- 投稿日:2020-09-10T23:32:50+09:00
djangoのmodelをインタプリタから使う
インタプリタから直でdjangoのモデルにアクセスしようとすると以下のエラーで怒られる。
django.core.exceptions.ImproperlyConfigured: Requested setting LOGGING_CONFIG, but settings are not configured. You must either define the environment variable DJANGO_SETTINGS_MODULE or call settings.configure() before accessing settings.コレを防ぐためにはまず、モデルをインポートする前に以下を呼ぶ必要があるようだ。
後に呼ぶとエラーになる。django.setup()加えて、環境変数を設定する必要がある
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'app_name.settings') 'app_name.settings'まとめると以下のようになる。
>>> import django >>> import os >>> os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'app_name.settings') 'app_name.settings' >>> django.setup() >>> from APP_NAME.models import YourModel >>> YourModel.objects.all() <QuerySet []>
- 投稿日:2020-09-10T23:23:53+09:00
pandas category 型集計の罠
pandas category 型集計の罠
dtypeがcategoryだと、存在しない値に対しても集計されてしまうことがある。
import pandas as pd # version 1.1.2 # DataFrame を定義 df = pd.DataFrame({ 'col1': ['a', 'a', 'b', 'b', 'c', 'c'], 'col2': [1, 2, 1, 2, 1, 2] }) # col1 を category 型にする df['col1'] = df['col1'].astype('category') # 先頭の3行をコピー df_sub = df.head(3).copy() # col1 で groupby して、col2 について集計 df_grp = df_sub.groupby('col1') df_agg = df_grp.agg({'col2': 'mean'}).reset_index() df_agg.columns = ['col1', 'mean_col2']df_subは以下のようになる。
col1 col2 0 a 1 1 a 2 2 b 1 df_aggは以下のようになる。
col1 mean_col2 0 a 1.5 1 b 1.0 2 c NaN 問題点
df_subに対して集計したはずなのに、col1がcの行がある。df_grp.groupsを確かめてみると、{'a': [0, 1], 'b': [2], 'c': []}となっている。
対策例
以下の行を追加
col1_values = df_sub['col1'].unique() df_agg = df_agg[df_agg['col1'].isin(col1_values)]
- 投稿日:2020-09-10T23:11:29+09:00
【Python】numpyでinfとNaNの扱い方
発生した問題
python3でnumpyを用いた画像処理(画像評価)ソフトの出力に,
平均・標準偏差・最大・最小にinfとNaNが含まれる.sample_code.pyimport numpy as np img = #なんか画像の配列 print(np.max(img)) print(np.min(img)) print(np.mean(img)) print(np.std(img)) >inf >-inf >NaN >NaNこんな感じ
結構ハマったinf,NaNとは
そもそもinfとかNaNってなんなんでしょうね?(激うまギャク)
調べると沢山情報が出てきました.inf
infinityの略.無限大を表す.
-infは負の無限大なわけですね.NaN
浮動小数点数にはNaN (Not a Number, 非数) と呼ばれる、実数の異常な値を表す特殊な数があります。
これは無限大-無限大、0.0/0.0といった不定形や、負数の平方根、負数の対数といった実数で表せない計算を行った場合に発生します。NaNのお話より
僕の理解では,考慮したくない・計算時に除外する値(数)って認識です.
対策方法
1.infをNaNに置き換える
sample_code.pyimport numpy as np img = #なんか画像の配列 img[img == -np.inf] = np.nan img[img == np.inf] = np.nanこれで配列からinfは消えました.次に進みましょう
2.NaNを考慮した関数を使う
sample_code.pyimport numpy as np img = #なんか画像の配列 img[img == -np.inf] = np.nan img[img == np.inf] = np.nan 最小, 最大 = np.nanmax(img), np.nanmin(img) 平均 = np.nanmean(img) 標準偏差 = np.nanstd(img) #他にも合計や分散もある参考:https://note.nkmk.me/python-numpy-nansum/
3.理解を深めるためのお話
これどういう処理をしてるんだろうってお話です.
最大や平均を求めるときにNaN要素を除外して計算しています.
例えば平均の計算ですと,全体の合計値に含ませないし要素の数にも含みません.配列の中からNaNってやつを削除してしまうイメージ.
じゃあ削除すればいいじゃんと思うかもしれませんが,画像処理ではそうもいかんです.
削除してしまったら画像の縦横の大きさとかくるってしまいますからね.とりあえず,0で割ったり0を割ったりしてるとinfやNaNが含まれてしまうので,
そういった処理をしているソフトなら基本的に上の処理を行いましょうねといった感じでしょうか.あとがき
このことに気づくのって結構大変でした.
自分はよくimageJでやるような画像処理の作業を自動化してるのですが,
ソフトの出力結果とimageJで処理した結果が違ってたので気づけました.
infは除外しちゃうんだ~って感じましたね.画像処理の世界では常識なんですかね?
- 投稿日:2020-09-10T23:11:29+09:00
【Python】numpyの平均、標準偏差、最大・最少におけるinfとNaNの扱い方
発生した問題
python3でnumpyを用いた画像処理(画像評価)ソフトの出力に,
平均・標準偏差・最大・最小にinfとNaNが含まれる.sample_code.pyimport numpy as np img = #なんか画像の配列 print(np.max(img)) print(np.min(img)) print(np.mean(img)) print(np.std(img)) >inf >-inf >NaN >NaNこんな感じ
結構ハマったinf,NaNとは
そもそもinfとかNaNってなんなんでしょうね?(激うまギャク)
調べると沢山情報が出てきました.inf
infinityの略.無限大を表す.
-infは負の無限大なわけですね.NaN
浮動小数点数にはNaN (Not a Number, 非数) と呼ばれる、実数の異常な値を表す特殊な数があります。
これは無限大-無限大、0.0/0.0といった不定形や、負数の平方根、負数の対数といった実数で表せない計算を行った場合に発生します。NaNのお話より
僕の理解では,考慮したくない・計算時に除外する値(数)って認識です.
対策方法
1.infをNaNに置き換える
sample_code.pyimport numpy as np img = #なんか画像の配列 img[img == -np.inf] = np.nan img[img == np.inf] = np.nanこれで配列からinfは消えました.次に進みましょう
2.NaNを考慮した関数を使う
sample_code.pyimport numpy as np img = #なんか画像の配列 img[img == -np.inf] = np.nan img[img == np.inf] = np.nan 最小, 最大 = np.nanmax(img), np.nanmin(img) 平均 = np.nanmean(img) 標準偏差 = np.nanstd(img) #他にも合計や分散もある参考:https://note.nkmk.me/python-numpy-nansum/
3.理解を深めるためのお話
これどういう処理をしてるんだろうってお話です.
最大や平均を求めるときにNaN要素を除外して計算しています.
例えば平均の計算ですと,全体の合計値に含ませないし要素の数にも含みません.配列の中からNaNってやつを削除してしまうイメージ.
じゃあ削除すればいいじゃんと思うかもしれませんが,画像処理ではそうもいかんです.
削除してしまったら画像の縦横の大きさとかくるってしまいますからね.とりあえず,0で割ったり0を割ったりしてるとinfやNaNが含まれてしまうので,
そういった処理をしているソフトなら基本的に上の処理を行いましょうねといった感じでしょうか.あとがき
このことに気づくのって結構大変でした.
自分はよくimageJでやるような画像処理の作業を自動化してるのですが,
ソフトの出力結果とimageJで処理した結果が違ってたので気づけました.
infは除外しちゃうんだ~って感じましたね.画像処理の世界では常識なんですかね?
- 投稿日:2020-09-10T23:10:47+09:00
Youtubeをmp3化して超安全にダウンロードする方法【Python】
今回はYouTubeにあげられている動画をmp3としてダウンロードする方法をまとめてみます。
参考サイトやgithubも載せます。
ミスや疑問点がありましたらコメントしていただけると幸いです。
*注意点*
あくまで個人的にYouTubeにアップロードした動画をダウンロード、そしてmp3化することを主としております。
そのため、自分以外の誰かが投稿した動画から手に入れた音源を使って問題が起きても一切の責任を負いません。
私的利用は大丈夫だという声も多いですが、自己判断で行うようにしてください。そのつもりで以下ごらんください!
完成品
あくまで例です。
https://www.youtube.com/watch?v=E8bUKuF9v10 をmp3化するとします。開いたところ
ファイル生成
日付もすべて揃えることができる。
つまり、ダウンロードした順に並ぶ。
ちなみに、最初の段階でQuitを押すとウィンドウが閉じ、何も入力していないときにTo Mp3,DeleteURL,Pasteを入力してもご作動は起きないように作ってあります。
環境
- windows10Home
- mac,linuxでもできるはずですが、windowsのみの動作確認となります。
- vscode
- youtube-dl(released 2020.09.06)
- ffmpeg(mp4(movie)→mp3(sound)software)
- pip
- PySimpleGUI==4.29.0
- subprocess
- sys
- os
- pyperclip==1.8.0
- win32_setctime==1.0.2
- datetime # ディレクトリ ...\ffmpeg~static\bin\ この中にffmpegの主要ファイルがあるので、そこにpathを通します。bin内に、youtue-dlのexeファイルも入れます。そうすることで、コマンドプロンプトのどこでもexeが起動できます。
-bin - ffmpeg.exe - ffplay.exe - ffprobe.exe - youtube-dl.exe作った背景と作りたかった構造
youtube動画ダウンローダーたるものはネット上に数え切れないほどありますが、どうしても得体のしれないサイトからデータを返してもらうことが嫌でした。
そのため自分のPCで完結させようと思いました。
最初は、専用のソフトウェアなど全く知りませんでしたが、ググるうちにいいものを見つけたので、これは実現できるのではないか、と感じました。
実装させる機能は至ってシンプルなもので良かったので、GUIで操作できるようにしました。
また、Pythonファイルであれば、すぐにexe化できるので、友人に配布することも可能であります。
GUIとしてはTkinterが有名でしたが、試しに使ったところ吐き気がするくらい嫌になったので、pysimpleguiを用いました。
そのおかげでGUIは短時間で完成したと思います。
コード
github:
https://github.com/cota-eng/youtube-dl-in-windows
コード解説
区切って解説していきます。
モジュール・ライブラリのimport
import subprocess import PySimpleGUI as sg import sys import re import os import pyperclip from win32_setctime import setctime from datetime import datetime関数内の最初
すべてpysimpleguiのプログラムです。
配色テーマを決め、レイアウトを作り、ウィンドウを開く流れです。それぞれのボタン、テキストフィールドの意味は英単語のそれの通りです。
sg.theme("SystemDefault") layout = [ [sg.Text("Please Input Youtube URL!")], [sg.Button( 'Quit', size=(34, 2))], [sg.Button('To Mp3', size=(34, 2))], [sg.InputText('', size=(39, 3))], [sg.Button('DeleteURL', size=(16, 2)), sg.Button('Paste', size=(16, 2))] ] window = sg.Window('From Youtube To mp3', layout)while True
while True: event, values = window.read() url = values[0]event=="Quit"
単純に、このボタンがおされるとwhileループを抜けるということです。
if event == 'Quit': breakwhileループの一番下にbreakがあるのではなく、if,elifなどで適切な場面においてbreakさせます。
mp3化する
event==" "というのは、ボタンがクリックされたときに発生するイベントということです。そのうち、ボタンの名前に一致させることで一意にプログラムを指定できます。
そのイベント中でinputされたurlの長さで簡単にバグ防止させてみます。youtubeのリンクのうち、必須の長さは40ほどなので、安全に32を基準としました。len > 32 が True
elif event == 'To Mp3': if len(url) > 32: cmd = r'youtube-dl {} -x --audio-format mp3 -o "C:\Users\INPUTUSERNAME\Music\youtube-dl\%(title)s.%(ext)s"'.format( url) subprocess.call( cmd, cwd=r"C:\Program Files\ffmpeg-20200831-4a11a6f-win64-static\bin") res = subprocess.check_output(f'youtube-dl -e {url}'.split()) res = res.decode('shift_jis').replace('\n', '') res += '.mp3' root = "C:\\Users\\INPUTUSERNAME\\Music\\youtube-dl\\" filename = root + res print(filename) date = datetime.now() year, month, day, hour, minute, second = date.year, date.month, date.day, date.hour, date.minute, date.second now = datetime(date.year, date.month, date.day, date.hour, date.minute, date.second).timestamp() os.chdir(root) setctime(filename, now) os.utime(filename, (now, now))さらに分けて解説します。
r"文字列"とすることで、紛らわしい記号もすべて文字として扱えます。raw文字列のrawです。
cmdというコマンドはyoutube-dlのreadmeより作成しました。
youtube-dl\%(title)s.%(ext)sというのは、ファイル名です。youtube-dl上の話なので、詳しくは自分で読むといいです。僕は試行錯誤して得ました。subprocessのcall関数で呼び出します。cwdでディレクトリも指定します。
cmd = r'youtube-dl {} -x --audio-format mp3 -o "C:\Users\INPUTUSERNAME\Music\youtube-dl\%(title)s.%(ext)s"'.format( url) subprocess.call( cmd, cwd=r"C:\Program Files\ffmpeg-20200831-4a11a6f-win64-static\bin")
resにファイル名を収めます。これも試行錯誤した結果なので、見て理解してください。
結局、以下のようにしたらfilenameにpathをすべて格納できるんです。res = subprocess.check_output(f'youtube-dl -e {url}'.split()) res = res.decode('shift_jis').replace('\n', '') res += '.mp3' root = "C:\\Users\\INPUTUSERNAME\\Music\\youtube-dl\\" filename = root + res print(filename)
datetimeライブラリより、作成時刻などを設定させます。厳密には、更新日時以外は、作成したときに自動的に設定されるのですが、なぜか更新日時が更新されませんでした。
そのため、以下のサイトを参考にし、自分なりにdatetimeを埋め込むことで実現できました。
参考URL:
https://srbrnote.work/archives/4054ちなみにpowershell 使うなら、
Set-ItemProperty hogehoge.txt -name CreationTime -value $(Get-Date)
Set-ItemProperty hogehoge.txt -name LastWriteTime -value $(Get-Date)
として簡単にできるのですが、pythonではpowershellが使えないとのことなので、osモジュールを使用した次第です。
date = datetime.now() year, month, day, hour, minute, second = date.year, date.month, date.day, date.hour, date.minute, date.second now = datetime(date.year, date.month, date.day, date.hour, date.minute, date.second).timestamp() os.chdir(root) setctime(filename, now) os.utime(filename, (now, now))len <= 32 のとき
単純に、一度ウィンドウを閉じ、最初に開いたときと同じ入力して実行したとき、弾かれます。
else: window.close() layout = [ [sg.Text("Please Input youtube URL!")], [sg.Button('Quit', size=(34, 2))], [sg.Button('To Mp3', size=(34, 2))], [sg.InputText('', size=(39, 3))], [sg.Button('DeleteURL', size=(16, 2)), sg.Button('Paste', size=(16, 2))] ] window = sg.Window('From youtube To mp3', layout)pasteイベント
pasteはそのとおり、コピーしたリンクを貼り付けます。ボタン操作の方が楽なので実装させました。
pyperclipだけでguiに入力はできないので、ウィンドウを閉じ、pyperclipの内容を変数に代入し、その変数を初期値とするウィンドウを開かせることで解決できました。
elif event == 'Paste': window.close() paste_url = pyperclip.paste() layout = [ [sg.Text("Please Input youtube URL!")], [sg.Button('Quit', size=(34, 2))], [sg.Button('To Mp3', size=(34, 2))], [sg.InputText(paste_url, size=(39, 3))], [sg.Button('DeleteURL', size=(16, 2)), sg.Button("Paste", size=(16, 2))] ] window = sg.Window('From youtube To mp3 ', layout)deleteイベント
これは先程と同じ考えです。削除させるのではなく、ウィンドウを閉じ、入力がされていないウィンドウを呼び出しました。
elif event == 'DeleteURL': window.close() layout = [ [sg.Text("Please Input youtube URL!")], [sg.Button('Quit', size=(34, 2))], [sg.Button('To Mp3', size=(34, 2))], [sg.InputText('', size=(39, 3))], [sg.Button('DeleteURL', size=(16, 2)), sg.Button('Paste', size=(16, 2))] ] window = sg.Window('From youtube To mp3', layout)以上
コードが汚くて申し訳ないですが、参考になれば幸いです。
この一連の流れを紹介・解説しているサイトを見つけられなかったので、Qiitaに上げました。
ありがとうございました。



- 投稿日:2020-09-10T22:55:36+09:00
強化学習で山を登りたい
強化学習ってかっこいいですよねえ。
今回は, pythonの環境「OpenAIGym」の「MountainCar」で遊んでみたので, 紹介します。
ちなみに, Google Colab使ってやってます。こちらの記事をかなり参考にしました。OpenAI Gym 入門
さらっとQ学習
学習方法としてQ学習を振り返ります。どうでもええ!という方は, 読み飛ばしてください。
Q学習において, $Q\left( s_{t},a_{t}\right)$は状態行動価値といい, ある状態$st$において, 行動$a_{t}$をとった際の価値を表します。ここで$t$という表記を使ったのは, 時間という意味ではなくある状態という単一的な状態を表します。
ここでいう価値とは, 状態遷移した際に一時的にもらえる報酬ではなく, エピソードを最後まで完遂した際にもらえるであろう累積的な報酬のことをさします。よって方策のとり方としては, ある状態$s_{t}$において$\max_{a\in At}(Q(s_{t},a))$となるような$a$を選べば良いということになります。
状態行動価値の更新
一般に状態行動価値の更新方法は, 以下のように表されます。
$\begin{aligned}Q\left( s_{t},a_{t}\right) \ \leftarrow Q\left( s_{t},a_{t}\right) \ +\alpha \left( G_{t}-Q\left( s_{t},a_{t}\right) \right) \end{aligned}$
ここで, Q学習の場合$G_{t}$は
$G_{t}=r_{t+1}+\gamma\max_{a\in At}[Q(s_{t+1},a)]$
$s_{t+1}$というように, 現在の状態ではなく次の状態においても考慮していることがわかります。これは未来に得られる報酬も考慮しているのだということだわかります。
$r_{t+1}$を即時報酬といい, 遷移してすぐにもらえる報酬, $\alpha$は学習率と呼び, 一回の学習でどの程度値を更新するのかを決めます。$\gamma$は割引率といい将来の報酬をどの程度参考にするかを決めます。エピソード(ゲーム)を繰り返すことでこの, 状態価値関数を更新し最適な方策を求めていくのがこの$Q$学習です。
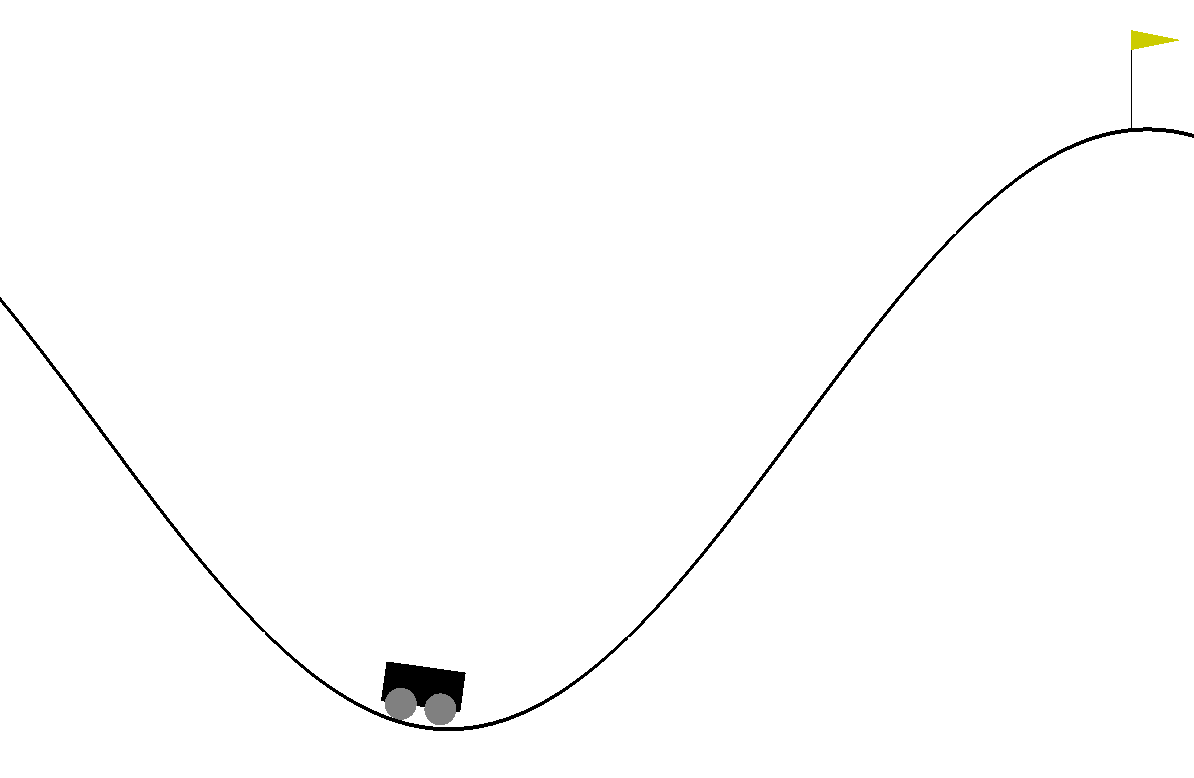
MountainCarルール
この環境では, 車の位置が右側の旗の位置に到達すると, ゲームが終了します。到達しない限り, 行動をするごとに-1の報酬を得ます。
もし、200回の行動を経てもゴールに達せれない場合もゲーム終了です。その場合、-200の報酬を得たことになります。つまり-200よりもより大きい報酬を得ようと強化学習させるわけです。行動は, 左に移動:0, 動かない:1, 右に移動:2の三つに制限されます。
準備
Google Colabで状態描写するために色んなもの入れてますが, 結局はgymさえ入れればいいです。
bash#gymのインストール $ pip install gym #必須ではない(colab使うときはおすすめ) $apt update $apt install xvfb $apt-get -qq -y install libcusparse8.0 libnvrtc8.0 $ibnvtoolsext1 > /dev/null $ln -snf /usr/lib/x86_64-linux-gnu/libnvrtc-builtins.so.8.0 /usr/lib/x86_64-linux-gnu/libnvrtc-builtins.so $apt-get -qq -y install xvfb freeglut3-dev ffmpeg> /dev/null $pip install pyglet $pip install pyopengl $pip install pyvirtualdisplayライブラリインポート
いらないものもあるので適宜選んでも構いません。
import gym from gym import logger as gymlogger from gym.wrappers import Monitor gymlogger.set_level(40) #error only import tensorflow as tf import numpy as np import random import matplotlib import matplotlib.pyplot as plt %matplotlib inline import math import glob import io import base64 from IPython.display import HTMLQ学習実装
行動の種類や, 環境の使い方はgithubを参考にしています。
GitHub MountainCarclass Q: def __init__(self, env): self.env = env self.env_low = self.env.observation_space.low # 位置と速度の最小値 self.env_high = self.env.observation_space.high # 位置と速度の最大値 self.env_dx = (self.env_high - self.env_low) / 40 # 50等分 self.q_table = np.zeros((40,40,3)) def get_status(self, _observation): position = int((_observation[0] - self.env_low[0])/self.env_dx[0]) velocity = int((_observation[1] - self.env_low[1])/self.env_dx[1]) return position, velocity def policy(self, s, epsilon = 0.1): if np.random.random() <= epsilon: return np.random.randint(3) else: p, v = self.get_status(s) if self.q_table[p][v][0] == 0 and self.q_table[p][v][1] == 0 and self.q_table[p][v][2] == 0: return np.random.randint(3) else: return np.argmax(self.q_table[p][v]) def learn(self, time = 5000, alpha = 0.4, gamma = 0.99): log = [] for j in range(time): total = 0 s = self.env.reset() done = False while not done: a = self.policy(s) next_s, reward, done, _ = self.env.step(a) total += reward p, v = self.get_status(next_s) G = reward + gamma * max(self.q_table[p][v]) p,v = self.get_status(s) self.q_table[p][v][a] += alpha*(G - self.q_table[p][v][a]) s = next_s log.append(total) if j %100 == 0: print(str(j) + " ===total reward=== : " + str(total)) return plt.plot(log) def show(self): s = self.env.reset() img = plt.imshow(env.render('rgb_array')) done = False while not done: p, v = self.get_status(s) s, _, done, _ = self.env.step(self.policy(s)) display.clear_output(wait=True) img.set_data(env.render('rgb_array')) plt.axis('off') display.display(plt.gcf()) self.env.close()扱う状態$s$としては, 現在の車の位置(position), 現在の速度(velocity)があります。どちらも連続値をとっているので, get_status関数で離散的な値(40, 40)にしています。q_tableは状態価値関数の保存場所で, (40, 40)の状態のそれぞれに, 行動の種類, (3)を乗じたものとなっています。
env = gym.make('MountainCar-v0') agent = Q(env) agent.learn()
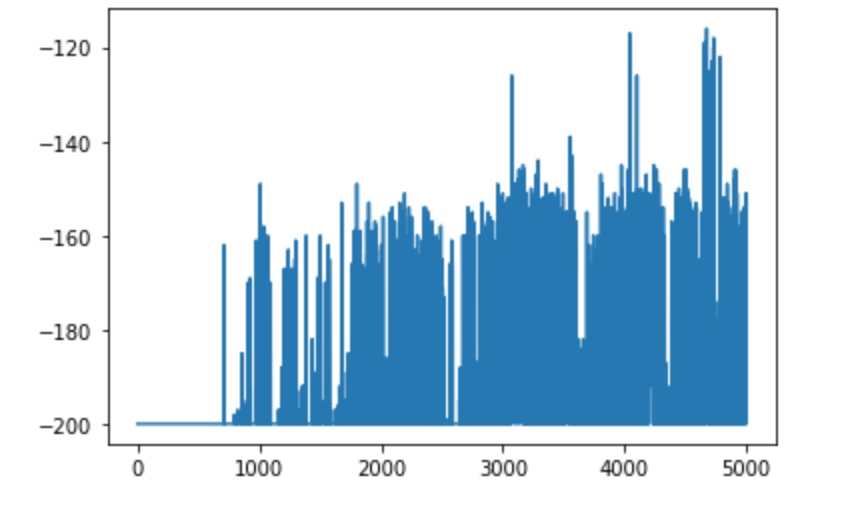
大体5000回の学習で, ゴールにも到達できる回数が増えてきました。
ちなみにgoogle colabでアニメーション確認したいときは,
from IPython import display from pyvirtualdisplay import Display import matplotlib.pyplot as plt d = Display() d.start() agent.show()でみれます。
感想
今回は説明がかなり雑になってるので, 徐々に更新していきます。もっとGymで遊んでいきつつ情報発信していきます。ではまた!

- 投稿日:2020-09-10T22:29:23+09:00
Python japanmap 可視化 都道府県 データ分析
同じ日本国内でも、地域によって物価が違うらしいです。可視化してみましょう。
統計データ
今回利用する統計データは下記です。
リンク先のページを辿ると、CSV形式でも統計データをダウンロードできます。e-Statは年々使いやすさが向上している印象があって良いですね。
10大費目別消費者物価地域差指数
10大費目というのは、1.食料、2.住居、3.光熱・水道、4.家具・家事用品、5.被服及び履物、6.保険医療、7.交通・通信、8.教育、9.教養娯楽、10.諸雑費の分類のことだそうです。また、それらの費目を足し合わせた「総合」と「家賃を除く総合」の項目があります。集計品目の一覧はここから確認できます。
データ準備
e-Statの統計表・グラフ表示のページからデータをダウンロードできます。その後、Excel等でデータ整形し、下記のようにCSV形式でエクスポートします。
price_index_by_prefecture_2019.csv都道府県,総合,食料,住居,光熱水道,家具家事用品,被服及び履物,保健医療,交通通信,教育,教養娯楽,諸雑費,家賃を除く総合 北海道,99.9,100.1,84.1,116.4,98.2,104.6,100.4,100.1,93.5,97.6,99.2,100.9 青森県,98.4,98,86,109.1,97.7,102.3,99.1,100.5,93.5,95.2,98.1,99.3 岩手県,99.1,97.4,93.1,110.1,101.1,97.4,100.1,99.2,90,100.5,98.6,99.4 宮城県,99.3,97.9,101.8,101.9,104.9,95.9,100.9,98,102.3,99.5,99.8,99.4 秋田県,98.4,97.6,86.2,107.8,101.7,100.2,99.2,98.6,88.9,98.6,100.4,98.9 山形県,100.2,101.4,90.7,111.4,94.6,98.4,97,99.9,104.7,98.5,97.6,100.7 福島県,99.6,99.5,96,108.8,102.3,104.2,99.7,98.5,91.8,94.8,101.4,100.1 茨城県,98.1,99,97.6,102.9,96.1,99.4,98.3,96.8,89.8,96.3,100.9,98.4 栃木県,98.2,98.6,85.7,98.7,101.6,112.5,100.1,97.7,99.8,96.1,99.5,98.7 群馬県,96.6,98.9,85.2,91.5,97.4,103.1,100.8,97.9,85.4,96.7,98.2,97.2 埼玉県,101,100.5,104.8,94.4,102.7,103.8,100.6,100.8,98.8,104.3,101.3,100.4 千葉県,100.7,101.2,104,101.8,100.9,96.1,100,99,97.8,102.7,99.6,100.6 東京都,104.7,103.4,132.3,95.5,103.8,100.1,101.5,104.8,106.7,104.1,100.2,103 神奈川県,104,101.7,125.1,98.4,100.2,102.1,101.5,103.2,111.9,105.2,102.6,103.2 新潟県,98.7,100,91.6,99.1,97.1,101,99.5,98.3,93.8,99.1,100.5,98.8 富山県,98.6,101.5,89.3,100.4,98.5,103.1,101.9,97.7,87.4,95.1,101.4,99.1 石川県,100.2,103.6,86.3,101.8,100.4,103.2,100.6,98.6,103.5,97.4,100.8,100.7 福井県,99.3,103.8,85.4,94.5,102.3,101,100.4,99,106.9,94,101.3,99.8 山梨県,98.7,100.6,93,96.4,99.3,102.4,99.3,99.1,89.9,98.3,99.1,99.2 長野県,97.7,95.2,90.4,102,101.3,104.4,98.2,100.1,88,98.5,101.5,98.2 岐阜県,97.3,98.1,85.2,93.7,94,104.2,99.3,100.2,92.5,98.2,100.2,97.9 静岡県,98.5,98.9,99.9,98,100.1,98.8,99.8,99,86,99.3,98.1,98.7 愛知県,97.6,97.2,95.2,95.9,96.6,95.5,99.9,97.7,98.2,99.8,99.1,97.7 三重県,98.7,100.6,92.9,99,98.5,98.5,99.2,99,99.8,95.5,99.6,99.3 滋賀県,99.5,99.8,89.5,99,98.4,103.1,100.6,100.4,109.1,97.4,102.3,100 京都府,100.6,100.8,94.5,97.7,100.9,98.9,97.9,102.5,115.6,100.5,100.5,100.8 大阪府,99.7,99.9,97.1,94.7,99.9,96.4,99,100.6,109.2,102.5,97.7,99.7 兵庫県,100.3,99.5,99.4,96.4,101.9,104,98.4,100.7,105.5,100.4,102.4,100.3 奈良県,97.5,96.7,87.1,98.4,99.3,100.1,99.1,99.7,94.2,99.1,100.1,97.8 和歌山県,99.2,100.7,90.3,98.4,95.9,102.2,101.4,100.1,108.6,95.4,99.9,99.9 鳥取県,98.6,101.7,81.7,106.2,100.8,106.9,99.4,97.1,91.3,93.9,98.8,99.2 島根県,99.5,101.5,87,111,98.4,95.1,99.8,99.6,96.6,96.9,99.7,100 岡山県,97.6,98.7,87.1,106.2,99.6,99.6,100.6,96.5,84.4,96.7,99.9,98.1 広島県,99,100.4,90.4,105.7,96.6,96.5,99.8,99.4,99.6,95.6,100.4,99.3 山口県,98.7,100.8,87.9,108.5,96,102.8,101.6,97.4,86.5,95.7,100.4,99.5 徳島県,100.1,100.9,96.5,104.5,103,110,98.2,97.6,96.1,97.5,100.5,100.6 香川県,98.3,99.5,85.5,105.5,101.9,92.4,99.5,99.8,93.4,94.9,103.5,99.2 愛媛県,97.9,99.5,82.4,106.8,100.8,98.4,99.5,97.6,94.1,97.7,97.6,98.7 高知県,99.8,102.4,93.6,103.6,99.5,100.4,100.7,98.9,92.4,96.6,101.1,100.5 福岡県,96.8,95.8,84.6,104.2,98.7,94,98.8,98.8,96.2,97.6,100.7,97.7 佐賀県,97.5,98.1,83.6,109.2,97.4,104.6,100.2,98.6,94.5,92.6,98.1,98.5 長崎県,99.8,98.9,93.4,109.5,103.6,108.5,100,100.1,90.5,96.3,99.9,99.9 熊本県,98.8,100.5,89.7,101.2,97.3,100.9,101.4,99.5,93.2,96.1,100.3,99.6 大分県,97.7,98.8,84.8,103.7,99.3,94.7,96.9,98.4,105.4,96,98.1,98.8 宮崎県,96,96.5,85.1,100.5,102.1,94.7,99,98.4,90.7,91.9,97.3,97 鹿児島県,96.3,98.9,85.2,99.3,97.5,90.6,99.3,99.4,92.9,91.8,94.4,97 沖縄県,98.4,103.2,85.6,103.8,96.1,98.9,98.5,97.8,93.4,97.9,94.8,99.8環境準備
可視化のため環境を準備します。
Jupyter Notebookの起動
今回は、Jupyter Notebookで可視化します。Windows環境では、下記コマンドでJupyter Notebookのインストールと起動ができます(公式ドキュメント)。
> pip install jupyter # Jupyterのインストール > python -m notebook # Jupyter Notebookの起動起動したら、Webブラウザで
http://localhost:8888にアクセスすると、Jupyter Notebook環境を利用できます。スクリプト
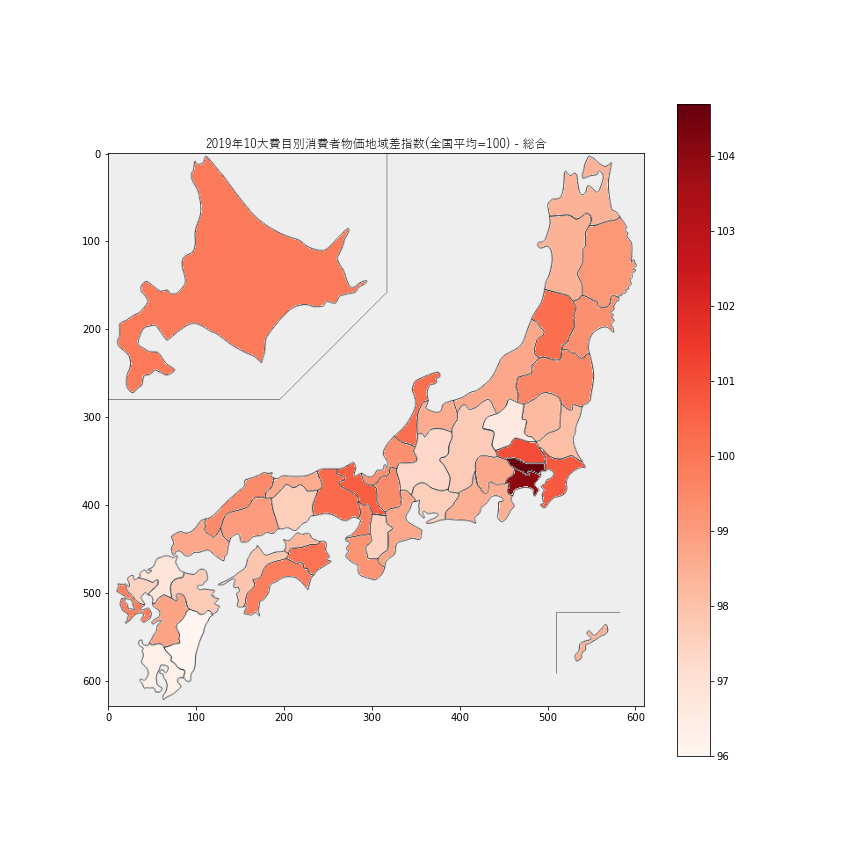
今回はjapanmapのライブラリを利用して、都道府県別に色分け表示します。下記スクリプトは「総合」列のデータについて可視化する例です。
import pandas as pd import matplotlib.pyplot as plt from japanmap import picture df = pd.read_csv('price_index_by_prefecture_2019.csv') # データファイル読込 df = df.set_index('都道府県') # indexを指定 cmap = plt.get_cmap('Reds') # 色の設定 norm = plt.Normalize(vmin=df.総合.min(), vmax=df.総合.max()) # 色の範囲を設定 fcol = lambda x: '#' + bytes(cmap(norm(x), bytes=True)[:3]).hex() # カラーコードを設定 plt.title('2019年10大費目別消費者物価地域差指数(全国平均=100) - 総合',fontname="Yu Gothic") # タイトル plt.rcParams['figure.figsize'] = 12, 12 # 図の大きさ plt.colorbar(plt.cm.ScalarMappable(norm, cmap)) # カラースケール表示 plt.imshow(picture(df.総合.apply(fcol))); # グラフ表示 plt.savefig('pricemap2019_general.png') # 画像ファイルに書き出し可視化結果
各項目についての可視化結果です。
総合
総合では、東京都と神奈川県の物価が全国平均よりも4-5%ほど高いようです。ただ、都会の物価が高いのかというと必ずしもそうでもなく、例えば大阪府の物価は
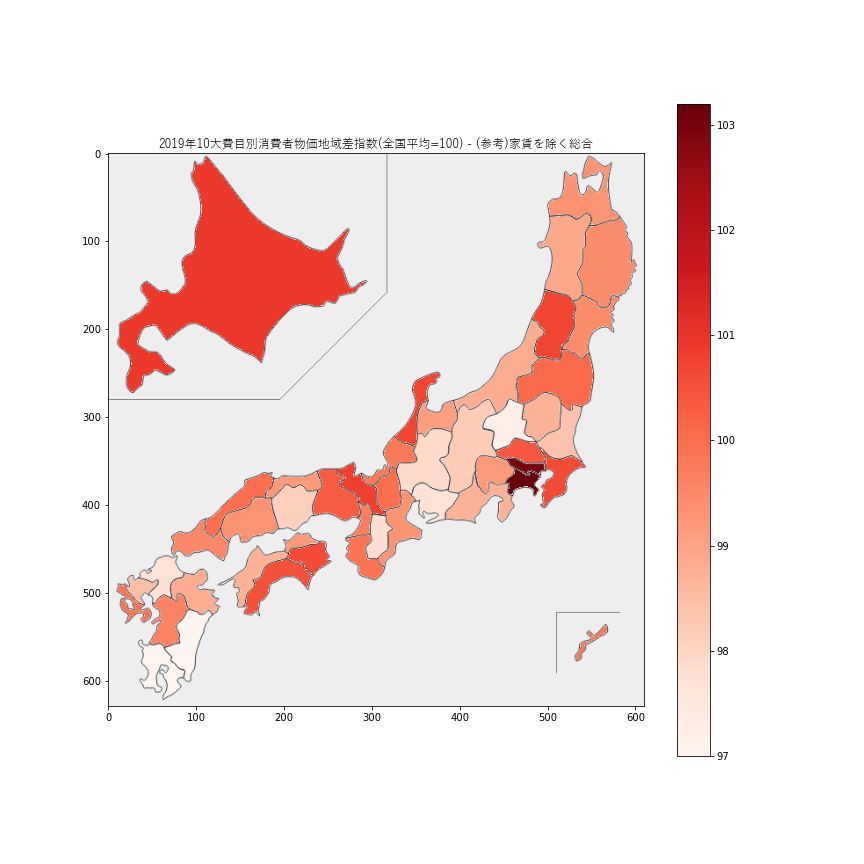
99.7と全国平均以下で、むしろ近隣の京都府100.6や兵庫県100.3の物価の方が高いようです。家賃を除く総合
家賃を除いても、東京都と神奈川県の物価がランキング1位と2位を占めるのは変わりませんでした。ただ、家賃を除かない総合指数よりもスケールの差はやや縮小しています。
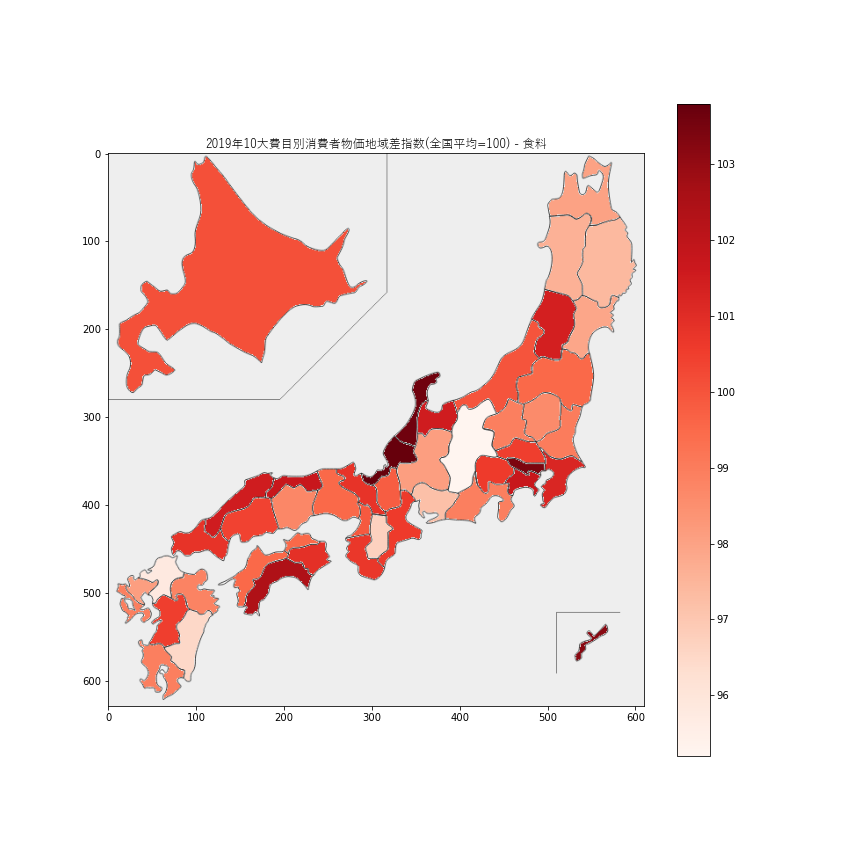
1.食料
食料価格が最も安いのは長野県
95.2、次いで福岡県95.8でした。最も高いのは順に福井県の103.8、石川県103.6、東京都103.4、沖縄県103.2で、北陸や東京、沖縄の食料品価格が高いようです。2.住居
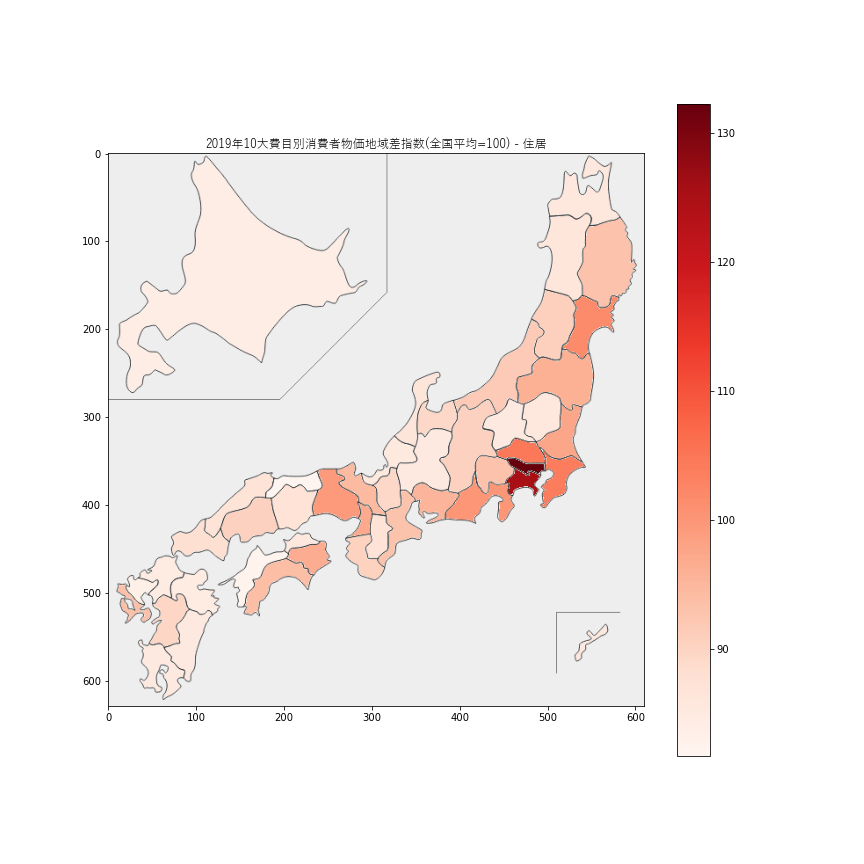
住居価格は、東京都で
132.3、神奈川県で125.1と他県と圧倒的な差をつけて高い値でした。住居価格が最も安いのは鳥取県81.7、次点で愛媛県82.4でした。福岡県も84.6と安いので、都会だからといって必ずしも住居価格が高いわけではなさそうです。3.家具・家事用品
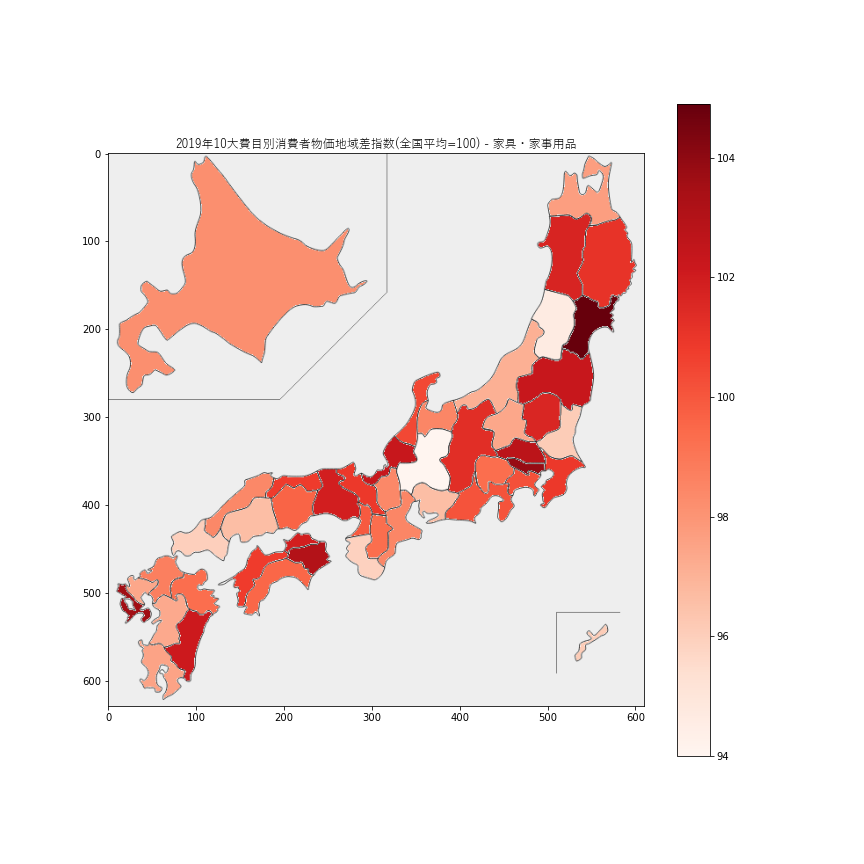
家具・家事用品の指数は94-104の範囲に収まっているので、全国でそれほど大きな差はなさそうです。宮城県が
104.9と最も高く、岐阜県が94.0と最も安い値でした。4.交通・通信
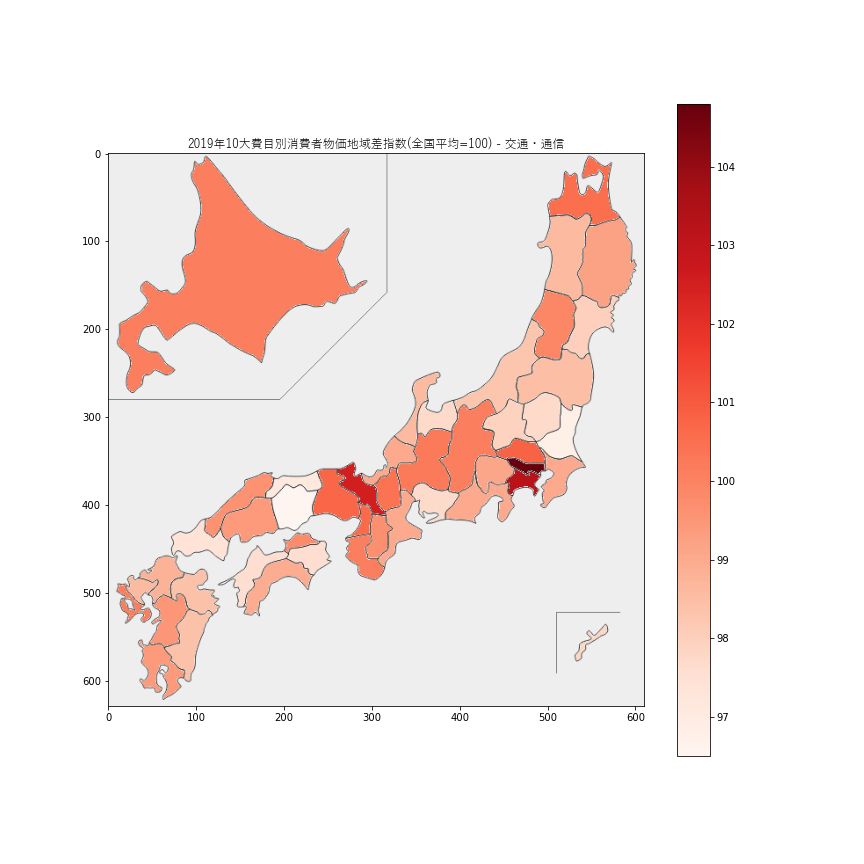
交通・通信価格の指数は96-105の範囲に収まっているので、地域差はそれほど大きくはなさそうです。最も高いのは東京都で
104.8,次に高いのは神奈川県で103.2でした。最も安いのは岡山県で96.5でした。5.光熱・水道
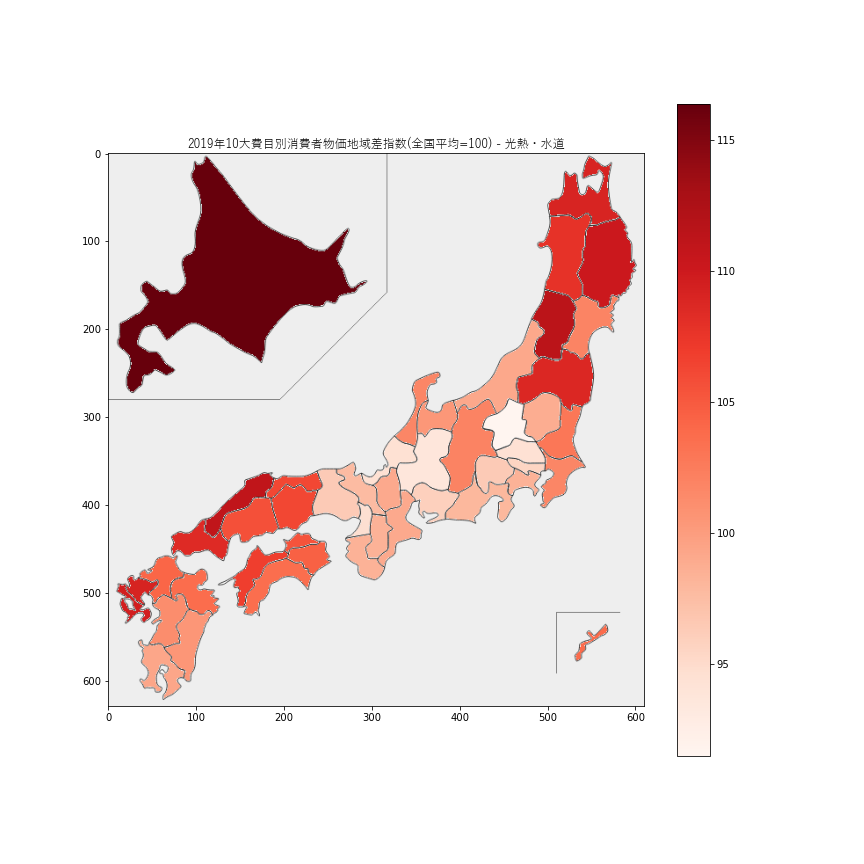
光熱・水道価格の指数が最も高いのが北海道の
116.4で、東北地方や中国・四国地方で高い傾向が伺えます。水道光熱費は住居費とは反対に、人口が少ないほど一人当たりの負担が高くなると言われていて、その傾向が出ているように思います。6.被服及び履物
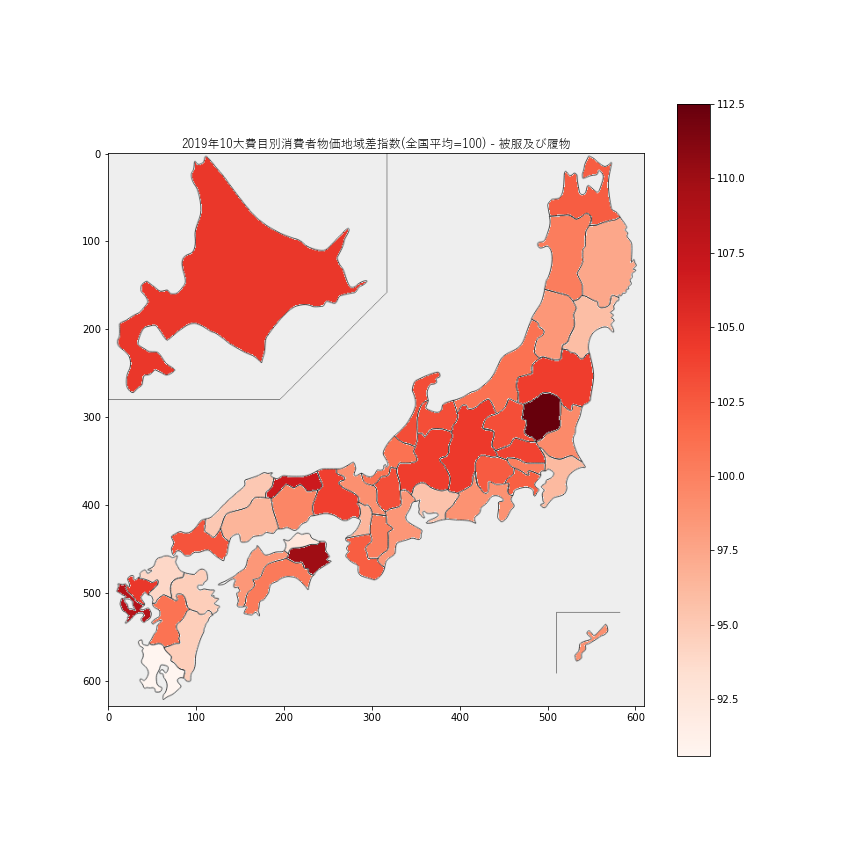
被服価格の差はそこそこ大きいように思えますが、なぜこのような地域差が出ているのかは不明です。最も被服価格が高いのは栃木県
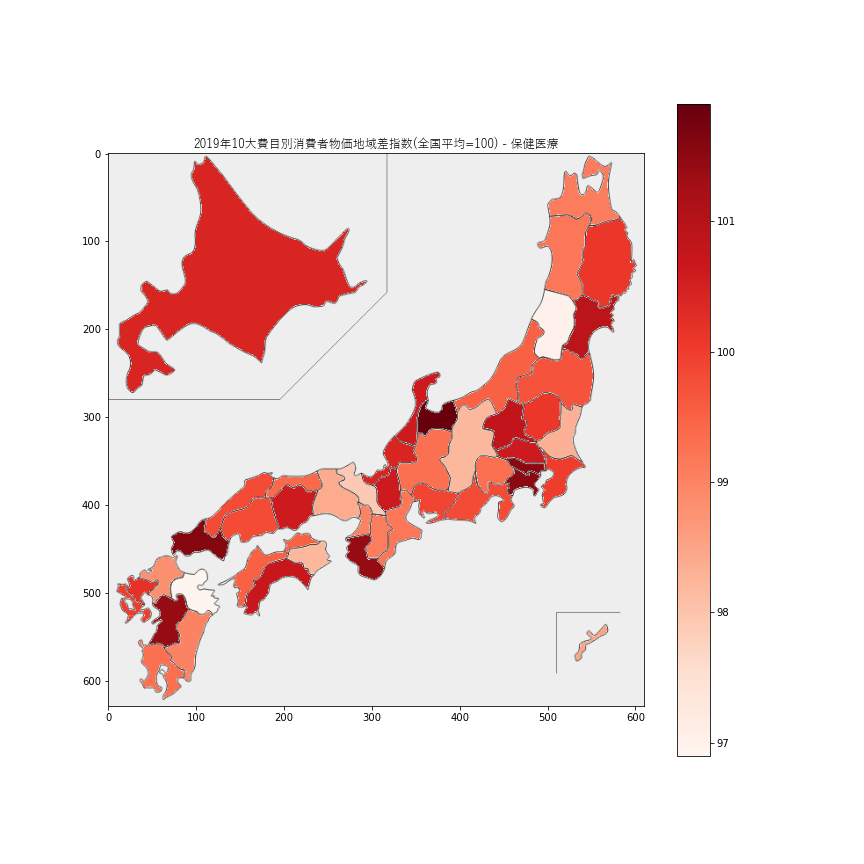
112.5で、最も安いのは鹿児島県90.6でした。7.保険医療
保険医療価格の指数は96-102の範囲内に収まっているので、地域差はあまりなさそうです。
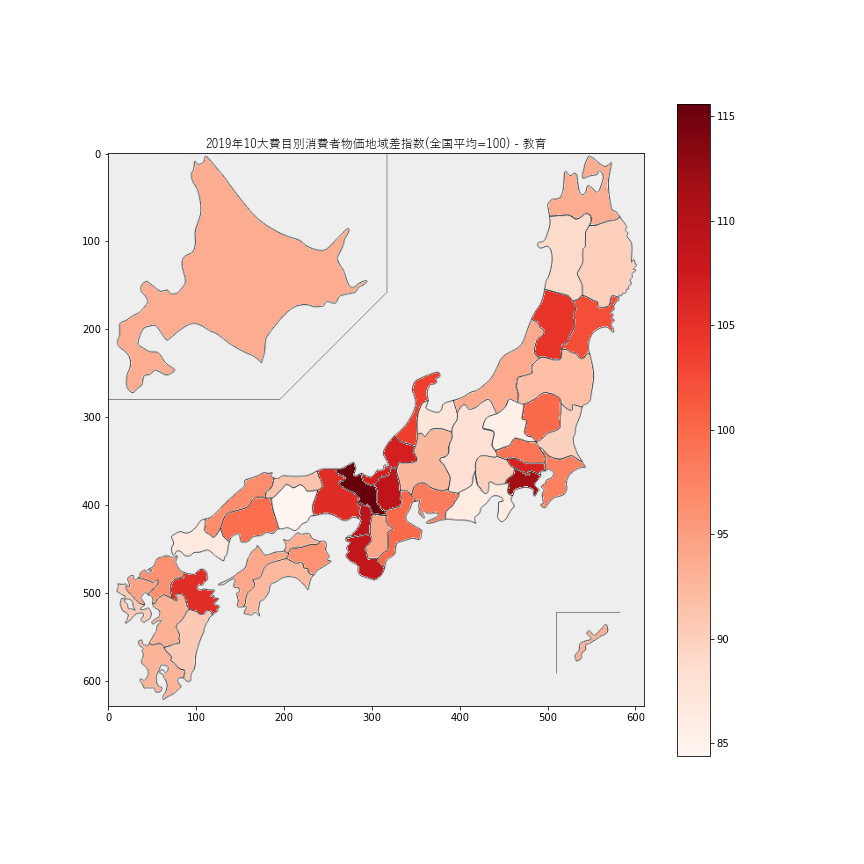
8.教育
教育価格は京都府が
115.6とトップでした。全体的に、近畿地方が高そうに見えます。9.教養娯楽
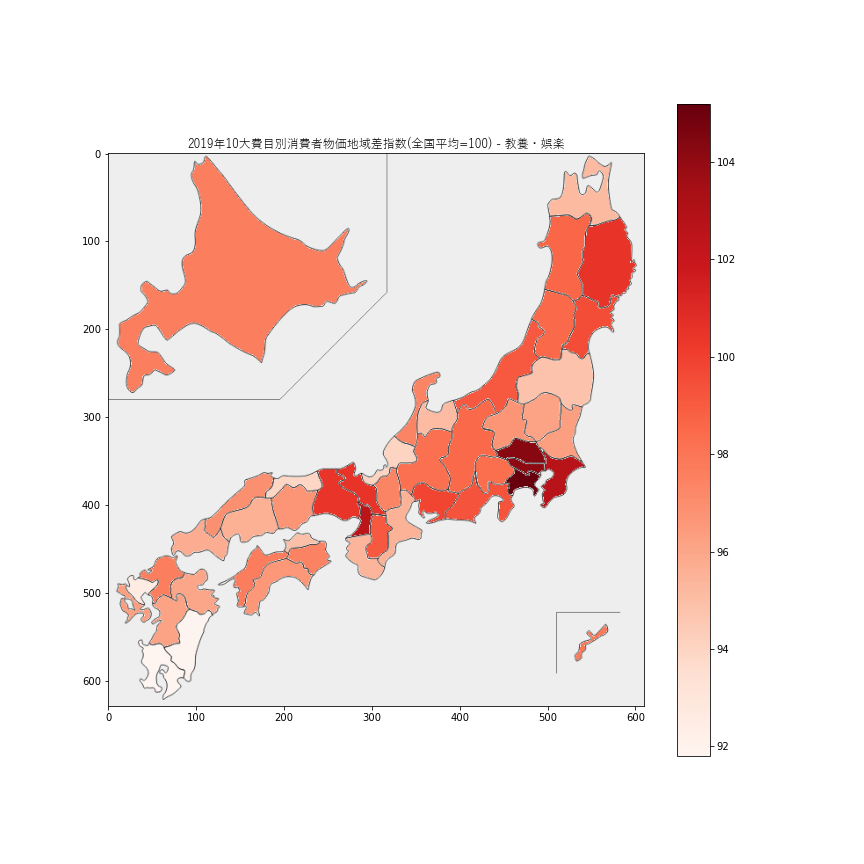
教育娯楽の価格は神奈川県の
105.2がトップでした。東京都近辺や大阪府近辺で高くなっているように見えます。10.諸雑費
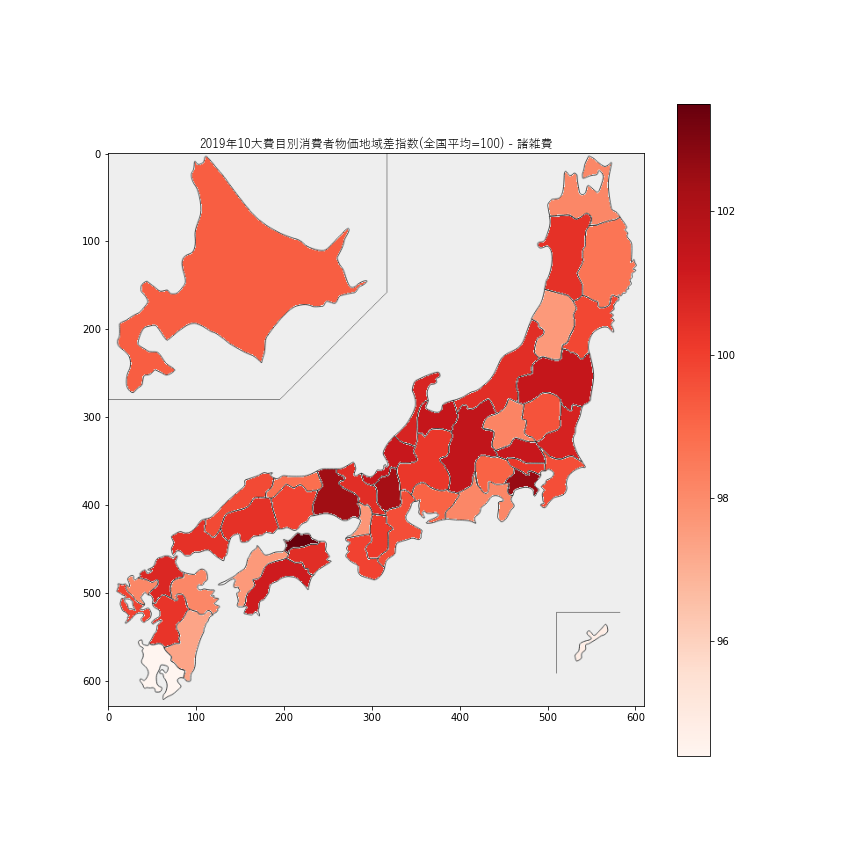
諸雑費の価格の指数は94-104の範囲に収まっているので、地域差はそれほど大きくなさそうです。
ランキング一覧
10大費目それぞれのランキングです。
順位 総合 食料 住居 光熱・水道 家具・家事用品 被服及び履物 保険医療 交通・通信 教育 教養娯楽 諸雑費 家賃を除く総合 1 東京都(104.7) 福井県(103.8) 東京都(132.3) 北海道(116.4) 宮城県(104.9) 栃木県(112.5) 富山県(101.9) 東京都(104.8) 京都府(115.6) 神奈川県(105.2) 香川県(103.5) 東京都(103.2) 2 神奈川県(104.0) 石川県(103.6) 神奈川県(125.1) 山形県(111.4) 東京都(103.8) 徳島県(110.0) 山口県(101.6) 神奈川県(103.2) 神奈川県(111.9) 埼玉県(104.3) 神奈川県(102.6) 神奈川県(103.0) 3 埼玉県(101.0) 東京都(103.4) 埼玉県(104.8) 島根県(111.0) 長崎県(103.6) 長崎県(108.5) 神奈川県(101.5) 京都府(102.5) 大阪府(109.2) 東京都(104.1) 兵庫県(102.4) 北海道(100.9) 45 群馬県(96.6) 宮崎県(96.5) 佐賀県(83.6) 埼玉県(94.4) 和歌山県(95.9) 福岡県(94.0) 京都府(97.9) 鳥取県(97.1) 静岡県(86.0) 佐賀県(92.6) 宮崎県(97.3) 群馬県(97.2) 46 鹿児島県(96.3) 福岡県(95.8) 愛媛県(82.4) 岐阜県(93.7) 山形県(94.6) 香川県(92.4) 山形県(97.0) 茨城県(96.8) 群馬県(85.4) 宮崎県(91.9) 沖縄県(94.8) 鹿児島県(97.0) 47 宮崎県(96.0) 長野県(95.2) 鳥取県(81.7) 群馬県(91.5) 岐阜県(94.0) 鹿児島県(90.6) 大分県(96.9) 岡山県(96.5) 岡山県(84.4) 鹿児島県(91.8) 鹿児島県(97.3) 宮崎県(97.0) 最後に
東京都・神奈川県以外の都市圏(大阪府、愛知県、福岡県、宮城県など)はそれほど物価が高くないようですので、住むなら狙い目かも。
参考サイト
参考にさせていただきました。
- 投稿日:2020-09-10T22:28:19+09:00
Djangoで、表示されている長い文字列を途中で....と略す方法
Djangoでブログを作っていてホームに長い文章があっても見にくいので何か略す方法はないかと調べていたらこんなものを見つけたので共有します。
Django version = 2.2.4
Python version = 3.8.2home_list.html<p>{{ post.text|linebreaksbr|truncatechars:250 }}</p>少しわかりにくいかもしれませんが、具体的にこの記事に関連しているのは最後の「truncatechars」だけです。
そこの数字を好きな数字にすることでその次の文字から...と略されて表示されるようになります。
- 投稿日:2020-09-10T22:22:07+09:00
データ分析のためのJupyterLab基本設定
A JupyterLab setting procedure
This is a base setting with minimum packages for my data analyses.
Prerequisite
- Windows 10
python3.8+nodejs10+- Microsoft Visual C++ 14.0 or greater (Build Tools for Visual Studio 2019)
Getting Started
JupyterLab installation
- install python (official not Anaconda)
- install node.js
- install Microsoft Visual C++ 14.0 or greater
- make a virtual environment
$ python -m venv /path/to/new/virtual/environment
- come into the virtual environment
$ cd /path/to/new/virtual/environment
- install jupyterlab
$ pip install jupyterlabExtensions
- Jupyter Widgets JupyterLab Extension: for Jupyter/IPython widgets
$ pip install ipywidgets $ jupyter nbextension enable --py widgetsnbextension $ jupyter labextension install @jupyter-widgets/jupyterlab-manager
- jupyterlab_variableinspector: variable inspector
$ jupyter labextension install @lckr/jupyterlab_variableinspector
- jupyterlab-toc: table of contents for markdown
$ jupyter labextension install @jupyterlab/toc
- jupyterlab_filetree: filetree view
$ jupyter labextension install jupyterlab_filetree
- Go to definition extension for JupyterLab: jump to definition
$ jupyter labextension install @krassowski/jupyterlab_go_to_definition
- Language Server Protocol : Python language server protocol
$ pip install jupyter-lsp $ jupyter labextension install @krassowski/jupyterlab-lsp $ pip install python-language-server[all]
- jupyterlab_code_formatter: code formatter (black, yapf, autopep8, or isort)
$ jupyter labextension install @ryantam626/jupyterlab_code_formatter $ pip install jupyterlab_code_formatter $ jupyter serverextension enable --py jupyterlab_code_formatter
- jupytext: .py file sync with .ipynb
$ pip install jupytext --upgrade $ jupyter labextension install jupyterlab-jupytext
- git: git control with jupyterlab
$ pip install --upgrade jupyterlab-git $ jupyter lab build
- github: github browsing via jupyterLab
$ jupyter labextension install @jupyterlab/github
- jupyterlab-shortcutui: ui for shortcut keys
$ jupyter labextension install @jupyterlab/shortcutuiOther standard packages
$ pip install numpy pandas scipy matplotlib seaborn statsmodelsLaunch
- Launch jupyterlab
$ jupyter labSave requirements file
$ pip freeze > requirements.txt
- 投稿日:2020-09-10T22:22:07+09:00
データ分析のためのJupyterLab基礎設定 (pip)
A JupyterLab setting procedure
A base setting with minimum packages via pip
pipによるJupyterLabの基礎設定です。Prerequisite
- Windows 10
python3.8+nodejs10+- Microsoft Visual C++ 14.0 or greater (Build Tools for Visual Studio 2019)
Getting Started
JupyterLab installation
- install python (official not Anaconda)
- install node.js
- install Microsoft Visual C++ 14.0 or greater
- make a virtual environment
$ python -m venv /path/to/new/virtual/environment
- come into the virtual environment
$ cd /path/to/new/virtual/environment
- install jupyterlab
$ pip install jupyterlabExtensions
- Jupyter Widgets JupyterLab Extension: for Jupyter/IPython widgets
$ pip install ipywidgets $ jupyter nbextension enable --py widgetsnbextension $ jupyter labextension install @jupyter-widgets/jupyterlab-manager
- jupyterlab_variableinspector: variable inspector
$ jupyter labextension install @lckr/jupyterlab_variableinspector
- jupyterlab-toc: table of contents for markdown
$ jupyter labextension install @jupyterlab/toc
- jupyterlab_filetree: filetree view
$ jupyter labextension install jupyterlab_filetree
- Go to definition extension for JupyterLab: jump to definition
$ jupyter labextension install @krassowski/jupyterlab_go_to_definition
- Language Server Protocol : Python language server protocol
$ pip install jupyter-lsp $ jupyter labextension install @krassowski/jupyterlab-lsp $ pip install python-language-server[all]
- jupyterlab_code_formatter: code formatter (black, yapf, autopep8, or isort)
$ jupyter labextension install @ryantam626/jupyterlab_code_formatter $ pip install jupyterlab_code_formatter $ jupyter serverextension enable --py jupyterlab_code_formatter
- jupytext: .py file sync with .ipynb
$ pip install jupytext --upgrade $ jupyter labextension install jupyterlab-jupytext
- git: git control with jupyterlab
$ pip install --upgrade jupyterlab-git $ jupyter lab build
- github: github browsing via jupyterLab
$ jupyter labextension install @jupyterlab/github
- jupyterlab-shortcutui: ui for shortcut keys
$ jupyter labextension install @jupyterlab/shortcutuiOther standard packages
$ pip install numpy pandas scipy matplotlib seaborn statsmodelsLaunch
- Launch jupyterlab
$ jupyter labSave requirements file
$ pip freeze > requirements.txt
- 投稿日:2020-09-10T22:08:04+09:00
Deep Learning に関する自分用まとめメモ -4.2 損失関数-
Deep Learning に関する自分用まとめメモ
4.2 損失関数 編
ニューラルネットワークの学習において性能を上げるには最適な重みパラメータを見つける必要があるが、このLoss function を使用して、目的の指標を手がかりに探索を行っていく 。
損失関数の種類
1. 二乗和誤差(Mean Squared Error)
二乗和誤差は以下の式
E = \frac{1}{N}\sum_{i=1}^{N}(y_i -t_i)^2で表すことができる。
式の説明をすると、出力値のデータ(yi)と正解値のデータ(ti)の差を二乗してN個で平均する。
二乗するのは誤差を正の値にするため。正の値にするのなら絶対値をとってE = \frac{1}{N}\sum_{i=1}^{N}|y_i -t_i|こうしてもいいのでは?と思ったのだが、どうやら微分を計算するときに2乗のほうが楽だかららしい。
なるほど!絶対値の微分は場合分けとかあるもんね...
さらには微分したときに2が前に出るので1/2を加えてE = \frac{1}{2}*\frac{1}{N}\sum_{i=1}^{N}(y_i -t_i)^2とすることもあるようだ。
二乗和誤差を使った例
今回は上の式のNを1として関数を定義して結果を見ていく。
yはSoftmax関数による出力結果である。import numpy as np #正解データ(one-hot-label) t = [0,0,1,0,0] #二乗和誤差の関数を定義 def mean_squared_error(y,t): return 0.5 * np.sum((y-t)**2) # パターン1(正解データに近い) y1 = [0.01,0.02,0.9,0.05,0.02] # パターン2(正解データから遠い) y2 = [0.5,0.1,0.2,0.2,0.1] out1 = mean_squared_error(np.array(y1),np.array(t)) out2 = mean_squared_error(np.array(y2),np.array(t))それぞれの結果は
print(out1) >>> 0.006699999999999998
print(out2) >>> 0.4750000000000001
となり誤差は正解データに近いと少なく、遠いと多くなった。
よってこの場合はパターン1の出力結果の方が教師データにより適合していることを2乗和誤差は示している。2. 交差エントロピー誤差(Cross Entropy Error)
交差エントロピー誤差は以下の式
E = -\sum_{k}t_klog_e{y_k}で表すことができる。
二乗和誤差と違うのは出力データと正解データをかけていることである。
これについてどのような利点があるかを説明すると、
正解データはone-hot 表現であり、正解ラベルのみ1,それ以外は0となる。
ということは上の式に当てはめるとEの値は正解ラベルのみ -logyk
それ以外は 0となることが分かるだろうか。
これにより交差エントロピー誤差は正解ラベルの出力結果により決まり、
正解ラベルに対応する出力ラベルが小さければEの値は大きくなり誤差が大きいことを示す。交差エントロピー誤差を使った例
二乗和誤差のときと同様に関数を定義していくが、
その前に、コード内で定義してある deltaについての説明を行っていく。y = logx のグラフを見ると分かるとおり、x->0においてlim y は負の∞になることが分かる。
仮に正解ラベルに対応する出力ラベルが0だった場合、交差エントロピー誤差を数値で表すことができなくなり、それ以上計算を進めることができなくなってしまうのである。これを回避するために微小な値であるdelta(コード内では10-7)を入れてlog中身が0になることを防いでいるのである。
import numpy as np #正解データ(one-hot-label) t = [0,0,1,0,0] #交差エントロピー誤差の関数を定義 def cross_entropy_error(y,t): #deltaを定義(スペース開けないように注意!) delta = 1e-7 return -np.sum(t * np.log(y + delta)) # パターン1(正解データに近い) y1 = [0.01,0.02,0.9,0.05,0.02] # パターン2(正解データから遠い) y2 = [0.5,0.1,0.2,0.2,0.1] out1 = cross_entropy_error(np.array(y1),np.array(t)) out2 = cross_entropy_error(np.array(y2),np.array(t))それぞれの結果は
print(out1) >>> 0.1053604045467214
print(out2) >>> 1.6094374124342252
となり、二乗和誤差のときと同様に正解データに近いほど値は小さくなることが分かっただろうか。まとめ
- 損失関数の出力は少ないほど正解データに近いことを示す。
参考書
- 投稿日:2020-09-10T22:03:25+09:00
pandasで横持ちデータを縦持ちデータへ変換する方法
まずは下記でデータフレームの用意をします。
DateFrameの用意import pandas as pd values = [['1', 'John', 'somekey1-1', 'somevalue1-1', 'time1-1', 'somekey2-1', 'somevalue2-1', 'time2-1'], ['2', 'Tom', 'somekey1-2', 'somevalue1-2', 'time1-2', 'somekey2-2', 'somevalue2-2', 'time2-2'],] df = pd.DataFrame(values, columns=['id', 'name', 'key1', 'value1', 'time1', 'key2', 'value2', 'time2']) df上記コードで下記のデータが作られます。
id name key1 value1 time1 key2 value2 time2 0 1 John somekey1-1 somevalue1-1 time1-1 somekey2-1 somevalue2-1 time2-1 1 2 Tom somekey1-2 somevalue1-2 time1-2 somekey2-2 somevalue2-2 time2-2 こちらの情報を下記のように縦持ちデータへ変換するコード4つを紹介していきます。
id name key value time 0 1 John somekey1-1 somevalue1-1 time1-1 1 2 Tom somekey1-2 somevalue1-2 time1-2 2 1 John somekey2-1 somevalue2-1 time2-1 3 2 Tom somekey2-2 somevalue2-2 time2-2 meltメソッドで実施する方法
meltメソッドを使うのが一般的らしく、この情報はたくさん載っていました。
カラムの配列を作るときはいくつか方法がありますので、それも載せておきます。カラム名の配列を作成# パターン① columns = df.columns.tolist() [value for value in columns if value.startswith('key')] # パターン② df.columns[df.columns.str.startswith('key')].tolist() # 結果 # ['key1', 'key2']一度、カラムの配列を作成して動かすパターン①の方が動きは軽そうなので、
下記ではそちらを使っています。meltを使って縦持ちデータへ変換columns = df.columns.tolist() pd.concat( [pd.melt(df, id_vars=['id', 'name'], value_vars=[value for value in columns if value.startswith('key')], value_name='key'), pd.melt(df, value_vars=[value for value in columns if value.startswith('value')], value_name='value'), pd.melt(df, value_vars=[value for value in columns if value.startswith('time')], value_name='time') ], axis=1 ).drop('variable', axis=1)wide_to_longメソッドで実施する方法
wide_to_longを使うと1行で作成ができるのでかなりシンプルです。
下記サイトを見ても最初はよくわからなかったのですが、
https://pandas.pydata.org/docs/reference/api/pandas.wide_to_long.html2つ目の引数で指定している配列では
特定の文字から始めるカラムを縦持ちへ変換する
という動きをするので1行で完結させることが可能です。
jで指定するのはカラムの余った部分
key1であれば1、key2であれば2を指定したカラム名で作成します。
下記コードでは'drop'というカラムが作成されるので、そのあとにdropメソッドで削除しています。wide_to_longを使って縦持ちデータへ変換pd.wide_to_long(df, ['key','value','time'], i='id', j='drop').reset_index().drop('drop', axis=1)wide_to_longでエラーが出た場合
下記のエラーが出た場合の対処法
下記のエラーはidとなる項目に重複がある場合にでるエラーです。errorValueError: the id variables need to uniquely identify each row例えば最初のデータフレームを少し変えて、idをどちらも
1にして実行した場合にエラーがでます。エラーが出るDataFrameimport pandas as pd values = [['1', 'John', 'somekey1-1', 'somevalue1-1', 'time1-1', 'somekey2-1', 'somevalue2-1', 'time2-1'], ['1', 'Tom', 'somekey1-2', 'somevalue1-2', 'time1-2', 'somekey2-2', 'somevalue2-2', 'time2-2'],] df = pd.DataFrame(values, columns=['id', 'name', 'key1', 'value1', 'time1', 'key2', 'value2', 'time2']) pd.wide_to_long(df,['key','value','time'], i='id', j='drop').reset_index().drop('drop', axis=1)その時は
reset_index()でindexの項目を作ってidへ指定することで解決できます。wide_to_longを使って縦持ちデータへ変換(エラー回避方法)pd.wide_to_long(df.reset_index(), ['key','value','time'], i='index', j='drop').reset_index().drop('drop', axis=1).drop('index', axis=1)lreshapeメソッドで実施する方法
lreshapeはgoogleで検索してもreshapeに直されるぐらいマイナーなメソッドみたいです。
個人的にはシンプルで好きなのですが、下記サイトに将来消えると書いてあるので、そのうち使えなくなりそうです。残念。
https://pandas.pydata.org/pandas-docs/version/1.0.0/whatsnew/v1.0.0.htmllreshapeを使って縦持ちデータへ変換d = {'key': df.columns[df.columns.str.startswith('key')].tolist(), 'value': df.columns[df.columns.str.startswith('value')].tolist(), 'time': df.columns[df.columns.str.startswith('time')].tolist(),} pd.lreshape(df, d)また実務で使用していると書き方はあっているはずなのになぜか下記の
エラーが起きることがあるのであまり使用しない方がよさそうです。error/usr/local/lib/python3.6/dist-packages/pandas/core/reshape/melt.py in <dictcomp>(.0) 188 mask &= notna(mdata[c]) 189 if not mask.all(): --> 190 mdata = {k: v[mask] for k, v in mdata.items()} 191 192 return data._constructor(mdata, columns=id_cols + pivot_cols) IndexError: boolean index did not match indexed array along dimension 0; dimension is 1210 but corresponding boolean dimension is 24200concatで頑張ってやる方法
多分かなりいけてないです。
最初上記のメソッドを知らない時はこれでやっていました。カラム名が同じだとconcatメソッドを使ったときに
縦に結合してくれるのでそれを利用する方法です。concatでの実施pd.concat([ df[['id', 'name', 'key1', 'value1', 'time1']].rename(columns={'key1': 'key', 'value1': 'value', 'time1': 'time'}), df[['id', 'name', 'key2', 'value2', 'time2']].rename(columns={'key2': 'key', 'value2': 'value', 'time2': 'time'}), ])
- 投稿日:2020-09-10T20:11:15+09:00
seleniumをとりあえずちゃちゃっと動かしてみたい[mac向け]
はじめに
seleniumっていうwebブラウザのテストツール、
ざっくり言えばちょっとコードを書けばweb画面を自動操作できてしまうというものがあると知って
とりあえず試したかった。先人の知恵を大いに借りたが、ところどころ躓きポイントがあったのでメモ。
写経に近いものになってしまうが、基本は
たった3行のpythonで始めるSelenium入門
に沿い、躓いたところを記録として残しておく。(2020.9.10時点)できること
seleniumを使ってブラウザ画面で
「たぬき 画像」という文字列の検索結果を自動で表示させる環境
- Mac
- python3.8
- Chrome
事前準備
- homebrewをインストール
- pythonをインストール
※ 上記は参考記事に記載あり。
手順
- chromedriverのインストール
$ brew install chromedriver # 上記でインストールできなかったので、エラー文のとおりこちらを試したらいけた $ brew cask install chromedriver
- seleniumをインストール
$ pip install selenium
- test.pyを作成し、下記を記述する
test.pyfrom selenium import webdriver driver = webdriver.Chrome("chromedriverのパス") driver.get("https://google.co.jp")chromedriverのパスは、
which chromedriverで調べられる
- test.pyを実行する
$ python test.pyここでポップアップでエラーが出たので、下記を参考にダウンロードしたアプリケーションの実行許可をした。
seleniumを使用しようとしたら、「"chromedriver"は開発元を検証できないため開けません。」と言われた
これでchromeのwebブラウザが開けるはず。
ここまでうまくできたら、下記を記述する
test.pyfrom selenium import webdriver from selenium.webdriver.common.keys import Keys # 追加 driver = webdriver.Chrome("/usr/local/bin/chromedriver") driver.get("https://google.co.jp") text = driver.find_element_by_name("q") # 検索ボックスのname属性を指定 text.send_keys("たぬき 画像")# 文字列"たぬき 画像"をテキストボックスに入力 text.send_keys(Keys.ENTER) # ENTERを押下する特殊キーを使う躓きポイント
- 検索ボックスのid属性が見つけられなかった
→name属性を指定することにした
- click()を使うと、test.pyの実行時に後述のエラーが出た
→ (検索ボタンを探してクリックするのではなく、)ENTERを押下する設定にした1
エラー内容
: selenium.common.exceptions.ElementNotInteractableException: Message: element not interactableまとめ
なぜこのようなエラーが出るのかまでは調査できなかったが、
ひとまず、自動でwebブラウザが開き、勝手に検索ボックスに文字が入力され
検索結果が表示されるところまでたどり着くことができた。
- 投稿日:2020-09-10T19:31:11+09:00
初心者がPythonでウェブスクレイピング(1)
クラウドのクの字も、Pythonのパの字も知らない、
イチからPython+GCPを勉強し始めてはや1ヶ月。
Pythonでのウェブスクレイピングに興味を持ち始め、
requestsの使い方、requestsオブジェクトの様々な属性、
BeutifuruSoupでのhtmlパースを学習しながら、
まずはYahooニュースのスクレイピングに挑戦します。
※この記事ではMacOS CatalinaにインストールしたPython3.7.3を使っています。Pythonでのウェブスクレイピング学習のロードマップ
(1)ローカルでとりあえず目的のブツのスクレイピングに成功する。
(2)ローカルでスクレイピングした結果をGoogleスプレッドシートに連携する。
(3)ローカルでcron自動実行を行う。
(4)クラウドサーバー上での無料自動実行に挑戦する。(Google Compute Engine)
(5)クラウド上で、サーバーレスでの無料自動実行に挑戦する。(たぶんCloud Functions + Cloud Scheduler)サンプルPGM(1)の機能
・requestsを利用してWEBサイトの情報をget
・BeautifulSoupでhtmlをパース
・文字列検索ができるreライブラリで特定の文字列を検索(ヘッドラインニュースの特定)
・取得した結果リストからニュースタイトルとリンクを全てコンソールに表示requestsって何?
PythonでHTTP通信を行うための外部ライブラリです。
シンプルにWebサイトの情報収集が可能となります。
pythonの標準ライブラリであるurllibを使ってもurlを取得できますが、
requestsを使うとコード量も少なくシンプルに書けます。
ただ、サードパーティーライブラリなのでインストールが必要です。requestsのインストール
pipでインストール可能です。
venvで作った仮想環境のまっさらな状態がこちら。bash$ virtualenv -p python3.7 env3 % source env3/bin/activate (env3) % pip list Package Version ---------- ------- pip 20.2.3 setuptools 49.2.1 wheel 0.34.2pipでインストール。pip listでちゃんと入ったか(Versionも)確認しましょう。
付随して、色んなものも入れてくれちゃいます。bash(env3) % pip install requests Collecting requests Using cached requests-2.24.0-py2.py3-none-any.whl (61 kB) Collecting idna<3,>=2.5 Using cached idna-2.10-py2.py3-none-any.whl (58 kB) Collecting chardet<4,>=3.0.2 Using cached chardet-3.0.4-py2.py3-none-any.whl (133 kB) Collecting urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 Using cached urllib3-1.25.10-py2.py3-none-any.whl (127 kB) Collecting certifi>=2017.4.17 Using cached certifi-2020.6.20-py2.py3-none-any.whl (156 kB) Installing collected packages: idna, chardet, urllib3, certifi, requests Successfully installed certifi-2020.6.20 chardet-3.0.4 idna-2.10 requests-2.24.0 urllib3-1.25.10 (env3) % pip list Package Version ---------- --------- certifi 2020.6.20 chardet 3.0.4 idna 2.10 pip 20.2.3 requests 2.24.0 setuptools 49.2.1 urllib3 1.25.10 wheel 0.34.2requestsのメソッド
requestsでは、一般的なHTTPリクエストのメソッドである、
get,post,put,deleteなどのメソッドをサポートしています。
今回はgetを使います。requestsのresponseオブジェクトの属性
requests.getで帰ってくるresponseオブジェクトには様々な属性が含まれています。
今回サンプルプログラムで、printで確認したのは以下の属性。
属性 確認できるもの url アクセスしたURLを取得できる。 status_code ステータスコード(HTTPステータス)を取得できる。 headers レスポンスヘッダを取得できる。 encoding Requestsが推測したエンコーディングを取得できる。 その他、text属性やcontent属性などがあります。
headers属性は、dict型(辞書)で、Yahooニュースでは以下のようにたくさんのキーが含まれているため、サンプルプログラムでは、headers属性のうち'Content-Type'キーを抜き出してprintしています。
bash{'Cache-Control': 'private, no-cache, no-store, must-revalidate', 'Content-Encoding': 'gzip', 'Content-Type': 'text/html;charset=UTF-8', 'Date': 'Wed, 09 Sep 2020 02:24:04 GMT', 'Set-Cookie': 'B=6rffcc5flgf64&b=3&s=sv; expires=Sat, 10-Sep-2022 02:24:04 GMT; path=/; domain=.yahoo.co.jp, XB=6rffcc5flgf64&b=3&s=sv; expires=Sat, 10-Sep-2022 02:24:04 GMT; path=/; domain=.yahoo.co.jp; secure; samesite=none', 'Vary': 'Accept-Encoding', 'X-Content-Type-Options': 'nosniff', 'X-Download-Options': 'noopen', 'X-Frame-Options': 'DENY', 'X-Vcap-Request-Id': 'd130bb1e-4e53-4738-4b02-8419633dd825', 'X-Xss-Protection': '1; mode=block', 'Age': '0', 'Server': 'ATS', 'Transfer-Encoding': 'chunked', 'Connection': 'keep-alive', 'Via': 'http/1.1 edge2821.img.kth.yahoo.co.jp (ApacheTrafficServer [c sSf ])'}requests.get部分のソース
requests.getと、取得したresponseオブジェクトの各属性表示部分のソース抜粋はこちら。
url = 'https://news.yahoo.co.jp/' response = requests.get(url) #print(response.text) print('url: ',response.url) print('status-code:',response.status_code) #HTTPステータスコード 大抵[200 OK] print('headers[Content-Type]:',response.headers['Content-Type']) #headersは辞書なのでキー指定でcontent-type出力 print('encoding: ',response.encoding) #エンコーディング結果がこちら。
bash(env3) % python requests-test.py url: https://news.yahoo.co.jp/ status-code: 200 headers[Content-Type]: text/html;charset=UTF-8 encoding: UTF-8Beautiful Soupって何?
Beautiful Soup(ビューティフル・スープ)とは、PythonのWEBスクレイピング用のライブラリで、
HTMLやXMLファイルからデータを取得し、解析することができます。
特定のhtmlタグを抽出するなんてことがカンタンに行えます。beautifulsoup4のインストール
requestsと同じです。pipでインストール可能です。
bash(env3) % pip install beautifulsoup4 Collecting beautifulsoup4 Using cached beautifulsoup4-4.9.1-py3-none-any.whl (115 kB) Collecting soupsieve>1.2 Using cached soupsieve-2.0.1-py3-none-any.whl (32 kB) Installing collected packages: soupsieve, beautifulsoup4 Successfully installed beautifulsoup4-4.9.1 soupsieve-2.0.1 (env3) % pip list Package Version -------------- --------- beautifulsoup4 4.9.1 certifi 2020.6.20 chardet 3.0.4 idna 2.10 pip 20.2.3 requests 2.24.0 setuptools 49.2.1 soupsieve 2.0.1 urllib3 1.25.10 wheel 0.34.2Beautiful Soupの引数
Beautiful Soupには、一つ目の引数として解析対象のオブジェクト(htmlやxml)
(サンプルで言うところの、requestsでgetしたresponseオブジェクト)
二つ目の引数として解析に利用するパーサーを指定します。
パーサー 使用例 強み 弱み Python’s html.parser BeautifulSoup(response.text, "html.parser") 標準ライブラリ Python2系/3.2.2未満非対応 lxml’s HTML parser BeautifulSoup(response.text, "lxml") 爆速 install必要 lxml’s XML parser BeautifulSoup(response.text, "xml") 爆速。唯一のxmlパーサー install必要 html5lib BeautifulSoup(response.text, "html5lib") HTML5を正しく処理できる install必要。とっても遅い。 soup = BeautifulSoup(response.text, "html.parser")BeautifulSoupには様々なメソッドがありますが、今回はfind_allメソッドを使います。
また、find_allメソッドにも様々な引数が設定できますが、今回はキーワード引数を使います。find_all:キーワード引数
キーワード引数としてタグの属性を指定し、一致するタグの情報を取得できます。
キーワード引数の値もまた、 文字列、正規表現、リスト、関数、True値をとることができます。そして、複数のキーワード引数も指定できます。
例えば、キーワード引数としてhref に値を渡すと、Beautiful SoupはHTMLタグのhref属性に対してフィルタリングを行います。
引用:https://ai-inter1.com/beautifulsoup_1/#find_all_detail
つまり、「href属性の値が指定の正規表現にマッチするもの」を、
soupオブジェクトの中からfind_allすることで、以下の例では、
href属性の中で"news.yahoo.co.jp/pickup"が含まれているもののみ全て抽出することが可能となります。elems = soup.find_all(href = re.compile("news.yahoo.co.jp/pickup"))最終的なサンプルソース
最後はfor文で回して、抽出したニュースのタイトルとリンクをコンソール表示。
最終的なサンプルソースはこちら。requests-test.pyimport requests from bs4 import BeautifulSoup import re #requestsを利用してWEBサイトの情報をダウンロード url = 'https://news.yahoo.co.jp/' response = requests.get(url) #print(response.text) print('url: ',response.url) print('status-code:',response.status_code) #HTTPステータスコード 大抵[200 OK] print('headers[Content-Type]:',response.headers['Content-Type']) #headersは辞書なのでキー指定でcontent-type出力 print('encoding: ',response.encoding) #エンコーディング #BeautifulSoup()に取得したWEBサイトの情報とパーサー"html.parser"を渡す soup = BeautifulSoup(response.text, "html.parser") #href属性の中で"news.yahoo.co.jp/pickup"が含まれているもののみ全て抽出 elems = soup.find_all(href = re.compile("news.yahoo.co.jp/pickup")) #抽出したニュースのタイトルとリンクをコンソール表示。 for elem in elems: print(elem.contents[0]) print(elem.attrs['href'])PGMの部分部分は、参考サイトに載せさせて頂いたサイトのパクリに近いです。
大いに参考にさせていただきました。あとがき
確認のためのrequestsのresponseオブジェクトのprintと、import部分をのぞき、
たったの7行でウェブスクレイピングできてしまう。
Pythonと先人たちのライブラリ、恐るべし。結果はこちら。とりあえずスクレイピングできました!
最後の一つの写真つきニュースは余計ですが、対処がわからないので、とりあえずこのまま。。。bash% python requests-test.py url: https://news.yahoo.co.jp/ status-code: 200 headers[Content-Type]: text/html;charset=UTF-8 encoding: UTF-8 ドコモ口座 連携銀の過半停止 https://news.yahoo.co.jp/pickup/6370639 菅氏 自衛隊に関する発言訂正 https://news.yahoo.co.jp/pickup/6370647 3年連続冠水 イチゴ農家苦悩 https://news.yahoo.co.jp/pickup/6370631 海に4人乗った車転落 2人死亡 https://news.yahoo.co.jp/pickup/6370633 新疆でムーラン撮影 再び反発 https://news.yahoo.co.jp/pickup/6370640 親が偏見 パニック障害で苦悩 https://news.yahoo.co.jp/pickup/6370643 平岡卓被告 懲役2年6カ月求刑 https://news.yahoo.co.jp/pickup/6370646 伊勢谷容疑者 巻紙500枚押収 https://news.yahoo.co.jp/pickup/6370638 <span class="topics_photo_img" style="background-image:url(https://lpt.c.yimg.jp/amd/20200909-00000031-asahi-000-view.jpg)"></span> https://news.yahoo.co.jp/pickup/6370647参考サイト:
https://requests-docs-ja.readthedocs.io/en/latest/
https://ai-inter1.com/beautifulsoup_1/
http://kondou.com/BS4/
- 投稿日:2020-09-10T18:09:28+09:00
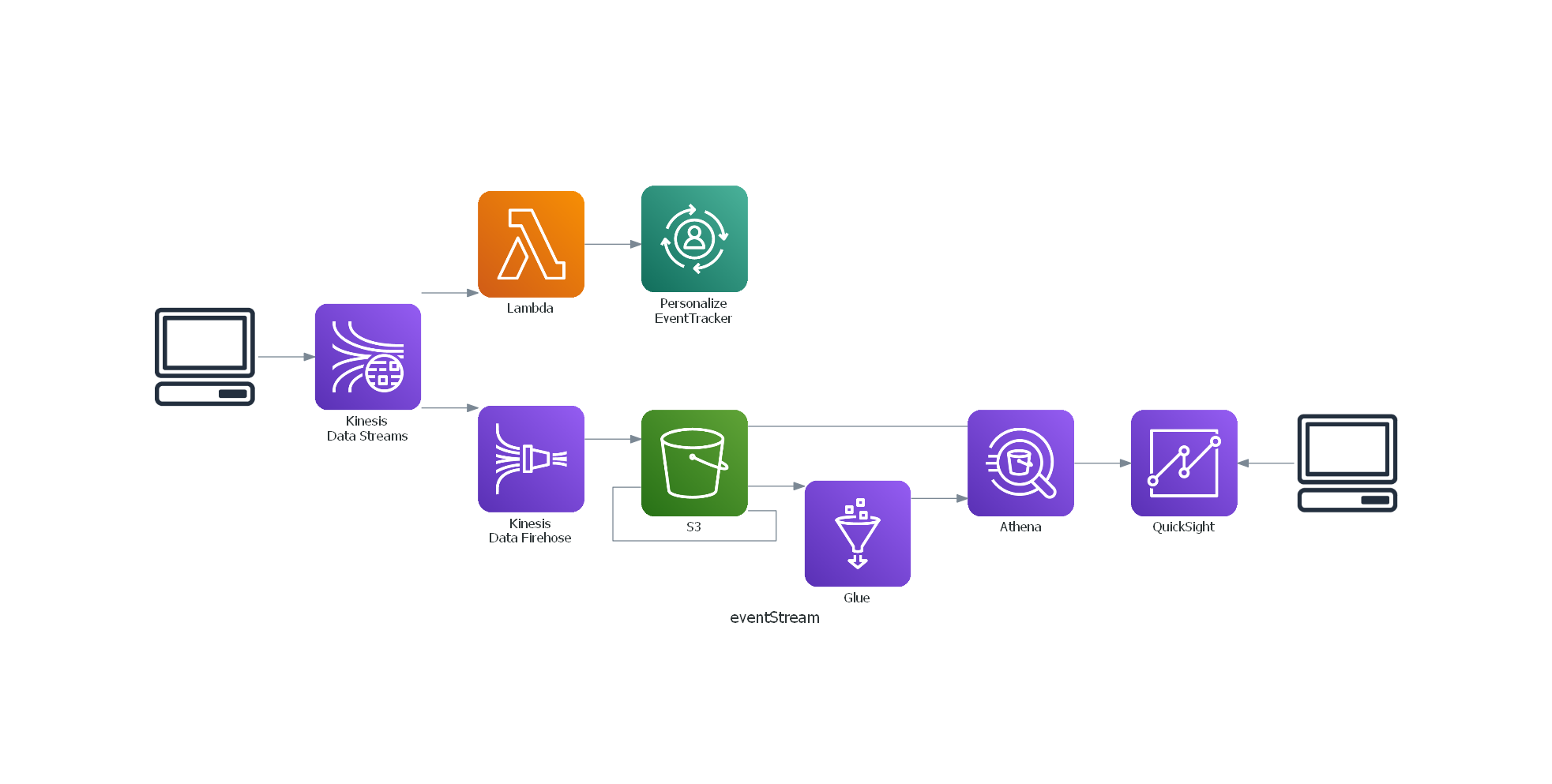
構成図を作成するため graphviz + diagrams の vscode の環境を chocolateyで30分ぐらいで作る
はじめに
AWSのシステム構成図を書くのにdiagramsといういいツールがあるというので環境作成した時のメモです
30分ぐらいでできます。順番
- chocolatey インストール
- graphviz インストール
- vscode インストール
- python インストール
- diagrams インストール
1. chocolatey インストール
powerShell を管理者モードで起動します
(スタートメニューの上で右クリック)
Get-ExecutionPolicyをAllSignedにしますWindows PowerShell Copyright (C) Microsoft Corporation. All rights reserved. PS C:\Users\lunar> Get-ExecutionPolicy Restricted (↑ Restricted なので、AllSigned に設定します) PS C:\Users\lunar> Set-ExecutionPolicy AllSigned 実行ポリシーの変更 実行ポリシーは、信頼されていないスクリプトからの保護に役立ちます。実行ポリシーを変更すると、about_Execution_Policies のヘルプ トピック (https://go.microsoft.com/fwlink/?LinkID=135170) で説明されているセキュリティ上の危険にさらされる可能性があります。実行ポリシーを変更しますか? [Y] はい(Y) [A] すべて続行(A) [N] いいえ(N) [L] すべて無視(L) [S] 中断(S) [?] ヘルプ (既定値は "N"):A PS C:\Users\lunar> Get-ExecutionPolicy AllSigned PS C:\Users\lunar>chocolateyをインストールします
Set-ExecutionPolicy Bypass -Scope Process -Force; iex ((New-Object System.Net.WebClient).DownloadString('https://chocolatey.org/install.ps1'))おわり
2. graphviz インストール
powerShell で実行します
choco install graphviz -yおわり
3. vscode インストール
powerShell で実行します
choco install vscode -yおわり
4. python インストール
powerShell で実行します
choco install python -ycommandプロンプトを起動して確認します
Win + r で cmd と入力してエンター
>python --version Python 3.8.5おわり
5. diagrams インストール
commandプロンプトで実行します。
pip install diagramsおわり
動作確認
クラスメソッドさんの記事のコードを使います
Diagramsを使ってPythonでシステム構成図を描く
https://dev.classmethod.jp/articles/diagrams-introduction/vscodeを起動して上記の sample.py をコピペして実行すると下記ができました
以上で完了です。
- 投稿日:2020-09-10T18:01:02+09:00
リストで利用できるメソッド
リストで利用できるメソッド
リストには、sort()の他にも便利なメソッドが定義されています。
よく使われるメソッドについて、簡単に解説します。
- l.reverse()メソッド:並び順を逆にする
リストの中身をすべて逆順で返す
reverse()l = [o,l,l,e,h]
print(l.reverse())reversed()
リストの並び順を反転します。
元のオブジェクトには何の影響も与えないとのことなのでreversed()を使うのが良いのではないかと思います。list_A = [o,l,l,e,h]
for x in reversed(sample_list):
print(x)l.reverse()を調べた結果からいうとリストの文字列を反転したいだけならスライスのほうが、安全そうでした。
[::-1]を使用すると逆順のリストが帰ってきます。なので、文字列リストを反転する場合は以下の様な形になりますprint([o,l,l,e,h][::-1])
- append()メソッド:末尾に追加する
L.append(追加する要素)
末尾に要素を追加したい場合に使用するlist_A
[h, e, l, l, o]list_A = [h, e, l]
list_A.append([l, o])list_A
[h, e, l[l, o]]
- extend()メソッド:末尾にシーケンスを追加する
L.extend(追加するシーケンス)
一つのリストの末尾に追加したい場合にextend()メソッドを使用する。
要素を追加したい場合に使用するとエラーが発生するのです注意list_A = [h, e, l]
list_A.extend([l, o])list_A
[h, e, l, l, o]
- remove()メソッド:要素を削除する
L.remove(取り除く要素)
リストLのなかから取り除く要素を探し出し、要素をL自体から削除します。l = ['h, e, l, l, o]
l.remove(‘h’)
print(l)['e, l, l, o']
引数として指定された要素が見つからない場合は、例外(エラー)を発生します。
l = ['h, e, l, l, o]
l.remove(‘a’)
print(l)ValueError: list.remove(x): x not in list
- 投稿日:2020-09-10T16:58:38+09:00
pythonでwordとexcelレポートを自動作成
excel編
excel作成
import openpyxl as opy book = opy.Workbook()シートの名前を確認
sheet1 = book.active sheet1.titleシートの名前を変更
sheet1.title = 'mysheet_1'excelファイルを作成
book.save('make_excel.xlsx')既にあるファイルを開く
my_made = opy.load_workbook('make_excel.xlsx')指定のシートを編集する
sheet2 = my_made.active table = my_made[sheet2.title]セルを指定して文字を書き込む
table['A1'] = 'How is the weather today'セルの書式変更する
from openpyxl.styles import Font table['A1'].font = Font(bold=True,italic=True,size=28)word編
pip install でdocxを指定するのは3.4まで
それ以降はパッケージ名をpython-docxで指定する。ファイルを作る
import docx doc = docx.Document()文章の書きこみ
doc.add_paragraph('How is the weather today') doc.add_paragraph() doc.add_paragraph(today_list) doc.add_paragraph()画像の挿入
doc.add_picture('pict.png')ファイルの保存
doc.save('make_word_today.doc')以上
- 投稿日:2020-09-10T16:22:33+09:00
GPU関連の用語集
概要
GPUを使用して機械学習を行うときに使用するツールだったりの用語を解説する
用語集
GPUとは
グラフィックスなどの描画に関して計算処理を行うプロセッサ
グラフィックスなどに特化して高い処理能力を持っていたGPUをグラフィックス以外にも応用しようと開発されたものがCUDAであるCUDAとは
GPUを使用するためのプログラミング環境を提供するもの
画像認識などの機械学習で用いられている
NVCCとは
CUDAコードをコンパイルするNvidia CUDAコンパイラのこと
ホストコード(CPU用のコード)とデバイスコード(GPU用のコード)に分離し、デバイスコードをコンパイルし、GCCなどのコンパイラがホストコードをコンパイルするGCCとは
複数のプログラミング言語のコンパイラである
以上
随時追記します
- 投稿日:2020-09-10T15:03:53+09:00
kabuステーション®API - REST API用のPythonラッパーをつくってみた
概要
以下のkabuステーションAPI記事回では辞書形式からjson形式への変換、requestsの作成、レスポンスのjson形式から辞書型への再変換を毎度行っていたが、このあたりを簡略化するモジュールを作成した。
環境
- Windows 10
- Python 3.8.5 ( Microsoft Store からインストール )
使い方
requests のインストールが必要である。
pip install requests以下よりダウンロードまたはcloneする。
kabusapi があるフォルダで起動した端末のインタプリタですぐに使うことができる。
PS C:\Users\Shirasu> python Python 3.8.5 (tags/v3.8.5:580fbb0, Jul 20 2020, 15:57:54) [MSC v.1924 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license" for more information. >>> import kabusapi >>> api = kabusapi.Context('localhost', '18080', 'password') >>> api.wallet.cash() {'StockAccountWallet': 123456.7} >>>他の使い方は同 Git の sample フォルダ内 sample.py を参照のこと。
- 投稿日:2020-09-10T14:28:35+09:00
【Python】ジェネレータ(generator)関数
はじめに
この記事はジェネレータ(generator)関数を理解せずに使用して失敗したため, ジェネレータ(generator)関数の勉強のための記事になります. 内容は, 参考文献を用いた自分用の備忘録です.
定義
まずはジェネレータ関数の定義を確認する.
- 定義:ジェネレータ関数1
関数定義の中でyield文が使われている場合、その関数はジェネレータ関数と呼ばれます。ジェネレータ関数はイテレータの一種です。
例:
yieldを使ったジェネレータ関数をPython3.7.4で実行. yieldにより区切られて値が返されます.def sample_generator_fun(): yield 1 yield 2 yield 3 check = sample_generator_fun() print(check.__next__()) print(check.__next__()) print(check.__next__())実行結果
1 2 3さらにcheckを実行すると...
print(check.__next__())--------------------------------------------------------------------------- StopIteration Traceback (most recent call last) <ipython-input-25-7029da5797f2> in <module> ----> 1 print(check.__next__()) StopIteration:反復停止と表示され, エラーとなります. つまり, sample_generator_funのyield文が順に実行され, 3番目の「yield 3」が実行されると反復が終了され, さらに実行しても値を返しません.
失敗例
ジェネレータ関数をきちんと理解せず, リストなどのイテレータオブジェクトと同じものとして考え, 下記の様な失敗をしました. ※そもそも, 恥ずかしながらジェネレータ関数の存在を知りませんでした
例:
取得されたジェネレータ関数のイテレータ数が2超であるのかを確認し, そうであれば実行する.失敗例
check = sample_generator_fun() if len(list(check)) > 2: print("True") for i in check: print(i) else: print("False")実行結果
Trueここで, 私はif文でTrueになっているのに, なぜその下のfor文が実行されないのか悩み, 色々と調べてジェネレータ関数にたどり着くことが出来ました. 条件式内のlist(check)を実行したことで, 最後の「yield 3」まで実行されたことになるので, 次のfor文ではcheckは値を返さないため, for文は実行されません.
解決策
簡単に思いつく範囲で下記2つが挙げられます. 工夫してジェネレータ関数を複数回呼び出し可能にする場合は, この記事2の様にするのが良いかもしれません.
- ジェネレータ関数で返される総データサイズが大きくなければ, リストに変換して使用する
check = sample_generator_fun() check_list = list(check) if len(check_list) > 2: print("True") for i in check_list: print(i) else: print("False")実行結果
True 1 2 3
- 単純に2回, ジェネレータ関数を呼び出す. この場合はジェネレータ関数のメリットであるメモリの節約は保持されます
check = sample_generator_fun() n = 0 for i in check: n += 1 if n > 2: print("True") check = sample_generator_fun() for j in check: print(j) break else: print("False")実行結果
True 1 2 3感想
スクリプト言語では型宣言などをしなくてもコードを書けますが, どんな型やどんな性質のオブジェクトを触っているのかは, きちんと把握していないと事故りますね. 今回は「リスト」と同様だろうなという希望的観測による失敗でした. 使用するライブラリの中身を全て把握するのは難しいですが, 今回のような基本的なことはきちんと正確に抑えるべきだと改めて痛感しました.
中久喜健司:科学技術計算のためのPython入門, 2016年, 技術評論社 ↩
- 投稿日:2020-09-10T14:23:42+09:00
Tellus GPUサーバ(さくら高火力コンピューティング)での機械学習環境構築
はじめに
- Tellus GPUサーバ(高火力コンピューティング)での機械学習環境構築について、手順を記載
- 動作確認として以下の3つの項目を確認
- PyTorchを用いたディープラーニングモデルのGPU学習
- MLFlowを用いた実験記録閲覧
- QGISを用いたサーバ内データ確認
検証環境
Item Version OS Ubuntu 18.04 OpenSSH 7.6p1 GPUサーバの申込み(Tellus経由)
Tellus
- Tellus
- 日本初の衛生データプラットフォーム
- データの取得だけでなく、開発環境の無償提供もしている(JupyterLab or GPUサーバ)
GPUサーバについて
- さくら高火力コンピューティングラインナップ
- 普通に借りようとすると100万円くらい
- レンタル期間はあるが期間内であれば使用時間制限はない
- 最終アクセスから1ヶ月アクセスしていないとレンタル終了とみなされる
- google colaboratoryだと90分/12時間ルールが存在
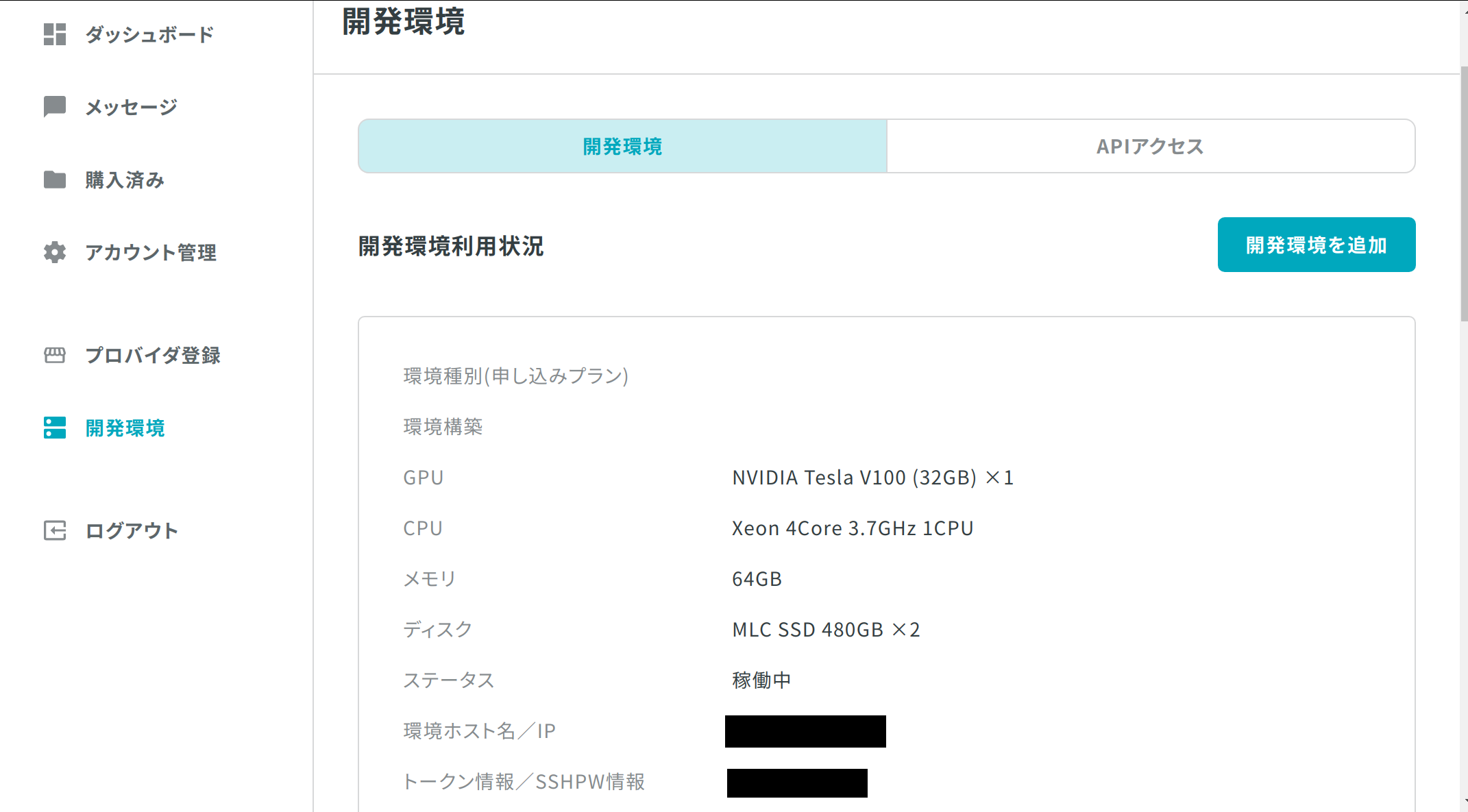
Item Spec OS Ubuntu 18.04(64bit) GPU NVIDIA Tesla V100 (32GB) ×1 CPU Xeon 4Core 3.7GHz 1CPU Disk MLC SSD 480GB ×2 Memory 64GB 申し込みの流れ
- Tellusに会員登録(無料)後、開発環境の申込みを行う
- 費用は無料
- 期間は1ヶ月, 3ヶ月 or それ以上(要相談)が選択できる
- 利用期間終了後であれば更新できる
- 申し込んでからしばらく経つと運営からログインIDの連絡が来る
- サーバの空き具合によって前後するが約1ヶ月程度
環境構築(GPU)
基本はCUDA Toolkit/GPUカードドライバー導入手順の手順に従う
サーバ情報
Tellusアカウントのダッシュボード → 開発環境を参照
Item 対応項目 サーバIP 環境ホスト名/IP ログインID 運営からメールで送られてくる 初期パスワード トークン情報/SSHPW情報
サーバへの接続
~/.ssh/configにサーバへの接続情報を記載~/.ssh/configHost tellus HostName [環境ホスト名/IP] User [ログインID] IdentityFile ~/.ssh/id_rsa
- Terminal上で
ssh tellusと入力、パスワードを聞かれるので初期パスワードを入力すれば接続完了パッケージのアップデートとインストール
GPUドライバを入れる前の下準備
sudo apt update sudo apt upgrade apt install build-essential apt install dkmsCUDA Toolkit
- CUDA Toolkit Archive
- 2020/09/09現在での最新版のCUDAは11.0
- PyTorch 1.6(最新版)で対応しているのは10.2までなのでダウングレードが必要
- runfile以外を使用すると、バージョン指定しても何故か11.0がインストールされたので必ずrunfile(local)を使用すること
- runfile実行時にsudoを抜かすとインストールに失敗したので追加
wget http://developer.download.nvidia.com/compute/cuda/10.2/Prod/local_installers/cuda_10.2.89_440.33.01_linux.run sudo sh cuda_10.2.89_440.33.01_linux.run chmod +x cuda_10.2.89_440.33.01_linux.run sudo ./cuda_10.2.89_440.33.01_linux.run --toolkit --samples --samplespath=/usr/local/cuda-samples --no-opengl-libs
- 環境変数の設定ファイル作成後、ログアウトし再度ログイン
/etc/profile.d/cuda.shexport CUDA_HOME="/usr/local/cuda" export PATH="$CUDA_HOME/bin:$PATH" export LD_LIBRARY_PATH="/usr/local/lib:$CUDA_HOME/lib64:$LD_LIBRARY_PATH" export CPATH="/usr/local/include:$CUDA_HOME/include:$CPATH" export INCLUDE_PATH="$CUDA_HOME/include"/etc/profile.d/cuda.cshexport CUDA_HOME="/usr/local/cuda" export PATH="$CUDA_HOME/bin:$PATH" export LD_LIBRARY_PATH="/usr/local/lib:$CUDA_HOME/lib64:$LD_LIBRARY_PATH" export CPATH="/usr/local/include:$CUDA_HOME/include:$CPATH" export INCLUDE_PATH="$CUDA_HOME/include"CUDA Driver
- CUDA Driver Download
- CUDA ToolkitでインストールできるDriverは古いため別途インストール
- Toolkitと同じく実行時にsudoを追加
wget https://us.download.nvidia.com/tesla/440.95.01/NVIDIA-Linux-x86_64-440.95.01.run chmod +x NVIDIA-Linux-x86_64-440.95.01.run sudo ./NVIDIA-Linux-x86_64-440.95.01.run --no-opengl-files --no-libglx-indirect --dkmscuDNN
- NVIDIA cuDNN
- 会員登録が必要(無料)
- クライアント側でダウンロードし、scpでサーバへ転送
- 転送後、解凍し中身を所定のディレクトリに移す
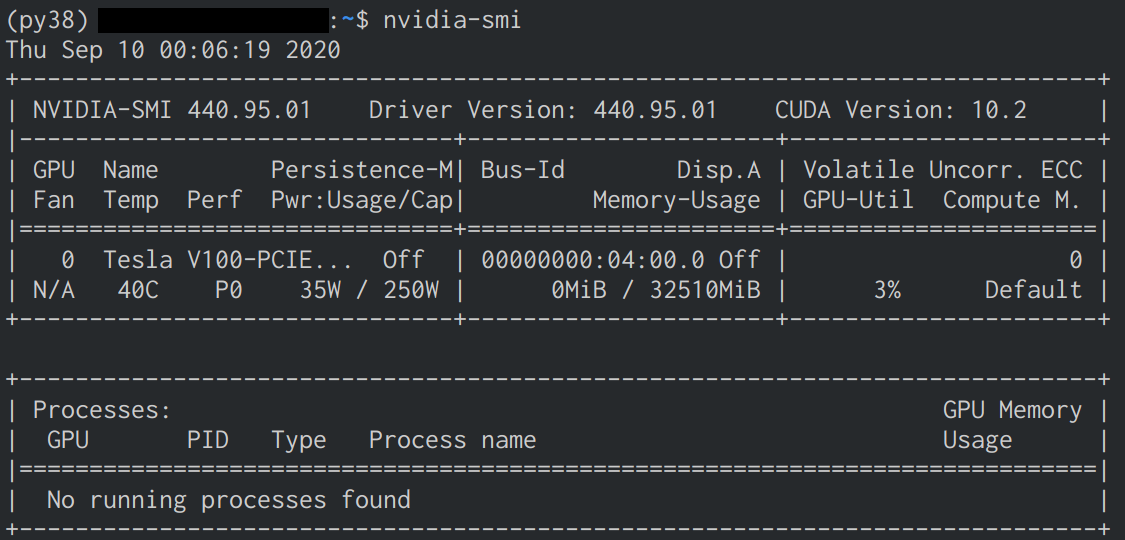
clientscp -r cudnn-10.2-linux-x64-v8.0.3.33.tgz tellus:~/servertar xvzf cudnn-10.2-linux-x64-v8.0.3.33.tgz sudo mv cuda/include/cudnn.h /usr/local/cuda/include/ sudo mv cuda/lib64/* /usr/local/cuda/lib64/インストール確認
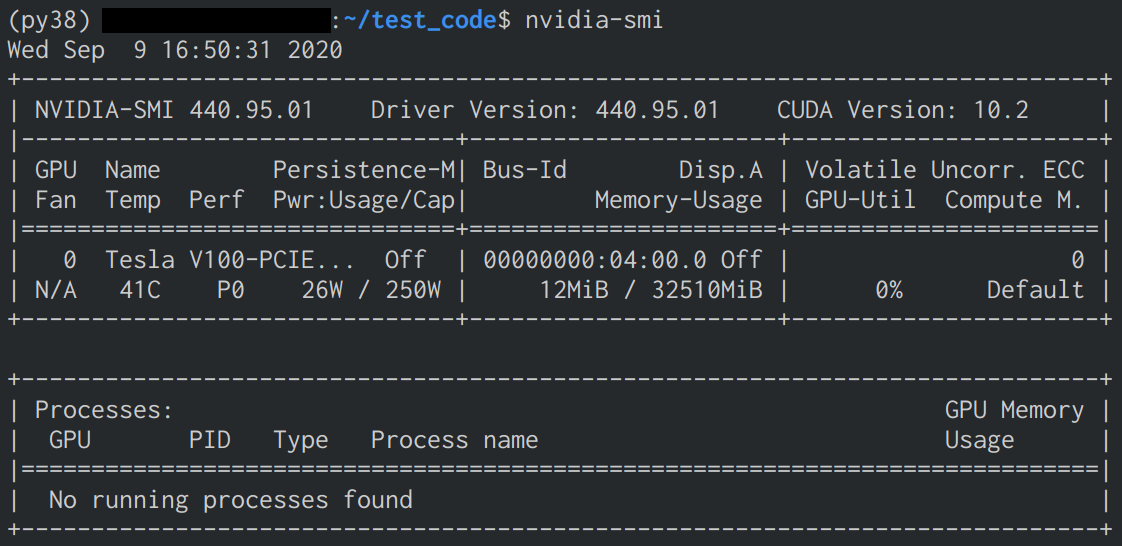
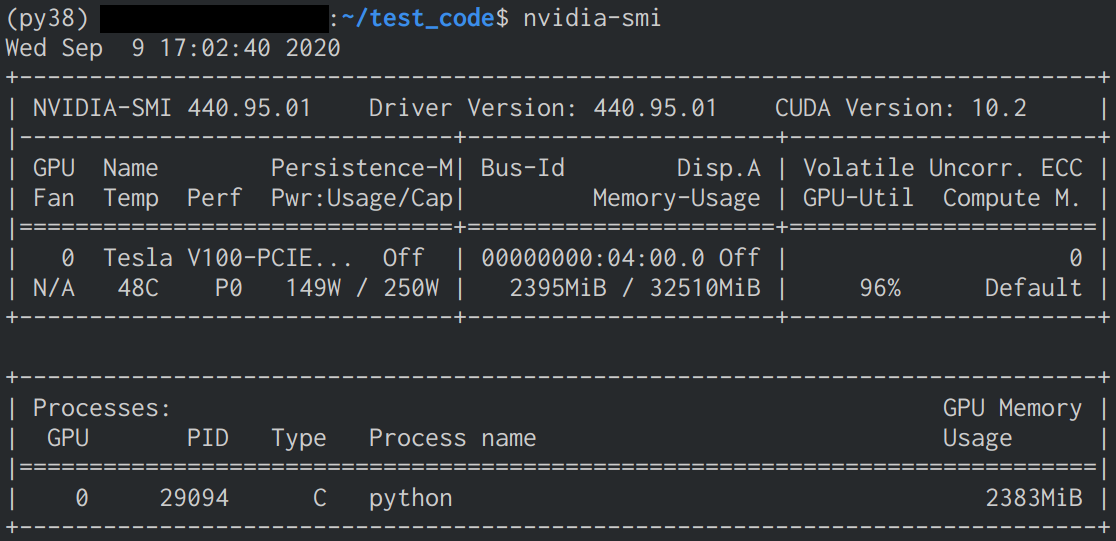
nvidia-smiで確認- インストールに成功していると下の画像のような表示が確認できる
環境構築(Python)
Anaconda
- Anaconda
- インストール後、環境を作るかはお好みで
wget https://repo.anaconda.com/archive/Anaconda3-2020.07-Linux-x86_64.sh sudo bash Anaconda3-2020.07-Linux-x86_64.sh conda update -n base conda
- 環境を作った際、そのままだと動かなかったので
.bashrcに以下を追加(py38は環境名).bashrcexport PYTHONPATH="/home/[ログインID]/anaconda3/envs/py38/lib/python3.8:/home/[ログインID]/anaconda3/envs/py38/lib/python3.8/site-packages:$PYTHONPATH"PyTorch
- PyTorch get-started
- conda以外を使用する場合はPackage部分を変えてコマンドを確認
conda install pytorch torchvision cudatoolkit=10.2 -c pytorchMLFlow
- MLFlow
- 機械学習の実験管理ライブラリ
conda install -c conda-forge mlflow
mlflow uiと入力するとlocalhost:5000にUIが立ち上がり、ブラウザで実験結果の確認が出来る
サーバ側でUIを立ち上げた時にクライアント側のブラウザで閲覧出来るようにするため、
~/.ssh/configにLocalForwardの設定を追加する~/.ssh/configHost tellus HostName [環境ホスト名/IP] User [ログインID] IdentityFile ~/.ssh/id_rsa LocalForward [クライアント側のポート番号] localhost:5000QGIS
- QGIS
- GeoTiffやShapefileなどの地理情報付きデータのビューワ
- 地理情報がついていない普通の画像も閲覧可能
- 最新版(3.14.15)だと動かなかったので3.10.8を使用
- libprotobuf-lite.so.23がないというエラー
conda install -c conda-forge qgis=3.10.8動作確認
GPU学習
- CPUとGPUの2つのモードで実行し、処理時間に差が出るか確認
- コード実行時に
nvidia-smiでGPUのMemoryとVolatileを確認- コードはPyTorchのCIFAR10 Tutorialを参考に下記の部分を変更
- モデルはResNet-18
- バッチサイズを1024、Worker数を8(= サーバのコア数)
- CPU実行は
device = torch.device("cpu")に書き換えて実行cifar10.pyimport os import torch import torch.nn as nn import torch.optim as optim import torchvision.models as models import torchvision.transforms as transforms from torch.utils.data import DataLoader from torchvision.datasets import CIFAR10 from tqdm import tqdm batch = 1024 device = torch.device("cuda" if torch.cuda.is_available() else "cpu") def dataloader(is_train: bool, transform: transforms.Compose) -> DataLoader: dataset = CIFAR10(root='./data', train=is_train, download=True, transform=transform) return DataLoader(dataset, batch_size=batch, shuffle=is_train, num_workers=os.cpu_count()) def model() -> nn.Module: model = models.resnet18(pretrained=True) model.fc = nn.Linear(512, 10) return model.to(device) def training(net: nn.Module, trainloader: DataLoader, epochs: int) -> None: # loss function & optimizer criterion = nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9) for epoch in range(epochs): # loop over the dataset multiple times running_loss = 0.0 bar = tqdm(trainloader, desc="training model [epoch:{:02d}]".format(epoch), total=len(trainloader)) for data in bar: # get the inputs; data is a list of [inputs, labels] inputs, labels = data[0].to(device), data[1].to(device) # zero the parameter gradients optimizer.zero_grad() # forward + backward + optimize outputs = net(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() running_loss += loss.item() bar.set_postfix(device=device, batch=batch, loss=(running_loss / len(trainloader))) print('Finished Training') transform = transforms.Compose( [transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]) trainloader = dataloader(True, transform) net = model() training(net, trainloader, 3)CPU結果
GPU結果
- GPU使用により約36倍高速化したことを確認
- GPU使用時にMemoryとVolatileの数値が変化したことを確認
MLFlow
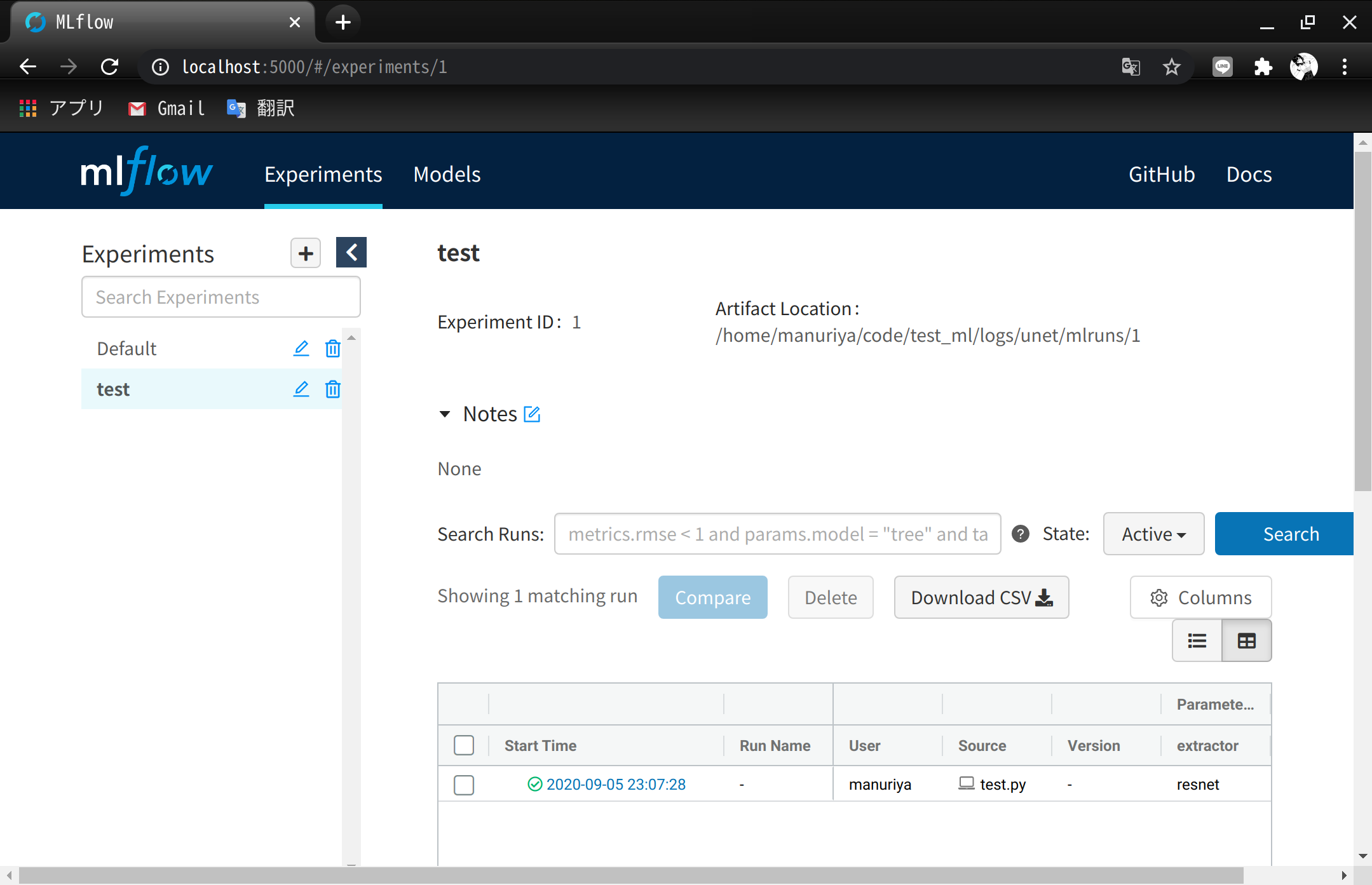
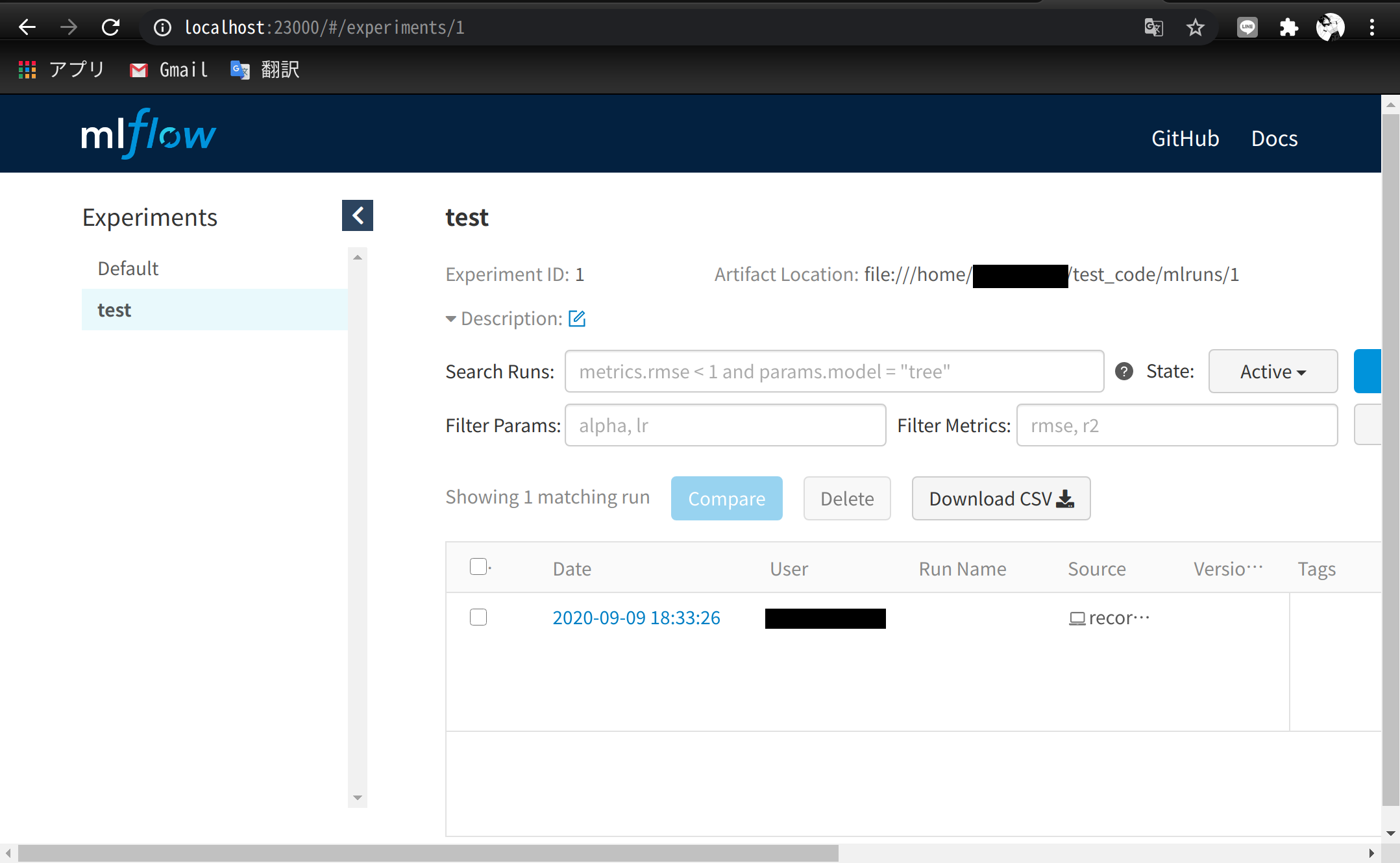
- サーバ上の実験記録がクライアント側のブラウザで閲覧できるか確認
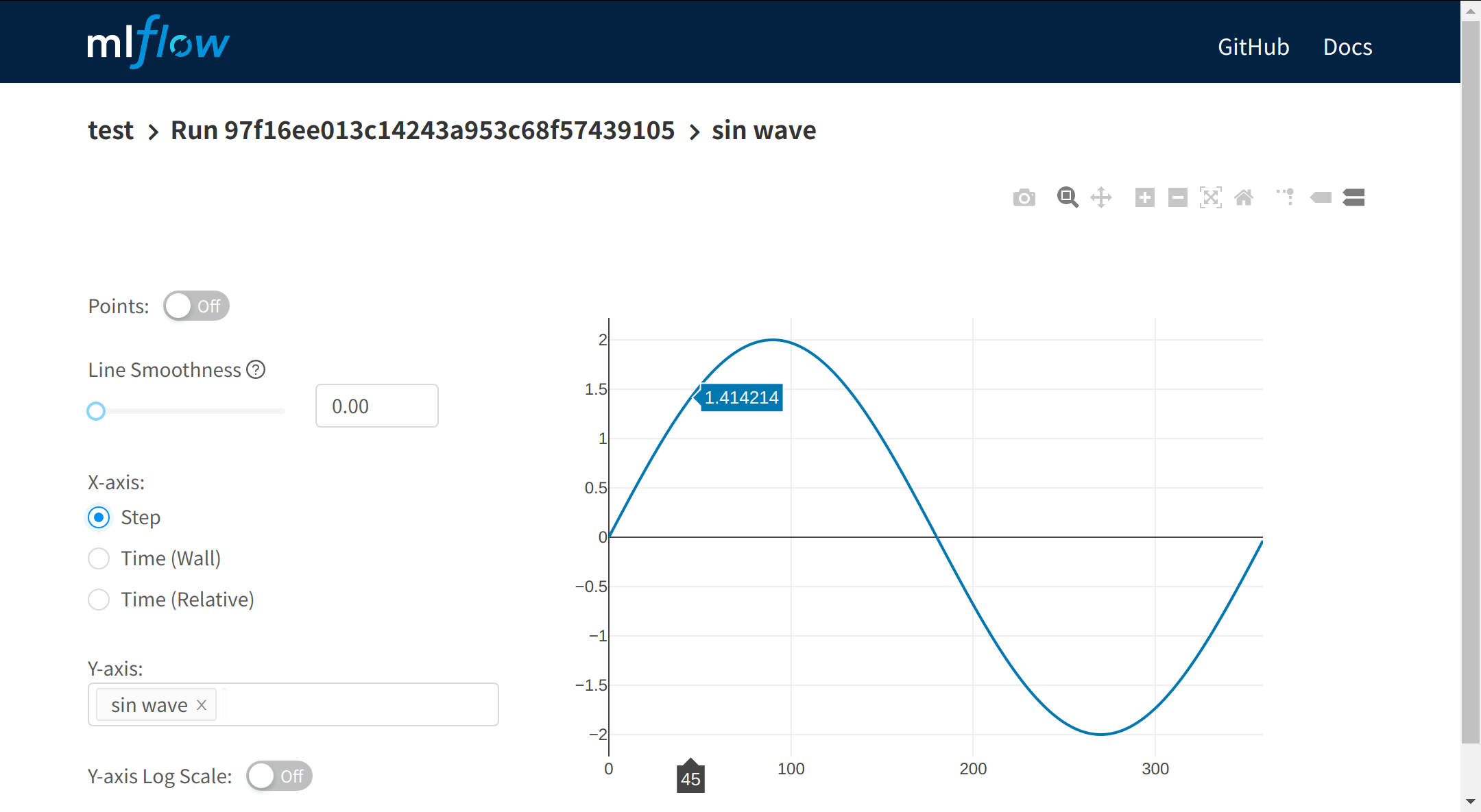
- 実験コードは振幅を2倍にしたSin波形のグラフ保存
- LocalForwardのポート番号は23000で確認
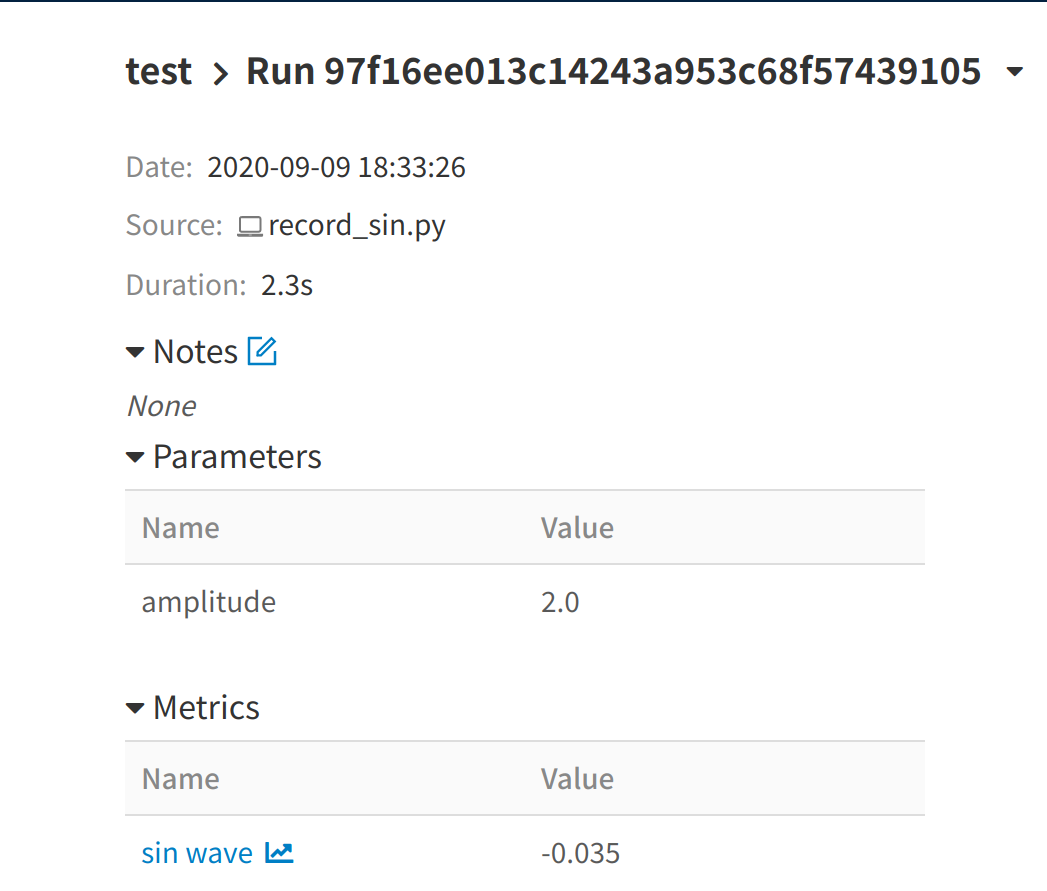
record_sin.pyfrom math import pi, sin import mlflow mlflow.set_experiment('test') amplitude = 2.0 with mlflow.start_run() as _: mlflow.log_param('amplitude', amplitude) for i in range(360): sin_val = amplitude * sin(i * pi / 180.) mlflow.log_metric('sin wave', sin_val, step=i)~/test_code/python record_sin.py mlflow ui結果画像
QGIS
- Data Source Managerでサーバ側のコード(test_code)が閲覧できるか確認
ssh -X tellus qgis
- 先程の
cifar10.pyとrecord_sin.pyがあることを確認
VSCodeの使用
- sshが使えるのでVSCodeのRemote Developmentも使用可能
- VSCodeでjupyter notebookファイルを作成する場合はipykernelのインストールが必要
conda install -c conda-forge ipykernelおわりに
- CUDA Toolkitインストールでdebファイルを選んで無駄な時間を使ったので手順をまとめました
- QGISの部分は他のビューワに置き換えてもほぼ同じ手順でいけるはず
- 高火力コンピューティングに限らず他のGPUサーバでもある程度使える手順かと思います
参考ページ


- 投稿日:2020-09-10T12:26:32+09:00
Pythonで記事テンプレを自動作成(Seleniumでスクレイピング)
まえがき
毎回定型文を書くことも面倒になってきたのでPythonを勉強して自動化してしまえと考えた次第です
本題
機器概要
・Windows10 Laptop
・Anaconda3 4.8.4
・Python3.8.5
・VScode手順
1. 環境構築
結局のところ環境を整えるのが一番面倒だと感じた(特にPath)
参考に分かりやすい解説等あるので参照してほしい
(※以前にVScodeのTerminalでLinuxと同じように実行できるようにしていたので困らなかったがどうやったか忘れた,cygwin64とか入れてPassを通した気がする)AnacondaとVScodeで利用できるようにした
Anacondaをインストールして,システム環境変数からPathを通す
再起動してAnaconda promptでPython -Vとconda -Vでバージョンが確認できればOk
VScodeではPythonの拡張機能を入れて,設定からpython python pathでインストールしたAnaconda3のpython.exeを絶対パスで指定して再起動すれば終わり,実行できるようになる2. 必要なファイルを用意する
Selenium
Terminalでpip install Seleniumでインストール
Webdriver
スクレイピングしたいブラウザに合わせて用意(バージョンも合わせる)
今回はChromeとEdgeを用意した3. code(python)
ブラウザを立ち上げてサイトにアクセス
ログイン処理を行い,記事を作成,下書き保存までを行うChrome用
Qiita_Chrome.pyimport time from selenium import webdriver from selenium.webdriver.chrome.options import Options from selenium.webdriver.support.select import Select from selenium.webdriver.common.by import By from selenium.webdriver.common.keys import Keys from selenium.webdriver.common.alert import Alert from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from selenium.common.exceptions import TimeoutException # Seleniumをあらゆる環境で起動させるChromeオプション options = Options() options.add_argument('--disable-gpu') options.add_argument('--disable-extensions') options.add_argument('--proxy-server="direct://"') options.add_argument('--proxy-bypass-list=*') options.add_argument('--start-maximized') # options.add_argument('--headless'); # ※ヘッドレスモードを使用する場合、コメントアウトを外す user_name = "{name}" #ログインする名前 passward = "{pass}" #パスワード url = 'https://qiita.com/drafts/new' DRIVER_PATH = (r'{#Driverのパス}') text_title = "{Title}" tag = "{tag1} {tag2} {tag3} {tag4} " text_body = "{本文}" # ブラウザの起動 driver = webdriver.Chrome(executable_path=DRIVER_PATH) driver.get(url) #指定したURLにアクセス time.sleep(2) #2秒あける # ログイン処理 user_box = driver.find_element_by_id('identity') #ログイン名の記入欄を指定 user_box.send_keys(user_name) #記入 pass_box = driver.find_element_by_id('password') #パスワードを pass_box.send_keys(passward) #記入 pass_box.submit() time.sleep(2) # 自動でフォーマット作成 new_title = driver.find_element_by_xpath('/html/body/div[1]/div[3]/div/div[1]/div/div/input') #タイトル記入欄を指定 new_title.send_keys(text_title) #記入 new_tag = driver.find_element_by_xpath('/html/body/div[1]/div[3]/div/div[2]/input')#タグ記入欄を指定 new_tag.send_keys(tag) #記入 new_body = driver.find_element_by_xpath('/html/body/div[1]/div[3]/div/div[3]/div/div[1]/div[2]/textarea') #本文記入欄を指定 new_body.send_keys(text_body) #記入 time.sleep(2) # 下書き保存 (なくても保存してた) # <a href="#" tabindex="43" class="MarkdownEditorFooterSelector__DropdownItem-sc-11l11zp-4 fUjZzp"><i class="fa fa-check"></i><i class="fa fa-save"></i>下書き保存</a> # save = driver.find_element_by_xpath('/html/body/div[1]/div[3]/div/div[4]/div/div[2]/div[2]/div/ul/li[1]/a') # save.click() # button = driver.find_element_by_xpath('/html/body/div[1]/div[3]/div/div[4]/div/div[2]/div[2]/div/button') # button.click() # driver.quit() driver = webdriver.Chrome(executable_path=DRIVER_PATH) driver.get('https://qiita.com/drafts') time.sleep(2) # ログイン処理 user_box = driver.find_element_by_id('identity') user_box.send_keys(user_name) pass_box = driver.find_element_by_id('password') pass_box.send_keys(passward) pass_box.submit()Edge用
Qiita_Edge.pyimport time from selenium import webdriver from selenium.webdriver.support.select import Select from selenium.webdriver.common.by import By from selenium.webdriver.common.keys import Keys from selenium.webdriver.common.alert import Alert from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from selenium.common.exceptions import TimeoutException user_name = "{name}" #ログインする名前 passward = "{pass}" #パスワード url = 'https://qiita.com/drafts/new' DRIVER_PATH = (r'{#Driverのパス}') text_title = "{Title}" tag = "{tag1} {tag2} {tag3} {tag4} " text_body = "{本文}" # ブラウザの起動 driver = webdriver.Edge(executable_path=DRIVER_PATH) driver.get(url) #指定したURLにアクセス time.sleep(2) # ログイン処理 user_box = driver.find_element_by_id('identity') #ログイン名の記入欄を指定 user_box.send_keys(user_name) #記入 pass_box = driver.find_element_by_id('password') #パスワードを pass_box.send_keys(passward) #記入 pass_box.submit() time.sleep(2) # 自動でフォーマット作成 new_title = driver.find_element_by_xpath('/html/body/div[1]/div[3]/div/div[1]/div/div/input') #タイトル記入欄を指定 new_title.send_keys(text_title) #記入 new_tag = driver.find_element_by_xpath('/html/body/div[1]/div[3]/div/div[2]/input')#タグ記入欄を指定 new_tag.send_keys(tag) #記入 new_body = driver.find_element_by_xpath('/html/body/div[1]/div[3]/div/div[3]/div/div[1]/div[2]/textarea') #本文記入欄を指定 new_body.send_keys(text_body) #記入 time.sleep(2) # 下書き保存 (なくても保存してた) # <a href="#" tabindex="43" class="MarkdownEditorFooterSelector__DropdownItem-sc-11l11zp-4 fUjZzp"><i class="fa fa-check"></i><i class="fa fa-save"></i>下書き保存</a> # save = driver.find_element_by_xpath('/html/body/div[1]/div[3]/div/div[4]/div/div[2]/div[2]/div/ul/li[1]/a') # save.click() # button = driver.find_element_by_xpath('/html/body/div[1]/div[3]/div/div[4]/div/div[2]/div[2]/div/button') # button.click() driver.quit() driver = webdriver.Edge(executable_path=DRIVER_PATH) driver.get('https://qiita.com/drafts') time.sleep(2) # ログイン処理 user_box = driver.find_element_by_id('identity') user_box.send_keys(user_name) pass_box = driver.find_element_by_id('password') pass_box.send_keys(passward) pass_box.submit()動作確認
pythonで自動化#Python #Python3 #Anaconda #VSCode pic.twitter.com/Ju6z8RTC41
— ゆーま (@sagirin262) September 10, 20204. batファイル作成
いちいちコマンド打つのは面倒なのでバッチファイルをワンクリックで実行できるようにします.
テキストファイルを作成し,コマンドを記入Qiita_new.txtcd {scriptのあるフォルダ} python {作成したpythonファイル} pause拡張子
.txt→.batに変更
これで完成実行例
ワンクリック? pic.twitter.com/wYjuh7OiHE
— ゆーま (@sagirin262) September 10, 2020
実行,動作事態は問題ないが,Debag.txtにエラーが吐き出されるので完全ではない
下書き保存の流れでクリック処理などがうまくいってないのかも...あとがき
いつもどんな感じで書いてたか忘れちゃうので少しは楽になったかな.
これでたくさん記事が書けますね?????参考
以前にまとめたのでこちらを参照して下さい
- 投稿日:2020-09-10T11:40:21+09:00
ビッグバンの定理を検証してみた【そろそろ帰着にかかるか】
ビッグバンの定理とは…
どんな言葉でも「ビッグバン」に帰着するという説
引用
どの言葉も辞書で意味を遡るとビッグバンに辿り着く説を検証してみた。
https://www.youtube.com/watch?v=CN7q1thA7mU実装
今回は「MediaWiki API」を使用し、記事へリンクしている記事の一覧を取得し
どれくらいの記事がビッグバンの記事にリンクされるか検証するソース
pythonurl = "http://ja.wikipedia.org/w/api.php" payload = {"format":"json", "action":"query", "list":"backlinks", "blnamespace":"0"} payload['bltitle'] = word r = requests.get(url, params=payload) # json整形 json_load = r.json() json_load = json.dumps(json_load) json_load = json.loads(json_load) # 一部切り出し json_load = json_load['query']['backlinks'] theList = [] # 記事分をループ for value in json_load: theDict = {} theDict['id'] = value['pageid'] theDict['title'] = value['title'] theDict['blTitle'] = word theDict['url'] = 'https://ja.wikipedia.org/wiki/' + value['title'] theDict['floor'] = floor theDict['ns'] = value['ns'] theList.append(theDict) dataFrame = pd.io.json.json_normalize(theList)参考
https://qiita.com/yubessy/items/16d2a074be84ee67c01f#記事へリンクしている記事の一覧を取得
検証結果
https://ja.wikipedia.org/wiki/Wikipedia:日本語版の統計
より記事総数を「1227198」件とする
※2020年9月現在
n=ビッグバンに帰着するまでの回数
代表値
n=0
・ビッグバンn=1
・物理学
・年表
・宇宙論n=2
・地理学
・生物
・生物学出力結果CSV
全取得結果(記事の重複あり)
https://github.com/Syogo-Suganoya/bigBanete/blob/master/downloads/record.csv全取得結果(記事の重複なし)
https://github.com/Syogo-Suganoya/bigBanete/blob/master/downloads/uniqueRecord.csv結論
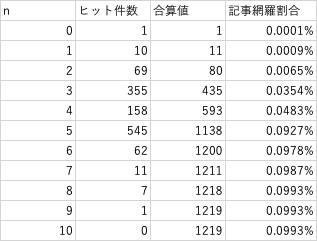
試行回数10回目で記事リンクのループが発生し、記事網羅率が天井に達した。
ビッグバンの日本語記事における網羅率(ビッグバネイト率)は0.0993%で、
命題「どんな言葉でも「ビッグバン」に帰着する」というのは間違いである。
github
- 投稿日:2020-09-10T11:40:21+09:00
ビッグバネイト説を検証してみた【そろそろ帰着にかかるか】
ビッグバネイト説とは…
どんな言葉でも「ビッグバン」に帰着するという説
引用
どの言葉も辞書で意味を遡るとビッグバンに辿り着く説を検証してみた。
https://www.youtube.com/watch?v=CN7q1thA7mU実装
今回は「MediaWiki API」を使用し、記事へリンクしている記事の一覧を取得し
どれくらいの記事がビッグバンの記事にリンクされるか検証するソース
pythonurl = "http://ja.wikipedia.org/w/api.php" payload = {"format":"json", "action":"query", "list":"backlinks", "blnamespace":"0"} payload['bltitle'] = word r = requests.get(url, params=payload) # json整形 json_load = r.json() json_load = json.dumps(json_load) json_load = json.loads(json_load) # 一部切り出し json_load = json_load['query']['backlinks'] theList = [] # 記事分をループ for value in json_load: theDict = {} theDict['id'] = value['pageid'] theDict['title'] = value['title'] theDict['blTitle'] = word theDict['url'] = 'https://ja.wikipedia.org/wiki/' + value['title'] theDict['floor'] = floor theDict['ns'] = value['ns'] theList.append(theDict) dataFrame = pd.io.json.json_normalize(theList)参考
https://qiita.com/yubessy/items/16d2a074be84ee67c01f#記事へリンクしている記事の一覧を取得
検証結果
https://ja.wikipedia.org/wiki/Wikipedia:日本語版の統計
より記事総数を「1227198」件とする
※2020年9月現在
n=ビッグバンに帰着するまでの回数
代表値
n=0
・ビッグバンn=1
・物理学
・年表
・宇宙論n=2
・地理学
・生物
・生物学出力結果CSV
全取得結果(記事の重複あり)
https://github.com/Syogo-Suganoya/bigBanete/blob/master/downloads/record.csv全取得結果(記事の重複なし)
https://github.com/Syogo-Suganoya/bigBanete/blob/master/downloads/uniqueRecord.csv結論
試行回数10回目で記事リンクのループが発生し、記事網羅率が天井に達した。
ビッグバンの日本語記事における網羅率(ビッグバネイト率)は0.0993%で、
命題「どんな言葉でも「ビッグバン」に帰着する」というのは間違いである。
github
- 投稿日:2020-09-10T11:31:46+09:00
Pythonメモ① フォルダ,ファイルの操作
pythonによるファイル、フォルダの基本操作
自分用メモです。バージョンはpython3.7.1です。随時追記します。
フォルダの作成
make_folder.py# make folder import os def make_folder(path): if os.path.exists(path)==False: os.mkdir(path)ファイルのみ取得する
get_files.pyimport os import sys def get_images(path): folder = os.listdir(path): files = [f for f in folder if os.path.isfile(os.path.join(path, f))] if len(files)==0: print("File does not exist") sys.exit() return filesファイルの名前と拡張子を取得
get_filename.pyname, ext = os.path.splitext(file)
- 投稿日:2020-09-10T10:32:13+09:00
Ubuntu 20.04のシステムを用意する
2018年からメインPCとしてUbuntu(18.04)を使っています。今年、新しいLTS 20.04がリリースされたので、初期バグフィックスを待って、20.04.1をゼロ()からインストールして使用中。こちらは自分のPCの初期設定・インストール手順になっています。ご参考までに
注意: linux kernel, "uname=Linux 5.4.0-47-generic x86_64"でタッチパッドやトラックポイントが動作しなくなったので、現状、"uname=Linux 5.4.0-42-generic x86_64"を使用している。
インストールしているPC情報:
項目 値 dmi.bios.date 07/08/2020 dmi.bios.version N2EET49W (1.31 ) dmi.board.vendor LENOVO dmi.product.family ThinkPad X1 Extreme dmi.product.name 20MFCTO1WW USBを準備
https://ubuntu.com/tutorials/create-a-usb-stick-on-ubuntu#1-overview
Ubuntu(18.04や20.04)上でdisk (ディスク)アプリによりUSBドライブを挿して、ダウンロードしたイメージを
リストアすることで、ブートできるUSBを作成ができる。OSインストールウイザードの手順
- 日本語を選択
最小インストールを選択
一回、最小インストール選択なしでやってみたが、起動が日本語入力対応が不完全だとのメッセージがでた。最小インストールの場合はでないようだ。
必要なドライバー・外部ドライバーを使用するを選択
インストールするパーティションを選択してすべて削除・インストールを選択
開発用環境を用意
snap (Ubuntu Software)アプリをインストール
- Chromium
- PyCharm (community edition) [python開発用]
- VSCode [javascript開発用]
publickeyを用意して、GITHUBに登録
ライブラリーをインストール
開発用にビルドなど(pythonのビルドできることを含む)できるようにする。
sudo apt update sudo apt install -y make build-essential libssl-dev zlib1g-dev libbz2-dev libreadline-dev libsqlite3-dev wget curl llvm libncurses5-dev libncursesw5-dev xz-utils tk-dev libffi-dev liblzma-dev python-openssl gitターミナルツールをインストール
htop/tmux
sudo apt install htop tmuxcurl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip" unzip awscliv2.zip sudo ./aws/installpython (pyenv)をインストール
pyenvとは、複数バージョンのPythonを使って、Pythonのバージョンを切り替えできる環境を用意してくれるツール。
pyenv インストール:
curl https://pyenv.run | bashインストール後、表示されているテキストを
~/.bashrcに追加するexport PATH="/home/shane/.pyenv/bin:$PATH" eval "$(pyenv init -)" eval "$(pyenv virtualenv-init -)"開いているターミナルに反映する:
source ~/.bashrc
pyenvによるpython各バージョンをインストール
# list available versions with command: # pyenv install --list # (2020-9-8現在) pyenv install 3.7.9 # upgrade pip/install pipenv pyenv global 3.7.9 python -m pip install pip -U python -m pip install pipenv pyenv install 3.8.5 pyenv global 3.8.5 python -m pip install pip -U python -m pip install pipenvglobal pythonを設定:
pyenv global 3.8.5他pythonツール
global pythonによく使われるツールを入れる (jupyterlab, pre-commit)
python -m pip install jupyterlab # ここに必要かどうかは疑問ですが、これで動いている # -- 開発時のGITコミット前のコードチェックツール実行するスクリプト設定してくれる python -m pip install pre-commit注意:
pre-commitを使う場合、pipenv/virtualenv内からpre-commit installを実行することアプリをインストール
Docker
https://www.digitalocean.com/community/tutorials/how-to-install-and-use-docker-on-ubuntu-20-04
dockerをインストール
sudo apt update sudo apt install apt-transport-https ca-certificates curl software-properties-commonDockerのリポジトリのGPGキーを追加 (
OKが返される):curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -Dockerリポジトリを追加
sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu focal stable"Dockerをインストール:
sudo apt update sudo apt install docker-ceDockerがインストールされて、起動していることを確認:
# docker.serviceが"active (running)" になっているはず sudo systemctl status docker
sudoが不要のように実行できるように
dockerのコマンドを使うときにsudoを打つ必要ないように、自分のユーザをdockerのユーザグループに追加sudo usermod -aG docker ${USER}追加後、PCを再起動してください。
再起動なしの方法があるのですが、うまく行かない場合がある
再起動後、ユーザがdockerに参加しているかは下記のコマンドで確認ができる:
id -nGdockerが正しく動作しているかは下記のコマンドで確認:
docker run hello-worlddocker-composeをインストール
このコマンドを実行すると、
/usr/local/bin配下に置かれる。sudo curl -L "https://github.com/docker/compose/releases/download/1.26.0/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose実行権限を追加
sudo chmod +x /usr/local/bin/docker-compose確認:
docker-compose --versionSlack
2020年8月の時点では、ubuntuのリポジトリに入っているSLACKアプリ(snap)は、日本語を打つことができないようなので、SLACKのサイトから、
.debをダウンロードして、インストールする。
- SLACK からダウンロード
slack-desktop-*.debをインストールsudo dpkg -i ~/ダウンロード/slack-desktop-*.debシステム設定
ubuntuの`ファイル`ツールを"WIN-E"により開けるようにShortcutキー設定
VPN設定
...TBC
- 投稿日:2020-09-10T08:42:26+09:00
Jupyter Notebookの基本操作とショートカットキー
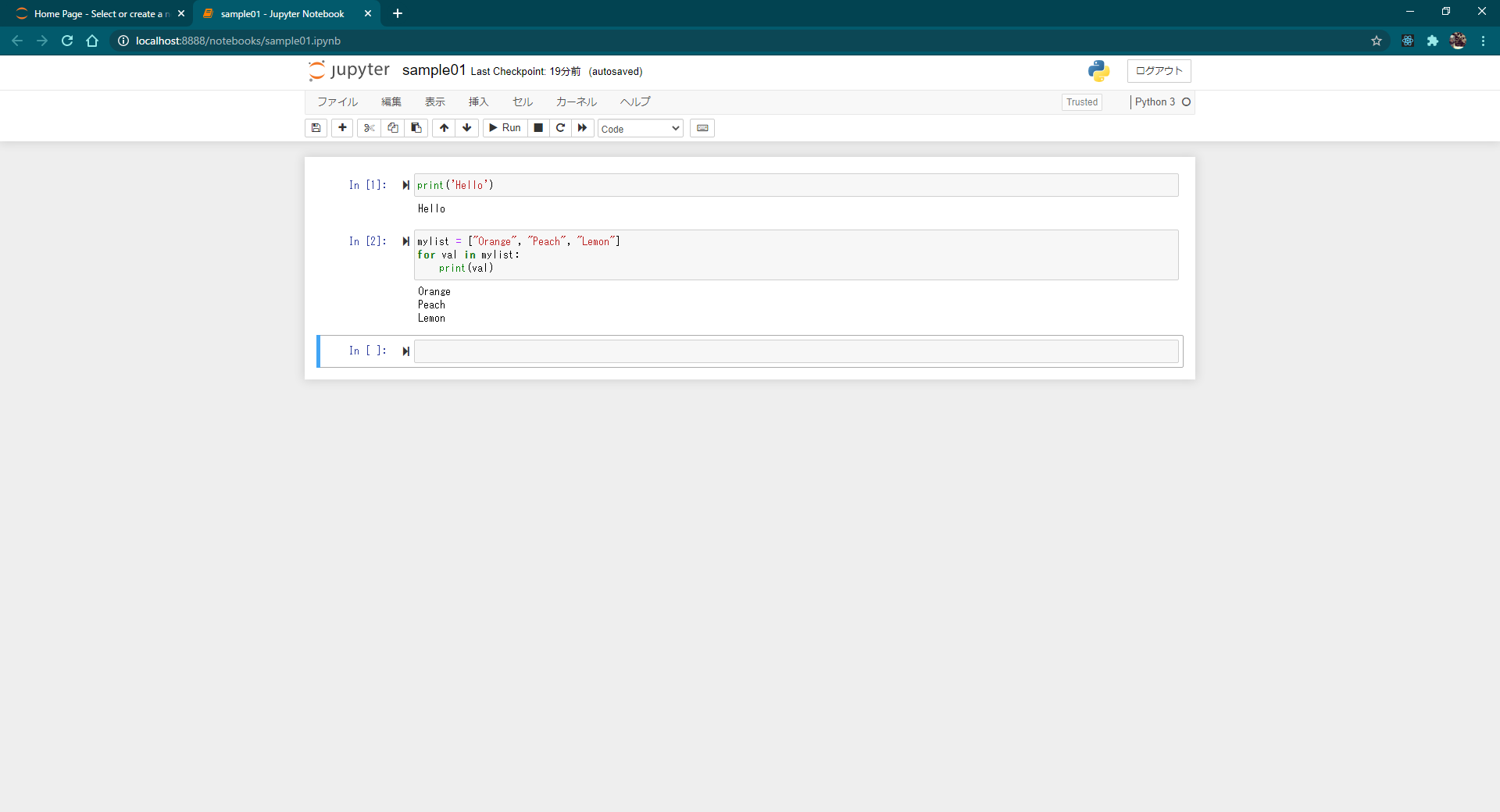
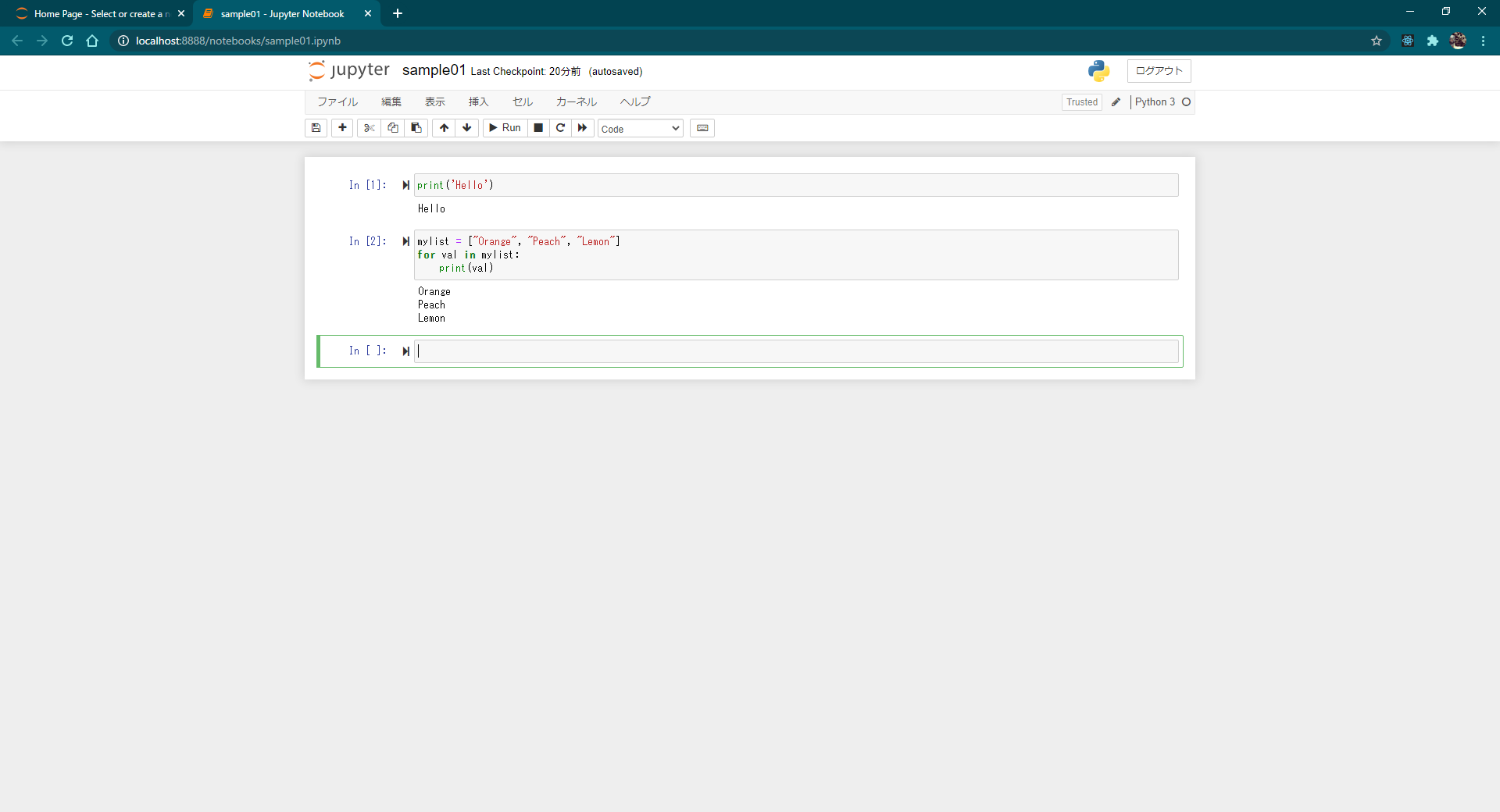
Jupyter Notebook で作成したノートブックにおける基本操作方法および利用できるショートカットキーについて解説します。
コマンドモードとエディットモードを切り替える
ノートブックで表示されているセルは、コマンドモードとエディットモードの 2 つのモードがあります。
コマンドモードはショートカットキーを使用してセルを追加したり削除したりといったセルに対する操作を行う場合に使用するモードです。セルの左側に青の線が表示されているときはコマンドモードです。
エディットモードはセルにプログラムを入力する場合に使用するモードです。セルの左側に緑の線が表示されているときはエディットモードです。
コマンドモードとエディットモードの切り替えは次のショートカットキーを使用します。
Enter: コマンドモードからエディットモードへ切り替える
Esc : エディットモードからコマンドモードへ切り替えるなおマウスを使って切り替える場合、テキストボックスの部分をクリックするとエディットモードになり、テキストボックスの左側部分をクリックするとコマンドモードになります。
- 投稿日:2020-09-10T07:00:19+09:00
Anacondaのダウンロード
Anacondaのダウンロード
Anaconda は Python 自身と Python でよく利用される NumPy や Jupyter といったライブラリをまとめてインストールしてくれるディストリビューション(必要なソフトウェアをまとめてパッケージしたもの)です。
Anaconda をインストールするには次の URL へアクセスしてください。
Anaconda は無料で利用可能な Individual Edition と有料で提供されている Team Edition と Enterprise Edition があります。今回は無料で利用可能な Individual Edition を利用します。
画面上部にある「Products」をクリックし、表示されたメニューの中から「Individual Edition」をクリックしてください。
「Individual Edition」の画面が表示されたら「Anaconda Installers」というところまでスクロールしてください。
今回は Windows 10 64bit の環境にインストールします。 Windows の下に表示されている「64-Bit Graphical Installer (466 MB)」をクリックしてください。(ご自身の環境に合わせて選択してください)。
ダウンロードが開始されます。任意の場所に保存しておいてください。(画面には 3 つほど案内が表示されていますが、 Anaconda のインストールとは直接関係ありませんので見ていただいても閉じていただいても構いません)。
Anacondaのダウンロードはこれで完了です。

- 投稿日:2020-09-10T05:50:40+09:00
過去の電力使用量取得 関西電力編
はじめに
電力使用量予測のセミナーをしていて、各電力会社の公表されている過去の使用電力量の形式がまちまちなので取得するのが難しいというご意見を聞いていました。
そこで、それぞれの電力会社別にデータの取得方法をまとめてみます。ちなみに、対象とする電力会社は、北海道電力、東北電力、東京電力、北陸電力、中部電力、関西電力、中国電力、四国電力、九州電力、沖縄電力で、今回は関西電力さんを扱ってみます。
注:大量のダウンロードを繰り返すとサーバに負担がかかるので、ダウンロードは一回だけにするか、対象期間を限定して行うよう心がけて下さい。
動作環境
GoogleさんのCoraboratoryという環境で動作させます。
Webサイト
以下のWebサイトからデータをダウンロードできそうです。
ダウンロード
for y in range(2016, 2020): for m in range(1,13): url = "https://www.kansai-td.co.jp/yamasou/{:04}{:02}_jisseki.zip".format(y, m) print(url) !wget $url from glob import glob files = glob("*.zip") files.sort() for f in files: !unzip $f読込と可視化
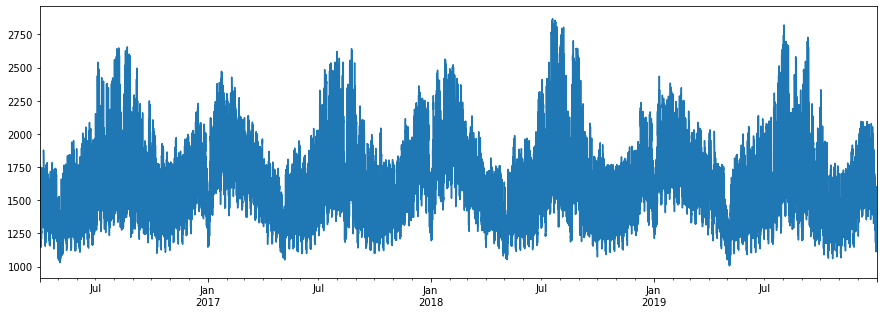
from glob import glob import pandas as pd files = glob("2*.csv") files.sort() df_juyo = pd.DataFrame() for f in files: print("\r", f, end="") try: df = pd.read_csv(f, encoding="Shift_JIS", skiprows=10, nrows=24) d = df.DATE + " " + df.TIME except: df = pd.read_csv(f, encoding="Shift_JIS", skiprows=16, nrows=24) #df.tail(25) #df.head() df_juyo = pd.concat([df_juyo, df]) print(df_juyo.shape) print(df_juyo.columns) df_juyo.index = pd.to_datetime(df_juyo["DATE"] + " " + df_juyo["TIME"]) df_juyo = df_juyo.sort_index() df_juyo["当日実績(万kW)"].plot(figsize=(15,5))
できた!
エリアの人口が多いので、必然的に多くの電力が使用される地域になっています。
電気使用量を見ると、色々な気付きがありますね。
以上、現場からきむらがお伝えしました。補足
記事を読んだ人から「時間がかかり過ぎるので、手っ取り早くデータが欲しい場合にはどうしたら良いか?」という質問があったので、ちょっとだけデータを販売してみることにしました。
データに興味があれば以下のURLをご覧下さい。https://ticket.tsuku2.jp/eventsDetail.php?ecd=16260900020422
- 投稿日:2020-09-10T04:42:23+09:00
絶賛!! Python Pocket Reference (O'REILLY)。日本語版も欲しいな。訳せないところが。。。あるんですっ。
目的
以下のPython Pocket Reference (O'REILLY)が、すごく、使いやすい!
Python Pocket Reference, 5th Edition
Python In Your Pocket
By Mark Lutz
Publisher: O'Reilly Media( 出典:http://shop.oreilly.com/product/0636920028338.do )
しかし。。。。。
うまく意味がとれない英語があるので、念のため(備忘のため)、記事にする。
(おそらく、将来の自分が解決することを期待して。。。)あとは、英語のことを書いていると、
少しづつ英語力が上がる期待。。。意味がわからない英語
[その1]Noneについて
None --- a false placeholder object;
Google翻訳(ママ)
偽のプレースホルダーオブジェクト
⇒ あまり、深い意味はないのだと思いますが、、、軽く、どういうつもりでこう言っているのか、ちょっと、わかりません。
まとめ
特にありません。
この記事で、役立つ情報としては、
Python Pocket Reference (O'REILLY) が、素晴らしいということぐらい。
おそらく、著者がハンパナイ人なんでしょう。
コメントなどあれば、お願いします。
