- 投稿日:2020-09-07T23:53:52+09:00
AWSを使ったWordPress環境構築(単一構成)
事前準備
EC2インスタンスを作成
SSH接続
$ssh -i .ssh/key.pem ec2-user@public_ip※key.pemはssh_key
※public_ipはインスタンスのpublic_ip
Apacheのインストール
- Apachのインストール・起動
$ sudo yum install -y httpd $ sudo systemctl start httpdMySQL5.7のインストール
MySQL Yum RepositoryからMySQL5.7をインストールする。
- Yumリポジトリの情報のインストール
$ sudo yum localinstall https://dev.mysql.com/get/mysql80-community-release-el7-3.noarch.rpm
- MySQL8.0リポジトリを無効にし、MySQL5.7リポジトリを有効にする
$ sudo yum-config-manager --disable mysql80-community $ sudo yum-config-manager --enable mysql57-community #適用されているか確認 $ cat /etc/yum.repos.d/mysql-community.repo
- MySQLのインストール・起動
$ sudo yum install -y mysql-community-server $ sudo systemctl start mysqld
- MySQLの初期パスワードの確認
$ sudo cat /var/log/mysqld.log | grep root@localhost [Note] A temporary password is generated for root@localhost: 12桁の文字列
- MySQLのパスワード変更
$ mysqladmin -uroot -p password Enter password:古いパスワード New password:新しいパスワード Confirm new password:新しいパスワード #Warnigがでても変更はできています Warning: Since password will be sent to server in plain text, use ssl connection to ensure password safety.
- WordPress用のDB・ユーザーを作成する
$ mysql -uroot -p Enter password:設定したパスワード #WordPress用のユーザー作成 mysql> CREATE USER 'wordpress'@'localhost' IDENTIFIED BY 'wordpressユーザーのパスワード'; #WordPress用のDB作成 mysql> CREATE DATABASE `wordpress`; #DB権限を作成したユーザーに付与 mysql> GRANT ALL PRIVILEGES ON `wordpress`.* TO "wordpress"@"localhost"; #設定反映 mysql> FLUSH PRIVILEGES; mysql> EXIT;PHP7.4のインストール
sudo yum install phpを実行すると、PHP5.4がインストールされてしまします。Amazon LinuxのリポジトリにPHP5.4しかないためです。
amazon-linux-extrasを使用することで解決できます。
- amazon-linux-extrasが存在するかの確認
$ which amazon-linux-extras /usr/bin/amazon-linux-extras
- amazon-linux-extrasがインストールされていない場合は、インストールを行う
$ sudo yum install -y amazon-linux-extras $ sudo yum update -y
- amazon-linux-extrasからPHP7.4をインストールする
$ sudo amazon-linux-extras install -y php7.4 $ sudo yum clean metadata #追加でパッケージをインストール(必要なければ不要です。) $ sudo yum install -y php-mbstring php-xml $ sudo yum update -yWordPressのインストール
- WordPressをインストール
#インストールしたいディレクトリに移動 $ cd ~ $ wget http://ja.wordpress.org/latest-ja.zip $ unzip latest-ja.zip
- 設定ファイルの編集を行います。
#サンプルをコピー $ cp wordpress/wp-config-sample.php wordpress/wp-config.php $ sudo vim wordpress/wp-config.php #DBの設定値を変更する。 define( 'DB_NAME', 'database_name_here' ); define( 'DB_USER', 'username_here' ); define( 'DB_PASSWORD', 'password_here' ); define( 'DB_HOST', 'localhost' ); #セキュリティーキーの変更する。 define( 'AUTH_KEY', 'put your unique phrase here' ); define( 'SECURE_AUTH_KEY', 'put your unique phrase here' ); define( 'LOGGED_IN_KEY', 'put your unique phrase here' ); define( 'NONCE_KEY', 'put your unique phrase here' ); define( 'AUTH_SALT', 'put your unique phrase here' ); define( 'SECURE_AUTH_SALT', 'put your unique phrase here' ); define( 'LOGGED_IN_SALT', 'put your unique phrase here' ); define( 'NONCE_SALT', 'put your unique phrase here' );※セキュリティキーはオンラインジェネレータ を使用してください。
- Apachの設定
Amazon Linuxの場合、
.htaccessがディフォルトで無効となっているため設定を行う必要がある。実際の親ファイル
/etc/httpd/conf/httpd.confではなくconf.dに設定を記載する。$ sudo vim /etc/httpd/conf.d/file_name.conf #「sample」にはアクセスしたいURIを指定 #「/home/ec2-user/wordpress/」にはインストールしたディレクトリを指定する Alias /sample/ /home/ec2-user/wordpress/ <Directory "/home/ec2-user/wordpress"> AllowOverride All Options None Require all granted #ipを制限する場合に記載 Require ip ×××××××××××× </Directory> #Apache文法の確認 $ sudo httpd -t Syntax OK $ sudo systemctl restart httpd
http://ホスト/sample/にアクセスしてWordPressの初期設定画面が開ければ成功です!アクセスした際に403エラーとなる場合は権限設定を行う。
#実行権限の付与 #「/home/ec2-user」にはインストールしたディレクトリを指定する $ sudo chmod o+x /home/ec2-user間違っている点があればお教えください!
冗長化構成は後日アップします!参考
Amazon Linux による WordPress ブログのホスティング
- 投稿日:2020-09-07T22:24:35+09:00
aws sts get-session-tokenの結果をexportするためのワンライナー
AWSやっているとよく出てくるこちらのSession TokenのExport。
aws sts get-session-tokenで取得すれば良いのですが毎度微妙に面倒でした。export AWS_ACCESS_KEY_ID=AKIAIOSFODNN7EXAMPLE export AWS_SECRET_ACCESS_KEY=wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY export AWS_SESSION_TOKEN=AQoDYXdzEJr1K...o5OytwEXAMPLE=Shellとかで実装されているのも見つけましたが、自分の好みでワンライナーにしました。
Qiitaの機能でコピーボタン押して使うと便利です。
出力して、別のターミナルに貼り付けたい時は、出力してコピペ。
aws sts get-session-token --query 'Credentials | {A:AccessKeyId,B:SecretAccessKey,C:SessionToken}' --output yaml | awk 'NR==1{print "export AWS_ACCESS_KEY_ID="$2} NR==2{print "export AWS_SECRET_ACCESS_KEY="$2} NR==3{print "export AWS_SESSION_TOKEN="$2}'自身のセッションで使う時にはevalすれば環境変数として読み込んでくれます。
eval $(aws sts get-session-token --query 'Credentials | {A:AccessKeyId,B:SecretAccessKey,C:SessionToken}' --output yaml | awk 'NR==1{print "export AWS_ACCESS_KEY_ID="$2} NR==2{print "export AWS_SECRET_ACCESS_KEY="$2} NR==3{print "export AWS_SESSION_TOKEN="$2}')WSLなら最後に
clip.exeを使ってクリップボードにCOPYしても便利です。aws sts get-session-token --query 'Credentials | {A:AccessKeyId,B:SecretAccessKey,C:SessionToken}' --output yaml | awk 'NR==1{print "export AWS_ACCESS_KEY_ID="$2} NR==2{print "export AWS_SECRET_ACCESS_KEY="$2} NR==3{print "export AWS_SESSION_TOKEN="$2}' | clip.exe
- 投稿日:2020-09-07T22:19:53+09:00
【AWS SAA】スケールアウトとスケールアップの違い
はじめに
AWS SAAの試験の中で高可用なアーキテクチャはどれか選ぶ問題がある。サーバの処理能力を向上させるアプローチとして、主に「スケールアウト」と「スケールアップ」があるが、その違いが曖昧であった為、本稿を通じて簡単にその違いについて整理したい。
スケールアウト
スケールアウトは水平スケールとも呼ばれ、Auto Scalingのように数の増減でスケーリングすることだ。
例:EC2を1つ→3つに変更
スケールアップ
垂直スケーリングとも呼ばれ、インスタンスそのものの性能を変更してスケーリングすること。(サーバそのものを増強すること。)
例:EC2インスタンスタイプをt2.micro→t2.largeに変更
※今回は比較しやすいように、EC2インスタンスタイプで例えたが、実際はデータベースなどでよく使われる手法とのこと。参考
https://dev83.com/aws-autoscaling/
https://japan.zdnet.com/article/20234267/
Ultimate AWS Certified SysOps Administrator Associate 2020


- 投稿日:2020-09-07T19:59:08+09:00
AWS 認定 クラウドプラクティショナーサンプル問題を解説します
こんにちは。気が付いたら梅雨に入り、雨の日が続きますがいかがお過ごしでしょうか。
そしてバタバタしているうちに梅雨も終わり夏になり、そろそろ秋めいてまいりました。当社でも4月に入社した新入社員が配属されました。
この記事を読まれている皆様も新人や後輩、部下が新たにつくといった状況でしょうか。
または、実際に配属される新人の皆様でしょうか。ようこそ!そこで、AWS認定のサンプル問題をもとに、深堀をして解説しようと思います。
今回は、AWS認定の入門・基礎的な資格である「クラウドプラクティショナー」のサンプル問題を取り上げます。
AWS認定とは
AWS 認定は、クラウドの専門知識を検証し、専門家が需要の高いスキルを強調し、組織が AWS を使用してクラウドイニシアチブにおける効果的で革新的なチームを構築するのに役立ちます。個人やチームが独自の目標を達成できるように、役割と専門分野ごとに設計したさまざまな認定試験から選択します。
AWS 認定は領域やレベルごとに分けられ、本校執筆時点(2020/09)では12の認定資格が存在しています。
- レベル
- 基礎
- アソシエイト(中級ととらえてください)
- プロフェッショナル(上級ととらえてください)
- 専門知識(対象分野に特化した高度な認定)
- 領域
- 全般
- ソリューション
- 開発
- 運用
- DBや機械学習といった専門分野
表にまとめると以下の通りです。
# レベル 認定名 1 基礎 クラウドプラクティショナー 2 アソシエイト ソリューションアーキテクトアソシエイト 3 アソシエイト デベロッパー アソシエイト 4 アソシエイト SysOps アドミニストレーター アソシエイト 5 プロフェッショナル ソシューションアーキテクト プロフェッショナル 6 プロフェッショナル DevOps エンジニア プロフェッショナル 7 専門知識 高度なネットワーク 8 専門知識 Alexaスキルビルダー 9 専門知識 セキュリティ 10 専門知識 機械学習 11 専門知識 データ分析 12 専門知識 データベース AWS認定クラウドプラクティショナー
試験の概要や出題割合などは、以下の試験ガイドをご確認ください。
https://d1.awsstatic.com/ja_JP/training-and-certification/docs-cloud-practitioner/AWS-Certified-Cloud-Practitioner_Exam-Guide.pdfとくに気にされる方が多いと考える「求められる知識」はこんな感じです。
推奨される AWS の知識
受験者は、テクノロジー、マネジメント、販売、購買、ファイナンスの分野で最低 6 か月の AWS クラウド使用経験があることが推奨されます。
つまり、基礎レベルではありますが、幅広い領域から問題がでるということです。
推奨される IT 全般の知識
受験者には、IT サービスの基本的な知識と、それらのサービスの AWS クラウドプラットフォームでの使用に関する知識があることが求められます。
サンプル問題を解いてみよう
それでは、サンプル問題を確認していきましょう。
※以降、Markdown記載に合わせて、サンプル問題のABCDを1234と置き換えています。
第1問
問題文
コンピューティングワークロードが変動するアプリケーションにとって、AWS が従来型データセンターよりも経済的であるのはなぜですか。
選択肢
- Amazon EC2 の利用料金は毎月請求される。
- ユーザーは常に、自分の Amazon EC2 インスタンスに対するフル管理アクセス権限を付与される。
- Amazon EC2 インスタンスは、必要に応じて起動できる。
- ユーザーは、ピーク時間帯のワークロードを処理するのに十分な数のインスタンスを常に実行できる。
回答
3
解説
問題文にある、「従来型データセンターよりも経済的であるのはなぜですか」に着目して考えます。
- Amazon EC2は必要に応じて起動停止ができます。停止している場合は課金されません。そのため、必ずしも毎月請求があるわけではありません。このことから「経済的であること」が結びつきません。
- フル管理アクセス権限が付与されることと「経済的であること」が結びつきません。
- 正答と考えます。クラウド利用のメリットである「従量課金」つまり、使った分だけに課金されることを表現しています。従来型データセンターの場合は、サーバー機器を必要な性能・台数をあらかじめ用意する必要があります。
- 「常に実行できる」の場合、必要な性能・台数をあらかじめ用意することになるので、従来型データセンターの場合と同じになってしまいます。(ピークに合わせて自動的に台数を増減する仕組み(Autoscaling)を用いれば経済的になります。
第2問
問題文
データベースを AWS に移行するプロセスを簡素化するには、どの AWS サービスを使用すればよいですか。
選択肢
- AWS Storage Gateway
- AWS Database Migration Service (AWS DMS)
- Amazon EC2
- Amazon AppStream 2.0
回答
2
解説
問題文にある、「データベースを AWS に移行する」に着目して考えます。
- 「AWS Storage Gateway」はオンプレミス(従来型のデータセンター)の AWS クラウドのストレージ(文字や画像などを格納する場所)へのアクセスを提供するサービスのため、回答として不適当です。
- 「AWS Database Migration Service (AWS DMS)」は名前の通り、データベースを移行するためのサービスのため、正答であると考えます。
- 「Amazon EC2」は仮想マシンが利用できるサービスのため、回答として不適当です。
- 「Amazon AppStream 2.0」はデスクトップアプリケーションをWebブラウザや専用クライアントで利用可能にするためのサービスのため、回答として不適当です。
第3問
問題文
ソフトウェアソリューションを探して購入し、AWS 環境ですぐに使い始めるには、どの AWS サービスを使用すればよいですか。
選択肢
- AWS Config
- AWS OpsWorks
- AWS SDK
- AWS Marketplace
回答
4
解説
問題文にある「ソフトウェアソリューションを探して購入し、AWS環境ですぐに使い始める」に着目します。
- 「AWS Config」は AWS リソースの設定を評価、監査、審査するサービスのため不適当です。
- 「AWS OpsWorks」はサーバーの構成を自動運用するサービスのため不適当です。
- 「AWS SDK」はプログラム言語からAWSを利用する際に使用するもののため不適当です(SDK:Software Development Kit)
- 「AWS Marketplace」は各種ソフトウェアがインストール、設定済みの Amazon Machine Image(AMI) などを購入できるサービスのため正答であると考えます。
第4問
問題文
AWS 内に仮想ネットワークを作成するには、どの AWS ネットワーキングサービスを使用すればよいですか。
選択肢
- AWS Config
- Amazon Route 53
- AWS Direct Connect
- Amazon Virtual Private Cloud (Amazon VPC)
回答
4
解説
問題文にある、「AWS 内に仮想ネットワークを作成する」に着目します。
- 「AWS Config」は AWS リソースの設定を評価、監査、審査するサービスのため不適当です。
- 「Amazon Route 53」はネットワーキングサービスの1つですが、 DNS(Domain Name System)などのサービスのため不適当です。
- 「AWS Direct Connect」はネットワーキングサービスの1つですが、 AWS クラウドと接続する専用線のサービスのため不適当です。
- 「Amazon Virtual Private Cloud (Amazon VPC)」は AWS クラウド内に仮想のネットワークを作成するネットワーキングサービスのため、正答であると考えます。
第5問
問題文
AWS 責任共有モデルにおいて、AWS 側の責任である作業はどれですか。
選択肢
- サードパーティ製アプリケーションを構成する。
- 物理ハードウェアを保守する。
- アプリケーションアクセスとデータをセキュア化する。
- ゲストオペレーティングシステムを管理する。
回答
2
解説
責任共有モデルとは AWS と利用者で役割や責任の範囲を分けて対応し、全体的なセキュリティを確保しようという考え方です。ざっくりと役割や範囲をまとめると以下のような図になります。
これを踏まえて、正答だと考えられるものを選びます。
- 「サードパーティ製アプリケーションを構成する」のは利用者の責任範囲ですので、不適当です。
- 「物理ハードウェアを保守する」のは AWS の責任範囲ですので、正答であると考えます。
- 「アプリケーションアクセスとデータをセキュア化する」のは利用者の責任範囲ですので、不適当です。
- 「ゲストオペレーティングシステムを管理する」のは利用者の責任範囲ですので、不適当です。
第6問
問題文
Amazon CloudFront において低レイテンシー配信を実現するために使用される、AWS グローバルインフラストラクチャのコンポーネントはどれですか。
選択肢
- AWS リージョン
- エッジロケーション
- アベイラビリティーゾーン
- Virtual Private Cloud (VPC)
回答
2
解説
まずは AWS グローバルインフラストラクチャとは何かをこことここでおさえましょう。
これを踏まえて、Amazon CloudFront はどこに配備されているサービスかがわかれば正答を導き出せるようになります。
- 「AWS リージョン」はデータセンターが集積されている(複数のアベイラビリティーゾーンで構成されている)世界中の物理的ロケーションのことのため、不適当です。
- 「エッジロケーション」はアクセス元となるクライアントに対して高速に応答を返すサービスを提供するデータセンターであり、コンテンツ配信ネットワークのサービスである Amazon CloudFront はこのエッジロケーションで提供されているので、正答であると考えます。
- 「アベイラビリティーゾーン」は1 つの AWS リージョン内でそれぞれ切り離され、冗長的な電力源、ネットワーク、そして接続機能を備えている 1 つ以上のデータセンターのことのため、不適当です。
- 「Virtual Private Cloud (VPC)」は AWS クラウド上に仮想的なネットワークを構成するサービスのため、不適当です。
第7問
問題文
システム管理者がユーザーの AWS Management Console にログインセキュリティレイヤーを追加するには、どうすればよいですか。
選択肢
- Amazon Cloud Directory を使用する。
- AWS Identity and Access Management (IAM) ロールを監査する。
- Multi-Factor Authentication (MFA) を有効化する。
- AWS CloudTrail を有効化する。
回答
3
解説
問題文の「AWS Management Console にログインセキュリティレイヤーを追加する」に着目します。ログインのセキュリティレイヤーつまり、セキュリティに関する層を追加するサービス・機能が正答であると考えます。
- 「Amazon Cloud Directory」は多次元のディレクトリサービス(Active DirectoryやOpen LDAPといったサービスをイメージするとわかりやすいと思います)を提供するサービスのため不適当です。
- 「AWS Identity and Access Management (IAM) 」は AWS リソースへのアクセスコントロールを提供するサービスです。「AWS Management Console」へのログインを許可するものですが、セキュリティレイヤーを追加するものではないので不適当です。
- 「Multi-Factor Authentication (MFA)」は その名の通り、多要素認証を提供する機能です。「AWS Management Console」へのログイン時に、MFAを用いることでセキュリティを強化、つまりセキュリティレイヤーの追加が可能になるため、正答であると考えます。
- 「AWS CloudTrail」は AWS リソースやAPIに対する使用状況の追跡、記録を行うサービスのため、ログインセキュリティレイヤーの追加として不適当です。
第8問
問題文
Amazon EC2 インスタンスが削除されたときに API を呼び出したユーザーを特定するには、どのサービスを使用すればよいですか。
選択肢
- AWS Trusted Advisor
- AWS CloudTrail
- AWS X-Ray
- AWS Identity and Access Management (AWS IAM)
回答
2
解説
問題文の「API を呼び出したユーザーを特定する」に着目して、正答を特定します。
- 「AWS Trusted Advisor」は AWS を利用する上でのベストプラクティスと比較して、コストやシステムパフォーマンス、セキュリティといった観点からチェックするサービスのため、EC2 インスタンスを削除する API を呼び出したユーザーを特定することはできないため不適当です。
- 「AWS CloudTrail」はAWS リソースやAPIに対する使用状況の追跡、記録を行うサービスのため、EC2 インスタンスを削除する API を呼び出したユーザーを特定できるので、正答と考えます。
- 「AWS X-Ray」はアプリケーションの分析やデバッグを行うサービスのため、EC2 インスタンスを削除する API を呼び出したユーザーを特定することはできないため不適当です。
- 「AWS Identity and Access Management (AWS IAM)」は AWS リソースへのアクセスコントロールを提供するサービスですが、EC2 インスタンスを削除する API を呼び出したユーザーを特定することはできないため不適当です。
第9問
問題文
Amazon CloudWatch アラームに基づいてアラートを送信するには、どのサービスを使用すればよいですか。
選択肢
- Amazon Simple Notification Service (Amazon SNS)
- AWS CloudTrail
- AWS Trusted Advisor
- Amazon Route 53
回答
1
解説
問題文から、「Amazon CloudWatch アラームに基づいてアラートを送信する」に着目します。ここでの「アラート」はメールや HTTP/HTTPS でリクエストを受け付けられる Web アプリケーションへの「通知」と考えてください。その「通知」を「送信する」サービスが正答と考えます。
- 「Amazon Simple Notification Service (Amazon SNS)」は、その名の通り、「通知する」サービスのため正答であると考えます。
- 「AWS CloudTrail」は AWS リソースやAPIに対する使用状況の追跡、記録を行うサービスで「通知」を「送信する」ことはできないため、不適当です。
- 「AWS Trusted Advisor」は AWS を利用する上でのベストプラクティスと比較して、コストやシステムパフォーマンス、セキュリティといった観点からチェックするサービスで「通知」を「送信する」ことはできないため、不適当です。
- 「Amazon Route 53」は DNS(Domain Name System)などのサービスで「通知」を「送信する」ことはできないため、不適当です。
第10問
問題文
AWS インフラストラクチャ上で禁止されているアクションに関する情報は、どこで見つけることができますか。
選択肢
- AWS Trusted Advisor
- AWS Identity and Access Management (IAM)
- AWS Billing Console
- AWS Acceptable Use Policy
回答
4
解説
この問題は AWS の「サービス」や「機能」を答えるものとは少々異なります。「AWS インフラストラクチャ上で禁止されているアクション」つまり、「AWS を利用する上でやってはならない行為を定義しているもの」が正答であると考えます。
- 「AWS Trusted Advisor」は AWS を利用する上でのベストプラクティスと比較して、コストやシステムパフォーマンス、セキュリティといった観点からチェックするサービスで「やってはならない行為」を定義しているものではないため、不適当です。
- 「AWS Identity and Access Management (IAM)」は AWS リソースへのアクセスコントロールを提供するサービスで、確かに、一部または全部の AWS リソースに対するアクセス拒否を定義することはできますが、「AWS を利用する上でやってはならない行為を定義しているもの」ではないため、不適当です。
- 「AWS Billing Console」は AWS 利用料といった請求情報が確認できる AWS Management Consoleの画面・機能です。いうまでもなく、「AWS を利用する上でやってはならない行為を定義しているもの」ではないため、不適当です。
- 「AWS Acceptable Use Policy」は その名の通り、AWS の利用規約のことです。つまり、AWS を利用する上でやってよいこと悪いこと(禁止されていること)を定義しているもので、正答であると考えます。
サンプル問題以外の学習リソース
様々な学習リソースが用意されています。
以下はその一例です。まとめ
このクラウドプラクティショナーは、エンジニアだけではなく営業職などの非エンジニアの方にも人気のある資格となっております。本記事から AWS を知るきっかけとして触り始めてみてはいかがでしょうか
記載されている会社名、製品名、サービス名、ロゴ等は各社の商標または登録商標です。
- 投稿日:2020-09-07T19:33:45+09:00
AWSのVPC周りをCloudFormationで作成
はじめに
以前この記事でAWS CLIを操ってVPC周りの作成を行いましたけど、
そもそもCloudFormationあるんだから、そっち使えるようになること必須だと思うので並行してCLIでやったことを、
CloudFormationでも実現するようにしていきたいと思いますCloudFormationってそもそも何?
AWSのシステム構成をJSONないしはYAMLで記述してテンプレート化し、構成の管理、修正、再利用を簡単にするサービスです。
構成情報がテンプレート化されるので、変更箇所などが後からログで追跡することができるので変更管理も容易です。
書き方などはJSON/YAMLともにAWSにてサンプルでの記載方法があるので、プログラム言語など少ししか齧ったことしかない人でもすぐに書けると思います。AWSサイトのサンプルコードが書かれているURLになります。
また組み込み関数のRefも本テンプレートでは扱っているのでRefについてはこちらを参照してください。今回は手始めにVPC周りのネットワーク作成を行いたいと思います。
で、実際に作ったYAML
各項目に説明を記載しています。
# 最新のテンプレートの形式バージョンは 2010-09-09 であり、現時点で唯一の有効な値です。 AWSTemplateFormatVersion: 2010-09-09 # 本テンプレートの説明です。 Description: VPC Network Create # VPCの作成です。CidrBlockに作成したいネットワーク、Tagsにつけたい名前をつけてください。 Resources: nnagashimaVPC: Type: 'AWS::EC2::VPC' Properties: CidrBlock: 10.40.0.0/16 Tags: - Key: Name Value: nnagashima # インターネットに出るRouteTableを作成し、先ほど上で作成したVPCに紐付けます。 PublicRouteTable: Type: 'AWS::EC2::RouteTable' DependsOn: AttachGateway Properties: VpcId: !Ref nnagashimaVPC Tags: - Key: Name Value: nnagashima-PublicRoute # プライベートで利用するRouteTableを作成し、先ほど上で作成したVPCに紐付けます。 PrivateRouteTable: Type: 'AWS::EC2::RouteTable' DependsOn: AttachGateway Properties: VpcId: !Ref nnagashimaVPC Tags: - Key: Name Value: nnagashima-PrivateRoute # パブリックサブネット/プライベートサブネットをAZ毎に作成します。今回はTokyoRegionにて作成しています。 # CidrBlockに作成したいネットワーク、AZにはResionに存在するAZをを記載し、先ほど作成したVPC上に作成します。 # MapPublicIpOnLaunchでは、インスタンスがパブリック IPv4 アドレスを受け取るかどうかを示します。デフォルト値はfalseです。 PublicSubnetA: Type: 'AWS::EC2::Subnet' Properties: CidrBlock: 10.40.1.0/24 AvailabilityZone: ap-northeast-1a MapPublicIpOnLaunch: 'true' VpcId: !Ref nnagashimaVPC Tags: - Key: Name Value: nnagashima-publicA # 作成したPublicSubnetAをPublicRouteTableに紐付けます。 PubSubnetARouteTableAssociation: Type: AWS::EC2::SubnetRouteTableAssociation Properties: SubnetId: !Ref PublicSubnetA RouteTableId: !Ref PublicRouteTable PublicSubnetC: Type: 'AWS::EC2::Subnet' DependsOn: AttachGateway Properties: CidrBlock: 10.40.2.0/24 AvailabilityZone: ap-northeast-1c MapPublicIpOnLaunch: 'true' VpcId: !Ref nnagashimaVPC Tags: - Key: Name Value: nnagashima-publicC PubSubnetCRouteTableAssociation: Type: AWS::EC2::SubnetRouteTableAssociation Properties: SubnetId: !Ref PublicSubnetC RouteTableId: !Ref PublicRouteTable PublicSubnetD: Type: 'AWS::EC2::Subnet' DependsOn: AttachGateway Properties: CidrBlock: 10.40.3.0/24 AvailabilityZone: ap-northeast-1d MapPublicIpOnLaunch: 'true' VpcId: !Ref nnagashimaVPC Tags: - Key: Name Value: nnagashima-publicD PubSubnetDRouteTableAssociation: Type: AWS::EC2::SubnetRouteTableAssociation Properties: SubnetId: !Ref PublicSubnetD RouteTableId: !Ref PublicRouteTable PrivateSubnetA: Type: 'AWS::EC2::Subnet' Properties: CidrBlock: 10.40.4.0/24 AvailabilityZone: ap-northeast-1a MapPublicIpOnLaunch: 'true' VpcId: !Ref nnagashimaVPC Tags: - Key: Name Value: nnagashima-privateA PriSubnetARouteTableAssociation: Type: AWS::EC2::SubnetRouteTableAssociation Properties: SubnetId: !Ref PrivateSubnetA RouteTableId: !Ref PrivateRouteTable PrivateSubnetC: Type: 'AWS::EC2::Subnet' DependsOn: AttachGateway Properties: CidrBlock: 10.40.5.0/24 AvailabilityZone: ap-northeast-1c MapPublicIpOnLaunch: 'true' VpcId: !Ref nnagashimaVPC Tags: - Key: Name Value: nnagashima-privateC PriSubnetCRouteTableAssociation: Type: AWS::EC2::SubnetRouteTableAssociation Properties: SubnetId: !Ref PrivateSubnetC RouteTableId: !Ref PrivateRouteTable PrivateSubnetD: Type: 'AWS::EC2::Subnet' DependsOn: AttachGateway Properties: CidrBlock: 10.40.6.0/24 AvailabilityZone: ap-northeast-1d MapPublicIpOnLaunch: 'true' VpcId: !Ref nnagashimaVPC Tags: - Key: Name Value: nnagashima-privateD PriSubnetDRouteTableAssociation: Type: AWS::EC2::SubnetRouteTableAssociation Properties: SubnetId: !Ref PrivateSubnetD RouteTableId: !Ref PrivateRouteTable # インターネットゲートウェイを作成します。 InternetGateway: Type: "AWS::EC2::InternetGateway" Properties: Tags: - Key: Name Value: nnagashima-IGW # 作成したインターネットゲートウェイを上で作成したVPCに紐付けします。 AttachGateway: Type: AWS::EC2::VPCGatewayAttachment Properties: VpcId: !Ref nnagashimaVPC InternetGatewayId: !Ref InternetGateway # インターネットゲートウェイ経由でインターネットにアクセスできるようにするためにDestinationCidrBlockを # 0.0.0.0/0としてルートテーブルのルートに追加します。 RouteTable: Type: AWS::EC2::Route DependsOn: InternetGateway Properties: RouteTableId: !Ref PublicRouteTable DestinationCidrBlock: 0.0.0.0/0 GatewayId: !Ref InternetGateway # 最後にCloudFormation上で作成した各サブネットとVPCのIDを表示させます。 Outputs: nnagashimaVPC: Value: !Ref nnagashimaVPC Export: Name: nnagashimaVPC PublicSubnetA: Value: !Ref PublicSubnetA Export: Name: PublicSubnetA PublicSubnetC: Value: !Ref PublicSubnetC Export: Name: PublicSubnetC PublicSubnetD: Value: !Ref PublicSubnetD Export: Name: PublicSubnetD PrivateSubnetA: Value: !Ref PrivateSubnetA Export: Name: PrivateSubnetA PrivateSubnetC: Value: !Ref PrivateSubnetC Export: Name: PrivateSubnetC PrivateSubnetD: Value: !Ref PrivateSubnetD Export: Name: PrivateSubnetD最後に
今回これを取り組むにあたって事前にCLIなどは結構前から触っていたので、なんとなくの感覚でサンプルを見ながら作れてしまいました。
そしていざ作れると本当便利だなと実感です!!自分もまだまだだなと痛感しました。。。
またこれを機会にGithubとVisualStadioCodeを真面目に使うようになりました。
今回VPCだけですが、他のサービス関連も作っていき最終的にはGitHubでコードを公開していきたいと思います。
- 投稿日:2020-09-07T18:56:47+09:00
Athenaとは
Athenaとは
Athena(アテナ)とはAWSのデータ分析サービスであり、S3に格納されたデータに対して、集計やソートなどの分析を実行することができます。分析する際に使用する言語はSQLになり、実行したクエリに対してのみ料金がかかる。
サーバーレスであるため、インフラの管理は不要。S3にはデータだけが置かれているようなものです。そのため、S3に直接Athenaがクエリを行ってもデータの構造が分からないためうまくいきません。そのテーブル構造(メタデータ)を定義するのがGlueカタログです。一つのテーブルにつき一つのGlueカタログを作成します。AthenaはこのGlueカタログを参照しながらクエリを行うといった感じになります。このGlueカタログを作成するサービスの一つとしてGlueクローラーというものがあります。GlueクローラーはS3等においてあるデータ構造を推測して、データカタログに表構造を登録するサービスです。そのためAthenaがS3にあるデータをSQLでクエリを行うには、データカタログの作成が必要であり、データカタログを作成するためにGlueクローラを使用するといった感じです。
ではRDSからS3 にどのようにしてデータを持ってくるのか??それは、RDSのスナップショットからParquet形式でS3にexportすることが出来ます。その際、RDSからスナップショットを作成しS3に保存するときは、KMSという暗号化を行うサービスを使用して暗号化し、S3に保存されることに注意が必要です。そのため、Glueクローラーでデータカタログを作成する際にはKMSで複合する操作が必要になってきます。Athenaの実装
今回はS3にあるデータをAthenaで分析するのを想定して行っていきます。
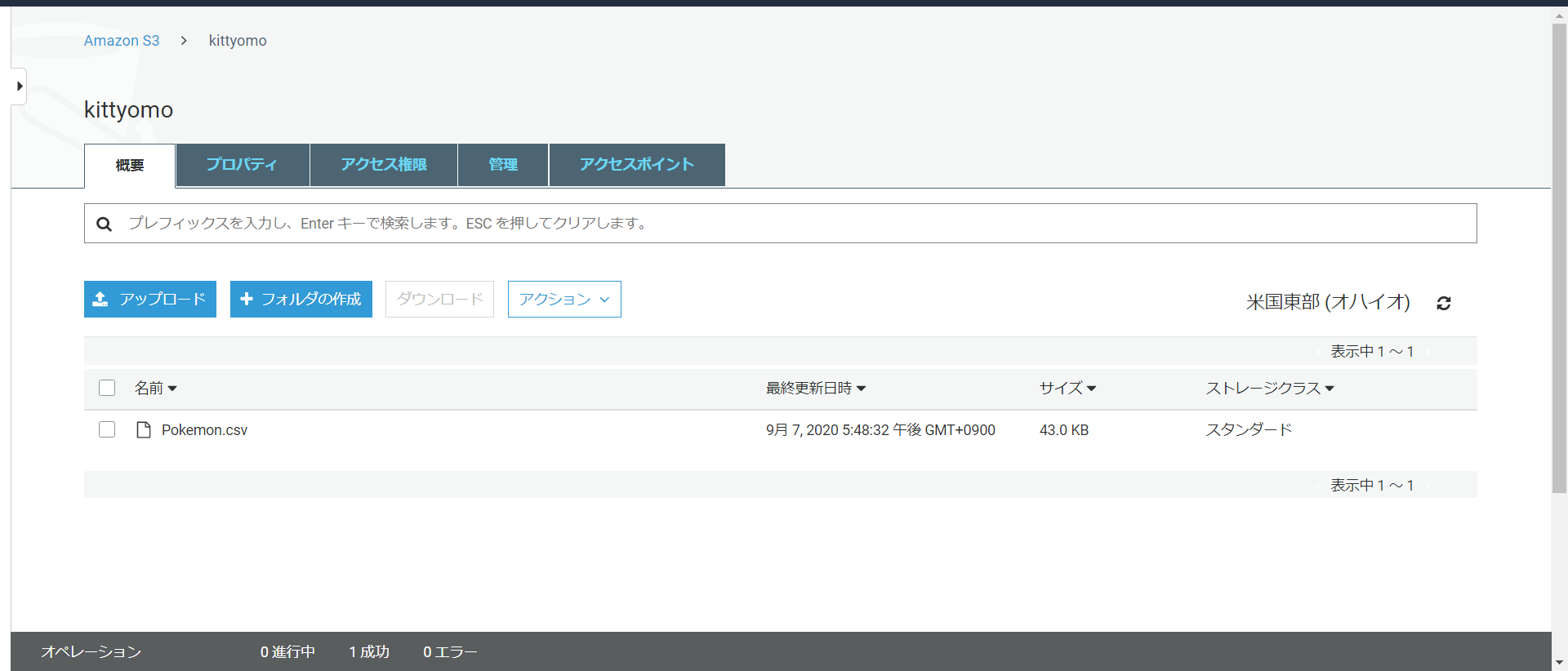
今S3には一つのCSVファイルが入っています。次にGlue クローラーでデータカタログを設定します。
Glueの画面に移動しクローラを選択。その後クローラの追加を押します。
クローラの名前は適当に設定し、source typeはDatastoreを設定します。
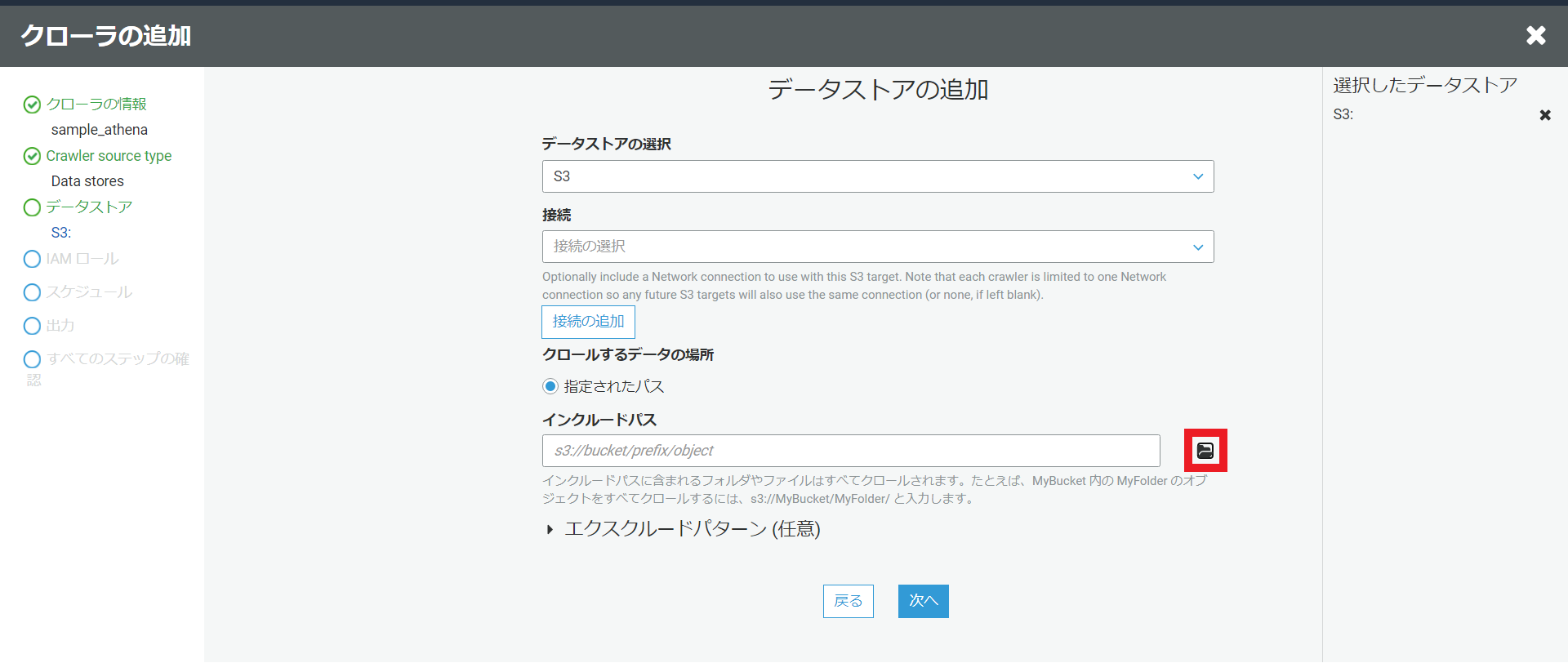
クロールするS3のパスを選択するには下図の赤いところを選択すると、自分のAWSアカウントのS3バケットの一覧が表示されるので使用するS3バケットを選択します。
別のデータストアの追加は今回は必要ないため、いいえを選択します。
Glueクローラー用のIAMを選択。今回は新しく作成しました。
Glueクローラのスケジュールは今回一回のみでよいのでオンデマンドで実行を選択します。Glueクローラーは定期的に実行することも可能であるので定期的に実行したいときは頻度に応じて設定を行います。
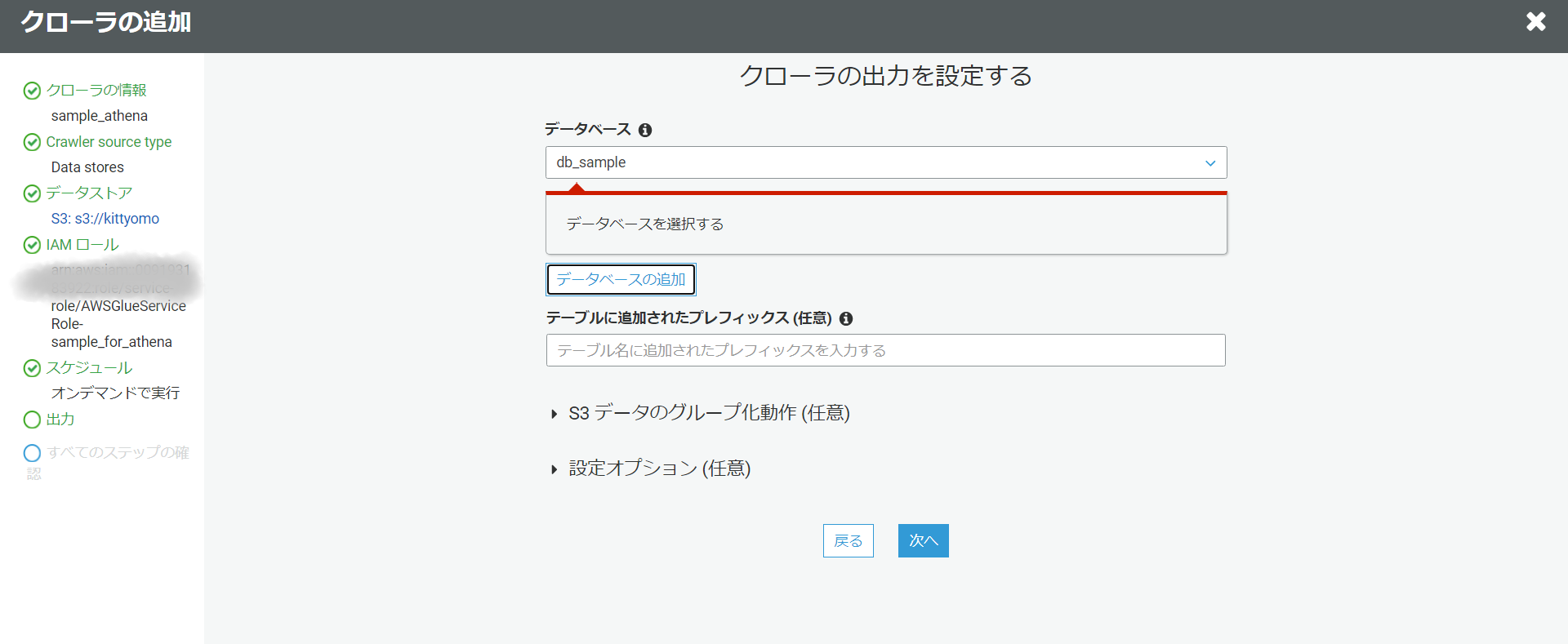
テーブル定義情報を取得したいデータベースの情報を入力します。今回は新しくデータベースを追加します。内容を確認し大丈夫であれば完了を押します。
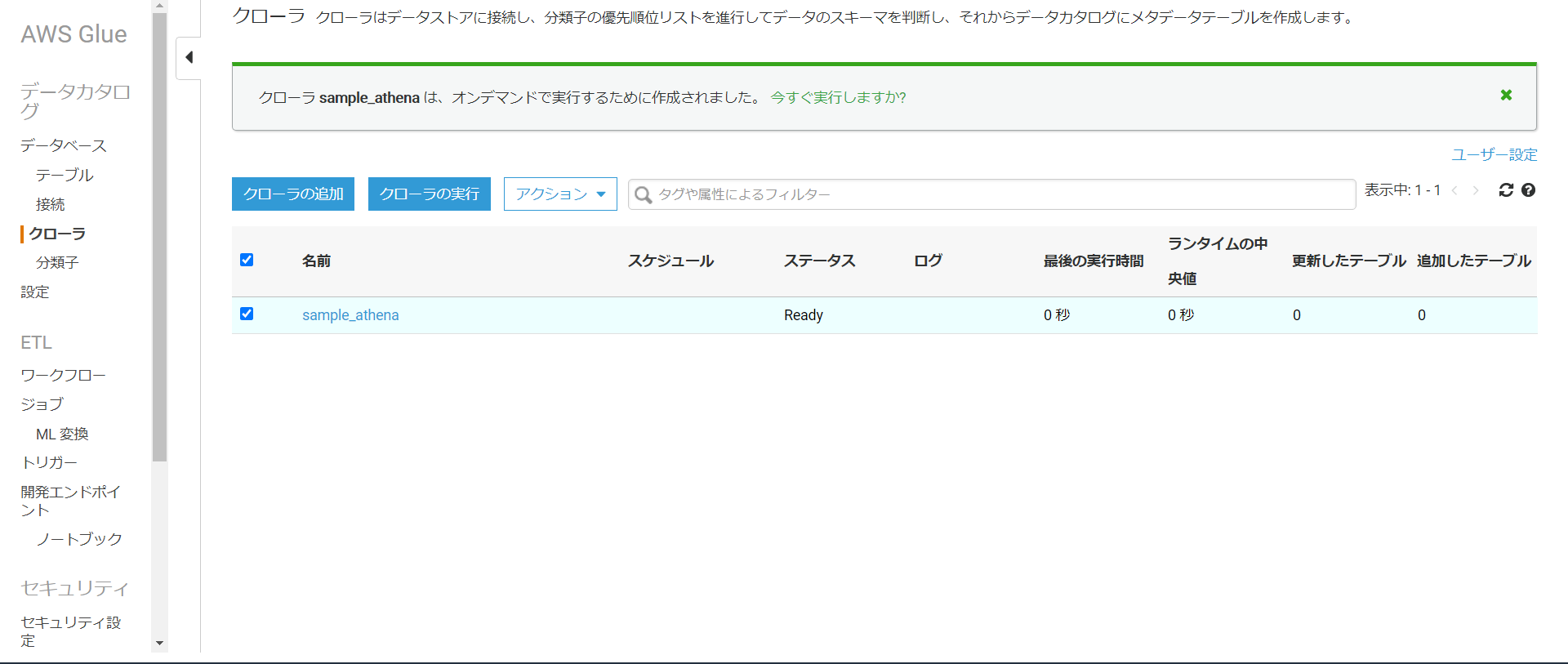
そしたら今作成したクローラを選択し、クローラの実行を押します。
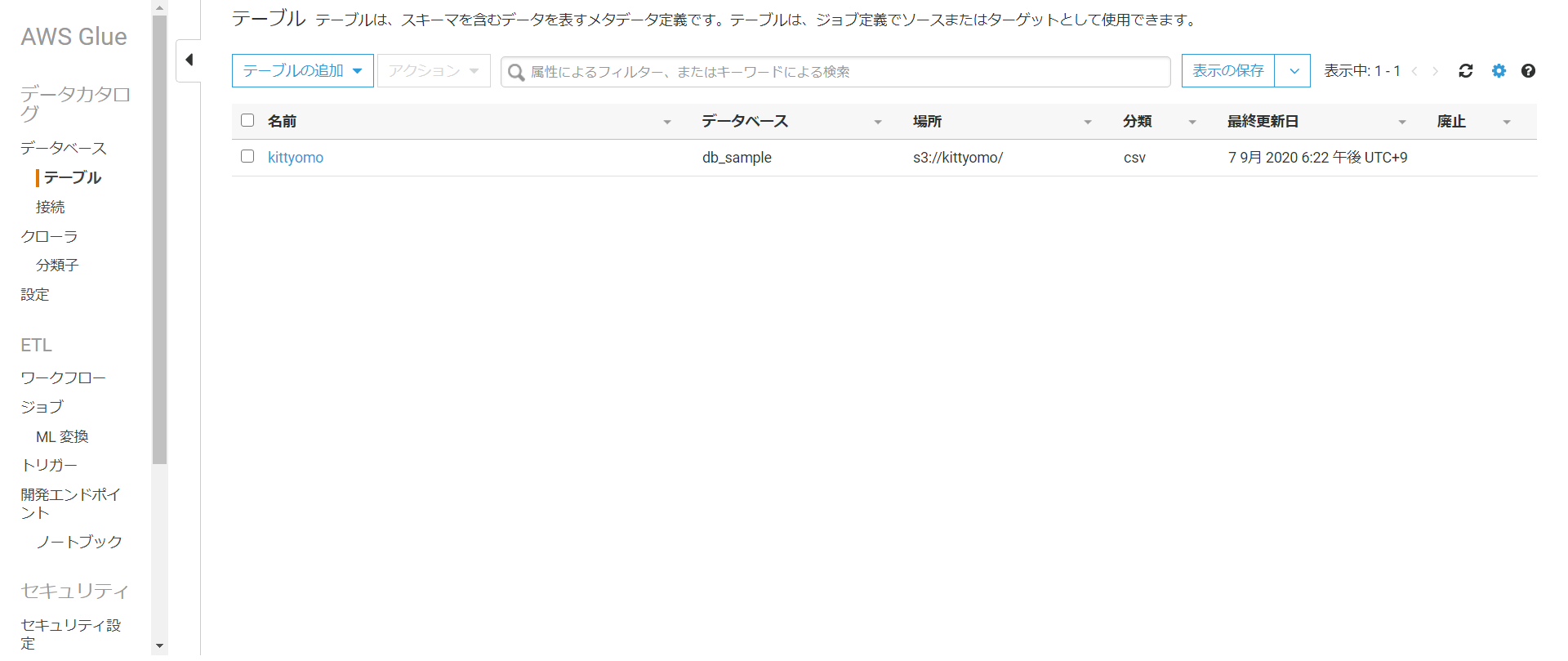
実行が終わるとテーブルでカタログが作成されていることが分かります。
これでAthenaを実行する環境が整ったのでAthenaのマネジメントコンソール画面に移動します。
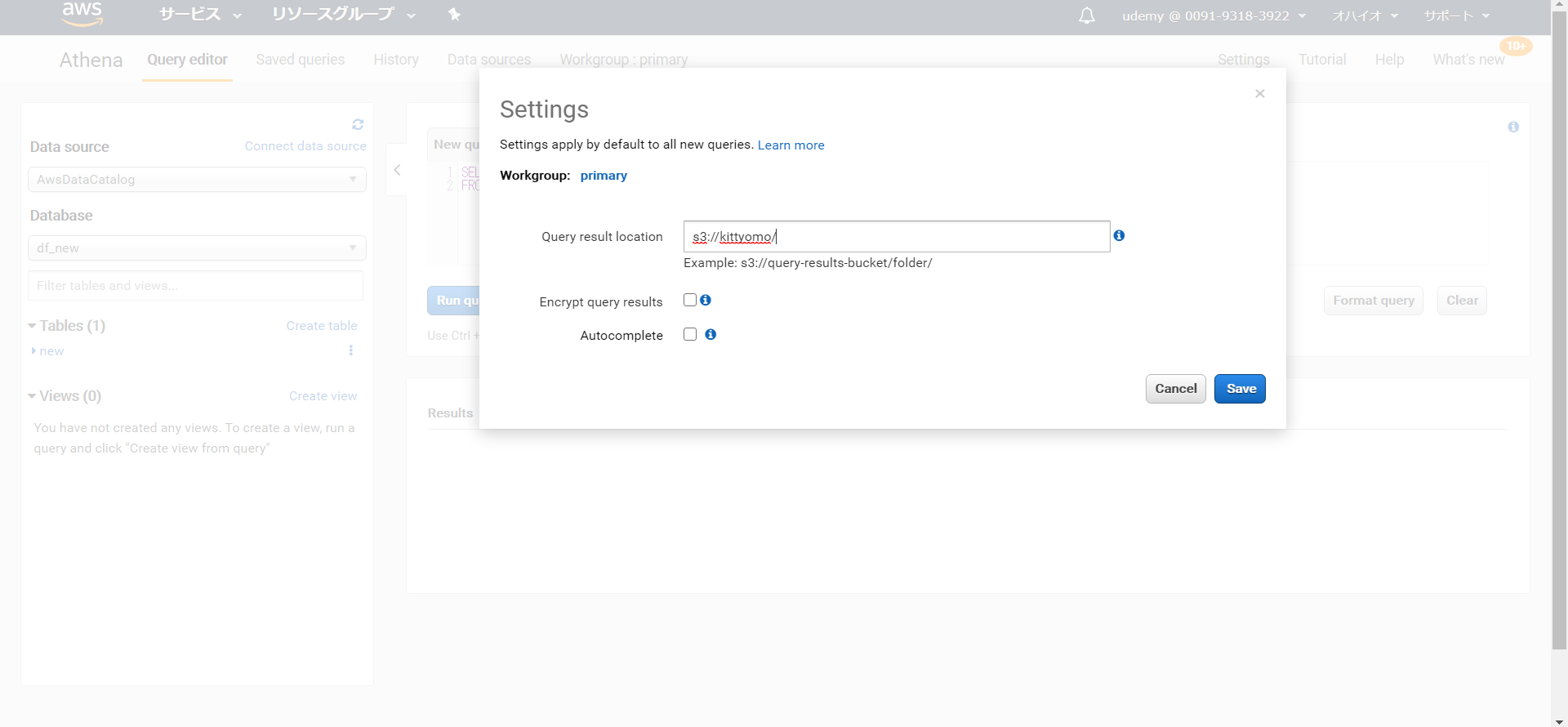
まずはsettingで結果の保存場所を指定します。
クエリを行うときはpreview tableを使用すると簡単なクエリが発行されます。
<参考させていただいたサイト>
Amazon Athenaによるデータ分析入門
- 投稿日:2020-09-07T18:28:49+09:00
【AWS ECS】Fargateの「コマンドの上書き」
はじめに
ECSで起動タイプFargateのタスクを実行する際の「コマンドの上書き」という項目について、「実行時パラメータを渡せるようなものかな」と思って使おうとしました。
この理解でざっくり正解と言えますが、正しく使うにはdockerのENTRYPOINT、CMDコマンドの知識が必要で、自分のようにdockerを使いこなす前にFargateを使おうとした人にとってはハマりどころかと思います。
これらについて調べた内容を記載しています。コマンドの上書き
ECSタスクの実行やタスクスケジュールの設定画面で「コンテナの上書き」という項目があり、ここで設定した内容をECSタスクに設定したコンテナ実行時に利用することができます。
「コンテナの上書き」の中に「コマンドの上書き」というフリー記述項目があります。
画面上のヒントメッセージに「コンテナに渡すCMD」とありますが、どういうことか次項で説明します。dockerのENTRYPOINTとCMD
dockerfileで「ENTRYPOINT」と「CMD」という命令があり、どちらもコンテナ実行時(docker run時)に実行されるコマンドです。
「コマンドの上書き」の挙動を理解するためにこれらの理解が必要となります。この2つは、コンテナ実行時に渡されるパラメータの扱いが異なります。
ENTRYPOINTはdocker runのパラメータをそのままENTRYPOINTのパラメータとして扱います。
CMDはdocker runのパラメータをCMD自体として扱います。(CMDの上書き)ENTRYPOINT
コンテナ実行時に必ず実行されるコマンドと引数(省略可)を設定します。
[書式]ENTRYPOINT ["実行可能なもの", "パラメータ1", "パラメータ2"][例]
ENTRYPOINT ["ping", "localhost"] →pingコマンドにlocalhostという引数を渡して実行CMD
コンテナ実行時のデフォルト実行コマンドと引数を設定します。
[書式]CMD ["実行バイナリ", "パラメータ1", "パラメータ2"][例]
CMD ["ping", "localhost"] →pingコマンドにlocalhostという引数を渡して実行併用
ENTRYPOINTとCMDを併用する場合、CMDにはENTRYPOINTに渡すパラメータを設定します。
[書式]ENTRYPOINT ["実行可能なもの", "パラメータ1", "パラメータ2"] CMD ["パラメータ3", "パラメータ4"][例]
以下の2例はどちらも同じコマンドが実行されるENTRYPOINT [“ping”] CMD[“-c”,”4”,“localhost”] →ping -c 4 localhost になるENTRYPOINT [“ping”,”-c”] CMD[”4”,“localhost”] →ping -c 4 localhost になる実行時(docker run時)のパラメータ
docker run実行時に指定したパラメータはコンテナ定義のCMDとしてコンテナに渡され、コンテナ起動時にはこのCMDが採用されます。(CMDの上書き)
前項の「コマンドの上書き」はこの仕様に相当します。[書式]
docker run <コンテナ指定> パラメータ1 パラメータ2[例]
コンテナ定義に「ENTRYPOINT [“ping”,”localhost”]」の設定がある場合、ENTRYPOINT + CMDの併用となるdocker run <コンテナ> -c 4 →ping localhost -c 4 になるコンテナ定義に「CMD [“ping”,”localhost”]」の設定がある場合、CMDを上書きとなる
docker run <コンテナ> echo hoge →pingは実行されず、echo hogeが実行されるコンテナ定義に「ENTRYPOINT [“ping”,”localhost”]」と「CMD [“-c”,”4”]」の設定がある場合、CMDを上書きとなる
docker run <コンテナ> -c 10 →ping localhost -c 10 になる動作確認
前項での実行時パラメータの仕様通りに動くか、「コマンドの上書き」の動作確認をします。
ENTRYPOINTを設定したもの、CMDを設定したもの、両方設定したもの、の3つのコンテナ定義を作成し、それぞれコマンドの上書きなし・ありで実行した場合の系6パターンの出力を確認します。テスト用ファイル
test_script.shを作成。シェルに渡された引数をechoする。
#!/bin/sh # 引数の数をecho echo arg length is $# # 渡された引数を全てecho for x do echo arg is "$x" doneコンテナ定義
[ENTRYPOINTを設定したもの]
FROM ubuntu COPY . . RUN chmod 777 test_script.sh ENTRYPOINT ["sh", "test_script.sh", "ENTRYPOINT"][CMDを設定したもの]
FROM ubuntu COPY . . RUN chmod 777 test_script.sh CMD ["sh", "test_script.sh", "CMD"][両方設定したもの]
FROM ubuntu COPY . . RUN chmod 777 test_script.sh ENTRYPOINT ["sh", "test_script.sh"] CMD ["BOTH"]テスト実行
ENTRYPOINT
[コマンドの上書きなし]
[コマンドの上書きあり]
[結果]
・コマンド上書きありなしどちらでも、arg is ENTRYPOINTが必ず出力されている
→ENTRYPOINTは必ず実行される
・コマンドの上書きを設定した場合、arg is override1, arg is override2が出力されている
→ENTRYPOINTにパラメータを渡すCMDとして処理されるCMD
[コマンドの上書きなし]
[コマンドの上書きあり]
[結果]
・arg is CMDはコマンド上書き時に出力されない
→コンテナ定義のCMDは無視され、コマンドの上書きの内容がCMDとして処理される両方設定したもの
[コマンドの上書きなし]
[コマンドの上書きあり]
[結果]
・test_script.shのecho処理が実行されている
→ENTRYPOINTは必ず実行される
・arg is BOTHはコマンド上書き時に出力されない
→コンテナ定義のCMDは無視され、コマンドの上書きの内容がCMDとして処理される調査結果
こちらで述べたように、Fargateの「コマンドの上書き」はコンテナ実行時にCMDとして渡されるものでした。
コンソールでの「コンテナに渡すCMD」というヒントメッセージがそのまま正解ですね。所感としては、「コマンド」というワードがここではdockerの用語の「CMD」を表しているようで、自分はこの点が少しわかりにくさを感じました。
(英語表記でも「Command」のようです)
使うのにdocker知識が前提に感じるので、どうせなら「CMDの上書き」の方がわかりやすい気がします。注意点
ECSの開発者ガイドで、コンテナ定義にENTRYPOINTがある場合とない場合の「コマンドの上書き」の設定について記載されていますが、誤解しそうな表現になっていると思います。
[ENTRYPOINTがない場合の説明]If your container definition does not specify an ENTRYPOINT, the format should be a comma-separated list of non-quoted strings. For example:
/bin/sh,-c,echo,$DATE[ENTRYPOINTがある場合の説明]
If your container definition does specify an ENTRYPOINT (such as sh,-c), the format should be an unquoted string, which is surrounded with double quotes and passed as an argument to the ENTRYPOINT command. For example:
while true; do echo $DATE > /var/www/html/index.html; sleep 1; done「ENTRYPOINTがない場合はカンマ区切り」という点と、ENTRYPOINTがある場合のサンプルから、「ENTRYPOINTがある場合はカンマ区切り指定ではない」と自分には見えましたが、動作確認で実証したようにENTRYPOINTがあってもカンマ区切り指定可能でした。
参考
ECSの開発者ガイド
https://docs.aws.amazon.com/ja_jp/AmazonECS/latest/developerguide/ecs_run_task_fargate.htmlDockerfile リファレンス
http://docs.docker.jp/v1.11/engine/reference/builder.htmlENTRYPOINTは「必ず実行」、CMDは「(デフォルトの)引数」
https://pocketstudio.net/2020/01/31/cmd-and-entrypoint/









- 投稿日:2020-09-07T15:38:30+09:00
AWS AmplifyでAndroid アプリを作るときの操作(Auth, S3, API->Lambda)[メモ]
AWSのAmplifyを使ってモバイルアプリを作ることになったので、その環境構築手順をメモしておく。基本は自分のための備忘録だが、誰かの参考になれば幸い。
前提
amplifyはインストール済み
pipenvが入っている
python 3.8.5がインストールされている参考
amplifyのインストール
npm install -g @aws-amplify/cli amplify configurepythonの設定
pip install pipenv pipenv --python 3.8.5 pipenv shellAndroidでの開発
Android Studioでプロジェクトを作成した後にamplify cliでバックエンドの設定を行う。1
Android Studioでのプロジェクト作成
一般的な方法と同じなため、省略。
ただし、.gitignoreの内容が上書きされてしまうのでプロジェクト作成後はどこかにコピーを退避させておく。(最近は上書きされなくなった??)amplify cliでバックエンド設定
ここでは、チュートリアルに倣いProdとDevの2stageで開発する想定とする。
Prod作成
まずはProdの作成。
$ amplify init Note: It is recommended to run this command from the root of your app directory ? Enter a name for the project fxxxxxxx ? Enter a name for the environment prod ? Choose your default editor: IntelliJ IDEA ? Choose the type of app that you're building android Please tell us about your project ? Where is your Res directory: app/src/main/res Using default provider awscloudformation ...<snip>auth設定
$ amplify add auth Using service: Cognito, provided by: awscloudformation The current configured provider is Amazon Cognito. Do you want to use the default authentication and security configuration? Default configuration with Social Provider (Federation) Warning: you will not be able to edit these selections. How do you want users to be able to sign in? Username Do you want to configure advanced settings? No, I am done. What domain name prefix do you want to use? fxxxxxx796012f-9796012f Enter your redirect signin URI: myapp://callback/ ? Do you want to add another redirect signin URI No Enter your redirect signout URI: myapp://signout/ ? Do you want to add another redirect signout URI No Select the social providers you want to configure for your user pool: Successfully added resource fxxxxx96012f locallyS3設定
$ amplify add storage ? Please select from one of the below mentioned services: Content (Images, audio, video, etc.) ? Please provide a friendly name for your resource that will be used to label this category in the project: fxxxx ? Please provide bucket name: fxxxx028f5691d9734f96b9559b3c1fbba634 ? Who should have access: Auth users only ? What kind of access do you want for Authenticated users? create/update, read, delete ? Do you want to add a Lambda Trigger for your S3 Bucket? No Successfully added resource fxxxxx locallyAPI Gateway & Lambda設定
$ amplify add api ? Please select from one of the below mentioned services: REST ? Provide a friendly name for your resource to be used as a label for this category in the project: fxxxx ? Provide a path (e.g., /book/{isbn}): /markers/{id} ? Choose a Lambda source Create a new Lambda function ? Provide a friendly name for your resource to be used as a label for this category in the project: fxxx12c31e67 ? Provide the AWS Lambda function name: fxxxx12c31e67 ? Choose the runtime that you want to use: Python ... <snip>Githubへ登録
ここで一度ProdブランチをGithubに登録
予め、amplifyにより作成された.gitignoreを退避させたAndroid Studioの.gitignoreをマージしておく。
$ git init $ git add <all project related files> $ git commit -m "Creation of a prod amplify environment" $ git checkout -b prod $ curl -u xxxxx --header 'x-github-otp: xxxxx' https://api.github.com/user/repos -d '{"name":"fxxxx"}' $ git remote add origin git@github.com:xxxx/xxxx.git $ amplify pushDev作成
$ amplify env add ? Do you want to use an existing environment? No ? Enter a name for the environment devGithub
$ git add . $ git commit -m "Creation of a dev amplify environment" $ git push -u origin prod $ git checkout -b dev $ git push -u origin dev環境切り替え
envをcheckoutすることで、それぞれ異なるバックエンドに接続するように
awsconfiguration.jsonやamplifyconfiguration.jsonが書き換わってくれる。$ amplify env checkout dev
逆の順番、つまり、amplify cliで環境を作ってからAndroid studioで同じフォルダにプロジェクトを作成すると、「すでにemptyではないフォルダがある」といったニュアンスの警告が出て、appのbuild.gradleやその他resourceが作成されない。復旧の仕方がよくわからないので、やめたほうがいい。やり方を知っている方がいらっしゃったら教えてください。 ↩
- 投稿日:2020-09-07T15:38:30+09:00
AWS AmplifyでAndroid アプリを作るときの作業(Auth, S3, API->Lambda)[メモ]
AWSのAmplifyを使ってモバイルアプリを作ることになったので、その環境構築手順をメモしておく。基本は自分のための備忘録だが、誰かの参考になれば幸い。
前提
amplifyはインストール済み
pipenvが入っている
python 3.8.5がインストールされている参考
amplifyのインストール
npm install -g @aws-amplify/cli amplify configurepythonの設定
pip install pipenv pipenv --python 3.8.5 pipenv shellAndroidでの開発
Android Studioでプロジェクトを作成した後にamplify cliでバックエンドの設定を行う。1
Android Studioでのプロジェクト作成
一般的な方法と同じなため、省略。
ただし、.gitignoreの内容が上書きされてしまうのでプロジェクト作成後はどこかにコピーを退避させておく。(最近は上書きされなくなった??)amplify cliでバックエンド設定
ここでは、チュートリアルに倣いProdとDevの2stageで開発する想定とする。
Prod作成
まずはProdの作成。
Androidのプロジェクトのrootで(配下にappがあるフォルダ)下記を実施。$ amplify init Note: It is recommended to run this command from the root of your app directory ? Enter a name for the project fxxxxxxx ? Enter a name for the environment prod ? Choose your default editor: IntelliJ IDEA ? Choose the type of app that you're building android Please tell us about your project ? Where is your Res directory: app/src/main/res Using default provider awscloudformation ...<snip>auth設定
$ amplify add auth Using service: Cognito, provided by: awscloudformation The current configured provider is Amazon Cognito. Do you want to use the default authentication and security configuration? Default configuration with Social Provider (Federation) Warning: you will not be able to edit these selections. How do you want users to be able to sign in? Username Do you want to configure advanced settings? No, I am done. What domain name prefix do you want to use? fxxxxxx796012f-9796012f Enter your redirect signin URI: myapp://callback/ ? Do you want to add another redirect signin URI No Enter your redirect signout URI: myapp://signout/ ? Do you want to add another redirect signout URI No Select the social providers you want to configure for your user pool: Successfully added resource fxxxxx96012f locallyS3設定
$ amplify add storage ? Please select from one of the below mentioned services: Content (Images, audio, video, etc.) ? Please provide a friendly name for your resource that will be used to label this category in the project: fxxxx ? Please provide bucket name: fxxxx028f5691d9734f96b9559b3c1fbba634 ? Who should have access: Auth users only ? What kind of access do you want for Authenticated users? create/update, read, delete ? Do you want to add a Lambda Trigger for your S3 Bucket? No Successfully added resource fxxxxx locallyAPI Gateway & Lambda設定
$ amplify add api ? Please select from one of the below mentioned services: REST ? Provide a friendly name for your resource to be used as a label for this category in the project: fxxxx ? Provide a path (e.g., /book/{isbn}): /markers/{id} ? Choose a Lambda source Create a new Lambda function ? Provide a friendly name for your resource to be used as a label for this category in the project: fxxx12c31e67 ? Provide the AWS Lambda function name: fxxxx12c31e67 ? Choose the runtime that you want to use: Python ... <snip>Githubへ登録
ここで一度ProdブランチをGithubに登録
予め、amplifyにより作成された.gitignoreを退避させたAndroid Studioの.gitignoreをマージしておく。
$ git init $ git add <all project related files> $ git commit -m "Creation of a prod amplify environment" $ git checkout -b prod $ curl -u xxxxx --header 'x-github-otp: xxxxx' https://api.github.com/user/repos -d '{"name":"fxxxx"}' $ git remote add origin git@github.com:xxxx/xxxx.git $ amplify pushDev作成
$ amplify env add ? Do you want to use an existing environment? No ? Enter a name for the environment devGithub
$ git add . $ git commit -m "Creation of a dev amplify environment" $ git push -u origin prod $ git checkout -b dev $ git push -u origin dev環境切り替え
envをcheckoutすることで、それぞれ異なるバックエンドに接続するように
awsconfiguration.jsonやamplifyconfiguration.jsonが書き換わってくれる。$ amplify env checkout devAndroid側の設定
build.gradle(Module:app)に下記のセクションを追加
compileOptions { // Support for Java 8 features coreLibraryDesugaringEnabled true sourceCompatibility JavaVersion.VERSION_1_8 targetCompatibility JavaVersion.VERSION_1_8 }dependenciesのセクションに下記を追加
implementation 'com.amplifyframework:core:1.3.1' coreLibraryDesugaring 'com.android.tools:desugar_jdk_libs:1.0.10' implementation 'com.amplifyframework:aws-auth-cognito:1.3.1' implementation 'com.amplifyframework:aws-api:1.3.1' implementation 'com.amplifyframework:aws-storage-s3:1.3.1' implementation "com.amazonaws:aws-android-sdk-apigateway-core:2.18.0"
逆の順番、つまり、amplify cliで環境を作ってからAndroid studioで同じフォルダにプロジェクトを作成すると、「すでにemptyではないフォルダがある」といったニュアンスの警告が出て、appのbuild.gradleやその他resourceが作成されない。復旧の仕方がよくわからないので、やめたほうがいい。やり方を知っている方がいらっしゃったら教えてください。 ↩
- 投稿日:2020-09-07T14:13:09+09:00
努力を可視化! 積み上げ管理アプリの開発〜5週間でSpringアプリリリース〜
はじめに
先日、「5週間でwebサービスリリース人集まれ!!!第三弾」という勉強会企画に参加し、約5週間の間Webアプリ開発・リリース作業を行った後、LTで成果物を発表しました。
使用したフレームワークはSpringです。
本記事では作成したWebアプリの機能の紹介や開発経緯、今後のWebアプリ改修の課題について記します。勉強会企画のURL(connpass):
5週間でwebサービスリリース人集まれ!!!第三弾※もくもく会のみ参加もOK
【朝活・新宿・もくもく会】第3弾 5週間でwebサービスリリースイベントのLT発表会作成したWebアプリの概要
今回作成したのは、毎日の努力=積み上げを記録・表示するアプリです。
Twitterで「今日の積み上げ」というハッシュタグがあり、勉強や筋トレといった毎日の努力やライフログが投稿されていますが、その積み上げを可視化したいと考えました。平たく言えば、日々の勉強や筋トレなどについて、
自分は今までこれだけ頑張ったんだ、ということを目に見える形で記録したいということです。作成したWebアプリのURL:
http://stackmanagement-env.eba-zmspvrm3.ap-northeast-1.elasticbeanstalk.com/loginWebアプリの機能
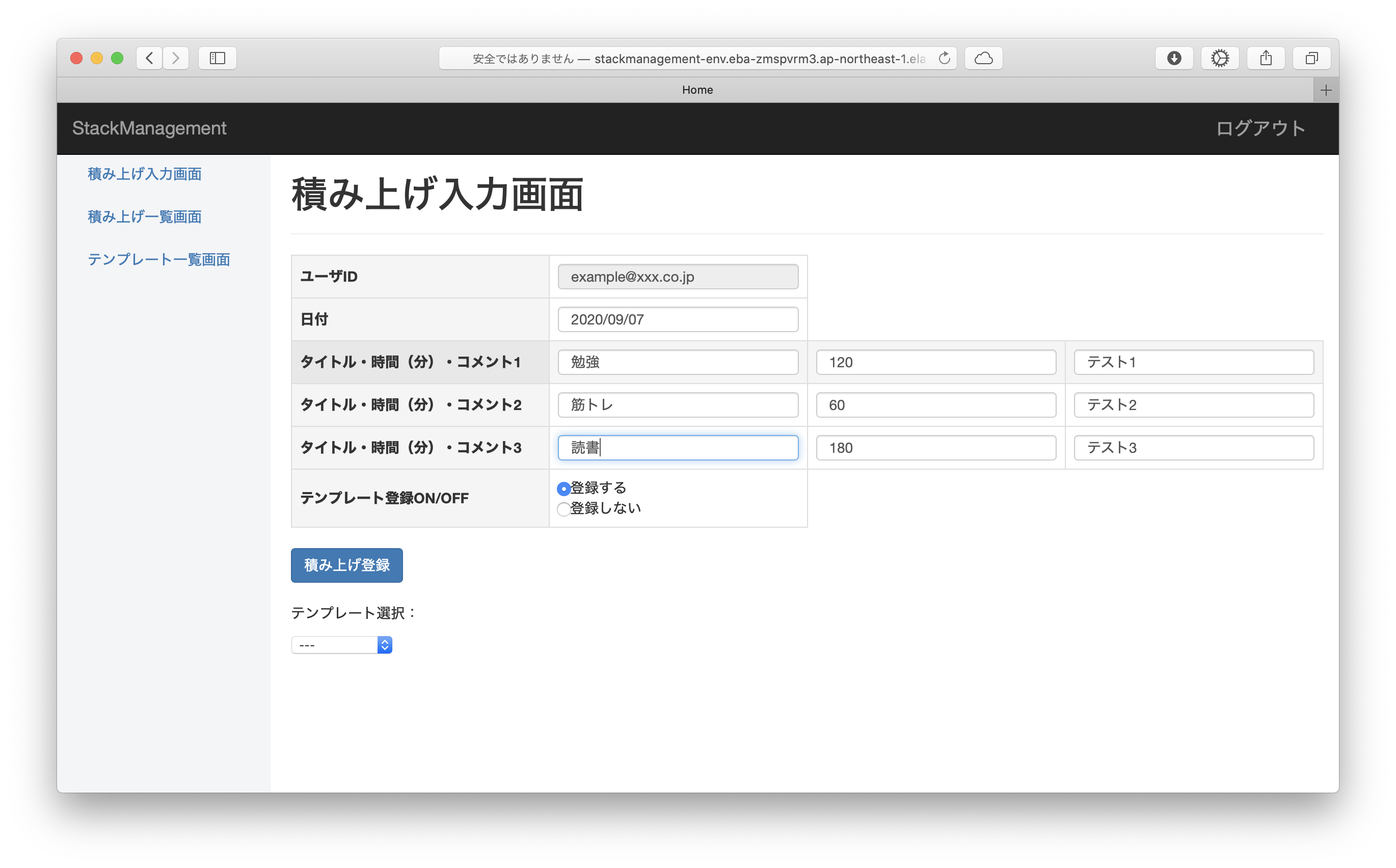
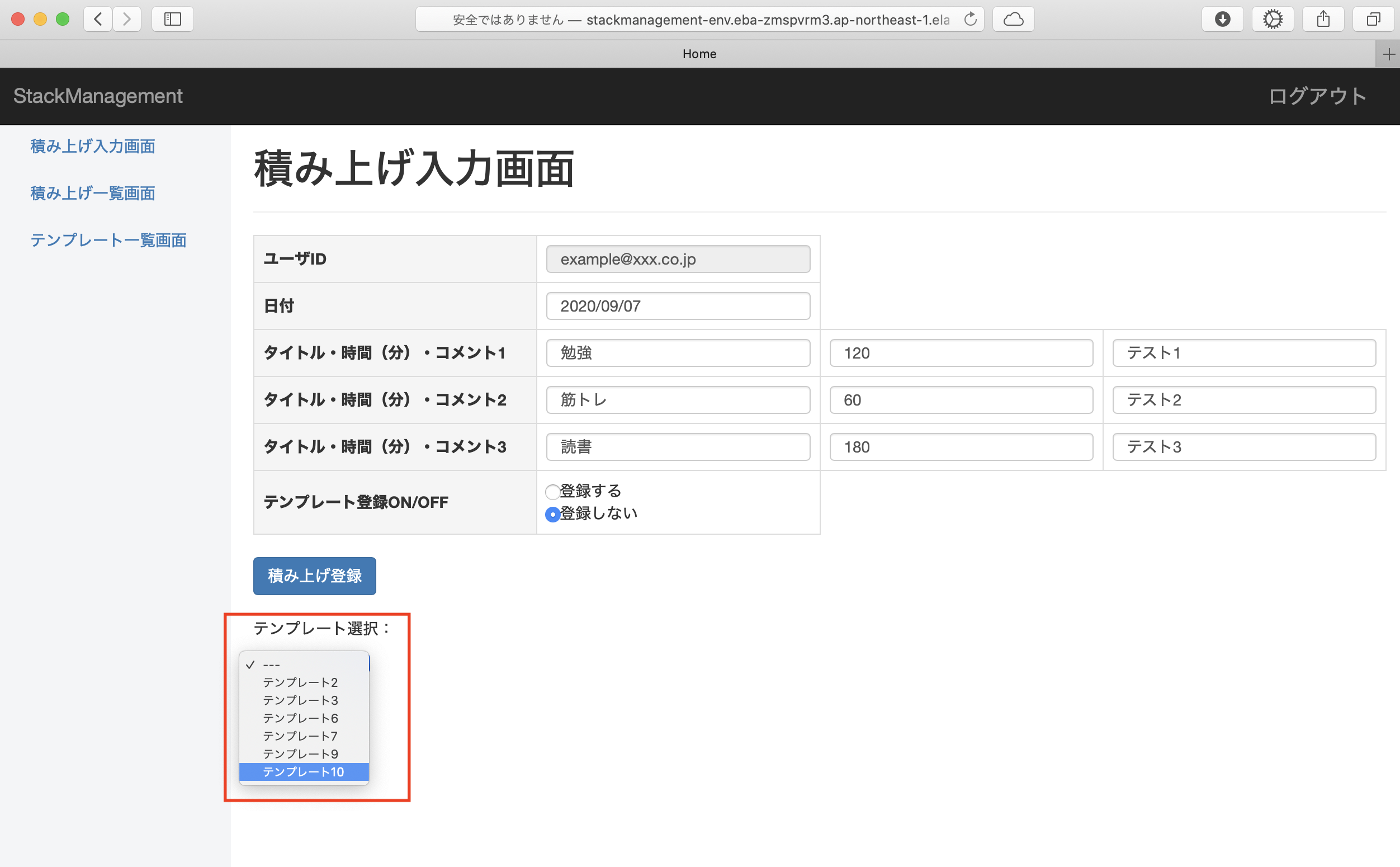
ユーザ登録・ログイン後、以下の入力フォームから1日ごとの積み上げの記録を登録できます。
1日3件ごと、積み上げのタイトル・費やした時間(分)・コメントを入力できます。
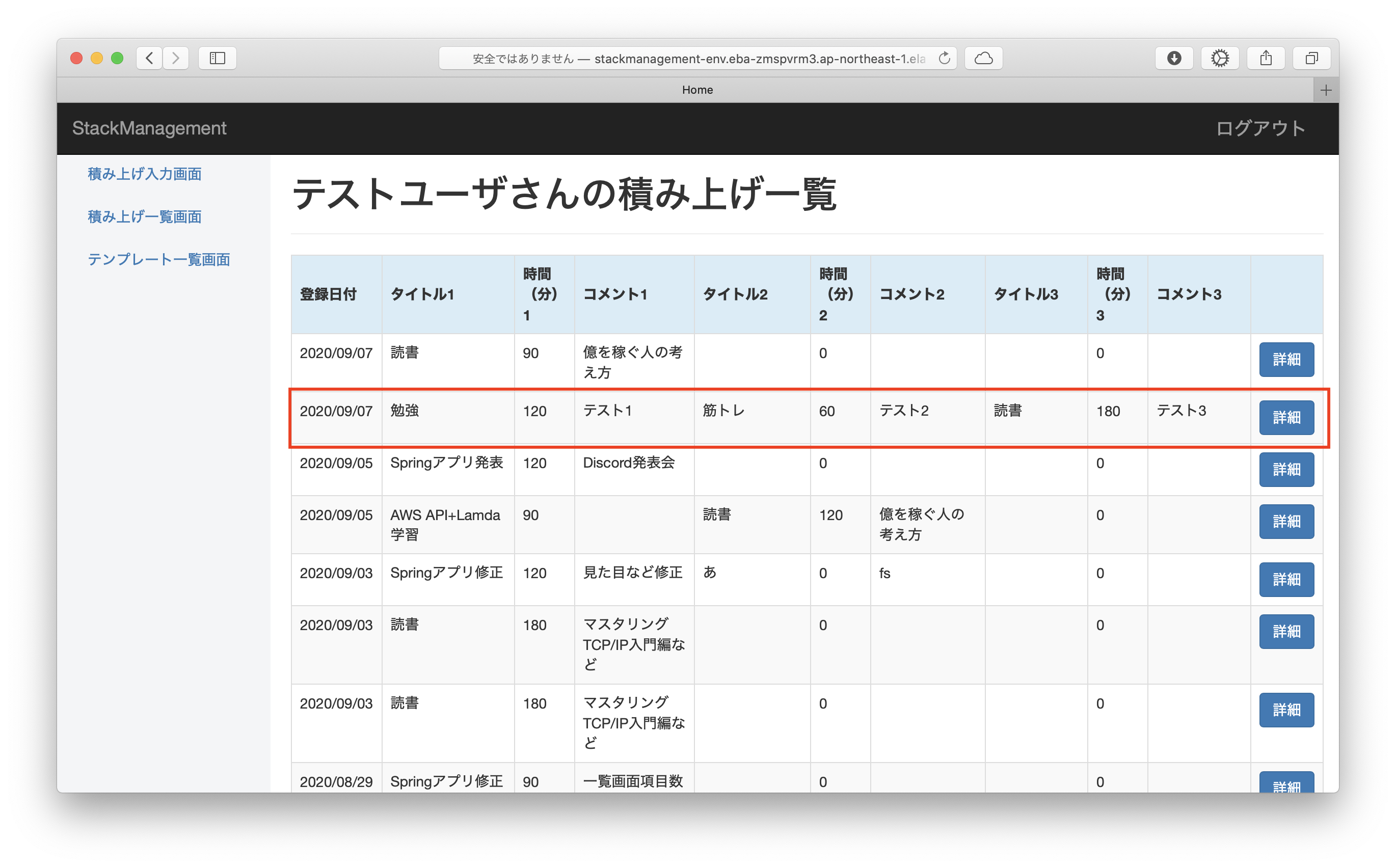
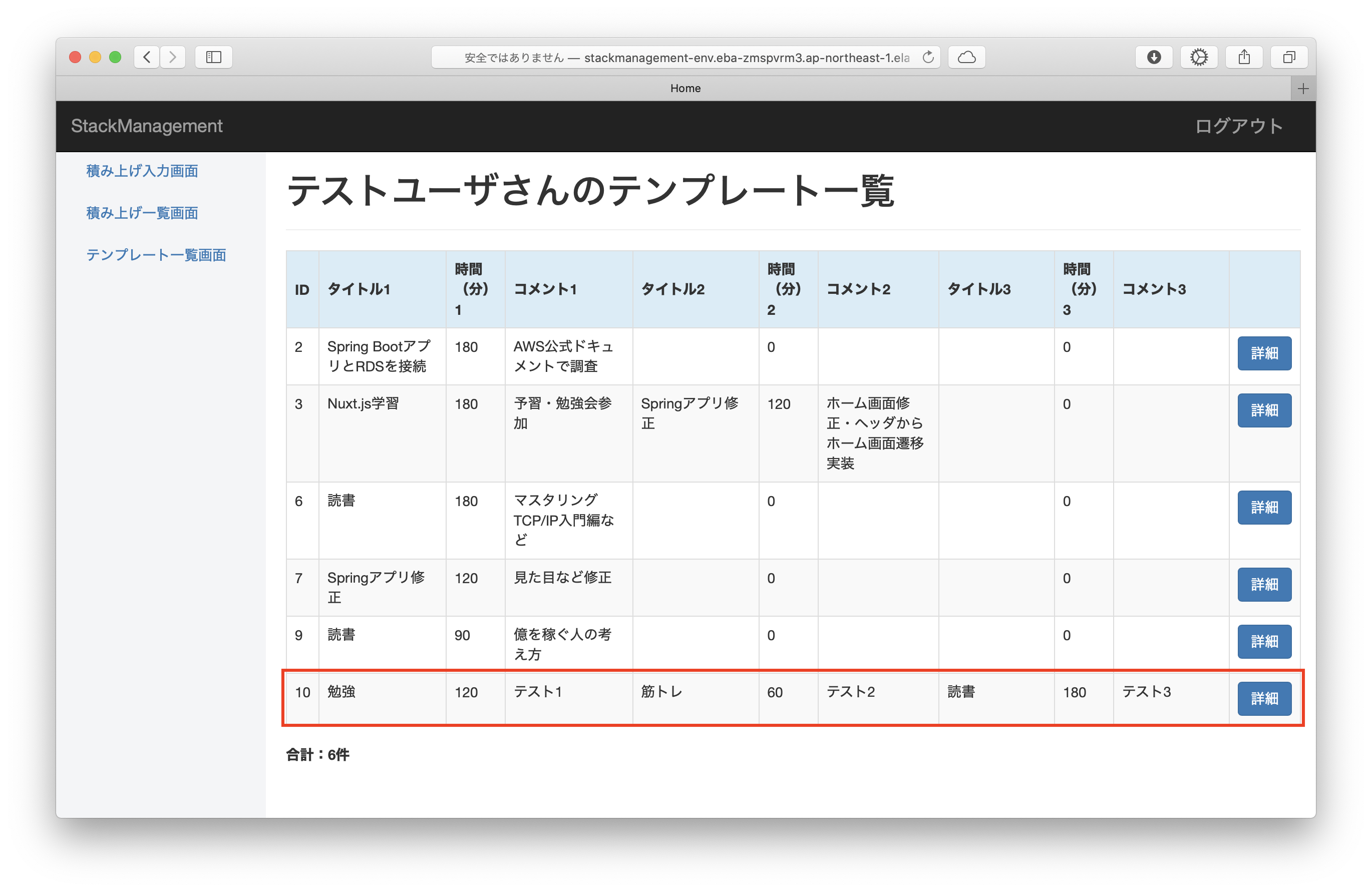
積み上げ登録ボタンを押下すると、入力内容が積み上げ一覧に登録されます。
入力画面で「テンプレート登録ON」を設定していた場合、入力内容がテンプレート一覧にも登録されます。
テンプレート一覧に登録した内容は入力画面の「テンプレート選択」のプルダウン選択によって呼び出すことができ、以前登録した内容と同じ内容を繰り返し入力することができます。
その他、詳細ボタンから登録内容の更新・削除、ADMINユーザからユーザ情報の更新・削除も行えます。
Webアプリ開発の経緯
以前転職活動を行っていた際にJavaの経験を活かそうと考えたものの、Springの知識がないために技術レベルの高い会社に入ることはできず、同じことは繰り返すまいとSpringを学ぼうと考えました。
Kindle Unlimitedで「Spring解体新書」という書籍を見かけて、この機に挑戦したいと考えたのもきっかけです。
Webアプリの土台は書籍中で作成するサンプルと同じですが、サンプルではユーザ登録・ユーザ情報更新・ユーザ情報削除・ログイン機能までしか作成しないため、積み上げ入力やテンプレート登録といった機能はオリジナルとなります。参考書籍:
Spring解体新書
Spring解体新書 セキュリティ編主な使用技術
•Spring Boot
Javaで動作するWebアプリフレームワークです。
Spring FrameworkというJavaのオープンソースフレームワークの集合体を、使いやすくまとめたものとなります。
Javaの標準機能であるJava ServletでもWebアプリは作成できますが、それに比べると、依存性の注入(DI)の機能によってインスタンス生成(new演算子)を省略できる、アスペクト指向プログラミング(AOP)によってメソッド開始・終了時などに共通処理を実行できるといった利点があります。
簡単な説明:SpringのDIとAOPの簡潔な説明•Bootstrap
Twitter社が開発したCSSフレームワークです。
今回は書籍の通りにMavenからBootstrap 3.3.7-1を導入しました。•PostgreSQL
オープンソース系のリレーショナルデータベースです。
書籍ではH2DBを使用していますが、そちらではSpring Bootアプリを終了するたびにデータが消えるため、最終的にPostgreSQLに切り替える必要がありました。
テーブル仕様が固まっていない時など試行錯誤の段階の場合は、H2DBの方が都合がいいと感じています。•AWS
Amazonが提供するクラウドサービスです。
今回はAWS Elastic Beanstalkに、Spring Bootアプリ一式を固めたjarファイルをアップロードすることでデプロイを行いました。
アップロードした時点でEC2インスタンス生成とデプロイが実行されるほか、Elastic BeanstalkのオプションとしてRDSと連携させることで、WebアプリからDBを使用できるようになります。参考資料:
SpringBootアプリをGithubActionsで超簡単にAWS ElasticBeanstalkにデプロイしてみた
Elastic BeanstalkでSpring Bootのアプリをデプロイしたときの手順と遭遇したエラー今後の課題
実際に自分で積み上げの記録を入力していくことで、こうだったらいいのにな、という点を見つけて改良していきたいと考えております。
例:
自分のアイデアを元に機能追加
- 単に記録を表で表示しているだけなので、それをグラフ化する
- スマホ表示時に最適化できるようにする
- 入力内容をTwitterに投稿できるようにする
類似アプリ(Trickle、23UPなど)を参考に機能追加
- カレンダー形式で記録を表示できるようにする
- 画像を投稿できるようにする
- 他のユーザの投稿をタイムラインのように表示させる
- 投稿にタグを付けて分類する最後に
今回の企画で、自分で継続的に運用して改修していけるアプリを作ることができたため、他分野の学習の傍らに、Springの学習も積み上げていける体制を整えることができたと考えております。
本記事内の記述に誤り等ございましたらご連絡をお願いいたします。
- 投稿日:2020-09-07T10:20:26+09:00
[神本]この本から培った基礎的なネットワークとサーバーの知識
はじめに
職場でインフラ系の仕事を任せられ、勉強することに。。
某スクール時代に少しかじったくらいでほとんど知識が無いので、どのように勉強しようか悩んでいると、この本(Amazon Web Service 基礎からのネットワーク&サーバー構築)が良いと言う記事を多く見かけて読んでみることにしました。
そこで学んだ基礎知識を忘れないようにアウトプットしようと思います。学んだこと(CHAPTER毎に)
CHAPTER1
インフラ知識を身につけると良いこと↓↓
障害に強くなる
アプリケーション開発の枠組みだけでなく、システム全体に対応出来る
- システムを運用していると、リソース不足に陥ることがあります。インフラの知識があれば対応できます。
リージョン...世界10箇所に分散されたデータセンター群のこと。
アベイラビリティゾーン(AZ)...リージョンをいくつかに分割したもので、それぞれ物理的に教理が離れている。もしもの自然災害にも他のAZが影響を受けないようにする耐障害性を高める概念。
CHAPTER2
インターネットで使われている「TCP/IP」というプロトコルは、通信先を特定するのに「IPアドレス」を用いる。
IPアドレスは32ビットで構成されている。8ビットずつ10進数で変換したものを、「.(ピリオド)」で区切って表記する。それぞれの数字は0~255までです。-例-
192.168.1.2パブリックIPアドレス...インターネットに接続する際に用いるIPアドレス。プロバイダーやサーバー業者から貸し出されます。
プライベートIPアドレス...インターネットで使わないIPアドレス。誰に申請するでもなく自由に使える。
<IPアドレス範囲と表記方法>
IPアドレスは前半の16or24ビットを「ネットワーク部」と呼び、残りを「ホスト部」と呼びます。このホスト部に数字を割り当てます。(※ネットワーク部は同じネットワークに属する限り同じ値です。)
ホスト部に割り当てるIPアドレスの範囲は「2のn乗個」で区切る。
一般的には「256個」か「65536個」で区切ります。256個...最後の8ビット分(=2の8乗)のため。
65536個...最後の16ビット分(=2の16乗)のため。<CIDR表記とサブネットマスク表記>
CIDR表記...IPアドレスを2進数で表記した時、ネットワークのビット長を「/ビット長」
で示す方法。このビット長を「プレフィックス」と言う。-例-
※ネットワーク長が24ビットの場合。
192.168.1.0 ~ 192.168.1.255 → 192.168.1.0/24サブネットマスク表記...プレフィックスのビット数だけ2進数の「1」を並べ、残りを「0」で記述する表記方法。(1というか255と考えた方がいいかも、、)
-例-
※ネットワーク長が24ビットの場合。
192.168.1.0 ~ 192.168.1.255 → 192.168.1.0/255.255.255.0<サブネットについて>
実際のネットワークでは、割り当てられたCIDRブロックは小さなブロックに分割して利用します。
その理由は、、
物理的な隔離
-社内LANを構築する際に、階別に分けたいように物理的に分けることで、障害が起きても、片方のサブネットに影響が出にくいため。セキュリティ上の理由
パブリックサブネット...インターネットからアクセスすることを目的としたサブネット。
プライベートサブネット...インターネットから隔離したサブネット。
インターネットゲートウェイ...インターネットに接続するために必要な出入り口のようなもの。
パケット...データを細切れにしたもの。ヘッダー情報と、データの実態を含んでいる。
ルートテーブル...パケットが到着した時に、ここに定義に従って次のネットワークへ転送する。各サブネットに設定する。
-例-
宛先アドレス(ディスティネーション) = 10.0.0.0/16流すべきネットワークの入り口となるルーター(ターゲット) = local
デフォルトゲートウェイ...転送先が何も設定されていない場合の転送先。「0.0.0.0/0」に設定される。(全てのIPアドレスの範囲を表す)
CHAPTER3
<SSH接続>
以下のコマンドを実行することでssh接続できる。$ ssh -i pemファイル名 ec2-user@パブリックIPアドレス $ ssh -i my-key.pem ec2-user@12.168.199.122<IPアドレスとポート番号>
インターネットでは、ルーター同士が通信してルートテーブルの情報をやり取りし、必要に応じて自動的に更新するようにしている。代表的な方法が「EGP」と「IGP」である。EGP...大きなネットワークはAS番号と言うものを持っている。この番号をやりとりしてどのネットワークの先に、どのネットワークが接続されているのかを大まかにやり取りする。住所で例えるとすると、日本や東京都といった部分の情報。
IGP...より詳細なやりとりをする。住所で例えると渋谷区〜以降の情報のこと。
ポート...他のコンピューターと、データを送受信するための出入り口。住所で例えると、部屋番号といった情報。
ウェルノウンポート番号...あらかじめ定められたポート番号。
-例-
SSH = 22番
SMTP = 25番
HTTP = 80番
HTTPS = 443番<ファイアーウォールについて>
ファイアーウォール...通して良いデータだけ通して、それ以外は遮断する機能のこと。CHAPTER4
<ドメイン名>
一般的には、Webサイトにアクセする際はIPアドレスでは無くドメイン名でアクセスします。これは、一意性が保証される必要があります。名前解決...あるドメイン名からそれに対応したIPアドレスを引き出すこと。
-例-
www.example.co.jp → 34.133.222.223CHAPTER5
HTTP...ハイパーテキストを伝送するための通信規約。クライアントとサーバー間でリクエストとレスポンスをやりとりしている。
-例-
(HTTPステータスコード)
コード 意味 1xx 処理中 2xx 成功 3xx リダイレクト 4xx クライアントエラー 5xx サーバーエラー CHAPTER6
<プライベートサブネットのついて>
サーバを隠すことができて、セキュリティを高められることで利用される。
(主にDBサーバなどを置く)プライベートサブネットにあるサーバーはインターネットに接続されていないので、SSH接続できないのか?
→踏み台サーバーを用いる!!踏み台サーバ...パブリックサブネットのサーバーにSSH接続し、そのサーバーからプライベートサブネットにあるサーバーにSSH接続すること。
-例-
ローカル
↓SSH接続
Webサーバー(パブリックサブネット)
↓SSH接続
DBサーバー(プライベートサブネット)CHAPTER7
<NATサーバーについて>
NATサーバー...IPアドレスを変換するサーバーで、2つのネットワークインターフェースを持ちます。片側には一般的にパブリックIPアドレスを設定し、もう一方にはプライベートIPアドレスを設定する。
NATサーバーを用いると、プライベートサブネット側からのインターネット接続はできるが、その逆はできなくなります。
CHAPTER8
PHPやMySQL、WordPressのインストールや設定がメインなので割愛。
CHAPTER9
TCP/IPモデル...役割ごとに4つの階層に分けたモデル。各層には、その層の役割を果たす書くプロトコルがある。各階層を独立化するために階層化しています。上位の階層は下位の階層が何でも良くて、下位の階層は上位の階層の内容を分からなくても良いです。
層 役割 代表的なプロトコル アプリケーション層 ソフトウェア同士が会話する HTTP SSH,DNS トランスポート層 データのやり取りを制御、エラー訂正など TCP,UDP インターネット層 IPアドレスの割り当て、ルーティング IP ICMP,ARP インターフェース層 ネット上で接続されている機器同士を通信する Ethernet,PPP 終わりに
全然インフラ系の知識を持ち合わせていなかった自分には基礎を固められた良い本でした。。
サーバー構築の手順などもありましたが、書いてもキリがないので割愛しました。
得た用語や知識を綴らせてもらいました。
ここからまた、色んな知識を身に付けていけたらと思います!参考
- 投稿日:2020-09-07T09:12:14+09:00
指定したEC2インスタンスのEIPを開放するスクリプ
時代遅れだけど。
cat <<EOD | xargs aws ec2 describe-instances --instance-ids \ | jq '.Reservations[].Instances[] | select(has("PublicIpAddress")) | .PublicIpAddress' -r \ | tee \ >(xargs -I{} aws ec2 disassociate-address --public-ip {}) \ >(xargs -I{} aws ec2 describe-addresses --filter Name=public-ip,Values={} | jq '.Addresses[].AllocationId' -r | xargs -I{} aws ec2 release-address --allocation-id {}) i-xxxxxxxxxxxxxxxxx i-xxxxxxxxxxxxxxxxx i-xxxxxxxxxxxxxxxxx i-xxxxxxxxxxxxxxxxx i-xxxxxxxxxxxxxxxxx i-xxxxxxxxxxxxxxxxx i-xxxxxxxxxxxxxxxxx (好きなだけ改行区切りでどうぞ) EOD
- 投稿日:2020-09-07T08:30:26+09:00
AWS認定資格 データアナリティクス – 専門知識 (DAS-C01) の学習ポイント
はじめに
AWS 認定 データアナリティクス – 専門知識 (DAS-C01)の試験に合格することができましたので、これから受験しようとしている初学者に向けて、簡単な学習ポイントをまとめてみました。
少しでも初学時の参考になれば幸いです。試験の出題範囲を把握する
どのような試験にも当てはまることですが、受験しようとする試験の出題範囲を確認し、これから学習する全体像を把握した上で、学習に着手した方が良いかと思います。
AWSの分析サービスについて確認する
AWSの分析サービスには、ユースケースに応じて、どのようなサービスがあるのか確認します。
参考:
AWS でのデータレイクと分析試験の出題範囲のサービスを把握する
下記の表のように、学習範囲を各分野と各サービス単位に細分化して、試験の範囲となっているサービスを把握します。
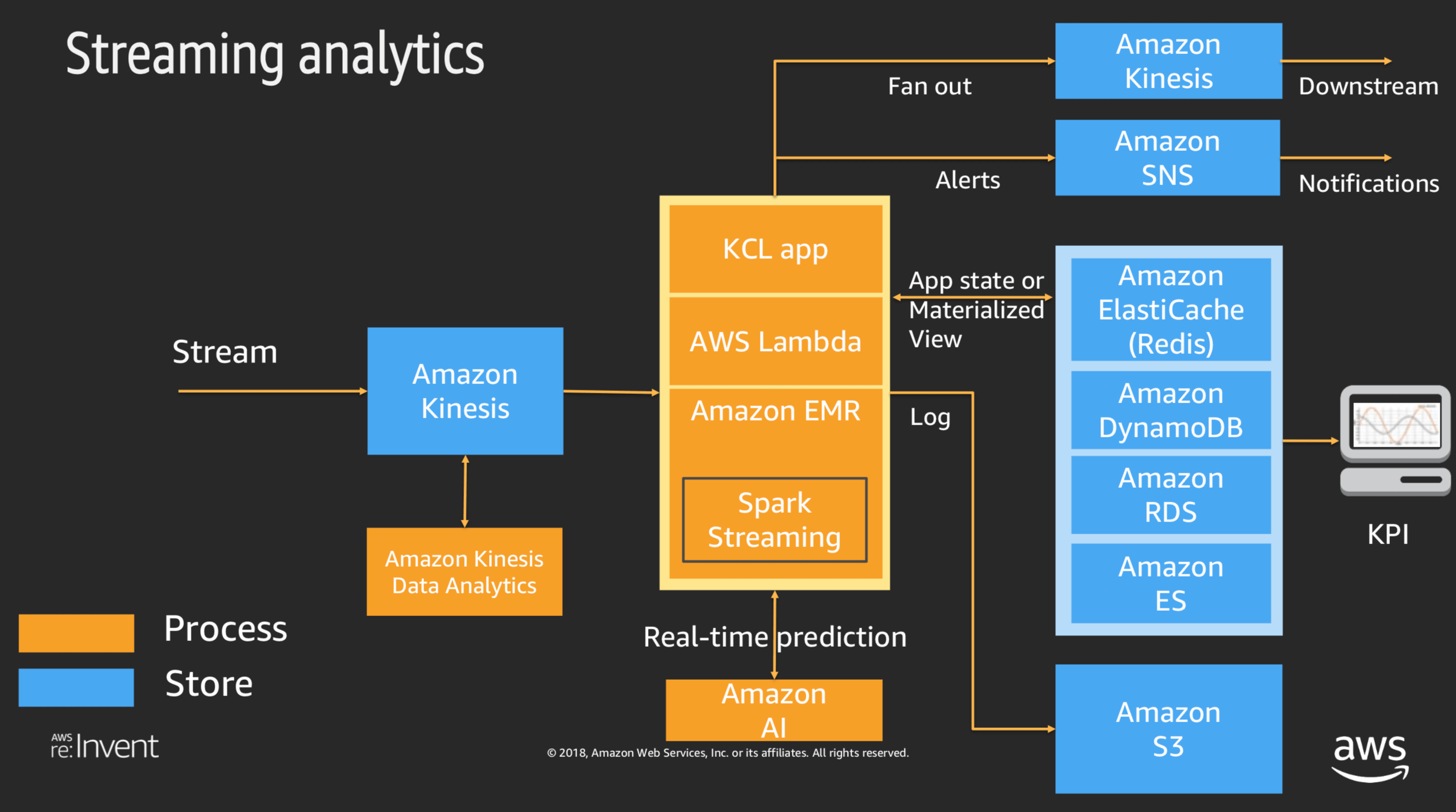
分野 サービス(参考) 分野1 : 収集 Kinesis Streams, Kinesis Firehose, SQS, IoT 分野2 : 格納 S3, DynamoDB, RDS 分野3 : 処理 EMR, Glue, Lambda 分野4 : 分析 Kinesis Analytics, Redshift, Redshift Spectrum, Athena, Elasticsearch,SageMaker 分野5 : 可視化 QuickSight, Kibana 分野6 : データセキュリティ IAM, KMS, CloudHSM AWSのデータ分析サービスの全体像を把握する
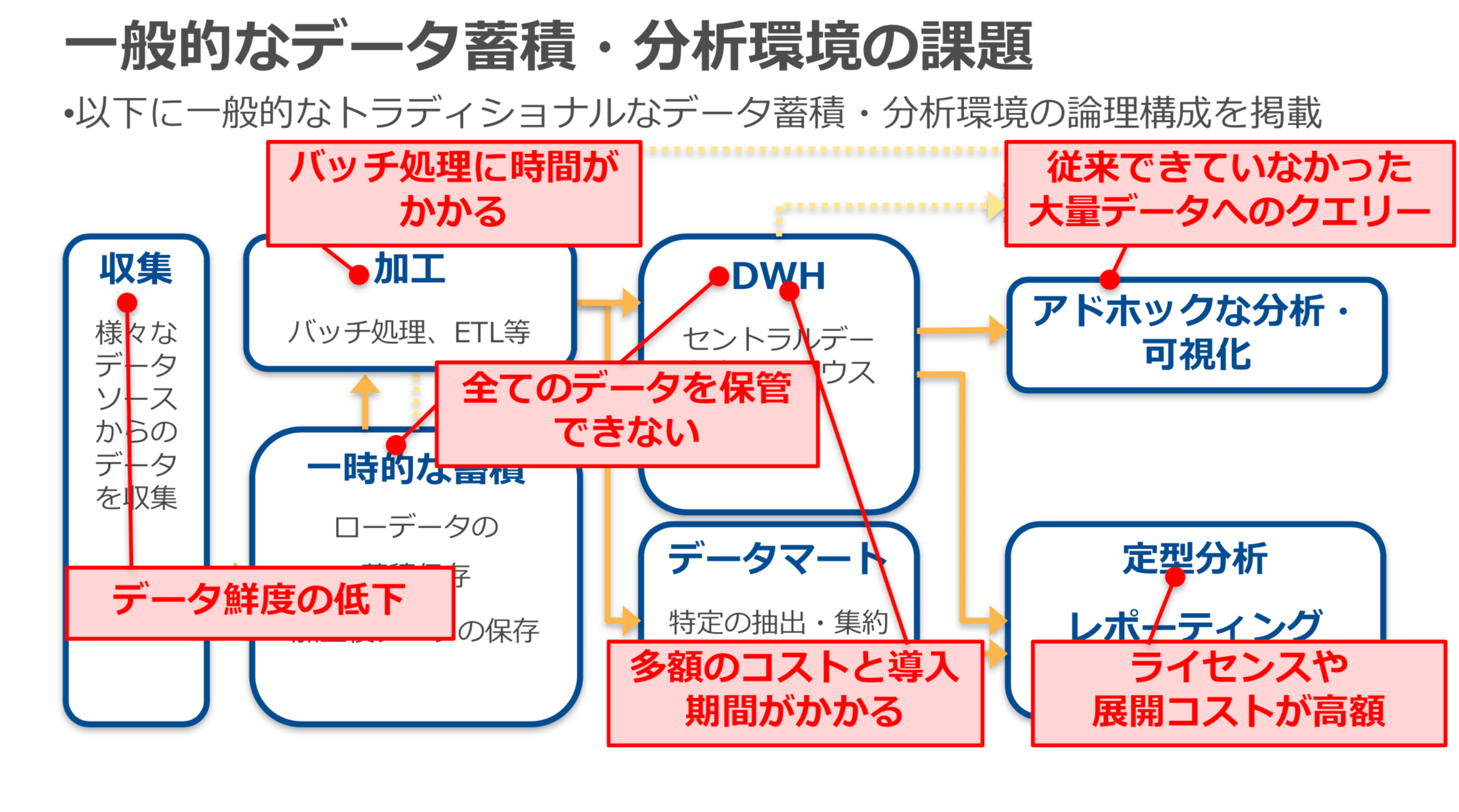
各分野の各サービスの機能をどのように学習していけば良いか把握するために、もう一度、データ分析サービスの全体像を把握します。
下記の資料を確認して、⼀般的なデータ蓄積・分析環境の論理的な構成を理解し、その構成の中で発生する課題をAWSの分析サービス使ってどのように解決するのかを理解して、AWSのデータ分析サービスの全体を把握します。
参考:
AWS のデータ分析⼊⾨
※上記資料より 抜粋
サービス単体の機能を理解する
AWSのデータ分析サービスの全体像が確認できたら、上記の表にある各分野ごとのサービスのBlackbelt を一通り読んでサービス単体の機能を理解します。
(初読の段階では、完全に理解しようとする必要はないと思います。)各サービス間の連係を理解する
各サービスを単体で理解するだけでなく、各サービスがどのように相互に連係されるかを理解する必要があります。
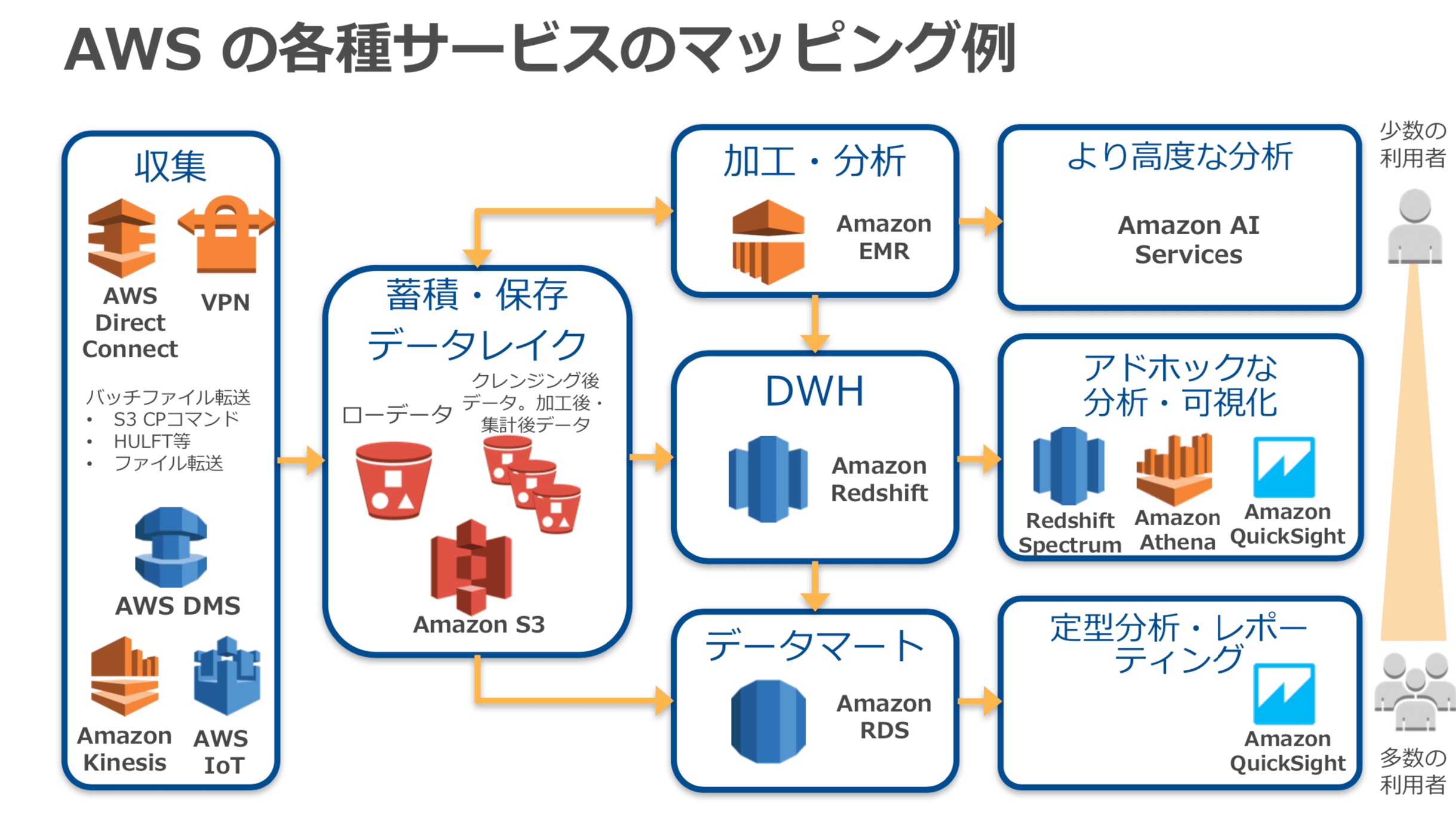
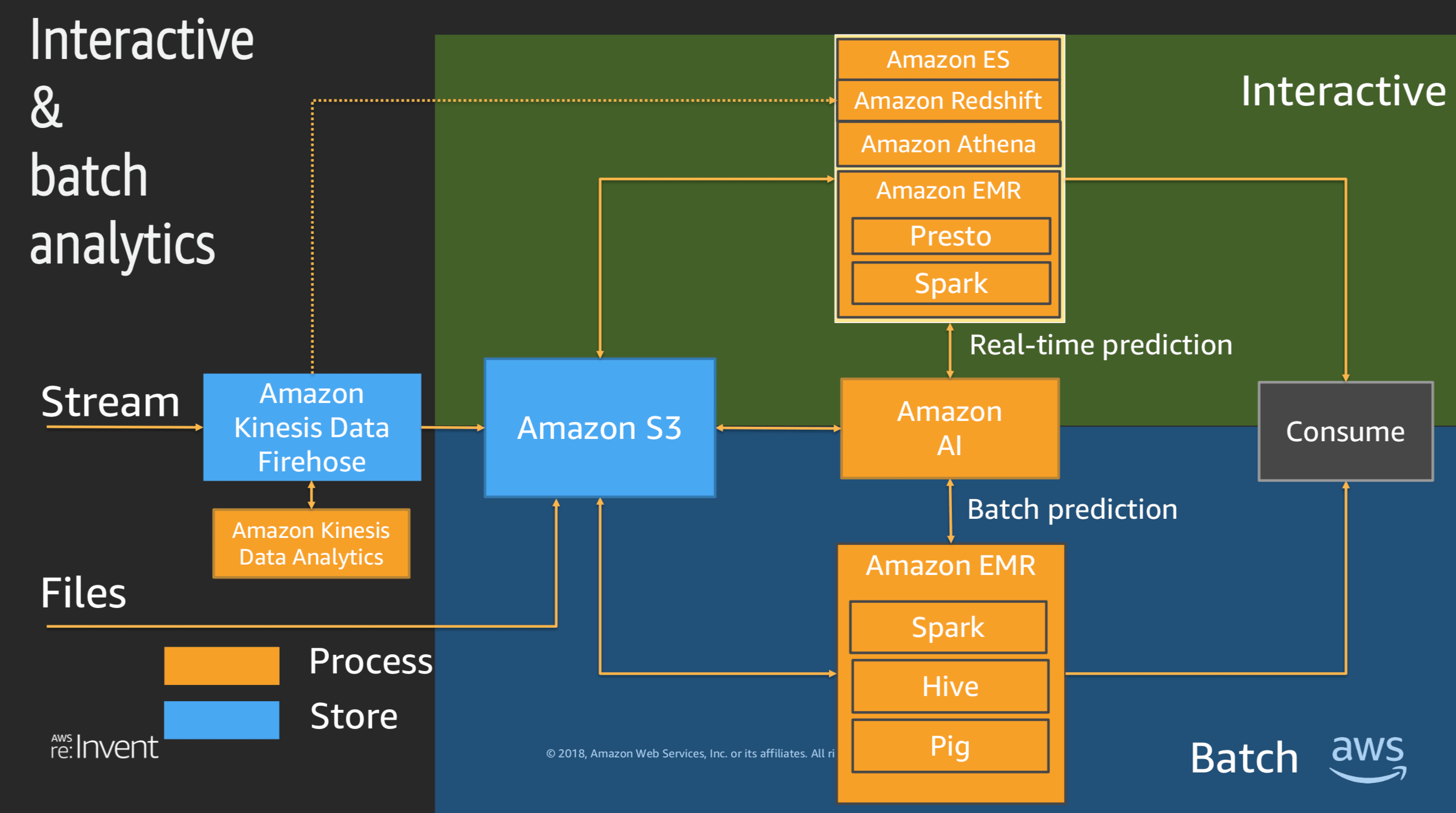
試験もユースケースごとに最適なサービス間の連係について問われます。各サービス間の連係を理解するには、英語ですが、下記の資料がよくまとまっていて、理解しやすいかと思います。
Slideshare:Big Data Analytics Architectural Patterns and Best Practices (ANT201-R1) - AWS re:Invent 2018Youtube:AWS re:Invent 2017: Big Data Architectural Patterns and Best Practices on AWS (ABD201)
※参考までに上記資料より 一部抜粋
上記の資料や動画を確認して、ユースケースに応じて適切なサービスを選択し、サービス間の連係を最適に設計するとはどういうことなのか?が漠然とでも良いので気づけたなら、それこそが、この試験で評価される能力ということになります。抜粋:試験ガイドでも下記のように記載されています。
この試験で評価する能力は次のとおりです。
• AWS の各種データ分析サービスについて定義し、これらのサービスの連係について理解
する。
• AWS のデータ分析サービスが、データライフサイクル (収集、格納、処理、および可視化)
にどのように関係しているかを説明する。各サービスの特徴をさらに深く理解する。
ユースケースに応じて、最適なサービスを選択できるように、各サービスの特徴をさらに深く理解するようにします。
実際の試験においては、プロフェッショナルや他の専門知識の試験と同じように初見で解答を選択できることは少ないかと思います。
解答方法としては、各サービスの特徴から類推して、明らかに違う選択肢を見つけ、消去法で正解を絞り込んでいくのが手堅いと思います。
各サービスの特徴を学習する上でのポイントを一例としてあげておきますので参考にしていただければと思います。
- ストリーミングデータを収集するユースケースにおいて、Kinesis Data Streamsと Kinesis Data Firehose のどちらが選択するのが最適なのか?
- S3とDynamoDBのどちらにデータを格納するのが最適なのか?
- S3に格納されているデータは、構造化データか? それとも非構造化データなのか?
- S3に格納されているデータは、圧縮されているのか? それとも圧縮されていないのか?
- EMRで処理したデータは、HDFS と EMRFS のどちらに格納するのが最適なのか?
- EMRのクラスタにおいて、一時的クラスタ と 永続的クラスタのどちらを選択するのが最適なのか?
- S3に格納されたビッグデータをRedshift にロードする場合のパフォーマンスを向上させるにはどのような方法を選択するのが最適なのか?
- Redshift に効率よくデータを格納するにはどのような分散スタイルを選択するのが最適なのか?
- 分析データを保護する必要があるユースケースにおいて、各サービスは、どのように「通信の暗号化」や「保管データの暗号化」を実装することができるのか?
さいごに
以上が、「AWS 認定 データアナリティクス – 専門知識 (DAS-C01)」の試験の簡単な学習ポイントです。
データ分析の知識は、今後もさらに需要が見込まれる分野かと思います。
この試験の学習を通じて、その知識を生かして、活躍するエンジニアが増えていくといいなと思います。



- 投稿日:2020-09-07T07:10:59+09:00
【AWS】EFS改めてまとめてみた
Elastic File Sysytem (EFS)とは
複数のEC2インスタンスからアクセス可能な共有ストレージ。シンプルでスケーラブルで柔軟に利用できるファイルストレージ。
特徴
- フルマネージド型サービス
- NFSv4プロトコルを利用して、関連ツールや標準プロトコル/APIでアクセス可能
- ペタバイトまでスケーラブルにデータを蓄積可能
- スループット/IOPS性能は自動的にスケーリングし、低レイテンシーを維持
- ファイルの減少に合わせて自動で拡張・縮小
- 従量課金
- 事前に容量を設定する必要なし
基本性能
基本性能
- 100MB
- ファイル名は255Byte
- 1ファイルの最大容量48TB
- インスタンス当たり128ユーザまでの同時オープンが可能
- 何千もの同時アクセスが可能
制限
- アカウント当たりのファイルシステム数:1000
- AZごとのファイルシステム当たりのマウントターゲット:1
- ファイルシステム当たりのタグ:50
- マウントターゲット当たりのセキュリティグループ:5
- ファイルシステム当たりのVPC数:1
- 各VPCのマウントターゲット数:400
パフォーマンスモード
汎用モード
- 一般的な用途を想定したモード
- デフォルトでは汎用モードとなり、推奨されている
- レイテンシーが最も低い
- 1秒当たりのファイルシステム操作を7000に制限
最大I/Oモード
- 何十〜何千というクライアントからの同時アクセスが必要な大規模な構築に利用
- 合計スループットを優先してスケールする
- レイテンシー型小長くなるスループットモード
バーストスループットモード
一時的な大量のトラフィックの発生やそれに伴いサーバの処理性能が一時的に向上するバースト機能を持ったモード。
- ピーク時にクレジットを消費してバーストを実行して一時的な性能を向上させる方式
- 最大スループットとバースト時間に制限がある
- スループット性能向上にはストレージ容量の増大が必要プロビジョンドスループットモード
バーストスループットモードで設定されているベースラインスループットを大幅に上回るスループットが必要な場合や最大スループットよりも高い性能が必要な場合に選択する。
- 一貫したスループットを事前に設定する方式
- 1日に一回スループット性能を減少できる
- 投稿日:2020-09-07T06:53:21+09:00
AWS CDK (Python) を使ってAPI Gateway + LambdaでPOSTを受け取る
AWS CDKとは大雑把に言うと、AWS上で構築するアプリケーションの設計書(CloudFormation)をプログラミング言語で書いてしまおうというもの。
本記事では、POSTされたJSONをAPI Gatewayを通してLambdaで処理するという単純な流れをPythonを用いて実装します。
AWS CDKを使えるようにするための設定は、以下の公式ドキュメント等を参照のこと:手順
まず適当なディレクトリを作り、以下の
cdk.jsonを作成します。cdk.json{ "app": "python3 app.py" }次にそのディレクトリ内に新しいディレクトリ(例えば
lambda)を作り、その中にLambdaの関数を作ります(ここではwebhook.py)。単純に、リクエストボディ部のJSONをそのまま返すだけの関数です。lambda/webhook.pyimport json def handler(event, content): try: body = event.get("body") print(body) status_code = 200 except Exception as e: status_code = 500 body = {"description": str(e)} return { "statusCode": status_code, "headers": { "Content-Type": "text/plain" }, "body": json.dumps(body) }最後に元のディレクトリに戻り、本丸のアプリを定義していきます(
app.py)。app.pyimport os from aws_cdk import ( core, aws_lambda as _lambda, aws_apigateway as apigw ) class PrintPostStack(core.Stack): def __init__(self, scope: core.App, name: str, **kwargs) -> None: super().__init__(scope, name, **kwargs) lambda_func = _lambda.Function( self, "PrintPostFunc", code=_lambda.Code.from_asset("lambda"), handler="webhook.handler", runtime=_lambda.Runtime.PYTHON_3_7, ) api = apigw.RestApi(self, "PrintPostApi") api.root.add_method("POST", apigw.LambdaIntegration(lambda_func)) app = core.App() PrintPostStack( app, "PrintPostStack", env={ "region": os.environ["CDK_DEFAULT_REGION"], "account": os.environ["CDK_DEFAULT_ACCOUNT"] } ) app.synth()
- Stackとは構築されるAWSのリソース全体の集合のことを指す用語です。
lambda_funcでLambda関数を設定しています。
code=_lambda.Code.from_asset("lambda")はLambda関数ファイルがlambdaディレクトリにあるよということhandler="webhook.handler"はwebhook.pyのhandler関数を見てねということruntime=_lambda.Runtime.PYTHON_3_7はPython3.7を使ってねということapiでAPI Gatewayを設定しています。
api.root.add_method("POST", apigw.LambdaIntegration(lambda_func))でPOSTメソッドを追加、lambda_funcと統合以上です。あとは下のコマンドでデプロイするだけ。
$ cdk deployうまくいくとエンドポイントURLが表示されます。cURLコマンドで適当なJSONをPOSTし、レスポンスを確認してみましょう。
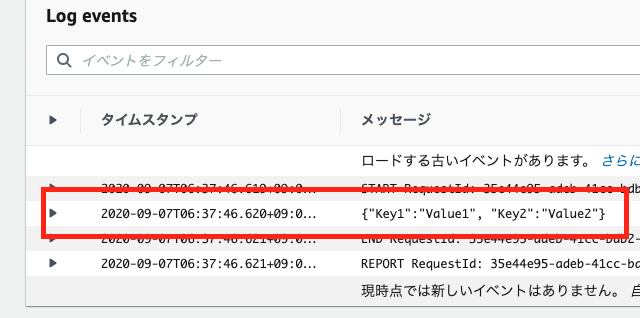
$ curl -X POST \ > -H "Content-Type: application/json" \ > -d '{"Key1":"Value1", "Key2":"Value2"}' \ > https://xxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/prod/ "{\"Key1\":\"Value1\", \"Key2\":\"Value2\"}"上のようにJSONがそのまま返ってきたら成功です。
また、
webhook.pyではリクエストボディ部をprint(body)しています。このログは、CloudWatchから確認することができます。AWSのコンソール > サービスから、CloudWatchを見つけてクリックし、ログ > ロググループからPrintPostStackの名前のついたログを見ましょう。以下のようにJSONが表示されているはずです。
以上です!超単純なAPI Gateway + Lambdaを通してAWS CDKを紹介してみました。
以下の公式の例も参考になると思うのでご覧ください。
- 投稿日:2020-09-07T00:20:37+09:00
AWS上にサーバーを作る(その01)
前回の投稿
AWS上にサーバーを作る(序章)サーバーに必要なAWSサービス
サーバー作るためには何が必要なんだっけ?
オンプレサーバーをベースにちょっと考えてみる。
- PC本体とOS
- ネットワーク
たぶん最低限このへんが必要だと思われる。
これをクラウドサーバーで実現したい。PC本体とOS
ここがAWSでいうところのEC2にあたるらしい。
Amazon Elastic Compute Cloud (Amazon EC2)
EC2ってワードは聞いたことがある。
ふむふむ。なんかAWSっぽくなってきたな。
しかし慌ててはいけない。
ここで高額な費用になっては、お金が払いきれない。
無料枠についてチェックしてみる。AWS の無料利用枠には、1 年間毎月 750 時間分の Linux および Windows の t2.micro インスタンス (t2.micro が利用できないリージョンでは t3.micro) が含まれています。使用量を無料利用枠内に抑えるには、EC2 マイクロインスタンスのみを使用してください。
なるほど。
「t2.micro インスタンス」ってのを指定しておけばとりあえず1年間は安くできそうだ。
それで、「t2.micro インスタンス」ってどんな内容なんだ??
タイプ vCPU ECU メモリ インスタンスストレージ 料金(2020年8月現在) t2.micro 1 変数 1 GiB EBS のみ 0.0152USD/時間 料金表には、指定されたオペレーティングシステムでプライベートやパブリックな AMI を稼動するためのコストが含まれています
0.0152USD/時間って書いてあるけれど、前述の通り1年目は毎月750時間無料になっているみたいなので、24時間×30日=720時間だから無料でいける!!もし有料になったとしたら、毎月10.944USDだ。
そして、先ほどのスペック料金表で見慣れない項目がある。
ECU:変数とインスタンスストレージ:EBSのみという記述。
これって何だろう。ECU(EC2 コンピューティングユニット)
ECUって何だろう?そしてECUが変数とは??
オフィシャルサイトのQ&Aに説明が出てた。Amazon EC2 よくある質問
Q:「EC2 コンピューティングユニット (ECU)」とは何ですか? またそれを導入する理由は何ですか?ユーティリティコンピューティングモデルへの移行は、デベロッパーが CPU リソースに対してこれまで持っていた考え方を根本的に変えるものです。特定のプロセッサを購入またはリースして数か月から数年間使用する代わりに、時間単位で処理能力をレンタルすることができます。Amazon EC2 は、コモディティなハードウェア上に構築されているため、EC2 インスタンスが内在する物理的なハードウェアの種類は、時間と共に異なる可能性があります。当社の目的は、実際に利用するハードウェアがどのようなものであろうと、一定量の CPU 能力を安定したかたちで供給することです。
Amazon EC2 は様々な手段を使用し、各インスタンスに安定した期待通りの CPU 能力を提供します。異なるインスタンスタイプ間でデベロッパーが簡単に CPU 能力値を比較できるように、Amazon EC2 コンピュートユニット (ECU) が定義されています。特定のインスタンスに配分されている CPU 量は、これらの EC2 コンピュートユニットで明示されます。当社はいくつかのベンチマークとテストを使用して、EC2 コンピュートユニットのパフォーマンスの安定性と予測可能性を管理します。EC2 コンピューティングユニット (ECU) は、Amazon EC2 インスタンスの整数処理能力を相対的に測定します。将来的に、コンピューティング性能についてお客様により明確な図を提供するメトリクスが見つかった場合には、EC2 コンピュートユニット (ECU) の定義方法が追加または交換される場合があります。
と書いてある。
物理サーバーで言うところのCPU的なとらえ方で良いのかな?
このECUが変数ってことは、良い感じに最適化して動作するものなんだろうと勝手に解釈しておく。(間違ってるかもしれないが)インスタンスストレージ
インスタンスストレージって何だろう?
HDDとかSSDみたいなストレージのことかな??
そしてインスタンスストレージがEBSのみとは??EBS(Amazon Elastic Block Store)
EBSって何だろう?
Amazon Elastic Block Store
やはり、予想した通りストレージ部分だな。
そして僕が選択しようとしているEC2はこのEBSからしか選択できないということか。無料利用枠
AWS 無料利用枠には、Amazon Elastic Block Store (EBS) のストレージ 30 GB、I/O 200 万回、スナップショットストレージ 1 GB が含まれています。お!早速無料枠発見!ストレージは30GBで決めてしまおう。
PC本体とOSについてのまとめ
僕はコストを抑えるために
- EC2はt2.microを1台選択(OSはLinux)
- EBSは30GBを1台選択
これでいくと決めた。
ネットワーク
ネットワークにつながっていないと、はっきりいって何もできない。
SSHすら接続できないので、もしコンソール画面の提供があるのなら最低限の操作はできるけど、そもそもAWSにはコンソールってあるのか??ネットワークにつなげてやりたいこと
今回、僕は、
- インターネット上で広くWebサイトを公開して見に来てもたうようなサーバーを立てる訳ではない
- 自分のお小遣いと相談しながら勉強のためにAWSにサーバーを立ててみたいと思っている
- クラウドサーバーは従量課金だという事は噂で聞いたことがある
- なるべく他の人からはアクセスできないような作り、あるいは非公開にしたいくらい
その場合どんなネットワーク接続構成が考えられるか。
- インターネット上にサーバーを公開し、ファイアウォールで接続元をしぼる
- 回線業者のクラウド直通接続サービスを利用する
- 接続元と接続先をVPNで接続する
こんな感じになると思うけど、
- は普通っぽい。
- は法人ならまだしも個人のおこづかいでは無理。
- は勉強にもなるし、なんだかそれっぽいね。
前回、非公開サーバーを立てる際にVPNが使えたらいいなって思っていたし・・・ってことで、拠点間VPN(Site-to-Site VPN 接続)を採用してみよう。
作る物の宣言
「僕は勉強のため、
- 初めてAWSのサービスを使い
- 自宅からVPNでのみアクセスできる(Site-to-Site VPN 接続)
- ランニングコストのかからない(無料枠が利用できるもの優先)
サーバーをインターネット上に立てます!!」
次回の内容
そろそろAWSに実際にログインして見てみましょうかねー
(まだAWSにログインすらしていないよ)To be continued...