= chat.message %></td> </tr> <% end %> </tbody> </table>
補足【f.hidden_field】
f.hidden_fieldは、表示はしていないものの、paramsとして送りたいものを送る際に活用します。参考
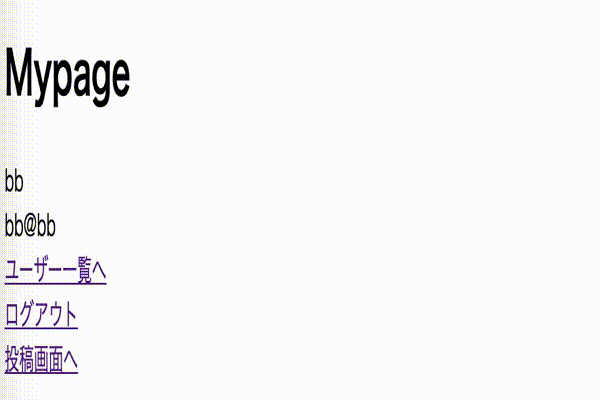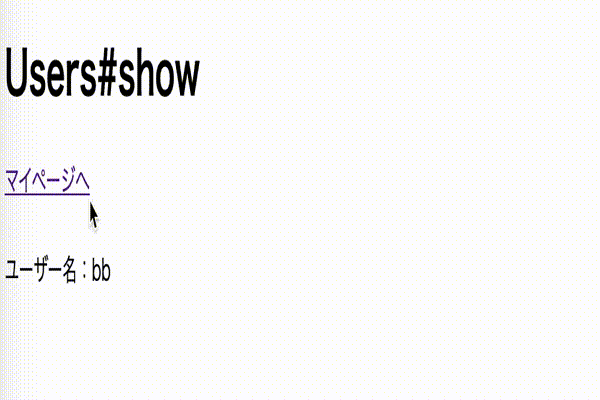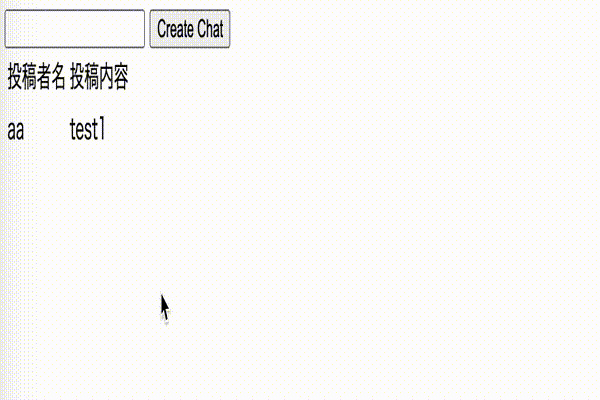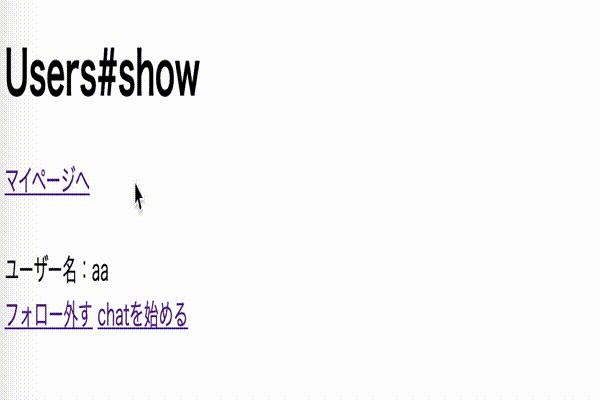
- 投稿日:2020-09-10T22:28:37+09:00
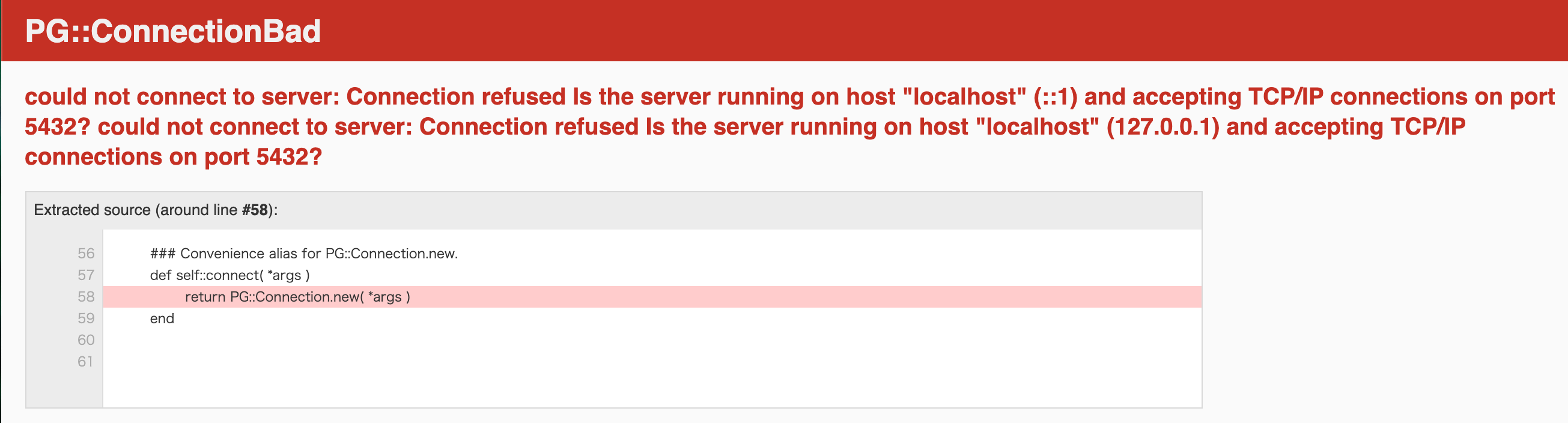
Postgresエラー「PG::ConnectionBad」
何度もつまづいたので一旦簡単にメモ
PG::ConnectionBad
could not connect to server: Connection refused Is the server running on host "localhost" (::1) and accepting TCP/IP connections on port 5432? could not connect to server: Connection refused Is the server running on host "localhost" (127.0.0.1) and accepting TCP/IP connections on port 5432?
% postgres -D /usr/local/var/postgres 2020-09-10 22:13:34.167 JST [8631] FATAL: lock file "postmaster.pid" already exists 2020-09-10 22:13:34.167 JST [8631] HINT: Is another postmaster (PID 494) running in data directory "/usr/local/var/postgres"?% rm /usr/local/var/postgres/postmaster.pidrmでpostmaster.pidを削除
% brew services restart postgresqlリスタートしてあげる。
% rails s起動して確認
ポイント
postmaster.pidが残っていること
正常にpostgresqlが終わらせられていないと
postmaster.pidというファイルが残ってしまった結果
接続できない起動できないエラーが発生するみたいです。もう少し詳しく調べて再度更新予定。
postgresqlの起動と停止についての仕組みをしる必要がありそう
今回はメモまで。参考記事
- 投稿日:2020-09-10T22:18:21+09:00
AWSを使ってアプリケーションを公開する手順(5)アプリケーションを公開する
はじめに
AWSを使ってアプリケーションを公開する手順を記載していく。
この記事ではアプリケーションを公開する。EC2のサーバにアプリケーションのコードをクローンする準備
「.ssh」ディレクトリに移動する
以下のコマンドを実行し、「.ssh」ディレクトリに移動する。
cd ~/.ssh/ssh接続
以下のコマンドを実行し、EC2インスタンスにsshでアクセスする。
(ダウンロードしたpemファイル名が「xxx.pem」、ElasticIPが123.456.789の場合)ssh -i xxx.pem ec2-user@123.456.789GithubにSSH鍵を登録する
EC2インスタンスからGithubにアクセスするために、EC2インスタンスのSSH公開鍵をGithubに登録する必要がある。
SSH鍵を登録しないとpermission errorとなりクローンできない。SSH鍵をGithubに登録することで認証されるようになりコードのクローンが可能になる。以下のコマンドを実行し、EC2サーバのSSH鍵ペアを作成する。
ssh-keygen -t rsa -b 4096以下のコマンドを実行し生成されたSSH公開鍵を表示し、値をコピーする。
cat ~/.ssh/id_rsa.pub以下のURLにアクセスすると画像のような画面に遷移する。
https://github.com/settings/keys
「Title」欄に任意のタイトルを記入、「Key」欄に先ほどコピーしたSSH公開鍵をペーストし、「Add SSH key」をクリックする。
以下のコマンドを実行しSSH接続できるか確認する。
ssh -T git@github.comPermission denied (publickey).と表示された場合にはSSH鍵の設定が間違っている。
「ssh-keygen」コマンドのオプションについて
「ssh-keygen」コマンドは公開鍵認証方式の秘密鍵と公開鍵を作成するコマンドである。
「-t」は作成する鍵の暗号化形式を「rsa」「dsa」「ecdsa」「ed25519」から指定するオプションである。
「-b」は作成する鍵のビット数を指定するコマンドである。
つまり上記のコマンドはRSA暗号化形式で4096ビットの鍵を生成するという意味である。アプリケーションサーバの設定
アプリケーションサーバとはブラウザからリクエストを受けてアプリケーションを動作させるソフトウェアである。
例えばローカル環境でRuby on Railsのアプリケーションの動作を確認する時、「rails s」というコマンドを入力する。これにより「puma」というアプリケーションサーバが起動する。
この状態でブラウザから「localhost:3000」にアクセスすることでrailsアプリケーションの動作確認を行うことができる。(localhost:3000は自身のPCを指す)同様に、EC2サーバ上でアプリケーションを動作させるためには、EC2サーバ上でアプリケーションサーバを起動する必要がある。
Unicornをインストールする
よく利用されるアプリケーションサーバの一つに、Unicornがある。Unicornは「rails s」コマンドの代わりに「unicorn_rails」コマンドで起動できる。
UnicornはRubyで作成されており、gem化されている。
Gemfileに以下の記述を追記する。
Unicornは本番環境のみで使用するので開発環境では不要。Gemfilegroup :production do gem 'unicorn', '5.4.1' endアプリケーションのディレクトリで以下のコマンドを実行する。
bundle installconfigディレクトリ直下に下記のようなUnicornの設定ファイルを作成する。
config/unicorn.rb#サーバ上でのアプリケーションコードが設置されているディレクトリを変数に入れておく app_path = File.expand_path('../../', __FILE__) #アプリケーションサーバの性能を決定する worker_processes 1 #アプリケーションの設置されているディレクトリを指定 working_directory app_path #Unicornの起動に必要なファイルの設置場所を指定 pid "#{app_path}/tmp/pids/unicorn.pid" #ポート番号を指定 listen 3000 #エラーのログを記録するファイルを指定 stderr_path "#{app_path}/log/unicorn.stderr.log" #通常のログを記録するファイルを指定 stdout_path "#{app_path}/log/unicorn.stdout.log" #Railsアプリケーションの応答を待つ上限時間を設定 timeout 60 preload_app true GC.respond_to?(:copy_on_write_friendly=) && GC.copy_on_write_friendly = true check_client_connection false run_once = true before_fork do |server, worker| defined?(ActiveRecord::Base) && ActiveRecord::Base.connection.disconnect! if run_once run_once = false # prevent from firing again end old_pid = "#{server.config[:pid]}.oldbin" if File.exist?(old_pid) && server.pid != old_pid begin sig = (worker.nr + 1) >= server.worker_processes ? :QUIT : :TTOU Process.kill(sig, File.read(old_pid).to_i) rescue Errno::ENOENT, Errno::ESRCH => e logger.error e end end end after_fork do |_server, _worker| defined?(ActiveRecord::Base) && ActiveRecord::Base.establish_connection endプロセスとは
プロセスとはPC(サーバ)上で動く全てのプログラムの実行時の単位のことを指す。ここでいうプログラムとはブラウザや音楽再生ソフト、ExcelなどのGUIやRubyなどのスクリプト言語の実行などが含まれる。プログラムが動いている数だけプロセスが存在する。
workerとは
Unicornはプロセスを分裂させることができる。分裂したプロセスをworkerと呼ぶ。プロセスを分裂させることでリクエストに対するレスポンスを高速にすることができる。worker_processesという項目でworkerの数を設定する。
ブラウザなどからリクエストが来るとUnicornのworkerがrailsアプリケーションを動かす。railsはリクエストの内容とルーティングを照らし合わせ最終的に適切なViewまたはjsonをレスポンスする。レスポンスを受け取ったUnicornはそれをブラウザに返す。この一連の流れは0.1〜0.5秒程度で行われる。常にそれ以上のスピードでリクエストが頻発するようなアプリケーションだと一つのworkerだけでは処理が追いつかずレスポンスまで長い時間がかかってしまったり、サーバが止まってしまうことがある。worker_processesの数を増やすことでアプリケーションのレスポンスを早くすることができる。Unicornの設定
設定項目 詳細 worker_processes リクエストを受付レスポンスを生成するworkerの数を決める working_directory Unicornがrailsのコードを動かす際、ルーティングなど実際に参照するファイルを探すディレクトリを指定する。 pid Unicornが起動する際にプロセスidが書かれたファイルを生成する場所を指定する。 listen どのポート番号のリクエストを受け付けるかを指定する。 Uglifierについての記述をコメントアウトする
UglifierというJavascriptを軽量化するためのgemがある。
Javascriptでテンプレートリテラル記法(`)を利用している場合、Uglifierはこれに対応していないのでデプロイ時にエラーの原因となるためコメントアウトする。config/environments/production.rbの以下の記述をコメントアウトする。
config/environments/production.rb# config.assets.js_compressor = :uglifier変更修正をリモートリポジトリに反映する
ファイルをコミットし、Githubにプッシュする。
ブランチを切っている場合にはmasterブランチにマージする。Githubからコードをクローンする
Unicornの設定を済ませたコードをEC2インスタンスにクローンする。
/var/wwwディレクトリを作成する
EC2インスタンスにSSH接続した後、以下のコマンドを実行し、/var/wwwディレクトリを作成する。
sudo mkdir /var/www/権限をec2-userに変更する
以下のコマンドを実行し、作成したwwwディレクトリの権限をec2-userに変更する。
sudo chown ec2-user /var/www/GithubからリポジトリURLを取得する
Githubのアプリケーションのページに移動し、以下の画像を参考にリポジトリURLをコピーする。
コードをクローンする
以下のコマンドを実行してコードをクローンする。
(以下の例はGithubのuser名が「test1234」、リポジトリ名が「testapp」の場合)cd /var/www/git clone https://github.com/test1234/testapp.git(先ほどコピーしたリポジトリURL)本番環境の設定
サービスを公開するための設定を行っていく。
EC2の能力を拡張する
現状のEC2インスタンスはメモリが足りず、gemのインストール時などにエラーが発生する可能性がある。
そこでまずはメモリを増強する。Swap領域を用意する
コンピュータが処理を行う際、メモリと呼ばれる場所に処理内容が一時的に記録される。メモリは容量が決まっておりそれを超えてしまうとエラーで処理が止まってしまう。Swap領域はメモリが使い切られそうになった時にメモリの容量を一時的に増やすために準備されるファイルである。
EC2はデフォルトではSwap領域が用意されていないため、これを用意することでメモリ不足のエラーを防ぐ。EC2インスタンスにSSH接続し、ホームディレクトリに移動する。
cd以下のコマンドを順に実行していき、Swap領域を確保する。
sudo dd if=/dev/zero of=/swapfile1 bs=1M count=512sudo chmod 600 /swapfile1sudo mkswap /swapfile1sudo swapon /swapfile1sudo sh -c 'echo "/swapfile1 none swap sw 0 0" >> /etc/fstab'gemをインストールする
クローンしたアプリケーションを起動するために必要なgemをインストールする。
以下のコマンドを実行し、クローンしたアプリケーションのディレクトリに移動する。
cd /var/www/testapp以下のコマンドを実行し、rbenvでインストールしたRubyのバージョンが使用されているかチェックする。
ruby -v本番環境でgemを管理するためのbundlerをインストールする
ローカル環境で以下のコマンドを実行し、開発環境で使用しているbundlerのバージョンを確認する。
bundler -v開発環境によってバージョンは異なるが、今回は2.0.1であったとする。
同じバージョンのものを本番環境にも導入するために、再度EC2インスタンスにSSH接続し、下記のコマンドを実行する。gem install bundler -v 2.0.1(ローカル環境と同じバージョン)bundle install環境変数の設定をする
データベースのパスワードなどセキュリティのためにGithubにアップロードできない情報は環境変数を利用して設定する。
環境変数はrailsでは「ENV['<環境変数名>']」という記述でその値を利用することができる。secret_key_baseを作成する
secret_key_baseとは、Cookieの暗号化に用いられる文字列である。railsアプリケーションを動作させる際は必ず用意する必要がある。外部に漏らしてはいけない値なので環境変数から参照する。
下記のコマンドを実行し、secret_key_baseを作成する。
コマンドを実行すると長い文字列が生成されるのでこれをコピーしておく。rake secretEC2インスタンスに環境変数を設定する
環境変数は/etc/environmentというファイルに保存することでサーバ全体に適用される。環境変数の書き込みはvimコマンドを用いて行う。
下記のコマンドを実行し/etc/enrvironmentを編集する。
sudo vim /etc/environment/etc/environmentを以下のように編集する。
/etc/environmentDATABASE_PASSWORD='<MySQLのrootユーザのパスワード>' SECRET_KEY_BASE='<先ほどコピーしたsecret_key_base>'編集し保存したら下記のコマンドを実行し、一度ログアウトする。
exit再度EC2インスタンスにSSH接続する。
下記のコマンドを実行し、環境変数が適用されているか確認する。env | grep DATABASE_PASSWORDenv | grep SECRET_KEY_BASEポートを解放する
立ち上げたばかりのEC2インスタンスはSSHでアクセスすることはできるがHTTPなどのその他の通信方法では一切接続できないようになっている。そのため、WEBサーバとして利用するEC2インスタンスは事前にHTTPがつながるようにポートを開放しておく必要がある。
ポートの設定をするためにはEC2のセキュリティグループという設定を変更する必要がある。
セキュリティグループとはEC2サーバが属するまとまりのようなもので、複数のEC2インスタンスのネットワーク設定を一括で行うためのものである。AWSにログインし、EC2インスタンス一覧画面から対象のインスタンスを選択し、セキュリティグループのリンクをクリックする。
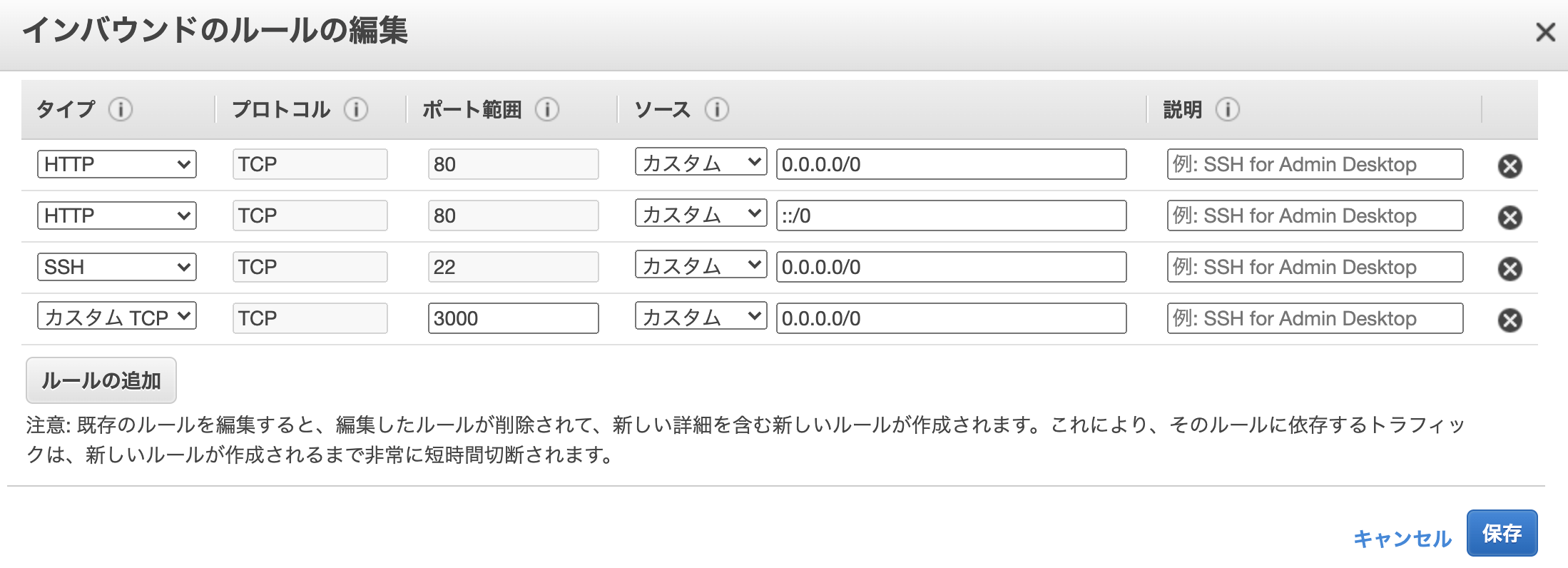
セキュリティグループの設定画面に遷移するのでインバウンドタブの編集をクリックする。
インバウンドのルールの編集ポップアップ画面が表示されたら、ルールの追加をクリックし、タイプを「カスタムTCPルール」、プロトコルを「TCP」、ポート範囲を「3000」、送信元を「カスタム」・「0.0.0.0/0」に設定する。
本番環境でrailsを起動する
本番環境でrailsを起動する前に、現状、開発環境と本番環境でMySQLの設定が異なるため、開発環境のMySQLの設定を本番環境に合わせる。
開発環境のconfig/database.ymlを以下のように編集し、コミット、Githubにプッシュする。
config/database.ymlproduction: <<: *default database: ~~~(それぞれのアプリケーション名によって異なるのでこれは編集しない) username: root password: <%= ENV['DATABASE_PASSWORD'] %> socket: /var/lib/mysql/mysql.sockEC2インスタンスにSSH接続し、下記のコマンドを実行する。
git pull origin master以下のコマンドを実行し、アプリケーションのディレクトリに移動する。
cd /var/www/testapp以下のコマンドを実行し、データベースを作成する。
rails db:create RAILS_ENV=production以下のコマンドを実行し、マイグレーションを実行する。
rails db:migrate RAILS_ENV=productionもしここでMysql2::Error: Can't connect to local MySQL server through socketというエラーが発生した場合にはMySQLが起動していない可能性があるため、以下のコマンドを実行し、MySQLの起動を行う。
sudo service mysqld start以下のコマンドを実行し本番環境でunicornを起動する。
「-c config/unicorn.rb」は設定ファイルの指定、「-E production」は本番環境で操作させることを意味する。
「-D」はDaemonの略で、プログラムを起動させつつターミナルで別のコマンドを打てるようにするコマンドである。bundle exec unicorn_rails -c config/unicorn.rb -E production -Dここで、ブラウザで http://123.456.789:3000/ にアクセスしてみる。(Elastic IPが123.456.789の場合)
cssが反映されていない画面が表示されていれば成功。アセットファイルをコンパイルする
開発環境ではアクセスごとにアセットファイル(image、css、javascript)を自動でコンパイルする仕組みが備わっているが、本番環境ではパフォーマンスのためアクセスごとに実行されないようになっている。
よって、本番環境では事前にアセットをコンパイルする必要がある。
以下のコマンドを実行し、アセットをコンパイルする。rails assets:precompile RAILS_ENV=productionコンパイルが成功したら反映を確認するためrailsを再起動する。
まず、ターミナルからUnicornのプロセスを確認しプロセスをkillする。以下のコマンドを実行しUnicornのコマンドを確認する。
psコマンドは現在動作しているプロセスを確認するためのコマンドで、auxはpsコマンドの表示結果を見やすくするオプションである。
| grep unicornとすることでpsコマンドの結果からunicorn関連のプロセスのみを抽出している。ps aux | grep unicorn表示結果からunicorn_rails masterのPIDを確認する。ここでは例として「17877」だったとする。
以下のコマンドを実行しUnicornのプロセスを停止する。
kill 17877下記のコマンドを実行し、再度Unicornを起動する。このときRAILS_SERVE_STATIC_FILES=1を先頭に付ける。これによりコンパイルされたアセットをUnicornが見つけられるようになる。
RAILS_SERVE_STATIC_FILES=1 unicorn_rails -c config/unicorn.rb -E production -D再度ブラウザで http://123.456.789:3000/ にアクセスしてみる。(Elastic IPが123.456.789の場合)
今度はcssが反映された状態で画面が表示されるはず。railsの起動がうまくいかない時に確認すること
- プッシュのし忘れ、EC2サーバのプルのし忘れ
- EC2サーバ側で/var/www/testapp/log/unicorn.stderr.logを確認しエラーが出ていないか確認する
- MySQLの起動は正しく行えているか
- SECRET_KEY_BASE等が正しく設定できているか
- EC2インスタンスの再起動を行ってみる
参考

- 投稿日:2020-09-10T21:53:32+09:00
Ruby on Rails でsimple_calendar実装するまでの流れをまとめました。
オリジナルアプリケーションでカレンダーを使った予約時間設定機能を実装したいと思いその流れをまとめました。
ruby '2.6.5'
rails '6.0.0'
simple_calendar "~> 2.0"
前提条件としてuserとdoctorでそれぞれ別のdeviseを作っています。
以下関連URLです。
複数のdeviseを作成して、別々のログイン画面を作る際のファイル作成からルーティング設定
複数のdeviseでログイン後、新規登録後のパスを変更したい。やりたい事
このようなカレンダー機能をuserとdoctor(それぞれ別のdevise)で出来る機能をそれぞれ作成します。
予約作成、予約時間編集、削除 → doctorが出来る機能
予約をする → userが出来る機能① Gemfileに 以下の記述し bundle install します。
gem "simple_calendar", "~> 2.0"② rails s 再起動します。
③ modelを作成します。今回は予約機能なのでreservationモデルを作成します。
% rails g model reservation④ マイグレーションファイルを作成します。
class CreateReservations < ActiveRecord::Migration[6.0] def change create_table :reservations do |t| t.references :doctor, foreign_key:true t.references :user, foreign_key:true t.datetime :start_time t.datetime :end_time t.timestamps end end end⑤モデルファイルにアソシエーションを組みます。userモデルdoctorモデルにも書きます(割愛)
class Reservation < ApplicationRecord belongs_to :doctor belongs_to :user, optional: true validates :start_time, presence: true validates :end_time, presence: true endoptional: trueは 外部キーのnilを許可するので記述します。新規予約作成時はuser_idはない状態だからです。予約はdoctorが作成するのでdoctor_idは必ずあります。
rails db;migrateを実行させます。
% rails db:migrate⑥ 次にコントローラーが必要ですが注意点があります。
userが出来る機能とdoctorが出来る機能が違いますし、セキュリティーの問題でuserとdoctorが同じコントローラーを通るのはおかしいです。なのでそれぞれ別のディレクトリ配下にあるコントローラーを作成します。
% rails g controller doctors/reservations% rails g controller users/reservations⑦ このようにすることによりuserが通るコントローラーとdoctorが通るコントローラーを分けれます。
⑧ ルーティングの設定します。それぞれのdeviseで指定のパスにしたいのでnamespaceを使います。
namespace :doctors do resources :reservations end namespace :users do resources :reservations endrails routesをするとそれぞれのルーティングが作成できているのが確認できます。
DELETE /users/:id(.:format) users#destroy doctors_reservations GET /doctors/reservations(.:format) doctors/reservations#index POST /doctors/reservations(.:format) doctors/reservations#create new_doctors_reservation GET /doctors/reservations/new(.:format) doctors/reservations#new edit_doctors_reservation GET /doctors/reservations/:id/edit(.:format) doctors/reservations#edit doctors_reservation GET /doctors/reservations/:id(.:format) doctors/reservations#show PATCH /doctors/reservations/:id(.:format) doctors/reservations#update PUT /doctors/reservations/:id(.:format) doctors/reservations#update DELETE /doctors/reservations/:id(.:format) doctors/reservations#destroy users_reservations GET /users/reservations(.:format) users/reservations#index POST /users/reservations(.:format) users/reservations#create new_users_reservation GET /users/reservations/new(.:format) users/reservations#new edit_users_reservation GET /users/reservations/:id/edit(.:format) users/reservations#edit users_reservation GET /users/reservations/:id(.:format) users/reservations#show PATCH /users/reservations/:id(.:format) users/reservations#update PUT /users/reservations/:id(.:format) users/reservations#update DELETE /users/reservations/:id(.:format) users/reservations#destroy⑨ 必要なビューを作成します。
doctorのshow画面に表示します。
doctorは doctorのshow画面でreservationの新規作成画面、編集画面、削除画面に遷移するリンクを作り、userはdoctorのshow画面で予約をする画面に遷移するリンクを作ります。まずはカレンダーをはめ込みます。
<%= month_calendar do |date| %> <%= date.day %> <% end %>これでカレンダーの雛形作成完了です。
⑩ doctorコントローラーに予約作成、編集、削除のメソッドを定義し、userコントローラーでは予約決定をします。
ここでuserの予約決定にはどのメソッドを使うかですが、結論から言うとeditです。
予約一覧の時点でreservationテーブルにはデータが入っているので、user_idを追加することはレコードの1つを追加すると考えです。doctors/reservations_controller.rbdef new @reservation = Reservation.new end def create @reservation = Reservation.new(reservation_params) if @reservation.save redirect_to doctor_path(current_doctor.id) else render :new end end def edit @reservation = Reservation.find(params[:id]) end def update @reservation = Reservation.find(params[:id]) if @reservation.update(reservation_params) redirect_to doctor_path(current_doctor.id) else render :edit end end def destroy @reservation = Reservation.find(params[:id]) if @reservation.destroy redirect_to doctor_path(current_doctor.id) else render :show end end private def reservation_params params.require(:reservation).permit(:start_time, :end_time).merge(doctor_id: current_doctor.id) end endusers/reservations_controller.rbdef edit @reservation = Reservation.find(params[:id]) @doctor = Doctor.find(params[:id]) end def update @reservation = Reservation.find(params[:id]) if @reservation.update(user_id: current_user.id) redirect_to doctor_path(@reservation.doctor_id) else render :edit end endビューの表示はまだ細かく設定が必要ですが、これで最低限のカレンダー予約機能を設定できます。
また追記していきます。
このようにしてsimple_calendarを導入しました。ご指摘等あればぜひお聞かせください!!



- 投稿日:2020-09-10T19:55:57+09:00
Railsアプリを独自ドメインでssl公開した手順
概要
今回そこそこ苦戦しながらポートフォリオのSSL対応したので忘れないうちに手順を書き留めておく。
殴り書き程度なのでこれを読んでSSL対応は難しいと思われます。前提
- EC2にRailsアプリをデプロイ済
- Nginx等のWebサーバーでhttpで外部公開している
- 独自ドメインを取得している。
- VPCなどで適切なネットワークを構築済
- httpですでにアプリケーションにアクセスできる
本題
1.
ACMでSSL証明書のリクエストを行う。
ここでリクエストするドメイン名が公開するドメイン名と違うとSSL化しないので注意リクエストするドメインがRoute53でレコード作成済だとCレコードの登録を勝手にやってくれるボタンが出るので便利
ex)
実際のサイトのドメイン www.hogehoge.com
証明書申請したドメイン hogehoge.com上の例だとドメインが違うためアウト
おすすめはサブドメインにワイルドカードを指定して *.hogehoge.com
とすること
こうすることでwww.hogehoge.comやunko.hogehoge.comなど様々なサブドメインに対応できる。2.
EC2のELB(ロードバランサー)を設定する。
- リスナー: https
- ターゲット: EC2のインスタンス(http)
- VPCとサブネット: 設定しているやつを入れとく
- 証明書: 1で申請した証明書を入れる。
3.
心配な場合はロードバランサーのDNSにアクセスしてアプリケーションが開けるかどうか確認4.
Route53でロードバランサーへのエイリアスを貼る
www.hogehoge.comとかでロードバランサーにアクセスするようAレコード(エイリアス)を作成する5.終わり
補足
・ELBの作成や証明書の認証などこの辺りはやたらと処理に時間がかかる模様で、設定はできてるのにうまく動かないとやたら焦ることもあるが気長に待つとなんかうまくいったりするので待ちの姿勢も重要。
・今回のSSL対応はあくまで外部とロードバランサーとの間をSSL化しているため、アプリケーションとロードバランサー間はhttp通信である。よってEC2側のWebサーバーの設定はhttpのままで一切いじる必要なし。ここを勘違いすると沼る
・当たり前っちゃ当たり前だけどロードバランサーにアタッチするセキュリティグループではインバウンドルールで443ポート(https)を許可していないと弾かれてアクセスできない。
ここらへんのセキュリティグループの設定もうまくいかなかったら見直す。・うまくいかなかったらぐぐる。
最後に
本当に殴り書きなので間違ってたりおかしかったりするところがあれば連絡ください?
また、同じような境遇の方がいてもし詳しく聞きたいことがあればできる限りお答えします
こちらのTwitterアカウントのDMやリプで連絡ください
https://twitter.com/TakeWeb1
- 投稿日:2020-09-10T17:33:39+09:00
Ruby on Rails × DockerでRspecを導入
目標
- rails × docker 環境でrspecを導入したい
前提
- Docker on mac
- Ruby on Rails
手順
1.Gemfileにgemを追加する
以下のgemを:develop, :testに追加する
gem "rspec-rails"
gem "factory_bot_rails"Gemfilegroup :development, :test do # Call 'byebug' anywhere in the code to stop execution and get a debugger console gem 'byebug', platforms: [:mri, :mingw, :x64_mingw] # テストフレームワーク gem "rspec-rails" gem "factory_bot_rails" end2.サーバーとは別のターミナルからrspecをインストールする
MacBook-Air アプリ名 % docker-compose run web rails g rspec:install Starting アプリ名_db_1 ... done Running via Spring preloader in process 64 create .rspec create spec create spec/spec_helper.rb create spec/rails_helper.rbこれで設定ファイルがディレクトリに作られる
さっそくテストを作成してみる
modelのspecを追加してみる
まずディレクトリを生成する。modelは自身がすでに生成したmodel.
MacBook-Air アプリ名 % docker-compose run web rails g rspec:model reception Starting アプリ名_db_1 ... done Running via Spring preloader in process 64 create spec/models/reception_spec.rb invoke factory_bot create spec/factories/receptions.rb生成できたら今回はバリデーションに関するテストを書く
spec/factories/reception.rbFactoryBot.define do factory :reception do name {"サンプル訪問者1"} purpose {"面談"} organization {"サンプル株式会社"} end endspec/models/reception_spec.rbRSpec.describe Reception, type: :model do reception = FactoryBot.create(:reception) it 'receptionインスタンスが有効' do expect(reception).to be_valid end endspecを追記したら、
MacBook-Air アプリ名 % docker-compose run web bundle exec rspecで実行完了
MacBook-Air アプリ名 % docker-compose run web bundle exec rspec Starting アプリ名_db_1 ... done . Finished in 0.22889 seconds (files took 6.32 seconds to load) 1 example, 0 failures参考文献
- 投稿日:2020-09-10T14:34:06+09:00
renderのcollectionオプションを使った繰り返し処理の省略
動作環境
Ruby 2.6.5
Rails 6.0.3.2collectionを使うことでrenderで呼び出した部分テンプレートを繰り返し処理する場合は、省略して記述できることを学んだので、投稿してみました。
collectionを使わない場合
index.html.erb<% @hoges.each do |hoge| %> <%= render partial: "huga", locals: {hoge: hoge} %> <% end %>上記のコードは、部分テンプレートhugaを呼び出し、その中でhogeという変数を渡して繰り返し処理を行うというコードです。
これをcollectionを使うとどうなるのかを見てみましょう。collectionを使う場合
index.html.erb<%= render partial: "huga", collection: @hoges %>こちらのコードは先ほどのコードと全く同じ意味を持ちます。3行のコードが1行で済むので、非常に楽に記述できることがわかると思います。
注意していただきたいのが、部分テンプレートhugaで@hogeや@hogesと記述してしまうとエラーが発生してしまうことです。collectionの後の@hogesはコントローラーから受け取っているインスタンス変数です。実際に、部分テンプレートに渡している変数は先ほどのコードと同じhogeですので気をつけてください。急にrenderのオプションでcollectionが出てきて、私は混乱してしまったことがあるので、この記事が少しでも役に立てればと思います。
- 投稿日:2020-09-10T14:17:43+09:00
【Rails】【Docker】コピペでOK! DockerでRails開発環境を構築する方法
【Rails】【Docker】コピペでOK! DockerでRails開発環境を構築する方法
目次
構築イメージ
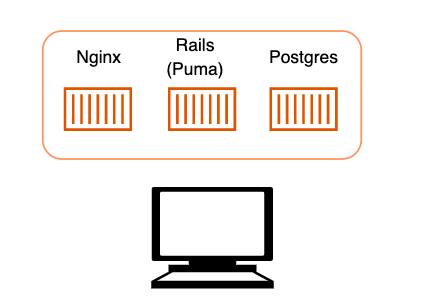
今回は3つのコンテナを作成します.
動作環境・前提条件
【動作環境】
OS : macOS 10.14.6
Docker : 19.03.8
ruby : 2.6.5
rails : 5.2.4【前提条件】
Docker for Macをインストール済みSTEP1. Dockerfileを作成する
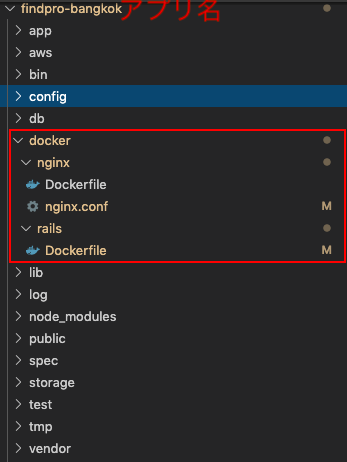
まずはDockerフォルダと空ファイルを作成します.
ファイルの内容は後述します.
STEP1-1. nginxのDockerfile
以下がnginxのdockerfileになります.
findpro-bangkokはアプリ名なので各自のアプリ名に変更してください.DockerfileFROM nginx:1.15.8 # インクルード用のディレクトリ内を削除 RUN rm -f /etc/nginx/conf.d/* # Nginxの設定ファイルをコンテナにコピー COPY /docker/nginx/nginx.conf /etc/nginx/conf.d/findpro-bangkok.conf # 画像などのpublicファイルはnginxに配置 RUN mkdir -p /findpro-bangkok/public COPY ./public /findpro-bangkok/public # ビルド完了後にNginxを起動 CMD /usr/sbin/nginx -g 'daemon off;' -c /etc/nginx/nginx.confSTEP1-2. nginxの設定ファイル
nginxの設定を記述するnginx.confを作成します.
nginx.conf# プロキシ先の指定 # Nginxが受け取ったリクエストをバックエンドのpumaに送信 upstream puma { # ソケット通信したいのでpuma.sockを指定 server unix:///findpro-bangkok/tmp/sockets/puma.sock; } server { listen 80 default; # ドメインもしくはIPを指定 server_name localhost; access_log /var/log/nginx/access.log; error_log /var/log/nginx/error.log; # ドキュメントルートの指定 root /findpro-bangkok/public; client_max_body_size 100m; error_page 404 /404.html; error_page 505 502 503 504 /500.html; try_files $uri/index.html $uri @puma; keepalive_timeout 5; # リバースプロキシ関連の設定 location @puma { proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; proxy_pass http://puma; } }STEP1-3. railsのDockerfile
次にrailsのDockerfileを作成します.
DockerfileFROM ruby:2.6.5 RUN apt-get update -qq && \ apt-get install -y apt-utils \ build-essential \ libpq-dev \ nodejs \ vim #各自のアプリ名に変更する ENV RAILS_ROOT /findpro-bangkok RUN mkdir $RAILS_ROOT WORKDIR $RAILS_ROOT COPY Gemfile Gemfile COPY Gemfile.lock Gemfile.lock RUN gem install bundler:2.1.4 RUN bundle install #プロジェクトフォルダ内のすべてのファイルをRailsコンテナ内にコピーする COPY . . #ソケット通信のためのディレクトリを作成 RUN mkdir -p tmp/socketsSTEP2. pumaの設定
以下のconfigフォルダ内のpumaの設定ファイルを編集します.
*pumaフォルダは本番用のフォルダのため今回は青のpuma.rbを編集します.
puma.rbthreads_count = ENV.fetch('RAILS_MAX_THREADS') { 5 }.to_i threads threads_count, threads_count port ENV.fetch('PORT') { 3000 } environment ENV.fetch('RAILS_ENV') { 'development' } plugin :tmp_restart app_root = File.expand_path('..', __dir__) bind "unix://#{app_root}/tmp/sockets/puma.sock" stdout_redirect "#{app_root}/log/puma.stdout.log", "#{app_root}/log/puma.stderr.log", trueSTEP3. docker-composeの作成
docker-composeは複数のコンテナのビルドをまとめて実行してくれる仕組みになります.
docker-composeファイルをプロジェクトフォルダ直下に作成します.
docker-compose.ymlversion: '3' volumes: tmp_data: public_data: services: nginx: build: context: ./ dockerfile: ./docker/nginx/Dockerfile ports: - '80:80' volumes: - public_data:/findpro-bangkok/public - tmp_data:/findpro-bangkok/tmp/sockets depends_on: - app links: - app app: build: context: ./ dockerfile: ./docker/rails/Dockerfile command: bundle exec puma volumes: #.:/findpro-bangkokでプロジェクトのカレントフォルダとコンテナのフォルダを同期しています.これによって変更した箇所を再度ビルドすることなく、コンテナに反映することができます. - .:/findpro-bangkok:cached #nginxとsocket通信するためにホストコンピュータ上にtmp_dataというファイルを作成し、nginxコンテナと共有しています. - tmp_data:/findpro-bangkok/tmp/sockets - public_data:/findpro-bangkok/public tty: true stdin_open: true db: image: postgres volumes: - ./tmp/db:/var/lib/postgresql/data environment: POSTGRES_PASSWORD: 'postgres'STEP4. データベースの設定
最後にdatabase.ymlでデータベースの設定をします.
今回はdevelopement環境のため、developmentまでの設定内容を記載します.
*testやproductionの記述が下のほうにあるので、そちらは消さずにそのままにしておきます.
# PostgreSQL. Versions 9.1 and up are supported. # # Install the pg driver: # gem install pg # On OS X with Homebrew: # gem install pg -- --with-pg-config=/usr/local/bin/pg_config # On OS X with MacPorts: # gem install pg -- --with-pg-config=/opt/local/lib/postgresql84/bin/pg_config # On Windows: # gem install pg # Choose the win32 build. # Install PostgreSQL and put its /bin directory on your path. # # Configure Using Gemfile # gem 'pg' # default: &default adapter: postgresql encoding: unicode host: db port: 5432 username: postgres password: postgres pool: 5 # For details on connection pooling, see Rails configuration guide # http://guides.rubyonrails.org/configuring.html#database-pooling pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %> development: <<: *default database: findpro-bangkok_development ###以下省略STEP5. コンテナのビルド
それではいよいよ作成したコンテナを起動します.
まずはターミナルでプロジェクトフォルダに移動し、以下のコマンドを実行します.
[JS-MAC findpro-bangkok]$ docker-compose buildビルドが成功したあとに以下のコマンドを実行します.
[JS-MAC findpro-bangkok]$ docker-compose upSTEP6. データベースの作成
最後にデータベースを作成する必要があるので
もう一つ新規にターミナルを起動し、Railsコンテナに入ります。[@JS-MAC findpro-bangkok]$ docker ps #Railsコンテナ(findpro-bangkok_app)のIDを確認 CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 4549423f21ed findpro-bangkok_nginx "/bin/sh -c '/usr/sb…" 44 minutes ago Up 3 seconds 0.0.0.0:80->80/tcp findpro-bangkok_nginx_1 22ecc47308ae findpro-bangkok_app "bundle exec puma" 44 minutes ago Up 5 seconds findpro-bangkok_app_1 755cb83a9bf4 postgres "docker-entrypoint.s…" 44 minutes ago Up 5 seconds 5432/tcp findpro-bangkok_db_1 [@JS-MAC findpro-bangkok]$ docker exec -it 22e /bin/sh #Railsコンテナにログインする.22eはappコンテナのIDの頭文字です. # rails db:create #データベースを作成する. Database 'findpro-bangkok_development' already exists Database 'findpro-bangkok_test' already exists # rails db:migrate #マイグレーションを実行する.STEP7. 確認
最後にchromeでlocalhostと打ち確認します.
- 投稿日:2020-09-10T13:07:17+09:00
【Appleサブスクリプションオファー】プロモーションオファー署名の作成方法
tl;dr
Appleのサブスクリプションオファーのプロモーションオファーに関しての情報がなかった。
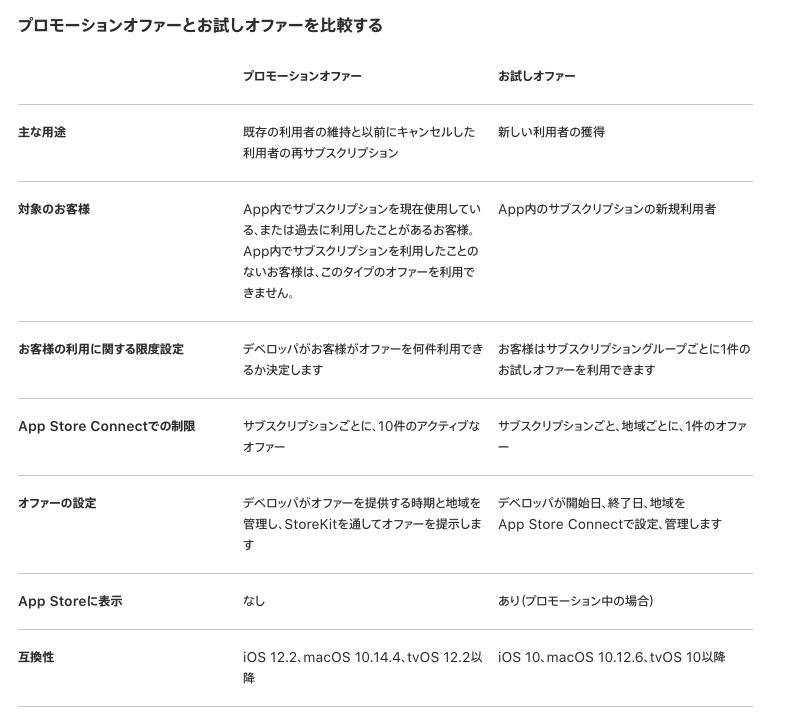
これが、日本初の資料。プロモーションオファーとは
WWDC 2019動画
https://developer.apple.com/videos/play/wwdc2019/305
Apple公式ドキュメント
https://developer.apple.com/jp/app-store/subscriptions/#subscription-offers
対象となるのは、そのサブスクリプションを現在利用している、または過去に利用したことがあるお客様です。
これらのオファーによって、ユーザー数の拡大や維持のため、
独自のプロモーションを柔軟に行うことができるようになります。
キャンペーンを通じて、サブスクリプションをキャンセルした利用者に再サブスクリプションを促したり、
別のサブスクリプションへのアップグレードを特別価格で提供したりすることができます。準備
Apple公式ドキュメント
サブスクリプションオファーの設定
実装
※今回は、サーバーサイドでの署名作成に関してのみ記載する
Apple公式ドキュメント
プロモーションオファー用の署名の生成
https://developer.apple.com/jp/documentation/storekit/in-app_purchase/generating_a_signature_for_subscription_offers/署名の生成に必要なもの
■appBundleID
環境変数で持つ
■keyIdentifier
環境変数で持つ
■productIdentifier
アプリ側からパラメータでもらう
■offerIdentifier
アプリ側からパラメータでもらう
■applicationUsername
アプリ側からパラメータでもらう
■nonce
サーバー側で生成する
■timestamp
サーバー側で生成する
署名
署名の生成
サンプルコード
本来はメソッドで分割するが、わかりやすさを重視するrequire 'openssl' require 'base64' require 'securerandom' require 'json' # 環境変数として読み込むが、あえて記載する private_key = '-----BEGIN PRIVATE KEY-----xxxxxxxxxxxxxxxxxxx-----END PRIVATE KEY-----' # 環境変数から読み込んだ秘密鍵の改行コードがエスケープされてしまうのを防ぐ private_key = OpenSSL::PKey::EC.new(private_key.gsub(/\\n/, "\n"))) app_bundle_id = 'xxxx' key_identifier = 'xxxx' product_identifier = 'xxxx' offer_identifier = 'xxxx' application_username = 'xxxx' nonce = SecureRandom.uuid timestamp = (Time.current.to_f * 1000).to_i.to_s # 不可視の分離文字('\u2063')をパラメータの間にはさみ、結合する payload = app_bundle_id + "\u{2063}" + key_identifier + "\u{2063}" + product_identifier + "\u{2063}" + offer_identifier + "\u{2063}" + application_username + "\u{2063}" + nonce + "\u{2063}" + timestamp # 署名 # Ruby2.4.0以降であれば # signature = private_key.sign(digest, data) # SHA-256ハッシュを使って署名 signature = private_key.dsa_sign_asn1(OpenSSL::Digest::SHA256.digest(payload)) # base64にエンコード # strict_encode64を使い、改行コードを消す signature_base64 = Base64.strict_encode64(signature) # 検証 # OpenSSL::PKey::ECオブジェクトを生成 ec = OpenSSL::PKey::EC.new(private_key.group) ec.public_key = private_key.public_key # SHA-256ハッシュで検証 digest = OpenSSL::Digest::SHA256.new # payloadを秘密鍵で署名したその署名文字列がsignatureであることを公開鍵を使って検証 ec.verify(digest, signature, payload) result = { key_identifier: key_identifier, nonce: nonce, timestamp: timestamp, signature: signature_base64 }.to_json楕円曲線デジタル署名アルゴリズム(ECDSA)について
最初はruby_ecdsaというgemを使おうかと検討していた
https://github.com/DavidEGrayson/ruby_ecdsarequire 'ecdsa' require 'securerandom' require 'digest/sha2' group = ECDSA::Group::Secp256k1 private_key = 1 + SecureRandom.random_number(group.order - 1) public_key = group.generator.multiply_by_scalar(private_key) message = 'ECDSA is cool.' digest = Digest::SHA2.digest(message) temp_key = 1 + SecureRandom.random_number(group.order - 1) signature = ECDSA.sign(group, private_key, digest, temp_key) valid = ECDSA.valid_signature?(public_key, digest, signature) puts "valid: #{valid}"が、秘密鍵が数値を想定したつくりになっていたので使用を見送った
Apple公式の署名作成サンプル
JavaScriptとNode.jsを使ったサンプル
サーバを起動して、アクセスするとレスポンスが返る


- 投稿日:2020-09-10T13:07:17+09:00
Appleのサブスクリプションオファーのプロモーションオファー署名作成
tl;dr
Appleのサブスクリプションオファーのプロモーションオファーに関しての情報がなかった。
これが、日本初の資料。プロモーションオファーとは
WWDC 2019動画
https://developer.apple.com/videos/play/wwdc2019/305
Apple公式ドキュメント
https://developer.apple.com/jp/app-store/subscriptions/#subscription-offers
対象となるのは、そのサブスクリプションを現在利用している、または過去に利用したことがあるお客様です。
これらのオファーによって、ユーザー数の拡大や維持のため、
独自のプロモーションを柔軟に行うことができるようになります。
キャンペーンを通じて、サブスクリプションをキャンセルした利用者に再サブスクリプションを促したり、
別のサブスクリプションへのアップグレードを特別価格で提供したりすることができます。準備
Apple公式ドキュメント
サブスクリプションオファーの設定
実装
※今回は、サーバーサイドでの署名作成に関してのみ記載します
Apple公式ドキュメント
プロモーションオファー用の署名の生成
https://developer.apple.com/jp/documentation/storekit/in-app_purchase/generating_a_signature_for_subscription_offers/署名の生成に必要なもの
■appBundleID
環境変数で持つ
■keyIdentifier
環境変数で持つ
■productIdentifier
アプリ側からパラメータでもらう
■offerIdentifier
アプリ側からパラメータでもらう
■applicationUsername
アプリ側からパラメータでもらう
■nonce
サーバー側で生成する
■timestamp
サーバー側で生成する
署名
署名の生成
サンプルコード
本来はメソッドで分割するが、わかりやすさを重視するrequire 'openssl' require 'base64' require 'securerandom' require 'json' # 環境変数として読み込むが、あえて記載する private_key = '-----BEGIN PRIVATE KEY-----xxxxxxxxxxxxxxxxxxx-----END PRIVATE KEY-----' # 環境変数から読み込んだ秘密鍵の改行コードがエスケープされてしまうのを防ぐ private_key = OpenSSL::PKey::EC.new(private_key.gsub(/\\n/, "\n"))) app_bundle_id = 'xxxx' key_identifier = 'xxxx' product_identifier = 'xxxx' offer_identifier = 'xxxx' application_username = 'xxxx' nonce = SecureRandom.uuid timestamp = (Time.current.to_f * 1000).to_i.to_s # 不可視の分離文字('\u2063')をパラメータの間にはさみ、結合する payload = app_bundle_id + "\u{2063}" + key_identifier + "\u{2063}" + product_identifier + "\u{2063}" + offer_identifier + "\u{2063}" + application_username + "\u{2063}" + nonce + "\u{2063}" + timestamp # 署名 # Ruby2.4.0以降であれば # signature = private_key.sign(digest, data) # SHA-256ハッシュを使って署名 signature = private_key.dsa_sign_asn1(OpenSSL::Digest::SHA256.digest(payload)) # base64にエンコード # strict_encode64を使い、改行コードを消す signature_base64 = Base64.strict_encode64(signature) # 検証 # OpenSSL::PKey::ECオブジェクトを生成 ec = OpenSSL::PKey::EC.new(private_key.group) ec.public_key = private_key.public_key # SHA-256ハッシュで検証 digest = OpenSSL::Digest::SHA256.new # payloadを秘密鍵で署名したその署名文字列がsignatureであることを公開鍵を使って検証 ec.verify(digest, signature, payload) result = { key_identifier: key_identifier, nonce: nonce, timestamp: timestamp, signature: signature_base64 }.to_json楕円曲線デジタル署名アルゴリズム(ECDSA)について
最初はruby_ecdsaというgemを使おうかと検討していた
https://github.com/DavidEGrayson/ruby_ecdsarequire 'ecdsa' require 'securerandom' require 'digest/sha2' group = ECDSA::Group::Secp256k1 private_key = 1 + SecureRandom.random_number(group.order - 1) public_key = group.generator.multiply_by_scalar(private_key) message = 'ECDSA is cool.' digest = Digest::SHA2.digest(message) temp_key = 1 + SecureRandom.random_number(group.order - 1) signature = ECDSA.sign(group, private_key, digest, temp_key) valid = ECDSA.valid_signature?(public_key, digest, signature) puts "valid: #{valid}"が、秘密鍵が数値を想定したつくりになっていたので使用を見送った
Apple公式の署名作成サンプル
JavaScriptとNode.jsを使ったサンプル
サーバを起動して、アクセスするとレスポンスが返ります
- 投稿日:2020-09-10T13:07:17+09:00
Appleのサブスクリプションオファーのプロモーションオファー署名の作成方法
tl;dr
Appleのサブスクリプションオファーのプロモーションオファーに関しての情報がなかった。
これが、日本初の資料。プロモーションオファーとは
WWDC 2019動画
https://developer.apple.com/videos/play/wwdc2019/305
Apple公式ドキュメント
https://developer.apple.com/jp/app-store/subscriptions/#subscription-offers
対象となるのは、そのサブスクリプションを現在利用している、または過去に利用したことがあるお客様です。
これらのオファーによって、ユーザー数の拡大や維持のため、
独自のプロモーションを柔軟に行うことができるようになります。
キャンペーンを通じて、サブスクリプションをキャンセルした利用者に再サブスクリプションを促したり、
別のサブスクリプションへのアップグレードを特別価格で提供したりすることができます。準備
Apple公式ドキュメント
サブスクリプションオファーの設定
実装
※今回は、サーバーサイドでの署名作成に関してのみ記載する
Apple公式ドキュメント
プロモーションオファー用の署名の生成
https://developer.apple.com/jp/documentation/storekit/in-app_purchase/generating_a_signature_for_subscription_offers/署名の生成に必要なもの
■appBundleID
環境変数で持つ
■keyIdentifier
環境変数で持つ
■productIdentifier
アプリ側からパラメータでもらう
■offerIdentifier
アプリ側からパラメータでもらう
■applicationUsername
アプリ側からパラメータでもらう
■nonce
サーバー側で生成する
■timestamp
サーバー側で生成する
署名
署名の生成
サンプルコード
本来はメソッドで分割するが、わかりやすさを重視するrequire 'openssl' require 'base64' require 'securerandom' require 'json' # 環境変数として読み込むが、あえて記載する private_key = '-----BEGIN PRIVATE KEY-----xxxxxxxxxxxxxxxxxxx-----END PRIVATE KEY-----' # 環境変数から読み込んだ秘密鍵の改行コードがエスケープされてしまうのを防ぐ private_key = OpenSSL::PKey::EC.new(private_key.gsub(/\\n/, "\n"))) app_bundle_id = 'xxxx' key_identifier = 'xxxx' product_identifier = 'xxxx' offer_identifier = 'xxxx' application_username = 'xxxx' nonce = SecureRandom.uuid timestamp = (Time.current.to_f * 1000).to_i.to_s # 不可視の分離文字('\u2063')をパラメータの間にはさみ、結合する payload = app_bundle_id + "\u{2063}" + key_identifier + "\u{2063}" + product_identifier + "\u{2063}" + offer_identifier + "\u{2063}" + application_username + "\u{2063}" + nonce + "\u{2063}" + timestamp # 署名 # Ruby2.4.0以降であれば # signature = private_key.sign(digest, data) # SHA-256ハッシュを使って署名 signature = private_key.dsa_sign_asn1(OpenSSL::Digest::SHA256.digest(payload)) # base64にエンコード # strict_encode64を使い、改行コードを消す signature_base64 = Base64.strict_encode64(signature) # 検証 # OpenSSL::PKey::ECオブジェクトを生成 ec = OpenSSL::PKey::EC.new(private_key.group) ec.public_key = private_key.public_key # SHA-256ハッシュで検証 digest = OpenSSL::Digest::SHA256.new # payloadを秘密鍵で署名したその署名文字列がsignatureであることを公開鍵を使って検証 ec.verify(digest, signature, payload) result = { key_identifier: key_identifier, nonce: nonce, timestamp: timestamp, signature: signature_base64 }.to_json楕円曲線デジタル署名アルゴリズム(ECDSA)について
最初はruby_ecdsaというgemを使おうかと検討していた
https://github.com/DavidEGrayson/ruby_ecdsarequire 'ecdsa' require 'securerandom' require 'digest/sha2' group = ECDSA::Group::Secp256k1 private_key = 1 + SecureRandom.random_number(group.order - 1) public_key = group.generator.multiply_by_scalar(private_key) message = 'ECDSA is cool.' digest = Digest::SHA2.digest(message) temp_key = 1 + SecureRandom.random_number(group.order - 1) signature = ECDSA.sign(group, private_key, digest, temp_key) valid = ECDSA.valid_signature?(public_key, digest, signature) puts "valid: #{valid}"が、秘密鍵が数値を想定したつくりになっていたので使用を見送った
Apple公式の署名作成サンプル
JavaScriptとNode.jsを使ったサンプル
サーバを起動して、アクセスするとレスポンスが返る
- 投稿日:2020-09-10T12:38:23+09:00
(ギリ)20代の地方公務員がRailsチュートリアルに取り組みます【第6章】
前提
・Railsチュートリアルは第4版
・今回の学習は3周目(9章以降は2周目)
・著者はProgate一通りやったぐらいの初学者基本方針
・読んだら分かることは端折る。
・意味がわからない用語は調べてまとめる(記事最下段・用語集)。
・理解できない内容を掘り下げる。
・演習はすべて取り組む。
・コードコピペは極力しない。続いて第6章入りまーす。こっから第12章まで、ログインと認証システムの開発に取り掛かるそうな。長丁場ですがやりきってやりましょう。
本日の一曲はこちら。
17歳とベルリンの壁 "プリズム"
ここ数年あんまり音楽開拓してなかったけど、良い国産シューゲバンドが出てきるな〜。
【6.1.1 データベースの移行 演習】
1. Railsはdb/ディレクトリの中にあるschema.rbというファイルを使っています。これはデータベースの構造 (スキーマ (schema) と呼びます) を追跡するために使われます。さて、あなたの環境にあるdb/schema.rbの内容を調べ、その内容とマイグレーションファイル (リスト 6.2) の内容を比べてみてください。
→ 何が正解か分かんないけど、マイグレーションファイルの中身は反映されてますね。
2. ほぼすべてのマイグレーションは、元に戻すことが可能です (少なくとも本チュートリアルにおいてはすべてのマイグレーションを元に戻すことができます)。元に戻すことを「ロールバック (rollback)と呼び、Railsではdb:rollbackというコマンドで実現できます。$ rails db:rollback上のコマンドを実行後、db/schema.rbの内容を調べてみて、ロールバックが成功したかどうか確認してみてください (コラム 3.1ではマイグレーションに関する他のテクニックもまとめているので、参考にしてみてください)。上のコマンドでは、データベースからusersテーブルを削除するためにdrop_tableコマンドを内部で呼び出しています。これがうまくいくのは、drop_tableとcreate_tableがそれぞれ対応していることをchangeメソッドが知っているからです。この対応関係を知っているため、ロールバック用の逆方向のマイグレーションを簡単に実現することができるのです。なお、あるカラムを削除するような不可逆なマイグレーションの場合は、changeメソッドの代わりに、upとdownのメソッドを別々に定義する必要があります。詳細については、Railsガイドの「Active Record マイグレーション」を参照してください。
→ rails db:migrateを実行。スキーマの中身が消えてます。schema.rbActiveRecord::Schema.define(version: 0) do end3. もう一度rails db:migrateコマンドを実行し、db/schema.rbの内容が元に戻ったことを確認してください。
→ 戻った!
【6.1.2 modelファイル 演習】
1. Railsコンソールを開き、User.newでUserクラスのオブジェクトが生成されること、そしてそのオブジェクトがApplicationRecordを継承していることを確認してみてください (ヒント: 4.4.4で紹介したテクニックを使ってみてください)。
2. 同様にして、ApplicationRecordがActiveRecord::Baseを継承していることについて確認してみてください。
→ コンソール上で下記実行。>> user = User.new => #<User id: nil, name: nil, email: nil, created_at: nil, updated_at: nil> >> user.class => User(id: integer, name: string, email: string, created_at: datetime, updated_at: datetime) >> user.class.superclass => ApplicationRecord(abstract) >> user.class.superclass.superclass => ActiveRecord::Base
【6.1.3 ユーザーオブジェクトを作成する 演習】
1. user.nameとuser.emailが、どちらもStringクラスのインスタンスであることを確認してみてください。
→ あいよ。>> user.name.class => String >> user.email.class => String
2. created_atとupdated_atは、どのクラスのインスタンスでしょうか?
→ 両方ともActiveSupport::TimeWithZoneクラス(この記事が参考になりそう)>> user.created_at.class => ActiveSupport::TimeWithZone >> user.updated_at.class => ActiveSupport::TimeWithZone
【6.1.4 ユーザーオブジェクトを検索する 演習】
1. nameを使ってユーザーオブジェクトを検索してみてください。また、 find_by_nameメソッドが使えることも確認してみてください (古いRailsアプリケーションでは、古いタイプのfind_byをよく見かけることでしょう)
→ 下記>> User.find_by(name: "shoji") User Load (0.2ms) SELECT "users".* FROM "users" WHERE "users"."name" = ? LIMIT ? [["name", "shoji"], ["LIMIT", 1]] => #<User id: 2, name: "shoji", email: "shoji@mail.com", created_at: "2020-09-08 22:54:09", updated_at: "2020-09-08 22:54:09"> >> User.find_by_name("shoji") User Load (0.1ms) SELECT "users".* FROM "users" WHERE "users"."name" = ? LIMIT ? [["name", "shoji"], ["LIMIT", 1]] => #<User id: 2, name: "shoji", email: "shoji@mail.com", created_at: "2020-09-08 22:54:09", updated_at: "2020-09-08 22:54:09">
2. 実用的な目的のため、User.allはまるで配列のように扱うことができますが、実際には配列ではありません。User.allで生成されるオブジェクトを調べ、ArrayクラスではなくUser::ActiveRecord_Relationクラスであることを確認してみてください。
→ 下記(ついでに上位クラスまで調べています)>> users = User.all User Load (0.2ms) SELECT "users".* FROM "users" LIMIT ? [["LIMIT", 11]] => #<ActiveRecord::Relation [#<User id: 1, name: "miura", email: "miura@mail.com", created_at: "2020-09-08 22:53:59", updated_at: "2020-09-08 22:53:59">, #<User id: 2, name: "shoji", email: "shoji@mail.com", created_at: "2020-09-08 22:54:09", updated_at: "2020-09-08 22:54:09">]> >> users.class => User::ActiveRecord_Relation >> users.class.superclass => ActiveRecord::Relation >> users.class.superclass.superclass => Object >> users.class.superclass.superclass.superclass => BasicObject >> users.class.superclass.superclass.superclass.superclass => nil
3. User.allに対してlengthメソッドを呼び出すと、その長さを求められることを確認してみてください (4.2.3)。Rubyの性質として、そのクラスを詳しく知らなくてもなんとなくオブジェクトをどう扱えば良いかわかる、という性質があります。これをダックタイピング (duck typing) と呼び、よく次のような格言で言い表されています「もしアヒルのような容姿で、アヒルのように鳴くのであれば、それはもうアヒルだろう」。(訳注: そういえばRubyKaigi 2016の基調講演で、Ruby作者のMatzがダックタイピングについて説明していました。2〜3分の短くて分かりやすい説明なので、ぜひ視聴してみてください!)
→ データ数が表示されました。>> User.all.length User Load (0.2ms) SELECT "users".* FROM "users" => 2
【6.1.5 ユーザーオブジェクトを更新する 演習】
1. userオブジェクトへの代入を使ってname属性を使って更新し、saveで保存してみてください。
→ 下記>> user1.name = "yongon" => "yongon" >> user1.save (0.1ms) SAVEPOINT active_record_1 SQL (0.6ms) UPDATE "users" SET "name" = ?, "updated_at" = ? WHERE "users"."id" = ? [["name", "yongon"], ["updated_at", "2020-09-08 23:12:52.428275"], ["id", 1]] (0.1ms) RELEASE SAVEPOINT active_record_1 => true
2. 今度はupdate_attributesを使って、email属性を更新および保存してみてください。
→ 下記(ミスっていろいろやり直してるのidがずれてます)>> user1.update_attributes(name: "yongon", email: "yongon@mail.com") (0.1ms) SAVEPOINT active_record_1 SQL (0.1ms) UPDATE "users" SET "email" = ?, "updated_at" = ? WHERE "users"."id" = ? [["email", "yongon@mail.com"], ["updated_at", "2020-09-09 03:12:33.687572"], ["id", 4]] (0.1ms) RELEASE SAVEPOINT active_record_1 => true
3. 同様にして、マジックカラムであるcreated_atも直接更新できることを確認してみてください。ヒント: 更新するときは「1.year.ago」を使うと便利です。これはRails流の時間指定の1つで、現在の時刻から1年前の時間を算出してくれます。
→ 下記>> user1.update_attribute(:created_at, 1.year.ago) (0.1ms) SAVEPOINT active_record_1 SQL (1.1ms) UPDATE "users" SET "created_at" = ?, "updated_at" = ? WHERE "users"."id" = ? [["created_at", "2019-09-09 03:18:24.829284"], ["updated_at", "2020-09-09 03:18:24.830017"], ["id", 4]] (0.1ms) RELEASE SAVEPOINT active_record_1 => true
【6.2.1 有効性を検証する メモと演習】
setupメソッドを使うと、メソッド内に書かれた処理がテスト直前に実行される。この中でインスタンス変数を定義しておけば、すべてのテスト内で使えるようになる。
1. コンソールから、新しく生成したuserオブジェクトが有効 (valid) であることを確認してみましょう。
→ 下記>> user = User.new => #<User id: nil, name: nil, email: nil, created_at: nil, updated_at: nil> >> user.valid? => true2. 6.1.3で生成したuserオブジェクトも有効であるかどうか、確認してみましょう。
→ 一回コンソール閉じてるから消えてるよ〜。どうせ有効なので割愛。
【6.2.2 存在性を検証する メモと演習】
assert_not @user.valid? がRED
→ 「@userは有効ちゃうよな?」と主張してるのに、「有効やんけ!」とツッコミが入ってる状態 と考えると分かりやすい。
validatesにも出てくるが、メソッドの最後の引数としてハッシュを渡す場合、{ }は省略可能1. 新しいユーザーuを作成し、作成した時点では有効ではない (invalid) ことを確認してください。なぜ有効ではないのでしょうか? エラーメッセージを確認してみましょう。
→ nameもemailも入力してないからヴァリデーションが働いてます。>> u = User.new => #<User id: nil, name: nil, email: nil, created_at: nil, updated_at: nil> >> u.valid? => false >> u.errors.full_messages => ["Name can't be blank", "Email can't be blank"]
2. u.errors.messagesを実行すると、ハッシュ形式でエラーが取得できることを確認してください。emailに関するエラー情報だけを取得したい場合、どうやって取得すれば良いでしょうか?
→ このページに書いてました。.messagesつけてもつけなくても一緒ですね。>> u.errors.messages => {:name=>["can't be blank"], :email=>["can't be blank"]} >> u.errors[:email] => ["can't be blank"] >> u.errors.messages[:email] => ["can't be blank"]
【6.2.3 長さを検証する 演習】
1. 長すぎるnameとemail属性を持ったuserオブジェクトを生成し、有効でないことを確認してみましょう。
2. 長さに関するバリデーションが失敗した時、どんなエラーメッセージが生成されるでしょうか? 確認してみてください。
→ まとめて下記>> user = User.new(name: "a"*55, email: "e"*244 + "@example.com") => #<User id: nil, name: "aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa...", email: "eeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeee...", created_at: nil, updated_at: nil> >> user.valid?=> false >> user.errors.full_messages=> ["Name is too long (maximum is 50 characters)", "Email is too long (maximum is 255 characters)"]
【6.2.4 フォーマットを検証する 演習】
正規表現は覚える必要あるでしょうか?ややこしいので、都度調べて実装する方がいいような。
1. リスト 6.18にある有効なメールアドレスのリストと、リスト 6.19にある無効なメールアドレスのリストをRubularのYour test string:に転記してみてください。その後、リスト 6.21の正規表現をYour regular expression:に転記して、有効なメールアドレスのみがすべてマッチし、無効なメールアドレスはすべてマッチしないことを確認してみましょう。
→ たしかめるだけ。
2. 先ほど触れたように、リスト 6.21のメールアドレスチェックする正規表現は、foo@bar..comのようにドットが連続した無効なメールアドレスを許容してしまいます。まずは、このメールアドレスをリスト 6.19の無効なメールアドレスリストに追加し、これによってテストが失敗することを確認してください。次に、リスト 6.23で示した、少し複雑な正規表現を使ってこのテストがパスすることを確認してください。
→ これもやるだけー。
3. foo@bar..comをRubularのメールアドレスのリストに追加し、リスト 6.23の正規表現をRubularで使ってみてください。有効なメールアドレスのみがすべてマッチし、無効なメールアドレスはすべてマッチしないことを確認してみましょう。
→ 確認しました。
【6.2.5 一意性を検証する メモと演習】
ここの内容ちょっとややこしいけど、要はメールアドレスに関して大文字・小文字を区別しないように設定してると。テストは大文字ユーザーが有効ででない(大文字でも同じアドレス)ことを確かめてるわけか。
そして、メールアドレスがデータベースに保存される前に、すべてを小文字にするためにコールバックメソッドが登場しました。軽く調べたところ、コールバックの利用は慎重にしないといけないようです。コールバックの中で条件分岐とか避けた方がいいみたい。1. リスト 6.33のように、メールアドレスを小文字にするテストをリスト 6.26に追加してみましょう。ちなみに追加するテストコードでは、データベースの値に合わせて更新するreloadメソッドと、値が一致しているかどうか確認するassert_equalメソッドを使っています。リスト 6.33のテストがうまく動いているか確認するためにも、before_saveの行をコメントアウトして redになることを、また、コメントアウトを解除すると greenになることを確認してみましょう。
→ 指示通り実行。before_saveで保存前に小文字に変換しているので、コメントアウトするとREDに、解除するとGREENになります。2. テストスイートの実行結果を確認しながら、before_saveコールバックをemail.downcase!に書き換えてみましょう。ヒント: メソッドの末尾に!を付け足すことにより、email属性を直接変更できるようになります (リスト 6.34)。
→ ここで出てくる「!」は、破壊的な処理を表します。つまり、メールアドレスが小文字変換されたままで維持されるということ。書き換えてもテストはGREENです。
【6.3.2 ユーザーがセキュアなパスワードを持つ 演習】
1. この時点では、userオブジェクトに有効な名前とメールアドレスを与えても、valid?で失敗してしまうことを確認してみてください。
2. なぜ失敗してしまうのでしょうか? エラーメッセージを確認してみてください。
→ まとめていくよ!パスワードが空白はダメだってよ。>> user = User.new(name: "kote", email: "kote@mail.com") => #<User id: nil, name: "kote", email: "kote@mail.com", created_at: nil, updated_at: nil, password_digest: nil> >> user.valid? User Exists (0.2ms) SELECT 1 AS one FROM "users" WHERE LOWER("users"."email") = LOWER(?) LIMIT ? [["email", "kote@mail.com"], ["LIMIT", 1]] => false >> user.errors.messages => {:password=>["can't be blank"]}
【6.3.3 パスワードの最小文字数 演習】
1. 有効な名前とメールアドレスでも、パスワードが短すぎるとuserオブジェクトが有効にならないことを確認してみましょう。
2. 上で失敗した時、どんなエラーメッセージになるでしょうか? 確認してみましょう。
→ 今回もまとめていくよ!もちろんパスワードが短すぎると怒られます。ここでhas_secure_passwordが働いて、パスワードがハッシュ化されているのが分かりますね。>> user = User.new(name: "kote", email: "kote@mail.com", password: "kotte") => #<User id: nil, name: "kote", email: "kote@mail.com", created_at: nil, updated_at: nil, password_digest: "$2a$10$7Svz/KnRoF7zab0PnhKFL.n/OsSltRvvREHECcmuq.D..."> >> user.valid? User Exists (0.2ms) SELECT 1 AS one FROM "users" WHERE LOWER("users"."email") = LOWER(?) LIMIT ? [["email", "kote@mail.com"], ["LIMIT", 1]] => false >> user.errors.messages=> {:password=>["is too short (minimum is 6 characters)"]}
【6.3.4 ユーザーの作成と認証 演習】
1. コンソールを一度再起動して (userオブジェクトを消去して)、このセクションで作ったuserオブジェクトを検索してみてください。
→ 下記>> user = User.find(1) User Load (0.1ms) SELECT "users".* FROM "users" WHERE "users"."id" = ? LIMIT ? [["id", 1], ["LIMIT", 1]] => #<User id: 1, name: "Michael Hartl", email: "mhartl@example.com", created_at: "2020-09-10 02:37:56", updated_at: "2020-09-10 02:37:56", password_digest: "$2a$10$A5n.HFBigQfwnWVJZw2N0e4M9sxPaR8ndLZwqtZWYS7...">
2. オブジェクトが検索できたら、名前を新しい文字列に置き換え、saveメソッドで更新してみてください。うまくいきませんね...、なぜうまくいかなかったのでしょうか?
→ 下記。saveメソッドだと全ての属性を更新しようとするから、パスワードの更新でエラー吐いてるみたい。>> user.name = "meshino" => "meshino" >> user.save (0.1ms) begin transaction User Exists (0.2ms) SELECT 1 AS one FROM "users" WHERE LOWER("users"."email") = LOWER(?) AND ("users"."id" != ?) LIMIT ? [["email", "mhartl@example.com"], ["id", 1], ["LIMIT", 1]] (0.0ms) rollback transaction => false >> user.errors.messages => {:password=>["can't be blank", "is too short (minimum is 6 characters)"]}
3. 今度は6.1.5で紹介したテクニックを使って、userの名前を更新してみてください。
→ ということで、update_attributeを使って更新します。(ただし、さっきエラー吐いたuserを再利用しているので、name更新後も有効ではありません。パスワードの再設定が必要と思われます)>> user.update_attribute(:name, "nakamura") (0.1ms) begin transaction SQL (4.2ms) UPDATE "users" SET "name" = ?, "updated_at" = ? WHERE "users"."id" = ? [["name", "nakamura"], ["updated_at", "2020-09-10 03:07:11.190666"], ["id", 1]] (6.4ms) commit transaction => true >> user.valid? User Exists (0.2ms) SELECT 1 AS one FROM "users" WHERE LOWER("users"."email") = LOWER(?) AND ("users"."id" != ?) LIMIT ? [["email", "mhartl@example.com"], ["id", 1], ["LIMIT", 1]] => false >> user.errors.messages=> {:password=>["can't be blank", "is too short (minimum is 6 characters)"]}
第6章まとめ
・データベースを更新する時はつどつどマイグレーションを作成してマイグレートしよう。
・Active Recordは便利。Railsは下火になってきてるけどActive Recordは利点とどっかで書かれてた。
・バリデーションで無効な入力内容を設定して弾こう。
・正規表現は多分そういうもんなんだと認識する程度でよいと思う。
・データベースにインデックス追加で検索効率向上。一意性も保証。
・has_secure_passwordはgemで利用しているわけだから、他にも便利なgemでセキュアな処理が実装できるんかな。と思って検索したらやっぱり出てきました。今後学んでいこう。
いろいろ気になることを寄り道して調べているので時間がかかります。でも絶対チュートリアルの内容だけでは通用しないと思うので、他の様々なことにも興味を持って吸収していきます。
さて次!第7章はユーザー登録の実装です!sign up!
⇦ 第5章はこちら
学習にあたっての前提・著者ステータスはこちら
なんとなくイメージを掴む用語集
・assert_not
notで否定してるので、まんま逆の意味。対象が真なら失敗、偽なら成功。・Active Record コールバック
何かの処理の前/後に呼び出すメソッドを設定できる。詳しくはRailsガイドへ。・スタブ
テスト時に用意する代用品。テスト対象の処理から呼び出される代用品がスタブ、テスト対象の処理を呼び出す代用品がドライバ。
- 投稿日:2020-09-10T10:55:15+09:00
[Rails]エラーStandardError: An error has occurred, all later migrations canceled: Column `外部キー名` on table `テーブル名` does not match column `id` on `テーブル名`の対処方法
エラー内容
$ rails db:migrate上記コマンドを実行すると発生するエラー。ターミナルでのエラー表記は以下の通り。
エラー文一部抜粋.Column `user_id` on table `items` does not match column `id` on `users`, which has type `bigint(20)`. To resolve this issue, change the type of the `user_id` column on `items` to be :bigint. (For example `t.bigint :user_id`).エラー文の一部を翻訳してみると...。
エラー文翻訳.テーブル `items` のカラム `user_id` が `users` のカラム `id` と一致しません。この問題を解決するには、`items` の `user_id` カラムの型を :bigint に変更します。(例えば `t.bigint :user_id`)。今回はitemsテーブルが外部キーとして指定しているカラムが参照元と一致しませんよ!というエラーですね。
対処法(仮説)
結論、Railsでは外部キーを使用する際は
references型を推奨しているので、bigint型を使用する必要はありません。このエラーのポイントは参照できませんということなので、マイグレーションファイルの作成順に問題があると仮説できます。
マイグレーションファイルの作成順とは?
外部キーを使用するテーブル(references型を記述するテーブル)と参照されるテーブルには作成順によって参照できなくなる場合があり、今回のエラーは作成順序の誤りで発生しました。
作成順は、①参照される側のテーブル→②外部キーを使用するテーブル(references型を記述するテーブル)です。
対処法はマイグレーションファイルの作成日時を修正してあげれば解決できます。対処法(仮設検証)
添付画像の数字部分を、参照される側のテーブルよりも外部キーを使用するテーブルの数字を大きくすれば解決します。エラー分からは少し推測しづらいエラーですね。
今回の場合だと、
create_itemsが20200909000000なら20200909100000でいいです。
ちなみに、最初の4桁は西暦、次の4桁は月日です。最後に
今回のエラーはテーブル数が増えると発生しやすいエラーなのかなと思います。
ただ、対象法を知っていれば問題なく解決できると思いますので、参考にしてみてください!

- 投稿日:2020-09-10T09:40:58+09:00
[Ransack] ransackable_scopesには気を付けろ
結論
ransackable_scopesで実行するscopeに渡す引数が以下の値だったら
ArgumentError wrong number of arguments (given 0, expected 1)
が発生するから気を付けろ!!!
"true","TRUE","t","T",1,"1""false","FALSE","f","F",0,"0"これらの値はそれぞれTrue, Falseに暗黙的に変換されるため、引数に渡せない。
解決策
config/initializers/ransack.rbRansack.configure do |config| config.sanitize_custom_scope_booleans = false endこれを追記するだけで、上述の値全てを渡せるようになります。1
渡せる値をカスタムしたいなら
諦めてください。
暗黙的に変換される値はRansack::Constants::BOOLEAN_VALUES2 で定義されています。
この定数はfreezeされています。
公式によるとfreezeしたオブジェクトをunfreezeする方法は無いそうです。3There is no way to unfreeze a frozen object.
変換される値のカスタマイズついてはかなり調べましたが、無理でした。。。
一応、「暗黙的に変換する値をカスタマイズできるようにしたよ!」って内容のPRがマージされていました。
これによると、以下のように変換する値をカスタマイズできるらしいです。Ransack.configure do |config| config.truthy_values_to_convert_in_custom_scopes = ['TRUE', 'true', '1'] config.falsey_values_to_convert_in_custom_scopes = ['FALSE', 'no way no how'] endしかし、それ通りに記述しても以下のようなエラーが発生しました。
=> NoMethodError: undefined method `truthy_values_to_convert_in_custom_scopes' for Ransack:Moduleファッ!?!?!?!?!?!?!?!?!?!?!?!?
PRの実装内容をを確認しましたが、概要で書かれているような内容は実装されていませんでした。。。
誰かここ分かる方がいれば教えてください。。。また、@t_oginoginさんがRansackを使わない解決策を提案してくれているので、皆さんの実装状況に合わせてご参考下さい。
https://qiita.com/t_oginogin/items/b45636d64c271ebc409c参考文献
sanitize_custom_scope_booleansについて(Ransack公式)
https://github.com/activerecord-hackery/ransack#using-scopesclass-methods ↩BOOLEAN_VALUESの中身(Ransack公式)
https://github.com/activerecord-hackery/ransack/blob/c9cc20de9e0f7bab92e0579c85bed64d614d23de/lib/ransack/constants.rb#L26 ↩unfreezeできない(Ruby公式)
https://ruby-doc.org/core-2.6.6/Object.html#method-i-freeze ↩
- 投稿日:2020-09-10T09:24:41+09:00
rails tutorial 第8章
はじめに
独学でrails tutorialを進めていく過程を投稿していきます。
進めていく上でわからなかった単語、詰まったエラーなどに触れています。
個人の学習のアウトプットなので間違いなどあればご指摘ください。
初めての投稿なので読みにくいところも多々あるかと思いますがご容赦ください。
第8章 基本的なログイン機構
8.1.2 ログインフォーム
ログインフォームを作成時のscopeの働きについてわからなかったので調べました。
form_with(url: login_path, scope: :session, local: true)参考
https://qiita.com/akilax/items/f36b13f377f7e442bc73あまり深く考え過ぎずにパラメーターを渡す際に必要なname値のプレフィックスと考えるのが良さそうです。
ざっくりと自分なりにまとめると、Active Recodeを継承しているオブジェクトのフォームでは
<%= form_with(model: @user, local: true) do |f| %> <%= f.label :name %> <%= f.text_field :name, class: 'form-control' %> . . <% end %>とし、入力された値(生成されたinputタグのname値) へのアクセスは
params[:user][:name]となり、入力結果をuserハッシュに保存していました。
今回のsessionフォームにおいても同様で、パラメーターに入力結果の値を渡すために、scopeで指定したハッシュに入力結果を保存しているということだと思います。
8.1.4 フラッシュメッセージを表示する
ログイン失敗時にエラーメッセージを表示します。
app/controllers/sessions_controller.rb#リスト 8.8: ログイン失敗時の処理を扱う(誤りあり) class SessionsController < ApplicationController def new end def create user = User.find_by(email: params[:session][:email].downcase) if user && user.authenticate(params[:session][:password]) # ユーザーログイン後にユーザー情報のページにリダイレクトする else flash[:danger] = 'Invalid email/password combination' # 本当は正しくない render 'new' end end def destroy end end実は上のコードのままでは、リクエストのフラッシュメッセージが一度表示されると消えずに残ってしまいます。リスト 7.27でリダイレクトを使ったときとは異なり、表示したテンプレートをrenderメソッドで強制的に再レンダリングしてもリクエストと見なされないため、リクエストのメッセージが消えません。例えばわざと無効な情報を入力して送信してエラーメッセージを表示してから、Homeページをクリックして移動すると、そこでもフラッシュメッセージが表示されたままになっています。(rails tutorial 8章より引用)
ここで、なぜリクエストと見なされなければメッセージが消えないのか、また、エラーメッセージ表示後にhomeページをクリックして移動する際にGETリクエストをしているから消えてもよいのでは?という疑問が生まれました。
この疑問を解消するため、まずは改めてrenderとredirect_toの違いについて調べてみた。
参考
https://qiita.com/january108/items/54143581ab1f03deefa1
この記事を読んでもやはりhomeページをクリックする時にリクエストしてるよな、、、という疑問が残りました。
その後も色々調べてようやく回答にたどり着きました。どうやらflashについての理解が足りなかったようです。参考
https://pikawaka.com/rails/flashつまりflashメッセージが表示されてから、リクエストを受け、アクションが実行されてからフラッシュメッセージが消去されるようです。
だからrenderメソッドでviewが表示された後、homeリクエストをしてもメッセージが残っているようでした。
試しに
1.無効な情報を入力して送信
2.エラーメッセージを確認
3.homeページに移動
4.homeページでもエラーメッセージ消えていないことを確認
5.再度homeページをクリック
とするとエラーメッセージは消えていました。凄いすっきりしました!!
8.2 ログイン
Railsのセッション用ヘルパーはビューにも自動的に読み込まれます。Railsの全コントローラの親クラスであるApplicationコントローラにこのモジュールを読み込ませれば、どのコントローラでも使えるようになります 。(rails tutorial 8章より引用)
注意
viewには自動で読み込まれますが、コントローラーなどで、ヘルパーに設定したメソッドなどを利用する場合はincludeで読み込む必要があります。8.2.2 現在のユーザー
このトピックではわかりにくいところがあり、初めてQiitaで質問を利用させていただきました。
内容を深堀したとき、なぜfindメソッドではなくfind_byメソッドを利用すべきだったのか、わかりませんでしたので質問をしました。
質問内容
https://qiita.com/shun_study_p/questions/da3de50fe7826dc151ed
回答をしていただいた方、ありがとうございます。
@current_user ||= User.find_by(id: session[:user_id])Userオブジェクトそのものの論理値は常にtrueになることです。そのおかげで、@current_userに何も代入されていないときだけfind_by呼び出しが実行され、無駄なデータベースへの読み出しが行われなくなります。(rails tutorial 8章より引用)
ここの文についても自分なりに補足
@current_user ||= User.find_by(id: session[:user_id])この一文は@current_userがnilの時はfind_byメソッドを実行しUserオブジェクトを作成するというもの。(@current_userにUserオブジェクトが代入される)
そうなった後は@current_userはUserオブジェクトとなり、またUserオブジェクトはtrueを返すので、以降は左辺がtrueとなり、無駄なfind_byメソッドは実行されず(@current_userがnilではないから)無駄なデータの呼び出しも行われなくなるということ。8.2.3 レイアウトリンクを変更する
<%= link_to "Profile", current_user %>復習も兼ねてこちらの一文に置いて何が行われているかというと
<%= link_to "Profile", "/users/#{current_user.id}" %> <%= link_to "Profile", user_path(current_user.id) %> <%= link_to "Profile", user_path(current_user) %> <%= link_to "Profile", current_user %>と省略されて行っています。
ここでまた一つの疑問が、
link_toの引数でモデルオブジェクトを渡すのはわかります。でも今回渡してるのってメソッドじゃないの、、、?
こちらに関しては以下の記事を参考にしました。
参考記事1(7章でも参考にしました)
https://qiita.com/Kawanji01/items/96fff507ed2f75403ecb参考記事2
https://teratail.com/questions/198096
どうやら戻り値にモデルのインスタンスを返すならそのメソッドはモデルオブジェクトとみなせるようですね。8.2.4 レイアウトの変更をテストする
def User.digest(string) cost = ActiveModel::SecurePassword.min_cost ? BCrypt::Engine::MIN_COST : BCrypt::Engine.cost BCrypt::Password.create(string, cost: cost) endこのdigestメソッドは、今後様々な場面で活用します。例えば9.1.1でもdigestを再利用するので、このdigestメソッドはUserモデル(user.rb)に置いておきましょう。この計算はユーザーごとに行う必要はないので、fixtureファイルなどでわざわざユーザーオブジェクトにアクセスする必然性はありません(つまり、インスタンスメソッドで定義する必要はありません)。(rails tutorial 8章より引用)
インスタンスメソッドとクラスメソッドの違いをあまり理解出来ていなかったのか、上の文の意味がよくわからない、、、
上の本文は
1.インスタンスメソッドで定義するとわざわざユーザーオブジェクトにアクセスする必要がある。
2.今回の"渡された文字列のハッシュを返すというdigestメソッド"はユーザーごとのインスタンスで行う必要はない。(クラスオブジェクトから直接実行すればよいもの)と言っている。なんとなくだがこの2つが言いたいことはわかるような、、、
まだふんわりとした理解ですが、記事を参考に自分でまとめてみました。
参考
https://qiita.com/tbpgr/items/56eb65c0ea5882abbb07つまり
クラスメソッドは○○クラス自身に関する情報の変更や参照の役割をもっている。なので今回のようなパスワードのハッシュ化、記事の例にあるように男女といった性別の属性、これらはクラスメソッドであらかじめ定義しておくことができる。
インスタンスメソッドは、個別のインスタンスに関する情報の変更や参照の役割りを持っている。
なので特定のデータのパスワードや名前と言った情報の参照をしたいなどといったときはインスタンスメソッドを使う。(ユーザーオブジェクトにアクセスする必要があることもイメージしやすい)
こんなところだろうか、、、難しい、、
終わりに
今回の章も難しく、7割程度の理解で進んでしまった部分もあるので、また復習が必要だと思いました。
- 投稿日:2020-09-10T08:36:46+09:00
[Rails]1対1対多の場合のdelegateとhas_many-throughの挙動の違い
下記のように1対1対多の関係のモデルがあるとします。
- UserとExamineeは1対1
- ExamineeとTestは1対多
class User has_one :examinee end class Examinee belongs_to :user has_many :tests end class Test belongs_to :examinee endでは、Userモデルから関連するTestモデルを取得したいときはどのように実装しますか?
様々なやり方がありますが、ActiveRecordの便利機能
delegateを使うか、has_many-throughを使うことが多いのではないでしょうか?
どちらもやりたいことは達成できますが、発行されるクエリが少し違うので紹介します。delegate
delegateを使うとメソッドを別クラスに委譲することが出来ます。
詳細はRailsガイドを参照してください。
3.4.1 delegate今回の場合、下記のように実装します。
app/models/user.rbdelegate :tests, to: :examinee実行すると下記の通り2つのクエリーが発行されます。
まず委譲先のexamineeを取得(1つ目のクエリー)して、その後、examinee.testsを実行(2つ目のクエリー)する挙動になっています。irb> user.tests Examinee Load SELECT `examinees`.* FROM `examinees` WHERE `examinees`.`user_id` = 1 LIMIT 1 Test Load SELECT `tests`.* FROM `tests` WHERE `tests`.`examinee_id` = 1has_many-through
has_many-throughは多対多の時に使われることが多いですが、今回のように1対多の場合も利用できます。
詳細はRailsガイドを参照してください。
2.4 has_many :through 関連付け今回の場合、下記のように実装します。
app/models/user.rbhas_many :tests, through: :examinee実行すると下記の通り1つのクエリーが発行されます。
こちらの場合はjoinしたクエリーが1つだけ発行されます。
この機能が多対多に対応するように実装されていると考えると、deletgateのように2段階では効率よく取得できないのでjoinで取得しているんだなと理解できると思います。irb> user.tests Test Load SELECT `tests`.* FROM `tests` INNER JOIN `examinees` ON `tests`.`examinee_id` = `examinees`.`id` WHERE `examinees`.`user_id` = 1最後に
2クエリーで取得するほうが良いのか、joinされた1クエリーで取得するほうが良いのかは実行環境によるので一概に良し悪しは判断出来ません。
というか大抵の場合はどちらで書いても問題なく動作するのでぶっちゃけどちらでもよいと思います。ただ、ブラックボックス的に見ると同じことをしているように見えても、今回のように内部で発行されるクエリーが違ったりします。
たまにはこういう細かな違いを機能の成り立ちや目的などを考えならが確認してみると面白いと思います。
- 投稿日:2020-09-10T08:16:55+09:00
Rails 6で認証認可入り掲示板APIを構築する #5 controller, routes実装
←Rails 6で認証認可入り掲示板APIを構築する #4 postのバリデーション、テスト実装
controllerを作る
前回はmodelを作ったので、今回はcontrollerを実装していきます。
$ rails g controller v1/posts実行するとcontrollerとrequest specファイルが生成されます。
とりあえずcontrollerを以下まで実装します。
app/controllers/v1/posts_controller.rb# frozen_string_literal: true module V1 # # post controller # class PostsController < ApplicationController before_action :set_post, only: %i[show update destroy] def index # TODO end def show # TODO end def create # TODO end def update # TODO end def destroy # TODO end private def set_post @post = Post.find(params[:id]) end def post_params params.permit(:subject, :body) end end end
- index: post一覧を取得する
- show: post1レコードの情報を取得する(R)
- create: post1レコードを作成する(C)
- update:post1レコードを更新する(U)
- destroy: post1レコードを削除する(D)
CRUDに沿ったcontrollerを、一旦ロジック無しで作ります。
なお、V1というnamespaceを切っているのはAPI開発ではよくやる手法です。
これにより後方互換の無いversion2を作る際、分離して開発がしやすくなります。続いてroutesを設定します。
config/routes.rb# frozen_string_literal: true Rails.application.routes.draw do + namespace "v1" do + resources :posts + end endこれでCRUDのroutesが設定されます。確認してみましょう。
$ rails routes ... Prefix Verb URI Pattern Controller#Action v1_posts GET /v1/posts(.:format) v1/posts#index POST /v1/posts(.:format) v1/posts#create v1_post GET /v1/posts/:id(.:format) v1/posts#show PATCH /v1/posts/:id(.:format) v1/posts#update PUT /v1/posts/:id(.:format) v1/posts#update DELETE /v1/posts/:id(.:format) v1/posts#destroy ...indexテストの実装
例によってテストを先に実装します。
挙動としては
- 登録されたpostを返す
- created_at降順でソート
- 20件でlimit
でいきます。
簡易的なテストアプリケーションのチュートリアルのためpagerは組み込みませんが、もしかしたら今後記事を書くかもしれません。spec/requests/v1/posts_controller.rb# frozen_string_literal: true require "rails_helper" RSpec.describe "V1::Posts", type: :request do describe "GET /v1/posts#index" do before do create_list(:post, 3) end it "正常レスポンスコードが返ってくる" do get v1_posts_url expect(response.status).to eq 200 end it "件数が正しく返ってくる" do get v1_posts_url json = JSON.parse(response.body) expect(json["posts"].length).to eq(3) end it "id降順にレスポンスが返ってくる" do get v1_posts_url json = JSON.parse(response.body) first_id = json["posts"][0]["id"] expect(json["posts"][1]["id"]).to eq(first_id - 1) expect(json["posts"][2]["id"]).to eq(first_id - 2) end end end
- beforeは、同ブロック以下itで毎回事前に実行されます。
create_list(:post, 3)はpostを3レコード生成しDBに保存する処理です。- また、itブロック終了時にテストDBはrollbackされます。
つまり挙動をまとめると、
LINE 10:it "正常レスポンスコードが返ってくる"ブロック開始
LINE 8:3件分のpostが保存される
LINE 11:v1_posts_url(v1/posts/index)にgetリクエストを行う
LINE 12:レスポンスコードが:ok(200 正常)
LINE 13:it "正常レスポンスコードが返ってくる"ブロック終了。rollbackされpostレコードは0件に
LINE 14:it "件数が正しく返ってくる"ブロック開始
LINE 8:3件分のpostが保存される
LINE 15:v1_posts_url(v1/posts/index)にgetリクエストを行う
LINE 16:response.bodyをJSON.parseしてRubyの配列に変換
LINE 17:レスポンスのpostが3レコード
LINE 18:it "件数が正しく返ってくる"ブロック終了。rollbackされpostレコードは0件に
↓
...となります。
この時点ではcontroller未実装なので、当然テストはコケます。
なお、最後のテストは厳密にはcreated_atの比較が必要ですが、簡易的にidで比較をしています。
本来はlimitのテストもすべきですが省略します。興味があれば、create_listで21件作って20件しか返ってこないことを確認するテストを実装してみてください。Tips.
ついでによく使うfactoryBotのメソッドを紹介しておきます。
build(:post)postを1レコード、メモリ上に生成。saveしない限りDBには反映されない。Post.newに相当create(:post)postを1レコード生成しDBに保存。Post.create!に相当build_list(:post, 5)postを5レコード生成。buildの複数版create_list(:post, 5)postを5レコード生成。createの複数版example.comをhostsに追加
なお、requestsテストは以下対応が必要です。
config/application.rb... config.hosts << ".amazonaws.com" + config.hosts << "www.example.com" ...なぜならrspecのテストはwww.example.comからのリクエストとして認識されるためです。
indexの実装
app/controllers/v1/posts_controller.rb... def index - # TODO + posts = Post.order(created_at: :desc).limit(20) + render json: { posts: posts } end ...これで一覧取得ができます。
試しにcurlでAPIを叩いてみます。$ curl localhost:8080/v1/posts {"posts":[{"id":2,"subject":"","body":"hoge","created_at":"2020-09-06T01:07:52.628Z","updated_at":"2020-09-06T01:07:52.628Z"},{"id":1,"subject":"hoge","body":"fuga","created_at":"2020-09-05T13:50:01.797Z","updated_at":"2020-09-05T13:50:01.797Z"}]}もし空のdataが返ってきた場合は、
rails cからpostのレコードを生成してみてください。ここまでできたら、rubocopやrspec実行を忘れずに行った後、git commitしましょう。
続き
→Rails 6で認証認可入り掲示板APIを構築する #6 show, create実装
【連載目次へ】
- 投稿日:2020-09-10T01:55:58+09:00
Ruby/Rust 連携 (5) Rutie で数値計算② ベジエ
連記事目次
- Ruby/Rust 連携 (1) 目的
- Ruby/Rust 連携 (2) 手段
- Ruby/Rust 連携 (3) FFI で数値計算
- Ruby/Rust 連携 (4) Rutie で数値計算①
- Ruby/Rust 連携 (5) Rutie で数値計算② ベジエ
はじめに
前回は Ruby と Rust をつなぐ Rutie というものを使って,Rust の簡単な数値計算関数を Ruby から呼び出してみた。
速度面では,同じ計算を Ruby でやらせたのよりずっと遅かった。これは Ruby から Rust の関数を呼ぶコストがそこそこあったからだろう。そのコストに比して,やらせた数値計算が軽すぎた。今回もまた Rutie を使い,Ruby から Rust を呼び出して数値計算をさせてみる。
前回と違うのは
- もう少しだけ複雑な計算をやらせる
- Rust で Ruby のクラスを作り,そのインスタンスのメソッドを呼び出す
というところ。
とくに,後者は重要で,これができれば Rust との連携でやれることがかなり広がる。題材
ベジエ曲線の計算をさせてみたい。
参考:ベジェ曲線 - Wikipedia3 次ベジエの場合,平面上に 4 つの点 $\boldsymbol{p}_0$, $\boldsymbol{p}_1$, $\boldsymbol{p}_2$, $\boldsymbol{p}_3$ を与えると曲線が決まる。
この曲線は以下のように媒介変数表示される。\boldsymbol{p}(t) = (1-t)^3 \boldsymbol{p}_0 + 3t(1-t)^2 \boldsymbol{p}_1 + 3t^2(1-t) \boldsymbol{p}_2 + t^3 \boldsymbol{p}_3 \quad\quad (0 \leqq t \leqq 1)すぐにわかるように,$t = 0$ のとき,$\boldsymbol p_0$ であり,$t=1$ のとき,$\boldsymbol p_3$ である。つまり,$\boldsymbol p_0$ から出発して $\boldsymbol p_3$ に至る曲線なわけだ。
$\boldsymbol{p}_1$ と $\boldsymbol{p}_2$ は一般には通らない(条件次第で通ることもある)。$\boldsymbol p_1$ と $\boldsymbol p_2$ は制御点とも呼ばれ,$\boldsymbol p_1 - \boldsymbol p_0$ は $t=0$ における接ベクトルであるし,$\boldsymbol p_3 - \boldsymbol p_2$ は $t=1$ における接ベクトルである。
さて,やりたいことは,$\boldsymbol p_0$, $\boldsymbol p_1$, $\boldsymbol p_2$, $\boldsymbol p_3$ を与えたときに,任意の $t$ における位置 $\boldsymbol p(t)$ を得ることだ。
$x$ 座標と $y$ 座標は互いに関係しないので,$a_0$, $a_1$, $a_2$, $a_3$ に対して,
B(t) = (1-t)^3 a_0 + 3t(1-t)^2 a_1 + 3t^2(1-t) a_2 + t^3 a_3という形の関数を考えればよい。
これを $x$ 座標用,$y$ 座標用それぞれ用意する。この関数は 3 次のベルンシュテイン多項式と呼ばれている1。つまり,今回のお題は「3 次のベルンシュテイン多項式の値を計算せよ」だ。
方針
さまざまな $t$ に対して,同じ係数($a_0$, $a_1$, $a_2$, $a_3$)で計算をするわけだから,クラスを作ろう。
係数を与えてインスタンスを生成し,あとは $t$ を与えて多項式の値を計算させるのだ。クラス名は,CubicBezier にしよう。いや,やっていることはベルンシュテイン多項式の計算なので CubicBernstein のほうが内容に合ってるかもしれないけど,「ベジエ」のほうが通りがいいしね。
Ruby で実装すると,
class CubicBezier def initialize(a0, a1, a2, a3) @a0, @a1, @a2, @a3 = a0, a1, a2, a3 end def value_at(t) s = 1 - t @a0 * s * s * s + 3 * @a1 * t * s * s + 3 * @a2 * t * t * s + @a3 * t * t * t end alias [] value_at endてな感じ。
value_atに対して[]というエイリアスを当てているのは,やはり[]で計算させるほうが Ruby らしい感じがするのでは,と思ってのこと。ともかく,これと同じ働きのクラスを Rutie で実装しようというわけ。
実装:Rust 側
インスタンス変数を持つようなクラスを Rutie でどうやって実装するのか。
幸い Rutie のコードには解説や例がついているので,それを見ながら試行錯誤してたら,なんか動くものができた。理屈は分かっていない。Cargo.toml 編集まで
いままでと同様
cargo new cubic_bezier --libとやる。そして Cargo.toml に
Cargo.toml[dependencies] lazy_static = "1.4.0" rutie = "0.7.0" [lib] crate-type = ["cdylib"]をぶっ込む。
今回は lazy_static クレートが必要になる。本体
方針
ぜんぜんよく分からないが,インスタンス変数を使うような Ruby のクラスを Rutie で定義する場合,Rust の構造体(struct)を用意し,それを wrap する,というやり方を取るものらしい(ここでいう wrap が何を意味するのかよく分からずに書いています)。
今の場合,a0,a1,a2,a3というインスタンス変数を持つ CubicBezier という Ruby のクラスを作りたいので,そういうフィールドを持つ構造体をまず定義する。構造体の名前を CubicBezier とするとかぶってしまうので,仕方なく RustCubicBezier にする。
それを wrap するように CubicBezier を定義する。コード
コードの全体はこのとおり。
src/lib.rs#[macro_use] extern crate lazy_static; #[macro_use] extern crate rutie; use rutie::{Object, Class, Float}; pub struct RustCubicBezier { a0: f64, a1: f64, a2: f64, a3: f64, } impl RustCubicBezier { pub fn value_at(&self, t: f64) -> f64 { let s = 1.0 - t; self.a0 * s * s * s + 3.0 * self.a1 * t * s * s + 3.0 * self.a2 * t * t * s + self.a3 * t * t * t } } wrappable_struct!(RustCubicBezier, CubicBezierWrapper, CUBIC_BEZIER_WRAPPER); class!(CubicBezier); methods!( CubicBezier, rtself, fn cubic_bezier_new(a0: Float, a1: Float, a2: Float, a3: Float) -> CubicBezier { let a0 = a0.unwrap().to_f64(); let a1 = a1.unwrap().to_f64(); let a2 = a2.unwrap().to_f64(); let a3 = a3.unwrap().to_f64(); let rcb = RustCubicBezier{a0: a0, a1: a1, a2: a2, a3: a3}; Class::from_existing("CubicBezier").wrap_data(rcb, &*CUBIC_BEZIER_WRAPPER) } fn value_at(t: Float) -> Float { let t = t.unwrap().to_f64(); Float::new(rtself.get_data(&*CUBIC_BEZIER_WRAPPER).value_at(t)) } ); #[allow(non_snake_case)] #[no_mangle] pub extern "C" fn Init_cubic_bezier() { Class::new("CubicBezier", None).define(|klass| { klass.def_self("new", cubic_bezier_new); klass.def("value_at", value_at); klass.def("[]", value_at); }); }以下の節で各部位に説明を加えていく。
RustCubicBezier
構造体とそのメソッドの定義:
pub struct RustCubicBezier { a0: f64, a1: f64, a2: f64, a3: f64, } impl RustCubicBezier { pub fn value_at(&self, t: f64) -> f64 { let s = 1.0 - t; self.a0 * s * s * s + 3.0 * self.a1 * t * s * s + 3.0 * self.a2 * t * t * s + self.a3 * t * t * t } }
RustCubicBezierの定義は,あまり説明は要らないと思う。Rust の関数は,第一引数を
&selfとかにして定義するとメソッドとして働く。ラッパー
私にはよく意味の分からない箇所がこれ。
wrappable_struct!(RustCubicBezier, CubicBezierWrapper, CUBIC_BEZIER_WRAPPER);さっき定義した構造体
RustCubicBezierと,ラッパーの関係を示しているらしい。
wrappable_struct!マクロのドキュメントはここ:
rutie::wrappable_struct - Rust(Rutie 0.7.0 版)Rust の構造体を Ruby のオブジェクトで wrap できるようにする,とか何とか書いてあるような気がする(英語苦手)。
第一引数は wrap したい Rust の構造体の名前を与えるようだ。この構造体は public でなければならないそうなので,さきほど定義したときに
pubを付けておいた。
第二引数は,第一引数を wrap するための構造体(ラッパー)の名前であるらしい。この構造体はマクロが自動的に定義してくれるとのこと。ただし,今回のコードでは第二引数として与えたCubicBezierWrapperが他の箇所には出てこない。
第三引数はラッパーを含む2 static 変数の名前とのこと。♪ 学ぶのやめたシニアエンジニア ♪ そんなお前は死にゃええんじゃ ♪ わくわく学ぶラストチャンス ♪ 反復スライス Rust の Chunk ♪ 叱ってくれよ鬼コンパイラ ♪ オレの頭はもう困憊だいや,ラッパーってそういうことじゃないから3。
クラスとメソッドの定義
まずクラス。これは単純。
class!(CubicBezier);次にメソッド。
methods!( CubicBezier, rtself, fn cubic_bezier_new(a0: Float, a1: Float, a2: Float, a3: Float) -> CubicBezier { let a0 = a0.unwrap().to_f64(); let a1 = a1.unwrap().to_f64(); let a2 = a2.unwrap().to_f64(); let a3 = a3.unwrap().to_f64(); let rcb = RustCubicBezier{a0: a0, a1: a1, a2: a2, a3: a3}; Class::from_existing("CubicBezier").wrap_data(rcb, &*CUBIC_BEZIER_WRAPPER) } fn value_at(t: Float) -> Float { let t = t.unwrap().to_f64(); Float::new(rtself.get_data(&*CUBIC_BEZIER_WRAPPER).value_at(t)) } );
methods!マクロの定義はこちら:
https://docs.rs/rutie/0.7.0/src/rutie/dsl.rs.html#356-398前回分からなかった,
methods!マクロの第二引数の意味がおぼろげに分かりそうになった(後述)。ここでは二つのメソッドを定義する。
cubic_bezier_newはインスタンスの生成(これがnewになる)。
value_atはtに対してベルンシュテイン関数の値を計算するもの。前回も書いたけど,この関数定義は,
methods!マクロの引数であって,これがそのまま Rust の関数になるわけではない。マクロの働きで Rust の関数定義になるのだが,その際にゴニョゴニョやっている。
Rust のマクロをよく知っている人なら,上記リンク先を見ればだいたい理解できると思う。
cubic_bezier_newの中では,引数に基づいて,wrap すべきRustCubicBezier型の構造体を生成している。
最終行のClass::from_existing("CubicBezier").wrap_data(rcb, &*CUBIC_BEZIER_WRAPPER)が肝なのだが,これまたよく分からない。
Class::from_existing("CubicBezier")は,要するにCubicBezierクラスを得ているらしい。Ruby でいうところのconst_get("CubicBezier")みたいなもんか?
wrap_dataのドキュメントはここ(いつか読む):
rutie::Class - Rust
value_atのほうはだいぶ分かりやすい。
肝はrtself.get_data(&*CUBIC_BEZIER_WRAPPER)のところ。ここでようやく
methods!マクロの第二引数rtselfが出てきた。
この式は,wrap した RustCubicBezier 構造体を返すようだ。
rtselfはたぶん Ruby の self みたいな役割のものだろう。初期化関数の定義
前回と同じ注意書きを。「初期化関数」というのは私が仮に名付けたもので,適切でないかもしれない。
#[allow(non_snake_case)] #[no_mangle] pub extern "C" fn Init_cubic_bezier() { Class::new("CubicBezier", None).define(|klass| { klass.def_self("new", cubic_bezier_new); klass.def("value_at", value_at); klass.def("[]", value_at); }); }
Init_cubic_bezierという名前の,外部から呼び出せる関数を定義している。
たぶん,これを実行することによって,実際に Ruby のクラスやメソッドが出来るのだと思う。クラスメソッドには
def_selfを用い(これは前回と同じ),インスタンスメソッドにはdefを使うようだ。
Rust 側のvalue_atに対し,Ruby 側でvalue_atおよび[]を割り当てている。これで,CubicBezier#value_atとCubicBezier#[]がエイリアスのようになる。ふー,まあ理解のおぼつかない箇所も少なくないけど,サンプルコードを参考にどうにかこうにか Rust 側のコードが出来た。
「原理が分かってないが何となく使えるものを組み合わせて動く」コードというのは 999 の機関車みたい4。コンパイル
プロジェクトのルートディレクトリーで
cargo build --releaseとやると,
target/release/libmy_rutie_math.dylibが出来る。ただし,拡張子は Linux だとたぶん.soだし,Windows だとたぶん.dllになる(.dylibなのは macOS の場合)。
Ruby 側で利用するのはこのファイルだけ。実装:Ruby 側
Rust 側のコードがいくぶんややこしかったのに対し,Ruby 側のコードはいたってシンプル。
前回同様,以下のコードは,Rust のプロジェクトのルートディレクトリーに存在するとする。
(そうでない場合は,適宜initメソッドの第二引数(あるいはそれとRutie.newのlib_path)を適切に。require "rutie" Rutie.new(:cubic_bezier, lib_path: "target/release").init "Init_cubic_bezier", __dir__ cb = CubicBezier.new(1.0, 2.0, 1.5, 0.0) 0.0.step(1, by: 0.1) do |t| puts cb[t] endこれで,3 次ベジエの計算が Ruby でできるようになった。
えっと,まともに使う場合は上のように横着せず,GemfileにGemfilegem "rutie", "~> 0.0.4"とかって書いて
Bundle.requireしてね。おまけ:ベジエ曲線の絵を描かせる
せっかくベジエ曲線の計算ができるようになったので,絵を描かせておこう。
Cairo を使う。require "rutie" require "cairo" Rutie.new(:cubic_bezier, lib_path: "target/release").init "Init_cubic_bezier", __dir__ size = 400 surface = Cairo::ImageSurface.new Cairo::FORMAT_RGB24, size, size context = Cairo::Context.new surface context.rectangle 0, 0, size, size context.set_source_color :white context.fill points = [[50, 100], [100, 300], [300, 350], [350, 50]] bezier_x = CubicBezier.new(*points.map{ |x, _| x.to_f }) bezier_y = CubicBezier.new(*points.map{ |_, y| y.to_f }) context.set_source_color :gray context.set_line_width 2 context.move_to(*points[0]) context.line_to(*points[1]) context.move_to(*points[2]) context.line_to(*points[3]) context.stroke n = 100 # 分割数 context.set_source_color :orange (1...n).each do |i| t = i.fdiv(n) context.circle bezier_x[t], bezier_y[t], 1.5 context.fill end context.set_source_color :red points.each do |x, y| context.circle x, y, 4 context.fill end surface.write_to_png "bezier.png"解説は略す(質問は歓迎)。
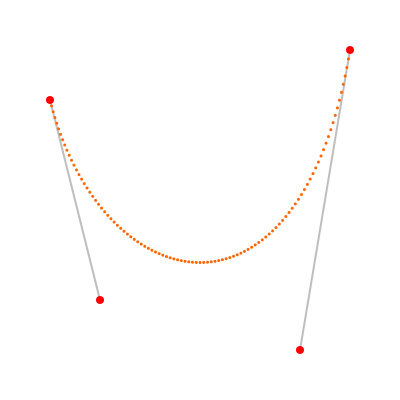
こんな絵が出来た。
赤い点は 3 次ベジエ曲線を規定する四つの点。灰色の線分は接ベクトル。オレンジの小さな点は,
CubicBezier#[]で計算した,ベジエ曲線上の点だ。
このオレンジの点の並びを見て,「ああ,なんかちゃんと計算できてるぽい」と分かる。ベンチマークテスト
さあ,いよいよベンチマークテストの時間ですよ。
そもそも今回の試みの目的の一つは,Rust によって高速化する実例を探ることだったんだからね。今回も benchmark_driver を使うので,まだインストールしてない人は
gem i benchmark_driverでインストールを。
テスコード
require "benchmark_driver" Benchmark.driver do |r| r.prelude <<~PRELUDE require "rutie" Rutie.new(:cubic_bezier, lib_path: "target/release").init "Init_cubic_bezier", "#{__dir__}" class RubyCubicBezier def initialize(x0, x1, x2, x3) @x0, @x1, @x2, @x3 = x0, x1, x2, x3 end def [](t) s = 1.0 - t @x0 * s * s * s + 3.0 * @x1 * t * s * s + 3.0 * @x2 * t * t * s + @x3 * t * t * t end end xs = [0.12, 0.48, 0.81, 0.95] rust_cubic_bezier = CubicBezier.new(*xs) ruby_cubic_bezier = RubyCubicBezier.new(*xs) PRELUDE r.report "rust_cubic_bezier[0.78]" r.report "ruby_cubic_bezier[0.78]" endこれを走らせ,Ruby による実装と Rust による実装の比較をする。
あらかじめ言っておくと,Ruby から Rust を呼ぶためのコストがあるので,Rust 版のほうが遅い,という可能性は十分にある。さて,結果はというと:
rust_cubic_bezier[0.78]: 6731741.2 i/s ruby_cubic_bezier[0.78]: 4733084.6 i/s - 1.42x slowerか,勝った,Rust 版が勝ったぞ! ひゃほーい!!
まあ,1.4 倍速程度なので,大したことない,と言えば,ない。はっきり言って。
しかし,この程度の(わりと単純な)関数でも Rust で高速化できることを示せた意義はあると思う。
また,それが数十行程度の Rust コードで実現できる,という点にも希望が持てた。今後はもっといろいろな処理を Rust でやらせてみて実用性を探っていきたい。
この多項式の名前は英語風の「バーンスタイン多項式」とかドイツ語風の「ベルンシュタイン多項式」と書かれることもあるが,旧ソビエト連邦の数学者 Бернштейн にちなむので,ロシア語風に「ベルンシュテイン多項式」とした。Wikipedia の セルゲイ・ベルンシュテイン によれば,出身地は黒海に面した都市オデッサ。現在はウクライナ共和国だが,当時はロシア帝国であったらしい。なお,この姓はイディッシュ語(ユダヤドイツ語)で琥珀の意である。 ↩
原文で「contain」となっていたので「含む」としたが,単に「値として持つ」(〜が代入されている)という意味だろうか? ↩
音楽に疎くヒップホップとか全く知らないんで,ラップの歌詞がこういうものなのかどうか分からんけどテキトーに作詞してみた。 ↩
松本零士作『銀河鉄道999』に出てくる銀河超特急 999 号の機関車は,宇宙の遺跡から発見された未知の文明による技術(中身はいまひとつ分からないが,どうにか使えるもの)を組み合わせて作られている。確かそういう設定だったはず。 ↩
- 投稿日:2020-09-10T01:35:30+09:00
rails newする際のオプションとrails newした後に行う設定
個人的に「
rails newをする際によく使うな」と感じるオプションと、新規プロジェクトを作成したときによく行う設定を備忘録を兼ねてまとめます。rails newをする際のオプション
まずは
rails newをする際によく付けるオプションについてです。
一つ一つのオプションについては後述します。rails _6.0.3.2_ new appname --database=mysql --skip-testrailsのバージョン指定
rails _6.0.3.2_ newこうするとrailsのバージョンを指定することができます。
_6.0.3.2_の部分はその都度値を変えてください。使用するデータベースの指定
--database=mysqlこのようにDBを指定しないと、デフォルトのDBは
sqliteというものになります。
今回はmysqlを使用する設定です。Minitestを生成しない
--skip-testデフォルトでプロジェクトを生成すると、Minitestというものが作られます。
私自身、テストにはRSpecを使用することが多いため、上記のようにMinitestを生成しないようにしています。rails newした後に行う設定
ここからは実際に
rails newをした後の設定となります。
rails gコマンド使用時に、不要ファイルを生成しないように設定config/application.rbmodule appname class Application < Rails::Application # 以下を追加 config.generators do |g| g.stylesheets false g.javascripts false g.helper false g.test_framework false end config.time_zone = "Tokyo" config.i18n.default_locale = :ja end end今回主に追加したのは下記の部分です。
config.generators do |g| g.stylesheets false g.javascripts false g.helper false g.test_framework false end
rails gコマンドでコントローラを作成すると、ファイルが自動的に生成されてしまいますが、不要なもの(coffeeやcss)を生成しないようにするのがこの記述です。
rails gコマンドは開発の過程で頻繁に使用するものなので、この設定を最初に済ませておくと非常に楽になります。config.time_zone = "Tokyo" config.i18n.default_locale = :jaまた、こちらでデフォルトの言語を日本語にし、タイムゾーンのデフォルトを東京に設定します。
- 投稿日:2020-09-10T00:39:22+09:00
二重ハッシュより値を取り出し、ゲッターにより出力致します。
class Fruits def initialize(name, color, variety) #仮引数(第一引数, 第二引数, 第三引数) #initializeメソッドは新たな呼び出しは不要です。 @name = name #インスタンス変数を定義 @color = color @variety = variety end def name #ゲッター(ゲッターメソッド名は、クラス外で出力する際に用いますので、重要です。) @name #インスタンスの値を取得している end def color #同じくゲッター @color end def variety @variety end end class InfoFruits #呼び出しが必要です。 def initialize(fruits) #インスタンス変数の定義 @fruits = fruits end def fruits #ゲッター @fruits #インスタンス変数の値の取得 #実引数三つ分の配列です。 end def info_fruits self.fruits.each do |fruit| #eachメソッドは配列の要素の数だけ、繰り返し処理を行います。 #self.fruitsはインスタンスの値、実引数三つ分の配列です。 puts "#{fruit.name}は#{fruit.color}です。品種は#{fruit.variety}です。" #ゲッターで取得しました値の出力の際は**インスタンス名.ゲッターメソッド名**と記述致します。 end end end array = [{info:{info_fruit_name: "りんご", info_fruit_color: "赤色"}}, #配列の中に二重ハッシュが含まれています。 {info:{info_fruit_name: "バナナ", info_fruit_color: "黄色"}}, {info:{info_fruit_name: "ぶどう", info_fruit_color: "紫色"}}] fruits = [] array.each do |double_hash| #eachメソッドは配列の要素の数だけ処理を繰り返し行います。 fruit_name = double_hash[:info][:info_fruit_name] #二重ハッシュの場合、keyを二つ選択することにより、目的のvalueの取得に成功いたします。 fruit_color = double_hash[:info][:info_fruit_color] puts "#{fruit_name}の品種はどちらになりますか?" double_hash[:info][:info_fruit_variety] = gets.chomp #ハッシュに新たなkeyを指定してあげることで、新たなvalueの追加が可能となります。 fruit_variety = double_hash[:info][:info_fruit_variety] if fruit_variety == "シャインマスカット" #条件分岐 fruit_color = "緑色" end fruits << Fruits.new(fruit_name, fruit_color, fruit_variety) #実引数をFruitsクラスに渡し、インスタンスを生成すると同時に、initializeメソッドが処理を行いインスタンス変数を定義し、その値をゲッターにより取得します。 #仮引数と実引数の数は合わせます。#値を取得することにより、クラスのスコープ外で出力が可能となります。出力の際は**インスタンス名.ゲッターメソッド名**と記述致します。 end info_fruit = InfoFruits.new(fruits) #三つ分の実引数を持った、配列fruitsをInfoFruitsクラスに渡し、インスタンスを生成し、initializeメソッドが処理を行い、インスタンス変数を定義、ゲッターにより、その値を取得します。 info_fruit.info_fruits #info_fruitsインスタンスメソッドの呼び出しです。#出力結果 りんごの品種はどちらになりますか? ふじ バナナの品種はどちらになりますか? ジャイアント・キャベンディッシュ ぶどうの品種はどちらになりますか? 巨峰 りんごは赤色です。品種はふじです。 バナナは黄色です。品種はジャイアント・キャベンディッシュです。 ぶどうは紫色です。品種は巨峰です。#出力結果 りんごの品種はどちらになりますか? ふじ バナナの品種はどちらになりますか? ジャイアント・キャベンディッシュ ぶどうの品種はどちらになりますか? シャインマスカット りんごは赤色です。品種はふじです。 バナナは黄色です。品種はジャイアント・キャベンディッシュです。 ぶどうは緑色です。品種はシャインマスカットです。誤っている箇所、認識が不足している部分について、ご指摘頂ければ幸いに存じます。