- 投稿日:2020-09-10T22:35:24+09:00
【Eclipse】初心者でも最初に覚えた方が良さそうなショートカット厳選5つ【Mac】
いろいろショートカットはあるけど、まずはめちゃくちゃ頻度が高いものをマスターしてから少しずつ数を増やす
まずは5つ
ショートカット 説明 command + D 行の削除 option + ↑↓ 行ごと移動(複数行可) command + / コメントアウト control + . 単語補完 option + command + R 同じ変数名を同時編集(リファクタリング) まあこのくらいを慣れて指が勝手に動くようになったら次のショートカットを選んで練習という流れが個人的には良いかと。
コメントアウトはだいたいのエディタで同じショートカットキーが割り当てられているっぽいです。
行の削除も同じものが多いと思いますが、VSCodeは違ったかと。。。
行ごとの移動も他のエディタでも同じだと思います。
いきなりたくさん練習しても、考えてしまうのでとりあえず片手くらいの数を無意識にできるようになってから次にいこう!
ショートカットキーは考えて使うものではないですし。
単語補完でtypoを減らす
個人的には変数名のタイプミスは多いので、エラーが出てからどこかなぁって探すより、短い変数名でも補完機能を使う方が良いと思っています。
ショートカット 説明 control + . 単語補完 option + command + R 同じ変数名を同時編集(リファクタリング) リファクタリングはVSCodeではcommand+Dで楽ちんでしたし、選択もしている状態にもなるので丸々変数名を変えたり、後ろに付け加えるのも楽でしたね。optionが押しにくいわ。おいおいショートカットの割り当てを変更すると思います。ちなみにcommand+shift+Lでショートカットの一覧などが表示されます!!
「速く打てる」というよりも「ミスを減らす」という意味で開発が速くなると信じていますんで、これでも十分便利です。
「めんどいなぁ」とか「これ結構頻度高いから楽にしたいなぁ」と感じるものがあればググればきっとショートカットが出てくる
練習段階はめんどくさくても自分で書いていく方が習得が速くなると思います。そしていっぱい書いてるうちに「めんどいなこれ」っていうのがあれば大体ショートカットが割り当てられていたり、プラグインがあったりすると思います。
その域に達するまではひたすら練習。欲張らない。イソガバマワレ。
- 投稿日:2020-09-10T22:23:36+09:00
Javaの型変換(StringとかintとかDateとかCalendar他)
普段開発とかやってると、ぽろりと忘れてたりするので忘備用。
思いつき次第、加筆修正。文字列⇔数値
String ⇔ int
qiita.java//int → String int num = 0; String intToString = String.valueOf(num); //String → int String number = "123"; int stringToInt = Integer.parseInt(number);double型、float型、long型からのString変換も同様に行えます。
とりあえずString.valueOf()に放り込んでおけばいい……はず。補足:(2020/09/11:修正)
qiita.javaString number = "123"; //String → double double d = Double.parseDouble(number); //String → float float f = Float.parseFloat(number); //String → long long l = Long.parseLong(number);文字列⇔文字列
String ⇔ char
qiita.java//char → String char chr = 'ち'; String charToString = String.valueOf(chr); //String → char String str = "すとりんぐ"; char stringToChar = str.charAt(0); //String → char[] char[] stringToCharList = str.toCharArray(); //char[] → String char[] charList = new char[] { '1', '文', '字' }; String charListToString = new String(charList);日付型⇔日付型、文字列
Calendar ⇔ Date
qiita.javaimport java.util.Date; import java.util.Calendar; //Date → Calendar Date date = new Date(); Calendar cal = Calendar.getInstance(); cal.setTime(date); //Calendar → Date Calendar cal = Calendar.getInstance(); Date calendarToDate = cal.getTime();Date ⇔ String
qiita.javaimport java.text.ParseException; import java.text.SimpleDateFormat; import java.util.Date; //Date → String Date date = new Date(); String dateToString = String.valueOf(date); //String → Date String day = "2020/09/10 21:00:00"; SimpleDateFormat sdf = new SimpleDateFormat(day); try{ Date stringToDate = sdf.parse(day); } catch(ParseException e){ e.printStackTrace(); }Calendar型から直接Stringにはできなさそう。
→String.valueOf()で変換できるにはできたけど、わかりやすい文字列ではなかった。
基本的にはCalendar ⇔ Date ⇔ Stringでいいか。.oO(String.valueOfってたくさん用意されてるんだな……。感謝感謝)
おわり
- 投稿日:2020-09-10T21:12:13+09:00
SelectItemのListをソートする方法
選択肢を設定するのによく使うSelectItemのList。データベースから取得した値を使ったりすると並べ替えをしたいことがある。そんな時用。
- 環境
- CentOS Linux release 7.8.2003 (Core)
- openjdk version "11.0.7" 2020-04-14 LTS
- JSF 2.3.9
例えばこんなSelectItemのListがある場合のこと
value label 1 いぬ 3 さる 0 くま 2 ねこ /** SelectItemのリスト. */ @Getter private List<SelectItem> items; /** SelectItemのリストを設定する. */ private void setItems() { this.items = new ArrayList<SelectItem>(); this.items.add(new SelectItem(1, "いぬ")); this.items.add(new SelectItem(0, "くま")); this.items.add(new SelectItem(3, "さる")); this.items.add(new SelectItem(2, "ねこ")); }valueの昇順でソートする
参考 : Collections (Java Platform SE 8)
value label 0 くま 1 いぬ 2 ねこ 3 さる Collections.sort(this.items, new Comparator<SelectItem>() { @Override public int compare(SelectItem item1, SelectItem item2) { if (item1 != null && item2 != null) { if (item1.getValue() != null && item2.getValue() != null) { return item1.getValue().toString().compareTo(item2.getValue().toString()); } } return 0; } });(おまけ)valueの最小値を取得する
SelectItem minItem = Collections.min(this.items, new Comparator<SelectItem>() { // 内容はソートと同じ }); var min = Integer.valueOf(minItem.getValue().toString());valueの降順でソートする
参考 : Comparator (Java Platform SE 8)
value label 3 さる 2 ねこ 1 いぬ 0 くま // 昇順のreturnにあるitem1とitem2を逆にしただけ Collections.sort(this.items, new Comparator<SelectItem>() { @Override public int compare(SelectItem item1, SelectItem item2) { if (item1 != null && item2 != null) { if (item1.getValue() != null && item2.getValue() != null) { return item2.getValue().toString().compareTo(item1.getValue().toString()); } } return 0; } });labelの昇順でソートする
参考 : ひらがなとアルファベットがまざったリストのソートをする - Qiita
value label 1 いぬ 0 くま 3 さる 2 ねこ Comparator.comparingを使う方法this.items = this.items.stream().sorted(Comparator.comparing(SelectItem::getLabel)).collect(Collectors.toList());Collator.getInstanceを使う方法Collections.sort(this.items, new Comparator<SelectItem>() { @Override public int compare(SelectItem item1, SelectItem item2) { if (item1 != null && item2 != null) { if (item1.getLabel() != null && item2.getLabel() != null) { return Collator.getInstance(Locale.JAPANESE).compare(item1.getLabel(), item2.getLabel()); } } return 0; } });labelの降順でソートする
value label 2 ねこ 3 さる 0 くま 1 いぬ Comparator.comparingを使う方法// reversed()をくっつけて降順にする this.items = this.items.stream().sorted(Comparator.comparing(SelectItem::getLabel).reversed()).collect(Collectors.toList());Collator.getInstanceを使う方法// 昇順のreturnにあるitem1とitem2を逆にしただけ Collections.sort(this.items, new Comparator<SelectItem>() { @Override public int compare(SelectItem item1, SelectItem item2) { if (item1 != null && item2 != null) { if (item1.getLabel() != null && item2.getLabel() != null) { return Collator.getInstance(Locale.JAPANESE).compare(item2.getLabel(), item1.getLabel()); } } return 0; } });ソートしようとして失敗したこと
Comparatorという便利なものを知ったので早速使おうとして失敗した。
Comparator.comparing(SelectItem::getValue)あたりでコンパイルエラーになる。
SelectItemのvalueはObjectなのでソートのキーにできないのか・・・な?this.items = this.items.stream().sorted(Comparator.comparing(SelectItem::getValue)).collect(Collectors.toList());
- 投稿日:2020-09-10T19:38:23+09:00
Javaの変数宣言の文について
Java 変数宣言
本日からJavaの学習を始めましたので、アウトプットがてら読んでくれた方の参考になれば嬉しいです。
先ず変数、及び変数宣言の文とは?
変数とはデータを格納するためにコンピューター内部に準備する箱のような物。
つまり変数宣言とは、コンピューターに対して「新たな変数を用意せよ」と指示する文のこと。変数宣言の文
型 変数名 ;型とは変数に入れることができるデータの種類のこと。
よく使われる型の種類(他にもあるよ)
分類 型名 格納するデータ 整数 int 普通の整数 少数 double 普通の小数 真偽値 boolean true か false 文字 char 1つの文字 文字列 String 文字の並び 使用例
今回は私の愛車を紹介がてら、例にしたいと思います。
分類 型名 格納するデータ 愛車(look)で例えると 整数 int 普通の整数 amount:金額 少数 double 普通の少数 weight:重量 真偽値 boolean true か false sell:売るか売らないか 文字 char 1つの文字 value:宝 文字列 String 文字の並び comment:愛してる 実際に書いてみました。
真偽値についてはこれから学習するので省略。look.javapublic class Main { public static void main(String[] args) { int amount = 700000; //金額の箱に値を代入 System.out.println(amount); //呼び出す記述 double weight = 7.9; //重量の箱に値を代入 System.out.println(weight); //呼び出す記述 char value = '宝'; //価値の箱に値を代入 System.out.println(value); //呼び出す記述 String comment = "愛してる"; //コメントの箱に値を代入 System.out.println(comment); //呼び出す記述 } }実行結果
700000 7.9 宝 愛してる感想
実は記事の投稿は初めてでした。
記事作成の所要時間は2時間です。(めっちゃかかった)
目標として1週間に1回は記事の投稿をしていきます。
最後まで読んでくれた方、ありがとうございます!
- 投稿日:2020-09-10T18:36:44+09:00
Python基礎備忘録その2
記事概要
Pythonを少しでも読めるようになってみようと思い、参考書に沿って学習した備忘録になります。
Javaと比較して自身が気になった点、便利と感じた点をまとめております。
その1はこちら
※かなり基礎的な内容になります。関数定義
pythonはメソッドのオーバーロードが出来ない代わりに、デフォルト引数を設定可能。
引数無し
def doFunc():
関数処理引数あり
def doFunc(a, b, c, ...):
関数処理例
java//引数無し void doFunc1() { print("関数が呼び出されました。"); } //引数あり void doFunc2(a, b) { print("a + b = " + (a + b)); } //return あり int doFunc3(a, b, c) { retrun a + b + c; } //オーバーロード void overFunc() { print("文字列はありません。") } void overFunc(String str) { print("文字列は" + str + "です。") }python#引数無し def doFunc1(): print("関数が呼び出されました。") #引数なし def doFunc2(a, b): print("a + b = " + str(a + b)) #return あり def doFunc3(a, b, c): return a + b + c #デフォルト引数を使用 def overFunc(str = None): if str is None: print("文字列はありません") else: print("文字列は" + str + "です。")ディクショナリ
JavaのMapのようなもの(?)
キーとバリューを格納する。例
javaMap<int, String> maps = new HashMap<>(); maps.put(1, "one"); maps.put(2, "two"); maps.put(3, "three"); maps.put(4, "four"); maps.put(5, "five"); //fiveを取り出す maps.get(5);pythonmaps = { 1: "one", 2: "two", 3: "three", 4: "four", 5: "five" } #fiveを取り出す maps[5]set(集合)
集合を扱うために実装された機能。
要素が重複しないリスト。
要素の追加、取り出しは行えない。
※Javaにはない機能!
求めたい集合 演算子 和集合 | 差集合 - 論理積 & 排他的論理和 ^ 部分集合 >= または <= 例
pythonset1 = {1, 2, 3, 4, 5} set2 = {3, 5, 7} #和集合 wa = set1 | set2 #差集合 sa = set1 - set2 #論理積 seki = set1 & set2 #排他的論理和 haita = set1 ^ set2 #部分集合 bubun = set1 <= set2タプル
要素の変更は行えない。
要素の追加、取り出しは可能。例
pythontuple1 = (1, 2, 3, 4, 5) tuple2 = (6, 7, 8, 9, 10) tuple2[2] >>8 tuple3 = tuple1 + tuple2 tuple3[9] >>10組み込みデータ型
ここまで書いていて、その1、その2で出てきたデータ型について整理を行わないと混同して覚えてしまいそうなので、一度書き出してみます。
参考文献を見て、使えそう、便利そうと感じたものを抜粋して残しています。#データ型を調べるにはtypeメソッドを使用する type(object)
- bool(immutable)
True or False のみを扱う
- int(immutable)
整数を扱う
- float(immutable)
少数点を含む数字を扱う
- str(immutable)
複数の文字を扱う
- list(mutable)
複数の要素をまとめて扱う
要素の追加、削除、並べ替え、要素の検索、特定の要素の取得が行える
list = [要素1, 要素2, ...]
- tuple(immutable)
複数の要素をまとめて扱う
・要素の追加、特定の要素の取得が行える
・利点
⇒ディクショナリのキーや、setの要素に出来るtuple = (要素1, 要素2, ...)
- set(mutable)
集合を扱う
・重複しない要素を格納する
・順番を持たない
・要素にアクセスできない
・要素の変更は可能
・集合演算は可能set = {要素1, 要素2, ...}
- dict(mutable)
複数の要素をまとめて扱う
キーとバリューを紐づけるset = { 要素1キー: 要素1, 要素2キー: 要素2, ... }
- bytes(immutable)
(エンコードされていない)複数の文字を扱う
ファイルやインターネットから取り込んだ文字列はbytes型として取り込まれる
bytes型の変換について掘り下げ
Webサイト作成やデータをやり取りする際にbytes型の変換が必須になりそうと思ったので、少し掘り下げて調べました。
encode([エンコード名[, エラー処理方法]])
decode([エンコード名[, エラー処理方法]])pythonstr = "こんにちは" #文字列⇒バイト型 enStr = str.encode("shift-jis", "strict") #バイト型⇒文字列 deStr = enStr.decode("shift-jis", "strict")あとがき
その1のコメントで教えていただいた、
Pythonにはプリミティブ型が無い
という点は勘違いせずに覚えなければと思います。
複数の要素をまとめて扱うデータ型の違いを理解して利用できるように理解を進めていきたいです。
ここまではオブジェクト指向について触れていないので、オブジェクト指向についてもまとめていこうかと思います。参考文献
柴田淳(2016)「みんなのPython 第4版」SBクリエイティブ株式会社
Python公式リファレンス
組み込みデータ型について、参考にさせていただいた記事
- 投稿日:2020-09-10T18:17:33+09:00
【Eclipse】Javaの開発環境として導入の流れ(それに際していろいろ調べたこと)
そもそも知らないことばかり
参考にしたページ。
Eclipse、はじめの一歩 - インストールから便利な日本語化プラグインの導入までふ〜ん、くらいで読めばいいんでしょうけど、なんかいろいろ気になる用語が出てきたので、しっかり理解したいので自分の言葉でまとめていきたいなと思いました。
Eclipseとは
IBMがJava開発ように作成。2001年にオープンソース化された。
オープンソースってなに?無料ってこと?
まあそういうことです。無料で使えるようになったということ。そしてそのソフトウェアのソースコードも見れるし、改良も自由にできるということ。
Wikipedia的な感じですね。IDEのデファクトスタンダードってなに?
de facto standard
de factoは事実上、実際にはというラテン語
つまり事実上の標準という意味ですな。つまり、ケータイといえばスマホがデファクトスタンダードと言える時代になっているということ。検索エンジンはGoogleがデファクトスタンダード。ネットショッピングはAmazonがデファクトスタンダード。SNSはTwitterがデファクトスタンダード。動画配信はYouTubeがデファクトスタンダード。そして未来には空飛ぶ車がデファクトスタンダードになる日がくる!!知らんけど。
今まで使っていたVSCodeはデファクトスタンダードちゃうの?
参考にしたページ【2020】IDEとエディタの違いは?VSCodeを使うべき?
Visual Stadio Codeはエディタということで、IDEではない。
しかし、プラグインをインストールしまうればIDEに近く。つまり、IDEはプラグインがすでに入っている。エディタはプラグインをいれなあかん。
Eclipseの特徴
IDEやから便利機能がめっちゃ入っている。
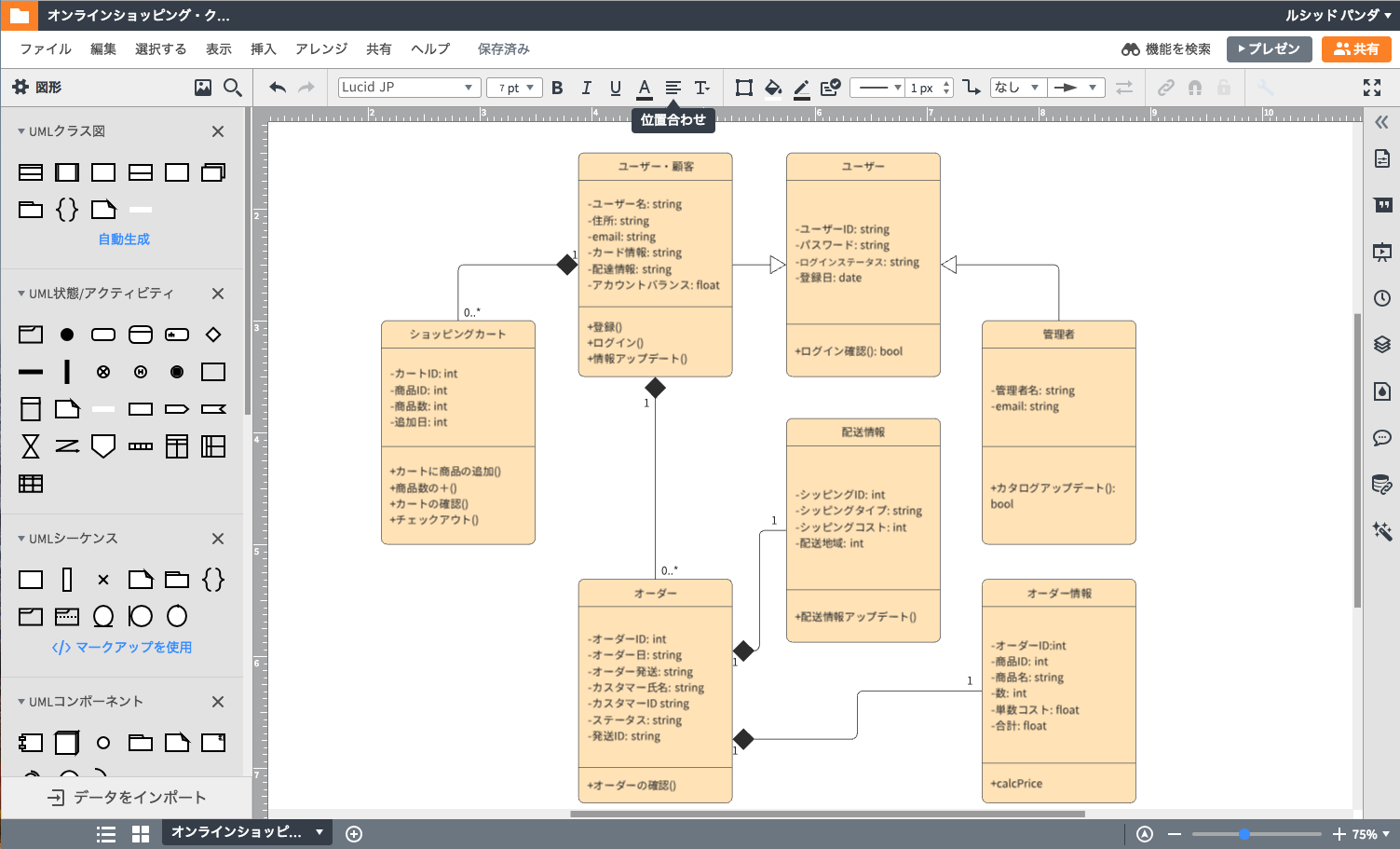
UMLやER図よる各縮景サポート。各種サーバへのアプリケーション配置、アップロードなどの機能がプラグインを入れることで可能になるらしい。結局IDEもプラグインのインストールが必要ってことかい!
UMLってなに?
Unified Modeling Language(統一モデリング言語)
UMLとは?書き方とクラス図・シーケンス図などの9つの図を解説UMLはシステムの全体像(もしくは局所的な部分)を、図形を使って表現します。文字ベースの設計書よりもシステムの概要を把握しやすく、問題点の発見も容易になるのがイメージできると思います。
つまり?図解でわかりやすくってことですかね。
文字だけやったらわかりやすくUMLで図解でわかりやすくした方がシステム全体がどうなってんのかわかりやすいやんってことですね。文字だけいややんってことですね。
また書き方が違うと困ることがあるので、記述ルールが明確になっているので、保守性に優れている。
保守性に優れていると言うのは、他の誰かが書いたUMLでもルール通りに書かれているから誰でもわかるようになっている。ということは修正をするにも、現状把握が容易になるので着手が早い。早いってことですね。
https://www.lucidchart.com/pages/ja/examples/uml-toolIDEとは(結局スマホ的な便利機能)
integrated Development Environment(統合開発環境)
1. コード入力
2. コンパイル
3. 実行
本来は別々のツールで行うらしい。それがIDEでは一つのアプリケーション上で実現できるという物らしい。つまり、現代でいうスマホですかね。従来は
1. 電話をかける → 携帯電話
2. 調べ物 → 図書館orパソコン
3. ゲーム → ゲーム機とテレビそれぞれ違うものを使っていたのがIDE的なスマホ(統合めちゃ便利電話環境)を使えばいろんなことがスマホ一台でできるということ。
実際の業務レベルの話はわかりませんが、現場での指定やセキュリーなどの関係で特に指定がなければ使わない手はないですね。
んでEclipseの特徴でも書いた通り、高機能なエディタというイメージを持っておけばいいのかな。
VSCodeだけだと、手動でプラグインを入れないとVSCode以外のソフトウェアを入れないと開発環境としては不十分ということがあるので、初心者にとってはEclipseのようなIDEを使用するとそういう苦労はないということですね。
Eclipse Photonってなに?
Eclipse
photonってやつと、あとは西暦の数字がついたバージョンがあるみたいで、この時点で初心者には??がつくかと。
- Eclipse 4.5 PhotonとEclipse2020とか2019は違うもの? って思ったけど、どうやらバージョン名みたいなものらしいですね、Photonというものは。Photonで調べてみると
https://www.eclipse.org/photon/上の方に
photonは古いバージョンですよ〜新しいのはダウンロードページからダウンロードできますよ〜ってメッセージが表示されました。ということで、PhotonはEcipseの古いバージョン。
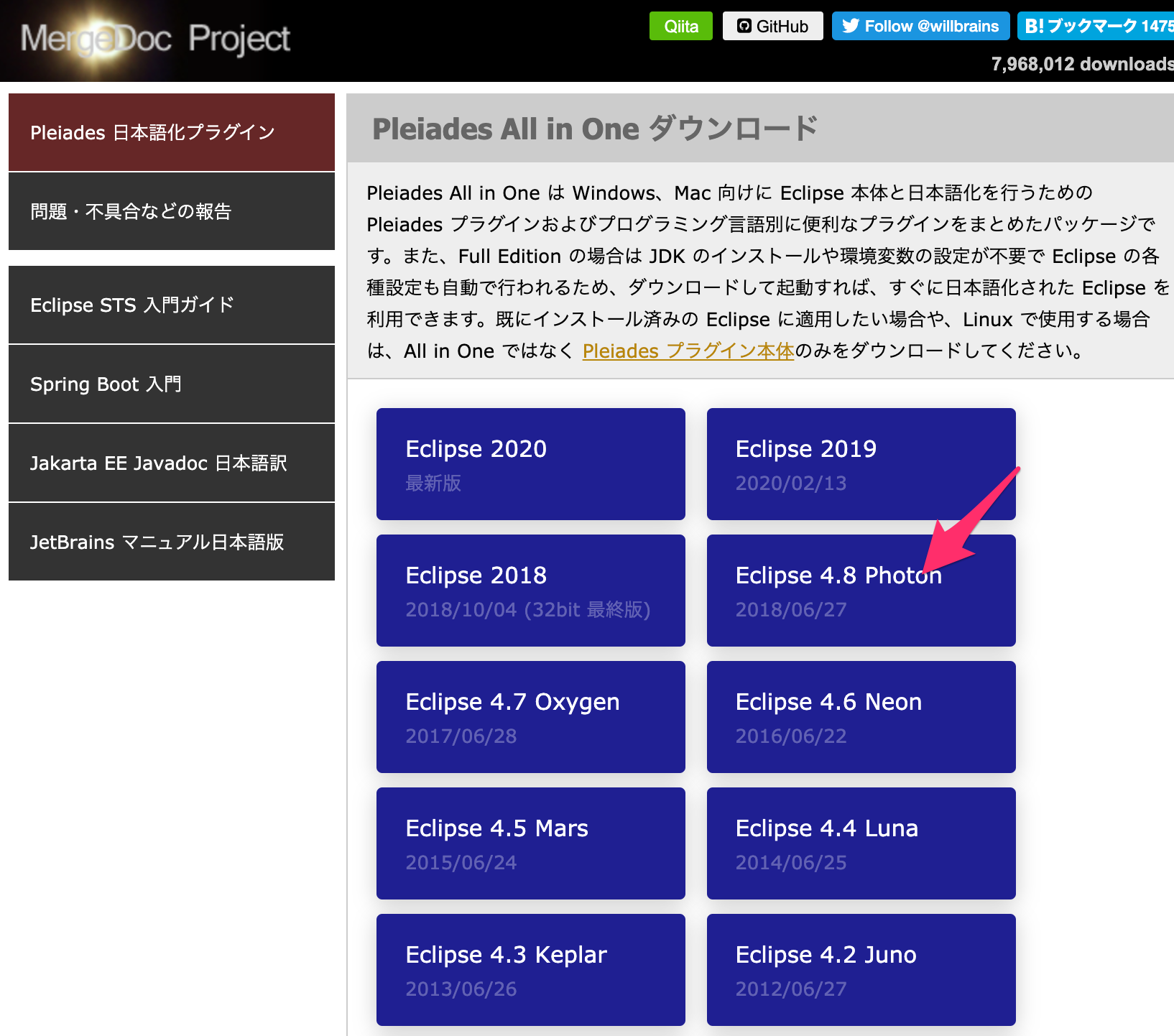
Eclipse2020が最新版のEclipseということがわかりました。EclipseをMacにインストール
Eclipseをダウンロード
https://mergedoc.osdn.jp/からダウンロードできます。
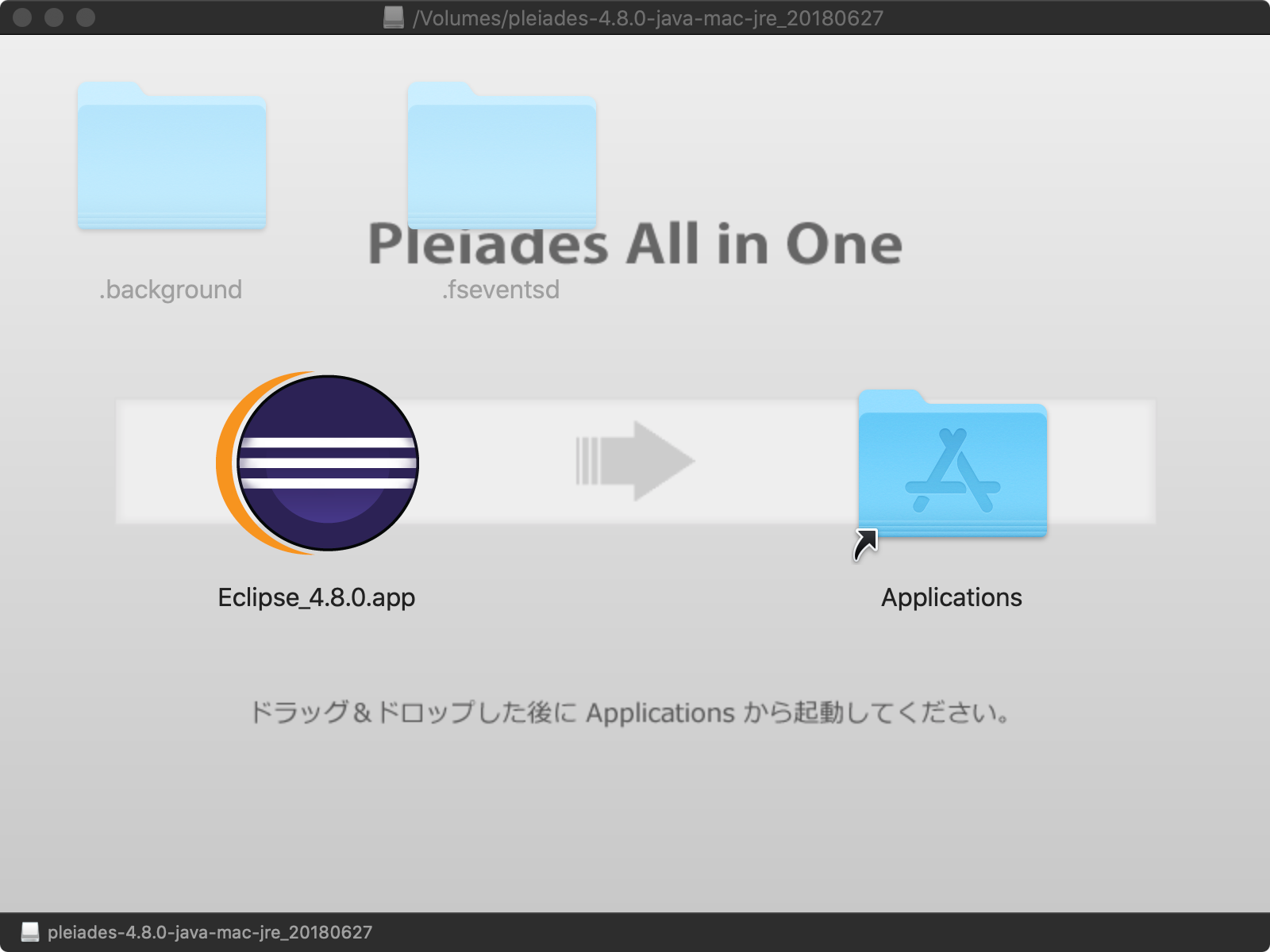
とりあえず初心者はPleiades All in Oneをダウンロードすればいいでしょう。
でもこここでPleiadesって何?ってなりました。Eclipseじゃねぇの?
Pleiades All in One は Windows、Mac 向けに Eclipse 本体と日本語化を行うための Pleiades プラグインおよびプログラミング言語別に便利なプラグインをまとめたパッケージです。また、Full Edition の場合は JDK のインストールや環境変数の設定が不要で Eclipse の各種設定も自動で行われるため、ダウンロードして起動すれば、すぐに日本語化された Eclipse を利用できます。既にインストール済みの Eclipse に適用したい場合や、Linux で使用する場合は、All in One ではなく Pleiades プラグイン本体のみをダウンロードしてください。
という風に上の方に書いてあります。
どやらEclipseを含んでPleadesというプラグインがセットになってるよっていうことらしい。
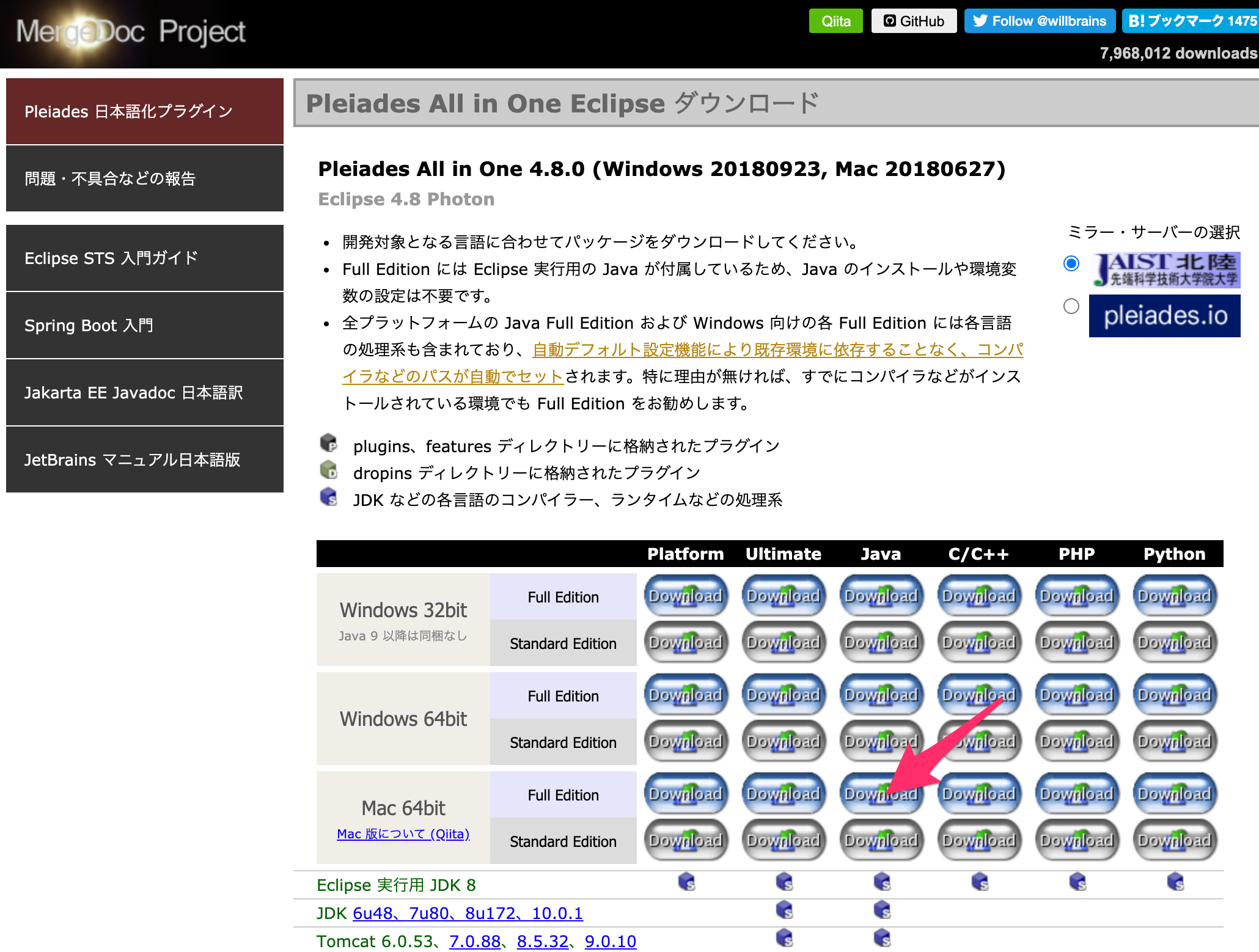
Full Editionの場合はJDKのインスオーツや環境変数の設定が不要で、Eclipseno各種設定も自動で行われるとあります。つまり、これからJavaを勉強しようというひとは間違いなく
Pleiades All in OneのFull Editionをインストールすればいいと言うことですね。便利だからね、ということ。環境変数などの設定は、初心者にはハードルが高いと言うか、マニュアル通りにやればできるんでしょうが、何がどうなっているのかわからないので頑張ってやっても達成感がないように思います。
いろいろバージョンというか、オプションがあるみたいですが、Javaを勉強するのでJavaって書いてるところのMac 64bitのFull Editionをダウンロード。
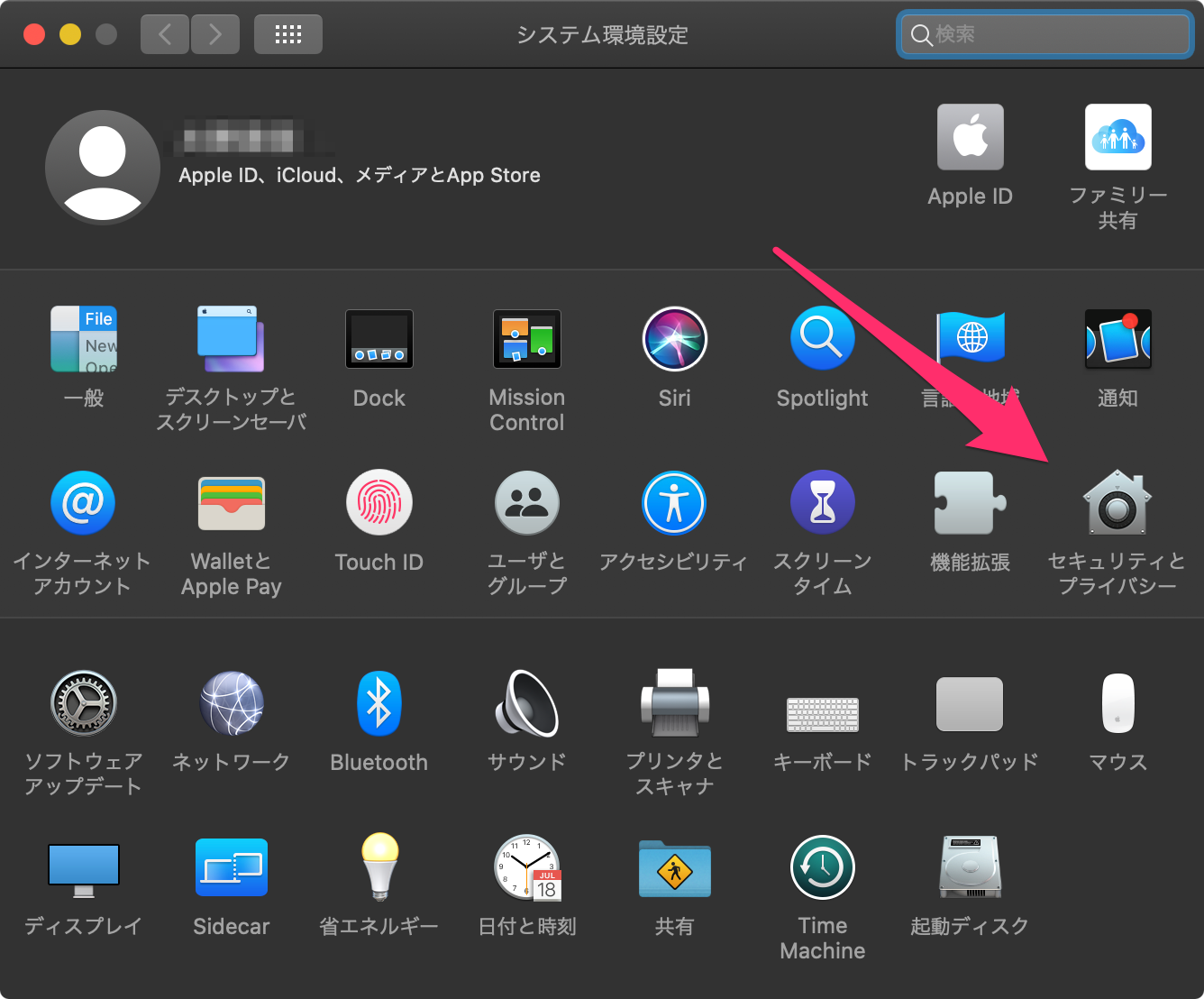
インストールを実行(セキュリティの問題でシステム環境設定から許可が必要!!)
指示通りにやっても途中でインストールが失敗したり、開けなかったりすることがあります。そいう時は「システム環境設定」の「セキュリティーとプライバシ」の「一般」というところで許可をする必要があります。
自動でそのようなエラ〜メッセージが出たり、許可を出すウインドウが表示されないので、戸惑う人もいると思います。最初から表示しておくといいと思います。
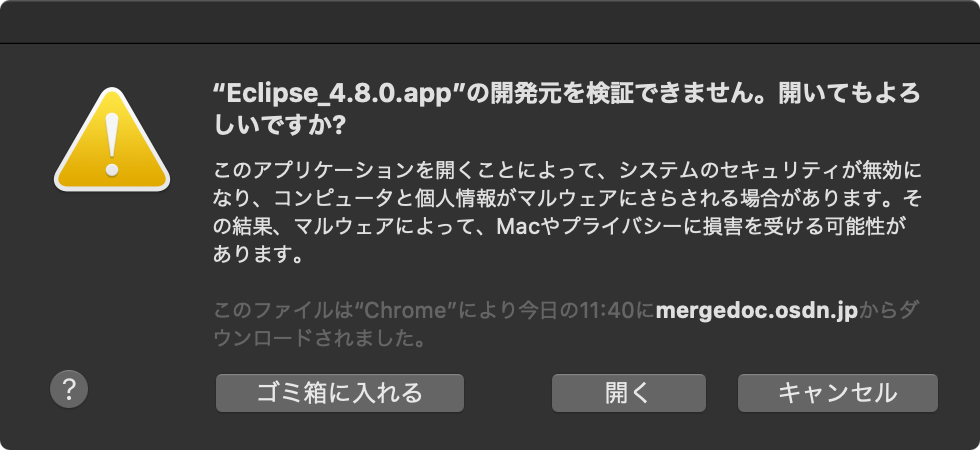
インストールしたファイルを実行すると
インストール自体は大丈夫でしたが、LaunchPadから開こうとするとびろ〜んって音がしました。
ここで「ゴミ箱に入れる」を選択してしまったらダメです。耐えましょう。
VitualBoxの時にもありましたが、Macのセキュリティーの問題で許可しないとインストールできないとか使用できないということがあるみたいです。
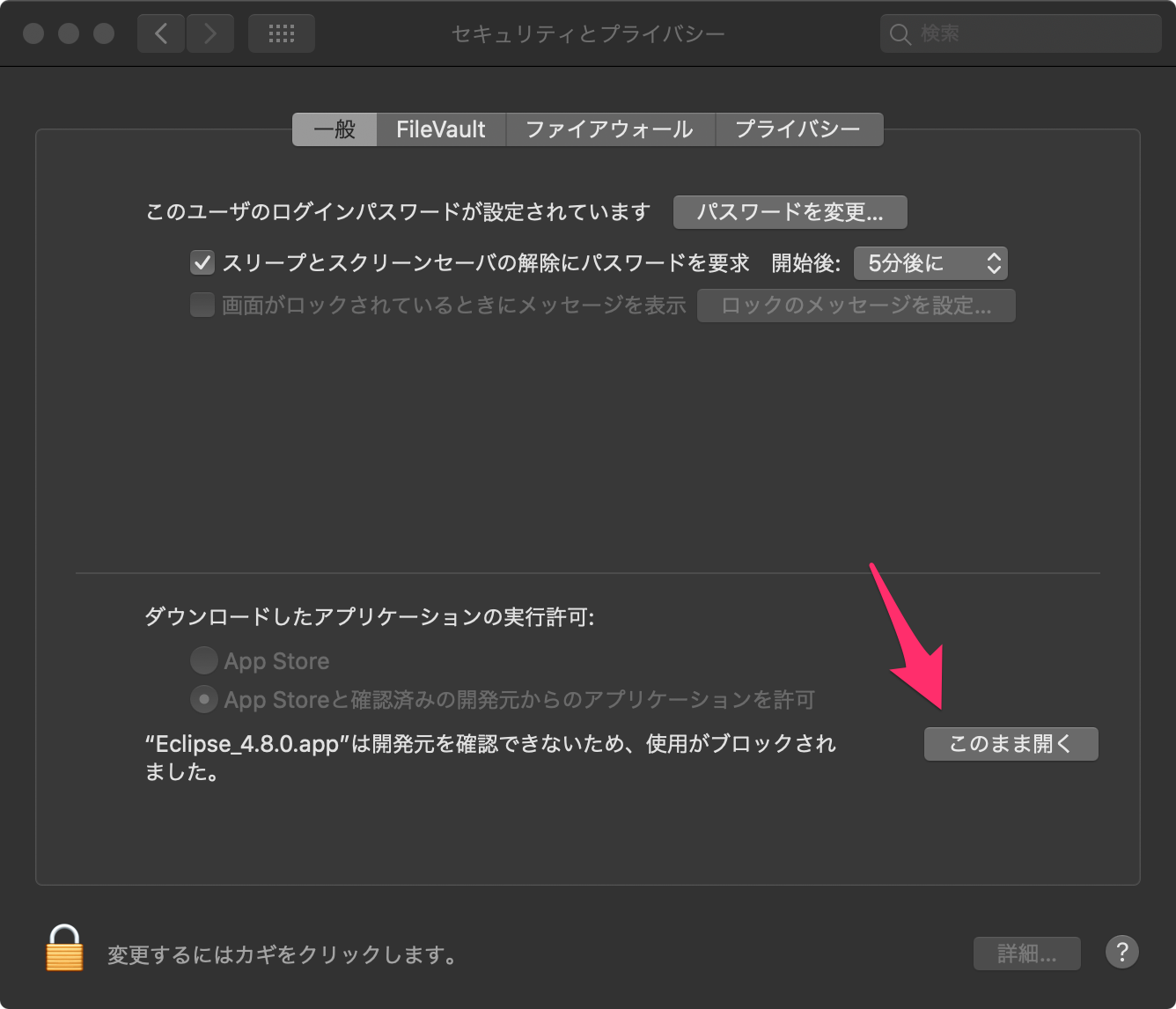
あれ?!って思ったらシステム環境設定のセキュリティとプライバシーを確認してみましょう。
下の方に何かメッセージが出てきていると思います。
この場合は「このまま開く」だったのでそれをクリックしちゃいましょう。
それで改めてEclipseを起動すれば開くことができると思います。
とりあえずこれでインストールはできました。
最初の設定
いきなりワークスペースとしてのディレクトリ選択ですって。なにそれおいしいの状態になりかけました。まあ結局作業スペースというか作業フォルダですね。とりあえずデフォルトで問題ないらしいですが、デスクトップがわかりやすい気がします。
参照からデスクトップを選択。
今回はjava_testとしました。
右下の完了ボタンを押すと
入力したプロジェクト名でフォルダが作成されました。
- ワークスペースはデスクトップ
- ワークスペースにプロジェクトを作成
- デスクトップにプロジェクト名のフォルダを作成
- そのフォルダの中にjavaファイルが入っていく
というイメージで大丈夫かと思います。
とりあえず導入まではここまでです。
これから使い方は勉強していきます。
おそらく初心者でインストールする時に、環境設定から許可を出さずに、「なんでインストールできへんの!」とか「開けないんですけど!?」ということがあると思いますので、その辺りを参考にしてもらえればと思います。




- 投稿日:2020-09-10T17:53:15+09:00
JavaはPowerPointドキュメントの背景色と背景画像を設定します
Powerpointドキュメントを作成する場合、背景が非常に重要です。背景を統一させたら、Powerpointのプレゼンテーションが 美しく見えるようになります。この記事では、JavaアプリケーションでFree Spire.Presentation for Javaを利用して、無地の背景色とグラデーションの背景色を設定や、PowerPointスライドの背景画像を追加する方法を紹介します。
JARパッケージのインポート
方法1: Free Spire.Presentation for Javaをダウンロードして解凍したら、libフォルダーのSpire.Presentation.jarパッケージを依存関係としてJavaアプリケーションにインポートします。方法2:Mavenリポジトリから直接にJARパッケージをインストールしたら、pom.xmlファイルを次のように構成します。
<repositories> <repository> <id>com.e-iceblue</id> <name>e-iceblue</name> <url>http://repo.e-iceblue.com/nexus/content/groups/public/</url> </repository> </repositories> <dependencies> <dependency> <groupId>e-iceblue</groupId> <artifactId>spire.presentation.free</artifactId> <version>2.6.1</version> </dependency> </dependencies>単色の背景色を設定する:
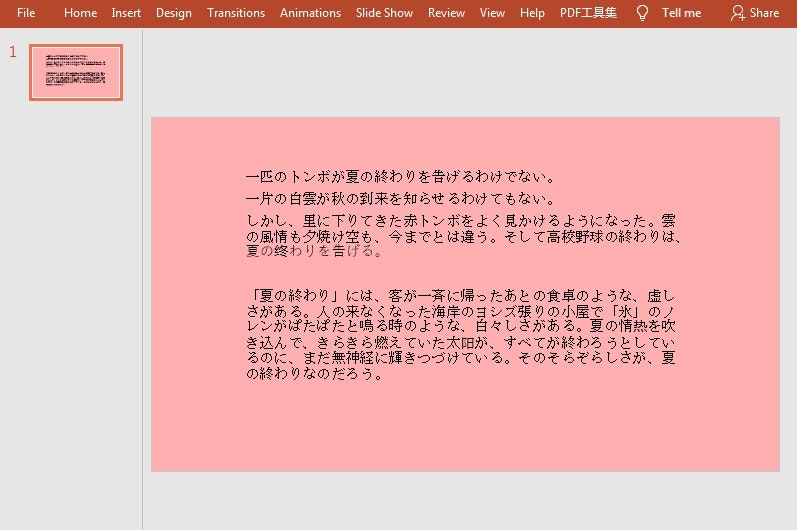
import com.spire.presentation.*; import com.spire.presentation.drawing.*; import java.awt.*; public class PPTbackground { public static void main(String[] args) throws Exception { //PowerPointドキュメントを読み込む Presentation ppt = new Presentation(); ppt.loadFromFile("file1.pptx"); //スライドの数を取得する int slideCount = ppt.getSlides().getCount(); ISlide slide = null; //スライドをループして、各スライドに無地の背景色を設定する for(int i = 0; i < slideCount;i++) { slide = ppt.getSlides().get(i); slide.getSlideBackground().setType(BackgroundType.CUSTOM); //単色の背景の塗りつぶしを設定する slide.getSlideBackground().getFill().setFillType(FillFormatType.SOLID); slide.getSlideBackground().getFill().getSolidColor().setColor(Color.PINK); } //結果ファイルを保存する ppt.saveToFile("bg1.pptx", FileFormat.PPTX_2010); } }無地の背景のエフェクト画像:
グラデーションの背景色を設定する:
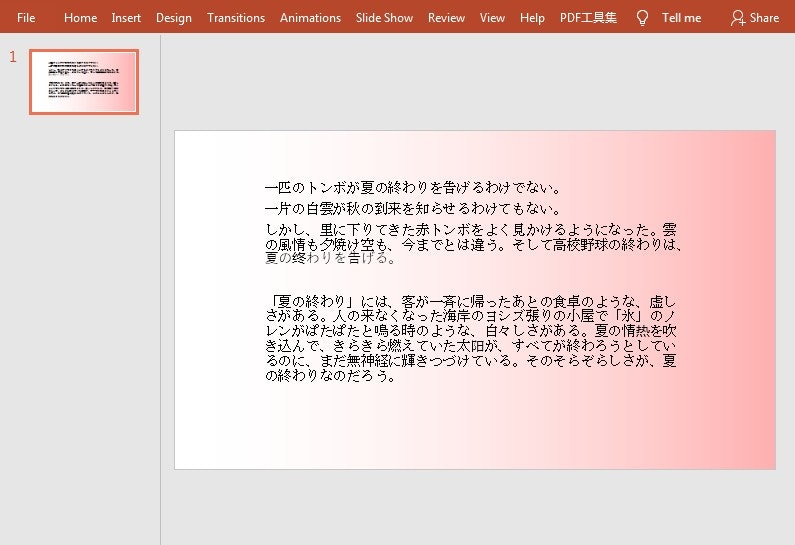
import com.spire.presentation.*; import com.spire.presentation.drawing.*; import java.awt.*; public class PPTbackground { public static void main(String[] args) throws Exception { //PowerPointドキュメントを読み込む Presentation ppt = new Presentation(); ppt.loadFromFile("file1.pptx"); //スライドの数を取得する int slideCount = ppt.getSlides().getCount(); ISlide slide = null; //スライドをトラバースし、各スライドにグラデーションの背景色を設定する for(int i = 0; i < slideCount;i++) { slide = ppt.getSlides().get(i); slide.getSlideBackground().setType(BackgroundType.CUSTOM); //グラデーションの背景色の塗りつぶしを設定する slide.getSlideBackground().getFill().setFillType(FillFormatType.GRADIENT); slide.getSlideBackground().getFill().getGradient().getGradientStops().append(0, Color.WHITE); slide.getSlideBackground().getFill().getGradient().getGradientStops().append(1, Color.PINK); } //結果ファイルを保存する ppt.saveToFile("bg2.pptx", FileFormat.PPTX_2010); } }グラデーション背景色の効果画像:
背景画像を追加する:
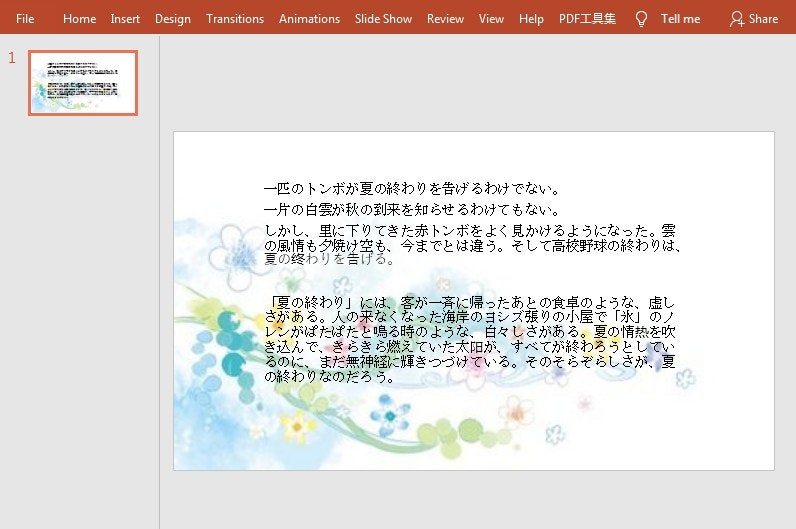
import com.spire.presentation.*; import com.spire.presentation.drawing.*; import java.awt.*; public class PPTbackground { public static void main(String[] args) throws Exception { //PowerPointドキュメントを読み込む Presentation ppt = new Presentation(); ppt.loadFromFile("file1.pptx"); //スライドの数を取得する int slideCount = ppt.getSlides().getCount(); ISlide slide = null; //スライドをループして、各スライドに背景画像を追加する for(int i = 0; i < slideCount;i++) { slide = ppt.getSlides().get(i); slide.getSlideBackground().setType(BackgroundType.CUSTOM); //画像の背景の塗りつぶしを設定する slide.getSlideBackground().getFill().setFillType(FillFormatType.PICTURE); slide.getSlideBackground().getFill().getPictureFill().setAlignment(RectangleAlignment.NONE); slide.getSlideBackground().getFill().getPictureFill().setFillType(PictureFillType.STRETCH); slide.getSlideBackground().getFill().getPictureFill().getPicture().setUrl((new java.io.File("background.jpg")).getAbsolutePath()); } //結果ファイルを保存する ppt.saveToFile("bg3.pptx", FileFormat.PPTX_2010); } }背景画像を追加する効果:
- 投稿日:2020-09-10T17:37:23+09:00
複雑なSQLクエリのメンテにうんざりしている君! Sparkの出番です
まず Spark SQL
Apache Sparkは何かを一言でいうのは難しいのですが、この記事ではSparkの(おそらく最重要機能の)Spark SQLについて説明します。これがわかってないとSparkの他のパートは理解できないでしょうし、またSpark SQLだけでも実業務のアプリに応用できる範囲はめっちゃ広いです。
どんなときに使うのか
Spark SQLの用途は一言でいうとこれです。
複数の表形式のデータを材料に、加工と集計をして別の表形式のデータを出力するたとえば
- お店の売り上げデータだったら→
- 日付ごとや商品ごとに売り上げがどう違うかをグラフにするとか、
- Webサイトの運営だったら→
- 訪問者が何の検索キーワードで入って、それぞれがどういうページ遷移をして、購入に至ったのか/至らなかったのか
- ソフトウェア開発なら→
- テストの実行件数と失敗数がどう変化したかを集計するとか、
いろいろありますよね。どの企業も手法の巧拙はあるにしてもやっていることじゃないかと思います。
別にまあ、データがちっちゃいときはExcelやらGoogle Spreadsheetで十分いけるんですが、サイズが大きくなると徐々に手に負えなくなってきます。
古く巨大なシステムであれば「バッチ処理」と言われるカテゴリーの処理になりますが、この手のやつはデータ処理の切り口を柔軟に変えたくなるものです。単に日付だけ見ていたものを、時間帯別にしてみようとか天候も考慮に入れてみようとかはよくあるストーリーだと思います。
また、処理が多段になるというのもよくあるでしょう。細かい売り上げデータから日次データを作り、さらに月次データへ加工し、最終的に前年同月比のグラフになる、とかのパターンです。
イメージ図ですがデータの加工が多段になっているようなやつです。
Sparkのいいところ
僕は今や、こういう系統のデータ処理が必要で、かつデータサイズがExcelでは間に合わないくらい大きいときは、Spark一択と信奉するまでになりました。とりわけ、現状の処理が次に当てはまる場合はぜひ考えるべきです。
- 無理やりSQLでやっている場合
- SQLでデータを取ってきたあと普通のプログラムで集計している場合
次にもうちょっと詳しく説明します。
無理やりSQLでやっている場合
SQLの
VIEW, JOIN, GROUP BYや、いわゆるストアドプロシージャを駆使して目的のデータを出しているケースです。このケースでのメンテナンス性の悪さはみんな心当たりあるんじゃないかと思います。SELECT C.CustomerID, C.CustomerName, C.CustomerType, C.Address1, C.City, C.State, S.TotalSales FROM Customers C INNER JOIN (SELECT CustomerID, SUM(Sales) as TotalSales FROM Sales GROUP BY CustomerID) S ON C.CustomerID = S.CustomerIDこの程度は簡単にWebで見つかりますが、もっとおぞましいSQLはきっと世の中には無数にあるんじゃないかと思います。しかも、データの切り口を変えたいのでそういう変なSQLをしょっちゅうメンテする羽目になるケースも多いでしょう。これはもうメンテ無理、というようなのあったらコメントしてくれると嬉しいです。
SQLと比較するとSparkにはこういういいところがあります。
プログラム言語のパワーが使える
SQLだけでできることは限りがあるが、集計と加工にモダンな言語のライブラリをいくらでも使えるのは圧倒的に優位だし、加工の部分をUnitTestに切り出せるのもオイシイ。SQLはDBに渡すまで単純な構文エラー( 括弧の対応誤りなど )すら検出されないが、Sparkならコンパイラに構文と型のチェックをかなり任せることができる
データ型が柔軟
GROUP BYした後などの集計過程の中間データにおいて、フィールドに配列や構造体を入れることもできて柔軟。DBはデータの保存 ( SQLの INSERT, UPDATE ) に専念してもらい、分析と加工をSpark側に分離できる。
複雑なクエリ実行中のためパフォーマンスが落ちる、とかを気にしなくていい。DBのインデックス一発で取ってこれるデータならいいんですが、SQLのLIKE文とかがでてきたらもうオワリです。Sparkの出番です。SQLでデータを取ってきたあと普通のプログラムで集計している場合
これもよくあるパターンと思います。ごく単純なSQLでデータをごそっと取ってきたあと、ループを回してデータを取り、
ArrayやHashMap等を駆使してゴリゴリ集計するタイプです。
単純な集計ならいいのですが、このやり方も、データ量が増えるにつれてメモリ消費量や実行時間がバカスカ増えますし、複雑な分析フロー(上の図で中間データがいくつもあり、フローの分岐があって最終データも複数あるようなやつ)だとどうしてもコードが複雑になります。Sparkの場合、かなりお手軽にクラスタを組むことができるので負荷分散は簡単です。もちろん、本質的に全データを見なくてはいけないような集計だと無理ですが、癖を把握すればシングルノードでの開発とテストのときと同じようにクラスタ対応ができるのは大きなポイントです。
イメージとしては、
- ユーザの書いたSparkアプリのJARファイルが各ノードに配布される
- 処理前のデータがノード数に等分されて渡される
- 処理後のデータを回収して連結する
という流れです。テーブルのJOINとかに威力を発揮します。
使える言語
Sparkの実装としてはScalaがオリジナルらしいですが、
- Java
- Python
- R
- .NET ( ただし今はまだ実験的な位置づけ? )
が利用可能になってます。一般のアプリからの親和性という点ではJavaかPythonでしょうか。
クエリーの例
Spark SQL では、SQLのキーワードや関数に寄せた感じで、気持ちよく集計コードが書けます。以下はJavaでの「SparkSQLらしさのにじみ出た」ところをさくっと切り出したサンプルです。どういうコーディングスタイルになるのか想像しながら読んでみてください。
withColumn
withColumnは、既存のカラムのデータを使って新しいカラムを動的に作ります。これは、timestampカラムに入ったミリ秒単位の整数の時刻をyyyy-MM-dd HH:mm:ssフォーマットで文字列化した新しいカラムdatetimeを作ります。data = data.withColumn("datetime", date_format( col("timestamp") .divide(1000) .cast(DataTypes.TimestampType), "yyyy-MM-dd HH:mm:ss") ));groupBy
groupByは、SQLでのそれと同様、対象レコードを同一のキー値をもったグループに分割し、そのグループ内で集計して新しい表を作るものです。これは、
nameカラムが同一であるもので全レコードをグループ化し、それぞれで
scoreの合計 :totalScoredurationの平均 :durationAvgdurationの標準偏差 :durationStddev- 件数 :
countとして新しい表を作るものです。
Dataset<Row> data = data.groupBy("name").agg( sum("score").as("totalScore"), avg("duration").as("durationAvg"), stddev("duration").as("durationStddev"), count("*").as("count"));こうやって、よくある処理はSparkで提供されているものでできますし、それで間に合わないものはJavaのパワーを駆使して処理を書くことができます。
苦しいSQLのメンテを頑張るより絶対いいと思いませんか?
こうやってJavaで書けば、ビルド後のJARがクラスタにデプロイされて分散処理ができるんですよ! あるいは、AWS Lambdaとかに乗せて集計処理を実施するときのみ料金を払うようなことももちろんできます。
RDD と Dataset
Spark SQLを学んでいくときにつまづきやすいのはここです。
どちらも巨大なテーブル"風"データを扱うためのクラスでどこがどう違うのか最初のうちはよくわからない(僕もそうでした)のですが、要点だけ押さえると:
- 実現目標の機能はどちらも同じ。
- RDDはSpark初期からあり、そこでわかった欠陥を修正して新版として整えたのがDatasetである
- 基本はDatasetが推奨されるが、アプリの書き方によってはRDDのほうがやりやすいケースもあり、使い分けが肝要
- 後発だけあってAPIはDatasetのほうがわかりやすく柔軟である。
- 特にJavaのRDDはGenericsを使いまくってて慣れないとびっくり。
- メモリ効率もDatasetのほうが大差でよいという情報もあるが、細かいところまでは検証不十分。裏方のコードとしてはどっちもかなりの割合同じものを使っているような気もしなくない。
なお、Spark関連情報を調べると
DataFrameというものもよく登場しますが、これはDataset<Row>のエイリアスです。Rowは特に型を指定しない汎用の行データに使えるクラスです。Hadoopとの関係
この手の分散処理フレームワークとしてはSparkよりHadoopが元祖で、Sparkも裏側ではHadoop File Systemを使っています。
ただ、Hadoopは一連の処理ごとに結果をディスクに保存しながら進む一方、Sparkの場合明示的に保存しない限りデータはメモリ上にあるだけなので、加工中の中間データは本当に大事なものだけ保存するとするだけで大幅に速度が稼げます。
もっとも、クラスタ中の全ノードのメモリを合計しても乗り切れないほどの膨大なデータを分析するのはSparkでは無理かもしれません。だめなところ
これまでSparkをほめてばかりでしたが、もちろんダメなところもあります。一番厄介なのは、エラーメッセージが不親切で、特に型のエラー(intとして読みだそうとしたが実際のデータはstringだった、等)に弱いことです。こういう場合には、ちょっと常識では考えられないような怪しげなエラーメッセージが出るので要注意です。
これはちょっと型を間違えたときのエラーメッセージの実例です。
generated.javaというソースコードを生成してそれをコンパイルしてるんですね...
そんな複雑なテクニックが必要な処理を書いているつもりはないんですが、何か理由があるんでしょうね。Caused by: org.codehaus.commons.compiler.CompileException: File 'generated.java', Line 562, Column 35: failed to compile: org.codehaus.commons.compiler.CompileException: File 'generated.java', Line 562, Column 35: A method named "toString" is not declared in any enclosing class nor any supertype, nor through a static import at org.apache.spark.sql.catalyst.expressions.codegen.CodeGenerator$.org$apache$spark$sql$catalyst$expressions$codegen$CodeGenerator$$doCompile(CodeGenerator.scala:1304) at org.apache.spark.sql.catalyst.expressions.codegen.CodeGenerator$$anon$1.load(CodeGenerator.scala:1376) at org.apache.spark.sql.catalyst.expressions.codegen.CodeGenerator$$anon$1.load(CodeGenerator.scala:1373) at org.spark_project.guava.cache.LocalCache$LoadingValueReference.loadFuture(LocalCache.java:3599) at慣れないうちは「まともなエラーメッセージも出せないSparkはクソ」と考えがちですが、まあ慣れです。こういう欠点を補ってなお余りある価値を持っているのがSparkです。バージョンアップが進めばもうちょっと何とかなるかもしれませんが、場合によっては気合を入れて自分で直してコントリビュートしてしまおうかと考えているくらいです。
複雑なSQLクエリにうんざりしているそこの君! Sparkはいいですよ!
- 投稿日:2020-09-10T15:46:21+09:00
Java予約語まとめ
Javaの予約語まとめ
目次
- 予約語とは
- 予約語の一覧
- 各予約語の説明
予約語とは
- プログラミング言語において、あらかじめ用途が決められた単語のこと。基本的に、識別子(クラス名、関数名、変数名)は自由に設定する事ができるが、予約語と同じ名前は使えない。
予約語の一覧
abstract assert boolean break byte case catch char class const continue default do double else enum extends final finally float for goto if implements import instanceof int interface long native new package private protected public return short static strictfp super switch synchrnized this throw throws transient try void volatile while _ 各予約語の説明
abstract
- 抽象クラスの宣言を行う際に用いられる。
- 抽象クラスとは、以下のような中身のないメソッドを持っているクラスのこと。
abstract メソッド名(引数, 引数, ...);どのような時に使うのか
- 複数人で開発を行う場合に、実装レベルのルールを作成したいとき。
- メソッド名を統一し、ロジックを共通化し、大体何の処理を行っているか把握したいとき。
- 共通の処理を全てのクラスの毎回書き込みたくないとき。
- 開発者がサブクラスを定義した時に、メソッドの実装忘れや、メソッド名に間違いがないか確認できるようにしたい時。
サンプルコード
abstract class AbstractClass { abstract public void method(); } class ConcreteClass extends AbstractClass{ public void method(){ // 実装内容 } } AbstractClass c = new AbstractClass(); // コンパイルエラー AbstractClass c = new ConcreteClass(); // 可 ConcreteClass c = new ConcreteClass(); // 可assert
- abstract:抽象クラスの宣言の際に使用する
- assert:プログラムの動作検証(アサーション)に使用される。
- アサーション(動作検証)とは:プログラムが正常に動作しているかどうか確認するための手法。プログラムの各所にその時点で必ず真(true)となる条件を宣言しておくと、実行時にその条件が満たされない状態になるとJavaが自動で検知し、AssertionErrorが返される。
- 実行の際に -enebleassertions(または -ea)というオプションを渡すことでアサーションの有効無効を切り替えられる。
どのような時に使うのか
- デバッグ支援を行いたいとき。
- ソースコードにおける開発者の意図をプログラムに記述したいとき。
サンプルコード
private int divide(int x, int y) { assert y != 0 : y + “は0より大きい数字でないといけない”; return x / y; }boolean
- trueまたはfalseのどちらかのデータが必ず入ることを表す、データ型。
- インスタンス変数として宣言した場合は、初期値でfalseが入るが、ローカル変数で宣言した場合は、初期値が設定されないので、設定しないといけない。
- インスタンス変数:クラス内で宣言した変数
- ローカル変数:メソッド内で宣言した変数
- Booleanというものもあり、こちらはクラスとして使用される。また、booleanはnullが表現できないのに対して、Booleanはnullも扱える。ただし、変数がnullであることを設定しないとNullPointerExceptionとなる。
どのような時に使うのか
- 数値や文字列の比較結果を表す時。
- if文で分岐の方向を表す時。
- for文やwhile文でループを続行するか決定する時。
サンプルコード
//if文での場合 public class Main { public static void main(String[] args) throws Exception { boolean bool1 = false; if(bool1) { System.out.println("bool1の値はtrueです"); } else { System.out.println("bool1の値はfalseです"); } int number = 100; boolean isResult = number < 200; if(isResult) { System.out.println("isResultの値はtrueです"); } else { System.out.println("isResultの値はfalseです"); } } } //実行結果 bool1の値はfalseです isResultの値はtrueです //while文の場合 public class Main { public static void main(String[] args) throws Exception { boolean bool = true; // 初期値設定 int count = 1; // 初期値設定 while(bool) { System.out.println("countの値は" + count + "です。"); if(count == 5) { bool = false; // countの値が5になれば実行される処理 } count++; // 変数「count」の値に1を足す。 } } } //実行結果 countの値は1です。 countの値は2です。 countの値は3です。 countの値は4です。 countの値は5です。 //Boolean型の場合 public class Main { public static void main(String[] args) throws Exception { Boolean bool = null; if(bool == null) { System.out.println("boolの値はnullです"); } else if(bool) { System.out.println("boolの値はtrueです"); } else { System.out.println("boolの値はfalseです"); } } } //実行結果 boolの値はnullですbreak
- break文はfor文、while文、do..while文、switch文のブロック内で使用され、処理の途中で抜け出すために使用される構文。最も内側の1つのループ(繰り返し処理)から抜け出す。二重ループを抜け出す際は、最初のfor文にラベル(名前のようなもの)を付け、breakで抜ける際にそのラベルを指定すると、抜けられる。
どのような時に使うのか
- 特定の条件で、その処理を終え、次の処理を実行させたい時。
サンプルコード
//switch文の場合 public static void main(String[] args) { int num = 3; switch(num) { case 1: System.out.println("1ですよ"); break; case 2: System.out.println("2ですよ"); break; case 3: System.out.println("3ですよ"); break; case 4: System.out.println("4ですよ"); break; default: System.out.println("defaultですよ"); } } //実行結果 3ですよ //for文の場合 public static void main(String[] args) { for (int i = 1; i <= 5; i++) { if (i == 3) { break; } System.out.println(i + "回目"); } System.out.println("終了です"); } //実行結果 1回目 2回目 終了です //while文の場合 public static void main(String[] args) { int num = 1; while(true) { if (num == 3) { break; } System.out.println(num + "回目です"); num++; } System.out.println("終了です"); } //実行結果 1回目です 2回目です 終了です //二重ループの場合 loop1: for(初期化式; 条件式; 変化式){//for文の名前をloop1に指定 for(初期化式; 条件式; 変化式){ if(forループを抜ける場合の条件式) break loop1;//抜けるfor文をloop1に指定 処理内容 } } //実行結果 条件に当てはまった時、loop1の処理を抜け出すbyte
- 整数のデータ型で、プリミティブ(primitive、基本データ型)と呼ばれるものの1つ。
- -128〜127の整数を表現できる。
どのような時に使うのか
- バイナリファイルや、バイナリデータを「そのまま」扱う時。
- バイナリファイル:バイナリデータのファイル。このうちテキストエディタで扱えるものはテキストファイルに分類される。
- バイナリデータ:コンピューターが直接処理するために2進数で表現されるデータのこと。
- 動画視聴の際のストリーミングの際にサーバから送られてくるデータはバイナリデータである。
- 1つの変数としてではなく、配列にしてバイナリデータの集まりを表すのによく用いられる。
サンプルコード
// byte型の変数の宣言と、初期値の代入 byte b = 100; // byte型の配列の宣言と、各インデックスへの値の代入 byte[] byteArray1 = new byte[3]; byteArray1[0] = 11; byteArray1[1] = 12; byteArray1[2] = 13; // byte型の配列の宣言と、初期化を同時に行う byte[] byteArray2 = { -128, 0, 127 };switch
- 条件分岐処理を行う予約語。
どのような時に使うのか
- 条件分岐先が複数ある際に用いる。
サンプルコード
public class Main { public static void main(String[] args) { int num = 3; switch(num) { case 1: System.out.println("変数numは1です"); break; case 2: System.out.println("変数numは2です"); break; case 3: System.out.println("変数numは3です"); break; case 4: System.out.println("変数numは4です"); break; default: System.out.println("変数numは1から4の整数ではありません"); } } } //実行結果 変数numは3ですcase
- switch文の条件分岐処理を行う際に使う予約語。
どのような時に使うのか
- switch文の条件分岐先を記述する際に使用する。
サンプルコード
public class Main { public static void main(String[] args) { int num = 3; switch(num) { case 1: System.out.println("変数numは1です"); break; case 2: System.out.println("変数numは2です"); break; case 3: System.out.println("変数numは3です"); break; case 4: System.out.println("変数numは4です"); break; default: System.out.println("変数numは1から4の整数ではありません"); } } } //実行結果 変数numは3ですdefault
- switch文で条件に当てはまらなかった際の処理を行うための予約語。
- interfaceに実装するメソッドを持たせるための予約語。
どのような時に使うのか
- switch文で条件に当てはまらない場合の処理を時実行する際に用いる。
- インターフェースにメソッドを持たせたいとき。
サンプルコード
public class Main { public static void main(String[] args) { int num = 5; switch(num) { case 1: System.out.println("変数numは1です"); break; case 2: System.out.println("変数numは2です"); break; case 3: System.out.println("変数numは3です"); break; case 4: System.out.println("変数numは4です"); break; default: System.out.println("変数numは1から4の整数ではありません"); } } } //実行結果 変数numは1から4の整数ではありません //interfeceの場合 interface Foo{ void print(String s); default void twice(String s){ print(s); print(s); } }try
- 例外が発生する可能性のある処理に使う予約語。
どのような時に使うのか
- 例外が発生した際の処理を行いたい場合に、例外が発生する可能性がある処理を記述するために用いる。
- 処理の中で、不具合が起きた際の原因を把握したい場合。
サンプルコード
public class Main { public static void main(String[] args) { int result; result = div(5, 0); System.out.println("戻り値 = " + result); } public static int div(int num1, int num2) { try { int result = num1 / num2; return result; } catch (ArithmeticException e) { System.out.println("例外が発生しました。"); System.out.println(e); return 0; } } }catch
- 例外が発生した時の処理を行うための予約語。
- 以下のように記述する。
catch(例外クラス 変数名) { 例外処理; }- 例外クラス:以下のようなものがある。
- Throwable
- Error
- Error系例外
- OutOfMemoryError
- ClassFormatError ...etc.
- Excption
- Exception系例外
- IOException
- ConnectException ...etc.
- RuntimeException系例外
- NullPointException
- ArrayIndexOUtOFBOUndsExeception ...etc.
どのような時に使うのか
- 例外が発生する可能性ある処理がある際に、実際に例外が起きた際に行いたい処理を記述する際に用いる。
サンプルコード
public class Main { public static void main(String[] args) { int result; result = div(5, 0); System.out.println("戻り値 = " + result); } public static int div(int num1, int num2) { try { int result = num1 / num2; return result; } catch (ArithmeticException e) { System.out.println("例外が発生しました。"); System.out.println(e); return 0; } } } //実行結果 例外が発生しました。 java.lang.ArithmeticException: / by zero 戻り値 = 0finally
- 例外の発生有無にかかわらず、実行する処理を宣言する予約語。
どのような時に使うのか
- 例外が発生しそうな処理がある際に、例外の発生の有無にかかわらず、実行したい処理を記述する際に使用する。
サンプルコード
int n[] = {18, 29, 36}; System.out.println("開始します"); try{ for (int i = 0; i < 4; i++){ System.out.println(n[i]); } } catch(ArrayIndexOutOfBoundsException e){ System.out.println("配列の範囲を超えています"); } finally{ System.out.println("配列の出力を終了しました"); } System.out.println("終了しました");throw
- 例外を意図的に起こし、例外処理するための予約語。
- 意図的に例外を起こすとは:ある条件と一致する場合に例外を発生させ、エラーメッセージを返すということ。
どのような時に使うのか
- 処理を行う際に例外を発生させたい時に使用する。
サンプルコード
public class Main { public static void main(String[] args) { int result; result = div(5, 0); System.out.println("戻り値 = " + result); } public static int div(int num1, int num2) { try { if (num2 == 0) { throw new ArithmeticException("0で割ったときの例外を発生させる"); } int result = num1 / num2; return result; } catch (Exception e) { System.out.println("例外が発生しました。"); System.out.println(e); return 0; } } } //実行結果 例外が発生しました。 java.lang.ArithmeticException: 0で割ったときの例外を発生させる 戻り値 = 0throws
- 例外が発生した場合に、呼び出し元に例外処理を行わせることができる予約語。
呼び出し元とは:以下のコードにおいて、mainはmathメソッドを呼び出しているので、mainが呼び出し元、mathが呼び出し先となる。
```
public static void main(String[] args) {
int num = 10;math(num);
math(int i) {
int i += 100;
}
}
```どのような時に使うのか
- 呼び出し元のメソッドで呼び出し先のメソッドの例外発生の処理を行いたい時に使用する。
- mainメソッドで様々なメソッドを呼び出して、そこで例外処理を行うことで可読性をあげることができる。
サンプルコード
public class Main { public static void main(String[] args) { int result = 0; try { result = div(5, 0); } catch (Exception e) { System.out.println("例外が発生しました。"); System.out.println(e); } System.out.println("戻り値 = " + result); } public static int div(int num1, int num2) throws ArithmeticException { int result = num1 / num2; return result; } } //実行結果 例外が発生しました。 java.lang.ArithmeticException: / by zero 戻り値 = 0for
- 繰り返し処理を作成できる予約語。
for(初期化式; 条件式; 変化式){ 実行する処理 }拡張for文というものもあり、以下のように記述する。
for (型 変数名: 配列名もしくはコレクション名){
実行する処理
}
どのような時に使うのか
繰り返し処理を行う際に用いる。
サンプルコード
public class sample { public static void main (String[] args){ int sum = 0;//[1] for (int number = 1; number <= 10; number++) {//[2] sum += number;//[3] } System.out.println("sum:" + sum);//[4] } } //実行結果 sum:55continue
- for文やwhile文などの繰り返し処理の途中で残りの処理をスキップして繰り返しの先頭に戻るための予約語。
どのような時に使うのか
- 繰り返し処理を行う際に一定の条件の際に残りの処理をスキップして繰り返し処理の先頭に戻る処理を行いたい場合に用いる。
- 繰り返し処理の中でしか、使えない。
サンプルコード
class sample{ public static void main(String args[]){ for (int i = 1; i < 10; i++){ if (i % 2 == 0){//この場合は、iの値が偶数の時だけ(1)の処理をスキップすることになる continue; } System.out.println("i = " + i);//(1) } } } //実行結果 i = 1 i = 3 i = 5 i = 7 i = 9if
- 条件分岐を行うための予約語。
どのような時に使うのか
- 以下の6つの使い方がある。
- 1.if-else文で複数条件がある場合の記述方法
- 2.比較演算子(等号・不等号)の使い方
- 3.論理演算子(OR・AND・NOT)の使い方
- 4.三項演算子でif-else文を1行に省略した記述方法
- 5.文字列の一致(イコール)/文字列を含むものを確認する方法
- 6.breakやcontinueでループを制御する方法
サンプルコード
//1の場合 public class Main{ public static void main(String[] args){ int number = 80; if (number > 90) { System.out.println("素晴らしい結果です!"); } else if (number > 60) { System.out.println("まぁまぁの結果です。"); } else { System.out.println("もう少し頑張りましょう。"); } } } //実行結果 まぁまぁの結果です。 //2の場合 public class Main{ public static void main(String[] args){ int number = 10; if (number < 20) { System.out.println(number + "は20より小さい値です"); } } } //実行結果 10は20より小さい値です //3の場合 public class Main{ public static void main(String[] args){ int number = 10; if ((number < 20) || (number >= 10)) { System.out.println(number + "は10以上または20未満の値です"); } } } //実行結果 10は10以上または20未満の値です //4の場合 public class Main { public static void main(String[] args) { int number = 10; String str = (number == 5) ? "numberは5です" : "numberは5ではありません"; System.out.println(str); } } //実行結果 numberは5ではありません //5の場合 public class Main { public static void main(String[] args) { String str1 = "ポテパン"; if(str1 == "ポテパン") { System.out.println("str1 は文字列「ポテパン」と一致します"); } else { System.out.println("str1 は文字列「ポテパン」と一致しません"); } } } //実効結果 str1 は文字列「ポテパン」と一致しますelse
- if文で条件分岐を行う際に、条件はfalseだった場合の処理を行うための予約語。
どのような時に使うのか
- if文において、条件を満たさない場合、の処理を記述する際に用いる。
サンプルコード
class sample { public static void main (String[] args){ int number = 200;//[1] if (number >= 1 && number <= 9){//[2] System.out.println("[3] number : 1 - 9"); } else if (number >= 10 && number <= 99) {//[4] System.out.println("[5] number : 10 - 99"); } else {//[6] System.out.println("[7] number >= 100"); } } } //実行結果 [7] number >= 100char
- 1文字を格納できる型。
- 16ビットUnicodeで表現したものを用いる。
- 16ビットUnicodeとは:文字に0~65535の番号を当てたもの。
どのような時に使うのか
- 1文字を格納する際に用いる。
サンプルコード
class sample { public static void main(String[] args) { char chrHensu1 = 'A'; // Aをそのまま代入 char chrHensu2 = 0x0041; // 0x0041を指定 char chrHensu3 = 65; // 65を指定 System.out.println(chrHensu1); System.out.println(chrHensu2); System.out.println(chrHensu3); } } //実行結果 A A Aclass
- クラスを宣言する予約語。
どのような時に使うのか
- クラスを宣言する際に用いる。
サンプルコード
class クラス名 { 実行処理... }const
- 無効な予約語。
- C言語/c++言語では「定数」を意味する予約語。
- Javaでは、「final」に相当する。
どのような時に使うのか
- 予約語であるので、変数名や、関数名、クラス名には使用できない。
サンプルコード
- なし
do
- while文と共に用いられる予約語。
どのような時に使うのか
- 繰り返し処理では普通、最初の条件式の評価を実行してから繰り返し処理を開始する。場合によっては一度も処理をされずに次の処理を実行する可能性もある。
- このような状況にならないように、まず一度だけwhile文の処理を行いたい場合に用いる。
サンプルコード
public class sample { public static void main(String[] args) { int i = 0; do { System.out.println((i + 1) + "回目の処理です"); i++; } while (i < 3); System.out.println("処理が終了しました"); } } //実行結果 1回目の処理です 2回目の処理です 3回目の処理です 処理が終了しましたdouble
- 少数を扱えるデータ型の1つ。
- クラスのDoubleもあり、これはnullも表現できる。
- 代入した数字にミスがあり、値がない時にnullとして表現できる。
どのような時に使うのか
- 10^303~10^-324乗の範囲の大きな数字を扱う場合に用いる。
- doubleの変数に代入できる数字の書き方は以下のとおり。
- 10進数(整数、小数)
- 10進数+指数表記
- 2進数(0b始まり、整数)、Java 7以降
- 8進数(0始まり、整数)
- 16進数(0x始まり、整数)
- 16進数+指数表記
サンプルコード
// 10進数の小数点ありの数字と、2進数・8進数・16進数の整数 double d1 = 12345; // 10進数(整数) double d2 = 1.2345; // 10進数(小数点以下あり) double d3 = -123_456.789_012; // 10進数、区切り文字あり double d4 = 0b0101; // 2進数の整数 double d5 = 012345; // 8進数の整数 double d6 = 0x12345; // 16進数の整数 // 10進数と16進数の指数表記 double d1 = 1.23e4; // 10進数 指数表記(1.23×10の4乗) → 12300 double d2 = -1.23e-4; // 10進数 指数表記(-1.23×10の-4乗) → -0.000123 double d3 = 0x1.23p4; // 16進数 指数表記(0x1.23×2の4乗) → 18.1875 double d4 = -0x1.23p-4; // 16進数 指数表記(-0x1.23×2の-4乗) → -0.071044921875 // 接尾語としてd/Dを付ければ、そのリテラルはdouble扱いになる double d1 = 5 / 10; // → 0、intの5をintの10で割るので、計算結果はintの0になる double d2 = 5 / 10d; // → 0.5、intの5をdoubleの10で割るので、5もdoubleになり、計算結果はdoubleの0.5になるenum
- 複数の定数を1つにまとめておくことができる型のこと。
- クラスであるので、フィールドやメソッドを定義することができる。
- 注意点
- Enumクラスの列挙子には値を付与することができますが、その場合はフィールドとコンストラクタを定義する必要がある。
- Enumクラスのコンストラクタのアクセス修飾子はprivateのみ許される。
- Enumクラスは別のクラスを継承することはできませんが、インターフェースを実装することはできる。
- 以下のように記述して使う。
アクセス修飾子 enum 列挙名 {列挙子1, 列挙子2, ・・・};どのような時に使うのか
- 決められた値に対して処理を行いたい場合に用いる。
- enumの中に自身で決めた定数を記述でき、その値に対してswitch文などで処理を記述できることから。
サンプルコード
switch文を用いる場合 public class Main { public static void main(String[] args) { Fruit fruit_type = Fruit.Orange; switch(fruit_type) { case Orange: System.out.println("おいしいみかん"); break; case Apple: System.out.println("りんごたべたい"); break; case Melon: System.out.println("メロンがすべて"); break; } } protected enum Fruit { Orange, Apple, Melon }; } //実行結果 おいしいみかん フィールドやメソッドを定義する場合 public class sample { public static void main(String[] args) { for(Fruit frt : Fruit.values()) { System.out.println(frt.ordinal() + ":" + frt.name() + "," + frt.getValue()); } } protected enum Fruit { Orange("Ehime"), Apple("Aomori"), Melon("Ibaraki"); // フィールドを定義 private String name; // コンストラクタを定義 private Fruit(String name) { this.name = name; } // メソッド public String getValue() { return this.name; } } } //実行結果 0:Orange,Ehime 1:Apple,Aomori 2:Melon,Ibarakiextends
- クラスの継承を行うための予約語。
- 継承元のクラスのことを「基底クラス」、「スーパークラス」、「親クラス」などと呼ぶ。
- 基底クラスを継承したクラスのことを「派生クラス」、「サブクラス」、「小クラス」などと呼ぶ。
- 派生クラスでは、基底クラスの処理を変えたい場合にその処理のメソッド名や引数を変えることなく別の処理を記述することもできる。これをオーバーライドと呼ぶ。
どのような時に使うのか
- プログラミングするコードの量を少なくでき、ソースコードの可読性を高めることができる。
- 親クラスを定義することで他の子クラスで使うことができるので、コードをまとめて扱うことができる。
サンプルコード
public class Student{ String name; int id; attend(){} } public class School extends Student{ test(){} }interface
- インターフェースを実装する際に使う予約語。
- インターフェースには定数とメソッドの定義しかできないというルールがある。
どのような時に使うのか
- インターフェースで定義した定数を定義したメソッドで使いまわせる。
- クラスの継承のように親クラスに定義したものを小クラスに定義すれば同じことであるが、クラスの継承との大きな違いは、クラスは一度に一つしか継承できないのに対して、インターフェースは1度に何個も実装することができる。その代わり、インターフェースを実装した先でインターフェースないに定義してあるメソッドを全て定義しなければならない。
サンプルコード
// インタフェースの作成 interface Calc { int NUM1 = 1; int NUM2 = 2; void calc(); } // インタフェースを実装し、足し算するクラスを作成 class Add implements Calc { public void calc() { System.out.println(NUM1 + NUM2); } } // インタフェースを実装し、引き算するクラスを作成 class Sub implements Calc { public void calc() { System.out.println(NUM1 - NUM2); } } // インターフェースを実装したクラスを実行するクラスを作成 public class sample { public static void main(String[] args) { Add add = new Add(); add.calc(); Sub sub = new Sub(); sub.calc(); } } //実行結果 3 -1implements
- クラス定義の際にインターフェースの実装を行う際に使う予約語。
どのような時に使うのか
- インターフェースが定義してある前提で、それをクラスに実装させたい時に使う。
サンプルコード
public class Sample implements インターフェース名 {}private
- アクセス修飾子。
- アクセス修飾子とは:定義したクラスや、そのメンバーがどこからアクセスできるか、アクセスの制限をコントロールするもの。
どのような時に使うのか
- そのクラス内部からのみアクセス可能とする修飾子。
サンプルコード
class PublicClass { private String fieldVariable = "PublicClassのフィールド変数."; public void publicMethod() { System.out.println(fieldVariable + "publicMethodより出力."); } } public class sample { public static void main(String[] args) { PublicClass pc = new PublicClass(); pc.publicMethod(); } } //実行結果 PublicClassのフィールド変数.publicMethodより出力.protected
- アクセス修飾子。
どのような時に使うのか
- 同じパッケージ内のクラスや、違うパッケージでも、そのクラスを継承したサブクラス内部からアクセスすることを可能とするアクセス修飾子。
サンプルコード
//サブクラスから参照する場合 class SuperClass { protected String str = "SuperClassの変数"; } public class sample extends SuperClass { public static void main(String[] args) { sample sc = new sample(); System.out.println(sc.str); } } //実行結果 SuperClassの変数 //同一クラスから参照する場合 public class sample{ public static void main(String[] args) { method(); } protected static void method() { System.out.println("protectedが付いたメソッド"); } } //実行結果 protectedが付いたメソッド //アクセスできない場合 class SuperClass { protected String str = "SuperClassの変数"; } class SubClass_NG { public static void main(String[] args) { SubClass_NG sc = new SubClass_NG(); System.out.println(sc.str); } } //実行結果 sample.java:9: エラー: シンボルを見つけられませんpublic
- アクセス修飾子。
どのような時に使うのか
- どこからでもアクセス可能とする修飾子。
- publicなクラス、インターフェースは1つのファイルに1つしか存在しない。
- また、拡張子を除くファイル名とクラス名、インターフェース名は同じでないといけない。
- パッケージ直下にあるクラス煮付けられるアクセス修飾子はpublicでないといけない。
サンプルコード
class PublicClass { public String fieldVariable = "PublicClassのフィールド変数."; public void publicMethod() { System.out.println(fieldVariable + "publicMethodより出力."); } } public class sample { public static void main(String[] args) { PublicClass pc = new PublicClass(); System.out.println(pc.fieldVariable); } } //実行結果 PublicClassのフィールド変数.package
- パッケージの作成の宣言するための予約語。
どのような時に使うのか
- パッケージを宣言する際に用いる。
- パッケージとは:クラスやインターフェースをグループ化して分ける仕組み。
- 基本的にクラス名の重複は許されないが、パッケージが異なればクラス名が被っていても問題ない。
- そのため複数人での開発の際にクラス名が被ってもいいようにパッケージは使用する。
サンプルコード
package lang.java.hello; public class HelloJava { public HelloJava() { System.out.println("Hello Java!"); } } package lang.cpp.hello; public class HelloCpp { public HelloCpp() { System.out.println("Hello C++!"); } }import
- パッケージをインポートするための予約語。
どのような時に使うのか
- パッケージをインポートする際に使用する。
- 以下のように記述する。
import パッケージ名.インポートしたいクラス名;- パッケージ名の後に.*(ワイルドカード)をつけるとパッケージ内の全てのクラスをインポートできる。
サンプルコード
import lang.cpp.hello.HelloCpp; import lang.java.hello.HelloJava; public class Main { public static void main(String[] args) { HelloJava hello1 = new HelloJava(); HelloCpp hello2 = new HelloCpp(); } }while
- 繰り返し処理を行うための構文。
どのような時に使うのか
- for文は繰り返し処理の回数指定ができるが、while文は回数指定が行われていない繰り返し処理を行い際に用いられる。
サンプルコード
public class sample { public static void main(String[] args) { int num = 0; while (num < 3) { System.out.println(num); num++; } } } //実行結果 0 1 2goto
- Javaにおいては無効な予約語。
- C言語/C++言語においては特定の行にジャンプするための予約語。
どのような時に使うのか
- 使えない。使った場合、コンパイルエラーとなる。
サンプルコード
- なし
void
- 戻り値がないことを示す予約語。
どのような時に使うのか
- メソッドの戻り値がない場合に用いる。
- 戻り値とは:メソッドないの処理を実行して返される値のこと
サンプルコード
public class sample { static String sampleMethod() { //文字列を返却する return "サンプルメソッドが呼び出されました"; } public static void main(String[] args) { //sampleMethodを呼び出し、その結果をstrという名前のString型変数に代入する String str = sampleMethod(); //str変数の内容を出力する System.out.println(str); } } //実行結果 サンプルメソッドが呼び出されましたreturn
- 戻り値を返す時の予約語。
どのような時に使うのか
- 1.戻り値を返す場合。
- 2.メソッドの途中に使用されるとそれ以降の処理を実行せずに呼び出し元へ処理を戻す。
サンプルコード
//2の場合 public class sample { public static void main(String[] args) { num(0, 2); } private static void num(int num1, int num2) { if (num1 == 0) { System.out.println("呼び出し元に戻ります。"); return; } int addAns = num1 + num2; System.out.println("答えは" + addAns + "です。"); } } //実行結果 答えは2です。 //同じソースコードでreturnがない場合 public class sample { public static void main(String[] args) { num(0, 2); } private static void num(int num1, int num2) { if (num1 == 0) { System.out.println("呼び出し元に戻ります。"); } int addAns = num1 + num2; System.out.println("答えは" + addAns + "です。"); } } //実行結果 呼び出し元に戻ります。 答えは2です。 //解説 retuenがないので、if文の次の処理を行われた。new
- インスタンス化(オブジェクトの生成)を行える予約語。
どのような時に使うのか
- インスタンス化を行う際に用いる。
- クラスを元に生成するオブジェクトのこと
- インスタンス化の際に同時実行されるものをコンストラクタという。
- この中には初期化する処理を書く。
サンプルコード
public class メインクラス名{ public static void main(String[] args) { //インスタンスの生成 クラス名 変数名 = new クラス名(); } } class クラス名{ //コンストラクタ(インスタンス生成時に実行される) public クラス名(){ 初期化処理など } }static
- クラスをインスタンス化せずに変数にアクセスできるようにするための予約語。
どのような時に使うのか
- クラス名.メソッド名();で呼び出すことができる。
- 呼び出すごとに毎回インスタンス生成して、初期化処理を行いたくない時。同じオブジェクトにアクセスしたい時に用いる。
サンプルコード
class ClassSample { private int val1 = 0; // 非static変数(インスタンス変数) private static int val2 = 0; // static変数(クラス変数) // コンストラクタ クラスがインスタンス化される度に変数に1加算する public ClassSample(int val1, int val2) { this.val1 += val1; ClassSample.val2 += val2; // 「クラス名.変数名」でstatic変数を宣言 } // 変数の値を表示 public void print(){ System.out.println("val1 = " + val1 + ", val2 = " + val2); } } public class sample { public static void main(String[] args) { for (int i = 0; i < 3; i++){ ClassSample cs = new ClassSample(1, 1); cs.print(); } } } //実行結果 val1 = 1, val2 = 1 val1 = 1, val2 = 2 val1 = 1, val2 = 3final
- 定数を表す予約語。
どのような時に使うのか
- クラス、メソッド、変数にそれぞれ使用することができる。
- 変数の場合:変数の値や、参照先を変更できなくする時に用いる。
- finalとできる変数はローカル変数、引数、フィールド(インスタンス変数、クラス変数)の全て。
- クラスの場合:そのクラスを継承できなくする時に用いる。
- メソッドの場合:オーバーライドできなくする時に用いる。
- 抽象クラス、インターフェースはfinalとはできない。
- 継承や実装ができなくなってしまうため。
サンプルコード
//変数の場合 int x = 0; // 普通の変数宣言、初期値あり x = 1; // 変数の値を変更 final int y = 10; // 変数をfinalで宣言、初期値あり y = 100; // finalとした変数は変更できず、コンパイルエラー!! String s = "A"; // 普通の参照型変数宣言、初期値あり s = "B"; // 参照型変数の参照先を変更 final String s2 = "C"; // 参照型変数をfinalで宣言、初期値あり s2 = "D"; // finalとした変数は変更できず、コンパイルエラー!! //クラスの場合 final class FinalSample { } class ChildFinalSample extends FinalSample { // コンパイルエラー!! finalなクラスは継承できない } //メソッドの場合 class FinalSample { final void method() { // finalなインスタンスメソッド } } class ChildFinalSample extends FinalSample { // finalなクラスではないので継承はできる void method() { // コンパイルエラー!! finalなインスタンスメソッドはオーバーライドできない } }_
- Javaでは無効な予約語。
どのような時に使うのか
- 使わない。
サンプルコード
- なし
float
- 32bitで小数の値を表す基本データ型。
どのような時に使うのか
- 浮動小数で値を表現したい場合に用いる。
- 浮動種数とは:計算で誤差が出ることを前提とした数値データのこと
- doubleとの違い:扱えるbit数の違い
- double : 64bit | float : 32bit
サンプルコード
public class sample { public static void main(String[] args) { float f = 1.25f; int num = 10; float addNum = num + f; System.out.println(num + " + " + f + " = " + addNum); } } //実行結果 10 + 1.25 = 11.25int
- 32bitで整数を表す基本データ型。
どのような時に使うのか
- 整数なので、1ずつ増減する値を扱う。±21億くらいまでの整数を表現できる。
- intのリテラルの書き方
- 2進数(“0b”で始まる、Java 7から)
- 8進数(“0”で始まる)
- 10進数(接頭語なし)
- 16進数(“0x”で始まる)
- Integerとは
- オブジェクト型なので、クラスとして扱う。
- int型からString型へキャストしたい時に用いる。
- nullを利用可能。
サンプルコード
int i1 = 123456789; // 10進数 int i2 = 0b1010101; // 2進数 int i3 = 012345670; // 8進数 int i4 = 0x123ABCDE; // 16進数 int i5 = 123_456_789; // 桁区切り(3桁ごと) int i6 = 0b1111_1010_0101; // 桁区切り(4ビットごと)long
- 64bitで整数を表す基本データ型。
どのような時に使うのか
- int型では扱えない大きな数値を扱う時に用いる。
- int
- 最大値:2^32-1
- 最小値:-2^31
- long
- 最大値:2^63-1
- 最小値:-2^63
サンプルコード
public class sample { public static void main(String [] args) { int m = 2147483647; System.out.println(m); m += 1; System.out.println(m); long n = 2147483647; System.out.println(n); n += 1; System.out.println(n); } } //実行結果 2147483647 -2147483648 2147483647 2147483648short
- 16bitで整数を表す基本データ型。
どのような時に使うのか
- -32768~32767の間の数値を扱う場合に用いる。
- 信用頻度としては高くない。
- int > long > short
- short型で演算を行うと演算結果はint型で返されるため、int型の変数で値を受け取らないとコンパイルエラーになる。
サンプルコード
public class sample { short a=100; short b=10; short c=0; c = a + d; System.out.println("c =" + c ); } //実行結果 sample.java:6: エラー: <identifier>がありませんinstanceof
- 変数が参照しているクラスが正しいかどうかを判断する予約語。
どのような時に使うのか
- データの型を参照する時。
- サブクラスがスーパークラスを継承しているかを判定する時。
- インターフェースを実装しているかを判定する時。
サンプルコード
//データの型を参照する場合 public class sample { public static void main(String[] args) { Object obj = "samurai"; System.out.println(obj instanceof String); System.out.println(obj instanceof Integer); } } //実行結果 true false //サブクラスがスパークラスを継承しているかを判定する場合 public class sample { public static void main(String[] args) { SubClass sub = new SubClass(); System.out.println(sub instanceof SubClass); System.out.println(sub instanceof SuperClass); } } class SuperClass {} class SubClass extends SuperClass{} //実行結果 true true //インターフェースを実装しているかを判定する場合 public class sample { public static void main(String[] args) { SubClass sub = new SubClass(); System.out.println(sub instanceof SubClass); System.out.println(sub instanceof Interface); } } interface Interface {} class SuperClass implements Interface {} class SubClass extends SuperClass {} //実行結果 true truethis
- 自分自身を意味する予約語。
どのような時に使うのか
- 同じクラスのメソッドや変数を参照する場合。
- 別のコンストラクタを呼び出す場合。
サンプルコード
//同じクラスのメソッドや変数を参照する場合 public class sample { //Sampleクラス変数 String animal = "うさぎ"; public void printAnimal() { //ローカル変数 String animal = "ねこ"; System.out.println("ローカル変数animal:" + animal); System.out.println("クラス変数animal:" + this.animal); } public static void main(String[] args) { sample s = new sample(); s.printAnimal(); } } //実効結果 ローカル変数animal:ねこ クラス変数animal:うさぎ //別のコンストラクタを呼び出す場合 class ThisSample8 { String name; int amount; // ①デフォルトコンストラクタ ThisSample8() { this("名無しの権兵衛", 10); // デフォルト値で③を呼び出す } // ②オーバーロードしたコンストラクタ(その1) ThisSample8(String name) { this(name, 20); // 引数を使いつつ、③を呼び出す } // ③オーバーロードしたコンストラクタ(その2) ThisSample8(String name, int amount) { // フィールドの初期化はこのコンストラクタだけで行う this.name = name; this.amount = amount; } void printProperty() { System.out.println(String.format("私の名前は%sです。所持金は%d円です。", name, amount)); } public static void sample(String[] args) { ThisSample8 sample1 = new ThisSample8(); sample1.printProperty(); // → 名無しの権兵衛、10円 ThisSample8 sample2 = new ThisSample8("山田太郎"); sample2.printProperty(); // → 山田太郎、20円 ThisSample8 sample3 = new ThisSample8("鈴木次郎", 1000); sample3.printProperty(); // → 鈴木次郎、1000円 } } //実行結果 私の名前は名無しの権兵衛です。所持金は10円です。 私の名前は山田太郎です。所持金は20円です。 私の名前は鈴木次郎です。所持金は1000円です。super
- スーパークラスのインスタンスやメンバーを参照するための予約語。
どのような時に使うのか
- スーパークラスのコンストラクタを呼ぶ場合。
- オーバーライド前のメソッドを呼ぶ場合。
サンプルコード
//スーパークラスのコンストラクタを呼ぶ場合 public class sample { public static void main(String[] args) throws Exception { SubClass sub = new SubClass(); } } class SuperClass { public SuperClass(){ System.out.println("Super_Const"); } public SuperClass(String str){ System.out.println("str : " + str); } public SuperClass(int num){ System.out.println("num : " + num); } } class SubClass extends SuperClass { public SubClass(){ super("apple"); } } //実行結果 str : apple //オーバライド前のメソッドを呼ぶ場合 class SuperClassSample { String str = "SuperClass"; public String getSrt() { return str; } } class SubClassSample extends SuperClassSample { String str = "SubClass"; public String getSrt() { return str; } public void print() { System.out.println("super.str = " + super.str); System.out.println("str = " + str); System.out.println("super.getSrt() = " + super.getSrt()); System.out.println("getSrt() = " + getSrt()); } } public class sample { public static void main(String[] args) { SubClassSample scs = new SubClassSample(); scs.print(); } } //実行結果 super.str = SuperClass str = SubClass super.getSrt() = SuperClass getSrt() = SubClassnative
- Java以外の言語で記述されたメソッドを示す修飾子。
どのような時に使うのか
- JNI(java Native Interface)と呼ばれる、C/C++言語などのネイティブコードを連携させる仕組みがある。
- 実際にUCSのソースコードにも使われている。
- Javaファイルでインターフェースのようにメソッド名を定義する。
- cファイルにJNIEXPORTで定義すると、Javaファイルとcファイルが関連づけられる。
- Javaファイルで記述するメソッド名はcファイルで実際に処理しているメソッド名。
サンプルコード
//Javaファイル pablic native boolean isCameraMute(); //cファイル JNIEXPORT jboolean JNICALL プレフィックス_isCameraMute(); return isCsmeraMute();strictfp
- 浮動小数点をIEEE754という規格で決められたルールで厳密に処理するための予約語。
- クラス、インターフェース、メソッドは就職できるが、変数は修飾できない。
どのような時に使うのか
- IEEE(Institute of Electrical and Electronics Enginners)とは:アメリカに本部をおく、電気・情報工学分野の学術研究団体。技術標準化機関。
- IEEE754とは:浮動小数点に関する標準。32bitや64bitによって浮動小数点演算の誤差が違う計算をどの環境でも同じ結果にするために用いる。
- strictfpを用いない場合は、PCのCPUに依存して処理される。
サンプルコード
public class sample { public static void main(String args[]) { new sample(); } //コンストラクタの生成 public sample() { this.strictfpTest(); } strictfp public void strictfpTest() { double a = 0.01; double b = 0.02; double c = 0.0001; System.out.println(a * b * c); } } //実行結果 2.0E-8synchronized
- 排他制御を行うための予約語。
どのような時に使うのか
- 排他制御を行い際に用いる。
- 排他制御とは:複数のプロセスが利用できる共有資源に対し、同時にアクセスすることを防ぐこと
サンプルコード
//synchronizedを用いない場合 public class sample{ public static void main(String[] args) { Bathroom bathroom = new Bathroom(); FamilyTread father = new FamilyTread(bathroom, "父"); FamilyTread mother = new FamilyTread(bathroom, "母"); FamilyTread sister = new FamilyTread(bathroom, "姉"); FamilyTread me = new FamilyTread(bathroom, "私"); father.start(); mother.start(); sister.start(); me.start(); } } class FamilyTread extends Thread { private Bathroom mBathroom; private String mName; FamilyTread(Bathroom bathroom, String name) { this.mBathroom = bathroom; this.mName = name; } public void run() { mBathroom.openDoor(mName); } } class Bathroom { void openDoor(String name) { System.out.println(name + "「お風呂に入ります!」"); for (int count = 0; count < 100000; count++) { if (count == 1000) { System.out.println(name + "「お風呂に入りました。」"); } } System.out.println(name + "「お風呂から出ました!」"); } } //実行結果 父「お風呂に入ります!」 母「お風呂に入ります!」 父「お風呂に入りました。」 姉「お風呂に入ります!」 私「お風呂に入ります!」 母「お風呂に入りました。」 私「お風呂に入りました。」 姉「お風呂に入りました。」 父「お風呂から出ました!」 姉「お風呂から出ました!」 私「お風呂から出ました!」 母「お風呂から出ました!」 //class Bathroomにsynchronizedを用いた場合 class Bathroom { synchronized void openDoor(String name) { System.out.println(name + "「お風呂に入ります!」"); for (int count = 0; count < 100000; count++) { if (count == 1000) { System.out.println(name + "「お風呂に入りました。」"); } } System.out.println(name + "「お風呂から出ました!」"); } //実行結果 父「お風呂に入ります!」 父「お風呂に入りました。」 父「お風呂から出ました!」 私「お風呂に入ります!」 私「お風呂に入りました。」 私「お風呂から出ました!」 母「お風呂に入ります!」 母「お風呂に入りました。」 母「お風呂から出ました!」 姉「お風呂に入ります!」 姉「お風呂に入りました。」 姉「お風呂から出ました!」transient
- オブジェクトをシリアライズ対象外とする修飾子。
どのような時に使うのか
- シリアライズとは:オブジェクトの内容をファイルに保存したり、他のマシンに送信したりできるようにバイト配列に変換する事。
- Serializableインターフェースを実装するとデフォルトですべてのフィールドをシリアライズ対象とするが、その対象から除外したい時に用いる。
- 状態を保存する必要がない場合。
- シリアライズしたものを復元する際に初期化したいフィールドが該当する。
- 直列化したいクラスに直列化不可能なフィールドがある場合。
- シリアライズするクラスのフィールドはプリミティブ型か、シリアライズ可能な型でないといけない。
- シリアライズできないクラス:List,Map,Connection,InputStreamなど
- シリアライズの入出力を実際に行うメソッド:write.Object()S
サンプルコード
//Main.java import java.io.ByteArrayInputStream; import java.io.ByteArrayOutputStream; import java.io.ObjectInputStream; import java.io.ObjectOutputStream; import java.io.Serializable; public class Main { public static void main(String[] args) throws Exception { Player player = new Player(new Badminton()); player.play(); System.out.println(); Player clonePlayer = deepCopy(player); clonePlayer.play(); System.out.println(); System.out.print("Playerのインスタンスが同じ:"); System.out.println(player == clonePlayer); System.out.print("Badmintonのインスタンスが同じ:"); System.out.println(player.getSports() == clonePlayer.getSports()); } @SuppressWarnings("unchecked") public static <T extends Serializable> T deepCopy(T t) throws Exception { if (t == null) { return null; } ByteArrayOutputStream byteOut = null; ObjectOutputStream objectOut = null; try { byteOut = new ByteArrayOutputStream(); objectOut = new ObjectOutputStream(byteOut); objectOut.writeObject(t); } finally { objectOut.close(); } ObjectInputStream objectin = null; T copy = null; try { objectin = new ObjectInputStream(new ByteArrayInputStream (byteOut.toByteArray())); copy = (T) objectin.readObject(); } finally { objectin.close(); } return copy; } } //Sports.java public interface Sports { void play(); } class Badminton implements Sports { @Override public void play() { System.out.println("バドミントンして遊びます。"); } } //Player.java import java.io.Serializable; @SuppressWarnings("serial") public class Player implements Serializable { private transient Sports sports; public Player(Sports sports) { this.sports = sports; System.out.println("コンストラクタです。"); } public Sports getSports() { return sports; } public void play() { System.out.println("ウォームアップします。"); sports.play(); System.out.println("クールダウンします。"); } }volatile
- 共有メモリと各スレッドの変数の値を一致させる修飾子。
どのような時に使うのか
- フィールドの値のキャッシュを抑制する場合。
- マルチスレッドの場合、それぞれのスレッドが同じフィールの値をキャッシュすることがある。この時、同じフィールドでも値が異なってくる危険性がある。
- キャッシュとは:メインメモリとは違う場所に値を誇示する事で、一般的にメモリに比べて保存量は少ないが、高速に値の呼び出しや、更新が行える。
- コンパイラで最適化されるのを防ぐ場合。
- コンパイラとは:人間にわかりやすく、複雑な機能や構文を持つ高水準プログラミング(CやJavaなど)で書かれたコンピュータープログラムをコンピュータが解釈・実行できる形式に一括して変換するソフトウェア。
サンプルコード
public class VolatileSample { private static volatile int count = 0; //private static int count = 0; public static void main(String[] args) { new MultiThread1().start(); new MultiThread2().start(); } static class MultiThread1 extends Thread { public void run() { int val = count; while(count < 3) { if (val != count) { String message = getName() + ": val = " + val + ", count = " + count; System.out.println(message + " 更新"); val = count; } } } } static class MultiThread2 extends Thread { public void run() { int val = count; while(count < 3) { try { Thread.sleep(500); } catch (InterruptedException e) { e.printStackTrace(); } String message = getName() + ": val = " + val + ", count = " + count; System.out.println(message); count = ++val; } } } } //実行結果 Thread-1: val = 0, count = 0 Thread-0: val = 0, count = 1 更新 Thread-1: val = 1, count = 1 Thread-0: val = 1, count = 2 更新 Thread-1: val = 2, count = 2
- 投稿日:2020-09-10T14:21:19+09:00
【備忘】S3からのダウンロード、S3へのアップロード
1.S3からのファイルダウンロード
今回は、バケットの対象パス下のファイルを全てダウンロードする場合を記述しました。AmazonS3 s3Client = AmazonS3ClientBuilder.standard().withRegion("リージョン名").build(); // S3上バケット下のファイル一覧を取得 ObjectListing objListing = s3Client.listObjects("バケット名"); List<S3ObjectSummary> objList = objListing.getObjectSummaries(); try { // S3上のファイル分処理する for (S3ObjectSummary obj : objList) { // objListにはバケット下全てのフォルダ、ファイル情報があるため対象パスで絞り込む必要がある // 対象パスを含んでいないか、または、サイズが0であればダウンロードしない if (!StringUtils.contains(obj.getKey(), "対象パス") || obj.getSize() == 0) { continue; } // 以下ダウンロード処理 // obj.getKey()は"対象パス/ファイル名"となっている GetObjectRequest request = new GetObjectRequest("バケット名", obj.getKey()); // ファイル名だけにする String fileName = obj.getKey().replace("対象パス", ""); // ダウンロード先のファイルを生成 File file = new File(fileName); if (s3Client.getObject(request, file) == null) { // ダウンロード失敗 } } } catch (IOException e) { throw e; }2.S3へのアップロード
ファイルをバケット下の対象パスへアップロードする場合try { AmazonS3 s3Client = AmazonS3ClientBuilder.standard().withRegion("リージョン名").build(); File file = new File("アップロード対象ファイル名"); PutObjectRequest request = new PutObjectRequest("バケット名", "対象パス" + file.getName(), file); request.setCannedAcl(CannedAccessControlList.PublicRead); s3Client.putObject(request); } catch (Exception e) { throw e; }
- 投稿日:2020-09-10T13:32:45+09:00
Javaログをクラウドに移行するための3つの強力なツール: Log4J、LogBack、Producer Lib
この記事では、Javaのログをクラウドに移行するための強力なツールを3つ紹介します。Log4J、LogBack、Producer Libです。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
ログの一元化への道
近年、ステートレスプログラミング、コンテナ、サーバレスプログラミングの登場により、ソフトウェアのデリバリやデプロイの効率が大きく向上しました。アーキテクチャの進化では、以下の2つの変化を見ることができます。
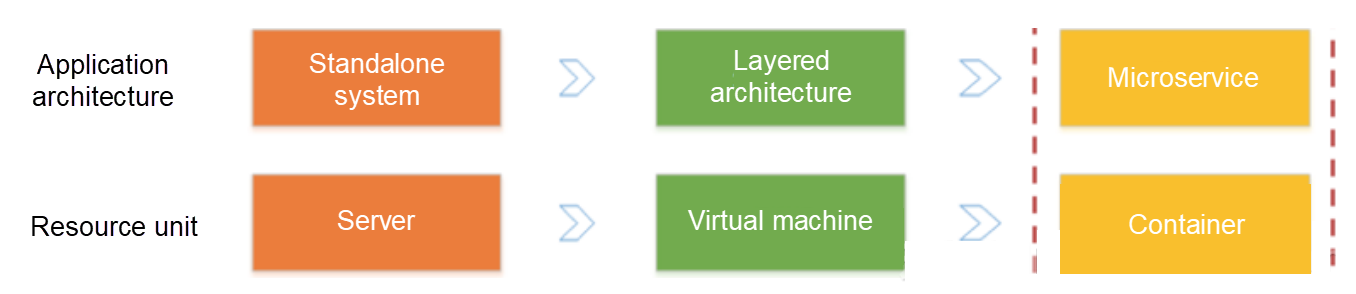
- アプリケーションアーキテクチャは、単一システムからマイクロサービスに変化しています。次に、ビジネスロジックがマイクロサービス間で呼び出しとリクエストに変化します。
- リソースの面では、従来の物理サーバがフェードアウトし、目に見えない仮想リソースへと変化しています。
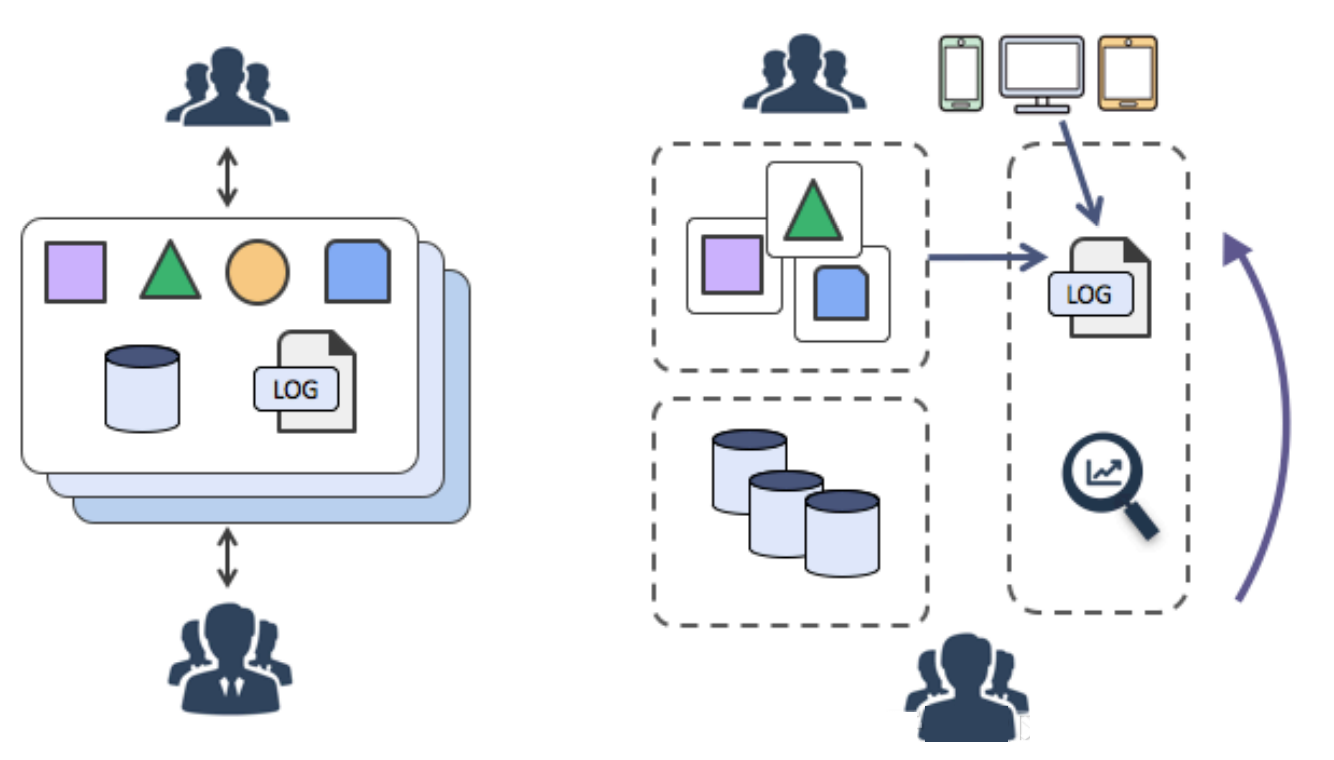
前述の2つの変化は、弾性的で標準化されたアーキテクチャの裏で、運用保守(O&M)や診断の要件が複雑化していることを示しています。10年前は、サーバにログオンしてログを素早くフェッチすることができました。しかし、もはやアタッチ処理モードは存在しません。現在は、標準化されたブラックボックスに直面しています。
こうした変化に対応するために、DevOpsに特化した診断・分析ツールが続々と登場しています。これらには、集中監視、集中ログシステム、各種SaaSの導入、監視などが含まれます。
ログを一元化することで、先行する課題を解決することができます。これを行うには、アプリケーションがログを生成した後、ログはリアルタイム(または準リアルタイム)で中央のノードサーバに送信されます。多くの場合、Syslog、Kafka、ELK、HBaseが集中型ストレージを実行するために使用されます。
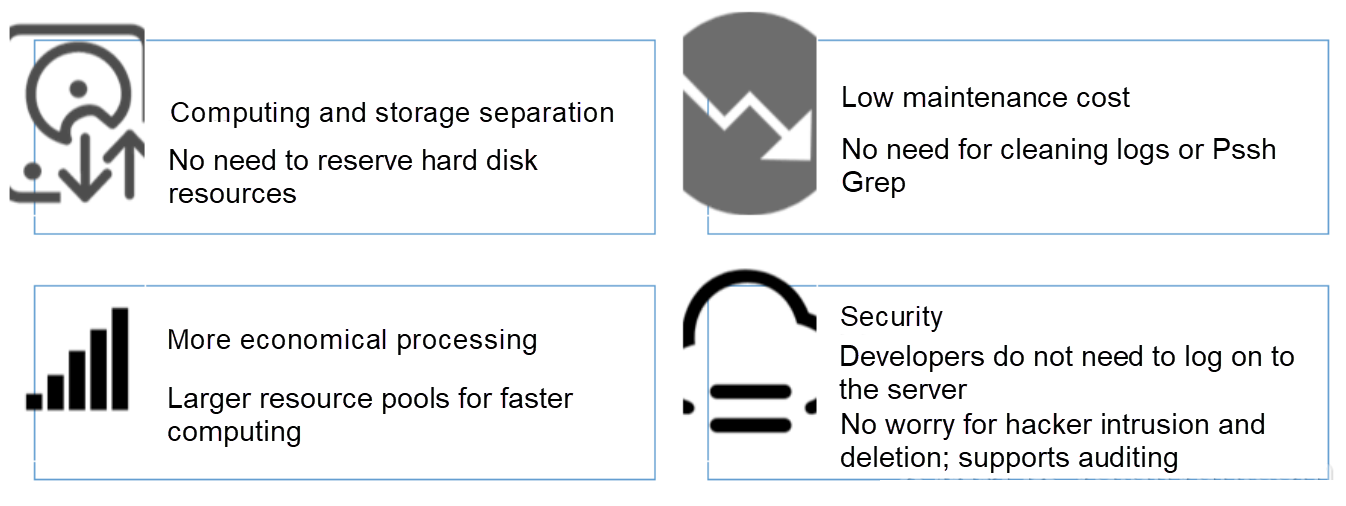
集中化の利点
- 使い勝手の良さ:Grepを使ってステートレスアプリケーションのログを照会するのは面倒です。集中型ストレージでは、前の長い処理が検索コマンドを実行することで置き換えられます。
- ストレージとコンピューティングの分離:マシンのハードウェアをカスタマイズする際に、ログのためのストレージスペースを考慮する必要がありません。
- コスト削減:集中型ログストレージでは、より多くのリソースを確保するためにロードシフトを行うことができます。
- セキュリティ:ハッカーの侵入や災害が発生した場合でも、重要なデータは証拠として保持されます。
コレクター (Javaシリーズ)
ログサービスは、サーバ、モバイル端末、組み込み機器、各種開発言語に対応した30以上のデータ収集方法と包括的なアクセスソリューションを提供しています。Java開発者にはおなじみのログフレームワークが必要です。Log4j、Log4j2、Logback Appenderです。
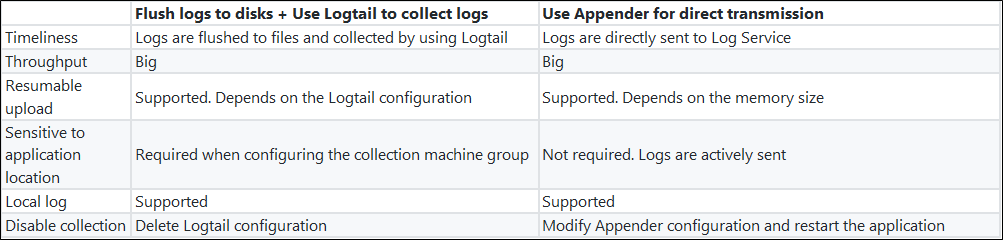
Javaアプリケーションには現在、2つの主流のログ収集ソリューションがあります。
- Javaプログラムはログをディスクにフラッシュし、Logtailをリアルタイム収集に使用します。
- Javaプログラムは、Log Serviceが提供するAppenderを直接設定します。プログラムが実行されると、ログはリアルタイムでLog Serviceに送信されます。 両者の違い:
Appenderを使用することで、Configを使用して、コードを変更することなく簡単にリアルタイムログ収集を完了させることができます。Log Serviceが提供するJavaシリーズのAppenderには、以下のようなメリットがあります。
- プログラムを変更せずにConfigの変更が有効になります。
- 非同期+ブレークポイント転送:I/Oはメインスレッドに影響を与えず、特定のネットワークやサービスの障害を許容することができます。
- 高カレンシー設計:大規模なログの書き込み要件を満たしています。
- コンテキストクエリをサポート:ログサービスの元のプロセスで、ログのコンテキスト(ログの前後にあるN個のログ)を正確に復元することをサポートします。
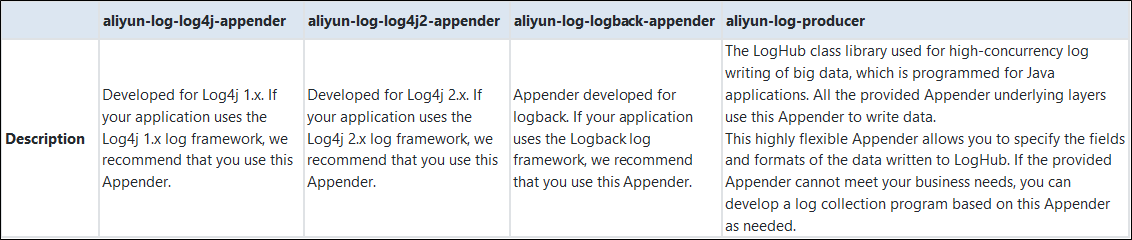
アペンダーの概要と使い方:
提供されているアペンダーは以下の通りです。基礎となるレイヤーはすべて、データを書き込むためにaliyun-log-producer-javaを使用します。aliyun-log-log4j-appender
aliyun-log-log4j2-appender
aliyun-log-logback-appender
4つの違い:
アペンダーの統合
aliyun-log-log4j-appenderの設定手順を実行することで、Appenderを統合することができます。
設定ファイル
log4j.propertiesの内容は以下の通りです。log4j.rootLogger=WARN,loghub log4j.appender.loghub=com.aliyun.openservices.log.log4j.LoghubAppender # Log Service project name (required parameter) log4j.appender.loghub.projectName=[your project] # Log Service LogStore name (required parameter) log4j.appender.loghub.logstore=[your logstore] #Log Service HTTP address (required parameter) log4j.appender.loghub.endpoint=[your project endpoint] # User identity (required parameter) log4j.appender.loghub.accessKeyId=[your accesskey id] log4j.appender.loghub.accessKey=[your accesskey]クエリと分析
前のステップで説明したようにアペンダーを設定すると、Java アプリケーションが生成したログが自動的に Log Service に送信されます。LogSearch/Analyticsを使用して、これらのログをリアルタイムで照会・分析することができます。次のようなサンプルのログ形式を参照してください。この例で使用したログ形式:
ログオンの動作を記録するログ:
level: INFO location: com.aliyun.log4jappendertest.Log4jAppenderBizDemo.login(Log4jAppenderBizDemo.java:38) message: User login successfully. requestID=id4 userID=user8 thread: main time: 2018-01-26T15:31+0000購入行動を記録するログ:
level: INFO location: com.aliyun.log4jappendertest.Log4jAppenderBizDemo.order(Log4jAppenderBizDemo.java:46) message: Place an order successfully. requestID=id44 userID=user8 itemID=item3 amount=9 thread: main time: 2018-01-26T15:31+0000クエリ解析を有効にする
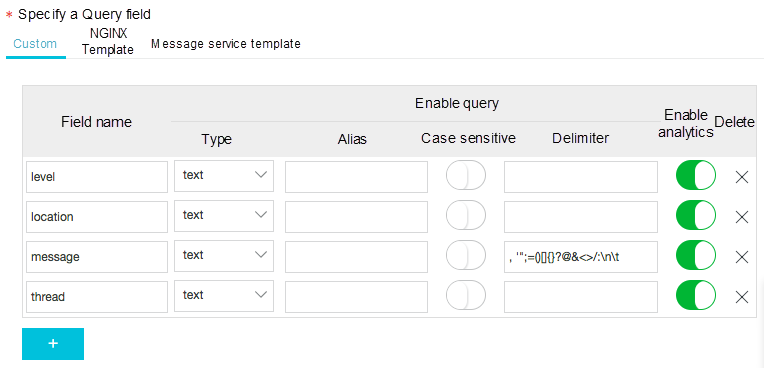
データを照会して分析する前に、照会および分析機能を有効にする必要があります。以下の手順に従って、機能を有効にしてください。
- ログサービスコンソールにログオンします。
- プロジェクト一覧ページで、プロジェクト名をクリックするか、右側の管理をクリックします。
- ログストアを選択し、ログ検索列で検索をクリックします。
- Set LogSearch and Analytics > Settings を選択します。
- 設定メニューに移動し、以下のフィールドのクエリを有効にします。
ログの分析
5つの分析例を見てみましょう。
1、過去1時間にエラーが最も多く発生した場所の上位3つを数えてください。
構文例:level: ERROR | select location ,count(*) as count GROUP BY location ORDER BY count DESC LIMIT 3
- 過去 15 分間にログレベルごとに生成されたログの数をカウントします。 構文例:
| select level ,count(*) as count GROUP BY level ORDER BY count DESC
- ログ コンテキストを照会します。
任意のログについて、元のログ ファイルのログ コンテキスト情報を正確に再構築できます。
詳細については、コンテキスト クエリを参照してください。
- 過去 1 時間に最も頻繁にログオンしたユーザーの上位 3 人をカウントします。
構文例:
login | SELECT regexp_extract(message, 'userID=(? <userID>[a-zA-Z\d]+)', 1) AS userID, count(*) as count GROUP BY userID ORDER BY count DESC LIMIT 3
- 各ユーザーの過去 15 分間の支払い合計統計をコンパイルします。
構文例:
order | SELECT regexp_extract(message, 'userID=(? <userID>[a-zA-Z\d]+)', 1) AS userID, sum(cast(regexp_extract(message, 'amount=(? <amount>[a-zA-Z\d]+)', 1) AS double)) AS amount GROUP BY userIDアリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ
- 投稿日:2020-09-10T13:15:44+09:00
ArrayList練習
◎二次元配列をArrayListに書き換え
package renshuu; import java.util.ArrayList; public class Array_pra { public static void main(String[] args) { //newでArrayリストのインスタンス生成 ArrayList<String> seasons=new ArrayList<String>(); //↑左辺は List<String> seasons でもok seasons.add("春"); seasons.add("夏"); seasons.add("秋"); seasons.add("冬"); for (int i = 0; i < seasons.size(); i++) { System.out.print("\"" + seasons.get(i) + "\" "); //実行結果 "春" "夏" "秋" "冬" } } }◎上記をfor文からfor拡張文に書き換え
package renshuu; import java.util.ArrayList; public class for_ver { public static void main(String[] args) { ArrayList<String> seasons=new ArrayList<String>(); seasons.add("春"); seasons.add("夏"); seasons.add("秋"); seasons.add("冬"); for(String a:seasons) { System.out.print("\""a+"\" "); } } } //実行結果 "春" "夏" "秋" "冬"◎Iteratorを使用してArrayListを出力
package renshuu; import java.util.ArrayList; import java.util.Iterator; public class Array_iterator { public static void main(String[] args) { ArrayList<String> seasons=new ArrayList<String>(); seasons.add("春"); seasons.add("夏"); seasons.add("秋"); seasons.add("冬"); Iterator<String>itSeason=seasons.iterator(); while(itSeason.hasNext()) { String PSeason=itSeason.next(); System.out.print("\""+PSeason+"\" "); } } } //実行結果 "春" "夏" "秋" "冬"◎二次元配列をArrayに書き換え
package renshuu; import java.util.ArrayList; import java.util.List; public class Nijigen_Array { public static void main(String[] args) { ArrayList<ArrayList<String>> Niji=new ArrayList<ArrayList<String>>(); ArrayList<String> a = new ArrayList<String>(); ArrayList<String> b = new ArrayList<String>(); a.add("春"); a.add("夏"); a.add("秋"); a.add("冬"); b.add("さくら"); b.add("うみ"); b.add("いちょう"); b.add("こたつ"); Niji.add(a); //Niji[0] ゼロ番目の要素にa(春・・)が入る Niji.add(b); //Niji[1] 1番目の要素にb(さくら・・)が入る for (List<String> datas : Niji) { //Niji[0] Nijiの0番目の要素をとりだし for (String data : datas) { //その0番目の中を1つづつ取り出す System.out.print("\"" + data + "\" "); } //Niji[0]のなかを全部取り出し終わったのでループをぬけて System.out.println(""); //改行して、for文の最初まで戻る。Niji[1]の処理をする } //↓春~とさくら~の行間の改行 System.out.println(""); } } } //実行結果 "春" "夏" "秋" "冬" "さくら" "うみ" "いちょう" "こたつ"
- 投稿日:2020-09-10T12:36:37+09:00
【java】switch文について基本的なことを整理してみた
【目的】
「switch文の意味をきちんと理解すること。」
?当初switch文は、「if文だと冗長になってしまう場合に、もっと見やすく書く手段」と理解。
?しかしこの理解だけで実際にコードを書くと、構文中の「break」でモヤみが発生。
?breakなくてもコンパイル、実行できる
?でも自分の思ったとおりの処理にならない
?とりあえず、書いとけばいい…わけではなさそう【switch文とは】
「条件に一致するcaseラベルまで処理をジャンプさせることができる。」
?switch文の正体がわかったので、構文内の「break」使用についてもスッキリ。
?正直この一文だけで、モヤみ解決(´-`)【switch文に書き換えることができる条件】
? 全ての条件式が、右辺と左辺が一致するかを比較する式になっていること。
例えば「変数 == 値」「変数 == 変数」のような式になっていればOK( ^ω^ )
「>」「<」「!=」が使われている式はNG(`ω´)? 比較する値が整数(byte、short、intのいずれか)であること。
? 文字列(String型)または文字(char型)であること。
小数や真偽値ではないこと。【switch構文】
・switch(条件値){ //switchの直後に書くのは、条件式ではなく、変数名 case 値1: //caseの横には値を書く。後ろに:をつける(よく;と間違える) 処理1 break; //case以降の処理の末尾にはbreakを付ける(付けない方法は【その他】参照) case 値2: 処理2 break; . . . default: //上記case以外の処理が不要であれば省略可能。 処理x }【switch構文を使用した例文】
public class Main{ public static void main(String[] args){ System.out.println(""); int n = new java.util.Random().nextInt(5) + 1; //1〜5までランダムに整数を選ぶ。 switch(n){ case 1: System.out.println(""); break; case 2: . . . } } }【その他】
「あえてbreak文を書かない」場合
「nが1か2なら...、3なら...」というふうに、複数の場合について同一の処理を行いたい時に、あえて書かない方法もある。
public class Main{ public static void main(String[] args){ System.out.println(""); int n = new java.util.Random().nextInt(5) + 1; //1〜5まで、ランダムに整数を選ぶ。 switch(n){ case 1: case 2: // break文を書かない。 System.out.println(""); break; case 3: System.out.println(""); break; . . . } } }
- 投稿日:2020-09-10T11:47:58+09:00
Javaパフォーマンス診断ツールの代表格「JProfiler」の基本原理とベストプラクティス
この記事では、いくつかの一般的なJavaパフォーマンス診断ツールについて説明し、JProfilerの基本的な原則とベストプラクティスを強調しています。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
背景
パフォーマンス診断は、ソフトウェアエンジニアが日々の業務の中で頻繁に直面し、解決しなければならない問題です。アプリケーションのパフォーマンスを向上させることで大きなメリットを得ることができます。Javaは最も人気のあるプログラミング言語の一つです。そのパフォーマンス診断は、以前から業界全体で注目を集めています。Javaアプリケーションでは、多くの要因がパフォーマンスの問題を引き起こす可能性があります。そのような要因には、スレッド制御、ディスクI/O、データベースアクセス、ネットワークI/O、ガベージコレクション(GC)などがあります。これらの問題を見つけるためには、優れた性能診断ツールが必要です。この記事では、いくつかの一般的なJavaパフォーマンス診断ツールについて説明し、これらのツールの代表格であるJProfilerの基本的な原理とベストプラクティスを紹介します。この記事で取り上げた JProfiler のバージョンは
JProfiler10.1.4です。Javaパフォーマンス診断ツールの簡単な紹介
Javaの世界には、jmapやjstatなどのシンプルなコマンドラインツールから、JVisualvmやJProfilerなどの包括的なグラフィカルな診断ツールまで、さまざまなパフォーマンス診断ツールが存在します。以下のセクションでは、これらのツールのそれぞれについて簡単に説明します。
シンプルなコマンドラインツール
Java開発キット(JDK)は、多くの組み込みコマンドラインツールを提供しています。これらのツールは、ターゲットJava仮想マシン(JVM)の情報をさまざまな側面や異なるレイヤーから取得するのに役立ちます。
- jinfo - ターゲットJVMの様々なパラメータをリアルタイムで表示したり、調整したりすることができます。
- jstack - ターゲットJavaプロセスのスレッドスタック情報を取得し、デッドロックを検出し、無限ループを見つけることができます。
- jmap - ターゲットJavaプロセスのメモリ関連情報を取得します。これには、異なるJavaヒープの使用状況、Javaヒープ内のオブジェクトの統計情報、ロードされたクラスなどが含まれます。
- jstat - 軽量で汎用性の高いモニタリングツールです。ターゲットJavaプロセスのロードされたクラス、ジャストインタイム(JIT)コンパイル、ガベージコレクション、メモリ使用量に関する様々な情報を得ることができます。
- jcmd - jstatよりも包括的です。ターゲットJavaプロセスのパフォーマンス統計、Java Flight Recorder (JFR)、メモリ使用量、ガベージコレクション、スレッドスタッキング、JVMランタイムに関する様々な情報を取得することができます。
包括的なグラフィカル診断ツール
ターゲットJavaアプリケーションに関する基本的なパフォーマンス情報を得るために、上記のコマンドライン・ツールの任意の、または任意の組み合わせを使用することができます。しかし、これらのツールには次のような欠点があります。
1、異なるメソッド間の呼び出し関係や、メソッドが呼び出される頻度や期間など、メソッドレベルの分析データを取得することはできません。これらは、アプリケーションのパフォーマンスのボトルネックを特定するために非常に重要です。
2、これらを使用するには、ターゲットJavaアプリケーションのホストマシンにログオンする必要がありますが、これはあまり便利ではありません。
3、分析データは端末で生成され、結果は表示されません。以下に、いくつかの包括的なグラフィカルなパフォーマンス診断ツールを紹介します。
JVisualvm
JVisualvm は、JDK が提供するビルトインのビジュアル性能診断ツールです。JMX、jstatd、Attach APIなどの各種メソッドを利用して、CPU使用率、メモリ使用率、スレッド数、ヒープ数、スタック数など、対象となるJVMの分析データを取得します。また、Javaヒープ内の各オブジェクトの量やサイズ、Javaメソッドの呼び出し回数、Javaメソッドの実行時間などを表示することができます。
JProfiler
JProfilerは、ej-technologies社が開発したJavaアプリケーションのパフォーマンス診断ツールです。4つの重要なトピックに焦点を当てています。
1、メソッドコール - メソッドコールの分析は、アプリケーションが何をしているかを理解し、パフォーマンスを向上させる方法を見つけるのに役立ちます。
2、割り当て - ヒープ上のオブジェクト、参照チェーン、ガベージコレクションの分析を通して、この機能はメモリリークを修正し、メモリ使用量を最適化することを可能にします。
3、スレッドとロック - JProfilerは、スレッドとロックに関する複数の解析ビューを提供し、マルチスレッドの問題を発見するのに役立ちます。
4、高レベルサブシステム - 多くのパフォーマンス問題は、より高いセマンティックレベルで発生します。たとえば、Java Database Connectivity (JDBC) の呼び出しでは、どの SQL 文が最も遅いかを調べたいと思うでしょう。JProfilerは、これらのサブシステムの統合的な解析をサポートしています。分散型アプリケーション性能診断
スタンドアロンJavaアプリケーションのパフォーマンスのボトルネックを診断するだけであれば、上記の診断ツールで十分にニーズを満たすことができます。しかし、スタンドアロン型の最新システムが徐々に分散システムやマイクロサービスへと進化していくと、上記のツールでは要件を満たすことができなくなります。そこで、JaegerやARMS、SkyWalkingなどの分散トレースシステムのエンドツーエンドのトレース機能を利用する必要があります。様々な分散トレースシステムが市販されていますが、実装の仕組みは似ています。コードトラッキングによってトレース情報を記録し、記録されたデータをSDKやエージェントを介して中央処理システムに送信し、結果を表示・分析するためのクエリインターフェースを提供します。分散トレースシステムの原理については、JaegerのOpenTracing実装というタイトルの記事を参照してください。
JProfilerの紹介
コアコンポーネント
JProfilerは、対象となるJVMから分析データを収集するためのJProfilerエージェント、データを視覚的に分析するためのJProfiler UI、各種機能を提供するコマンドラインユーティリティで構成されています。これらの間の重要な相互作用の全体像を以下に示します。
JProfilerエージェント
JProfilerエージェントはネイティブ・ライブラリとして実装されています。パラメータ-agentpath:を使用してJVMの起動時にロードするか、JVM Attachメカニズムを使用してアプリケーションの実行中にロードすることができます。JProfilerエージェントがロードされた後、JVMツール・インターフェース(JVMTI)環境を設定し、スレッドの作成やクラスのロードなど、JVMによって生成されるあらゆる種類のイベントを監視します。例えば、クラス・ローディング・イベントを検出すると、JProfilerエージェントは、これらのクラスに独自のバイトコードを挿入して測定を実行します。
JProfiler UI
JProfiler UIは個別に起動され、ソケットを介してプロファイリングエージェントに接続します。つまり、プロファイリングされたJVMがローカルマシン上で実行されているか、リモートマシン上で実行されているかは関係ありません - プロファイリングエージェントとJProfiler UI間の通信メカニズムは常に同じです。
JProfiler UIから、エージェントにデータの記録、UIでのプロファイリングデータの表示、ディスクへのスナップショットの保存を指示することができます。
コマンドラインツール
JProfilerは、さまざまな機能を実装するための一連のコマンドラインツールを提供します。
- jpcontroller - エージェントがデータを収集する方法を制御するために使用します。エージェントによって登録された JProfiler MBean を介してエージェントに命令を送信します。
- jpenable - 実行中のJVMにエージェントをロードするために使用します。
- jpdump - 実行中のJVMのヒープスナップショットをキャプチャするために使用します。
- jpexport & jpcompare - 以前に保存されたスナップショットからデータを抽出し、HTMLレポートを作成するために使用します。
インストール
JProfilerは、ローカルとリモートの両方のJavaアプリケーションのパフォーマンス診断をサポートします。リモートJVMの分析データをリアルタイムで収集して表示する必要がある場合は、以下の手順を実行します。
1、ローカルに JProfiler UI をインストールします。
2、リモートホストマシンに JProfiler エージェントをインストールし、ターゲット JVM にロードします。
3、JProfiler UI をエージェントに接続します。インストール手順の詳細については、「JProfiler のインストール」と 「JVM のプロファイリング」を参照してください。
ベストプラクティス
ここでは、LogHubクラスライブラリであるAlibaba Cloud LOG Java Producer(以下、Producer)のパフォーマンスをJProfilerを使って診断する方法を紹介します。お使いのアプリケーションや Producer を使用した際にパフォーマンスに問題が発生した場合は、同様の対策を行うことで根本原因を探ることができます。Producerをご存じない方は、まずこの記事をお読みになることをお勧めします。Alibaba Cloud LOG Java Producer - ログをクラウドに移行するための強力なツールです。
ここで使用したサンプルコードはSamplePerformance.javaを参照してください。
JProfilerの設定
データ収集モード
JProfilerには、サンプリングと計測の2つのデータ収集方法があります。
- サンプリング - 高いデータ収集精度を必要としないシナリオに適しています。この方法の利点は、システム・パフォーマンスへの影響が少ないことです。欠点は、メソッドレベルの統計などの一部の機能がサポートされていないことです。
- インストルメンテーション - 高精度をサポートする完全なデータ収集モードです。欠点は、多くのクラスを分析しなければならないことと、アプリケーションのパフォーマンスへの影響が比較的重いことです。影響を軽減するには、フィルタと一緒に使用するとよいでしょう。 この例では、メソッドレベルの統計情報を取得する必要があるため、インストルメンテーション方式を選択します。フィルタは、エージェントがjavaパッケージの下で
com.aliyun.openservices.aliyun.log.producerとcom.aliyun.openservices.log.Clientの2つのクラスのみのCPUデータを記録するように構成されています。アプリケーションの起動モード
JProfilerエージェントにさまざまなパラメータを指定して、アプリケーションの起動モードを制御することができます。
JProfiler GUIからの接続を待つ - JProfiler GUIがプロファイリングエージェントとの接続を確立し、プロファイリング設定が完了した場合にのみ、アプリケーションが起動します。このオプションを使用すると、アプリケーションの起動フェーズをプロファイリングすることができます。このオプションを有効にするために使用できるコマンド:
-agentpath:<path to native library>=port=8849すぐに起動して、後で JProfiler GUI で接続 - JProfiler GUI は、必要なときにプロファイリングエージェントとの接続を確立し、プロファイリング設定を送信します。このオプションは柔軟性がありますが、アプリケーションの起動フェーズをプロファイリングすることはできません。このオプションを有効にするために使用できるコマンド:
-agentpath:<path to native library>=port=8849,nowait.プロファイルがオフライン、JProfiler が接続できない場合 - データを記録し、後で JProfiler GUI で開くことができるスナップショットを保存するトリガーを設定する必要があります。このオプションを有効にするために使用できるコマンドは、
-agentpath:<path to native library>=offline,id=xxx,config=/config.xml.テスト環境では、起動フェーズでアプリケーションのパフォーマンスを判断する必要があります。そこで、ここではデフォルトのWAITオプションを使用します。
JProfilerを使用してアプリケーションのパフォーマンスを診断
プロファイリングの設定が完了すると、プロデューサーのパフォーマンス診断に進むことができます。
概要
概要ページでは、メモリ、GC活動、クラス、スレッド、CPU負荷など、様々なメトリクスに関するグラフ(テレメトリ)を明確に見ることができます。
このテレメトリに基づいて、以下のような前提を立てることができます。
1、アプリケーションの実行中に大量のオブジェクトが生成されます。これらのオブジェクトのライフサイクルは非常に短く、ほとんどのオブジェクトはガベージコレクタによって速やかにリサイクルされます。これらのオブジェクトは、メモリ使用量が継続的に増加する原因にはなりません。
2、予想通り、ロードされるクラスの数は起動期間中に急速に増加し、その後は安定します。
3、アプリケーションの実行中は、多くのスレッドがブロックされます。この問題には特に注意が必要です。
4、アプリケーションの起動時には、CPUの使用率が高くなります。その原因を探る必要があります。CPUビュー
アプリケーション内の各メソッドの実行回数、実行時間、呼び出し関係は、CPU ビューで表示されます。これらは、アプリケーションのパフォーマンスに最も大きな影響を与えるメソッドを見つけるのに役立ちます。
コールツリー
コールツリーは、ツリーグラフを使って、異なるメソッド間のコール関係を階層的に表示します。さらに、JProfiler はサブメソッドを総実行時間でソートするので、キーとなるメソッドを素早く見つけることができます。
Producerの場合、
SendProducerBatchTask.run()というメソッドの実行にほとんどの時間がかかっています。下を見続けると、ほとんどの時間がClient.PutLogs()メソッドの実行にかかっていることがわかります。ホットスポット
多くのアプリケーション・メソッドがあり、サブ・メソッドの多くが短い間隔で実行されている場合、ホット・スポット・ビューを使用すると、パフォーマンスの問題を素早く見つけることができます。このビューでは、個別の実行時間、合計実行時間、平均実行時間、呼び出し回数などのさまざまな要因に基づいてメソッドを並べ替えることができます。個々の実行時間は、メソッドの合計実行時間からすべてのサブメソッドの合計実行時間を差し引いたものです。
このビューでは、次の3つのメソッドが最も実行に時間がかかっていることがわかります。
Client.PutLogs()、LogGroup.toByteArray()、SamplePerformance$1.run()の3つのメソッドが個別に実行されるのに最も時間がかかることがわかります。コールグラフ
キーメソッドを見つけた後、コールグラフビューでは、これらのキーメソッドに直接関連するすべてのメソッドを表示することができます。これは、問題の解決策を見つけ、最適なパフォーマンス最適化ポリシーを開発するのに役立ちます。
ここでは、メソッド Client.PutLogs() の実行時間のほとんどがオブジェクトのシリアライズに費やされていることがわかります。したがって、パフォーマンスを最適化する鍵は、より効率的なシリアライズメソッドを提供することです。
ライブメモリ
ライブメモリビューでは、メモリの詳細な割り当てと使用状況を知ることができ、メモリリークがあるかどうかを判断するのに役立ちます。
All Objects
All Objects ビューには、現在のヒープ内の様々なオブジェクトの数と合計サイズが表示されます。次の図からわかるように、アプリケーションの実行中に多数の LogContent オブジェクトが作成されます。
Allocation Call Tree
Allocation Call Tree ビューには、各メソッドに割り当てられたメモリ量がツリー図の形で表示されます。ご覧のように、
SamplePerformance$1.run()とSendProducerBatchTask.run()は大量のメモリを消費しています。
Allocation Hot Spots
多くのメソッドがある場合は、Allocation Hot Spots ビューで、どのメソッドに最も多くのオブジェクトが割り当てられているかをすぐに確認できます。
Thread History
Thread Historyビューでは、異なる時点での各スレッドの状態が表示されます。
異なるスレッドによって実行されるタスクは、異なる特徴を持っています。
スレッド
Pool-1-thread-<M>は定期的にProducer.send()メソッドを呼び出して非同期にデータを送信しています。これらはアプリケーションの起動中は実行を続けていましたが、その後はほとんどがブロックされていました。この現象の原因は、データ生成速度よりも Producer のデータ送信速度が遅いことと、各 Producer インスタンスのキャッシュサイズが制限されていることにあります。アプリケーション起動後、Producerには送信待ちのデータをキャッシュするための十分なメモリがあったため、pool-1-thread-<M>はしばらく起動したままでした。これは、アプリケーションの起動時にCPU使用率が高かった理由を説明するものです。pool-1-thread-<M>はプロデューサーが十分なスペースを解放するまで待たなければなりません。そのため、大量のスレッドがブロックされています。
aliyun-log-producer-0-moverは、期限切れのバッチを検出し、iothreadPoolに送信します。データ蓄積速度が速く、キャッシュされたデータサイズが上限に達した直後に、pool-1-thread-<M>によってプロデューサバッチがIOThreadPoolに送信されます。そのため、ムーバースレッドはほとんどの時間アイドル状態のままでした。
aliyun-log-producer-0-io-thread-<N>は、IOThreadPoolから指定したログストアにデータを送信し、ネットワークのI/O状態にほとんどの時間をかけています。
aliyun-log-producer-0-success-batch-handlerは、ログストアに正常に送信されたバッチを処理します。コールバックはシンプルで、実行にかかる時間は非常に短いです。そのため、SuccessBatchHandlerはほとんどの時間アイドル状態のままでした。
aliyun-log-producer-0-failure-batch-handlerは、ログストアへの送信に失敗したバッチを処理します。私たちの場合、送信に失敗したデータはありません。それはずっとアイドルのままでした。
私たちの分析によると、これらのスレッドのステータスは私たちの予想の範囲内です。検出されたオーバーヘッドホットスポット
アプリケーションの実行が終了すると、JProfilerは、実行時間が非常に短い頻繁に呼び出されるメソッドを表示するダイアログボックスを表示します。次回は、これらのメソッドを無視するようにJProfilerエージェントを設定することで、JProfilerによるアプリケーションのパフォーマンスへの影響を軽減することができます。
概要
JProfilerの診断に基づき、アプリケーションには大きなパフォーマンスの問題やメモリリークはありません。次の最適化のステップは、オブジェクトのシリアライズ効率の向上です。
参考文献
アリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ

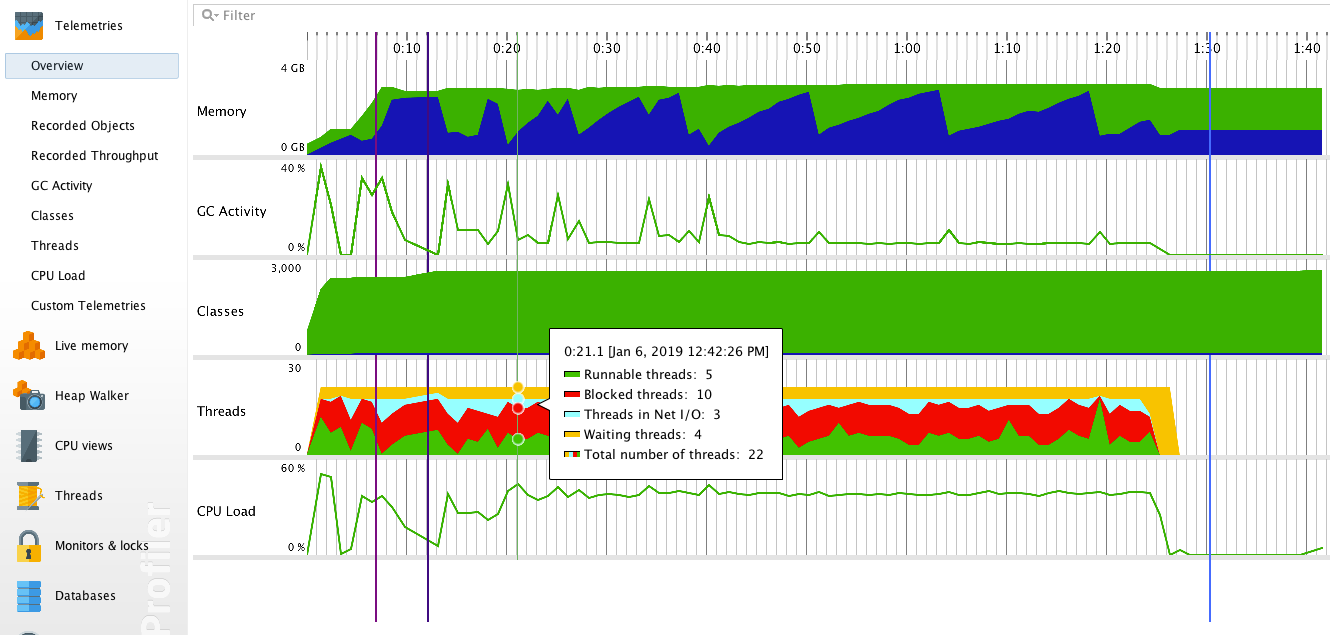
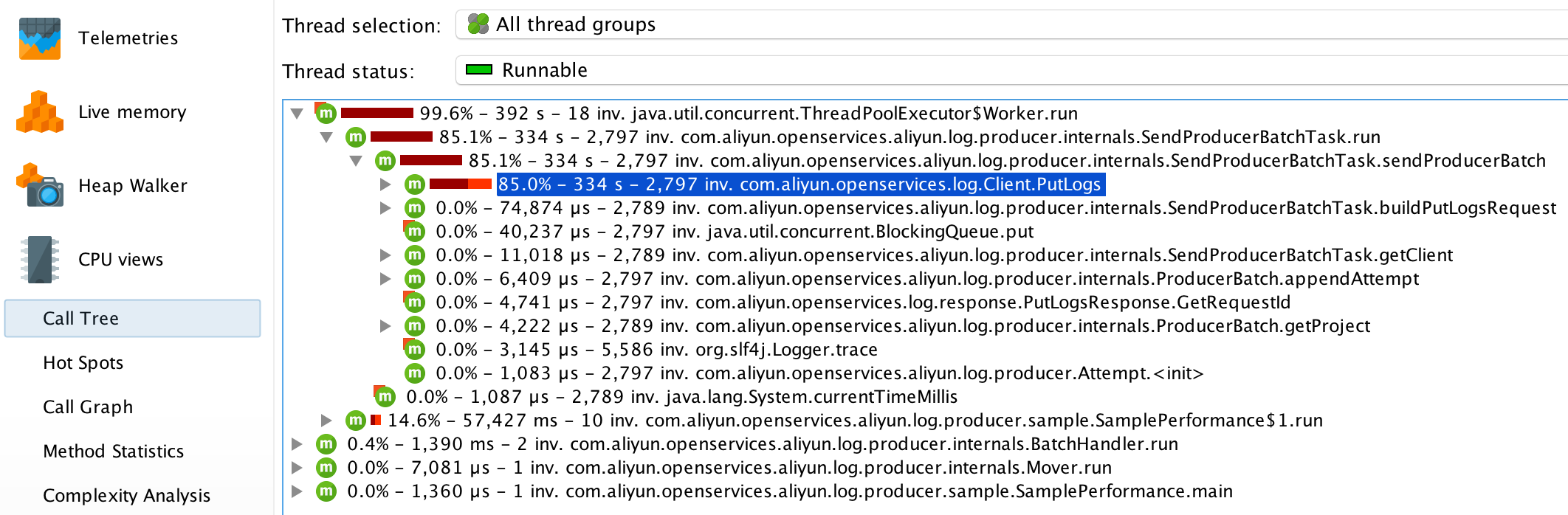
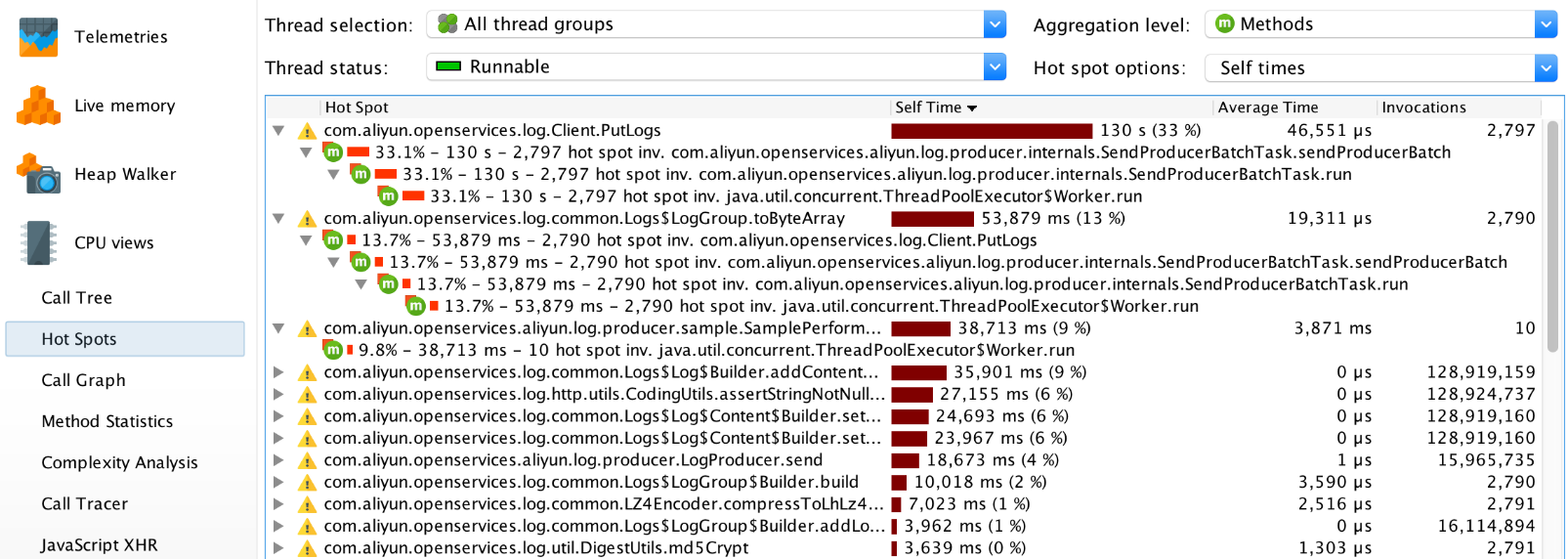
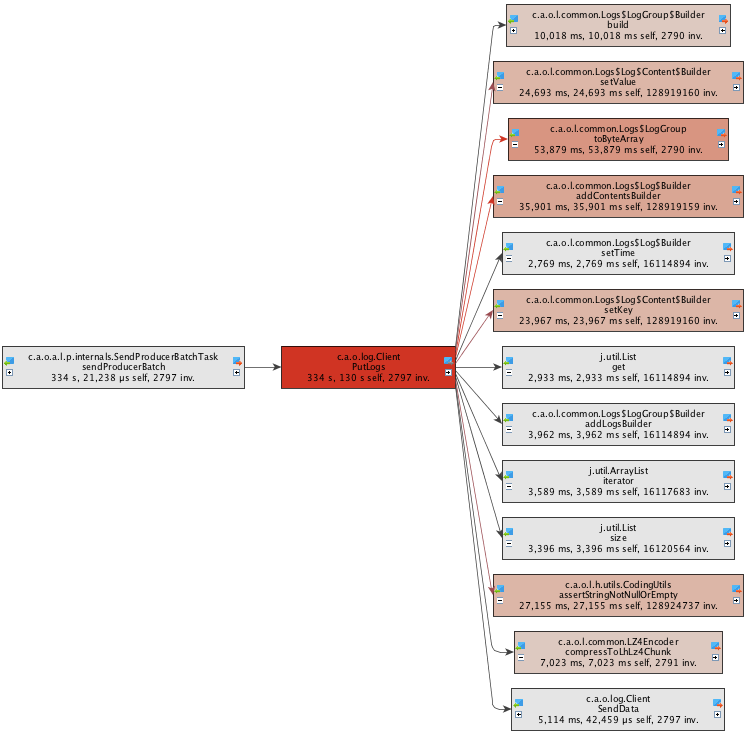
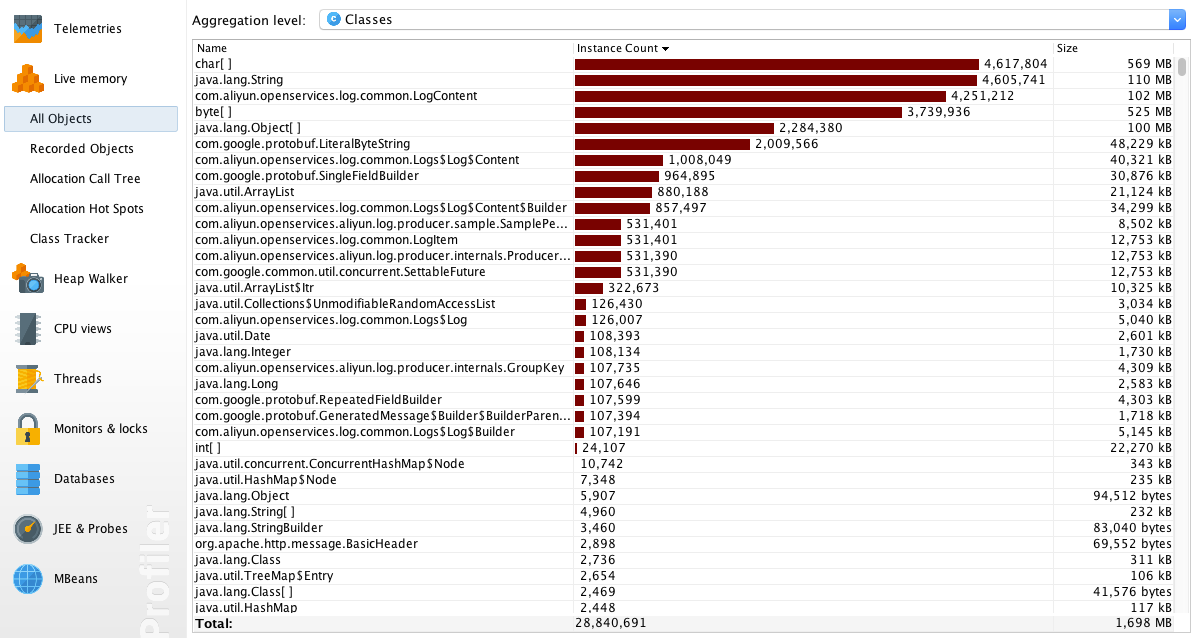
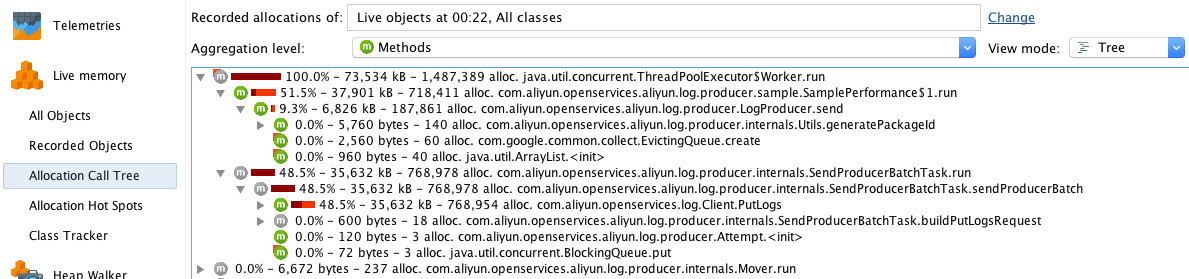
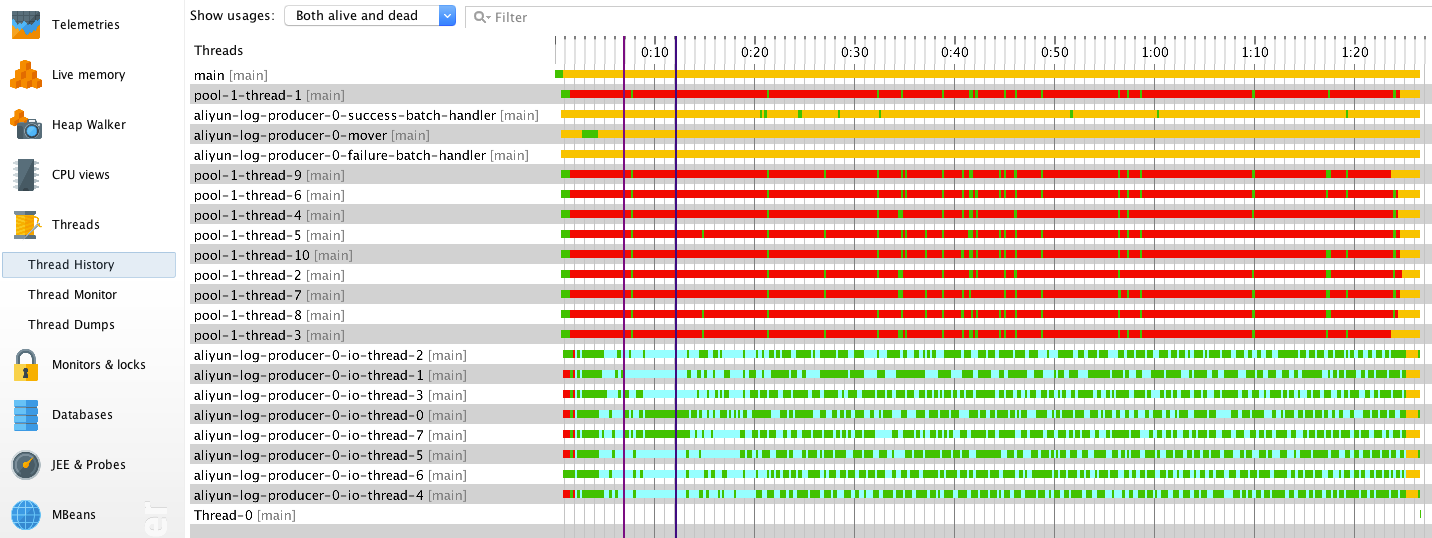
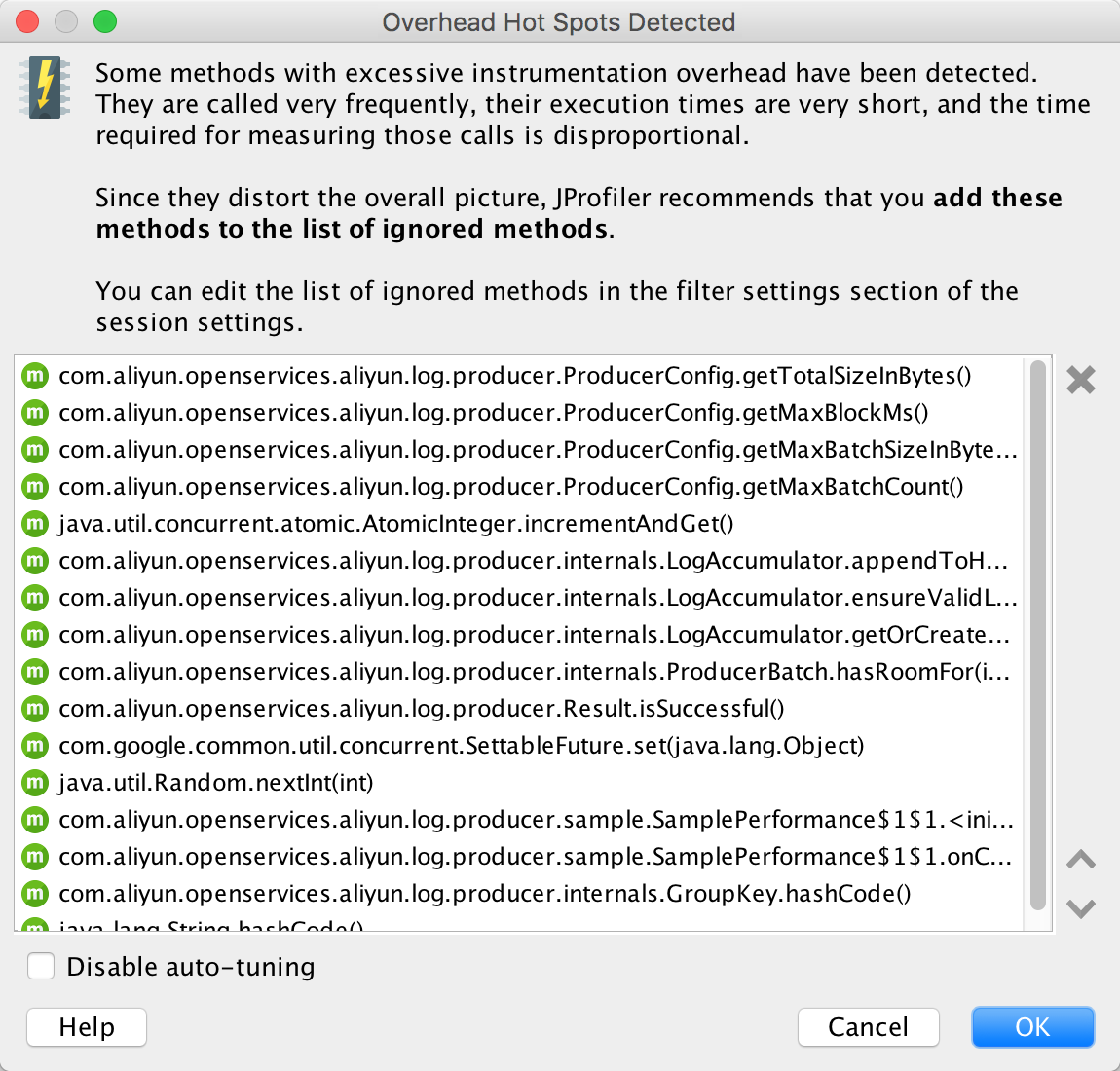
- 投稿日:2020-09-10T10:17:16+09:00
Javaの配列・リスト・ストリーム相互変換一覧表
インスタンスメソッドで直接変換できたり、クラスメソッドで用意されていたり、もっと複雑なことが必要だったり、ややこしかったので纏めておく。
from \ to T[]List<T>Stream<T>T[] arrayArrays.copyOf(array, array.length)Arrays.asList(array)(固定長・配列と連動)Arrays.stream(array)Stream.of(array)List<T> listlist.toArray(new T[0])new ArrayList<>(list)Collections.unmodifiableList(list)(変更不可)list.stream()list.parallelStream()(並列)Stream<T> streamstream.toArray(T[]::new)stream.collect(Collectors.toList())※コピー不可、データソースから組み直すこと
ドキュメント:
- 型
- ユーティリティクラス
- java.util.Arrays : 配列の各種操作
- java.util.Collections : リストやマップなどの各種操作
- java.util.stream.Collectors :
Stream#collect()の引数の生成その他:
- 投稿日:2020-09-10T10:14:19+09:00
JavaのTimerで時間指定の処理を作ろう!!
JavaTimer
一定間隔の時間を指定して、処理を実行したいときに使える
JavaTimerimport java.util.Timer; import java.util.TimerTask; public class TimeAction { public static void main(String[] args) { Timer timer = new Timer(); TimerTask tt = new TimerTask() { int count = 0; public void run() { // 定期的に実行したい処理 count++; System.out.println(count + "回目のタスクだよん。"); } }; //2秒後に、5秒間隔で実行する timer.scheduleAtFixedRate(tt,2000,5000); } }
- 投稿日:2020-09-10T09:57:55+09:00
JavaでDBlayerの実装(RDB、MySQL)
MySQL
DBConstants
まず、DB接続用の定数を定義しよう!!
DBConstantspublic class Constants { public static final String DB_SERVER = "localhost"; public static final String DB_PORT = "0000"; public static final String DB_DRIVER = "com.mysql.jdbc.Driver"; public static final String DB_USERNAME = "root"; public static final String DB_PASSWORD = "root"; public static final String DB_URL = "jdbc:mysql://localhost:0000/schema?autoReconnect=true&useSSL=false"; }DBConection
つぎに、データベースに接続するためのクラスをつくろう!!
DBConectionimport java.sql.Connection; import java.sql.DriverManager; import java.sql.SQLException; import java.sql.Statement; public class DBConn { //MySQLに接続 public Connection conn; //ステートメントを作成 public Statement stmt; public DBConn() { try { Class.forName(Constants.DB_DRIVER); conn = DriverManager.getConnection(Constants.DB_URL, Constants.DB_USERNAME, Constants.DB_PASSWORD); stmt = conn.createStatement(); } catch (Exception e) { e.printStackTrace(); } } public void finalize() { try { conn.close(); stmt.close(); } catch (SQLException e) { e.printStackTrace(); } } }DBEntity
お次は、Entityクラスをつくろう!!
DBEntitypublic class UserEntity { private int id = 1; private String username = null; private String password = null; private Date lastlogin = null; private boolean deleteflg = false; private String name = null; public UserEntity() { this(0, null, null); } public UserEntity(int id, String username, String password) { this.setId(id); this.setUsername(username); this.setPassword(password); } public int getId() { return id; } public void setId(int id) { this.id = id; } public String getUsername() { return username; } public void setUsername(String username) { this.username = username; } public String getPassword() { return password; } public void setPassword(String password) { this.password = password; } public Date getLastlogin() { return lastlogin; } public void setLastlogin(Date lastlogin) { this.lastlogin = lastlogin; } public boolean getDeleteflg() { return deleteflg; } public void setDeleteflg(boolean deleteflg) { this.deleteflg = deleteflg; } public String getName() { return name; } public void setName(String name) { this.name = name; } }DBDAO
最後に、DAOクラスをつくろう!!
(先につくったDBConnectionクラスを継承させよう)DBDAOimport java.sql.ResultSet; import java.sql.SQLException; import java.sql.*; import java.util.ArrayList; import java.util.Date; import java.util.List; public class UserDAO extends DBConn { public List<UserEntity> read(String wherestatement, String orderby, String ascdsc) throws SQLException { List<UserEntity> listuserEntity = new ArrayList<>(); String sqlQuery = "SELECT * FROM user"; if(wherestatement != "") { sqlQuery += " WHERE " + wherestatement; } if(orderby != "") { sqlQuery += " ORDER BY " + orderby; } if(ascdsc != "") { sqlQuery += " " + ascdsc; } //SELECT ResultSet rset = stmt.executeQuery(sqlQuery); while(rset.next()) { UserEntity userEntity = new UserEntity(); userEntity.setId(rset.getInt("id")); userEntity.setUsername(rset.getString("username")); userEntity.setPassword(rset.getString("password")); userEntity.setLastlogin(rset.getDate("lastlogin")); userEntity.setDeleteflg(rset.getBoolean("deleteflg")); userEntity.setName(rset.getString("name")); listuserEntity.add(userEntity); } //結果セットをクローズ rset.close(); return listuserEntity; } public UserEntity readId(int id) throws SQLException { UserEntity userEntity = new UserEntity(); //SELECT ResultSet rset = stmt.executeQuery("SELECT * FROM user WHERE id = "+ id); while(rset.next()) { userEntity.setId(rset.getInt("id")); userEntity.setUsername(rset.getString("username")); userEntity.setPassword(rset.getString("password")); userEntity.setLastlogin(rset.getDate("lastlogin")); userEntity.setDeleteflg(rset.getBoolean("deleteflg")); userEntity.setName(rset.getString("name")); } //結果セットをクローズ rset.close(); return userEntity; } public void add(UserEntity userEntity) throws SQLException { int id = userEntity.getId(); String username = userEntity.getUsername(); String password = userEntity.getPassword(); Date lastlogin = userEntity.getLastlogin(); boolean deleteflg = userEntity.getDeleteflg(); String name = userEntity.getName(); //INSERT int insert = stmt.executeUpdate("INSERT INTO user VALUES ("+ id +",'" +username +"','" + password +"'," + lastlogin + "," + deleteflg + ",'" + name + ")"); } public void update(int id, UserEntity userEntity) throws SQLException { int userid = userEntity.getId(); String username = userEntity.getUsername(); String password = userEntity.getPassword(); Date lastlogin = userEntity.getLastlogin(); boolean deleteflg = userEntity.getDeleteflg(); String name = userEntity.getName(); //UPDATE int rset = stmt.executeUpdate("UPDATE user SET id =" + userid +"," + "username = '" +username +"'," + "password = '" + password +"'," + "lastlogin =" + lastlogin + "," + "deleteflg =" + deleteflg + "," + "name = '" + name + " WHERE id =" + id); } public void delete(int id) throws SQLException { //DELETE int rset = stmt.executeUpdate("DELETE FROM user WHERE id = "+ id); } public List<UserEntity> readwhere(String wherestatement, String orderby, String ascdsc) throws SQLException { List<UserEntity> listuserEntity = new ArrayList<>(); //SELECT ResultSet rset = stmt.executeQuery("SELECT * FROM user WHERE " + wherestatement + " ORDER BY " + orderby +" " + ascdsc); while(rset.next()) { UserEntity userEntity = new UserEntity(); userEntity.setId(rset.getInt("id")); userEntity.setUsername(rset.getString("username")); userEntity.setPassword(rset.getString("password")); userEntity.setLastlogin(rset.getDate("lastlogin")); userEntity.setDeleteflg(rset.getBoolean("deleteflg")); userEntity.setName(rset.getString("name")); listuserEntity.add(userEntity); } rset.close(); return listuserEntity; } }