- 投稿日:2020-09-10T22:45:17+09:00
AWS上にサーバーを作る(その02:Amazon VPC)
前回の投稿
AWS上にサーバーを作る(その01)AWSのネットワーク
AWS上にサーバーを作るあたり、AWSにはどんなネットワーク設定が必要なのだろう?
「VPC」っていう名称だけはよく聞くよね。
公式のドキュメント「Amazon VPC とは?」を見ると、
- Amazon VPC(Amazon Virtual Private Cloud)
- サブネット
- ルートテーブル
- ゲートウェイ
このあたりが必要っぽい。
Amazon VPC(Amazon Virtual Private Cloud)
そもそもVPCって何だろう?
物理サーバーしかいじった事のない僕にとっては、今回が「初めまして」だね。Amazon VPC とは?
Amazon Virtual Private Cloud (Amazon VPC) を使用すると、定義した仮想ネットワーク内で AWS リソースを起動できます。仮想ネットワークは、お客様自身のデータセンターで運用されていた従来のネットワークによく似ていますが、AWS のスケーラブルなインフラストラクチャを使用できるというメリットがあります。とドキュメントに記載があった。
どうやら、
- 自分のAWSアカウント専用
- サーバーを立てるために必要な設定
- AWS上に作る仮想でできたネットワーク
という事らしい。
サーバーを作るには必須のサービスなんだね。
そこでやっぱり気になるのがAmazon VPCの料金。Amazon VPC の料金表
Amazon VPC は追加料金なしで使用できます。使用するインスタンスおよびその他の Amazon EC2 機能に対して標準料金がかかります。Site-to-Site VPN 接続、PrivateLink、トラフィックのミラーリング、NAT ゲートウェイの使用には料金がかかります。ほほう。
VPC自体は無料だけど、僕がやろうとしている拠点間VPNについては料金がかかるってことか。
それからVPC上に立てたEC2の通信量が合算されるってことね。
じゃあいくらかかるんだろう??AWS サイト間 VPN および Accelerated サイト間 VPN への接続料金
サイト間 VPN 接続ごとに 0.048USD/時間 ※東京リージョン30日間、1日24時間アクティブになるはずなので、AWSサイト間VPN接続料金は、
0.048USD/時間 × 24時間 × 30日 = 34.56USD/月 = 約3,800円/月
となることが予想される。(他にEC2の通信量が発生する予定)
・・・「結構高いな」っていう印象。
使わない時、止めておくとかできるかな・・・??サブネット
ようやく見慣れたワード、「サブネット」。
念のため、Amazon VPC の概念で確認するとサブネット — VPC の IP アドレスの範囲。
と書いてある。
VPCを作成するときに一緒に設定するんだね。ルートテーブル
これも知ってる。
このIPアドレス帯の通信がきたら、どこに接続させる?みたいなやつだね。
Amazon VPC の概念によるとルートテーブル — ネットワークトラフィックの経路を判断する際に使用される、ルートと呼ばれる一連のルール。
使うのはこっち(仮想プライベートゲートウェイへのルーティング)かな?
ゲートウェイ
VPCを作っただけだと、インターネットなど、VPCの外にはつながらないらしい。
そこで、このゲートウェイを作り、通信の出入り口にすることになります。
僕はプライベートゲートウェイとカスタマーゲートウェイを作ることになるのかな?次回の内容
そろそろAWSの作業できる??
(まだ引っ張る)To be continued...
- 投稿日:2020-09-10T22:18:21+09:00
AWSを使ってアプリケーションを公開する手順(5)アプリケーションを公開する
はじめに
AWSを使ってアプリケーションを公開する手順を記載していく。
この記事ではアプリケーションを公開する。EC2のサーバにアプリケーションのコードをクローンする準備
「.ssh」ディレクトリに移動する
以下のコマンドを実行し、「.ssh」ディレクトリに移動する。
cd ~/.ssh/ssh接続
以下のコマンドを実行し、EC2インスタンスにsshでアクセスする。
(ダウンロードしたpemファイル名が「xxx.pem」、ElasticIPが123.456.789の場合)ssh -i xxx.pem ec2-user@123.456.789GithubにSSH鍵を登録する
EC2インスタンスからGithubにアクセスするために、EC2インスタンスのSSH公開鍵をGithubに登録する必要がある。
SSH鍵を登録しないとpermission errorとなりクローンできない。SSH鍵をGithubに登録することで認証されるようになりコードのクローンが可能になる。以下のコマンドを実行し、EC2サーバのSSH鍵ペアを作成する。
ssh-keygen -t rsa -b 4096以下のコマンドを実行し生成されたSSH公開鍵を表示し、値をコピーする。
cat ~/.ssh/id_rsa.pub以下のURLにアクセスすると画像のような画面に遷移する。
https://github.com/settings/keys
「Title」欄に任意のタイトルを記入、「Key」欄に先ほどコピーしたSSH公開鍵をペーストし、「Add SSH key」をクリックする。
以下のコマンドを実行しSSH接続できるか確認する。
ssh -T git@github.comPermission denied (publickey).と表示された場合にはSSH鍵の設定が間違っている。
「ssh-keygen」コマンドのオプションについて
「ssh-keygen」コマンドは公開鍵認証方式の秘密鍵と公開鍵を作成するコマンドである。
「-t」は作成する鍵の暗号化形式を「rsa」「dsa」「ecdsa」「ed25519」から指定するオプションである。
「-b」は作成する鍵のビット数を指定するコマンドである。
つまり上記のコマンドはRSA暗号化形式で4096ビットの鍵を生成するという意味である。アプリケーションサーバの設定
アプリケーションサーバとはブラウザからリクエストを受けてアプリケーションを動作させるソフトウェアである。
例えばローカル環境でRuby on Railsのアプリケーションの動作を確認する時、「rails s」というコマンドを入力する。これにより「puma」というアプリケーションサーバが起動する。
この状態でブラウザから「localhost:3000」にアクセスすることでrailsアプリケーションの動作確認を行うことができる。(localhost:3000は自身のPCを指す)同様に、EC2サーバ上でアプリケーションを動作させるためには、EC2サーバ上でアプリケーションサーバを起動する必要がある。
Unicornをインストールする
よく利用されるアプリケーションサーバの一つに、Unicornがある。Unicornは「rails s」コマンドの代わりに「unicorn_rails」コマンドで起動できる。
UnicornはRubyで作成されており、gem化されている。
Gemfileに以下の記述を追記する。
Unicornは本番環境のみで使用するので開発環境では不要。Gemfilegroup :production do gem 'unicorn', '5.4.1' endアプリケーションのディレクトリで以下のコマンドを実行する。
bundle installconfigディレクトリ直下に下記のようなUnicornの設定ファイルを作成する。
config/unicorn.rb#サーバ上でのアプリケーションコードが設置されているディレクトリを変数に入れておく app_path = File.expand_path('../../', __FILE__) #アプリケーションサーバの性能を決定する worker_processes 1 #アプリケーションの設置されているディレクトリを指定 working_directory app_path #Unicornの起動に必要なファイルの設置場所を指定 pid "#{app_path}/tmp/pids/unicorn.pid" #ポート番号を指定 listen 3000 #エラーのログを記録するファイルを指定 stderr_path "#{app_path}/log/unicorn.stderr.log" #通常のログを記録するファイルを指定 stdout_path "#{app_path}/log/unicorn.stdout.log" #Railsアプリケーションの応答を待つ上限時間を設定 timeout 60 preload_app true GC.respond_to?(:copy_on_write_friendly=) && GC.copy_on_write_friendly = true check_client_connection false run_once = true before_fork do |server, worker| defined?(ActiveRecord::Base) && ActiveRecord::Base.connection.disconnect! if run_once run_once = false # prevent from firing again end old_pid = "#{server.config[:pid]}.oldbin" if File.exist?(old_pid) && server.pid != old_pid begin sig = (worker.nr + 1) >= server.worker_processes ? :QUIT : :TTOU Process.kill(sig, File.read(old_pid).to_i) rescue Errno::ENOENT, Errno::ESRCH => e logger.error e end end end after_fork do |_server, _worker| defined?(ActiveRecord::Base) && ActiveRecord::Base.establish_connection endプロセスとは
プロセスとはPC(サーバ)上で動く全てのプログラムの実行時の単位のことを指す。ここでいうプログラムとはブラウザや音楽再生ソフト、ExcelなどのGUIやRubyなどのスクリプト言語の実行などが含まれる。プログラムが動いている数だけプロセスが存在する。
workerとは
Unicornはプロセスを分裂させることができる。分裂したプロセスをworkerと呼ぶ。プロセスを分裂させることでリクエストに対するレスポンスを高速にすることができる。worker_processesという項目でworkerの数を設定する。
ブラウザなどからリクエストが来るとUnicornのworkerがrailsアプリケーションを動かす。railsはリクエストの内容とルーティングを照らし合わせ最終的に適切なViewまたはjsonをレスポンスする。レスポンスを受け取ったUnicornはそれをブラウザに返す。この一連の流れは0.1〜0.5秒程度で行われる。常にそれ以上のスピードでリクエストが頻発するようなアプリケーションだと一つのworkerだけでは処理が追いつかずレスポンスまで長い時間がかかってしまったり、サーバが止まってしまうことがある。worker_processesの数を増やすことでアプリケーションのレスポンスを早くすることができる。Unicornの設定
設定項目 詳細 worker_processes リクエストを受付レスポンスを生成するworkerの数を決める working_directory Unicornがrailsのコードを動かす際、ルーティングなど実際に参照するファイルを探すディレクトリを指定する。 pid Unicornが起動する際にプロセスidが書かれたファイルを生成する場所を指定する。 listen どのポート番号のリクエストを受け付けるかを指定する。 Uglifierについての記述をコメントアウトする
UglifierというJavascriptを軽量化するためのgemがある。
Javascriptでテンプレートリテラル記法(`)を利用している場合、Uglifierはこれに対応していないのでデプロイ時にエラーの原因となるためコメントアウトする。config/environments/production.rbの以下の記述をコメントアウトする。
config/environments/production.rb# config.assets.js_compressor = :uglifier変更修正をリモートリポジトリに反映する
ファイルをコミットし、Githubにプッシュする。
ブランチを切っている場合にはmasterブランチにマージする。Githubからコードをクローンする
Unicornの設定を済ませたコードをEC2インスタンスにクローンする。
/var/wwwディレクトリを作成する
EC2インスタンスにSSH接続した後、以下のコマンドを実行し、/var/wwwディレクトリを作成する。
sudo mkdir /var/www/権限をec2-userに変更する
以下のコマンドを実行し、作成したwwwディレクトリの権限をec2-userに変更する。
sudo chown ec2-user /var/www/GithubからリポジトリURLを取得する
Githubのアプリケーションのページに移動し、以下の画像を参考にリポジトリURLをコピーする。
コードをクローンする
以下のコマンドを実行してコードをクローンする。
(以下の例はGithubのuser名が「test1234」、リポジトリ名が「testapp」の場合)cd /var/www/git clone https://github.com/test1234/testapp.git(先ほどコピーしたリポジトリURL)本番環境の設定
サービスを公開するための設定を行っていく。
EC2の能力を拡張する
現状のEC2インスタンスはメモリが足りず、gemのインストール時などにエラーが発生する可能性がある。
そこでまずはメモリを増強する。Swap領域を用意する
コンピュータが処理を行う際、メモリと呼ばれる場所に処理内容が一時的に記録される。メモリは容量が決まっておりそれを超えてしまうとエラーで処理が止まってしまう。Swap領域はメモリが使い切られそうになった時にメモリの容量を一時的に増やすために準備されるファイルである。
EC2はデフォルトではSwap領域が用意されていないため、これを用意することでメモリ不足のエラーを防ぐ。EC2インスタンスにSSH接続し、ホームディレクトリに移動する。
cd以下のコマンドを順に実行していき、Swap領域を確保する。
sudo dd if=/dev/zero of=/swapfile1 bs=1M count=512sudo chmod 600 /swapfile1sudo mkswap /swapfile1sudo swapon /swapfile1sudo sh -c 'echo "/swapfile1 none swap sw 0 0" >> /etc/fstab'gemをインストールする
クローンしたアプリケーションを起動するために必要なgemをインストールする。
以下のコマンドを実行し、クローンしたアプリケーションのディレクトリに移動する。
cd /var/www/testapp以下のコマンドを実行し、rbenvでインストールしたRubyのバージョンが使用されているかチェックする。
ruby -v本番環境でgemを管理するためのbundlerをインストールする
ローカル環境で以下のコマンドを実行し、開発環境で使用しているbundlerのバージョンを確認する。
bundler -v開発環境によってバージョンは異なるが、今回は2.0.1であったとする。
同じバージョンのものを本番環境にも導入するために、再度EC2インスタンスにSSH接続し、下記のコマンドを実行する。gem install bundler -v 2.0.1(ローカル環境と同じバージョン)bundle install環境変数の設定をする
データベースのパスワードなどセキュリティのためにGithubにアップロードできない情報は環境変数を利用して設定する。
環境変数はrailsでは「ENV['<環境変数名>']」という記述でその値を利用することができる。secret_key_baseを作成する
secret_key_baseとは、Cookieの暗号化に用いられる文字列である。railsアプリケーションを動作させる際は必ず用意する必要がある。外部に漏らしてはいけない値なので環境変数から参照する。
下記のコマンドを実行し、secret_key_baseを作成する。
コマンドを実行すると長い文字列が生成されるのでこれをコピーしておく。rake secretEC2インスタンスに環境変数を設定する
環境変数は/etc/environmentというファイルに保存することでサーバ全体に適用される。環境変数の書き込みはvimコマンドを用いて行う。
下記のコマンドを実行し/etc/enrvironmentを編集する。
sudo vim /etc/environment/etc/environmentを以下のように編集する。
/etc/environmentDATABASE_PASSWORD='<MySQLのrootユーザのパスワード>' SECRET_KEY_BASE='<先ほどコピーしたsecret_key_base>'編集し保存したら下記のコマンドを実行し、一度ログアウトする。
exit再度EC2インスタンスにSSH接続する。
下記のコマンドを実行し、環境変数が適用されているか確認する。env | grep DATABASE_PASSWORDenv | grep SECRET_KEY_BASEポートを解放する
立ち上げたばかりのEC2インスタンスはSSHでアクセスすることはできるがHTTPなどのその他の通信方法では一切接続できないようになっている。そのため、WEBサーバとして利用するEC2インスタンスは事前にHTTPがつながるようにポートを開放しておく必要がある。
ポートの設定をするためにはEC2のセキュリティグループという設定を変更する必要がある。
セキュリティグループとはEC2サーバが属するまとまりのようなもので、複数のEC2インスタンスのネットワーク設定を一括で行うためのものである。AWSにログインし、EC2インスタンス一覧画面から対象のインスタンスを選択し、セキュリティグループのリンクをクリックする。
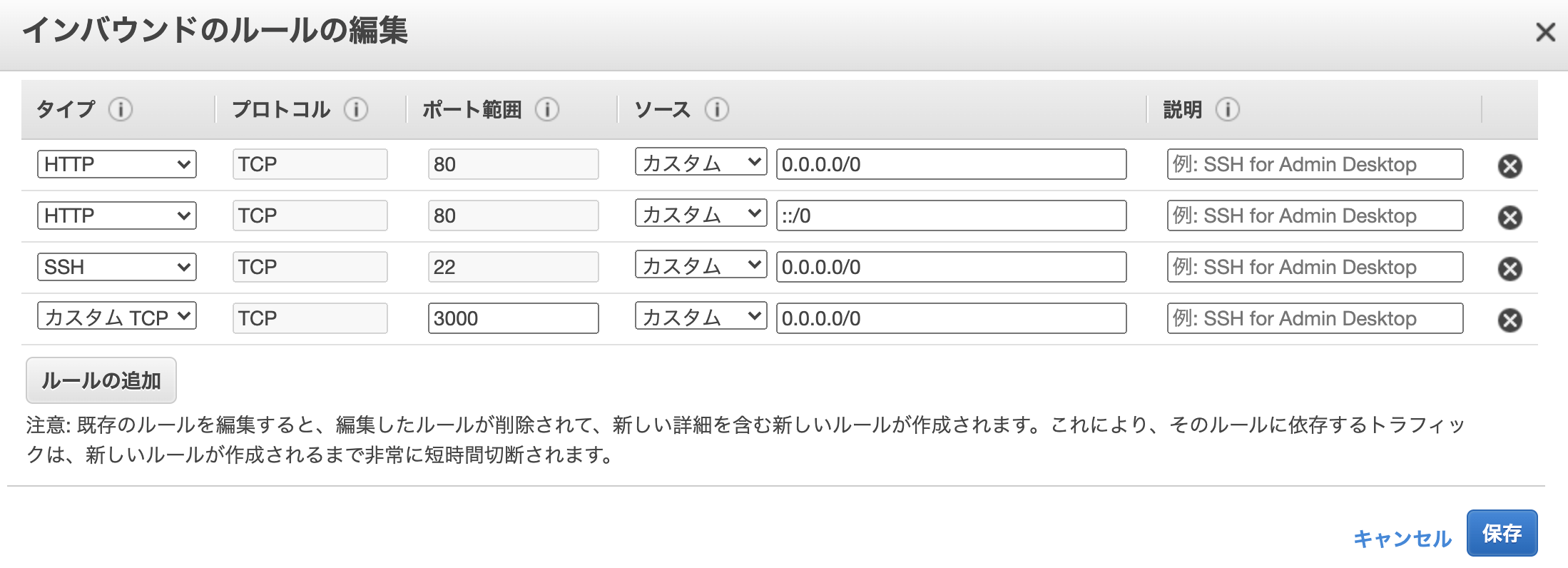
セキュリティグループの設定画面に遷移するのでインバウンドタブの編集をクリックする。
インバウンドのルールの編集ポップアップ画面が表示されたら、ルールの追加をクリックし、タイプを「カスタムTCPルール」、プロトコルを「TCP」、ポート範囲を「3000」、送信元を「カスタム」・「0.0.0.0/0」に設定する。
本番環境でrailsを起動する
本番環境でrailsを起動する前に、現状、開発環境と本番環境でMySQLの設定が異なるため、開発環境のMySQLの設定を本番環境に合わせる。
開発環境のconfig/database.ymlを以下のように編集し、コミット、Githubにプッシュする。
config/database.ymlproduction: <<: *default database: ~~~(それぞれのアプリケーション名によって異なるのでこれは編集しない) username: root password: <%= ENV['DATABASE_PASSWORD'] %> socket: /var/lib/mysql/mysql.sockEC2インスタンスにSSH接続し、下記のコマンドを実行する。
git pull origin master以下のコマンドを実行し、アプリケーションのディレクトリに移動する。
cd /var/www/testapp以下のコマンドを実行し、データベースを作成する。
rails db:create RAILS_ENV=production以下のコマンドを実行し、マイグレーションを実行する。
rails db:migrate RAILS_ENV=productionもしここでMysql2::Error: Can't connect to local MySQL server through socketというエラーが発生した場合にはMySQLが起動していない可能性があるため、以下のコマンドを実行し、MySQLの起動を行う。
sudo service mysqld start以下のコマンドを実行し本番環境でunicornを起動する。
「-c config/unicorn.rb」は設定ファイルの指定、「-E production」は本番環境で操作させることを意味する。
「-D」はDaemonの略で、プログラムを起動させつつターミナルで別のコマンドを打てるようにするコマンドである。bundle exec unicorn_rails -c config/unicorn.rb -E production -Dここで、ブラウザで http://123.456.789:3000/ にアクセスしてみる。(Elastic IPが123.456.789の場合)
cssが反映されていない画面が表示されていれば成功。アセットファイルをコンパイルする
開発環境ではアクセスごとにアセットファイル(image、css、javascript)を自動でコンパイルする仕組みが備わっているが、本番環境ではパフォーマンスのためアクセスごとに実行されないようになっている。
よって、本番環境では事前にアセットをコンパイルする必要がある。
以下のコマンドを実行し、アセットをコンパイルする。rails assets:precompile RAILS_ENV=productionコンパイルが成功したら反映を確認するためrailsを再起動する。
まず、ターミナルからUnicornのプロセスを確認しプロセスをkillする。以下のコマンドを実行しUnicornのコマンドを確認する。
psコマンドは現在動作しているプロセスを確認するためのコマンドで、auxはpsコマンドの表示結果を見やすくするオプションである。
| grep unicornとすることでpsコマンドの結果からunicorn関連のプロセスのみを抽出している。ps aux | grep unicorn表示結果からunicorn_rails masterのPIDを確認する。ここでは例として「17877」だったとする。
以下のコマンドを実行しUnicornのプロセスを停止する。
kill 17877下記のコマンドを実行し、再度Unicornを起動する。このときRAILS_SERVE_STATIC_FILES=1を先頭に付ける。これによりコンパイルされたアセットをUnicornが見つけられるようになる。
RAILS_SERVE_STATIC_FILES=1 unicorn_rails -c config/unicorn.rb -E production -D再度ブラウザで http://123.456.789:3000/ にアクセスしてみる。(Elastic IPが123.456.789の場合)
今度はcssが反映された状態で画面が表示されるはず。railsの起動がうまくいかない時に確認すること
- プッシュのし忘れ、EC2サーバのプルのし忘れ
- EC2サーバ側で/var/www/testapp/log/unicorn.stderr.logを確認しエラーが出ていないか確認する
- MySQLの起動は正しく行えているか
- SECRET_KEY_BASE等が正しく設定できているか
- EC2インスタンスの再起動を行ってみる
参考

- 投稿日:2020-09-10T19:55:57+09:00
Railsアプリを独自ドメインでssl公開した手順
概要
今回そこそこ苦戦しながらポートフォリオのSSL対応したので忘れないうちに手順を書き留めておく。
殴り書き程度なのでこれを読んでSSL対応は難しいと思われます。前提
- EC2にRailsアプリをデプロイ済
- Nginx等のWebサーバーでhttpで外部公開している
- 独自ドメインを取得している。
- VPCなどで適切なネットワークを構築済
- httpですでにアプリケーションにアクセスできる
本題
1.
ACMでSSL証明書のリクエストを行う。
ここでリクエストするドメイン名が公開するドメイン名と違うとSSL化しないので注意リクエストするドメインがRoute53でレコード作成済だとCレコードの登録を勝手にやってくれるボタンが出るので便利
ex)
実際のサイトのドメイン www.hogehoge.com
証明書申請したドメイン hogehoge.com上の例だとドメインが違うためアウト
おすすめはサブドメインにワイルドカードを指定して *.hogehoge.com
とすること
こうすることでwww.hogehoge.comやunko.hogehoge.comなど様々なサブドメインに対応できる。2.
EC2のELB(ロードバランサー)を設定する。
- リスナー: https
- ターゲット: EC2のインスタンス(http)
- VPCとサブネット: 設定しているやつを入れとく
- 証明書: 1で申請した証明書を入れる。
3.
心配な場合はロードバランサーのDNSにアクセスしてアプリケーションが開けるかどうか確認4.
Route53でロードバランサーへのエイリアスを貼る
www.hogehoge.comとかでロードバランサーにアクセスするようAレコード(エイリアス)を作成する5.終わり
補足
・ELBの作成や証明書の認証などこの辺りはやたらと処理に時間がかかる模様で、設定はできてるのにうまく動かないとやたら焦ることもあるが気長に待つとなんかうまくいったりするので待ちの姿勢も重要。
・今回のSSL対応はあくまで外部とロードバランサーとの間をSSL化しているため、アプリケーションとロードバランサー間はhttp通信である。よってEC2側のWebサーバーの設定はhttpのままで一切いじる必要なし。ここを勘違いすると沼る
・当たり前っちゃ当たり前だけどロードバランサーにアタッチするセキュリティグループではインバウンドルールで443ポート(https)を許可していないと弾かれてアクセスできない。
ここらへんのセキュリティグループの設定もうまくいかなかったら見直す。・うまくいかなかったらぐぐる。
最後に
本当に殴り書きなので間違ってたりおかしかったりするところがあれば連絡ください?
また、同じような境遇の方がいてもし詳しく聞きたいことがあればできる限りお答えします
こちらのTwitterアカウントのDMやリプで連絡ください
https://twitter.com/TakeWeb1
- 投稿日:2020-09-10T19:43:28+09:00
【LINUXカーネル再構築】バージョンアップ(4.18.0→5.8.8)
目標
AWS EC2(Red Hat Enterprise Linux 8 (HVM), SSD Volume Type)に搭載されているカーネルのバージョンアップ(4.18.0→5.8.8)を完了すること。
前提
AWS EC2サーバ1台(Red Hat Enterprise Linux 8 (HVM), SSD Volume Type)が構築済みであること。
なお、カーネル再構築はコンパイルやインストール時にある程度高いシステムリソース(CPU、メモリ等)を用意した方が時間短縮されスムーズになります。
また、ある程度のディスク容量がないとコンパイル時にエラーとなる可能性があります。
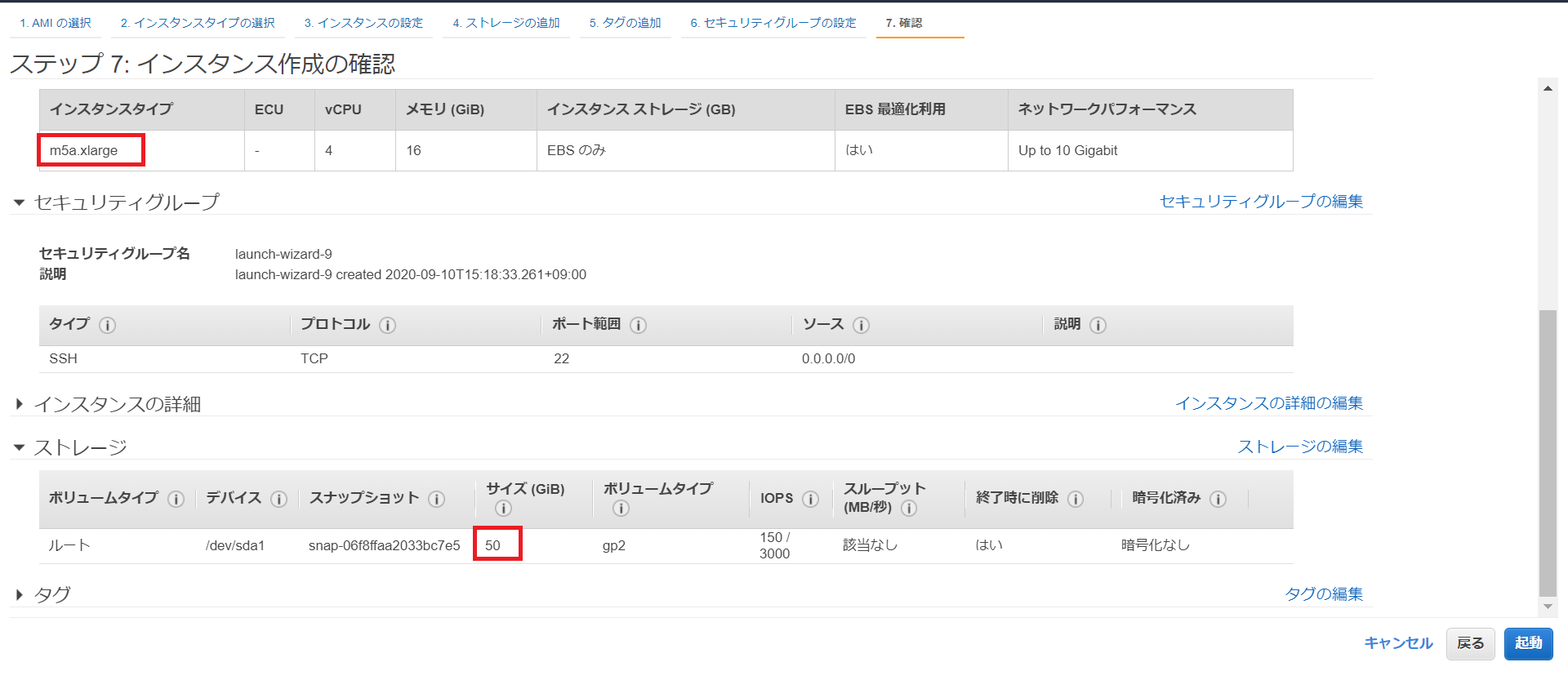
本記事ではインスタンスタイプm5a.xlarge(0.344USD/時間)、ディスク容量は50GBとしました。
また、コンパイルやインストールにはスペックにもよりますが1時間以上かかる可能性があることを留意してください。カーネル再構築とは(LPICテキストより)
カーネルを必要に応じてコンパイルし、インストールすることを「カーネルの再構築」といいます。
以下のパターンにおいて、カーネル再構築を検討する必要があるようです。・必要なデバイスドライバ(カーネルモジュール)がカーネルに含まれていない。
・使用しているハードウェアに最適化したカーネルを利用したい。
・カーネルの最新機能を使いたい。カーネルを再構築するにはgccコンパイラやmakeユーティリティ、カーネルソース、カーネルヘッダが必要となります、
また、カーネル再構築時にはカーネルモジュールも合わせてコンパイルし直す必要があります。作業の流れ
項番 タイトル 1 カーネルソースを用意する 2 カーネルの設定 3 カーネルとカーネルモジュールのコンパイル 4 カーネルモジュールとカーネルのインストール 5 完了確認 参考書籍と参考サイト
Linux教科書 LPICレベル2 Version4.5対応
CentOSでカーネルの再構築を行いカーネルモジュールを有効にする方法
カーネル(Linux-4.8.6)をコンパイルしてインストールしてみた手順
1.カーネルソースを用意する
①開発ツールのインストール
OSログイン後、ルートスイッチsudo su -現在のカーネルバージョンを
uname -rで確認# 現在のカーネルバージョンは4.18.0 [root@ip-172-31-42-117 ~]# uname -r 4.18.0-193.el8.x86_64カーネル再構築に必要なツールをインストールします(※)。
インストールされていないツールが異様に多かったですが、気にしないことにします。。※参考にさせて頂いた記事
カーネル(Linux-4.8.6)をコンパイルしてインストールしてみた(1-1.開発ツールのインストール)# 参考サイトを基にインストール yum groupinstall "Development Tools" yum install kernel-devel yum install rpm-build redhat-rpm-config unifdef yum install ncurses ncurses-devel # 以降はmake(コンパイル)時に実際に発生したエラーを基に追加インストール yum install elfutils-libelf-devel yum install openssl-devel yum install bc②カーネルソースのダウンロード
wgetコマンド(URLを指定してファイルをダウンロードする)をインストールします。yum install wgetカーネルソースをhttps://www.kernel.org/から選び、ダウンロードします。
今回はカーネルバージョン5.8.8(09-Sep-2020)を取得します。wget https://mirrors.edge.kernel.org/pub/linux/kernel/v5.x/linux-5.8.8.tar.xz解凍と展開を行います。
tar Jxvf linux-5.8.8.tar.xz展開したカーネルソースのディレクトリ配下に移動
cd linux-5.8.82.カーネルの設定
①既存設定ファイルをmake oldconfigでアップデート
現在のカーネルで利用されている設定ファイルを.config(カーネルの設定ファイル)にコピーし、ゼロからのカーネル設定ファイル作成を回避します。cp -p /boot/config-4.18.0-193.el8.x86_64 .configカーネルコンフィギュレーションのアップデートを行います。
make oldconfigを利用することで、新しいカーネルで付け加えられた機能についてのみ問い合わせを行い、
従来から存在する設定については既存の設定をそのまま流用することが可能です。本記事では新規項目に関しては全てデフォルト設定(yやnを入力せずただEnterを押す)とし、
設定が必要な「Kernel compression mode」については、今回は「1. Gzip (KERNEL_GZIP)」としました。make oldconfig# make oldconfigの出力例 [root@ip-172-31-42-117 linux-5.8.8]# make oldconfig scripts/kconfig/conf --oldconfig Kconfig .config:1089:warning: symbol value 'm' invalid for NF_CT_PROTO_GRE .config:2949:warning: symbol value 'm' invalid for ISDN_CAPI * * Restart config... * * * General setup * # 従来から存在する項目はそのまま自動で流用 Compile also drivers which will not load (COMPILE_TEST) [N/y/?] n Local version - append to kernel release (LOCALVERSION) [] Automatically append version information to the version string (LOCALVERSION_AUTO) [N/y/?] n # (NEW)と記載されている新規項目のみこちらに問い合わせてくる Build ID Salt (BUILD_SALT) [] (NEW) Kernel compression mode > 1. Gzip (KERNEL_GZIP) 2. Bzip2 (KERNEL_BZIP2) 3. LZMA (KERNEL_LZMA) 4. XZ (KERNEL_XZ) 5. LZO (KERNEL_LZO) 6. LZ4 (KERNEL_LZ4) choice[1-6?]: 1 (省略)②make menuconfigを利用してカーネル設定を微調整
更にmake menuconfigを利用することで、カーネルの各設定項目の選択式で調整することが可能です。
今回は検証段階でコンパイルエラーとなった原因のカーネル設定を事前にmake menuconfigで修正(※)します。※エラー解決時に参考にさせて頂いたサイト
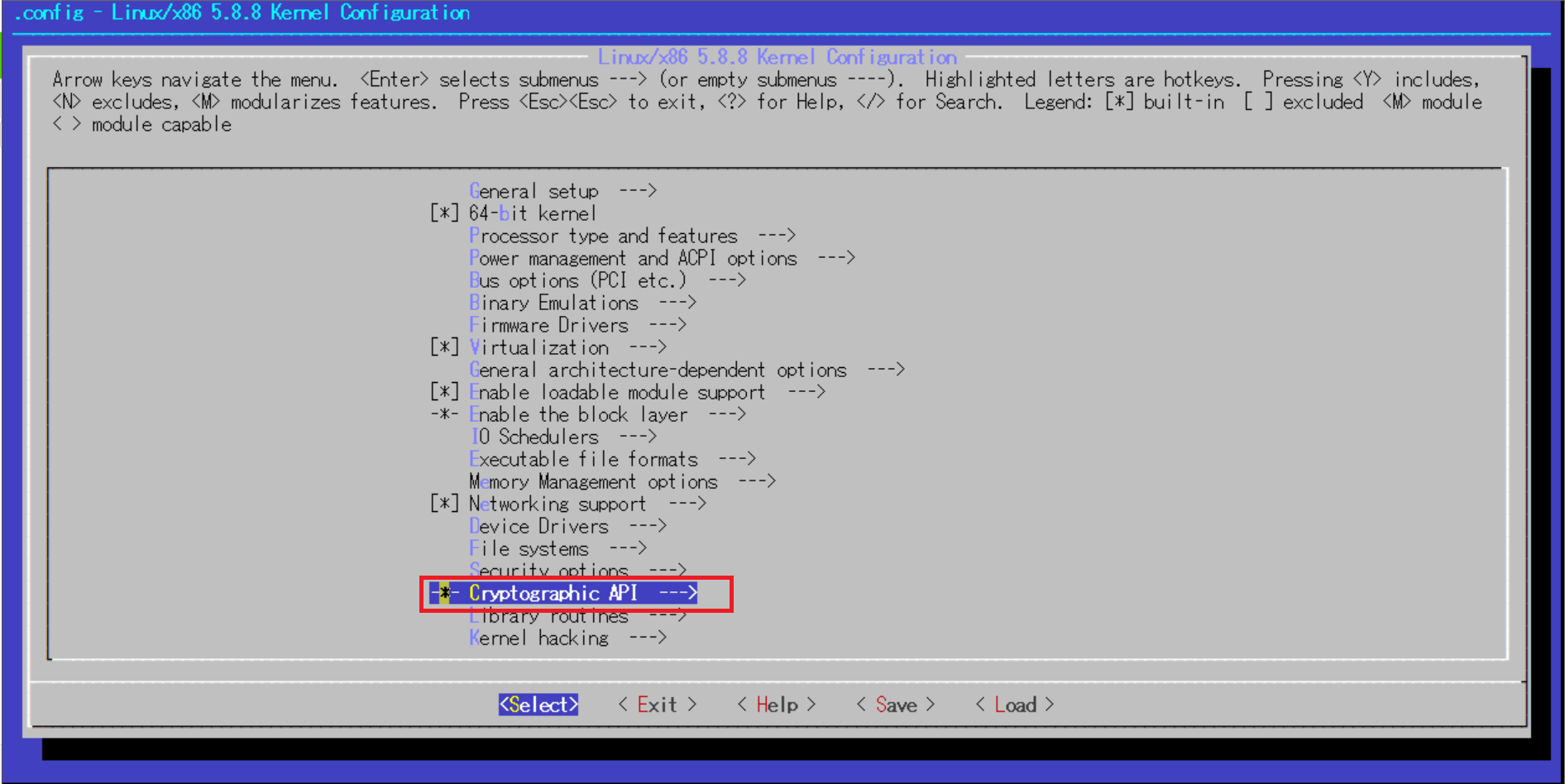
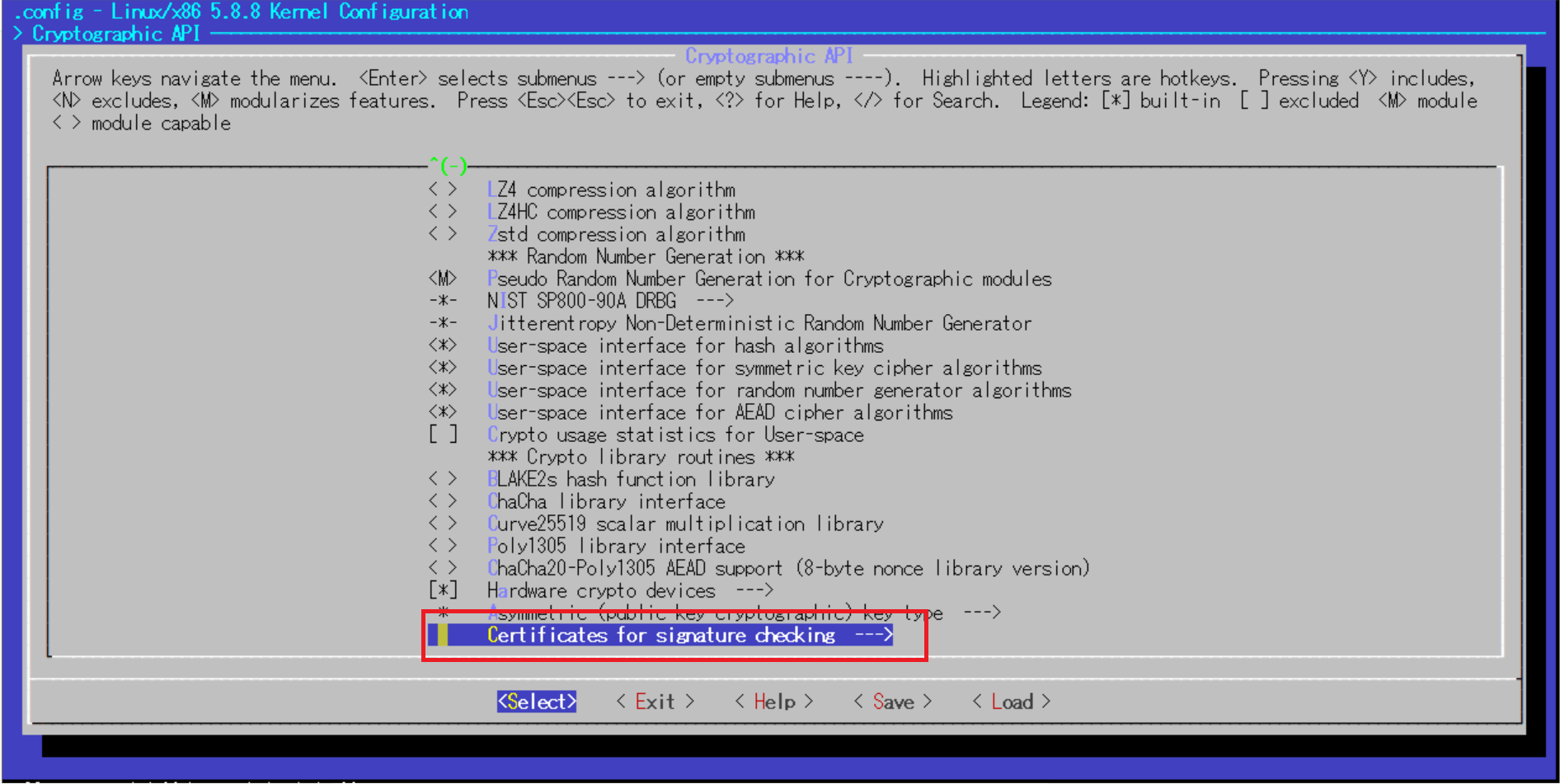
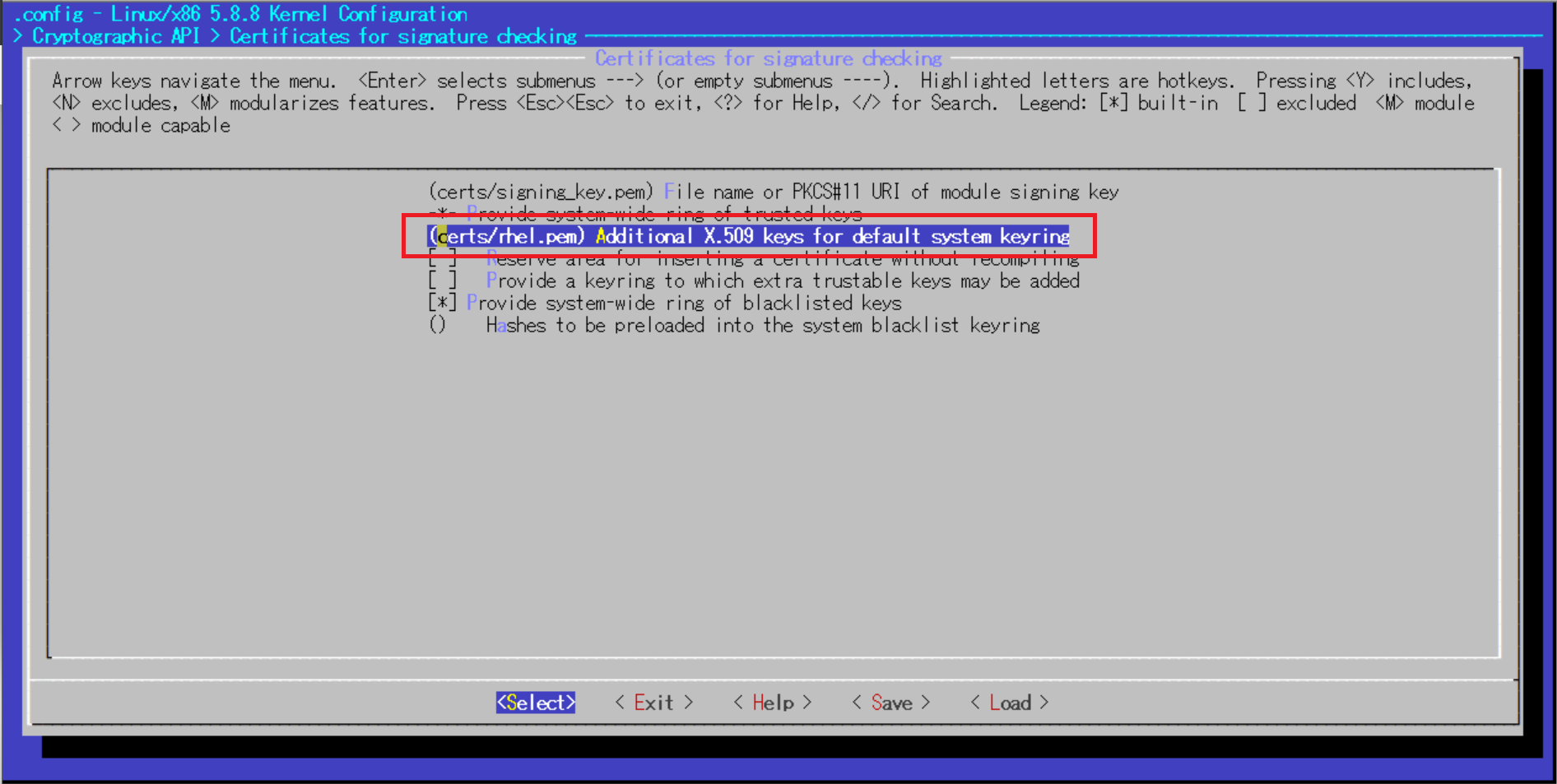
"No rule to make target 'debian/certs/debian-uefi-certs.pem', needed by 'certs/x509_certificate_list'. Stop."を解決する参考サイトによるとエラー原因となっているカーネル設定はCONFIG_SYSTEM_TRUSTED_KEYSという項目(/boot以下の既存カーネル設定ファイルをコピーした場合、この項目は空文字列に修正しないとコンパイルエラーとなってしまうようです)
[root@ip-172-31-42-117 linux-5.8.8]# cat .config | grep "CONFIG_SYSTEM_TRUSTED_KEYS" CONFIG_SYSTEM_TRUSTED_KEYS="certs/rhel.pem"カーネル設定の修正を開始します。
make menuconfig以下のようなコンソールが出たら、カーソルを利用してカーネルコンフィギュレーションの設定が可能です。
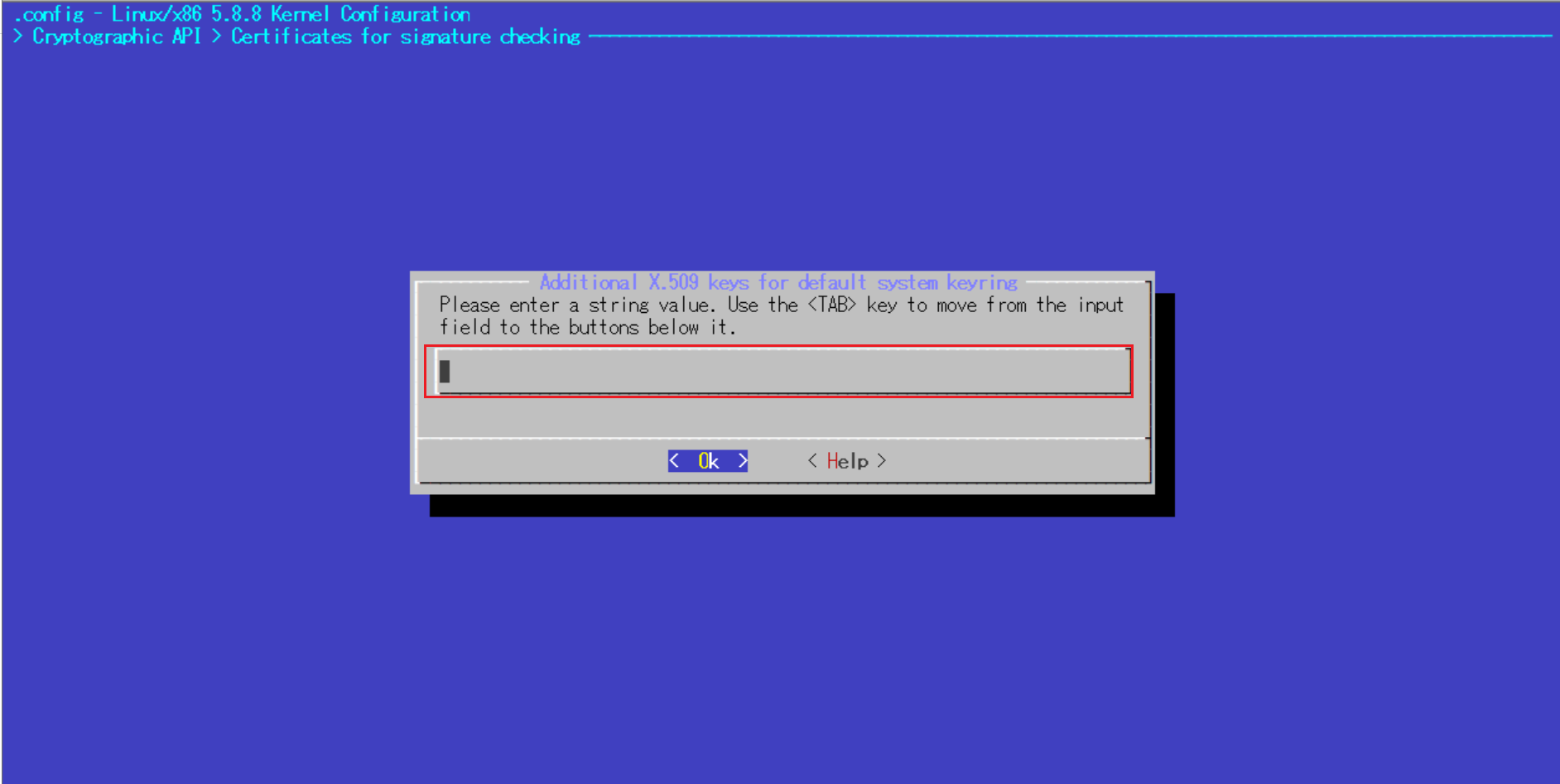
以下画像の赤枠の部分までカーソルで移動してEnterで選択していきます。
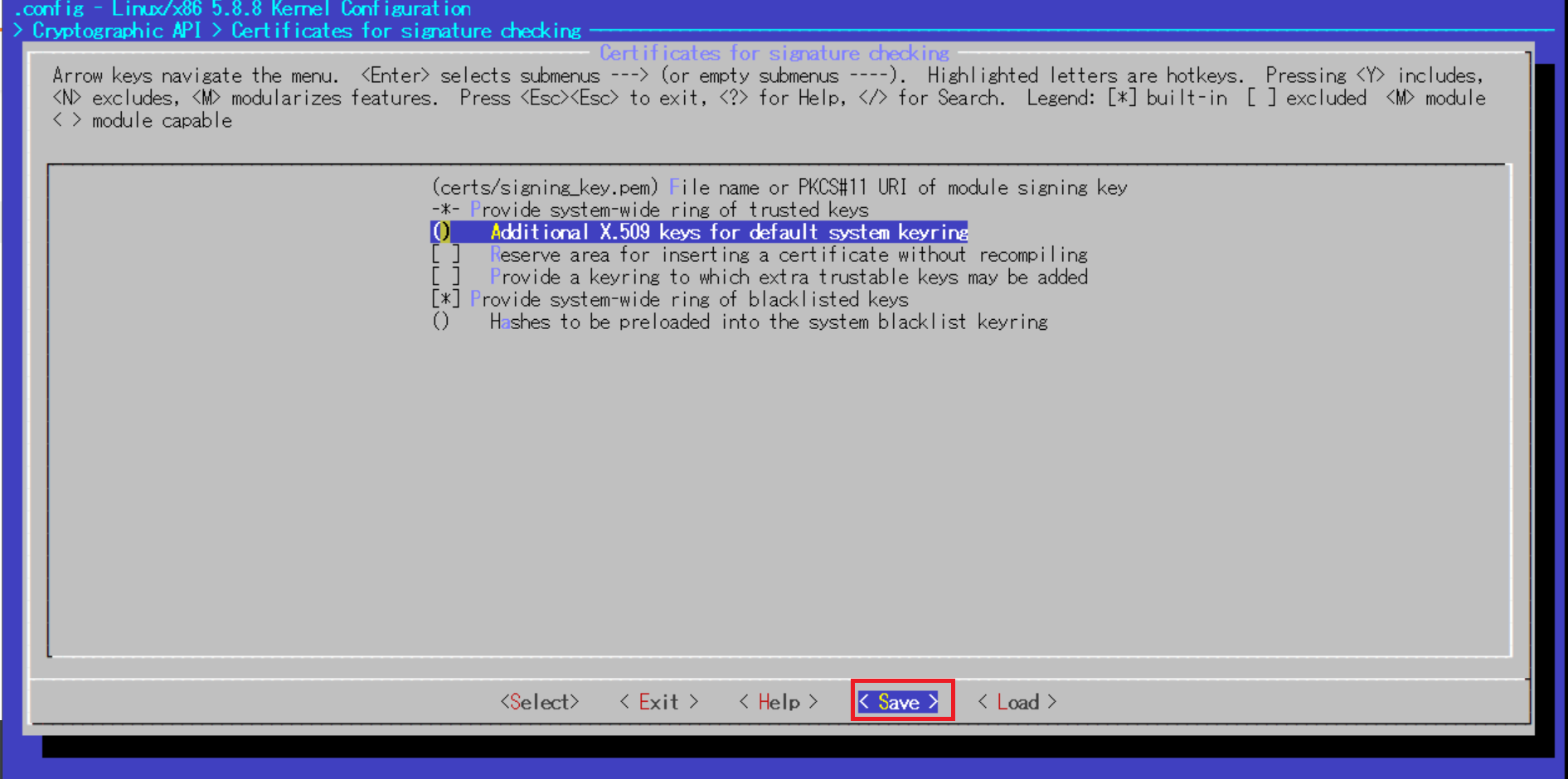
デフォルトで記載されている文字列を消去し、空にしたらEnter
最後に.configにSave
変更が反映されているか.configの中身確認
[root@ip-172-31-42-117 linux-5.8.8]# cat .config | grep "CONFIG_SYSTEM_TRUSTED_KEYS" CONFIG_SYSTEM_TRUSTED_KEYS=""3.カーネルとカーネルモジュールのコンパイル
makeでカーネルとカーネルモジュールのコンパイルをします。
引数なしでも実行可能ですがこのコンパイル作業がかなり時間がかかるため-jオプションを利用して並列処理数を変更し、コンパイル時間の短縮を図ります(※)。
本記事での構成ですと約1時間弱コンパイルに時間かかりました。※参考にさせて頂いた記事
コア数に応じた最適なmake実行# CPUコア数に応じた最適なプロセス数を起動する JOBS=$[$(grep cpu.cores /proc/cpuinfo | sort -u | sed 's/[^0-9]//g') + 1] make -j${JOBS}※なお、コンパイル中にCONFIG_DEBUG_INFO_BTFという設定項目に関するエラーでたので修正しました。
# make中以下エラー発生 BTF: .tmp_vmlinux.btf: pahole (pahole) is not available Failed to generate BTF for vmlinux Try to disable CONFIG_DEBUG_INFO_BTF # 言われた通りCONFIG_DEBUG_INFO_BTFを無効化 [root@ip-172-31-42-117 linux-5.8.8]# cat .config | grep CONFIG_DEBUG_INFO_BTF CONFIG_DEBUG_INFO_BTF=n4.カーネルモジュールとカーネルのインストール
①カーネルモジュールのインストール
# 特にエラーなく完了すること make modules_install以下のように
/lib/modules/カーネルバージョンディレクトリが構成されていればOKです。[root@ip-172-31-42-117 linux-5.8.8]# ls -l /lib/modules/5.8.8/ total 3440 lrwxrwxrwx. 1 root root 17 Sep 10 09:46 build -> /root/linux-5.8.8 drwxr-xr-x. 13 root root 141 Sep 10 09:47 kernel -rw-r--r--. 1 root root 873761 Sep 10 09:47 modules.alias -rw-r--r--. 1 root root 837562 Sep 10 09:47 modules.alias.bin -rw-r--r--. 1 root root 8171 Sep 10 09:46 modules.builtin -rw-r--r--. 1 root root 10467 Sep 10 09:47 modules.builtin.bin -rw-r--r--. 1 root root 62064 Sep 10 09:46 modules.builtin.modinfo -rw-r--r--. 1 root root 278819 Sep 10 09:47 modules.dep -rw-r--r--. 1 root root 389096 Sep 10 09:47 modules.dep.bin -rw-r--r--. 1 root root 405 Sep 10 09:47 modules.devname -rw-r--r--. 1 root root 99497 Sep 10 09:46 modules.order -rw-r--r--. 1 root root 521 Sep 10 09:47 modules.softdep -rw-r--r--. 1 root root 422378 Sep 10 09:47 modules.symbols -rw-r--r--. 1 root root 510059 Sep 10 09:47 modules.symbols.bin lrwxrwxrwx. 1 root root 17 Sep 10 09:46 source -> /root/linux-5.8.8②カーネルのインストール
# 特にエラーなく完了すること(エラーが出ずに終了することは必ず確認してください。筆者はエラーがでたまま再起動したらサーバが立ち上がらなくなりました。。) make install -j${JOBS}以下のようにカーネルイメージ
/boot/vmlinuz-カーネルバージョンが/boot内に存在していればOKです。[root@ip-172-31-42-117 ~]# ls -l /boot/vmlinuz* lrwxrwxrwx. 1 root root 19 Sep 10 09:47 /boot/vmlinuz -> /boot/vmlinuz-5.8.8 -rwxr-xr-x. 1 root root 8913760 Apr 23 05:16 /boot/vmlinuz-0-rescue-bb64a14c7512444f9744c3076505b65f -rwxr-xr-x. 1 root root 8920432 Sep 10 08:05 /boot/vmlinuz-0-rescue-ec211058807a3398326019a9b3f9e8bf -rwxr-xr-x. 1 root root 8920432 Aug 26 19:47 /boot/vmlinuz-4.18.0-193.19.1.el8_2.x86_64 -rwxr-xr-x. 1 root root 8913760 Mar 27 14:48 /boot/vmlinuz-4.18.0-193.el8.x86_64 -rw-r--r--. 1 root root 8613632 Sep 10 09:47 /boot/vmlinuz-5.8.85.完了確認
再起動後、以下のようにカーネルバージョンが変更されていればOKです。
[root@ip-172-31-42-117 ~]# uname -r 5.8.8
- 投稿日:2020-09-10T15:58:46+09:00
AWS FireLensってなんだ?
What's?
AWS FireLensについて、知っておきたかったので軽く調べてみました、と。
AWS FireLensとは?
AWS FireLensとは、2019年9月に発表された、Amazon ECSで使用できるログルーターのことです。
タスク定義の中に含めてサイドカーとして配置しつつ、他のコンテナからはログドライバーとして使用します。
AWS FireLensからは、Amazon CloudWatch LogsまたはAmazon Kinesis Data Streams、Amazon Kinesis Data Firehose、そして別のFluentdやFluent Bitに転送することができます。
以下のタスク定義サンプルは、Firelens の発表 – コンテナログの新たな管理方法からの抜粋です。
{ "family": "firelens-example-cloudwatch", "taskRoleArn": "arn:aws:iam::365489000573:role/ecsInstanceRole", "executionRoleArn": "arn:aws:iam::365489300073:role/ecsTaskExecutionRole", "containerDefinitions": [ { "essential": true, "image": "906394416424.dkr.ecr.us-east-1.amazonaws.com/aws-for-fluent-bit:latest", "name": "log_router", "firelensConfiguration": { "type": "fluentbit" }, "logConfiguration": { "logDriver": "awslogs", "options": { "awslogs-group": "firelens-container", "awslogs-region": "us-west-2", "awslogs-create-group": "true", "awslogs-stream-prefix": "firelens" } }, "memoryReservation": 50 }, { "essential": true, "image": "nginx", "name": "app", "portMappings": [ { "containerPort": 80, "hostPort": 80 } ], "logConfiguration": { "logDriver":"awsfirelens", "options": { "Name": "cloudwatch", "region": "us-west-2", "log_group_name": "firelens-fluent-bit", "auto_create_group": "true", "log_stream_prefix": "from-fluent-bit" } }, "memoryReservation": 100 } ] }AWS for Fluent Bitイメージ
AWS FireLensとここまで書いてきましたが、ドキュメントをちゃんと眺めてみます。
Amazon ECS 対応 FireLens では、タスク定義パラメータを使用して AWS のサービスや AWS パートナーネットワーク (APN ) の宛先にログをルーティングし、ログを保存および分析できます。FireLens は Fluentd および Fluent Bitで動作します。提供されている AWS for Fluent Bit イメージを使用することも、独自の Fluentd または Fluent Bit イメージを使用することもできます。
このように書かれているので、AWS FireLensそのものは、Amazon ECSのコンテナログを同タスク定義内のサイドカーとして配置されたFluentdまたはFluent Bitに転送することができる仕組みだ、と考えた方がよさそうな気がします。
また、他のコンテナには、FluentdまたはFluent Bitへの接続情報が渡されるようです。
awsfirelens ログドライバーがタスク定義で指定されている場合、ECS エージェントは次の環境変数をコンテナに挿入します。
FLUENT_HOST および FLUENT_PORT 環境変数を使用すると、コードからログ ルータに直接ログできます。
よって、AWS FireLensはFluentdまたはFluent Bitのコンテナイメージが必要になります。
そしてFluent BitのコンテナイメージをAWSが提供しているものを、AWS for Fluent Bitと言います。
AWS for Fluent BitはDocker Hubにも置かれていますが、上記のドキュメントにあるようにAmazon ECRが使える場合はそちらで提供されているものを使った方が良さそうです。
Docker Hub / amazon/aws-for-fluent-bit
Docker Hubに置かれているイメージのソースコード(GitHubリポジトリ)は、こちら。
GitHub / AWS for Fluent Bit Docker Image
現時点のAWS for Fluent Bitのバージョンは、
2.6.1のようです。
Dockerfileを中心に、少し中身を見てみましょう。ビルドは、AWS CodeBuildで行っているようですね。
https://github.com/aws/aws-for-fluent-bit/blob/v2.6.1/buildspec.yml
make releaseに対応するところを見ると、2つのDockerイメージをビルドしています。https://github.com/aws/aws-for-fluent-bit/blob/v2.6.1/Makefile#L17-L19
3種類のプラグインが入っているようで、
- amazon-kinesis-firehose-for-fluent-bit
- amazon-cloudwatch-logs-for-fluent-bit
- amazon-kinesis-streams-for-fluent-bit
それが組み込まれているのがこちら。
Dockerfileの前に、Dockerfile.pluginsで作るイメージがビルドされます。https://github.com/aws/aws-for-fluent-bit/blob/v2.6.1/Dockerfile.plugins
本体の
Dockerfileはこちら。https://github.com/aws/aws-for-fluent-bit/blob/v2.6.1/Dockerfile
中を見ていくと、マルチステージビルド構成になっていてFluent Bitのビルドをして
https://github.com/aws/aws-for-fluent-bit/blob/v2.6.1/Dockerfile#L41-L56
ビルドしたFluent Bitやプラグインを、ここまでに作ったイメージから
COPYしてくるという構成になっています。https://github.com/aws/aws-for-fluent-bit/blob/v2.6.1/Dockerfile#L81-L98
ベースとなっているFluent Bitのバージョンは、こちらに定義されています。
https://github.com/aws/aws-for-fluent-bit/blob/v2.6.1/Dockerfile#L4
最終的なコンテナイメージのベースイメージは、Amazon Linux 2ですね。
https://github.com/aws/aws-for-fluent-bit/blob/v2.6.1/Dockerfile#L72
ENTRYPOINTの定義。https://github.com/aws/aws-for-fluent-bit/blob/v2.6.1/entrypoint.sh
exec /fluent-bit/bin/fluent-bit -e /fluent-bit/firehose.so -e /fluent-bit/cloudwatch.so -e /fluent-bit/kinesis.so -c /fluent-bit/etc/fluent-bit.conf最終的に含まれる設定としては、
INPUTとしてforward、OUTPUTとしてcloudwatchというシンプルなものです。https://github.com/aws/aws-for-fluent-bit/blob/v2.6.1/fluent-bit.conf
[INPUT] Name forward Listen 0.0.0.0 Port 24224 [OUTPUT] Name cloudwatch Match ** region us-east-1 log_group_name fluent-bit-cloudwatch log_stream_prefix from-fluent-bit- auto_create_group trueとはいえ、この設定は
logConfigurationの指定で動的に変わりそうですけどね。Amazon ECS はログ設定を変換し、Fluentd または Fluent Bit 出力設定を生成します。出力設定は、/fluent-bit/etc/fluent-bit.conf (Fluent Bit) および /fluentd/etc/fluent.conf (Fluentd) のログルーティングコンテナにマウントされます。
logConfiguration オブジェクトのオプションとして指定されたキーと値のペアは、Fluentd または Fluent Bit 出力設定の生成に使用されます。
ところで、ドキュメントにはAmazon ECRにあるイメージの方が可用性が高いと書いてあるのですが、
AWS for Fluent Bit イメージは Docker Hub で利用できます。ただし、Amazon ECR では、以下のイメージを使用することをお勧めします。これらのイメージにより、可用性が向上します。
Amazon ECRにPushしているAWS CodeBuildの内容を見る限りコンテナイメージ自体に差があるわけではなさそうなので、可用性というのはDocker HubとAmazon ECRの比較をしているのでしょうね。
https://github.com/aws/aws-for-fluent-bit/blob/v2.6.1/buildspec_publish_ecr.yml
AWS for Fluent Bitを試してみる
あとは、少しだけローカルでAWS for Fluent Bitを使ってみます。
今回の環境は、こちら。
$ uname -srvmpio Linux 5.4.0-47-generic #51-Ubuntu SMP Fri Sep 4 19:50:52 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux $ lsb_release -a No LSB modules are available. Distributor ID: Ubuntu Description: Ubuntu 20.04.1 LTS Release: 20.04 Codename: focal $ docker version Client: Docker Engine - Community Version: 19.03.12 API version: 1.40 Go version: go1.13.10 Git commit: 48a66213fe Built: Mon Jun 22 15:45:44 2020 OS/Arch: linux/amd64 Experimental: false Server: Docker Engine - Community Engine: Version: 19.03.12 API version: 1.40 (minimum version 1.12) Go version: go1.13.10 Git commit: 48a66213fe Built: Mon Jun 22 15:44:15 2020 OS/Arch: linux/amd64 Experimental: false containerd: Version: 1.2.13 GitCommit: 7ad184331fa3e55e52b890ea95e65ba581ae3429 runc: Version: 1.0.0-rc10 GitCommit: dc9208a3303feef5b3839f4323d9beb36df0a9dd docker-init: Version: 0.18.0 GitCommit: fec3683とりあえず、イメージを取得して起動。
$ docker image pull amazon/aws-for-fluent-bit:2.6.1 $ docker container run -it --rm --name fluent-bit amazon/aws-for-fluent-bit:2.6.1起動時のログ。今回は、Fluent Bit 1.5.2で動作しています。AWS for Fluent Bitとしては、
2.6.1ですね。AWS for Fluent Bit Container Image Version 2.6.1 Fluent Bit v1.5.2 * Copyright (C) 2019-2020 The Fluent Bit Authors * Copyright (C) 2015-2018 Treasure Data * Fluent Bit is a CNCF sub-project under the umbrella of Fluentd * https://fluentbit.io [2020/09/10 06:49:53] [ info] [engine] started (pid=1) [2020/09/10 06:49:53] [ info] [storage] version=1.0.4, initializing... [2020/09/10 06:49:53] [ info] [storage] in-memory INFO[0000] [cloudwatch 0] plugin parameter log_group = 'fluent-bit-cloudwatch' INFO[0000] [cloudwatch 0] plugin parameter log_stream_prefix = 'from-fluent-bit-' INFO[0000] [cloudwatch 0] plugin parameter log_stream = '' INFO[0000] [cloudwatch 0] plugin parameter region = 'us-east-1' INFO[0000] [cloudwatch 0] plugin parameter log_key = '' INFO[0000] [cloudwatch 0] plugin parameter role_arn = '' INFO[0000] [cloudwatch 0] plugin parameter auto_create_group = 'true' INFO[0000] [cloudwatch 0] plugin parameter endpoint = '' INFO[0000] [cloudwatch 0] plugin parameter sts_endpoint = '' INFO[0000] [cloudwatch 0] plugin parameter credentials_endpoint = INFO[0000] [cloudwatch 0] plugin parameter log_format = '' [2020/09/10 06:49:53] [ info] [storage] normal synchronization mode, checksum disabled, max_chunks_up=128 [2020/09/10 06:49:53] [ info] [input:forward:forward.0] listening on 0.0.0.0:24224 [2020/09/10 06:49:53] [ info] [sp] stream processor startedちょっとコンテナの中に入って
$ docker container exec -it fluent-bit bash確認。
# /fluent-bit/bin/fluent-bit --version Fluent Bit v1.5.2いくつか、見慣れない設定ファイルもありますね。
# ls -l /fluent-bit/etc total 36 -rw-r--r-- 1 root root 251 Jul 30 21:32 fluent-bit.conf -rw-r--r-- 1 root root 4664 Jul 30 21:41 parsers.conf -rw-r--r-- 1 root root 584 Jul 30 21:41 parsers_ambassador.conf -rw-r--r-- 1 root root 226 Jul 30 21:41 parsers_cinder.conf -rw-r--r-- 1 root root 2798 Jul 30 21:41 parsers_extra.conf -rw-r--r-- 1 root root 240 Jul 30 21:41 parsers_java.conf -rw-r--r-- 1 root root 845 Jul 30 21:41 parsers_mult.conf -rw-r--r-- 1 root root 2954 Jul 30 21:41 parsers_openstack.conf
/fluent-bit/etc/fluent-bit.conf[INPUT] Name forward Listen 0.0.0.0 Port 24224 [OUTPUT] Name cloudwatch Match ** region us-east-1 log_group_name fluent-bit-cloudwatch log_stream_prefix from-fluent-bit- auto_create_group true設定まわり
実際に使う時の設定としては、こちらのドキュメントを見ると
これが
{ "essential": true, "image": "httpd", "name": "app", "logConfiguration": { "logDriver":"awsfirelens", "options": { "Name": "firehose", "region": "us-west-2", "delivery_stream": "my-stream" } }, "memoryReservation": 100 }こうなると言っているので
[OUTPUT] Name firehose Match app-firelens* region us-west-2 delivery_stream my-stream各コンテナの
logConfiguration / optionsとnameあたりがAWS FireLens側のOUTPUTの設定に反映されると思っていたらいいんでしょうかね?AWS FireLensとして動作しているFluentd、Fluent Bit自体のログ出力は、自身の
logConfigurationで決まるようですが…。このあたりは、また試してみましょう。
firelensConfigurationについては、こちら。Fluentd、Fluent Bitの設定ファイルを追加で指定したり(
config-file-type / config-type-value)、Amazon ECSのメタデータを含めたりするようにできるようです。設定ファイルの追加のイメージは、
@INCLUDEみたいです。
- 投稿日:2020-09-10T15:48:43+09:00
Cloudendure使用してオンプレミスからクラウドへ移行
Cloudendure使用してオンプレミスからクラウドへ移行
- 投稿日:2020-09-10T15:45:13+09:00
AWSテスト環境構築
- 投稿日:2020-09-10T15:45:13+09:00
AWS移行環境構築
AWSテスト環境構築
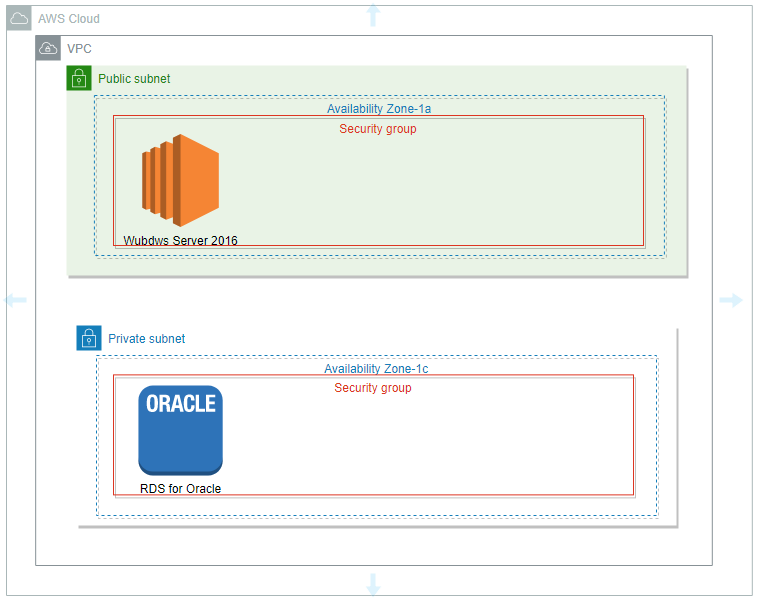
1.仕組み図
2.パラメータ設定
2.1 VPCパラメータ設計
VPC 10.0.0.0/16 リネーム EC2 Subnet1 10.0.0.0/24 sb-1a-om-ec2 EC2 Subnet2 10.0.1.0/24 sb-1c-om-ec2 RDS Subnet3 10.0.2.0/24 sb-1a-om-db RDS Subnet4 10.0.3.0/24 sb-1c-om-db 2.2 internet Gateway 作成
VPC attach
VPC 10.0.0.0/162.3 Route Table
2.2 セキュリティグループ設計
2.2.1 EC2側
Security Group Port Port http 80 My Ip address ssh 22 My Ip address 2.2.2 DB側
Security Group Port Port db 3306 10.0.1.0/24 db 3306 10.0.0.0/24 2.VPC作成
2.1 VPC作成
2.2 サブネット追加
2.3 インタネットゲートウェイ作成
2.4 ルートテーブルのルール追加インタネットゲートウェイ
- 投稿日:2020-09-10T14:21:19+09:00
【備忘】S3からのダウンロード、S3へのアップロード
1.S3からのファイルダウンロード
今回は、バケットの対象パス下のファイルを全てダウンロードする場合を記述しました。AmazonS3 s3Client = AmazonS3ClientBuilder.standard().withRegion("リージョン名").build(); // S3上バケット下のファイル一覧を取得 ObjectListing objListing = s3Client.listObjects("バケット名"); List<S3ObjectSummary> objList = objListing.getObjectSummaries(); try { // S3上のファイル分処理する for (S3ObjectSummary obj : objList) { // objListにはバケット下全てのフォルダ、ファイル情報があるため対象パスで絞り込む必要がある // 対象パスを含んでいないか、または、サイズが0であればダウンロードしない if (!StringUtils.contains(obj.getKey(), "対象パス") || obj.getSize() == 0) { continue; } // 以下ダウンロード処理 // obj.getKey()は"対象パス/ファイル名"となっている GetObjectRequest request = new GetObjectRequest("バケット名", obj.getKey()); // ファイル名だけにする String fileName = obj.getKey().replace("対象パス", ""); // ダウンロード先のファイルを生成 File file = new File(fileName); if (s3Client.getObject(request, file) == null) { // ダウンロード失敗 } } } catch (IOException e) { throw e; }2.S3へのアップロード
ファイルをバケット下の対象パスへアップロードする場合try { AmazonS3 s3Client = AmazonS3ClientBuilder.standard().withRegion("リージョン名").build(); File file = new File("アップロード対象ファイル名"); PutObjectRequest request = new PutObjectRequest("バケット名", "対象パス" + file.getName(), file); request.setCannedAcl(CannedAccessControlList.PublicRead); s3Client.putObject(request); } catch (Exception e) { throw e; }
- 投稿日:2020-09-10T12:00:31+09:00
EC2再起動時もスクリプト(ユーザデータ)を実行させる
ユーザデータ
ユーザデータとは、EC2初回起動時に動作するスクリプトを登録できる設定です。
sshポート変更など、サーバ構築後によくやる作業を設定しておくと
初回起動時点に環境に反映してくれます。
設定方法は以下。
1. EC2の停止
2. 対象インスタンスを右クリック>インスタンスの設定>ユーザーデータの表示/変更
上記のように実行したいスクリプトを記載できます。ただ、ユーザデータはインスタンス構築後の初回起動時のみしか実行されません。
再起動時もユーザデータを動作させる方法
MIMEマルチパートファイルを使用して、ユーザデータの実行頻度を起動の都度に変更できます。
参考:https://aws.amazon.com/jp/premiumsupport/knowledge-center/execute-user-data-ec2/ユーザデータに以下を張り付けてください。
★部分が実際に実行するスクリプトなので、ここだけ変えればOKです。Content-Type: multipart/mixed; boundary="//" MIME-Version: 1.0 --// Content-Type: text/cloud-config; charset="us-ascii" MIME-Version: 1.0 Content-Transfer-Encoding: 7bit Content-Disposition: attachment; filename="cloud-config.txt" #cloud-config cloud_final_modules: - [scripts-user, always] --// Content-Type: text/x-shellscript; charset="us-ascii" MIME-Version: 1.0 Content-Transfer-Encoding: 7bit Content-Disposition: attachment; filename="userdata.txt" ★↓ #!/bin/bash /bin/echo "Hello World" >> /tmp/testfile.txt --//これでEC2起動の都度、スクリプトを実行できます。

- 投稿日:2020-09-10T10:49:39+09:00
Amazon Linux 2 で PHP を簡単にアップデートする方法
Amazon Linux 2 の、ここ1年位の Amazon Linux Extra を使って、PHP をインストールしている人は、Amazon Linux Extra でパッケージの Disable & Enable をするだけで、結構簡単に PHP のアップデートができるという話です。
参考: Amazon linux 2でのphpの更新方法 (感謝!)
自分の環境
- AWS
- 開発用のサーバー
- Amazon Linux 2
- PHP 7.1 の Extra を導入
- 導入済みの PHP 一覧
libmcrypt php php-bcmath php-cli php-common php-dba php-embedded php-enchant php-fpm php-gd php-gmp php-intl php-json php-ldap php-mbstring php-mysqlnd php-odbc php-opcache php-pdo php-pecl-igbinaryphp-pecl-mcrypt php-pecl-zip php-pgsql php-process php-pspell php-recode php-soap php-xml php-xmlrpc- この Ansible を使ってサーバーの初期構築をしています
- Apache, MariaDB
- concrete5 CMS を動かしています。
ec2-userなどの sudo 権限のあるユーザーで実行手順
- Amazon Extra の PHP7.1 を無効化:
$ sudo amazon-linux-extras disable php7.1- Amazon Extra の PHP7.3 を有効化:
$ sudo amazon-linux-extras enable php7.3sudo yum update
- 本当は PHP だけをアップデートするべきですが、開発なので、まとめて実行しました。もしも本番環境であれば、PHP だけを選択してアップデートするように走らせたらよいかと
- 例:
sudo yum update php*
- 投稿日:2020-09-10T10:08:08+09:00
Next.js+TypeScript+AWS Amplify+RecoilでToDoリストを作る
本記事ではNext.js+TypeScript+AWS Amplify+Recoilを使って、モダンなToDoリストを作る方法を紹介します。
作ったアプリケーションは公開しています。
https://master.d182t7iqbd44r9.amplifyapp.comGithubリポジトリを公開しますので、不具合や不適切な実装を見つけた場合はドシドシIssueかPull-Requestいただけると幸いです。
https://github.com/yuuu/next-ts-amplify-recoil-todolist
背景
私自身普段はRuby on Railsを使って開発しています。JavaScriptは正直まだ苦手です。
Railsは爆速でアプリを開発出来る点が魅力的ですが、一方でモバイルアプリとの連携やリッチなUIが求められる案件では、フロントエンドとバックエンドを分離した構成にせざるをえないケースがあります。
そのような構成だと、かえってRailsがリッチ過ぎるとも感じており、AWS Amplifyのようにバックエンドをスピーディーに構築してくれるサービスを一度使ってみたいと思っていました。そのため、Next.js+AWS Amplisyで簡単なアプリを作ってみて、いわゆるモダンなアプリ開発のノウハウを学んでみることにしました。
使用する技術要素
- Next.js(React.js)
- AWS Amplify
- TypeScript
- Recoil
- React Hook Form
プロジェクトの作成
Next.jsのexamplesにwith-typescript-eslint-jestが公開されているので、これをベースにしました。
$ create-next-app ✔ What is your project named? … next-ts-amplify-recoil-todolist ✔ Pick a template › Example from the Next.js repo ✔ Pick an example › with-typescript-eslint-jest # 省略Amplifyのセットアップ
続いて、AWS Amplifyをセットアップします。
初期化
amplify initを実行して初期化します。$ cd next-ts-amplify-recoil-todolist $ amplify init ? Enter a name for the project todolist ? Enter a name for the environment dev ? Choose your default editor: Visual Studio Code ? Choose the type of app that you\'re building javascript Please tell us about your project ? What javascript framework are you using react ? Source Directory Path: src ? Distribution Directory Path: out ? Build Command: npm run-script build ? Start Command: npm run-script start ? Do you want to use an AWS profile? Yes ? Please choose the profile you want to use (使用するprofile)Hostingのときにハマらないよう、Distribution Directory Pathは
outにしています。
詳細は こちらの記事 を参照ください。ホスティング(CI/CD含む)
経験上、後からホスティングを追加するとトラブルシューティングが難しくなるので、できるだけ早い段階でCI/CDによるホスティングを設定しておきます。
❯ amplify add hosting ? Select the plugin module to execute Hosting with Amplify Console (Managed hosting with custom domains, Continuous deployment) ? Choose a type Continuous deployment (Git-based deployments) ? Continuous deployment is configured in the Amplify Console. Please hit enter once you connect your repository # ブラウザでAWS Amplify Consoleが表示されるので諸々設定をした後、Enterを入力 Amplify hosting urls: ┌──────────────┬──────────────────────────────────────────────┐ │ FrontEnd Env │ Domain │ ├──────────────┼──────────────────────────────────────────────┤ │ master │ https://master.d14mfq14xzgfle.amplifyapp.com │ └──────────────┴──────────────────────────────────────────────┘
buildの出力先をoutに変更するため、手元の環境でpackage.jsonを一部修正する必要があります。
詳細は こちらの記事 を参照ください。また、Amplify Consoleの「ビルドの設定」からamplify.ymlを次のように修正します。
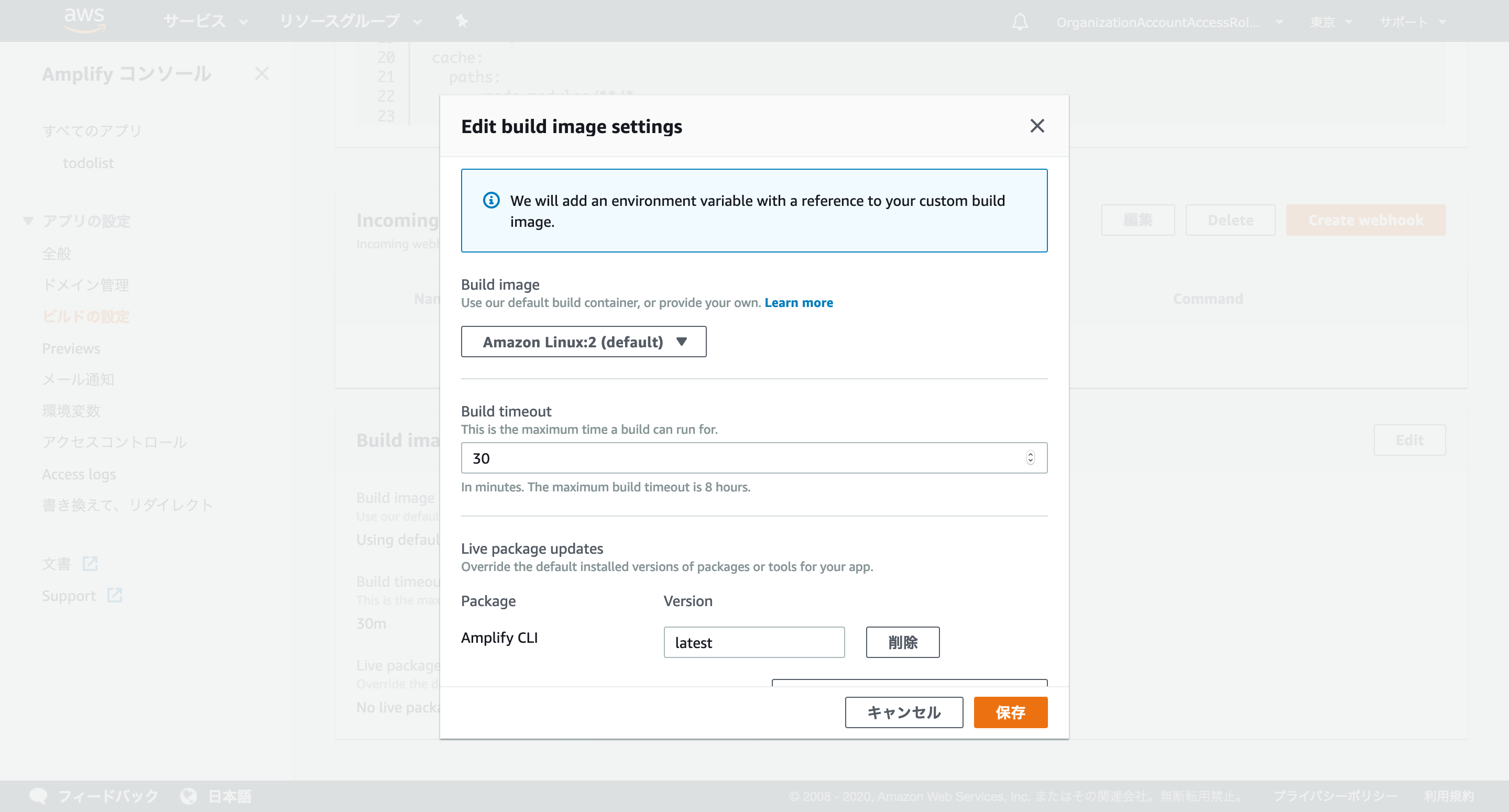
amplify.ymlversion: 1 backend: phases: build: commands: - '# Execute Amplify CLI with the helper script' - amplifyPush --simple frontend: phases: preBuild: commands: - yarn install build: commands: - yarn run build artifacts: baseDirectory: out files: - '**/*' cache: paths: - node_modules/**/*さらに、「ビルドの設定」→「Build image settings」→「Edit」→「Live package updates」で
Amplify CLIをlatestとする必要があります。これをしていないと、デプロイに失敗するので要注意です。
デプロイが終わり、表示されたURLにアクセスすると、ページが表示されます。
認証基盤
以下コマンドで認証基盤を追加します。
$ amplify add auth ? Do you want to use the default authentication and security configuration? Default configuration ? How do you want users to be able to sign in? Username ? Do you want to configure advanced settings? No, I am done. # 省略 $ amplify push ✔ Successfully pulled backend environment production from the cloud. Current Environment: production | Category | Resource name | Operation | Provider plugin | | -------- | -------------------- | --------- | ----------------- | | Auth | besttodolistf818478c | Create | awscloudformation | | Hosting | amplifyhosting | No Change | | ? Are you sure you want to continue? Yes # 省略GraphQL API
予めGraphQLのスキーマファイルを作成しておきます。
./schema.graphqltype Todo @model { id: ID! name: String! completed: Boolean! timestamp: AWSTimestamp! }以下コマンドでバックエンドのGraphQL APIを追加します。
$ amplify add api ? Please select from one of the below mentioned services: GraphQL ? Provide API name: todolist ? Choose the default authorization type for the API Amazon Cognito User Pool Use a Cognito user pool configured as a part of this project. ? Do you want to configure advanced settings for the GraphQL API No, I am done. ? Do you have an annotated GraphQL schema? Yes ? Provide your schema file path: ./schema.graphql # 省略念の為mockサーバを起動して動作確認をしておきます。
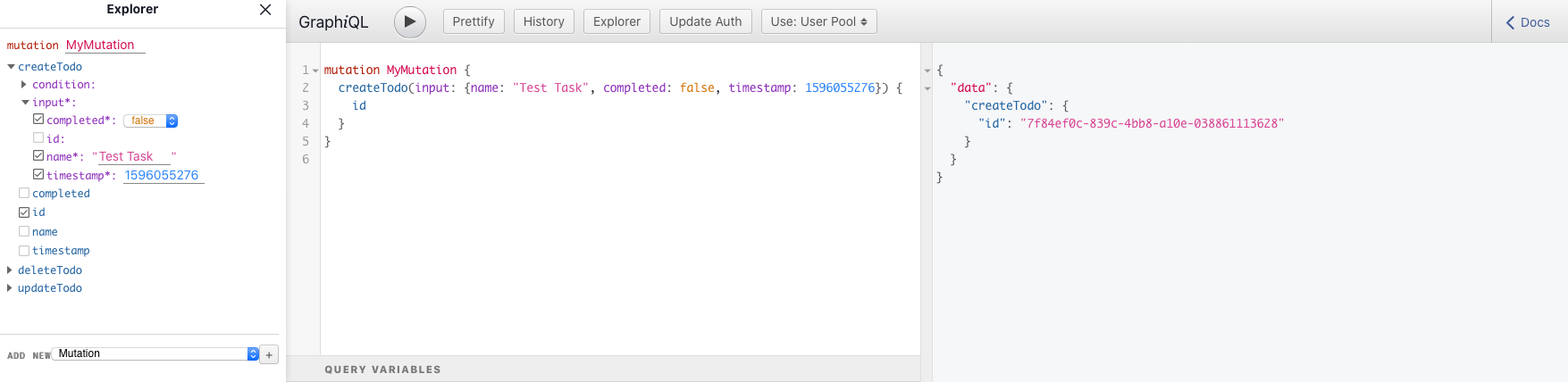
このとき、クライアントのコードも生成されます。$ amplify mock api # 省略 Running GraphQL codegen ? Choose the code generation language target typescript ? Enter the file name pattern of graphql queries, mutations and subscriptions src/graphql/**/*.ts ? Do you want to generate/update all possible GraphQL operations - queries, mutations and subscriptions Yes ? Enter maximum statement depth [increase from default if your schema is deeply nested] 2 ? Enter the file name for the generated code src/API.ts ? Do you want to generate code for your newly created GraphQL API Yes # 省略 AppSync Mock endpoint is running at http://xxx.xxx.xxx.xxx:20002表示されたURLにアクセスすると、Graphiqlの画面が表示され、GraphQLのリクエストを試すことができます。
特に問題がなければ、
amplify pushしておきましょう。❯ amplify push ✔ Successfully pulled backend environment production from the cloud. Current Environment: production | Category | Resource name | Operation | Provider plugin | | -------- | -------------------- | --------- | ----------------- | | Api | bestTodolist | Create | awscloudformation | | Hosting | amplifyhosting | No Change | | | Auth | besttodolistf818478c | No Change | awscloudformation | ? Are you sure you want to continue? Yes # 省略 ? Do you want to update code for your updated GraphQL API Yes ? Do you want to generate GraphQL statements (queries, mutations and subscription) based on your schema types? This will overwrite your current graphql queries, mutations and subscriptions Yes # 省略フロントエンドの実装
npmパッケージのインストール
以下コマンドでインストールします。
$ yarn add @material-ui/core @material-ui/icons aws-amplify @aws-amplify/ui-react react-hook-form recoilLint/Formatterのignoreを追加
Next.jsがexportしたファイルやAWS Amplifyで自動生成したコードはLint/Formatterの対象外にしておきます。
.eslintignore**/node_modules/* **/out/* **/.next/* src/aws-exports.js.prettierignorenode_modules .next yarn.lock package-lock.json public out一覧ページの実装
以下ファイルを所定のディレクトリへコピペしてください。
ページ
ベースとなる
_app.tsxと_document.tsxも必要です。
_document.tsxは、まだFunction Componentでは書けないようです。https://github.com/yuuu/next-ts-amplify-recoil-todolist/blob/master/pages/_app.tsx
https://github.com/yuuu/next-ts-amplify-recoil-todolist/blob/master/pages/_document.tsx
https://github.com/yuuu/next-ts-amplify-recoil-todolist/blob/master/pages/index.tsxコンポーネント
各ページの部品となるコンポーネントを作成します。
https://github.com/yuuu/next-ts-amplify-recoil-todolist/blob/master/src/component/Header.tsx
https://github.com/yuuu/next-ts-amplify-recoil-todolist/blob/master/src/component/Footer.tsx
https://github.com/yuuu/next-ts-amplify-recoil-todolist/blob/master/src/component/Todo.tsxストア
正直TodoListのレベルであれば、ストアを使う必要は無いのですが、前々から使ってみたいと思っていたRecoilを使うことにしました。
https://github.com/yuuu/next-ts-amplify-recoil-todolist/blob/master/src/store/todos.ts
テーマ
Material UIのベースとなるテーマを定義します。
https://github.com/yuuu/next-ts-amplify-recoil-todolist/blob/master/src/theme.ts
動作確認
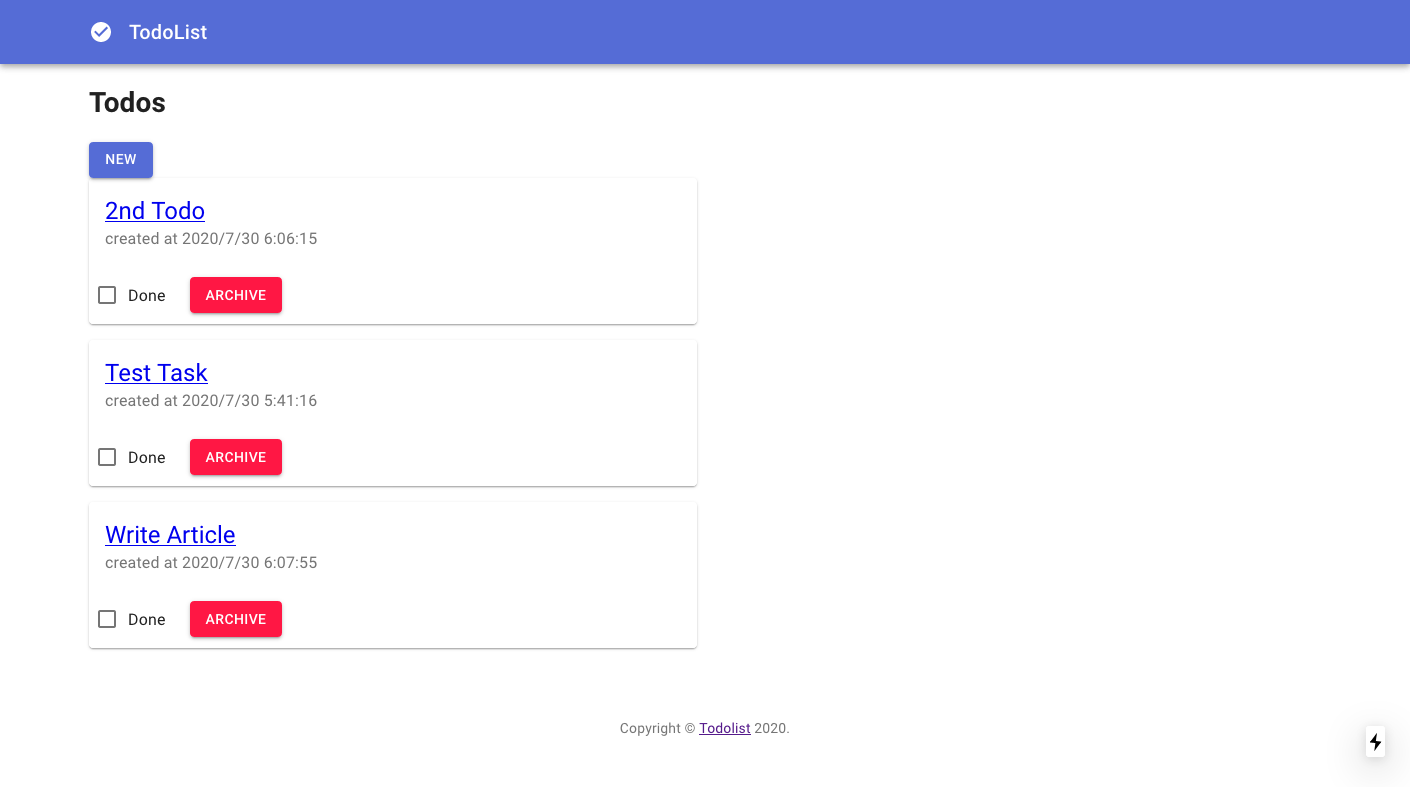
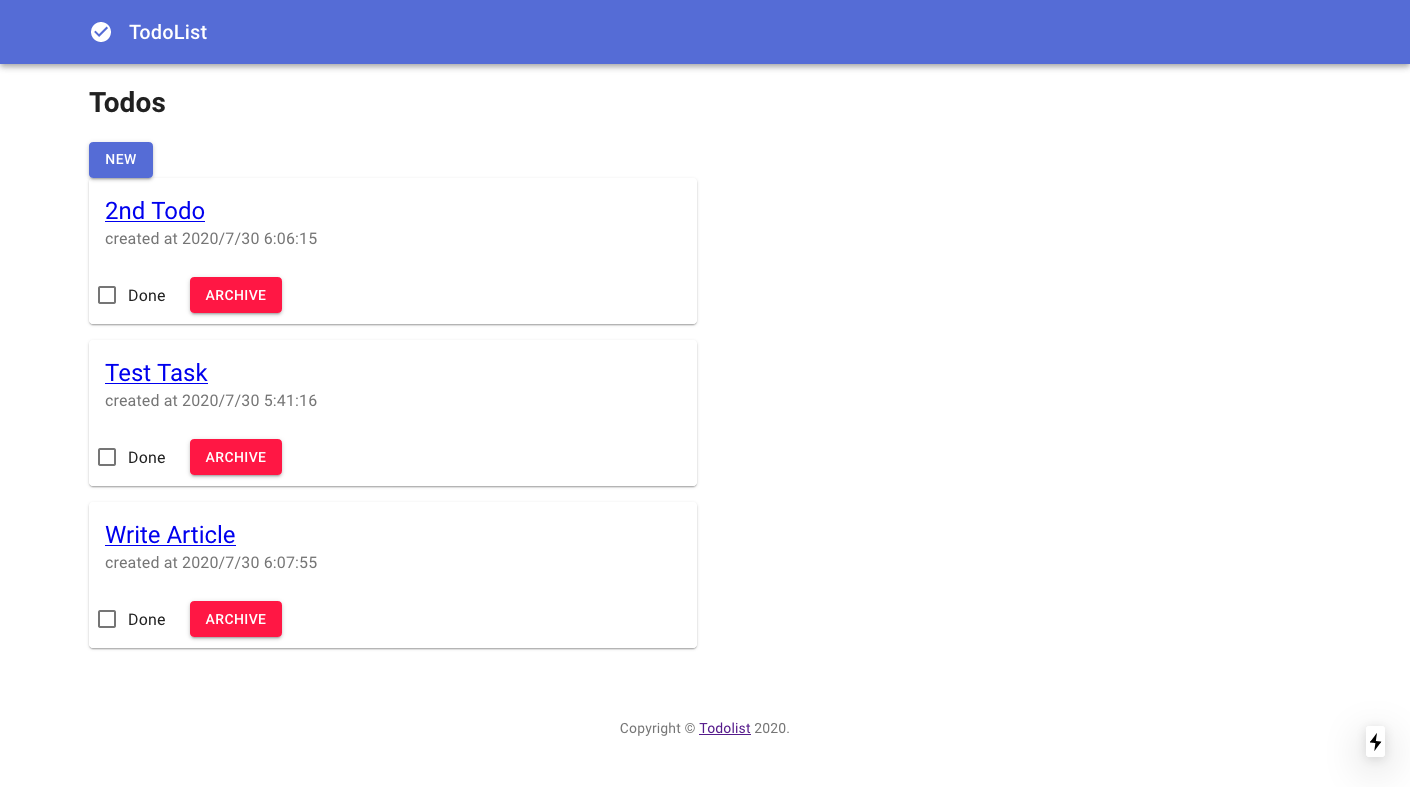
CI/CDが無事に完了し、ページにアクセスするとログイン画面が表示されます。
Create Accountでアカウント作成するとログインができるようになります。
無事、一覧画面が無事表示されました。
その他の画面の実装
新規登録画面
次のファイルを
pagesに追加します。https://github.com/yuuu/next-ts-amplify-recoil-todolist/blob/master/pages/todos/new.tsx
フォームは編集画面でも使うためコンポーネント化しておきます。
https://github.com/yuuu/next-ts-amplify-recoil-todolist/blob/master/src/component/Form.tsx
詳細画面
次のファイルを
pagesに追加します。https://github.com/yuuu/next-ts-amplify-recoil-todolist/blob/master/pages/todos/%5Bid%5D.tsx
編集画面
次のファイルを
pagesに追加します。https://github.com/yuuu/next-ts-amplify-recoil-todolist/blob/master/pages/todos/%5Bid%5D/edit.tsx
まとめ
手元の環境でアプリを開発して画面を揃えるところまでは順調に進んだのですが、CI/CDでハマりどころが多く苦労しました。
ここまでの環境が揃っていれば、あとはスピーディーに開発していけそうな気がしています。ぜひ、お試しください。


- 投稿日:2020-09-10T01:10:43+09:00
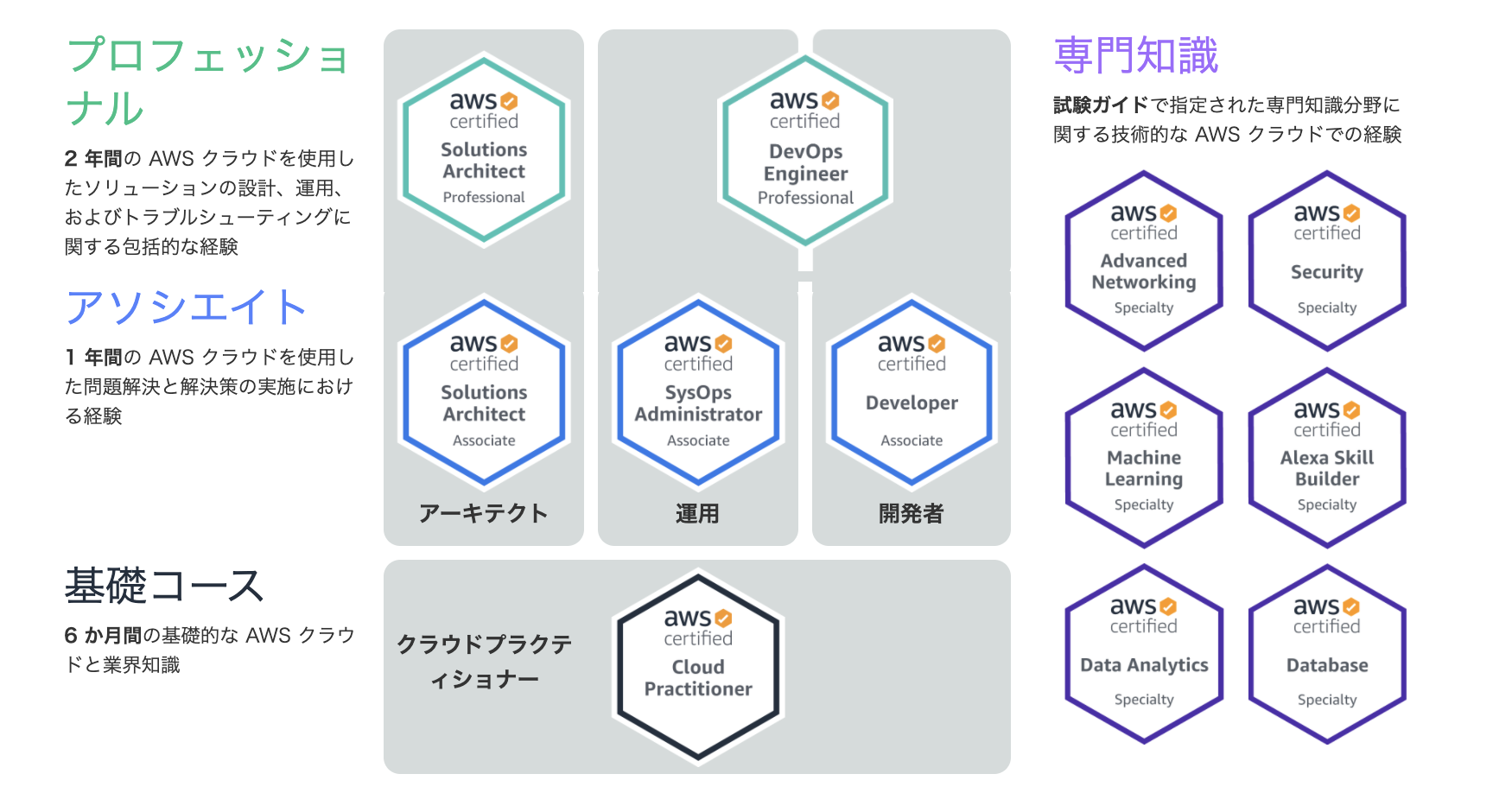
AWS認定ソリューションアーキテクトプロフェッショナルに合格するまで〜プロフェッショナル編〜
はじめに
AWS認定ソリューションアーキテクトプロフェッショナルに合格するまで〜アソシエイト編〜の続きです。今回はプロフェッショナル編です。
SAA取得後4ヶ月でSAPも無事一発で合格することができました。SAP試験について
詳細は公式ページを参照。
難易度
SAA試験の上位試験で、AWS認定試験最難関との噂。
AWS認定より抜粋受験対象は
AWS におけるシステムの管理および運用に関する2年以上の実務経験を持つソリューションアーキテクト担当者を対象としています。
となっています。資格の取得だけなら実務経験2年も必要ないですが、受験した感触として、アソシエイトよりもかなり幅広い知識に加えてしっかり考える力が問われている印象でした。
試験形式など
- 実施形式
テストセンターまたはオンラインプロクター試験- 時間
180分間- 問題数
75問- 受験料金
30,000 円(税別)/ 模擬試験 4,000 円(税別)- 言語
英語、日本語、韓国語、中国語 (簡体字)実施形式はアソシエイトと同じです。違う点は
試験時間、問題数、受験料金です。SAA合格時に受験料を半額にしてくれるクーポンがもらえているはずなので使いましょう。16,500円も安くなります。点数は100~1000点(スケールドスコア)で採点され、合格ラインは750点です。試験時間は180分という長丁場ですが、問題数も75問と多く、時間に余裕はありません。1問あたり2分から2分半くらいのペースで解いていってギリギリ終わるくらいです。しかも1問1問しっかりボリュームのある長文かつ選択肢も文が長いので、問題文と選択肢から要点を素早く読み解いて回答しないといけません。また傾向として暗記していればパッと答えがわかるような問題は少ないです。そもそも選択肢には実際に実現可能なものが複数含まれている場合も多く、その場合は「最適なものを選択」といった問題文になっているので設計の原則に従ってより最適な選択肢を選ぶ必要があります。このようにAWSの幅広い知識に加えて、180分間の試験に耐える集中力、文章から的確に重要な情報を抽出する読解力、どれも正解に見える選択肢から正しい答えを選択する判断力が求められます。アソシエイトに比べて段違いに難しいなというのが正直な感想です。。
利用した教材など
購入教材は以下の3つです。例のごとくUdemyの講座は必ずセール時に買うようにしましょう。
- Ultimate AWS Certified Solutions Architect Professional 2020
- AWS 認定ソリューションアーキテクト プロフェッショナル模擬試験問題集(全5回分375問)
- AWS WEB問題集で学習しよう
Ultimate〜は英語ですが、SAP試験で理解しておく必要があるポイントを押さえてくれています。きっちり通しで試聴するというよりはざっと流し見て、模擬試験やりながら弱いところを集中的に見返すという使い方をしました。
プロフェッショナル模擬試験問題集は繰り返し演習用に使いました。180分で本番形式の問題を75問解く訓練にはなります。ただ問題が本番試験のものに近いかと言えば微妙だった気がします。とはいえ勉強になる問題ばかりなのでやってよかったと思います。
WEB問題集は最後の4日間くらいで補強のために利用しました。7問単位で解いて解説読んで、って感じでサクサク進められるのでやりやすかったです。プロフェッショナル模擬試験問題集より本番試験に類似した問題が多かったかなという印象です。全部やり切る前に本番を迎えてしまったので、もしかしたら最後まで演習問題やってたらもっと自信を持って答えられる問題は多かったのかも?購入教材以外では、以下のようなものを利用しました。公式のトレーニングやドキュメント系。
あとはqiitaにまとめ記事書いてくれてる人がいたので試験前の総ざらいに使いました。情報が更新されているかは各自確認してください。
勉強の流れ
- Udemyの
Ultimate〜講座をざっと視聴- Udemyの
プロフェッショナル模擬試験問題集を本番形式で1周- 間違えた問題を見直して弱い分野を
Ultimate〜で補強- 必要に応じて、AWSコンソールで実際に触ってみる
- 全模擬試験で9割くらい取れるように2~4を繰り返し(3周くらいしたかな)
- 公式の模擬試験(SAA合格時の特典の無料チケットを利用)
WEB問題集で最後の追い込みおわりに
SAP試験についてでも書いた通り、試験はかなり難しいです。難しさの最大の理由は試験時間の長さ+問題の量の多さだと思います。正解とそれ以外の違いがかなり微妙な問題はじっくり時間をかけて解きたいので、知識があればすぐに正解を導き出せるタイプの問題は瞬殺で次に行けるようにしておきたいところですね。エッジケースを押さえておくとすぐに間違いの選択肢を消去していけるのでそういう問題はかなり楽になります。(例えば、api gatewayを使う場合のタイムアウト設定の上限、作成できるIAMユーザの上限など)
また、問題文の最後の一文もしっかり読む癖を付けましょう。「最適なものを選べ」なのか、「コスト効率の良い方法を選べ」なのか、で選択が変わってくる場合もあります。求められる要件とそれを満たすどのような答えが求められているのかをしっかり把握して答えるようにしましょう。
最後は根性論ですが、諦めずに頑張ることです。私は受験日の5日前くらいに最後の仕上げのつもりで公式の模擬試験を受けたら5割くらいしか取れませんでした。かなりショックだったのですが、受験予約をしちゃってたので少しでも悪あがきして本番に臨むしかないと思い、追加の教材で最後の追い込みをして、結果合格できました。試験本番も自信を持って回答できた問題数える程度しかなかったですし、最後の問題を回答した時点で残り時間1分を切ってました。それでも合格できたのでこれからSAP受験を考えている方も頑張ってください。少しでも参考になれば幸いです!コメントや指摘事項あればよろしくお願いします。