- 投稿日:2020-09-07T22:36:02+09:00
Pythonでコンフィグファイルを簡単に読み込むライブラリを作った
はじめに
Pythonでアプリケーションを作成する際に、
設定やパラメータをiniやjson,yaml形式のコンフィグファイルで持つことが多いと思います。
そのコンフィグファイルを簡単に読み込めるライブラリ:confileを作成しました!インストール
インストールはpipで行います。
pip install confile使用方法
下記はデータベースの接続情報が記述されたiniファイルの例です。
database.ini[mysql] host=localhost port=3306 user=user password=password db=db使い方は
read_configでファイルを読み込み、get_property,to_dictで値を取得します。>>> import confile # MySQL接続用 >>> import pymysql >>> db_config = confile.read_config('database.ini') >>> db_config.get_property('mysql', 'host') 'localhost' >>> db_config.get_property('mysql', 'port') 3306 # int型で返却 >>> db_config.get_property('mysql') {'host': 'localhost', 'port': 3306, 'user': 'user', 'password': 'password', 'db': 'db'} >>> db_config.to_dict() {'mysql': {'host': 'localhost', 'port': 3306, 'user': 'user', 'password': 'password', 'db': 'db'}} # MySQLに接続 >>> conn = pymysql.connect(**db_config.get_property('mysql'))ファイル種別の判別には拡張子を利用しています。そのため
cnf・conf・cfgのような拡張子の場合は、明示的にファイルの種別を指定する必要があります。>>> config = confile.read_config('db.conf', file_type='ini')
file_typeに指定できるものは、ini,json,yml,yamlのみです。コンフィグファイル
下記の3ファイルはライブラリから読み込むことで、同じ結果を返却します。
sample.ini[test] string = string int = 0 float = 0.0 date = 2001-01-23 boolean_true = True boolean_false = False list = ['a' ,'b', 'c'] dict = {'a': 1, 'b': 2, 'c': 3}sample.json{ "test": { "string": "string", "int": 0, "float": 0.0, "date": "2001-01-23", "boolean_true": true, "boolean_false": false, "list": [ "a", "b", "c" ], "dict": { "a": 1, "b": 2, "c": 3 } } }sample.ymltest: string: string int: 0 float: 0.0 date: 2001-01-23 boolean_true: True boolean_false: False list: - a - b - c dict: a: 1 b: 2 c: 3iniファイルは読み込む際に
astを利用しているため、Pythonの記法を利用することでリスト・辞書を表現できます。おわりに
コンフィグファイルを読み込むためのライブラリを作成しました。
初めてのライブラリを作成しため、おかしなところもあると思いますがぜひ利用してみてください!
Github
- 投稿日:2020-09-07T22:33:40+09:00
FastAPIについて ~エンドポイントエラーハンドリング~
FastAPIエラーハンドリングサンプル
FastAPI version_0.61.1
Documentation: https://fastapi.tiangolo.com
Source Code: https://github.com/tiangolo/fastapiFastAPIのエンドポイントは下記のように実装することで
エラーハンドリング可能になる。sample.pyfrom fastapi import routing def handle_wrapper(func): def routing_wrapper(*args, **kwargs): routing_api = func(*args, **kwargs) async def api_handle(request: Request) -> Response: try: http_response = await routing_api(request) except Exception as ex: """ここに任意の例外処理を記述する""" return http_response return api_handle return routing_wrapper routing.get_request_handler = handle_wrapper(routing.get_request_handler)http_response = await routing_api(request)このコードの7行目↑にてエンドポイントが呼び出されるため、
上記コードを応用してコールバック関数を定義することも可能となる。
- 投稿日:2020-09-07T22:31:54+09:00
PythonでPDFファイルを統合する
はじめに
Pythonの基本文法を勉強するために、複数のPDFファイルを1つのPDFファイルに統合するプログラムを書きました。PDFファイルの結合・書き込みにはPyPDF2を使用しています。
PyPDF2をインストール
pipを使用してPyPDF2をインストールします。
> pip install PyPDF2インポート
PDFファイルを統合するために
PdfFileMergerを、フォルダ指定時にPDFファイルを自動的に見つけるためにos,globをインポートしておきます。merge.py(1)from PyPDF2 import PdfFileMerger import os import glob初期化
統合するための初期化を行います。
merge.py(2)def main(): merger = PdfFileMerger() merge_files = []統合するファイルの指定
指定終了処理
まずは、
mと入力されるまで指定を続け、mが入力された場合にはファイルの指定を終了して次の処理に進むようにしておきます。変数iはファイルの数をカウントするためのものです。merge.py(3)i = 1 while True: print("Merge file or Folder ", i, " (Type 'm' to merge.) -> ", sep='', end='') in_file = input() if in_file == 'm': breakファイルを指定
入力されたパスがファイル名であり、PDFファイルである場合にはマージするファイルリストに追加していきます。拡張子がPDFではない場合にはそれを伝えるメッセージを出力しています。
merge.py(4)elif os.path.isfile(in_file): ext = os.path.splitext(in_file) if ext == '.pdf': merge_files.append(in_file) i += 1 else: print("指定したファイルはPDFファイルではありません.")ここではまず、
os.path.isfile()によって引数がファイルであるかフォルダであるかを識別しています。次に、os.path.splitext()を使って拡張子を識別しています。
指定したファイルがPDFファイルであった場合には、append()によってマージするファイルのリストに追加します。フォルダを指定
入力されたパスがフォルダ名だった場合には、そのディレクトリ下にあるpdfファイルを全てリストに追加し、追加したファイル名を出力しています。
merge.py(5)else: for file in glob.glob(in_file + '*.pdf'): merge_files.append(file) print("Add " + file) i += 1
glob.glob()によって指定フォルダ内のPDFファイルをリスト化し、順にマージするリストに追加しています。出力ファイルの指定
出力するPDFファイルの名前を指定します。指定した名前の拡張子が
merge.py(6)print("Generated file -> ", end='') out_file = input() ext = os.path.splitext(out_file) if ext != '.pdf': out_file = out_file + '.pdf'ここでも
os.path.splitext()を使って拡張子を調べています。ファイルを統合・出力
統合するファイルはmergerに一旦追加してから指定ファイルに書き込みます。
merge.py(7)for file in merge_files: merger.append(file) merger.write(out_file) merger.close() print("File merge completed!!")
append()によってmergerに追加してから、write()によって指定出力先にPDFファイルを作成します。最後に
コード全体はgithubからご確認ください → ( PDF-Handler )
Pythonは初心者なので読みづらい部分があるかと思いますがご了承ください。
- 投稿日:2020-09-07T21:44:27+09:00
過去の電力使用量取得 四国電力編
はじめに
電力使用量予測のセミナーをしていて、各電力会社の公表されている過去の使用電力量の形式がまちまちなので取得するのが難しいというご意見を聞いていました。
そこで、それぞれの電力会社別にデータの取得方法をまとめてみます。ちなみに、対象とする電力会社は、北海道電力、東北電力、東京電力、北陸電力、中部電力、関西電力、中国電力、四国電力、九州電力、沖縄電力で、今回は四国電力さんを扱ってみます。
注:大量のダウンロードを繰り返すとサーバに負担がかかるので、ダウンロードは一回だけにするか、対象期間を限定して行うよう心がけて下さい。
動作環境
GoogleさんのCoraboratoryという環境で動作させます。
Webサイト
以下のWebサイトからデータをダウンロードできそうです。
ダウンロード
for y in range(2016, 2020): url = "https://www.yonden.co.jp/nw/denkiyoho/csv/juyo_shikoku_{:04}.csv".format(y) print(url) !wget $url読込と可視化
from glob import glob import pandas as pd files = glob("*.csv") files.sort() df_juyo = pd.DataFrame() for f in files: print("\r", f, end="") df = pd.read_csv(f, skiprows=2, encoding="Shift_JIS") df_juyo = pd.concat([df_juyo, df]) df_juyo.index = pd.to_datetime(df_juyo["DATE"] + " " + df_juyo["TIME"]) df_juyo.pop("実績(万kW)").plot(figsize=(15,5))
できた!
沖縄電力さんの上限が140万kWh、九州電力さんは1500万kWh、四国電力さんが500万kWh...次の電力会社さんが楽しみになります!
電気使用量を見ると、色々な気付きがありますね。
以上、現場からきむらがお伝えしました。補足
記事を読んだ人から「時間がかかり過ぎるので、手っ取り早くデータが欲しい場合にはどうしたら良いか?」という質問があったので、ちょっとだけデータを販売してみることにしました。
データに興味があれば以下のURLをご覧下さい。https://ticket.tsuku2.jp/eventsDetail.php?ecd=16260900020422
- 投稿日:2020-09-07T21:40:46+09:00
初投稿!!
投稿していく記事について
何かインターネット上にアウトプットする練習がしたい。でも何をしたらよいかわからない。
ということで、いつもお世話になっているQiitaで投稿を始めることにしました。
書く記事としては今のところ主に下の二つくらいかなと考えています。
アウトプットに慣れて様々なジャンルの記事が書けるように頑張りたいと思います!!AtCoder記
何か新しいシステムやアプリを作ることができないか、日々考えながら生活していますが
どうもアイディアが浮かばない。浮かんだとしてもそれは二番煎じのものであったり、
既存システムの派生したものしか浮かんでこない、、。「どうしたらよいものか、、」と思うことは多々ありますが、兎にも角にも新しいアイディアというものは斬新な考え方と柔軟な発想からできているなぁとよく思います。
僕自身、この二つのどちらかでも持ち合わせているとよいのですが、そうじゃないのが現実。
でも、考え方や発想というものは鍛えることができると思うのでここにその日記をつけていきたいと思います。(こういうように宣言しないと続かないのが事実)
温かい目で見守ってもらえるとありがたいです。
また、「この部分こういう考えのほうがスマートじゃん!」や「もっと改善できる」などの
アイディアがあればぜひぜひお願いいたします。システム・アプリ開発記
アイディアを浮かべるだけでなくアウトプットもしなければいけないと思うので、AtCoder記とは別で作成途中のシステムを記事に起こしていこうと思います。
正直、開発に関してはあんまり得意ではないのでこちらの更新は少々遅めになると思います。
最近はLINEを扱って何かできないかという記事を漁りながらシステムを作成中です。
皆さんが面白そうだけど、自分ではやる気にならないと思うようなことでもアイディアの一つとして教えていただければ幸いです!終わりに
普段、TwitterやInstagramのアカウントを持っているのに全く投稿しない僕としてはかなり珍しく文章を書いています。自分でもびっくりです。
この調子で他の記事も続けて出せるように時間を作って頑張ります。ではまた次回、別の記事でお会いしましょう。
- 投稿日:2020-09-07T21:39:59+09:00
蟻本をpythonで(chapter3 中級編~)
はじめに
プログラミングコンテストチャレンジブック(通称:蟻本)の問題をpythonで解いていきます。
類題も交えながら少しずつ更新していく予定です。初級編については@sabaさんの記事を参照するのが良いと思います。
https://qiita.com/saba/items/affc94740aff117d2ca93-1 値の探索だけじゃない!"二分探索"
p128 lower_bound
N = 5 A = [2, 3, 3, 5, 6] K = 3 # K以上であるAiのうち最も左にあるもののインデックス print(bisect_left(A, K))p129 cable master
N = 4 K = 11 L = [8.02, 7.43, 4.57, 5.39] def f(target): cnt = 0 for i in range(N): cnt += math.floor(L[i] / target) #各紐から長さtargetの紐がいくつ取れるか if cnt >= K: #K本以上取れれば return True else: return False ng = 0 ok = 10 ** 9 + 1 for i in range(100): mid = (ng + ok) / 2 if f(mid): ng = mid else: ok = mid print(math.floor(ok * 100) / 100) # 小数点2位まで求めるp131 aggressive cows
N = 5 M = 3 X = [1, 2, 8, 4, 9] X.sort() def c(d): last = 0 # 現在の地点を記録する # M - 1回現在の場所からd以上離れた場所に飛べるか for _ in range(M - 1): crt = last + 1 # crtを進めて次に飛ぶ場所を探す while crt < N and X[crt] - X[last] < d: crt += 1 if crt == N: # 次に飛ぶ場所が見つからなければ return False last = crt # 次の場所に飛ぶ return True # M - 1回飛べれば ok = -1 ng = 10 ** 9 + 1 while abs(ok - ng) > 1: mid = (ok + ng) // 2 if c(mid): ok = mid else: ng = mid print(ok)p132 平均最大化
N = 3 K = 2 W = [2, 5, 2] V = [2, 3, 1] def c2(x, w, v): # 「単位重さあたりの価値がx以上になる」を満たすよう選んだ商品の集合を # S([w1, v1], [w2, v2]...[wk, vk])とする。この時 # sum(v1, v2...vk) / sum(w1, w2...wk) >= x より # sum(v1, v2...vk) - x * sum(w1, w2...wk) >= 0 # sum(v1 - x * w1, v2 - x * w2, ...vk - x * wk) >= 0 # v[i] - x * w[i]を大きい順にk個取ったときそれが0以上になればいい cnt = 0 items = [v[i] - x * w[i] for i in range(N)] items.sort(reverse = True) for i in range(K): cnt += items[i] return cnt >= 0 ok = 0 ng = 10 ** 9 + 1 for i in range(100): mid = (ng + ok) / 2 if c2(mid, W, V): ok = mid else: ng = mid print(ok)3-2 厳選!頻出テクニック(1)
- 投稿日:2020-09-07T20:32:54+09:00
ちょっと最適化問題が解けるplatypusを動かしてみた-その2
前の記事の
ちょっと最適化問題が解けるplatypusを動かしてみた
で、ドキュメントのDTLZ2 問題問題を動かしてみた。
でも、このドキュメントが細かく書いてないので、よくわかりません。ちょっと簡単な問題で、どう計算されるか、動かしてみて、理解しようと思います。
minimize (x,-x)\qquad for\quad x\in[-10,10]plotypusの例題にある問題を少し変えてます。
この問題の意味は、$x$が$-10$から$10$を取った時に、二つの関数y=f(x)\qquad y=-f(x)を最小にする答えは何か?という問題です。
まず
importです。この3つでよさそうです。
from platypus import NSGAII, Problem, Real次に多目的解の元となる関数を作ります。
def schaffer(x):return [x[0], (x[0]*(-1))]
problem = Problem(1, 2)で、説明変数の数と目的変数の数を設定します。つまり、説明変数の$x$が一つで、目的変数が2つと言っているのだと思います。
次に
problem.types[:] = Real(-10, 10)で、xに与える数値の型と範囲を設定します。Realは,たぶん実数であるという宣言だと思います。
problem.function = schafferで、計算する関数を宣言します。schaffer関数を問題として解くと宣言します。
algorithm = NSGAII(problem)で、NSGAIIでproblemで宣言してきた関数の問題を解くというインスタンスを作ります。
algorithm.run(10000)で、10000回繰り返して計算すると設定して、計算を行います。これが基本で、設定を変えていけば、なんとか動きそうです。
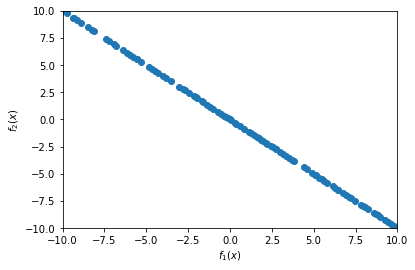
from platypus import NSGAII, Problem, Real def schaffer(x): return [x[0], (x[0]*(-1))] problem = Problem(1, 2) problem.types[:] = Real(-10, 10) problem.function = schaffer algorithm = NSGAII(problem) algorithm.run(10000)答えが出て、勝手に
resultに入っているようなので、それを取り出して、グラフを描きます。import matplotlib.pyplot as plt plt.scatter([s.objectives[0] for s in algorithm.result], [s.objectives[1] for s in algorithm.result]) plt.xlim([-10, 10]) plt.ylim([-10, 10]) plt.xlabel("$f_1(x)$") plt.ylabel("$f_2(x)$") plt.show()結果です。
まぁ、予想通りの答えです。
- 投稿日:2020-09-07T19:25:16+09:00
Blender 2.8, Python, カメラ移動、乱数色指定
Blender 2.8, Python での3D動画作り、
今回は円周沿いカメラ移動と乱数色彩の素材指定と太陽光です。
動画はこちら
blender 2.8, python movie 1 sec. 360kB. camera motion along a circle.100個くらい建物(単に直方体)作ると1秒で800px*600pxでも682kBになりました。
まだまだ色の指定と光の具合がうまくつかめません。
太陽光が届かない建物の影には空の青い色が反映されているのだろうなと考えてます。ところで、良いプログラム(ソースコード)の条件。
自分が何度か書いて、忘れて、また見直して、再利用して、の経験で考える良いプログラムはこんな感じ。
◎適度にコメントが付いている
◎変数名は英語なりローマ字なり意味あるものになっている
◎後で変数(variable, parameter) を変更しやすいよう設定部分をまとめてある
◎(一時使用のような、不要なコメント行は消してある)
◎他の資料からコピーした部分は引用元を書く(数年でURL先では消えるが?)# bpy_nh18 (random color, brown)2020/9/6日曜 (静止画茶色平板と、動画で茶色建物) import bpy import random # ========= DELETE ALL mesh, light, camera, みな削除する2行 ========= for item in bpy.data.objects: bpy.data.objects.remove(item) # ======================== add cubes, random resize , random color for x in range(16): for y in range(16): bpy.ops.mesh.primitive_cube_add(size=2.0, location=(4*x-4, 5*y-5, 0.0)) bpy.ops.transform.resize(value=(1.0, 1.0, (random.randint(2, 8)))) obj = bpy.context.view_layer.objects.active mat = bpy.data.materials.new('Cube') r1=0.15+ 0.8*random.random() g1=0.07+ 0.3*random.random() b1=0.01+ 0.05*random.random() mat.diffuse_color = (r1, g1, b1, 0) #====== random BROWN COLOR obj.data.materials.append(mat) # Add a plane for ground ================== bpy.ops.mesh.primitive_plane_add(size=200.0, align='WORLD', location=(0.0, 0.0, 0.0), rotation=(0.0, 0.0, 0.0) ) matp = bpy.data.materials.new('Plane') matp.diffuse_color = (0.4, 0.2, 0.01, 0) obj.data.materials.append(matp) # ================== # world - surface - background (背景) bpy.data.worlds["World"].node_tree.nodes["Background"].inputs[0].default_value = (0.01, 0.15, 0.25, 1) bpy.data.worlds["World"].node_tree.nodes["Background"].inputs[1].default_value = 0.7 # ============== "light" # create light datablock, set attributes #light_data = bpy.data.lights.new(name="light_spot1", type='SPOT') light_data = bpy.data.lights.new(name="light_spot1", type='SUN') light_data.energy = 5 # create new object with our light datablock light_object1 = bpy.data.objects.new(name="light_spot1", object_data=light_data) # link light object bpy.context.collection.objects.link(light_object1) # make it active bpy.context.view_layer.objects.active = light_object1 #change location light_object1.location = (-3, -10, 50) light_object1.delta_rotation_euler = (1.3, 0, -0.3) #ゼロゼロゼロで真下を向く。 # update scene, if needed dg = bpy.context.evaluated_depsgraph_get() dg.update() # ================ # ================== ================= camera movement bpy.ops.curve.primitive_bezier_circle_add(enter_editmode=False, align='WORLD', location=(20, 20, 30)) bpy.context.object.scale[0] = 50 bpy.context.object.scale[1] = 50 bpy.ops.object.empty_add(type='CUBE', align='WORLD', location=(0,0,0)) bpy.ops.object.camera_add(enter_editmode=False, align='VIEW', location=(0,0,0), rotation=(0, 0, 0)) bpy.data.objects['Empty'].select_set(True) bpy.data.objects['Camera'].select_set(True) bpy.context.view_layer.objects.active = bpy.data.objects['Empty'] bpy.ops.object.parent_set(type='OBJECT') bpy.data.objects['Camera'].select_set(False) bpy.data.objects['Empty'].select_set(True) bpy.ops.object.constraint_add(type='FOLLOW_PATH') bpy.context.object.constraints["Follow Path"].target = bpy.data.objects["BezierCircle"] bpy.context.object.constraints["Follow Path"].use_curve_follow = True bpy.context.object.constraints["Follow Path"].use_fixed_location = True bpy.data.objects['Empty'].select_set(False) bpy.data.objects['Camera'].select_set(True) bpy.ops.object.constraint_add(type='TRACK_TO') #bpy.context.object.constraints["Track To"].target = bpy.data.objects["Cube.016"] bpy.context.object.constraints["Track To"].target = bpy.data.objects["Cube.052"] bpy.context.object.constraints["Track To"].up_axis = 'UP_Y' bpy.context.object.constraints["Track To"].track_axis = 'TRACK_NEGATIVE_Z' #5m00sec #Camera Keyframe #(Insert keyframe to object's Offset Factor Python API - stack exchange) bpy.data.objects['Camera'].select_set(False) bpy.data.objects['Empty'].select_set(True) bpy.context.scene.frame_current = 1 bpy.context.object.constraints["Follow Path"].offset_factor = 0 ob = bpy.context.object # ob.constraints['Follow Path'] # bpy.data.objects['Empty'].constraints["Follow Path"] # [bpy.data.objects['Empty'].constraints["Follow Path"]] con = ob.constraints.get("Follow Path") con.offset_factor = 0.0 con.keyframe_insert("offset_factor", frame=1) con.offset_factor = 0.25 con.keyframe_insert("offset_factor", frame=8) con.offset_factor = 0.50 con.keyframe_insert("offset_factor", frame=16) con.offset_factor = 0.75 con.keyframe_insert("offset_factor", frame=23) con.offset_factor = 0.99 con.keyframe_insert("offset_factor", frame=30) # ==== END of camera movement

- 投稿日:2020-09-07T19:23:10+09:00
XGBoostのcallbackを使ってearly_stoppingがかかったときのnum_boost_roundの回数を表示させたい(未達成)
前提
筆者超絶弱者なので備忘録として残してます。
間違いがあったら優しく指摘してくださいメンタル豆腐なので
参考サイトのコードを自分なりにわかりやすくした備忘録
環境はazuremlでハイパラ探しにoptuna回してます前提知識
- num_boost_roundは勾配ブースティングのイテレーションの回数
- early_stoppingはvalidationに対して指定回数、予測精度が向上しなかった際にそのroundを終わらせる
- callbackはXGBoostに搭載されてるデバッグのような機能(曖昧)
- 参考https://xgboost.readthedocs.io/en/latest/python/python_api.html#callback-api
実装
最低限の実装
def return_callback(): def print_num_boost_round(env): iteration = env.iteration msg = '\t'.join([str(x) for x in env.evaluation_result_list]) print(i, msg)得られる結果として
0 ('validation_0-mae', 2657.650391) 1 ('validation_0-mae', 2657.609375) 0 ('validation_0-mae', 2624.649658) 2 ('validation_0-mae', 2657.425049) 1 ('validation_0-mae', 2624.609131)のようなものが得られる
次にコードを以下に変更するdef return_callback(): def print_num_boost_round(env): print(env)XGBoostCallbackEnv(model=<xgboost.core.Booster object at 0x7fa972703208>, cvfolds=None, iteration=0, begin_iteration=0, end_iteration=100, rank=0, evaluation_result_list=[('validation_0-mae', 2657.623047)]) XGBoostCallbackEnv(model=<xgboost.core.Booster object at 0x7fa972703208>, cvfolds=None, iteration=1, begin_iteration=0, end_iteration=100, rank=0, evaluation_result_list=[('validation_0-mae', 2657.463379)]) XGBoostCallbackEnv(model=<xgboost.core.Booster object at 0x7f7a8224c208>, cvfolds=None, iteration=0, begin_iteration=0, end_iteration=100, rank=0, evaluation_result_list=[('validation_0-mae', 2624.622314)]) XGBoostCallbackEnv(model=<xgboost.core.Booster object at 0x7fa972703208>, cvfolds=None, iteration=2, begin_iteration=0, end_iteration=100, rank=0, evaluation_result_list=[('validation_0-mae', 2657.411377)]) XGBoostCallbackEnv(model=<xgboost.core.Booster object at 0x7f7a8224c208>, cvfolds=None, iteration=1, begin_iteration=0, end_iteration=100, rank=0, evaluation_result_list=[('validation_0-mae', 2624.467285)]) XGBoostCallbackEnv(model=<xgboost.core.Booster object at 0x7fa972703208>, cvfolds=None, iteration=3, begin_iteration=0, end_iteration=100, rank=0, evaluation_result_list=[('validation_0-mae', 2657.355957)]) XGBoostCallbackEnv(model=<xgboost.core.Booster object at 0x7f0ced02c208>, cvfolds=None, iteration=0, begin_iteration=0, end_iteration=100, rank=0, evaluation_result_list=[('validation_0-mae', 2639.834229)]) XGBoostCallbackEnv(model=<xgboost.core.Booster object at 0x7f7a8224c208>, cvfolds=None, iteration=2, begin_iteration=0, end_iteration=100, rank=0, evaluation_result_list=[('validation_0-mae', 2624.416016)])iterationの値をenv.iterationで取得していることがわかった
参考(https://kunsen.net/2020/05/02/post-3199/)
Optunaでnum_boost_roundを回してみて判断する
param_list['num_boost_round'] = trial.suggest_int("num_boost_round", 100, 500)まずこれで初期値の100から500くらいでnum_boost_roundを回してみる
指定済みのパラメータ
- "objective": "reg:gamma",
- "eval_metric": "mae",
- "verbosity": 0,
- "booster": "gbtree",
- "subsample": 1,
- "subsample_freq": 0,
- "early_stopping": 5,
- "colsample_bylevel": 1,
Optunaで指定するパラメータ一覧
- "min_child_weight": ""
- "eta": "",
- "lambda": "",
- "alpha": "",
- "num_leaves": "",
- "colsample_bytree": "",
- "num_boost_round": "",
このまま回すと
{ 'max_depth': 20, 'eta': 0.22613771945050443, 'num_leaves': 2560, 'lambda': 6.0425529841148486e-05, 'alpha': 6.69043393720362e-07, 'num_boost_round': 236, 'colsample_bytree': 0.9727432424922707, 'min_child_weight': 239.6173703091301 }num_boost_roundは236となる(Optunaの気まぐれなので毎回同じにはならない)
では何が236なのか...
そもそも236回回っているのか(ちなみに再度実行したら253だった)
結果の出力として0 ('validation_0-mae', 2657.650391) 1 ('validation_0-mae', 2657.609375) 0 ('validation_0-mae', 2624.649658) 2 ('validation_0-mae', 2657.425049) 1 ('validation_0-mae', 2624.609131)のように出力されるのだが、iterationはend_iterationが示しているように100までしか回らない
次に値が最小になるところを探した(手作業)
135.56956というのが最小の値だったので、その値が出た行数をカウントした
結果は482結論
よく観察するとiterationが同じだからといって値が同じとは限らない
XGBoostの論文とか読んで前提知識として持ってるとわかりやすかったのかもしれない...
今はゴリ押しでいくしかないのか...??
- 投稿日:2020-09-07T18:54:35+09:00
マルコフ連鎖でレポートを自動作成してみた
マルコフ連鎖とは
マルコフ連鎖を簡単に説明すると、前の時点の状態によって次の時点の状態が決まるというものです。
文章での具体例を見てみると、「おなかが」という言葉を見たら次に「空いた」が来そうな感じがしますよね。でもこれは「空いた」だけが正解ではなく、他にも「いっぱい」が来てもいいわけです。なので、これを確率で表すことを考えようと思います。
「おなかが」の次に続く言葉は、60%の確率で「空いた」、40%の確率で「いっぱい」になると仮定しましょう。この確率が遷移確率と呼ばれる次のそれぞれの状態の確率になります。
ここまでで簡単にですが、マルコフ連鎖について説明しました。ここら辺の話を詳しく知りたい方は マルコフ連鎖の基本とコルモゴロフ方程式(高校数学の美しい物語) 読んでみてくださいただし、文章がマルコフ連鎖ですべて説明できるかといわれたらそうではありません。例えば「僕は おなかが」ときたら「空いた」になる確率が高そうですが、「もう おなかが」ときたら「いっぱい」になる確率が高そうです。
これは文章は一つ前だけでなくもっと前の言葉にも依存しているということです。もっと言えば文脈なんてのにも依存します。しかし、この記事ではマルコフ連鎖を扱うのでここら辺は別の記事で紹介できればと思います。プログラム
今回作成したプログラムは自分で作成した報告書のデータを用いて新たなレポートを自動生成することを目的としました。ということでまずファイルを読み込んでいきます。
import random from janome.tokenizer import Tokenizer with open("data.csv", "rt", encoding="utf-8_sig") as f: text_raws = f.read() text_raws = text_raws.replace("\n", "@\n").split("\n")data.csvを読み込みました。ここでは筆者の報告書のデータですがこれを外部に公開するのは多少まずい気がするので、githubに載せる際は適当な文章にしておきます。
読み込んでから置換しているのは文末のマークとして@を挿入したかったからです。text_lists = [] t = Tokenizer() for text_raw in text_raws: text_list = [] tokens = t.tokenize(text_raw, wakati=True) for token in tokens: text_list.append(token) text_lists.append(text_list)Tokenizerを用いて形態素解析を行っていきます。形態素解析とは文章を単語に分かち書きするもので、例えば以下のようになります。
["僕はqiitaに記事を投稿する。"]
↓
['僕', 'は', 'qiita', 'に', '記事', 'を', '投稿', 'する', '。']また、デフォルトでは品詞などの余分な情報も付記されてしまうのでパラメーターを
wakati=Trueとすることで言葉だけを取り出しています。dic = {} for text_list in text_lists: for i in range(len(text_list) - 1): if text_list[i] in dic: lists = dic[text_list[i]] else: lists = [] lists.append(text_list[i + 1]) dic[text_list[i]] = listsここでは、{"おなか":["すいた","いっぱい"]}のような辞書形式で前の言葉と次の言葉の対応関係を生成しています。
word = input("最初の言葉を入力してください") generate = word word = list(t.tokenize(word, wakati=True))[-1] limit = 10000 cnt = 0 while cnt < limit: try: word = random.choice(dic[word]) if word == "@": break except: break cnt += 1 generate += word print(generate)最初の言葉は入力してもらう形式にしました。そして入力した言葉を形態素解析して、その最後の単語からマルコフ連鎖をスタートさせます。遷移確率に関しては辞書の中からランダムに取り出すことで、出現回数に応じて比例させることにしています。
最後に文末のしるしとして導入した、@に到達するか無限ループしないように上限を決めて終了です。以上で、プログラムは完成しました。実際に試してみましょう。
入力「今日は」
生成「今日はあまり満足の手順を集約して不自然な技術を踏まえることを利用することが遅れができた。」入力「人」
生成「人に着けようともっと多くている将来に具体的大雨のデータの手順を技術支援という流れを見ることが必要と思った。」ちょっと何言ってるかわかんないですね。冒頭でも述べましたが、言語は直前の言葉だけで決まるものではないため、「多く→て→いる」のように不自然なつながり方をしてしまいました。次回はLSTMなどを使ってより多くの過去の状態から最適な語を判断できるように改良したいと思います。
ソースコードはこちら参考文献
Pythonでツイートを生成したい! -マルコフ連鎖編-
マルコフ連鎖の基本とコルモゴロフ方程式(高校数学の美しい物語)
- 投稿日:2020-09-07T18:50:34+09:00
AtCoder ABC177 A-Dをpythonで
AtCoder ABC177 A-D問題までpythonで解いてみた.
AtCoder ABC177に参加したのでその記録として投稿しようと思います.
A問題
高橋君は青木君と待ち合わせをしています。
待ち合わせ場所は高橋君の家からDメートル離れた地点であり、待ち合わせの時刻はT分後です。
高橋君は今から家を出発し、分速Sメートルで待ち合わせ場所までまっすぐ移動します。
待ち合わせに間に合うでしょうか?考えたこと
分速Sメートルで移動できる高橋君がT分で移動できる最大距離はS*Tです.
この値とDを比較すれば良いです.(不等号を間違えて1WA出しました())d, t, s = map(int, input().split()) if s*t >= d: print("Yes") else: print("No")B問題
2つの文字列S,Tが与えられます。TがSの部分文字列となるように、Sのいくつかの文字を書き換えます。
少なくとも何文字書き換える必要がありますか?考えたこと
len(S)>=len(T)より文字列TをSの中で動かしていき,その一致した最大文字数だけlen(T)から引いた値が答えとなります.
s = input() t = input() sl = len(s) tl = len(t) cnt = 0 ans = 0 for i in range(sl-tl+1): for j in range(tl): if t[j] == s[i+j]: cnt += 1 ans = max(cnt, ans)#ans:一致した文字数の最大値 cnt = 0 print(tl - ans)C問題
N個の整数A1,…,ANが与えられます。1≤i<j≤Nを満たす全ての組(i,j)についての Ai×Ajの和を mod(10**9+7)で求めてください。
考えたこと
愚直にfor文を二重で回すとO(N^2)よりTLEになってしまう...
とりあえず書き出してみると以下のことが分かった.
ex.i=1, 2,...の時を考える.
sum = A1+A2+...ANとする.
i=1の時
A1 x A2 + A1 x A3 + A1 x A4 + ・・・・ + A1 x AN
= A1 x (sum - A1)
i=2の時
A2 x A3 + A2 x A4 + A2 x A5 + ・・・・ + A2 x AN
= A2 x (sum - A1 - A2)
これならばO(N)で抑えられる.
これをPythonで実装すると,n = int(input()) A = [0]+list(map(int, input().split())) mod = 10**9 + 7 S = sum(A) ans = 0 for i in range(1, n): ans += A[i]*(S-A[i]) ans %= mod S -= A[i] print(ans)D問題
人1から人NまでのN人の人がいます。「人Aiと人Biは友達である」という情報がM個与えられます。同じ情報が複数回与えられることもあります。
XとYが友達、かつ、YとZが友達ならば、XとZも友達です。また、M個の情報から導くことができない友達関係は存在しません。
悪の高橋君は、このN人をいくつかのグループに分け、全ての人について「同じグループの中に友達がいない」という状況を作ろうとしています。
最小でいくつのグループに分ければ良いでしょうか?考えたこと
UnionFindTreeで最大の集合の要素数を答えれば良いです.
最大の集合を分解しその1つ1つの要素にその他の集合の要素を割り振れば良いからです.
UnionFindTreeの解説はYoutubeでかつっぱさんの動画をみれば理解できると思います.
'Friend'という文字列が入った問題はUnionFind使いがちらしいです()import sys sys.setrecursionlimit(10 ** 9) class UnionFind(): def __init__(self, n): self.n = n self.root = [-1]*(n+1) self.rnk = [0]*(n+1) def Find_Root(self, x): if(self.root[x] < 0): return x else: self.root[x] = self.Find_Root(self.root[x]) return self.root[x] def Unite(self, x, y): x = self.Find_Root(x) y = self.Find_Root(y) if(x == y): return elif(self.rnk[x] > self.rnk[y]): self.root[x] += self.root[y] self.root[y] = x else: self.root[y] += self.root[x] self.root[x] = y if(self.rnk[x] == self.rnk[y]): self.rnk[y] += 1 def isSameGroup(self, x, y): return self.Find_Root(x) == self.Find_Root(y) def Count(self, x): return -self.root[self.Find_Root(x)] n, m = map(int, input().split()) uf = UnionFind(n) for i in range(m): a, b = map(int, input().split()) uf.Unite(a, b) ans = 0 for i in range(n): ans = max(ans, uf.Count(i)) print(ans)
- 投稿日:2020-09-07T18:14:32+09:00
時系列データの扱い方&実装
はじめに
CS専攻のM2の者です。普段は画像処理が中心ですが、先日時系列データを扱う機会がありましたので備忘録として残しておきます。時系列データの処理をやってみたい方の参考に少しでもなればと思います。数式等は省いていますので雰囲気を掴みたい方向けだと思います。また、ミス等がありましたらご指摘ビシバシお願いします。
時系列データとは
時系列データとは、「ある一定の間隔で測定された結果の集まり」です。気温の変化や降水量、店舗の売り上げの情報に加えて、それが測定された時間の情報をセットで持っているイメージです。
時系列データに使えるモデル+用語
ARモデル(自己回帰モデル)
- 将来のyは、過去のyによって説明される
- 過去の自分のデータを説明変数とする
- 過去のデータに係数をかけたものをいくつか組み合わせて注目するデータを表現
- 定常過程が前提
MAモデル(移動平均モデル)
- 将来のyは過去の誤差によって説明される
- 将来の予測値は過去の予測値と実績値との誤差により決まる
- (例)今月の売り上げ量が、本来の売り上げる量より多かったら、来月の売り上げ量は増える
- 注目しているデータと過去のデータに共通する項を持たせることで関係性を表現
- 定常過程が前提
ARMAモデル(自己回帰移動平均モデル)
- AR + MA 過程、いずれかの強い方の性質に従う
- そのため自己相関、偏自己相関はともにラグの大きさに応じて減衰していく
- ARMAモデルは、データ系列の定常性の下で推定や予測を行うが、現実データは非定常が多い。
- 定常過程が前提
ARIMAモデル(自己回帰和分移動平均モデル)
- ARMAモデルとの違いは、差分過程を組み込んでいる点
- ARMAに何階差分をとれば定常になるかを付与したもの
- d階差分をとった系列が定常かつ反転可能なARMA(p,q)過程に従う過程
SARIMAモデル(季節自己回帰和分移動平均モデル)
- ARIMAとの違いは、季節性を考慮するかどうか?
- 時系列方向のARIMA(p,d,q)に加え、季節性差分方向ARIAM(P,D,Q),さらに周期s
単位根(Unit root process)
- 値が足し合わされて出来上がったデータである
- 単位根を持つデータを「単位根過程」と呼ぶ
- ex) ランダムウォーク(ホワイトノイズの累積和)
- ホワイトノイズ : 自己相関も何もない、正規分布に従ったただの「ノイズ」
ADF検定
- 多くの時系列モデルでは定常過程を前提としているので時系列に対してまず最初に単位根を確認する事が多い
- 帰無仮説:単位根過程, 対立仮説 : 定常過程
- P値が0.05以下なら帰無仮説が棄却され、定常過程になる
- 一般的に「差分系列」をとったり、「対数変換」すると、その系列は定常性を持ちやすくなる
自己相関( ACF : Autocorrelation Function )
- 過去の値が現在のデータにどのくらい影響しているか?
- ズラしたデータのステップ数をラグと呼ぶ
偏自己相関( PACF : Partial Autocorrelation Function)
- 自己相関係数から時間によって受ける影響を除去した自己相関
- 今日と2日前の関係には間接的に1日前の影響が含まれる
- 偏自己相関を使うと、1日前の影響を除いて今日と2日前だけの関係を調べる事ができる
コレログラム
- ラグ+自己相関
分析
import numpy as np import pandas as pd日付の扱い
pd.date_range('2020-1-1', freq='D', periods=3) ''' DatetimeIndex(['2020-01-01', '2020-01-02', '2020-01-03'], dtype='datetime64[ns]', freq='D') '''df = pd.Series(np.arange(3)) df.index = pd.date_range('2020-1-1', freq='D', periods=3) df ''' 2020-01-01 0 2020-01-02 1 2020-01-03 2 Freq: D, dtype: int64 '''idx = pd.date_range('2020-1-1',freq='D',periods=365) df = pd.DataFrame({'商品A' : np.random.randint(100, size=365), '商品B' : np.random.randint(100, size=365)}, index=idx) df ''' 商品A 商品B 2020-01-01 99 23 2020-01-02 73 98 2020-01-03 86 85 2020-01-04 44 37 2020-01-05 67 63 ... ... ... 2020-12-26 23 25 2020-12-27 91 35 2020-12-28 3 23 2020-12-29 92 47 2020-12-30 55 84 365 rows × 2 columns '''#特定の日付のデータ取得 df.loc['2020-2-3'] ''' 商品A 51 商品B 46 Name: 2020-02-03 00:00:00, dtype: int64 ''' #スライスによるデータ取得 df.loc[:'2020-1-4'] ''' 商品A 商品B 2020-01-01 99 23 2020-01-02 73 98 2020-01-03 86 85 2020-01-04 44 37 ''' df.loc['2020-1-4':'2020-1-7'] ''' 商品A 商品B 2020-01-04 44 37 2020-01-05 67 63 2020-01-06 6 94 2020-01-07 47 11 ''' df.loc['2020-1'] ''' ### ``1月分のデータ全部表示(省略) ''' # 月の取得 df.index.month ''' Int64Index([ 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ... 12, 12, 12, 12, 12, 12, 12, 12, 12, 12], dtype='int64', length=365) '''簡単なデータ分析
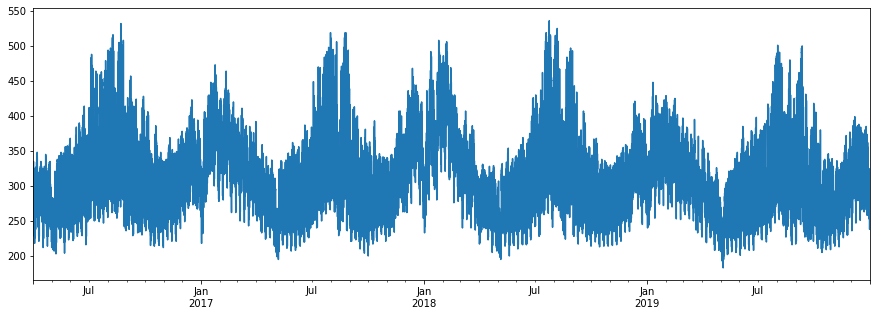
今回は時系列データで有名な'AirPassengers'のデータセットを使用します。
データの読み込みと表示
import pandas as pd import numpy as np import matplotlib.pyplot as plt data = pd.read_csv('AirPassengers.csv', index_col=0, parse_dates=[0]) plt.plot(data)
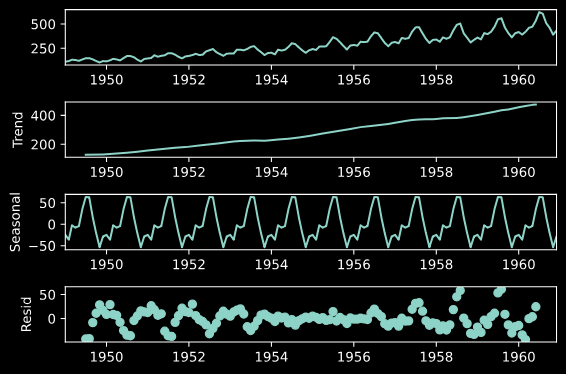
statsmodelsを利用し、trend, seasonal, residへ分解
import statsmodels.api as sm res = sm.tsa.seasonal_decompose(data) fig = res.plot()
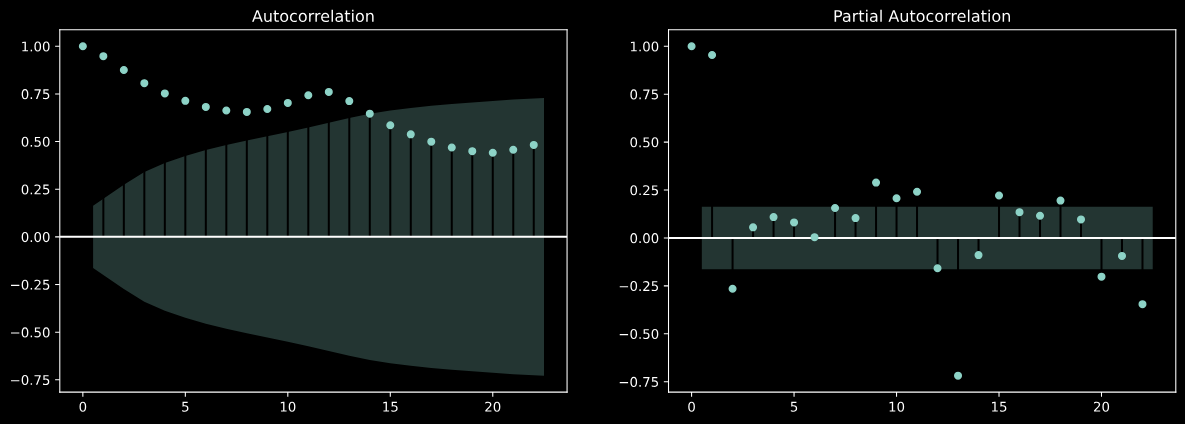
自己相関と偏自己相関の表示
fig, axes = plt.subplots(1,2, figsize=(15,5)) sm.tsa.graphics.plot_acf(data, ax=axes[0]) sm.tsa.graphics.plot_pacf(data, ax=axes[1])
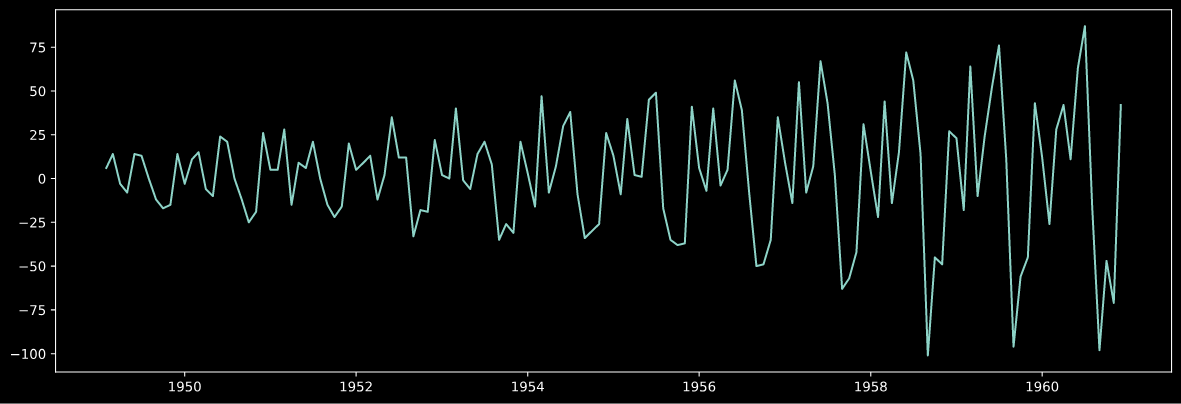
トレンドの除去
plt.figure(figsize=(15,5)) plt.plot(data.diff(1))
ADF検定
タプルで値が返ってくるのでそれの1番目の要素がP値になります。
P値が0.05以下だと帰無仮説を棄却できます。#元データ sm.tsa.adfuller(data)[1] 0.991880243437641 #対数変換 ldata = np.log(data) sm.tsa.adfuller(ldata)[1] 0.42236677477039125 #対数変換+階差 sm.tsa.adfuller(ldata.diff().dropna())[1] 0.0711205481508595SARIMAモデルの推定
orderとseasonal_orderでパラメータを設定。
fit()でモデルの学習。
学習範囲外の予想は、forecast()
学習データを含む点の予測はpredict()
パラメータのチューニングは総当たりで計算した方が良い。
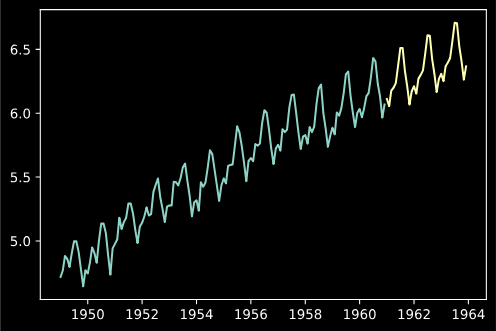
(statsmodelsないの関数はベストなモデルが見つけれらない?)model = sm.tsa.SARIMAX(ldata, order=(1,1,1),seasonal_order=(0,1,2,12)) res_model = model.fit() pred = res_model.forecast(36) plt.plot(ldata, label='Original') plt.plot(pred, label='Pred')
時系列データにおける特徴量作成
時系列で特徴量になりそうな情報
- 月
- 曜日
- 週数
- 週末フラグ
- 祝日
- 休日
- 気象
- 連休フラグ
- 連休何日目 etc...
# 簡単なテーブル作成 df = pd.DataFrame(np.arange(6).reshape(6, 1),columns=['values']) # 差分 df['diff_1'] = df['values'].diff(1) # 2回分の差分 df['diff_2'] = df['values'].diff(2) # 値をshiftさせるだけ df['shift'] = df['values'].shift(1) # 変化率 df['ch'] = df['values'].pct_change(1) # 窓関数で移動平均 df['rolling_mean'] = df['values'].rolling(2).mean() df['rolling_max'] = df['values'].rolling(2).max()
その他のメモ
tsfreshというライブラリで特徴量作成可能- sklearnの
TimeSeriesSplitでCVできる- 機械学習系のモデルは、定常過程を過程しているから統計的なモデルの方が良いのでは?
- SARIMAモデルはnan扱えない
参考文献
終わりに
簡単にですが、時系列についてまとめてみました。気になるところは機械学習モデルと統計モデルどちらを採用すべきかですね。個人的には、統計モデルの方が結果としては良いように感じています(今回のデータではありませんが、、、)。

- 投稿日:2020-09-07T17:57:21+09:00
リスト型、タプル型
リスト型、タプル型を使いこなす
リストをソートする
Pythonのリスト型では、要素の並び順を入れ替えるソートを簡単に行なえます。
数値を要素として持つリストに対してsort()メソッドを呼び出すと、要素を昇順に並べ替えることができます。
リスト型は変更可能なデータ型であることから、sort()メソッドを呼び出した結果、リストオブジェクト自体が書き換わります。【昇順に並び替える】
monk_fish_team = [158, 157, 163, 157, 145]
monk_fish_team.sort()
monk_fish_team
↓
145, 157, 157, 158, 163sort()メソッドは、なにも引数を与えずに呼び出すデフォルトの動作では、数値を昇順にソートするようになっています。
プログラムではそのような処理を行うことが多いためです。しかし、引数を与えることで並び替えの仕方を変更することができます。
例えば、reverseというキーワード引数をしていしてTrueを渡すと、並び順を降順にできます。【降順に並び替える】
monk_fish_team = [158, 157, 163, 157, 145]
monk_fish_team.sort(reverse = True)
monk_fish_team
↓
163, 158, 157, 157, 145ソート順をカスタマイズする
ソートという操作は、データの大小や優劣を比較して、順番を決める処理に他なりません。
sort()メソッドは、順番を決めるための基準を別途与えることで、単純な数値の大小以外に基づいた
ソート順のコントロールが可能になります。【sort()メソッド】
S.sort(Key, reverse)
※Sは処理の対象となるリストを表していますsort()メソッドの引数は、他のメソッドとは違い、引数のキーワード指定が必須になっています。
Keyには、順番を決める基準を返す関数を渡すことで、ソート順をカスタマイズできます。
また、reverse引数は先程紹介しましたが、並び順を降順にする場合にTrueを指定します。
デフォルトはFaldeで、昇順に並び替えます。具体的な例を使って、ソート順をカスタマイズする方法について説明します。
文字列型のsplit()メソッドのときに使った、茨城県のとある女子校の持っている戦車の
名前、速度や装甲厚などのデータを元に、戦車を強い順にソートすることを考えます。
まず、1つの戦車についてのデータを表現する方法について考えます。
名前や数値など、異質なデータを並べて管理するのに向いているのはタプル型です。
戦車ごとに、名前、速度、装甲厚、主砲の口径のデータをタプルにして
「(”八九式中戦車”, 20, 17, 57)」のように記述します。
このデータを、5台分並べます。【タプルのリストを作る】
tank_data = [(“IV号戦車”, 38, 80, 75), (“LT-38”, 42, 50, 37),
(”八九式中戦車”, 20, 17, 57), (“III号突撃砲”, 40, 50, 75), (“M3中戦車”, 39, 51, 75)]このデータをソートするためには、何を持って強いとするか、ということを明確に定義する必要があります。
厳密な定義は難しいですが、ここでは簡易に「速度、装甲厚、主砲口径を足した数値が大きいほうが強い」
というルールを作ってみます。
リストの要素を数値にして返す関数を作ります。この場合は、リストに入っている戦車データのタプルを渡すと
諸元を足して返す関数を作ればよいです。
タプルの1番目から先の数値を足して返す関数を作ります。
【戦車の諸元を足して返す関数evaluate_tankdata()】
def evaluate_tankdata(tap):
return tup[1]+tup[2]+tup[3]上記のevaluate_tankdata()関数を使えば、戦車を数値的に比較できます。
定義したタプルのリストを使って、戦車の強さを数値化してみましょう。
【各戦車の強さを表示する】
evaluate_tankdata(tank_data[0])
↓
193evaluate_tankdata(tank_data[4])
↓
165これで、リストの中にあるデータを比較することができるようになりました。
この関数を、sort()メソッドの引数keyに渡します。
そうすると、リストの要素を関数に渡しながら評価して、要素をソートしてくれます。
では、実際にsort()メソッドを使ってデータを並び替えてみます。
その後、並び替えたリストを表示してみます。
【戦車の強さでソートする】
tank_data,sort(key=evaluate_tankdata, reverse=True)
tank_data
↓
[(“IV号戦車”, 38, 80, 75), (“III号突撃砲”, 40, 50, 75), (“M3中戦車”, 39, 51, 75), (“LT-38”, 42, 50, 37),(”八九式中戦車”, 20, 17, 57)]sort()メソッドは昇順に並び替えを行うのがデフォルトの動作です。
Reverse引数にTrueを渡して順番を降順にし、強い順、つまりevaluate_tankdata()関数の返す数値が大きい順に並べています。
IV号戦車の性能が一番高いことがわかりました。
このように、リストの要素を評価する関数を作って引数を与えると、sort()メソッドの動きをきめ細かくカスタマイズすることができます。
- 投稿日:2020-09-07T17:07:41+09:00
pythonでキーボード・マウス操作を自動化して日常業務を効率化【RPA】
今回で習得できること
pythonでキーボード操作やマウス操作を自動化。
「艦〇れ」だろうが「城プ〇」だろうが周回を自動化できる。
高いライセンス料金でRPAツールを導入しなくても日常業務が効率化できる。
(実際に周回自動化をして見ようかと思ったが規約とか厄介なのでおとなしくやめておく)
リモートワークで離席しててもログイン状態を保てるので気付かれることなく・・・操作したい画面のサイズを取得
pythonでキーボードやマウス操作を自動化するためのパッケージといえばpyautogui。
import pyautogui as pa pa.size()Size(width=1920, height=1200)確認しやすさのためにtimeを使って動作の前に一旦停止させる。
自動操作の入力が早すぎて画面処理やブラウザが反応に追いつけない時があるので都合に合わせてtimeを使っていく。原点からのマウスの移動
画面左上を(0,0)の座標として位置操作を行う。
moveToで(0,0)から指定の位置へマウスを移動させる。
durationで何秒かけて移動するかを指定する。import time time.sleep(1) pa.moveTo(100,100,duration=1)現在の位置を知る
pa.position()Point(x=1735, y=157)現在位置から動かす
現在位置から指定位置まで動かすのはmoveRel
time.sleep(1) pa.moveRel(100,100,duration=1)クリック・特殊クリック・ダブルクリック
pa.click(x=1839, y=293, button='left')pa.leftClick() pa.rightClick() pa.doubleClick()マウスの押し込み・離し
pa.mouseDown(x=1735, y=157) pa.mouseUp()moveRelと組み合わせればドラック&ドロップができる。
でもドラック&ドロップなら専用のものがある
pa.dragTo() pa.dragRel()スクリーンショット
ss =pa.screenshot()画像を認識して場所を返してくれる
スクリーンショットやsnipping toolで認識したい物を用意
今回はゴミ箱をgomi.pngとして保存しておく。
スクリーン上から画像と一致する位置を返す
list(pa.locateAllOnScreen('gomi.png'))[Box(left=16, top=4, width=65, height=81)]画像で認識したものの中心位置を返す
pa.center(pa.locateAllOnScreen('gomi.png'))中心を認識したらクリックと組み合わせればショートカットを実行できる
文字を打ち込む
画像認識で検索バーやメモ帳の位置を指定してからtypewrite
pa.leftClick() pa.typewrite('HHH',1)スケジュール実行する
import schedule import time def job(): print("関数内にclickとか処理を入れる")10分ごとにjob関数の操作を実行
schedule.every(10).minutes.do(job)その他の指定
#一時間おき schedule.every().hour.do(job) #毎日10:30になったら schedule.every().day.at("10:30").do(job) #月曜になったら schedule.every().monday.do(job) #曜日・時間指定 schedule.every().wednesday.at("13:15").do(job)スケジュール実行を停止
schedule.run_pending()以上
hotkeyとしてshift長押しやwindowsボタンを押す事もできる

- 投稿日:2020-09-07T16:22:41+09:00
Jupyter上でDashを使えるjupyter_dash
Dashは可視化をインタラクティブに行えるウェブフレームワークです。そしてDashにはJupyter上でアプリケーションを動作させるjupyter_dashというパッケージが存在しています。そして最近、Google Colab上でjupyter_dashが動作するようになりました。
今回はjupyter_dashの使い方に加えて、Jupyter上でDashが使えるメリットを紹介したいと思います。
今回はグーグルコラボ上で全ての作業を行います。サンプルのノートは次のリンク先にあります。
https://colab.research.google.com/drive/1eUlcEKeHLzN7zBYPutFeU9yRPOwnWqKi?usp=sharing
準備
jupyter_dashはコラボにインストールされていません。あと可視化に使うplotlyのバージョンが古いものになっているので、更新します。
!pip install jupyter_dash !pip install --upgrade plotly次に今回利用するライブラリをインポートします。
import dash from jupyter_dash import JupyterDash import dash_core_components as dcc import dash_html_components as html import plotly.express as px from dash.dependencies import Input, Outputjupyter_dashはJupyter上でDashを使うためのパッケージです。dash_core_componentsは様々なツール、dash_html_componentsはHTMLコンポーネントを提供するパッケージです。plotly.expressはグラフ作成のパッケージです。
実践
ここからはPlotly ExpressのGapminderデータを使って進めます。Gapminderデータは1952年から2007年までの世界の国々の平均寿命、人口、1人当たりGDPを持つデータセットです。
gapminder = px.data.gapminder() gapminder.head()
平均寿命を線グラフで可視化(1つの国)
まずは、国ごとの平均寿命を観察したいとします。Plotly Expressのグラフの書き方は、次のようになります。
- 描きたいグラフ種類の関数を使う
- グラフに描画したいデータフレームを渡す
- 各要素に利用する要素を引数に渡す
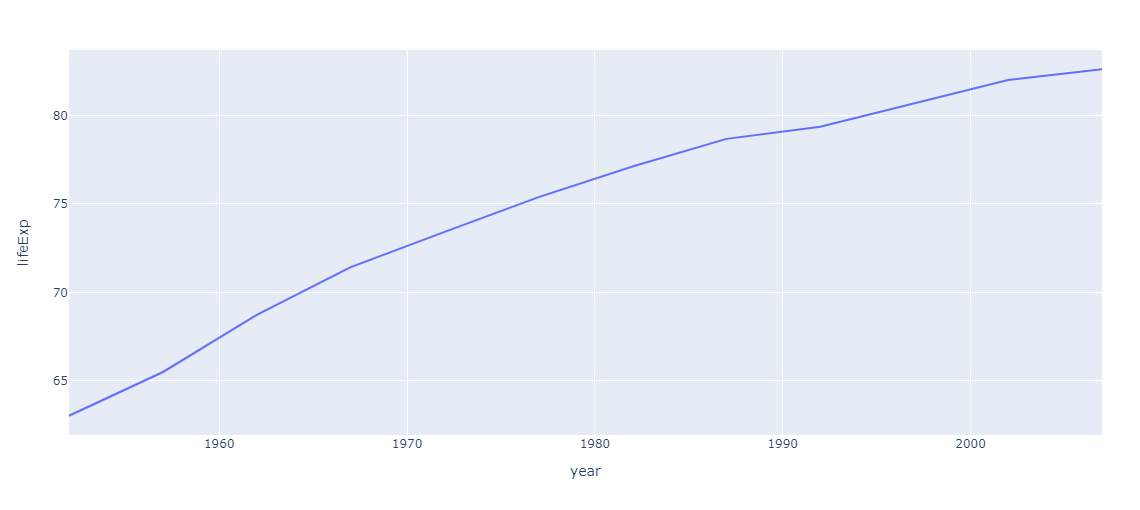
まずは日本の平均寿命の推移を可視化します。
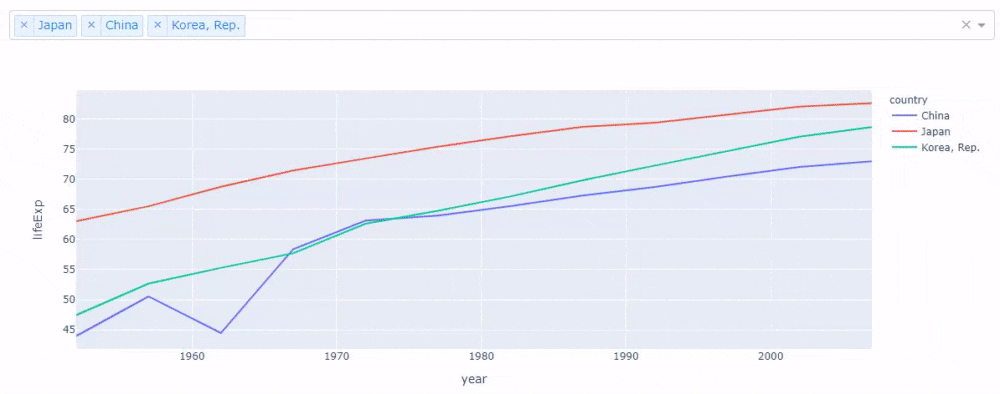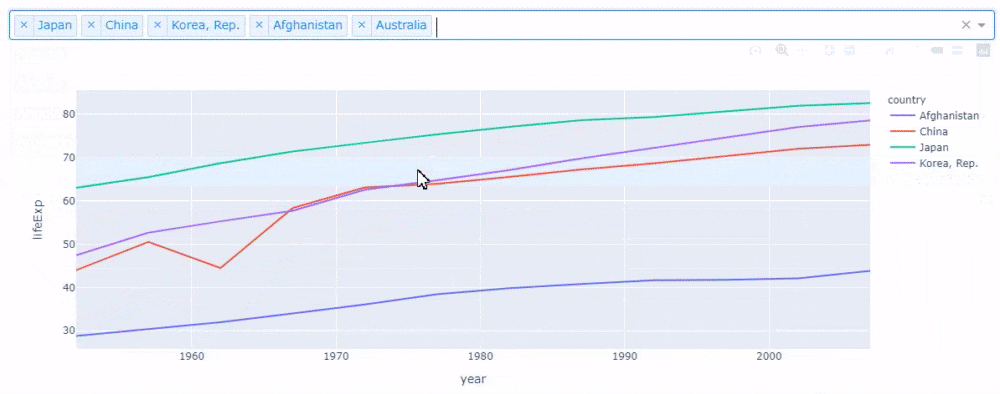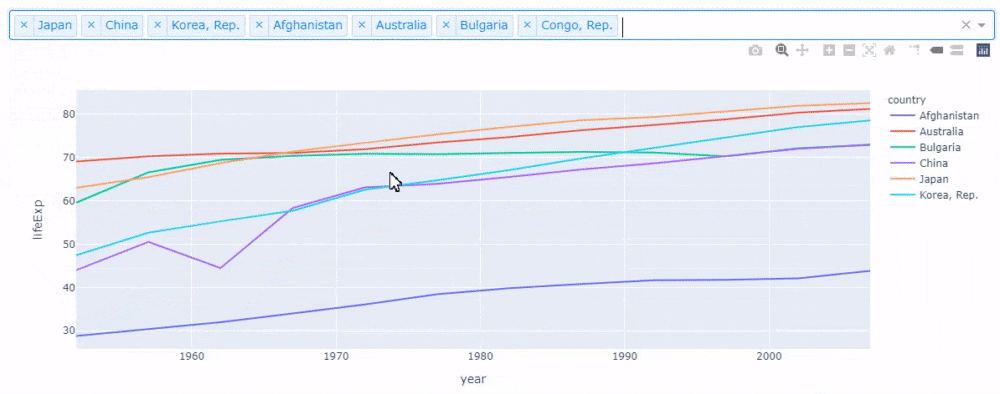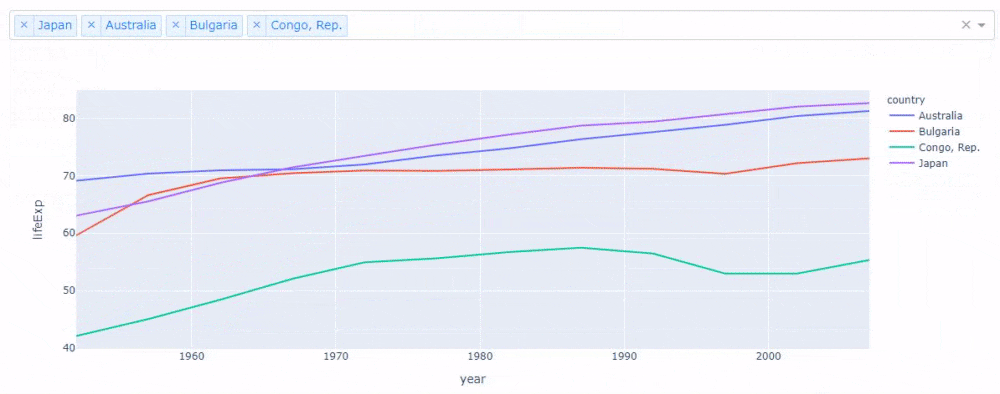
# コード1 jp_gapminder = gapminder[gapminder["country"] == "Japan"] # Japanのデータフレーム作成 px.line(jp_gapminder, x='year', y="lifeExp") # グラフ描画
次に中国の平均寿命を観察したい場合だと、たいていの場合中国のデータフレームを作成し、同じように関数の引数にデータを渡し、シフト+エンターという感じで実行すると思います。
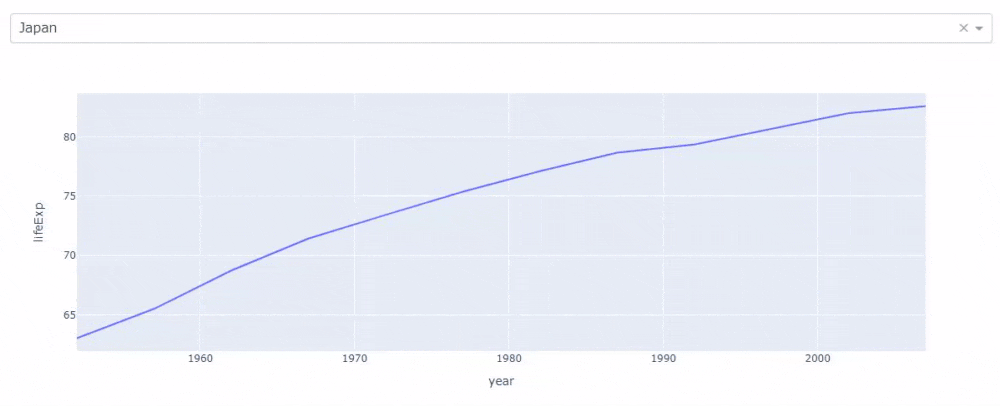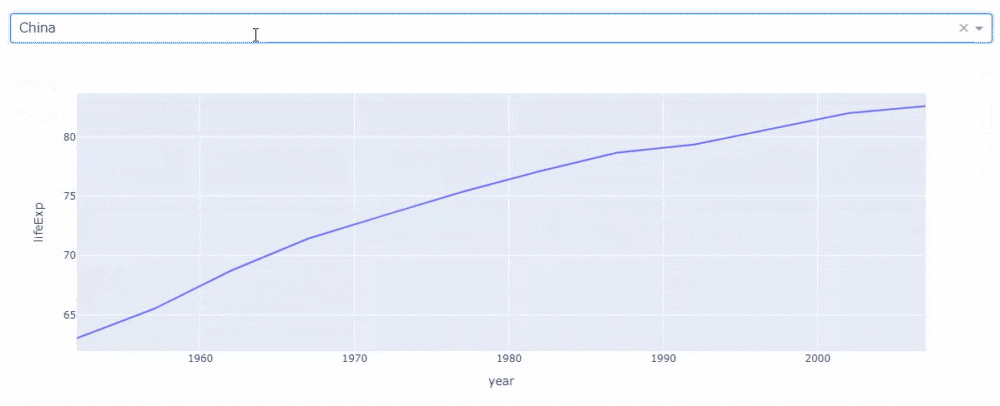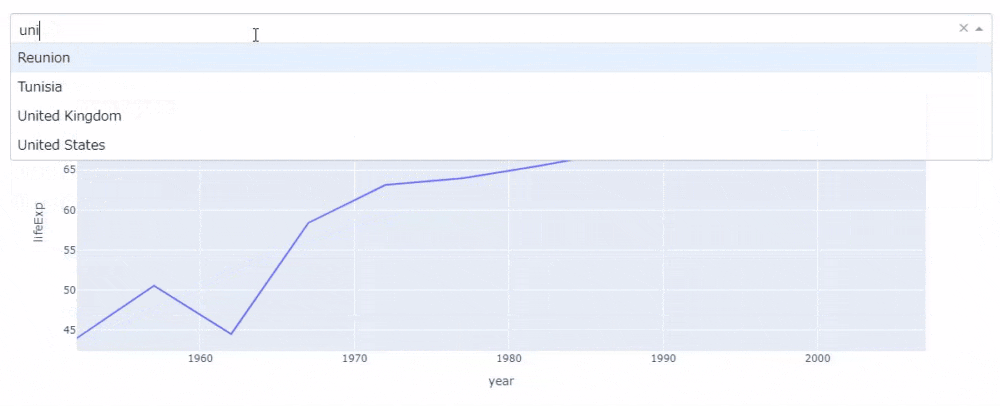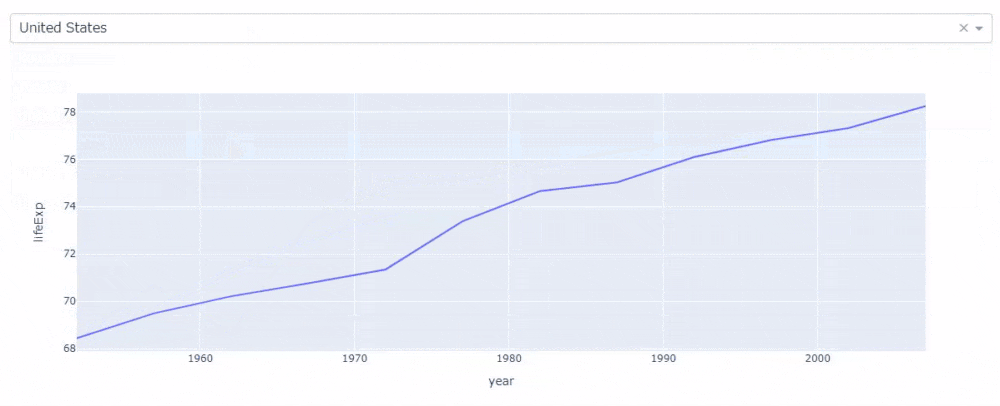
しかし、jupyter_dashを使うとドロップダウンを選択するだけで、グラフを切り替えられ、良い感じにシフトとエンターの摩耗を防げます。
# コード2 # JupyterDashインスタンスの作成 app = JupyterDash(__name__) # layout属性にレイアウトを渡す(ドロップダウンとグラフ) app.layout = html.Div([ dcc.Dropdown(id="my_dropdown", options=[{"value": cnt, "label": cnt} for cnt in gapminder.country.unique()], value="Japan" ), dcc.Graph(id="my_graph") ]) # ドロップダウンの選択値をグラフに反映するためのコールバック関数 @app.callback(Output("my_graph", "figure"), Input("my_dropdown", "value")) def update_graph(selected_country): selected_gapminder = gapminder[gapminder["country"] == selected_country] return px.line(selected_gapminder, x="year", y="lifeExp") # ノート上で実行 app.run_server(mode="inline")上のようなコードでドロップダウンの選択が反映されたグラフが描画されます。
平均寿命を線グラフで作成(複数国)
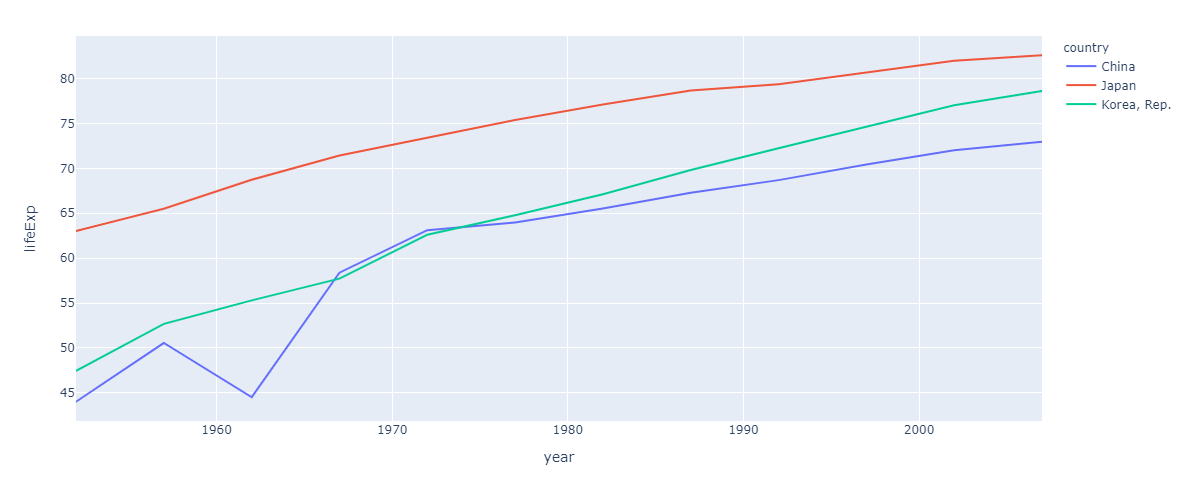
複数国を描画する場合、Plotly Expressでは色(引数color)で国を分けます。
# コード3 country_list = ["China", "Korea, Rep.", "Japan"] selected_gapminder = gapminder[gapminder["country"].isin(country_list)] px.line(selected_gapminder, x='year', y="lifeExp", color="country")
これを国を入れ替えながら詳細に見るのは結構手間です。しかし、jupyter_dashを使うと先ほどのコードを少し変えるだけで、次のような感じで簡単に複数国の表示を切り替えられるアプリケーションが作成できます。
# コード4 app = JupyterDash(__name__) app.layout = html.Div([ dcc.Dropdown(id="my_dropdown", options=[{"value": cnt, "label": cnt} for cnt in gapminder.country.unique()], value=["Japan", "China", "Korea, Rep."], # ➊ multi=True # ➋ ), dcc.Graph(id="my_graph") ]) @app.callback(Output("my_graph", "figure"), Input("my_dropdown", "value")) def update_graph(selected_country): selected_gapminder = gapminder[gapminder["country"].isin(selected_country)] # ➌ return px.line(selected_gapminder, x="year", y="lifeExp", color="country") # ➍ app.run_server(mode="inline")変更点は番号を振ったところです。➊ではドロップダウンで複数国が最初から選ばれるように、リストに入れて国名を渡します。➋では引数multiにTrueを渡しドロップダウンで複数国を選択できるようにします。➌では複数国が選択されたデータフレームが作成されます。➍では引数colorに"country"を渡し、線の色が国名ごとに変更されるよう指定します。
作成したアプリケーションは次のように動作します。
ツリーマップを使って可視化
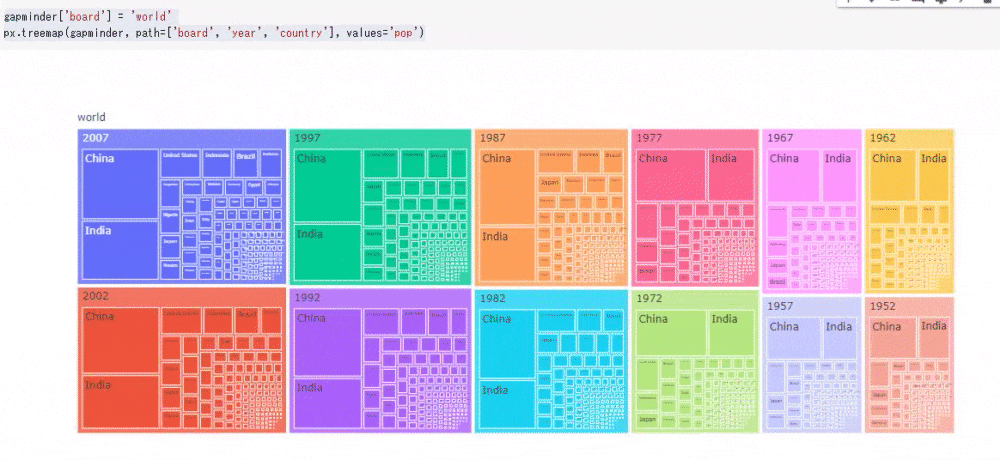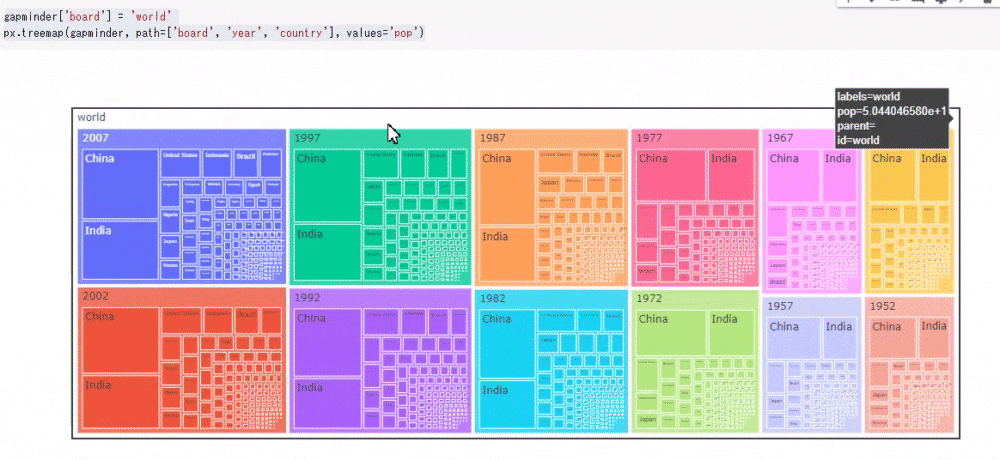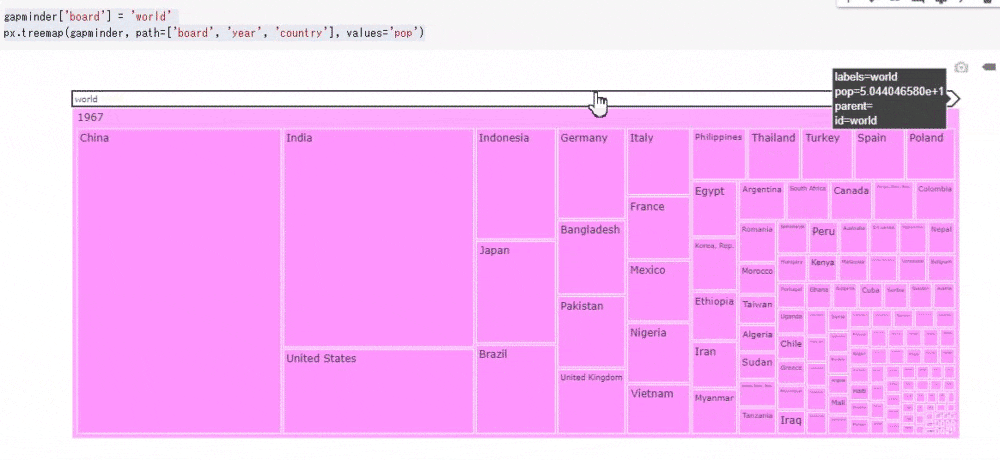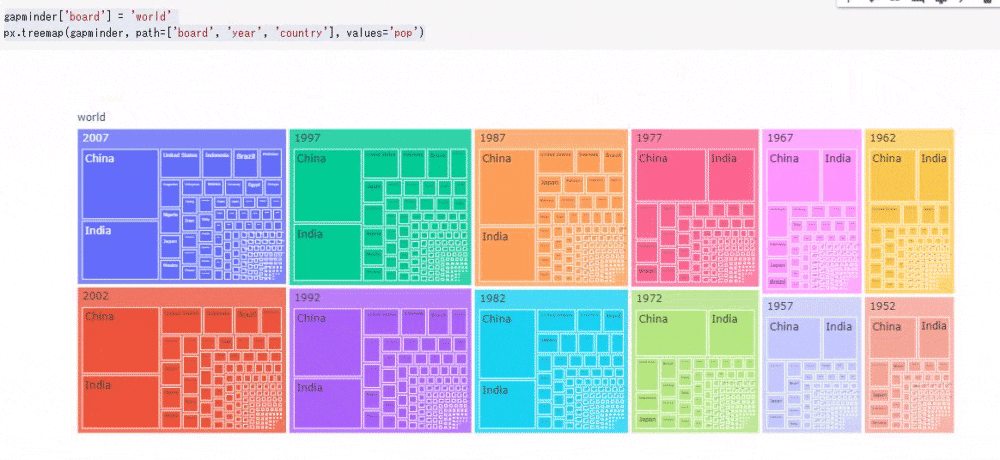
最後にツリーマップを使った可視化を作成します。ツリーマップを文字で解説する文章力がないので、まず作成してみます。
# コード5 gapminder['board'] = 'world' # "board"列を追加し、'world'という文字列を追加する px.treemap(gapminder, path=['board', 'year', 'country'], values='pop')
今回は人口のみを可視化してみました。ツリーマップは次のように動的に数値を確認できます。ツリーマップはデータを入れ子にしてみることができるため、その順番を変えるだけでもデータとして新たな発見があります。
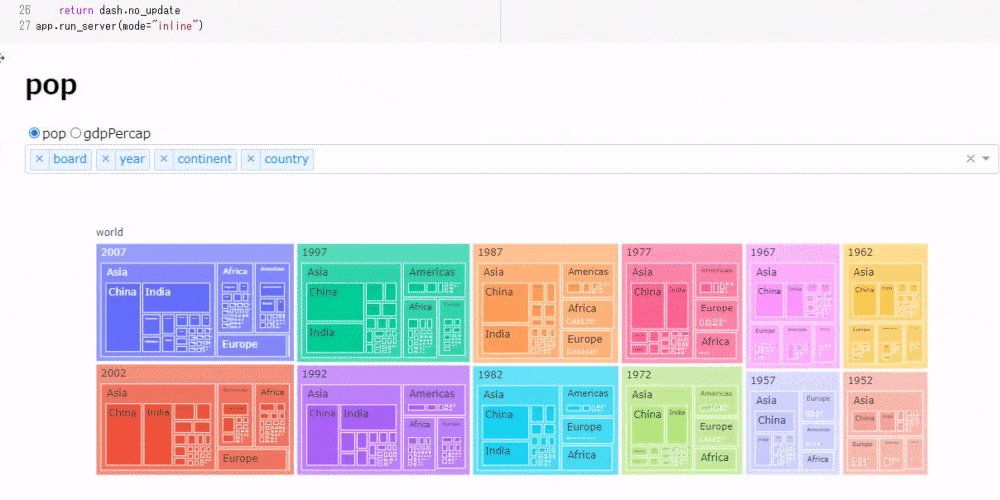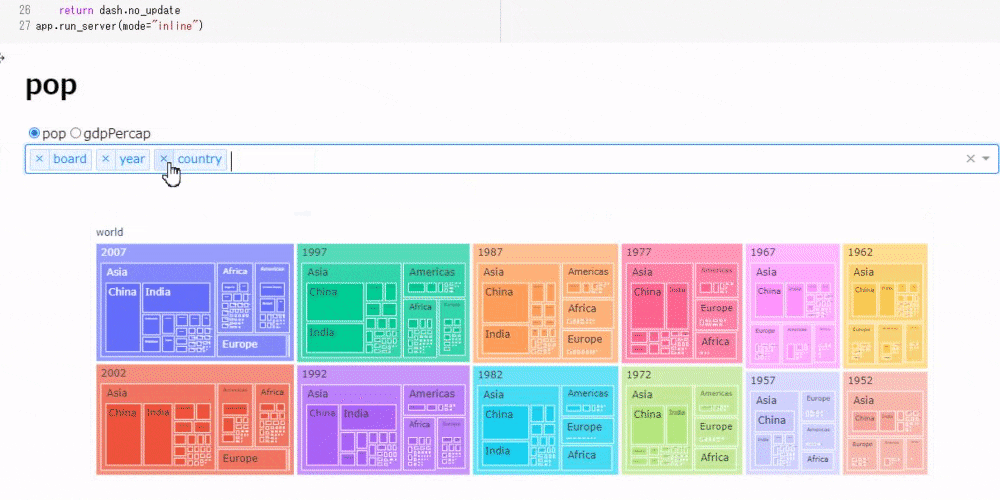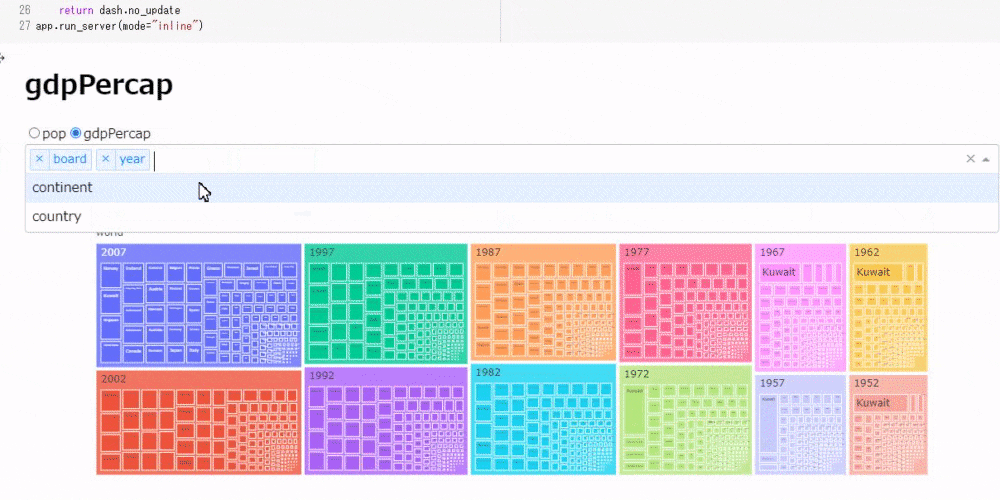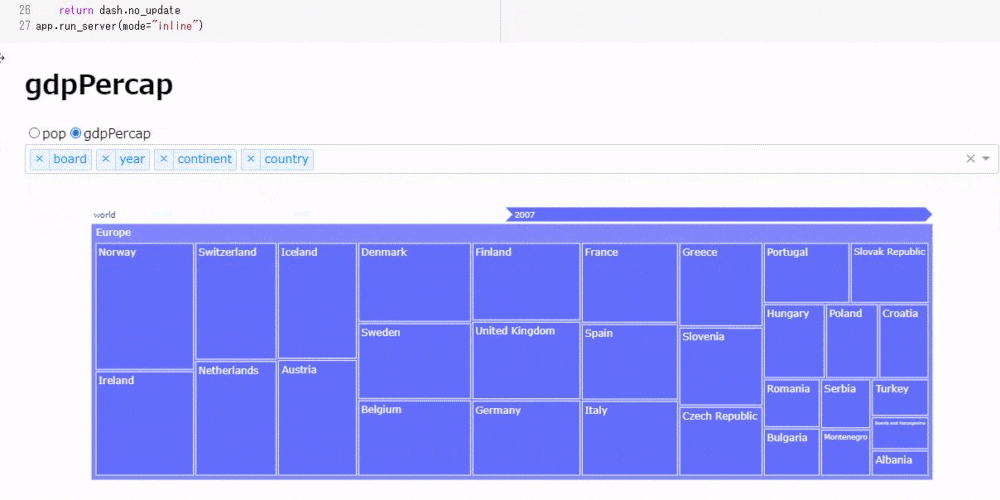
次に、ラジオボタンで人口、1人当たりGDPの表示を切り替えながら、ドロップダウンでツリーマップの表示順を切り替えられるツールを作成します。
# コード6 app = JupyterDash(__name__) app.layout = html.Div([ html.H1(id="title"), # ラジオボタンの選択を表示する dcc.RadioItems( id="my_radio", options=[{"label": i, "value": i} for i in ["pop", "gdpPercap"]], value = "pop" ), dcc.Dropdown( id="my_drop", options=[{"label": i, "value": i} for i in ['board', 'year', 'continent', 'country']], value = ['board', 'year', 'continent', 'country'], multi=True ), dcc.Graph(id="my_graph") ]) @app.callback([Output('title', 'children'),Output('my_graph', "figure")], [Input("my_radio", "value"), Input("my_drop", "value")]) def update_tree(radio_select, drop_select): # ドロップダウンで3つ以上の要素が選択されている場合のみグラフを描画 if len(drop_select) == 3: return radio_select, px.treemap(gapminder, path=drop_select, values=radio_select) else: return dash.no_update app.run_server(mode="inline")30行に満たないコードですが、次のように結構複雑な動作をしてくれます。
まとめ
以上のようにjupyter_dashを使うことにより、グラフ描画でのちょっとした面倒を削減することができます(そして多分キーボードも長持ちします)。
もうちょっとDashを詳しく知りたいと思われた方は、過去の記事をご参照ください。
https://qiita.com/OgawaHideyuki/items/6df65fbbc688f52eb82c
もうちょっと実際のデータを使った事例を知りたいという方は、WEB+DB PRESS VOL118に記事を書かせていただいたので、手に取っていただけますと幸いです。
https://gihyo.jp/magazine/wdpress
また、PyConJP2020で行ったTutorialの資料を公開しているので、これも参考になるかと思います。こちらはデータの前処理、可視化、機械学習との流れとなっています。スターをつけてもらえると嬉しいです。
https://github.com/hannari-python/tutorial
もっと詳しく知りたいという方は、本家のドキュメントを参照していただくか、11月ごろに出る本を購入していただけますと幸いです。宣伝です。
http://www.asakura.co.jp/books/isbn/978-4-254-12258-9/
あと、PyCon mini Hiroshima2020で話す機会をいただいたので、アイデアを練っています。イベントに参加いただき、当日のトークを聞いていただけると嬉しいです!
- 投稿日:2020-09-07T16:20:08+09:00
PyQt5とPyQtGraphで3Dモデルビューワーを作る
はじめに
なんとなくPyQtGraphのドキュメントを眺めていたら,APIの中に3D Graphicsの機能があることに気づきました.気になったので試しにPyQt5と組み合わせて3Dモデルを表示する簡単なGUIアプリケーションを作ってみました.
私が3Dプリンタをよく使う関係で,ここでいう3DモデルはSTLファイル形式のものを指しています.
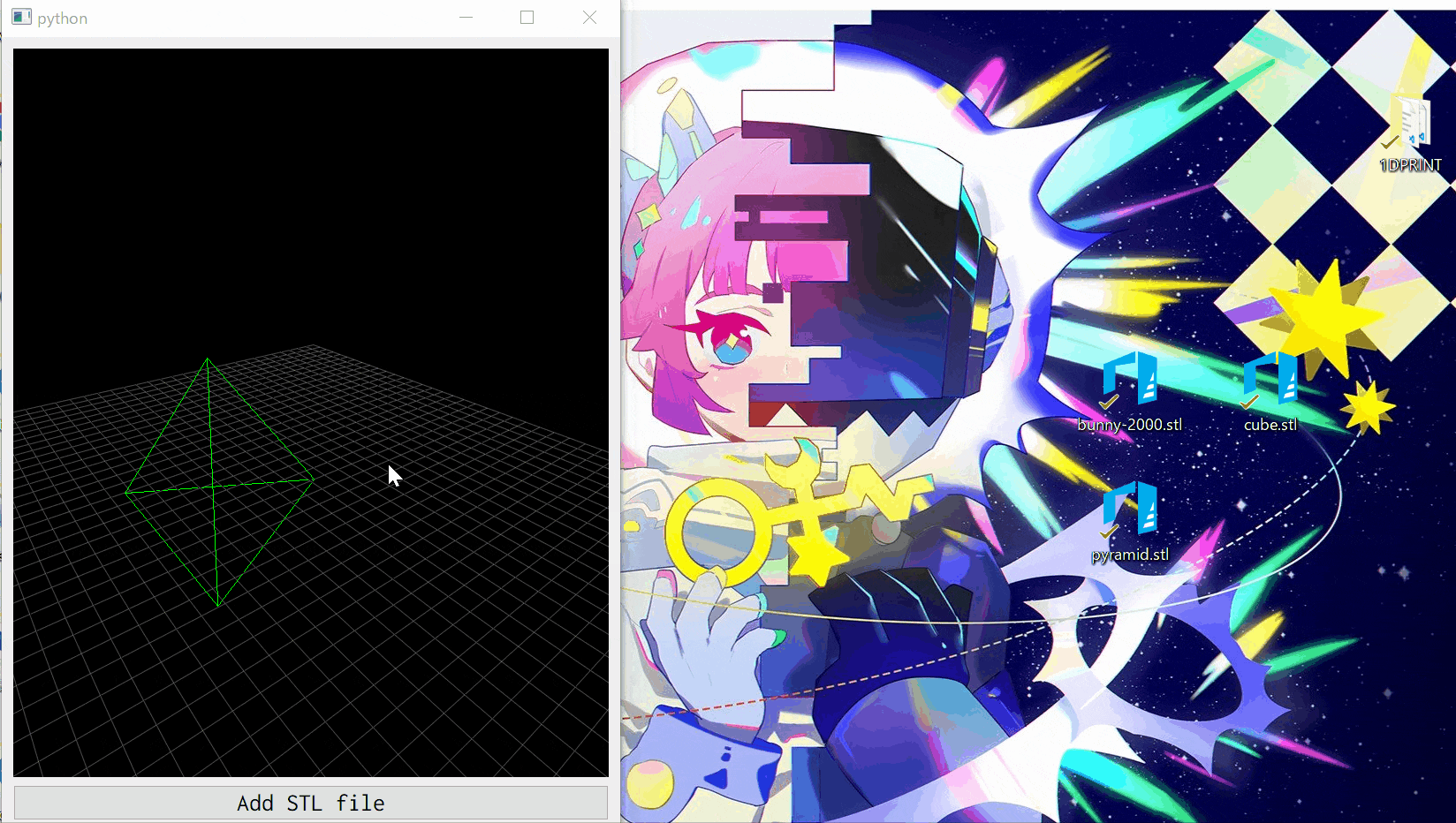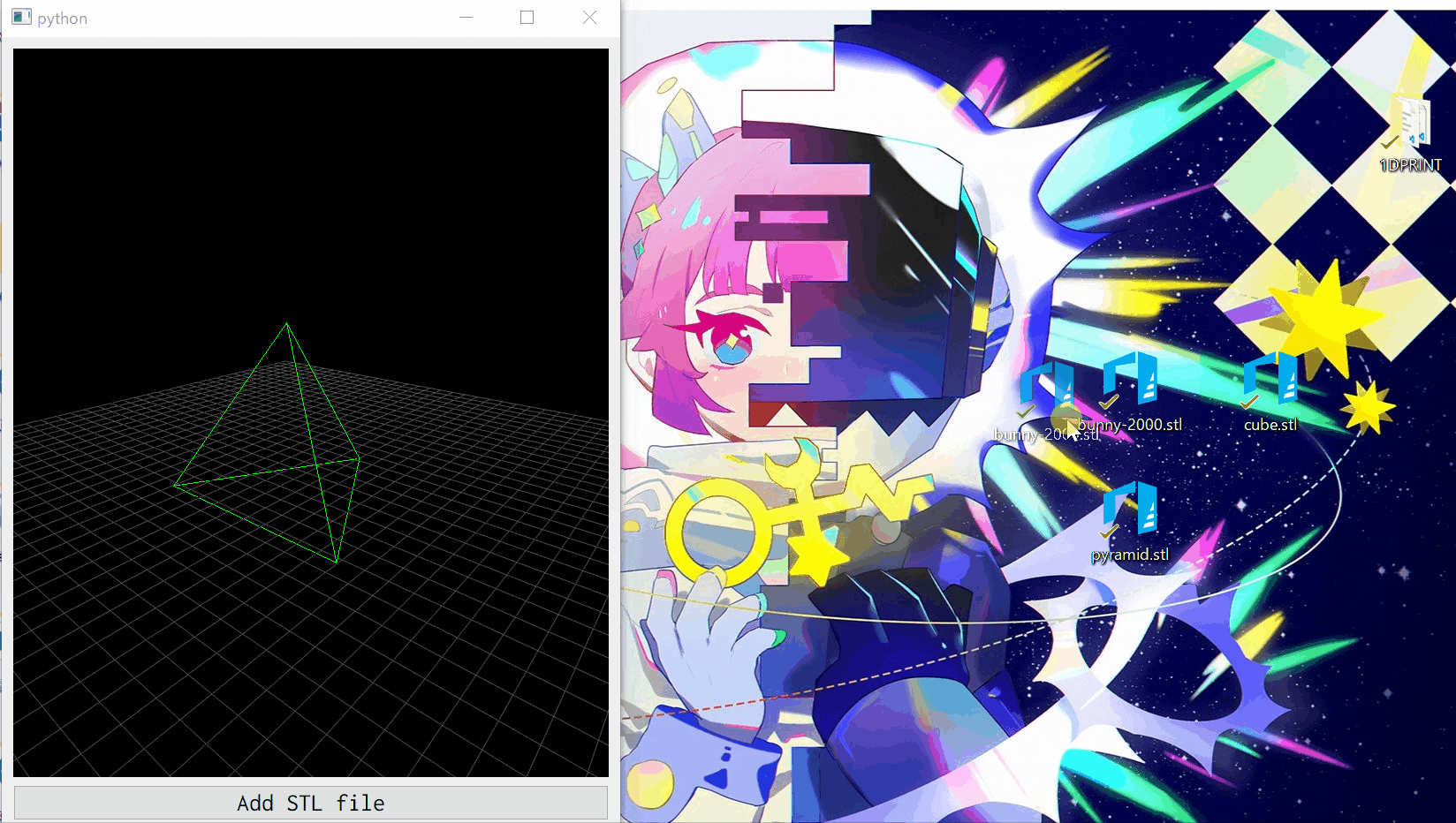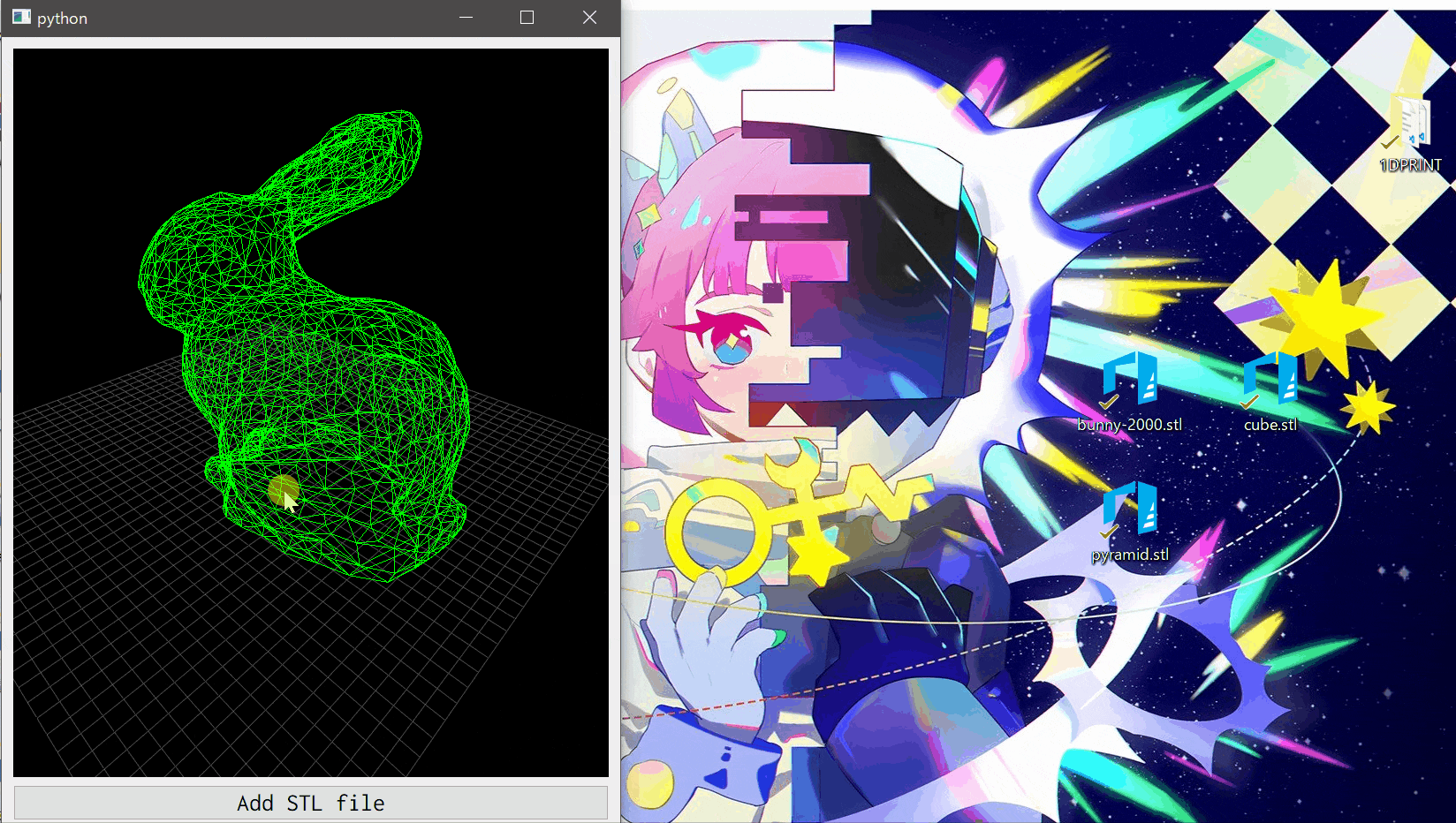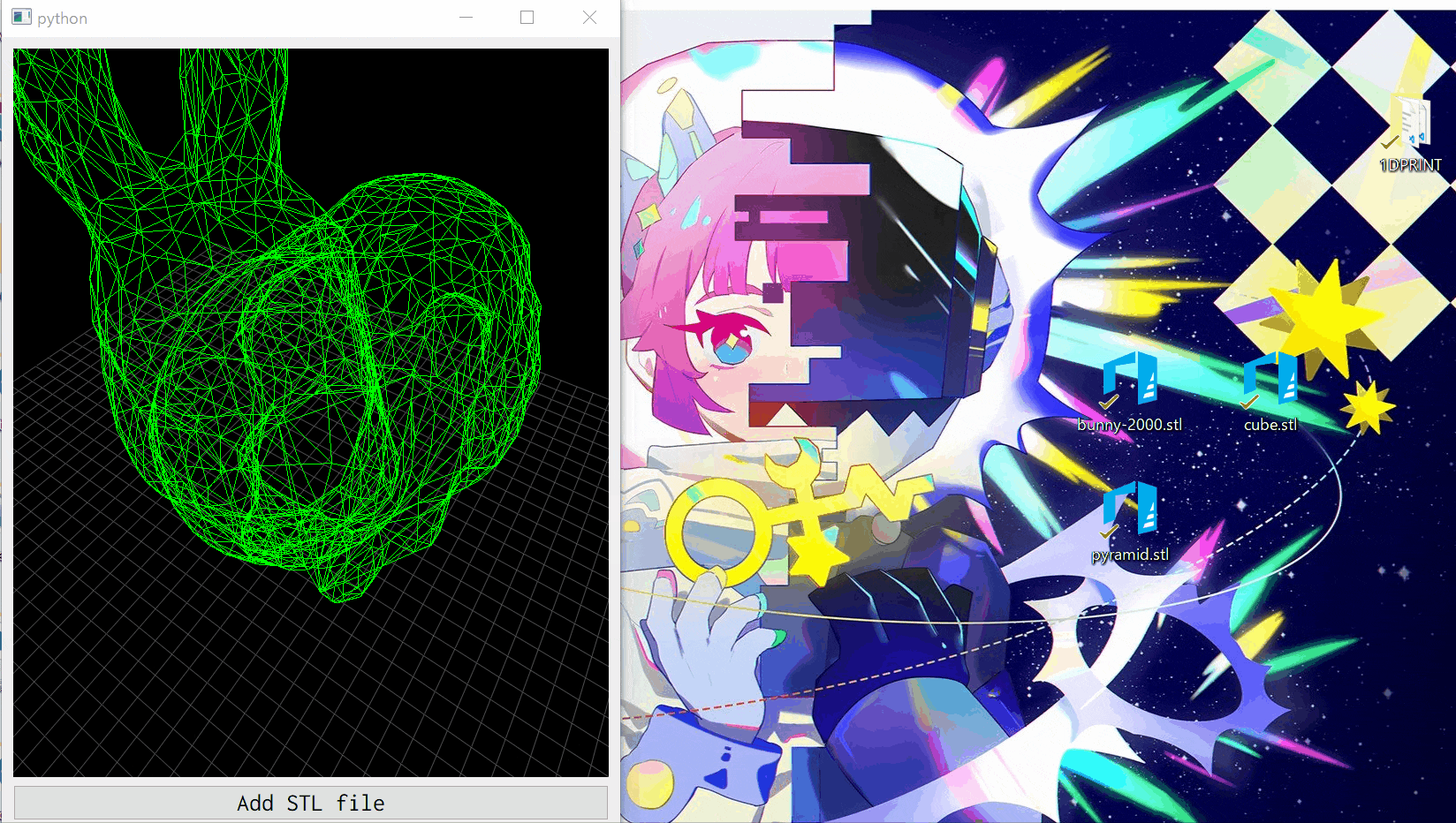
作ったもの
STLファイルを選択するかドラッグアンドドロップすることで,STLファイルをワイヤフレーム表示できます.1度に1つのSTLファイルのみを表示するシンプルなプログラムです.コードはGitHubにもあります.
GitHub:https://github.com/Be4rR/STLViewerPyQtGraphとは?
PyQtGraphはグラフ描画用のライブラリで,単体でも使えますが,作成したグラフをPyQt製のGUIに埋め込むことも簡単にできます.定番のMatplotlibと比べると機能は弱いですが,非常に軽いためリアルタイムにデータをプロットするような場合に適しています.あまり知られていないライブラリではありますが,個人的に重宝しています.
公式ページ:http://www.pyqtgraph.org/
公式ドキュメント:https://pyqtgraph.readthedocs.io/en/latest/index.html環境
Python3.8,PyQt5,PyQtGraph,PyOpenGL,Numpy,Numpy-STLを使用しています.
PyOpenGLはPyQtGraphで3D Graphicsの機能を使う際に必要になります.またNumpy-STLでSTLファイルを読み込みます.conda create -n stlviewer python=3.8 pyqt pyqtgraph numpy numpy-stl pyopenglプログラム
少し長いです.
stl-viewer.py
from pyqtgraph.Qt import QtCore, QtGui import pyqtgraph as pg import pyqtgraph.opengl as gl from PyQt5.QtWidgets import * from PyQt5.QtCore import * from PyQt5.QtGui import * import numpy as np from stl import mesh from pathlib import Path class MyWindow(QMainWindow): def __init__(self): super(MyWindow, self).__init__() self.setGeometry(0, 0, 700, 900) self.setAcceptDrops(True) self.initUI() self.currentSTL = None self.lastDir = None self.droppedFilename = None def initUI(self): centerWidget = QWidget() self.setCentralWidget(centerWidget) layout = QVBoxLayout() centerWidget.setLayout(layout) self.viewer = gl.GLViewWidget() layout.addWidget(self.viewer, 1) self.viewer.setWindowTitle('STL Viewer') self.viewer.setCameraPosition(distance=40) g = gl.GLGridItem() g.setSize(200, 200) g.setSpacing(5, 5) self.viewer.addItem(g) btn = QPushButton(text="Load STL") btn.clicked.connect(self.showDialog) btn.setFont(QFont("Ricty Diminished", 14)) layout.addWidget(btn) def showDialog(self): directory = Path("") if self.lastDir: directory = self.lastDir fname = QFileDialog.getOpenFileName(self, "Open file", str(directory), "STL (*.stl)") if fname[0]: self.showSTL(fname[0]) self.lastDir = Path(fname[0]).parent def showSTL(self, filename): if self.currentSTL: self.viewer.removeItem(self.currentSTL) points, faces = self.loadSTL(filename) meshdata = gl.MeshData(vertexes=points, faces=faces) mesh = gl.GLMeshItem(meshdata=meshdata, smooth=True, drawFaces=False, drawEdges=True, edgeColor=(0, 1, 0, 1)) self.viewer.addItem(mesh) self.currentSTL = mesh def loadSTL(self, filename): m = mesh.Mesh.from_file(filename) shape = m.points.shape points = m.points.reshape(-1, 3) faces = np.arange(points.shape[0]).reshape(-1, 3) return points, faces def dragEnterEvent(self, e): print("enter") mimeData = e.mimeData() mimeList = mimeData.formats() filename = None if "text/uri-list" in mimeList: filename = mimeData.data("text/uri-list") filename = str(filename, encoding="utf-8") filename = filename.replace("file:///", "").replace("\r\n", "").replace("%20", " ") filename = Path(filename) if filename.exists() and filename.suffix == ".stl": e.accept() self.droppedFilename = filename else: e.ignore() self.droppedFilename = None def dropEvent(self, e): if self.droppedFilename: self.showSTL(self.droppedFilename) if __name__ == '__main__': app = QtGui.QApplication([]) window = MyWindow() window.show() app.exec_()解説
あまり複雑なことはしていませんが,いくつかポイントとなる部分を説明します.
3D表示用のウィジェット
GLViewWidgetPyQtGraphのドキュメントの3D Graphics Systemに様々なGraphics Itemが挙げられています.
- GLViewWidget
- GLGridItem
- GLSurfacePlotItem
- GLVolumeItem
- GLImageItem
- GLMeshItem
- GLLinePlotItem
- GLAxisItem
- GLGraphicsItem
- GLScatterPlotItem
- MeshData
1番目の
GLViewWidgetは3Dモデルなどを表示するためのウィジェットです.このウィジェットに2番目以降のGraphics Itemを追加していきます.たとえばGLGridItemでグリッド平面を追加したり,GLMeshItemでSTLファイルなどのメッシュデータを追加できます.詳しくは公式のドキュメントを見てください.
GLViewWidgetはPyQtのウィジェットと全く同じように扱えるので,PyQtのGUIにそのまま埋め込むことができます.GLMeshItemで3Dモデルを表示
def showSTL(self, filename): # 既に他の3Dモデルを表示している場合,その3Dモデルを取り除く. if self.currentSTL: self.viewer.removeItem(self.currentSTL) # STLファイルから頂点points,面facesを抽出する. points, faces = self.loadSTL(filename) # メッシュを作成し,3Dモデルを表示するウィジェット(self.viewer)に追加する. meshdata = gl.MeshData(vertexes=points, faces=faces) mesh = gl.GLMeshItem(meshdata=meshdata, smooth=True, drawFaces=False, drawEdges=True, edgeColor=(0, 1, 0, 1)) self.viewer.addItem(mesh) self.currentSTL = mesh
loadSTL関数はSTLファイルから頂点と面の情報を抽出します.points,facesのいずれもNumpy配列で,pointsは(頂点の数, 3),facesは(面の数,3)の形をしています.上のプログラムでは頂点と面の情報を
MeshDataに渡してmeshdataを作成し,さらにそれをもとにgl.GLMeshItemを作成して描画方法(面や辺の色など)を決めるという二段階を踏んでいます.そして作成した
GLMeshItemをGLViewWidgetであるself.viewerに追加します.self.viewer.addItem(mesh)グリッドを表示する
グリッドも
GLMeshItemと同じGraphics Itemなので,同じようにして表示できます.
initUI関数の部分です.g = gl.GLGridItem() g.setSize(200, 200) g.setSpacing(5, 5) self.viewer.addItem(g)
GLGridItem()で作成後,setSize関数でサイズを決め,setSpacing関数でグリッド1つ分の大きさを指定しています.最後にGLViewWidgetのself.viewerにaddItem関数で追加します.
- 投稿日:2020-09-07T16:11:51+09:00
pytorchでcannot assign module before Module.init() callが出た時
すごく簡単な話なのですが、いつかやらかして長時間溶かしそうなので備忘録です。
該当コードとエラー内容
import torch import torch.nn as nn class Encoder(nn.Module): def __init__(self, p_n_features_num, timesteps) -> None: self.p_n_features_num = p_n_features_num self.linear = nn.Linear( p_n_features_num, p_n_features_num, bias=True) self.leakyrelu = nn.LeakyReLU() def forward(self, input_net): input_net = input_net.view(input_net.size(0), self.p_n_features_num) return self.leakyrelu(self.linear(input_net))ここでEncoderの__init__を呼び出すと
cannot assign module before Module.init() callのエラーが出ます。
解決策、修正コード
これはinitのときにnn.Moduleを継承しているのでsuperメソッドを始めに呼び出さなかったのが原因です。そのため、以下のように修正してあげれば直ります。
import torch import torch.nn as nn class Encoder(nn.Module): def __init__(self, p_n_features_num, timesteps) -> None: super(Encoder, self).__init__() self.p_n_features_num = p_n_features_num self.linear = nn.Linear( p_n_features_num, p_n_features_num, bias=True) self.leakyrelu = nn.LeakyReLU() def forward(self, input_net): input_net = input_net.view(input_net.size(0), self.p_n_features_num) return self.leakyrelu(self.linear(input_net))
- 投稿日:2020-09-07T16:04:48+09:00
Pythonで自作したイントロクイズを改善してみる
以前PythonとVLCを用いて作ったイントロクイズですが、これを試しにDiscordで友人と通話をつないでやってみたら予想以上にウケが良かったです。
みんな楽しんでくれた一方で、実際にプレイしてみての不満を頂いたりもしたので、そのような点を改善してみました。
改善前のコードのGistはこちら
改善後のコードのGistはこちら環境
以前のものと同じです。
Python: 3.8.2
python-vlc: 3.0.7110
VLC Media Player: 3.0.8 Vetinari不満ポイント
実際に指摘されたり、プレイしてみて不便だなと思った点を挙げていきます。
あとで問題点と比較して改善点を述べるため、便宜上番号をつけています。1. リプレイができない
クイズをやっていると「もう一回再生して」という要望が時々ありましたが、実装していなかったためできませんでした。
2. 大文字・小文字が厳密に区別される
例えば、「Nirv lucE」という楽曲があります。この曲が正解のとき、「nirv luce」や「NirvlucE」などは不正解と判定されてしまいます。改善前のプログラムでもパーフェクト(完全一致)と正解(部分一致)を分けてはいましたが、大文字小文字の違いで完全不正解扱いされてしまうのはいくらなんでもないなと思いました。
3. 正解表示後すぐに次の曲が始まってしまう
このプログラムはもともと一人で遊ぶために作っていたので問題はなかったのですが、皆で遊んでみると正解を出すかギブアップしてしまった後に正解を見て喜んだり悔しがったりするという時間がほしくなりました。
4. イントロの無音区間が長い曲がある
イントロで音楽が始まらないまま答えの入力画面に移ってしまうことが稀にありました。
5. 何度もやると皆覚えてしまう
決まった時間、決まった部分が流れるので、だんだん覚えてきてしまい、つまらなくなっていくという問題がありました。
6. 一部判定バグが存在していた
曲名のうち1文字だけ入力して正解にしてしまうことを防ごうと、最低でも3文字以上入力させるようにしていたのですが、(説明には対応していると書いているにもかかわらず)2文字以下の曲名を正しく入力しても「入力文字数が少なすぎる」という判定を食らうようになってしまっていました。
7. 少しだけ入力して正解になってしまう例があった
問題6とは逆なのですが、長い曲名(例えば「私の中の幻想的世界観及びその顕現を想起させたある現実での出来事に関する一考察」)であっても「私の中」「世界観」「出来事」と入力してしまえば正解扱いにされるというような抜け穴が存在しました。非常に長い曲名を持つ曲はそう多くはないものの、このような抜け穴が残ってしまうのは嫌でした。
改善
上で挙げた7つの問題を解決していきます。
1. コマンドシステムを実装する
問題点1を解決するついでにヒント機能を実装するため、曲名入力画面でコマンドを打つことができるようにしました。
_で始まっている文字列はコマンドとして扱うということにしました。
prefixとしてアンダーバーを選んだのは、単にアンダーバーで始まる曲名がなさそうだと思ったからです(!だと「!!!カオスタイム!!!」などが存在しているので)。
このコマンドシステムにギブアップ機能やヒント機能を組み込みました。
以下に実際に実装したコマンドの一覧を載せます。
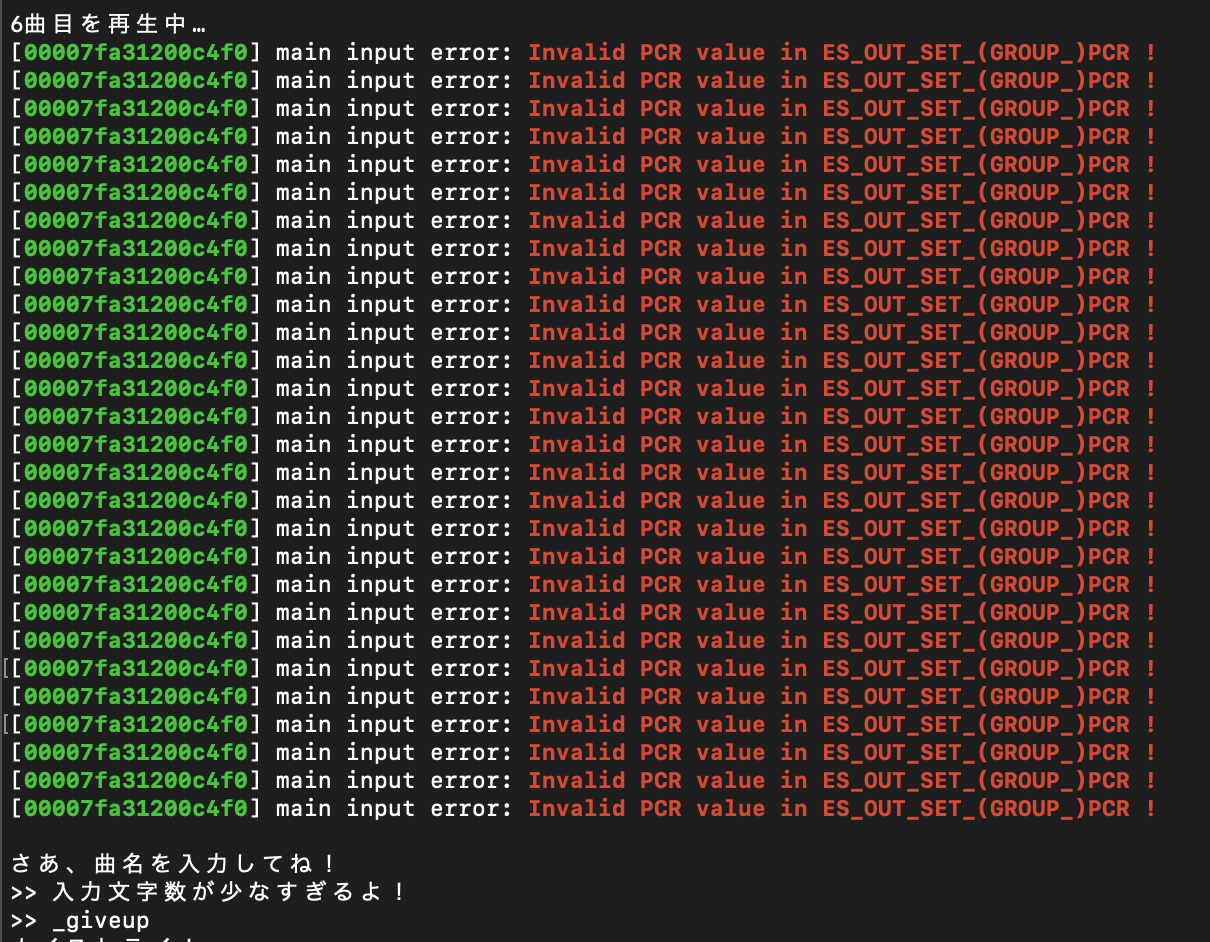
-_giveup: ギブアップ機能。答えがわからないときに入力する。
-_replay: リプレイ機能。もう一度再生する。
-_length: 曲名の長さを表示する。
-_letter: 曲名の最初の1文字を表示する。この画像では実際にコマンド機能を利用しています。5曲目のところで使っています。
コマンドは自由に追加できるような構造にしているので、ヒントをさらに充実させることも可能です。
2. 文字を小文字に統一し、スペースをなくす
問題点2を解決するため、入力されたアルファベットを小文字に変換するようにしました。
これにはPythonに備わっているlower()メソッドを用いました。
ただし、パーフェクト判定のためにもともとの正しい曲名も残すようにしています。
詳しくはGistにアップしたコードを見ていただきたいのですが、
- 入力された文字列ともともとの曲名を比較してパーフェクト判定をする
- 1がFalseだった場合入力された文字列を
lower()したものともともとの曲名をlower()したものを比較して正解判定をする- 2でもFalseだった場合不正解と判定する
という手順で判定しています。
3. 次の曲までの間にインターバルを設ける
これは単純に
input()を入れて、次の曲に行くにはEnterを押さなければいけないようにしました。
最初はtime.sleep()を使おうかとも考えていましたが、別にここの時間を固定長にする必要はないと気づいてこのような実装になりました。4/5. 再生部分・時間をランダムにした
問題点4と5をまとめて解決するため、楽曲をイントロではなく途中のランダムな点から再生されるようにしました。また、再生時間も3秒から7秒の間でランダムに選ばれるようにして、高い難易度と低い難易度をバランス良く混ぜることができるようにしました。
6/7. 正解文字数に対する割合で判定するようにした
問題点6と7はまとめて解説します。
以下に該当部分のコードを貼ります。# 長さ判定部 if len(answer) >= min(len(music_name)//3, len(music_name_lower)): # 正解判定部 if answer == music_name: print("パーフェクト!すごいね!") break elif answer_lower in music_name_lower: print("正解!おめでとう!") break else: print("残念!不正解!") else: print("入力文字数が少なすぎるよ!")2行目で分かる通り、条件を『3文字以上』から『曲名の1/3以上』に変更しました(問題点7の解決)。
また、こうすることで曲名が1文字であっても正常に動作するようになりました(問題点6の解決)。改善・修正できなかったこと/したいこと
時々エラーが発生する
たまに、曲が再生されずにこういったエラーが発生してしまいますが、原因がわからず今の所放置してしまっています。Discordと連携したい
今はこの音楽クイズをDiscordで友達と遊ぶことが多いので、友達が入力した答えをそのままプログラムに流し込んで判定をもう少し楽にしたいです。現時点では私が自力で皆の答えをコピペする必要があります。
上限回数を設定したい
最初に何曲分遊ぶかを設定したり、解答できる上限を設定したりしたいです。
ファイル名ではなく曲名を直接取ってきたい
「TiamaT:F minor」という曲があるのですが、
:はファイル名に使えない文字なのでTiamaT-F minorやTiamaTF minorというような表記に置き換わってしまっています。
ファイルそのものに設定された曲名は正しいので、そちらを判定に用いるようにしたいです。まとめ
結局イントロクイズではなく音楽クイズになってしまいましたが、より退屈することも減ったので満足しています。またCDを購入して曲のバリエーションを増やして遊びたいと思います。

- 投稿日:2020-09-07T15:59:27+09:00
Codeforces Round #666 (Div. 2) バチャ復習(9/2)
今回の成績
今回の感想
また悪いパターンに陥ってしまいました。方針としては合っていたのですが解けない焦りで完全に諦めてしまいました。
基本的にはdiv2で出るレベルの問題は考察を固められれば解けるので、集中力を保つようにしたいです。
後、沼にハマりそうになったら、一回思考をクリアにしてから考えるようにしようと思います。A問題
全てを同じにできるかを考えます。この時、それぞれのアルファベットの出てくる回数が$n$の倍数になれば良いです。
よって、出てくる文字列を全てつなげた後にlistに直してソートし、groupby関数で同じものをまとめることにしました。
終わってから気付きましたが、groupby関数ではなくCounterを使えばもっと楽に実装ができると思います。A.pyfrom itertools import groupby for _ in range(int(input())): n=int(input()) s="" for i in range(n): s+=input() s=list(s) s.sort() for i,j in groupby(s): if len(list(j))%n!=0: print("NO") break else: print("YES")B問題
初めの問題に手こずると失敗する確率が高いので、初めの問題はできるだけ慎重に取り組むようにします。
($a_i$は昇順で並んでいるものとします。)
まず、$c^i$について$c$を増やすと指数的に増加するので、$c$の値はそこまで大きくならないのではと考えます。
このことに注目して考察を行うと以下のようになります。また、以下では$\sum$は$i$=0~$n$-1の範囲で行っています。
まず、$c=1$の時は全ての値が1になり$a_i \geqq 1$なので、$\sum{|a_i-c^i|}=\sum{(a_i-1)}$となります。したがって、$\sum{c^i} < \sum{a_i}+(\sum{(a_i-1)})$の元で探せば良いです($\because$これを満たさない時$\sum{|a_i-c^i|} \geqq \sum{(a_i-1)}$となります。)。また、このままだと$c$の上限を求めるのが難しいので、以下のような式変形を施します。
\begin{align} &\sum{c^i} < \sum{a_i}+(\sum{(a_i-1)}) \\ &\rightarrow c^{n-1}< 2\sum{a_i}-n\\ &\rightarrow c< \sqrt[n-1]{2\sum{a_i}-n}\\ \end{align}よって、$c$の上限を決めることができました。また、これは今回の問題の条件下ではあまり大きくならないことが実験を行えばわかります。ここの式変形を間違えて無駄に時間を使い過ぎてしまいました。
B.pyn=int(input()) a=list(map(int,input().split())) a.sort() ans=10**18 for c in range(2,int((2*sum(a)-n)**(1/(n-1)))+1): x=1 ans_sub=abs(a[0]-x) for i in range(n-1): x*=c ans_sub+=abs(a[i+1]-x) ans=min(ans,ans_sub) print(min(ans,sum(a)-n))C問題
うまく考察が行えたので個人的に好きな問題です。
構築問題なので、いい感じに操作を抽象化することを考えます。サンプルを見て実験していたところ、二回の操作で全ての数を$n$の倍数にすることができれば最終操作で全体を選択することで全ての数を0にできることに気づきました。さらに、長さ$n-1$のセグメントを選択して操作を行えば、$n-1$と$n$は互いに素なので中国剰余定理から任意の数を$n$の倍数にできそうなことに気づきました。したがって、具体的に操作をシミュレートして考えます。
以下では、長さ$n$のセグメント→長さ1のセグメント→長さ$n-1$のセグメントの順で選択して操作を行うことを考えます。
(1)長さ$n$のセグメントを選択した時
操作により$a[i]+n \times x$が$n-1$の倍数になれば良いです($n \times x$がその要素に加える数です)。ここで、式変形を行うと$(a[i]+x)+(n-1) \times x$となるので、$x=(n-1)-a[i] \%(n-1)$とすることで$a[i]+n \times x$を$n-1$の倍数にすることができます。これを任意の$i$について行います。(2)長さ1のセグメントを選択した時
操作により任意の数が$n-1$の倍数となりますが、最後に選択できるセグメントの長さは$n-1$なので、一つの要素をすでに0にしておく必要があります。ここでは初めの要素を0にしておきます。(3)長さ$n-1$のセグメントを選択した時
(1),(2)より、(初めの要素を除く)長さ$n-1$のセグメントについては全て$n-1$となっているので操作を行うことができます。また、$n=1$の場合は0除算が発生し、$n=2$の場合も自分の実装だと予期せぬ挙動をするので、これらの場合はコーナーケースとして別で処理しておきます。
C.pyn=int(input()) a=list(map(int,input().split())) #first if n==1: print(f"1 1") print(f"{-a[0]}") print(f"1 1") print("0") print(f"1 1") print("0") exit() if n==2: print(f"1 1") print(f"{-a[0]}") print(f"2 2") print(f"{-a[1]}") print(f"1 1") print("0") exit() print(f"1 {n}") x=[(n-1-a[i]%(n-1))*n for i in range(n)] print(" ".join(map(str,x))) print(f"1 1") print(f"{-a[0]-x[0]}") print(f"2 {n}") print(" ".join(map(str,[-(a[i]+x[i]) for i in range(1,n)])))D問題
最終的な局面までは最悪の状態さえ避けられれば良いというイメージで考えるとゲームの問題はうまくいくかもしれません(非常に苦手ですが)。
ここで、最後に二つの石の塔が余ったとしそれぞれの石の数を$x,y$とします。この時、多い方の塔を選択している人が勝利します。なぜなら、いずれの人も最初に選んだ塔しか選べないために先に石がなくなる人が負けるからです。また、ここでは二つの塔の間の比較だったので多い塔を選択している人が勝利するとしましたが、複数の塔がある場合でも最も石の数の多い塔の石の数が他の塔の合計の石の数より多い場合(ある塔の石の数が合計の石の数の過半数を超える場合)は勝利することができます。つまり、初めからこの状態である時は先行の$T$の勝利となります。また、$n=1$のときも自明に$T$の勝利となります。
その他の場合については過半数を超えるような石がないように行動する($\leftrightarrow$石の多い塔から順に選択する)ことがお互いに最適となります。したがって、これを繰り返すことで最終的に塔は二つのみが残り石の数も$1,1$となります。この時、お互いに選択することができるので、最後の石をとった人の勝利となります。すなわち、石の合計の数の偶奇を考えればよく、奇数の時は先攻の$T$の勝利で偶数のときは後攻の$HL$の勝利となります。
D.pyfor _ in range(int(input())): n=int(input()) a=list(map(int,input().split())) if n==1: print("T") elif max(a) > sum(a)//2: print("T") else: print(["T","HL"][(sum(a)-1)%2])E問題以降
今回は飛ばします

- 投稿日:2020-09-07T15:26:28+09:00
Pythonで二次関数のグラフを描写
概要
PythonのライブラリMatplotlibの練習です。
何番煎じかわからないくらいありふれてますがご容赦ください。Matplotlibのインストール
pipでインストールします。
pip install matplotlib描写
import matplotlib.pyplot as plt import numpy as np # -10 < x < 10 x = np.arange(-10, 10, 0.1) # a, b, cにそれぞれ値を代入 a = int(input("a : ")) b = int(input("b : ")) c = int(input("c : ")) # y = ax^2 + bx + c y = a*x**2 + b*x + c # グラフへのプロット実行 plt.plot(x, y) plt.show()実行結果
a=1, b=2, c=2 | y=x^2+2x+2
a=4, b=5, c=2 | y=4x^2+5x+2
しっかり描写することができました。
改良
もう改良したい思います。
タイトルを設定
plt.title("y=" + str(a) + "x²+" + str(b) + "x+" + str(c))x軸、y軸のラベル表示
plt.xlabel("x") plt.ylabel("y", rotation = 0)yの表示範囲を -5 < y < 10 に設定
plt.ylim(-5, 10)グリッド線を表示
plt.grid()再び描写
import matplotlib.pyplot as plt import numpy as np # -10 < x < 10 x = np.arange(-10, 10, 0.1) # a, b, cにそれぞれ値を代入 a = int(input("a : ")) b = int(input("b : ")) c = int(input("c : ")) # y = ax^2 + bx + c y = a*x**2 + b*x + c # タイトルを設定 plt.title("y=" + str(a) + "x²+" + str(b) + "x+" + str(c)) # その他調整 plt.xlabel("x") # x軸のラベル表示 plt.ylabel("y", rotation = 0) # y軸のラベル表示" plt.ylim(-5, 10) # yの表示範囲を -5 < y < 10 に設定 plt.grid() # グリッド線を表示 # グラフへのプロット実行 plt.plot(x, y)実行結果
a=3, b=2, c=4 | y=3x^2+2x+4
a=2, b=6, c=1 | y=2x^2+6x+1
より精度の高いものになったかと思います。
追記
a, bにそれぞれ1を代入した際のタイトルに違和感を覚えたので少し変更します。
例 : a=1, b=1, c=5 | y=x^2+x+5 → "y=1x²+1x+5"
# タイトルを設定 if a == 1 and b == 1: plt.title("y=x²+x+" + str(c)) elif a == 1: plt.title("y=x²+" + str(b) + "x+" + str(c)) elif b == 1: plt.title("y=" + str(a) + "x²+" + "x+" + str(c)) else: plt.title("y=" + str(a) + "x²+" + str(b) + "x+" + str(c))実行結果
a=1, b=4, c=1 | y=x^2+4x+1
a=-3, b=1, c=6 | y=-3x^2+x+6
とりあえず解決しましたが、あまりスマートなコードとは言えない気がするのでもう少し学習したいと思います。







- 投稿日:2020-09-07T15:16:32+09:00
WindowsのDockerコンテナ上でmatplotlibを動作させる
はじめに
WindowsのDockerコンテナ上でmatplotlibを動作させる方法について記載します。
Windowsは、Windows 10 Pro 64Bit バージョン2004で試しました。これより古いバージョンでも試しました。
Docker Desktopは、WSL2に対応させても以前のままでもどちらも大丈夫です。
Dockerコンテナ内なので、そのままだとmatplotlib等のグラフはホスト側に表示されません。
ホスト側(Windows側)のディスプレイに表示させるようにするには、コンテナOSはlinux系だと思いますので、XServerをWindows側に立ち上げて、そのXServerに表示を流し込むようにする必要があります。VcXsrvをインストール
まず、VcXsrvをインストールします。
インストールが終わったら、WindowsメニューからVcXsrvにあるXLaunchをクリックします。
デフォルトの設定のままでいけます。Firewallの設定は不要のはずです。
また、同じPCで実行するなら不要なはずですが、認証等でエラーになるのであれば下記を試してみてください。
C:\Program Files\VcXsrvなどにある
X0.hostsというファイルを開いてホストのIPアドレスまたはホスト名を追記します。
このファイルは権限がないと編集できないので、プロパティ等で権限追加などを行ってください。
(ちなみに、VS Codeで開くと編集できます)起動すると、画面右下にVcXsrv X Serverのアイコンが表示されるはずです。
そのアイコンを右クリックして表示されるメニューからApplicationsのxclockを選ぶと下記のようにxclockが起動するはずです!
docker-compose.yml
ディスプレイの設定として、docker-compose.ymlに下記を追加します。
docker-compose.ymlenvironment: DISPLAY: host.docker.internal:0.0日本語表示
日本語表示が必要であれば、Dockerfileに以下を追記してください。
fonts-ipafontとしていますが、もちろん別のフォントでも構いません。RUN apt-get update && apt-get install -y fonts-ipafont動作させたプログラム
動作させたプログラムとしてはこんな感じです。
test.pyimport numpy as np import matplotlib.pyplot as plt x = np.arange(-3, 3, 0.1) y = np.sin(x) fig = plt.plot(x, y) plt.show()matplotlib
Docker内で上記プログラムを実行すると下記のようなグラフが表示されます。
おわりに
うまくグラフが表示されましたでしょうか!?
以上ですが、皆様の開発効率向上に寄与できれば幸いです。

- 投稿日:2020-09-07T15:01:01+09:00
Pythonのseabornで描画したヒートマップ上に垂直線を引く方法
はじめに
ヒートマップは、横軸と縦軸に空間的な座標をとって表示することが良くあります。それに加え、横軸に時間、縦軸に周波数をとるSTFT(Short-Time Fourier Transform)の結果を描画するといったように、横軸を時間に取りたいという時があります。その時に、解析においてイベントがいつ発火したのかを図に入れるために、任意の場所に垂直線を入れたいなと思いました。seabornで垂直線を引く方法が、なかなか見つからなかったので備忘録として残しておきます。
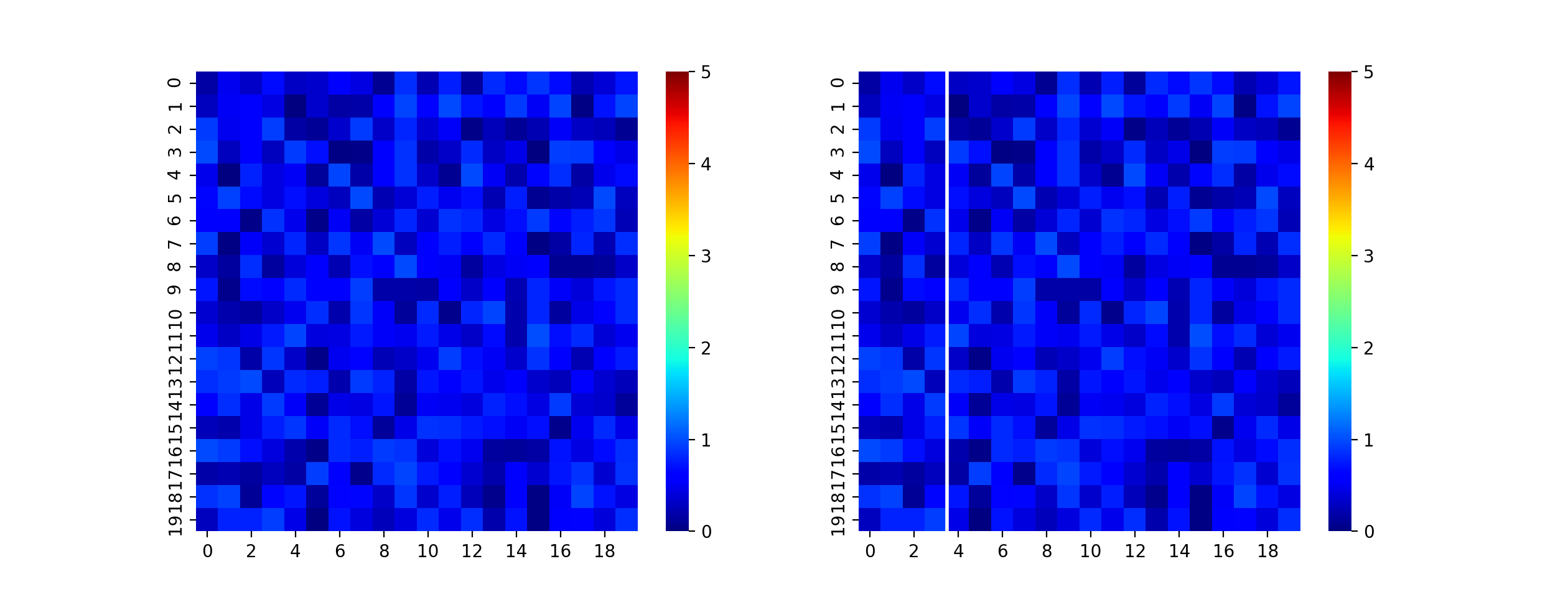
目標
ヒートマップに垂直線を入れる
方法
普通にaxvlineを使って入れることが出来るらしい。ということで、実際にやってみた。
vline_heatmap.pyimport matplotlib.pyplot as plt import numpy as np import seaborn as sns # サンプルの配列作成 arr = np.random.rand(20, 20) # ヒートマップの表示(左側) fig, (ax1, ax2) = plt.subplots(1, 2) sns.heatmap(arr, vmin=0, vmax=5, cmap="jet", ax=ax1) # ヒートマップに垂直線を入れて表示(右側) sns.heatmap(arr, vmin=0, vmax=5, cmap="jet", ax=ax2) ax2.axvline(x=4, linewidth=2, color="w") # 描画 plt.show()描画結果
左に垂直線なし、右側に垂直線ありの描画結果を示します。
ご意見など
本記事のコメントに書いていただくか、以下のメールアドレスまでお願いします([at]を@に変えてください)。
akira.kashihara[at]hotmail.com
参考
1の記事を参考に、垂直線を調べて辿ったところ、2の記事に行き当たり、試してみました。
直接書いている他の記事などありましたら、教えていただけると助かります。1) seabornを使ったグラフで、任意のy軸上の位置に横線を引く
2) matplotlib.pyplot.axvline
- 投稿日:2020-09-07T14:54:00+09:00
Codeforces Round #646 (Div. 2) バチャ復習(9/6)
今回の成績
今回の感想
昨日と全く同じ感想です。C問題までは軽い考察で解けましたが、E問題で集中力を失ってバチャコン中にYouTubeを見ていました。ここは自分で踏ん張る以外に方法はないと思うので、踏ん張りを効かせられるよう頑張ります。
また、E問題は早とちりしてDPにこだわり過ぎてしまいましたが工夫した貪欲法で解けるので、見極めも冷静にできるようにします。
A問題
適当に考え過ぎて1WAを出しました。反省です。
合計を奇数にするために、偶数と奇数を入れ替えることで偶奇の調整ができることに注目しました。
偶数と奇数を入れ替えるという条件から偶数のみまたは奇数のみの時は入れ替えることができないので場合分けが必要です。さらに、$x=n$となる時も全ての要素を選ぶので、入れ替えることは不可能となります。よって、以下のような場合分けを実装すれば良いです。(1)偶数のみの場合
任意の要素の和は偶数なので、Noを出力します。
(2)奇数のみの場合
選ぶ要素の個数が奇数の場合はその和は奇数なのでYesを出力し、選ぶ要素の個数が偶数の場合はその和は偶数なのでNoを出力します。
(3)$x=n$の場合
全ての要素の和が奇数であればYes,偶数であればNoをそれぞれ出力します。A.pyfor _ in range(int(input())): n,x=map(int,input().split()) a=list(map(int,input().split())) l,r=sum(a[i]%2==1 for i in range(n)),sum(a[i]%2==0 for i in range(n)) if l==0: print("No") elif x==n: print(["No","Yes"][sum(a)%2]) elif r==0: print(["No","Yes"][x%2]) else: print("Yes")B問題
$010$または$101$を部分列として含まない文字列の条件を言い換えます。これは、例えば1で文字列が始まるとすれば次に0が来た時はそれ以降に1が現れないと言えます(0始まりのときも同様)。
したがって、次のような文字列が題意を満たすような文字列であると言えます。
0…01…1 1…10…0よって、元の文字列を
0…0に変えて必要な操作回数を計算し、その状態から1を左側から増やしていく場合と右側から増やしていく場合の2つのパターンについて差分を管理しながらそれぞれ必要な操作回数を計算し、その中で最小の操作回数を求めれば良いです。また、差分については$s[i]="0"$の場合は操作回数に+1し、$s[i]="1"$の場合は操作回数に-1すれば良いですが、考察で実装まで詰め切れておらず時間がかかりました。反省です。
B.pyfor _ in range(int(input())): s=input() n=len(s) c0,c1=s.count("1"),s.count("1") ans=min(c0,c1) #0...0の場合の左から変化 for i in range(n): if s[i]=="0": c0+=1 else: c0-=1 ans=min(ans,c0) #右から for i in range(n-1,-1,-1): if s[i]=="0": c1+=1 else: c1-=1 ans=min(ans,c1) print(ans)C問題
ギャグと見ぬけてしまうと簡単な問題です。このような問題を安定的に通せる考察力が欲しいです。
次数が1からものから除いていくことを考えます。この時、与えられた頂点$x$について初めから次数が1以下のときはその頂点を先攻のAyushが削除できるので、この場合は除いて考えます。
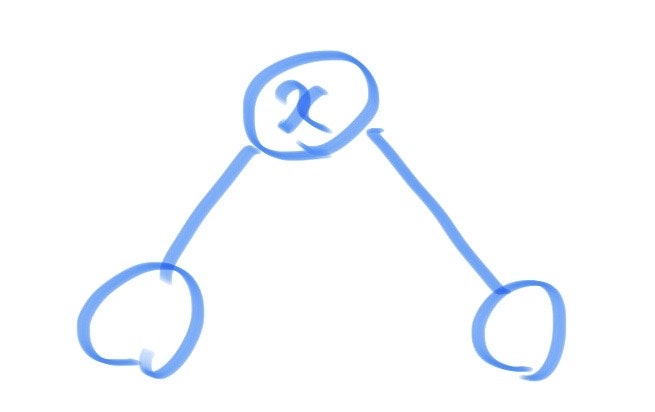
したがって、与えられた頂点$x$について次数は2以上になります。また、$x$の次数が1になると相手に$x$を選ばれてしまうので、その状態を避けます。さらに、下図のように頂点$x$から二頂点が伸びているような状態になった時は敗北が確定することにも気付きました。
以上より言えるのは、頂点$x$の次数が2以上である時、お互いが最適な行動をとることで最終的に上図の形に行き着く(最終状態に注目!)ということです。よって、頂点$x$の次数が2以上である時は勝敗はその木の形状ではなく頂点数$n$のみに依存します。また、最終的に三頂点残った場合は負けるので、$n$が奇数のときは先攻のAyushの負けで,$n$が偶数のときは後攻のAshishの負けとなります。
C.pyname=["Ayush","Ashish"] for _ in range(int(input())): n,x=map(int,input().split()) check=0 for i in range(n-1): u,v=map(int,input().split()) if u==x or v==x: check+=1 if check==0 or check==1: print(name[0]) else: print(name[n%2])D問題
インタラクティブなので解いてません。
E問題
感想にもあるように集中していれば解けた問題です。メンタルや集中力は日頃の生活から鍛えていかないとと思っているので改善したいと思います。また、この問題では再帰を使ってPyPyで書いたところMLEしたので、Codeforcesで再帰を書くときはC++で書くようにしたいと思います。
まず、$b[i]=c[i]$の場合は変える必要がないので、$b[i] \neq c[i]$のものを入れ替えるための部分木内でのシャッフルを行います。このとき、$b[i]=0$かつ$c[i]=1$であるタイプ(タイプ0)と$b[i]=1$かつ$c[i]=0$であるタイプ(タイプ1)の二つのタイプがあり、これらの和が等しくない場合は題意を満たすことができません。また、逆に等しい場合は必ず題意を満たします。
この元で、一番簡単に求められるのは頂点1を頂点とみなした部分木を選択する時です。しかし、より葉に近い部分木を選択してシャッフルを行うのが最適である場合も存在します。以上を一般化すれば、ある頂点の親のコストの方が小さい場合はその親のコストをその頂点のコストとして良いということです。したがって、これはDFS(またはBFS)を行って上の頂点から順に更新していくことが可能です。
以上より、それぞれの頂点のコストの更新が行われ、根から葉の方向へ単調減少するようにコストを設定することができました。したがって、この元では葉の方から貪欲にシャッフルを行うことができます。つまり、部分木に含まれるタイプ$i$の頂点数を$c_i$として、シャッフルを行って一致させることのできる頂点数は$2 \times min(c_0,c_1)$なので、これを葉に近い頂点から順に行います。また、いずれか一方のタイプはその部分木のみでは一致させられてない可能性があるので、その親を根とする部分木でシャッフルを行って一致させます。また、葉に近い頂点から順に行うので、ここではDFSによって実装を行います。
E.cc//デバッグ用オプション:-fsanitize=undefined,address //コンパイラ最適化 #pragma GCC optimize("Ofast") //インクルードなど #include<bits/stdc++.h> using namespace std; typedef long long ll; //マクロ //forループ //引数は、(ループ内変数,動く範囲)か(ループ内変数,始めの数,終わりの数)、のどちらか //Dがついてないものはループ変数は1ずつインクリメントされ、Dがついてるものはループ変数は1ずつデクリメントされる //FORAは範囲for文(使いにくかったら消す) #define REP(i,n) for(ll i=0;i<ll(n);i++) #define REPD(i,n) for(ll i=n-1;i>=0;i--) #define FOR(i,a,b) for(ll i=a;i<=ll(b);i++) #define FORD(i,a,b) for(ll i=a;i>=ll(b);i--) #define FORA(i,I) for(const auto& i:I) //xにはvectorなどのコンテナ #define ALL(x) x.begin(),x.end() #define SIZE(x) ll(x.size()) //定数 #define INF 1000000000000000 //10^12:∞ #define MOD 1000000007 //10^9+7:合同式の法 #define MAXR 100000 //10^5:配列の最大のrange //略記 #define PB push_back //挿入 #define MP make_pair //pairのコンストラクタ #define F first //pairの一つ目の要素 #define S second //pairの二つ目の要素 vector<ll> a,b,c; vector<vector<ll>> tree; vector<bool> check; vector<ll> ans; void dfs1(ll i,ll m){ FORA(j,tree[i]){ if(!check[j]){ check[j]=true; a[j]=min(a[j],m); dfs1(j,a[j]); } } } pair<ll,ll> dfs2(ll i){ ll ret=0; pair<ll,ll> now={(b[i]==0 and c[i]==1),(b[i]==1 and c[i]==0)}; FORA(j,tree[i]){ if(!check[j]){ check[j]=true; pair<ll,ll> d=dfs2(j); ret+=ans[j]; now.F+=d.F; now.S+=d.S; } } ret+=(min(now.F,now.S)*a[i]*2); ans[i]=ret; return MP(now.F-min(now.F,now.S),now.S-min(now.F,now.S)); } signed main(){ //入力の高速化用のコード //ios::sync_with_stdio(false); //cin.tie(nullptr); ll n;cin>>n; a=vector<ll>(n);b=vector<ll>(n);c=vector<ll>(n); REP(i,n)cin>>a[i]>>b[i]>>c[i]; tree=vector<vector<ll>>(n); REP(i,n-1){ll u,v;cin>>u>>v;tree[u-1].PB(v-1);tree[v-1].PB(u-1);} if(accumulate(ALL(b),0)!=accumulate(ALL(c),0)){cout<<-1<<endl;return 0;} check=vector<bool>(n,false);check[0]=true; dfs1(0,a[0]); ans=vector<ll>(n,INF); check=vector<bool>(n,false);check[0]=true; dfs2(0); cout<<ans[0]<<endl; }F問題以降
今回は飛ばします

- 投稿日:2020-09-07T12:48:40+09:00
FXのCSVデータを読み込んで大量のチャート画像を作成するプログラムをPythonで作ってみた
本記事について
深層学習(CNN)でFXの予測をするために、
CSVデータ(日時、始値、高値、安値、終値が記載されたもの)から
大量のチャート画像を生成してみようと思います。成果物
以下のようなチャート画像をCSVから作成します。
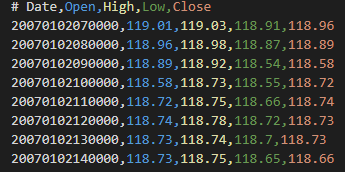
CSVファイルについて
CSVファイルは、USDJPYの1時間足です。(2007年1月~2020年9月まで)
1時間足のCSVデータなんて無いよという方は、こちらの記事を参照してください。
CSVの中身は下記のような感じです。8万行以上あります。
コード
コードは以下の通りです。
import matplotlib.pylab as plt import pandas as pd import numpy as np def make_sma(parab, arr=None): """ 関数の説明:引数で受け取ったarrayに平均移動線を追加します。 parab:期間 arr:日時、始値、高値、安値、終値で構成されたarray """ row = arr.shape[1] #配列の列数を取得 arr = np.c_[arr, np.zeros((len(arr),1))] # 列の追加 for i in range(parab, len(arr)): tmp = arr[i-parab+1:i+1,4].astype(np.float) #期間内の数値を入れる arr[i,row] = np.mean(tmp) #移動平均の値を記入 return arr def dataframe_to_img(chart_range, img_name, df=None): """ 関数の説明:DataFrameを画像に変換して保存する。 chart_range:DataFrameの範囲 img_name:画像の保存先 df:描画するDataFrame """ df = df[0:chart_range] plt.figure() df.plot(legend=None) #凡例を削除 plt.axis('off') #枠線の削除 plt.tick_params(labelbottom=False, labelleft=False, bottom=False, left=False) #枠線の削除 plt.box(False) #枠線の削除 plt.savefig(img_name,bbox_inches="tight") #余白を削除して保存 plt.close('all') #csvをarrayに読み込む arr = np.loadtxt(r'CSVファイル', delimiter=",", skiprows=1, dtype='object') #テクニカル指標を追加 arr = make_sma(parab=25, arr=arr) #DataFrameに変換 col_name = ['Date',"Open","High","Low","Close","SMA"] df = pd.DataFrame(arr,columns=col_name) #DataFrameに変換して、画像を保存 df = df[df!=0].dropna() #0の行を削除 df = df[['Close','SMA']] #グラフに描画する列だけにする df = df.astype('float') #floatに変換 chart_range = 360 for i in range(20): try: img_name = str(i) + '.png' #画像の保存先 dataframe_to_img(chart_range, img_name, df=df[i:chart_range+i]) except IndexError: pass #あとで正解ラベルとして利用するので、DataFrameも保存 df.to_csv(r'tarintest_labels.csv',encoding='utf_8_sig')コードの解説です。
最初に、CSVをnumpyで読み込んでます。その後、
arr = make_sma(parab=25, arr=arr)で、
arrに移動平均線を追加します。移動平均線の期間はparabで指定します。
25だけじゃなく、75や200などの長期線を追加したい場合は、
parabの数値を変更して追加すればドンドン追加できます。テクニカル指標の追加が終わったら、
df = pd.DataFrame(arr,columns=col_name)で
arrをDataFrameに変換します。
chart_range = 360は表示するチャートの範囲です。
今回は1時間足のCSVなので、360だと360時間分表示です。最後はfor文で
dataframe_to_img関数にDataFrameを渡して1枚1枚保存していきます。
dataframe_to_imgでは、matplotlibを使っています。
枠線などは、深層学習での学習に邪魔なので削除しています。画像の出力が終わったら、DataFrameはCSVで保存しておきましょう。
深層学習の正解ラベルとして流用するためです。確認
画像が保存されたことを確認してください。
今回はシンプルな移動平均線だけですが、
ボリンジャーバンドや一目均衡表などを表示することも可能です。ちょっとでも参考になられた方はLGTMをお願いします。
更新の励みになります。
- 投稿日:2020-09-07T12:41:05+09:00
簡易LISP処理系の実装例(Python版)
この記事は,下記拙作記事のPython版を抜粋・修正したものを利用した,簡易LISP処理系の実装例をまとめたものです.
LISP処理系本体である超循環評価器(meta-circular evaluator)の簡易実装は,原初の実装例("McCarthy's Original Lisp")やSICP 4.1のような記述例が昔から公開されていることもあり,とても簡単です.むしろ,字句・構文解析を行うS式入出力やリスト処理実装の方が開発言語ごとの手間が多く,それが敷居になっている人向けにまとめてみた次第です.
上記2記事はPythonの他に,C言語,Ruby,JavaScriptについても実装していることから,これらの言語バージョンの同記事も作成するかもしれません(そのため,タイトルを『Python版』としています).
処理系の概要
実行例は次の通り.Python2では
input()をraw_input()に読み替えて下さい.>>> s_rep("(car (cdr '(10 20 30)))") '20' >>> s_rep(input()) ((lambda (x y) (car (cdr x))) '(abc def ghi)) 'def' >>> s_rep("((lambda (f x y l) (f x (f y l))) + '10 '20 '0)") '30' >>> s_rep("((lambda (f x y l) (f x (f y l))) cons '10 '20 '())") '(10 20)' >>> s_rep(" \ ... ((fix (lambda (fact) (lambda (n) \ ... (if (eq? n '0) '1 \ ... (* n (fact (- n '1))))))) \ ... '10)") '3628800' >>> fassoc = " \ ... (fix (lambda (assoc) (lambda (k) (lambda (v) \ ... (if (eq? v '()) \ ... #f \ ... (if (eq? k (car (car v))) \ ... (car v) \ ... ((assoc k) (cdr v))))))))" >>> s_rep("((" + fassoc + \ ... "'Orange) \ ... '((Apple . 110) (Orange . 210) (Lemmon . 180)))") '(Orange . 210)'実装内容は次の通り.
- 数字を含むアトムは全てシンボルとし,値とする場合は
quote(')を用いる.- 構文として
quoteの他,ifとlambdaが使用可能.- 組込関数:
conscarcdreq?pair?(内部でコンスセルを作成)- 疑似数値演算子:
+-*/(クォートされた数字を数値とみなして演算)- 事前定義:
#t(真)#f(偽)fix(不動点コンビネータ)- エラーチェックなし,モジュール化なし,ガーベジコレクションなし
名前を定義する機能がない代わりに,再帰手続きが定義できる
fixがあるため,純LISPよりもLispKit Lispに近いかもしれません.実装例
リスト処理
先の記事よりそのまま抜粋.
def cons(x, y): return (x, y) def car(s): return s[0] def cdr(s): return s[1] def eq(s1, s2): return s1 == s2 def atom(s): return isinstance(s, str) or eq(s, None) or isinstance(s, bool)S式入出力
先の記事から,字句解析部を
()および'の識別に変更(s_lex),抽象構文木生成部をドット対とクォート記号対応としつつ,リスト処理関数でコンスセルによる構文木を生成するよう変更(s_syn),それらをまとめたS式入力関数s_readを定義.def s_lex(s): for p in "()'": s = s.replace(p, " " + p + " ") return s.split() def s_syn(s): def quote(x): if len(s) != 0 and s[-1] == "'": del s[-1] return cons("quote", cons(x, None)) else: return x t = s[-1] del s[-1] if t == ")": r = None while s[-1] != "(": if s[-1] == ".": del s[-1] r = cons(s_syn(s), car(r)) else: r = cons(s_syn(s), r) del s[-1] return quote(r) else: return quote(t) def s_read(s): return s_syn(s_lex(s))S式出力部
s_stringは新規に作成.内部ではNoneである空リストは()を,真偽値は#t#fを出力するよう設定.def s_strcons(s): sa_r = s_string(car(s)) sd = cdr(s) if eq(sd, None): return sa_r elif atom(sd): return sa_r + " . " + sd else: return sa_r + " " + s_strcons(sd) def s_string(s): if eq(s, None): return "()" elif eq(s, True): return "#t" elif eq(s, False): return "#f" elif atom(s): return s else: return "(" + s_strcons(s) + ")"超循環評価器
SICP 4.1を参考に
s_eval関数を作成.組込関数および疑似数値演算子の適用は,Peter Norvig氏の『lis.py』を参考に,本来の環境envを用いた関数適用と分けて実装.不動点コンビネータは,Yコンビネータのクロージャ版であるZコンビネータを環境envに事前設定.s_builtins = { "cons": lambda x, y: cons(x, y), "car": lambda s: car(s), "cdr": lambda s: cdr(s), "eq?": lambda s1, s2: eq(s1, s2), "pair?": lambda s: not atom(s), "+": lambda s1, s2: str(int(int(s1) + int(s2))), "-": lambda s1, s2: str(int(int(s1) - int(s2))), "*": lambda s1, s2: str(int(int(s1) * int(s2))), "/": lambda s1, s2: str(int(int(s1) / int(s2))) } def lookup_variable_value(var, env): def loop(env): def scan(vars, vals): if eq(vars, None): return loop(cdr(env)) elif eq(var, car(vars)): return car(vals) else: return scan(cdr(vars), cdr(vals)) frame = car(env) fvar = car(frame) fval = cdr(frame) return scan(fvar, fval) return loop(env) def s_eval(e, env): def sargs(a, env): if eq(a, None): return None else: return cons(s_eval(car(a), env), sargs(cdr(a), env)) if atom(e): if e in s_builtins: return e else: return lookup_variable_value(e, env) elif eq(car(e), "quote"): return car(cdr(e)) elif eq(car(e), "if"): pred = car(cdr(e)) texp = car(cdr(cdr(e))) fexp = cdr(cdr(cdr(e))) if eq(s_eval(pred, env), True): return s_eval(texp, env) else: return False if eq(fexp, None) else s_eval(car(fexp), env) elif eq(car(e), "lambda"): lvars = car(cdr(e)) lbody = car(cdr(cdr(e))) return cons("lambda", cons(lvars, cons(lbody, cons(env, None)))) else: f = s_eval(car(e), env) args = sargs(cdr(e), env) return s_apply(f, args) def s_apply(f, args): def pargs(al): if eq(al, None): return [] else: return [car(al)] + pargs(cdr(al)) if atom(f): return s_builtins[f](*pargs(args)) else: lvars = car(cdr(f)) lbody = car(cdr(cdr(f))) lenvs = car(cdr(cdr(cdr(f)))) env = cons(cons(lvars, args), lenvs) return s_eval(lbody, env) fixproc = s_eval(s_read( \ "(lambda (f) ((lambda (x) (f (lambda (y) ((x x) y)))) (lambda (x) (f (lambda (y) ((x x) y))))))" \ ), None) s_init_env = cons(cons( \ cons("fix", cons("#t", cons("#f", None))), \ cons(fixproc, cons(True, cons(False, None))) \ ), None)REP (no Loop)
s_read→s_eval→s_stringをまとめたs_repを定義.def s_rep(s): return s_string(s_eval(s_read(s), s_init_env))備考
記事に関する補足
- 超循環評価器のみで約70行/2400バイトほど.もっと短くしたかったけど,コンスセルのリスト処理をベースにしたかったので….
fixを標準装備しているLISPということで,密かにFixLispと呼んでいたり.ダメかな.更新履歴
2020-09-07:実行例を修正
2020-09-07:初版公開
- 投稿日:2020-09-07T11:25:09+09:00
「そくめん君」でカジュアル面談を実施してみた感想
「そくめん君」と呼ばれるカジュアル面談サービスの紹介、そしてカジュアル面談を実施してみた感想を紹介します。
本記事の内容
- そくめん君とは
- そくめん君でのカジュアル面談の応募から当日までの流れ
- 先日実施したカジュアル面談でのお話内容、いただいた質問の例
- 利用者としてのそくめん君のメリット
- 面談する側としてのそくめん君のメリット
※本記事の内容は、2020年9月5日に段階に基づいています
※適宜、サービスの進化に合わせて更新しますそくめん君とは
そくめん君とは、エムスリーの西場さんが立ち上げてくださった、
「即面談の日程調整ができる、企業の側面が分かる」
そんな、カジュアル面談のサービスです。
https://sokumenkun.com/カジュアル面談とは、選考や面接とは異なり、企業の人があなたに事業内容・組織・キャリア等について紹介したり、あなたの質問に回答するため面談です。転職意向に関わらず、気軽に申し込みましょう。
と解説があるように、このサイトから、1分でカジュアル面談の申込みと日程調整を行うことができます。
- 気になる企業の側面が分かる
- すぐにカジュアル面談をセッティングできる(そく、面談の調整ができる)
ので、「そくめん君」というネーミングです(と思います)。
https://sokumenkun.com/そくめん君でのカジュアル面談の応募から当日までの流れ
[1] 「そくめん君」にアクセスします
https://sokumenkun.com/[2] 以下のようにカジュアル面談を受け付けている各社の社員の方がずらりと並んでいます。
エムスリーの西場さんをはじめ、「あの有名な講演スライドの人」や「読んだことある技術書の著者」や、「業界で有名な人」みたいな人がずらりとならんでいます。
[3] 気になる人を選択したり、キーワード検索で気になるワード(例えば、"ディープラーニング")などで検索して、面談してみたい人を選びます。
その人の画像をクリックすると、その人の詳細メージが表示されます。その人の詳細ページは下のような感じです。下の画像は途中で切れているので、まだまだ画面は続きます。
私の場合、詳細ページは以下です。
●小川雄太郎(電通国際情報サービス ISID)
https://sokumenkun.com/2020/08/17/yutaro-ogawa/[4] 面談受付者のページの最下部に
応募フォーム
※ コメント欄にプロフィール等が分かる情報を記載ください。
(例: wantedly, lapras, linkedin, blogなどのURL)
https://timerex.net/s/ogawa.yutaro/3dd4ea39のような記載があります。
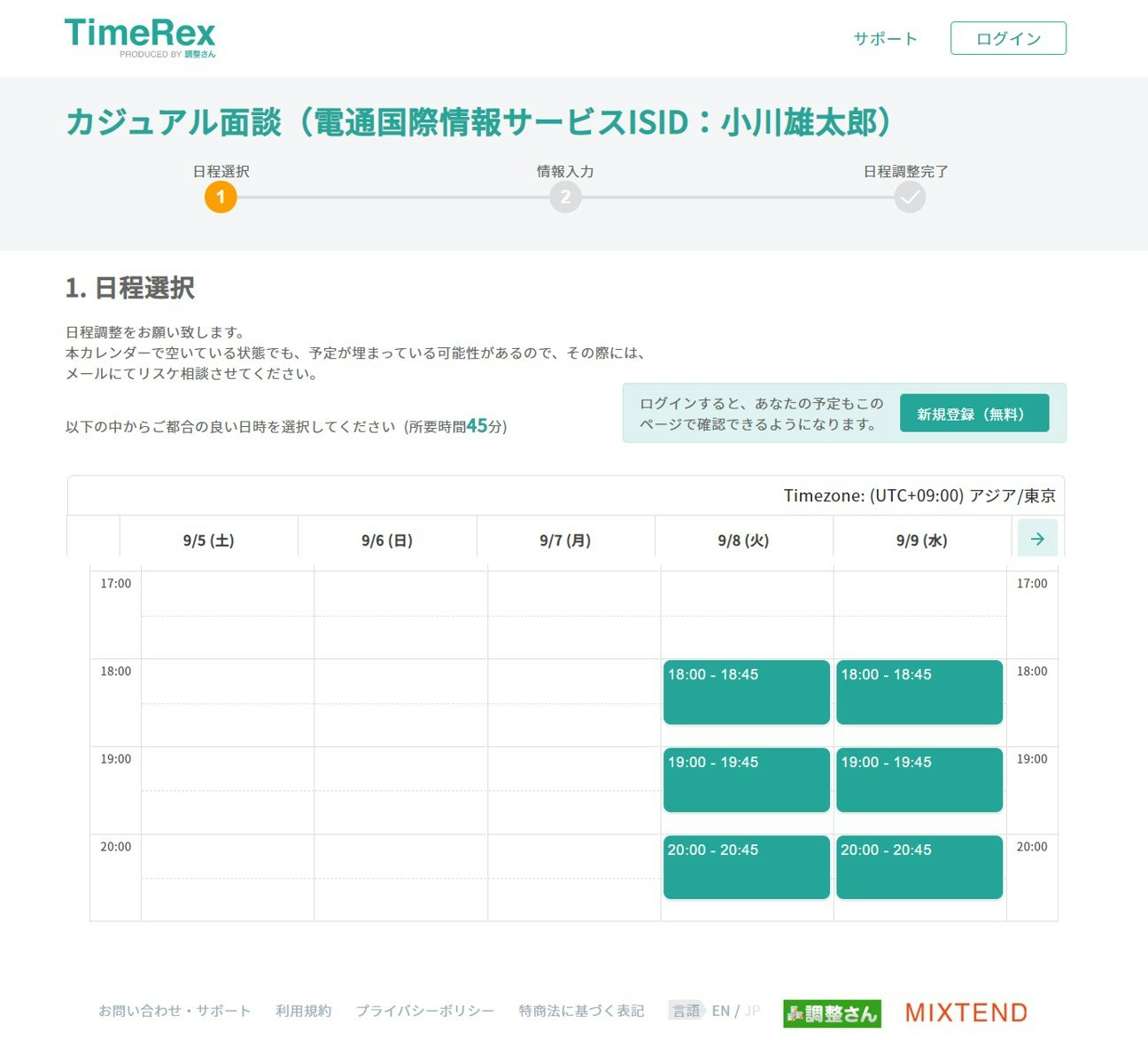
上記のリンクは私の場合で、リンクは面談受付者によって異なります。[5] 応募フォームのリンクをクリックすると、以下のように日時調整画面に移ります
上記の場合、9/8(火)、9/9(水)の夕方が空いています。
好きな時間枠をクリックし、あとは、氏名や連絡先等を入力して、「上記内容で日程調整を完了する」をクリックすれば、カジュアル面談の応募が完了です。
本当に1分で、カジュアル面談の応募が完了します!!
[6] その後の流れ
面談応募者には、「応募完了しました。いついつに、このZoomのMTG-URL:hogehogeにアクセスしてください」と、カジュアル面談用のテレカンURLが届きます。面談受付者には、「面談の応募が来ました。応募者の情報はfugfugaです。いついつに、このZoomのMTG-URL:hogehogeにアクセスしてください」と、応募者が入力した情報とカジュアル面談用のテレカンURLが届きます。
[7] 以降
これで当日のその時間にZoomのMTG-URLにアクセスしてカジュアル面談開始です。面談受付者にも寄りますが、私の場合は、
- カジュアル面談受け付けました。緊急連絡先はこちらです
- いただいた日時で問題ありません
- カジュアル面談なので質問リストなどは事前に送っていただかなくて大丈夫です(もし事前に聞きたいことメモなどを既に用意している場合は、送っていただければ、回答用意しておきます)
という旨をメールし、当日のカジュアル面談を向かえます。
先日実施したカジュアル面談でのお話内容、いただいた質問の例
先日私が実施したカジュアル面談でのお話内容、いただいた質問の一部を紹介します。
質問への回答は省略します。なお、私は45分で枠を設定しているのですが、その日はお互いに時間があったので、2時間ほどお話していました♪
【お話した内容・質問例】
[1] まずは簡単に面談応募者から、ご自身の簡単な自己紹介
[2] 働き方・職場関係
●職務要件だけを見ると、DL/MLコンサルティング〜アルゴリズム開発がメインなのでしょうか?
個人的には、クラウドサービスの設計や実システムの設計・インテグレーションにも興味があるのですが、別部隊がご担当なのでしょうか?●(幾つかの記事を拝見した限り)マルチスキルのメンバーでチームを組まれているようですが、現状だと、こういったスキルを持っているメンバが比較的足りない、等の感触はありますか?
例:データサイエンス(ビジネス/サイエンス/実装)ITスキル(Web/クラウド基盤)●メンバの方々はどのような出自の方が多いですか?(新卒/転職,データサイエンス経験者/未経験,等々…)
●組織図を見る限り「Xイノベーション本部」がAITCのメニューを対応しているのでしょうか?(プリセールスから実システムのデリバリまで?)
●NLPナイトのTexaInteligenceの発表を拝見したのですが、内製したプロダクトの運用も自組織で行っているのでしょうか?
●前述のTexaInteligence等、そもそもサービス化の企画〜開発はどういった動機づけで始まったのでしょうか?
●HPや事例を拝見した限り、個別SIもサービス化も両方取り組まれていると思うのですが、個別のSI要件ドリブンなのか、SIをやっていく中で見つけたマーケットドリブンなのかが気になっています
●個別SIとサービスは、どの程度の割合で取り組まれているのでしょうか?
●関西支社での業務(募集)はまだされていますか?最近募集要項から勤務地「大阪」が消えたような…
●その他、普通に気になる事(制度等)はだいたい小川さんのQiitaに書いてありました…
小川の記事:AI部・開発チームの働き方(私の場合)
※上記記事、withコロナの最近の働き方を追記してアップデートしました[3] もう少しカジュアルな、ビジネスや技術へのスタンスに関する質問
●「DX」という言葉についてどう思われますか? また、SIerが顧客のDXに貢献…というストーリー、実際の所どう思われますか?
●AI周りのビジネス、個人的にはどうも「カナヅチとクギ」のように感じてしまうのですが、なにか意識されていることはありますか?
●B2BビジネスにおけるAI/ML系モデルの作り込みって、今後も需要あるのでしょうか?(研究系以外)
Azure Custom VisionやIntel OpenVino等を触ったりしたのですが、画像系はこういったものでも結構出来てしまうという感覚があり…●個人的に「個別の問題に対して取り組んでいくAIビジネスのスタイル(分析やモデル構築、提供)は結局スケールしないのでは?」という疑念をずっと持っており、するとSIerのような組織で取り組む意義をどう(組織に)示せば良いのだろうと悩んでいます。お考えがあればお聞かせ頂きたいです。
[4] さらにカジュアルな、非面談者の考え方に関する質問
●NLPは記号表現(シニフィアン)を後付で整理しているだけで、感覚的には意味される対象(シニフィエ)の認識には何時までも繋がらない気がしています。Deep Learning的なアプローチが人の心の解読に繋がったりすることが、有りそうでしょうか?
先日はこんな感じでした。
面談応募者の方も、最近転職を意識し、ちょうどいろいろな企業を調べていたので、固めのしっかりした質問が多かったです。
(そのため、回答もだいぶしっかりとしたものになったのと、とても盛り上がったので45分の予定が、2時間ほど話していましたwww)上記、一例を挙げましたが、カジュアル面談なので、もっともっと適当な感じでも良いかと思います♪
利用者としてのそくめん君のメリット
私が思う利用者のメリットは、
- 本当に簡単にカジュアル面談が設定できて、当日も簡単に面談が実施できること
- 上記と重複しますが、履歴書も職務経歴書も、人材会社に登録も必要なく、簡単にカジュアル面談に応募できること
- 面談受付側に豪華なメンバ、いろんな企業の人が揃っていること
- カジュアル面談であり、選考面接ではないこと
です。
ただし、あくまでカジュアル面談であって、その企業や働き方を知る場であり、雑談の場ではない点は注意です。
(面談受付者のページに雑談でも良いよ、と書いていれば雑談でも良いですが)面談する側としてのそくめん君のメリット
面談受付者になるには、以下のリンクから応募します。
https://sokumenkun.com/speaker-form/
面談する側の人間のメリットは
- カジュアルに自社や自分たちのチームのことを知ってもらえる、広報できる
- 面倒な日程調整のやりとりをすることなく、勝手にカジュアル面談が入ってくる
が大きいです。
ただ、他に私が思うメリットとしては、
● 西場さんからの毎月の「そくめん君」のレポート情報や、西場さんが意識しているカジュアル面談の運営方法情報が貴重
です。
また、私としては、
●PdMとして西場さんが「そくめん君」というサービスを、リーンに必要最低限な機能から実装し、各種KPIを測りながら、段階的にサービス開発し、機能追加されていく過程、西場さんのPdMをなんとなく真横で感じられること
もとても魅力的です。
さいごに
私とカジュアル面談した際には最後にいつも、以下の質問をしています。
「そくめん君」を提供してくださっている、エムスリーの西場さんにはきちと礼儀を果たしたいです。
そのため、情報の収集と拡散に少しお力を貸していただけませんか。質問[1]:どこで「そくめん君」を知りましたか?
(今回の例の場合は、私のTwitterをフォローされていて、私が「そくめん君でカジュアル面談受け付けています」とtweetしたのを見て、知ったとのことでした)質問[2]:「そくめん君」を多くの人に知ってもらうために、以下のどちらかに協力いただけますか?
[プラン1] 小川とカジュアル面談をやったことをTwitterで投稿いただく
(これは、面談者のアカウントを周囲が知っている際、えっ転職考えているの?って言われかねないので場合によっては注意が必要)[プラン2] 小川からカジュアル面談をやったことをTwitter投稿 or Qiita記事にする。なお、質問内容は一部掲載しますが、回答は掲載しません。プライベートに立ち入った質問内容も記載しません。
(今回の例の場合はプラン2を選択されました)以上、「そくめん君」で、カジュアル面談を実施してみた感想です。
ぜひ皆さま気軽にご活用ください♪
「そくめん君」
https://sokumenkun.com/
備考
【執筆者】電通国際情報サービス(ISID)AIトランスフォーメーションセンター 開発Gr
小川 雄太郎(主書「つくりながら学ぶ! PyTorchによる発展ディープラーニング」 、その他「自己紹介詳細」)【Twitter】
IT・AI関連やビジネス・経営系を中心に、私が面白いと思った記事や最近読んだ新刊書籍の感想などを発信しています。これらの分野の情報を収集したい方はぜひフォローしてみてください♪(海外情報が多めです)小川雄太郎@ISID_AI_team
https://twitter.com/ISID_AI_team【その他】
私がリードする、「AIトランスフォーメーションセンター 開発チーム」ではメンバを募集中です。ご興味をお持ちの方は、こちらのページから、ご応募お待ちしております。【そくめん君】
いきなり応募は・・・という方は、カジュアル面談を「そくめん君」で行わせていただいております。
こちらもぜひご利用ください♪
https://sokumenkun.com/2020/08/17/yutaro-ogawa/【免責】本記事の内容そのものは著者の意見/発信であり、著者が属する企業等の公式見解ではございません



- 投稿日:2020-09-07T10:21:28+09:00
8週間で150問解いた私がお勧めする、LeetCodeで始める競技プログラミング
はじめに
こんにちは。皆さんは競プロしていますか。
私はついこの間までずっと、「競プロやるやる詐欺」を続けていました(笑)。競技プログラミングに興味がありつつも、「コンテスト参加のハードルが高い」などと言い訳を見つけては逃げ続けて早二年が経ち、「これではコンピュータサイエンスの基礎知識がいつまでも身につかない」と危機感に迫られ始めたのがきっかけです。
今では次のような状態になりました。
- LeetCode / AtCoder(ABC)をメインに、なるべくコンテストに参加
- それ以外の時間は LeetCode Problems を解く
- AtCoder ABC はボロボロの4完、 LeetCode は3完が限界
今回はゼロから競技プログラミングを始めた私が
- どんな過程を経たか
- これから競技プログラミングに参入する方へのおすすめ学習法
を中心に解説したいと思います。
TL;DR
- LeetCode の Easy 問題から解くのがおすすめ
- 競技プログラミングを続けることで、以下の効用がある
- 時間計算量 / 空間計算量を意識したコードが書ける
- 脳内でロジックを組み立てるスピードが向上する
- 言語そのものの勉強になる
- 競技プログラミングはやはり楽しい(重要)
競技プログラミングとは
自ら書いたアルゴリズムで問題を解く競技です。
例えば、次のような問題が出題されます。
0を言うと勝ちとなるゲームがあります。 二人のプレーヤーでゲームを行い、ある数字 n から1~3までの数を減らしていきます。 自分が必ず先行です。 また、自分と相手は常に最善の手を打ちます。 例えば n = 4 の場合、結果は以下となります。 自分:3(1つ減らした) 相手:2,1,0(3つ減らして0を宣言し勝利) n に対して自分が勝利できるかどうかを boolean で判定するプログラムを書いてください。興味を持って取り組める問題が豊富であるのも競技プログラミングの良さですね。
AtCoder と LeetCode の違い
個人的には AtCoder と LeetCode では主に次の違いがあると思っています。
AtCoder
データ構造、アルゴリズム、数学、考察力、知識 etc... など、バランス良く求められる
LeetCode
データ構造とアルゴリズムに特化した問題が多い
肌感では、 AtCoder の方が難しいです。
LeetCode はデータ構造とアルゴリズムに特化しているため、特に Easy 問題などはある程度の問題数を解くと他の問題も解けるようになるかと思います。よって LeetCode の Easy 問題から入門すると、比較的短時間で競技プログラミングの楽しさを実感できるのではないでしょうか。
競技プログラミングにおける言語選択
C++ が人気ですが、私は Python3 で書いています。
業務で Python を使っていたり、言語として好きだからというのが理由です。Python3 はスピードでは C++ に劣りますが、記述量を減らすことができるのもメリットです。
ある程度問題が解けるようになって、競技プログラミングをもっと極めようと決断したときに別の言語に変更するかもしれません。
競技プログラミングの過程
8週間の間にどのような成長があったかを簡潔に記してみます。
解き始め
- 一問一問解くのに非常に時間がかかる
- 実装スピード自体も遅い
- 時間計算量や空間計算量を全く意識できない
- 解けたら楽しいけど、全く解けない
50問解くまで
- 本当に簡単な問題は解けるようになった
- Binary Search Tree などのデータ構造に少しずつ親しみを覚える
- Dynamic Programming / Depth First Search / Breadth First Search などの概念を理解する
- 成績を気にせずコンテストに参加するようになる(重要)
100問解くまで
- 解ける問題は解けるが、解けない問題はいくら考えても解けない
- LTE(Limit Time Exceeded)になりまくることで、半強制的に時間計算量を気にするようになる
- 考察力がボトルネックだと気づく(重要)
現在まで
- Easy 問題であれば大体は解けると思えるようになる
- 実装スピードが向上した
- 時間計算量や空間計算量を意識できる
- 問題を解くことの楽しさが増した
私の場合、50問ごとに一つの小さなブレークスルーが訪れた気がします。
これは後述する「問題数をこなす」ことに繋がっており、納得感がありました。解き方
今は次のような解き方で問題を解いています。
- 問題をきちんと理解する
- あらゆる方法を考察する(出来たら3種類以上)
- コーナーケースを洗い出す
- 時間計算量を意識する
- コードを書く
上記手順の 1,2,3,4 が重要だと思っています。 つまり、実装する前が勝負なのです。
- 手順1を疎かにすると、簡単な問題が解けない問題に様変わりします(笑)。
- 手順2を疎かにすると、絶対解けない方針で細かい実装をリファクタリングし続け、結局解けない、といった事象が頻発します。
- 手順3を疎かにすると、 WA ( Wrong Answer )となる回数が増えます。
- 手順4を疎かにすると、 LTE( Limit Time Exceeded )となる回数が増えます。
競技プログラミングの力を伸ばしていくには
次の指針が重要だと思っています。
- 問題が解けてもそのデータ構造やアルゴリズムを完璧に理解したわけではなく、
- 逆に解けなくても理解できていた部分がなかったかを必ず振り返る
この考え方は詰まるところ、競技プログラミングに限ったものではありません。
どんな分野にでも応用できるのではないでしょうか。上記を基に、どのようなアクションをしていくべきかを以下に記載します。
問題数をこなす
データ構造やアルゴリズムを完璧に理解するには、全く同じ問題を復習することも大事ですが、いろいろな角度で出題される問題を大量に解くことが重要だと思っています。
違う解き方を知る
もし問題が解けない場合、答えを見ると思います。あるいは、答えを見ずに自力で解くまで考えるかもしれません。
ここで重要なのは、 自分の考え方と解答の考え方の違いを認識することです。問題が解けた場合は、いろいろな解答に目を通します。
これを私は序盤から継続したことで、非常に効果があったように思います。
解けなくていい問題、解かなくていい問題に手を出さない
前者は「今の自分のレベルに対して難易度が高すぎる問題」です。では、後者はどんな問題でしょうか。
「競技プログラミングとは」で紹介した以下の問題を覚えていますか。
0を言うと勝ちとなるゲームがあります。 二人のプレーヤーでゲームを行い、ある数字 n から1~3までの数を減らしていきます。 自分が必ず先行です。 また、自分と相手は常に最善の手を打ちます。 例えば n = 4 の場合、結果は以下となります。 自分:3(1つ減らした) 相手:2,1,0(3つ減らして0を宣言し勝利) n に対して自分が勝利できるかどうかを boolean で判定するプログラムを書いてください。この問題、ある解き方をすれば一瞬で解けてしまいます。
逆に、アルゴリズムで解こうとすると LTE(Limit Time Exceeded)になる場合があります( LeetCode ではそうでした)。もし前者でしか解けないとなると、(考え方は正しいのに)問題が解けないため、正しくないと誤認識してしまう恐れがあります。
これは非常に危険です。このような問題は教育的観点からすれば(いい薬にはなるかもしれませんが)あまり効果が高いとは思えません。
解けなくて時間を使いすぎるのも良くありません。自分の癖や苦手なことを自覚する
初期の段階からある程度問題が解けるようになると、苦手な種類の問題が見えてくると思います。
今度はその問題を如何に解けるようにできるかが次のブレークスルーに繋がります。逆にどんな問題であっても、どうすれば解けるのかを考え続けることでしか解く方法はありません。
解き方の手順2「あらゆる方法を考察する」ができるほど問題を解ける可能性は高まるため、自分の癖や苦手を減らしていくことは問題の正解率向上に直結します。
成績を気にせずコンテストに参加する
成績はあくまで結果です。結果を追い求めるのはプロだけで十分、というのは極論かもしれませんが、初学者にとっては「練習の成果を確認する場」が何よりも重要です。
「練習のための練習」を続けていると、モチベーションも落ちて成果には繋がらないと個人的には思っています。
よって、何よりも重要なのは「本番の機会を増やす」ことであり、それが競技プログラミングにおいては「成績を気にせずコンテストに参加すること」なのです。
さいごに
今回は LeetCode をおすすめしましたが、 AtCoder の方が解ける方は AtCoder で問題を解いた方が良いです。
何よりも「競技プログラミングをやっていて楽しい」という実感が重要だからです。この記事をご覧になって、一人でも競技プログラミングを始める方が増えたなら、これほどの幸せはありません。
それでは、コンテストでお会いしましょう!
- 投稿日:2020-09-07T09:25:39+09:00
Pythonで二分探索を書く
TL;DR
- 基礎的な点でありますが、しっかり頭に入れておくためPythonで二分探索のコードを書いたり説明をまとめたりしていきます。
- 勉強のため自前でコードを書いて進めます(二分探索用の標準モジュールなどは使わずに)。
- 元々デザイン方面の学校卒なので、コンピューターサイエンス方面で知識的に雑な点などはご容赦ください。
つかうもの
- Python 3.8.5
- VS Code
二分探索とは
二分探索とはソート済みの配列に対する値の検索のアルゴリズムの一つです。
バイナリサーチ(binary search)とも呼ばれます。検索対象の配列がソート済みという条件が付きますが、通常の検索よりも対象のリストが巨大になっても検索が遅くなりにくいという性質を持ちます。
方法としては、まずリストの中央に位置している値を取得し、その中央の値が検索対象の値と比べて大きいのか小さいのかを比較します。
検索対象の値が配列の中央の値よりも小さい場合には、今度は左端から中央の値の手前の範囲に配列の範囲を絞り込みます。
逆に検索対象の値が中央の値よりも大きい場合には今度は中央の値の1つ右の値から配列の右端までの範囲に配列の範囲を絞り込みます。
その後は絞り込んだ配列の範囲でさらに中央の値を取り、再び検索対象の値が中央の値よりも大きいか小さいかを判定し、配列を絞り込みます。
もし検索対象の値と配列の中央の値が一致した場合、対象の値が見つかったことになるのでそこで検索が終了です。
[1, 1, 2, 3, 3, 4, 5, 6, 6, 7, 8]というソート済みのリストで2の値を検索するようなケースを考えてみます。まずはリストの中央の値を取得します。最初の中央の値は
4です。
検索対象の値の2は中央の値の4よりも小さいため、リストを4の部分よりも左側に絞りこみ、[1, 1, 2, 3, 3]という値にします。絞り込んだ後のリストで再度中央の値を取得します。今度はリストの中央の値が
2となっています。これは検索対象の2と一致ずるため、対象が存在するという判定で検索が終了します。通常の検索との計算オーダーの比較
通常の検索処理は先頭から順番に一致するか検索を実施します。計算オーダーは$O(n)$(ただし、検索対象の値が先頭の方に存在すればもっと少なくなります)となり、配列の件数($n$)が大きくなればなるほど線形で処理時間が長くなっていきます。
一方で二分探索の場合には計算オーダーは$O(log_2 n)$となるため、配列のサイズが大きくなっても処理時間がひたすら肥大化する・・・といったことは軽減されます。
どういった時に使えるのか
通常の検索よりも二分探索の方が処理が速くなる一方で、二分探索にはソートされている配列でのみしか使えません(ソートされていないと配列を分割時に大小関係がおかしなことになります)。
そのため検索対象の配列がソートされておらず、且つ検索が1回しか実行しない・・・といったケースだと通常の検索よりもソートの方が計算コストが高くなってしまい、二分探索を使うメリットはありません。
一方で配列が既にソート済みの場合や、もしくはなんども検索処理を繰り返す場合などにはソートを実行しても二分探索を使った方が計算コストが低く抑えられます。
Pythonで自分で書いてみる
文字などのリストでも数値と同様に二分探索を使ったりはできますが、今回は整数を格納するリストでサンプルとして進めます。
また、検索結果のインデックスを返すといった制御ではなくシンプルにリストに値が含まれるかを調べる形で進めます。
from typing import List list_value: List[int] = [ 100, 23, 33, 51, 70, 32, 34, 13, 3, 79, 8, 12, 16, 134, 83] sorted_list: List[int] = sorted(list_value) def binary_search(sorted_list: List[int], search_value: int) -> bool: """ 二分探索を実施し、検索対象の値がリスト内に含まれるかどうかの 真偽値を取得する。 Parameters ---------- sorted_list : list of int ソート済みの整数値を格納したリスト。 search_value : int 検索対象の値。 Returns ------- value_exists : bool 値がリスト内に含まれるかどうか。 """ left_index: int = 0 right_index: int = len(sorted_list) - 1 while left_index <= right_index: middle_index: int = (left_index + right_index) // 2 middle_value: int = sorted_list[middle_index] if search_value < middle_value: right_index = middle_index - 1 continue if search_value > middle_value: left_index = middle_index + 1 continue return True return False順番にコードに触れていきます。
まずは二分探索では対象のリストはソートしてある必要があるため、sorted関数を使ってリストをソートしています(sortメソッドなどでも変わりありません)。
list_value: List[int] = [ 100, 23, 33, 51, 70, 32, 34, 13, 3, 79, 8, 12, 16, 134, 83] sorted_list: List[int] = sorted(list_value)続いて二分探索の関数の処理です。
left_index: int = 0 right_index: int = len(sorted_list) - 1対象とするリストのインデックス範囲を扱うための変数をleft_indexとright_indexとして設定しています。リストの左端のインデックスをleft_index、右端をright_indexとしています。これらの値はループで検索が終わるまで、二分されるたびに片側を更新していきます。
while left_index <= right_index:二分する処理はwhileのループで繰り返し実行します。このループは左端のインデックスが右端のインデックスよりも左にあるかもしくは同じインテックスである限り繰り返します。もし右端のインデックスよりも右になった場合は対象とするリストの範囲が無くなった(全ての対象を検索し終わった)状態となるので、そこでループを終了し対象が見つからなかったとして判定します。
middle_index: int = (left_index + right_index) // 2 middle_value: int = sorted_list[middle_index]ループ内でのmiddle_indexは対象の配列範囲の中の中央の値を格納しています。
// 2で2で割って端数を切り捨てています(//は除算に加えてfloor的な挙動になります)。また、中央のインデックスだけでなくそのインデックスを参照して中央の値を変数に設定もしています(
middle_value)。if search_value < middle_value: right_index = middle_index - 1 continueif文で、もし検索対象の値が中央の値よりも小さければ配列を左半分のみに二分するため、右端のインデックス(right_index)を中央のインデックスの左隣りに設定しています(
middle_index - 1)。※if文の判定で中央の値自体は対象ではないことは分かっているので、中央のインデックスではなく
-1したインデックスを設定します。if search_value > middle_value: left_index = middle_index + 1 continue反対に検索対象の値が中央の値よりも大きい場合には配列を右半分のみになるように左端のインデックス(left_index)の値を調整します。
return True検索対象の値が中央の値よりも小さくも大きくも無い場合、つまり中央の値と同一の場合には、検索対象の値が存在するとしてTrueを返却しています。
return False実際に実行してみます。まずは対象がリスト内に存在する条件から試してみます。
value_exists = binary_search( sorted_list=sorted_list, search_value=83) print(value_exists)True正常にTrueが返ってきました。続いて検索対象がリストに含まれない条件を指定してみます。
value_exists = binary_search( sorted_list=sorted_list, search_value=84) print(value_exists)Falseこちらも想定通りFalseとなりました。
参考文献と参考サイト
- 投稿日:2020-09-07T09:20:04+09:00
初心者がWordファイルを一括でPDFに変換してみる
取り組みのきっかけ
仕事柄よくWordを使って書類を作るのですが、
ペーパーレス化の推進、グループウェア導入を経て、
「WordファイルをPDFにして書類を一元管理しよう!!」という上司の一声でスタート。いくつあるかわからない無数の「.doc」「.docx」との戦いが始まる...
もちろん社内でpython使える人はおらず、それとなくやってみました。実装
import win32com.client import os #必要なモジュールをインストールする wd = win32com.client.Dispatch('Word.Application') #「Wordを操作する」という宣言 documents_path = 'C:/test/' word_list = [] #ファイルが保管されているフォルダのパスを設定 #word_file_nameを格納する空のリスト(word_list)を作成 for word_file_name in os.listdir(documents_path): if os.path.isfile(os.path.join(documents_path, word_file_name)): word_list.append(word_file_name) for i in range(0,len(word_list)): try: word_file = wd.Documents.Open(documents_path + '/' + word_list[i]) base_name, ext = os.path.splitext(word_list[i]) #base_name, ext により、extに拡張子が入り、ファイル名がbase_nameに格納される word_file.SaveAs2(FileName = documents_path + base_name + '.pdf', FileFormat = 17) #ファイル名を指定、フォーマット(17がPDF[https://docs.microsoft.com/ja-JP/office/vba/api/word.wdsaveformat])を設定 except Exception as e: print(e) #try以外の例外処理をeに格納、あれば表示する finally: word_file.Close() print('complete')色々試行錯誤し、上記のコードとなりました。
初心者故にかなり冗長な作りになっていると思います。documents_pathは、今回掲載用なので、testとしていますが、
使用する際にはWordファイルが保管されているフォルダのパスを指定します。課題
・for文が2回入っており、本来は1つにまとめたかったのですが、
with文の中で、pywin32が上手く動作しなかったので、今後改善策を講じる必要がある。・pywin32以外のモジュールでも試してみる。
・冗長的な部分をキレイにしてあげる。
初めて自作してみて
pythonはもともと興味があり、色々取り組んできていましたが実際になにかを完成させたというのは初めてでした。まだまだ本職の人から見れば下手くそかもしれませんが、まずは些細なものでもコード書いてみて書くことに慣れていきたいです。
社内で自動化を用いて改善できる部分は多々あるので、取り組み結果を備忘録も兼ねてコツコツQiitaに投稿していきます。改善点やアドバイスいただけたら幸いです!よろしくお願いいたします。
- 投稿日:2020-09-07T09:02:49+09:00
Python OpenCVを使ってマークシートの読み取り作成(うまく読み取りするコツ)
紙のアンケートを仕事で行うことになったため、主にこちらの記事(PythonとOpenCVで簡易OMR(マークシートリーダ)を作る)を参考に作ってみました。空白行を誤認識することが多かったので、参考にしていただければ幸いです。
※他にもいろいろと参考していますが、それは個別で書いていますアンケート全体の流れ
ExcelでQRコードを埋め込んだアンケートの用紙の作成
アンケート用紙のページ番号や個人を特定するためにQRコードに情報入れて埋め込みました印刷して配布します
回収したアンケート用紙をスキャンして、PDF→JPGへ
ネットにあるフリーの変換サイトで適当に変換しました変換されたJPGファイルからアンケート結果を読み取り
環境
1. アンケート用紙作成
- Python 3.5
- QrCode
- pillow
- Excel
2. スキャン
- 職場のスキャナー(複合機)
- PDF => JPG変換サイト 例:https://pdftoimage.com/ja/
3. マークシート読み取り
- Python 3.5
- OpenCV-Contrib-Python 4.4
- numpy 1.15
ポイント
1. アンケート用紙作成時のポイント
- 位置マーカー(特徴点)のサイズは用紙とプログラム参照用の位置マーカーの画像ファイルはサイズを合わせる
- アンケート用紙内のマーク位置を等間隔に設置する
- 上側の位置マーカー(特徴点)はきっちりマーカー位置と定数倍の等間隔になるよう配置する
2. スキャン時のポイント
- ファイル名に全角文字を入れない。OpenCVが対応してない。 なんか処理入れれば対応できると思いますが、途中ファイルなので全角入れなきゃいいだけやし、何もしませんでした
3. マークシート読み取り時のポイント
- 回答条件(複数選択の有無、未回答の有無)により抽出条件の設定をする 今回は複数選択なし、未回答ありで行いました
詳細
1. アンケート用紙作成
1. QRコードの作成
今回は設問用紙が複数枚あるため、どの設問用しか、その設問用紙が誰が記載したのかを判別するため、QRコードを設問用紙に埋め込んで読み込み時にその情報ととともに回答をCSVで取り込むことにしました。
def makeQr(qrMessage, fileName='result.png', filePath='resultQrCode/'): """引数qrMessageとなるQRコードを作成し、resultQrCodeに保存する Args: qrMessage (str): 作るQRコード fileName (str, optional): 出力ファイル名. Defaults to 'result.png'. filePath (str, optional): 出力ファイルパス ※要末尾に「/」. Defaults to 'resultQrCode/'. """ import qrcode import os img = qrcode.make(qrMessage) if not os.path.isdir(filePath): os.makedirs(filePath) if not(filePath[-1] == '\\' or filePath[-1] == '/'): filePath = filePath + '\\' img.save(filePath + fileName) print('File out:' + filePath + fileName) if __name__ == '__main__': import re import sys args = sys.argv if 1 < len(args): if re.findall('[/:*?"<>|]', args[1]): print('[Error]禁則文字「/:*?"<>|」') elif 2 == len(args): makeQr(args[1]) elif re.findall('[:*?"<>|]', args[2]): print('[Error]ファイル名に禁則文字「:*?"<>|」') elif 3 == len(args): makeQr(args[1],args[2]) elif re.findall('[*?"<>|]', args[3]): print('[Error]フォルダ名に禁則文字「*?"<>|」') elif 4 == len(args): makeQr(args[1],args[2],args[3]) else: qrMessage = args[1] for qrMessageList in args[4:]: qrMessage = qrMessage + '\r\n' + qrMessageList makeQr(qrMessage,args[2],args[3]) else: print('error: args is one') print('usage1: makeQr.exe [QR_Text]') print('usage2: makeQr.exe [QR_Text] [Output_FileName]') print('usage3: makeQr.exe [QR_Text] [Output_FileName] [Output_FilePath]') print('usage4: makeQr.exe [QR_Text] [Output_FileName] [Output_FilePath] [QR_Text_Line2...]')あとで誰でも使えるようにこれを。py2exeでexe化しました。(pyinstallerでもいいですが、重かったのでここでは、py2exeにしました。)
- 参考:py2exeをpython 3.5 - 3.7で使う2.マーカーの用意
設問とマークシートを一緒にするため、マークシートの範囲を切り取る。切り取る箇所の四隅に特徴のある白黒画像を用意する。今回はQRコードを使用するため、下図QRコードで使用しているマーカー(赤枠で囲った)は使用できません。また、Excelを使用しているため、図形(オートシェイプ)でテキストとして★にすれば、栗なものとなると判断し、図形として★を用意しました。
解析プログラムにマーカである★を画像ファイルとして渡す必要があるため、ペイントなどでExcelのシェープを張り付けて保存しました。サイズや余白がオートシェイプと同じ必要があるため、一旦縦横幅を最小にしてから張り付けるといいです。3. マークの用意
Excelで設問とマークを用意します。ポイントは以下の通り。
- マークするセル及びマーカーの左上を高さ、幅を等間隔にする
- マーカーの左上は高さがはみ出さないようにする
- マーク記号([a]等)は薄い文字、縦書き
4.用紙幅に合わせてマーカーをリサイズとマーカーの貼り付け
Excelなので、印刷を拡大縮小してしまい、画像として保存したマーカーと印刷時のマーカーのサイズが異なり、うまく認識できなくなることがあるため、シートごとに拡大倍率を取得(参照)する必要があります。
-参照ExecuteExcel4Macro "Page.Setup()"Public Function getPrintZoomPer(sheetName As String) As Integer Worksheets(sheetName).Activate ExecuteExcel4Macro "Page.Setup(,,,,,,,,,,,,{1,#N/A})" ExecuteExcel4Macro "Page.Setup(,,,,,,,,,,,,{#N/A,#N/A})" getPrintZoomPer = ExecuteExcel4Macro("Get.Document(62)") End Functionどこかのシートにマーカーソースを置き、そのマーカーソースを張り付けたいシートの4角に貼り付ける。マーカー貼り付け時には取得した拡大率を逆数でかける。設問数とか選択肢が可変するので、固定化せずvbaで作りました。
Public Sub insertMaker(sheetName As String, pasteCellStr As String, _ printZoomPer As Integer) ' sheetName:貼り付け先のシート名 ' paseteCellStr:貼り付け先のセル文字列 例:A4、B1等 Dim srcShape As shape Set srcShape = Worksheets("sheet1").Shapes("marker") ' sheet1:貼り付け元のマーカーShapeがあるシート名 ' marker:貼り付け元のマーカーShapenamae名前 srcShape.Copy With Worksheets(sheetName).Pictures.Paste .Top = Worksheets(sheetName).Range(pasteCellStr).Top .Left = Worksheets(sheetName).Range(pasteCellStr).Left .Name = "marker" .Width = .Width * 100 / printZoomPer End With End Sub5.QRコードの挿入
QRコードに「アンケート種類+アンケートページ番号+支店+人の番号+選択肢数+設問数」を入れ作成します。Excelマクロから「1.」で作ったexeファイルをWScript.Shellで呼び出します。
Public Function makeQr(ByVal QrMessage As String, ByVal fileName As String) As String Dim WSH, wExec, sCmd As String Set WSH = CreateObject("WScript.Shell") sCmd = ThisWorkbook.Path & "makeQR.exe " & QrMessage & " " & fileName & " " & _ ThisWorkbook.Path & "resultQrCode" Set wExec = WSH.Exec("%ComSpec% /c " & sCmd) Do While wExec.Status = 0 DoEvents Loop makeQr = wExec.StdOut.readall Set wExec = Nothing Set WSH = Nothing End Functionいろいろとやって、出来上がったのが下の通り
こんな感じで作ったものを印刷して配布します。
2. スキャン
アンケート終了後、スキャンを行います。マークシート読み取り側で解像度の設定があるため、200dpi固定に今回はしました。(なお、職場の複合機は直接jpg形式に保存できなかったので、PDFで保存しPDF => JPG変換サイトで変換しました。
また、マークシート読み取り側でopenCVを使うのですが、ファイル名に全角文字が使えなかったので、注意してください。3. マークシート読み取り
1.QRコードの読み取り
集計したJPGファイルたちを一つのフォルダに入れて、QRコードを読み取り、引数で返します。
def qrCodeToStr(filePath): """QRコードから文字列を読み取る Args: filePath (String): QRコードを含む画像ファイルのパス Returns: String: QRコードを読み取った結果(失敗したnullString) """ import cv2 img = cv2.imread(filePath, cv2.IMREAD_GRAYSCALE) # QRコードデコード qr = cv2.QRCodeDetector() data,_,_ = qr.detectAndDecode(img) if data == '': print('[ERROR]' + filePath + 'からQRコードが見つかりませんでした') else: print(data) return data2.マークシート読み取り
ここは、こちらの記事(PythonとOpenCVで簡易OMR(マークシートリーダ)を作る)を参考にしてますので、ほぼ同じです。
少し変えているのは、以下の通りです。
- threshold値をfor文で高いものからループし、うまくいく値を探っている
- 塗っている、塗っていないかの判定を今回は未回答を認め、複数回答を認めていないので、平均値の4倍以上でいったん抽出し、回答が複数あった場合は、最大値の半分以上とした。
def changeMarkToStr(scanFilePath, n_col, n_row, message): """マークシートの読み取り、結果をFalse,Trueの2次元配列で返す Args: scanFilePath (String): マークシート形式を含むJPEGファイルのパス n_col (int): 選択肢の数(列数) n_row (int): 設問の数(行数) Returns: list: マークシートの読み取った結果 False,Trueの2次元配列 """ ### n_col = 6 # 1行あたりのマークの数 ### n_row = 9 # マークの行数 import numpy as np import cv2 ### マーカーの設定 marker_dpi = 120 # 画面解像度(マーカーサイズ) scan_dpi = 200 # スキャン画像の解像度 # グレースケール (mode = 0)でファイルを読み込む marker=cv2.imread('img/setting/marker.jpg',0) # マーカーのサイズを取得 w, h = marker.shape[::-1] # マーカーのサイズを変更 marker = cv2.resize(marker, (int(h*scan_dpi/marker_dpi), int(w*scan_dpi/marker_dpi))) ### スキャン画像を読み込む img = cv2.imread(scanFilePath,0) res = cv2.matchTemplate(img, marker, cv2.TM_CCOEFF_NORMED) ## makerの3点から抜き出すのを繰り返す 抜き出すときの条件は以下の通り margin_top = 1 # 上余白行数 margin_bottom = 0 # 下余白行数 for threshold in [0.8, 0.75, 0.7, 0.65, 0.6]: loc = np.where( res >= threshold) mark_area={} try: mark_area['top_x']= sorted(loc[1])[0] mark_area['top_y']= sorted(loc[0])[0] mark_area['bottom_x']= sorted(loc[1])[-1] mark_area['bottom_y']= sorted(loc[0])[-1] topX_error = sorted(loc[1])[1] - sorted(loc[1])[0] bottomX_error = sorted(loc[1])[-1] - sorted(loc[1])[-2] topY_error = sorted(loc[0])[1] - sorted(loc[0])[0] bottomY_error = sorted(loc[0])[-1] - sorted(loc[0])[-2] img = img[mark_area['top_y']:mark_area['bottom_y'],mark_area['top_x']:mark_area['bottom_x']] if (topX_error < 5 and bottomX_error < 5 and topY_error < 5 and bottomY_error < 5): break except: continue # 次に,この後の処理をしやすくするため,切り出した画像をマークの # 列数・行数の整数倍のサイズになるようリサイズします。 # ここでは,列数・行数の100倍にしています。 # なお,行数をカウントする際には,マーク領域からマーカーまでの余白も考慮した行数にします。 n_row = n_row + margin_top + margin_bottom img = cv2.resize(img, (n_col*100, n_row*100)) ### ブラーをかける img = cv2.GaussianBlur(img,(5,5),0) ### 50を閾値として2値化 res, img = cv2.threshold(img, 50, 255, cv2.THRESH_BINARY+cv2.THRESH_OTSU) ### 白黒反転 img = 255 - img cv2.imwrite('img/res.png',img) # マークの認識 ### 結果を入れる配列を用意 result = [] ### 行ごとの処理(余白行を除いて処理を行う) for row in range(margin_top, n_row - margin_bottom): ### 処理する行だけ切り出す tmp_img = img [row*100:(row+1)*100,] area_sum = [] # 合計値を入れる配列 ### 各マークの処理 for col in range(n_col): ### NumPyで各マーク領域の画像の合計値を求める area_sum.append(np.sum(tmp_img[:,col*100:(col+1)*100])) ### 画像領域の合計値が,平均値の4倍以上かどうかで判断 ### 実際にマークを縫っている場合、4.9倍から6倍 全く塗っていないので3倍があった ### 中央値の3倍だと、0が続いたときに使えない ressss = (area_sum > np.average(area_sum) * 4) # 上記条件だと複数条件を抽出しやすいため、最大値の半分以上を抽出 if np.sum(ressss == True) > 1: ressss = (area_sum > np.max(area_sum) * 0.5) result.append(ressss) for x in range(len(result)): res = np.where(result[x]==True)[0]+1 if len(res)>1: message.append('multi answer:' + str(res)) elif len(res)==1: message.append(res[0]) else: message.append('None') message.insert(0,scanFilePath) print(message) return message自分のメモ用なのでだいぶ走り書きですが、参考になれば